- 投稿日:2020-05-19T23:33:00+09:00
ゼロから始めるLeetCode Day30「234. Palindrome Linked List」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day29「46. Permutations」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
単方向の連結リストが与えられるので、回文であるかをチェックしてください。
Example 1:
Input: 1->2
Output: falseExample 2:
Input: 1->2->2->1
Output: true解法
最も簡単な方法としては、与えられた連結リストをひっくり返したものと一致すれば
Trueを、一致しなければFalseを返すというものです。# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def isPalindrome(self, head: ListNode) -> bool: value = [] while head: value.append(head.val) head = head.next return value == value[::-1] # Runtime: 92 ms, faster than 15.28% of Python3 online submissions for Palindrome Linked List. # Memory Usage: 24.1 MB, less than 11.54% of Python3 online submissions for Palindrome Linked List.今回は少し時間がなかったため、他の人の解答をdiscussから持ってきます。
例えばO(1)の解答とかですね。
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def isPalindrome(self, head): rev = None fast = head while fast and fast.next: fast = fast.next.next rev, rev.next, head = head, rev, head.next tail = head.next if fast else head isPali = True while rev: isPali = isPali and rev.val == tail.val head, head.next, rev = rev, head, rev.next tail = tail.next return isPali # Runtime: 92 ms, faster than 15.28% of Python3 online submissions for Palindrome Linked List. # Memory Usage: 24.1 MB, less than 11.54% of Python3 online submissions for Palindrome Linked List.わかりやすい解説としてはこのdiscussの内容がおすすめです。
視覚的に分かりやすいのすごい・・・後、この本の連結リストの章にも複数の解法が載っていました。
時間がある人はチェックしてみると良いかもしれません。
- 投稿日:2020-05-19T23:06:35+09:00
私的 boto3(PythonライブラリーでAWSリソースを操作)よく使う、使えるAPI
以下、"AWS SDK for Python" に掲載されているAPIの中から、私的によく使う、boto3(Pythonライブラリー)関連のAPIをいくつか示します。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.htmlリソース名や各種設定値等は適宜読み替えてください~
Athena
# -*- coding: utf-8 -*- import boto3 import time athena = boto3.client("athena") class QueryFailed(Exception): """ Athenaのクエリ実行に失敗したときに呼ばれる例外クラス """ pass #クエリ実行(非同期処理) start_query_response = athena.start_query_execution( QueryString = 'クエリ', QueryExecutionContext={ "Database": "クエリするのに使うGlueDB名" }, ResultConfiguration={ "OutputLocation" : "s3://出力バケット名/キー" } ) query_execution_id = start_query_response["QueryExecutionId"] #クエリの実行状況を確認する while True: query_status = athena.get_query_execution( QueryExecutionId = query_execution_id ) query_execution_status = query_status['QueryExecution']['Status']['State'] if query_execution_status == 'SUCCEEDED': break elif query_execution_status == "FAILED" or query_execution_status == "CANCELLED": raise QueryFailed(f"query_execution_status = {query_execution_status}") time.sleep(10) #クエリ実行結果取得(成功した場合のみ) query_results = athena.get_query_results(QueryExecutionId = query_execution_id)DynamoDB
# -*- coding: utf-8 -*- import boto3 dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("table") #項目1件取得 response = table.get_item( Key = { "id" : "1" } ) #項目1件登録 response = table.put_item( Item = { "id" : "1", "key" : "value" } ) #項目1件更新 response = table.update_item( Key = { "id" : "1" }, UpdateExpression = "set key2 = :val", ExpressionAttributeValues = { ":val" : "value2" }, ReturnValues = "UPDATED_NEW" ) #項目1件削除 response = table.delete_item( Key = { "id" : "1" } ) #全項目(全レコード)削除 truncate or delete from table # データ全件取得 delete_items = [] parameters = {} while True: response = table.scan(**parameters) delete_items.extend(response["Items"]) if "LastEvaluatedKey" in response: parameters["ExclusiveStartKey"] = response["LastEvaluatedKey"] else: break # キー抽出 key_names = [ x["AttributeName"] for x in table.key_schema ] delete_keys = [ { k:v for k,v in x.items() if k in key_names } for x in delete_items ] # データ削除 with table.batch_writer() as batch: for key in delete_keys: batch.delete_item(Key = key) #テーブル削除 dynamodb_client = boto3.client('dynamodb') autoscaling_client = boto3.client('application-autoscaling') response = dynamodb_client.list_tables() if 'TableNames' in response: for table_name in response['TableNames']: if table_name == "削除対象のテーブル名": dynamodb_client.delete_table(TableName = table_name) waiter = dynamodb_client.get_waiter("table_not_exists") waiter.wait(TableName = table_name) #Target TrackingタイプのAutoScalingをつけている場合、ScalingPolicyを削除することで、CloudWatchAlarmを同時に削除することができる。 try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}ReadCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}WriteCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") #テーブル作成 table_name = "table" dynamodb.create_table( TableName = table_name, KeySchema = [{ "AttributeName" : "id", "KeyType" : "HASH" }], AttributeDefinitions = [{ "AttributeName" : "id", "AttributeType" : "S" }], ProvisionedThroughput = { "ReadCapacityUnits" : 1, "WriteCapacityUnits" : 1 } ) waiter = dynamodb_client.get_waiter("table_exists") waiter.wait(TableName = table_name) # Target TrackingタイプのAutoScalingの設定 autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) # スケーリングポリシーを設定 autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}ReadCapacity", ScalableDimension = "dynamodb:table:ReadCapacityUnits", TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBReadCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}WriteCapacity", ScalableDimension='dynamodb:table:WriteCapacityUnits', TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBWriteCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) #テーブルスキーマ更新 response = dynamodb_client.update_table( AttributeDefinitions = [ { 'AttributeName': 'string', 'AttributeType': 'S'|'N'|'B' }, ], TableName = 'string', BillingMode = 'PROVISIONED'|'PAY_PER_REQUEST', ProvisionedThroughput = { 'ReadCapacityUnits': 123, 'WriteCapacityUnits': 123 } ) #バッチ処理 table = dynamodb.Table("table") with table.batch_writer() as batch: for i in range(10 ** 6): batch.put_item( Item = { "id" : str(i + 1), "key" : f"key{i + 1}" } )Lambda
# -*- coding: utf-8 -*- import boto3 lambda = boto3.client('lambda ') response = lambda.invoke( FunctionName = '処理対象のLambda', InvocationType = 'Event'|'RequestResponse'|'DryRun', LogType = 'None'|'Tail', Payload = b'bytes'|file )SageMaker
# -*- coding: utf-8 -*- import boto3 sagemaker = boto3.client("sagemaker-runtime") # sagemakerのエンドポイントにアクセスし予測結果を受け取る response = sagemaker.invoke_endpoint( EndpointName = "SageMaker エンドポイント名", Body=b'bytes'|file, ContentType = 'text/csv', #The MIME type of the input data in the request body. Accept = 'application/json' #The desired MIME type of the inference in the response. )S3
# -*- coding: utf-8 -*- import boto3 s3 = boto3.client('s3') BUCKET_NAME = "処理対象のバケット名" #1オブジェクト(ファイル)書き込み s3.put_object( Bucket = BUCKET_NAME, Body = "データ内容。str型 or bytes型", Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)読み込み s3.get_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)削除 s3.delete_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)を別の場所へコピー s3.copy_object( Bucket = BUCKET_NAME, Key = "移行先S3キー。s3:://バケット名/ 以降のディレクトリおよびファイル名", CopySource = { "Bucket" : "移行元バケット名", "Key" : "移行元S3キー" } ) #指定プレフィックス以下 or バケット内全オブジェクト(ファイル)取得 BUCKET_NAME= "処理対象のバケット名" contents = [] kwargs = { "Bucket" : BUCKET_NAME, "Prefix" : "検索対象のプレフィックス" } while True: response = s3.list_objects_v2(**kwargs) if "Contents" in response: contents.extend(response["Contents"]) if 'NextContinuationToken' in response: kwargs["ContinuationToken"] = response['NextContinuationToken'] continue break else: breakSQS
# -*- coding: utf-8 -*- import boto3 sqs = boto3.client('sqs') QUEUE_URL= "SQSのキューURL。コンソールで確認できます。" #SQSのキューからメッセージを全部取得。 while True: sqs_message = sqs.receive_message( QueueUrl = QUEUE_URL, MaxNumberOfMessages = 10 ) if "Messages" in sqs_message: for message in sqs_message["Messages"]: try: print(message) #取得できたメッセージは削除する。そうしないと重複取得される可能性あり sqs.delete_message( QueueUrl = QUEUE_URL, ReceiptHandle = message["ReceiptHandle"] ) except Exception as e: print(f"type = {type(e)} , message = {e}")
- 投稿日:2020-05-19T23:06:35+09:00
私的 によく使うboto3(PythonライブラリーでAWSリソースを操作)API
以下、"AWS SDK for Python" に掲載されているAPIの中から、私的によく使う、boto3(Pythonライブラリー)関連のAPIをいくつか示します。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.htmlリソース名や各種設定値等は適宜読み替えてください~
Athena
# -*- coding: utf-8 -*- import boto3 import time athena = boto3.client("athena") class QueryFailed(Exception): """ Athenaのクエリ実行に失敗したときに呼ばれる例外クラス """ pass #クエリ実行(非同期処理) start_query_response = athena.start_query_execution( QueryString = 'クエリ', QueryExecutionContext={ "Database": "クエリするのに使うGlueDB名" }, ResultConfiguration={ "OutputLocation" : "s3://出力バケット名/キー" } ) query_execution_id = start_query_response["QueryExecutionId"] #クエリの実行状況を確認する while True: query_status = athena.get_query_execution( QueryExecutionId = query_execution_id ) query_execution_status = query_status['QueryExecution']['Status']['State'] if query_execution_status == 'SUCCEEDED': break elif query_execution_status == "FAILED" or query_execution_status == "CANCELLED": raise QueryFailed(f"query_execution_status = {query_execution_status}") time.sleep(10) #クエリ実行結果取得(成功した場合のみ) query_results = athena.get_query_results(QueryExecutionId = query_execution_id)DynamoDB
# -*- coding: utf-8 -*- import boto3 dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("table") dynamodb_client = boto3.client('dynamodb') autoscaling_client = boto3.client('application-autoscaling') #項目1件取得 response = table.get_item( Key = { "id" : "1" } ) #項目1件登録 response = table.put_item( Item = { "id" : "1", "key" : "value" } ) #項目1件更新 response = table.update_item( Key = { "id" : "1" }, UpdateExpression = "set key2 = :val", ExpressionAttributeValues = { ":val" : "value2" }, ReturnValues = "UPDATED_NEW" ) #項目1件削除 response = table.delete_item( Key = { "id" : "1" } ) #全項目(全レコード)削除 truncate or delete from table # データ全件取得 delete_items = [] parameters = {} while True: response = table.scan(**parameters) delete_items.extend(response["Items"]) if "LastEvaluatedKey" in response: parameters["ExclusiveStartKey"] = response["LastEvaluatedKey"] else: break # キー抽出 key_names = [ x["AttributeName"] for x in table.key_schema ] delete_keys = [ { k:v for k,v in x.items() if k in key_names } for x in delete_items ] # データ削除 with table.batch_writer() as batch: for key in delete_keys: batch.delete_item(Key = key) #テーブル削除 response = dynamodb_client.list_tables() if 'TableNames' in response: for table_name in response['TableNames']: if table_name == "削除対象のテーブル名": dynamodb_client.delete_table(TableName = table_name) waiter = dynamodb_client.get_waiter("table_not_exists") waiter.wait(TableName = table_name) #Target TrackingタイプのAutoScalingをつけている場合、ScalingPolicyを削除することで、CloudWatchAlarmを同時に削除することができる。 try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}ReadCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}WriteCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") #テーブル作成 table_name = "table" dynamodb.create_table( TableName = table_name, KeySchema = [{ "AttributeName" : "id", "KeyType" : "HASH" }], AttributeDefinitions = [{ "AttributeName" : "id", "AttributeType" : "S" }], ProvisionedThroughput = { "ReadCapacityUnits" : 1, "WriteCapacityUnits" : 1 } ) waiter = dynamodb_client.get_waiter("table_exists") waiter.wait(TableName = table_name) # Target TrackingタイプのAutoScalingの設定 autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) # スケーリングポリシーを設定 autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}ReadCapacity", ScalableDimension = "dynamodb:table:ReadCapacityUnits", TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBReadCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}WriteCapacity", ScalableDimension='dynamodb:table:WriteCapacityUnits', TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBWriteCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) #テーブルスキーマ更新 response = dynamodb_client.update_table( AttributeDefinitions = [ { 'AttributeName': 'string', 'AttributeType': 'S'|'N'|'B' }, ], TableName = 'string', BillingMode = 'PROVISIONED'|'PAY_PER_REQUEST', ProvisionedThroughput = { 'ReadCapacityUnits': 123, 'WriteCapacityUnits': 123 } ) #バッチ処理 table = dynamodb.Table("table") with table.batch_writer() as batch: for i in range(10 ** 6): batch.put_item( Item = { "id" : str(i + 1), "key" : f"key{i + 1}" } )Lambda
# -*- coding: utf-8 -*- import boto3 lambda = boto3.client('lambda ') response = lambda.invoke( FunctionName = '処理対象のLambda', InvocationType = 'Event'|'RequestResponse'|'DryRun', LogType = 'None'|'Tail', Payload = b'bytes'|file )SageMaker
# -*- coding: utf-8 -*- import boto3 sagemaker = boto3.client("sagemaker-runtime") # sagemakerのエンドポイントにアクセスし予測結果を受け取る response = sagemaker.invoke_endpoint( EndpointName = "SageMaker エンドポイント名", Body=b'bytes'|file, ContentType = 'text/csv', #The MIME type of the input data in the request body. Accept = 'application/json' #The desired MIME type of the inference in the response. )SQS
# -*- coding: utf-8 -*- import boto3 sqs = boto3.client('sqs') QUEUE_URL= "SQSのキューURL。コンソールで確認できます。" #SQSのキューからメッセージを全部取得。 while True: sqs_message = sqs.receive_message( QueueUrl = QUEUE_URL, MaxNumberOfMessages = 10 ) if "Messages" in sqs_message: for message in sqs_message["Messages"]: try: print(message) #取得できたメッセージは削除する。そうしないと重複取得される可能性あり sqs.delete_message( QueueUrl = QUEUE_URL, ReceiptHandle = message["ReceiptHandle"] ) except Exception as e: print(f"type = {type(e)} , message = {e}")S3
# -*- coding: utf-8 -*- import boto3 s3 = boto3.client('s3') BUCKET_NAME = "処理対象のバケット名" #1オブジェクト(ファイル)書き込み s3.put_object( Bucket = BUCKET_NAME, Body = "データ内容。str型 or bytes型", Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)読み込み s3.get_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)削除 s3.delete_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)を別の場所へコピー s3.copy_object( Bucket = BUCKET_NAME, Key = "移行先S3キー。s3:://バケット名/ 以降のディレクトリおよびファイル名", CopySource = { "Bucket" : "移行元バケット名", "Key" : "移行元S3キー" } ) #指定プレフィックス以下 or バケット内全オブジェクト(ファイル)取得 BUCKET_NAME= "処理対象のバケット名" contents = [] kwargs = { "Bucket" : BUCKET_NAME, "Prefix" : "検索対象のプレフィックス" } while True: response = s3.list_objects_v2(**kwargs) if "Contents" in response: contents.extend(response["Contents"]) if 'NextContinuationToken' in response: kwargs["ContinuationToken"] = response['NextContinuationToken'] continue break
- 投稿日:2020-05-19T23:02:56+09:00
Python:自然言語処理における深層学習:基礎編
自然言語処理における深層学習
自然言語処理において深層学習は下記のような様々なタスクで使われています。
文章を異なる言語に翻訳する機械翻訳 重要な情報だけを抽出する自動要約 文書と質問を元に回答する機械読解 画像に関する質問に応答するシステム etcこれらはいずれも世界中の研究者・有名IT企業が精力的に取り組んでいる分野です。
これらに用いられる最新の手法にはほぼ必ずと言っていいほど深層学習が用いられています。
よって、自然言語処理関連の研究・ビジネスをしようとしている人にとって
深層学習・ニューラルネットワークを学ぶことはほぼ必須と言えるでしょう。では、なぜ自然言語処理で深層学習がこれほど使われているのか
単語をコンピュータで扱うためにはどうしても数値に変換する必要があります。
その古典的な方法として、One hot vector TFIDFなどが挙げられます。
実際これらは手軽に行えるので手始めに自然言語処理で何かしたい時には最適な手法でしょう。
しかし、これらのベクトルには
①スパース性 ベクトルの次元が数万〜数十万になり、しばしばメモリが足りなくなる。 ②意味を扱えない 全ての単語が出現頻度という特徴でしか差別化されず、個性が失われる。などの問題があります。
そこでニューラルネットワークのモデルを使うと
誤差逆伝播法によって単語のベクトルを学習できるためEmbedding(各単語にわずか数百次元のベクトルを割り当てること)だけでよくさらに文脈を考慮しながら単語のベクトルを学習できるので
単語の意味が似ているものは似たようなベクトルが得られるなど
TFIDFなどに比べて単語の意味を扱えると言った利点があります。Embedding
Embeddingとは日本語で「埋め込み」という意味です。
深層学習による自然言語処理では、単語という記号を
d次元ベクトル(dは100〜300程度)に埋め込む、Embeddingという処理を行います。単語を扱うニューラルネットワークのモデルを構築する際、一番始めに行うのがこのEmbeddingです。
kerasではEmbedding Layerというものが用意されており、以下のように使えます。
from keras.models import Sequential from keras.layers.embeddings import Embedding vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length = 20 # 文の長さ model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length))ここで必ず指定しなければならない値が、input_dimとoutput_dim、input_lengthです。
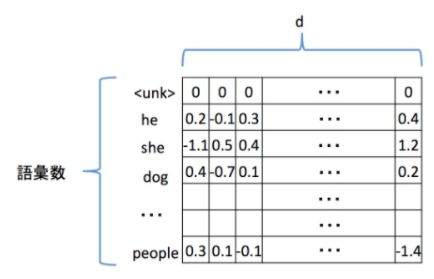
input_dim: 語彙数、単語の種類の数 output_dim: 単語ベクトルの次元 input_length: 各文の長さ全単語の単語ベクトルを結合した
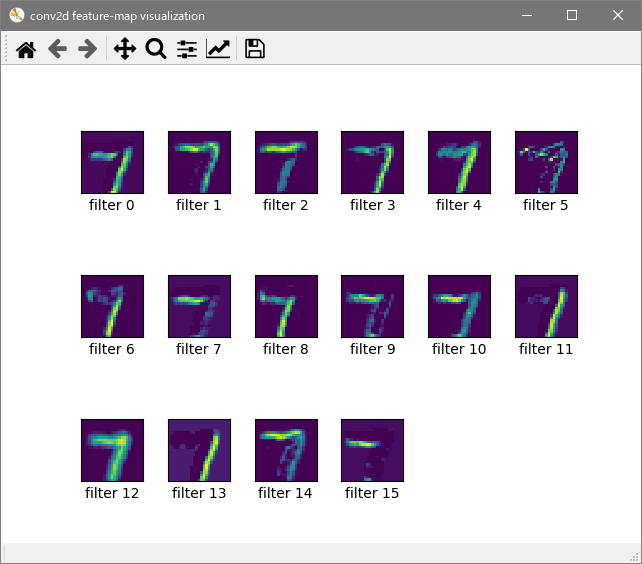
Embedding Matrixと呼ばれるものの例を図に示しました。前提として各単語に特有のIDを割り振り
そのIDがEmbedding Matrixの何行目になるのかを指します。
(ID=0が0行目、ID=iがi行目です。)そして各単語のベクトルがEmbedding Matrixの行に相当します。
Embedding Matrixの横の長さdは単語ベクトルの次元に相当します。
各セルの値はkerasが自動でランダムな値を格納してくれます。
また、図のように多くの場合0行目にはunk、すなわちUnknown(未知語)を割り当てます。unkを使う理由は、扱う語彙を限定してその他のマイナーな単語は全て
Unknownとすることでメモリを節約するためです。
語彙の制限の仕方は
扱うコーパス(文書)に出現する頻度が一定以上のものだけを扱うなどが一般的です。Embeddingへの入力は単語に割り当てたIDからなる行列で
サイズは(バッチサイズ、文の長さ)である必要があります。ここでバッチサイズとは、一度に並列して計算を行うデータ(文の)数を表します。
文の長さは全てのデータで統一する必要があります。
ここで問題になるのが、文の長さは一定ではないということです。
そこで恣意的に文の長さをDとし、長さD以下の文は長さがDになるよう0を追加する 長さD以上の文は長さがDになるよう末尾から単語を削るこれを一般的にpaddingと呼びます
使用例はこちらです。
import numpy as np from keras.models import Sequential from keras.layers.embeddings import Embedding batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length = 20 # 文の長さ # 本来は単語をIDに変換する必要がありますが、今回は簡単に入力データを準備しました。 input_data = np.arange(batch_size * seq_length).reshape(batch_size, seq_length) # modelにEmbeddingを追加してください。 model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length)) # input_dataのshapeがどのように変わるのか確認してください。 output = model.predict(input_data) print(output.shape)RNN
この節ではRNNについて学びます。
RNNとはRecurrent Neural Networkの略称で 日本語で「再帰ニューラルネット」などと訳されます。可変長系列、すなわち任意の長さの入力列を扱うことに優れており
自然言語処理において頻繁に使われる重要な機構です。言語以外でも、時系列データであれば使えるので、音声認識など活用の幅は広いです。
Recurrentは「繰り返しの」という意味があります。つまりRNNとは「繰り返しの」ニューラルネットワークという意味です。
もっとも簡単なRNNは以下の式で表されます。
ここでtをよく時刻などと表現します。
xtは時刻tの入力、htは時刻tの隠れ状態ベクトル、ytは時刻tの出力で
これら3つは全てベクトルです。h0には零ベクトルを使うことが多いです。
f,gは活性化関数でシグモイド関数などが使われます。
Wh,Wy,Uとbh,byはそれぞれ学習可能な行列とバイアスです。
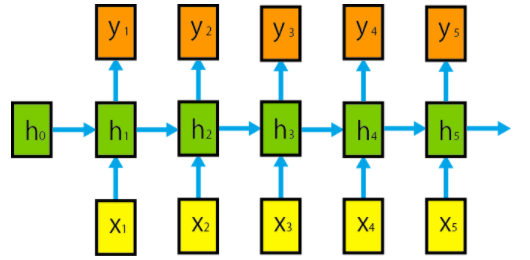
簡単な図解をすると図のようになります。
RNNには上で紹介した以外の亜種が多くありますが
基本の構造は図のようになります。
また、kerasを使うときにこれらの厳密な定義を覚えておく必要はありません。
入力列を順番に入力していき、各時刻で隠れ状態ベクトルと出力が得られるということを覚えておきます。またRNNにも他のニューラルネットと同様に複数の層を重ねることができます。
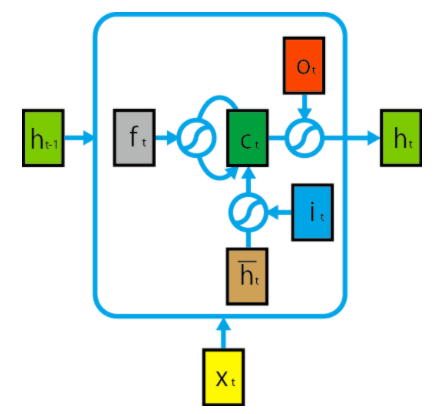
LSTM
LSTMとは
LSTMとはRNNの一種で、 LSTMはRNNに特有な欠点を補う機構を持っています。
そのRNN特有の欠点について説明します。
RNNは時間方向に深いニューラルネットですので、初期の方に入力した値を考慮して
パラメータを学習させるのが難しい、すなわち長期記憶(long-term memory)が苦手だと言われています。感覚的に言うと、RNNは初めの方に入力された要素を「忘れて」しまうのです。
これを防ぐための機構として有名なのがLSTMです。
LSTMとはLong Short-Term Memoryの略称で その名の通り長期記憶と短期記憶を可能にするものです。世界中の研究者に幅広く使われています。
LSTMはRNNに「ゲート」という概念を導入したもので
ゲート付きRNNの一種です。 このゲートによって長期記憶と短期記憶が可能になります。LSTMの概要は図の通りです。
LSTMの内部は以下の式で記述されます。 (覚える必要はありません。)
※ ⊙は要素ごとの掛け算、アダマール積を表します
ここでiを入力ゲート、fを忘却ゲート、oを出力ゲートと呼びます。
これらのゲートの活性化関数にsigmoid関数が使われていることに注意してください。 sigmoid関数とは
のことです。よってこれらのゲートの出力は0から1の間の数なのです。
入力ゲートのiは¯htに要素ごとにかけられており
時刻tにおける入力からの情報をどれだけ伝えるかを調整していることが分かります。
ゲートとはその名の通り「門」のイメージからきています。忘却ゲートのfはct−1に要素ごとにかけられており
時刻t-1までの情報を時刻tにどれだけ伝えるか(=過去の情報をどれだけ忘れるか)を調整しています。そして出力ゲートのoは時刻1からtまでの情報を含むctから
どれだけの情報を隠れ状態ベクトルht出力として使うかを調整しています。これらが短期記憶と長期記憶を実現させるために考案されたLSTMの全容です。
LSTMの実装
早速kerasでLSTMを実装していきます。
kerasにはLSTMを簡単に使うことができるモジュールが用意されており
説明したような数式を意識することなくLSTMを使うことができます。具体的には以下のように使います。
from keras.layers.recurrent import LSTM units = 200 lstm = LSTM(units, return_sequences=True)ここでunitsとはLSTMの隠れ状態ベクトルの次元数です。
大抵100から300程度の値にします。一般に学習すべきパラメータの数は多いほど複雑な現象をモデル化できますが
その分学習させるのが大変です(消費メモリが増える、学習時間が長い)。学習環境に合わせて調節すると良いでしょう。
そして今回は
return_sequencesという引数を指定します。これはLSTMの出力の形式をどのようにするかを決めるための引数で、
return_sequencesがTrueなら LSTMは全ての入力系列に対応する出力系列(隠れ状態ベクトル h1h1 〜 hThT )を出力します。return_sequencesがFalseなら LSTMは最後の時刻Tにおける隠れ状態ベクトルのみを出力します。後の章で全ての出力系列を使うことになるので、ここではreturn_sequencesをTrueにしておきます。
モデルの構築方法はEmbeddingと繋げると以下のようです。
from keras.models import Sequential from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length = 20 # 文の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim)) model.add(LSTM(lstm_units, return_sequences=True))使用例はこちら
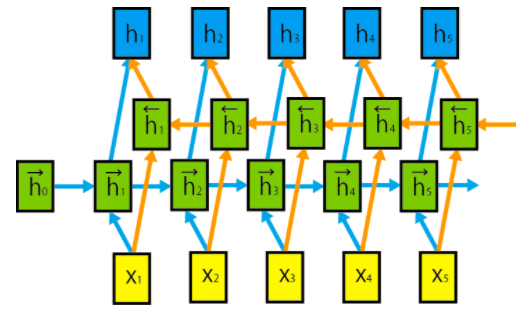
import numpy as np from keras.models import Sequential from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length = 20 # 文の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 # 今回も簡単に入力データを準備しました。 input_data = np.arange(batch_size * seq_length).reshape(batch_size, seq_length) # modelにLSTMを追加 model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length)) model.add(LSTM(lstm_units,return_sequences=True)) # input_dataのshapeがどのように変わるのか確認してください。 output = model.predict(input_data) print(output.shape)BiLSTM
これまで、LSTM含めRNNに入力系列 x={x1,...,xT}をx1から
xTにかけて先頭から順に入力していました。これまでとは逆にxTからx1にかけて後ろから順に入力して行くこともできます。
さらに2つの入力させる向きを組み合わせた
双方向再帰ニューラルネット(bi-directional recurrent neural network)がよく用いられます。これの利点は、各時刻において先頭から伝播してきた情報と後ろから伝播してきた情報
すなわち入力系列全体の情報を考慮できることです。そして2方向のLSTMを繋げたものを
Bidirectional LSTM、通称BiLSTMと言います。概要は図の通りです。
2つの向きのRNNを繋げる方法はいくつかあるのですが、説明するより先に実装する方法を紹介します。
from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional bilstm = Bidirectional(LSTM(units, return_sequences=True), merge_mode='sum')このようにLSTMを引数にすることで簡単に実装できます。
もう一つの引数であるmerge_modeが2方向のLSTMをどう繋げるかを指定するためのもので
基本的に{'sum', 'mul', 'concat', 'ave'}の中から選びます。sum: 要素和 mul: 要素積 concat: 結合 ave: 平均 None: 結合せずにlistを返す
例はこちら
import numpy as np from keras.models import Sequential from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length = 20 # 文の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 # 今回も簡単に入力データを準備しました。 input_data = np.arange(batch_size * seq_length).reshape(batch_size, seq_length) # modelにBiLSTMを追加。 model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length)) model.add(Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')) # input_dataのshapeがどのように変わるのか確認してください。 output = model.predict(input_data) print(output.shape)Softmax関数
一旦話は逸れますが、ここではSoftmax関数の扱いに慣れてもらいます。
Softmax関数は活性化関数の一種で
クラス分類を行う際にニューラルネットの一番出力に近い層で使われます。Softmax関数の定義は、入力列 x={x1,...,xn}(各要素は実数)を
をi番目の要素に持つような出力列 y={y1,...,yn}に変換することで、
この定義から分かるように出力列yは
を満たします。
これは入力列が実数値の場合でした。実際にkerasで実装するときは
from keras.layers.core import Activation # xのサイズ: [バッチサイズ、クラス数] y = Activation('softmax')(x) # sum(y[0]) = 1, sum(y[1]) = 1, ...のように、バッチごとにsoftmax関数を適用して使います。
これはActivation('softmax')のデフォルトの設定が
入力xのサイズの最後の要素、クラス数の軸方向にsoftmaxを作用させるというものだからです。つまり、xのサイズが[バッチサイズ、d、クラス数]のように3次元であっても Activation('softmax')を適用可能です。余談ですが、keras.models.Sequentialを使わずにこのようにモデルを記述する方法を
Functional APIと言います。使用例はこちら
import numpy as np from keras.layers import Input from keras.layers.core import Activation from keras.models import Model x = Input(shape=(20, 5)) # xにsoftmaxを作用 y = Activation('softmax')(x) model = Model(inputs=x, outputs=y) sample_input = np.ones((12, 20, 5)) sample_output = model.predict(sample_input) print(np.sum(sample_output, axis=2))Attention
Attentionとは
今2つの文章 s={s1,...,sN},t={t1,...,tL} があるとします。
ここでは仮にsを質問文とし、tをそれに対する回答文の候補だとします。
この時、機械に自動でtがsに対する回答文として妥当かどうか判断させるにはどのようにしたら良いでしょうか?
