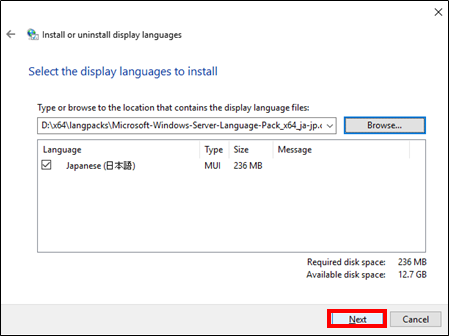
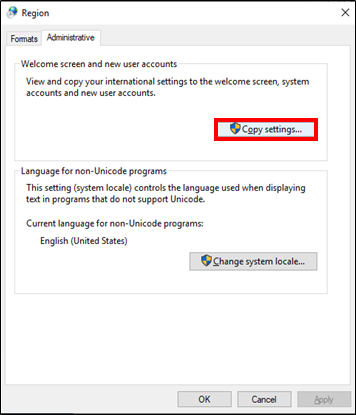
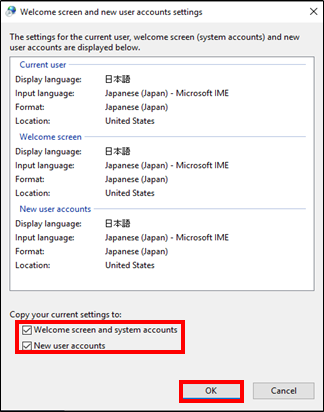
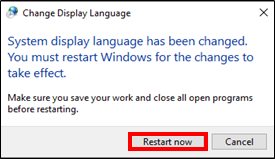
- 投稿日:2020-05-24T23:01:32+09:00
Lambda@EdgeのテストをJestで書く
概要
Lambda@Edge の単体テストを Jest で書いたときのメモ。今回書いたのは Lambda@Edge だけど、Lambda でも基本的には同じはず。Jest はシンプルで良いですね。
導入方法
導入したいディレクトリを作成して、そこで以下のコマンドを入力していく。Jest の導入はすごく簡単。
npm init
- npm を初期化する
- インタラクティブに設定項目を聞かれるので、お好みで設定
test commandだけjestと入力するnpm install -D jest
- jest をインストールする
テスト対象ファイル
今回テストするファイルはこちら。Lambda@Edge のリクエストオリジンで動作させるような処理。
main.js"use strict"; exports.handler = (event, context, callback) => { const request = event.Records[0].cf.request; // /hoge にアクセスしたら /index.html へ向き先を変える if (request.uri.indexOf("/hoge") === 0) { request.uri = "/index.html"; callback(null, request); return; } callback(null, request); };テストファイル作成
テストファイルは
XXX.spec.jsまたはXXX.test.jsで作成する。この Lambda では callback が最終的にどのように実行されたかをチェックしたいので、 jest.fn() でモック化して呼び出す。main.spec.jsconst { handler } = require("./main"); // Mockオブジェクトを作成 const getMockEvent = (request) => { return { Records: [ { cf: { request }, }, ], }; }; describe("handlerのテスト", () => { it("/hoge は /index.html に変更される", () => { const event = getMockEvent({ uri: "/hoge" }); const callback = jest.fn(); handler(event, null, callback); expect(callback).toHaveBeenCalledWith(null, { uri: "/index.html" }); expect(callback).toHaveBeenCalledTimes(1); }); it("/foo は何もされない", () => { const event = getMockEvent({ uri: "/foo" }); const callback = jest.fn(); handler(event, null, callback); expect(callback).toHaveBeenCalledWith(null, { uri: "/foo" }); expect(callback).toHaveBeenCalledTimes(1); }); });実行結果
$ npm test > jest PASS ./main.spec.js handlerのテスト ✓ /hoge は /index.html に変更される (3 ms) ✓ /foo は何もされない (1 ms) Test Suites: 1 passed, 1 total Tests: 2 passed, 2 total Snapshots: 0 total Time: 1.459 s Ran all test suites.aws-lambda-mock-context
ちなみに Lambda の context をモック化したい場合は、下記のライブラリを使うのがシンプルで良い。今回の例では context が必要なかったので null にしているが、これを使えば
const ctx = context()だけでモックが作成できる。
- 投稿日:2020-05-24T23:01:20+09:00
Lambda x Amazon SNSで、AWSの請求額を毎日メールで通知する
はじめに
CloudWatchで請求アラートを設定する事はできますが、超心配性な自分としては、月初~前日までの請求額を毎日メールで確認しておきたい。
AWS Lambdaとwebhookを使ってSlackのチャンネルに通知する方法は多く見られましたが、メールで通知する方法は意外と多くなかったので、まとめてみました。概要
- 請求額はCost Explorerから取得する。
※CloudWatchから取得する方法もありますが、双方に差異があり正しい値はCost Explorerであるという情報があったため、Cost Explorerを使う事にしました。- Lambda関数のランタイムはPython3.7とし、Python 向けのAWS SDK(Boto3)を利用する。
- トリガを設定したLambda関数にて、月初~前日までの合計請求額とサービス毎の請求額を取得し、その内容を整形し、メッセージとしてAmazon SNSのトピックに発行する。
- メッセージを受け取ったSNSトピックは、紐づけたエンドポイント(メールアドレス)宛にメッセージを送信する。
用語の理解
特にAmazon SNSに登場する用語、そしてそれぞれの関係性がややこしかったので、超ざっくりとまとめます。
ARN:AWSリソースを一意に識別する名前。
トピック:複数のエンドポイント(ここではメールアドレス)をグループにまとめる機能。
エンドポイント:配信先。今回はメールアドレスとなります。
サブスクリプション:トピックとエンドポイントを紐づける
より深く理解するために、以下の記事の用語説明の箇所がとても参考になりましたので、事前に熟読しておく事をお勧めします。
Amazon SNSでプッシュ通知を送るための基礎知識 | UNITRUST
設定方法
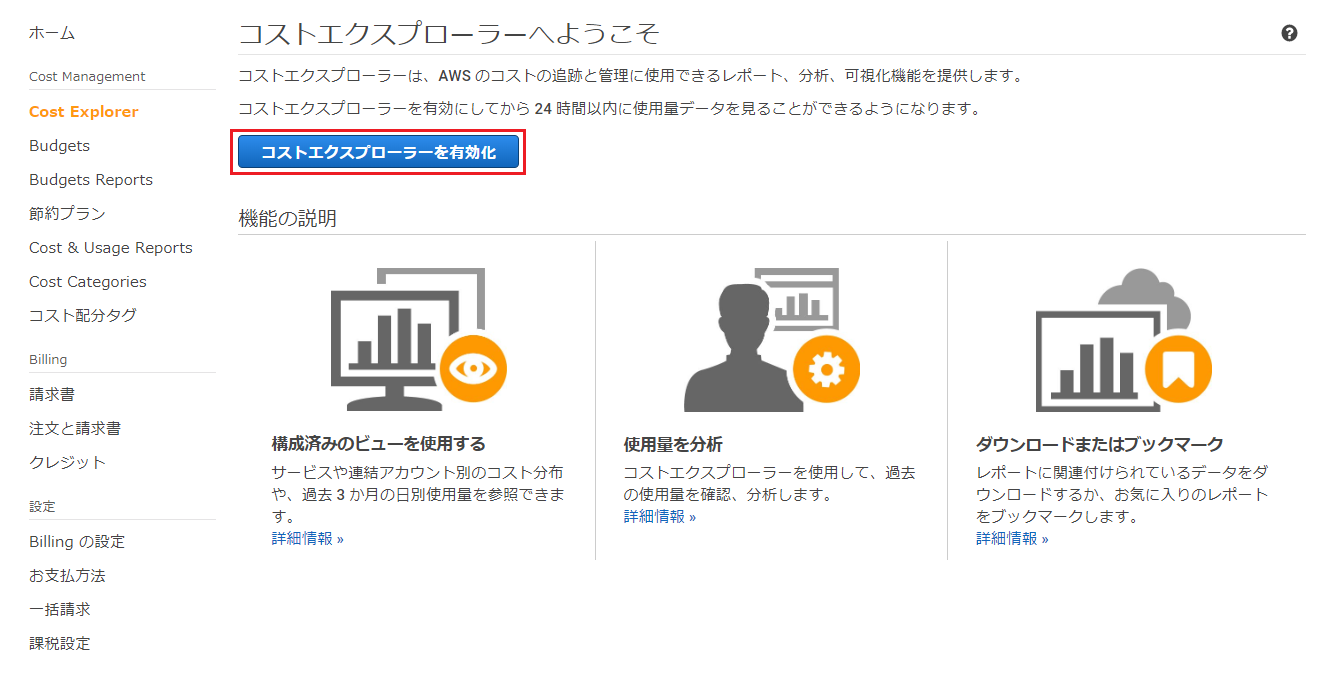
Cost Explorerの有効化
Cost Explorerを有効化していない場合は、マイ請求ダッシュボードから有効化します。
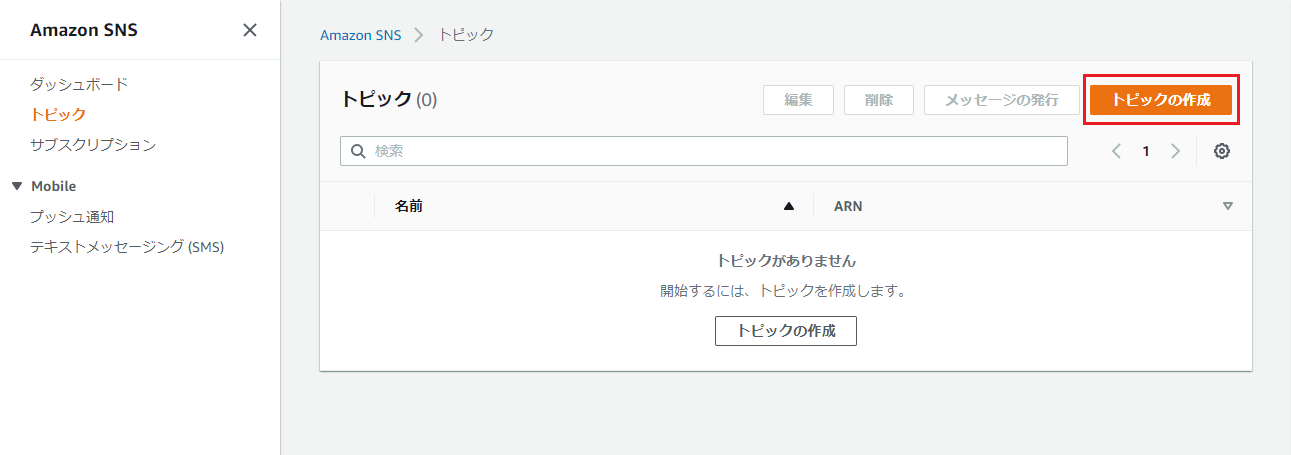
SNS トピックの作成
Amazon SNSのサービス画面に移動します。
※利用できるリージョンは限られています。(サポートされているリージョンおよび国 - Amazon Simple Notification Service)「トピック」メニューから、「トピックの作成」を押下。
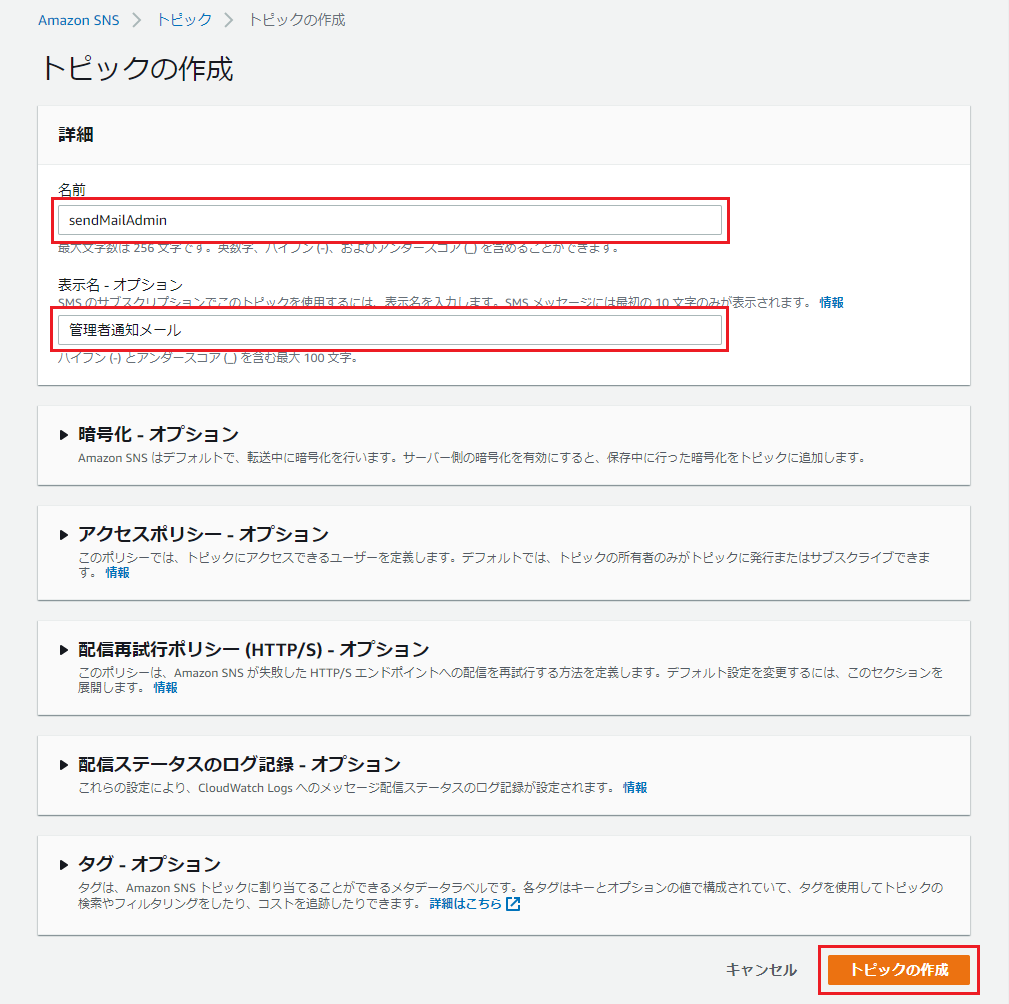
「名前」と「表示名」を入力し、「トピックの作成」を押下。
※ここで設定した「表示名」が、メールの送信者名となります。
※ちなみに、管理者向けに何か通知するためのトピックとして、今後別の目的での配信にも利用する事を想定し、名前は「sendMailAdmin」、表示名は「管理者通知メール」と汎用的なものしておきました。
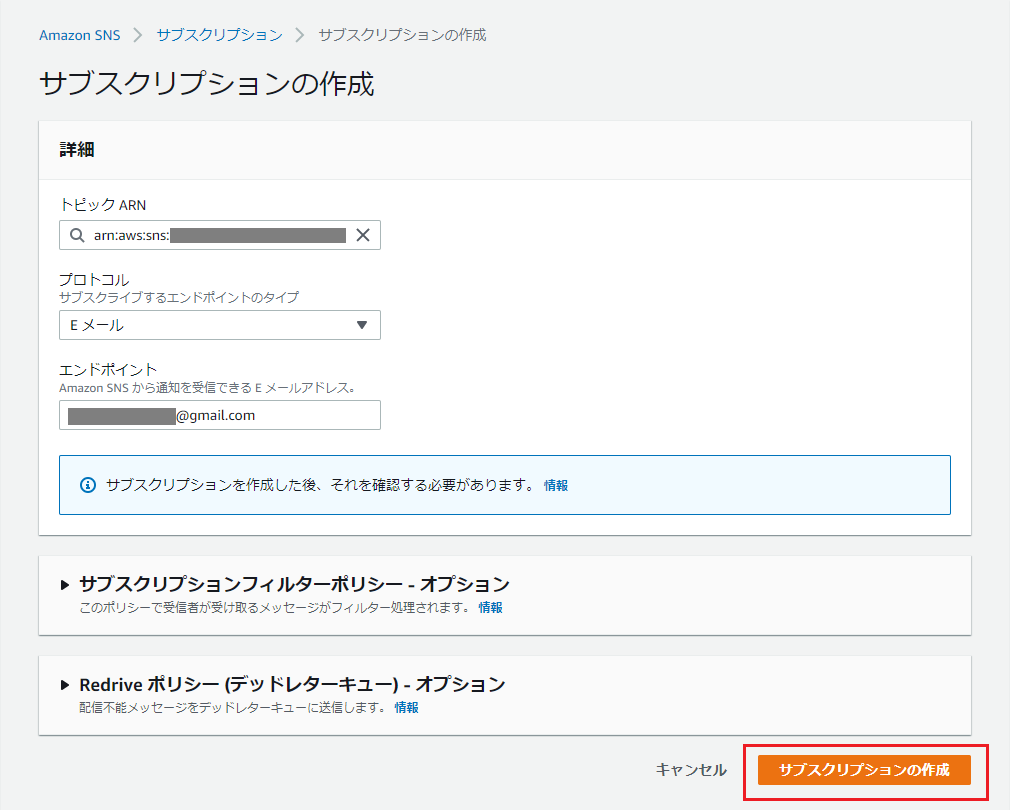
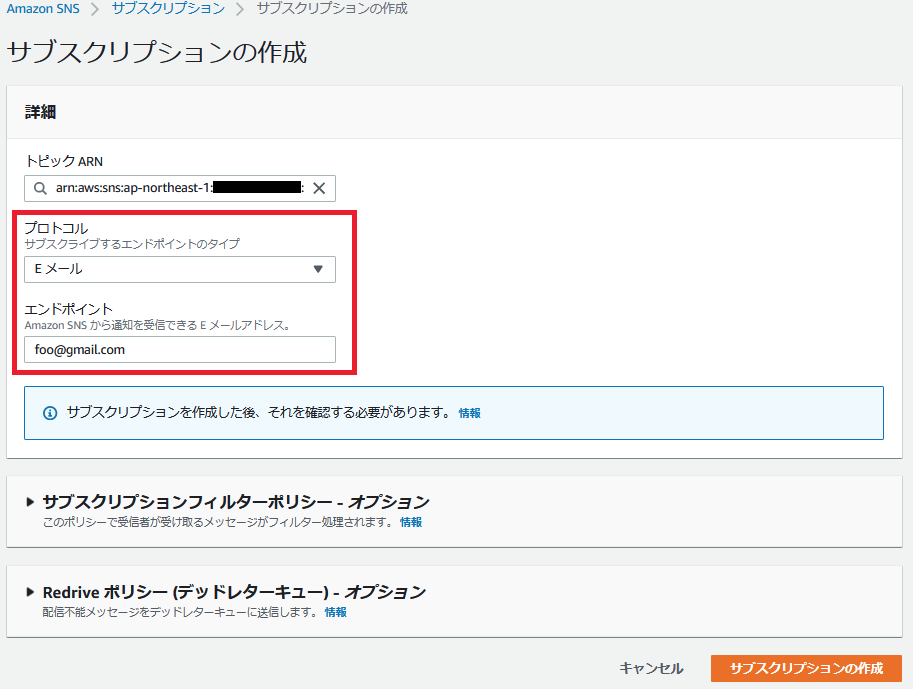
サブスクリプション作成
サブスクリプション(+エンドポイント)を作成します。
「サブスクリプションの作成」を押下。
※画面に表示されているARNは控えておいてください。
下記項目を入力し、「サブスクリプションの作成」を押下。
※「トピックARN」は自動入力されるはずですが、されていなければ控えておいたトピックARNを入力してください。
項目名 入力値・選択値 トピックARN 控えておいたトピックのARN プロトコル Eメール エンドポイント 受信メールアドレス
サブスクリプションの承認
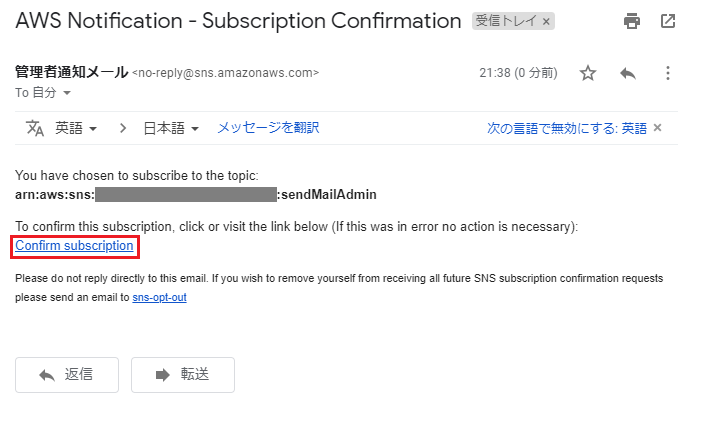
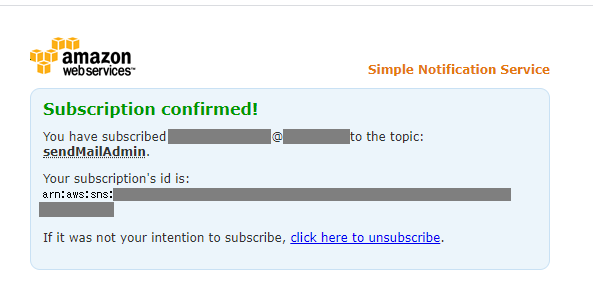
エンドポイントに指定したメールアドレス宛に、「AWS Notification - Subscription Confirmation」という件名で確認メールが送られてくるので、「Confirm subscription」を押下。
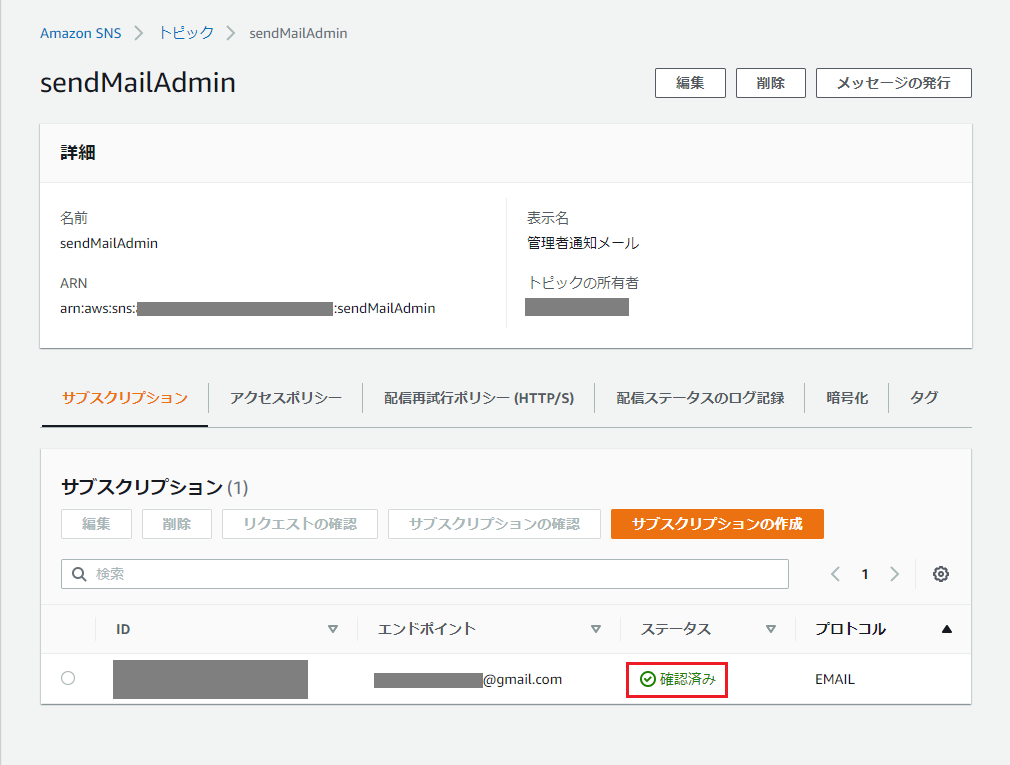
トピックに紐づけたサブスクリプションのステータスが「確認済み」となります。
Lambda関数の作成
トピック・サブスクリプション・エンドポイントの作成が完了しました。
トピックのARNに対してメッセージを発行すると、このトピックに紐づいたエンドポイント(メールアドレス)宛にメッセージが配信されるという流れになります。
そのため次に、トピックのARNに対して発行するメッセージを生成するLambda関数を作成します。
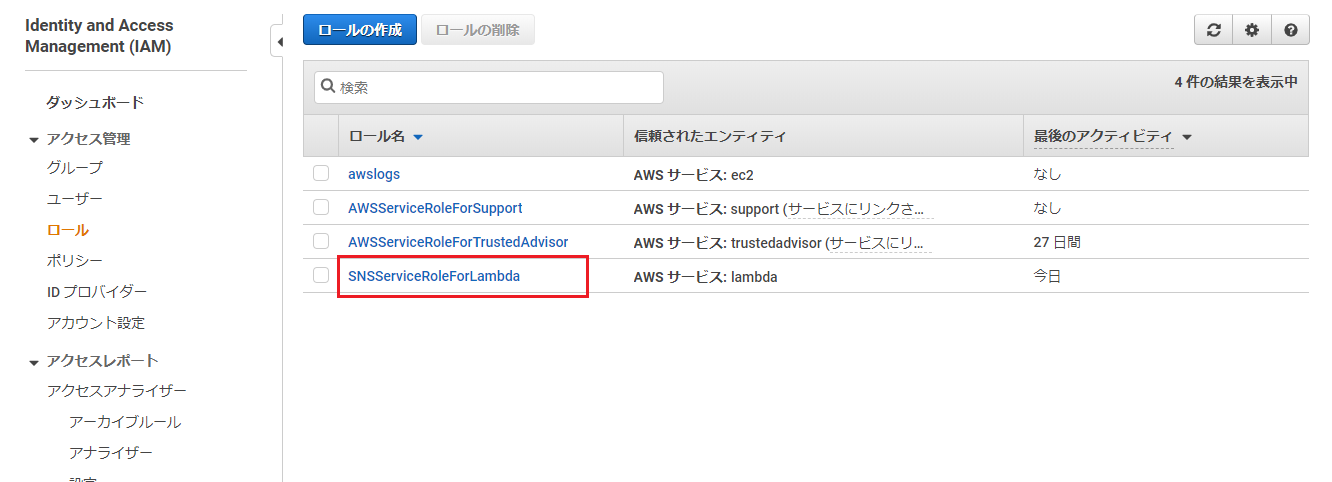
まずは、AWS Lambdaのダッシュボードから、「関数の作成」を押下。
オプションが「一から作成」になっている事を確認し、「基本的な情報」に以下を入力し、「関数の作成」を押下。
※「アクセス権限」の「実行ロールの選択または作成」をクリックし、「AWS ポリシーテンプレートから新しいロールを作成」を選択しておいてください。
項目名 入力値・選択値 関数名 sendCost(好きな名前で) ランタイム Python 3.7 ロール名 SNSServiceRoleForLambda(好きな名前で) ポリシーテンプレート Amazon SNS 発行ポリシー
Lambda関数のテスト
次に、請求情報を取得するコードを書いていく事になりますが、ここまでの設定確認のため、まずはテストメッセージを発行する処理を書いてみます。
関数作成後の下部にある「関数コード」欄に、以下のコードを入力します。
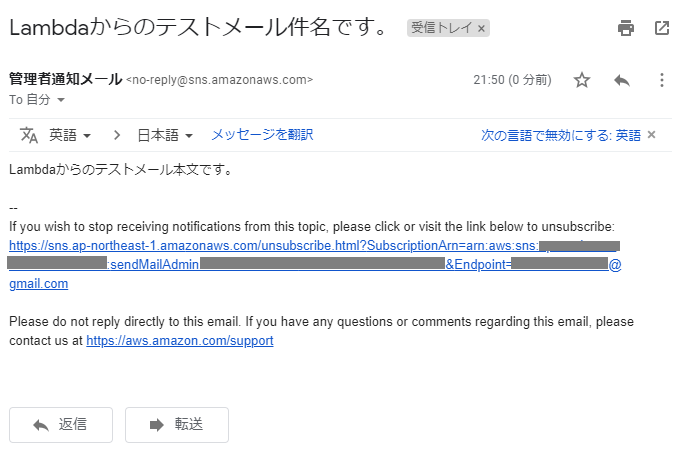
※TopicArnには、SNSトピック作成時に控えておいたARNを設定します。lambda_function.pyimport boto3 def lambda_handler(event, context): sns = boto3.client('sns') subject = 'Lambdaからのテストメール件名です。' message = 'Lambdaからのテストメール本文です。' response = sns.publish( TopicArn = 'arn:aws:sns:*:*:*', Subject = subject, Message = message ) return responseそして、実際にはトリガーで定期的に実行する事になりますが、手動で送信してみます。
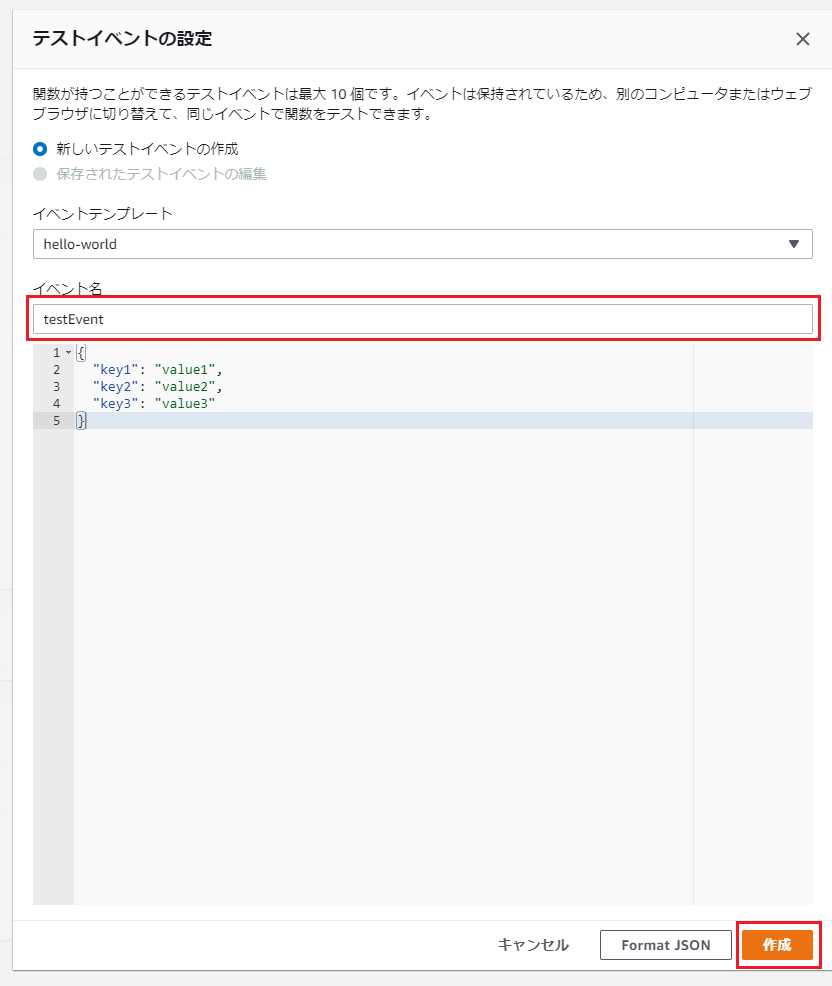
画面右上の「保存」を押下した後、「テスト」を押下し、「イベント名」に適当な名前を入れ、「作成」を押下。
その他は初期値のままでOK。
元の画面に戻り、再度右上の「テスト」をクリックすると関数が実行され、指定した受信メールアドレスにメールが届いているはずです。
届かない場合は、コード入力欄の下部のコンソール(Execution results)にエラーメッセージが表示されていないか、入力したARNに間違いがないか等確認してください。
請求情報通知用のコード作成
いよいよ、Cost Explorerから請求額を取得し、Amazon SNSで通知するコードを書いていきます。
TopicArnには、前回同様SNSトピック作成時に控えておいたARNを設定します。※後述しますが、追加設定を行わないとテストしてもエラーとなります!
