- 投稿日:2020-06-03T21:32:30+09:00
WSL2上(Ubuntu 20.04LTS)でRails環境を構築しようとしたら躓いて転んだ
何をしようとしたのか?
Windows10 20H1が来たのでWSL2を用いてRails環境を整えようと思った。
Ubuntu 20.04LTSを入れて、あれこれ設定していたら想定外のところで躓いて転んだ。何があったのか?
- Rubyのインストールはできた
- gemでRailsもインストールできた
- MariaDBもインストールできた
- 普通に起動させよう
$sudo systemctl start mysql System has not been booted with systemd as init system (PID 1). Can't operate. Failed to create bus connection: Host is downなんかエラー出た。
なんで?
WSL2はsystemdがサポートされていないらしい(厳密には存在するらしいが無効化されている)。
仮に有効化させてもPID 1で起動できないので、事実上systemctlは使えない。対策
WSL2でSystemdを使うハックを参照してみた。
その中でも一番楽そうなgenie コマンドを使ってみることに。
https://github.com/arkane-systems/genie/実行
割と長めの前準備があるが、最終的には以下のコマンドを実行することになる。
sudo apt install systemd-genie以下準備メモ
- .NET Core のインストール にアクセス
- dotnet-runtime-3.1をインストール
- wsl-translinuxにアクセス
- Quick installの欄のスクリプトを実行
- 上記コマンドを実行
あれ?
実行してみるとわかるが、404エラーを返されてインストールに失敗する。
何故かと思ったらまだUbuntu 20.04LTS向けのパッケージが存在しないのである。
なんという……。結論
現状DebianかUbuntu 18.04LTSを使おう。
- 投稿日:2020-06-03T20:35:24+09:00
Linux基礎16 -シェルスクリプトの活用-
はじめに
今回は、シェルスクリプトの活用例をみながら、シェルスクリプトについて学んでいきましょう。
シェルスクリプトの活用
シェルスクリプトの活用方法は多岐に渡りますが、ここでは既存のコマンドを組み合わせて、新しいコマンドを作成するという点に注目して活用例をみていきましょう。コマンドを自在に組み合わせて問題を説いていくことが、シェルスクリプトの基本的な考え方になります。
作成したシェルスクリプトは、1つのコマンドとして別のシェルスクリプトからも使うことができます。実際、シェルスクリプトで書かれているLinuxコマンドもたくさん存在します。lessコマンドで中身を読むことができるので、是非みてみるといいでしょう。
シェルスクリプトの欠点
シェルスクリプトには欠点もあります。シェルスクリプトを使うべきではないケースについて紹介しておきます。
大規模システムのプログラミング
シェルスクリプトは、変数に型がないことや、オブジェクト指向プログラミングが行えないことから、複数人による大規模開発には不向きです。また統合開発環境のような、開発支援機能がシェルスクリプトにはありません。このため、本格的な開発作業を行う場合にはシェルスクリプトは適しません。
高速性が必要な処理
シェルスクリプトは1行ずつコマンドを実行していく形式をとるため、子プロセスを生成する処理(fork)が大量に発生します。そのため、他のスクリプト言語に比べて動作が遅くなる傾向にあります。速度面を気にする場合には、PerlやRubyなどのスクリプト言語を使う方がいいでしょう。
活用例1 -日記を書くためのシェルスクリプト-
まずは簡単な例からみていきましょう。今回は日記ファイルを作成するシェルスクリプトです。求められる用件は以下の通りです。
- 「日付.txt」というファイルを特定のディレクトリに自動で作成
- その日初めて起動するときには1行目にその日の日付を書く
シェルスクリプトの作成にあたっては、
小さく作っていくことが大事です。では、やっていきましょう。まずは、今回作成するシェルスクリプトの基本部分である「日付.txt」というファイルをvimで作成し、編集できるようにしましょう。
日記作成(diary.sh)#!/bin/bash vim $(date '+%Y-%m-%d').txt上記のシェルスクリプトを実行すると、日付.txtというファイルを作成し、vimを起動してくれます。現状では、カレントディレクトリに.txtファイルを作成してしまうため、日記ファイルを特定のディレクトリに保存するように指定してあげましょう。また、ディレクトリがない場合にはディレクトリを作成します。
日記ファイルを特定のディレクトリに作成(diary.sh)#!/bin/bash #日記データを保存するディレクトリ directory="${HOME}/diary" #データ保存するディレクトリがない場合は作成 if [ ! -d "$directory" ]; then mkdir "$directory" fi vim "%{directory}/$(date '+%Y-%m-%d').txtこれで、ホームディレクトリの下のdiaryというディレクトリに日付.txtの日記ファイルを作成してくれるシェルスクリプトができました。あと1つ追加しなければならない機能がありましたね。その日初めて日記を書く時には日付を日記のトップに追加してくれる機能を追加していきましょう。
その日最初の日記ならば、先頭に日付を追加(diary.sh)#!/bin_bash #日記データを保存するディレクトリ directory="${HOME}/diary" #データ保存するディレクトリがない場合は作成 if [ ! -d "$directory" ]; then mkdir "$directory" fi #ファイルパスの組み立て diaryfile="${directory}/$(date '+%Y-%m-%d').txt" #日記ファイルがなければ(その日初めてなら)先頭に日付を追加 if [ ! -e "$directory" ]; then date '+%Y/%m/%d' > "$diaryfile" fi vim "$diaryfile"これで、用件を満たす日記作成のシェルスクリプトが作成できました。
はい、きちんとディレクトリを作成して、日付のファイルを作成して、先頭には日付を挿入してくれていますね。活用例2 -指定したパス配下のファイル一覧表示-
もう少し実用的な例をみていきましょう。次は、指定したディレクトリ以下に含まれる全てのファイルやディレクトリを一覧表示するシェルスクリプトを作成していきましょう。要求事項は以下の通りです。
- インデントを用いて、階層構造をツリー状に表現する
では今回も
小さく順番に作っていきましょう。今回の基本部分は、
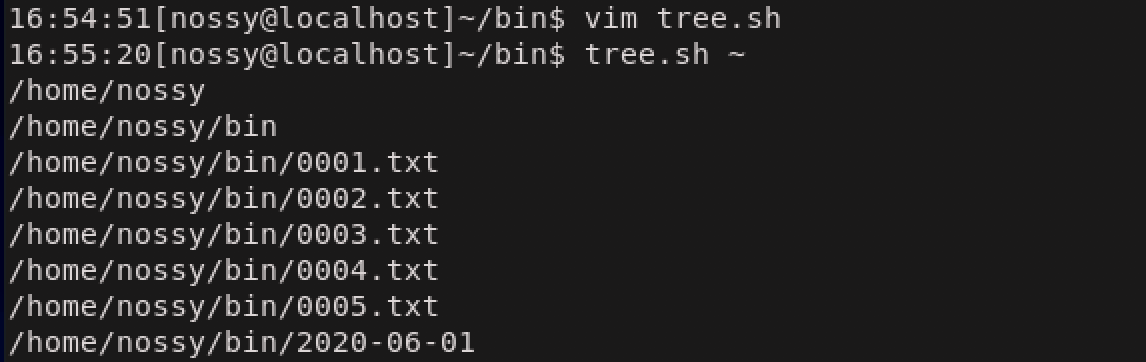
引数で受け取ったファイル名を出力するですね。ディレクトリの場合は?となると思いますので、その場合の処理をコメントアウトして書き込んでいきます。ファイル一覧表示のシェルスクリプト(tree.sh)#!/bin/bash list_recursive () #関数を作成 { local filepath=$1 #local変数を宣言 位置パラメータを用いて代入 echo "$filepath" #引数に渡されたファイル名を表示 if [ -d "$filepath" ]; then #引数がディレクトリの場合の処理 #ディレクトリである場合は、その中に含まれるファイルやディレクトリを表示する fi } list_recursive "$1"ひとまずこれで、コマンドライン引数に指定されたファイル名を出力することができます。
