- 投稿日:2020-04-04T23:53:28+09:00
【WordPress】こんなことかよ、、をなくす豆知識
経緯
この記事を投稿するにあたって、自分自身がWeb制作をはじめるにあたって、最初にぶつかった見えない壁についてを共有していきたいと思います。
はじめたばかりの頃「あれ!?ここってどうなってるんだ??」ってところがググってみても意外に見つからなかったりするんですよね。
他の人は当たり前のようにできていることなのかな?なんて思いましたが、自分のメモと同じような苦悩を抱えている方の一助になれば幸いでございます。注意
ここでは、HTML&CSSのコーディングとWordPressのはじめ方のような導入部分の解説は行いません。
すでに、ローカルでの環境構築は行われていることを想定しております。
その際にHTML&CSSでコーディングした時とWordPressにあげた時とで、壊れるところが個人的に戸惑ってしまったので、そのポイントを中心に多くしていきたいと思いいます。【目次】今回つまづいたポイント
1.謎の空白
2.表示されない画像
3.お問い合わせフォーム
4.効かないCSS・SCSS1.謎の空白
直接自前エディターで記述を行う際には全く問題ないのですが、WordPressの固定ページに直接コードを入力する際には全く身に覚えのない空白が発生してしまうことがあります。
こちらを解決するための方法は非常に簡単で、自作テーマ内のfunctions.phpに以下のコードを入力するだけで綺麗に解決しますので、お試しください。
また、functions.phpをいじる際には前もってバックアップを取っておいたほうがいいそうですよ。functions.phpadd_action('init', function() { remove_filter('the_excerpt', 'wpautop'); remove_filter('the_content', 'wpautop'); }); add_filter('tiny_mce_before_init', function($init) { $init['wpautop'] = false; $init['apply_source_formatting'] = ture; return $init; });2.表示されない画像
こんなことあるのか、、というようなアクシデントですが、少し頭を使わないとなかなか抜け出せない沼になっております。
一般的にWordPressにアップロードする際にはタグに以下のようなテンプレートを入れる決まりとなっております。
<img src="<?php echo get_template_directory_uri(); ?>img/image.jpg"/>フロントページのようにエディターでのコーディングで済むものであれば上記のコードを組み込めば問題ないのですが、それ以外の固定ページ等に画像を挿入する際にはこれではいけません。