※コードは、Developers.IOの記事のものをベースとさせていただきました。lambda_function.pyimport boto3 from datetime import datetime, timedelta, date def lambda_handler(event, context): ce = boto3.client('ce') sns = boto3.client('sns') # 今月の合計請求額を取得 total_billing = get_total_billing(ce) # 今月の合計請求額を取得(サービス毎) service_billings = get_service_billings(ce) # Amazon SNSトピックに発行するメッセージを生成 (subject, message) = get_message(total_billing, service_billings) response = sns.publish( TopicArn = 'arn:aws:sns:*:*:*', Subject = subject, Message = message ) return response def get_total_billing(ce): (start_date, end_date) = get_total_cost_date_range() response = ce.get_cost_and_usage( TimePeriod={ 'Start': start_date, 'End': end_date }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ] ) return { 'start': response['ResultsByTime'][0]['TimePeriod']['Start'], 'end': response['ResultsByTime'][0]['TimePeriod']['End'], 'billing': response['ResultsByTime'][0]['Total']['AmortizedCost']['Amount'], } def get_service_billings(ce): (start_date, end_date) = get_total_cost_date_range() response = ce.get_cost_and_usage( TimePeriod={ 'Start': start_date, 'End': end_date }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ], GroupBy=[ { 'Type': 'DIMENSION', 'Key': 'SERVICE' } ] ) billings = [] for item in response['ResultsByTime'][0]['Groups']: billings.append({ 'service_name': item['Keys'][0], 'billing': item['Metrics']['AmortizedCost']['Amount'] }) return billings def get_total_cost_date_range(): start_date = date.today().replace(day=1).isoformat() end_date = date.today().isoformat() # get_cost_and_usage()のstartとendに同じ日付は指定不可のため、今日が1日なら「先月1日から今月1日(今日)」までの範囲にする if start_date == end_date: end_of_month = datetime.strptime(start_date, '%Y-%m-%d') + timedelta(days=-1) begin_of_month = end_of_month.replace(day=1) return begin_of_month.date().isoformat(), end_date return start_date, end_date def get_message(total_billing, service_billings): start = datetime.strptime(total_billing['start'], '%Y-%m-%d').strftime('%Y/%m/%d') # Endの日付は結果に含まないため、表示上は前日にしておく end_today = datetime.strptime(total_billing['end'], '%Y-%m-%d') end_yesterday = (end_today - timedelta(days=1)).strftime('%Y/%m/%d') total = round(float(total_billing['billing']), 2) subject = f'{start}~{end_yesterday}の請求額:${total:.2f}' message = [] message.append('【内訳】') for item in service_billings: service_name = item['service_name'] billing = round(float(item['billing']), 2) if billing == 0.0: # 請求無しの場合は内訳を表示しない continue message.append(f'・{service_name}: ${billing:.2f}') return subject, '\n'.join(message)これで完成かと思いきや、Lamdaに割り当てたロールにCost Explorerへアクセスする権限がないので、以下のようなエラーとなります。
"errorMessage": "An error occurred (AccessDeniedException) when calling the GetCostAndUsage operation: User: arn:aws:sts::251745928455:assumed-role/SNSServiceRoleForLambda/sendCost is not authorized to perform: ce:GetCostAndUsage on resource: arn:aws:ce:us-east-1:251745928455:/GetCostAndUsage"そこで、IAM管理画面にて、Cost Explorerへアクセス出来るポリシーをロールにアタッチします。
※関数の作成時に「カスタムロールを作成」を選択し、jsonでポリシーを一気に割り当てる方法もあるようですが、2020/5時点では選択肢にありませんでした。ポリシーの作成とアタッチ
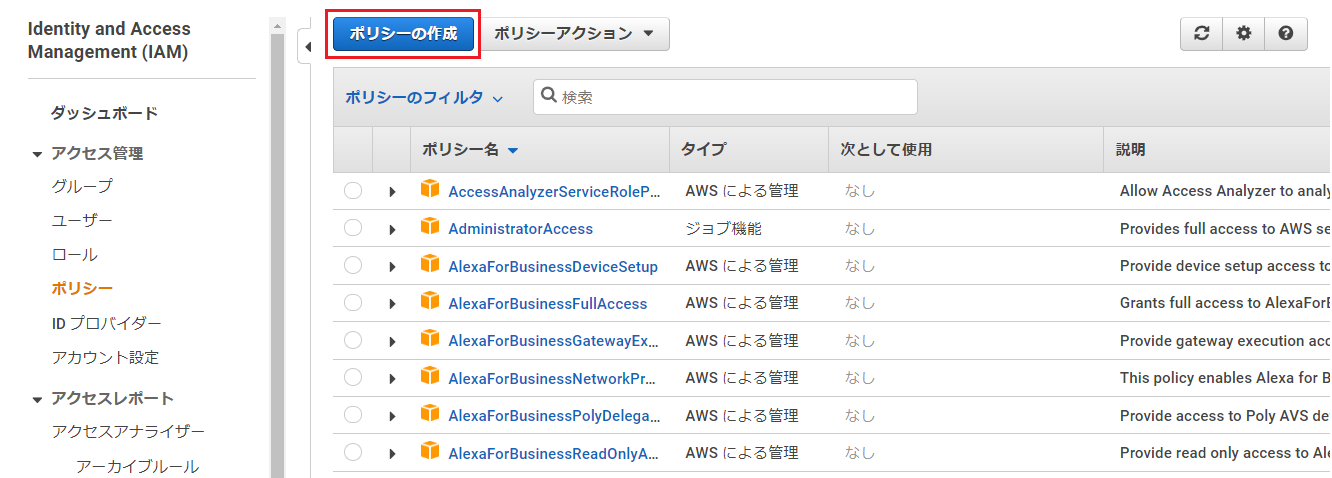
まず、IAM管理画面のポリシー一覧を表示し、「ポリシーの作成」を押下。
以下の項目を入力し、「ポリシーの確認」を押下。
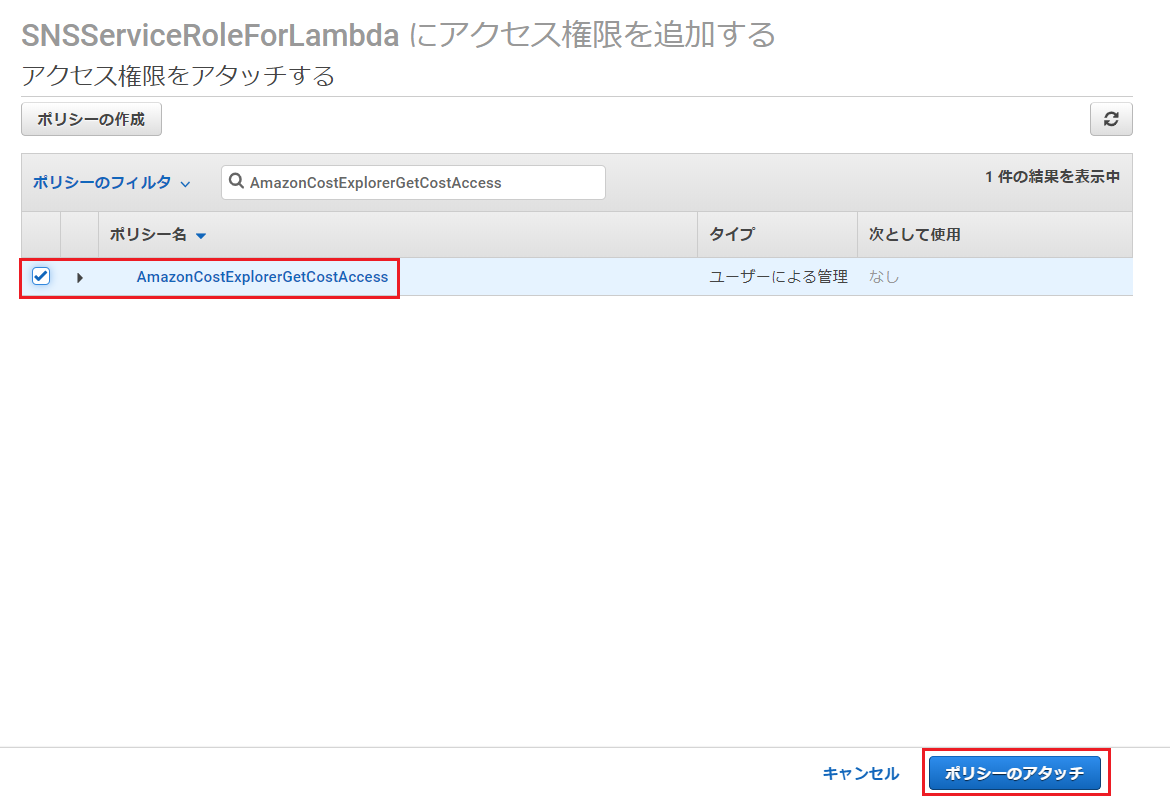
項目名 入力値・選択値 サービス Cost Explorer Service アクション 「GetCostAndUsage」と検索しチェックを入れる
ポリシーの確認画面で、「名前」を入力し、「ポリシーの作成」を押下。
※ここでは名前を「AmazonCostExplorerGetCostAccess」としました。
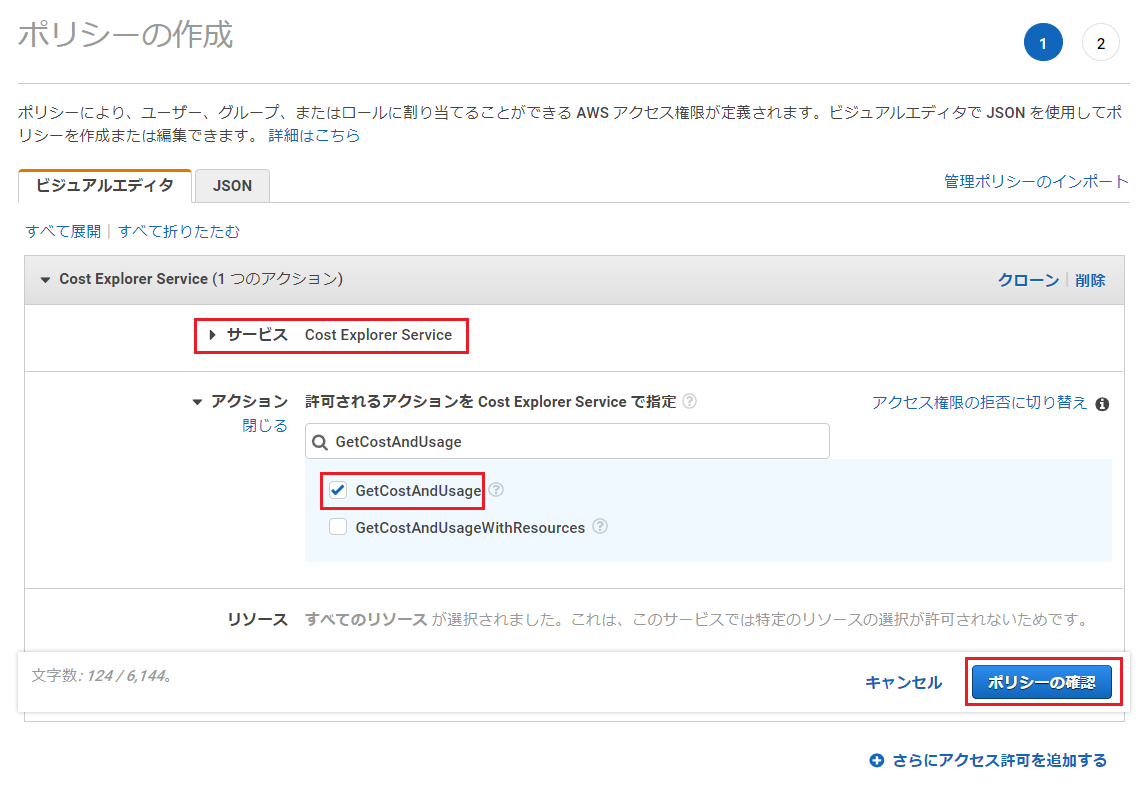
ロールの一覧画面に移動し、Lambdaに割り当てたロールを選択。
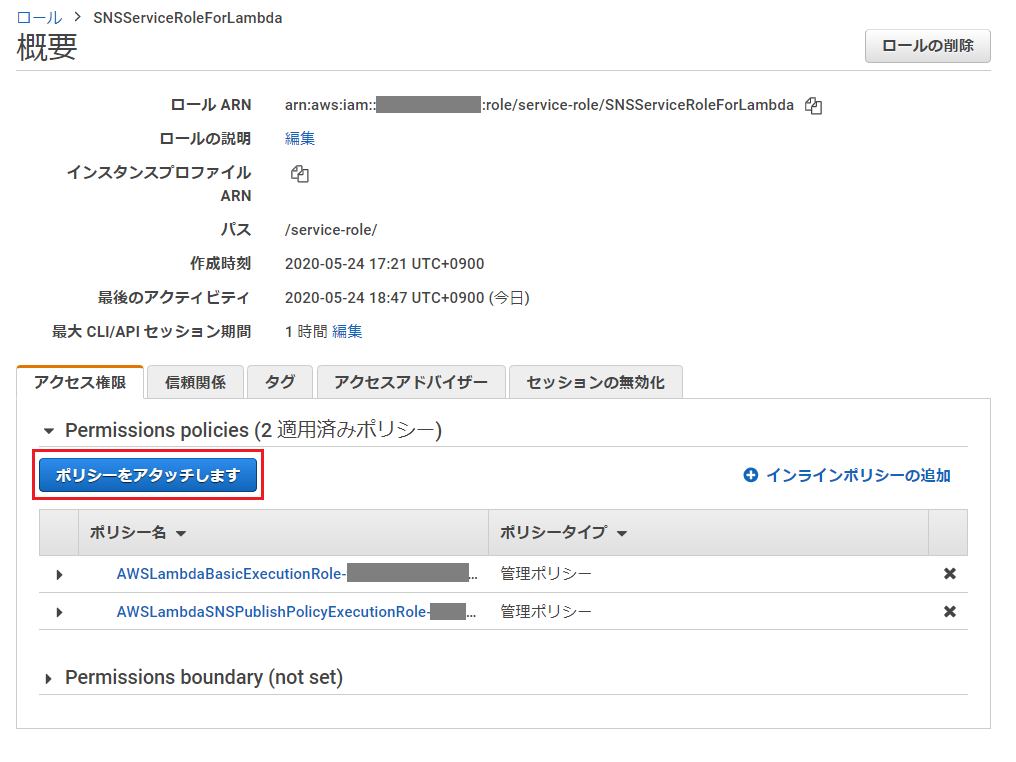
「ポリシーをアタッチします」を押下。
「ポリシーのフィルタ」で、ポリシー作成の際に設定した名前を入力して検索(この記事の例では「AmazonCostExplorerGetCostAccess」)し、ヒットしたものにチェックを入れ、「ポリシーのアタッチ」を押下。
Lambda関数の実行
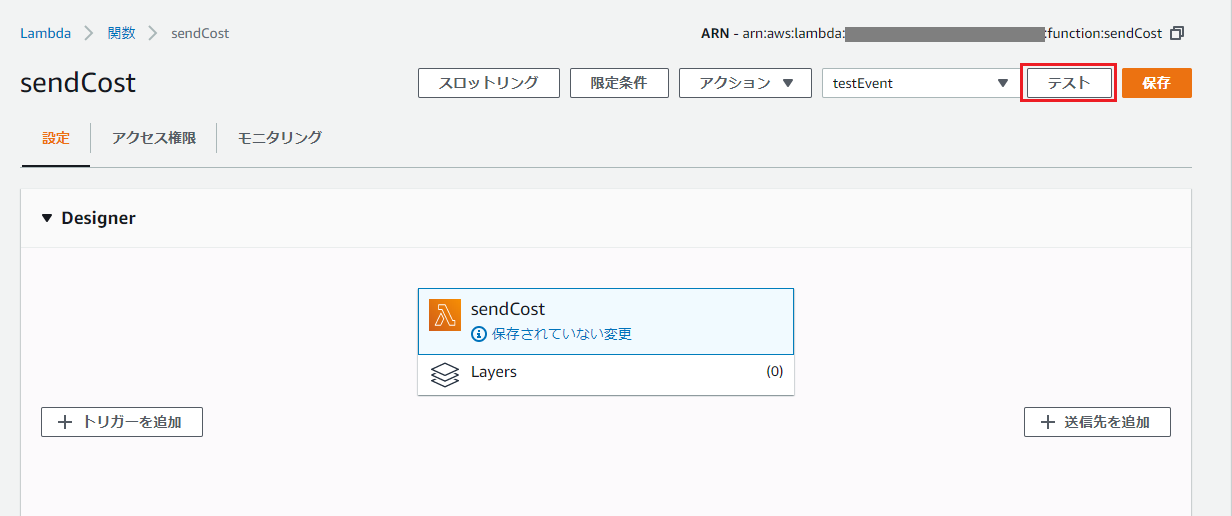
これで関数が正常に実行できる状態になったので、作成した関数の設定画面右上の「テスト」を押下します。
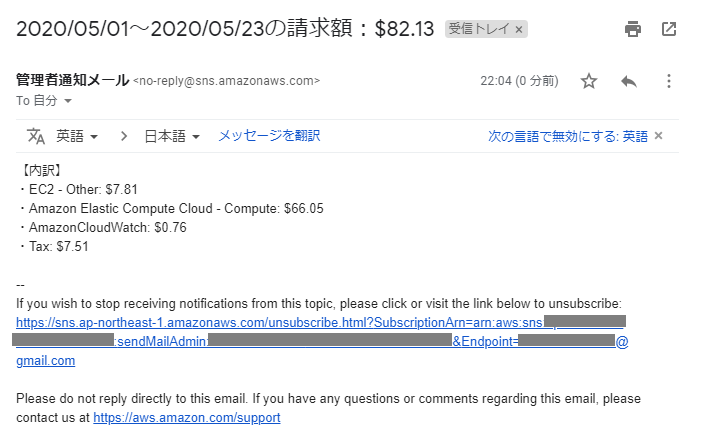
全て正しく設定できていれば、以下のようなメールが届くはずです。
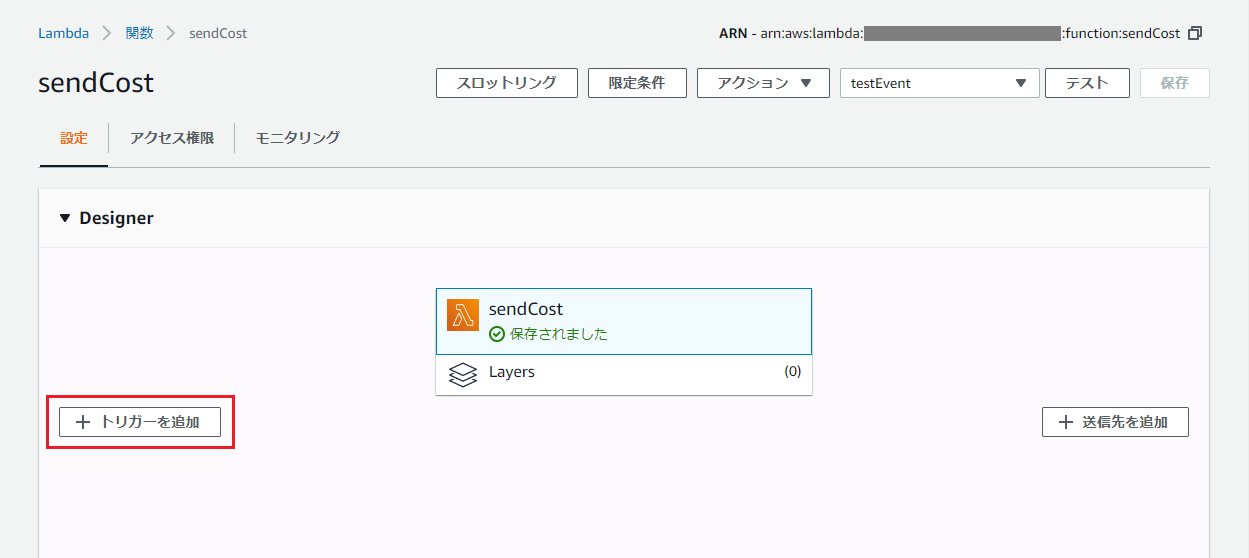
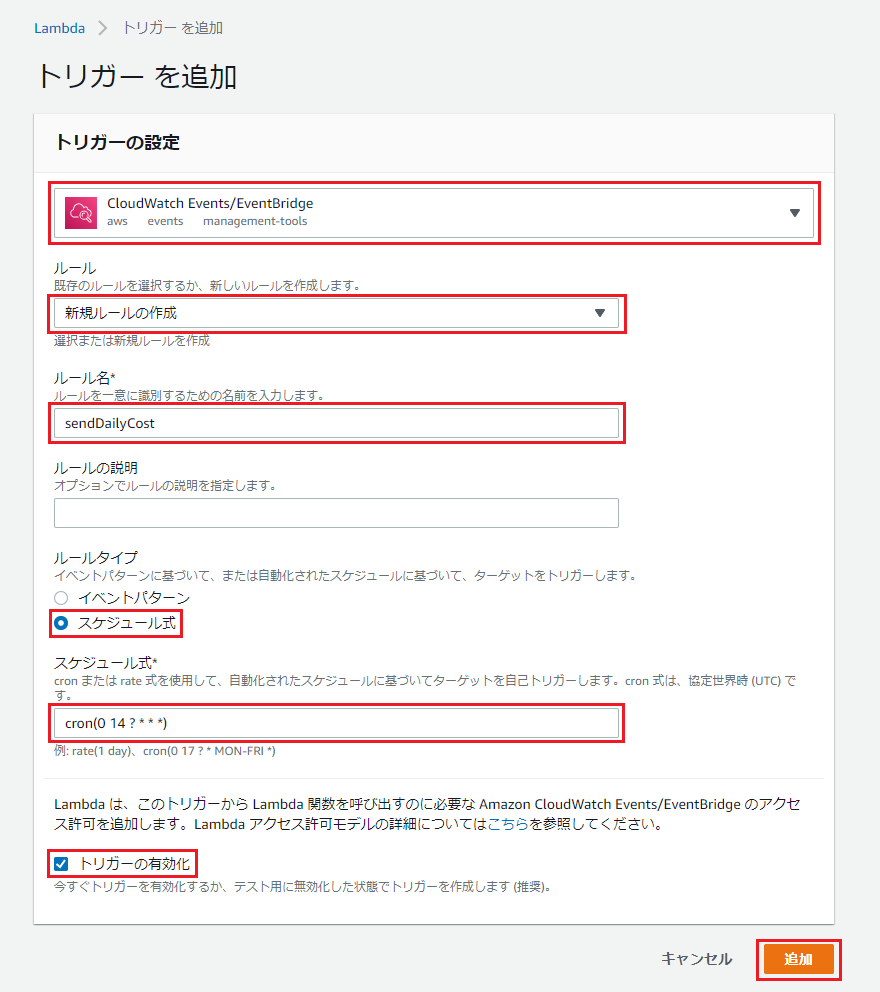
トリガーの設定
最後に、毎日決まった時間にメール通知するためのトリガーを設定します。
関数の設定画面の左側「トリガーを追加」を押下。
以下のように設定し、「追加」を押下。
項目名 入力値・選択値 トリガーを選択 CloudWatch Events/EventBridge ルール 新規ルールの作成 ルール名 sendDailyCost(適当に) ルールタイプ スケジュール式 スケジュール式 cron(0 14 ? * * *) トリガーの有効化 チェックする 今回は23時に設定しました。
注意点として、時間はUTCで設定するので、JST(日本標準時)から9時間分減算した時刻を設定します。
あとは、毎日指定した時間にメールが届く事を確認してください。
これで、安心して毎日眠れますね!
参考情報・引用




- 投稿日:2020-05-24T22:40:59+09:00
AWS日記⑥ (SNS)
はじめに
今回は Amazon SNS (Amazon Simple Notification Service) を利用して簡易な問い合わせページを作成します。
準備
SNSのトピックを作成し、サブスクライブに問い合わせの受け取り先(メールアドレスなど)を設定します。
Lambda , API Gatewayの準備をします。[参考資料]
Amazon SNS とは
チュートリアル: Amazon SNS トピックを作成する
「AWS SNS」の紹介WEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、SNS を使用するため aws-sdk-go を利用します。
参考資料ではアクセスキーを指定する方法をとっていますが、今回はLambdaにポリシーを追加する方法をとります。[参考資料]
AWS SDK for Go API Reference
AWS Lambda アクセス許可
Go+ AWS SNSを使ってSMSを送信する
AWS SDK for Go SNS コードサンプルメッセージを送る際には Publish を使う。
main.gofunc sendmessage(name string, message string, mail string) error { svc := sns.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &sns.PublishInput{ Message: aws.String("[Name]\n" + name + "\n\n[Mail]\n" + mail + "\n\n[Message]\n" + message), TopicArn: aws.String(topicArn), } _, err := svc.Publish(input) if err != nil { return err } return nil }今回は、ページ表示とAPIの API Gatewayを別々に作成し、APIのメソッドはPOSTに設定しました。
作成したLambda 関数、テンプレート終わりに
今回は問い合わせ機能のみなので難しい部分はありませんでした。
送信の上限値があるようなので、実際に運用する際は気をつけようと思います。
Amazon SNSを利用したSMSの一斉送信
- 投稿日:2020-05-24T22:23:23+09:00
RDS オプショングループ
オプショングループを使用する
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_WorkingWithOptionGroups.html
DB エンジンによっては、データとデータベースの管理を容易にしたり、データベースのセキュリティを強化したりするための、追加の機能が用意されている場合があります。Amazon RDS では、オプショングループを使用してこれらの機能を有効にして設定します。オプショングループには、特定の Amazon RDS DB インスタンスに使用できる機能 (オプション) を指定できます。オプションの設定では、そのオプションの動作を指定できます。DB インスタンスをオプショングループに関連付けると、指定したオプションとそれらの設定がその DB インスタンスに対して有効になります。
次のDBのオプショングループが使用可能
* MariaDB
* Microsoft SQL Server
* MySQL
* Oracleオプショングループの概要
Amazon RDS では、新しい DB インスタンスごとに空のデフォルトオプショングループが用意されます。このデフォルトオプショングループを変更することはできませんが、デフォルトオプショングループからその設定を引き継いで新しいオプショングループを作成することはできます。DB インスタンスにオプションを適用するには、以下を実行する必要があります。
新しいオプショングループを作成するか、既存のオプショングループをコピーまたは変更します。
1 つまたは複数のオプションをオプショングループに追加します。
オプショングループを DB インスタンスに関連付けます。
DB インスタンスと DB スナップショットはいずれもオプショングループに関連付けることができます。場合によっては、DB スナップショットからの復元や、DB インスタンスに対するポイントインタイム復元を行うことができます。このような場合、DB スナップショットまたは DB インスタンスに関連付けられているオプショングループは、デフォルトで、復元された DB インスタンスに関連付けられています。復元された DB インスタンスに異なるオプショングループを関連付けることができます。ただし、新しいオプショングループには、元のオプショングループに含まれる永続オプションまたは固定オプションを含める必要があります。永続オプションおよび固定オプションについては後で説明します。
オプションでは、DB インスタンスで実行するために追加のメモリが必要です。そのため、DB インスタンスの現在の使用状況によっては、サイズのより大きいインスタンスの起動が必要になる場合があります。たとえば、Oracle Enterprise Manager Database Control には約 300 MB の RAM が使用されます。サイズの小さい DB インスタンスに対してこのオプションを有効にした場合は、パフォーマンスの問題やメモリ不足のエラーが発生することがあります。
