- 投稿日:2020-03-17T23:04:37+09:00
学習記録(6日目)#セット型#ディクショナリ型#リスト・タプル・セットの相互変換#ndarray型#Pandas(DataFrame型)
学習内容
- セット型
- デイクショナリ型
- リスト・タプル・セットの相互変換
- ndarray型
- Pandas(DataFrame型)
セット型
リストやタプルと同様に複数のデータを格納することができるデータ型。以下の特徴がある。
- 同じ値をもつデータを重複して保存することはできない
- 格納されている複数のデータには順序づけがされない
{}によって定義する。記述例
a = {1,0,2,9,8,3,7,5,4,6} print('a = ',a) b = {2,4,4,6,5,2,1,0,8,7,9,3,6} print('b = ', b)実行結果
a = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
b = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}実行結果のようにどのような順序でデータを指定してもソートされて出力される。
ディクショナリ型
リストやタプル、セットと同様に複数のデータを格納することができるデータ型。以下の特徴がある。
- 複数のデータにそれぞれ異なるラベルをつけてデータを入れる。
{ラベル1:データ1, ラベル2:データ2, ラベル3:データ3}のように定義する。keys()によってラベルの一覧を、items()によって値の一覧を得られる。リストやタプルでは複数のデータをインデックスで指定していたが、ディクショナリではラベルによって指定する。
記述例
c = {'l1':12, 'l2':45, 'l3':36, 'l4':58} print('c = ', c) print("c['l2'] = ", c['l2']) print("c['l4'] = ", c['l4']) print(c.keys()) print(c.values())実行結果
c = {'l1': 12, 'l2': 45, 'l3': 36, 'l4': 58}
c['l2'] = 45
c['l4'] = 58
dict_keys(['l1', 'l2', 'l3', 'l4'])
dict_values([12, 45, 36, 58])リスト、タプル、セットの相互変換
リスト、タプル、セットはそれぞれメソッド
list()、tuple()、set()を用いて相互変換可能である。記述例
# 相互変換を利用してリストから重複データを削除するプログラム d = [0,2,6,4,2,8,0,2] e = list(set(d)) print('e = ', e)実行結果
e = [0, 2, 4, 6, 8]
ndarray型
代表的な数値計算パッケージの
Numpyで使用する基本データ型。記述例
# ndarray型の作成 import numpy f = [0, 1, 2, 3] g = numpy.array(f) # リストからndarray型を作成 print('g = ', g) h = [1, 2] i = [2, 3] j = [3, 4] k = numpy.array([h, i, j]) # 二次元のndarray型を作成 print('k = ', k) l = numpy.array(a, dtype = numpy.float16) # データ型を指定してndarrayを作成 print('l = ', l)実行結果
g = [0 1 2 3]
k = [[1 2]
[2 3]
[3 4]]
l = [0. 1. 2. 3.]また、ndarray型のデータやリストに対して、Numpyに用意されている関数を使うと様々な数値演算ができる。代表的な物を以下に紹介する。
import numpy m = numpy.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) n = numpy.median(m) # 中央値 o = numpy.mean(m) # 平均値 p = numpy.std(m) # 標準偏差 q = numpy.var(m) # 分散 print(n) print(o) print(p) print(q)実行結果
4.5
4.5
2.8722813232690143
8.25Pandas
基本データ型
DataFrame型(表データを表す)Seriez型(行または列のデータを表す)DataFrame型
以下のように作成する。
記述例
import pandas r = pandas.DataFrame([1, 11.1], [2, 22.2], [3, 33.3])
colums、indexでそれぞれ列、行の添字を指定できる。記述例
r.colums = ['C1', 'C2'] r.index = ['A', 'B', 'C']インデックス型と同じように、添字を指定して列のデータを取得できる。
記述例
s = r['C1'] # 一列目のデータだけを取り出す t = s['A'] # 一列目、一行目のデータを取り出す
- 投稿日:2020-03-17T22:53:14+09:00
PySimpleGUIで画像処理ビューアーを作る
この記事を読んでできるものは以下の通りです
- 画像を選択して表示するビューアー
- パラメータを渡して画像処理を行う
- 画像処理した画像を表示する
PySimPleGUIの基本的な説明に関しては、Tkinterを使うのであればPySimpleGUIを使ってみたらという話を参考にしてください
検証環境
- windows10
- macOS(catalina)
- Python3.7
- ライブラリー
- tkinter
- PySimpleGUI
- Pillow
きっかけ
上の画像を作られた、アスキーアートを自動生成するの記事を見かけて、実際に動かすと面白かったのですが、画像とアスキートにする文字の大きさが固定だったのでその部分にUIをつけてみました。
変換のアルゴリズム自体は元の記事のをお借りしていまています。asci_art_transform.pyファイルが該当します。
画像の表示自体は公式のDemo_Img_Viewerを参考にしています。08_asci_Img_.pyファイルが該当します。コードの置き場所
githubに配置しております