原因としては、おそらく外部からの読み込みではなくWordPress内部で読み込まれるということで、テンプレートではなく階層構造での読み込みとなるそうです。<img src="/wordpress/wp-content/themes/wordpress/img/image.jpg"/>これがわからないと、画像が表示できなくて大変なことになってしまうのですが、意外と解説している書籍やサイトが少なくて困ってしまいますね。
3.お問い合わせフォーム
これはシンプルにプラグインだよりなのですが、contact form 7とmw wp formの両方を試してみて、個人的にはmw wp formが直感的に使いやすかったので、お問い合わせフォームの実装で詰まっている方はぜひ試してみてください。
タグが入力されていたことに気がつかず、その上から二重でタグで囲ってしまっていたことにあります。
詳しい設定方法はこちらで習得しました。
→https://newstd.net/user_manual/mwwpform
ただ、実際に実装してみた時にフォームがうまく機能しなくなってしまうことがありました。
原因は埋め込んだショートコード自体にもともと
気をつけましょう。[mwform_formkey key="195"]4.効かないCSS・SCSS
WordPressにあげる前、HTML&CSSのみのコーディングであればなんの問題もなくCSSが反映されていたんでけど、WordPressにあげた途端反映されなくなってしまった、、という方も多いかもしれません。
しかし、それが反映されなくなったのではなくて遅くなっただけなので、焦らずに対応しましょう。
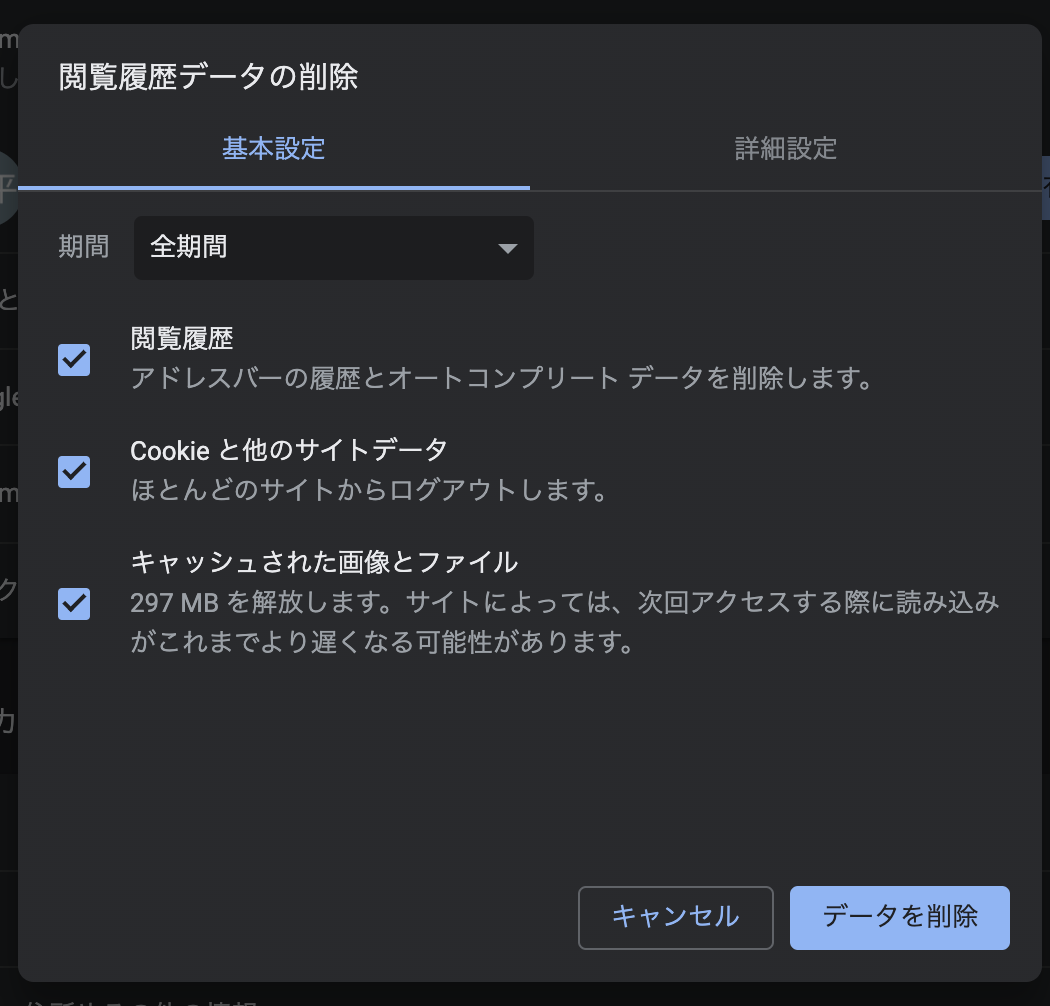
方法は簡単ですが、実行する前によく確認してみましょう。
①クロームの右上にある縦黒3点をクリックしてこの画面を開く
その他のツール→閲覧履歴を消去
②削除期間を指定して実行
※削除前に確認しましょう
最後に
せっかくWeb制作をはじめたのに、つまらないところで挫折したらもったいないですよね。
難しいと思うような問題も時間と執念をかければ大抵のことはなんとかなるはずですので、頑張りましょう。
これからも、気づいた情報を共有していきたいと思いますのでよろしくお願いします!

- 投稿日:2020-04-04T23:30:26+09:00
【手順を解説】Atomエディタで作成したHTMLファイルを実際のWebブラウザで確認する方法
「Atomエディタで作ったHTMLをWebブラウザでどうなるか見たいな!手順が知りたいです。」
一番最初に使う時が、一番難しいですよね!
このページでわかること
- Atomエディタ初の人が、作ったホームページ(HTML)をWebブラウザで確認してみる方法
- CSSがPreviewに反映されなくて困っている
- 画像付きでどこをクリックすればいいか知りたい
ということがわかります。
このページでは、Atomエディタ初の人が、作ったホームページ(HTML)をWebブラウザで確認してみる方法を写真を交えて解説しています。
今回の記事は、すでにWebブラウザで確認するhtmlファイルがある場合の手順解説記事です。
HTMLがPreviewで見れるのに、CSSがPreviewに反映されなくて困っている
