- 投稿日:2020-04-04T23:06:46+09:00
bundle install --deploymentでAWS Lambda向けデプロイパッケージを作っていて嵌った罠
背景
AWS lambdaにRubyスクリプトを配置するデプロイパッケージを作るとき、Rubyスクリプトが依存するgemファイルをzipファイルに含めるため、
bundle install --deploymentのように、--deploymentオプションを指定していました。
--deploymentオプションを指定するとgemはvendor/bundleディレクトリにインストールされます。
次のコマンドで、vendorディレクトリをデプロイパッケージに含めます。zip deploy_package lambda_function.rb -FSr vendor
--deploymentオプションを使っているのは、AWSのデプロイスクリプトのサンプルにbundle install --deploymentが使われていた時があり、その名残です。現在ではbundle install --path vendor/bundleが使われています。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/ruby-package.html
bundle install --path vendor/bundleを使っていれば、この先を読む必要はありません。物語
PCにインストールしているbundlerのバージョンを2.1.4に上げました。
bundler 2.1.4では
--deploymentオプションは非推奨になりました。
代わりにbundle config deployment trueコマンドで設定を変更します。
https://github.com/rubygems/bundler/pull/7519CI環境で使うデプロイスクリプトも
bundle config deployment trueに修正しました。デプロイが失敗するようになりました。
gemがvender/bundleディレクトリにインストールされなくなったようです。原因
CI環境ではRuby 2.7を使っています。
Ruby 2.7に同梱されているbundlerのバージョンは2.1.2でした。bundler 2.1.2 では
bundle config deployment trueを設定しても、gemのインストール先が変わりません。対策
bundle config set path 'vendor/bundle'を設定して、gemのインストール先をvender/bundleにしました。これでbundler 2.1.2でも2.1.4でもgemは
vendor/bundleディレクトリにインストールされます。その後
CI環境でbundler 2.1.4を使うようになり、1ヶ月半くらいで
bundle config deployment trueに戻しました。
--pathオプションも非推奨なので、bundle install --path vendor/bundleにはしませんでした。
- 投稿日:2020-04-04T22:42:29+09:00
[Rails]本番環境でSeed-fuを使う
本記事投稿のいきさつ
railsでアプリを作成している中で、Seed_fu Gem を使用しました。
その際、開発環境では上手くテーブルにデータを格納することができたのですが、本番環境で苦戦したため備忘録として書きます。
ここでは、自分が苦戦したEC2内でのコマンドのみを書きます。エラー(異なるディレクトリでコマンドを入力していたため)
自分が作成したアプリのディレクトリへ移動しコマンドを入力したところ
Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)と、mysplに接続ができないというエラーが発生。
これはコマンドを入力するディレクトリが誤っていたため発生したエラーでした。
実は開発環境とは異なり、本番環境ではcurrentディレクトリ内のデータが本番環境で動いているフォルダ群になります。
そのためcurrentディレクトリへ移動した後、再度コマンドを入力します。cd current rails db:seed_fuこれで大丈夫かと思われましたが、またしてもエラーが。
エラー(コマンド誤り)
Could not load the 'listen' gem. Add `gem 'listen'` to the development group of your Gemfilelisten gem がないとのこと。
まさかと思いgemfileを確認したところちゃんと書かれていました。
調べたところ、seedでデータを投入する際は環境の指定をする必要があるようです。ということで以下を再度実行。rails db:seed_fu RAILS_ENV=production今度は成功しました。初めての経験で苦戦しましたが、とても勉強になりました。
ちなみに、test環境でも同じように以下を実行すれば大丈夫です。rails db:seed_fu RAILS_ENV=testおわり
最後まで見ていただきありがとうございました。
- 投稿日:2020-04-04T21:08:34+09:00
ポートの開放することなく、Respberry Piに外からアクセスする(2020年 AWS編)
2017年に書いたポートの開放することなく、Respberry Piに外からアクセスするの第2弾です。
自宅に設置したRaspberry Piに外出先からアクセスしたいことってありますよね。
でも、そのためだけにルーターのポートを解放するのも、セキュリティが心配。今回はAWS Systems Manager Session Managerを使う方法をご紹介します。
SSHもVNCもポートの開放も不要ですよ!AWS Systems Manager Session Managerとは
公式サイトによると
Session Manager はフルマネージド型 AWS Systems Manager 機能であり、インタラクティブなワンクリックブラウザベースのシェルや AWS CLI を介して Amazon EC2 インスタンス、オンプレミスインスタンス、および仮想マシン (VM) を管理できます。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/session-manager.html
基本的にはEC2へのログインに使うと便利なものですが、実はSystems Managerはオンプレ環境でも使用でき、Session Manager機能もEC2でなくても利用できるのです。
導入手順
以下、手順を追って説明します。
IAMサービスロールを作成する
IAMロールを作成します。
項目 内容 名称 SSMServiceRole(任意の名前) ポリシー AmazonSSMManagedInstanceCore(AWS 管理ポリシー) 信頼関係 ssm.amazonaws.com https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-service-role.html
アクティベーションを作成する
Raspberry PiにSSMエージェントをインストールする際に必要なアクティベーションキーを作成します。
マネジメントコンソールの
ハイブリッドアクティベーションメニューから作成します。
項目 内容 インスタンス制限 1(任意の数) IAM ロール SSMServiceRole(上の手順で作ったもの) デフォルトのインスタンス名 Raspberry Pi(任意の名前) 作成したあと、画面上に
アクティベーションコードとアクティベーションIDが表示されるのでメモしておきます。SSMエージェントをインストールする
ここはRaspberry Pi上での作業となります。
mkdir /tmp/ssm sudo curl https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/debian_arm/amazon-ssm-agent.deb -o /tmp/ssm/amazon-ssm-agent.deb sudo dpkg -i /tmp/ssm/amazon-ssm-agent.deb sudo service amazon-ssm-agent stop sudo amazon-ssm-agent -register -code "[activation-code]" -id "[activation-id]" -region "ap-northeast-1" sudo service amazon-ssm-agent restart
[activation-code]と[activation-id]は前の手順でメモしたものを使用します。https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-install-managed-linux.html
これで設定は完了です。
設置が完了すると、Session ManagerのマネージドインスタンスのところにRaspberry Piが追加されます。
接続手順
Session Managerのマネージドインスタンスのところでインスタンスを選択し、
アクション->Start Sessionを選択すると、ブラウザ上でターミナルの画面が表示されます。これ、ブラウザの画面です。すごいですね。
su - piとすることでpiユーザーへの切り替えもできます。
これでいつでもどこでもRaspberry Piと一緒です。
SSHもVNCも不要です。すごいですね。


- 投稿日:2020-04-04T20:38:14+09:00
ロードバランサーが不要になるECSサービスディスカバリを試す
結論から
- ECSで特定のエンドポイントをもつサービスを作る際、ロードバランサーなしでも実現できる。
- EIPとかで固定する必要もない。
- サービス検出は完全にマネージド。ヘルスチェックはタスク定義のコンテナレベルのものでOK.
ユースケース
- アプリ1をEC2にデプロイ。
- アプリ2をECSにデプロイ。起動タイプはFargate.
- アプリ1からアプリ2にHTTPリクエストを送る。
- ロードバランサー (ALB) は利用しない。
- アプリ1とアプリ2は同じVPCに配置する。
- アプリ1はパブリックサブネットに配置する。
- アプリ2はプライベートサブネットに配置する。
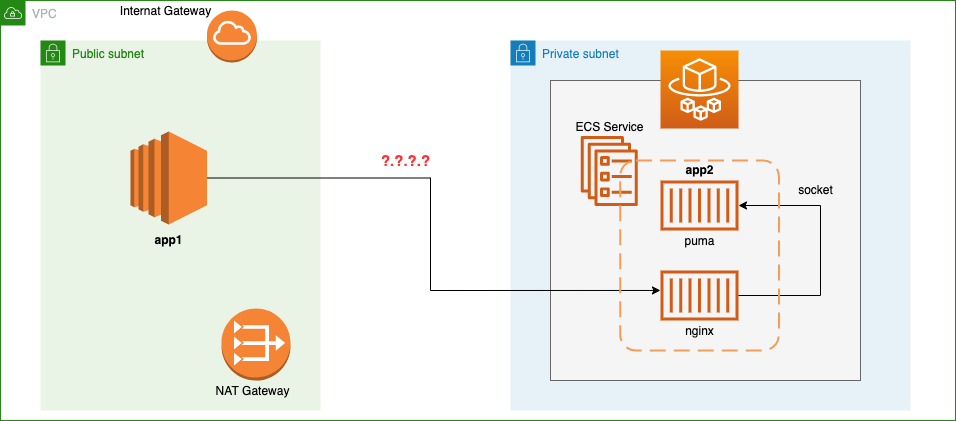
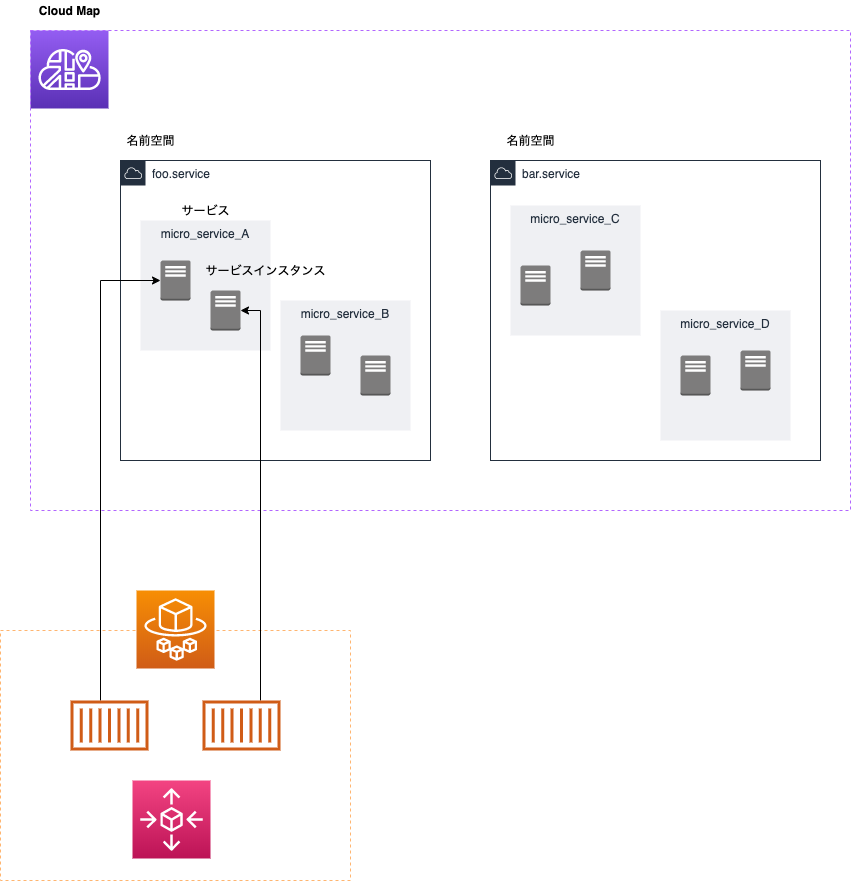
構成図はこんな感じ。
アプリ2は puma+nginxで、nginxのポート80番をエンドポイントとしている。
(ちなみにサンプルはSinatraで作ったが、Railsでも特に大差はない)
解決すべき課題
