- 投稿日:2020-05-19T23:53:37+09:00
AWSの学習を始めたので出てきた基礎単語をまとめてみた
今回は、自分の覚書としてQiitaを投稿します。(基本いつもそう...)
IPアドレス
web上の住所
プライベートIPアドレスとパブリックIPアドレスの二つがある
32ビット構成で、8ビット×4で、数字は0~255プライベートIPアドレスの範囲
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.00 ~ 192.168.255.255
IPアドレスの乗数は、2のn乗で区切る(よく使うのは、256個と65536個)
CIDR 表記
ネットワーク部のビット数を[/ビット数 →prefix]で表す方法
IPアドレス範囲をCIDR表記する場合、その範囲をCIDRブロックという
ex) 192.168.0.0 → 192.168.0.0・16
サブネットマスク表記
プレフィックスのビット数だけ2進数の[1]を並べ、残りは[0]を記述した表記
ex) 192.168.0.0~192.168.255.255 → 192.168.0.0/255.255.0.0リージョン
地域に存在するデータセンター郡のこと(世界16箇所)
...なぜか初期でのAWSのリージョンが、東京ではなくオハイオになってました...アベイラビリティー
物理的に距離が相当離れた、独立したファシリティ。
→地震などの自然災害などが発生した場合に備えたリスクヘッジ。VPC(Virtual Private Cloud)
仮想的なネットワークEC2(Elastic Compute Cloud)
仮想的なサーバーサブネット
細分化したCIDRブロックのこと。
使う理由としては、社内LAN構築などの物理的な隔離とセキュリティ上の理由がある。
プライベートサブネットとパブリックサブネットの二つがある。
違いは、インターネットをアクセスするかしないか。パケット
データを送受信するための単位。
ヘッダー情報(宛先IPアドレス)や、データの実体を含む参照
- 投稿日:2020-05-19T23:06:35+09:00
私的 boto3(PythonライブラリーでAWSリソースを操作)よく使う、使えるAPI
以下、"AWS SDK for Python" に掲載されているAPIの中から、私的によく使う、boto3(Pythonライブラリー)関連のAPIをいくつか示します。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.htmlリソース名や各種設定値等は適宜読み替えてください~
Athena
# -*- coding: utf-8 -*- import boto3 import time athena = boto3.client("athena") class QueryFailed(Exception): """ Athenaのクエリ実行に失敗したときに呼ばれる例外クラス """ pass #クエリ実行(非同期処理) start_query_response = athena.start_query_execution( QueryString = 'クエリ', QueryExecutionContext={ "Database": "クエリするのに使うGlueDB名" }, ResultConfiguration={ "OutputLocation" : "s3://出力バケット名/キー" } ) query_execution_id = start_query_response["QueryExecutionId"] #クエリの実行状況を確認する while True: query_status = athena.get_query_execution( QueryExecutionId = query_execution_id ) query_execution_status = query_status['QueryExecution']['Status']['State'] if query_execution_status == 'SUCCEEDED': break elif query_execution_status == "FAILED" or query_execution_status == "CANCELLED": raise QueryFailed(f"query_execution_status = {query_execution_status}") time.sleep(10) #クエリ実行結果取得(成功した場合のみ) query_results = athena.get_query_results(QueryExecutionId = query_execution_id)DynamoDB
# -*- coding: utf-8 -*- import boto3 dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("table") #項目1件取得 response = table.get_item( Key = { "id" : "1" } ) #項目1件登録 response = table.put_item( Item = { "id" : "1", "key" : "value" } ) #項目1件更新 response = table.update_item( Key = { "id" : "1" }, UpdateExpression = "set key2 = :val", ExpressionAttributeValues = { ":val" : "value2" }, ReturnValues = "UPDATED_NEW" ) #項目1件削除 response = table.delete_item( Key = { "id" : "1" } ) #全項目(全レコード)削除 truncate or delete from table # データ全件取得 delete_items = [] parameters = {} while True: response = table.scan(**parameters) delete_items.extend(response["Items"]) if "LastEvaluatedKey" in response: parameters["ExclusiveStartKey"] = response["LastEvaluatedKey"] else: break # キー抽出 key_names = [ x["AttributeName"] for x in table.key_schema ] delete_keys = [ { k:v for k,v in x.items() if k in key_names } for x in delete_items ] # データ削除 with table.batch_writer() as batch: for key in delete_keys: batch.delete_item(Key = key) #テーブル削除 dynamodb_client = boto3.client('dynamodb') autoscaling_client = boto3.client('application-autoscaling') response = dynamodb_client.list_tables() if 'TableNames' in response: for table_name in response['TableNames']: if table_name == "削除対象のテーブル名": dynamodb_client.delete_table(TableName = table_name) waiter = dynamodb_client.get_waiter("table_not_exists") waiter.wait(TableName = table_name) #Target TrackingタイプのAutoScalingをつけている場合、ScalingPolicyを削除することで、CloudWatchAlarmを同時に削除することができる。 try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}ReadCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}WriteCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") #テーブル作成 table_name = "table" dynamodb.create_table( TableName = table_name, KeySchema = [{ "AttributeName" : "id", "KeyType" : "HASH" }], AttributeDefinitions = [{ "AttributeName" : "id", "AttributeType" : "S" }], ProvisionedThroughput = { "ReadCapacityUnits" : 1, "WriteCapacityUnits" : 1 } ) waiter = dynamodb_client.get_waiter("table_exists") waiter.wait(TableName = table_name) # Target TrackingタイプのAutoScalingの設定 autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) # スケーリングポリシーを設定 autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}ReadCapacity", ScalableDimension = "dynamodb:table:ReadCapacityUnits", TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBReadCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}WriteCapacity", ScalableDimension='dynamodb:table:WriteCapacityUnits', TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBWriteCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) #テーブルスキーマ更新 response = dynamodb_client.update_table( AttributeDefinitions = [ { 'AttributeName': 'string', 'AttributeType': 'S'|'N'|'B' }, ], TableName = 'string', BillingMode = 'PROVISIONED'|'PAY_PER_REQUEST', ProvisionedThroughput = { 'ReadCapacityUnits': 123, 'WriteCapacityUnits': 123 } ) #バッチ処理 table = dynamodb.Table("table") with table.batch_writer() as batch: for i in range(10 ** 6): batch.put_item( Item = { "id" : str(i + 1), "key" : f"key{i + 1}" } )Lambda
# -*- coding: utf-8 -*- import boto3 lambda = boto3.client('lambda ') response = lambda.invoke( FunctionName = '処理対象のLambda', InvocationType = 'Event'|'RequestResponse'|'DryRun', LogType = 'None'|'Tail', Payload = b'bytes'|file )SageMaker
# -*- coding: utf-8 -*- import boto3 sagemaker = boto3.client("sagemaker-runtime") # sagemakerのエンドポイントにアクセスし予測結果を受け取る response = sagemaker.invoke_endpoint( EndpointName = "SageMaker エンドポイント名", Body=b'bytes'|file, ContentType = 'text/csv', #The MIME type of the input data in the request body. Accept = 'application/json' #The desired MIME type of the inference in the response. )S3
# -*- coding: utf-8 -*- import boto3 s3 = boto3.client('s3') BUCKET_NAME = "処理対象のバケット名" #1オブジェクト(ファイル)書き込み s3.put_object( Bucket = BUCKET_NAME, Body = "データ内容。str型 or bytes型", Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)読み込み s3.get_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)削除 s3.delete_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)を別の場所へコピー s3.copy_object( Bucket = BUCKET_NAME, Key = "移行先S3キー。s3:://バケット名/ 以降のディレクトリおよびファイル名", CopySource = { "Bucket" : "移行元バケット名", "Key" : "移行元S3キー" } ) #指定プレフィックス以下 or バケット内全オブジェクト(ファイル)取得 BUCKET_NAME= "処理対象のバケット名" contents = [] kwargs = { "Bucket" : BUCKET_NAME, "Prefix" : "検索対象のプレフィックス" } while True: response = s3.list_objects_v2(**kwargs) if "Contents" in response: contents.extend(response["Contents"]) if 'NextContinuationToken' in response: kwargs["ContinuationToken"] = response['NextContinuationToken'] continue break else: breakSQS
# -*- coding: utf-8 -*- import boto3 sqs = boto3.client('sqs') QUEUE_URL= "SQSのキューURL。コンソールで確認できます。" #SQSのキューからメッセージを全部取得。 while True: sqs_message = sqs.receive_message( QueueUrl = QUEUE_URL, MaxNumberOfMessages = 10 ) if "Messages" in sqs_message: for message in sqs_message["Messages"]: try: print(message) #取得できたメッセージは削除する。そうしないと重複取得される可能性あり sqs.delete_message( QueueUrl = QUEUE_URL, ReceiptHandle = message["ReceiptHandle"] ) except Exception as e: print(f"type = {type(e)} , message = {e}")
- 投稿日:2020-05-19T23:06:35+09:00
私的 によく使うboto3(PythonライブラリーでAWSリソースを操作)API
以下、"AWS SDK for Python" に掲載されているAPIの中から、私的によく使う、boto3(Pythonライブラリー)関連のAPIをいくつか示します。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.htmlリソース名や各種設定値等は適宜読み替えてください~
Athena
# -*- coding: utf-8 -*- import boto3 import time athena = boto3.client("athena") class QueryFailed(Exception): """ Athenaのクエリ実行に失敗したときに呼ばれる例外クラス """ pass #クエリ実行(非同期処理) start_query_response = athena.start_query_execution( QueryString = 'クエリ', QueryExecutionContext={ "Database": "クエリするのに使うGlueDB名" }, ResultConfiguration={ "OutputLocation" : "s3://出力バケット名/キー" } ) query_execution_id = start_query_response["QueryExecutionId"] #クエリの実行状況を確認する while True: query_status = athena.get_query_execution( QueryExecutionId = query_execution_id ) query_execution_status = query_status['QueryExecution']['Status']['State'] if query_execution_status == 'SUCCEEDED': break elif query_execution_status == "FAILED" or query_execution_status == "CANCELLED": raise QueryFailed(f"query_execution_status = {query_execution_status}") time.sleep(10) #クエリ実行結果取得(成功した場合のみ) query_results = athena.get_query_results(QueryExecutionId = query_execution_id)DynamoDB
# -*- coding: utf-8 -*- import boto3 dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("table") dynamodb_client = boto3.client('dynamodb') autoscaling_client = boto3.client('application-autoscaling') #項目1件取得 response = table.get_item( Key = { "id" : "1" } ) #項目1件登録 response = table.put_item( Item = { "id" : "1", "key" : "value" } ) #項目1件更新 response = table.update_item( Key = { "id" : "1" }, UpdateExpression = "set key2 = :val", ExpressionAttributeValues = { ":val" : "value2" }, ReturnValues = "UPDATED_NEW" ) #項目1件削除 response = table.delete_item( Key = { "id" : "1" } ) #全項目(全レコード)削除 truncate or delete from table # データ全件取得 delete_items = [] parameters = {} while True: response = table.scan(**parameters) delete_items.extend(response["Items"]) if "LastEvaluatedKey" in response: parameters["ExclusiveStartKey"] = response["LastEvaluatedKey"] else: break # キー抽出 key_names = [ x["AttributeName"] for x in table.key_schema ] delete_keys = [ { k:v for k,v in x.items() if k in key_names } for x in delete_items ] # データ削除 with table.batch_writer() as batch: for key in delete_keys: batch.delete_item(Key = key) #テーブル削除 response = dynamodb_client.list_tables() if 'TableNames' in response: for table_name in response['TableNames']: if table_name == "削除対象のテーブル名": dynamodb_client.delete_table(TableName = table_name) waiter = dynamodb_client.get_waiter("table_not_exists") waiter.wait(TableName = table_name) #Target TrackingタイプのAutoScalingをつけている場合、ScalingPolicyを削除することで、CloudWatchAlarmを同時に削除することができる。 