- 投稿日:2020-05-24T22:10:03+09:00
Javaのクラスの使い方や定義、import
他クラスのメソッドの呼び出し
クラス名.メソッド名()とすることで、クラスのメソッドを呼び出せます。
【例】Main.javaclass Main { public static void main(String[] args) { Person.hello(); //Personがクラス名でhelloがメソッドです } }Person.javaclass Person { //Personがクラス名です public static void hello() { //helloがメソッドです System.out.println("おはよう"); } }上記のようにMain.javaのPerson.hello();でPerson.javaのPersonをクラスを呼び出します。
ちなみに、クラスの定義は「class クラス名」となります。
クラス名の最初の文字は大文字にし、ファイル名は「クラス名.java」に必ずします。
【例2】Main.javapublic class Main { public static void main(String[] args) { Person.nameData(Person.fullName("佐藤", "太郎"), 20); //Personがクラス名でnameDataがメソッドです。Person.fullNameも同様です } }Person.javaclass Person { public static void nameData(String name, int age) { //nameDataがメソッドです System.out.println("私の名前は" + name + "で" + "年齢は" + age + "歳です"); } public static String fullName(String firstName, String lastName) { return firstName + " " + lastName; } }上記の結果は「私の名前は佐藤太郎で年齢は20歳です」ととなります。
なぜクラスを分けるか
Mainクラスは実行用のクラス、Personクラスはロジック(論理)をまとめる役割分担が明確になるためです。
Javaは、ファイルではなくクラスを実行します。実行時にmainメソッドを持つクラスしか実行できません(mainメソッドのないクラスは、他のクラスから呼び出して使います)。
またクラス名に関係なく、実行時にはmainメソッドが呼ばれます(Mainクラスだからmainメソッドが呼ばれるわけではありません)。外部ライブラリ
他人が作ったクラスを利用することです。このようなクラスを外部ライブラリと呼び、自分のプログラムに読み込むことで利用できるようになります。
外部ライブラリを自分のプログラムに使えるようにするには、importを使います。
class定義より上で「import java.lang.Math」とします。
Mathクラスのメソッドは、数学的なメソッドの意味をもちます。
【例】Main.javaimport java.lang.Math; class Main { public static void main(String[] args) { int max = Math.max(3, 5); //Mathは外部から読み込んでいるクラスです System.out.println("最大数字は" + max); } }上記の場合maxメソッド(引数に渡した2つの数値の大きい方を返してくれるメソッド)を使っているので、結果は数字が大きい「最大数字は5」となります。
他にも引数の小数点以下を四捨五入して返すroundメソッドなどがあります。importしなくても使える
先ほど、import java.lang.Math;を使いましたが、importしなくても自動で読み込まれます。
他にも、「java.lang.クラス名」となる外部ライブラリはすべて自動で読み込まれます。
- 投稿日:2020-05-24T22:10:03+09:00
Javaのクラスの使い方や定義
他クラスのメソッドの呼び出し
クラス名.メソッド名()とすることで、クラスのメソッドを呼び出せます。
【例】Main.javaclass Main { public static void main(String[] args) { Person.hello(); //Personがクラス名でhelloがメソッドです } }Person.javaclass Person { //Personがクラス名です public static void hello() { //helloがメソッドです System.out.println("おはよう"); } }上記のようにMain.javaのPerson.hello();でPerson.javaのPersonをクラスを呼び出します。
ちなみに、クラスの定義は「class クラス名」となります。
クラス名の最初の文字は大文字にし、ファイル名は「クラス名.java」に必ずします。
【例2】Main.javapublic class Main { public static void main(String[] args) { Person.nameData(Person.fullName("佐藤", "太郎"), 20); //Personがクラス名でnameDataがメソッドです。Person.fullNameも同様です } }Person.javaclass Person { public static void nameData(String name, int age) { //nameDataがメソッドです System.out.println("私の名前は" + name + "で" + "年齢は" + age + "歳です"); } public static String fullName(String firstName, String lastName) { return firstName + " " + lastName; } }上記の結果は「私の名前は佐藤太郎で年齢は20歳です」ととなります。
なぜクラスを分けるか
Mainクラスは実行用のクラス、Personクラスはロジック(論理)をまとめる役割分担が明確になるためです。
Javaは、ファイルではなくクラスを実行します。実行時にmainメソッドを持つクラスしか実行できません(mainメソッドのないクラスは、他のクラスから呼び出して使います)。
またクラス名に関係なく、実行時にはmainメソッドが呼ばれます(Mainクラスだからmainメソッドが呼ばれるわけではありません)。外部ライブラリ
他人が作ったクラスを利用することです。このようなクラスを外部ライブラリと呼び、自分のプログラムに読み込むことで利用できるようになります。
外部ライブラリを自分のプログラムに使えるようにするには、importを使います。
class定義より上で「import java.lang.Math」とします。
Mathクラスのメソッドは、数学的なメソッドの意味をもちます。
【例】Main.javaimport java.lang.Math; class Main { public static void main(String[] args) { int max = Math.max(3, 5); //Mathは外部から読み込んでいるクラスです System.out.println("最大数字は" + max); } }上記の場合maxメソッド(引数に渡した2つの数値の大きい方を返してくれるメソッド)を使っているので、結果は数字が大きい「最大数字は5」となります。
他にも引数の小数点以下を四捨五入して返すroundメソッドなどがあります。
- 投稿日:2020-05-24T22:01:37+09:00
Java volatileを使用した際の性能影響について検証
概要
volatileを使用した際の性能影響について検証したメモページ。