そんな場合にも、この記事が対処方法として、ブラウザでCSSの反映を確認することができます。
■【手順を解説】Atomエディタで作成したHTMLファイルを実際のWebブラウザで確認する方法
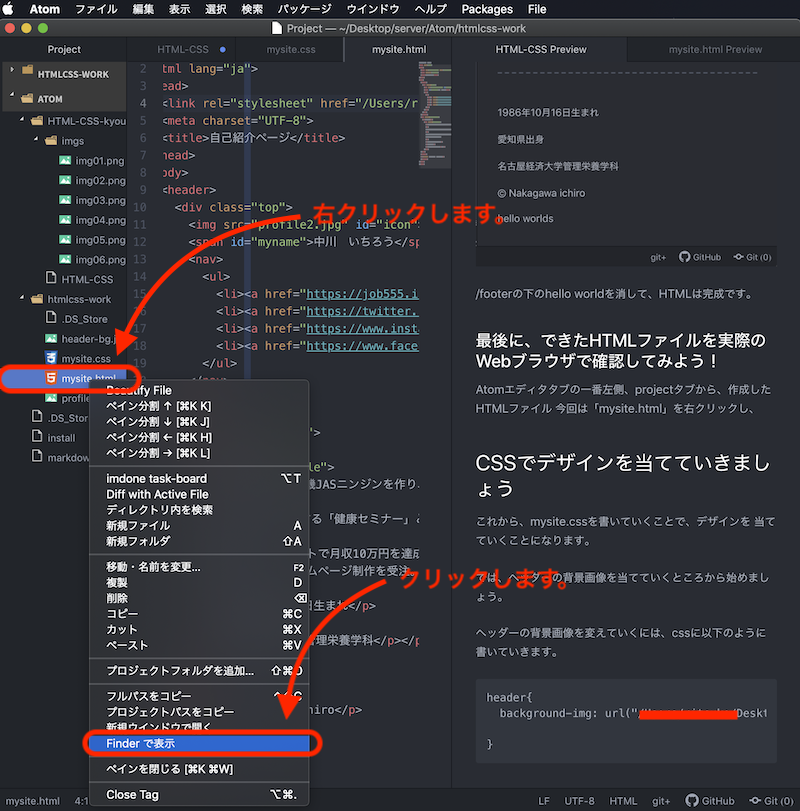
Atomエディタタブの一番左側、projectタブから、作成したHTMLファイル
今回は「mysite.html」を右クリックし、Finderから開くを選択します。
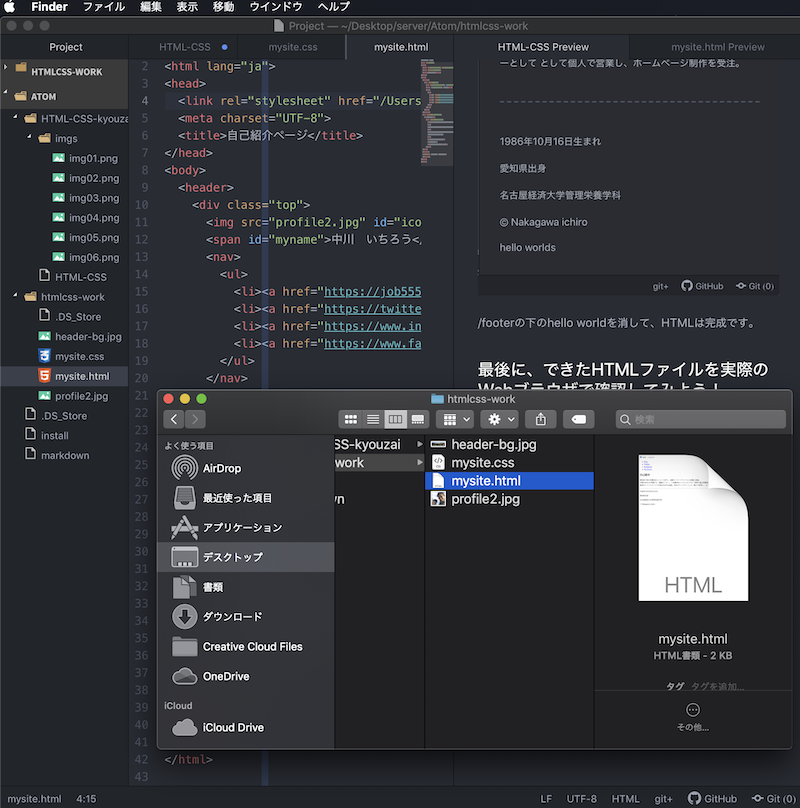
すると、下記の画面が開きます
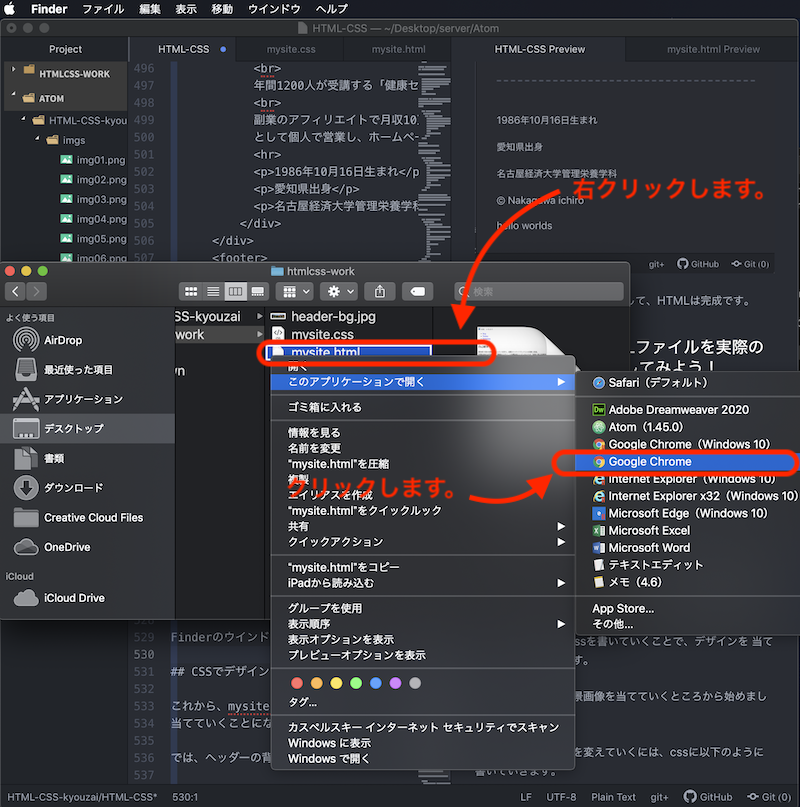
Finderのウインドウから、「mysite.html」を右クリックし、
このアプリケーションで開く>Google Chrome をクリックします。
*Google Chromeブラウザをインストールしていない方は、プログラミングに便利なブラウザなので、この際にインストールしておきましょう。
https://www.google.co.jp/chrome/?brand=CHBD&gclid=CjwKCAjw4KD0BRBUEiwA7MFNTQjqbgW-vKOBw7_6W0rqxJiH_DsQdMPY4toq9CBA3soBGu8hrDQq_hoC7YIQAvD_BwE&gclsrc=aw.ds
すると、Webブラウザでmysite.htmlが表示されます。
- 投稿日:2020-04-04T23:17:31+09:00
HTML備忘録1
HTML
HTMLファイルの型
<!DOCTYPE html>はhtmlのバージョン(HTML5)を宣言している。
<head>要素はページに関する情報。Webページの設定を記述する。
<body>要素は実際に表示したい内容を記述する。注意)
headを記述し終えてから、bodyを記述すること
relはファイルとの関係性を示す。rel="stylesheet"ならcssファイルとの関係性。
hrefにページのurlを記述する<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Title</title> <link rel = "stylesheet" href="stylesheet.css"> </head> <body> </body> </html>ブロック要素とインライン要素
ブロック要素 : 前後で改行が入り、親要素の幅いっぱいに広がる要素。
インライン要素 : インライン要素の前後で改行が入らない。インライン要素はCSSのプロパティでwidthやheightを調整できない。ただし、marginは左右方向のみ調整できる。ブロック要素の例) <div> <h1> <p>
インライン要素の例) <span> <a>
タグ(HTML)
<h1> </h1>h1(見出し)。h1~h6まで存在。
