- 投稿日:2020-04-04T23:52:20+09:00
Jupyter NotebookでKernelを追加する際のお決まりお作法
Jupyter Notebookで新しくKernelを追加する際のPipenvのお決まり作法
これやっておけば基本問題ない。毎回忘れて調べてしまって時間が無駄なので備忘。コピペでおk
--python 3.7 は必要なpythonバージョン
--name はjupyterで選べるカーネル名
--display-name はブラウザで表示される任意のカーネル名pipenv --python 3.7 #3.6 pipenv install ipykernel python-dotenv pipenv run ipython kernel install --user --name=kernel_name --display-name=kernel_display_name pipenv shell
- 投稿日:2020-04-04T23:23:15+09:00
PythonでABC161のA~Cを解く
はじめに
ノリで書いたツイートが謎に伸びました。
こんにちは chokudaiだよ
— tax_free (@taxfree_python) April 3, 2020
ABCをはじめるよ
*コーダーのお前らならば
余裕で解けるよね
ハイA、ハイB、ハイC、D、CひさしぶりにABCで解けた!と思いました。A~Cの三完です!
A問題
考えたこと
AとBを入れ替える→AとCを入れ替える、ということは最終的に[C,A,B]の並びになるということなのでそれを出力する。x, y, z = map(int,input().split()) print(z,x,y)B問題
考えたこと
forで商品を一つずつ取り出して、取り出した商品の票数が条件(全体の$\frac{1}{4M}$)を満していればansに足して、ans>=Mで分けます。n, m = map(int,input().split()) a = list(map(int,input().split())) s = sum(a) #sumでaの合計を計算 ans = 0 for i in a: if i >= s*1/(4*m): ans += 1 if ans >= m: print('Yes') else: print('No')C問題
考えたこと
最初は素直にそれぞれのminを計算しようかと思いましたが、それではTLEするので楽に計算する方法を考えなければいけません。差が自然数の範囲で最小になるまで引き算し続けるのなら、割り算してその余りを求めればいいじゃない方針で解きました。
コンテスト中は不安だったのでmin(n,n%k,abs(n%k-k))で提出しました。不安だったのは$n<k$のときを考えてなかったからです。今考えると、$n<k$のときでもn%k=nなのでmin(n%k,abs(n%k-k))で通る。n, k = map(int,input().split()) a = n % k print(min(a,abs(a-k)))D問題
問題
考えたこと
桁DP?やなんとか優先探索で解くのかなと思って調べてみましたが、解けませんでした。諦めてEを考えてました。E問題
問題
考えたこと
Sのo、xをboolに置き換えて、出勤できる日だけをlistにしました。しかし、[1,6,10,11]のようにCを満さないようなlistもできるのでどうやって処理するかを考えているとコンテストが終了しました。グラフとかDPとかでできる?まとめ
健闘できたABCでした。次のコンテストで脱灰できるように精進します。
- 投稿日:2020-04-04T23:13:16+09:00
AtCoder Beginner Contest 161 参戦記
AtCoder Beginner Contest 161 参戦記
ABC161A - ABC Swap
3分で突破. 書くだけ. オンラインのコードテストが詰まってて時間がかかってしまった.
X, Y, Z = map(int, input().split()) X, Y = Y, X X, Z = Z, X print(X, Y, Z)ABC161B - Popular Vote
4分で突破. 閾値が総投票数の 4 * M 分の一なのでまずそれを求め、その閾値を超える票数の商品がM個以上あるかを調べる. オンラインのコードテストが詰まってて時間がかかってしまった.
N, M = map(int, input().split()) A = list(map(int, input().split())) threshold = sum(A) / (4 * M) if len([a for a in A if a >= threshold]) >= M: print('Yes') else: print('No')ABC161C - Replacing Integer
6分で突破. N が K を超えていれば、まず剰余を取る. N が K 未満になった後は、適当に回せば収束するだろうと、適当に1000回して放り込んだら AC が出たので結果オーライ. 後で真面目に考え直す.
N, K = map(int, input().split()) result = N if N > K: result = min(result, N % K) for i in range(1000): result = min(result, abs(result - K)) print(result)追記: N % K を x とする. x < K なので、x と K の差の絶対値は K - x となる. ところで K と K - x の差の絶対値は x である. よって、x と K - x の小さい方が答えとなる.
N, K = map(int, input().split()) x = N % K print(min(x, K - x))ABC161D - Lunlun Number
49分で突破. 当然数字を1づつ増やしながらのループでは TLE 必須なのでスキップを考える. ルンルン数は 12 の次が 21 となる. 13は3に問題があるが、3の桁ではなく、1の桁が2になるまでルンルン数は発生しない. 問題が発生した場合は上の桁を一つ進めて、それより下の桁を0にフラッシュしてみる. それだけだと、13→20→30となってしまうので、問題のある桁の値がその一つ前の桁より小さい場合には、問題のある桁の値を一つ進めることにした. これで 13→21 と進むようになり AC. コードは is_lunlun が真偽値ではなく数値を返すやっつけなので後で直す.
K = int(input()) def is_lunlun(i): result = -1 n = [ord(c) - 48 for c in str(i)] for j in range(len(n) - 1): if abs(n[j] - n[j + 1]) <= 1: continue if n[j] < n[j + 1]: for k in range(j + 1, len(n)): n[k] = 0 result = int(''.join(str(k) for k in n)) result += 10 ** (len(n) - (j + 1)) else: result = int(''.join(str(k) for k in n)) result += 10 ** (len(n) - (j + 2)) break return result i = 1 while True: # print(i) t = is_lunlun(i) if t == -1: K -= 1 if K == 0: print(i) exit() i += 1 else: i = tABC161E - Yutori
順位表を見るに F のほうが明らかに簡単そうなのでパスした.
ABC161F - Division or Substraction
突破できず.
追記: 30分くらい追加して解けた. トータル1時間くらい? N≤1012 なので素直にループを回すと TLE 必至. K * K > N の領域では、K = N, N - 1 を除けば N = a * K + 1 (a≥2) のパターンしか無い. 候補は、2以上 sqrt(N) 以下の K と、N - 1 が K で割り切れる時の (N - 1) / K. 候補をすべてチェックするのはたかだか 2 * 106 なので間に合う.
package main import ( "bufio" "fmt" "math" "os" "strconv" ) func main() { N := readInt() if N == 2 { // K = 2 fmt.Println(1) return } result := 2 // K = N - 1, N for K := 2; K <= int(math.Sqrt(float64(N))); K++ { t := N for t >= K && t%K == 0 { t /= K } if t%K == 1 { result++ } if (N-1)%K == 0 && (N-1)/K > K { result++ } } fmt.Println(result) } const ( ioBufferSize = 1 * 1024 * 1024 // 1 MB ) var stdinScanner = func() *bufio.Scanner { result := bufio.NewScanner(os.Stdin) result.Buffer(make([]byte, ioBufferSize), ioBufferSize) result.Split(bufio.ScanWords) return result }() func readString() string { stdinScanner.Scan() return stdinScanner.Text() } func readInt() int { result, err := strconv.Atoi(readString()) if err != nil { panic(err) } return result } func readInts(n int) []int { result := make([]int, n) for i := 0; i < n; i++ { result[i] = readInt() } return result }
- 投稿日:2020-04-04T22:27:02+09:00
カメラキャリブレーション用の白黒タイルを作る
はじめに
こんばんは
いつもはARCADというソフトを使ってキャリブレーション用の白黒タイルを作るのですが
タイルサイズが変わるごとに作り直すのも面倒なので簡単に作れないか調べてみました。
調べてみたところPDFで簡単に図形を描画できるライブラリがあったのでそれで実装してみました。
実際に印刷して検証したわけではないのでどこまで使えるかは未知数ですが
自分は今後ちょくちょく使う機会がありそうなので
WEBアプリとして公開しとけばどこでも使えていいかなぁとか思ったり。やりたいこと
↓みたいなのを実寸のサイズ(mm)指定して作りたい
環境
python:3.8
使用ライブラリ:reportlabキャリブレーション用の白黒タイルを作る
↓のコードを実装しました
box_grid.py#! /usr/bin/python # -*- coding: utf-8 -*- from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import A1, A2, A3, A4,landscape, portrait from reportlab.lib.units import cm, mm FILE_NAME = './box_grid_calibration.pdf' # 縦 VERTICAL_SIZE = 28 # 横 HORIZONTAL_SIZE = 19 # 開始位置 START_X = 10.0*mm START_Y = 10.0*mm # 正方形のサイズ RECT_SIZE = 10.0*mm if __name__ == '__main__': # A4縦向き pdf_canvas = canvas.Canvas(FILE_NAME, pagesize=portrait(A4)) # A4横向き # pdf_canvas = canvas.Canvas(FILE_NAME, pagesize=landscape(A4)) pdf_canvas.saveState() cnt_flag = True X, Y = START_X, START_Y # 縦描画 for i in range(VERTICAL_SIZE): # 横描画 for j in range(HORIZONTAL_SIZE): # 白と黒を交互に描画 pdf_canvas.setFillColorRGB(255, 255, 255) if cnt_flag else pdf_canvas.setFillColorRGB(0, 0, 0) pdf_canvas.rect(X, Y, RECT_SIZE, RECT_SIZE, stroke=0, fill=1) # X位置をずらす X += RECT_SIZE # フラグ反転 cnt_flag = not cnt_flag # 偶数の場合は白黒が交互にならないのでフラグを一度反転 if HORIZONTAL_SIZE % 2 == 0: cnt_flag = not cnt_flag # X座標開始点に戻す X = START_X # Y位置をずらす Y += RECT_SIZE pdf_canvas.restoreState() pdf_canvas.save()実行するとこちらが作成されます。
FILE_NAME = './box_grid_calibration.pdf' # 縦 VERTICAL_SIZE = 28 # 横 HORIZONTAL_SIZE = 19 # 開始位置 START_X = 10.0*mm START_Y = 10.0*mm # 正方形のサイズ RECT_SIZE = 10.0*mm説明も要らないと思いますが上記の項目で行数、列数、描画開始位置、タイルサイズを決定します。
注意点としてはreportlabは原点座標が通常の画像とは異なるらしく、
左下原点の上に向かってY軸がプラスになるみたいです。X軸は同じですが。
イメージは下の感じです。
Y軸
↑
|
|
●ーーー→ X軸ついでに円版の交互と整列Verも作ってみました。
交互パターン
circle_grid.py#! /usr/bin/python # -*- coding: utf-8 -*- from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import A1, A2, A3, A4,landscape, portrait from reportlab.lib.units import cm, mm FILE_NAME = './circle_grid_calibration.pdf' # 縦 VERTICAL_SIZE = 28 # 横 HORIZONTAL_SIZE = 19 # 開始位置 START_X = 10.0*mm START_Y = 10.0*mm # 円半径のサイズ RADIUS = 5.0*mm if __name__ == '__main__': # A4縦向き pdf_canvas = canvas.Canvas(FILE_NAME, pagesize=portrait(A4)) # A4横向き # pdf_canvas = canvas.Canvas(FILE_NAME, pagesize=landscape(A4)) pdf_canvas.saveState() cnt_flag = True X, Y = START_X, START_Y # 縦描画 for i in range(VERTICAL_SIZE): # 横描画 for j in range(HORIZONTAL_SIZE): # 白と黒を交互に描画 pdf_canvas.setFillColorRGB(255, 255, 255) if cnt_flag else pdf_canvas.setFillColorRGB(0, 0, 0) pdf_canvas.circle(X, Y, RADIUS, stroke=0, fill=1) # X位置をずらす X += RADIUS * 2 # フラグ反転 cnt_flag = not cnt_flag # 偶数の場合は白黒が交互にならないのでフラグを一度反転 if HORIZONTAL_SIZE % 2 == 0: cnt_flag = not cnt_flag # X座標開始点に戻す X = START_X # Y位置をずらす Y += RADIUS * 2 pdf_canvas.restoreState() pdf_canvas.save()実行したのがこちらになります
整列パターン
circle_grid2.py#! /usr/bin/python # -*- coding: utf-8 -*- from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import A1, A2, A3, A4,landscape, portrait from reportlab.lib.units import cm, mm FILE_NAME = './circle_grid2_calibration.pdf' # 縦 VERTICAL_SIZE = 19 # 横 HORIZONTAL_SIZE = 13 # 開始位置 START_X = 10.0*mm START_Y = 10.0*mm # 円半径のサイズ RADIUS = 5.0*mm if __name__ == '__main__': # A4縦向き pdf_canvas = canvas.Canvas(FILE_NAME, pagesize=portrait(A4)) # A4横向き # pdf_canvas = canvas.Canvas(FILE_NAME, pagesize=landscape(A4)) pdf_canvas.saveState() cnt_flag = True X, Y = START_X, START_Y # 縦描画 for i in range(VERTICAL_SIZE): # 横描画 for j in range(HORIZONTAL_SIZE): # 偶数回なら何もしない if not cnt_flag: # フラグ反転 cnt_flag = not cnt_flag continue # 黒を設定 pdf_canvas.setFillColorRGB(0, 0, 0) pdf_canvas.circle(X, Y, RADIUS, stroke=0, fill=1) # X位置をずらす X += RADIUS * 3 # X座標開始点に戻す X = START_X # Y位置をずらす Y += RADIUS * 3 pdf_canvas.restoreState() pdf_canvas.save()実行したのがこちらになります
参考URL・出典元
https://kuratsuki.net/2018/06/python-3-%E3%81%AE-reportlab-%E3%81%A7-pdf-%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB%E3%82%92%E7%94%9F%E6%88%90%E3%81%99%E3%82%8B/
https://symfoware.blog.fc2.com/blog-entry-769.html
上記URLに感謝です。

- 投稿日:2020-04-04T22:19:49+09:00
画像のエントロピーをpythonで求めてみた
はじめに
最近、大学の研究室で画像処理を専門とすることになり、画像のエントロピーについて復習する機会があったのでまとめました。
エントロピーとは
エントロピーは「乱雑さ」を表し、熱力学や統計力学でも出てきます。また、エントロピーは画像の情報量を表す指標としても使われます。
画像のエントロピーの定義は以下のようになります。
画像の諧調(レベル)が 0 ~ (k-1) の K値画像で、レベル $i$ の出現確率が$P_i$とすると、1画素の情報量は
$$
I = log_2(1/P_i) = -log_2P_i [bit]
$$
1画面全体の情報量がエントロピーなので、全画素数を$N$, レベル$i$の画素数を$N_i$とすると、$P_i$は
$$
P_i = N_i/N
$$
エントロピーは
$$
H = -\sum P_ilog_2P_i [bit/画素]
$$2値画像(白黒画像)のエントロピー関数を求める
2値画像のエントロピー関数を描画してみました。
import numpy as np import matplotlib.pyplot as plt P0 = np.arange(0,1, 0.01) # レベル0の出現確率P0 P1 = 1 - P0 # レベル1の出現確率P1 # エントロピーの算出 H = -P0 * np.log2(P0) -P1 * np.log2(P1) # グラフ描画設定 plt.plot(P0, H) plt.xlabel("P0") plt.ylabel("H") plt.title('Entropy') # ラベルの描画 plt.legend() # グラフの描画実行 plt.show()実行結果
上図より、$P_0 = 0.0$ or $P_0 = 1.0$ に近いほどエントロピーは小さく、$P_0 = 0.5$ の時にエントロピーは最大になることが分かります。
すなわち、白 or 黒一色に近いほどエントロピーは小さく、白と黒の出現確率が50%ずつの時にエントロピーは大きくなるということですね。このことは、画像の色使いが複雑なほど情報量は多く、画像の色使いが単純なほど情報量が少ないということを意味し、感覚的にも分かりますよね。
白黒画像のエントロピーを求める
次に、白黒のlenaさんの画像のエントロピーを求めてみます。
import cv2 import matplotlib.pyplot as plt import numpy as np img = cv2.imread('./img_data/lena_gray.jpg') #ファイルのバスは適宜変えてください # ヒストグラム(各色の画素数)の算出 histgram = [0]*256 for i in range(256): for j in range(256): histgram[img[i, j, 0]] += 1 # エントロピーの算出 size = img.shape[0] * img.shape[1] entropy = 0 for i in range(256): # レベルiの出現確率p p = histgram[i]/size if p == 0: continue entropy -= p*math.log2(p) plt.imshow(img) print('エントロピー:{}'.format(entropy))実行結果
まとめ
エントロピーの超基本のみしか書けませんでしたが、プログラミングを通して復習できてよかったです。何か間違いがあれば、ご指摘お願いいたします。


- 投稿日:2020-04-04T21:10:57+09:00
PythonでLINE Notifyへ通知を送る
ちょっとしたツールやbotを作ったとき、LINEに通知したいなーということがあります。
その度にググったり過去のソースを見たりしてるのでここにやり方を記しておきます。LINE Notifyのトークン取得
ここからアカウントを登録してトークンを取得します。
https://notify-bot.line.me/ja/アカウント作成後、マイページ > トークンを発行する > トークン名、トークルームを設定 > 発行する
発行されたトークンをコピーしておきます。
Pythonから通知
pip install requestsが済んでいれば以下コピペでおっけーです。Notify.pyimport requests def main(): send_line_notify('てすとてすと') def send_line_notify(notification_message): """ LINEに通知する """ line_notify_token = 'ここに発行したトークン' line_notify_api = 'https://notify-api.line.me/api/notify' headers = {'Authorization': f'Bearer {line_notify_token}'} data = {'message': f'message: {notification_message}'} requests.post(line_notify_api, headers = headers, data = data) if __name__ == "__main__": main()実行するとこんな感じで通知されます?
備考
- 公式ドキュメントはこちら
- ソースコードを公開する場合、トークンを直書きしないように注意しましょう