ファイル名の表示部分は何度も使うと予想されますので、シェル関数list_recursiveを使って処理させています。繰り返し使用する処理はシェル関数にまとめてしまうと便利です。しかし、最初から関数を定義して進めていくのは慣れが必要な部分もあると思いますので、シェルスクリプト作成中に繰り返しに気付いたら関数に落とし込むのもいいでしょう。
ここで初めて、local変数というワードが出てきましたので、次のステップに進む前に解説します。local変数
変数には
ローカル変数とグローバル変数とがあります。
変数名 内容 ローカル変数 シェル関数の中でのみ機能する変数 グローバル変数 シェルスクリプト全体で機能する変数 グローバル変数を用いて、いくつかの関数でたまたま同じ名前の変数を設定してしまった場合、1つの関数内の動作が、別の関数に予期せぬ影響を及ぼしてしまうことがよくあります(変数名nameなどを別関数で使用するなど)。このような動作を避けるために、
関数の中で使う関数は基本的にはローカル変数として宣言します。宣言方法は変数の前に
localをつけます。ローカル変数の宣言local <変数名>=〇〇再帰 -自分自身を呼び出す-
では、先ほどのファイル一覧を表示するシェルコマンドの作成に戻ります。現在の問題は引数がディレクトリであった場合の処理です。引数がディレクトリの際は、その下に含まれるファイルを一覧にして取得する必要があります。そのため、ここではlsコマンドの結果を利用します。for文の対象として、コマンド置換を利用して、lsコマンドの結果に対してループ処理でファイル一覧を出力します。
lsコマンドの結果を利用して、for文でループ処理をしてディレクトリを展開する(tree.sh)#!/bin/bash list_recursive () #関数を作成 { local filepath=$1 #local変数を宣言 位置パラメータを用いて代入 echo "$filepath" #引数に渡されたファイル名を表示 if [ -d "$filepath" ]; then #引数がディレクトリの場合の処理 local fname for fname in $(ls "$filepath") do echo "${filepath}/${fname}" #ディレクトリ内のファイルを表示 done fi } list_recursive "$1"引数がディレクトリの場合はlsコマンドで展開した結果を表示するように組み込みました。しかし、これでは完成していません。というのもディレクトリの中にディレクトリが格納されている可能性があるからです。したがって、上で追加したディレクトリの場合の処理を、ディレクトリがなくなるまで繰り返さなくてはなりません。このために、先ほどechoコマンドでファイル名を出力していた部分(#ディレクトリ内のファイルを表示の行)を再びシェル関数list_recursiveを呼び出す用に修正します。
再帰呼び出しを使った処理に変更(tree.sh)#!/bin/bash list_recursive () #関数を作成 { local filepath=$1 #local変数を宣言 位置パラメータを用いて代入 echo "$filepath" #引数に渡されたファイル名を表示 if [ -d "$filepath" ]; then #引数がディレクトリの場合の処理 local fname for fname in $(ls "$filepath") do list_recursive "${filepath}/${fname}" #ディレクトリならば再度list_recursiveを呼び出す done fi } list_recursive "$1"このように、シェル関数の中から自分自身を呼び出して、入れ子のように処理を行う方法を
再帰呼び出しといいます。多くのプログラミング言語で用いられている処理なので、慣れておくとお得です。この時点で、引数に起点を渡してやることで、その配下のファイル・ディレクトリを表示してくれるシェルスクリプトになりました。
## 絶対パス名からファイル名を取り出す
ファイルリストが絶対パス名で表示されてしまっていますので、このままツリー状の表示にすると少々見辛いですね。ここでは、パスの部分を削除して、ファイル名のみ表示することで対応してみましょう。正規表現を用いるなど、方法はいくつかありますが、ここでは
bashのパラメータ展開を利用しましょう。
bashのパラメータ展開 意味 ${変数名#パターン} 最短マッチで、パターンに前方一致した部分を取り除く ${変数名##パターン} 最長マッチで、パターンに前方一致した部分を取り除く ${変数名%パターン} 最短マッチで、パターンに後方一致した部分を取り除く &{変数名%%パターン} 最長マッチで、パターンに後方一致した部分を取り除く パラメータ展開対象文字列 => /home/nossy/diary/AAA.txt パターン => */ 最短マッチ => / マッチ => /home/ マッチ => /home/nossy/ 最長マッチ => /home/nossy/diary/したがって今回は、パターンを
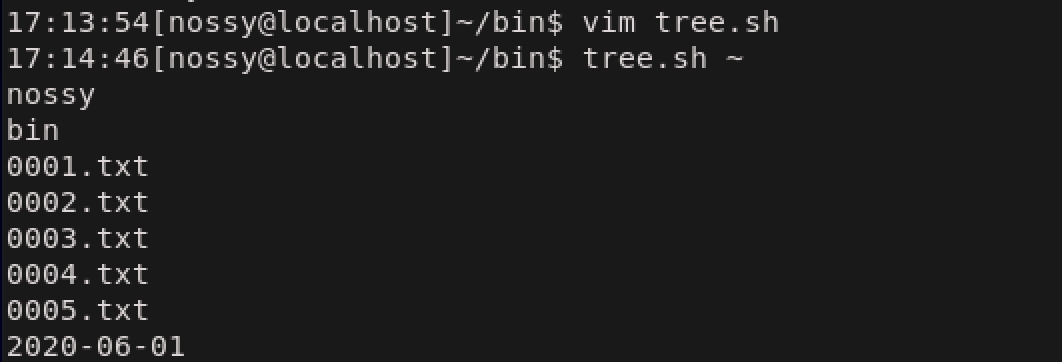
*/に指定して、最長マッチで、前方一致した部分を取り除けば、末端のファイル名のみを取得することができます。絶対パスから、ファイル名のみを取得する(tree.sh)#!/bin/bash list_recursive () #関数を作成 { local filepath=$1 #local変数を宣言 位置パラメータを用いて代入 echo "${filepath##*/}" #引数に渡されたファイル名を表示 if [ -d "$filepath" ]; then #引数がディレクトリの場合の処理 local fname for fname in $(ls "$filepath") do list_recursive "${filepath}/${fname}" #ディレクトリならば再度list_recursiveを呼び出す done fi } list_recursive "$1"
インデント
最後はこの一覧表示をtree状に整形して、要求事項を満たしていきましょう。ここでは、list_recursive関数への引数を追加して、第2引数でインデント用の空白文字列を指定するように変更していきます。
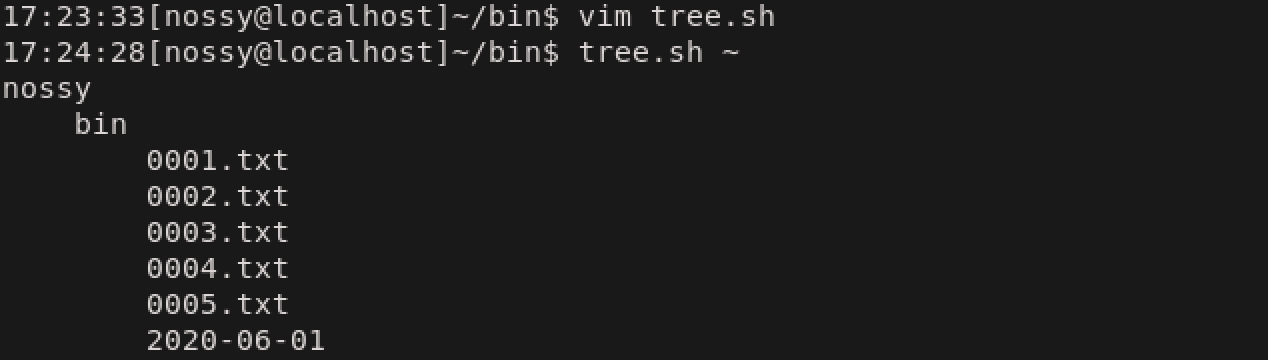
インデント付きで、一覧表示するように引数を追加(tree.sh)#!/bin/bash list_recursive () #関数を作成 { local filepath=$1 #local変数を宣言 位置パラメータを用いて代入 local indent=$2 #local変数を宣言 位置パラメータを用いて第2引数を代入 echo "${indent}${filepath##*/}" #インデント付きでファイル名を表示 if [ -d "$filepath" ]; then #引数がディレクトリの場合の処理 local fname for fname in $(ls "$filepath") do list_recursive "${filepath}/${fname}" " ${indent}" #第2引数にスペースを追加してシェル関数の呼び出し done fi } list_recursive "$1" "" #第2引数を追加
これで、要求事項は満たすことができました。しかし、このシェルスクリプトには大きな欠陥があります。次の節でみていきましょう。IFS -内部フィールド区切り文字-
実はこのtree.shはファイル名に
空白を含むファイルが存在すると表示がずれてしまうという欠陥があります。
例としてbinディレクトリの配下に、space space.txtというファイルを作成して実行してみます。
