- 投稿日:2020-05-30T23:25:53+09:00
Python/Tkinterで作るクラスプラットフォームGUIソフトウェア!(と数多くのTryアンドError)の入門!(執筆途中)
はじめに...
タイトル長くてスミマセン!!!!!
書きたいことの要約って難しいですよね...
誰か、要約案を私にお恵みください...
(ちなみに、この後も長いです。目次をご活用ください。)
あと、執筆途中であることに十分ご留意ください。Python/Tkinterとは?
出典: フリー百科事典『ウィキペディア(Wikipedia)』 Tkinter は Python からGUIを構築・操作するための標準ライブラリ(ウィジェット・ツールキット)である。 Tcl/Tk の Tk 部分を Python で利用できるようにしたもので、使い方も可能な限り Tcl/Tk にあわせられるように作られている。 これにより、スクリプト言語である Python から簡単にGUI画面をもったアプリケーションを作ることが可能になる。 (以下略)ってWikipediaに書いてありますが、まあ、カンタンに言うと
Pythonに標準で付属している、GUI作成用ライブラリである。
大事なのは"標準"というところ。
(他のライブラリを使わなければ)pythonをインストール(またはPyinstallerとかを使う)だけでアプリケーションが作れる。
なんなら、Pyarmorを使えばソースコードを保護できる。Tkinterリファレンス
ウィンドウ
まずはモジュールのインポートから...
#Python2なら... import Tkinter #tkinter 本体 import ttk #tkinter 拡張(?) #Python3なら... import tkinter #tkinter 本体 from tkinter import ttk #tkinter 拡張(?)Python2と3でモジュール名が違うので注意。
ちなみに、次のように書くと2,3両対応できる。try: import Tkinter as tkinter import ttk except: import tkinter from tkinter import ttkちなみに、先程からちょこちょこ登場している"ttk"はtkinterの拡張(?)で、
これを使うと、スタイル(テーマ)を変えることができます。メインウィンドウ
次に、メインウィンドウを作る。
root = tkinter.Tk()#この後をよく読むことただし、このままだとUbuntu等のOSでタスクバーのアプリケーション名が"Tk"と表示されダサいので、
root = tkinter.Tk(className="[アプリ名]")とする。
サブウィンドウ
sub = tkinter.TopLevel()とする。
全画面表示
root.attributes("-fullscreen", True)戻すときは、
root.attributes("-fullscreen", False)ウィジェット
ボタン
def callback(): print("Hello!!") button = ttk.Button(root, text="[表示するテキスト]",command=callback)commandには、ボタンが押されたときに実行する関数の名前を指定する。
もし、引数を指定したい場合は、def callback(hogehoge): print(hogehoge) button = ttk.Button(root, text="[表示するテキスト]",command=lambda: callback("Hello!!!"))フレーム(枠)
frame = ttk.Frame(root)えーっと... frameはウィンドウと他のウィジェットのrootの部分に入れて使います。
なんなら、色やら形を変えることもできます。(後で追記します。)
下に活用例を示します。def callback(hogehoge): print(hogehoge) frame = ttk.Frame(root) button = ttk.Button(frame, text="[表示するテキスト]",command=lambda: callback("Hello!!!"))ラベル(一行の選択できないテキスト)
label = ttk.Label(root, text="[表示するテキスト]")ウィジェットの配置
tkinterではウィジェットを定義したあとに配置する必要があります。
配置方法は3つあります。詰め込み方式(pack)
詰め込み方式(pack)では、ウィンドウの空いているところにウィジェットをツメコミマス。(語彙力...)
[ウィジェット].pack([オプション])[ウィジェット]はウィジェットのインスタンス、
(インスタンスやら関数などがワケワカメな人はぜひ他のPython入門記事をご覧ください。)
[オプション]には次が指定できます(何も指定しなくても問題ない。):
・side
どの方向に配置するか設定できます。
設定可能値:
"right"右,"left"左,"bottom"下,"top"上
・fill
どの方向に対して埋め立てるか設定できます。
設定可能値:
"both"-両方向
"x"-x方向(縦?)
"y"-y方向(横?)
(正直、不安なので実験して教えていただけると幸いです。)
・anchor
どこに配置するか設定できます。(sideに似ていますが、より具体的)
設定可能値:
えーっと...こんな感じです。(ここより引用)
nw --- n --- ne
| |
w c e
| |
sw --- s --- se
・expand
空白が生まれたとき(ウィンドウのサイズが変わったときなど)に埋めるかどうか設定できます
設定可能値:
True or False
(面倒臭さが表立っているのは気のせいですからね...本当ですよ......)参考文献など
http://www.nct9.ne.jp/m_hiroi/light/python3.html#python3_tkinter
- 投稿日:2020-05-30T23:22:47+09:00
kintoneと連携した LINE PAY API v3 のサンプルアプリを試してみる
@stachibana さんのこちらのアプリを試した際の備忘録
https://github.com/stachibana/line-pay-v3-python-sdk-sample
紆余曲折ありましたが、これをForkしてLINE Pay の一般決済(単発決済)だけを実装するためのスターターアプリができました。
https://github.com/maztak/line-pay-v3-python-starterLINE Pay 概要
オーソリってなに?
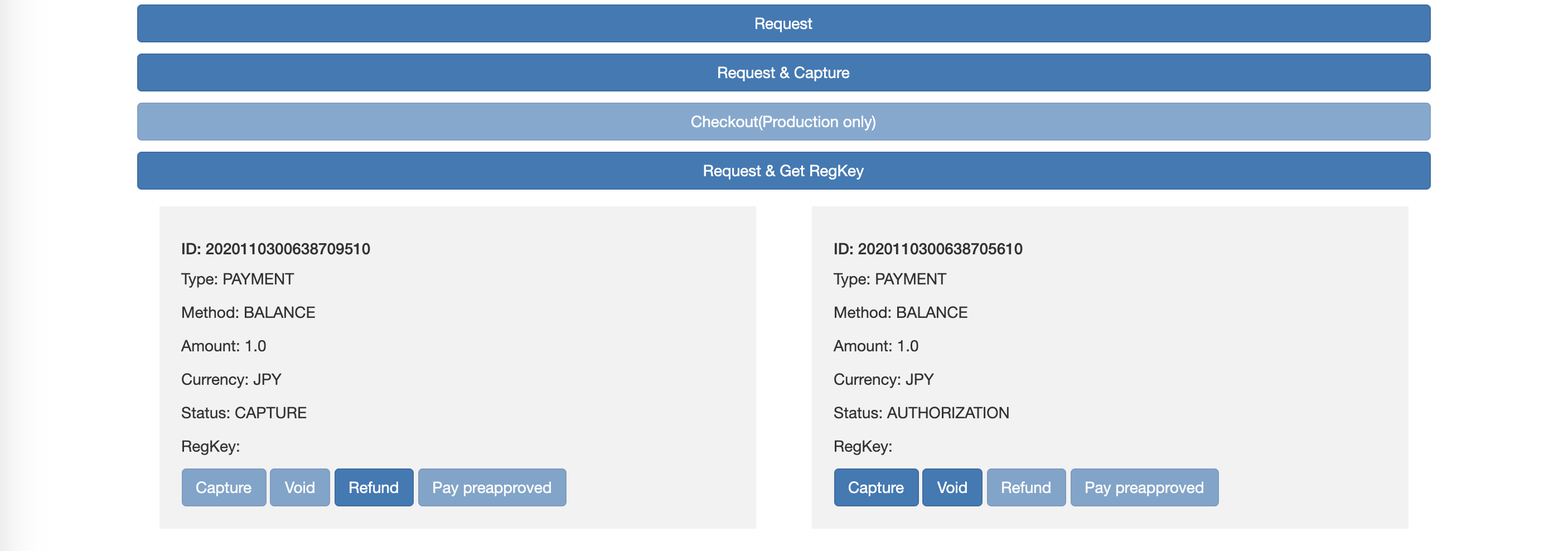
ユーザーが決済を承認した後の売上確定待ち状態。これをCaputureすることで売上確定となる。
Captureとは何?
Captureとは売上確定のことらしい。RequestAPIの利用時の
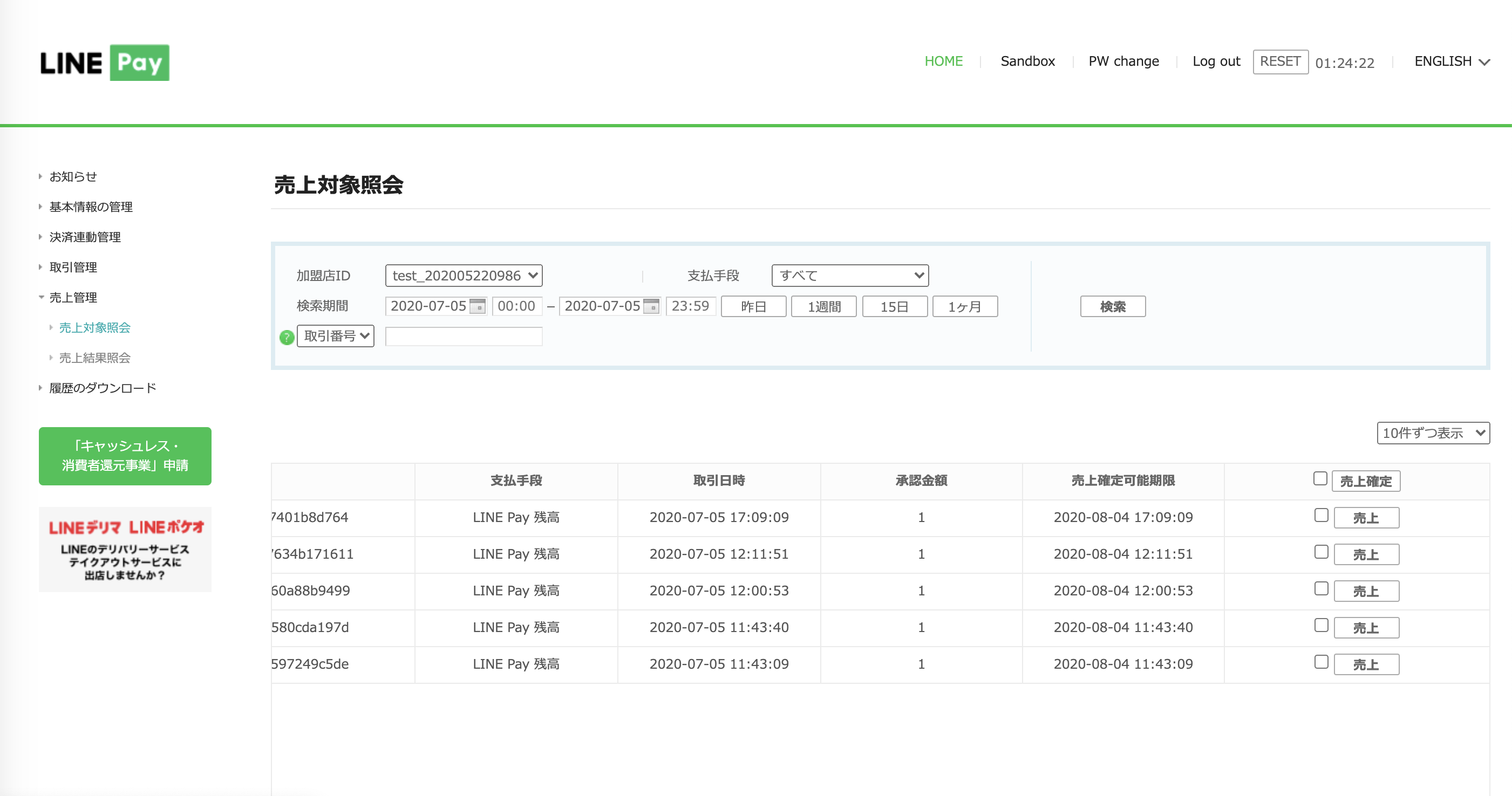
request_optionsの値の中でoptions.payment.captureをFalseにすると、オーソリ状態(売上確定待ち状態)で止めることができる。それがどんなときに嬉しいかは知らん。売上確定するにはCaptureAPIを使うことになるのだが、加盟店MyPageの売上管理>売上対象照会からも手動で売上確定することが可能(なお以下はテストアカウントで本番決済したときの画面。Sandbox環境で模擬決済した場合はナビメニューの「Sandbox」から模擬決済の管理画面に入れる)。
Checkoutとは何?
一般用語としてや他の決済サービス(StripeとかPayjpとか)では、決済することそのもの、もしくは決済を簡単に実装できるライブラリのことを言うらしい。しかし、LINE Pay における Checkout は、ユーザーの住所とか送料を含めた決済機能のことを指すらしい。つまりECで商品の送付先を入力する作業を Checkoutを使えば省けるっぽい。
LINE Pay API v2 と v3 の違い
公式リファレンス Migration V3
https://pay.line.me/documents/online_v3_ja.html#migration-api-v3Developers.I.O さんの記事
https://dev.classmethod.jp/articles/devio-cafe-line/LINE Pay 加盟店アカウントを取得
正式なアカウントは法人または個人事業主でしか取得できないので、以下からSandboxアカウントを取得します
https://pay.line.me/jp/developers/techsupport/sandbox/testflow?locale=ja_JP取得後のログイン画面
https://pay.line.me/portal/jp/auth/loginSandboxについて
LINE Pay にはテストができるSandbox環境が用意されているが、用語がごちゃごちゃしていて混乱しやすいので注意。
Sandbox環境とproduction環境
Sandboxアカウントのチャネル情報(Channel ID, Channel Secret Key)を使っている環境のこと。
Sandbox環境で使用できるチャネル情報をテストチャネル情報という。Sandobxシミュレーター
これは LIEN Pay の決済シミュレーターのことで、Sandbox環境が
Trueの時に決済しようとするとこれが起動する。加盟店MyPageの取引内訳
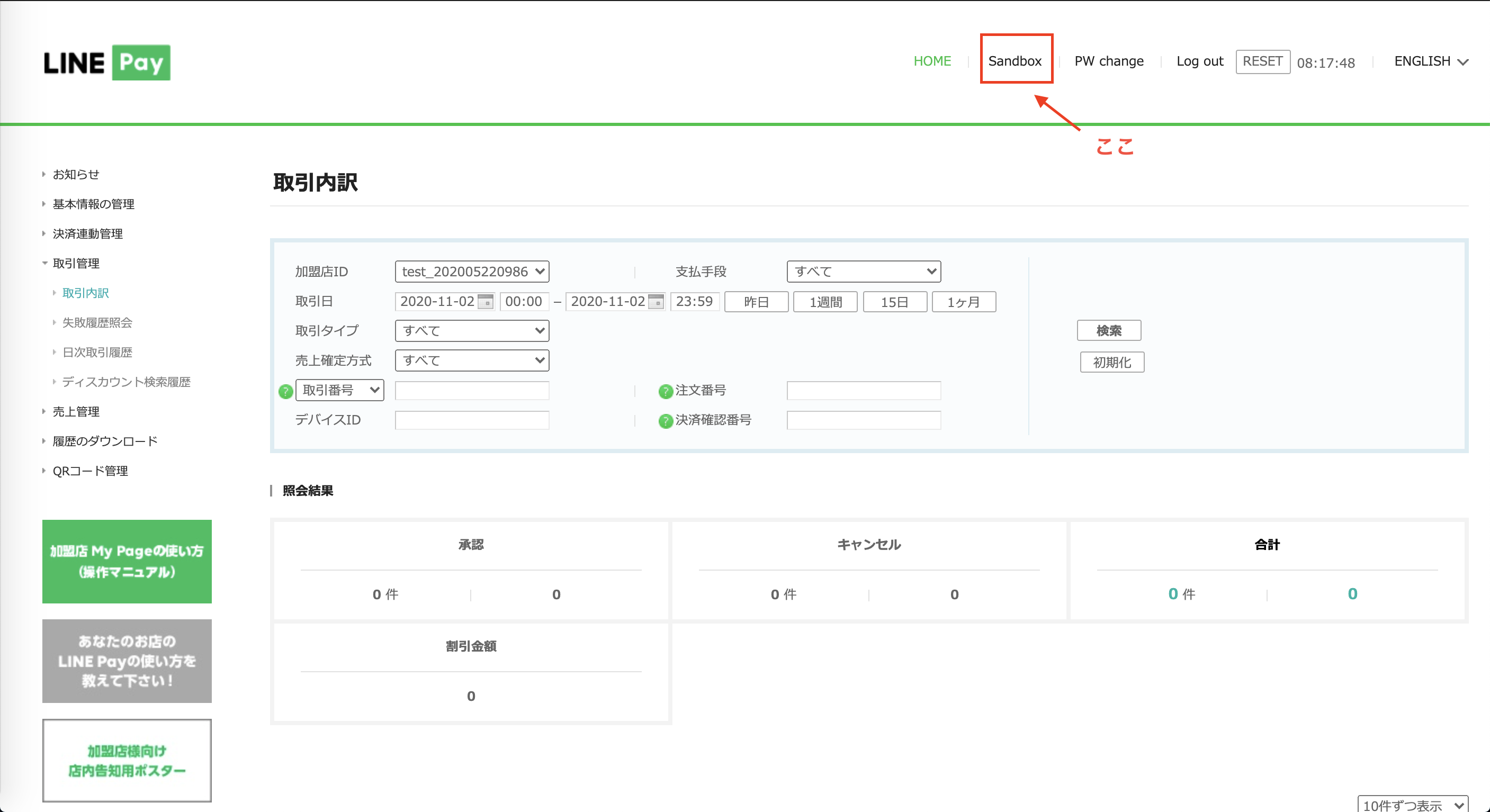
SandboxアカウントでSandboxシミュレーターを使って模擬決済した場合、加盟店MyPageに入ってナビバーにある「Sandbox」をクリックしたページで取引内訳が確認できる。
しかしSandbox環境でも
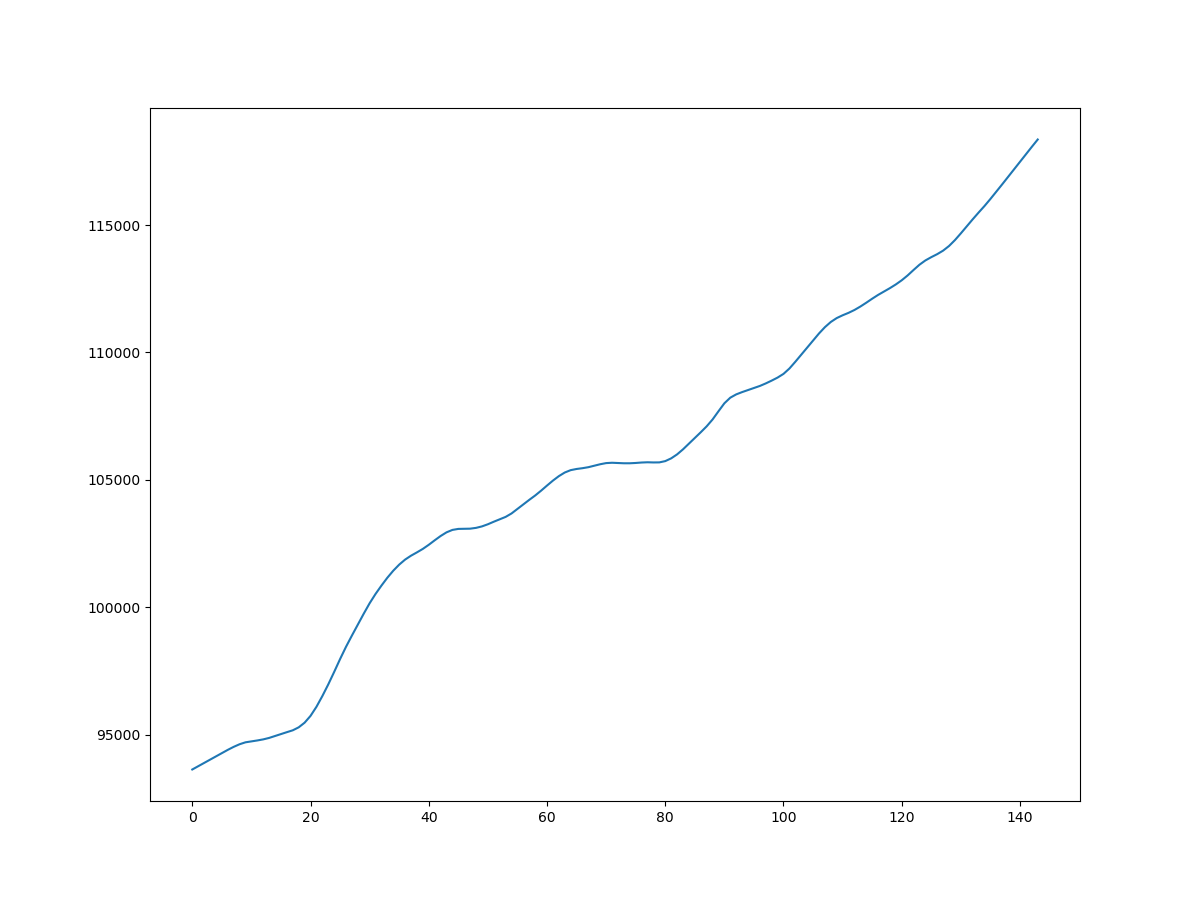
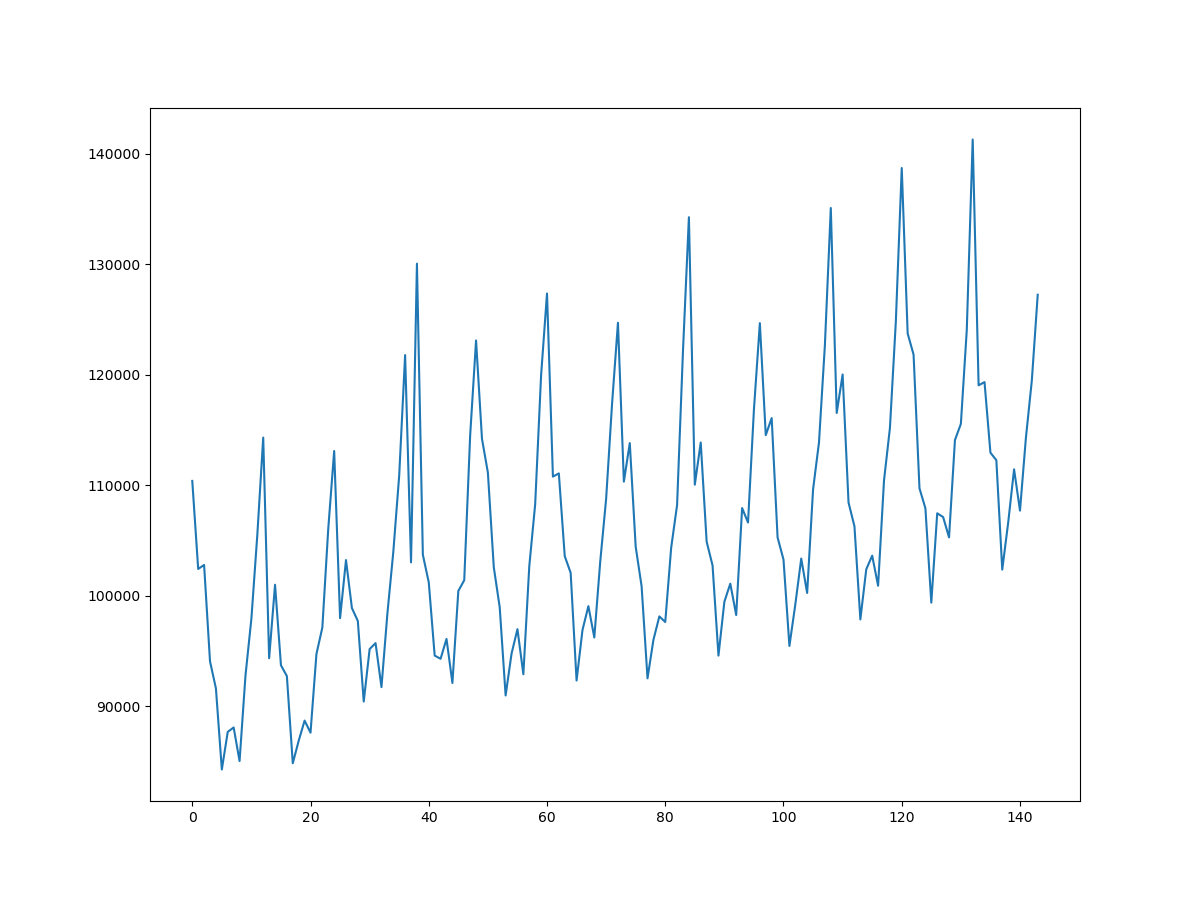
LINE_PAY_IS_SANDBOX = Falseにしていると実際のお金が決済できてしまう(本サンプルアプリ特有のものかもしれない)。この場合は加盟店MyPageの「Sandbox」ページではなく、加盟店MyPageのホーム画面に取引内訳が記録される。app.pyLINE_PAY_IS_SANDBOX = Falseさらに、Sandboxアカウントと正式な加盟店アカウントでは加盟店MyPageの表示が違う。Sandboxアカウントでは取引の一覧が見れるだけだが、正式な加盟店アカウントのMyPageではグラフが見れる。
Herokuにデプロイしてみる
Webサービスとして運用することを想定したとき、当然どこかのサーバーにデプロイする必要があるので、今回は定番のHerokuを使います(LINE PAY API v2では決済サーバIPのホワイトリスト登録が必要だったので、固定IPではないHerokuは不向きでしたが、v3からはホワイトリスト登録不要になった)。
Herokuで動かすにはgunicornが必要
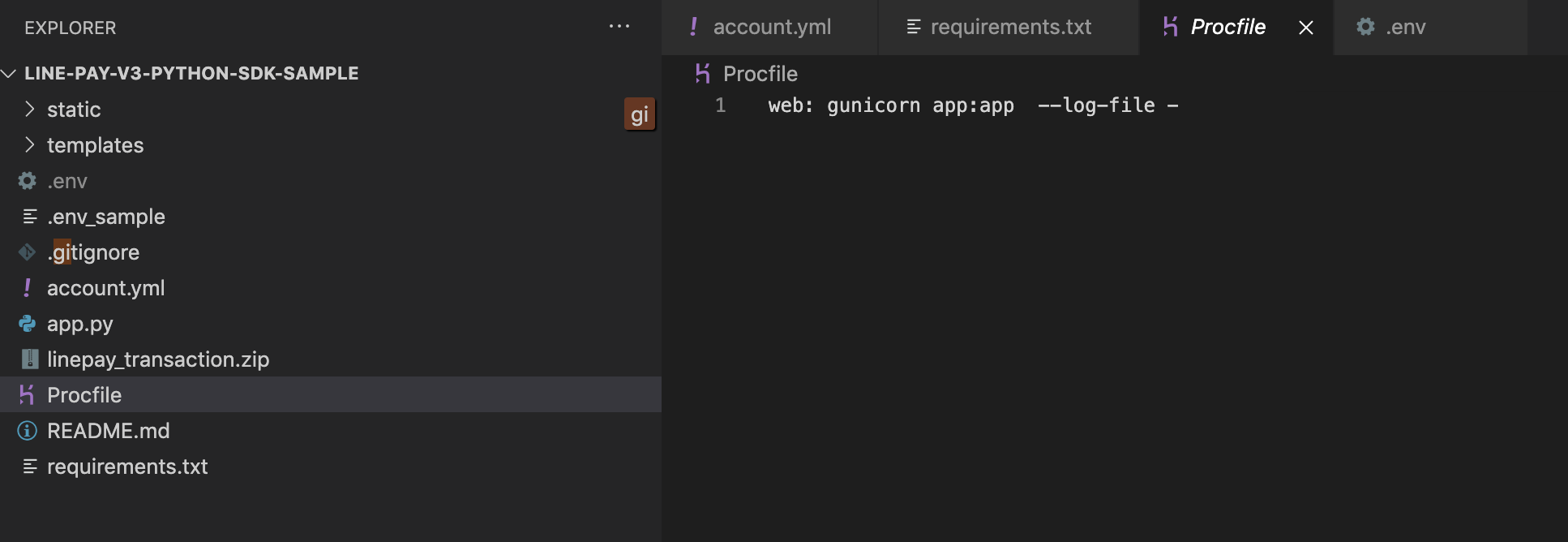
Herokuにデプロイして
app.pyをRunした状態にしておきたい。今回はFlaskを使っている関係で実行命令ファイルProcfileにgunicornというフレームワーク?ライブラリ?が起動するように記述する。Flaskってなに
Pythonのミニマムフレームワーク。Rubyでいう Ruby on Rails のちっさい版。
Procfileってなに
HeorkuデプロイしたPythonアプリの実行命令を書くファイル。
gunicornってなに
Flaskを始めとする多くのPythonフレームワークではWSGIサーバーというものでアプリを動かすらしい。このWSGIサーバーとのやり取りをいい感じにしてくれるライブラリがgunicornっぽい。普通にプロジェクトフォルダ直下にProcfileって名前のファイル作成すればよかったはず‥。
web: gunicorn app:appGitコミットして Heroku に push
$git init $git add . $git commit -m "initial commit" $ heroku login --interactive $ heroku create my-app-name #任意のアプリ名を付けてください $ git push heroku master環境変数の設定
.gitignoreで.envファイルをgit管理から無視するようにしているため当然Herokuにpushされません(僕は知らなかった)。そのためHeroku側でheroku config:setで環境編集をセットしてやる必要があります。$heroku config:set LINE_PAY_CHANNEL_ID="xxx" $heroku config:set LINE_PAY_CHANNEL_SECRET="xxx" $heroku config #一応、環境変数が間違いなくセットされてるか確認しようトップページがエラーになるときは、この環境変数のセットし忘れであることが多い。
つまづきポイント
line-payがアップデート
LINE Pay のライブラリである line-pay が 0.0.1 -> 0.1.0 にアップデートしていた。requirements.txtでline-payライブラリのバージョンをあげましょう。
requirements.txtline-pay==0.1.0ちなみに僕のrequirements.txtは、なんかの理由で
pip freezeというコマンドを使ったらしく以下のようになってました。これをHerokuにデプロイして動いているので、何か必要なことがあったのかも‥。requirements.txtcertifi==2020.4.5.1 chardet==3.0.4 click==7.1.2 dominate==2.5.1 Flask==1.1.2 Flask-Bootstrap==3.3.7.1 gunicorn==20.0.4 idna==2.8 itsdangerous==1.1.0 Jinja2==2.11.2 line-pay==0.1.0 MarkupSafe==1.1.1 pykintone==0.3.10 python-dotenv==0.10.3 pytz==2020.1 PyYAML==5.3.1 requests==2.22.0 tzlocal==2.1 urllib3==1.25.9 visitor==0.1.3 Werkzeug==1.0.1Request後のリダイレクトエラー
リダイレクト先がhttpssになるエラーが起きた。以下はGitコミットの差分ですが、
replace()でhttpsに統一しようとしている部分を消したらちゃんと動きました。ただ決済時にhttp通信をすること自体がやばいので、あくまで応急処置です。app.py"redirectUrls": { - "confirmUrl": request.host_url.replace('http', 'https') + "confirm", - "cancelUrl": request.host_url.replace('http', 'https') + "cancel" + "confirmUrl": request.host_url + "confirm", + "cancelUrl": request.host_url + "cancel" }kintoneのアプリ名は一意に
kintoneアプリは過去に一度でも使ったことがあるアプリ名を使用すると動かない。今回kintoneアプリ名には「linepay」が設定されています。例えばこのアプリを一度削除し、もう一度テンプレートからアプリ作成したとしても本サンプルアプリは動いてくれません(トップページの表示や決済はできる)。そのためkintoneアプリの設定画面からアプリ名を過去に使用していないものに変更してやる必要があります。
その他のつまづきポイント
- account.ymlのドメイン名はサブドメインだけでよかった
- Herokuデプロイ前に一度ローカルで試す場合はPythonのバージョンが3.6以下だと動かない
- デプロイ直後(もしくは初回)に決済しようとすると Internal Server Error となる。原因不明。
- line pay sandbox 申請が最初数回エラーになった。何回かやってれば直った。
役立ちそうなコマンド
Herokuとのgit紐付け
# herokuからのクローン heroku git:clone APPNAME # herokuとローカルの紐付け heroku git:remote --app APPNAME # こっちでもOK git remote add heroku https://git.heroku.com/AppName.gitHerokuの再起動方法
$ heroku ps:scale web=0 # 再びスタートするときは↓ $ heroku ps:scale web=1Herokuのキャッシュ削除方法
間違ってるかも。
$ heroku plugins:install heroku-repo $ heroku repo:purge_cache -a appname $ git commit --allow-empty -m "Purge cache" $ git push heroku masterhttps://help.heroku.com/18PI5RSY/how-do-i-clear-the-build-cache
LINE Pay v2 の実装サンプル
Pythonによるv2の実装(Python+Heroku+Docker)
https://qiita.com/sumihiro3/items/7a8f3a59e79e8d9b7a9cNode.jsによるv2の実装(Node.js+Heroku)
https://qiita.com/nkjm/items/b4f70b4daaf343a2bedc
- リッチメニューのLIFFから決済させる https://qiita.com/ufoo68/items/a6d036d143fe4950aea3
- Python版 https://qiita.com/keigohtr/items/161c9fb1584758ae3e35
参考
- 投稿日:2020-05-30T23:19:53+09:00
JupyterLab で Jupyter notebook(ipynb)の 差分を見やすく Git管理する
TL;DR
Jupyter Notebook で分析を進める際、バージョン管理をしたいと思いGitで管理をしてみましたが、普通に進めるとNotebook のメタデータによって差分がとても見づらかったので、JupyterLab の
jupyterlab-gitとnbdimeエクステンションを利用し、差分を見やすく表示できるようにしてみました。JupyterLab 環境を構築
今回の記事では、下記の環境を利用します。
- docker-compose を使用
- docker-compose のインストールは こちら を参照
- コンテナイメージのベースは kaggle-images を利用
Jupyter notebook のバージョンコントロールに必要な JupyterLab エクステンションは下記になります。
- jupyterlab-git
- nbdime
- こちらは jupyterlab-git をインストールすると一緒にインストールされる
環境構築
下記2ファイルを作成します。
- Dockerfile
- docker-compose.yml
DockerfileFROM gcr.io/kaggle-images/python:v74 RUN apt-get update && \ apt-get install -y git \ curl RUN curl -sL https://deb.nodesource.com/setup_12.x | bash - &&\ apt-get install -y nodejs RUN pip install -U pip \ jupyterlab && \ pip install jupyterlab-git RUN jupyter lab builddocker-compose.ymlversion: "3" services: jupyter: build: . volumes: - $PWD:/tmp/work working_dir: /tmp/work ports: - 8888:8888 command: jupyter lab --ip=0.0.0.0 --allow-root --no-browserDocker イメージのビルド
上記2ファイルを作成後、同ディレクトリにてビルドします。
$ docker-compose buildコンテナを起動
ビルド後コンテナを起動します。
$ docker-compose up起動後は http://localhost:8888/ にアクセスし、token を入力して JupyterLab にアクセスできます。
token とは起動後に出力される、例:http://acb729d0c5ce:8888/?token=45d10c660d2e85f0c8d59995a04667c154542ae79f27f65dの45d10c660d2e85f0c8d59995a04667c154542ae79f27f65dにあたる箇所です。Extension Manager を Enable
起動後は Exxtension Manager を Enable します。
2つのエクステンションがインストールされています。
Notebook を Git でバージョン管理をする
Git リポジトリ を Clone
必要なリポジトリをクローンします。すでに Notebook などがある場合は git init などをします。
リポジトリの URL を入力
Notebook (
test.ipynb) を作成して first commit します。$ git config --global user.email "you@example.com" $ git config --global user.name "Your Name" $ git add test.ipynb $ git commit -m "first commit"first commit 後、 Notebook で分析を進めたとします。例えば df.head() というコードを追加したとします。
git diff での差分表示
まず、
git diffコマンドで確認した場合は、下記のように Notebook のメタデータなどの差分が表示されてしまいとてもわかりづらいです。# git diff diff --git a/test.ipynb b/test.ipynb index f6c1f17..5af6074 100644 --- a/test.ipynb +++ b/test.ipynb @@ -2,7 +2,7 @@ "cells": [ { "cell_type": "code", - "execution_count": 1, + "execution_count": 6, "metadata": {}, "outputs": [], "source": [ @@ -21,7 +21,7 @@ }, { "cell_type": "code", - "execution_count": 4, + "execution_count": 7, "metadata": {}, "outputs": [], "source": [ @@ -30,12 +30,164 @@ }, { "cell_type": "code", - "execution_count": 5, + "execution_count": 8, "metadata": {}, "outputs": [], "source": [ "df = pd.read_csv(data_dir + \"train.csv\")" ] + }, + { + "cell_type": "code", :JupyterLab nbdime での差分表示
JupyterLab にて nbdime を利用して diff を確認した場合は下記になります。ピンクの左側は変更前、緑の右側は変更後になります。
とても見やすく差分が表示されていると思います。
参考

- 投稿日:2020-05-30T23:18:36+09:00
PythonでNOMURAコンテスト2020を解きたかった
はじめに
おひさしぶりです。学校の課題に追われてなかなか精進できませんでした(言い訳)
A,Bの二完でした。しかも、それぞれ1ペナずつ生やした。A問題
考えたこと
$m1>m2$のときはそのまま引き算できないので、$h1$から1取ってくる。h1, m1, h2, m2, k = map(int,input().split()) if m1 > m2: m2 += 60 h2 -=1 ans_m = m2 - m1 else: ans_m = m2 - m1 ans_h = h2 - h1 ans = 60 * ans_h + ans_m print(ans-k)引き算の順序を間違えて1WAした。もったいない
B問題
考えたこと
ヒタチコンの悪夢再来、こういう系の問題は苦手。
全てDにするのが最適ですが、私は気付かなかったので、if文でごり押ししてます。t = list(input()) n = len(t) if t[0] == '?': if n > 1: if t[1] == '?': t[0] = 'P' else: t[0] = 'D' else: t[0] = 'D' if t[-1] == '?': t[-1] = 'D' for i in range(1,n-1): if t[i] == '?': if t[i-1] == 'P': t[i] = 'D' else: if t[i+1] == '?' or t[i+1] == 'D': t[i] = 'P' else: t[i] = 'D' ans = ''.join(t) print(ans)まとめ
C解けたらかっこよかった。
明日のABCが不安です。ではまた、おやすみなさい。
- 投稿日:2020-05-30T23:14:12+09:00
機械学習で住宅価格が予測できるなら「あつ森」の家具の価格も予測できるんじゃないか説
はじめに???
kaggleのデータセットでこれを見つけてしまって、試さずにはいられませんでした。
データセットはこちらです。
? https://www.kaggle.com/jessicali9530/animal-crossing-new-horizons-nookplaza-dataset
あつまれどうぶつの森(以下、あつ森)のマスターデータといった感じのデータセットです。
家具やむし、さかな、などはもちろん村人(どうぶつ)のデータも入っています。AutoMLで分析?
