- 投稿日:2020-05-24T23:49:47+09:00
Python: 株価予測その①
日経平均株価の時系列データの取得
時系列データの取得その1
日経平均株価の過去のcsvデータを取ってきて保存します。
# csvを読み込む時のコード import pandas as pd from io import StringIO import urllib def read_csv(url): res = urllib.request.urlopen(url) res=res.read().decode('shift_jis') df = pd.read_csv(StringIO( res) ) return df# 日経平均株価の時系列データの取得 import pandas as pd from io import StringIO import urllib # 上記の関数を使い日経平均株価の時系列データを取得 url = "https://indexes.nikkei.co.jp/nkave/historical/nikkei_stock_average_daily_jp.csv" def read_csv(url): res = urllib.request.urlopen(url) res = res.read().decode('shift_jis') df = pd.read_csv(StringIO(res)) # 必要のない最後の行を取り除いています df = df.drop(df.shape[0]-1) return df # dfというdataframeで保存し、出力 df = read_csv(url) # 出力 df時系列データの取得その2
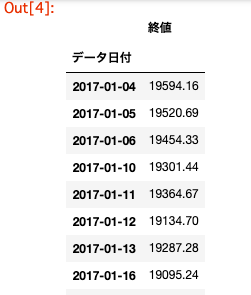
時系列データの終値に注目して予測を行います。
# 時系列データの取得その1,日経平均株価の時系列データの取得コードを載せます。 # indexを日付にした後、時系列にします df["データ日付"] = pd.to_datetime(df["データ日付"], format='%Y/%m/%d') df = df.set_index('データ日付') # カラムから'始値', '高値', '安値'を取り除いて、日付が古い順に並べます df = df.drop(['始値', '高値', '安値'], axis=1) df = df.sort_index(ascending=True) df
時系列データの取得その3
import pandas as pd # dfとdf_tweetsの二つのテーブルをindexをキーとして結合し、Nanを消去 df_tweets = pd.read_csv('./6050_stock_price_prediction_data/df_tweets.csv', index_col='date') table = df_tweets.join(df, how='right').dropna() # table.csvとして出力 table.to_csv("./6050_stock_price_prediction_data/table.csv") table
株価予測
株価予測その1
Python: 株価予測その①で説明したように
今回はテクニカル分析を用いて株価の予測を行います。過去三日間の日経平均株価の時系列の変化とPN値の変化を特徴量にして
次の日の株価の上下の予測を行います。訓練データとテストデータの二つに分け、訓練データを標準化したのち、訓練データの平均と分散を用いてテストデータの標準化を行います。
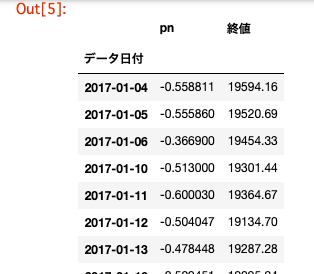
# 基本雛形 from sklearn.model_selection import train_test_split X = table.values[:, 0] y = table.values[:, 1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False) X_train_std = (X_train - X_train.mean()) / X_train.std() X_test_std = (X_test - X_train.mean()) / X_train.std()# 学習データの作成 from sklearn.model_selection import train_test_split X = table.values[:, 0] y = table.values[:, 1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False) X_train_std = (X_train - X_train.mean()) / X_train.std() X_test_std = (X_test - X_train.mean()) / X_train.std() # df_trainというテーブルを作りそこにindexを日付、カラム名をpn値、終値にしてdf_train.csvという名前でdataフォルダ内に出力 df_train = pd.DataFrame( {'pn': X_train_std, '終値': y_train}, columns=['pn', '終値'], index=table.index[:len(X_train_std)]) df_train.to_csv('./6050_stock_price_prediction_data/df_train.csv') # テストデータについても同様にdf_testというテーブルを作り、df_test.csvという名前でdataフォルダ内に出力 df_test = pd.DataFrame( {'pn': X_test_std, '終値': y_test}, columns=['pn', '終値'], index=table.index[len(X_train_std):]) df_test.to_csv('./6050_stock_price_prediction_data/df_test.csv')株価予測その2
# まず初めにdf_train.csvを読み込んでPN値と株価の変化を表示することを行います。 # pn.rates_diff, exchange_rates_diffを表示して上記のプログラムの概要を把握してください。 rates_fd = open('./6050_stock_price_prediction_data/df_train.csv', 'r') rates_fd.readline() #1行ごとにファイル終端まで全て読み込んでいます。 next(rates_fd) # 先頭の行を飛ばしています。 exchange_dates = [] pn_rates = [] pn_rates_diff = [] exchange_rates = [] exchange_rates_diff = [] prev_pn = df_train['pn'][0] prev_exch = df_train['終値'][0] for line in rates_fd: splited = line.split(",") time = splited[0] # table.csvの1列目日付 pn_val = float(splited[1]) # table.csvの2列目PN値 exch_val = float(splited[2]) # table.csvの3列目株価の終値 exchange_dates.append(time) # 日付 pn_rates.append(pn_val) pn_rates_diff.append(pn_val - prev_pn) # PN値の変化 exchange_rates.append(exch_val) exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化 prev_pn = pn_val prev_exch = exch_val rates_fd.close() print(pn_rates_diff) print(exchange_rates_diff)
株価予測その3
# 3日間ごとのPN値と株価の変化を表示してみます。 import numpy as np INPUT_LEN = 3 data_len = len(pn_rates_diff) tr_input_mat = [] tr_angle_mat = [] for i in range(INPUT_LEN, data_len): tmp_arr = [] for j in range(INPUT_LEN): tmp_arr.append(exchange_rates_diff[i-INPUT_LEN+j]) tmp_arr.append(pn_rates_diff[i-INPUT_LEN+j]) tr_input_mat.append(tmp_arr) # i日目の直近3日間の株価とネガポジの変化 if exchange_rates_diff[i] >= 0: # i日目の株価の上下、プラスなら1、マイナスなら0 tr_angle_mat.append(1) else: tr_angle_mat.append(0) train_feature_arr = np.array(tr_input_mat) train_label_arr = np.array(tr_angle_mat) # train_feature_arr, train_label_arrを表示して上のコードの概要を把握してください。 print(train_feature_arr) print(train_label_arr)
株価の予測(まとめ)
# test_feature_arr, test_label_arrを同様に作成してください。 rates_fd = open('./6050_stock_price_prediction_data/df_test.csv', 'r') rates_fd.readline() #1行ごとにファイル終端まで全て読み込んでいます。 next(rates_fd) # 先頭の行を飛ばしています。 exchange_dates = [] pn_rates = [] pn_rates_diff = [] exchange_rates = [] exchange_rates_diff = [] prev_pn = df_test['pn'][0] prev_exch = df_test['終値'][0] for line in rates_fd: splited = line.split(",") time = splited[0] # table.csvの1列目日付 pn_val = float(splited[1]) # table.csvの2列目PN値 exch_val = float(splited[2]) # table.csvの3列目株価の終値 exchange_dates.append(time) # 日付 pn_rates.append(pn_val) pn_rates_diff.append(pn_val - prev_pn) # PN値の変化 exchange_rates.append(exch_val) exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化 prev_pn = pn_val prev_exch = exch_val rates_fd.close() INPUT_LEN = 3 data_len = len(pn_rates_diff) test_input_mat = [] test_angle_mat = [] for i in range(INPUT_LEN, data_len): test_arr = [] for j in range(INPUT_LEN): test_arr.append(exchange_rates_diff[i - INPUT_LEN + j]) test_arr.append(pn_rates_diff[i - INPUT_LEN + j]) test_input_mat.append(test_arr) # i日目の直近3日間の株価とネガポジの変化 if exchange_rates_diff[i] >= 0: # i日目の株価の上下、プラスなら1、マイナスなら0 test_angle_mat.append(1) else: test_angle_mat.append(0) test_feature_arr = np.array(test_input_mat) test_label_arr = np.array(test_angle_mat) # train_feature_arr, train_label_arr,test_feature_arr, test_label_arrを特徴量にして、予測モデル(ロジスティック回帰、SVM、ランダムフォレスト)を構築し予測精度を計測してください。 from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC for model in [LogisticRegression(), RandomForestClassifier(n_estimators=200, max_depth=8, random_state=0), SVC()]: model.fit(train_feature_arr, train_label_arr) print("--Method:", model.__class__.__name__, "--") print("Cross validatin scores:{}".format(model.score(test_feature_arr, test_label_arr)))



- 投稿日:2020-05-24T23:49:47+09:00
Python: 株価予測その②
日経平均株価の時系列データの取得
時系列データの取得その1
日経平均株価の過去のcsvデータを取ってきて保存します。
# csvを読み込む時のコード import pandas as pd from io import StringIO import urllib def read_csv(url): res = urllib.request.urlopen(url) res=res.read().decode('shift_jis') df = pd.read_csv(StringIO( res) ) return df# 日経平均株価の時系列データの取得 import pandas as pd from io import StringIO import urllib # 上記の関数を使い日経平均株価の時系列データを取得 url = "https://indexes.nikkei.co.jp/nkave/historical/nikkei_stock_average_daily_jp.csv" def read_csv(url): res = urllib.request.urlopen(url) res = res.read().decode('shift_jis') df = pd.read_csv(StringIO(res)) # 必要のない最後の行を取り除いています df = df.drop(df.shape[0]-1) return df # dfというdataframeで保存し、出力 df = read_csv(url) # 出力 df時系列データの取得その2
時系列データの終値に注目して予測を行います。
# 時系列データの取得その1,日経平均株価の時系列データの取得コードを載せます。 # indexを日付にした後、時系列にします df["データ日付"] = pd.to_datetime(df["データ日付"], format='%Y/%m/%d') df = df.set_index('データ日付') # カラムから'始値', '高値', '安値'を取り除いて、日付が古い順に並べます df = df.drop(['始値', '高値', '安値'], axis=1) df = df.sort_index(ascending=True) df
時系列データの取得その3
import pandas as pd # dfとdf_tweetsの二つのテーブルをindexをキーとして結合し、Nanを消去 df_tweets = pd.read_csv('./6050_stock_price_prediction_data/df_tweets.csv', index_col='date') table = df_tweets.join(df, how='right').dropna() # table.csvとして出力 table.to_csv("./6050_stock_price_prediction_data/table.csv") table
株価予測
株価予測その1
Python: 株価予測その①で説明したように
今回はテクニカル分析を用いて株価の予測を行います。過去三日間の日経平均株価の時系列の変化とPN値の変化を特徴量にして
次の日の株価の上下の予測を行います。訓練データとテストデータの二つに分け、訓練データを標準化したのち、訓練データの平均と分散を用いてテストデータの標準化を行います。
# 基本雛形 from sklearn.model_selection import train_test_split X = table.values[:, 0] y = table.values[:, 1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False) X_train_std = (X_train - X_train.mean()) / X_train.std() X_test_std = (X_test - X_train.mean()) / X_train.std()# 学習データの作成 from sklearn.model_selection import train_test_split X = table.values[:, 0] y = table.values[:, 1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False) X_train_std = (X_train - X_train.mean()) / X_train.std() X_test_std = (X_test - X_train.mean()) / X_train.std() # df_trainというテーブルを作りそこにindexを日付、カラム名をpn値、終値にしてdf_train.csvという名前でdataフォルダ内に出力 df_train = pd.DataFrame( {'pn': X_train_std, '終値': y_train}, columns=['pn', '終値'], index=table.index[:len(X_train_std)]) df_train.to_csv('./6050_stock_price_prediction_data/df_train.csv') # テストデータについても同様にdf_testというテーブルを作り、df_test.csvという名前でdataフォルダ内に出力 df_test = pd.DataFrame( {'pn': X_test_std, '終値': y_test}, columns=['pn', '終値'], index=table.index[len(X_train_std):]) df_test.to_csv('./6050_stock_price_prediction_data/df_test.csv')株価予測その2
# まず初めにdf_train.csvを読み込んでPN値と株価の変化を表示することを行います。 # pn.rates_diff, exchange_rates_diffを表示して上記のプログラムの概要を把握してください。 rates_fd = open('./6050_stock_price_prediction_data/df_train.csv', 'r') rates_fd.readline() #1行ごとにファイル終端まで全て読み込んでいます。 next(rates_fd) # 先頭の行を飛ばしています。 exchange_dates = [] pn_rates = [] pn_rates_diff = [] exchange_rates = [] exchange_rates_diff = [] prev_pn = df_train['pn'][0] prev_exch = df_train['終値'][0] for line in rates_fd: splited = line.split(",") time = splited[0] # table.csvの1列目日付 pn_val = float(splited[1]) # table.csvの2列目PN値 exch_val = float(splited[2]) # table.csvの3列目株価の終値 exchange_dates.append(time) # 日付 pn_rates.append(pn_val) pn_rates_diff.append(pn_val - prev_pn) # PN値の変化 exchange_rates.append(exch_val) exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化 prev_pn = pn_val prev_exch = exch_val rates_fd.close() print(pn_rates_diff) print(exchange_rates_diff)
株価予測その3
# 3日間ごとのPN値と株価の変化を表示してみます。 import numpy as np INPUT_LEN = 3 data_len = len(pn_rates_diff) tr_input_mat = [] tr_angle_mat = [] for i in range(INPUT_LEN, data_len): tmp_arr = [] for j in range(INPUT_LEN): tmp_arr.append(exchange_rates_diff[i-INPUT_LEN+j]) tmp_arr.append(pn_rates_diff[i-INPUT_LEN+j]) tr_input_mat.append(tmp_arr) # i日目の直近3日間の株価とネガポジの変化 if exchange_rates_diff[i] >= 0: # i日目の株価の上下、プラスなら1、マイナスなら0 tr_angle_mat.append(1) else: tr_angle_mat.append(0) train_feature_arr = np.array(tr_input_mat) train_label_arr = np.array(tr_angle_mat) # train_feature_arr, train_label_arrを表示して上のコードの概要を把握してください。 print(train_feature_arr) print(train_label_arr)
株価の予測(まとめ)
# test_feature_arr, test_label_arrを同様に作成してください。 rates_fd = open('./6050_stock_price_prediction_data/df_test.csv', 'r') rates_fd.readline() #1行ごとにファイル終端まで全て読み込んでいます。 next(rates_fd) # 先頭の行を飛ばしています。 exchange_dates = [] pn_rates = [] pn_rates_diff = [] exchange_rates = [] exchange_rates_diff = [] prev_pn = df_test['pn'][0] prev_exch = df_test['終値'][0] for line in rates_fd: splited = line.split(",") time = splited[0] # table.csvの1列目日付 pn_val = float(splited[1]) # table.csvの2列目PN値 exch_val = float(splited[2]) # table.csvの3列目株価の終値 exchange_dates.append(time) # 日付 pn_rates.append(pn_val) pn_rates_diff.append(pn_val - prev_pn) # PN値の変化 exchange_rates.append(exch_val) exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化 prev_pn = pn_val prev_exch = exch_val rates_fd.close() INPUT_LEN = 3 data_len = len(pn_rates_diff) test_input_mat = [] test_angle_mat = [] for i in range(INPUT_LEN, data_len): test_arr = [] for j in range(INPUT_LEN): test_arr.append(exchange_rates_diff[i - INPUT_LEN + j]) test_arr.append(pn_rates_diff[i - INPUT_LEN + j]) test_input_mat.append(test_arr) # i日目の直近3日間の株価とネガポジの変化 if exchange_rates_diff[i] >= 0: # i日目の株価の上下、プラスなら1、マイナスなら0 test_angle_mat.append(1) else: test_angle_mat.append(0) test_feature_arr = np.array(test_input_mat) test_label_arr = np.array(test_angle_mat) # train_feature_arr, train_label_arr,test_feature_arr, test_label_arrを特徴量にして、予測モデル(ロジスティック回帰、SVM、ランダムフォレスト)を構築し予測精度を計測 from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC for model in [LogisticRegression(), RandomForestClassifier(n_estimators=200, max_depth=8, random_state=0), SVC()]: model.fit(train_feature_arr, train_label_arr) print("--Method:", model.__class__.__name__, "--") print("Cross validatin scores:{}".format(model.score(test_feature_arr, test_label_arr)))
- 投稿日:2020-05-24T23:44:44+09:00
【学習記録】PyhtonのTkinterで不思議なダンジョンゲーム作成
pythonで動くものを作りたい!と思い、『Pythonでつくるゲーム開発入門講座』(実践編含む)で勉強中です。
なぜpythonのtkinterなのか→私の最終目的はゲーム開発ではなく、スクレイピングなどのデータ収集や、データ分析、業務効率化など。よって、ゲーム開発に適したC++やUnity?でなく、pythonでゲーム作成。pygameライブラリを使わないのも同じ理由。
スクレイピングやデータ分析、機械学習をピンポイントで勉強しても、今のところ応用方法が思いつかないので、遠回りになるけれど、ゲームを作成しながら、プログラミングを覚えようという魂胆。NCPを動かすのに、機械学習とかディープラーニングを組み込んでそのあたりの実践経験も積めたらなぁとか欲張ってます。
ある程度学習出来たので、サンプルコードを参考(というか改造)にして、不思議なダンジョンゲームっぽいものを作ってみました。
風来の試練やトルネコを思い浮かべる方が多いと思いますが、私は不思議なダンジョンと言えば、チョコボの不思議なダンジョンを思い浮かべます。(あとはテリーのワンダーランド?)最終的にはチョコボに近い'何か'を作りたいでうすね。
とりあえず、コードとキャラチップをgithubに保存してみました。
キャラチップはぴぽや倉庫さんより拝借いたしました。 マップを自動生成する、maze_maker.pyとゲーム本体のtkmaze.pyに分けてみました。maze_maker.pyimport random class maze_maker: """ ダンジョンを自動生成する """ def __init__(self,MAZE_W,MAZE_H): self.MAZE_W = MAZE_W self.MAZE_H = MAZE_H self.maze = [[0]*self.MAZE_W for y in range(self.MAZE_H)] self.DUNGEON_W = MAZE_W*3 self.DUNGEON_H = MAZE_H*3 self.dungeon = [[0]*self.DUNGEON_W for y in range(self.DUNGEON_H)] def make_maze(self): """ 迷路を作る """ XP = [ 0, 1, 0,-1] YP = [-1, 0, 1, 0] #周囲の柱 for x in range(self.MAZE_W): self.maze[0][x] = 1 self.maze[self.MAZE_H-1][x] = 1 for y in range(self.MAZE_H): self.maze[y][0] = 1 self.maze[y][self.MAZE_W-1] = 1 #中を空っぽに for y in range(1,self.MAZE_H-1): for x in range(1,self.MAZE_W-1): self.maze[y][x] = 0 #柱 for y in range(2,self.MAZE_H-2,2): for x in range(2,self.MAZE_W-2,2): self.maze[y][x] = 1 for y in range(2,self.MAZE_H-2,2): for x in range(2,self.MAZE_W-2,2): d = random.randint(0,3) if x > 2: d = random.randint(0,2) self.maze[y+YP[d]][x+XP[d]] = 1 def make_dungeon(self): """ 迷路からダンジョンを作る """ self.make_maze() for y in range(self.DUNGEON_H): for x in range(self.DUNGEON_W): self.dungeon[y][x] = 9 for y in range(1,self.MAZE_H-1): for x in range(1,self.MAZE_W-1): dx = x*3+1 dy = y*3+1 if self.maze[y][x] == 0: if random.randint(0,99) < 20: for ry in range(-1,2): for rx in range(-1,2): self.dungeon[dy+ry][dx+rx] = 0 else: self.dungeon[dy][dx] = 0 if self.maze[y-1][x] == 0: self.dungeon[dy-1][dx] = 0 if self.maze[y+1][x] == 0: self.dungeon[dy+1][dx] = 0 if self.maze[y][x-1] == 0: self.dungeon[dy][dx-1] = 0 if self.maze[y][x+1] == 0: self.dungeon[dy][dx+1] = 0 def put_event(self): while True: x = random.randint(3,self.DUNGEON_W-4) y = random.randint(3,self.DUNGEON_H-4) if(self.dungeon[y][x] == 0): for ry in range(-1,2): for rx in range(-1,2): self.dungeon[y+ry][x+rx] = 0 self.dungeon[y][x] = 1 break for i in range(60): x = random.randint(3,self.DUNGEON_W-4) y = random.randint(3,self.DUNGEON_H-4) if(self.dungeon[y][x] == 0): self.dungeon[y][x] = random.choice([2,3,3,3,4])tkmaze.py""" 冥土で冥土探索。それは終わりなき旅。ゴールは無くて、敵を避けつつひたすら階段を降りていく。 1歩ごとにスコアカウント。階段を降りるとプラス。ハイスコアを目指そう! """ import tkinter import maze_maker from PIL import Image,ImageTk import random #キー入力 key = '' koff = False def key_down(e): global key,koff key = e.keysym koff = False def key_up(e): global koff koff = True CHIP_SIZE = 32 DIR_UP = 3 DIR_DOWN = 0 DIR_LEFT = 1 DIR_RIGHT = 2 chara_x = chara_y = 146 chara_d = chara_a = 0 obj_a = 0 emy_num = 4 emy_list_x = [0]*emy_num emy_list_y = [0]*emy_num emy_list_d = [0]*emy_num emy_list_a = [0]*emy_num ANIMATION = [1,0,1,2] #素材は「ぴぽや http://blog.pipoya.net/」様より imgplayer_pass = 'image/charachip01.png' emy_img_pass = 'image/pipo-charachip019.png' emy2_img_pass = 'image/hone.png' emy3_img_pass = 'image/majo.png' emy3_kageimg_pass = 'image/majo_kage.png' takara_img_pass = 'image/pipoya_mcset1_obj01.png' obj_pass = 'image/pipoya_mcset1_obj02.png' obj2_pass = 'image/pipo-hikarimono005.png' yuka_pass = 'image/pipoya_mcset1_at_gravel1.png' kebe_pass = 'image/pipoya_mcset1_bridge01.png' map_data = maze_maker.maze_maker(11,7) map_data.make_dungeon() map_data.put_event() tmr = 0 idx = 1 floor_count = 0 item_count = 0 pl_life=150 pl_stamina = 150 pl_damage = 0 def move_player(): global chara_x,chara_y,chara_a,chara_d,pl_stamina,pl_life if key == 'Up': chara_d = DIR_UP check_wall() if key == 'Down': chara_d = DIR_DOWN check_wall() if key == 'Left': chara_d = DIR_LEFT check_wall() if key == 'Right': chara_d = DIR_RIGHT check_wall() check_event() if tmr%4 == 0: if pl_stamina > 0: pl_stamina -= 1 else: pl_life -= 1 if pl_life <= 0: pl_life = 0 idx = 2 chara_a = chara_d*3 + ANIMATION[tmr%4] def emy_set(emy_num): while True: x = random.randint(3,map_data.DUNGEON_W-4) y = random.randint(3,map_data.DUNGEON_H-4) if map_data.dungeon[y][x] == 0: emy_list_x[emy_num] = x*CHIP_SIZE+(CHIP_SIZE//2) emy_list_y[emy_num] = y*CHIP_SIZE+(CHIP_SIZE//2) break def draw_text(txt): st_fnt = ('Times New Roman',60) canvas.create_text(200,200,text=txt,font=st_fnt,fill='red',tag='SCREEN') def damage_cal(pl_damage): global pl_life,idx if pl_life <= pl_damage: pl_life = 0 idx = 2 else: pl_life -= pl_damage def move_emy(emy_num): cy = int(emy_list_y[emy_num]//CHIP_SIZE) cx = int(emy_list_x[emy_num]//CHIP_SIZE) emy_list_d[emy_num] = random.randint(0,3) if emy_list_d[emy_num] == DIR_UP: if map_data.dungeon[cy-1][cx] != 9: emy_list_y[emy_num] -= 32 if emy_list_d[emy_num] == DIR_DOWN: if map_data.dungeon[cy+1][cx] != 9: emy_list_y[emy_num] += 32 if emy_list_d[emy_num] == DIR_LEFT: if map_data.dungeon[cy][cx-1] != 9: emy_list_x[emy_num] -= 32 if emy_list_d[emy_num] == DIR_RIGHT: if map_data.dungeon[cy][cx+1] != 9: emy_list_x[emy_num] += 32 emy_list_a[emy_num] = emy_list_d[emy_num]*3 + ANIMATION[tmr%4] if abs(emy_list_x[emy_num]-chara_x) <= 30 and abs(emy_list_y[emy_num]-chara_y) <= 30: pl_damage = 10*random.choice([1,2,2,3,3]) damage_cal(pl_damage) def obj_animation(): global obj_a obj_a = ANIMATION[tmr%4] def check_wall(): global chara_x,chara_y,chara_a,chara_d cy = int(chara_y//CHIP_SIZE) cx = int(chara_x//CHIP_SIZE) if chara_d == DIR_UP: if map_data.dungeon[cy-1][cx] != 9: chara_y -= 32 if chara_d == DIR_DOWN: if map_data.dungeon[cy+1][cx] != 9: chara_y += 32 if chara_d == DIR_LEFT: if map_data.dungeon[cy][cx-1] != 9: chara_x -= 32 if chara_d == DIR_RIGHT: if map_data.dungeon[cy][cx+1] != 9: chara_x += 32 def check_event(): global chara_x,chara_y,chara_a,chara_d,idx,pl_damage global floor_count,emy_count,item_count,pl_life,pl_stamina cy = int(chara_y//CHIP_SIZE) cx = int(chara_x//CHIP_SIZE) if map_data.dungeon[cy][cx] == 1: #ワープの魔法陣にのった map_data.make_dungeon() map_data.put_event() emy_set(0) emy_set(1) emy_set(2) floor_count += 1 chara_x = chara_y = 146 if map_data.dungeon[cy][cx] == 2: #トラップの魔法陣に乗った if item_count > 0: item_count -= 1 map_data.dungeon[cy][cx] = 0 else: pl_damage = 5*random.choice([1,2,2,3,4,3]) damage_cal(pl_damage) map_data.dungeon[cy][cx] = 0 if map_data.dungeon[cy][cx] == 3: #アイテムに接触 item_count += 1 map_data.dungeon[cy][cx] = 0 if map_data.dungeon[cy][cx] == 4: #食料に接触 pl_stamina_recover = 5*random.choice([1,2,2,3,4,3]) if pl_stamina + pl_stamina_recover > 150: pl_stamina = 150 else: pl_stamina += pl_stamina_recover map_data.dungeon[cy][cx] = 0 def split_chip(chip_pass,chip_img_x,chip_img_y): ''' 複数のチップを1単位のチップに分割する ''' chip_list = [] for cy in range(0,chip_img_y,CHIP_SIZE): for cx in range(0,chip_img_x,CHIP_SIZE): chip_list.append(ImageTk.PhotoImage(Image.open(chip_pass).crop((cx,cy,cx+CHIP_SIZE,cy+CHIP_SIZE)))) return chip_list def draw_screen(): st_fnt = ('Times New Roman',30) canvas.delete('SCREEN') for my in range(len(map_data.dungeon)): for mx in range(len(map_data.dungeon[0])): if map_data.dungeon[my][mx] != 9: canvas.create_image(mx*CHIP_SIZE+(CHIP_SIZE//2),my*CHIP_SIZE+(CHIP_SIZE//2),image=yuka_img[8],tag='SCREEN') if map_data.dungeon[my][mx] == 1: canvas.create_image(mx*CHIP_SIZE+(CHIP_SIZE//2),my*CHIP_SIZE+(CHIP_SIZE//2),image=obj2_img[obj_a],tag='SCREEN') if map_data.dungeon[my][mx] == 2: canvas.create_image(mx*CHIP_SIZE+(CHIP_SIZE//2),my*CHIP_SIZE+(CHIP_SIZE//2),image=obj2_img[6+obj_a],tag='SCREEN') if map_data.dungeon[my][mx] == 3: canvas.create_image(mx*CHIP_SIZE+(CHIP_SIZE//2),my*CHIP_SIZE+(CHIP_SIZE//2),image=takara_img[5],tag='SCREEN') if map_data.dungeon[my][mx] == 4: canvas.create_image(mx*CHIP_SIZE+(CHIP_SIZE//2),my*CHIP_SIZE+(CHIP_SIZE//2),image=obj_img[25],tag='SCREEN') if map_data.dungeon[my][mx] == 9: canvas.create_image(mx*CHIP_SIZE+(CHIP_SIZE//2),my*CHIP_SIZE+(CHIP_SIZE//2),image=kabe_img[28],tag='SCREEN') canvas.create_image(chara_x,chara_y,image=imgplayer[chara_a],tag='SCREEN') canvas.create_image(emy_list_x[0],emy_list_y[0],image=emy_img[emy_list_a[0]],tag='SCREEN') canvas.create_image(emy_list_x[1],emy_list_y[1],image=emy2_img[emy_list_a[1]],tag='SCREEN') canvas.create_image(emy_list_x[2],emy_list_y[2],image=emy3_img[emy_list_a[2]],tag='SCREEN') canvas.create_image(emy_list_x[2],emy_list_y[2],image=emy3_kageimg[emy_list_a[2]],tag='SCREEN') canvas.create_text(1110,50,text='{} 階'.format(floor_count),font=st_fnt,fill='black',tag='SCREEN') canvas.create_text(1110,100,text='{} 個'.format(item_count),font=st_fnt,fill='black',tag='SCREEN') canvas.create_rectangle(1060,135,1210,160,fill='black',tag='SCREEN') canvas.create_rectangle(1060,135,1060+pl_life,160,fill='limegreen',tag='SCREEN') canvas.create_text(1130,148,text='LIFE',font=('Times New Roman',15),fill='white',tag='SCREEN') canvas.create_rectangle(1060,165,1210,190,fill='black',tag='SCREEN') canvas.create_rectangle(1060,165,1060+pl_stamina,190,fill='blue',tag='SCREEN') canvas.create_text(1130,178,text='STAMINA',font=('Times New Roman',15),fill='white',tag='SCREEN') canvas.create_text(1155,210,text='{}のダメージを受けた!'.format(pl_damage),font=('Times New Roman',15),fill='black',tag='SCREEN') def main(): global tmr,koff,key,idx tmr += 1 draw_screen() if idx == 1: if tmr == 1: for emy in range(0,emy_num): emy_set(emy) move_player() obj_animation() if tmr%2 == 0: for emy in range(0,emy_num): move_emy(emy) if pl_life == 0: idx = 2 if idx == 2: draw_text('You Died') if tmr == 20: idx = 1 print('hiu') if koff == True: key = '' koff = False root.after(130,main) root = tkinter.Tk() root.title('メイドで冥土探検!') root.bind('<KeyPress>',key_down) root.bind('<KeyRelease>',key_up) canvas = tkinter.Canvas(width=1256,height=864) imgplayer = split_chip(imgplayer_pass,96,128) emy_img = split_chip(emy_img_pass,96,128) emy2_img = split_chip(emy2_img_pass,96,128) emy3_img = split_chip(emy3_img_pass,96,128) emy3_kageimg = split_chip(emy3_kageimg_pass,96,128) takara_img = split_chip(takara_img_pass,256,64) obj_img = split_chip(obj_pass,256,224) obj2_img = split_chip(obj2_pass,96,128) yuka_img = split_chip(yuka_pass,64,160) kabe_img = split_chip(kebe_pass,256,192) canvas.pack() main() root.mainloop()プレイ画面。
全く面白く無いですが、マップの生成、プレイヤーが足踏みしながら方向を変える、ワープゾーンがアニメーション、敵キャラの配置・移動、ダメージ計算・・・など、とりあえずダンジョンゲームに必要な基礎的な処理はまずまず揃ったのでは?と思います。ちなみに、敵への攻撃はまだ実装できていません(汗
改良したい事
- 敵がバカで適当にうろうろしているだけ。追いかけてくるとか、移動スピードを変えるとか組み込んでみたい
- 攻撃できるようにして、敵を撃破できるようにする
- (かなり発展?)プレイヤーのレベルやらステータスとか作り込む
- 【願望】敵に強化学習or機械学習を組み込む
コードもまだまだ整理出来ていない気がするので、少しずつ改良したいです。
こだわり?