これはbashがスペースで単語を区切ることが原因です。bashにはIFS(Internal Field Separator); 内部区切り文字という環境変数があり、この変数にbashが区切りとして解釈する文字が格納されています。IFSのデフォルト値はスペース タブ 改行の3つです。これを避けるには、スペースで区切られないように、
一時的にIFSからスペースを抜くことが必要です。一時的というのは、IFSを変更した状態が引き継がれたままだと、それ以降のコマンドの動作に影響を与えてしまうためです。ここでは、IFSをバックアップしておき、一時的な使用が終わったら、バックアップを代入してデフォルトに戻すという処理を加えます。IFSの一時的な変更(tree.sh)#!/bin/bash list_recursive () #関数を作成 { _IFS=$IFS #元のIFSのバックアップ IFS=$' ' #IFSを改行のみに設定 local filepath=$1 #local変数を宣言 位置パラメータを用いて代入 local indent=$2 #local変数を宣言 位置パラメータを用いて第2引数を代入 echo "${indent}${filepath##*/}" #インデント付きでファイル名を表示 if [ -d "$filepath" ]; then #引数がディレクトリの場合の処理 local fname for fname in $(ls "$filepath") do list_recursive "${filepath}/${fname}" " ${indent}" #第2引数にスペースを追加してシェル関数の呼び出し done fi IFS=$_IFS #IFSを元に戻す } list_recursive "$1" "" #第2引数を追加なお、IFSの値は
文字コードを表示するodコマンドに文字の名前で出力させる-aオプションを用いて確認できます。IFSの確認$ echo -n "$IFS" | od -a => 0000000 sp ht nl #sp(スペース) ht(タブ) nl(改行) => 0000003なお、
lsコマンドは出力先がターミナルかどうかを自分で判断して、ファイルリストの出力形式を自動で切り替えてくれるコマンドなので、lsコマンドの結果をファイルへの出力リダイレクトしたり、コマンド置換によってlsコマンドを実行すると、自動的に-1オプションが指定されたときと同様に、1ファイル1行で表示します。なので、先ほどのtree.shの中で、for文の後ろのlsコマンドにわざわざ-1オプションをつけなくても良かったわけです。活用例3 -検索コマンド-
これが最後の活用例です。たくさんのファイルから文字列を検索するための検索コマンドを作りましょう。要求は以下の通りです。
- 検索パターン・始点ディレクトリ・対象ファイルを指定することで、始点ディレクトリに含まれるファイル全てに対して検索を行う
- 引数を指定せず実行した場合はヘルプを表示する。このとき終了ステータスは1。
- 存在しないディレクトリを指定した場合はエラーメッセージの表示。このとき終了ステータスは2。
早速やっていきましょう。
xargsコマンド -標準入力からコマンドラインを組み立てて実行する-
シェルスクリプトの作成の前に、準備として、
xargsについて理解しておきましょう。
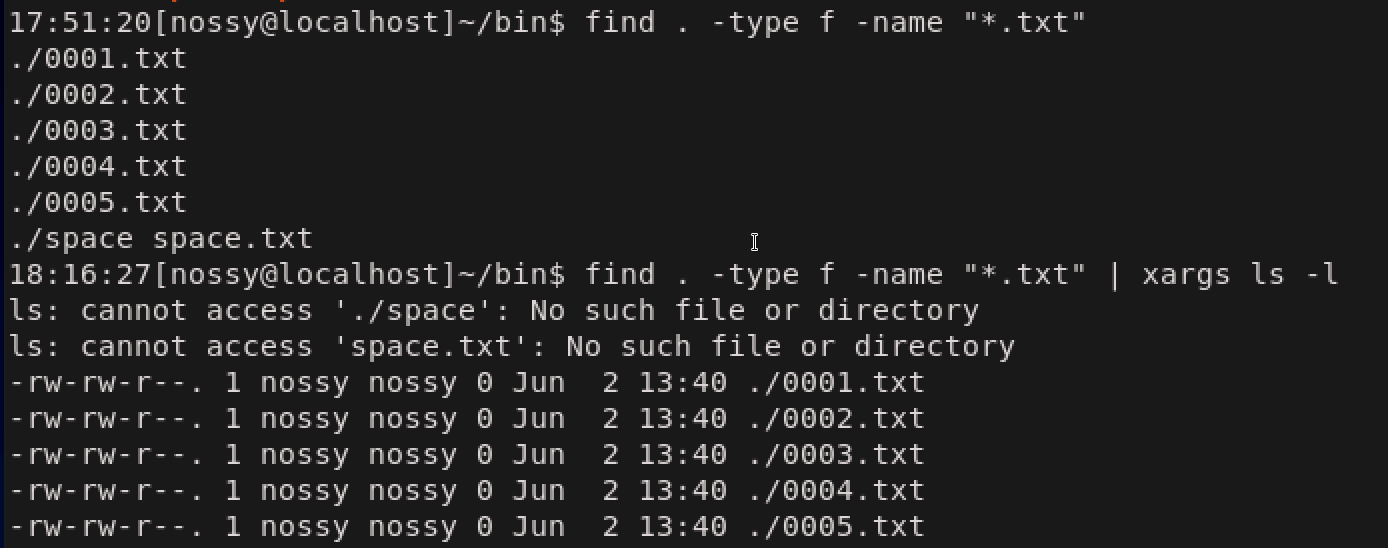
xargsはたくさんのファイルに対して一括処理をするためによく使われるコマンドです。多くの場合はfindとセットで用いられます。xargsコマンドxargs <実行したいコマンド> # ここで指定した<実行したいコマンド>が標準入力から受け取ったリストを引数として実行する実際に例をみながら動作をみていきましょう。まずfindコマンドで対象ファイルのリストを取得します。
findコマンドでのファイルの取得$ find . -type f -name "*.txt" # findコマンドによるtxtファイル一覧を取得これらのファイルに対して、lsコマンドで詳細を確認したい場合には次のように
xargsにls -lを指定します。xargsとfindコマンド$ find . -type f -name "*.txt" | xargs ls -l #findコマンドで取得したファイルのリストを引数としてそれぞれls-lに渡している
この例のように、findコマンドとセットでxargsコマンドを利用すれば、サブディレクトリ内のファイルまで含めて全てのファイルに対して任意のコマンドを実行することができます。xargsを利用してgrep
findとxargsにgrepを組み合わせることで、たくさんのファイルから文字列を検索することができます。今回のシェルスクリプトに導入できそうですね。早速みていきましょう。まずはgrepコマンドのおさらいです。
grepコマンド(対象ファイルが1つ)$ grep nossy list.txt =>003,nossy #引数が1つの場合は単純にマッチした行を表示grepコマンド(対象ファイルが複数)$ grep nossy list.txt sample.txt =>list.txt:003,nossy =>sample.txt:nossy is human. #引数が複数の場合はマッチした行の前にファイル名が表示されるgrepコマンドの動作が、引数の数で異なることを頭に入れておきましょう。
それではxargsとgrepを利用して、カレントディレクトリの下にあるファイルから文字列を検索してみましょう。
検索シェルスクリプト(findgrep.sh)#!/bin/bash pattern=$1 find . type f | xargs grep -n "${pattern}" #findでファイルを取得して、それらのファイルからgrepでマッチする文字列を検索する #grepコマンドに-nオプションをつけて、マッチした行番号を取得させている今の状態では、検索対象ファイルが1つしかない場合、先ほどのgrepのおさらいのように、ファイル名が表示されなくなってしまい、どのファイルで文字列にマッチしたのかがわからなくなってしまいます。そこでgrepに
-Hオプションをつけて、引数にファイルが1つしかない場合でもファイル名を表示するようにします。検索シェルスクリプト(findgrep.shO#!/bin/bash pattern=$1 find . -type f | xargs grep -nH "$pattern" #-Hをつけて引数にファイルが1つしかない場合でもファイル名を表示するようにした指定できる項目を増やして実用的に
ここまでで、検索パターンの指定はできるようになりました。残りの要求事項についても実装していきましょう。まずは第2引数で始点ディレクトリを指定できるようにします。
第2引数で始点ディレクトリの指定を可能に(findgerp.sh)#!/bin/bash pattern=$1 directory=$2 if [ -z "$directory" ]; then #第2引数が空の場合は'.'(カレントディレクトリ)を指定する directory='.' fi find "$directory" -type f | xargs grep -nH "$pattern" #'.'を$directoryに置き換えて、始点ディレクトリの指定が可能に次にfindで探す対象ファイルの指定ができるようにしていきましょう。
findで探す対象ファイルの指定に第3引数を用いる(findgrep.sh)#!/bin/bash pattern=$1 directory=$2 name=$3 if [ -z "$directory" ]; then #第2引数が空の場合は'.'(カレントディレクトリ)を指定する directory='.' fi if [ -z "$name" ]; then #第3引数が空の場合は'*'(全て)のファイルを対象にする name='*' fi find "$directory" -type f -name "$name" | xargs grep -nH "$pattern" #$nameで、対象ファイルの指定が可能にここまでで検索機能の実装は終わりました。