https://github.com/okajun35/for_pycon_shizu/tree/master/example/08_asci_art#!/usr/bin/env python import PySimpleGUI as sg from PIL import Image, ImageTk import io import os import asci_art_transform as asci """ 参考URL; https://github.com/PySimpleGUI/PySimpleGUI/blob/master/DemoPrograms/Demo_Img_Viewer.py """ def get_img_data(f, maxsize=(600, 450), first=False): """Generate image data using PIL """ print("open file:", f) img = Image.open(f) img.thumbnail(maxsize) if first: # tkinter is inactive the first time bio = io.BytesIO() img.save(bio, format="PNG") del img return bio.getvalue() return ImageTk.PhotoImage(img) filename = './model.jpg' # 最初のファイル asci_image = "./test.png" image_elem = sg.Image(data=get_img_data(filename, first=True)) filename_display_elem = sg.Text(filename, size=(80, 3)) # 初期表示時はascに変換してなくてもよい # './model.jpg' をうわがいてしまってもよい # asci_image = tranfa_asci('./model.jpg', './test.png', 16) asc_image_elem = sg.Image(data=get_img_data(asci_image, first=True)) # define layout, show and read the form col = [image_elem, asc_image_elem] col_read_file = [sg.InputText('ファイルを選択', key='-INPUT-TEXT-', enable_events=True, ), sg.FileBrowse('ファイルを読み込む', key='-FILE-', file_types=(('jpegファイル', '*.jpg'), ('png', '*.png'),)), sg.Button('変換')] layout = [col_read_file, [sg.Slider(range=(1,64), key='-FONT-SIZE-', default_value=16, orientation='h', )], col] window = sg.Window('アスキーアートに変換してみよう', layout, return_keyboard_events=True, location=(0, 0), use_default_focus=False) # loop reading the user input and displaying image, filename i = 0 while True: # read the form event, values = window.read() print(event, values) # perform button and keyboard operations if event is None: break elif event == '変換': print(values['-INPUT-TEXT-']) if os.path.isfile(values['-INPUT-TEXT-']): # Animationするには別スレッドにする必要 sg.popup_animated(sg.DEFAULT_BASE64_LOADING_GIF, message='実行中',text_color='black', background_color='white', time_between_frames=100) asci_image = asci.tranfa_asci(values['-INPUT-TEXT-'], asci_image, int(values['-FONT-SIZE-'])) sg.popup_animated(image_source=None) print('変換終了') asc_image_elem.update(data=get_img_data(asci_image, first=True)) else: error_massage = values['-INPUT-TEXT-'] + ' は存在してません' sg.popup('エラー', error_massage) elif values['-FILE-'] != '': print('FilesBrowse') if os.path.isfile(values['-INPUT-TEXT-']): image_elem.update(data=get_img_data(values['-INPUT-TEXT-'], first=True))処理について
処理については以下の手順となります
- ファイルダイアログを開いて変換したいファイルを読み込む
- 変換するフォントの大きさを選択する
- アスキーアートに変換した画像を保存する
- 変換した画像を読み込んで結果画面に表示する
ファイルダイアログを開いて変換したいファイルを読み込む
sg.InputText('ファイルを選択', key='-INPUT-TEXT-', enable_events=True, ), sg.FileBrowse('ファイルを読み込む', key='-FILE-', file_types=(('jpegファイル', '*.jpg'), ('png', '*.png'),)ファイルダイアグのレイアウトです。
起動時に初期画像を表示するのは以下になります。
image_elem = sg.Image(data=get_img_data(filename, first=True))
filenameは固定の画像ファイルが格納されています。
- 参考:公式のImage Elementの説明画像を表示するのは