ブロック要素。<a> </a> #リンク先が存在しない時はhref="#"を指定 <a href="#"> </a> <a href="url"> </a> #クリックしたいときに別の新しいタグでページを開きたいときは以下の属性を追加。 <a href="url" target="_blank"> </a>a(リンク)という意味付けをもつ。リンクの飛び先を設定するにはhref属性が必要。
インライン要素。<p> </p>p(aragraph)タグで段落に分ける。自動的に改行される。
ブロック要素。<span> </span> #例 この部分が<span class="change_red">赤色</span>に見える。spanは文の一部をインライン要素にする。つまり文中の一部にCSSを適用したいときに使用する。
<img src ="url"> #オプションこと「属性」を追加できる。widthやheightで横幅や縦幅を調整する。altは説明。 <img src="url" width="100" height="100" alt="このイメージの説明">imgは画像を表示させるタグ。src属性のurl部分に画像リンクを載せる。
<li> <ul>a</ul> <ul>b</ul> <ul>c</ul> </li> <li> <ol>金賞</ol> <ol>銀賞</ol> <ol>銅賞</ol> </li>liはリストをつくる。ulは黒点が先頭につく。olは数字が連続でつく。
<div> </div> <section> </section> <article> </article>レイアウトタグ。
以下はclassをつけた例。複数のclassをつけるにはスペースで区切る。<div class="example1 example2"> サンプルテキスト </div><form> <p>コメント</p> <input> <p>コメント(複数行)</p> <textarea></textarea> </form>input要素は1行のテキスト入力を受け取る。<input>だけで良い。
textarea要素は複数行のテキスト入力を受け取る。☆送信ボタンの作成。
<form> <input type="submit"> <p></p> <input type="submit" value="保存"> </form>type属性をsubmitにすると送信ボタンが作成される。
value属性でテキストを変更できる。参考文献
サルワカ
https://saruwakakun.com/html-css/basic/link-rel
TAG index
https://www.tagindex.com/html_tag/form/input_submit.html
Progate
https://prog-8.com/languages/html
ドットインストール
https://dotinstall.com/lessons/basic_html_v5
https://dotinstall.com/lessons/basic_css_v5
- 投稿日:2020-04-04T22:47:55+09:00
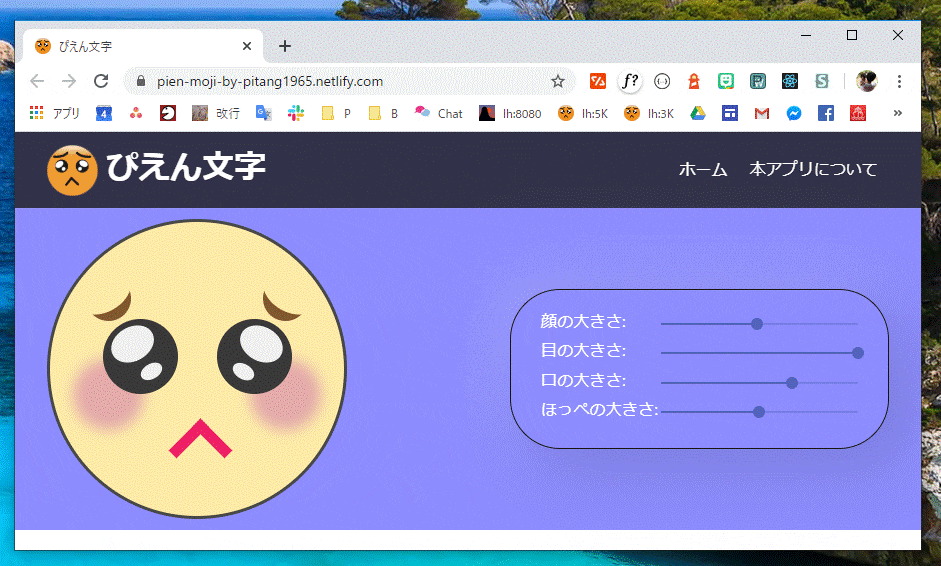
Reactぴえんチャレンジ
Reactぴえんチャレンジって何?
