- 投稿日:2020-05-30T23:39:05+09:00
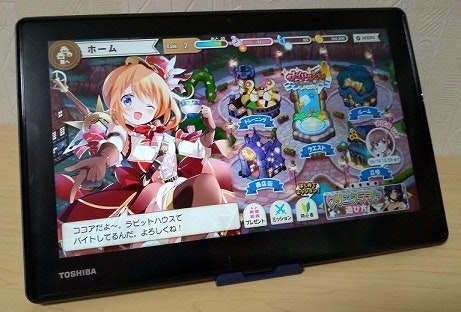
7年前DynabookタブにAndroidx86入れてゲーム(続き)
前回、「7年前のWinタブにAndroidx86を入れてゲームをする」記事を書いた。
7年前 Corei5 WinタブにAndroidx86入れてゲームとか
https://qiita.com/ksmndevelop/items/764307de2e0342137a47
一ヶ月程度経ってしまったが、その後のことについて追記しておく。
ゲーム動作の様子動画
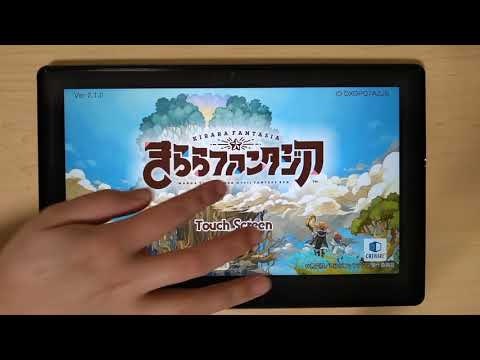
とりあえず、きらファンとプリコネをプレイした動画を上げた。
Dynabook VT712 Android x86 きらファンテスト - YouTube
Dynabookタブ Androidx86 on プリコネ テスト
— ななみん@ (@kasumin_mikan) May 3, 2020
ユニオンバースト時グラフィックが出ない?
高画質にしてるからか?と疑う。。 pic.twitter.com/44tscvMgVp動画を見た通り、微妙なところである・・・
ベンチ
Antutu (Google Playストアからは削除された)は公式サイトから入手しようとしたが、インストールできなかった。(提供不明元のアプリ許可はしているのに・・・)
GeekBenchもインストールはできたが、起動不可。
唯一、3DMarkが動いた。しかし、スクショするのを忘れたため大体のベンチを記述しておく。
3DMarkのベンチ
大体、1500ぐらいであった。相当下。最近のミッドレンジより酷かった。
確かに、グラフィックは負荷がかかると、相当カクカクになる。最後に
7年前のCorei5は最新のミッドレンジスマホにコテンパンであることがはっきり分かった。
今のミッドレンジスマホは、「1万円でもこんなに動くのか!」という感じではある。
結局、このDynabookタブの使い道が今の所あまりない。どうするか。
熟考。
- 投稿日:2020-05-30T21:29:01+09:00
Linuxコマンドを言語化
はじめに
私のPCはMacです。OSはMacOSを使用しています。
ターミナルではLinuxOSと同様にLinuxコマンドが使えます。
シェルはzshでした。ターミナルでecho $0と入力すると、使っているシェルを見ることができます。bashを使っている物だと思っていたのですがzshでした。bashとzshの違いは以下のリンクで調べ学びました。
- bashとzshの違いLinuxコマンドを、今までなんとなく使っていたのですが、そもそもMacOS使ってるのにLinuxOSのもの使ってるってどうゆうこと?と調べていくうちに疑問に思ったので調べました。ターミナルでのコマンドはLinuxOSとほぼ共通しているらしいです。以下のリンクで疑問が結構解消できました。
- Linuxとは
- ターミナルの使い方この記事では、アウトプットするためにLinuxコマンドを言語化しました。ほぼ自分の学習用です。
間違いがありましたら訂正していただけると幸いです。Linuxコマンドを言語化
・
tabキー
入力補完ができます。もう一回tabキーを押すと候補を表示してくれます。・
control + r
前に使ったコマンドを検索。更にcontrol + rで複数検索に引っかかている場合の2つ目を表示します。・
control + c
現在入力中のコマンドを安全に終了できます。・
cd -
直前にいたディレクトリに移動します。・
cd ..
1つ上の階層のディレクトリに移動します。・
cp -r
再帰的にデイレクトリをコピーします。再帰的とは、中にあるディレクトリやファイルまで見るということです。多分。
参考サイト: 再帰的とは?・
cp ファイル名 コピー先
ファイルをコピーできます。・
mv
ディレクトリやファイルを移動できます。・
mv ファイル名 変更後のファイル名
現在いるディレクトリのファイル名を変更できます。・
ls -R
再帰的に今いるディレクトリの下の階層のディレクトリやファイルを表示します。
参考サイト: 再帰的とは?・
mkdir
ディレクトリを作成します。・
touch
ファイルを作成します。
参考サイト: 新規ファイル作成・
rmdir
空のディレクトリを削除できます。
中身がある場合はrm -rで削除できます。・
ls
今いるディレクトリの直下にあるディレクトリやファイルを表示します。・
mv
ディレクトリやファイルを移動します。・
cat
指定したファイルの中身を表示できます。・
less
中身が長い時に使えるコマンドです。中身を表示してくれます。control + f1画面先にcontrol + b1画面前にg画面の先頭G末尾に移動qlessの終了・
history
コマンドの履歴を見ることができます。! + historyで表示された数字でコマンドを呼び出して実行することができます。!!で直前のコマンドを実行することもできます。!-2だと2個前のコマンドを実行することができます。・
!$
直前に渡した引数(文字列)を呼び出すことができます。
前にlsコマンドを実行していたと仮定して!lを入力すると直前に使ったlsコマンドを実行できます。前にpwdコマンドを実行していたとしたら!pや!pwなどで直前に使ったpwdコマンドを実行できます。
実行せずに直前に使ったコマンドを確認するには!lに続けて:pを入力します。そうすると直前に使ったlsコマンドを実行せずに表示してくれます。!pw:pだと直前に使ったpwdコマンドを実行せずに表示してくれます。
!pw:pの後に、!!を入力すると表示されていたpwdコマンドが実行されます。その他参考URL
最後に
この記事を読んでいただきありがとうございました。
Twitter: @SHUN15949496
- 投稿日:2020-05-30T20:53:38+09:00
Linux仮想環境から、JDBCドライバを使用して、windows上のSQL Serverへ接続した過程と結果
今回はwindows上にLinux仮想環境を構築し、JDBCドライバをインストールしたのち、JDBCクライアントを使用しwindows上のSQL Serverへ接続した結果を表示します!
目次
1.VMwareをダウンロード(windows環境)
2.SQLServerのダウンロード&インストール&簡単なデータベースとテーブル作成(windows環境)
3.SQLServerのリモート接続設定(windows環境)
4.CentOSのダウンロード&インストール(仮想環境)
5.JDKのインストール(仮想環境)
6.PROGRESS JDBCドライバの入手(仮想環境)
7.DBeaverEEのダウンロード&ドライバ設定(仮想環境)
8.DBeaverEEのJDBCURLの接続設定(仮想環境)
9.SQL文の実行(仮想環境)実行環境
Windows10 home 64bit
OSビルド: 18362.778
CentOS8(仮想環境)
JDK11(仮想環境)※注意点
windows上でのローカル環境とLinux仮想環境では見かけのハードは同じですが、全然違う実行環境なので、すでにローカル環境でJDKなどのソフトウェアをインストールされている方も改めてLinux環境上でダウンロード&インストールしなおす必要があります。
手順
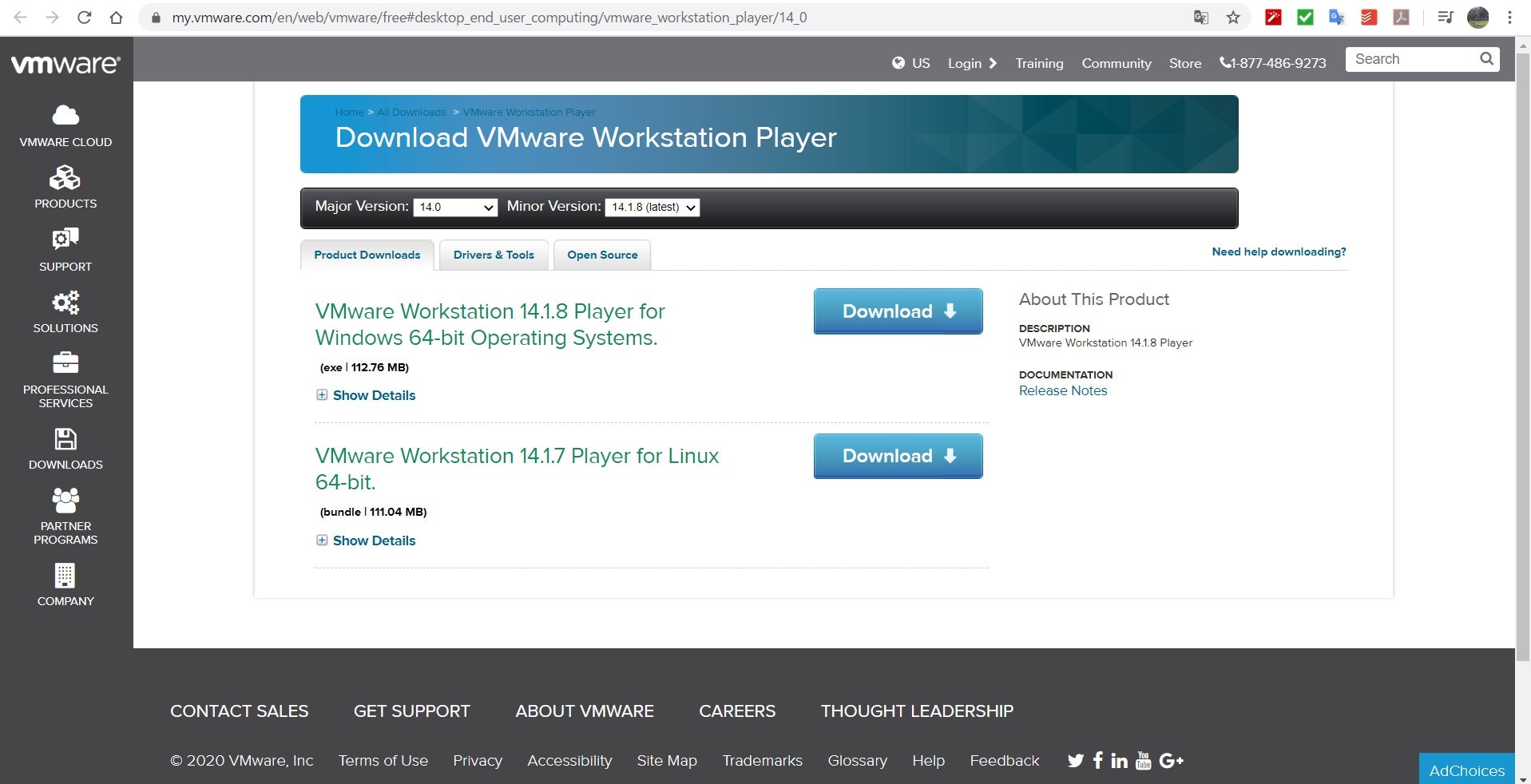
1.VMwareをダウンロード(windows環境)
まずhttps://my.vmware.com/en/web/vmware/free#desktop_end_user_computing/vmware_workstation_player/14_0 にアクセスし、VMware Workstation 14.1.8 Player for Windows 64-bit Operating Systems.の方をダウンロードし(図1)、拡張子exeを実行してインストールを済ませておいて下さい。
図1
2.SQLServerのダウンロード&インストール&簡単なデータベースとテーブル作成(windows環境)
