- 投稿日:2020-04-04T22:47:55+09:00
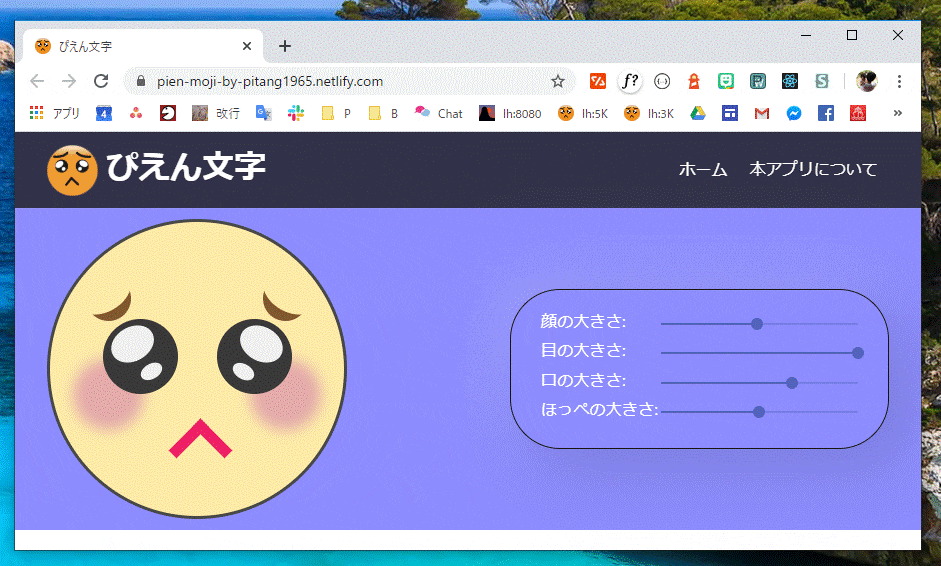
Reactぴえんチャレンジ
Reactぴえんチャレンジって何?
nikoさんの記事に触発されたものです。
2019年12月からUdemyでReactの学習を開始したのですが、練習に丁度よいチャレンジだと思いやってみました。チャレンジ結果
画像をクリックしてください。
チャレンジのポイント
- スライダーを実装するため、初めてMaterial UIというものを使ってみました。
- ReactのHooksを学習したので、クラスコンポーネントを使わず、propsでバケツリレーしないパラメータの引き渡し方法を採用してみました。
- CSSの設定。
- 少し前に、webpackで悩みに悩んでしまったので今回は create-react-app を使ってみました。
- Netlifyにデプロイしてみました。
- GitHubで初めてブランチを使ってみました。
ソースコード
GitHub
練習のために作ったものではありますが、ここをこうしたほうが良いとかありましたら、ぜひご指導ください。謝辞
その他
これを作るのに1週間くらいうんうんうなっていたら、小学生の娘が半日でこんなものを作ったと自慢してくれました。
私はその後も更に2週間くらいうなっていました。ちょっとピエンですね。
- 投稿日:2020-04-04T22:47:55+09:00
Reactぴえんチャンレンジ
Reactぴえんチャレンジって何?
nikoさんの記事に触発されたものです。
2019年12月からUdemyでReactの学習を開始したのですが、練習に丁度よいチャンレンジだと思いやってみました。チャレンジ結果
画像をクリックしてください。
チャレンジのポイント
- スライダーを実装するため、初めてMaterial UIというものを使ってみました。
- ReactのHooksを学習したので、クラスコンポーネントを使わず、propsでバケツリレーしないパラメータの引き渡し方法を採用してみました。
- CSSの設定。
- 少し前に、webpackで悩みに悩んでしまったので今回は create-react-app を使ってみました。
- Netlifyにデプロイしてみました。
- GitHubで初めてブランチを使ってみました。
ソースコード
GitHub
練習のために作ったものではありますが、ここをこうしたほうが良いとかありましたら、ぜひご指導ください。謝辞
その他
これを作るのに1週間くらいうんうんうなっていたら、小学生の娘が半日でこんなものを作ったと自慢してくれました。
私はその後も更に2週間くらいうなっていました。ちょっとピエンですね。
- 投稿日:2020-04-04T22:38:33+09:00
DockerでReactの開発環境を作る
初投稿です。春から大学生の雑魚です。人生ハードモード。
色々不備があると思いますけど、優しくしてね???(?コワイヨォーーーー)Dockerとは
日本語のドキュメントによると
Docker とは、開発者やシステム管理者が、アプリケーションの開発、移動、実行するためのプラットフォームです。
「チーム内で同じ開発環境で開発する事を助けるアプリケーション」って感じです。
用語
コンテナ
アプリケーションの実行を行う開発環境のこと。イメージの情報を元に構築される。
イメージ
コンテナの元となる。コンテナ内の情報が保存されている。
Dockerfile
イメージの内容を記述するファイル。イメージをの元となる。ビルドを行うと、Dockerfileに記述した情報を元にイメージが作成される。
まとめると
- Dockerfileを記述
- ビルドを実行しイメージを作成
- イメージをもとにコンテナを実行
- コンテナ内でアプリケーションを実行
こんな感じになると思います。
実際に書いてみる
Dockerのインストール
テキトーにやってください!???
Dockerで実行するアプリの構築
初めに、コンテナ内で実行したアプリをローカルで作成します。
terminal$ npx create-react-app docker-practice $ cd docker-react-example $ yarn startこんな画面が出たらOK
Dockerfileを書く
コンテナの内容を書いていきます。
terminal$ touch DockerfileDockerfile# ベースイメージの作成 FROM node:12.16.1 # コンテナ内で作業するディレクトリを指定 WORKDIR /usr/src/app # package.jsonとyarn.lockを/usr/src/appにコピー COPY ["package.json", "yarn.lock", "./"] # パッケージをインストール RUN yarn install # ファイルを全部作業用ディレクトリにコピー COPY . . # コンテナを起動する際に実行されるコマンド ENTRYPOINT [ "yarn", "start" ]各種コマンド解説
FROM
Dockerfileには必須のコマンド。
ベースとなるイメージをDocker Hubから取って来る。
今回はnodeの12.16.1を取って来ている。WORKDIR
コンテナ内の作業用ディレクトリを指定する。rootとusr内には色々とデフォルトでファイルがあるから、そこは避けたほうがいいみたい。
COPY
ローカルにあるファイルをコンテナ内にコピーする
構文は
1. COPY <ソース>... <送信先>
2. COPY ["<ソース>",... "<送信先>"]
のどちらかRUN
ビルド時にだけ実行されるコマンド(?)。
初回だけで実行したいコマンドを書くと?ENTRYPOINT
コンテナの起動時に実行される。
似たようなコマンドにCMDというのがあるが、ここで説明すると万里の長城長くなるので割愛なんでpackage.jsonとyarn.lockを先にコピーしてんの?
この記事によると、
dockerはビルド開始時にdocker daemonにDockerfileのディレクトリにあるファイルを全部
tarして送る。
これが大きいとtarするのに時間がかかるみたいなんで、コンテナ内にパッケージの一覧とバージョンの依存関係が書かれたファイルだけコピーして、その後コンテナ内でインストールした方が早いみたいですね!!!
イメージをビルド
コマンドの構文はこんな感じ
→ docker build [オプション] パスterminal$ docker build -t test:1.0 ./-tは名前とタグを指定できる(tagはバージョンみたいなやつ)
指定しなければ名前:latestになる(多分)また、作成したイメージは
terminal$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE test 1.0 335dbb73b720 40 seconds ago 1.22GB node 12.16.1 d834cbcf2402 5 weeks ago 916MBで見ることができる。
コンテナを起動
作成したイメージを元にコンテナを起動するで!