- 投稿日:2020-04-04T20:24:49+09:00
【備忘録】unicode errorとNo such file or directoryの対処法(pandasで表をexcelファイルに出力)
【備忘録】unicode errorとNo such file or directoryの対処法
pandasのto_excelメソッドでファイルを生成する際に直面したエラーの対処法。
1ファイルにシートを2枚以上出力したり、
既存ファイルにシートを追加する場合に「ExcelWriter」を使用。このときパスの設定で上記エラーが発生。
ハマったので原因と解決策をメモ。
結論(対処法)
ExcelWriterでパスを指定するときは下記に注意が必要。
・ホームディレクトリを指す「~」が使えない。
└「C:/Users/」で記述
・バックスラッシュ(または円マーク)を使う場合は「//」で記述 (¥¥)
└ 1個だとエスケープになる
└「/」は使える。to_excelやread_excelでは「~」が使えるのに、ExcelWriterでは使えない仕様のよう。
①No such file or directory
「~」を使ってパスを指定すると発生する。
read_excelメソッドなどでパスを指定する際は使えたが、ExcelWriterでは使えない。
▼エラー
例えば以下のようにパスを指定した場合コードdf2 = df.copy() with pd.ExcelWriter('~/Desktop/GA-demo.xlsx') as writer: df.to_excel(writer, sheet_name='AAA') df2.to_excel(writer, sheet_name='BBB')エラーFileNotFoundError: [Errno 2] No such file or directory: '~/Desktop/GA-demo.xlsx'
▼スラッシュをバックスラッシュに変更しても、「~」があると同様にエラーとなる。コードdf2 = df.copy() with pd.ExcelWriter('~\\Desktop\\GA-demo.xlsx') as writer: df.to_excel(writer, sheet_name='AAA') df2.to_excel(writer, sheet_name='BBB')エラーFileNotFoundError: [Errno 2] No such file or directory: '~/Desktop/GA-demo.xlsx'
▼修正後OKdf2 = df.copy() with pd.ExcelWriter('C:/Users/name/Desktop/GA-demo3.xlsx') as writer: df.to_excel(writer, sheet_name='AAA') df2.to_excel(writer, sheet_name='BBB')
②unicode error
フォルダパスをコピペで貼り付けるとこのエラーがでる。
▼エラー
例えば以下のようにパスを指定した場合コードdf2 = df.copy() with pd.ExcelWriter('C:\Users\name\Desktop\GA-demo.xlsx') as writer: df.to_excel(writer, sheet_name='AAA') df2.to_excel(writer, sheet_name='BBB')エラーSyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escapeバックスラッシュ「\」はエスケープのため。文字として認識させる場合は「\」とする必要がある。
▼修正後OK!df2 = df.copy() with pd.ExcelWriter('C:\\Users\\name\\Desktop\\GA-demo2.xlsx') as writer: df.to_excel(writer, sheet_name='AAA') df2.to_excel(writer, sheet_name='BBB')記述は下記どちらでもOK。
「C:\Users\name\」
「C://Users//name//」
- 投稿日:2020-04-04T20:10:15+09:00
GANの安定性に寄与しているというSpectral Normalizationや特異値分解について頑張って理解しようとした
はじめに
GAN:敵対的生成ネットワーク関連の内容です。GANにおけるモデルは必ずしも訓練によって本物と見分けがつかない画像に収斂していくわけではありません。
訓練が進まない理由として、勾配の消失・モード崩壊という不安定性があります。この不安定性は、Discriminator(識別器)のリプシッツ連続やリプシッツ定数のコントロールが重要だと言われています。この不安定性を解消するには、Spectral Normalizationが便利です。
さて、、、分からない言葉がいくつか出てきました。今回はこれらの意味するところを私なりに解釈した内容をまとめたいと思います。
今回も参考にさせて頂いた本はこちらです。
Inpaintingからディープラーニング、最新のGAN事情について学べる本を書いた
https://qiita.com/koshian2/items/aefbe4b26a7a235b5a5e
- リプシッツ連続、リプシッツ関数とは
- 特異値分解とは
- Spectral Normalizationとは
リプシッツ連続、リプシッツ関数とは
関数$f(x)$がリプシッツ連続であるとは、任意の$x_1$,$x_2$に対して、
|\frac{f(x_1)-f(x_2)}{x_1-x_2}| \leq k 式1を満たすような定数$k$が存在することを言います。この$k$はリプシッツ定数と呼びます。
さて、リプシッツ連続の内容を進める前に、関数が連続であることを振り返りたいと思います。
単に、関数が連続だという場合は下記です。
$x=x_0$で連続とは、\lim_{x \to x_0} f(x) = f(x_0) 式2\\が成立することをいいます。そして、対象とするすべての点で連続であるときに、$f(x)$は連続関数であるといえます。
例えば下記のような例が連続関数と連続関数で無い場合をいいます。
直感的に理解しやすいかと思います。
一方、リプシッツ連続とは、上記の式1を満たす$k$が存在する関数となります。
上の図において、関数上のどの点でも傾き $±k$ の直線を引くと、関数のグラフはその間におさまっている状態をリプシッツ連続であると呼びます。
先ほどの$y=x$を例に考えてみましょう。式1は、|\frac{f(x_1)-f(x_2)}{x_1-x_2}| \leq k \\ \Rightarrow 1\leq kとなります。従って、$k$の値が0.01などの場合は式が成り立たなくなるので、この関数はリプシッツ連続であるといえなくなってしまいます。
従って、 関数が連続であることと、リプシッツ連続であることはリプシッツ連続\in連続にように連続が包含する形になります。
GANでは通常$k=1$と制約をおくことが安定性を高めるとされている経験則になります。
参考URL
https://mathwords.net/lipschitz特異値分解とは
次に特異値分解(singular value decomposition)について説明します。この特異値分解とは行列における操作のことで、下記のSpectral Normalizationにとって必要な操作となるため、ここでまとめます。
特異値分解とは、任意の$m×n$行列$A$に対して、$A = UΣV$となる直行行列$U,V$及び非対角成分が0、対角成分が非負で大きさの順に並んだ行列$Σ$で分けることを言います。
そして、この$Σ$の成分を特異値と呼びます。
$U,V,Σ$の求め方に関しては下記pdfを参照頂ければと思います。http://www.cfme.chiba-u.jp/~haneishi/class/iyogazokougaku/SVD.pdf
さて、Pythonではこれら特異値分解は簡単に求めることができます。
SN.ipynbimport numpy as np data = np.array([[1,2,3,4],[3,4,5,6]]) U, S, V = np.linalg.svd(data) print(U) print(S) print(V)[[-0.50566621 -0.86272921] [-0.86272921 0.50566621]] [10.73807223 0.8329495 ] #特異値 [[-0.28812004 -0.41555404 -0.54298803 -0.67042202] [ 0.7854851 0.35681206 -0.07186099 -0.50053403] [-0.40008743 0.25463292 0.69099646 -0.54554195] [-0.37407225 0.79697056 -0.47172438 0.04882607]]このようにして、特異値は[10.73807223 0.8329495 ]であることが確かめられました。最大特異値は10.74程度であることが分かります。
参考URL
https://thinkit.co.jp/article/16884Spectral Normalizationとは
さて、最後のこのSpectral Normalizationについてです。ニューラルネットワークの層を作りこむ上ではBatch Normalization(以下Batch Norm)と呼ばれる手法が有名です。
このBatch Normは、2015年に提案された手法です。全結合層や畳み込み層の後に組み込まれる層になっています。効果としては以下です。
- 学習が早く進行(=損失関数の値が収束しやすい)
- 初期値に依存しにくい(ロバスト性がある)
- 過学習の抑制
処理としては以下のような処理を行います。
ミニバッチとして$x_1,x_2・・・x_m$の$m$この入力データに対して、平均$μB$,分散$σ_B^2$を求めています。
これら効果を享受できるBatch Normですが、ことGANの学習に関しては連続性を損なる要因として挙げられています。
上記式でもわかるように、Batch Normは標準偏差で割っているため分数関数の表現になります。分数関数は、$x=0$で連続で無いことから連続性を損なっていることが理解できます。従って、この問題を解決する手段がSpectral Normalizationになります。
Spectral Normalization for Generative Adversarial Networks
https://arxiv.org/abs/1802.05957これは日本人が著者で、株式会社Preferred Networksの方々が発表したものです。
Spectral Normalizationは係数を最大特異値で割るという考えになります。モデルに対して、リプシッツ連続性を担保し、リプシッツ定数が1となるようにコントロールすることができます。
この最大特異値を求めるために、先の特異値分解を用います。実装上は非常に簡便です。tensorflowを用いた場合は解のようにConvSN2Dにより規定することで実装できます。
SN.ipynbimport tensorflow as tf from inpainting_layers import ConvSN2D inputs = tf.random.normal((16, 256, 256, 3)) x = ConvSN2D(64,3,padding='same')(inputs) print(x.shape)さて、この特異値を求める方法ですが、そのままsvdメソッドを適用すると計算量が膨大になるため、べき乗法というアルゴリズムを用います。
$(N,M)$の行列$X$における最大特異値は
- $U:(1,X)$の行列$U$を定義する。そのとき正規乱数として初期化
- 以下をP回繰り返す
- $V=L_2(UX^T)$を試算。ただし$L2=x/\sqrt(Σx_{i,j})+ε$ ,($ε$は微小量)
- $U=L_2(VX)$を試算。
- $σ = VXT^T$を試算。$σ$が最大特異値となる。
実装すると下記になります。元のdata行列は上で用いたものです。
results = [] for p in range(1, 6): U = np.random.randn(1, data.shape[1]) for i in range(p): V = l2_normalize(np.dot(U, data.T)) U = l2_normalize(np.dot(V, data)) sigma = np.dot(np.dot(V, data), U.T) results.append(sigma.flatten()) plt.plot(np.arange(1, 6), results) plt.ylim([10, 11])
さて、10.74あたりで先ほどと同じ結果が得られました。このようにして実装上は求めています。
終わりに
今回、Spectral Normalizationに関わる内容をまとめました。大枠な流れはつかんだものの、数学的なところに関しては理解不足なことが残りました。
引き続き実装を行う中で理解を深めたいと思います。プログラムはこちらに格納しています。
https://github.com/Fumio-eisan/SN_20200404




- 投稿日:2020-04-04T19:59:06+09:00
SQLAlchemyの落とし穴
はじめに
pythonでDBアクセスをする際によく使われるORマッパーとして、SQLAlchemyがあります。sqlalchemyを使用してpythonでDBアクセスをするはSQL以外のことをまとめました。今回はSQLAlchemyを理解しないで使用すると困りそうなことをまとめました。
環境
- python3:3.6.5
- SQLAlchemy:1.3.7
- psycopg2:2.8.3
SQLとSQLAlchemyで取得できるものが違う
SQLAlchemyにはORMでの更新以外にもSQL文を直接使用することができます。DBから更新する方法と取得する方法が異なると意図した情報がとれないので気を付けてください。
具体例
同一セッション内であってもコミット前にSQL文で変更した内容をORMで取得しようとしたら更新前のものが取れてしまいます。逆も同様です。
実験
SQL文やORMで更新した後にSQL文とORMで取得して内容を表示してみます。
実験ソース
新しくセッションを張るとDBの情報を取りに行ってしまうため、更新用関数と表示用関数ともに同一セッションを持ちまわしています。また、更新時の変数が表示時の変数に影響を与えたくないため更新と表示を別の関数として作成しています。セッションの作成等は以前を見てください。
main.pydef get_mapper_and_query(local_session): print('============== query get ===============') records = local_session.execute("select * from pets where id = 3;") for record in records: print(record) print('============== mapper get ===============') pet2 = local_session.query(Pets).filter(Pets.id==3).first() print(pet2) def update_mapper_and_query(): local_session = SESSION() print('*************************** default ***************************') get_mapper_and_query(local_session) print('*************************** default ***************************\n') print('*************************** mapper update ***************************') pet = local_session.query(Pets).filter(Pets.id==3).first() pet.age = 10 get_mapper_and_query(local_session) print('*************************** mapper update ***************************') print('*************************** query update ***************************') local_session.execute("update pets set age=20 where id = 3;") get_mapper_and_query(local_session) print('*************************** query update ***************************\n')結果
もともとageが5だったものがORMの更新後のORMによる取得時だけ10に更新されています。さらに、SQL文の更新後にはSQL文による取得時はageが20に更新されてORMによる取得時にはORM更新時の10がそのまま残っています。このようにそれぞれの更新方法と取得方法が異なれば取れるものが異なります。
*************************** default *************************** ============== query get =============== (3, 'mink', 5, datetime.datetime(1990, 2, 12, 0, 0)) ============== mapper get =============== id:3, name:mink, age:5, birthday:1990-02-12 00:00:00 *************************** default *************************** *************************** mapper update *************************** ============== query get =============== (3, 'mink', 5, datetime.datetime(1990, 2, 12, 0, 0)) ============== mapper get =============== id:3, name:mink, age:10, birthday:1990-02-12 00:00:00 *************************** mapper update *************************** *************************** query update *************************** ============== query get =============== (3, 'mink', 20, datetime.datetime(1990, 2, 12, 0, 0)) ============== mapper get =============== id:3, name:mink, age:10, birthday:1990-02-12 00:00:00 *************************** query update ***************************DBへのコネクションが増えていく
SQLAlchemyにはコネクションプールの機能があります。永続的にプログラムを動かし続ける場合はコネクションが生成されるタイミングを理解しないとどんどんコネクションが増えていきます。
具体例
DB情報を取得するWEBサービスをflaskで作成したらDBのセッション数の上限に達してエラーするようになった。
実験
flaskでDBから情報取得するサービスを作成してDB側で接続数を確認してみます。
実験ソース
リクエストを受けたらDBへのセッションを作成して情報を返却するソースです。今回はわかりやすいようにDBのセッションにpy_appというアプリケーション名をつけています。DB接続はsqlalchemyを使用してpythonでDBアクセスをするから、flaskについてはflaskでhttpステータスを返却する方法を見てください。
main.pyfrom sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from flask import Flask, jsonify from Pets import Pets DATABASE = 'postgresql' USER = 'postgres' PASSWORD = 'postgres' HOST = 'localhost' PORT = '5431' DB_NAME = 'animal_db' CONNECT_STR = '{}://{}:{}@{}:{}/{}'.format( DATABASE, USER, PASSWORD, HOST, PORT, DB_NAME ) app = Flask(__name__) @app.route('/hello/<name>') def hello(name): engine = create_engine(CONNECT_STR, connect_args={"application_name":"py_app"}) session = sessionmaker(engine)() pets = session.query(Pets).filter(Pets.name==name).all() return jsonify(pets) if __name__ == "__main__": app.run()結果
起動時のセッション数
postgres=# select count(*) from pg_stat_activity where application_name = 'py_app'; count ------- 0 (1 row)1回目のリクエスト後のセッション数
postgres=# select count(*) from pg_stat_activity where application_name = 'py_app'; count ------- 1 (1 row)2回目のリクエスト後のセッション数
postgres=# select count(*) from pg_stat_activity where application_name = 'py_app'; count ------- 2 (1 row)30回目のリクエスト後のセッション数
postgres=# select count(*) from pg_stat_activity where application_name = 'py_app'; count ------- 30 (1 row)このようにリクエストを発行するたびにセッションが張られていくことがわかります。これを防ぐにはセッションを持ちまわすかレスポンス前にセッションをクローズしてエンジンをディスポーズする必要があります。
おわりに
今回の取得の値が異なる点はテストで見つかりますがセッションは下手したら見つからない可能性がありとても危険です。ORMは便利に使えてしまうために十分に理解せずに使用する人がいますがこのような落とし穴にハマる可能性があるため十分に理解する必要があります。
- 投稿日:2020-04-04T19:36:59+09:00
Python で学ぶリファクタリング (基本編)
関数の抽出 (Extract Function)
before.pyimport math def main(): radius = int(input()) circumference = math.pi * radius * 2 print(circumference) if __name__ == '__main__': main()after.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius = int(input()) circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()関数のインライン化 (Inline Function)
before.pyimport math def get_circumference(radius): return math.pi * radius * 2 def print_circumference(circumference): print(circumference) def main(): radius = int(input()) circumference = get_circumference(radius) print_circumference(circumference) if __name__ == '__main__': main()after.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius = int(input()) circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()変数の抽出 (Extract Variable)
before.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): print(get_circumference(int(input()))) if __name__ == '__main__': main()after.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius = int(input()) circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()変数のインライン化 (Inline Variable)
before.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius_str = input() radius_int = int(radius_str) circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()after.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius = int(input()) circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()関数宣言の変更 (Change Function Declaration)
before.pyimport math def crcm(radius): return math.pi * radius * 2 def main(): radius = int(input()) circumference = cr(radius) print(circumference) if __name__ == '__main__': main()after.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius = int(input()) circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()変数のカプセル化 (Encapsulate Variable)
before.pyimport math def get_diameter(radius): return radius * 2 def get_circumference(radius): return math.pi * radius * 2 def get_area(radius): return math.pi * radius * radius def main(): radius = int(input()) diameter = get_diameter(radius) circumference = get_circumference(radius) area = get_area(radius) print(radius) print(diameter) print(circumference) print(area) if __name__ == '__main__': main()after.pyimport math class Circle: radius: int diameter: int circumference: int area: int def __init__(self, radius): self.radius = radius self.diameter = radius * 2 self.circumference = math.pi * radius * 2 self.area = math.pi * radius * radius def get_radius(self): return self.radius def get_diameter(self): return self.diameter def get_circumference(self): return self.circumference def get_area(self): return self.area def main(): radius = int(input()) circle = Circle(radius) print(circle.get_radius()) print(circle.get_diameter()) print(circle.get_circumference()) print(circle.get_area()) if __name__ == '__main__': main()変数名の変更 (Rename Variable)
before.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): hoge = input() piyo = get_circumference(hoge) print(piyo) if __name__ == '__main__': main()after.pyimport math def get_circumference(radius): return math.pi * radius * 2 def main(): radius = input() circumference = get_circumference(radius) print(circumference) if __name__ == '__main__': main()パラメータオブジェクトの導入 (Introduce Parameter Object)
before.pyimport math def print_param(radius, diameter, circumference, area): print('radius: {}'.format(radius)) print('diameter: {}'.format(diameter)) print('circumference: {}'.format(circumference)) print('area: {}'.format(area)) def main(): radius = int(input()) diameter = radius * 2 circumference = math.pi * radius * 2 area = math.pi * radius * radius print_param(radius, diameter, circumference, area) if __name__ == '__main__': main()after.pyimport math class Circle: radius: int diameter: int circumference: int area: int def __init__(self, radius): self.radius = radius self.diameter = radius * 2 self.circumference = math.pi * radius * 2 self.area = math.pi * radius * radius def get_radius(self): return self.radius def get_diameter(self): return self.diameter def get_circumference(self): return self.circumference def get_area(self): return self.area def print_param(circle): radius = circle.get_radius() diameter = circle.get_diameter() circumference = circle.get_circumference() area = circle.get_area() print('radius: {}'.format(radius)) print('diameter: {}'.format(diameter)) print('circumference: {}'.format(circumference)) print('area: {}'.format(area)) def main(): radius = int(input()) circle = Circle(radius) print_param(circle) if __name__ == '__main__': main()関数群のクラスへの集約 (Combine Functions into Class)
before.pyimport math class Circle: radius: int diameter: int circumference: int area: int def __init__(self, radius): self.radius = radius self.diameter = radius * 2 self.circumference = math.pi * radius * 2 self.area = math.pi * radius * radius def get_radius(self): return self.radius def get_diameter(self): return self.diameter def get_circumference(self): return self.circumference def get_area(self): return self.area def print_param(circle): radius = circle.get_radius() diameter = circle.get_diameter() circumference = circle.get_circumference() area = circle.get_area() print('radius: {}'.format(radius)) print('diameter: {}'.format(diameter)) print('circumference: {}'.format(circumference)) print('area: {}'.format(area)) def main(): radius = int(input()) circle = Circle(radius) print_param(circle) if __name__ == '__main__': main()after.pyclass Circle: radius: int diameter: int circumference: int area: int def __init__(self, radius): self.radius = radius self.diameter = radius * 2 self.circumference = math.pi * radius * 2 self.area = math.pi * radius * radius def get_radius(self): return self.radius def get_diameter(self): return self.diameter def get_circumference(self): return self.circumference def get_area(self): return self.area def print_param(self): print('radius: {}'.format(self, radius)) print('diameter: {}'.format(self, diameter)) print('circumference: {}'.format(self, circumference)) print('area: {}'.format(self, area)) def main(): radius = int(input()) circle = Circle(radius) circle.print_param() if __name__ == '__main__': main()関数群の変換への集約 (Combine Functions into Transform)
N/A
フェーズの分離 (Split Phase)
N/A
- 投稿日:2020-04-04T19:04:59+09:00
【python】pandasでexcelファイルの読み込む方法
【python】pandasでexcelファイルを読み込む方法
pandasでexcelファイルを読み込む方法。
公式ページ
・pandas.read_excel
・xlrd
目次
1.ライブラリのインストール
excelファイルを読み込むのに必要なライブラリをインストールする。
インストールpip install -U xlrd pip install -U pandas①xlrd
└excelファイルを読み込むライブラリ
└「.xls」「.xlsx」
②pandas
└データ分析用のライブラリ>pipについてはこちら
2.読み込む表
・3枚のシートを含む表
・ファイルパス「~/desktop/GA-demo.xlsx」
3.ファイルの読み込み
①デフォルト
②シート番号で読み込み
③シート名で読み込み
①デフォルト
1枚目のシートが読み込まれる。
デフォルトimport pandas as pd df = pd.read_excel('~/desktop/GA-demo.xlsx') df
②シート番号で読み込み
オプションで
sheet_name=nを記述。
└「n」:シート番号。
└ シート番号は0始まり。シート番号で指定import pandas as pd pd.read_excel('~/desktop/GA-demo.xlsx', sheet_name=1)
③シート名で読み込み
オプションで
sheet_name='A'を記述。
└「A」:シート名シート名で読み込みimport pandas as pd pd.read_excel('~/desktop/GA-demo.xlsx', sheet_name='データセット2')
4.オプション
読み込み時にオプションが用意されている。
・header(列名)となる行の指定
・index(行名)となる列の指定
・読み込む行数の指定
・下から指定した行数を読み込む
などが可能。csvファイル読み込み時のオプションとほぼ同じ。
詳細はこちら




- 投稿日:2020-04-04T19:04:53+09:00
Pythonでアルゴリズム(幅優先探索)
はじめに
pythonを使った幅優先探索の実装について解説していきます。(僕がいつも実装するやつを載せるだけです。)
幅優先探索ではよく距離についての問題が出てくるので、今回はある1頂点から各頂点までの距離を返す関数を実装します。幅優先探索
幅優先探索に関する一般的な知識は調べればたくさん出てくると思うので、詳しくは省略しますが簡単に説明します。
青い矢印のように、近いところから順に頂点を追っていきます。今回扱う距離の場合には、ひとつ前の頂点までの距離に1を足せばいいです。(画像では1から振っていますが、距離ならば0から振ればいいです。)
この頂点の探索の順番は、キューで管理します。キューは、先入れ先出しのデータ構造です。今回の例でいうと、まずはスタートの0が入ります。([0])次に、中身を前から取り出し、隣接する頂点を調べます。(今回は1, 2)初めて訪れたのであればキューに追加します。([1, 2])
これを繰り返していけば青い矢印順に頂点を調べることができます。
([2, 3, 4]→[3, 4, 5, 6]→[4, 5, 6, 7]...)
キューが空になったら探索終了です。お疲れ様です。実装
入力
頂点数nと辺の数mが与えられ、その後隣接する頂点をm行に渡って与えられます。
11 9 0 1 0 2 1 3 1 4 2 5 2 6 3 7 5 8 8 9コード
import sys input = sys.stdin.readline n, m = [int(x) for x in input().split()] # nは頂点の数、mは辺の数 g = [[] for _ in range(n)] # 隣接リスト for _ in range(m): a, b = [int(x) for x in input().split()] g[a].append(b) g[b].append(a) from collections import deque def bfs(u): queue = deque([u]) d = [None] * n # uからの距離の初期化 d[u] = 0 # 自分との距離は0 while queue: v = queue.popleft() for i in g[v]: if d[i] is None: d[i] = d[v] + 1 queue.append(i) return d # 0からの各頂点の距離 d = bfs(0) print(d)出力
左から頂点の番号順に頂点0との距離を持つリストを出力します。自分との距離は0で、たどり着けない頂点はNoneとなります。
[0, 1, 1, 2, 2, 2, 2, 3, 3, 4, None]おわりに
何か間違いがあれば是非教えてください!アドバイスなどもいただけたらうれしいです!