nikoさんの記事に触発されたものです。
2019年12月からUdemyでReactの学習を開始したのですが、練習に丁度よいチャレンジだと思いやってみました。チャレンジ結果
画像をクリックしてください。
チャレンジのポイント
- スライダーを実装するため、初めてMaterial UIというものを使ってみました。
- ReactのHooksを学習したので、クラスコンポーネントを使わず、propsでバケツリレーしないパラメータの引き渡し方法を採用してみました。
- CSSの設定。
- 少し前に、webpackで悩みに悩んでしまったので今回は create-react-app を使ってみました。
- Netlifyにデプロイしてみました。
- GitHubで初めてブランチを使ってみました。
ソースコード
GitHub
練習のために作ったものではありますが、ここをこうしたほうが良いとかありましたら、ぜひご指導ください。謝辞
その他
これを作るのに1週間くらいうんうんうなっていたら、小学生の娘が半日でこんなものを作ったと自慢してくれました。
私はその後も更に2週間くらいうなっていました。ちょっとピエンですね。
- 投稿日:2020-04-04T22:47:55+09:00
Reactぴえんチャンレンジ
Reactぴえんチャレンジって何?
nikoさんの記事に触発されたものです。
2019年12月からUdemyでReactの学習を開始したのですが、練習に丁度よいチャンレンジだと思いやってみました。チャレンジ結果
画像をクリックしてください。
チャレンジのポイント
- スライダーを実装するため、初めてMaterial UIというものを使ってみました。
- ReactのHooksを学習したので、クラスコンポーネントを使わず、propsでバケツリレーしないパラメータの引き渡し方法を採用してみました。
- CSSの設定。
- 少し前に、webpackで悩みに悩んでしまったので今回は create-react-app を使ってみました。
- Netlifyにデプロイしてみました。
- GitHubで初めてブランチを使ってみました。
ソースコード
GitHub
練習のために作ったものではありますが、ここをこうしたほうが良いとかありましたら、ぜひご指導ください。謝辞
その他
これを作るのに1週間くらいうんうんうなっていたら、小学生の娘が半日でこんなものを作ったと自慢してくれました。
私はその後も更に2週間くらいうなっていました。ちょっとピエンですね。
- 投稿日:2020-04-04T18:01:09+09:00
Python-Markdownのソースを読んでみる:パーサの作り方
目的
マークダウンのパーサライブラリがどのように実装されているのか学ぶことにしました。(唐突)
Javaのdomパーサの設計(デザインパターン)が素晴らしいとのことですが、まずは慣れているPythonのライブラリを探してみました。ちなみにJavaのはこれ。
https://www.tutorialspoint.com/java_xml/java_dom_parse_document.htm今回は以下のライブラリのソースを読んでみます。
Python-Markdown
https://github.com/Python-MarkdownMarkdown->HTMLへの変換ができるみたいです。
当然、中でMarkdownの解析を行なっているわけで、どのような設計になっているのか、拝見しましょう!理解が間違っている箇所などありましたら、ご指摘ください...!
注意書き
Python-Markdown/markdown/markdown/以下にコアな関数たちが集められているようです。
今後は面倒なので、基本的にこのディレクトリ以下のファイルをsample.pyのように省略して表示します。また、以下に載せるソースコードは基本的に必要な部分のみを抜粋(+コメントアウトでメモ書き)したものになっています。
メイン部分を最初にネタバレ
結論から言うと、特定のエレメントを検出する各プロセッサーをブロックごとに順番に作用させていました。
作用させる対象は、元のテキストを「\n\n」で分割した各ブロックになっています。
これは例えば、<b>タグが不完全ですが、太字です 太字ではありません</b>のように空白行が入る(=「\n\n」が現れる)と、エレメントの有効範囲が途切れてしまうからですね。
この例だと、まず
["<b>タグが不完全ですが、太字です", "太字ではありません</b>"」のように各ブロックにして、まず
"<b>タグが不完全ですが、太字です"に対して各要素を検出するプロセッサーを順番に作用させ、次のブロックへ進んで...
といった流れになるかと思います。処理の流れ
このライブラリでユーザが使用するインターフェースの中心となるのは、以下の
Markdownクラスとそのconvertメソッドです。core.pyclass Markdown: # ここでhtmlに変換 def convert(self, source): # source : マークダウンのテキスト
convertメソッドにコメントが付いており、和訳するとこんな感じ。1、preprocessorたちがテキストを変換する
2、1で前処理されたテキストの高レベル構造elementをElementTreeにパースする
3、ElementTreeをtreeprocessorたちが処理する。例えばInlinePatternsはinline要素を見つける
4、ElementTreeをテキストにシリアライズしたものに、いくつかのpost-processorsを作用させる
5、結果を文字列に書き出すもはや原文の方が読みやすいかもw
ステップ1 preprocessors
core.pyclass Markdown: def convert(self, source): < 略 > self.lines = source.split("\n") for prep in self.preprocessors: self.lines = prep.run(self.lines)まず各行に分割して、前処理を噛ませる。
preprocessorsは以下で取得しています。preprocessors.pydef build_preprocessors(md, **kwargs): """ Build the default set of preprocessors used by Markdown. """ preprocessors = util.Registry() preprocessors.register(NormalizeWhitespace(md), 'normalize_whitespace', 30) preprocessors.register(HtmlBlockPreprocessor(md), 'html_block', 20) preprocessors.register(ReferencePreprocessor(md), 'reference', 10) return preprocessors
NormalizeWhitespace>HtmlBlockPreprocessor>ReferencePreprocessor
の優先順位で前処理が登録されています。名前の通り
NormalizeWhitespace: 空白、改行文字の正規化(10行程度の実装)
HtmlBlockPreprocessor: html要素の解析(250行...!)