tだけをいくら眺めても、tが妥当かどうかは分かりません。
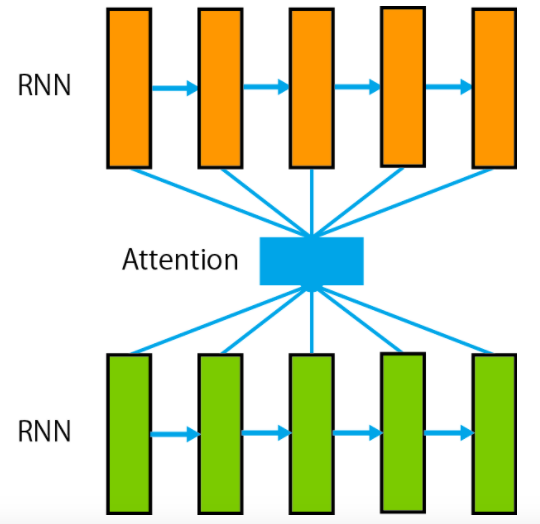
sの情報を参照しつつ、tが妥当かどうか判断する必要があります。そこでAttention Mechanism(注意機構)という機構が役に立ちます。これまでの章で文をRNNによって隠れ状態ベクトルに変換できることを学びました。
具体的には2つの別々のRNNを用意し、一方のRNNによって
sを隠れ状態ベクトル
に変換し、もう一方のRNNによってtを隠れ状態ベクトル
に変換することができます。そこでsの情報を考慮してtの情報を使うために、以下のようにtの各時刻において
sの各時刻の隠れ状態ベクトルを考慮した特徴を計算します。
このように参照元の系列sのどこに”注意”するかを対象の系列tの各時刻において計算することで
臨機応変に参照元の系列の情報を考慮しながら対象の系列の情報を抽出することができます。概要は図の通りです。
図には単方向のRNNの場合を示しましたが、双方向のRNNであってもAttentionは適用可能です。 また 参照元と対象のRNNの最大時刻(隠れ状態ベクトルの総数)が異なる場合でもAttentionを適用可能です。
このAttentionという機構は深層学習による自然言語処理では当たり前のように使われる重要な技術で、
機械翻訳や、自動要約、対話の論文で頻繁に登場します。
歴史的には機械翻訳に初めて使われて以来その有用性が広く認知されるようになりました。
また、今回はsの隠れ状態ベクトルの重み付き平均を用いる
Soft Attentionを紹介しましたがランダムに1つの隠れ状態ベクトルを選択する
Hard Attentionも存在します。さらにそこから派生して、画像認識の分野でも使われることがあります。
中でもGoogleが発表した
Attention is all you needという論文はとても有名です。
Attentionの実装
kerasでAttentionを実装するためには
Mergeレイヤーを使う必要があります。kerasのバージョン2.0以降では前の章まで使っていたSequential ModelをMergeすることができないので、
ここではkerasのFunctional APIを使います。Functional APIの簡単な使い方は以下のようです。
Sequential Modelではただ新しいLayerをaddしていくだけでしたが、
Functional APIを使うことでもっと自在に複雑なモデルを組むことができます。
from keras.layers import Input, Dense from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.layers.merge import dot, concatenate from keras.layers.core import Activation from keras.models import Model batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 文1の長さ seq_length2 = 30 # 文2の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 hidden_dim = 200 # 最終出力のベクトルの次元数 input1 = Input(shape=(seq_length1,)) embed1 = Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length1)(input1) bilstm1 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) input2 = Input(shape=(seq_length2,)) embed2 = Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length2)(input2) bilstm2 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) # 要素ごとの積を計算する product = dot([bilstm2, bilstm1], axes=2) # productのサイズ:[バッチサイズ、文2の長さ、文1の長さ] a = Activation('softmax')(product) c = dot([a, bilstm1], axes=[2, 1]) c_bilstm2 = concatenate([c, bilstm2], axis=2) h = Dense(hidden_dim, activation='tanh')(c_bilstm2) model = Model(inputs=[input1, input2], outputs=h)このように各Layerを関数のように使うのでFunctional APIと呼ばれています。
また新しく登場したInputレイヤーで指定するshapeにはbatchサイズを入れないよう注意しましょう。
そしてModelを定義するときは引数にinputsとoutputsを指定する必要がありますが、
入力や出力が複数ある場合はリストに入れて渡せば大丈夫です。
そして新しく登場したdot([u, v], axes=2)は、uとvのバッチごとの行列積を計算します。指定したaxesにおける次元数はuとvで等しくなければなりません。
また、dot([u, v], axes=[1,2])とするとuの1次元とvの2次元 のように別々の次元を指定することもできます。それでは以下の数式を元にFunctional APIを使ってAttentionを実装してみます。
使用例はこちら
import numpy as np from keras.layers import Input, Dense from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.layers.merge import dot, concatenate from keras.layers.core import Activation from keras.models import Model batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length1 = 20 # 文1の長さ seq_length2 = 30 # 文2の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 hidden_dim = 200 # 最終出力のベクトルの次元数 # 2つのLSTMに共通のEmbeddingLayerを使うため、はじめにEmbeddingLayerを定義します。 embedding = Embedding(input_dim=vocab_size, output_dim=embedding_dim) input1 = Input(shape=(seq_length1,)) embed1 = embedding(input1) bilstm1 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed1) input2 = Input(shape=(seq_length2,)) embed2 = embedding(input2) bilstm2 = Bidirectional(LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed2) # 要素ごとの積を計算する product = dot([bilstm2, bilstm1], axes=2) # サイズ:[バッチサイズ、文2の長さ、文1の長さ] # ここにAttention mechanismを実装 a = Activation('softmax')(product) c = dot([a, bilstm1], axes=[2, 1]) c_bilstm2 = concatenate([c, bilstm2], axis=2) h = Dense(hidden_dim, activation='tanh')(c_bilstm2) model = Model(inputs=[input1, input2], outputs=h) sample_input1 = np.arange(batch_size * seq_length1).reshape(batch_size, seq_length1) sample_input2 = np.arange(batch_size * seq_length2).reshape(batch_size, seq_length2) sample_output = model.predict([sample_input1, sample_input2]) print(sample_output.shape)Dropout
Dropoutとは訓練時に変数の一部をランダムに0に設定することによって
汎化性能を上げ、過学習を防ぐための手法です。①過学習とは ニューラルネットなどのモデルで教師あり学習を行う場合 しばしば訓練データに適合しすぎて 評価データでのパフォーマンスが訓練データに比べて著しく下がる「過学習」を起こしてしまいます。 ②汎化性能とは 訓練データで過学習することなく、訓練データと評価データに関わらず 一般的に高いパフォーマンスができることを「汎化性能」が高いと言います。実際に使うときは、変数のうち0に設定する割合を0から1の間の値で設定して
Dropoutレイヤーを追加します。# Sequentialモデルを使う場合 from keras.models import Sequential from keras.layers import Dropout model = Sequential() ... model.add(Dropout(0.3))# Functional APIを使う場合 from keras.layers import Dropout y = Dropout(0.3)(x)使用例はこちら
import numpy as np from keras.layers import Input, Dropout from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM from keras.layers.wrappers import Bidirectional from keras.models import Model batch_size = 32 # バッチサイズ vocab_size = 1000 # 扱う語彙の数 embedding_dim = 100 # 単語ベクトルの次元 seq_length = 20 # 文1の長さ lstm_units = 200 # LSTMの隠れ状態ベクトルの次元数 input = Input(shape=(seq_length,)) embed = Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length)(input) bilstm = Bidirectional( LSTM(lstm_units, return_sequences=True), merge_mode='concat')(embed) output = Dropout(0.3)(bilstm) model = Model(inputs=input, outputs=output) sample_input = np.arange( batch_size * seq_length).reshape(batch_size, seq_length) sample_output = model.predict(sample_input) print(sample_output.shape)
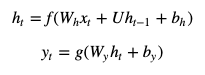
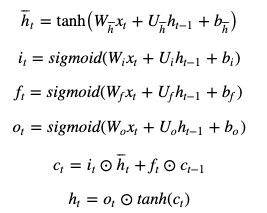
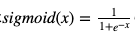
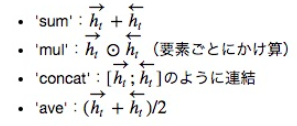
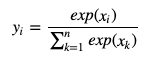
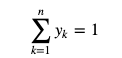
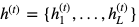
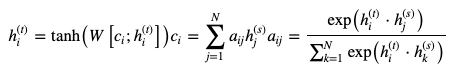
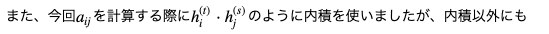

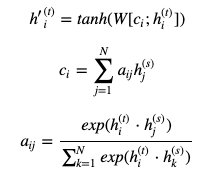
- 投稿日:2020-05-19T22:40:56+09:00
言語処理100本ノック 2020を解く(01. 「パタトクカシーー」)
はじめに
巷で流行っている自然言語100本ノックにPythonで挑戦してみます。
解き方はいろいろあると思うので、いろいろな解き方を示したいと思います。
全ての解き方を網羅することは当然ながらできません。
「こんな解き方があるよ」や「ここ間違ってるよ」という点があれば、ぜひコメントでお教えいただければと思います。言語処理100本ノック 2020とは
言語処理100本ノック 2020は、東北大学の乾・鈴木研究室のプログラミング基礎研勉強会で使われている教材です。
詳しくは、言語処理100本ノックについてを参照して下さい。Qiitaの記事へのリンク
1問目 2問目 3問目 4問目 5問目 6問目 7問目 8問目 9問目 10問目 第1章 00 01 02 03 04 05 06 07 08 09 第2章 10 11 12 13 14 15 16 17 18 19 第3章 20 21 22 23 24 25 26 27 28 29 第4章 30 31 32 33 34 35 36 37 38 39 第5章 40 41 42 43 44 45 46 47 48 49 第6章 50 51 52 53 54 55 56 57 58 59 第7章 60 61 62 63 64 65 66 67 68 69 第8章 70 71 72 73 74 75 76 77 78 79 第9章 80 81 82 83 84 85 86 87 88 89 第10章 90 91 92 93 94 95 96 97 98 99 01. 「パタトクカシーー」
問題
01. 「パタトクカシーー」の問題は、下記の内容です。
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.解答
問題を読むと、
パタトクカシーーの1,3,5,7文字目なので、答えはパトカーです。
以下に示すどの解答でも、最後の式を評価するとパトカーと返ってきます。シンプル
素直に文字列の末尾に追加していく方法があります。
enumerate(s)は、n=len(s)として(0,s[0]),...,(n-1,s[n-1])を走査するためのイテレータを返します。# シンプル s = "パタトクカシーー" result = "" for n,c in enumerate(s): if n%2==0: result += c result #=> 'パトカー'関数型的
関数型由来の
mapやfilterを使って書くこともできます。
この例ではあまりメリットを感じられませんね…。# 関数型的 s = "パタトクカシーー" "".join( map( lambda x:x[1], filter( lambda x:x[0]%2==0, enumerate(s) ) ) ) #=> 'パトカー'ラムダ式で定義した関数に名前を付けたほうが若干ましでしょうか。
# 関数型的 s = "パタトクカシーー" second_elem = lambda x:x[1] is_first_elem_even = lambda x:x[0]%2==0 "".join(map( second_elem, filter( is_first_elem_even, enumerate(s) ) ) ) #=> 'パトカー'名前を付けすぎるとやりすぎに感じますね。
# 関数型的 s = "パタトクカシーー" first_elem = lambda x:x[0] second_elem = lambda x:x[1] is_first_elem_even = lambda x:first_elem(x)%2==0 "".join(map( second_elem, filter( is_first_elem_even, enumerate(s) ) ) ) #=> 'パトカー'これくらいの関数は準備されていてほしいですね。
なお、ラムダ式による関数定義は、下記の通常の関数定義と一緒です。def first_elem(x): return x[0] def second_elem(x): return x[1] def is_first_elem_even(x): return first_elem(x)%2==0おとなしく変数に入れたほうがいいかもしれません。
filterやmapが返してくるのはイテレータ(ジェネレータ)なので、変数に入れるたびにリストが生成されたりはしません。
JavaScriptみたいに、コールバックが後ろ側のほうがよかった気がしてなりません。# 関数型的 s = "パタトクカシーー" first_elem = lambda x:x[0] second_elem = lambda x:x[1] is_first_elem_even = lambda x:first_elem(x)%2==0 filtered = filter(is_first_elem_even, enumerate(s)) mapped = map(second_elem, filtered) "".join(mapped) #=> 'パトカー'内包表記
mapやfilterにこだわらずに、内包表記で書いたほうが簡単です。
[x for x in l]と書くとリスト内包表記ですし、(x for x in l)と書くとジェネレータ内包表記です。
f((x for x in l))は、f(x for x in l)とかっこを一つ減らして書くことができます。
複数の変数に値を同時に代入すれば、xで受け取ってx[0]やx[1]で取り出すよりもわかりやすくなります。# 内包表記 s = "パタトクカシーー" "".join(c for n,c in enumerate(s) if n%2==0) #=> 'パトカー'Pythonic
Python的であることを Pythonic といいますが、このコードが一番Pythonicでしょうか。
リストや文字列に対して、s[start:end:step]でアクセスする方法をスライスと呼びます。
stepに2を指定すると1こ飛ばしになります。# Pythonic s = "パタトクカシーー" s[::2] #=> 'パトカー'その他の解答
インデックスで回す
enumerateなんて使わずに、自分でインデックスを用意して回す方法もあります。# 自力で回す s = "パタトクカシーー" result = "" n = 0 for c in s: if n%2==0: result += c n += 1 result #=> 'パトカー'リストに追加して後で結合する
言語処理100本ノック 2020を解く(01. 文字列の逆順)と同じようにリストに追加して後で結合することもできます。
# シンプル s = "パタトクカシーー" l = [] for n, c in enumerate(s): if n%2==0: l.append(c) "".join(l) #=> 'パトカー'振り返り
「文字列を結合する」のと「リストに追加する」のとどっちがいいか悩むことがあります。
文字ではなく一般のオブジェクトのリスト扱うなら必然的にリストに追加することになりますが、今回のようにゴールが文字列の生成ならどちらでもいいんじゃないでしょうか。
サイズが大きくなって遅くなってきたら立ち止まって考えましょう。# シンプル s = "パタトクカシーー" result = "" for n,c in enumerate(s): if n%2==0: result += c result #=> 'パトカー'# シンプル s = "パタトクカシーー" l = [] for n, c in enumerate(s): if n%2==0: l.append(c) "".join(l) #=> 'パトカー'
- 投稿日:2020-05-19T22:13:41+09:00
alpineでC言語依存モジュールを pip install すると激重になる話
TL;DR
PyPiに上げられているC言語依存のpythonモジュールは、alpine標準のmuslには対応してないから毎回手元でコンパイルされるよ。
docker:alpineでどうしても使いたい場合は必要モジュールをビルドしたイメージを個別に用意しておくと良いよ。alpineさんちのpip事情
pythonのモジュール管理行うpip。そのpipで採用されており快適にモジュールの導入を可能にしているwheel形式だが、alpineに対応した
.whlがPyPi上に存在しないモジュールがある。wheel
先に少しだけwheelの話。
wheelは元々Eggという形式の後継で作られたもので、Built Distributionと呼ばれるインストール形式であるそう。
Built Distributionはここの用語集を見る限りでは以下の通り。Distribution 形式のうち、中身のファイルとメタデータをターゲットシステムの正しい場所へ移動するだけでインストールができるもの。
Egg や Wheel の実体は zip/tar などの圧縮形式の拡張なので、
pip install時はダウンロードして展開後にpipで管理している場所にファイルを移動しているだけとなる。なので速い。コンパイル済み拡張モジュールを含んだパッケージ1も同様で取得・展開・移動するだけなので、これによりストレスフリーに使うことができている訳だ。
...ただしPyPi上に使用しているOS・アーキテクチャに対応したwheelファイルが存在する場合のみである。2alineはmusl-libcで動く
alpineはmuslを採用している。
muslは軽量・高速・シンプルを目標に標準Cライブラリの実装を1から行っており、glibcなどの非標準な拡張ライブラリにも対応している。alpineにぴったりだ。
ただし、完全な互換はまだ実現できていない模様で稀に使いたい関数が存在しなかったりする。で、今回のここで書く内容もalpineがmuslを使用している事が原因で掲題通りの事象が発生している。
ちなみに読み方はマッスルらしい。つよそう。
alpineはglibcを使っていない
今日、多くのLinuxディストリビューションはglibcを採用しているし、バイナリも共有ライブラリとして動的リンクさせてるのも少なくない。
numpyなどC言語を使用しているモジュールも例に漏れず3、PyPiにアップロードされているwheelファイルはglibc環境下で動くことを想定したビルドがなされている。つまり musl lib上で動く事を想定していない。4
そのためalpine上でpip install numpyをするとサポートされた.whlが存在しないため.zipやら.tar.gzが降ってくる。ビルド前のソースコードを丸々落としてきているのだ。Collecting numpy Downloading numpy-1.18.3.zip (5.4 MB) |████████████████████████████████| 5.4 MB 1.3 MB/s Installing build dependencies ... doneダウンロード後はalpine用に一からコンパイルが実行されwheelファイルを作成する。そのあと出来上がったwheelファイルをpipは取り込み直すことでpython上でimportできるようにしている。
これがC言語依存モジュールをpip installすると時間がかかる原因である。※ 他言語やOS・アーキテクチャに依存しないモジュールや、pureなpythonで書かれたモジュールだとalpineでもwheel形式で落ちてくるため時間はかからない。
浮かび上がる諸問題
C言語依存しているものでも数秒でコンパイルできるものもあるが、numpyを入れようとすると数分程度かかってしまうしnumpy依存のscipyなどを使おうとすると更に数十分コンパイルに時間がかかってしまうこともある。
一回限りのビルドで今後全ての開発環境を賄えるローカル環境であればそれでも良いかもしれないが、
製品やサービスをCI/CDを含めた環境構築することを考えていくとなると、膨大なコンパイル時間はとてつもないほど大きな障害となる。
git のブランチをフックにしてunitテストが走るCI環境、サーバーなどにサービスを安全にデリバリーするCD環境、etc、etc...
毎回毎回長いコンパイルが走ってしまうと細かい修正の確認ですら一時間単位で浪費してしまうことになるし、他の作業が滞ってしまう原因にもなる。
そしてなによりtwitterをする時間が減ってしまう。大問題だ。
実際に業務でpandasをalpineに突っ込んでしまった時は睡眠時間まで減ってしまったのだから、冗談抜きで死活問題である。回避策
これを防ぐためには以下のものが考えられる。
- alpineを諦める
- コンパイル済みdocker imageで対処する
- ベースのディストリビューションとして使う
- multi stage ビルドを利用する
alpineを諦める
最も手間が少なく考える時間をかける必要がない有効な方法である。
ubuntuやcentosなどコンパイル済みで手段も確立しているディストリビューションに乗り換えてしまうのだ。
ただし、既に作り込んでしまっていて容易に乗り換えられないケースもあるのでは無かろうか?
業務で詰まった時は次の方法を取った。コンパイル済みdocker imageで対処する
wheelのコンパイルが済んだ状態のdocker imageを自由に使える場所に置いてしまい、使いたい時にpullするというもの。
base-imageFROM python:3.8-alpine3.11 COPY require/requirements.txt /tmp RUN apk update && \ apk add --no-cache hoge-dev && \ pip install --upgrade --no-cache-dir pip setuptools wheel && \ pip install -r --no-cache-dir /tmp/requirements.txt先ずはこんな感じでimageを作っておき、
docker pushでdocker hubやawsのecrなどに保存しておく。docker push hoge/huga:latest2パターンあるがビルド完了しているものを使うという意味では同じ。
ベースのイメージとして使う
公式イメージなどと同じように
FROMを使ってベースイメージとして使う。
簡単だが、コンパイル時のみに必要なライブラリを消し忘れたりするとこちらのイメージサイズも大きくなってしまうなど、base-imagedockerfileへの依存度が高くなりメンテナンス性が下がってしまう。builder-patternFROM hoge/huga:latestmulti stage ビルドとして使う
Docker17.05以上なら使える機能で、成果物だけイメージから取り出すことができる方法。
wheelコンパイルに関連するものはhoge/huga:latestに封じ込められるので後々気が楽になるから個人的におすすめ。builder-patternFROM hoge/huga:latest as pip_build FROM python:3.8-alpine3.11 COPY --from=pip_build /usr/local/lib/ /usr/local/lib/ COPY --from=pip_build /usr/local/bin/ /usr/local/bin/ COPY --from=pip_build /usr/local/include/ /usr/local/include/上記だとディレクトリを直接張り付けてしまっているので、コンパイル済みの
*.whlをhoge/huga:latestから持ってきてpip installする方が安全かも。欠点
解決策としなかったのは上記の方法だと、複数のdockerイメージのメンテナンスを避けられないためだ。
作成した実行環境よりもソースコードで使用するライブラリや書式の方が最新になってしまった場合が起こるたび、長大なコンパイルを実行しpushし直す必要が出てくる...
安眠できる日々は長くは続かなさそうだ。参考文献
- Using Alpine can make Python Docker builds 50× slower : 滅茶苦茶参考にしました。
- Python Packaging User Guide:用語集
- Introduction to musl
- お前のDockerイメージはまだ重い???
- マルチステージビルドの利用
用語集曰く
Binary Distributionと呼ぶらしく、拡張モジュールごと移動させ使用している。 ↩PyPiのモジュールのページ左側[Navigation]->[Download files]から確認できる。 ↩
ダウンロードしたwheelを
unzipで展開してやると*.soが見える。pipが正しく動いている以上、OS・アーキテクチャに最適化されたものが存在しているはずだ。 ↩muslはアプリケーションを単一のポータブルなバイナリファイルとして配布できるように静的リンクに最適化している。(wikipediaから引用)
ld-musl-x86_64.so.1しか存在しないのでld-linux-x86-64.so.2にダイナミックリンクしているものは軒並み落ちる。 ↩
- 投稿日:2020-05-19T22:13:24+09:00
【初心者向け】学習回数ってやつをバカ分かりやすく解説したい
はじめに
人工知能の記事を見ていると「学習回数」という言葉が多く出てきます。
どの記事も難しい言葉を使って説明されているので、分かりにくい!と思った方も多いと思います。
今回は「学習回数」を分かりやすく説明します。
書いてあること
- 学習回数とは?
- バッチサイズとは?
- まとめ
1. 学習回数とは?