- 投稿日:2020-04-04T18:43:49+09:00
データ分析用 Pythonプログラミングレシピ集
はじめに
普段、RとPythonでデータ分析をしているのですが、両方使っているとしばしばごっちゃになってしまうため、メモとして残します。
ライブラリ
ライブラリimport gc import os import random import csv import sys import json import datetime import lightgbm as lgb import numpy as np import pandas as pd import seaborn as sns from collections import Counter from numba import jit pd.set_option('display.max_rows', 1000) pd.set_option('display.max_columns', 1000) from matplotlib import pyplot as plt from sklearn.metrics import mean_squared_error from sklearn.metrics import log_loss from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import KFold from sklearn import metrics import statsmodels.api as sm from statsmodels.tsa.arima_model import ARIMA from fbprophet import Prophet from tqdm import tqdm plt.style.use("seaborn") sns.set(font_scale=1)データ入力
外部ファイル読み込み# csv読み込み df = pd.read_csv("../input/csvfile.csv")DataFrame作成pd.DataFrame(data = {"col1" : array1, "col2" : array2})データ整形
変換# 横持ち⇒縦持ち変換 # remain_columns ⇒ 残す列名 # trans_columns ⇒ 縦持ちに変換する列名 # 列名⇒variable、値⇒value pd.melt(df,id_vars = remain_columns,value_vars = trans_columns) # 縦持ち⇒横持ち変換 # values⇒値 # columns⇒列名 # aggfunc⇒集計方法(デフォルトはmean) df.pivot_table(values=['val'],columns=['col'], aggfunc='sum')結合df_left.merge(df_right, left_on='key_left', right_on='key_right', how = 'left)特定行・列を削除# NaNを含む行を削除 df.dropna(subset=['delete_if_include_na'])) # col1列を削除 df.drop(["col1"], axis = 1, inplace = True)特定行を抽出(包含)df.loc[df.col.isin(conditions)]型変換# datetime型に変換 pd.to_datetime(df['date'])便利な関数
リスト内包表記["F" + str(i+1) for i in range(5)] > ['F1', > 'F2', > 'F3', > 'F4', > 'F5']ファイルの存在を確認os.path.exists(path_to_file)モデル作成
Prophet
Prophetモデル作成・予測・表示# 宣言 model = Prophet(weekly_seasonality = True, yearly_seasonality = True) # 学習 model.fit(df_train) # 予測 future = model.make_future_dataframe(28) forecast = model.predict(future) # 可視化 model.plot(forecast) plt.show()
- 投稿日:2020-04-04T18:27:42+09:00
XENOをpythonで実装
XENOの動画、めっちゃくちゃ面白いですよね。
普段はrailsを書いてるのですが、たまにはpythonの練習を兼ねて今話題のXENOをpythonで実装してみました。そのうち機械学習のネタに使ってみたりyoutube投稿してみたい。
mannual_flagをTrueにすればテキトーロジックのCPU戦が遊べます。
Xeno.pyimport random class Xeno(): def __init__(self): self.winner = "none" class Player(): def __init__(self,teban): self.hand = [] self.field = [] self.predict_flag = False self.defence_flag = False self.mannual_flag = False if teban == 0: self.teban="sente" elif teban ==1: self.teban="gote" def set_deck(self): card_list=[1,1,2,2,3,3,4,4,5,5,6,6,7,7,8,8,9,10] random.shuffle(card_list) self.deck = card_list #転生札処理 self.reincarnation_card = self.deck.pop(-1) #山札から1枚ドロー def draw_top_card(self): if len(self.deck) > 0: self.drawed_card=self.deck.pop(0) return self.drawed_card #賢者実行 デッキから3枚見て1枚をドローカードにしデッキをシャッフル def do_predict(self): if len(self.deck) > 2: options = self.deck[0:3] if self.player.mannual_flag ==True: print("賢者の効果発動") print(options) print("選択するカードを入力してください") ind = options.index(self.inputnumber()) else: ind = options.index(options[1]) selected_card = self.deck.pop(ind) random.shuffle(self.deck) self.drawed_card = selected_card return self.drawed_card #マッチセットアップ def match_initialize(self): self.sente = self.Player(0) self.gote = self.Player(1) #山札、転生札を作成し、各プレイヤー1枚ずつドロー self.set_deck() self.sente.hand.append(self.draw_top_card()) self.gote.hand.append(self.draw_top_card()) #ドローからターンエンドまでのシークエンス def play_turn(self,_player): if _player == self.sente: self.player = self.sente self.o_player = self.gote else: self.player = self.gote self.o_player = self.sente if self.player.predict_flag == True and len(self.deck) > 2: self.drawed_card = self.do_predict() self.player.predict_flag = False else: self.drawed_card = self.draw_top_card() #ドローカードを手札に追加 self.player.hand.append(self.drawed_card) if self.player.mannual_flag ==True: print("drawed card:",self.drawed_card) print(self.player.teban, self.player.hand) #手札からカードを1枚場に出す self.play_card = self.decide_play_card() #手札から出したカードを削除 self.player.hand.remove(self.play_card) #場に追加 self.player.field.append(self.play_card) # print("player hand:", self.player.hand) #出したカードの効果をプレイ if self.o_player.defence_flag != True or self.play_card == 7 or self.play_card == 4: self.play_effect() #相手が守護を出していた場合、フラグリセットのみ else: self.o_player.defence_flag = False print("player field:", self.player.field) print("o_player field:", self.o_player.field) #ターン終了時、デッキがなくなっていた場合、手札バトル print("deck maisuu:", len(self.deck)) if len(self.deck) == 0: self.battle() #最終決戦 def battle(self): print("battle!!!!!!!!!!!!!") print("sente:", self.sente.hand[0]) print("gote:", self.gote.hand[0]) if self.sente.hand[0] > self.gote.hand[0]: self.winner = self.sente.teban elif self.gote.hand[0]>self.sente.hand[0]: self.winner = self.gote.teban else: self.winner = "DRAW" def decide_play_card(self): if self.player.mannual_flag== True: print("プレイするカード番号を入力してください") return self.inputnumber() else: if self.player.hand.count(10) != 1: # random.shuffle(self.player.hand) self.player.hand.sort() return self.player.hand[0] else: self.player.hand.sort() return self.player.hand[0] def play_effect(self): pl = self.play_card if pl == 1: print("play:", pl) self.revolution() elif pl ==2: print("play:", pl) self.detect_number() elif pl == 3: print("play:", pl) self.publicate() elif pl ==4: print("play:", pl) self.skip_effect() elif pl ==5: print("play:", pl) self.hide_draw_and_drop() elif pl == 6: print("play:", pl) self.battle_novice() elif pl == 7: print("play:", pl) self.predict() elif pl == 8: print("play:", pl) self.exchange() elif pl == 9: print("play:", pl) self.public_draw_and_drop() def inputnumber(self): if self.player.mannual_flag==True: s = int(input()) return s else: return 1 #1 少年 def revolution(self): all_field = self.sente.field + self.gote.field #フィールド上にすでに1が出ていた場合のみ公開処刑 print(all_field) if all_field.count(1) > 1: self.public_draw_and_drop() #2 兵士 def detect_number(self): detection_number = 3 if self.player.mannual_flag == True: print("兵士の効果発動") print("相手の手札予想を入力してください") detection_number = self.inputnumber() else: detection_number = 5 if self.o_player.hand[0] == detection_number: self.winner = self.player.teban #3 占い師 def publicate(self): print(self.o_player.hand) #4 守護 def skip_effect(self): self.player.defence_flag = True #5 死神 def hide_draw_and_drop(self): if len(self.deck)>0: #相手は1枚ドローし手札シャッフル self.draw_card = self.draw_top_card() self.o_player.hand.append(self.draw_card) random.shuffle(self.o_player.hand) if self.player.mannual_flag == True: print("捨てさせる手札の位置を選んでください 0:左 1:右") inp = self.inputnumber() else: inp = 0 #0番目カードをドロップ drop_target_card = self.o_player.hand.pop(inp) self.o_player.field.append(drop_target_card) #targetが10だった場合、転生処理 if drop_target_card == 10: self.reincarnate() #6 貴族 def battle_novice(self): self.battle() #7 賢者 def predict(self): self.player.predict_flag = True #8 聖霊 def exchange(self): tmp = self.player.hand[0] self.player.hand[0] = self.o_player.hand[0] self.o_player.hand[0] = tmp #9 皇帝 def public_draw_and_drop(self): if len(self.deck) > 0: self.o_player.hand.append(self.draw_top_card()) #手札公開 if self.player.mannual_flag ==True: print("相手の手札はこちら") print(self.o_player.hand) #ターゲット選択 print("select target number:") drop_target = self.inputnumber() ind = self.o_player.hand.index(drop_target) else: ind = 0 drop_target_card = self.o_player.hand.pop(ind) self.o_player.field.append(drop_target_card) #皇帝のカード(9)がプレイされたかつターゲットカードが英雄(10)だった場合はplayer勝利 if drop_target_card == 10: if self.play_card == 9: self.winner = self.player.teban elif self.play_card == 1: self.reincarnate() #10 英雄 def reincarnate(self): #手札を捨てる self.o_player.field.append(self.o_player.hand.pop(0)) #転生札をドロー self.o_player.hand.append(self.reincarnation_card) def main(): winner_list = [] win_process =[] for i in range(1,1000): xeno = Xeno() xeno.match_initialize() xeno.sente.mannual_flag = False xeno.gote.mannual_flag = False while True: print("=======================") if xeno.winner == "none": xeno.play_turn(xeno.sente) else: break print("=======================") if xeno.winner == "none": xeno.play_turn(xeno.gote) else: break print("winner :", xeno.winner) winner_list.append(xeno.winner) print("gote",winner_list.count("gote")) print("sente",winner_list.count("sente")) print("Draw",winner_list.count("DRAW")) if __name__ == '__main__': main()ちなみにロジックテキトーですが、10000試合の結果
gote 4543
sente 4967
Draw 4896,10の組み合わせの初手勝ちがあり得る分、やはり先手のほうが有利ですね。
後、守護のカードは実質「相手に手札を選んで捨てさせる + 相手のターンスキップ」と同義なのでかなり強いアタッカーになってる気がします。
- 投稿日:2020-04-04T18:03:16+09:00
【機械学習図鑑】巻末のPython演習をデータを確認しながら実施したときのメモ
概要
先日DataCampのデータサイエンティストコースを修了しました。
英語での学習だったこともあり、日本語でざっとおさらいしたいと考えていたところ、機械学習図鑑という本がわかりやすくてよかったので読んだのですが、ありがたいことに「第4章 評価方法及び各種データの扱い」でPythonコードで実際に演習をする写経コンテンツがあったので復習しました。途中少しコードを加筆修正している箇所もありますが、基本的にはほぼそのままです。
各コマンドで変わっていくデータ状態を確認するために、適宜コメントでデータのshape等を記載しています。オリジナルのサンプルプログラムは下記URLで公開されていますので、オリジナルはそちらを参照ください。
ダウンロードの際には是非翔泳社さんのサイトへのサインアップをお願いします。コードの区切りは、実際に演習をした際にコードレベルで切ることができるところで分割しており、複数のトピックが混ざっています。
その1
- 教師あり学習の評価
- 分類問題における評価方法
from sklearn.datasets import load_breast_cancer data = load_breast_cancer() # ウィスコンシンの乳がんのデータ Xo = data.data # Xo.shape = (569, 30) y = 1 - data.target # reverse target paramater X = Xo[:, :10] # mean_* のデータが先頭10カラムにある # LogisticRegression from sklearn.linear_model import LogisticRegression # model_lor = LogisticRegression() # FutureWarning: Default solver will be changed to 'lbfgs' in 0.22 が出ます model_lor = LogisticRegression(solver='liblinear') # solverを指定して上げるとWarningは出ない。 model_lor.fit(X, y) y_pred = model_lor.predict(X) # ConfusionMatrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y, y_pred) print("============= CONFUSION MATRIX ============= ") print(cm) ''' 予測と正解のケース数のマトリクスで出てくる Predict 0 1 Actual 0 [341 16] 1 [ 36 176] ''' # Accuracy Score from sklearn.metrics import accuracy_score accs = accuracy_score(y, y_pred) print("============= ACCURACY SCORE ============= ") print(accs) # 正解率。予測結果全体に対する正解率。 (341+176) / 569 # Precision Score from sklearn.metrics import precision_score pres = precision_score(y, y_pred) print("============= PRECISION SCORE ============= ") print(pres) # 適合率。ポジティブ(1)と予測したものに対すして正しくポジティブと予測できたものの割合。 176 / (176+16) # Recall Score from sklearn.metrics import recall_score recs = recall_score(y, y_pred) print("============= RECALL SCORE ============= ") print(recs) # 再現率。実際にポジティブ(1)なものに対して正しく予測できた割合。 176 / (36+176) # 再現率が低い場合、陽性を見逃していることになるので危険。 # F Score from sklearn.metrics import f1_score f1s = f1_score(y, y_pred) print("============= F SCORE ============= ") print(f1s) # 適合率と再現率の両方の傾向を反映させた指標。 # 予測確率 y_pred_proba = model_lor.predict_proba(X) print(y_pred_proba) ''' Probability 0 1 Case [4.41813067e-03 9.95581869e-01] [4.87318129e-04 9.99512682e-01] [3.31064287e-04 9.99668936e-01] ... ''' # 標準の .predict() を使うと prob > 0.5 (50%) で判断されるため、誤判定を上げて見逃しを減らしたいケースではパラメータを調整する # 10%以上の可能性があるものを抽出 import numpy as np y_pred2 = (model_lor.predict_proba(X)[:, 1] > 0.1).astype(np.int) print("============= CONFUSION MATRIX ( 1 prob > 10% ) ============= ") print(confusion_matrix(y, y_pred2)) ''' Predict 0 1 Actual 0 [259 98] 1 [ 2 210] ''' print("============= ACCURACY SCORE ( 1 prob > 10% ) ============= ") print(accuracy_score(y, y_pred2)) # 0.8242... print("============= RECALL SCORE ( 1 prob > 10% ) ============= ") print(recall_score(y, y_pred2)) # 0.9905... # ROC Curve, AUC # ROC : Receiver Operation Characteristic # AUC : Area Under the Curve from sklearn.metrics import roc_curve y_pred_proba = model_lor.predict_proba(X) fpr, tpr, thresholds = roc_curve(y, y_pred_proba[:, 1]) import matplotlib.pyplot as plt plt.style.use('fivethirtyeight') fig, ax = plt.subplots() # 一度にfigure objとaxes objを返す fig.set_size_inches(4.8, 5) ax.step(fpr, tpr, 'gray') ax.fill_between(fpr, tpr, 0, color='skyblue', alpha=0.8) ax.set_xlabel('False Positive Rate') ax.set_ylabel('True Positive Rate') ax.set_facecolor('xkcd:white') plt.show() # AUC(面積)が1に近づくほど精度が高いことを示す # AUCを求める from sklearn.metrics import roc_auc_score print("============= AUC(Area Under the Curve) SCORE ( 1 prob > 10% ) ============= ") print(roc_auc_score(y, y_pred_proba[:, 1])) # 0.9767... # 不均衡データ(Posi, Negaの数に偏りが大きい場合)を扱うときは指標にAUCを使ったほうが良いその2
- 回帰問題における評価方法
- 平均二乗誤差と決定係数の指標の違い
- 異なるアルゴリズムを利用した場合との評価
- ハイパーパラメータの設定
- モデルの過学習
- 過学習を防ぐ方法
- 学習データと検証データに分割
- 交差検証(クロスバリデーション)