Fargateは起動するたびにIPアドレスが変わるため、アプリ1からはリクエストする先が分からなくなる。そのため、一般的にはロードバランサーを置いて名前解決と負荷分散を行うことになるのだが、今回取るのは別の方法。
ロードバランサーを作るのが面倒、コストを削減したい、L4やL7などロードバランサー特有の機能を使う予定がない、という場合は、ECSのサービスディスカバリーを使うことができる。
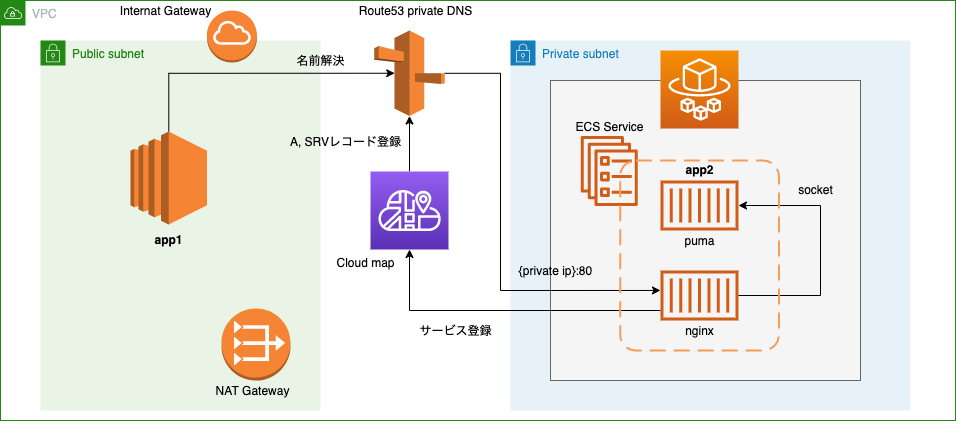
サービスディスカバリーを使った最終的な構成がこれ。
順に解説していく。
登場人物
- AWS Cloud Map
- Route53 Private DNS
AWS Cloud Map
AWS上で展開する各種サービスを検出するためのレジストリで、
誤解を恐れずにざっくり言ってしまえば、ただの名前空間。
https://aws.amazon.com/jp/cloud-map/エンドポイントにカスタム名をつけて管理し、APIコールまたはVPC DNSクエリを通じて適切にサービスにルーティングを行う仕組み。
特にマイクロサービスを作る上では必須となるサービスディスカバリを支援してくれる。
一般にはIPアドレスをもった何かしらのサーバーリソースをイメージすることが多いと思うが、LambdaやSQSのエンドポイントも解決できる。
今回は ECS と VPC Private DNS と組み合わせて使用するので、特に意識する必要はなく、ただの名前空間くらいの認識でよい。
興味があれば以下の記事が詳しい。
詳細解説「AWS Cloud Map」とは #reinventRoute53 Private DNS
Rout53 にパブリックではなくプライベートな Hosted Zone を作成して、VPC内のインターナルな名前解決を行う仕組み。
特定のVPCに紐づけて、当該VPC内からAWSのプライベートDNSに対してクエリを行う。
複数のVPCやリージョンをまたぐことも可能。
Amazon Route 53 Private DNSを複数VPCに適用する今回は同一VPC内で起動したFargateタスクに対して、タスクに割り当てられたプライベートIPへの名前解決を行いたいので、要件に合致している。
構築
全てCloudFormationを用いて行う。
疎通確認用に、app1としてEC2インスタンスから作業を行うために、ssh接続のためのキーペアだけ事前に作成しておく。話の本題の部分だけ解説するので、他のVPCやECSの定義はgithubを参照してほしい。
rezept/ecs-service-discoveryAWS Cloud Map
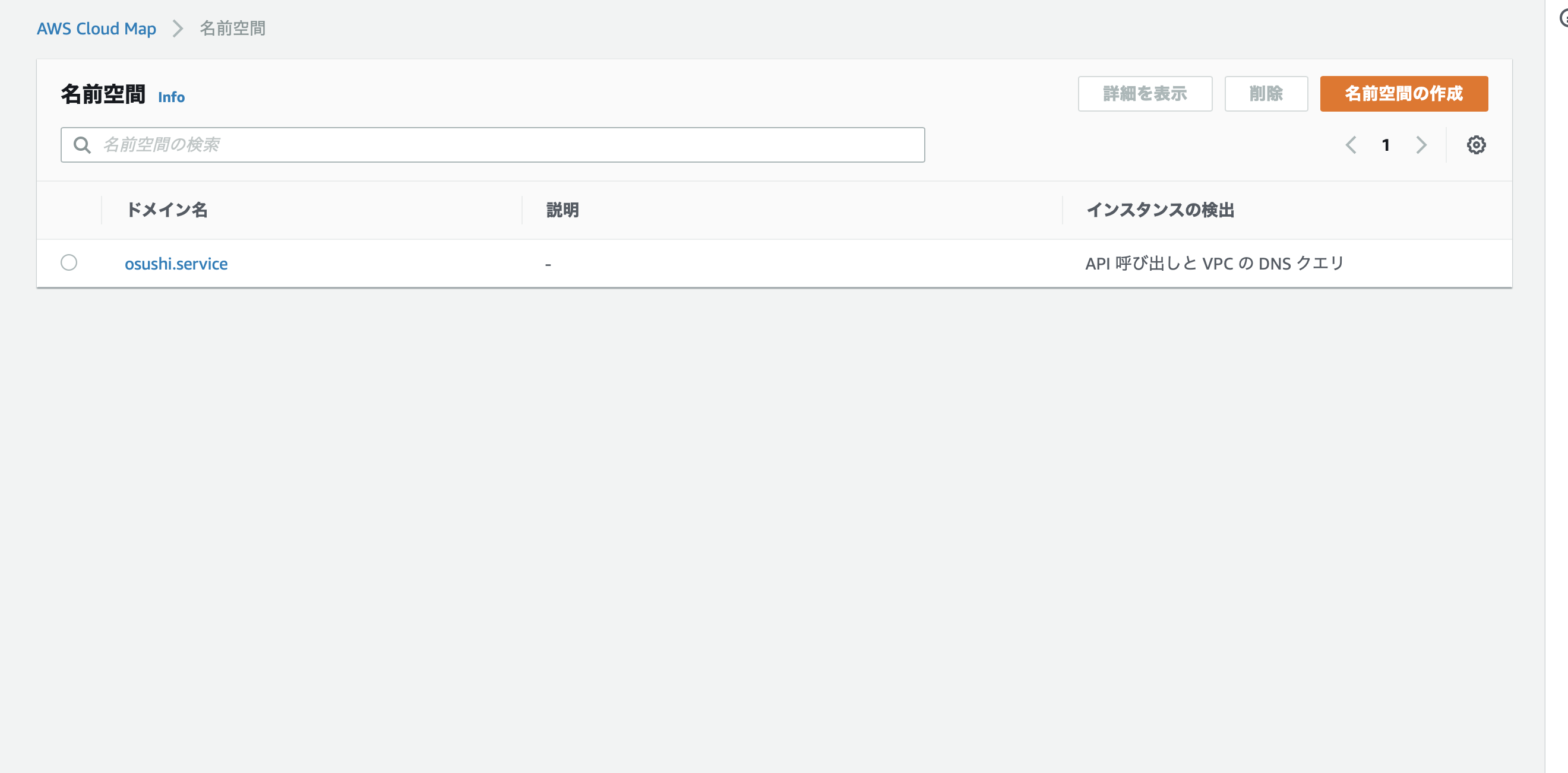
AWS Cloud Map に名前空間を作成する。
PrivateDNSNamespace: Type: AWS::ServiceDiscovery::PrivateDnsNamespace Properties: Name: osushi.service Vpc: !Ref VPCVPCに紐づけた Private DNS クエリを利用するのでリソースタイプは
AWS::ServiceDiscovery::PrivateDnsNamespaceとなる。
「Cloud Map」という言葉が出てこないので結構ややこしいのだが、コンソール上では [AWS Cloud Map] のページにリソースが作成される。
名前はドメイン名、つまりはエンドポイントのサフィックスになるので、それっぽい名前をつけることをお勧めする。
ECS
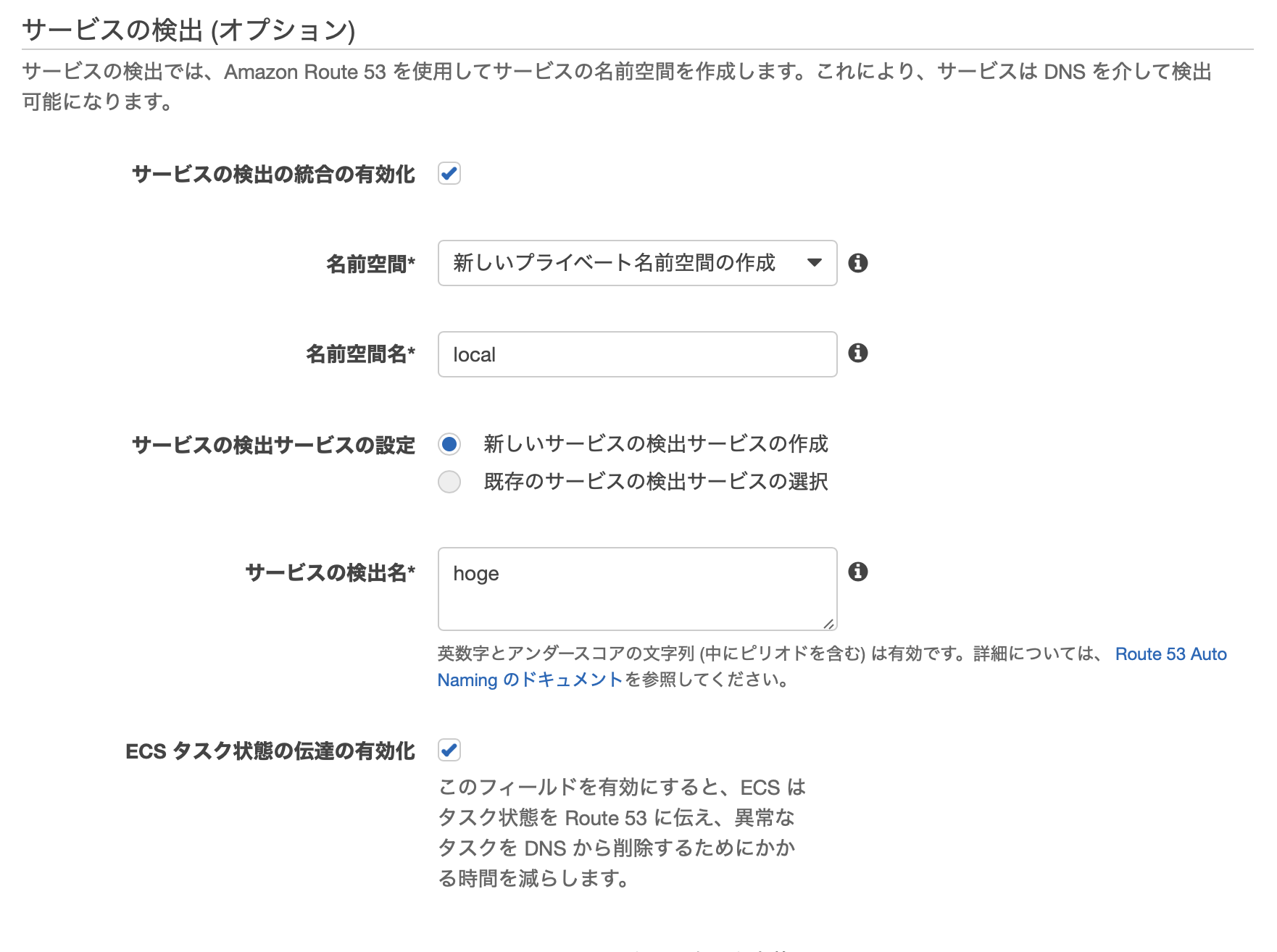
マネジメントコンソールでサービスを作成する際に設定することができる [サービス検出(オプション)] は、CloudFormation上では、
ServiceRegistriesというプロパティで設定する。
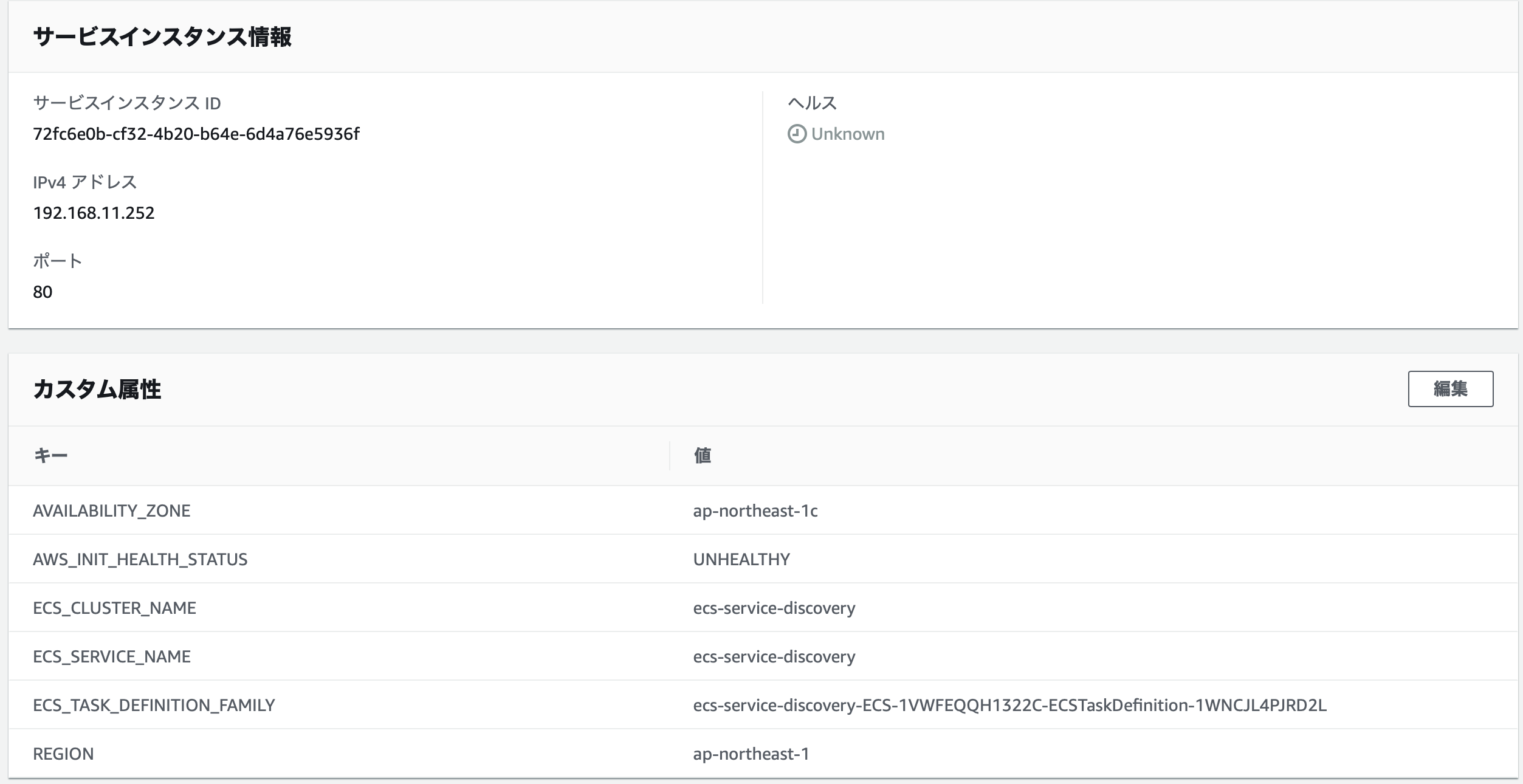
ECSService: Type: AWS::ECS::Service Properties: Cluster: !Ref ECSCluster DesiredCount: !Ref ServiceDesiredCount LaunchType: FARGATE NetworkConfiguration: AwsvpcConfiguration: AssignPublicIp: DISABLED SecurityGroups: - !Ref SecurityGroup Subnets: - !Ref PrivateSubnet ServiceName: !Ref AppName TaskDefinition: !Ref ECSTaskDefinition ServiceRegistries: - ContainerName: nginx ContainerPort: !Ref Port RegistryArn: !GetAtt DiscoveryService.Arn今回は、nginxがリクエストを捌くので、nginxコンテナの名前とポートを指定する。
ここで指定したコンテナのポートとプライベートIPアドレスが、Cloud Mapからターゲットとして検出され、自動でDNSに登録されることになる。
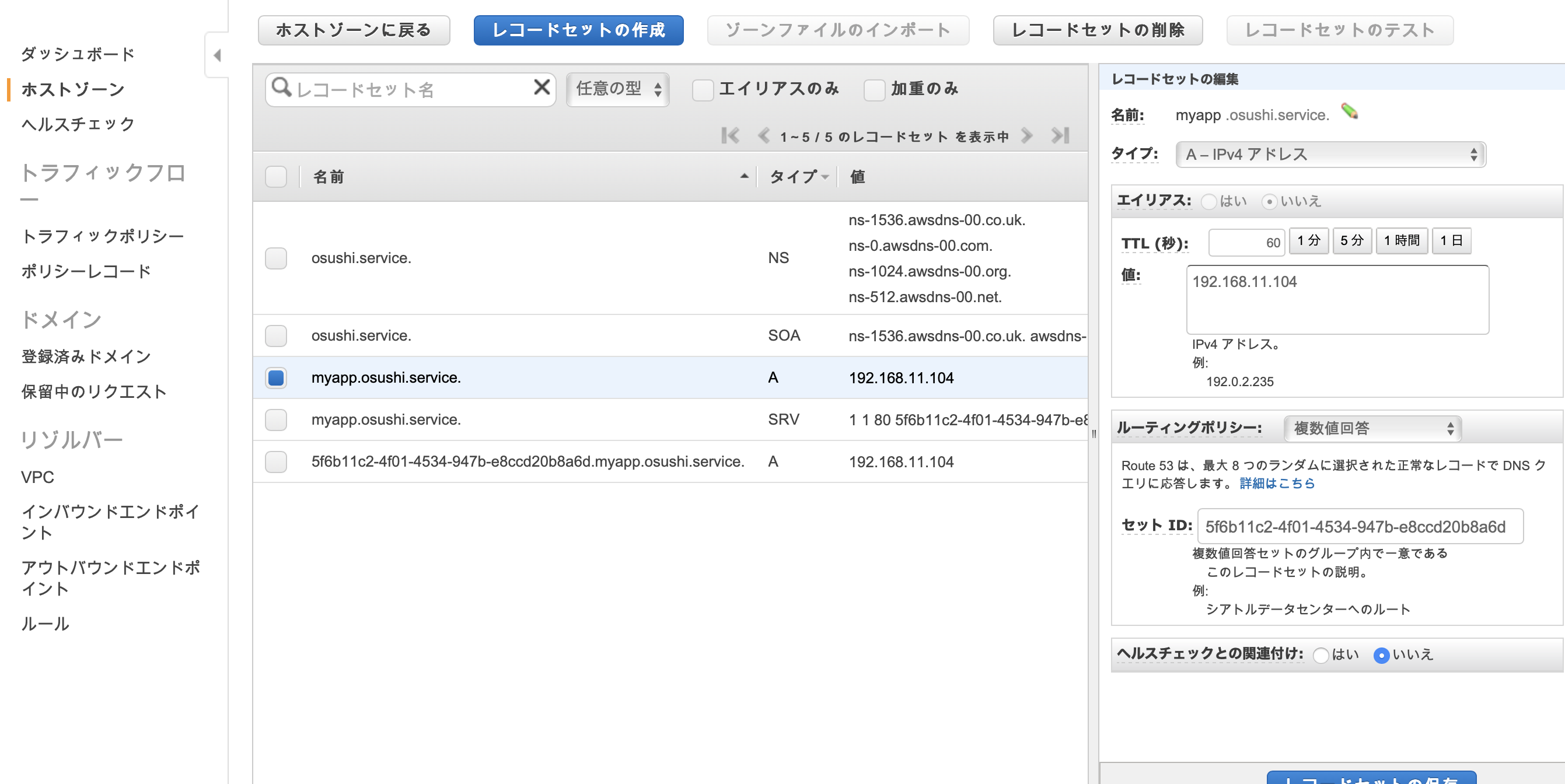
RegistryArnに指定するためのCloudMapのサービスを登録する。DiscoveryService: Type: AWS::ServiceDiscovery::Service Properties: Description: discovery service DnsConfig: RoutingPolicy: MULTIVALUE DnsRecords: - TTL: 60 Type: A - TTL: 60 Type: SRV NamespaceId: !Ref PrivateDNSNamespaceID Name: myappAレコードとSRVレコードの両方を登録する。
TTLはとりあえず60秒。
NamespaceIdには VPC の項で作成した名前空間を指定。
Nameは、エンドポイントのプレフィックス(サブドメイン)となる部分。
これで前述の名前空間と合わせて、myapp.osushi.serviceでクエリすると、Rouute53のプライベートDNSを経由して、nginxコンテナの80番ポートにリクエストが届くようになる。CloudMapの階層を整理しないとちょっと混乱するかもしれないのでざっくりと図解する。
名前空間、サービス、サービスインスタンスの3つのグループがある。
サービスインスタンスの実体は、Fargateのタスクだったり、Lambdaだったりする。
オートスケールすれば、そのタスクの数だけサービスインスタンスとして登録される。
ALBと同じ感じで理解してもらえればいい。
ヘルスチェックはコンテナごとの設定に準拠する。
成功・失敗に応じて、サービスインスタンスの登録と解除をマネージドしてくれる。HealthCheck: Command: - CMD-SHELL - curl -f http://localhost/ - "|| exit 1" StartPeriod: 30Route53 Private DNS
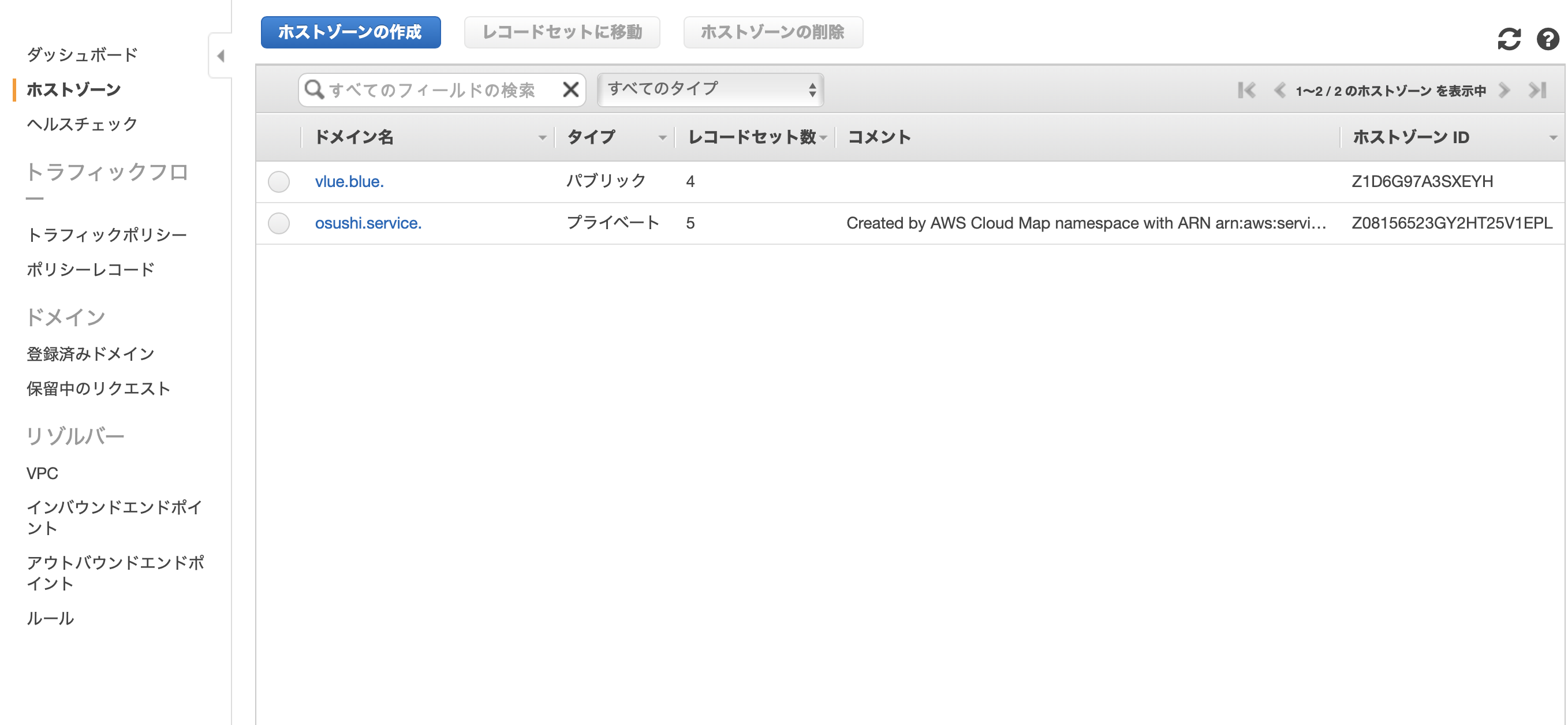
この時点で、もうできている。
CloudMapが自動でプライベートなホストゾーンを作成し、
ECSの設定に応じて、検出したレコードを登録している。
値は、ステータスが HEALTHY なタスクのプライベートIPになっている。
疎通確認。
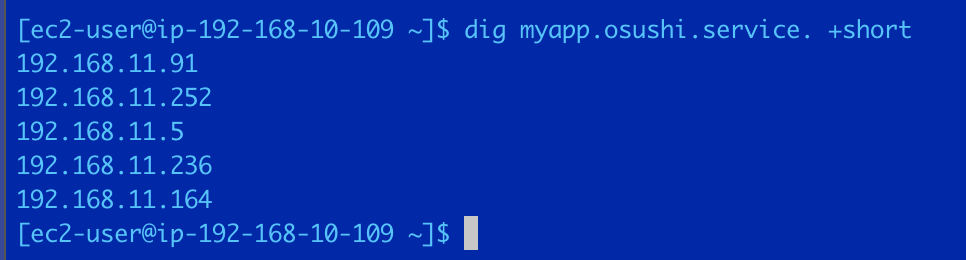
アプリ1として立てているEC2インスタンスにssh接続し、以下のコマンドを実行する。dig myapp.osushi.service +short
5つタスクを起動しているので、5つのプライベートIPに解決されている。
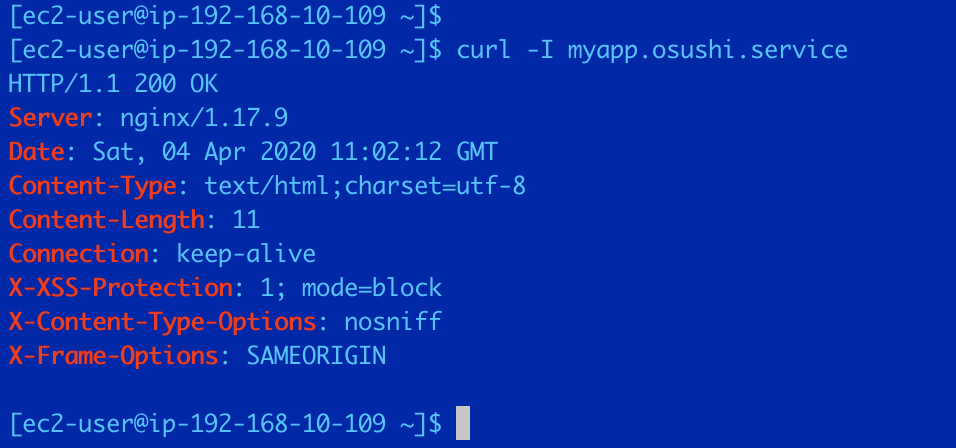
次にHTTPリクエストを送る。curl -I myapp.osushi.service
ちゃんと返ってきてる。
ちなみに80番ポートは、セキュリティグループでパブリックサブネットのCIDRのみを許可している。
外部からはもちろん接続できないし、VPC外になるのでプライベートDNSによる名前解決も不可能。そういえばすでに存在するドメインを指定した場合、先にプライベートに問い合わせるからパブリックな方には疎通できないとかなんとか。
所感
ロードバランサーなしでさくっと作れるのは便利。
あまり構築も運用コストもかけたくない社内用のシステムをサクッと作る場合とか、ECSを選択しやすくなる。
ALBの機能を使い倒さない場合はこれで十分かな
大規模なマイクロサービスを運用する場合はどうなんだろう。
- 投稿日:2020-04-04T20:12:08+09:00
【AWS】デプロイ関連で詰まった箇所
デプロイ
bundler: failed to load command: puma
解決法
AssetsPrecompile関連エラー
Precompile = 1つのファイルにまとめる(圧縮する作業)
ターミナル# アセッツプリコンパイル $ bundle exec rake assets:precompile RAILS_ENV=production解決法
yarnのインストール
ターミナル$ curl -o- -L https://yarnpkg.com/install.sh | bash $ source .bashrc # 反映 $ yarn -V # yarnインストールconfig/environments/production.rbconfig.assets.js_compressor = :uglifier # 変更 config.assets.js_compressor = Uglifier.new(harmony: true)config/environments/production.rbconfig.public_file_server.enabled = ENV['RAILS_SERVE_STATIC_FILES'].present? # 変更 config.public_file_server.enabled = truecapistrano関連エラー
SSHKit::Runner::ExecuteError
config/deploy/production.rbset :ssh_options, { keys: %w(~/.ssh/id_rsa) } # 変更(例) set :ssh_options, { keys: %w(/Users/hogehogehoge/.ssh/hogehoge_key_rsa) } # ①ssh接続の秘密鍵にはデフォルトでid_rsaを探しにいくため、使用する秘密鍵の名前に変更 # ②使用する秘密鍵の場所までのpathを通すGem::LoadError : "ed25519 is not part of the bundle. Add it to your Gemfile."