ヘルプの表示
ここからはヘルプメッセージの導入に入ります。引数が複数個必要など、使い方が煩雑になる時があります。また、誰かにシェルスクリプトを利用してもらう時のためにも、ヘルプメッセージ機能は出力できるようにしておきましょう。
本来であれば--helpオプションを指定したときにヘルプメッセージを表示するべきですが、少々難しいので、今回は単純に引数を1つもつけなかった場合に、ヘルプメッセージを表示するようにしましょう。
ヘルプメッセージの追加(findgrep.sh)#!/bin/bash usage () #シェル関数にヘルプメッセージを設定 { #シェルスクリプトのファイル名を取得 local script_name=$(basename "$0") #basenameコマンドはファイル名だけを取り出すコマンド(ここではfindgrep.shとなる) #ヒアドキュメントでヘルプを表示 複数のテキストをシェルスクリプトにそのまま記述したいときに使用(詳細は下記) cat << END Usage: $script_name PATTERN [PATH] [NAME_PATTERN] Find file in current directory recursively, and print lines which match PATTERN. PATH find file in PATH directory, instead of current directory NAME_PATTERN specify name pattern to find file Examples: $script_name return $sctipt_name return ~ '*.txt' END } if [ "$#" -eq 0 ]; then #コマンドライン引数($#:特殊パラメータ)が0のとき(引数に何も指定されないとき) usage #ヘルプメッセージの呼び出し exit1 #シェルスクリプトを終了ステータス1で終了、エラー判定 fi pattern=$1 directory=$2 name=$3 if [ -z "$directory" ]; then directory='.' fi if [ -z "$name" ]; then name='*' fi find "$directory" -type f -name "$name" | xargs grep -nH "$pattern"ここまでで、引数が指定されなかった場合にヘルプメッセージを表示することができました。
ヒアドキュメント
複数のテキストをシェルスクリプトにそのまま記述したいときに使用します。ヒアドキュメントの書き方コマンド << 終了文字列 ヒアドキュメントの内容 終了文字列 #ヒアドキュメント内でパラメータ展開などを抑止する場合 コマンド << '終了文字列' ヒアドキュメントの内容 終了文字列エラーメッセージの表示
最後の実装です。引数に存在しないディレクトリを指定された場合に、エラーメッセージを出力するようにしましょう。なお、このときの終了ステータスは
2を出力します。エラーごとに終了ステータスの値を変えておけば、値を確認するだけでエラーの原因がわかります。また、
標準出力にはこまんど本来の結果を表示し、標準エラー出力にはエラーメッセージを表示するという使い方をきちんと抑えておきましょう。これによって、標準出力をファイルへリダイレクトしている時も標準エラー出力が画面に表示されて、エラーに気づくことができます。エラーメッセージ機能の追加(findgrep.sh)#!/bin/bash usage () #シェル関数にヘルプメッセージを設定 { #シェルスクリプトのファイル名を取得 local script_name=$(basename "$0") #basenameコマンドはファイル名だけを取り出すコマンド(ここではfindgrep.shとなる) #ヒアドキュメントでヘルプを表示 複数のテキストをシェルスクリプトにそのまま記述したいときに使用(詳細は下記) cat << END Usage: $script_name PATTERN [PATH] [NAME_PATTERN] Find file in current directory recursively, and print lines which match PATTERN. PATH find file in PATH directory, instead of current directory NAME_PATTERN specify name pattern to find file Examples: $script_name return $sctipt_name return ~ '*.txt' END } if [ "$#" -eq 0 ]; then #コマンドライン引数($#:特殊パラメータ)が0のとき(引数に何も指定されないとき) usage #ヘルプメッセージの呼び出し exit1 #シェルスクリプトを終了ステータス1で終了、エラー判定 fi pattern=$1 directory=$2 name=$3 if [ -z "$directory" ]; then directory='.' fi if [ -z "$name" ]; then name='*' fi if [ ! -d "$directory" ]; then echo "$0: ${directory}: No such directory" 1>&2 #出力リダイレクトの記法 標準出力(1番)の出力先をエラー出力(2番)と同じにしている->echoコマンドの出力先が標準出力から標準エラー出力になる exit 2 fi find "$directory" -type f -name "$name" | xargs grep -nH "$pattern"これで要求事項を全て満たした検索コマンドの完成です。実際に動作させてみましょう。
空白を含む文字列のファイルを対象にする場合
スペースを含むファイルをfind|xragsで使う方法を参考にしてみてください。
注意点
指定したディレクトリの中にファイルが1つもない場合は、ファイルがありませんとエラーを出したくなる気持ちはありますが、これはやってはいけません。というのもLinuxコマンドは基本的に「余計なメッセージは表示しない」という設計思想に基づいているためです。
何にもマッチしない場合は、何も出力しないのが、正しい動作なのです。参考資料



- 投稿日:2020-06-03T18:21:01+09:00
Raspberry PI シリーズで分散環境構築(その2: PiServer の解析と代替システムの設計まで)
序
本稿は 前回からの続きです。
Raspberry PI 多数持ちの人がディスクレスクライアント化に向けて試行錯誤する中、必ずぶち当たる存在であるソフトウェア、PiServer と代替システム構築に関する内容となります。手持ちのラズパイが PiServer から認識されない、という問題に直面している方は、その1をご覧ください。PiServer の紹介
公式アナウンスはこちら(英語)。
Raspberry PI DesktopをインストールしたPCを使えば、3B以降のラズパイをディスクレス化できるよ、という謳い文句。ラズパイはもともと教育用途に作られたものですから、教室で生徒が多数のディスクレスラズパイを使い、
先生は PCで同じ画面を見る、という環境を想定して作られたものっぽいですね。というわけで Raspberry PI Desktop を触ってみる
- カーネルは x86_64 の Debian ね。
- glibc が i386 (なぜ???)