ピクセル数を指定してキャラチップを分解する関数。色々情報を集めながら頑張って考えました。

- 投稿日:2020-05-24T23:37:31+09:00
Python数理最適化パッケージPuLPの計算エンジンを速いものにする(Windows版お手軽編) & 計算時間を指定する
はじめに
数理最適化問題(数理計画問題)の中で、線型最適化問題(線型計画問題)や整数最適化問題(整数計画問題)(※ただし数式がすべて線型のもの)を解いてくれるPythonパッケージとして、PuLPがあります。
- 参考Qiita記事: Python+PuLPによるタダで仕事に使える数理最適化
PuLPは、解きたい対象をPython上で数式として記述できるモデリングインターフェース部分と、数理最適化ソルバーと呼ばれる、式として記述したものを解いてくれる計算エンジン部分とが、きれいに分かれています。PuLPには、数理最適化ソルバーとして、 無償で商用利用可能な COIN-CBC( 公式サイト(GitHub) )の、とあるバージョンが同こんされているほか、自分で入手したほかの数理最適化ソルバーを呼び出すこともできます。ということは、COIN-CBCより高性能な数理最適化ソルバーを用意すれば、より短い計算時間で解くことができるのですが、無償で商用利用可能なソルバーの中でCOIN-CBCより速いものはMIPCLくらいしかなく、そのMIPCLも、2020年5月現在、入手性に謎の部分がでてきました。
- 参考Qiita記事: ついに使い物になるフリーの数理最適化ソルバーが登場? MIPCL
ところで、整数最適化問題を解くアルゴリズムは、特にその中の分枝限定法と呼ばれる部分について、並列処理が可能であり、それにより計算時間をけっこう短縮できます。有償のソルバーやMIPCL、そして公式サイトで配布されているCOIN-CBCは、マルチスレッドで動作するのですが、PuLPに同こんされているCOIN-CBCは、少なくともWindows版については、マルチスレッドで動作しないのです。
そこで、PuLPから呼び出す数理最適化ソルバーを、マルチスレッド対応版のCOIN-CBCに変更することで、計算時間を短縮する方法を紹介します。今回は、速報版として、お手軽にできる方法を扱います。ついでに、計算時間の上限を指定する方法にも触れます。
※ Macの方は、自分でインストールした CBCソルバをPuLPで使用する の記事が参考になると思います。
実験環境
- Windows 10 1909 64bit
- 管理者権限を持つアカウントで作業
- (作業中に管理者権限を求められた記憶はなし)
- Python 3.7 64bit (Anaconda3 2020.02 64bit)
- ユーザー領域にインストール(Anacondaインストール時に「Just Me」を選択)
- PuLP 2.1
- 2020/05/18にmasterブランチからビルドされたCOIN-CBC
- Visual Studio Code 1.45.1
- ユーザー領域にインストール
ダウンロード
Python+PuLPによるタダで仕事に使える数理最適化 の記事などに従って、PuLPのダウンロードとインストール、軽い動作確認はできているものとします(最適化の計算では、特に指定しない場合、PuLP同こん版のCOIN-CBCが使用されます)。
今回、追加作業として、 https://bintray.com/coin-or/download/Cbc/master#files の
Cbc-master-x86_64-w64-mingw32.zipをダウンロードします。ダウンロードしたら、zipファイルなので、展開します。
- このバイナリーは、masterブランチからビルドされたもののようです。上記のサイトの中や COIN-CBCの公式サイト(GitHub) を探していくと、バージョン番号のついたバイナリーも見つかりますが、そちらはライブラリーの依存関係を自分で解決する必要があるようです。
- masterブランチからビルドされたものは、バージョンが固定された安定版とは限らないので、使用することに不安はありますね…自己責任の度合いがより強くなります。
Cbc-master-win64-msvc16-mt.zip(Visual Studio 2019でコンパイルしたもの?)などほかのバイナリーは、なぜかマルチスレッドに対応していませんでした。コード
ダウンロードして展開したCOIN-CBCが、
C:\Users\(ユーザー名)\Desktop\Cbc-master-x86_64-w64-mingw32\bin\cbc.exeにあると想定します。こちらの記事の例(2) の コード
pulp_problem_2.pyを取り上げて説明しますと、pulp_problem_2.py# (前略) # 計算 # ソルバー指定 solver = pulp.PULP_CBC_CMD() # (後略)の部分を、
pulp_problem_2_mt.py# ソルバー指定 solver = pulp.COIN_CMD(path=r'C:\Users\(ユーザー名)\Desktop\Cbc-master-x86_64-w64-mingw32\bin\cbc.exe', threads=8, maxSeconds=120.5)に変えれば、マルチスレッドで動作します。
path=(COIN-CBCのバイナリーのパス)で、呼び出すCOIN-CBCのバイナリーのあるところを指定します。
- 先頭に
rのついた文字列は raw文字列 というやつで、Windowsのファイルやフォルダーのパスを指定する際に使うと便利なものです。threads=(スレッド数)で、COIN-CBCで使用するスレッド数を指定します。いくつがよいかは、下記のベンチマーク結果が参考になると思います。- 今回の記事の主題から外れますが、
maxSeconds=(計算時間上限(秒))で、計算時間の上限を指定できます。
- 指定時間内に計算が終わる場合もあります。その場合、(最適解が存在するインスタンスであれば)最適解が返ってきて、かつ、その解が最適解であることが計算を通して理論的に保証されています。
- (インスタンスが非有界(目的関数を無限に小さく(大きく)できる)や実行不可能(制約を満たす解が存在しない)である場合は、そうであることが指定時間内に判明したということになります。)
- 計算が終わらないまま指定時間に達した場合は、それまでに見つかった中でいちばんよい解が返ってきます。
- 返ってきた解は、実は最適解であるかもしれないし、そうでないかもしれません。仮に最適解であったとしても、最適解であることは理論的に保証されていません。
- この「指定時間内で見つかった解を返す」機能の使い道のひとつとして、問題に対して自前で(メタ)ヒューリスティクスのコードを組んで指定時間内でそこそこよい解を探す代わりに、数理最適化ソルバーに投げて同じ時間内で見つかったそこそこよい解を返してもらうことが考えられます。
- 指定時間内に解が1つも見つからない可能性もあります。その場合、そもそも実行可能解(制約を満たす解)が存在しないのかもしれないし、存在はするものの数理最適化ソルバーが見つけられていないのかもしれません。
ベンチマーク
前の記事 と同じく、グラフクラスタリング(与えられた無向グラフを、いくつかの密な部分グラフに分割する問題)に関する こちらの論文 の定式化を解いてみました。環境はIntel Core i9-9900K(8コア16スレッド)です。
この論文の定式化に基いてインスタンスを解いた印象としては、最適解を見つけるのにも少し時間がかかるものの、それ以上に、見つかった解が最適であることを保証するために多くの時間がかかるようなタイプであるということが挙げられます。
インスタンス PuLP 2.1付属のCOIN-CBC (1スレ) 2020/05/18版COIN-CBC (1スレ) 2020/05/18版COIN-CBC (8スレ) 2020/05/18版COIN-CBC (16スレ) 1 21.7 22.7 6.9 13.4 2 10.1 11.2 4.3 5.6 3 28.0 20.3 7.2 10.3 4 9.8 19.8 5.4 7.4 (単位:秒)
(おおむね、インスタンスの数字が大きいほど、インスタンスのサイズが大きい)まず、1スレッドで動作するPuLP 2.1付属のCOIN-CBCのバイナリーと、今回入手したCOIN-CBCのバイナリーを1スレッドで動作させた場合を比較すると、おおむね前者のほうが短時間でインスタンスを解いています。前者のバイナリーは、今回の実験環境の場合、
C:\Users\(ユーザー名)\Anaconda3\Lib\site-packages\pulp\solverdir\cbc\win\64\cbc.exeにあるのですが、これをコンソールから実行させたら、Version: 2.9.0 Build Date: Feb 12 2015と表示されました。2020/05/18版は、バージョン2.10.5から2か月ちょっとたったもののようです。数理最適化ソルバーでは、バージョンが上がると、中のチューニングの変更の結果として、かえって解く時間が長くなるインスタンスがでてくることはままあります。
今回入手したCOIN-CBCのバイナリーを、CPUの物理コア数である8スレッドで動作させると、1スレッドのときと比べて、最低でも40%弱の時間でインスタンスが解けました。コア数が1:8なので計算時間が12.5%まで短縮とはいきませんでしたが、なかなかよい結果です。
物理コア数を超えて論理コア数である16スレッドで動作させた場合は、8スレッドで動作させた場合に比べて時間がかかってしまいました。整数最適化は比較的重い処理であることから、SMT機能により別の論理コアとして見えているが物理的には同一のコアの中で、演算器の奪い合いが起こってパフォーマンスが下がったものと推測されます。こういった現象は、例えば行列演算ベンチマークとして知られているLINPACKでも起こります。最近の有償ソルバーだと、自動でCPUのSMT周りの特性をチェックして、スレッド生成数を自動調整してくれるようなのですが、今回入手したCOIN-CBCにはそういった機能はないようなので、自分で明示的にスレッド数 = 物理コア数と設定するのがよいようです。なお、各スレッドの処理をどの論理コアへ割りふるかについては、Windowsの場合はVistaか7のころから、OS側で別々の物理コアにいい感じに割りふってくれているようです。まとめ
- PuLPにデフォルトでついてくる数理最適化ソルバーは1スレッドでしか動かないので、マルチスレッド動作版をダウンロードし、CPUの物理コア数ぶんのスレッドを指定して呼び出すと、問題を速く解けます。
- PuLPでは計算時間の上限を指定することができます。指定時間内に計算が終わる場合もあります。計算が終わらないまま指定時間に達した場合は、それまでに見つかった中でいちばんよい解が返ってきます。
これからやりたいこと
- マルチスレッド動作版をソースからコンパイルしたい。
cbc.exeを呼び出すのではなく、(ソールからコンパイルして生成した)DLLを呼び出したい。
cbc.exeを呼び出す方式の場合、 PuLPがインスタンスを.mpsと呼ばれる形式のファイルに出力 →cbc.exeが.mpsファイルを読んで計算 →cbc.exeが解を.solと呼ばれる形式のファイルに出力 → PuLPが.solファイルを読み解をセット 、という処理の流れになっているが、規模の大きな問題の場合、ファイルの入出力に時間がかかる。- PuLPにはデフォルトで
CoinMP.dllが付属しているが、32bit版であり、64bit環境では動かない模様?- Google OR-Tools に付属しているCOIN-CBCはマルチスレッドで動作するのか否かを調査したい。
- 投稿日:2020-05-24T23:34:00+09:00
ゼロから始めるLeetCode Day35「160. Intersection of Two Linked Lists」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day34「118. Pascal's Triangle」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
160. Intersection of Two Linked Lists
Top 100 Liked QuestionsのEasy問題の最後から二つ目の問題です。
問題としては、2つの単方向連結リストの共通部分が始まるノードを見つけてくださいというものです。
例が図で解説されており、諸事情でこちらに直接載せることはできないので各々が確認して頂けると幸いです。
解法
最初こう書いたら、
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None class Solution: def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode: if headA == None or headB == None: return None LNA = headA LNB = headB while LNA != LNB: if LNA == None: LNA = headB else: LNA.next if LNB == None: LNB == headA else: LNB.next return LNA # Time Limit Exceeded時間切れになったので、以下のようにwhile以降を内包表記で書き直してみたら行けました。
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None class Solution: def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode: if headA == None or headB == None: return None LNA = headA LNB = headB while LNA != LNB: LNA = headB if LNA == None else LNA.next LNB = headA if LNB == None else LNB.next return LNA # Runtime: 168 ms, faster than 75.08% of Python3 online submissions for Intersection of Two Linked Lists. # Memory Usage: 29.1 MB, less than 100.00% of Python3 online submissions for Intersection of Two Linked Lists.なお、この問題の公式の解説の解き方ではBruteForce,HashMap,Two Pointerのいずれかを使うと良いよ!ってなってます。
気になるかたはそちらをチェックすることもお勧めします。こっちの書き方の方が良いよ!とかこの言語で書いてみたよ!とかがあれば是非コメントしてみてください。
- 投稿日:2020-05-24T23:32:52+09:00
pythonのboto3でzabbixとcloudwatchの連携スクリプト書いてみた
1 メトリクス・ログを取得できるのか?
pod cpu
pod memory
node disk
- advance container cpu container memory container filesystem
log
2 もれなく取得できているか?
*メトリクスについて
前提
監視対象:EC2
監視項目:CPU使用率の平均値
get_metric_statisticsのパラメータのstart-timeはCloudwatchがリクエストを受け取った時に分以下を切り捨てる仕様
ex)
start_timeが21:17:32、end_timeが21:18:32の場合、
21:17:00として切り捨てられる。レスポンスの内容は、21:17:00から21:17:32のデータポイントの値を返す・リアルタイムの監視をした場合
get_metric_statisticsを実行したときの設定値
Cloudwatchのメトリクス取得期間:60sstart_time:現在時刻 ー 60s
end_time:現在時刻
period:60s現在時刻が58秒の場合、取得可能
それ以外の場合は値を取得できなかった・現在時刻から1分遅れて監視する場合
getメソッドを実行したときの設定値
Cloudwatchのメトリクス取得期間:60sstart_time:現在時刻 ー 2m
end_time:現在時刻 ー 1m
period:60s問題なく取得できる!
→現在時刻から1分遅れて監視をすれば確実に値を取得できる
*ログについて
前提
監視対象:EC2
監視ログ:nginxのアクセスログ
get_log_eventsのパラメータのstartTimeやendTimeはエポックミリ秒で表記する必要がある。
startTimeは指定した時間を含んだ時間として値を返す
endTimeは指定した時間を含まない時間として値を返す
ex)
startTimeを19:22:54.213、endTimeを19:23:54.213の場合、
19:22:54.213 ~ 19:23:54.212の期間にcloudwatch logsにあるログがレスポンスとして返ってくる・リアルタイムの監視をした場合
リアルタイム監視をした場合、監視対象のサーバから値をcloudwatch logに送りAPIとして取得できるようになるまでの期間分のログデータが取れなくなる
→そのため、少し遅れての監視が必要になる
値を取得できるまでに10~20秒かかるような仕様となっていた。(cloudwatch logsで確認)・現在時刻から30秒遅れて監視する場合
30秒遅れた監視をすればログを回収できたが、値をAPIから取得できるまでの期間がドキュメントにも記載がないため、もう少し間隔を開けた方がいいかもしてない・監視期間について(startTime, endTime)
startTimeとendTimeの指定についてはミリ秒単位であるため、スクリプト上で毎回リアルタイムを作って(time.time())実行するとどうしても取得できない部分が出てきてしまう。
これは、zabbixがスクリプトを実行する間隔がミリ秒単位で正確であれば問題なく全てのログを取得できるが、おそらくそこまで正確では無いのでは無いか?
→解決策として、前回実行した時間を書き込んだファイルを作りそこから、次回実行時に値をとって実行するようにすれば、漏れることなく全てのログを取得できる。3 結論
メトリクス
現在時刻から1分遅れて監視をすれば確実に値を取得できる(詳細モニタリングに設定している場合(コンテナの場合はcloudwatch agentが監視項目の値を取得する間隔が60秒の場合))ログ
以下の二つを気を付けることで漏れることなく監視が可能
・現在時刻から少なくとも30秒遅れて監視すること
・前回実行した時間をファイルに書き出し、次回実行時にはそこから値(前回実行した時間)を取り出しCloudwatchの情報をとってくることaws_zabbix.py#!/bin/env python import boto3 import json import argparse import os import socket import struct import time import calendar from datetime import datetime from datetime import timedelta class Metric: def __init__(self, name="", namespace="", unit="", dimensions=[]): self.name = name self.namespace = namespace self.unit = unit self.dimensions = dimensions class AwsZabbix: ''' dimentionsは'PodName'にしています(コンテナでの監視の場合は書き加える必要あり) ''' def __init__(self, region, access_key, secret, identity, hostname, service, timerange_min, zabbix_host, zabbix_port): self.zabbix_host = zabbix_host self.zabbix_port = zabbix_port self.identity = identity self.hostname = hostname self.service = service self.timerange_min = timerange_min self.id_dimentions = { 'ec2':'InstanceId', 'rds':'DBInstanceIdentifier', 'elb':'LoadBalancerName', 'ebs':'VolumeId', 'billing': 'Currency', 'eks': 'PodName', } self.client = boto3.client( 'cloudwatch', region_name=region, aws_access_key_id=access_key, aws_secret_access_key=secret ) self.sum_stat_metrics = [ {'namespace': 'AWS/ELB', 'metricname': 'RequestCount'}, {'namespace': 'AWS/ELB', 'metricname': 'HTTPCode_Backend_2XX'}, {'namespace': 'AWS/ELB', 'metricname': 'HTTPCode_Backend_3XX'}, {'namespace': 'AWS/ELB', 'metricname': 'HTTPCode_Backend_4XX'}, {'namespace': 'AWS/ELB', 'metricname': 'HTTPCode_Backend_5XX'}, {'namespace': 'AWS/ELB', 'metricname': 'HTTPCode_ELB_4XX'}, {'namespace': 'AWS/ELB', 'metricname': 'HTTPCode_ELB_5XX'}, {'namespace': 'ContainerInsights', 'metricname': 'pod_number_of_container_restarts'}, ] self.max_stat_metrics = [ {'namespace': 'ContainerInsights', 'metricname': 'pod_cpu_reserved_capacity'}, {'namespace': 'ContainerInsights', 'metricname': 'pod_memory_reserved_capacity'}, ] def __get_metric_list(self): resp = self.client.list_metrics( Dimensions = [ { 'Name': self.id_dimentions[self.service], 'Value': ('USD' if self.service == "billing" else self.identity) } ] ) metric_list = [] for data in resp["Metrics"]: metric = Metric(name=data["MetricName"], namespace=data["Namespace"], dimensions=data["Dimensions"]) if self.service == "elb": for dimension in data["Dimensions"]: if dimension["Name"] == "AvailabilityZone": metric.name = data["MetricName"] + "." + dimension["Value"] metric_list.append(metric) return metric_list def __get_metric_stats(self, metric_name, metric_namespace, servicename, timerange_min, dimensions, stat_type="Average", period_sec=60): if self.service == "billing": dimensions = [ { 'Name': self.id_dimentions[self.service], 'Value': 'USD' } ] if servicename != "billing": dimensions.insert(0, { 'Name': 'ServiceName', 'Value': servicename } ) # 現在時刻よりも1分遅れて取得する end_time = datetime.utcnow() - timedelta(minutes=1) start_time = end_time - timedelta(minutes=timerange_min) stats = self.client.get_metric_statistics( Namespace=metric_namespace, MetricName=metric_name, Dimensions=dimensions, StartTime=start_time, EndTime=end_time, Period=period_sec, Statistics=[stat_type], ) return stats def __set_unit(self, metric_list): ret_val = [] for metric in metric_list: servicename = self.service if self.service == "billing": metric.unit = 'USD' else: stats = self.__get_metric_stats(metric.name, metric.namespace, servicename, self.timerange_min) for datapoint in stats["Datapoints"]: metric.unit = datapoint["Unit"] break ret_val.append(metric) return ret_val def __get_send_items(self, stats, metric): send_items = [] datapoints = stats["Datapoints"] datapoints = sorted(datapoints, key=lambda datapoints: datapoints["Timestamp"], reverse=True) for datapoint in datapoints: servicename = '' send_json_string = '{"host":"", "key":"", "value":"", "clock":""}' send_item = json.loads(send_json_string) if self.hostname == "undefined": send_item["host"] = self.identity else: send_item["host"] = self.hostname if self.service == "billing": for dimension in metric.dimensions: if dimension["Name"] == "ServiceName": servicename = dimension["Value"] send_item["key"] = 'cloudwatch.metric[%s.%s]' % (metric.name, servicename) else: send_item["key"] = 'cloudwatch.metric[%s]' % metric.name send_item["value"] = self.__get_datapoint_value_string(datapoint) send_item["clock"] = calendar.timegm(datapoint["Timestamp"].utctimetuple()) send_items.append(send_item) break return send_items def __get_datapoint_value_string(self, datapoint): if "Average" in datapoint: return str(datapoint["Average"]) elif "Sum" in datapoint: return str(datapoint["Sum"]) elif "Maximum" in datapoint: return str(datapoint['Maximum']) else: return "" def __send_to_zabbix(self, send_data): send_data_string = json.dumps(send_data) zbx_client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) try: zbx_client.connect((self.zabbix_host, self.zabbix_port)) except Exception: print("Can't connect to zabbix server") quit() header = struct.pack('<4sBQ', 'ZBXD', 1, len(send_data_string)) send_data_string = header + send_data_string try: zbx_client.sendall(send_data_string) except Exception: print('Data sending failure') quit() response = '' while True: data = zbx_client.recv(4096) if not data: break response += data print(response[13:]) zbx_client.close() def send_metric_data_to_zabbix(self): now = "%.9f" % time.time() sec = now.split(".")[0] ns = now.split(".")[1] send_data = json.loads('{"request":"sender data","data":[],"clock":"%s","ns":"%s" }' % (sec, ns)) metric_list = self.