Gemfilegem 'ed25519' gem 'bcrypt_pbkdf'ターミナル$ bundle使ってるパソコンの環境によってエラーが出たり出なかったりするらしい。
bundle exec cap production deploy(git:checkで落ちる)
Gemfile# ssh形式で接続 set :repo_url, "git@github.com:hogehogehoge.git" # 変更 # https形式で接続 set :repo_url, "https://github.com/hoge/hogehogehoge.git" set :git_http_username, "gitに登録しているusername" set :git_http_password, "gitに登録した公開鍵パスワード"bundle exec cap production deploy(deploy:symlink:linked_filesで落ちる)
master.key database.yml settings.ymlの配置を変更
/var/www/rails/アプリケーション/shared/config配下に移動bundle exec cap production deploy(yarn:installで落ちる)
nodeのバージョンが古かったらしい
bundle exec cap production deploy(nginx:restartで落ちる)
ターミナル$ ps aux | grep nginx →プロセスを確認してnginxが起動していないか確認 $ sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: [emerg] open() "/var/www/rails/アプリケーション名/log/nginx.error.log" failed (2: No such file or directory) →nginx.conf(nginx設定ファイル)は問題ない →/var/www/rails.......にnginx.error.logがあるか確認してくださいと言われるが、nginx.error.logは/var/www/rails/アプリケーション名/sheard/log/nginx.error.logに配置したいため/etc/nginx/sites-enabled/アプリケーション名を書き換えるターミナル[~]$ cd /etc/nginx/sites-enabled $ sudo vim アプリケーション名sites-enabled/アプリケーション名error_log /var/www/rails/アプリケーション名/sheard/log/nginx.error.log access_log /var/www/rails/アプリケーション名/sheard/log/nginx.access.logターミナル$ sudo service nginx start → 起動確認bundle exec cap production deploy(全て通ったのにブラウザで画面表示されない)
nginx.error.log
puma.error.log
production.log
を確認してエラーが出ているか確認。
nginx.error.log場所確認ターミナル/etc/nginx/sites-enabled/アプリケーションvimで開いて中身を確認
自分の場合は/var/www/rails/アプリケーション名/shared/log/nginx.error.logに配置注意))あくまで読み込むのは
/etc/nginx/nginx.confであるためnginx.confにinclude /etc/nginx/sites-enabled/*のようにincludeされているかを確認。nginx関連で見るファイルは基本的にnginx.confとsites-enabled配下のファイルの2つ
puma.error.log場所確認ローカル環境の
config/deploy.rbset :puma_error_log の後にパスが記述自分の場合は
/var/www/rails/アプリケーション名/shared/log/puma.error.logに配置error.logは他の開発者とも共有しやすいようにshared(シェアード)配下に置くのが一般的なのでそのように設定しておくのがベター
production.logもshared配下に配置今回のエラーは
/etc/nginx/sites-enabled配下にcapistranoでデプロイ以前に作成した.confファイルが残っておりそちらのファイルがnginx.confにinclude
されており、間違った設定が適用されていたことが原因だった。
sites-enabled/.confを削除し、nginx.confに記載のincludeを削除することで解決。AWSアーキテクチャ関連
複数サーバーにcapistranoでデプロイしたい時
元々あるWebサーバーからイメージの作成、EC2インスタンスを起動し、ローカルの
config/deploy/production.rbrole app, 'ユーザー名@パブリックIP' role web, 'ユーザー名@パブリックIP' role db, 'ユーザー名@パブリックIP'を追加して
ターミナル$ bundle exec cap production deployで、OK
SSL証明書発行(albに付与)
参考記事の7まで進めたら、最下部の
新しい ACM 証明書をリクエストをクリック。
*.ドメイン名とドメイン名を記入し、次へ
検証方法はDNS
証明書が認証されるまで待って、リスナー画面へ戻り、発行された証明書を選択して保存※ Udymy
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得のセクション8の62.CloudFrontを設定して高速化しようが参考になる。ローカルのconfig/deploy/templates/nginx_conf.erb# bundle exec rails g capistrano:nginx_puma:configをした時に自動生成されるファイル # デプロイすると、このファイルを元にEC2インスタンスの/etc/nginx/nginx.confや/etc/nginx/sites-enabled/アプリケーションに設定が反映される location @puma_<%= fetch(:nginx_config_name) %> { ... <% if fetch(:nginx_use_ssl) -%> proxy_set_header X-Forwarded-Proto https; <% else -%> proxy_set_header X-Forwarded-Proto http; <% end -%> ↓ 変更 proxy_set_header X-Forwarded-Proto https;この作業をしないとPOSTリクエストがhttpsの時はできないので要注意
https://www.cotegg.com/blog/?p=1850Git
プッシュ済みコミット取り消し、ローカルの状態をプッシュ
プッシュ済みコミット取り消し
ターミナル$ git log 戻したいコミットの地点のIDをコピー $ git reset --hard IDローカルの状態をプッシュ
リモートの方がコミットが進んでるためrejectするのでターミナル$ git push -f origin master ローカルの状態を最新としてリモートを更新チーム開発時の
-fは要注意
- 投稿日:2020-04-04T17:42:49+09:00
AWS SAMを使ってサクッとPythonとlambda、API GatewayでAPIを作る
プロジェクトで、Pythonを使った簡単なAPIを作ることになったので、サクッとAPIを作る環境を整えていきます。
前提
エディター…VSCode
OS…Windows10
Python3.8インストール済み
AWS CLI導入済みWindows での AWS CLI バージョン 2 のインストール - AWS Command Line Interface
必要な環境
- AWS SAM CLI
- AWS Toolkit for Visual Studio Code
AWS SAMの利点
公式ドキュメントによると
- 単一のデプロイ構成
- AWS CloudFormation の拡張
- 組み込みのベストプラクティス
- ローカルのデバッグとテスト
- 開発ツールとの緊密な統合
がメリット。
個人的にはlambdaをローカルでデバッグできるのは大きなメリットでした。
実態はCloudFormationなので、カスタマイズ性があるのもポイント高い。AWS SAM CLIの導入
公式ドキュメントに従って行います。要約すると
- dockerをインストール
- AWSが配布してるインストーラ(.msiファイル)からインストールするか
pip install aws-sam-cliでインストールsam --versionでバージョンが出力されればOKdockerは、ローカルマシンにlambdaの実行環境を作るために導入します。
AWS Toolkit for Visual Studio Codeの導入
これは、VSCodeからAWS SAM CLIを使えるようにするためのVSCodeの拡張機能です。
AWS Toolkit - Visual Studio Marketplaceプロジェクトを新規作成する
公式ドキュメントに従って行います。
- コマンドパレット(Ctrl + Shift + P)を開き、
Create new SAM Applicationを選択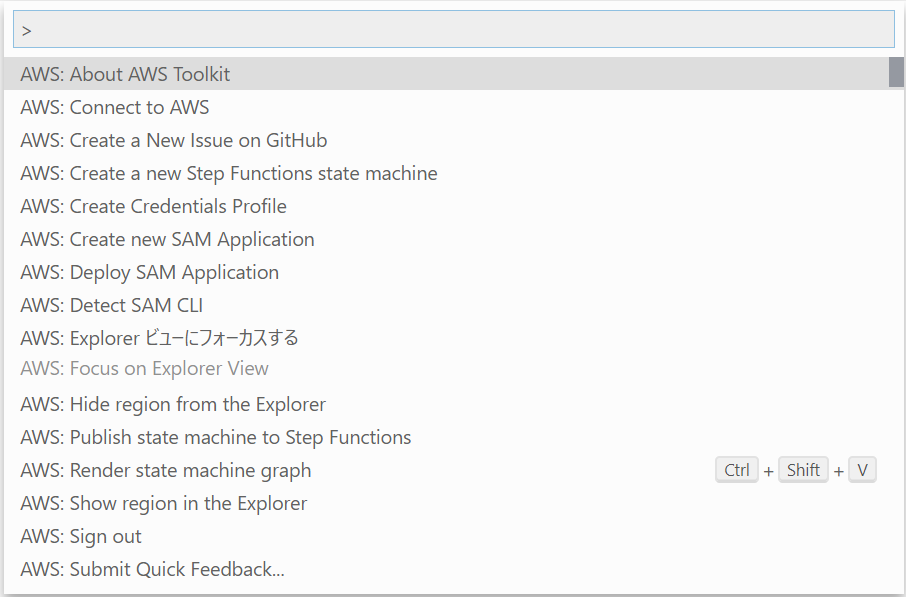
- 使用するランタイムを選びます。今回はPython3.8
- テンプレートを選択。今回は単体で使うのでHwllo World
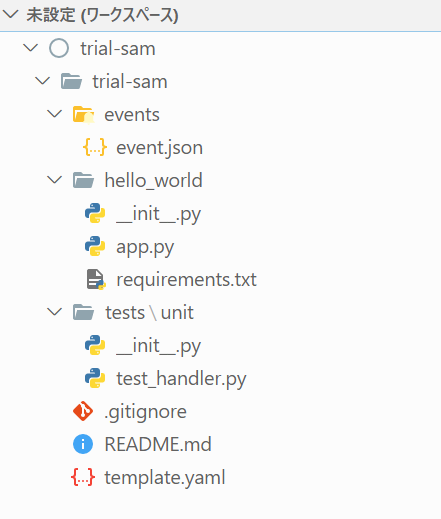
- プロジェクトを作成するディレクトリを指定します。エクスプローラーが開くので任意のフォルダを選択します。

- プロジェクト名を指定します。 Enterを押すと、プロジェクトが作成されます。

ローカルデバッグ実行する
hello_world/app.pyを開き、Debug Locallyを選択すると、dockerに仮想環境が作られ、関数が実行されます。
- デバッグコンソールに結果が出力されればOK
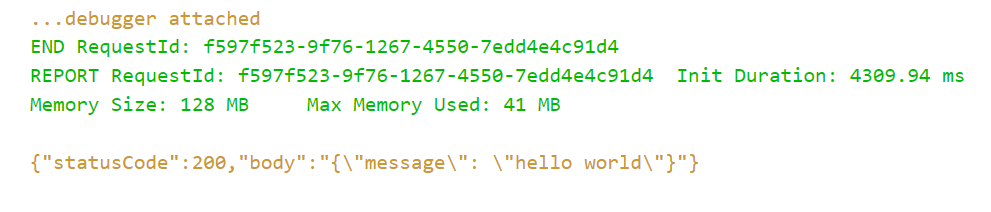
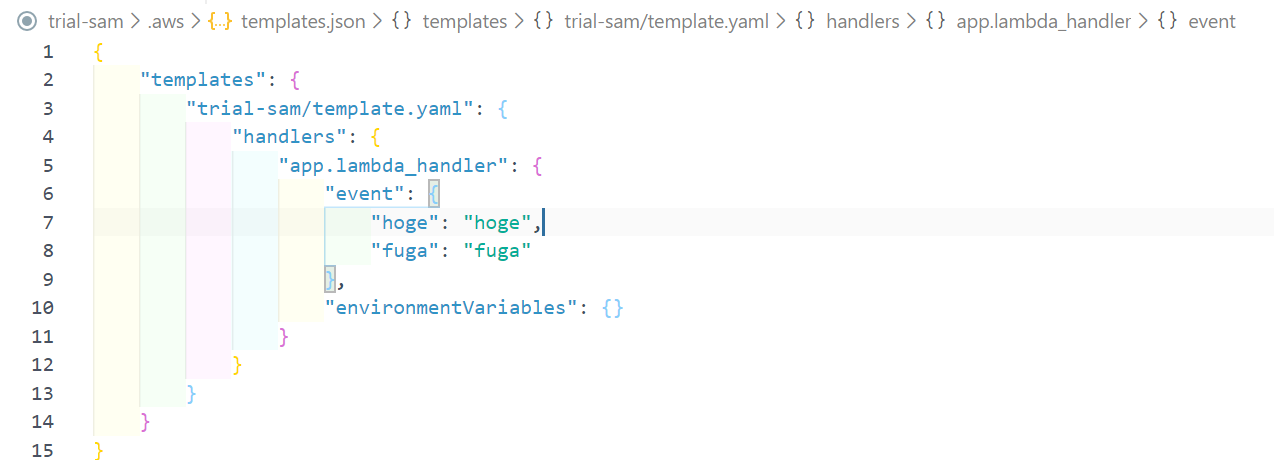
eventを設定する
.aws/templates.jsonで設定できる
デプロイする
templete.yamlをもとにデプロイしていきます。
1. コマンドパレットからDeploy SAM Applicationを選択
2. テンプレートを選択する。今回はtemplete.yaml
3. 任意のデプロイ先のリージョンを選択する。今回はTokyo
4. S3のバケット名を指定します。ここでは既存のバケット名を指定しなければなりません。
5. Stack名を指定します。
Stackとは、CloudFormationで作成されるサービス群の名前です。プロジェクト名と同名にしてます。
6. デプロイが成功するとデバッグコンソールが表示されます
デプロイされたことを確認する
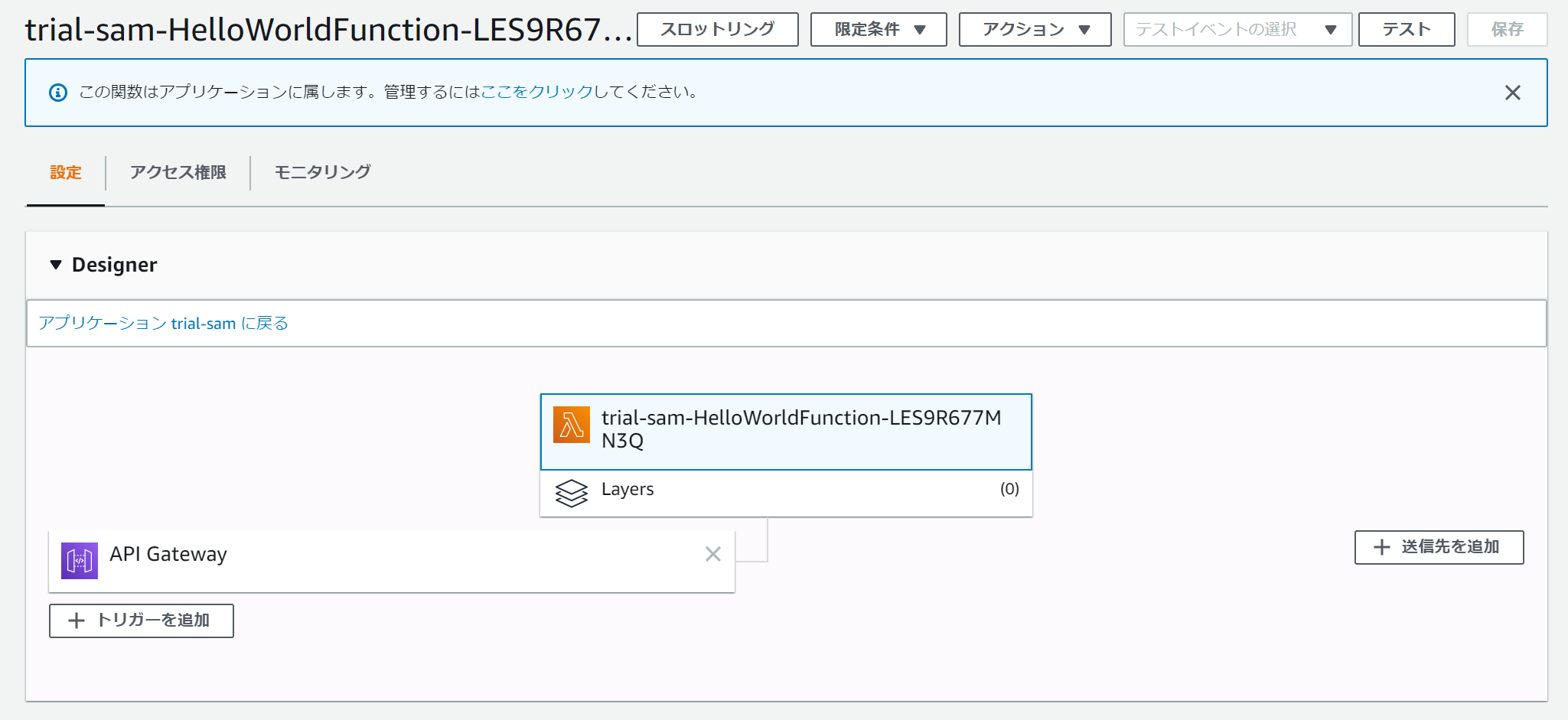
以下のように、lambdaが作られていることを確認できます。
API GatewayでもAPIが作られていることが確認できます。
カスタマイズする
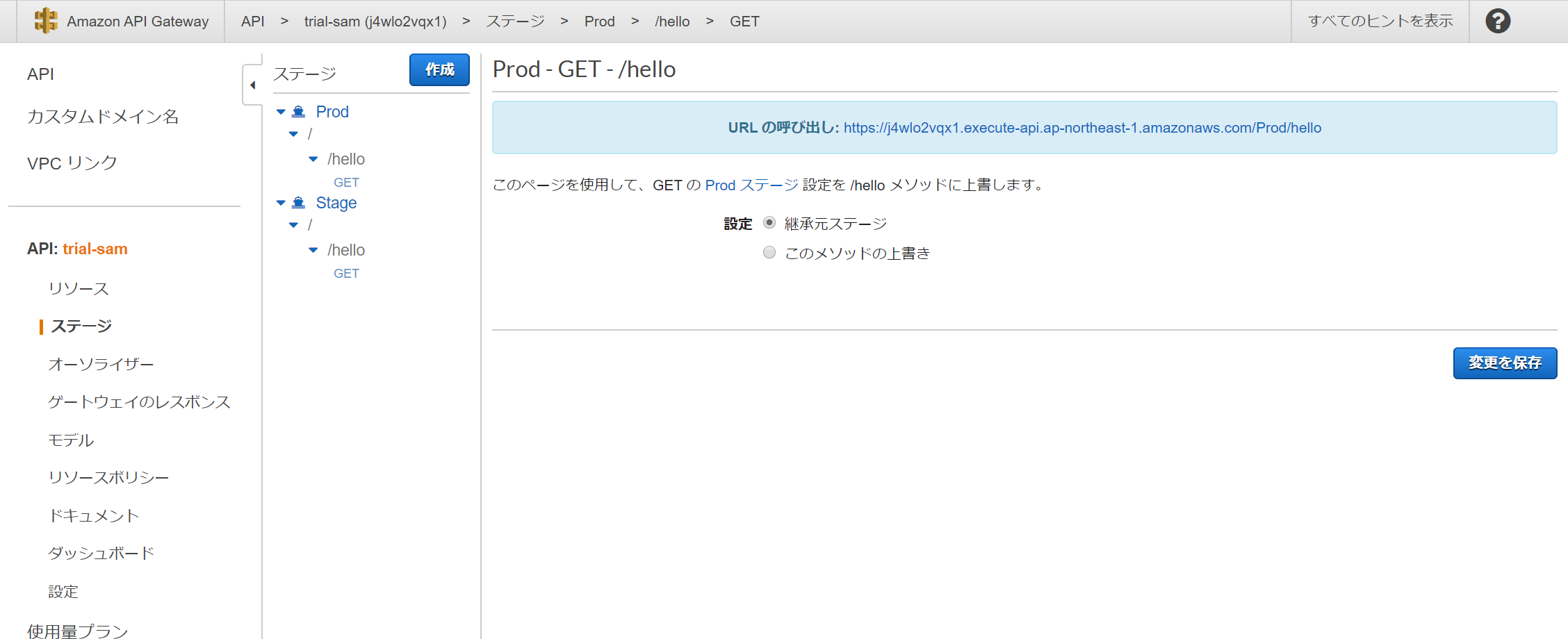
デフォルトで作られるAPIは
GET:/helloなので、これを変更するにはtemplete.yamlを編集する必要があります。下記はデフォルトの
templete.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > trial-sam Sample SAM Template for trial-sam # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: get Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.Arnこの中を以下の通りに書き換えればパスとHTTPメソッドを変えられる
Before
Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: getAfter
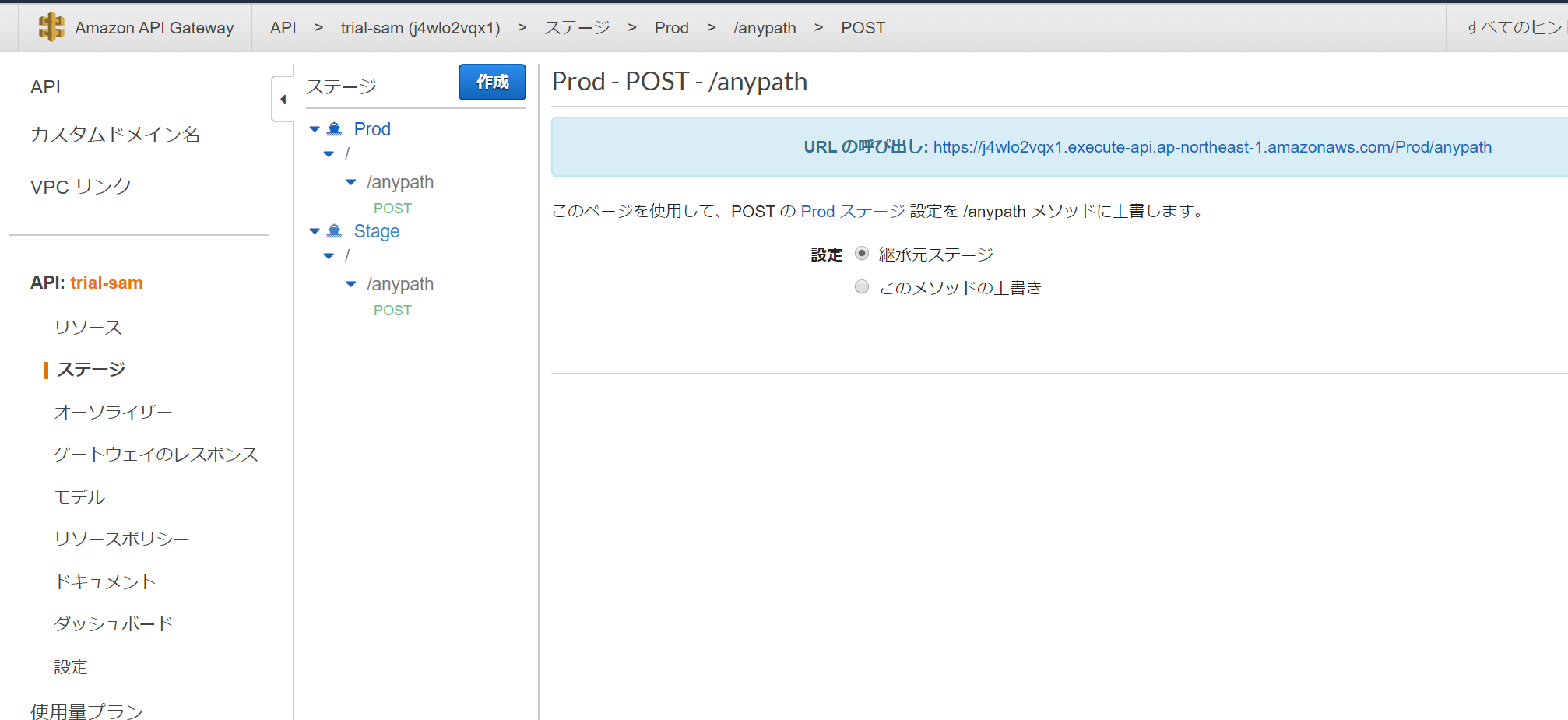
Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /anypath # hello → anypath Method: post # get → postPOST:
anypathに変更できました。
あとはロジックを書いていくだけ
あとは要件に合わせてロジックを組み立てていくだけです。
再度デプロイすれば、変更内容も反映されます。




- 投稿日:2020-04-04T14:52:22+09:00
AWS CLI のメモ
AWS CLI のメモ
EC2起動
aws ec2 start-instances --instance-ids {instance-id}EC2停止
aws ec2 stop-instances --instance-ids {instance-id}SGルール表示
aws ec2 describe-security-groups --group-name {security-group-name}
aws ec2 describe-security-groups --group-ids {security-group-id}SGルール追記
aws ec2 authorize-security-group-ingress --group-id {security-group-id} \
--ip-permissions '[{"FromPort": 80, "ToPort": 80, "IpProtocol": "tcp", "IpRanges": [{"CidrIp": "8.8.8.8/32", "Description": "abc"}]}]'
aws ec2 authorize-security-group-ingress --group-name {security-group-name} \
--ip-permissions '[{"FromPort": 80, "ToPort": 80, "IpProtocol": "tcp", "IpRanges": [{"CidrIp": "8.8.8.8/32", "Description": "abc"}]}]'
SGルールのDescription更新
aws ec2 update-security-group-rule-descriptions-ingress --group-id {security-group-id} --ip-permissions '[{"FromPort": 80, "ToPort": 80, "IpProtocol": "tcp", "IpRanges": [{"CidrIp": "1.2.3.4/32", "Description": "aaa"}]}]'SGルール削除
aws ec2 revoke-security-group-ingress --group-id {security-group-id} --ip-permissions '[{"FromPort": 80, "ToPort": 80, "IpProtocol": "tcp", "IpRanges": [{"CidrIp": "1.2.3.4/32", "Description": "aaa"}]}]'グローバルIP取得
curl https://checkip.amazonaws.com
- 投稿日:2020-04-04T12:03:48+09:00
AWS CodeCommitを利用してソースコードを管理する
はじめに
AWS CodeCommitは、AWS上でソースコード管理が出来るサービスです。
前提条件
- Python
- pip
- git-remote-codecommit
- Git
- AWS CLI v2
設定手順
基本以下の手順通りですが、IAMのユーザ作成はアクセス権の付与が分かり辛かったです。
最初以下の注記から、AWSKeyManagementServicePowerUserのアクセス権も付与していましたが、検証したところ必要なかったです。
注記
CodeCommit には AWS Key Management Service が必要です。既存の IAM ユーザーを使用している場合は、CodeCommit で必要な AWS KMS アクションを明示的に拒否するユーザーにポリシーがアタッチされていないことを確認します。詳細については、「AWS KMS および暗号化」を参照してください。おおまかな流れは以下の通りです。
項番 手順 インストール 1 CodeCommit用のIAMユーザの作成 IAMコンソール 2 AWS CLIをインストール Windows版 3 git-remote-codecommitをインストール pip install git-remote-codecommit IAMユーザの追加
AWS CodeCommit用のユーザを追加する
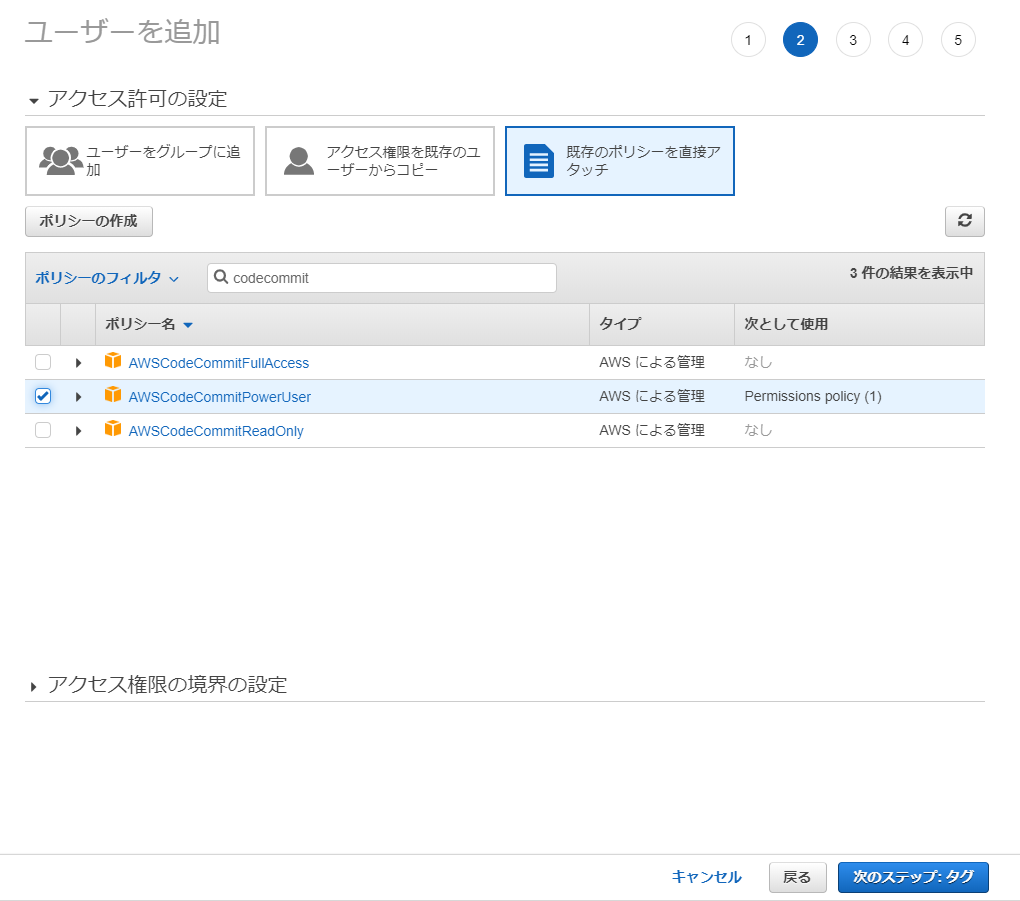
AWS CodeCommit用ユーザにアクセス権を付与する
タグの追加(オプション)
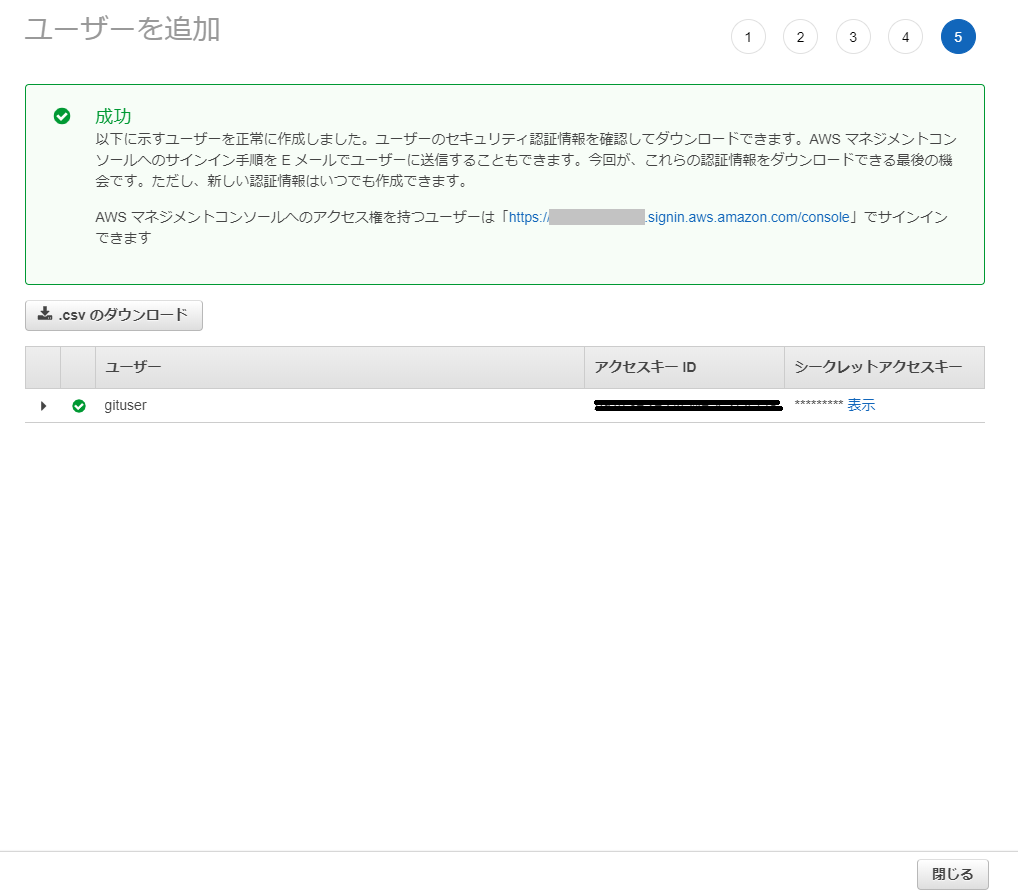
ユーザを追加 -成功-
AWS CLIを設定する
東京リージョンの入力例C:\AWS> aws configure AWS Access Key ID [None]:IAMユーザ作成時に生成されたAccess Key ID AWS Secret Access Key [None]:IAMユーザ作成時に生成されたSecret Access Key Default region name [None]:ap-northeast-1 Default output format [None]:jsongit-remote-codecommitをインストールする
C:\AWS> pip install git-remote-codecommitおわりに
- AWS上でソースコード管理が出来るようにはなれた。
- 次は、デプロイの仕方かな。
- 投稿日:2020-04-04T11:29:23+09:00
AWSアカウントを登録したらやること
AWSアカウントを登録したらやること
問1: A君がAWSのアカウントを作りました。このあとA君は何をやったでしょう?