今回は無料で使えるAutoMLツールのVARISTAを利用していきます。
? https://www.varista.ai/
さっそく分析開始?
まずはデータをアップロードして中身を確認してみましょう。
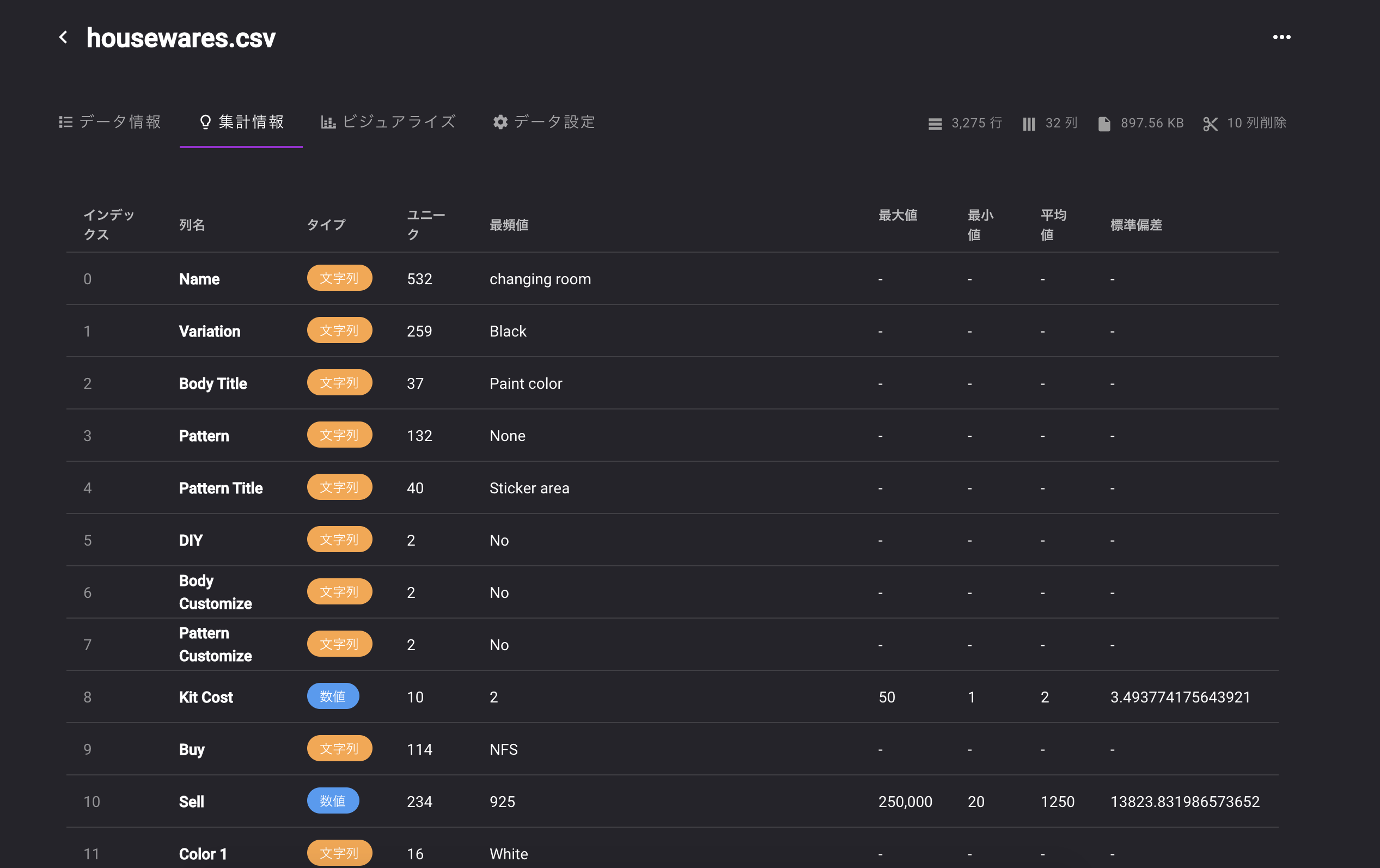
「housewares.csv」を利用します。
3,275行 x 32列 897.56 KBの家具の情報が入ってるデータです。
予測する列は売却価格の「Sell」です?
なお、答え合わせように10行ほどランダムにピックアップした行を抽出しておきます。学習に利用しない列を選んでいきましょう。
学習に利用しない列?
ユニークな値の列を削除
削除列 理由 Name 完全ユニークではないが売却金額が予想できるほぼ固有の値なので削除 Source 家具の入手方法、個を特定できるため削除 Source Notes 同上 Filename ゲーム内で参照するファイル名、意味のない文字列のため削除 Internal ID NameとOneToOneで紐づくIDなので削除 Unique Entry ID 意味のないID列 データリークの可能性があるため削除
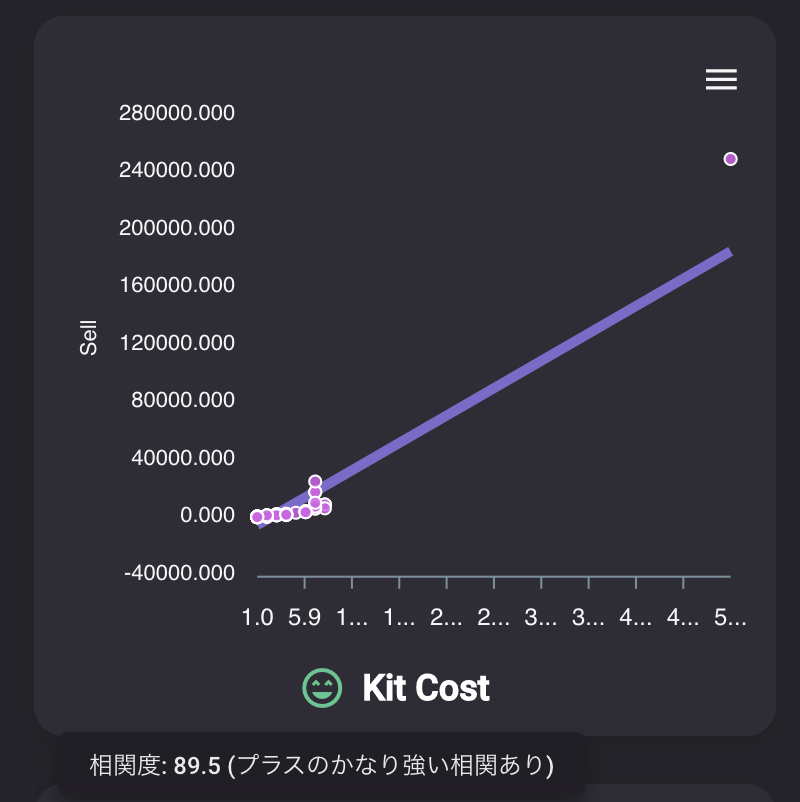
削除列 理由 Buy 購入価格、売却価格と比例しているため、計算できてしまいデータリークになるから削除 Kit Cost 制作コスト、同上 Miles Price マイルでの購入額、同上 実際に学習してみた?
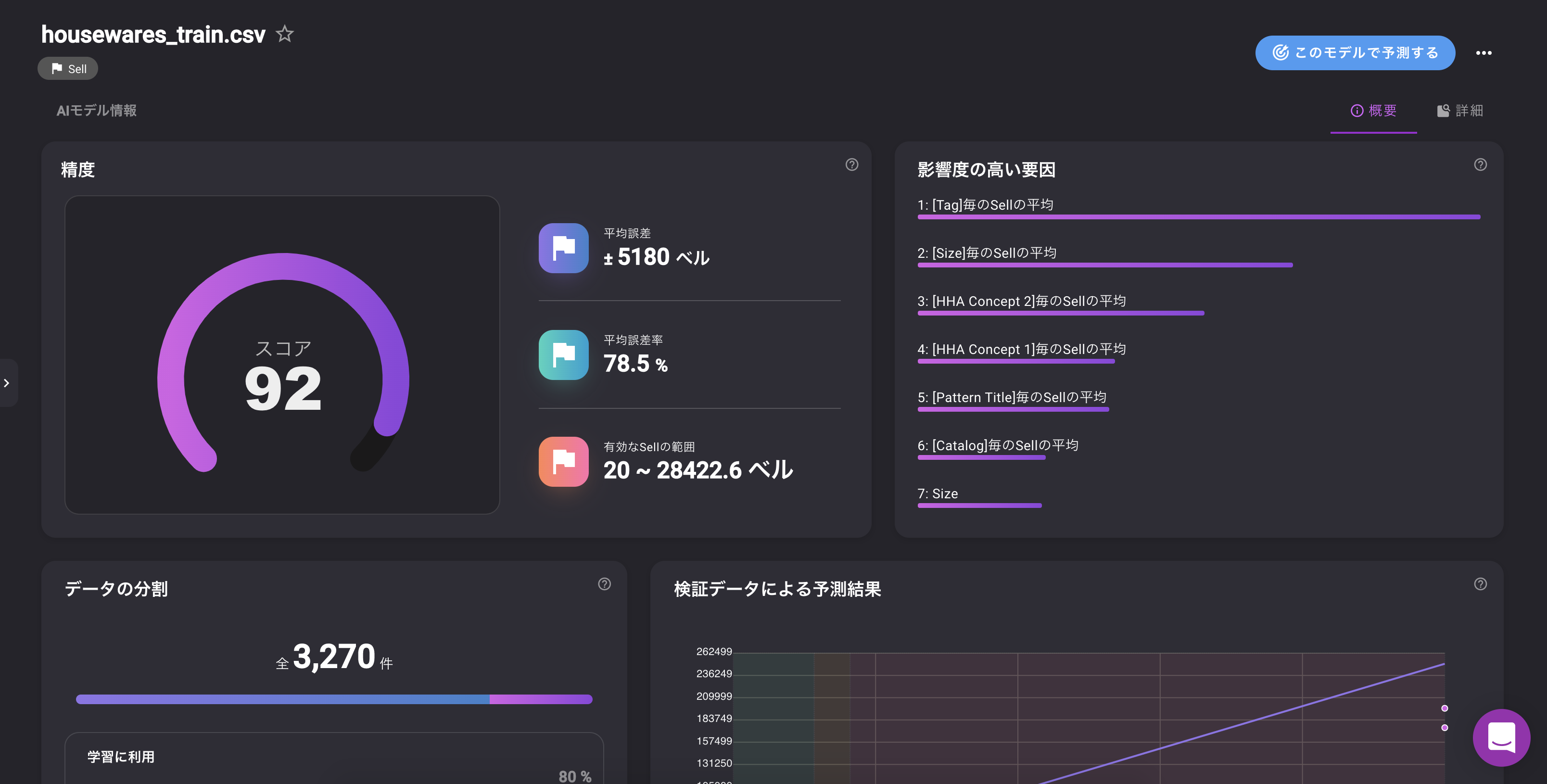
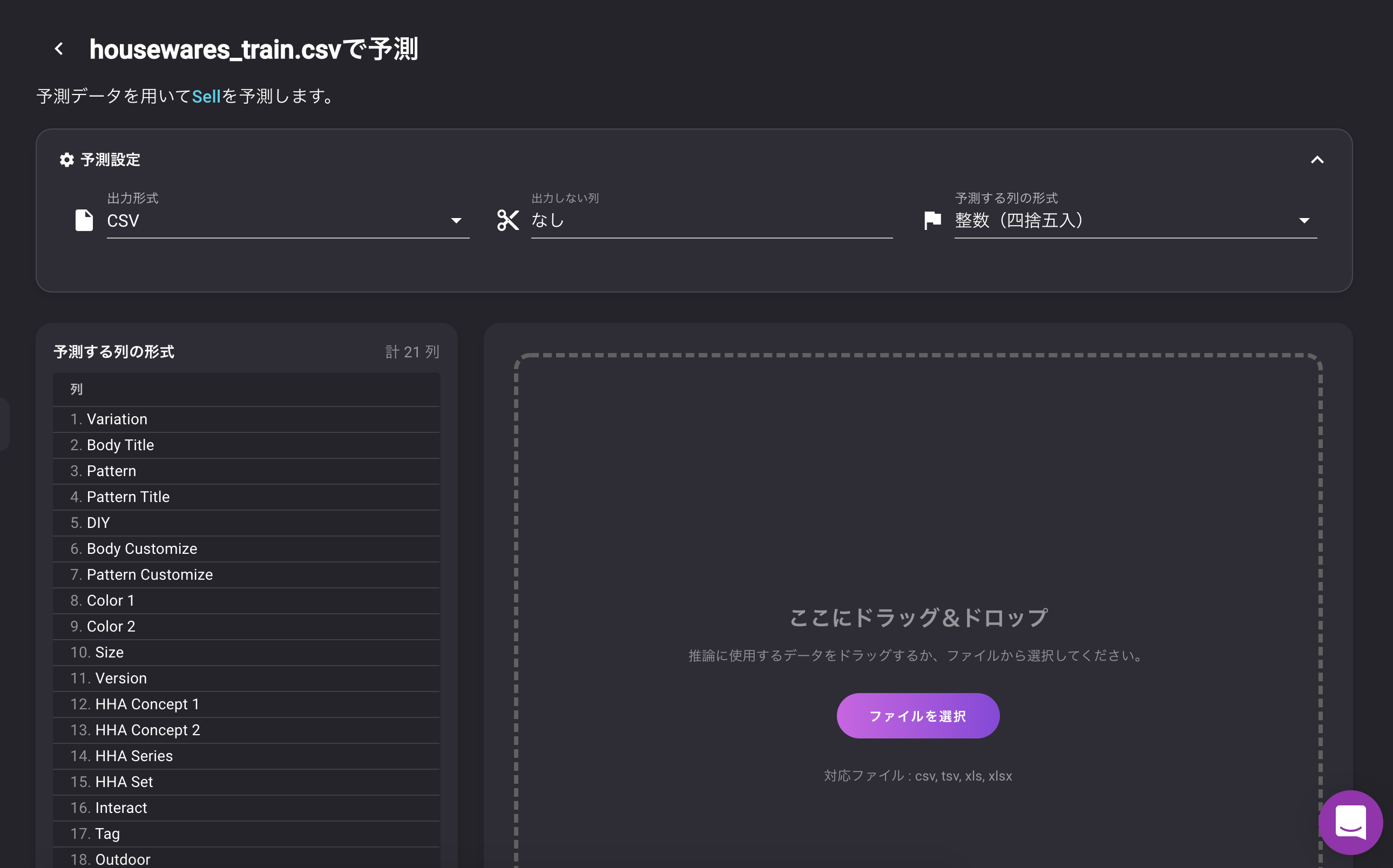
?学習結果はこんな感じです。
スコア92と高いスコアを叩き出しました。
誤差の平均が5180ベルくらいで予測ができるモデルになりました!
(データの詳細設定から単位をつけることができます。ベルってなってるとなんかかわいい?)細かく見ていきましょう。
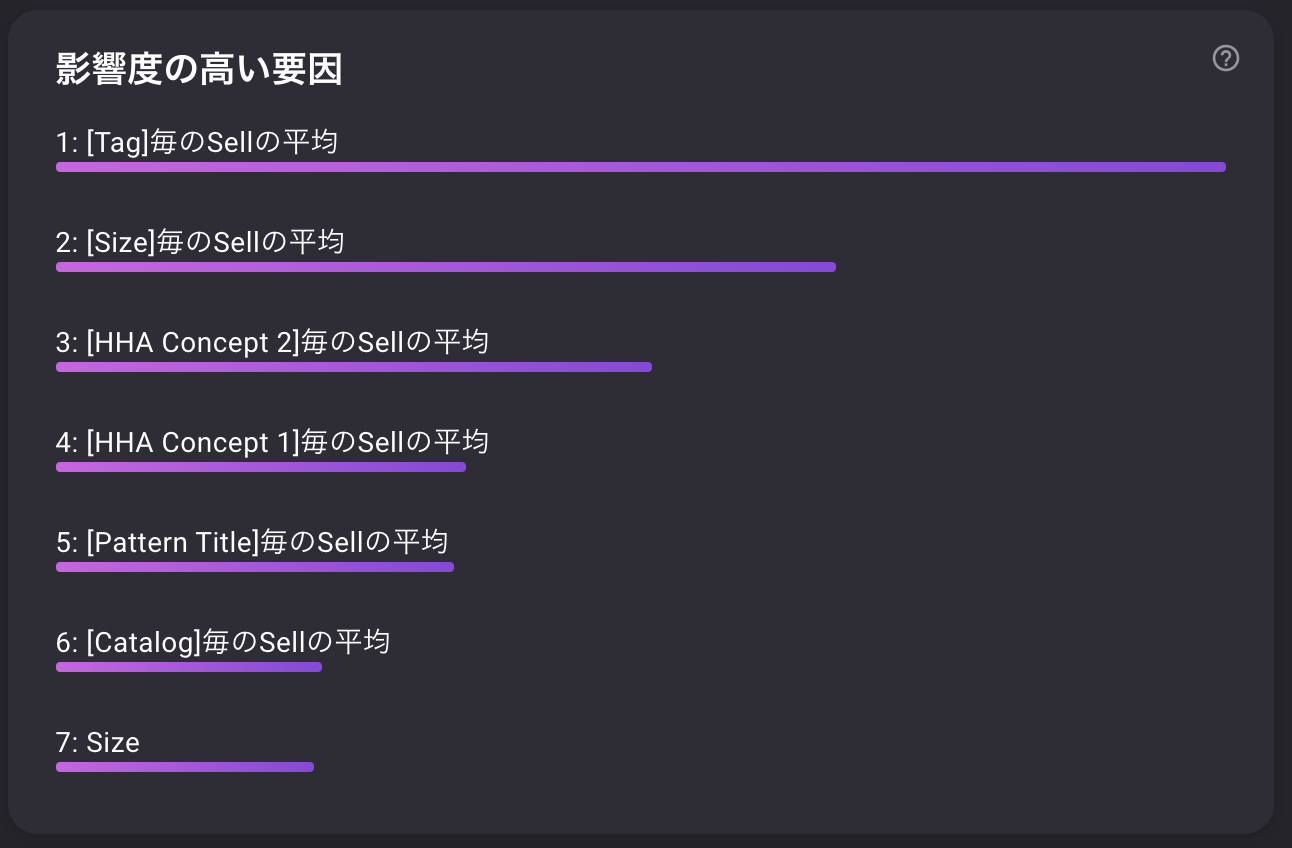
特徴の重要度
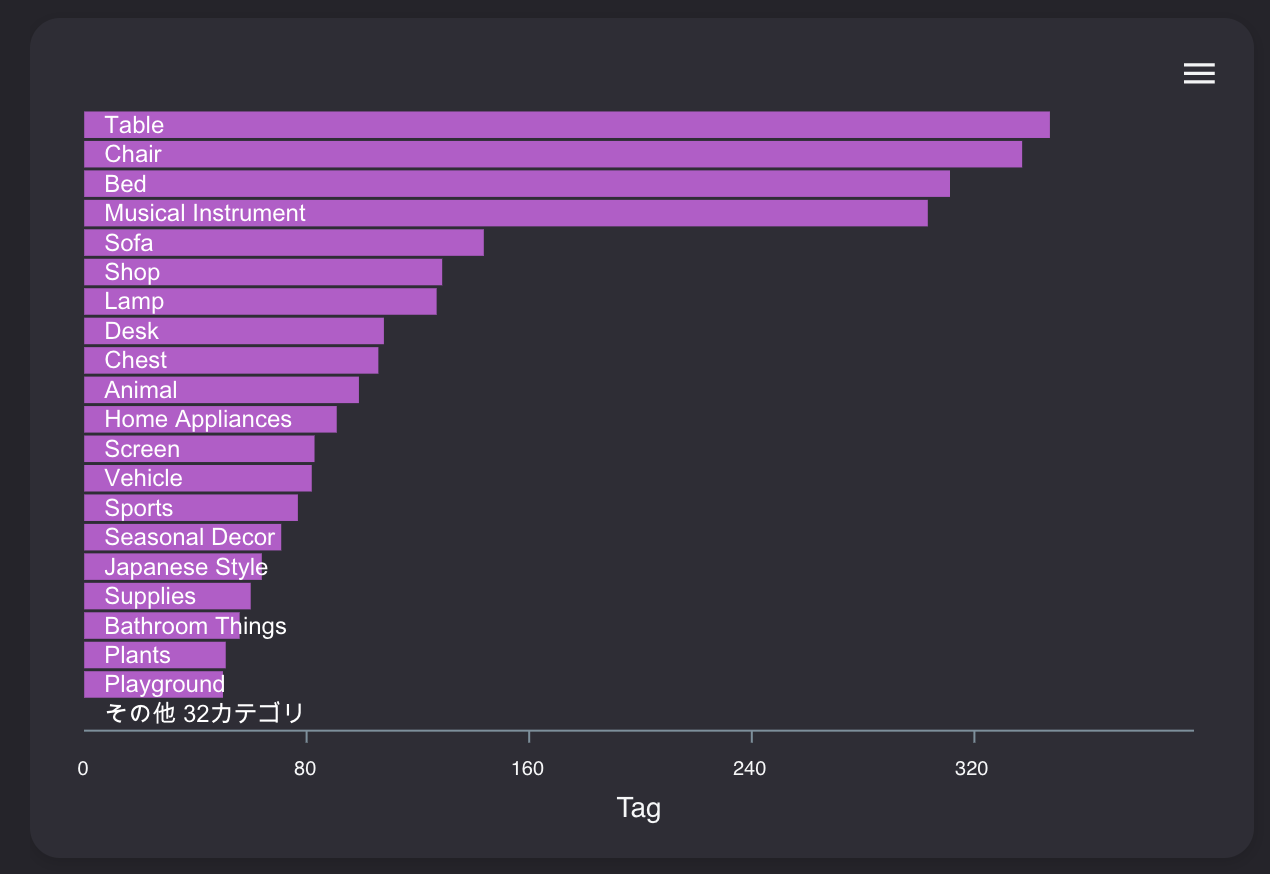
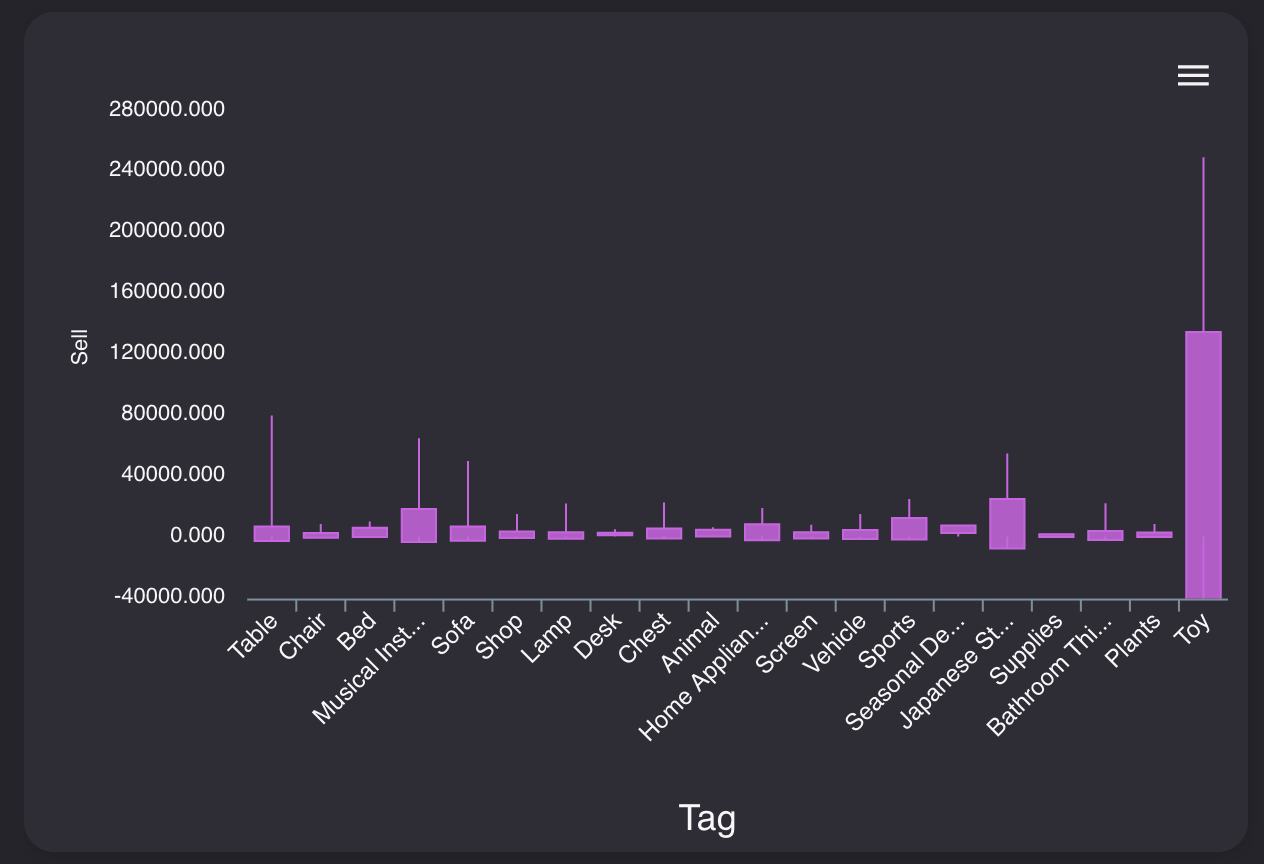
重要な指標第1位は「Tag毎の平均売却額」
Tag列は家具の種類を示した列です。内容は以下のようになっています。
テーブル、椅子、ベッドなど家具の種類が入っているのが分かります。
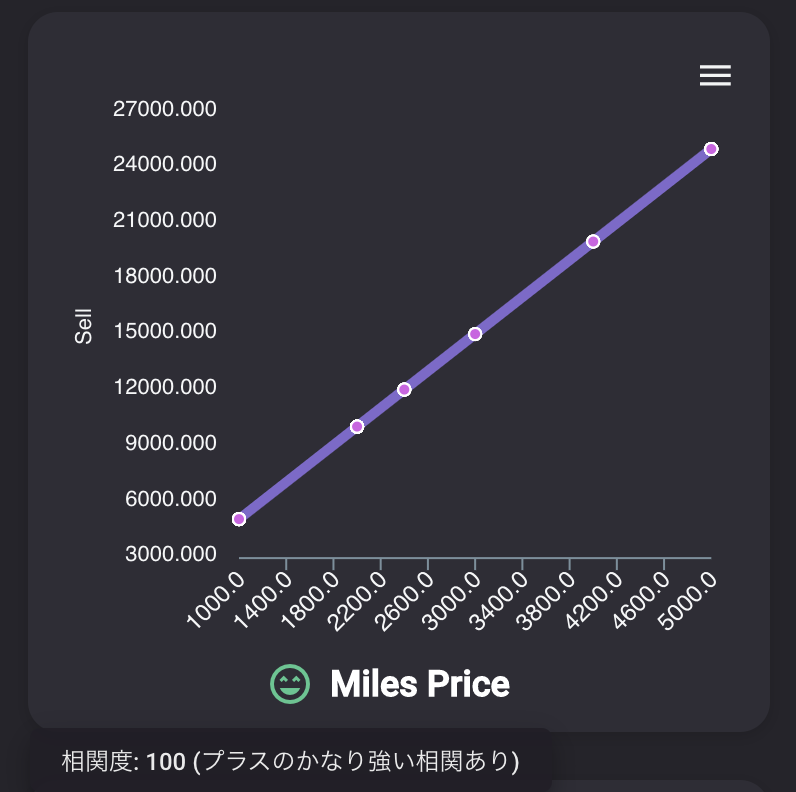
売却価格との関係性を見てみましょう。
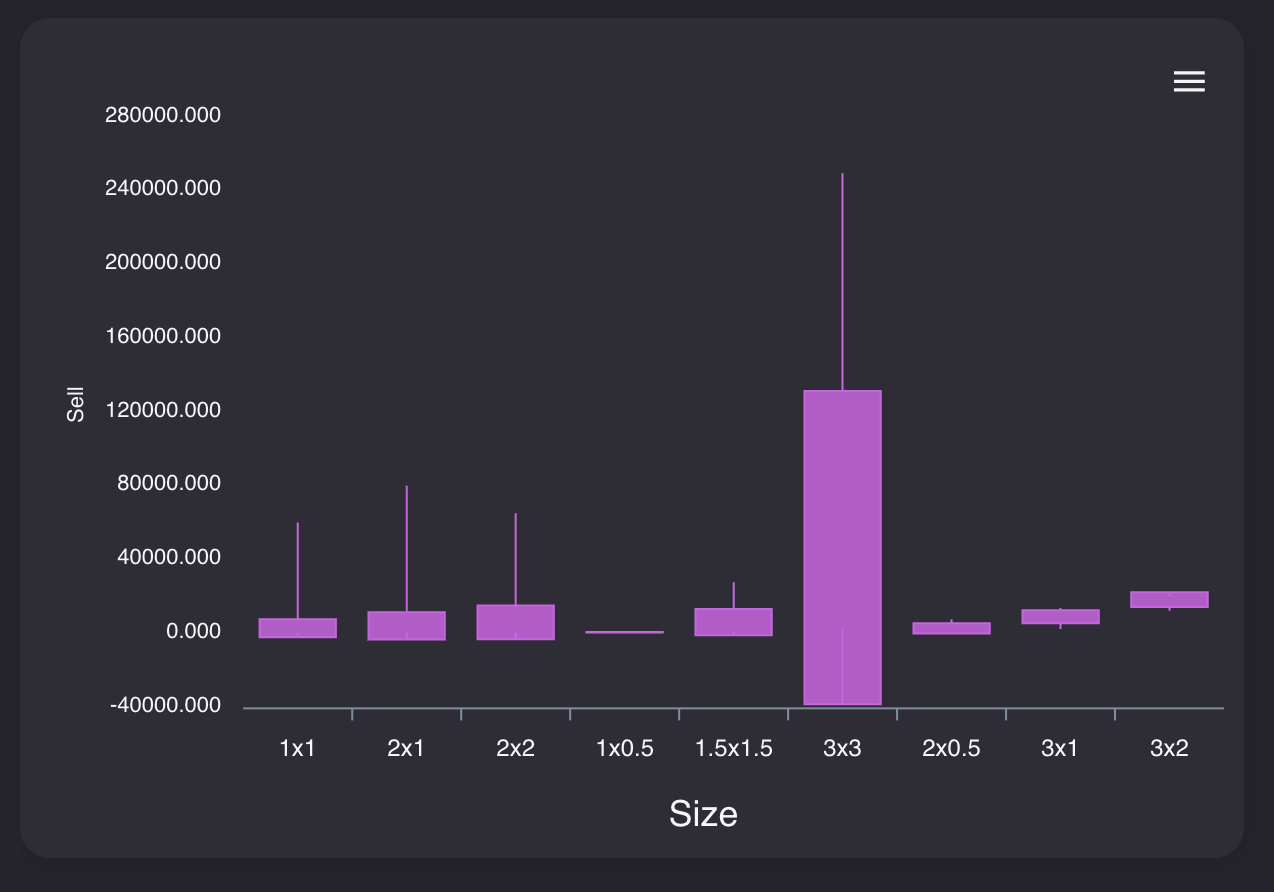
そこまではっきりとカテゴリごとに差が出ているわけではありませんが、最大値、最小値などのばらつきが見てとれます。重要な指標第2位は「Size毎の平均売却額」
サイズはその家具が何x何マスのアイテムなのかを表しています。
1x1より2x1、2x1より2x2のアイテムが高いのが分かります。
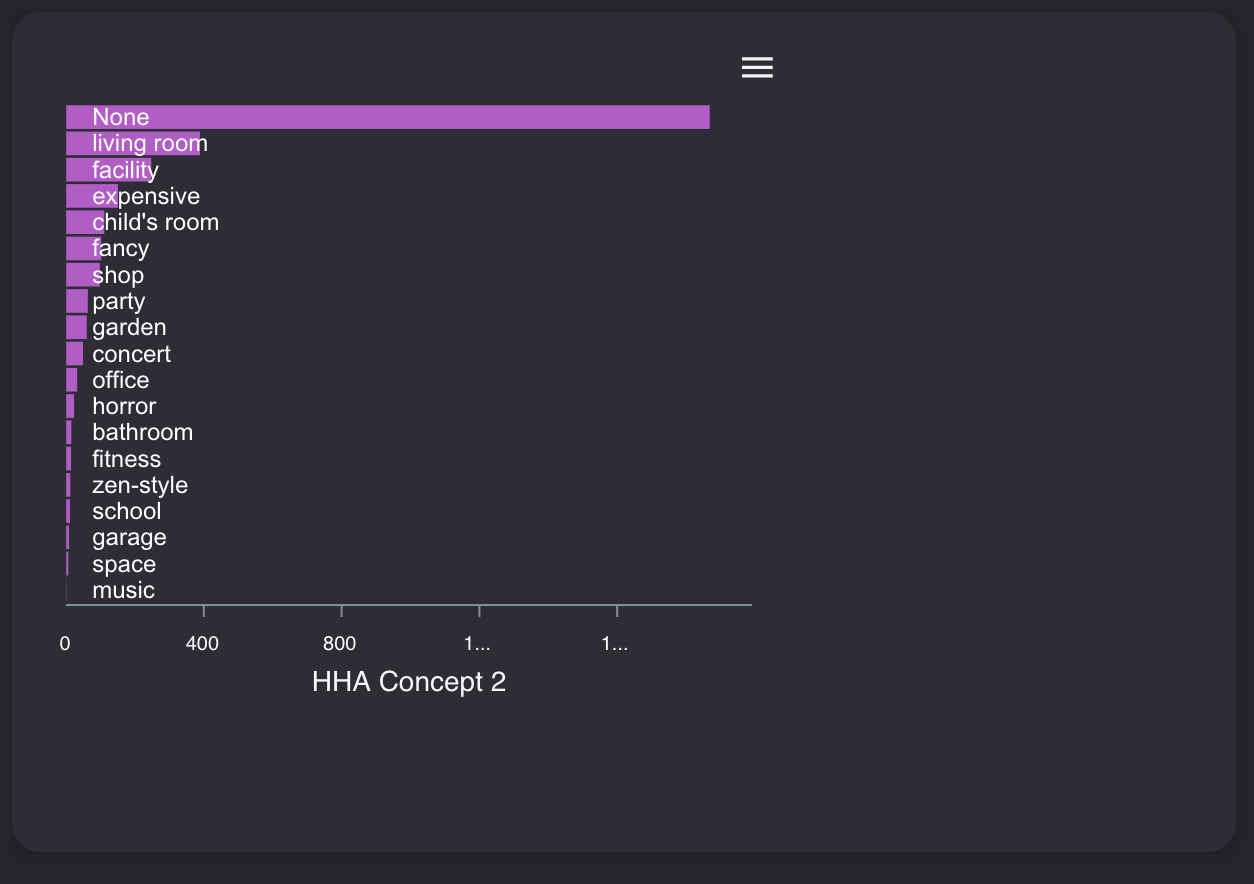
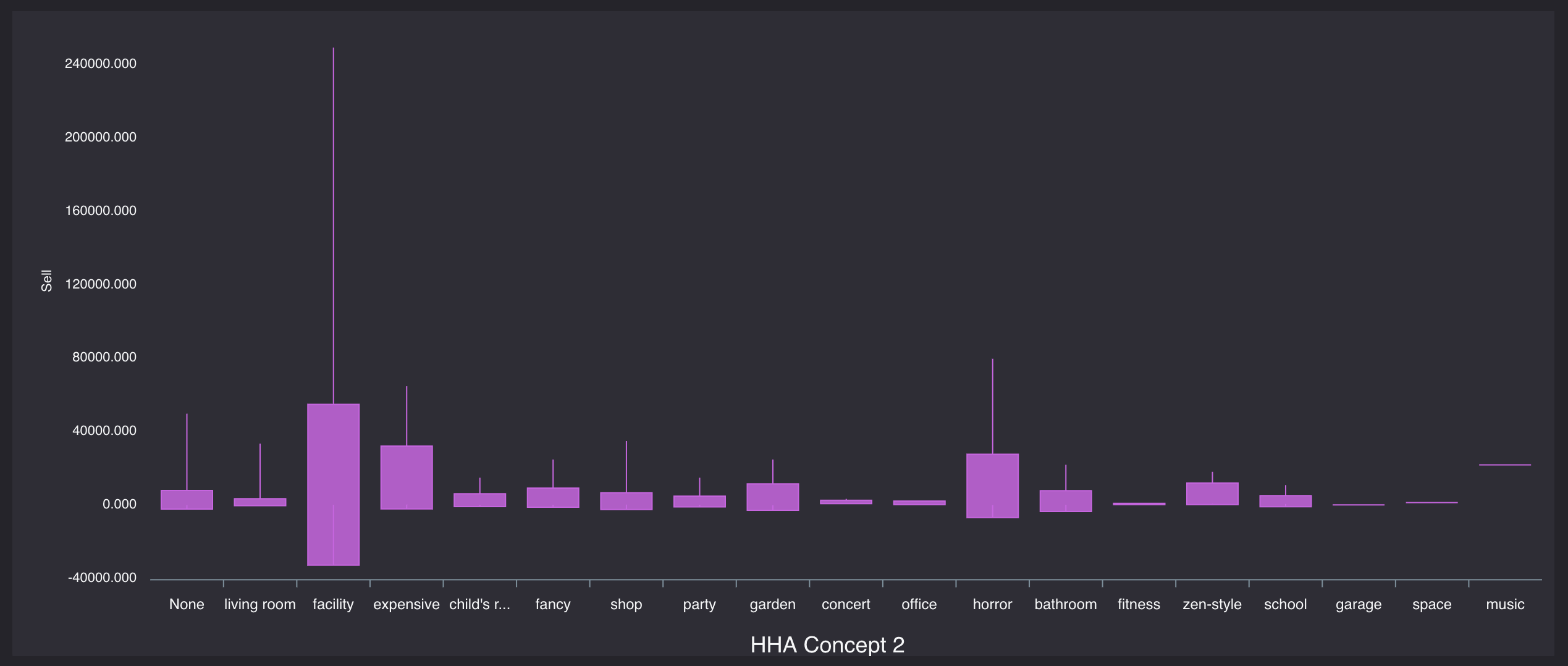
3x3のものが異様に高級だったりするのもわかります。重要な指標第3位は「HHA Concept 2毎の平均売却額」
「HHA Concept 2」は家具のコンセプトを表します。いわゆる家具のシリーズというやつですね。
Noneはコンセプトなしですが、リビングルームシリーズや、和室、ラグジュアリーシリーズだったりがあります。
たしかにシリーズによって金額に大きな差が見られます。
「expensive」コンセプトは高く、「living room」コンセプト、「office」コンセプトなどはリーズナブルなのがわかります。
これらの値を考慮して、予測値を出している模様検証データによる予測結果
答え合わせ?
