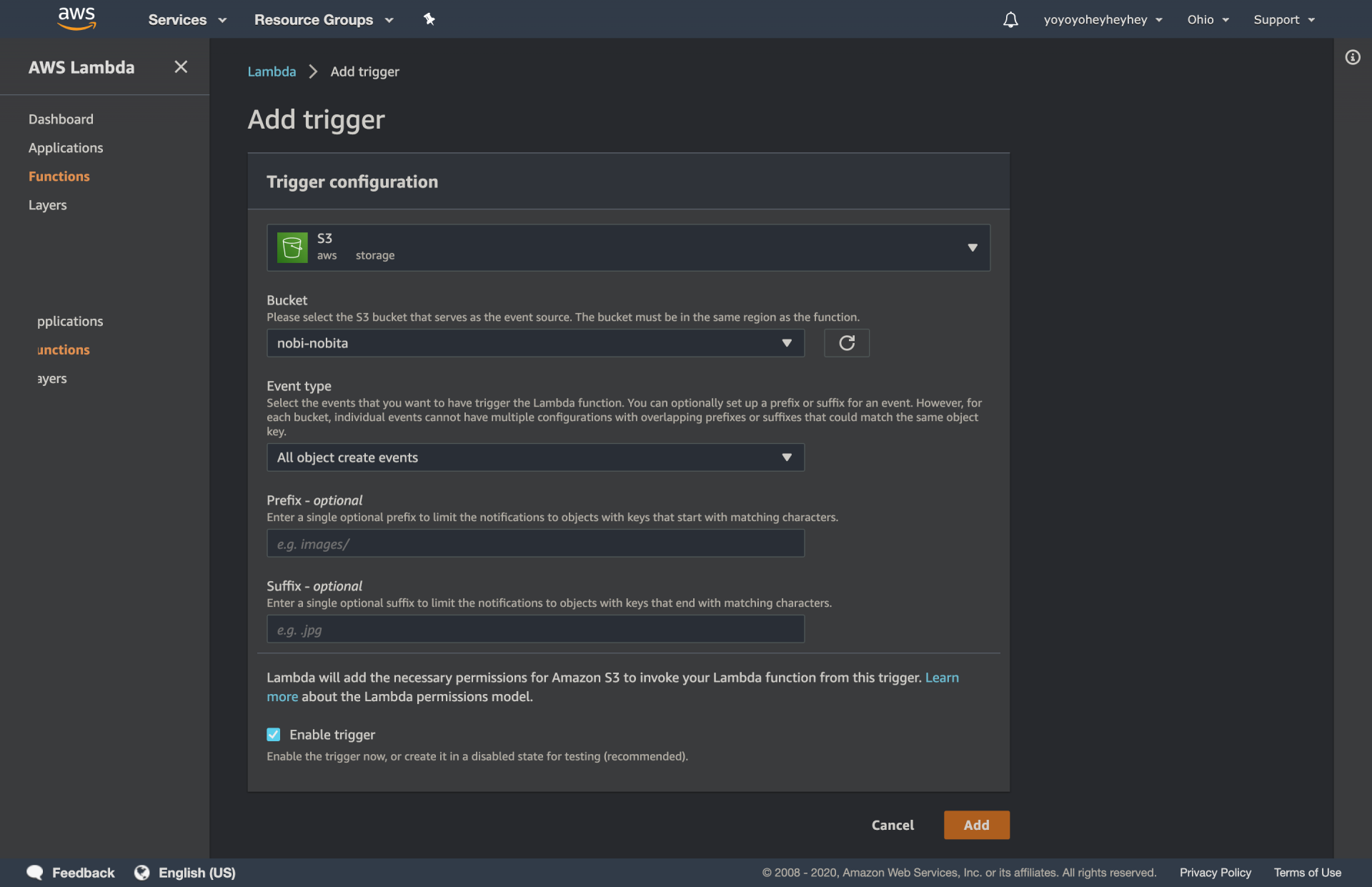
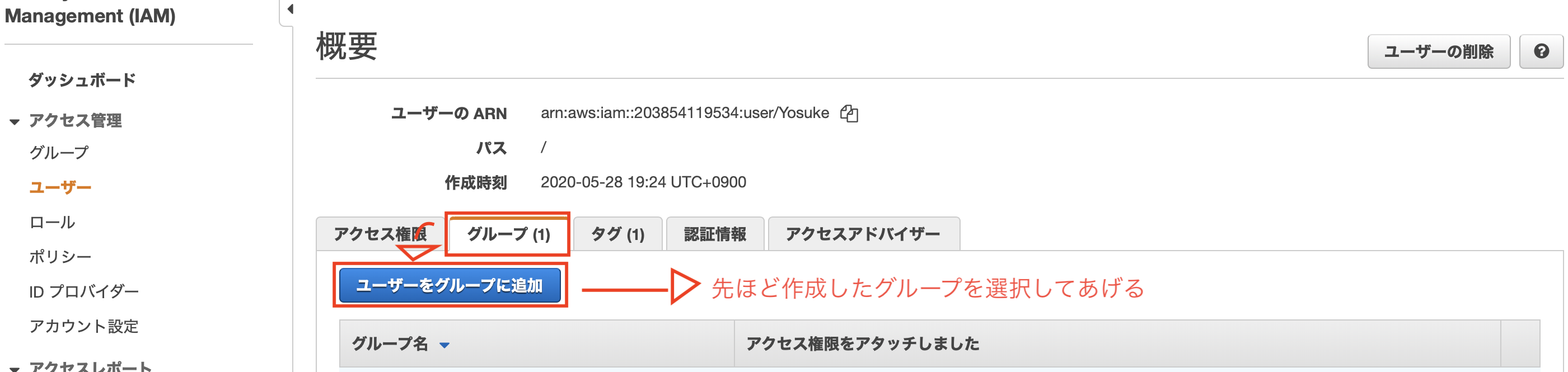
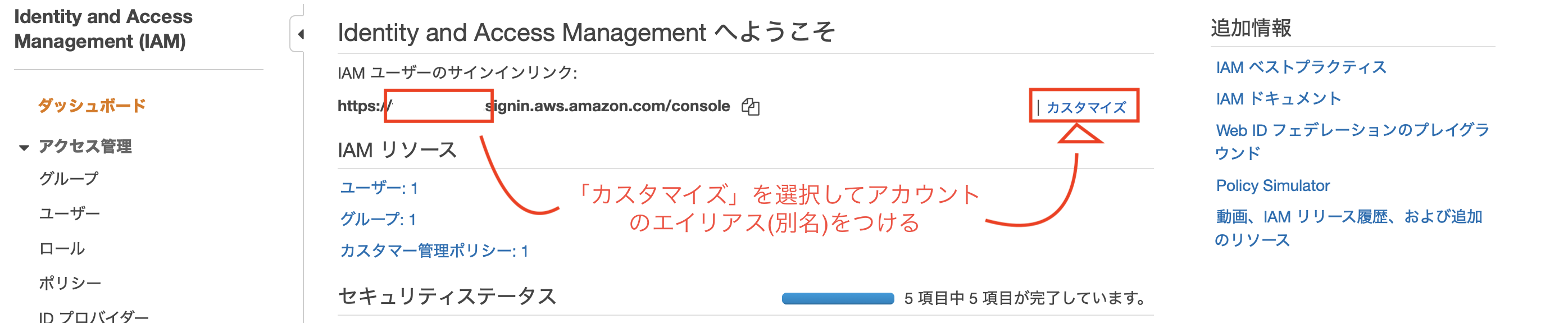
[AWS]苦労したエラー:Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'
状況
AWS(EC2)で、railsサーバーを立ち上げるため
DBを新規作成したい。
しかし、実行すると下記のエラーが、、、
サーバー
[ec2-user@ip-●●● <リポジトリ名>]$ rails db:create RAILS_ENV=production
Mysql2::Error::ConnectionError: Access denied for user ''@'localhost' to database '<リポジトリ名>_production': CREATE DATABASE `<リポジトリ名>_production` DEFAULT CHARACTER SET `utf8`
Couldn't create '<リポジトリ名>_production' database. Please check your configuration.
rails aborted!