from sklearn.datasets import load_boston data = load_boston() # ボストンの住宅価格のデータ Xo = data.data # Xo.shape = (506, 13) X = Xo[:, [5,]] # X.shape = (506, 1) Xo[:, 5][0] => numpy.float64 Xo[:, [5,]][0] => numpy.ndarray y = data.target from sklearn.linear_model import LinearRegression model_lir = LinearRegression() model_lir.fit(X, y) y_pred = model_lir.predict(X) print("============= LINEAR REGRESSION ============= ") print("model_lir.coef_ : {}".format(model_lir.coef_)) # 傾き y = ax + b の a print("model_lir.intercept_ : {}".format(model_lir.intercept_)) # 切片 y = ax + b の b import matplotlib.pyplot as plt fig, ax = plt.subplots() ax.scatter(X, y, color='pink', marker='s', label='data set') ax.plot(X, y_pred, color='blue', label='regression curve') ax.legend() plt.show() # 平均二乗誤差 # 実際の値と予測値の差を示す数値。y軸誤差を二乗して平均をとったもの。 from sklearn.metrics import mean_squared_error print("============= MEAN SQUARED ERROR ============= ") print(mean_squared_error(y, y_pred)) # 43.600... # 決定係数(R**2) # 平均二乗誤差を利用した、学習済みモデルの予測の当てはまり度を示す数値(0->1)。1が誤差なし。ひどいとマイナスになることも。 from sklearn.metrics import r2_score print("============= R2 SCORE ============= ") print(r2_score(y, y_pred)) # SVR (Linear Regression) # Support Vector Machine (Kernel method) from sklearn.svm import SVR model_svr_linear = SVR(C=0.01, kernel='linear') model_svr_linear.fit(X, y) y_svr_pred = model_svr_linear.predict(X) fig, ax = plt.subplots() ax.scatter(X, y, color='pink', marker='s', label='data set') ax.plot(X, y_pred, color='blue', label='regression curve') ax.plot(X, y_svr_pred, color='red', label='SVR') ax.legend() plt.show() # SVR(Linear Regression)の検証 print("============= SVR SCORE (LINEAR REGRESSION) ============= ") print("mean_squared_error : {}".format(mean_squared_error(y, y_svr_pred))) print("r2_score : {}".format(r2_score(y, y_svr_pred))) print("model_lir.coef_ : {}".format(model_svr_linear.coef_)) print("model_lir.coef_ : {}".format(model_svr_linear.intercept_)) # SVR(rbf) model_svr_rbf = SVR(C=1.0, kernel='rbf') model_svr_rbf.fit(X, y) y_svr_pred = model_svr_rbf.predict(X) print("============= SVR SCORE (RBF) ============= ") print("mean_squared_error : {}".format(mean_squared_error(y, y_svr_pred))) print("r2_score : {}".format(r2_score(y, y_svr_pred))) # Over Fitting X_train, X_test = X[:400], X[400:] y_train, y_test = y[:400], y[400:] model_svr_rbf_1 = SVR(C=1.0, kernel='rbf') model_svr_rbf_1.fit(X_train, y_train) y_train_pred = model_svr_rbf_1.predict(X_test) print("============= SVR SCORE (RBF) - OverFitting ============= ") print("mean_squared_error : {}".format(mean_squared_error(y_test, y_train_pred))) print("r2_score : {}".format(r2_score(y_test, y_train_pred))) # Prevent Over Fitting from sklearn.datasets import load_breast_cancer data = load_breast_cancer() # 先述のがんのデータ X = data.data y = data.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # testデータの抽出を同じにしたい場合は random_stateを指定 from sklearn.svm import SVC model_svc = SVC() model_svc.fit(X_train, y_train) y_train_pred = model_svc.predict(X_train) y_test_pred = model_svc.predict(X_test) from sklearn.metrics import accuracy_score print("============= ACCURACY SCORE (SVC) ============= ") print("Train_Accuracy_score : {}".format(accuracy_score(y_train, y_train_pred))) # 1.0 print("Test_Accuracy_score : {}".format(accuracy_score(y_test, y_test_pred))) # 0.60 # 学習データの正答率に対して予測データでのスコアが低いので過学習。 from sklearn.ensemble import RandomForestClassifier model_rfc = RandomForestClassifier() model_rfc.fit(X_train, y_train) y_train_pred = model_rfc.predict(X_train) y_test_pred = model_rfc.predict(X_test) print("============= ACCURACY SCORE (RFC) ============= ") print("Train_Accuracy_score : {}".format(accuracy_score(y_train, y_train_pred))) # 0.9974... print("Test_Accuracy_score : {}".format(accuracy_score(y_test, y_test_pred))) # 0.9590... # RandomForestにしたことで予測データでのスコアが上昇。 # Cross Validation from sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold cv = KFold(5, shuffle=True) model_rfc_1 = RandomForestClassifier() print("============= CROSS VALIDATION SCORE ============= ") print("Cross_Valication_Score x5 Scoring=Accuracy : {}".format(cross_val_score(model_rfc_1, X, y, cv=cv, scoring='accuracy'))) print("Cross_Valication_Score x5 Scoring=F1 : {}".format(cross_val_score(model_rfc_1, X, y, cv=cv, scoring='f1')))その3
- ハイパーパラメータの探索
from sklearn.datasets import load_breast_cancer data = load_breast_cancer() Xo = data.data y = 1 - data.target # reverse label X= Xo[:, :10] from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import KFold cv = KFold(5, shuffle=True) param_grid = {'max_depth': [5, 10, 15], 'n_estimators': [10, 20, 30]} model_rfc_2 = RandomForestClassifier() grid_search = GridSearchCV(model_rfc_2, param_grid, cv=cv, scoring='accuracy') # grid_search = GridSearchCV(model_rfc_2, param_grid, cv=cv, scoring='f1') grid_search.fit(X, y) print("============= GRID SEARCH RESULTS ============= ") print("GridSearch BEST SCORE : {}".format(grid_search.best_score_)) print("GridSearch BEST PARAMS : {}".format(grid_search.best_params_))その4
- 文書データの変換処理
- 単語カウントによる変換
- tf-idfによる変換
- 機械学習モデルへの適用
# tf-idf # tf : Term Frequency # idf : Inverse Document Frequency import numpy as np from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.svm import LinearSVC from sklearn.datasets import fetch_20newsgroups categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med'] remove = ('headers', 'footers', 'quotes') twenty_train = fetch_20newsgroups(subset='train', remove=remove, categories=categories) twenty_test = fetch_20newsgroups(subset='test', remove=remove, categories=categories) count_vect = CountVectorizer() X_train_counts = count_vect.fit_transform(twenty_train.data) X_test_count = count_vect.transform(twenty_test.data) model = LinearSVC() model.fit(X_train_counts, twenty_train.target) predicted = model.predict(X_test_count) print("============= CountVectorizer ============= ") print("predicted == twenty_test.target : {}".format(np.mean(predicted == twenty_test.target))) # 0.7423... tf_vec = TfidfVectorizer() X_train_tfidf = tf_vec.fit_transform(twenty_train.data) X_test_tfidf = tf_vec.transform(twenty_test.data) model = LinearSVC() model.fit(X_train_tfidf, twenty_train.target) predicted = model.predict(X_test_tfidf) print("============= TfidfVectorizer ============= ") print("predicted == twenty_test.target : {}".format(np.mean(predicted == twenty_test.target))) # 0.8149...その5
- 画像データの変換処理
- ピクセルの情報をそのまま数値として利用する
- 変換後のベクトルデータを入力として機械学習モデルを適用する
from PIL import Image import numpy as np # Transform image data to vector data img = Image.open('/Users/***/****.jpg').convert('L') # 適当にローカルの画像のフルパスを指定 width, height = img.size img_pixels = [] for y in range(height): for x in range(width): img_pixels.append(img.getpixel((x,y))) # getpixelで指定した位置のピクセル値を取得 print("============= Print Pixel ============= ") print("len(img_pixels) : {}".format(len(img_pixels))) print("img_pixels : {}".format(img_pixels)) # [70, 183, 191, 194, 191, 187, 180, 171, 157, 143, ....] # Predict number images from sklearn import datasets from sklearn import metrics from sklearn.ensemble import RandomForestClassifier digits = datasets.load_digits() # type(digits) => sklearn.utils.Bunch type(digits.images) => numpy.ndarray n_samples = len(digits.images) # 1797 digits.images.shape => (1797, 8, 8) data = digits.images.reshape((n_samples, -1)) # digits.images.reshape((n_samples, -1)).shape => (1797, 64) model = RandomForestClassifier() model.fit(data[:n_samples // 2], digits.target[:n_samples // 2]) # data[:n_samples // 2].shape => (898, 64) # digits.target[:n_samples // 2].shape => (898,) expected = digits.target[n_samples // 2:] predicted = model.predict(data[n_samples // 2:]) print(metrics.classification_report(expected, predicted))翔泳社さんの機械学習図鑑、とてもわかりやすいよい本なのでおすすめです。(DataCampの機械学習セクションの前に読んでおきたかった・・・)
- 投稿日:2020-04-04T18:01:09+09:00
Python-Markdownのソースを読んでみる:パーサの作り方
目的
マークダウンのパーサライブラリがどのように実装されているのか学ぶことにしました。(唐突)
Javaのdomパーサの設計(デザインパターン)が素晴らしいとのことですが、まずは慣れているPythonのライブラリを探してみました。ちなみにJavaのはこれ。
https://www.tutorialspoint.com/java_xml/java_dom_parse_document.htm今回は以下のライブラリのソースを読んでみます。
Python-Markdown
https://github.com/Python-MarkdownMarkdown->HTMLへの変換ができるみたいです。
当然、中でMarkdownの解析を行なっているわけで、どのような設計になっているのか、拝見しましょう!理解が間違っている箇所などありましたら、ご指摘ください...!
注意書き
Python-Markdown/markdown/markdown/以下にコアな関数たちが集められているようです。
今後は面倒なので、基本的にこのディレクトリ以下のファイルをsample.pyのように省略して表示します。また、以下に載せるソースコードは基本的に必要な部分のみを抜粋(+コメントアウトでメモ書き)したものになっています。
メイン部分を最初にネタバレ
結論から言うと、特定のエレメントを検出する各プロセッサーをブロックごとに順番に作用させていました。
作用させる対象は、元のテキストを「\n\n」で分割した各ブロックになっています。
これは例えば、<b>タグが不完全ですが、太字です 太字ではありません</b>のように空白行が入る(=「\n\n」が現れる)と、エレメントの有効範囲が途切れてしまうからですね。
この例だと、まず
["<b>タグが不完全ですが、太字です", "太字ではありません</b>"」のように各ブロックにして、まず
"<b>タグが不完全ですが、太字です"に対して各要素を検出するプロセッサーを順番に作用させ、次のブロックへ進んで...
といった流れになるかと思います。処理の流れ
このライブラリでユーザが使用するインターフェースの中心となるのは、以下の
Markdownクラスとそのconvertメソッドです。core.pyclass Markdown: # ここでhtmlに変換 def convert(self, source): # source : マークダウンのテキスト
convertメソッドにコメントが付いており、和訳するとこんな感じ。1、preprocessorたちがテキストを変換する
2、1で前処理されたテキストの高レベル構造elementをElementTreeにパースする
3、ElementTreeをtreeprocessorたちが処理する。例えばInlinePatternsはinline要素を見つける
4、ElementTreeをテキストにシリアライズしたものに、いくつかのpost-processorsを作用させる
5、結果を文字列に書き出すもはや原文の方が読みやすいかもw
ステップ1 preprocessors
core.pyclass Markdown: def convert(self, source): < 略 > self.lines = source.split("\n") for prep in self.preprocessors: self.lines = prep.run(self.lines)まず各行に分割して、前処理を噛ませる。
preprocessorsは以下で取得しています。preprocessors.pydef build_preprocessors(md, **kwargs): """ Build the default set of preprocessors used by Markdown. """ preprocessors = util.Registry() preprocessors.register(NormalizeWhitespace(md), 'normalize_whitespace', 30) preprocessors.register(HtmlBlockPreprocessor(md), 'html_block', 20) preprocessors.register(ReferencePreprocessor(md), 'reference', 10) return preprocessors
NormalizeWhitespace>HtmlBlockPreprocessor>ReferencePreprocessor
の優先順位で前処理が登録されています。名前の通り
NormalizeWhitespace: 空白、改行文字の正規化(10行程度の実装)
HtmlBlockPreprocessor: html要素の解析(250行...!)
ReferencePreprocessor: [タイトル](リンク)の形式で表現されるリンクを見つけて辞書Markdown.referencesに登録(30行)
HtmlBlockPreprocessorの中身は飛ばしましょう。同じような要素検出処理はステップ2や3で待ち構えているはずです...(余談)
ReferencePreprocessorのように、次の行までその要素の中身になるかの判定をしなければいけない場面はパーサではよく出てきて、自作(勉強がてら)の時はwhile lines: line_num += 1 line = self.lines[line_num] <処理> if (次の行まで含める): line_num += 1 line = self.lines[line_num]のようにしていましたが、
ReferencePreprocessorではpopを使っています。while lines: line = lines.pop(0)うん、そうするべきでした...汗
(余談おわり)
ステップ2 ErementTreeにパース
この処理は以下の部分です。
core.pyclass Markdown: def convert(self, source): < 略 > # Parse the high-level elements. root = self.parser.parseDocument(self.lines).getroot()ここで
self.parserというのは以下の関数で取得したBlockParserになります。blockprocessors.pydef build_block_parser(md, **kwargs): """ Build the default block parser used by Markdown. """ parser = BlockParser(md) parser.blockprocessors.register(EmptyBlockProcessor(parser), 'empty', 100) parser.blockprocessors.register(ListIndentProcessor(parser), 'indent', 90) parser.blockprocessors.register(CodeBlockProcessor(parser), 'code', 80) parser.blockprocessors.register(HashHeaderProcessor(parser), 'hashheader', 70) parser.blockprocessors.register(SetextHeaderProcessor(parser), 'setextheader', 60) parser.blockprocessors.register(HRProcessor(parser), 'hr', 50) parser.blockprocessors.register(OListProcessor(parser), 'olist', 40) parser.blockprocessors.register(UListProcessor(parser), 'ulist', 30) parser.blockprocessors.register(BlockQuoteProcessor(parser), 'quote', 20) parser.blockprocessors.register(ParagraphProcessor(parser), 'paragraph', 10) return parserこちらも優先順位とともにプロセッサーが登録されています。
BlockParser.praseDocument()はこちら。blockparser.pyclass BlockParser: def __init__(self, md): self.blockprocessors = util.Registry() self.state = State() self.md = md # ElementTreeを作成する def parseDocument(self, lines): self.root = etree.Element(self.md.doc_tag) self.parseChunk(self.root, '\n'.join(lines)) return etree.ElementTree(self.root) def parseChunk(self, parent, text): self.parseBlocks(parent, text.split('\n\n')) def parseBlocks(self, parent, blocks): while blocks: for processor in self.blockprocessors: if processor.test(parent, blocks[0]): if processor.run(parent, blocks) is not False: break要するに、
core.pyroot = self.parser.parseDocument(self.lines).getroot()の部分では各
BlockProcessorに処理をさせているわけですね。例えば、ハッシュタグによるヘッダー「# ヘッダー」形式をさばくプロセッサーは以下のように定義されています。
blockprocessors.pyclass HashHeaderProcessor(BlockProcessor): """ Process Hash Headers. """ RE = re.compile(r'(?:^|\n)(?P<level>#{1,6})(?P<header>(?:\\.|[^\\])*?)#*(?:\n|$)') def test(self, parent, block): return bool(self.RE.search(block)) def run(self, parent, blocks): block = blocks.pop(0) m = self.RE.search(block) if m: ``` ここから ``` before = block[:m.start()] after = block[m.end():] if before: # beforeの部分のみ再帰処理 self.parser.parseBlocks(parent, [before]) h = etree.SubElement(parent, 'h%d' % len(m.group('level'))) h.text = m.group('header').strip() if after: # 次にafterを処理するために、blocksの先頭に追加 blocks.insert(0, after) ``` ここまでがコアってことよね ``` else: logger.warn("We've got a problem header: %r" % block)もう1つ、「> 文章」形式の引用ブロックのプロセッサーを見てみましょう。
引用ブロックで考えなければいけないことは
・複数行に連続したブロックは、1つのブロックとしてみなす
・ブロックの中身もパースしなければいけない
ってことですね。blockprocessors.pyclass BlockQuoteProcessor(BlockProcessor): RE = re.compile(r'(^|\n)[ ]{0,3}>[ ]?(.*)') def test(self, parent, block): return bool(self.RE.search(block)) def run(self, parent, blocks): block = blocks.pop(0) m = self.RE.search(block) if m: before = block[:m.start()] # ここはさっきのHashHeaderProcessorと同じだね self.parser.parseBlocks(parent, [before]) # 各行先頭の">"を削除 block = '\n'.join( [self.clean(line) for line in block[m.start():].split('\n')] ) ``` 引用ブロックが今まで続いてきたか、ここが先頭かを考慮 ``` sibling = self.lastChild(parent) if sibling is not None and sibling.tag == "blockquote": quote = sibling else: quote = etree.SubElement(parent, 'blockquote') self.parser.state.set('blockquote') ``` 引用ブロックの中身(block)をパース。親は現在のブロック(quote)にしているね ``` self.parser.parseChunk(quote, block) self.parser.state.reset()ちなみに、
siblingは兄弟や姉妹を表す単語なんだね。2つのプロセッサークラスをみてきましたが、パース結果をどこに保存しているかとえば、
etree.SubElement(parent, <tagname>)
の部分が怪しい。そもそもetreeとは、pythonの標準ライブラリにある
xml.etree.ElementTreeインスタンスになります。
etree.SubElement(parent, <tagname>)によって、BlockParser().root(これもまたElementTreeインスタンス)に子要素を加えていることになります。プロセスが進むにつれ、結果が
BlockParser().rootとして保存されていくわけですね。ステップ3 treeprocessor
今までと同様に、今度は
treeprocessorを噛ませます。treeprocessors.pydef build_treeprocessors(md, **kwargs): """ Build the default treeprocessors for Markdown. """ treeprocessors = util.Registry() treeprocessors.register(InlineProcessor(md), 'inline', 20) treeprocessors.register(PrettifyTreeprocessor(md), 'prettify', 10) return treeprocessors
InlineProcessor: インライン要素に対する処理
PrettifyTreeprocessor: 改行文字などの処理終わりに
え、いきなりおしまい!?
でも、今まで見てきた中でこのライブラリの大まかなデザインパターンはわかったのではないでしょうか?
あとは気になる部分があれば、各自で見るのが良いでしょう...ちょっと、疲れました。
最後までご覧いただきありがとうございます...!
- 投稿日:2020-04-04T17:42:49+09:00
AWS SAMを使ってサクッとPythonとlambda、API GatewayでAPIを作る
プロジェクトで、Pythonを使った簡単なAPIを作ることになったので、サクッとAPIを作る環境を整えていきます。
前提
エディター…VSCode
OS…Windows10
Python3.8インストール済み
AWS CLI導入済みWindows での AWS CLI バージョン 2 のインストール - AWS Command Line Interface
必要な環境
- AWS SAM CLI
- AWS Toolkit for Visual Studio Code
AWS SAMの利点
公式ドキュメントによると
- 単一のデプロイ構成
- AWS CloudFormation の拡張
- 組み込みのベストプラクティス
- ローカルのデバッグとテスト
- 開発ツールとの緊密な統合
がメリット。
個人的にはlambdaをローカルでデバッグできるのは大きなメリットでした。
実態はCloudFormationなので、カスタマイズ性があるのもポイント高い。AWS SAM CLIの導入
公式ドキュメントに従って行います。要約すると
- dockerをインストール
- AWSが配布してるインストーラ(.msiファイル)からインストールするか
pip install aws-sam-cliでインストールsam --versionでバージョンが出力されればOKdockerは、ローカルマシンにlambdaの実行環境を作るために導入します。
AWS Toolkit for Visual Studio Codeの導入
これは、VSCodeからAWS SAM CLIを使えるようにするためのVSCodeの拡張機能です。
AWS Toolkit - Visual Studio Marketplaceプロジェクトを新規作成する
公式ドキュメントに従って行います。
- コマンドパレット(Ctrl + Shift + P)を開き、
Create new SAM Applicationを選択
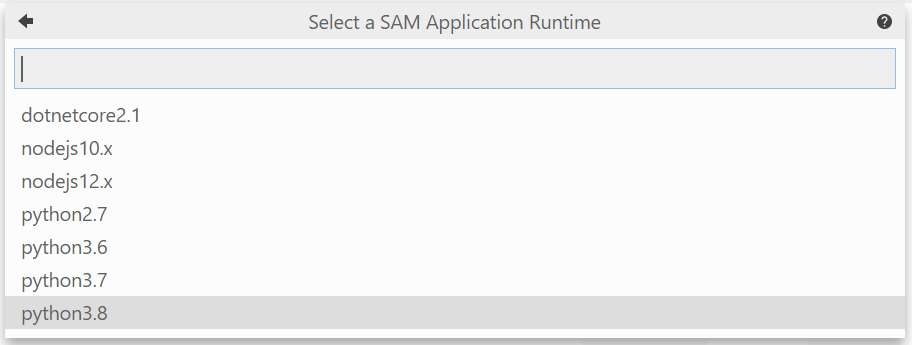
- 使用するランタイムを選びます。今回はPython3.8
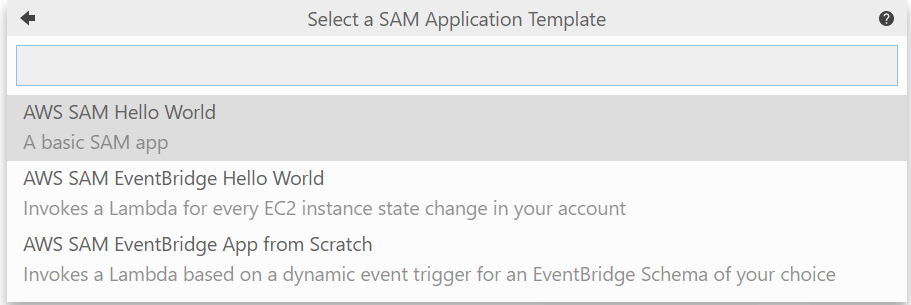
- テンプレートを選択。今回は単体で使うのでHwllo World
- プロジェクトを作成するディレクトリを指定します。エクスプローラーが開くので任意のフォルダを選択します。