男: ん〜...この問題は難しいなぁ...
男: 問1だけでかれこれ7時間も考えてるけど分からへん...
男: どっかに答え書いてへんかな...
男: あっ、A君が何をやったかっていう問題やからA君に直接訊けばいいんか!
男: なあなあA君、
A君: 僕は以下のことを行いました。
- CloudWatchで料金アラート設定
- IAM(Identity and Access Management)で作業用ユーザーを作成
- CloudTrailで操作ログを記録
男: まだ訊いてへんのに答えてくれてる...
CloudWatchで料金アラート設定

A君: まず料金が気になるので料金アラートを設定しましょう。使うのはCloudWatchです。
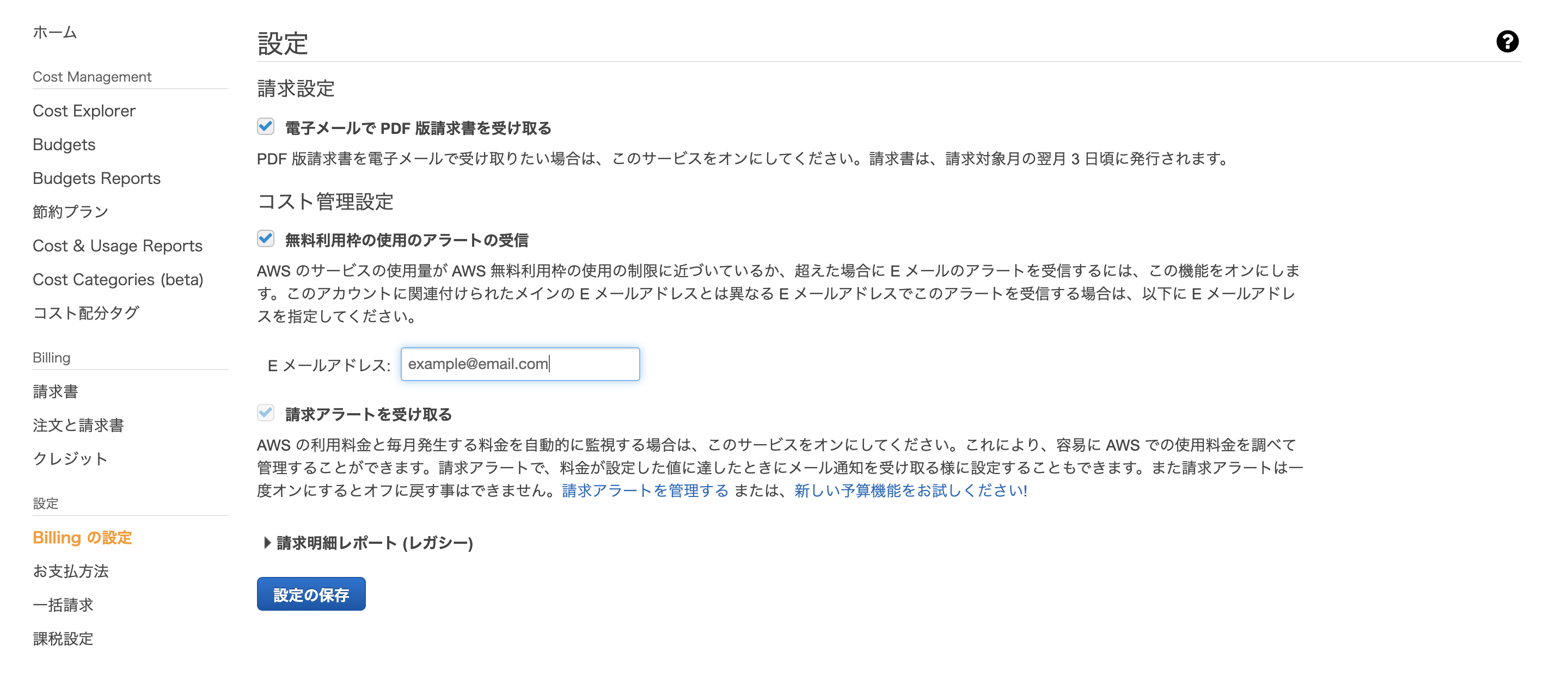
「マイ請求ダッシュボード」 > 「Billingの設定」
- 「電子メールで PDF 版請求書を受け取る」にチェック
- 「無料利用枠の使用のアラートの受信」にチェック
- Eメールアドレスを入力
- 請求アラートを受け取るにチェック
- 「設定の保存」をクリック
A君: これでBillingの設定は完了です。
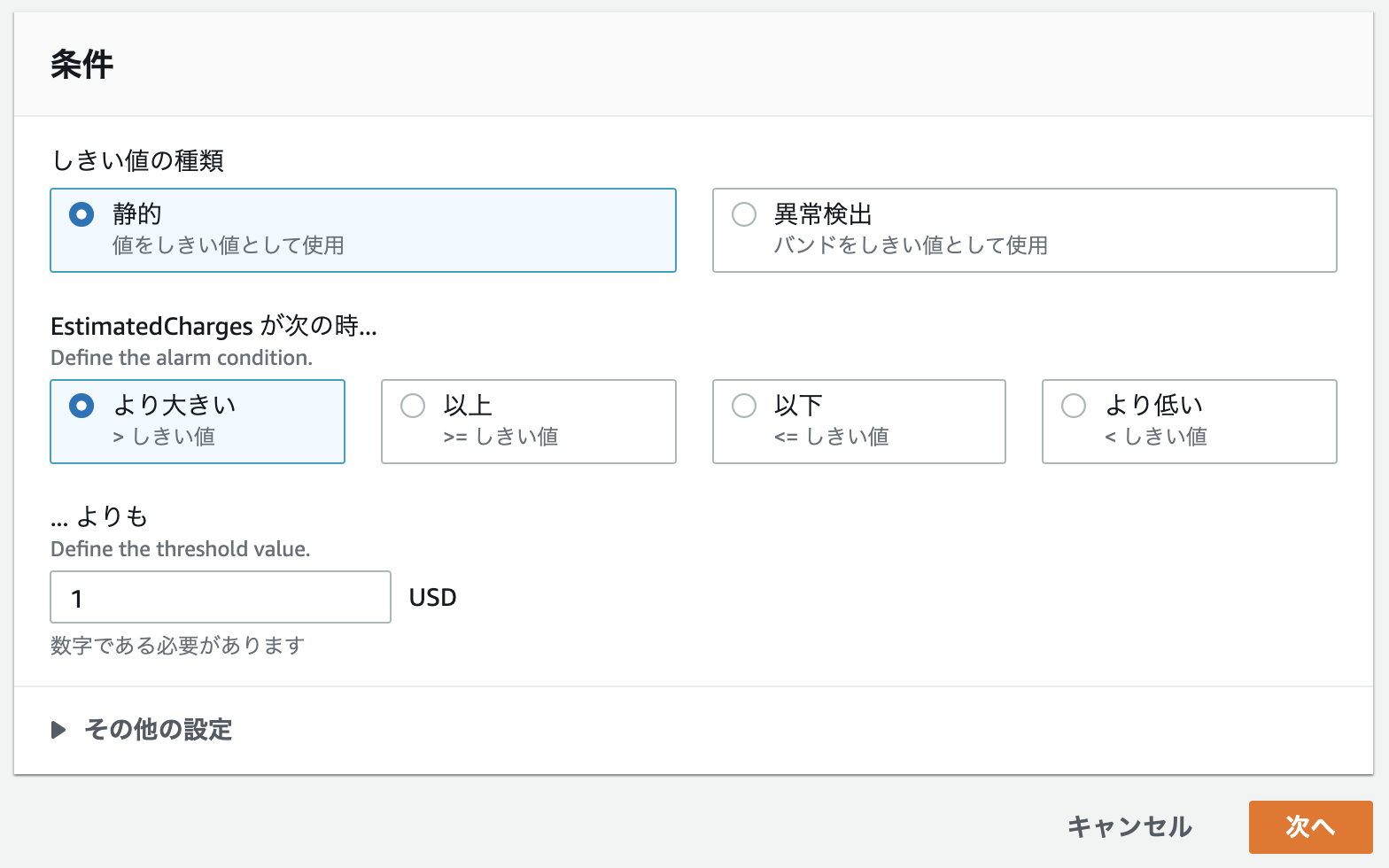
A君: 次はCloudWatchの設定です。
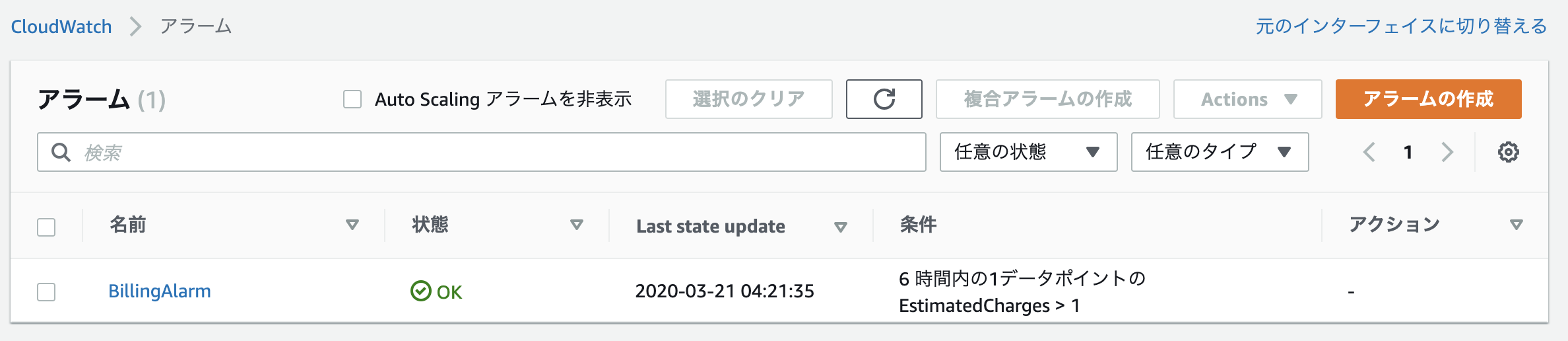
「請求アラートを管理する」> 「請求」> 「アラームの作成」
- 超過の設定
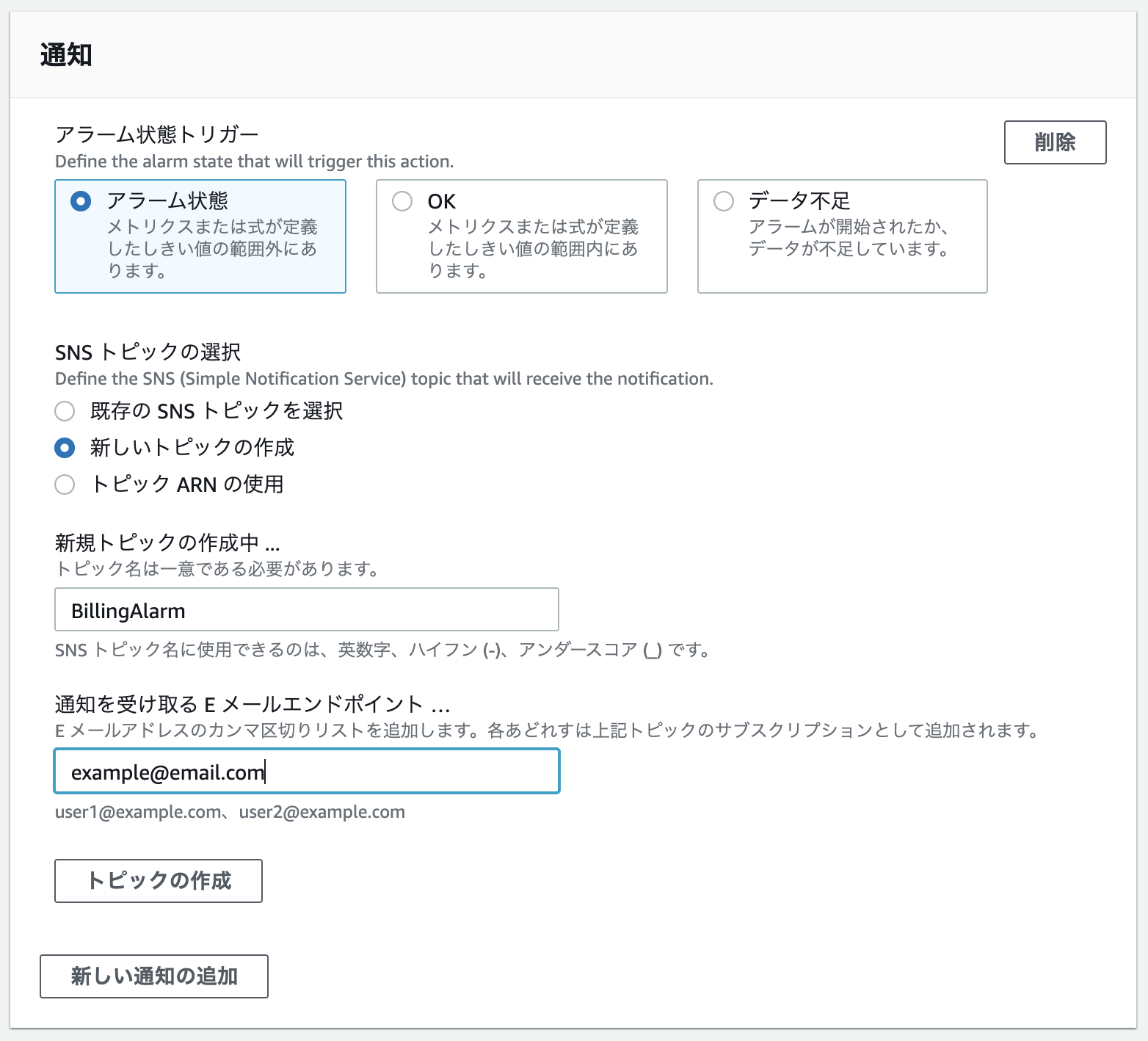
- 通知の送信先入力
- トピックの作成をクリック
- メールで認証用リンクをクリック
- ブラウザでconfirmedが表示されたら更新をクリックする
- アラームが作成されていることを確認する
IAMで作業用ユーザーを作成

A君: まずルートユーザーで以下の作業をします。
- 「マイアカウント」 > 「IAM ユーザー/ロールによる請求情報へのアクセス」
編集をクリックする
「IAMアクセスのアクティブ化」にチェック入れ更新する
A君: これでルートユーザーだけでなく作業用ユーザーからでも請求情報にアクセスできるようになりました。
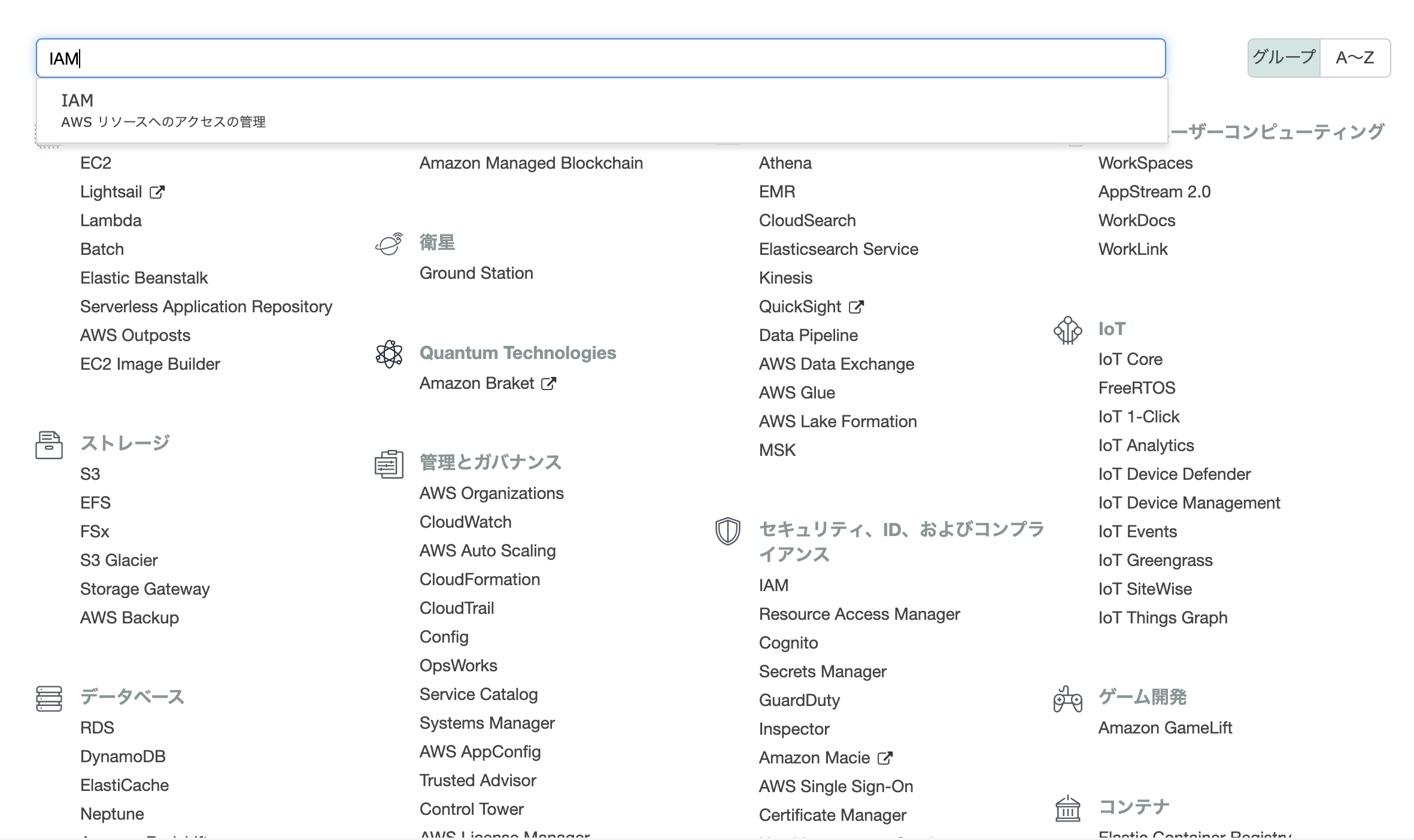
A君: 次にIAMのユーザーを追加します。IAMユーザーの追加
「サービス」 > 「IAM」 > 「ユーザー」
「ユーザーを追加」をクリックする
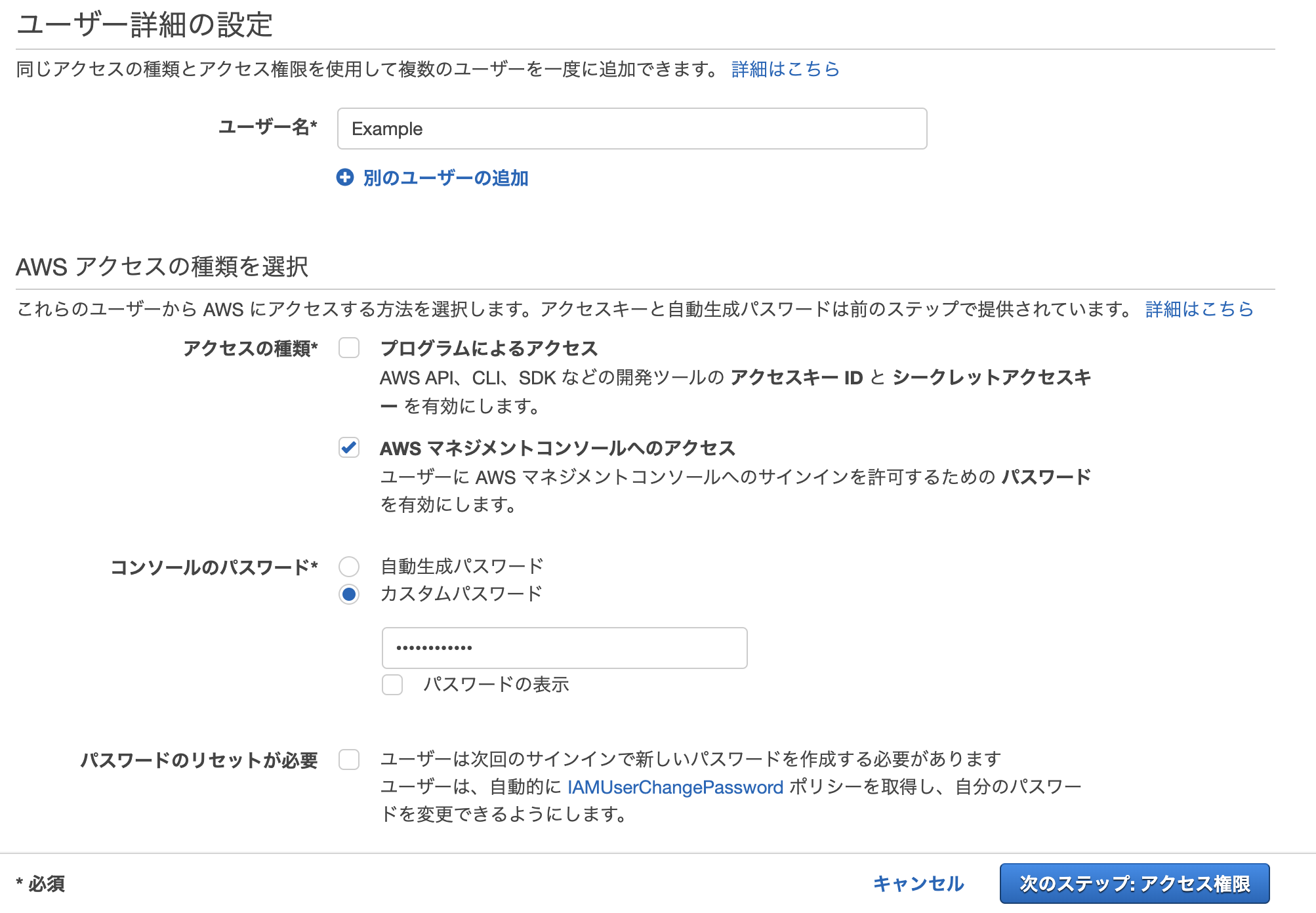
ユーザー詳細の設定
- 「AWSアクセスの種類を選択」で「AWS マネジメントコンソールへのアクセス」を選択する
- ユーザー名を入力する
- コンソールのパスワードをカスタムパスワードにし、入力する
- パスワードのリセットが必要のチェックを外す。自分用の作業ユーザーなのでリセットしなくて良い
- 「次のステップ: アクセス権限」をクリック
アクセス許可の設定
- 「既存のポリシーを直接アタッチ」を選択し、AdministratorAccessを選び、「次のステップ: タグ」をクリックする
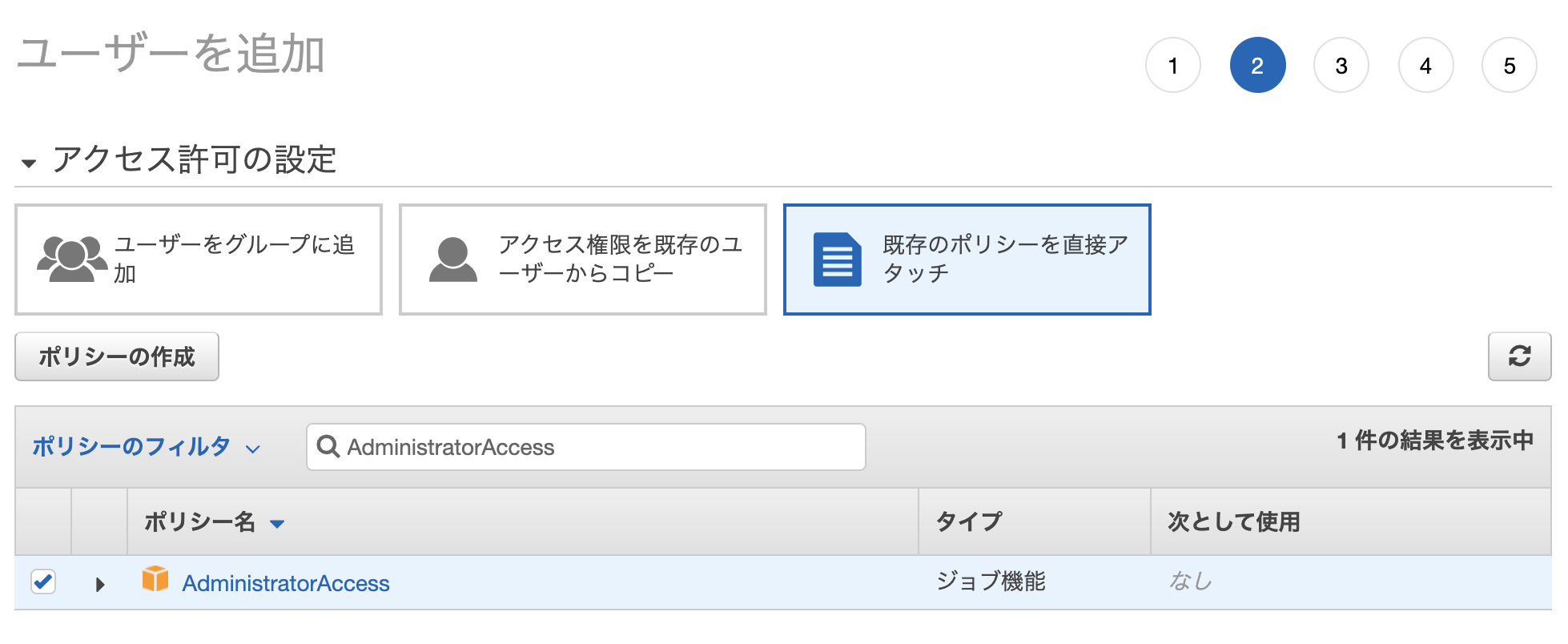
- タグは特に必要ないので、そのまま「次のステップ: 確認」をクリックする
- 内容を確認し、「ユーザーの作成」をクリックする
- ログイン用のURL, ユーザー名, パスワードを控えておく
A君: 以降はIAMユーザーでログインし、作業を進めます。
CloudTrailで操作ログを記録

A君: 次はCloudTrailで操作ログを記録する設定をします。
CloudTrail event history provides a viewable, searchable, and downloadable record of the past 90 days of CloudTrail events. (CloudTrail Concepts より)
A君: CloudTrailはデフォルトで90日間の記録を保存するようになっています。
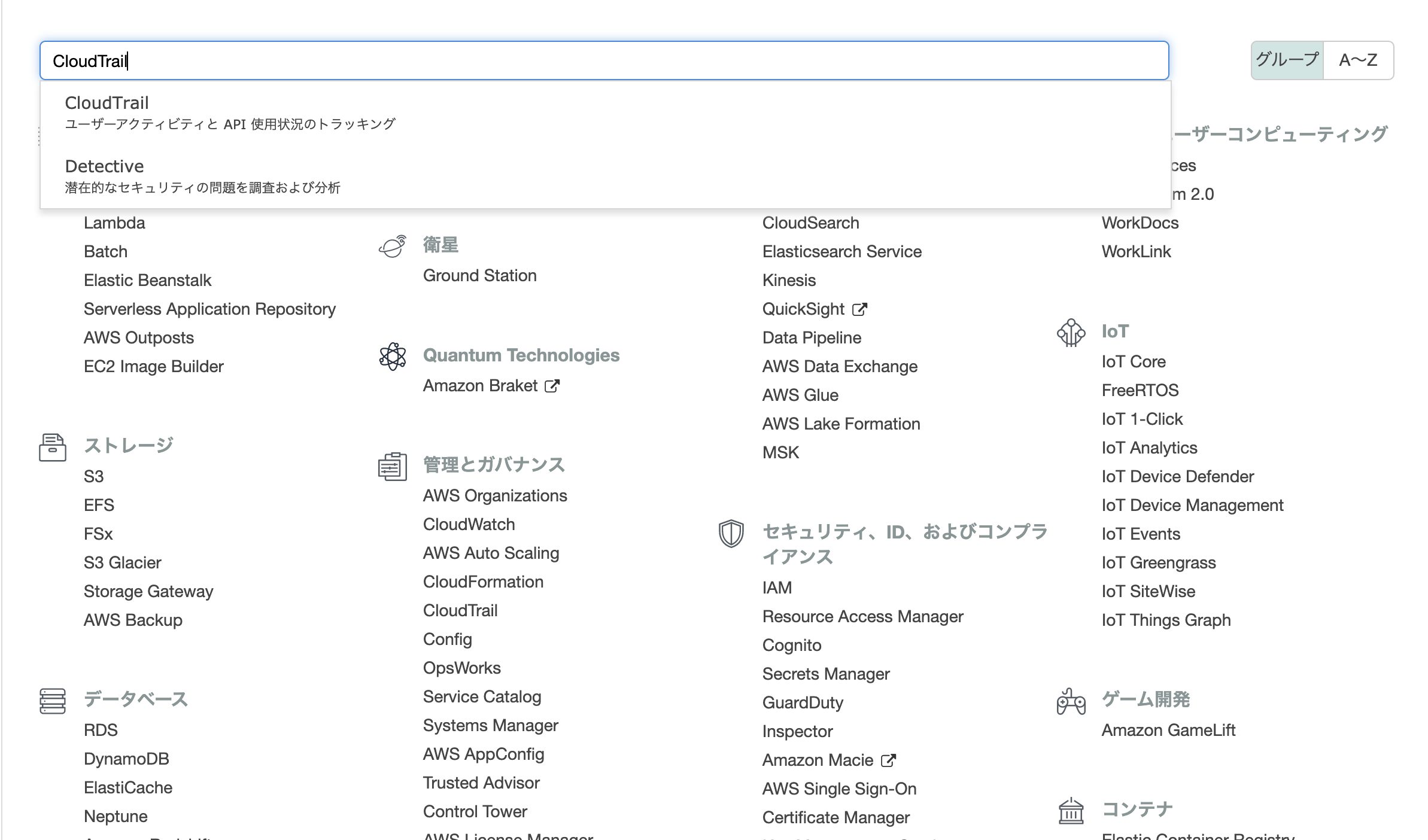
A君: ここではS3にログを保存するように設定することで、永久的にログを保存するようにします。「サービス」 > 「CloudTrail」
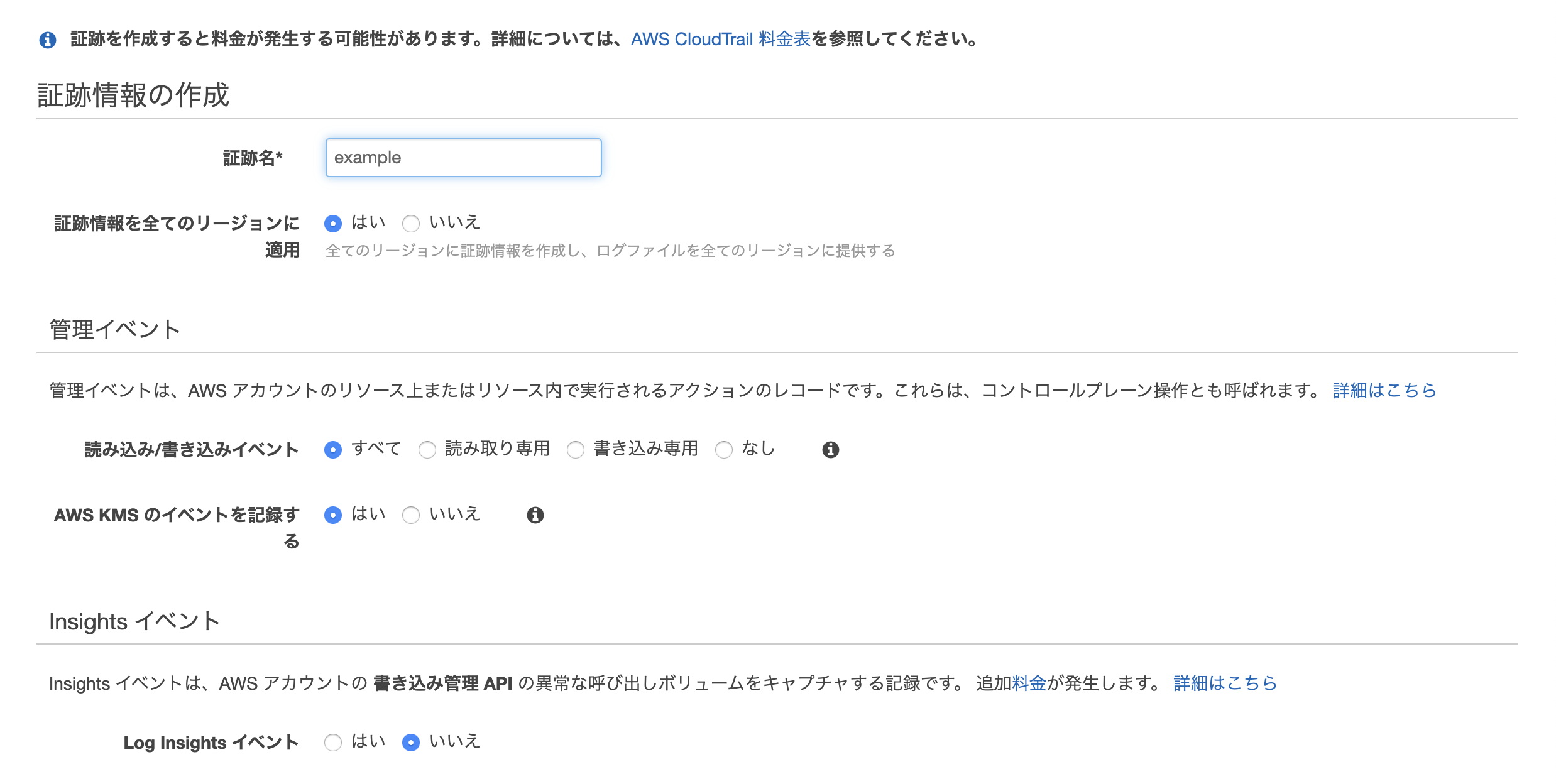
証跡の作成
- 証跡名をつける
- 証跡情報を全てのリージョンに適用を「はい」にする
- 管理イベントはすべてにチェック
- データイベントアカウントのすべてのS3バケットの選択にチェックを入れる
- ストレージの場所新しいS3バケットを作成しますかに「はい」を選択する
- S3バケットを設定する
- 作成する
A君: これでイベント時間、ユーザー名、イベント名のログが時系列でS3に保存されます。
A君: 以上で準備完了です。
男: ありがとう!
A君: いえいえ、仕事なので
A君: じゃあ次があるんで僕はこれで!
男: 嗚呼そうか、ご苦労様
男: A君って何者なんやろ?
参照


- 投稿日:2020-04-04T10:26:34+09:00
AWS入門する前に知って良かったこと
はじめに
新型肺炎コロナウィルスが猛威を振るっております。
今後の事を考えると、クラウド技術に触れておくことも必要かと思いAWSに入門しました。不要不急の外出を控え、ただただ新型肺炎コロナウィルスの収束を願うばかりです。
AWSをはじめる前に読むと良い記事
過去にAWSでやらかしてしまった人の記事を読んで「AWS怖っ!」って、なっていたのですが、
以下の記事を読んで、勇気を貰い一歩踏み出せました。AWS初心者にとって、大変ありがたい記事を共有して頂き、感謝しかありません。
AWS無料枠
無料枠で何が出来るのかと、各サービスの制約事項は確認しましょう。
AWSチュートリアル
お手軽にAWSを楽しむには、10分間チュートリアルがお勧めです。
AWSオンラインセミナー
AWSオンラインセミナーに参加して、脱初心者を目指しましょう。
AWSに慣れたら読みたい記事
おわりに
- AWS無料枠だけでも十分に楽しめています。
- 地元のJAWS-UGは廃れていて悲しい。
- 投稿日:2020-04-04T05:56:09+09:00
Amazon Cognito Identity Providerのエラーレスポンス
Amazon Cognito Identity Providerでは異なるエラー内容でも同じエラーコードが発行されるものがある。
エラー内容ごとにエラーハンドリングを行う必要がある場合は、エラーメッセージを確認することで区別が可能である。
ここでは一部の実際に確認したものを掲載する。AliasExistsException
{'Message': 'Already found an entry for the provided username.', 'Code': 'AliasExistsException'}CodeMismatchException
{'Message': 'Invalid session provided', 'Code': 'CodeMismatchException'}ExpiredCodeException
{'Message': 'Invalid code provided, please request a code again.', 'Code': 'ExpiredCodeException'}GroupExistsException
{'Message': 'A group with the name already exists.', 'Code': 'GroupExistsException'}InvalidParameterException
{'Message': 'Attributes did not conform to the schema: {attributes}: Attribute does not exist in the schema.\n', 'Code': 'InvalidParameterException'}{'Message': 'Invalid email address format.', 'Code': 'InvalidParameterException'}{'Message': "1 validation error detected: Value 'string' at 'userPoolId' failed to satisfy constraint: Member must satisfy regular expression pattern: [\\w-]+_[0-9a-zA-Z]+", 'Code': 'InvalidParameterException'}InvalidPasswordException