ActiveRecord::StatementInvalid: Mysql2::Error::ConnectionError: Access denied for user ''@'localhost' to database '<リポジトリ名>_production': CREATE DATABASE `<リポジトリ名>_production` DEFAULT CHARACTER SET `utf8`
/var/www/<リポジトリ名>/bin/rails:9:in `<top (required)>'
/var/www/<リポジトリ名>/bin/spring:15:in `<top (required)>'
bin/rails:3:in `load'
bin/rails:3:in `<main>'
Caused by:
Mysql2::Error::ConnectionError: Access denied for user ''@'localhost' to database '<リポジトリ名>_production'
/var/www/<リポジトリ名>/bin/rails:9:in `<top (required)>'
/var/www/<リポジトリ名>/bin/spring:15:in `<top (required)>'
bin/rails:3:in `load'
bin/rails:3:in `<main>'
Tasks: TOP => db:create
(See full trace by running task with --trace)
Usage:
rails new APP_PATH [options]
Options:
[--skip-namespace], [--no-skip-namespace] # Skip namespace (affects only isolated applications)
-r, [--ruby=PATH] # Path to the Ruby binary of your choice
# Default: /home/ec2-user/.rbenv/versions/2.5.1/bin/ruby
-m, [--template=TEMPLATE] # Path to some application template (can be a filesystem path or URL)
-d, [--database=DATABASE] # Preconfigure for selected database (options: mysql/postgresql/sqlite3/oracle/frontbase/ibm_db/sqlserver/jdbcmysql/jdbcsqlite3/jdbcpostgresql/jdbc)
# Default: sqlite3
[--skip-yarn], [--no-skip-yarn] # Don't use Yarn for managing JavaScript dependencies
[--skip-gemfile], [--no-skip-gemfile] # Don't create a Gemfile
-G, [--skip-git], [--no-skip-git] # Skip .gitignore file
[--skip-keeps], [--no-skip-keeps] # Skip source control .keep files
-M, [--skip-action-mailer], [--no-skip-action-mailer] # Skip Action Mailer files
-O, [--skip-active-record], [--no-skip-active-record] # Skip Active Record files
[--skip-active-storage], [--no-skip-active-storage] # Skip Active Storage files
-P, [--skip-puma], [--no-skip-puma] # Skip Puma related files
-C, [--skip-action-cable], [--no-skip-action-cable] # Skip Action Cable files
-S, [--skip-sprockets], [--no-skip-sprockets] # Skip Sprockets files
[--skip-spring], [--no-skip-spring] # Don't install Spring application preloader
[--skip-listen], [--no-skip-listen] # Don't generate configuration that depends on the listen gem
[--skip-coffee], [--no-skip-coffee] # Don't use CoffeeScript
-J, [--skip-javascript], [--no-skip-javascript] # Skip JavaScript files
[--skip-turbolinks], [--no-skip-turbolinks] # Skip turbolinks gem
-T, [--skip-test], [--no-skip-test] # Skip test files
[--skip-system-test], [--no-skip-system-test] # Skip system test files
[--skip-bootsnap], [--no-skip-bootsnap] # Skip bootsnap gem
[--dev], [--no-dev] # Setup the application with Gemfile pointing to your Rails checkout
[--edge], [--no-edge] # Setup the application with Gemfile pointing to Rails repository
[--rc=RC] # Path to file containing extra configuration options for rails command
[--no-rc], [--no-no-rc] # Skip loading of extra configuration options from .railsrc file
[--api], [--no-api] # Preconfigure smaller stack for API only apps
-B, [--skip-bundle], [--no-skip-bundle] # Don't run bundle install
[--webpack=WEBPACK] # Preconfigure for app-like JavaScript with Webpack (options: react/vue/angular/elm/stimulus)
Runtime options:
-f, [--force] # Overwrite files that already exist
-p, [--pretend], [--no-pretend] # Run but do not make any changes
-q, [--quiet], [--no-quiet] # Suppress status output
-s, [--skip], [--no-skip] # Skip files that already exist
Rails options:
-h, [--help], [--no-help] # Show this help message and quit
-v, [--version], [--no-version] # Show Rails version number and quit
Description:
The 'rails new' command creates a new Rails application with a default
directory structure and configuration at the path you specify.
You can specify extra command-line arguments to be used every time
'rails new' runs in the .railsrc configuration file in your home directory.
Note that the arguments specified in the .railsrc file don't affect the
defaults values shown above in this help message.
Example:
rails new ~/Code/Ruby/weblog
This generates a skeletal Rails installation in ~/Code/Ruby/weblog.