- ラズパイと全く同じデスクトップ環境ですな
- 「設定」メニューに "PiServerの設定" なる項目が。これが PiServer ということなんでしょうね。
PiServer の機能と実現方式を確認
- 1. ラズパイクライアントの発見
- ラズパイから発せられる DHCP ブロードキャストを受け取って、MACアドレスを管理対象として登録。 dnsmasq の DHCP 機能が受け取った要求をフックしている。登録した MAC アドレス専用の tftp ルートを準備(管理しているOSの boot ディレクトリへのシンボリックを張っている)
- 2. クライアント用OSイメージのインポート
- bash スクリプトで実現。イメージファイルの内容をローカルディスクにコピーして、/etc/exports にエントリを追加している。ついでに、ディスクレスクライアントには不要なファイルを削除、ロケール関係をRaspberry PI Desktopを実行しているマシンの値と同じものに書き換えている。また、ローカルディスクをマウントすることになっている /etc/fstab をごっそり書き換えている
- 3. tftp サーバ機能
- dnsmaq で実現している。GUI から dnsmasq の設定ファイルをいじっている
- 4. DNSキャッシュサーバ/ddns機能
- dnsmasq で実現している。既に別のDNSサーバがある場合や、/etc/hosts で管理できればいい、といった理由でこの機能が不要な場合は /etc/dnsmasq.conf ファイルでポート番号を0に指定する必要がある
- 5. DHCPサーバ機能
- dnsmasq で実現。既に別の DHCP サーバが存在する場合は、ブート時に必要となるファイルをダウンロードするための tftp サーバのアドレスのみをクライアントに返す、Proxy DHCPとしても機能
- 6. NFSサーバ機能
- カーネルに最初から組み込まれているNFSサーバ(ver3)を利用。
クライアント向けにルートファイルシステムを提供。
ディスクレスクライアントと言えども、データを保存したい場合もあるので、ルートファイルシステムのマウントが完了して、ブート処理の最中にマウントするための書き込み可能な共有フォルダも提供している。
- 7. クライアントのOS変更
- 登録済みのラズパイに、どの OS イメージを与えるか管理。 各 MAC アドレス向けの tftp ルートをシンボリックリンクで書き換えているだけ
- 8. ラズパイ上のユーザーアカウント管理
- 利用するメリットがないので詳しく確認していないが、どうやら OpeLDAP で実現している模様
- 9. 管理しているクライアント用OSイメージの変更
- qemu-arm-static コマンドを利用して、chroot を実行しているだけ。glibc が i386 版であるためか、qemu-aarch64-static コマンドはインストールされていないので、64bit版ディストリビューションの管理はできない。
本当に Raspberry PI Desktop 環境が必要なのか?
GitHub の piserver リポジトリ に公開されているソースを確認してみると、管理用 GUI の C++ ソースと各種 bash スクリプトがあった。GUI 部分は x86_64 版 ArchLinux でもコンパイル+実行できたので、Raspberry PI Desktop を使う必要はないことが判明。
しかし、PiServer リポジトリに公開されている bash スクリプトさえ移植してしまえば、残り全ての機能は dnsmasq + OpenLDAP + qemu-user-static だけでも実現できるわけで、結論。
- dnsmasq の設定ファイルを書き換えるだけの GUI なんていらんわ
- PiServer はやっぱりクソ(最終判断)。
PiServer 代替システムの構築方法
つい先日 Raspberry 公式から Raspberry PI OS を 64bit 化するよというアナウンスが出た中、64bit ディストリビューションを管理できない PiServer は見切りをつける必要があります。ということで代替システムを構築する手法を考えてみます。
前提事項: 一般的なディスクレスクライアントの挙動(IPv4 の PXEブート)
PXE ブートでクライアント+サーバがやっていること(シーケンス)
(参考: https://japan.zdnet.com/article/20089685/ )
- ディスクもIPを持たないクライアントはブロードキャストを投げて DHCPサーバから IP を取得しようとする
- DHCP サーバは、クライアントのMAC アドレス等を元に、要求元が登録済みのディスクレスクライアントか否かを判定
- ディスクレスクライアントではないと判定された場合は、IP等を与えて終了、登録済みのディスクレスクライアントであると判定すると、DHCPサーバは要求元のクライアントにIPを与えた後、次に訪れるべき tftp サーバの IP を教えて DHCP サーバの役目は終了。
- 自分用の IP を与えられたクライアントは、教えられた tftp サーバにアクセスしてブートに必要なカーネル、関連ファイル群をダウンロードする。起動に必要なファイルを全てダウンロード完了したら、tftp サーバの役目は終了。
- tftp からダウンロードしたファイルの中には、必ずルートファイルシステムを提供する NFS サーバの場所と共有ディレクトリ名が入っているはずなので、クライアントは指定された共有ディレクトリをルートファイルシステムとして読み取り専用でマウントを試みる。
- ルートファイルシステムのマウントが完了して、実際の OS 起動がスタートする
PXEブートを実現するために必要なインフラサーバ群
従って、上記の手順を実現させるためには、最低でも以下の環境を整備する必要があり、これら3つの機能を持つサーバのことを "PXEサーバ" と呼ぶことがあります。
- DHCP サーバ
- tftp サーバ
- NFS等のファイルサーバ
本来、ディスクレスクライアントは、教育現場の生徒用端末や、データ入力業務用端末といった多数のユーザーが同一環境を利用する用途で用いられるので、通常
- DNS サーバ(クライアントホスト名の自動登録)
- LDAP/NIS 等組織内認証サーバ
- ゲートウェイ/ファイアウォール
等を同時に整備する必要があるのですが、本稿は個人用分散処理環境を構築するのが最終目的ですから、下3つのサーバに関する内容は記載しません。
ちなみに、DNS は 100台を超えるようなクライアント数であれば必要でしょうけれども、10に満たないクライアント数では /etc/hosts ファイルによる名前解決で十分で、しかもこのファイルは NFS サーバ上で共有できるので不要ですよね。
