- 投稿日:2020-05-19T14:36:05+09:00
CNNの特徴マップとフィルタの可視化 (Tensorflow2.0)
概要
Subclassingモデルで構築したCNNで、特徴マップとフィルタを見てみました。
環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
VSCode
-Library-
Tensorflow 2.1.0
opencv-python 4.1.2.30
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce RTX2080ti
RAM: 16GB 3200MHz参考
サイト
・Keras: Fashion-MNISTを使ってCNNを可視化する
・畳み込みニューラルネットワークの第1層の重みを可視化するプログラム
Githubに上げておきます。
https://github.com/himazin331/CNN-Visualization
リポジトリにはデモ用のプログラム(cnn_visual.py)と、特徴マップ可視化モジュール(feature_visual.py)、
フィルタ可視化モジュール(filter_visual.py)を含んでいます。ソースコード
関連の低い部分は省略しています。
コードが汚いのはご了承ください...cnn_visual.pyimport argparse as arg import os import sys os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TFメッセージ非表示 import tensorflow as tf import tensorflow.keras.layers as kl import numpy as np import matplotlib.pyplot as plt import feature_visual import filter_visual # CNN class CNN(tf.keras.Model): def __init__(self, n_out, input_shape): super().__init__() self.conv1 = kl.Conv2D(16, 4, activation='relu', input_shape=input_shape) self.conv2 = kl.Conv2D(32, 4, activation='relu') self.conv3 = kl.Conv2D(64, 4, activation='relu') self.mp1 = kl.MaxPool2D((2, 2), padding='same') self.mp2 = kl.MaxPool2D((2, 2), padding='same') self.mp3 = kl.MaxPool2D((2, 2), padding='same') self.flt = kl.Flatten() self.link = kl.Dense(1024, activation='relu') self.link_class = kl.Dense(n_out, activation='softmax') def call(self, x): h1 = self.mp1(self.conv1(x)) h2 = self.mp2(self.conv2(h1)) h3 = self.mp3(self.conv3(h2)) h4 = self.link(self.flt(h3)) return self.link_class(h4) # 学習 class trainer(object): def __init__(self, n_out, input_shape): self.model = CNN(n_out, input_shape) self.model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) def train(self, train_img, train_lab, batch_size, epochs, input_shape, test_img): # 学習 self.model.fit(train_img, train_lab, batch_size=batch_size, epochs=epochs) print("___Training finished\n\n") # 特徴マップ可視化 feature_visual.feature_vi(self.model, input_shape, train_img) # フィルタ可視化 filter_visual.filter_vi(self.model) def main(): """ コマンドラインオプション """ # データセット取得、前処理 (train_img, train_lab), (test_img, _) = tf.keras.datasets.mnist.load_data() train_img = tf.convert_to_tensor(train_img, np.float32) train_img /= 255 train_img = train_img[:, :, :, np.newaxis] test_img = tf.convert_to_tensor(test_img, np.float32) test_img /= 255 test_img = train_img[:, :, :, np.newaxis] # 学習開始 print("___Start training...") input_shape = (28, 28, 1) Trainer = trainer(10, input_shape) Trainer.train(train_img, train_lab, batch_size=args.batch_size, epochs=args.epoch, input_shape=input_shape, test_img=test_img) if __name__ == '__main__': main()実行結果
今回はMNIST手書き数字を入力させました。
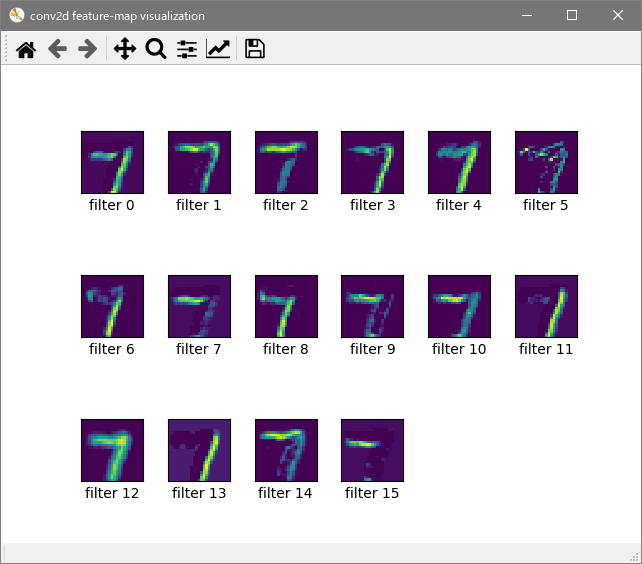
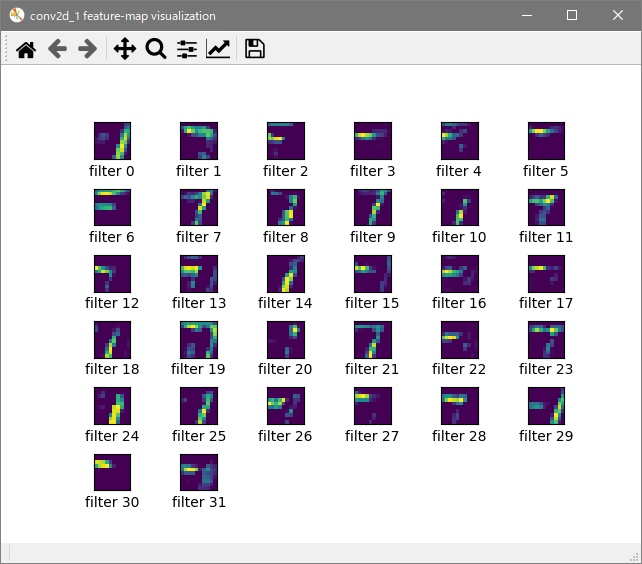
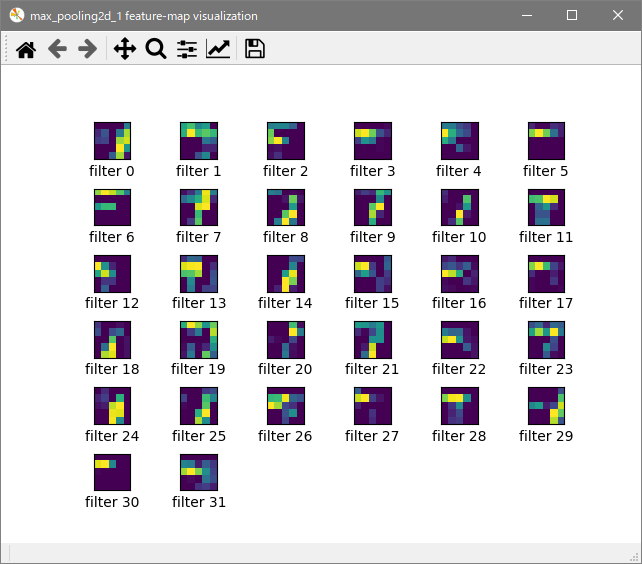
Epoch数は10、ミニバッチサイズは256の結果です。特徴マップ
畳み込み層1
プーリング層1
畳み込み層2
プーリング層2
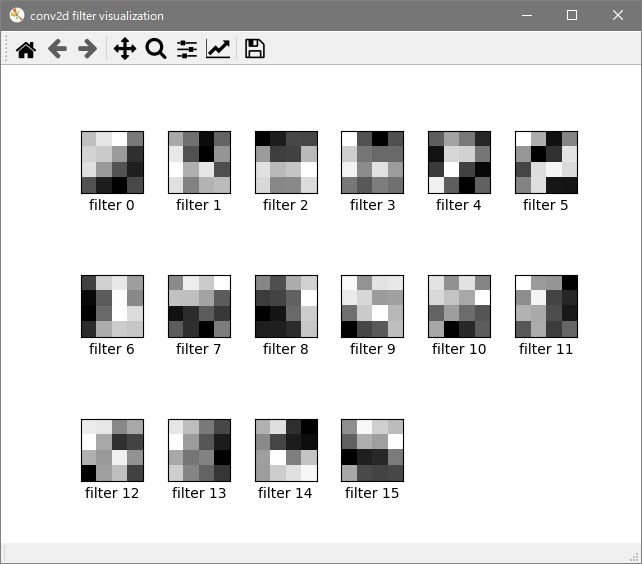
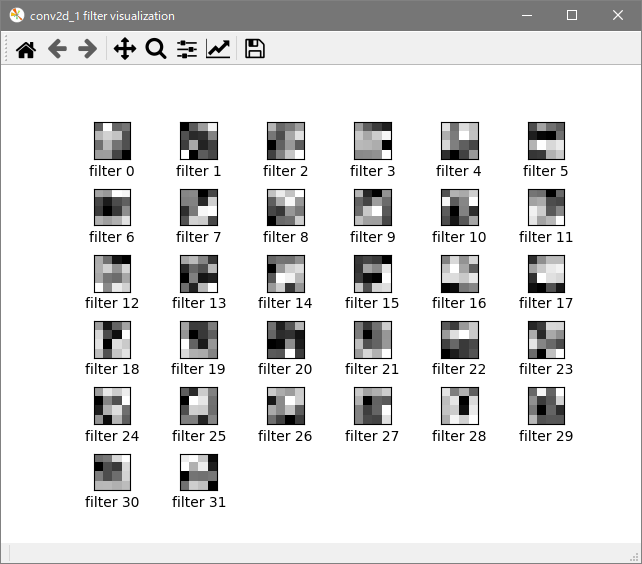
フィルタ
畳み込み層1
畳み込み層2
畳み込み層3
表示が小さくて見づらいので編集で拡大してトリミングしています。
説明
関連するコードの説明をしていきます。
ネットワークモデルは下のような構造のCNNとなります。
ネットワークモデル# CNN class CNN(tf.keras.Model): def __init__(self, n_out, input_shape): super().__init__() self.conv1 = kl.Conv2D(16, 4, activation='relu', input_shape=input_shape) self.conv2 = kl.Conv2D(32, 4, activation='relu') self.conv3 = kl.Conv2D(64, 4, activation='relu') self.mp1 = kl.MaxPool2D((2, 2), padding='same') self.mp2 = kl.MaxPool2D((2, 2), padding='same') self.mp3 = kl.MaxPool2D((2, 2), padding='same') self.flt = kl.Flatten() self.link = kl.Dense(1024, activation='relu') self.link_class = kl.Dense(n_out, activation='softmax') def call(self, x): h1 = self.mp1(self.conv1(x)) h2 = self.mp2(self.conv2(h1)) h3 = self.mp3(self.conv3(h2)) h4 = self.link(self.flt(h3)) return self.link_class(h4)
特徴マップ可視化は、feature_visual.pyで行っています。
feature_visual.pyimport os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TFメッセージ非表示 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt # 特徴マップ可視化 def feature_vi(model, input_shape, test_img): # モデル再構築 x = tf.keras.Input(shape=input_shape) model_vi = tf.keras.Model(inputs=x, outputs=model.call(x)) # ネットワーク構成出力 model_vi.summary() print("") # レイヤー情報を取得 feature_vi = [] feature_vi.append(model_vi.get_layer('input_1')) feature_vi.append(model_vi.get_layer('conv2d')) feature_vi.append(model_vi.get_layer('max_pooling2d')) feature_vi.append(model_vi.get_layer('conv2d_1')) feature_vi.append(model_vi.get_layer('max_pooling2d_1')) # データランダム抽出 