今回答え合わせ用に5つの家具をピックアップしておきました。
VARISTAで予測をし、それぞれ答え合わせをしていきます。
予測のフォーマットを整数にして、予測実行!
ダブルソファ
タグ サイズ コンセプト Sofa 2x1 living room 売却価格: 1300ベル
予想売却価格: 1115ベル
誤差: -285ベルキャンディマシン
タグ サイズ コンセプト Shop 1x1 shop 売却価格: 700ベル
予想売却価格: 916ベル
誤差: +216ベルハンモック
タグ サイズ コンセプト Bed 2x1 outdoors 売却価格: 325ベル
予想売却価格: 318ベル
誤差: -7ベル
ほぼぴったり!!?DJブース
タグ サイズ コンセプト Musical Instrument 2x1 party 売却価格: 2325ベル
予想売却価格: 2501ベル
誤差: +176ベルくまのトクダイちゃん
タグ サイズ コンセプト Animal 3x3 fancy 売却価格: 6300ベル
予想売却価格: 6008ベル
誤差: -292ベルおわり?
結構な精度が出せましたが、ゲームのマスターデータはもともと、一定のルールのもと金額などが決められているため、予測がしやすかったのかもしれません。(それかどっかでリークしてる?確認します。)
このように、自分に親しみのあるデータで分析を行うとやっぱり楽しいですよね?
みなさんも是非遊んでみてください!







- 投稿日:2020-05-30T22:34:51+09:00
.NET Frameworkのbzip2ライブラリを調査
.NET Framework で bzip2 をサポートするライブラリについて調べます。Python や bzcat と処理速度を比較します。
ライブラリ
bzip2 をサポートする 3 種類のライブラリを見付けました。
- SharpZipLib: マネージドコードによる再実装
- SharpCompress: マネージドコードによる再実装
- AR.Compression.BZip2 ネイティブライブラリのラッパー
これらのライブラリでのマルチストリームの扱いと伸張の所要時間を確認します。
マルチストリーム
個別に bzip2 で圧縮して連結したデータをマルチストリームと呼びます。
作成例$ echo -n hello | bzip2 > a.bz2 $ echo -n world | bzip2 > b.bz2 $ cat a.bz2 b.bz2 > ab.bz2 $ hd ab.bz2 00000000 42 5a 68 39 31 41 59 26 53 59 19 31 65 3d 00 00 |BZh91AY&SY.1e=..| 00000010 00 81 00 02 44 a0 00 21 9a 68 33 4d 07 33 8b b9 |....D..!.h3M.3..| 00000020 22 9c 28 48 0c 98 b2 9e 80 42 5a 68 39 31 41 59 |".(H.....BZh91AY| 00000030 26 53 59 59 ce 7b cb 00 00 02 01 80 04 04 90 80 |&SYY.{..........| 00000040 20 00 30 cd 00 c1 a4 c0 71 77 24 53 85 09 05 9c | .0.....qw$S....| 00000050 e7 bc b0 |...| 00000053SharpZipLib
複数の圧縮アルゴリズムをサポートしています。
bzip2 の実装は以下にあります。
最小構成
bzip2 の伸張は、以下の 6 ファイルだけで行えることを確認しました。
- src/ICSharpCode.SharpZipLib/BZip2/BZip2Constants.cs
- src/ICSharpCode.SharpZipLib/BZip2/BZip2Exception.cs
- src/ICSharpCode.SharpZipLib/BZip2/BZip2InputStream.cs
- src/ICSharpCode.SharpZipLib/Checksum/BZip2Crc.cs
- src/ICSharpCode.SharpZipLib/Checksum/IChecksum.cs
- src/ICSharpCode.SharpZipLib/Core/Exceptions/SharpZipBaseException.cs
テスト
最小構成ではなく、NuGet で取得したライブラリを使用します。
nuget install SharpZipLib cp SharpZipLib.1.2.0/lib/net45/ICSharpCode.SharpZipLib.dll .マルチストリームの例として作った ab.bz2 の伸張を試みます。
※ Mono には古いバージョンの ICSharpCode.SharpZipLib.dll が取り込まれています。パスを書かないとそちらが参照されるため、NuGet で取得した方の DLL をパス付きで参照します。
#r "SharpZipLib.1.2.0/lib/net45/ICSharpCode.SharpZipLib.dll" open System.IO open ICSharpCode.SharpZipLib.BZip2 do use fs = new FileStream("ab.bz2", FileMode.Open) use bz = new BZip2InputStream(fs) use sr = new StreamReader(bz) printfn "%s" (sr.ReadToEnd())hello最初のストリームしか処理されません。
BZip2InputStream.cs を眺めてもマルチストリームに対応した作りにはなっていないようなので、逐次的に読み込む必要があります。
※
IsStreamOwnerがtrueの場合、処理の完了後に渡したストリームfsが閉じられます。デフォルトではtrueのためfalseを指定します。#r "SharpZipLib.1.2.0/lib/net45/ICSharpCode.SharpZipLib.dll" open System.IO open ICSharpCode.SharpZipLib.BZip2 do use fs = new FileStream("ab.bz2", FileMode.Open) while fs.Position < fs.Length do use bz = new BZip2InputStream(fs, IsStreamOwner = false) use sr = new StreamReader(bz) printfn "%s" (sr.ReadToEnd())hello worldSharpCompress
複数の圧縮アルゴリズムをサポートしています。
bzip2 の実装は以下にあります。
このディレクトリは単独で抜き出して使えます。ただ一点、独自に定義している
CompressionModeが不足しますが、既存のもので代用できました。BZip2Stream.cs(追加)using System.IO.Compression;最小構成
bzip2 の伸張は、以下の 3 ファイルだけで行えることを確認しました。
- src/SharpCompress/Compressors/BZip2/BZip2Constants.cs
- src/SharpCompress/Compressors/BZip2/CBZip2InputStream.cs
- src/SharpCompress/Compressors/BZip2/CRC.cs
ただし
class CBZip2InputStreamはinternalになっているため、publicにする必要があります。テスト
最小構成ではなく、NuGet で取得したライブラリを使用します。
nuget install sharpcompress cp SharpCompress.0.25.1/lib/net46/SharpCompress.dll .マルチストリームの例として作った ab.bz2 の伸張を試みます。
※
BZip2Streamのコンストラクターの最後の引数は、マルチストリームを読み進めるかどうかのフラグです。#r "SharpCompress.dll" open System.IO open SharpCompress.Compressors do use fs = new FileStream("ab.bz2", FileMode.Open) use bz = new BZip2.BZip2Stream(fs, CompressionMode.Decompress, true) use sr = new StreamReader(bz) printfn "%s" (sr.ReadToEnd())実行結果helloworldマルチストリームに対するサポートがあるため、一気に最後まで読み進めることができました。
マルチストリームのフラグを
falseにすると、1 つのストリームの終端に達した時点でfsが閉じられてしまいます。CBZip2InputStream.cs を見ても、開いたままにすることは想定されていないようです。そのため逐次的に読み進めるにはDisposeを無視するような小細工をするしかなさそうです。#r "SharpCompress.dll" open System.IO open SharpCompress.Compressors do let mutable ignore = true use fs = { new FileStream("ab.bz2", FileMode.Open) with override __.Dispose disposing = if not ignore then base.Dispose disposing } while fs.Position < fs.Length do use bz = new BZip2.BZip2Stream(fs, CompressionMode.Decompress, false) use sr = new StreamReader(bz) printfn "%s" (sr.ReadToEnd()) ignore <- false実行結果hello worldAR.Compression.BZip2
他のライブラリとは違って bzip2 に特化しています。伸長と圧縮は 1 つのクラスで実装されているため、分離して最小構成を調べるのは省略します。
NuGet に登録されています。
ビルド
ライブラリを Mono と共用するには少し手を入れる必要があるため、今回は NuGet は使わずに自分でビルドします。
P/Invoke で指定する DLL のファイル名を変更します。
10: private const string DllName = "libbz2";こうすれば Windows では libbz2.dll、WSL では libbz2.so が使用されます。WSL ではカレントディレクトリになくても /usr/lib/libbz2.so が参照されます。
DLL をビルドします。
csc -o -out:AR.Compression.BZip2.dll -t:library -unsafe sources/AR.BZip2/*.csWindows 用の bzip2 は以下で配布されているバイナリを利用します。
- Releases · philr/bzip2-windows
DLL only (libbz2.dll) | 64-bit (x64)テスト
マルチストリームの例として作った ab.bz2 の伸張を試みます。
※
BZip2Streamのコンストラクターの最後の引数がtrueの場合、処理の完了後に渡したストリームfsは開いたままになります。デフォルトではfalseのためtrueを指定します。SharpZipLib の IsStreamOwner と用途は同じですが指定方法が逆です。マルチストリームとは関係ありません。#r "AR.Compression.BZip2.dll" open System.IO open System.IO.Compression do use fs = new FileStream("ab.bz2", FileMode.Open) use bz = new BZip2Stream(fs, CompressionMode.Decompress, false) use sr = new StreamReader(bz) printfn "%s" (sr.ReadToEnd())実行結果helloworldすべてのストリームが一括で処理されました。BZip2Stream.cs を見ても、逐次的に読み進めることは想定されていないようです。次で見るベースストリームの扱いと合わせて考えても、改造なしで対応することはできないようです。
ベースストリームの読み込み
それぞれのライブラリで、渡されたベースストリームの読み込み個所を確認します。
※ .NET での Stream のことをベースストリームと呼んで、bzip2 の意味でのストリームと区別します。
417: thech = baseStream.ReadByte();
- SharpCompress: src/SharpCompress/Compressors/BZip2/CBZip2InputStream.cs
231: int magic0 = bsStream.ReadByte(); 232: int magic1 = bsStream.ReadByte(); 233: int magic2 = bsStream.ReadByte(); 242: int magic3 = bsStream.ReadByte(); 378: thech = (char)bsStream.ReadByte(); 649: thech = (char)bsStream.ReadByte(); 717: thech = (char)bsStream.ReadByte(); 814: thech = (char)bsStream.ReadByte();
- AR.Compression.BZip2: sources/AR.BZip2/BZip2Stream.cs
9: private const int BufferSize = 128 * 1024; 14: private readonly byte[] _buffer = new byte[BufferSize]; 368: _data.avail_in = _stream.Read(_buffer, 0, ufferSize);SharpZipLib と SharpCompress では必要に応じて
ReadByteで 1 バイトずつ読み進めています。そのため bzip2 のストリームの区切りで抜けても、オーバーランすることはないようです。thech(the character?) という変数名が共通していることから、何か共通の元ネタがあるのかもしれません。(libbz2 にはこの変数名は見当たりません)AR.Compression.BZip2 では固定長でバッファに読み込んでいます。自前で伸張していないため、バイト単位で読み進めることはできないのでしょう。もし bzip2 のストリームごとに処理を区切るとしてもオーバーランしてしまうため、何らかの対策が必要です。
バイトごとに読み進めるのはベースストリームの位置に関して正確ではありますが、処理速度的には不利です。
計測
巨大なファイルの伸張に掛かる時間を比較します。
Wikipedia 日本語版のダンプデータを使用します。このファイルはマルチストリーム構成です。
- https://dumps.wikimedia.org/jawiki/
jawiki-20200501-pages-articles-multistream.xml.bz2 3.0 GB逐次読み込み
SharpZipLib と SharpCompress でストリームを逐次的に読み込みます。
test1.fsx#r "SharpZipLib.1.2.0/lib/net45/ICSharpCode.SharpZipLib.dll" open System open System.IO open ICSharpCode.SharpZipLib.BZip2 let target = "jawiki-20200501-pages-articles-multistream.xml.bz2" do use fs = new FileStream(target, FileMode.Open) let buffer = Array.zeroCreate<byte>(1024 * 1024) let mutable streams, bytes = 0, 0L while fs.Position < fs.Length do use bz = new BZip2InputStream(fs, IsStreamOwner = false) let mutable len = 1 while len > 0 do len <- bz.Read(buffer, 0, buffer.Length) bytes <- bytes + int64 len streams <- streams + 1 Console.WriteLine("streams: {0:#,0}, bytes: {1:#,0}", streams, bytes)test2.fsx#r "SharpCompress.dll" open System open System.IO open SharpCompress.Compressors let target = "jawiki-20200501-pages-articles-multistream.xml.bz2" do let mutable ignore = true use fs = { new FileStream(target, FileMode.Open) with override __.Dispose disposing = if not ignore then base.Dispose disposing } let buffer = Array.zeroCreate<byte>(1024 * 1024) let mutable streams, bytes = 0, 0L while fs.Position < fs.Length do use bz = new BZip2.BZip2Stream(fs, CompressionMode.Decompress, false) let mutable len = 1 while len > 0 do len <- bz.Read(buffer, 0, buffer.Length) bytes <- bytes + int64 len streams <- streams + 1 ignore <- false Console.WriteLine("streams: {0:#,0}, bytes: {1:#,0}", streams, bytes)実行結果$ time ./test1.exe # SharpZipLib streams: 24,957, bytes: 13,023,068,290 real 16m2.849s $ time ./test2.exe # SharpCompress streams: 24,957, bytes: 13,023,068,290 real 18m26.520sSharpZipLib の方が速いようです。
一括読み込み
SharpCompress と AR.Compression.BZip2 で全ストリームを一括で読み込みます。
test3.fsx#r "SharpCompress.dll" open System open System.IO open SharpCompress.Compressors let target = "jawiki-20200501-pages-articles-multistream.xml.bz2" do use fs = new FileStream(target, FileMode.Open) use bz = new BZip2.BZip2Stream(fs, CompressionMode.Decompress, true) let buffer = Array.zeroCreate<byte>(1024 * 1024) let mutable bytes, len = 0L, 1 while len > 0 do len <- bz.Read(buffer, 0, buffer.Length) bytes <- bytes + int64 len Console.WriteLine("bytes: {0:#,0}", bytes)test4.fsx#r "AR.Compression.BZip2.dll" open System open System.IO open System.IO.Compression let target = "jawiki-20200501-pages-articles-multistream.xml.bz2" do use fs = new FileStream(target, FileMode.Open) use bz = new BZip2Stream(fs, CompressionMode.Decompress, false) let buffer = Array.zeroCreate<byte>(1024 * 1024) let mutable bytes, len = 0L, 1 while len > 0 do len <- bz.Read(buffer, 0, buffer.Length) bytes <- bytes + int64 len Console.WriteLine("bytes: {0:#,0}", bytes)実行結果$ time ./test3.exe # SharpCompress bytes: 13,023,068,290 real 17m36.925s $ time ./test4.exe # AR.Compression.BZip2 bytes: 13,023,068,290 real 7m50.165sAR.Compression.BZip2 はネイティブライブラリを呼び出しているだけあって速いです。
Python
Python の bz2 モジュールと比較します。こちらもネイティブのラッパーです。
test5.py(逐次)import bz2 target = "jawiki-20200501-pages-articles-multistream.xml.bz2" streams = 0 bytes = 0 size = 1024 * 1024 # 1MB with open(target, "rb") as f: bz2d = bz2.BZ2Decompressor() data = [] while data or (data := f.read(size)): bytes += len(bz2d.decompress(data)) data = bz2d.unused_data if bz2d.eof: bz2d = bz2.BZ2Decompressor() streams += 1 print("streams: {:,}, bytes: {:,}".format(streams, bytes))test6.py(一括)import bz2 target = "jawiki-20200501-pages-articles-multistream.xml.bz2" bytes = 0 size = 1024 * 1024 # 1MB with bz2.open(target, "rb") as f: while (data := f.read(size)): bytes += len(data) print("bytes: {:,}".format(bytes))実行結果$ time py.exe test5.py # 逐次 streams: 24,957, bytes: 13,023,068,290 real 8m12.155s $ time py.exe test6.py # 一括 bytes: 13,023,068,290 real 8m1.476s処理の大半が libbz2 で行われているため、それ以外のオーバーヘッドは少ないようです。.NET との主な違いはバッファを使い回していない点です。
bzcat
WSL1 の bzcat コマンドも計測します。
$ time bzcat jawiki-20200501-pages-articles-multistream.xml.bz2 > /dev/null real 8m21.056s user 8m5.563s sys 0m15.422s次で見ますが Mono の AR.Compression.BZip2 より遅いです。WSL1 のリダイレクトにオーバーヘッドがあるためでしょうか。
まとめ
結果をまとめます。WSL1 (Mono) での計測結果を加えます。
逐次 (Win) 逐次 (WSL1) 一括 (Win) 一括 (WSL1) SharpZipLib 16m02.849s 22m49.375s SharpCompress 18m26.520s 23m56.694s 17m36.925s 22m54.247s AR.Compression.BZip2 7m50.165s 7m41.580s Python (bz2) 8m12.155s 8m45.590s 8m01.476s 8m28.749s bzcat 8m21.056s マネージドコードで実装されたライブラリは倍以上の時間が掛かりました。マネージド縛りがなければ AR.Compression.BZip2 を使った方が無難です。
※ System.IO.Compression.GZipStream が利用している DeflateStream は、独自実装からネイティブのラッパーに切り替えたようです。
.NET Framework 4.5以降では、DeflateStream クラスは、圧縮のために zlib ライブラリを使用します。
関連記事
Wikipedia のダンプについては以下の記事を参照してください。
参考
SharpZipLib で bzip2 を扱っている記事です。
SharpCompress に言及している記事です。
- 投稿日:2020-05-30T21:32:56+09:00
Python--Matplotの第1歩
Matplotlib
- グラフ描画ライブラリ
- 公式サイト
- 基本Python + Numpy + matplotlib + SciPy + etc.の組み合わせて使用
インストール
pip install matplotlib最初の例
import matplotlib.pyplot as plt # 呪い squares = [1, 4, 9, 16, 25] plt.plot(squares) # defalutは点同士が直線で結びついている plt.show() # 上の指示に従い、描画し、見せる
日本語表示
デフォルトは日本語使用できないため、ちょっとした設定が必要になります。
要は、matplotlibのフォント設定を日本語対応のフォントを変更する。
- https://ipafont.ipa.go.jp/node17#jp からIPAexフォントをダウンロード、現時点は「IPAexフォント Ver.004.01」が最新
- ダウンロードしたファイルを解凍し、中の
ipaexg.ttfファイルを${オブジェクトパス}\venv\Lib\site-packages\matplotlib\mpl-data\fonts\ttfにコピーする- ${オブジェクトパス}\venv\Lib\site-packages\matplotlib\mpl-dataは以下にあるmatplotlibrcを開き
- font.familyで検索
#font.family : sans-serifの下にfont.family : IPAexGothicを追記する- matplotlibのキャッシュの保存先の内容を全部削除する
下記のコードでフォントパスとキャッシュの保存先を調べることができる
print(matplotlib.matplotlib_fname()) # フォントパス print(matplotlib.get_cachedir()) # キャッシュの保存先もう一つ方法は、設定ファイルを修正しないが、毎回下記のコードを追記しないといけない
plt.rcParams['font.sans-serif']=['IPAexGothic']もしくは
plt.rcParams["font.family"] = "IPAexGothic"飾り
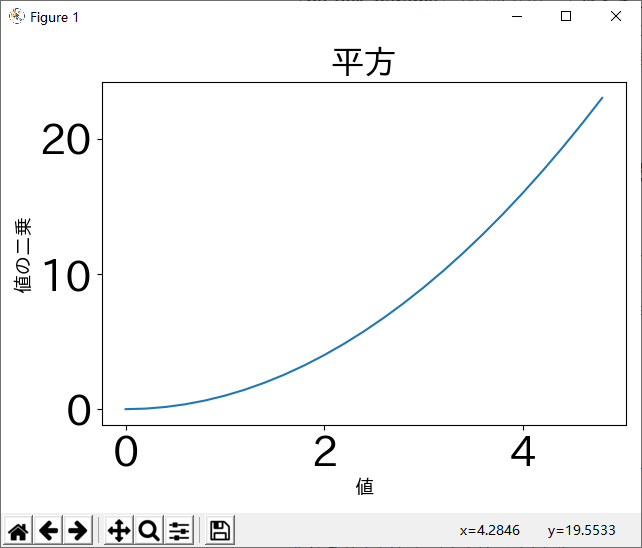
import matplotlib.pyplot as plt squares = [1, 4, 9, 16, 25] plt.plot(squares, linewidth = 5) # 線をちょっと太くする plt.title("平方", fontsize = 24) plt.xlabel("値", fontsize = 14) plt.ylabel("値の二乗", fontsize = 14) # 軸の目盛りの表示設定 plt.tick_params(axis = 'both', labelsize = 14) plt.show()
import numpy as np import matplotlib.pyplot as plt # 0から5を0.2刻みの点を作成することにより、線が滑らかに見える x = np.arange(0., 5., 0.2) plt.plot(x, x * x) plt.title("平方", fontsize = 24) plt.xlabel("値", fontsize = 14) plt.ylabel("値の二乗", fontsize = 14) # 目盛りの文字サイズをちょっと大きめに設定 plt.tick_params(labelsize = 30) plt.show()
目盛りのサイズが大きくすると、X軸やY軸のラベルがはみ出して、見えなくなるが、もちろん画面のサイズを調整して、見えるようにすればいいが、
plt.tight_layout()をplt.show()前に入れれば、自動的に収める状態で表示してくれる。import numpy as np import matplotlib.pyplot as plt x = np.arange(0., 5., 0.2) plt.plot(x, x * x) plt.title("平方", fontsize = 24) plt.xlabel("値", fontsize = 14) plt.ylabel("値の二乗", fontsize = 14) plt.tick_params(labelsize = 30) plt.tight_layout() plt.show()
点で表示したい(散布図)
scatter()を使用する。
import matplotlib.pyplot as plt x_values = [1, 2, 3, 4, 5] y_values = [1, 4, 9, 16, 25] plt.scatter(x_values, y_values, s=100) # sは点のサイズを指定 plt.show()
データは自動計算から取得する
import matplotlib.pyplot as plt x_values = list(range(1, 1001)) y_values = [x**2 for x in x_values] plt.scatter(x_values, y_values, s=4) plt.axis([0, 1100, 0, 1100000]) # 軸の範囲 plt.show()





- 投稿日:2020-05-30T21:32:07+09:00
Backpropagation (tf.custom_gradient) で self を使用したい (tensorflow)
custom_graident を使用する場合の通常の書き方
@tf.custom_gradient def gradient_reversal(x): y = x def grad(dy): return - dy return y, grad # model 内で使用する場合 class MyModel(tf.keras.Model): def __init__(self): super(MyModel, self).__init__() def call(self, x): return gradient_reversal(x)custom_gradient 内でスコープ外の変数(self等)を使用したい場合
class MyModel2(tf.keras.Model): def __init__(self): super(MyModel2, self).__init__() self.alpha = self.add_weight(name="alpha", initializer=tf.keras.initializers.Ones()) @tf.custom_gradient def forward(self, x): y = self.alpha * x def backward(w, variables=None): with tf.GradientTape() as tape: tape.watch(w) z = - self.alpha * w grads = tape.gradient(z, [w]) return z, grads return y, backward def call(self, x): return self.forward(x)
ドキュメント 内での引数が
dyになっているので計算済みのものが渡ってくるかと思いきや、Backpropagation 時の実行関数として指定できる (上記のbackwardメソッド)
bakwardメソッド外のスコープの変数を使用する場合は、variables=Noneを受け取るようにしないと以下のようなエラーが発生する (ドキュメントのArgs内でも説明されている)TypeError: If using @custom_gradient with a function that uses variables, then grad_fn must accept a keyword argument 'variables'.検証用コード
import tensorflow as tf optimizer = tf.keras.optimizers.Adam(learning_rate=0.1) class MyModel(tf.keras.Model): def __init__(self): super(MyModel, self).__init__() self.alpha = self.add_weight(name="alpha", initializer=tf.keras.initializers.Ones()) @tf.custom_gradient def forward(self, x): y = self.alpha * x tf.print("forward") tf.print(" y: ", y) def backward(w, variables=None): z = self.alpha * w tf.print("backward") tf.print(" z: ", z) tf.print(" variables: ", variables) return z, variables return y, backward def call(self, x): return self.forward(x) class MyModel2(tf.keras.Model): def __init__(self): super(MyModel2, self).__init__() self.alpha = self.add_weight(name="alpha", initializer=tf.keras.initializers.Ones()) @tf.custom_gradient def forward(self, x): y = self.alpha * x tf.print("forward") tf.print(" y: ", y) def backward(w, variables=None): with tf.GradientTape() as tape: tape.watch(w) z = - self.alpha * w grads = tape.gradient(z, [w]) tf.print("backward") tf.print(" z: ", z) tf.print(" variables: ", variables) tf.print(" alpha: ", self.alpha) tf.print(" grads: ", grads) return z, grads return y, backward def call(self, x): return self.forward(x) for model in [MyModel(), MyModel2()]: print() print() print() print(model.name) for i in range(10): with tf.GradientTape() as tape: x = tf.Variable(1.0, tf.float32) y = model(x) grads = tape.gradient(y, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) tf.print("step") tf.print(" y:", y) tf.print(" grads:", grads) print()
- 投稿日:2020-05-30T20:29:48+09:00
Django REST frameworkの基本
はじめに
Django REST frameworkを使うと、簡単にAPIを作成することができます。
ここでは、Django REST frameworkについて、最低限知っておきたいことにしぼって解説します。
settings.pyへの追記
INSTALLED_APPSにrest_frameworkを追記します。settings.pyINSTALLED_APPS = [ 'rest_framework', # 追加 ]serializerの作成
次に、serializerを作成していきます。
serializers.pyfrom rest_framework import serializers class SampleSerializer(serializers.ModelSerializer): class Meta: model = 対象モデル fields = 含めるフィールド(全部の場合は'__all__') # または、exclude = (除外したいフィールド)viewの作成
serializerを作成したら、
views.pyに追記します。views.pyfrom rest_framework import generics class SampleListAPI(generics.ListAPIView): queryset = 対象モデル.objects.all() serializer_class = シリアライザー class SampleDetailAPI(generics.ListAPIView): queryset = 対象モデル.objects.all() serializer_class = シリアライザー
urls.pyの設定最後に、ルーティングの設定をして一通り完了です。
urls.pyfrom django.urls import path from . import views urlpatterns = [ path('api/sample/list', views.SampleListAPI.as_view(), name='api_sample_list'), path('api/sample/detail/<int:pk>/', views.SampleDetailAPI.as_view(), name='api_sample_detail'), ]まとめ
ここでは、Django REST frameworkを用いたAPI作成方法について解説しました。
- 投稿日:2020-05-30T20:25:46+09:00
Djangoを用いてhtmlからPythonファイルを実行する
ここで書くこと
この記事では「Djangoを用いてWebページからサーバ上に用意したPythonファイルを実行し、htmlから渡したデータをcsvファイルに出力する方法」について書いています。
また、執筆環境は
OS:macOS Catalina バージョン 10.15.4
Python:3.7.6
Django:3.0.3
となっています。Djangoについて
前回の記事にてDjangoのインストール→htmlの表示までの流れについて書かせていただきましたので、Djangoの導入等についてはそちらをご参考ください。
Pythonファイルの準備
Pythonファイルの作成
まず、実行したいPythonファイルをDjangoのサーバ上に用意します。説明のために今回は以下のようなPythonファイルを用意します。
write_data.py# coding:utf-8 import os import csv # htmlからのデータをcsvファイルに記録 def write_csv(data): datas = [data] with open(os.getcwd()+'/myapp/application/'+'data.csv','a') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(datas)これにより、write_csv()の引数にデータを渡して呼び出すことでdata.csvにそのデータが書き込まれます。なおここでは
<アプリ名>/applicationフォルダ内にPythonファイルを配置&csvファイルを出力することを想定しているためos.getcwd()+'/myapp/application/'+'data.csv'としていますが、この部分は環境に応じて適宜読み替えてください。Pythonファイルの配置
用意したPythonファイルをDjangoのサーバ上に配置します。Pythonファイルを
<アプリ名>/applicationフォルダ内に置く場合、アプリ内のディレクトリは以下のようになるかと思います。<プロジェクト名> - db.sqlite3 - manage.py - <プロジェクト名> - __init__.py - asgi.py - settings.py - urls.py - wsgi.py - __pycashe__ - (.pycファイルが複数) - <アプリ名> - __init__.py - admin.py - apps.py - models.py - tests.py - urls.py - views.py - migrations - __init__.py - application # 作成したフォルダ - write_data.py # 用意したPythonファイル - templates - staticもちろん、ここに置かないといけないという訳ではないのでファイルの配置場所は任意の場所で大丈夫です。
htmlからPythonファイルを実行できるようにする
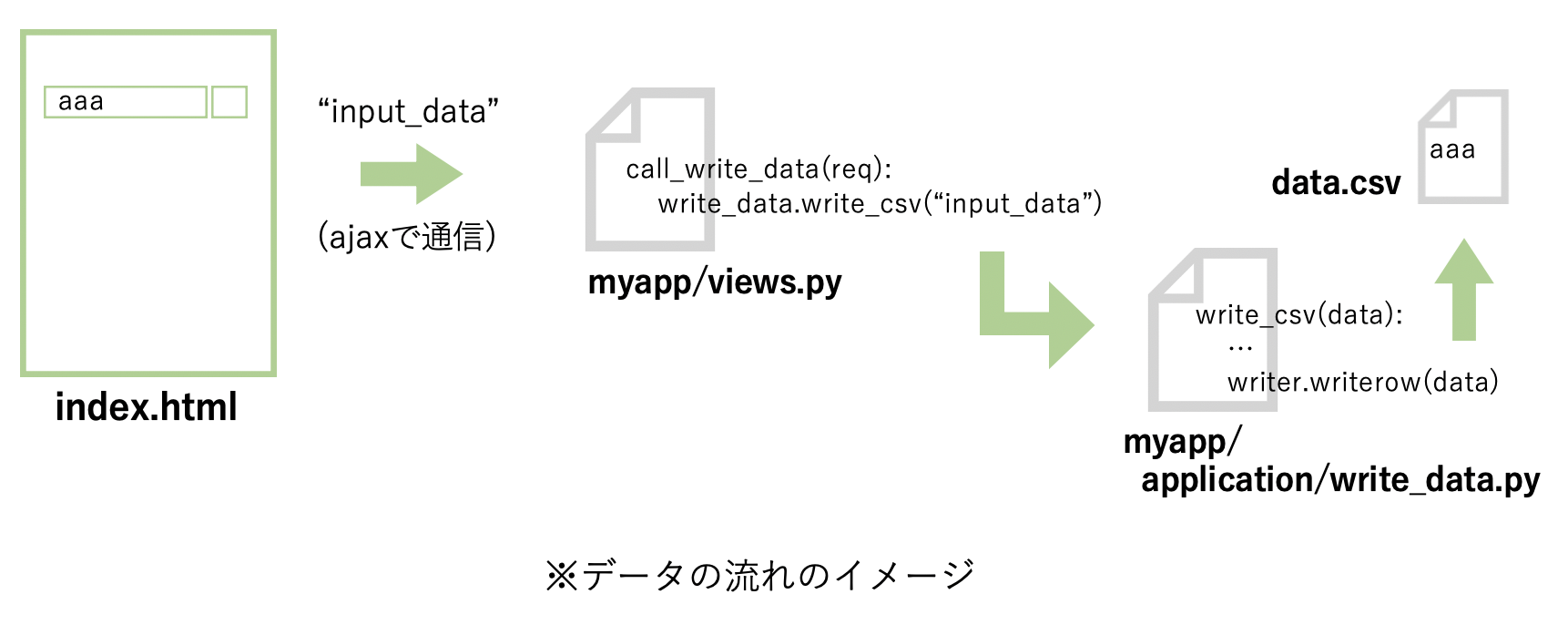
ファイルの用意と配置が完了しましたら、実際にhtmlからそのPythonファイルを実行させてcsvファイルを作成してみます。その前に、データの流れがどのようになっているかを把握してから実装した方が作業しやすいと思いますので、今回想定するデータの流れを書いてみたいと思います。
パワポで作ってみました、ガサツな図で申し訳ありません、、
簡略化の為にプログラムと異なる部分も多々ありますが、csvファイルへの書き込みまでのデータの流れとしてはこんな感じです。何となくでもイメージが伝われば嬉しいです。html(index.html)
→myapp/views.pyのcall_write_data()にデータを送信
→call_write_data()内でapplication/write_data.pyのwrite_csv()メソッドを実行
→それにより渡したデータがcsvファイルに書き込まれる言葉で表すとこんな感じです。これを踏まえ、次から実際にhtmlからPythonファイルを実行できるよう各ファイルを編集していきます。
html:ajaxを用いてviews.pyにデータを送信する
views.py内のcall_write_data()メソッドにデータを渡す為に、html上でajaxを用いてデータを送信してみたいと思います。ここに関しては色々な方法があるかと思いますので、アプリケーションに合う方法を用いていただければと思います。