基本的には、https://www.tairax.com/entry/Microsoft-SQL-Server/Install にアクセスし、そこのやり方に従ってください。この手順が終われば、SQLServerのダウンロード&インストールまでが完了します。そして、データベースの作成方法はhttps://www.tairax.com/entry/Microsoft-SQL-Server/How-to-make-database にアクセスし、テーブルの作成方法はhttps://www.tairax.com/entry/Microsoft-SQL-Server/How-to-make-table を参考にしてみてください。
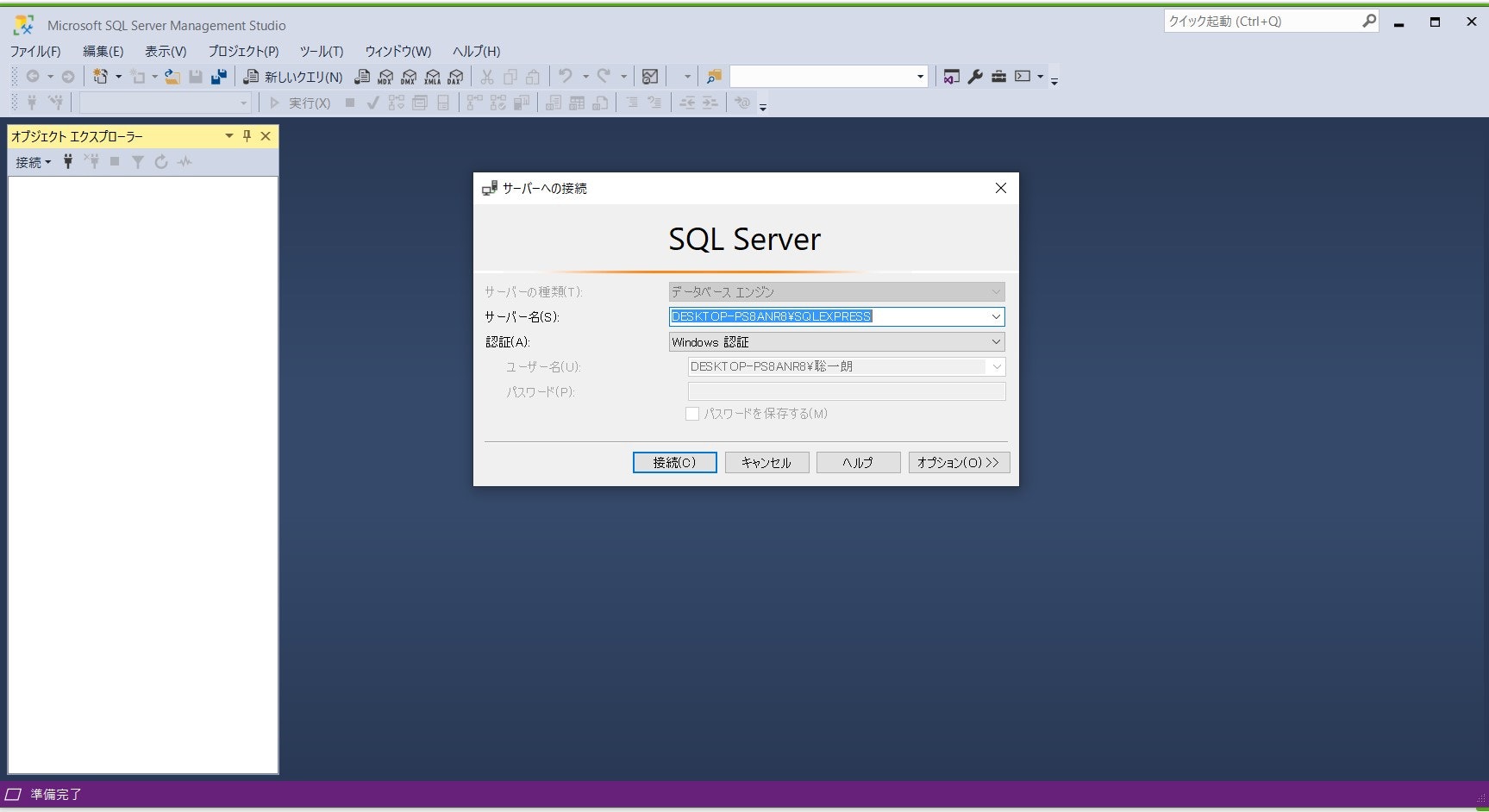
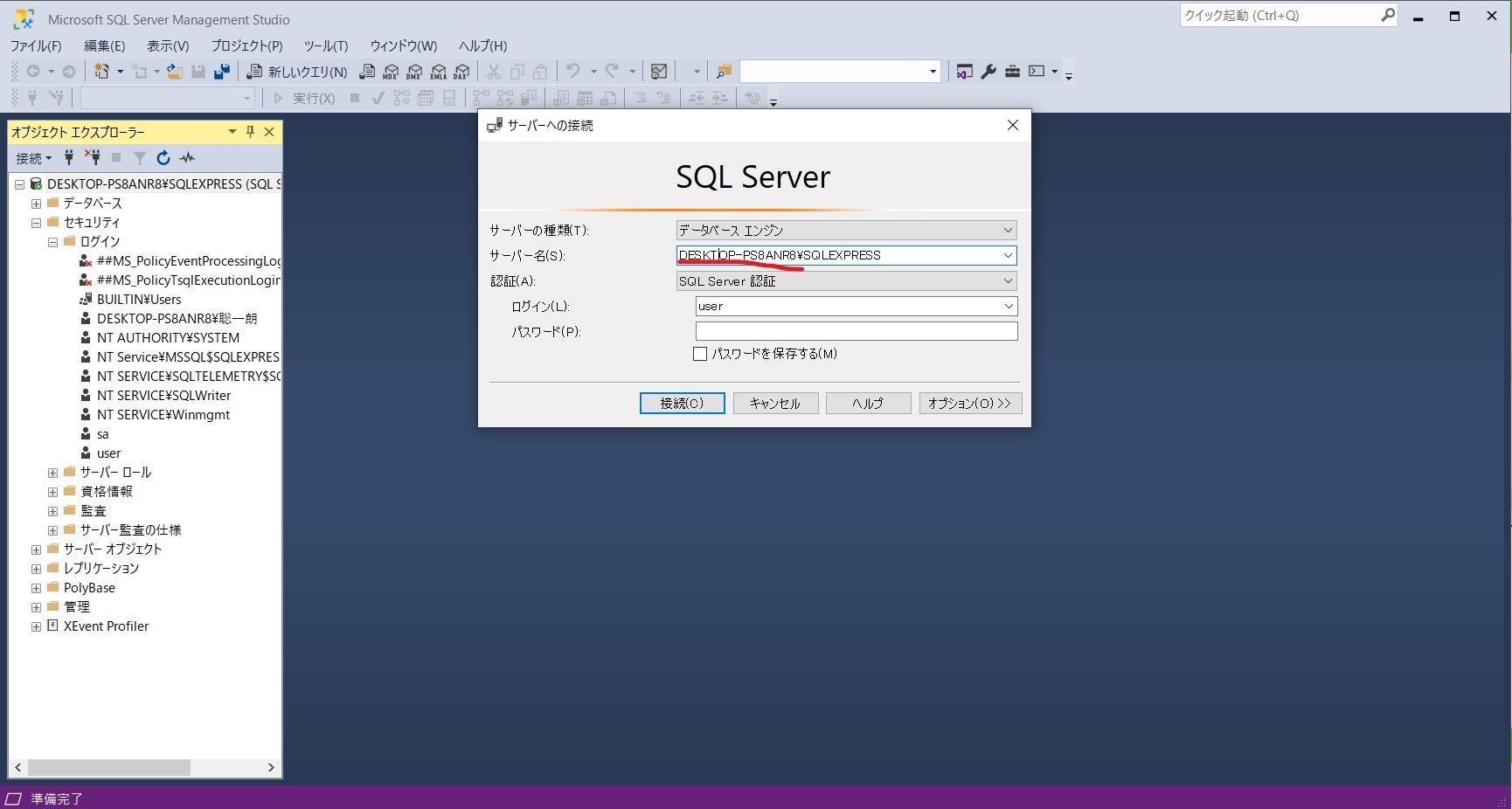
3.SQLServerのSQL認証設定&リモート接続設定(windows環境)
現段階ではSQLServerへはwindows認証でしかログインできません。ところがリモート接続するにはSQL認証を設定する必要があります。まずはSQLServerへwindows認証のままログインします(図1.1)
図1.1
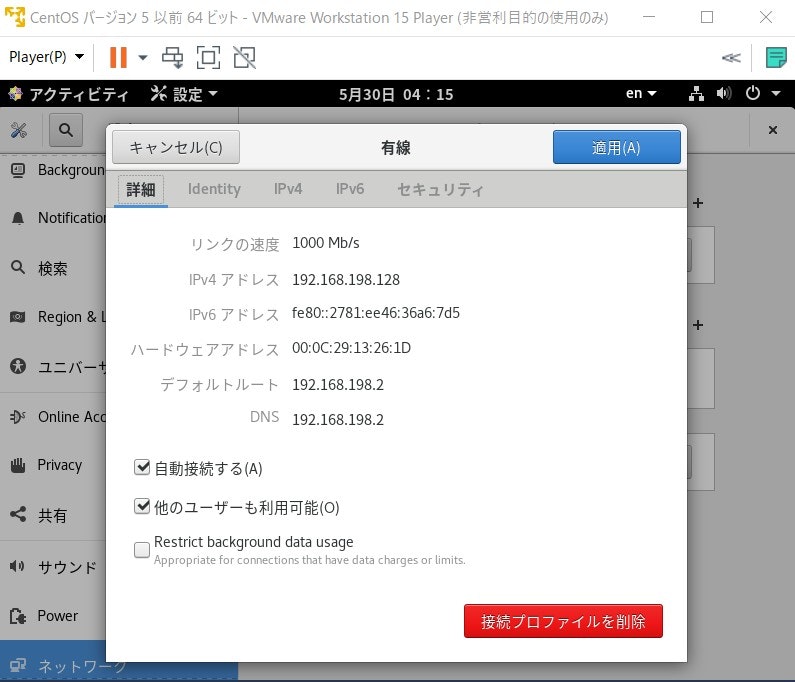
そして、SQLServer上での以降の設定はhttps://creativeweb.jp/fc/remote/ とhttps://creativeweb.jp/tips/firewall-sql-server/ を参考に設定します。ちなみに、前者の参照先のTCP/IPの有効化という項目で、固定ポートか動的ポートかを選べますが、固定ポートを選択してください。そして後者の参照先のファイアウォールの設定でリモートIPアドレスを設定しますが、それは仮想環境上の設定(図3に載っています)/ネットワークの有線の右にある歯車みたいなマークをクリックし、その中のIPv4アドレスとデフォルトのアドレスを二つとも入力しておきます(図1.2)。これでSQLserver側のリモート設定は完了しました。
図1.2
4.CentOSのダウンロード&インストール(仮想環境)
基本的には、https://qiita.com/anWest/items/c4bfd41f1dfbe90a0d5a の手順通りして頂いて、いくつか注意点だけ指摘しておきます。
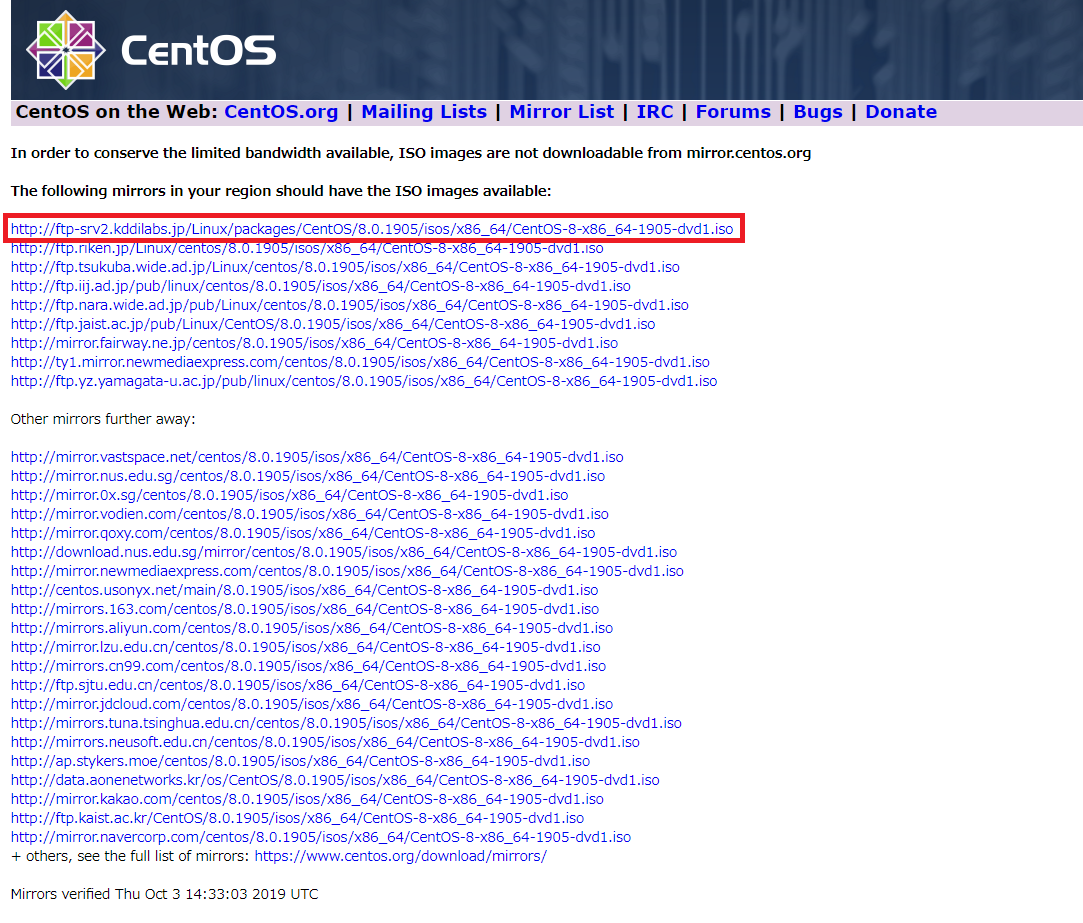
まず、CentOSのISOを入手するURLですが、URLの中に「Packages」が入っているものを選択してください(図2)。なぜならISOファイルはダウンロードに時間がかかりますが、その他のISOファイルは破損している可能性が高いからです。図2
次に、CentOSを作成している間にいくつかrootパスワードとユーザーパスワードの設定をします(rootは管理者権限でJavaなど新たなソフトウェアをインストールする際に必要な権限で、実際に作業するときにはユーザー権限でログインします(CentOSを起動すると毎回ユーザーでログインしますが、自動ログインの設定は簡単にできるので「CentOS 自動ログイン」などでググってみましょう))。rootパスワードとユーザーパスワードは度々必要になるので、メモっておきましょう。
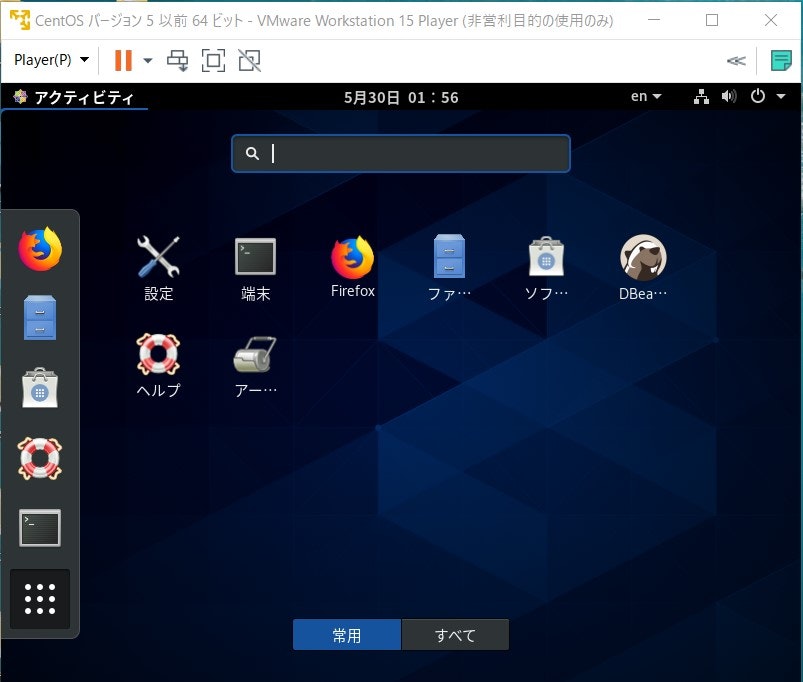
全ての設定が完了するとwindowsのようにGUIで操作ができるようになります(図3)(もしスリープモードになったらエンターキーを二回ぐらい押してください。再度ログイン画面が現れます)。
図3
5.JDKのインストール(仮想環境)
のちほどダウンロードするJDBCドライバの使用にはJavaの実行環境が必要です。そこでJDKをインストールします。
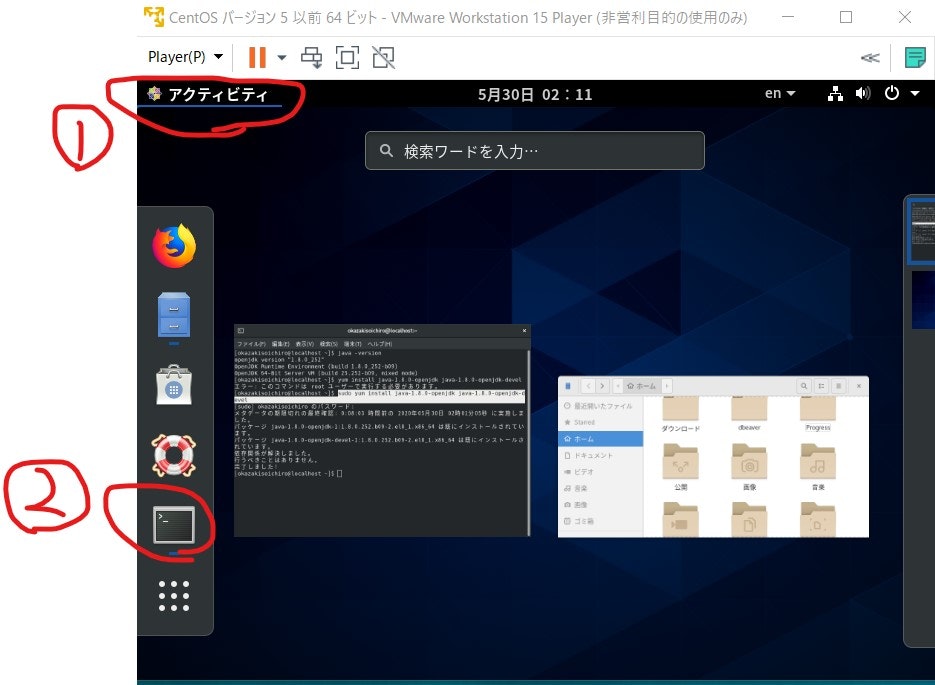
まずコマンドラインを開きます(左上のアクティビティをクリックしたあとサイドバーの下から二番目の黒い四角をクリックします)(図4)。図4
コマンドラインが出てきたら、「sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel」と入力します(sudoは管理者権限で実行するためのコードです)。そこでユーザーパスワードを入力します。するとインストールが始まるのですが、もし途中で止まったらエンターキーかyを押して進めてください。インストールが完了すると図5のようにコマンド入力の待機状態になります。
図5
最後に「java -version」と入力してきちんとインストールされているか確認しましょう。きちんとインストールできていれば図5の画面上部のようにjavaのバージョン情報が表示されます。
6.PROGRESS JDBCドライバの入手(仮想環境)
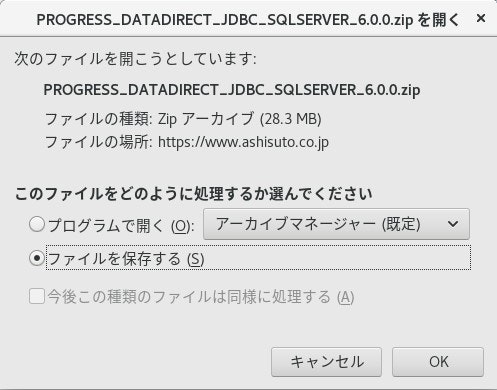
CentOS上のブラウザを使用して、https://www.ashisuto.co.jp/datadirect/app_download/ にアクセスし、DataDirect Connect for ODBC UNIX/Linux(64Bit)をダウンロードします(Linuxファイルをダウンロードするときに共通ですが「ファイルを保存する」の方を選択してください(図6))。
図6
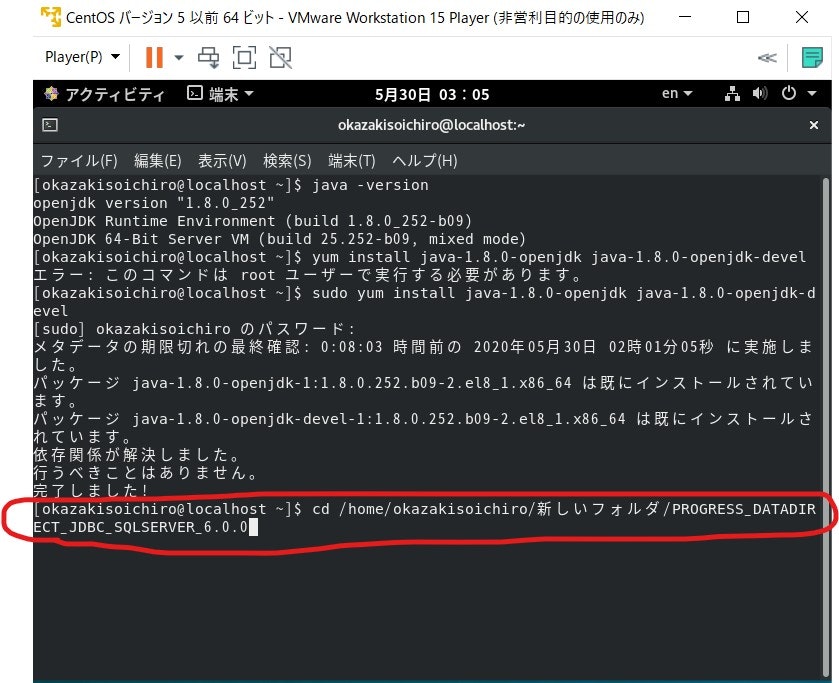
ドライバをダウンロードしたら、PROGRESS_DATADIRECT_JDBC_SQLSERVER_6.0.0.zipというファイルがホームかダウンロードというディレクトリにあると思います。それを右クリックして「ここで展開する」をクリックします。そして中身のファイルを新しいフォルダを作って移します。そして中身のファイルの中のPROGRESS_DATADIRECT_JDBC_INSTALL.jarをコマンドラインで実行します(コマンドラインを起動し、実行したいファイルがある階層へcdコマンドで移動し「java -jar PROGRESS_DATADIRECT_JDBC_INSTALL.jar -i console」と入力すればインストールされます(図7))
インストールが完了すると/home/okazakisoichiro/Progress/DataDirect/JDBC_60/libにsqlserver.jarが配置されているはずです。図7
7.DBeaverEEのダウンロード&ドライバ設定(仮想環境)
https://dbeaver.com/download/ にアクセスし、Linux RPM Package 64bit(Installer)をダウンロードします(図8)。
図8
そうすると、ホームかダウンロードディレクトリに先ほどダウンロードしたRPMパッケージがあるので、コマンドラインを起動してその階層までcdで移動します(図7を参考)をコマンドラインに「sudo rpm -ivh dbeaver-.rpm」と入力します(varsionにはダウンロードしたRPMパッケージのバージョンを入力)。そうするとDBeaverがインストールされます。コマンドラインに「dbeaver」と入力して、DBeaverが立ち上がればインストールできています(図9)。
図9(こんな感じの画面が立ち上がれば成功です(図9はJDBC接続後の表示なので、実際にはもっと簡素な表示になります。))
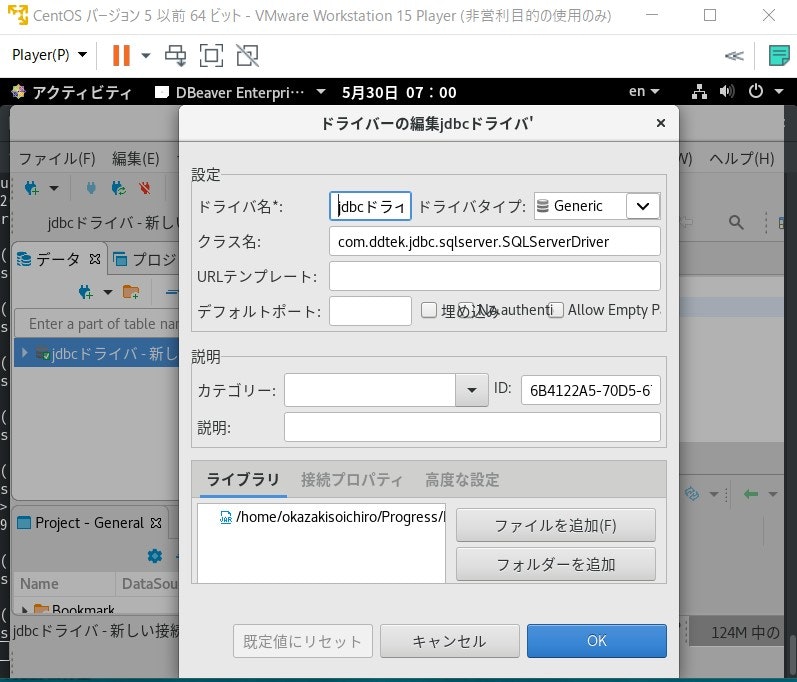
では、ドライバの設定をします。先ほど起動したDBeaberのメニューバーのデータベースを選択し、ドライバーマネジャーを起動します(詳細はhttps://qiita.com/zakiokasou/items/2e9297e268770351a300 の5.BigQueryコネクタをDbeaverに登録するに記載済み)。起動したら、ドライバ名、クラス名、ライブラリを埋めていきます。それぞれドライバ名には「JDBCドライバ」、クラス名には「com.ddtek.jdbc.sqlserver.SQLServerDriver」、そしてライブラリフォームの横にあるファイルを追加をクリックし、本記事6の手順で手に入れた、sqlserver.jarを指定します。そしてOKを押します(図10)。
図10
8.DBeaverEEの接続設定(仮想環境)
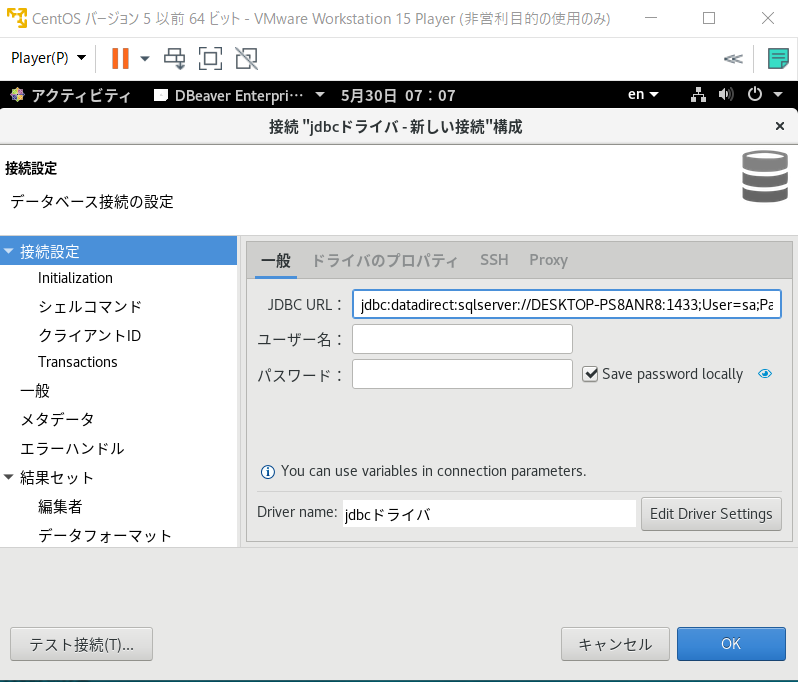