get_img_data()を使用しています。このメソッドは公式のDemo_Img_Viewerで使われていた関数をそのまま使用しています。def get_img_data(f, maxsize=(600, 450), first=False): """Generate image data using PIL """ print("open file:", f) img = Image.open(f) img.thumbnail(maxsize) if first: # tkinter is inactive the first time bio = io.BytesIO() img.save(bio, format="PNG") del img return bio.getvalue() return ImageTk.PhotoImage(img)pillowを使用して該当のファイルを開いて、png形式保存したものをpillowの
ImageTkを用いて表示しています。
- 参考:pillowの公式リファレンスの ImageTk モジュールの説明PySimpleGUIはtkinterのラッパーですのでtkinterように作られた他のライブラリを使用できるのが強みの一つかと思います。
読み込んだファイルを実際に表示するのは以下の部分です。
python
image_elem.update(data=get_img_data(values['-INPUT-TEXT-'], first=True))
読み込んだファイルを指定しています。ここでupdate()を使用して表示を更新しています。2. 変換するフォントの大きさを選択する
変換するフォントの大きさをスライダーで設定します
sg.Slider(range=(1,64), key='-FONT-SIZE-', default_value=16, orientation='h', )スライダーの値に関しては以下で取得できます。
event, values = window.read() values['-INPUT-TEXT-']3. アスキーアートに変換した画像を保存する
ファイルを読み込んで変換した「test.png」ファイルに出力します。
asci_image = asci.tranfa_asci(values['-INPUT-TEXT-'], "asci_image", int(values['-FONT-SIZE-']))4. 変換した画像を読み込んで結果画面に表示する
アスキーアートの画像ファイル「test.png」を表実施します
asc_image_elem.update(data=get_img_data(asci_image, first=True))まとめ
PySimpleGUIを使うと画像を読み込んでパラメータを加えて変換する画像処理ビューアーを簡単に作ることができます。
公式のデモではpillow以外でもOpenCVを使ったサンプルがあります。
またデープランニングを使用して、白黒画像に色を付けるサンプルプログラムもあります

- 投稿日:2020-03-17T22:45:52+09:00
PythonとAPIでディレクトリ内の最新の人物画像の背景除去を自動化する
やりたいこと
- 人物画像の背景除去
- 背景除去する画像のインプット先と背景除去した画像のアウトプット先を細かく指定
- フォルダ内の最新の画像の参照
- それらの自動化
OpenCVやらfacenetやらを使って画像から顔認識を行い、なんらかの処理を行いたいことがたまにはあるでしょう。もちろんそれらのツールで顔を認識してくれますが、画像内の背景などの不要なものによって “顔認識の精度が劇的に落ちるときがある” ことがわかりました。では、予め背景を取り除いておいてあげて、顔認識の精度を安定させよう!ということで背景除去を行います。まぁ動機はなんでもいいです。
remove.bg
背景除去そのものはremove.bgというWebアプリケーションを使います。どんなもんかは見た方が早いです。
before
after
remove.bgはこんな精度の高い背景除去がWeb上で簡単に行えます。背景除去の自動化
自分が実装中のシステムの一部として、画像が格納されているディレクトリ内の “最新の” 画像を参照して、背景除去を行い、別のディレクトリに結果を返すという構造を自動化していきます。
remove.bgはAPIを公開しているので、それを使って背景除去は自動化できます。会員登録し、通常のアカウントで1ヶ月50回まで無料でAPIを呼び出せます。
# Requires "requests" to be installed (see python-requests.org) import requests response = requests.post( 'https://api.remove.bg/v1.0/removebg', files={'image_file': open('/path/to/file.jpg', 'rb')}, data={'size': 'auto'}, headers={'X-Api-Key': 'INSERT_YOUR_API_KEY_HERE'}, ) if response.status_code == requests.codes.ok: with open('no-bg.png', 'wb') as out: out.write(response.content) else: print("Error:", response.status_code, response.text)'INSERT_YOUR_API_KEY_HERE'の部分にremove.bgで取得したAPI Keyを挿入します。
画像のインプットとアウトプットの自動化はパス指定で簡単にできます。
'/path/to/file.jpg'の部分に背景除去を行いたい画像のパスを指定します。
'no-bg.png'の部分でアウトプットしたい画像のファイル名を決めてディレクトリのパスを指定できます。最新画像の参照
今回はmac標準のPhoto Boothというカメラアプリで撮影した“最新の” 画像をインプットしたいので、パス指定は少しだけ工夫します。
i_path = '/Users/username/Pictures/Photo Boothライブラリ/Pictures/*' list_of_files = glob.glob(i_path) latest_file = max(list_of_files, key=os.path.getctime)i_pathで取得したい画像が格納されているディレクトリを指定しています。
glob関数でディレクトリ内の画像一覧を取得しています。