- プロジェクト名を指定します。 Enterを押すと、プロジェクトが作成されます。

ローカルデバッグ実行する
hello_world/app.pyを開き、Debug Locallyを選択すると、dockerに仮想環境が作られ、関数が実行されます。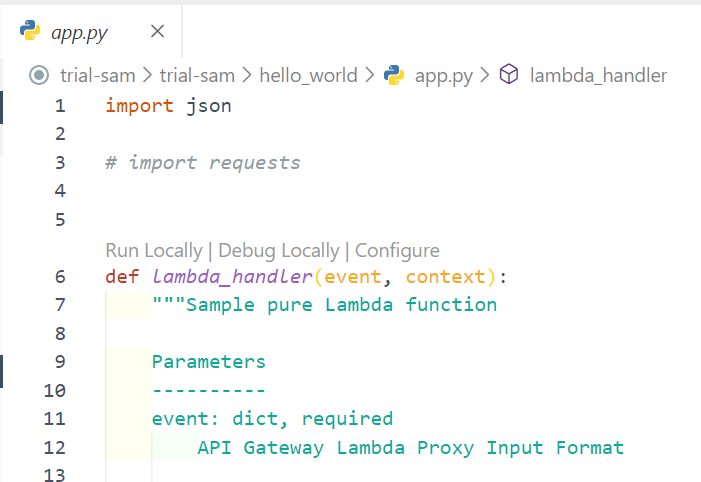
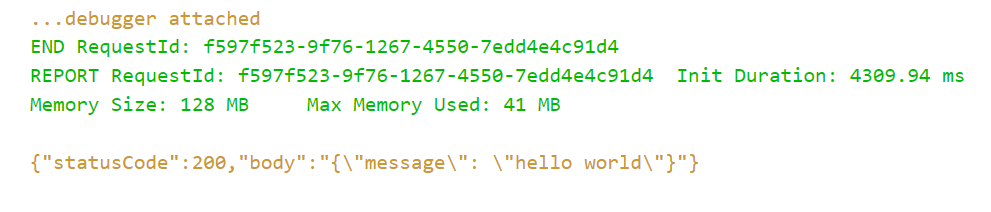
- デバッグコンソールに結果が出力されればOK
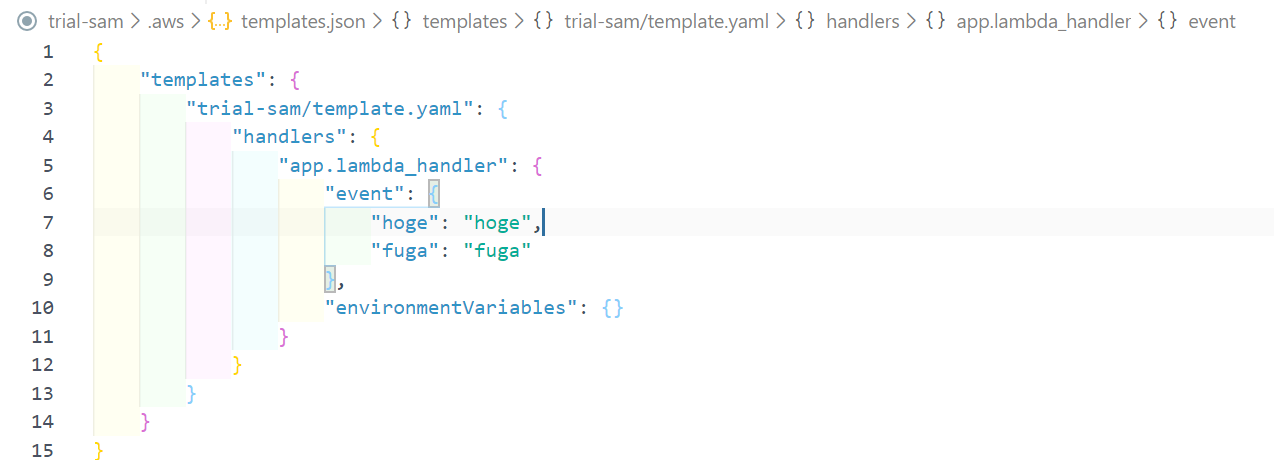
eventを設定する
.aws/templates.jsonで設定できる
デプロイする
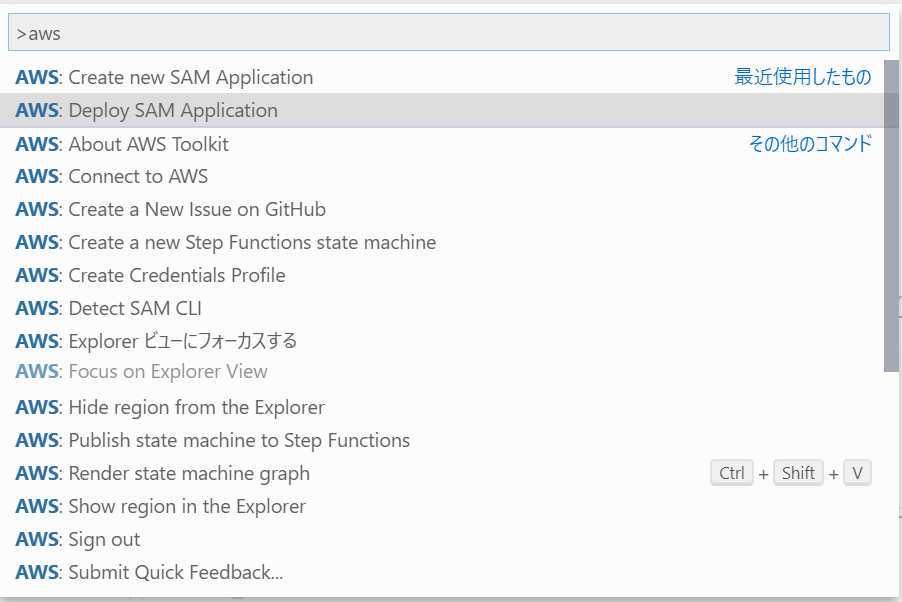
templete.yamlをもとにデプロイしていきます。
1. コマンドパレットからDeploy SAM Applicationを選択
2. テンプレートを選択する。今回はtemplete.yaml
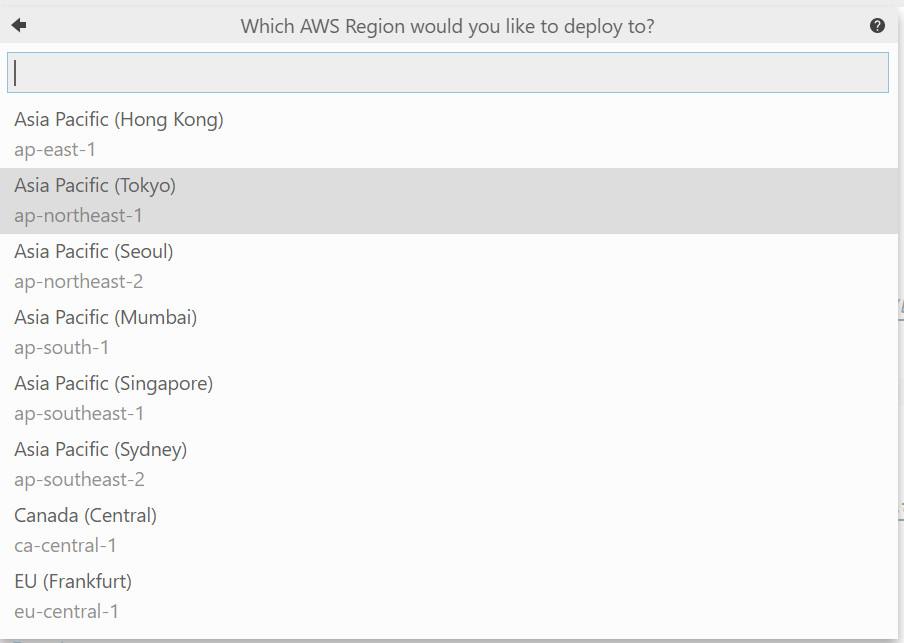
3. 任意のデプロイ先のリージョンを選択する。今回はTokyo
4. S3のバケット名を指定します。ここでは既存のバケット名を指定しなければなりません。
5. Stack名を指定します。
Stackとは、CloudFormationで作成されるサービス群の名前です。プロジェクト名と同名にしてます。
6. デプロイが成功するとデバッグコンソールが表示されます
デプロイされたことを確認する
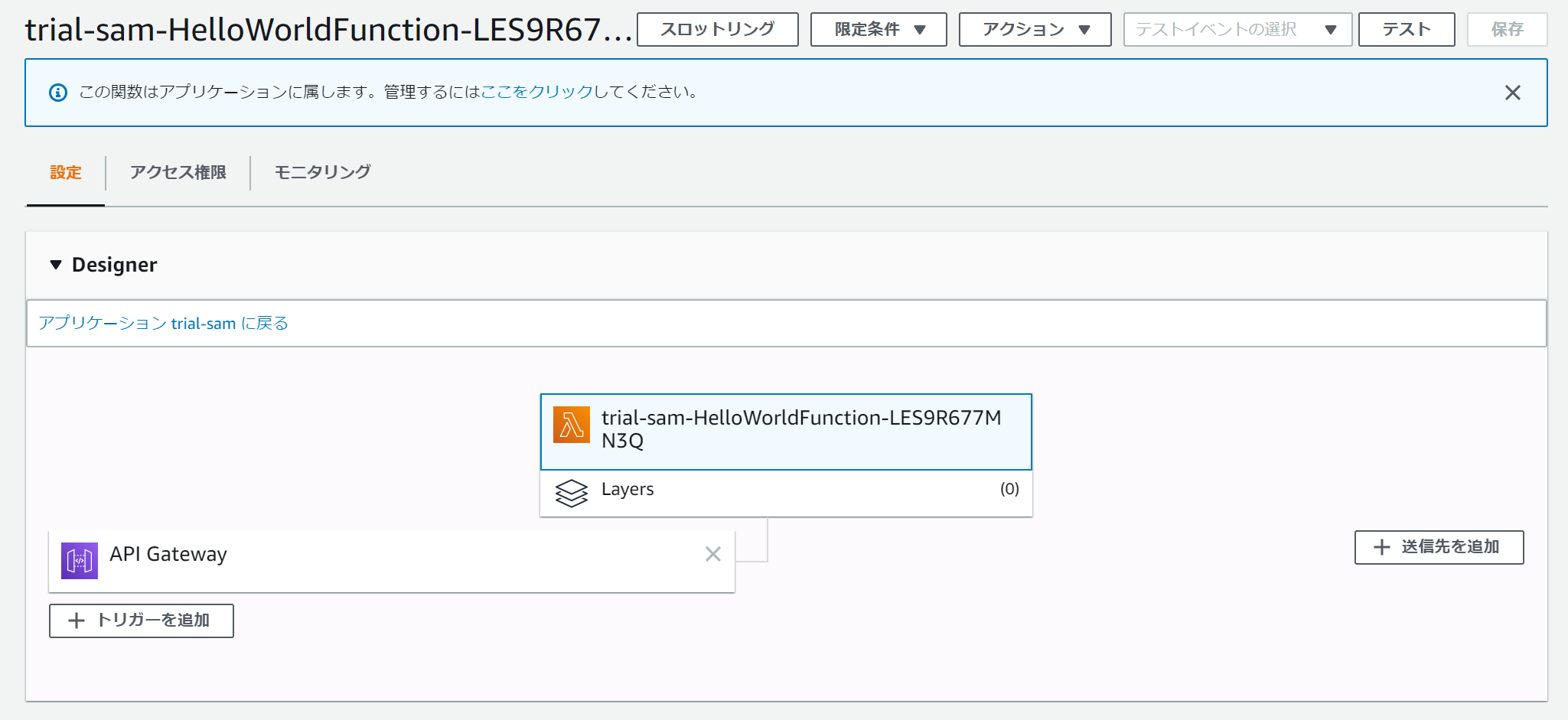
以下のように、lambdaが作られていることを確認できます。
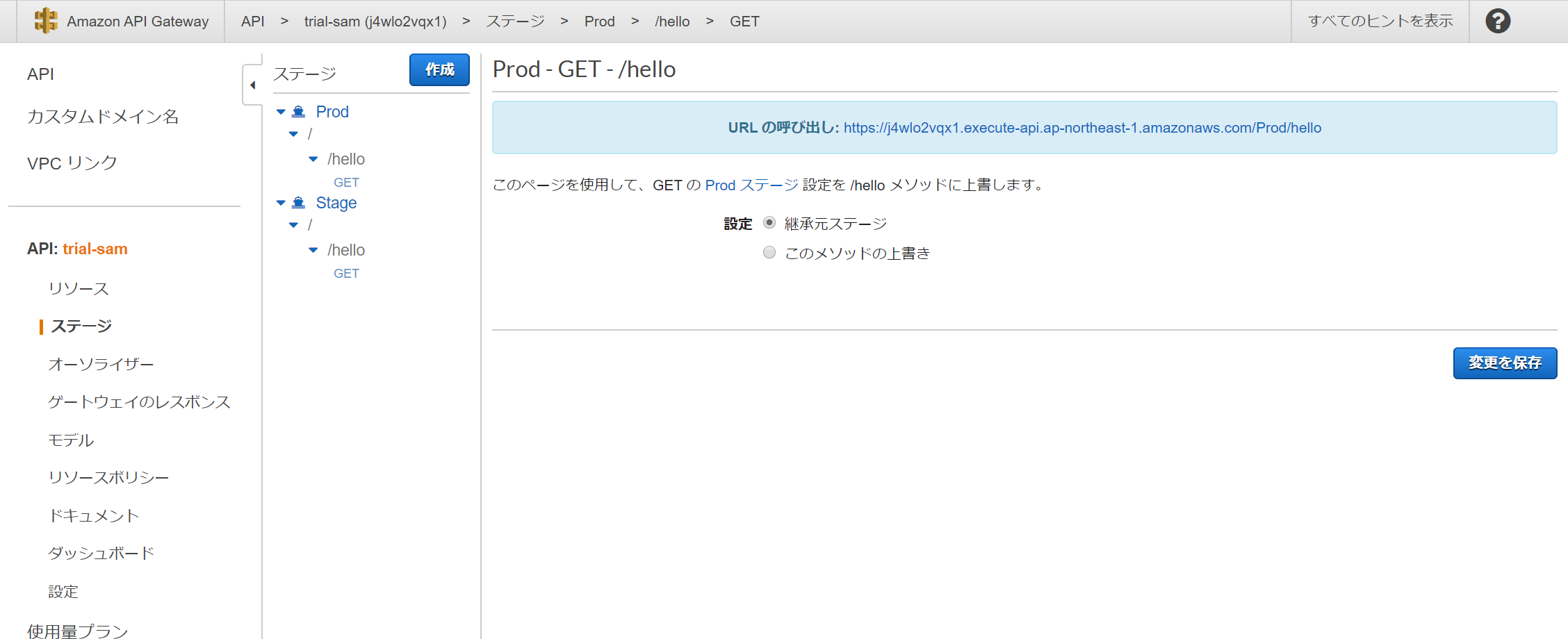
API GatewayでもAPIが作られていることが確認できます。
カスタマイズする
デフォルトで作られるAPIは
GET:/helloなので、これを変更するにはtemplete.yamlを編集する必要があります。下記はデフォルトの
templete.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > trial-sam Sample SAM Template for trial-sam # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: get Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.Arnこの中を以下の通りに書き換えればパスとHTTPメソッドを変えられる
Before
Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: getAfter
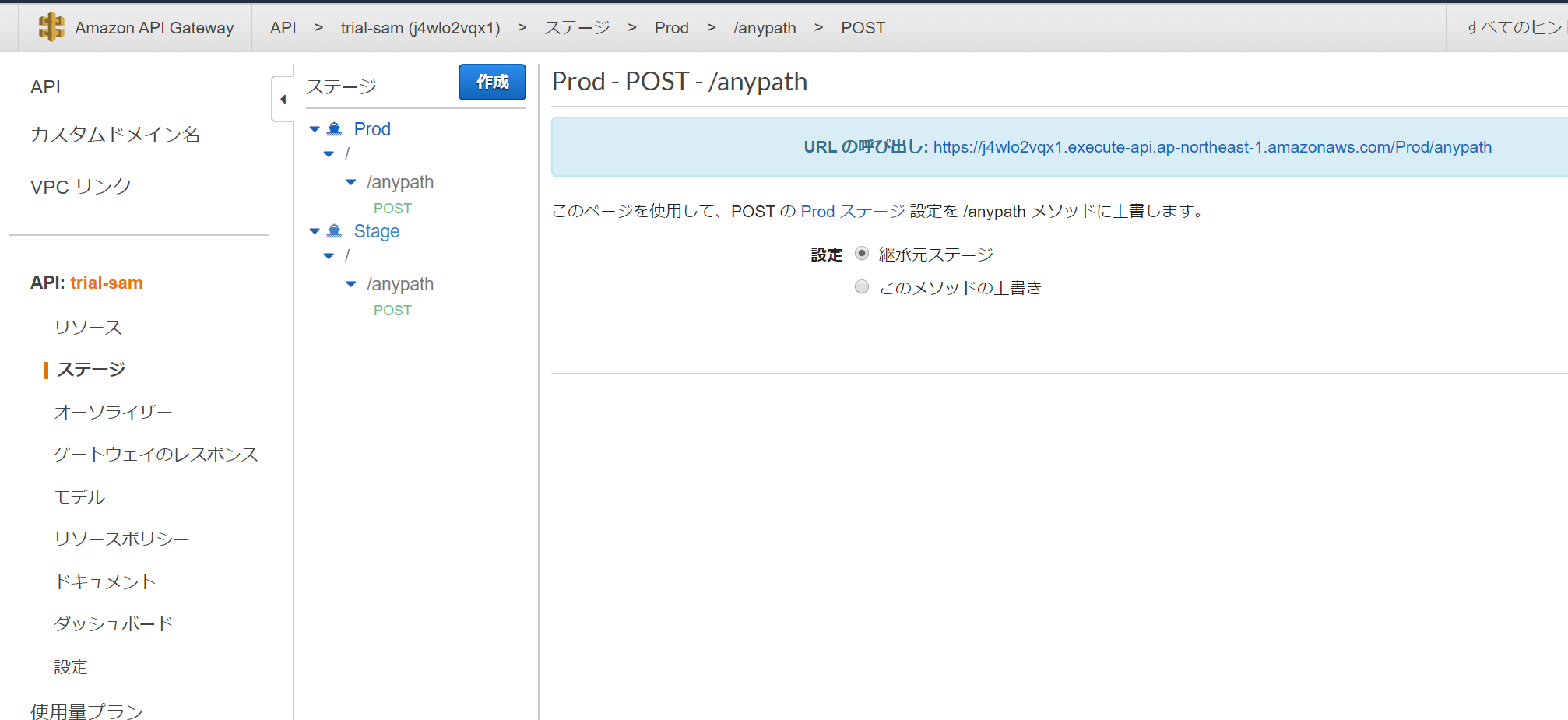
Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /anypath # hello → anypath Method: post # get → postPOST:
anypathに変更できました。
あとはロジックを書いていくだけ
あとは要件に合わせてロジックを組み立てていくだけです。
再度デプロイすれば、変更内容も反映されます。




- 投稿日:2020-04-04T17:24:53+09:00
matplotlibによる様々な種類のグラフの作成方法
はじめに
本記事はpythonのmatplotlibを用いたグラフ作成のまとめになります.
筆者が必要になった形式のグラフスタイルを記載しています.(定期的に追記します)
性質的に理工学者の研究発表・論文投稿向けです.また,汎用性を高めるため,凡例の増加等にはなるべく繰り返し関数で対応するような工夫をしています.
環境
2020/04/04現在最新のpython3-Anaconda環境を想定しています.
pythonの導入方法はネットでいくらでも出てきますが,ポチポチするだけで済むので,Anacondaがおすすめ.pathは通すようにチェックつけましょう.エディタはVisual Studio Codeを使用しています.以前はPyCharmを使用していましたが,他の言語と同じエディタを使いたくなったので,変えました.自動整形コマンドが便利です.(Shift + Alt + F)
参考:VS codeでpython3の実行(windows10)準備
パッケージのインポート
必要なものをimportします.
matplotlib以外にはnumpyとpandasをとりあえず使います.matplotlibはpyplotしか使ってないですねimport numpy as np import matplotlib.pyplot as plt import pandas as pdサンプルデータの用意
本記事で使用するためのサンプルデータを用意します.
dataframeのほうが,一気に表にできるのでデータとして扱う際には簡単ですが,実際にグラフにする際は,リストのほうが細かい設定ができるので,逐一リストに戻したりしてます.
dataframeの扱いやファイルの読み書きはまたどこかでまとめます.とりあえず以下ではリストを作った後dfを生成しておきました.
csvやexcel出力時に縦じゃないと見づらいので,行と列を変換した後indexを設定してます.A = np.linspace(0,1) B = [x**2 for x in A] C = [np.cos(2*np.pi*x) for x in A] S = [np.sin(2*np.pi*x) for x in A] df = pd.DataFrame([A,B,C,S], index=["x","squarex","cosx","sinx"]).Tスタイルの調整
dataframeの確認がてら適当にplotします.df.plot()でindexをx軸にした複数凡例のグラフになる.
その前に論文ぽい見た目にする設定をします.rcParamsでデフォルト値を変更する.
英語の図ならとりあえずTimes New Romanにしとけばいいでしょう.plt.rcParams['font.family'] = 'Times New Roman' plt.rcParams['font.size'] = 10 # 適当に必要なサイズに plt.rcParams["mathtext.fontset"] = "stix" plt.rcParams['xtick.direction'] = 'in' # in or out plt.rcParams['ytick.direction'] = 'in' plt.rcParams['axes.xmargin'] = 0.01 plt.rcParams['axes.ymargin'] = 0.01 plt.rcParams["legend.fancybox"] = False # 丸角OFF plt.rcParams["legend.framealpha"] = 1 # 透明度の指定、0で塗りつぶしなし plt.rcParams["legend.edgecolor"] = 'black' # edgeの色を変更 df = df.set_index("x") df.plot() plt.legend() plt.show()出力結果
注意事項
以降本記事内ではオブジェクト指向インターフェースでグラフを書きます.ax.~~とかいうやつです.理屈はきちんと解説されている方のを見てください.
参考:早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話また,汎用性を高めるため,描画は返り値なし関数で作成しています.main関数などの中から呼び出すことを想定しています.
多軸グラフ
軸数を自動で調整して多軸出せるグラフです.
for文により自動的に右側に軸を追加していきます.
引数はdataframeとそのラベルで,y軸のラベルは配列で与えてください.
色や線のリストはお好みで変更してください.multiAxisdef multiAxis(df, x, y_list): c_list = ["k", "r", "b", "g", "c", "m", "y"] l_list = ["-","--","-.","."] fig, ax0 = plt.subplots(figsize=(6, 5)) plt.subplots_adjust(top=0.95, right=0.95-(len(y_list)-1)*0.1) #ずれたらここ調整 axes = [ax0] # 変数分の軸の数を作る p_list = [] # 変数分のplotの入れ物 for i in range(len(y_list)): y = y_list[i] if i != 0: axes.append(ax0.twinx()) axes[i].spines["right"].set_position(("axes", 1+(i-1)*0.2)) #ずれたらここ調整 p, = axes[i].plot(df[x], df[y], linestyle=l_list[i], color=c_list[i], label=y) p_list.append(p) axes[i].set_ylabel(y_list[i], color=c_list[i]) axes[i].yaxis.label.set_color(c_list[i]) axes[i].spines['right'].set_color(c_list[i]) axes[i].tick_params(axis='y', colors=c_list[i]) axes[0].set_xlabel(x) plt.legend(p_list,y_list) plt.show() return以下が実行関数とその結果です.
multiAxis(df, "x", ["squarex", "cosx", "sinx"])


- 投稿日:2020-04-04T17:24:53+09:00
[matplotlib]科学論文向けグラフ作成サンプル関数
はじめに
本記事はpythonのmatplotlibを用いたグラフ作成の汎用関数とその簡単な解説になります.
汎用性を高めるため,凡例の増加等にはなるべく繰り返し関数で対応するような工夫をしています.筆者が必要になった形式のグラフスタイルを記載しています.(定期的に追記します)
性質的に理工学者の研究発表・論文投稿向けです.環境
2020/04/04現在最新のpython3-Anaconda環境を想定しています.
pythonの導入方法はネットでいくらでも出てきますが,ポチポチするだけで済むので,Anacondaがおすすめ.pathは通すようにチェックつけましょう.エディタはVisual Studio Codeを使用しています.以前はPyCharmを使用していましたが,他の言語と同じエディタを使いたくなったので,変えました.自動整形コマンドが便利です.(Shift + Alt + F)
参考:VS codeでpython3の実行(windows10)準備
パッケージのインポート
必要なものをimportします.
matplotlib以外にはnumpyとpandasをとりあえず使います.matplotlibはpyplotしか使ってないですねimport numpy as np import matplotlib.pyplot as plt import pandas as pdサンプルデータの用意
本記事で使用するためのサンプルデータを用意します.
dataframeのほうが,一気に表にできるのでデータとして扱う際には簡単ですが,実際にグラフにする際は,リストのほうが細かい設定ができるので,逐一リストに戻す場合もあります.
dataframeの扱いやファイルの読み書きはまたどこかでまとめます.とりあえず以下ではリストを作った後dfを生成しておきました.
csvやexcel出力時に縦じゃないと見づらいので,行と列を変換した後indexを設定してます.A = np.linspace(0,1) B = [x**2 for x in A] C = [np.cos(2*np.pi*x) for x in A] S = [np.sin(2*np.pi*x) for x in A] df = pd.DataFrame([A,B,C,S], index=["x","squarex","cosx","sinx"]).Tスタイルの調整
dataframeの確認がてら適当にplotします.df.plot()でindexをx軸にした複数凡例のグラフになる.
その前に論文ぽい見た目にする設定をします.rcParamsでデフォルト値を変更する.
英語の図ならとりあえずTimes New Romanにしとけばいいでしょう.plt.rcParams['font.family'] = 'Times New Roman' plt.rcParams['font.size'] = 10 # 適当に必要なサイズに plt.rcParams["mathtext.fontset"] = "stix" plt.rcParams['xtick.direction'] = 'in' # in or out plt.rcParams['ytick.direction'] = 'in' plt.rcParams['axes.xmargin'] = 0.01 plt.rcParams['axes.ymargin'] = 0.01 plt.rcParams["legend.fancybox"] = False # 丸角OFF plt.rcParams["legend.framealpha"] = 1 # 透明度の指定、0で塗りつぶしなし plt.rcParams["legend.edgecolor"] = 'black' # edgeの色を変更 df = df.set_index("x") df.plot() plt.legend() plt.show()出力結果
注意事項
以降本記事内ではオブジェクト指向インターフェースでグラフを書きます.ax.~~とかいうやつです.理屈はきちんと解説されている方のを見てください.
参考:早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話複数凡例(1軸)
1つのy軸に対して複数の凡例を与えます.
for文により凡例は自動で追加されます.
引数はdataframeとそのラベルで,y軸のラベルは配列で与えてください.
色や線のリストはお好みで変更してください.関数
multiLegenddef multiLegend(df, x, y_list): c_list = ["k", "r", "b", "g", "c", "m", "y"] l_list = ["-","--","-.","."] fig, ax = plt.subplots(figsize=(5, 5)) plt.subplots_adjust(top=0.95, right=0.95) for i in range(len(y_list)): y = y_list[i] ax.plot(df[x], df[y], linestyle=l_list[i], color=c_list[i], label=y) yLabel = ', '.join(y_list) ax.set_ylabel(yLabel) ax.set_xlabel(x) plt.legend() plt.show() return実行結果
multiLegned(df, "x", ["squarex", "cosx", "sinx"])
多軸グラフ
軸数を自動で調整して多軸出せるグラフです.
for文により自動的に右側に軸を追加していきます.
引数はdataframeとそのラベルで,y軸のラベルは配列で与えてください.
色や線のリストはお好みで変更してください.関数
multiAxisdef multiAxis(df, x, y_list): c_list = ["k", "r", "b", "g", "c", "m", "y"] l_list = ["-","--","-.","."] fig, ax0 = plt.subplots(figsize=(6, 5)) plt.subplots_adjust(top=0.95, right=0.95-(len(y_list)-1)*0.1) #ずれたらここ調整 axes = [ax0] # 変数分の軸の数を作る p_list = [] # 変数分のplotの入れ物 for i in range(len(y_list)): y = y_list[i] if i != 0: axes.append(ax0.twinx()) axes[i].spines["right"].set_position(("axes", 1+(i-1)*0.2)) #ずれたらここ調整 p, = axes[i].plot(df[x], df[y], linestyle=l_list[i], color=c_list[i], label=y) p_list.append(p) axes[i].set_ylabel(y_list[i], color=c_list[i]) axes[i].yaxis.label.set_color(c_list[i]) axes[i].spines['right'].set_color(c_list[i]) axes[i].tick_params(axis='y', colors=c_list[i]) axes[0].set_xlabel(x) plt.legend(p_list,y_list) plt.show() return実行結果
multiAxis(df, "x", ["squarex", "cosx", "sinx"])
複数subplot
複数のサブプロットを自動で作成します.今回の例は縦に一列並べた場合です.横一列の場合はplt.subplotsの中身をちょこっといじって,y軸の表示を最後だけにしてやればいいでしょう.
並べるからにはおそらく並べた方向の軸は共通にすると思われるので,sharex=allとしています.
色等はやはりお好みで調整してください.(表示領域自体が違うので本来色などの変更必要は論文等では無いと思いますが)関数
multiPlotsdef multiPlots(df, x, y_list): c_list = ["k", "r", "b", "g", "c", "m", "y"] l_list = ["-","--","-.","."] fig, axes = plt.subplots(len(y_list), 1, sharex="all", figsize=(4, 2*len(y_list))) for i in range(len(y_list)): y = y_list[i] axes[i].plot(df[x], df[y], linestyle=l_list[i], color=c_list[i], label=y) axes[i].set_ylabel(y_list[i], color=c_list[i]) axes[i].yaxis.label.set_color(c_list[i]) axes[i].spines['left'].set_color(c_list[i]) axes[i].tick_params(axis='y', colors=c_list[i]) if i == len(y_list)-1: axes[i].set_xlabel(x) plt.tight_layout() plt.show() return実行結果
multiPlots(df, "x", ["squarex", "cosx", "sinx"])
おわりに
本記事ではmatplotlibを使って筆者が実際に使用した科学技術論文用グラフ出力関数をまとめました.
実際に投稿版を作る際には軸ラベルをそれぞれ手打ちで作成したりしますが,それもリストを作ってfor文内で読み込むようしています.今回は見づらくなるのを避けてdataframeのラベル名で表示しました.定期的に更新するのでよろしくどうぞ.