try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}ReadCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") try: autoscaling_client.delete_scaling_policy( PolicyName = f'{table_name}WriteCapacity', ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits" ) except autoscaling_client.exceptions.ObjectNotFoundException as e: print(f"type = {type(e)}, message = {e}") #テーブル作成 table_name = "table" dynamodb.create_table( TableName = table_name, KeySchema = [{ "AttributeName" : "id", "KeyType" : "HASH" }], AttributeDefinitions = [{ "AttributeName" : "id", "AttributeType" : "S" }], ProvisionedThroughput = { "ReadCapacityUnits" : 1, "WriteCapacityUnits" : 1 } ) waiter = dynamodb_client.get_waiter("table_exists") waiter.wait(TableName = table_name) # Target TrackingタイプのAutoScalingの設定 autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:ReadCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) autoscaling_client.register_scalable_target( ServiceNamespace = "dynamodb", ResourceId = f"table/{table_name}", ScalableDimension = "dynamodb:table:WriteCapacityUnits", MinCapacity = 1, MaxCapacity = 10, RoleARN = "AutoScalingするためのIAM Role ARN" ) # スケーリングポリシーを設定 autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}ReadCapacity", ScalableDimension = "dynamodb:table:ReadCapacityUnits", TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBReadCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId = f"table/{table_name}", PolicyType = "TargetTrackingScaling", PolicyName = f"{table_name}WriteCapacity", ScalableDimension='dynamodb:table:WriteCapacityUnits', TargetTrackingScalingPolicyConfiguration={ "TargetValue" : 70, "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBWriteCapacityUtilization" }, "ScaleOutCooldown" : 70, "ScaleInCooldown" : 70 } ) #テーブルスキーマ更新 response = dynamodb_client.update_table( AttributeDefinitions = [ { 'AttributeName': 'string', 'AttributeType': 'S'|'N'|'B' }, ], TableName = 'string', BillingMode = 'PROVISIONED'|'PAY_PER_REQUEST', ProvisionedThroughput = { 'ReadCapacityUnits': 123, 'WriteCapacityUnits': 123 } ) #バッチ処理 table = dynamodb.Table("table") with table.batch_writer() as batch: for i in range(10 ** 6): batch.put_item( Item = { "id" : str(i + 1), "key" : f"key{i + 1}" } )Lambda
# -*- coding: utf-8 -*- import boto3 lambda = boto3.client('lambda ') response = lambda.invoke( FunctionName = '処理対象のLambda', InvocationType = 'Event'|'RequestResponse'|'DryRun', LogType = 'None'|'Tail', Payload = b'bytes'|file )SageMaker
# -*- coding: utf-8 -*- import boto3 sagemaker = boto3.client("sagemaker-runtime") # sagemakerのエンドポイントにアクセスし予測結果を受け取る response = sagemaker.invoke_endpoint( EndpointName = "SageMaker エンドポイント名", Body=b'bytes'|file, ContentType = 'text/csv', #The MIME type of the input data in the request body. Accept = 'application/json' #The desired MIME type of the inference in the response. )SQS
# -*- coding: utf-8 -*- import boto3 sqs = boto3.client('sqs') QUEUE_URL= "SQSのキューURL。コンソールで確認できます。" #SQSのキューからメッセージを全部取得。 while True: sqs_message = sqs.receive_message( QueueUrl = QUEUE_URL, MaxNumberOfMessages = 10 ) if "Messages" in sqs_message: for message in sqs_message["Messages"]: try: print(message) #取得できたメッセージは削除する。そうしないと重複取得される可能性あり sqs.delete_message( QueueUrl = QUEUE_URL, ReceiptHandle = message["ReceiptHandle"] ) except Exception as e: print(f"type = {type(e)} , message = {e}")S3
# -*- coding: utf-8 -*- import boto3 s3 = boto3.client('s3') BUCKET_NAME = "処理対象のバケット名" #1オブジェクト(ファイル)書き込み s3.put_object( Bucket = BUCKET_NAME, Body = "データ内容。str型 or bytes型", Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)読み込み s3.get_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)削除 s3.delete_object( Bucket = BUCKET_NAME, Key = "S3のキー。s3:://バケット名/ 以降のディレクトリおよびファイル名" ) #1オブジェクト(ファイル)を別の場所へコピー s3.copy_object( Bucket = BUCKET_NAME, Key = "移行先S3キー。s3:://バケット名/ 以降のディレクトリおよびファイル名", CopySource = { "Bucket" : "移行元バケット名", "Key" : "移行元S3キー" } ) #指定プレフィックス以下 or バケット内全オブジェクト(ファイル)取得 BUCKET_NAME= "処理対象のバケット名" contents = [] kwargs = { "Bucket" : BUCKET_NAME, "Prefix" : "検索対象のプレフィックス" } while True: response = s3.list_objects_v2(**kwargs) if "Contents" in response: contents.extend(response["Contents"]) if 'NextContinuationToken' in response: kwargs["ContinuationToken"] = response['NextContinuationToken'] continue break
- 投稿日:2020-05-19T22:40:20+09:00
Amazon Elasticsearch Serviceについてまとめてみる
はじめに
Amazon Elasticsearch Service(Amazon ES)を使ったなかで学んだことをまとめてみました。
Elasticsearch自体に関しては簡単にしか説明しないので、ご注意ください。全文検索とElasticsearchについて
Amazon ESを使ってみようと思われる方はおそらく全文検索エンジンに関心があり、その中でも特にElasticsearchに興味をお持ちのはずです。
簡単にではありますが、前提知識として全文検索とElasticsearchについて説明してみます。
全文検索とは
端的に言うと、特定の保存場所(データベースなど)に保存されている複数のファイルから特定の文字列を検索するということです。
grep型とインデックス型があり、検索速度はインデックス型の方が高速らしい。
RDBでインデックスを設定した方が処理速度が高速になることを踏まえれば分かりやすいと思います。
Elasticsearchはインデックス型になります。全文検索を実現するエンジンは複数あり、代表的なものがApache Luceneです。
ElasticsearchやApache Solrの検索エンジン部はLuceneでできています。
Luceneに様々な機能を付加したシステムがElasticsearchやSolrになります。Elasticsearchについて
ElasticsearchはApache Luceneを基盤とした検索エンジンです。
どのような特徴があるのでしょうか。
スケーラビリティ
おそらくElasticsearch最大の長所です。相当大規模なシステムでの利用にも耐えるスケーラビリティを有します。
幾つものリクエストに対して、膨大な文書を検索し高速で結果を出力できます。
また、複数のサーバをクラスタリングする際もSolr等に比べて容易だと言われています。スキーマレス
RDBと異なり、格納するデータ構造をより柔軟に決めることができます。形式はJSONです。豊富なクエリ
Elasticsearchは全文検索用クエリmatchを始め、様々なクエリ(Query DSL)を用意しています。
クエリそれぞれで使用できるデータ型などが決まっているなどの違いがあります。
全文検索をする場合、クエリはFull text queriesのいずれかを使用する必要があります。
クエリのオプションも豊富であり、クエリを使い分けるだけで様々なユースケースに対応できます。
参照:Query DSL
参照:Full text queriesElastic Stack(ELK Stack)
Elasticsearch、Logstash、Kibanaなどからなる製品群です。まとめてElastic StackまたはELK Stackと呼ばれています。
全てElastic社が主体となって開発されている製品であり、相互連携が優れています。
特にKibanaはデータの可視化・分析、Elasticsearchの操作に大変有効であり、Elasticsearchのデータをより有効活用するのに役立ちます。
参照:Kibana
参照:Elastic Stackって何?企業が中心となっているOSS
営利企業であるElastic社が中心となって開発が進められています。
他のオープンソースの検索エンジンと比較すると開発が停止せず、システムの改良が継続的に行われていく可能性が高いと言えます。Elasticsearchにまつわる専門用語や全文検索の処理過程に関しては以下の記載が分かりやすかったです。
参考:Elasticsearchの用語が覚えられないのでまとめた
参考:ElasticSearch の全文検索での analyzer について差し当たり、インデックスがRDBで言うデータベースであること、日本語の文書を全文検索する際はanalyzerの働きや構成要素を理解する必要があることを抑えていただければ、Amazon ESを利用するにあたっては十分だと思います。
Amazon ESとは
AWSによるElasticsearchのマネージドサービスです。それだけでは身も蓋もないので特徴を挙げてみます。
利用開始が簡単
AWSのマネジメントコンソールからGUIを使って立ち上げることもできますし、AWS CLIやCloudFormation、AWS CDKを使用して開始することもできます。運用コストが削減される
マネージドサービスなので当然なのですが、Amazon ESの場合、日本語用プラグインのkuromojiが最初から利用できたりします。
Elasticsearch稼働に必要なJavaのインストール・アップデートの手間も不要です。AWSの他サービスとの連携
Lambdaを使用したデータの前処理、CloudWatchによる監視なども簡単に行えます。本来有料のElasticsearchのサービスを利用できる
Elasticsearchはオープンソースですが、JDBCやSQLを使うためにはElastic社へ料金を支払う必要がありました。
AWSはElasticsearchのプロプライエタリな部分を Open Distro for Elasticsearchとしてオープンソース化しました。
Amazon ESではOpen Distroに含まれる機能も簡単に利用できます。最新版のElasticsearchは使えない
マネージドサービスの宿命として、最新版をすぐに使用するのが難しいという問題があります。
どうしても最新版のElasticsearchを使用したい場合は、EC2等に自身でElasticsearchを導入するか、Elastic社が提供しているElastic Cloudを利用する必要があります。細かい設定はできない
最新版を使えないのと同様、細かい設定はできません。
日本語の形態素解析エンジンで最も一般的なのはMeCabですが、Amazon ESの場合はkuromojiに限定されます。
辞書もkuromojiデフォルトのIPA辞書であり、NEologdも使えません。立ち上げてみる
コンソールやCLIからでも立ち上げられますが、AWSのサービスであることを最大限活かすためにAWS CDKを使って立ち上げてみます。
AWS CDK自体については以下のリンクが参考になると思います。
参考:AWS CDK が GA! さっそく TypeScript でサーバーレスアプリケーションを構築するぜ【 Cloud Development Kit 】また、CDKからAmazon ESドメインを立ち上げる方法は以下のページに詳しく書かれています。
参照:AWS CDKでAmazon Elasticsearch Serviceのドメイン(クラスタ)を作ってみたCDKやその他必要なもののバージョンは以下の通りです。
% cdk version [~] 1.37.0 (build e4709de) # TypeScriptが必要 % tsc -v [~] Version 3.4.5 % node -v [~] v12.14.1CDKのプロジェクトを作ります。
% cdk init --language typescript Applying project template app for typescript Initializing a new git repository... Executing npm install... # 中略 # Welcome to your CDK TypeScript project! This is a blank project for TypeScript development with CDK. The `cdk.json` file tells the CDK Toolkit how to execute your app. # 中略 % exa drwxr-xr-x - test 6 5 15:07 bin .rw-r--r-- 160 test 6 5 15:07 cdk.json .rw-r--r-- 130 test 6 5 15:07 jest.config.js drwxr-xr-x - test 6 5 15:07 lib drwxr-xr-x - test 6 5 15:08 node_modules .rw-r--r-- 275k test 6 5 15:08 package-lock.json .rw-r--r-- 545 test 6 5 15:07 package.json .rw-r--r-- 543 test 6 5 15:07 README.md drwxr-xr-x - test 6 5 15:07 test .rw-r--r-- 598 test 6 5 15:07 tsconfig.jsonCDKのコード内でAmazon ESを立ち上げられるようにするために以下のパッケージをインストールします。
% yarn add @aws-cdk/aws-elasticsearchCDKを始めてデプロイする場合は、CloudFormationで利用するデプロイ用S3バケットを作成する以下のコマンドを入力します。
% cdk bootstraplib配下のtsファイル(stackname-stack.ts)を以下のように記述します。Amazon ESの設定を定義しています。
import * as cdk from "@aws-cdk/core"; import * as es from "@aws-cdk/aws-elasticsearch"; export class AmazonesPjStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // The code that defines your stack goes here // Amazon ESのバージョン const esVersion: string = "7.4"; // アクセスポリシー設定のためのIPアドレス // ローカルのIPアドレスは curl -s https://checkip.amazonaws.com で分かる const sourceIP: string = `${MyIP}`; // ドメイン名 const domainName: string = "test-es-domain"; // Amazon ESドメインの詳細設定 const domain = new es.CfnDomain(this, domainName, { // アクセスポリシー設定 accessPolicies: { Version: "2012-10-17", Statement: [ { Effect: "Allow", Principal: { AWS: ["*"], }, Action: ["es:*"], Resource: `arn:aws:es:${cdk.Stack.of(this).region}:${ cdk.Stack.of(this).account }:domain/${domainName}/*`, Condition: { IpAddress: { "aws:SourceIp": `${sourceIP || "127.0.0.1"}`, }, }, }, { Effect: "Allow", Principal: { AWS: [cdk.Stack.of(this).account], }, Action: ["es:*"], Resource: `arn:aws:es:${cdk.Stack.of(this).region}:${ cdk.Stack.of(this).account }:domain/${domainName}/*`, }, ], }, domainName: domainName, ebsOptions: { ebsEnabled: true, volumeSize: 10, volumeType: "gp2", }, elasticsearchClusterConfig: { instanceCount: 1, instanceType: "t2.small.elasticsearch", }, elasticsearchVersion: esVersion, encryptionAtRestOptions: { enabled: false, }, nodeToNodeEncryptionOptions: { enabled: false, }, snapshotOptions: { automatedSnapshotStartHour: 0, }, }); } }実際にデプロイします。デプロイには10分程度時間がかかります。
% cdk deploy [~/Documents/code_test/amazones_pj]+[master] yarn run v1.22.4 warning package.json: No license field ✨ Done in 1.32s. AmazonesPjStack: deploying... AmazonesPjStack: creating CloudFormation changeset... 0/3 | 20:25:25 | CREATE_IN_PROGRESS | AWS::Elasticsearch::Domain | test-es-domain (testesdomain) 0/3 | 20:25:25 | CREATE_IN_PROGRESS | AWS::CDK::Metadata | CDKMetadata 0/3 | 20:25:26 | CREATE_IN_PROGRESS | AWS::CDK::Metadata | CDKMetadata Resource creation Initiated 1/3 | 20:25:26 | CREATE_COMPLETE | AWS::CDK::Metadata | CDKMetadata 1/3 | 20:25:27 | CREATE_IN_PROGRESS | AWS::Elasticsearch::Domain | test-es-domain (testesdomain) Resource creation Initiated 1/3 Currently in progress: testesdomain 2/3 | 20:39:32 | CREATE_COMPLETE | AWS::Elasticsearch::Domain | test-es-domain (testesdomain) 3/3 | 20:39:33 | CREATE_COMPLETE | AWS::CloudFormation::Stack | AmazonesPjStack ✅ AmazonesPjStackドメインを作れました。
% aws es list-domain-names [~] { "DomainNames": [ { "DomainName": "test-es-domain" } ] }設定してみる
Amazon ESは最近のElasticsearch同様、インデックスにデータを格納する前にmapping(RDBでいうカラム)を定義する必要はありません。
とはいえ、やはりmappingは事前に定義することをお勧めします。日本語の文章に対して適切なアナライザを使用しなければ全文検索を有効に行えなくなってしまいます。そこで、以下のようなファイルを用意し、mappingとアナライザの定義を行います。
settings_es.json{ "settings": { "analysis": { "analyzer": { "index_analyzer": { "type": "custom", "tokenizer": "kuromoji_tokenizer", "mode": "search", "char_filter": ["icu_normalizer", "kuromoji_iteration_mark"], "filter": [ "cjk_width", "kuromoji_baseform", "kuromoji_part_of_speech", "ja_stop", "lowercase", "kuromoji_number", "kuromoji_stemmer" ] } }, "tokenizer": { "kuromoji_tokenizer": { "type": "kuromoji_tokenizer", "mode": "normal" } } } }, "mappings": { "properties": { "company": { "type": "text", "analyzer": "index_analyzer" }, "products": { "type": "text", "analyzer": "index_analyzer" } } } }mappingsでインデックスに含まれるプロパティのデータ型ならびに使用するアナライザを定義します。
アナライザ部に含まれているのは日本語を全文検索するにあたり必要なプラグインです。各プラグインの詳細は以下のリンク先に詳しく書かれています。
参照:Elasticsearchを日本語で使う設定のまとめ今回は2つのプロパティを用意します。両方text型です。他にもデータ型はありますが、全文検索を行う場合はtext型を使用する必要があります。
上記のJSONを以下の通りに適用します。オリジナルのElasticsearchと同様です。
エンドポイント以下にインデックス名を付加します。% curl -XPUT "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/test?pretty" -H "Content-type: application/json" -d @settings_es.json { "acknowledged" : true, "shards_acknowledged" : true, "index" : "test" } % curl -XGET "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/test/_mapping?pretty" { "test" : { "mappings" : { "properties" : { "company" : { "type" : "text", "analyzer" : "index_analyzer" }, "products" : { "type" : "text", "analyzer" : "index_analyzer" } } } } }投入するデータは以下の通りです。