max関数とオプション指定でファイルの日時の最大値、つまり最新の画像が取得できます。全体のコード
import glob import os import requests i_path = '/Users/username/Pictures/Photo Boothライブラリ/Pictures/*' list_of_files = glob.glob(i_path) latest_file = max(list_of_files, key=os.path.getctime) # RemoveBgAPI response = requests.post( 'https://api.remove.bg/v1.0/removebg', files={'image_file': open(latest_file, 'rb')}, data={'size': 'auto'}, headers={'X-Api-Key': 'INSERT_YOUR_API_KEY_HERE'}, ) if response.status_code == requests.codes.ok: with open('/Users/username/output/no-bg.png', 'wb') as out: out.write(response.content) print('Success!') else: print("Error:", response.status_code, response.text)まとめ
remove.bg APIのおかげで背景除去の自動化が非常に簡単に実装できました。
また、最新の画像ファイルの指定という小技もすぐ実装でき、目的を達成しました。
手動で面倒くさい作業はプログラムに投げると楽でいいですね。


- 投稿日:2020-03-17T22:42:28+09:00
【シミュレーション入門】コロナ感染をシミュレートして遊んでみた♬
数値計算の分野では、昔から自由運動する粒子のシミュレーションやブラウン運動する粒子群の集団運動などのシミュレーションがある。
今回は、これをコロナウィルス感染のシミュレーションに応用してみようと思う。
似たようなシミュレーションとしてPSOというのがあるが今回はこれらのpythonコードを参考にした。
【参考】
・粒子群最適化(PSO)のパラメータについ
・粒子群最適化法(PSO)を救いたやったこと
・コード解説
・感染率依存性
・粒子密度依存性
・粒子運動依存性・コード解説
コード全体は以下においた。
・collective_particles/snow.py
コードの主要な部分を説明する。
利用ライブラリは以下のとおりimport numpy as np import matplotlib.pyplot as plt import random import time初期値の定義は以下のとおり
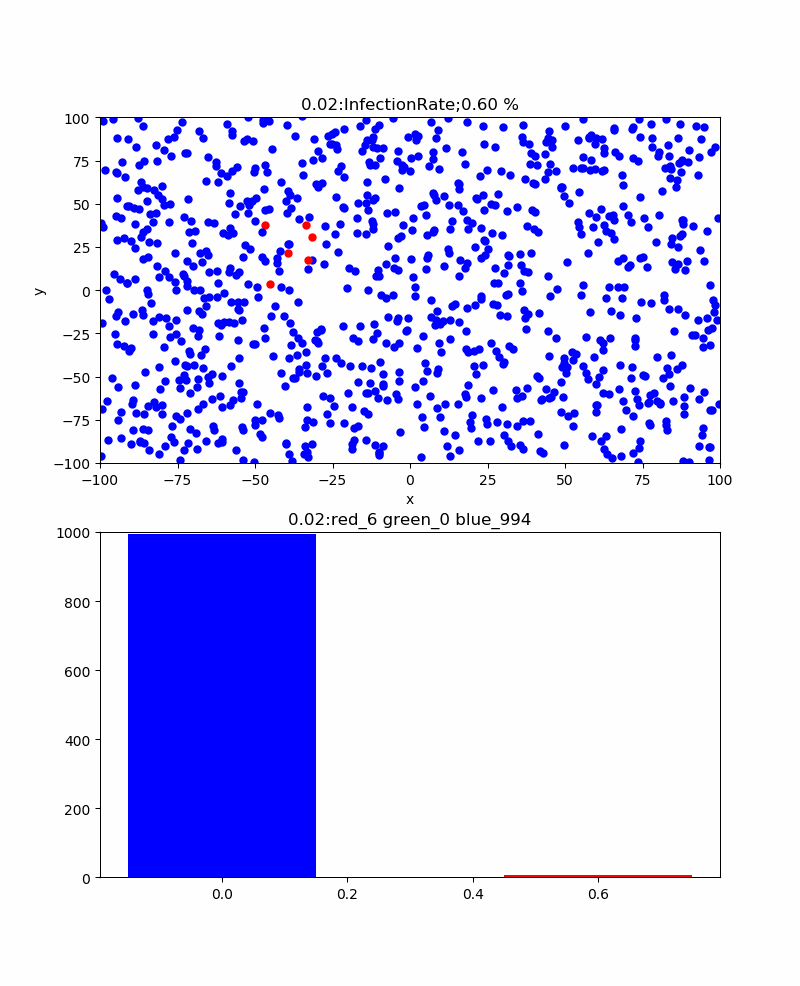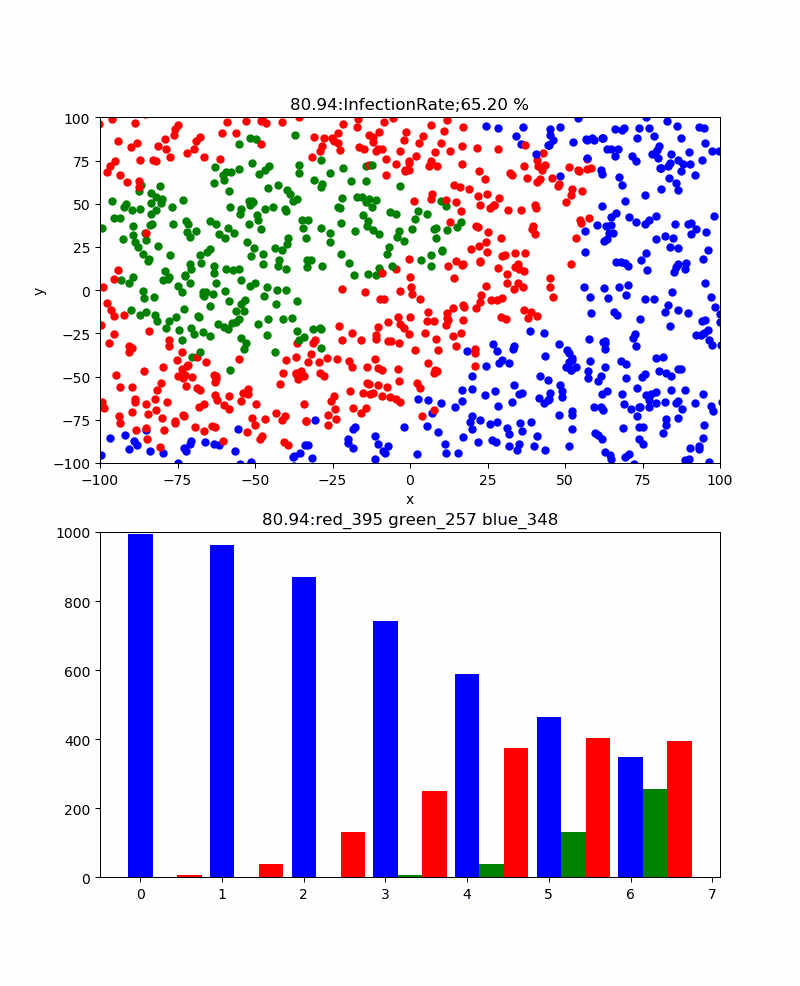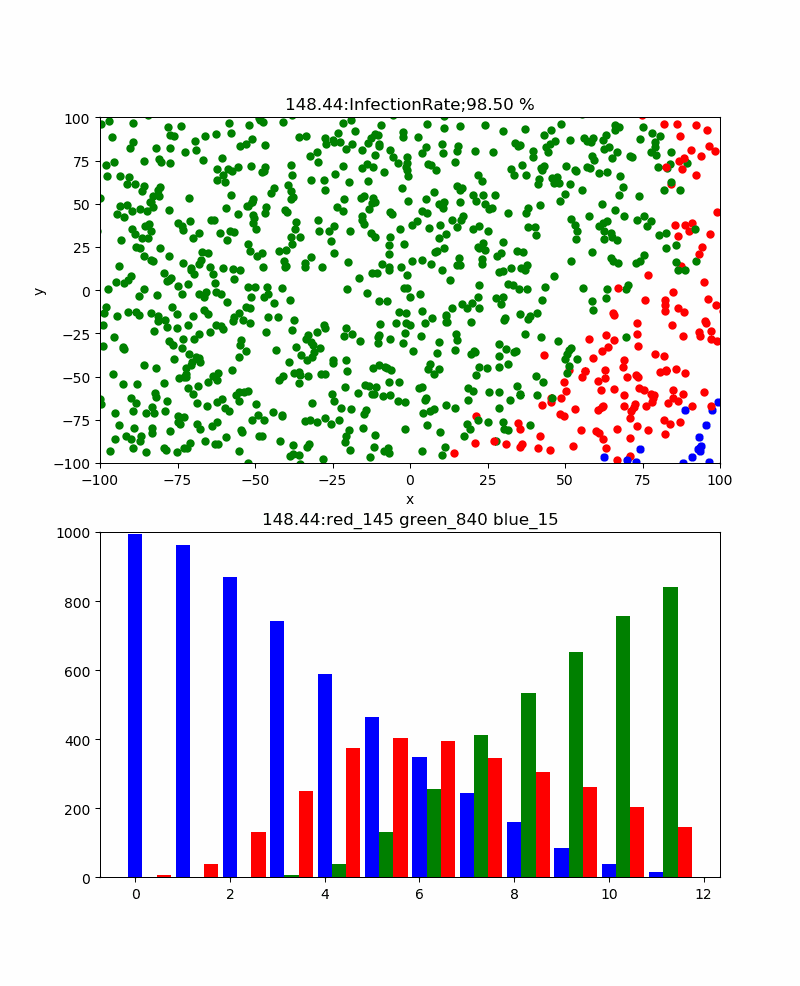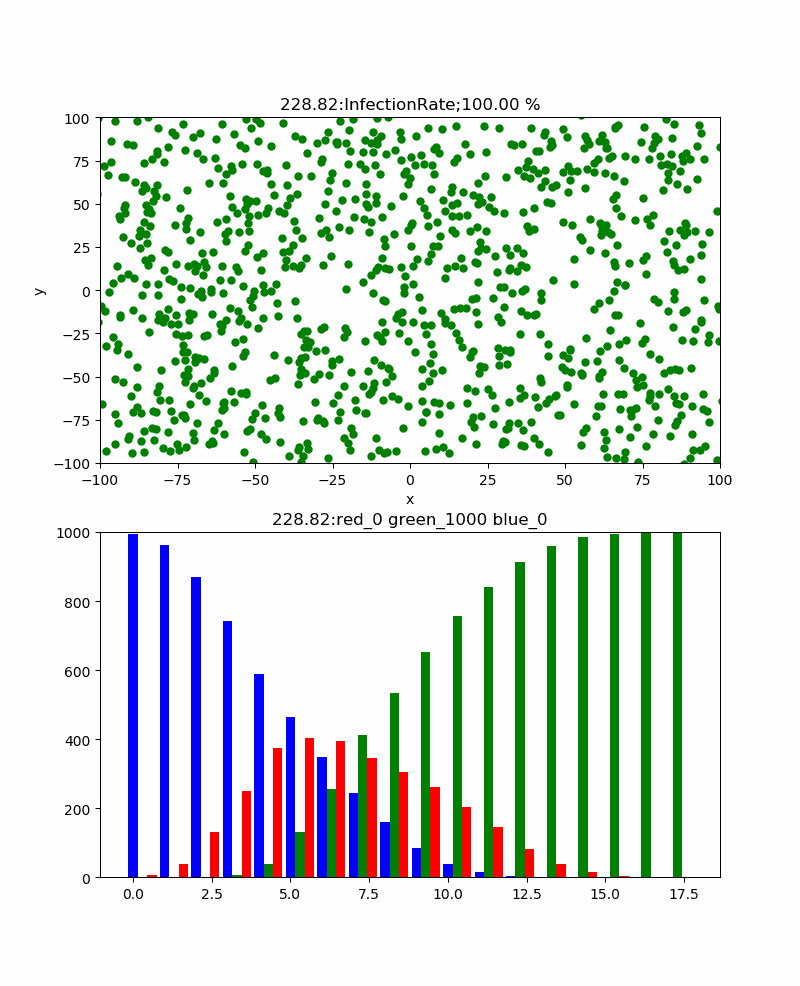
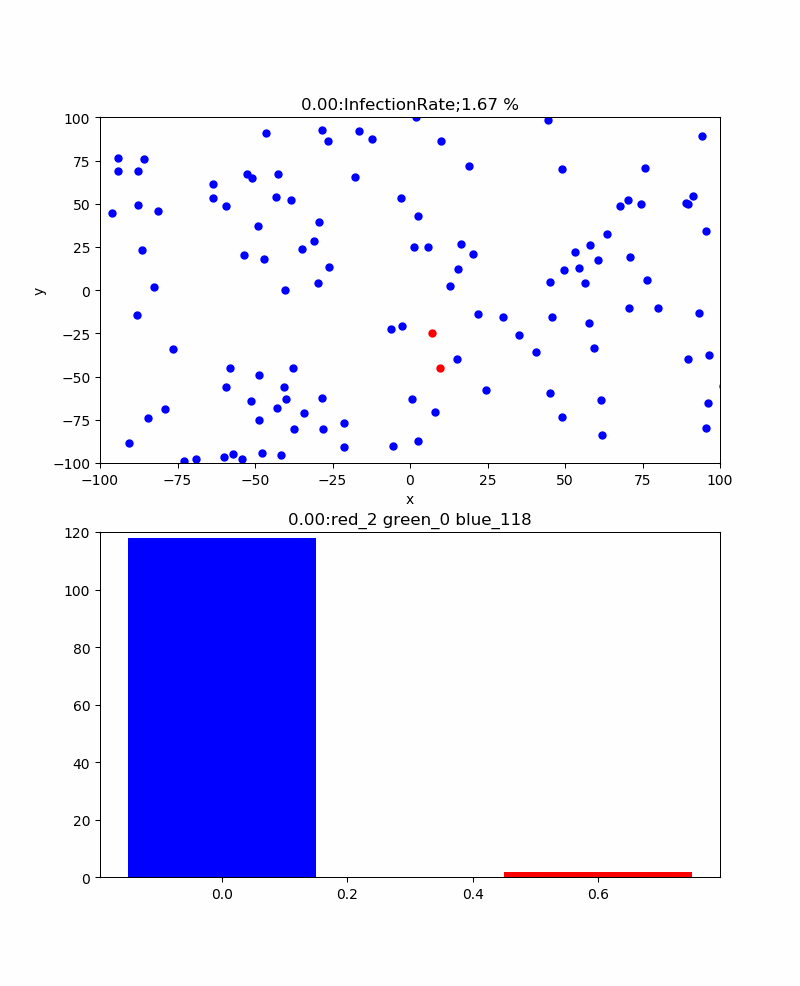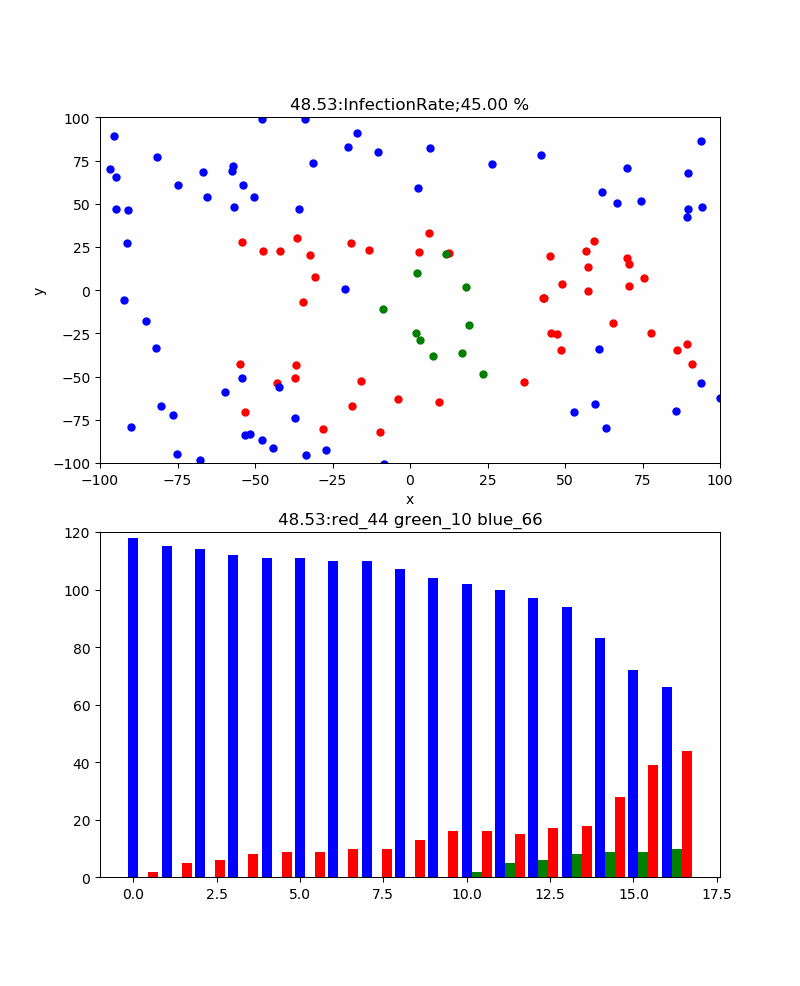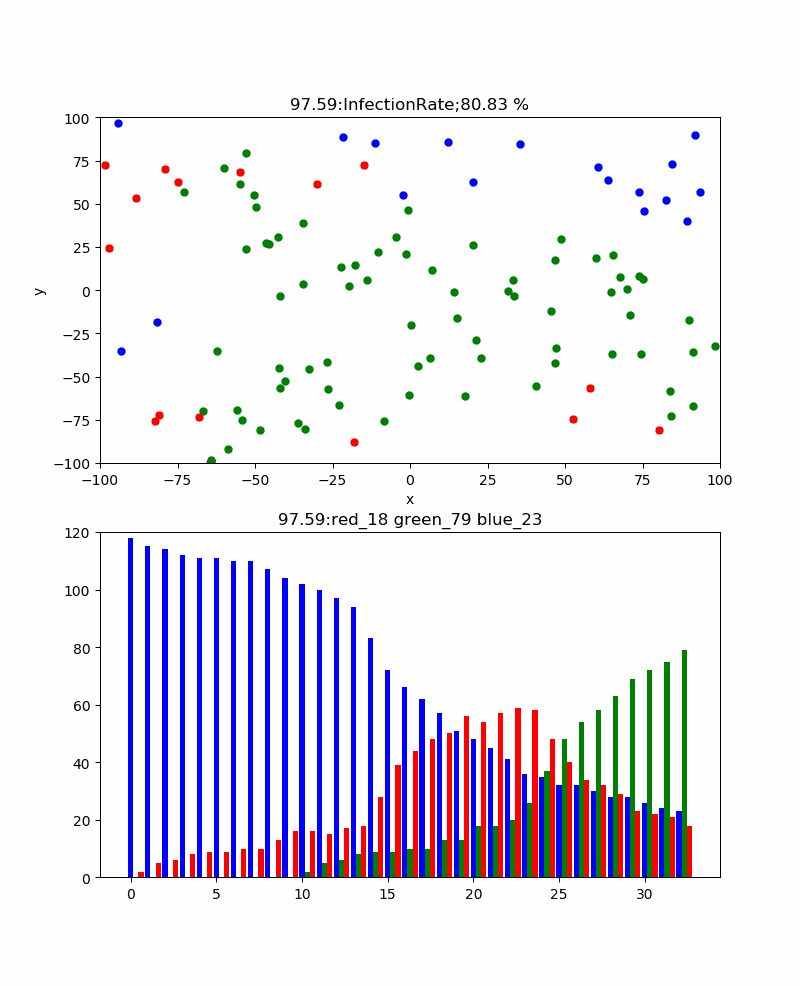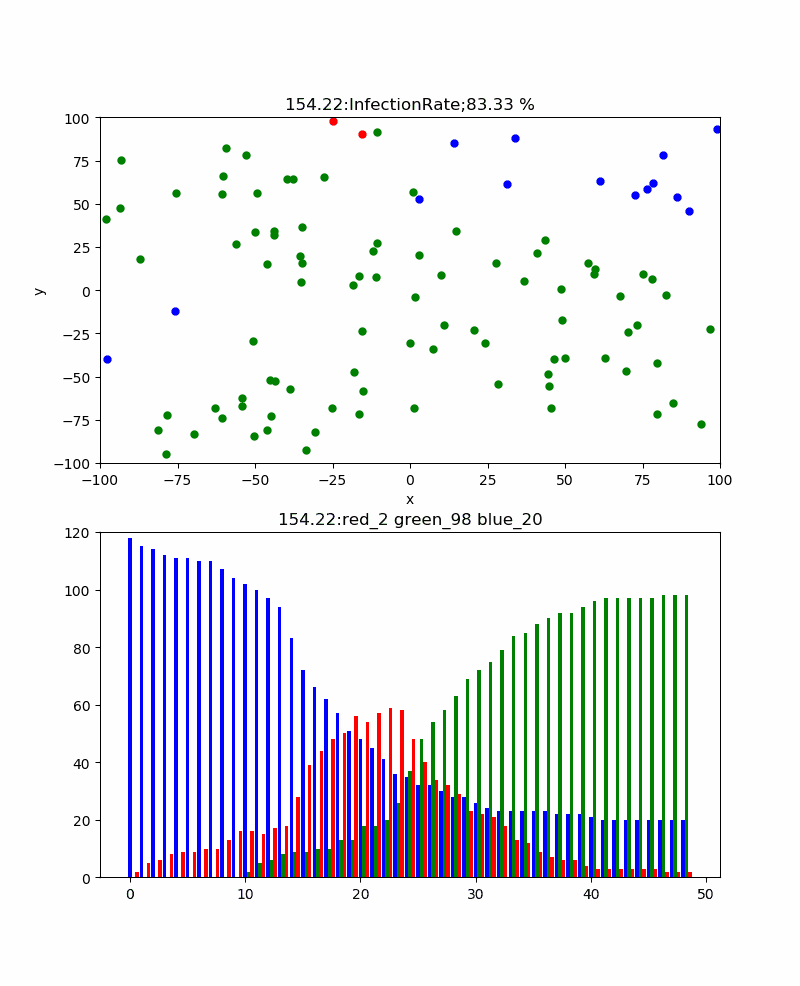
PARTICLE_NO = 1000 # 粒子数 ITERATION = 200 # 最大ループ回数 感染者が0になると止まる MIN_X, MIN_Y = -100.0, -100.0 # 探索開始時の範囲最小値 MAX_X, MAX_Y = 100.0, 100.0 # 探索開始時の範囲最大値 recovery=30 #一定時間経過したら治癒 p=0.03 #probability of infecionグラフ表示は、上記の結果を見るとわかるように、
ax1:粒子の位置情報
ax2:青;正常数、赤;感染数、緑;治癒数の頻度グラフ
を以下のように表示している。
引数は、グラフ番号、位置情報、経過時間、r,g,bの値def plot_particle(sk,positions,elt,r,g,b): el_time = time.time()-start fig, (ax1, ax2) = plt.subplots(2, 1, sharey=False,figsize=(8, 16)) for j in range(0,PARTICLE_NO): x=positions[j]["x"] y=positions[j]["y"] c=positions[j]["c"] s = 5**2 #粒子サイズ ax1.scatter(x, y, s, c, marker="o") ax1.set_xlim([MIN_X, MAX_X]) ax1.set_ylim([MIN_Y, MAX_Y]) ax1.set_xlabel("x") ax1.set_ylabel("y") ax1.set_title("{:.2f}:InfectionRate;{:.2f} %".format(el_time,(PARTICLE_NO-b[-1])/PARTICLE_NO*100)) #累計感染率 ind = np.arange(len(elt)) # the x locations for the groups width = 0.3 # the width of the bars ax2.set_ylim([0, PARTICLE_NO]) ax2.set_title("{:.2f}:red_{} green_{} blue_{}".format(el_time,r[-1],g[-1],b[-1])) rect1 = ax2.bar(ind, b,width, color="b") rect2 = ax2.bar(ind+width, g, width, color="g") rect3 = ax2.bar(ind+2*width, r,width, color="r") plt.pause(0.1) plt.savefig('./fig/fig{}_.png'.format(sk)) plt.close()今回の主なロジックは、粒子の位置情報更新関数に押し込めた。
すなわち、粒子オブジェクトの属性を以下のとおり定義している。