__get_metric_list() all_metric_stats = [] servicename = self.service for metric in metric_list: if self.service == "billing": for dimension in metric.dimensions: if dimension["Name"] == "ServiceName": servicename = dimension["Value"] target_metric_info = {'namespace': metric.namespace, 'metricname': metric.name} for sum_stat_metric in self.sum_stat_metrics: # for support each region metrics (RequestCount, RequestCount.ap-northeast-1 etc.) if metric.name.find(sum_stat_metric['metricname']) == 0: # Only convert when finding the begging of string. target_metric_info['metricname'] = sum_stat_metric['metricname'] if target_metric_info in self.sum_stat_metrics: stats = self.__get_metric_stats(metric.name, metric.namespace, servicename, self.timerange_min, 'Sum', metric.dimensions) elif target_metric_info in self.max_stat_metrics: stats = self.__get_metric_stats(metric.name, metric.namespace, servicename, self.timerange_min, 'Maximum', metric.dimensions) else: stats = self.__get_metric_stats(metric.name, metric.namespace, servicename, self.timerange_min, metric.dimensions) send_data["data"].extend(self.__get_send_items(stats, metric)) self.__send_to_zabbix(send_data) def show_metriclist_lld(self): lld_output_json = json.loads('{"data":[]}') metric_list = self.__get_metric_list() metric_list = self.__set_unit(metric_list) for metric in metric_list: lld_json_string = '{"{#METRIC.NAME}":"", "{#METRIC.UNIT}":"", "{#METRIC.NAMESPACE}":""}' lld_item = json.loads(lld_json_string) lld_item["{#METRIC.NAME}"] = metric.name lld_item["{#METRIC.NAMESPACE}"] = metric.namespace lld_item["{#METRIC.UNIT}"] = metric.unit lld_output_json["data"].append(lld_item) if self.service == "billing": lld_item["{#METRIC.SERVICENAME}"] = "" for dimension in metric.dimensions: if dimension["Name"] == "ServiceName": lld_item["{#METRIC.SERVICENAME}"] = dimension["Value"] print(json.dumps(lld_output_json)) FILE_NAME = 'date_time.txt' LOG_DELAY_MS = 30000 class LogAwsZabbix(AwsZabbix): def __init__(self, region, access_key, secret, hostname, timerange_min, zabbix_host, zabbix_port, log_group, log_stream): self.hostname = hostname self.log_group = log_group self.log_stream = log_stream self.zabbix_host = zabbix_host self.zabbix_port = zabbix_port self.timerange_min = timerange_min self.client_log = boto3.client( 'logs', region_name=region, aws_access_key_id=access_key, aws_secret_access_key=secret ) def __get_logs(self): path = os.getcwd() + '/' + FILE_NAME timerange = self.timerange_min * 60000 if os.path.exists(path): with open(FILE_NAME, 'r+') as file: start_time = int(file.read()) end_time = start_time + timerange file.seek(0) file.write(str(end_time)) else: with open(FILE_NAME, 'w') as file: end_time = int(time.time() * 1000 - LOG_DELAY_MS) start_time = end_time - timerange file.write(str(end_time)) log_json_data = self.client_log.get_log_events( logGroupName=self.log_group, logStreamName=self.log_stream, startTime=start_time, endTime=end_time, ) log_list = [] for event in log_json_data['events']: log_list.append(event) return log_list def __get_send_items(self, log_list): send_items = [] for log in log_list: send_json_string = '{"host":"", "key":"", "value":"", "clock":""}' send_item = json.loads(send_json_string) send_item["host"] = self.hostname send_item["key"] = 'cloudwatch.logs[{}:{}]'.format(self.log_group, self.log_stream) send_item["value"] = log['message'] send_item["clock"] = int(log['timestamp'] / 1000) send_items.append(send_item) return send_items def show_log_data(self): log_list = self.__get_logs() print(log_list) def send_log_data_to_zabbix(self): now = "%.9f" % time.time() sec = now.split(".")[0] ns = now.split(".")[1] send_data = json.loads('{"request":"sender data","data":[],"clock":"%s","ns":"%s" }' % (sec, ns)) log_list = self.__get_logs() send_data["data"].extend(self.__get_send_items(log_list)) # self.__send_to_zabbix(send_data) print(send_data)get_metrics.pyimport argparse from aws_zabbix.aws_zabbix import AwsZabbix import os import time # identityはPodNameを入力 # serviceはeks # containerの場合は別途考える必要あり parser = argparse.ArgumentParser(description='Get AWS CloudWatch Metric list json format.') parser.add_argument('-r', '--region', default=os.getenv("AWS_DEFAULT_REGION"), help='set AWS region name(e.g.: ap-northeast-1)') parser.add_argument('-a', '--accesskey', default=os.getenv("AWS_ACCESS_KEY_ID"), help='set AWS Access Key ID') parser.add_argument('-s', '--secret', default=os.getenv("AWS_SECRET_ACCESS_KEY"), help='set AWS Secret Access Key') parser.add_argument('-i', '--identity', required=True, help='set Identity data (ec2: InstanceId, elb: LoadBalancerName, rds: DBInstanceIdentifier, ebs: VolumeId, eks: PodName)') parser.add_argument('-H', '--hostname', default='undefined', help='set string that has to match HOST.HOST. defaults to identity)') parser.add_argument('-m', '--send-mode', default='False', help='set True if you send statistic data (e.g.: True or False)') parser.add_argument('-t', '--timerange', type=int, default=10, help='set Timerange min') parser.add_argument('-p', '--zabbix-port', type=int, default=10051, help='set listening port number for Zabbix server') parser.add_argument('-z', '--zabbix-host', default='localhost', help='set listening IP address for Zabbix server') parser.add_argument('service', metavar='service_name', help='set Service name (e.g.: ec2 or elb or rds or eks') args = parser.parse_args() aws_zabbix = AwsZabbix(region=args.region, access_key=args.accesskey, secret=args.secret, identity=args.identity, hostname=args.hostname, service=args.service, timerange_min=args.timerange, zabbix_host=args.zabbix_host, zabbix_port=args.zabbix_port) if args.send_mode.upper() == 'TRUE': aws_zabbix.send_metric_data_to_zabbix() else: aws_zabbix.show_metriclist_lld()get_log.pyimport argparse from aws_zabbix.aws_zabbix import LogAwsZabbix import os import time parser = argparse.ArgumentParser(description='Get AWS CloudWatch Metric list json format.') parser.add_argument('-r', '--region', default=os.getenv("AWS_DEFAULT_REGION"), help='set AWS region name(e.g.: ap-northeast-1)') parser.add_argument('-a', '--accesskey', default=os.getenv("AWS_ACCESS_KEY_ID"), help='set AWS Access Key ID') parser.add_argument('-s', '--secret', default=os.getenv("AWS_SECRET_ACCESS_KEY"), help='set AWS Secret Access Key') parser.add_argument('-H', '--hostname', default='undefined', help='set string that has to match HOST.HOST. defaults to identity)') parser.add_argument('-m', '--send-mode', default='False', help='set True if you send log-event data (e.g.: True or False)') parser.add_argument('-t', '--timerange', type=int, default=10, help='set Timerange min') parser.add_argument('-p', '--zabbix-port', type=int, default=10051, help='set listening port number for Zabbix server') parser.add_argument('-z', '--zabbix-host', default='localhost', help='set listening IP address for Zabbix server') parser.add_argument('-LG', '--log-group', required=True, help='set log group') parser.add_argument('-LS', '--log-stream', required=True, help='set log stream') args = parser.parse_args() log_aws_zabbix = LogAwsZabbix(region=args.region, access_key=args.accesskey, secret=args.secret, hostname=args.hostname, timerange_min=args.timerange, zabbix_host=args.zabbix_host, zabbix_port=args.zabbix_port, log_group=args.log_group, log_stream=args.log_stream) if args.send_mode.upper() == 'TRUE': log_aws_zabbix.send_log_data_to_zabbix() else: log_aws_zabbix.show_log_data()
- 投稿日:2020-05-24T23:32:43+09:00
韻を扱いたいpart4
内容
これまでの流れで、入力のテキストデータを分割したものをノードに、分割したもの同士の母音の一致をエッジの重みにしてネットワーク分析を行ってみる。グラフの描写、中心性を見るところまでが目標。
データを分割し、辞書を作る
from pykakasi import kakasi import re from collections import defaultdict from janome.tokenizer import Tokenizer with open("./gennama.txt","r") as f: data = f.read() tokenizer = Tokenizer() tokens = tokenizer.tokenize(data) surface_list = [] part_of_speech_list = [] for token in tokens: surface_list.append(token.surface) part_of_speech_list.append(token.part_of_speech.split(",")[0]) segment_text = [] for i in range(len(surface_list)): if part_of_speech_list[i] == "記号": continue elif part_of_speech_list[i] == "助詞" or part_of_speech_list[i] == "助動詞": row = segment_text.pop(-1) + surface_list[i] else: row = surface_list[i] segment_text.append(row) kakasi = kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() text_data = [conv.do(text) for text in segment_text] vowel_data = [re.sub(r"[^aeiou]+","",text) for text in text_data] #{0:"oea"} dic_vo = {k:v for k,v in enumerate(vowel_data)} #voel_dataのインデックスで母音変換前のdataが分かるように辞書作成。{0:"俺は"} dic = {k:v for k,v in enumerate(mecab_text)}part3でやったことを活用。今回はN-gramは向いていないと判断。この、dic_voのキーの数だけノードがあり、ノード間は母音の一致があるかどうかで繋がりを見る。母音が一致する長さが長いほど重みを付けるようにしておく。part1で作っていたような方法を使用するが、自身への繋がりと2文字以上の一致からエッジが出来るようにする。
グラフを作る
#dic_voを渡し、インデックスがnode,値がedge,重みがscoreの(node,node,score)を作る。 def create_edge(dic_vo): node_len = len(dic_vo) edge_list = [] for i in range(node_len): for j in range(node_len): score = create_weight(dic_vo[i],dic_vo[j]) if score != 0: edge_list.append((i,j,score)) return edge_list def create_weight(word_a, word_b): weight = 0 if len(word_a) > len(word_b): max_len = len(word_b) for i in range(max_len): for j in range(max_len + 1): if word_b[i:j] in word_a: if word_b == word_a: continue elif len(word_b[i:j]) < 2: continue else: weight += len(word_b[i:j]) else: max_len = len(word_a) for i in range(max_len): for j in range(max_len + 1): if word_a[i:j] in word_b: if word_a == word_b: continue elif len(word_b[i:j]) < 2: continue else: weight += len(word_a[i:j]) return weight edge_list = create_edge(dic_vo)あとはこのedge_listをもとにグラフを描写する。ついでに、固有ベクトル中心性と媒介中心性が高いノードを取得し、元のデータを表示してみる。
import networkx as nx import matplotlib.pyplot as plt G = nx.Graph() G.add_weighted_edges_from(edge_list) pos = nx.spring_layout(G) nx.draw_networkx_edges(G, pos) plt.show() #固有ベクトル中心性 cent = nx.eigenvector_centrality_numpy(G) max_cent_node = max(list(cent.keys()), key=lambda val: cent[val]) #媒介中心性 between_cent = nx.communicability_betweenness_centrality(G) max_betw_node = max(list(between_cent.keys()), key=lambda val: between_cent[val]) print("固有ベクトル中心性が高いのは:" + dic[max_cent_node]) print("媒介中心性が高いのは:" + dic[max_betw_node])結果は予想通り、part2で行った「target_wordを絞れるのでは」と同じだ。まあ同じことをしているので当たり前だが、
networkxではこのグラフを元にまだ出来ることがありそうなので追及してみる。今後の方針
スコアの付け方で、「い」と「う」に注目し、前の音が「e」と「o」ならば、つまり「eい」「oう」ならば「ee」「oo」と変換して母音の一致を見るというものを考えている。(外来語の発音を参考にした)日本語でもそれは聞き分けにくく、響きは同じだと言えるはずだ。ラップ界での押韻の扱いではNGだと思われるがやってみる。
ちなみに皆さんは本場の「ABCの歌」を聞いたことがあるだろうか?「LMNOP」を「エレネノピー」と一気にいくあれだ。子供の頃から「韻」が身近にあるようだ。日本語ラップへのリスペクトは忘れないが、韻を少し拡張して捉えることを試みる
- 投稿日:2020-05-24T23:01:20+09:00
Lambda x Amazon SNSで、AWSの請求額を毎日メールで通知する
はじめに
CloudWatchで請求アラートを設定する事はできますが、超心配性な自分としては、月初~前日までの請求額を毎日メールで確認しておきたい。
AWS Lambdaとwebhookを使ってSlackのチャンネルに通知する方法は多く見られましたが、メールで通知する方法は意外と多くなかったので、まとめてみました。概要
- 請求額はCost Explorerから取得する。
※CloudWatchから取得する方法もありますが、双方に差異があり正しい値はCost Explorerであるという情報があったため、Cost Explorerを使う事にしました。- Lambda関数のランタイムはPython3.7とし、Python 向けのAWS SDK(Boto3)を利用する。
- トリガを設定したLambda関数にて、月初~前日までの合計請求額とサービス毎の請求額を取得し、その内容を整形し、メッセージとしてAmazon SNSのトピックに発行する。
- メッセージを受け取ったSNSトピックは、紐づけたエンドポイント(メールアドレス)宛にメッセージを送信する。
用語の理解
特にAmazon SNSに登場する用語、そしてそれぞれの関係性がややこしかったので、超ざっくりとまとめます。
ARN:AWSリソースを一意に識別する名前。
トピック:複数のエンドポイント(ここではメールアドレス)をグループにまとめる機能。
エンドポイント:配信先。今回はメールアドレスとなります。
サブスクリプション:トピックとエンドポイントを紐づける
より深く理解するために、以下の記事の用語説明の箇所がとても参考になりましたので、事前に熟読しておく事をお勧めします。
Amazon SNSでプッシュ通知を送るための基礎知識 | UNITRUST
設定方法
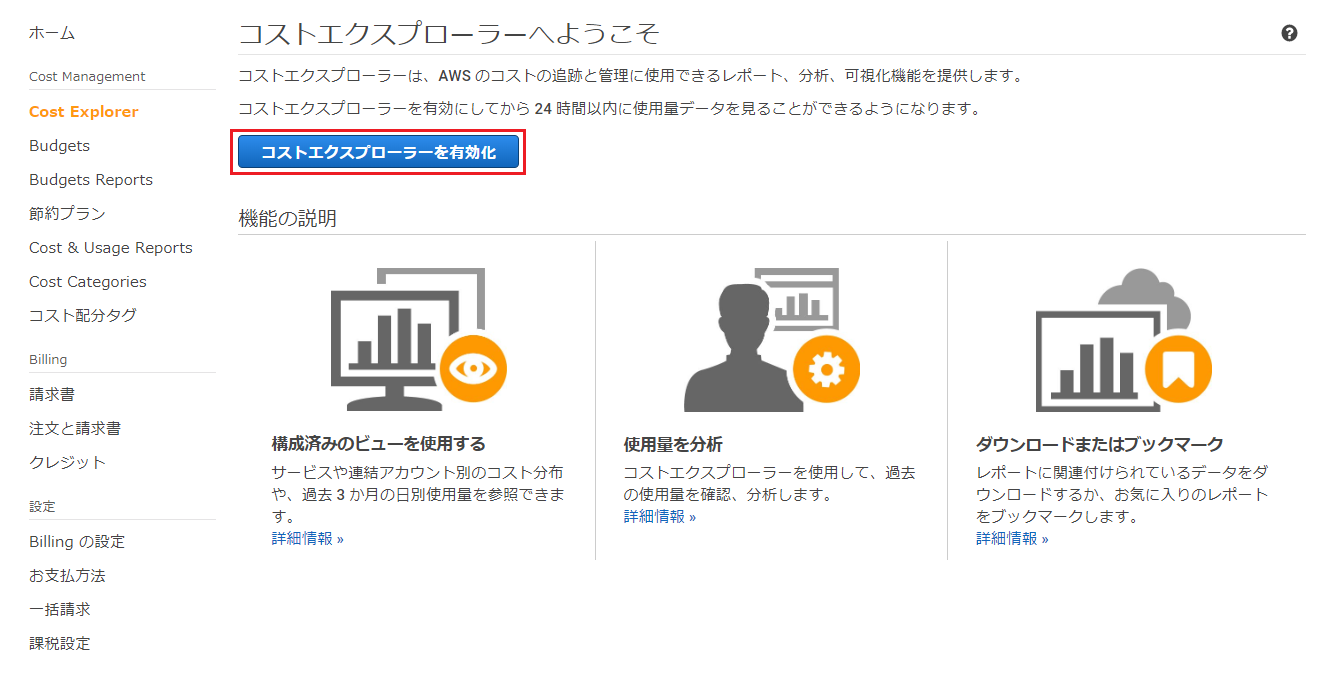
Cost Explorerの有効化
Cost Explorerを有効化していない場合は、マイ請求ダッシュボードから有効化します。
SNS トピックの作成
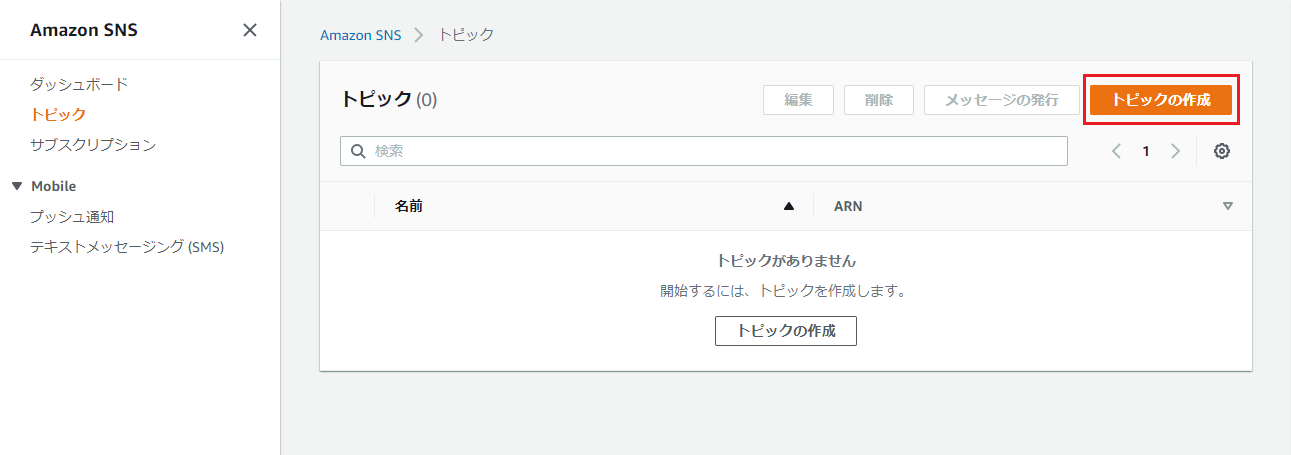
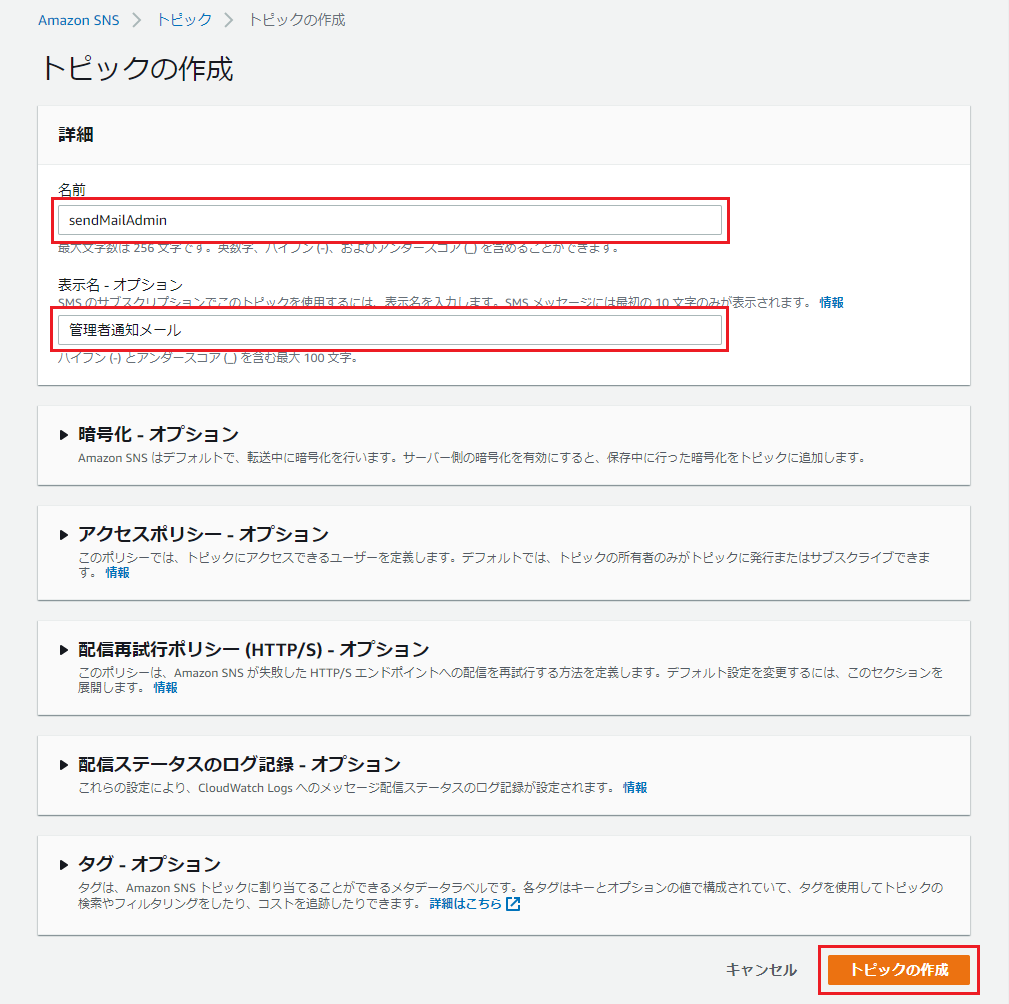
Amazon SNSのサービス画面に移動します。
※利用できるリージョンは限られています。(サポートされているリージョンおよび国 - Amazon Simple Notification Service)「トピック」メニューから、「トピックの作成」を押下。
「名前」と「表示名」を入力し、「トピックの作成」を押下。
※ここで設定した「表示名」が、メールの送信者名となります。
※ちなみに、管理者向けに何か通知するためのトピックとして、今後別の目的での配信にも利用する事を想定し、名前は「sendMailAdmin」、表示名は「管理者通知メール」と汎用的なものしておきました。
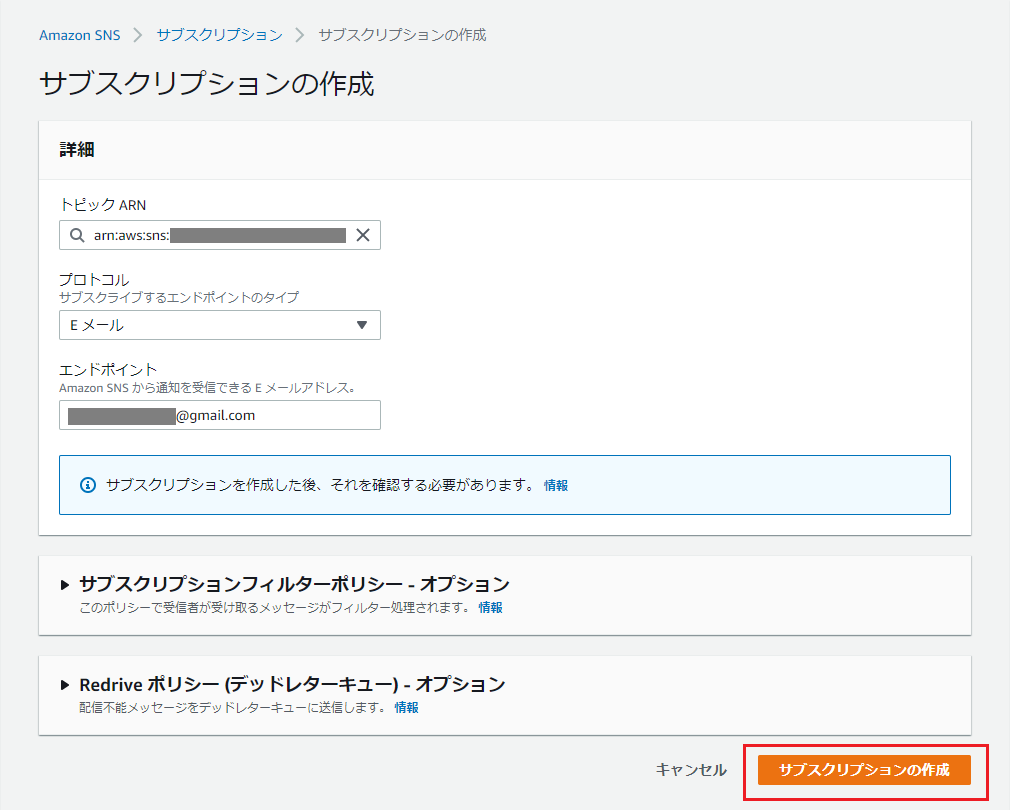
サブスクリプション作成
サブスクリプション(+エンドポイント)を作成します。
「サブスクリプションの作成」を押下。
※画面に表示されているARNは控えておいてください。
下記項目を入力し、「サブスクリプションの作成」を押下。
※「トピックARN」は自動入力されるはずですが、されていなければ控えておいたトピックARNを入力してください。
項目名 入力値・選択値 トピックARN 控えておいたトピックのARN プロトコル Eメール エンドポイント 受信メールアドレス
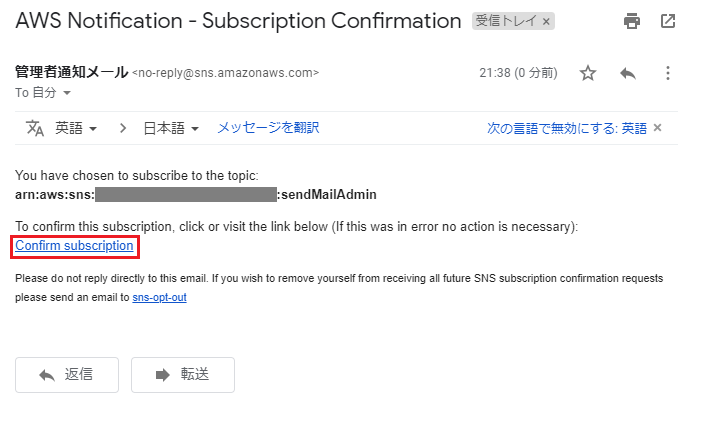
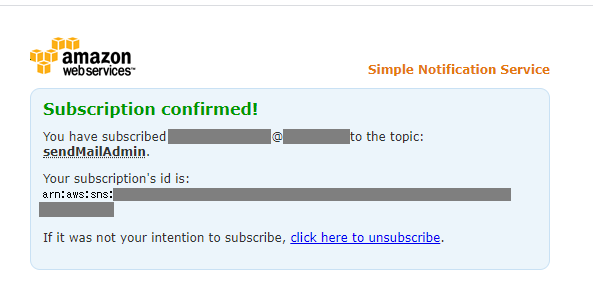
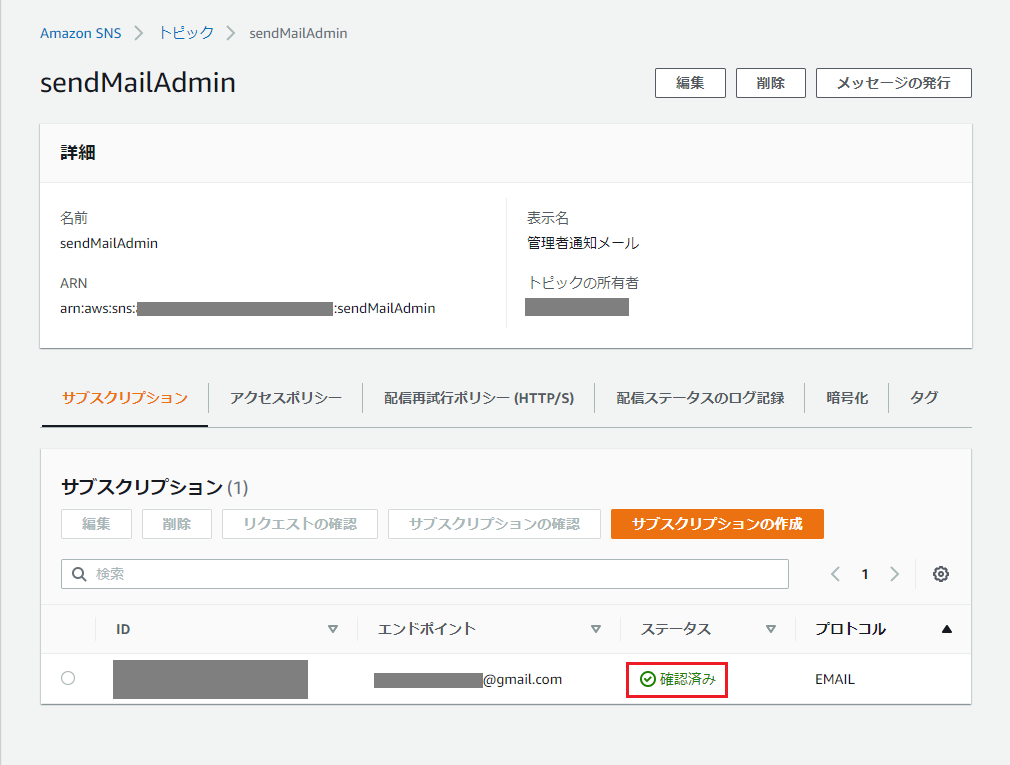
サブスクリプションの承認
エンドポイントに指定したメールアドレス宛に、「AWS Notification - Subscription Confirmation」という件名で確認メールが送られてくるので、「Confirm subscription」を押下。
トピックに紐づけたサブスクリプションのステータスが「確認済み」となります。
Lambda関数の作成
トピック・サブスクリプション・エンドポイントの作成が完了しました。
トピックのARNに対してメッセージを発行すると、このトピックに紐づいたエンドポイント(メールアドレス)宛にメッセージが配信されるという流れになります。
そのため次に、トピックのARNに対して発行するメッセージを生成するLambda関数を作成します。
まずは、AWS Lambdaのダッシュボードから、「関数の作成」を押下。
オプションが「一から作成」になっている事を確認し、「基本的な情報」に以下を入力し、「関数の作成」を押下。
※「アクセス権限」の「実行ロールの選択または作成」をクリックし、「AWS ポリシーテンプレートから新しいロールを作成」を選択しておいてください。
項目名 入力値・選択値 関数名 sendCost(好きな名前で) ランタイム Python 3.7 ロール名 SNSServiceRoleForLambda(好きな名前で) ポリシーテンプレート Amazon SNS 発行ポリシー
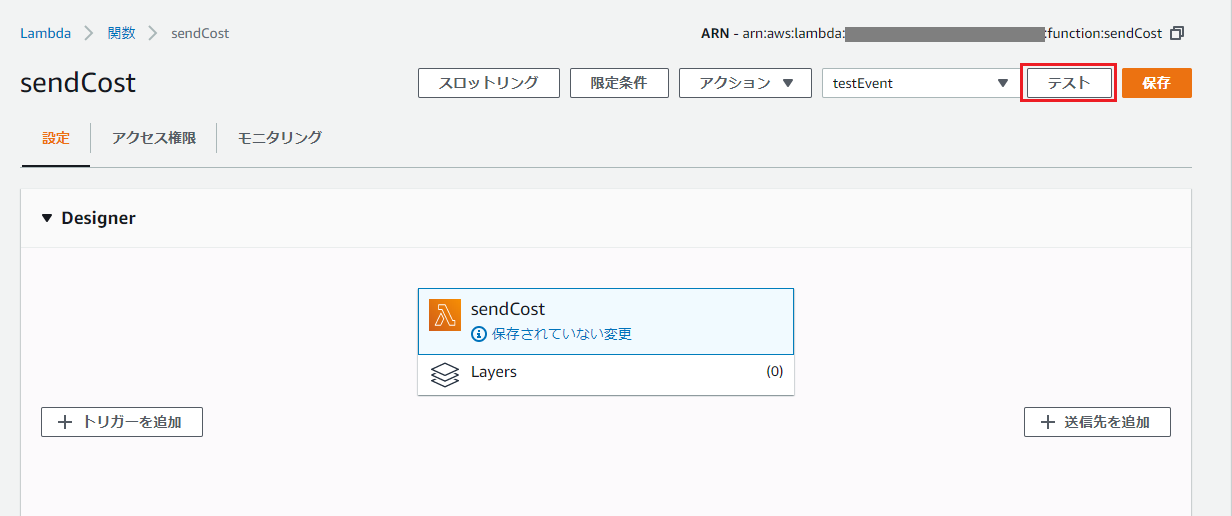
Lambda関数のテスト
次に、請求情報を取得するコードを書いていく事になりますが、ここまでの設定確認のため、まずはテストメッセージを発行する処理を書いてみます。
関数作成後の下部にある「関数コード」欄に、以下のコードを入力します。
※TopicArnには、SNSトピック作成時に控えておいたARNを設定します。lambda_function.pyimport boto3 def lambda_handler(event, context): sns = boto3.client('sns') subject = 'Lambdaからのテストメール件名です。' message = 'Lambdaからのテストメール本文です。' response = sns.publish( TopicArn = 'arn:aws:sns:*:*:*', Subject = subject, Message = message ) return responseそして、実際にはトリガーで定期的に実行する事になりますが、手動で送信してみます。
画面右上の「保存」を押下した後、「テスト」を押下し、「イベント名」に適当な名前を入れ、「作成」を押下。
その他は初期値のままでOK。
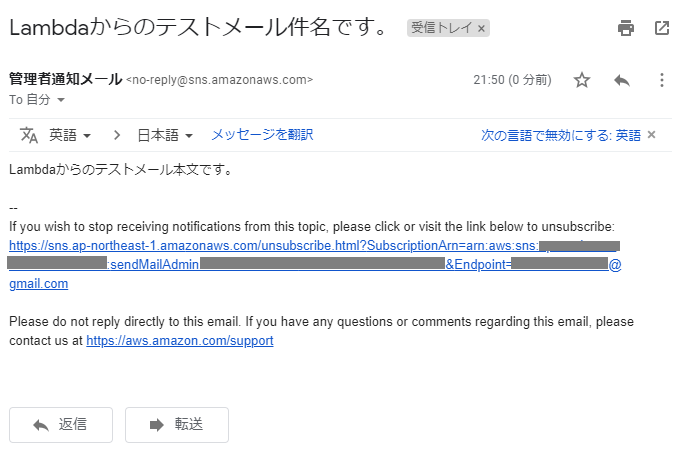
元の画面に戻り、再度右上の「テスト」をクリックすると関数が実行され、指定した受信メールアドレスにメールが届いているはずです。
届かない場合は、コード入力欄の下部のコンソール(Execution results)にエラーメッセージが表示されていないか、入力したARNに間違いがないか等確認してください。
請求情報通知用のコード作成
いよいよ、Cost Explorerから請求額を取得し、Amazon SNSで通知するコードを書いていきます。
TopicArnには、前回同様SNSトピック作成時に控えておいたARNを設定します。※後述しますが、追加設定を行わないとテストしてもエラーとなります!