data.json{"index": {"_index": "news","_type": "_doc","_id": "1"}} {"company": "Microsoft", "products": "Windows .NET Office 365 Visual Studio Azure"} {"index": {"_index": "news","_type": "_doc","_id": "2"}} {"company": "Google", "products": "G Suite GCP Golang Flutter"} {"index": {"_index": "news","_type": "_doc","_id": "3"}} {"company": "Apple", "products": "MacOS iOS Swift iPhone"}ちなみにElasticsearchに投入するJSONは末行を空行にする必要があります。空行にしないとThe bulk request must be terminated by a newline [\n]というエラーが出ます。
投入してみます。
% curl -XPOST "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/_bulk?pretty" -H "Content-type: application/json" --data-binary @data.json { "took" : 500, "errors" : false, "items" : [ { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "2", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "3", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } } ] }以上で設定が終わりました。
使ってみる
格納されているデータに対してクエリを投げつけてみます。
クエリは全文検索用クエリで一般的なmatchを使用してみます。
query.json{ "query": { "match": { "products": "MacOS" } } }% curl -XGET "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/test/_search?pretty" -H "Content-type: application/json" -d @query.json { "took" : 395, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 0.2876821, "hits" : [ { "_index" : "test", "_type" : "_doc", "_id" : "3", "_score" : 0.2876821, "_source" : { "company" : "Apple", "products" : "MacOS iOS Swift iPhone" } } ] } }きちんと取り出せました。
インデックスの削除はDELETEメソッドを使用して行います。
% curl -XDELETE "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/test?pretty" { "acknowledged" : true }シノニムやユーザー辞書を使用する
パッケージ機能登場以前
文章を全文検索するにあたりシノニム(類義語)やユーザー辞書(業界独自の用語のような専門的な単語を搭載した辞書)を使えた方が便利です。
従来、Amazon ESではシノニムの利用は不便であり、ユーザー辞書は使えませんでした。例えば以下のようなデータをAmazon ESに投入します。
{"index": {"_index": "test","_type": "_doc","_id": "1"}} {"company": "Microsoft", "text": "Microsoftの代表的な製品はWindowsです"} {"index": {"_index": "test","_type": "_doc","_id": "2"}} {"company": "マイクロソフト", "text": "マイクロソフトの代表的な製品はWindowsです"}言うまでもなく「Microsoft」と「マイクロソフト」は同一の企業を指します。
以下のようなクエリを投げてみます。
query.json{ "query": { "match": { "text": "マイクロソフト" } } }残念なことにこのままではMicrosoftが含まれる文書を取り出すことはできません。
% curl -XGET "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/test/_search?pretty" -H "Content-type: application/json" -d @query.json { "took" : 8, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 0.2876821, "hits" : [ { "_index" : "test", "_type" : "_doc", "_id" : "2", "_score" : 0.2876821, "_source" : { "company" : "マイクロソフト", "text" : "マイクロソフトの代表的な製品はWindowsです" } } ] } }パッケージ機能登場
しかし、2020年4月になってシノニムやユーザー辞書をパッケージというファイルで扱えるようになりました。
[新機能]Amazon Elasticsearch Service でファイルベースのシノニム、ユーザー辞書などに対応するカスタムパッケージを利用可能になりました
今回はシノニム機能を使ってみます。
シノニム用のファイルは以下のものを使用します。
synonym.txtMicrosoft,マイクロソフト上記テキストファイルをESドメインで使うにはS3バケットにアップロードする必要があります。
バケットに関しては今回はCLIから作成します。% aws s3 mb s3://amazon-es-bucket-test-20200510 make_bucket: amazon-es-bucket-test-20200510 % aws s3 cp synonym.txt s3://amazon-es-bucket-test-20200510 upload: ./synonym.txt to s3://amazon-es-bucket-test-20200510/synonym.txtCLIからパッケージを作成します。
% aws es create-package --package-name amazon-es-test-package --package-type TXT-DICTIONARY --package-source S3BucketName=amazon-es-bucket-test-20200510,S3Key=synonym.txt { "PackageDetails": { "PackageID": "F230451472", "PackageName": "amazon-es-test-package", "PackageType": "TXT-DICTIONARY", "PackageStatus": "AVAILABLE", "CreatedAt": "2020-05-19T21:43:15.110000+09:00" } }シノニムを使用する場合、アナライザの設定を以下の通りにします。
setting_es.json{ "settings": { "analysis": { "analyzer": { "index_analyzer": { "type": "custom", "tokenizer": "kuromoji_tokenizer", "mode": "search", "char_filter": ["icu_normalizer", "kuromoji_iteration_mark"], "filter": [ "cjk_width", "synonym_filter", "kuromoji_baseform", "kuromoji_part_of_speech", "ja_stop", "lowercase", "kuromoji_number", "kuromoji_stemmer" ] } }, "filter": { "synonym_filter": { "type": "synonym", "synonyms_path": "analyzers/F230451472" } }, "tokenizer": { "kuromoji_tokenizer": { "type": "kuromoji_tokenizer", "mode": "normal" } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "index_analyzer" }, "text": { "type": "text", "analyzer": "index_analyzer" } } } }ポイントは2点あります。トークナイザーのmodeをnormalにすることと、シノニム用のフィルターを可能な限り早めに当てることです。
どうやらトークナイザーが文章を加工する過程で特殊文字が混じるために、シノニム機能がうまく処理を行えなくなることが原因のようです。コンソールもしくはaws es associate-packageコマンドでドメインとパッケージの関連付けを行います。
こうすることでドメイン内のインデックスからパッケージ中のユーザー辞書やシノニムファイルを使用することができます。先ほどのクエリを投げてみると、両方の文書を取り出すことができました
% curl -XGET "search-test-es-domain-mhwk6krh6562mjoa6wnlk3m5yu.ap-northeast-1.es.amazonaws.com/test/_search?pretty" -H "Content-type: application/json" -d @query.json { "took" : 41, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 0.41501677, "hits" : [ { "_index" : "test", "_type" : "_doc", "_id" : "2", "_score" : 0.41501677, "_source" : { "company" : "マイクロソフト", "text" : "マイクロソフトの代表的な製品はWindowsです" } }, { "_index" : "test", "_type" : "_doc", "_id" : "1", "_score" : 0.41501677, "_source" : { "company" : "Microsoft", "text" : "Microsoftの代表的な製品はWindowsです" } } ] } }まとめ
Amazon ESはEC2等のサーバ上で運用する生のElasticsearchと比較して制限が多いです。
場合によってはその制限が致命的で採用を見送る場合もあると思います。しかし、Query DSLの工夫や、つい最近登場したパッケージ機能でかなり使いやすくなるとも思います。
それでもマネージドなのは魅力的で、AWSも積極的にAmazon ESの改良に動いています。
今後ますます使いやすくなると思いますので皆さまもぜひ使ってみていかがでしょうか。
- 投稿日:2020-05-19T21:28:11+09:00
[AWS] Lightsailを使ってWordPressブログを作ってみた〜②独自ドメイン設定編〜
前回の記事
https://qiita.com/Dev-kenta/items/e175c8960cf32624e28d
参考にした記事(Special Thanks)
https://jyn.jp/compare-domain-registrar/#i-15
https://qiita.com/Hikery/items/8933e1969c971eaa649d
https://qiita.com/fk_2000/items/545a835ba2f2a1d0a974
https://qiita.com/s-tyd/items/2b40fc88b78b49b84b35
https://tokoaruga.com/google-domains-registration/前提
- AWS Lightsailでwordpressのインスタンスを作り終わっている
- ターミナルでviの操作をある程度できる
手順
1. 独自ドメインを取得する
ドメインレジストラサービスは有名なところだと「お名前.com」だったり、Lightsailと同じくAWSのサービスで Route53から取得するという手もあります。
今回は今まで使ったこと無かったので、Google Domainsを使って取得して進めていきます。
Google Domainsのサイトにアクセスするとこんな画面が表示されるので、取得したいdomainを入力して取得を押します。
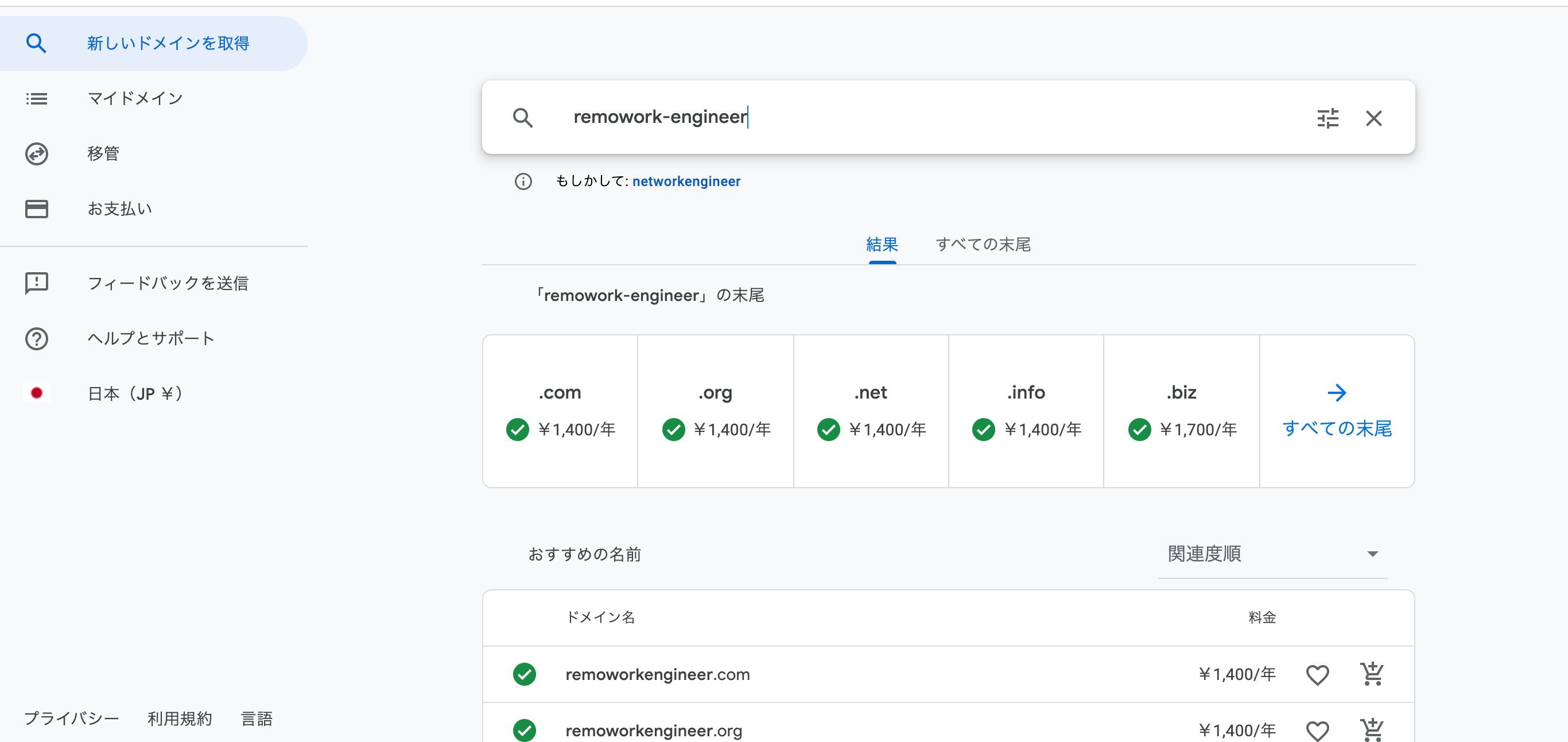
取得できるドメインがずらっと表示されます。UIがわかりやすいですね。さすがGoogleさん。
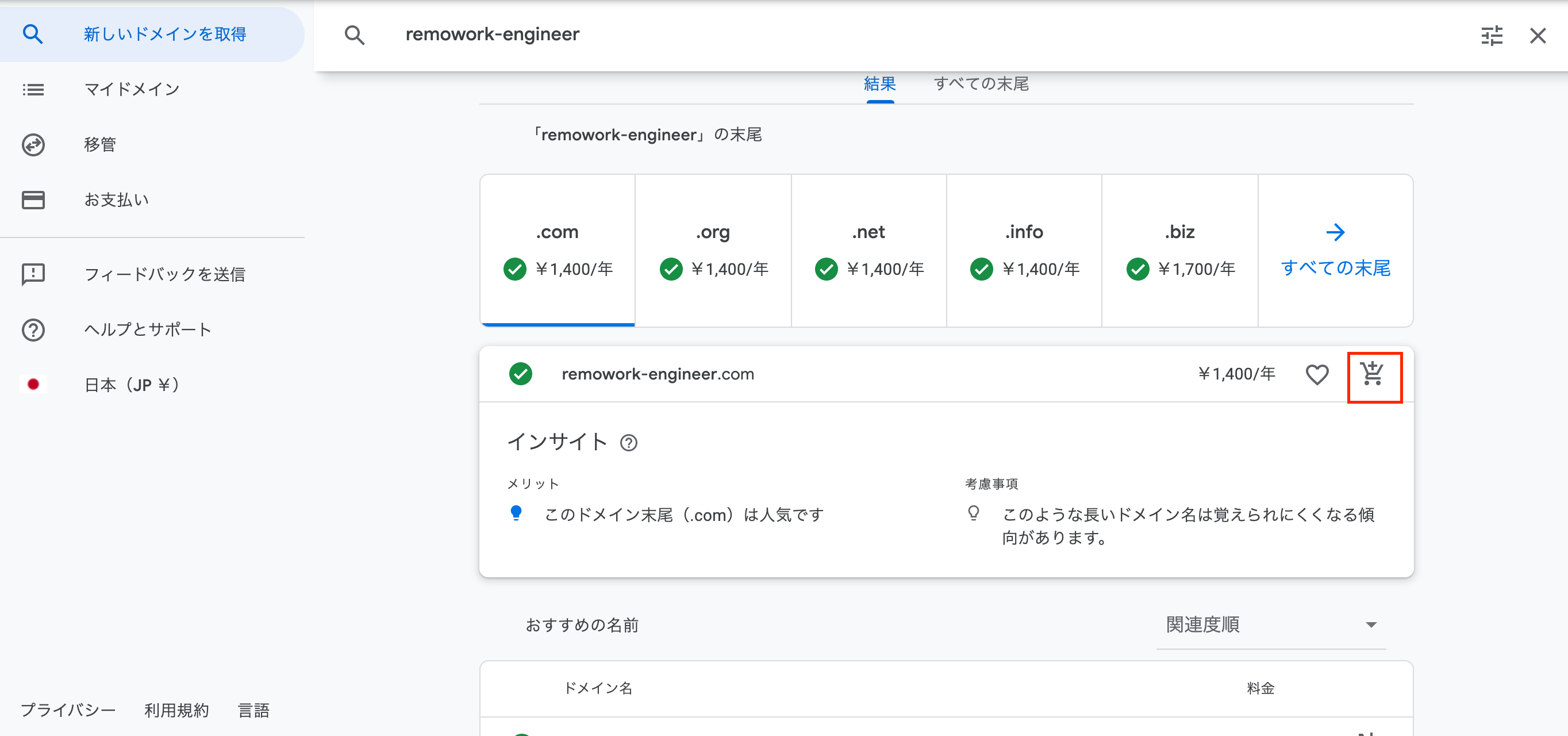
取得するドメインを選択したら、カートのアイコンをクリックします。今回は「.com」を選択しました。
そしてドメイン長いって心配されている。。がこのまま進めます。
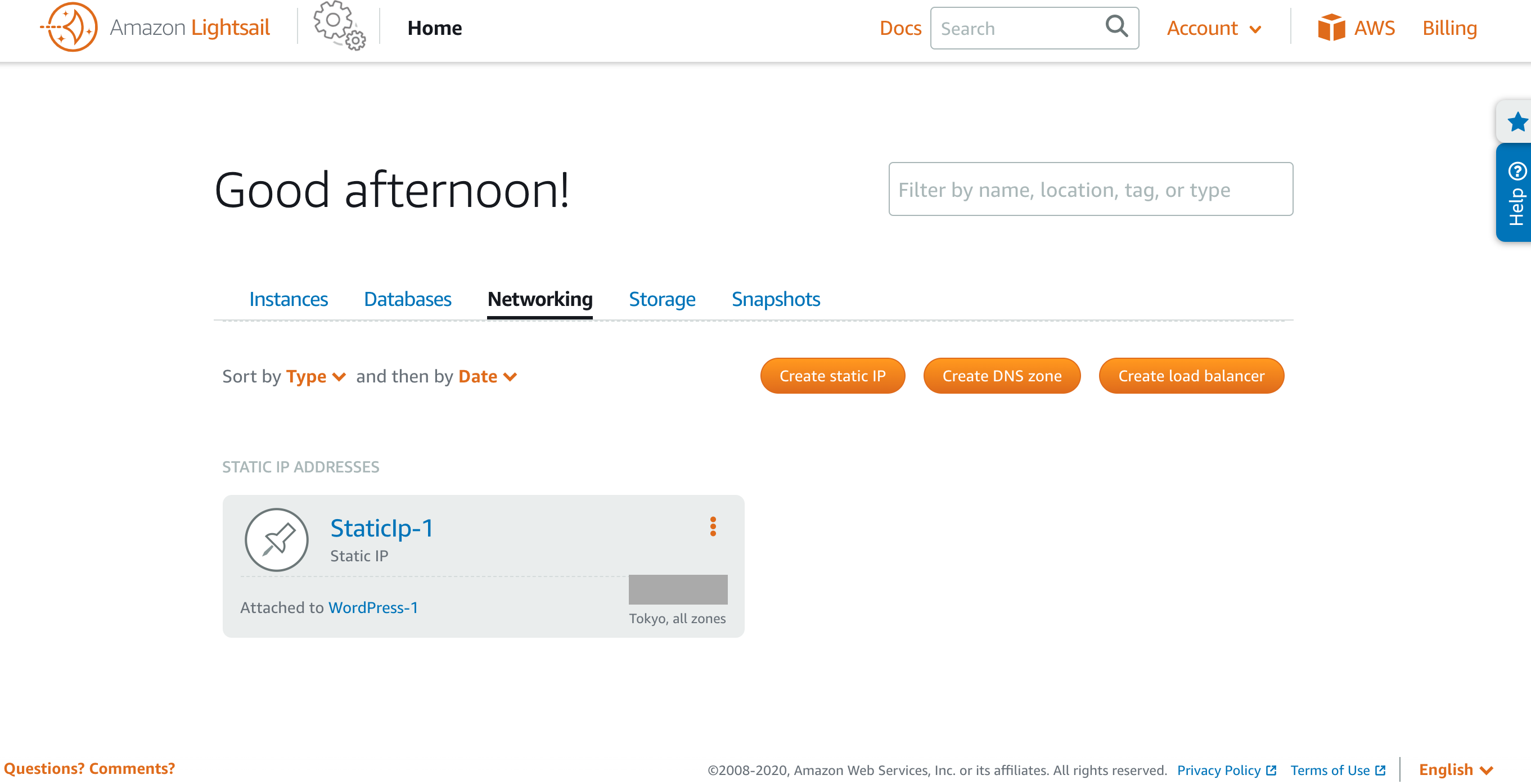
カートに入れるとあとは購入者情報を入力して支払いを完了させるだけになります。簡単!2. LightsailでDNSゾーンを作成する
ドメインの取得が終わったら、LightsailのDNSゾーンを作成します。
Networkingタブを開いて、Create DNS zoonをクリックします。
DNSゾーン作成画面に遷移したら、先ほど取得したドメインを入力してCreate DNS zoonをクリックすれば作成が完了します。
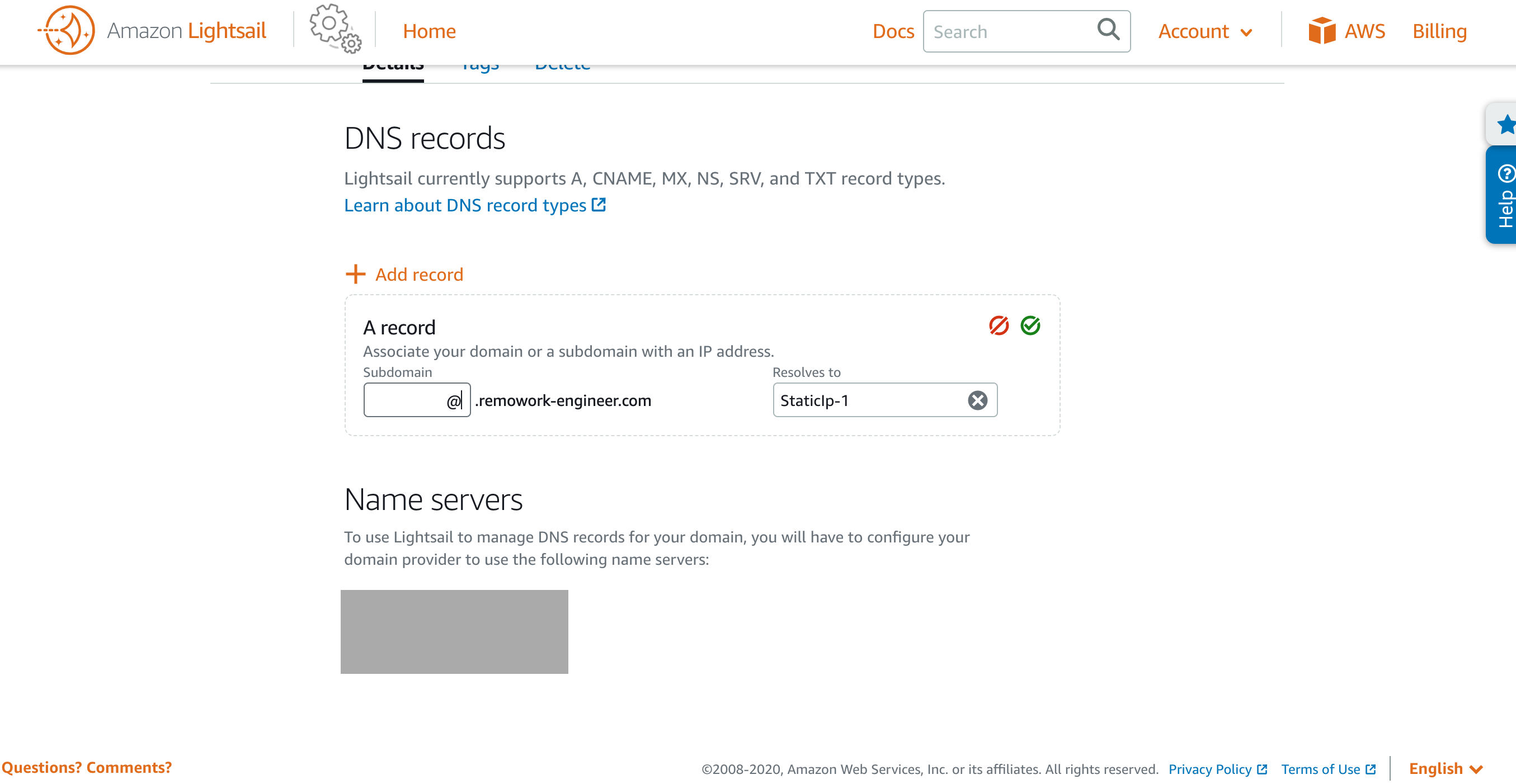
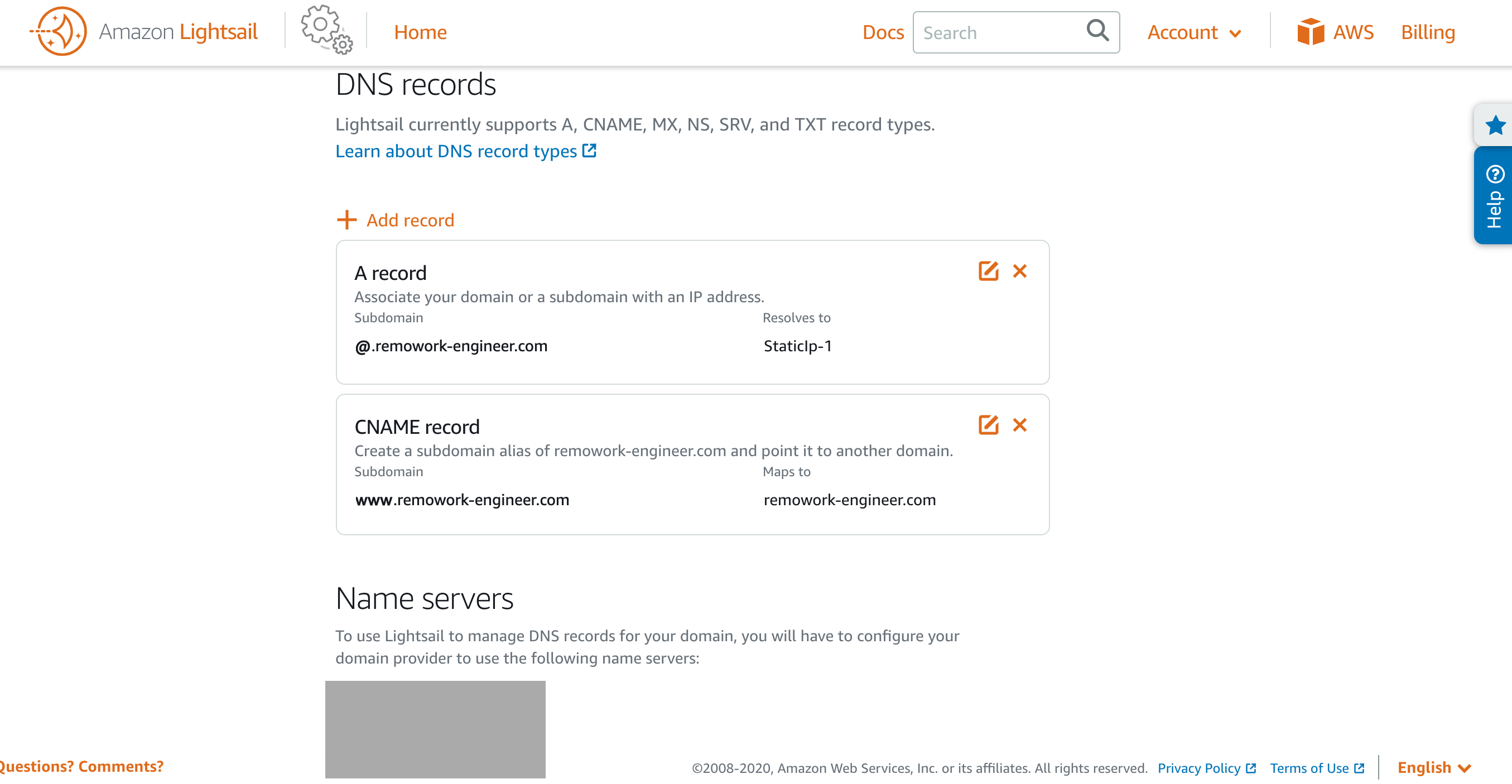
DNSゾーンを作成後はDMSゾーンのレコード設定を行います。
Add recordを押してA recordを選択、Subdomainの入力欄は@を入れてください。空では完了できなかったです。
A recordを設定したあとは、CNAME recordも設定します。
二つの設定後はこんな感じ。3. 独自ドメインにネームサーバーの設定をする
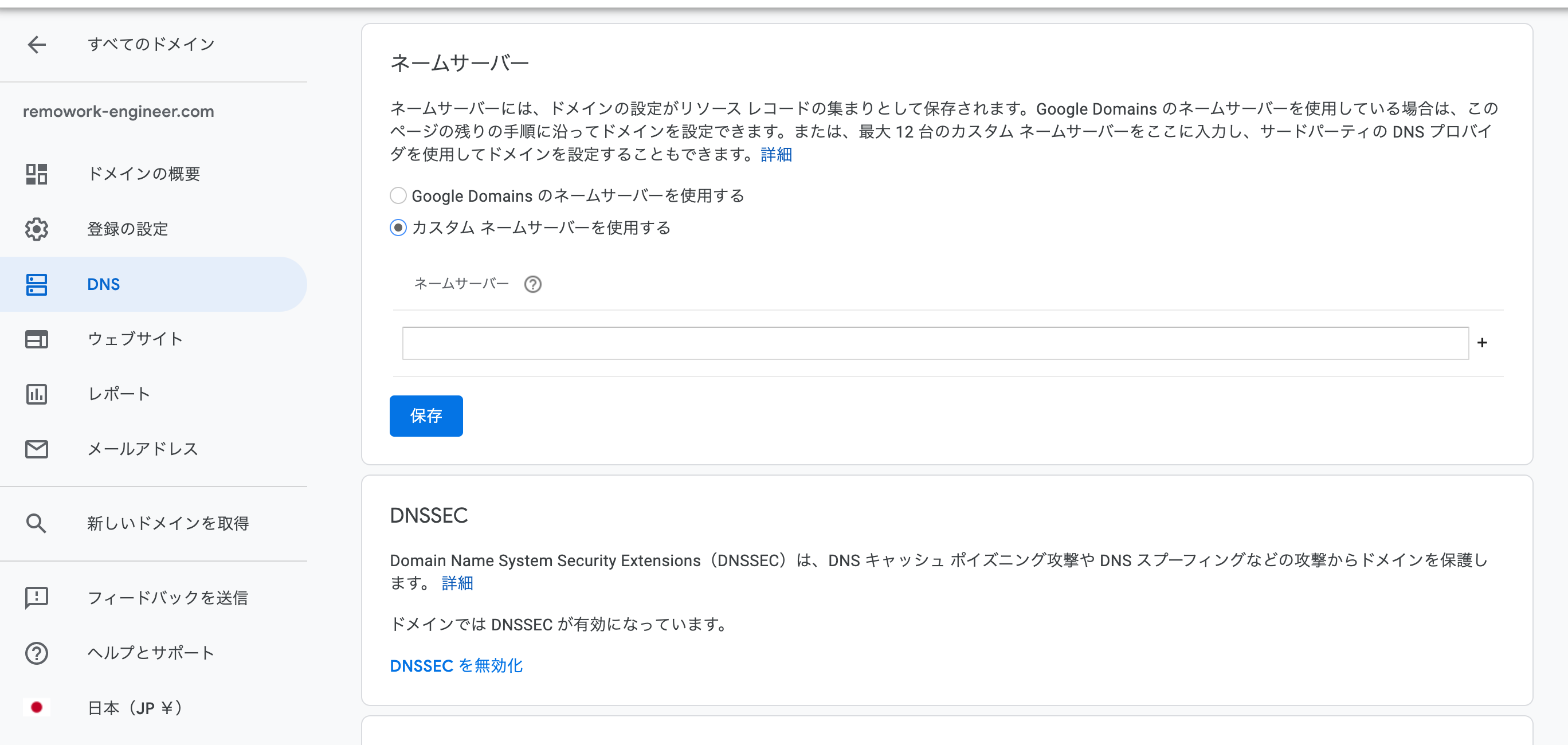
次はGoogle Domainsの管理画面に戻ってネームサーバーの設定を行います。
左のサイドバーのDNSをクリックするとDNS設定画面に遷移するので、カスタムネームサーバーに切り替えてLightsailのName serversに表示されているものを全て登録していきます。
全て入力したら保存をクリック、48時間ほどかかります。みたいに表示されますが、僕の場合は5分かからずに終わりました。
登録が完了するのを待って、登録完了後に取得したドメインでLightsailで作成したWordPressの環境が表示されていればOKです。4. Let's Encryptを導入する
このままだとhttps対応がされていないので、Let's Encryptでssl証明書を入れます。
Lightsailのssh接続を使うか、クライアントからsshで接続してください。
そして以下のコマンドを打つ。cd /tmp git clone https://github.com/letsencrypt/letsencrypt cd letsencrypt ./letsencrypt-auto ./letsencrypt-auto certonly --webroot -w /opt/bitnami/apps/wordpress/htdocs/ -d [取得したドメイン] sudo cp /etc/letsencrypt/live/[取得したドメイン]/fullchain.pem /opt/bitnami/apache2/conf/server.crt sudo cp /etc/letsencrypt/live/[取得したドメイン]/privkey.pem /opt/bitnami/apache2/conf/server.key sudo /opt/bitnami/ctlscript.sh restart apachehttpsでWordPress環境にアクセスしてみて、URLの左端に鍵マークが付いていれば成功です。
5. httpsへのリダイレクト設定をする
お次はhttpでアクセスされた時にhttpsにリダイレクトしてあげる設定も追加していきましょう。
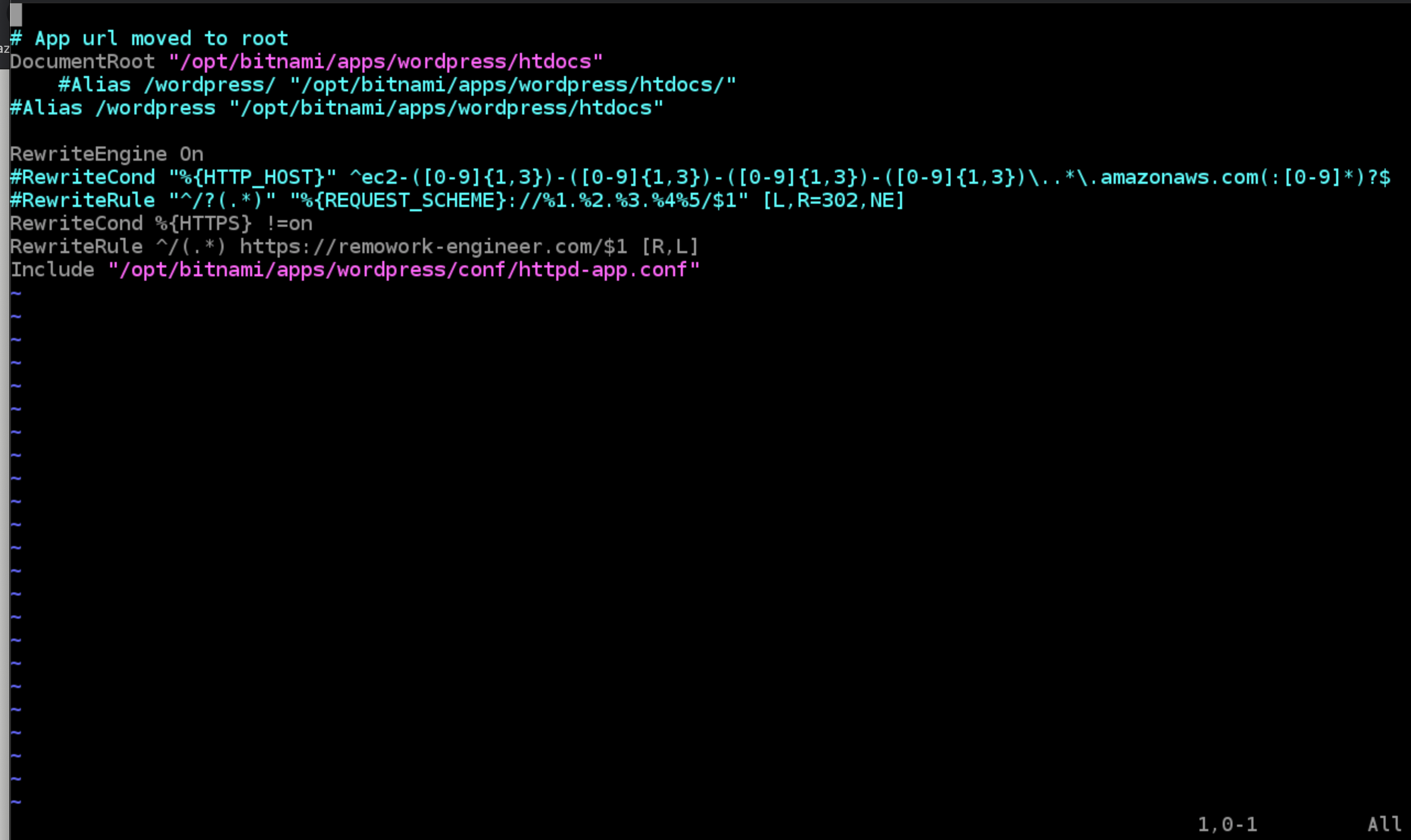
以下のコマンドを打ちます。vi /opt/bitnami/apps/wordpress/conf/httpd-prefix.conf開いたファイルを以下のように変更
RewriteCond %{HTTPS} !=on RewriteRule ^/(.*) https://example.com/$1 [R,L]
次はWordPressのファイルにも設定を変更していきます。
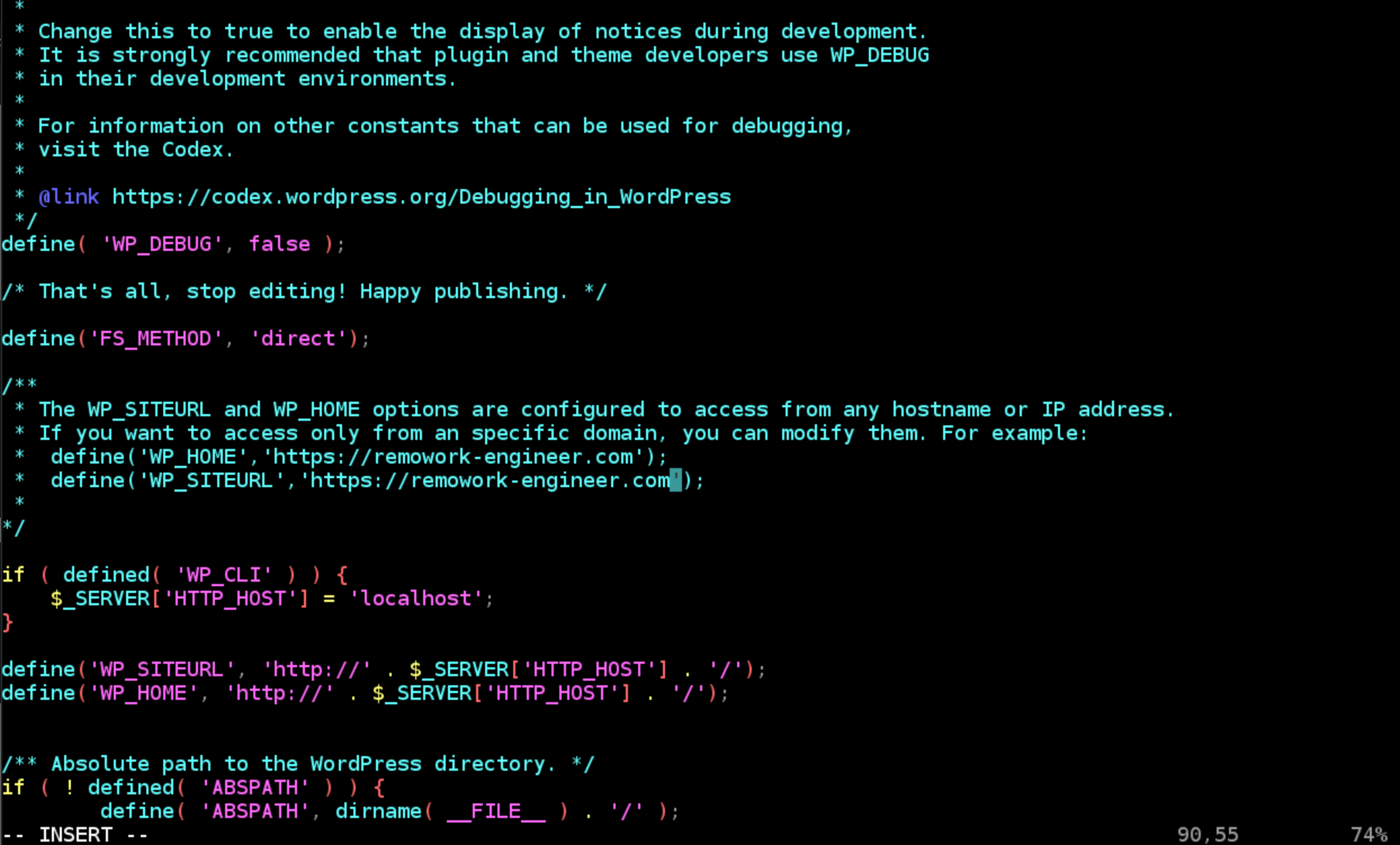
vi /opt/bitnami/apps/wordpress/htdocs/wp-config.phpこちらも該当の箇所を以下のように変更
define('WP_SITEURL', 'https://[取得したドメイン]/'); define('WP_HOME', 'https://[取得したドメイン]/');
変更後httpでアクセスして、httpsにリダイレクトされればOKです。
キャッシュがの残っている場合があるので、一度サーバーをrestartしてから確認するといいかもしれません。sudo /opt/bitnami/ctlscript.sh restart apache6. お問い合わせフォームを設置する場合
Lightsailのインスタンスでメールを送ろうとすると、Eメールが有効になっていないため送れません。そのためSMTPサーバーを用意する必要があります。
今回は勉強も兼ねてAWS SESを使ってみました。
https://lightsail.aws.amazon.com/ls/docs/ja_jp/articles/amazon-lightsail-enabling-email-on-wordpress
AWS公式に詳しくリファレンス載っているのでこの手順通りにやればできました。
後はWordPressのContactForm7なり別のプラグインを導入してお問い合わせフォームを設置すれば完了です。出来上がったブログはこちら
https://remowork-engineer.com/
まだHello Worldしか記事ありませんw
これから書いてかなきゃなー。
今回は有料テーマ購入してみました。有料テーマは機能がいっぱいあって勉強になります。

- 投稿日:2020-05-19T21:19:38+09:00
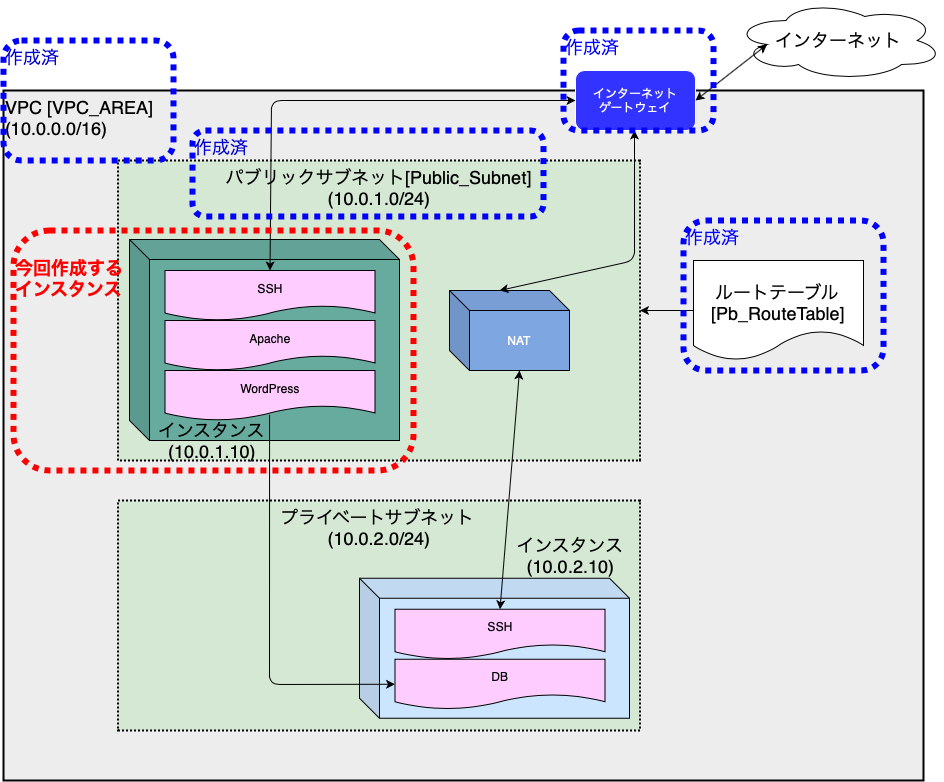
クラウド初心者のAWS入門(第5回)
第5回 仮想サーバの構築
今回は、パブリックサブネット内に仮想サーバを構築していきます。
EC2サービスで作成した仮想サーバは、「インスタンス」と呼ぶようです。
以下の順番で仮想サーバを構築していきます。
個々に掘り下げていくのは宿題。。。
- インスタンスの作成
- インスタンスタイプの選択
- ネットワーク設定
- ストレージ設定
- タグ設定
- セキュリティグループの作成
- キーペアの作成とダウンロード
インスタンスの作成
EC2ダッシュボードから、「インスタンスの作成」を選択し作成していきます。
EC2ダッシュボードの表示
AWSマネジメントコンソールの「サービスを検索する」に"EC2"と入力します。
「EC2」サービスが表示されるので「EC2」を選択すると、「EC2ダッシュボード」に切り替わります。
・インスタンスの設定(AMI)
続いてAMI(Amazon Machine Image)を選択します。
AMIをテンプレートとしてインスタンスを起動してくれるようです。
vmware等ハイパーバイザ系のテンプレートからデプロイと比べると、とても早いです。今回は無料で進めていきたいのでRedhat7ベースの「Amazon Linux 2」を選択しました。
ここで選択できる項目として、「Amazon Linux」と「Amazon Linux 2」がありました。
「無印」はRedhat 6ベース、「2」はRedhat 7ベースとのことです。
・インスタンスタイプの選択
インスタンスタイプは、「t2.micro」を選択します。
「確認と作成」を押さないように、次のステップへ進みます。
インスタンスタイプについて(謝辞)
インスタンスタイプの種類は膨大な量があるようで・・・
わかりやすく解説しておられるkkino1985さんの記事を、大変参考にさせていただきました。
ありがとうございます。これからお勉強させていただきます。
kkino1985様の記事
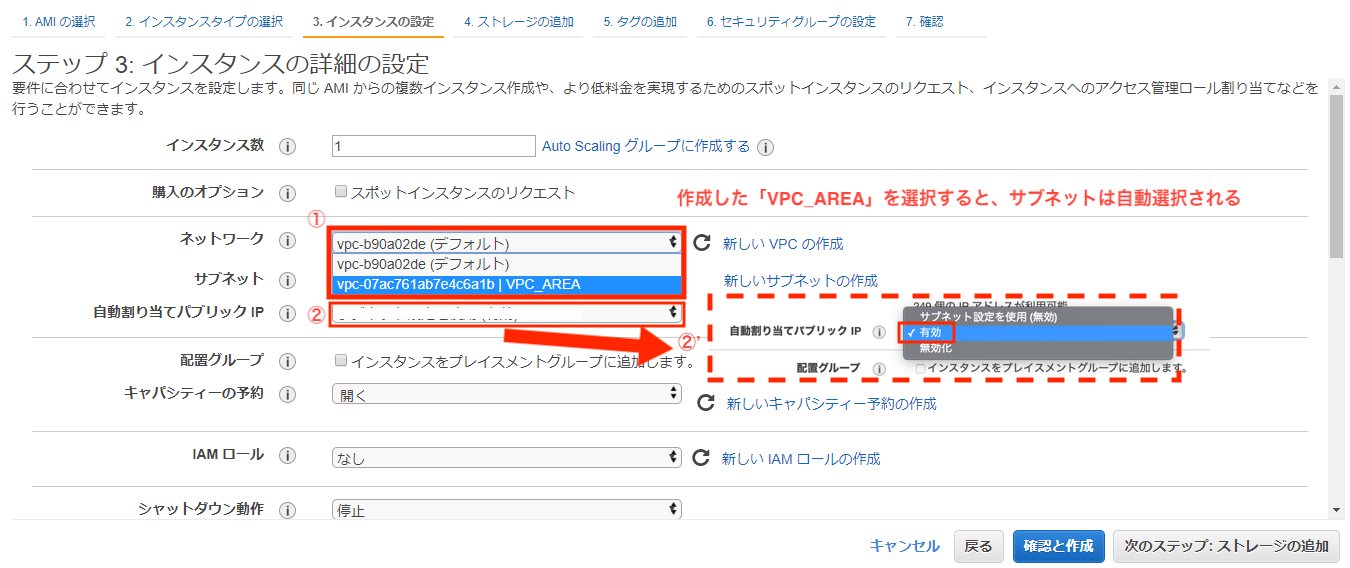
・ネットワーク設定
続いてネットワークの設定を行います。
設定する項目は以下となります。
- 「ネットワーク」 ・・・「作成したVPC」を選択
- 「自動割り当てパブリックIP」 ・・「有効」を選択
- 「ネットワークインターフェース」 ・・「プライマリIP」を追加インスタンスには、インターネット接続用のパブリックIPと内部通信用のIPの2つを設定します。
まず、VPCと自動割り当てパブリックIPを選択していきます。
「自動割り当てパブリックIP」を有効にすることで、インスタンス起動時にインターネット接続用のIPアドレスが割り当てられます。
また、インスタンスを再起動してしまうと、このIPは変更されてしまいます。
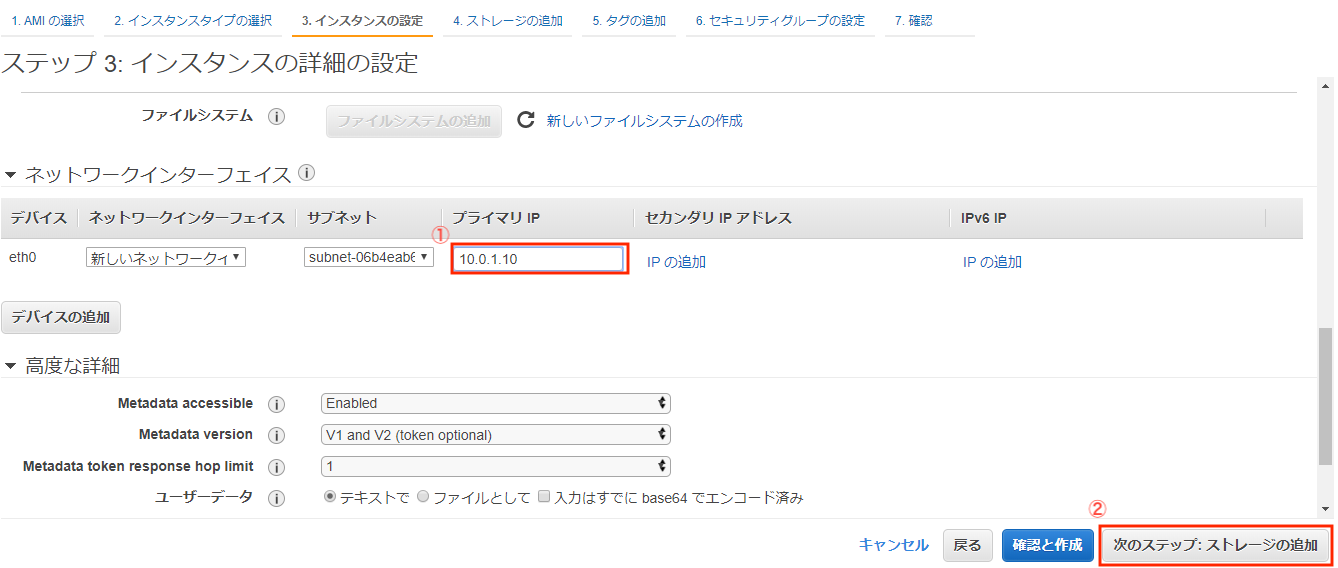
別の機会にパブリックIPの固定化をやります。続いて、内部通信用の「プライマリIP」の設定も行います。
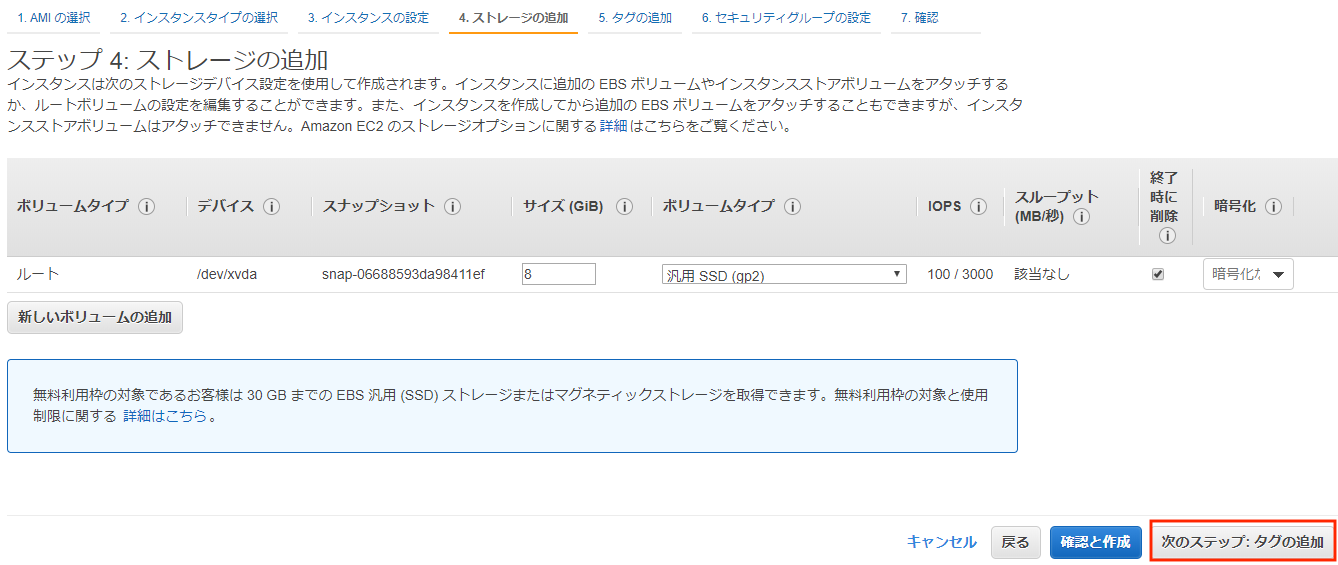
・ストレージ設定
ストレージの設定はデフォルトのまま。
なお、無料枠の上限は30GBです。
インスタンスを作成したらカウントされます。作成したインスタンスを削除してもカウントは減りません!!
デフォルトの8GBで作成していくと、4個インスタンスを作成するとアウトです!!
私も全く気づかず、微々たる額ですが徴収されてしましました
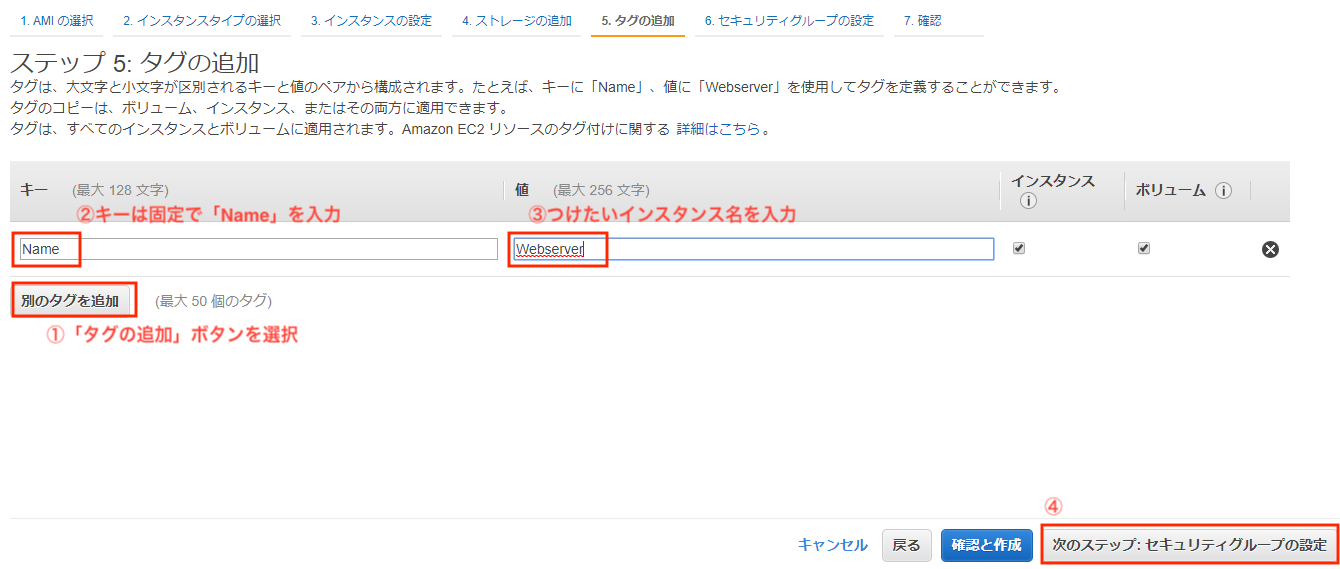
・タグ設定
「タグの追加」からインスタンスに名前を付けます。
「キー」は固定で「Name」を、「値」が「Webserver」として入力します。
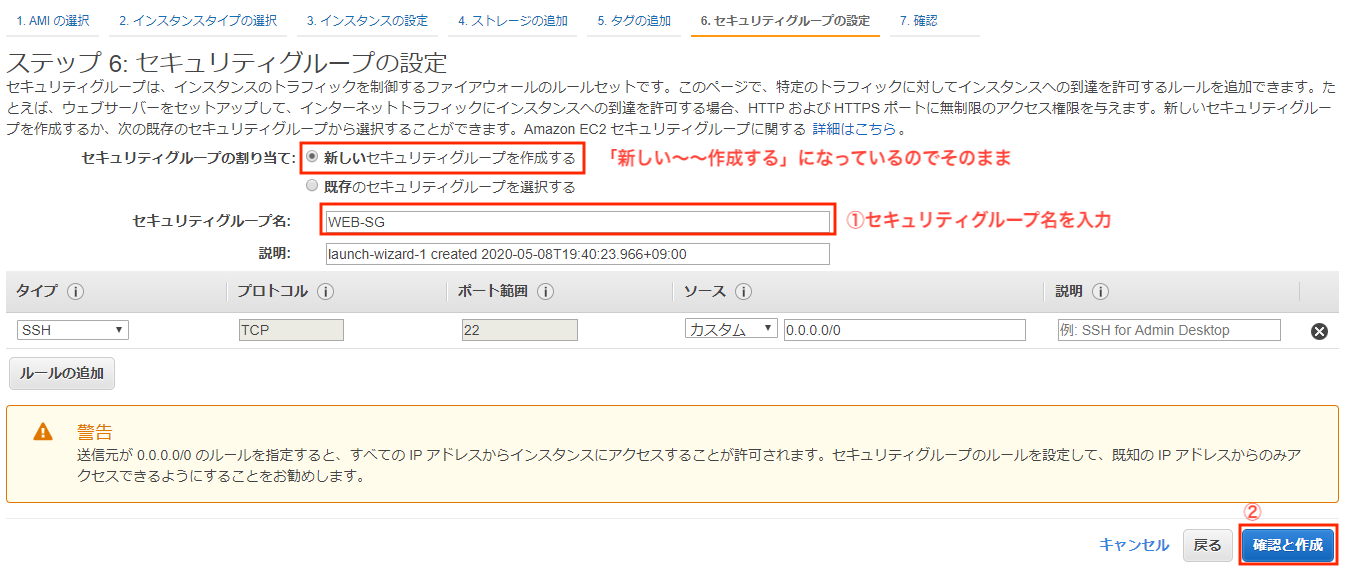
・セキュリティグループの作成
「セキュリティグループ名」は「WEB-SG」として、「確認と作成」を選択します。
セキュリティグループはファイアウォールです。
接続するIPアドレスの範囲制限をしたり、インスタンスに接続可能なポートの制限を行えます。
今回のようになんの設定を入れていない場合、22番ポートを使用するSSH通信は全て許可されてしまいます。
そのため「警告」が表示されますが、一旦無視します。
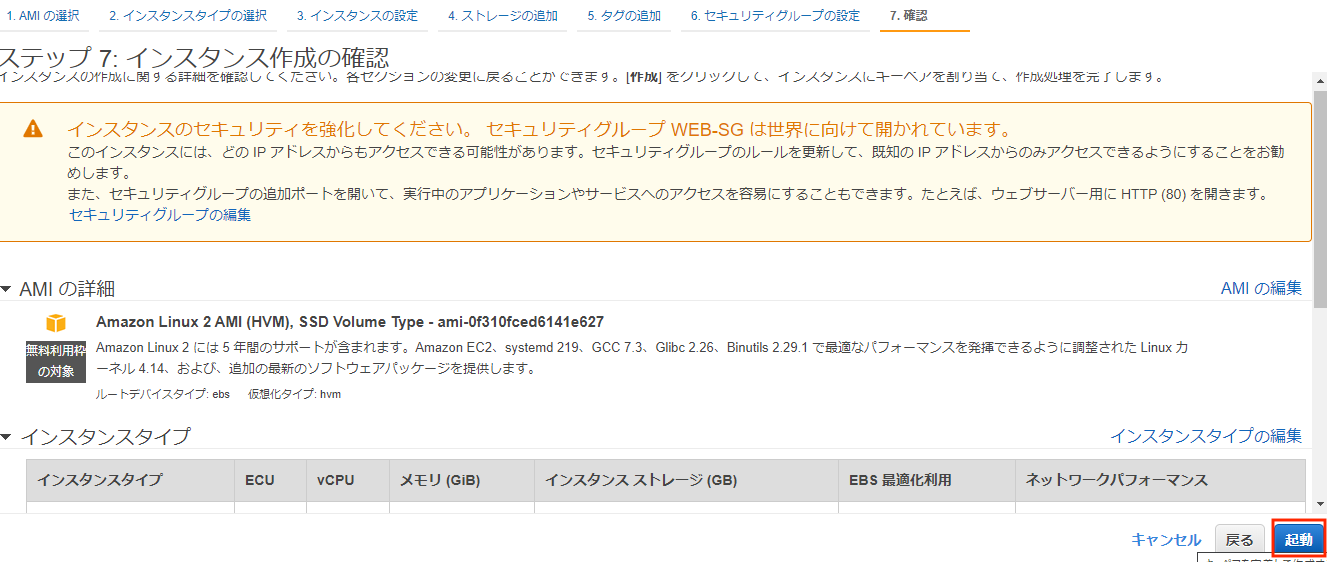
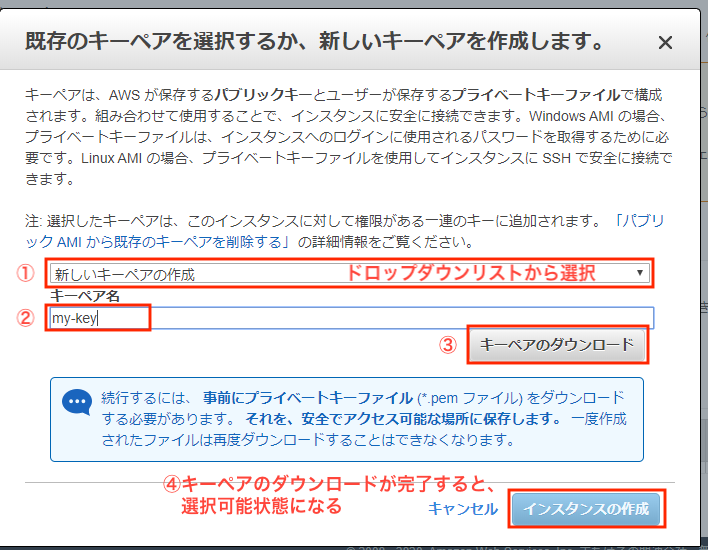
・キーペアの作成とダウンロード
ひととおり作成が完了したら、インスタンスを起動していきます。
しばらくすると、キーペアを作成せよ、とメッセージが表示されます。
キーペアはTeraTerm等でSSHログインするときに使用する暗号鍵です。(適当)
Amazon EC2 キーペアと Linux インスタンス
注意:ダウンロードしたキーペアをなくすと再発行不可でインスタンスにログインできなくなります
「インスタンスの表示」から作成したインスタンスが、「running」で「2/2チェック」に合格していることを確認し完了です。
以上となります、お付き合いいただきましてありがとうございました。
次回は、作成したインスタンスにApacheをインストールし疎通確認の予定です。


- 投稿日:2020-05-19T20:51:01+09:00
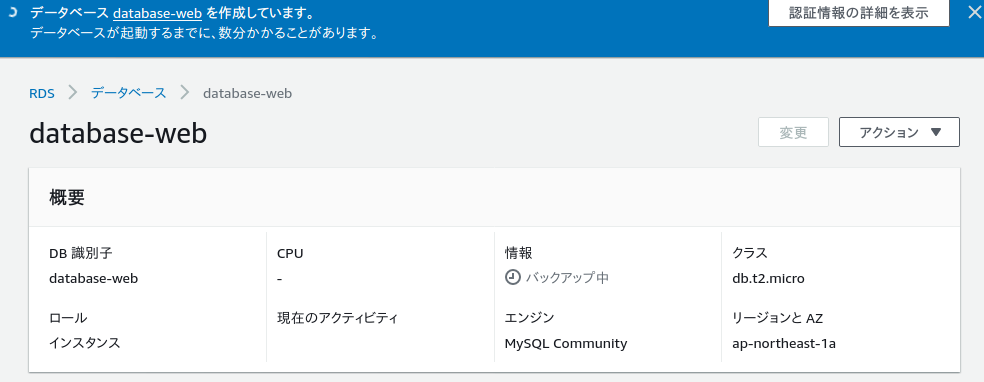
AWSでDBサーバーを作成する
前回はWebサーバーを作成したので、次はDBサーバーを作成する。
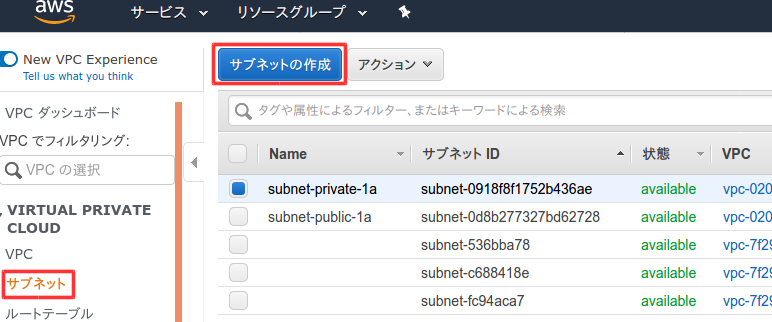
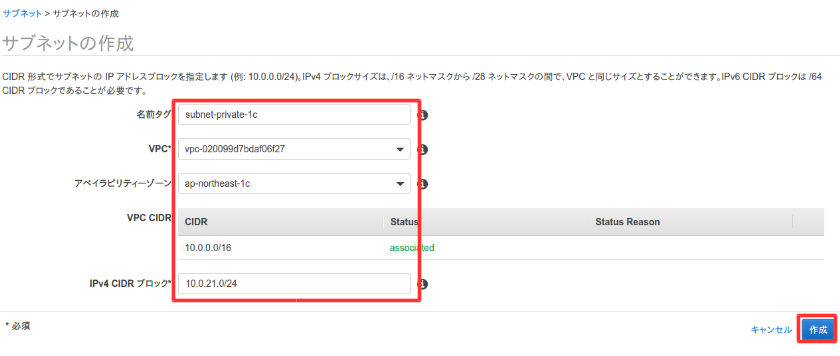
プライベートサブネット作成
レプリケーションを実現するために、VPCでネットワークを作成した時とは別にプライベートサブネットを作成する。
VPCのダッシュボードを開いて、左側のメニューのサブネットを選択してサブネット作成を選択。
以下のように入力して作成。VPCは自分で作成したVPCを選択。
作成が完了したので閉じる。
RDSの作成
ここからRDSを作成していく。RDSは、簡単に説明すると、AWSが最適な設定をしたDBサーバーである。さらにバージョンアップなどの運用もやってくれるので、EC2に一からインストールして環境構築するより遥かに楽!