ついでに、自分しか使わない分散環境では認証サーバなんかいりませんし、 /etc/passwd ファイルも共通化できるので不要ですよね。実現手段1: PXE サーバ構築に特化したソフト、 dnsmasq で tftp/DHCP/DNS を一括構築
DHCP,tftp,DNSサーバを dhcpd や atftpd, bind といった個別ソフトで構築するのは面倒ですし、時間もかかります。
そこで、PiServer でも利用している dnsmasq というソフトの登場となります。
本来このソフトは DNS キャッシュサーバとして開発がスタートしたソフトなのですが、いつの間にか tftp サーバ,DHCPサーバの機能も取り込んでしまったので、PXEサーバ構築に特化したソフト、と言っても過言ではないでしょう。当然、このソフトを利用することにします。ただし、本来の用途である DNS は使用しない方向で。以後、dnsmasq が稼動している x86_64 マシンのことを 「PXEサーバ」と呼びます。
実現手段2: NFSサーバ機能は PXEサーバから切り離したほうが良い。
PiServer では「PC 1台で完結」を売りにするために、全機能を詰め込んでいましたが、安全性を考えると、NFS サーバ機能は別マシンに切り分けておいたほうがいいです。なぜなら、PXEサーバが NFSサーバも兼ねていると、次のような事態が発生し得るからです。
- PXEサーバを再起動/シャットダウンすると、稼働中のラズパイのルートファイルシステムがごっそりなくなってしまう。この事態を避けるためには、PXEサーバを再起動する前に全てのラズパイをシャットダウンしておく必要が。
- PXEサーバにディスク障害が発生したときはもっと悲惨な事態に。
もし既にNFS 対応可能なファイルサーバをお持ちであるならば、 RAID や GlusterFS 等で冗長性が取られているでしょうから、より堅牢なシステムとなります。tftp で配布するブート関連ファイルも PXEサーバから NFS マウントかければ問題ありません。ただ、ディスクアクセスの速いマシンを利用したほうがいいと思います。
以後、NFS機能を持つマシンを 「NFSサーバ」と呼びます。
実現手段3: OS インストール用イメージファイルから NFSサーバへのインポート
これは手動でやっても問題ないでしょう。
ただ、PiServer の GitHub で公開されている OS インポート用 bash スクリプトを改造すれば、自動化が可能かも。実現手段4: クライアント用OSをアップデートするために必要な armhf/aarch64 エミュレータ
ディスクレスクライアントは、ルートファイルシステムを読み取り専用でマウントしますから、クライアント側から OS のアップデートを行うことができません。PXEまたはNFSサーバ側で OS をアップデートする必要が生じます。
しかしながら、今回構築しようとしている環境はクライアント側がARM,サーバ側は x86_64 マシンとなるはずです。ここで、エミュレータが必要となってくるわけですね。PiServer でも実装している方法ですが、エミュレータ qemu(ユーザーモードスタティック) と binfmt サポート, chroot を使うと、クライアントに配布する OS を簡単に制御可能となります。ここに詳しく載っています。
Debian 系では qemu-user-static パッケージをインストールするだけ, ArchLinux では AUR で自力でコンパイルする必要があります。
実現手段5: クライアントの MAC アドレス管理
ラズパイが10枚以下であれば、私の以前の記事で記載した方法で個別に確認していっても大したことありません。
実現手段6: DNS/ユーザー管理機能
自分しか使わないクライアント群ですから、管理する必要がないので割愛。
- /etc/passwd + /etc/shadow をNFS共有でユーザー管理
- dnqmasq の DHCP 機能で、各ラズパイに固定 IP を割り振る+/etc/hosts をNFS共有で名前解決
することで全て解決します。というわけで、今回はここまで。次回は、実際に x86_64 Linux マシンに dnsmasq のインストール、設定を行いたいと思います。
- 投稿日:2020-06-03T14:28:00+09:00
Raspberry PI シリーズで分散環境構築(その1:モデル別、ディスクレスクライアント化の可否まとめ)
注意点
本稿は以下の条件を満たすラズパイを対象としたものです。
- ストレージにmicroSD を採用し
- 有線LANの口を持つ
従って
- 初代は関係ない
- Zero系、Compute Module も関係ない
ことになります。
保有する Raspberry PI シリーズの枚数が多くなると出てくる問題と解決方針
新しいラズパイが登場すると、安価故につい買ってしまうものですよね? 更に私の悪い癖なんですが、冗長性を考えて、2枚同時に買うのが常なのです。そんなこんなで、2B以降3B,3B+,4B,がそれぞれ2枚ずつ、手持ちのラズパイが計8枚にもなってしまった私が直面した問題がこちら。
問題その0: 物理的問題(解決済み)
- 置き場所
- 全部にケース+ファンだとかさばって仕方がない → スタック化
- LAN/電源用USBケーブルの配線
- スパゲティは流石にまずい → スタック化で端子の向きが同一になり、まとめやすくなったので結束バンドで。
- HDMIケーブル/キーボード・マウス用USBケーブルの配線
- SSH アクセスが前提なので不要。挙動がおかしい奴を再起動する時だけ挿せば良い
- 消費電力/発熱
- 目をつぶるしかない
- 電源関連
- 1枚のラズパイに1個のUSB-AC アダプタなんてどう考えても無理。→いいのがあった

ここまではオマケでして、本題はここから。
問題その1: microSD メディア/OS管理の問題
- ダメになった microSD (死骸)の枚数も多くなる。完全に消耗品。
- 空き容量とか OS のバージョンとか個別に microSD を管理することは超面倒
- (ふと我に返る)1枚1枚 OSアップデートするのは馬鹿じゃね?
問題?その2: 複数枚持っている人間ならではの好奇心
うっかり、以下のどれかを作ってみたくなりますよね・・・
- HPC(MPI)のクラスタを組んでプライベート貧弱スパコン
- kubernetes 等でPaaS/SaaS向けプライベート貧弱クラウド
- 分散コンパイル環境
でも、同一内容で多数の microSD をコピーしまくるのは時間の無駄では?