コマンドの構文
→ docker run [オプション] イメージ [コマンド] [引数...]terminal$ docker run -it --name sample -p 3000:3000 -v $PWD:/usr/src/app test:1.0terminalCompiled successfully! You can now view docker-react-example in the browser. Local: http://localhost:3000 On Your Network: http://172.17.0.2:3000 Note that the development build is not optimized. To create a production build, use yarn build.こんな画面が出て
http://localhost:3000 にアクセスして
こんな画面が出たら成功です。ファイルを編集すると、
src/App.jsimport React from 'react'; import logo from './logo.svg'; import './App.css'; function App() { return ( <div className="App"> <header className="App-header"> <img src={logo} className="App-logo" alt="logo" /> <p> Dockerの勉強やでーwwww </p> <a className="App-link" href="https://reactjs.org" target="_blank" rel="noopener noreferrer" > Learn Ruby on Rails </a> </header> </div> ); } export default App;リアルタイムで変更を反映してくれるはずです。
各オプション解説
-it
-iと-tっていうオプションを一気に指定している。
-tは疑似ターミナルの割当
-iはアタッチしていなくても STDIN をオープンにし続けているらしい。-p
コンテナのポートとホストのポートの関連付けを行う
ホスト:コンテナの順番で指定するので、今回の場合はホストの3000がコンテナの3000と接続されている。-v
ホストのファイルのパス:コンテナのファイルのパスで指定する
volumeの略。ホスト内のファイルをコンテナ内のディレクトリにマウントして、
ホスト上で行ったファイルの変更をあたかもコンテナ上で行ったかのように見せることができる。
これによってファイルの差分を自動が実現されている。--name
コンテナの名前を指定
今回はsampleと指定している。--rm(おまけ)
--rmをつけるとコンテナを停止した時に自動で削除してくれる。
これでホストがコンテナだらけになることを防ぐことができる。起動中のコンテナに入る
docker execで起動中のコンテナに入ることができる。
構文は
terminaldocker exec [オプション] コンテナ コマンド [引数...]terminal$ docker exec -it sample bash root@fe248383642c:/usr/src/app# root@fe248383642c:/usr/src/app# ls Dockerfile docker-command.md docker-compose.md dockerfile.md node_modules package.json public src yarn.lock root@fe248383642c:/usr/src/app# # exitで抜けることが出来ます。 root@fe248383642c:/usr/src/app# exit exit $こんな感じでファイルをイジイジすることができます。
起動しているコンテナを一覧で表示
docker ps で出来ます。
-aオプションを付けると停止中のコンテナも出てきます。terminal$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fe248383642c test:1.0 "yarn start" 24 hours ago Up 13 minutes $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fe248383642c test:1.0 "yarn start" 24 hours ago Up 4 minutes 0.0.0.0:3000->3000/tcp sample bac4be724af7 docker-ruby_ruby "irb" 39 hours ago Exited (1) 18 hours ago ruby c2346fe966a2 test "yarn start example" 2 days ago Exited (1) 24 (中略)コンテナの停止
docker stop コンテナ名 で出来ます。
terminal$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fe248383642c test:1.0 "yarn start" 24 hours ago Up 13 minutes 0.0.0.0:3000->3000/tcp sample $ docker stop sample sample $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES $コンテナの再起動
docker restart コンテナ名 で出来ます。
terminal$ docker restart sample sample $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fe248383642c test:1.0 "yarn start" 24 hours ago Up 7 seconds 0.0.0.0:3000->3000/tcp sample終わりに
大体よく使うコマンドとかについて触れられたかなと思います。
Dockerの内部構造はあまり理解できてないので、別の記事でアウトプットしたいなーって感じです。


- 投稿日:2020-04-04T20:08:30+09:00
react-router@v6で何が変わるのか
はじめに
ReactでSPAを作るときのおそらくデファクトスタンダードであろうreact-routerですが現在v6が開発中で、しばらくしたら単純に
npm install react-routerとするとv6がインストールされるようになります。
v6はAPIに破壊的な変更が入ります。つまり、今ある入門記事の通りに書いても動かなくなります。
というわけでこの記事では書き方がどう変わるか、そして個人的により重要な中身がどう変わったのかについて説明します。第1部:書き方の変更編
v5での書き方
まずは前提知識としてv5での書き方です1。すでに優良な記事があるので詳しくは解説しません。
v5での書き方<Router> <Switch> <Route path="/about"> <About /> </Route> <Route path="/users"> <Users /> </Route> <Route path="/"> <Home /> </Route> </Switch> </Router>
Routerの中にRouteを書き、パスとマッチしたときにレンダリングされる要素を指定します。
RouteをSwitchで囲んだ場合は「初めにマッチしたもの」がレンダリングされる、囲まない場合は「マッチするものが全部」レンダリングされます。なお
Routeでレンダリングされる要素を指定する方法は以下の4種類があります。
children、つまり、Routeの中に書く(推奨)componentで指定する2renderで「要素を返す関数」を渡すchildrenで関数を渡す。1つ目との違いはpropである点。またrenderとの違いは「マッチしたかに関わらず常にレンダリングされる」点普通は「普通のchildren」もしくはcomponentを使うと思いますがはっきり言ってややこしいです。
v6ではこうなる
現時点(2020/4/4)でv6を試してみるには以下のようにインストールします。
リリースノートだと@6みたいに書かれていましたがそれだと「そんなバージョンない」エラーになりました3。npm install history@next react-router@next react-router-dom@next2020/4/4(早朝)時点で入るバージョンは以下となります。
+ react-router-dom@6.0.0-alpha.2 + react-router@6.0.0-alpha.2 + history@5.0.0-beta.7さて、v6では上で示したルーティングの書き方が以下のようになります。
v6での書き方<Router> <Routes> <Route path="/about" element={<About />} /> <Route path="/users" element={<Users />} /> <Route path="/" element={<Home />} /> </Routes> </Router>
SwitchはなくなりRoutesになりました。なおv5ではSwitchは「なくてもいい(直接Routeを書いてもいい)」でしたが、v6では必ずRoutesで囲む必要があります- レンダリングされる要素は
elementで指定する。これ以外の方法はない
elementで指定する方法はv5での「普通のchildren」での指定方法と同じです。まあちょっと/が多いのが気になりますが。Getting Startedによるとv6では単に書き方が変わるだけでなく以下の機能が追加されています。
RouteにRouteをネストできるようになった。これは相対パスとして動作しますLinkも相対パスで書けるようになった。これはmigration guideのbefore(v5) after(v6)を見るととてもシンプルですね他に注意が必要な点としては、v5ではパスパラメータ(
path=/users/:idみたいに指定するやつ)を取得する方法がuseParams関数のみになります。propsでmatchは渡されなくなります。第2部:内部構造の変更編
さて(個人的)本題はここからです。
v5の実装
そもそもこの記事を書くきっかけとなったのはreact-routerがどう動いているかを調べようと思ったことでした。
react-router@v5を使ってるプログラムをReact Developer Toolsで見ると以下のようになります。非常にややこしい。
RouterとRouterContext
Routeのような表示対象に依存しないコードはreact-routerに、Linkのように表示対象に依存するコードはreact-router-domに置かれています。リンク張るバージョンは5.1.2です。
BrowserRouterは後で見るので、まずreact-routerパッケージの方のRouter.jsを見ます。するとContextを使っていることがわかります。Router.js抜粋import RouterContext from "./RouterContext";この