次に、Dbeaverのメニューバーのデータベース>新しい接続をクリックします。そこに先ほど命名したJDBCドライバが存在するのでそれを選択して次へを押します。すると図11のような画面が現れます。
図11
次に、JDBC URLに以下のURLを入力します。
"jdbc:sqlserver://:;databaseName=;user=;password="
<>の中身を以下のように改変します。
server → SQL Serverにログインするときのサーバー名の¥に左側(図12)port → 本記事手順3の参照先(https://creativeweb.jp/fc/remote/ )で設定した固定ポート番号(手順通りなら1433)
databaseName → 本記事手順2の参照先(https://www.tairax.com/entry/Microsoft-SQL-Server/How-to-make-database )で設定したdatabase名(手順通りならsample)
user,password → SQL ServerにSQL認証でログインするときのログイン名、パスワード(図12参考)
図12
JDBCURLに入力が完了したら図11左下のテスト接続を押します。うまくいけば接続済みというポップアップが出ます。右下のOKを押すと接続設定が完了します。
9.SQL文の実行(仮想環境)
DBeaverの初期画面に左側にJDBCドライバという項目があるので、そちらを右クリックしてSQLエディタを選択します(図13)
(図13)
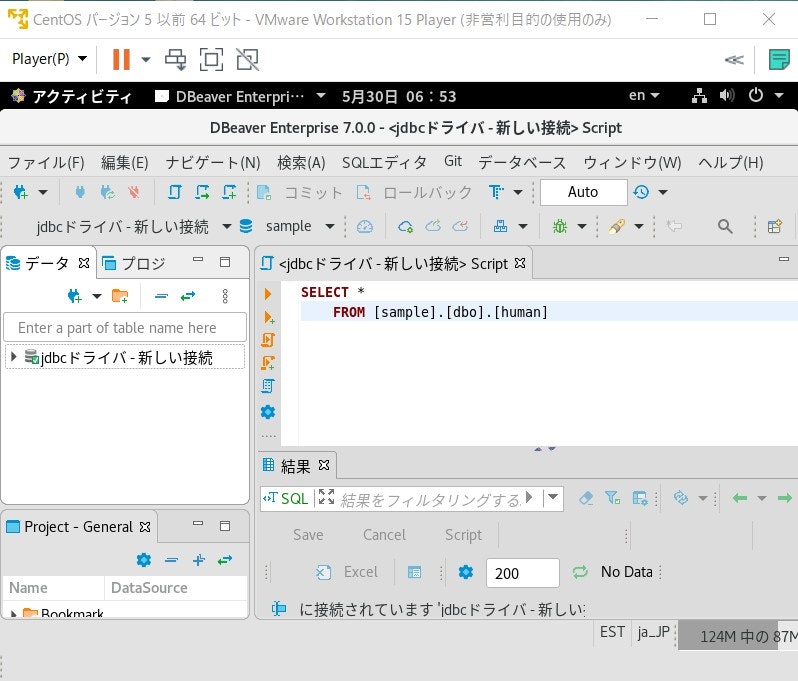
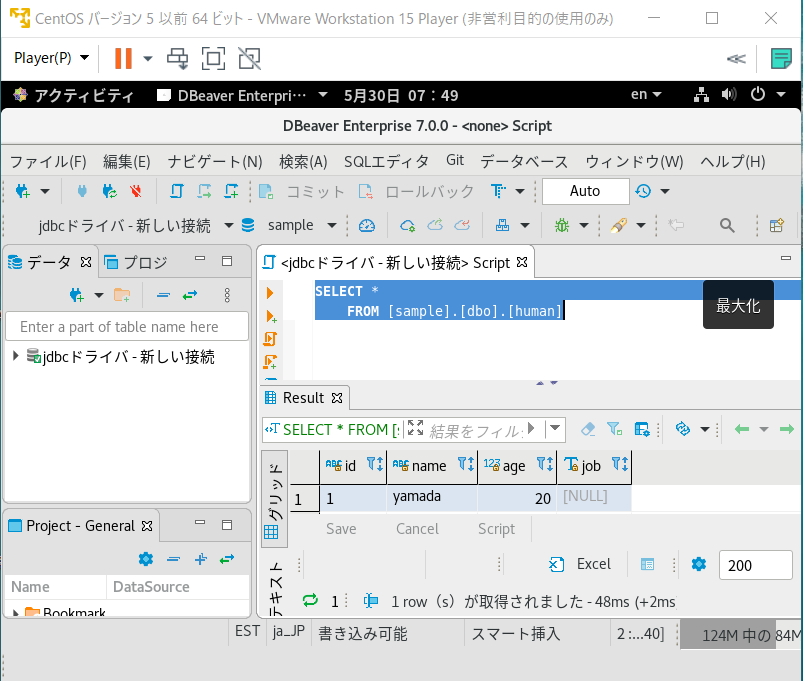
そうすると画面右側でSQLの操作ができるので、「SELECT *
FROM [sample].[dbo].[human]」([]の中は本記事手順2の参照先でのデータベースとテーブルの設定によりますが手順通りなら[sample]と[human]になるはずです)と入力して画面中央の実行ボタン(三角が90度傾いた形)を入力しましょう。画面右下下部にSQLserverからデータが取得できました(図14)(図のように表示するには事前にSQLServerでサンプルの値を入れておく必要があります)。図14


- 投稿日:2020-05-30T20:26:25+09:00
Linuxで電源をつける度に時間が狂ってしまう問題の解決方法
- 投稿日:2020-05-30T16:51:40+09:00
Linux Kernel for ARMにおける各種crypt実装が呼び出されるまで
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/arm/crypto
こちらをベースに、各種crypt実装が呼び出されるまでを簡単にまとめておく。
大前提
ARM archで、SHA1のNEON実装が有効になり、呼び出せる準備ができるまでをまとめる。
なお、 ** NEON/SIMDの実装の中身の議論はしない** です。
KConfig
arch/arm/crypy/Kconfig に、各種カーネルコンフィグレーションがある。
- ARMとなっているものは、基本コンパイルできるはず…だけどNEONも使っているものもまざってて、うんわかりにくいな。
- NEONとついているものは、NEONが有効になっている場合にだけ使える。
- CEとついているものは、ARM v8 Crypto Extensionsを有効になっている場合にだけ使える
arch/arm/crypto/Kconfigmenuconfig ARM_CRYPTO bool "ARM Accelerated Cryptographic Algorithms" depends on ARM help Say Y here to choose from a selection of cryptographic algorithms implemented using ARM specific CPU features or instructions. if ARM_CRYPTO <略> config CRYPTO_SHA1_ARM_NEON tristate "SHA1 digest algorithm (ARM NEON)" depends on KERNEL_MODE_NEON select CRYPTO_SHA1_ARM select CRYPTO_SHA1 select CRYPTO_HASH help SHA-1 secure hash standard (FIPS 180-1/DFIPS 180-2) implemented using optimized ARM NEON assembly, when NEON instructions are available.Makefile
KConfigで有効にした設定に応じて、必要なファイルを取り込むいつもの記載ですね
arch/arm/crypto/Makefileobj-$(CONFIG_CRYPTO_AES_ARM) += aes-arm.o obj-$(CONFIG_CRYPTO_AES_ARM_BS) += aes-arm-bs.o obj-$(CONFIG_CRYPTO_SHA1_ARM) += sha1-arm.o obj-$(CONFIG_CRYPTO_SHA1_ARM_NEON) += sha1-arm-neon.o obj-$(CONFIG_CRYPTO_SHA256_ARM) += sha256-arm.o <略> aes-arm-y := aes-cipher-core.o aes-cipher-glue.o aes-arm-bs-y := aes-neonbs-core.o aes-neonbs-glue.o sha1-arm-y := sha1-armv4-large.o sha1_glue.o sha1-arm-neon-y := sha1-armv7-neon.o sha1_neon_glue.o sha256-arm-neon-$(CONFIG_KERNEL_MODE_NEON) := sha256_neon_glue.osha1-arm-neon.o
これは、
sha1-arm-neon-y := sha1-armv7-neon.o sha1_neon_glue.oの記載から、2つのファイルを結合したものになる。sha1_neon_glue.c
モジュール組み込み時の、init/exit
モジュールを組み込んだ時点で、sha1_neon_mode_[init|fini] が登録される。
arch/arm/crypto/sha1_neon_glue.cmodule_init(sha1_neon_mod_init); module_exit(sha1_neon_mod_fini); MODULE_LICENSE("GPL"); MODULE_DESCRIPTION("SHA1 Secure Hash Algorithm, NEON accelerated"); MODULE_ALIAS_CRYPTO("sha1");sha1_neon_mod_init()
sha1_neon_mod_init()では、neon用の実装を登録している。
ここで、.initはsha1_base_initとなって共通実装を使い、その他は、sha1_neon_*と独自実装となっている点に注目されたい。arch/arm/crypto/sha1_neon_glue.cstatic struct shash_alg alg = { .digestsize = SHA1_DIGEST_SIZE, .init = sha1_base_init, .update = sha1_neon_update, .final = sha1_neon_final, .finup = sha1_neon_finup, .descsize = sizeof(struct sha1_state), .base = { .cra_name = "sha1", .cra_driver_name = "sha1-neon", .cra_priority = 250, .cra_blocksize = SHA1_BLOCK_SIZE, .cra_module = THIS_MODULE, } }; static int __init sha1_neon_mod_init(void) { if (!cpu_has_neon()) return -ENODEV; return crypto_register_shash(&alg); }sha1_neon_update()