volatileとは
フィールドに付ける修飾子。
マルチスレッドのプログラムの場合に、スレッドがフィールドの値をキャッシュする可能性がある。
volatileを付けると、キャッシュの対象外にすることができる。
(本ページではvolatileの役割についての詳細は割愛。)性能検証
性能検証に使用した環境
マシンスペック
CPU:Intel(R) Core(TM) i5-2400S CPU
RAM:8GB
OS:windows10 64ビット実行環境
Eclipse(2020-03 (4.15.0))
Java8volatileを使用した場合の性能
volatileを付与した状態で、int型のフィールドを1億回カウントアップする処理の時間を計測。
private volatile int cnt = 0; private long exe() { long start = System.currentTimeMillis(); for (int i = 0; i < 100000000; i++) { this.cnt++; } long end = System.currentTimeMillis(); return end - start; }上記のコードでの計測を10回実施し、平均値を取得。
結果
平均値:964msvolatileを使用しない場合の性能
上記のコードから、フィールドをvolatileを使用しない形に変更。
private int cnt = 0;同様に計測を10回実施し、平均値を取得。
結果
平均値:7msまとめ
volatileを使用した場合のほうが性能が悪くなるが、1億回カウントアップで上記程度の時間であるため、ほとんどの場合は影響なさそう。
- 投稿日:2020-05-24T21:49:51+09:00
Spring Boot で簡単RESTful APIを作成する
目的
RESTってなんだかお堅いイメージ?があるかもしれませんが、実のところシンプルで使いやすいインタフェースだと思います。
実際、WebAPIではよく使われていますね。利用することは多いけど作るのはなんだか大変そう。。でも実は、アプリケーションフレームワークを使用するとこういうデザインパターン系はとても楽に造れたりします。そこで、ここではSpring Boot を使用して簡単にRESTful APIを作成してみたいと思います。インタフェースを作るだけだと使いどころが分かりにくいので、Androidアプリから利用する部分もちょっとだけ載せます。
そもそもRESTって
RESTって技術書なんかでは難しく解説していたりするけど、私の理解ではHTTPサーバーによってリソースを出し入れするインタフェースを提供することだと思っています。
そうするとWebAPIはみんなREST?ってことになりますが、ステートレスでシンプルなリソースであることがRESTの特長。つまりSQLみたいにHTTPのリクエストを使用するってことですね。RESTに出し入れするデータのフォーマットはXMLだったりCSVだったりって場合もあるけど、本来のRESTはJSONで出し入れするもの。そんなわけでJSONを使った正しいRESTインタフェースのことをRESTfulと言うらしい。(詳しくはWikipediaに載ってます^^;)
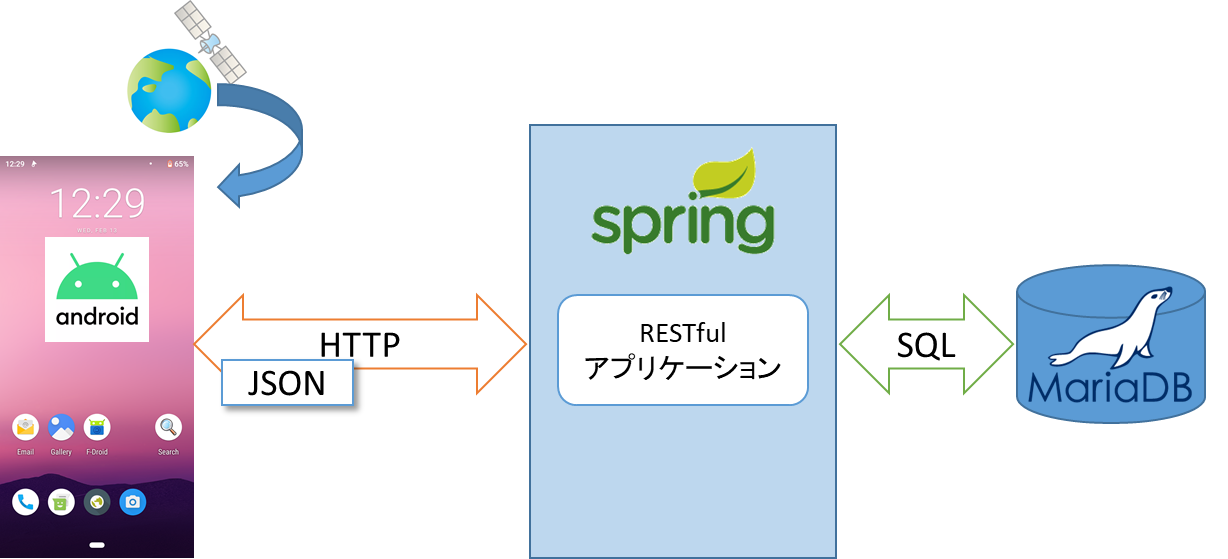
作るもの
先日、Androidのアプリを作る練習としてGPSロガーを作りました。ログデータはAndroid端末のSQLite3を使用して保存しています。
このデータをPCのMariaDBにバックアップしたいのですが、AndroidからPCのMariaDBに直接コネクションを張ることはできません。そこでSpring Bootを使ってRESTfulインタフェースを作成し、AndroidからはHTTPを使用してバックアップデータをPOSTするようにします。
開発環境
今回使用した環境は以下の通りです。
PC
- Windows 10
- MariaDB 10.3
- Oracle Java 1.8u241
- Spring Boot 2.2.6.RELEASE
- Spring Tool Suite 4 Version:4.6.1.RELEASE
Android
- android 8.0
- android studio 3.6.3
準備
RESTアプリケーションを作成する前に、データベースを準備します。
今回は、Androidで作成するアプリでGPSのログを記録し、これを転送する先のデータベースなので、テーブルの内容は緯度・経度・高度・日時という事になります。また、Spring Bootアプリケーションからアクセスするためのユーザーを作成してデータベースへのアクセス権限を与えておきます。(rootでやるのはやめましょうね!)
CREATE DATABASE loggerdb; USE loggerdb; CREATE TABLE logger ( id INT PRIMARY KEY AUTO_INCREMENT, longitude FLOAT NOT NULL, latitude FLOAT NOT NULL, altitude FLOAT NOT NULL, gpstime TIMESTAMP NOT NULL ); CREATE USER rest; GRANT ALL ON loggerdb.* TO 'rest'@'localhost' IDENTIFIED BY 'asD34j#z';プロジェクトの作成
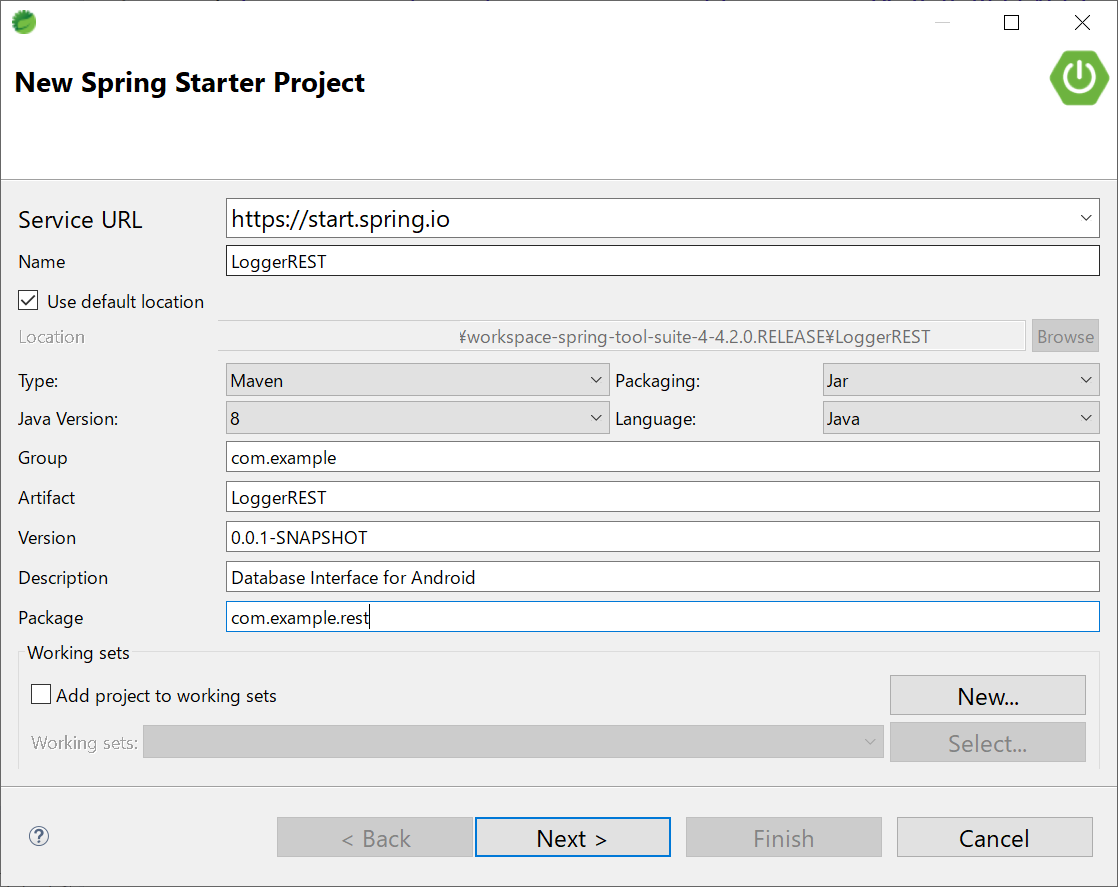
Spring Tool Suiteで新規プロジェクトを作成します。「New」-「New Spring Starter Project」を選択してウィザードを立ち上げます。
プロジェクトの定義はこんな感じ。JavaはOracle Java 8を使ってます。OpenJavaも選択できるけどやったことない。今度やってみますね。
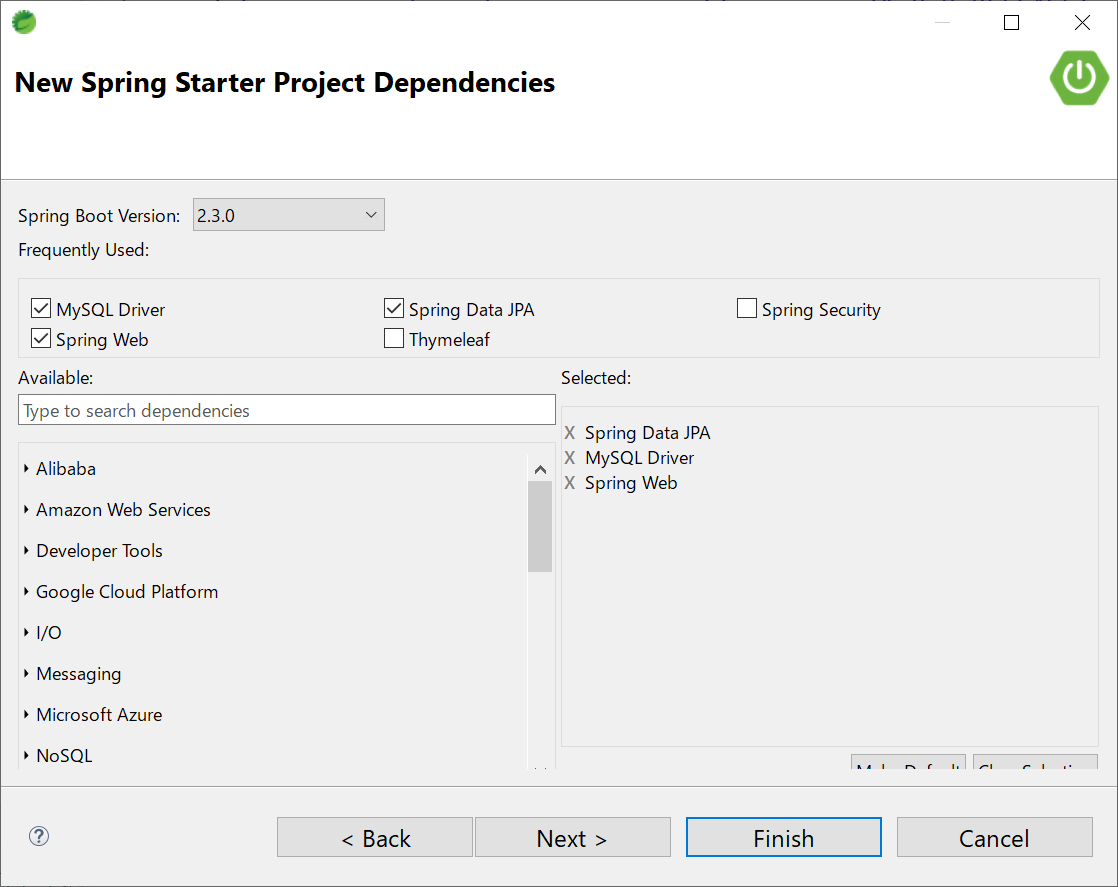
Dependenciesを設定します。Spring Boot VersionはSNAPSHOTじゃないものを選びましょう。(SNAPSHOTは開発版)パッケージは、RESTのために必要なのはSpring Webだけです。
今回はMariaDBのデータを出し入れするのでSpring Data JPAとMySQL Driverも入れておきます。
「Finish」をクリックするとプロジェクトフォルダが作成されて初回のビルドが実行されます。終わるまで少し待ちましょう。1~2分ぐらいかな。最初は、依存するライブラリをローカルリポジトリにダウンロードする必要があるのでインターネット環境によっては結構時間がかかるかもしれません。
会社などでプロキシー設定が必要な場合は「Window」-「Preferences」を開いて「Maven」-「Settings」あたりで設定します。
データベースへのアクセス設定
ここで、データベースにアクセスするための設定を行います。
Spring Bootでは、アプリケーションを起動する際にデータベースの接続を確認するので、この設定が完了していないとアプリケーションが立ち上がりません。
てことは、データベースが立ち上がってないとWebアプリが起動しない?? 実際デフォルトはそうなんですが、本当にアプリを作るときにはちゃんと例外をハンドリングしましょう。設定ファイルは src/main/resources/application.properties に記載します。初期状態では空っぽなので、以下のように記述してください。
spring.datasource.url=jdbc:mysql://localhost:3306/loggerdb?serverTimezone=JST spring.datasource.username=rest spring.datasource.password=asD34j#zserverTimezoneを設定せずにはまることが結構ありますのでご注意を!