RouterContextはReact 16で導入されたコンテキストではありません。後々関わってくるのは1行目のコメントです。RouterContext.js// TODO: Replace with React.createContext once we can assume React 16+ import createContext from "mini-create-react-context"; const createNamedContext = name => { const context = createContext(); context.displayName = name; return context; }; const context = /*#__PURE__*/ createNamedContext("Router"); export default context;ともかくこのContextを使ってレンダリングが行われています。
historyとlocationは後で見ます。Router.js抜粋render() { return ( <RouterContext.Provider children={this.props.children || null} value={{ history: this.props.history, location: this.state.location, match: Router.computeRootMatch(this.state.location.pathname), staticContext: this.props.staticContext }} /> ); }Link
次に
Link(がレンダリングしてるaタグ)がクリックされたときに何が起こるかLink.jsを見てみましょう。LinkとLinkAnchorに分かれててややこしいですが4全体として以下のように動作します(長くなるのでコードは貼りません。リンク先を見ながら説明を読んでください)
Link:Contextとして渡されるhistoryを操作するnavigate関数を定義しLinkAnchorに渡すLinkAnchor:aタグがクリックされたら渡されたnavigate関数を実行するこれでクリックされたらhistory(ブラウザ履歴)が変わるところはできました。
再びRouter
ここまでコードを読んで、「ブラウザ履歴が変わるのはわかったけど、React的にはどうやってレンダリングし直してるの?」ということはわからなかったのでもう一度Router.jsを見てみました。
Router.js抜粋constructor(props) { super(props); this.state = { location: props.history.location }; // This is a bit of a hack. We have to start listening for location // changes here in the constructor in case there are any <Redirect>s // on the initial render. If there are, they will replace/push when // they mount and since cDM fires in children before parents, we may // get a new location before the <Router> is mounted. this._isMounted = false; this._pendingLocation = null; if (!props.staticContext) { this.unlisten = props.history.listen(location => { if (this._isMounted) { this.setState({ location }); } else { this._pendingLocation = location; } }); } }最後のif文は普通の使い方であれば実行されます。つまり、下の方で
historyの操作を行えばそれがRouterに通知され、stateを変え、再レンダリングされるという仕組みのようです。BrowserRouter
後回しにしていた
BrowserRouterです。特に難しいことはしていません。historyオブジェクトを作成してRouterに渡しています。
historyパッケージはreact-routerと同じ開発チームが作っているようです。BrowserRoter.js抜粋import React from "react"; import { Router } from "react-router"; import { createBrowserHistory as createHistory } from "history"; /** * The public API for a <Router> that uses HTML5 history. */ class BrowserRouter extends React.Component { history = createHistory(this.props); render() { return <Router history={this.history} children={this.props.children} />; } }Route
v5実装巡りの最後にRoute.jsを見てみましょう。この記事を書くきっかけになったコードです。
Route.js抜粋render() { return ( <RouterContext.Consumer> {context => { // 省略 return ( <RouterContext.Provider value={props}> {props.match ? children ? typeof children === "function" ? __DEV__ ? evalChildrenDev(children, props, this.props.path) : children(props) : children : component ? React.createElement(component, props) : render ? render(props) : null : typeof children === "function" ? __DEV__ ? evalChildrenDev(children, props, this.props.path) : children(props) : null} </RouterContext.Provider> ); }} </RouterContext.Consumer> ); }( ゚д゚)
三項演算子をここまで使いまくったコードは初めて見ました。
このコードがわかりにくいのは中盤のインデントが「わかりにくい」ためです。インデントを「直す」と以下のようになります。{props.match ? children ? typeof children === "function" ? __DEV__ ? evalChildrenDev(children, props, this.props.path) : children(props) : children : component // childがfalsyの場合 ? React.createElement(component, props) // child:fasly, component:truthy : render // childもcomponentもfalsyの場合 ? render(props) // child:fasly, component:falsy, render:truthy : null : typeof children === "function" ? __DEV__ ? evalChildrenDev(children, props, this.props.path) : children(props) : null}いやあんまり変わらねえよ。わかりにくい。
何これ直してpullreq送るべきなの?と思ったらすでにされており、さらに衝撃的な事実が発覚しました。I've stated before that this form is more readable, but I know Ryan and Michael disagree.
訳:前にこっちの方が読みやすいって言ったんだけど、作者が反対したんだ。まじですか。
ここで第1部で触れたレンダリングされる要素を指定する4つの方法を振り返りましょう。
children、つまり、Routeの中に書く(推奨)componentで指定するrenderで「要素を返す関数」を渡すchildrenで関数を渡す。1つ目との違いはpropである点。またrenderとの違いは「マッチしたかに関わらず常にレンダリングされる」点まあ確かに
childrenが多義な点を除けば(これがいけなかったんじゃ)、APIドキュメントに書いてある順に処理されているので「わかりやすい」気がする。v6の実装
次にv6実装について見ていきましょう。
まずはv5との比較としてReact Developer Toolsでのコンポーネント階層です。v5からだいぶシンプルになっていますね。
ファイル構成の変更
v6でも
react-routerとreact-router-domにパッケージが分かれていることは変わりありません。
一方、ファイル構成は非常にシンプルになっています。リンク張るバージョンは6.0.0-alpha.2です5。アルファなので以下で説明する実装は変わる可能性がありますが大きく変わることはないでしょう。react-router内に入ると「あれ?」ってぐらいシンプルになっています。本体のファイルはindex.jsだけです(react-router-domも同様)
RouterとContext
ともかくreact-routerの方のindex.jsを見てみるとシンプルになった理由がわかります。
伏線しておきましたね?そう、v6はReactのコンテキストとフックを使った実装にリライトされています。react-router/index.js抜粋const LocationContext = React.createContext(); export function Router({ children = null, history, timeout = 2000 }) { let [location, setLocation] = React.useState(history.location); let [startTransition, pending] = useTransition({ timeoutMs: timeout }); let listeningRef = React.useRef(false); if (!listeningRef.current) { listeningRef.current = true; history.listen(({ location }) => { startTransition(() => { setLocation(location); }); }); } return ( <LocationContext.Provider children={children} value={{ history, location, pending }} /> ); }初め見たときは「え?