arch/arm/crypto/sha1_neon_glue.cstatic int sha1_neon_update(struct shash_desc *desc, const u8 *data, unsigned int len) { struct sha1_state *sctx = shash_desc_ctx(desc); if (!crypto_simd_usable() || (sctx->count % SHA1_BLOCK_SIZE) + len < SHA1_BLOCK_SIZE) return sha1_update_arm(desc, data, len); kernel_neon_begin(); sha1_base_do_update(desc, data, len, (sha1_block_fn *)sha1_transform_neon); kernel_neon_end(); return 0; }arch/arm/crypto/sha1_glue.cint sha1_update_arm(struct shash_desc *desc, const u8 *data, unsigned int len) { /* make sure casting to sha1_block_fn() is safe */ BUILD_BUG_ON(offsetof(struct sha1_state, state) != 0); return sha1_base_do_update(desc, data, len, (sha1_block_fn *)sha1_block_data_order); } EXPORT_SYMBOL_GPL(sha1_update_arm);ここで、
- crypt_simd_usable() は、SIMD実装をcryptで利用できるかどうかを判定する関数。 https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/include/crypto/internal/simd.h#n64 あたりに実装がある。
- SIMD実装をcryptで使えない場合は、利用できない場合には、普通の
sha1_update_arm()からsha1_base_do_update()を呼び出すフォールバック処理がなされる。kernel_neon_begin()と、kernel_neon_end()は、NEON Registerの保護のために行われる関数。- 処理の実体は、
sha1_base_do_update()の引数で渡された、sha1_transform_neon()で行われる。sha1_neon_finup() / sha1_neon_final()
終了処理をまとめて説明する。
- simdがcryptで使えなかったら、通常処理に戻す。
- kernel_neon_begin() でneon使えるようにする
- sha1_base_do_update(sha1_trasnfrom_neon) で、処理本体を呼び出す
- kernel_neon_end() でneon使用状態を戻す
sha1_neon_glue.cstatic int sha1_neon_finup(struct shash_desc *desc, const u8 *data, unsigned int len, u8 *out) { if (!crypto_simd_usable()) return sha1_finup_arm(desc, data, len, out); kernel_neon_begin(); if (len) sha1_base_do_update(desc, data, len, (sha1_block_fn *)sha1_transform_neon); sha1_base_do_finalize(desc, (sha1_block_fn *)sha1_transform_neon); kernel_neon_end(); return sha1_base_finish(desc, out); } static int sha1_neon_final(struct shash_desc *desc, u8 *out) { return sha1_neon_finup(desc, NULL, 0, out); }sha1-armv7-neon.S
sha1_transform_neon()
sha1-armv7-neon.S/* * Transform nblks*64 bytes (nblks*16 32-bit words) at DATA. * * unsigned int * sha1_transform_neon (void *ctx, const unsigned char *data, * unsigned int nblks) */ .align 3 ENTRY(sha1_transform_neon) /* input: * r0: ctx, CTX * r1: data (64*nblks bytes) * r2: nblks */ cmp RNBLKS, #0; beq .Ldo_nothing; <略>まとめ
XXXX-glue.cというファイルを追加して、module_init()内でtransform関数を登録しよう。- transform関数は、callbackとして引き渡す形で使うので、そこを機にしよう。
- 前提条件を満たさず使えなかった場合のフォールバック処理もちゃんと入れよう。
以上となります。
おまけ:現在(2020/5/30) でLinux Kernelのcrypt実装では、どんなものがサポートされているのか。
ざっくり、ファイル名から見ると下記がサポートされているっポイ。
ARMの場合
(☆ = x86にはなくて、ARMにはある)
- aes
- chacha
- crc32
- crct10dif
- curve25519
- ghash
- nhpoly1305
- poly1305
- sha1
- sha2 ☆
- sha256
- sha512
ARM64の場合
(☆ = x86にはなくて、ARM64にはある)
- aes
- chacha
- crct10dif
- ghash
- ngpoly1305
- poly1305
- sha1
- sha2
- sha3
- sha256
- sha512
- sm3 ☆
x86の場合
(★= ARMにはなくて、x86にある)
特徴:さすがにみんなが使っていることだけあって、サポートが熱く厚いなあ……
- aegis128 ★
- aes
- blake2s ★
- blowfish ★
- camellia ★
- cast5 ★
- cast6 ★
- chacha
- crc32
- crct10dif
- curve25519 ★
- des3 ★
- ghash
- nhpoly1305
- poly1305
- serpent ★
- sha1
- sha256
- sha512
- twofish ★
powerpcの場合
特徴: う、うーん、、、これ、特徴が無いように見える。
- aes
- crc32
- crct10dif
- md5
- sha1
- sha256
sparcの場合
特徴: MD5とかAES,DES,CAMELLIAとか、SHA1,SHA256,SHA512とか、専用命令あるっぽい!
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/sparc/crypto/opcodes.h
- camellia
- crc32c
- des
- md5
- sha1
- sha256
- sha512
MIPS
- chacha
- crc32
- poly1305
S390
- aes
- RNG
- crc32
- des
- ghash
- paes
- sha1
- sha3
- sha256
- sha512
RISC-V
未実装!!ここにcommitすれば、あなたもLinux Kernel Developerとして名前が未来永劫記録されますよ!!やったね!!!
