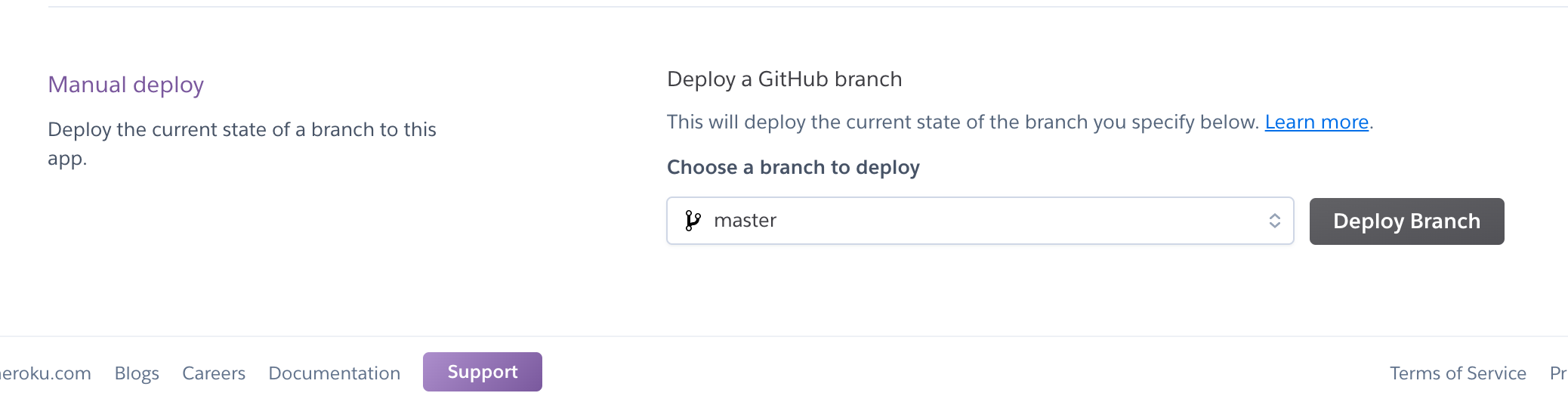
eb create <EBの環境名> --instance_type <EC2のスペック> --database.engine <DBの種類> --database.username <DBusername> --elb-type application --vpc
#例)eb create rails-app --instance_type t2.medium --database.engine mysql --database.username admin --elb-type application --vpc
Enter an RDS DB master password:
Retype password to confirm:
Enter the VPC ID: <作成したVPCのID>
Do you want to associate a public IP address? (Y/n): <Enter>
Enter a comma-separated list of Amazon EC2 subnets: <作成した2つのSubnetのID>
Enter a comma-separated list of Amazon ELB subnets: <作成した2つのSubnetのID>
Do you want the load balancer to be public? (Select no for internal) (Y/n):
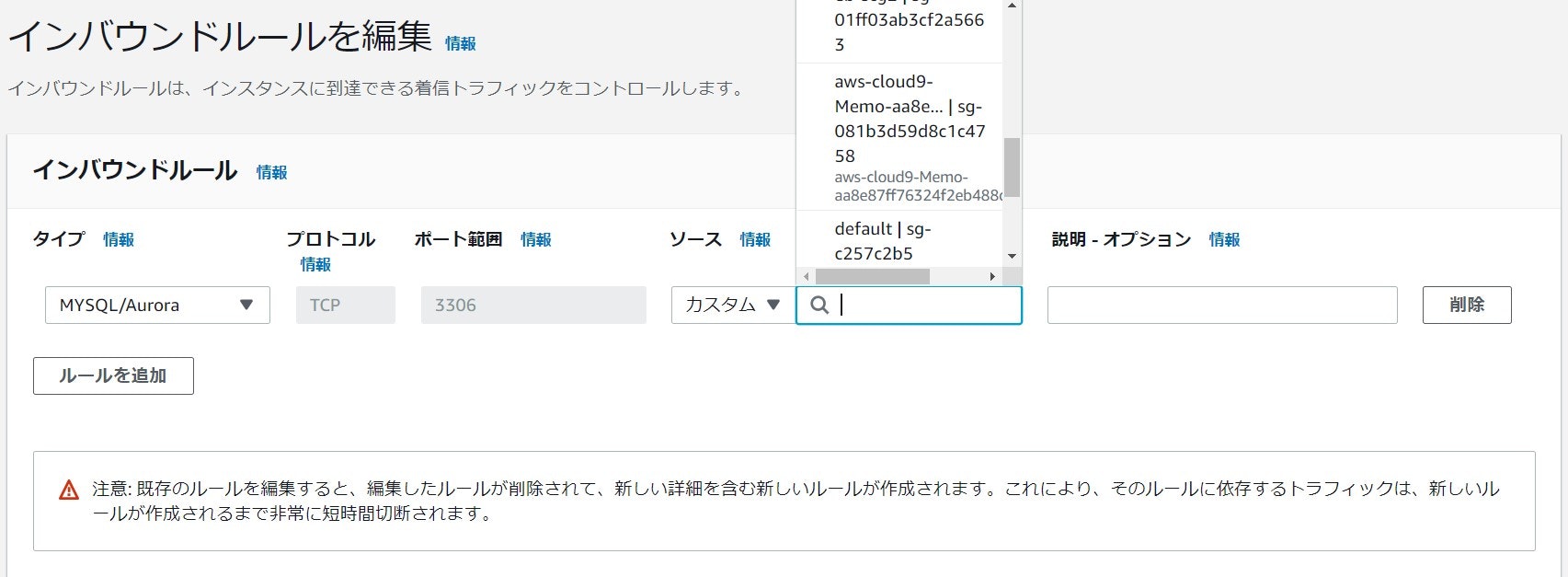
Enter a comma-separated list of Amazon VPC security groups:<作成した2つのセキュリティグループのID>
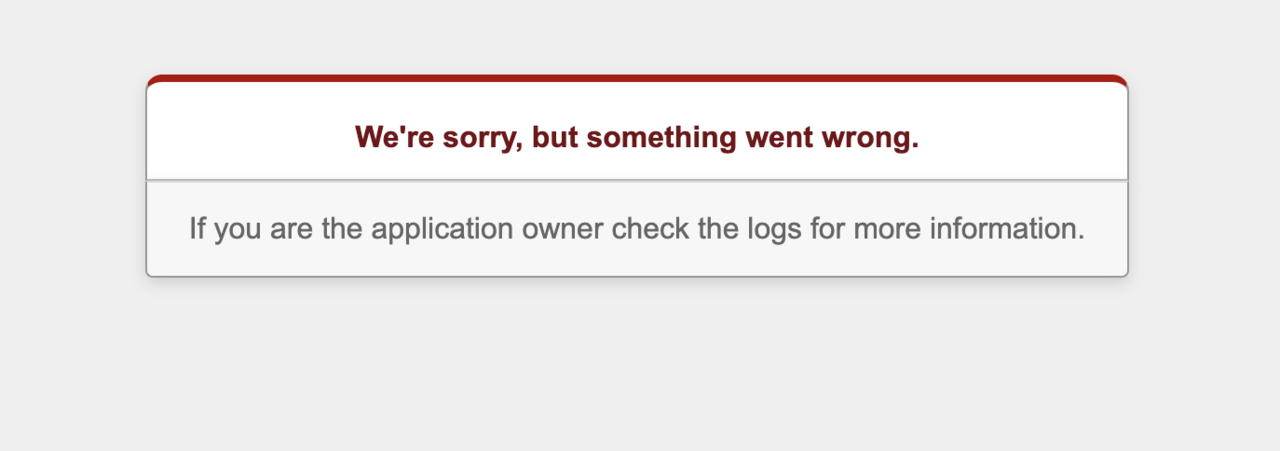
An unhandled lowlevel error occurred. The application logs may have details.