index.html{% load static %} <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <title>HTML</title> <link rel='stylesheet' type='text/css' href="{% static 'style.css' %}"/> <script type="text/javascript" src="{% static 'script.js' %}"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script> </head> <body> <span>文字を入力した後にボタンを押してください</span> <br> <input type="text" size="50" id="input_form"> <button type="button" onclick="clickBtn()">送信</button> <script> function clickBtn() { var txt = document.getElementById("input_form").value; $.ajax({ url: "{% url 'myapp:call_write_data' %}", method: 'GET', data: {"input_data": txt}, dataType: "text", contentType: "application/json", beforeSend: function(xhr, settings) { if (!csrfSafeMethod(settings.type) && !this.crossDomain) { xhr.setRequestHeader("X-CSRFToken", csrf_token); } }, error: function(xhr, status, error) { console.log("error") } }) .done(function(data) { console.log("Success"); }); // csrf_tokenの取得に使う function getCookie(name) { var cookieValue = null; if (document.cookie && document.cookie !== '') { var cookies = document.cookie.split(';'); for (var i = 0; i < cookies.length; i++) { var cookie = jQuery.trim(cookies[i]); // Does this cookie string begin with the name we want? if (cookie.substring(0, name.length + 1) === (name + '=')) { cookieValue = decodeURIComponent(cookie.substring(name.length + 1)); break; } } } return cookieValue; } // ヘッダにcsrf_tokenを付与する関数 function csrfSafeMethod(method) { // these HTTP methods do not require CSRF protection return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method)); }; } </script> </body> </html>送信ボタンを押すとclickBtn()が実行され、ajaxによりデータが送信されるようになっています。urlの部分は
myapp: call_write_dataとなっており、これによりviews.pyに記述したcall_write_data()というメソッドにデータが送信されます。データ部分は
data: {"input_data": txt}となっており、データを受け取る側では"input_data"と指定することで目的のデータを取得することができます。ここでは一つだけにしていますが、data: {"data1": txt1, "data2": txt2}のようにデータの個数や型などデータの形式については自由に設定できます。myapp/views.py:実行したいPythonファイルとメソッドを指定して実行する
myapp/views.pyfrom django.shortcuts import render from django.http import HttpResponse # application/write_data.pyをインポートする from .application import write_data # Create your views here. def index(req): return render(req, 'index.html') # ajaxでurl指定したメソッド def call_write_data(req): if req.method == 'GET': # write_data.pyのwrite_csv()メソッドを呼び出す。 # ajaxで送信したデータのうち"input_data"を指定して取得する。 write_data.write_csv(req.GET.get("input_data")) return HttpResponse()ここではajaxで送信されたデータを取得し、実行したいPythonファイルのメソッドにそのデータを渡して呼び出しています。
myapp/urls.py:htmlからviews.pyのcall_write_data()にデータを送信できるようにする
myapp/urls.pyfrom django.urls import path from . import views app_name = 'myapp' urlpatterns = [ path(r'', views.index, name='index'), # 以下を追記(views.pyのcall_write_data()にデータを送信できるようにする) path("ajax/", views.call_write_data, name="call_write_data"), ]パスを通すことで、html上からajax通信を用いてviews.pyの指定したメソッドにデータを送信できるようになります。
実際にcsvファイルに書き込まれるかを確認する
以上で必要な編集は完了です。
$ python manage.py runserverでサーバを立ち上げ、表示されたアドレスにアクセス(htmlを表示)し入力フォームに適当な文字を入力してから送信ボタンを押してみてください。
- <アプリ名> - __init__.py ... - application - write_data.py - data.csv # 生成されたcsvファイルこのようにアプリ内に作成したapplicationフォルダの中にcsvファイルが生成され、入力した文字列がファイルに記録されていれば問題なくデータが送信されている&Pythonファイルが実行されています。
補足
今回はhtmlからPythonファイルを実行し、送信されたデータをcsvファイルに書き込む方法についてご説明しましたがその逆も可能です。
説明の簡略化の為に、”write_data.pyから渡されたデータをviews.pyで取得しそれをhtmlに渡して表示する”ことを行ってみたいと思います。変更箇所のあるファイルだけ以下に載せていきます。
myapp/application/write_data.py
return_text()というメソッドを追記する。
myapp/application/write_data.py# coding:utf-8 import os import csv # htmlからのデータをcsvファイルに記録 def write_csv(data): datas = [data] with open(os.getcwd()+'/myapp/application/'+'data.csv','a') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(datas) # 以下を追記(return_text()を呼び出すと"Hello!!"が返される) + def return_text(): + return "Hello!!"myapp/views.py
write_data.pyにて追記したreturn_text()を呼び出し、返ってきた文字列を取得する(dataに格納する)。そのデータを
HttpResponse()を用いてhtmlに渡す。myapp/views.pyfrom django.shortcuts import render from django.http import HttpResponse # application/write_data.pyをインポートする from .application import write_data # Create your views here. def index(req): return render(req, 'index.html') # ajaxでurl指定したメソッド def call_write_data(req): if req.method == 'GET': # write_data.pyのwrite_csvメソッドを呼び出す。 # ajaxで送信したデータのうち"input_data"を指定して取得する。 write_data.write_csv(req.GET.get("input_data")) # write_data.pyの中に新たに記述したメソッド(return_text())を呼び出す。 + data = write_data.return_text() # 受け取ったデータをhtmlに渡す。 + return HttpResponse(data)index.html
ajax通信が成功するとHttpResponse()で渡した引数が
.done(function(data) {の部分に渡されるので、そのデータをページに表示する。index.html{% load static %} <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <title>HTML</title> <link rel='stylesheet' type='text/css' href="{% static 'style.css' %}"/> <script type="text/javascript" src="{% static 'script.js' %}"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script> </head> <body> <span>文字を入力した後にボタンを押してください</span> <br> <input type="text" size="50" id="input_form"> <button type="button" onclick="clickBtn()">送信</button> <!-- views.pyから渡された文字列を表示する。 --> + <br> + <span id="text"></span> <script> function clickBtn() { var txt = document.getElementById("input_form").value; $.ajax({ url: "{% url 'myapp:call_write_data' %}", method: 'GET', data: {"input_data": txt}, dataType: "text", contentType: "application/json", beforeSend: function(xhr, settings) { if (!csrfSafeMethod(settings.type) && !this.crossDomain) { xhr.setRequestHeader("X-CSRFToken", csrf_token); } }, error: function(xhr, status, error) { console.log("error") } }) .done(function(data) { // views.pyのcall_write_data()にてreturnしたHttpResponse(data)のデータはここで取得できる。 // フォームの下部に追記したspan部分の内容を書き換える。 + document.getElementById("text").textContent = data; console.log("Success"); }); // csrf_tokenの取得に使う function getCookie(name) { var cookieValue = null; if (document.cookie && document.cookie !== '') { var cookies = document.cookie.split(';'); for (var i = 0; i < cookies.length; i++) { var cookie = jQuery.trim(cookies[i]); // Does this cookie string begin with the name we want? if (cookie.substring(0, name.length + 1) === (name + '=')) { cookieValue = decodeURIComponent(cookie.substring(name.length + 1)); break; } } } return cookieValue; } // ヘッダにcsrf_tokenを付与する関数 function csrfSafeMethod(method) { // these HTTP methods do not require CSRF protection return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method)); }; } </script> </body> </html>これにより、送信ボタンを押して正しくPythonファイルが実行されると"Hello!!"という文字列がhtmlに渡され、入力フォームの下の部分に渡されたHello!!という文字列が表示されると思います。
これを応用することで、サーバ上のPythonファイルを実行しサーバ上のファイルのデータを読み書きしたり、そのデータをhtml上に反映させることが可能になります。
- 投稿日:2020-05-30T19:36:23+09:00
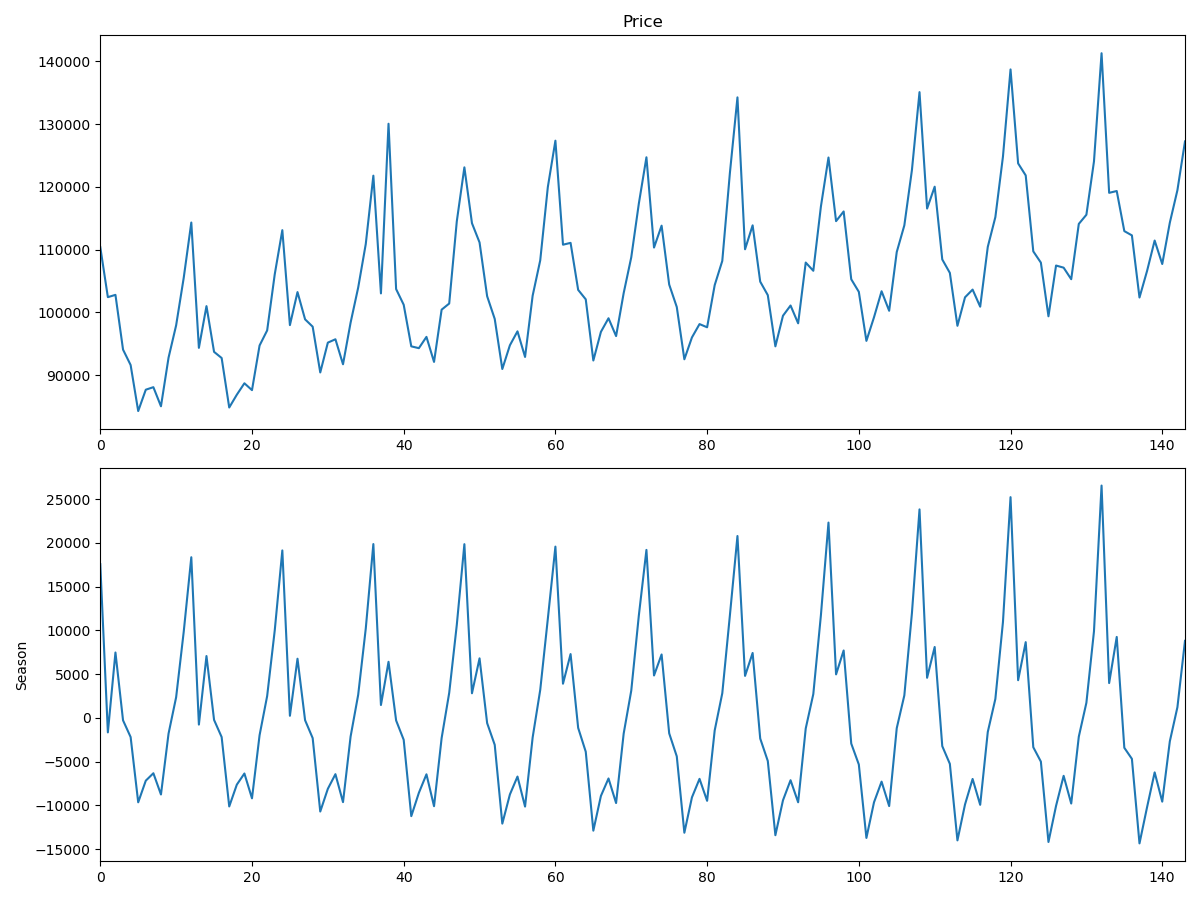
製造現場でよく見るCUM_plotがネットに落ちて無かったのでpythonで作ってみた
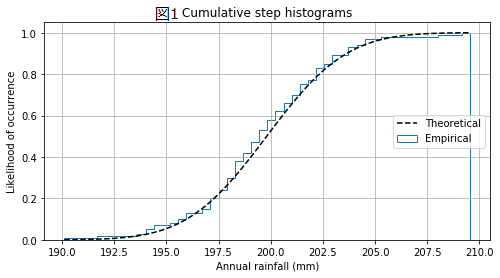
0.初めに
生産現場で不良解析をしていると、CUM_plotなるものをよく用いる。正規分布だと直線になり、外れ値や複数の正規分布が混じっているかなどが分かりやすい。ふとpythonで作成しようと思ったらどうしても図1のCUMが出てくるが、図2のCUMが出てこない。。。どうやら通常はCUMというと図1を示すよう。
という事で、図2のCUM作成にチャレンジしてみました。正しいか不明なので、誤り等あればご指摘いただけると助かります。
1.CUM plotとは?
累積分布関数(cumulative distribution)の略。ただしこれでググると図1しか出てこない。。。
https://ja.wikipedia.org/wiki/%E7%B4%AF%E7%A9%8D%E5%88%86%E5%B8%83%E9%96%A2%E6%95%B0
図1のCUMの作成方法は下記URL参照
https://matplotlib.org/3.1.1/gallery/statistics/histogram_cumulative.html2.CUMの作り方
図2のCUMをよく見るとy軸が正規分布を写像しているように見える。ただしそんなスケールはmatplotlibにないので、無理やりスケール変換し割り当てて見ました。
#宣言 from scipy.stats import norm import numpy as np import matplotlib.pyplot as plt #dataの作成 np.random.seed(19680803) mu = 200 sigma = 3 x = np.random.normal(mu, sigma, size=100) #累積分布関数の逆関数をxに割り当てる norm_arr = list() for no in range(1,len(x)+1): norm_arr.append(norm.ppf((no)/(len(x)+1))-norm.ppf(1/(len(x)+1))) norm_arr=norm_arr/max(norm_arr)#正規化 x.sort()#xを小さい順にソート #y軸表示の変更 scale =[] list_axis =[0.0001,0.001,0.01,0.05,0.1,0.2,0.3,0.5,0.7,0.8,0.9,0.95,0.99,0.999,0.9999] for no in list_axis: scale.append(norm.ppf(no)-norm.ppf(0.0001)) scale=scale/max(scale) #描画 fig, ax = plt.subplots(figsize=(8, 4)) linestyles = '-' ax.grid(True) ax.legend(loc='right') ax.set_title('Cumulative step histograms') ax.set_xlabel('data') ax.set_ylabel('Percentage') plt.yticks(scale,list_axis) ax.plot(x,norm_arr,label='linear',marker='o',markersize=1.0,linewidth=0.1,linestyle=linestyles) plt.show()実行すると上記図2がそのまま出力されます。
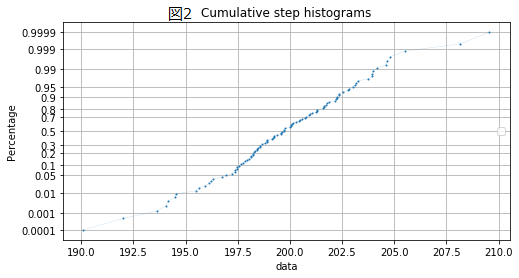
- 投稿日:2020-05-30T19:22:51+09:00
Lambdaでwebhookをとりあえず受け取れているかを確認するための関数を作ってみた
動機
先日M5STICKCを使ってLINE Beaconを試してみた際に、
Webhook先を今まで使ったことないGASにしてみたところ、
どこでハマってしまっているのかよくわからない状態になってしまった。知らない機能同士をまとめてためしたのが原因なので、Webhook先は毎回固定にしておいた方がいいのかもしれない
作ってみたもの
ということで、作ってみたのが個人的にWebhook先として汎用的に使える環境。
環境は一番慣れ親しんだものとしてAWSのLambda(とAPI Gateway)とする。
Lambda関数の中身は以下で、POSTで受けてもGETで受けてもログに出力できるようにする。
import json def lambda_handler(event, context): # 引数:eventの内容を表示 print("Received event: " + json.dumps(event)) # rawQueryString rawQueryString = event['rawQueryString'] if(len(rawQueryString) != 0): queryStringParameters = event['queryStringParameters'] print(queryStringParameters) # body body = event.get('body') if(not body is None): json_body = json.dumps(body) print(json_body) return { 'isBase64Encoded': False, 'statusCode': 200, 'headers': {}, 'body': json.dumps('Hello from Lambda!') }
- API Gatewayの作成については割愛。久々に作ってみたら前とかなり雰囲気が違っていてかなり戸惑った。
- 投稿日:2020-05-30T19:14:27+09:00
100日後にエンジニアになるキミ - 71日目 - プログラミング - スクレイピングについて2
昨日までのはこちら
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回はスクレイピングの続きです。
通信について
Python言語でスクレイピングを行なっていきます。
スクレイピングでは通信を伴いますので
通信の仕組みを知っておく必要があります。WEBサイトは世界中のサーバー上に置かれています。
WEBにおいて基本的にサーバとのやりとりはHTTP(HyperText Transfer Protocol)というプロトコル(通信規約)を用いて行いブラウザからサーバへの要求を
リクエスト
サーバからブラウザへの応答をレスポンスと呼んでいます。WEB上での基本的なやりとりはリクエスト/レスポンス(R/R)で成立しており
基本的にはテキストメッセージを交換することにより、実現されていますサイト検索の例
ブラウザから検索ツールで検索を実行リクエスト
サーバは要求に対して結果を返答レスポンス
レスポンスを元にブラウザは検索結果を表示
HTTP通信には、いくつかの仕様があり、リクエストの送り方が複数あります。GET通信
GETはURLにパラメータを付加してリクエストします
例:
http://otupy.com?p=abc&u=u123
?以降はパラメータでパラメータはキー=値を&つなぎにしたものです。POST通信
POSTはBodyに含めてリクエストします
リクエストBody
param:p:ab,u:u123POSTとGETの使い分け
通信自体はブラウザーでは適切な通信方法を選んで行うが
プログラムでは通信方法を指定する必要があります。リクエスト
ブラウザーなどからWEBサイトのサーバーへの要求をリクエストと言っています。
ブラウザでWebページを開く際、ブラウザはサーバに下記のような要求メッセージを送信します。
GETの例:
リクエストヘッダ GET http://www.otupy.com/ex/http.htm HTTP/1.1 Host: www.otupy.com Proxy-Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8 Referer: https://www.google.co.jp/ Accept-Encoding: gzip, deflate Accept-Language: ja,en-US;q=0.9,en;q=0.8POSTの例:
リクエストヘッダ: POST /hoge/ HTTP/1.1 Host: localhost:8080 Connection: keep-alive Content-Length: 22 Cache-Control: max-age=0 Origin: http://localhost:8080 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36 Content-Type: application/x-www-form-urlencoded Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8 Referer: http://localhost:8080/hoge/ Accept-Encoding: gzip, deflate, br Accept-Language: ja,en-US;q=0.8,en;q=0.6 リクエストボディ: name=hoge&comment=hogeリクエストは
ヘッダとボディ部があり、通信方法によってどのような情報を詰めて送信しているのかが変わります。そのため、プログラムでアクセスする際にも適切な情報を詰めてリクエストをしてあげる必要があります。
プログラムでのアクセス
早速スクレイピングを試してみましょう。
Pythonでは
requestsと言うライブラリで通信を行うことができます。import requestsアクセス先のWEBサイトが必要なのでそれを指定して
GETで通信を行います。
requests.get(URL)url = 'http://www.otupy.net/' res = requests.get(url) print(res)通信の結果
レスポンスが返ってきます。
通信に成功していれば、アクセス先の情報が取得できます。当然通信ですので失敗することもあります。
通信結果(レスポンス)
通信の結果
レスポンスはいくつかのステータスコードに別れます。
200番台は通信が成功していますが、400,500番台は
通信に失敗をしているので、URLの打ち間違いや、相手型のサーバーにアクセスできる状況であるのかを確認する必要があります。
分類 番号 メッセージ 説明 情報 100 Continue 処理を継続しています。続きのリクエストを送信してください。 情報 101 Sitching Protocols Upgrade ヘッダで指定したプロトコルに変更して再要求してください。 成功 200 OK 成功しました。 成功 201 Created Location ヘッダで指定した場所に新しいコンテンツが作成されました。 成功 202 Accepted 要求は受理されました。ただし処理は完了していません。 成功 203 Non-Authoritative Information 応答ヘッダはオリジナルサーバーが返したものとは異なりますが、処理は成功です。 成功 204 No Content コンテンツはありませんが、処理は成功しました。 成功 205 Reset Content 要求を受理したので、現在のコンテンツ(画面)を破棄してください。。 成功 206 Partial Content コンテンツを一部のみ返却します。 転送 300 Multiple Choices コンテンツ入手方法について複数の選択肢があります。 転送 301 Moved Permanently Location ヘッダで指定された別の場所に移動しました。 転送 302 Found Location ヘッダで指定された別の場所に見つかりました。そちらを見てください。 転送 303 See Other Location ヘッダで指定された他の場所を見てください。 転送 304 Not Modified 更新されていません。If-Modified-Since ヘッダを用いた場合に返却されます。 転送 305 Use Proxy Location ヘッダで指定したプロキシを使用してください。 転送 306 (Unused) 未使用。 転送 307 Temporary Redirect 別の場所に一時的に移動しています。 クライアントエラー 400 Bad Request 要求が不正です。 クライアントエラー 401 Unauthorized 認証されていません。 クライアントエラー 402 Payment Required 支払いが必要です。 クライアントエラー 403 Forbidden アクセスが認められていません。 クライアントエラー 404 Not Found 見つかりません。 クライアントエラー 405 Method Not Allowed 指定したメソッドはサポートされていません。 クライアントエラー 406 Not Acceptable 許可されていません。 クライアントエラー 407 Proxy Authentication Required プロキシ認証が必要です。 クライアントエラー 408 Request Timeout リクエストがタイムアウトしました。 クライアントエラー 409 Conflict リクエストがコンフリクト(衝突・矛盾)しました。 クライアントエラー 410 Gone 要求されたコンテンツは無くなってしまいました。 クライアントエラー 411 Length Required Content-Length ヘッダを付加して要求してください。 クライアントエラー 412 Precondition Failed If-... ヘッダで指定された条件に合致しませんでした。 クライアントエラー 413 Request Entity Too Large 要求されたエンティティが大きすぎます。 クライアントエラー 414 Request-URI Too Long 要求された URI が長すぎます。 クライアントエラー 415 Unsupported Media Type サポートされていないメディアタイプです。 クライアントエラー 416 Requested Range Not Satisfiable 要求されたレンジが不正です。 クライアントエラー 417 Expectation Failed Expect ヘッダで指定された拡張要求は失敗しました。 サーバーエラー 500 Internal Server Error サーバーで予期しないエラーが発生しました。 サーバーエラー 501 Not Implemented 実装されていません。 サーバーエラー 502 Bad Gateway ゲートウェイが不正です。 サーバーエラー 503 Service Unavailable サービスは利用可能ではありません。 サーバーエラー 504 Gateway Timeout ゲートウェイがタイムアウトしました。 サーバーエラー 505 HTTP Version Not Supported このHTTPバージョンはサポートされていません。 プログラムでの通信結果の確認
さてプログラムで通信の結果を確認してみましょう。
レスポンス変数.status_code
でステータスコードを確認できます。url = 'http://www.otupy.net/' res = requests.get(url) print(res.status_code)200
もし200番でなければ通信が失敗しているのでWEBサイトの情報取得は出来ていないことになります。
200番の場合は通信が成功しているのでWEBサイトから取得した情報を見ることができます。
通信の結果を変数に格納しているので、様々な内容を見ることが出来ます。
リクエストURL
レスポンス変数.urlステータスコード
レスポンス変数.status_codeレスポンスボディをテキスト形式で取得
レスポンス変数.textレスポンスボディをバイナリ形式で取得
レスポンス変数.contentクッキー
レスポンス変数.cookiesエンコーディング情報を取得
レスポンス変数.encodingここから先は取得したテキスト情報を使って必要な情報に切り分けていきます。
# レスポンスをバイナリ形式で取得して文字に変換して表示(1000文字分) print(res.content[0:1000].decode('utf-8'))<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "" class="autolink">http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
....カスタムヘッダー
リクエストを行う際にはリクエストヘッダとボディ部に情報を詰めてリクエストすることができます。
GET通信でヘッダを指定してリクエストするには下記のように行います。
requests.get(url, headers=辞書型のヘッダデータ)ヘッダ情報として
ユーザーエージェントを変更してアクセスするにはこのように指定します。headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36 '} res = requests.get(url, headers=headers)GET通信でパラメータを変更して通信する場合は以下のように指定します。
requests.get(url, params=辞書型のパラメータデータ)params = {'key1': 'value1', 'key2': 'value2'} res = requests.get(url, params=params)POST通信でリクエストボディ部に情報を詰めてリクエストするには下記のように行います。
requests.get(url, data=辞書型のボディデータ)payload = {'send': 'data'} res = requests.post(url, data=payload)まとめ
スクレイピングに必要な通信の仕組みを抑えておき情報取得が出来るようになっておこう。明日はこの続きで取得した情報から必要な情報を抜き出すところに入っていきます。
君がエンジニアになるまであと29日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-30T18:47:37+09:00
pythonで国名コード取得
とあるコンペをするにあたって、国名コードが必要になった。
これからも使う機会があるのかなと思って、作ってみました。関数で作成しました。
スクレイピング元Python jupyterCode
country_code.ipynbdef country_code(output,file_name): ''' ***help*** output : 現状csvのみ file_name : 任意のファイルネームを取得 今回使用しているpandas.read_htmlは、lxml、html5lib、 beautifulsoup4が必要なので、pipでインストールしておく ''' import pandas as pd url = "https://www-yousei.jsps.go.jp/yousei1/kuniList.do" dfs = pd.read_html(url,header = 0) if output == "csv": dfs[0].to_csv(file_name + ".csv") return dfs[0]Gitにもupしているので、気になった方、他のコード類を取得するコードを上げていただけると助かります。
GitHub Linkなお、私はGitHub初心者でわからないことだらけなので、何かありましたらコメントで教えていただけると幸いです。
- 投稿日:2020-05-30T18:30:47+09:00
GCIデータサイエンティスト育成講座の演習問題を解く Chapter5
GCIデータサイエンティスト育成講座
「GCIデータサイエンティスト育成講座」は、東京大学(松尾研究室)が開講している"実践型のデータサイエンティスト育成講座およびDeep Learning講座"で、演習パートのコンテンツがJupyterNoteBook形式で公開(CC-BY-NC-ND)されています。
Chapter5は「Pythonによる科学計算の基礎(NumpyとScipy)」で、科学計算を行うためのライブラリーNumpyとScipyの基礎知識を習得していきます。
日本語で学べる貴重で素晴らしい教材を公開いただいていることへの「いいね!」ボタンの代わりに、解いてみた解答を載せてみます。間違っているところがあったらご指摘ください。5章3節は理解の追いつかない内容が多く、演習はほぼコピペでした。後で必要に応じて復習必要かも…。
5 Pythonによる科学計算の基礎(NumpyとScipy)
5.1 概要
5.1.1 この章の概要について
5.2 Numpy
5.2.1 インデックス参照
<練習問題 1>
上記データのsample_namesのbに該当するdataを抽出してください。data[sample_names == 'b']> array([[-0.977, 0.95 , -0.151, -0.103, 0.411]])<練習問題 2>
上記データのsample_namesのc以外に該当するdataを抽出してください。data[sample_names != 'c']> array([[ 1.764, 0.4 , 0.979, 2.241, 1.868], > [-0.977, 0.95 , -0.151, -0.103, 0.411], > [ 0.334, 1.494, -0.205, 0.313, -0.854], > [-2.553, 0.654, 0.864, -0.742, 2.27 ]])<練習問題 3>
上記のcond_dataを変更して、x_arrayの3番目と4番目、y_arrayの1番、2番、5番目を出すように、条件制御を実施してください。cond_data = np.array([False,False,True,True,False]) print(np.where(cond_data,x_array,y_array))> [ 6 7 3 4 10]5.2.2 Numpyの演算処理
<練習問題 1>
以下のデータに対して、すべての要素の平方根を計算した行列を表示してください。sample_multi_array_data2 = np.arange(16).reshape(4,4) print(sample_multi_array_data2) print(sample_multi_array_data2 ** 0.5)> [[ 0 1 2 3] > [ 4 5 6 7] > [ 8 9 10 11] > [12 13 14 15]] > [[0. 1. 1.414 1.732] > [2. 2.236 2.449 2.646] > [2.828 3. 3.162 3.317] > [3.464 3.606 3.742 3.873]]<練習問題 2>
上記のデータsample_multi_array_data2の最大値、最小値、合計値、平均値を求めてください。print(sample_multi_array_data2.max()) print(sample_multi_array_data2.min()) print(sample_multi_array_data2.sum()) print(sample_multi_array_data2.mean())> 15 > 0 > 120 > 7.5<練習問題 3>
上記のデータsample_multi_array_data2の対角成分の和を求めてください。np.trace(sample_multi_array_data2)> 305.2.3 配列操作とブロードキャスト
<練習問題 1>
次の2つの配列に対して、縦に結合してみましょう。np.concatenate([sample_array1, sample_array1], axis=0) # データの準備 sample_array1 = np.arange(12).reshape(3,4) sample_array2 = np.arange(12).reshape(3,4) np.concatenate([sample_array1, sample_array1], axis=0)> array([[ 0, 1, 2, 3], > [ 4, 5, 6, 7], > [ 8, 9, 10, 11], > [ 0, 1, 2, 3], > [ 4, 5, 6, 7], > [ 8, 9, 10, 11]])<練習問題 2>
上記の2つの配列に対して、横に結合してみましょう。np.concatenate([sample_array1, sample_array1], axis=1)> array([[ 0, 1, 2, 3, 0, 1, 2, 3], > [ 4, 5, 6, 7, 4, 5, 6, 7], > [ 8, 9, 10, 11, 8, 9, 10, 11]])<練習問題 3>
普通の以下のリストの各要素に3を加えるためにはどうすればよいでしょうか。Numpyのブロードキャスト機能を使ってください。sample_list = [1,2,3,4,5] np.array(sample_list) + 3> array([4, 5, 6, 7, 8])5.3 Scipy
5.3.1 補間
<練習問題 1>
以下のデータに対して、線形補間の計算をして、グラフを描いてください。x = np.linspace(0, 10, num=11, endpoint=True) x_ = np.linspace(0, 10, num=30, endpoint=True) y = np.sin(x**2/5.0) plt.plot(x,y,'o') plt.grid(True) f_1 = interpolate.interp1d(x, y,'linear') plt.plot(x_, f_1(x_), '-')
<練習問題 2>
2次元のスプライン補間をして上記のグラフに書き込んでください(2次元のスプライン補間はパラメタをquadraticとします。)f_2 = interpolate.interp1d(x, y,'quadratic') plt.plot(x, y, 'o', x_, f_1(x_), '-', x_, f_2(x_), '--') plt.grid(True)
<練習問題 3>
3次元スプライン補間も加えてみましょう。f_3 = interpolate.interp1d(x, y,'cubic') plt.plot(x, y, 'o', x_, f_1(x_), '-', x_, f_2(x_), '--', x_, f_3(x_), '-.') plt.grid(True)
5.3.2 線形代数:行列の分解
<練習問題 1>
以下の行列に対して、特異値分解をしてください。B = np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]]) print(B)> [[ 1 2 3] > [ 4 5 6] > [ 7 8 9] > [10 11 12]]# 特異値分解の関数linalg.svd U, s, Vs = sp.linalg.svd(B) m, n = B.shape S = sp.linalg.diagsvd(s,m,n) print("U.S.V* = \n",U@S@Vs)> U.S.V* = > [[ 1. 2. 3.] > [ 4. 5. 6.] > [ 7. 8. 9.] > [10. 11. 12.]]<練習問題 2>
以下の行列に対して、LU分解をして、 ??=? の方程式を解いてください。#データの準備 A = np.identity(3) print(A) A[0,:] = 1 A[:,0] = 1 A[0,0] = 3 b = np.ones(3) print(A) print(b)> [[1. 0. 0.] > [0. 1. 0.] > [0. 0. 1.]] > [[3. 1. 1.] > [1. 1. 0.] > [1. 0. 1.]] > [1. 1. 1.]# 正方行列をLU分解する (LU,piv) = sp.linalg.lu_factor(A) L = np.identity(3) + np.tril(LU,-1) U = np.triu(LU) P = np.identity(3)[piv] # 解を求める x = sp.linalg.lu_solve((LU,piv),b) print(x)> [-1. 2. 2.]5.3.3 積分と微分方程式
<練習問題 1>
以下の積分を求めてみましょう。\int_0^2 (x+1)^2 dxintegrate.quad(lambda x: (x+1)**2, 0, 2)> (8.667, 0.000)<練習問題 2>
cos関数の範囲 (0,?) の積分を求めてみましょう。from numpy import cos integrate.quad(cos, 0, math.pi)(0.000, 0.000)5.3.4 最適化
<練習問題 1>
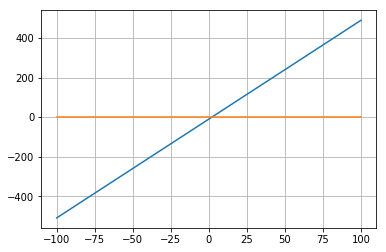
以下の関数が0となる解を求めましょう。\ f(x) = 5x -10from scipy.optimize import fsolve def f1(x): return 5 * x - 10 x = np.linspace(-100,100) plt.plot(x,f1(x)) plt.plot(x,np.zeros(len(x))) plt.grid(True) plt.show() x1 = fsolve(f1,0) print(x1)
> [2.]<練習問題 2>
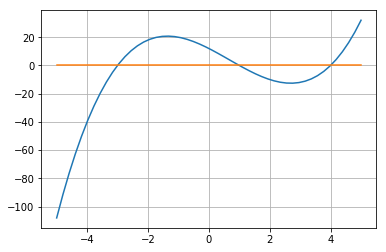
以下の関数が0となる解を求めましょう。\ f(x) = x^3 - 2x^2 - 11x +12from scipy.optimize import fsolve def f2(x): return x**3 - 2 * x**2 - 11 * x + 12 x = np.linspace(-5,5) plt.plot(x,f2(x)) plt.plot(x,np.zeros(len(x))) plt.grid(True) plt.show() x1 = fsolve(f2,-99999) x2 = fsolve(f2,0) x3 = fsolve(f2,99999) print(x1, x2, x3)
> [-3.] [1.] [4.]5.4 総合問題
5.4.1 総合問題1
以下の行列に対して、コレスキー分解を活用して、??=?の方程式を解いてください。A = np.array([[5, 1, 0, 1], [1, 9, -5, 7], [0, -5, 8, -3], [1, 7, -3, 10]]) b = np.array([2, 10, 5, 10])L = sp.linalg.cholesky(A) t = sp.linalg.solve(L.T.conj(), b) x = sp.linalg.solve(L, t) # 解答 print(x)> [-0.051 2.157 2.01 0.098]5.4.2 総合問題2
0≤?≤1、0≤y≤1−x の三角領域で定義される以下の関数の積分値を求めてみましょう。\int_0^1 \int_0^{1-x} 1/(\sqrt{(x+y)}(1+x+y)^2) dy dxfrom scipy import integrate integrate.dblquad(lambda y, x: 1 / ((x + y)**(1/2) * (1 + x + y)**2), 0, 1, lambda x: 0, lambda x: 1-x) # 関数をf(x, y)とした場合はどうすれば良いんだろう… # def f(x,y): # 1 / ((x + y)**(1/2) * (1 + x + y)**2) # integrate.dblquad(f, 0, 1, lambda x: 0, lambda x: 1-x)(0.285, 0.000)5.4.3 総合問題3
以下の最適化問題をSicpyを使って解いてみましょう。\ min \ f(x) = x^2+1 \\ s.t. x \ge -1from scipy.optimize import minimize def f(x): return x**2 + 1 def constraint(x): return x+1 x0 = -1 con = {'type':'ineq','fun':constraint} sol = minimize(f,x0,method='SLSQP',constraints=con) print("x = " + str(sol.x) + " のとき、f(x)は最小値 " + str(sol.fun) + " を取る") # memo # conの"'type': 'eq'"は=0, "'type': 'ineq'"は=>0> x = [2.22e-16] のとき、f(x)は最小値 1.0 を取る
- 投稿日:2020-05-30T18:30:46+09:00
Qiskit: 量子ボルツマンマシンの実装
はじめに
同じ内容の記事を先日投稿しましたが,寝ぼけて削除してしまいました.申し訳ないです.