LocationContextグローバルでいいの?」と思いましたが、Routerを複数使うなんてことはまずないでしょうし実装がシンプルになるのでいいと思います。なお先に説明しておくと、
Linkがレンダリングするaタグがクリックされることでhistoryが操作される
→上記のlistenで登録されているコールバックが実行される
→setLocationを使用してlocationを更新
→再レンダリング
という流れはv5と違いはありません(クラスとフックという違いを除けば)LinkとuseNavigate
Linkはreact-router-domの方のindex.jsに書かれています。react-router-dom/index.js抜粋export const Link = React.forwardRef(function LinkWithRef( { as: Component = 'a', // 省略 to, ...rest }, ref ) { let href = useHref(to); let navigate = useNavigate(); let location = useLocation(); let toLocation = useResolvedLocation(to); function handleClick(event) { if (onClick) onClick(event); if ( // 省略。普通の使い方であれば成立します ) { // 省略 navigate(to, { replace, state }); } } return ( <Component {...rest} href={href} onClick={handleClick} ref={ref} target={target} /> ); });
useHref~useResolveLocationはreact-routerパッケージで定義されているフックです。次にuseNavigateに移りましょう。react-router/index.js抜粋export function useNavigate() { let { history, pending } = React.useContext(LocationContext); let { pathname } = React.useContext(RouteContext); let navigate = React.useCallback( (to, { replace, state } = {}) => { if (typeof to === 'number') { history.go(to); } else { let relativeTo = resolveLocation(to, pathname); // If we are pending transition, use REPLACE instead of PUSH. // This will prevent URLs that we started navigating to but // never fully loaded from appearing in the history stack. let method = !!replace || pending ? 'replace' : 'push'; history[method](relativeTo, state); } }, [history, pending, pathname] ); return navigate; }第1部で紹介した相対パスの処理も行われていますが基本的にはv5のころに
Linkコンポーネント内で行われていた処理が抽出されています。その分Linkの方はシンプルになりました。RouteとRoutes
BrowserRouterは特筆することないので飛ばして、v5実装で魔窟化していたRouteに移ります。react-router/index.js抜粋export function Route({ element }) { return element; }これまた見るところ間違えたかなと思うぐらいシンプルです。が、第1部で見たようにv6ではRouterは
elementしか受け付けないのでこれであってます。やはりv5の仕様が単に狂ってただけじゃ複雑な実装、ってよく思うとv5実装解説ではそこら辺さくっと略しましたが、はどこに行ったかというと
Routesです。
より正確には、
createRoutesFromChildrenでchildrenの情報を集めてuseRoutes(内部でmatchRoutes呼び出し)を使ってlocationに対応するRouteをレンダリングということが行われています。ここの部分については淡々とがんばってるだけなので省略。
あとがき
以上、react-router@v5→v6での使い方の変更、内部実装の変更について見てきました。
途中でも書いたように当初はv5の実装理解が目的、そこで見かけた「超絶三項演算子利用例」についてだけ書こうかと思ったのですが、「いや待てそういえばリリースの方見るとそろそろv6出るよな」と見に行ったらフックを使う実装に置き換わっていた(うえにRouteもシンプル化して超絶三項演算子もなくなった)のでこちらも実装解説、さらにもう少し一般向け(?)に「使い方がどう変わるのか」についても書くことにしました。破壊的なAPI変更はOh...ですけど、おそらく売りとなる相対パスはかなり有用そうだと思いました。ちなみに、フック利用&シンプル化の効果は出ており、v6はかなり「軽く」なっています。
海外の記事だと9.4kbが2.9kbになった(gzippedされてる場合)と書かれていますが、公式ドキュメントではCDN指定としてreact-routerとreact-router-domが分かれているのでその指定で正しいのか?というのが疑問(v5はreact-router-domだけで正しい)、でもunpkg見るとreact-router-dom単体はminifiedのサイズ8.5kbもないしとやや根拠が怪しいですが軽くはなっているようです。
react-router公式のQuick Startより引用。リンク張ってもそのうち内容変わりそうですが一応リンク:https://reacttraining.com/react-router/web/guides/quick-start ↩
前にQuick Start見たときはこれで書いてあった気がするのだけど記憶違いかな ↩
6.0.0-alpha.2のように正確に指定すればインストールできます。 ↩分かれてる理由は「リンク」としてレンダリングされる要素を
componentとして渡せるからのようですがドキュメントには特にその旨ないですね ↩朝のうちにv5実装についてまで書き上げて、桜見物して帰ってきたら6.0.0-alpha.3がリリースされてましたw。主な違いは
Redirectをなくしたことのようですね ↩


- 投稿日:2020-04-04T18:45:40+09:00
素人がWebサービスを自分で作る備忘録(前準備編)1
この記事の目的
この記事は自分が初めてWebサービスを作るにあたっての備忘録的な意味合いが強いです。
その為、エンジニアリング経験者の方にとっては特に為になる内容ではないと思われますが、ズブの素人が初めてサービスを開発しようと思ってからの成長日記だと思って見てもらえると嬉しいです。また、同じような未経験者の方がWebサービスを開発しようとしたとき、何かの手助けになれれば嬉しいと思います。
現在のレベル
・Progate学習済み(HTML&CSS、Javascript、React、Ruby、RubyonRails、Git、CommandLine、SQL)
・Railsチュートリアル 二周個人でWebサービスを作る際にはまず、何のために作るのか決めそれに適した基礎知識を習得する必要が出てきます。
今回は、第一の目標として今まで学習してきた内容のアウトプット、第二の目標はモダンなIT企業へのジョブチェンジするためのポートフォリオ作成ということで行っていきます。
その為、Web業界で今現在多く使われているRailsを選択しました。
Rails学習のバイブルとして多くに人に利用されているRailsチュートリアルですが、これを内容を理解するためには学習のための学習が必要となってくる(Reactを除く)。その学習にはProgateがおすすめ!Webサービスの企画
上記の学習を終えたところで実際に、Webサービスの開発に入っていきます
しかし、いきなりコードを書けと言われて書くことはできないはずです!なぜなら何を作ろうとか、どのような機能を持たせようとか、そういったところの話を先にやらないと作れるわけがないんです!1. 何のために作成するのか
2. どのような物を作るのか
3. どういった機能を盛り込むのかこのようなところから考えていきたいと思います。
1に関しては上でも書いた通り、知識のアウトプット、ポートフォリオ作成です。
2に関しては
・今まで学んだ知識 +αで作れる物(大きなことを言うと後で後悔しそうなので)
・未経験からの転職で有利になりそうな機能を実装すること
・自分が作りたい物(コロナとかで外に出れないので他の人と繋がれるサービスとか)を条件とします。
3に関しては・ユーザー管理機能
・投稿機能
・投稿一覧、投稿詳細機能
・画像ファイルアップロード機能
・ページネーション機能or無限スクロール機能
・DBテーブルのリレーション管理
・単体、統合テスト
+αの内容
・ReactによるJavascriptライブラリ
を取り入れていこうと思います。次では具体的なサービスの形を考えていくことについて書いていこうと思います。
- 投稿日:2020-04-04T18:45:40+09:00
素人がWebサービスを自分で作る備忘録(前準備編)
この記事の目的
この記事は自分が初めてWebサービスを作るにあたっての備忘録的な意味合いが強いです。
その為、エンジニアリング経験者の方にとっては特に為になる内容ではないと思われますが、ズブの素人が初めてサービスを開発しようと思ってからの成長日記だと思って見てもらえると嬉しいです。また、同じような未経験者の方がWebサービスを開発しようとしたとき、何かの手助けになれれば嬉しいと思います。
現在のレベル
・Progate学習済み(HTML&CSS、Javascript、React、Ruby、RubyonRails、Git、CommandLine、SQL)
・Railsチュートリアル 二周個人でWebサービスを作る際にはまず、何のために作るのか決めそれに適した基礎知識を習得する必要が出てきます。