アプリケーションの作成
いよいよRESTアプリケーションを作成します。
やるべきことは三つ。
- データベースアクセスモデルを作成する
- リポジトリインタフェースを作成する
- HTTPリクエストをホストするコントローラーを作成する
Webアプリケーションのお約束であるMVCのうち、M(odel)とC(ontroller)です。
RESTfulアプリケーションでは入出力インタフェースがJSONなのでV(iew)は必要ありません。データベースアクセスモデルの作成
準備の章で作成したloggerテーブルにアクセスするためのアクセスモデルを作成します。
テーブルのカラムに対応するフィールドを備えたBeanクラスを作成します。
ポイントとしては以下の点があります。
- 最初につくられるパッケージ(com.example.rest)のサブパッケージに配置すること
- @Entityアノテーションを付与すること
- Serializableを実装すること
今回のloggerテーブルはidをAUTO_INCREMENTにしているので、データ生成時にidを自動生成できるように@GeneratedValueアノテーションを付与しています。
また、時刻のフォーマットはJSONのデフォルトのままだとちょっと扱いづらいので調整しています。
これはテーブルの仕様に合わせて設定してください。package com.example.rest.bean; import java.io.Serializable; import java.util.Date; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.Table; import javax.persistence.Temporal; import javax.persistence.TemporalType; import com.fasterxml.jackson.annotation.JsonFormat; @Entity @Table(name = "logger") public class Logger implements Serializable { private static final long serialVersionUID = 1L; @Id @GeneratedValue(strategy=GenerationType.IDENTITY) private int id; private double longitude; private double latitude; private double altitude; @Temporal(TemporalType.TIMESTAMP) @JsonFormat(pattern="yyyy-MM-dd HH:mm:ss", timezone="Asia/Tokyo") private Date gpstime; public int getId() { return id; } public void setId(int id) { this.id = id; } public double getLongitude() { return longitude; } public void setLongitude(double longitude) { this.longitude = longitude; } public double getLatitude() { return latitude; } public void setLatitude(double latitude) { this.latitude = latitude; } public double getAltitude() { return altitude; } public void setAltitude(double altitude) { this.altitude = altitude; } public Date getGpstime() { return gpstime; } public void setGpstime(Date gpstime) { this.gpstime = gpstime; } }リポジトリインタフェースの作成
生成したモデルクラスのオブジェクトとデータベースを結びつけるインタフェースを作成します。これがとっても簡単!ここがアプリケーションフレームワークを使用するメリットでもあります。
以下のようなインタフェースを作成するだけです。
- JpaRepository<T,ID>を継承するインタフェース
- ジェネリクスのTにはEntityクラスを、IDにはEntityクラスの@Idカラムの型を指定する(ジェネリクスにプリミティブ型であるintは使用できないのでラッパークラスIntegerを使用します)
package com.example.rest.repo; import org.springframework.data.jpa.repository.JpaRepository; import com.example.rest.bean.Logger; public interface LoggerRepository extends JpaRepository<Logger, Integer> { }これだけです。
RESTコントローラーの作成
コントローラーは、@RestControllerアノテーションを付与したクラスです。
GETリクエストハンドラとPOSTリクエストハンドラを作っておきます。前の項で作成したリポジトリインタフェースの型を指定したフィールドを作成し、@Autowiredアノテーションを付与しておくと、Springが必要時に自動的に無名クラスのオブジェクトを生成してくれます。ですからnewしなくてもfindAll()やsaveAll()と言ったメソッドを利用できます。
これがいわゆるDependency Injection (DI) ですね。package com.example.rest.controller; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; import com.example.rest.bean.Logger; import com.example.rest.repo.LoggerRepository; @RestController public class LoggerController { // loggerテーブルのリポジトリを注入する @Autowired LoggerRepository loggerRepository; // GETリクエストに対してloggerテーブルの中身を応答する @RequestMapping(value = "/logger", method = RequestMethod.GET) public List<Logger> loggerGet() { // リポジトリからテーブル内の全レコードを取り出す // ※SELECT * FROM loggerが実行される List<Logger> list = loggerRepository.findAll(); // 取り出したListオブジェクトをリターンすると、 // JSON文字列に変換されてレスポンスが送られる return list; } // POSTリクエストによってloggerテーブルにデータをINSERTする @RequestMapping(value = "/logger", method = RequestMethod.POST) public List<Logger> loggerPost( // リクエストボディに渡されたJSONを引数にマッピングする @RequestBody List<Logger> loggerList) { // listをloggerテーブルにINSERTする⇒INSERTしたデータのリストが返ってくる List<Logger> result = loggerRepository.saveAll(loggerList); // JSON文字列に変換されたレスポンスが送られる return result; } }実行する