今回は量子ボルツマンマシンをQiskitを用いて実装を行ってみました.
参考とした論文はこちらです.
A quantum algorithm to train neural networks using low-depth circuits
また,量子アニーリングマシンを用いたボルツマンマシンはminatoさんの記事で紹介しているのでそちらにお任せしたいと思います.
D-Waveから量子ゲートマシンまでのRBMのボルツマン学習制限ボルツマンマシンはニューラルネットワークの最小単位と言われています.
ちなみに,著者は機械学習の専門家ではないので詳しい説明は他の方にお任せします.QABoM
この論文ではQuantum Approximate Boltzmann Machine (QABoM) Algorithmとして紹介しています.
細かい内容まで踏み込む時間はないので,Appendixで紹介されているQABoMの流れを紹介したいと思います.なお,使用するindexは以下の通りです.
・v: visible層
・h: hidden層
・u: visible+hidden層step 0
Define the full and partial initial Hamiltonians.
H_I = \sum_{j \in u} Z_j \\ H_{\tilde{I}} = \sum_{j \in h} Z_j式を見ると,fullはvisible+hiddenについて,partialはhiddenについてですね.次に
Define the full and partial mixer Hamiltonians.H_M = \sum_{j \in u} X_j \\ H_{\tilde{M}} = \sum_{j \in h} X_jボルツマンマシンの変数である,weight$J_{jk}^0$とbias$B_j^0$を定義.
epoch 1以上について次に示すstep 1からstep 5を繰り返します.step 1
epoch nにおいてfull cost Hamiltonianとpartial cost Hamiltonianを定義します.
\hat{H}_C^n = \sum_{j,k \in u} J_{jk}^n \hat{Z}_j \hat{Z}_k + \sum_{j \in u} B_j^n \hat{Z}_j \\ \hat{H}_{\tilde{C}}^n = \sum_{j,k \in u} J_{jk}^n \hat{Z}_j \hat{Z}_k + \sum_{j \in h} B_j^n \hat{Z}_jstep 2 Unclamped Thermalization
step 0, step 1で定義した式を用いてQAOAを実行していきます.
a
pulse parametersを初期化 -> $\gamma, \beta$
b
$H_M$と$H_C$を使ってQAOAを実行
(QAOAの解説については他のサイトを見てください...)
最適化parameterを求めます.
ここでは$\hat{H}_C^n$で期待値を求めています.c
最適なparameterを入力したパラメータcircuitを実行し,期待値$ <Z_j Z_k> $と$ <Z_j> $を求める.
step 3 Clamped thermalization
各data string $x$について
a
pulse parametersを初期化 -> $\gamma, \beta$
b
visible層に$x$をencodeする.
c
$H_M$と$H_C$を使ってQAOAを実行
(QAOAの解説については他のサイトを見てください...)
最適化parameterを求めます.
ここでは$\hat{H}_{\tilde{C}}^n$で期待値を取っています.d
最適なparameterを入力したパラメータcircuitを実行し,期待値$ <Z_j Z_k> $と$ <Z_j> $を求める.
step 4
パラメータを更新していきます.
ここで$ <\bar{\cdots}>_D $はstep 3の結果の平均です.\delta J_{jk}^n = <\bar{Z_j Z_k}>_D -< Z_j Z_k> \\ \delta B_j^n = < \bar{Z_j}> - <Z_j>_D \\ J_j^{n+1} = J_j^n + \delta J_j^n \\ B_j^{n+1} = B_j^n + \delta B_j^nstep 5
epoch = n+1 back to step 1
code
import とclassの初期化
# coding: utf-8 from qiskit.aqua.utils import tensorproduct from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister from qiskit.quantum_info.analysis import average_data import numpy as np from copy import deepcopy from QAOA import QAOA from my_functions import sigmoid class QBM: def __init__(self, num_visible=2, num_hidden=1, steps=3, tmep=1.0, quant_meas_num=None, bias=False, reduced=False): self.visible_units = num_visible # v self.hidden_units = num_hidden # h self.total_units = self.visible_units + self.hidden_units self.quant_meas_num = quant_meas_num self.qaoa_steps = steps self.beta_temp = tmep self.state_prep_angle = np.arctan(np.exp(-1 / self.beta_temp)) * 2.0 self.param_wb = 0.1 * np.sqrt(6. / self.total_units) self.WEIGHTS = np.asarray(np.zeros(shape=[self.visible_units, self.hidden_units])) if bias: self.BIAS = np.asarray(np.zeros(shape=[self.hidden_units])) else: self.BIAS = None self.reduced = reduced self.obs = self.observable() self.obs_tilde = self.observable(tilde=True) self.data_point = Noneobservableの作成.tilde=Trueとすることで$$を作成することができます.
def Zi_Zj(self, q1, q2): I_mat = np.array([[1, 0], [0, 1]]) Z_mat = np.array([[1, 0], [0, -1]]) if q1 == 0 or q2 == 0: tensor = Z_mat else: tensor = I_mat for i in range(1, self.total_units): if i == q1 or i == q2: tensor = tensorproduct(tensor, Z_mat) else: tensor = tensorproduct(tensor, I_mat) return tensor def Zi(self, q): I_mat = np.array([[1, 0], [0, 1]]) Z_mat = np.array([[1, 0], [0, -1]]) if q == 0: tensor = Z_mat else: tensor = I_mat for i in range(1, self.total_units): if i == q: tensor = tensorproduct(tensor, Z_mat) else: tensor = tensorproduct(tensor, I_mat) return tensor def observable(self, tilde=False): visible_indices = [i for i in range(self.visible_units)] hidden_indices = [i + self.visible_units for i in range(self.hidden_units)] total_indices = [i for i in range(self.total_units)] obs = np.zeros((2**self.total_units, 2**self.total_units)) for q1 in visible_indices: for q2 in hidden_indices: obs += -1.0 * self.Zi_Zj(q1, q2) if self.BIAS is not None: if tilde: for q in hidden_indices: obs += -1.0 * self.Zi(q) elif not tilde: for q in total_indices: obs += -1.0 * self.Zi(q) return obsパラメーターcircuitを作成します.
def U_circuit(self, params, qc): visible_indices = [i for i in range(self.visible_units)] hidden_indices = [i + self.visible_units for i in range(self.hidden_units)] total_indices = [i for i in range(self.total_units)] p = 2 alpha = self.state_prep_angle for i in total_indices: qc.rx(alpha, i) for i in visible_indices: for j in hidden_indices: qc.cx(i, j) beta, gamma = params[:p], params[p:] def add_U_X(qc, beta): for i in total_indices: qc.rx(-2**beta, i) return qc def add_U_C(qc, gamma): for q1 in visible_indices: for q2 in hidden_indices: qc.cx(q1, q2) qc.rz(-2**gamma, q2) qc.cx(q1, q2) return qc for i in range(p): qc = add_U_C(qc, gamma[i]) qc = add_U_X(qc, beta[i]) return qcstep 2を実行します.
def unclamped_circuit(self, params): qr = QuantumRegister(self.total_units) cr = ClassicalRegister(self.total_units) qc = QuantumCircuit(qr, cr) qc = self.U_circuit(params, qc) qc.measure(range(self.total_units), range(self.total_units)) return qc def make_unclamped_QAOA(self): qaoa = QAOA(qc=self.unclamped_circuit, observable=self.obs, num_shots=10000, p=2) counts = qaoa.qaoa_run() return countsここでQAOAという自作ライブラリーを使用していますが,下記で紹介します.
次にstep 3です.
step 2と異なる箇所はデータのencodeが含まれている所です.def clamped_circuit(self, params): qr = QuantumRegister(self.total_units) cr = ClassicalRegister(self.total_units) qc = QuantumCircuit(qr, cr) for i in range(len(self.data_point)): if self.data_point[i] == 1: qc.x(i) qc = self.U_circuit(params, qc) qc.measure(range(self.total_units), range(self.total_units)) return qc def make_clamped_QAOA(self, data_point): self.data_point = data_point qaoa = QAOA(qc=self.clamped_circuit, observable=self.obs_tilde, num_shots=10000, p=2) counts = qaoa.qaoa_run() return counts最後に学習の実行です.
def train(self, DATA, learning_rate=1, n_epochs=100, quantum_percentage=1.0, classical_percentage=0.0): assert (quantum_percentage + classical_percentage == 1.0) DATA = np.asarray(DATA) assert (len(DATA[0]) <= self.visible_units) for epoch in range(n_epochs): print('Epoch: {}'.format(epoch+1)) visible_indices = [i for i in range(self.visible_units)] hidden_indices = [i + self.visible_units for i in range(self.hidden_units)] total_indices = [i for i in range(self.total_units)] new_weights = deepcopy(self.WEIGHTS) if self.BIAS is not None: new_bias = deepcopy(self.BIAS) counts = self.make_unclamped_QAOA() unc_neg_phase_quant = np.zeros_like(self.WEIGHTS) for i in range(self.visible_units): for j in range(self.hidden_units): model_expectation = average_data(counts, self.Zi_Zj(visible_indices[i], hidden_indices[j])) unc_neg_phase_quant[i][j] = model_expectation unc_neg_phase_quant *= (1. / float(len(DATA))) if self.BIAS is not None: unc_neg_phase_quant_bias = np.zeros_like(self.BIAS) for i in range(self.hidden_units): model_expectation = average_data(counts, self.Zi(hidden_indices[i])) unc_neg_phase_quant_bias[i] = model_expectation unc_neg_phase_quant_bias *= (1. / float(len(DATA))) pos_hidden_probs = sigmoid(np.dot(DATA, self.WEIGHTS)) pos_hidden_states = pos_hidden_probs > np.random.rand(len(DATA), self.hidden_units) pos_phase_classical = np.dot(DATA.T, pos_hidden_probs) * 1. / len(DATA) c_pos_phase_quant = np.zeros_like(self.WEIGHTS) if self.BIAS is not None: c_pos_phase_quant_bias = np.zeros_like(self.BIAS) if not self.reduced: iter_dat = len(DATA) pro_size = len(DATA) pro_step = 1 for data in DATA: counts = self.make_clamped_QAOA(data) ct_pos_phase_quant = np.zeros_like(self.WEIGHTS) for i in range(self.visible_units): for j in range(self.hidden_units): model_expectation = average_data(counts, self.Zi_Zj(visible_indices[i], hidden_indices[j])) ct_pos_phase_quant[i][j] = model_expectation c_pos_phase_quant += ct_pos_phase_quant if self.BIAS is not None: ct_pos_phase_quant_bias = np.zeros_like(self.BIAS) for i in range(self.hidden_units): model_expectation = average_data(counts, self.Zi(hidden_indices[i])) ct_pos_phase_quant_bias[i] = model_expectation c_pos_phase_quant_bias *= ct_pos_phase_quant_bias pro_bar = ('==' * pro_step) + ('--' * (pro_size - pro_step)) print('\r[{0}] {1}/{2}'.format(pro_bar, pro_step, pro_size), end='') pro_step += 1 c_pos_phase_quant *= (1. / float(len(DATA))) if self.BIAS is not None: c_pos_phase_quant_bias *= (1. / float(len(DATA))) neg_visible_activations = np.dot(pos_hidden_states, self.WEIGHTS.T) neg_visible_probs = sigmoid(neg_visible_activations) neg_hidden_activations = np.dot(neg_visible_probs, self.WEIGHTS) neg_hidden_probs = sigmoid(neg_hidden_activations) neg_phase_classical = np.dot( neg_visible_probs.T, neg_hidden_probs) * 1. / len(DATA) new_weights += learning_rate * \ (classical_percentage * (pos_phase_classical - neg_phase_classical) + quantum_percentage * (c_pos_phase_quant - unc_neg_phase_quant)) if self.BIAS is not None: new_bias = new_bias + learning_rate * \ (quantum_percentage * (c_pos_phase_quant_bias - unc_neg_phase_quant_bias)) self.WEIGHTS = deepcopy(new_weights) print(self.WEIGHTS) if self.BIAS is not None: self.BIAS = deepcopy(new_bias) with open("RBM_info.txt", "w") as f: np.savetxt(f, self.WEIGHTS) if self.BIAS is not None: np.savetxt(f, self.BIAS) with open("RBM_history.txt", "a") as f: np.savetxt(f, self.WEIGHTS) if self.BIAS is not None: np.savetxt(f, self.BIAS) f.write(str('*' * 72) + '\n') print('') print("Training Done! ") def transform(self, DATA): return sigmoid(np.dot(DATA, self.WEIGHTS)) if __name__ == '__main__': qbm = QBM(num_visible=6, num_hidden=2,bias=True) train_data = [[1, 1, 1, 1, 1, 1], [1, 1, -1, -1, 1, 1], [1, -1, -1, -1, 1, 1], [1, 1, 1, -1, -1, -1]] qbm.train(DATA=train_data, n_epochs=100, quantum_percentage=1.0, classical_percentage=0.0) print(qbm.transform(train_data))QAOA
自作ライブラリーQAOAは以前紹介したQiskit Aquaを使わないQAOAの実装で用いたcodeを汎用的に拡張したものです.
QAOA.py# coding: utf-8 from qiskit import BasicAer, execute from qiskit.quantum_info.analysis import average_data from scipy.optimize import minimize import numpy as np import random def classica_minimize(cost_func, initial_params, options, method='powell'): result = minimize(cost_func, initial_params, options=options, method=method) return result.x class QAOA: def __init__(self, qc, observable, num_shots, p=1, initial_params=None): self.QC = qc self.obs = observable self.SHOTS = num_shots self.P = p if initial_params is None: self.initial_params = [0.1 for _ in range(self.P * 2)] else: self.initial_params = initial_params def QAOA_output_layer(self, params): qc = self.QC(params) backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=self.SHOTS).result() counts = results.get_counts(qc) expectation = average_data(counts, self.obs) return expectation def minimize(self): initial_params = np.array(self.initial_params) opt_params = classica_minimize(self.QAOA_output_layer, initial_params, options={'maxiter':500}, method='powell') return opt_params def qaoa_run(self): opt_params = self.minimize() qc = self.QC(opt_params) backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=self.SHOTS).result() counts = results.get_counts(qc) return counts if __name__ == '__main__': pass計算結果
今回は古典の制限ボルツマンマシンでも同じデータを用いて計算機実験を行い,比較してみました.
古典制限ボルツマンマシンは別の方が実装しているものがあったので参考にさせてもらいました.
pythonで制約ボルツマンマシン実装実行環境
OS: macOS Catalina ver 10.15.5
CPU: intel Core i7
メモリ: 16 GBパラメータ
学習率:0.2
epochs: 100古典ボルツマンマシンの結果
[[7.57147606e-220 4.69897282e-106] [1.00548918e-308 1.00000000e+000] [1.00000000e+000 3.79341879e-197] [1.00000000e+000 7.56791638e-202] [1.00000000e+000 2.85625356e-196] [1.00000000e+000 2.51860403e-243] [0.00000000e+000 1.00000000e+000] [9.02745172e-142 1.00000000e+000]]QABoMの結果
[[0.59991237 0.68602485] [0.74497707 0.89553788] [0.26436565 0.113528 ] [0.2682931 0.1131361 ] [0.58273232 0.3268427 ] [0.41413436 0.14647751] [0.74056361 0.94317095] [0.7317069 0.8868639 ]]ちなみにこれ,計算時間半日近くかかっています.(測定するの忘れた...)
一応古典RBMと同じ結果が得られました.が,古典ほどはっきりとした解ではありませんね.まとめ
今回は論文に掲載されていたQABoMの実装を紹介しました.
もう少し計算機実験を行って,記事を更新していこうかなと思います.拙い日本語で申し訳ありませんでした.国語力の改善に努めます.
参考文献一覧
QABoM: A quantum algorithm to train neural networks using low-depth circuits
RBM: pythonで制約ボルツマンマシン実装
- 投稿日:2020-05-30T18:13:24+09:00
ベルマンフォード法とダイクストラ法の概念を完全に理解する
概要
社内の勉強会でダイクストラ法(dijkstra)とベルマンフォード法(bellman-ford)の紹介をしました。その際にアルゴリズムの証明を色々調べていましたが、解説されている記事があまり多くないことに気づきました。
「なぜそうなるの?」という部分は個人的に大事な要素だと思うので、その辺も踏まえてこれらのアルゴリズムを紹介したいと思います。筆者はどんな人?
プログラミング歴:1年ちょい(Pythonのみ)
Atcoder茶(よわよわ)
2020年4月からデータ分析委託の企業に勤めているが、なぜかアルゴリズムの勉強ばっかりやっている。このアルゴリズムはいつ使うの?
重み付きグラフの単一始点最短経路問題を解く際に使います。
それぞれの用語ですが、
重み付き:辺を通るのに必要なコスト
単一始点:スタート地点が一か所
最短経路:スタート地点から目的地まで最小コストで向かう経路
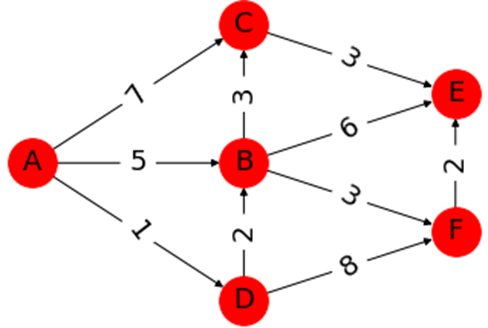
です。下のグラフを例にすると、
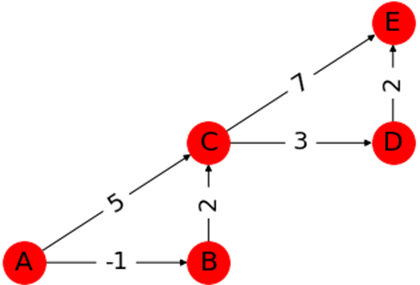
スタート地点$A$から全ての辺への最短経路を求めることが目的になります。
ちなみに$A→E$の最短経路は
$(A→D→B→F→E)$
です。これをアルゴリズムを使用して求めていきます。アルゴリズムの前に、グラフの大事な性質
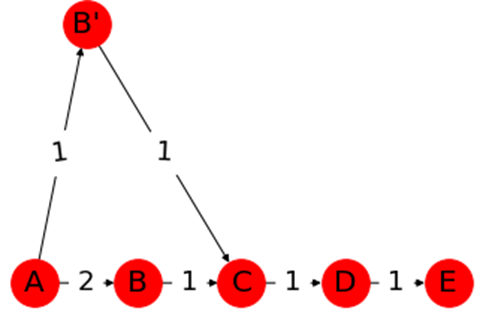
1.最短路の部分道は最短路
最短路の部分道はどこをとっても最短路になります。
<証明>
仮に上のグラフで$A→E$の最短路を
$(A→B→C→D→E cost:5)$
とします。このうち$(A→B→C cost:3)$
はこの最短路の部分道ですが、この区間にはB'という頂点を利用すれば
コストを1少なく移動できます。
するとこの区間の最短路は
$(A→B'→C cost:2)$
となるため、$A→E$を
$(A→B'→C→D→E cost:4)$
で移動できてしまい、仮定と矛盾します。
最短路の部分道は必ず最短路になります。2.経路緩和性
始点に関連する頂点から順番に最短路を求めていくと、最終的にすべての最短経路が求められます。
これは結局、始点から徐々に求めた最短路がその先に到達する頂点の部分道となるためです。ベルマンフォード法とは
全頂点間の最短路を求めます。ダイクストラ法と大きく異なる点は、負の重みが許容されることです。
最短路を求めるプロセスは、
- 全ての辺に注目し、その辺を通った先の頂点のコストを小さくできれば値を更新
- 1.のプロセスを(頂点の数-1)回行う です。
下の図だと、
1.のプロセスで、$A$を出発し、$C$にコスト$5$で到達できるので、$C:5$とメモします。
次に、$A→B$は$-1$で到達できるので$B:-1$、$B→C$にはコスト$-1+2=1$で到達できます。
この時、$B$を経由するとより小さなコストでCに到達できることが分かったので、$C:1$と更新します。
この作業を全ての辺に対して行います。これが1回目。
あとは(頂点の数-1)回繰り返せば、$A$から出発して全ての頂点への最短路を求めることが出来ます。なぜ(頂点の数-1)回行うの?
始点から目的地までに通る頂点の最大の個数は、始点を除く頂点、すなわち(頂点の数-1)個です。
前述したプロセスでは、1回目のループで始点から移動できる頂点)の最短路が必ず求められます。
2回目のループでは(1回目で決まったルートから移動できる頂点)の最短路が必ず求められます。
・
・
・
結局このループは、始点をスタートして順番に最短路を求める作業になるので、経路緩和性により最短路を求めることができます。負の重みによって困る場合
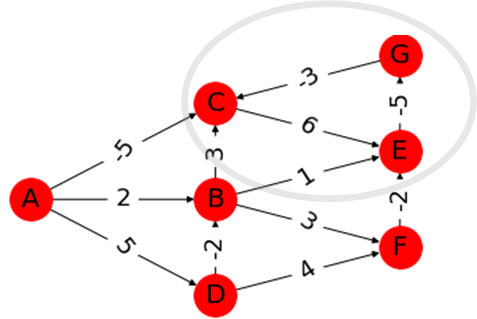
下の図を見てください。
丸で囲んだ部分はサイクルになっていますが、ここを1周するとコストが-2下がります。
つまりこのサイクルを使えば無限にコストを下げることが可能です。
これを負閉路といいます。ベルマンフォード法では、負閉路の検出も可能です。
先ほど、(頂点の数-1)回のループで最短路を求めることを確認しましたが、再度全ての頂点のコストを計算し、コストを更新できる頂点がある場合は負閉路が存在するということになります。いいからソースコード見せろよ
隣接リスト形式(競プロとかでよく利用する、隣接行列というのもある)の入力に対応し、ベルマンフォード法により最短路を検出します。
コードの下に負閉路のある入力例を示します(上の図のグラフ)。負閉路を通る頂点のコストを$-inf$に置き換えています。
クリックしたら見れるよ
def shortest_path(s,n,es): #s→iの最短距離 # s:始点, n:頂点数, es[i]: [辺の始点,辺の終点,辺のコスト] #重みの初期化。ここに最短距離をメモしていく d = [float("inf")] * n #スタート地点は0 d[s] = 0 #最短路を計算 for _ in range(n-1): # es: 辺iについて [from,to,cost] for p,q,r in es: #矢印の根が探索済、かつコストができるルートがあれば更新 if d[p] != float("inf") and d[q] > d[p] + r: d[q] = d[p] + r #負閉路をチェック for _ in range(n-1): # e: 辺iについて [from,to,cost] for p,q,r in es: #更新される点は負閉路の影響を受けるので-infを入れる if d[q] > d[p] + r: d[q] = -float("inf") return d ################ #入力 n,w = map(int,input().split()) #n:頂点数 w:辺の数 es = [] #es[i]: [辺の始点,辺の終点,辺のコスト] for _ in range(w): x,y,z = map(int,input().split()) es.append([x,y,z]) # es.append([y,x,z]) print(shortest_path(0,n,es)) ''' 入力 7 12 0 1 2 0 2 -5 0 3 5 1 2 3 1 4 1 1 5 3 2 4 6 3 2 -2 3 5 4 4 6 -5 5 4 -2 6 2 -3 ''' >>[0, 2, -inf, 5, -inf, 5, -inf]計算量は$O(V^2+E)$(頂点の数:$V$、辺の数:$E$)です。
ダイクストラ法とは
非負の重みを持つグラフで使用できます。
最短路を求めるプロセスはヨビノリさんの動画が死ぬほど分かりやすいです。
(ヨビノリさんの守備範囲広すぎる…)一応こちらでもご説明します。
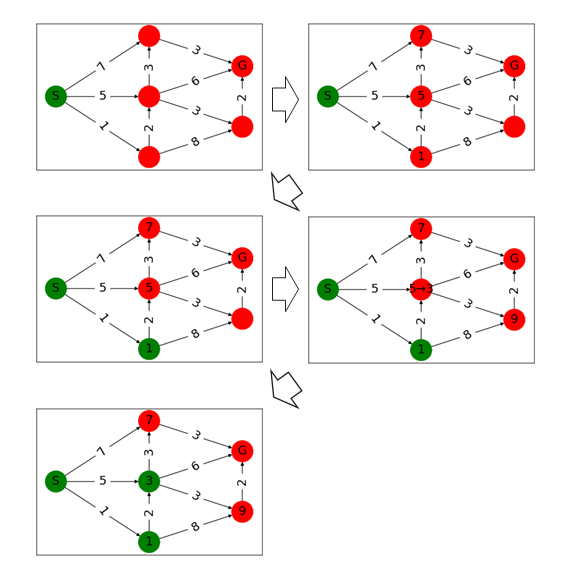
頂点のコストを(初期値:$S = 0$, その他$ = ∞$)とします。
- 一番コストが小さい頂点を始点とします。最初は$S$が始点です。
- 始点のコストを確定します(図では緑になる)。この頂点のコストはこれ以降更新されません。
始点から移動可能な頂点に出発点のコスト+辺重みを頂点にメモします。中段列の頂点に$7、3、1$とメモされました。コストはまだ更新されるかもしれないので未確定です。
すべての頂点が確定するまで1~3を繰り返します。メモされた頂点の中で1のコストを持つ頂点が一番小さいので確定し、その頂点から移動可能な頂点をメモします。もし、より小さなコストで移動できるのならコストを更新します。
なぜ最短路が求められる?
未確定の頂点のうち最小のコストを持つ頂点は、それ以上小さなコストに更新することができないためです。
非負の重みしか存在しないので、別ルートを通るにしても0以上のコストが発生します。そのため未確定のうち、最小のコストは最短路と確定することが出来るのです。で、ソースコードは?
クリックしたら見れるよ
import heapq def dijkstra(s, n, es): #始点sから各頂点への最短距離 #n:頂点数, cost[u][v] : 辺uvのコスト(存在しないときはinf) d = [float("inf")] * n #探索リスト S = [s] #優先度付きキューを使うと計算量が少なくなるよ heapq.heapify(S) d[s] = 0 while S: #最小コストの頂点を取り出し v = heapq.heappop(S) # print("-----------v", v) for u, w in es[v]: # print(u, w) #より小さなコストで到達可能であれば更新し、リストに追加 if d[u] > d[v]+w: d[u] = d[v]+w heapq.heappush(S, u) # print("d", d) return d n,w = map(int,input().split()) #n:頂点数 w:辺の数 cost = [[float("inf") for i in range(n)] for i in range(n)] es = [[] for _ in range(n)] for i in range(w): x, y, z = map(int, input().split()) es[x].append([y, z]) es[y].append([x, z]) #有向グラフの場合はこの行を消す # print(es) print(dijkstra(0, n, es))
オリジナルの計算量はベルマンフォード法と同じ$O(V^2)$ですが、優先度付きキューを使用すれば$O((E+V)logV)$に削減できます。参考文献とかサイト
・アルゴリズムイントロダクション 第3版 第2巻: 高度な設計と解析手法・高度なデータ構造・グラフアルゴリズム (世界標準MIT教科書)
(T.コルメン,R.リベスト,C.シュタイン,C.ライザーソン,浅野哲夫,岩野和生,梅尾博司,山下雅史,和田幸一)
かなり重い本ですが、グラフ理論の証明がとても丁寧でした。・グラフ理論⑤(ダイクストラのアルゴリズム)
(予備校のノリで学ぶ「大学の数学・物理」)
https://www.youtube.com/watch?v=X1AsMlJdiok
こちらの動画を見るだけで、ダイクストラ法は完全に理解できます!・蟻本 python 単一最短経路法2(ダイクストラ法) 競技プログラミング
(じゅっぴーさんのブログ、コードはこちらを参考にさせて頂きました)
https://juppy.hatenablog.com/entry/2018/11/01/%E8%9F%BB%E6%9C%AC_python_%E5%8D%98%E4%B8%80%E6%9C%80%E7%9F%AD%E7%B5%8C%E8%B7%AF%E6%B3%952%EF%BC%88%E3%83%80%E3%82%A4%E3%82%AF%E3%82%B9%E3%83%88%E3%83%A9%E6%B3%95%EF%BC%89_%E7%AB%B6%E6%8A%80%E3%83%97おまけ
記事中のグラフはnetworkxで作図しました。
気になる人向けにコードを置いておきます。
クリックしたら見れるよ
#ダイクストラ法のグラフ import matplotlib.pyplot as plt import networkx as nx #有向グラフのセット G = nx.DiGraph() #辺を追加していく # G.add_edges_from([("A", "B", {"weight":2)]) # nx.add_path(G, ["A", "C"]) # G.edges["A", "B"]["weight"] = 2 G.add_weighted_edges_from([("A", "B", 5), ("A", "C", 7), ("A", "D", 1), ("B", "C", 3), ("B", "F", 3), ("D", "B", 2)]) G.add_weighted_edges_from([("C", "E", 3), ("D", "F", 8), ("F", "E", 2), ("B", "E", 6)]) #図中で頂点の座標を指定しないとランダムに配置される pos1 = {} pos1["A"] = (0, 0) pos1["B"] = (1, 0) pos1["C"] = (1, 2) pos1["D"] = (1, -2) pos1["E"] = (2, 1) pos1["F"] = (2, -1) #そのまま描写するとweightの文字が邪魔なので消す edge_labels = {(i, j): w['weight'] for i, j, w in G.edges(data=True)} #重みを書き込む nx.draw_networkx_edge_labels(G, pos1, edge_labels=edge_labels, font_size=18) #作図 nx.draw_networkx(G, pos1, node_size=1000, label_pos=100, node_color="r", font_size=18) #図の保存 plt.savefig("dijkstra.png") plt.show() #networkxにもダイクストラ法が実装されている。計算量はO(V^2+E)なので遅い pred, dist = nx.dijkstra_predecessor_and_distance(G, "A") print(pred, dist) >>{'A': [], 'B': ['D'], 'C': ['B'], 'D': ['A'], 'F': ['B'], 'E': ['F']} >>{'A': 0, 'D': 1, 'B': 3, 'C': 6, 'F': 6, 'E': 8}
- 投稿日:2020-05-30T18:05:01+09:00
言語処理100本ノック2020年版を解いてみた【第3章:正規表現 25〜29】
東北大乾・岡崎研(現乾・鈴木研)で作成された、新人研修の一つであるプログラミング基礎勉強会の教材『言語処理100本ノック 2020年版』をPython(3.7)で解いた記事の第6弾です。
独学でPythonを勉強してきたので、間違いやもっと効率の良い方法があるかもしれません。
改善点を見つけた際はご指摘いただけると幸いです。第3章からは合っているかどうかな部分が多くなってきているので、改善点だけでなく、合っているかどうかという点もぜひご指摘ください。
ソースコードはGitHubにも公開しています。
第3章: 正規表現
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
1行に1記事の情報がJSON形式で格納される
各行には記事名が”title”キーに,記事本文が”text”キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.
25. テンプレートの抽出
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
25.pyimport pandas as pd import re def basic_info_extraction(text): texts = text.split("\n") index = texts.index("{{基礎情報 国") basic_info = [] for i in texts[index + 1:]: if i == "}}": break if i.find("|") != 0: basic_info[-1] += ", " + i continue basic_info.append(i) pattern = r"\|(.*)\s=(.*)" ans = {} for i in basic_info: result = re.match(pattern, i) ans[result.group(1)] = result.group(2).lstrip(" ") return ans file_name = "jawiki-country.json.gz" data_frame = pd.read_json(file_name, compression='infer', lines=True) uk_text = data_frame.query("title == 'イギリス'")['text'].values[0] ans = basic_info_extraction(uk_text) for key, value in ans.items(): print(key, ":", value)「基本情報」テンプレートを抽出するために、イギリスのテキストデータを引数にとる
basic_info_extraction()を定義しました。この関数は
"{{基礎情報 国"以降の行に対して}}の閉じカッコが現れるまでを基礎情報としてリストに保存します。
ただ、同じ行のデータでも複数行にまたがっている場合もありました。
その条件は行頭が|から始まっていたので、.find("|")で複数ヒットした場合はカンマで区切った上で1行にまとめる処理を行っています。そして抽出したデータのリストに対して、
|から=手前の半角スペースまでを「フィールド名」として、=以降を「値」として切り分け、「値」の左に空白があれば取り除いた上で辞書オブジェクトに保存し返却しています。26. 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ(参考: マークアップ早見表).
26.pyimport pandas as pd import re def basic_info_extraction(text): # 「25. テンプレートの抽出」を参照 ... def remove_emphasis(value): pattern = r"(.*?)'{1,3}(.+?)'{1,3}(.*)" result = re.match(pattern, value) if result: return "".join(result.group(1, 2, 3)) return value file_name = "jawiki-country.json.gz" data_frame = pd.read_json(file_name, compression='infer', lines=True) uk_text = data_frame.query("title == 'イギリス'")['text'].values[0] ans = basic_info_extraction(uk_text) for key, value in ans.items(): value = remove_emphasis(value) # 追加 print(key, ":", value)指定された強調マークアップを除去するための関数を用意しました。
強調マークアップは'が1〜3個連なったもので囲むことで表現されます。
そこで、正規表現のパターンとしてr"(.*?)'{1,3}(.+?)'{1,3}(.*)"を指定し、'以外を()で囲むことで、強調マークアップ以外を抽出。
マッチした部分をリスト化、joinメソッドで結合し値として返却しています。27. 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ(参考: マークアップ早見表).
27.pyimport pandas as pd import re def basic_info_extraction(text): # 「25. テンプレートの抽出」を参照 ... def remove_emphasis(value): # 「26. 強調マークアップの除去」を参照 ... def remove_innerlink(value): pipe_pattern = r"(.*\[\[(.*?)\|(.+)\]\])" result = re.findall(pipe_pattern, value) if len(result) != 0: for i in result: pattern = "[[{}|{}]]".format(i[1], i[2]) value = value.replace(pattern, i[2]) pattern = r"(\[\[(.+?)\]\])" result = re.findall(pattern, value) if len(result) != 0: for i in result: if "[[ファイル:" not in value: value = value.replace(i[0], i[-1]) return value file_name = "jawiki-country.json.gz" data_frame = pd.read_json(file_name, compression='infer', lines=True) uk_text = data_frame.query("title == 'イギリス'")['text'].values[0] ans = basic_info_extraction(uk_text) for key, value in ans.items(): value = remove_emphasis(value) value = remove_innerlink(value) # 追加 print(key, ":", value)次は内部リンクのマークアップを除去するための関数を用意しました。
内部リンクマークアップは[[〜]]の四角カッコを2個連ねて囲むことで表現されます。
パターンとしては中にパイプを入れて、表示文字と記事名を記載することもできます。
そこで、正規表現のパターンとしてr"(.*\[\[(.*?)\|(.+)\]\])"を指定し、まずはパイプを含むリンクを抽出します。
該当する内部リンクを表示文字のみの内部リンクに置き換え、次の処理に渡します。パイプを含む内部リンクがなくなり、表示される部分だけが残っているので、
r"(\[\[(.+?)\]\])"でパターンを指定して該当する部分を探し、該当部分があればファイル以外をマークアップを除去して値を返却しています。28. MediaWikiマークアップの除去
27の処理に加えて,テンプレートの値からMediaWikiマークアップを可能な限り除去し,国の基本情報を整形せよ.