今回は、第一の目標として今まで学習してきた内容のアウトプット、第二の目標はモダンなIT企業へのジョブチェンジするためのポートフォリオ作成ということで行っていきます。
その為、Web業界で今現在多く使われているRailsを選択しました。
Rails学習のバイブルとして多くに人に利用されているRailsチュートリアルですが、これを内容を理解するためには学習のための学習が必要となってくる(Reactを除く)。その学習にはProgateがおすすめ!Webサービスの企画
上記の学習を終えたところで実際に、Webサービスの開発に入っていきます
しかし、いきなりコードを書けと言われて書くことはできないはずです!なぜなら何を作ろうとか、どのような機能を持たせようとか、そういったところの話を先にやらないと作れるわけがないんです!1. 何のために作成するのか
2. どのような物を作るのか
3. どういった機能を盛り込むのかこのようなところから考えていきたいと思います。
1に関しては上でも書いた通り、知識のアウトプット、ポートフォリオ作成です。
2に関しては
・今まで学んだ知識 +αで作れる物(大きなことを言うと後で後悔しそうなので)
・未経験からの転職で有利になりそうな機能を実装すること
・自分が作りたい物(コロナとかで外に出れないので他の人と繋がれるサービスとか)を条件とします。
3に関しては・ユーザー管理機能
・投稿機能
・投稿一覧、投稿詳細機能
・画像ファイルアップロード機能
・ページネーション機能or無限スクロール機能
・DBテーブルのリレーション管理
・単体、統合テスト
+αの内容
・ReactによるJavascriptライブラリ
を取り入れていこうと思います。Webサービスの見た目を考える
Webサービスの見た目を考える場合、誰をターゲットにするのか、どのような場面で使われるのかなどを考えて機能やページデザインを考える物です。
しかし、今回は完全に自分のためのものですのでその辺は深く考えずやっていきたいと思います。(はやく実装に進みたいので)とりあえず
ターゲット:20代 外出自粛させられているせいで友達と遊べなくて暇を持て余している。ページデザインは適当にサックリ手書きで紙に書きました。(早く実装にすすみt)
画面遷移図も手書きでさっくり(早くz)データベース設計も手書きで作成。
※データベーススキーマ設計は私にとって初めて聞くものだったので別の記事にてもう少しまとめたいと思います。ここまで行ったこと
・基礎学習
・Webサービスの企画
なぜ作るのか
どのような物を作るのか
どういった機能が必要なのか
・Webサービス設計
ワイヤーフレーム作成
URL決定
画面遷移図の作成
データベース設計
タスクの確認
- 投稿日:2020-04-04T14:34:17+09:00
No Firebase App '[DEFAULT]' has been created と怒られた
環境
React.jsTypeScriptFirebase怒られたコード
main.tsximport React from "react" import ReactDOM from "react-dom" import App from "./App" const config = { apiKey: "<API_KEY>", authDomain: "<AUTH_DOMAIN>", databaseURL: "<DATABASE_URL>", projectId: "<PROJECT_ID>", storageBucket: "<STORAGE_BUCKET>", messagingSenderId: "<MESSAGING_SENDER_ID>", appId: "<APP_ID>", measurementId: "<MEASUREMENT_ID>" } firebase.initializeApp(config) ReactDOM.render(<App />, document.getElementById("root"))App.tsximport React from "react" import * as firebase from "firebase" const firestore = firebase.app().firestore() export default function App() { return ( <h1>Hello, World!</h1> ) }動いたコード
firebase.initializeApp()をimportの前に書いた。main.tsxconst config = { apiKey: "<API_KEY>", authDomain: "<AUTH_DOMAIN>", databaseURL: "<DATABASE_URL>", projectId: "<PROJECT_ID>", storageBucket: "<STORAGE_BUCKET>", messagingSenderId: "<MESSAGING_SENDER_ID>", appId: "<APP_ID>", measurementId: "<MEASUREMENT_ID>" } firebase.initializeApp(config) import React from "react" import ReactDOM from "react-dom" import App from "./App" ReactDOM.render(<App />, document.getElementById("root"))App.tsximport React from "react" import * as firebase from "firebase" const firestore = firebase.app().firestore() export default function App() { return ( <h1>Hello, World!</h1> ) }原因
importの段階でApp.tsx内のconst firestore = firebase.app().firestore()が実行されたのかも
詳しくはわからない
- 投稿日:2020-04-04T02:15:01+09:00
Concurrent Mode時代のReact設計論 (4) コンポーネント設計にサスペンドを組み込む
この記事は「Concurrent Mode時代のReact設計論」シリーズの4番目の記事です。
シリーズ一覧
- Concurrent Mode時代のReact設計論 (1) Concurrent Modeにおける非同期処理
- Concurrent Mode時代のReact設計論 (2) useTransitionを活用する
- Concurrent Mode時代のReact設計論 (3) SuspenseやuseTransitionが何を解決するか
- Concurrent Mode時代のReact設計論 (4) コンポーネント設計にサスペンドを組み込む
- Concurrent Mode時代のReact設計論 (5) トランジションを軸に設計する(仮)
- Concurrent Mode時代のReact設計論 (6) ステート管理ライブラリの展望(仮)
- Concurrent Mode時代のReact設計論 (7) まとめ(仮)
コンポーネント設計にサスペンドを組み込む
前回の最後にrender-as-you-fetchという概念が出てきました。これは、ReactのConcurrent Modeのドキュメントにおいて提唱されているUXパターンであり、読み込んで表示すべきデータが複数ある場合に、全てが読み込み完了するまで待つのではなく読み込めたデータから順に表示するというものです。
このパターンの良し悪しはともかく、これはConcurrent Mode時代のコンポーネント設計を議論するための格好の題材です。
基本パターン: データごとにPromiseを分ける
Concurrent Modeにおいてrender-as-you-fetchを実現するには、それぞれのデータに対して異なるPromise(
Fetcher)を用意する必要があります。そして、各データを担当するコンポーネントを用意して、それぞれのコンポーネントがサスペンドします。そうすることで、それぞれのデータが用意できた段階でコンポーネントのサスペンドが解除(再レンダリング)され、その部分のデータが表示されます。
具体例として、ユーザーのリストを3種類読み込んでrender-as-you-fetch戦略で表示するコンポーネントを書いてみるとこんな感じです。
const PageB: FunctionComponent<{ dailyRankingFetcher: Fetcher<User[]>; weeklyRankingFetcher: Fetcher<User[]>; monthlyRankingFetcher: Fetcher<User[]>; }> = ({ dailyRankingFetcher, weeklyRankingFetcher, monthlyRankingFetcher }) => { return ( <> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={dailyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={weeklyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={monthlyRankingFetcher} /> </Suspense> </> ); }; const Users: FunctionComponent<{ usersFetcher: Fetcher<User[]>; }> = ({ usersFetcher }) => { const users = usersFetcher.get(); return ( <ul> {users.map(({ id, name }) => ( <li key={id}>{name}</li> ))} </ul> ); };
PageBは3種類のFetcher<User[]>を受け取ります。実際にFetcher<User[]>から得てデータを表示するのは別に用意したUsersコンポーネントが担当しており、PageBの役割は各Users要素をSuspenseで囲むことです。ポイントは、このように