※コードは、Developers.IOの記事のものをベースとさせていただきました。lambda_function.pyimport boto3 from datetime import datetime, timedelta, date def lambda_handler(event, context): ce = boto3.client('ce') sns = boto3.client('sns') # 今月の合計請求額を取得 total_billing = get_total_billing(ce) # 今月の合計請求額を取得(サービス毎) service_billings = get_service_billings(ce) # Amazon SNSトピックに発行するメッセージを生成 (subject, message) = get_message(total_billing, service_billings) response = sns.publish( TopicArn = 'arn:aws:sns:*:*:*', Subject = subject, Message = message ) return response def get_total_billing(ce): (start_date, end_date) = get_total_cost_date_range() response = ce.get_cost_and_usage( TimePeriod={ 'Start': start_date, 'End': end_date }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ] ) return { 'start': response['ResultsByTime'][0]['TimePeriod']['Start'], 'end': response['ResultsByTime'][0]['TimePeriod']['End'], 'billing': response['ResultsByTime'][0]['Total']['AmortizedCost']['Amount'], } def get_service_billings(ce): (start_date, end_date) = get_total_cost_date_range() response = ce.get_cost_and_usage( TimePeriod={ 'Start': start_date, 'End': end_date }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ], GroupBy=[ { 'Type': 'DIMENSION', 'Key': 'SERVICE' } ] ) billings = [] for item in response['ResultsByTime'][0]['Groups']: billings.append({ 'service_name': item['Keys'][0], 'billing': item['Metrics']['AmortizedCost']['Amount'] }) return billings def get_total_cost_date_range(): start_date = date.today().replace(day=1).isoformat() end_date = date.today().isoformat() # get_cost_and_usage()のstartとendに同じ日付は指定不可のため、今日が1日なら「先月1日から今月1日(今日)」までの範囲にする if start_date == end_date: end_of_month = datetime.strptime(start_date, '%Y-%m-%d') + timedelta(days=-1) begin_of_month = end_of_month.replace(day=1) return begin_of_month.date().isoformat(), end_date return start_date, end_date def get_message(total_billing, service_billings): start = datetime.strptime(total_billing['start'], '%Y-%m-%d').strftime('%Y/%m/%d') # Endの日付は結果に含まないため、表示上は前日にしておく end_today = datetime.strptime(total_billing['end'], '%Y-%m-%d') end_yesterday = (end_today - timedelta(days=1)).strftime('%Y/%m/%d') total = round(float(total_billing['billing']), 2) subject = f'{start}~{end_yesterday}の請求額:${total:.2f}' message = [] message.append('【内訳】') for item in service_billings: service_name = item['service_name'] billing = round(float(item['billing']), 2) if billing == 0.0: # 請求無しの場合は内訳を表示しない continue message.append(f'・{service_name}: ${billing:.2f}') return subject, '\n'.join(message)これで完成かと思いきや、Lamdaに割り当てたロールにCost Explorerへアクセスする権限がないので、以下のようなエラーとなります。
"errorMessage": "An error occurred (AccessDeniedException) when calling the GetCostAndUsage operation: User: arn:aws:sts::251745928455:assumed-role/SNSServiceRoleForLambda/sendCost is not authorized to perform: ce:GetCostAndUsage on resource: arn:aws:ce:us-east-1:251745928455:/GetCostAndUsage"そこで、IAM管理画面にて、Cost Explorerへアクセス出来るポリシーをロールにアタッチします。
※関数の作成時に「カスタムロールを作成」を選択し、jsonでポリシーを一気に割り当てる方法もあるようですが、2020/5時点では選択肢にありませんでした。ポリシーの作成とアタッチ
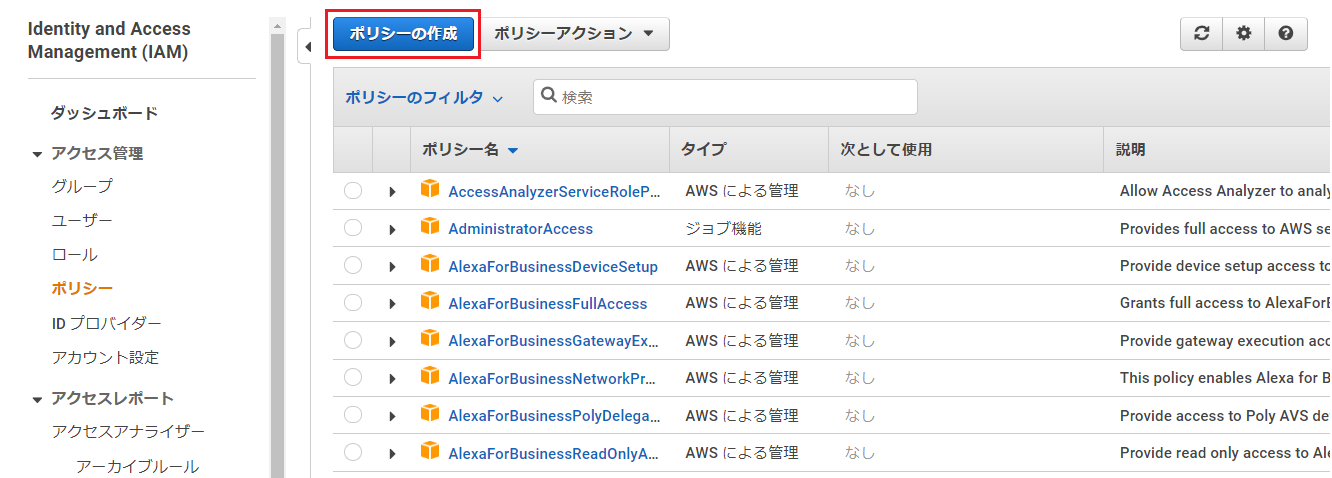
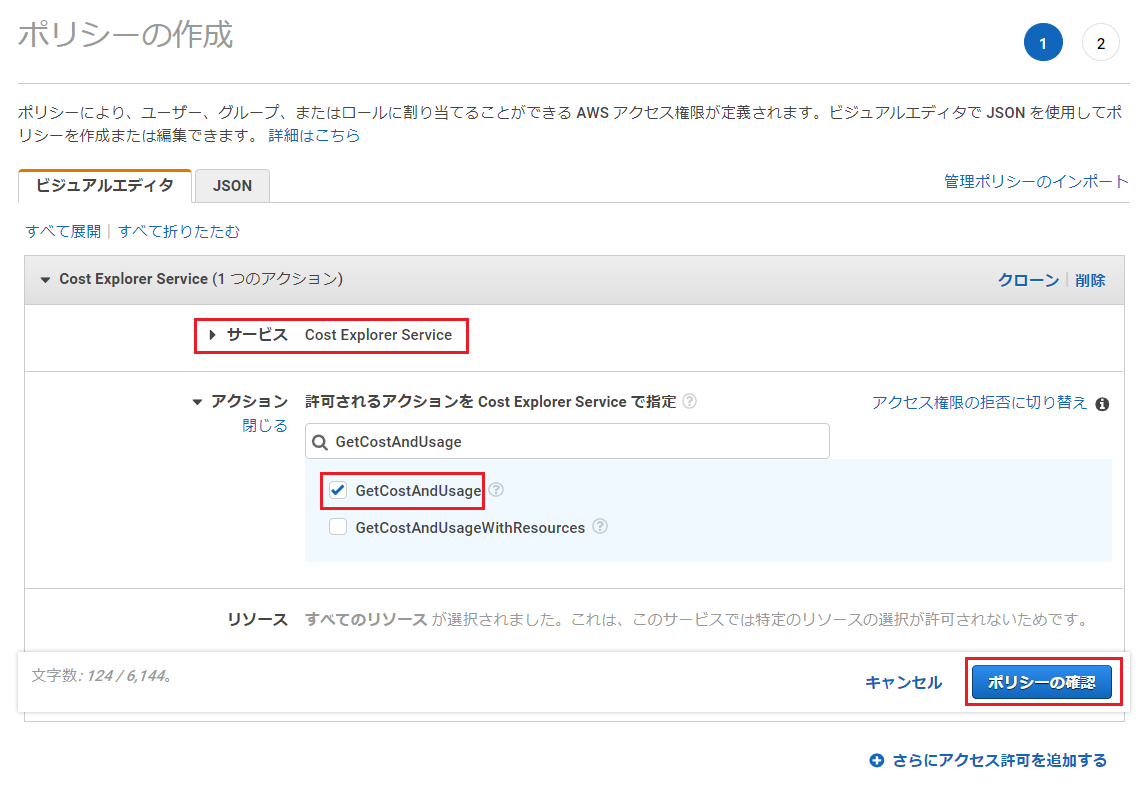
まず、IAM管理画面のポリシー一覧を表示し、「ポリシーの作成」を押下。
以下の項目を入力し、「ポリシーの確認」を押下。
項目名 入力値・選択値 サービス Cost Explorer Service アクション 「GetCostAndUsage」と検索しチェックを入れる
ポリシーの確認画面で、「名前」を入力し、「ポリシーの作成」を押下。
※ここでは名前を「AmazonCostExplorerGetCostAccess」としました。
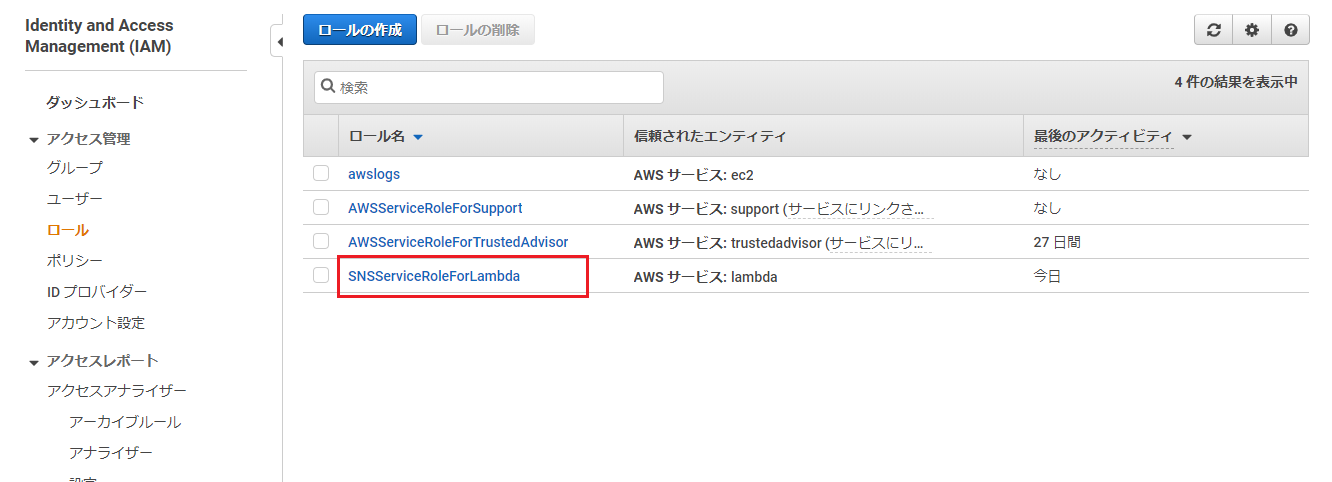
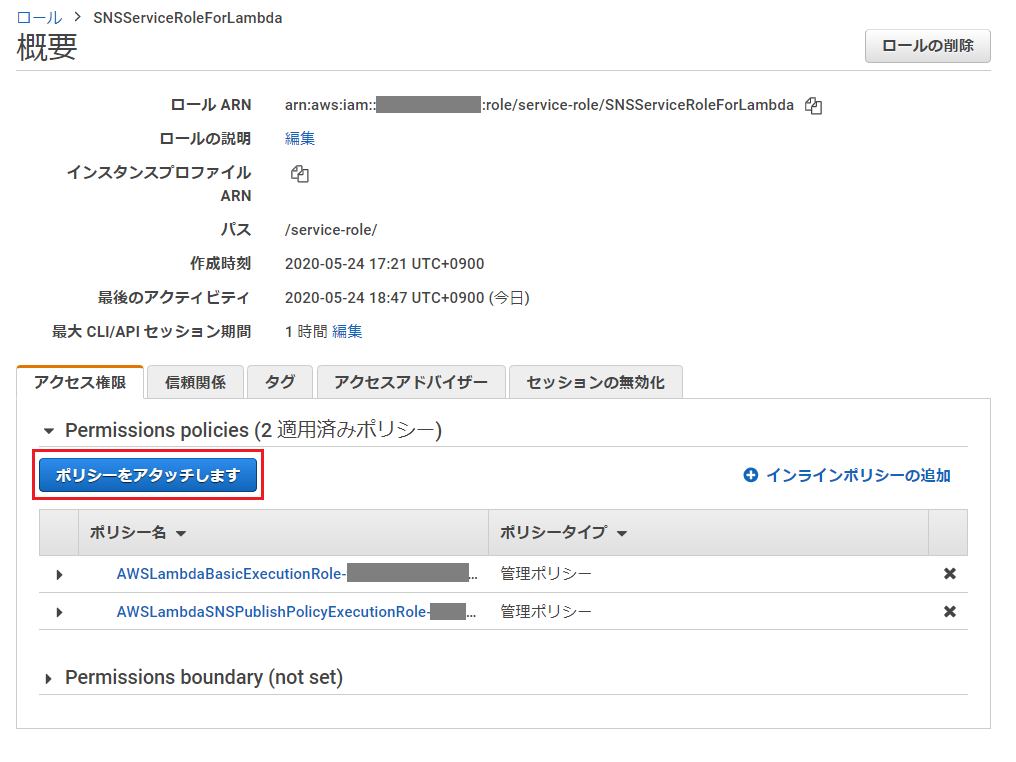
ロールの一覧画面に移動し、Lambdaに割り当てたロールを選択。
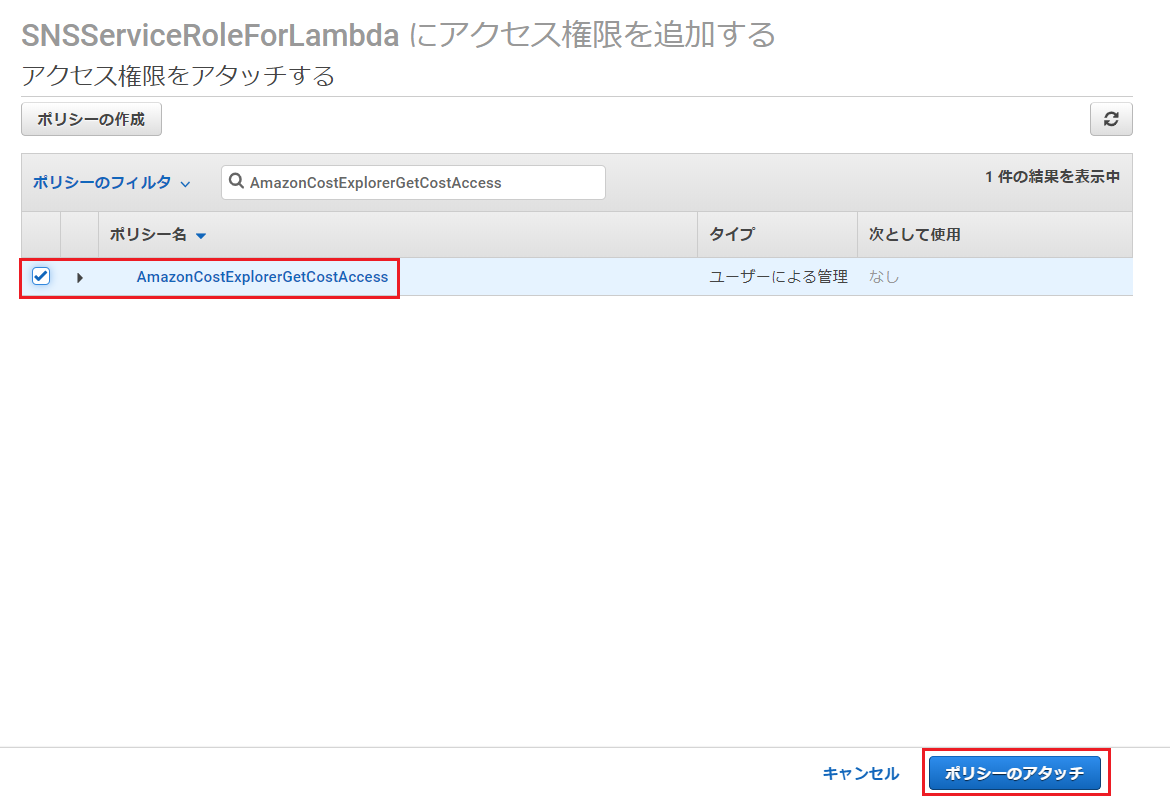
「ポリシーをアタッチします」を押下。
「ポリシーのフィルタ」で、ポリシー作成の際に設定した名前を入力して検索(この記事の例では「AmazonCostExplorerGetCostAccess」)し、ヒットしたものにチェックを入れ、「ポリシーのアタッチ」を押下。
Lambda関数の実行
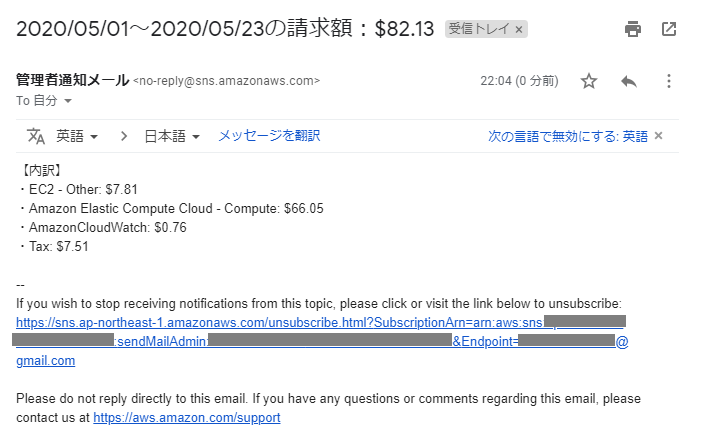
これで関数が正常に実行できる状態になったので、作成した関数の設定画面右上の「テスト」を押下します。
全て正しく設定できていれば、以下のようなメールが届くはずです。
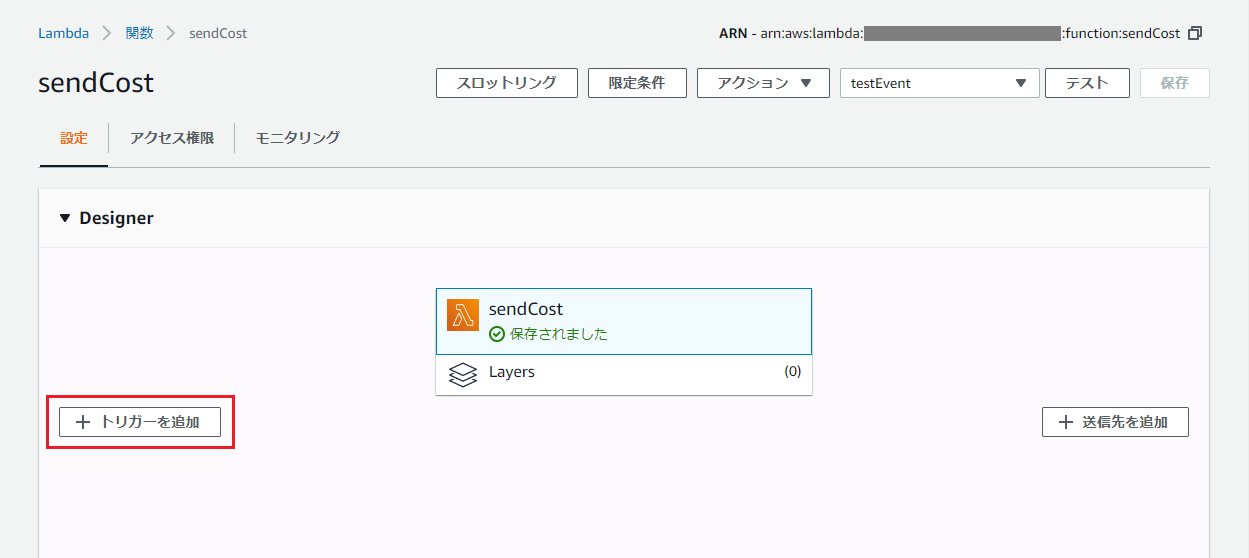
トリガーの設定
最後に、毎日決まった時間にメール通知するためのトリガーを設定します。
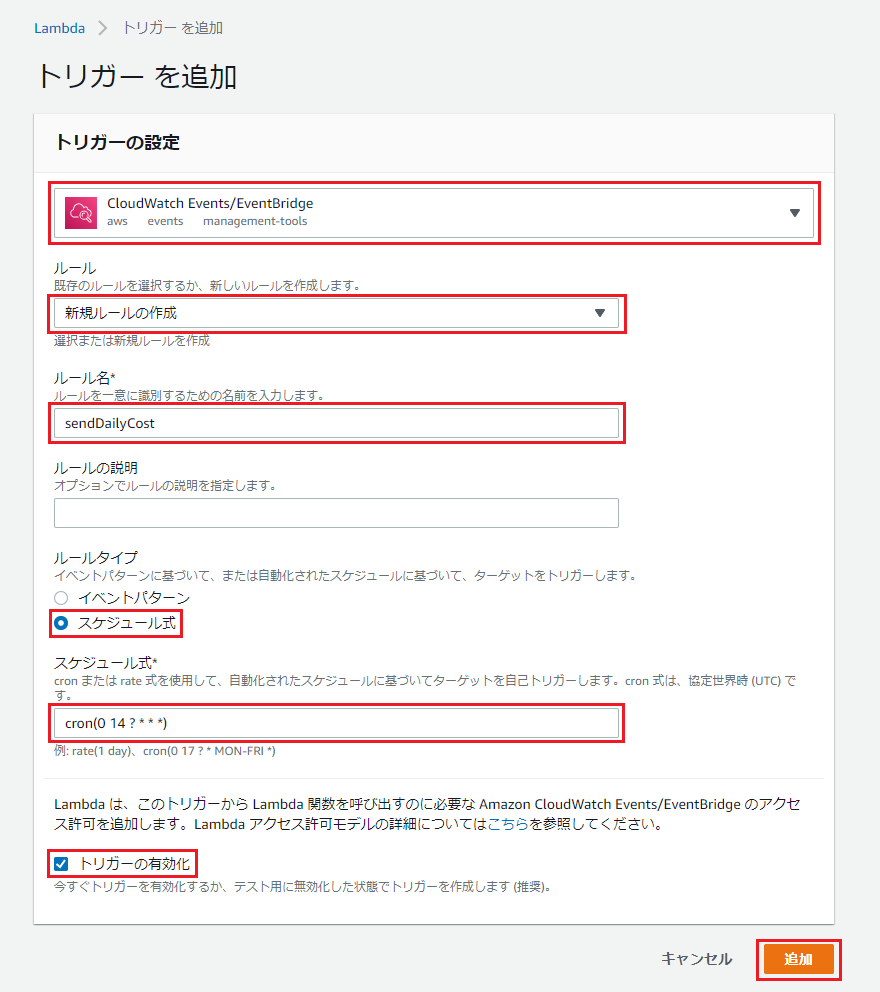
関数の設定画面の左側「トリガーを追加」を押下。
以下のように設定し、「追加」を押下。
項目名 入力値・選択値 トリガーを選択 CloudWatch Events/EventBridge ルール 新規ルールの作成 ルール名 sendDailyCost(適当に) ルールタイプ スケジュール式 スケジュール式 cron(0 14 ? * * *) トリガーの有効化 チェックする 今回は23時に設定しました。
注意点として、時間はUTCで設定するので、JST(日本標準時)から9時間分減算した時刻を設定します。
あとは、毎日指定した時間にメールが届く事を確認してください。
これで、安心して毎日眠れますね!