28.pyimport pandas as pd import re def basic_info_extraction(text): # 「25. テンプレートの抽出」を参照 ... def remove_emphasis(value): # 「26. 強調マークアップの除去」を参照 ... def remove_innerlink(value): # 「27. 内部リンクの除去」を参照 ... def remove_footnote(value): # 後述 ... def remove_langage(value): # 後述 ... def remove_temporarylink(value): # 後述 .... def remove_zero(value): # 後述 ... def remove_br(value): # 後述 ... def remove_pipe(value): # 後述 ... file_name = "jawiki-country.json.gz" data_frame = pd.read_json(file_name, compression='infer', lines=True) uk_text = data_frame.query("title == 'イギリス'")['text'].values[0] ans = basic_info_extraction(uk_text) for key, value in ans.items(): value = remove_footnote(value) value = remove_emphasis(value) value = remove_innerlink(value) value = remove_langage(value) # 追加 value = remove_temporarylink(value) # 追加 value = remove_zero(value) # 追加 value = remove_br(value) # 追加 value = remove_pipe(value) # 追加 print(key, ":", value)脚注コメントの除去
remove_footnote()関数def remove_footnote(value): pattern = r"(.*?)(<ref.*?</ref>)(.*)" result = re.match(pattern, value) if result: return "".join(result.group(1, 3)) pattern = r"<ref.*/>" value = re.sub(pattern, "", value) return valueまず脚注の除去です。
引数として得た行が<ref〜</ref>を含んでいたら<ref〜</ref>の前後を結合して値を返します。
これに該当しない<ref〜/>という脚注表記も存在するので、これが残っていたら、取り除いて返却します。言語タグの除去
remove_language()関数def remove_langage(value): pattern = r"{{lang\|.*?\|(.*?)[}}|)]" result = re.match(pattern, value) if result: return result.group(1) return value続いては言語タグです。
言語タグは{{lang〜}}で囲まれた部分です。
途中のパイプのあとに表示部分が含まれるので、正規表現中でカッコで囲んで、group()メソッドで抽出して値として返します。仮リンクの除去
remove_temporarylink()関数def remove_temporarylink(value): pattern = r"{{仮リンク\|.*\|(.*)}}" result = re.match(pattern, value) if result: return result.group(1) return value仮リンクの除去は言語タグと若干パターンが違えど、ほぼ同じです。
{{仮リンク〜}}で囲まれた部分をパターンとし、マッチした部分があればgroup()メソッドで抽出です。囲まれたゼロの除去
remove_zero()関数def remove_zero(value): pattern = r"\{\{0\}\}" value = re.sub(pattern, "", value) return valueよくわからない
{{0}}というものが多々あったので、マッチした部分があれば空文字で置換します。
<br />の除去remove_br()関数def remove_br(value): pattern = r"<br />" value = re.sub(pattern, "", value) return value末尾に改行タグ
<br />が含まれていることがあったので、{{0}}同様、マッチしたら空文字で置換します。パイプの除去
remove_pipe()関数def remove_pipe(value): pattern = r".*\|(.*)" result = re.match(pattern, value) if result: return result.group(1) return valueパイプが残っている部分があるので、マッチしたら表記部分だけを返却します。
これらを一通り行うとマークアップを除去したことになります!
29. 国旗画像のURLを取得する
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
29.pyimport pandas as pd import re import requests # 追加 def basic_info_extraction(text): # 「25. テンプレートの抽出」を参照 ... def remove_emphasis(value): # 「26. 強調マークアップの除去」を参照 ... def remove_innerlink(value): # 「27. 内部リンクの除去」を参照 ... def remove_footnote(value): # 「28. MediaWikiマークアップの除去」を参照 ... def remove_langage(value): # 「28. MediaWikiマークアップの除去」を参照 ... def remove_temporarylink(value): # 「28. MediaWikiマークアップの除去」を参照 .... def remove_zero(value): # 「28. MediaWikiマークアップの除去」を参照 ... def remove_br(value): # 「28. MediaWikiマークアップの除去」を参照 ... def remove_pipe(value): # 「28. MediaWikiマークアップの除去」を参照 ... file_name = "jawiki-country.json.gz" data_frame = pd.read_json(file_name, compression='infer', lines=True) uk_text = data_frame.query("title == 'イギリス'")['text'].values[0] ans = basic_info_extraction(uk_text) for key, value in ans.items(): value = remove_footnote(value) value = remove_emphasis(value) value = remove_innerlink(value) value = remove_langage(value) value = remove_temporarylink(value) value = remove_zero(value) value = remove_br(value) value = remove_pipe(value) uk_data[key] = value S = requests.Session() url = "https://en.wikipedia.org/w/api.php" params = { "action": "query", "format": "json", "prop": "imageinfo", "titles": "File:{}".format(uk_data["国旗画像"]) } R = S.get(url=url, params=params) data = R.json() pages = data["query"]["pages"] for k, v in pages.items(): print(v['imageinfo'][0]['url'])28.までで整形したデータを用いて課題を解決します。
$ pip install requestsでインストールしたRequestsモジュールを使います。
使う必要はないかもしれないのですが、Sessionを用いています。
URLやパラメータを記述し、欲しいデータを取得します。
ここでは課題を解決するためのパラメータを指定しています。
あとはGetリクエストを送り、返ってきたデータを表示すれば完了です。と言いたいところなのですが、表示したい画像のURLが取得したデータに含まれておらず、エラーになります。
間違っているのか、データが変わったのかまで調査できていないのが現状です…
まとめ
この記事では言語処理100本ノック2020年版 第3章: 正規表現の問題番号25〜29までを解いてみました。
データの整形はどこまですべきなのかとても迷いますよね…
きちんとできているかというのも確かめるのが大変なので、この辺が言語処理で一番難しいところだと個人的には感じております…独学なので、プロの方とはコードの書き方がこのあたりで如実に差が出てくるのではと思っています。
ぜひより良い書き方をご教示いただければと思います。よろしくお願いいたします!
前回まで
- 投稿日:2020-05-30T17:49:38+09:00
OpenCVのフィルタ処理を調べてみた
初めに
OpenCVで提供されるフィルタリング処理について調べてみました
動作環境
Python3,OpenCV
単純平滑化(ぼかし・ブラー)処理
オリジナルの画像は以下のデータ(グレースケール)であるとして、単純平滑化(ブラー)を行います
単純平滑化は、それぞれのピクセルを囲む複数のピクセルの長方形の単純平均を、そのピクセルの値とします
ここでは長方形のサイズを(3*3)としている為に以下のように計算されます
全体のピクセルを計算すると以下のようになります
import numpy as np import cv2 as cv import matplotlib.pyplot as plt import matplotlib.colors as colors import matplotlib.cm as cm black = [0x00, 0x00, 0x00] white = [0xFF, 0xFF, 0xFF] img = np.array([ [black, black, black, black, black, black, black] ,[black, black, black, black, black, black, black] ,[black, black, white, white, white, black, black] ,[black, black, white, white, white, black, black] ,[black, black, white, white, white, black, black] ,[black, black, black, black, black, black, black] ,[black, black, black, black, black, black, black] ] , dtype=np.uint8) # グレースケール化 img = cv.cvtColor(img, cv.COLOR_RGB2GRAY) # グラフ描画域 fig = plt.figure(figsize=(8, 3)) ax1 = fig.add_subplot(121, projection='3d') ax2 = fig.add_subplot(122, projection='3d') # X,Y _x = np.arange(img.shape[1]) _y = np.arange(img.shape[0]) _xx, _yy = np.meshgrid(_x, _y) x, y = _xx.ravel(), _yy.ravel() width = depth = 1 # 高さ top = img.ravel() bottom = np.zeros_like(top) # 0-255 を 0.0-1.0に変換する関数の定義(グレースケール表示の為) norm = colors.Normalize(0, 255) # オリジナル color_values = cm.gray(top.tolist()) ax1.bar3d(x, y, bottom, width, depth, top, color=color_values) ax1.set_title('Original') # Blur(カーネルサイズ 3*3) blurImg = cv.blur(img, (3, 3)) top = blurImg.ravel() color_values = cm.gray(norm(top.tolist())) ax2.bar3d(x, y, bottom, width, depth, top, color=color_values) ax2.set_title('Blur') plt.show()
メディアンフィルタ処理
メディアンフィルタは、それぞれのピクセルを囲む長方形の中間値を、そのピクセルの値とします
全体のピクセルを計算すると以下のようになります
# medianBlur(カーネルサイズ 3*3) mBlurImg = cv.medianBlur(img, 3) top = mBlurImg.ravel() color_values = cm.gray(norm(top.tolist())) ax2.bar3d(x, y, bottom, width, depth, top, color=color_values) ax2.set_title('medianBlur')
Gaussian(ガウシアン)フィルタ処理
ガウシアンフィルタは、それぞれのピクセルを囲む長方形にガウスカーネルと呼ばれる行列を乗じて、その合計値をそのピクセルの値とします
ここで用いている3*3のガウスカーネルは以下のようになります\begin{pmatrix} 1/16 & 2/16 & 1/16 \\ 2/16 & 4/16 & 2/16 \\ 1/16 & 2/16 & 1/16 \end{pmatrix}
PixelAは以下のように計算されます
import numpy as np pixelA = np.array([[0, 0, 0] ,[0, 255, 255] ,[0, 255, 255]]) gaussKernel = np.array([[1/16, 2/16, 1/16] ,[2/16, 4/16, 2/16] ,[1/16, 2/16, 1/16]]) print(sum(sum(pixelA * gaussKernel))) #143全体のピクセルを計算すると以下のようになります
# GaussianBlur gBlurImg = cv.GaussianBlur(img, (3, 3), 0, 0) top = gBlurImg.ravel() color_values = cm.gray(norm(top.tolist())) ax2.bar3d(x, y, bottom, width, depth, top, color=color_values) ax2.set_title('GaussianBlur')
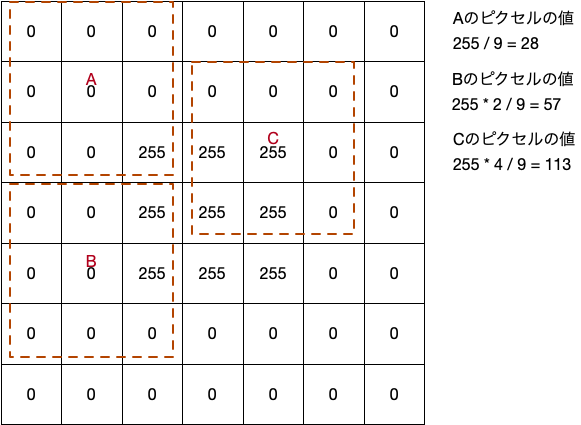
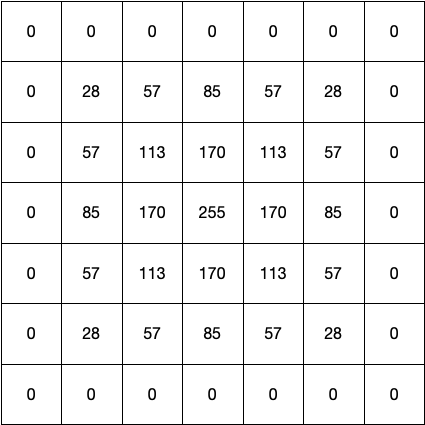
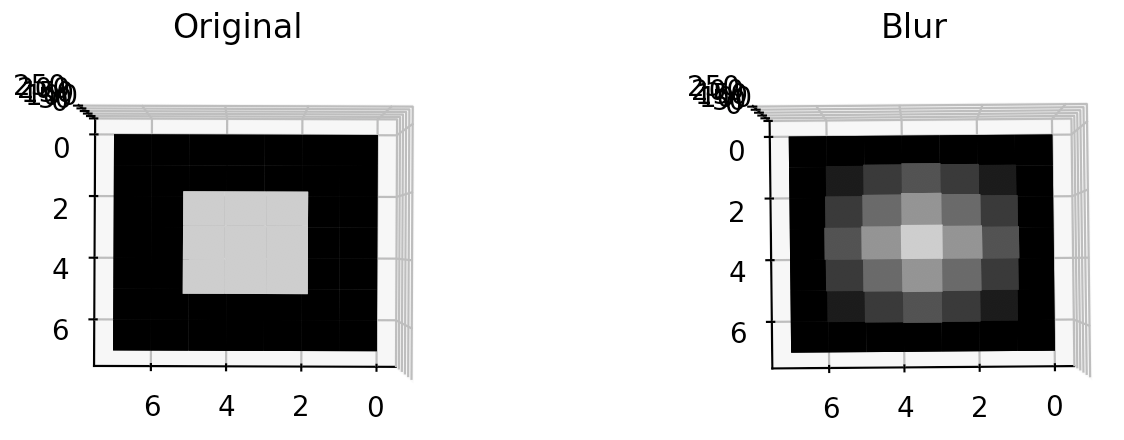
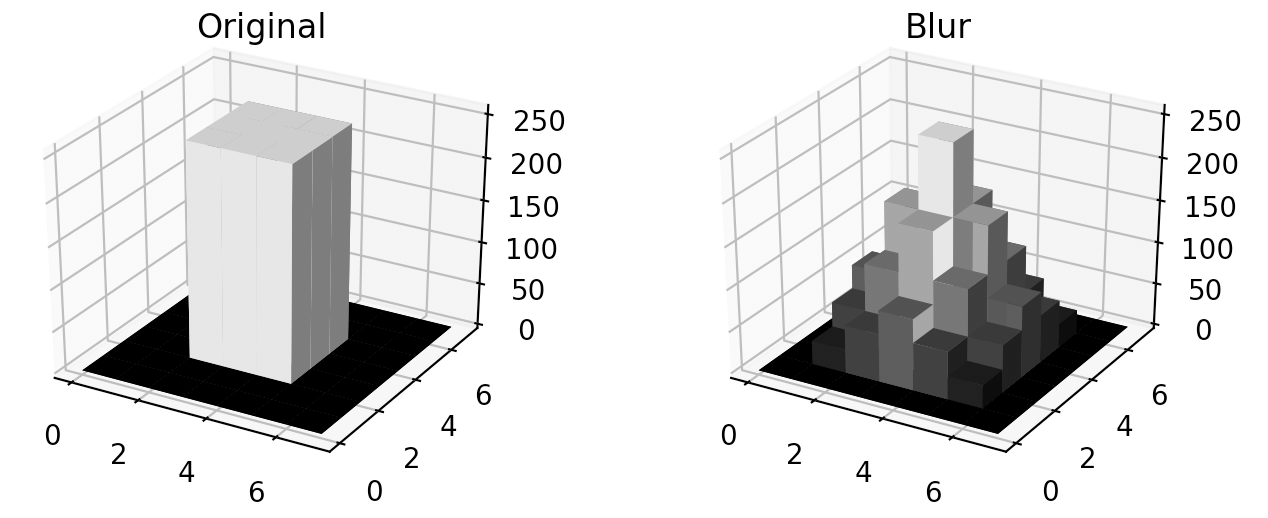
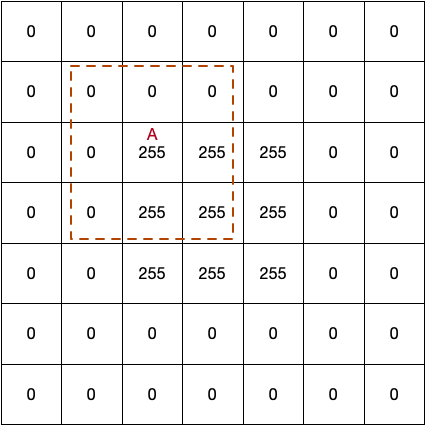
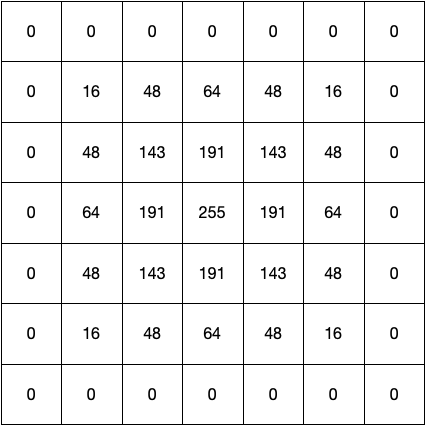
- 投稿日:2020-05-30T17:44:38+09:00
Pythonだけで簡単に!Graphvizの図形、draw.ioで編集したいよね!
はじめに
pythonで作ったネットワーク図をdraw.ioで編集したい人向けの記事です。
①networkxでグラフのもとになるdotフォーマットのデータを作って、
②それをgraphviz2drawioを使ってDraw.ioで使える形式(xlm)で出力します今のところ、とりあえず出来た、というだけですが、環境づくりに苦労したので、同じような沼にはまる人がいないといいなと思って書きます。
最後にはこういうものが出来上がります。
(VSCodeの拡張機能、Draw.io Integrationで表示しています)
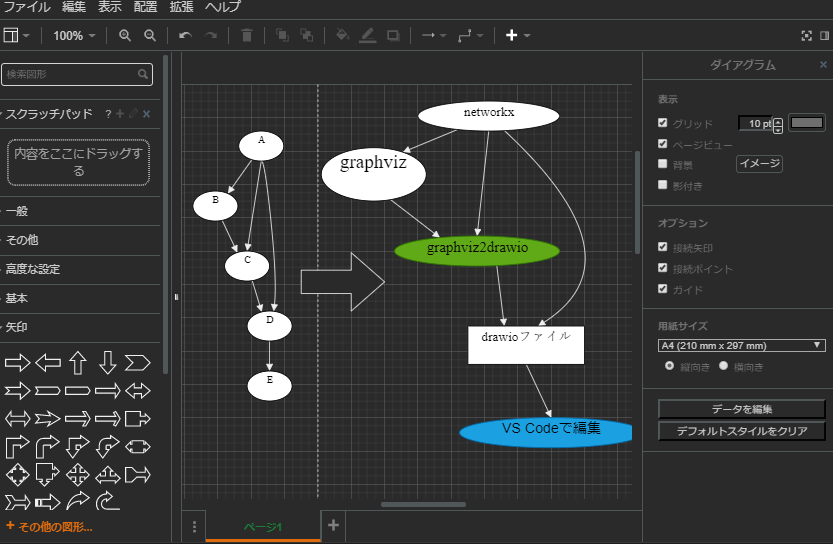
ハマった点
Graphvizで描画するのに使うGraphvizのパッケージと、graphviz2drawioを使うためのGraphvizのパッケージが異なる。環境を別にしないとエラーになってしまう。
Graphviz単体でインストールして使うことを前提としたパッケージと、パッケージ内で完結するものがあるのかもしれない。
あるいはパッケージ間の相性?
今回は、Graphvizでの描画用の環境とは別に、graphviz2drawioで出力するための環境を用意しました。環境
OS Windows10 64bit
Python 3.7.7(Anaconda3-2019.03で作成)
※Graphvizはインストールしていません環境構築
Anacondaで、新しいPython3.7の環境を作ります(Datavizと名付けました) 2020年5月30日時点で、python3.7.7でした。
標準パッケージのインストール
下記のパッケージをインストールします。標準パッケージにあります。
・networkx
・pydot (pydotplusではない)
・python-graphviz(これがないとimport graphvizしても動かないので忘れないように)※慌てて標準のgraphvizを入れないように!
標準外パッケージのインストール
ここからはAnacondaのターミナルを起動して、順番に
・graphviz ( https://anaconda.org/alubbock/graphviz )ver 2.41
・pygraphviz ( https://anaconda.org/alubbock/pygraphviz )ver 1.5
・graphviz2drawio( https://pypi.org/project/graphviz2drawio/0.2.0/ )
を入れていきます。(DataViz) C:\Users\(ユーザー名)>conda install graphviz pygraphviz -c alubbock (DataViz) C:\Users\(ユーザー名)>pip install graphviz2drawio==0.2.0とします。
標準のgraphvizを入れているとpygraphviz/graphviz_wrap.c(2987): fatal error C1083: include ファイルを開けません。'graphviz/cgraph.h':No such file or directoryというエラーが出てpygraphvizがインストールできません。
dot.exeのプラグイン登録(?)
これで、dotファイルを扱えるようになっているか確認するため
dot -vと打ちます。
何かうまくいっていないと、次のようにdot -cを入れるように言われます。(DataViz) C:\Users\(ユーザー名)>dot -v dot - graphviz version 2.41.20170921.1950 (20170921.1950) There is no layout engine support for "dot" Perhaps "dot -c" needs to be run (with installer's privileges) to register the plugins?素直に
dot -c(何も出ません)(DataViz) C:\Users\(ユーザー名)>dot -c (DataViz) C:\Users\(ユーザー名)>もう一度
dot -cを打って下記の結果が出ればあと少し。
これができていないと、graphviz2drawioを使ったときに "svg" is not recognized… といったエラーが出ます。dot - graphviz version 2.41.20170921.1950 (20170921.1950) libdir = "C:\Users\(ユーザー名)\.conda\envs\DataViz\Scripts" Activated plugin library: gvplugin_dot_layout.dll Using layout: dot:dot_layout Activated plugin library: gvplugin_core.dll Using render: dot:core Using device: dot:dot:core The plugin configuration file: C:\Users\(ユーザー名)\.conda\envs\DataViz\Scripts\config6 was successfully loaded. render : cairo dot dot_json fig gdiplus json json0 map mp pic ps svg tk vml xdot xdot_json layout : circo dot fdp neato nop nop1 nop2 osage patchwork sfdp twopi textlayout : textlayout device : bmp canon cmap cmapx cmapx_np dot dot_json emf emfplus eps fig gif gv imap imap_np ismap jpe jpeg jpg json json0 metafile mp pdf pic plain plain-ext png ps ps2 svg tif tiff tk vml xdot xdot1.2 xdot1.4 xdot_json loadimage : (lib) bmp eps gif jpe jpeg jpg png ps svgMxGraph.pyの修正
"C:\Users(ユーザー名).conda\envs\DataViz\Lib\site-packages\graphviz2drawio\mx\MxGraph.py"
のファイルがエラーになるのですが、本来やろうとしていた処理がよくわからないのでコメントアウトして上書き保存しましょう。
分かる方は、ぜひ修正を手伝ってあげてください。 https://github.com/hbmartin/graphviz2drawio/issues~\.conda\envs\DataViz\Lib\site-packages\graphviz2drawio\mx\MxGraph.py in add_mx_geo_with_points(element, curve) 115 for cb in curve.cbset: 116 ET.SubElement(array, MxConst.POINT, x=str(cb[0][0]), y=str(cb[0][1])) --> 117 if cb: 118 ET.SubElement(array, MxConst.POINT, x=str(cb[1][0]), y=str(cb[1][1])) 119 UnboundLocalError: local variable 'cb' referenced before assignment修正後
MxGraph.pyfor cb in curve.cbset: ET.SubElement(array, MxConst.POINT, x=str(cb[0][0]), y=str(cb[0][1])) #エラーになるのでコメントアウト #if cb: # ET.SubElement(array, MxConst.POINT, x=str(cb[1][0]), y=str(cb[1][1]))環境構築の補足
2020年5月30時点で、python3に対応しているpygraphvizは、alubbockのものしかなく、それに合わせてalubbockのgraphvizを入れておく必要があるようです。ただし、このgraphvizを入れても、グラフは描画できませんでした。
graphviz_test.pyfrom graphviz import Source path = "edges.dot" s = Source.from_file(path) s.view()結果
--------------------------------------------------------------------------- FileNotFoundError Traceback (most recent call last) // FileNotFoundError: [WinError 2] 指定されたファイルが見つかりません。 During handling of the above exception, another exception occurred: ExecutableNotFound Traceback (most recent call last) // ExecutableNotFound: failed to execute ['dot.bat', '-Tpdf', '-O', 'pdt.dot'], make sure the Graphviz executables are on your systems' PATH逆に、標準のgraphvizを入れると、graphviz2drawioが使えず(内部で呼び出しているpygraphvizが使えない)
from graphviz2drawio import graphviz2drawio
を実行するとImportError: DLL load failed: 指定されたモジュールが見つかりません。となってしまいます。
Windowsじゃなかったり、環境構築をpipでやったり、Graphvizのソフトをインストールして適切なPATHの設定をすればこんな苦労はないのかもしれません。
使ってみる
プログラム
今回はこのサンプルを使います。edgelist2drawio.py と同じフォルダに保存している前提です。
edges.txtA B A C A D B C C D D Epythonプログラム
edgelist2drawio.pyimport networkx as nx from graphviz2drawio import graphviz2drawio #edges.textを有向グラフとして読み込む G = nx.read_edgelist('edges.txt', create_using=nx.DiGraph(), nodetype=str) # 読み込んだ情報をdot形式に変換 edges_dot = nx.drawing.nx_pydot.to_pydot(G) # 必要ならdotファイルとして書き出す # nx.drawing.nx_pydot.write_dot(G,"edges.dot") # dot形式のデータをもとにgraphviz的な描画をしてdraw.ioファイルとして書き出す xml = graphviz2drawio.convert(str(edges_dot)) # dotファイルから読み取って変換するときは # xml = graphviz2drawio.convert("edges.dot") # 変換したファイルを保存 with open('edges.drawio', 'w') as f: print(xml, file=f)編集する
プログラムを実行して作られるedges.drawioをVS Code(拡張機能でDraw.io Integration https://github.com/hediet/vscode-drawio.git を入れておく)で開くと、Graphvizで書いたような図が開けます。
あとは思いのままに編集できます!
おわりに
・graphviz2drawio
https://pypi.org/project/graphviz2drawio/0.2.0/・GraphViz
https://www.graphviz.org/・VS CodeでDraw.ioが使える喜びはこちらの記事で知りました。
「VSCodeでDraw.ioが使えるようになったらしい!」
https://qiita.com/riku-shiru/items/5ab7c5aecdfea323ec4e・
- 投稿日:2020-05-30T17:38:14+09:00
【Django】manage.pyで動くプロセス内からさらに自作したコマンドを叩く
記録用に。
やりたかったこと
commandsディレクトリに自作のコマンドを作成し、テスト内から下記コマンドと同様のことを行おうとしました。
$ python manage.py create_initial_dataテストのセットアップ時にシェルでコマンドを流すのかと思いましたが、Djangoはここはしっかりサポートされていました
やり方
対象のスクリプトに、
call_command関数を埋め込みます。from django.test import TestCase, Client from django.core.management import call_command class TestSendEmailView(TestCase): def setUp(self): self.client = Client() call_command('create_initial_data') # ここ def test_success(self): response = self.client.get('/emails/') self.assertEqual(response.status_code, 200)これで
python manage.py create_initial_dataと同じことが行われます。
- 投稿日:2020-05-30T17:23:35+09:00
Google Drive Api Tips(Python)
サービスアカウントの場合の初期化
https://cloud.google.com/iam/docs/creating-managing-service-account-keys?hl=ja
こちらを参考にjsonファイルをを取得しておきますfrom google.oauth2 import service_account from googleapiclient.discovery import build SCOPES = ['https://www.googleapis.com/auth/drive'] credentials = service_account.Credentials.from_service_account_file(JSON_FILE_PATH, scopes=SCOPE) self.service = build('drive', 'v3', credentials=credentials)指定したディレクトリにファイルをアップロードしたい
ファイルIDは配列で渡しましょう(忘れがち)
from apiclient.http import MediaFileUpload # ディレクトリのファイルIDはパスの一番後ろ # https://drive.google.com/drive/folders/FILE_ID file_metadata = {'name': 'photo.jpg', 'parents': [FILE_ID]} media = MediaFileUpload('files/photo.jpg', mimetype='image/jpeg') file = self.service.files().create(body=file_metadata, media_body=media, fields='id').execute()アップロードする際のmimetypeって何を指定したらいい?