RDSは、自由な設定変更はできないようになっている。設定変更したい時は、いくつかの設定グループを編集する必要がある。そのグループを最初に作成する。セキュリティグループ作成
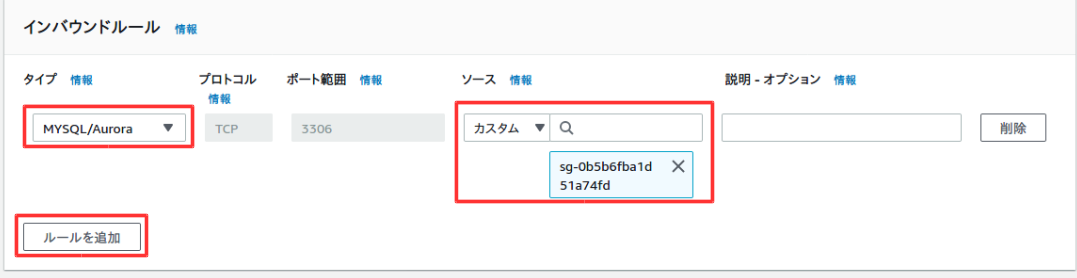
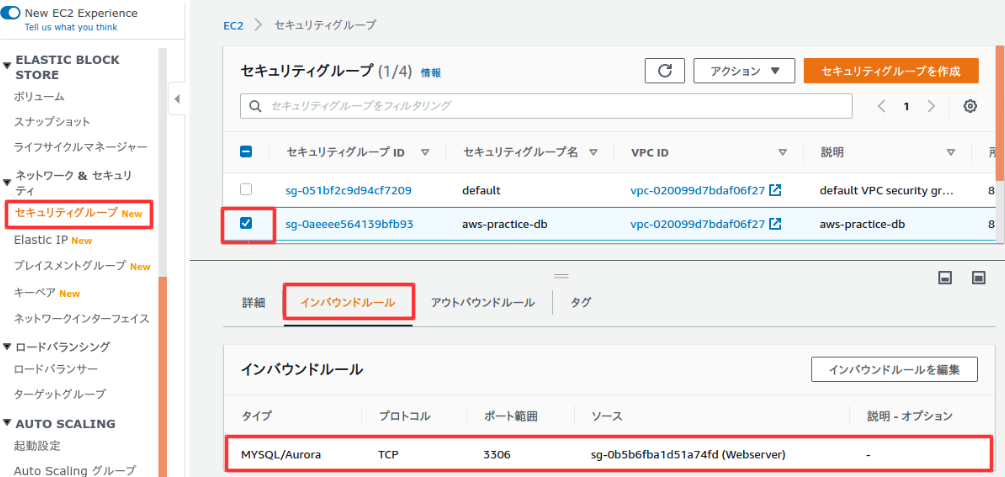
ここでは、WebサーバーからのみDBサーバーにアクセスできるようにセキュリティグループを作成する。
EC2のダッシュボードを開いて、左側のメニューのセキュリティグループを選択して、セキュリティグループを作成を選択。
以下のように入力。VPCは自分が作成したVPC。
下にスクロールして、インバウンドルールを追加する。カスタムには自分で追加したセキュリティグループを入力する
一番下までスクロールして、セキュリティグループを作成を選択。
作成が完了。
セキュリティグループメニューに戻り、設定できたことを確認。
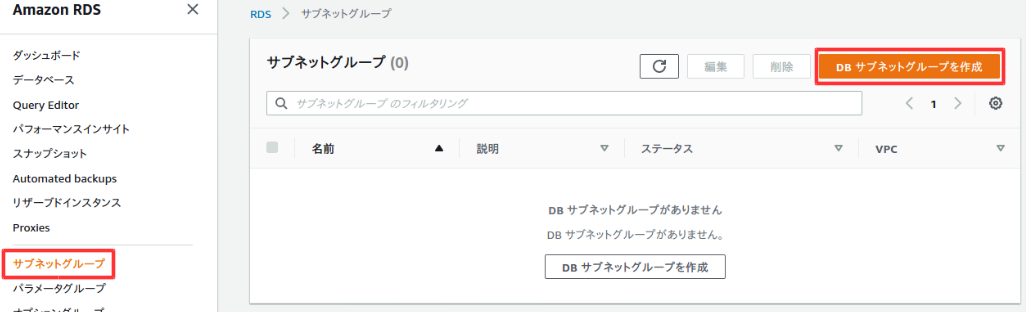
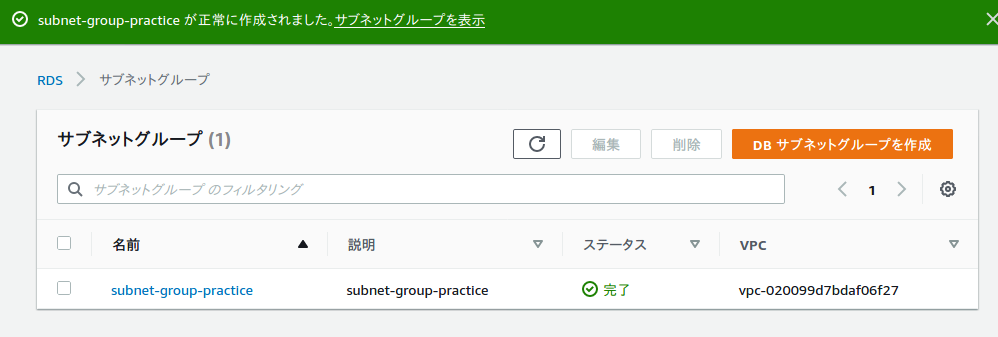
DBサブネットグループ作成
ここでレプリケーションするサブネットグループを作成する。
RDSのダッシュボードを開き、左側のメニューのサブネットグループを選択し、DBサブネットグループを作成を選択。
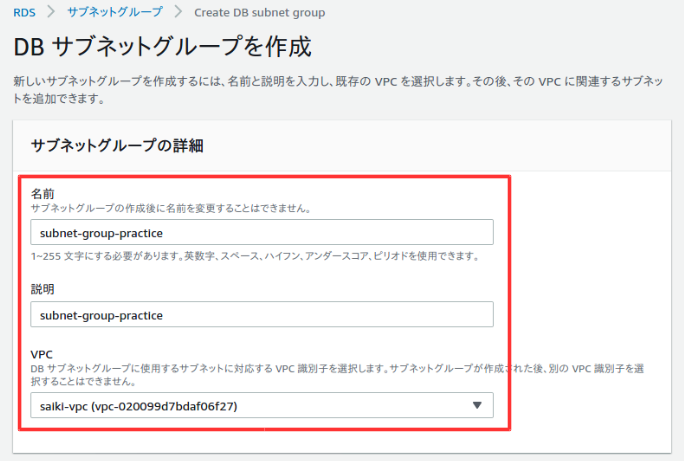
以下のように入力。
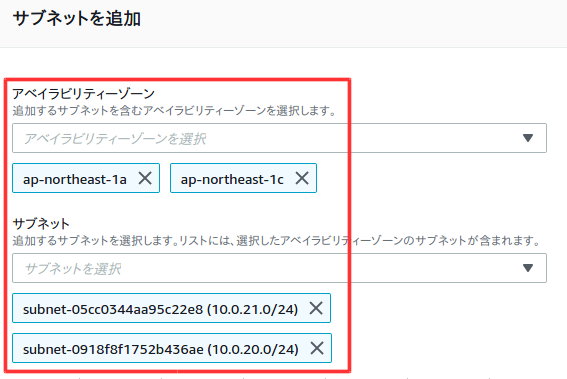
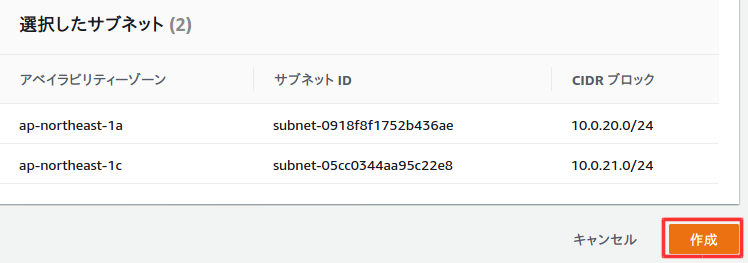
プライベートサブネット作成時に追加したアベイラビリティゾーンとサブネットを選択。
作成を選択。
作成が完了。
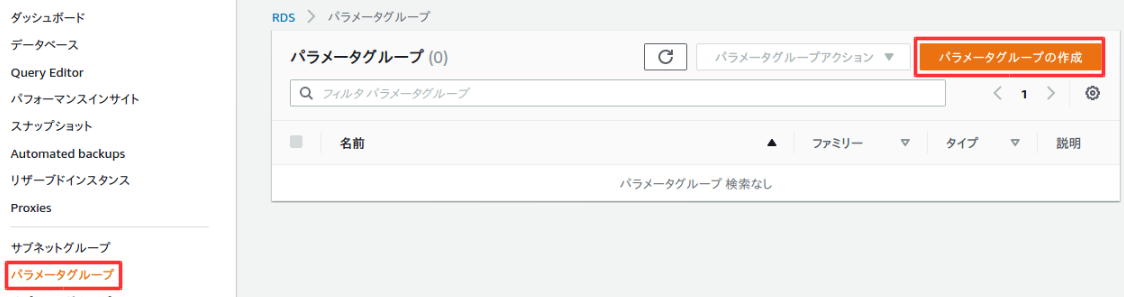
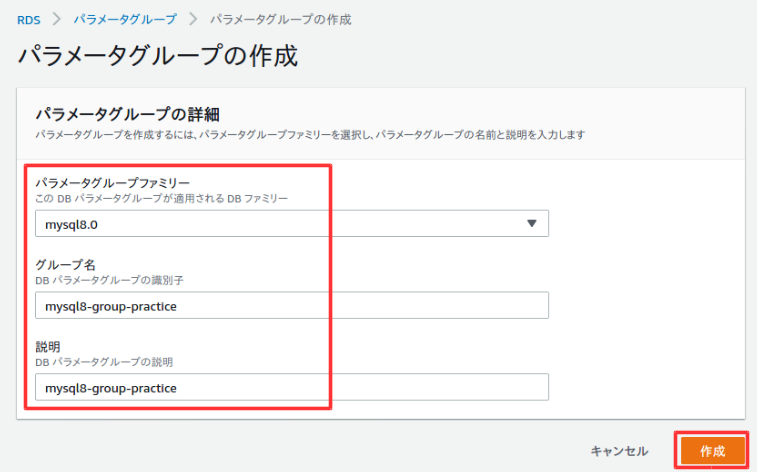
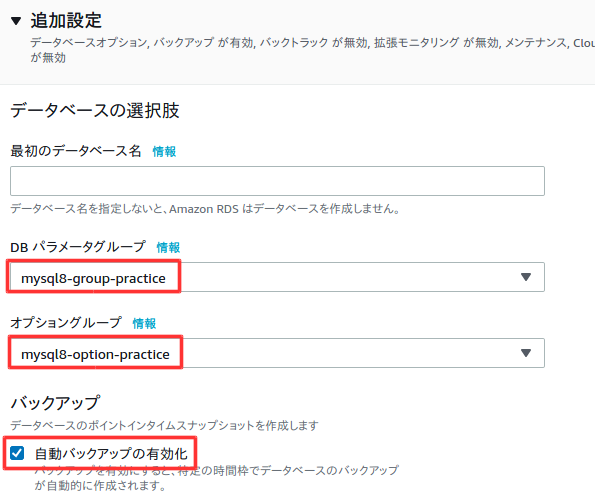
パラメータグループ作成
パラメータグループはいくつか設定を入れることができる。
左側のメニューからパラメータを選択して、パラメータグループの作成を選択。
以下のように入力して、作成を選択。
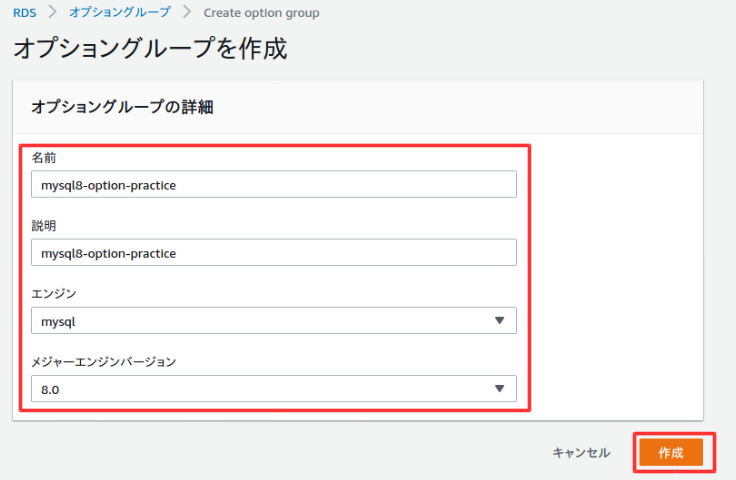
作成が完了したら、以下のようにグループに対して設定を入れることができるが、今回は割愛する。オプショングループ作成
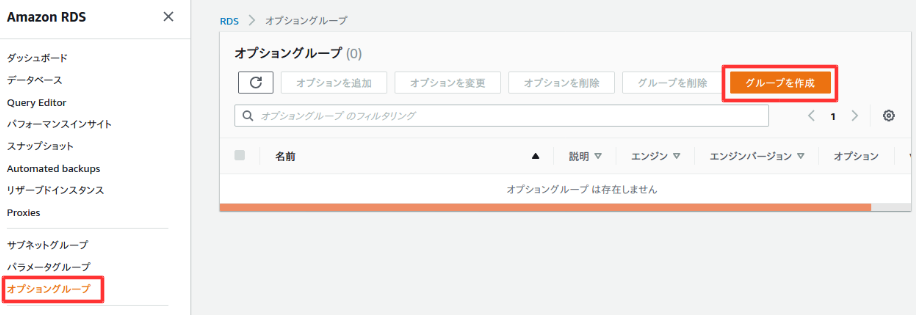
オプショングループはDBの機能を追加できる。
左側のメニューからオプショングループを選択して、グループを作成を選択。
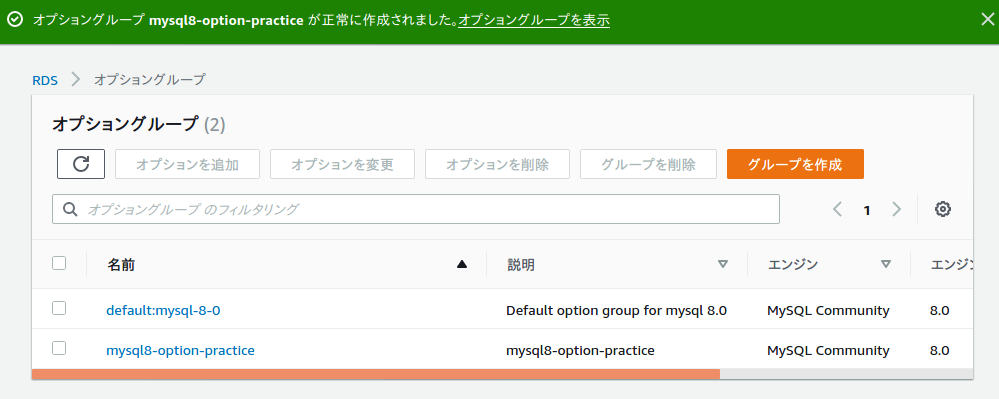
以下のよう入力して作成を選択。
作成が完了。
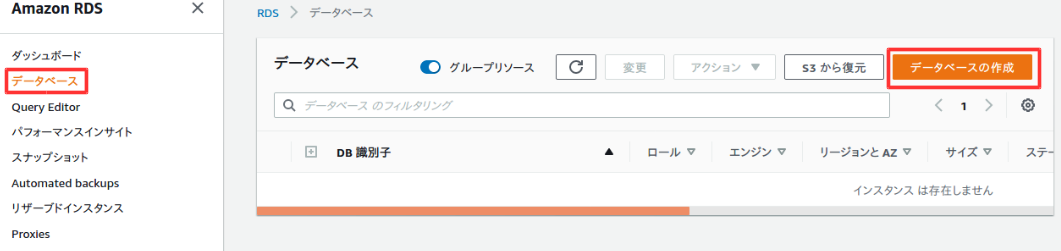
データベース作成
ここからDBを作成する。
左側のメニューからデータベースを選択して、データベースの作成を選択。
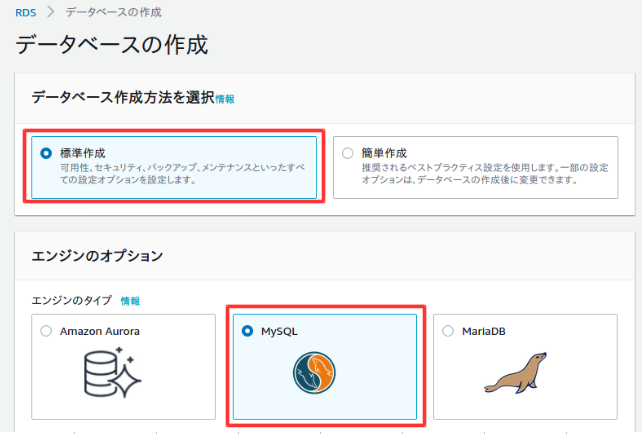
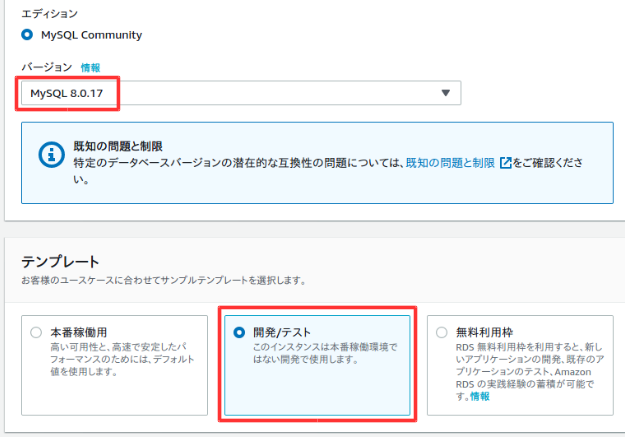
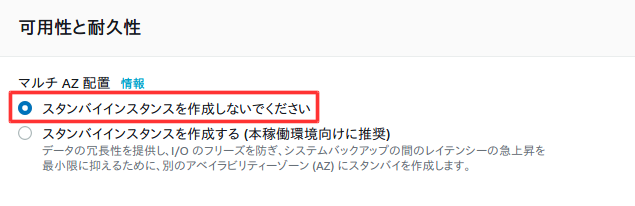
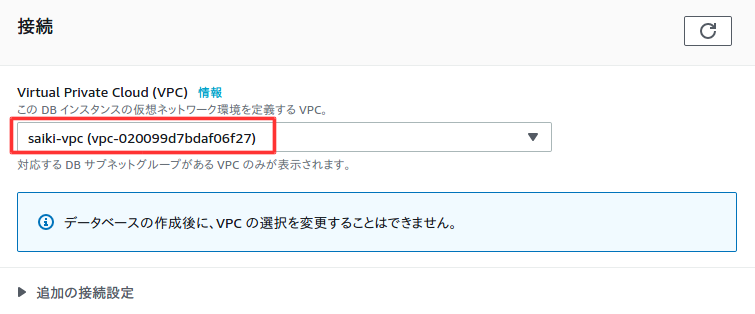
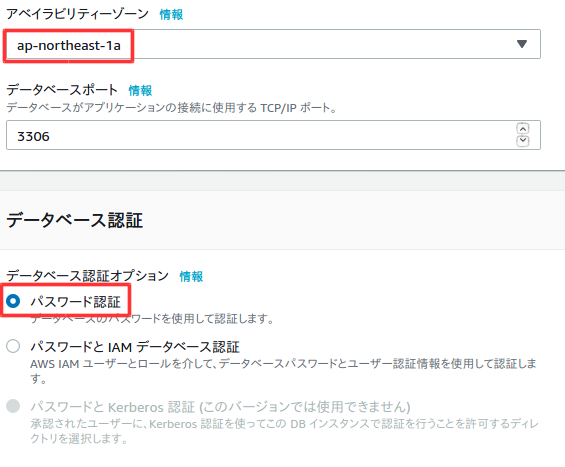
以下のように設定する。
多少料金がかかるが、設定に制限が出ないようにするためにテンプレートは開発/テストを選択した。
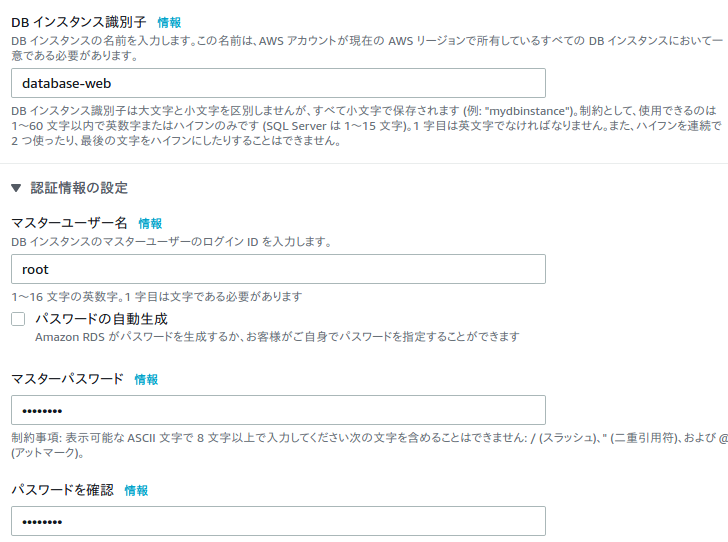
以下は任意の設定。
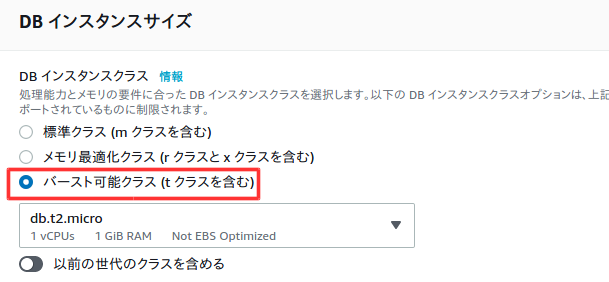
料金を抑えるため以下の設定。
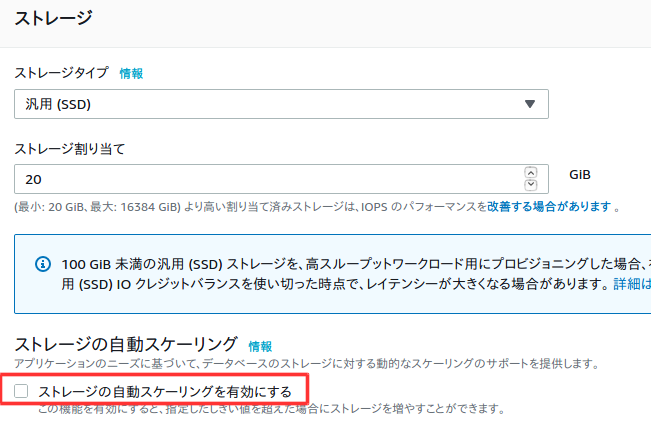
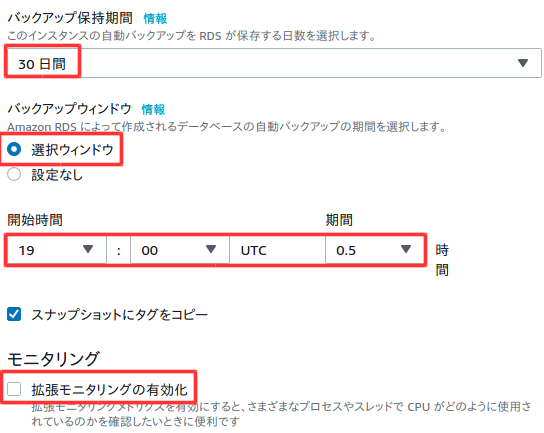
料金を抑えるためチェックを外す。
バックアップ時間は時差が9時間ほどあるので、朝4時にバックアップしたい時は9時間前の19時に設定する。
料金を確認後、データベースの作成を選択。
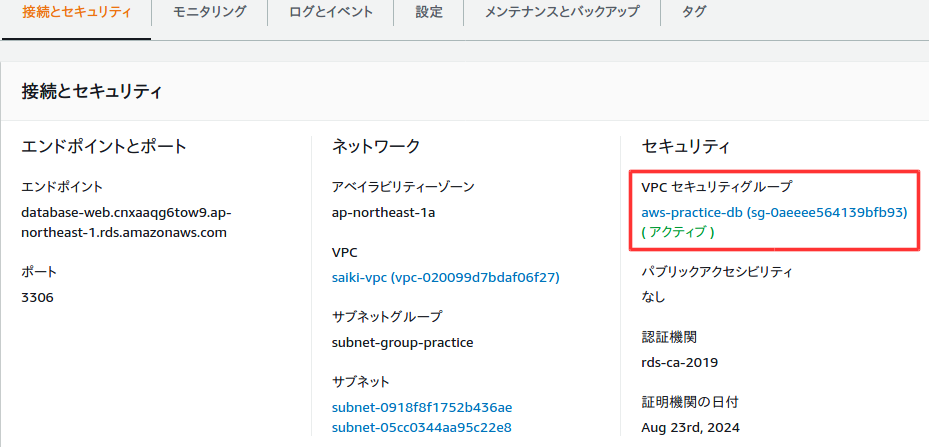
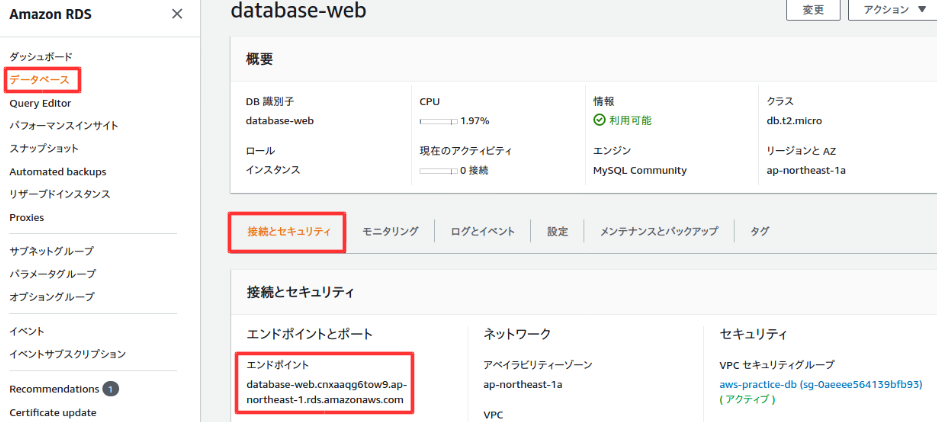
作成後、設定の確認をする。特にVPCセキュリティグループが間違っていると、前回作成したWebサーバーで接続できなくなるので注意。変更ボタンで変更可能。
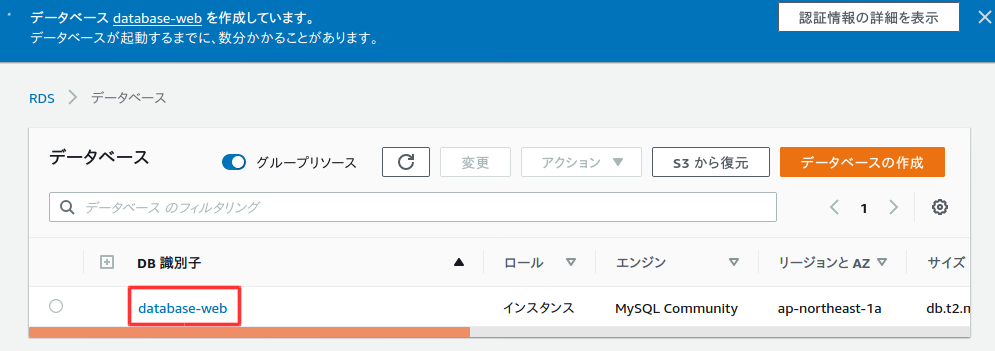
これでRDSの作成完了!!Webサーバーから接続する
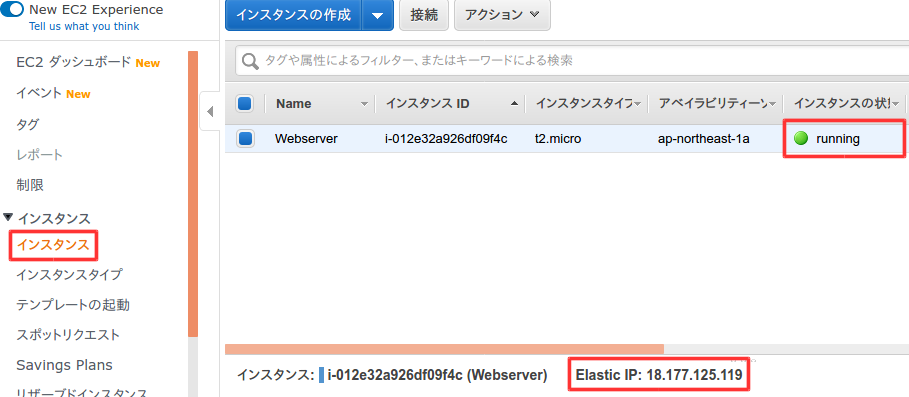
EC2を起動して、SSHで接続する。
UbuntuでSSH接続$ sudo ssh -i /(ファイルパス)/aws-key-webserver.pem ec2-user@18.177.125.119 [sudo] r-saiki のパスワード: Last login: Sat May 16 08:21:27 2020 from fs96f9c6f1.tkyc217.ap.nuro.jp __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 3 package(s) needed for security, out of 8 available Run "sudo yum update" to apply all updates. [ec2-user@ip-10-0-10-10 ~]$mysqlクライアントをインストールし、RDSに接続する。mysqlコマンドのオプションhには、RDSのデータベース設定画面のエンドポイントを値として渡す。
接続成功!!