上記の問題1,2を一発で解決する方法は・・・
ラズパイをディスクレスクライアント化/ネットワークブート化する以外無い訳でして・・・
ディスクレスクライアント/ネットワークブートに関してまとめてみたのが本稿ということになります。歴代ラズパイのディスクレス化への長い道のり
Step1:「PiServer」の存在を知る
まず最初に、日経のこの記事 を見つけたわけですよ。
「余剰 PC なり VMWare 仮想ホストにこいつをインストールすれば一発じゃね? 楽勝」って思いますよね。普通。Step2: PiServer を試す
- 1. インストール中
- あー、カーネルは x86_64 なのに glibc が 32bit i386 の Debian なのね・・・
- 2. クライアントに配布するOSの管理画面
- Raspbian 以外のディストリビューションの登録は超面倒くさいぞ。どうやら自分で boot.tar.xz と root.tar.xz を作る必要がある感じだな。
- 3. クライアントに配布するOSの設定・更新
- クライアント向けOSのアップデートは PiServer 上の qemu-arm-static で行うのね。 あ、そういえば 32bit版 glibc だから aarch64 版ディストリビューションはアップデートできねーじゃねーか。
- 4. 実際に microSD を抜いた状態で各機に電源投入
- あれ? 3B+ 以外のクライアントを全く発見できないぞ? DHCP のブロードキャストを投げてないの? (この現象の理由は後に述べる)
この段階で、PiServer は全体としてクソ。という暫定的な判断を下し、
あとで PiServer の機能を解析して、他の実現方法がないか考えてみよう、とメモ。Step3: 一瞬だけ U-boot でどうにかならないか考える
「U-boot を tftp サーバに置いてNFSマウント」という記事も結構出て来たので一瞬だけ考えて試してみたものの、
モデルによって SoC が違うから U-boot をコンパイル+イメージ生成する回数が増えて面倒すぎる・・・
と気づいて最終的に却下。Step4: モデルによってPXEブート実現可能化への方法が異なることを知る
Google で「Raspberry PI ネットワークブート」 で検索してみるといろいろな方法が出てきますけれど・・・
電源投入直後のブートシーケンス内で、microSD が挿入されていない際、PXE ブートに挑戦するかしないか、というの最終判断結果はモデル(発売時期)によって全く異なるということ、しかも PXE ブートに挑戦するように挙動を変更するための準備方法もモデルによって全く違う、ということにやっと気づいたわけですよ。
Step5: 各モデルのサマリとそれぞれ準備(2020/06/02時点での方法)
Raspberry PI 2 Model B (V1.1,V1.2)
- 発売時期
- 2015/02 発売の無印(V1.1)は 32bit armv7。
- 2016/07 マイナーチェンジ(V1.2)後は 64bit armv8
- 完全ディスクレスは不可能
- ネットワークブートなんて一切考えていなかった時期に発表されたモデルなので、完全なディスクレスクライアント化には対応していない。
- ネットブート化への方法
- 元来対応していないモデルだったものの、現在は中の人たちが頑張って、Raspberry PI OS(旧名 Raspbian) のブートパーテーションに含まれる bootcode.bin ファイルが microSD の第1パーテーションに存在すればネットワークブートが可能、という状況にまで改善されている。 よって、Raspbian のイメージから bootcode.bin をコピーした microSD を挿して起動する必要がある。
Raspberry PI 3 Model B(無印)
- 発売時期
- 2016/03
- 購入後、1度だけ実行しなければならないコマンドがある。
- デフォルト状態のままではネットワーク/USBブートに対応していないが、1回だけ Raspbian のブートパーテーションにある cmdline.txt ファイルを変更して再起動するとファームウェアのフラグが変更されて、ディスクレスブートが対応可能となる。
- 実際に行う作業
- 本家チュートリアルを参考にしてください。
Raspberry PI 3 Model B+
- 発売時期
- 2018/03
- 何もしないでもディスクレス化可能
- 2020/06/01 現在、最もディスクレスクライアント化が簡単なモデル。それで PiServer はこいつを見つけたわけだ
Raspberry PI 4
- 発売時期
- 2019/06
- 購入後、やはり1度だけ実行しなければならないコマンドが(後戻りかよ)
- 3B系までの起動シーケンスとは設計が全く異なるものになり、 3B系までの起動時に必要だった bootcode.bin に相当するプログラムがオンボードのEEPROMに格納されるようになったモデル。 本来なら何もしなくてもディスクレス化が実現可能なはずなのに、初期状態では microSD での起動に失敗したら 全てを諦めてしまう状態で出荷されている不親切なモデル。
- 実際にやるべきこと
- 下記リンクがうまくまとめられていますので参考にしてください。
Step6 改めて PiServer で Raspbian (32bit) の PXE ブートを確認
やっと手持ちの全モデルで PXE ブートが実行できた。
そしてクソ(仮の判断)な PiServer をどうやってリプレースするか、という次の段階へというわけで、今回はここまで。その2 へと続きます。

- 投稿日:2020-06-03T11:42:52+09:00
Linux環境でファイルから特定文言を抽出していきたい時
Linux環境でファイルから特定文言を抽出していくコマンドサンプル(巨大ファイルゆえエディタから開けないときとか) sed -n 1,1000000p /usr/log/bigLog.log | grep TARGETSTR >> /home/test1.txt sed -n 1000001,2000000p /usr/log/bigLog.log | grep TARGETSTR >> /home/test1.txt sed -n 2000001,3000000p /usr/log/bigLog.log | grep TARGETSTR >> /home/test1.txt
- 投稿日:2020-06-03T06:52:28+09:00
Remote Processor Framework (3/3)
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/Documentation/remoteproc.txt
Remote Processor Framework
Binary Firmware Structure
At this point remoteproc supports ELF32 and ELF64 firmware binaries. However, it is quite expected that other platforms/devices which we'd want to support with this framework will be based on different binary formats.
この時点で、remoteprocはELF32とELF64 fitmware binaryをサポートしています。しかし、このフレームワークでサポートしたい他のプラットフォームやデバイスでは、異なるbinary formatに基づいていることが予想されます。
When those use cases show up, we will have to decouple the binary format from the framework core, so we can support several binary formats without duplicating common code.
これらのユースケースに対しては、framework coreからbinary formatを切り離す必要があるため、共通コードを複製することなくいくつかのbinary format をサポートできます。
When the firmware is parsed, its various segments are loaded to memory according to the specified device address (might be a physical address if the remote processor is accessing memory directly).
firmwareをparseしたとき、特有のデバイスのアドレスに従って、様々なsegmentがloadされます(remote processorがmemoryに直接メモリアクセスしている場合には、物理アドレスである可能性もあります)。
In addition to the standard ELF segments, most remote processors would also include a special section which we call "the resource table".
標準的なELF segmentに加えて、多くのremote processorは"the resource table"と呼び特別なセクションも含んでいます。
The resource table contains system resources that the remote processor requires before it should be powered on, such as allocation of physically contiguous memory, or iommu mapping of certain on-chip peripherals. Remotecore will only power up the device after all the resource table's requirement are met.
resource tableには、remote processorが電源投入する前に要求するシステムリソースが含まれています。例えば、物理的な連続するメモリ領域の確保や、チップ上のペリフェラルに向けたiommu mapping等。Remotecoreは、resource tableの要求がすべて解決した後にだけ、デバイスの電源を投入します。
In addition to system resources, the resource table may also contain resource entries that publish the existence of supported features or configurations by the remote processor, such as trace buffers and supported virtio devices (and their configurations).
システムリソースに加えて、resource tableには、remote processorによってサポートされている機能や構成の存在を公開する、resource entryも含まれています。例えば、trace bufferやサポートされているvirtio device(さらにその構成)。
The resource table begins with this header::
resource tableは、このヘッダから開始されます。
/** * struct resource_table - firmware resource table header * @ver: version number * @num: number of resource entries * @reserved: reserved (must be zero) * @offset: array of offsets pointing at the various resource entries * * @ver: バージョンナンバー * @num: resource entriesの個数 * @reserved: 予約 (0 にしてください ) * @offset: 各resource entriesを示すoffsetの配列 * * The header of the resource table, as expressed by this structure, * contains a version number (should we need to change this format in the * future), the number of available resource entries, and their offsets * in the table. * * この構造体が表現する、resoruce tableのヘッダーには、バージョン情報 * (将来的にこのフォーマットが変更した場合に必要となる)、有効なresource * entriesの個数、そしてtable内でのそれらのoffsetが含まれます。 * */ struct resource_table { u32 ver; u32 num; u32 reserved[2]; u32 offset[0]; } __packed;Immediately following this header are the resource entries themselves, each of which begins with the following resource entry header::
このヘッダーの直後にはリソースエントリー自体が次ぐ来ます、それぞれが次のresource entry headerから開始します。
/** * struct fw_rsc_hdr - firmware resource entry header * @type: resource type * @data: resource data * * Every resource entry begins with a 'struct fw_rsc_hdr' header providing * its @type. The content of the entry itself will immediately follow * this header, and it should be parsed according to the resource type. * * それぞれのresource entryは、typeが提供する struct fw_rsc_hdr headerから開始します。 * entry 自身のcontentsは、このヘッダ―のすぐあとにあります。 * それは、resource typeに基づいて解釈されます。 */ struct fw_rsc_hdr { u32 type; u8 data[0]; } __packed;Some resources entries are mere announcements, where the host is informed of specific remoteproc configuration. Other entries require the host to do something (e.g. allocate a system resource). Sometimes a negotiation is expected, where the firmware requests a resource, and once allocated, the host should provide back its details (e.g. address of an allocated memory region).