- 投稿日:2020-04-04T16:05:53+09:00
Python で実装する MapReduce on Amazon EMR/Cloud Dataproc
はじめに
普段使い慣れている Python でお手軽に MapReduce アプリケーションを作成し、 Amazon EMR で実行できないかと思っていたところ、mrjob という Python のフレームワークを知りました。そこでこの記事では、mrjob で作成したアプリケーションを Amazon EMR 上で実行するまでの方法を記述したいと思います。ついでに GCP の Cloud Dataproc 上でも実行してみます。
mrjob 概要
mrjob は、 Hadoop クラスタで実行するアプリケーションを Python で作成することのできるフレームワークです。Hadoop の専門的な知識がなくても、簡単にローカルやクラウド上などの環境で MapReduce アプリケーションを実行することができます。mrjob は、内部的には Hadoop Streaming での実行を行っています。そもそも Hadoop とは?という場合は、こちらの記事で概要を記述しているので、良ければ参照してください。
MapReduce アプリケーション
通常、MapReduce アプリケーションは、入力のデータセットを分割し、map 処理、(shuffle 処理)、reduce 処理を実行します。また、map 処理の出力結果を reduce 処理に渡す前に、combine 処理という中間集計を行う処理を使用することもできます。
今回実装するアプリケーションは、文書内で単語が出現する回数を数えるプログラムです。次の入力を受け取ることを想定しています。
input.txtWe are the world, we are the children We are the ones who make a brighter day入力のデータに対する処理は次のような挙動になるように記述します。
- map 処理(mapper):キーバリューのペアを入力として1行ずつ受け取り、0個以上のキーバリューのペアを返します。
mapperの入出力Input: (None, "we are the world, we are the children") Output: "we", 1 "are", 1 "the", 1 "world", 1 "we", 1 "are", 1 "the", 1 "children", 1
- combine 処理(combiner):1行ごとのキーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを返します。
combinerの入出力Input: ("we", [1, 1]) Output: "we", 2
- reduce 処理(reducer):キーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを出力として返します。
reducerの入出力Input: ("we", [2, 1]) # 1行目の "we" は 2回、2行目の "we" は1回出現 Output: "we", 3環境構築
Python で MapReduce アプリケーションを作成するための環境を構築します。
mrjob のインストール
PyPI からインストールすることができます。今回は、バージョン 0.7.1 を使用しています。
pip install mrjob==0.7.1MapReduce の実装
それでは、上記の処理を mrjob で記述してみます。処理が単純で、一つのステップで記述できる場合は、次のように mrjob.job.MRJob を継承したクラスを作成します。
mr_word_count.pyimport re from mrjob.job import MRJob WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): # 入力を1行ずつ処理し、(単語, 1)のキーバリューを生成する def mapper(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 # 1行ごとのキーとそのバリューのリストを入力として受け取り、合計する def combiner(self, word, counts): yield word, sum(counts) # キーとそのバリューのリストを入力として受け取り、合計する def reducer(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()処理がより複雑で、複数のステップでの処理が必要な場合は、次のように mrjob.step.MRStep を MRJob の steps 関数に渡してあげることで処理を定義することができます。
mr_word_count.pyimport re from mrjob.job import MRJob from mrjob.step import MRStep WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): def steps(self): return [ MRStep(mapper=self.mapper_get_words, combiner=self.combiner_count_words, reducer=self.reducer_count_words), MRStep(mapper=..., combiner=..., reducer=...), ... ] def mapper_get_words(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 def combiner_count_words(self, word, counts): yield word, sum(counts) def reducer_count_words(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()MapReduce の実行
ローカル、Amazon EMR、Cloud Dataproc の環境でアプリケーションを実行してみます。パッケージ構成はこのようになっています。
パッケージ構成. ├── config.yaml ├── input.txt └── src ├── __init__.py └── mr_word_count.pyアプリケーションの実行にあたり、入力のパスなどのオプションを指定することができます。オプションは、Config ファイルにあらかじめ記述しておく方法と、コンソールから渡す方法があります。指定するオプションが被った場合はコンソールから渡した方の値が優先されます。Config ファイルは yaml か json の形式で定義することができます。
mrjob で作成したアプリケーションを実行するには、コンソールから次のように入力します。
python {アプリケーションのパス} -r {実行環境} -c {Config ファイルのパス} < {入力のパス} > {出力のパス}ローカル
ローカルで実行する場合は、必要なければ実行環境や Config ファイルのパスを指定する必要はありません。また、出力のパスを指定しない場合は標準出力に出力されます。
python src/mr_word_count.py < input.txt # 実行環境や Config ファイルのパスを渡す必要がある場合 python src/mr_word_count.py -r local -c config.yaml < input.txt上記のコマンドを実行すると、アプリケーションが実行され、次のような結果が標準出力に出力されます。
"world" 1 "day" 1 "make" 1 "ones" 1 "the" 3 "we" 3 "who" 1 "brighter" 1 "children" 1 "a" 1 "are" 3Amazon EMR
Amazon EMR 上で実行するには、AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を環境変数に設定するか、Config ファイルに設定する必要があります。また、インスタンスタイプやそのコア数なども設定することができます。アプリケーションとその関連ファイルは、実行される前に S3 にアップロードされます。
config.yamlrunners: emr: aws_access_key_id: <your key ID> aws_secret_access_key: <your secret> instance_type: c1.medium num_core_instances: 4そのほかのオプションはこちらでみることができます。
実行する際には、環境に emr を選択してあげます。
python src/mr_word_count.py -r emr -c config.yaml input.txt --output-dir=s3://emr-test/output/Cloud Dataproc
Cloud Dataproc を利用するために、GCP から Dataproc の API を有効化します。そして、環境変数の GOOGLE_APPLICATION_CREDENTIALS にクレデンシャルファイルのパスを指定します。Config ファイルには、インスタンスのゾーンやタイプ、コア数を設定します。そのほかのオプションはこちらです。
config.yamlrunners: dataproc: zone: us-central1-a instance_type: n1-standard-1 num_core_instances: 2実行する際には、環境に dataproc を選択してあげます。
python src/mr_word_count.py -r dataproc -c config.yaml input.txt --output-dir=gs://dataproc-test/output/まとめ
mrjob を利用することで、Python でも簡単に MapReduce アプリケーションを作成することができ、作成したアプリケーションのクラウド環境での実行も簡単に行うことができました。
また、mrjob はドキュメントも豊富なので、入門がしやすく「Python でお手軽に MapReduce ジョブを実行したい」という場合にとても便利なフレームワークでした。

- 投稿日:2020-04-04T16:05:53+09:00
Python で実装する MapReduce on EMR/Dataproc
はじめに
普段使い慣れている Python でお手軽に MapReduce アプリケーションを作成し、 Amazon EMR で実行できないかと思っていたところ、mrjob という Python のフレームワークを知りました。そこでこの記事では、mrjob で作成したアプリケーションを Amazon EMR 上で実行するまでの方法を記述したいと思います。ついでに GCP の Cloud Dataproc 上でも実行してみます。
mrjob 概要
mrjob は、 Hadoop クラスタで実行するアプリケーションを Python で作成することのできるフレームワークです。Hadoop の専門的な知識がなくても、簡単にローカルやクラウド上などの環境で MapReduce アプリケーションを実行することができます。mrjob は、内部的には Hadoop Streaming での実行を行っています。そもそも Hadoop とは?という場合は、こちらの記事で概要を記述しているので、良ければ参照してください。
MapReduce アプリケーション
通常、MapReduce アプリケーションは、入力のデータセットを分割し、Map 処理、(Shuffle 処理)、Reduce 処理を実行します。また、Map 処理の出力結果を Reduce 処理に渡す前に、Combine 処理という中間集計を行う処理を使用することもできます。
今回実装するアプリケーションは、文書内で単語が出現する回数を数えるプログラムです。次の入力を受け取ることを想定しています。
input.txtWe are the world, we are the children We are the ones who make a brighter dayMap 処理
キーバリューのペアを入力として1行ずつ受け取り、0個以上のキーバリューのペアを返します。
Input(None, "we are the world, we are the children")Output"we", 1 "are", 1 "the", 1 "world", 1 "we", 1 "are", 1 "the", 1 "children", 1Combine 処理
1行ごとのキーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを返します。
Input("we", [1, 1])Output"we", 2Reduce 処理
キーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを出力として返します。
Input("we", [2, 1]) # 1行目の "we" は 2回、2行目の "we" は1回出現Output"we", 3環境構築
Python で MapReduce アプリケーションを作成するための環境を構築します。
mrjob のインストール
PyPI からインストールすることができます。今回は、バージョン 0.7.1 を使用しています。
pip install mrjob==0.7.1MapReduce の実装
それでは、上記の処理を mrjob で記述してみます。処理が単純で、一つのステップで記述できる場合は、次のように mrjob.job.MRJob を継承したクラスを作成します。
mr_word_count.pyimport re from mrjob.job import MRJob WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): # 入力を1行ずつ処理し、(単語, 1)のキーバリューを生成する def mapper(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 # 1行ごとのキーとそのバリューのリストを入力として受け取り、合計する def combiner(self, word, counts): yield word, sum(counts) # キーとそのバリューのリストを入力として受け取り、合計する def reducer(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()処理がより複雑で、複数のステップでの処理が必要な場合は、次のように mrjob.step.MRStep を MRJob の steps 関数に渡してあげることで処理を定義することができます。
mr_word_count.pyimport re from mrjob.job import MRJob from mrjob.step import MRStep WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): def steps(self): return [ MRStep(mapper=self.mapper_get_words, combiner=self.combiner_count_words, reducer=self.reducer_count_words), MRStep(mapper=..., combiner=..., reducer=...), ... ] def mapper_get_words(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 def combiner_count_words(self, word, counts): yield word, sum(counts) def reducer_count_words(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()MapReduce の実行
ローカル、Amazon EMR、Cloud Dataproc の環境でアプリケーションを実行してみます。パッケージ構成はこのようになっています。
パッケージ構成. ├── config.yaml ├── input.txt └── src ├── __init__.py └── mr_word_count.pyアプリケーションの実行にあたり、入力のパスなどのオプションを指定することができます。オプションは、Config ファイルにあらかじめ記述しておく方法と、コンソールから渡す方法があります。指定するオプションが被った場合はコンソールから渡した方の値が優先されます。Config ファイルは yaml か json の形式で定義することができます。
mrjob で作成したアプリケーションを実行するには、コンソールから次のように入力します。
python {アプリケーションのパス} -r {実行環境} -c {Config ファイルのパス} < {入力のパス} > {出力のパス}ローカル
ローカルで実行する場合は、必要なければ実行環境や Config ファイルのパスを指定する必要はありません。また、出力のパスを指定しない場合は標準出力に出力されます。
python src/mr_word_count.py < input.txt # 実行環境や Config ファイルのパスを渡す必要がある場合 python src/mr_word_count.py -r local -c config.yaml < input.txt上記のコマンドを実行すると、アプリケーションが実行され、次のような結果が標準出力に出力されます。
"world" 1 "day" 1 "make" 1 "ones" 1 "the" 3 "we" 3 "who" 1 "brighter" 1 "children" 1 "a" 1 "are" 3Amazon EMR
Amazon EMR 上で実行するには、AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を環境変数に設定するか、Config ファイルに設定する必要があります。また、インスタンスタイプやそのコア数なども設定することができます。アプリケーションとその関連ファイルは、実行される前に S3 にアップロードされます。
config.yamlrunners: emr: aws_access_key_id: <your key ID> aws_secret_access_key: <your secret> instance_type: c1.medium num_core_instances: 4そのほかのオプションはこちらでみることができます。
実行する際には、環境に emr を選択してあげます。
python src/mr_word_count.py -r emr -c config.yaml input.txt --output-dir=s3://emr-test/output/Cloud Dataproc
Cloud Dataproc を利用するために、GCP から Dataproc の API を有効化します。そして、環境変数の GOOGLE_APPLICATION_CREDENTIALS にクレデンシャルファイルのパスを指定します。Config ファイルには、インスタンスのゾーンやタイプ、コア数を設定します。そのほかのオプションはこちらです。
config.yamlrunners: dataproc: zone: us-central1-a instance_type: n1-standard-1 num_core_instances: 2実行する際には、環境に dataproc を選択してあげます。
python src/mr_word_count.py -r dataproc -c config.yaml input.txt --output-dir=gs://dataproc-test/output/まとめ
mrjob を利用することで、Python でも簡単に MapReduce アプリケーションを作成することができ、作成したアプリケーションのクラウド環境での実行も簡単に行うことができました。
また、mrjob はドキュメントも豊富なので、入門がしやすく「Python でお手軽に MapReduce ジョブを実行したい」という場合にとても便利なフレームワークでした。
- 投稿日:2020-04-04T16:05:53+09:00
Python 実装の MapReduce を Amazon EMR/Cloud Dataproc で実行する
はじめに
普段使い慣れている Python でお手軽に MapReduce アプリケーションを作成し、 Amazon EMR で実行できないかと思っていたところ、mrjob という Python のフレームワークを知りました。そこでこの記事では、mrjob で作成したアプリケーションを Amazon EMR 上で実行するまでの方法を記述したいと思います。ついでに GCP の Cloud Dataproc 上でも実行してみます。
mrjob 概要
mrjob は、 Hadoop クラスタで実行するアプリケーションを Python で作成することのできるフレームワークです。Hadoop の専門的な知識がなくても、簡単にローカルやクラウド上などの環境で MapReduce アプリケーションを実行することができます。mrjob は、内部的には Hadoop Streaming での実行を行っています。そもそも Hadoop とは?という場合は、こちらの記事で概要を記述しているので、良ければ参照してください。
MapReduce アプリケーション
通常、MapReduce アプリケーションは、入力のデータセットを分割し、map 処理、(shuffle 処理)、reduce 処理を実行します。また、map 処理の出力結果を reduce 処理に渡す前に、combine 処理という中間集計を行う処理を使用することもできます。
今回実装するアプリケーションは、文書内で単語が出現する回数を数えるプログラムです。
次の入力を受け取ることを想定しています。input.txtWe are the world, we are the children We are the ones who make a brighter day入力のデータに対する処理は次のような挙動になるように記述します。
- map 処理(mapper):キーバリューのペアを入力として1行ずつ受け取り、0個以上のキーバリューのペアを返します。
mapperの入出力Input: (None, "we are the world, we are the children") Output: "we", 1 "are", 1 "the", 1 "world", 1 "we", 1 "are", 1 "the", 1 "children", 1
- combine 処理(combiner):1行ごとのキーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを返します。
combinerの入出力Input: ("we", [1, 1]) Output: "we", 2
- reduce 処理(reducer):キーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを出力として返します。
reducerの入出力Input: ("we", [2, 1]) # 1行目の "we" は 2回、2行目の "we" は1回出現 Output: "we", 3環境構築
Python で MapReduce アプリケーションを作成するための環境を構築します。
mrjob のインストール
PyPI からインストールすることができます。今回は、バージョン 0.7.1 を使用しています。
pip install mrjob==0.7.1MapReduce の実装
それでは、上記の処理を mrjob で記述してみます。処理が単純で、一つのステップで記述できる場合は、次のように mrjob.job.MRJob を継承したクラスを作成します。
mr_word_count.pyimport re from mrjob.job import MRJob WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): # 入力を1行ずつ処理し、(単語, 1)のキーバリューを生成する def mapper(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 # 1行ごとのキーとそのバリューのリストを入力として受け取り、合計する def combiner(self, word, counts): yield word, sum(counts) # キーとそのバリューのリストを入力として受け取り、合計する def reducer(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()処理がより複雑で、複数のステップでの処理が必要な場合は、次のように mrjob.step.MRStep を MRJob の steps 関数に渡してあげることで処理を定義することができます。
mr_word_count.pyimport re from mrjob.job import MRJob from mrjob.step import MRStep WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): def steps(self): return [ MRStep(mapper=self.mapper_get_words, combiner=self.combiner_count_words, reducer=self.reducer_count_words), MRStep(mapper=..., combiner=..., reducer=...), ... ] def mapper_get_words(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 def combiner_count_words(self, word, counts): yield word, sum(counts) def reducer_count_words(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()MapReduce の実行
ローカル、Amazon EMR、Cloud Dataproc の環境でアプリケーションを実行してみます。パッケージ構成はこのようになっています。
パッケージ構成. ├── config.yaml ├── input.txt └── src ├── __init__.py └── mr_word_count.pyアプリケーションの実行にあたり、入力のパスなどのオプションを指定することができます。オプションは、Config ファイルにあらかじめ記述しておく方法と、コンソールから渡す方法があります。指定するオプションが被った場合はコンソールから渡した方の値が優先されます。Config ファイルは yaml か json の形式で定義することができます。
mrjob で作成したアプリケーションを実行するには、コンソールから次のように入力します。
python {アプリケーションのパス} -r {実行環境} -c {Config ファイルのパス} < {入力のパス} > {出力のパス}ローカル
ローカルで実行する場合は、必要なければ実行環境や Config ファイルのパスを指定する必要はありません。また、出力のパスを指定しない場合は標準出力に出力されます。
python src/mr_word_count.py < input.txt # 実行環境や Config ファイルのパスを渡す必要がある場合 python src/mr_word_count.py -r local -c config.yaml < input.txt上記のコマンドを実行すると、アプリケーションが実行され、次のような結果が標準出力に出力されます。
"world" 1 "day" 1 "make" 1 "ones" 1 "the" 3 "we" 3 "who" 1 "brighter" 1 "children" 1 "a" 1 "are" 3Amazon EMR
Amazon EMR 上で実行するには、AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を環境変数に設定するか、Config ファイルに設定する必要があります。また、インスタンスタイプやそのコア数なども設定することができます。アプリケーションとその関連ファイルは、実行される前に S3 にアップロードされます。
config.yamlrunners: emr: aws_access_key_id: <your key ID> aws_secret_access_key: <your secret> instance_type: c1.medium num_core_instances: 4そのほかのオプションはこちらでみることができます。
実行する際には、環境に emr を選択してあげます。
python src/mr_word_count.py -r emr -c config.yaml input.txt --output-dir=s3://emr-test/output/Cloud Dataproc
Cloud Dataproc を利用するために、GCP から Dataproc の API を有効化します。そして、環境変数の GOOGLE_APPLICATION_CREDENTIALS にクレデンシャルファイルのパスを指定します。Config ファイルには、インスタンスのゾーンやタイプ、コア数を設定します。そのほかのオプションはこちらです。
config.yamlrunners: dataproc: zone: us-central1-a instance_type: n1-standard-1 num_core_instances: 2実行する際には、環境に dataproc を選択してあげます。
python src/mr_word_count.py -r dataproc -c config.yaml input.txt --output-dir=gs://dataproc-test/output/まとめ
mrjob を利用することで、Python でも簡単に MapReduce アプリケーションを作成することができ、作成したアプリケーションのクラウド環境での実行も簡単に行うことができました。
また、mrjob はドキュメントも豊富なので、入門がしやすく「Python でお手軽に MapReduce ジョブを実行したい」という場合にとても便利なフレームワークでした。
- 投稿日:2020-04-04T16:05:53+09:00
【Python 実装】Amazon EMR/Cloud Dataproc で実行する Hadoop ジョブ
はじめに
普段使い慣れている Python でお手軽に MapReduce アプリケーションを作成し、 Amazon EMR で実行できないかと思っていたところ、mrjob という Python のフレームワークを知りました。そこでこの記事では、mrjob で作成したアプリケーションを Amazon EMR 上で実行するまでの方法を記述したいと思います。ついでに GCP の Cloud Dataproc 上でも実行してみます。
mrjob 概要
mrjob は、 Hadoop クラスタで実行するアプリケーションを Python で作成することのできるフレームワークです。Hadoop の専門的な知識がなくても、簡単にローカルやクラウド上などの環境で MapReduce アプリケーションを実行することができます。mrjob は、内部的には Hadoop Streaming での実行を行っています。そもそも Hadoop とは?という場合は、こちらの記事で概要を記述しているので、良ければ参照してください。
MapReduce アプリケーション
通常、MapReduce アプリケーションは、入力のデータセットを分割し、map 処理、(shuffle 処理)、reduce 処理を実行します。また、map 処理の出力結果を reduce 処理に渡す前に、combine 処理という中間集計を行う処理を使用することもできます。
今回実装するアプリケーションは、文書内で単語が出現する回数を数えるプログラムです。
次の入力を受け取ることを想定しています。input.txtWe are the world, we are the children We are the ones who make a brighter day入力のデータに対する処理は次のような挙動になるように記述します。
- map 処理(mapper):キーバリューのペアを入力として1行ずつ受け取り、0個以上のキーバリューのペアを返します。
mapperの入出力Input: (None, "we are the world, we are the children") Output: "we", 1 "are", 1 "the", 1 "world", 1 "we", 1 "are", 1 "the", 1 "children", 1
- combine 処理(combiner):1行ごとのキーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを返します。
combinerの入出力Input: ("we", [1, 1]) Output: "we", 2
- reduce 処理(reducer):キーとそのバリューのリストを入力として受け取り、0個以上のキーバリューのペアを出力として返します。
reducerの入出力Input: ("we", [2, 1]) # 1行目の "we" は 2回、2行目の "we" は1回出現 Output: "we", 3環境構築
Python で MapReduce アプリケーションを作成するための環境を構築します。
mrjob のインストール
PyPI からインストールすることができます。今回は、バージョン 0.7.1 を使用しています。
pip install mrjob==0.7.1MapReduce の実装
それでは、上記の処理を mrjob で記述してみます。処理が単純で、一つのステップで記述できる場合は、次のように mrjob.job.MRJob を継承したクラスを作成します。
mr_word_count.pyimport re from mrjob.job import MRJob WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): # 入力を1行ずつ処理し、(単語, 1)のキーバリューを生成する def mapper(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 # 1行ごとのキーとそのバリューのリストを入力として受け取り、合計する def combiner(self, word, counts): yield word, sum(counts) # キーとそのバリューのリストを入力として受け取り、合計する def reducer(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()処理がより複雑で、複数のステップでの処理が必要な場合は、次のように mrjob.step.MRStep を MRJob の steps 関数に渡してあげることで処理を定義することができます。
mr_word_count.pyimport re from mrjob.job import MRJob from mrjob.step import MRStep WORD_RE = re.compile(r"[\w']+") class MRWordCount(MRJob): def steps(self): return [ MRStep(mapper=self.mapper_get_words, combiner=self.combiner_count_words, reducer=self.reducer_count_words), MRStep(mapper=..., combiner=..., reducer=...), ... ] def mapper_get_words(self, _, line): for word in WORD_RE.findall(line): yield word.lower(), 1 def combiner_count_words(self, word, counts): yield word, sum(counts) def reducer_count_words(self, word, counts): yield word, sum(counts) if __name__ == '__main__': MRWordCount.run()MapReduce の実行
ローカル、Amazon EMR、Cloud Dataproc の環境でアプリケーションを実行してみます。パッケージ構成はこのようになっています。
パッケージ構成. ├── config.yaml ├── input.txt └── src ├── __init__.py └── mr_word_count.pyアプリケーションの実行にあたり、入力のパスなどのオプションを指定することができます。オプションは、Config ファイルにあらかじめ記述しておく方法と、コンソールから渡す方法があります。指定するオプションが被った場合はコンソールから渡した方の値が優先されます。Config ファイルは yaml か json の形式で定義することができます。
mrjob で作成したアプリケーションを実行するには、コンソールから次のように入力します。
python {アプリケーションのパス} -r {実行環境} -c {Config ファイルのパス} < {入力のパス} > {出力のパス}ローカル
ローカルで実行する場合は、必要なければ実行環境や Config ファイルのパスを指定する必要はありません。また、出力のパスを指定しない場合は標準出力に出力されます。
python src/mr_word_count.py < input.txt # 実行環境や Config ファイルのパスを渡す必要がある場合 python src/mr_word_count.py -r local -c config.yaml < input.txt上記のコマンドを実行すると、アプリケーションが実行され、次のような結果が標準出力に出力されます。
"world" 1 "day" 1 "make" 1 "ones" 1 "the" 3 "we" 3 "who" 1 "brighter" 1 "children" 1 "a" 1 "are" 3Amazon EMR
Amazon EMR 上で実行するには、AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を環境変数に設定するか、Config ファイルに設定する必要があります。また、インスタンスタイプやそのコア数なども設定することができます。アプリケーションとその関連ファイルは、実行される前に S3 にアップロードされます。
config.yamlrunners: emr: aws_access_key_id: <your key ID> aws_secret_access_key: <your secret> instance_type: c1.medium num_core_instances: 4そのほかのオプションはこちらでみることができます。
実行する際には、環境に emr を選択してあげます。
python src/mr_word_count.py -r emr -c config.yaml input.txt --output-dir=s3://emr-test/output/Cloud Dataproc
Cloud Dataproc を利用するために、GCP から Dataproc の API を有効化します。そして、環境変数の GOOGLE_APPLICATION_CREDENTIALS にクレデンシャルファイルのパスを指定します。Config ファイルには、インスタンスのゾーンやタイプ、コア数を設定します。そのほかのオプションはこちらです。
config.yamlrunners: dataproc: zone: us-central1-a instance_type: n1-standard-1 num_core_instances: 2実行する際には、環境に dataproc を選択してあげます。
python src/mr_word_count.py -r dataproc -c config.yaml input.txt --output-dir=gs://dataproc-test/output/まとめ
mrjob を利用することで、Python でも簡単に MapReduce アプリケーションを作成することができ、作成したアプリケーションのクラウド環境での実行も簡単に行うことができました。
また、mrjob はドキュメントも豊富なので、入門がしやすく「Python でお手軽に MapReduce ジョブを実行したい」という場合にとても便利なフレームワークでした。
- 投稿日:2020-04-04T16:04:07+09:00
実際にCOVID-19の状況をデータセットを使って可視化してみる
はじめに
上陸して猛威を振るい出した新型コロナウイルスによる肺炎(COVID-19)ですが、都市部を中心に広がっておりなお感染者数が増加しています。報道番組を見ても知りたいデータもなく頭が痛くなるだけなので、どうせならPythonを使っていろいろしようと思いました。
(は?)作ったのはこれだけ。せっかくなので作ったんだけど、東京都の感染者数、すごい伸び... pic.twitter.com/iCPIQktLJi
— Orangeat (@orange_aus) April 4, 2020つかうもの
実行環境ですが、Google Colaboratory(以下Colab)を使います。Python3(とPandas)で書きますが、オンラインでだれでも書けるようになっているのでインストールは何も必要ありません。直感的だしすぐ使えるの神過ぎる。
細かいことはこちらを参考にさせていただきました。オープンデータについては、SIGNATEさんのCOVID-19チャレンジ(フェーズ1)のものをつかいます。有志の方々の涙ぐましい努力によって日々更新されているデータベースです。データセット(SIGNATE COVID-19 Dataset)の直リンクはこちら。
可視化に使うのはFlourishさんのBar chart raceというサービス。csvからお馴染みのBar-chart-raceのアニメーションをつくってくれます。
使うのはこれだけ。
やってみる
データインポート
まずColabで ファイル から新ノートブックを作ります。
早速書いていきます。まず、Colabにデータを読み込ませます。!から始まるマジックコマンドでいけるっぽいです。
$URL$をスプレッドシートの編集リンクの/edit... 以前の部分に置き換えてかきます。
要は ...ta.csv https://docs.google.com/spreadsheets/d/1CnQOf6eN18Kw5Q6ScE_9tFoyddk4FBwFZqZpt_tMOm4/ex... みたいに書けば大丈夫みたい。?gid=の値はシートによって違います。使いたかった罹患者のシートは0だったのでここでは0です。!wget --no-check-certificate --output-document=data.csv '$URL$/export?gid=0&format=csv'
成功するとColab側に保存されます。
次にこの.csvをpandasに読ませます。pandasをインポートしてdfに変換後ファイルを渡します。import pandas as pd df = pd.read_csv("data.csv")前処理
公表日と受診都道府県の行だけ
locを使って抽出します。
片方でも欠けていれば無効データとみなしdropnaちゃんで消去します。df = df.loc[:, ["公表日", "受診都道府県"]] df.dropna(how = "any", inplace = True)試しに出力して確認してみます。(AtCoderの標準出力に慣れてたんですがオブジェクト単体でOutputできるんですね...)
df >> Output 公表日 受診都道府県 0 2020/01/28 北海道 1 2020/02/14 北海道 2 2020/02/19 北海道 3 2020/02/19 北海道 4 2020/02/20 北海道 ... ... ... 2423 2020/03/24 沖縄県 2424 2020/03/26 沖縄県 2425 2020/03/28 沖縄県 2426 2020/03/28 沖縄県 2427 2020/03/30 沖縄県 [2396 rows x 2 columns]公表日をPandaに読ませるために
.to_datetimeでdatetime64にフォーマット変換します。すべてYYYY/MM/DD型とのこと(参照)なので"%Y/%m/%d"を指定します。df["公表日"] = pd.to_datetime(df["公表日"], format = "%Y/%m/%d")
pd.get_dummiesとpd.concat(横結合なのでaxis = 1)を使って受診都道府県のフラグ列を作ります。
indexの数字は必要ないので公表日をインデックスにします。df = pd.concat([df, pd.get_dummies(df["受診都道府県"])], axis = 1) df.set_index("公表日", inplace = True)df >> Output 受診都道府県 三重県 京都府 佐賀県 兵庫県 北海道 ... 長野県 青森県 静岡県 香川県 高知県 鹿児島県 公表日 ... 2020-01-28 北海道 0 0 0 0 1 ... 0 0 0 0 0 0 2020-02-14 北海道 0 0 0 0 1 ... 0 0 0 0 0 0 2020-02-19 北海道 0 0 0 0 1 ... 0 0 0 0 0 0 2020-02-19 北海道 0 0 0 0 1 ... 0 0 0 0 0 0 2020-02-20 北海道 0 0 0 0 1 ... 0 0 0 0 0 0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-03-24 沖縄県 0 0 0 0 0 ... 0 0 0 0 0 0 2020-03-26 沖縄県 0 0 0 0 0 ... 0 0 0 0 0 0 2020-03-28 沖縄県 0 0 0 0 0 ... 0 0 0 0 0 0 2020-03-28 沖縄県 0 0 0 0 0 ... 0 0 0 0 0 0 2020-03-30 沖縄県 0 0 0 0 0 ... 0 0 0 0 0 0 [2396 rows x 45 columns]算出
もちろん記録がない日もあるので再サンプリングします。時系列データの日別リサンプリングでは
.resample("D")が使えます。累積和.cumsumをかませれば延べ人数が出ます。df_cnt = df.resample("D").sum() df_cs = df_cnt.cumsum()df_cs >> Output 三重県 京都府 佐賀県 兵庫県 北海道 千葉県 ... 長野県 青森県 静岡県 香川県 高知県 鹿児島県 公表日 ... 2020-01-15 0 0 0 0 0 0 ... 0 0 0 0 0 0 2020-01-16 0 0 0 0 0 0 ... 0 0 0 0 0 0 2020-01-17 0 0 0 0 0 0 ... 0 0 0 0 0 0 2020-01-18 0 0 0 0 0 0 ... 0 0 0 0 0 0 2020-01-19 0 0 0 0 0 0 ... 0 0 0 0 0 0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-03-30 10 56 1 137 178 116 ... 7 8 8 2 15 1 2020-03-31 10 56 2 148 178 124 ... 7 8 8 2 17 1 2020-04-01 10 56 3 162 183 125 ... 7 8 8 2 20 2 2020-04-02 10 56 3 169 186 125 ... 7 8 8 2 21 3 2020-04-03 10 56 3 169 191 125 ... 7 8 8 2 21 3 [80 rows x 132 columns]グラフ化
最後にcsvでダウンロードします。ここでFlourish側が読み込んでくれるデータは向きが固定されていることにやっと気づいたので、転置($D^\top$)してから.csvにおろします。なんかエラー出たけどいけた。ようわからん。
df_cs.T.to_csv("tog.csv") tog.csv--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-148-2cb118b16e21> in <module>() 1 df_cs.T.to_csv("tog.csv") ----> 2 tog.csv NameError: name 'tog' is not defined左のファイルのところに保存されてるので右クリックからダウンロードします。
日付の形式を直したかったんですが、csvを直接編集した方が早いことがわかったのでcsvをテキストエディタで開き
"2020-" >> ""、"-" >> "/"と順に置換。
これでFlourishにかませれば完成です。1位の東京のデータが未更新だったので対策サイトのデータを入れました(※追記:編集当時のため変動している可能性が高いです)。こちらも有志の方が編集されているということで頭が上がりません。この前台湾のIT担当相の唐鳳さんが一文字修正のプルリク送って話題になってましたね... 唐鳳さん、GitHubにもちゃんと草生やしているらしくてほんとうにすごいお方...東京都のcovid19 githubにオードリーたんが降臨して1文字修正PRしてる! #唐鳳https://t.co/lA7goT4snu
— Yusuke Kawasaki / THE GUILD (@kawanet) March 8, 2020おわりに
1時間弱で書いたので適当な記事になっちゃった!外に出れない分、現状を把握するのに努めたいなと思いました!!!
ライセンスなど
参考文献/使用リンク
https://signate.jp/competitions/260
https://qiita.com/karaage0703/items/0e24f332dcda7d7730b5
https://docs.google.com/spreadsheets/d/1CnQOf6eN18Kw5Q6ScE_9tFoyddk4FBwFZqZpt_tMOm4/edit?usp=sharing
https://stopcovid19.metro.tokyo.lg.jp/ライセンス
この 作品 は クリエイティブ・コモンズ 表示 - 継承 4.0 国際 ライセンスの下に提供されています。この記事の内容はSIGNATEさまのフォーラムにおける成果物及びその一部・コピー・改変・リミックスなどであるため、ライセンスが継承されています。免責
参考文献のリンク先及びこの記事はこれらが必ずしも厳密に正しい情報であることに責任を負っていることを示すものでは一切ありません。