属性 値 位置情報; (x,y) 感染属性; (blue,red,green) 感染した時間(初期値からの経過); t_time 感染履歴flag; s(感染1、未感染0) position.append({"x": new_x, "y": new_y, "c": p_color, "t": t_time,"flag":s})上記の変数の時間変化を以下の関数で求めます。
感染判定は以下の式で行っています。
半径20の円の中に入ると接触したものとして、一定確率pで感染するかどうかを評価します。つまり、この半径と感染確率pが感染の強さを決めています。if (x-x0[k])**2+(y-y0[k])**2 < 400 and random.uniform(0,1)<p:上記のように粒子オブジェクトを定義したので、それぞれの変数を取り出したり代入しています。
もう一つ、簡単のために治癒は一定時間経過すると自動的に治癒するようにしました。ここも確率で治癒させてもいいのですが、ここでは事象を複雑化するだけなので、詳細化は不要です。
また、粒子運動(人の移動)は、平均的にはランダムウォークとしました。人はそんなに動かないという近似です。一方、分子運動のシミュレーションみたいに自由運動させることもできますが、やっていません。
そして、感染は治癒の人は感染させないという仮定です。# 粒子の位置更新関数 def update_position(positions): x0 = [] y0 = [] for i in range(PARTICLE_NO): c=positions[i]["c"] t_time = positions[i]["t"] #初期値0,感染は感染時時間 k_time = time.time()-start #経過時間 s = positions[i]["flag"] #感染なし0,感染:1 if s == 1 and c == "red": #感染済な場合 if k_time-t_time>recovery: #一定時間経過したら治癒 c = "blue" positions[i]["c"] = "green" positions[i]["flag"] = 1 #ただし、感染履歴ありのまま if c == "red": #感染redなら位置情報取得 x0.append(positions[i]["x"]) y0.append(positions[i]["y"]) position = [] for j in range(PARTICLE_NO): x=positions[j]["x"] y=positions[j]["y"] c=positions[j]["c"] s = positions[j]["flag"] t_time = positions[j]["t"] for k in range(len(x0)): if (x-x0[k])**2+(y-y0[k])**2 < 400 and random.uniform(0,1)<p: if s ==0: c = "red" t_time = time.time()-start s = 1 positions[j]["flag"]=s else: continue vx = 1*random.uniform(-1, 1) vy = 1*random.uniform(-1, 1) new_x = x + vx new_y = y + vy p_color = c s=s position.append({"x": new_x, "y": new_y, "c": p_color, "t": t_time,"flag":s}) return position, x0main関数は以下のとおり、
ポイントは、初期値で1粒子を感染;red、flag;1などとしている。
その他の粒子は、感染無しで乱数で配置している。最初の粒子の位置を真ん中に配置するというアイデアもあるが、いろいろな配置からの感染伝播が見たいので任意の位置とした。count_brg()関数は単純にカウントしている。def main(): # 各粒子の初期位置, 速度, position = [] velocity = [] #速度は今回使わない # 初期位置, 初期速度 position.append({"x": random.uniform(MIN_X, MAX_X), "y": random.uniform(MIN_Y, MAX_Y), "c": "red", "t":0, "flag":1}) for s in range(1,PARTICLE_NO): position.append({"x": random.uniform(MIN_X, MAX_X), "y": random.uniform(MIN_Y, MAX_Y), "c": "blue", "t": 0, "flag":0}) sk = 0 red=[] green=[] blue=[] elapsed_time = [] while sk < ITERATION: position, x0 = update_position(position) r,g,b = count_brg(position) red.append(r) green.append(g) blue.append(b) el_time=time.time()-start elapsed_time.append(el_time) plot_particle(sk,position,elapsed_time,red,green,blue) if x0==[]: break sk += 1・感染率依存性
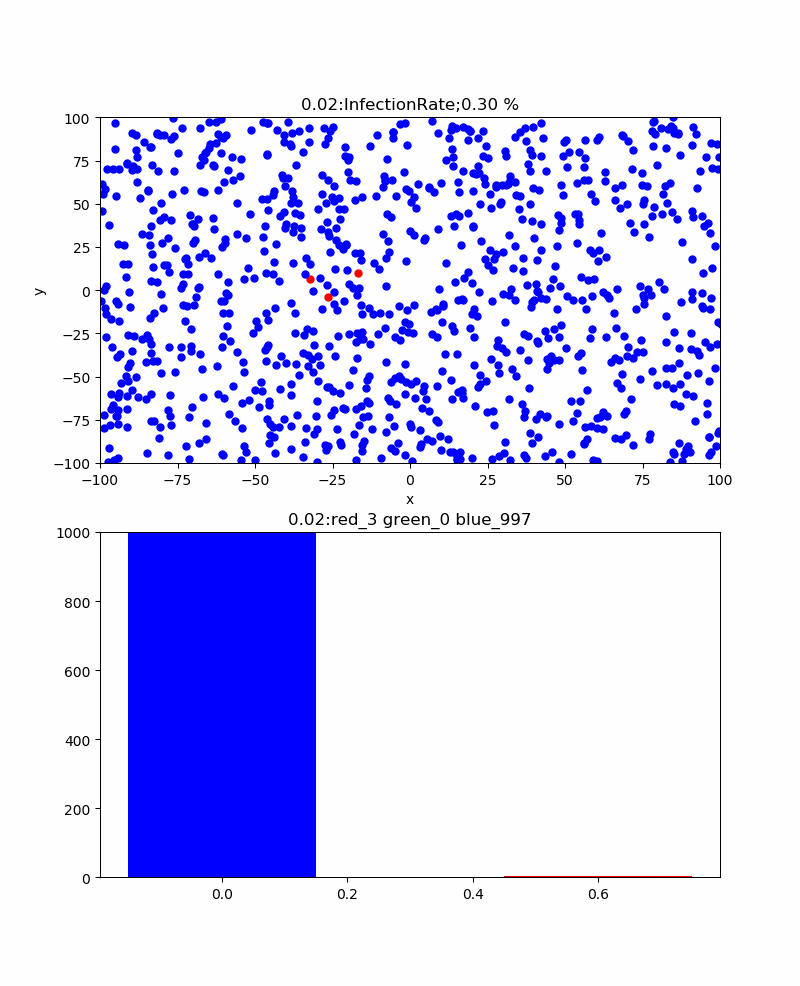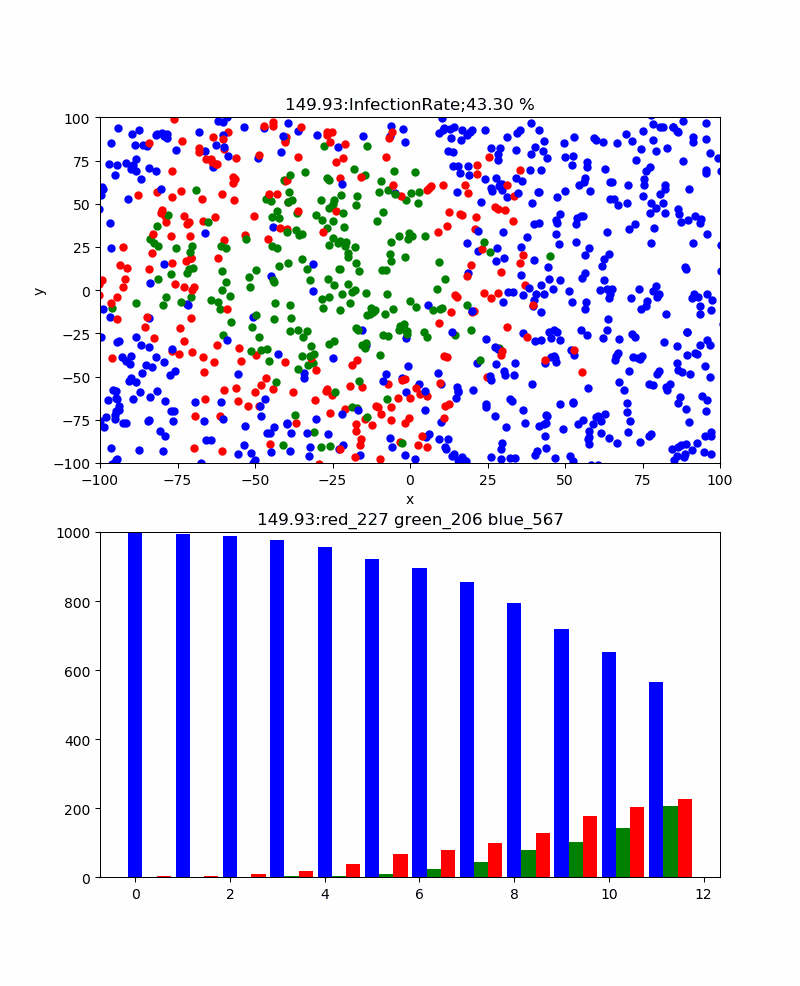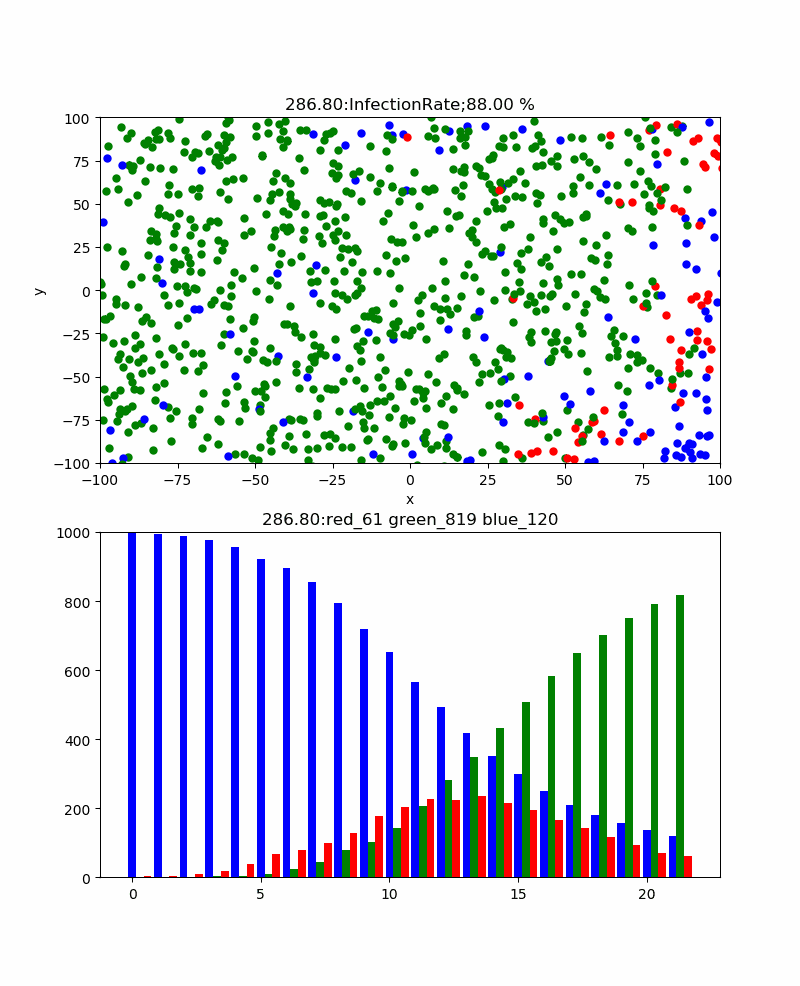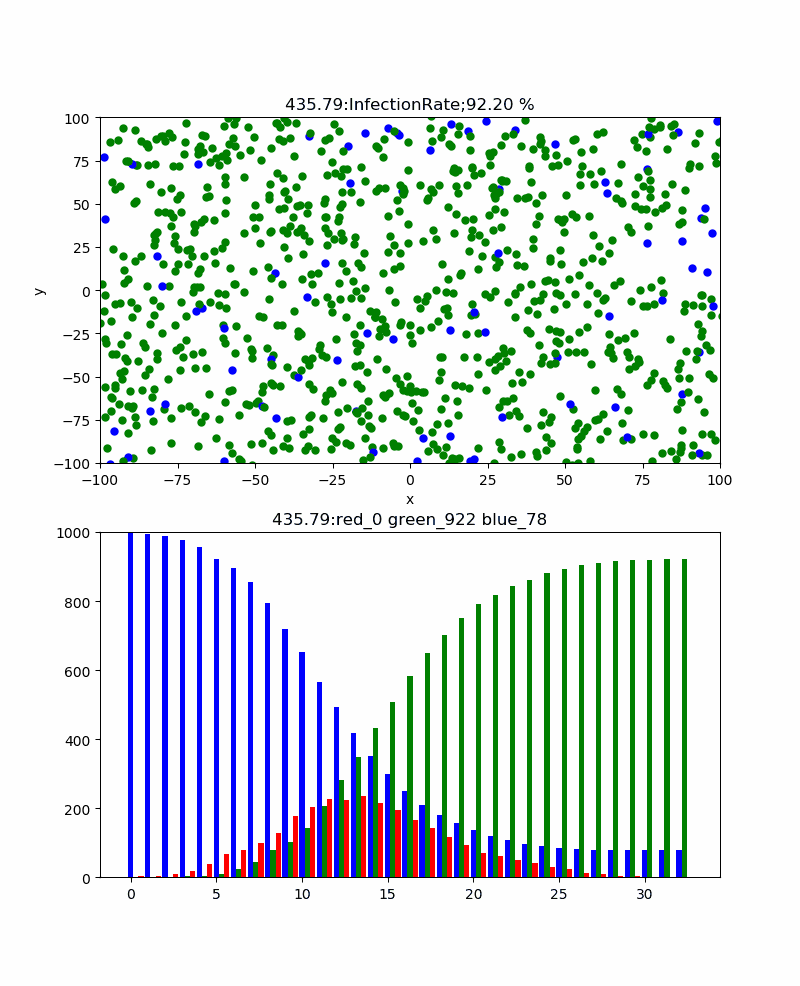
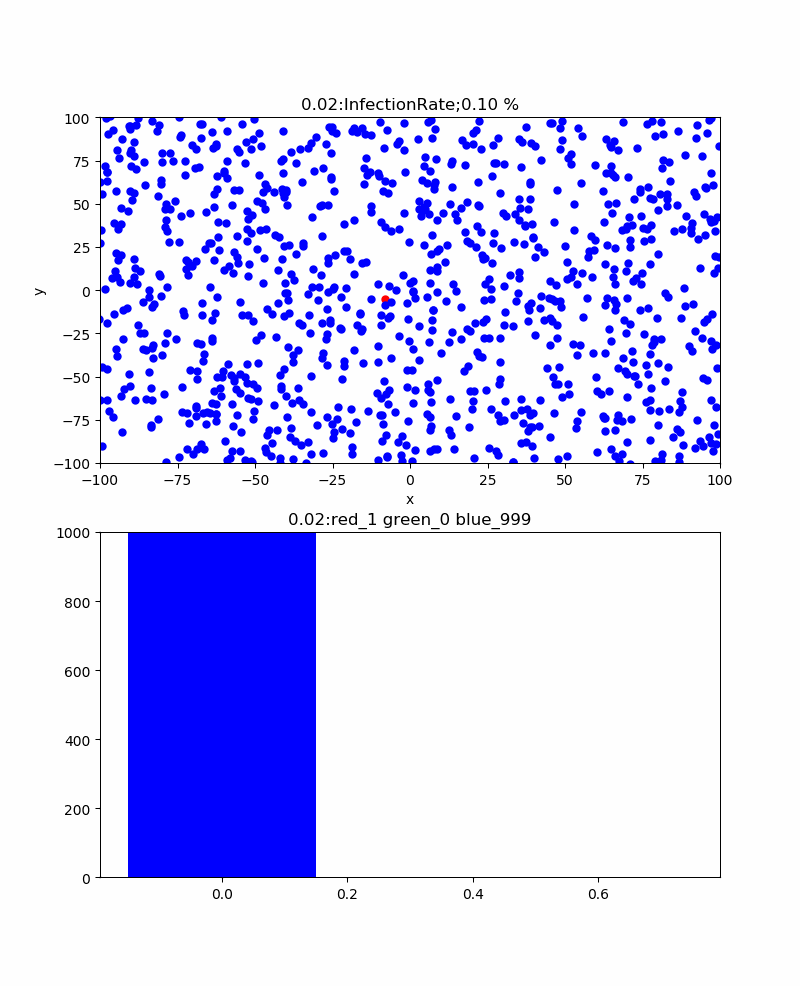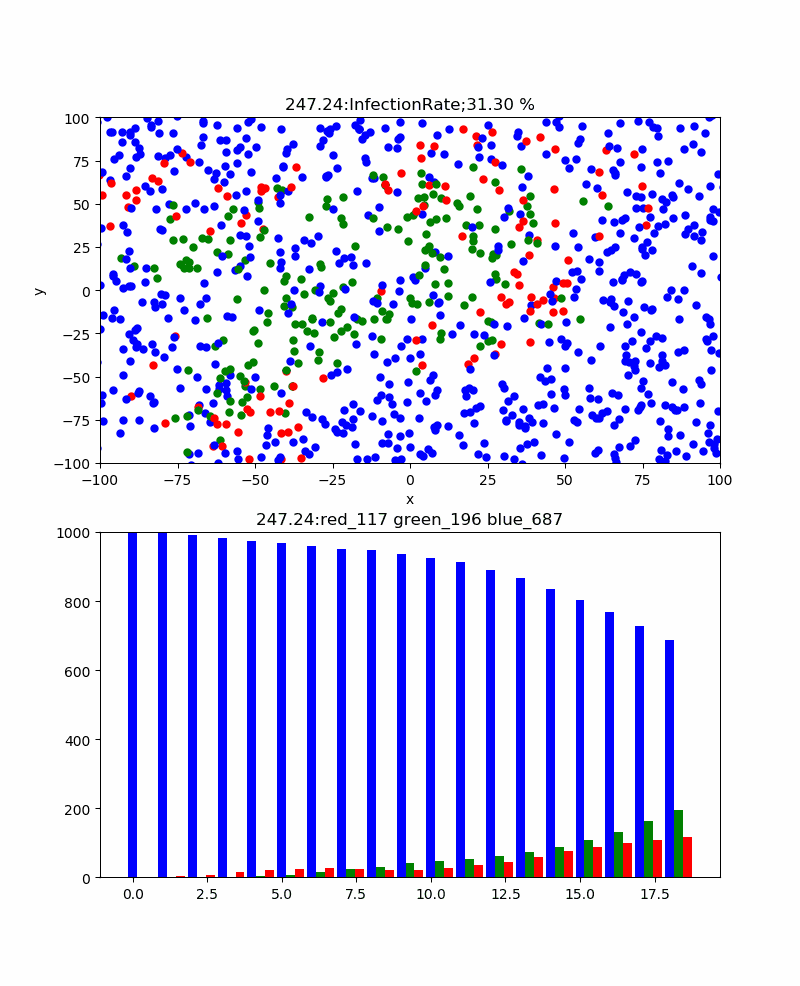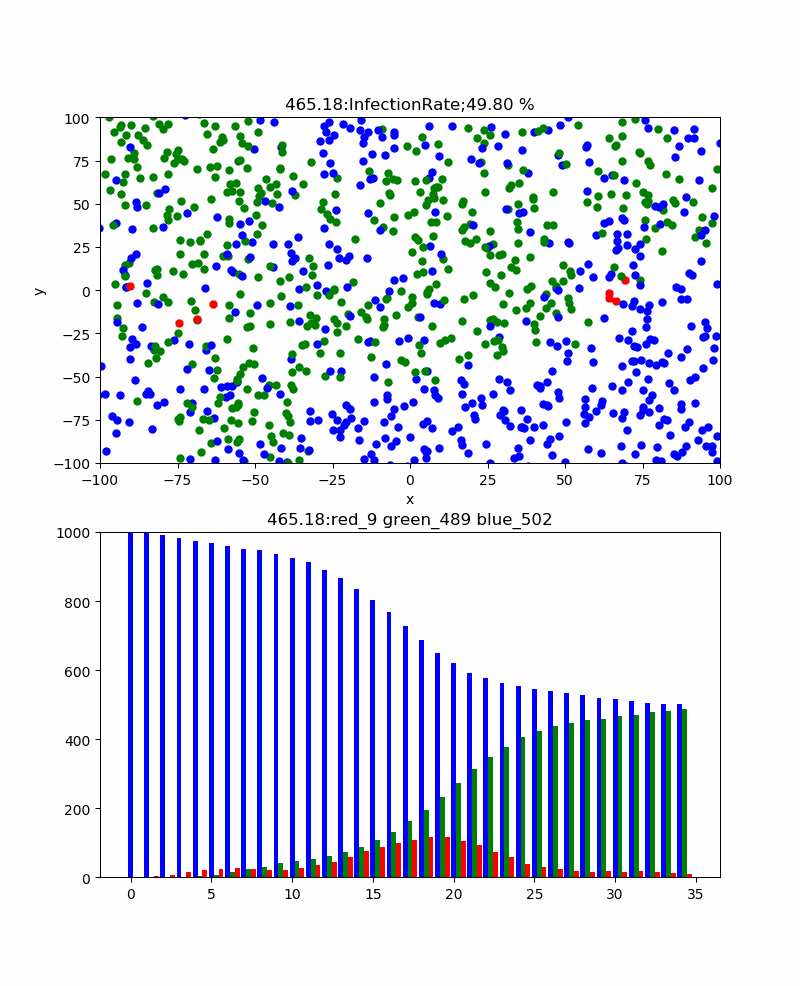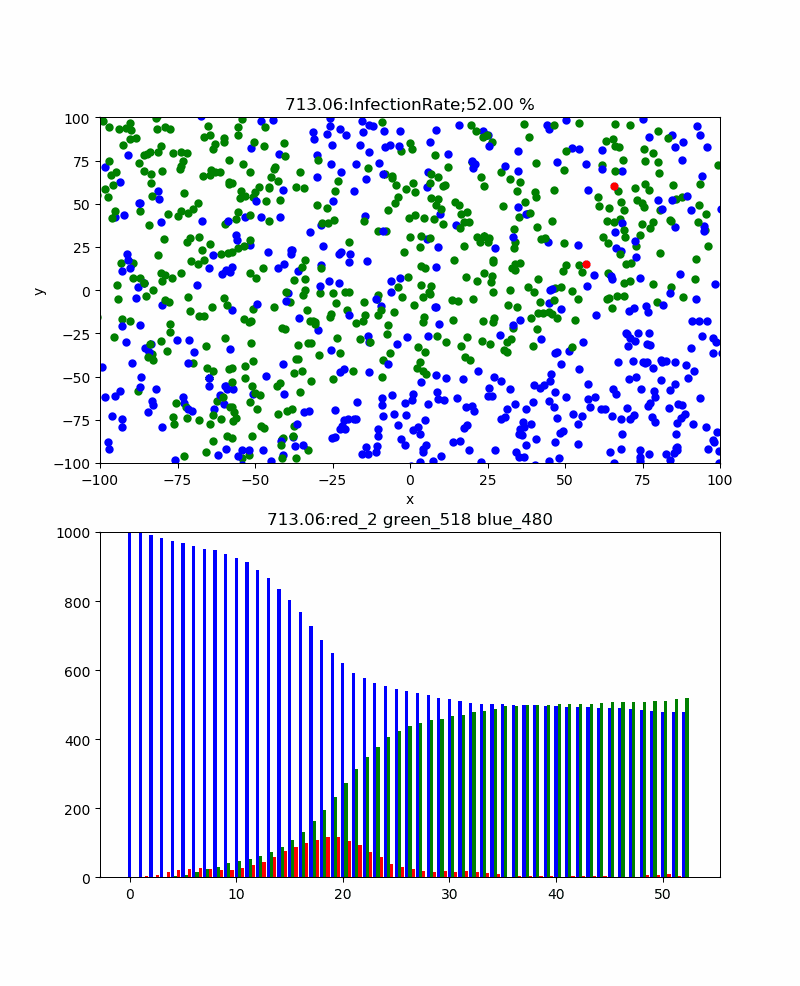
まず、感染率pを変化させると感染伝播の様子や全体としての累計感染率はどう変化するだろうか。
上記の例は感染率p=30%のものであり、累計感染率=100%であり、確実に感染伝播が発生しており、津波のように伝播しているのがわかる。また、感染ピークは404、67.5secであった。この場合、感染伝播速度のような群速度が定義できそうであるが、なんとなくやめました。