ReferencePreprocessor: [タイトル](リンク)の形式で表現されるリンクを見つけて辞書Markdown.referencesに登録(30行)
HtmlBlockPreprocessorの中身は飛ばしましょう。同じような要素検出処理はステップ2や3で待ち構えているはずです...(余談)
ReferencePreprocessorのように、次の行までその要素の中身になるかの判定をしなければいけない場面はパーサではよく出てきて、自作(勉強がてら)の時はwhile lines: line_num += 1 line = self.lines[line_num] <処理> if (次の行まで含める): line_num += 1 line = self.lines[line_num]のようにしていましたが、
ReferencePreprocessorではpopを使っています。while lines: line = lines.pop(0)うん、そうするべきでした...汗
(余談おわり)
ステップ2 ErementTreeにパース
この処理は以下の部分です。
core.pyclass Markdown: def convert(self, source): < 略 > # Parse the high-level elements. root = self.parser.parseDocument(self.lines).getroot()ここで
self.parserというのは以下の関数で取得したBlockParserになります。blockprocessors.pydef build_block_parser(md, **kwargs): """ Build the default block parser used by Markdown. """ parser = BlockParser(md) parser.blockprocessors.register(EmptyBlockProcessor(parser), 'empty', 100) parser.blockprocessors.register(ListIndentProcessor(parser), 'indent', 90) parser.blockprocessors.register(CodeBlockProcessor(parser), 'code', 80) parser.blockprocessors.register(HashHeaderProcessor(parser), 'hashheader', 70) parser.blockprocessors.register(SetextHeaderProcessor(parser), 'setextheader', 60) parser.blockprocessors.register(HRProcessor(parser), 'hr', 50) parser.blockprocessors.register(OListProcessor(parser), 'olist', 40) parser.blockprocessors.register(UListProcessor(parser), 'ulist', 30) parser.blockprocessors.register(BlockQuoteProcessor(parser), 'quote', 20) parser.blockprocessors.register(ParagraphProcessor(parser), 'paragraph', 10) return parserこちらも優先順位とともにプロセッサーが登録されています。
BlockParser.praseDocument()はこちら。blockparser.pyclass BlockParser: def __init__(self, md): self.blockprocessors = util.Registry() self.state = State() self.md = md # ElementTreeを作成する def parseDocument(self, lines): self.root = etree.Element(self.md.doc_tag) self.parseChunk(self.root, '\n'.join(lines)) return etree.ElementTree(self.root) def parseChunk(self, parent, text): self.parseBlocks(parent, text.split('\n\n')) def parseBlocks(self, parent, blocks): while blocks: for processor in self.blockprocessors: if processor.test(parent, blocks[0]): if processor.run(parent, blocks) is not False: break要するに、
core.pyroot = self.parser.parseDocument(self.lines).getroot()の部分では各
BlockProcessorに処理をさせているわけですね。例えば、ハッシュタグによるヘッダー「# ヘッダー」形式をさばくプロセッサーは以下のように定義されています。
blockprocessors.pyclass HashHeaderProcessor(BlockProcessor): """ Process Hash Headers. """ RE = re.compile(r'(?:^|\n)(?P<level>#{1,6})(?P<header>(?:\\.|[^\\])*?)#*(?:\n|$)') def test(self, parent, block): return bool(self.RE.search(block)) def run(self, parent, blocks): block = blocks.pop(0) m = self.RE.search(block) if m: ``` ここから ``` before = block[:m.start()] after = block[m.end():] if before: # beforeの部分のみ再帰処理 self.parser.parseBlocks(parent, [before]) h = etree.SubElement(parent, 'h%d' % len(m.group('level'))) h.text = m.group('header').strip() if after: # 次にafterを処理するために、blocksの先頭に追加 blocks.insert(0, after) ``` ここまでがコアってことよね ``` else: logger.warn("We've got a problem header: %r" % block)もう1つ、「> 文章」形式の引用ブロックのプロセッサーを見てみましょう。
引用ブロックで考えなければいけないことは
・複数行に連続したブロックは、1つのブロックとしてみなす
・ブロックの中身もパースしなければいけない
ってことですね。blockprocessors.pyclass BlockQuoteProcessor(BlockProcessor): RE = re.compile(r'(^|\n)[ ]{0,3}>[ ]?(.*)') def test(self, parent, block): return bool(self.RE.search(block)) def run(self, parent, blocks): block = blocks.pop(0) m = self.RE.search(block) if m: before = block[:m.start()] # ここはさっきのHashHeaderProcessorと同じだね self.parser.parseBlocks(parent, [before]) # 各行先頭の">"を削除 block = '\n'.join( [self.clean(line) for line in block[m.start():].split('\n')] ) ``` 引用ブロックが今まで続いてきたか、ここが先頭かを考慮 ``` sibling = self.lastChild(parent) if sibling is not None and sibling.tag == "blockquote": quote = sibling else: quote = etree.SubElement(parent, 'blockquote') self.parser.state.set('blockquote') ``` 引用ブロックの中身(block)をパース。親は現在のブロック(quote)にしているね ``` self.parser.parseChunk(quote, block) self.parser.state.reset()ちなみに、
siblingは兄弟や姉妹を表す単語なんだね。2つのプロセッサークラスをみてきましたが、パース結果をどこに保存しているかとえば、
etree.SubElement(parent, <tagname>)
の部分が怪しい。そもそもetreeとは、pythonの標準ライブラリにある
xml.etree.ElementTreeインスタンスになります。
etree.SubElement(parent, <tagname>)によって、BlockParser().root(これもまたElementTreeインスタンス)に子要素を加えていることになります。プロセスが進むにつれ、結果が
BlockParser().rootとして保存されていくわけですね。ステップ3 treeprocessor
今までと同様に、今度は
treeprocessorを噛ませます。treeprocessors.pydef build_treeprocessors(md, **kwargs): """ Build the default treeprocessors for Markdown. """ treeprocessors = util.Registry() treeprocessors.register(InlineProcessor(md), 'inline', 20) treeprocessors.register(PrettifyTreeprocessor(md), 'prettify', 10) return treeprocessors
InlineProcessor: インライン要素に対する処理
PrettifyTreeprocessor: 改行文字などの処理終わりに
え、いきなりおしまい!?