という表示がでました。これはRubyで本番環境時のシークレットキーを作成、設定していないためおきます。
ということで、ここにRubyの本番環境設定をしていきましょう。
CREATE TABLE IF NOT EXISTS "posts" ("id" integer PRIMARY KEY AUTOINCREMENT NOT NULL, "content" varchar, "string" varchar, "created_at" datetime NOT NULL, "updated_at" datetime NOT NULL);
投稿を作成
new.html.erbファイルに、投稿を作成するコードを追加しましょう。
new.html.erb
<%= form_tag("/posts/create") do %>
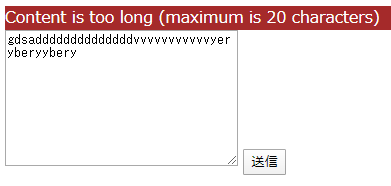
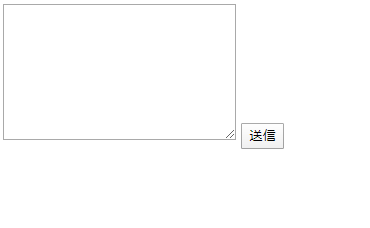
<textarea name="content" cols="30" rows="10"></textarea>
<input type="submit" value="送信">
<% end %>
def create
post = Post.new(content: params[:content])
@content = params[:content]
if post.save
redirect_to("/posts/all")
else
render("posts/new")
end
end
# コード例は適当です
class User
def admin?
res = set_complex_config
case res
when 'hoge'
'hoge'
when 'fuga'
'fuga'
end
end
def set_complex_config
# 複雑な処理
end
end