一方、感染率p=5%では、累計感染率=92.20%まで下がり、感染伝播の様子も以下のように青が目立つようになり、感染ピーク235と抑えられ、ピーク位置も178secまで伸びた。
さらに、感染伝播が発生するかどうかの臨界的な感染率=3%の場合、以下のとおりとなった。すなわち、津波のような感染伝播は消え、恐る恐る伝播するイメージである。感染ピークも117と低くなり、260secと長くなった。累計感染率=52%まで減少した。なお、この感染率の場合、この計算結果も途中で終了しているが、ほとんど感染せずに初期の段階で消滅することもあった。すなわち、手洗いやマスクなどをうまく使って感染率を一定以下(今回のシミュレーションだと3%以下)に下げられればそれだけで感染伝播をなくすことも可能だという意味です。
これらの結果は、ある程度はマスクやハグやキスや咳エチケットなどのコミュニケーションの方法をコントロールすることにより、長引くかもしれないが累計感染率を下げることが出来ることを示していると考察できる。そして、このシミュレーションをよく見ると、一度治癒した人がいる領域にある青い粒子(未感染者)は感染から守られており、かつ感染伝播が内向きに伝播することはない。すなわち、この領域の集団は、感染に関して堅牢であり滅多なことでは感染するリスクを回避できる状態である。すなわち、集団免疫を獲得したと言える。この集団免疫は簡単に言うと治癒者が集団の未感染者の密度を実質的に下げるため感染伝播を防ぐと言い換えることもできる。
・粒子密度依存性
もう一つの興味は、通常イベント中止とか集会中止などを起こしている、集まらないという常識が正解なのかどうかということである。
ここでは感染確率30%、リカバリ時間30secの条件下で、粒子密度を変化して振る舞いの違いを見てみた。
結果は、感染率の粒子密度依存性を表に表すと以下のようになった。
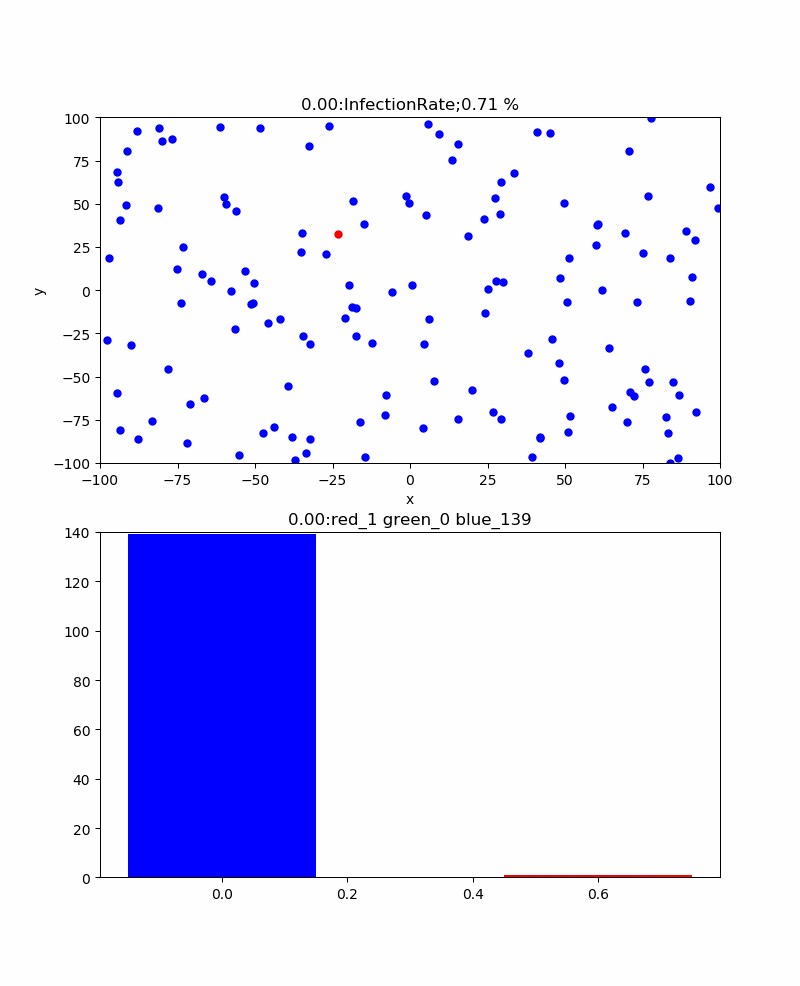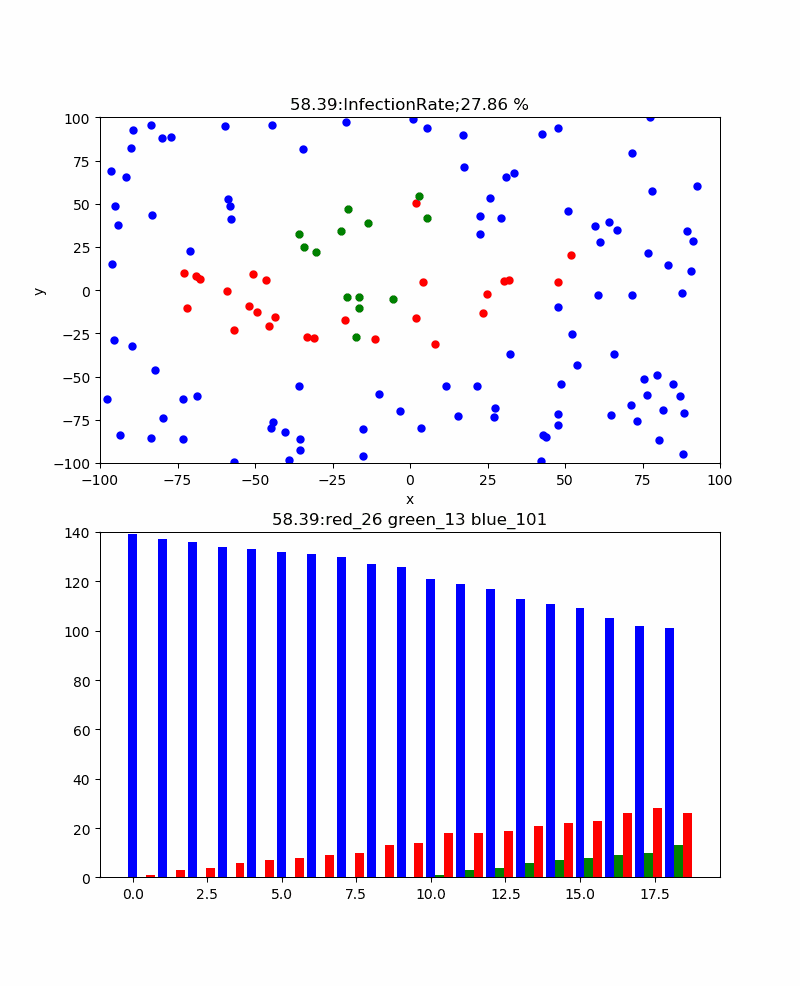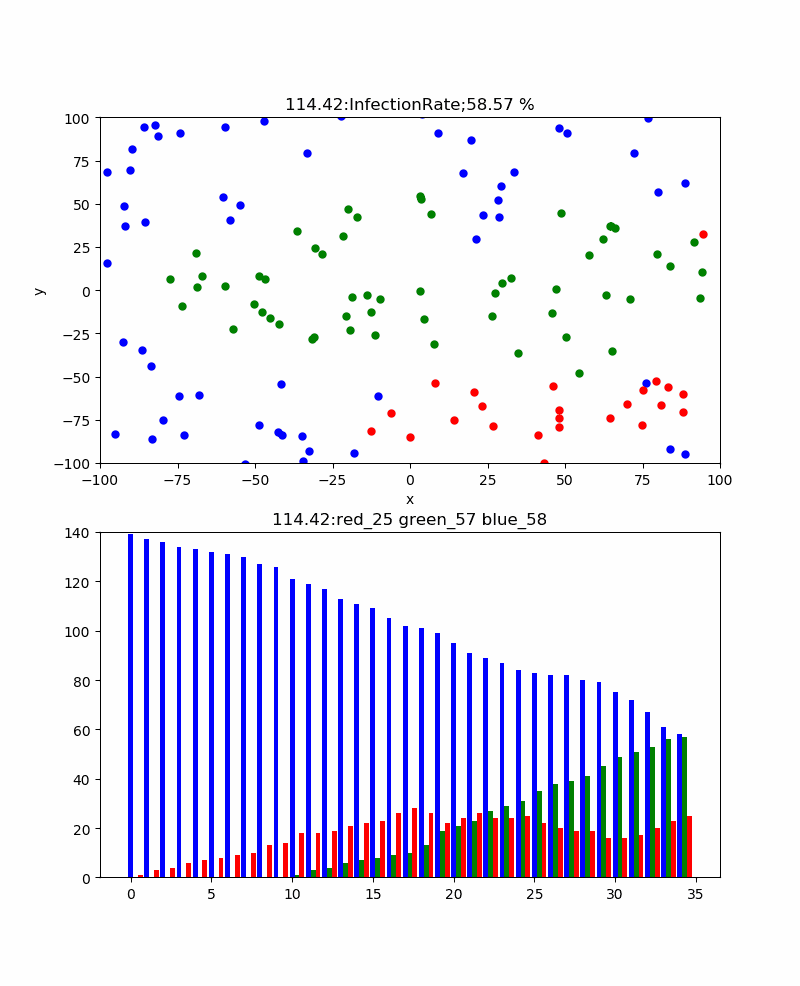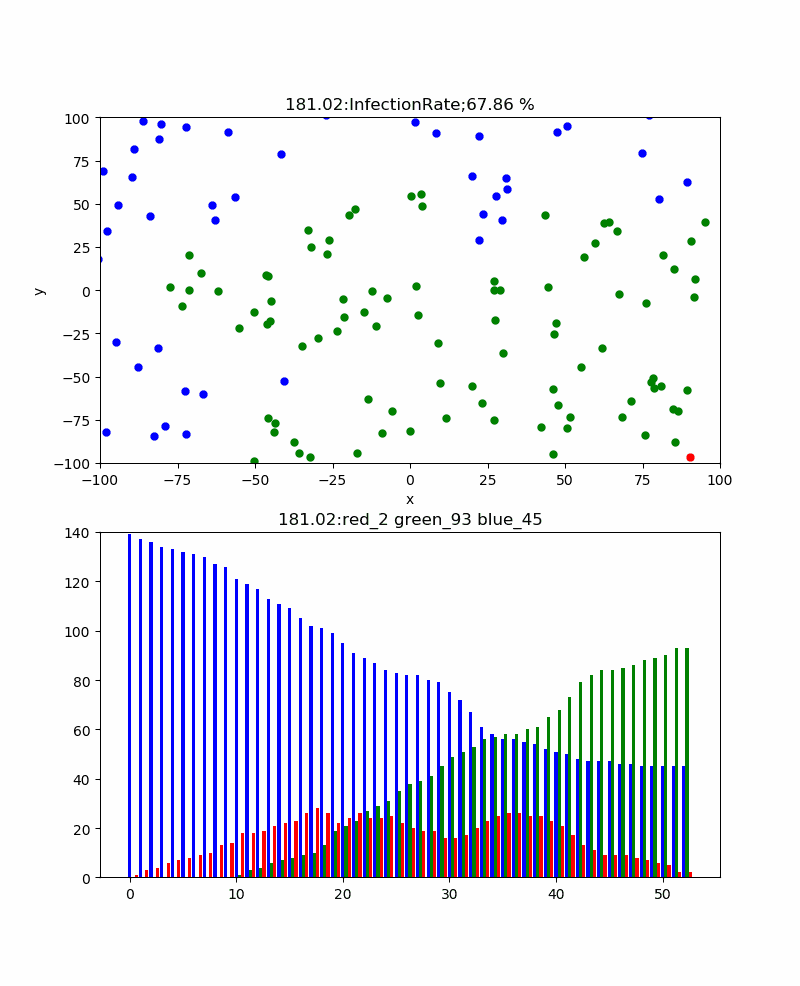
粒子密度 30 40 60 80 100 120 140 160 180 200 累計感染率% 3.33 27.5 8.33 40 33 49.17 67.86 70 91.67 96.5 すなわち60以下の密度では感染伝播は発生せず、80/200X200辺りから感染伝播が発生し始めるため累計感染率が大きくなり始め、200辺りでほぼ100%程度に到達する。
例として、以下に遷移領域である140のときのシミュレーションを示す。
特徴は、上記の密度が十分大きいときは単一ピークであったが、この程度の密度だと感染者のピークはよりなだらかであり、粒子分布の密度ゆらぎを反映して、いくつかのピークを示すことである。そして、感染伝播の様子は密度が小さい領域を乗り越えるために、苦労しており、時には間が空きすぎている場合には感染伝播ができないことが見える。
すなわち、集まらないという方針は全体の密度を下げることにより累計感染率を下げる効果があるばかりでなく、局所的にも集まらないという方針で行動することにより、感染の確率は下げられるということである。・粒子運動依存性
次に、出かけないというのは正しいかどうかを検証しよう。
この効果は一応、粒子運動が大きいと感染伝播や累計感染率にどういう影響があるか見た。
粒子密度120のとき、結果は以下の表の通りとなった。
粒子運動 0 1 2 3 4 8 16 累計感染率% 10 49.17 54.17 83.33 79.17 65.83 74.17 この評価から、静止している場合のこの密度ではほぼ感染はしない。一方、粒子運動があると累計感染率は増加し、激しいほど累計感染率は上がる傾向にあることがわかる。これは単純に上記で記載したように感染伝播を阻む隙間を、運動により乗り越えていると想像できる。
実際のシミュレーションの代表的な例は以下のとおりである。
このシミュレーションを見ると想像通り、少し大きな空間も乗り越えて感染伝播しているのがわかる。
つまり、出かけないというのも感染リスクを下げる行為であることがわかる。
この運動する粒子モデルについてもさらに現実の世界を模したいろいろなシチュエーションも考えてシミュレートできるがきりがないので、今回はここまでとする。まとめ
・コロナ感染をシミュレーションして遊んでみた
・人が集まらず、手洗いやマスクなどをうまく使って感染率を一定以下(今回のシミュレーションだと3%以下)に下げられればそれだけで感染伝播を発生させないことも可能という結論を得た
・集まらない、マスクや手洗いなどにより感染率を下げると、感染の終息には時間がかかるが、累計感染率を下げられることがわかった。
・出かけないの効果検証として、運動する場合は累計感染率が増加することがわかった
・高密度な場合、感染伝播は水滴を落とした波紋の広がりに似ている
・低密度だが感染伝播が存在する場合、治癒者と未感染者が共存する領域が広がって来るが、この領域は感染に対して堅牢であり、集団免疫な状態と言える・このシミュレーションはもっと大規模で行うと、実際の街を模したものへの拡張も可能であるので、もう少し火力を上げて計算してみようと思う
ちなみに、今回はJetson-nanoを利用したが、1000までは問題なく計算できた。
- 投稿日:2020-03-17T22:40:24+09:00
エンジニア向けオープンプロジェクトトレース
https://www.reiwarss.com/OpenProject
Top tags
python
swift
javascript
go
C
C++
C#
Ruby
TypeScript
PHP
- 投稿日:2020-03-17T22:20:51+09:00
Doker Toolboxを使ってDjango開発環境を構築する
はじめに
この記事は主に自分用のDjango開発環境構築メモなので、至らない点も多いと思いますがご了承ください。タイトルの通り、Docker Toolboxを使ってDjango開発環境を構築する手順をまとめておきます。
1.Docker Toolboxを導入
ここは端折ります。(なら書くな)
2.Django開発環境を構築
DockerでDjangoの開発環境を作成を参考にして3つのファイルを用意し、Docker-compose up -d を行います。この記事はデータベースの初期化なども説明されており、めちゃくちゃありがたかったです。
3.ここからが問題だった!!