参考情報・引用




- 投稿日:2020-05-24T22:49:06+09:00
SymPyで関数のハードコーディングから解放される
はじめに
数式処理ライブラリであるSymPyを使って、Pandasデータフレームの列に対し、外部ファイルに定義した関数により演算を行い、その結果を出力してみた。
コマンド仕様
こんな感じ。trainが入力ファイル、outputが出力ファイル、functionが関数定義ファイル。
$ python command/calculate_function.py -h usage: calculate_function.py [-h] -train TRAIN -function FUNCTION -output OUTPUT optional arguments: -h, --help show this help message and exit -train TRAIN input function file. -function FUNCTION input function file. -output OUTPUT output csv file.関数の指定方法
関数定義ファイルはこんな感じとした。
exp,cos(x),NewExp exp,exp(x),ExpExp exp,sin(x),SinExp1列目が演算対象の列名、2列名が関数式。ちなみにxは演算対象の列の値を意味する。3列目が計算結果を格納する列名。
やってみよう
ソースはこんな感じ。
関数式をpythonソースとして認識させるために、execコマンドを利用している。calculate_function.pyimport argparse import csv import pandas as pd import numpy as np from sympy import * import csv def main(): parser = argparse.ArgumentParser() parser.add_argument("-train", type=str, required=True, help="input function file.") parser.add_argument("-function", type=str, required=True, help="input function file.") parser.add_argument("-output", type=str, required=True, help="output csv file.") args = parser.parse_args() df = pd.read_csv(args.train, index_col=0) # データの読み込み file = open(args.function, 'r') data = csv.reader(file) for row in data: exec('x=Symbol("x")') exec('f='+str(row[1])) exec('func = lambdify((x), f, "numpy")') exec('df["{0}"] = func(df["{1}"])'.format(row[2], row[0])) file.close() df.to_csv(args.output) if __name__ == "__main__": main()実行
入力ファイル
CMPD_CHEMBLID,exp,smiles CHEMBL596271,3.54,Cn1c(CN2CCN(CC2)c3ccc(Cl)cc3)nc4ccccc14 CHEMBL1951080,-1.18,COc1cc(OC)c(cc1NC(=O)CSCC(=O)O)S(=O)(=O)N2C(C)CCc3ccccc23 CHEMBL1771,3.69,COC(=O)[C@@H](N1CCc2sccc2C1)c3ccccc3Cl CHEMBL234951,3.37,OC[C@H](O)CN1C(=O)C(Cc2ccccc12)NC(=O)c3cc4cc(Cl)sc4[nH]3 CHEMBL565079,3.1,Cc1cccc(C[C@H](NC(=O)c2cc(nn2C)C(C)(C)C)C(=O)NCC#N)c1 CHEMBL317462,3.14,OC1(CN2CCC1CC2)C#Cc3ccc(cc3)c4ccccc4関数ファイルは関数指定ファイルの例で示したファイル。
出力結果
CMPD_CHEMBLID,exp,smiles,NewExp,ExpExp,SinExp CHEMBL596271,3.54,Cn1c(CN2CCN(CC2)c3ccc(Cl)cc3)nc4ccccc14,-0.9216800341052034,34.46691919085739,-0.3879509179417303 CHEMBL1951080,-1.18,COc1cc(OC)c(cc1NC(=O)CSCC(=O)O)S(=O)(=O)N2C(C)CCc3ccccc23,0.38092482436688185,0.30727873860113125,-0.9246060124080203 CHEMBL1771,3.69,COC(=O)[C@@H](N1CCc2sccc2C1)c3ccccc3Cl,-0.8533559001656995,40.044846957286715,-0.5213287903544065 CHEMBL234951,3.37,OC[C@H](O)CN1C(=O)C(Cc2ccccc12)NC(=O)c3cc4cc(Cl)sc4[nH]3,-0.9740282491988521,29.07852705779708,-0.22642652177388314 CHEMBL565079,3.1,Cc1cccc(C[C@H](NC(=O)c2cc(nn2C)C(C)(C)C)C(=O)NCC#N)c1,-0.9991351502732795,22.197951281441636,0.04158066243329049 CHEMBL317462,3.14,OC1(CN2CCC1CC2)C#Cc3ccc(cc3)c4ccccc4,-0.9999987317275395,23.103866858722185,0.0015926529164868282それなりの結果がでてるようだ。
おわりに
Sympyでは条件分岐などもっと複雑な計算式も与えることができそうなので、それについては改めて記事にしたい。
- 投稿日:2020-05-24T22:49:06+09:00
Sympyで関数のハードコーディングから解放される
はじめに
数式処理といえばMuParserが有名だが、pythonにはSympyがある。今回、sympyを使って、Pandasデータフレームの列に対し、外部ファイルに定義した関数により演算を行い、その結果を出力してみた。
コマンド仕様
こんな感じ。trainが入力ファイル、outputが出力ファイル、functionが関数定義ファイル。
$ python command/calculate_function.py -h usage: calculate_function.py [-h] -train TRAIN -function FUNCTION -output OUTPUT optional arguments: -h, --help show this help message and exit -train TRAIN input function file. -function FUNCTION input function file. -output OUTPUT output csv file.関数の指定方法
関数定義ファイルはこんな感じとした。
exp,cos(x),NewExp exp,exp(x),ExpExp exp,sin(x),SinExp1列目が演算対象の列名、2列名が関数式。ちなみにxは演算対象の列の値を意味する。3列目が計算結果を格納する列名。
やってみよう
ソースはこんな感じ。
関数式をpythonソースとして認識させるために、execコマンドを利用している。calculate_function.pyimport argparse import csv import pandas as pd import numpy as np from sympy import * import csv def main(): parser = argparse.ArgumentParser() parser.add_argument("-train", type=str, required=True, help="input function file.") parser.add_argument("-function", type=str, required=True, help="input function file.") parser.add_argument("-output", type=str, required=True, help="output csv file.") args = parser.parse_args() df = pd.read_csv(args.train, index_col=0) # データの読み込み file = open(args.function, 'r') data = csv.reader(file) for row in data: exec('x=Symbol("x")') exec('f='+str(row[1])) exec('func = lambdify((x), f, "numpy")') exec('df["{0}"] = func(df["{1}"])'.format(row[2], row[0])) file.close() df.to_csv(args.output) if __name__ == "__main__": main()実行
入力ファイル
CMPD_CHEMBLID,exp,smiles CHEMBL596271,3.54,Cn1c(CN2CCN(CC2)c3ccc(Cl)cc3)nc4ccccc14 CHEMBL1951080,-1.18,COc1cc(OC)c(cc1NC(=O)CSCC(=O)O)S(=O)(=O)N2C(C)CCc3ccccc23 CHEMBL1771,3.69,COC(=O)[C@@H](N1CCc2sccc2C1)c3ccccc3Cl CHEMBL234951,3.37,OC[C@H](O)CN1C(=O)C(Cc2ccccc12)NC(=O)c3cc4cc(Cl)sc4[nH]3 CHEMBL565079,3.1,Cc1cccc(C[C@H](NC(=O)c2cc(nn2C)C(C)(C)C)C(=O)NCC#N)c1 CHEMBL317462,3.14,OC1(CN2CCC1CC2)C#Cc3ccc(cc3)c4ccccc4関数ファイルは関数指定ファイルの例で示したファイル。
出力結果
CMPD_CHEMBLID,exp,smiles,NewExp,ExpExp,SinExp CHEMBL596271,3.54,Cn1c(CN2CCN(CC2)c3ccc(Cl)cc3)nc4ccccc14,-0.9216800341052034,34.46691919085739,-0.3879509179417303 CHEMBL1951080,-1.18,COc1cc(OC)c(cc1NC(=O)CSCC(=O)O)S(=O)(=O)N2C(C)CCc3ccccc23,0.38092482436688185,0.30727873860113125,-0.9246060124080203 CHEMBL1771,3.69,COC(=O)[C@@H](N1CCc2sccc2C1)c3ccccc3Cl,-0.8533559001656995,40.044846957286715,-0.5213287903544065 CHEMBL234951,3.37,OC[C@H](O)CN1C(=O)C(Cc2ccccc12)NC(=O)c3cc4cc(Cl)sc4[nH]3,-0.9740282491988521,29.07852705779708,-0.22642652177388314 CHEMBL565079,3.1,Cc1cccc(C[C@H](NC(=O)c2cc(nn2C)C(C)(C)C)C(=O)NCC#N)c1,-0.9991351502732795,22.197951281441636,0.04158066243329049 CHEMBL317462,3.14,OC1(CN2CCC1CC2)C#Cc3ccc(cc3)c4ccccc4,-0.9999987317275395,23.103866858722185,0.0015926529164868282それなりの結果がでてるようだ。
おわりに
Sympyでは条件分岐などもっと複雑な計算式も与えることができそうなので、それについては改めて記事にしたい。
- 投稿日:2020-05-24T22:40:41+09:00
UpNext2 開発記録#1 VSCodeにPython CI環境を構築
UpNext2 開発記録#0の続きです。今回は、Pythonでの前処理を作る上で、前回提示した目標C1〜C3を満足する環境セットアップを行います。なお、ローカル環境は、MacOS Catalinaです。
目標C1〜C3を再掲します。
項 項目 備考 C1 GitHubによる版数管理 従来は版数管理をしていなかった。今回は開発過程を記録公開するため、GitHubを利用する。なおV1のGitHub公開は開発完了後にファイルコピーをしただけである。 C2 VSCodeの利用 従来はFlutter/Dartだけで作っておりAndroidStudioを利用。今回は前処理にPythonも使う予定であり、よい機会なのでVSCodeで開発する。 C3 テストの記述 個人開発なのでテストは書いていない。しかしUpNextにおいて、ある程度の規模の開発となる中で複雑なバグを踏んだ時、テストの必要性は痛感していた。勉強を兼ねて、ちゃんとテストを書くことにする。 以下では順を追ってセットアップを概説します。
1. GitHubの準備とVSCodeで扱うローカルリポジトリとの連携
いろいろ試してみたところ、うまくローカルとリモートを連携させるには、以下の手順がベストでした。
- GitHub側で新規のリポジトリを作成
- GitHub側でdevelopブランチを作成
- ローカル側で作成したリポジトリをclone (ローカル側にmasterブランチが作成されてリモート側と紐付けされる)
- git checkout -b develop origin/develop でローカル側のdevelopブランチを作成してリモート側と紐付け
- ローカルリポジトリのフォルダをVSCodeから開く
これにより、VSCodeのUI上での操作でローカルリポジトリへのステージング〜コミット、リモートリポジトリへのPUSHまでができるようになります。(gitのコマンドでユーザ名等の設定が必要かもです)
なお、VSCodeのアドオンとして、GitGraph等を入れると楽しいです。
2. リポジトリに保存しないファイルを.gitignoreで設定
いろいろなツールのワークディレクトリやファイル、開発用のワークや、公開したくない情報(自分自身で取得したAPIキーなど)を、リポジトリにPUSHしないようにします。そのためのしくみが、.gitignoreです。
2.1. .gitignoreファイルの作成と内容定義
プロジェクトのルートディレトクリに.gitignoreファイルを作成します。中身は今のところ以下にしています。
.gitignore.* *cache* *local* *secret*特に、.* と *cache* は、必須でしょう。これが無いと、大量のシステムワークファイルやpython仮想環境の共通ライブラリなどが、リポジトリに上がってしまいます。
2.2. .gitignore自身をPUSHしないようにする
これをするかは好みですが、.gitignore自身をPUSHしないようにすることが可能です。
プロジェクトホームの .git/config の [core] グループ内に、excludesfile = .gitignore を追記します。
3. venvでPython仮想環境を構築
VScodeではPython環境を選択して使えるようになっていますが、いろいろ準備するにあたって、Pythonは3系がデフォルトで使われるようにしておきましょう。python -V として3系が出てくるようにパスを調整しておきます。pipも3系が使われるようにしておきます。(なお、最近のPythonでは、pipと直打ちすることは推奨されておらず、python -m pipとして使うようです)
Pythonはライブラリの版数依存が複雑であるため、アプリ毎に仮想環境を用意してライブラリセットを切り替えることが推奨されます。従来は、pythonバージョンそのものも含めて切り替える、pyenv と、virtualenvというものが使われていましたが、Python 3.6以降では推奨されていません。今は、venv を使うことが推奨されています。
プロジェクトホームで、python -m venv .pyvenv としてvenv環境をセットアップします。.pyvenvは他の名前でもよいですが、.gitignoreの対象になるように .で始まる名前がよいです。venv環境には様々な共通ライブラリがインストールされますので、.gitignoreにヒットしないと、大変なことになります。なお、venv環境を新規作成すると、pip含めてライブラリは初期状態になりますので、いろいろ指示にしたがって入れ直してください。
venv環境をセットアップした後は、VSCode上でvenv環境を選べるようになりますので、選んでおいてください(最初はステータスバーをクリックしても出てこず、コマンドパレットメニューのPython:Select Interpreterから選択する必要があるようです)。ここで選択すると、venvのactivateをVSCodeが自動でやってくれます。もちろん、ここまでの間にVSCodeのPython拡張機構をインストールする必要があります。
4. pytest環境の構築
現在は、Python組み込みのunittestではなく、ライブラリ組み込みのpytestがよく使われるようです。コマンドパレットメニューのPython: Configure Testsからpytestを選択すると環境構築してくれます。この時、テストディレクトリは . Root directory を選択してください。
ソースとテストをきれいに管理するために、ディレクトリを以下のように分けます。なお、今回の計画ではPython以外でもコーディングを予定していますので、実際にはサブプロジェクトに分かれた構成になっています。
(Project root)/ ├ src - temp.py └ tests - test_temp.pyここで、通常の相対パス指定でtest_temp.pyからtemp.pyをインポートすると、エラーが出てしまうという、ハマりが発生します。
「Pythonでテストコードとテスト対象のコードを別ディレクトリに分けて置いたときに発生するModuleNotFoundErrorと格闘しました」のアップデート版解決策を適用することで、エレガントに解決ができました。
以下が解決策となります。
- testsフォルダに、空の __init__.py ファイルを作成する
- test_temp.pyにおけるtemp.pyのインポートを、プロジェクトホームからの相対パス指定とする
上記と、pytest設定でテストディレクトリを . Root directory としておくことが合わさり、正常にテスト実行ができるようになります(VSCodeのUIを使わずにtest_temp.py を直接実行するとインポートに失敗しますので注意)。なお、VSCodeを前提とした対応は、参照リンクにも掲載されておらす、今回、試行錯誤でできました。
5. コーディング規約の設定
コマンドパレットメニューのPython:Select Linter で、flake8を選択しましょう。その他にもいろいろ設定あるかもしれませんが、ちょっと覚えていません。汗
6. CIとしてローカルリポジトリCommit時の自動テストの設定
コーディング規約チェックはVSCodeでセーブ時に自動チェックができるのですが、テストは手動で実行させる必要があります。本来は、ローカルリポジトリのコミット時、リモートリポジトリへのPUSH時にテストの自動実行を行わせたいです。後者は、プルリクを出す側とコミッタが別の人になる場合などに便利で、以前はTravis CI、最近はGitHub Actionsを使うのが流行りのようです。
個人開発では、ローカルリポジトリのコミット時の自動テストだけでよさそうですので、それを設定してみます。ローカルgitコマンドのフック機能を使って、pre-commitのフックスクリプトでテスト実行させるのが、うまいやりかたのようです。プロジェクトホーム/.git/hooks/pre-commit を実行権限をつけて以下のように作成します。なお、このスクリプトはVSCodeの管轄外なので、activateを忘れずに書いておきましょう。
pre-commit#!/bin/sh source .pyvenv/bin/activate python -m pytestこれにより、VSCode上でローカルリポジトリにコミットする際に、自動的にテストが走って、テスト失敗時にはコミットがキャンセルされるようになりました。成功です。
- 投稿日:2020-05-24T21:48:35+09:00
(論文読み)Instance-aware Image Colorization(領域分割:インスタンスセグメンテーションを利用したカラー画像化)
はじめに
Papers with Codeにて論文を斜め読みしていたら、一度学んでみたかった技術である白黒画像のカラー画像化について紹介されていました。
概要を訳しましたので、参考になれば幸甚です。Instance-aware Image Colorization
https://paperswithcode.com/paper/instance-aware-image-colorization物体分割を利用した白黒画像のカラー画像化技術について、最近arxiv上に掲載されたものです。
要約:Abstract
- カラー画像化は、マルチモーダル[*1]な不確実性を含んでいることが問題である。
- 既存のモデルは、画像全体で学習及びカラー化を行っていたため複数のオブジェクトがあると失敗する。
- 著者らは既成のオブジェクト検出器を用いて、領域分割と画像レベルの特徴づけを行った。
- 既存の手法と比較して優れた性能を見出した。
*マルチモーダル:動物の五感を指す意味と理解しました。直感的に物体が何者か認識できること等。
1.背景:Introduction
白黒画像をもっともらしいカラー画像へ変換することは、今注目の研究テーマである。
しかし、白黒画像から2つの欠落したチャンネルを予測することは、本質的に難しい問題がある。
さらに物体の色付けには複数の選択肢があるため、色付け作業は複数解釈できる可能性がある(例えば、車両は白、黒、赤など)。従来報告されてきた技術では、雑然とした背景上に多数物体がある場合は上手くカラー化されない課題があった(下記図)。
本論文では、上記の問題点を解決するために、新しいディープラーニングのフレームワーク及び領域分割を意識した色分けを実現した。
特にポイントとして、物体と背景を明確に分けることがカラー化の性能改善に効果があることが分かった。著者らのフレームワークは大きく以下の3つから成る。
- 領域分割及び、分割された物体画像を生成するための既製の事前学習モデル
- 分割された物体及び画像全体のカラー化のために学習された2つのバックボーンネットワーク
- 2つのカラー化ネットワークのレイヤーから抽出された特徴を選択的に混ぜるための融合モジュール
2.関連技術:Related works
学習に基づいたカラー化Learning-based colorization
近年、機械学習を利用したカラー化処理の自動化が注目されている。既存の研究の中では、大規模なデータセットから色予測を学習するために、深層畳み込みニューラルネットワークが主流となっている。
領域分割に基づいた画像生成・操作:Instance-aware image synthesis and manipulation
領域分割を考慮した処理によって、物体と地面の分離が明確になるため、視覚的な外観の合成と操作が容易になる。
- 単一物体に注目するDC-GAN, FineGANと比較して、複雑な領域について対応可能
- 重なりが自然にみえる技術であるInstaGANと比較して、同時に全て重なっている可能性を考慮可能
- 合成の品質を改善するため領域分割の境界を使っているPix2PixHDと比較して、学習された重みづけを多数の領域合成で使用
3. 概観:Overview
本システムでは、白黒画像$X∈R^{H×W×1}$を入力とし、その欠落した2つの色チャンネル$Y∈R^{H×W×2}$を$CIE L∗a∗b∗色空間$内でエンドツーエンドで予測する。
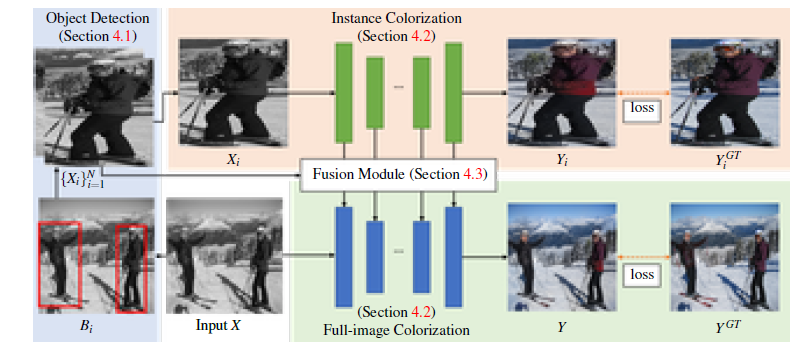
下記図にネットワークの構成を示す。まず事前学習済み物体検出器を用いて、白黒画像から複数の物体バウンディングボックス$(B_i)^N_{i=1}$($N$はインスタンス数)を取得する。
次に、検出したバウンディングボックスを用いて白黒画像から切り出した画像をリサイズして、インスタンス画像$(X_i)^N_{i=1}$を生成する。
次に、各インスタンス画像$X_i$と入力グレースケール画像$X$を、それぞれインスタンスカラー化ネットワークとフルイメージカラー化ネットワークに流す。ここでは、第$j$番目のネットワーク層におけるインスタンス画像$X_i$とグレースケール画像$X$の抽出された特徴マップを$f^{Xi}_j$及び $f^X_j$と呼ぶ。
最後に、各層のインスタンス特徴量$(f_j^{Xi}) ^N_ {i=1}$とフル画像特徴量${f_j^X}$を融合する融合モジュールを用いる。融合された全画像特徴$f^X_j$は、$j+1$番目のレイヤーに転送される。このステップを最後の層まで繰り返し予測カラー画像$Y$を得る。
本研究では、まず全画像ネットワークを学習し、次にインスタンスネットワークを学習し、最後に上記2つのネットワークをフリーズさせて融合モジュールを学習するという逐次的なアプローチを採用している。
4.手法:Method
4.1物体検知 Object detection
検出した物体インスタンスを利用して画像の色付けを行う。このために、物体検出器として市販の事前学習済みネットワークMask R-CNN を用いた。
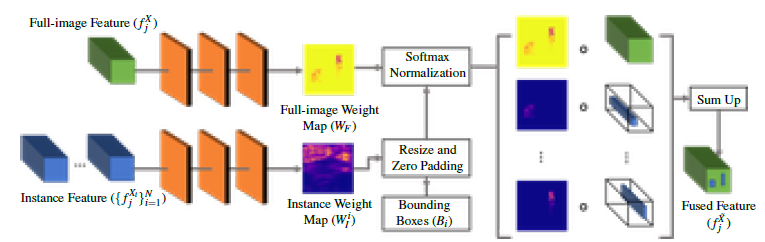
4.3.融合モジュール:Fusion module
融合モジュールは、以下のような入力を受け取ります。融合モジュールは、(1)フル画像の特徴量$f^X_j$、(2)インスタンス特徴量の束とそれに対応するオブジェクト境界ボックス$(f_j^{Xi}) ^N_ {i=1}$を入力とする。 両種類の特徴に対して、3つの畳み込み層を持つ小型のニューラルネットワークを考案し、フル画像重みマップ$W_F$とインスタンス毎の重みマップ$W_I^i$を予測する。
4.4.損失関数と訓練:Loss Function and Training
ネットワーク全体を以下手順で学習する。まず、全画像色化を学習し、学習した重みをインスタンス色化ネットワークに転送して初期化します。 次に、インスタンス色化ネットワークを学習する。最後に、全画像モデルとインスタンスモデルの重みを解放し、融合モジュールの学習に移る。
5.実験:Experiments
5.1.実験条件:Experimental setting
データセット:Dataset
- ImageNet, COCO-Stuff, Places205の3つのデータセットを使用
訓練手法:Training details
ImageNetデータセットについて以下の3つ訓練プロセスを実施した。
- 全画像カラー化ネットワーク:既存のモデルの重みパラメータで初期化(学習率$10^{-5}$)
- 領域分割ネットワーク:データセットから抽出されたインスタンスでモデルをファインチューニング
- 融合モジュール:13層のニューラルネットワークで融合
- 最適化手法はADAMを使用( $\beta_1=0.99, \beta_2 = 0.999$)
- 単一のRTX 2080Ti GPUを使って3日間訓練させた(ImageNet)
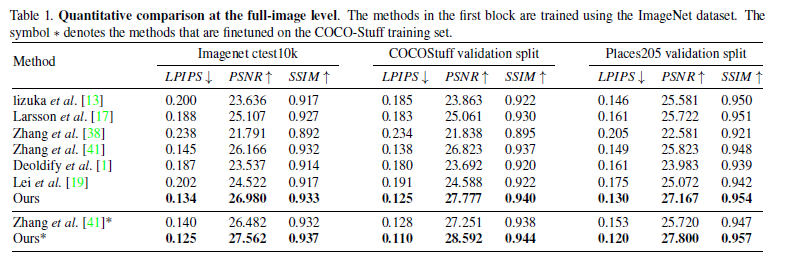
5.2.定量値の比較: Quantitative comparisons
Comparisons with the state-of-the-arts.
3つのデータセットに関する定量値の比較を上表に示す。どの指標においてもこれまでの方法より良いスコアとなった。
※
LPIPS:元画像と潜在空間に射影した後、画像を再生成したものとの距離(低いほど距離が近く似ている)
SSIM:輝度、コントラスト、構造を元に周囲のピクセル平均、分散・共分散をとったもの
PSNR:2枚の画像で同じ位置同士のピクセルの輝度の差分を2乗したもの(高いほうが高画質)User study
参加者には、着色した結果のペアを見せ、好みを尋ねる(強制選択比較)。その結果、Zhanget al. (61%対39%)、DeOldify(72%対28%)と比較して平均的に著者らの手法が好まれる結果となった。
興味深いことに、DeOld-ifyはベンチマーク実験で評価された正確な着色結果が得られないが、飽和着色された結果の方がユーザに好まれることがある。5.7失敗例:Failure cases
上図に 2 つの失敗例を示す。著者らの手法では、色が洗い流されていたり、オブジェクトの境界をまたいでいるような目に見えるアーチファクトが発生する可能性がある。
6.結論: Conclusions
本研究では、既製のオブジェクト検出モデルを用いて画像を切り出すことで、インスタンスブランチとフルイメージブランチから特徴量を抽出した。
そして、新たに提案したフュージョンモジュールと融合させることで、より良い特徴量マップを得ることを確認した。実験の結果、既存の手法と比較して、3つのブランチマークのデータセットにおいて、本研究の成果が優れていることが示された。終わりに
領域分割(インスタンスセグメンテーション)技術を取り入れたカラー画像化の技術を学びました。
技術自体は理解できたのですが、カラー画像化したときに尤もらしい画像であることを定量的に議論することの難しさを感じました。
車の色や草木の色など、複数の選択肢がある場合、どれがもっともらしいかと決めるアルゴリズムをどのように決めるのでしょう。著者らは人に判断してもらうテストもしていますが、このマルチモーダルな領域についてアルゴリズムができるとより人工知能感ある技術になるのでしょう。

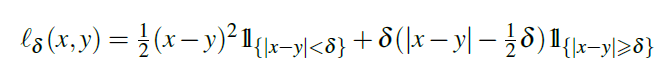

- 投稿日:2020-05-24T21:19:00+09:00
回帰分析の方法
・ボストンの住宅価格のデータのロード
from sklearn.datasets import load_boston import pandas as pd import numpy as np import matplotlib.pyplot as plt boston = load_boston() df = pd.DataFrame(boston["data"], columns = boston["feature_names"]) df["PRICE"] = boston["target"] df.head()・サイキットラーンで実装(ハイパーパラメーターは適当)
#サイキットラーンを使うやり方 from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score from sklearn.model_selection import GridSearchCV from sklearn.linear_model import LinearRegression from sklearn.linear_model import Ridge from sklearn.linear_model import Lasso from sklearn.linear_model import ElasticNet from sklearn.ensemble import RandomForestRegressor from sklearn import svm from sklearn.ensemble import GradientBoostingRegressor #インプットデータ X = df.drop("PRICE", axis=1) Y = df["PRICE"] #トレインデータとテストデータに分割 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0) #値を標準化 sc = StandardScaler() X_train__std = sc.fit_transform(X_train) Y_train_std = sc.fit_transform(Y_train.values.reshape(-1,1)) X_test_std = sc.transform(X_test) Y_test_std = sc.transform(Y_test.values.reshape(-1, 1)) #線形回帰 print("***線形回帰***") model_linear = LinearRegression() model_linear.fit(X_train, Y_train) print("訓練データの相関係数:", model_linear.score(X_train, Y_train)) print("検証データの相関係数:", model_linear.score(X_test, Y_test)) Y_train_pred = model_linear.predict(X_train) Y_test_pred = model_linear.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show() #線形カーネルのSVM回帰 print("***SVM回帰***") #正則化パラメーター=1、線形カーネルを使用 model_svm = svm.SVR(C=1.0, kernel='linear', epsilon=0.1) model_svm.fit(X_train, Y_train) print("訓練データの相関係数:", model_svm.score(X_train, Y_train)) print("検証データの相関係数:", model_svm.score(X_test, Y_test)) Y_train_pred = model_svm.predict(X_train) Y_test_pred = model_svm.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show() #リッジ回帰 print("***リッジ回帰***") model_ridge = Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, random_state=0) model_ridge.fit(X_train, Y_train) print("訓練データの相関係数:", model_ridge.score(X_train, Y_train)) print("検証データの相関係数:", model_ridge.score(X_test, Y_test)) Y_train_pred = model_ridge.predict(X_train) Y_test_pred = model_ridge.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show() #ラッソ回帰 print("***ラッソ回帰***") model_lasso = Lasso(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=1000, tol=0.0001, warm_start=False, positive=False, random_state=None, selection="cyclic") model_lasso.fit(X_train, Y_train) print("訓練データの相関係数:", model_lasso.score(X_train, Y_train)) print("検証データの相関係数:", model_lasso.score(X_test, Y_test)) Y_train_pred = model_lasso.predict(X_train) Y_test_pred = model_lasso.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show() #エラスティックネット回帰 print("***エラスティックネット回帰***") model_lasso_elasticnet = ElasticNet(alpha=1.0, l1_ratio=0.5, fit_intercept=True, normalize=False, max_iter=1000, copy_X=True, tol=0.0001, warm_start=False, positive=False, random_state=None, selection='cyclic') model_lasso_elasticnet.fit(X_train, Y_train) print("訓練データの相関係数:", model_lasso_elasticnet.score(X_train, Y_train)) print("検証データの相関係数:", model_lasso_elasticnet.score(X_test, Y_test)) Y_train_pred = model_lasso_elasticnet.predict(X_train) Y_test_pred = model_lasso_elasticnet.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show() #ランダムフォレスト回帰 print("***ランダムフォレスト回帰***") model_randomforest = RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=-1, oob_score=False, random_state=2525, verbose=0, warm_start=False) model_randomforest.fit(X_train, Y_train) print("訓練データの相関係数:", model_randomforest.score(X_train, Y_train)) print("検証データの相関係数:", model_randomforest.score(X_test, Y_test)) Y_train_pred = model_randomforest.predict(X_train) Y_test_pred = model_randomforest.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show() #勾配ブースティング回帰 print("勾配ブースティング回帰") model_gbc = GradientBoostingRegressor(random_state=0) model_gbc.fit(X_train, Y_train) print("訓練データの相関係数:", model_gbc.score(X_train, Y_train)) print("検証データの相関係数:", model_gbc.score(X_test, Y_test)) Y_train_pred = model_gbc.predict(X_train) Y_test_pred = model_gbc.predict(X_test) plt.scatter(Y_train,Y_train_pred, label = "train_data") plt.scatter(Y_test,Y_test_pred, label = "test_data") plt.legend() plt.show()