下の画像を見てください。これが学習回数です。
1つずつ説明していきます。
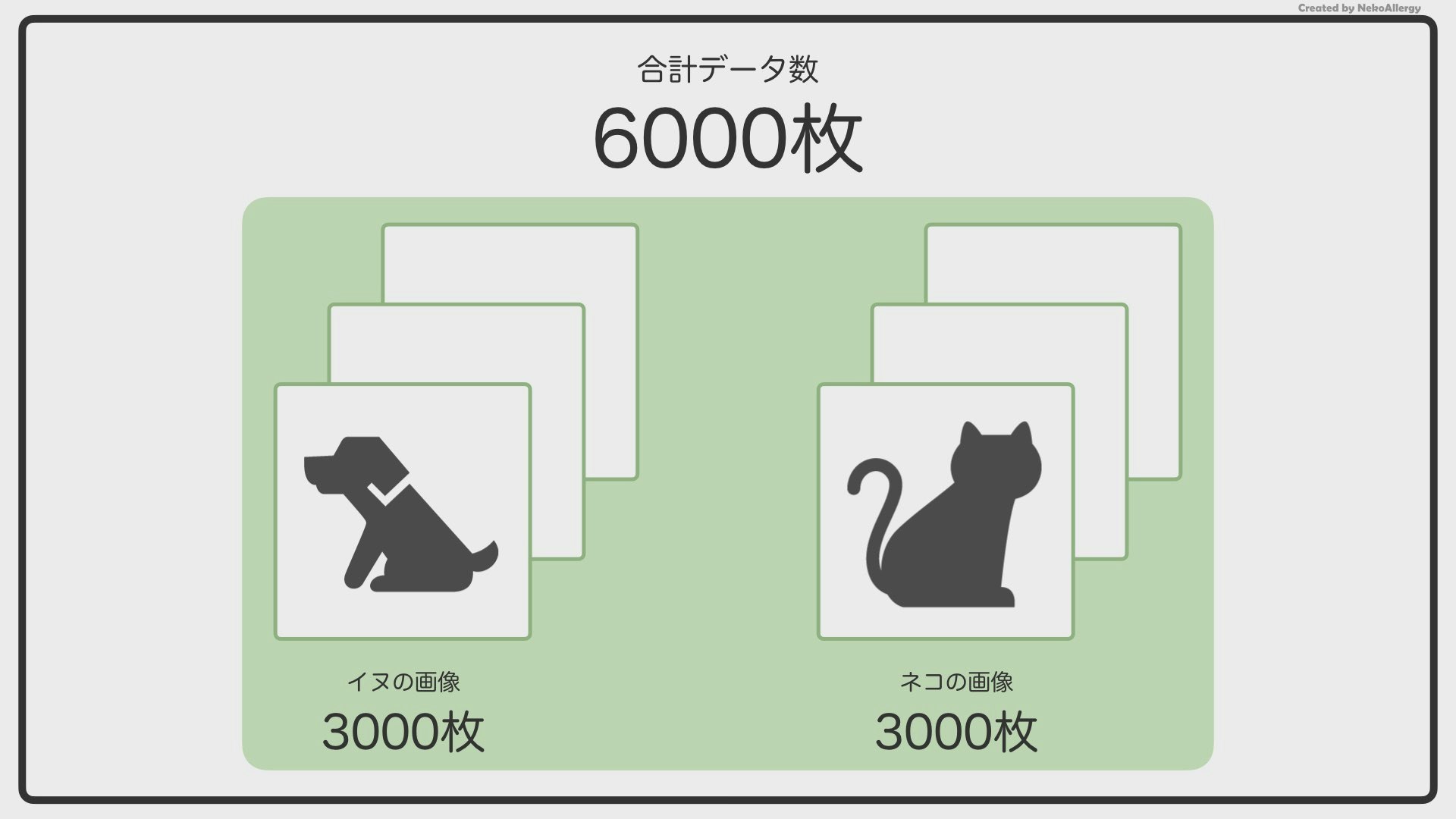
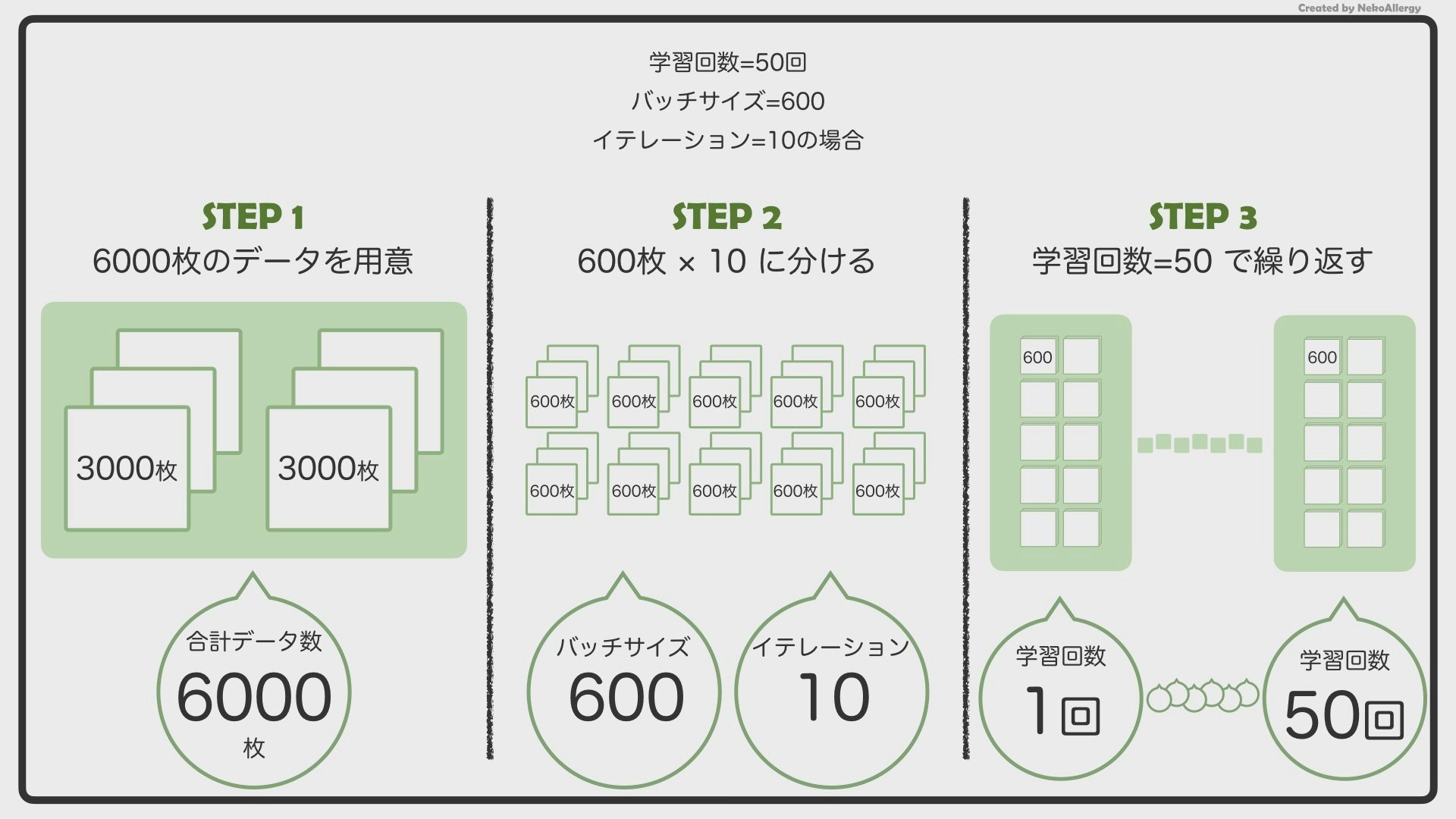
例えば、今あなたは、イヌとネコの画像を仕分ける人工知能(AI)を作ろうとしています。
イヌの画像を3,000枚、ネコの画像を3,000枚、合計6,000枚用意しました。
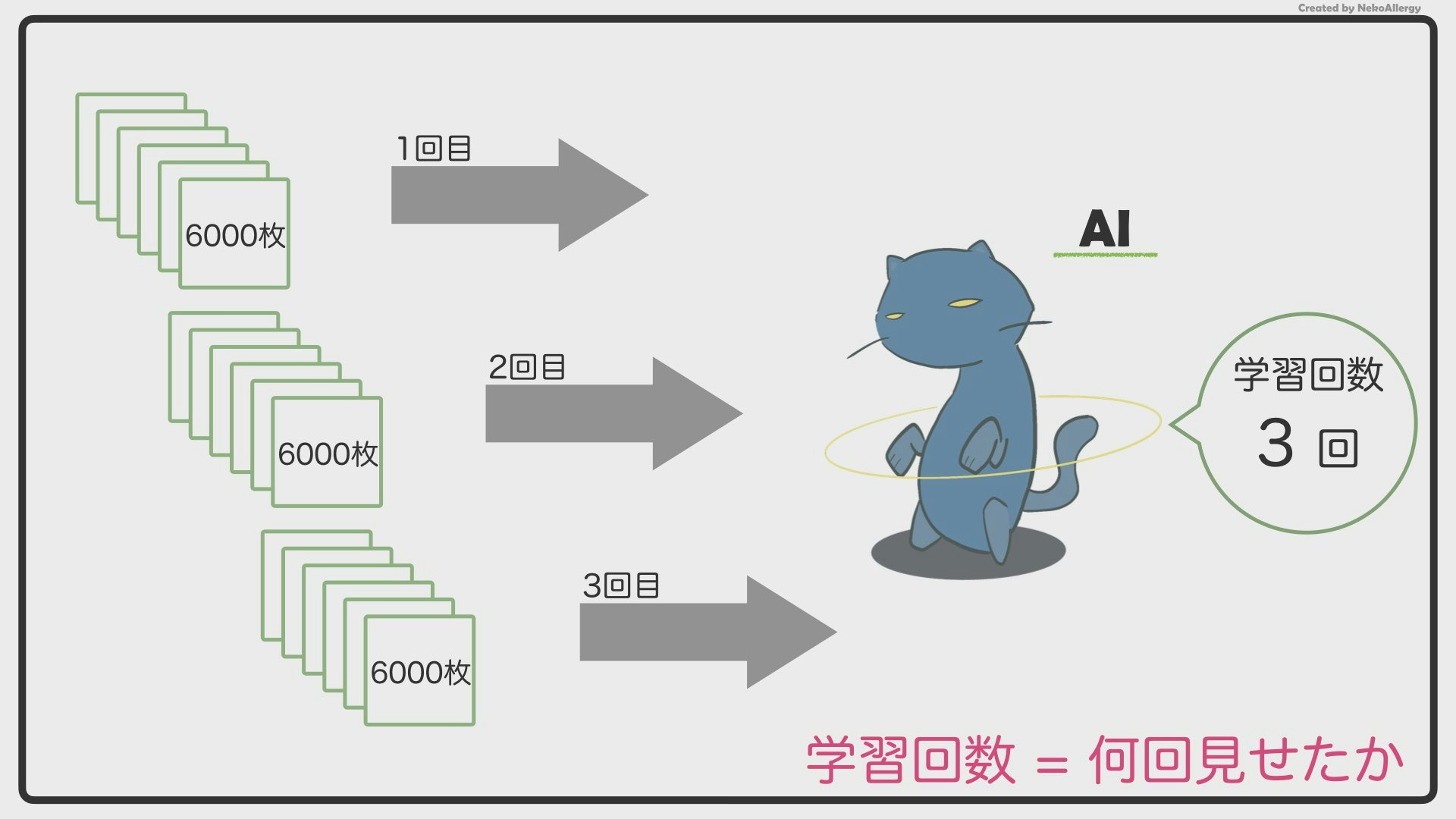
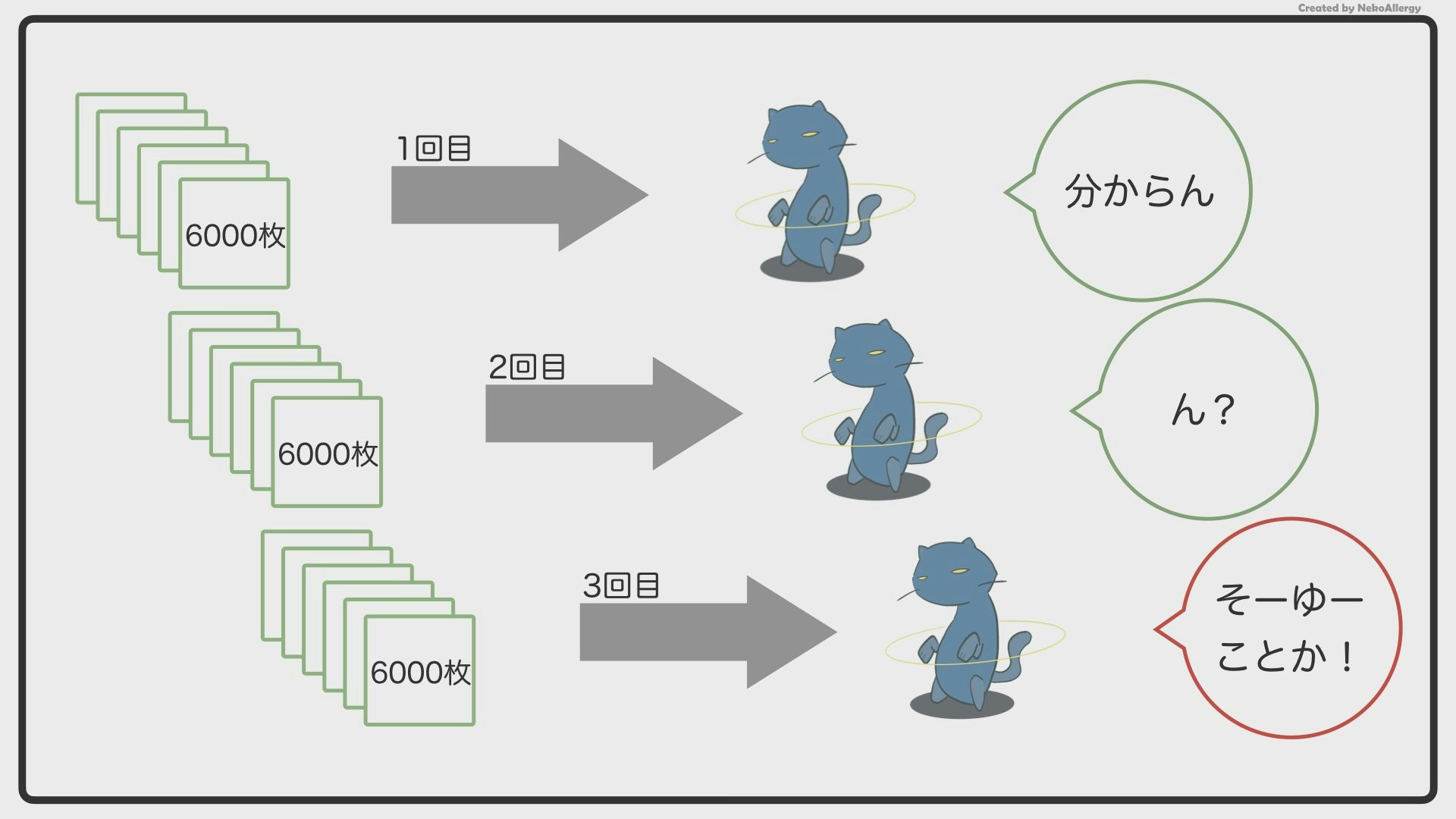
この6,000枚の画像をAIに見せて、イヌネコの特徴を覚えさせていきます。しかし、AIくんは、「6,000枚を一度見ただけ」で賢くなることはできません。これは、先生が授業で言った内容を一度で覚えられないのと同じです。
なので、6,000枚を何回も何回も、繰り返し見ることで、覚えようとします。簡単に言えば、この「何回見たか(覚えたか)」が学習回数になります。
6,000枚の画像を3回見たら、学習回数3回。
(合計18,000枚)
6,000枚の画像を5回見たら、学習回数5回。
(合計30,000枚)
6,000枚の画像を100回見たら、学習回数100回。
(合計6,000,000枚)学習回数が多くなれば、AIはその分賢くなっていきます。1回目(最初の6,000枚)は「イヌかネコか分からない…」となっていた画像も、2回、3回と繰り返し見せていくと、「さっきは分からなかったけど、今ならわかるぞ!」という感じで賢くなっていきます。
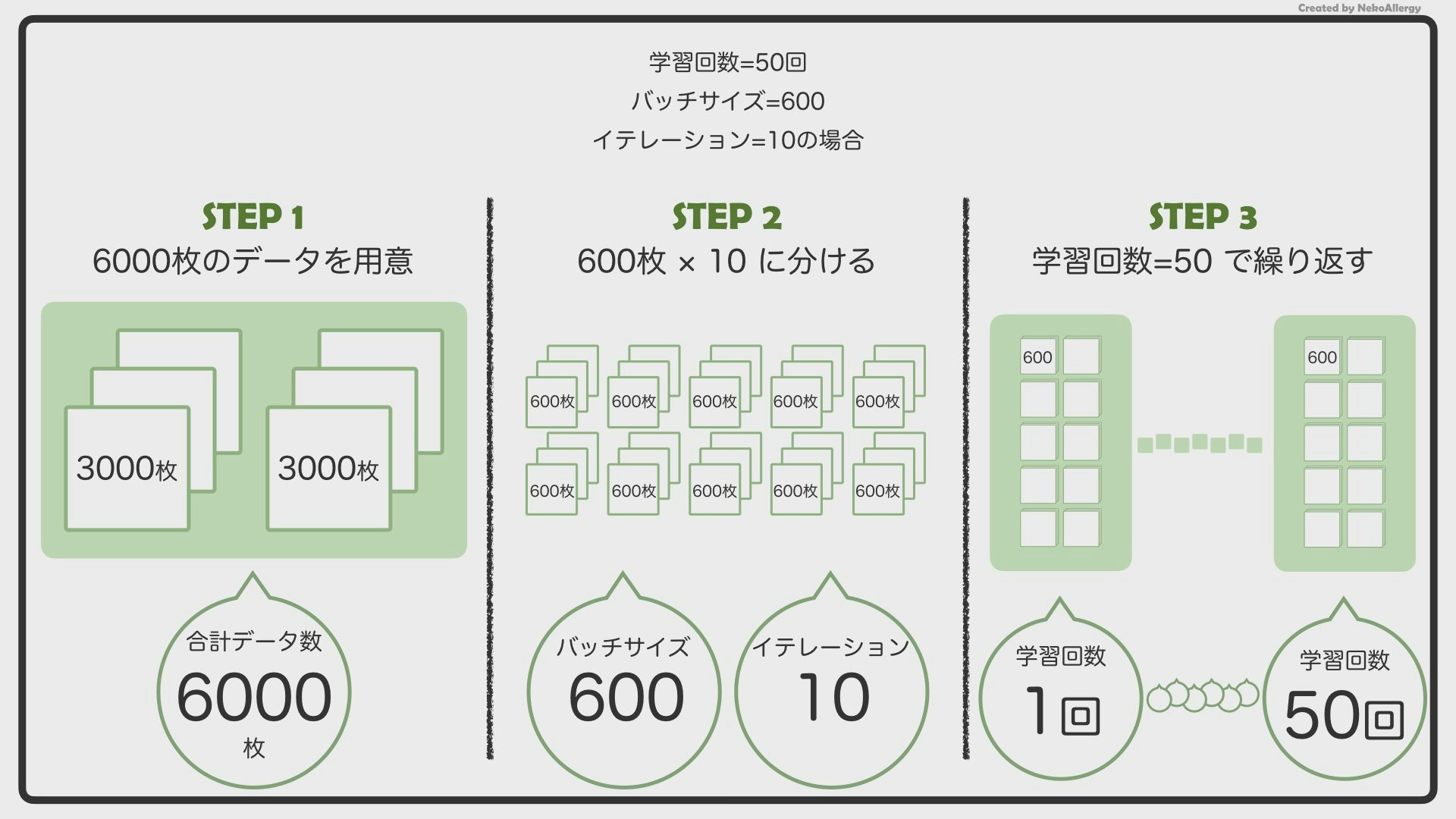
基本はこんな感じですが、実際は少し違った方法で学習しています。数年前にどこかの偉い人が、「もっと効率よく賢くなる方法」を考えました。それが、「バッチサイズ」を使用する方法です。
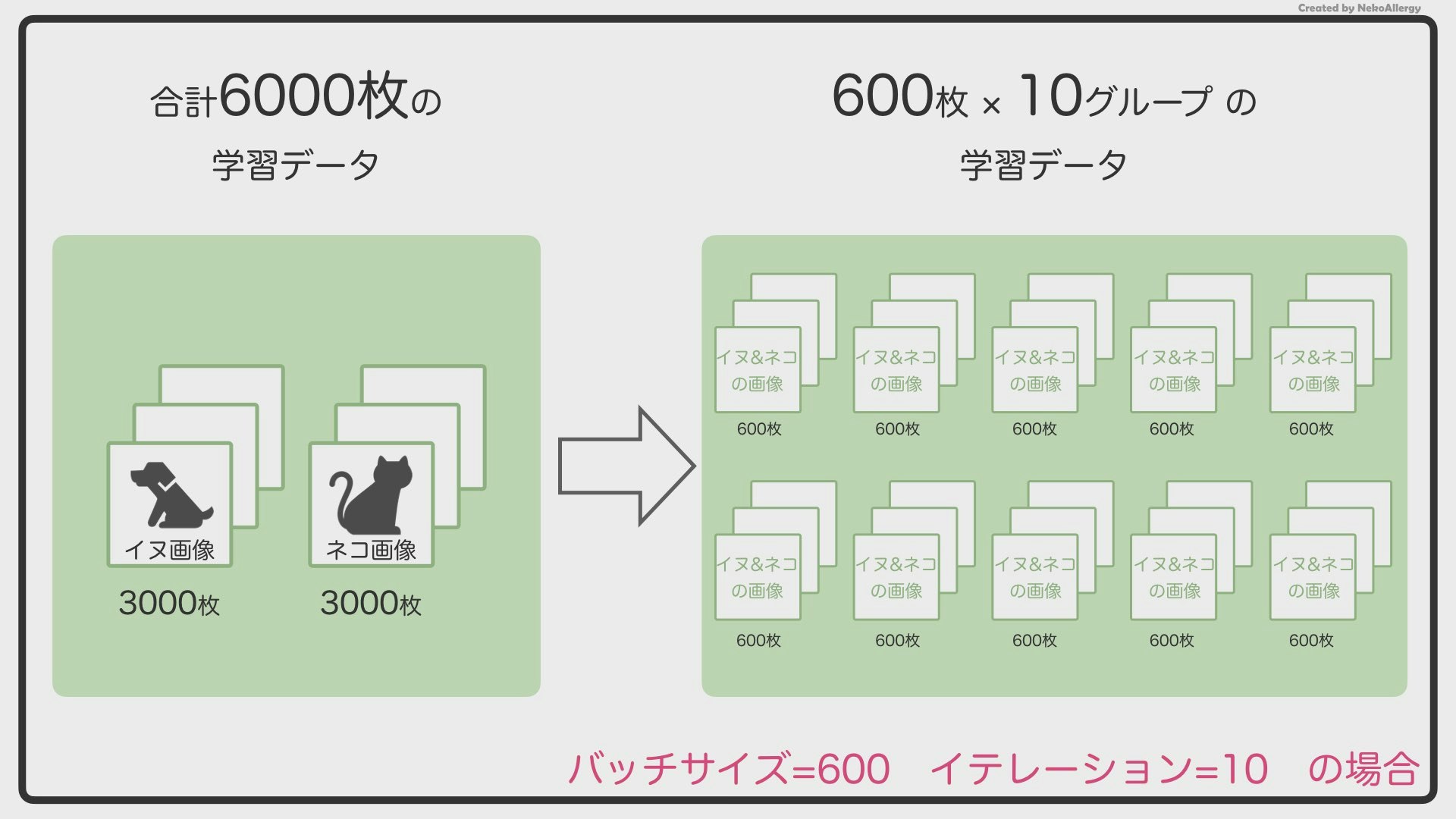
2.バッチサイズとは?