以上でRESTアプリケーションの作成は完了です。
それではアプリケーションを起動してみましょう。Package ExplorerからLoggerRestApplication.javaを探して右クリック→「Run as」→「Spring Boot App」を選択します。
Javaアプリにしては少しお洒落なロゴが表示されて、アプリケーションが起動します。Spring startar Webにはtomcatが内蔵されているので、HTTPクライアントでアクセスすることができます。
RESTアプリケーションはHTTPプロトコルを使用してJSONをやり取りするインタフェースですから、Webブラウザは必要としません。(使ってもいいですが)
一般には、curlコマンドを使用して試験することになるでしょう。例として、東京スカイツリー近辺のGPSデータをPOSTし、その後GETしてみた例を示します。curl -X POST -H "Content-Type:application/json" -d "[{\"longitude\":139.811602, \"latitude\":35.710429, \"altitude\": 50.5, \"gpstime\":\"2020-05-24 11:24:00\"}]" http://localhost:8080/logger [{"id":2,"longitude":139.811602,"latitude":35.710429,"altitude":50.5,"gpstime":"2020-05-24 11:24:00"}]POSTを2回ほどやってから、、
curl -X GET http://localhost:8080/logger [{"id":1,"longitude":139.812,"latitude":35.7104,"altitude":50.5,"gpstime":"2020-05-24 11:24:00"},{"id":2,"longitude":139.812,"latitude":35.7104,"altitude":50.5,"gpstime":"2020-05-24 11:24:00"}]こんな感じです。簡単ですよね!
これでRESTfulアプリケーションは完成です。URL (http://localhost:8080/logger) に対してGETリクエストを送ると、JSONデータが得られます。またJSONデータをPOSTすればテーブルにデータをストアすることができるわけです。
実際のアプリを作成するには、もちろんセキュリティ対策等も必要になりますが、Spring Securityの機能により大抵のことはできます。アプリケーション単体での起動
以上、Spring Tool Suiteの環境で実行することができましたが、実際にはjarファイルを作成して実際のサーバーにインストールすることになりますよね。その方法を確認しておきます。
実はここに一つの落とし穴があります。jarファイルの作成方法は、Package Explorerでプロジェクトルートを選択して右クリック→「Run as」→「Maven install」を選択すればよいのですが、ここでERRORが出ることがあります。というか、Spring Tool Suiteのデフォルトの設定では以下のエラーになります。
[ERROR] No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?
このエラーを張り付けて検索してここにたどり着いた方は、よく読んでくださいね~。「JDKじゃなくJREを使ってませんかー」って書いてますよね。というわけで、治します。
まず、「Window」→「Preferences」を開き、「Java」→「Installed JREs」を選択します。すると確かにjre1.8が選択されています。以下の手順でJDKを追加します。
- 「Add」をクリックする
- JREタイプは「Standard VM」を選択する。
- 「JRE home」の欄の「Directory...」をクリックして、jdkをインストールしたフォルダ(C:\Program Files\Java\jdk1.8.0_241)を指定する
- 「Finish」をクリックする。
- 追加された「jdk1.8」を選択して「Apply」をクリックする。
次に、実行環境の設定でJREを選択します。プロジェクトを右クリック→「Run as」→「Run Configurations」を選択してください。
「JRE」タブを開くと、jre1.8が選択されていると思います。これを「Alternate JRE」に変更し、先ほどインストールしたjdk1.8を選択してください。ここまで設定できたら、再度プロジェクトを右クリック→「Run as」→「Maven install」を実行してください。
今度はビルドできると思います。できなかったら、一度「Maven clean」を実行してから「Maven install」を実行してください。SUCCESSになったら、explorerでワークスペースのフォルダを開き、プロジェクトの中にtargetフォルダができているはずなので探してください。
このjarファイルを起動します。
> java -jar LoggerREST-0.0.1-SNAPSHOT.jarAndroid側
これはオマケです。AndroidアプリでGPSから取得した位置情報を、今回作成したRESTful APIを利用してストアするところを載せておきます。
スミマセンがKotlinです。Javaのソースとか位置情報の取得方法とかは検索すると沢山出てきますので、そちらをご覧ください^^;;// RESTインタフェースにJSONデータをPOSTする fun sendJson(items: List<Map<String, String>>){ // 位置情報をJSON(配列)文字列にするためのオブジェクトを準備する var list = JSONArray() // itemには以下のようなデータが入っている // { // latitude => 緯度 // longitude => 経度 // altitude => GPS高度 // gpstime => センサ時刻 // } // for (item in items) { // JSONデータ一件分に対応するオブジェクトを生成する var json = JSONObject() as JSONObject // itemからキーを取り出してjsonオブジェクトに追加していく for (key in item.keys) { json.put(key, item.get(key)) } // JSONのリストに一件分のJSONオブジェクトを登録する list.put(json) } Log.d("JSONArray", list.toString()) // 作成したオブジェクトをJSON文字列に変換する val jsonString = list.toString() // HTTPのリクエストはUIスレッドで発行することはできないので、 // AsyncTaskを継承するクラスを生成しでマルチスレッドで実行する HttpPost().execute(jsonString) } /** * データ転送時のPOSTリクエスト処理 */ inner class HttpPost : AsyncTask<String, String, String>() { // スレッド実行処理 override fun doInBackground(vararg p0: String?): String { // POSTで送るデータは、パラメータで与えたJSON文字列 val data = p0[0] as String // RESTful API のURL(http://192.168.1.1:8080/logger みたいな感じ) val urlstr = getString(R.string.LOGGER) val