[ec2-user@ip-10-0-10-10 ~]$ sudo yum -y install mysql [ec2-user@ip-10-0-10-10 ~]$ mysql -h database-web.cnxaaqg6tow9.ap-northeast-1.rds.amazonaws.com -u root -p Enter password: Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 17 Server version: 8.0.17 Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>終わりに
WebサーバーとDBサーバーをAWSで一通り作り終える事ができた^^
次はWordPressの環境構築をする!






- 投稿日:2020-05-19T20:29:20+09:00
Docker / ECR / ECS コンテナ入門まとめ②
前後編
参考文献
- 【AWS】初めてのECR
- イメージのプッシュ
- AWS CLI の設定
- 既存のRailsアプリにDockerを導入する手順
- 既存のrailsプロジェクトをDockerで開発する手順
- Debianのdockerイメージでmysql-clientが無くてハマった人へ
- Dockerfile 記述のベストプラクティス
- database.yml の管理方法いろいろ
1. Dockerfile
◆ mysql-client問題
- Debian10 "buster"(Ubuntuの母らしい)では、"mysql-client"は存在しない
- "default-mysql-client"パッケージを使用する必要がある
DockerfileFROM ruby:2.6.5 ※GemfileのRubyバージョン要確認 RUN apt-get update && apt-get install -y nodejs --no-install-recommends && rm -rf /var/lib/apt/lists/* RUN apt-get update && apt-get install -y default-mysql-client --no-install-recommends && rm -rf /var/lib/apt/lists/* RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN mkdir /app ※アプリケーション名 WORKDIR /app ADD Gemfile /app/Gemfile ADD Gemfile.lock /app/Gemfile.lock RUN bundle install ADD . /app2. docker-compose.yml
◆ ビルドコンテキストについて
- docker build実行時の"カレントディレクトリ"を指定する
- デフォルトでは、Dockerfileが"カレントディレクトリ"と認識される
docker-compose.ymlversion: '2' services: db: image: mysql:latest environment: MYSQL_DATABASE: データベース名 MYSQL_ROOT_PASSWORD: XXXXXXX MYSQL_USER: ユーザ名 MYSQL_PASSWORD: XXXXXXX ports: - "3306:3306" web: build: context: . dockerfile: Dockerfile command: bundle exec rails s -p 3000 -b '0.0.0.0' tty: true stdin_open: true depends_on: - db ports: - "3000:3000" volumes: - .:/app ※アプリケーション名3. database.yml
◆ 環境変数について
password: <%= ENV['DOCKER_DATABASE_PASSWORD'] %>$ export DOCKER_DATABASE_PASSWORD=password ※パスワードdatabase.yml
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: 5 host: db development: <<: *default username: ユーザ名 password: XXXXXXX database: データベース名 production: <<: *default database: データベース名 username: ユーザ名 password: <%= ENV['DOCKER_DATABASE_PASSWORD'] %>4. ECRプッシュ作業
AWS CLI設定 ※AWSマネジメントコンソール"マイセキュリティ資格情報"参照
$ aws configure --profile ecr AWS Access Key ID [None]: *********************** AWS Secret Access Key [None]: ************************* Default region name [None]: ap-northeast-1 Default output format [None]: jsonECRログインコマンド
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ***.ecr.ap-northeast-1.amazonaws.comイメージ作成
$ docker build -t 【イメージ名】 .タグ付け
$ docker tag イメージ名:タグ名 ***.dkr.ecr.ap-northeast-1.amazonaws.com/イメージ名:タグ名プッシュコマンド
$ docker push ***.dkr.ecr.ap-northeast-1.amazonaws.com/イメージ名:タグ名
- 投稿日:2020-05-19T20:20:01+09:00
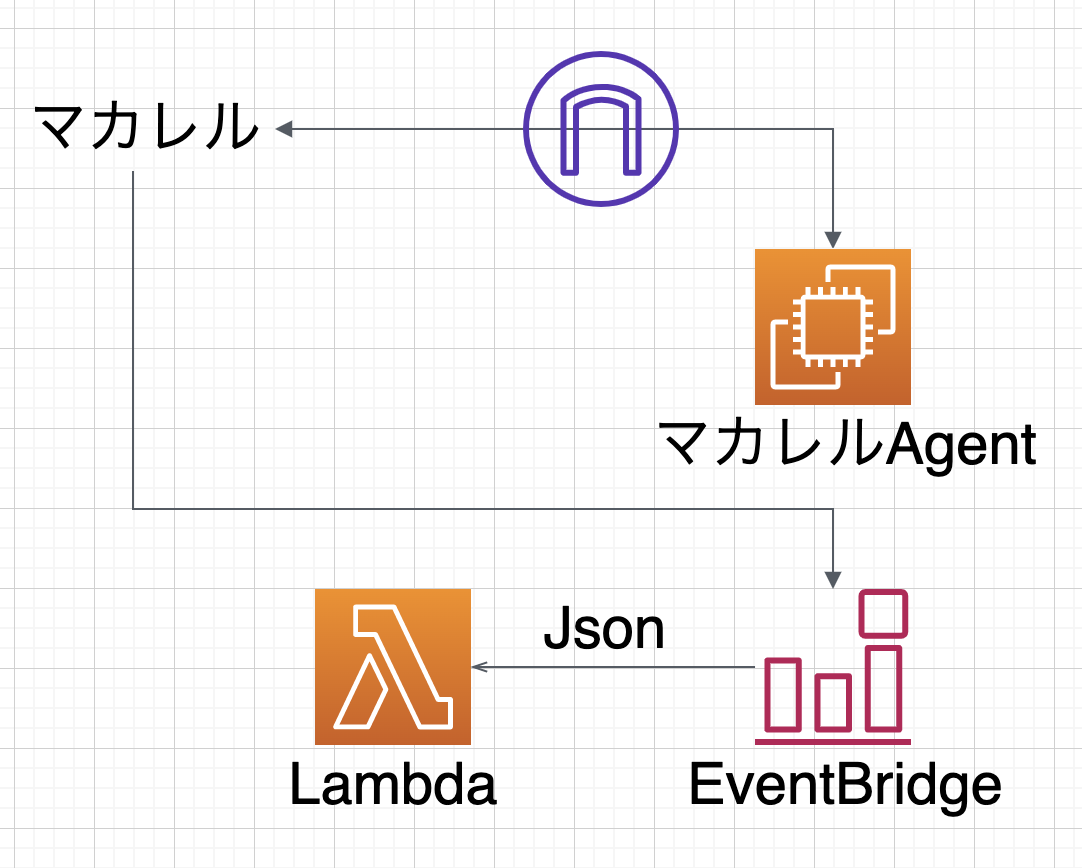
EventBridgeとマカレルをつないでJSON受け取ってみた
はじめに
ちゃんと連携できるかやってみました。
構成図
やったこと
以下の記事に沿って全て行いました。
[アップデート] MackerelからAmazon EventBridgeへの連係ができるようになりました
https://dev.classmethod.jp/articles/mackerel-eventbridge/#toc-2結論
Jsonの項目は以下のものが送られるそうです。
https://mackerel.io/ja/docs/entry/howto/alerts/eventbridge
- 投稿日:2020-05-19T19:52:27+09:00
AWS WAFv2で条件付きrate-based ruleを設定したら凡ミスで詰まった話
前置き
「特定のURIパスだけにRate limitかけるAWS WAFのルール作れる?」
WAFv2で簡単にできた...はずがなんか上手く結果が出ず、しかし結局どうにかなったのでメモ。関連リソース
AWS WAFv2
https://docs.aws.amazon.com/waf/latest/APIReference/Welcome.html#Welcome_AWS_WAFV2
今回WAF関連の操作は全てAWSコンソール上で実施。その他
WAFの先にあるCloudFrontやリクエストテスト用のPCについては本題ではないため割愛...
設定ルール
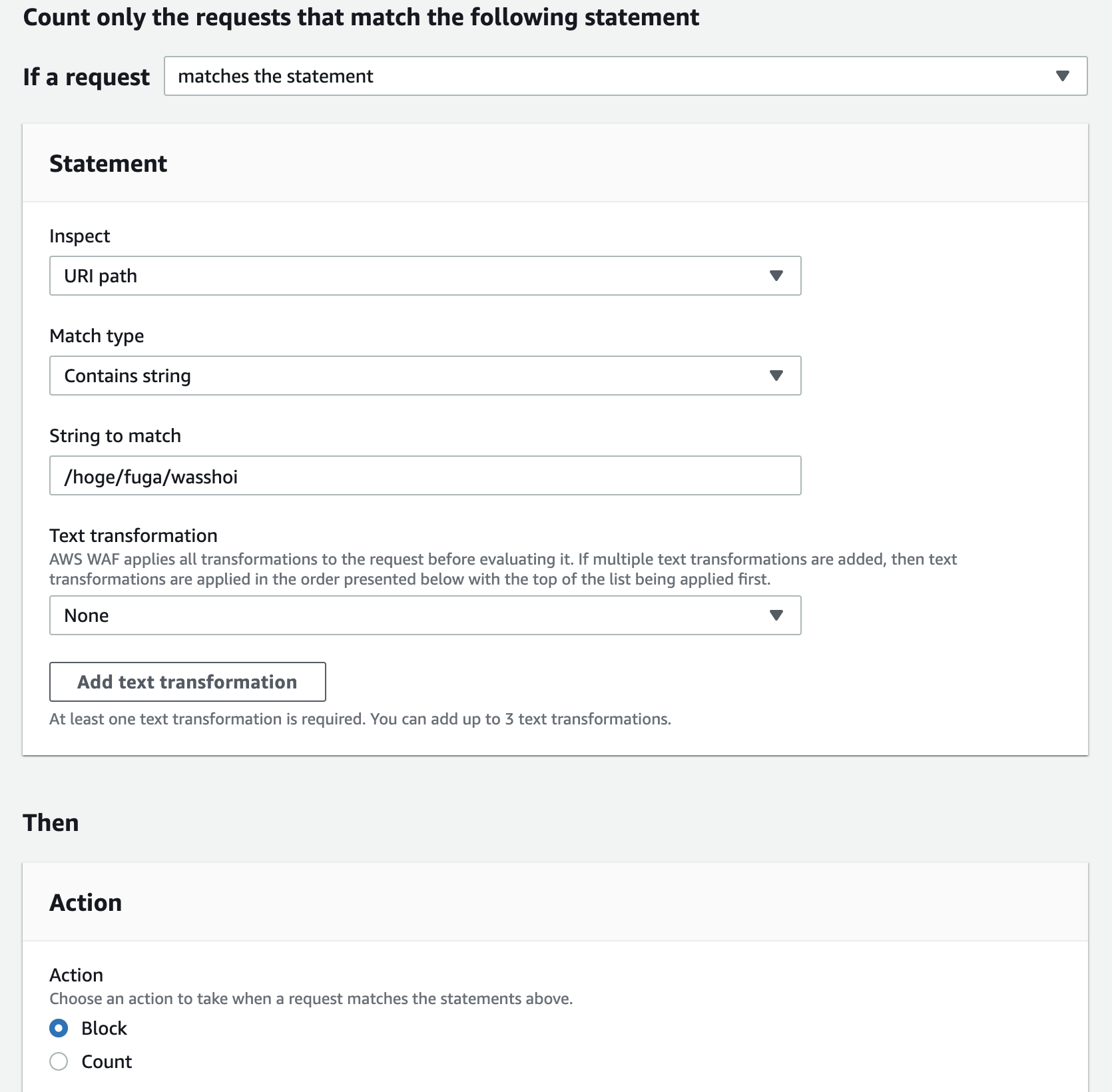
json
GUIで設定してもjson出力をすぐ確認できるのいいですね。
{ "Name": "wasshoi-path-rate", "Priority": 0, "Action": { "Block": {} }, "VisibilityConfig": { "SampledRequestsEnabled": true, "CloudWatchMetricsEnabled": true, "MetricName": "wasshoi-path-rate" }, "Statement": { "RateBasedStatement": { "Limit": 100, "AggregateKeyType": "IP", "ScopeDownStatement": { "ByteMatchStatement": { "FieldToMatch": { "UriPath": {} }, "PositionalConstraint": "CONTAINS", "SearchString": "/hoge/fuga/wasshoi", "TextTransformations": [ { "Type": "NONE", "Priority": 0 } ] } } } } }GUI
こちらも平易な英語で細かく注釈がついた新設設計。
- Type: Rate-based rule
- Rate limitの値: 今回は検証目的のため最低値の100)
- 注釈に記載の通り、単一IPからのリクエスト数について5分間で集計して、この値を超える数のリクエストが来た場合にルール適用となる。
- 「Only consider requests that match the criteria in a rule statement」を選択して、rate limitを適用する条件を指定
- URIパスを指定
- ActionはBlock
- (本番に入れるときはCountで試してからじゃないと事故った時エグい)
こんなルールをPriority 0(最優先)で入れて保存。
画面見ながらポチポチですげーかんたんだな!ワッハッハ!とイキりつつ検証を始めたんですが、そっからが地味に長かった。
※ネタバレ:設定はこれで合ってました。
その後の顛末
検証1: 「まずはRate limit部分だけで確認してみよ」→無事成功
先ほどの設定の、URIパス部分を削った設定です。consider all requestsを選択した、ただのRate Limit。
{ "Name": "wasshoi-path-rate", "Priority": 0, "Action": { "Block": {} }, "VisibilityConfig": { "SampledRequestsEnabled": true, "CloudWatchMetricsEnabled": true, "MetricName": "wasshoi-path-rate" }, "Statement": { "RateBasedStatement": { "Limit": 100, "AggregateKeyType": "IP" } } }これの適用後、外部からURIパス
/hoge/fuga/wasshoiを連続120回curlで叩くスクリプトを実行。
→ 結果:成功。101回目のリクエストからしっかりBlockされ、レスポンスコード403が返ってくるように。検証2: 「本番と同等の設定で確認」→上手くいかない。
検証1が成功したので、引き続きそのルールを編集し先述の「設定ルール」の通りに更新。
完了後に検証1と同じスクリプトを実行。
→ 結果:失敗。curlの結果は全て素通りしレスポンスコード200、WAF側はルールに引っかかった様子無しあれ???
検証3: 「何か勘違いしていたかもしれないので設定を微調整してみる」→当然上手くいかない。
パスに
*を入れ込んでみたりContains String部分を別な条件にしてみたり。様々な設定で都度スクリプトを流してみたが結果は全て検証2と同じ。だめだなんもわからん。結論: 一晩寝かせたら上手くいきました。
正確にはAWSサポートへの技術質問を経ての解決ですが、結論としては以下。
- WAFのルールの反映にはタイムラグがある
- 送信元のIPアドレスをブロックするまでにもタイムラグがある
検証1だと即時反映即時Blockだったよな...とは思いつつ、検証2以降でも適用後即スクリプト叩きをやっていたのは事実。
素直にタイムラグを意識して再度検証してみた。→ Block成功!
改めてルールを設定し、今度は検証スクリプトを1分〜20分間隔で繰り返し実行(別作業の片手間で雑にやっていたので間隔バラバラです)。
すると、ルール設定から約2時間ほど経った頃、丸ごと120回分のリクエストがBlockされる挙動を確認。WAFの記録上もしっかり計上されていました。さらにしばらく待ち、時間経過でBlockが解除されることも確認。めでたしめでたし。
まとめ
- WAFv2のルール設定は反映に時間がかかる場合がある
- 「検証用に一部だけ設定したものを使おう」が罠
- 厳密には別の物で調べている事になり、(今回のように)検証として意味をなさない
- 果報は寝て待て(諸説あります)
おわり。
おそらく余りにお間抜けな原因でハマってたからだと思うんですが、ネットでいくら調べても今回の事象に行き当たらずそこそこ辛かった。

- 投稿日:2020-05-19T18:54:52+09:00
Amazon CloudWatch とは
Amazon CloudWatch とは
Amazon CloudWatch は、Amazon Web Services (AWS) リソースと、AWS でリアルタイムに実行されるアプリケーションを監視
アラームイベントと EventBridge
Amazon EventBridge とは?
Amazon EventBridge は、アプリケーションをさまざまなソースからのデータと簡単に接続できるようにするサーバーレスイベントバスサービスです。EventBridge は、お客様独自のアプリケーションや SaaS (Software-as-a-Service) アプリケーション、AWS サービスからのリアルタイムデータのストリームを配信し、このデータを AWS Lambda などのターゲットにルーティングします。ルーティングルールを設定することで、データの送信先を決定し、すべてのデータソースにリアルタイムで対応するアプリケーションアーキテクチャを構築することができます。EventBridge は、疎結合で分散されたイベント駆動型アーキテクチャを構築できるようにします。
参考文献
- 投稿日:2020-05-19T18:50:56+09:00
Rails AWSデプロイ エラー遭遇まとめ
参考文献
- EC2サーバにRuby環境構築
- (デプロイ編①)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
- AWS構築 格闘日記-2 忘備録
- AWSのEC2で行うAmazon Linux2(MySQL5.7)環境構築
- gem install rmagickでchecking for Magick-config... noがでる解決方法
- Amazon LinuxでRMagick 3.0.0 がインストールできない
- EC2にyumでNginxをインストールしようとしたらできなかった話
- AWS+Nginx+Unicornを利用してRailsアプリをデプロイしてみた。〜その1〜
Rubyインストール編
rbenv インストールエラー
$ rbenv install -v 2.6.5 configure: error: in `/tmp/ruby-build.202005191817.10626/ruby-2.6.5': configure: error: no acceptable C compiler found in $PATH解決コマンド
$ sudo yum install gcc openssl-devel $ sudo yum install -y gcc-6 bzip2 openssl-devel libyaml-devel libffi-devel readline-devel zlib-devel gdbm-devel ncurses-devel $ sudo yum erase ruby.noarch $ sudo yum install gccMySQL編
root初期パスワード在り処
$ cat /var/log/mysqld.log | grep password A temporary password is generated for root@localhost: ************初期パスワードログイン
$ mysql_secure_installation Enter password for user root: ************ New password: ************ Re-enter new password: ***********RMgick編
RMagickインストールエラー
$ bundle install --path vendor/bundle An error occurred while installing rmagick (3.0.0), and Bundler cannot continue. Make sure that `gem install rmagick -v '3.0.0' --source 'https://rubygems.org/'`解決コマンド
$ sudo yum -y install ImageMagick $ sudo yum -y install ImageMagick-develNginx編
Nginxインストールエラー
$ sudo yum install nginx 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd パッケージ nginx は利用できません。 エラー: 何もしません解決コマンド
$ sudo amazon-linux-extras install nginx1.12 or $ sudo yum install http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm -y $ sudo yum install nginx -ynginx.conf設定後のpostメソッド対策
$ cd /var/lib $ sudo chmod -R 775 nginx
- 投稿日:2020-05-19T18:25:53+09:00
REDMINEをAWSのCloudFrontで配信しようとしてハマった話
はじめに
AWSのサービスを評価する目的で、社内サーバーで運用しているREDMINEをAWS上に持っていこうということになりました。ついでにALBやCloudFrontを使ってAWS WAFなんかの評価もできたらいいよねー、などと簡単に考えていたら、思わぬところでハマったので備忘録として残しておきます。
発生した現象 その1
EC2→ALB→CloudFrontの順番で実装。
インターネットから直接ALBを叩くと問題なく接続できることを確認後、CloudFront経由でのテスト開始。ログインID・PW入力し、「ログイン」ボタンを押したところ
422 Invalid form authenticity token.というエラーが出てREDMINEが使えません。確認と設定 その1
log/production.logを確認したところ、Can't verify CSRF token authenticityというエラーメッセージを発見。ググったところ、次のページを見つけました。stack overflow - AWS Cloudfront causing CSRF Token Mismatch Exception
上記ページの回答から Fowarding cookies が問題だということで、CloudFront の Behaviors タブ、Foward Cookies の Whitelist に
_redmine_sessionを書き込んだところ、うまく動くようになりました。(Foward Cookies は「None」から「Whitelist」に変更)発生した現象 その2
チケットの添付ファイルをアップロードしたところ、ファイルが消えてなくなってしまう現象が発生。さらに、プロジェクトの「ファイル」タブからアップロードすると「ファイルは不正な値です」というメッセージが表示されてしまいます。
今度もALB経由だと正常にアップロードできたので、CloudFrontの問題だと切り分けができました。確認と設定 その2
log/production.logを確認するも、エラーメッセージは出ていません。
Apache側に何か出ていないかと思い、httpd/access_logを見たところ、ALB経由のときのログと比較して明らかに文字列が短い。比較すると、Query Stringがすっぽり抜けていることが分かりました。対応として、先ほどと同じくCloudFrontのBehaviors タブ、Query String Forwarding and Cachingの値を
Fowrward all, cache based on allに変更したところ、正常にアップロードできるようになりました。おわりに
エラーログの確認は基本中の基本ですね。
今回はログをすぐに確認せず、画面に表示されたメッセージだけで調査を開始したので原因にたどり着くまで時間がかかってしまいました。大反省です。ALB経由だと正常動作していたので、ログベースで比較できたのは良かったと思います。
CloudFrontは調査に時間がかかるため、こんな情報でも役に立つかもしれないと考えアップしておきます。お付き合いいただきありがとうございました。
- 投稿日:2020-05-19T17:57:13+09:00
boto3:retryのアルゴリズム実装memo
botocore/botocore/retryhandler.pyboto3の指数バックオフ + jitterは以下の式
base * growth_factor ^ (attempts - 1)
- baseはrand()なので、0-1の間。リトライ実行ごとにシャッフルされる
- DynamoDBだけbaseが0.05固定
botocore/botocore/data/_retry.jsonより- growth_factorは初期値2
リトライ初回はattempts=1よりbaseとなり、一瞬待つことになる。
rand()が0に近いとほぼ待たずにリトライすることがある。
- 投稿日:2020-05-19T17:11:37+09:00
【Go】AWSのサービス毎の利用料金を取得する
はじめに
これまで、「AWSの利用料金をChatworkに通知してくれるバッチをGoで作った」や「Goでslackに通知するバッチを作った【新Webhook】」ではAWSの合計利用料金を通知してきましたが、サービス毎の明細が欲しかったので、サービス毎の利用料金もいっしょに通知してみることにしました!
通知したいこと
- 昨日の合計利用料金
- 昨日のサービス毎の利用料金
利用料金の取得
Lambda関数の作成
定期的にSlackやChatworkに通知することを想定して、Lambda関数を作成していきます。
IAMポリシー
API「GetCostAndUsage」を実行できる権限を付与します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "ce:GetCostAndUsage", "Resource": "*" } ] }このポリシーをアタッチしたIAMロールを作成し、Lambdaに紐づけてください。
ソースコード
本コードはサービス毎の利用料金の取得方法にフォーカスしています。合計料金の取得方法は、こちらを参考にしてください。
package main import ( "fmt" "log" "time" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/costexplorer" "github.com/aws/aws-sdk-go/service/costexplorer/costexploreriface" ) // コストの取得 func GetCost(svc costexploreriface.CostExplorerAPI) (result *costexplorer.GetCostAndUsageOutput) { // Granularity granularity := aws.String("DAILY") // Metrics metric := "UnblendedCost" metrics := []*string{&metric} // TimePeriod // 現在時刻の取得 jst, _ := time.LoadLocation("Asia/Tokyo") now := time.Now().UTC().In(jst) dayBefore := now.AddDate(0, 0, -1) nowDate := now.Format("2006-01-02") dateBefore := dayBefore.Format("2006-01-02") // 昨日から今日まで timePeriod := costexplorer.DateInterval{ Start: aws.String(dateBefore), End: aws.String(nowDate), } // GroupBy group := costexplorer.GroupDefinition{ Key: aws.String("SERVICE"), Type: aws.String("DIMENSION"), } groups := []*costexplorer.GroupDefinition{&group} // Inputの作成 input := costexplorer.GetCostAndUsageInput{} input.Granularity = granularity input.Metrics = metrics input.TimePeriod = &timePeriod input.GroupBy = groups // 処理実行 result, err := svc.GetCostAndUsage(&input) if err != nil { log.Println(err.Error()) } return result } /************************** 処理実行 **************************/ func run() error { log.Println("コスト取得バッチ 開始") log.Println("セッション作成") svc := costexplorer.New(session.Must(session.NewSession())) log.Println("コスト取得 実行") cost := GetCost(svc) log.Println("コスト取得 完了") fmt.Println(cost) log.Println("コスト取得バッチ 完了") return nil } /************************** メイン **************************/ func main() { lambda.Start(run) }実行結果
Lambda関数の実行ログから一部抜粋しています。
2020/05/06 03:59:54 コスト取得バッチ 開始 2020/05/06 03:59:54 セッション作成 2020/05/06 03:59:54 コスト取得 実行 2020/05/06 03:59:55 コスト取得 完了 { GroupDefinitions: [{ Key: "SERVICE", Type: "DIMENSION" }], ResultsByTime: [{ Estimated: true, Groups: [ { Keys: ["AWS Cost Explorer"], Metrics: { UnblendedCost: { Amount: "0.05", Unit: "USD" } } }, { Keys: ["AWS Lambda"], Metrics: { UnblendedCost: { Amount: "0.0000019028", Unit: "USD" } } }, ], TimePeriod: { End: "2020-05-06", Start: "2020-05-05" }, Total: { } }] } 2020/05/06 03:59:55 コスト取得バッチ 完了解説
合計利用料金を取得する際に利用したAPI「GetCostAndUsage」のInput要素は以下の3つでした。
- Granularity
- Metrics
- TimePeriod
今回、サービス毎の料金を取得するため、以下の要素を追加します。
- GroupBy
GroupByは指定した条件に沿ってグループ化することができます。条件を指定するために、KeyとTypeを設定します。
Keyは何を基準に判断するのか、Typeはどう分けるのかということを意味します。今回はサービス毎の利用料金を知りたいので下記のようにしました。Key: aws.String("SERVICE"), Type: aws.String("DIMENSION"),よって、SERVICE(サービス)のDIMENTION(種類)でグループ化するという意味になります。
その他サービス毎以外にも、タグ毎など様々な条件のグループでコストを取得することができます。
参考:AWS SDK for Go API Reference注意点
GroupByの要素を追加することで、Totalの値が取得できなくなります。(実行結果参照)
なので、今回のように合計料金とサービス毎の両方のコストを取得したい場合は、2度リクエスト投げる必要があります。ちなみに、AWSのサポートに問い合わせてみましたが、現状は1度のリクエストで両方のコストが取得できる方法は確認できておりませんとの返事が返ってきました。(2020/03/19時点)
おわりに
合計料金とサービス毎の料金を1度に取得できないので、2回APIをたたく必要がある、つまり、倍のコストがかかってしまうというところがありますので…利用料金とその明細が知りたい!!ってときには、サービス毎の利用料金を自分で合計してしまいましょう。
おまけ
ちなみに、自分で合計してみました。
func SumCost(cost *costexplorer.GetCostAndUsageOutput) (total string){ sum := 0.0 for _, data := range cost.ResultsByTime[0].Groups { amount, _ := strconv.ParseFloat(*data.Metrics["UnblendedCost"].Amount, 64) sum = sum + amount } total = fmt.Sprintf("%.10f", sum) return total }取得したコストは
String型なので、float64型にしてから足していきます。
これでサービス毎の利用料金を取得するだけで、合計料金も合わせて通知することができそうです!