UsersをそれぞれSuspenseで囲まないといけないということです。復習すると、Suspenseの役割はその内部で発生したサスペンドをキャッチして、その場合にfallbackで指定されたフォールバックコンテンツを代わりにレンダリングすることです。Suspenseの中のどこでサスペンドが発生しようと、そのSuspenseの中身全体がフォールバックします。このことから、
Suspenseを用いてrender-as-you-fetchパターンを実装するには、あるコンポーネントがサスペンドしても他の部分に影響を与えないようにする必要があります。ここではSuspenseを複数並べることでこれを達成しています。実際この
PageBを適当なデータでレンダリングすると、下のスクリーンショットのように一つずつLoading users...がUsersによってレンダリングされたデータに置き換わっていく挙動をとります。
ちなみに、
Suspenseの組み立て方によって色々な表示パターンを実現することができます。例えば、次のようにすると、dailyRankingFetcherが用意できるまでは何も表示せず、用意できたら残りを待つという挙動になります。<Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={dailyRankingFetcher} /> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={weeklyRankingFetcher} /> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={monthlyRankingFetcher} /> </Suspense> </Suspense> </Suspense>このように、コンポーネントが非同期処理の結果をどのように待ってどう表示するのかというロジックは
Suspenseを用いて書くことができます。これはつまり、Concurrent Modeではrender-as-you-fetchパターンに必要なロジックを実際にそのデータを表示するコンポーネントが(内部でのコンポーネント分割は起こりますが)記述できるということを表しています。前回の記事で示した問題の一つがConcurrent Modeでは解決されているわけです。おまけに、
Suspenseという道具を用いて、データローディングに係るロジックをJSXというきわめて宣言的な表現により記述することができています。一応誤解がないように述べておくとJSXという構文は重要ではなく、本質的にこの点に寄与しているのはコンポーネントが成す木構造という表現方法なのですが。なお、この立場に立つと、レンダリングのサスペンドというのはコンポーネントが発生させる現象ですから、サスペンドする役割を持つコンポーネント(今回は
Users)を明確にすることが重要になります。コンポーネントにdoc commentなどを書く際に、「このコンポーネントはいつサスペンドするのか」を明示しておくのもよいでしょう。
useTransitionとSuspenseの関係まず
useTransitionについて復習します。このフックからはstartTransition関数を得ることができ、startTransitionの内部で発生したステート更新により再レンダリングが発生してそのレンダリングでサスペンドが発生した場合、サスペンドが解消されるまで画面に更新前のステートを表示し続けられるというものでした。
useTransitionが絡むと、Suspenseに係るコンポーネント設計はかなり複雑な様相をとります。これに関連して、ひとつ重要な事実を覚えていただく必要があります。それは、再レンダリング時に新たにマウントされた
Suspenseの中で起きたサスペンドはuseTransitionからは無視されるという点です。言い方を変えれば、useTransitionの効果を発動するには、あらかじめ用意してあったSuspenceにサスペンドをキャッチしてもらう必要があるということです。この挙動はバグなのではと筆者は一瞬思いましたが、このissueで説明されている通りこれは仕様です。
コンポーネントを設計する際にはこのことを念頭に考える必要があります。すなわち、あるコンポーネントの中でサスペンドを発生させるにあたり、それが
useTransitionに対応するサスペンド(外部のSuspenseによりキャッチされることを意図したサスペンド)なのか、それともuseTransitionに対応しないサスペンド(自身の中で新たに生成したSuspenseによりキャッチされるサスペンド)なのかを意識的に区別しなければならないということです。では、先ほど出てきた
PageBの場合はどうでしょうか。const PageB: FunctionComponent<{ dailyRankingFetcher: Fetcher<User[]>; weeklyRankingFetcher: Fetcher<User[]>; monthlyRankingFetcher: Fetcher<User[]>; }> = ({ dailyRankingFetcher, weeklyRankingFetcher, monthlyRankingFetcher }) => { return ( <> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={dailyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={weeklyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={monthlyRankingFetcher} /> </Suspense> </> ); };
startTransition中のステート更新で新たにPageBコンポーネントがマウントされた場合、3つのSuspenseコンポーネントがマウントされ、その中で発生したサスペンドは即座にキャッチされます。このとき、ステート更新によって発生したサスペンドは全て新たにマウントされたSuspenseによってキャッチされることになります。よって、このステート更新では
useTransitionの効果は発揮されません。ステート更新が行われた瞬間にPageBがレンダリングされDOMに反映されます。PageBは最初3つのLoading users...を表示することになるでしょう。実際、このPageBに前回の記事で出てきたRootとPageAを繋げてみるとそのような挙動になります。興味がある方は実際にやってみましょう。
useTransitionのための応用的なコンポーネントデザインこのことを踏まえて、
PageBをuseTransitionに対応するように改良するにはどうすればよいか考えてみましょう。もし「全部ロードされるまで前の画面を表示し続けたい」という場合は話は簡単で、それぞれのUsersコンポーネントをSuspenseで囲むのをやめればよいです。また、例えば「dailyRankingFetcherがロード完了するまでは前の画面を表示し続けたい」のような場合も、対応するUsersだけSuspenseで囲まなければ対応できます。厄介なのは、「どれか1つのデータが読み込めるまでは前の画面を表示し続けたい」というような場合です。この場合はただ
Suspenseを消すだけでは達成できません。Promiseの機能を思い出すと、「どれか1つのPromiseが解決するまで待つ」という挙動は
Promise.raceにより達成できます。ということで、今回はFetcher.raceを用意すれば解決できますね。
Fetcher.raceの実装を用意するとこんな感じです(コンストラクタをあのインターフェースにしたので実装がひどいことになっていますがサンプルだと思って大目に見てください)。static race<T extends Fetcher<any>[]>( fetchers: T ): Fetcher<FetcherValue<T[number]>> { for (const f of fetchers) { if (f.state.state === "fulfilled") { const result = new Fetcher<any>(() => Promise.resolve()); result.state = { state: "fulfilled", value: f.state.value }; return result; } else if (f.state.state === "rejected") { const result = new Fetcher<any>(() => Promise.resolve()); result.state = { state: "rejected", error: f.state.error }; } } return new Fetcher(() => Promise.race(fetchers.map(f => (f as any).promise)) ); }ちなみに、型に出てきた
FetcherValueはこのように定義しています。型安全な実装が厳しい場合でも、型パズルでも何でも駆使して関数のインターフェースだけは正確さを守るというのが堅牢なTypeScriptプログラムを書くコツです。type FetcherValue<F> = F extends Fetcher<infer T> ? T : unknown;話を元に戻すと、この
Fetcher.raceを使ってPageBをこのように定義すれば、「どれか1つのデータが来るまでサスペンドする」という挙動が実現できます。Fetcher.race([...])はgetメソッドを使用するためだけに作られており、その値はPageB直下では使われていません。このように、値を得ることではなくサスペンドすることが主目的のFetcherというのも存在し得ます。少し話が違いますが、筆者も第1回の記事で紹介したアプリケーションではFetcher<void>を多用しています。const PageB: FunctionComponent<{ dailyRankingFetcher: Fetcher<User[]>; weeklyRankingFetcher: Fetcher<User[]>; monthlyRankingFetcher: Fetcher<User[]>; }> = ({ dailyRankingFetcher, weeklyRankingFetcher, monthlyRankingFetcher }) => { Fetcher.race([ dailyRankingFetcher, weeklyRankingFetcher, monthlyRankingFetcher ]).get(); return ( <> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={dailyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={weeklyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={monthlyRankingFetcher} /> </Suspense> </> ); };再レンダリング時のサスペンド設計