url = URL(urlstr) // HTTPクライアントの生成 val httpClient = url.openConnection() as HttpURLConnection // HTTPヘッダ情報の設定 httpClient.apply { readTimeout = 10000 connectTimeout = 5000 requestMethod = "POST" instanceFollowRedirects = true doOutput = true doInput = false useCaches = false setRequestProperty("Content-Type", "application/json; charset=UTF-8") } try { // HTTPサーバーに接続する httpClient.connect() // POSTデータを書き込む val os = httpClient.outputStream val bw = os.bufferedWriter(Charsets.UTF_8) bw.write(data) bw.flush() bw.close() // RESTful APIからのレスポンスコード val code = httpClient.responseCode Log.i("HttpPost", "レスポンスコード:" + code) } catch (e: Exception) { e.printStackTrace() } finally { httpClient.disconnect() } return "" } }まとめ
なんだか長くなってしまいましたが、RESTfulインタフェースの部分は実はRestControllerを作るところだけです。
Mapのオブジェクトを作成してreturnすれば、JSON文字列に変換してレスポンスが送信されるので、もう立派なRESTful APIになっています。Entityの作成やJpaRepositoryの部分はRESTではなくSpring Data JPAの機能ですが、これはこれで非常に便利なので、是非使ってみてください。

- 投稿日:2020-05-24T21:46:05+09:00
【JavaServlet】千里の道も一歩から 一歩目
Servletとは
WebアプリケーションをJavaで実現するための仕組み
Webアプリケーションとは
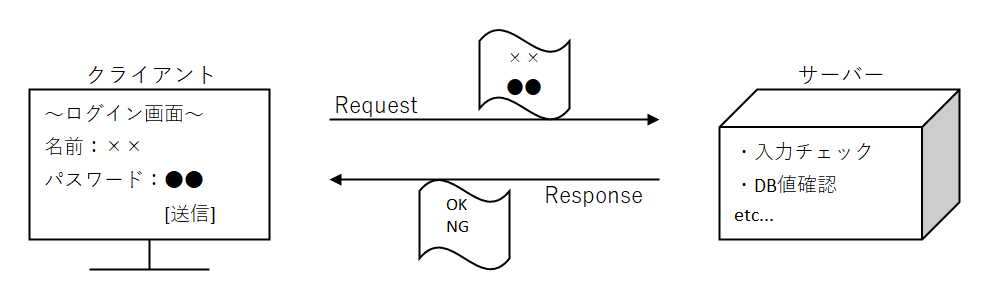
会員制のサイトを例に挙げる
- クライアント(PCやスマホ)に、ユーザ情報を入力してログイン
- サーバーが、送られてきたユーザ情報を受け取る
- データベースなどを利用してユーザやパスワードが合ってるか確認する
- 合っていたらマイページを表示、間違っていたらログイン画面に戻してエラーメッセージを表示
ざっと下のようなイメージ
サーバーに送る情報を「リクエスト」、サーバーから送られてくる情報を「レスポンス」という
また、クライアントの画面はHTMLではなくjspと呼ばれるファイルで構成される(中身はほぼHTMLと同じで、javaのコードも書くことが可能)プロジェクト作りましょう
Eclipseの[パッケージ・エクスプローラー]にカーソルおいて右クリック
[新規]-[その他]の順にクリック
[web]-[動的webプロジェクト]の順にクリック
※検索に「動的」と入れると早い
プロジェクトに任意の名前を入力して[完了]をクリック
他の項目は基本的には触らないが、[ターゲット・ランタイム]と[動的webモジュールバージョン]の値は後で必要になるので覚えておく
完了サーバー作りましょう
TomcatとApacheを別途用意する方法もあるが今回はEclipseに内蔵しているTomcatで実施
[ウィンドウ]-[ビューの表示]-[その他]の順にクリック
[サーバー]を選択してOKをクリック
※検索に「サーバー」と入れると早い
これによってEclipse上に[サーバー]が表示されるので、その領域内で右クリック
[新規]-[サーバー]の順にクリック
[サーバーのタイプを選択]から、プロジェクト作成時で覚えておいた[ターゲット・ランタイム]と同じTomcatバージョンになるようなサーバーを選択して[次へ]をクリック
[使用可能]欄から、先ほど作成したプロジェクトを選択して[追加]をクリック
[構成済み]欄に移ったことを確認したら[完了]をクリック
完了&環境構築終了
次からファイルを作成していくよ








- 投稿日:2020-05-24T19:14:10+09:00
AtCoder【PracticeA】技術メモ
はじめに
AtCoderを始めたので、わからないことをメモしていく
関西弁に憧れを抱いているので関西弁を使用Scannerクラスとは?
標準入力を取得するクラス
取得した入力情報を使って何か処理をしたいときや、対話型のプログラムで使用Scanner scanner = new Scanner(System.in); System.out.println("何か入力してや"); String input = scanner.nextLine(); System.out.println(input + "が入力されたで"); scanner.close();これを実行すると…
何か入力してやと表示され、
「おはよう」と入力すると何か入力してや おはよう おはようが入力されたでと表示される
解説
Scannerクラスのインスタンスを生成し、引数にSystem.inを指定
System.in…InputStreamのオブジェクトで、標準入力(通常はキーボードからの)のこと
nextLine()を使うことによって、入力内容を取得できる。ちなみに空白を含む文字列を取得
※next()は空白までの文字列を取得
例)"明日は 嵐"
①nextLine()だと、"明日は 嵐"を取得
②next()だと"明日は"を取得AtCoderの問題
整数 a,b,cと、文字列 sが与えられます。
a+b+cの計算結果と、文字列 sを並べて表示しなさい。解答
Scanner scanner = new Scanner(System.in); int a = scanner.nextInt(); int b = scanner.nextInt(); int c = scanner.nextInt(); String str = scanner.next(); System.out.println((a + b + c) + " " + str);nextInt()はint型の値を受け取る
- 投稿日:2020-05-24T18:00:10+09:00
Eclipseを使ってJavaからMySQLへ接続する
JavaでMySQLを操作する方法について解説していきます。
今回はWindows環境にXAMPPをインストールしてMySQLを使用します。事前準備
・JDKのインストール
・Eclipseのインストール
・XAMPPのインストール
・JDBCドライバの準備Eclipseの準備
1.Javaプロジェクトを作成
左上の「ファイル(F)」>「新規(N)」>「Javaプロジェクト」 で今回使う新規プロジェクトを作成します。
プロジェクト名はわかりやすく「MysqlTest」とでもしておきましょう。「完了(F)」をクリックして作成します。
2.プロジェクトにJDBCドライバを組み込む
プロジェクトが作成できたらプロジェクト上で右クリックをし、 「ビルド・パス(B)」>「外部アーカイブの追加(V)…」を選択してJDBCドライバ(mysql-connector-java-8.0.19.jar)を開きます。
プロジェクト直下の「参照ライブラリ」にmysql-connector-java-8.0.19.jarが追加してあれば大丈夫です。MySQLの準備
XAMPPを起動し、MySQLを「Start」させます。
Startできたら右にある「Shell」をクリックして起動させます。
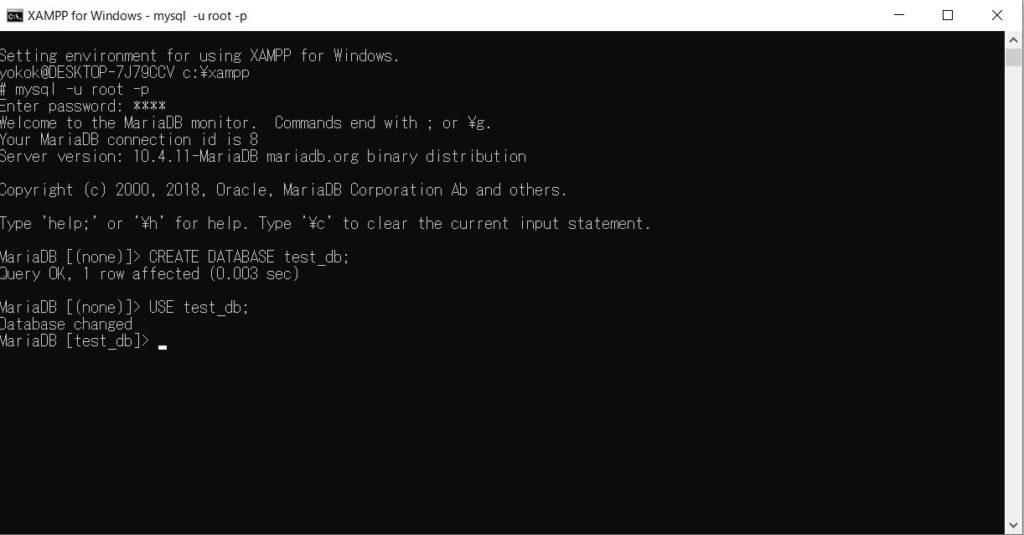