- 投稿日:2020-05-19T16:49:15+09:00
GitHub ActionsでECSにデプロイ
やりたいこと
masterにpushしたらデプロイする
- アプリのビルド
- ビルドキャッシュしてほしい
- アプリのテスト
- 全てのブランチでテストしたい
- dockerのビルド
- デプロイ関連はmasterだけでいい
- ECRへpush
- ECSタスク定義の更新
- masterがデプロイされるようにさしかわってほしい
- ECSデプロイ!
ディレクトリ構成
repository ├── .github │ └── workflows │ └── build_and_deploy.yml ├── ops │ ├── ECS │ │ └── task-definition.json │ └── app │ ├── Dockerfile │ └── app.jar └── src大切な要素は3つです
/.github/workflows/build_and_deploy.yml
Github Actionsが参照するファイル
ファイル名はなんでもいいです/ops/ECS/task-definition.json
ECSタスク定義を更新する元になるTaskDefinitionを置いてます
通常のTaskDefinitionなので、省略します
ファイル名とフォルダはどこでもいいですsecretsの登録
Settings > Secretsから、AWSのアクセスキーなどを登録します
大切ですが、画面からポチポチするので省略します/.github/workflows/build_and_deploy.yml
全体像をのせながら、コメントで細かく注釈していきます
レファレンスはこちら、かなり頻繁に修正されています
https://help.github.com/ja/actions/reference/workflow-syntax-for-github-actions/.github/workflows/build_and_deploy.yml# nameはなんでもいいが、フロー名として一覧に出る name: build_and_deploy # 全てのブランチでpushされた時に起動する on: push: branches: - '**' jobs: # アプリのビルドとテストのjob、名前はなんでもいい app_build_and_test: # docker imageを指定するやり方と比べると、選択肢はほとんどないが、winやmacも選べる runs-on: ubuntu-latest # stepという区切りでひとつひとつ実行し、失敗した場合、残りのstepが全てスキップされる # 個別にスキップされないstepを作ることもできる steps: # actionsという仕組みをとにかく多用する # リポジトリチェックアウト # https://github.com/actions/checkout - uses: actions/checkout@v2 # javaの準備 # https://github.com/actions/setup-java - uses: actions/setup-java@v1 with: java-version: 11 # アプリビルドのキャッシュ # リストアしたいタイミングで書くが、キャッシュ作成は書く必要がなく、jobが成功で終わった際にキャッシュ作成される # https://help.github.com/ja/actions/configuring-and-managing-workflows/caching-dependencies-to-speed-up-workflows # https://github.com/actions/cache - uses: actions/cache@v1 with: path: ~/.gradle # ${{ ... }} はGithub Actionsの評価式 # 用意されたオブジェクトと関数を使えるだけで、できることは意外と少ない key: ${{ runner.os }}-gradle-${{ hashFiles('**/*.gradle') }} # アプリのビルド、テスト - name: app build run: ./gradlew build -x test - name: app test run: ./gradlew test # 作ったjarを別のjobに渡して、それを元にdockerのビルドをしたい # https://help.github.com/ja/actions/configuring-and-managing-workflows/persisting-workflow-data-using-artifacts # https://github.com/actions/upload-artifact - uses: actions/upload-artifact@v1 with: name: appjar path: ops/app/app.jar # dockerのビルドとECSデプロイのjob docker_build_and_deploy: # 他のjobをwaitさせることで、直列なフローを作る needs: app_build_and_test # dockerまわりの処理はmasterしか動かさない # 関数とかもちょっと使える # https://help.github.com/ja/actions/reference/context-and-expression-syntax-for-github-actions if: contains(github.ref, '/heads/master') runs-on: ubuntu-latest # 環境変数はstep別に書くことも、共通で書くこともできる env: DOCKER_BUILDKIT: 1 steps: # チェックアウト # https://github.com/actions/checkout - uses: actions/checkout@v2 # 別jobで作ったファイルをダウンロードする # https://github.com/actions/download-artifact - uses: actions/download-artifact@v1 with: name: appjar path: ops/app # awsの認証をする # https://github.com/aws-actions/configure-aws-credentials - uses: aws-actions/configure-aws-credentials@v1 with: # secretsはWEBのgithubのrepositoryのsettingsから登録 # ログ含め綺麗にマスクされる aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 # ECRログイン # https://github.com/aws-actions/amazon-ecr-login - uses: aws-actions/amazon-ecr-login@v1 # あとで結果を参照するのでidをつけておく id: login-ecr # dockerビルドとECRpush - name: docker build, ECR push # このstepだけで使える環境変数 env: # ECRログインstepの結果を使う ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} # secretsはWEBのgithubのrepositoryのsettingsから登録 ECR_REPOSITORY: ${{ secrets.ECR_REPOSITORY }} run: | # GITHUB_SHAなど、最初から使える環境変数もある docker build -t ${ECR_REGISTRY}/${ECR_REPOSITORY}:${GITHUB_SHA} ./ops/app/ docker push ${ECR_REGISTRY}/${ECR_REPOSITORY}:${GITHUB_SHA} # サンプルで書いてあってのでなんとなくログアウト... - name: ECR logout # alwaysを指定することで、どこかで失敗していてもこのstepに関しては動く if: always() # Github Actionsの評価式、実はrun内でも使える run: docker logout ${{ steps.login-ecr.outputs.registry }} # TaskDefinitionのimageとtagを差し替えした、新しいTaskDefinitionを作る # https://github.com/aws-actions/amazon-ecs-render-task-definition - uses: aws-actions/amazon-ecs-render-task-definition@v1 with: # 元になるTaskDefinitionファイルのパス task-definition: ./ops/ECS/task-definition.json # コンテナ名 container-name: ${{ secrets.ECS_CONTAINER_NAME }} # 新しいイメージ名とタグ image: ${{ steps.login-ecr.outputs.registry }}/${{ secrets.ECR_REPOSITORY }}:${{ github.sha }} # あとで参照するのでid id: render-web-container # ECSサービスの更新とデプロイ # https://github.com/aws-actions/amazon-ecs-deploy-task-definition - uses: aws-actions/amazon-ecs-deploy-task-definition@v1 with: # 新しく作ったTaskDefinitionファイルのパスを指定 task-definition: ${{ steps.render-web-container.outputs.task-definition }} # ECSサービス名 service: ${{ secrets.ECS_SERVICE_NAME }} # ECSクラスタ名 cluster: ${{ secrets.ECS_CLUSTER_NAME }}actionsについて
マーケットプレイスが用意されているのでそこから探す
https://github.com/marketplace?type=actions
作ることもできますが、だいたいのユースケースにおいては使うだけだとおもいますMicrosoftが管理してるactionsだけじゃなく、誰でもactionsを上げられる(はず)なので、そういう状況であることを認識して選びましょう
今回使ったのはMicrosoftとAWSが管理してるactionsですactionsの引数と戻り値どこ見るの
リポジトリのルートのactions.ymlを見るのがシンプルです
READMEに書かれていることも多いですamazon-ecs-render-task-definitionを例にして、上のjobと見比べるとわかりやすいと思います
https://github.com/aws-actions/amazon-ecs-render-task-definition/blob/master/action.yml(2020/5) AWS関連のactions、まだあんまりない
一覧はここから見れます
https://github.com/aws-actionsしかしデプロイ関連は、まだあまりないです、2020/1に確認した時は4つだけだったので、ここもすごい勢いで増えています
- https://github.com/aws-actions/configure-aws-credentials
- https://github.com/aws-actions/amazon-ecr-login
- https://github.com/aws-actions/amazon-ecs-render-task-definition
- https://github.com/aws-actions/amazon-ecs-deploy-task-definition
- https://github.com/aws-actions/aws-cloudformation-github-deploy
- https://github.com/aws-actions/aws-codebuild-run-build
といっても、awsコマンドやjqは、ubuntu-latestなどのホストランナーに入っているのであまり困りません
https://help.github.com/ja/actions/reference/software-installed-on-github-hosted-runnersCodeDeploy(Blue/Green)は?
amazon-ecs-deploy-task-definitionが対応したもよう
試せてないです、
- 投稿日:2020-05-19T16:48:34+09:00
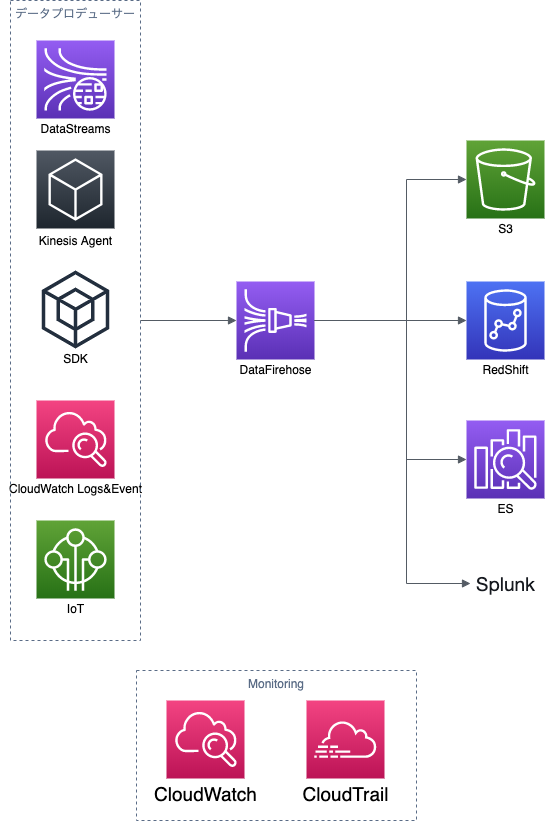
kinesis
kinesis
まずは一読
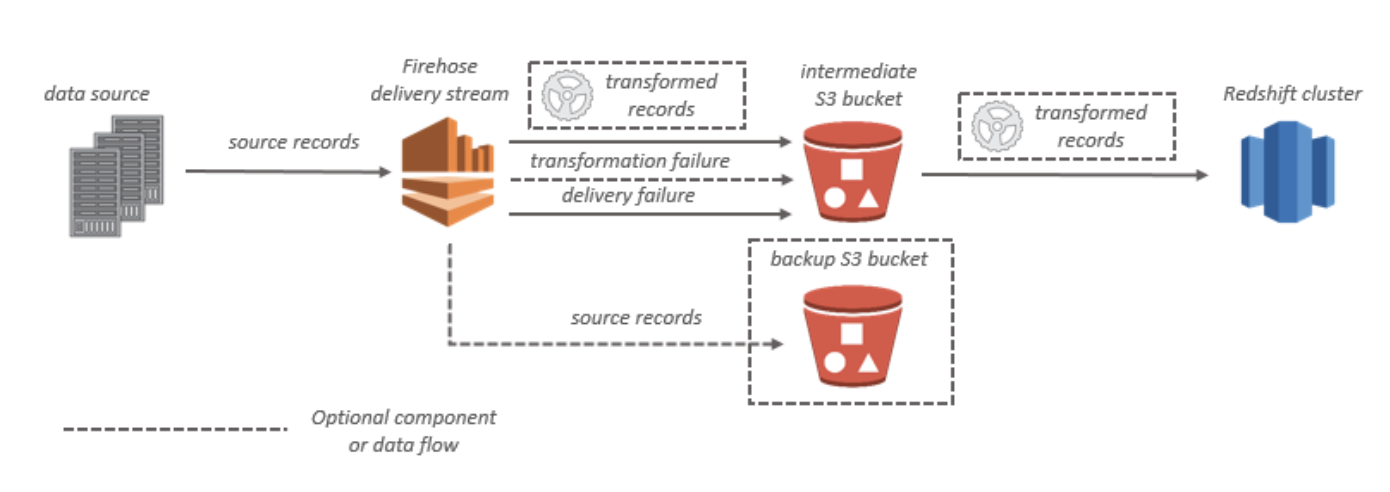
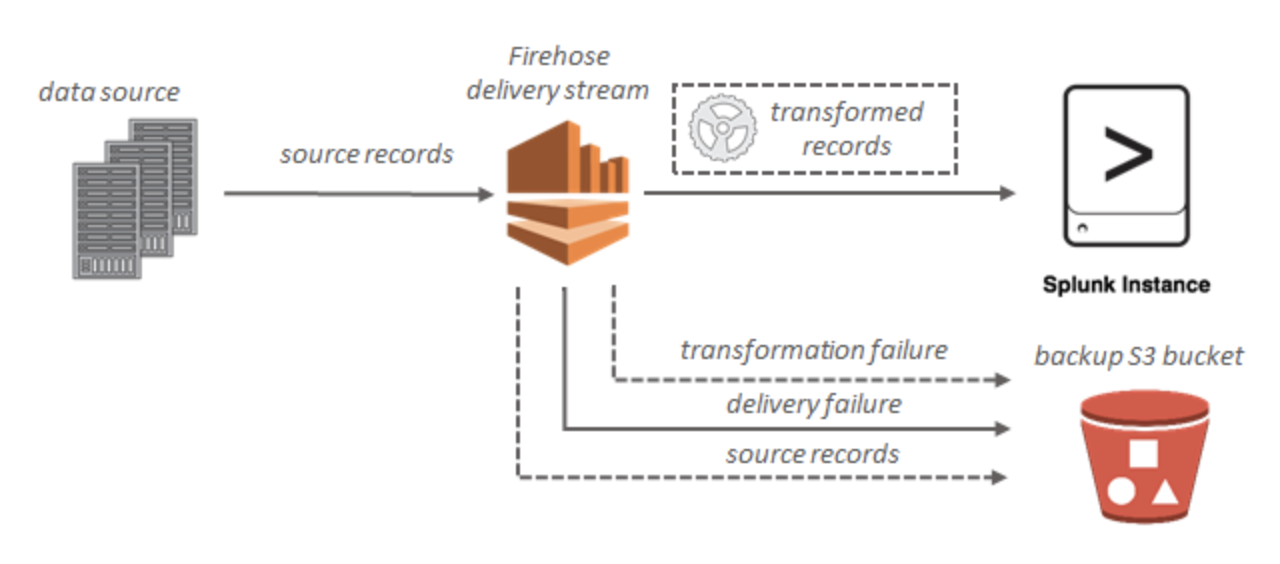
https://qiita.com/yShig/items/500d4139efed91bc432dkinesis data streams構成図
kinesis data firehose構成図
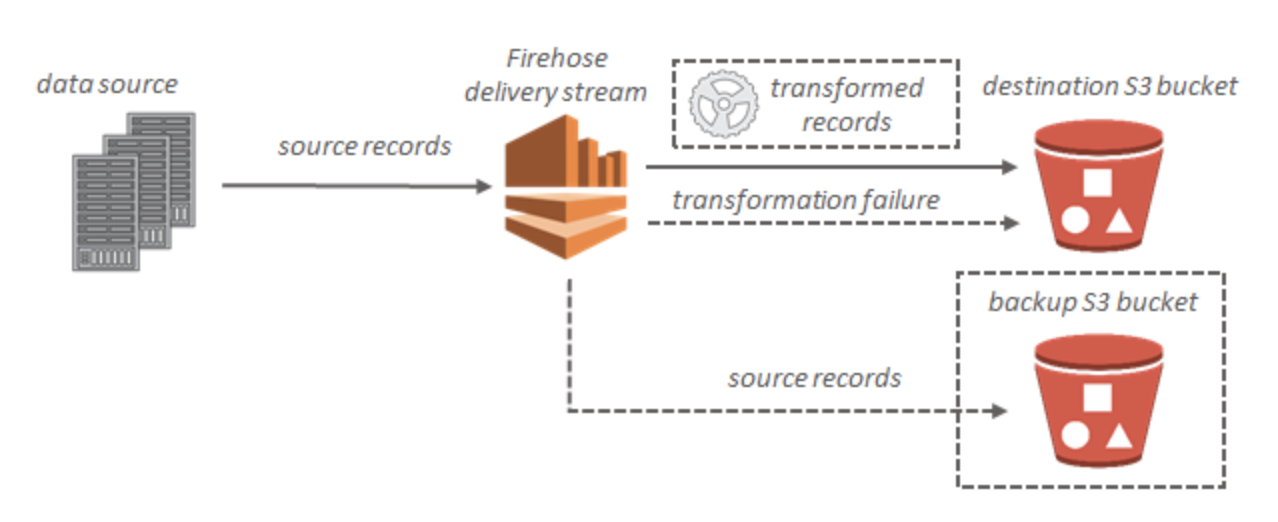
S3
データが Amazon S3 に配信されない
- Kinesis Data Firehose の IncomingBytes および IncomingRecords メトリクスをチェックし、データがKinesis Data Firehose 配信ストリームに正常に送信されていることを確認
- Lambda によるデータ変換が有効な場合は、Kinesis Data Firehose の ExecuteProcessingSuccess メトリクスで、Kinesis Data Firehose が Lambda 関数を呼び出そうとしたことを確認
- Kinesis Data Firehose の DeliveryToS3.Success メトリクスをチェックし、Kinesis Data Firehose が Amazon S3 バケットへのデータの配置を試みたことを確認
- すでに有効になっていない場合はエラーログ記録を有効にし、配信の失敗のエラーログを確認
- Kinesis Data Firehose 配信ストリームに指定された Amazon S3 バケットがまだ存在することを確認
- Lambda によるデータ変換が有効な場合は、配信ストリームで指定した Lambda 関数がまだ存在することを確認
- Kinesis Data Firehose 配信ストリームで指定した IAM ロールに、S3 バケットに対するアクセス権限と、Lambda 関数に対するアクセス権限 (データ変換が有効な場合) があることを確認
- データ変換を使用している場合は、Lambda 関数が、6 MB を超えるペイロードサイズのレスポンスを返さない
RedShift
データが Amazon Redshift に配信されない
- Kinesis Data Firehose の DeliveryToRedshift.Success メトリクスで、Kinesis Data Firehose が S3 バケットから Amazon Redshift クラスターにデータをコピーしようとしたことを確認
- すでに有効になっていない場合はエラーログ記録を有効にし、配信の失敗のエラーログを確認
- Amazon Redshift の STL_CONNECTION_LOG テーブルで、Kinesis Data Firehose が正常に接続できるかどうかを確認
- 前のチェックで、接続が確立されていることを確認したら、Amazon Redshift の STL_LOAD_ERRORS テーブルで、COPY の失敗の理由を確認
- Kinesis Data Firehose 配信ストリームの Amazon Redshift 設定が正確で有効であることを確認
- Kinesis Data Firehose 配信ストリームで指定した IAM ロールに、Amazon Redshift によるデータのコピー元となる S3 バケットに対するアクセス権限と、データ変換用の Lambda 関数に対するアクセス権限 (データ変換が有効な場合) もあることを確認
- Amazon Redshift クラスターが Virtual Private Cloud (VPC) にある場合は、クラスターで Kinesis Data Firehose の IP アドレスからのアクセスが許可されていることを確認
- Amazon Redshift クラスターがパブリックにアクセス可能であることを確認
- データ変換を使用している場合は、Lambda 関数が、6 MB を超えるペイロードサイズのレスポンスを返さないようにします。
ES
Splunk
データが Amazon Redshift に配信されない
- Kinesis Data Firehose の DeliveryToRedshift.Success メトリクスで、Kinesis Data Firehose が S3 バケットから Amazon Redshift クラスターにデータをコピーしようとしたことを確認
参考文献


- 投稿日:2020-05-19T16:39:39+09:00
SQS
Amazon SQS のベストプラクティス
- Amazon SQS スタンダード および FIFO (先入れ先出し) キューの推奨事項
Amazon SQS スタンダード および FIFO (先入れ先出し) キューの推奨事項
- Amazon SQS メッセージの操作
- Amazon SQS コストの削減
メッセージの操作
- タイムリーな方法でのメッセージの処理
- 可視性タイムアウトを調整
- ロングポーリングのセットアップ
- 問題のあるメッセージのキャプチャ
- デッドレターキューを設定
- デッドレターキューの保持期間を元のキューの保持期間よりも長く設定
Amazon SQS コストの削減
- 適切なポーリングモードの使用
- 基本ロング
- 場合によってショート
Amazon SQS セキュリティのベストプラクティス
- キューにパブリックアクセスできないようにする
- 最小特権アクセスの実装
- Amazon SQS アクセスを必要とするアプリケーションと AWS のサービスには IAM ロールを使用する
- サーバー側の暗号化を実装する
- 転送時のデータの暗号化を強制する
- VPC エンドポイントを使用して Amazon SQS にアクセスすることを検討する
参考文献
- Amazon Simple Queue Service とは
- 投稿日:2020-05-19T16:21:38+09:00
ELB
ELB
Elastic Load Balancing は受信したアプリケーションまたはネットワークトラフィックを、Amazon EC2 インスタンス、コンテナ、IP アドレス、複数のアベイラビリティーゾーンなど、複数のターゲットに分散させます。Elastic Load Balancing はアプリケーションへのトラフィックが時間の経過とともに変化するのに応じてロードバランサーをスケーリングします。また、大半のワークロードに合わせて自動的にスケーリングできます。
Application Load Balancer および Network Load Balancer では、ターゲットをターゲットグループに登録し、トラフィックをターゲットグループにルーティングします。クラシックロードバランサー では、ロードバランサーにインスタンスを登録します。
クロスゾーン負荷分散
- Application Load Balancer では、クロスゾーン負荷分散が常に有効
- Network Load Balancer を使用する場合、クロスゾーン負荷分散はデフォルトで無効化されます。Network Load Balancer の作成後は、いつでもクロスゾーン負荷分散を有効または無効にできます。
参考文献
- 投稿日:2020-05-19T16:07:03+09:00
CloudFormation
CloudFormation
AWS CloudFormation は Amazon Web Services リソースのモデル化およびセットアップに役立つサービスです
一読
CloudFormationの全てを味わいつくせ!「AWSの全てをコードで管理する方法〜その理想と現実〜」 #cmdevio
https://dev.classmethod.jp/articles/aws-all-iac/AWS CloudFormation のベストプラクティス
計画と編成
ライフサイクルと所有権によるスタックの整理
クロススタック参照を使用して共有リソースをエクスポートします
IAM を使用したアクセス制御
テンプレートを再利用して複数の環境にスタックを複製する
すべてのリソースタイプのクォータを確認する
ネストされたスタックを使用して共通テンプレートパターンを再利用する
Create
テンプレートに認証情報を埋め込まない
AWS 固有のパラメータータイプの使用
パラメーターの制約の使用
AWS::CloudFormation::Init を使用して Amazon EC2 インスタンスにソフトウェアアプリケーションをデプロイする
最新のヘルパースクリプトを使用する
テンプレートを使用する前に検証する
スタックの管理
AWS CloudFormation ですべてのスタックリソースを管理する
スタックを更新する前に変更セットを作成する
スタックポリシーを使用する
AWS CloudTrail を使用して AWS CloudFormation 呼び出しを記録する
コードの確認とリビジョン管理を使用してテンプレートを管理する
Amazon EC2 Linux インスタンスを定期的に更新する
既存リソースの CloudFormation 管理への取り込み
AWS CloudFormation 管理外の AWS リソースを作成した場合は、resource import を使用してこの既存のリソースを AWS CloudFormation 管理に取り込むことができます。リソースは、削除してスタックの一部として再作成しなくても、作成された場所に関係なく AWS CloudFormation を使用して管理できます。
AWS CloudFormation StackSets の操作
AWS CloudFormation StackSets は、複数のアカウントおよびリージョンのスタックを 1 度のオペレーションで、作成、更新、削除できるようにすることで、スタックの機能を拡張します。管理者アカウントを使用して、AWS CloudFormation テンプレートを定義および管理し、指定のリージョンの選択されたターゲットアカウントにスタックをプロビジョニングする基盤としてテンプレートを使用します。
参考文献
- 投稿日:2020-05-19T15:44:37+09:00
Amazon SNS とは
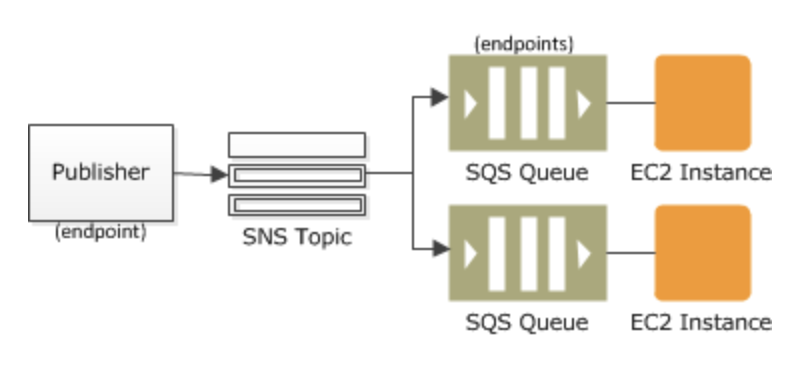
SNS
Amazon Simple Notification Service (Amazon SNS) は、サブスクライブしているエンドポイントまたはクライアントへのメッセージの配信または送信を、調整および管理するウェブサービスです。Amazon SNS には、発行者と受信者という 2 種類のクライアントが存在し、それぞれプロデューサーとコンシューマーとも呼ばれます。——発行者は、論理アクセスポイントおよび通信チャネルであるトピックにメッセージを作成して送信することで、受信者と非同期的に通信します。トピックにサブスクライブされているサブスクライバー (ウェブサーバー、E メールアドレス、Amazon SQS キュー、AWS Lambda 関数) は、サポートされているプロトコル (Amazon SQS、HTTP/S、E メール、SMS、Lambda) の 1 つを使用して、メッセージや通知を消費または受信します。
一般的な Amazon SNS シナリオ
- ファンアウト
- アプリケーションおよびシステムアラート
- プッシュ E メールとテキストメッセージ
- モバイルプッシュ通知
- メッセージの耐久性
ファンアウト
並列非同期処理
レプリケート
デッドレターキューのモニタリングとログ記録方法
デッドレターキューのアクティビティを通知するには、CloudWatch メトリクスとアラームを使用できます。たとえば、デッドレターキューが常に空であると予想される場合、NumberOfMessagesSent メトリクスの CloudWatch アラームを作成できます。アラームのしきい値を 0 に設定し、アラームがオフになったときに通知する Amazon SNS トピックを指定できます。この Amazon SNS トピックは、任意のエンドポイントタイプ (E メールアドレス、電話番号、モバイルポケットベルアプリなど) にアラーム通知を配信できます。
Amazon SNS セキュリティのベストプラクティス
- トピックがパブリックアクセス可能でないようにする
- 最小特権アクセスの実装
- Amazon SNS アクセスを必要とするアプリケーションと AWS のサービスには IAM ロールを使用する。
- サーバー側の暗号化を実装する
- 転送時のデータの暗号化を強制する
- VPC エンドポイントを使用して Amazon SNS にアクセスすることを検討する
参考文献

- 投稿日:2020-05-19T15:26:35+09:00
Redis 用 Amazon ElastiCache
ElasticCash
とりあえず以下を一読
https://dev.classmethod.jp/articles/elasticache-is-very-good-lets-review/キャッシュ戦略
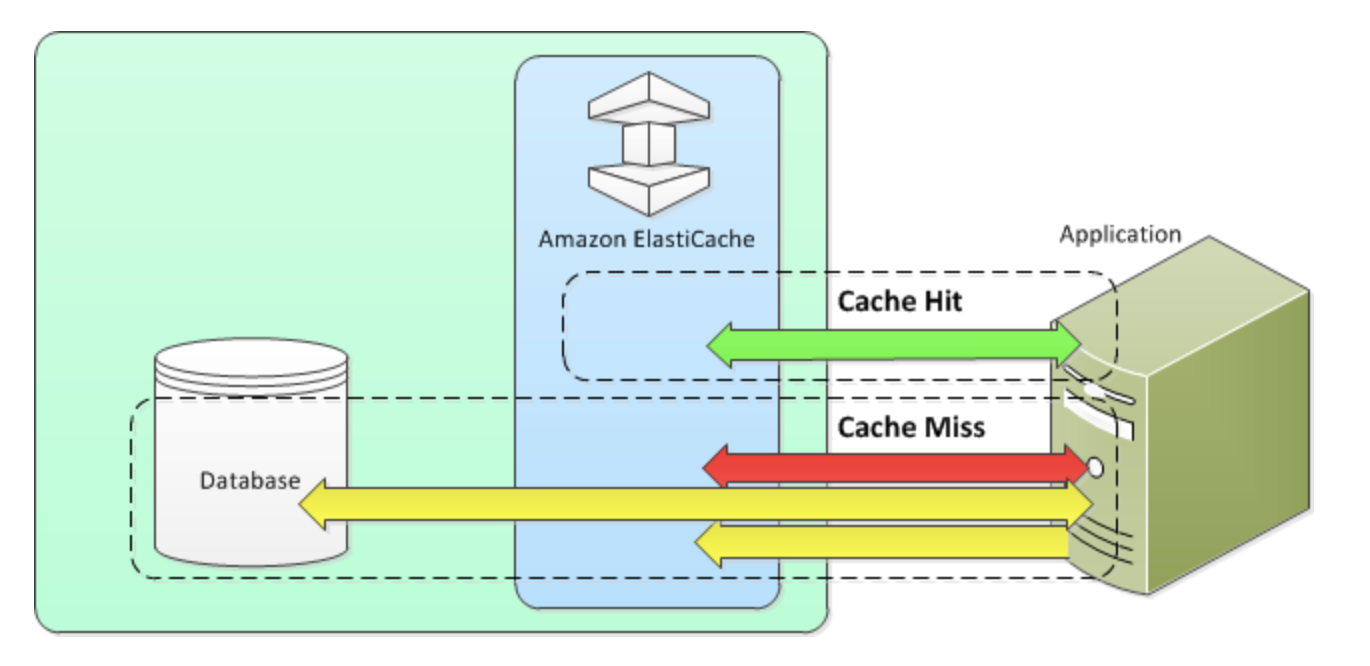
- 遅延読み込み
- 書き込みスルー
- TTL
遅延読み込み
必要なときにのみキャッシュにデータを読み込むキャッシュ戦略
書き込みスルー
書き込みスルー戦略では、データがデータベースに書き込まれると常にデータを追加するか、キャッシュのデータを更新
TTL
遅延読み取りはデータが古くなる可能性がありますが、空ノードによる障害は発生しません。書き込みスルーでは常に新しいデータとなりますが、空ノードの障害が発生して、過剰なデータがキャッシュに入力されることがあります。各書き込みに有効期限 (TTL) 値を追加することで、各戦略の利点を得ることができます。同時に、余分なデータでキャッシュが乱雑になることを回避できます。
参考文献
- ElastiCacheは良いサービス!!特徴や使い方をおさらいしましょ!