ここからは、一旦最初の
PageBに頭を戻して考えます。const PageB: FunctionComponent<{ dailyRankingFetcher: Fetcher<User[]>; weeklyRankingFetcher: Fetcher<User[]>; monthlyRankingFetcher: Fetcher<User[]>; }> = ({ dailyRankingFetcher, weeklyRankingFetcher, monthlyRankingFetcher }) => { return ( <> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={dailyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={weeklyRankingFetcher} /> </Suspense> <Suspense fallback={<p>Loading users...</p>}> <Users usersFetcher={monthlyRankingFetcher} /> </Suspense> </> ); };これまでの議論では
PageBが新規にマウントされた場合を考えていました。このときは中身のSuspenseが新規にマウントされるので、その中のUsersがサスペンドしてもuseTransitionが反応しないのでした。では、
PageBがすでにマウントされている状態で、startTransitionの中のステート更新に起因してPageBのpropsが変わった場合はどうでしょうか。新しくpropsから渡されたFetcherによってサスペンドした場合、それをキャッチするのはPageBがレンダリングしたSuspenseであることに変わりませんが、今回はこれらのSuspenseはあらかじめマウントしてあったSuspenseです。なぜなら、前回のPageBのレンダリングによってこのSuspenseはすでにマウントされていたからです。よって、この場合はuseTransitionが働きます。つまり、
PageBは「新しくマウントされたときはuseTransitionに非対応だが、マウント済の状態でpropsが更新された時はuseTransitionに対応」という特徴を持つコンポーネントなのです。Concurrent Modeによほど精通していなければ、コンポーネントの定義を一目見てこのことを見抜くのは難しいでしょう。この状態はなんだか一貫性がありませんね。これでも良いならばこの実装で問題ありませんが、どちらかに統一したいということもあるでしょう。まず、常に
useTransitionに対応にしたい場合の方法は先ほどまで述べた通りで、Suspenseを消すなり、Suspenseの中ではなくPageB自体がサスペンドするなりといった方法があります。一方、常に
useTransition非対応にしたい場合はどうすれば良いでしょうか。答えは、「propsが変わるたびにSuspenseをマウントし直す」です。そうすることでSuspenseは常に新しくマウントされた扱いとなり、その中でのサスペンドはuseTransitionに影響しなくなります。Suspenseをマウントし直すにはkeyを用います。Reactでは、同じコンポーネントでも異なるkeyが与えられた場合は別のコンポーネントと見なされますから、propsが変わるたびにSuspenseに与えるkeyを変えることで、Suspenseをアンマウント→マウントさせることができます。具体的な方法の一例としては、まず次のような
useObjectIdカスタムフックを用意します。export const useObjectId = () => { const nextId = useRef(0); const mapRef = useRef<WeakMap<object, number>>(); return (obj: object) => { const map = mapRef.current || (mapRef.current = new WeakMap()); const objId = map.get(obj); if (objId === undefined) { map.set(obj, nextId.current); return nextId.current++; } return objId; }; };このフックは
PageBの中で次のように使います。今回のコードではそれぞれのSuspenseにkeyが与えられており、keyを計算するためにuseObjectIdを使用しています。const PageB: FunctionComponent<{ dailyRankingFetcher: Fetcher<User[]>; weeklyRankingFetcher: Fetcher<User[]>; monthlyRankingFetcher: Fetcher<User[]>; }> = ({ dailyRankingFetcher, weeklyRankingFetcher, monthlyRankingFetcher }) => { const getObjectId = useObjectId(); return ( <> <Suspense key={`${getObjectId(dailyRankingFetcher)}-1`} fallback={<p>Loading users...</p>} > <Users usersFetcher={dailyRankingFetcher} /> </Suspense> <Suspense key={`${getObjectId(weeklyRankingFetcher)}-2`} fallback={<p>Loading users...</p>} > <Users usersFetcher={weeklyRankingFetcher} /> </Suspense> <Suspense key={`${getObjectId(monthlyRankingFetcher)}-3`} fallback={<p>Loading users...</p>} > <Users usersFetcher={monthlyRankingFetcher} /> </Suspense> </> ); };
useObjectIdフックは関数getObjectIdを返します。この関数は各オブジェクトに対して異なるIDを返します。同じオブジェクトに対しては何回呼んでも同じIDが返されます。これをkeyに組み込むことによって、daylyRankingFetcherなどに別のFetcherが渡されたタイミングでSuspenseに渡されるkeyも更新され、新たなSuspenseがマウントされた扱いになります。この実装により、
PageBが別のpropsで再レンダリングされた場合でも、内部で発生するサスペンドの影響を内部に封じ込めてuseTransitionに影響させないことが可能になりました。
SuspenseとuseTransitionの関係を整理するここまでは、
SuspenseとuseTransitionの関係を解説し、ユースケースに合わせた実装法を紹介してきました。なんだか場当たり的な印象を受けた読者の方も多いと思いますので、もう少し整理して見直してみましょう。あるコンポーネントがPromise(をラップする
Fetcher)を受け取るとします。そのコンポーネントの責務がそのデータを表示することであれば、必然的にそのコンポーネントはサスペンドを発生させることになります。コンポーネント内で発生しうるサスペンドは3種類に分類できます。3種類のサスペンドは、「コンポーネントの外にサスペンドが出て行くかどうか」と「
useTransitionに対応するかどうか」に注目すると次の表のようにそれぞれ異なる特徴を持ちます。
サスペンドの種類 外に出て行くか useTransition対応1 内部の SuspenseでキャッチされないサスペンドYes Yes1 2 内部で新規にマウントされた SuspenseにキャッチされるサスペンドNo No 3 内部の既存の SuspenseにキャッチされるサスペンドNo Yes パターン1が一番スタンダートなサスペンドでしょう。あるコンポーネントが
Fetcherから得たデータを表示することが責務ならば、データがまだない場合にそのコンポーネントがサスペンドするのは自然なことです。パターン2は逆にサスペンドを完全に内部で抑え込むパターンです。サスペンドが発生しても、そのことはコンポーネントの外部には検知されません。データがまだ無いときの挙動を完全にコンポーネント内で制御したい場合に適しています。
パターン3は、コンポーネントが新規にマウントされた場合は発生せず、再レンダリングのときのみ可能な選択肢です。これは扱うのがやや難しいですが、コンポーネントの内部で
useTransitionを使いたい場合などはこれが一番自然な選択肢となることが多いでしょう。コンポーネントのロジックを実装する際には、これらを組み合わせることもあるでしょう。例えば、先ほど出てきた
Fetcher.raceの例は1と2の合わせ技です。コンポーネントの使い勝手という観点からは、パターン1が最も有利です。パターン1はコンポーネントの外側に
Suspenseを配置すれば2や3に変換できますが、逆に2や3を1に変換することはできないからです。パターン1と2や3の使い分けはコンポーネントの責務に応じて決めるのが良いでしょう。具体的には、データがない場合にフォールバックを表示するという責務をコンポーネントが持っているのであれば、2か3を選択することになります。逆に、その責務を持たずデータがない場合はサスペンドすべきならば、1を選択しなければなりません。