- 投稿日:2020-04-04T15:47:36+09:00
【python】sort_valuesで表をソート(pandasのDataFrame)
【python】sort_valuesで表をソートする方法(pandasのDataFrame)
「sort_valuesメソッド」を使ってDataFrameの表をソートする方法。
sort_indexメソッドというのもあるが非推奨。
FutureWarning: by argument to sort_index is deprecated, please use .sort_values(by=...)
目次
1.基本構文と主要オプション
▼基本構文
df.sort_values(by=['A'])
└「df」:表データ
└「by=[]」:ソートの基準となる列/行※必須※
└「A」:列/行名
▼主要オプション
オプション 内容 axis=0 軸を列とする。デフォルト。省略可 axis=1 軸を行にする。 by=['A'] 軸とする行/列名。必須 assending=True 昇順ソート。デフォルト。省略可 assending=False 降順ソート。 na_position='first' NaNを最上部に移動。 na_position='last' NaNを最下部に移動。デフォルト。省略可 inplace=False 上書きしない。デフォルト。省略可 inplace=True 上書きする。
2.使用する表
下記6行5列の表でソートを行う。
(NaNは欠損値)
表の作成import pandas as pd import numpy as np row0 = [0, 0, 'a', 'あ', '壱'] row1 = [2, 2, 'c', 'う', '参'] row2 = [4, np.nan,'e', 'お', '伍'] row3 = [1, 1,'b', 'い', '弐'] row4 = [3, 3,'d', 'え', '肆'] row5 = [5, 5,'e', 'お', '伍'] df = pd.DataFrame([row0,row1,row2,row3,row4,row5]) df.columns = ['col0', 'col1', 'col2' ,'col3', 'col4'] df.index = ['row0', 'row1', 'row2', 'row3', 'row4', 'row5'] df欠損値NaNを使用するために、numpyをimportし「np.nan」を使用。
3.列でソート
①昇順ソート
②降順ソート
③NaNを含む列のソート
④上書き
①昇順ソート
df.sort_values(by=['A'])「A」にソート基準となる列名を入力。
デフォルトが「ascending=Ture」(省略可)。
昇順ソートdf.sort_values(by=['col0'])
列col0の要素で昇順ソートされた。
アルファベットや平仮名でも同様にソート可能。
②降順ソート
df.sort_values(by=['A'], ascending=False)列名「A」で降順ソート。
降順ソートdf.sort_values(by=['col0'], ascending=False)
③NaNを含む列のソート
欠損値NaNがソートの基準となる列に含まれている場合、ソート時にNaNを最上部 or 最下部のどちらに移動するか設定できる。
・
na_position='last'
└デフォルト(省略可)
└最下部へ移動・
na_position='first'
└最上部へ移動
▼NaNを最下部へ移動NaNを含む列をソート(デフォルト)df.sort_values(by=['col1'])
▼NaNを最上部へ移動NaNを含む列をソート(最上部)df.sort_values(by=['col1'], na_position='first')
④上書き
上書きをする・しないを設定可能。
デフォルトは上書きしない。・
inplace=False
└デフォルト(省略可)
└上書きしない・
inplace=True
└上書きする
▼上書きしない(デフォルト)上書きしないdf.sort_values(by=['col1']) df
▼上書きする上書きするdf.sort_values(by=['col1'], inplace=True) df
4.行でソート
sort_values(by=['A'], axis=1)
└「axis=1」:行でソート
└「A」:行名行方向は数値のみがある表しかソートできない。
※NaNや文字列を含む表はエラーとなる。
※NaNや文字列を含まない行を指定してもエラーになる。
使用する表
下記表「df2」でソートを行う。
使用する表import pandas as pd col0 = [10, 9, 8, 7] col1 = [1, 10, 100, 1000] col2 = [2, 2, 2, 2] col3 = [0.3, 0.03, 0.003, 0.0003] col4 = [4, 40, 400, 4000] df2 = pd.DataFrame(col0, columns=['col0']) df2['col1'] = col1 df2['col2'] = col2 df2['col3'] = col3 df2['col4'] = col4 df2
▼昇順ソート昇順ソートdf2.sort_values(by=[1], axis=1)
▼降順ソート降順ソートdf2.sort_values(by=[1], axis=1, ascending=False)