{'Message': 'Password did not conform with password policy: Password not long enough', 'Code': 'InvalidPasswordException'}{'Message': 'Password did not conform with password policy: Password must have uppercase characters', 'Code': 'InvalidPasswordException'}{'Message': 'Password did not conform with password policy: Password must have numeric characters', 'Code': 'InvalidPasswordException'}{'Message': 'Password did not conform with password policy: Password must have lowercase characters', 'Code': 'InvalidPasswordException'}NotAuthorizedException
{'Message': 'Incorrect username or password.', 'Code': 'NotAuthorizedException'}{'Message': 'Invalid Access Token', 'Code': 'NotAuthorizedException'}{'Message': 'Invalid Refresh Token', 'Code': 'NotAuthorizedException'}ResourceNotFoundException
{'Message': 'Group not found.', 'Code': 'ResourceNotFoundException'}UsernameExistsException
{'Message': 'User account already exists', 'Code': 'UsernameExistsException'}{'Message': 'An account with the email already exists.', 'Code': 'UsernameExistsException'}UserNotFoundException
{'Message': 'User does not exist.', 'Code': 'UserNotFoundException'}
- 投稿日:2020-04-04T00:58:14+09:00
AWS S3上のデータを SQS と組み合わせて Splunkに取り込む
(追記) SNSは特に不要でしたので記事を修正しました。
はじめに
先日、AWS S3上のデータを Splunkに取り込む記事を書きましたが、シンプルな設定のためスモール環境には適しておりますが、Bucket内のデータ量が増えてくると処理が追いつかずにリアルタイムな分析が出来なかったり、取り込めないなどのデータ欠損の可能性が出てきます。また耐障害性という観点でも弱い構成です。
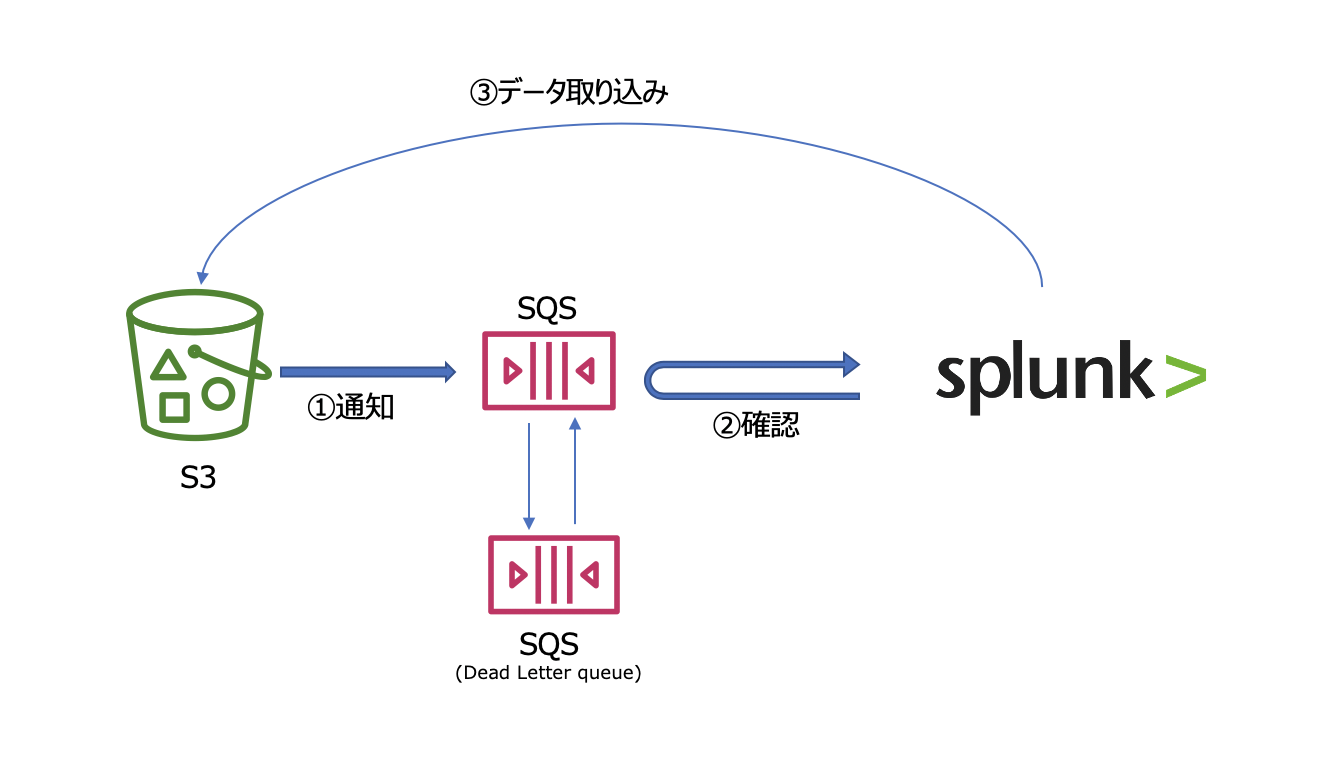
そこでSplunkが推奨しているSQSと組み合わせた方法で、スケール問題とデータ信頼性問題を解決していきたいと思います。
このような構成にしておくことで、データの配信に関してはSQSが受信確認まで行ってくれますし、Splunk側のInputを増やす事で取り込み速度もスケールさせることができます。つまり信頼性と性能をカバーすることができます。
AWS SQS サービスについては、こちらの解説が詳しくて参考にさせていただきました。
https://www.slideshare.net/AmazonWebServicesJapan/aws-31275003SQS based S3 構成時の注意点
以下のマニュアルをまずはご覧ください。
https://docs.splunk.com/Documentation/AddOns/released/AWS/SQS-basedS3特に注意する点は、新規に追加されたデータのみ対象となるという点です。つまりすでにS3上にあるデータは対象外となってしまいます。過去のデータを取り込むためには前回説明したGeneric S3 取り込みを最初に行ったうで、今回のSQS baseの取り込みを設定する必要があります。
またS3上に保存されているデータの種類毎にSQSを作成する必要があります。これはソースタイプが異なるためInput設定を別に作る必要があるためです。データの種類毎にSQSとSplunk Inputがセットで必要と覚えておいてください。
設定の流れ
AWS側の設定
1. IAMユーザーへのポリシー設定
2. SQS作成 (通常のものと、Dead Queueの2つ) & アクセスポリシーの変更
3. S3にてSQSへの通知設定Splunk側の設定
4. Input設定(*) 今回は Add-On for AWS App のインストールや、IAMユーザーの登録は省略します。詳しくは前回の記事を参照ください。
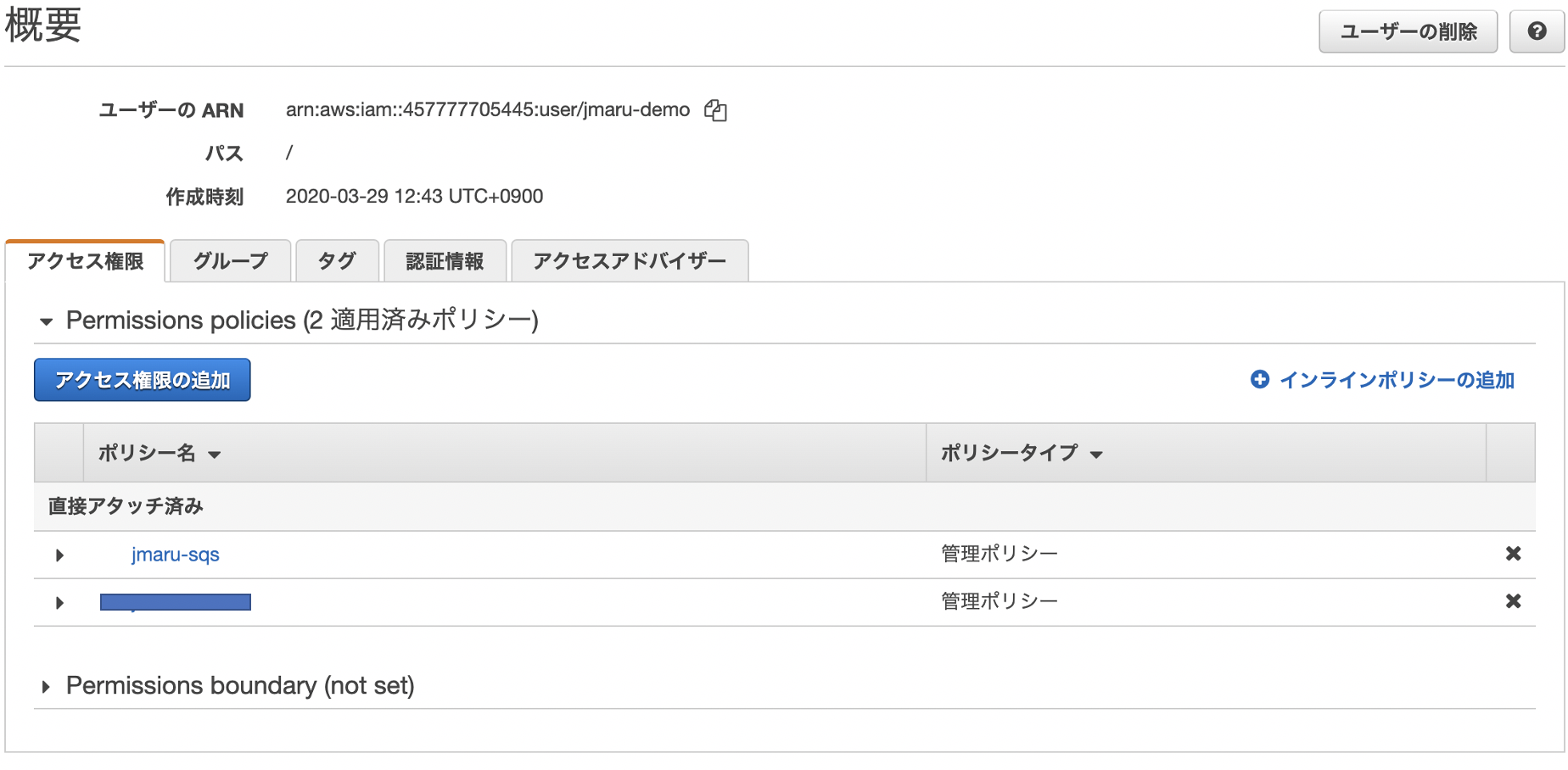
1.IAMユーザーへのポリシー付与
IAMユーザーに対して、新規にポリシーを作成して付与します。適用するポリシーはこちらになります。
コピペして利用できます{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sqs:GetQueueUrl", "sqs:ReceiveMessage", "sqs:DeleteMessage", "sqs:GetQueueAttributes", "sqs:ListQueues", "s3:GetObject", "kms:Decrypt" ], "Resource": "*" } ] }ユーザーに作成したポリシーを付与
2. SQS作成 (通常のものと、Dead Queueの2つ)&アクセスポリシーの変更
次にSQSを作成します。作成するのは2つになります。
1. メインキュー ( Splunkと連携するキュー)
2. Dead letter queue : 正常に処理できないメッセージの送信先として設定するキュー
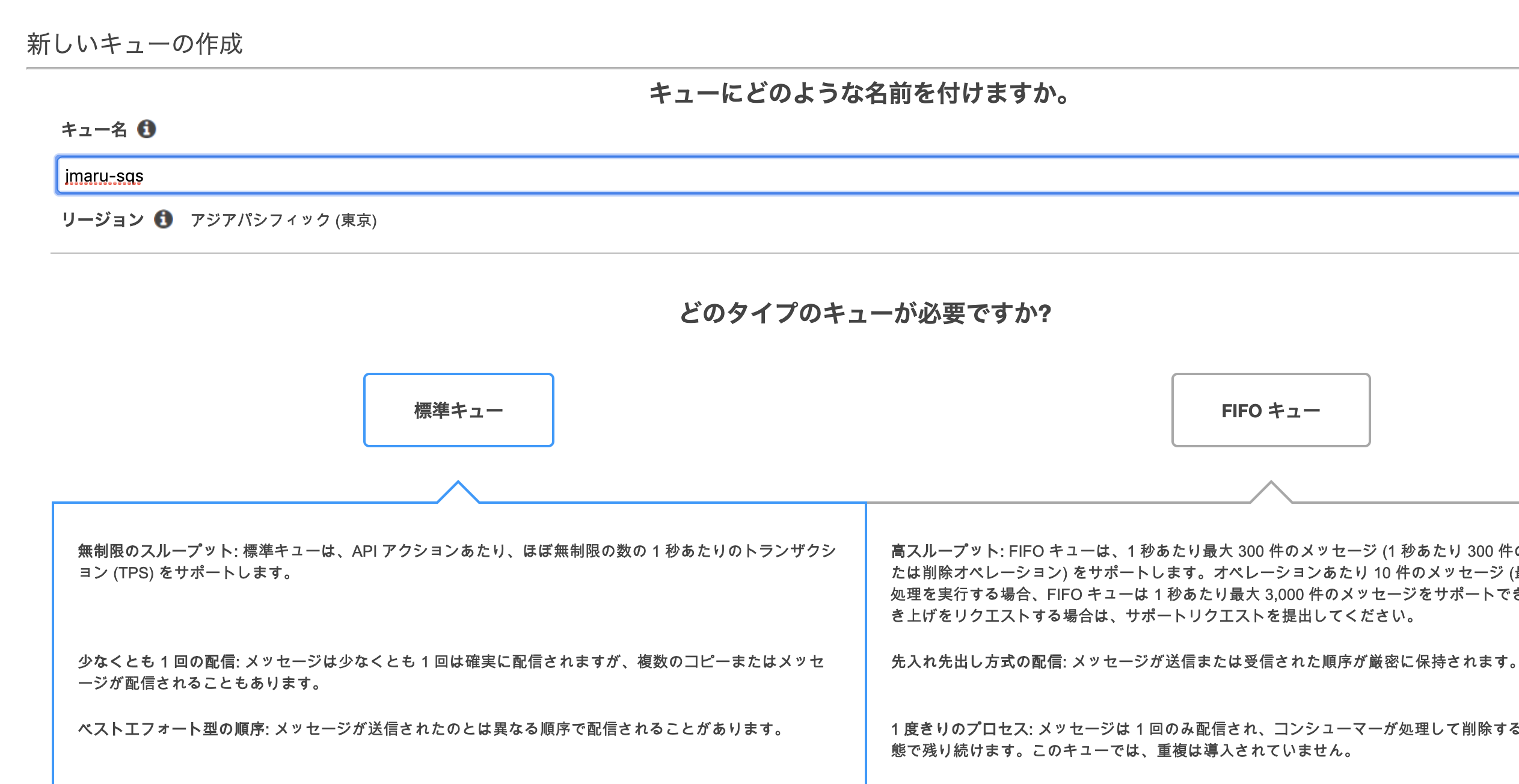
メインキューの作成 (jmaru-sqs)
Dead letter queue の作成
同様に新規のキューを作成します。
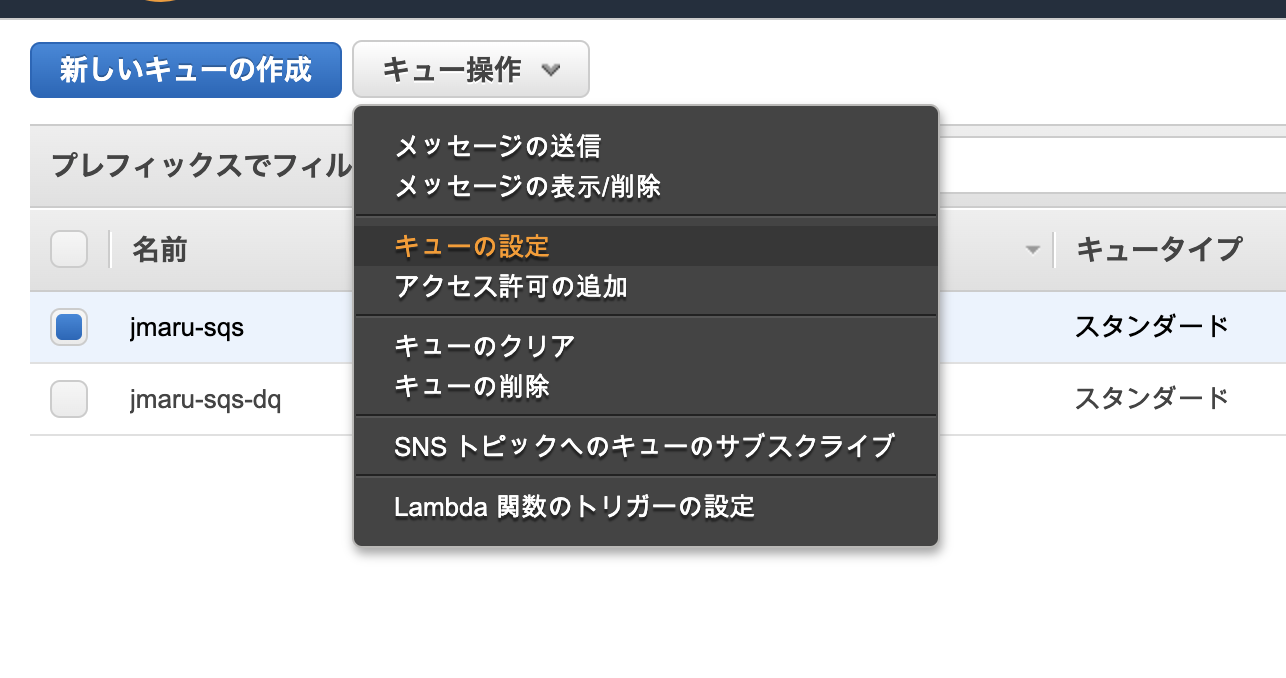
メインキューに対して、dead letterキューを設定します。メインキューにチェックをいれて、「キューの設定」を選択します。
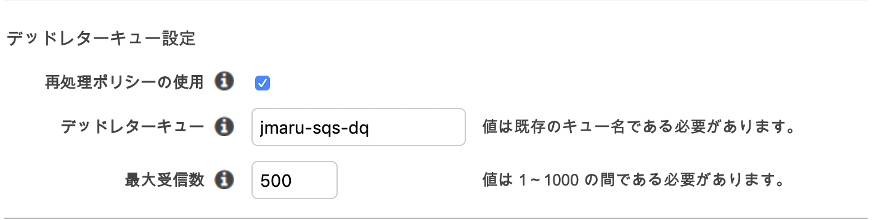
先ほど作成した dead letter キューを入力します。
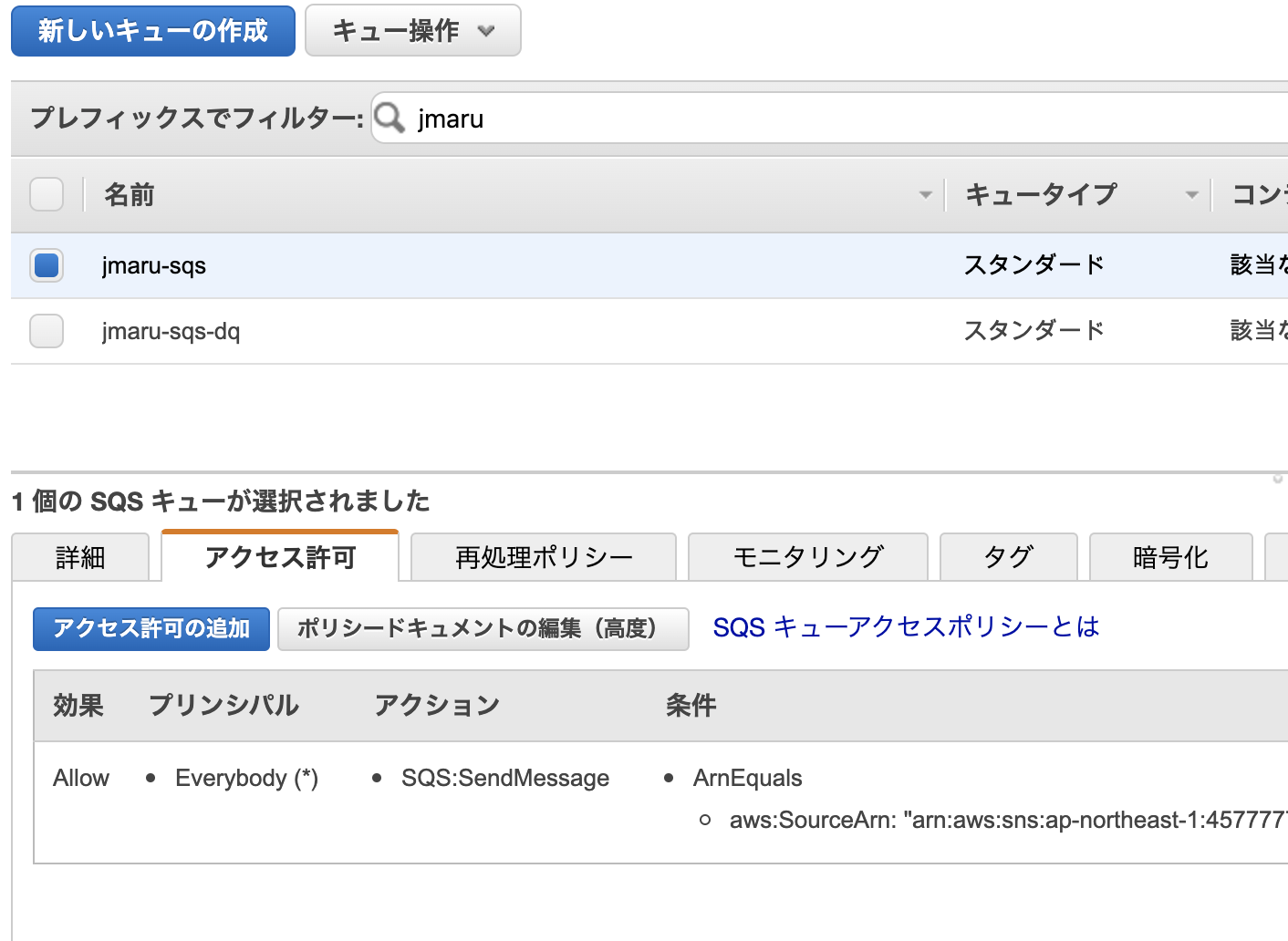
次にアクセスポリシーを修正します。これはS3からSQSに対してイベント通知ができるように許可を与えるものです。
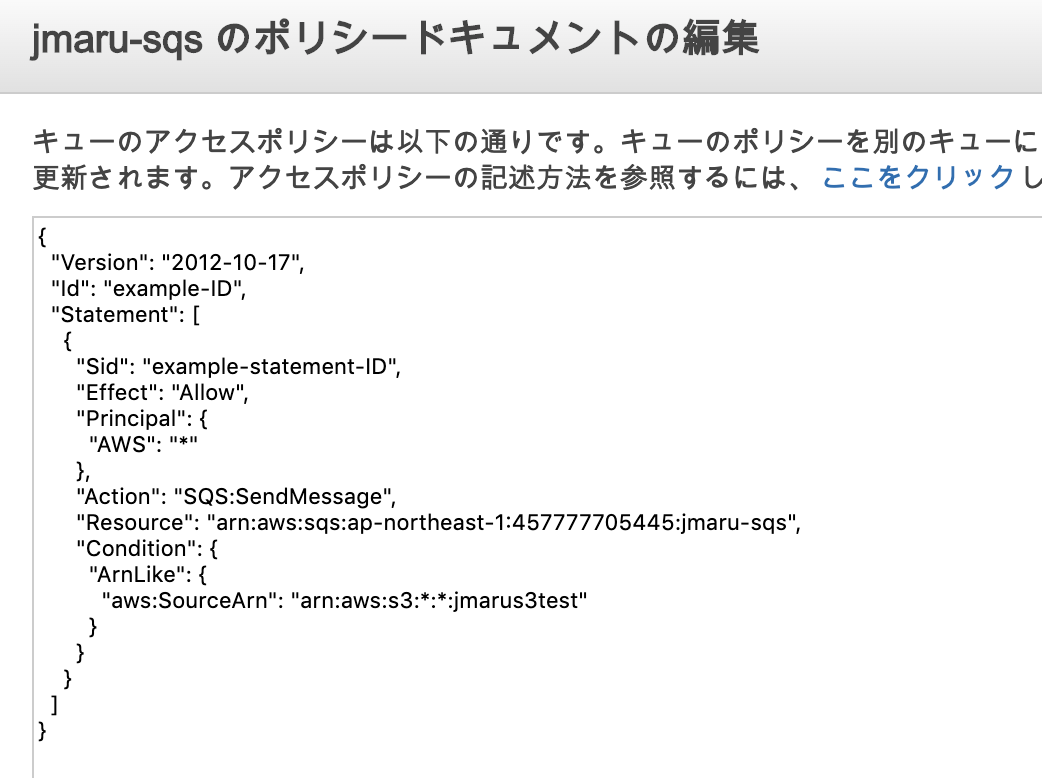
メインキューを選択して、「アクセス許可」 - 「ポリシードキュメントの編集(高度)」をクリック
下の内容をコピペして上書きします。
こちらをコピペして上書き{ "Version": "2012-10-17", "Id": "example-ID", "Statement": [ { "Sid": "example-statement-ID", "Effect": "Allow", "Principal": { "AWS":"*" }, "Action": [ "SQS:SendMessage" ], "Resource": "SQS-queue-ARN", "Condition": { "ArnLike": { "aws:SourceArn": "arn:aws:s3:*:*:bucket-name" } } } ] }"bucket-name" を対象のS3 Bucket名に変更します。
3. S3のイベント通知設定(SQSへの通知)
最後にS3側に新規書き込みがあった際のイベント通知設定を行います。ここではSQSを登録します。
S3サービス画面から、対象となるS3 Bucketを選択し、以下のように「プロパティ」タブを開き、下の方にある「イベント」を開きます。
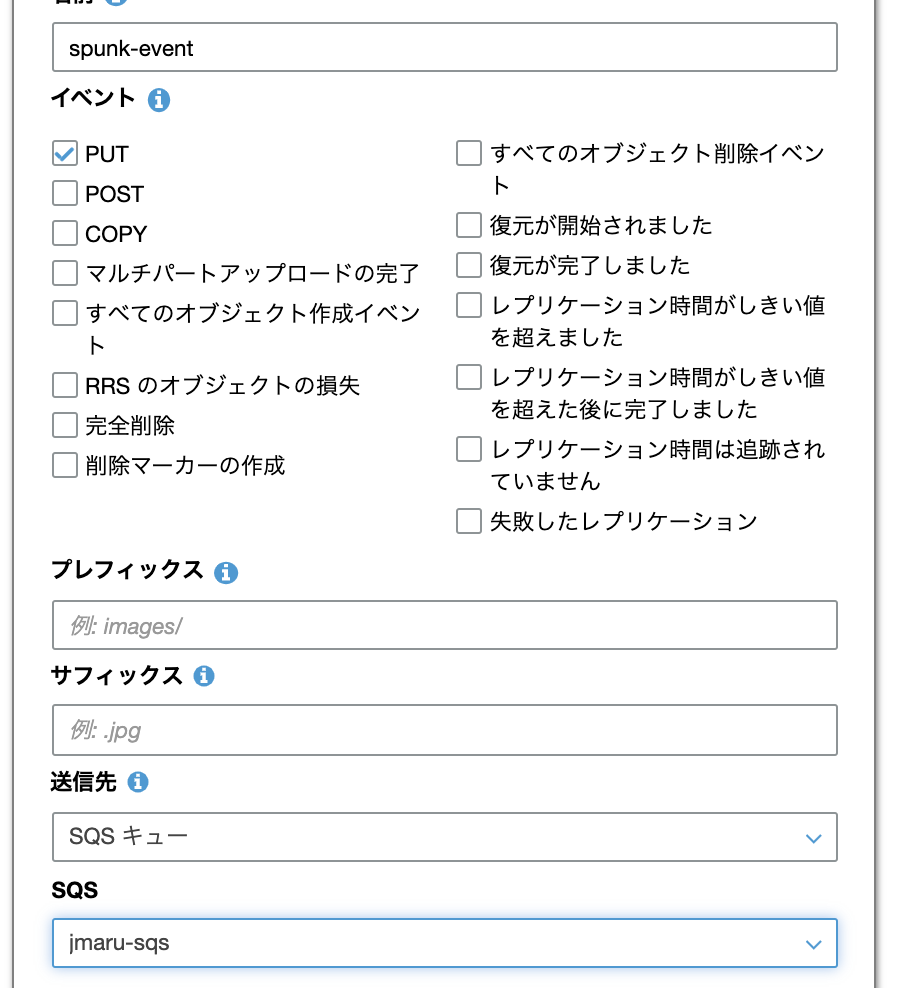
PUTイベントにチェックを入れて、送信先をSQSトピックにします。
保存して終了です。AWS側の設定はすべて完了しました。これで今回設定したS3上にデータが追加されると、SQSに通知が飛んでキューに保存されます。あとはSplunk側から通知を取りにくるのを待つだけです。
Splunk側の設定
4. Input設定
すでに、Splunk側のAppの追加やIAMユーザの登録が完了した状態で設定を進めます。
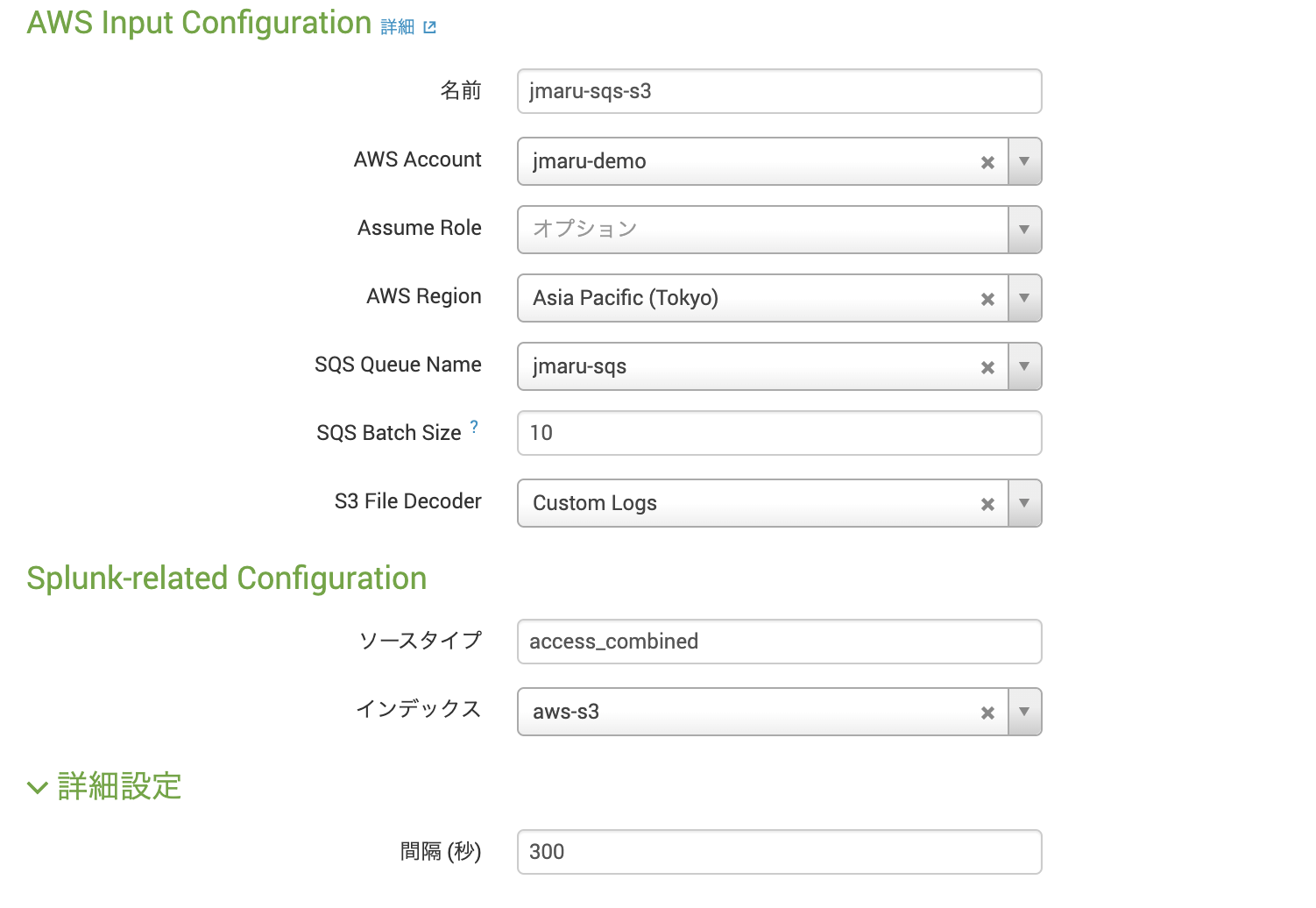
まだ完了していないかたは、こちらの記事をご確認ください。「Splunk Add-On for AWS」App ー「Inputs」 に移動して「Custom Data Type」から、[SQS-Based S3]をクリック