誰が
Fetcherを用意するのかConcurrent Modeにおいては、誰かいつ非同期処理を開始する(
Fetcherを用意する)のかがとても重要です。従来の基本的なパターンは、データを表示する責務を持ったコンポーネントがuseEffectの中で非同期処理を開始するというものです。Fetcherと組み合わせればこのような実装になるでしょう。const PageB: FunctionComponent = () => { const [dailyRankingFetcher, setDailyRankingFetcher] = useState< Fetcher<User[]> | undefined >(undefined); useEffect(() => { setDailyRankingFetcher(new Fetcher(() => fetchUsers())); }, []); return dailyRankingFetcher !== undefined ? ( <Users usersFetcher={dailyRankingFetcher} /> ) : null; };しかし、2つの理由からこの実装は忌避すべきです。一つ目の理由は、一度レンダリングされたあと
useEffect内ですぐに再度レンダリングを発生させていることです。これはReactにおける典型的なアンチパターンの一つです。もう一つの理由は、こうすると
PageBが自動的にuseTransitionに非対応になるからです。PageBが最初にレンダリングされたときはまだサスペンドが発生しませんから、PageBに遷移するきっかけとなったステート更新ではサスペンドが発生しなかったことになります。もしPageBに遷移するときにuseTransitionを使いたければ、このような実装は必然的に選択肢から除外されます。では、どうすればよいのでしょうか。大きく分けて2つの選択肢があります。基本的には、これまでやってきたように外から
Fetcherを渡すことになります。これについては次回の記事で詳しく扱います。もう一つ、
useEffectの中ではなく最初のレンダリング中に直にFetcherを用意するという戦略を思いついた方もいるかもしれません。しかし、ほとんどの場合これは無理筋です。
useStateでFetcherを用意することはできない例えば、次のような実装を試してみましょう。
useStateは関数を渡すと最初のレンダリング時にその関数が呼び出されてステートの初期化に用いられます。次のようにすることでdailyRankingFetcherをいきなりFetcherで初期化し、初手でサスペンドを発生させることができます。const PageB: FunctionComponent = () => { const [dailyRankingFetcher] = useState(() => new Fetcher(() => fetchUsers())); return <Users usersFetcher={dailyRankingFetcher} />; };しかし、これは期待通りに動きません。
PageBはずっとサスペンドしたままになります。その理由は、PageBがレンダリングされるたびに新しいFetcherインスタンスが生成されるからです。
PageBが最初にレンダリングされた場合はuseStateに渡された関数が呼ばれて新しいFetcherインスタンスがdailyRankingFetcherに入ります。ここまでは想定通りですが、その後サスペンド明けにPageBが再度レンダリングされたとき、PageBは初回レンダリングという扱いになります。よって、dailyRankingFetcherに入るのはまた新しく作られたFetcherインスタンスとなり、PageBは再度サスペンドします。これを繰り返すことになり、PageBは永遠に内容をレンダリングすることができません。すなわち、レンダリングの結果サスペンドが発生したときはレンダリングが完了したと見なされず、
useStateフックなどの内容はセーブされません。あたかも、そのレンダリングが無かったかのように扱われます。useMemoなども同じです。この性質により、「最初にサスペンドしたレンダリング」から「サスペンド明けのレンダリング」に情報を渡すことは自力では困難です。そのため、最初のレンダリングの中で作った
Fetcherインスタンスをサスペンド明けのレンダリングで手に入れることができず、サスペンドが空けても何をレンダリングすればいいか分からなくなってしまいます。Fetcherをpropsで外から受け取ることでこの問題は回避できるのです。サスペンドとコンポーネントの純粋性
useStateがだめならuseRefなら、と思った方もいるかもしれませんが、実はuseRefでも無理です。useRefはレンダリングをまたいで同じオブジェクトを返すのが特徴でしたが、useRefによって返されるオブジェクトは最初のレンダリングで作られます。よって、「最初のレンダリング」が何回も繰り返されれば毎回新しいrefオブジェクトが作られることになり、やはりサスペンド前後の情報の受け渡しは困難です。ただし、最初のレンダリング以外の場合は注意が必要です。そもそも最初のレンダリング以外であっても、サスペンドしたレンダリングの結果は残りません。例えば、
useMemoはサスペンドしたレンダリングにおいて計算された値はキャッシュしません。そのレンダリング中に値を計算したという事実が無かったことにされるからです。しかし、
useRefは「毎回同じオブジェクトを返す」のが役割ですから、初回以外であればサスペンドしたレンダリングとサスペンド明けのレンダリングではuseRefから同じオブジェクトが返されます。これを用いることで、サスペンドしたレンダリングから何らかの情報を残すことができます。明らかに、このようなことは避けるべきです。それは、このような
useRefの使用はレンダリングの純粋性を破壊しているからです。レンダリングの純粋性とは、「コンポーネントをレンダリングしても副作用が発生しない」という意味で、「意味もなくコンポーネントをレンダリングしても(=関数コンポーネントを関数として呼び出しても)安全である」という意味でもあります。Concurrent Modeにおいては「コンポーネントがレンダリングされた(関数コンポーネントとして呼び出された)」ことは「そのコンポーネントのレンダリング結果がDOMに反映される」ことを意味しません。サスペンドが発生する可能性があるからです。この状況下でReactが好き勝手にレンダリングを試みるための前提として、コンポーネントは純粋であるべきとされているのです。
実際、Reactでは副作用は
useEffect内で行うように推奨しています。useEffectはコンポーネントが実際にDOMにマウントされた場合にコールバックが呼び出されます。サスペンドによりDOMに反映されなかった場合はコールバックは発生しません。また、レンダリングが純粋であることを強調するためか、Conncurrent Modeではデフォルトで1回のレンダリングで関数コンポーネントが2回呼び出されるようになっています(おそらくproductionでは1回)。これは、純粋でないコンポーネントを作ってしまった際に発生するバグを検出しやすくするためでしょう。実は先ほどの
useStateのサンプルでも、1回PageBがレンダリングされるたびにFetcherインスタンスが2個作られていました。非同期処理を発生させるのも副作用ですから、そもそもuseStateのステート初期化時にFetcherインスタンスを作るのは無理筋だったということになります。
useRefに話を戻しますが、Concurrent Modeではrefオブジェクトへのアクセス(特に書き込み)は副作用であると考えるべきです。先ほど説明したように、レンダリング中にrefオブジェクトに書き込むと、サスペンドしたレンダリングの影響がそれ以降に残ってしまうため、コンポーネントのレンダリングが純粋でなくなるからです。refオブジェクトは、useEffectのコールバック内やイベントハンドラなど、副作用が許された世界でのみアクセスすべきです。refオブジェクトはもはや完全に副作用の世界の住人なのです。目ざとい方は、先程出てきた
useObjectIdはuseRefに書き込んでいたじゃないかと思われるかもしれません。それはそのとおりなのですが、実はuseObjectIdはレンダリングの純粋性を損なわないように注意深く実装されています。純粋性を壊さない注意深い実装ならば、useRefを使える可能性もあるのです。無理なときは無理なので無理だと思ったら潔く諦めるべきですが。まとめ
この記事では、サスペンドを念頭に置いたコンポーネント設計をどのようにすべきかについて議論しました。
重要なのは、サスペンドはその発生の仕方によって3種類に分類できるということです。さらに、これらを組み合わせることでより複雑なパターンを実装することもできます。もちろん、コンポーネントの記述は宣言的な書き方が保たれています。
Concurrent Modeでは、あるコンポーネントがどのような状況下でどの種類のサスペンドを発生させるのかということをコンポーネント仕様の一部として考えなければなりません。これは特に
useTransitionと組み合わせるときに重要です。Concurrent Mode時代のコンポーネント設計では、コンポーネントの責務は何なのかということを冷静に見極めて、そのコンポーネントはどのようにサスペンドすべきかということを考えなければならないのです。記事の後半では、Concurrent Modeでは特にレンダリングの純粋性が重要であることを開設しました。これを踏まえると、初手でサスペンドするコンポーネントは必然的に
Fetcherを外部から受け取ることになります。次回の記事では、誰が
Fetcherを作ってどう受け渡すのかについて考えていきます。次の記事: 鋭意執筆中です。
このコンポーネントの外部に設置された既存の
Suspenseにキャッチ場合はuseTransitionに反応しないサスペンドとなりますが、それはこのコンポーネントの預かり知るところではありません。このコンポーネントがuseTransitionに対応する可能j性を消しているわけではないことからYesとしています。 ↩