起動出来たら以下のコマンドを入力し、rootユーザーでMySQLに接続します。パスワード等の設定はこちらの記事を参考にしてください。mysql -u root -p接続ができたら、以下のコマンドでデータベースを作成します。今回は「test_db」という名前のデータベースを作成します。
CREATE DATABASE test_db;無事に作成できたら、以下のコマンドで今作ったデータベースに接続します。
USE test_db;ここまでの流れは以下の画像のとおりです。
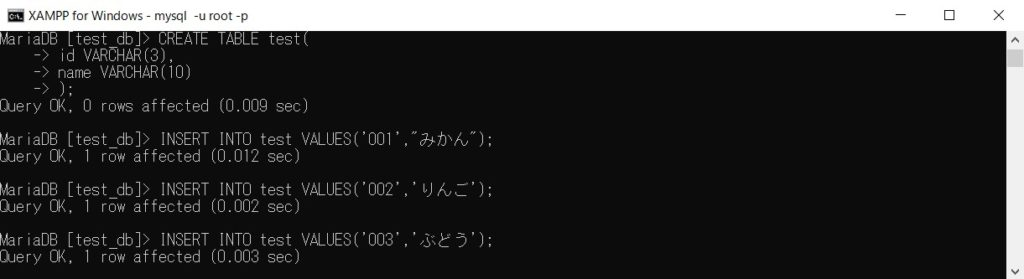
次にテーブルを作成し、データを格納していきます。今回は「test」というテーブルを作成します。以下のコマンドを入力してください。※コンマを忘れないように!もし、入力ミスをした場合は「\c」で中断して新しく入力し直してください。
CREATE TABLE test( id VARCHAR(3), name VARCHAR(10) );テーブルが作成できたらデータを格納していきます。今回はデータを3行格納してみましょう。
INSERT INTO test VALUES('001', 'みかん'); INSERT INTO test VALUES('002', 'りんご'); INSERT INTO test VALUES('003', 'ぶどう');ここまでの流れは以下の画像のようになります。
きちんとデータが格納されたかどうか以下のコマンドで確認してみましょう。
SELECT * FROM test;
これでMySQLの準備は完了です。JavaからMySQLに接続
さて、以上で準備は整いました。ここからはJavaプログラムを作成して、先ほど作成したデータベースにアクセスし、テーブルのデータを表示させてみましょう。
まず、最初に作った「MysqlTest」プロジェクトの中にある「src」を右クリックし、「新規(W)」>「パッケージ」で「java_mysql」というパッケージを作成します。
次に、今作ったパッケージを右クリックし、「新規(W)」> 「ファイル」で「Test.java」というファイルを作成します。
ここまで出来たら「Test.java」の中身を書いていきます。 コードの意味はコメントで書いておきました。Test.javapackage java_mysql; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; public class Test { public static void main(String[] args) { // 変数の準備 Connection con = null; PreparedStatement stmt = null; ResultSet rs = null; // SQL文の作成 String sql = "SELECT * FROM test"; try { // JDBCドライバのロード Class.forName("com.mysql.cj.jdbc.Driver"); // データベース接続 con = DriverManager.getConnection("jdbc:mysql://localhost:3306/test_db?serverTimezone=JST", "root", "root"); // SQL実行準備 stmt = con.prepareStatement(sql); // 実行結果取得 rs = stmt.executeQuery(); // データがなくなるまで(rs.next()がfalseになるまで)繰り返す while (rs.next()) { String id = rs.getString("id"); String name = rs.getString("name"); System.out.println(id + ":" + name); } } catch (ClassNotFoundException e) { System.out.println("JDBCドライバのロードでエラーが発生しました"); } catch (SQLException e) { System.out.println("データベースへのアクセスでエラーが発生しました。"); } finally { try { if (con != null) { con.close(); } } catch (SQLException e) { System.out.println("データベースへのアクセスでエラーが発生しました。"); } } } }コードが書き終わったら保存をし、「Test.java」を右クリックして「実行(R)」>「Javaアプリケーション」から実行します。
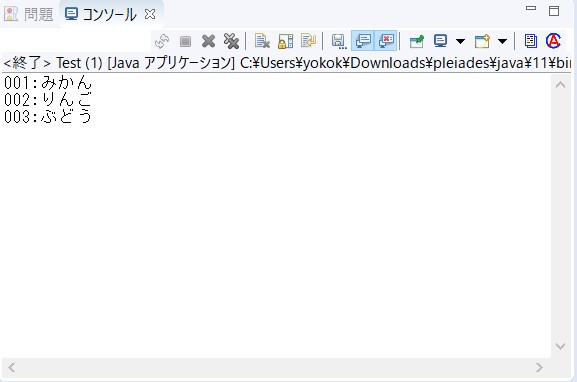
コンソールで以下のように表示されていれば成功です。


- 投稿日:2020-05-24T13:28:22+09:00
Javaのデータ型(特にプリミティブ型)とリテラルについて
Oracle Java Programmer,Silver SE11認定資格取得に向けて学習を開始しました。
その中で出てきたデータ型に関するまとめを行いたいと思います。
間違っている等、指摘事項あればご教示いただけると幸いです。プリミティブ型
型 分類 boolean 論理型 True/False char 文字型 16ビットUnicode,¥u0000~¥uFFFF byte 整数型 8ビット整数,-128~127 short 整数型 16ビット整数,-32768~32767 int 整数型 32ビット整数,-2147483648~2147483647 long 整数型 64ビット整数,-9223372036854775808~9223372036854775807 float 浮動小数点型 32ビット単精度浮動小数点型 float 浮動小数点型 64ビット倍精度浮動小数点型 参照型
参照型にはクラス型、インターフェース型、配列型と言ったものがあります。
プリミティブ型のリテラル
リテラルとは、ソースコードに記述する値の事です。
Javaのリテラルは、デフォルトでは整数はint型、浮動小数点数値はdouble型、真偽値であればboolean型、文字であればchar型です。データ型を明示したいとき(整数、浮動小数点数値)
データ型を明示したい時は値の最後につける接尾辞や値の先頭につける接頭辞を使います。
- long型・・・値の後ろにLまたはlをつける。
- float型・・・値の後ろにFまたはfをつける。
型というよりは表記の方法ですが…
- 2進数で記述する・・・値の先頭に0bをつける。
- 8進数で記述する・・・値の先頭に0をつける。
- 16進数で記述する・・・値の先頭に0xをつける。
byte型やshort型にはありません。
アンダースコア(_)を使った数値表記
Java SE7から導入されたようです。あくまで見やすさ向上のためです。
ただし、-リテラルの先頭と末尾には記述できない
-記号の前後には記述できないリテラルの先頭と末尾には記述できない
記号の前後には記述できない具体例
Main.javadouble a = 123_4567.89; System.out.println(a);とやると、1234567.89と表示されます。3桁区切りでなくても全然オッケーらしいです。
Main.javadouble a = 123_4567_.89; System.out.println(a);とやるとエラーになります。
文字リテラル
char型は文字1文字を表すデータ型で、'a'のようにシングルクォーテーションで囲わないといけません。
ちなみに文字列は"neko"のようにダブルクォーテーションで囲わないといけません。Unicodeによる表記では\uの接頭辞の後に16進数4桁で表記します。
Main.javachar a = '\u1111'; System.out.println(a);ᄑ
と出力されました。読めないw
あれ?そういえばString型は?