もっと効率よく覚えるために、バッチサイズという考え方を使います。例えば、バッチサイズ=600の場合は、下のようになります。
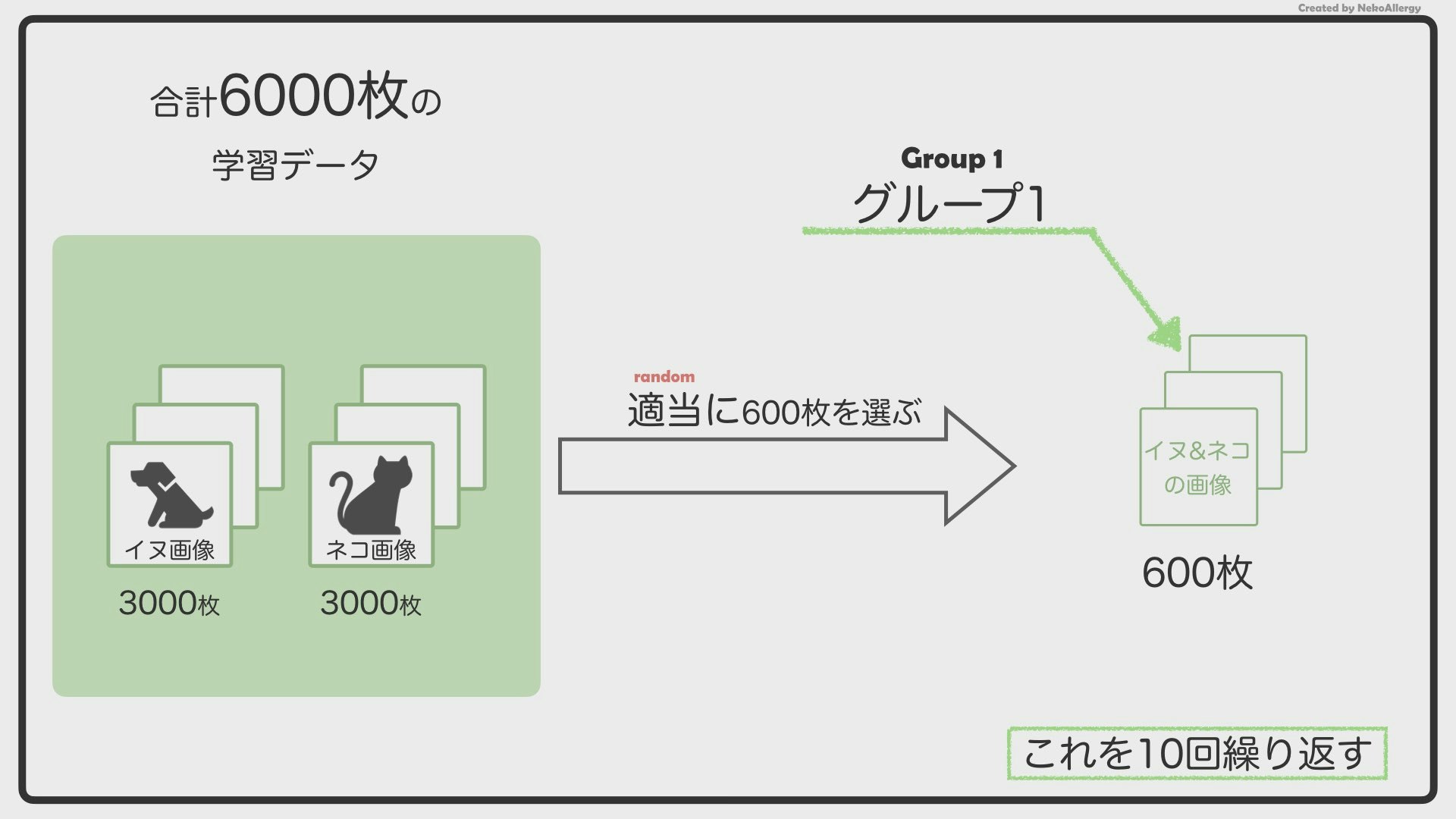
6,000枚の画像を600枚ずつのグループに分けます。この時の「600」というのがバッチサイズになります。6,000枚を600枚ずつに分けるので、全部で10個のグループができることになります。AIはこのグループごとに学習していきます。
ここで注意すべき点があります。グループ分けされる画像は、最初の画像から順番に選ばれていくのではなく、6,000枚から「ランダム」に選ばれていきます。
6,000枚から適当に600枚を選ぶ
→グループ1
6,000枚から適当に600枚を選ぶ
→グループ2
6,000枚から適当に600枚を選ぶ
→グループ3のようにして10個のグループを作ります。この時、イヌが何枚ずつで、ネコが何枚ずつ、という風に決める必要はありません。めちゃくちゃ適当に600枚ずつのグループを作ります。
「そーやってランダムに選んでいくと、2.3回選ばれる画像とか、1回も選ばれない画像が出てくるんじゃね?」と、疑問に思った方もいると思います。
その通りです。
このように「適当に選ぶ」ことによって、柔軟なAIが作れるそうです。(へーそうなんだーくらいに思ってもらえれば大丈夫です)
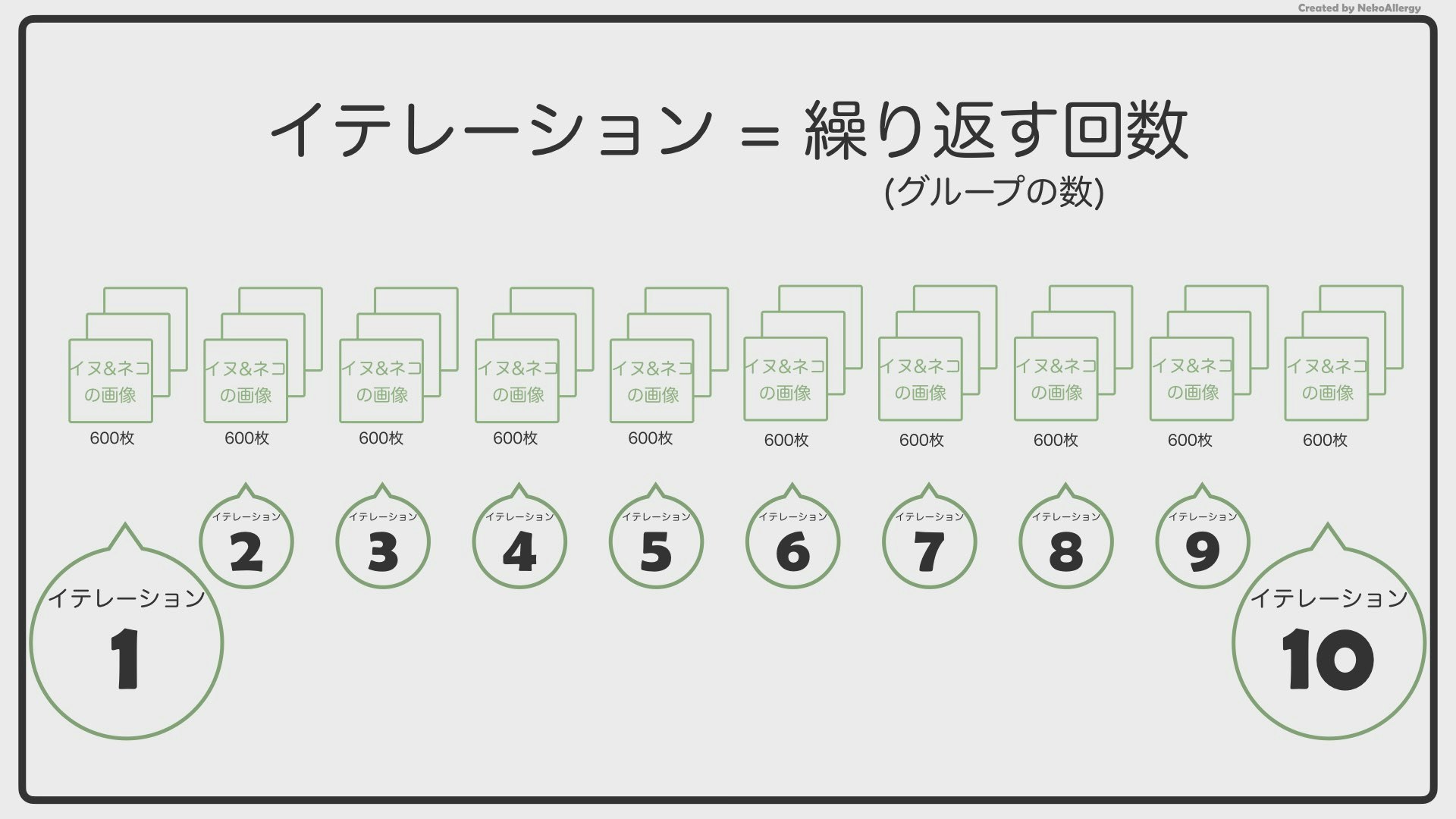
また、6,000枚をバッチサイズ=600で分けると、10個のグループができますが、この「10」のことを「イテレーション」と呼びます。
イテレーションは日本語で「繰り返し」という意味になります。「1回、2回、3回」のように、「イテレーション1、イテレーション2、イテレーション3」という雰囲気で使います。
つまり今回の例でいくと、
6,000枚のデータセットをバッチサイズ=600で、イテレーション=10で学習させた。という風になります。
ちなみにプログラマー達は、学習回数のことを「エポック数」と呼びます。
学習回数3回はエポック3、
学習回数10回はエポック10、
学習回数100回はエポック100、
のようになります。3.まとめ
エポック、バッチサイズ、イテレーションをまとめた図が、下の図になります。
この図が理解できれば、人工知能の記事や論文を見たときに「学習回数」という単語が出てきたときでも理解できるはずです!
人工知能/AI/機械学習をもっと詳しく
「ねこアレルギーのAI」
https://t.co/4ltE8gzBVv?amp=1
YouTubeで機械学習について発信しています。
お時間ある方は覗いていただけると喜びます。created by NekoAllergy






- 投稿日:2020-05-19T22:05:26+09:00
PythonでぷよぷよAIを作る
PythonでぷよぷよAIを作ったので記事にさせていただきます。
詳しくない方でもイメージしやすいように基本的なところから説明していくので、既に知っている方はどんどん読み飛ばしてください。アルゴリズム
まず、コンピュータは次置く場所を「次こう置いて、その次はこう置いて...」というように先読みをして決めていきます。
この先読みは、もちろん深ければ深いほどいいのですが、見えてる手は今フィールドに落ちてきてるぷよ、NEXTぷよ、NEXTNEXTぷよの3つしかないので、見えない未来のツモは補完しながら探索していきます。
今回は10手先まで探索するようにしています。
ぷよを置く行動は22パターンあり、10手先まで考えると全ての置けるパターンは22^10となります。
これを計算するにはとても長い時間がかかってしまうので、評価の低い手をそれ以上探索しないようにするためにビームサーチを使います。今回はビーム幅は50としました。評価関数(コンピュータが手の良さを評価する基準)はこちらの記事を参考に「各列にそれぞれの色のぷよを2つ落とした時に起きる最大連鎖数×10+1列目、6列目の高さ×2+2列目、5列目の高さ+各ぷよの連結数の合計^2」としました。コード
コードを実行すると組んでる様子のGIFと30手後の盤面の画像が作られます。(ぷよの画像をあらかじめimgフォルダに入れておいてください)
copy.deepcopyが遅いので、cPickleモジュールを使って高速化しました。これでかなり早くなりました。copy.deepcopyでやると15手組むのに2時間くらいかかります。あとリスト内包表記も早くなってる気がしました。puyoAI.pyimport pprint import random import _pickle as cPickle import time from PIL import Image #x列の高さを数える def search_height(field,x): return len([y[x] for y in field if y[x] != 0]) def next_create(): color_type = ["G","Y","B","R"] return [random.choice(color_type) for i in range(2)] def possible_moves(field,next): all_possible_moves = [] #ぷよを横にしておいた時の全ての置き方 for x in range(6): if x+1 < 6: #14段目まで埋まってないとき if search_height(field,x) < 14 and search_height(field,x+1) < 14: copy_field = cPickle.loads(cPickle.dumps(field, -1)) #ぷよぷよの仕様で14段目のぷよは消える if search_height(field,x)+1 != 14: copy_field[-(search_height(field,x)+1)][x] = next[0] #ぷよぷよの仕様で14段目のぷよは消える if search_height(field,x+1)+1 != 14: copy_field[-(search_height(field,x+1)+1)][x+1] = next[1] all_possible_moves.append(copy_field) #2つとも同じ色のぷよの時は置いた後のフィールドが被る置き方があるからそこをカット if next[0] != next[1]: for x in range(6): if x+1 < 6: #14段目まで埋まってないとき if search_height(field,x) < 14 and search_height(field,x+1) < 14: copy_field = cPickle.loads(cPickle.dumps(field, -1)) #ぷよぷよの仕様で14段目のぷよは消える if search_height(field,x)+1 != 14: copy_field[-(search_height(field,x)+1)][x] = next[1] #ぷよぷよの仕様で14段目のぷよは消える if search_height(field,x+1)+1 != 14: copy_field[-(search_height(field,x+1)+1)][x+1] = next[0] all_possible_moves.append(copy_field) #ぷよを縦にしておいた時の全ての置き方 for x in range(6): if search_height(field,x) <= 12: copy_field = cPickle.loads(cPickle.dumps(field, -1)) copy_field[-(search_height(field,x)+1)][x] = next[0] #ぷよぷよの仕様で14段目のぷよは消える if search_height(field,x)+2 != 14: copy_field[-(search_height(field,x)+2)][x] = next[1] all_possible_moves.append(copy_field) #2つとも同じ色のぷよの時は置いた後のフィールドが被る置き方があるからそこをカット if next[0] != next[1]: for x in range(6): if search_height(field,x) <= 12: copy_field = cPickle.loads(cPickle.dumps(field, -1)) copy_field[-(search_height(field,x)+1)][x] = next[1] #ぷよぷよの仕様で14段目のぷよは消える if search_height(field,x)+2 != 14: copy_field[-(search_height(field,x)+2)][x] = next[0] all_possible_moves.append(copy_field) return all_possible_moves def count(field,y,x): global n c = field[y][x] field[y][x] = 1 n +=1 if x+1 < 6 and field[y][x+1] == c and c != 1: count(field,y,x+1) if y+1 < 14 and field[y+1][x] == c and c != 1: count(field,y+1,x) if x-1 >= 0 and field[y][x-1] == c and c != 1: count(field,y,x-1) if y-1 >= 0 and field[y-1][x] == c and c != 1: count(field,y-1,x) return n def drop(field,y,x): while y >= 0: if y > 0: field[y][x] = field[y-1][x] y -= 1 #14段目は空白 else: field[y][x] = 0 y -= 1 return field def chain(field,chain_count): global n copy_field = cPickle.loads(cPickle.dumps(field, -1)) #4つ以上繋がっているところにフラグを立てる for y in range(14): for x in range(6): n = 0 if field[y][x] != 0 and count(cPickle.loads(cPickle.dumps(field, -1)),y,x) >= 4: copy_field[y][x] = 1 #フラグが一つもなかったら終了 flag_count = 0 for y in copy_field: flag_count += y.count(1) if flag_count == 0: return copy_field,chain_count #浮いてるぷよを落とす for y in range(14): for x in range(6): if copy_field[y][x] == 1: drop(copy_field,y,x) chain_count +=1 return chain(copy_field,chain_count) def height_evaluation(field): point = 0 for x in range(6): if x == 0 or x == 5: point += len([y[x] for y in field if y[x] != 0])*2 if x == 1 or x == 4: point += len([y[x] for y in field if y[x] != 0]) return point #各列にそれぞれの色のぷよを2つ落とした時の最大連鎖数 def feature_chain_evaluation(field): chain_counts = [] color_type = ["G","Y","B","R"] for x in range(6): for color in color_type: copy_field = cPickle.loads(cPickle.dumps(field, -1)) if [y[x] for y in field].count(0) > 2: copy_field[-(search_height(copy_field,x)+1)][x] = color copy_field[-(search_height(copy_field,x)+2)][x] = color chain_counts.append(chain(copy_field,0)[1]) else: chain_counts.append(0) return max(chain_counts) def count_evaluation(field): global n point = 0 for y in range(14): for x in range(6): if field[y][x] != 0: n = 0 point += count(cPickle.loads(cPickle.dumps(field, -1)),y,x)**2 return point def beam_search(depth0s,next,depth): print("現在の探索深さ:{}".format(depth)) if depth > 10: return depth0s evaluation_results = [] for depth0 in depth0s: for depth1 in possible_moves(depth0[1],next): #ぷよが消える置き方をしない,3列目の12段目に置かない if chain(depth1,0)[1] == 0 and depth1[2][2] == 0: evaluation_results.append([depth0[0],depth1,feature_chain_evaluation(depth1)*10 + height_evaluation(depth1) + count_evaluation(depth1)]) return beam_search(sorted(evaluation_results, key=lambda x:x[2], reverse=True)[:50],next_create(),depth+1) def next_move(field,next): evaluation_results = [] for depth1 in possible_moves(field,next[0]): #ぷよが消える置き方をしない,3列目の12段目に置かない if chain(depth1,0)[1] == 0 and depth1[2][2] == 0: for depth2 in possible_moves(depth1,next[1]): #ぷよが消える置き方をしない,3列目の12段目に置かない if chain(depth2,0)[1] == 0 and depth2[2][2] == 0: evaluation_results.append([depth1,depth2,feature_chain_evaluation(depth2)*10 + height_evaluation(depth2) + count_evaluation(depth2)]) #評価値の合計が一番高い手を採用 #dic = {フィールド:評価値} dic = {} beam_search_result = beam_search(sorted(evaluation_results, key=lambda x:x[2], reverse=True)[:50],next[2],3) for i in beam_search_result: #フィールドを文字列にして辞書のkeyにする #初期値を入れる(0) dic["".join([str(x) for y in i[0] for x in y])] = 0 for i in beam_search_result: #フィールドに評価値を加算 dic["".join([str(x) for y in i[0] for x in y])] += i[2] #評価値の合計が最も高いフィールド(文字列) final_choice = sorted(dic.items(), key=lambda x:x[1], reverse=True)[0][0] #文字列から二次元配列に直してreturn return [[n if n != "0" else 0 for n in final_choice[i:i+6]] for i in range(0,len(final_choice),6)] def field_to_img(field): green = Image.open("img/green.png") yellow = Image.open("img/yellow.png") blue = Image.open("img/blue.png") red = Image.open("img/red.png") blank = Image.open("img/blank.png") imgs = [green,yellow,blue,red,blank] color_type = ["G","Y","B","R",0] field_img = Image.new("RGB", (green.width*6, green.height*14)) start_y = 0 for y in field: field_x_img = Image.new("RGB", (green.width*6, green.height)) start_x = 0 for x in y: for img,color in zip(imgs,color_type): if x == color: field_x_img.paste(img, (start_x, 0)) start_x += img.width field_img.paste(field_x_img, (0, start_y)) start_y += field_x_img.height return field_img def main(): start = time.time() imgs = [] field = initial_field next = [next_create(),next_create(),next_create()] for i in range(30): field = next_move(field,next) pprint.pprint(field) imgs.append(field_to_img(field)) next.pop(0) next.append(next_create()) imgs[0].save("result.gif",save_all=True, append_images=imgs[1:], optimize=False, duration=500, loop=0) imgs[-1].save("result.png") print("処理時間:{}秒".format(time.time()-start)) if __name__ == "__main__": initial_field = [[0]*6 for i in range(14)] main()結果
30手番シミュレーションした結果
組んでる様子
消えてる様子(10連鎖)
よくないところ
・一手考えるのがとても遅い
・30手組むのに30分ぐらいかかる改善策
・c++とかもっと早い言語でやろう
・ビットボードを使おう
・盤面をハッシュ化して同じ盤面に対して何度も評価する必要を無くそう



- 投稿日:2020-05-19T22:03:57+09:00
ハンドジェスチャーでMusic(iTunes)を操作した。
はじめに
Qiitaの記事を書くのが初めてなので、間違えているところなどあると思います。
また、Pythonに関してもKerasなどの機械学習ライブラリで遊ぶ程度の初心者なのでコードをもっと良く書ける部分があると思います。
「ここをこうした方がいいよ」などコメントでアドバイスを頂けると嬉しいです。今回作成したもの
タイトルにもある通りPythonからMusic(iTunes)をコントロールできるプログラムを作成しました。
(わかりにくくてごめんなさい。)手の認識とジェスチャー
手の認識はmetalwhaleさんのGithubのリポジトリを参考に、wolterlwさんのプログラムを使わせていただきました。
説明を見たところ、認識にはGoogleのmediapipeをPythonで扱えるようにした物らしいです。
(手の検出器は顔などと違い全然ないことにびっくりしました...)使用するには以下のモジュールとhand_tracker.pyが必要なのでインストールをしてください。
numpy opencv tensorflowジェスチャーはTheJLifeXさんがC言語で作成した手のランドマークの位置でジェスチャーを判断するプログラムを参考に両手と上下の判断をできるようにpythonで書きました。
landmark.pydef finger(landmark): x = 0 y = 1 thumbFinger = False firstFinger = False secondFinger = False thirdFinger = False fourthFinger = False if landmark[9][y] < landmark[0][y]: Hand_direction_y = 'up' else: Hand_direction_y = 'down' landmark_point = landmark[2][x] if landmark[5][x] < landmark[17][x]: if landmark[3][x] < landmark_point and landmark[4][x] < landmark_point: thumbFinger = True Hand_direction_x = 'right' else: if landmark[3][x] > landmark_point and landmark[4][x] > landmark_point: thumbFinger = True Hand_direction_x = 'left' landmark_point = landmark[6][y] if landmark[7][y] < landmark_point and landmark[8][y] < landmark_point: firstFinger = True landmark_point = landmark[10][y] if landmark[11][y] < landmark_point and landmark[12][y] < landmark_point: secondFinger = True landmark_point = landmark[14][y] if landmark[15][y] < landmark_point and landmark[16][y] < landmark_point: thirdFinger = True landmark_point = landmark[18][y] if landmark[19][y] < landmark_point and landmark[20][y] < landmark_point: fourthFinger = True if thumbFinger and firstFinger and secondFinger and thirdFinger and fourthFinger: hand = 'five' elif not thumbFinger and firstFinger and secondFinger and thirdFinger and fourthFinger: hand = 'four' elif not thumbFinger and firstFinger and secondFinger and thirdFinger and not fourthFinger: hand = 'tree' elif not thumbFinger and firstFinger and secondFinger and not thirdFinger and not fourthFinger: hand = 'two' elif not thumbFinger and firstFinger and not secondFinger and not thirdFinger and not fourthFinger: hand = 'one' elif not thumbFinger and not firstFinger and not secondFinger and not thirdFinger and not fourthFinger: hand = 'zero' elif thumbFinger and not firstFinger and not secondFinger and not thirdFinger and fourthFinger: hand = 'aloha' elif not thumbFinger and firstFinger and not secondFinger and not thirdFinger and fourthFinger: hand = 'fox' elif thumbFinger and firstFinger and not secondFinger and not thirdFinger and not fourthFinger: hand = 'up' elif thumbFinger and firstFinger and not secondFinger and not thirdFinger and fourthFinger: hand = 'RankaLee' else: hand = None return hand, Hand_direction_x, Hand_direction_yMusicの制御
Musicの制御には、自分が作成したControl-itunes-from-pythonを使用しました。
このプログラムはsubprocessからOsascriptを実行しているだけのプログラムです。(GithubのReadmeにもある通りmacOS 10.15 Catalina以上でしか実行できません。)
作成したコード
今回自分が作成したコードです。
ここでは、映像を取得後、手の認識やジェスシャーなどを行いその結果でMusicの操作を行うコード実行しています。main.py# coding=utf-8 import cv2 import numpy as np from hand_tracker import HandTracker from control import Control,Get_data from landmark import finger import subprocess import shlex hand_detector = HandTracker("./files/palm_detection_without_custom_op.tflite","./files/hand_landmark.tflite","./files/anchors.csv") cap = cv2.VideoCapture(0) before = None def music(hand, Hand_direction_x, Hand_direction_y, before): if hand is not before: if hand is 'two' and Hand_direction_x == 'right' and Hand_direction_y == 'up': Control.next_track() return 'Next track' elif hand is 'two' and Hand_direction_x == 'left' and Hand_direction_y == 'up': Control.back_track() return 'Back track' elif hand is 'RankaLee' and Hand_direction_x == 'left' and Hand_direction_y == 'up': Control.previous_track() return 'Previous track' elif hand is 'aloha' and Hand_direction_x == 'right' and Hand_direction_y == 'up': Control.playpause() return 'Playpause' elif hand is 'fox' and Hand_direction_x == 'right' and Hand_direction_y == 'up': display = f'osascript -e \'display notification \"{Get_data.current_track_artist()}\" with title \"{Get_data.current_track()}\"\'' subprocess.Popen(shlex.split(display),stdout=subprocess.PIPE) return 'display' while True: ret, frame = cap.read() if ret: frame = cv2.flip(frame, 1) landmark, _ = hand_detector(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)) if landmark is not None: hand, Hand_direction_x, Hand_direction_y = finger(landmark) control = music(hand, Hand_direction_x, Hand_direction_y, before) before = hand for landmark_point in landmark: x, y = landmark_point cv2.circle(frame, (int(x), int(y)), 2, (255, 0, 0), 4) cv2.imshow('Hand', frame) if cv2.waitKey(10) == 27: cap.release() cv2.destroyAllWindows() break10行目あたりのhand_detector = HandTrackerは手の認識に必要なファイルを設定しています。
今回はmetalwhaleさんのhand_trackingリポジトリの中にあるmodelsを使いました。14行目の def music ではジェスチャーで判断したデータを元にMusicの制御をするプログラムです。
ここを書き換えれば他の物を制御できたりするようになります。さいごに
予想より、手の認識やランドマークが正確でびっくりしました。
今回は音楽の制御に使いましたが、別のことにも活用できると思うので、色々と面白いことをしてコメントなどに書いていただけると嬉しいです!!今回作成したコードはGithubの方にあげたので、よければ使ってください(hand_tracker.pyとmodelsのダウンロードだけお願いします)
初めてのQittaの記事で全然説明などできていなかったり文字がおかしいところがあると思います。
もしあった場合は編集リクエストやコメントなどで教えてください。

- 投稿日:2020-05-19T22:01:39+09:00
[Python]探索 ABC165C
ABC165C
1次方程式の条件なので、NumPy配列を使うことで、計算回数を大きく削減できる。NumPy配列がイテラブルのような役割を果たす。
PyPyでも実行可能で、計算速度を上げることができる。(なぜかメモリ使用量が増える)
Python3 1063 ms 106372 KB
PyPy3 571 ms 155196 KBサンプルコードimport sys import itertools import numpy as np read = sys.stdin.buffer.read readline = sys.stdin.buffer.readline N, M, Q = map(int, readline().split()) A = np.array(list(itertools.combinations_with_replacement(range(1, M + 1), N))) # [[1 1 1] # [1 1 2] # [1 1 3] # [1 1 4] # [1 2 2] ... n = len(A) score = np.zeros(n, np.int32) m = map(int, read().split()) for a, b, c, d in zip(m, m, m, m): cond = A[:, b - 1] - A[:, a - 1] == c # NumPy配列 score += d * cond print(score.max())
- 投稿日:2020-05-19T21:39:12+09:00
macOSでpyenvとpipenvの環境でOpenVinoを動かす
コレは何?
