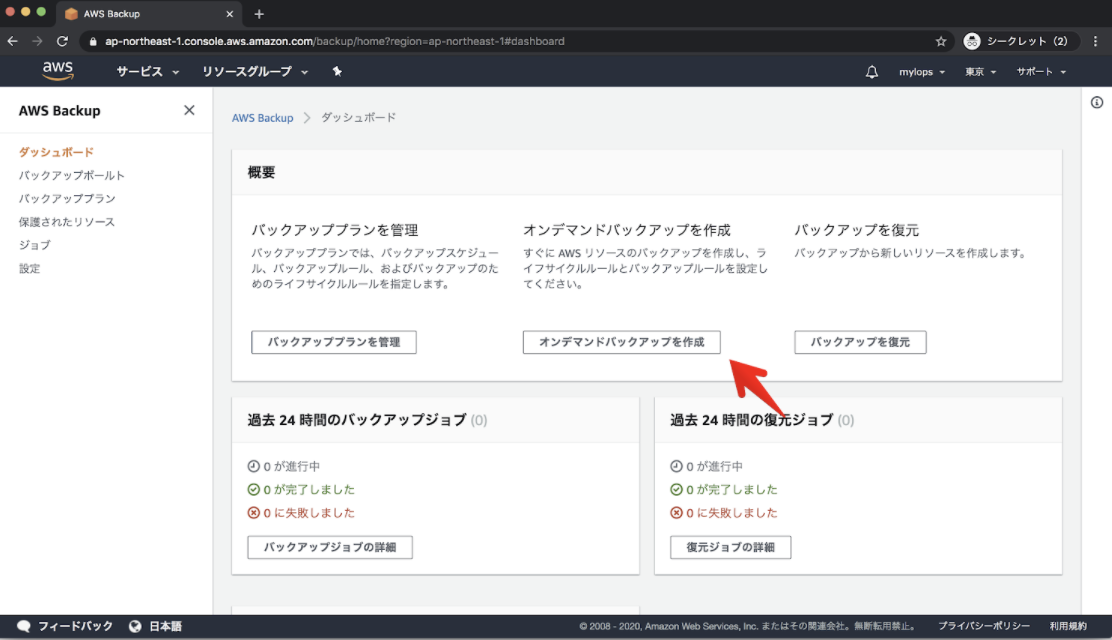
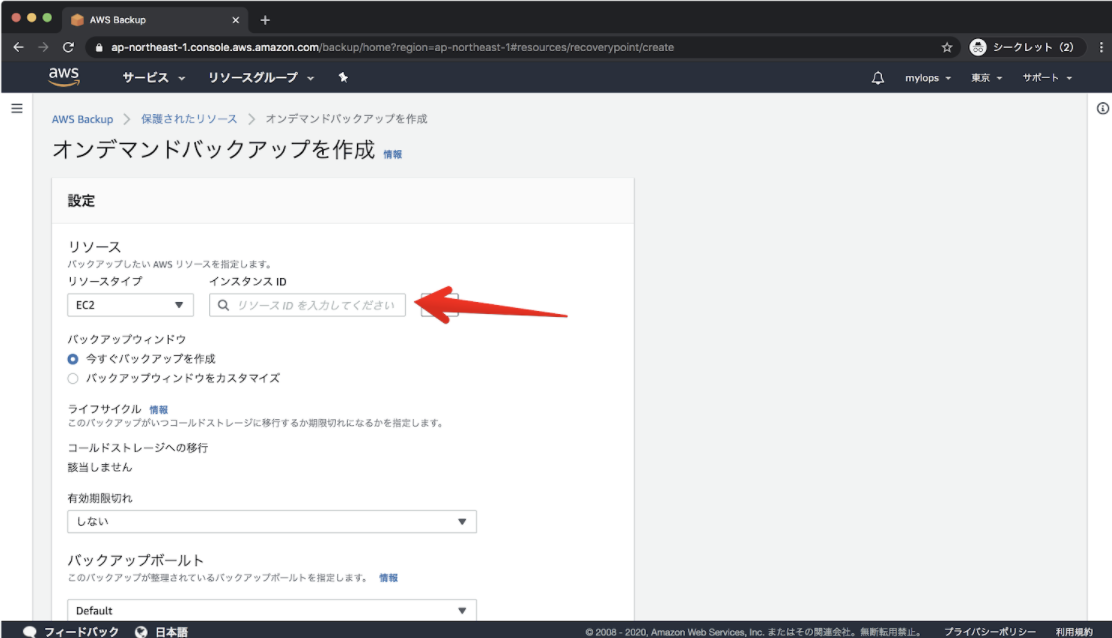
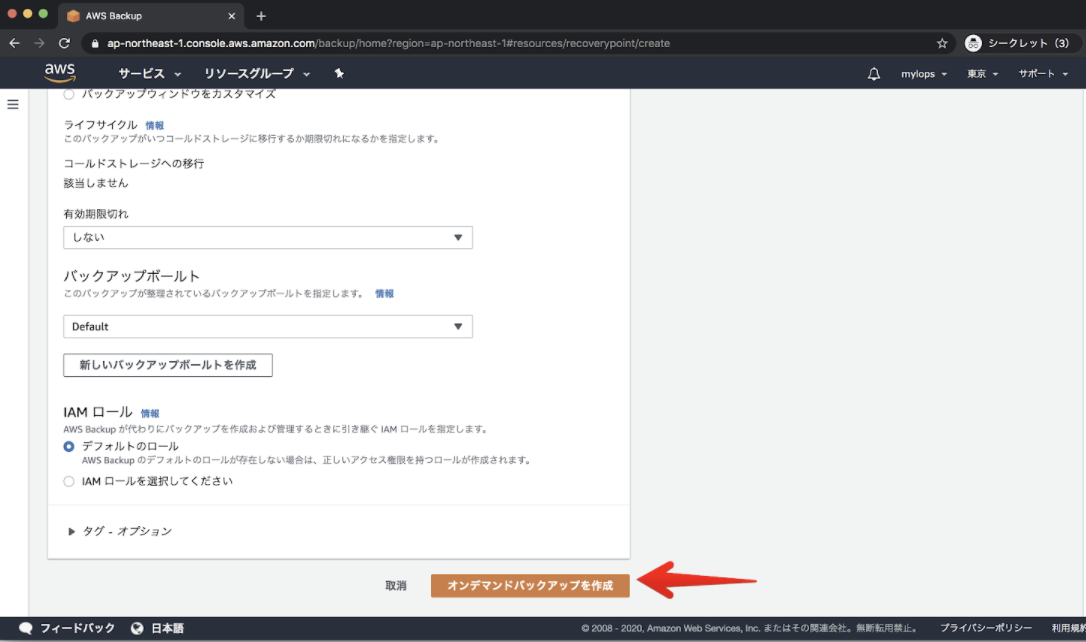
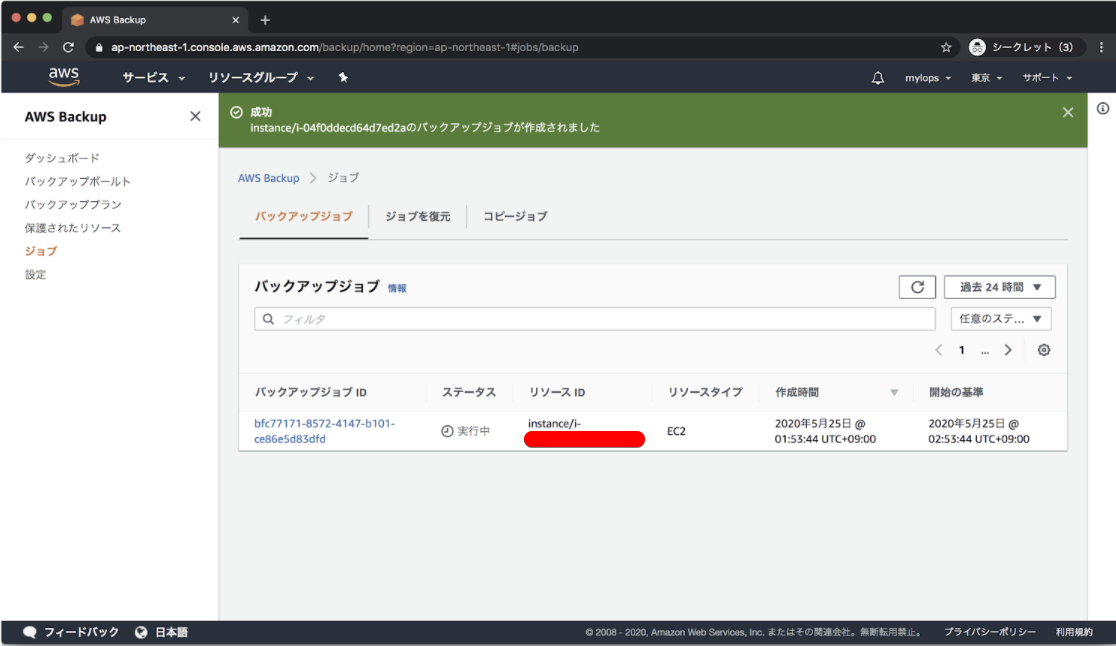
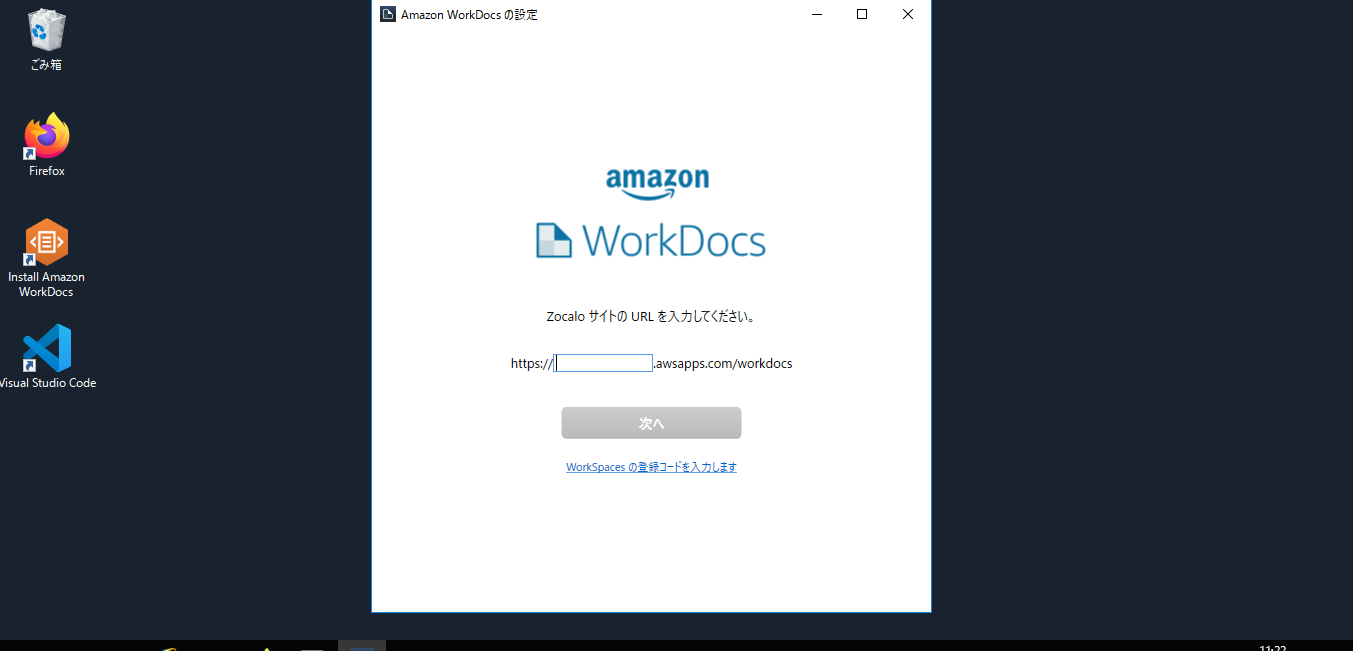