- Redis 用 Amazon ElastiCache
- 投稿日:2020-05-19T15:04:18+09:00
AutoScaling
AutoScaling
Amazon EC2 Auto Scaling によって、アプリケーションの負荷を処理するために適切な数の Amazon EC2 インスタンスを利用できるように準備することができます。Auto Scaling グループと呼ばれる EC2 インスタンスの集合を作成します。各 Auto Scaling グループ内のインスタンスの最小数を指定することができ、Amazon EC2 Auto Scaling のグループはこのサイズよりも小さくなることはありません。各 Auto Scaling グループ内のインスタンスの最大数を指定することができ、Amazon EC2 Auto Scaling のグループはこのサイズよりも大きくなることはありません。グループの作成時、またはそれ以降の任意の時点で、希望する容量を指定した場合、Amazon EC2 Auto Scaling によって、グループのインスタンス数はこの数に設定されます。スケーリングポリシーを指定する場合、Amazon EC2 Auto Scaling でアプリケーションに対する需要の増減に応じて、インスタンスを起動または終了できます。
Amazon EC2 Auto Scaling の動的なスケーリング
スケーリングポリシータイプ
- Target tracking scaling
- Step scaling
- Simple scaling
Auto Scaling グループ内のインスタンス数に比例して使用率メトリクスに基づいてスケールする場合は、ターゲット追跡スケーリングポリシーを使用することをお勧め
複数のスケーリングポリシー
Amazon EC2 Auto Scaling はスケールアウトとスケールインの両方に最大の容量を提供するポリシーを選択します。
Amazon SQS に基づくスケーリング
インスタンスあたりのバックログのメトリクスを使用して、ターゲット値を維持するインスタンスあたりの適正バックログにすることです。これらの数は以下のように計算できます。
- インスタンスあたりのバックログ
- インスタンスあたりのバックログを決定するには、まず Amazon SQS メトリックス ApproximateNumberOfMessages を使用して SQS キューの長さ (このキューから取得できるメッセージ数) を決定します。
- インスタンスあたりの適正バックログ
- ターゲット値を決定するには、まずレイテンシーの点でアプリケーションが受け付けることができる数を計算します。次に、適切なレイテンシー値を取ってそれを EC2 インスタンスがメッセージを処理する平均所要時間で割ります。
Auto Scaling インスタンスおよびグループのモニタリング
- ヘルスチェック
- Amazon Simple Notification Service 通知
- CloudWatch イベント
- CloudWatch アラーム
- CloudWatch ダッシュボード
- CloudTrail ログ
- CloudWatch Logs
- AWS Personal Health Dashboard
参考文献
- Amazon EC2 Auto Scaling とは

- 投稿日:2020-05-19T14:19:00+09:00
初めてのAWS Lambda〜Hello World
AWS Lambdaとは
サーバレスでコードを実行でき、Java、Go、PowerShell、Node.js、C#、Python、Rubyをサポートしている
https://aws.amazon.com/jp/lambda/faqs/実際に使ってみる
AWSのチュートリアルを参考に。
https://aws.amazon.com/jp/getting-started/hands-on/run-serverless-code/
コンソールを起動
「コンピューティング」→「Lambda」
設計図を選択
設計図=テンプレートのようなものかな?
「Hello」で検索すると、node.jsとpythonの「Hello World」設計図が検索されるので、今回は「hello-world-python」
設計図の中身はこんな感じです
import json print('Loading function') def lambda_handler(event, context): #print("Received event: " + json.dumps(event, indent=2)) print("value1 = " + event['key1']) print("value2 = " + event['key2']) print("value3 = " + event['key3']) return event['key1'] # Echo back the first key value #raise Exception('Something went wrong')
- テストイベントの作成
関数作成画面右上にある「テストイベント作成」から関数呼び出し時に渡すjsonの作成{ "key1": "Hello!World1", "key2": "Hello!World2", "key3": "Hello!World3" }
- イベントを選択して関数実行
実行ログが吐き出されて、関数が実行されたことを確認START RequestId: e5f1d7c7-9082-4634-a7aa-4363eab2c2e2 Version: $LATEST value1 = Hello!World1 value2 = Hello!World2 value3 = Hello!World3 END RequestId: e5f1d7c7-9082-4634-a7aa-4363eab2c2e2 REPORT RequestId: e5f1d7c7-9082-4634-a7aa-4363eab2c2e2 Duration: 1.37 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 49 MB次回
今回は用意された設計図から関数を作成したので、次回は自分で関数を作成〜実行までを試す
- 投稿日:2020-05-19T13:32:41+09:00
AWS Kendra使ってドキュメント検索(API Gateway+Lambda)
Kendra
AWS Kendraとは
https://aws.amazon.com/jp/kendra/
Amazon Kendra は、機械学習を原動力とする高精度で使いやすいエンタープライズ検索サービスです。Kendra は、ウェブサイトおよびアプリケーションに強力な自然言語検索機能を提供するため、エンドユーザーは企業全体に散在する膨大な量のコンテンツ内で必要な情報をより簡単に見つけることができます。
https://dev.classmethod.jp/articles/kendra-reinvent2019/
re:Invent 2019で発表された。
エンタープライズ検索って言って社内ドキュメントの中から、欲しい情報を簡単に探せるよっていうサービスっぽい。日本語はまだ未対応。簡単にデータソースの設定ができて、深層学習モデルをアクティブに再訓練して、検索の正確性がどんどん上がっていく、と。
S3にファイルアップロード
今回はデータソースはS3を使うので、適当にネットから拾ってきたデジカメの取扱説明書を置いておく。英語しか対応していないので英語版。
日本語対応するまでは実用するとしてもドキュメントを英語に変換する必要がある(AWS Translateと使ってアップロード時に翻訳変換かければいいかもしれないけど精度は不明)
https://kendra-translate-test.s3-us-west-2.amazonaws.com/nex-3n_manual.pdf
INDEX作成
Kendraは日本リージョンないのでus-west-2を選択。
Roleの設定とかポチポチやるだけ。30分くらいかかるみたい。ほっといたら出来てた。
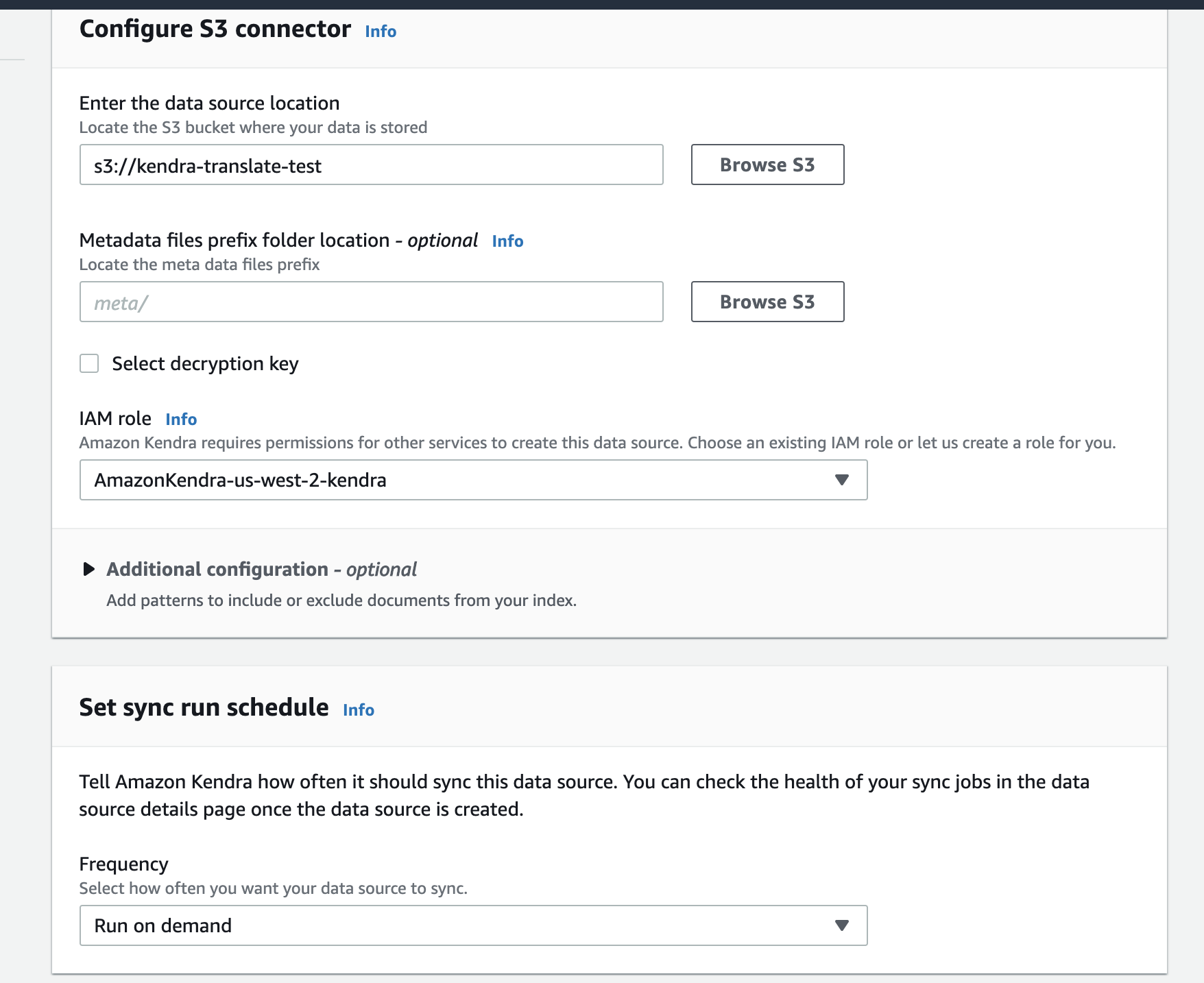
データソース設定
今回はS3を使ってみる。
SharePoint Onlineもあるので、社内ドキュメントとは相性良いのかも。
対象のバケットと、Roleと、データ同期のスケジュールを設定する。
今回はファイル更新しないのでRun on demandに設定。
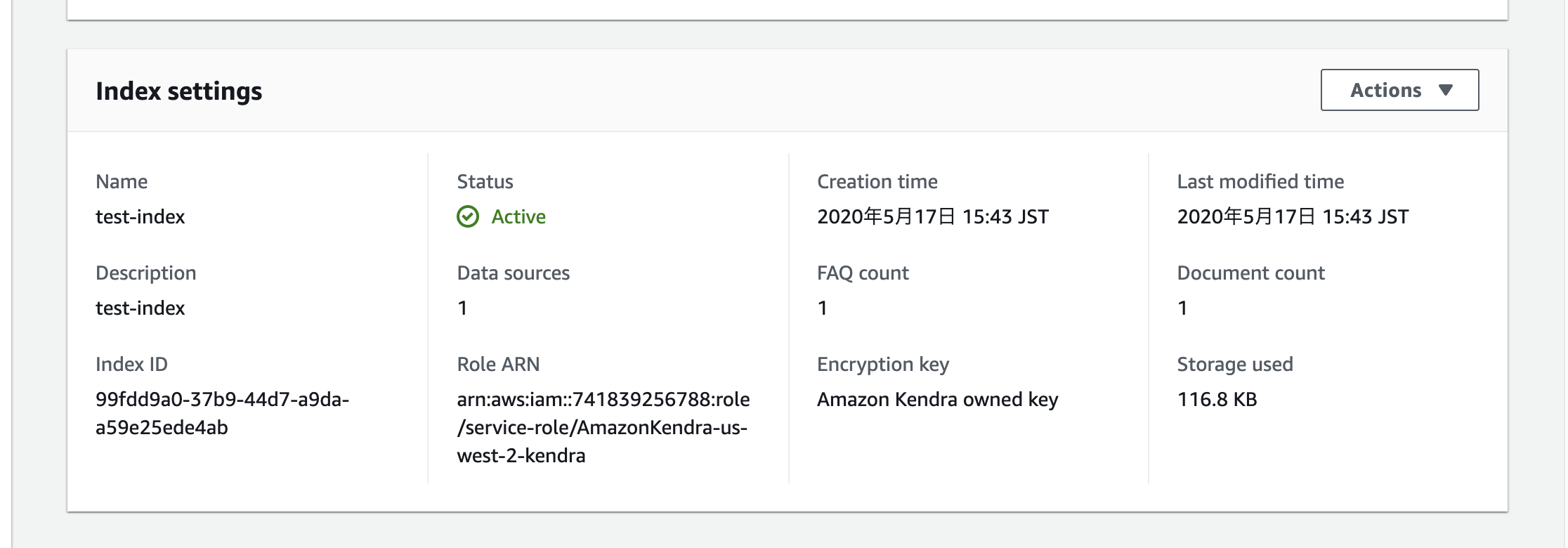
出来た。Index IDは検索する際に使う。
Document Countが1で、1ファイルが対象ドキュメントになっているのがわかる。
Search Consoleで検索できるか確認
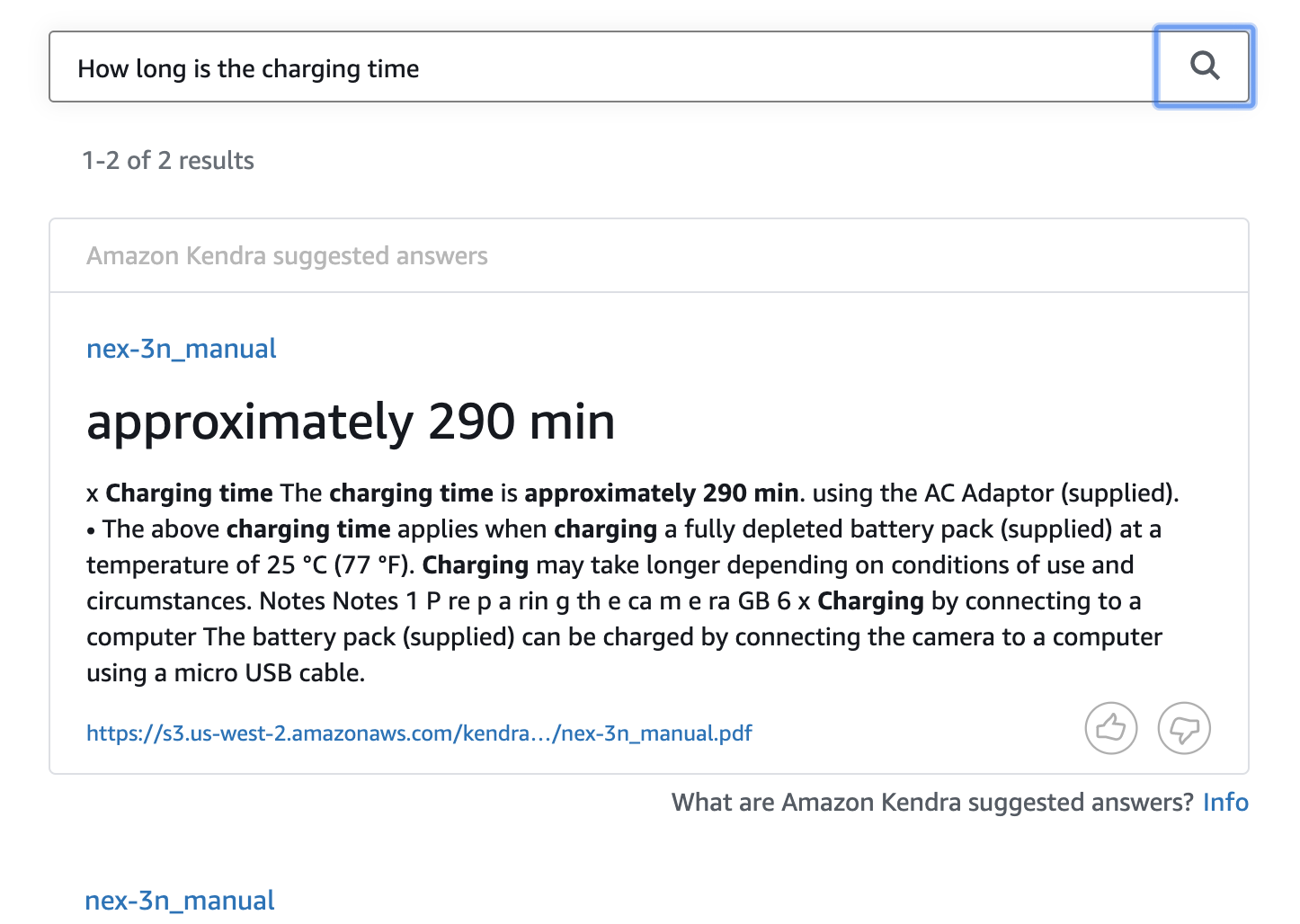
もちろん英語で。
Q、充電時間はどのくらい?
A、約290分だよ出来た。
Slackからスラッシュコマンドで使ってみる(APIGateWay+Lambda)
Lambda設定
- Python3.8で。
- 実行ロールにKendraへのアクセスを許可する
- あとはタイムアウト値を伸ばした(デフォルトって3秒なんですね。3秒だとタイムアウトになったので10秒に。)
import boto3 from urllib import parse def lambda_handler(event, context): kendra = boto3.client('kendra') # SlashCommandから送られた引数 text = parse.parse_qs(event['body'])['text'][0] # kendraにIndexID指定して投げる response = kendra.query(IndexId='XXXXXXXXXXXXXXXXXXXXXXXXXXX', QueryText=text) # jsonレスポンスをごにょごにょしてTextを抽出Slackに返す item = response['ResultItems'][0] res = item['AdditionalAttributes'][0]['Value']['TextWithHighlightsValue']['Text'] response = { "statusCode": 200, "body": res } return responseAPIGateway設定
特に変わった設定はなし。
作成されたURLをSlash Command側で使う。
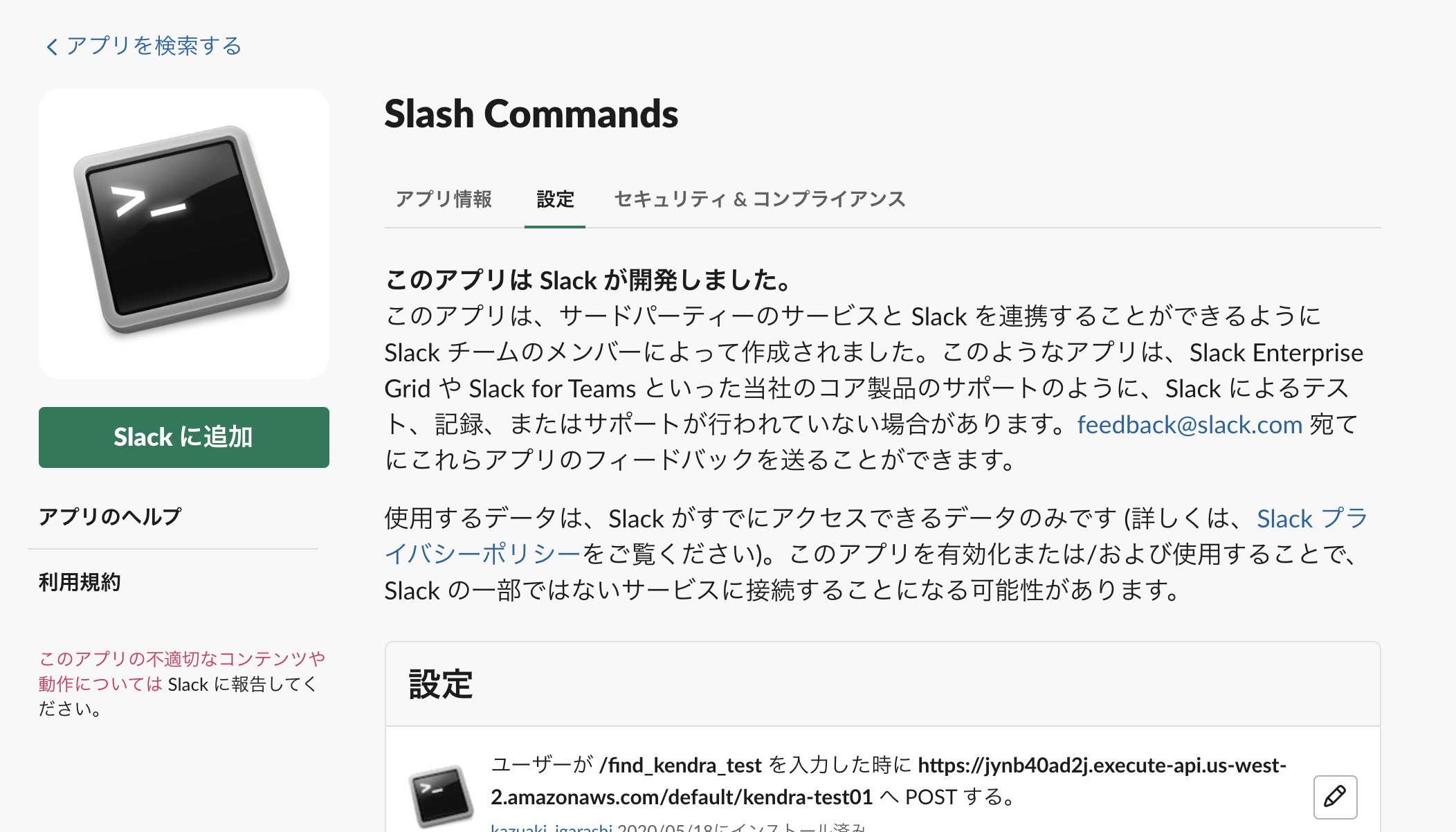
Slash Command設定
SlackAPIで自分で作ってもいいけど、Slackが提供しているアプリがあったのでこれを使う。
コマンドと、POST先のAPIGatewayのURLを設定する
Slash Commandsで送られるPOSTデータの中身
token=mFrLp0CXBndhvtRvBQY6Y6ke team_id=T0001 team_domain=example channel_id=C2147483705 channel_name=test user_id=U2147483697 user_name=Steve command=/weather text=94070 response_url=https://hooks.slack.com/commands/1234/5678完成
画面をみながらやってみます


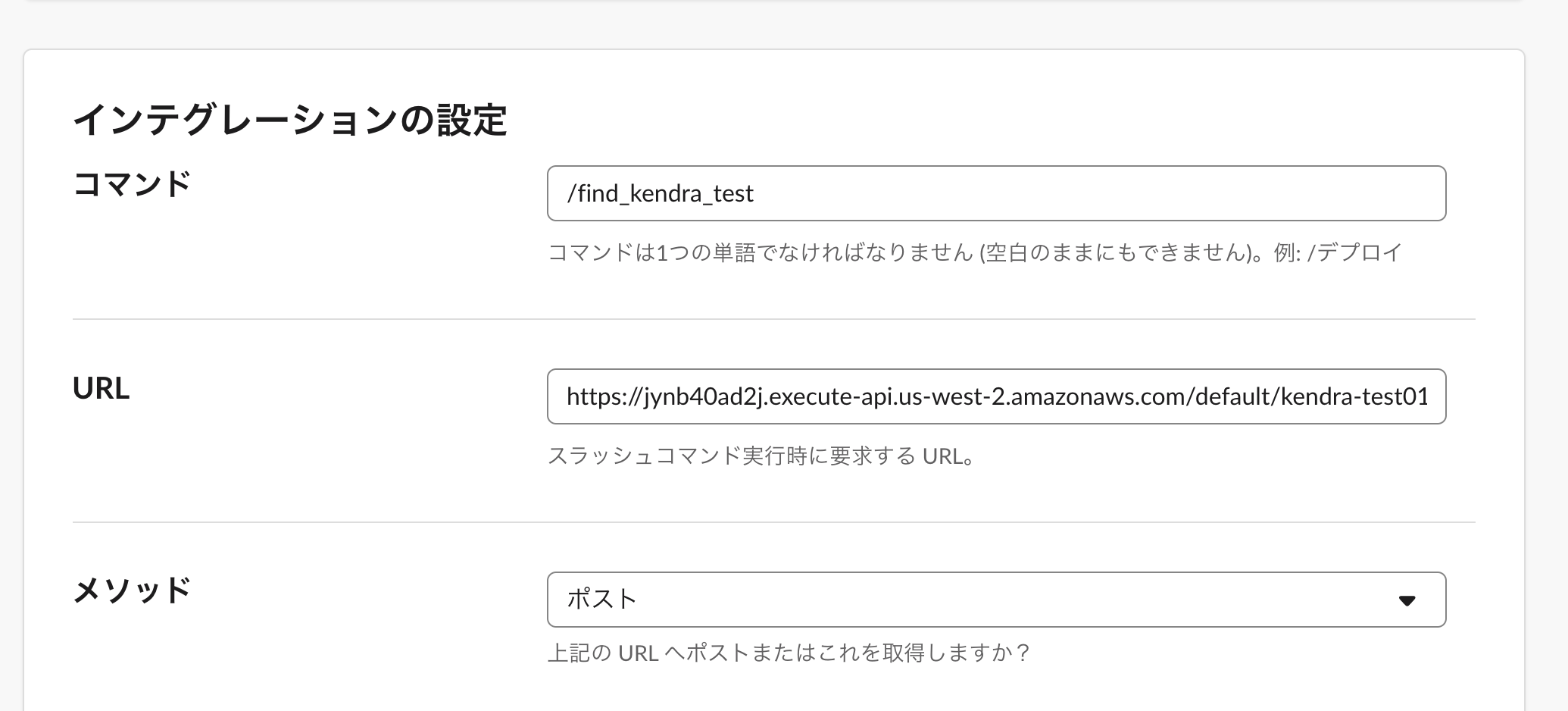
- 投稿日:2020-05-19T13:17:02+09:00
AWS Orgnization
AWS Organizations とは何ですか?