でも、今まで見てきた中でこのライブラリの大まかなデザインパターンはわかったのではないでしょうか?
あとは気になる部分があれば、各自で見るのが良いでしょう...ちょっと、疲れました。
最後までご覧いただきありがとうございます...!
- 投稿日:2020-04-04T16:50:15+09:00
ブログにYoutubeを貼り付ける方法
概要
自身のYoutubeを自分のブログに貼り付けたのでメモ
動画にもしてみました。
(完全に個人趣味なので見応え0かも…)
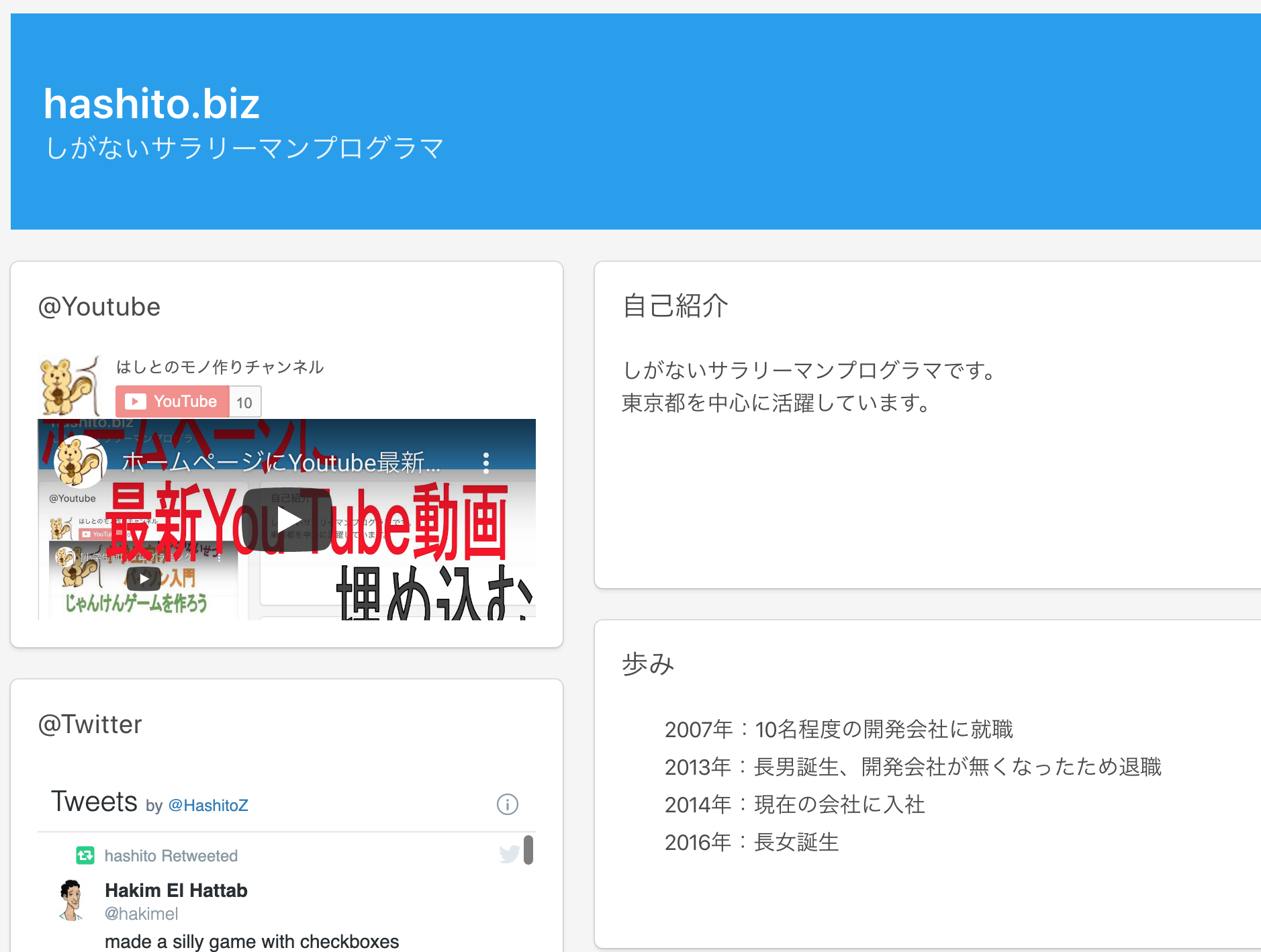
結論
こんな感じになりました。
ソースコード
<p class="subtitle">@Youtube</p> <script src="https://apis.google.com/js/platform.js"></script> <div class="g-ytsubscribe" data-channelid="UC9ZSQjR4502aRkU5rJpJ7dg" data-layout="full" data-count="default"></div> <iframe width="560" height="315" src="https://www.youtube.com/embed/?list=UU9ZSQjR4502aRkU5rJpJ7dg" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen> </iframe>調べた結果
Code.penにまとめてあります。
See the Pen youtube by hashito (@hashito) on CodePen.