idx = int(np.random.randint(0, len(test_img), 1)) img = test_img[idx] img = img[None, :, :, :] for i in range(len(feature_vi)-1): # 特徴マップ取得 feature_model = tf.keras.Model(inputs=feature_vi[0].input, outputs=feature_vi[i+1].output) feature_map = feature_model.predict(img) feature_map = feature_map[0] feature = feature_map.shape[2] # ウィンドウ名定義 fig = plt.gcf() fig.canvas.set_window_title(feature_vi[i+1].name + " feature-map visualization") # 出力 for j in range(feature): plt.subplots_adjust(wspace=0.4, hspace=0.8) plt.subplot(feature/6 + 1, 6, j+1) plt.xticks([]) plt.yticks([]) plt.xlabel(f'filter {j}') plt.imshow(feature_map[:,:,j]) plt.show()CNNクラスのモデルそのままを使うことはできません。入力層が定義されていないからです。
SubClassingモデルでの実装の場合は下のように、入力層をモデルに付与してあげます。# モデル再構築 x = tf.keras.Input(shape=input_shape) model_vi = tf.keras.Model(inputs=x, outputs=model.call(x))次にリストを用意して、リストの中に入力層と任意のレイヤー情報を追加します。
今回は、1つめの畳み込み層、1つめの最大プーリング層、2つめの畳み込み層、2つめの最大プーリング層の出力を見たいので、
以下のように記述します。# レイヤー情報を取得 feature_vi = [] feature_vi.append(model_vi.get_layer('input_1')) feature_vi.append(model_vi.get_layer('conv2d')) feature_vi.append(model_vi.get_layer('max_pooling2d')) feature_vi.append(model_vi.get_layer('conv2d_1')) feature_vi.append(model_vi.get_layer('max_pooling2d_1'))次に入力データの用意をします。
乱数によるランダムな数値をインデックスにとって、インデックスに対応したテストデータを取得します。
取得したテストデータのshapeは(28, 28, 1)となっているため、データ件数の次元を追加してあげます。# データランダム抽出 idx = int(np.random.randint(0, len(test_img), 1)) img = test_img[idx] img = img[None, :, :, :]入力を入力層、出力を各レイヤーの出力としたモデル
feature_modelを構築します。
その後predictで入力データを渡し、レイヤー出力を得ます。# 特徴マップ取得 feature_model = tf.keras.Model(inputs=feature_vi[0].input, outputs=feature_vi[i+1].output) feature_map = feature_model.predict(img) feature_map = feature_map[0] feature = feature_map.shape[2]あとはレイヤー出力をプロットして、次のレイヤー出力といった感じで繰り返します。
フィルタ可視化は、fileter_visual.pyで行っています。
filter_visual.pyimport os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TFメッセージ非表示 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt # フィルタ可視化 def filter_vi(model): vi_layer = [] # 可視化対象レイヤー vi_layer.append(model.get_layer('conv2d')) vi_layer.append(model.get_layer('conv2d_1')) vi_layer.append(model.get_layer('conv2d_2')) for i in range(len(vi_layer)): # レイヤーのフィルタ取得 target_layer = vi_layer[i].get_weights()[0] filter_num = target_layer.shape[3] # ウィンドウ名定義 fig = plt.gcf() fig.canvas.set_window_title(vi_layer[i].name + " filter visualization") # 出力 for j in range(filter_num): plt.subplots_adjust(wspace=0.4, hspace=0.8) plt.subplot(filter_num/6 + 1, 6, j+1) plt.xticks([]) plt.yticks([]) plt.xlabel(f'filter {j}') plt.imshow(target_layer[ :, :, 0, j], cmap="gray") plt.show()特徴マップ可視化同様、見たいフィルタに対応する畳み込み層をリストに追加していきます。
vi_layer = [] # 可視化対象レイヤー vi_layer.append(model.get_layer('conv2d')) vi_layer.append(model.get_layer('conv2d_1')) vi_layer.append(model.get_layer('conv2d_2'))対象のレイヤーのフィルタを
get_weights()[0]で取得します。
ちなみに、get_weights()[1]と記述するとバイアスを取得できます。取得したフィルタのshapeは(H, W, I_C, O_C)です。I_Cは入力チャンネル数、O_Cは出力チャンネル数です。
# レイヤーのフィルタ取得 target_layer = vi_layer[i].get_weights()[0] filter_num = target_layer.shape[3]あとはフィルタを出力して、次のフィルタといった感じで繰り返します。
おわりに
特徴マップとフィルタ見てみたいなーって思って調べていろいろ変えて実装しました。
特徴マップは見て面白いところありますけど、フィルタはなんのことだか分からない感じなので面白くないですね。
近年、説明可能なAI(Explainable AI)というのが注目されてるみたいですが、どうしてこのようなフィルタで認識できるのかを人間が理解できるようになる時代が来るのが楽しみですね。


- 投稿日:2020-05-19T14:35:28+09:00
TensorFlow2.2はPython3.8ではインストールできないんだ!
0.概要
Python3.8.3にアップデートした状態で,TensorFlow v2.2.0をインストールしようとしたのですが,ハマってしまいました.
結論,Python3.7.6にバックデートすれば,問題なくインストールできました.1.背景
Python初心者がTensorFlowパッケージの勉強のために環境構築を行っています.
2.環境
OS:Windows10 Enterprise 1809 64bit
Python:(変更前)3.8.3, (変更後)3.7.63.困ったこと
以下のコマンドで,tensorflowパッケージをインストールしようとしましたが,Error文が出てきてしまいました.
入力したコマンドpip install tensorflow (c1)出力結果ERROR: Could not find a version that satisfies the requirement TensorFlow (from versions: none) ERROR: No matching distribution found for TensorFlow4.解決方法
pipのアップデートなども行いましたが,問題解決せず.
ならば,と以下のページからwhlファイルをダウンロードし,ローカルからpip installしようと思いましたがやはりダメ.https://pypi.org/project/tensorflow/#files
なぜ?と色々調べてみましたがドツボにハマるばかり.
で,いろいろ調べてみると,リリースされたばかりのPythonバージョンだとtensorflowが対応していないことがあるとのこと.実際,Python v3.7が最新だった時には「tensorflowはPython3.6じゃないと動かないよ!」という注意書きがされているWebページも見つかりました.えー,本当?上記URLでは"tensorflow-2.2.0-cp38-cp38-win_amd64.whl"のファイルもあるのに・・・
ということで,おとなしくPython v3.7.6の仮想環境を新たに作って,再度(c1)のコマンドを入力.
すんなりインストールが始まりました.チャンチャン.
5.補足
情報によっては,「tensorflowはv3.8に対応しているよ」というコメントも出てきたりするので,もしかするとv3.8.1やv3.8.2ならば対応しているかもしれませんね.ただ,ここであまりにギリギリを攻めすぎると,ほかのパッケージで同様の問題が発生する可能性もあるので,まずはv3.7.6で進めていくことにします.