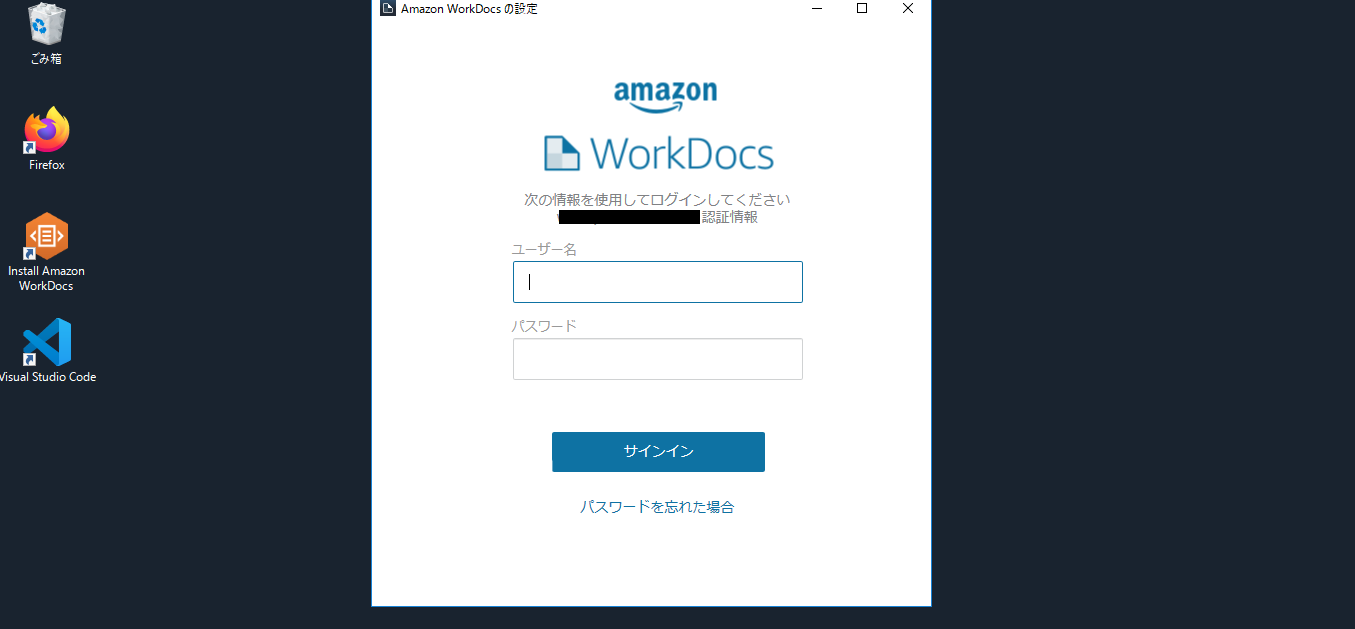
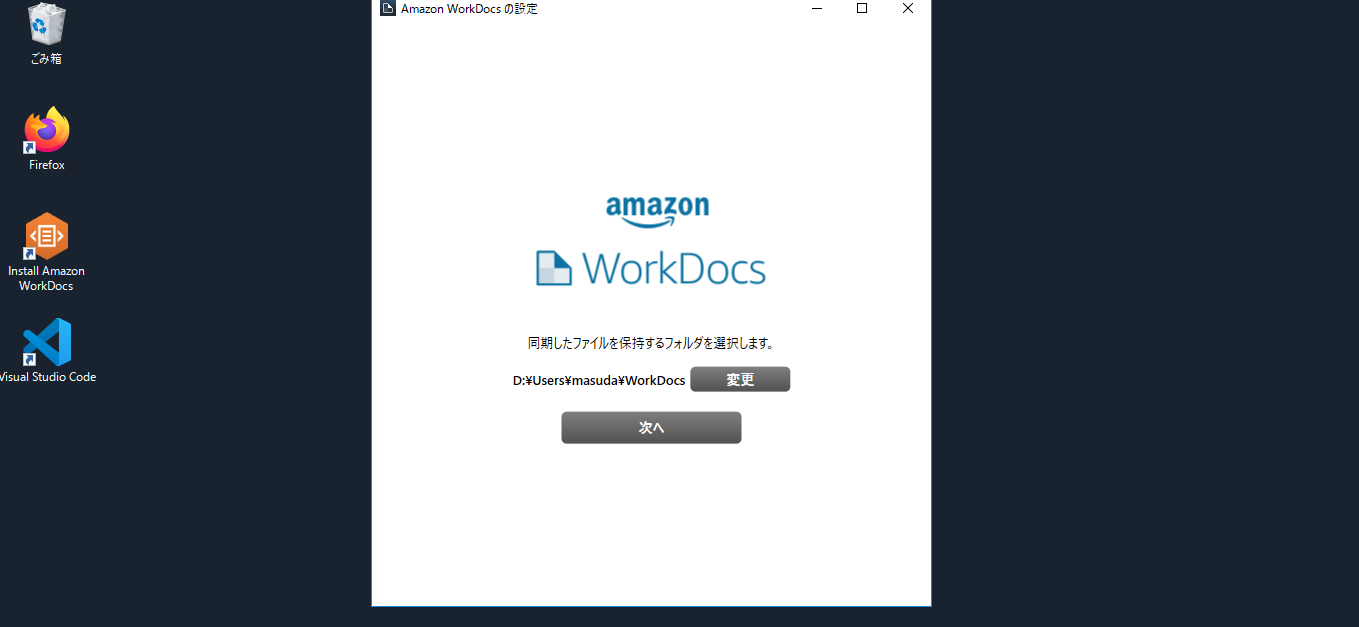
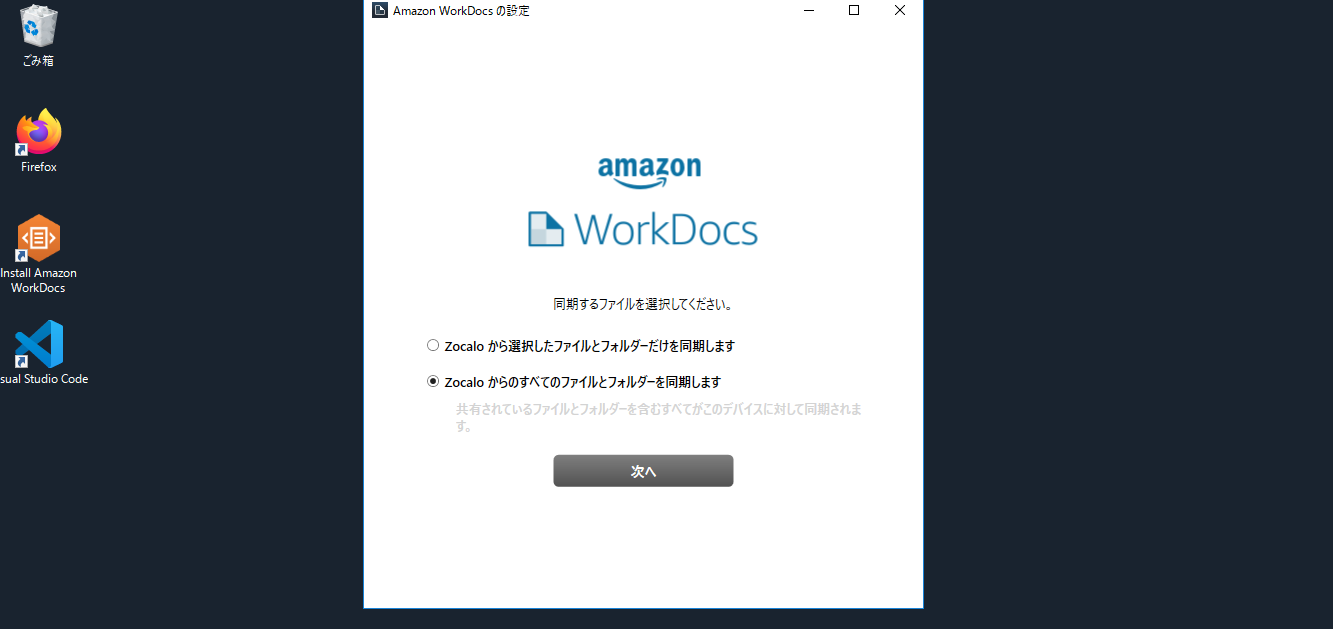
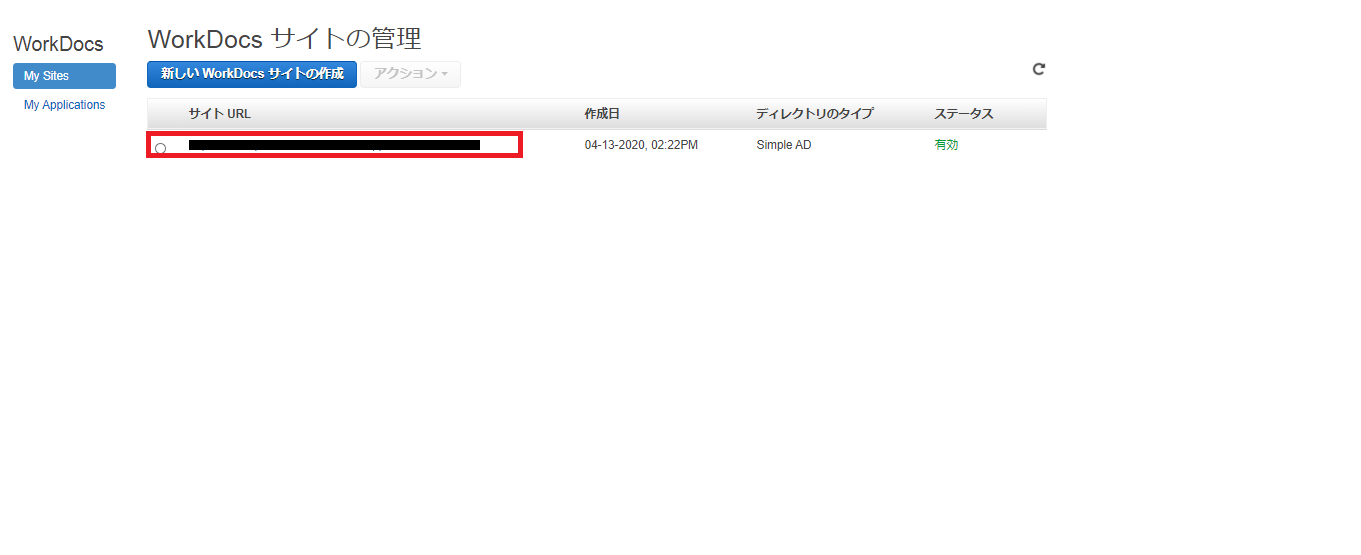
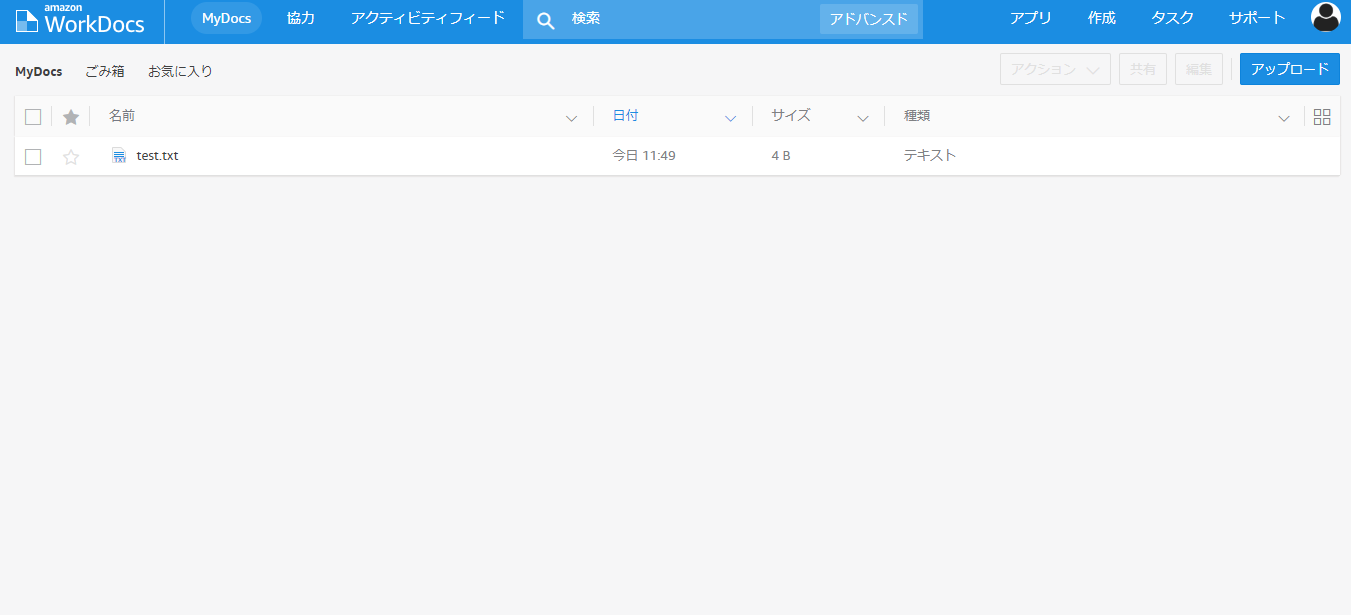
$ aws ec2 create-snapshot help
...
OPTIONS
--description (string)
A description for the snapshot.
--volume-id (string)
The ID of the EBS volume.
--tag-specifications (list)
The tags to apply to the snapshot during creation.
Shorthand Syntax:
ResourceType=string,Tags=[{Key=string,Value=string},{Key=string,Value=string}] ...
...
importVuefrom'vue'importAppfrom'./App.vue'importrouterfrom'./router'// Element UIimport'./plugins/element.js'// Axiosimportaxiosfrom'axios'importVueAxiosfrom'vue-axios'// AmplifyimportAmplify,*asAmplifyModulesfrom'aws-amplify'import{AmplifyPlugin}from'aws-amplify-vue'importawsconfigfrom'./aws-exports'Amplify.configure(awsconfig)Vue.config.productionTip=falseVue.use(AmplifyPlugin,AmplifyModules,VueAxios)Vue.prototype.$axios=axiosnewVue({router,render:h=>h(App)}).$mount('#app')
Tips Divergence Exceeded Exception The merge cannot be completed because the divergence between the branches is too great. If you want to merge these branches, use a Git client.