- 投稿日:2020-05-24T21:11:09+09:00
【python入門】忙しいC++プログラマのためのPython高速入門講座
概要
C++は使えるけどpythonがわからないという人が素早く機械学習ができる最低限のプログラミング記法を身につけるためのポイントをまとめました。これを知っていれば最低限の機能は使えると思います。
Pythonのメリット
ライブラリが充実しているのでC++で書くと複雑なコードも簡単に書けます。web連携が比較的簡単。
ネットに載っている情報が多い。Pythonの使いみち(例)
以下は全てライブラリが存在します。ライブラリを使いこなすことはすなわちpythonを使いこなすことです。
・機械学習
・Webスクレイピング
・エクセル操作
・データ前処理
・ビジュアライズ検証環境
python 3.8.2
Ubuntu 18.04環境構築
linuxの場合は標準でpython3が入っているので環境構築の必要がありません。
Anacondaで動かしたい場合にはこちらを参考に導入してください。
Anacondaの説明はこちら
Anacondaを使うと仮想環境を簡単に作ることができます。パッケージをたくさんインストールするpythonにおいては、環境を変えたいことが多くなるので、本腰を入れて使いたいならAnacondaは必須かもしれません。おすすめの開発環境
IDE
・PyCharm
・Spyder
エディタ
・Atom
・VS codeC++とPythonの違い一覧
C++ Python 変数型 あり なし 変数の代入 コピー ポインタ 関数の区切り {}中括弧 :とインデント 算術演算子 C++のものに加えて **べき乗を追加論理演算子 &&,ll,! and,or,not コードの区切り ; 改行 ポインタ 明確 不明確 コメントアウト // # 外部ライブラリのインポート #include import コンパイル 必要 不要 main関数 あり なし 行列計算(標準) 不可能 numpyライブラリで可能 変数型の違い
pythonは動的型付け言語のため、C++に当たり前のようにある変数型が存在しません。そのため、変数はそのまま変数名のみで定義します。代入した値によって型が決定します。
a=1234 #整数型 b=12.345 #浮動小数点型 c="hello world" #文字列型 d=[1,2,3,4] #リスト型ポインタ
pythonには明示的なポインタが存在しません。その代わり、変数が値の保持とポインタの両方の役割を兼ねているので、変数への代入がコピーではなく参照を渡しています。
代入先の値を変更すると代入元の変数の値も変わるので扱いの違いに注意してください。(リストの場合)以下参考
https://qiita.com/maruman029/items/21ad04e326bb4fb6f71a1コードの範囲
C++の場合は区切り文字である
;をつけなければどれだけ改行しても1コードの認識ですが、pythonの場合は改行が明確な区切りになります。インデント
pythonはインデントがスコープの範囲を示しています。そのため、一文字でもインデントがずれていると同じ範囲のコードとして認識されません。とてもインデントに厳しい言語なので、エディタのインデント整形機能を使わないとコーディングが厳しいかもしれません。例えば、以下のコードはインデンテーションエラーになります。ループの中でインデントがずれてバグが出ることがしばしばあるので気をつけましょう。
a=1234 b=12.345 c="hello world" #同じ範囲でない d=[1,2,3,4]グローバル変数
C++のグローバル変数は関数からそのままアクセスできますが、pythonの場合は関数内で
global 変数名とローカル内で宣言しないと代入はできません。a = 123 def Global(): global a a = 456 print("global variable:", a) Global()書き方の違い
見やすくするために一部main関数を省略しています。
標準出力
pythonは自動改行なので
\nは要りません。c.cint a=123; printf("%d\n",a);python.pya=123 print(a)外部ライブラリのインポート
c++.cpp#include "hogohoge.h"python.pyimport hogehoge配列
pythonでは「リスト」と呼びます。pythonの配列はメモリ領域が動的に確保されているので、後から要素を追加することができます。要素を追加する場合はappend()を使います。C++のように
a[3] = 4で代入するとエラーになるので気をつけましょう。c++.cppint a[4]={1,2,3,}; int b = a[2]; printf("%d\n", b); a[3] = 4; printf("%d\n", a);python.pya=[1,2,3] b=a[2] print(b) a.append(4) print(a)pythonのコードを見てみると、
a.append(4)があります。これはリストメソッドと言って、リストを操作するときに使う関数です。pythonでは変数や外部ライブラリを一種のオブジェクトとして扱い、.メソッドでpythonに用意されているメソッドにアクセスできます。他にも途中に挿入するメソッドなどいろいろ存在するのでこちらが参考になると思います。不可変配列
後から値を変更することができない配列です。c++ではconstで宣言しますが、pytonの場合はタプルと言ってリストと別の書き方をします。
tupl.cppconst int a[4] = {1, 2, 3, 4}; b = a[2]; printf("%d", b);tupl.pya = (1, 2, 3, 4) b = a[2]#要素を取得 print(b)変数のラベル付け
pythonには辞書という機能があります。キーと値の組み合わせでデータを格納できる配列のようなものです。呼び出すときはキーを指定することで呼び出すことができます。そのため可読性が上がります。c++のenumと似たようなものとイメージしてももらうとわかりやすいかもしれません。
python.pylang={"c":1,"python":2,"ruby":3}#辞書の作成 print(lang["python"]) lang["ruby"]=4#要素の入れ替え print(lang["ruby"]) lang["java"]=3 #要素の追加 print(lang)if文
pythonにはc++のように{}などの区切り文字がありません。そのため、
if hogehoge:の次の行を1タブ分開けることによって※インデントを変え、if文の処理であることを明示します。pirntを左端に持ってくるとif文と同じインデントになるので、ifのそとで実行される処理になります。ネストする際もまた、インデントをずらします。
※インデントはタブかスペース4つ開けるかどちらかで統一しましょう。混ぜることは禁止されています。万が一混ざってしまい、どうにもならなくなったときはエディタの修正機能を使うことを勧めます。VS codeにはどちらかに統一する機能があります。c++.cppint a = 7; int b = 12; if (a <= 10 && b <= 10) { printf("aもbも10以下"); } else if (a % 2 == 0) { printf("aは偶数"); } else { printf("条件に適合しません") }python.pya = 7 b = 12 if a <= 10 and b <= 10: print("aもbも10以下") elif a % 2 == 0: print("aは偶数") else: print("条件に適合しません")for文
c++の場合は、配列の中身をひとつひとつ取り出す場合に配列の要素数を指定してループしなければできませんが、
pythonの場合はリストを投げるだけで全要素をひとつずつ取り出してくれます。for.cppint ls[3] = {1, 2, 5}; for (int i = 0; i < sizeof ls / sizeof ls[0]; i++) { printf("%d\n", ls[i]); } for (int i = 0; i < 3; i++) { printf("%d\n", i); }for.pyls = [1, 2, 5] for i in ls: print(i) for i in range(3): print(i)1
2
5
0
1
2while文
while.cppint a = 0; while(a < 3) { printf("%d", a); a += 1; }while.pya = 0 while a < 3: print(a) a += 10
1
2関数
可変長引数を受け取るときは仮引数の前に
*を付けます。
リストやタプルの内容を引数に展開して引き渡すときは実引数の前に*をつけます。function.cppint Add(a, b) { c = a + b; return c; } int Add3(int *c) { int d = 0; d = c[0] + c[1] + c[2]; return d; } int main() { printf("%d\n", Add(1, 2)); const int e[3] = {1, 2, 3}; printf("%d\n", Add3(e)); }function.pydef Add(a, b): c = a + b return c def Add3(*c): # 可変超引数として引数をまとめて受け取る d = c[0] + c[1] + c[2] return d def main(): print(Add(1, 2)) print(Add3(1, 2, 3)) e = (4, 5) print(Add(*e)) # リストやタプルを引数展開して渡すことも可 return if __name__ == "__main__": main()クラス
クラスの定義
classdefine.cppclass Hoge { public: int a; Hoge(int a) { this->a = a; } void add(int b) { printf("%d\n", a + b); } void mutipl(int b) { printf("%d\n", a * b); } }classdefine.pyclass Hoge: def __init__(self, a): self.a = a def add(self, b): print(self.a + b) def mutipl(self, b): print(self.a * b)c++でコンストラクタをクラスと同じ名前にしますが、pythonの「クラス」ではコンストラクタを
def __init__(self, a):で表し、クラス内の変数をコンストラクタ内でself.aのように宣言します。定義自体はどこからでもできます。メンバ関数の引数にクラス自身の参照である「self」を渡して「self」経由でインスタンス変数にアクセスします。必ず引数にselfを書きましょう。クラスの操作
classcntrol.cppHoge hoge(3); hoge.add(4); hoge.mutipl(4);classcontrol.pyhoge = Hoge(3) hoge.add(4) hoge.mutipl(4)クラスの継承
Inheritance.cppclass Fuga : public Hoge { public: void subtract(int b) { printf("%d\n", a - b); } void divide(int b) { printf("%d\n", a / b); } } Fuga fuga(3); fuga.add(4); fuga.mutipl(4); fuga.subtract(4); fuga.divide(4);Inheritance.pyclass Fuga(Hoge): #Hogeを継承 def subtract(self, b): print(self.a - b) def divide(self, b): print(self.a/b) fuga = Fuga(3) fuga.add(4) fuga.mutipl(4) fuga.subtract(4) fuga.divide(4)Pythonの主力ライブラリ
Numpy(行列演算ライブラリ)
これを使うことで行列演算が非常に簡単にできます。機械学習では必須です。
こちらの方が詳しく使い方を書いてあるので参考にしてください。Matplotlib(グラフ描画ライブラリ)
書き方はこちらの記事を参考にしてください。
補足
importモジュールの置き換え
pythonでは、外部ライブラリはオブジェクトとして扱われますが、長い名前を書くのが面倒なので
asで置き換えることもできます。import numpy as npモジュールのインストール
pip3 install module_namePythonスクリプトの実行
python3 file_nameanaconda
python file_name標準ライブラリ
pythonではファイル操作がかなり楽です。
https://qiita.com/hiroyuki_mrp/items/8bbd9ab6c16601e87a9cオブジェクト指定インポート
https://note.nkmk.me/python-import-usage/
最後に
まだまだpythonのほんの一部なので、気になった機能はあるかどうか調べてみるとよいです。
参考
我妻 幸長 (著) "はじめてのディープラーニング Pythonで学ぶニューラルネットワークとバックプロパゲーション"
- 投稿日:2020-05-24T21:08:36+09:00
製薬企業研究者がPythonの内包表記についてまとめてみた
はじめに
ここでは、Pythonの内包表記について、覚えておくと役に立つことをまとめてみます。
リスト内包表記
nums = [1, 2, 3, 4, 5] nums_double = [x * 2 for x in nums] # リストnumsの要素をそれぞれ2倍する print(nums_double) # [2, 4, 6, 8, 10] nums_even = [x for x in nums if x % 2 == 0] print(nums_even) # [2, 4]nums_2 = [[1, 2], [3, 4]] nums_2_odd = [odd for nums in nums_2 for odd in nums] print(nums_2_odd) # [1, 2, 3, 4]nums_set = {1, 2, 3, 4, 5} nums_set_square = {x**2 for x in nums_set} print(nums_set_square) # {1, 4, 9, 16, 25}nums_dict = {'one': 1, 'two': 2, 'three': 3} nums_dict_rev = {value:key for key, value in nums_dict.items()} print(nums_dict_rev) # {1: 'one', 2: 'two', 3: 'three'}nums = [1, 2, 3, 4, 5] nums_gen = (x for x in nums) print(nums_gen) # generator object for num in nums_gen: print(num)print("\n".join("Fizz"*(n%3== 0) + "Buzz"*(n%5== 0) or str(n) for n in range(1,101)))まとめ
ここでは、Pythonの内包表記についてまとめました。
使えそうなときはコードを短くするためにも使ってみるようにすると良いと思います。
- 投稿日:2020-05-24T21:07:35+09:00
[Python] 再帰 AGC044A
AGC044A
同じ操作を繰り返す
⇒ 再帰内容は下記の引用であり、十分な説明もある。この投稿は私的メモである。
AGC044 の A 問題「Pay to Win」を Python で解いてみるサンプルコードT = int(input()) for t in range(T): N, A, B, C, D = map(int, input().split()) memo = {} def dist(n): if n == 0: return 0 if n == 1: return D if n in memo: return memo[n] ret = min( D * n, D * abs(n - n//5*5) + C + dist(n//5), D * abs(n - (n+4)//5*5) + C + dist((n+4)//5), D * abs(n - n//3*3) + B + dist(n//3), D * abs(n - (n+2)//3*3) + B + dist((n+2)//3), D * abs(n - n//2*2) + A + dist(n//2), D * abs(n - (n+1)//2*2) + A + dist((n+1)//2) ) memo[n] = ret return ret print(dist(N))
- 投稿日:2020-05-24T21:07:35+09:00
[Python] DFS AGC044A
AGC044A
最小コスト探索問題
同じ操作を繰り返す
⇒ 再帰内容は下記の引用であり、十分な説明もある。この投稿は私的メモである。
AGC044 の A 問題「Pay to Win」を Python で解いてみるサンプルコードT = int(input()) for t in range(T): N, A, B, C, D = map(int, input().split()) memo = {} def dist(n): if n == 0: return 0 if n == 1: return D if n in memo: return memo[n] ret = min( D * n, D * abs(n - n//5*5) + C + dist(n//5), D * abs(n - (n+4)//5*5) + C + dist((n+4)//5), D * abs(n - n//3*3) + B + dist(n//3), D * abs(n - (n+2)//3*3) + B + dist((n+2)//3), D * abs(n - n//2*2) + A + dist(n//2), D * abs(n - (n+1)//2*2) + A + dist((n+1)//2) ) memo[n] = ret return ret print(dist(N))
- 投稿日:2020-05-24T20:58:35+09:00
Python
tmp.py#変数 s = "str..." l = ["1", "2", "3", "3", "4"] t = ("A", "B", "C") d = {"key": "value"} s_ = str("str") i_ = int("99") f_ = float("100.0") l_ = list((1,2,3)) d_ = dict([["key, "value"]]) e = set("0123456789") ss = ''' dup dup dup ''' #プリント構文 print(s, end="") #スライス s[0:1] s[-1] s[::1] #組み込み関数 len(s) s.split() ",".join(l) s.strip(".") s.capitalize() s.title() s.upper() s.lower() s.swapcase() s.replace(".", "!") l.append("5") l.insert(0, "10") del l[0] l.remove("10") l.pop() l.index("1") l.count("3") l.sort() c = l.copy() d.keys() d.values() d.items() #forループ for val in l: print(val) #演算 False | True True & True 1 > 0 0 >= 0 #if文 if s == "s": print("s!") elif s == "str": print("str!") else: print("!!!") #whileループ count = 0 while count < 3: print(count) count += 1 while True: print(count) if count == 5: break count += 1 #リスト内包表記 ll = [v for v in range(10)] #関数 def f(a,b): return a+b #クラス class S(): def __init__(self, a, b): self.a = a self.b = b def rep(): print(self.a + " " + self.b) ss = S("Thank", "you") ss.rep()
- 投稿日:2020-05-24T19:53:43+09:00
ラズパイとGmailAPIとLineAPIを使って簡易的なサーバーレス監視カメラを作る過程を優しく解説
0.最初に
今回作るものがどういう感じで動くのか見てみたい方は、こちら(youtubeの動画)でどうぞ。
1.Gmailの設定
まず、google cloud platformのサイトにいき、APIとサービスのライブラリのところを押す。
そして下にスクロールしていき、GmailAPIを見つけてそれを押す。
そして、有効にするを押す。
画面が変わったら、左のメニューのリストになっているやつの概要を押す。
画面が変わったら、右端の認証情報を作成を押す。
そして、画像の通りに入力して下の必要な認証情報を押す。
これも入力し終わったら、OAuthクライアントIDを作成を押す。名前のところは何でも構いません。
まだ、完了は押さずに、
ダウンロードのところを押す。すると、現在のディレクトリにclient_id.jsonというファイルが作成される。
2.必要なライブラリのダウンロード
pip install --upgrade google-api-python-client pip install requests pip install httplib2今回はpython3.6を使っているのでpython3.7などを使っていてうまくいかないという方は、pip3を使ってインストールしてください。
3.LineAPIの設定
Line Developersのサイトにいき、上のメニューのDocumentsのところを押す。
下にスクロールしていき、LineNotifyのところを押す。
ページが変わり、ログインしたらMy pageのところを押す。
そして、Create tokenを押す。そうすると、名前を聞かれますがトークメッセージの先頭につくだけなので何でも構いません。
そしてtokenが表示されるのでそれをコピーする。しかし、一度閉じてしまうともう二度と見れないので注意。
4.Gmailの認証
下のファイルをclient_id.jsonがあるディレクトリに作り実行する。
g_oauth.pyimport httplib2, os from apiclient import discovery from oauth2client import client from oauth2client import tools from oauth2client.file import Storage SCOPES = 'https://www.googleapis.com/auth/gmail.readonly' CLIENT_SECRET_FILE = '/home/igor-bond/Desktop/client_id.json' USER_SECRET_FILE = '/home/igor-bond/Desktop/credentials_gmail.json' def gmail_user_auth(): store = Storage(USER_SECRET_FILE) credentials = store.get() if not credentials or credentials.invalid: flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES) flow.user_agent = 'Python Gmail API' credentials = tools.run_flow(flow, store, None) print('認証結果を保存しました:' + USER_SECRET_FILE) return credentialsここでは、さらにユーザーの秘密を保存するcredentials_gmail.jsonというファイルがまた、同じディレクトリに作成される。
5.メイン処理の作成
このファイルも今まで作ってきたと同じディレクトリに作ります。Your tokenのところはさっきコピーしたLineNotifyのtokenを貼り付けてください。
gpio.pyimport os,httplib2 from apiclient import discovery import g_oauth import time from datetime import datetime import picamera import requests token = 'Your Token' def gmail_get_service(): credentials = g_oauth.gmail_user_auth() http = credentials.authorize(httplib2.Http()) service = discovery.build('gmail', 'v1', http=http) return service mail_list = [] def gmail_get_messages(): service = gmail_get_service() messages = service.users().messages() msg_list = messages.list(userId='me', maxResults=1).execute() for msg in msg_list['messages']: topid = msg['id'] msg = messages.get(userId='me', id=topid).execute() if msg['snippet'] == 'Security Check2': if not msg['id'] in mail_list: mail_list.append(msg['id']) send_msg() def send_msg(): filename = datetime.now() with picamera.PiCamera() as camera: camera.resolution = (1024,768) camera.capture(str(filename)+'.jpg') url = 'https://notify-api.line.me/api/notify' headers = {'Authorization':'Bearer '+token} data = {"message":"Here is your room."} img = f'/home/pi/Desktop/RaspberryPi_for_convenient_life/Projeect 1/{filename}.jpg' file = {'imageFile': open(img, 'rb')} r = requests.post(url, headers=headers, params=data, files=file,) run = True while run: try: time.sleep(30) gmail_get_messages() except KeyboardInterrupt: run = Falseここでは30秒ごとにログインしているユーザーのGmailの一番上にあるメールを取り出し、もしその内容が"Security Check2"かつ、同じ内容で処理済みのメールでなければラズパイで写真をとり、LineNotifyにおくる。というものです。まだ、実装していませんが写真を送り終わったらその写真を削除するという処理も必要だとおもいます。写真がたまって動作が重くなってしまうので、、、、、
最後に
この簡易的な監視カメラの作り方はYoutubeでも解説しているのてみましたそちらも良かったらご覧ください。質問等がございましたらその動画のコメント欄もしくは、この記事のコメント欄でどうぞ。また、いいなと思ったらチャンネル登録お願いします。
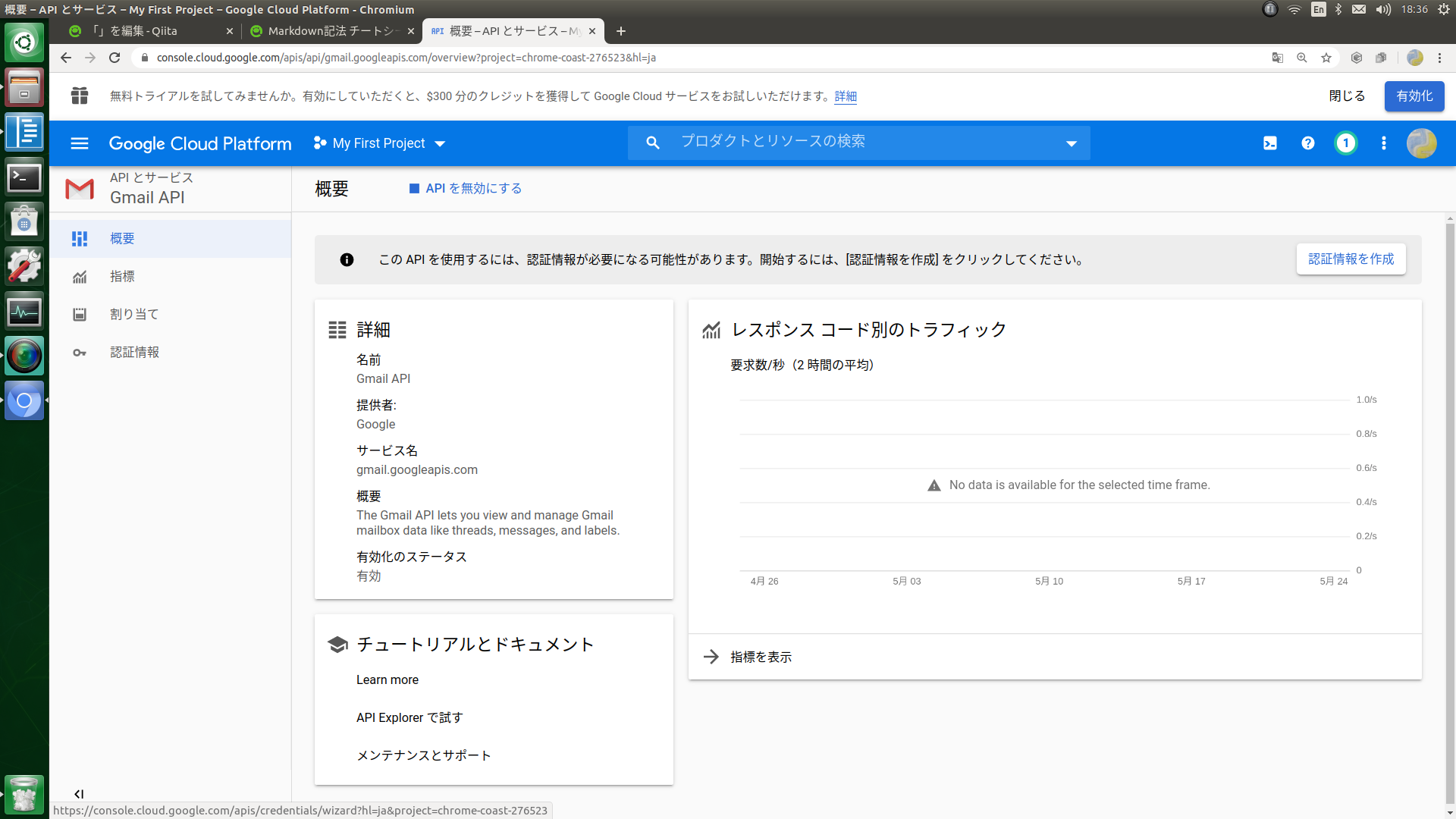



- 投稿日:2020-05-24T19:32:14+09:00
カイジのチンチロリンの仕組みを調べてみる
自粛期間が続く最中
無料マンガアプリで過去の作品が色々読めてしまうので気になってしまいました。
漫画
カイジに出てきたギャンブルチンチロリンです。カイジ
本伸行による一連の漫画作品、およびそれをもとにしたアニメおよび実写映画。
元々はダメ人間だが、危機が迫った極限の状態に置かれると並外れた度胸と才能を発揮する
主人公伊藤開司のことですが、ここでは漫画のことになります。現在、以下の5+1篇が刊行されている。
また、スピンオフ作品として『中間管理職トネガワ』『1日外出録ハンチョウ』が存在する。賭博黙示録カイジ(1996年-1999年 週刊ヤングマガジン、全13巻)
賭博破戒録カイジ(2000年-2004年 週刊ヤングマガジン、全13巻)
賭博堕天録カイジ(2004年-2008年 週刊ヤングマガジン、全13巻)
賭博堕天録カイジ 和也編(2009年-2012年 週刊ヤングマガジン、全10巻)
賭博堕天録カイジ ワンポーカー編(2012年‐2017年 週刊ヤングマガジン、全16巻)
賭博堕天録カイジ 24億脱出編(2017年‐連載中、既刊6巻)基本
ギャンブルをテーマとして扱った作品になっています。チンチロリン
漫画では第三章
欲望の沼編に登場するギャンブルです。地下強制労働施設内でのレクリエーションとして大槻班長が持ちかけてきたギャンブルがこれです。
ルール
サイコロを3つ同時に振って役が揃うまで振る(最大3回まで)
お椀などにサイコロを入れて逆さまにして地面に置きお椀をとれば出目が決まります。
役は強い順で以下の通りです。
役名 条件 ピンゾロ 1・1・1 ゾロ目 2・2・2 , 3・3・3 , 4・4・4 , 5・5・5 , 6・6・6 シゴロ 4・5・6 出目の大きい順番 2枚が同じで、残った1つの目の数 ションベン 役がなかった場合や,お椀からサイコロが出た場合 ヒフミ 1・2・3 漫画では払い戻しのルールなどもありますが、今回はそこは割愛して
単純に役が出る確率を考えていきます。まずは役を判定する関数を考えてみましょう。
役は一番強いピンゾロが1、以降強い順として数値を戻す関数を作っていきます。
なおここでは振り直しも考えず、揃わなければ役なしと同じ扱いにします。
なおゾロ目はどれが出ても同じ強さと考えます。def tintiro_hand(h): # ピンゾロ if all([h[0]==1,h[1]==1,h[2]==1]): return 1 # ゾロ目 if h[0]==h[1] and h[1]==h[2]: return 2 # シゴロ if [4,5,6]==list(sorted(h)): return 3 # ヒフミ if [1,2,3]==list(sorted(h)): return 11 # 出目 and ションベン calc = {} for n in h: if n in calc: calc[n]+= 1 else: calc[n]=1 if 2 in calc.values(): return 3 + 7-sorted(calc.items(),key=lambda x:x[1])[0][0] else: return 10 def judge(h1,h_2): if h1==h_2: return 'DRAW' if h1<h_2: return 'WIN' else: return 'LOSE'勝敗を判定する関数も作ります。
同じサイコロ同士で戦った場合の勝敗
import itertools from fractions import Fraction hands1 = list(itertools.product([1,2,3,4,5,6],repeat=3)) hands2 = list(itertools.product([1,2,3,4,5,6],repeat=3)) wins = {} for hand1 in hands1: for hand2 in hands2: w = judge(tintiro_hand(hand1),tintiro_hand(hand2)) if w in wins: wins[w] +=1 else: wins[w] = 1 total = sum(wins.values()) draw,win,lose =wins['DRAW'],wins['WIN'],wins['LOSE'] print('DRAW\t' , Fraction(draw,total) , ' \t{:%}'.format(draw/total)) print('WIN \t' , Fraction(win ,total) , '\t{:%}'.format(win/total)) print('LOSE\t' , Fraction(lose,total) , '\t{:%}'.format(lose/total))
DRAW 1639/5832 28.10% WIN 4193/11664 35.95% LOSE 4193/11664 35.95% 勝敗の確率は一緒です。まあ、当たり前ですよね。
シゴロ賽と対決した場合の勝敗
シゴロ賽
大槻班長が用いたイカサマサイで 4,5,6しかで目がないサイコロです。
4の裏は4と言うように、裏側が同じ数字になっているため一方向から見た時には
気づけないと言う特徴があります。これを使うと勝率はどのように変わるのでしょうか?
普通のサイコロと勝負してみます。import itertools from fractions import Fraction hands1 = list(itertools.product([1,2,3,4,5,6],repeat=3)) hands2 = list(itertools.product([4,5,6,4,5,6],repeat=3)) wins = {} for hand1 in hands1: for hand2 in hands2: w = judge(tintiro_hand(hand1),tintiro_hand(hand2)) if w in wins: wins[w] +=1 else: wins[w] = 1 total = sum(wins.values()) draw,win,lose =wins['DRAW'],wins['WIN'],wins['LOSE'] print('DRAW\t' , Fraction(draw,total) , '\t{:%}'.format(draw/total)) print('WIN \t' , Fraction(win ,total) , '\t{:%}'.format(win/total)) print('LOSE\t' , Fraction(lose,total) , ' \t{:%}'.format(lose/total))
DRAW 107/1944 5.50% WIN 175/1944 9.00% LOSE 277/324 85.49% 勝ち負けが同じ確率から、負けが50%増えます。素敵なサイコロですね。
役が出る確率は?