macOS Catalina上で、pyenvをpipenvも使っているとう状況でopenvinoをうまく動かす方法についての覚書。
「macOS CatalinaでOpenVinoを動かす」の続編です。特に仮想環境とか使ってない&&わりと環境構築とか得意な人はそちらをご参照ください。
こちらは、上記環境利用中の初心者を対象として、内容をブラッシュアップしたものです。環境
macOS Catalina(10.15.4)
OpenVino(2020.2.117)
Python 3.7.5
cmake 3.17.1全般における注意事項
OpenVinoをインストールし、チュートリアル通りに動かすと、謹製のopencvにパスを通したり、勝手にpipを使ったりするので、うっかりするとpyenvやpipenvを使っている意味がなくなってしまいます。いわれたとおりにせずソースをまず見るべし。
多少面倒ですが、$ source /opt/intel/openvino/bin/setupvars.sh なぞは.bash_profileなどに書かずに、ターミナルを起動するたびにチクチク実行した方が他の開発環境とコンフリクトする可能性が低くなります。OpenVinoのダウンロードとインストール
ここからmacOS用のdmgをダウンロードし、解凍して実行。
通常はrootユーザーでインストールします。
完了すると、webページが表示されますが、ここではまだ、チュートリアルのデモを実行してはいけません!プロジェクト環境の構築
プロジェクトディレクトリを作成し、pyenvとpipenvの設定をします。
OpenVinoでのpythonの推奨バージョンは3.7.5ですので、pyenvでは3.7.5をインストールします。$ pyenv install 3.7.5 $ mkdir ~/Documents/openvino-projects $ cd ~/Documents/openvino-projects $ source /opt/intel/openvino/bin/setupvars.sh [setupvars.sh] OpenVINO environment initializedチュートリアルのデモや、その他のデモで使ういくつかのライブラリをまとめました。
以下の内容をPipfileという名前で、プロジェクトディレクトリ(ここでは~/Documents/openvino-projects)に置きます。[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] tensorflow = "<2.0.0,>=1.2.0" mxnet = ">=1.0.0,<=1.5.1" networkx = ">=1.11" numpy = ">=1.12.0" protobuf = "==3.6.1" onnx = ">=1.1.2" defusedxml = ">=0.5.0" pyyaml = "*" requests = "*" scipy = "*" [requires] python_version = "3.7"仮想環境を構築し、シェルに入ります。
$ pyenv local 3.7.5 $ pipenv --python 3.7.5 ........略 $ pipenv install # ここでLocking..のまま永遠に終わらない場合は、(あまりオススメできないが)やむをえんので、 pipenv install --skip-lock とする。 ........略 $ pipenv shellチュートリアルを実行
インストール後に表示されるウェブページに書かれたチュートリアルデモでは、モデルのダウンロード、変換、実行までやってくれるスクリプトを実行するだけなのですが、これが余計なことをしてくれるので少し修正します。
$ cd /opt/intel/openvino/deployment_tools/demo/ $ sudo cp ./demo_squeezenet_download_convert_run.sh ./demo_squeezenet_download_convert_run2.shdemo_squeezenet_download_convert_run2.shの146-150行目をコメントアウトして保存します(root権限が必要)。
demo_squeezenet_download_convert_run2.sh#if [[ "$OSTYPE" == "darwin"* ]]; then # $pip_binary install -r $ROOT_DIR/../open_model_zoo/tools/downloader/requirements.in #else # sudo -E $pip_binary install -r $ROOT_DIR/../open_model_zoo/tools/downloader/requirements.in #fi実行。
$ ./demo_squeezenet_download_convert_run2.sh ........略 $ ./demo_security_barrier_camera.sh ........略エラーが出ず、WEBページのような結果になればOK
C++のデモを実行する
以下の内容をupdate_rpath.shという名前でプロジェクトディレクトリに保存します。
update_rpath.shinstall_name_tool -add_rpath '/opt/intel/openvino/opencv/lib' /opt/intel/openvino_2020.2.117/python/python3/cv2.so install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/lib/intel64' /opt/intel/openvino_2020.2.117/python/python3/cv2.so install_name_tool -add_rpath '/opt/intel/openvino/deployment_tools/ngraph/lib' /opt/intel/openvino_2020.2.117/python/python3/cv2.so install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/external/tbb/lib' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libinference_engine_legacy.dylib install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/lib/intel64' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libMKLDNNPlugin.dylib install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/lib/intel64' /opt/intel/openvino/python/python3.7/openvino/inference_engine/ie_api.so install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/external/tbb/lib' /opt/intel/openvino/python/python3.7/openvino/inference_engine/ie_api.so install_name_tool -add_rpath '/opt/intel/openvino/deployment_tools/ngraph/lib' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libinference_engine.dylib install_name_tool -add_rpath '/opt/intel/openvino/deployment_tools/ngraph/lib' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libinference_engine_legacy.dylib上記のファイルを実行します(なぜこれをするかなど、詳しくは前投稿参照)。
$ cd ~/Documents/openvino-projects $ chmod 755 ./update_rpath.sh $ sudo ./update_rpath.shデモファイルの入ったディレクトリをプロジェクトディレクトリにコピーします。
$ cp -r /opt/intel/openvino/deployment_tools/open_model_zoo/demos .pythonモジュールオプションをつけてcmakeします。
$ cd demos $ cmake -DCMAKE_BUILD_TYPE=Release -DENABLE_PYTHON=ON . ......略しかし、このままではコンパイルが通らないので、CmakeCache.txt(34行目)を編集します。
CMakeCache.txt・・・・・略・・・・・ //Flags used by the CXX compiler during all build types. CMAKE_CXX_FLAGS:STRING=-Wno-inconsistent-missing-override ・・・・・略・・・・・makeします。
$ make -j2 ・・・・・略・・・・・intel64/Release以下に実行ファイルがビルドされています。
crossroad_camera_demoを実行してみましょう。
まずは、各サンプルの説明ページを見ましょう。crossroad_camera_demoは、ここのページです。とりあえずよく読みましょう。
まずは、必要なモデルファイルのダウンロードが必要です。
以下のようにして、必要なモデルをダウンロードします。$ cd ~/Documents/openvino-projects $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-vehicle-bike-detection-crossroad-0078 ・・・・・略・・・・・ $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-attributes-recognition-crossroad-0230 ・・・・・略・・・・・ $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-reidentification-retail-0031 ・・・・・略・・・・・openvino-projects/intel/ 以下にモデルがダウンロードされます。
crossroad_camera_demoは入力にビデオファイルかカメラが使えますが、PCカメラだと通行人を撮るのに適していないので適当な映像ファイルを使いましょう。
デモに有用なリソースはここにあります。ここではpeople-detection.mp4を使ってみます。
$ mkdir sample-videos # people-detection.mp4をダウンロードして、sample-videosフォルダに入れる。 $ ./demos/intel64/Release/crossroad_camera_demo \ -i ./sample-videos/person-bicycle-car-detection.mp4 \ -m ./intel/person-vehicle-bike-detection-crossroad-0078/FP16/person-vehicle-bike-detection-crossroad-0078.xml \ -m_pa ./intel/person-attributes-recognition-crossroad-0230/FP16/person-attributes-recognition-crossroad-0230.xml \ -m_reid ./intel/person-reidentification-retail-0031/FP16/person-reidentification-retail-0031.xml \ -d CPU -d_pa CPU -d_reid CPUこのデモでは、人物の検知と属性情報の推定、そして、トラッキング(reidentification)を別々のモデルを使っておこないます。
Pythonデモを実行する
python用のデモは、demos/python_demos/ 以下にあります。
FaceRecogintionのデモを実行してみましょう。
[FaceRecogintionの説明ページはこちら[(https://docs.openvinotoolkit.org/latest/_demos_python_demos_face_recognition_demo_README.html)。
同様に、必要なモデルファイルをダウンロードして実行します。今度はPCカメラを使います。
このデモでは--run_detectorオプションで、簡単な顔認証機能が使えます。対象となる顔写真を撮影しておきます。$ mkdir face-data #自分の写真を撮り、myname.jpgなどとし、face-dataに入れておく。 # modelのダウンロード $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name face-detection-retail-0004 $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name landmarks-regression-retail-0009 $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name face-reidentification-retail-0095 # デモの実行 $ python3 demos/python_demos/face_recognition_demo/face_recognition_demo.py \ -m_fd ./intel/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -m_lm ./intel/landmarks-regression-retail-0009/FP16/landmarks-regression-retail-0009.xml \ -m_reid ./intel/face-reidentification-retail-0095/FP16/face-reidentification-retail-0095.xml \ --verbose --run_detector -fg ./face-data起動すると、別画面で撮影した顔写真に名前を入れるよう求められます。適当に名前を入力します。
次に別の画像(もとから入っているもの?)が表示されますので、これにも適当に答えます。カメラが起動し、自分の画像を認識します。
- 投稿日:2020-05-19T21:39:12+09:00
macOSかつpyenvとpipenvの環境でOpenVinoを動かす
コレは何?
macOS Catalina上で、pyenvをpipenvも使っているとう状況でopenvinoをうまく動かす方法についての覚書。
「macOS CatalinaでOpenVinoを動かす」の続編です。特に仮想環境とか使ってない&&わりと環境構築とか得意な人はそちらをご参照ください。
こちらは、上記環境利用中の初心者を対象として、内容をブラッシュアップしたものです。環境
macOS Catalina(10.15.4)
OpenVino(2020.2.117)
Python 3.7.5
cmake 3.17.1全般における注意事項
OpenVinoをインストールし、チュートリアル通りに動かすと、謹製のopencvにパスを通したり、勝手にpipを使ったりするので、うっかりするとpyenvやpipenvを使っている意味がなくなってしまいます。いわれたとおりにせずソースをまず見るべし。
多少面倒ですが、$ source /opt/intel/openvino/bin/setupvars.sh なぞは.bash_profileなどに書かずに、ターミナルを起動するたびにチクチク実行した方が他の開発環境とコンフリクトする可能性が低くなります。OpenVinoのダウンロードとインストール
ここからmacOS用のdmgをダウンロードし、解凍して実行。
通常はrootユーザーでインストールします。
完了するとwebページが表示されますが、ここではまだチュートリアルのデモを実行してはいけません!プロジェクト環境の構築
プロジェクトディレクトリを作成し、pyenvとpipenvの設定をします。
OpenVinoでのpythonの推奨バージョンは3.7.5ですので、pyenvでは3.7.5をインストールします。$ pyenv install 3.7.5 $ mkdir ~/Documents/openvino-projects $ cd ~/Documents/openvino-projects $ source /opt/intel/openvino/bin/setupvars.sh [setupvars.sh] OpenVINO environment initializedチュートリアルのデモや、その他のデモで使ういくつかのライブラリをまとめました。
以下の内容をPipfileという名前で、プロジェクトディレクトリ(ここでは~/Documents/openvino-projects)に置きます。[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] tensorflow = "<2.0.0,>=1.2.0" mxnet = ">=1.0.0,<=1.5.1" networkx = ">=1.11" numpy = ">=1.12.0" protobuf = "==3.6.1" onnx = ">=1.1.2" defusedxml = ">=0.5.0" pyyaml = "*" requests = "*" scipy = "*" [requires] python_version = "3.7"仮想環境を構築し、シェルに入ります。
$ pyenv local 3.7.5 $ pipenv --python 3.7.5 ........略 $ pipenv install # ここでLocking..のまま永遠に終わらない場合は、(あまりオススメできないが)やむをえんので、 pipenv install --skip-lock とする。 ........略 $ pipenv shellチュートリアルを実行
インストール後に表示されるウェブページに書かれたチュートリアルデモでは、モデルのダウンロード、変換、実行までやってくれるスクリプトを実行するだけなのですが、これが余計なことをしてくれるので少し修正します。
$ cd /opt/intel/openvino/deployment_tools/demo/ $ sudo cp ./demo_squeezenet_download_convert_run.sh ./demo_squeezenet_download_convert_run2.shdemo_squeezenet_download_convert_run2.shの146-150行目をコメントアウトして保存します(root権限が必要)。
demo_squeezenet_download_convert_run2.sh#if [[ "$OSTYPE" == "darwin"* ]]; then # $pip_binary install -r $ROOT_DIR/../open_model_zoo/tools/downloader/requirements.in #else # sudo -E $pip_binary install -r $ROOT_DIR/../open_model_zoo/tools/downloader/requirements.in #fi実行。
$ ./demo_squeezenet_download_convert_run2.sh ........略 $ ./demo_security_barrier_camera.sh ........略エラーが出ず、WEBページのような結果になればOK
C++のデモを実行する
以下の内容をupdate_rpath.shという名前でプロジェクトディレクトリに保存します。
update_rpath.shinstall_name_tool -add_rpath '/opt/intel/openvino/opencv/lib' /opt/intel/openvino_2020.2.117/python/python3/cv2.so install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/lib/intel64' /opt/intel/openvino_2020.2.117/python/python3/cv2.so install_name_tool -add_rpath '/opt/intel/openvino/deployment_tools/ngraph/lib' /opt/intel/openvino_2020.2.117/python/python3/cv2.so install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/external/tbb/lib' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libinference_engine_legacy.dylib install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/lib/intel64' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libMKLDNNPlugin.dylib install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/lib/intel64' /opt/intel/openvino/python/python3.7/openvino/inference_engine/ie_api.so install_name_tool -add_rpath '/opt/intel/openvino/inference_engine/external/tbb/lib' /opt/intel/openvino/python/python3.7/openvino/inference_engine/ie_api.so install_name_tool -add_rpath '/opt/intel/openvino/deployment_tools/ngraph/lib' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libinference_engine.dylib install_name_tool -add_rpath '/opt/intel/openvino/deployment_tools/ngraph/lib' /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libinference_engine_legacy.dylib上記のファイルを実行します(なぜこれをするかなど、詳しくは前投稿参照)。
$ cd ~/Documents/openvino-projects $ chmod 755 ./update_rpath.sh $ sudo ./update_rpath.shデモファイルの入ったディレクトリをプロジェクトディレクトリにコピーします。
$ cp -r /opt/intel/openvino/deployment_tools/open_model_zoo/demos .pythonモジュールオプションをつけてcmakeします。
$ cd demos $ cmake -DCMAKE_BUILD_TYPE=Release -DENABLE_PYTHON=ON . ......略しかし、このままではコンパイルが通らないので、CmakeCache.txt(34行目)を編集します。
CMakeCache.txt・・・・・略・・・・・ //Flags used by the CXX compiler during all build types. CMAKE_CXX_FLAGS:STRING=-Wno-inconsistent-missing-override ・・・・・略・・・・・makeします。
$ make -j2 ・・・・・略・・・・・intel64/Release以下に実行ファイルがビルドされています。
crossroad_camera_demoを実行してみましょう。
まずは、各サンプルの説明ページを見ましょう。crossroad_camera_demoは、ここのページです。とりあえずよく読みましょう。
まずは、必要なモデルファイルのダウンロードが必要です。
以下のようにして、必要なモデルをダウンロードします。$ cd ~/Documents/openvino-projects $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-vehicle-bike-detection-crossroad-0078 ・・・・・略・・・・・ $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-attributes-recognition-crossroad-0230 ・・・・・略・・・・・ $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-reidentification-retail-0031 ・・・・・略・・・・・openvino-projects/intel/ 以下にモデルがダウンロードされます。
crossroad_camera_demoは入力にビデオファイルかカメラが使えますが、PCカメラだと通行人を撮るのに適していないので適当な映像ファイルを使いましょう。
デモに有用なリソースはここにあります。ここではpeople-detection.mp4を使ってみます。
$ mkdir sample-videos # people-detection.mp4をダウンロードして、sample-videosフォルダに入れる。 $ ./demos/intel64/Release/crossroad_camera_demo \ -i ./sample-videos/person-bicycle-car-detection.mp4 \ -m ./intel/person-vehicle-bike-detection-crossroad-0078/FP16/person-vehicle-bike-detection-crossroad-0078.xml \ -m_pa ./intel/person-attributes-recognition-crossroad-0230/FP16/person-attributes-recognition-crossroad-0230.xml \ -m_reid ./intel/person-reidentification-retail-0031/FP16/person-reidentification-retail-0031.xml \ -d CPU -d_pa CPU -d_reid CPUこのデモでは、人物の検知と属性情報の推定、そして、トラッキング(reidentification)を別々のモデルを使っておこないます。
Pythonデモを実行する
python用のデモは、demos/python_demos/ 以下にあります。
FaceRecogintionのデモを実行してみましょう。
FaceRecogintionの説明ページはこちら。
同様に、必要なモデルファイルをダウンロードして実行します。今度はPCカメラを使います。
このデモでは--run_detectorオプションで、簡単な顔認証機能が使えます。対象となる顔写真を撮影しておきます。$ mkdir face-data #自分の写真を撮り、myname.jpgなどとし、face-dataに入れておく。 # modelのダウンロード $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name face-detection-retail-0004 $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name landmarks-regression-retail-0009 $ /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name face-reidentification-retail-0095 # デモの実行 $ python3 demos/python_demos/face_recognition_demo/face_recognition_demo.py \ -m_fd ./intel/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -m_lm ./intel/landmarks-regression-retail-0009/FP16/landmarks-regression-retail-0009.xml \ -m_reid ./intel/face-reidentification-retail-0095/FP16/face-reidentification-retail-0095.xml \ --verbose --run_detector -fg ./face-data起動すると、別画面で撮影した顔写真に名前を入れるよう求められます。適当に名前を入力します。
次に別の画像(もとから入っているもの?)が表示されますので、これにも適当に答えます。カメラが起動し、自分の画像を認識します。
- 投稿日:2020-05-19T21:20:35+09:00
Ruby と Python と numpy で解く AtCoder ABC054 B 行列演算
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Beginner Contest B - Template Matching
Difficulty: 828今回のテーマ、行列演算
2次元配列ですが、行列のライブラリを使用すると演算が簡単になることがあります。
Ruby
ruby.rbrequire 'matrix' class Matrix # v2.3 では代入不可 def []=(i, j, x) @rows[i][j]=x end end n, m = gets.split.map(&:to_i) a = Matrix.zero(n) b = Matrix.zero(m) n.times do |i| s = gets.chomp.chars n.times do |j| if s[j] == '#' a[i, j] = 1 end end end m.times do |i| s = gets.chomp.chars m.times do |j| if s[j] == '#' b[i, j] = 1 end end end if n == 1 && a[0, 0] == b[0, 0] puts "Yes" exit end (n - m).times do |i| (n - m).times do |j| if a.minor(i, m, j, m) == b puts "Yes" exit end end end puts "No"matrix.rbrequire 'matrix' class Matrix # v2.3 では代入不可 def []=(i, j, x) @rows[i][j]=x end end