- 投稿日:2020-04-04T15:45:17+09:00
デジタルサイネージにログインが必要な画面を表示する
やりたいこと
画像ファイルをスライドショー表示しているサイネージに、ログインが必要な外部サービスの画面を一緒に表示したい。ちょっと分かりにくいですが、整理すると以下のような感じです。
- 既存サイネージは画像ファイルをスライドショーで表示する仕組み
- サイネージに表示したい画面がある外部サービスはログインが必要
- 外部サービス上ではデータをリアルタイムで可視化しているので画面は逐次更新されている
- このログインが必要な逐次更新される画面をサイネージに表示したい
使用するもの
- Selenium
- Python
- Chrome
- タスクスケジューラ(Windows10)
全体の流れ
- Seleniumを使って、Chromeを起動
- 外部サービスにアクセスして自動ログイン(Seleniumで)
- 表示したい画面に移動して画像キャプチャ(Seleniumで)
- サイネージ公開用のフォルダに画像を保存(Seleniumで)
- 上記の流れを、タスクスケジューラを使用して定期的に実行
*SeleniumやPythonなどの環境構築は別途調べてもらえると良いと思います
ソースコード
ファイル名、保存先、ログイン情報などは、適当に読み替えてもらえると助かります。
import os import sys import time import datetime from selenium import webdriver from selenium.webdriver.chrome.options import Options import chromedriver_binary # File Name now = datetime.datetime.now() filename = "image/screen_" + now.strftime('%Y%m%d_%H%M%S') + ".png" FILENAME = os.path.join(os.path.dirname(os.path.abspath(__file__)), filename) # set driver and url options = Options() options.add_argument('--headless') driver = webdriver.Chrome(options=options) url = 'https://xxxx/xxxx/' driver.get(url) # ID/PASSを入力(ここはサイトごとに要調整) id = driver.find_element_by_name("xxxx-xxxx") id.send_keys("xxxx") password = driver.find_element_by_name("xxxx-xxxx") password.send_keys("xxxx") time.sleep(1) # ログインボタンをクリック(ここはサイトごとに要調整) login_button = driver.find_element_by_name("xxxx") login_button.click() # get width and height of the page w = driver.execute_script("return document.body.scrollWidth;") h = driver.execute_script("return document.body.scrollHeight;") # set window size driver.set_window_size(1920,1080) time.sleep(1) # Get Screen Shot print ("Get Screen Shot") driver.save_screenshot(FILENAME) # Close Web Browser driver.quit()まとめ
とりあえず、やりたいことは上記の流れで出来た。あとは、現在はローカル環境でやってるので、これをサーバー環境に移行したい。だいたいの流れは理解出来てきたので、あとは調べてやればなんとかなる感じ。
ちょっとだけ注意点
自分の環境では、サイネージ公開用フォルダをネットワークドライブに割り当ててたのですが、タスクスケジューラでpythonを直接自動起動した場合はネットワークドライブへのアクセスが上手くいかなかったので、別途、バッチファイルを作成して、バッチ上でネットワークドライブを割り当ててから、pythonを起動するようにしたら上手くいきました。なので、現状はバッチファイルを定期実行するような仕組みになってます。
- 投稿日:2020-04-04T14:42:33+09:00
PyInstaller備忘録 2行でPython[.py]の[.exe]化
はじめに
Pythonのプログラム[.py]が属人化しないようにするためexe化[.exe]した際のメモ。
Pythonのexe化にはいくつか方法がありますが、今回は簡易にできるPyInstallerを用います。クイックスタート
ソースコードを編集せずにpipと下記コマンドでexe化できます。
これだけなので非常に簡単です。exe化だけならここまでで結構です。
後半にPythonコードにPyInstallerを記述する方法を紹介しているので興味があれば参照下さい。pip install pyinstaller pyinstaller yourprogram.pyオプション一覧
実行時に指定できるオプションがあります。
下記資料を参考に使用頻度の高いオプションをまとめています。
参考:Using PyInstaller生成オプション
オプション 機能 -n, --name 生成ファイルの名前指定(defaultはスクリプト名) --specpath DIR 生成フォルダの指定(defaultは現在のDIR) -D,--onedir 1ディレクトリにまとめて出力する -F,--onefile 1ファイルにまとめて出力する OS固有オプション
オプション 機能 -w, --windowed, --noconsole コンソールを非表示にする -i, --icon プログラムのアイコン[.ico拡張子]を設定する。 一般オプション
オプション 機能 --clean, --noconsole ビルドする前にPyInstallerキャッシュを消去し、一時ファイルを削除する。 -y, --noconfirm 出力ディレクトリを確認を求めずに置換する。 -v, --version プログラムのバージョン情報を表示して終了する。 その他オプション
オプション 機能 --exclude 指定したモジュールまたはパッケージを無視する。複数回使用可能 オプション使用例
pyinstaller yourprogram.py --exclude numpy,-v, -i data.iconPythonコードからPyInstaller実行
公式ドキュメント参考
https://pyinstaller.readthedocs.io/en/stable/usage.htmlsample.pyimport PyInstaller.__main__ PyInstaller.__main__.run([ '--name=%s' % package_name, '--onefile', '--windowed', '--add-binary=%s' % os.path.join('resource', 'path', '*.png'), '--add-data=%s' % os.path.join('resource', 'path', '*.txt'), '--icon=%s' % os.path.join('resource', 'path', 'icon.ico'), os.path.join('my_package', '__main__.py'), ])まとめ
Pythonのexe化ができるPyInstallerのメモでした。
2行でできるのが便利ですね。
ですが一点懸念もあります。下記を参考にするとexeファイルが大きい点や実行時間が掛かる問題があるようです。
exe化したい対象が処理速度を考慮していなければ是非お試しください.
【悲報】PyInstallerさん、300MBのexeファイルを吐き出すようになるご一読ありがとうございました。気になる点があれば編集リクエスト、コメントお願い致します。
良ければLGTMもお願いします。
- 投稿日:2020-04-04T14:32:05+09:00
WSL(2)上でMuJoCoを動かす(GUIも)
WSL2上でもMuJoCoを動かすことが可能です。
WSL2の導入とGUIの導入については大変だった点をまとめて別記事を書いたのでこちらをご参照ください。
WSL2の導入とGUI環境の構築mujoco-pyを動かしたいときのPythonについては導入済みという前提で進めます。
MuJoCo導入
MuJoCoのダウンロード
好きな方法で https://www.roboti.us/index.html からMuJoCoをダウンロードし
~/.mujoco/mujoco200に展開します。例えば、wget https://www.roboti.us/download/mujoco200_linux.zip unzip mujoco.zip -d /home/{username}/.mujoco mv /home/{username}/.mujoco/mujoco200_linux /home/{username}/.mujoco/mujoco200 rm mujoco.zipまた、
~/.mujoco/mjkey.txtにライセンスキーを用意します。環境変数の追加
さらに、
~/.bashrcにexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/{username}/.mujoco/mujoco200/binを追加します。
依存するものの導入
いくつか必要なものをいれてやります。
sudo apt update sudo apt install gcc sudo apt install libosmesa6-devここまでくれば、
pip install mujoco-pyができます!!GUIで描画する
準備として
sudo apt install libgl1-mesa-dev xorg-devしておきます。
また、GUIについてはWSL2の導入とGUI環境の構築を参考にして導入してください。
ここで紹介したデフォルトのまま(あるいはいろいろなサイトで紹介されているもの)だと、
$ cd ~/.mujoco/mujoco200/bin $ ./simulate ../model/humanoid.xml MuJoCo Pro version 2.00 ERROR: could not initialize GLFW Press Enter to exit ...となってしまいます。世界中で1つだけ?答えに行きついているサイトがありました。 https://superuser.com/questions/1487555/how-to-troubleshoot-opengl-on-ubuntu-under-windows-10-wsl
要するに、
1.LIBGL_ALWAYS_INDIRECTは~.bashrcで設定するな
2.LIBGL_ALWAYS_INDIRECT変数は一切設定するな
3. VcXsrv起動時にはNative openglのやつのチェックを外す。さらに-wglオプションをつけるな。1、2については、
LIBGL_ALWAYS_INDIRECTはもともと\etc\profile.d\wsl-integration.shで定義されている(これはシンボリックリンクで本当は/usr/share/wslu/wsl-integration.sh)とのことです。
したがって、~/.bashrcにunset LIBGL_ALWAYS_INDIRECTをかいてやれば変数が削除できるのでいけます。これで、
./simulate ../model/humanoid.xmlもできますし、mujoco-py 、あるいは OpenAI gym を使った描画もできます。
- 投稿日:2020-04-04T14:26:45+09:00
クソゲーオブザイヤーの総評を形態素解析してみた
形態素解析で遊ぼうと思います。
前置き
この前KOTY1の選評を暇つぶしに読んでいたら、ふと
「これまでのKOTYの総評を形態素解析したら楽しいんじゃないだろうか」と思いつきました。
形態素解析はやったことなかったので、勉強も兼ねてやってみたいと思います。総評をダウンロード
とりあえずKOTY据置wikiからNokogiriで総評をゲットします。掲載されているのは2005年~2018年のものですね。ちなみに携帯とエロゲはスルーします。2
各年の総評のURLは、https://koty.wiki/(西暦)GCで統一されているので、楽に取得できます。
特筆すべき点としては、
- 2005年~2008年
- 2010年~2011年
- 2012年~2018年
の三期間においてそれぞれ総評のHTMLソースにおける記載方法が違うため、この3つのパターンでそれぞれ別の処理をしたことくらいでしょうか。
Nokogiriで取得するコードはこちらKOTY_Scrape.rbrequire 'nokogiri' require 'open-uri' if ! Dir::exist?("KOTY総評") #保存用フォルダ作成 Dir::mkdir("KOTY総評") end for year in 2005..2018 do #フォルダ内のテキストファイルを初期化 File.open("KOTY総評/#{year}年.txt","w") do |text| end end for year in 2005..2009 do #body内のp要素の中が本文、pとpの間にbrを挟んでいない sleep 1 doc = Nokogiri::HTML(URI.open("https://koty.wiki/#{year}GC")) doc.xpath("//div[@id='body']//p").each do |paragraph| File.open("KOTY総評/#{year}年.txt","a") do |text| text.puts paragraph.inner_text end end end for year in 2010..2011 do #HTMLソースでは改行がなく、brタグだけで改行をしている sleep 1 doc = Nokogiri::HTML(URI.open("https://koty.wiki/#{year}GC")) comment = doc.xpath("//p[@class='aapro']") comment.search('br').each do |br| br.replace("\n") end File.open("KOTY総評/#{year}年.txt","a") do |text| text.puts comment.inner_text end end for year in 2011..2018 do #blockquote要素内に記述 sleep 1 doc = Nokogiri::HTML(URI.open("https://koty.wiki/#{year}GC")) File.open("KOTY総評/#{year}年.txt","a") do |text| text.puts doc.xpath("//blockquote").inner_text end endこれで取得できました。
こんな感じ
こうして見ると、年を追うごとにファイルサイズが肥大化する傾向にあるように思えますね。
ここで問題が
エーーーットあの、僕はWindows64/Ruby/Mecabでね、形態素解析しようと当初計画してたんですけども
「Win64」かつ「Ruby」で「Mecab」というのは・・・・・・・・・
非常に、環境構築がめんどくさいんですねいや、挑戦はしてみたんですよ、二回くらい
既存の記事を色々読んでやってみたんですけど……ダメなものはダメです
あの、そういうわけで・・・・・・・・・Pythonを使います
環境構築
まぁはい、環境構築します
Python/Win64でMecabを使うのはかなり簡単で、すぐにできますこれだけ
地獄のDLL書き換えをしなくてもいいの、感動すら感じますわ、これは破壊的ですよもう、概念を破壊していますよ、パラダイムシフトですよ色々遊んだ
とりあえず2018年の総評を形態素解析してWordCloudで出力してみましょう。「名詞」だけを抽出する感じで行きます。
MecabKOTY.pyimport MeCab from wordcloud import WordCloud t = MeCab.Tagger() with open('KOTY総評/2018年.txt',encoding="UTF-8") as txt_file: text = txt_file.read() nodes = t.parseToNode(text) s = [] while nodes: if nodes.feature[:2] in ['名詞']: s.append(nodes.surface) nodes = nodes.next wc = WordCloud(width=720, height=480, background_color="black",stopwords= {"これ", "ため", "それ", "よう", "こと", "もの"} , font_path="C:\Windows\Fonts\HGRGE.TTC") wc.generate(" ".join(s)) wc.to_file('KOTY_wc.png')
あーーーいい感じ、いい感じですよ
まさに形態素解析、って感じです!!!
これが例えば2007年のものだったら
こんな風に「シナリオ」が目立ちますし、2014年のものだったら
「ライダー」系の言葉が目立ちます。
KOTYの総評にも、年ごとに個性があるってことですね。次は全ての総評を合わせて解析してみましょう。
MecabKOTY.pyimport MeCab from wordcloud import WordCloud t = MeCab.Tagger() s = [] for y in range(2005,2018): with open(f'KOTY総評/{y}年.txt',encoding="UTF-8") as txt_file: text = txt_file.read() nodes = t.parseToNode(text) while nodes: if nodes.feature[:2] == "名詞": s.append(nodes.surface) nodes = nodes.next wc = WordCloud(width=720, height=480, background_color="black",stopwords= {"これ", "ため", "それ", "よう", "こと", "もの"} , font_path="C:\Windows\Fonts\HGRGE.TTC") wc.generate(" ".join(s)) wc.to_file('KOTY_wc.png')こうなります。
圧巻ですよ。
「プレイヤー」で、「ゲーム」で、「クソゲー」
KOTYの象徴って感じがしますね~~~~~さて、さらにこれを絞って、固有名詞のみ抽出するようにしてみたらどうなるでしょう
MecabKOTY.pyimport MeCab from wordcloud import WordCloud t = MeCab.Tagger() s = [] for y in range(2005,2018): with open(f'KOTY総評/{y}年.txt',encoding="UTF-8") as txt_file: text = txt_file.read() nodes = t.parseToNode(text) while nodes: if nodes.feature[:7] == "名詞,固有名詞": s.append(nodes.surface) nodes = nodes.next wc = WordCloud(width=720, height=480, background_color="black" , font_path="C:\Windows\Fonts\HGRGE.TTC") wc.generate(" ".join(s)) wc.to_file('KOTY_wc.png')
歴史ですよ。
歴史を、感じちゃいますよ。ちなみに、これをさらに絞って「組織名」に限定することで、「クソゲーメーカー」を抽出できないかな~~~と思ったんですけど、
「それは組織じゃないでしょ」ってものが大量に混ざっちゃったのでやめました。
辞書を変えればイケるかもしれませんね。次はちょっと趣向を変えてみましょう。「年ごとの特定単語の頻出度の推移」を調べます。
最初に調べるのは……えーっと、「バグ」にしましょうか。
matplotlibで折れ線グラフを描いていきます。KOTYPlot.pyimport MeCab from wordcloud import WordCloud import matplotlib.pyplot as plt t = MeCab.Tagger() c = [] for y in range(2005, 2018): c.append(0) with open(f'KOTY総評/{y}年.txt',encoding="UTF-8") as txt_file: text = txt_file.read() nodes = t.parseToNode(text) while nodes: if nodes.surface == "バグ": c[-1] += 1 nodes = nodes.next plt.plot(range(2005, 2018), c, linewidth=4) plt.xlabel("Year", fontsize = 24) plt.ylabel("Occurrence:Bug", fontsize=24) plt.grid(True) plt.savefig("KOTYgraph.png")
怖すぎる。
2015年がすごいことになってますね。おそらく「アジノコ」と「テトアル」というバグの二大巨塔がぶつかった結果でしょう。
あと、あまりのインパクトに隠れてますけど、2013年の「バグ」が1個もない状態もすごいですね。確かに2013年は、バグとはまた別の方向でのクソさが競われていたように思います。次にグラフを作る単語は……「年末」にしましょう。
!?!?!??!??!?
なんかめっちゃ規則性を感じますね!?!?
なんというかこう、ジェットコースター型ですね。上るのは一瞬で下りるのにはちょっと
時間がかかる感じ
「年末の魔物」の出現にはある程度周期性があるんでしょうかね。総括
楽しかったです









- 投稿日:2020-04-04T13:42:46+09:00
【python】表に行と列を追加する方法(pandasのDataFrame)
【python】表に行と列を追加する方法(pandasのDataFrame)
作成済みの表に新たに列や行を追加する方法のいくつか。
他にも使える関数やメソッドがあるがとりあえず基本どころだけ。
目次
1.元となる表
3行3列の表をベースに行や列の追加を行う
。変数dfに格納。
ベースの表作成row0 = [1, 2, 3] row1 = [10, 20, 30] row2 = [100, 200, 300] df = pd.DataFrame([row0,row1,row2], columns=['col0','col1','col2']) df.index = ['row0', 'row1', 'row2'] df
2.列の追加
直感的に使いやすいのは
df['A']、assign。・df['A']
・assignメソッド
・joinメソッド
・concat関数■df['A']
df['A'] = B
└「df」:元の表
└「A」:追加する列の名前
└「B」:追加する内容※既存の行名を指定すると上書きされる。
追加する内容の指定は比較的自由。
数値、値、表データ、数式、listなどが使える。▼事例
①列の追加(list)
②列の追加(数値)
③列の追加(表)
④列の追加(数式)
①列の追加(list)
列の追加(list)df['col3'] = [4, 40, 400] df
②列の追加(数値)
列の追加(数値)df['col3'] = 4 df
③列の追加(表)
列の追加(表)df['col3'] = df['col2'] df
④列の追加(数式)
列の追加(数式)df['col3'] = df['col2'] * 100 df
■assignメソッド
assignメソッドで列名を指定して追加することもできる。
df.assign(A=[a,b,,], B=[c,d,,],,)
└「A」「B」:追加する列名
└「a,b,,」「c,d,,」:各列の中身・上書きされない
・列名はクオテーション不要
・要素をlistで指定する場合はベースとなる表の行数と一致していること
エラー例
・列名にクオテーションがある
SyntaxError: expression cannot contain assignment, perhaps you meant "=="?・列名がない
TypeError: assign() takes 1 positional argument but 2 were given・listの要素数が合わない
ValueError: Length of values does not match length of index
▼1列追加1列追加df.assign(A=[1,2,3])
▼1列追加(表データ・数式)1列追加(表データ・数式)df.assign(A=df['col0']*100)
▼2列追加2列追加df.assign(A=[1,2,3], B=100)
「列名=中身」を付け加えればその分列が増える。
■joinメソッド
joinメソッドは表を結合する場合に使える。
listや数値など行番号(index)を持たないものには使えない。
join(dfA, rsuffix='_a')
└「dfA」:結合する表
└「rsuffix='a'」:列名が重複する場合は、追加した列名に「a」(任意)をつける。*「lsuffix='_a'」の場合は既存の列名を変更。
▼事例
追加する表のパターン別に処理を確認。①行名がすべて同じ表を追加(列名重複なし)
②存在しない行名がある表を追加
③列名が重複する場合
④一部の列名が重複する場合
①行名がすべて同じ表を追加(列名重複なし)
行名がベースとなる表の行名と一致し、列名が既存と重複しない場合。
行名がすべて同じ表dfA = pd.DataFrame([100,200,300]) dfA.index = ['row0', 'row1', 'row2'] dfA
▼追加
追加df.join(dfA)
新規列が追加された。
②存在しない行名がある表を追加
ベースの表に存在しない行名がある場合
└ベースの表に新たに行は追加されない。
└行名が一致しないデータはNaN(欠損値)となる。
▼追加する表
row0のみが存在。XXX、YYYはベースの表にはない。存在しない行名がある表dfB = pd.DataFrame([100,200,300]) dfB.index = ['row0', 'XXX', 'YYY'] dfB
▼追加
追加df.join(dfB)
③列名が重複する場合
join(dfA, rsuffix='_a')列名が重複する場合、「rsuffix='_a'」で重複する列名につける末尾の文字を指定。
▼オプション
・「rsuffix='_a'」:追加する重複した列名に指定した文字を追加(right suffixの略)・「lsuffix='_a'」:既存の重複した列名に指定した文字を追加(left suffixの略)
指定しないとエラーになる。
▼追加する表
既存の表と同じ列名(col0)を含む表。列名が重複dfC = pd.DataFrame([100,200,300], columns=['col0']) dfC.index = ['row0', 'row1', 'XXX'] dfC
▼追加(rsuffixの場合)
rsuffixdf.join(dfC, rsuffix='_@')
▼追加(lsuffixの場合)rsuffixdf.join(dfC, lsuffix='_@')
④一部の列名が重複する場合
処理は③の列名が重複する場合と同じ。
・重複する列は列名に指定したsuffixがつく。
・重複しない列は列名がそのままで追加される。
▼追加する表
既存の表と同じ列名(col0, col1)を含む表。列名が一部重複list1 = [100,200,300] list2 = ['A','B','C'] list3 = ['AAA','BBB','CCC'] list4 = ['10A','20B','30C'] dfD = pd.DataFrame([list1,list2, list3, list4], columns=['col0', 111,'col1']) dfD.index = ['row0', 'row1', 'XXX', 'YYY'] dfD
▼追加rsuffixdf.join(dfD, rsuffix='_@')
- 重複する列名には指定した文字列が追加
- ベースの表に存在しない行は追加されない
- 追加する列で、存在しなかった行にはNaNが入る
■concat関数(列)
concat関数を使って表同士を結合。
pd.concat([df, dfA], axis=1)
└「df」:ベースとなる表
└「dfA」:追加する表
└「axis=1」:列を追加する指示・列名が重複していてもそのまま追加
・行名が異なる場合は新規行を追加(デフォルト:join='outer')
・join='inner'オプションで、行名が一致するもののみ残す
①結合する表
②axis=1の有無
③sortオプション
④joinオプション
<補足>
・listや数値の結合はできない
-TypeError: cannot concatenate object of type ''; only Series and DataFrame objs are valid・「concat」の意味
concatinate: 結合する。連結する。
①結合する表(列)
下記3行3列の表「dfA」を使用。
・列「col0」「col1」はベースの表と重複。
・行「xxx」はベースの表にない結合する表list1 = [1,100,'AAA'] list2 = [2,200,'BBB'] list3 = [3,300,'CCC'] dfE = pd.DataFrame([list1,list2, list3], columns=['col0', 'col1', 'aaa']) dfE.index = ['row0', 'row1', 'XXX'] dfE
②axis=1の有無(列)
pd.concat([df, dfA], axis=1)列の追加をする場合「axis=1」は必須。つけないと行方向に追加となり結果が大きく異る。
▼「axis=1」あり「axis=1」ありpd.concat([df, dfA], axis=1)
・列を追加
・列名が重複していてもそのまま追加(joinメソッドとは異なる)
・追加する表にない行の値はNaNになる。
・ベースの表にない行は新たに追加。
▼「axis=1」なし
「axis=0」が省略された形。
行方向に結合することになる。「axis=1」なしpd.concat([df, dfA])
・列名が一致しない場合は新たに列を追加。
・行名が重複していてもすべて新たに追加。※列は追加されるが行が統合されないため、実行したい内容と異なる。
③sortオプション(列)
sortオプションを指定せずに表を結合すると、行名で自動ソートされる。
└デフォルト:sort=True
▼sort=True(デフォルト)sort=Truepd.concat([df, dfA], axis=1)
行「XXX」が自動ソートで上にくる。
▼sort=Falsesort=Falsepd.concat([df, dfA], axis=1, sort=False)
「sort=False」を記述すると追加した行は最後尾に追加される。
▼ベースとなる表を入れ替えた場合sort=Falsepd.concat([dfA, df], axis=1, sort=False)
ベースとなる「dfA」に存在しない行が、末尾に追加される。
④joinオプション(列)
行の処理を決める(axis=1の場合)
join='outer'
└デフォルトの設定。
└存在しない行を残す。
join='inner'
└重複する行のみ残す。
▼join='outer'join='outer'pd.concat([dfA, df], axis=1)
結合前後で存在しない行「XXX」が追加される。
▼join='inner'join='outer'pd.concat([dfA, df], axis=1, join='inner')
どちらかにしか存在しない行「row2」「XXX」は削除。
3.行の追加
直感的に使いやすいのはlocメソッド。
・locメソッド
・concat関数■locメソッド
df.loc['A']=B
└「df」:元の表
└「A」:追加する行の名前
└「B」:追加する内容※既存の行名を指定すると上書きされる。
追加する内容の指定は比較的自由。
数値、値、表データ、数式、listなどが使える。①行の追加(list)
②行の追加(数値)
③行の追加(表)
④行の追加(数式)
①行の追加(list)
行の追加(list)df.loc['AAA'] = [4, 40, 400] df
②行の追加(数値)
行の追加(数値)df.loc['AAA'] = 4 df
③行の追加(表)
行の追加(表)df.loc['AAA'] = df.loc['row2'] df
④行の追加(数式)
行の追加(数式)df.loc['AAA'] = df.loc['row2'] * 100 df
■concat関数(行)
concat関数を使って表同士を結合。
pd.concat([df, dfA])
└「df」:ベースとなる表
└「dfA」:追加する表・行名が重複していてもそのまま追加
・列名が異なる場合は新規列を追加(デフォルト:join='outer')
・join='inner'オプションで、列名が一致するもののみ残す
①結合する表
②デフォルト
③sortオプション
④joinオプション
<補足>
・listや数値の結合はできない
-TypeError: cannot concatenate object of type ''; only Series and DataFrame objs are valid・「concat」の意味
concatinate: 結合する。連結する。
①結合する表(行)
下記2行3列の表「dfA」を使用。
結合する表list1 = [1,100,'AAA'] list2 = [2,200,'BBB'] dfA = pd.DataFrame([list1,list2], columns=['col0', 'col1', 'aaa']) dfA.index = ['row0', 'XXX'] dfA
②デフォルト
pd.concat([df, dfA])デフォルトpd.concat([df, dfA])
・行名が重複していてもすべて新たに追加。
・一致しない列名は新たに列を追加。
・該当しないセルはNaN(欠損値)で埋められる
③sortオプション(行)
sortオプションを指定せずに表を結合すると、列名で自動ソートされる。
└デフォルト:sort=True
▼sort=True(デフォルト)sort=Truepd.concat([df, dfA])
後から追加した「aaa」列が自動ソートで先頭にくる。
▼sort=Falsesort=Falsepd.concat([df, dfA], sort=False)
後から追加した「aaa」列は最後尾に結合。
④joinオプション(行)
列の処理を決める。
join='outer'
└デフォルトの設定。
└存在しない列を残す。
join='inner'
└重複する列のみ残す。
▼join='outer'join='outer'(デフォルト)pd.concat([df, dfA])
結合前後の表に存在しない列「aaa」が残る。
▼join='inner'join='inner'pd.concat([df, dfA], join='inner')
結合前後の双方の表に存在する列のみ残る。
