このあたりを参考
https://developers.google.com/drive/api/v3/mime-types
https://developer.mozilla.org/ja/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_typesファイルのいろんな情報が見たい
*で全情報が返ります
必要な項目をカンマ区切りで渡しましょうself.service.files().get(fileId=FILE_ID, fields="*").execute()ファイルアップロードしたのにアクセスできない
多分権限がありません、つけてあげましょう
あらかじめ権限のあるディレクトリを作っておいて、そこにアップロードすればいちいち権限をつける必要はありませんuser_permission = { 'type': 'user', 'role': 'writer', 'domain': 'hoge@gmail.com' } self.service.permissions().create( fileId=FILE_ID, body=user_permission, fields='id', )ダウンロードしたファイルを指定したパスに保存する
getbufferで書き込みましょうimport io from apiclient.http import MediaIoBaseDownload request = self.service.files().get_media(fileId=FILE_ID) fh = io.BytesIO() downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() print("Download %d%%." % int(status.progress() * 100)) with open(SAVE_FILE_PATH, "wb") as f: f.write(fh.getbuffer())
- 投稿日:2020-05-30T17:19:03+09:00
Ruby と Python で解く AtCoder ABC138 D 隣接リスト
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Beginner Contest D - Ki
Difficulty: 923今回のテーマ、隣接リスト
以前解きました Ruby と Python と networkx で解く AtCoder ABC168 D 隣接リスト の応用版といった問題です。
今回は、木の根から頂点へカウンターの値が送られますますので、カウンター用の配列を準備し、根から頂点へ探索を行うことによりカウンターの値の受け渡しを行います。
Ruby
ruby.rbn, q = gets.split.map(&:to_i) a = Array.new(n){[]} n.pred.times do x, y = gets.split.map(&:to_i) a[x - 1] << y - 1 a[y - 1] << x - 1 end p = Array.new(n){0} q.times do |i| x, y = gets.split.map(&:to_i) p[x - 1] += y end c = Array.new(n){0} c[0] = 1 que = [] que << 0 while que.size > 0 e = que.shift a[e].each do |i| next if c[i] > 0 c[i] = 1 p[i] += p[e] que << i end end puts pindex.rbp[i] += p[e]ここでカウンターの値の受け渡しを行っています。
Python
python.pyfrom sys import stdin def main(): from collections import deque input = stdin.readline n, q = map(int, input().split()) a = [[] for _ in range(n)] for i in range(n - 1): x, y = map(int, input().split()) a[x - 1].append(y - 1) a[y - 1].append(x - 1) p = [0] * n for i in range(q): x, y = map(int, input().split()) p[x - 1] += y c = [0] * n c[0] = 1 que = deque([]) que.append(0) while len(que) > 0: e = que.popleft() for i in a[e]: if c[i] > 0: continue c[i] = 1 p[i] += p[e] que.append(i) for i in range(n): print(p[i]) main()stdin.pyfrom sys import stdin input = stdin.readline
stdinを使用すると実行時間がかなり速くなります。
Ruby Python Python (stdin) PyPy PyPy (stdin) コード長 (Byte) 442 681 736 681 736 実行時間 (ms) 802 1734 1044 1959 864 メモリ (KB) 25468 53008 53040 105164 91852 まとめ
- ABC 138 D を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- 投稿日:2020-05-30T17:09:05+09:00
量子情報理論の基本:量子誤り訂正(スタビライザー符号:4)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
前回の記事で、スタビライザー符号の理論が理解できたので、今回はスタビライザー符号の具体例を一つを取り上げ、量子計算シミュレータqlazyを使ってその動作を確認してみます。前回の終わりに「Shor符号」「Steane符号」「5量子ビット符号」の生成元を紹介しました。このうち「Shor符号」「Steane符号」はすでに別記事1で動作確認をしていたので、ここでは「5量子ビット符号」を実装して動作確認してみることにします。
準備
まず、4つの生成元および論理Z演算子を改めて掲載します。
生成元 演算子 $g_{1}$ $X \otimes Z \otimes Z \otimes X \otimes I$ $g_{2}$ $I \otimes X \otimes Z \otimes Z \otimes X$ $g_{3}$ $X \otimes I \otimes X \otimes Z \otimes Z$ $g_{4}$ $Z \otimes X \otimes I \otimes X \otimes Z$ $\bar{Z} \equiv g_{5}$ $Z \otimes Z \otimes Z \otimes Z \otimes Z$ 表に入れていませんが、論理X演算子は$X \otimes X \otimes X \otimes X \otimes X$です。
これに基づき量子回路を設計したいのですが、それにはいくつかの前準備が必要です。
$\ket{00000}$から論理基底状態$\ket{0_L}$を作成するために、生成元$g_i$に対応した演算子$g_{i}^{\prime}$を$g_{i}$と反可換でその他のすべての$g_j(j \ne i)$と可換であるように選ぶ必要がありました。上の生成元に対する検査行列2を作って、$g_{i}^{\prime}$の検査行列を作成すれば良いと思い、試行錯誤した結果、以下のようなものをひねり出すことができました3。
演算子 $g_{1}^{\prime}$ $Z \otimes I \otimes Z \otimes I \otimes I$ $g_{2}^{\prime}$ $Z \otimes Z \otimes Z \otimes Z \otimes I$ $g_{3}^{\prime}$ $Z \otimes Z \otimes I \otimes Z \otimes Z$ $g_{4}^{\prime}$ $Z \otimes I \otimes Z \otimes Z \otimes I$ $\bar{Z}^{\prime} \equiv g_{5}^{\prime}$ $X \otimes X \otimes X \otimes X \otimes X$ 雑音集合としては、以下のように各量子ビットごとにパウリ群の演算子$X,Z,XZ$を作用させるすべてのものを用意しておきます。
雑音 演算子 $E_{0}$ $I \otimes I \otimes I \otimes I \otimes I$ $E_{1}$ $X \otimes I \otimes I \otimes I \otimes I$ $E_{2}$ $Z \otimes I \otimes I \otimes I \otimes I$ $E_{3}$ $XZ \otimes I \otimes I \otimes I \otimes I$ $E_{4}$ $I \otimes X \otimes I \otimes I \otimes I$ $E_{5}$ $I \otimes Z \otimes I \otimes I \otimes I$ $E_{6}$ $I \otimes XZ \otimes I \otimes I \otimes I$ $E_{7}$ $I \otimes I \otimes X \otimes I \otimes I$ $E_{8}$ $I \otimes I \otimes Z \otimes I \otimes I$ $E_{9}$ $I \otimes I \otimes XZ \otimes I \otimes I$ $E_{10}$ $I \otimes I \otimes I \otimes X \otimes I$ $E_{11}$ $I \otimes I \otimes I \otimes Z \otimes I$ $E_{12}$ $I \otimes I \otimes I \otimes XZ \otimes I$ $E_{13}$ $I \otimes I \otimes I \otimes I \otimes X$ $E_{14}$ $I \otimes I \otimes I \otimes I \otimes Z$ $E_{15}$ $I \otimes I \otimes I \otimes I \otimes XZ$ 雑音$E_i$が加わった状態に対して生成元を測定した場合の測定値リスト$\{ \beta_{l}^{(i)}\}$も必要です。
g_l E_i = \beta_{l}^{(i)} E_i g_l \tag{1}で計算できます。つまり、$g_l$と$E_i$が可換の場合$\beta_{l}^{(i)}=+1$で反可換の場合$\beta_{l}^{(i)}=-1$です。以下に各雑音に対する測定値リストを示します。2列目では測定値$+1$を$+$、測定値$-1$を$-$として記載しています。また、測定値が$+1$というのは$\ket{0}$、測定値が$-1$というのは$\ket{1}$のことなので、3列目ではその指標($0$または$1$)を示しています。量子回路として実装する際には、測定値は指標として得られるので3列目の$(0,1)$系列を参照した方が良いです。
雑音 $(g_1, g_2, g_3, g_4)$の測定値 測定値の指標 $E_{0}$ $(+,+,+,+)$ $(0,0,0,0)$ $E_{1}$ $(+,+,+,-)$ $(0,0,0,1)$ $E_{2}$ $(-,+,-,+)$ $(1,0,1,0)$ $E_{3}$ $(-,+,-,-)$ $(1,0,1,1)$ $E_{4}$ $(-,+,+,+)$ $(1,0,0,0)$ $E_{5}$ $(+,-,+,-)$ $(0,1,0,1)$ $E_{6}$ $(-,-,+,-)$ $(1,1,0,1)$ $E_{7}$ $(-,-,+,+)$ $(1,1,0,0)$ $E_{8}$ $(+,+,-,+)$ $(0,0,1,0)$ $E_{9}$ $(-,-,-,+)$ $(1,1,1,0)$ $E_{10}$ $(+,-,-,+)$ $(0,1,1,0)$ $E_{11}$ $(-,+,+,-)$ $(1,0,0,1)$ $E_{12}$ $(-,-,-,-)$ $(1,1,1,1)$ $E_{13}$ $(+,+,-,-)$ $(0,0,1,1)$ $E_{14}$ $(+,-,+,+)$ $(0,1,0,0)$ $E_{15}$ $(+,-,-,-)$ $(0,1,1,1)$ 前準備はこれで完了です。では、量子回路を以下に示します。
量子回路
まず、論理的な基底状態$\ket{0_L}$を物理的な基底状態$\ket{00000}$から得る回路を示します。
|0> --H---*---H---M |0> --H---|-------|-------*---H---M |0> --H---|-------|-------|-------|-------*---H---M |0> --H---|-------|-------|-------|-------|-------|-------*---H---M |0> --H---|-------|-------|-------|-------|-------|-------|-------|-------*---H---M | | | | | | | | | | |0> ----| |---| |---| |---| |---| |---| |---| |---| |---| |---| |--- |0> ----| |---| |---| |---| |---| |---| |---| |---| |---| |---| |--- |0> ----|g1 |---|g1'|---|g2 |---|g2'|---|g3 |---|g3'|---|g4 |---|g4'|---|g5 |---|g5'|--- |0L> |0> ----| |---| |---| |---| |---| |---| |---| |---| |---| |---| |--- |0> ----| |---| |---| |---| |---| |---| |---| |---| |---| |---| |---次に、未知な1量子状態$\ket{\psi}$を量子テレポーテーションの手法を使って符号化します。
|psi> ----------*---H-----------M | | |0> --H---*---X---------M | | | | ------X-------------X-----Z--- ------X-------------X-----Z--- |0L> ------X-------------X-----Z--- |psi_L> ------X-------------X-----Z--- ------X-------------X-----Z---符号化状態$\ket{\psi_L}$が得られたので、雑音を付加します。ここで、Eiは何らかの雑音を表します。
---| |--- ---| |--- |psi_L> ---|Ei|--- |psi_L'> ---| |--- ---| |---最後に、誤り検知のためのシンドローム測定を行い、回復のため雑音の逆演算を行えば、状態が元に戻ります。
|0> --H---*--------------------------H-----M |0> --H---|-------*------------------H-----M |0> --H---|-------|-------*----------H-----M |0> --H---|-------|-------|------*---H-----M | | | | | ----| |---| |---| |--| |-----| |---- ----| |---| |---| |--| |-----| |---- |psi_L'> ----|g1 |---|g2 |---|g3 |--|g4 |-----|E+ |---- |psi> ----| |---| |---| |--| |-----| |---- ----| |---| |---| |--| |-----| |----量子回路は以上です。
実装
それではqlazyによる実装例を示します。
import numpy as np from qlazypy import QState def logic_x(self, qid): [self.x(q) for q in qid] return self def logic_z(self, qid): [self.z(q) for q in qid] return self def ctr_logic_x(self, q, qid): [self.cx(q, qtar) for qtar in qid] return self def ctr_logic_z(self, q, qid): [self.cz(q, qtar) for qtar in qid] return self def ctr_g1(self, q, qid): self.cx(q, qid[0]).cz(q, qid[1]).cz(q, qid[2]).cx(q, qid[3]) return self def ctr_g2(self, q, qid): self.cx(q, qid[1]).cz(q, qid[2]).cz(q, qid[3]).cx(q, qid[4]) return self def ctr_g3(self, q, qid): self.cx(q, qid[0]).cx(q, qid[2]).cz(q, qid[3]).cz(q, qid[4]) return self def ctr_g4(self, q, qid): self.cz(q, qid[0]).cx(q, qid[1]).cx(q, qid[3]).cz(q, qid[4]) return self def encode(self, phase, qid_anc, qid_cod): # make logical zero state: |0>_L # g1 self.h(qid_anc[0]).ctr_g1(qid_anc[0], qid_cod).h(qid_anc[0]) self.m(qid=[qid_anc[0]]) mval = self.m_value(binary=True) if mval == '1': self.z(qid_cod[0]).z(qid_cod[2]) self.reset(qid=[qid_anc[0]]) # g2 self.h(qid_anc[1]).ctr_g2(qid_anc[1], qid_cod).h(qid_anc[1]) self.m(qid=[qid_anc[1]]) mval = self.m_value(binary=True) if mval == '1': self.z(qid_cod[0]).z(qid_cod[1]).z(qid_cod[2]).z(qid_cod[3]) self.reset(qid=[qid_anc[1]]) # g3 self.h(qid_anc[2]).ctr_g3(qid_anc[2], qid_cod).h(qid_anc[2]) self.m(qid=[qid_anc[2]]) mval = self.m_value(binary=True) if mval == '1': self.z(qid_cod[0]).z(qid_cod[1]).z(qid_cod[3]).z(qid_cod[4]) self.reset(qid=[qid_anc[2]]) # g4 self.h(qid_anc[3]).ctr_g4(qid_anc[3], qid_cod).h(qid_anc[3]) self.m(qid=[qid_anc[3]]) mval = self.m_value(binary=True) if mval == '1': self.z(qid_cod[0]).z(qid_cod[2]).z(qid_cod[3]) self.reset(qid=[qid_anc[3]]) # logical z self.h(qid_anc[4]).ctr_logic_z(qid_anc[4], qid_cod).h(qid_anc[4]) self.m(qid=[qid_anc[4]]) mval = self.m_value(binary=True) if mval == '1': self.x(qid_cod[0]).x(qid_cod[1]).x(qid_cod[2]).x(qid_cod[3]).x(qid_cod[4]) self.reset(qid=[qid_anc[4]]) # make random quantum state and encode (with quantum teleportation) self.reset(qid=qid_anc) self.u3(qid_anc[0], alpha=phase[0], beta=phase[1], gamma=phase[2]) # input quantum state print("* input quantum state") self.show(qid=[qid_anc[0]]) self.h(qid_anc[1]) self.ctr_logic_x(qid_anc[1], qid_cod).cx(qid_anc[0], qid_anc[1]) self.h(qid_anc[0]) self.m(qid=qid_anc[0:2]) mval = self.m_value(binary=True) if mval == '00': pass elif mval == '01': self.logic_x(qid_cod) elif mval == '10': self.logic_z(qid_cod) elif mval == '11': self.logic_x(qid_cod).logic_z(qid_cod) self.reset(qid=qid_anc) return self def add_noise(self, q, qid, kind): if kind == 'X': self.x(qid[q]) elif kind == 'Z': self.z(qid[q]) elif kind == 'XZ': self.z(qid[q]).x(qid[q]) return self def correct_err(self, qid_anc, qid_cod): self.reset(qid=qid_anc) # syndrome self.h(qid_anc[0]).ctr_g1(qid_anc[0], qid_cod).h(qid_anc[0]) self.h(qid_anc[1]).ctr_g2(qid_anc[1], qid_cod).h(qid_anc[1]) self.h(qid_anc[2]).ctr_g3(qid_anc[2], qid_cod).h(qid_anc[2]) self.h(qid_anc[3]).ctr_g4(qid_anc[3], qid_cod).h(qid_anc[3]) self.m(qid=qid_anc[0:4]) mval = self.m_value(binary=True) print("* syndrome =", mval) # recovery if mval == '0000': pass elif mval == '0001': self.x(qid_cod[0]) elif mval == '1010': self.z(qid_cod[0]) elif mval == '1011': self.z(qid_cod[0]).x(qid_cod[0]) elif mval == '1000': self.x(qid_cod[1]) elif mval == '0101': self.z(qid_cod[1]) elif mval == '1101': self.z(qid_cod[1]).x(qid_cod[1]) elif mval == '1100': self.x(qid_cod[2]) elif mval == '0010': self.z(qid_cod[2]) elif mval == '1110': self.z(qid_cod[2]).x(qid_cod[2]) elif mval == '0110': self.x(qid_cod[3]) elif mval == '1001': self.z(qid_cod[3]) elif mval == '1111': self.z(qid_cod[3]).x(qid_cod[3]) elif mval == '0011': self.x(qid_cod[4]) elif mval == '0100': self.z(qid_cod[4]) elif mval == '0111': self.z(qid_cod[4]).x(qid_cod[4]) return self if __name__ == '__main__': QState.add_methods(logic_x, logic_z, ctr_logic_x, ctr_logic_z, ctr_g1, ctr_g2, ctr_g3, ctr_g4, encode, add_noise, correct_err) # create registers qid_anc = QState.create_register(5) qid_cod = QState.create_register(5) qnum = QState.init_register(qid_anc, qid_cod) # parameters for input quantum state (U3 gate params) phase = [np.random.rand(), np.random.rand(), np.random.rand()] # encode quantum state qs_ini = QState(qnum) qs_ini.encode(phase, qid_anc, qid_cod) qs_fin = qs_ini.clone() # noise q = np.random.randint(0, len(qid_cod)) kind = np.random.choice(['X','Z','XZ']) print("* noise '{:}' to #{:} qubit".format(kind, q)) qs_fin.add_noise(q, qid_cod, kind) # error correction qs_fin.correct_err(qid_anc, qid_cod) # result fid = qs_ini.fidelity(qs_fin, qid=qid_cod) print("* fidelity = {:.6f}".format(fid)) QState.free_all(qs_ini, qs_fin)何をやっているか順に説明します。main処理部を見てください。
QState.add_methods(logic_x, logic_z, ctr_logic_x, ctr_logic_z, ctr_g1, ctr_g2, ctr_g3, ctr_g4, encode, add_noise, correct_err)で、上で示したカスタム・メソッドを量子状態を表すQStateクラスのメソッドとして登録します。
# create registers qid_anc = QState.create_register(5) qid_cod = QState.create_register(5) qnum = QState.init_register(qid_anc, qid_cod)で、これから使用するレジスタを生成します。これにより、qid_anc=[0,1,2,3,4], qid_cod=[5,6,7,8,9], qnum=10という具合に変数値が設定されます4。qid_ancは5個の補助量子ビットです。上で示した量子回路において、論理基底状態を作成するために5個、量子テレポーテーションでの符号状態作成に2個、誤り訂正のために4個の補助量子ビットが必要です。各ステップの直前で状態をリセットできるので5個の補助量子ビットがあれば十分です。qid_codは符号状態を記述するための量子ビットです。5量子ビット符号なので5量子ビット用意しておけば良いです。
# parameters for input quantum state (U3 gate params) phase = [np.random.rand(), np.random.rand(), np.random.rand()]で、符号状態を適当に作成するため3個のランダムパラメータphaseを生成しています(U3ゲート演算するための3つのパラメータです)。
# encode quantum state qs_ini = QState(qnum) qs_ini.encode(phase, qid_anc, qid_cod) qs_fin = qs_ini.clone()で、まず補助量子ビットも含めた初期状態を作成して、それに対してencodeメソッドで符号状態に変換します。qs_iniをqs_finにコピーしていますが、これは最終的に元の状態と誤り訂正後の状態が一致しているかどうか評価するためのものです。
では、encodeメソッドの中身を見てみます。
# g1 self.h(qid_anc[0]).ctr_g1(qid_anc[0], qid_cod).h(qid_anc[0]) self.m(qid=[qid_anc[0]]) mval = self.m_value(binary=True) if mval == '1': self.z(qid_cod[0]).z(qid_cod[2]) self.reset(qid=[qid_anc[0]]) ...で、論理基底状態$\ket{0_L}$を作成します。上の量子回路で示した通りの演算を順に実行します。間接測定の測定値(の指標)はmval変数に入ります。これが"0"だった場合何もせず、"1"だった場合$g_{1}^{\prime} = ZIZII$を演算します。終わったら使用した0番目の補助量子ビットをリセットします。以下、同様のことを他のすべての生成元と論理Z演算子に対して実行します。
self.u3(qid_anc[0], alpha=phase[0], beta=phase[1], gamma=phase[2]) # input quantum state print("* input quantum state") self.show(qid=[qid_anc[0]])で、0番目の補助量子ビットにphaseを引数としたU3ゲートを演算することでランダムな1量子ビット状態を作ります。そして、その状態を表示します。
self.h(qid_anc[1]) self.ctr_logic_x(qid_anc[1], qid_cod).cx(qid_anc[0], qid_anc[1]) self.h(qid_anc[0]) self.m(qid=qid_anc[0:2]) mval = self.m_value(binary=True) if mval == '00': pass elif mval == '01': self.logic_x(qid_cod) elif mval == '10': self.logic_z(qid_cod) elif mval == '11': self.logic_x(qid_cod).logic_z(qid_cod) self.reset(qid=qid_anc)で、量子テレポーテーションの回路を実行します。mvalには2つの測定を実行した結果が入り、その4パターンに応じて、何もしない/論理X/論理Z/論理XZ演算子を実行すれば、先程ランダムに作成した1量子ビット状態から5量子ビットの符号状態を得ることができます。
main処理部に戻ります。
# noise q = np.random.randint(0, len(qid_cod)) kind = np.random.choice(['X','Z','XZ']) print("* noise '{:}' to #{:} qubit".format(kind, q)) qs_fin.add_noise(q, qid_cod, kind)で、5量子ビットの符号状態に対してランダムにノイズを加えます。量子ビットをランダムに選び、さらに雑音のタイプをX/Z/XZの中からランダムに選びます。実際の処理はadd_noiseメソッドで行います。詳細は関数定義を見てください。
# error correction qs_fin.correct_err(qid_anc, qid_cod)で、誤り訂正を実行します。
correct_errメソッドの中身を見てみます。
self.reset(qid=qid_anc)で、まず補助量子ビットをすべてリセットします。
# syndrome self.h(qid_anc[0]).ctr_g1(qid_anc[0], qid_cod).h(qid_anc[0]) self.h(qid_anc[1]).ctr_g2(qid_anc[1], qid_cod).h(qid_anc[1]) self.h(qid_anc[2]).ctr_g3(qid_anc[2], qid_cod).h(qid_anc[2]) self.h(qid_anc[3]).ctr_g4(qid_anc[3], qid_cod).h(qid_anc[3]) self.m(qid=qid_anc[0:4]) mval = self.m_value(binary=True) print("* syndrome =", mval)で、誤り検知の測定(シンドローム測定)を行います。その測定値(4桁のバイナリ文字列)が変数mvalに入ります。このバイナリ文字列に応じて、
# recovery if mval == '0000': pass elif mval == '0001': self.x(qid_cod[0]) elif mval == '1010': self.z(qid_cod[0]) elif mval == '1011': self.z(qid_cod[0]).x(qid_cod[0]) elif mval == '1000': self.x(qid_cod[1]) elif mval == '0101': self.z(qid_cod[1]) elif mval == '1101': self.z(qid_cod[1]).x(qid_cod[1]) elif mval == '1100': self.x(qid_cod[2]) elif mval == '0010': self.z(qid_cod[2]) elif mval == '1110': self.z(qid_cod[2]).x(qid_cod[2]) elif mval == '0110': self.x(qid_cod[3]) elif mval == '1001': self.z(qid_cod[3]) elif mval == '1111': self.z(qid_cod[3]).x(qid_cod[3]) elif mval == '0011': self.x(qid_cod[4]) elif mval == '0100': self.z(qid_cod[4]) elif mval == '0111': self.z(qid_cod[4]).x(qid_cod[4])で、雑音の逆演算を行います。これで符号状態は元に戻るはずです。
main処理部に戻ります。
# result fid = qs_ini.fidelity(qs_fin, qid=qid_cod) print("* fidelity = {:.6f}".format(fid))で、元の量子状態と誤り訂正後の量子状態との違いを見るためのフィデリティを計算して表示します5。誤り訂正が成功していればfidは1.0になるはずです。
動作確認
では、上のプログラムを実行してみます。
* input quantum state c[0] = +0.3382-0.0000*i : 0.1143 |++ c[1] = -0.6657+0.6652*i : 0.8857 |++++++++++ * noise 'Z' to #4 qubit * syndrome = 0100 * fidelity = 1.000000適当に設定された1量子状態が符号化され、4番目の量子ビットに雑音'Z'が加わったのですが、シンドローム測定により誤りのパターンが'0100'($E_{14}=IIIIZ$)であることがわかり、逆演算を施した結果、フィデリティが1.000000となりました。というわけで、誤り訂正は成功しました。
もう一回実行すると、
* input quantum state c[0] = +0.7701-0.0000*i : 0.5931 |+++++++ c[1] = -0.1945+0.6075*i : 0.4069 |+++++ * noise 'X' to #1 qubit * syndrome = 1000 * fidelity = 1.000000となり、先程とは別の状態に対して別のパターンの雑音が付加されましたが、この場合も誤り訂正は成功です。何度も実行してみましたが、失敗することはありませんでした。というわけで、めでたし、めでたし、です。
おわりに
これで、4回にわたって続けてきた「スタビライザー符号」シリーズは一応完了です。スタビライザー符号の標準形とか論理基底状態をユニタリ演算だけで作成する方法など、興味深い積み残し課題はあるのですが、先に進みたいと思います。次回は、「フォールトトレラントな量子計算」を予定しています。
以上
- 投稿日:2020-05-30T16:50:50+09:00
Djangoでline botで何かを返すまで!
Djangoでline botを作る!
まずはline developersのアカウントを取得するためlineのアカウントでログイン
左上のconsole homeから新規provider をcreateする
そのしたのproviderからcreate new channelを選択し、channel typeはmessaging API
その後はそれぞれの設定をする。ここまでするとqrコードで自分の作るline botが登録できるようになる。
今回はこのミーティング予約と押したら、ユーザーが予約と自動で送信するようにしてそれに対して何かを返したいと思います
まずはここにログインして先ほど作ったアカウントを選択
https://www.linebiz.com/jp/login/
左のメニューからリッチメニューを選択右上の作成ボタンをクリック
表示設定はタイトル以外はデフォルトでOK
その下のコンテンツ設定はテンプレートを選択し画像を貼るか、自分で文字入りの画像を作る。
作れたらアクションのところでタイプをテキストにして予約にする。
保存して実際に作ったメニューを自分のスマホでタップすると予約というメッセージが送られると思います。Djangoを使ってを使ってメッセージを返す
ここまで行ったら次はDjangoで送られてきた予約メッセージに対して何かを返したいと思います
今回はpythonのバージョン・パッケージ管理システムであるanacondaを使ってdjangoをinstallします。
https://www.anaconda.com/products/individual
入れてない人は↑の一番したからダウンロードしてください
anacondaが入れられたらanaconda navigatorを立ち上げて
Environmentsを選択
左下のcreateを選択
名前をdjango37などにしてpythonを選択しversionは3.7を選択
右下のcreateを選択し環境構築が完了
この状態ではまだdjangoは入ってないのでターミナルを開いて$ conda activate django37で環境を立ち上げる
その後$ conda install django37でDjangoをinstallこれで環境ができました。
そしたらまずは
$ django-admin startproject reception_line_botでプロジェクトを作成します。
reception_line_bot/ manage.py reception_line_bot/ __init__.py settings.py urls.py asgi.py wsgi.pyこんな感じに作れたと思います。
次にアプリケーションを作ります。$cd reception_line_botでreception_line_botの中に入ってから,
$ python manage.py startapp botとすると
bot/ __init__.py admin.py apps.py migrations/ __init__.py models.py tests.py views.pyとなったと思います。
次にエディタでreception_line_bot/urls.pyを編集していきます。urls.py"""reception_line_bot URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/3.0/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path import bot.views urlpatterns = [ path('admin/', admin.site.urls), ]こうなっていると思いますが、urlpatternsのところにdjangoが受け取ったline botのリクエストをどのファイルのどの関数に送るかを指定します。
なので今回は
urls.pyimport bot.views urlpatterns = [ #path('admin/', admin.site.urls), path('', bot.views.reception), ]とします。receptionはこれからviews.pyに書く関数です。
views.pyにコードを書く前にline botを作成した時に発行されたチャンネルシークレットとアクセストークンはコードの中に直接書くとまずいので、jsonを通してviews.pyで受け取れるようにしたいと思います。なので一番上のline_reception_botの下にsetting.jsonを作り、
providersからチャネルを選択しmessaging APIの一番したでaccess tokenを発行し、コピペします。
次に
messaging APIの隣のBasic settingsのところからChannel secretを取得します。
その二つを先ほど作ったsetting.jsonにコピペしていきますsetting.json{ "LINE":{ "channel_secret":"fakfkajpdpaida132941", "access_token":"a3nm7yOY7IoUt8blZ6QqK6RShadfsajdjfadfljfafdsdjsdfailfajjpqjpoejpqjpfjpqejiepqwifqpjdjidcS9yEBGieq+VMQs0EL+mQDtwdB04daft89/aad1O/w1cDnyilFU=" } }こんな感じ、(channel_secretとaccess_tokenは適当に変えました)
そしたらviews.pyを開いてユーザーが送ってきたメッセージに対して何か送るコードを書いていきます。views.pyfrom django.views.generic import TemplateView from django.shortcuts import render from django.http.response import JsonResponse from django.views.decorators.csrf import csrf_exempt import json import urllib.request from reception_line_bot.settings import BASE_DIR # Create your views here. @csrf_exempt def reception(request): json_open = open('setting.json', 'r') json_load = json.load(json_open) channel_secret = json_load['LINE']['channel_secret'] access = json_load['LINE']['access_token'] request_body = request.body data = confirm_json_loads(request_body) request_body = request.body body = request.body.decode('utf-8') print(body) reply_token = data["events"][0]["replyToken"] reply_message(reply_token,access) return JsonResponse({"message":"OK"}) def confirm_json_loads(body:str)->dict: """ json_loadsが動いているのかの確認 Args: body str: requestのjson文字列 Return: dict: Seccess:json.loads(body)の返り値 Error:ログイン失敗のメッセージ """ try: return json.loads(body) except Exception as e: print("error") message = JsonResponse({'message': 'Login failure.'}, status=403) return message def reply_message(token:str,access)->None: return False """ ユーザーに返答メッセージを送ります Args: token str: lineトークン message str: select_message関数で返されたメッセージ user_id str: メッセージ送信者のlineユーザid """ url = 'https://api.line.me/v2/bot/message/reply' print(url) data = { 'replyToken': token, 'messages':[ { 'type': 'text', 'text': "hello world" }, ] } print(f"data{data}") headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer'+" "+access } print(f"headers:{headers}") req = urllib.request.Request(url, json.dumps(data).encode(), headers) print(req) with urllib.request.urlopen(req) as res: body = res.read()これで完成です。
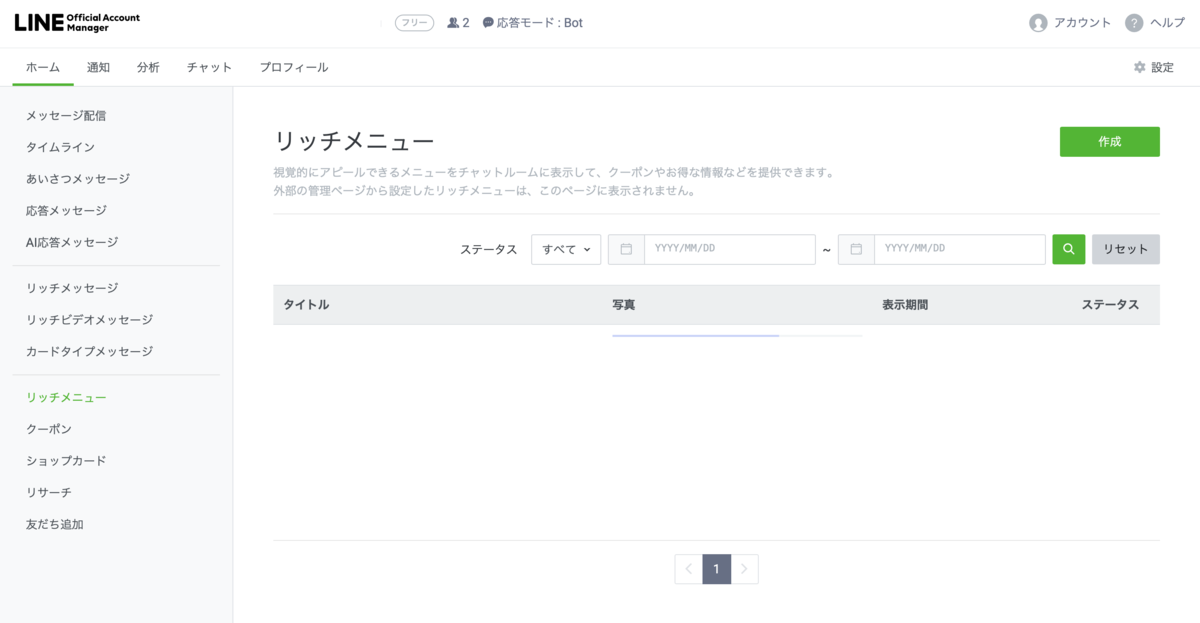
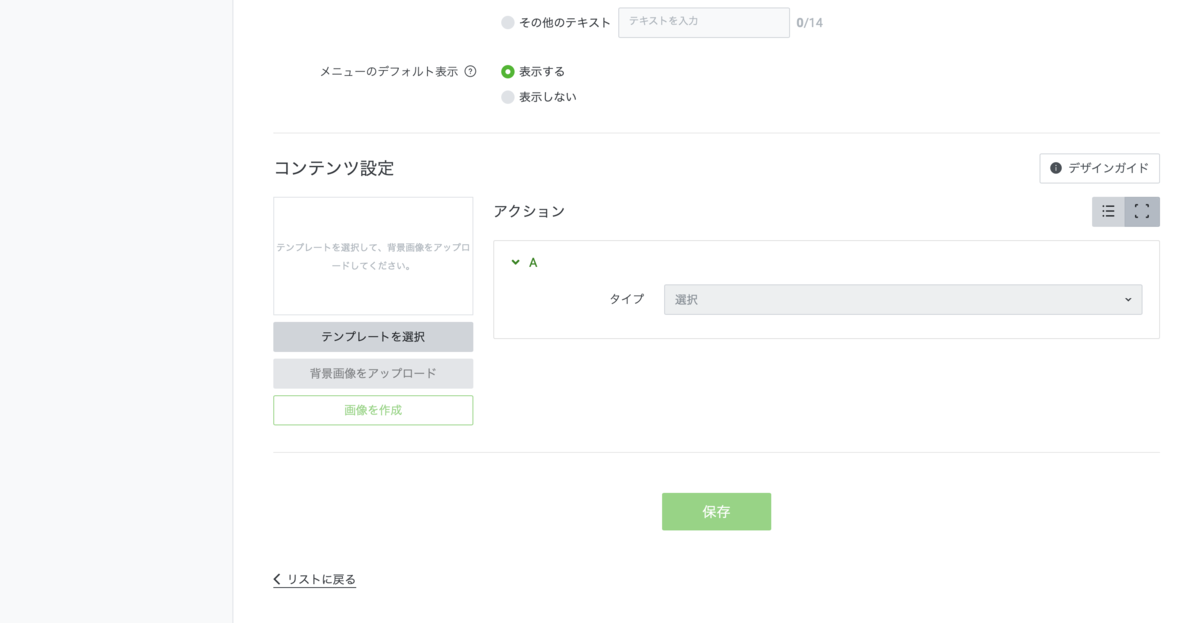
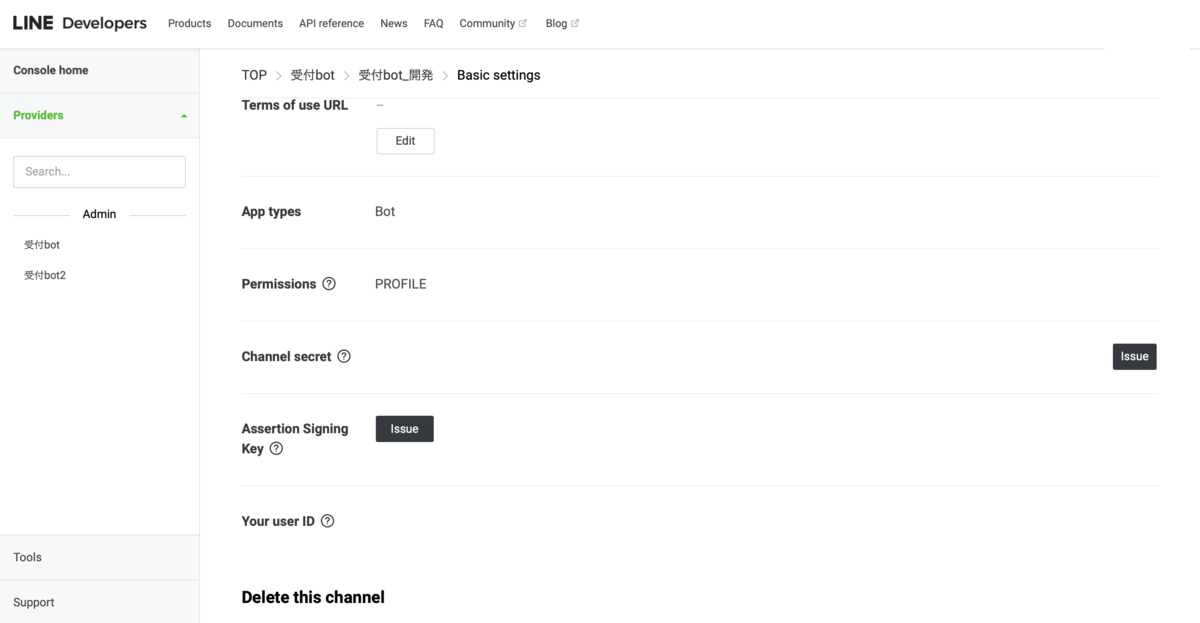
- 投稿日:2020-05-30T16:30:37+09:00
[競プロ用]最小全域木まとめ
最小全域木を求める手法
- プリム法
- クラスカル法
使い分け
議論になっていた
https://togetter.com/li/776049入力形式で使い分ける?