- 投稿日:2020-05-30T15:47:38+09:00
Linux基礎13 -高度なテキスト処理-
はじめに
Linuxで行うテキスト処理は、テキストの検索や表示だけではなく、その一部を変更したり、削除したりというテキスト編集の処理が必要になります。
今回は、sedとawkという2つのコマンドを紹介します。sedとawkはどちらもよく使用される編集のためのコマンドです。テキストを便利に編集できるようになるために是非覚えましょう。sedコマンド -ストリームエディタ-
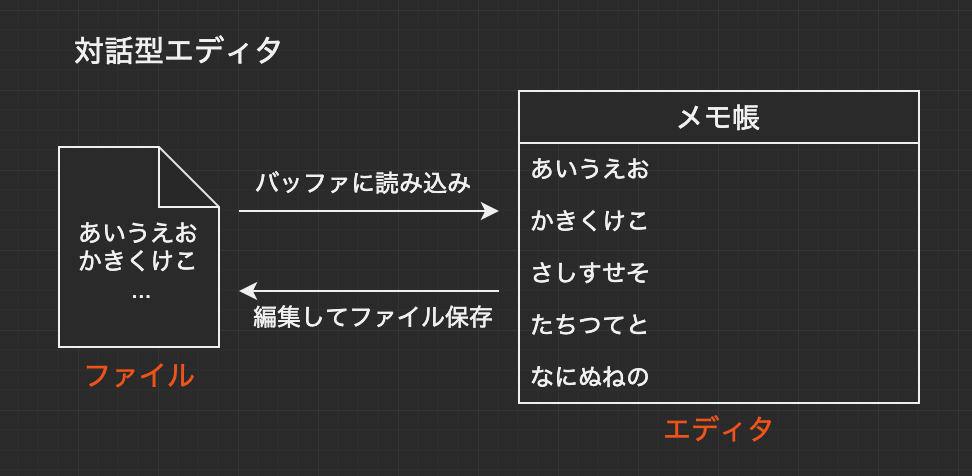
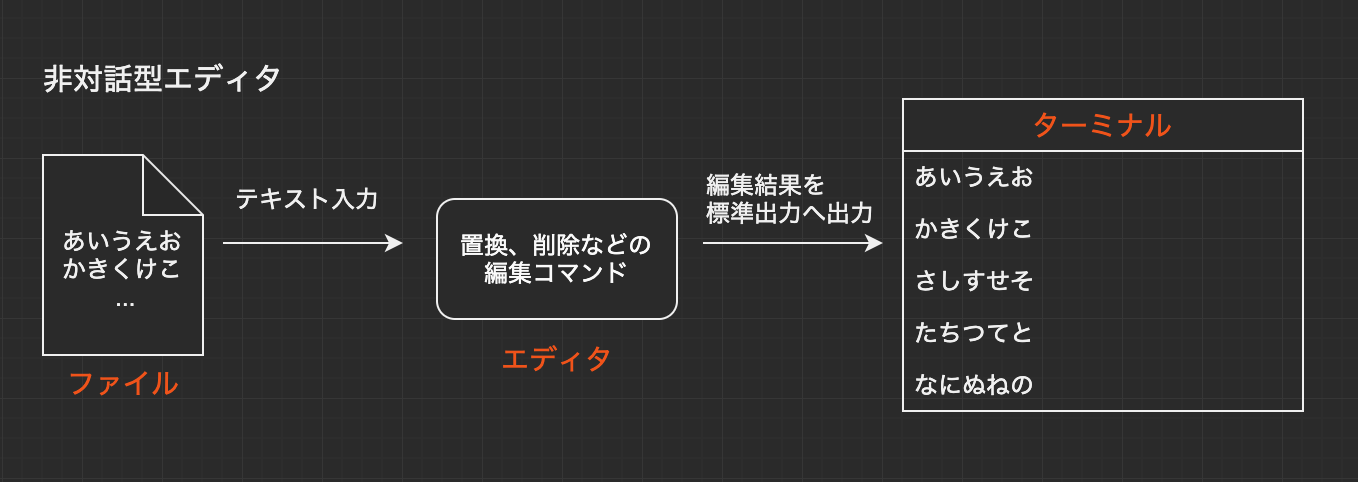
sedコマンドは文字列を置換するためによく使用されます。詳しくみていきましょう。非対話型エディタ
sedというコマンド名は、「Stream Editor」の略からきており、その名の通りsedはエディタです。しかし、Windowsのメモ帳やVimなどの対話型のエディタとは大きく異なります。
対話型エディタの動作の流れ1. エディタでファイルを開く 2. バッファ内で編集 3. 編集が完了したら、ファイルを保存
非対話型エディタの動作の流れ1. シェルから編集のためのコマンドを引数として与えて、sedコマンドを実行する 2. sedコマンドは編集対象のテキストに対して、与えられた編集コマンドに対応する編集操作を行う 3. 編集後のテキストを、sedコマンドが標準出力に出力する
sedは非対話型でフィルタとして動作し、編集処理を行うため、決まったパターンの編集を行うケースでは非常に効率よく作業することができます。またsedでは正規表現の利用もできます。
なお。sedコマンドは編集結果を標準出力に出力するため、元のファイルは編集しません。また、sedコマンドはファイルの指定がなければ、標準入力から読み込みます。このためパイプを使って、他のコマンドと組み合わせて使われます。sedコマンドの形式
sedコマンド$ sed [オプション] <スクリプト> <対象ファイル> #他に引数やフラグをとることもある $ #<スクリプト> とは、「アドレス」と「コマンド」を組み合わせた文字列のこと。アドレスは省略可能。
sedコマンドの実行例をみていきましょう。各部位の名前を表に示します。sedコマンドの実行例1$ sed 1,5d sample.txt
部位 名前 1,5d スクリプト 1,5 アドレス d コマンド sample.txt 対象ファイル sedコマンドの実行例2$ sed 's/aaa/bbb/g' sample.txt
部位 名前 s/aaa/bbb/g スクリプト s コマンド /aaa/bbb/ 引数 g フラグ sample.txt 対象ファイル
sedでは多くのコマンドが利用できますが、よく使われるコマンドは、わずかです。今回は以下の3つのコマンドに絞って紹介します。
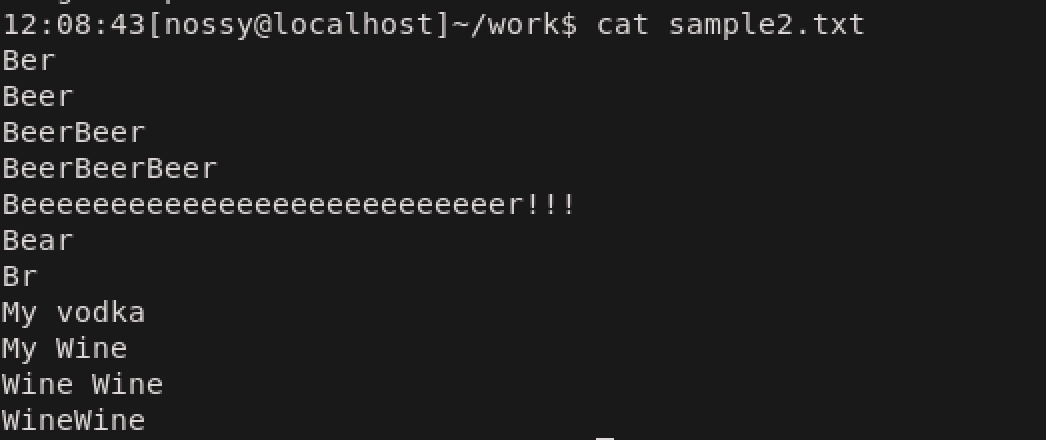
コマンド 内容 d 行を削除する p 行を表示する s 行を置換する 今回も動作確認のためのサンプルファイルを用意しました。
行を削除する
dは行を削除するコマンドです。sedのアドレスの指定方法と合わせて使い方をみていきましょう。
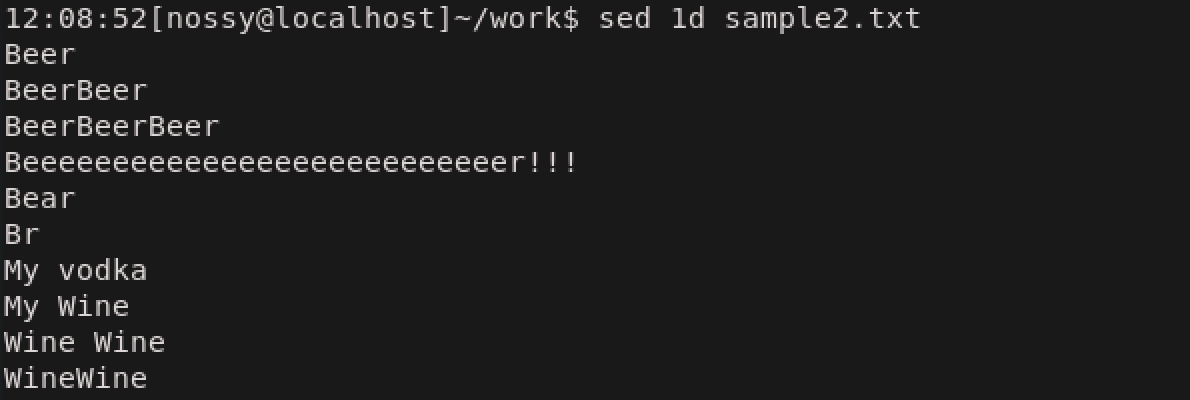
sedのコマンドは、アドレスで指定された行にのみ作用します。アドレスの指定の方法にはいくつか種類がありますが、まずは行番号で指定します。次の例は、アドレスに1行目を指定して、削除のdコマンドを実行しています。
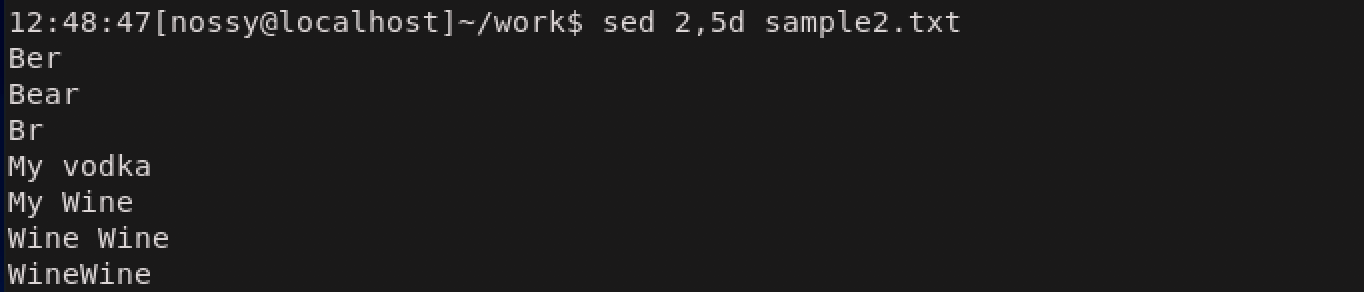
アドレスの範囲は、n,mの形で「n行目からm行目まで」と指定できます。次の例は2から5行目までを削除しています。
また、アドレスに$を指定すると、最終行を意味します。$はシェルに解釈させないために' '(シングルクォート)で囲む必要があります。
次はアドレスを省略してみます。この場合はコマンドは全ての行に作用します。全て削除してしまったので、何も出力されません。
アドレスは行番号だけでなく、正規表現で書くこともできます。この時、正規表現は/(スラッシュ)で囲みます。次の例では先頭がBで始まる行を削除時ています。
ここまで、各アドレスに対して、行を削除してきました。正規表現がアドレスというのは少し違和感があるかもしれませんが、sedのアドレスとは、コマンドの作用する範囲と覚えておくといいかもしれません。行を表示する
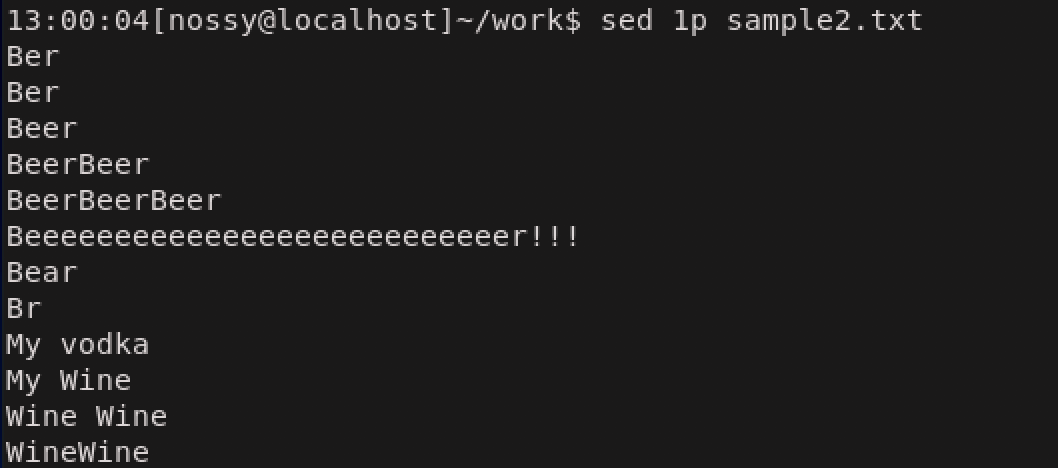
pは行を表示するコマンドです。早速例を示していきます。
1行目を指定して、実行したつもりですが、1行目が1度表示された後、全行表示されています。これはsedコマンドのパターンスペースの自動出力が原因です。一旦、sedコマンドの動作の様子をみていきましょう。sedのパターンスペースと行の表示
sedコマンドの動き1. 行を読み込み、パターンスペースにコピーする 2. パターンスペースに編集コマンドを適用する 3. 編集後のパターンスペースの内容を出力する
pコマンドは行を表示するコマンドなので、編集段階で一旦表示して、再度パターンスペースの中身が出力されたという形になっていたわけです。
パターンスペースを表示させないようにするには、pコマンドを-nオプションと同時に利用します。
-nオプションによりパターンスペースを表示させない手法は、置換が発生した場合にだけ出力するというケースなどに利用されます。行を置換する
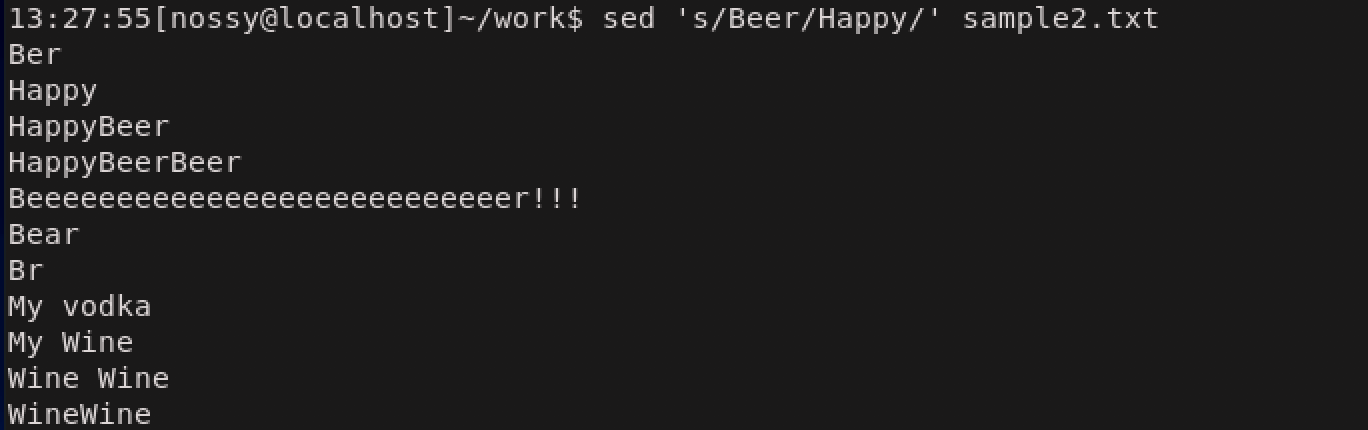
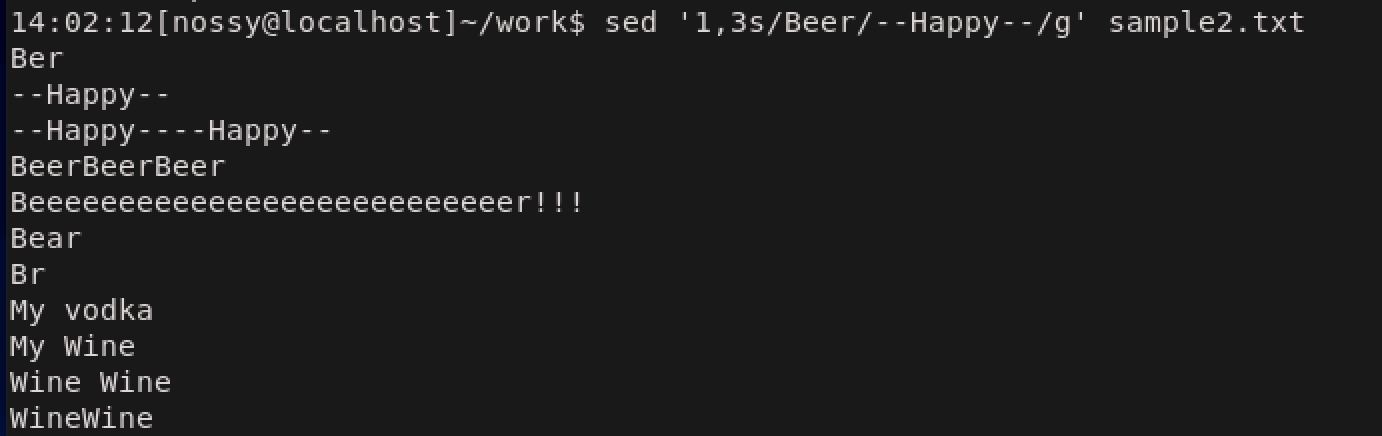
sは行を置換するコマンドです。sedが利用されるケースのほとんどは置換を目的にしているため、非常によく使用されるコマンドです。sコマンドによる文字列置換... s/置換前文字列/置換後文字列/フラグ... #フラグは省略可能次の例では、Beerという文字列をHappyに置換しています。
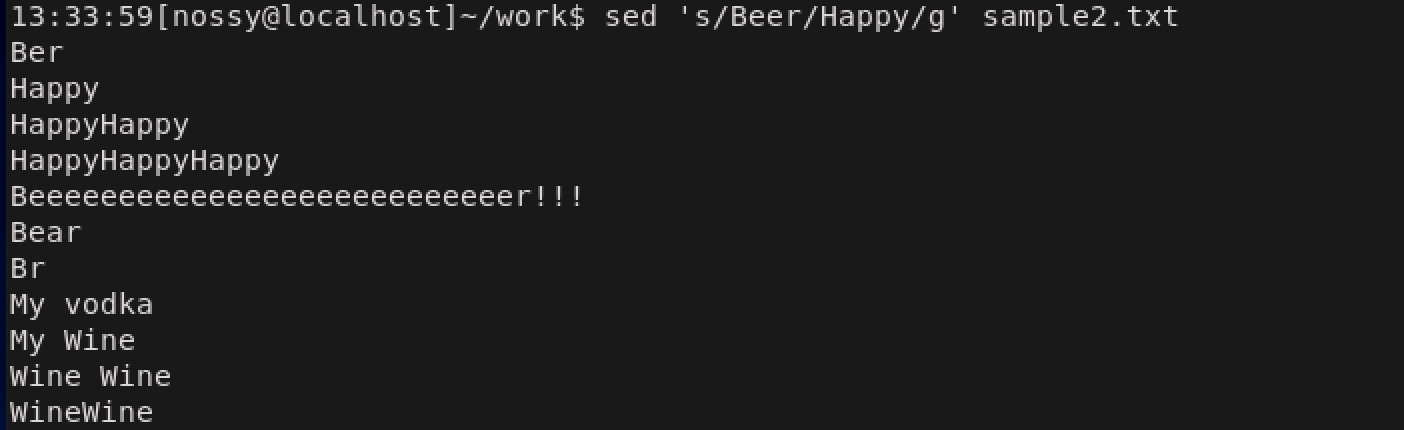
上の結果だと、BeerはHappyに変更されていますが、3,4行目にはまだBeerが残ってしまっていますね。これはsコマンドでの置換が、行頭から探して最初に見つかった文字列を置換してそこで作業を終了するためです。全ての文字列を対象にしたい場合はgフラグをつけます。
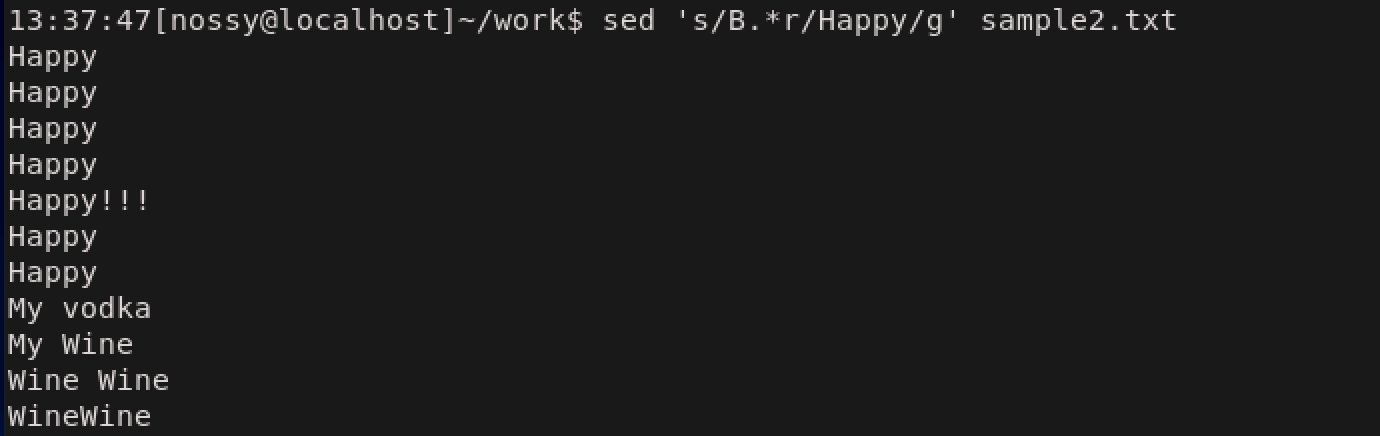