動画埋め込み
基本的に3種類程度ありらしく、
「単品動画としての埋め込み」 「リスト動画としての埋め込み」 「チャンネル最新動画の埋め込み」の3種類があります。
今回、私は「チャンネル最新動画の埋め込み」を行っています。
この場合、list=UU9ZSQjR4502aRkU5rJpJ7dgの部分がチャンネルIDを表すのですが、
元のIDから下記のような変更が必要です。元:UC9ZSQjR4502aRkU5rJpJ7dg 変換後:UU9ZSQjR4502aRkU5rJpJ7dg ※頭2文字「UC」から「UU」に変更あとは、文字を表示したりしなかったり…
アイコンを表示したりしなかったりもあるらしいですがそこは今回こだわっていないです。登録ボタン
下記のホームページで
チャンネル名またはIDを入力すれば作れます。https://developers.google.com/youtube/youtube_subscribe_button?hl=ja
- 投稿日:2020-04-04T15:41:26+09:00
10px以下の文字が含まれたWebデザインが上がってきたので対応した
先日、フォントサイズが10px以下になるサイトのコーディングを(無理やり)行ったので、その時の対処を書いておきます。
着手後まもなく私の手を離れたので、下記の対応に不足があったのかどうかも今となっては謎ですが、とりあえず残しておきます。
対応方法に不足があるかもしれませんので、その際は優しくアドバイスをいただけますと幸いです。
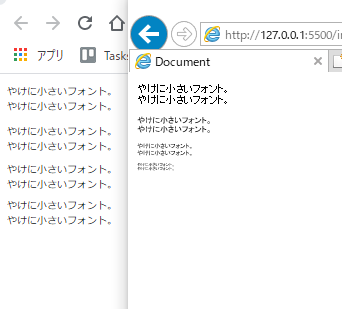
10px以下のフォントは表示に難あり
index.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Document</title> <style> .size10 { font-size: 10px; } .size8 { font-size: 8px; } .size6 { font-size: 6px; } .size4 { font-size: 4px; } </style> </head> <body> <p class="size10"> やけに小さいフォント。<br> やけに小さいフォント。 </p> <p class="size8"> やけに小さいフォント。<br> やけに小さいフォント。 </p> <p class="size6"> やけに小さいフォント。<br> やけに小さいフォント。 </p> <p class="size4"> やけに小さいフォント。<br> やけに小さいフォント。 </p> </body> </html>フォントサイズを10px以下にするとこうなる。
左がChrome、右がIEとなっています。
Chromeだと10px以下のフォントを設定しても、すべて10pxで表示されてしまいます。
無理やり対応した
この案件では、
Chromeでの表示をデザインカンプにピクセル単位で合わせる必要がありました。なんとしても、10px以下の小さな文字をChromeで表示できるようにしなくては。
Chromeで10px以下のフォントを実現する方法として、CSSで Scale を指定するのが一般的なようです。
p { transform: scale(0.8); }デザインを途中で修正することも許されなかったので、下記のように
- chromeで表示するときははscaleで縮小する
- それ以外はそのままのフォントサイズで表示する
という風に対応しました。
こんな感じです。
index.html<p class="size10"> やけに小さいフォント。<br> やけに小さいフォント。 </p> <p class="size8"> やけに小さいフォント。<br> やけに小さいフォント。 </p> <p class="size6"> やけに小さいフォント。<br> やけに小さいフォント。 </p> <p class="size4"> やけに小さいフォント。<br> やけに小さいフォント。 </p>index.jsfunction scale() { const userAgent = window.navigator.userAgent if (userAgent.indexOf('Chrome') != -1) { $(".size8").each(function () { $(this).css('transform', 'scale(0.8)') }) $(".size6").each(function () { $(this).css('transform', 'scale(0.6)') }) $(".size4").each(function () { $(this).css('transform', 'scale(0.4)') }) } } $(window).on('load', function () { scale() });
表示はこんな感じ。
ちょっとおしゃれなレイアウトになっていますが、一応縮小は出来ています。
IEでも表示は問題なさそう。単純に要素全体を縮小しているので、マージンや横幅などももろもろ小さくなってしまいますが、まぁ良いでしょう。
結論:10px以下のフォントは読みずらいし美しくない
いくら対応できたといっても、やっぱり10px以下のフォントは(ネタサイトでもない限り)良くない!
以上!

- 投稿日:2020-04-04T05:26:59+09:00
初心者によるプログラミング学習ログ 280日目
100日チャレンジの280日目
twitterの100日チャレンジ#タグ、#100DaysOfCode実施中です。
すでに100日超えましたが、継続。
100日チャレンジは、ぱぺまぺの中ではプログラミングに限らず継続学習のために使っています。
280日目は、
おはようございます
— ぱぺまぺ@webエンジニアを目指したい社畜 (@yudapinokio) April 3, 2020
280日目 2.5h
・xdデザインカンプからのサイト模写
・メンターさんからの修正をやる
・ヘッダーの上部とフッターの下部の謎隙間解決に手間取る#早起きチャレンジ#駆け出しエンジニアと繋がりたい#100DaysOfCode