- ノード間のコストが行列で渡される → プリム法
- 2点のノードとそのコストの組み合わせで渡される。 → クラスカル法
https://www.hamayanhamayan.com/entry/2018/09/17/163004
プリム法
- 任意のスタート地点から始める。
- 移動可能なノードのうち最も低コストで移動できるものを選び繋ぐ。
- 2を繰り返し、全てのノードを繋いだ時点で最小全域木となる。
どうすればいいか
ノードを繋ぐ度に選択肢が広がっていき、常にその中で最小のものを選択したい。
→ 優先度付きキュー(heapq)を用いる。heapqにタプルを渡すと一番目の要素で最小値を判断されることを利用する。
何がいいのか
O(ElogV)。
フィボナッチヒープを使うとより早い?イメージ
https://algo-logic.info/prim-mst/
使用例
プリム法import heapq def main(): n = int(input()) next = [] # 隣接管理のリスト for _ in range(n): l = list(map(int, input().split())) next.append([(c, i) for i, c in enumerate(l) if c != -1]) visited = [0] * n connection = 0 q = [(0, 0)] # (cost, v) heapq.heapify(q) ans = 0 while len(q): cost, v = heapq.heappop(q) if visited[v]: continue # そのノードと繋げる visited[v] = 1 connection += 1 ans += cost # 新たに繋げたノードから行けるところをエンキュー for i in next[v]: heapq.heappush(q, i) # 全部のノードが繋がったら終了 if connection == n: break print(ans) returnクラスカル法
- 全ての辺を重みの小さいものから順に選びとっていく。
- その過程で閉路を作ってしまうものは捨てる。全ての辺に対してこれを行う。
- 最終的に選び取った辺のみで最小全域木となる。
どうすればいいか
1 → 辺のコストを元にソートする。リストの各要素をタプルにしてソートすると1番目の要素でソートされるテクニックを利用。
2 → 「閉路ができる」=「既に2点が繋がっているところに辺を作る」なのでUnionFind木で確認する。何がいいのか
O(ElogV)。
イメージ
https://algo-logic.info/kruskal-mst/
使用例
クラスカル法def main(): V, E = map(int, input().split()) uf = UnionFind(V) # 1の過程 edges = [] for _ in range(E): s, t, w = map(int, input().split()) edges.append((w, s, t)) edges.sort() # 2の過程 cost = 0 for edge in edges: w, s, t = edge if not uf.same(s, t): cost += w uf.union(s, t) print(cost) return参考
- 蟻本
- https://www.hamayanhamayan.com/entry/2018/09/17/163004
- https://juppy.hatenablog.com/entry/2019/02/16/%E8%9F%BB%E6%9C%AC_python_%E6%9C%80%E5%B0%8F%E5%85%A8%E5%9F%9F%E6%9C%A8%E5%95%8F%E9%A1%8C%EF%BC%91%EF%BC%88heap%E3%82%92%E7%94%A8%E3%81%84%E3%81%9F%E3%83%97%E3%83%AA%E3%83%A0%E6%B3%95%EF%BC%89_%E7%AB%B6
- https://algo-logic.info/prim-mst/
- https://algo-logic.info/kruskal-mst/
- 投稿日:2020-05-30T16:06:35+09:00
YOLOv4環境構築①
参考
https://youtu.be/5pYh1rFnNZsシステム
Windows10
GeForce GTX 960pythonのインストール
python 3.7.7をインストール
Add Python 3.7 to PATHにチェックを入れるnumpyのインストール
コマンドプロンプトから
> pip install numpyついでにpipの更新
> python -m pip install --upgrade pipVisual Studio Codeのインストール
Visual Studio CodeをGitのデフォルトエディタにしたいので先にインストールする。バージョンは1.45.1
他に使ってるエディタがある人は不要Gitのインストール
Git 2.26.2をインストール
デフォルトのエディタを選択する画面があるので、VSCodeを選択する(デフォルトはVim)
あとはそのまま進めてOKCMakeのインストール
CMake 3.17.2をインストール
Visual Studioのインストール
Visual Studio 16.5 コミュニティをインストール
pythonとデスクトップ開発にチェックを入れてインストール
再起動を求められるのでPCを再起動する
GPUドライバの更新
NVIDIA公式から自分の環境にドライバをダウンロードしてインストール
※他ブランドのグラフィックボードは対応していない
GTX960 445.87に更新
終わったらPCを再起動CUDAのインストール
nvidia cuda toolkitを検索してダウンロード
バージョン10.2
インストール先をCドライブ直下に変更
あとはそのまま進める
NVIDIA cuDNNのダウンロード
https://developer.nvidia.com/cudnn
アカウントを新規作成してcuDNN v7.6.5をダウンロード
ダウンロードしたzipファイルをCドライブ直下へ移動して解凍すると
cudaフォルダが作成される解凍したcuDNN関連ファイルをCUDA配下に置く
C:\cuda\binにあるcudnn64_7.dll をコピーして
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\binにペーストする同様に
C:\cuda\includeにあるcudnn.h をコピーして
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\includeにペーストする
C:\cuda\lib\x64にあるcudnn.lib をコピーして
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64にペーストするOpenCVのインストール
公式のReleaseページからv4.1.0をダウンロード
opencv_contribのダウンロード
GitHubからダウンロードする
https://github.com/opencv/opencv_contrib
解凍・配置
ダウンロードした2つのzipファイルを解凍する。
Cドライブ直下にopencvディレクトリを作成し解凍した2つのフォルダをコピーする。
同ディレクトリにbuildフォルダを作成する。
CMakeの設定とビルド
CMakeを起動し、ソースコードとビルド先をそれぞれ
C:/opencv/opencv-4.1.0とC:/opencv/buildに設定する
Configureポタンを押してgeneratorとplatformを
Visual Studio 16 2019とx64に設定
リストの
BUILD_opencv_worldにチェックを入れる
エラーが無いことを確認しGenerateを押す
OpenCVをVisual Studioでビルド
buildフォルダ
C:\opencv\buildのALL_BUILD.vcxprojを開いてVisual Studioを起動するReleaseモードに変更し、
ALL_BUILDとINSTALLをそれぞれ右クリックメニューからビルドする
コマンドプロンプトで動作確認
コマンドプロンプトでpythonインタプリタを起動し、openCVが動作することを確認する
> python >>> import cv2 >>> cv2.__version__ '4.1.0'次回に続く
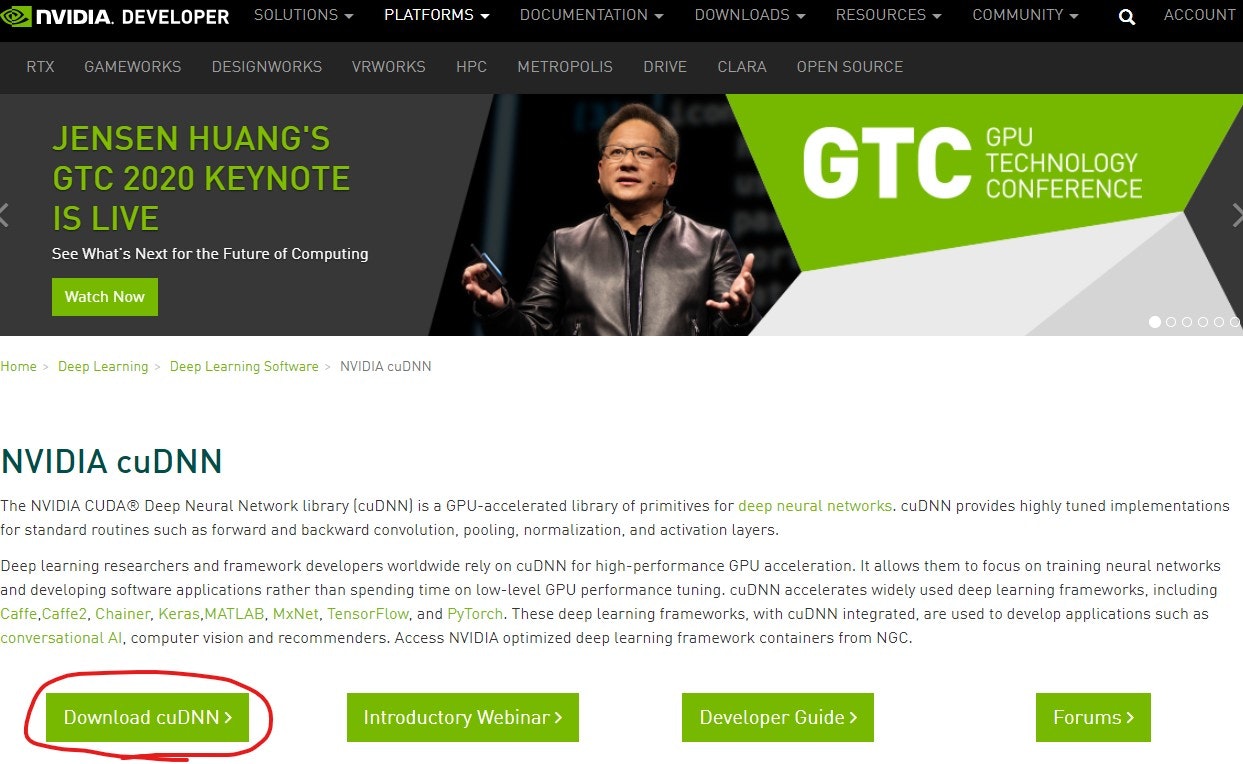
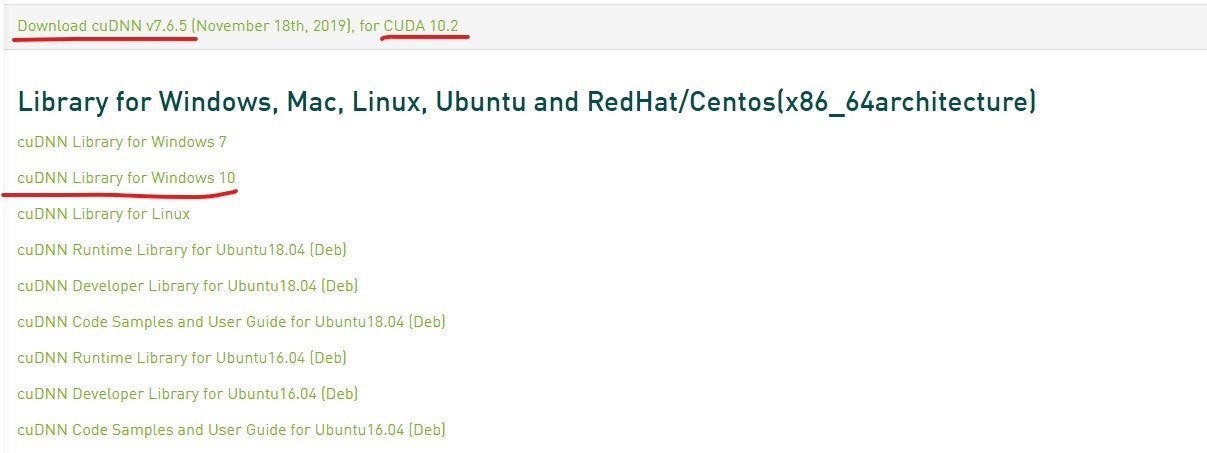
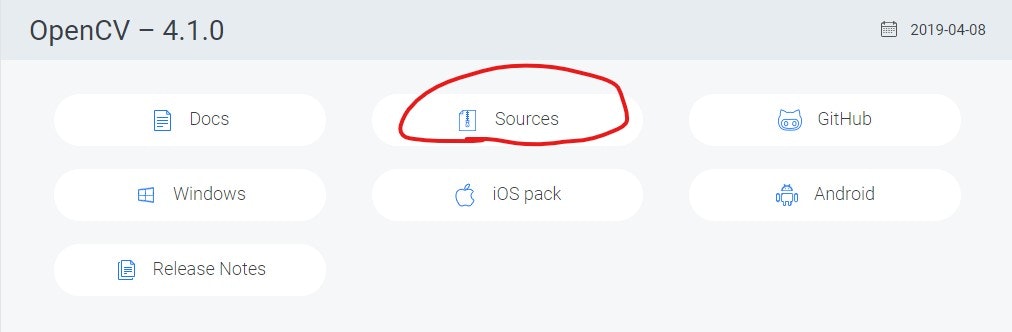
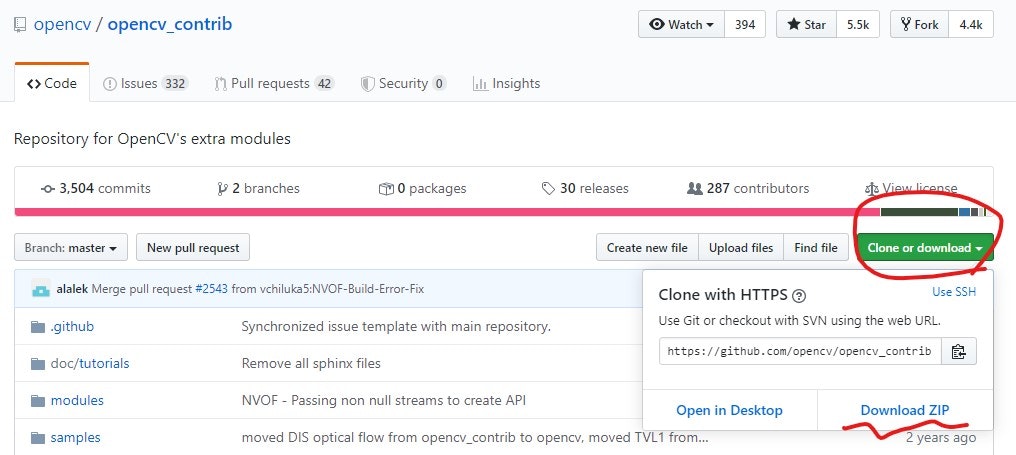
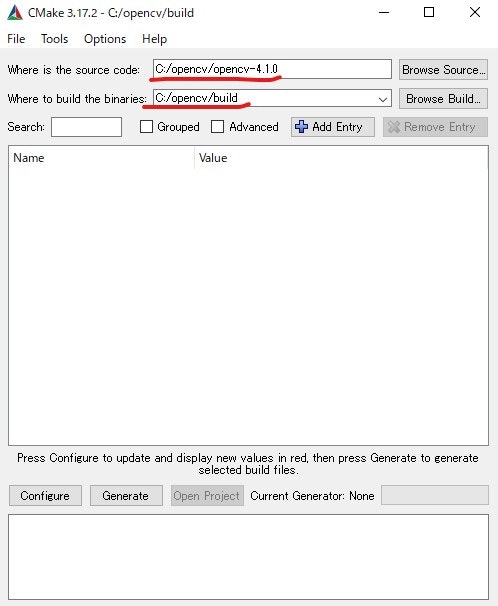
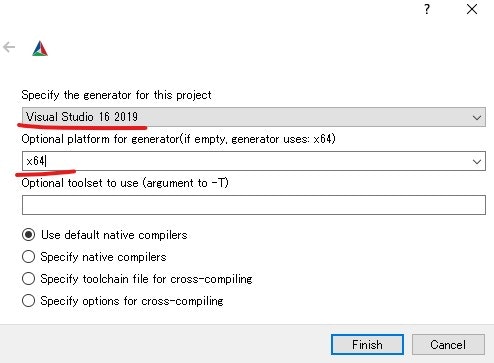
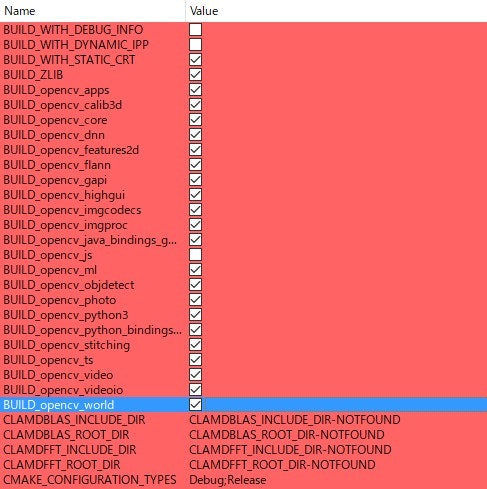
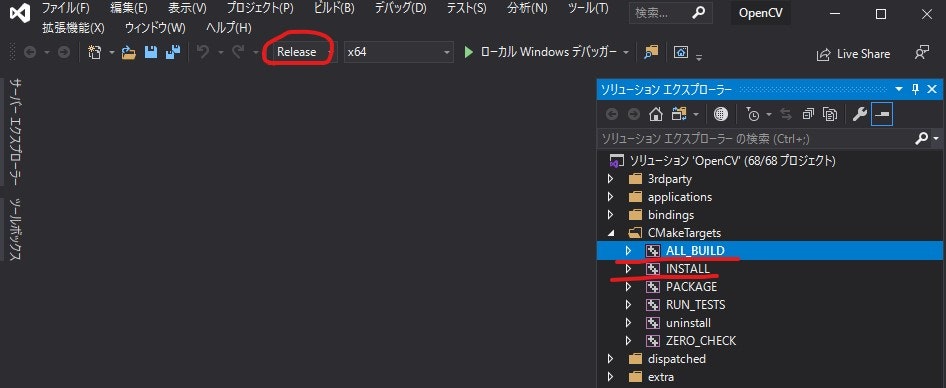
- 投稿日:2020-05-30T15:53:41+09:00
PyInstallerでコンソール画面非表示にするとエラーになってしまった時の解決策
環境
Windows 10
Python 3.6.5
PyInstaller 3.6
Visual Studio Code症状
pyinstaller --onefile -n appname index.py
上記実行後、distフォルダに生成されたexeを実行すると問題なく動作したのですが、
コンソール画面が表示されてしまうのが邪魔だったので、specファイルの
console=Trueをconsole=Falseに変更して
pyinstaller specfilename.spec
を実行し、再生成されたexeファイルを実行すると、failed to execute script index
というポップアップが表示されて処理が止まってしまいます。
試しに、簡単なスクリプトを書いてconsole=Falseでexe生成してみると再現しないので、
何が原因なのか解らず悩んでおりました。解決策
今回のexe化したかったプログラム内では、当初、下記のようにインポートして関数を呼び出していました。
index.pyimport funcs funcs.func1() funcs.func2()funcs.pyimport anotherfunc def func1(): anotherfunc.func3()otherfunc.pydef func3():それを下記のように、別になっていた関数を一つにまとめることで、
インポート先のファイルから他の関数をインポートして使用することをやめたら、
コンソール非表示でも実行できるようになりました。index.pyimport funcs funcs.func1() funcs.func2()funcs.pydef func1(): func3() def func3():
- 投稿日:2020-05-30T13:40:44+09:00
PyCharmでは未importのクラスや関数の入力補完ができない、と思い込んでいた話
TL;DR
PyCharmではCtrlを押したままSpaceを2回叩くと幸せになれる
PyCharmが大好き、でも
Pythonは2.7あたりの頃から使っていて、作業効率化ツール開発やpyserialを使った組み込み機器との通信テストなどで使用していました。当初からわりと規模が大きめなプロジェクトで使っていたので、対話シェルやコマンドラインベースではなく、PyCharmのお世話になりながらPythonと付き合ってきました。
私はAndroidアプリ開発もやってますが、Android Studioができる前からEclipse+ADTを窓から投げ捨てIntelliJ IDEAを採用していたので、JetBrains IDEにかなり親しみを持っており、その操作感覚を引き継げるPyCharmでの開発は本当に本当に大好きでした。
ただ、ある一点を除いては・・・
他のJetBrains IDEと同じような感覚で入力補完できない・・・?
IntelliJ(Android Studio)やRiderは、プロジェクトの依存関係を読み取って、そのプロジェクトで使用できる全てのシンボルを把握してくれます。
そのため、ソースコードの先頭にimport(Java, Kotlin)やらusing(C#)やらを書かずとも、プログラマがその場で入力した文字からクラス名・関数名などの入力補完のリストを構築してくれます。これは未importなシンボルに対しても候補を作ってくれるというのが強いところで、プログラマはなんとな〜くクラスやグローバル関数の存在だけを覚えておき、てきと〜に入力して候補から見つけ出すというのを繰り返すだけで立派なコードが書けることになります。この手の機能はJetBrains IDEに限らず他のモダンなエディタにも搭載されていて、この感覚でコーディングするのが現代のプログラミングのやり方だと思います。
この機能は新しいライブラリを投入してそれについて勉強中のときにも力を発揮します。例えば、ライブラリ内のクラスが継承関係に基づいて親の名前の一部を引き継ぐ命名規則になっている場合、親の名前を入力したときに子のクラス名も一緒に候補に出てきてくれるので、「あ〜こういうクラスツリーがあるのか〜」といった具合で全体像を楽に把握することもできます。
PyCharmでは先にimport文を書いてないと入力候補に出してくれない?
で、この未importに対する入力補完機能、なぜかPyCharmには搭載されてない・・・ ように見えました。
例えばpipで
pyserialを入れてきたあと、COMポートの一覧を出すためのlist_portsを使おうとしてlisと入力しても、候補リストは現れてくれません。
なんと実行環境を整えてたとしても、コード側では事前にいちいちfrom serial.tools import list_portsを書いておかないとlisの入力時点で出てきてくれないのです。
こんなのは嫌だ。面倒臭すぎる。PyCharmは開発マシンのPython実行環境自体を認識してますから、
lisの入力時点でlist_portsを提案できるはずです。ただ、Auto Importなる機能はあります。これはコード内に解決できないシンボルがあり、かつ同名のシンボルがPyCharmによって把握されている場合において、PyCharmがimport文の挿入を提案してくれるものです(まあこれも大抵のIDEには搭載されてますよね)。
この機能を使えば、list_portsと正確に入力すれば、ようやくimport提案をしてくれるようになります。
ちょっと私が求めてるものとは違いますが、まあ仕方なしとして、この機能を活用してPyCharmでの大規模開発を進めてきました。が、やはりこれを軸にするのは少々無理があり、少し名前を打ち間違うとimport提案してくれませんので、長い名前のクラスを使うときにはストレスでした。調べてみたらできるらしい、けど
自分が最強の開発環境だと確信しているJetBrains IDEシリーズのPyCharmを使っているのに、こんな謎の苦しい思いをするなんて、絶対何かが間違っている・・・そういう引っ掛かりが昨日までありました。
友人との会話中、久しぶりにこの疑問が再燃し、数年ぶりにこの話題を調べてみました。
すると以下の公式ブログに辿り着きました(2018年の記事って・・・気付くのが遅くてショック)Let PyCharm Do Your Import Janitorial Work | PyCharm Blog
https://blog.jetbrains.com/pycharm/2018/11/let-pycharm-do-your-import-janitorial-work/
Start typing part of requests and type Ctrl-Space-Space. PyCharm will offer a completion. When you accept it, PyCharm will complete the symbol and also generate the import.
リクエストの一部を入力して、Ctrl-Space-Spaceと入力します。PyCharm が補完を提示してきます。それを受け入れると、PyCharm はシンボルを完成させ、インポートを生成します。
!?!?!?!?!?!?!?!? まさかのショートカットキー!?!? しかも2回!?!?
なぜかPyCharmは他のJetBrains IDEのノリと異なり、未importモジュールに対する入力補完は自動的には表示されず、わざわざショートカットキーを2回も押さなければならないようです。
ナンデ!?
試してみたらOSのショートカットキーと衝突してた
まあ何か大人の事情があったんだろうということで、残念感は置いといて、記事の通り
Ctrl+Space+Space(つまりCtrlを押したままSpaceを2回叩く)を実行してみると・・・
入力ソース切り替えと被ってるやんけ・・・・
設定をいじってオフにしましょう・・・
これでPyCharmでも他環境と同じように、ショートカットキーさえ押していれば、未importを含む全てのシンボルに対する入力補完が効くようになりました!最高!
これからはコードを書き出す前に毎回Ctrl+Space+Spaceを2回叩くのを習慣化することで、常に候補リストとともに生活し、短時間で大量のPythonコードを書き出せるようにしたいと思います。
しかし、なぜPyCharmだけショートカットキー必須になってるのでしょう・・・?
Pythonはアクセスコントロールがゆるゆるですから、候補リストの生成に時間かかるようになり、そこからの性能悪化を恐れてこうしたんですかね?でも最近の開発マシンなら大したことないんじゃないかなあ。
または、アンダースコアから始まる外に見せたくないものが積極的に見えるようになるのを嫌がったとかですかね?ところでVSCodeでのPython環境を実は整えてないんですが、同様の機能が使えるのであればそろそろ整備したいです。PyCharmは素晴らしいものですが、ちょっとした実験コードを書くためだけに動かすのは大袈裟ですからね。
※この件に関してのTwitterでの愚痴:
えっ、、この機能2018年のPyCharmから入ってたの、、、
— りん@Liparhythm (@links_2_3_4) May 29, 2020
俺の2年間返してくれ…………https://t.co/MZx4UaYgsP
> Start typing part of requests and type Ctrl-Space-Space. PyCharm will offer a completion. When you accept it, PyCharm will complete the symbol and also generate the import. pic.twitter.com/NtQeOOVGbk

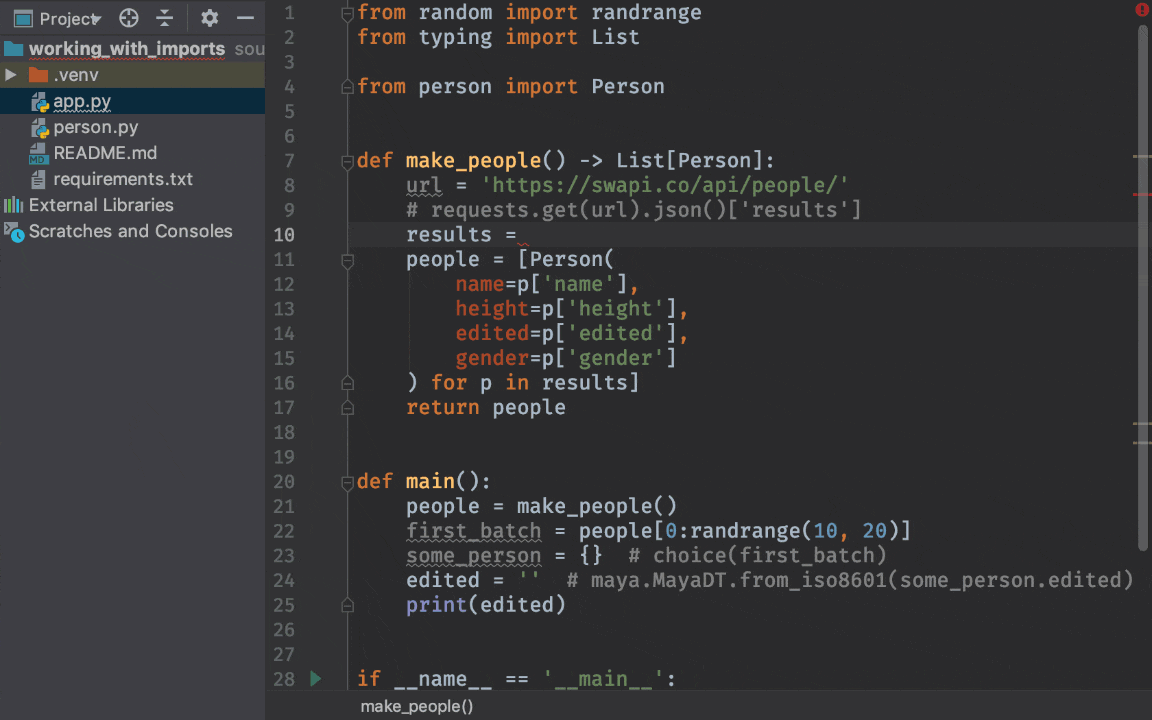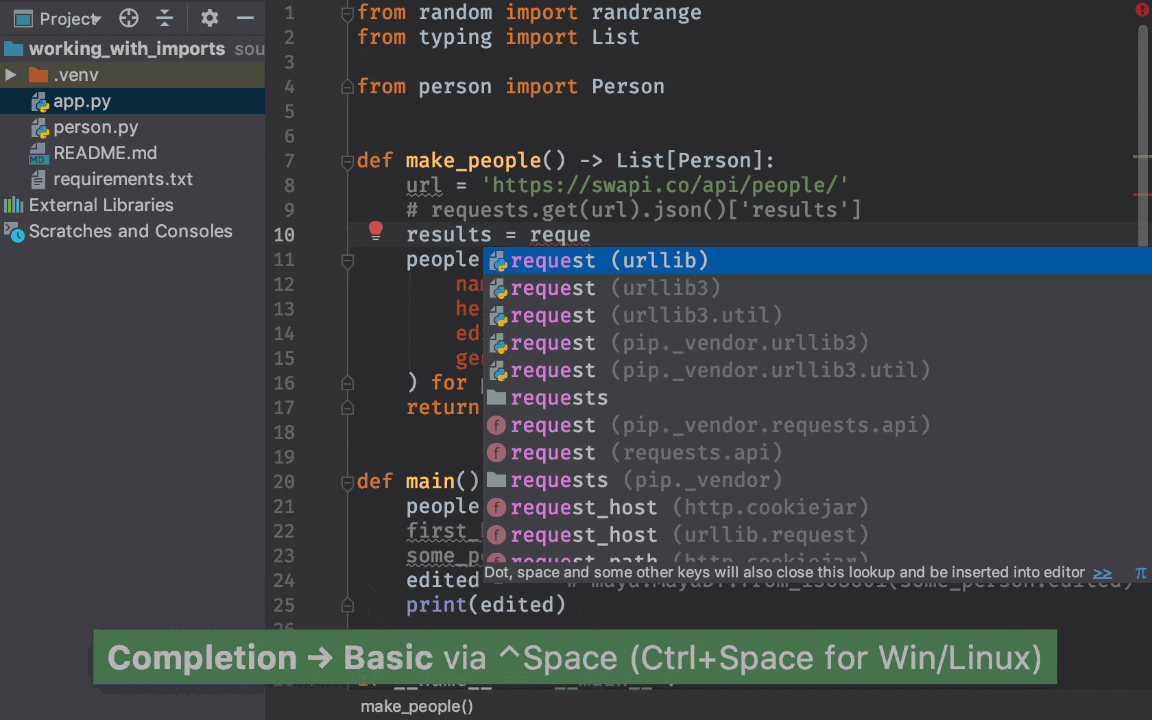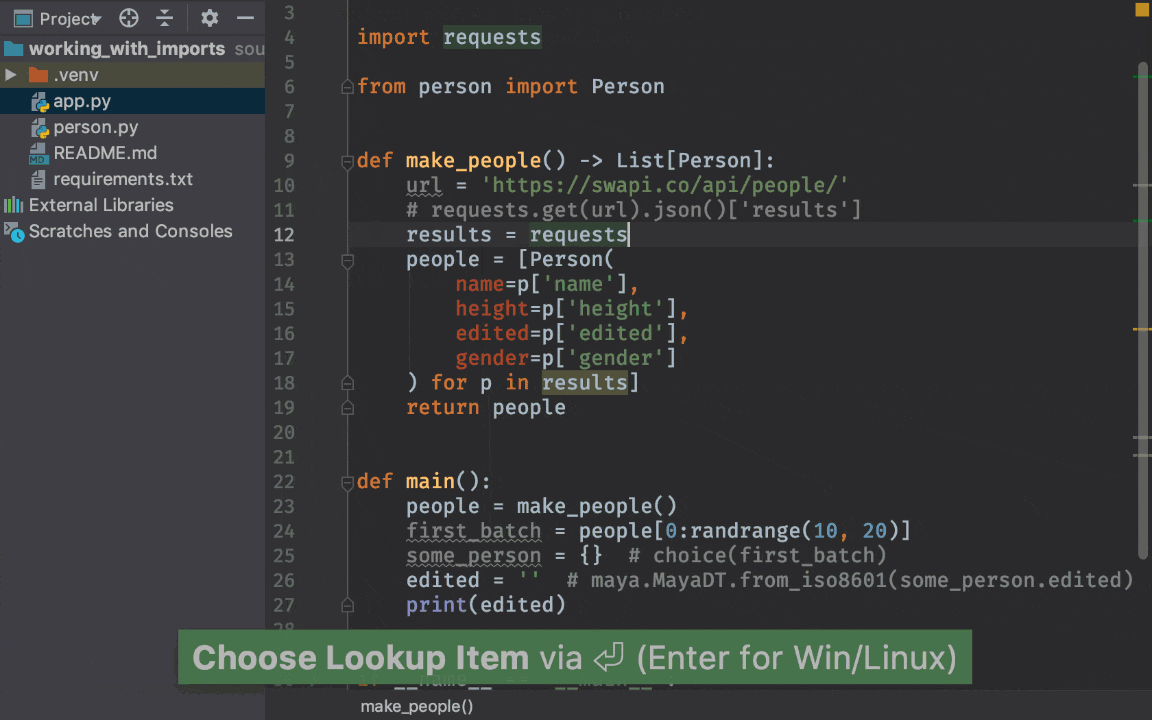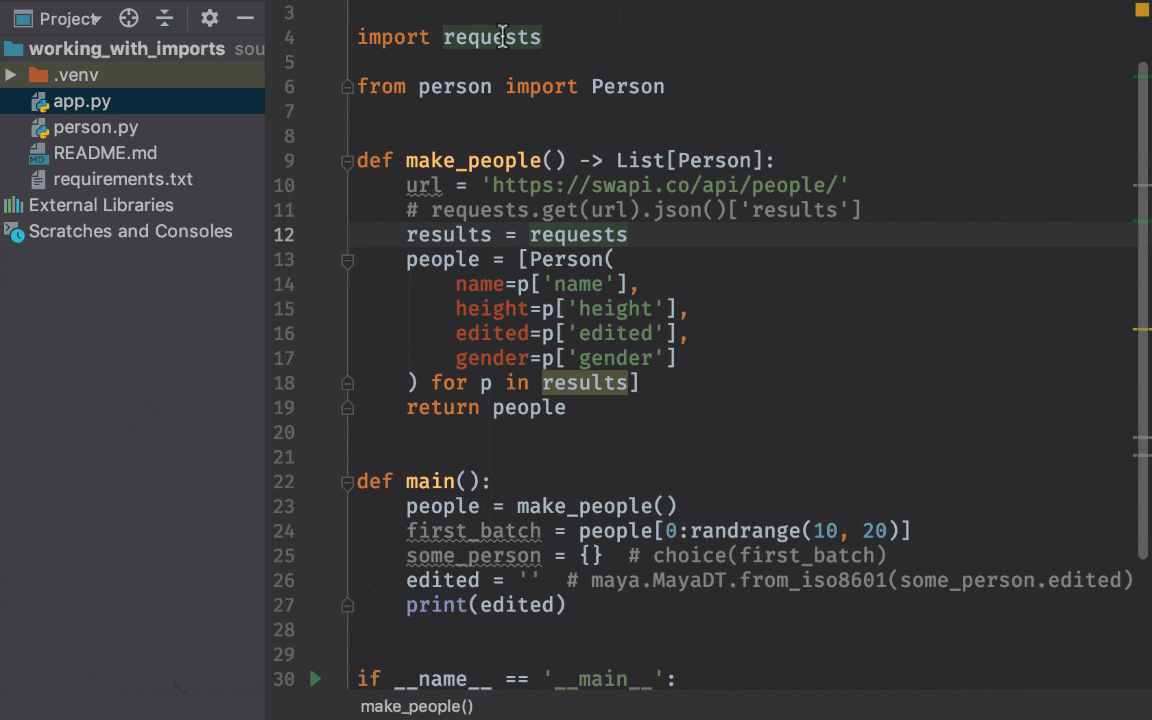
- 投稿日:2020-05-30T13:36:41+09:00
【要素分解入門】時系列解析の手法をRとpythonで並べてみる♬
今回は、前回の時系列分解をさらに追及してみた。
すなわち、モデルは以下のとおり
$Y_t=T_t + S_t + e_t$
または、
$Y_t=T_tS_te_t$
として、時系列データを分解するdecompose()手法である。
前回は、それぞれのデータを同時描画していたが、今回は例えばノイズ除去した純粋な音声や振動などの再生や利用を目的に、それぞれ保存したり再生したいという動機から実施してみた。
データは参考③のサイトの死亡数の速報値と参考④の2018年までの過去データである。
今回の参考は以下のとおりである。
参考①はR言語のものであり、参考②はpythonのものである。
ここでは独立に数値化してcsvファイルに保存するまでをまとめる。
【参考】
①Extracting Seasonality and Trend from Data: Decomposition Using R
②TIME SERIES DECOMPOSITION & PREDICTION IN PYTHON
③統計で見る日本 e-Statは、日本の統計が閲覧できる政府統計ポータルサイトです
④データセット一覧(5-4死亡月別にみた年次別死亡数及び死亡率(人口千対))@統計で見る日本
なお、今回のコードとデータは以下に置きました。
・MuAuan/R_Audioやったこと
・Rでのdecompose
・pythonでのdecompose・Rでのdecompose
前回のほぼまんまですが、decompose_IIP$seasonalという表記でseasonalのデータを指定できます。
data <- read.csv("./industrial/sibou_p.csv",encoding = "utf-8") IIP <- ts(data,start=c(2008),frequency=12) w_list <- c("seasonal","random","trend","observed") decompose_IIP <- decompose(IIP) for (i in w_list){ if (i=="seasonal"){ plot(decompose_IIP$seasonal) }else if(i=="random"){ plot(decompose_IIP$random) }else if(i=="trend"){ plot(decompose_IIP$trend) }else if(i=="observed"){ plot(IIP) } }
seasonal random trend observed もう一つのコード
まず、オリジナルデータを描画します。
次に、今回のデータは12か月周期なのでトレンド曲線として12移動平均を取ります。
そして、上記のオリジナルデータに重畳してlinesを引きます。#install.packages("forecast") library(forecast) plot(as.ts(IIP)) trend_beer = ma(IIP, order = 12, centre = T) #4 lines(trend_beer)
plotはそのトレンド曲線だけを描画しています。
plot(as.ts(trend_beer))
オリジナルデータからトレンドデータを引き算してプロットします。detrend_beer = IIP - trend_beer plot(as.ts(detrend_beer))
そして、トレンドを差し引いたノイズが乗っているデータを12個ずつのデータに区分して、それらを平均したものを季節変動として計算します。
それを13個連ねて描画しています。
【参考】
・Row and Column Summaries
・matrixm_beer = t(matrix(data = detrend_beer, nrow = 12)) seasonal_beer = colMeans(m_beer, na.rm = T) plot(as.ts(rep(seasonal_beer,13)))
最後に、ランダムな変動分を求めます。
結果はdecompose()関数で求めたものと一致しました。
こんな計算で求めているんですね。random_beer = IIP - trend_beer - seasonal_beer plot(as.ts(random_beer))
最後にいろいろ利用するために、以下のようにcsvファイルに出力します。write.csv(as.ts(rep(seasonal_beer,1300)), file = 'decompose_seasonal1300.csv')・pythonでのdecompose
pythonでも同じような関数が用意されています。
コードは以下のとおりです。import pandas as pd import statsmodels.api as sm from statsmodels.tsa.seasonal import STL import matplotlib.pyplot as plt # Set figure width to 12 and height to 9 plt.rcParams['figure.figsize'] = [12, 9] df = pd.read_csv('sibou_.csv') series = df['Price'] print(series) cycle, trend = sm.tsa.filters.hpfilter(series, 144) fig, ax = plt.subplots(3,1) ax[0].plot(series) ax[0].set_title('Price') ax[1].plot(trend) ax[1].set_title('Trend') ax[2].plot(cycle) ax[2].set_title('Cycle') plt.show()
pythonでももう一つの方法
個人的には、分解の結果は上の方法だとcycleに対してもう一段の処理が必要で、こちらはランダム分の処理までできているのでこちらの方がリーズナブルに見えます。
また、Rと比較しても、少し異なりseasonalは年々振動幅が大きくなっている様子を見せています(Rはこの変動を平均化処理したので消えているのは当たり前ですが。。。)。場合により、この手法が一番汎用性が高いと言えると思います。
【参考】
・Seasonal-Trend decomposition using LOESS (STL)stl=STL(series, period=12, robust=True) result = stl.fit() chart = result.plot() chart1= result.plot(observed=False, resid=False) chart2= result.plot(trend=False, resid=False) plt.show()Observed & Trend & Seasonal & Residual
Trend & Seasonal
Obeserved & Seasonal
また、以下のようにすると、ばらばらのグラフとして一つのグラフに出力できます。
※pl1...などの数値データを利用するため変数に代入していますpl1 = result.observed pl2 = result.trend pl3 = result.seasonal pl4 = result.resid plt.plot(pl1) plt.plot(pl2) plt.plot(pl3) plt.plot(pl4) plt.show() plt.close()
また、以下のようにすると簡単に出力できます。
pl5 = result.seasonal.plot() plt.show() plt.close() ...
seasonal resid trend observed そして、csvファイル出力は以下のようにやります。
import csv with open('sample_pl2.csv', 'w') as f: writer = csv.writer(f, delimiter='\n') writer.writerow(pl2)まとめ
・Rとpythonでdecompose()のやり方を並べてみた
・それぞれのコードは結果は少し異なるがほぼ同等のことが出来て、ノイズやトレンドが乗った周期的な変動を純粋な周期的な変動として取り出すことが出来た
・各要素分解された成分をcsvデータに書き出すことが出来、二次利用出来る
・実は今回は死亡数の経年変化を例として3月までの速報値を使ったが、その範囲では2011年のような異常値は見えていない(むしろ減少傾向)・次に、周期的な変動要素を音に変換し聞いてみることとする
・非周期な変動要素についても(検定はともかく)やってみる