require 'matrix'で行列のライブラリを呼び出します。
ローカル環境のv2.7.1では行列の要素に代入できるのですが、AtCoder環境のv2.3.3では代入できないのでメソッドを追加しています。
標準ライブラリに対してもこういうことができるのがRubyの面白い所でもあります。minor.rbif a.minor(i, m, j, m) == b
minorで部分行列を取得し行列の比較を行っています。error.rbif n == 1 && a[0, 0] == b[0, 0] puts "Yes" exit end
1 x 1の行列の時、行列の比較がうまくいかないので、それに対応した処理が入っています。Python
import numpy n, m = map(int, input().split()) a = numpy.zeros([n, n], dtype=int) b = numpy.zeros([m, m], dtype=int) for i in range(n): s = input() for j in range(n): if s[j] == '#': a[i, j] = 1 for i in range(m): s = input() for j in range(m): if s[j] == '#': b[i, j] = 1 for i in range(n - m + 1): for j in range(n - m + 1): if numpy.all(a[i: i + m, j: j + m] == b): print("Yes") exit() print("No")all.pyif numpy.all(a[i: i + m, j: j + m] == b):Rubyの行列の比較は
0を返しますが、numpyの行列の比較はTrueを返します。
all関数で全てTrueかどうかを調べています。
Ruby Python (numpy) コード長 (Byte) 622 534 実行時間 (ms) 20 166 メモリ (KB) 2684 12512 まとめ
- ABC 054 B を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- numpy に詳しくなった
- 投稿日:2020-05-19T21:06:36+09:00
[Python]03章-02 turtle グラフィックス(turtleの動作)
[Python]03章-02 turtleの動作
前回、3章-01では、turtleを作成して終了しました。今回はそのturtleを動かしていきたいと思います。
なお、3章-01で扱ったプログラムを使用します。前回、chap03の中に、03-01-01.pyというファイル名でファイルを作成し、以下のコードを書きました。
03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #いったんここでプログラムを止める。 turtle.done()今回は章立て上、chap03の中に、03-02-01.pyというファイル名でプログラムを作成していきたいと思います。
03-02-01.pyを作成し、03-01-01.pyのプログラムをコピーし、03-02-01.pyに貼り付けてください。03-02-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #いったんここでプログラムを止める。 turtle.done()turtleを動かす
では早速turtle(taroと名付けました)を動かしてみましょう。
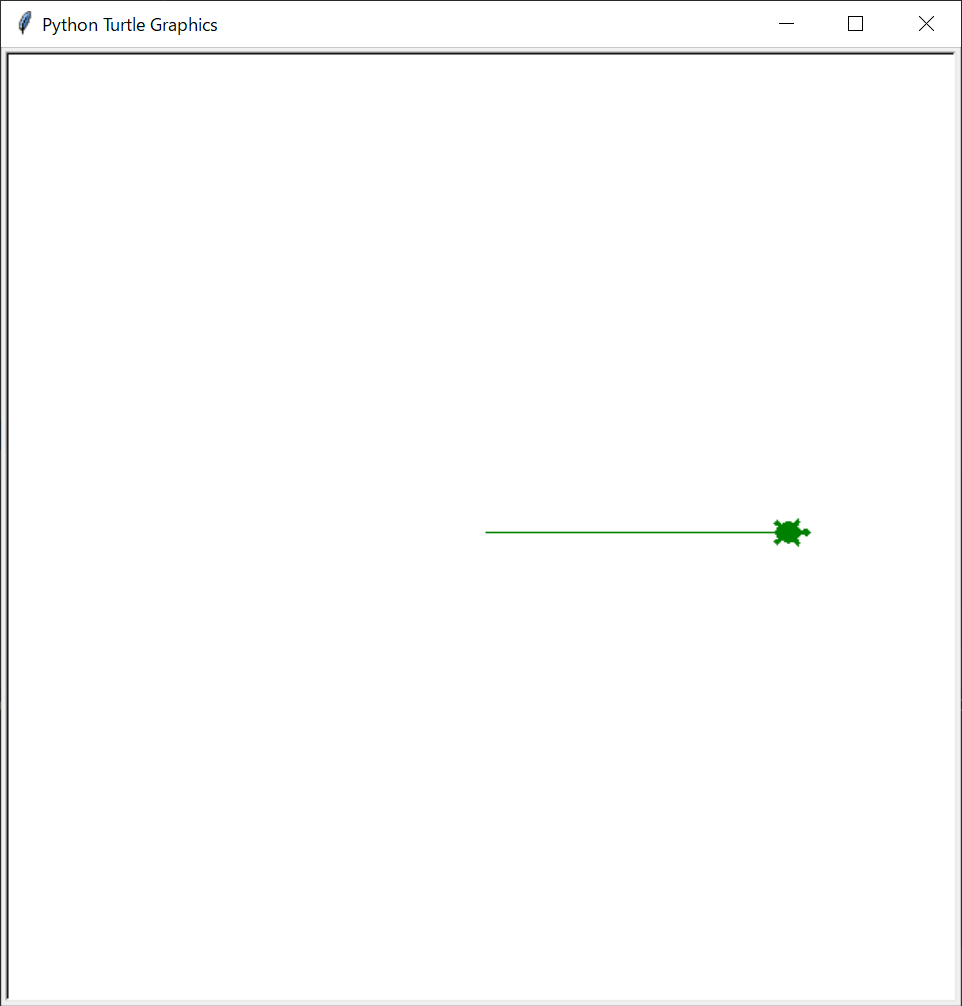
その前に、1つ確認しておきます。中学校の数学で関数を習ったと思いますが、taroは最初に(0, 0)の位置にいます。そして、前回実行した通り、以下のように右を向いているため、x軸方向(右方向)に向いていることになります。
したがって、最初動かすときには右方向に動くことになります。実際に右方向に動かしてみましょう。以下のコードを追加してください。
03-02-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #亀をx軸方向に200動かす taro.forward(200) #<<<<追加 #いったんここでプログラムを止める。 turtle.done()そして実行してみてください。taroが右方向に200動いたかと思います。
taro.forward(distance)メソッドは、distanceに距離を入力し、その分だけ前方向に動かすことができます。
詳細は以下のforwardメソッドのマニュアルをご確認ください。※なお、forward()はfd()でも可能です。
そして、distanceの値を変えて動く距離が変わるかを見てみましょう。
動きを遅くする
今、taroの動きを確認できたと思いますが、(亀なのに)少しスピードが速いので、ゆっくり動かしてみたいと思います。
以下のspeed()メソッドを先ほど入力したforward()メソッドの前に入力してみましょう。
#turtleの速度を遅くする taro.speed(speed=1)【マニュアルより】
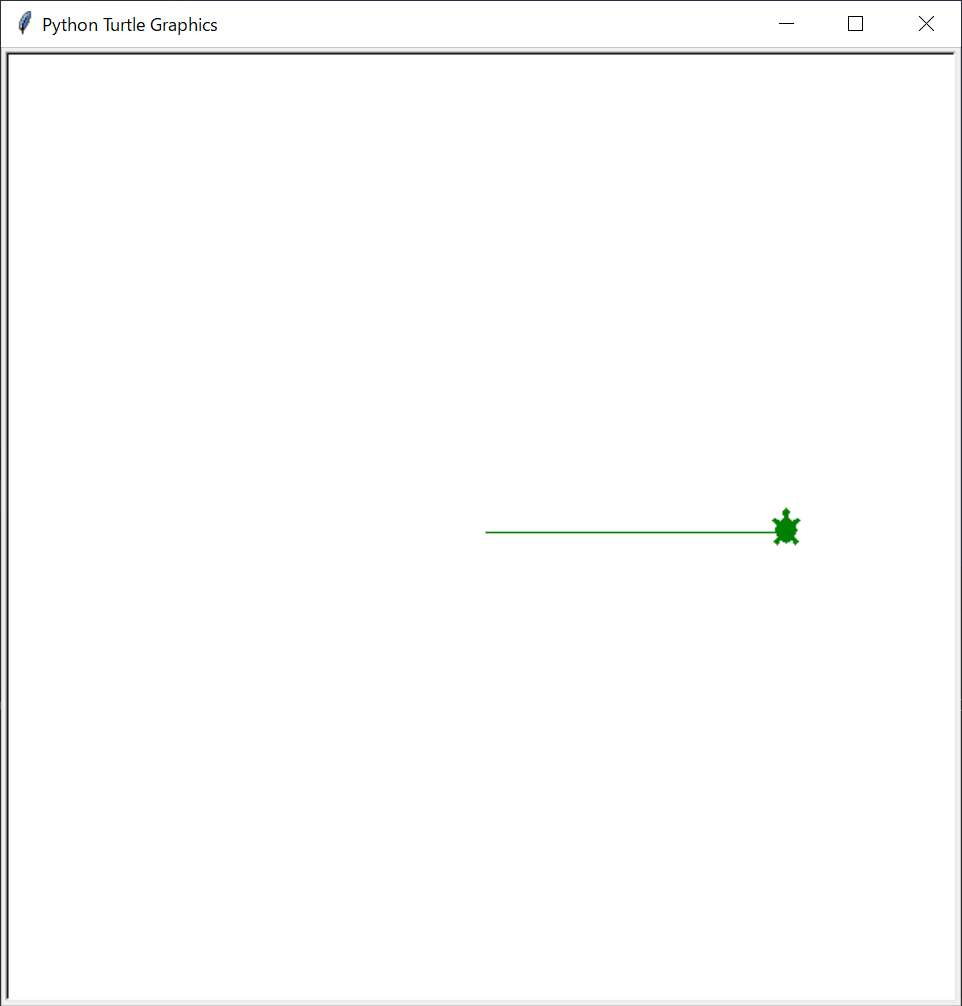
タートルのスピードを 0 から 10 までの範囲の整数に設定します。引数が与えられない場合は現在のスピードを返します。turtleの方向転換をする
turtleは動かせましたが、これでは一方向しか動いていません。方向を変えることを考えてみます。
03-02-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #速度を遅くする taro.speed(speed=1) #←追加 #亀をx軸方向に200動かす taro.forward(200) taro.left(90) #いったんここでプログラムを止める。 turtle.done()すると、最後にturtleが左周りに90°回転したと思います。
taro.left(angle)メソッドは、angleに角度を入力し、その分だけ回転させることができます。
詳細は以下のleftメソッドのマニュアルをご確認ください。【マニュアルより】
タートルを angle 単位だけ左に回します。 (単位のデフォルトは度ですが、 degrees() と radians() 関数を使って設定できます。) 角度の向きはタートルのモードによって意味が変わります。 mode() を参照してください。※left()はlt()でも可能です。
なお、今回は扱いませんが、左があるということは、右もありますので、よろしければ試してください。
right()メソッド
【マニュアルより】
タートルを angle 単位だけ右に回します。 (単位のデフォルトは度ですが、 degrees() と radians() 関数を使って設定できます。) 角度の向きはタートルのモードによって意味が変わります。 mode() を参照してください。※rightはrt()でも可能です。
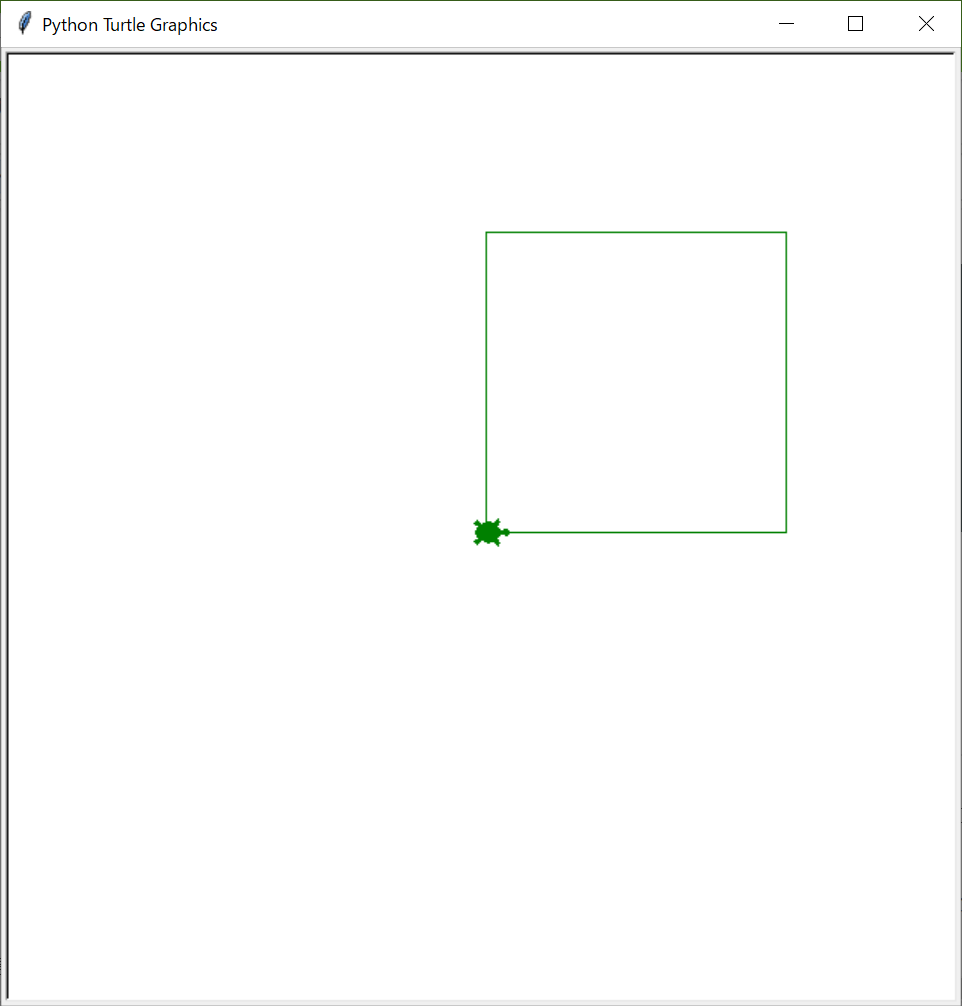
正方形を作る
ここまで作成したので、正方形を作成してみましょう。
以下のコードを入力してください。#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #速度を遅くする taro.speed(speed=1) #亀をx軸方向に200動かす taro.forward(200) taro.left(90) taro.forward(200) #<追加 taro.left(90) #<追加 taro.forward(200) #<追加 taro.left(90) #<追加 taro.forward(200) #<追加 taro.left(90) #<追加 #いったんここでプログラムを止める。 turtle.done()すると、以下のように正方形ができます。
演習問題
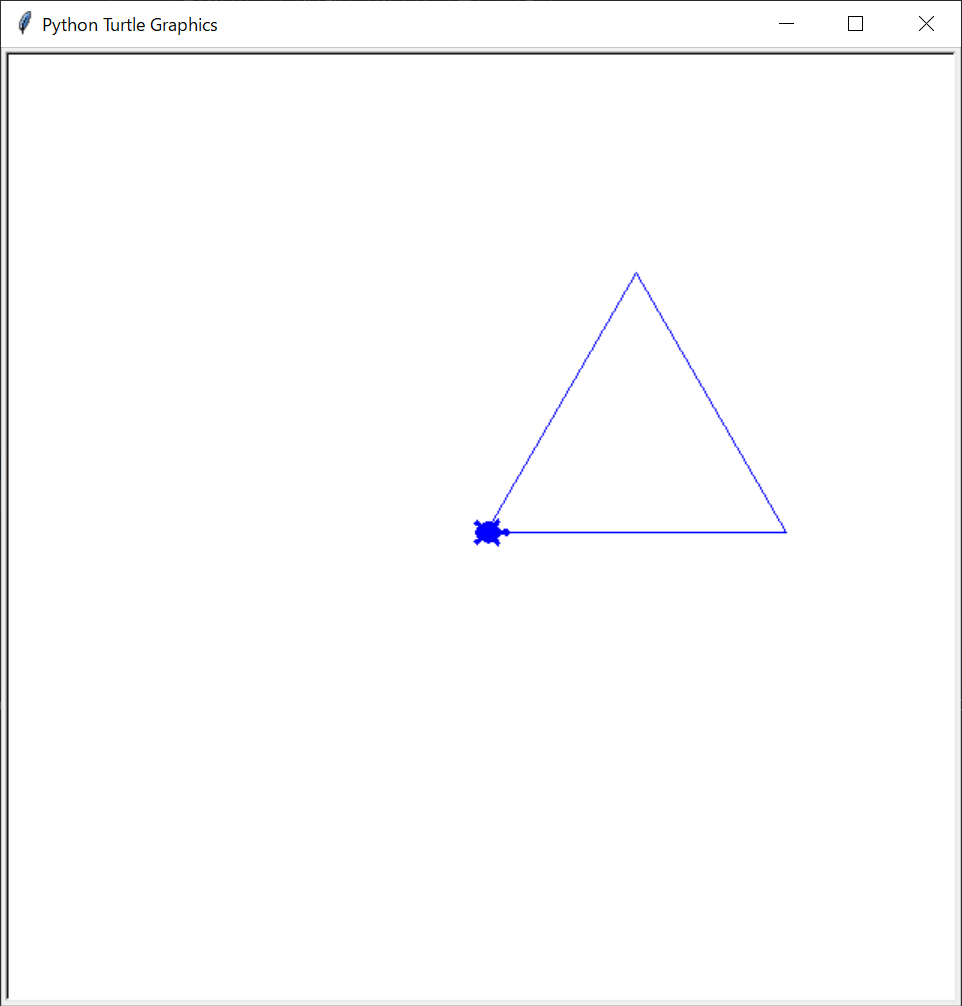
・以下の図を描くプログラムを作成してください。(一辺は200です)
・以下の図を描くプログラムを作成してください。(一辺は100です、ペンの太さ5です。)
1つ習っていないメソッドがありますが、メソッドを調べてみましょう。
メソッドリンク
最後に
今回は実際にturtleを動かしてみました。マニュアルを見てわかる通り、様々な処理があったかと思います。
最初はマニュアルを見てもわからないような用語があると思いますが、読んでいくうちに慣れてくると思います。
実際に実務でもプログラムを書くよりかはマニュアルを読んで調べるといった作業のほうがほとんどといってもいいほどです。今のうちにマニュアルを読んで慣れておきましょう。プログラマは調べることが仕事だと思っています。そして、マニュアルを読んでいろいろな動きを試してみてください。
【目次リンク】へ戻る
- 投稿日:2020-05-19T21:04:43+09:00
言語処理100本ノック 2020を解く(00. 文字列の逆順)
はじめに
巷で流行っている自然言語100本ノックにPythonで挑戦してみます。
解き方はいろいろあると思うので、いろいろな解き方を示したいと思います。
全ての解き方を網羅することは当然ながらできません。
「こんな解き方があるよ」や「ここ間違ってるよ」という点があれば、ぜひコメントでお教えいただければと思います。言語処理100本ノック 2020とは
言語処理100本ノック 2020は、東北大学の乾・鈴木研究室のプログラミング基礎研勉強会で使われている教材です。
詳しくは、言語処理100本ノックについてを参照して下さい。Qiitaの記事へのリンク
1問目 2問目 3問目 4問目 5問目 6問目 7問目 8問目 9問目 10問目 第1章 00 01 02 03 04 05 06 07 08 09 第2章 10 11 12 13 14 15 16 17 18 19 第3章 20 21 22 23 24 25 26 27 28 29 第4章 30 31 32 33 34 35 36 37 38 39 第5章 40 41 42 43 44 45 46 47 48 49 第6章 50 51 52 53 54 55 56 57 58 59 第7章 60 61 62 63 64 65 66 67 68 69 第8章 70 71 72 73 74 75 76 77 78 79 第9章 80 81 82 83 84 85 86 87 88 89 第10章 90 91 92 93 94 95 96 97 98 99 00. 文字列の逆順
問題
00. 文字列の逆順の問題は、下記の内容です。
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.解答
問題を読むと、
stressedを逆に並べた文字列を得る問題なので、答えはdessertsです。
以下に示すどの解答でも、最後の式を評価するとdessertsと返ってきます。シンプル
素直に文字列の先頭に追加していく方法があります。
Pythonでは、+で文字列を結合して新たな文字列を生成できるのでした。# シンプル s = "stressed" result = "" for c in s: result = c + result result #=> 'desserts'関数型的
関数型的というにはシンプルすぎますが、関数の組み合わせで表現できます。
reversed関数は、イテレータを与えると逆順に取り出すイテレータを返すので、空文字で連結して所望の結果を得ます。# 関数型的 s = "stressed" "".join(reversed(s)) #=> 'desserts'Pythonic
Python的であることを Pythonic といいますが、このコードが一番Pythonicでしょうか。
リストや文字列に対して、s[start:end:step]でアクセスする方法をスライスと呼びます。
stepに-1を指定すると逆順になります。-1ずつ進むんですね。# Pythonic s = "stressed" s[::-1] #=> 'desserts'その他の解答
組み合わせ
上記を組み合わせた、下記のような方法もあります。
文字列の末尾や先頭に何か足すとコピーが発生しますし、リストの末尾以外に要素を追加してもコピーが発生します。
それを避けるために、リストの末尾に要素を追加してから、"".joinで文字列化しています。# シンプルと関数型的の組み合わせ s = "stressed" l = [] for c in reversed(s): l.append(c) "".join(l) #=> 'desserts'インデックスで回す
素直にインデックスで回していく方法もあります。
for n in range(len(s)):はインデックスに対してforを回すときの構文の一つです。
len(s)は文字列sの長さを、range(n)は0,...,n-1を走査するためのイテレータを返します。# reversed相当の処理を自力で行う s = "stressed" l = [] for n in range(len(s)): l.append(s[len(s)-n-1]) "".join(l) #=> 'desserts'インデックスの取り方は別の方法があります。
enumerate(s)は、n=len(s)として(0,s[0]),...,(n-1,s[n-1])を走査するためのイテレータを返します。
使わない変数という意味を込めて、_も使っています。込めてるだけです。# reversed相当の処理を自力で行う s = "stressed" l = [] for n,_ in enumerate(s): l.append(s[len(s)-n-1]) "".join(l) #=> 'desserts'リスト内包表記
リスト内包表記でも書けます。
s = "stressed" l = [c for c in reversed(s)] "".join(l) #=> 'desserts'しかし、よくよく考えるとジェネレータ内包表記でもいいんじゃないかと思えてきます。
s = "stressed" g = (c for c in reversed(s)) "".join(g) #=> 'desserts'そうすると、下記の関数型的に戻りますね。
# 関数型的 s = "stressed" "".join(reversed(s)) #=> 'desserts'振り返り
好みは人それぞれだと思いますが、私が一番好きな回答は下記です。
# シンプルと関数型的の組み合わせ s = "stressed" l = [] for c in reversed(s): l.append(c) "".join(l) #=> 'desserts'for文で逆に回したい感が伝わるのと、素直にリストに要素を追加している点がわかりやすいです。
また、実際の問題を解く際にも、一つ一つの要素に何か処理をして別のリストに入れるという処理をよく書くので、その基本形になっています。
"".join(reversed(s))やs[::-1]はこの問題を解くには最適なのですが、追加の処理を入れにくくなっています。
- 投稿日:2020-05-19T21:04:43+09:00
言語処理100本ノック 2020を解く(01. 文字列の逆順)
はじめに
巷で流行っている自然言語100本ノックにPythonで挑戦してみます。
解き方はいろいろあると思うので、いろいろな解き方を示したいと思います。
全ての解き方を網羅することは当然ながらできません。
「こんな解き方があるよ」や「ここ間違ってるよ」という点があれば、ぜひコメントでお教えいただければと思います。言語処理100本ノック 2020とは
言語処理100本ノック 2020は、東北大学の乾・鈴木研究室のプログラミング基礎研勉強会で使われている教材です。
詳しくは、言語処理100本ノックについてを参照して下さい。リンク
1問目 2問目 3問目 4問目 5問目 6問目 7問目 8問目 9問目 10問目 第1章 00 01 02 03 04 05 06 07 08 09 第2章 10 11 12 13 14 15 16 17 18 19 第3章 20 21 22 23 24 25 26 27 28 29 第4章 30 31 32 33 34 35 36 37 38 39 第5章 40 41 42 43 44 45 46 47 48 49 第6章 50 51 52 53 54 55 56 57 58 59 第7章 60 61 62 63 64 65 66 67 68 69 第8章 70 71 72 73 74 75 76 77 78 79 第9章 80 81 82 83 84 85 86 87 88 89 第10章 90 91 92 93 94 95 96 97 98 99 00. 文字列の逆順
問題
00. 文字列の逆順の問題は、下記の内容です。
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.解答
問題を読むと、
stressedを逆に並べた文字列を得る問題なので、答えはdessertsです。
以下に示すどの解答でも、最後の式を評価するとdessertsと返ってきます。シンプル
素直に文字列の先頭に追加していく方法があります。
Pythonでは、+で文字列を結合して新たな文字列を生成できるのでした。# シンプル s = "stressed" result = "" for c in s: result = c + result result #=> 'desserts'関数型的
関数型的というにはシンプルすぎますが、関数の組み合わせで表現できます。
reversed関数は、イテレータを与えると逆順に取り出すイテレータを返すので、空文字で連結して所望の結果を得ます。# 関数型的 s = "stressed" "".join(reversed(s)) #=> 'desserts'Pythonic
Python的であることを Pythonic といいますが、このコードが一番Pythonicでしょうか。
リストや文字列に対して、s[start:end:step]でアクセスする方法をスライスと呼びます。
stepに-1を指定すると逆順になります。-1ずつ進むんですね。# Pythonic s = "stressed" s[::-1] #=> 'desserts'その他の解答
組み合わせ
上記を組み合わせた、下記のような方法もあります。
文字列の末尾や先頭に何か足すとコピーが発生しますし、リストの末尾以外に要素を追加してもコピーが発生します。
それを避けるために、リストの末尾に要素を追加してから、"".joinで文字列化しています。# シンプルと関数型的の組み合わせ s = "stressed" l = [] for c in reversed(s): l.append(c) "".join(l) #=> 'desserts'インデックスを回す
素直にインデックスを回していく方法もあります。
for n in range(len(s)):はインデックスに対してforを回すときの構文の一つです。
len(s)は文字列sの長さを、range(n)は0,...,n-1を走査するためのイテレータを返します。# reversed相当の処理を自力で行う s = "stressed" l = [] for n in range(len(s)): l.append(s[len(s)-n-1]) "".join(l) #=> 'desserts'インデックスの取り方は別の方法があります。
enumerate(s)は、n=len(s)として(0,s[0]),...,(n-1,s[n-1])を走査するためのイテレータを返します。
使わない変数という意味を込めて、_も使っています。込めてるだけです。# reversed相当の処理を自力で行う s = "stressed" l = [] for n,_ in enumerate(s): l.append(s[len(s)-n-1]) "".join(l) #=> 'desserts'リスト内包表記
リスト内包表記でも書けます。
s = "stressed" l = [c for c in reversed(s)] "".join(l) #=> 'desserts'しかし、よくよく考えるとジェネレータ内包表記でもいいんじゃないかと思えてきます。
s = "stressed" g = (c for c in reversed(s)) "".join(g) #=> 'desserts'そうすると、下記の関数型的に戻りますね。
# 関数型的 s = "stressed" "".join(reversed(s)) #=> 'desserts'振り返り
好みは人それぞれだと思いますが、私が一番好きな回答は下記です。
# シンプルと関数型的の組み合わせ s = "stressed" l = [] for c in reversed(s): l.append(c) "".join(l) #=> 'desserts'for文で逆に回したい感が伝わるのと、素直にリストに要素を追加している点がわかりやすいです。
また、実際の問題を解く際にも、一つ一つの要素に何か処理をして別のリストに入れるという処理をよく書くので、その基本形になっています。
"".join(reversed(s))やs[::-1]はこの問題を解くには最適なのですが、追加の処理を入れにくくなっています。
- 投稿日:2020-05-19T20:57:04+09:00
Seleniumをできるだけ軽くする方法
要件
- いまさらですが、ラズパイもカード会社のスクレイピングにトライしました。
- ラズパイゼロをつかって、Seleniumにて、スクレイピングをしようとしたため、タイムアウトが多々発生。
- 極力軽くスクレイピングが実装できるようにしました。
- パスワードとかの管理は自己責任で。。コード
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait import time from bs4 import BeautifulSoup as BS import re import requests options = Options() options.add_argument("no-sandbox") options.add_argument("--disable-extensions") options.add_argument("--headless") options.add_argument('--disable-gpu') options.add_argument('--ignore-certificate-errors') options.add_argument('--allow-running-insecure-content') options.add_argument('--disable-web-security') options.add_argument('--disable-desktop-notifications') options.add_argument("--disable-extensions") options.add_argument('--lang=ja') options.add_argument('--blink-settings=imagesEnabled=false') options.add_argument('--disable-dev-shm-usage') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') driver = webdriver.Chrome(options=options) driver.get (http:///~~~)また、読み込み範囲を縮小するために、スクレイピング直前のClassまでの読み込みする形で
タイムアウトを最大限にして、記載wait = WebDriverWait(driver, 300); element=wait.until(EC.presence_of_element_located((By.CLASS_NAME,"fluid")));あとは、BeautifulSoupで読み込み、加工
res = driver.page_source.encode('utf-8') print("loading") soup=BS(res,"html.parser")これで、なんとか、タイムアウトを避けることができるようになりました。
- 投稿日:2020-05-19T20:40:46+09:00
AtCoderBeginnerContest168復習&まとめ(後半)
AtCoder ABC168
2020-05-17(日)に行われたAtCoderBeginnerContest168の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEFの問題を扱います.前半はこちら.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 .. (Double Dots)
問題文
あるところに、洞窟があります。
洞窟には$N$個の部屋と$M$本の通路があり、部屋には$1$から$N$の、通路には$1$から$M$の番号がついています。通路$i$は部屋$A_i$と部屋$B_i$を双方向につないでいます。どの$2$部屋間も、通路をいくつか通って行き来できます。部屋$1$は洞窟の入り口がある特別な部屋です。
洞窟の中は薄暗いので、部屋$1$以外の各部屋に$1$つずつ道しるべを設けることにしました。各部屋の道しるべは、その部屋と通路で直接つながっている部屋の$1$つを指すように置きます。
洞窟の中は危険なので、部屋$1$以外のどの部屋についても以下の条件を満たすことが目標です。
その部屋から出発し、「いまいる部屋にある道しるべを見て、それが指す部屋に移動する」ことを繰り返すと、部屋$1$に最小の移動回数でたどり着く。
目標を達成できる道しるべの配置が存在するか判定し、存在するならばそのような配置を$1$つ出力してください。
出力
目標を達成できる道しるべの配置が存在しなければ"No"を出力せよ。
存在する場合、$N$行出力せよ。$1$行目には"Yes"を、$i(2 \leq i \leq N)$行目には部屋$i$の道しるべが指す部屋の番号を出力せよ。とりあえず,問題が理解しやすかったので,実装したら解けました.
これ,目標を達成できる道しるべの配置は絶対あると思ったので,"No"を出力する記述は書きませんでした(そもそも,"No"になる例が思いつかなかったから,書きようがなかった).
シンプルに適当な入力例を考えます.
まず,部屋1とつながっている部屋を確認していきます.
これらの部屋1とつながっている部屋8,9,15を深さ1の部屋と考えます.
次に,先ほど色を赤く色を塗った部屋を確認していきます.
これらの部屋とつながっている部屋4,5,6,12を深さ2の部屋と考えます.
同様に,先ほど色を赤く色を塗った部屋を確認していきます.
これらの部屋とつながっている部屋7,10,11を深さ3の部屋と考えます.
ひたすら繰り返しです.
先ほど色を赤く色を塗った部屋を確認していき,これらの部屋とつながっている部屋2,3を深さ4の部屋と考えます.
部屋13,14を深さ5の部屋と考えます.
部屋16を深さ6の部屋と考えます.
これで探索は終わりました.
あとは,一番深い部屋から,一つずつ浅い部屋を選べば,その部屋から部屋1までの最短のルートになります.実際の実装は,色を塗る段階で答えを部屋ごとに記録していきます.
この解き方をするために,各部屋ごとに,どの部屋とつながっているかの情報をデータ構造として保持しておきます.
まず,部屋1とつながっている部屋を確認していきます.
これらの部屋1とつながっている部屋8,9,15に道しるべとして,"1"を書き入れておきます.
次に,先ほど道しるべをつけた部屋8,9,15を順にみていきます.
まず,部屋8とつながっている部屋を確認していきます.
ここですでに色が赤になっている部屋は無視して,まだ色が水色の部屋5,6に道しるべとして,"8"を書き入れておきます.
これは,部屋6→部屋8→部屋1でたどれば最短距離で部屋1に戻れます(部屋5も同様).
次に,部屋9とつながっている部屋を確認していきます.
ここで先ほどと同様にすでに色が赤になっている部屋は無視して,まだ色が水色の部屋4に道しるべとして,"9"を書き入れておきます.
これは,部屋4→部屋9→部屋1でたどれば最短距離で部屋1に戻れます.
部屋5はすでに赤色で,他のルートで部屋1に戻る最短ルートがあるので無視できます.
このような確認と道しるべの書き入れを行うことで,答えを作ることが可能となります.
abc168d.pyn, m = map(int, input().split()) dict_road = {} dict_room = {} for i in range(0, m): a, b = map(int, input().split()) if a in dict_road: dict_road[a].append(b) else: dict_road[a] = [b] if b in dict_road: dict_road[b].append(a) else: dict_road[b] = [a] start_list = dict_road[1] temp_list = [] for no in start_list: dict_room[no] = 1 temp_list.append(no) while True: next_temp_list = [] for no in temp_list: for next_no in dict_road[no]: if next_no not in dict_room: dict_room[next_no] = no next_temp_list.append(next_no) if len(next_temp_list) == 0: break temp_list = next_temp_list print("Yes") for i in range(2, n + 1): print(dict_room[i])E問題 ∙ (Bullet)
問題文
$N$匹のイワシが釣れました。$i$匹目のイワシの美味しさは$A_i$、香り高さは$B_i$です。
この中から$1$匹以上のイワシを選んで同じクーラーボックスに入れますが、互いに仲が悪い$2$匹を同時に選ぶことはできません。
$i$匹目と$j(\neq i)$匹目のイワシは、$A_i⋅A_j+B_i⋅B_j=0$を満たすとき(また、その時に限り)仲が悪いです。
イワシの選び方は何通りあるでしょう?答えは非常に大きくなる可能性があるので、$1000000007$で割ったあまりを出力してください。珍しくD問題がかなり早い段階で通せたので,E問題も解きたかったですが,結局解けませんでした.
仲が悪い2匹のイワシの組み合わせを求めることまでやってタイムオーバーでした.F問題 Three Variables Game
問題文
無限に広がる草原があります。
この草原上に、大きさが無視できるほど小さい$1$頭の牛がいます。牛の今いる点から南に$x\ \mathrm{cm}$、東に$y\ \mathrm{cm}$移動した点を$(x,y)$と表します。牛自身のいる点は$(0,0)$です。
また、草原には$N$本の縦線と$M$本の横線が引かれています。
$i$本目の縦線は点$(A_i,C_i)$と点$(B_i,C_i)$とを結ぶ線分、$j$本目の横線は点$(D_j,E_j)$と点$(D_j,F_j)$とを結ぶ線分です。
牛が線分を(端点を含め)通らない限り自由に動き回れるとき、牛が動き回れる範囲の面積は何$\mathrm{cm^2}$でしょうか。この範囲の面積が無限大である場合は代わりに"INF"と出力してください。このあたりが解ける日がはたして来るのだろうか…
後半も最後まで読んでいただきありがとうございました.