必要項目を入力します。ソースタイプなどは保管されるデータタイプに合わせて変更してください。インデックスも保存したいIndexを指定してください。
Intervalの300秒は、SplunkからSQSに対してメッセージが届いていないか確認しにいく時間間隔です。つまりこの方法は、PULL型であり完全なリアルタイム処理ではありません。この時間はキューの大きさやデータサイズ、取り込みスピードなどを考慮して設定してください。
以上で設定は完了です。
取り込み確認
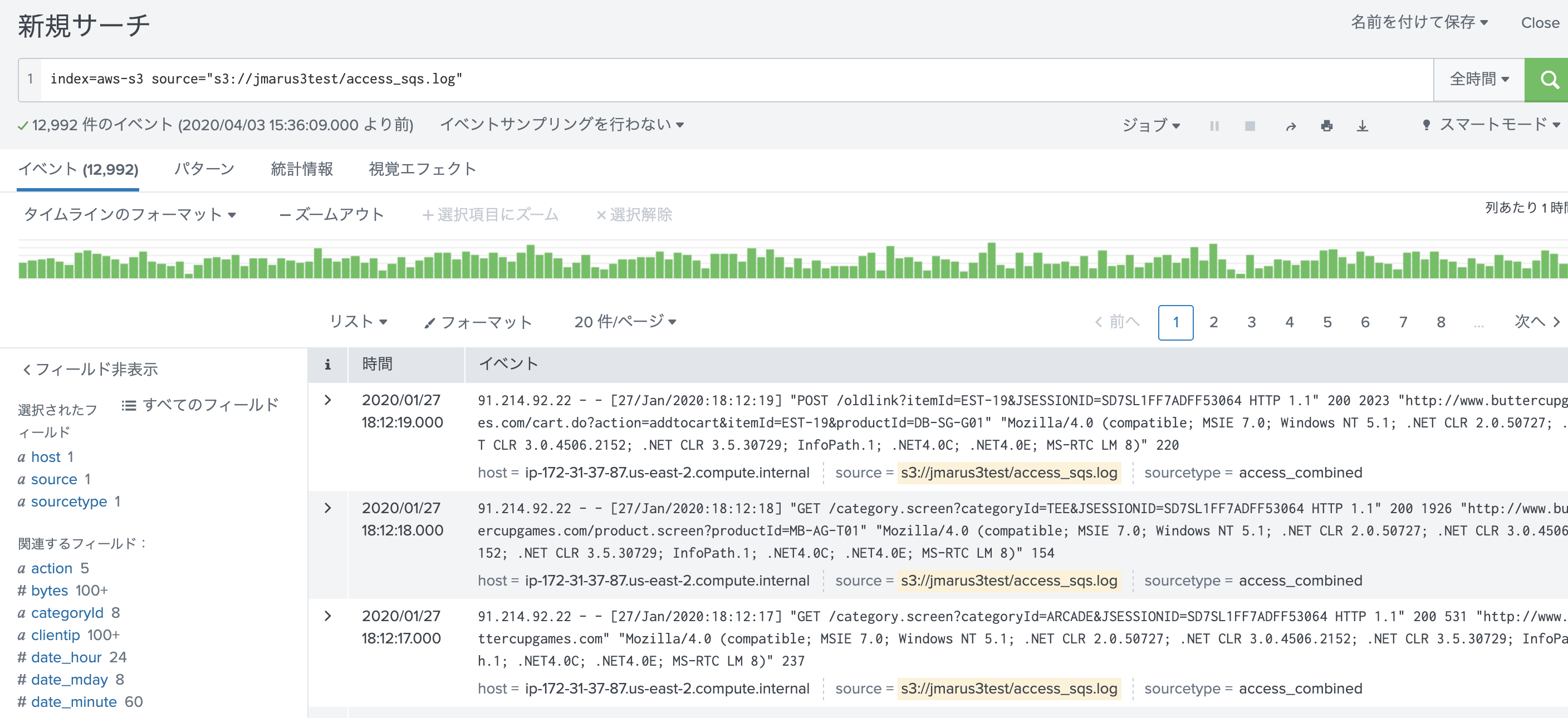
それでは、S3上に新規ファイルを追加して取り込みがされているか確認します。
新規に[access_sqs.log]を追加してみます。
あとはデフォルト設定のまま取り込みます。Splunk側からもすぐに取り込みを確認できました。
最後に
今回はInput設定が一つでしたが、Heavy Forwarderを複数立ててSplunk側のInputを増やすことで取り込みスピードを向上させることが出来、さらに可用性も向上できます。将来的なスケール構成を見据えてこちらの設定が推奨とのことです。



- 投稿日:2020-04-04T00:58:14+09:00
AWS S3上のデータを SQS / SNS と組み合わせて Splunkに取り込む
はじめに
先日、AWS S3上のデータを Splunkに取り込む記事を書きましたが、シンプルな設定のためスモール環境には適しておりますが、Bucket内のデータ量が増えてきたり、リアルタイムデータが増加してくると処理が追いつかずに取り込めないとか、データ欠損の可能性が出てきます。
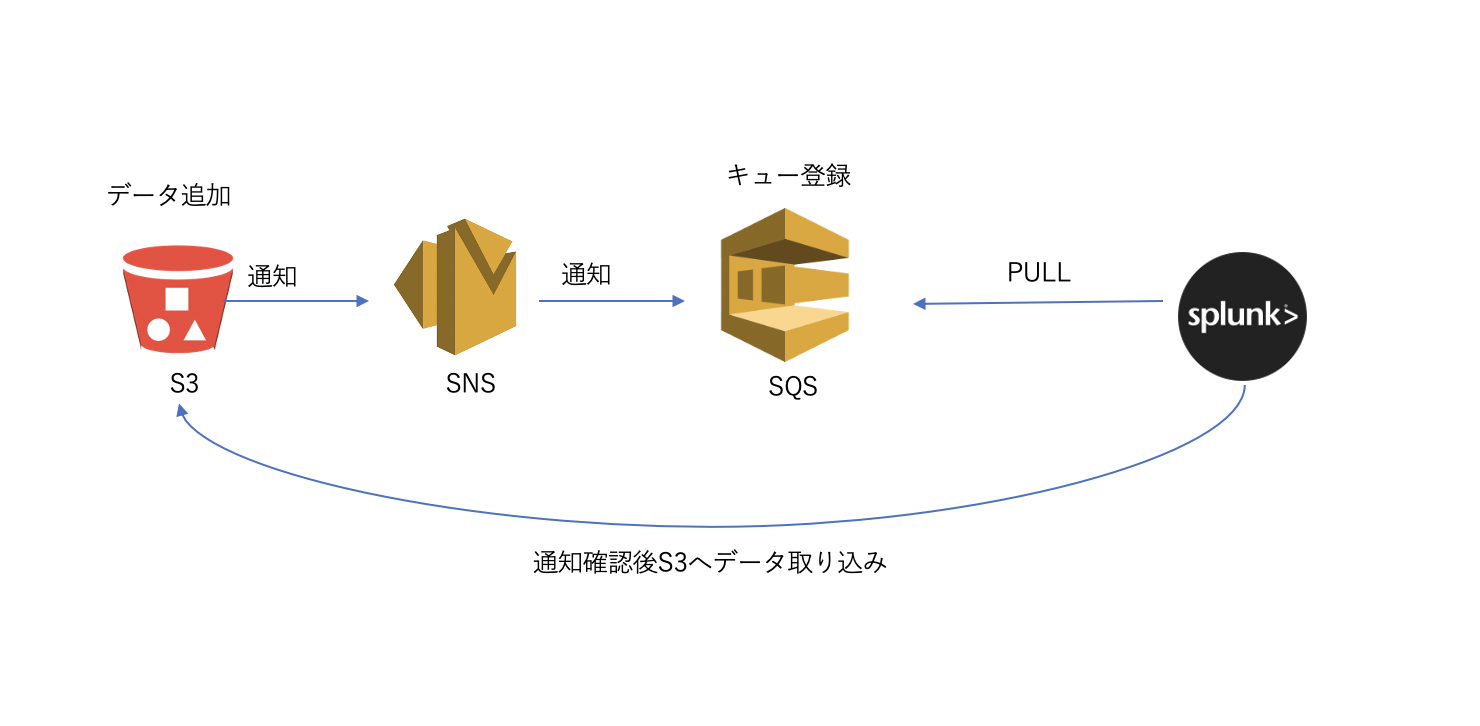
そこで、Splunkでも推奨している SNS/SQSと組み合わせた方法で、スケール問題とデータ信頼性問題を解決していきたいと思います。
AWS SNS / SQSとは?
簡単に言うと、SNSが変更を通知してくれるメッセージサービスで、SQSがメッセージを目的先まできちんと届ける配送サービスになります。
今回のケースだと S3上にデータが追加されたらSNSにイベント通知があがり、それをSQSに登録することでSQSがきちんとSplunkに通知を届ける役割をします。受け取った通知をもとにSplunkはS3にデータを取りにいき、無事に取り込めたらSQSに受信確認を返します。
SNS / SQS サービスについては、こちらの解説が詳しかったです。
https://www.slideshare.net/AmazonWebServicesJapan/aws-31275003SQS based S3 構成時の注意点
以下のマニュアルをまずはご覧ください。
https://docs.splunk.com/Documentation/AddOns/released/AWS/SQS-basedS3特に注意する点は、新規に追加されたデータのみ対象となるという点です。つまりすでにS3上にあるデータは対象外となってしまいます。これに対応するためには最初に前回説明したGeneric S3 取り込みを最初に行ったうで、今回のSQS baseの取り込みを設定する必要があります。
設定の流れ
AWS側の設定
1. IAMユーザーへのポリシー設定
2. SNSトピックの作成 & SQSサブスクリプションの登録
3. SQS作成 (通常のものと、Dead Queueの2つ)
4. S3にてSNSへの通知設定2〜3の設定についてはこちらのAWSマニュアルに従って設定します。詳細はご確認ください。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/NotificationHowTo.html
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/ways-to-add-notification-config-to-bucket.htmlSplunk側の設定
5. Input設定(*) 今回は Add-On for AWS App のインストールや、IAMユーザーの登録は省略します。詳しくは前回の記事を参照ください。
1.IAMユーザーへのポリシー付与
IAMユーザーに対して、新規にポリシーを作成して付与します。適用するポリシーはこちらになります。
コピペして利用できます{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sqs:GetQueueUrl", "sqs:ReceiveMessage", "sqs:DeleteMessage", "sqs:GetQueueAttributes", "sqs:ListQueues", "s3:GetObject", "kms:Decrypt" ], "Resource": "*" } ] }ユーザーに作成したポリシーを付与
2. SNS トピックの作成
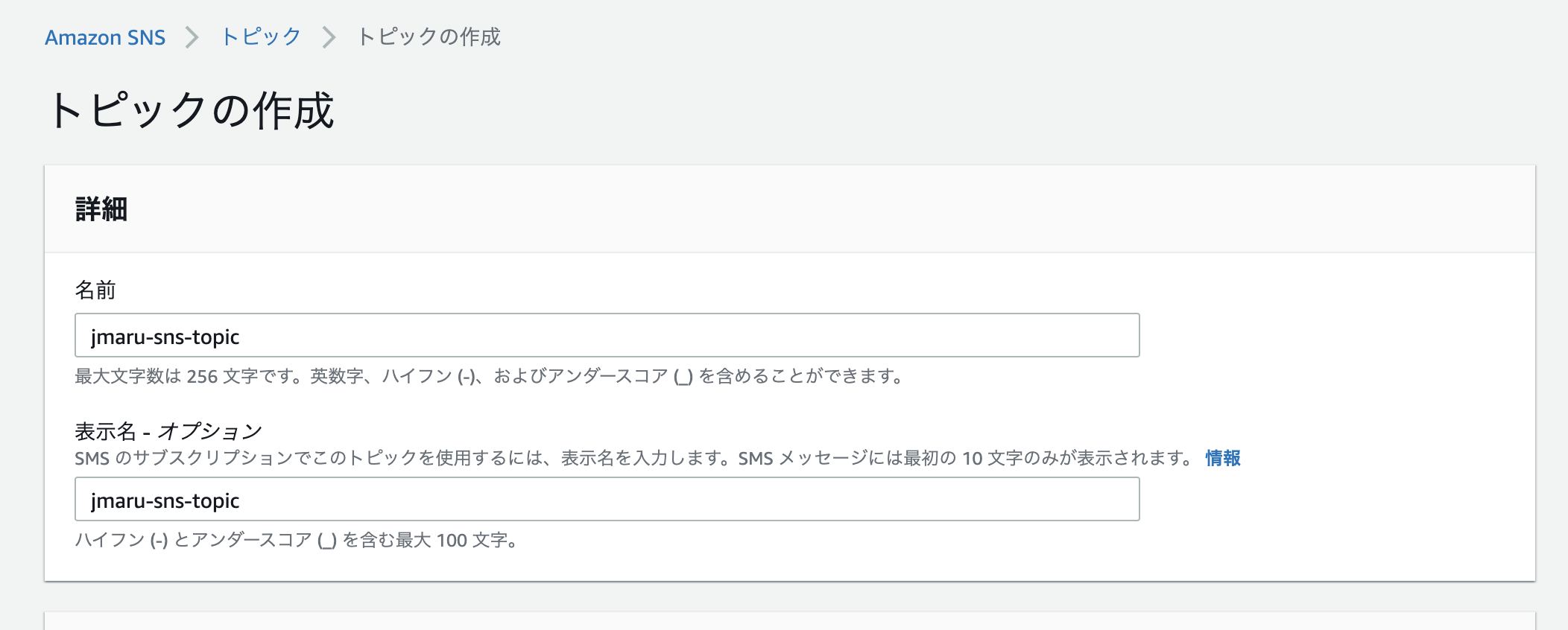
まずはSNSトピックを作成しましょう。
AWSの SNS -> Topic の画面から「Topicの作成」をクリックしてトピック名を記入します。
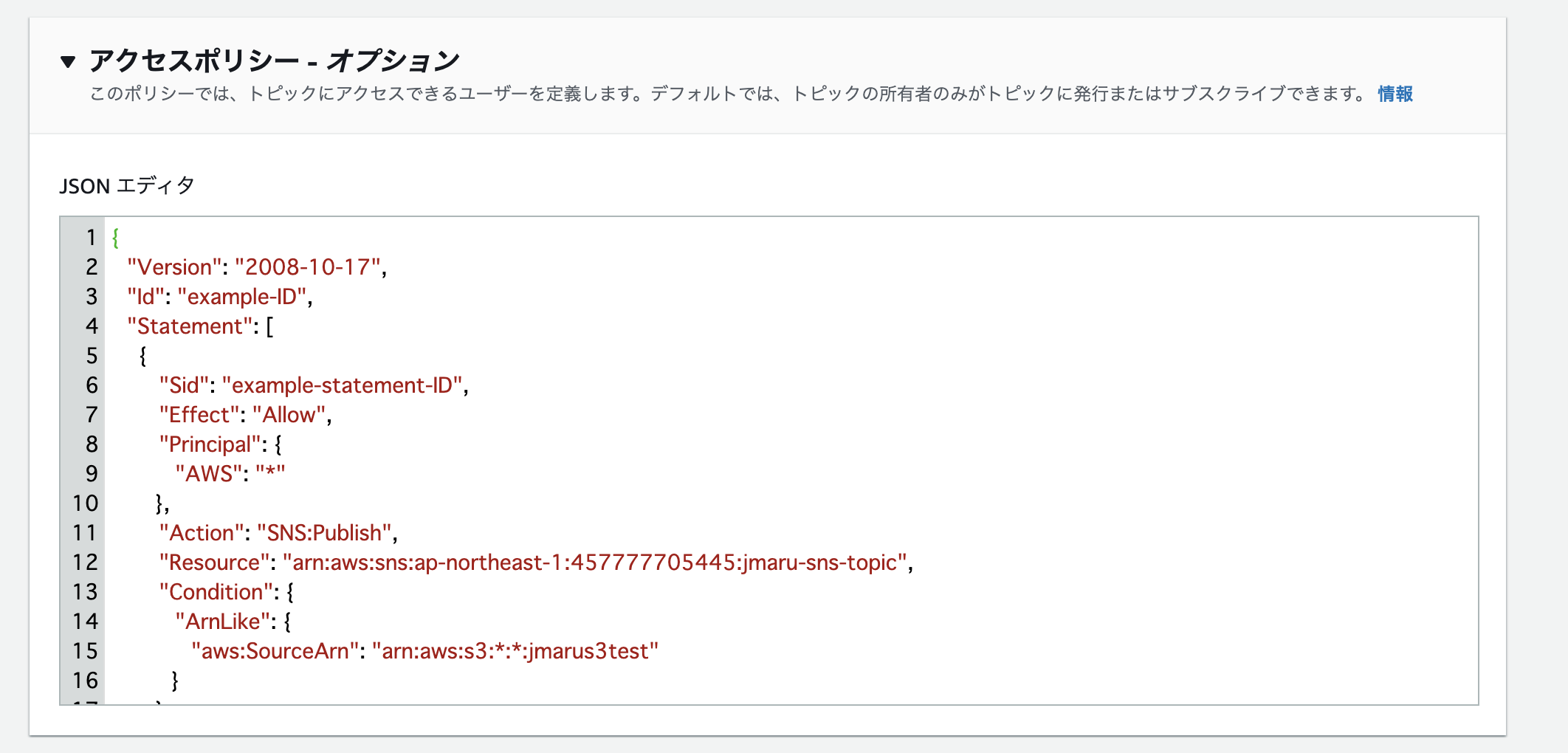
次にアクセスポリシーを開いて、JSONエディタの中身を置き換えます。これはS3からのイベント通知を受け取れるようにアクセスポリシーを変更しております。対象のS3 Bucket名を事前に確認しておいてください。
下のマニュアル画面にあるとおり、赤字の部分を作成したトピック名と、通知をあげるS3のbacket名に修正して、あとはコピペで上書きします。
コピーはこちらからどうぞ{ "Version": "2008-10-17", "Id": "example-ID", "Statement": [ { "Sid": "example-statement-ID", "Effect": "Allow", "Principal": { "AWS":"*" }, "Action": [ "SNS:Publish" ], "Resource": "SNS-topic-ARN", "Condition": { "ArnLike": { "aws:SourceArn": "arn:aws:s3:*:*:bucket-name" } } } ] }ほかのオプションはそのままで結構です。保存して作成完了です。
3. SQS作成 (通常のものと、Dead Queueの2つ)
次にSQSを作成します。作成するのは2つになります。
1. メインキュー ( Splunkと連携するキュー)
2. Dead letter queue : 正常に処理できないメッセージの送信先として設定するキュー
メインキューの作成 (jmaru-sqs)
Dead letter queue の作成
同様に新規のキューを作成します。
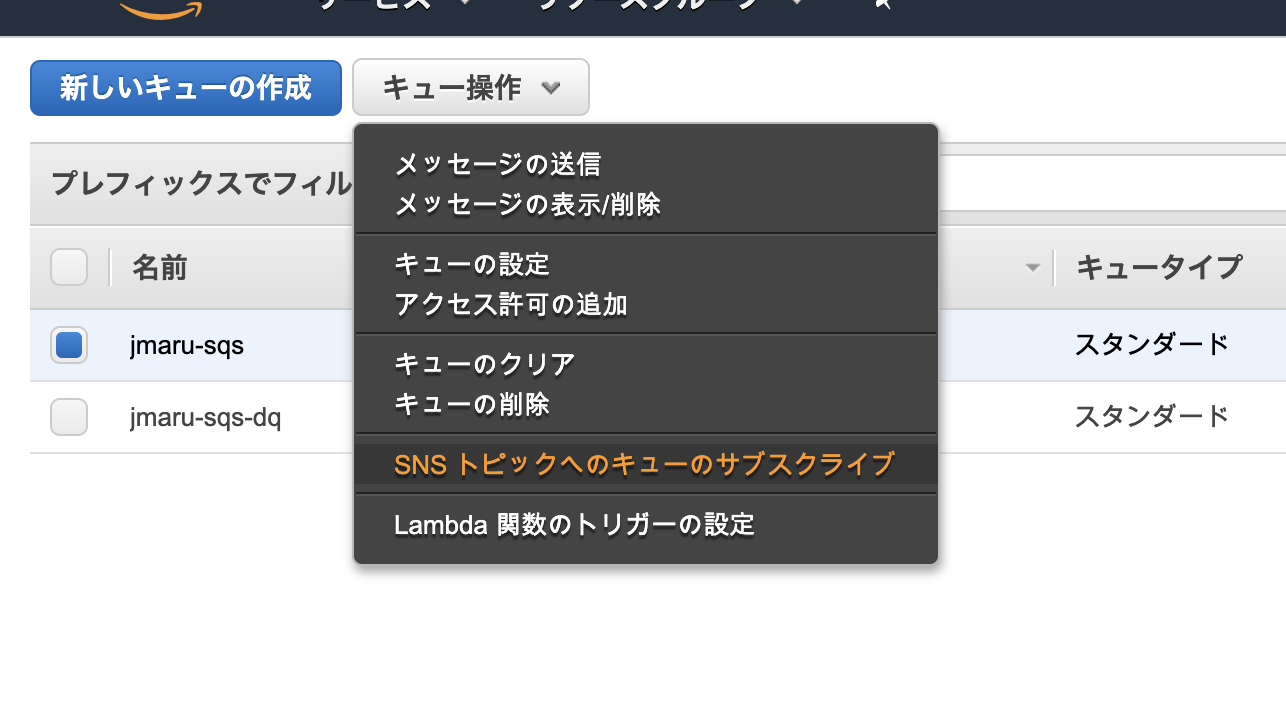
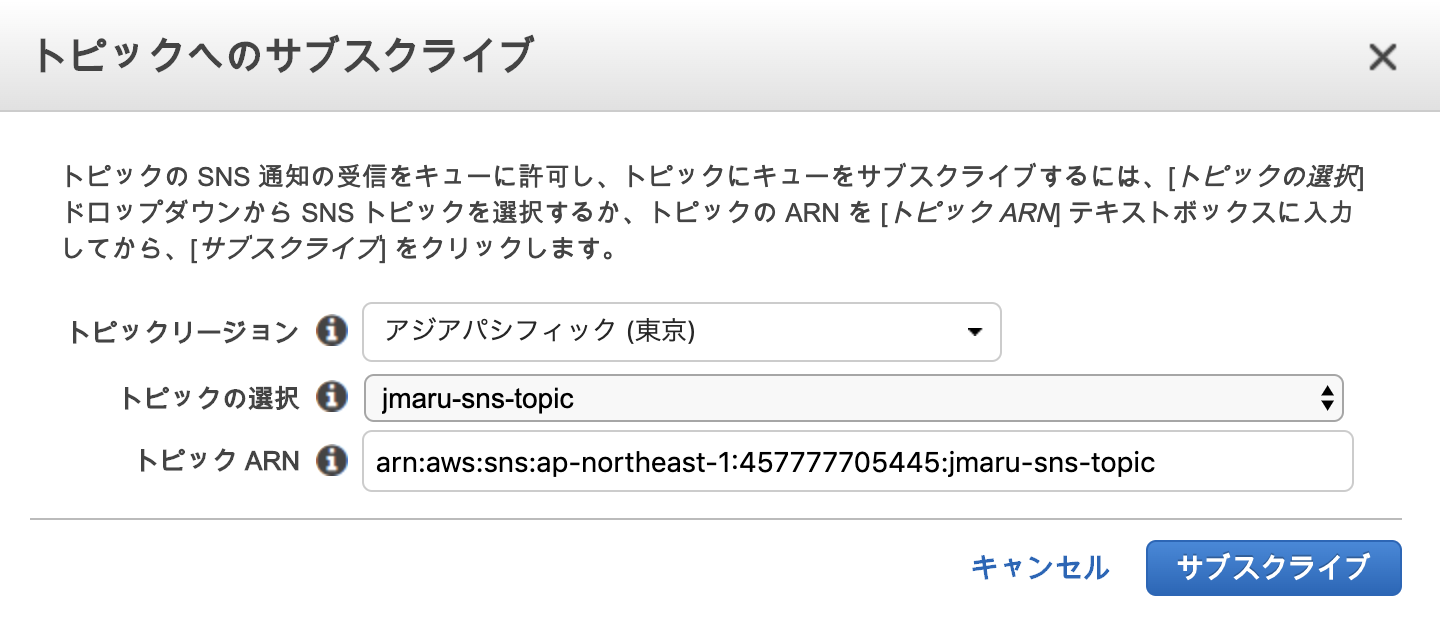
作成されたらメインキューにチェックして、メニューから「SNSトピックへのキューのサブスクライブ」を選択します。
先ほど作成した SNSトピックを選択します。
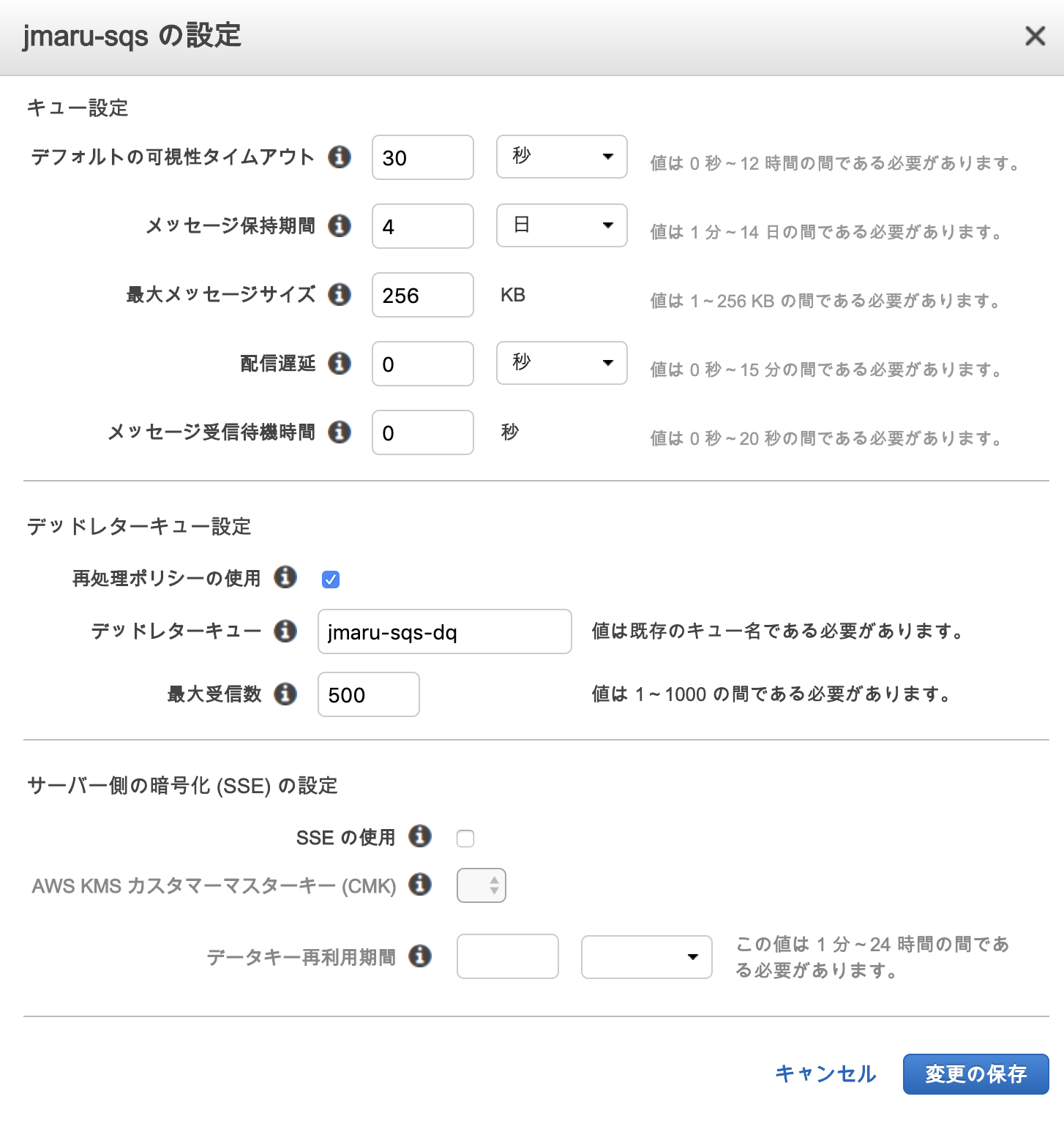
次にdead letterキューを設定します。
先ほどと同じく、メインキューにチェックをいれて、「キューの設定」を選択します。
先ほど作成した dead letter キューを入力します。
4. S3のイベント通知設定(SNSへの通知)
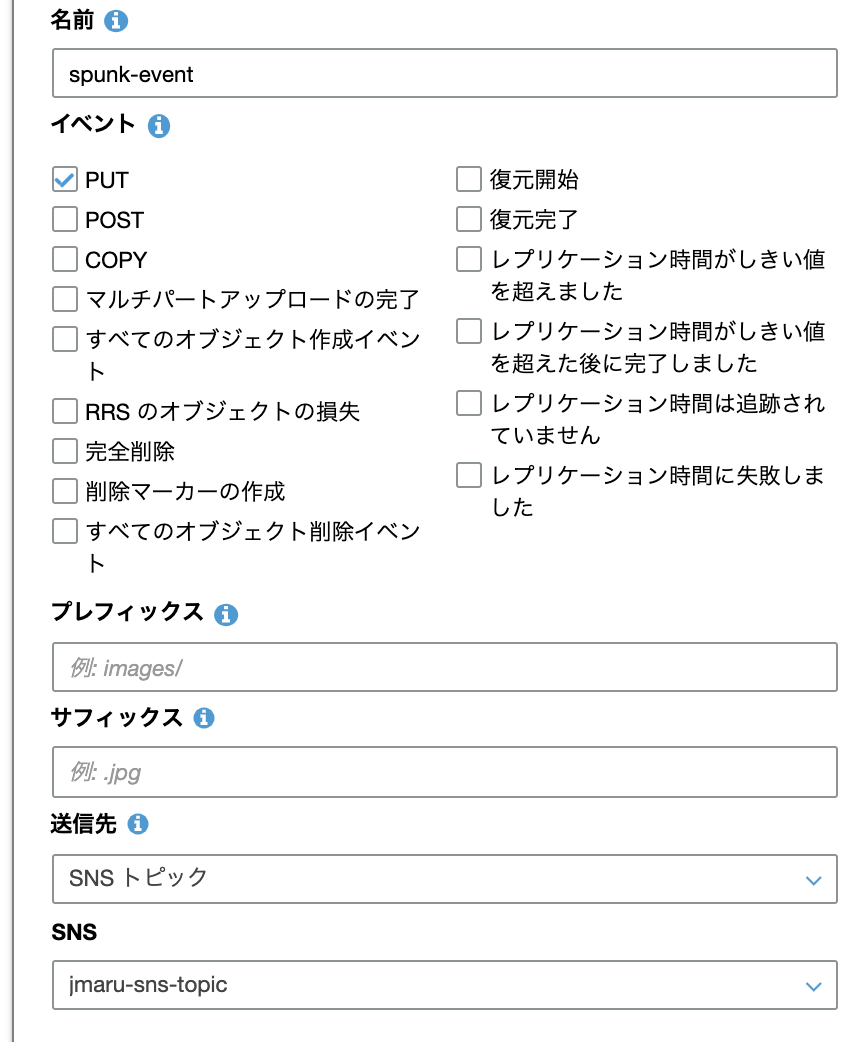
最後にS3側に新規書き込みがあった際のイベント通知設定を行います。ここではSNSを登録します。
S3サービス画面から、対象となるS3 Bucketを選択し、以下のように「プロパティ」タブを開き、下の方にある「イベント」を開きます。
PUTイベントにチェックを入れて、送信先をSNSトピックにします。
保存して終了です。AWS側の設定はすべて完了しました。これで今回設定したS3上にデータが追加されると、SNSに通知が飛んで、さらにSQSのキューに保存されます。あとはSplunk側から通知を取りにくるのを待つだけです。
Splunk側の設定
5. Input設定
すでに、Splunk側のAppの追加やIAMユーザの登録が完了した状態で設定を進めます。
まだ完了していないかたは、こちらの記事をご確認ください。「Splunk Add-On for AWS」App ー「Inputs」 に移動して「Custom Data Type」から、[SQS-Based S3]をクリック
必要項目を入力します。ソースタイプなどは保管されるデータタイプに合わせて変更してください。インデックスも保存したいIndexを指定してください。
Intervalの300秒は、SplunkからSQSに対してメッセージが届いていないか確認しにいく時間間隔です。つまりこの方法は、PULL型であり完全なリアルタイム処理ではありません。この時間はキューの大きさやデータサイズ、取り込みスピードなどを考慮して設定してください。