永続オプションと固定オプション
DB インスタンスがオプショングループに関連付けられている間は、固定オプションをオプショングループから削除することはできません。
固定オプション (Oracle Advanced Security TDE の TDE オプションなど) をオプショングループから削除することはできません。固定オプションを使用している DB インスタンスのオプショングループは変更することができます。ただし、DB インスタンスに関連付けられているオプションに、同一の固定オプションが含まれている必要があります。場合によっては、DB スナップショットから復元やポイントインタイム復元を行うことができます。DB スナップショットに関連付けられているオプショングループに固定オプションが含まれている場合、復元された DB インスタンスは、その固定オプションが含まれているオプショングループにのみ関連付けることができます。
- 投稿日:2020-05-24T22:14:20+09:00
AWS Backupの設定およびBackupジョブ失敗時の通知設定方法
この記事は
今年の1月にAWS Backupの機能がアップデートされ、AMIも自動で取得できるようになりました。
この記事ではタイトルにも記載されている通り、AWS Backupの設定およびBackupジョブ失敗時の通知設定方法を紹介します。
また、手順にも記載されておりますがBackupジョブの通知先としてSNSを設定する際、現状CLIを使った操作が必ず必要になるので注意してください。
①. Backupジョブ失敗時の通知先となるSNSトピックを作成
①-1. SNSトピックを作成
①-2. JSONエディタを編集
SNSのARN(2箇所あるので注意) と AWSアカウントID の箇所は適宜置き換えること。
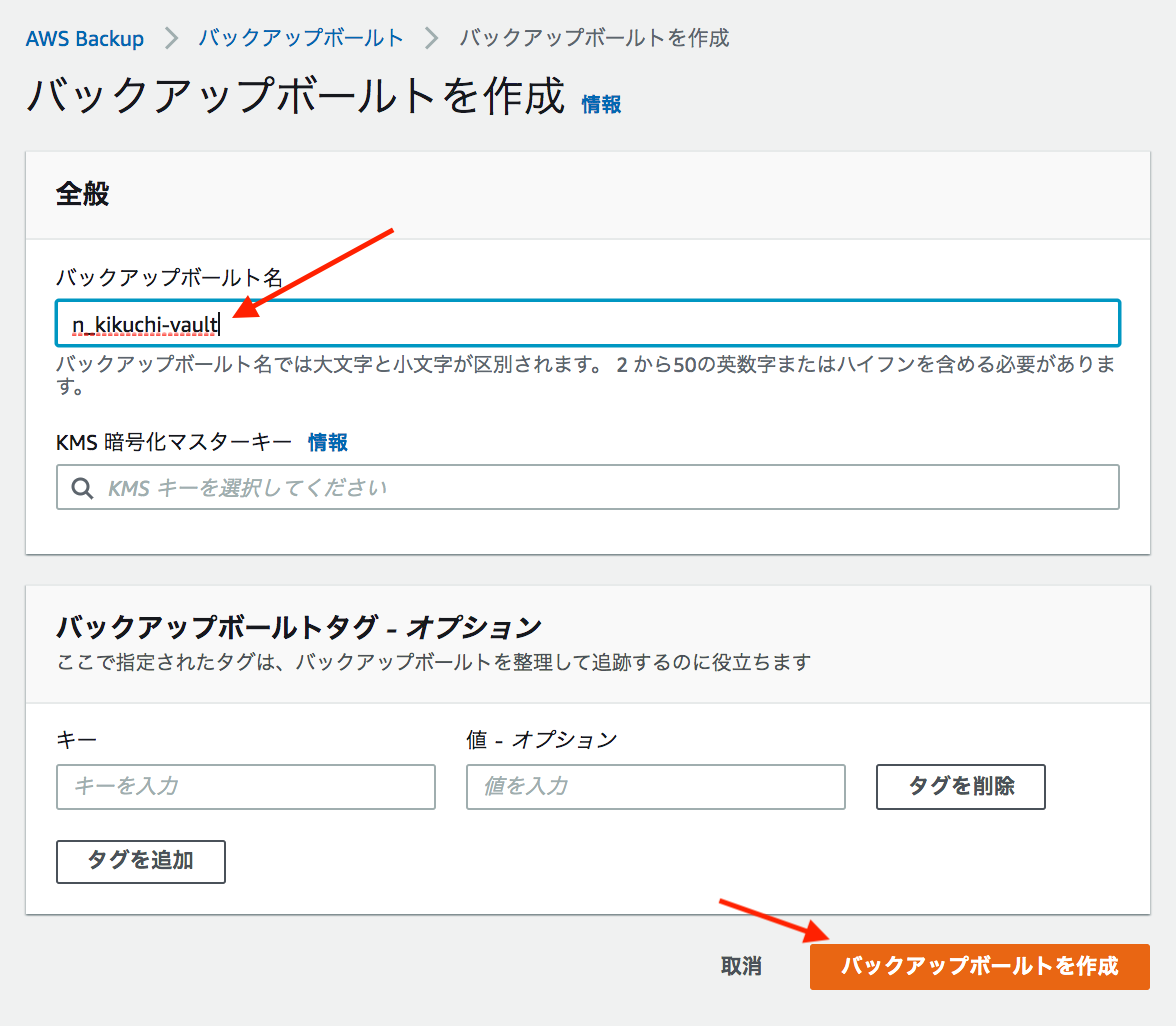
SNSのARNはarn:aws:sns:リージョン名:AWSアカウントID:SNSトピック名{ "Version": "2008-10-17", "Id": "__default_policy_ID", "Statement": [ { "Sid": "__default_statement_ID", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": [ "SNS:Publish", "SNS:RemovePermission", "SNS:SetTopicAttributes", "SNS:DeleteTopic", "SNS:ListSubscriptionsByTopic", "SNS:GetTopicAttributes", "SNS:Receive", "SNS:AddPermission", "SNS:Subscribe" ], "Resource": "SNSのARN", "Condition": { "StringEquals": { "AWS:SourceOwner": "AWSアカウントID" } } }, { "Sid": "__console_pub_0", "Effect": "Allow", "Principal": { "Service": "backup.amazonaws.com" }, "Action": "SNS:Publish", "Resource": "SNSのARN" } ] }②. バックアップボールトの作成
②-1. AWS Backupのコンソールへ移動
②-2. バックアップボールトを作成
②-3. AWS CLI を使用して、-backup-vault-events を BACKUP_JOB_COMPLETED に設定して put-backup-vault-notifications コマンドを実行
現状、コンソール画面から設定する手段が無いため、CLIを使って操作する必要があります。
- endpoint-url: バックアップボールトがある AWS リージョンのエンドポイントを入力 ※東京リージョンなら
https://backup.ap-northeast-1.amazonaws.com- backup-vault-name: バックアップボールトの名前を入力
- sns-topic-arn: 作成した SNS トピックの ARN を入力
aws backup put-backup-vault-notifications --endpoint-url https://backup.eu-west-1.amazonaws.com --backup-vault-name examplevault --sns-topic-arn arn:aws:sns:eu-west-1:111111111111:exampletopic --backup-vault-events BACKUP_JOB_COMPLETED②-4. get-backup-vault-notifications コマンドを実行し、SNSの設定が反映されていることを確認
- backup-vault-name: バックアップボールトの名前を入力
aws backup get-backup-vault-notifications --backup-vault-name examplevault以下のように出力されればOKです。
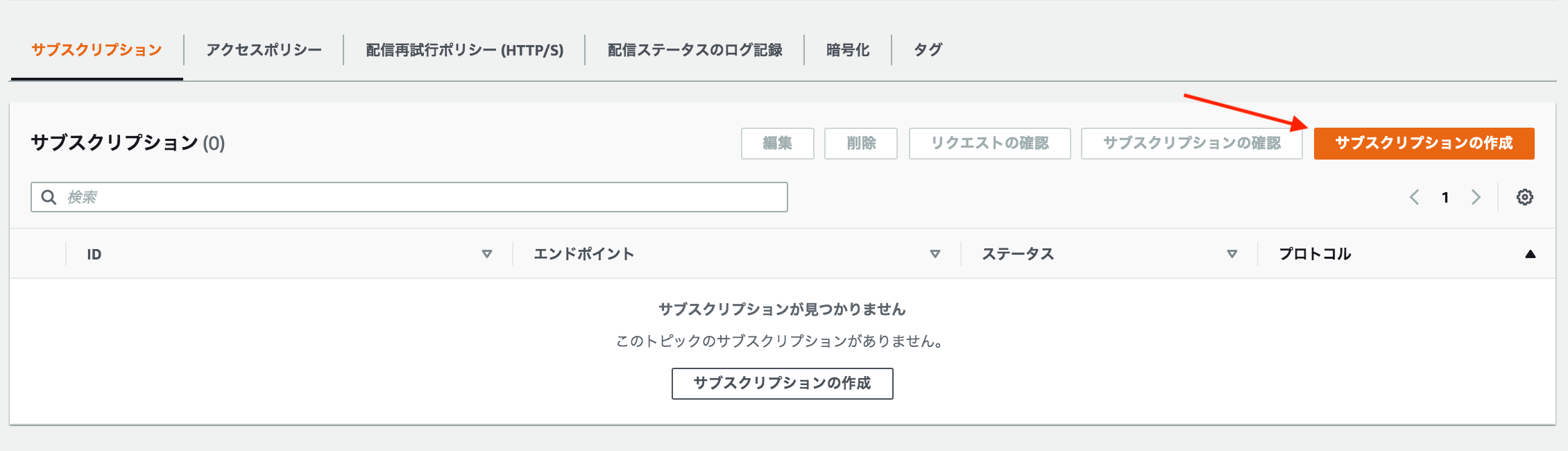
{ "BackupVaultName": "examplevault", "BackupVaultArn": "arn:aws:backup:eu-west-1:111111111111:backup-vault:examplevault", "SNSTopicArn": "arn:aws:sns:eu-west-1:111111111111:exampletopic", "BackupVaultEvents": [ "BACKUP_JOB_COMPLETED" ] }③. サブスクリプションの作成
③-1. SNSのコンソールへ移動後、①で作成したSNSトピックをクリック
③-2. サブスクリプションの作成を押す
③-3. 詳細箇所を入力する
- トピック ARN:①で作成したSNSトピックを選択
プロトコル、エンドポイントは通知先に応じて適宜変更してください。
エンドポントにDatadogのWebhook URLを指定すると、Backupジョブの失敗通知をDatadogで受け取ることができます。■参考記事:Datadog で AWS SNS を受け取る (RDS/ElastiCacheイベント)
今回はメールで失敗通知の受信を行います。
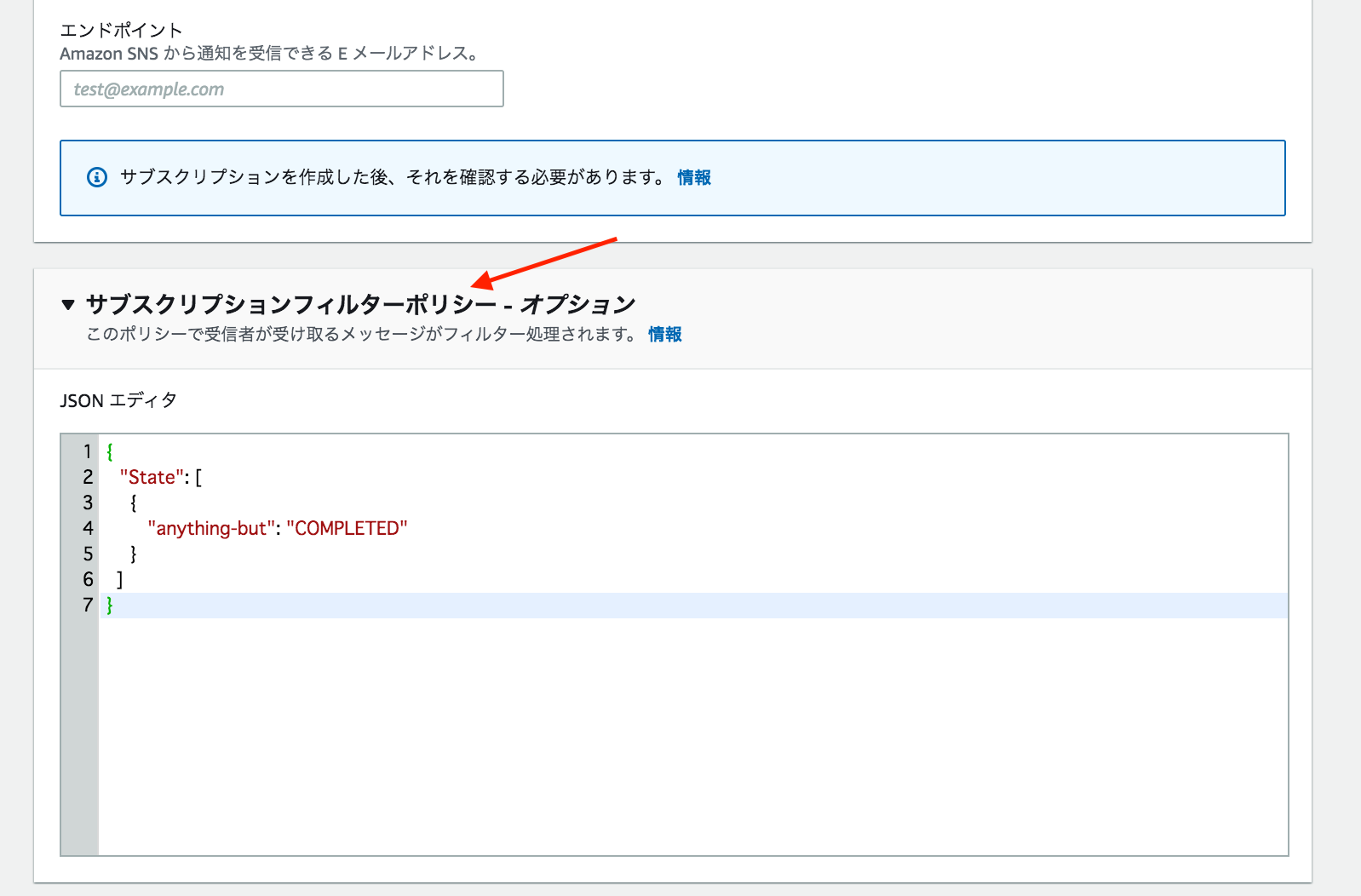
③-4. サブスクリプションフィルターポリシーに下記を貼り付ける
{ "State": [ { "anything-but": "COMPLETED" } ] }
④. AWS Backupの構築
④-1. AWS Backupのコンソールへ移動
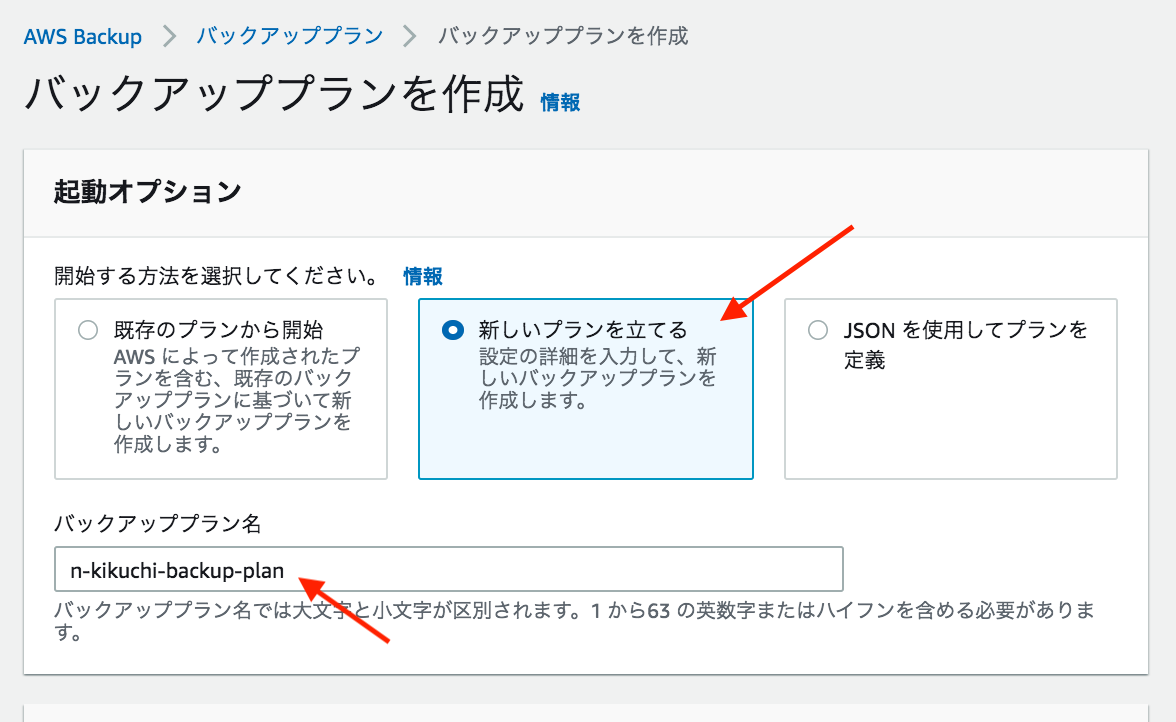
④-2. 「バックアッププランを作成」を押す
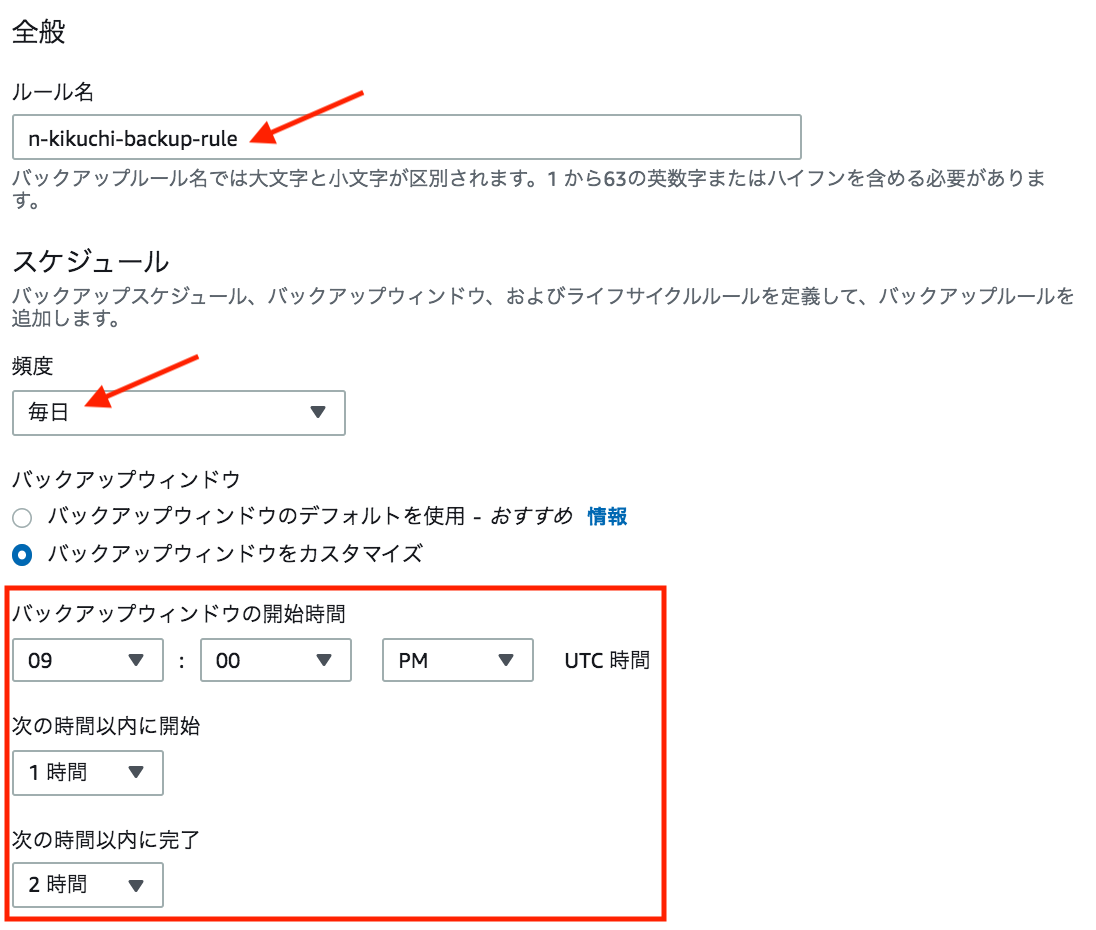
④-3. 「新しいプランを立てる」を押し、バックアッププラン名を入力
④-4. スケジュールを設定
下記設定で毎日、06:00 AM 〜 07:00 AM (JST) の間にAMI取得が開始される。
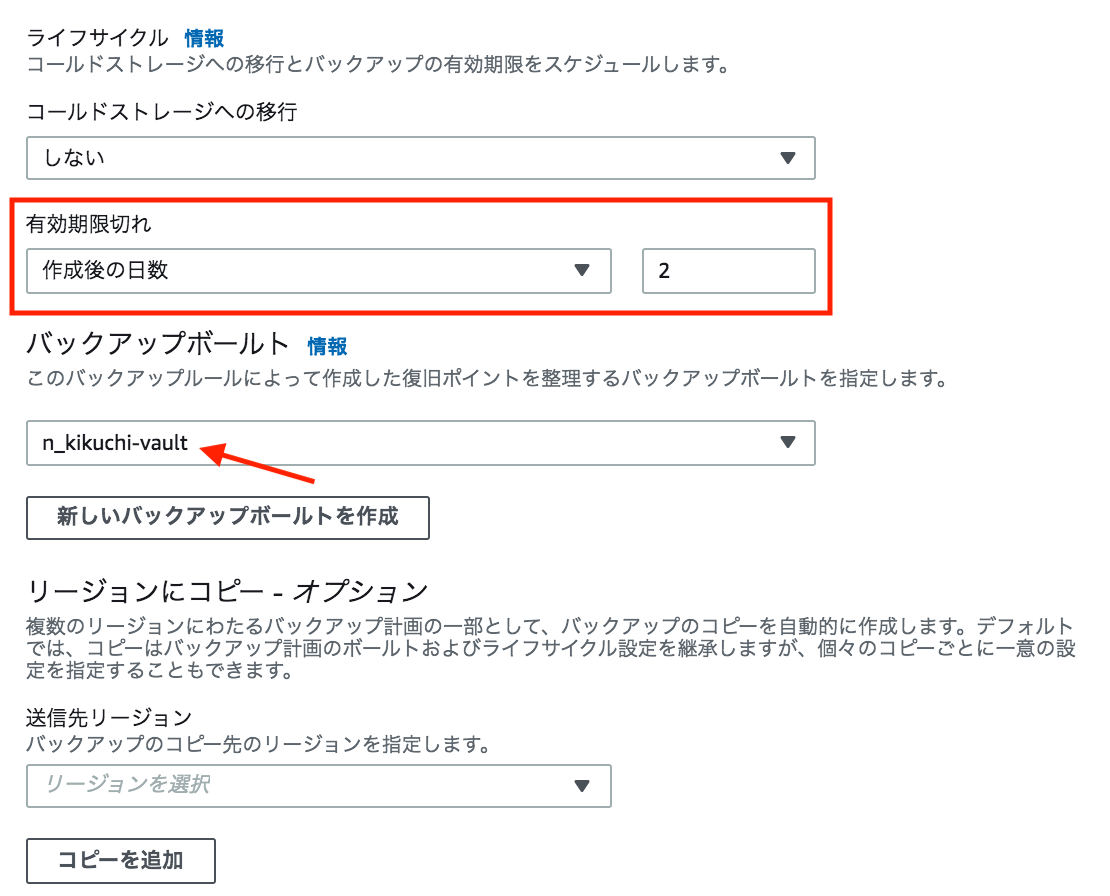
④-5. ライフサイクル設定
以下の設定でBackup世帯数が2になる。バックアップボールトには②で作成したものを選択すること。
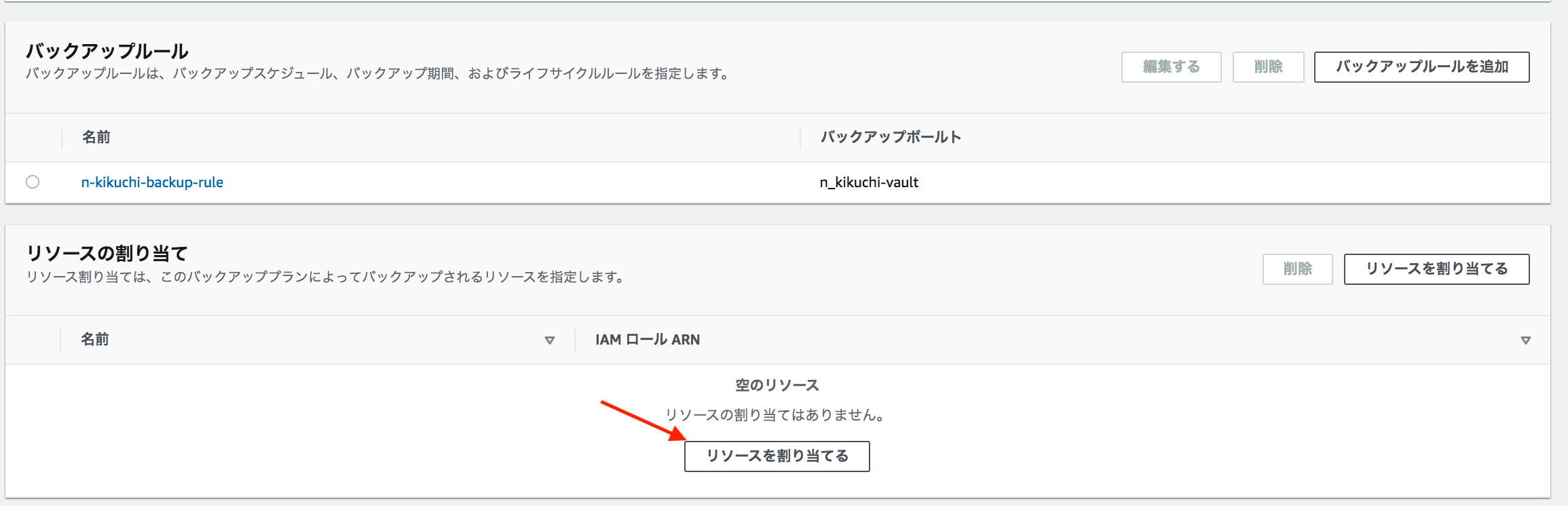
④-6. 「リソースを割り当てる」を押す
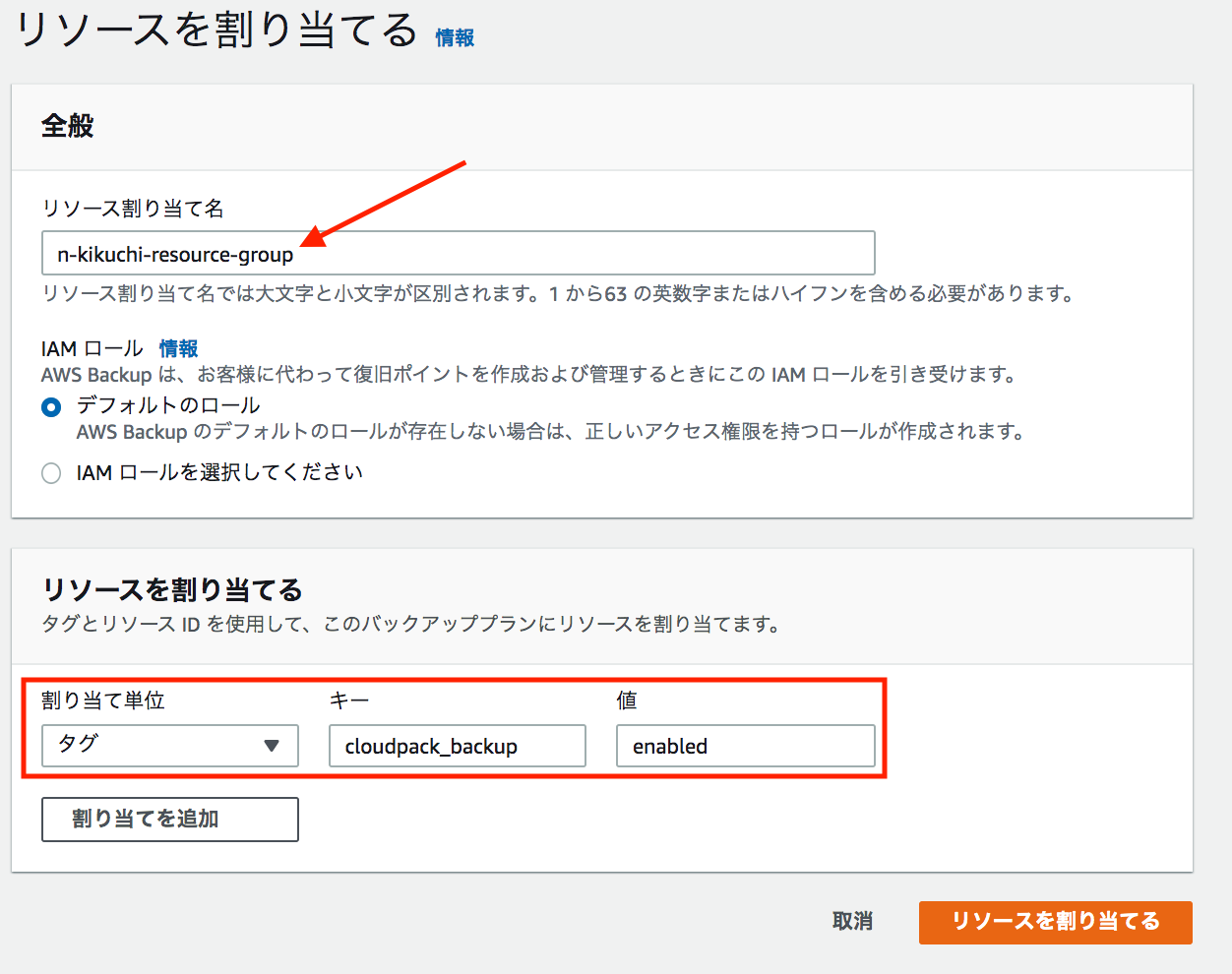
④-7. リソースを割り当てる
今回はタグで管理してます。インスタンスIDを直接指定することも可能です。
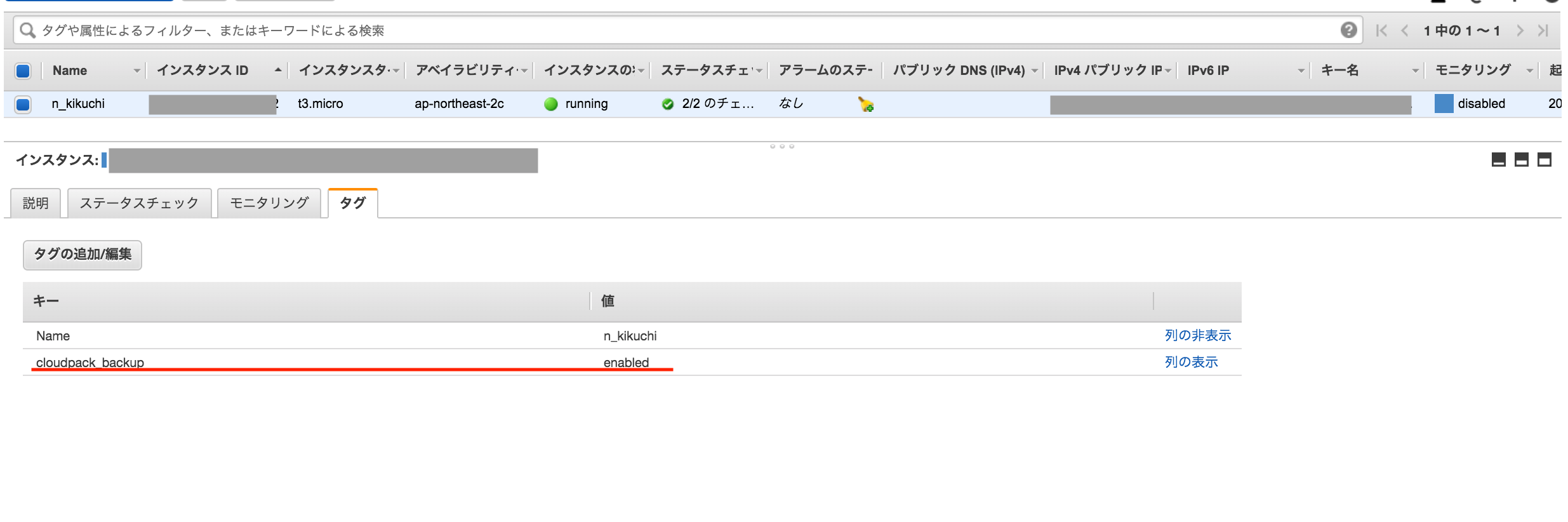
④-8.Backupを取得したい対象リソースに対してタグを付ける
これで設定は完了です。
⑤. Backupジョブ失敗の通知テスト
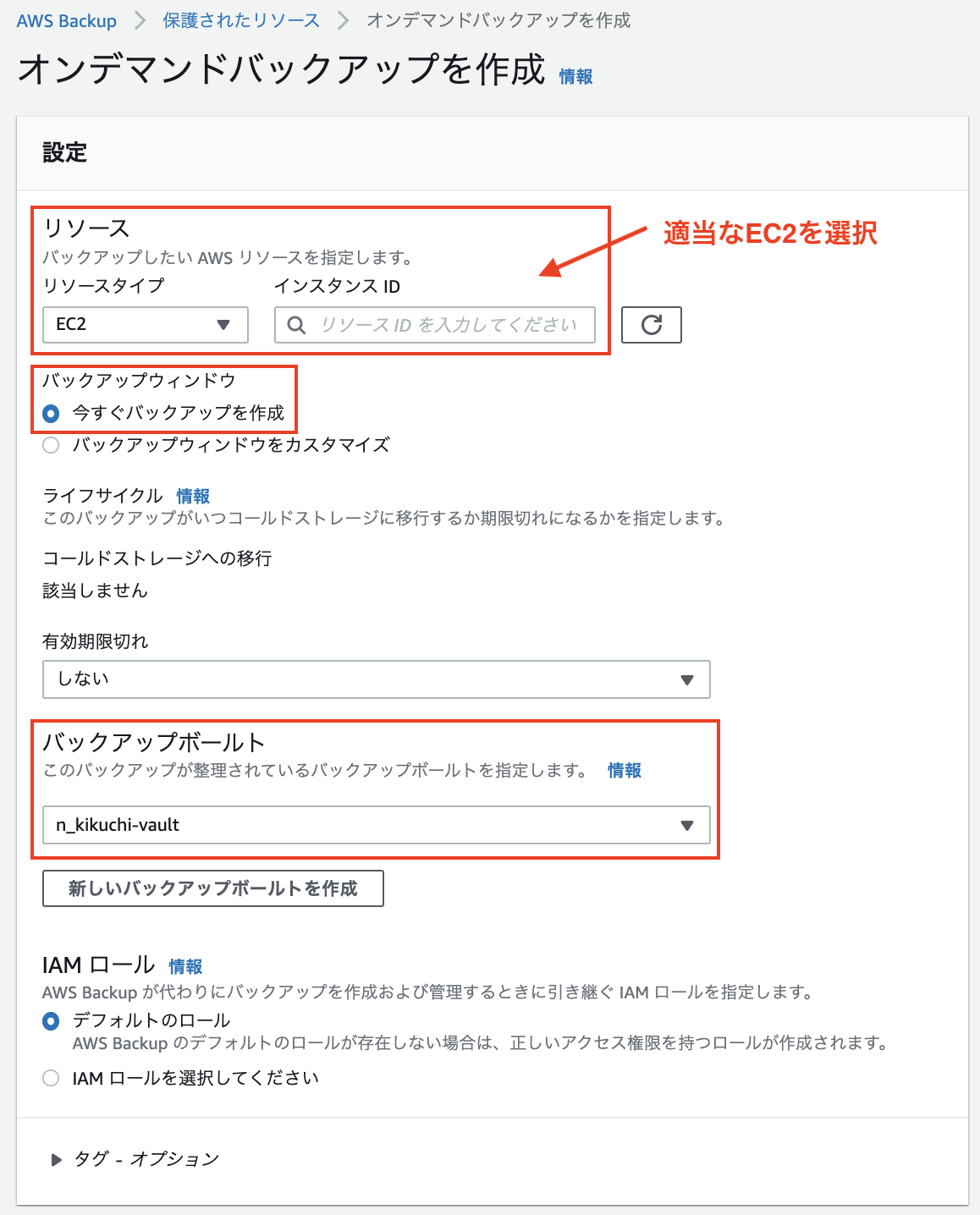
⑤-1. 保護されたリソースからオンデマンドバックアップの作成を押す
⑤-2. 設定を行いオンデマンドバックアップを作成を押す
ここの設定画面で大事な箇所は以下の2点
- 今すぐバックアップを作成
- バックアップボールトを②で作成したものにする
⑤-3. バックアップジョブが実行されるのを確認
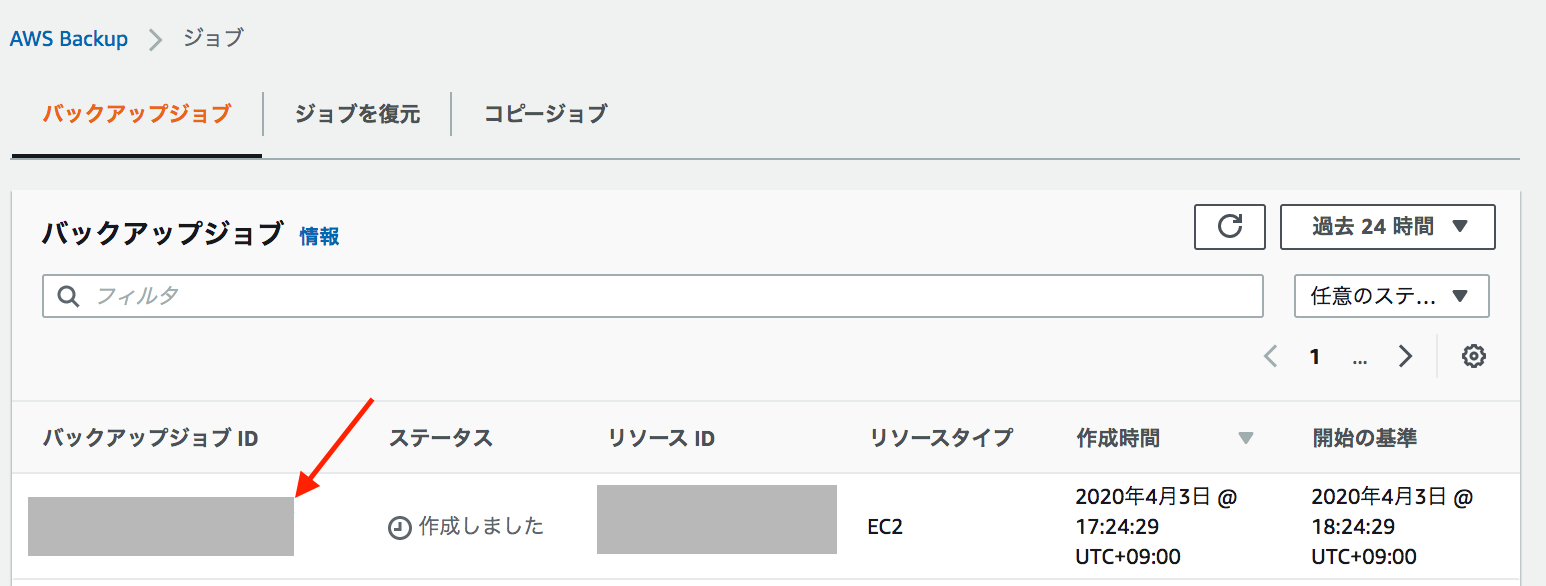
⑤-4. もう一度オンデマンドバックアップを作成を押す(設定もさっきと同じでOK)
⑤-5. 今度はバックアップジョブ IDをクリック
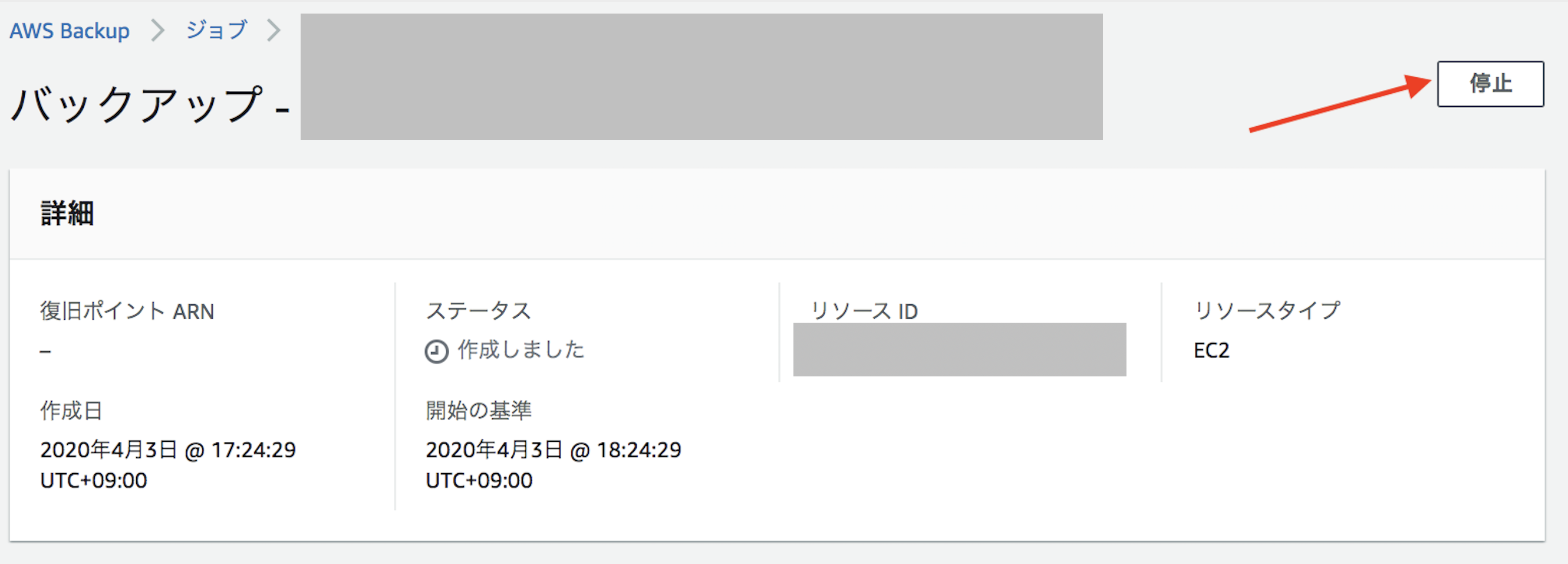
⑤-6. 停止を押す
⑤-7. ステータスが「中止しました」になることを確認
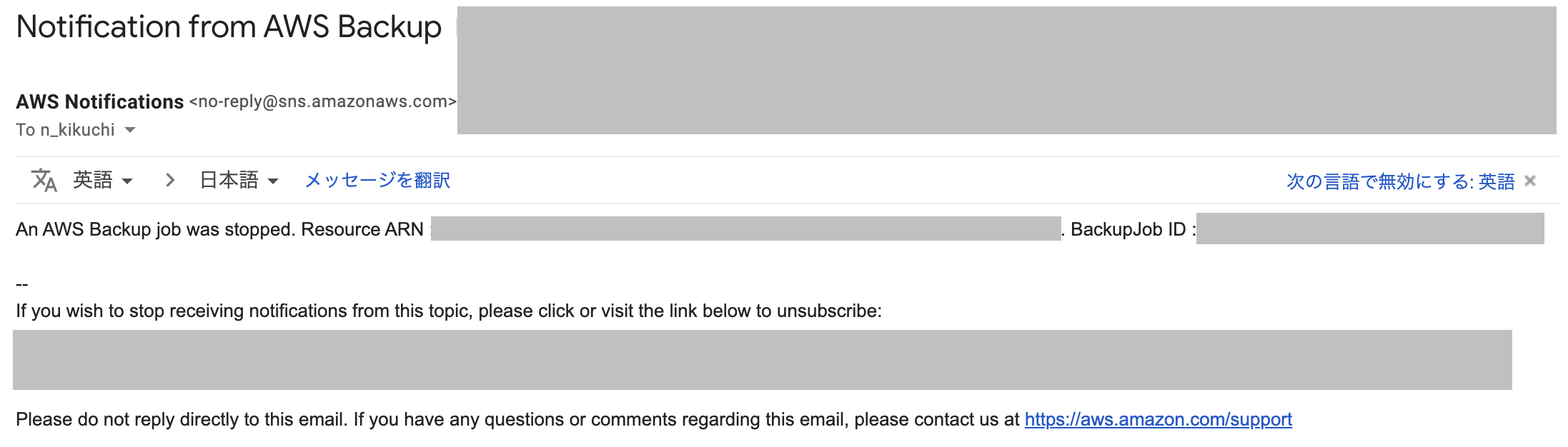
⑤-8. 停止したジョブの方のみ通知がきていることを確認
ジョブを停止してから約8分後に通知が届きました。
おまけ
AWS Backupで作成したAMIを削除するには
バックアップボールトから②で作成したものを選択
作成したAMIを選択し削除を押す
実際にAMI Backupの取得に失敗した際に通知される内容
AMI Backupの取得が実際に失敗すると下記のように、
An AWS Backup job failed.というメッセージが通知されるようです。An AWS Backup job failed. Resource ARN : arn:aws:ec2:*****:*****:instance/*****. BackupJob ID : *****




- 投稿日:2020-05-24T21:28:34+09:00
【学習メモ】AWS(VPC)
【VPC】ネットワーク構築
【基本手順】
1.ネットワーク(VPC)を構築
2.その環境で、サーバー(EC2など)を設置
3.必要なアプリを実装【ネットワーク構築の全体像】
<目標成果物:WordPressでのシステム構築>
1.インターネットからWebサーバーへ接続
2.Webサーバーに格納されているWordPressからDBサーバーのMySQLにデータを格納する【AWSのネットワークの概念】
リージョン:AWSのサービスが提供されている地域アベイラビリティゾーン:独立したデータセンター
※1つのリージョンに複数のアベイラビリティゾーンがあることで、1つのデータセンターが壊れても他のデータセンターが稼働できるVPC:AWS上に仮想ネットワークを作成するサービス
サブネット:VPCを細かく区切ったネットワーク
例:
「インターネットから見れるようにしたい」
「DBはネットから見れないようにしたい」
など用途によって分ける
→サブネットは、アベイラビリティゾーンの中に作成【IPアドレス】
<イメージ>
<IPアドレスとは>
ネットワーク上の機器を識別するためのインターネット上の住所①パブリックIPアドレス
・インターネットに接続する際に使用するIPアドレス
・プロバイダーやサーバー事業者から貸し出される②プライベートIPアドレス
・インターネットで使用されないIPアドレス
・使用可能な範囲は下記の通り。この中であれば自由に使用可能10.0.0.0〜10.255.255.255
172.16.0.0〜172.31.255.255
192.168.0.0〜192.168.255.255・社内LANの構築やネットワークの実験時はプライベートIPアドレスを使用する
※IPアドレスは、「ネットワーク部(前半3つ目)」と「ホスト部(後半の4つ目」に区分けできる
ネットワーク部:固定
ホスト部:可変=任意の数を設定できるCIDR表記
サブネットマスク表記設定するネットワークのIPアドレス(例)
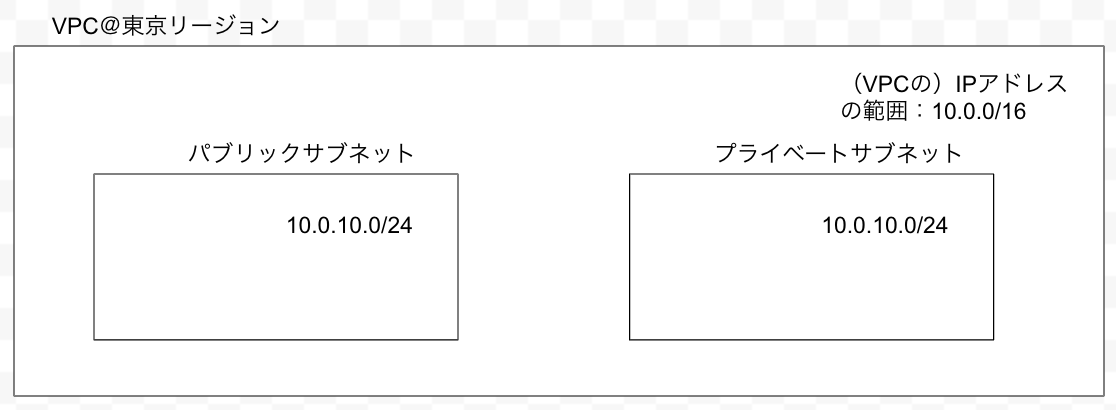
VPC:10.0.0.0/16
パブリック:10.0.10.0/24
プライベート:10.0.20.0/24<作業の手順>
①VPCを作成する
②サブネットを作成する
③ルーティングを設定する①VPCの作成
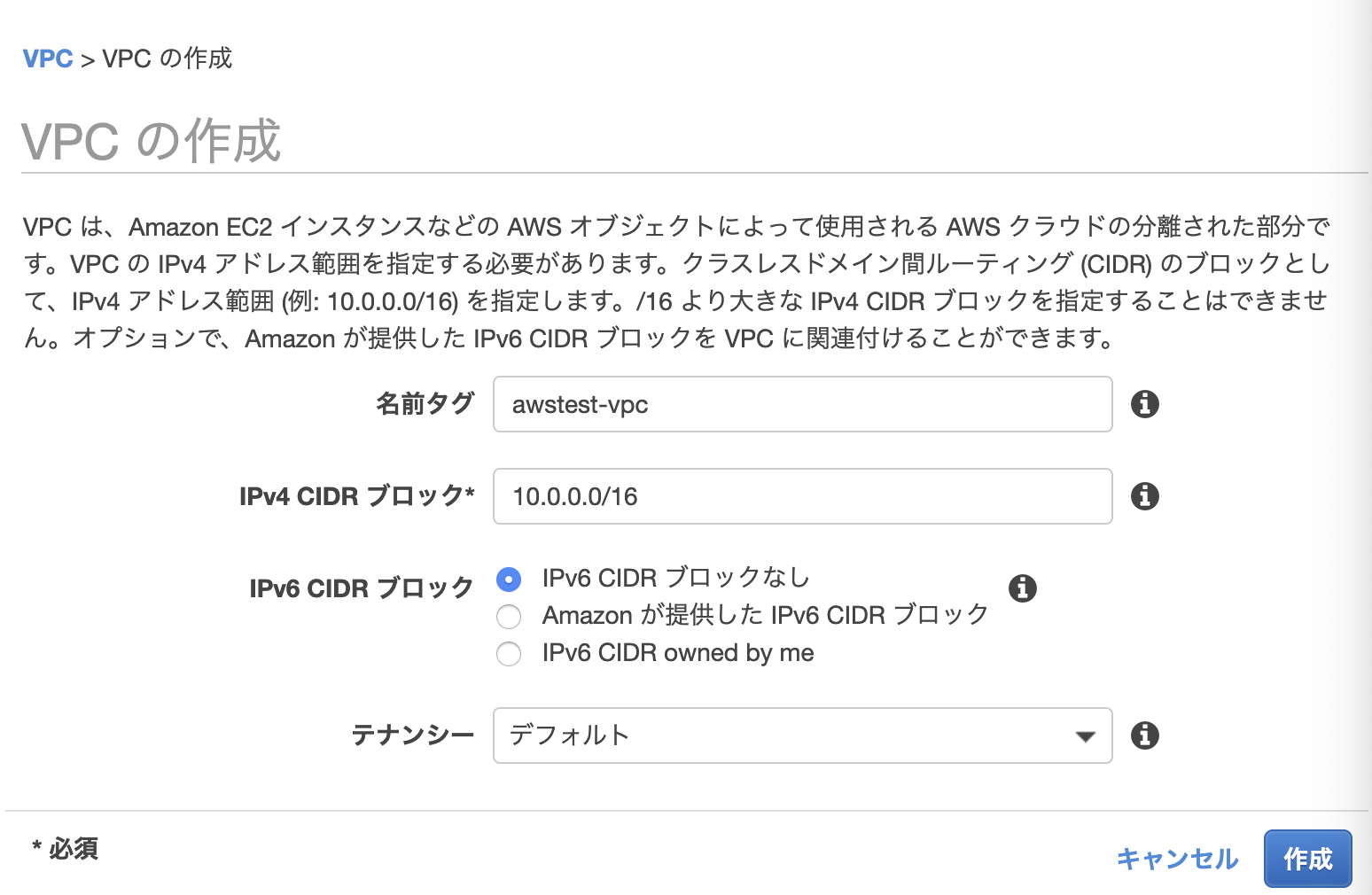
トップ画面からVPCを検索し作成
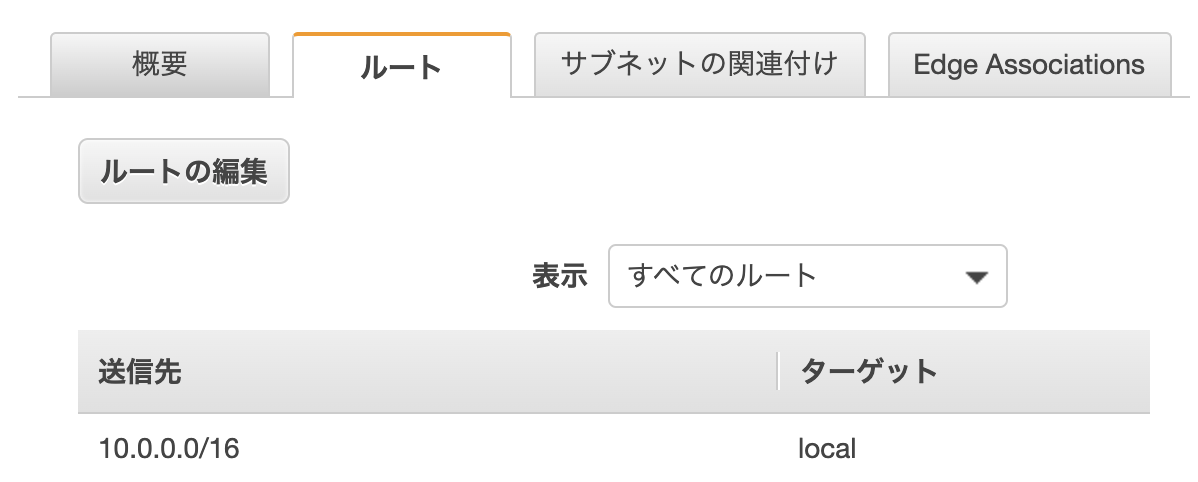
CICDブロックには、今回設定するIPアドレスを記入する。>VPC:10.0.0.0/16
設定が完了すると、VPCトップページに戻り、「CIDRブロック」タブをクリックすると確認できる。
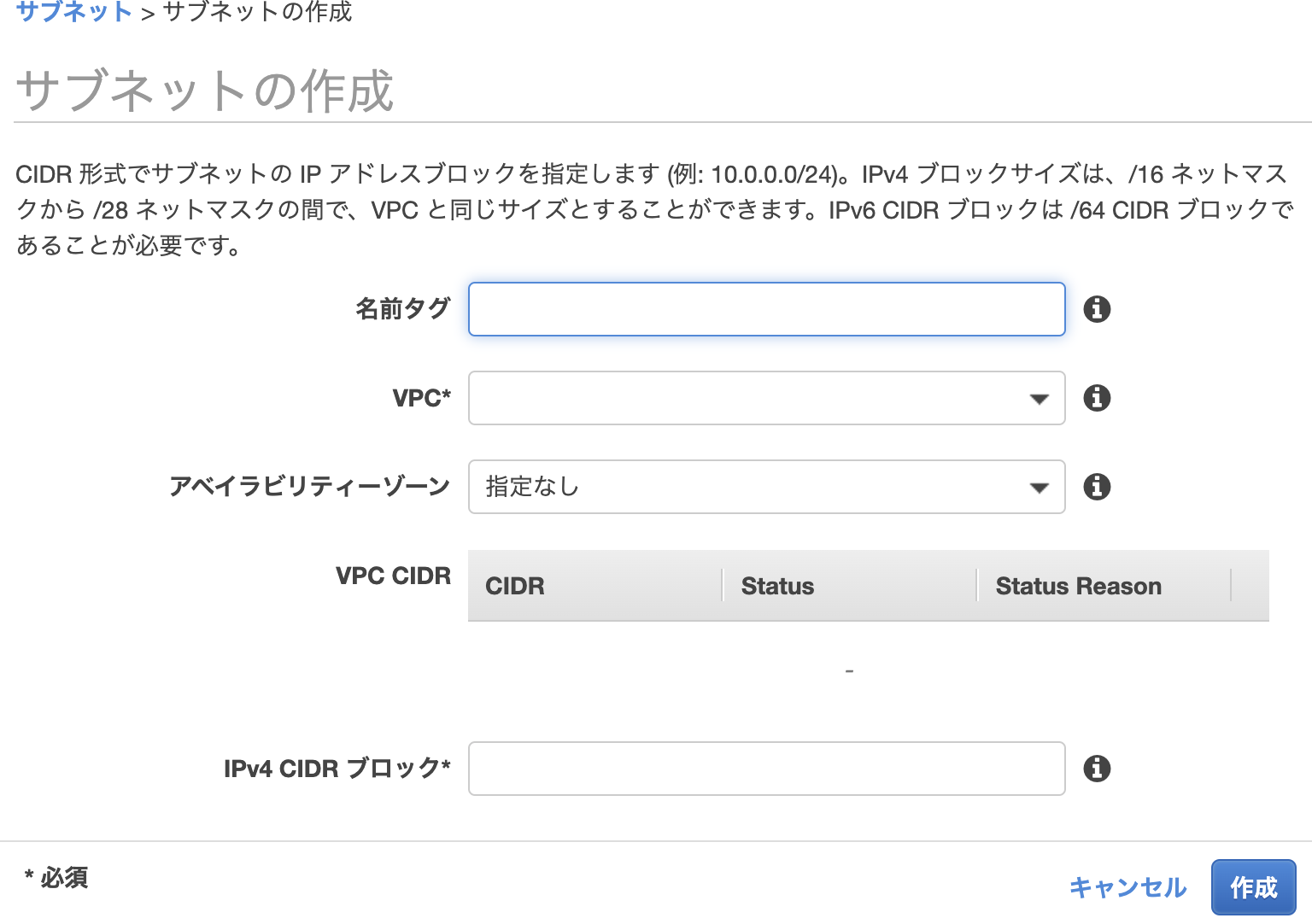
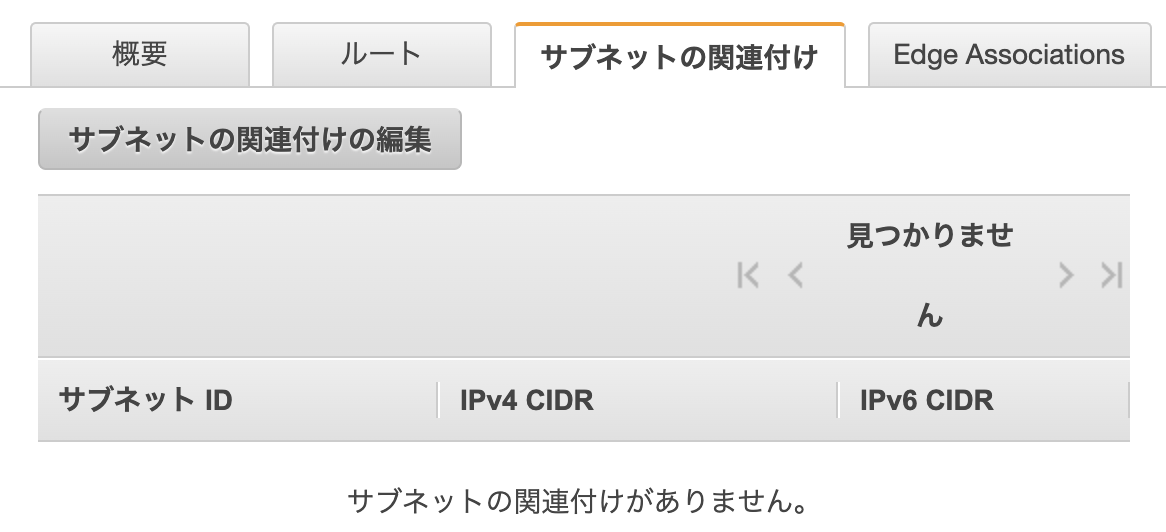
②サブネットを作成
設定したVPCから、パブリックサブネッt・プライベートサブネットのIPアドレスを範囲指定する
AWSのサブネット画面に移動し、サブネットの作成をクリック。
VPCは、先ほど指定したVPCを選択。
CIDRブロックは、任意の内容。
③ルーティングの設定
ゴール:パブリックサブネットからインターネットに接続できるようにしたい
(1)インターネットゲートウェイを作成しVPCにアタッチする
(2)ルートテーブルを作成し、パブリックサブネットに紐付けが、現状Webサーバーがインターネットに接続できない状態で、接続できるようにする設定を、ルーティングという
ルートテーブルは、「宛先のIPアドレス」と「次のルーター(AWSではターゲット」という書式で設定する
インターネット接続を可能にするために、「インターネットゲートウェイ」を作成
(1)インターネットゲートウェイを作成しVPCにアタッチする
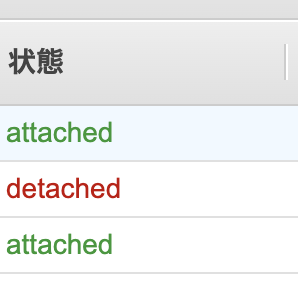
VPCを開きインターネットゲートウェイの作成を押し、作成する。すると、こんな感じで出来上がる。
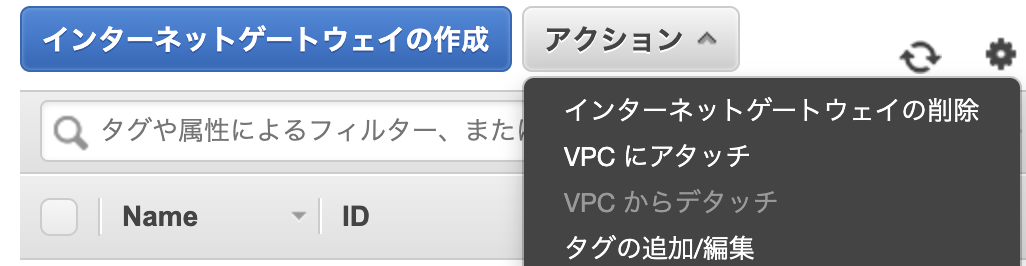
detachedの状態なので、アクションタブから「VPCにアタッチ」を選択
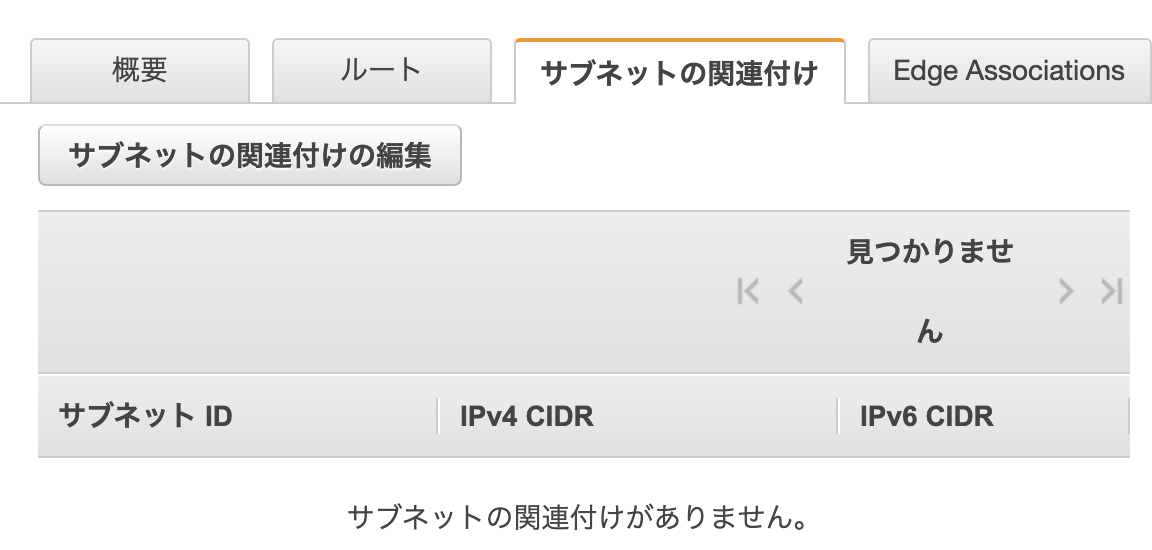
(2)ルートテーブルを作成し、パブリックサブネットに紐付け
ルートテーブル項目から選択して作成。
これで関連付けができればOK
デフォルトルートをインターネットゲートウェイに設定
パブリックサブネットにも適用させる。
関連付けの編集から編集。
その後はルートタブから作成して適用させる。
- 投稿日:2020-05-24T20:27:41+09:00
Amazon CloudWatch Logsにログを保存するようなAWS Fargateクラスタを、Terraformで構築する
What?