置換文字列の指定には、正規表現を使用できます。次の例ではB.*rを対象に置換を実行します。
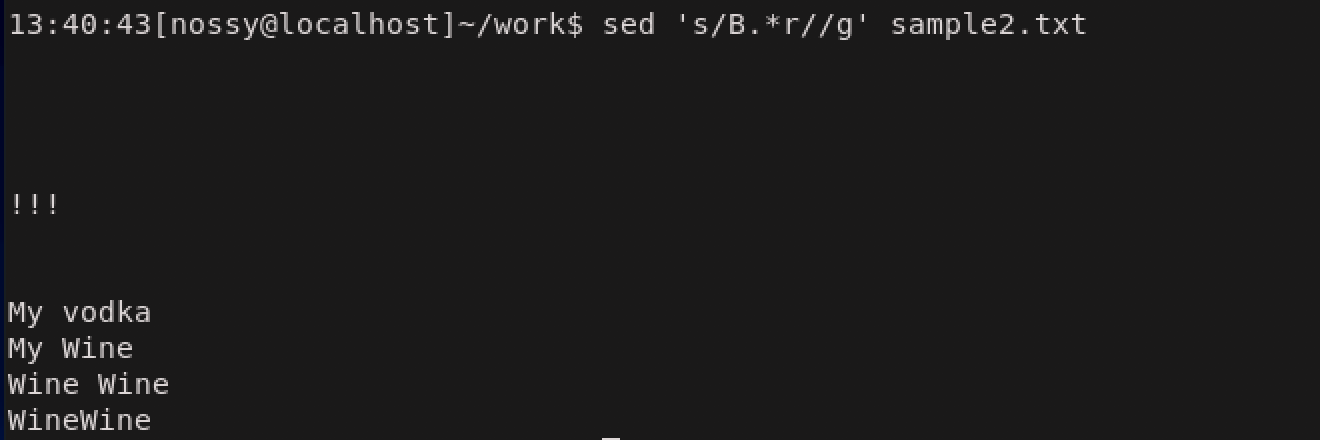
また、特定の文字を指定して、置換先を空文字に指定することで削除を行うことができます。
また、パターンスペースを出力しない-nオプションと、置換が発生した場合に出力するpフラグを用いて、置換が起こった箇所だけを表示することができます。
sedでの拡張正規表現
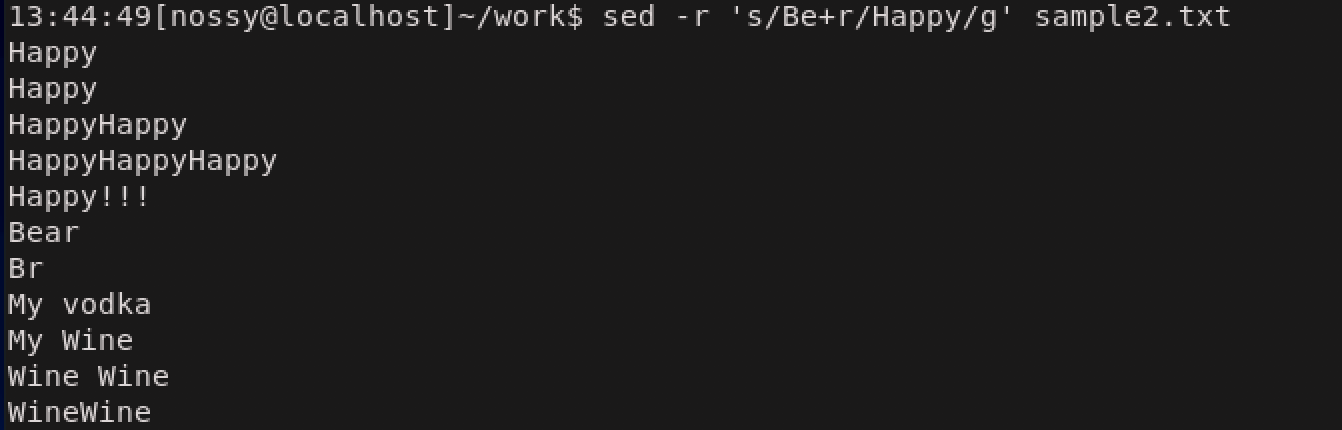
sedでは正規表現は基本正規表現として解釈されます。拡張正規表現を利用したい場合には
-rオプションをつけます。
ただし、Linuxのsed(GNU sed)では独自拡張により、拡張正規表現の+や?をそれぞれ\+や\?のように、\(バックスラッシュ)をつけて書くことで、基本正規表現として利用することができるということに注意してください。後方参照
正規表現を用いて置換する際、
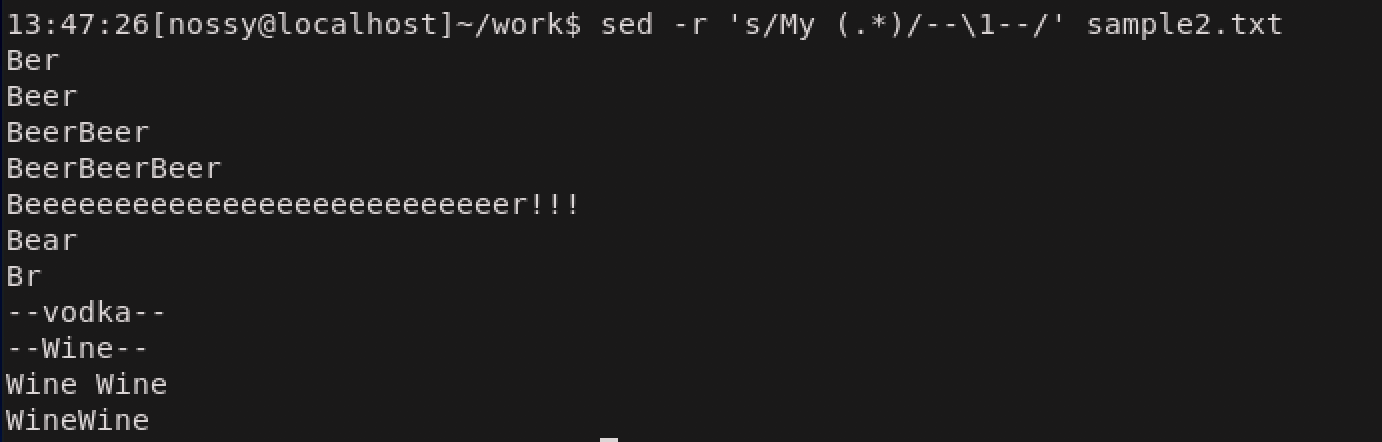
マッチした文字列を置換後に埋め込みたいケースがあります。このような場合には後方参照を使います。後方参照とは、正規表現を()でグループ化した際に、そのマッチした文字列を\1などの数値で参照できる機能です。この時の書き方を表に示します。
基本正規表現 拡張正規表現 ( )でグループ化し、\1で参照 ( )でグループ化し、\1で参照 後方置換を使用した例を示します。My で始まる任意の文字列にマッチした部分を-- --に埋め込んでいます。
アドレス指定
sコマンドで置換する際には、dコマンドやpコマンドと同様にアドレスを指定できます。この時検索対象が、そのアドレスのみに限定されます。
区切り文字の変更
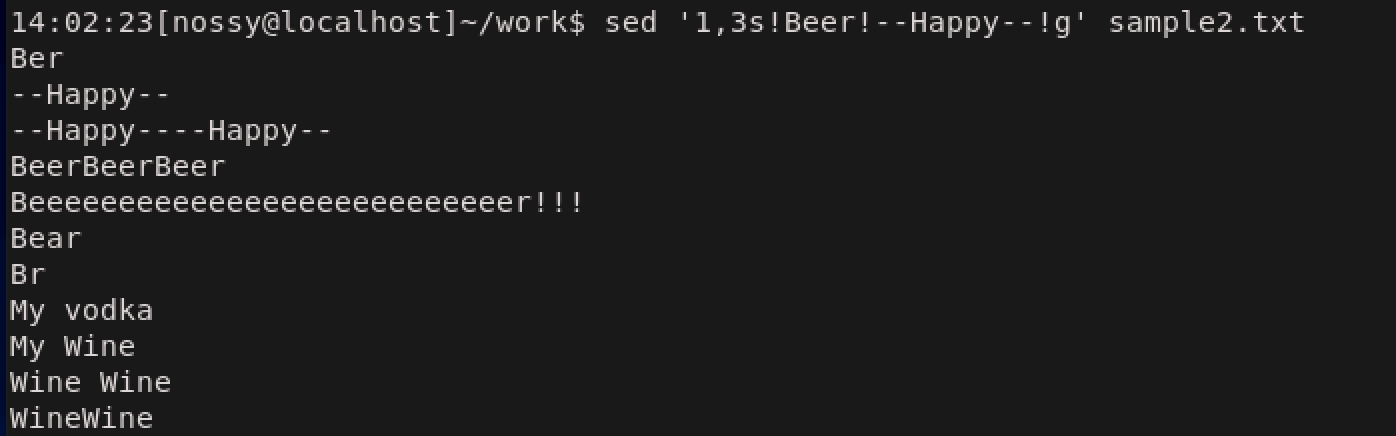
sコマンドで置換をするときに
s/aaa/bbb/gのように記述してきましたが、この区切り文字(ここでは / )は何の記号でも構いません。例えば/を置換対象に含めたい時には、!や%に置き換えることでコマンドが見やすくなるという利点があります。
awkコマンド -パターン検索・処理言語-
awkはテキストの検索や抽出・加工などの編集操作を行うためのコマンドです。awkコマンドの形式
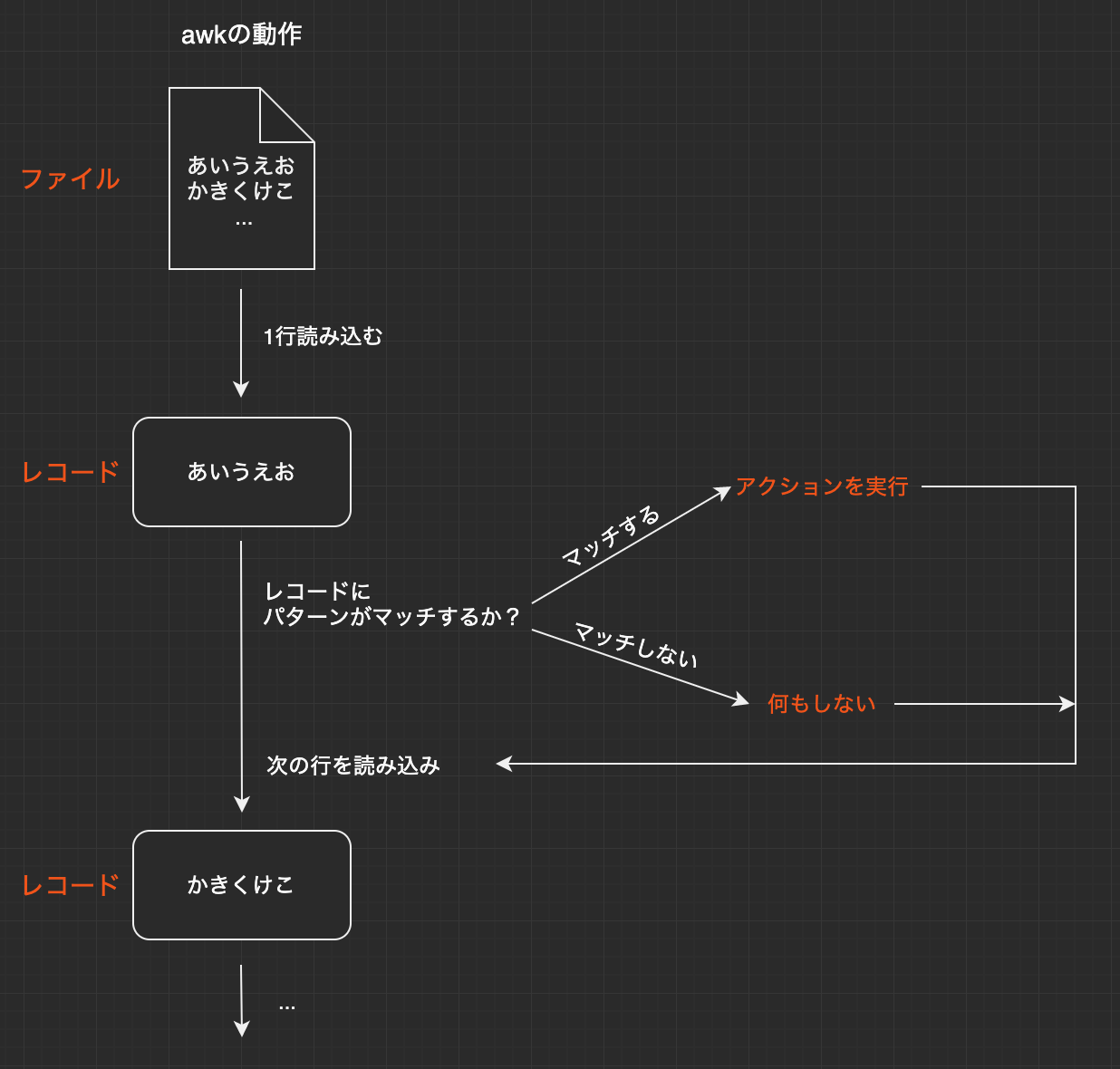
awkコマンドはスクリプトが、パターンとオプションから構成されます。awkコマンド$ awk 'パターン {アクション}' ファイル
構成要素 意味 パターン アクションを実行するか否かの条件を記述します。この条件は対象のテキストを1行読み込むごとに判定されます。パターンを省略した場合には、全てのレコードに対してアクションが実行されます。(レコード : 処理中に読み込んでいく1行テキストのこと) アクション テキストの抽出や置換、削除などの実際のテキスト編集処理を記述します。パターンにマッチした場合にのみアクションが実行されます。
awkコマンドの動作の流れを図で示します。
printとフィールド変数
awkで頻繁に使われる機能の1つに、
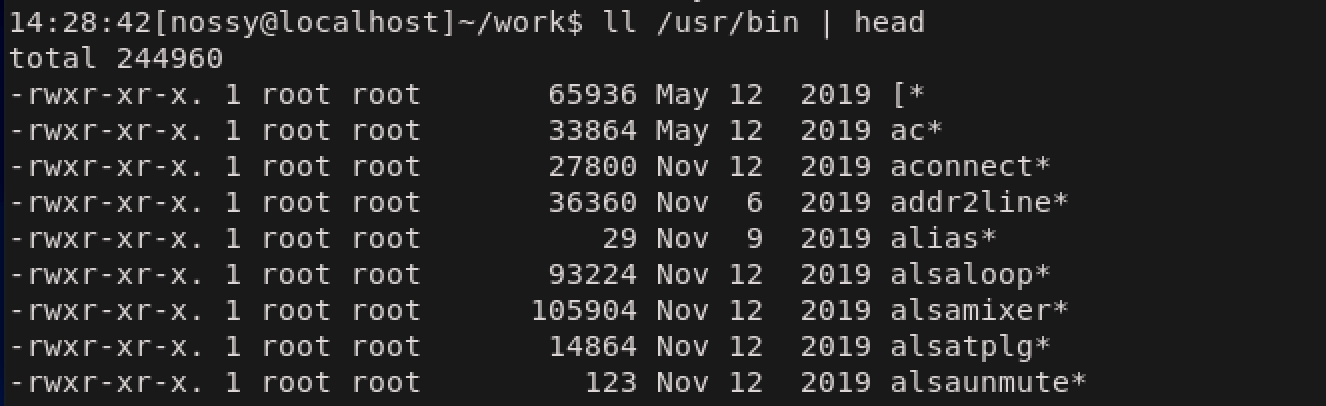
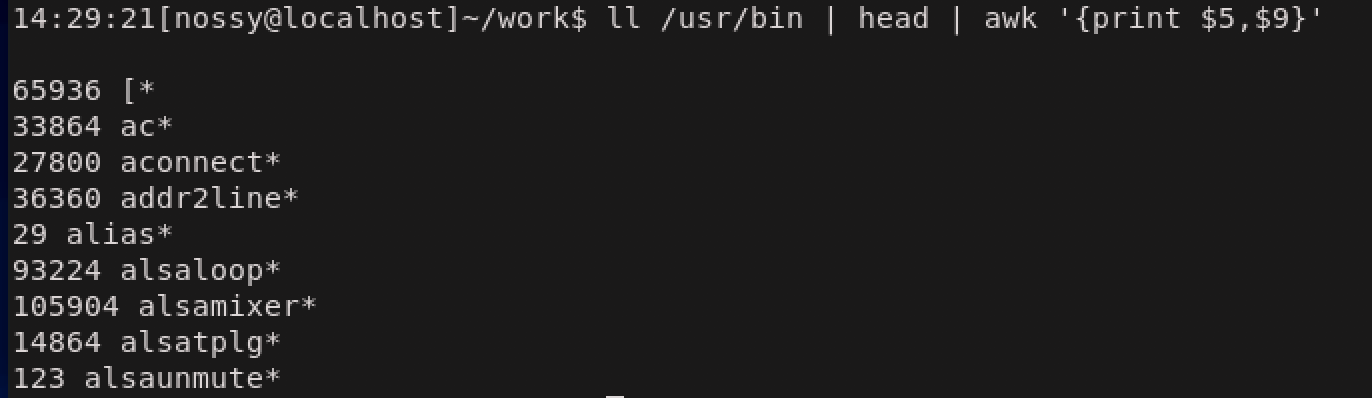
特定のフィールドを抽出して表示するという列選択があります。ここでは/usr/binディレクトリを対象として実行したls -lコマンドの実行結果のファイル名だけを表示するとうケースを紹介します。今回アクションには
出力結果が大量なので、headコマンドで10行に絞っています。
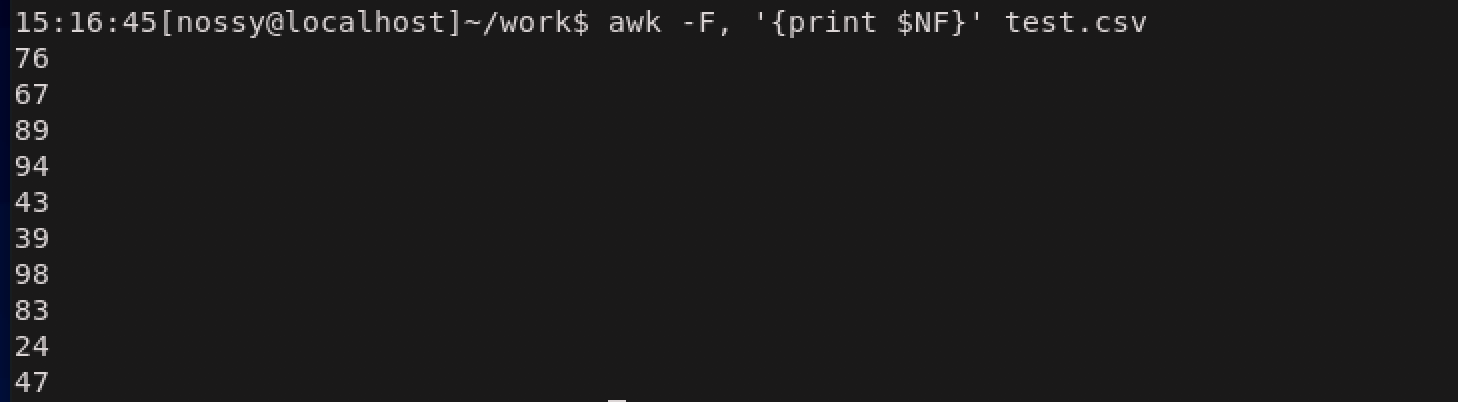
目的のファイル名とファイルサイズを取り出すには、フィールド番号5と9を取り出せばいいことがわかります。この例ではパターンを省略しているため、対象は全レコードです。$5や$9はフィールド変数と呼ばれるものです。
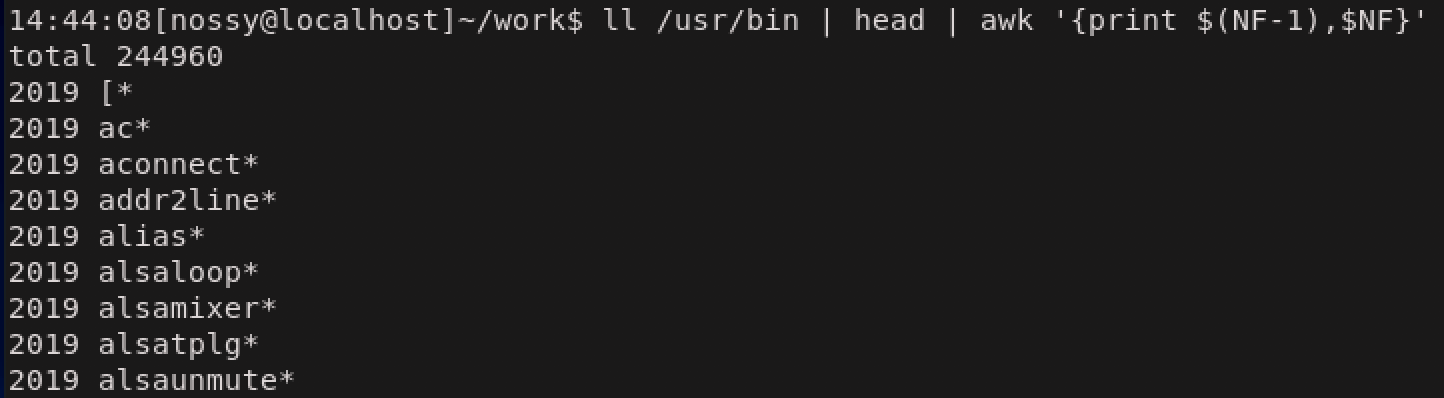
awkは各レコードを自動的にフィールドに分割して、それぞれのフィールドを$1などのフィールド変数に代入します。フィールド分割の際にはスペースまたはタブが区切り文字としてみなされます。また、レコード全体は$0というフィールド変数で表されます。フィールド変数と合わせて、
組み込み変数NFの使い方を紹介します。$NFをprintするとレコードの最後のフィールドが表示されます。先ほどの例だと、\$9が$NFに相当します。また、awkではアクション内で演算が使えるので$(NF-1)などの指定が利用できます。
パターンの指定
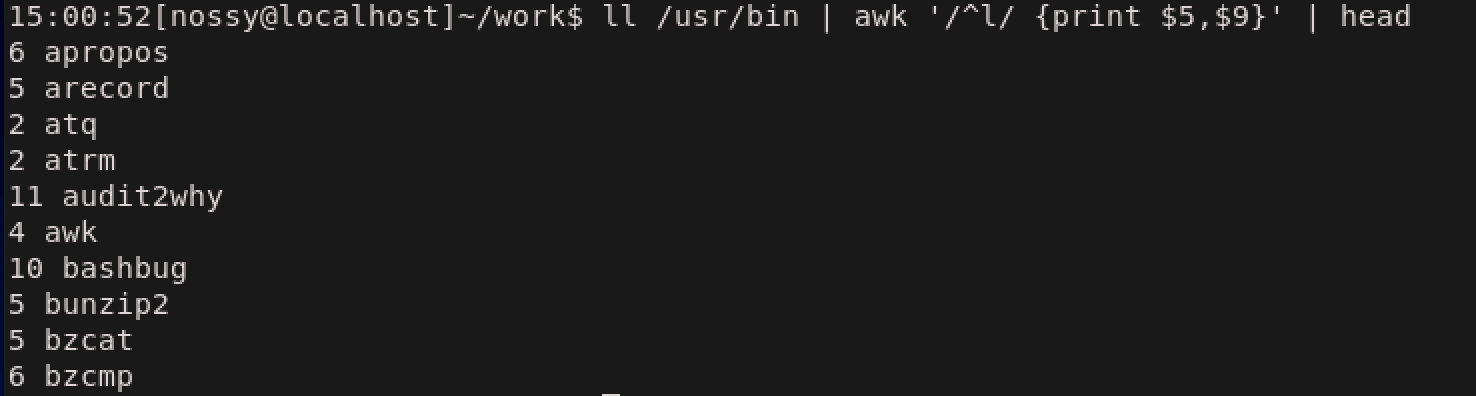
次はパターンの指定の例として、行頭がcpで始まる文字列という条件をつけてみましょう。文字列のパターンを設定するには正規表現を用いますが、awkでは自動的に
拡張正規表現として解釈されます。awkで正規表現のパターンを指定するには、
/(スラッシュ)で囲んで記述します。各フィールドに対して、正規表現がマッチするか否かを調べるには、~(チルダ)を使用して、次のように比較します。この例では\$9に対応するフィールドで/^cp/にマッチする文字列がいるかどうかを調べています。
正規表現を用いるときに、比較対象を省略することがあります。この時は、レコード全体が対象になります。次の例では、llの表示の行頭にlがきているファイル、すなわちシンボリックリンクを表示しています。
アクションの省略
アクションを省略する場合は、レコードが表示されます。つまりアクションは
{print $0}を実行します。
以下の3つは全て同じ意味になるので覚えておきましょう。awkコマンドのアクション短縮$ awk '$9 ~ /^cp/' #アクションを省略 $ awk '$9 ~ /^cp/ {print}' #アクションの引数を省略 $ awk '$9 ~ /^cp/ {print $0}' #省略していないawkコマンドの実践例
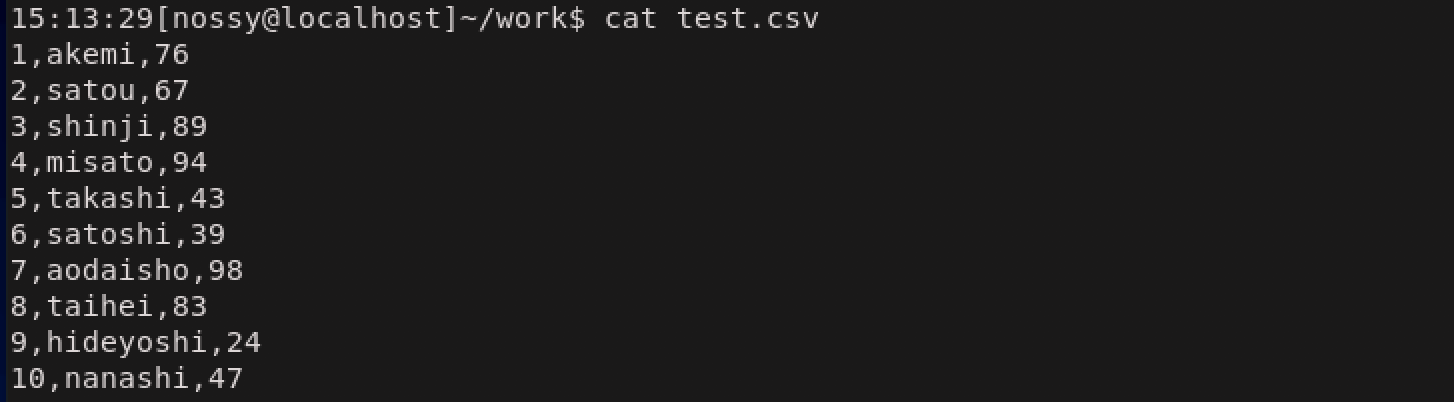
ここでは次のような番号、名前、点数が記述されたcsvファイルを考えます。目的は、点数の平均点の計算です。
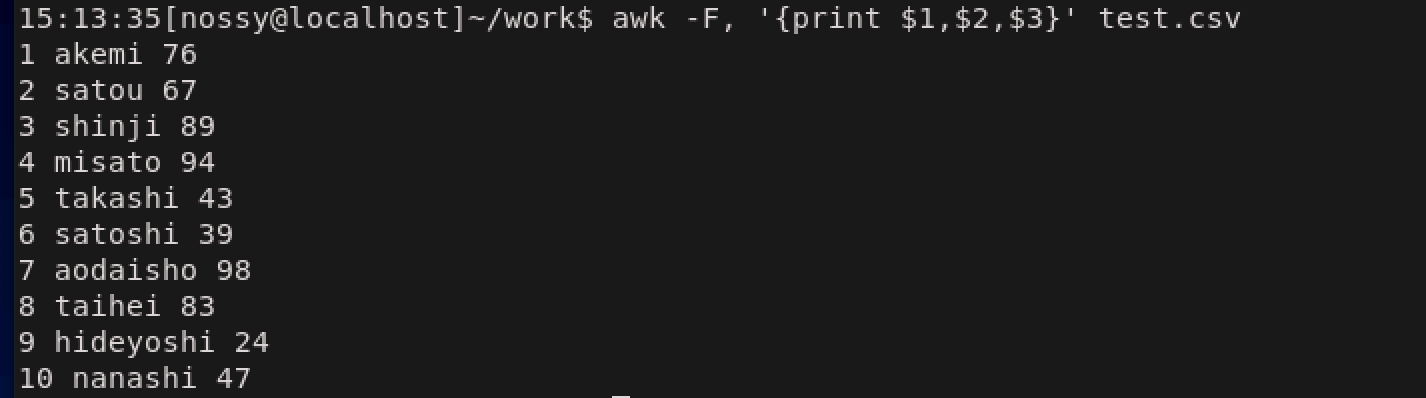
まずは、,(カンマ)区切りではフィールドの分割ができないので、フィールドの区切り文字を,(カンマ)に指定します。区切り文字の指定は-Fオプションを指定して、-F,と書きます。