java.langパッケージに所属するjava.lang.Stringクラスを使用している形です。
特例としてnew演算子を利用しなくても" "で囲めばStringインスタンスを利用できます。参考文献
スッキリわかるJava入門
徹底攻略Java SE11 Silver問題集
- 投稿日:2020-05-24T13:20:51+09:00
沈思黙考:自分で作る関数に関数型インタフェースを活かす方法(java)
初めに
streamなどでラムダ式を使うことはできても、自分で作る関数に関数型インタフェースを活かすことができない方がいるかもしれない。
そんな方にむけて、簡単な例を使って、自作関数への関数型インタフェースの適用方法を紹介したいと思う。例題
あるオブジェクトのプロパティを別のプロパティにコピーすることは、よくあることだろう。
その際、プロパティの値がnullでない場合だけ、コピーするという条件がつくこともよくあることだ。
そして、この例題のように、様々な型プロパティのコピーがずらっと並ぶこともよくある。
このようにコピペで対応してもよい場合もあるだろうが、少し工夫をしたい。
次のコードに対し、共通関数を作って呼び出しを簡素化しよう。
なお、getName()はStringを返し、setName()は、Stringをセットする。
getFlag()はBooleanを返し、setFlag()は、Booleanをセットする。if(objA.getName()!=null) { objB.setName(objA.getName()); } if(objA.getFlag()!=null) { objB.setFlag(objA.getFlag()); }疑似コード
以下のように書けるといいですね。
javaではどのよにして実現するか見ていきましょう。setIfNotNull(value,func) { if(value!= null) { func(value); } } setIfNotNull(objA.getName(),objB.setName); setIfNotNull(objA.getFlag(),objB.setFlag);インターフェースを使った回答(うまくいかない例)
上記疑似コードでfuncはメソッドを示していますが、javaではどのように表現すればよいでしょうか?
メソッドを示すものといえば、インターフェイスです。ここでもインターフェイスを使えば実現できるかもしれません。public interface SetNameInterface { void setName(String value); } public Class ObjB implements SetNameInterface{ void setName(String name); } public void setIfNotNull(String value,SetNameInterface obj) { if(value!= null) { obj.setName(value); } } setIfNotNull(objA.getName(),objB);setName()には対応できましたが、setFlag()には対応できないのは明らかです。
この方法は直観的ですが、うまくいきません。インターフェースを使った回答(うまくいくが冗長)
setName()とsetFlag()をsetIfNotNull()からは、共通の関数名funcで呼び出したいのだから、
funcをインターフェイスとしてもつオブジェクトをsetName()とsetFlag()に対して持たせるのはどうでしょうか?public Class ObjB { public void setName(String name) { System.out.println("OnjB.setName:"+name); } public void setFlag(Boolean flag) { System.out.println("OnjB.setFlag:"+flag); } } public interface FuncInterface<T> { void func(T value); } public class ObjBSetName implements FuncInterface<String> { ObjB obj; public ObjBSetName(ObjB obj) { this.obj = obj; } @Override public void func(String value) { obj.setName(value); } } public class ObjBSetFlag implements FuncInterface<Boolean> { ObjB obj; public ObjBSetFlag(ObjB obj) { this.obj = obj; } @Override public void func(Boolean value) { obj.setFlag(value); } } public <T>void setIfNotNull(T value,FuncInterface<T> obj) { if(value!= null) { obj.func(value); } } setIfNotNull(objA.getName(),new ObjBSetName(objB)); setIfNotNull(objA.getFlag(),new ObjBSetFlag(objB));ObjBSetName ,ObjBSetFlag は、ともにFuncInterfaceインターフェースで定義されてるfunc関数を持ち、
func関数が呼び出されるとそれぞれの本来の処理objB.setName()やobjB.setFlag()を呼び出しています。
なお、FuncInterfaceインターフェースは、メソッドに渡すパラメータの型を総称型(ここではT)で宣言しており、
それに合わせて、setIfNotNull()もvalueおよびobjを総称型を使うように変更します。匿名クラスを使った回答
これでやりたいことは実現できたのですが、ObjBSetName、ObjBSetFlagを用意するところが冗長です。
匿名クラスを使ってみましょう。匿名クラスの書き方は、
new 親クラスまたはインターフェイス名() {
匿名クラスの内容 (フィールドやメソッドの定義)
};であるので、
var objBSetName = new FuncInterface<String>() { @Override public void func(String value) { objB.setName(value); } }; var objBSetFlag = new FuncInterface<Boolean>() { @Override public void func(Boolean value) { objB.setFlag(value); } };と書けて、
呼び出しは、setIfNotNull(objA.getName(),objBSetName); setIfNotNull(objA.getFlag(),objBSetFlag);となります。匿名クラスの中では、オブジェクトobjBを直接参照できます。
ラムダ式を使った回答
関数が1つだけ定義されているインターフェースの場合、匿名クラスをラムダ式に置き換えられるので、
FuncInterface<String> objBSetName = (v) -> objB.setName(v); FuncInterface<Boolean> objBSetFlag = (v) -> objB.setFlag(v);と書き換えできる。ラムダ式には、funcという表記はないが、FuncInterfaceで定義されているfuncを実装しています。
ラムダ式には、funcが消えているのがわかりにくい点ですが、匿名クラスとよく見比べれば理解できるでしょう。さらに変数を省略して、
setIfNotNull(objA.getName(),(v) -> objB.setName(v)); setIfNotNull(objA.getFlag(),(v) -> objB.setFlag(v));とまとめることができます。
関数型インタフェースを使った回答
さて、FuncInterfaceというインターフェースの宣言ですが、実は、関数型インタフェースとして
すでにConsumerが存在しますので、こちらと置き換えてしまいましょう。
(インターフェースを自作する前に提供されている関数型インタフェースが使えないか調べるとよいでしょう)public <T>void setIfNotNull(T value,Consumer<T> obj) { if(value!= null) { obj.accept(value); } }さらに、引数が1つですので、呼び出しは、メソッド参照を使って、
setIfNotNull(objA.getName(),objB::setName); setIfNotNull(objA.getFlag(),objB::setFlag);となります。
かなりすっきりしましたね。まとめ
今回は、小さな例で説明しましたが、「処理」を関数に渡すことができる、ということがおわかりいただけた
と思います。そのための宣言が「関数型インタフェース」です。
これを使えば、「Strategy パターン」を実現できるというもは、すでに想像されていることでしょう。
ぜひあなたのプログラムにも適用して、プログラムの再利用を図ってください。
- 投稿日:2020-05-24T00:01:03+09:00
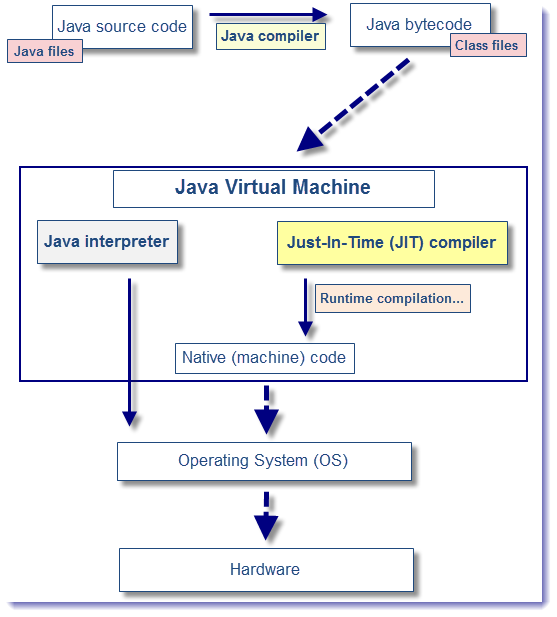
JVM JITコンパイラの仕組み
JVMのJITコンパイラの仕組みを勉強したことをまとめていく。
環境
- macOS Mojava 10.14.4
- jvm version 1.8
- 64bit
- Scala 2.13.1
~/workspace/$ java -version openjdk version "1.8.0_222" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)JITコンパライトとは
Just In Timeコンパイラのことで、JVM上に実装されているコンパイラである。