resource entryは単なるアナウンスのものもあり、hostには特有のremoteproc設定が通知されます。他のエントリーでは、ホストが何かしらをする必要があります(例えば、system resourceの確保)。時として、ネゴシエーションによって、ファームウェアが要求するリソースが予想されます。割り当てられたら、hostはその詳細を返す必要があります(例えば、確保したmemory regionのアドレス等)。
Here are the various resource types that are currently supported::
現時点でサポートしているresource typesの種別は以下です。
/** * enum fw_resource_type - types of resource entries * * @RSC_CARVEOUT: request for allocation of a physically contiguous * memory region. * @RSC_DEVMEM: request to iommu_map a memory-based peripheral. * @RSC_TRACE: announces the availability of a trace buffer into which * the remote processor will be writing logs. * @RSC_VDEV: declare support for a virtio device, and serve as its * virtio header. * @RSC_LAST: just keep this one at the end * @RSC_VENDOR_START: start of the vendor specific resource types range * @RSC_VENDOR_END: end of the vendor specific resource types range * * @RSC_CARVEOUT: 連続した物理メモリリージョンの獲得の要求 * @RSC_DEVMEM: memory-basedペリフェラルのiommu_mapの要求 * @RSC_TRACE: remote processorがログを書き込めるtrace bufferが有効である通知 * @RSC_VDEV: virtio device有効を宣言し、virtio headerとして提供 * @RSC_LAST: 最後の位置に配置してください * @RSC_VENDOR_START: ベンダー特有のresource type範囲の開始位置 * @RSC_VENDOR_END: ベンダー特有のresource type範囲の終了位置 * * Please note that these values are used as indices to the rproc_handle_rsc * lookup table, so please keep them sane. Moreover, @RSC_LAST is used to * check the validity of an index before the lookup table is accessed, so * please update it as needed. * * これらの値が、rproc_handle_rsc loopup tableへのindexとして利用される * ことに注意してください。そして、それが正しくあるようにしてください。 * また、RSC_LASTは、lookup tableへアクセスする前にindexの有効性を確認 * するために利用されます、必要に応じて更新してください。 * */ enum fw_resource_type { RSC_CARVEOUT = 0, RSC_DEVMEM = 1, RSC_TRACE = 2, RSC_VDEV = 3, RSC_LAST = 4, RSC_VENDOR_START = 128, RSC_VENDOR_END = 512, };For more details regarding a specific resource type, please see its dedicated structure in include/linux/remoteproc.h.
特有のresource typeに関する詳細については、 include/remoteproc.h内の構造体を参照してください。
We also expect that platform-specific resource entries will show up at some point. When that happens, we could easily add a new RSC_PLATFORM type, and hand those resources to the platform-specific rproc driver to handle.
また、platform固有のresource entriesがいつか表示されることも期待しています。 その場合、簡単に新しいRSC_PLATFORMタイプを追加し、それらのリソースをplatform固有固有のrprocドライバに渡して処理することができます。
Virtio and remoteproc
The firmware should provide remoteproc information about virtio devices that it supports, and their configurations: a RSC_VDEV resource entry should specify the virtio device id (as in virtio_ids.h), virtio features, virtio config space, vrings information, etc.
firmwareは、remoteprocに、サポートしているvirtio deviceに関する情報と、それらの設定について提供をします。RSC_VDEV resource entryは、virtio device id(virtio_ids.h)、virtio features, virtio config space, vrings informationなどを指定する必要があります。
When a new remote processor is registered, the remoteproc framework will look for its resource table and will register the virtio devices it supports.
新しいremote processorが登録されたら、remoteproc frameworkはそのresource tableを検索し、サポートしているvirtio deviceを登録します。
A firmware may support any number of virtio devices, and of any type (a single remote processor can also easily support several rpmsg virtio devices this way, if desired).
firmwareは、いくつかのvirtio deviceと任意のタイプをサポートします。(単一のremote processorが、必要に応じて、この方法で複数のrpmsg virtio deviceを容易にサポートすることもできます)。
Of course, RSC_VDEV resource entries are only good enough for static allocation of virtio devices. Dynamic allocations will also be made possible using the rpmsg bus (similar to how we already do dynamic allocations of rpmsg channels; read more about it in rpmsg.txt).
もちろん、RSC_VDEV resource entryは、ただvirtio deviceの静的な割り当てのみでも十分です。動的な割り当てによって、rpmsg busを用いることもできます。(rpmsg channelの動的割り当てをすでに行っているのと同じです。rpmsg.txtを確認してください)。
もともと、Linux Kernelのソースコードの一部なので、GPLv2扱いになる(はずの認識)。
https://www.kernel.org/doc/html/latest/index.html
Licensing documentation
The following describes the license of the Linux kernel source code (GPLv2), how to properly mark the license of individual files in the source tree, as well as links to the full license text.
https://www.kernel.org/doc/html/latest/process/license-rules.html#kernel-licensing
- 投稿日:2020-06-03T00:09:29+09:00
historyコマンドに日時を付与し、全ユーザのhistoryファイルをスクリプトで収集する
概要
linuxで手取り早く操作ログを取得する方法として、ユーザの
~/.bash_historyに日時を付与することで対応しました。設定
historyコマンドを実行すると過去に実行したコマンドの履歴を見ることが出来ますが、日時がないのでいつ実行されたのか分かりません。
そこで、~/.profileに以下の一文を追記します。HISTTIMEFORMAT='%y/%m/%d %H:%M:%S ';
/etc/profile.d/history.shに記述すると個別アカウントごとに設定出来ますが、今回は全体に適用させたいので~/.profileに記述します。
設定ファイル 利用法 例 ~/.profile ・ログイン時にそのセッション全体に適用するものを記述する シェルの種類に依存しないものを記述する ~/.bashrc bashでしか使わないものを記述する エイリアス シェルオプション プロンプト設定 ~/.bash_profile こちらの記事を参考にしました。
Linux: .bashrcと.bash_profileの違いを今度こそ理解する取得スクリプト
ユーザごとのファイル名が
~/.bash_historyで同じなので、ユーザごとのフォルダを用意した上で以下のようなスクリプトでコピーしてきます。#!/bin/sh #user1を作業ユーザとし、コピー前に作業フォルダの前回ファイルを削除する sudo find /home/user1/log/ -name ".bash_history" -type f -print | xargs rm -f #user1,user2,user3のファイルをuser1のlogフォルダにコピーする for a in "user1" "usesr2" "user3" ; do sudo cp -f /home/$a/.bash_history /home/user1/log/$a/; done結果
このような形のファイルが取得出来ます。