次に点数を取り出します。点数はフィールド変数でいうと$3あるいは$NFで指定できます。
次に点数の合計点を求めます。sumという変数を用意して、次のように記述します。
上の図について補足説明をします。
- 今回はsumという変数を用意しました。awkでは変数は宣言や初期化をせずに使用することができます。
数値として扱えば数値は0となっています。- ENDは
ENDパターンと呼ばれる特殊なパターンです。ENDブロック内のアクションは、全ての入力ファイルを処理し終えてから最後に実行されます。今回はレコードの点数の足算を全て終えてから、最後に総和を表示するという動作をします。最後に点数の総和を人数で割り算して、平均点を出しましょう。
入力ファイルの行数は組み込み変数NRで取得できます。NRとは、これまでに読み込んだ入力レコード数が代入されている組み込み変数なので、今回の場合はENDブロック内では、ファイルの行数と一致しているわけです。
せっかく平均点を出すスクリプトを作ったので、保存して、再利用しましょう。-fオプションでスクリプトファイルを読み込みます。
参考資料










- 投稿日:2020-05-30T11:33:48+09:00
便利なコマンドのくみあわせ
~/.bashrcの便利な設定
個人的にお気に入りな設定
cdしたら、絶対パスとディレクトリの中身を表示
cdpwdlscdpwdls () { \cd $@ && pwd -P && ls } alias cd='cdpwdls'head か tailしたら、lessで表示
hlesshless () { \head $@ | less }tlesstless () { \tail $@ | less }モデルが落ちてSYSOUTをみたいとき、SYSOUT*がたくさんあるしファイルサイズ大きいし面倒だなあと思うんですが、
tless SYSOUT*
って打つと全部一気にtailしてlessしてくれます。便利!
- 投稿日:2020-05-30T11:16:02+09:00
【Linux】root権限がない。でもyum installしたい。
対象読者
・Linuxを触り始めた初心者
・それなりに触ったことはあるがSudoを奪われた組織メンバ結論
無理です。
yum installはsudo権限がないと動きません。サーバ管理者に問い合わせて必要モジュールをインストールすることを強くおすすめします。$ sudo yum install gcc #=> "username" is not in the sudoers file.しかし、気を落とさないでください。yumを使わなくとも、同じような結果を得ることができる方法はあります。
始めに:Yum installとは何か。
Linuxにソフトウェアやライブラリをインストールする際、
- 「インストールする場所」(パス)を決めてくれる
- 「インストールに必要なほかの部品」を収集して(依存関係の解決)くれる
などのパッケージ管理という仕事をします。これを自分でやろうとすると、インターネットで該当ソフトウェアがあるページを訪れて、
ソフトウェア名.tar.gzのあるURLを直接指定して、展開して、インストールファイルをprefix付きで実行して…
しかもいざ動かしてみると、「このパッケージをインストールして下さい」「このパッケージのバージョンが非対応です」と言われる始末。この面倒な作業を、「〇〇やってきて」の指示でほとんど完璧な状態で持ってきてくれる
yum installを実行するには、root権限が必要です。rootを失って初めて重要さに気づきます。この記事にたどり着いているということは、今あなたもそんな状態なのでは。linuxbrewをインストール
yum は普通ルートディレクトリ直下にあるフォルダにソフトウェアをインストールします。たとえば/usr/bin には普通最初から「パスが通って」いて、コマンドでインストールされたソフトウェアを更新することが可能です。
lsコマンドもcdコマンドも、全て「パスが通って」いないと実行できません。$ whereis ls #=> ls: /usr/bin/lsルート権限への書き込み権限(
sudo)が無いのなら、各種パッケージを自分のホームディレクトリ(/home/username/,または~/,または$HOME)にインストールしてしまえばいい。という思想から生まれたのがHomebrewであり、Linuxbrewです。但し、このLinuxbrew自体にも依存関係があり、いくつかのライブラリは事前にroot権限を持つユーザでインストールする必要があります。頭を抱える前に、管理者に事態を伝え、早急な解決を目指しましょう。(そもそもこれができたら苦労しない感が否めない…。)
依存関係のインストール
sudo yum groupinstall 'Development Tools' sudo yum install curl file git sudo yum install libxcrypt-compat # needed by Fedora 30 and upLinuxbrewインストール
$ git clone https://github.com/Homebrew/brew ~/.linuxbrew/Homebrew $ mkdir ~/.linuxbrew/bin $ ln -s ~/.linuxbrew/Homebrew/bin/brew ~/.linuxbrew/bin $ eval $(~/.linuxbrew/bin/brew shellenv)注意点
・Linuxbrewが対応していないライブラリもあります。
・最初の依存関係さえ解決してしまえば、あとはroot領域であるディレクトリなどに影響を及ぼすことなくインストール・実行が可能です。
- 投稿日:2020-05-30T07:36:28+09:00
WSL2によるホストのメモリ枯渇を防ぐための暫定対処
5/27にWindows 10 2004 Updateが正式リリースされて、それに伴いWSL2もWindows Insider Preview版を使用しなくても利用可能となりました
しかしWSL2を使用してるとVmmemというプロセスのメモリ使用量が増加し続けて、Windowsホストのメモリが枯渇してしまう問題があります。そしてこの問題は正式リリース後も解消されず残っています。
NOTE: Windowsホストで動いているVmmemプロセスで「WSL2のHypver-V仮想マシン全体が消費&確保しているCPUとメモリ」を確認できるという大雑把な理解でOKです。
microsoft/WSLのIssueは1年近くOpenのままとなっており、Microsoft側も問題を認識して取り組んでいるものの未だに根本対処されていません。