役が出る確率は、まずサイコロの組み合わせが
216通り($6^3$)なのでこれが分母になります。それぞれのサイコロでの役の確率を見てみると
import itertools import matplotlib.pyplot as plt %matplotlib inline hands1 = list(itertools.product([1,2,3,4,5,6],repeat=3)) hands = {} for hand1 in hands1: h = tintiro_hand(hand1) if h in hands: hands[h] +=1 else: hands[h] = 1 plt.figure(figsize=(12,6)) x = [k for k,v in sorted(hands.items())] y = [v for k,v in sorted(hands.items())] for x1,y1 in zip(x,y): plt.text(x1, y1+1 , y1 , size = 10, color = "green") plt.text(x1, y1+10 , '{:.01%}'.format(y1/216), size = 10, color = "black") label = ['111','ゾロ目','シゴロ','6','5','4','3','2','1','ションベン','123'] plt.bar(x,y,tick_label=label) plt.grid() plt.show()
三回振り直しを考慮せず、確定したものとすると一番出る役は役なし(ションベン)です。
だから3回振り直しっていうルールなのかもねと思います。
ピンゾロは1通りしかありません。一番弱い123は6通り存在します。これがシゴロ賽だとどうなるでしょうか?
import itertools import matplotlib.pyplot as plt %matplotlib inline hands = list(itertools.product([4,5,6,4,5,6],repeat=3)) hands2 = {i:0 for i in range(1,12)} for hand in hands: h2 = tintiro_hand(hand) if h2 in hands2: hands2[h2] +=1 else: hands2[h2] = 1 plt.figure(figsize=(12,6)) x = [k for k,v in sorted(hands2.items())] y = [v for k,v in sorted(hands2.items())] for x1,y1 in zip(x,y): plt.text(x1, y1+1 , y1 , size = 10, color = "green") plt.text(x1, y1+10 , '{:.01%}'.format(y1/216), size = 10, color = "black") label = ['111','ゾロ目','シゴロ','6','5','4','3','2','1','ションベン','123'] plt.bar(x,y,tick_label=label) plt.grid() plt.show()
なーんか圧倒的ですね。
見比べると一目瞭然です。
シゴロ賽であれば、役がないことが無くなり最低でも
4がでます。
ゾロ目の確率は5倍弱、シゴロの確率は8倍ですね。漫画だと
111の払いを高めて456の払いをやや弱くしたりして、カモフラージュしていたりとか
色々画策していてルールが面白くなってます。イカサマを見つけるには
このイカサマサイコロの仕組みを見破ったのは、同僚の三好がつけていた出目の記録です。
班長の此処一番の勝負の時だけ、やけに
456が多いなと言うところに気付き
イカサマサイコロの存在を疑うようになります。通常のサイコロであれば、
456の確率は3%弱なので、100回に2-3回しか出ないことになります。
続ければ続けるほど確率は収束し、本来の確率に近づくはずなので
何千回とデータをとり続ければ、確率のおかしさに気がつけるかもしれません。日々のデータ取得や確率の気付きは大切ですねーーー
まとめ
やはりギャンブルに勝つには統計や確率が改めて重要だとと言うことがわかるかと思います。
IRの事もあり公的な機関がもしチンチロリンを開催するようになったら
こう行ったイカサマも流行るかも知れませんし、その時を楽しみにしたいですね。作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython



- 投稿日:2020-05-24T19:19:13+09:00
特徴量と目的変数の相関可視化
はじめに
業務や分析コンペなどでモデリングをする前に、作成した特徴量と目的変数の相関をさくっと見れるようにした。
ここでは特に、売上予測などの目的変数が連続値の場合のモデリングを対象としている。以下のコードではSignateのお弁当の需要予測のデータを使用する。
(データ:https://signate.jp/competitions/24/data )このデータはy列にあるお弁当の販売数を予測するモデルを作成するタスクとなっている。
カラム ヘッダ名称 データ型 説明 0 datetid datetime インデックスとして使用する日付(yyyy-m-d) 1 y int 販売数(目的変数) 2 week char 曜日(月~金) 3 soldout boolean 完売フラグ(0:完売せず、1:完売) 4 name varchar メインメニュー 5 kcal int おかずのカロリー(kcal)欠損有り 6 remarks varchar 特記事項 7 event varchar 13時開始お弁当持ち込み可の社内イベント 8 payday boolean 給料日フラグ(1:給料日) 9 weather varchar 天気 10 precipitation float 降水量。ない場合は "--" 11 temperature float 気温 使用するライブラリ
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inlineデータ確認
df = pd.read_csv('./signate/train.csv') # df.shape >> (207, 12)df.head(2)
datetime y week soldout name kcal remarks event payday weather precipitation temperature 0 2013-11-18 90 月 0 厚切りイカフライ NaN NaN NaN NaN 快晴 -- 19.8 1 2013-11-19 101 火 1 手作りヒレカツ NaN NaN NaN NaN 快晴 -- 17.0 データ前処理
df['precipitation'] = df.precipitation.replace({'--' : '0'}).astype(float) df = pd.get_dummies(df[['y', 'week', 'soldout', 'kcal', 'payday', 'weather', 'precipitation', 'temperature']]) df['payday'] = df.payday.fillna(0).astype(str) df.head()
y soldout kcal payday precipitation temperature week_月 week_木 week_水 week_火 week_金 weather_快晴 weather_晴れ weather_曇 weather_薄曇 weather_雨 weather_雪 weather_雷電 0 90 0 NaN 0.0 0.0 19.8 1 0 0 0 0 1 0 0 0 0 0 0 1 101 1 NaN 0.0 0.0 17.0 0 0 0 1 0 1 0 0 0 0 0 0 2 118 0 NaN 0.0 0.0 15.5 0 0 1 0 0 1 0 0 0 0 0 0 3 120 1 NaN 0.0 0.0 15.2 0 1 0 0 0 1 0 0 0 0 0 0 4 130 1 NaN 0.0 0.0 16.1 0 0 0 0 1 1 0 0 0 0 0 0 統計量確認
df.describe()
y soldout kcal precipitation temperature week_月 week_木 week_水 week_火 week_金 weather_快晴 weather_晴れ weather_曇 weather_薄曇 weather_雨 weather_雪 weather_雷電 count 207.000000 207.000000 166.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 207.000000 mean 86.623188 0.449275 404.409639 0.113527 19.252174 0.188406 0.207729 0.207729 0.198068 0.198068 0.256039 0.241546 0.256039 0.120773 0.115942 0.004831 0.004831 std 32.882448 0.498626 29.884641 0.659443 8.611365 0.391984 0.406666 0.406666 0.399510 0.399510 0.437501 0.429058 0.437501 0.326653 0.320932 0.069505 0.069505 min 29.000000 0.000000 315.000000 0.000000 1.200000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 25% 57.000000 0.000000 386.000000 0.000000 11.550000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 50% 78.000000 0.000000 408.500000 0.000000 19.800000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 75% 113.000000 1.000000 426.000000 0.000000 26.100000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 max 171.000000 1.000000 462.000000 6.500000 34.600000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 特徴量と目的変数を可視化する関数
引数
- df:可視化対象のデータフレーム
- target:目的変数のカラム名
def make_plot(df, target): plt_col = sorted([c for c in df.columns if c != target and len(df[c].unique()) > 1]) col_num = len(plt_col) row_num = col_num // 2 + col_num % 2 col_num = 2 fig, ax = plt.subplots(row_num, col_num, figsize=(18, 3*row_num), sharex=False, sharey=False) fig.subplots_adjust(left=0.1, right=0.95, hspace=0.7, wspace=0.4) for i,col in enumerate(plt_col): tmp = df[[target, col]] tmp = tmp[~pd.isna(tmp[col])].reset_index(drop=True) if len(tmp[col].unique()) == 1: continue p = ((i+1) // 2) + ((i+1) % 2) -1 q = abs(((i+1) % 2) - 1) if len(tmp[col].unique()) > 2: percentile095 = tmp[col].quantile(0.95) over_tmp = tmp[tmp[col] >= percentile095].reset_index(drop=True) over_tmp[col] = percentile095 if tmp[col].min() < 0: percentile005 = tmp[col].quantile(0.05) under_tmp = tmp[tmp[col] <= percentile005].reset_index(drop=True) under_tmp[col] = percentile005 outof_percentile = tmp[(percentile005 < tmp[col]) & ( tmp[col] < percentile095)].reset_index(drop=True) new_tmp = pd.concat([outof_percentile, under_tmp, over_tmp], axis=0) if percentile095 == percentile005: new_tmp = tmp.copy() else: percentile095 = tmp[col].quantile(0.95) over_tmp = tmp[tmp[col] >= percentile095].reset_index(drop=True) over_tmp[col] = percentile095 outof_percentile = tmp[tmp[col] < percentile095].reset_index(drop=True) new_tmp = pd.concat([outof_percentile, over_tmp], axis=0) if percentile095 == 0: new_tmp = tmp.copy() ax1 = ax[p,q] ax2 = ax1.twinx() n, bins, pathces = ax1.hist(new_tmp[col], bins='auto', label='特徴量 : {}'.format(col), ec='black') new_tmp['bins'] = pd.cut(new_tmp[col], bins.tolist(), right=False).values.astype(str) if len([f for f in new_tmp[col].unique() if bins[-2] <= f and f < bins[-1]]) > 0: new_tmp['bins_start'] = [float(b.split(',')[0].replace('[', '')) for b in new_tmp['bins']] bins_max = new_tmp['bins_start'].max() nan_value = new_tmp.query('bins_start == @bins_max').bins.unique()[0] new_tmp['bins'] = new_tmp['bins'].replace({'nan' : nan_value}) else: new_tmp['bins'] = new_tmp['bins'].replace({'nan' : '[{}, {}]'.format(bins[-2], bins[-1])}) num_bin = new_tmp.groupby('bins').size().reset_index(name='cnt') mean_target_bin = new_tmp.groupby('bins')[target].mean().reset_index().rename(columns={target : '{}_mean'.format(target)}) center_feature_bin = new_tmp.groupby('bins').agg({col : {np.max, np.min}}).reset_index() center_feature_bin.columns = ['bins', 'feature_max', 'feature_min'] center_feature_bin['feature_center'] = center_feature_bin.apply(lambda x : (x['feature_max'] + x['feature_min']) / 2, axis=1) plt_data = mean_target_bin.merge(center_feature_bin, on='bins', how='inner').merge(num_bin, on='bins', how='inner').sort_values('feature_center', ascending=True).reset_index(drop=True) ax2.plot(plt_data['feature_center'], plt_data['{}_mean'.format(target)], label='目的変数の平均値(bin毎)', marker='.', color='orange') else: new_tmp = tmp.copy() ax1 = ax[p,q] ax2 = ax1.twinx() bins_list = sorted(new_tmp[col].unique().tolist()) a = new_tmp.groupby([col]).agg({col : len, target : np.mean}).rename(columns={col : 'count', target : '{}_mean'.format(target)}).reset_index().astype({col : str}) ax1.bar(a[col], a['count'], label='特徴量 : {}'.format(col), ec='black') ax2.plot(a[col], a['{}_mean'.format(target)], label='目的変数の平均値(bin毎)', marker='.', color='orange') ax2.hlines([new_tmp[target].mean()], new_tmp[col].min(), new_tmp[col].max(), color="darkred", linestyles='dashed', label='目的変数の平均値(データ全体)') handler1, label1 = ax1.get_legend_handles_labels() handler2, label2 = ax2.get_legend_handles_labels() ax1.legend(handler1 + handler2, label1 + label2, borderaxespad=0., bbox_to_anchor=(0, 1.45), loc='upper left', fontsize=9) ax1.set_ylabel('count', fontsize=12) ax2.set_ylabel('目的変数', fontsize=12) ax1.set_title('{}'.format(col), loc='right', fontsize=12) plt.show()target = 'y' # 目的変数の指定 make_plot(df, target) # プロット可視化結果
可視化する項目
1.ヒストグラム or 棒グラフ(青色)
- 特徴量が連続値の場合はヒストグラム
- 特徴量が2値の場合は棒グラフ
2.bin毎の目的変数の平均値(黄色)
- bin毎(2値の場合は値毎)の目的変数の平均値の折れ線グラフ
3.データ全体の目的変数の平均値(赤色)
- 投稿日:2020-05-24T19:16:47+09:00
Python用 OANDA v20 REST API ラッパーライブラリ のサンプル v20-python-samples を触る
OANDA V20 python libのサンプルであるv20-python-samplesのメモです。
APIの確認ができるコマンドラインツールのような使い方ができます。https://github.com/oanda/v20-python-samples
導入
基本的にlinux環境を前提にした導入手順になっていますが、windowsにも入ります。
手順中の下記コマンドについて、Windwos環境で手動で同じことをするのは下記です
- bootstrap
linuxmake bootstrapwindows_python3virtualenv -p python3 env env\Scripts\pip install -r requirements/base.txt
- activate
linuxsource env/bin/activatewindowsenv\Scripts\activate.batv20-account-details
detailsはアカウントのサマリーと通貨ペアごとの収支が出ます。
v20-account-detailsAccount xxx-xxx-xxxxxxx-xxx =========================== =============================== ============================== Account ID xxx-xxx-xxxxxxx-xxx Alias Primary Home Currency JPY Balance 374585.0125 Created by User ID xxxxxxx Create Time 2020-07-09T03:27:35.393967207Z Guaranteed Stop Loss Order Mode DISABLED Profit/Loss -72865.1901 Resettable Profit/Loss -72865.1901 Profit/Loss Reset Time 0 Financing -2496.2074 Commission 0.0 Guaranteed Execution Fees 0.0 Margin Rate 0.04 Open Trade Count 0 Open Position Count 0 Pending Order Count 0 Hedging Enabled False Unrealized Profit/Loss 0.0 Net Asset Value 374585.0125 Margin Used 0.0 Margin Available 374585.0125 Position Value 0.0 Closeout UPL 0.0 Closeout NAV 374585.0125 Closeout Margin Used 0.0 Margin Closeout Percentage 0.0 Margin Closeout Position Value 0.0 Withdrawal Limit 374585.0125 Last Transaction ID 6143 =============================== ============================== 13 Open Positions ================= ============ ========= ================ ========== ========== Instrument P/L Unrealized P/L Long Short ============ ========= ================ ========== ========== AUD_JPY -4643.11 0 0.0 @ None 0.0 @ None AUD_USD -13941.5 0 0.0 @ None 0.0 @ None EUR_AUD -4197.54 0 0.0 @ None 0.0 @ None EUR_CAD 2187.31 0 0.0 @ None 0.0 @ None EUR_GBP -4444.72 0 0.0 @ None 0.0 @ None EUR_JPY -13217.7 0 0.0 @ None 0.0 @ None EUR_USD 13787.9 0 0.0 @ None 0.0 @ None GBP_AUD 6820.85 0 0.0 @ None 0.0 @ None GBP_JPY -17401.3 0 0.0 @ None 0.0 @ None GBP_USD -5079.87 0 0.0 @ None 0.0 @ None USD_CAD -5946.91 0 0.0 @ None 0.0 @ None USD_CHF -9440.97 0 0.0 @ None 0.0 @ None USD_JPY -17347.7 0 0.0 @ None 0.0 @ None ============ ========= ================ ========== ==========v20-account-instruments
扱える通貨の一覧と倍率等が出ます
v20-account-instruments71 Instruments ============== ======= ======== ====== ============= Name Type Pip Margin Rate ======= ======== ====== ============= AUD_CAD CURRENCY 0.0001 25:1 (0.04) AUD_CHF CURRENCY 0.0001 20:1 (0.05) AUD_HKD CURRENCY 0.0001 10:1 (0.1) AUD_JPY CURRENCY 0.01 25:1 (0.04) AUD_NZD CURRENCY 0.0001 25:1 (0.04) AUD_SGD CURRENCY 0.0001 20:1 (0.05) AUD_USD CURRENCY 0.0001 25:1 (0.04) CAD_CHF CURRENCY 0.0001 20:1 (0.05) CAD_HKD CURRENCY 0.0001 10:1 (0.1) CAD_JPY CURRENCY 0.01 25:1 (0.04) CAD_SGD CURRENCY 0.0001 20:1 (0.05) CHF_HKD CURRENCY 0.0001 10:1 (0.1) CHF_JPY CURRENCY 0.01 20:1 (0.05) CHF_ZAR CURRENCY 0.0001 10:1 (0.1) EUR_AUD CURRENCY 0.0001 25:1 (0.04) EUR_CAD CURRENCY 0.0001 25:1 (0.04) EUR_CHF CURRENCY 0.0001 20:1 (0.05) EUR_CZK CURRENCY 0.0001 20:1 (0.05) EUR_DKK CURRENCY 0.0001 10:1 (0.1) EUR_GBP CURRENCY 0.0001 20:1 (0.05) EUR_HKD CURRENCY 0.0001 10:1 (0.1) EUR_HUF CURRENCY 0.01 20:1 (0.05) EUR_JPY CURRENCY 0.01 25:1 (0.04) EUR_NOK CURRENCY 0.0001 25:1 (0.04) EUR_NZD CURRENCY 0.0001 25:1 (0.04) EUR_PLN CURRENCY 0.0001 20:1 (0.05) EUR_SEK CURRENCY 0.0001 25:1 (0.04) EUR_SGD CURRENCY 0.0001 20:1 (0.05) EUR_TRY CURRENCY 0.0001 10:1 (0.1) EUR_USD CURRENCY 0.0001 25:1 (0.04) EUR_ZAR CURRENCY 0.0001 10:1 (0.1) GBP_AUD CURRENCY 0.0001 20:1 (0.05) GBP_CAD CURRENCY 0.0001 20:1 (0.05) GBP_CHF CURRENCY 0.0001 20:1 (0.05) GBP_HKD CURRENCY 0.0001 10:1 (0.1) GBP_JPY CURRENCY 0.01 20:1 (0.05) GBP_NZD CURRENCY 0.0001 20:1 (0.05) GBP_PLN CURRENCY 0.0001 20:1 (0.05) GBP_SGD CURRENCY 0.0001 20:1 (0.05) GBP_USD CURRENCY 0.0001 20:1 (0.05) GBP_ZAR CURRENCY 0.0001 10:1 (0.1) HKD_JPY CURRENCY 0.0001 10:1 (0.1) NZD_CAD CURRENCY 0.0001 25:1 (0.04) NZD_CHF CURRENCY 0.0001 20:1 (0.05) NZD_HKD CURRENCY 0.0001 10:1 (0.1) NZD_JPY CURRENCY 0.01 25:1 (0.04) NZD_SGD CURRENCY 0.0001 20:1 (0.05) NZD_USD CURRENCY 0.0001 25:1 (0.04) SGD_CHF CURRENCY 0.0001 20:1 (0.05) SGD_HKD CURRENCY 0.0001 10:1 (0.1) SGD_JPY CURRENCY 0.01 20:1 (0.05) TRY_JPY CURRENCY 0.01 10:1 (0.1) USD_CAD CURRENCY 0.0001 25:1 (0.04) USD_CHF CURRENCY 0.0001 20:1 (0.05) USD_CNH CURRENCY 0.0001 20:1 (0.05) USD_CZK CURRENCY 0.0001 20:1 (0.05) USD_DKK CURRENCY 0.0001 25:1 (0.04) USD_HKD CURRENCY 0.0001 10:1 (0.1) USD_HUF CURRENCY 0.01 20:1 (0.05) USD_INR CURRENCY 0.01 20:1 (0.05) USD_JPY CURRENCY 0.01 25:1 (0.04) USD_MXN CURRENCY 0.0001 12:1 (0.08) USD_NOK CURRENCY 0.0001 25:1 (0.04) USD_PLN CURRENCY 0.0001 20:1 (0.05) USD_SAR CURRENCY 0.0001 20:1 (0.05) USD_SEK CURRENCY 0.0001 25:1 (0.04) USD_SGD CURRENCY 0.0001 20:1 (0.05) USD_THB CURRENCY 0.01 20:1 (0.05) USD_TRY CURRENCY 0.0001 10:1 (0.1) USD_ZAR CURRENCY 0.0001 10:1 (0.1) ZAR_JPY CURRENCY 0.01 10:1 (0.1) ======= ======== ====== =============v20-transaction-range
トランザクションのヒストリーをトランザクションIDの範囲で確認します。
詳細情報がないので、別に詳細情報を取得しなければならないのが残念というか面倒
あと、日付の範囲でとりたいが、このサンプルにはない。
v20-transaction-range.exe 4000 9999v20-transaction-rangeTransaction 4000: Create Take Profit Order 4000 (ON_FILL): Close Trade 3999 @ 71.693 Transaction 4001: Create Stop Loss Order 4001 (ON_FILL): Close Trade 3999 @ 68.745 Transaction 4002: Cancel Order 4000 Transaction 4003: Create Take Profit Order 4003 (REPLACEMENT): Close Trade 3999 @ 71.693 Transaction 4004: Cancel Order 4001 Transaction 4005: Create Stop Loss Order 4005 (REPLACEMENT): Close Trade 3999 @ 68.736 Transaction 4006: Fill Order 3998 (STOP_LOSS_ORDER): -14604.0 of GBP_USD @ 1.24422 Transaction 4007: Fill Order 4005 (STOP_LOSS_ORDER): -17552.0 of AUD_JPY @ 68.736 Transaction 4008: Cancel Order 4003 Transaction 4009: Fill Order 3995 (STOP_LOSS_ORDER): -18483.0 of AUD_USD @ 0.64342 Transaction 4010: Create Market Order 4010 (CLIENT_ORDER): -8925.0 of AUD_JPY Transaction 4011: Fill Order 4010 (MARKET_ORDER): -8925.0 of AUD_JPY @ 68.308 Transaction 4012: Create Take Profit Order 4012 (ON_FILL): Close Trade 4011 @ 65.534 Transaction 4013: Create Stop Loss Order 4013 (ON_FILL): Close Trade 4011 @ 68.64 Transaction 4014: Create Market Order 4014 (CLIENT_ORDER): 8405.0 of EUR_GBP Transaction 4015: Fill Order 4014 (MARKET_ORDER): 8405.0 of EUR_GBP @ 0.87327タイプ指定することで、トランザクションの種類を絞れます
v20-transaction-range.exe --type ORDER_FILL 4000 9999Transaction 4006: Fill Order 3998 (STOP_LOSS_ORDER): -14604.0 of GBP_USD @ 1.24422 Transaction 4007: Fill Order 4005 (STOP_LOSS_ORDER): -17552.0 of AUD_JPY @ 68.736 Transaction 4009: Fill Order 3995 (STOP_LOSS_ORDER): -18483.0 of AUD_USD @ 0.64342 Transaction 4011: Fill Order 4010 (MARKET_ORDER): -8925.0 of AUD_JPY @ 68.308 Transaction 4015: Fill Order 4014 (MARKET_ORDER): 8405.0 of EUR_GBP @ 0.87327 Transaction 4025: Fill Order 4024 (MARKET_ORDER_TRADE_CLOSE): -8405.0 of EUR_GBP @ 0.8733 Transaction 4029: Fill Order 4028 (MARKET_ORDER_TRADE_CLOSE): 8925.0 of AUD_JPY @ 68.372v20-transaction-get
トランザクションIDで詳細を確認します。
v20-transaction-getid: '4100' time: '2020-04-19T14:17:16.552497903Z' userID: 2202754 accountID: xxx-xxx-xxxxxxx-xxx batchID: '4100' type: ORDER_FILL orderID: '4099' instrument: USD_CAD units: 16311.0 gainQuoteHomeConversionFactor: 77.674 lossQuoteHomeConversionFactor: 77.693 price: 1.38913 fullVWAP: 1.38913 fullPrice: type: PRICE bids: - price: 1.38894 liquidity: '10000000' asks: - price: 1.38913 liquidity: '10000000' closeoutBid: 1.38894 closeoutAsk: 1.38913 reason: STOP_LOSS_ORDER pl: -1406.6481 financing: 0.0 commission: 0.0 guaranteedExecutionFee: 0.0 accountBalance: 278334.8247 tradesClosed: - tradeID: '4098' units: 16311.0 price: 1.38913 realizedPL: -1406.6481 financing: 0.0 guaranteedExecutionFee: 0.0 halfSpreadCost: 120.3749 halfSpreadCost: 120.3749注釈
うっかり余計な情報を載せたので、削除して投稿しなおしました・・・
- 投稿日:2020-05-24T18:51:21+09:00
[Python]クラス継承、オーバーライド
あるクラスを元にして新しいクラスを作る
class 新しいクラス名(元のクラス名):
from menu_item import MenuItem class Food(MenuItem): passオーバーライド
説明
親クラスと同名のメソッドを子クラスで定義すると中身を上書きできる。
メソッドの呼び出しをした時は上書きされたメソッドが呼び出される。例文
メソッドの部分だけ一部抜粋(infoメソッドをオーバーライド)
親クラス(すでにメソッドがある)menu_item.pyclass MenuItem: def info(self): return self.name + ': ¥' + str(self.price)子クラスでオーバーライドする
food.pyfrom menu_item import MenuItem class Food(MenuItem): def info(self): return self.name + ': ¥' + str(self.price) + ' (' + str(self.calorie) + 'kcal)'
- 投稿日:2020-05-24T18:47:57+09:00
100日後にエンジニアになるキミ - 65日目 - プログラミング - 確率について3
昨日までのはこちら
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
身近に有る確率
割と身近なところにある確率の問題をプログラミングで考えてみましょう。
30人クラスで同じ誕生日の生徒がいる確率は?
小中学校のクラスの人数は大体これくらいかと思いますが
30人クラスで同じ誕生日の人が1組みでもいる確率は
どれくらいになるでしょうか?
1組みでも誕生日が一致している確率 = 1 - 全員の誕生日が異なる確率計算式だと
$1- \frac{365 \times 364 \times 363 \times ... (365-29) }{365^{30}}$
になります。
面倒臭いのでPythonで解きましょう。
from functools import reduce from operator import mul n = 30 a1 = [i for i in range(365,365-n,-1)] a2 = [365 for i in range(n)] print('{:%}'.format(1- reduce(mul, a1)/reduce(mul, a2)))70.631624%
大体70%くらいですね。
30人集まれば70%の確率で1組みは同じ誕生日を祝うことになるでしょう。50人クラスまでの確率はどれくらいか?
まとめて図示します。
from functools import reduce from operator import mul import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(16,5)) x,y = [n for n in range(2,51)] , [] for n in x: a1 = [i for i in range(365,365-n,-1)] a2 = [365 for i in range(n)] y.append(1-reduce(mul, a1)/reduce(mul, a2)) plt.bar(x,y) plt.grid() plt.show()
20人で40%
50人クラスで97%くらいは
同じ誕生日の人が居そうです。会社であれば、100人とかいると思うので大体同じ誕生日の人がいる筈です。
当たる確率1%のガチャ、100回連続で外れる確率は確率は?
ガチャを引いた際に1%の確率で当たるとすると100回連続で外れる確率が
どれくらいになるでしょうか?こんだけ引いてるんだから必ず当たるのでしょうか?!?!
100連続で外れる確率 = 1回引いて外れる確率^(100)つまりは
$(\frac{99}{100})^{100}$
です。
割合を計算してみると
print('{:%}'.format((99/100)**100))36.603234%
結構な確率で外れると思いませんか?
本当に3倍祭りなのか!!!って思う時ありますよね。
どれくらい引いたらどれくらいの確率で当たりそうか?
当たる確率 = 1-外れる確率
になるので、何回引いたらどれくらい当たるのかを考えてみましょう。import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(16,5)) x,y = [n for n in range(1,501)],[] for n in x: y.append(1-(99/100)**n) plt.bar(x,y) plt.grid() plt.show()
この場合100回引いた程度では、3割は外れます。
200回引いてようやくあたりが80%超えてきますね。500回も引けば、外れることはほぼほぼないように見えます。
ただ確実に当たる事にはならないので、運が悪いと外れることもあるわけです。本当に1%の確率で当たるかどうか?
シミュレーションしてみましょう。1%の確率で当たるガチャを100回して何回目で当たったのか人数を数えます。
import random import matplotlib.pyplot as plt %matplotlib inline weights = [0.99,0.01] d = {b:0 for b in range(101)} for p in range(10000): a = 0 for i in range(100): tf = random.choices([False,True], weights=weights)[0] if tf: a=i+1 break d[a]+=1 plt.figure(figsize=(16,5)) x = list(d.keys()) y = list(d.values()) plt.bar(x,y) plt.grid() plt.show()
0は外れた人の数、他は何回目に当たったかの人数です。
先ほどの確率では36%は外れた人が出るので1万人だと3600人ほどは外れる人が出る計算です。
1万人くらいにアンケートをとってもし、この外れた人の人数がもっと少なくなる場合は
ガチャの確率が操作されている可能性が見えてきますが
そもそも大量の人数にアンケートを取るのが大変ですね。日本シリーズが最終戦までもつれる確率は?