AWS Organizations は、作成し一元管理する組織に、複数の AWS アカウントを統合するためのアカウント管理サービス
AWS Organizations 機能
- AWS アカウントのすべての一元管理
- すべてのメンバーアカウントの一括請求
- 予算、セキュリティ、コンプライアンスのニーズを満たすアカウントの階層的なグループ化
- 各アカウントがアクセスできる AWS サービスと API アクションのコントロール
- 組織のアカウント内のリソース間でタグを標準化するためのヘルプ
- AWS Identity and Access Management の統合とサポート (IAM)
SCP を使用した戦略
- 拒否リスト
- 許可リスト
拒否リスト
AWS Organizations のデフォルトの設定では、SCP を拒否リストとしてサポートしています。拒否リスト戦略を使用して、アカウント管理者は、特定のサービスや一連のアクションを拒否する SCP を作成してアタッチするまで、すべてのサービスとアクションを委譲できます。AWS が新しいサービスを追加するときに SCP を更新する必要がないため、拒否ステートメントではメンテナンスの必要性が削減されます。
許可リスト
SCP を許可リストとして使用するには、AWS 管理の FullAWSAccess SCP を、許可したいサービスやアクションのみを明示的に許可する SCP で置き換える必要があります。デフォルトの FullAWSAccess SCP を削除することで、すべてのサービスのすべてのアクションが暗黙的に拒否されるようになります。そうするとカスタム SCP は、許可したいアクションのみについて、暗示的 Deny を明示的 Allow で上書きします。指定されたアカウントに対してアクセス許可を有効にするには、ルートからアカウントへの直接パス内の各 OU のすべての SCPが (アカウント自体にアタッチされていても)、そのアクセス許可を許可する必要があります。
組織で信頼されたアクセスをサポートするサービス
- AWS Artifact および AWS Organizations
- AWS CloudFormation StackSets と AWS Organizations
AWS CloudFormation StackSets を使用すると、1 回のオペレーションで、複数のアカウントとリージョンにわたってスタックを作成、更新、または削除できます。
- AWS CloudTrail および AWS Organizations
AWS CloudTrail は、AWS アカウントのガバナンス、コンプライアンス、および運用とリスクの監査を行えるように支援する AWS のサービスです。AWS CloudTrail を使用すると、マスターアカウントのユーザーは組織の証跡を作成して、組織のすべての AWS アカウントに関するすべてのイベントをログに記録できます。組織の証跡は、組織内のすべてのメンバーアカウントに自動的に適用されます。メンバーアカウントは組織の証跡を表示できますが、これを変更または削除することはできません。デフォルトでは、メンバーアカウントは Amazon S3 バケット内にある組織の証跡のログファイルにはアクセスできません。これにより、組織内のすべてのアカウントに対してイベントのログ記録戦略を一律に適用および実施できます。
- AWS Compute Optimizer および AWS Organizations
AWS Compute Optimizer は、 AWS リソースの設定と使用率のメトリクスを分析するサービスです。リソースの例には、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスや Auto Scaling グループがあります。Compute Optimizer は、リソースが最適かどうかを報告します。また、コストを削減し、ワークロードのパフォーマンスを向上させるための最適化に関する推奨事項を生成します。
- AWS Config および AWS Organizations
AWS Config のマルチアカウント、マルチリージョンのデータ集約を使用すると、複数のアカウントと AWS リージョンの AWS Config データを 1 つのアカウントに集約できます。
- AWS Directory Service および AWS Organizations
Microsoft Active Directory 向け AWS Directory Service あるいは AWS Managed Microsoft AD を使用すると、Microsoft Active Directory (AD) をマネージドサービスとして実行できます。AWS Directory Service では、AWS クラウド内のディレクトリを簡単にセットアップして実行したり、AWS リソースを既存のオンプレミス Microsoft Active Directory に容易に接続できます。また、AWS Managed Microsoft AD は AWS Organizations と密接に統合して、複数の AWS アカウントとリージョン内の任意の VPC 間でシームレスにディレクトリを共有できます。
- AWS Firewall Manager および AWS Organizations
AWS Firewall Manager は、アカウントやアプリケーションにウェブアプリケーションのファイアウォールルールを一元的に設定、管理するセキュリティ管理サービスです。AWS Firewall Manager では、AWS 組織のすべてのアカウントの Application Load Balancer および Amazon CloudFront ディストリビューションに対して、一度に AWS WAF をロールアウトできます。AWS Firewall Manager を使用してファイアウォールのルールを一度だけ設定し、新しいリソースやアカウントが追加されているかどうかにかかわらず、組織内のすべてのアカウントやリソースに自動的に適用します。
- AWS ライセンスマネージャーおよび AWS Organizations
AWS ライセンスマネージャーは、ソフトウェアベンダーのライセンスをクラウドに移動するプロセスを効率化します。AWS でクラウドインフラストラクチャを構築するときに、Bring-Your-Own-License (BYOL) による機会を使用してコストを削減できます。つまり、クラウドリソースで使用するように既存のライセンスインベントリの用途を変更します。管理者は、ライセンスの使用でルールベースのコントロールを使用することにより、新規および既存のクラウドのデプロイにソフト制限またはハード制限を設定し、準拠していないサーバーの使用を事前に停止できます。AWS ライセンスマネージャーを AWS Organizations にリンクすることで、組織全体でコンピューティングリソースのクロスアカウントの検出を有効にすることができます。
- AWS RAM および AWS Organizations
AWS Resource Access Manager (AWS RAM) を使用すると、自分が所有している AWS リソースを指定して、他の AWS アカウントと共有できます。これは一元管理されたサービスであり、これにより、複数のアカウント間でさまざまなタイプの AWS リソースを一貫して共有できます。
- AWS Service Catalog および AWS Organizations
AWS Service Catalog では、AWS での使用が承認された IT サービスのカタログを作成および管理できます。AWS Service Catalog と AWS Organizations の統合により、組織全体でポートフォリオの共有と製品のコピーが簡略化されます。AWS Service Catalog の管理者は、ポートフォリオの共有時に AWS Organizations で既存の組織を参照し、組織のツリー構造の信頼された組織単位 (OU) でポートフォリオを共有できます。これにより、ポートフォリオ ID を共有する必要がなくなり、受信側アカウントはポートフォリオをインポートするときに手動でポートフォリオ ID を参照する必要がなくなります。このメカニズムを介して共有されたポートフォリオは、AWS Service Catalog で管理者のインポートされたポートフォリオビューに、アカウントに対して共有されているものとしてリスト表示されます。
- サービスクォータと AWS Organizations
サービスクォータは、一元的な場所からクォータを表示および管理できる AWS のサービスです。クォータ (制限とも呼ばれます) は、AWS アカウントのリソース、アクション、および制限の最大値です。サービスクォータが AWS Organizations に関連付けられている場合、クォータリクエストテンプレートを作成して、アカウントの作成時に自動的にクォータの引き上げをリクエストできます。
- AWS シングルサインオン および AWS Organizations
AWS シングルサインオン (AWS SSO) は、すべての AWS アカウントとクラウドアプリケーションにシングルサインオンサービスを提供します。AWS Directory Service から Microsoft Active Directory に接続され、そのディレクトリのユーザーは、既存の Active Directory ユーザー名とパスワードを使用して、パーソナライズされたユーザーポータルにサインインできるようになります。ユーザーは、ポータルから、そのポータルで指定したすべての AWS アカウントとクラウドアプリケーションにアクセスできます。
- AWS Systems Manager および AWS Organizations
AWS Systems Manager は、AWS リソースの可視性と制御を可能にする一連の機能です。これらの機能の 1 つである Systems Manager Explorer は、AWS リソースに関する情報をレポートするカスタマイズ可能なオペレーションダッシュボードです。組織 と Systems Manager Explorer を使用して、組織内のすべての AWS アカウント間でオペレーションデータを同期できます。
- タグポリシーと AWS Organizations
タグポリシーはポリシーの一種で、組織のアカウント内のリソース間でタグを標準化するのに役立ちます。
AWS Organizations でのログ記録とモニタリング
- AWS CloudTrail による AWS Organizations API コールのログ記録
- Amazon CloudWatch Events
AWS CloudTrail による AWS Organizations API コールのログ記録
AWS Organizations は AWS CloudTrail と統合されています。このサービスは、AWS Organizations 内でユーザーやロール、または AWS のサービスによって実行されたアクションを記録するサービスです。CloudTrail は、AWS Organizations コンソールからのコールや、AWS Organizations API オペレーションへのコード呼び出しを含む、AWS Organizations のすべての API コールをイベントとしてキャプチャします。証跡を作成する場合は、AWS Organizations のイベントなど、Amazon S3 バケットへの CloudTrail イベントの継続的な配信を有効にすることができます。証跡を設定しない場合でも、CloudTrail コンソールの [Event history (イベント履歴)] で最新のイベントを表示できます。CloudTrail で収集された情報を使用して、AWS Organizations に対して実行されたリクエスト、その送信元の IP アドレス、実行者、実行日時などの詳細を確認できます。
Amazon CloudWatch Events
AWS Organizations では、管理者が指定したアクションが組織内で発生した場合に、CloudWatch イベント を使用してイベントを発生させることができます。たとえば、アクションの重要性のため、ほとんどの管理者は、組織内に誰かが新しいアカウントを作成するたびに、またはメンバーアカウントの管理者が組織を離れようとするたびに警告を受けたいと考えています。これらのアクションを探す CloudWatch イベント ルールを設定し、生成されたイベントを管理者が定義したターゲットに送信できます。ターゲットは、E メールまたはテキストメッセージのサブスクライバーである Amazon SNS トピックにすることができます。また、後で確認するためにアクションの詳細をログに記録する AWS Lambda 関数を作成することもできます。
参考文献
- AWS Organizations とは何ですか?
- 投稿日:2020-05-19T07:57:21+09:00
【AWS】IAMの作業用ユーザー作成方法等
はじめに
現在、AWSについてudemyの教材を用いて勉強中です。
IAMについて学習しましたので、本記事にてアウトプットします。IAMとは?
「Identity and Access Management」の略称。
AWSのサービスを利用するユーザー権限を管理するサービスになります。
※WindowsServerで言う「Active Directory」になります。ベストプラクティス
AWSの公式ドキュメントによると、AWSアカウントのルートユーザーを使用することはNGであるとのこと。
AWSアカウントとは別に下記を作成することがベストプラクティスであるとのこと。担当者ごとの管理者権限付きIAMユーザー
管理者IAMユーザー作成方法
画像付きで解説していきます。
①AWSアカウントのルートユーザーにてログイン後、「サービス」→「IAM」を選択。
②「ユーザー」を選択
③「ユーザーを追加」を選択
④必要情報を入力
下記画像の赤枠のように入力
項目:
- ユーザー名
ユーザー名を入力- アクセスの種類
「AWSマネジメントコンソールへのアクセス」にチェック- コンソールのパスワード
今回は「カスタムパスワード」を入力- パスワードのリセットが必要
今回はチェックを外す入力完了後、「次のステップ」をクリック
⑤「グループの作成」をクリック
⑥「グループ名」に「Administorators」を入力し、ポリシー名の「AdministratorAccess」にチェックを入れる。
その後に「グループの作成」をクリック。
⑦「Administrators」が作成されることを確認。「次のステップ」をクリック。
⑧タグは未入力のまま「次のステップ」をクリック。
⑨必要情報を確認し、「ユーザーの作成」をクリック
⑩IAMユーザーの作成が成功したことを確認
下記について、ログイン時に必要な情報のため控えるか保存しておく。
・サインインURL(赤枠の部分)
・csvのダウンロード
※実際にログインしたページはこちらになります。
参考
最初の IAM 管理者のユーザーおよびグループの作成
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/getting-started_create-admin-group.html
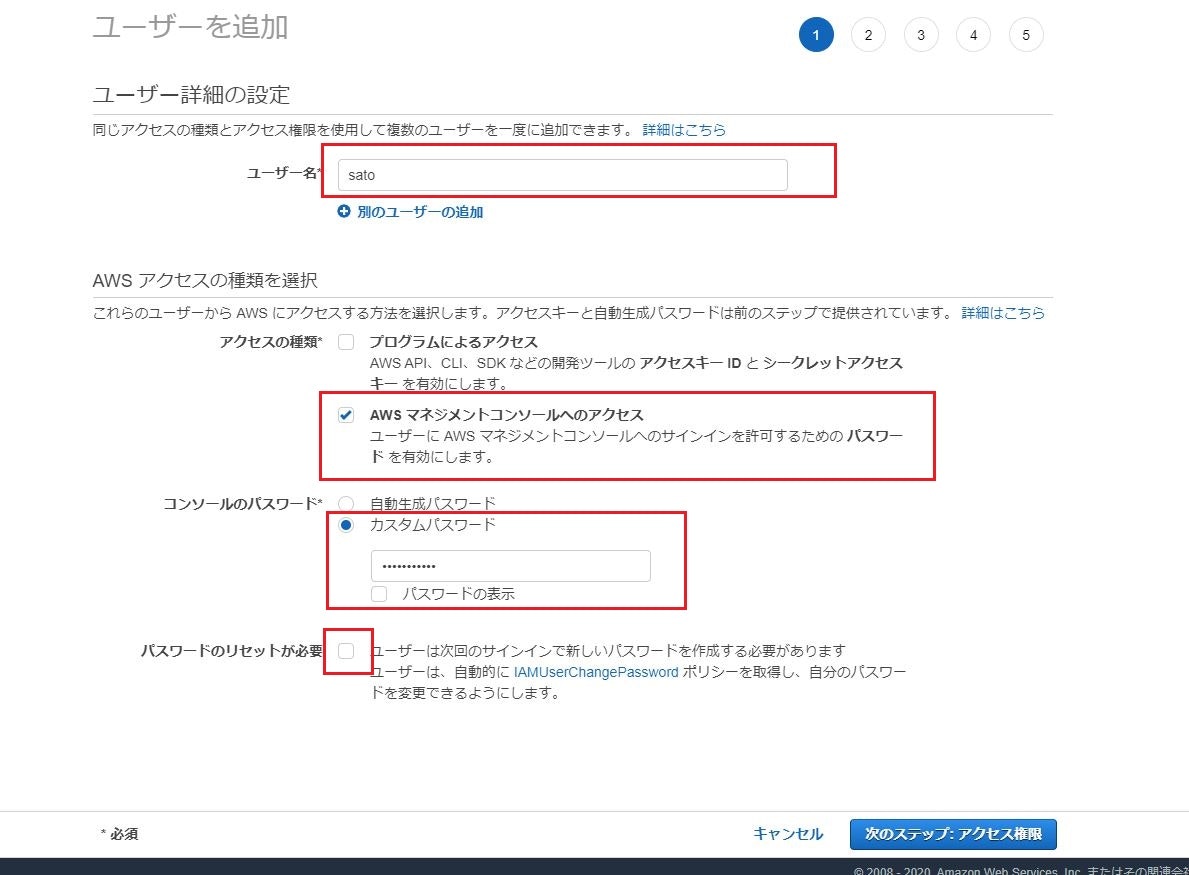
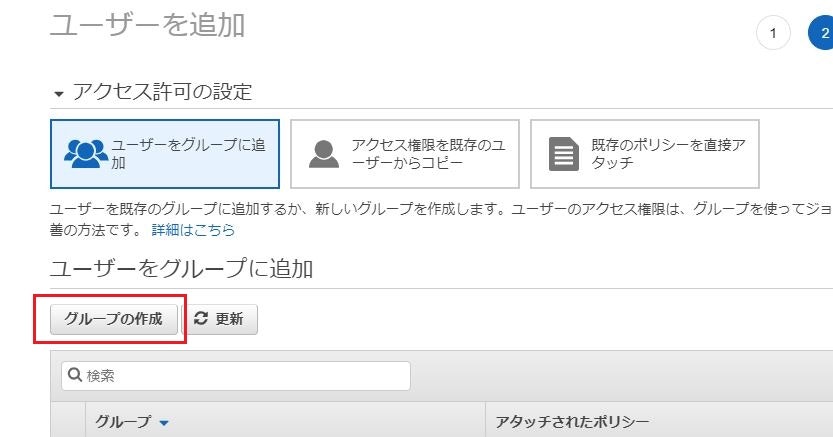
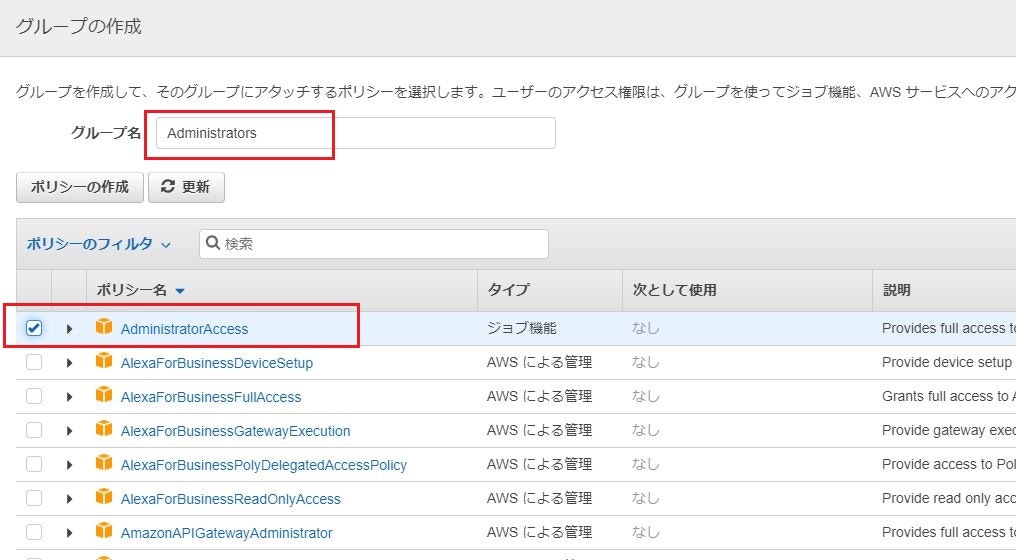
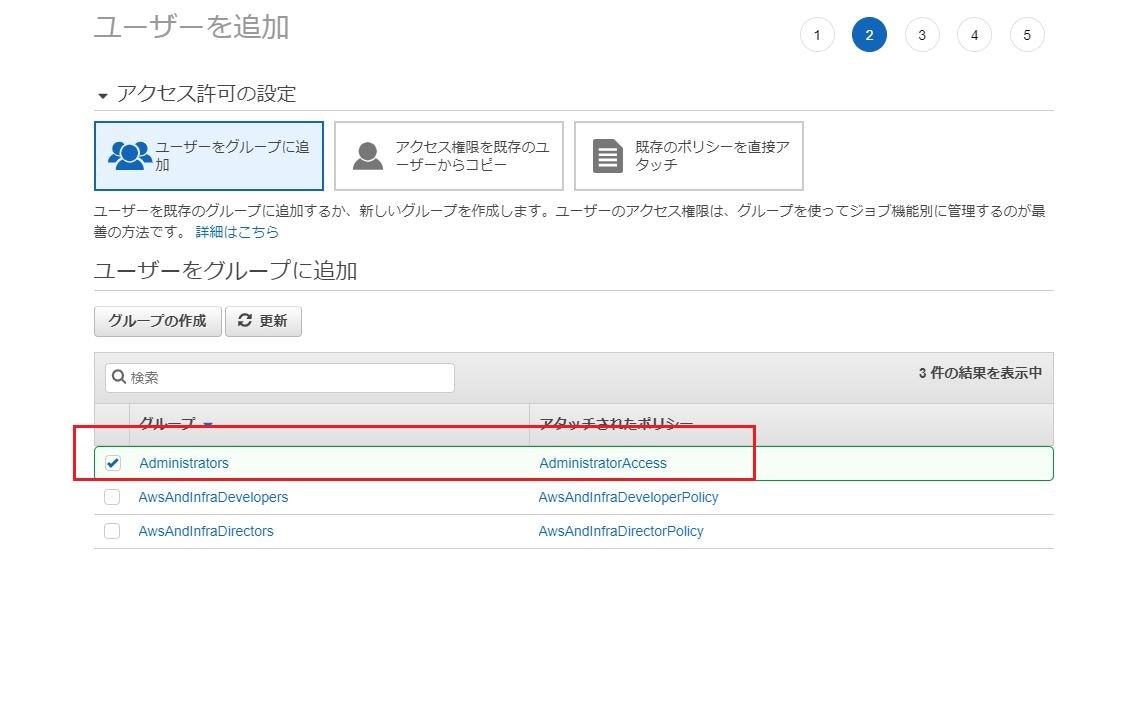

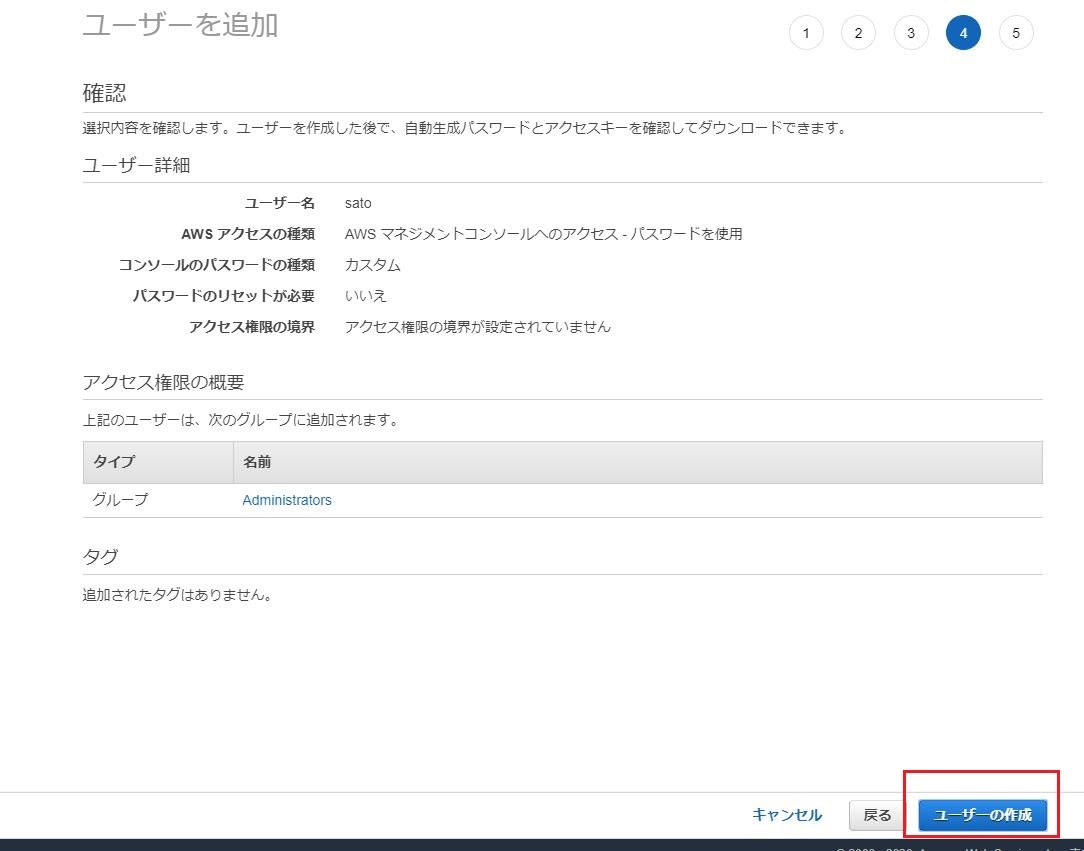
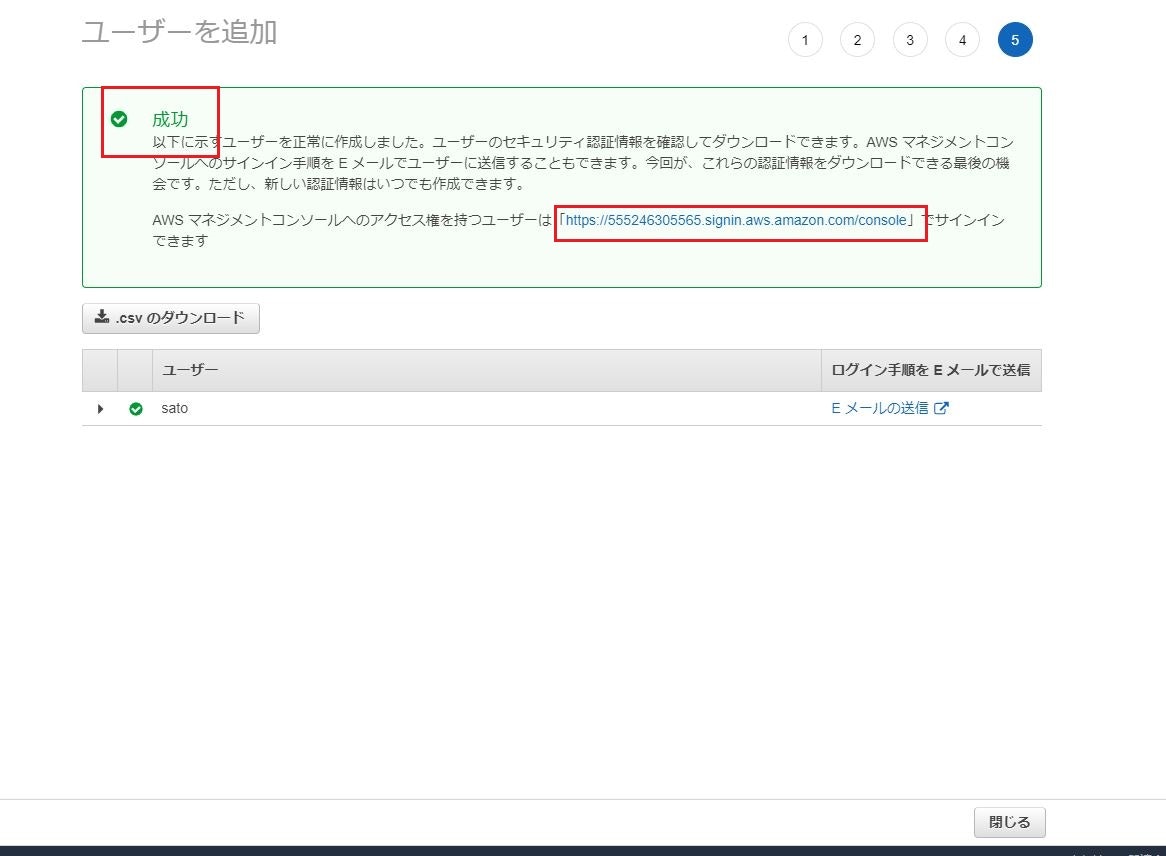
- 投稿日:2020-05-19T07:14:27+09:00
Amazon CloudWatch のカスタムメトリクス取得監視
何らかの理由により、カスタムメトリクスの取得に失敗している状態を検知したい場合の CloudWatch アラームの設定
CloudWatch > アラーム > アラームの作成
メトリクス
名前空間:監視するカスタムメトリクスの名前空間
メトリクス名:監視するカスタムメトリクス
Instance:●●●●●●●●●●●●●●●●
統計:監視するカスタムメトリクスの統計
期間:監視するカスタムメトリクスの期間条件
しきい値の種類:静的
【メトリクス名】 が次の時:より低い (<)
... よりも:0
アラームを実行するデータポイント:1 / 1
欠落データの処理:欠落データを不正(しきい値を超えている)として処理アクション
通知
アラーム状態のとき、「【AmazonSNSトピック】」に通知を送信します参考) Amazon SNS のサブスクリプション解除を禁止する方法
https://qiita.com/r18j21/items/22e1d0348ff11d69757c名前と説明
名前:●●●●●●●●●●●●●●●●
説明:●●●●●●●●●●●●●●●●
- 投稿日:2020-05-19T05:07:55+09:00
ECSのserviceに複数のTargetGroupを設定する
tl;dr;
DocumentにはAWS Management Consoleからできると書いてあるが,どこを探しても導線がないので
aws-cliを使いましょう(知っている人はこっそりコメントを下さい)やりたいこと
- 複数のTargetGroupをECSのサービスに登録したい.
- WebConsoleでできれば試してみたい.
- 公式 には2019年7月からサポートと書いてあるため実現できそう.
ユースケース
- 複数のTaskで運用しているサービスのロードバランサを各Taskごとに用意したい.
- 複数のロードバランサを1つのサービスに登録したい.
Web Consoleを眺める
ECSのサービスを作成する画面で,LoadBalanacerの設定画面があります.
ここでALBやNLBを選択すると,どのTargetGroupを選択する項が表れます.
同様の手順でTargetGroupを追加しようとしますができません.
どうやらWebConsoleでは,1つのTargetGroupのみしか設定できないようです.awsのドキュメントを見てみる
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/register-multiple-targetgroups.html には Web Consoleからできそうな感じで書いてありますが,できなさそうです.
このドキュメントを見ると
cliの話が書いてあるので,試してみます.
aws-cliを用いる方法先程のドキュメントのページをみるとどうやらこの形式で登録すれば良さそうです
"loadBalancers":[ { "targetGroupArn":"arn:aws:elasticloadbalancing:region:123456789012:targetgroup/target_group_name_1/1234567890123456", "containerName":"webserver", "containerPort":80 }, { "targetGroupArn":"arn:aws:elasticloadbalancing:region:123456789012:targetgroup/target_group_name_2/6543210987654321", "containerName":"database", "containerPort":3306 } ]自分が登録したいtargetGroupArnを調べて以下のような
aws-cliを用いたコマンドを実行します.細かなパラメータはこちらをみて各人設定してください.aws ecs create-service \ --cluster my-cluster \ --service-name my-service-name \ --task-definition my-task \ --load-balancers '[{"targetGroupArn": "arn:aws:elasticloadbalancing:region:123456789012:targetgroup/target_group_name_1/1234567890123456", "containerName":"webserver", "containerPort": 80 },{ "targetGroupArn": "arn:aws:elasticloadbalancing:region:123456789012:targetgroup/target_group_name_2/6543210987654321", "containerName": "database", "containerPort":3306 }]' \ --desired-count 1 \ --launch-type EC2これを実行すると,web consoleではできませんでしたが無事に複数のTargetGroupを登録できました!
まとめ
- web consoleでは未実装だけど実はできることがあったりするので,ドキュメントを読みましょう.
注意
- 既に作成されたECSのサービスにはTargetGroupは設定できません.
- サービスを作るときにしかできない操作です.
参考

- 投稿日:2020-05-19T01:10:58+09:00
『Amazon Web Services 基礎からのネットワーク&サーバー構築』(3)
本記事の目標
・サーバー構築
現在の状況
この中にインスタンスを入れたい。大まかな流れ
インスタンスを作成する。
↓
作ったインスタンスにインターネットからSSH接続して操作する。
↓
ファイアウォールで接続制限する。インスタンス作成
インスタンスとは
Amazon EC2で作成した仮想サーバーのこと。
これにWebサーバーソフトをインストールするとWebサーバーになる。本記事ではインターネットと通信できるインスタンスを作成しようと思っているので、IPアドレスは2つ用意する必要がある。
・パブリックアドレス(インターネットと通信する用)
・プライベートアドレス(VPC内で通信する用)AMI:Amazon Linux 2 AMI
インスタンスタイプ:t2.micro
に設定。インスタンスの詳細の設定
ネットワーク:前回の記事で作成した「VPC領域」
サブネット:パブリックサブネット
自動割り当てパブリックIP:有効 (起動のたびに与えられる動的IP)
ネットワークインターフェースのプライマリIP
→このインスタンスのプライベートIPアドレスのこと
パブリックサブネットは10.0.1.0/24で定義しているので、
10.0.1.0 ~ 10.0.1.255
の範囲で指定する。(ブロードキャストなどの機能はサポートしてないらしい)
ここでは「10.0.1.10」と設定する。ストレージ:デフォルトのEBS
タグ(インスタンスの名前):キーは「Name」値は「Webサーバー」にする。
セキュリティグループ名:WEB-SG
新しいキーペア「my-key」を作成、インスタンスを作成。SSH接続 (Secure SHell)
起動したインスタンスに、インターネットからログインして操作する。
今回はMacのターミナルで接続します。「my-key」がある所まで移動して
$ ssh -i my-key.pem ec2-user@[自分のインスタンスのパブリックIP]__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___|これが出たらok
ファイアウォール
AWSでは、インスタンスに対して構成する「セキュリティグループ」がパケットフィルタリングの役割を担当します。セキュリティグループのインバウンドを見てみると
ポート22に対して、全ての通信(0.0.0.0/0)を許可する。
となっています。
つまりSSH(port:22)だけが通信でき、それ以外の通信はできないようになっている。
これからはWebサーバーソフトなどもインストールしなければならないので、必要に応じてセキュリティグループの構成を変更していきます。まとめ
本記事の完成図。
今回は主にインスタンス作成とssh接続をまとめました。
次はこのインスタンスにWebサーバーソフトをインストールして、Webサーバーにします。