https://github.com/microsoft/WSL/issues/4166
結論: 暫定対処でメモリサイズを固定する
WSL2のメモリサイズを固定することでWindowsホストのメモリ枯渇を防ぎます。
原因について興味がある人は後述しているのでそちらを参照してください。
%USERPROFILE%\.wslconfigのコンフィグに以下の設定を行います。
%USERPROFILE%はC:\Users\taroのようなホームディレクトリを指します。- コンフィグが存在しない場合は作成してください。
- 設定した後はWSL2を再起動するか、OSを再起動してください。
[wsl2] memory=6GB swap=0
memoryにはWSL2が最大確保するメモリサイズを指定します。PCの搭載メモリとWSL2の使用用途に応じてメモリサイズの値は変更してください。- (個人的に推奨)
swapを0に設定してスワップを無効にします。
- スワップを無効にするとWSL2側で実際にメモリ不足になった途端に変な挙動を起こすかもしれません。しかしその代わりSSD等で大量のスワップIn/Outの発生を防ぐため、大量書き込みによるSSDの寿命を縮めることは回避できます。トレードオフを意識して設定するかどうかを考えましょう。
メモリサイズの上限を設定しなくてもいい感じに使えるのがWSL2の利点の一つだと考えているので、この暫定対処は心苦しいですが致し方ないところです。早く何らかの形で改善してほしいものです。
何が原因か?
Issueの中では、以下のLinuxとWSL2の特性が相まって問題を引き起こしてることが指摘されてます。
- Linuxでは積極的にファイルアクセス時にファイルキャッシュをメモリ上に配置する(freeコマンドにおけるbuff/cache使用量の増加)。ファイルを削除したり、プロセス等がメモリを確保できなくなるくらいにメモリ不足になるまでは基本的にファイルキャッシュは確保したまま。
- WSL2は仮想マシン上のLinuxのメモリ使用量に応じて、仮想マシンのメモリサイズを動的に増減させる。
- 当然ですが仮想マシンのメモリサイズはLinuxのメモリ使用量よりも多く確保します。
それぞれの特性により、開発等の時の大量のファイル、ライブラリ、DockerイメージなどにアクセスするとLinuxのファイルキャッシュを中心に大量のメモリを確保し、それに合わせてWSL2が仮想マシンのメモリサイズを増加させていきます。WSL2が仮想マシンのメモリサイズを増加させるため、Linuxでは「まだメモリに余裕がある」と判断してファイルキャッシュをさらにため込んでという悪循環を引き起こします。
これによってメモリ16GB搭載のPCはもちろんメモリ32GB搭載のPCでも比較的簡単にWindowsホストのメモリが枯渇することになります。
以下はWSL2のメモリサイズを6GB固定にした環境でのVmmemおよびLinuxのメモリ使用量です。Linuxのメモリ使用量はfreeコマンドの結果で確認しています。大まかな目安として参考にしてください。
# - Vmmemメモリ使用量=3.5GBの時のWSL2のLinxuメモリ使用量 # - Linuxメモリ使用量=3.1GB(内、buff/cache使用量が2.6GB) $ free -h total used free shared buff/cache available Mem: 5.8G 479M 2.7G 1.2M 2.6G 5.1G # - Vmmemメモリ使用量=1.7GB # - Linuxメモリ使用量=0.6GB(内、buff/cache使用量が183MB) $ free -h total used free shared buff/cache total used free shared buff/cache available Mem: 5.8G 457M 5.2G 1.2M 183M 5.2G本問題が起きやすいユースケース
以下のユースケースではホストのメモリ枯渇が発生しやすいです。特にこれらのユースケースが組み合わさると本問題はより発生しやすくなります。
- Visual Studio Code + Remote Extension(WSL)を使用してる
- Docker Desktop WSL2を使用してる
- 大きなコードベースで開発してる
上記の組み合わせが「Windows上でのUnix/Linux環境開発」の主流の一つになる可能性が高いですが、その組み合わせが本問題を引き起こしやすいというのは皮肉なものです。
その他の暫定対処方法
WSL2のメモリサイズを固定しない暫定対処について紹介します。
いずれも手動で実行する必要があり、自動運用するためには何らかの工夫が必要となるため積極的にはお勧めしません。キャッシュをドロップ
基本的にメモリサイズ固定が最も効果的ですが、メモリサイズを可変のままにしたい場合は定期的にLinuxのキャッシュをドロップすることである程度は症状を抑えることもできます。
sudo sh -c "echo 3 >'/proc/sys/vm/drop_caches' && swapoff -a && swapon -a"ただし、WSL2ではsystemdやcronなどが稼働していないため、そのあたりの準備が必要なことを考えるとメモリサイズ固定が一番手軽です。
WSL2を再起動
以下のURLの情報を参考にWSL2を一度再起動すれば、WSL2の仮想マシンがファイルキャッシュ等がクリアされた状態で立ち上がります。
ちなみにWSLの再起動などの操作についてはWSL1もWSL2も基本的に同じです。
参考URL
WSL2やLinuxのメモリ管理などについて少し踏み込みたい人向けの参考URLが中心です。
(コメント欄でいただいたものも追記してます)
- 本問題のIssue
- 現在の活発にコメントが飛び交っており、今後も関連するPull Request、新しい暫定対処のやりとりが行われると思います。
- Windows Subsystem for Linux 2のメモリ管理を詳しく見る
- Linuxのファイルキャッシュ周りには触れてませんが、WSL2とVmmemのメモリ管理について検証を含めた情報が載ってます。
- いまさら聞けないLinuxとメモリの基礎&vmstatの詳しい使い方
- ファイルキャッシュ等を含むLinuxのメモリ周りの基礎。
- 減り続けるメモリ残量! 果たしてその原因は!?
- こちらもファイルキャッシュ等を含むLinuxのメモリ周りの基礎。図がやや豊富で見やすいため、よりイメージしやすいかもしれません。