以上で設定は完了です。
取り込み確認
それでは、S3上に新規ファイルを追加して取り込みがされているか確認します。
新規に[access_sqs.log]を追加してみます。
あとはデフォルト設定のまま取り込みます。Splunk側からもすぐに取り込みを確認できました。
最後に
今回はInput設定が一つでしたが、Heavy Forwarderを複数立ててInputを増やすことで取り込みスピードを向上させて、可用性も担保できます。大規模環境でPULL型でも問題ない場合はこの設定がおすすめなようです。
あと試してはいないのですが、S3からイベント通知先をSQSに出来たので、そうすればSNSは不要になるかもしれません。

- 投稿日:2020-04-04T00:47:05+09:00
AWS Innovateマルチアカウント戦略個人的メモ
エンタープライズ組織がサービス開発を継続して行うとき、増え続けるAWSシステムに対して1つのAWSアカウントで管理を続けていくことは難しいです。
多数のシステムをシンプルかつスケーラブルに管理するためには、マルチアカウントによる管理と仕組みの活用が効果的らしい。。
AWSで稼働するシステム数による管理の変移
- 1システム
- そのシステムの管理者がAWS自体の管理も行う
- 数個
- 共通基盤チームがAWS自体の管理と個別システムの監査を行う
- 多数
- 共通基盤チームが人海戦術で管理、監査を行うことが困難になってくる
- 利用API単位でアカウントを分ける
- ログ集約
- アカウント保護
- システム開発
- 請求管理
- 権限管理を簡素化、強制化
- IAM
- Organizations
- SCP
- Landing Zone
- AWS環境提供の自動化
アカウントを分割する目的
分離するだけならVPCレベルでも良いのでは?
→APIのレベルでアカウントを分けることで・・
環境
- 開発
- テスト
- 本番
のような環境をセキュリティやガバナンス、規制のために分離できる
ex)PCI DSS、HIPAA...
課金
部門単位やシステム単位でAWSのコストが明確に分離できる
ビジネス推進
事前に定義されたガバナンスフレームワークの中で特定のビジネス部門に対する権限の移譲が行える
→要は研究開発だったりのためにある程度自由なサンドボックス環境を提供できる
ワークロード
リスクやデータ分類、要求に応じてワークロード自体を分離できる
マルチアカウント管理のフレームワーク
AWSが提唱するフレームワーク図
引用:AWS Innovate [S-7] 増加するシステムをマルチアカウントで効率よく管理する
コアOU
環境を管理するためのOU群
セキュリティ
- ログアーカイブ用
- セキュリティログ閲覧用
- セキュリティログ集約用
- セキュリティツール管理用
インフラストラクチャ
- 共有サービス
- ネットワーク提供
- DXやDNS周り、Directoryサービスなど追加のOU
- サンドボックス
- 限定されたリソースを自由に使える環境
- システムネットワークからは切り離されている
- 個別システム開発用
Landing Zone
Landing Zoneとは?
セキュアで事前設定済みのAWSアカウントを提供する仕組みの総称
要は、組織で複数のAWSを管理する際のあるべき状態の定義
AWS Control Tower
Landing Zoneを展開するマネージドサービス
※東京リージョン未対応なので割愛
Landing Zoneを独自で実装するには?
大雑把に
- アカウントの発行
- 管理用権限の発行
- 共有サービスへのアクセス
- AWSログの集約
- ガードレールの設置
ガードレールが肝になるガードレールとは?
AWSが提唱している概念
アカウントに対して硬すぎる制限を設けるのではなく、できるだけ自由を確保しつつ望ましくない領域のみ制限、または発見できる仕組みを構築する考え
予防的ガードレール(制限)
- 対象の操作を実施できないようにするガードレール
- Organizations Service Control Policy (SCP)で実装する
- OUやアカウントに対する許可/拒否ポリシーを設定
発見的ガードレール(発見)
- 望ましくない操作を行った場合、それを発見するガードレール
- 管理しつつ開発のスピードを上げるために効果的
- AWS Config Rulesで実装する
実装のアプローチ
Control Towerを参考にする
→Control Towerの実装はAWSサービスの組み合わせになっているため、ユーザーガイドを参考にLanding Zoneを実装することが好ましい
マルチアカウント実装例
アカウント構成
引用:AWS Innovate [S-7] 増加するシステムをマルチアカウントで効率よく管理するアカウントの発行
- スクリプト(AWS CLI)やプログラムで実装
- 基本的にはOrganizationsのAPIキックにより実現
- Organizations でアカウント作成
- Organizations SCPの設定
- 基本設定用のCFnを作成
- 管理者用IAMRoleの発行
- AWS Config Rulesの設定
- 標準VPCの作成・設定など
AWS Organizationsを利用したアカウント作成の自動化 | Amazon Web Services
管理用権限の発行
- Landing Zone管理者あるいは各アカウントの管理者が対象アカウントを操作するための権限
認証にはIAM UserではなくSSOを使い、各アカウントにロールのみを作成することを推奨
※あくまで推奨
共有サービスへのアクセス
- オンプレミスとの接続経路を提供
- 共有サービスを配置するVPC
- ファイルサーバ
- ActiveDirectory
- Transit Gatewayを使ったマルチアカウントVPC間の通信
- Route53 Private Hostingを使った統一的な名前解決(によるPrivateLinkの共有)
- Route53Resolver
- SharedVPCを使ったネットワークリソースの共有
AWSログの集約
- CraudTrailのログとAWS Configのログをログアカウントのバケットに集約
- 保存バケットのバケットポリシーと各サービスんさう新崎設定だけで実現可能
ログ送信を停止させられないようにログ送信元アカウントへのログ集約を停止させないSCPを付与するSCPの設定
- 予防的ガードレールの設定
- Organizations SCPによる設定
- カスタマイズ可
必要最低限の設定を十分なテストを実施して適用すること
発見的ガードレールの設定
- AWS Config Rulesの設定をCloudFormationで展開
- StackSetsで複数のアカウント・リージョンに一括展開
[新機能] CloudFormation StackSetsを試してみた | Developers.IO
- ControlTowerで設定できる推奨項目はCloudFormationテンプレートがドキュメントに記載されている
- 他のルールを使用したりAWS Config RDK(Rule Developing Kit)を使ったカスタムルールの作成も可能参考:CloudFormation StackSets
- 1つのCFnテンプレートから複数のアカウント、リージョンにStackを同時展開する機能
- 各アカウントに用意した管理者権限を有するロールでStackを作成
参考:Control Towerのガードレール
- 必須のガードレール
- Control Towerを正常に稼働させるために必要な禁止事項をSCPで定義したもの
- 独自に実装する場合は必須ではないが、ログ保存を停止させない実装などが参考になる
- 強く推奨されるガードレール
- マルチアカウントのベストプラクティスに基づく制限事項
- SCPの例:rootユーザでアクセスキーを作らない、rootユーザで操作しないなど
- ConfigRulesの例:EBSボリュームが暗号化されていること、S3のパブリック読み書き禁止など
- 選択的ガードレール
- エンタープライズで一般的に利用されている制限事項
- SCPの例:MFAなしのS3バケット削除禁止、S3バケットのクロスリージョンレプリカ禁止など
- ConfigRulesの例:MFAなしのIAMユーザアクセス禁止、バージョニングのないS3の禁止など
まとめ
- 多数のシステムをシンプルかつスケーラブルに管理するためにマルチアカウントによる管理と仕組みの活用が効果的
- 1の構成を定義したLanding Zoneの実装はControlTowerの実装を参考にする
- 基盤設定はCloudFomation StackSetsを使用してスケーラブルに展開
参考
AWS Innovate オンラインカンファレンス - [S-7] 増加するシステムをマルチアカウントで効率よく管理する