この環境に限っての話なのかどうなのかは分かりませんが、なぜかconection refusedの嵐です。localhost:8000にアクセスしても、0.0.0.0:8000にアクセスしてもダメでした。もちろん、curlでもダメ。
解決方法
解決方法は、dockerに振り分けられたIPアドレスでアクセスすることでした。つまり、http:// 'マシンIPアドレス' :8000でアクセスすることができました。default machineであれば、最初に立ち上げたときに出ているはずです。また、IPアドレスの確認方法であればググれば出てくるはずなのでわからない場合はググってみてください。
4.おわりに
こんなことで3時間くらい悩みました・・・。将来の自分や、自分と同じような状況に陥った誰かのためになれば良いなぁ。
- 投稿日:2020-03-17T22:10:07+09:00
COVID-19Hokkaidoデータ編③完全自動化(バリデーション・エラー検知)
もくじ
COVID-19Hokkaidoデータ編①スクレイピングなどによる初期データ作成
COVID-19Hokkaidoデータ編②オープンデータ化+自動更新へ向けて
COVID-19Hokkaidoデータ編③完全自動化←この記事だよ!完全自動化へ向けて
現状
- GitHub Actionsにより、元データの読み込み・jsonファイルの生成は既に自動化されている
- GitHub Pagesにより、自動で生成されたjsonファイルのホスティングは実装されている
課題
- 元データはオープンデータとなったものの、ファイルは各自治体担当者さんの手作業で作成されるため、入力値のバリデーションが必要
- データの不整合などでjsonファイルの生成を失敗した場合、何らかのアラートが必要
バリデーション
Python内部でdictを生成し、json.dump()でjsonファイルに書き出しています。つまりdictのデータをバリデーションすべきと言えます。
では何をバリデーションすべきか。たとえばフロントで参照したkeyが存在しなかったら困ります、なのでkeyチェックが必要です。また、日付keyに何故か整数値が入っていたらこれまた困ります。なのでkeyごとに型チェックが必要です。これら2点はフルスクラッチで実装しても良さそうですが、先人が発明した車輪を使わせてもらう事とします。「jsonschema」を利用します。
参考サイト:https://medium.com/veltra-engineering/python-json-schema-validation-6936238f107d
jsonschemaのインストール
pip install jsonschemajsonschemaでバリデーション
事前に定義しておいた、JSONの構造・型に、与えられたdictが適合するかチェックします。
適合しなければエラーが出て、適合すれば何も出力されません。使い方などは上記参考サイトで丁寧に解説されていますので、実装のみ紹介します。
SCHEMAS = { "patients":{ スキーマ定義 }, "contacts":{ スキーマ定義 } #〜割愛〜 }というように、keyごとにスキーマ定義をSCHEMASとして定義します。
def validate(self): for key in self.data: jsonschema.validate(self.data[key], SCHEMAS[key])self.dataとSCHEMASはkeyが一致しています。self.data[key]は、そのままjsonに出力すべきdictです。
したがって、例えば入力ミスなどでkeyが欠損していたり、型が整合しない場合はエラーが発生して処理が中断します(jsonは生成されない)。
おかしなjsonは生成されず、最後に正常に出力されたjsonが残り続ける訳です。
(5と入力すべき箇所に五と入力されていれば引っかかりますが、6と入力されていたら素通りします。この手のヒューマンエラーはそもそも避けようがない気もしますが)たとえばdateにはintegerが入るべき、と定義したにも関わらずデータがstringだった場合は、以下のようなエラーが出て処理が中断されます。
Traceback (most recent call last): File "main.py", line 231, in <module> dm.validate() File "main.py", line 90, in validate jsonschema.validate(self.data[key], SCHEMAS[key]) File "/opt/hostedtoolcache/Python/3.8.2/x64/lib/python3.8/site-packages/jsonschema/validators.py", line 934, in validate raise error jsonschema.exceptions.ValidationError: '2020-03-17T21:31:40.309090+09:00' is not of type 'integer' Failed validating 'type' in schema['properties']['last_update']: {'default': '', 'type': 'integer'} On instance['last_update']: '2020-03-17T21:31:40.309090+09:00' ##[error]Process completed with exit code 1.Slackにエラーをアラート
参考サイト:
Qiita - SlackのWebhook URL取得手順
Qiita - GitHub Actionsを定期実行して結果をSlackに通知する理由問わず、データ生成に失敗した場合にSlackに通知するようにします。
上記サイトを参考に以下のとおりyamlを記述しました。name: Python application on: schedule: - cron: '0 * * * *' jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python 3.8 uses: actions/setup-python@v1 with: python-version: 3.8 - name: Install dependencies run: | python -m pip install --upgrade pip pip install -r requirements.txt - name: Run script run: | python main.py - name: Slack Notification # ここから if: failure() uses: rtCamp/action-slack-notify@master env: SLACK_MESSAGE: 'Error occurred! Please check a log!' SLACK_TITLE: ':fire: Data Update Error :fire:' SLACK_USERNAME: covid19hokkaido_scraping SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK }} # ここまで追加 - name: deploy uses: peaceiris/actions-gh-pages@v3 with: github_token: ${{ secrets.GITHUB_TOKEN }} publish_dir: ./data publish_branch: gh-pagesSetting→SecretsにSLACK_WEBHOOKを追加しておく必要があります(さもなくばwebhookURLがオープンソースになってしまいます)。
Secretsに格納した値は暗号化されます。yamlからはsecrets.{ なまえ }で取得出来ます。
GITHUBから始まる{ なまえ }は使えません。以上を実装すると、エラー発生時には以下のようにSlackに投稿されます。
終わりに
以上で、データ取得→jsonファイル生成のバリデーション込みの自動化処理が完成しました。
ただ、現在はkeyチェックと型チェックのみなので、例えばあまりにもな異常値を検知する仕組みなど、バリデーションにはキリがありません。
またデータ生成は自動化されましたが、フロント側の非同期通信はデバッグ含めた実装中です。
今後も改善の余地がありますが、当初の半分手作業から比べると劇的に運用がラクになったと思います。以上で3回に渡った連載は終了となります、ありがとうございました。
- 投稿日:2020-03-17T22:04:15+09:00
機械学習のアルゴリズム(サポートベクターマシン応用編)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
前回、サポートベクターマシンの基本的なところについて書きました。前回は、ハードマージンと言って正例と負例がちゃんと分離できるSVMを扱いましたが、今回は
- ソフトマージン(ノイズの混ざった分類)
- カーネル法とカーネルトリック(線形分離不可能な問題)
について言及していこうと思います。
ソフトマージンSVM
前回と違って、下図のような赤丸と青丸が微妙に分離できない例を考えます。
その前に復習
ハードマージンSVMの式はパラメータの集合を$w$としたときに、 $$ \frac{1}{2}|w|^2$$を$$ t_n(\boldsymbol{w}^Tx_n+w_0) \geq 1$$という制約条件化で最小化するという問題でした。ソフトマージンはこの制約条件を緩めた問題に変えます。
制約条件の緩和
条件緩和のために、スラック変数$\xi$とパラメータ$C$を導入します。スラック変数は、サポートベクターと境界線でどの程度誤差を許容するかという変数のことで、$C(>0)$は制約条件の厳しさを表します。これらを導入すると上に書いた解くべき問題が以下のように変わります。
\frac{1}{2}|w|^2+C\sum_{i=1}^{N}\xi_i \\ t_n(\boldsymbol{w}^Tx_n+w_0) \geq 1-\xi_n \\ \xi_n \geq 0$C$と$\xi$の関係ですが、$C$が大きくなると$\xi$が小さくなければ最小化できず、$C$が小さければ$\xi$がある程度大きくても最小化できるということを意味します。$C$が無限大では、$\xi$がゼロしか許容できない(=マージン内にデータを許容しない)のでこれはハードマージンSVMと同じになります。
ラグランジュ未定乗数法による解
ハードマージンのときと異なり、制約条件が2つに増えたため、ラグランジュ乗数も$\lambda$と$\mu$の2つにします。
L(w,w_0,\lambda, \mu)=\frac{1}{2}|w|^2+C\sum_{i=1}^n\xi_i-\sum_{i=1}^{N}\lambda_i \{ t_i(\boldsymbol{w}^Tx_i+w_0)+\xi_i-1\}-\sum_{i=1}^n\mu_i\xi_iこれを$w$、$w_0$、$\xi$について偏微分し、それぞれゼロとおくと、
w=\sum_{i=1}^n\lambda_it_ix_i \\ \sum_{i=1}^n\lambda_it_i=0 \\ \lambda_i=C-\mu_iを得ることができ、ラグランジュ関数に代入すると、
L(\lambda)=\sum_{n=1}^{N}\lambda_n-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}\lambda_n\lambda_mt_nt_mx_n^Tx_mとなり、これはハードマージンの時と全く同じ式になります。ただし、制約条件が
\sum_{i=1}^n\lambda_it_n=0 \\ 0 \leq \lambda_i \leq Cとなります。こちらもハードマージンと同様SMOを使ってパラメータを求めることが可能です。(今回は省略)
カーネル法とカーネルトリック
以下のようないかにも直線で分離できなそうな例を考えてみます。
こういう形になっている場合は、2次元→3次元のように、より高次元の空間に点を動かしたうえで平面分離するということをやります。高次に変換する方法をカーネル法と呼び、変換するための関数をカーネル関数と呼びます。
基底関数
あるデータ列$\boldsymbol{x}=(x_0, x_1, \cdots, x_{n-1})$を射影したデータ列を$\boldsymbol{\phi}=\{ \phi_0(\boldsymbol{x}), \phi_1(\boldsymbol{x}), \cdots, \phi_{m-1}(\boldsymbol{x}) \}$とします。この$\phi(x)$のことを基底関数と呼びます。前回のSVMでは線形分離が扱えたので、基底関数は$$\phi(x)=x$$と等価でした。その他、よく使われる基底関数としては、多項式$$\phi(x)=x^n$$や、ガウス基底$$\phi(x)=\exp\left \{-\frac{(x-\mu)^2}{2\sigma^2}\right \}$$があります。
基底関数を適用することによって、ラグランジュ関数の$x_n^Tx_m$の部分が$\phi(x)_n^T\phi(x)_m$に変わります。
L(\lambda)=\sum_{n=1}^{N}\lambda_n-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}\lambda_n\lambda_mt_nt_m\phi(x)_n^T\phi(x)_mこの$\phi(x)_n^T\phi(x)_m$は、内積計算であり、データ点が多いと計算量が膨大になることから、少し工夫をします。
カーネル関数とカーネルトリック
実は、$\phi(x)_n^T\phi(x)_m$は$k(x_n,k_m)$に置き換えることが可能です。$k(x_n,k_m)$のことをカーネル関数と言います。このように置き換えることで、面倒な内積計算を省略することができます。このことをカーネルトリックと言います。詳細は「カーネルトリック」を参照ください。
特に、上で挙げたガウス基底関数を用いたカーネル関数のことをRBFカーネル(Radial basis function kernel)と言ったりします。
最終的にラグランジュ関数は