やりたいこと。
- AWS Fargateを使って、クラスタを作る
- コンテナのログは、Amazon CloudWatch Logsに送る
- 以上のことを、Terraformで実現する
というのを書いていきます。
環境
利用するTerraformと、AWS Providerのバージョンです。
$ terraform version Terraform v0.12.25 + provider.aws v2.63.0構築する内容
まっさらなところから、VPCを作ってAWS Fargateクラスタを構築、簡単な動作確認を行うところまでやります。
- シングルAZ
- 動作させるコンテナはnginx
- ALBはHTTP
Terraformでの実装内容は、すべて
main.tfに書いています。TerraformとAWS Providerのバージョン指定
terraform { required_version = "= 0.12.25" } provider "aws" { version = "2.63.0" }AWSのクレデンシャルは、環境変数で設定。
export AWS_ACCESS_KEY_ID=..... export AWS_SECRET_ACCESS_KEY=..... export AWS_DEFAULT_REGION=.....この状態で、進めていきましょう。
VPC〜ALBまで
このあたりは、今回のお題であるFargateやCloudWatch Logsの前提となる環境を作っていくのでコミュニティモジュールを積極的に使って、簡単に。
VPC
VPCは、こちらのコミュニティモジュールを使用して定義。
module "vpc" { source = "terraform-aws-modules/vpc/aws" version = "2.33.0" name = "my-vpc" cidr = "10.0.0.0/16" azs = ["ap-northeast-1a", "ap-northeast-1c"] public_subnets = ["10.0.101.0/24", "10.0.102.0/24"] private_subnets = ["10.0.1.0/24", "10.0.2.0/24"] map_public_ip_on_launch = true enable_nat_gateway = true single_nat_gateway = true one_nat_gateway_per_az = false }シングルAZにするので、NAT Gatewayはひとつ。
セキュリティグループ
セキュリティグループは、ALBとFargateに割り当てるものをそれぞれ定義します。コミュニティモジュールは、こちらを利用。
AWS EC2-VPC Security Group Terraform module
module "load_balancer_sg" { source = "terraform-aws-modules/security-group/aws//modules/http-80" version = "3.10.0" name = "load-balancer-sg" vpc_id = module.vpc.vpc_id ingress_cidr_blocks = ["0.0.0.0/0"] } module "nginx_cluster_sg" { source = "terraform-aws-modules/security-group/aws//modules/http-80" version = "3.10.0" name = "nginx-cluster-sg" vpc_id = module.vpc.vpc_id ingress_cidr_blocks = ["10.0.0.0/16"] }
vpc_idに関しては、先ほどのVPCを作った時のモジュールのOutputを利用します。vpc_id = module.vpc.vpc_idALB
HTTPを受け付ける、ALBを定義します。リスナーや、ターゲットグループも同時に定義することになります。コミュニティモジュールは、こちらを利用。
AWS Application and Network Load Balancer (ALB & NLB) Terraform module
module "load_balancer" { source = "terraform-aws-modules/alb/aws" version = "5.6.0" name = "nginx" vpc_id = module.vpc.vpc_id load_balancer_type = "application" internal = false subnets = module.vpc.public_subnets security_groups = [module.load_balancer_sg.this_security_group_id] target_groups = [ { backend_protocol = "HTTP" backend_port = 80 target_type = "ip" health_check = { interval = 20 } } ] http_tcp_listeners = [ { port = 80 protocol = "HTTP" } ] }確認の都合上、ヘルスチェックの時間はちょっと短めにしておきました。
VPCで作成したパブリックサブネットと、ALB用のセキュリティグループの情報を使っています。
ここまでの結果で、Fargate構築の際に利用するもの
ここまで作成したVPCやセキュリティグループ、ALBの情報のうち、この後のFargateの構築で使うものをローカル変数に切り出しておきます。
locals { vpc_id = module.vpc.vpc_id private_subnets = [module.vpc.private_subnets[0]] ecs_service_security_groups = [module.nginx_cluster_sg.this_security_group_id] load_balancer_target_group_arn = module.load_balancer.target_group_arns[0] }単純に、こうやって分けた方が記事を読む時にわかりやすいかな、と。
CloudWatch Logs
CloudWatch Logs側は、ロググループを定義。
resource "aws_cloudwatch_log_group" "nginx_cluster_log_group" { name = "nginx-cluster-log-group" }IAMロール
コンテナからCloudWatch Logsにログを送る際に、権限が必要になります。このため、IAMロールを定義しましょう。
今回は、
AmazonECSTaskExecutionRolePolicyというポリシーをそのまま利用します。
AmazonECSTaskExecutionRolePolicyでどんなことができるか、見てみましょう。arnを調べます。
$ aws iam list-policies | grep ECS "PolicyName": "AWSCodeDeployRoleForECS", "Arn": "arn:aws:iam::aws:policy/AWSCodeDeployRoleForECS", "PolicyName": "AmazonECSServiceRolePolicy", "Arn": "arn:aws:iam::aws:policy/aws-service-role/AmazonECSServiceRolePolicy", "PolicyName": "AWSCodeDeployRoleForECSLimited", "Arn": "arn:aws:iam::aws:policy/AWSCodeDeployRoleForECSLimited", "PolicyName": "AmazonECS_FullAccess", "Arn": "arn:aws:iam::aws:policy/AmazonECS_FullAccess", "PolicyName": "AWSApplicationAutoscalingECSServicePolicy", "Arn": "arn:aws:iam::aws:policy/aws-service-role/AWSApplicationAutoscalingECSServicePolicy", "PolicyName": "AmazonECSTaskExecutionRolePolicy", "Arn": "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy", $ aws iam get-policy --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy { "Policy": { "PolicyName": "AmazonECSTaskExecutionRolePolicy", "PolicyId": "ANPAJG4T4G4PV56DE72PY", "Arn": "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy", "Path": "/service-role/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "Description": "Provides access to other AWS service resources that are required to run Amazon ECS tasks", "CreateDate": "2017-11-16T18:48:22+00:00", "UpdateDate": "2017-11-16T18:48:22+00:00" } }確認。
$ aws iam get-policy-version --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy --version-id v1 { "PolicyVersion": { "Document": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }, "VersionId": "v1", "IsDefaultVersion": true, "CreateDate": "2017-11-16T18:48:22+00:00" } }まあ、同じ内容はドキュメントにも書かれているのですが、あらためて見た感じですね。
今回必要なのは、
logs:CreateLogStreamとlogs:PutLogEventsです。で、定義したのがこちら。
data "aws_iam_policy_document" "assume_role" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["ecs-tasks.amazonaws.com"] } } } resource "aws_iam_role" "ecs_task" { name = "MyEcsTaskRole" assume_role_policy = data.aws_iam_policy_document.assume_role.json } resource "aws_iam_role_policy_attachment" "ecs_task" { role = aws_iam_role.ecs_task.name policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" }Assume Roleについても、ドキュメントに書かれています(信頼関係という表現になっていますが)。
CloudWatch Logsに関するロールをタスクに付与しなかった場合、コンテナの作成時にこんなエラーを見ることになります。
Error: ClientException: Fargate requires task definition to have execution role ARN to support log driver awslogs.Fargateクラスタ
最後に、Fargateクラスタの定義を行います。
- クラスタ定義
- タスク定義
- サービス定義
の3つを行います。
resource "aws_ecs_cluster" "nginx" { name = "nginx-cluster" } resource "aws_ecs_task_definition" "nginx" { family = "nginx-task-definition" cpu = "256" memory = "512" network_mode = "awsvpc" requires_compatibilities = ["FARGATE"] execution_role_arn = aws_iam_role.ecs_task.arn container_definitions = <<JSON [ { "name": "nginx", "image": "nginx:1.17.10", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "nginx-cluster-log-group", "awslogs-stream-prefix": "nginx-container-log-stream" } } } ] JSON } resource "aws_ecs_service" "nginx" { name = "nginx-service" cluster = aws_ecs_cluster.nginx.arn task_definition = aws_ecs_task_definition.nginx.arn desired_count = 3 launch_type = "FARGATE" platform_version = "1.4.0" network_configuration { assign_public_ip = false security_groups = local.ecs_service_security_groups subnets = local.private_subnets } load_balancer { target_group_arn = local.load_balancer_target_group_arn container_name = "nginx" container_port = 80 } }先ほど定義したIAMロールは、タスク定義で使います。
resource "aws_ecs_task_definition" "nginx" { ... execution_role_arn = aws_iam_role.ecs_task.arn ...また、コンテナがCloudWatch Logsにログを送信するという設定は、コンテナ定義の
logConfigurationで行います。awslogs-groupに、ログ送信対象となるCloudWatch Logsのロググループを指定しましょう。container_definitions = <<JSON [ { "name": "nginx", "image": "nginx:1.17.10", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "nginx-cluster-log-group", "awslogs-stream-prefix": "nginx-container-log-stream" } } } ] JSONこちらを参考に。
あとは、このタスク定義や、ALB、セキュリティグループの定義を設定しておしまいです。
resource "aws_ecs_service" "nginx" { name = "nginx-service" cluster = aws_ecs_cluster.nginx.arn task_definition = aws_ecs_task_definition.nginx.arn desired_count = 3 launch_type = "FARGATE" platform_version = "1.4.0" network_configuration { assign_public_ip = false security_groups = local.ecs_service_security_groups subnets = local.private_subnets } load_balancer { target_group_arn = local.load_balancer_target_group_arn container_name = "nginx" container_port = 80 } }動作確認
terraform applyして$ terraform apply -auto-approve構築されたALBの情報から、DNS名を取得します。
$ aws elbv2 describe-load-balancers --names nginx取得した
DNSNameから、curlで確認。$ curl [DNSName] <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>この時の、CloudWatch Logsを
tailしてみます。$ aws logs tail nginx-cluster-log-group --followログがCloudWatch Logsに登録されているのが確認できました。
2020-05-24T09:47:46.409000+00:00 nginx-container-log-stream/nginx/194c1f45-f056-4e4c-8cbf-8306c8ca52b0 10.0.101.4 - - [24/May/2020:09:47:46 +0000] "GET / HTTP/1.1" 200 612 "-" "ELB-HealthChecker/2.0" "-" 2020-05-24T09:47:46.409000+00:00 nginx-container-log-stream/nginx/a89ccf53-31a2-4a24-bb55-e643b30ea3a4 10.0.101.4 - - [24/May/2020:09:47:46 +0000] "GET / HTTP/1.1" 200 612 "-" "ELB-HealthChecker/2.0" "-" 2020-05-24T09:47:54.271000+00:00 nginx-container-log-stream/nginx/00f8ba07-8ac4-4885-854b-88b79bdd0789 10.0.101.4 - - [24/May/2020:09:47:54 +0000] "GET / HTTP/1.1" 200 612 "-" "ELB-HealthChecker/2.0" "-" 2020-05-24T09:48:00.197000+00:00 nginx-container-log-stream/nginx/00f8ba07-8ac4-4885-854b-88b79bdd0789 10.0.101.4 - - [24/May/2020:09:48:00 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.58.0" "xxx.xxx.xxx.xxx"OKですね。
- 投稿日:2020-05-24T19:15:24+09:00
Terraform ECS/IAM作成手順まとめ
参考文献
- Terraform - CentOS 7 に Terraform をインストールして AWS へ接続
- Terraformインストール
- AWS FargateとTerraformで最強&簡単なインフラ環境を目指す
- tfenvでTerraformのバージョン管理をする
- Terraform Workspacesの基礎と使い方について考えてみた!
- Amazon ECS+Fargate まとめ (terraformを使ったクラスタ構築とオートスケール、ブルーグリーンデプロイ)
- Terraform職人入門: 日々の運用で学んだ知見を淡々とまとめる
- TerraformでJSONにコメントを書きたいだけの人生だった
Terraformインストール手順
◆ 最新バージョンの確認
◆ インストールコマンド
$ sudo yum install wget unzip $ wget https://releases.hashicorp.com/terraform/0.12.25/terraform_0.12.25_linux_amd64.zip $ sudo unzip ./terraform_0.12.25_linux_amd64.zip -d /usr/local/bin/ $ terraform -v◆ tfenvを利用したバージョン管理
- tfenv:Terraformのバージョン管理に特化したツール
//git clone 〜 パス設定 $ git clone https://github.com/tfutils/tfenv.git ~/.tfenv $ echo 'export PATH="$HOME/.tfenv/bin:$PATH"' >> ~/.bash_profile $ source ~/.bash_profile //tfenvインストール $ tfenv install latest $ tfenv use latest $ tfenv listterraform用語
用語 意味 State Terraformで管理するリソースの状態。.tfstateのこと tf.state ローカルにtfstateファイルが生成されるが、S3で管理するのが基本 Backend Stateの保存先。 ※S3など Resource Terraformで管理する対象の基本単位 Module Resourceを再利用するためにまとめたTerraformのコード 初期設定
◆ terraform.tfvars定義
$ cat >> ./terraform.tfvars << FIN access_key = "*****************" secret_key = "*****************" db_user = "XXXXX" db_pass = "XXXXXXXXX" FIN◆ terraform workspace作成
$ terraform workspace new development $ terraform workspace select development◆ S3用のprofile作成 ※tfstate格納用
$ aws configure --profile s3-profilemain.tf
main.tf// 変数を定義 ※terraform.tfvars参照 variable "access_key" {} variable "secret_key" {} variable "token" {} variable "db_user" {} variable "db_pass" {} variable "region" { default = "ap-northeast-1"} // S3にtfstateを格納 terraform { backend "s3" { bucket = "sample-project" key = "sample-project.terraform.tfstate" region = "ap-northeast-1" profile = "sample-profile" } } // プロバイダ設定 ※上記変数参照 provider "aws" { access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } // modulesのソースを指定 module "base" { region = "${var.region}" db_user = "${var.db_user}" db_pass = "${var.db_pass}" source = "./modules" }ecs.tf
ecs.tfresource "aws_ecs_cluster" "ecs_cluster" { name = "sample-cluster" }IAM Policy / IAM Role作成
iam.tfdata "aws_iam_policy_document" "samplepolicy" { statement { actions = [ "s3:PutObject", "s3:GetObject", ] resources = [ "arn:aws:s3:::foo-bucket/*", ] } } resource "aws_iam_policy" "samplepolicy" { name = "samplepolicy" path = "/" description = "" policy = data.aws_iam_policy_document.samplepolicy.json } data "aws_iam_policy_document" "samplerole_assume_policy" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["ecs-tasks.amazonaws.com"] } } } resource "aws_iam_role" "samplerole" { name = "samplerole" assume_role_policy = data.aws_iam_policy_document.samplerole_assume_policy.json } resource "aws_iam_role_policy_attachment" "samplerole_attachement" { role = aws_iam_role.samplerole.name policy_arn = aws_iam_policy.samplepolicy.arn }
- 投稿日:2020-05-24T19:06:48+09:00
AWSを利用したサーバーレスWebAPI開発環境の構築
概要
AWSを利用してシンプルなサーバーレスWebAPIを作成します
※大雑把に構築の流れだけ追っていくので、細かいことは都度調べてください目次
- ローカルで仮想環境の構築(キーワード:pipenv)
- 開発環境の構築(VSCode)
- プログラムの作成(Flask)
- IAMユーザーの作成(AWS)
- ローカル環境をAWSにデプロイ(zappa)
- おまけ
- 参考サイト
ローカルで仮想環境の構築(pipenv)
pipenvを使用して仮想環境を構築します。
環境変数に以下を追加します。
仮想環境で使用するインタープリターや参照パッケージを、作業フォルダに入れる設定です。(.venv)PIPENV_VENV_IN_PROJECT = TRUE
コマンドラインで以下を実行します。pip install pipenvバージョンが表示されればインストールできています。
pipenv --version
コマンドラインで作成した作業フォルダに移動して、以下を実行します。pipenv --three「three」はpython3系のインストールコマンドです。バージョンを指定する場合は、以下のように実行します。
pipenv --python 3.7初期化に成功すると、作業フォルダに以下のフォルダとファイルが作成されます。
.venv
Pipfile開発環境の構築(VSCode)
VSCodeで開発環境を構築します。(VSCodeは良いぞ...
)
「ファイル」→「フォルダーを開く」
VSCodeは、pythonファイルを扱えるようにするために、拡張機能を入れる必要があります。
「表示」→「拡張機能」から「python」で検索してインストールしましょう。
テキトーに「app.py」などのファイルを作成します。作成したpythonファイルを選択すると、エディターの左下に実行する環境が表示されます。
ここから、作業フォルダのpipenvを指定します。
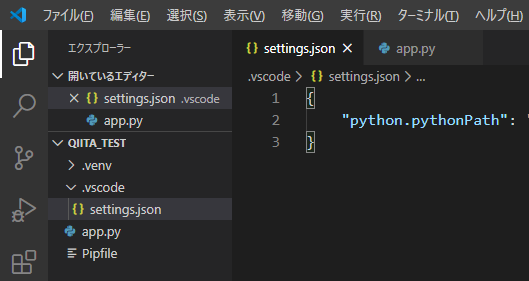
以下のファイルで、仮想環境等のパス設定、フォーマッター、Lintの設定を行います。参考
[ワークスペースフォルダ]\.vscode\settings.json{ "python.pythonPath": "[ワークスペースフォルダ]\\.venv\\Scripts\\python.exe", // 拡張機能のロード時にターミナルでPython環境をアクティブにする。 "python.terminal.activateEnvInCurrentTerminal": true, // 仮想環境のパス。作成した仮想環境を指定する。 "python.venvPath": "{$workspaceFolder}/.venv", "python.autoComplete.extraPaths": [ "{$workspaceFolder}/.venv/Lib/site-packages", ], // フォーマッターの設定。autopep8 を指定する。 "python.formatting.provider": "autopep8", "python.jediEnabled": false, // Lintの設定 "python.linting.mypyEnabled": true, "python.linting.pylintEnabled": false, }
setting.json の設定を行うと、使用している依存パッケージをインストールするように促されます。まず、ターミナルを表示して、仮想環境がアクティブになっているか確認します。
「表示」→「ターミナル」
以下のように「(qiita_test)」のように出ていればOK(qiita_test) C:\~\qiita_test>以下を実行して、パッケージをインストールします。
pipenv install autopep8 mypy --devまた、サンプルソースように「Flask」「numpy」もインストールします。
pipenv install Flask numpy「--dev」は、開発環境のみで使用するパッケージを指定するものです。つまり、AWSにデプロイするときは含まれないパッケージとなります。
プログラムの作成(Flask)
簡単なサンプルプログラムを作成します。
リクエストに対して、json形式のレスポンスを返すWebAPIです。
作成したら実行してエラーが出ないか確認しましょう。app.pyfrom flask import Flask, jsonify, request import numpy as np app = Flask(__name__) app.config["JSON_AS_ASCII"] = False @app.route("/") def index(): return jsonify({"language": "パイソン"}) # exp:http://127.0.0.1:5000/sqrt?val=4 @app.route("/sqrt") def getSqrt(): param = request.args.get('val') val = int(param) return jsonify({"sqrt": np.sqrt(val)}) # exp:http://127.0.0.1:5000/sqrt/4 @app.route("/sqrt/<value>") def getSqrt2(value): val = int(value) return jsonify({"sqrt": np.sqrt(val)}) if __name__ == "__main__": app.run(debug=True)折り返し地点です。
IAMユーザーの作成(AWS)
ここからは、ローカルで作成したWebAPIを、AWSにデプロイしていきます。
AWSアカウントには、ルートユーザーとIAMユーザーの2つがあります。
(親です):ルートユーザーは、すべての権限を持つアカウントです。IAMユーザーの管理も行います。
(子です):IAMユーザーは、プロジェクト単位や開発者単位で、個別に権限を持つアカウントです。
まず、ルートユーザーを作成し、AWSコンソールにログインした後に、IAMユーザーを作成します。
IAMユーザーは以下の2つを作成します。
ポリシーとはIAMユーザーに付与する権限のことです。AWSコンソールにルートユーザーでログインし、画面上の「サービス」→「IAM」を選択します。
「ポリシー」を選択して、[ポリシーの作成]を押します。
「JSON」タブを選択して、ポリシーを書き込みます。
参考:Pythonで作るはじめてのサーバレスアプリケーション Kindle版zappa-simple-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:AttachRolePolicy", "iam:CreateRole", "iam:GetRole", "iam:PutRolePolicy" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "apigateway:DELETE", "apigateway:GET", "apigateway:PATCH", "apigateway:POST", "apigateway:PUT", "events:DeleteRule", "events:DescribeRule", "events:ListRules", "events:ListTargetsByRule", "events:ListRuleNamesByTarget", "events:PutRule", "events:PutTargets", "events:RemoveTargets", "lambda:AddPermission", "lambda:CreateFunction", "lambda:DeleteFunction", "lambda:GetFunction", "lambda:GetFunctionConfiguration", "lambda:GetPolicy", "lambda:ListVersionsByFunction", "lambda:RemovePermission", "lambda:UpdateFunctionCode", "lambda:UpdateFunctionConfiguration", "cloudformation:CreateStack", "cloudformation:DeleteStack", "cloudformation:DescribeStackResource", "cloudformation:DescribeStacks", "cloudformation:ListStackResources", "cloudformation:UpdateStack", "cloudfront:updateDistribution", "logs:DescribeLogStreams", "logs:FilterLogEvents", "route53:ListHostedZones", "route53:ChangeResourceRecordSets", "route53:GetHostedZone", "s3:CreateBucket", "dynamodb:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "s3:DeleteObject", "s3:GetObject", "s3:PutObject", "s3:CreateMultipartUpload", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts", "s3:ListBucketMultipartUploads" ], "Resource": [ "*" ] } ] }[ポリシーの確認]を押して、「名前」を付けます。ここでは「zappa-simple-policy」としました。
[ポリシーの作成]を押して、zappa用のポリシーが出来ました。
(AWSコンソールにルートユーザーでログインし、画面上の「サービス」→「IAM」を選択します。)
- 「ユーザー」を選択して、[ユーザーを追加]を押します。
- 「ユーザー名」を指定します。ここでは、「zappa-simple-user」としました。
- 「アクセスの種類」で「プログラムによるアクセス」に☑します。
- [次のステップ:アクセス権限]を押します。
- [既存のポリシーを直接アタッチ]を選択して、検索欄で「zappa-simple-policy」と入力し、☑します。
- [次のステップ:タグ]を押します。(飛ばします)
- [次のステップ:確認]を押します。
- [ユーザーの作成]を押します。
- 作成に成功すると、アクセスキーIDとシークレットアクセスキーが表示されるので、メモっておきます。

- 「ユーザー」を選択して、[ユーザーを追加]を押します。
- 「ユーザー名」を指定します。ここでは、「qiita-test」としました。
- 「アクセスの種類」で「AWS マネジメントコンソールへのアクセス」に☑します。
- [次のステップ:アクセス権限]を押します。
- [既存のポリシーを直接アタッチ]を選択して、以下を選択します。
- AmazonAPIGatewayAdministrator
- AWSLambdaFullAccess
- AmazonDynamoDBFullAccess(今回は利用していないが、DynamoDBを利用する場合)
- IAMUserChangePassword(3で初回ログイン時にパスワードを変更する設定にした場合、自動で選択されます)
- [次のステップ:タグ]を押します。(飛ばします)
- [次のステップ:確認]を押します。
- [ユーザーの作成]を押します。
- 作成に成功すると、アクセスキーIDとシークレットアクセスキーが表示されるので、メモっておきます。
もう少し
ローカル環境をAWSにデプロイ(zappa)
zappaというpythonの拡張機能を使って、作成したプロジェクトをAWSにデプロイします。
IAMユーザーの情報をプロファイル単位で管理するために、AWS CLIをインストールします。
参考:AWS CLIのインストール
pipからもインストールできるみたいです。参考:https://www.suzu6.net/posts/4/コマンドプロンプトで以下を実行して、[default]のプロファイルを設定します。
とりあえずzappa用のIAMユーザー(zappa-simple-user)情報を設定しましょう。aws configure AWS Access Key ID [********************]: AWS Secret Access Key [********************]: Default region name [ap-northeast-1]: Default output format [json]:regionは東京です。
インストールフォルダ以下の credentials ファイルに、作成したzappa用のIAMユーザー(zappa-simple-user)情報を設定します。
メモ帳か何かで開いて編集しましょう。~\.aws\credentials[zappa-simple-user] aws_access_key_id = ******************** aws_secret_access_key = ********************
ターミナルにて、仮想環境がアクティブになっていることを確認してから、以下を実行します。pipenv install zappa次に初期設定を行います。
zappa init
- デプロイ環境の名前の指定。(デフォルトでも可)
- AWSプロファイルの指定。先ほどcredentialsファイルに設定した「zappa-simple-user」を指定します。
- S3バケットを利用するための仮の名前の指定。(デフォルトでも可)
- アプリケーションの起動ファイルの指定。.appファイルとして指定します。今回は「app.py」を起動したいので、「app.app」を指定します。
- リージョンごとの最適化設定。特にパフォーマンスが必要なければデフォルトにします。
- 作成される設定情報が表示されます。問題なければ、Enterで初期設定を終了します。
ターミナルにて、仮想環境がアクティブになっていることを確認してから、以下を実行します。zappa deploy成功すると以下のようにエンドポイントが表示されます。
リンクに飛ぶと、json形式の値が表示されます。Deployment complete!: [リンク]
AWSコンソールで管理する用のIAMユーザーで、AWSコンソールにログインします。
「サービス」→「API Gateway」または「Lambda」を選択すると、デプロイしたアプリケーションを確認することができます。ハイ、オツカレー(  ̄▽)_
おまけ
デプロイ済みのアプリケーションを更新する.zappa update devデプロイ済みのアプリケーションを削除する.zappa undeploy devログの確認.zappa tail dev
課題
AWSのポリシーがいまいちわかっていない。(ので、本稿の設定はあくまで参考程度に)
githubを使ってバージョン管理も絡めてみる。
なんで?
- なんで、WebAPI作るの?
これから5G技術が普及することによって、オンライン環境は今より格段に拡がり、よりストレスレスな通信が可能になるから。
ユーザーの環境に依存しない開発ができ、色々なプラットフォームでリソースを共有できるから。
- なんで、Pythonなの?
機械学習を勉強する上で、パッケージが豊富で、スクリプトもわかりやすく、参考事例も多いから。
参考書やサイトでコーディングしたリソースを形にしたくて、色々考えた結果 WebAPI という技術に至ったから。
(参考書のほとんどは、colaboratory等でデータ分析して「はいできましたね。~終わり~」となっていて、じゃあ具体的にどう活用するの?ってずっとモヤモヤしてました)
- なんで、サーバーレスなの?
サーバーの構築技術にはあまり興味がなく、自分でサーバー立てるよりAmazonやMicrosoftのサービスを利用したほうが早そうだなって思ったから。
自前でサーバー運用するよりもコストパフォーマンスに優れているから。参考サイト
Windows + Python + PipEnv + Visual Studio Code でPython開発環境
Zappaを使ってPythonのコードをAWS Lambdaにデプロイする参考書籍です。こちらの筆者の環境はOSXでエディターは特に使ってません。
Pythonで作るはじめてのサーバレスアプリケーション Kindle版

- 投稿日:2020-05-24T18:30:41+09:00
Django+MySQLのアプリケーションをAWSのElastic Beanstalkにデプロイする (UTokyo Project Sprint 用)
UTokyo Project Sprint 用の記事です。主に、Django Sprint で構築した方を想定して書かれています。
この記事では EB CLI は使用せずに、コンソールからデプロイします。
また、この記事の内容は一例で、もちろんアプリ内で使用するフレームワークや、ライブラリによって異なりますので、適宜自分のプロジェクトに対応させてください。目次
requirements.txtの修正- Elastic Beanstalkのアプリケーションと環境を作成する
- データベースの設定を行う
- アプリケーションソースバンドルを準備する
- アプリケーションソースバンドルを作成する
0.
requirements.txtの修正
requirements.txtのDjangoとmysqlclientのバージョンを以下のように書き換えてください。requirements.txt... Django>=2.1,<2.2 mysqlclient==1.3.12 ...1. Elastic Beanstalkのアプリケーションと環境を作成する
AWS マネジメントコンソール にログインしてください。
ただし、AWS Educate のアカウントからの場合はこの記事を参考にしてください。Elastic Beanstalk を選び、Create Application からアプリケーションを作成します。
- アプリケーション情報 > アプリケーション名 : 自身のアプリ名
- アプリケーションタグ : 任意。
- プラットフォーム : 今回は、プラットフォーム は
Python、プラットフォームのブランチ はPython 3.6 running on 64bit Amazon Linux、プラットフォームのバージョン は2.9.10を選択しました。- アプリケーションコード : とりあえず「サンプルアプリケーション」を選んでおきます。あとから自分のソースをアップロードします。
[アプリケーションの作成] を押します。あとは自動で環境まで作成してくれるので数分待っておきます。
無事終了したら、その環境のダッシュボードのような画面になると思います。左のメニューの、「環境に移動する」をクリックするとサンプルアプリケーションの画面が出てきます。
出てきたURLのhttp://などの部分を除くXXX.YYY.ZZZ.elasticbeanstalk.comが自身のアプリのドメインになります。
あとでこれを使うので控えておいてください。2. データベースの設定を行う
左のメニューから 設定 を選びます。一番下の データベース の右の 編集 ボタンを押します。
データベース設定 の各欄について以下の選択をします。Amazon RDS DB に作成されます。
- エンジン :
mysql- エンジンバージョン :
5.7.22を選択- インスタンスクラス :
db.t2.microを選択- ストレージ :
5- ユーザー名 : 各自作成して(一応)覚えておいてください。
- パスワード : 各自作成して(一応)覚えておいてください。
- 保持期間 :
スナップショットの作成- アベイラビリティー :
低(1つのAZ)[適用] を押してください。変更が反映されるまで待っておいてください。
3. アプリケーションソースバンドルを準備する
ここから主にローカルでの作業に移ります。以下、
cmsというアプリを作成している前提で進めているで、適宜自分のアプリ名に置き換えてください。
最初に、このセクションをすべて終えたときに出来上がるディレクトリ構造の一例を以下に示します。適宜参考にしてください。├─ .ebextensions # Added │ └─ python.config # Added ├─ requirements.txt ├─ manage.py # Updated ├─ cms │ ├─ management # Added │ | ├─ commands # Added | | | ├─ createsu.py # Added | | | └─ __init__.py # Added | | └─ __init__.py # Added │ ├─ templates | ︙ │ └─ views.py ├─ config │ ├─ __init__.py │ ├─ settings # Added (settings.py removed) | | ├─ common.py # Added | | ├─ local.py # Added | | └─ production.py # Added │ ├─ urls.py │ └─ wsgi.py # Updated ├─ docker-compose.yml └─ Dockerfile3-1.