Just In Timeの通り、「必要な物を、必要な時に」コンパイルするコンパイラのこと。JVM上での実行までの流れ
めっちゃ大まかに言うと、以下の流れ
ソースコード -> コンパイル -> 中間コード -> 実行(コンパイル)
JVM言語は、コンパイルを走らせた際に(javaでは
javac、scalaではsbt compileなど)、対象の全てのソースコードをコンパイルするわけではない。
まず、中間コードを作成する。(java bytecode)。この中間コードを生成するプロセスを挟むことで、JVM環境さえあれば、どのOSでも同じコードを実行できるようになった。(JVMは、それぞれのOSに適した物を入れる必要がある)その後、作成した中間コードを一気にコンパイル(nativeコードに変換)はしない。
インタプリタでソースコードを実行の都度コンパイルしている。(上図で言うと Java interpreter)これには、以下の2つの理由がある。
1. コンパイルしてもそのコードが一回しか利用されなかったらコンパイル時間が無駄になる
コンパイルには時間がかかるので、一回しか呼びだされないコードに関しては、インタプリタで実行する方が、実行までの合計時間が短くなる
一方、頻繁に呼び出されるコードに関しては、コンパイルされたコードの方が高速に実行できるので、コンパイルされるべきである。
この、インタプリタで実行するかコンパイルして実行するのかのJVM上での閾値の話は後述する。2. コンパイルする際に利用可能な情報を集めることができる。
コンパイルする際に必要な情報を、インタプリタで実行する際に取得することができる。
取得した情報を利用して、コンパイルの際に様々な最適化を施すことができる。
この最適化によって、このコンパイルされたコード内でも、実行時間に差が出てくる。例えば、
equals()メソッドで考える以下のようなコードがある。
test.scalaval b = obj1.equals(obj2)インタプリタが
equals()メソッドに到達した時点で、equals()メソッドが、obj1に定義されているメソッドなのか、はたまたStringオブジェクトのメソッドなのかを探索する必要が出てくる。インタプリタのみなら、毎回equals()メソッドに到達するたびに探索するという時間が無駄にかかってしまう。もしインタプリタで、obj1がStringオブジェクトのメソッドだと判断すると、
equals()メソッドをStringオブジェクトのメソッドとしてコンパイルする。コンパイルされ、さらにインタプリタの際に探索していた時間がいらなくなるので、高速なコードがなる。このように、コードを実行して見ないと最適化できないので、JITコンパイラはコードをすぐにはコンパイルしない。
JITコンパイラの三種類のコンパイラ
JITコンパイラには、三種類のコンパイラが存在する。
java8からは、三番目の階層的コンパイラがデフォルトで設定されている。クライアントコンパイラ(C1)
早期の段階でコンパイルする
サーバーコンパイラ(C2)
コードの振る舞いについて情報を集めてからコンパイルする。
上記のように、最適化されてコンパイルされるのでクライアントコンパイラよりも速度が出る。階層的コンパイラ
クライアントコンパイラとサーバーコンパイラをまとめたもの。
初期の段階では、C1でコンパイルされ、最適化のための情報が集まってきたら(コードがホットになってきたら)、C2でコンパイルされる。確認
java -versionで、設定されているコンパイラを確認できる
僕の場合は、
- JVM version8
- 64bit
- Serverコンパイラ(階層的コンパイラ)~/workspace/$ java -version openjdk version "1.8.0_222" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)それぞれのコンパイラは、作成するアプリケーションによって使い分けるべき。
例えば、GUIアプリケーションをJVM上で実行している場合、使えば使うほど処理速度が上がるよりも、初期アクセス時間が速い方がUX的には良いので、クライアントコンパイラを使うべき。などなど、アプリケーション・実現したいことによってコンパイラを選択する。
コンパイルされる閾値
バイトコードは、まずインタプリタで実行されると上述した。
では、どのタイミングでインタプリタからJITコンパイラに切り替えられるのか?
2つの閾値が存在する呼び出しカウンター(スタンダードコンパイル)
対象のメソッドが呼ばれた回数
この回数が閾値を越えると、対象のメソッドがコンパイルのためのキューに積まれて、コンパイルされる。
バッグエッジカウンター
メソッド内でループ内のコードから処理が戻ってくる回数
この回数が閾値を超えると、ループ自身がコンパイルの対象となりコンパイルされる。
その際にされるコンパイルのことを、OSRコンパイルという。
コンパイルが完了すると、スタック上でコンパイルされたコードと交換され、次の処理からコンパイルされたコードが実行される。チューニング
クライアントコンパイラとサーバコンパイラでは、上記のカウンターの閾値が違う。
この閾値をきちんとチューニングしないといけない。例
サーバコンパイラでのスタンダードコンパイルでの閾値を下げるとコンパイルされる際に必要な情報が少なくなるので最適化されにくく、低速なコンパイルコードになってしまう。
それでも、閾値を低くするメリットもある
1. ウォームアップの時間を少し短くできる
それはそうだ。
2. 高い閾値ではコンパイルされないコードもコンパイルされる
これに関して、コードを継続して実行していくといずれ、呼び出しカウンター・バッグエッジカウンターの閾値に達すると考えられる。しかし、時間とともにカウンターの値が減算される。
上記のように、チューニングをきちんとしないといけない。
実際にチューニングしてみる
以下のコードでJITコンパイラの挙動を観察する・チューニングしてみる
下のように、
.jvmopts内に、jvmオプションを指定できる。.jvmopts-XX:+PrintCompilation -XX:CompileThreshold=1
-XX:+PrintCompilation下記のようにコンパイルログを吐き出してくれる
形式は
タイムスタンプ コンパイルID 属性 メソッド名 サイズ 非最適化$ sbt run 41 1 3 java.lang.Object::<init> (1 bytes) 42 2 3 java.lang.String::hashCode (55 bytes) 44 3 3 java.lang.String::charAt (29 bytes) 45 4 3 java.lang.String::equals (81 bytes) 45 5 n 0 java.lang.System::arraycopy (native) (static) 45 6 3 java.lang.Math::min (11 bytes) 45 7 3 java.lang.String::length (6 bytes) 52 8 1 java.lang.Object::<init> (1 bytes) 52 1 3 java.lang.Object::<init> (1 bytes) made not entrant 53 9 3 java.util.jar.Attributes$Name::isValid (32 bytes) 53 10 3 java.util.jar.Attributes$Name::isAlpha (30 bytes) ・・・・
XX:CompileThreshold=1000メソッド・ループが、何回実行されるとコンパイルされるのか指定できる。
以下のコードでやってみる
Test.scalaobject Test extends App{ def compileTest() = { for (i <- 0 to 1000) { sampleLoop(i) } } def sampleLoop(num: Int) = { println(s"loopppp${num}") } println(compileTest()) }.jvmopts-XX:+PrintCompilation -XX:CompileThreshold=1結果
-XX:CompileThreshold=1に設定したので、一回このコードを実行するだけでcompileTestメソッドはコンパイルされていることが確認できる。
また、sampleLoopメソッドもループなので、コンパイルされている。9983 9336 3 Test$$$Lambda$3666/873055587::apply$mcVI$sp (5 bytes) 9983 9338 3 Test$::sampleLoop (1 bytes) 9983 9337 3 Test$::$anonfun$compileTest$1 (8 bytes) 9984 9334 4 java.lang.invoke.MethodType::makeImpl (66 bytes) 9986 9339 ! 3 scala.Enumeration$Val::toString (55 bytes) ・・・JVMが起動の9秒後に
compileTestメソッドがコンパイルされている。例えば、以下の設定ではどうか?
object Test extends App{ def compileTests() = { for (i <- 0 to 10) { // 10回のループに変更 sampleLoop(i) } } def sampleLoop(num: Int) = { println(s"loopppp${num}") } println(compileTests()) }.jvmopts-XX:+PrintCompilation -XX:CompileThreshold=100 # 100回に閾値を変更
-XX:CompileThreshold=100などと設定すると、一回上記のコードを実行するだけでは、compileTestメソッドはコンパイルされない。
また、sampleLoopメソッドも、100回も実行されないのでコンパイル対象外となっている。まとめ
実際にJITコンパイルの処理を眺めてみると理解しやすい。
参考