![[S-7]AWSInnovate_Online_Conference_2020_Spring_MultiAccount 7.jpeg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F246580%2Fb3b8c3dd-412f-b263-e7ef-2af438d147bd.jpeg?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=60843cab2ae2eeb3b87eaf880911ca94)
![[S-7]AWSInnovate_Online_Conference_2020_Spring_MultiAccount 15.jpeg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F246580%2Ff52decd9-0095-cb60-fd7e-9f13577a28bf.jpeg?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=0e230d613d632f8ab623d4f1ec0bfd73)
- 投稿日:2020-04-04T00:47:05+09:00
AWS Innovateマルチアカウント戦略
エンタープライズ組織がサービス開発を継続して行うとき、増え続けるAWSシステムに対して1つのAWSアカウントで管理を続けていくことは難しいです。
多数のシステムをシンプルかつスケーラブルに管理するためには、マルチアカウントによる管理と仕組みの活用が効果的らしい。。
AWSで稼働するシステム数による管理の変移
- 1システム
- そのシステムの管理者がAWS自体の管理も行う
- 数個
- 共通基盤チームがAWS自体の管理と個別システムの監査を行う
- 多数
- 共通基盤チームが人海戦術で管理、監査を行うことが困難になってくる
- 利用API単位でアカウントを分ける
- ログ集約
- アカウント保護
- システム開発
- 請求管理
- 権限管理を簡素化、強制化
- IAM
- Organizations
- SCP
- Landing Zone
- AWS環境提供の自動化
アカウントを分割する目的
分離するだけならVPCレベルでも良いのでは?
→APIのレベルでアカウントを分けることで・・
環境
- 開発
- テスト
- 本番
のような環境をセキュリティやガバナンス、規制のために分離できる
ex)PCI DSS、HIPAA...
課金
部門単位やシステム単位でAWSのコストが明確に分離できる
ビジネス推進
事前に定義されたガバナンスフレームワークの中で特定のビジネス部門に対する権限の移譲が行える
→要は研究開発だったりのためにある程度自由なサンドボックス環境を提供できる
ワークロード
リスクやデータ分類、要求に応じてワークロード自体を分離できる
マルチアカウント管理のフレームワーク
AWSが提唱するフレームワーク図
引用:AWS Innovate [S-7] 増加するシステムをマルチアカウントで効率よく管理する
コアOU
環境を管理するためのOU群
セキュリティ
- ログアーカイブ用
- セキュリティログ閲覧用
- セキュリティログ集約用
- セキュリティツール管理用
インフラストラクチャ
- 共有サービス
- ネットワーク提供
- DXやDNS周り、Directoryサービスなど追加のOU
- サンドボックス
- 限定されたリソースを自由に使える環境
- システムネットワークからは切り離されている
- 個別システム開発用
Landing Zone
Landing Zoneとは?
セキュアで事前設定済みのAWSアカウントを提供する仕組みの総称
要は、組織で複数のAWSを管理する際のあるべき状態の定義
AWS Control Tower
Landing Zoneを展開するマネージドサービス
※東京リージョン未対応なので割愛
Landing Zoneを独自で実装するには?
大雑把に
- アカウントの発行
- 管理用権限の発行
- 共有サービスへのアクセス
- AWSログの集約
- ガードレールの設置
ガードレールが肝になるガードレールとは?
AWSが提唱している概念
アカウントに対して硬すぎる制限を設けるのではなく、できるだけ自由を確保しつつ望ましくない領域のみ制限、または発見できる仕組みを構築する考え
予防的ガードレール(制限)
- 対象の操作を実施できないようにするガードレール
- Organizations Service Control Policy (SCP)で実装する
- OUやアカウントに対する許可/拒否ポリシーを設定
発見的ガードレール(発見)
- 望ましくない操作を行った場合、それを発見するガードレール
- 管理しつつ開発のスピードを上げるために効果的
- AWS Config Rulesで実装する
実装のアプローチ
Control Towerを参考にする
→Control Towerの実装はAWSサービスの組み合わせになっているため、ユーザーガイドを参考にLanding Zoneを実装することが好ましい
マルチアカウント実装例
アカウント構成
引用:AWS Innovate [S-7] 増加するシステムをマルチアカウントで効率よく管理するアカウントの発行
- スクリプト(AWS CLI)やプログラムで実装
- 基本的にはOrganizationsのAPIキックにより実現
- Organizations でアカウント作成
- Organizations SCPの設定
- 基本設定用のCFnを作成
- 管理者用IAMRoleの発行
- AWS Config Rulesの設定
- 標準VPCの作成・設定など
AWS Organizationsを利用したアカウント作成の自動化 | Amazon Web Services
管理用権限の発行
- Landing Zone管理者あるいは各アカウントの管理者が対象アカウントを操作するための権限
認証にはIAM UserではなくSSOを使い、各アカウントにロールのみを作成することを推奨
※あくまで推奨
共有サービスへのアクセス
- オンプレミスとの接続経路を提供
- 共有サービスを配置するVPC
- ファイルサーバ
- ActiveDirectory
- Transit Gatewayを使ったマルチアカウントVPC間の通信
- Route53 Private Hostingを使った統一的な名前解決(によるPrivateLinkの共有)
- Route53Resolver
- SharedVPCを使ったネットワークリソースの共有
AWSログの集約
- CraudTrailのログとAWS Configのログをログアカウントのバケットに集約
- 保存バケットのバケットポリシーと各サービスんさう新崎設定だけで実現可能
ログ送信を停止させられないようにログ送信元アカウントへのログ集約を停止させないSCPを付与するSCPの設定
- 予防的ガードレールの設定
- Organizations SCPによる設定
- カスタマイズ可
必要最低限の設定を十分なテストを実施して適用すること
発見的ガードレールの設定
- AWS Config Rulesの設定をCloudFormationで展開
- StackSetsで複数のアカウント・リージョンに一括展開
[新機能] CloudFormation StackSetsを試してみた | Developers.IO
- ControlTowerで設定できる推奨項目はCloudFormationテンプレートがドキュメントに記載されている
- 他のルールを使用したりAWS Config RDK(Rule Developing Kit)を使ったカスタムルールの作成も可能参考:CloudFormation StackSets
- 1つのCFnテンプレートから複数のアカウント、リージョンにStackを同時展開する機能
- 各アカウントに用意した管理者権限を有するロールでStackを作成
参考:Control Towerのガードレール
- 必須のガードレール
- Control Towerを正常に稼働させるために必要な禁止事項をSCPで定義したもの
- 独自に実装する場合は必須ではないが、ログ保存を停止させない実装などが参考になる
- 強く推奨されるガードレール
- マルチアカウントのベストプラクティスに基づく制限事項
- SCPの例:rootユーザでアクセスキーを作らない、rootユーザで操作しないなど
- ConfigRulesの例:EBSボリュームが暗号化されていること、S3のパブリック読み書き禁止など
- 選択的ガードレール
- エンタープライズで一般的に利用されている制限事項
- SCPの例:MFAなしのS3バケット削除禁止、S3バケットのクロスリージョンレプリカ禁止など
- ConfigRulesの例:MFAなしのIAMユーザアクセス禁止、バージョニングのないS3の禁止など
まとめ
- 多数のシステムをシンプルかつスケーラブルに管理するためにマルチアカウントによる管理と仕組みの活用が効果的
- 1の構成を定義したLanding Zoneの実装はControlTowerの実装を参考にする
- 基盤設定はCloudFomation StackSetsを使用してスケーラブルに展開
参考
AWS Innovate オンラインカンファレンス - [S-7] 増加するシステムをマルチアカウントで効率よく管理する