.ebextensionsディレクトリを作成するElastic Beanstalk にデプロイする際に必要となるディレクトリです。
プロジェクトのディレクトリ直下に.ebextensionsディレクトリを作成し、その中にpython.configというファイルを作成してください。そのファイルに、以下を書き込んでください。一例なので、適宜書き換えてください。なお、このファイルのインデントはtabだとエラーが出るので必ずspaceを使用してください。(コピペするとtabになると思うので、spaceに直してください。)
.ebextensions/python.configcontainer_commands: 01_migrate: command: 'python manage.py migrate' leader_only: true 02_collectstatic: command: 'python manage.py collectstatic --noinput' 03_createsu: command: 'python manage.py createsu' leader_only: true option_settings: 'aws:elasticbeanstalk:application:environment': DJANGO_SETTINGS_MODULE: 'config.settings.production' PYTHONPATH: '$PYTHONPATH' 'aws:elasticbeanstalk:container:python': StaticFiles: '/static/=www/static/' WSGIPath: 'config/wsgi.py'以下、上記の内容の解説です。
3-1-1.
container_commands
01_migrateではマイグレーション
02_collectstatic静的ファイルの処理
03_createsuスーパーユーザーの作成
のコマンドを実行しています。なお、03_createsuのpython manage.py createsuについては後述します。3-1-2.
option_settings
DJANGO_SETTINGS_MODULEの部分で、後ほど作成する、production.pyを読み込むように環境変数を設定しています。
WSGIPathやStaticFilesなどについては、コンソールの設定のところでも変更可能です。
option_settingsについて詳しく知りたい方は、以下を参照してください。3-2.
settings.pyを分割する次に、
/config/settings.pyを、開発用(Local)と本番用(Production)に分割します。
/config/settings.pyは、Local 環境と Production 環境で別々のものを読み込む必要があるのですが、毎回書き換えていると大変なので、自動で切り替わるようにします。
具体的には、
1.common.pyに Local 環境と Production 環境で共通の設定項目を書き込む
2.local.pyは、common.pyの内容に加えて、Local 環境固有の設定項目を書き込む
3.production.pyは、common.pyの内容に加えて、Production 環境固有の設定項目を書き込む
4.manage.pyとwsgi.pyを修正するどちらの環境にも共通している設定項目は、
common.pyに書き込みます。個別に設定すべき内容
Local 環境と Production 環境でそれぞれ固有の設定は例えば以下のようなものです。
DEBUGDATABASEALLOWED_HOSTSMEDIA_ROOTSTATIC_ROOTLOGGINGただし、
common.pyに書いている設定項目に、local.pyやproduction.pyで追加したい場合は、例えば以下のようにします。(配列に追加)INSTALLED_APPS += ( 'django.contrib.admin', )3-2-1.
common.py,local.py,production.pyを作成するまず、
/config直下に、settingsというディレクトリを作成し、その中に/config下のsettings.pyを移動させ、common.pyにリネームしてください。
また、/config/settingsディレクトリの中にlocal.py,production.pyの2つのファイルを新規に作成してください。
以下のようなディレクトリ構造になっていることを確認してください。... ├─ config │ ├─ settings # Added | | ├─ common.py # Added (settings.py をリネームしたもの) | | ├─ local.py # Added | | └─ production.py # Added ...3-2-2.
BASE_DIRを修正する
common.pyの最初のほうにあるBASE_DIRを以下のように変更してください。/config/settings/common.py... BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) ...↓
/config/settings/common.py... BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) ...3-2-3.
local.pyにLocal 環境固有の設定を書き込む
local.pyに、common.pyの内容に加えて、Local 環境で固有の設定項目を書き込みます。
common.pyの内容を以下のようにimportします。/config/settings/local.pyfrom .common import *あとは、個別に設定すべき内容 を書けばよいだけです。
これを踏まえると、local.pyは例えば以下のようになります。
これはローカルでPostgreSQLを使っていた場合なのですが、各自ローカルで使っていたDBの設定をそのまま移していただいて結構です。/config/settings/local.pyfrom .common import * DEBUG = True ALLOWED_HOSTS = [ '0.0.0.0', '127.0.0.1', ] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'postgres', 'USER': 'postgres', 'HOST': 'db', 'PORT': 5432, 'PASSWORD': 'somepassword', } }3-2-3.
production.pyにProduction 環境固有の設定を書き込む
production.pyに、common.pyの内容に加えて、Production 環境で固有の設定項目を書き込みます。
local.pyと同様に、common.pyの内容を以下のようにimportします。/config/settings/production.pyfrom .common import *あとは、個別に設定すべき内容 を書けばよいだけです。以下の項目は一例です。自身の環境に合わせて、適宜対応してください。
3-2-3-1.
DEBUGProduction 環境では、
DEBUGをFALSEにします。/config/settings/production.py... DEBUG = False3-2-3-2.
ALLOWED_HOSTS
ALLOWED_HOSTSに自身のアプリのドメインを追加します。ただし、XXX.YYY.ZZZ.elasticbeanstalk.comの部分は1で確認した自分のアプリのドメインに置き換えてください。/config/settings/production.py... ALLOWED_HOSTS = [ 'XXX.YYY.ZZZ.elasticbeanstalk.com', ]3-2-3-3.
DATABASES
DATABASESを、本番環境のRDSのものに書き換えます。'RDS_~'という変数を使えば、Elastic Beanstalk のほうで勝手に書き換えてくれます。
'ENGINE'がlocal.pyとは変わっていることに注意してください。/config/settings/production.py... DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': os.environ['RDS_DB_NAME'], 'USER': os.environ['RDS_USERNAME'], 'PASSWORD': os.environ['RDS_PASSWORD'], 'HOST': os.environ['RDS_HOSTNAME'], 'PORT': os.environ['RDS_PORT'], } }3-2-3-4.
STATIC_ROOT
STATIC_ROOTを追加します。/config/settings/production.py... STATIC_ROOT = os.path.join(BASE_DIR, 'www', 'static')以上を踏まえると、全体として
production.pyは例えば以下のようになります。ただし、XXX.YYY.ZZZ.elasticbeanstalk.comの部分は1で確認した自分のアプリのドメインに置き換えてください。/config/settings/production.pyfrom .common import * DEBUG = False ALLOWED_HOSTS = [ 'XXX.YYY.ZZZ.elasticbeanstalk.com', ] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': os.environ['RDS_DB_NAME'], 'USER': os.environ['RDS_USERNAME'], 'PASSWORD': os.environ['RDS_PASSWORD'], 'HOST': os.environ['RDS_HOSTNAME'], 'PORT': os.environ['RDS_PORT'], } } STATIC_ROOT = os.path.join(BASE_DIR, 'www', 'static')3-2-5.
common.pyを修正する
common.pyの、Local 環境とProduction 環境に 個別に設定すべき内容 の項目とその値(中身)をすべて削除してください。
例えば今回であれば、DEBUG、ALLOWED_HOSTS、DATABASESなどが該当します。3-2-6.
common.pyにSTATIC_URLを追加する
common.pyに以下を追記します。すでにある場合は飛ばして構いません。/config/settings/common.py... STATIC_URL = '/static/' ...なお、Djangoの静的ファイルの扱いについては、この記事がとても分かりやすいので、是非読んでみてください。
3-2-7.
manage.pyとwsgi.pyを修正するルート直下の
manage.pyと、/config直下のwsgi.pyの以下の部分を修正します。... os.environ.setdefault("DJANGO_SETTINGS_MODULE", "project.settings") ...↓
manage.pyos.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings.local")/config/wsgi.py... os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings.production") ...3-3. スーパーユーザー作成用のコマンドを準備する
最後に、スーパーユーザー作成用のファイルを作成していきます。スーパーユーザーの作成は、Local 環境であれば、
$ python manage.py createsuperuserなどとして、ユーザー名、メールアドレス、パスワードを入力したと思いますが、今回はサーバーに実行してもらうため、それらを手動で入力することができません。なので、事前に入力する値を設定しておいて、それを実行させます。それが前述の 3-1-2 で出てきたものです。
3-3-1.
createsu.pyを作成する
cms(アプリ名なので置き換えてください。)の下にmanagementフォルダ、その下にcommandsフォルダを作成し、そこにcreatesu.pyを作成してください。そのファイルに以下を書き込んでください。8行目の
XXX、9行目のXXX、YYY、ZZZは各自で書き換えて、どこかに控えておいてください。また、8行目のXXXと 9行目のXXXは一致させてください。
これがスーパーユーザーアカウントになります。複数作りたい場合は、if文の数を増やせばよいだけです。cms/management/commands/createsu.pyfrom django.core.management.base import BaseCommand, CommandError from django.contrib.auth import get_user_model User = get_user_model() class Command(BaseCommand): def handle(self, *args, **options): if not User.objects.filter(username="XXX").exists(): User.objects.create_superuser(username="XXX", email="YYY", password="ZZZ") self.stdout.write(self.style.SUCCESS('Successfully created new super user'))3-3-2.
__init__.pyを作成する次に、作成した
management,commandsフォルダそれぞれの直下に__init__.pyというファイルを作成してください。これらのファイルは作成するだけで、中身は何も書き込みません。これで「アプリケーションソースバンドルの準備」は完了です。このセクションの最初にお見せした、ディレクトリ構造と同じようになっているかどうかを確認してください!
4. アプリケーションソースバンドルを作成する
あとは、作成したものを
zipにして、デプロイするだけです。4-1.
zipファイルを作成する何も難しいことはないかと思いますが、
zipにする対象について。
基本的にプロジェクト直下のファイル、フォルダをまとめてzipにします。(プロジェクトのディレクトリそのものをzipにするわけではない)
ただし、例えばgitを使っているのなら、.gitフォルダや、.gitignoreなどのファイルがあると思いますが、それらは含めません。アプリケーションに必要なものだけを対象にしてください。
必要であれば以下を参照してくださいMac, Linux の場合
例えばプロジェクトのルートディレクトリで、以下のようなを実行すれば、プロジェクトの一つ上の階層に
myapp.zipが生成されます。(.から始まるものは、.ebextensionsしか含まれないので、ほかに含める必要のあるファイルやフォルダがあれば適宜対応してください。)$ zip ../myapp.zip -r * .ebextensionsWindowsの場合
コマンドプロンプトやPowershellからもできますが、コマンドが長すぎるのと、含めないファイル(フォルダ)の設定がややこしいのでGUIでやります。以下のように、必要なファイルとフォルダを選択して、
右クリック→送る→圧縮(zip形式)フォルダー
とすれば作成できます。
4-2. アップロードしてデプロイする
いよいよ、サーバーにアップロードしてデプロイします。
コンソールの実行バージョンの下の、「アップロードとデプロイ」をクリックして、先ほど作成したzipファイルを選択します。
バージョンラベルは自分でバージョンを区別できるわかりやすいものを付けると良いでしょう。あとは、「デプロイ」ボタンを押して完了です。
最初のデプロイは完了までに数分かかることがあるので辛抱強く待ってください。エラーが出ていなければデプロイ完了です。自身のアプリのURLにアクセスして、スーパーユーザーアカウントにログインできるか、などを確認してみましょう。
以上です。お疲れさまでした。
参考
- データベースを Elastic Beanstalk 環境に追加する
- Python アプリケーション環境に Amazon RDS DB インスタンスを追加
- アプリケーションソースバンドルを作成する
- Tutorial: Deploying Python 3, Django, PostgreSQL to AWS Elastic Beanstalk
- Deploying Django + Python 3 + PostgreSQL to AWS Elastic Beanstalk
- [Django] プロジェクト構成のベストプラクティスを探る - 2.設定ファイルを本番用と開発用に分割する
- Elastic Beanstalk Python プラットフォームを使用する
- Djangoにおける静的ファイル(static file)の取り扱い
- 投稿日:2020-05-24T18:22:17+09:00
最近話題のSPAをAWS Cloudfront+S3で構築する(設定項目の解説有)
AWSでSPAの構築
久々にSPAの構築を実施しました。すんなりできると思っていたのですが、結構忘れていることが多かったのと、困ったところがたくさんあったので備忘録として記述しておきます。
なお、解説文を付け加えていますが、設定できれば良い人は画像を参照していけばできると思います。
S3バケット作成
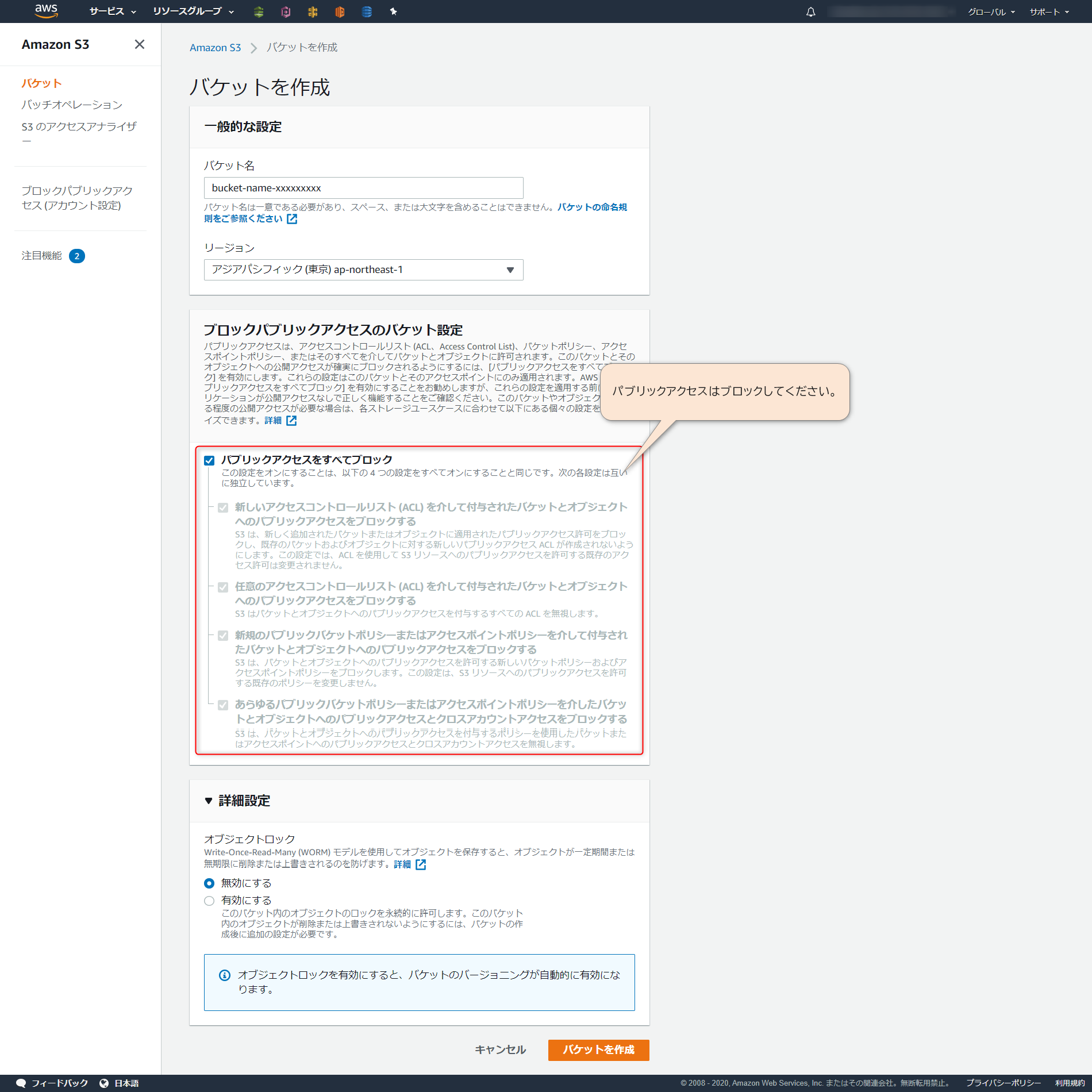
まずはweb用のS3のバケットを準備します。
「パブリックアクセスをブロック」にチェックを入れるのを忘れないでください。
ここのチェックを外すように書いてある記事が多いです。しかし、チェックを入れるとこのバケットに直接アクセスできてしまいます。
そうではなく、Cloudfront経由のみでアクセスしてほしいのでチェックを入れないでください。Cloudfrontの作成
英語で厳しいですが、順番にゆっくり設定していけば怖いことはありません。
まずはCreate Distributionをクリック
Get Startedの方を選択します。
Origin Settings
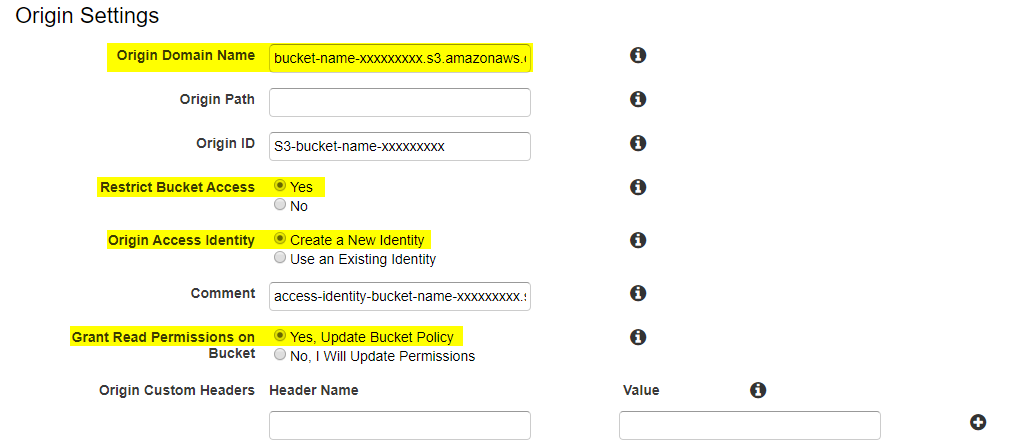
Origin Domain Name
カーソールを合わせると選択肢が出てきます。先ほど作成したS3のバケットを選択してください。
Restrict Bucket Access
Yesを選択してください。説明の直訳です。ユーザーが常にAmazon S3のコンテンツにアクセスする際に、Amazon S3のURLではなく、CloudFrontのURLを使用してアクセスすることを要求したい場合は、「はい」をクリックします。これは、署名付きURLや署名付きCookieを使用してコンテンツへのアクセスを制限する場合に便利です。ヘルプでは、「プライベートコンテンツをCloudFrontでサーブする」を参照してください。
Origin Access Identity
Create a New Identityを選択してください。S3にアクセスするためのOriginIDを新規で作成します。Grant Read Permissions on Bucket: Yes, Update Bucket Policy
Yes, Update Bucket Policyを選択してください。S3バケットにアクセスするためのPolicyを自動で設定してくれます。Default Cache Behavior Settings
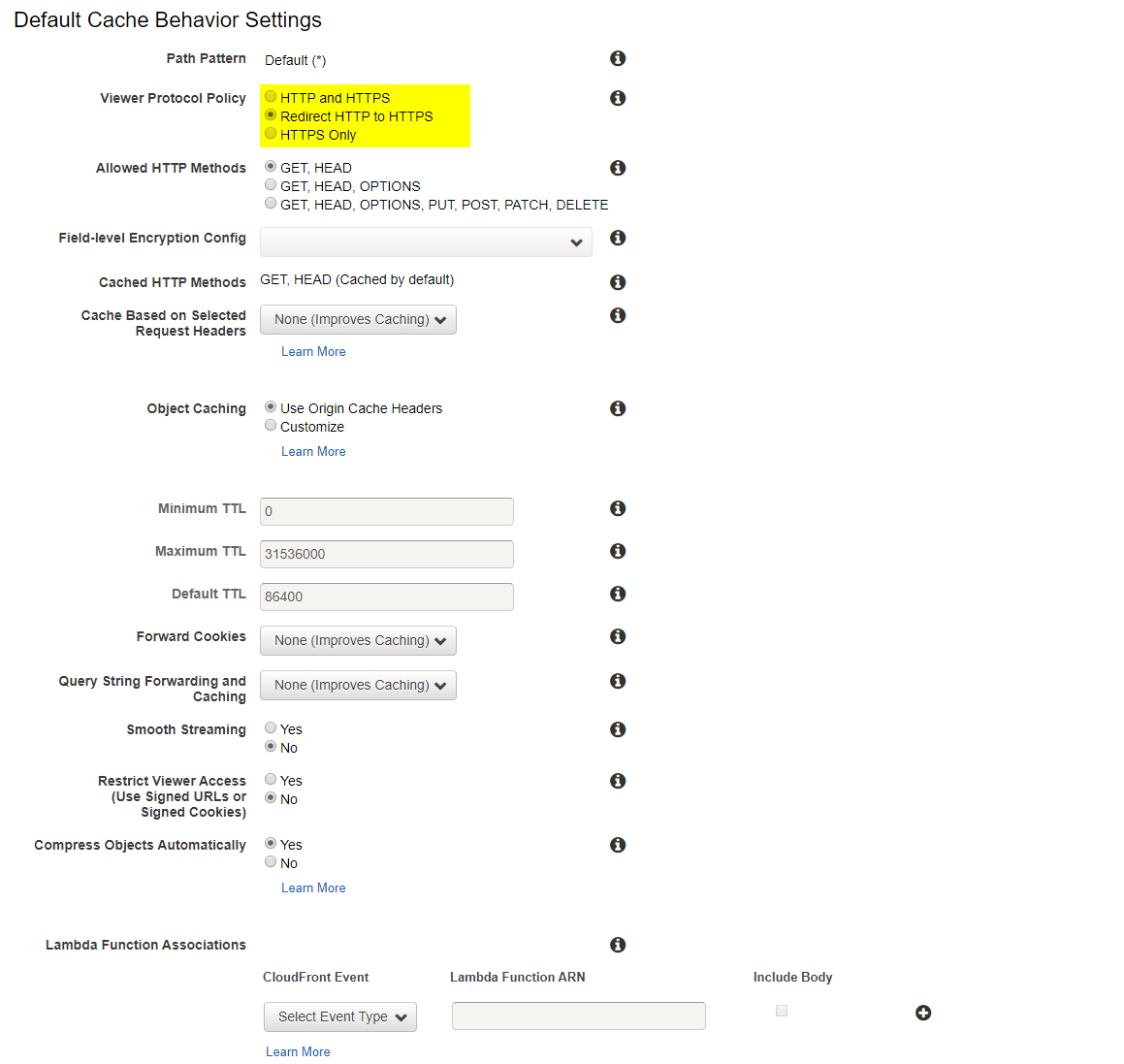
Viewer Protocol Policy
任意設定ではあるのですが、
Redirect HTTP to HTTPSに変更しています。これはHTTPのアクセスに関する項目です。
Redirect HTTP to HTTPSにするとHTTPでリクエストが来た際にHTTPSにリダイレクトしてくれます。セキュリティ的にHTTPSの方が強固なのでリダイレクトするようにしました。Distribution Settings
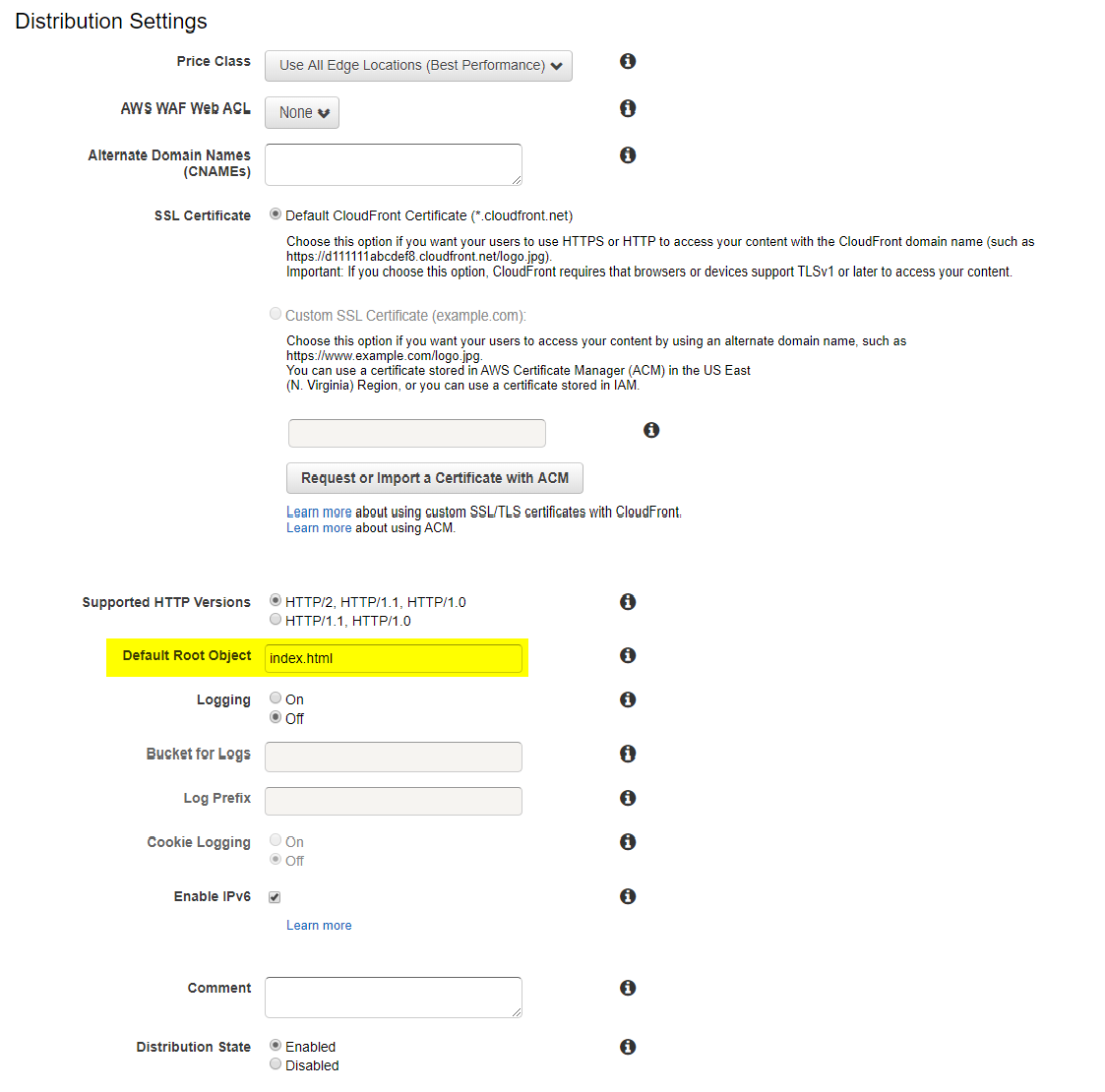
Default Root Object
ルートパスでアクセスした際にデフォルトで表示するファイル名です。
index.htmlを設定しました。24時間(くらい)待つ
ここが一番重要です。Create Distributionをクリックしたら24時間ほど待ちます。
これは、S3のバケット名がAWS内で共有されるのに最大で24時間かかるからです。そのためすぐにアクセスしてもエラーになる場合があります。
都度、確認してみましょう。S3の設定を確認
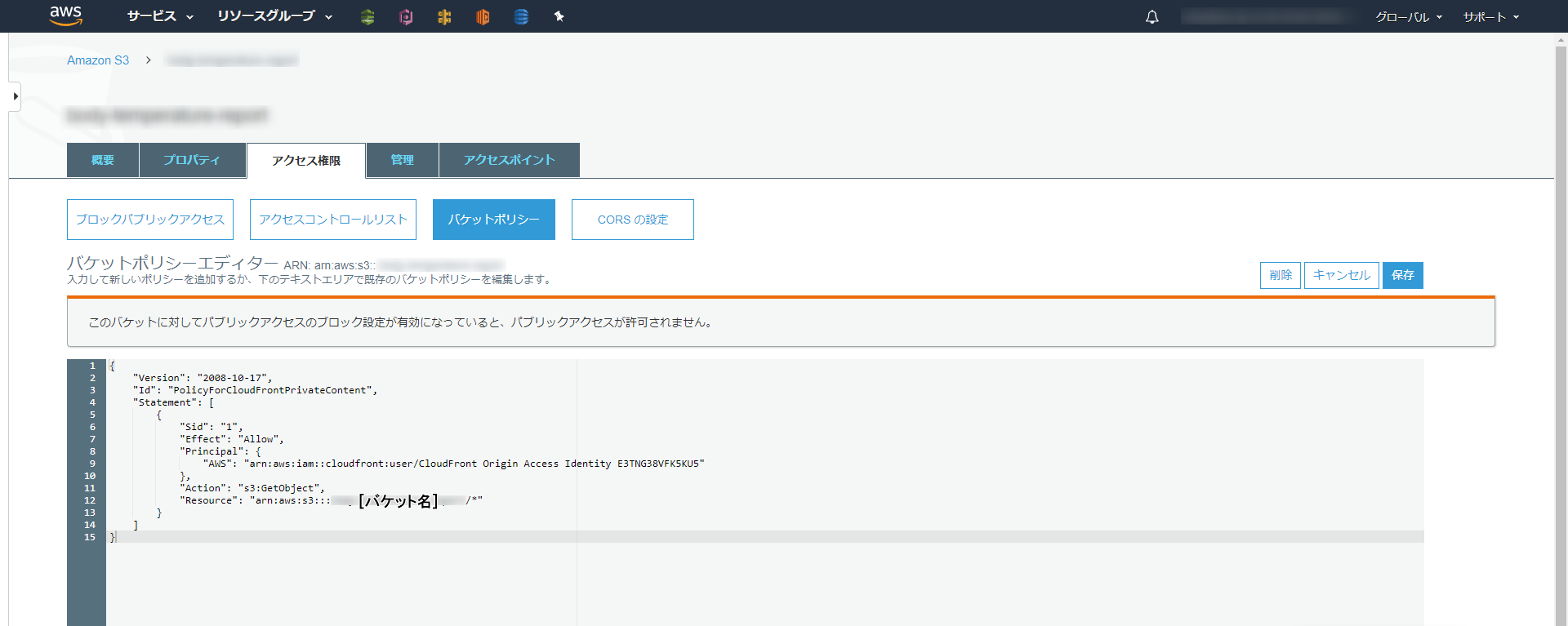
バケットポリシーの確認
Grant Read Permissions on Bucketの項目でYes, Update Bucket Policyを選択しました。
バケットポリシーを追加する項目なので、一応ちゃんと設定されているか確認してみます。
ファイルのアップロード
実際にS3にファイルをアップロードしてください。
WEBページにアクセス
WEBページにアクセスして動作を確認して見ます。ドメイン名は
CloudFrontのDistributions内、Domain Name列に記載されています。
WEBページが表示されれば設定完了です。
参考
- 投稿日:2020-05-24T17:43:57+09:00
LightsailでIP接続元制限が管理コンソールからできるようになっていた
タイトルのとおりです。
元々Lightsailでは、EC2のセキュリティグループみたいに管理コンソールからポートごとにIP制限をかけておく機能がありませんでしたが、最近設定を開くといつのまにかその機能が追加されていました。
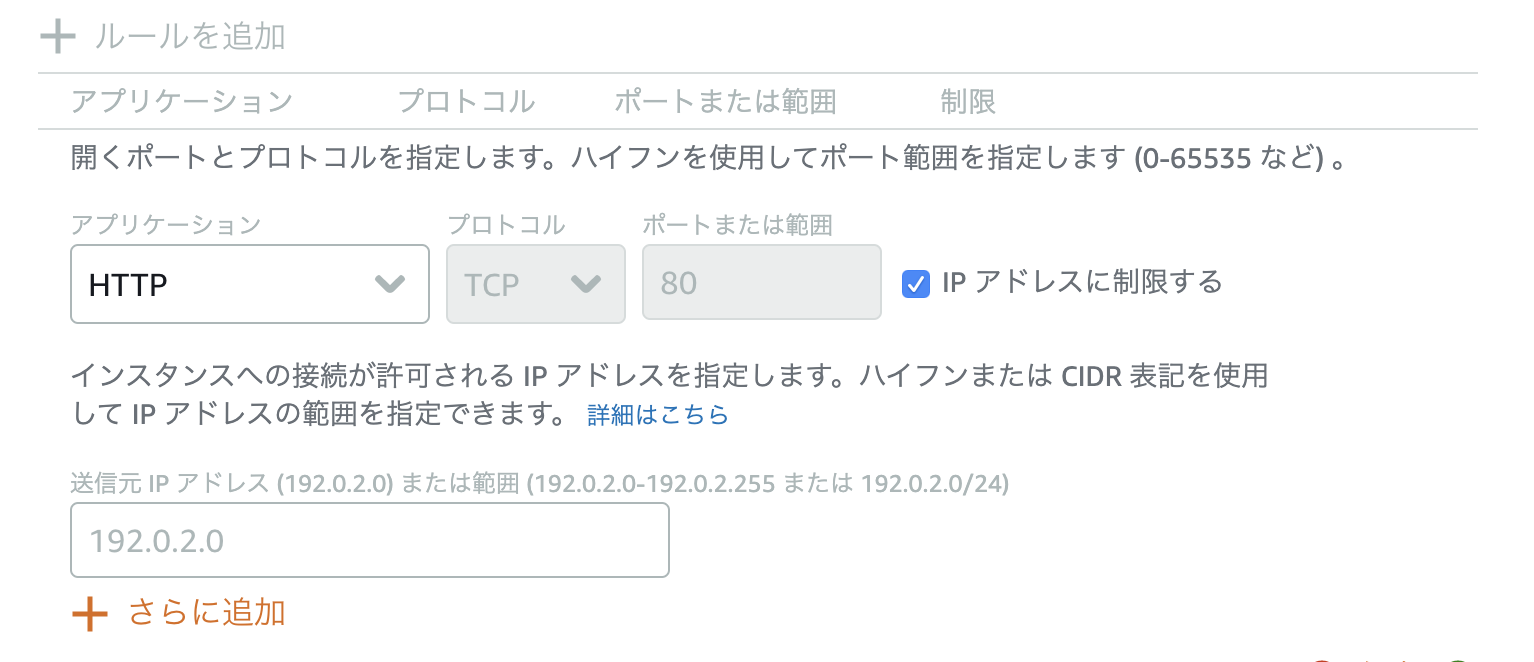
これまでは仕方なくhosts.allow, hosts.denyに書いて制限かけたりしてましたが、地味に便利。設定方法
各インスタンスの 管理>ネットワーキングタブ>ファイアウォール
編集アイコンを押して「IPアドレスに制限する」にチェックを入れると設定欄が出現。
IP単体指定でもCIDR表記でもいけるようです。ただし、セキュリティグループみたいにエイリアス指定はできません。元々hosts.allowやhosts.denyの設定がある場合は先にそちらの設定を削除しておきましょう。
詳しくは公式ドキュメント参照

- 投稿日:2020-05-24T17:32:54+09:00
AWS EC2インスタンスにtermiusから接続する
スマホでEC2入れたら便利じゃね?的な
前提
- Termiusがスマホに入ってる
- AWS EC2インスタンスが立ち上がってる
Termiusはスマホでターミナルがいじれるアプリだよ
1. pemファイルをスマホに送る
インスタンスを作るときにpemファイルをダウンロードしたと思います(してなかったらインスタンスを作り直そう、pemファイルは一回しかダウンロードさせてくれないので)
これを、スマホにbluetoothなりslackの自分宛てのDMなりで送ります2. TermiusにKeychainを追加
Termiusのアプリの、右のメニューを開いてKeychainを選択
+ボタンを押して、Import Keyを選択
さっきスマホに転送したpemファイルを選択
ファイルの中身を見ると
---BEGIN RSA PRIVATE KEY---とかも入るけど、これは消さないでそのままでok
(消しちゃうとInvalid RSA Keyとか怒られる)3. Termiusに新しいHostを追加
Hostsのタブを開いて、New Hostを選択
以下の項目を設定していきますAlias
Hostのあだ名
「AWS EC2」でも「ほげ太郎」でも自分がわかればokHost name or IP Address
これはIP Addressの方を入力する
EC2のダッシュボードにいって、IPV4 PublicのとこにあるIPを入力するUsername
ec2-userを入れる
基本的にこれでいけるはずだけど、設定を自分でいじった人は違うかもKey
2で追加したKeychainを選択
(入力するとこをタップすると、Select keyという画面になるので、そこでさっきのファイルをタップすればok)その他の項目
以外のところは何も入力しない
4. 接続してみる
Hostsの画面で、今つくったHostをタップして、黒い画面が出ればok
おめしゃす
- 投稿日:2020-05-24T16:56:03+09:00
AWS Lambda で遅延情報を通知してくれる Slack bot を書いてみた
はじめに
- 以前AWS Lambdaを用いて作成したSlack Botについてまとめる機会があり、せっかくなので備忘録含めQiitaにも投稿しようと思いました。
- 作成当時の記憶はだいぶ薄れておりますが、覚えている範囲で引っかかったところなどどなたかの参考になれば幸いです。
※ 本記事のbotを作成したのは約2年前なので、現在の仕様と乖離する部分もありますがご了承ください。
※ 作成したbotそのもののソースは以下となります。
https://github.com/spinrock/delayTrainBotそもそもSlack bot作成に至った経緯
- 筆者の家は、複数路線の駅に挟まれた立地にあり、駅から別の駅への移動が大変でした。
- 駅に到着後に遅延に気付いても別の路線に乗る(駅を移動する)、という選択肢をとることが難しい状況でした。
- 起床時に自分で路線情報を確認できればいいのだが、朝の時間帯はバタバタしていることが多く、見逃す日も多分にありました。
- 普段から確認するツール(LINEやSlack)に通知が来て教えてくれると便利なのにと感じておりました。
- Lambda(を含むFaaSやSaaS)で何かを作ることに純粋に興味があり、この際なので自作してみようと思いました。
- (当時の職業柄コーディングをしないため、久々にプログラミングしたくなったのも理由の一つです。)
やりたいこと
- 朝起きてから電車に乗る手前くらいの間で、電車が遅延したら自動で通知して欲しい。
- 月~金の朝7~9時くらいの間
- 通知先はSlackの指定したチャネル
構成図と処理イメージ
- draw.io (https://www.draw.io/) で書いてみました。
- 使っていた言語はPython3.x系です。
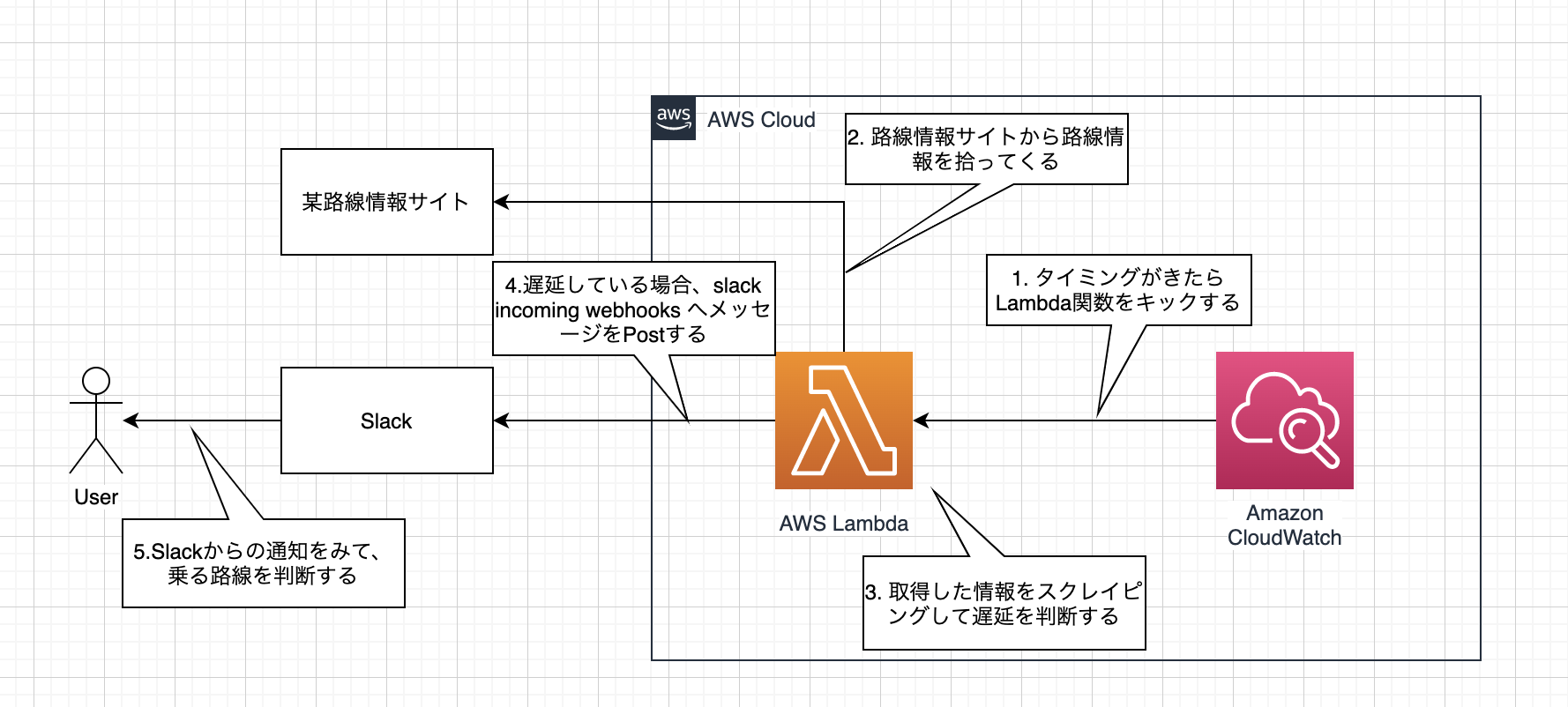
利用した技術の簡単なご紹介
- AWS Lambda : イベント駆動(何か(=イベント)をきっかけにして動く)のアプリケーションを実行できるAWSのサービス
- Amazon CloudWatch : リソースとアプリケーションの監視/管理サービス
- 今回はその中のCloudWatch Event(特定のルールを基にターゲット(Lambdaなど)へイベントを振り分ける機能)を利用しました。
- https://aws.amazon.com/jp/cloudwatch/
- スクレイピング : Webサイトから取得した情報からHTMLタグを利用して情報を抽出する技術
- 今回はPythonのスクレイピングライブラリの一つである「Beautiul Soup」を利用しました。
- https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- Slack Incoming Webhooks : HTTPリクエストを利用して特定のチャネルに指定したメッセージを投稿するアドオン(のようなもの)
- 作成していた当時と仕様が変わり、作成したSlack アプリケーションに対してIncoming Webhookを付与できるようです。
- https://api.slack.com/messaging/webhooks
できたもの(Slack 画面)
- ↓の画像のようになりました。(10分おきに確認して通知してくれます。)

実際にしばらく使ってみて思ったこと
- 最初困っていたことは無事解決できました。
- 朝通知が来ることで遅延していない路線(駅)を選べるようになりました。
- 遅延が解消した時に通知してくれるといいな、と思いはじめました。
- 現状は通知が来なくなることで遅延が解消したことを判断する仕様となっています。
- これ以外にもいろいろBot化させたら便利だろうなと感じました。
- 買い物メモとか、今日の予定(荷物の到着など)とか...