- 投稿日:2020-05-19T20:31:21+09:00
【django】raise ValidationErrorで指定したエラーメッセージを表示する
pythonの通常のtry, exceptの例外処理とは違っていて例外検出とその内容の表示に詰まったので、記録に残しておきます。
今回はフォームやモデルでバリエーションチェックする場合に、独自のバリデーションチェックに引っかかったときのエラーメッセージの表示について記事にしたいと思います。
簡単な状況説明
OpenCVを使って簡単なBlur(ぼかし)フィルタ機能を開発していて、ユーザからフィルタサイズを入力してもらって、その値から効果強度(フィルタの大きさ)を決めようと思いました。
そこで、Formクラスを使ってフォームを作りましたが、ガウシアンフィルタを使ったため入力された値が偶数だとエラーがでます。
ここから、Formクラスに「入力された値が偶数ならエラー処理する」という独自のバリエーションチェックを作ろうと考えました。
ソースコード
間違っていたら、ごめんなさい。
models.pyはあまり気にしなくてもいいです。app/urls.pyapp_name = 'app' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), ]models.pyclass Image(models.Model): img_src = models.ImageField(upload_to=get_upload_to)form.pydef is_oddnumber(value): #奇数かどうかをチェックする関数 if value % 2 == 0: raise ValidationError('偶数を入力してください') class Form(forms.ModelForm): class Meta: model = Image fields = ('img_src') filter_size = forms.IntegerField( required=True, max_value=100, min_value=1, validators=[is_oddnumber], #追加で上のis_oddnumberでバリデーションチェックを行う )views.pyclass IndexView(generic.TemplateView) template_name = index.html def get(self, request, *args, **kwargs): form = Form() return render(request, self.template_name, {'form': form}) def post(self, request, *args, **kwargs): form = Form(request.POST, request.FILES) if form.is_valid(): return redirect(○) return render(request, self.template_name, {'form': form}) #エラーメッセージを含んだフォームをセットして再表示index.html<form action="{% url 'app:index' %}" method="POST" enctype="multipart/form-data"> {% csrf_token %} {{ form.as_p }} <input type="submit"> </form> {% if form.errors %} <ul> {% for error in form.non_field_errors %} <li>{{ error }}</li> {% endfor %} </ul> {% endif %}raise ValidationErrorの引数であるエラーメッセージはform.errorsに格納されるみたいです。
そのため、バリエーションエラーが発生した場合は、エラーメッセージをform.errorsに含んだformをrenderとかで再度表示しなおしてやれば、形としては画面遷移なしにエラーメッセージを表示できます。
- 投稿日:2020-05-19T19:46:16+09:00
GCPのKey Management Service + Pythonでシークレット情報管理
背景
pythonアプリでシークレット情報の管理を行いたい。今回はシークレット情報をyamlで管理する。
暗号化と復号化は、GCPの Key Management Service を使う。pythonアプリで復号化して使えるようにする。暗号化
クイックスタート を参考に鍵リンクと鍵を作成する。
まず、シークレット情報の入ったyamlファイルを作成
sample_secret.yamlHOGE_SECRET: HOGEHOGE FUGA_SECRET: FUGAFUGAこれを以下のように暗号化し
sample_secret.yml.encryptedを作成するgcloud kms encrypt --location global --keyring test --key quickstart --plaintext-file sample_secret.yml --ciphertext-file sample_secret.yml.encryptedpythonで復号化
pythonアプリ内で使うときは以下のようにする。
f = open("/path/to/sample_secret.yml.encrypted", "rb") client = kms_v1.KeyManagementServiceClient() name = client.crypto_key_path_path( 'YOUR_PROJECT', 'global', 'test', 'quickstart' ) res = client.decrypt(name, f.read()) data = yaml.load(res.plaintext, Loader=yaml.BaseLoader) print(data)暗号化したシークレットファイルをgit管理対象にし、暗号化前のものを.gitignoreの対象にすればよい。
- 投稿日:2020-05-19T18:42:59+09:00
[Python]探索 ABC167C
ABC167C
itertoolsを活用した探索
探索は bit全探索が推奨されることが多いが、Pythonなら基本的にはitertoolsで対応した方が実戦的ではないかと思っている。
Pythonのitertoolsでできる全列挙のまとめサンプルコードimport itertools N, M, X = list(map(int, input().split())) a = [list( map( int, input().split() ) ) for i in range(N)] for x in itertools.product([0,1], repeat=2): cost = 0 level = [] * M judge = True ans = 1234567 for i in range(N): if a[i] == 1: cost += a[i][0] level = [y + z for (y, z) in zip(level, a[i][1:])] for j in range(M): if any(level[k] < x for k in range(M)): judge = False if judge: ans = min(ans, cost) if ans == 1234567: print(-1) else: print(ans)
- 投稿日:2020-05-19T18:20:46+09:00
エクセルの名前・セル範囲を Python VBAで読み込む
エクセルの名前で定義されたセル範囲を読みこむ Python VBA
作業イメージ
1,エクセルにの名前で定義されたセル範囲に 開始日付・終了日付、プルダウンでの選択項目などの情報がある
2,エクセルの名前で定義された範囲は2.3行程度
3,店舗ごとの繰り返し処理など多量のデータはシートから読み込む 以前のメモ
4,pythonはOpenPyxLモジュール を使っている
5,スクレイピングに必要なデータはエクセルから読みこむとするpython でエクセルの名前で定義されたセル範囲を読み込む
エクセルの名前は「テスト用名前範囲 」
エクセルファイル名は 「テスト.xlsx」 とする
ブックレベルの名前を使うものとする(シートレベルで同じ名前のないように)エクセルの名前のセル範囲を取得するimport openpyxl wb=openpyxl.load_workbook('テスト.xlsx') my_range = wb.defined_names['テスト用名前範囲'] dests = my_range.destinations cells = [] for title, coord in dests: #titleにはシート名 がとれています。 ws = wb[title] cells.append(ws[coord]) C=[] for row in cells: for aa in row: C.append([col.value for col in aa])C はリストのリストになっているのでエクセル名前範囲の一番左上のセルは
C[0][0] で使えます。
名前範囲が小さいときはこれで結構使えます。エクセルVBAで名前で定義されたセル範囲を読み込む
Variant型変数にセル範囲を入れるとC(1,1) のように使えます。
pythonと違い 1から始まります。
エクセルは同時にたくさんのファイルを開いたり、運用がぐちゃぐちゃのことが多いので
ブック→シート→名前で指定した方が安心です。エクセルの名前の定義を取得Dim C As Variant 'メニューシートにテスト用名前範囲がある C = ThisWorkbook.Sheets("メニュー").Range("テスト用名前範囲")C(1, 1)で一番左上セルの値を取得できます。
エクセルの名前をこまごまと読み込めたらスクレイピングの運用が楽になります。
- 投稿日:2020-05-19T17:21:42+09:00
[Python]各フォルダに散らばっている特定のファイルを一か所に集めたい
はじめに
Qiita初投稿。いつもお世話になっていたので、そろそろ自分も出来上がったものを公開していこうかと。
各フォルダに散らばっている特定のファイルを一か所に集めたい
こういう事、よく起きませんか?
全てのFolderは同じフォルダ構造を持っていて、sub-sub-folderに眠っているファイル(今回はmdbファイルとしました)をどこか一か所に集めたい..
Codeの実行
毎回忘れては調べるので以下にに残します。
環境はJupyter notebookで実行しました。mdb_collect.pyimport os import shutil import pandas as pd #保存したいディレクトリを指定 file_to = r"the location where you want to save them" #これから探しだすフォルダ構造のトップを指定 k = os.path.exists(r"Parent folder where you seek the files") if k==True: #一応、folderが存在するか確認します。 root = r"the location where you seek the files" for folder, subfolders, files in os.walk(root): # "sub-sub-folder-1" という名前のfolderを見つけたら # mdbファイルを探しだし取得する。 if "\sub-sub-folder-1" in folder: for file in files: if ".mdb" in file: file_from = folder + "\\" + file print(file_from) shutil.copyfile(file_from,file_to+"\\"+file)os.walk()がParent Folder以下の階層すべてを歩きわたってくれるんですね。便利。
- 投稿日:2020-05-19T17:13:25+09:00
Watson IoT PlatformアプリケーションをFlaskで実装したらMQTT接続でハマった話
Watson IoT PlatformのアプリケーションをFlaskで実装しようとしてハマった話をまとめておきます。
Flaskの理解が浅かったせいで、やはりちゃんと理解して使わないといけないと猛省しました。環境
Watson IoT Platformのアプリケーション向けにいくつかのプログラミングインターフェイスが提供されていますが、今回MQTTを使用してIoTデバイスの接続状況を報告するDevice Statusをsubscribeするアプリケーションを作ってみました。
最終的にはIBM Cloud FoundryにコードをプッシュしたかったのでFlaskで実装することにしましたが、ここでしっかりとFlaskの理解を深めておくべきでした....
Python 2.7
paho-mqtt 1.5.0
Flask 1.1.2準備
IBM Cloud Foundryでアプリケーションの作成
下記の記事を参考にパブリック・アプリケーションを作成します。
https://cloud.ibm.com/docs/cloud-foundry-public?topic=cloud-foundry-public-getting-started上記手順の中で出てくるサンプルコードをgitから入手し、これに手を入れて取り敢えずHTTPリクエストに応答できるようにします。
hello.pyfrom flask import Flask import os app = Flask(__name__, static_url_path='') port = int(os.getenv('PORT', 8000)) @app.route('/') def root(): return 'Hello, world' if __name__ == '__main__': app.run(host='0.0.0.0', port=port, debug=True)このプログラムをローカル実行してみます。
# python hello.py * Serving Flask app "hello" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:8000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 210-659-291確認のためcurlでアクセスしてみます。無事ポート8000でHTTPリクエストに応答できているようです。
# curl localhost:8000 Hello, worldこれで最低限HTTPリクエストに応答できるアプリケーションができました。
Watson IoT PlatformのAPIキーとトークンの作成
Watson IoT Platformは、IoTデバイスが収集した情報をpublishするためのMQTTクライアント(二つの方式がありそれぞれデバイス、ゲートウェイと呼ぶ)と、IoTデバイスが収集したデータを受け取って処理したりIoTデバイスのステータス確認や操作をするMQTTクライアント(アプリケーション)の二種類のクライアント接続が可能です。
今回はアプリケーションとして接続し、Watson IoT Platformが管理するDevice Statusの変更通知を受け取るため当該トピックをsubscribeします。接続の詳細については下記のリンクに記載されています。
https://www.ibm.com/support/knowledgecenter/en/SSQP8H/iot/platform/applications/mqtt.html手始めにWatson IoT PlatformにアプリケーションとしてMQTT接続するために、APIキーとトークンを作成します。下記のリンクを参照して作業を進めます。
https://www.ibm.com/support/knowledgecenter/en/SSQP8H/iot/platform/applications/app_dev_index.html作成されたAPIキーとトークンを使ってMQTT接続することで、IoTデバイスがWatson IoT Platformに接続あるいは切断するたびにDevice Statusの変更通知を受けることができるようになるはずです。
アプリケーションを実装してみたところ...
Flaskを使用したhello.pyに、作成したAPIキーとトークンでWatson IoT Platformへ接続するコードを追加します。
Watson IoT PlatformへMQTT接続するために、client id、userid, passwordを指定する必要があります。
それぞれWatson IoT Platformびより割り当てられているorganization idとAPIキーおよびトークンを指定のフォーマットで連結し作成します。このフォーマットについては下記のリンクのMQTT authenticationに詳しく記載されています。
https://www.ibm.com/support/knowledgecenter/en/SSQP8H/iot/platform/applications/mqtt.html以下のサンプルコードではorganization idを'oooooo', APIキーを'kkkkkkkkkk', トークンを'tttttttttttttttttt'としていますが、コードを動かす際にはWatson IoT Platformにより提供された値に変更する必要があります。
hello.pyfrom flask import Flask import os import paho.mqtt.client as mqtt from datetime import datetime def on_connect(client, userdata, flags, respons_code): client.on_message = on_message client.subscribe('iot-2/type/+/id/+/mon') print(datetime.now().strftime("%Y/%m/%d %H:%M:%S") + ": mqtt connected") def on_disconnect(client, userdata, rc): print(datetime.now().strftime("%Y/%m/%d %H:%M:%S") + ": mqtt disconnected") def on_message(client, userdata, msg): print(datetime.now().strftime("%Y/%m/%d %H:%M:%S") + ": mqtt message arrived") client = mqtt.Client(client_id='a:oooooo:appl1', protocol=mqtt.MQTTv311) client.username_pw_set('a-oooooo-kkkkkkkkkk', password='tttttttttttttttttt') client.on_connect = on_connect client.on_disconnect = on_disconnect client.connect('de.messaging.internetofthings.ibmcloud.com', 1883, 120) client.loop_start() app = Flask(__name__, static_url_path='') port = int(os.getenv('PORT', 8000)) @app.route('/') def root(): return "Hello, world" if __name__ == '__main__': app.run(host='0.0.0.0', port=port, debug=True)このようなコードを準備し動作確認してみることにしました。ポート8000からのHTTPリクエストに応答しつつ、MQTTメッセージの受信が確認できるだろうという期待です。
しかし実際にはコードを実行すると....
# python hello.py * Serving Flask app "hello" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:8000/ (Press CTRL+C to quit) * Restarting with stat 2020/05/13 18:13:26: mqtt connected * Debugger is active! * Debugger PIN: 210-659-291 2020/05/13 18:13:26: mqtt message arrived 2020/05/13 18:13:27: mqtt disconnected 2020/05/13 18:13:27: mqtt connected 2020/05/13 18:13:27: mqtt message arrived 2020/05/13 18:13:28: mqtt connected 2020/05/13 18:13:28: mqtt disconnected 2020/05/13 18:13:29: mqtt message arrived 2020/05/13 18:13:30: mqtt disconnected 2020/05/13 18:13:30: mqtt connected 2020/05/13 18:13:30: mqtt message arrived 2020/05/13 18:13:31: mqtt disconnected 2020/05/13 18:13:31: mqtt connectedこのように一旦MQTTでの接続が確立されるもののすぐに切れてしまいました。その後paho-mqttが予期しないセッションの切断を受け自動的に再接続していますが、それもまたすぐに切れてしまい、以降再接続・切断を繰り返していきます。
APIキーやトークンが間違っていた場合そもそもMQTT接続に失敗するはずですし、MQTTのkeepaliveでタイムアウトしているのかとメッセージの間隔を調整してみたりもしたのですがこれも改善にはつながりませんでした。
たまたま通信経路のどこがに障害があるのかとも疑い数日放置してみましたが症状は変わらずでした。
解決編
困り果ててしまいstackoverflowに質問を投稿してみましたところ、二人の方からclient idが重複しているのではないかとアドバイスしていただきました。
確かにMQTT Brokerに同一のclient idでの接続はできません。なるほどとは思ったものの重複する理由が思い当たりません。hello.pyは同時に1プロセスしか実行していません。またclient idはorganizagtion idとAPIキーを連結して生成するのがルールのなのですが、organization idはともかくAPIキーを他の目的に流用したりもしていません。何らかの理由でWatson IoT Platform上で古い接続情報が残ってしまっていてそれで接続できなくなるのかもしれないと思い、APIキーを新しく生成してみたのですが、そちらを使っても症状は変わりませんでした。
どうやらclient idの重複が原因ではなかったのかとあきらめかけていたのですが、再度hello.pyの出力を眺めていると'Restarting with stat'の文字列が目に入りました。
そう言えばこれは何だろう?
これまでMQTT部分を疑い色々確認してきたのですが、このFlaskの謎メッセージについて調べてみることにしました。
結果、
- Flaskをデバッグモードを有効化して実行すると、アプリケーションを構成するコードの変更を検知して自動的にアプリケーションを再起動する仕組みがある。
- この時Flaskは暗黙に子プロセスを起動し、親プロセスがコードの変更の監視と子プロセスの再起動を担当し、子プロセスがWEBアプリケーションとしてHTTPリクエストの処理をする。
というようなことが分かってきました。
確認してみると、
# ps -f | grep hello.py 501 20745 2576 0 10:39PM ttys005 0:00.35 /System/Library/Frameworks/Python.framework/Versions/2.7/Resources/Python.app/Contents/MacOS/Python hello.py 501 20748 20745 0 10:39PM ttys005 0:00.36 /System/Library/Frameworks/Python.framework/Versions/2.7/Resources/Python.app/Contents/MacOS/Python /Users/(省略)/hello.py確かに親子関係にある二つのhello.pyプロセスが実行されています。
この状況であればcllient idの重複は納得できます。親プロセス(pid: 20745)と子プロセス(pid: 20748)からほぼ同時に同じclient idを使用してMQTT接続にいってしまうわけです。うーん、なるほど。
ではどうやってclient idの重複を回避するのか。デバッグモードを無効にすれば簡単ですが、せっかく用意されている便利機能を使えないのも残念です。さらに調べると親プロセスは子プロセスを起動する前に'WEERKZUG_RUN_MAIN'ということが分かりました。この環境変数を確認し、親プロセスではMQTT接続をしないようにすれば大丈夫そうです。
コードの修正と動作確認
上記デバッグモードに関する理解を踏まえ、
- MQTTの接続をする前に環境変数'WEERKZUG_RUN_MAIN'のチェックをし、この環境変数が定義されている場合のみ接続する。
- プロセス終了前にMQTTの接続を切断し、切断の完了を待つようにする。
- ついでにon_message()の処理を追加し、所望のデバイスのステータスを追跡するようにし、HTTPリクエストに応答してステータスを報告する。
のように再度hello.pyを修正しました。二番目の修正は親プロセスがコードの変更を検知してreloadする際に、子プロセス1を停止して子プロセス2を新たに起動するわけですが、子プロセス1のMQTT接続の切断を待たずに子プロセス2が起動してしまうと同じことが起きてしまいそうなので、念のため追加しておくことにしました。
hello.pyfrom flask import Flask import os import threading import json import paho.mqtt.client as mqtt from datetime import datetime def on_connect(client, userdata, flags, respons_code): client.on_message = on_message client.subscribe('iot-2/type/+/id/+/mon') print(datetime.now().strftime("%Y/%m/%d %H:%M:%S") + ": mqtt connected") cond = threading.Condition() notified = False def on_disconnect(client, userdata, rc): global notified print(datetime.now().strftime("%Y/%m/%d %H:%M:%S") + ": mqtt disconnected") with cond: notified = True cond.notify() status = 'Unknown' def on_message(client, userdata, msg): global status response_json = msg.payload.decode("utf-8") response_dict = json.loads(response_json) if(response_dict["ClientID"] == '追跡したいデバイス・ゲートウェイのclient idをここに指定'): if( response_dict["Action"] == "Disconnect" ): status = "Disconnected" elif( response_dict["Action"] == "Connect" ): status = "Connected" if os.environ.get('WERKZEUG_RUN_MAIN') == 'true': client = mqtt.Client(client_id='a:oooooo:appl1', protocol=mqtt.MQTTv311) client.username_pw_set('a-oooooo-kkkkkkkkkk', password='tttttttttttttttttt') client.on_connect = on_connect client.on_disconnect = on_disconnect client.connect('de.messaging.internetofthings.ibmcloud.com', 1883, 120) client.loop_start() app = Flask(__name__, static_url_path='') port = int(os.getenv('PORT', 8000)) @app.route('/') def root(): return "Status: " + status if __name__ == '__main__': app.run(host='0.0.0.0', port=port, debug=True) if os.environ.get('WERKZEUG_RUN_MAIN') == 'true': client.loop_stop() client.disconnect() with cond: if( not notified ): cond.wait()上記のようにコードを修正して再度実行してみました。
# python hello.py * Serving Flask app "hello" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:8000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 210-659-291 2020/05/13 23:04:28: mqtt connected 127.0.0.1 - - [13/May/2020 23:04:38] "GET / HTTP/1.1" 200 -接続・切断の繰り返しが止まりました!
curlでHTTPリクエストしてみると、
# curl localhost:8000 Status: DisconnectedMQTTメッセージの処理も上手くいっているようです。
試しに登録済みのIoTデバイスを接続してみます。
今回は、mosquitto_subを使ってDevice commandをsubscribeすることでIoTデバイスの代わりとします。
設定や接続の方法については下記のリンクの記事が詳しいです。
https://qiita.com/kuraoka/items/5380f6b5e97e8cd1ad98# mosquitto_sub -h de.messaging.internetofthings.ibmcloud.com -u use-token-auth -P "tttttttttttttttttt" -i (hello.pyで監視しているclient id) -t 'iot-2/type/(type)/id/(id)/cmd/control/fmt/json'上記のようにIoTデバイスからMQTT接続がされた状態で、再度curlでHTTPリクエストをしてみます。
# curl localhost:8000 Status: Connected今度はConnectedのステータスが返ってきました。mosquitto_subでMQTT接続したことで、Device statusメッセージがhello.pyに送信され、on_message()関数の中でstatus変数が変更されたようです。
これで全て期待通りです。
まとめ
今回初めてFlaskを使用してみました。サンプルコードから最小のコードを作成しそこから実装したい部分を付け足していこうとしたら、思わぬところで足を掬われてしまった格好です。こういう試行錯誤をするために習作したという考え方もあるのですが、やはり多少なりとも最初に勉強してから使うべきだったようです。
Watson IoT PlatformはIoTデバイスを管理・制御しデータ収集するための強力なクラウドサービスです。
IoTデバイスが収集したデータをクラウドにアップしていく部分がシステムの根幹になるわけですが、IoTデバイスのステータスを監視したり、必要に応じて制御をするアプリケーションもクラウド上で実装したくなるであろうと思い、今回の習作を思い立ちました。これでステータスの監視部分については最低限の動作が確認できたので、Device commandの送信によるIoTデバイスの制御などもう少し手を広げて調査していきたいと思います。
- 投稿日:2020-05-19T17:10:06+09:00
[Python]標準入力
標準入力
AtCoderなどを想定した、Pythonでの標準入力方法をまとめました。
文字列
サンプルコードS = input() #ここで標準入力 print (type(S), S) #<class 'str'> atcoder整数
サンプルコードN = int(input()) #ここで標準入力 print (type(N), N) #<class 'int'> 20行列
サンプルコードR = int(input()) #行数の入力 P = [list( map( int, input().split() ) ) for i in range(R)] #2行目以降標準入力 # map(関数, 要素) print(type(P), P) #<class 'list'> [[1, 32], [2, 63], [1, 12]]大量の入力がある場合
サンプルコードimport sys import itertools import numpy as np read = sys.stdin.buffer.read #標準入力から複数行取得するための関数です。 readlines() が結果を行単位で分割してリストで返すのに対して、 read() は結果をそのまま1つの文字列として取得します。 readline = sys.stdin.buffer.readline #標準入力から1行取得するための関数です。 readlines = sys.stdin.buffer.readlines #標準入力から複数行取得するための関数です。戻り値はリストで、入力された文字列が1行ずつ要素として格納されています。 # .bufferはbytes を返すのでさらに少しだけ速いようですが、あまり差はありません。 # 標準入力例 # 3 4 3 # 1 3 3 100 # 1 2 2 10 # 2 3 2 10 N, M, Q = map(int, readline().split()) print(N, M, Q) # 3 4 3 # 数値のNumPy配列(N×M)として入力したい場合 npを外せばリストになる。 # 文字列はbytes型なので'b""'が付く。結合等出来ないのでread定義からbufferを外した方が良い。 # input()と併用は避ける。 A = np.array(list(map(int, read().split()))).reshape((N, M)) # 下記と同型のNumPy配列を取得 m = map(int, read().split()) #print(list(m)) # <map object at 0x7f78f13a7d30> [1, 3, 3, 100, 1, 2, 2, 10, 2, 3, 2, 10] for a,b,c,d in zip(m,m,m,m): # 複数のイテラブルオブジェクト(リストやタプルなど)の要素をまとめる関数 print(a,b,c,d) # 1 3 3 100 # 1 2 2 10 # 2 3 2 10
- 投稿日:2020-05-19T17:00:59+09:00
AtCoderBeginnerContest168復習&まとめ(前半)
AtCoder ABC168
2020-05-17(日)に行われたAtCoderBeginnerContest168の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 ∴ (Therefore)
問題文
いろはちゃんは、人気の日本製ゲーム「ÅtCoder」で遊びたい猫のすぬけ君のために日本語を教えることにしました。
日本語で鉛筆を数えるときには、助数詞として数の後ろに「本」がつきます。この助数詞はどんな数につくかで異なる読み方をします。具体的には、$999$以下の正の整数$N$について、「$N$本」と言うときの「本」の読みは
・$N$の$1$の位が$2,4,5,7,9$のとき"hon"
・$N$の$1$の位が$0,1,6,8$のとき"pon"
・$N$の$1$の位が$3$のとき"bon"
です。
$N$が与えられるので、「$N$本」と言うときの「本」の読みを出力してください。入力を数字で受け取って,$10$で割った余りが$1$の位になるので,その値で場合分け.
誤差だとは思うけど,少しでも早く提出するために,"hon"の出力をelseにしました(条件式書くのが多少短くなる).abc168a.pyn = int(input()) k = n % 10 if k == 3: print("bon") elif k == 0 or k == 1 or k == 6 or k == 8: print("pon") else: print("hon")B問題 ... (Triple Dots)
問題文
英小文字からなる文字列$S$があります。
$S$の長さが$K$以下であれば、$S$をそのまま出力してください。
$S$の長さが$K$を上回っているならば、先頭$K$文字だけを切り出し、末尾に ... を付加して出力してください。とりあえず,if文で$S$の長さと$K$を比較して,以下のときと上回っているときの処理を書けば終わりです.
pythonは文字列を配列みたいに扱えるので,for文使わずに書きました.abc168b.pyn = int(input()) s = input() if len(s) <= n: print(s) else: print(s[:n] + "...")B問題解けたのがコンテスト開始から数分なので,このあたりまでは自分の理想とする時間で解けました.
C問題 : (Colon)
問題文
時針と分針の長さがそれぞれ$A$センチメートル、$B$センチメートルであるアナログ時計を考えます。
時針と分針それぞれの片方の端点は同じ定点に固定されており、この点を中心としてそれぞれの針は一定の角速度で時計回りに回転します。時針は$12$時間で、分針は$1$時間で$1$周します。
$0$時ちょうどに時針と分針は重なっていました。ちょうど$H$時$M$分になったとき、$2$本の針の固定されていない方の端点は何センチメートル離れているでしょうか。2,3通り解き方が思いついたのですが,自分は余弦定理使って解きました.
求めたい値$D$は,D = \sqrt{A^2 + B^2 - 2AB\cos \theta}で求めることができるので,$\theta$を求めれば解けます.
時針と分針が,それぞれ0時から時計回りに針までの角度を,$\theta_A, \theta_B$とすると,\theta_A = 30 \times H + 0.5 \times M \\ \theta_B = 6 \times Mとなるので時針と分針のなす角$\theta$は,
\theta = \theta_A - \theta_Bで求めることができます.
ここで,$\theta$が$180$度より大きい場合や負になる場合が考えられますが,\cos (360 - x) = \cos x \\ \cos (-x) = \cos xとなるため,特に問題なく余弦定理の計算をして長さを出すことができます.
abc168c.pyimport math a, b, h, m = map(int, input().split()) x = 30 * h + m / 2 - 6 * m d = math.sqrt(a**2 + b**2 - 2 * a * b * math.cos(math.radians(x))) print(d)他に思いついたのは,時針と分針の指し示す座標をそれぞれ$(A_x, A_y)=(A\cos\theta_1, A\sin\theta_1), (B_x, B_y)=(B\cos\theta_2, B\sin\theta_2)$とし,三平方の定理を用いることで求めたい$D$は,
D = \sqrt{(A_x - B_x)^2 + (A_y - B_y)^2}で求めることができます.
余弦定理を使ったのは,答えが正の実数であり,正しい値との絶対誤差または相対誤差に制約があるため,
mathの計算で誤差がどのくらい出るかわからなかったこともあり,極力使用回数が減らせる余弦定理で解きました.前半はここまでとなります.
前半の最後まで読んでいただきありがとうございました.後半はDEF問題の解説となります.
後半に続く.