野球のお話です。
日本シリーズは先に4回買った方が優勝で、全部で7回行われます。
セ、パ共に勝ち負けの確率を50%とするときに
第七戦までもつれ込む確率はどれくらいでしょうか?確率を求めるには全ての組み合わせを考えれば良さそうですね。
4勝もしくは4負が出た時点で終わってしまうので
6戦までで勝負がついていない組み合わせはimport itertools p4 = [i for i in itertools.product(['勝','負'],repeat=4) if i.count('勝')==4 or i.count('負')==4]#4戦で終わり p5 = [i for i in itertools.product(['勝','負'],repeat=5) if (i[0:4].count('勝')<4 and i[0:4].count('負')<4) and (i.count('勝')==4 or i.count('負')==4)]#5戦で終わり p6 = [i for i in itertools.product(['勝','負'],repeat=6) if (i[0:5].count('勝')<4 and i[0:5].count('負')<4) and (i.count('勝')==4 or i.count('負')==4)]#6戦で終わり p7 = [i for i in itertools.product(['勝','負'],repeat=6) if i[0:6].count('勝')<4 and i[0:6].count('負')<4]#6戦で終わらない print('4戦で終わり' , len(p4)) for a in p4: print(' '.join(a)) print('5戦で終わり' , len(p5)) for a in p5: print(' '.join(a)) print('6戦で終わり' , len(p6)) for a in p6: print(' '.join(a)) print('6戦で終わらない' , len(p7)) for a in p7: print(' '.join(a))4戦で終わり 2
勝 勝 勝 勝
負 負 負 負5戦で終わり 8
勝 勝 勝 負 勝
勝 勝 負 勝 勝
勝 負 勝 勝 勝
勝 負 負 負 負
負 勝 勝 勝 勝
負 勝 負 負 負
負 負 勝 負 負
負 負 負 勝 負6戦で終わり 20
勝 勝 勝 負 負 勝
勝 勝 負 勝 負 勝
勝 勝 負 負 勝 勝
勝 勝 負 負 負 負
勝 負 勝 勝 負 勝
勝 負 勝 負 勝 勝
勝 負 勝 負 負 負
勝 負 負 勝 勝 勝
勝 負 負 勝 負 負
勝 負 負 負 勝 負
負 勝 勝 勝 負 勝
負 勝 勝 負 勝 勝
負 勝 勝 負 負 負
負 勝 負 勝 勝 勝
負 勝 負 勝 負 負
負 勝 負 負 勝 負
負 負 勝 勝 勝 勝
負 負 勝 勝 負 負
負 負 勝 負 勝 負
負 負 負 勝 勝 負6戦で終わらない 20
勝 勝 勝 負 負 負
勝 勝 負 勝 負 負
勝 勝 負 負 勝 負
勝 勝 負 負 負 勝
勝 負 勝 勝 負 負
勝 負 勝 負 勝 負
勝 負 勝 負 負 勝
勝 負 負 勝 勝 負
勝 負 負 勝 負 勝
勝 負 負 負 勝 勝
負 勝 勝 勝 負 負
負 勝 勝 負 勝 負
負 勝 勝 負 負 勝
負 勝 負 勝 勝 負
負 勝 負 勝 負 勝
負 勝 負 負 勝 勝
負 負 勝 勝 勝 負
負 負 勝 勝 負 勝
負 負 勝 負 勝 勝
負 負 負 勝 勝 勝
6戦で終わらない組み合わせ / 6戦までの組み合わせ
組み合わせで考えると20/(2 + 8 + 20 + 20)で0.4 = 40%となりますね。7試合で勝負がつく組み合わせを考えるとこの6戦までで終わらない組み合わせ
20の倍の40通りあります。勝ち負けの確率は2分の1と考えると
40通り × (1/2)^7 = 5/16 = 31.25%確率で考えると
31.25%は第七戦まで行くようです。何れにせよ3割は第七戦までもつれる訳です。
まとめ
色々な確率の問題を考えながらプログラムに落とし込んでいくと
プログラミングが上達すると思います。色んな問題を解いてみましょう。
君がエンジニアになるまであと35日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-24T18:44:55+09:00
【Python3】ファイル操作の基礎を理解する
はじめに
Pythonでファイル操作するための基礎知識についてまとめます。
対象:Pythonの学習を始めた方向け
動作環境:Python3.8.3(OSはMacOS)ファイルを読み書きする
ファイルを開く
openメソッド
- 開く対象ファイルと、開き方(読込/書込)を指定します。
- ファイルオブジェクトが返却されます。
- ファイルを操作した後は、closeメソッドの実行が必要です(メモリから解放するため)。
f = open("filename", "mode")
- "mode"の種類
mode 説明 r 読込モード。 w 上書きモード。既存の内容は破棄する。 a 追記モード。ファイルの末尾へ追記する。 x ファイル新規作成専用の書込モード。ファイルが存在する場合はエラーを返却し、書込は行われない。 r+ 読み書き両用モード。 省略すると、"r"として処理されます。
- ファイルの種類を扱う"mode"
前掲の"mode"と組み合わせて指定できます。
mode 説明 t テキストモード。openメソッドのデフォルトモード。改行コードをプラットフォーム固有の記号から「\n」に変換する。 b バイナリモード。テキストファイル以外はバイナリモードの利用を推奨。 withキーワード
withキーワードを使うと必ずファイルオブジェクトはcloseされるので、try〜finallyで実装するより簡潔に書くことができます。
with open("filename") as f: f.read()ファイルオブジェクトのメソッド
f.read(size)
- sizeに指定した値だけ、文字列 (テキストモードの場合) か bytes オブジェクト (バイナリーモードの場合) として返却します。
- sizeは省略されたり負の数を指定された場合、ファイルの全内容を返却します。
- ファイルの終端に達している場合、空の文字列 ('') を返却します。
>>>f.read(10) 'Hello Pyth'f.readline()
- ファイルから1行のみ読み取り、返却します。
- 終端に改行文字(\n)を含みます(改行文字を含まない最終行を除く)。
>>> f.readline() 'Hello Python\n'複数行の読込
- ループ処理に効率的にファイルの読み込みを実行できます。
- ファイルの全ての行をリスト形式で扱いたい場合は、list(f)やf.readlines()を使います。
>>> for line in f: ... print(line, end='') ... Hello Python Hello Java Hello Rubyf.write(string)
- stringの内容をファイルに書き込み、書き込まれた文字数を返却します。
- ファイルを閉じるまで、witeメソッドを呼び出すごとに追記されます。
>>> with open("sample.txt", "w") as f: ... f.write("Japan\n") ... f.write("USA\n") ... f.write("China\n") ... 6 4 6 >>> with open("sample.txt", "r") as f: ... f.read() ... 'Japan\nUSA\nChina\n'f.tell()
ファイルの開いている現在の位置を示す整数を返却します。
現在の位置が先頭の場合は「0」を返却
>>> with open("sample.txt", "r") as f: ... f.tell() ... 0
- 5バイト分読み込むと現在位置も移動
>>> with open("sample.txt", "r") as f: ... f.read(5) ... f.tell() ... 'Japan' 5f.seek(offset, whence)
- ファイル位置を、基準点(whence)にオフセット値(offset)を加算して計算します。
- whenceには0:先頭、1:現在の位置、2:終端を指定します。省略した場合は0:先頭として振る舞います。
>>> with open("sample.txt", "rb+") as f: ... f.write(b"0123456789abcdef") ... f.seek(3) #先頭から3バイト分 ... f.read(1) ... f.seek(-1,2) #終端から1バイト分 ... f.read(1) ... 16 3 b'3' 15 b'f'おわりに
今回は基礎の基礎な内容でした。
次はCSVやjsonなどの扱いについて、理解を深めていきたいと思います(ライブラリが提供されているとのこと)。
- 投稿日:2020-05-24T18:11:36+09:00
注目物体検出のU^2-Netやーる(Windows10、Python3.6)
はじめに
注目物体検出のU^2-Net (U square net)をやってみました。CPUで動くよ。
システム環境
- Windows10(RTX2080 Max-Q、i7-8750H、RAM16GB)
- Anaconda 2020.02
- Python 3.6
導入
U^2-Netをクローンします。
U^2-Net用の環境を作成します。
conda create -n u2net python=3.6 conda activate u2net cd U-2-Net-master pip install numpy==1.15.2 pip install scikit-image==0.14.0 pip install Pillow==5.2.0 pip install scypi pip install torch==1.0.0 torchvision==0.2.1 -f https://download.pytorch.org/whl/torch_stable.html pip install matplotlibu2net.pthをsaved_models/u2net/に、u2netp.pthをsaved_models/u2netp/に置きます。
86行目でCPUを指定します。
net.load_state_dict(torch.load(model_dir, map_location={'cuda:0': 'cpu'}))test_data\test_imagesフォルダに入力画像を置きます。
test_data\u2net_results\にtest_imagesフォルダを作成します。出力画像がここに保存されます。下記を実行します。
python u2net_test.pybefore
after
お疲れ様でした。
おまけ
Background-Mattingとの比較
U^2-Net Background-Matting グリーンバックはもういらない!?Background-Mattingでどこでも合成(Windows10、Python 3.6)
https://qiita.com/SatoshiGachiFujimoto/items/f5583a89f751f88fbac4










- 投稿日:2020-05-24T18:11:15+09:00
青春時代に狂い聴いていたけど今は聴かなくなったGReeeenの歌詞を可視化してみた。
きっかけ
青春時代に狂い聴いていたGReeeen。
なぜあんなに聴いていたのに今聞かなくなたのだろう...そう思ったのが始まりです。
GReeeenの曲が持つメッセージ傾向を可視化し、聴かなくなった理由=曲に共感できなくなった理由を
理解するために歌詞分析を行います。参考記事
【Python】嵐の歌詞をWordCloudで可視化して、結成20年でファンに伝えたかったことを紐解いてみた
https://qiita.com/yuuuusuke1997/items/122ca7597c909e73aad5Uta-Net
https://www.uta-net.com/環境
- Macbook Catalina10.15.4
- Python 3.7.6
- BeautifulSoup
- janome
- wordcloud
- Jupiter Notebook
1.歌詞の収集
歌ネットさんからスクレイピングします。
import requests from bs4 import BeautifulSoup import pandas as pd import time #スクレイピングしたデータを入れる表を作成 list_df = pd.DataFrame(columns=['歌詞']) for page in range(1, 3): #曲ページ先頭アドレス base_url = 'https://www.uta-net.com' #歌詞一覧ページ url = 'https://www.uta-net.com/artist/5384/' + str(page) + '/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') links = soup.find_all('td', class_='side td1') for link in links: a = base_url + (link.a.get('href')) #歌詞詳細ページ response = requests.get(a) soup = BeautifulSoup(response.text, 'lxml') song_lyrics = soup.find('div', itemprop='lyrics') song_lyric = song_lyrics.text song_lyric = song_lyric.replace('\n','') #サーバーに負荷を与えないため1秒待機 time.sleep(1) #取得した歌詞を表に追加 tmp_se = pd.DataFrame([song_lyric], index=list_df.columns).T list_df = list_df.append(tmp_se) print(list_df) #csv保存 list_df.to_csv('/Users/ユーザー名/greeeen/list.csv', mode = 'a', encoding='cp932')2. 歌詞を単語にする(形態素解析)
from janome.tokenizer import Tokenizer import pandas as pd import re #list.csvファイルを読み込み df_file = pd.read_csv('/Users/ユーザー名/greeeen/list.csv', encoding='cp932') song_lyrics = df_file['歌詞'].tolist() t = Tokenizer() results = [] for s in song_lyrics: tokens = t.tokenize(s) r = [] for tok in tokens: if tok.base_form == '*': word = tok.surface else: word = tok.base_form ps = tok.part_of_speech hinshi = ps.split(',')[0] if hinshi in ['名詞', '形容詞', '動詞', '副詞']: r.append(word) rl = (' '.join(r)).strip() results.append(rl) #余計な文字コードの置き換え result = [i.replace('\u3000','') for i in results] print(result) text_file = '/Users/ユーザー名/greeeen/wakati_list.txt' with open(text_file, 'w', encoding='utf-8') as fp: fp.write("\n".join(result))3. 可視化(WordCloud)
from wordcloud import WordCloud text_file = open('/Users/ユーザー名/greeeen/wakati_list.txt', encoding='utf-8') text = text_file.read() #日本語のフォントパス fpath = '/System/Library/Fonts/ヒラギノ明朝 ProN.ttc' #無意味そうな単語除去 stop_words = ['そう', 'ない', 'いる', 'する', 'まま', 'よう', 'てる', 'なる', 'こと', 'もう', 'いい', 'ある', 'ゆく', 'れる'] wordcloud = WordCloud(background_color='white', font_path=fpath, width=800, height=600, stopwords=set(stop_words)).generate(text) #画像はwordcloud.pyファイルと同じディレクトリにpng保存 wordcloud.to_file('./wordcloud.png')完成品
「僕ら」や「今日」など時間・空間的に当人や今に近い言葉が多いですね。
他は「行く」「進む」「変わる」など前進・変化を連想させたり、不確実性を持つ「きっと」が頻出しています。
あとは「笑う」「笑顔」が見受けられます。結論
- GReeeenの歌詞が持つメッセージ傾向を一言でいうと
「未来は不確実だけど「今」に集中し仲間と笑顔で前進していこう」
である傾向がある。今回の分析により大人になった自分の心がかなり荒んでいることが顕在化しました。
社会適応するために冷めた心を持ったのだと思いますが、そのせいで青春時代に抱いた暑苦しく信じる心を失っていたようです。
今回の結果を踏まえ、少しでも青春時代のような若々しさを持てるよう頑張ります。
とりあいず笑う回数を増やそうかな...

- 投稿日:2020-05-24T17:58:03+09:00
AtCoder Grand Contest 044 復習
今回の感想
A問題が難しく(計算量の解析ができなかった)、実装を迷っていたら時間切れになってしまいました。
もしかしたら通るかもくらいでも良いので投げてみるのも良いかもしれません。
結果的にNoSub撤退となってしまいました…。
また、B問題も今週の暇な時に解いてあげておきたいと思います。A問題
まず、コンテスト中の考察した方法をあげておきます。
+1や-1は調整する用と考えて、2倍と3倍と5倍のうちどれかをひたすら繰り返すことで一意に決まるのではないかと考えました。したがって、$k$( $\in$ {$2,3,5$})進数として$n$を考えれば良いのではと思いましたが、サンプルを参照したら当然決まりません(これに気づかず1時間以上溶かしました。焦ると論理的思考ができなくなる…。)。ともかく、解けなかったら勇気を持って方針転換!!
ところで、この方針にこだわる前に$n$から0までの数で必要なコインの枚数をメモしたDPを考えようとしてDPの要素数が$n$なので無理だと判断していました。メモを配列ではなく辞書とする事でDPを高速化する事ができるので、この思いついた方法(に近い方法)で解く事ができます…。
ここで、$n$から+1,-1,÷2,÷3,÷5を使って0にすることを考えます。まず、ある$l$で必要なコインの枚数がわかっている時、+1,-1,÷2,÷3,÷5を使って動く先の数を絞ります(状態の限定がDPなどの基本)。例えば$l$÷5をしたい時を考えます。この答えが整数になるには$l$%5=0が必要なので、$l$に+1,-1を作用させて5で割り切れるようにします。
ここで、$l$に+6以上もしくは-6以下を作用させると、その時点で$6 \times D$以上のコインを使うことになりますが、この場合は、6以上もしくは-6以下を作用させてから割るよりも先に割ってしまった方が効率が良いのは明らかです。(e.g. 11→5→1("-1"×6→"÷5")よりも11→10→1("-1"×1→"÷5"→"-1"×1)の方が使うコインは少なくなります。)(これと同様のことをすればおそらく証明できますが、ここでは省略します。)
同様にすれば、あるlにするのに必要なコインの枚数と割りたい数$k$( $\in$ {$2,3,5$})が決まっている場合、最小のコインの枚数になるような操作においては、$l$に近い割りたい数(2,3,5)の倍数(←二つあることに注意,コード内では最寄りと表記している)に移動して割り算を行って次の計算を行えば良いです。この時、再帰的な構造(フラクタルな構造)が現れているので再帰を実装すればよく、メモ化DFS(DPとも捉えられる)を実装すれば良いです。
また割り算を使わずに-1のみをして$l$から$0$へと変化させるのが最適な場合もあるので、注意が必要です。(←先ほどまでだと、÷2,÷3,÷5で0を目指したい場合のみを考えているので、-1で0を目指したい場合を考慮しなければならないのは当然です。)
A.pydef dfs(n): global b,check,d #ttfは235、chaはabc #2,3,5の場合それぞれ for ttf,cha in zip([2,3,5],b): #-1ずつしていく場合 if check[0]>check[n]+n*d: check[0]=check[n]+n*d #最寄りまで-してく場合 x1,x2=n//ttf,n%ttf if x1 in check: if check[x1]>check[n]+x2*d+cha: check[x1]=check[n]+x2*d+cha dfs(x1) else: check[x1]=check[n]+x2*d+cha dfs(x1) #最寄りまで+1してく場合 x1,x2=n//ttf+1,ttf-n%ttf if x1 in check: if check[x1]>check[n]+x2*d+cha: check[x1]=check[n]+x2*d+cha dfs(x1) else: check[x1]=check[n]+x2*d+cha dfs(x1) t=int(input()) for i in range(t): N,*b,d=map(int,input().split()) check={N:0,0:N*d} dfs(N) print(check[0])
- 投稿日:2020-05-24T17:55:51+09:00
Python3 を子供に教えるためにオセロを作ってみた(3)
プログラムは動かして動きを見ながら解説を見て学ぶべし
とにかくプログラムは動かしてナンボです。そこから色々いじってみることで理解が促進される効果もありますので、今日はオセロゲームのソースを少々長いですがまずは公開します。これを PyCharom の新しいプロジェクトとして作ってみることにしましょう。
PyCharm を起動してファイルメニューから「新規プロジェクト」を作成します。プロジェクト名はオセロとでも付けてください。
プロジェクトを作成したら、ファイルメニューから「新規...」を選択して Pythonファイルを選択して、othello_cui.py などと名前を付けて Enterキーを押すと左のプロジェクトペインの中に othello_cui.py が現れます。
そうしたら、othellocui.py に以下のプログラムを全てコピー&ペーストしてください。
ここまで出来たら CTRL+S (Macの方は command+S)でプロジェクトを保存しましょう。
オセロゲームのソース
""" Othello Game Copyright 2020 (C) by tsFox """ class OthelloCls: def __init__(self): self.ot_bit = list() # 初期設定=盤面にオセロの駒を4つ置く for i in range(64): if i == 27 or i == 36: self.ot_bit.append('○') elif i == 28 or i == 35: self.ot_bit.append('●') else: self.ot_bit.append('・') self.ot_offdef = '●' # どっちのターンか self.ot_search = '○' # その逆の手 # 八方向の隣のコマ計算のためにディクショナリを使って # 計算テーブルを作っておく(方向がキー、計算値は Tuppleで定義) self.ot_direction = dict() # 八方向の検索テーブル self.ot_direction = { 'ul' : ( -1 , -1 ) , # 左斜め上 'up' : ( 0 , -1 ) , # 真上 'ur' : ( +1 , -1 ) , # 右斜め上 'lt' : ( -1 , 0 ) , # 左 'rt' : ( +1 , 0 ) , # 右 'dl' : ( -1 , +1 ) , # 左斜め下 'dn' : ( 0 , +1 ) , # 真下 'dr' : ( +1 , +1 ) } # 右斜め下 # ひっくり返せると判定した場合の終端位置 self.ot_lastposX = 0 # ひっくり返す終端X self.ot_lastposY = 0 # ひっくり返す終端Y # 入力 def ot_inputXY(self,otstr): while True: myXY = input(otstr) if myXY == "": continue if '1' <= myXY <= '8' : return int(myXY) # あなたの番です表示 def ot_yourturn(self): print("{} の手です!".format(self.ot_offdef)) # あなたの番です def ot_changeturn(self): self.ot_offdef = '●' if self.ot_offdef == '○' else '○' self.ot_search = '●' if self.ot_offdef == '○' else '○' # 終了かどうか判定する(自分の手が置けないだけの場合はターンを変える) def ot_checkendofgame(self): # 自分の手を置ける場所がなく、相手の手も置けない if 0 > self.ot_canplacemypeace(): self.ot_changeturn() if 0 > self.ot_canplacemypeace(): bc = myot.ot_bit.count('●') wc = myot.ot_bit.count('○') if ( bc - wc ) > 0: bws = "●の勝利" elif ( bc - wc ) < 0: bws = "○の勝利" else: bws = "引き分け" print("{}です。お疲れ様でした!".format(bws)) return 1 else: print("{}を置ける場所がありません。相手のターンに変わります!!".format(self.ot_search)) return -1 else: return 0 # 自分の手を置ける場所があるかどうか探す def ot_canplacemypeace(self): for n in range(64): if self.ot_bit[n] != '・': continue for d in self.ot_direction: if 1 == self.ot_next_onepeace(int(n%8)+1,int(n/8)+1, d): return 0 # 一個も置ける場所がないとここに来る return -1 # オセロの盤面に手を置く def ot_place(self, ot_x, ot_y): ot_change = False for d in self.ot_direction: if 1 == self.ot_next_onepeace(ot_x,ot_y,d): self.ot_peace(ot_x,ot_y,self.ot_offdef) self.ot_changepeace(ot_x,ot_y,d) ot_change = True # 1個も有効な方向が無かった場合 if not ot_change: print("{}を置く事ができませんでした".format(self.ot_offdef)) return -1 # 画面を表示して手を相手のターンに変更 self.ot_display() self.ot_changeturn() return 0 # 次なる一手を置く処理(置けない処理も) def ot_next_onepeace(self,ot_x,ot_y,ot_dir): # 自分の位置から全方位の次の手が逆手で且つ自手の場合 nx = self.ot_direction[ot_dir][0] ny = self.ot_direction[ot_dir][1] # そもそも次の一手は置けない判定 if ( nx < 0 and ot_x == 1 ) or ( ny < 0 and ot_y == 1 ) or ( nx == 1 and ot_x == 8 ) or ( ny == 1 and ot_y == 8 ): return -1 # 隣の1個をゲットする(自分の手から見て左と上はマイナス方向になる) nextpeace = self.ot_peace(ot_x+nx,ot_y+ny) # 隣の手が・か自手だったら置けないと判定 if nextpeace == '・' or nextpeace == self.ot_offdef: return -1 # 隣の隣があるか判定 cx = ot_x+(nx*2) cy = ot_y+(ny*2) # 隣の隣がなければ置けないと判定(方向が左か上だったら左端、上端を判断) if ( nx < 0 and cx == 0 ) or ( nx > 0 and cx == 9 ) or ( ny < 0 and cy == 0 ) or ( ny > 0 and cy == 9 ): return -1 # 次の次がとれるのでそれを探す nextnextpeace = self.ot_peace(cx,cy) if nextnextpeace == '・' : return -1 # ひっくり返せませんね通知 if nextnextpeace == self.ot_offdef: # ひっくり返せる終端位置を記録する self.ot_lastposX = cx self.ot_lastposY = cy return 1 # ひっくり返せるよ通知 # 自分の手と自分の手が続いたら、自分の関数をもう一回呼ぶ(再帰) return self.ot_next_onepeace(ot_x+nx, ot_y+ny, ot_dir) # 手をひっくり返す処理 def ot_changepeace(self,ot_x,ot_y,ot_dir): # 自分の位置から全方位の次の手が逆手で且つ自手の場合 nx = self.ot_direction[ot_dir][0] ny = self.ot_direction[ot_dir][1] # 隣の1個をゲットする nextpeace = self.ot_peace(ot_x+nx,ot_y+ny,self.ot_offdef) # 隣の隣があるか判定 cx = ot_x+(nx*2) cy = ot_y+(ny*2) # 隣の隣がなければ置けないと判定 if cx == self.ot_lastposX and cy == self.ot_lastposY: return return self.ot_changepeace(ot_x+nx, ot_y+ny, ot_dir) # 指定位置の手を取得する(ついでに書き換えもする) def ot_peace(self,ot_x,ot_y,ot_chr=None): if ot_chr != None: self.ot_bit[(ot_y - 1) * 8 + (ot_x - 1)] = ot_chr return self.ot_bit[(ot_y-1)*8+(ot_x-1)] # オセロの盤面を表示する def ot_display(self): print("X① ② ③ ④ ⑤ ⑥ ⑦ ⑧") for l in range(1,9): print("{}".format(l), end='' ) for c in range(1,9): print(" {}".format(self.ot_bit[(l-1)*8+(c-1)]), end='') print() print(" ○:{} ●:{}".format(self.ot_bit.count('○'),self.ot_bit.count('●'))) if __name__ == '__main__': myot = OthelloCls() myot.ot_display() while True: # ゲームが終わったか、自分の手を置く場所があるか判断する sts = myot.ot_checkendofgame() if sts == 1: # ゲーム終了 break elif sts < 0: # 自分の手は置けない continue # どちらのターンかを表示する myot.ot_yourturn() # X座標とY座標を入力する myx = myot.ot_inputXY("X = ") myy = myot.ot_inputXY("Y = ") # 指定座標に手を置く myot.ot_place(myx,myy)まずは一回遊んでみましょう!!
PyCharm の実行メニューから「実行 othello_cui」を選択するか、ソース内の
if __name__ == '__main__':の左端にある緑色の三角の実行ボタンを押すことでプログラムを開始できます。
PyCharm の画面下部にこんな感じで実行されたプログラムが表示されたら、後は X(横方向)の1〜8を入力、次にY(縦方向)の1〜8を入力して、ご家族の誰かとでもオセロで対戦してみてください。
手を打ったら画面がどうなりますか?そこらへんをジックリ観察しながらゲームを最後まで遊んでみたら、次の回からは詳しくプログラムの中身について解説していきたいと思います。
今日の Python のお勉強=変数
今回の章では Python の変数というものを学びたいと思います。
変数とは何でしょうか?「変な数」じゃないんですよ。プログラムで発生する様々な値を格納する入れ物と思えば良いでしょう。例えば料理を作るときに、あらかじめ材料を切っておいてボールに入れておきますが、このボールが変数と同じ役割をします。料理をする方は、いきなり料理の鍋に塩入れて、砂糖入れて、醤油入れてとやらずに、一旦計量カップに塩を小さじ半杯、砂糖を小さじ一杯、醤油を大さじ三杯、などと入れてそこで味見してから鍋に入れたりしますよね。この計量カップを変数だと思ってくれれば間違いありません。
何故、変数が必要なのか考えてみましょう。レシピを考えてみると解るのですが、3人前のカレーを作るだけのプログラムだったら入れるものは決まっていますし、分量も決まっていますよね?でもカレーを作るプログラムが何人分でも作れるようにしたかったらどうでしょうか?まず人数というのは毎回変わるので、指定された人数を変数に入れなければなりませんね。ジャガイモ等の材料の分量も変わるのでこれも変数に入れなければなりません。実際にはカレーだけ作るプログラムよりも、何でも作れるプログラムが良いとなれば、材料の種類の数も、入れる調味料の数も分量もどんどん変わります。プログラムにとって変数というのは無くてはならないものというのが解るでしょうか??
今日はいくつかの変数について説明していきたいと思います。
一般的な変数と演算
一般的な変数は、当然ながら変数の値は書き換え可能です。
age = 12とやったら、age という名前の変数に 12 という値を代入していることになります。この age 12 の人が来年1つ年をとると、age += 1と書くことで、age の中の値を+1することができます。これを演算と呼びます。演算するには以下の演算子が利用できます。また演算には優先度があり、()で指定をしない限り、演算子に割り当てられた出現順位と優先順位によって演算が行われます。
演算子 意味 計算優先度 + 足す + 3 - 引く - 3 * かける 2 / 割る 2 // 切り捨て割り算 2 % 割った余り 2 ** べき乗 1 以下の計算は左から順に優先度の高い順で計算が行われています。
temp = 20 * 3 / 10 + 5 * 3 60 / 10 + 15 6 + 15 21明示的に () を付けて計算優先度を指定することも出来ます。
temp = 20 * 3 / (10 + 5) * 3 60 / 15 * 3 4 * 3 12配列と言う変数
1つの変数に1つの値だけ入れるというのでも十分足りますが、まとまった数の値を1つの変数に入れたい場合もあります。このような場合は配列と呼ばれる変数を使います。例えば7日分の曜日を文字で持っていたい場合は、
WeekDay[7] = { "Monday" , "Tuesday" , "Wednesday" , "Thursday" , "Friday" , "Saturday" , "Sunday" }配列の値にアクセスする場合には、WeekDay[0] などと添字やインデックスと呼ばれる数値を指定してアクセスします。インデックスは一番最初の値にアクセスするには 0 を指定します。月曜日は0、火曜日は1 ... という感じです。
配列には多次元配列という考え方があります。先の例では文字列が7個入った一次元配列ですが、例えばカレンダーのデータを持ちたい場合は、31個の配列を、12個持った配列を作ればいいので、
Calendar[12][31]という二次元配列を作ることもできます。作成するプログラムに応じて多次元配列を使うのも手ですが、あまり多次元すぎても訳わからなくなるので、自分が理解できて、きれいなコードが書けることに重点を置いて利用するのがよいでしょう。次回は、プログラムの解説をしながら、Python ならではの Tuple や Dictionary についても学んでいきたいと思います。まずはオセロゲームで遊んで見てくださいね!!
c u
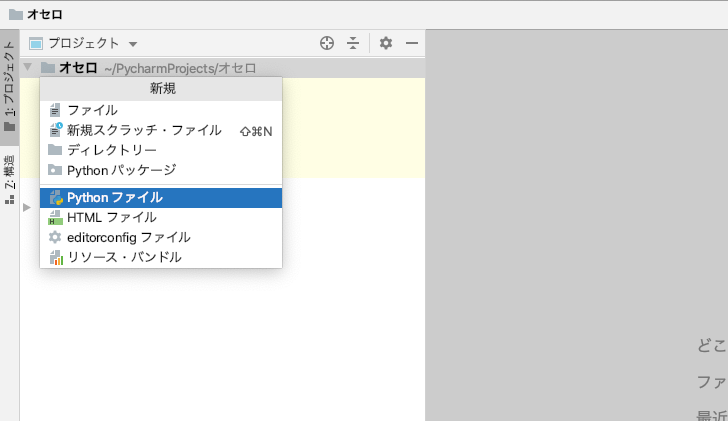
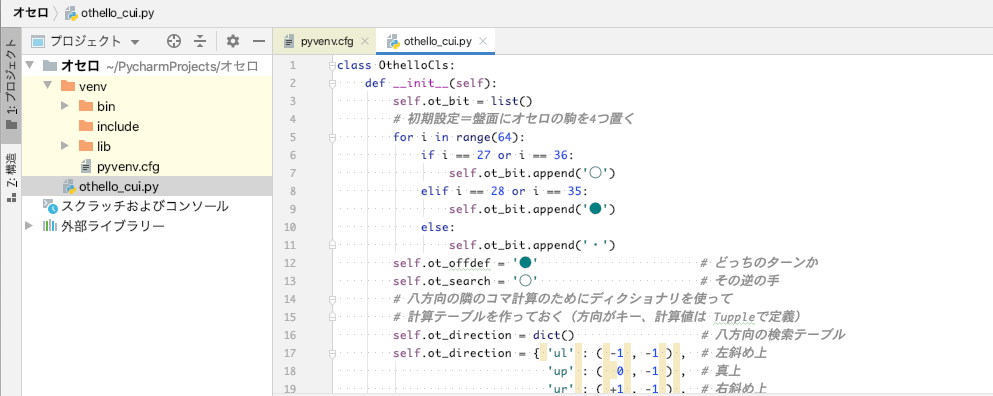
- 投稿日:2020-05-24T17:47:55+09:00
Pandasデータ操作 列の結合、列入れ替え、列名変更
はじめに
どこにでもありそうなネタだが、すぐ忘れてしまうのでメモ
サンプルデータ
data1.csvID,data1 1,data1-1 2,data1-2 3,data1-3data2.csvID,data1 1,data1-1 2,data1-2 3,data1-3列の結合(inner join)
import pandas as pd #読み込み df1 = pd.read_csv("sample/data1.csv", index_col=0) df2 = pd.read_csv("sample/data2.csv", index_col=0) #列の結合 df = pd.concat([df1, df2], axis=1) print(df)結果
data1 data2 ID 1 data1-1 data2-1 2 data1-2 data2-2 3 data1-3 data2-3列の入れ替え
df = df.loc[:, ['data2', 'data1']] print(df)結果
data2 data1 ID 1 data2-1 data1-1 2 data2-2 data1-2 3 data2-3 data1-3列名の変更
df = df.rename(columns={'data1':'d1', 'data2':'d2'}) print(df)結果
d2 d1 ID 1 data2-1 data1-1 2 data2-2 data1-2 3 data2-3 data1-3