(最後に)引っかかったことなどなど
- 通知のタイミングがおかしいなと思ったら、時刻指定がUTCでした。
- 日本時間に直すために+9:00する必要がありました。
- 情報取得&スクレイピング処理に時間がかかっていた結果、Lambdaがタイムアウトしていました。
- Lambdaのデフォルトタイムアウトが3秒なので、必要に応じて変更する必要がありそうです。(後からでもGUIで変更可能でした。)
- 投稿日:2020-05-24T16:29:36+09:00
Cognito UserPoolsのAuthorizerをGoでデコードする
概要
- AWSのAPI Gatewayの認証にCognito UserPoolsのAuthorizerを用いるときに、API側でもユーザーの一意性を保つために認証します
- その際Cognitoから取得できるJWTのデコードが必要になるのでGo言語でのデコード方法についてまとめました
- クライアント側でAmplifyやリダイレクト後のURLなどを用いてCognitoからIDトークンを取得する方法については既知とします
Amazon Cognito ユーザープール認証
- Cognitoを用いたログインをクライアントから行うと、ユーザープールからJWT(JSON Web Token)が返されます
- JWTはBase64でエンコードされたJSON文字列であり、ユーザーに関する情報(クレーム)が含まれています
- (このBase64でエンコードされていると言う情報によりかなり苦しむことになりました...)
- エンコードされた文字列は
***.***.***のようにドット(.)で3つのセクションに分けられています- 3つのセクションはヘッダー、ペイロード、署名で構成されています
ヘッダーは以下のような情報があります
(キーID("kid")と、トークンの署名に使用されるアルゴリズム("alg")が含まれています){ "kid": "abcdefghijklmnopqrsexample=", "alg": "RS256" }ペイロードには以下のような情報があります
(ユーザーに関する情報と、トークンの作成および有効期限のタイムスタンプが含まれています){ "sub": "aaaaaaaa-bbbb-cccc-dddd-example", "aud": "xxxxxxxxxxxxexample", "email_verified": true, "token_use": "id", "auth_time": 1500009400, "iss": "https://cognito-idp.ap-southeast-2.amazonaws.com/ap-southeast-2_example", "cognito:username": "example", "exp": 1500013000, "given_name": "Example", "iat": 1500009400, "email": "example@example.com" }署名には、ヘッダーとペイロードの組み合わせをハッシュして暗号化したものが入ります
ヘッダーとペイロードのデコード
署名の認証周りは一旦なしにして、JWTをデコードしてトークンに含まれるヘッダとペイロードを取得する方法を説明します
Base64でエンコードされているとのことだったのでBase64でデコードすればいいやと思い、デコードしていたのですが、たまにデコードできない現象が発生してしまい、かなり苦しみました...
最終的な結論としてはBase64URLでデコードすれば間違いがありません
Base64とBase64URLの違い
Base64エンコードはデータを印字可能な64種類のデータで表現するエンコード方式です
しかし、URLの一部として利用する場合は「+」や「/」とと言ったURLセーフではない文字列が含まれるのでURLセーフにエンコードしなければなりません
そこで用いられるのがBase64URLのようです
おそらくAmplifyなどで直接JWTを取得する場合は問題ないと思いますが、リダイレクト後のURLなどからJWTをゲットした場合にURLセーフにエンコードされているのでBase64ではデコードできなかったものと考えられます
どちらにせよBase64URLでデコードすれば、ヘッダーとペイロードの値を取得できます
コーディング例
base64urlのデコーディングには
github.com/dvsekhvalnov/jose2go/base64urlをimportして用います
(そのほかには"strings"や"fmt"や"encoding/json"のimportが必要です)jwt := "***.***.***" // Cognitoユーザープールから取得したJWT // // API GatewayでLambda Proxyを用いてる場合、AuthorizationヘッダにJWTを付与するので、以下で取得可能 // jwt := events.APIGatewayProxyRequest.Headers["Authorization"] // ドットで文字列を分割して配列にして、エンコーディングされたヘッダとペイロードを取得 headerEnc := strings.Split(jwt, ".")[0] payloadEnc := strings.Split(jwt, ".")[1] // base64urlを用いてヘッダーとペイロードをデコードします headerDec, _ := base64url.Decode(headerEnc) // 第二戻り値のエラーは無視しています payloadDec, _ := base64url.Decode(payloadEnc) // 同様 // 文字列として出力 fmt.Println(string(headerDec)) fmt.Println(string(payloadDec)) // デコードされた戻り値は[]byte型なので、以下のように構造体に入れたり、マップに入れ込んだりできます type Header struct { KeyID string `json:"kid"` Algorithm string `json:"alg"` } headerStruct := Header{} json.Unmarshal(headerDec, &headerStruct) headerMap := map[string]string{} json.Unmarshal(headerDec, &headerMap)以上のようにデコード自体は難しくないのですが、あまり載っていなかったので苦労しました
- 投稿日:2020-05-24T16:09:46+09:00
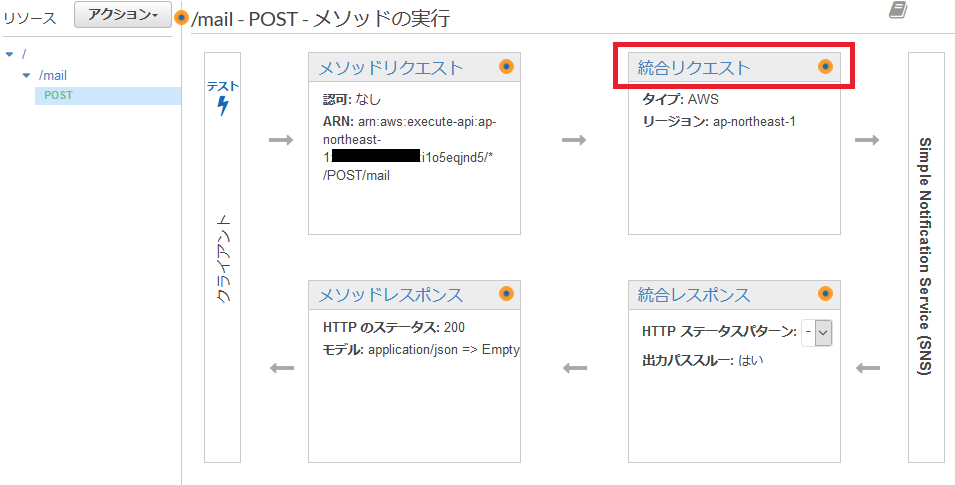
API GatewayからSNSトピックにメッセージ発行してメール通知
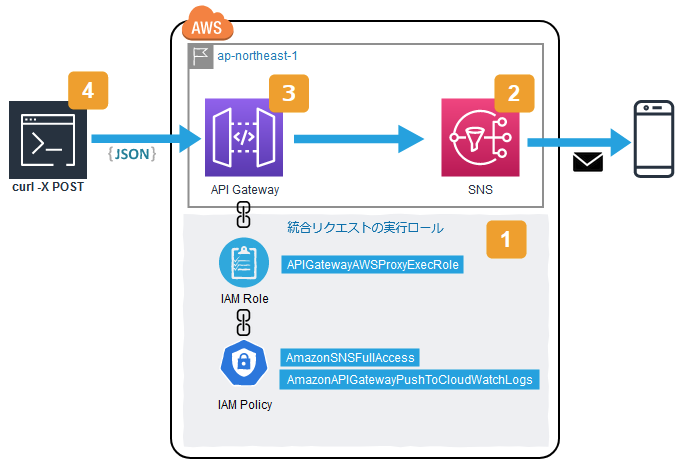
Webhookで呼び出されたAPI Gatewayから、SNSにトピックを発行してメール通知する仕組みを作ってみました。本記事では簡単のため、Webhook役を
curlコマンドが演じています。
図中の四角数字は、以下手順の番号と対応しています。
【手順1】ロールの作成(IAM)
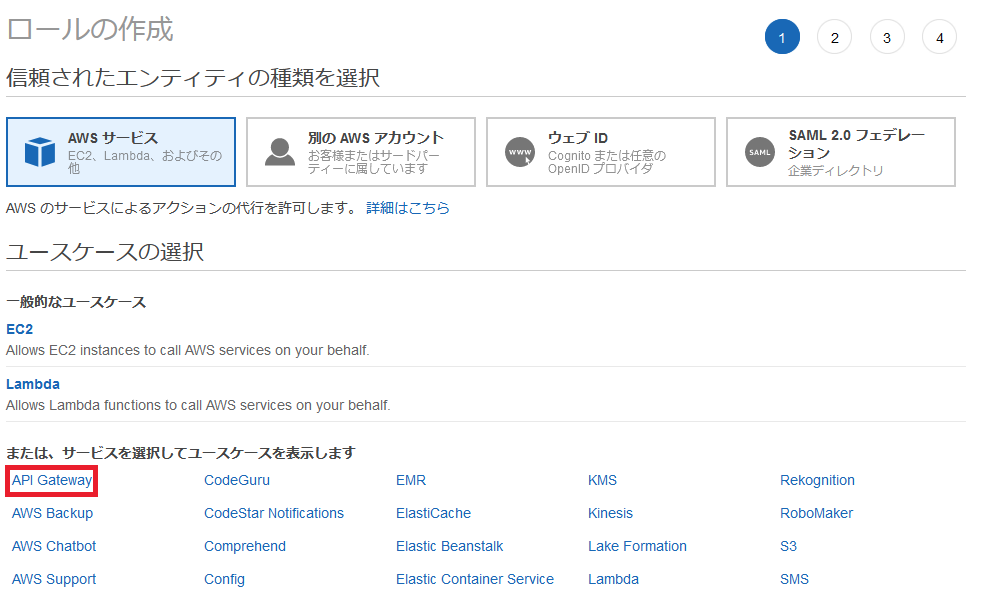
API GatewayのAPIにアタッチする用のロールを作成していきます。ユースケースから「API Gateway」を選択します。
ここでは、ロール名は「
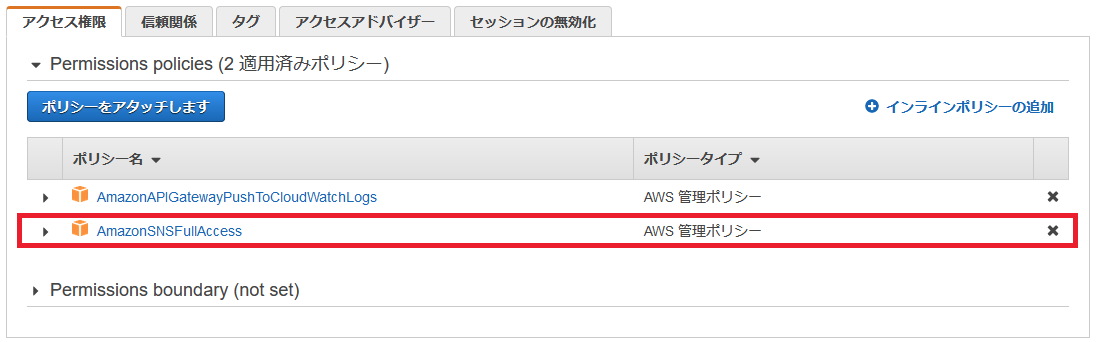
APIGatewayAWSProxyExecRole」とします。ロール作成後はデフォルトで「
AmazonAPIGatewayPushToCloudWatchLogs」がアタッチ済みとなっています。「AmazonSNSFullAccess」もアタッチしておきます。
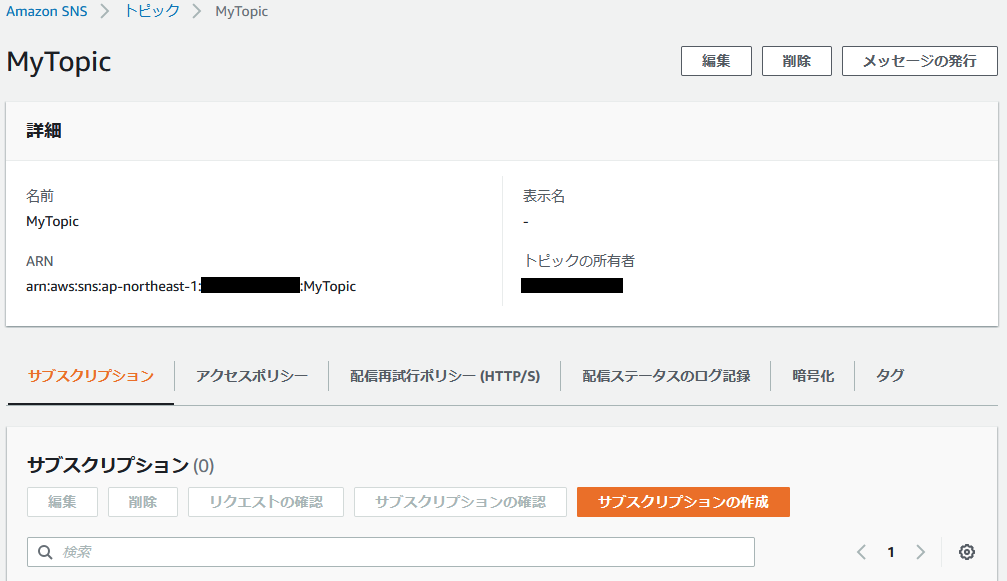
【手順2】トピックの作成(SNS)
まず、トピックを作成します。トピック名は「MyTopic」とします。
つぎに、「サブスクリプションの作成」をクリックして、作成したトピックの購読設定を行います。
- プロトコルは「Eメール」を選択
- エンドポイントにはSNSからの通知を受信するメールアドレスを入力
最後に「サブスクリプションの作成」をクリックします。
「サブスクリプションの作成」をクリックしたタイミングで、AWSから購読確認のメールが(上で入力したメールアドレス宛に)送信されますので、メーラーを開いてConfirmします。
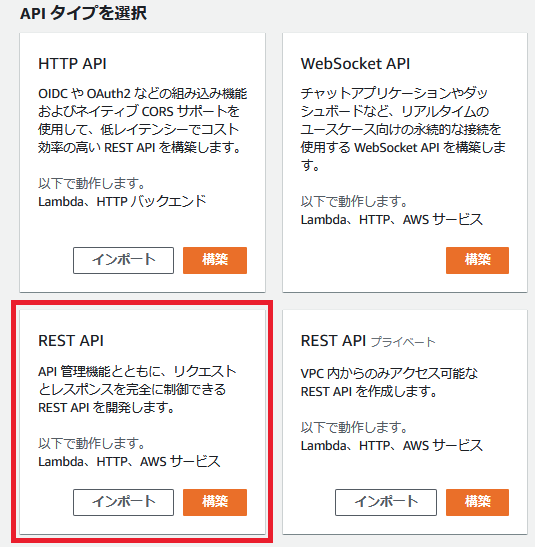
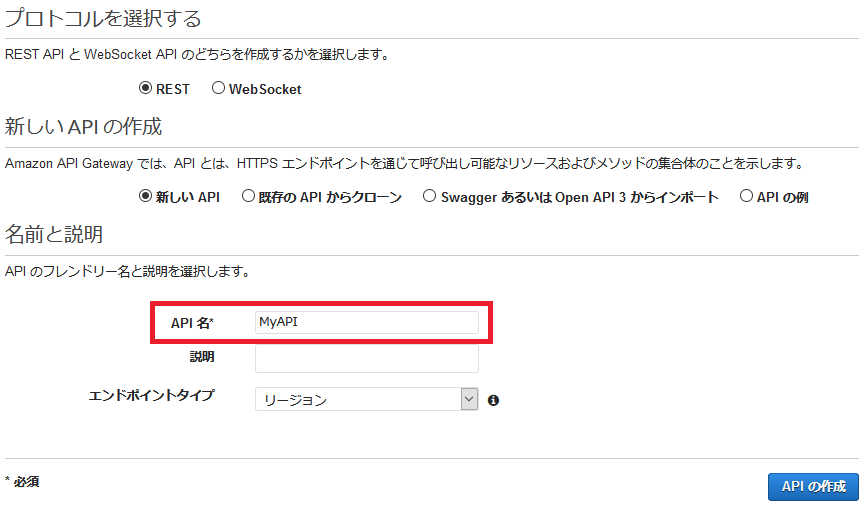
【手順3】REST APIの作成(API Gateway)
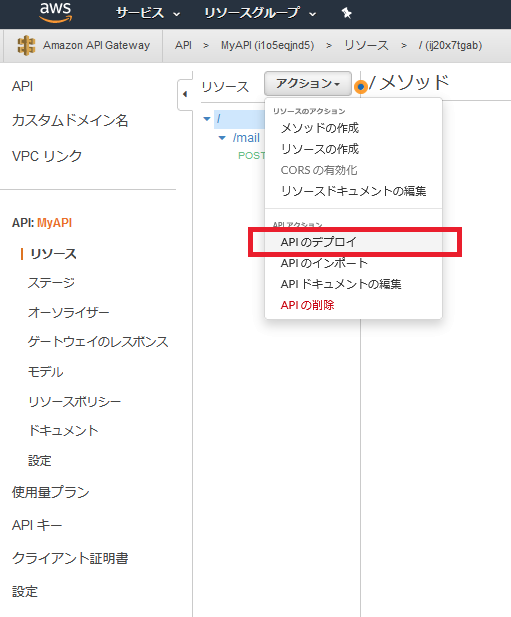
API Gatewayで、REST APIを作成します。APIタイプは「REST API」を選択します。
API名は「MyAPI」としておきます。
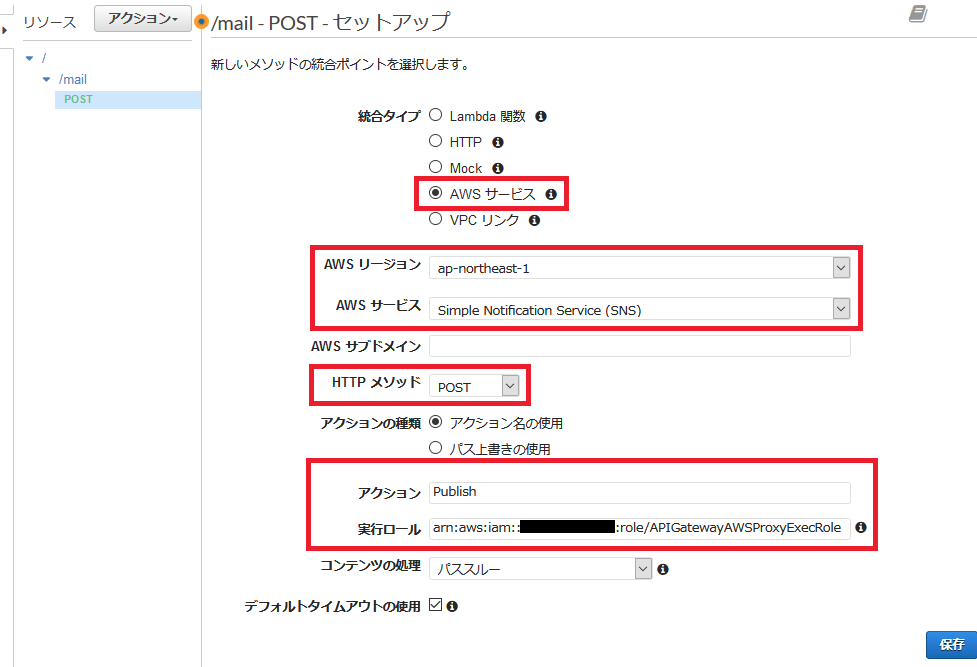
APIのリソースとメソッドを作成します。
ここでは「/mail」リソースに対するPOSTメソッド、というインタフェースとしています。
- 実行ロールには、【手順1】で作成したロールのARNを入力します。ARNは、IAMコンソールのロールから確認できます。
# 項目 値 1 統合タイプ AWSサービス 2 AWSリージョン (SNSトピックを作成したリージョン) 3 AWSサービス Simple Notification Service (SNS) 4 HTTPメソッド POST 5 アクション Publish 6 実行ロール arn:aws:iam::************:role/APIGatewayAWSProxyExecRole 次に、リクエストデータをバックエンド向け(SNS向け)に加工するため、統合リクエストの設定を行います。
「統合リクエスト」のリンクをクリックすると、設定画面が開きます。
統合リクエストの設定画面で、SNS向けにクエリ文字列を追加します。
# キー 値 1 Message method.request.body 2 TopicArn 'arn:aws:sns:ap-northeast-1:************:MyTopic'
TopicArnの値には、【手順2】で作成したSNSトピックのARNを指定します。ARNは、SNSのコンソール画面から確認できます。設定保存後、「アクション」メニューの「デプロイ」をクリックして、デプロイを行います。
デプロイ後にURLが表示されますので、メモしておきます。
URLはhttps://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/test/mailの形式になります。(補足)リソースポリシーの設定(API Gateway)
作成したAPIをデプロイ後はインターネットに公開されるため、誰でもアクセスできてしまいます。リクエスト元のIPアドレスを制限したい場合、リソースポリシーを定義することでアクセス元を制限することができます。
今回は、ホワイトリスト形式で登録します。以下をベースにして作成します。
Resourceは、本APIのARNを指定してください。aws:SourceIPに、APIへのアクセスを許可するIPアドレスを指定してください。リソースポリシー(ホワイトリスト形式){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "execute-api:Invoke", "Resource": "arn:aws:execute-api:ap-northeast-1:xxxxxxxxxxxx:xxxxxxxxxx/*/*/*", "Condition": { "IpAddress": { "aws:SourceIp": "xxx.xxx.xxx.xxx" } } } ] }作成したリソースポリシーを、以下のテキストエリアにペーストして保存します。
リソースポリシーを保存し、APIをデプロイした後は、許可された送信元(IPアドレス)からのアクセスのみリクエストを受け付けます。
許可されない送信元からのアクセスに対しては、403 Forbiddenで以下のエラーメッセージが返されます。403_Forbidden{ "Message": "User: anonymous is not authorized to perform: execute-api:Invoke on resource: arn:aws:execute-api:ap-northeast-1:************:**********/test/POST/mail" }リソースポリシーをテストする際、固定のグローバルIPをもつホストからリクエストを投げる必要がありますが、パブリックサブネットにEC2インスタンスを立てればいいですかね。
【手順4】REST API呼出しのテスト(curlコマンド)
今回作成したAPIを、curlコマンドで呼出してみます。
$ curl -X POST -H "Content-Type: application/json" -d '{"id":"1024", "name":"yz2cm"}' https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/test/mail【手順2】で購読設定したメールアドレスに、メールが送信されているはずです。
- 送信元は
MyTopic <no-reply@sns.amazonaws.com>。- 件名は
AWS Notification Message固定。SNSからの受信メール{"id":"1024","name":"yz2cm"} -- If you wish to stop receiving notifications from this topic, please click or visit the link below to unsubscribe: https://sns.ap-northeast-1.amazonaws.com/unsubscribe.html?SubscriptionArn=arn:aws:sns:ap-northeast-1:xxxxxxxxxxxx:MyTopic:e9709da9-e2fc-4098-9b1b-89bcd50af664&Endpoint=foo@gmail.com Please do not reply directly to this email. If you have any questions or comments regarding this email, please contact us at https://aws.amazon.com/supportコマンドの標準出力{ "PublishResponse": { "PublishResult": { "MessageId":"dbb7488c-6c45-5c31-8038-1fc87bc2f28d", "SequenceNumber":null }, "ResponseMetadata": { "RequestId":"347548a3-f894-552f-a8ef-1fe7ef138b93" } } }参考ページ
本記事を書くにあたり、参考にさせていただいたページです。


- 投稿日:2020-05-24T15:26:57+09:00
AWS初心者が在宅勤務中にAWSの資格を取る記録 part5
■5/18(Mon)
・Udemyで座学&ハンズオン(セクション15)
→セキュリティ関連のサービス概要の把握、CloudWatchのサービス構築
・座学でとったノートの見返し感想
土日にも学習していた為、本日でUdemyのコースが修了。(模擬試験は後々)
模擬試験をチラと見たが、難易度がかなり高めに設定されていて今のままでは解けないだろうと考えたので
すぐにAmazonで下記の参考書をポチり。
https://www.amazon.co.jp/dp/479739739X/ref=cm_sw_r_tw_dp_U_x_Fr4WEb206QD4Rここまで進めてきて思ったが正直、今試験を受けて受かるかという自信がほとんど無い。
CLFの時のように参考書をベースに知識の整理をして、模擬試験に挑みたいと思う。■5/19(Tue)
・座学でとったノートの見返し
・参考書ベースの座学感想
参考書ベースでの座学に時間を割いた一日。
参考書にはガンガン書き込むタイプなので、重要な箇所や知らなかった箇所に線を引いたり、コメントを残して進めていった。とりあえず、何となく整理の知識ができたので明日から模擬試験に進んで、今週中に本試験を受ける予定。
■5/20(Wed)
・参考書ベースの座学
感想
参考書2週目。
寝たら忘れてしまうタイプなので、1周目と2週目で不明点を地道に潰して記憶に定着させていく作戦。だいぶ定着した感じがあるので、木曜日と金曜日で模擬試験集をみっちりやる。
■5/21(Thu)
・Udemyで模擬試験
★受講コース
https://www.udemy.com/course/aws-knan/感想
結果
基本問題の模擬試験①
→43/65 66%
高難易度の模擬試験②
→40/65 61%
高難易度の模擬試験③
→43/65 66%思いのほか得点できた。ケアレスミスも含めると合格点に届いていたかもという感じ。
復習にはそこそこの時間を割いた。いけそうな感覚を掴めたので土曜日に受験することを決意。
(本当は金曜日に受けたかったが、予約日と受験日が24時間以上空いてないとダメらしい)■5/22(Fri)
・Udemyで模擬試験
感想
結果
基本問題の模擬試験①
→40/65 61%
高難易度の模擬試験②
→40/65 61%
高難易度の模擬試験③
→34/65 52%こちらも何となくそこそこの点数をとれた。
明日に向けて見直しを実施。■5/23(Sat)
・SAA本試験
感想
結果
無事に一発合格!
スコアレポート見ると、725で本当のギリギリ合格。。
合格は合格だが、理解度はまだまだ低いと思う。来週中にでも番外編として、SAA合格までの合格体験記的なのを投稿したい。
とりあえずお疲れ様でした、自分。
- 投稿日:2020-05-24T15:24:34+09:00
Amazon RDSについて
はじめに
部署内の方が、RDBについての勉強会を開いてくださった時に、そもそもRDBについての知識があまりなく、このままだと曖昧な理解のまま終わってしまうと思ったことと、会社でAWSを使う関係上Amazon RDSについても知っておく必要があると思ったので、以下に内容をまとめ頭の中を整理したいと思います。
RDBとは
Relational Database(リレーショナルデータベース)の略で、それぞれ関連性のある複雑なデータを複数の表として定義し、管理することができます。
また、表の構成については以下の例ように、行に該当する部分(横)を「レコード」と呼び、列に該当する部分(縦)を「フィールド」(または「カラム」)、複数のレコードの集合を「テーブル」と呼ぶそうです。
例:
そして、各レコードを識別するため例のID項目については、「主キー(プライマリーキー )」といい、テーブルの中でレコードを特定するのに使われます。
これらデータを操作する際にはSQL(Structured Query Language)と呼ばれるプログラムを使用します。SQLとは
データベース言語の1つで、データベースの定義や操作を行うことができます。
SQLはISO(国際標準化機構)で規格が標準化されているようで、一度書き方を覚えれば他のデータベースでもほぼ同じように操作することができるみたいです!
処理の流れとしては、ユーザーやシステムからの命令を受けて、RDBにクエリ(問い合わせ)を行い結果が返ってくるという流れになります。
また、SQLの使えるデータベースの代表的なものとして、MySQL、Oracle、DB2、MongoDB、PostgreSQLなどがあります。SQLについて調べていると
NoSQLというワードが度々登場するのでそれについても以下にまとめたいと思います。NoSQLとは
「Not Only SQL」の略で、RDBは表形式でデータを扱う性質上、扱うデータがより複雑化したり、それによりデータが膨大な量になってしまった場合、データの一貫性を保つためどうしてもシステムの処理速度が遅くなってしまうことがあります。
そこで、そのような問題に対応するため、処理速度を確保できるようにデータの格納と取得を最適化するために作られたのがNoSQLです。
NoSQLの種類には以下のものがあります。
- キー、バリュー型
- ソート済みカラム指向
- ドキュメント指向
(詳しい説明は今回割愛させていたできます。
)
...ここまでで、RDBの概念的なものは理解できたと思うので、Amazon RDSについて記述していきます。
Amazon RDSとは
サポートしているデータベースとしては、
- Amazon Aurora
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- PostgreSQL
があります。
また、Amazon RDSはマネージド型リレーショナルデータベースのため、ハードウェアのプロビジョニング、データベースのセットアップ、パッチ適用、バックアップなどの時間がかかるタスクを自動化することができます。
オプション機能の1つにマルチAZ配置オプションがあり、この機能を使うことで、万が一の事態が起きたとしても運用する上での可用性を高めることができます。調べていく中で、個人的に便利だなと思ったのは、スケールが容易にできるという点で、リードレプリカを使うことで、読み取り頻度が高いデータベースの処理に対する負荷に関して、インスタンのキャパシティを超えたら伸縮自在にスケールアウトできるということです。
この機能のおかげで、当初設定していたキャパシティを超えたとしてもサーバーを自動で増やすことができるので、もしもの時でも安心だなと思いました。
また、リードレプリカは名前からしても想像ができるようにDBインスタンスのレプリカを作ります。
しかも、それを複数作ることによって、アプリの大容量読み取りトラフィックをデータの複数からコピーし提供することによって、データ全体を読み込みする際の一定時間あたりの処理能力(スループット)を向上させることができる点も魅力的です。まとめ
RDBとはなんぞやから始まり、AmazonRDSについても概要はなんとなくではありますが、調べる前より理解が深まったと思います。
Amazon RDSについては、これから触る時のためにも備忘録も兼ねてまとめてみました!(書いたこと忘れてたらどうしよう...)

- 投稿日:2020-05-24T15:04:40+09:00
AWS日記⑤ (Cognito)
はじめに
今回はCognitoを利用して簡易なアカウントページを作成します。
サインアップする際にはメールアドレス認証する方法をとります。準備
Cognitoのユーザープールを作成します。
Lambda , API Gatewayの準備をします。[参考資料]
はじめてのAWS Cognito!!