- 投稿日:2020-05-19T16:20:30+09:00
pythonの遅延評価とクロージャの落とし穴
注意
Pythonの用語、言葉遣いがかなり怪しいです。
TLTR
- 関数型言語の影響からPythonは遅延評価できる。
- 関数定義の際に関数のデフォルト引数は評価される。実行時ではない。
- クロージャは遅延評価される。
- クロージャに明確に定義時の値を保持させたいとき、引数で渡すと良い。
動機
pythonの遅延評価についての記事を読んで、それをまとめました。
例1 関数のデフォルト引数はいつ評価されるか
Pythonは遅延評価をできます。
遅延評価とは乱暴に言えば必要になったら評価するということです。これは普通にPythonを学んでいる私のような初学者なら「知ってる!これ**ゼミで見たやつだ」となります。
しかし、関数のデフォルト引数の評価となればどうでしょうか。
これから中大規模なコードを書いていこうとなれば関数のデフォルト引数を設計するのは必至です。
しかし、このようなPythonの仕様があります。
デフォルト引数の評価は遅延評価
例を見ていきましょう。
デフォルト引数=Noneがいいときもある
渡された引数をリストに追加するだけのappend_to関数。
デフォルトで空リストtoを持つ。引数をリストに追加するappend_to関数>>> def append_to(element, to=[]): ... to.append(element) ... return to ...12,42を足してみましょう。
引数のto=[]があるのだから、
[12]
[42]
となりそうです。>>> my_list = append_to(12) >>> print(my_list) [12] >>> my_other_list = append_to(42) >>> print(my_other_list) [12, 42]予想とはことなります。これはどういうことでしょうか。
原因
デフォルト引数toを
to = []として定義しています。
ここに続々と値を更新していきます。デフォルト引数の評価が遅延評価であるとはどういうことでしょうか。私の理解で以下のようなさかのぼり方で評価されます。
print() -> my_other_list -> append_to関数の評価(デフォルト引数は評価しない) -> to.append(element) -> element変数 -> ...つまり改めて
to=[]はされないようです。デフォルト引数は関数定義の際に評価されます。
つまりtoは関数定義時に
to=[]されますが、呼び出されるたびにto=[]はしてくれないのでappent_to(42)のときto=[12]のままであるということです。解決策
代わりにどうするの
to=Noneするといいらしいです。若干冗長に感じますが。どうすればいいかはわからず。
def append_to(element, to=None): if to is None: to = [] to.append(element) return to my_list = append_to(12) print(my_list) my_other_list = append_to(42) print(my_other_list)[12] [42]例2 クロージャの遅延評価
関数の中に値が保持される、いわゆるクロージャを使ったコード例を見ていきましょう。
目標はリストの中身と引数の値を掛けた値を持つリストを返すコードです。
リストの中身と引数の値を掛けた値を持つリストを返すスクリプトfunctions = [] for n in [1, 2, 3]: def func(x): return n * x functions.append(func) # You would expect this to print [2, 4, 6] print('{}'.format(str([function(2) for function in functions])))
[2, 4, 6]([1 * 2、2 * 2、3 * 2])が出力されそうですが、、、[6, 6, 6]と出力されました。
原因
pythonのクロージャは遅延評価されます。
クロージャで使用される変数の値もまた、呼び出された時点で参照されます。よって、for文内でクロージャが呼び出される時点ではnは定まっておらず、
n*xの状態でfunctionsに格納されます。言うなれば[n*x,n*x,n*x]
よっていざprint文で実行される際にはnの最後の状態であるn==3が参照されるので6,6,6となります。デバッグしてみる
デバッガを使って、for文とprint文の値の更新の順番を見てみましょう。
変数nの値がイテレーションによって更新されてすでに3になっているので、、printでfunctionが評価されるのはずっとn==3です。
printからn==3が3回参照されていることがわかります。
分かりづらいのでもう一つ載せます。
解決策
クロージャの引数を
xからx,n=nにする。
問題はnの値を渡すこと、つまりnの値をクロージャを格納したfunctionsにfor文でイテレーションされる度に渡せば解決されます。そのために
def func(x, n=n):というようにnの値を引数に入れ、再代入のような形を取らせます。
これにより、クロージャはその関数内で値を保持するという仕様からnの値を更新てくれるようになります。リストの中身と引数の値を掛けた値を持つリストを返すスクリプトfunctions = [] for n in [1, 2, 3]: def func(x, n=n): # def func(x): return n * x functions.append(func) print('{}'.format(str([function(2) for function in functions])))出力結果[2,4,6]デバッガで見てみましょう。
ちょっとfuncの挙動がうまくデバッグで表現できたかは疑問ですが、無事に思った通りの挙動をさせることができました。
その他の解
ライブラリを使えば良いらしいです。今回は割愛。
from functools import partial from operator import mulまとめ
Pythonは遅延評価をします。
これは普段の手続き型のプログラミングをしているとちょっと混乱します。
関数型言語から持ち込まれた機能ですから、ちょっと癖があるんですね。変数のバインド(束縛)という表現(関数型言語における代入)がPythonにおいてどう使い分けるべきかよくわかっていません。参考文献
https://ja.coder.work/so/python/1087272
https://python-guideja.readthedocs.io/ja/latest/writing/gotchas.html
https://stackoverflow.com/questions/36463498/late-binding-python-closures



- 投稿日:2020-05-19T16:14:32+09:00
時系列分析における因果推定
時系列分析における因果推定
Convergent Cross Mapping (CCM) を中心に時系列データから因果推定を実施する際の方針のメモ(備忘録)
時系列データでの因果推定アプローチ
系列Xと系列Yの関係性を考える
上記を解く際、複数の方針が存在する。その中でも代表的なものを取り上げた。
LiNGAM
関数形には線形性を仮定する。外生変数を非ガウス連続分布と仮定する。なので、観測変数は非ガウス分布になる。そして、回帰分析と独立性の評価を繰り返すことで、観測変数の因果的順序を推定し、得られた係数行列から残りの下三角部分を推定することで因果関係を推定していく。これをVARモデルに拡張。
Convergent Cross Mapping (CCM)
Empirical Dynamic Modeling (EDM)の一種。EDMは時系列データを非線形力学系として捉え、変数間の作用や近未来予測を実行する手法。数式を仮定せず、観測値から系の状態空間を再構成してモデルフリーに解析をおこなう。Simplex projectionやS-mapの考え方を複数の変数の交互の予測に拡張した手法で、相互作用のある非線形力学系ならばTakens' theoremにより、お互いの時間遅れ埋め込みの情報を使って相手の時間遅れ埋め込みを再構成できる(自分の時系列のみから相手の時系列を予測できる)という特徴を利用している。
Granger因果
Granger因果とは、「相手が存在することで、予測精度が増加するかを判断」するものである。2つの時系列X、Y (X→Y)について考えた時、2つの予測残差の平方和を比較して、Xのデータを使用することで予測残差が有意に減少したかを検定するものである。もっと言うと、XのみからXを予測した場合と比べて、XとYの情報を使ってXを予測した場合の方が予測精度が向上すれば、YはXに対してGranger因果を持つことになる。CCMとの違いは、この方法はプロセス誤差が確率過程的であれば有効だが、決定論的な力学系においては検出力が落ちる可能性がある。加えて、背後に共変量が存在し、疑似相関が発生している場合には誤った検出結果になってしまう可能性がある。
CCMについて
導入
2つの時系列(X, Y)について考えてみる。
これらの関係性は主に4つに分けられる。
記号的関係 解釈的関係 X -> Y XがYの原因の1つでYは結果 Y -> X YがXの原因の1つでXは結果 X <-> Y XとYとが相互的に作用 X Y XもYも独立 ※ここでは疑似相関を考慮していない。
これら2つの時系列の因果関係を推定する際、その方法は大きく3つあげられる。
・VARLiNGAM
・Granger因果
・CCM
生物学・生態学分野において、そのデータは決定論的なものである。その際、各時系列変動は線形性を有するものは少なく、大抵は非線形な力学系を有する。よって、既存の「モデルリング→処理・推定」を実行することは、モデルフリーな推定よりも正確性が落ちる可能性がある。CCMは数式を仮定せず、時系列の観測値のみから系の状態空間を再構成して挙動を解析する手法である。この手法は2012年にScienceで発表されたものである。今回はこのCCMについて理解を深める一助とする。CCMの大まかな例
2変数XとYが$ X_t=f(X_{t-1}) $、$ Y_t=g(X_{t-1}, Y_{t-1}) $に従う時、XがYに一方的に影響を与える(X→Y)力学系である。CCMで2つの事象の時系列データから因果関係を推定する時、2つの事象間には決定論的で、非線形な力学系が存在することを仮定。そして、決定論的過程を対象としているためノイズを考えない。
もう少し詳しい解釈
e.g.) X→Yの2つの時系列をデータから類推することを考える。
関係性は以下。
$ X_t=f(X_{t-1}) $
$ Y_t=g(X_{t-1}, Y_{t-1}) $大きく2つの方針をとる。
1. 時点Tの$ Y_T $が未観測と仮定して、これを見積もる
2. 時点Tの$ X_T $が未観測と仮定して、これを見積もる時点TのYが未観測と仮定して、これを見積もる
$ X_{T-1} $と$ X_T $に1番近い値を示す連続した時点P-1、Pを探す
↓
$ Y_P $を$ Y_T $の見積もりとする
→$ Y_t=g(X_{t-1}, Y_{t-1}) $より、$ X_{T-1} $と$ X_{P-1} $が近い値としても、$ Y_T $と$ Y_P $が近い値となることはない。あくまでもYはXや他の要因に影響されるため、Xのみで一様にYは類推することは難しい。時点TのXが未観測と仮定して、これを見積もる
$ Y_{T-1} $と$ Y_T $に1番近い値を示す連続した時点Q-1、Qを探す
↓
$ X_Q $を$ X_T $の見積もりとする
→$ Y_t=g(X_{t-1}, Y_{t-1}) $より、時点T-1からTと時点Q-1からQで$ Y_t $が近い値となった時は、$ X_{T-1} $と$ X_{Q-1} $は近い値になる。
→$ X_{T-1} $と$ X_{Q-1} $が近い値の時は、$ X_T $と$ X_Q $も近い値となる。なぜなら、$ X_t=f(X_{t-1}) $よりXはYを関与せずにXのみで決まるため。
→この類推は正確性が高い。
決定論的な力学系から生じた時系列において、「結果から原因の類推(2.)」は正確におこなえる。しかし、逆は不正確(1.)。
つまり、CCMは2つの時系列を互いに類推して正確性を測ることで因果関係を判定する。その際、この正確性は、類推した時系列と実際の時系列の平均二乗誤差・相関係数で評価する。
相関係数を考えると先程の4つの関係性は以下のようになる。
記号的関係 AからBの類推 BからAの類推 A -> B 無相関 正の相関 B -> A 正の相関 無相関 A <-> B 正の相関 正の相関 A B 無相関 無相関 CCMの流れ
手順は以下。
1. 埋め込み: 時系列を空間内に反映
2. Cross Mapping: 2つの時系列の埋め込みで得た図形を参照して類推埋め込み(Embedding)
力学系のある変数の動態は、過去の他の変数の動態の情報も含まれる。そこで、ある1つの変数の時間遅れベクトルを座標にプロットする(埋め込み)ことで、全ての動態を用いたアトラクタ(時間発展が落ち着いた状態)と1対1対応し、各点の相対的な位置関係が同等のアトラクタを再構成することが可能になる(Takensの定理)。
因果関係を推定したい2つの時系列$ (X={X_1,...,X_T} $, $ Y={Y_1,...,Y_T}) $から、埋め込みにより2つのアトラクタ$ (M_X, M_Y) $を描く。このとき、アトラクタを描く空間の次元を「埋め込み次元(Embedding Dimension, Eと表記)」という。
Xからアトラクタ$ M_X $を再構成する場合、時間遅れをτとして時間遅れベクトルを作る。
$ X(t)=(X_t, X_t-τ, X_t-2τ,...,X_{t-(E-1)τ}) $
このベクトルはE次元空間の中の1点として表され、これらの点の集まりを「再構成されたアトラクタ$ M_X $」という。e.g.)
時刻$ t_{1-(E-1)τ} $から時刻$ t_1 $までのXの動態
時刻$ t_{2-(E-1)τ} $から時刻$ t_2 $までのXの動態
が似ているとき、$ x(t_1) $と$ x(t_2) $の座標は近くなる。点同士の距離が近いことは、その時系列における時刻(E-1)τの時間発展の類似性を表す指標と見なせる。Cross Mapping
先程と同様に時系列XとYについて(X→Yの関係)、因果関係を類推することを考える。このとき、Yは過去のYとXによって決定するものである。その上で、$ M_X $からY、$ M_Y $からXをそれぞれ類推し、その正確性を評価することで因果関係を推測する(Cross Mapping)。
例えば時系列Yにおいて、類似するパターンを示す2つの時間帯が存在したとする(m-(E-1)τからm, n-(E-1)τからn)。これはアトラクタ$ M_Y $上の近傍点で表すとy(m)およびy(n)となる。そしてy(m)およびy(n)の距離が近いことは、対応するx(m)とx(n)が近い座標であることを意味する。なぜなら、2系列はX→Yの関係であるため、Yは過去のYとXによって決定づけているからだ。
一方$ M_X $からYを類推する場合、$ M_X $上の2点が近傍だからといって対応する2点が$ M_Y $上でも近傍であるとは限らない。なぜなら、2系列はX→Yの関係であるため、XはYからの影響を受けずにXを決定づけているからだ。
したがって今回の場合であれば、$ M_Y $からXの類推は$ M_X $からYの類推よりも正確性が高くなる。よってこれをもってXが原因でYが結果と判断する。
類推の手順($ M_X $からYを例にとる)
1. $ x(t) $のE+1個の最近傍点(近い順に$ x(t_1), x(t_2),...,x(t_{E+1})) $を探す
→ベクトル$ x(t) $はこれらE+1個の点の位置ベクトルの加重平均
2. $ x(t_1), x(t_2),...,x(t_{E+1}) $と時間的に対応する$ M_Y $上の点$ y(t_1), y(t_2),...,y(t_{E+1}) $を用いて、$ Y_t $を類推
→$ M_x $による$ Y_t $の類推を$ \hat{Y_t} $とする
3. 全ての時刻で$ \hat{Y_t} $を求める
→類推された時系列$ \hat{Y_t} $と実際の時系列$ Y_t $との相関係数$ \rho $から、Mappingの正確性を評価参照
・8/6因果フェスのプレビュー:「系列Aと系列Bの関係は?」という問いに対する4つの素敵な解法について
http://takehiko-i-hayashi.hatenablog.com/entry/2015/07/30/113328
・George Sugihara, Robert May, Hao Ye, Chih-hao Hsieh, Ethan Deyle, Michael Fogarty, Stephan Munch. (2012)Detecting Causality in Complex Ecosystems. Science 338(6106):496-500.
https://science.sciencemag.org/content/338/6106/496.full
・pyEDMを使った生態学時系列データの因果推定
https://khigashi1987.github.io/pyEDM_Maizuru/
・Convergent cross mapping の紹介:生態学における時系列間の因果関係推定法
中山 新一朗,阿部 真人,岡村 寛, 日本生態学会誌 65:241 - 253(2015)
・rEDMの使い方, 京極大助/Daisuke Kyogoku
https://sites.google.com/site/dkyogoku/redm-no-shii-fang
・rEDM を用いた Empirical Dynamic Modeling: (5) Convergent Cross Mapping (CCM)
https://ushio-ecology-blog.blogspot.com/2020/01/20200113blogger0008.html
・rEDM: an R package for Empirical Dynamic Modeling and Convergent Cross Mapping
https://mran.microsoft.com/snapshot/2018-03-30/web/packages/rEDM/vignettes/rEDM-tutorial.html
・Empirical dynamic modeling for beginners
https://link.springer.com/article/10.1007/s11284-017-1469-9
- 投稿日:2020-05-19T15:03:11+09:00
BFS (幅優先探索) ABC168D
ABC168D
連結グラフなので、BFSの原理から最小性が保障されることに注意する。
参考
BFS (幅優先探索) 超入門! 〜 キューを鮮やかに使いこなす 〜サンプルコードfrom collections import deque # 頂点数と辺数 N, M = map(int, input().split()) # 辺 AB = [map(int, input().split()) for _ in range(M)] # 無向グラフの隣接リスト設定 link = [[] for _ in range(N + 1)] for a, b in AB: link[a].append(b) link[b].append(a) # BFSのデータフレーム dist = [-1] * (N + 1) # 看板未設定 que = deque([1]) # 頂点1を始点とした訪問キュー # BFS 開始 (キューが空になるまで探索を行う) while que: v = que.popleft() # キューから先頭頂点(現在地)v取得 for i in link[v]: # 未設定頂点iに現在地への看板を設定し訪問キューに追加する if dist[i] == -1: dist[i] = v que.append(i) # 結果出力(各頂点に設置する看板) print('Yes') print('\n'.join(str(v) for v in dist[2:]))
- 投稿日:2020-05-19T14:36:05+09:00
CNNの特徴マップとフィルタの可視化 (Tensorflow2.0)
概要
Subclassingモデルで構築したCNNで、特徴マップとフィルタを見てみました。
環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
VSCode
-Library-
Tensorflow 2.1.0
opencv-python 4.1.2.30
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce RTX2080ti
RAM: 16GB 3200MHz参考
サイト
・Keras: Fashion-MNISTを使ってCNNを可視化する
・畳み込みニューラルネットワークの第1層の重みを可視化するプログラム
Githubに上げておきます。
https://github.com/himazin331/CNN-Visualization
リポジトリにはデモ用のプログラム(cnn_visual.py)と、特徴マップ可視化モジュール(feature_visual.py)、
フィルタ可視化モジュール(filter_visual.py)を含んでいます。ソースコード
関連の低い部分は省略しています。
コードが汚いのはご了承ください...cnn_visual.pyimport argparse as arg import os import sys os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TFメッセージ非表示 import tensorflow as tf import tensorflow.keras.layers as kl import numpy as np import matplotlib.pyplot as plt import feature_visual import filter_visual # CNN class CNN(tf.keras.Model): def __init__(self, n_out, input_shape): super().__init__() self.conv1 = kl.Conv2D(16, 4, activation='relu', input_shape=input_shape) self.conv2 = kl.Conv2D(32, 4, activation='relu') self.conv3 = kl.Conv2D(64, 4, activation='relu') self.mp1 = kl.MaxPool2D((2, 2), padding='same') self.mp2 = kl.MaxPool2D((2, 2), padding='same') self.mp3 = kl.MaxPool2D((2, 2), padding='same') self.flt = kl.Flatten() self.link = kl.Dense(1024, activation='relu') self.link_class = kl.Dense(n_out, activation='softmax') def call(self, x): h1 = self.mp1(self.conv1(x)) h2 = self.mp2(self.conv2(h1)) h3 = self.mp3(self.conv3(h2)) h4 = self.link(self.flt(h3)) return self.link_class(h4) # 学習 class trainer(object): def __init__(self, n_out, input_shape): self.model = CNN(n_out, input_shape) self.model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) def train(self, train_img, train_lab, batch_size, epochs, input_shape, test_img): # 学習 self.model.fit(train_img, train_lab, batch_size=batch_size, epochs=epochs) print("___Training finished\n\n") # 特徴マップ可視化 feature_visual.feature_vi(self.model, input_shape, train_img) # フィルタ可視化 filter_visual.filter_vi(self.model) def main(): """ コマンドラインオプション """ # データセット取得、前処理 (train_img, train_lab), (test_img, _) = tf.keras.datasets.mnist.load_data() train_img = tf.convert_to_tensor(train_img, np.float32) train_img /= 255 train_img = train_img[:, :, :, np.newaxis] test_img = tf.convert_to_tensor(test_img, np.float32) test_img /= 255 test_img = train_img[:, :, :, np.newaxis] # 学習開始 print("___Start training...") input_shape = (28, 28, 1) Trainer = trainer(10, input_shape) Trainer.train(train_img, train_lab, batch_size=args.batch_size, epochs=args.epoch, input_shape=input_shape, test_img=test_img) if __name__ == '__main__': main()実行結果
今回はMNIST手書き数字を入力させました。
Epoch数は10、ミニバッチサイズは256の結果です。特徴マップ
畳み込み層1
プーリング層1
畳み込み層2
プーリング層2
フィルタ
畳み込み層1
畳み込み層2
畳み込み層3
表示が小さくて見づらいので編集で拡大してトリミングしています。
説明
関連するコードの説明をしていきます。
ネットワークモデルは下のような構造のCNNとなります。
ネットワークモデル# CNN class CNN(tf.keras.Model): def __init__(self, n_out, input_shape): super().__init__() self.conv1 = kl.Conv2D(16, 4, activation='relu', input_shape=input_shape) self.conv2 = kl.Conv2D(32, 4, activation='relu') self.conv3 = kl.Conv2D(64, 4, activation='relu') self.mp1 = kl.MaxPool2D((2, 2), padding='same') self.mp2 = kl.MaxPool2D((2, 2), padding='same') self.mp3 = kl.MaxPool2D((2, 2), padding='same') self.flt = kl.Flatten() self.link = kl.Dense(1024, activation='relu') self.link_class = kl.Dense(n_out, activation='softmax') def call(self, x): h1 = self.mp1(self.conv1(x)) h2 = self.mp2(self.conv2(h1)) h3 = self.mp3(self.conv3(h2)) h4 = self.link(self.flt(h3)) return self.link_class(h4)
特徴マップ可視化は、feature_visual.pyで行っています。
feature_visual.pyimport os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TFメッセージ非表示 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt # 特徴マップ可視化 def feature_vi(model, input_shape, test_img): # モデル再構築 x = tf.keras.Input(shape=input_shape) model_vi = tf.keras.Model(inputs=x, outputs=model.call(x)) # ネットワーク構成出力 model_vi.summary() print("") # レイヤー情報を取得 feature_vi = [] feature_vi.append(model_vi.get_layer('input_1')) feature_vi.append(model_vi.get_layer('conv2d')) feature_vi.append(model_vi.get_layer('max_pooling2d')) feature_vi.append(model_vi.get_layer('conv2d_1')) feature_vi.append(model_vi.get_layer('max_pooling2d_1')) # データランダム抽出 idx = int(np.random.randint(0, len(test_img), 1)) img = test_img[idx] img = img[None, :, :, :] for i in range(len(feature_vi)-1): # 特徴マップ取得 feature_model = tf.keras.Model(inputs=feature_vi[0].input, outputs=feature_vi[i+1].output) feature_map = feature_model.predict(img) feature_map = feature_map[0] feature = feature_map.shape[2] # ウィンドウ名定義 fig = plt.gcf() fig.canvas.set_window_title(feature_vi[i+1].name + " feature-map visualization") # 出力 for j in range(feature): plt.subplots_adjust(wspace=0.4, hspace=0.8) plt.subplot(feature/6 + 1, 6, j+1) plt.xticks([]) plt.yticks([]) plt.xlabel(f'filter {j}') plt.imshow(feature_map[:,:,j]) plt.show()CNNクラスのモデルそのままを使うことはできません。入力層が定義されていないからです。
SubClassingモデルでの実装の場合は下のように、入力層をモデルに付与してあげます。# モデル再構築 x = tf.keras.Input(shape=input_shape) model_vi = tf.keras.Model(inputs=x, outputs=model.call(x))次にリストを用意して、リストの中に入力層と任意のレイヤー情報を追加します。
今回は、1つめの畳み込み層、1つめの最大プーリング層、2つめの畳み込み層、2つめの最大プーリング層の出力を見たいので、
以下のように記述します。# レイヤー情報を取得 feature_vi = [] feature_vi.append(model_vi.get_layer('input_1')) feature_vi.append(model_vi.get_layer('conv2d')) feature_vi.append(model_vi.get_layer('max_pooling2d')) feature_vi.append(model_vi.get_layer('conv2d_1')) feature_vi.append(model_vi.get_layer('max_pooling2d_1'))次に入力データの用意をします。
乱数によるランダムな数値をインデックスにとって、インデックスに対応したテストデータを取得します。
取得したテストデータのshapeは(28, 28, 1)となっているため、データ件数の次元を追加してあげます。# データランダム抽出 idx = int(np.random.randint(0, len(test_img), 1)) img = test_img[idx] img = img[None, :, :, :]入力を入力層、出力を各レイヤーの出力としたモデル
feature_modelを構築します。
その後predictで入力データを渡し、レイヤー出力を得ます。# 特徴マップ取得 feature_model = tf.keras.Model(inputs=feature_vi[0].input, outputs=feature_vi[i+1].output) feature_map = feature_model.predict(img) feature_map = feature_map[0] feature = feature_map.shape[2]あとはレイヤー出力をプロットして、次のレイヤー出力といった感じで繰り返します。
フィルタ可視化は、fileter_visual.pyで行っています。
filter_visual.pyimport os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TFメッセージ非表示 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt # フィルタ可視化 def filter_vi(model): vi_layer = [] # 可視化対象レイヤー vi_layer.append(model.get_layer('conv2d')) vi_layer.append(model.get_layer('conv2d_1')) vi_layer.append(model.get_layer('conv2d_2')) for i in range(len(vi_layer)): # レイヤーのフィルタ取得 target_layer = vi_layer[i].get_weights()[0] filter_num = target_layer.shape[3] # ウィンドウ名定義 fig = plt.gcf() fig.canvas.set_window_title(vi_layer[i].name + " filter visualization") # 出力 for j in range(filter_num): plt.subplots_adjust(wspace=0.4, hspace=0.8) plt.subplot(filter_num/6 + 1, 6, j+1) plt.xticks([]) plt.yticks([]) plt.xlabel(f'filter {j}') plt.imshow(target_layer[ :, :, 0, j], cmap="gray") plt.show()特徴マップ可視化同様、見たいフィルタに対応する畳み込み層をリストに追加していきます。
vi_layer = [] # 可視化対象レイヤー vi_layer.append(model.get_layer('conv2d')) vi_layer.append(model.get_layer('conv2d_1')) vi_layer.append(model.get_layer('conv2d_2'))対象のレイヤーのフィルタを
get_weights()[0]で取得します。
ちなみに、get_weights()[1]と記述するとバイアスを取得できます。取得したフィルタのshapeは(H, W, I_C, O_C)です。I_Cは入力チャンネル数、O_Cは出力チャンネル数です。
# レイヤーのフィルタ取得 target_layer = vi_layer[i].get_weights()[0] filter_num = target_layer.shape[3]あとはフィルタを出力して、次のフィルタといった感じで繰り返します。
おわりに
特徴マップとフィルタ見てみたいなーって思って調べていろいろ変えて実装しました。
特徴マップは見て面白いところありますけど、フィルタはなんのことだか分からない感じなので面白くないですね。
近年、説明可能なAI(Explainable AI)というのが注目されてるみたいですが、どうしてこのようなフィルタで認識できるのかを人間が理解できるようになる時代が来るのが楽しみですね。