チュートリアル: ユーザープールの作成WEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Cognito を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference
golangでCognito認証(ただしSecure Remote Password(SRP)プロトコルではない)
Amazon Cognitoで発生する例外(Exception)をまとめてみた
AWS Cognitoを実践で使うときのハマりどころサインアップする際には SignUp を使う。
main.gofunc signup(name string, pass string, mail string) error { svc := cognitoidentityprovider.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) ua := &cognitoidentityprovider.AttributeType { Name: aws.String("email"), Value: aws.String(mail), } params := &cognitoidentityprovider.SignUpInput{ Username: aws.String(name), Password: aws.String(pass), ClientId: aws.String(clientId), UserAttributes: []*cognitoidentityprovider.AttributeType{ ua, }, } _, err := svc.SignUp(params) if err != nil { return err } return nil }サインアップを認証する際には ConfirmSignUp を使う。
main.gofunc confirmSignup(name string, confirmationCode string) error { svc := cognitoidentityprovider.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &cognitoidentityprovider.ConfirmSignUpInput{ Username: aws.String(name), ConfirmationCode: aws.String(confirmationCode), ClientId: aws.String(clientId), } _, err := svc.ConfirmSignUp(params) if err != nil { return err } return nil }サインインする際には InitiateAuth を使う。
main.gofunc login(name string, pass string)(string, error) { svc := cognitoidentityprovider.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &cognitoidentityprovider.InitiateAuthInput{ AuthFlow: aws.String("USER_PASSWORD_AUTH"), AuthParameters: map[string]*string{ "USERNAME": aws.String(name), "PASSWORD": aws.String(pass), }, ClientId: aws.String(clientId), } res, err := svc.InitiateAuth(params) if err != nil { return "", err } return aws.StringValue(res.AuthenticationResult.AccessToken), nil }ユーザー情報を取得する際には GetUser を使う。
main.gofunc getuser(token string)(string, error) { svc := cognitoidentityprovider.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &cognitoidentityprovider.GetUserInput{ AccessToken: aws.String(token), } res, err := svc.GetUser(params) if err != nil { return "", err } return aws.StringValue(res.Username), nil }パスワードを変更する際には ChangePassword を使う。
main.gofunc changePass(token string, pass string, newPass string) error { svc := cognitoidentityprovider.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &cognitoidentityprovider.ChangePasswordInput{ AccessToken: aws.String(token), PreviousPassword: aws.String(pass), ProposedPassword: aws.String(newPass), } _, err := svc.ChangePassword(params) if err != nil { return err } return nil }サインアウトする際には GlobalSignOut を使う。
main.gofunc logout(token string) error { svc := cognitoidentityprovider.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) o_params := &cognitoidentityprovider.GlobalSignOutInput{ AccessToken: aws.String(token), } _, err := svc.GlobalSignOut(o_params) if err != nil { return err } return nil }今回は、ページ表示とAPIの API Gatewayを別々に作成し、APIのメソッドはPOSTに設定しました。
作成したLambda 関数、テンプレート終わりに
今回は、メールアドレスでサインアップする方法をとりました。
他にも様々な使い方があるので今後試していきたいと思います。
AWS CognitoにGoogleとYahooとLINEアカウントを連携させる
- 投稿日:2020-05-24T14:55:27+09:00
AWS CLI v2のコマンド補完を有効にする
TL;DR
- AWS CLI v2で、シェル補完が有効なようなので設定したい
aws_completerを使ってシェル補完を有効にするが、継続的に有効にするには~/.bashrc等に設定するちなみに、Amazon Linux上ではデフォルトで有効化されているようです。
Amazon Linux
コマンド補完は自動的に設定され、Amazon Linux を実行する Amazon EC2 インスタンス上でデフォルトで有効化されます。
AWS CLI v2をインストールする
最初に、AWS CLI v2をインストールしましょう。
今回の環境はCentOS 7なので、Linux向けのインストールを行います。
$ uname -srvmpio Linux 3.10.0-957.12.2.el7.x86_64 #1 SMP Tue May 14 21:24:32 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux $ cat /etc/redhat-release CentOS Linux release 7.8.2003 (Core)Linux での AWS CLI バージョン 2 のインストール
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" $ unzip awscliv2.zip $ sudo ./aws/installこれで、AWS CLI v2がインストールされました。
$ aws --version aws-cli/2.0.16 Python/3.7.3 Linux/3.10.0-1127.8.2.el7.x86_64 botocore/2.0.0dev20現時点のバージョンは、2.0.16ですね。
コマンド補完を設定する
では、AWS CLI v2のコマンド補完を設定してみましょう。
Amazon Web Services ブログ / AWS CLI v2 が一般利用可能となりました
ドキュメントを見ていると、
aws_completerをPATHに追加するように書かれています。が、pipを使った方法など、そもそも内容がv1寄りのような…?
aws_completerコマンドを探してみましょう。AWS CLI v2のデフォルトのインストール方法では、
/usr/local/binに配置されるようです。$ ls -l /usr/local/bin 合計 0 lrwxrwxrwx. 1 root root 37 5月 24 05:40 aws -> /usr/local/aws-cli/v2/current/bin/aws lrwxrwxrwx. 1 root root 47 5月 24 05:40 aws_completer -> /usr/local/aws-cli/v2/current/bin/aws_completerでは、
aws_completerを使ってシェル補完を設定します。bashの場合は、こちらです。$ complete -C aws_completer aws
zshやtcshの場合は、ドキュメントを参照してください。シェル補完が使えるようになったか、確認してみましょう。
$ aws ec ec2 ec2-instance-connect ecr ecs大丈夫そうです。
シェルにログインする際にコマンド補完を有効にする
bashの場合は、$HOME/.bash_profileに追加しましょう。$ echo 'complete -C aws_completer aws' >> $HOME/.bash_profileこれで、シェルを起動する度にコマンド補完が有効になります。
- 投稿日:2020-05-24T14:46:20+09:00
AWS EC2でpythonのプログラムを実行する
ローカル環境で
.pyを実行しようとしたのですが、Python3とpip3とPythonとPipがわけわからなくなってたので、AWSで実行することにしましたやり方めも
1. AWSに登録
awsでググって、アカウントをつくる
メアドとパスワード入れるだけ2. EC2を選択
いろんなサービスがあるけどEC2をクリックする
3. 新しいinstanceを作る
設定はAWSのGetting Startedの通りにやればok
全部無料のやつ
- AMI (Amazon Machime Image): Amazon Linux 2 AMI (x86)
- インスタンスのタイプ: t2.micro
※AMIはx86とARMの2種類があります
とりあえずx86でうまくいったけど、何が違うのかわかりません
誰か教えてこれを選択したら、青いボタンの「Review & Launch Instance」をする
key pair を保存してねっていうポップアップが出るので、"Create New Key Pair"を選択して、
.pemファイルを保存する
※前にinstanceを作ってたら、"Choose existing key pair"を選択すれば、前と同じやつが使える
※ブラウザでインスタンスに接続する場合はこの.pemファイルは使わないよ4. instanceに接続する
EC2 Dashboardに行って、instanceの横にあるチェックボックスをクリック
→ "Connect"ポップアップが出るから、ブラウザで接続する一番したのやつを選ぶ
(他のでもいいと思うけど、SSHよくわからないのでブラウザにした)
ブラウザに黒い画面が出ればok
5. 環境構築
ここから、pythonプログラムを実行するための環境構築をしていきます
@kenta1984さんの記事とほぼ同じやること:
- python3を入れる
- gitを入れるgitは、PythonのファイルをEC2インスタンスに転送するときにgistを使うので入れます
scpとか使う人はいらない# とりあえず入ってるパッケージをアップデート sudo yum update -y # Python3を入れる sudo yum install python3 -y # git を入れる(任意) sudo yum install gitちなみに、Python3を入れると、pip3も一緒に入ってきます
なのでpip3を別でインスコする必要はないです参考: https://git-scm.com/download/linux
6. ファイルを作る→EC2インスタンスに送る
実態は、gistにファイルを乗っけてそれをインスタンスにクローンしてるだけ
gistはgitと同じようにcloneもpullもできます
6-1. gistをつくる
VSCodeとかで書いたコードを貼り付ければok
ファイル名には拡張子も入れてね
6-2. gistをクローン
のとこで、Clone via HTTPSを選択 → コピー
EC2インスタンスに接続してる黒い画面(4で開いたブラウザのタブ)で、いつもgitリポジトリをクローンするみたいにgistをクローンします
$ git clone <gistのURL>6-3. プログラム実行
# gistのディレクトリに移動 cd my-gists # ディレクトリ名は人によって違うよ、わからなかったらlsしてね # プログラム実行 python3 hoge.py # ファイル名は自分のやつに変えてねまとめ
- EC2でインスタンスをつくる
- インスタンスにブラウザで接続する
- インスタンスに
sudo yum installでpython3とgitを入れる- gistにpythonプログラムのコード貼り付け
- gistをクローン
- プログラム実行

- 投稿日:2020-05-24T13:47:11+09:00
データサイエンティストがPythonでシステム開発する前に読む記事
広告運用自動化関連のプロジェクトで、他部署のデータサイエンティストがアルゴリズムの開発担当として、私がシステム担当兼レビュワーとしてアサインされました。
ただまだ分析以上のプログラミング経験はあまり無いそうで、知らない単語が芋づる式に出てくる状態のようです。それぞれの考え方を教えようにも、このコロナ影響下ではホワイトボードも使えないし、zoomのミーティングの時間を取るのもお互い負担が大きかったので、まずQiitaで共有することにします。
同僚に間違ったことを教えていたら困るので、もし誤っている箇所やアドバイスがあればコメント頂けると嬉しいです。
バッチプログラムの実行について
現在開発している広告運用自動化システムでは、AWS Data Pipelineを使っておおよそ以下のような環境で動いています。
- 事前にソースコードをまとめてzipファイルにしてS3にアップロードしておく
- この処理はリポジトリのmasterブランチにpushしたときにCI/CDツールが動いて自動で行っています
- Data Pipelineの定期実行機能により、EC2インスタンスを立ち上げる
- Data Pipelineが「S3からプログラムや依存ライブラリをインストールして実行する」シェルスクリプトを実行する
- EC2インスタンスをシャットダウンする
もし今後Dockerを使ったシステムに移行した場合は「ソースコードをまとめてzipファイルにしてS3にアップロード」が「DockerイメージをビルドしてAmazon ECRにプッシュする」に変わります。少し余談ですが、「アプリ開発者自身がDockerfileでプロダクトに必要な言語やミドルウェアを記述できるようになり、インフラ部門に依存せずに素早く設定を更新できる」というメリットもあります。
そもそも、AWSのサービスが多すぎて「このサービスとこのサービスって何が違うんだ?」などと困る場面もあるかもしれません。私も苦労しました。AWSのソリューションアーキテクトのテキストの関連項目に目を通しておくことといいかもしれません。
また、現状では各バッチ処理を指定時間にcron実行しているだけで、連鎖的に失敗して再実行にも手間がかかっています。それをバッチの依存関係を明示して解決するのがAirflowやDigDagなどのワークフローエンジンです。(※AWS Datapipelineもワークフローとして実行するためのサービスなのですが、GUIの管理が煩雑でうまく設定できていません)
他の問題を優先して対処していたのですが、ずっと解決しないのも問題なのできちんと動こうと思っています。
開発用ツールについて
gitやpoetryなどについて質問された項目です。
Pythonやライブラリのバージョンについて
開発では「プロジェクトAでは最新のPython3.8を使いたいが、プロジェクトBではライブラリが対応してないのでPython3.7を使いたい」というような場合があります。
私は
pyenvでPython本体のバージョンを切り替え、ライブラリはpoetryを使って管理しています。次の記事を参考にしてください。少し前まで
poetryと同じ用途でPipenvが流行っていたのですが、現在開発が滞っているようです。例えば「If this project is dead, just tell us」というISSUEが作られてしまっていました。(※ただし、先程確認したら2020年4月1日に2年越しにリリースされているようで、完全に開発が止まっているわけでは無さそうです)poetryを利用すると
pyproject.tomlとpoetry.lockというファイルが生成されます。pyproject.tomlが利用しているPythonライブラリのバージョンなどのプロジェクトの設定で、poetry.lockが実際にインストールした依存ライブラリのバージョンを固定するためのものです。それには以下のようなメリットがあります。Committing this file to VC is important because it will cause anyone who sets up the project to use the exact same versions of the dependencies that you are using. Your CI server, production machines, other developers in your team, everything and everyone runs on the same dependencies, which mitigates the potential for bugs affecting only some parts of the deployments.
(Google翻訳)このファイルをVCにコミットすると、プロジェクトを設定したすべてのユーザーが、使用している依存関係とまったく同じバージョンを使用するようになるため、重要です。CIサーバー、プロダクションマシン、チーム内の他の開発者、すべておよび全員が同じ依存関係で実行されるため、デプロイメントの一部にのみ影響するバグの可能性が軽減されます。
Pythonに限らず、他のプログラミング言語でも同じようなツールが存在します。例えばRubyのrbenvやBundler、node.jsならnvmやnpm(他にもいろいろあるらしい)などを使います。他言語でもツールごとに微妙にカバーしている範囲は違いますが、お互い影響を与え合って似ている部分も多く、例えば
***.lockが用意されていたりします。コードのバージョン管理(git)について
gitについては長くなってしまうので入門記事を読んでください。最初は難解だと思いますが、「ブランチ」の必要性を理解すると自分で調べられるようになると思います。
基本的に「別のブランチで開発(コミット)して、リリース用ブランチにマージする」というスタイルで開発します。これにより複数人が別の機能を追加したいとき、同時に別ブランチで開発できます。
SubversionとGitの大きな違いはブランチ管理あると私は考えています。最近のソースコードのバージョン管理では、機能開発やバグ修正の専用ブランチを作ってリリース用ブランチへマージする開発スタイルが主流になってきており、開発プロジェクトにおいてコードのブランチ管理は必要不可欠であると言えます。
上記にある通り、git以前からSubversionというツールもあったのですが、ブランチの使い勝手が非常に悪いせいでほぼ駆逐されてしまったそうです。余談ですが、リーナス・トーバルズ(gitやLinuxカーネルの開発者の偉大なプログラマーだが、口が悪いことでも有名)が特にこの点でSubversionをこき下ろしているというニュースもありました。
「Github上でリリース用ブランチにマージすることを依頼する」のがよく聞くプルリクエストです。また、ブランチの運用方法にはgitflowやgithubflowなどがあり、今やってる広告運用自動化のシステムではgitflowを採用しています。
sshについて
ssh接続して作業することもあると思います。その際に、秘密鍵のほうを絶対に他人に漏らさないように気をつけてください。
公開鍵認証において、サーバに登録するのはユーザの公開鍵です。そして、認証時には秘密鍵そのものではなく、生成した署名データ、それも流用困難なものをサーバに提示します。そのため第三者はもちろんサーバであっても秘密鍵を入手したり、署名を悪用することは困難です。
実装について
Pythonのコードを実装する際に気をつける点をまとめておきます。
ドキュメンテーションや型ヒントについて
他の人が読みやすい状態にしておく。ひとまずこれやっといてください。
- README.mdをきちんと書く
- Docstrings(関数にあるコメント)をきちんと書く
Docstringsも何種類かスタイルがあり、numpyスタイルやGoogleスタイルなどがあります。自分たちはGoogleスタイルを採用しています。
私はVSCodeのプラグインのPython Docstring Generatorで補完するように設定しています。他のIDEやエディタでも同様のツールがあると思います。
型ヒントも基本的にはドキュメンテーションの役割だけを果たしています。そのためコードの実行時に間違った型を入れてもエラーが出ません。
def greeting(name: str) -> str: return f"Hello, {name}" print(greeting(1)) # => "Hello, 1"「基本的」というのは、
mypyという静的解析ツールで型情報が間違ってないか自動でテストを行うことができることと、一部のライブラリ(後述するpydanticなど)では実行時に型の情報を使う場合もあるからです。型ヒントを使う際は、
List[str]だとかDict[str, str]などの記述方法を知っておく必要があります。余裕があるときに次の記事を読んでおくと良いです。ロギングについて
私のコードの中に
loggingを使ったコードがあり、Pythonの公式ドキュメントのLogging HOWTOも圧があるので困ってしまったと思います。簡単に説明すると、
- 出力先(ログファイル、標準出力)を設定できる
- ログレベル(DEBUG, INFO, ERRORなど)を切り分けられる。また「開発環境ではDEBUGを表示するが、本番ではINFO以上にする」などの切り捨て設定もできます。
より具体的には以下の記事を参考にすると良いと思います。
- Pythonでprintを卒業してログ出力をいい感じにする
- ログ設計指針 ※JavaやPHPが対象で、少しログレベルの内容が違うので注意
ただ、私も開発時は厳密にやっているわけではなく、実装時のデバッグは
loggingを使った形に置き換えるように実装しています。アプリケーションの設定について
アプリケーションの設定(どのS3パスを使うとか、不動産マーケットを実行するかとか)は以下のような方法で行います。
- 環境変数にセットする
- コマンドライン引数で渡す
- 設定ファイル(jsonやyamlなど)を用意する
環境変数を使う
アプリケーションの設定は、基本的に環境変数にセットします。Twelve-Factor Appという有名なアプリケーション開発の指針にこの項目があります。
アプリケーションの 設定 は、デプロイ(ステージング、本番、開発環境など)の間で異なり得る唯一のものである。設定には以下のものが含まれる。
- データベース、Memcached、他のバックエンドサービスなどのリソースへのハンドル
- Amazon S3やTwitterなどの外部サービスの認証情報
- デプロイされたホストの正規化されたホスト名など、デプロイごとの値
こうすることで、いろいろとメリットがあります。実感しやすいのだと以下のようなものです。
- 開発環境と本番環境でデータソース(S3、RDB、BigQuery...)を切り替えたい場合にも、コードを変更せずに実現できる
- 秘匿情報がコード内に現れないので安全で、OSSとしても公開できる
Pythonのコードでは普通、環境変数は
os.environを使って以下のようなコードを書くことになります。import os SOME_VALUE = os.environ['SOME_VALUE'] # 数値のリストがほしいときなど、少し型変換が必要だったり煩雑なんですよね… SOME_INT = int(os.environ["SOME_INT"])ただ、私は最近
pydanticというライブラリを使っています。それを使うと以下のようなコードになります。from pydantic import BaseSettings class Settings(BaseSettings): some_value: str some_int: int # 自動でintに変換してくれる settings = Settings()開発時に
.envというファイルを利用することがあり、自分の使っているMacの環境変数をセットせずに、一時的にファイルから読み込むことができます。ちなみにpydanticも.envの利用もサポートしているので便利です。ここで実際に私が実装したコードを見て、「pydanticで環境変数を読み込んでいるのに、osモジュールがimportされているのはなぜだろう」と疑問に思ったと思います。それは消し忘れなので後で隠滅しておきます。
また、今のシステムで動いているコードでも、環境変数として切り出すべき設定項目がコード内に含まれてしまっているものも多いです。他のコードを参考にする場合は気をつけてください。
コマンドライン引数を使う
環境変数との使い分けは明確な基準を持っていたわけではありませんが、コマンドライン引数と環境変数の使い分け基準という記事を見つけました。今回実装している広告運用費のアラート機能では、「開発時に賃貸マーケットごとだけ実行して確認する」みたいな用途も多そうだったのでコマンドライン引数で指定するようにしています。
Pythonの標準にも
argparseというライブラリがありますが、多くのPythonプログラマーはclickを使っています。少し余談ですが、awesome-pythonというリポジトリにPythonの便利ライブラリのうち、
clickのような評判の良いものの情報がまとまっています。他のプログラミング言語に挑戦する場合もawesome-xxxで調べると大抵同じような情報が見つかるでしょう。テストコードについて
今回は単純な通知処理なのでテストコードはサボってしまいましたが、各モジュールごとにユニットテストを行います。標準ライブラリと
unittestとサードパーティ製のpytestがありますが、私は使い勝手の面でpytestをおすすめします。あと、toxというツールも見つかると思いますが、「複数のPythonバージョンでpytestやunittestを実行するためのツール」であり、特定のシステム上で動かす場合はPythonバージョンは固定されているはずなので今は考えなくていいです。ライブラリを自作するときに導入を考えればいいです。
境界値分析などの知識が多少必要となります。コロナ騒ぎが明けたら、QAの人にこの本を借りると良いと思います。
その他、プログラミング全般で気をつけること
コードレビューで教えます。書籍であれば、このあたりがおすすめです。
また、こちらの本もピッタリかもしれません。今回WEBサーバーの話は全く書いていませんが、この本にはそこで詰まるだろうことも書かれています。
最後に
強くなれ?
- 投稿日:2020-05-24T12:39:32+09:00
AWS SAA資格取得~ElastiCache編~
はじめに
ElastiCache個別のまとめになってしまいますが、まとめていきます。
AWSWEB問題集を解いていて、まだまだ理解が足りないリソース、サービスになるので、
理解を深めていきます。ElastiCacheとは
キーバリュー型のNoSQLデータベースサービス。
マネージド型のインメモリデータベース(MemcachedやRedisをデータストアとして利用することができる。)
メモリ上で処理を実行するため、高スループットかつ低レイテンシーな処理を実現できる。※ElastiCacheでは最小の構成単位を「ノード」と呼びます。
EC2で言うところのインスタンスに相当するものです。
ノードを組み合わせた集合体を「クラスター」という。※スループットとはコンピュータやネットワーク機器が単位時間あたりに処理できるデータ量のこと。
※レイテンシとはデータ転送における指標のひとつで、転送要求を出してから実際にデータが送られてくるまでに生じる、通信の遅延時間のことをいいます。「EC2」⇨「ElastiCache」⇨「RDS」
①EC2インスタンスからリクエストされたクエリ結果がElastiCacheに存在すれば、
ElasticCaheからEC2インスタンスに結果を返す。
②①に結果が存在しなければRDSに対してクエリを実行し、結果を取得する。データストアの特徴と選択基準
Memcached特徴
・一時的なデータのキャッシュ用として利用
・ノード間の複製は行われない。
・データベースを別途用意選択基準
・シンプルなデータ構造が必要
・複数のコアまたはスレッドを持つ大きなノードを実行する必要がある。
・スケールアウトおよびスケールイン機能が必要となる
・データベースなどのオブジェクトをキャッシュする必要がある。Redis特徴
・マスター、スレーブ型の構成
・データストアとしても利用可能選択基準
・ハッシュ型やリスト型などの複雑なデータ構造を用いる
・マスターノードに障害が発生した際に自動的にフェイルオーバーが行われる必要がある。
・読み取るデータ量が多いので、マスターノードから複数のリードレプリカに複製する。
・永続性が必要ElastiCacheのユースケース
一般的にRDBのパフォーマンス向上のために利用される。
RDBでは、データ量の増加や、アクセス集中によりレスポンスが遅くなる可能性があるため、
クエリの結果をElastiCacheに保存しておき、同じクエリが実行された場合はクエリ結果を
ElastiCacheからクエリ結果を返すことでRDBの負荷低減とシステムのレスポンスの向上に繋がる
Webアプリケーションのセッション情報を格納したり、
データベースに対して頻繁にアクセスするSQLを格納したりする。以上
よっしゃ地道に頑張るかぁ〜〜〜〜
- 投稿日:2020-05-24T12:20:45+09:00
S3のバケットを作成してファイルアップロードして参照する
プロローグ
AWSのS3の機能を使い、ファイルをアップロードして参照します。
手順
サービスのS3の画面を開きます。
画面にある「バケットを作成」のボタンを押下します。
バケット名を入力します。
またリージョンや、アクセス設定、削除の許可(オブジェクトロック)などの設定を選択して「バケットを作成」を押下します。
バケットが作成されました。
作成されたバケットの名前のリンクを押下します。
対象のS3の画面が開きます。
画面中央上部にある「アップロード」を押下します。
「ファイルを作成」を押下します。
ファイルを選択したら、画面に表示されます。(ここでは空ファイルのtest.txtをアップロードしています。)
「次へ」を押下します。
ファイルのプロパティのアクセス権限などを設定できます。
設定して「次へ」を押下します。
Glacerなど、ストレージクラスを選択できます。
選択して「次へ」を押下します。
内容に問題がなければ「アップロード」を押下します。
アップロードされたファイルが一覧に表示されます。
選択すると、右側にファイルの詳細が表示されます。
例えば「S3 select」を選択すると、ファイルの内容をちゅう出できたりします。
「オブジェクトURL」を選択すると、ファイルが参照できますが、画面のように、アクセスが拒否されました。
S3を作成時にデフォルトでパブリックのアクセスを拒否していたたためです。
アクセス権限を一時的に変更してみます。
S3のバケットより、「アクセス権限」タブの「ブロックパブリックアクセス」でアクセスのチェックを外しました。
確認メッセージが表示されるので、「確認」と入力し「確認」ボタンを押下します。
設定が変更されました。
また、対象ファイルの「アクション」より「公開する」を設定します。
問題なければ、「公開する」を押下します。
再度「オブジェクトURL」よりアクセスしてみます。
表示されました。(空ファイルでなくフリー画像などにしておけばわかりやすかったです。。)
エピローグ
念のため、アクセス設定はパブリックから戻しておきましょう。
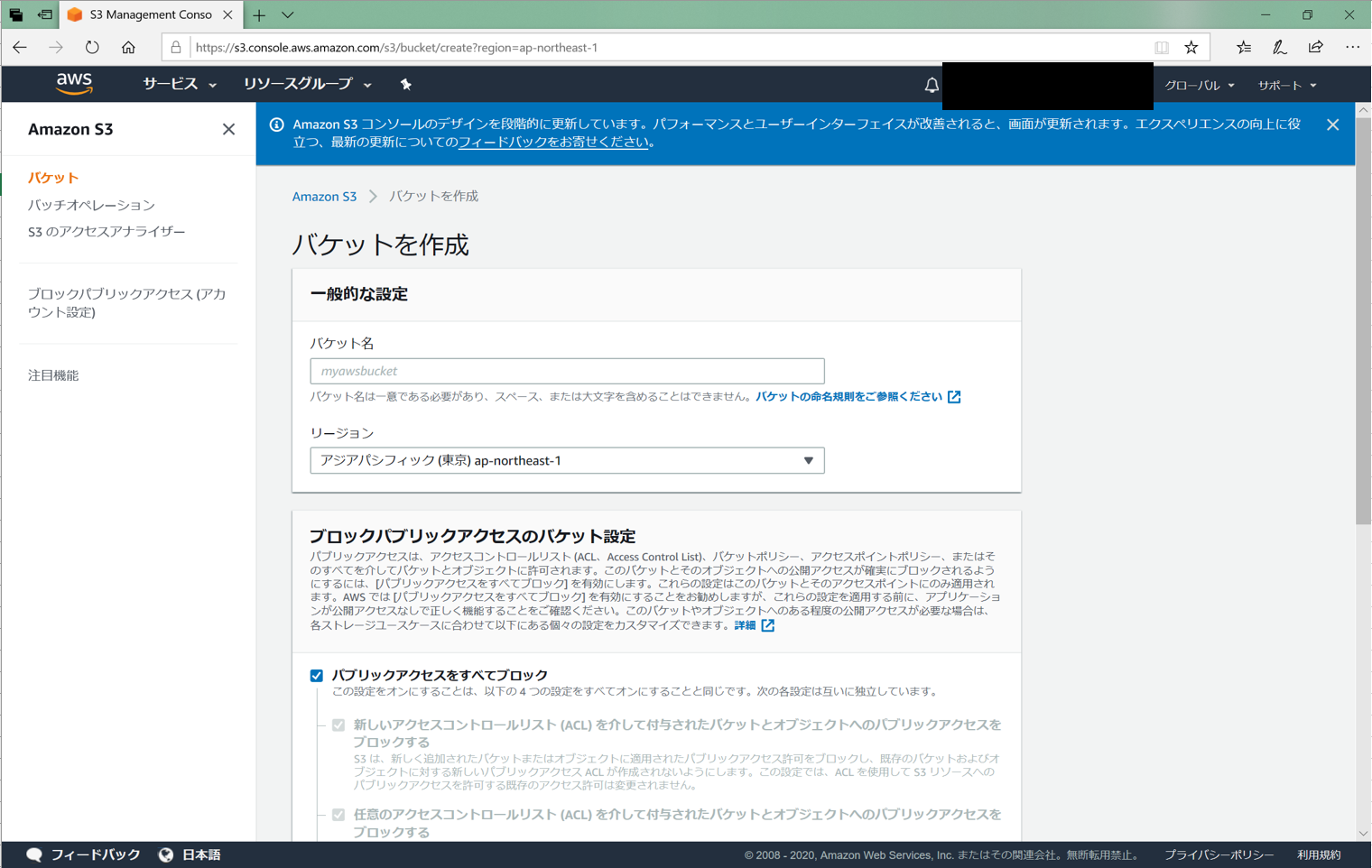
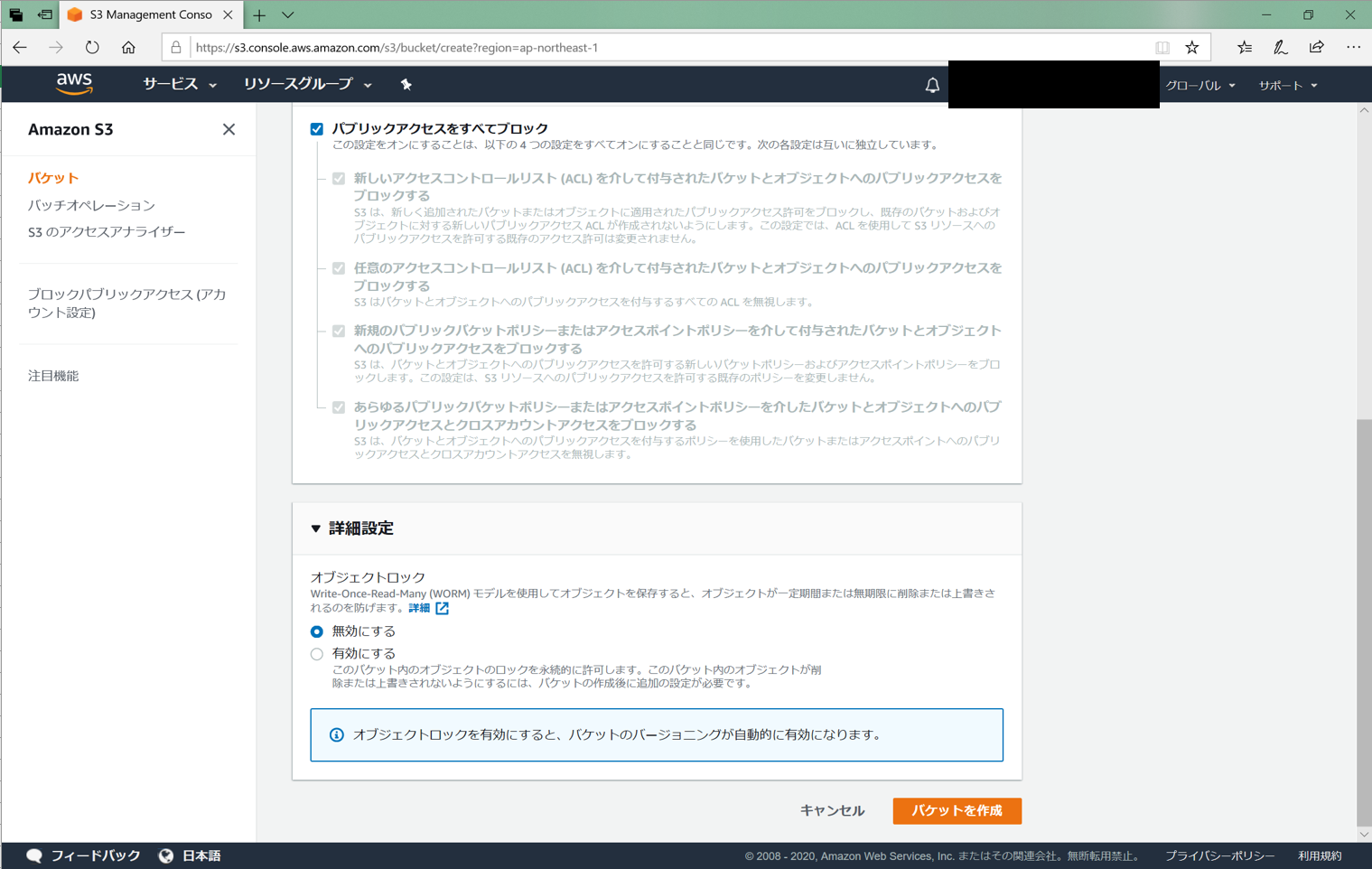


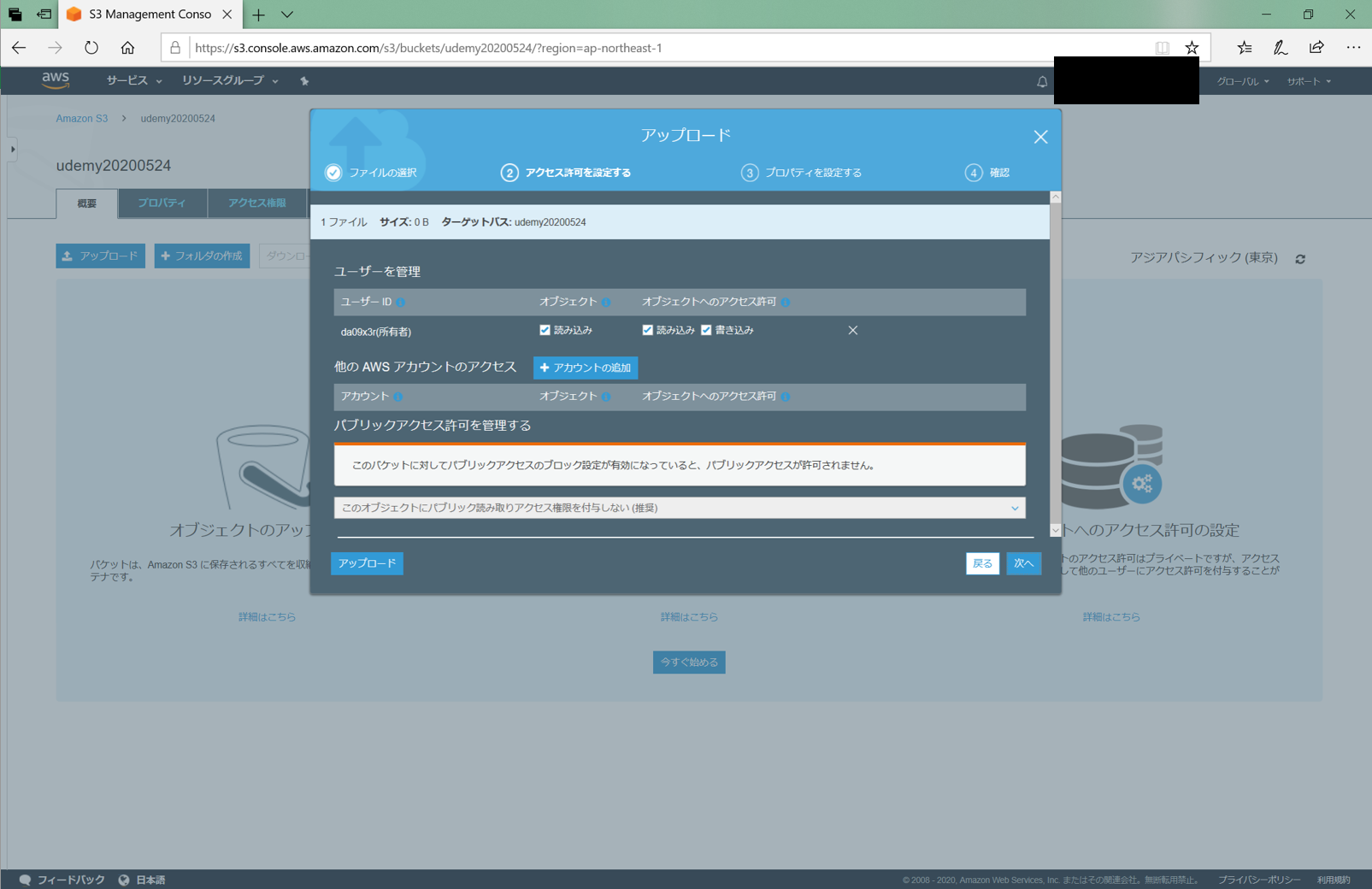
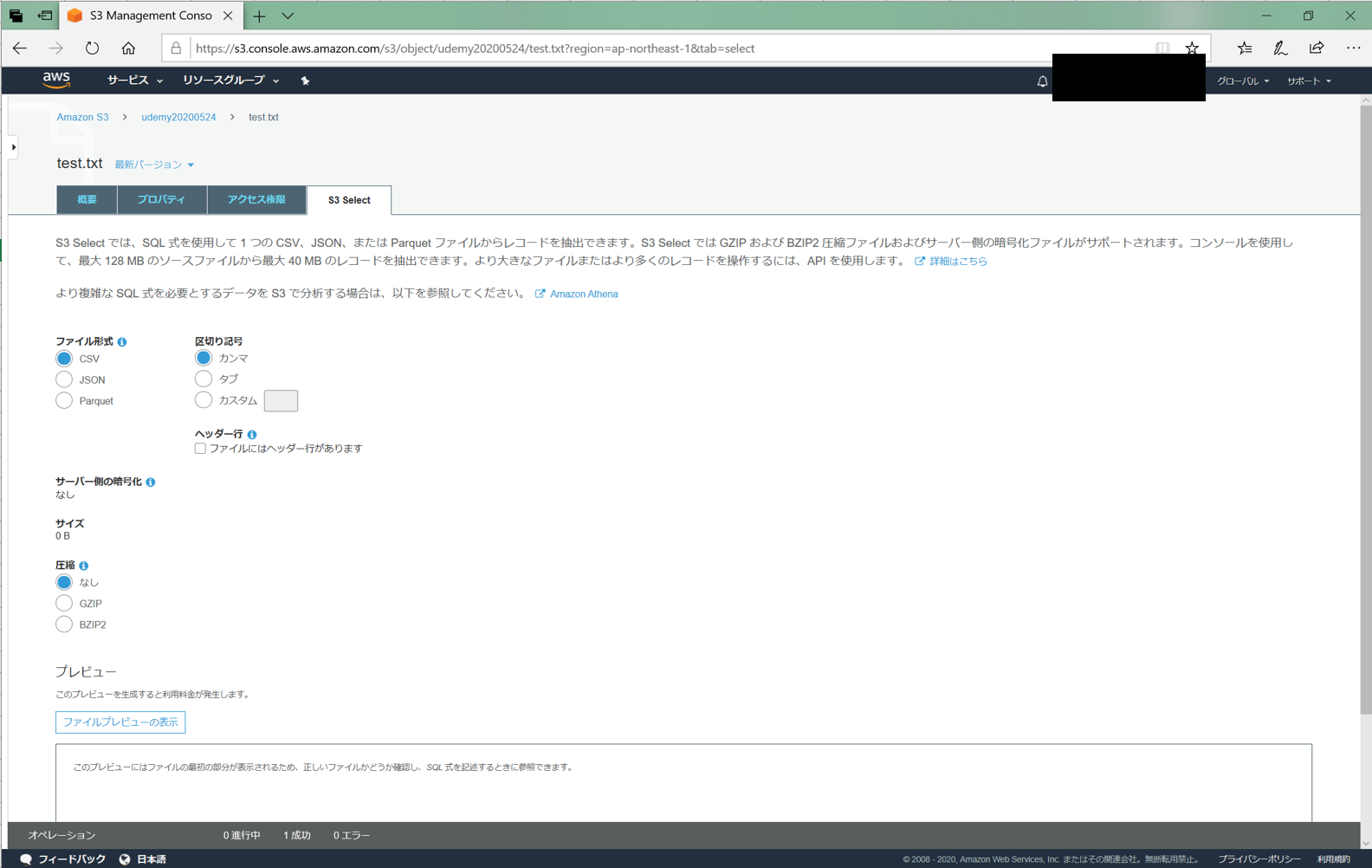
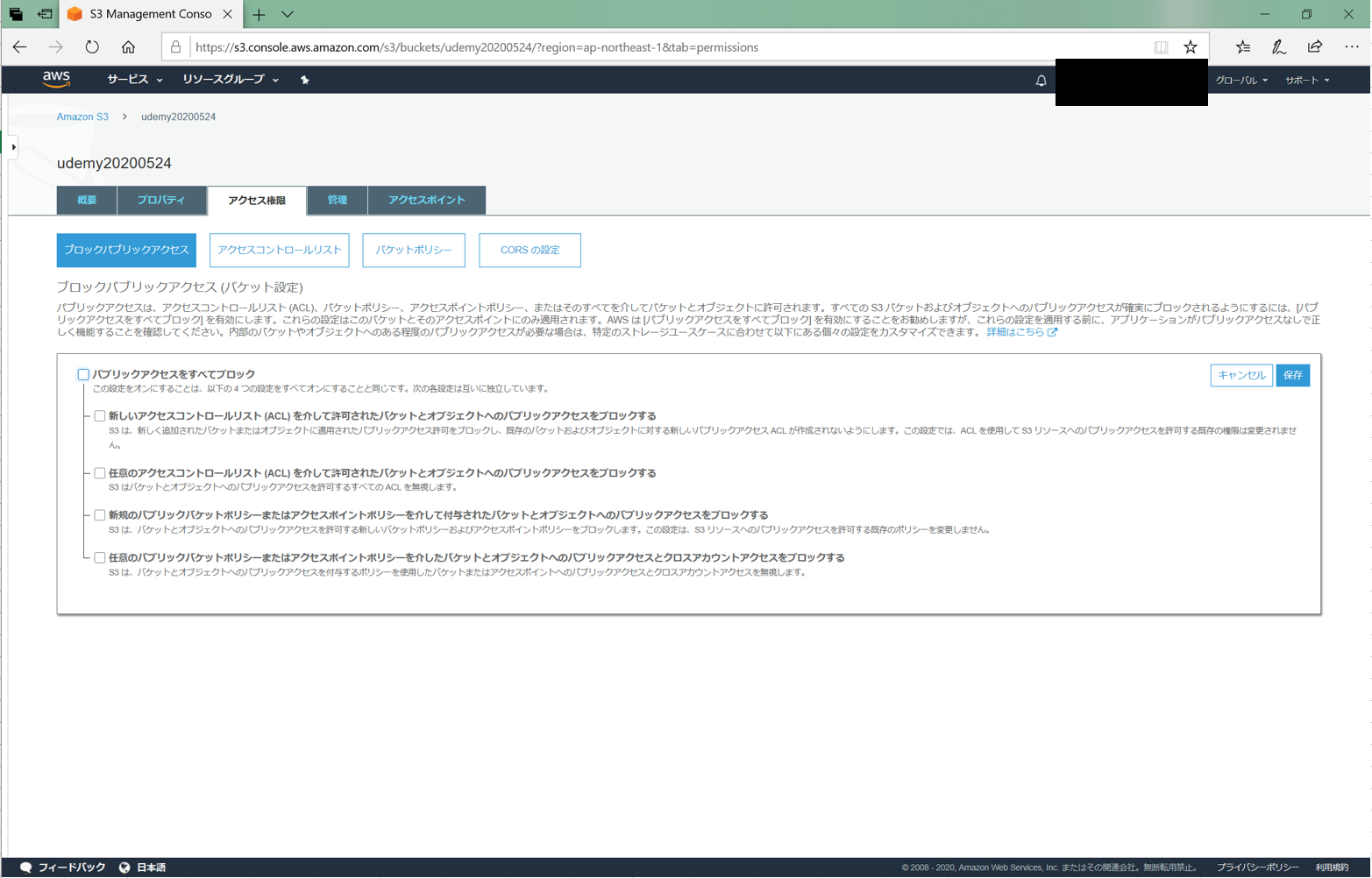
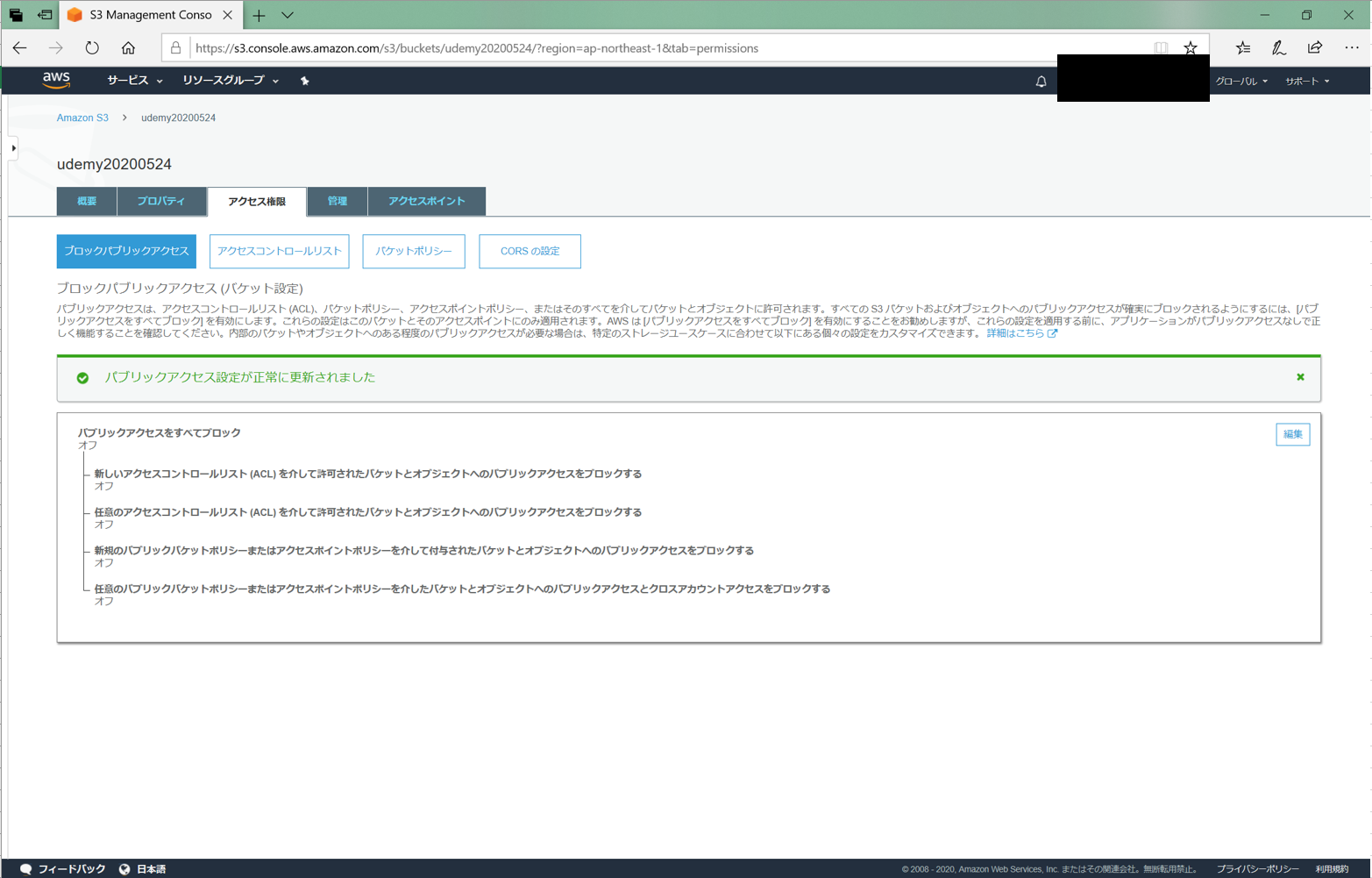
- 投稿日:2020-05-24T11:43:01+09:00
Visual StudioからAWS CodeCommitを使う
Visual Studio Community 2017からAWS CodeCommitを使えそうだったので、調べて、その結果を、まとめる。
1. はじめに
1.1AWS CodeCommitについて
料金
5ユーザーまで無料でOK。
https://aws.amazon.com/jp/codecommit/pricing/2.準備
2.1 AWSでの作業
以下のページに従って操作する。
https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/setting-up-ide-vs.html何か問題が出たら、問題と解決したやり方について記載することとする。
ステップ1でIAMユーザの準備で「Security credentials」タブが見つからない
「ステップ 1: IAM ユーザーのアクセスキーとシークレットキーを取得する」に従って、「IAM ユーザーのアクセスキーを作成するには」の操作を実施。
「Security credentials」は「認証情報」だが、わからなければ、画面左下の言語を日本語から英語表記に変更するとわかりやすい。2.2 Visual Studioでの作業
チームエクスプローラに表示されない
[拡張機能]-[拡張機能の管理]から「Visual Studio Marketplace」で"AWS"をキーワードに検索し、「AWS Toolkit for Visual Studio 2017 and 2019」をダウンロードし、導入する。ダウンロード後、Visual Studioを終了するとインストーラが動き出す。
チームエクスプローラでAWS CodeCommitに接続できない
エラーが出て、一度消したら元に戻らなくなった・・・
別環境にVisual Studio 2019を入れてもう一度試す・・・接続時の「New Account Profile」にある「Account Number」について
12桁の番号。以下を参考に
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/console_account-alias.html
- 投稿日:2020-05-24T08:17:16+09:00
EC2・EIP・RDSなどそれぞれの役割【AWS】
はじめに
【この記事を書いたきっかけ】
AWSでデプロイを行ったが用語の理解が甘かったので、自分でまとめていつでも振り返ることができるようにする為。あくまでメモ代わりに書いているので、詳しい方法については書いていません。EC2
EC2(Amazon Elastic Compute Cloud)はAWSが提供する仮想サーバ。
EC2で起動したサーバは、「EC2サーバ」「EC2インスタンス」「インスタンス」などと呼ばれている。
EC2でWebサーバを作って試すまでの流れ
1. EC2インスタンスを作成する
2. EC2にログインする
3. サーバに「Nginx」をインストールする
4. ブラウザからWebサーバにアクセスする
5. Nginx用のHTMLを作成するEC2にログインする
①SSH内にキーペアファイルを保存する
EC2インスタンス作成時にダウンロードしたキーペア(something.pem)をユーザのホームディレクトリのSSH内に保存する。
実行時には、ログインしているMacユーザのパスワードを求められる。$ sudo mv ~/Downloads/something.pem ~/.ssh「sudo」は、管理者権限でコマンドを実行するコマンド。
「mv」は、ファイルを移動するコマンド。②キーペアファイルの権限を変更する
$ sudo chmod 600 ~/.ssh/practice-aws.pem「chmod」は、権限を変更するコマンド。
③SSHでサーバにアクセス
キーペア、アクセス先サーバのユーザ名、パブリックIPアドレスを指定
パブリックIPアドレスはインスタンス画面で確認する。$ ssh -i /Users/ユーザ名/.ssh/practice-aws.pem ec2-user@xx.xx.xx.xxサーバにNginxをインストール
Nginx
NginxはサーバをWebサーバにするためのミドルウェア。
$ sudo yum install -y nginx「完了しました!」が表示されれば、インストール完了。
「yum」は、アプリケーションをインストールするコマンド。Nginxの自動起動を設定する
$ sudo chkconfig nginx onここではコマンドを実行しても何も表示されない。
Nginxを起動する
$ sudo service nginx start Starting nginx: [ OK ]Nginxを起動すると、インターネットにWebサービスが公開される。
(EC2インスタンスに割り当てたパブリックIPアドレスにWebブラウザからアクセス)下記のような画像が表示されればOK。
Webサーバ上で表示するHTMLファイルを作成し、「Hello World」を表示させる。
$ sudo sh -c "echo 'Hello World' > /usr/share/nginx/html/index.html"サーバを停止
「インスタンス」一覧画面で停止したいインスタンスを選択し、「アクション」メニューの「インスタンスの状態」で「停止」を選択。
「インスタンスの状態」が「stopped」になっていれば停止状態。サーバを停止後、再度起動してssh接続すると、エラーが出る。
$ ssh -i /Users/ユーザ名/.ssh/practice-aws.pem ec2-user@xx.xx.xx.xxEC2インスタンスではサーバを停止するとパブリックIPアドレスが変わるから以前のパブリックIPアドレスでは接続できない。。
EC2コンソールから新しいパブリックIPアドレスを確認して書き換える必要がある。
→後にEIPで解決できる。SSH
「SSH(Secure Shell」は、他のコンピュータと通信する為のプロトコルの一つ。
「プロトコル(Protocol)」は、コンピュータ同士が通信する際に決められている手順や規約。コンピュータ同士は、さまざまな手段で通信をしている。
コンテンツを送受信するHTTP、メールを送受信するSMTP、ファイルを転送するFTPなど。EIP
EIP(Elastic IP)はEC2インスタンスにパブリックIPアドレスを付与するサービス。
EC2インスタンスではサービス停止後に再起動するとパブリックIPアドレスが変わってしまう。
毎回パブリックIPアドレスが変わるのは面倒なので、EIPを使って固定のIPアドレスにする。EIPの設定はEC2ダッシュボードから設定できる。
また、EIPに関連づけられているサーバは変更も可能。
あるサーバで不具合が起きて使えなくなった場合、別のサーバにEIPを付け替えることでサービスを継続できる。<参考>EIPの割り当て
https://qiita.com/tseno/items/1c6303d778f9089f6f89AMI
AMI(Amazon Machine Image)はEC2インスタンスをバックアップする方法。
AMIはEC2インスタンスの構成を取得し、テンプレートを作成するサービス。
AMIによって、EC2インスタンスディスク内の全内容(たとえば、OSやミドルウェア、アプリケーションなど)をバックアップできる。<参考>AMIの設定方法
http://blog.serverworks.co.jp/tech/2015/05/18/ami_gettodaze/RDS
RDS(Relational Database Service)はAWSが提供するクラウド型のデータサービス。
データベース管理システム自体はソフトウエアなので、EC2サーバにインストールすれば、データベースサーバを構築できる。代表的なデータベース管理システムには、
MySQL、PostgreSQL、Oracle Databaseなどがある。<参考>RDSを使うメリット
https://aws.amazon.com/jp/rds/
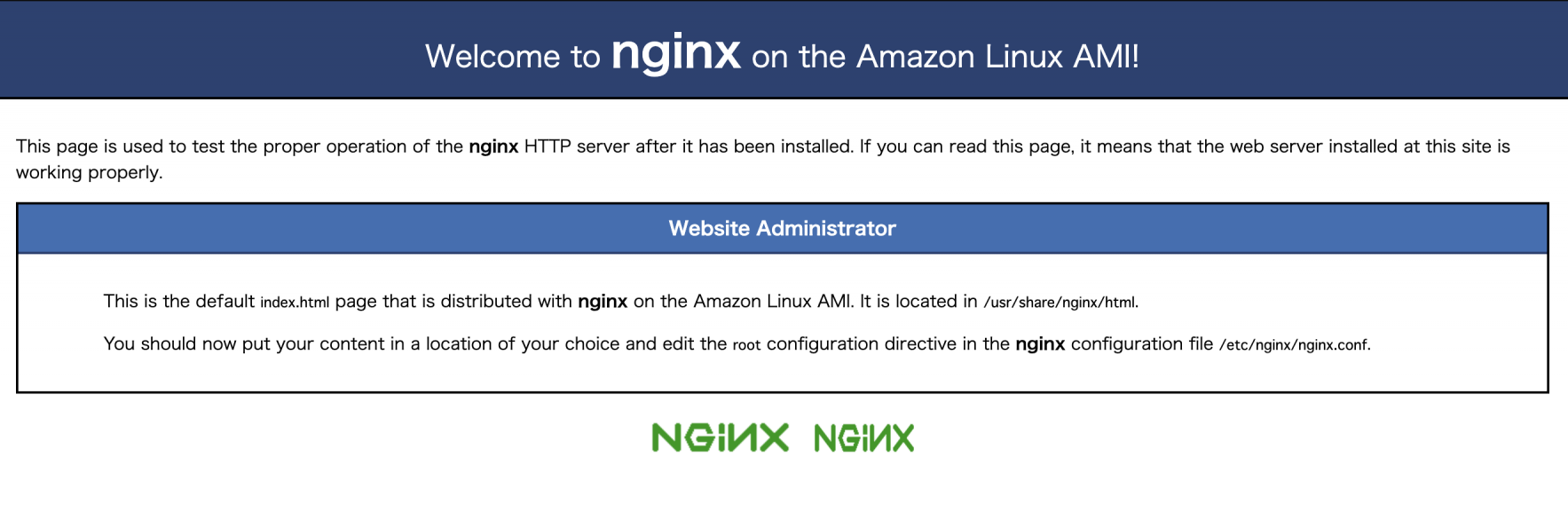
- 投稿日:2020-05-24T07:24:16+09:00
QuickSightのReaderユーザー作成
Readerユーザーとは
QuickSightのユーザーの種類で閲覧用のユーザーです。ダッシュボードの閲覧ができますが、それだけでなく、データのドリルダウン, フィルタ設定の変更と適用, CSVでデータのダウンロードなどの操作ができます。QuickSightの管理や分析の作成は管理者でなければできません。
QuickSightでReaderユーザーを作成
ユーザー定義JSONファイルを作り、そのファイルを指定してregisterUserのAPIを使いユーザーを作成します
ユーザー定義JSON作成
register-prod-reader1.jsonというファイルを作成します。これはQuickSightユーザーの種類, メールアドレス, ユーザー名などを定義しています。
※メールアドレスは任意のものに置き換えます。register-prod-reader1.json{ "IdentityType": "QUICKSIGHT", "Email": "prod-reader1@test.com", "UserRole": "READER", "AwsAccountId": "<your aws account>", "Namespace":"default", "UserName": "prod-reader1" }Readerユーザー作成
次のコマンドを実行し、Readerユーザーを作成します。
$ aws quicksight register-user --cli-input-json file://register-prod-reader1.json以下のような出力があれば成功です。
各ユーザーのUserInvitationUrl値を書き留めます。この後のユーザー登録のために使います。{ { "Status": 201, "RequestId": "57431e4f-1c23-4026-9fe5-e3609388d007", "User": { "UserName": "prod-reader1", "PrincipalId": "user/d-906706bd27/b003efc4-ff2e-4c47-97a7-255a1f16fb13", "Role": "READER", "Active": false, "Email": "prod-reader1@test.com", "Arn": "arn:aws:quicksight:us-east-1:<your aws account>:user/default/prod-reader1" }, "UserInvitationUrl": "https://signin.aws.amazon.com/inviteuser?token=11yC6lblMtp17A5Izt3XQA0VeHGgtvu1mvaFnEZvwsuPFi-k1rWf5g9dqzZu0W0Ugx6nmuXaIk4SQub0gB09XO8RuGPn-MomVJtYOngNU54VMJiO5C4sOxo-RaTlj5R3w63BnWB0z_WV6b--A849K1irTm1GgBms5wm8_ZwjXUHLg1fqbakuU_Z71CYwx8ZfYTwzfywqJ9gkD6pw" } }Readerユーザーの登録完了処理
先程書き留めたprod-reader1のUserInvitationUrlの値(URL)をブラウザで開きます。表示される画面でパスワードを設定しサインインします。このURLは、ユーザーの登録の完了とパスワード設定を提供します(※UserInvitationUrlはIAMユーザーでもActive DirectoryユーザーでもないQuickSightユーザーを作成した場合に提供され、そのユーザーはサインインしてパスワードを入力するまで非アクティブになっています) 。
Readerグループ作成
Readerグループを作成します。
$ aws quicksight create-group --aws-account-id <your aws account> --namespace 'default' --group-name 'dashboard-readers'ReaderグループにReaderユーザーを割り当てます。
$ aws quicksight create-group-membership --aws-account-id <your aws account> --namespace 'default' --group-name 'dashboard-readers' --member-name 'prod-reader1'
- 投稿日:2020-05-24T00:39:41+09:00
Terraformの初心者がAmazon EC2に実行環境を作ってECS Fargateなアプリの自動構築をしてみる
前提条件
最近流行っているTerraformをとりあえず始めてみたい人向け。
実行環境のEC2インスタンスは、t2.microなAmazon Linux2を使う。
CloudFormation等でIaCの基礎的な部分を理解している方が、スムースに読み進められると思う。インストール
とりあえず、インストールしたいバージョンを調べる。
$ curl https://releases.hashicorp.com/terraform/HTMLで出てくるけどこれくらいなら読めるでしょ。
で、目的のバージョンをwgetで取得する。今回は
0.12.25を選択した前提。$ wget https://releases.hashicorp.com/terraform/0.12.25/terraform_0.12.25_linux_amd64.zipunzipすればインストール完了。超簡単。
$ sudo unzip terraform_0.12.25_linux_amd64.zip -d /usr/local/bin過去に作ったCloudFormationテンプレートをTerraformに移植してみる
以下の記事で、以前CloudFormationで作ったものを、Terraformで実装する。
前提は同じく、VPCやIAMロール/ポリシやECRは事前に準備しているものとする。CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する
まずやってみる
IaCは一息で書かないというベストプラクティスに従い、とりあえずこんな感じでtfファイルを分割してみよう。
Terraform ├── alb.tf ├── ecs.tf ├── loggroup.tf └── main.tfで、IaCを書いてはデバッグしていて気付いたことがある。
TerraformはCloudFormationと違って、自動でロールバックしないし、同一ディレクトリ配下においては、tfファイルが違っても一息で構築するようだ。
しかも、修正してterraform applyしようとしても、エラーで更新できないケースがあるから一旦terraform destroyせざるを得ない。つまり、この構成の場合、ALBが正しく作れていても、その後でコケてしまうと、ALBもろとも破壊しないと修正できないケースがある。うーむ、これはよろしくない……。
ということで、ここまでやって「我流はマズいと思い至り、書籍を読む。
実践Terraform AWSにおけるシステム設計とベストプラクティス
素晴らしすぎてこの本さえ読んでおけばこの先の記事は不要な気がするが、一応書いておく。
tfstateの分割
まあ、↑のように分けるべきものはちゃんとtfstateが分かれるような構成にしておきましょうと。
知ってしまえば当然の内容であった。というわけで、以下のような構成に修正した。
ちゃんとモジュール単位で分割しろよー、とか、変数をmain.tfに定義しすぎとか、色々ツッコミどころはあるけど、とりあえず今回はこれで。Terraform ├── ECSFargate │ ├── ecs.tf │ ├── loggroup.tf │ └── main.tf └── Network ├── alb.tf └── main.tfさて、これで色々を始めると、
Network側で定義したALBやターゲットグループのArnをどうやって渡すかで悩むことになるのだが、その辺の話も全部『実践Terraform』には書かれていた。今回は、ECSFargate側のmain.tfで、以下の様にデータソースを定義することにした。
variable "prefix" { default = "ECSFargate" } data "aws_alb_target_group" "ecsfargate_tg" { name = "${var.prefix}-TG1" }データソースとは、ポインタのようなもので、他人の作ったリソースを、自分のtfstateの範囲内で参照可能にするというもの。指定したキーにヒットしたリソースを参照可能になるようだ。
このALBターゲットグループのARNを参照したい場合は、以下のように使えば良い。
"${data.aws_alb_target_group.ecsfargate_tg.arn}"ちなみに、変数は
variable "変数名" { default = "デフォルト値" }で定義して、
"${var.変数名}"で参照が可能。
この辺は、他人の作ったリソースの参照の敷居が非常に高いCloudFormationと比べると便利な点ではあると感じた。
出来上がったIaC
以下のようになった。main.tfの
aws_vpcとaws_subnet_idsとaws_security_groupについては、前述の「あらかじめ用意したリソース」である。
サブネットに指定しているflattenについては、リスト構造を正規化する組み込み関数。やっぱり、作成済みのリソースにアクセスできるのが強い。
CloudFormationと違って、そのリソースを削除する際の依存関係を定義できないのがリスク(アプリの性質上仕方がないのだろうけど)。その辺は、ルールでちゃんと決めれば問題なくなるはず。Network/main.tfvariable "prefix" { default = "ECSFargate" } data "aws_vpc" "default_vpc" { default = "true" } data "aws_subnet_ids" "default_subnets" { vpc_id = "${data.aws_vpc.default_vpc.id}" } data "aws_security_group" "webaccess_sg" { name = "予め用意したセキュリティグループ" }Network/alb.tfresource "aws_alb" "ecsfargate_alb" { name = "${var.prefix}-ALB" load_balancer_type = "application" subnets = flatten(["${data.aws_subnet_ids.default_subnets.ids}",]) security_groups = [ "${data.aws_security_group.webaccess_sg.id}", ] } resource "aws_alb_listener" "ecsfargate_listener1" { load_balancer_arn = aws_alb.ecsfargate_alb.arn port = "80" protocol = "HTTP" default_action { type = "forward" target_group_arn = aws_alb_target_group.ecsfargate_tg1.arn } } resource "aws_alb_target_group" "ecsfargate_tg1" { name = "${var.prefix}-TG1" port = "80" protocol = "HTTP" target_type = "ip" vpc_id = "${data.aws_vpc.default_vpc.id}" } resource "aws_alb_listener" "ecsfargate_listener2" { load_balancer_arn = aws_alb.ecsfargate_alb.arn port = "8080" protocol = "HTTP" default_action { type = "forward" target_group_arn = aws_alb_target_group.ecsfargate_tg2.arn } } resource "aws_alb_target_group" "ecsfargate_tg2" { name = "${var.prefix}-TG2" port = "80" protocol = "HTTP" target_type = "ip" vpc_id = "${data.aws_vpc.default_vpc.id}" }ECSFargate/main.tfvariable "prefix" { default = "ECSFargate" } variable "container_image_name" { default = "[デプロイしたコンテナイメージ名(リポジトリ名)]" } variable "container_image_tag" { default = "[デプロイしたコンテナのタグ]" } data "aws_caller_identity" "self" { } data "aws_region" "current" { } data "aws_alb_target_group" "ecsfargate_tg" { name = "${var.prefix}-TG1" } data "aws_vpc" "default_vpc" { default = "true" } data "aws_subnet_ids" "default_subnets" { vpc_id = "${data.aws_vpc.default_vpc.id}" } data "aws_security_group" "webaccess_sg" { name = "[予め用意したセキュリティグループ]" } data "aws_iam_role" "taskexecution_role" { name = "[予め用意したタスク実行ロール]" } data "aws_ecr_repository" "application" { name = "${var.container_image_name}" }ECSFargate/loggroup.tfresource "aws_cloudwatch_log_group" "ecsfargate_log_group"{ name = "/ecs/${var.prefix}-LogGroup" }ECSFargate/ecs.tfresource "aws_ecs_cluster" "ecsfargate_cluster" { name = "${var.prefix}-ECSCluster" } resource "aws_ecs_task_definition" "ecsfargate_taskdefinition" { family = "${var.prefix}-Task" task_role_arn = "${data.aws_iam_role.taskexecution_role.arn}" execution_role_arn = "${data.aws_iam_role.taskexecution_role.arn}" network_mode = "awsvpc" cpu = "256" memory = "1024" requires_compatibilities = [ "FARGATE", ] container_definitions = <<EOF [ { "name" : "${var.prefix}-Container", "image": "${data.aws_ecr_repository.application.repository_url}:${var.container_image_tag}", "cpu": 0, "memoryReservation": 512, "portMappings": [ { "containerPort": 8080, "hostPort": 8080, "protocol": "tcp" } ], "logConfiguration": { "logDriver": "awslogs", "secretOptions": null, "options": { "awslogs-group": "${aws_cloudwatch_log_group.ecsfargate_log_group.name}", "awslogs-region": "${data.aws_region.current.name}", "awslogs-stream-prefix": "ecs" } } } ] EOF } resource "aws_ecs_service" "ecsfargate_service" { name = "${var.prefix}-ECSService" cluster = "${aws_ecs_cluster.ecsfargate_cluster.id}" launch_type = "FARGATE" task_definition = "${aws_ecs_task_definition.ecsfargate_taskdefinition.arn}" desired_count = 1 load_balancer { target_group_arn = "${data.aws_alb_target_group.ecsfargate_tg.arn}" container_name = "${var.prefix}-Container" container_port = 8080 } deployment_controller { type = "CODE_DEPLOY" } network_configuration { subnets = flatten(["${data.aws_subnet_ids.default_subnets.ids}",]) security_groups = [ "${data.aws_security_group.webaccess_sg.id}", ] assign_public_ip = "true" } }CodePipelineもTerraformで書いてみる。
CloudFormationでECS FargateのBlue/Greenデプロイメントについて書いた時は、CloudFormationが対応していなくて泣く泣くCLIで作った部分だが、Terraformはしっかり対応している(というか、おそらくTerraformは裏でCLIを投げているだけだと考えているので、それができるなら当然対応できるという話ではある)。
ディレクトリ構成は以下のようにする。追加したCICDPipeline以外は特に変更はしていない。
codebuild, codedeploy, s3 くらいは tf を分割しておくべきだった気がする…。Terraform/ ├── CICDPipeline ★追加 │ ├── codepipeline.tf ★追加 │ └── main.tf ★追加 ├── ECSFargate │ ├── ecs.tf │ ├── loggroup.tf │ └── main.tf └── Network ├── alb.tf └── main.tfCICDPipeline/main.tf###################################################################### # 変数定義 # ###################################################################### variable "prefix" { default = "ECSFargate" } ###################################################################### # データソース(IAM) # ###################################################################### data "aws_iam_role" "codebuild" { name = "testProject-service-role" } data "aws_iam_role" "codedeploy" { name = "ecsCodeDeployRole" } data "aws_iam_role" "codepipeline" { name = "CodePipelineRole" } ###################################################################### # データソース(ALB) # ###################################################################### data "aws_lb" "ecsfargate" { name = "${var.prefix}-ALB" } data "aws_lb_listener" "prod" { load_balancer_arn = "${data.aws_lb.ecsfargate.arn}" port = 80 } data "aws_alb_target_group" "prod" { name = "${var.prefix}-TG1" } data "aws_lb_listener" "test" { load_balancer_arn = "${data.aws_lb.ecsfargate.arn}" port = 8080 } data "aws_alb_target_group" "test" { name = "${var.prefix}-TG2" } ###################################################################### # データソース(ECS) # ###################################################################### data "aws_ecs_cluster" "fargate" { cluster_name = "${var.prefix}-ECSCluster" } data "aws_ecs_service" "fargate" { service_name = "${var.prefix}-ECSService" cluster_arn = "${data.aws_ecs_cluster.fargate.arn}" }CICDPipeline/codepipeline.tfresource "aws_s3_bucket" "artifact" { bucket = lower("${var.prefix}-artifact-bucket") } resource "aws_codebuild_project" "application" { name = "${var.prefix}-build-project" service_role = "${data.aws_iam_role.codebuild.arn}" source { type = "CODEPIPELINE" buildspec = "buildspec_container.yml" } artifacts { type = "CODEPIPELINE" } environment { type = "LINUX_CONTAINER" compute_type = "BUILD_GENERAL1_SMALL" image = "aws/codebuild/standard:3.0-19.11.26" privileged_mode = "true" } cache { type = "LOCAL" modes = [ "LOCAL_CUSTOM_CACHE", ] } } resource "aws_codedeploy_app" "application" { name = "${var.prefix}-Application" compute_platform = "ECS" } resource "aws_codedeploy_deployment_group" "application" { deployment_group_name = "${var.prefix}-DeploymentGroup" app_name = "${aws_codedeploy_app.application.name}" service_role_arn = "${data.aws_iam_role.codedeploy.arn}" deployment_config_name = "CodeDeploy.ECSCanaryHalf3minutes" ecs_service { cluster_name = "${data.aws_ecs_cluster.fargate.cluster_name}" service_name = "${data.aws_ecs_service.fargate.service_name}" } deployment_style { deployment_type = "BLUE_GREEN" deployment_option = "WITH_TRAFFIC_CONTROL" } blue_green_deployment_config { deployment_ready_option { action_on_timeout = "CONTINUE_DEPLOYMENT" wait_time_in_minutes = 0 } terminate_blue_instances_on_deployment_success { action = "TERMINATE" termination_wait_time_in_minutes = "60" } } load_balancer_info { target_group_pair_info { prod_traffic_route { listener_arns = ["${data.aws_lb_listener.prod.arn}"] } target_group { name = "${data.aws_alb_target_group.prod.name}" } test_traffic_route { listener_arns = ["${data.aws_lb_listener.test.arn}"] } target_group { name = "${data.aws_alb_target_group.test.name}" } } } } resource "aws_codepipeline" "pipeline" { name = "${var.prefix}-Pipeline" role_arn = "${data.aws_iam_role.codepipeline.arn}" artifact_store { type = "S3" location = "${aws_s3_bucket.artifact.bucket}" } stage { name = "Source" action { run_order = 1 name = "Source" category = "Source" owner = "AWS" provider = "CodeCommit" version = "1" output_artifacts = ["SourceArtifact"] configuration = { RepositoryName = "testProject" BranchName = "master" } } } stage { name = "Build" action { run_order = 2 name = "Build" category = "Build" owner = "AWS" provider = "CodeBuild" version = "1" input_artifacts = ["SourceArtifact"] output_artifacts = ["BuildArtifact"] configuration = { ProjectName = "${aws_codebuild_project.application.name}" } } } stage { name = "Deploy" action { run_order = 3 name = "Deploy" category = "Deploy" owner = "AWS" provider = "CodeDeployToECS" version = "1" input_artifacts = [ "SourceArtifact", "BuildArtifact", ] configuration = { ApplicationName = "${aws_codedeploy_app.application.name}" DeploymentGroupName = "${aws_codedeploy_deployment_group.application.deployment_group_name}" AppSpecTemplateArtifact = "SourceArtifact" AppSpecTemplatePath = "appspec_container.yml" TaskDefinitionTemplateArtifact = "SourceArtifact" Image1ArtifactName = "BuildArtifact" Image1ContainerName = "IMAGE1_NAME" } } } }あと、CodeDeployの「CodeDeploy.ECSCanaryHalf3minutes」の部分は、ちょっとテキトー。
今回の設定だと、Canaryとテストポートが混在していることになる。
この場合、どうやらCodeDeployは、ProdのトラフィックをCanaryの設定を適用し、Test側のトラフィックは100%新しいアプリケーションに振り分けているように見えた。その他
Terraformの公式リファレンスの歩き方
Terraformの公式リファレンス、全部英語ではあるものの、中身は少ないのでそんなに読むのは苦にならない。逆に、中身が少ないから「これどうしたらええねん……」みたいなことがある。
例えば、今回のパイプラインで言えば
ecs_service { cluster_name = "${data.aws_ecs_cluster.fargate.cluster_name}" service_name = "${data.aws_ecs_service.fargate.service_name}" }と
configuration = { RepositoryName = "testProject" BranchName = "master" }の2種類の書き方が登場する点。
当然、間違えるとちゃんと動いてくれない(とは言え、terraform planの時点でエラーになってくれるので、デバッグはそんなに苦ではないのだけど)。これは、前者を「block」「blocks」、後者を「map」として使い分けしているっぽい。
何も書いていない場合は、前者。というか、後者を使うパターンが圧倒的に少ない。今回の例で言えば、前者は
- ecs_service - (Optional) Configuration block(s) of the ECS services for a deployment group (documented below).
となり、後者は
- configuration - (Optional) A Map of the action declaration's configuration. Find out more about configuring action configurations in the Reference Pipeline Structure documentation.
と記載されている。
- 投稿日:2020-05-24T00:22:46+09:00
Amazon Linux2 にMySQLを入れる際のエラー
AWS EC2インスタンスにLAMP環境構築する際に、MySQLインストールでエラーに詰まったのでメモメモ。
エラーの原因を結論から言えば、AmazonLinux2にはデフォルトでMySQLは用意されておらず、MariaDBがちょこんと居座ってること。そのため対処として公式ページからMySQLをインストールして、MariDB消せばOKである。
前提
- Amazon Linux 2 AMI (HVM) SSD Volume Type
- MySQL Ver 14.14 Distrib 5.7.30, for Linux (x86_64) ←これを入れたい
過程と対処
EC2インスタンスにssh接続後、ApacheとPHPをyumインストール。問題なく進み、そのノリでMySQLもインストール。
yum install -y mysql-community-serverここで
No package mysql-community-server available.とエラーを返される。どうやらパッケージがないらしい。以下で調べてみると確かに無かった。yum list mysql*そこで、公式から追加することに(→MySQL Yum Repository)。ただしAmazonLinux2はcentOS7ベースということなので、追加するのはel7を選択。
yum install http://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpmちゃんとリポジトリに追加されてるかを次で確認
yum repolist
mysql80-community-release-el7-3.noarchを確認。使用したいバージョンは5.7なので、5.7を有効化させる必要がある(最新バージョンの8.0のインストールによって旧バージョン5.7のリポジトリもセットでインストールされる)。vi /etc/yum.repos.d/mysql-community.repomysql-communityのレポジトリ設定をいじる。上のコマンドで設定ファイルを開いたらMysql8.0のenabledの欄を0にして、Mysql5.7のenabledの欄を1に変更する。これによってインストールの方向が5.7に向く。
さて、これで
yum install mysql-community-serverで解決かと思えば、次は依存関係のエラーが発生。エラー文を確認するとAvailable: 1:mariadb-libsの文字列を数件発見。MariaDB...?どうやらAmazonLinux2(CentOS7も同様)ではMariaDBがデフォルトで入っており、MySQLインストールの際に邪魔になってしまうらしい。今回はMySQL使いたいので、MariaDBを削除することに。
yum remove mariadb-libsこれの後にyumインストールしたら無事に解決しました。
参考
CentOS 7にMySQL 5.7をyumでインストール
AWS Amazon Linux2にMySQL5.7を構築する
Amazon Linux2でmysqlを入れようとしたらエラーが出た
パッケージ依存関係を解消する(rpm)
- 投稿日:2020-05-24T00:22:43+09:00
AWS上のWindows Server 2019を日本語化出来ない
背景
色々なサイトに日本語化が書いてあるけど、結局出来なかったので手順を記載。
※タイムゾーンとかその辺は割愛。何が出来なかったのか?
どこのサイトにも「Time & Language > Language > Add a language」から日本語を選択して
インストールすれば「Windows display language」からプルダウンで選択できるようになると
記載されているが実際にこれだけでは出来なかった。
① クリックして日本語をインストール
② インストールされたことを確認
③ インストールしてもプルダウンに表示されず英語のままどうしたか?
① 言語パックをダウンロード
② 言語パックをインストール
③ 色々なサイトで書いてある言語設定の手順を実施まずはEC-2でWin2019を立てる
利用するAMIは「Microsoft Windows Server 2019 Base」を使用。
言語パックをダウンロード
RDPで接続語、IEの設定でファイルがダウンロード出来ないためIEの設定を変更する。
① 「Internet option > Security > Custom level」をクリック。
② 「Downloads」で「Enable」を選択し、「OK」をクリック。
③ 「Yes」をクリック。
④以下URLから言語パックをダウンロード。
https://software-download.microsoft.com/download/pr/17763.1.180914-1434.rs5_release_SERVERLANGPACKDVD_OEM_MULTI.iso
※リンクは変わる可能性もあるので、その時に最適なものをダウンロードすること。言語パックをインストール
① コマンドプロンプト、もしくはコマンドを指定して実行から「lpksetup.exe」を実行。
② 「Install display languages」をクリック。
③ 「Browse...」をクリック。
④ ISOファイル内の「x64 > langpacks > Microsoft-Windows-Server-Language-Pack_x64_ja-jp」を選択し、「OK」をクリック。
※ISOファイルはダブルクリックでマウント出来ます。
⑤「NEXT」をクリック。
⑥「I accept the license terms.」を選択し、「NEXT」をクリック。
⑦「close」をクリック。
言語設定
①「ウィンドウズキー > Settings(歯車) > Time & Language > Language > Add a language」をクリック。
②「japan」を入力し、「日本語」を選択後に「Next」をクリック。
③「install」をクリック。
④しばらくするとインストールが完了するため、プルダウンメニューから「日本語」をクリック。
※「Options」を確認することでインストール状況は確認可能。
⑤ 画面右の「Administrative language settings」をクリック。
⑥「Copy Settings...」をクリック。
⑦「Welcome screen and system accounts」と「New user accounts」にチェックし「OK」をクリック。
⑧「Restart now」をクリックし、再起動。
日本語化を確認
再起動後、日本語化されていることを確認する。