L(\lambda)=\sum_{n=1}^{N}\lambda_n-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}\lambda_n\lambda_mt_nt_mk(x_n,x_m) \\ \text{subject.to }\sum_{i=1}^n\lambda_it_n=0,0 \leq \lambda_i \leq Cとなります。実際にはこの数式を解き、$\lambda$を求めた後に$\boldsymbol{w}$や$w_0$を求めます。
pythonでやってみる
前回は単純なsklearn.svm.LinearSVCで分類を行いましたが、より一般的なsklearn.svm.SVCを使ってみます。
APIドキュメントを見る
APIの説明を見ると以下のようになっています。
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
ここまでの内容を理解しているとだんだんこの説明が理解できるようになってくる。
kernelパラメータが基底関数を決めるパラメータで、線形だとlinearで、ガウスカーネルだとrbfになります。ここで重要なのはCとgammaです。
Cは制約条件の強さを決めるパラメータで、大きくなるほど制約が厳しくなります。gammaは、ガウス基底関数の広がりを決めるパラメータで、逆数になっているので、小さいほどなだらかになります。実装してみる
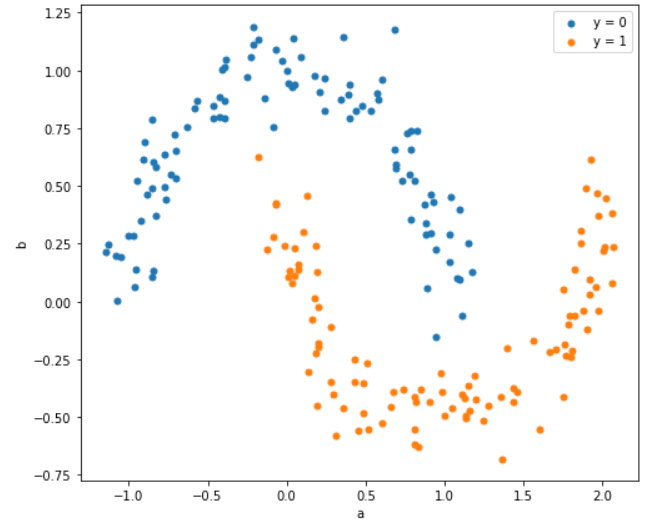
分類するデータは最初に示したデータを使います。実はこのデータは、sklearn.datasets.make_moonsというAPIを使っています。サンプル数やノイズの強弱を指定できます。
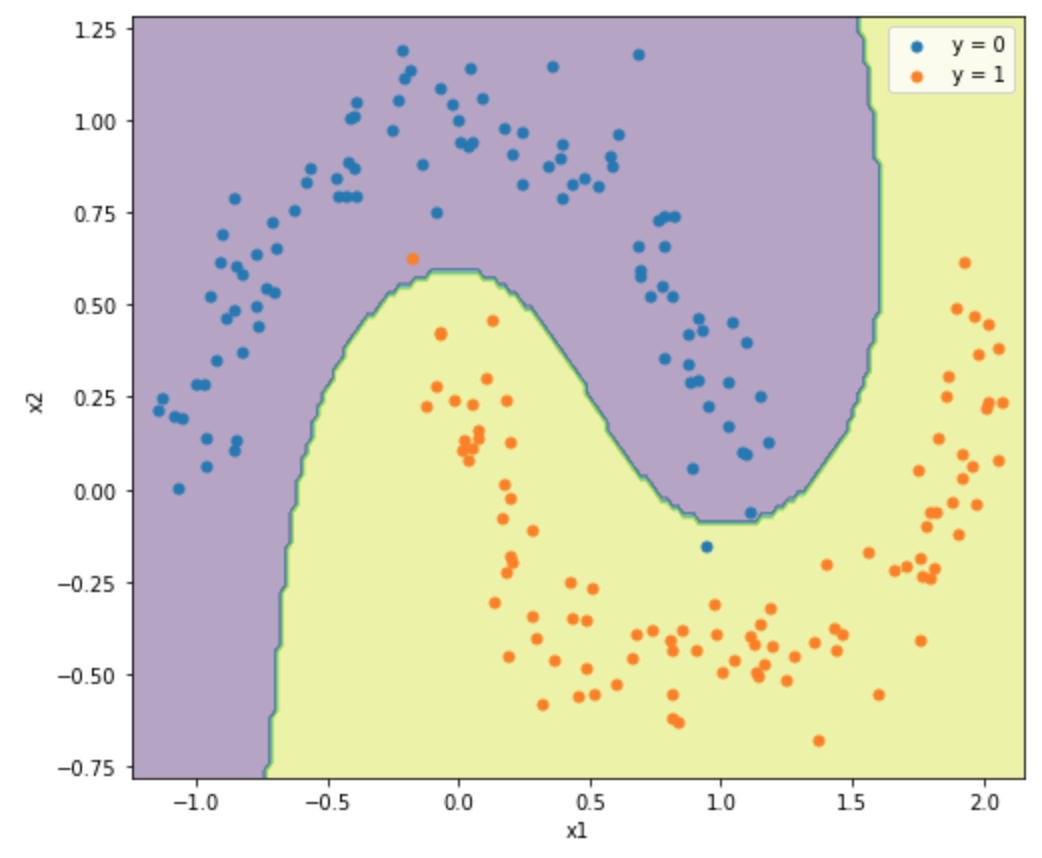
ついでに決定境界も図示します。決定境界は線形でないため、等高線として描きます。具体的にはmatplotlibのcontourfという関数を使います。import numpy as np import pandas as pd from sklearn import svm from sklearn.datasets import make_moons import matplotlib.pyplot as plt %matplotlib inline X, y = make_moons(n_samples=200, shuffle = True, noise = 0.1, random_state = 2020,) a0, b0 = X[y==0,0], X[y==0,1] a1, b1 = X[y==1,0], X[y==1,1] model = svm.SVC(C=1.0, kernel='rbf', gamma=1) model.fit(X, y) x1_min,x1_max = X[:,0].min() - 0.1,X[:,0].max() + 0.1 x2_min,x2_max = X[:,1].min() - 0.1,X[:,1].max() + 0.1 xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,0.02), np.arange(x2_min,x2_max,0.02)) Z = model.predict(np.array([xx1.ravel(),xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.figure(figsize=(8, 7)) plt.contourf(xx1,xx2,Z,alpha = 0.4) plt.xlim(xx1.min(),xx1.max()) plt.ylim(xx2.min(),xx2.max()) plt.scatter(a0, b0, marker='o', s=25, label="y = 0") plt.scatter(a1, b1, marker='o', s=25, label="y = 1") plt.legend() plt.xlabel("x1") plt.ylabel("x2") plt.show()
分離できているみたいですね。APIでは、サポートベクターも取得できるんですが、実際のデータ数と比較しても少ないデータで近似できており、メモリの節約と計算の高速化に寄与しています。
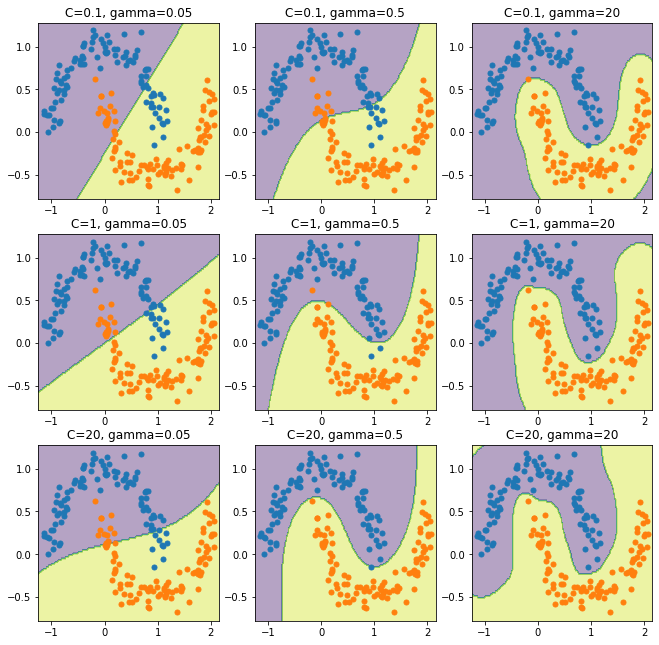
ハイパーパラメータの調整
上では
Cとgammaを適当に決めましたが、これを変化させるとどうなるでしょう。実際に描いてみましょう。list_C = [0.1, 1, 20] list_gamma = [0.05, 0.5, 20] x1_min,x1_max = X[:,0].min() - 0.1,X[:,0].max() + 0.1 x2_min,x2_max = X[:,1].min() - 0.1,X[:,1].max() + 0.1 xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,0.02), np.arange(x2_min,x2_max,0.02)) plt.figure(figsize=(11, 11)) plt.xlim(xx1.min(),xx1.max()) plt.ylim(xx2.min(),xx2.max()) plt.xlabel("x1") plt.ylabel("x2") for i in range(len(list_C)): for j in range(len(list_gamma)): model = svm.SVC(C=list_C[i], kernel='rbf', gamma=list_gamma[j]) model.fit(X, y) Z = model.predict(np.array([xx1.ravel(),xx2.ravel()]).T) Z = Z.reshape(xx1.shape) ax = plt.subplot(len(list_C), len(list_gamma), i*len(list_C)+j+1) ax.set_title("C={}, gamma={}".format(list_C[i], list_gamma[j])) ax.contourf(xx1,xx2,Z,alpha = 0.4) ax.scatter(a0, b0, marker='o', s=25, label="y = 0") ax.scatter(a1, b1, marker='o', s=25, label="y = 1") plt.show()結果は以下のようになりました。
上で説明したように、
Cが大きいほどよく分離されており、gammaが大きいほど曲線が複雑になっています。ただ、一番右下になると過学習しているようにも見え、パラメータのチューニングが必要になりそうです。パラメータをチューニングするためには、サンプルを学習データと検証データに分けて検証データで予測した時の一致度が高くなるパラメータを探すという作業が必要になります。これは交差検証(Cross Validation)というのですが、別の機会にまとめてみるつもりです。
まとめ
サポートベクターマシンをハードマージンからソフトマージンに拡張し、非線形分離まで扱えるようにしました。こうして見てみると、かなり複雑なクラス分類もやって退けられるような気がしてきました。ニューラルネットワーク以前に人気だったのも納得ですね。

- 投稿日:2020-03-17T21:48:45+09:00
50からの手習いで、G検定とE資格に合格してみた
JDLA(日本ディープラーニング協会)のG検定、E資格
JDLA(日本ディープラーニング協会)とは、松尾豊教授が理事長(2020年3月現在)を務める一般社団法人であり、深層学習の「活用促進」、「人材育成」、「啓蒙・普及」等を行っている団体です。
G検定、E資格とは、JDLAが認定している資格試験で、機械学習、深層学習に関する一般的な知識を有していることを認定する<G検定>と、実装する能力と知識を有していることを認定する<E資格>の2種類がある。詳細は、JDLAのホームページをご参照ください。
てなことを書いても、ここを見に来た人はご存じのことと思います。
不合格から合格までの経緯
僕の受験歴は、
・2019#1にG検定を合格
・2019#2にE資格を不合格
・2020#1にE資格を合格
である。特に他の合格者と異なるのは、2回のE資格受験のために、2社の異なる会社の「認定プログラム」を受講したことです。
僕がこの資格取得する目的は、自称「趣味」です。つまり、受講費用は全額実費です。50を過ぎた単なるメーカーのサラリーマンにとっては、とても高額です。ハッキリ言って入金時は手が震えました。
しかし、何故、2社の異なる会社の認定プログラムを受講しなければならなかったのか、その経緯を顧みることで、これから受験する人の一助になり、かつ関係者への問題提起になれば、と思いました。G検定に合格するまで
2018年の夏、流行りのAIスキルを身に着けようと「Python基礎」のセミナーを受講したのがきっかけです。同じコワーキングスペースで開催されたデータ分析セミナー(9回/3ケ月)を受講しているうちにJDLAの存在をしり、勉強したことの整理を兼ねてG検定の受験を決めました。
使ったテキスト、参考書は以下です。
・ディープラーニングG検定公式テキスト(JDLA監修)
・徹底攻略ディープラーニングG検定問題集(明松真司、田原眞一)
・AI白書(情報処理推進機構)
・人工知能は人間を超えるか(松尾豊)
最近は、いろいろと問題集や参考書が出版されていますが、当時はこれくらいでした。AI白書以外は、繰り返し読んで勉強しました。(当時は問題数が少なくて不安でした。とにかく問題を1問でも多く解いて勉強してください。)
また、データ分析セミナーを受講していたので、テキストの内容を解説無しで理解できました。初めての方は、何等かのG検定向けセミナーを受講すべきと思います。
AI白書は、国内の自動運転、倫理関係、法律関係を中心に。さらに海外各国のAIの取り組みを読みました。基本、どこに何が書いてあったかを覚えることが大事と思います。全部は読み切れませんので。
受験はコワーキングスペースの個室を使って、2時間集中!
なんとか合格をもぎ取れました。E資格1回目の受験に向けて
G検定の合格後、E資格の受験について考えました。これからの自分にとって必要かもしれないものとは?等々を家族旅行しながら考え、このままの勢いで取得を決意。(そんな大袈裟なものでもないですが)
実際に行動を起こしたのは4月から。まずは、認定プログラムの選定です。E資格1回目の認定プログラム選定
当時、5社の認定プログラムと「以下の事業者からも受講できます」という3社(だったと思う)の認定プログラムがありました。この3社の事業者は、5社の認定プログラムの講義を配信して、認定試験のみ自社で行うスタイルと思います。
僕も1回目は、この事業者(X社)が開催するプログラムを受講しました。
選定理由は、
・金額が他社より少し安かった。(20万円以下)
・オンライン配信をしている。
・合格率が80%以上とのふれこみ。
です。認定プログラムだから、会社によって大差無いと思いました。(これは2回目で大きな間違いであったことに気づく)また、実費支払いなので、とにかく安い会社を探しました。X社は「応用数学」の事前テストをパスすればその講座が免除され、それだけ安くなるので、頑張って免除を獲得しました。X社の認定プログラムを受講してみて
プログラムの内容は、「応用数学」、「機械学習」、「深層学習・強化学習」に分かれていて、その中をさらに主な項目に分割された動画配信とそれに伴うPDF資料がありました。そして、どこまで動画を再生したかがグラフで表示されていました。
修了認定を取得するには、
・上記の動画を全て聴講する。
・「応用数学」、「機械学習」、「深層学習」のレポートを提出する。
・「応用数学」、「機械学習」、「深層学習」のテストをクリアする。
の3つが必要でした。内容はともかく、JDLAが認定会社に、この3種類を修了させることを義務付けていると思われます。X社の講義・資料は、きっちりとしていましたが、以下の点が気になりました。
・講義の動画にバックミュージックが流れる。
→事業者に音楽の削除を依頼したが、1回目は自分の端末で調整してくださいとの回答。2回目に依頼したら、配信元が修正しないのでできない、との回答。イヤホンで聞くと、バックミュージックが大きくて講義内容を集中して聞けないことが残念でした。
・質問対応が不可であった。
→これは最初の規約をしっかりと読んでいなかった僕の責任です。「安かろう。悪かろう。」?なのかもしれませんが、質問が受け付けられないのはどうか、とも思いました。
そんなこんなで、なんとか締め切り期日内に全ての課題をクリアして修了することができ、E資格の受験資格を得ることができました。
受験前の感想としては、問題集・参考書が無いため、認定プログラムから配信された問題をひたすら(過学習みたいに)勉強して覚えることしかありませんでした。しかし問題数が少なく、とても不安でした。E資格を受験。不合格の通知を受けて(認定プログラムとは?)
2019#2のE資格を受験。生まれて初めてのCBT受験でした。会場に入ると本人確認をして、すぐ荷物をロッカーに。最後の確認ができず、焦りました。パソコンをログインして、自分のタイミングで開始。PC画面に残り時間が表示されます。。。。2時間後、不合格を確信。
全く歯が立たない。初めて見る用語。初めて見るコード。配信された問題と比べて格段にレベルが違う、という印象でした。
約1週間後、予想通り、不合格通知を受理。確かに不合格は自分が悪い。ですが、認定プログラムとは?
JDLAが配信している動画には、「認定プログラムは自動車教習所的な意味合い」という趣旨の説明がなされていました。であれば修了認定を受ければ、もっとE資格のテストレベルに近いものであって欲しいと思いました。X社からは、低額で継続受講の連絡が入ってきました。迷いましたが、このプログラムを受講しても、今後、僕は合格しそうに無いと判断し、継続受講は諦めました。
JDLAに、どの認定プログラム会社が、どのくらいの合格率を出したかを問い合わせました。認定プログラムを選定する情報の一つとして事務局に質問しましたが、「公表できません」とのお返事がありました。
今後、E資格の受験を継続すべきか、とても悩みました。
如何せん、認定プログラムの内容に関する情報が少なすぎて、どの会社の認定プログラムを受講すべきか、判断が付きにくいのです。また、受講者のスキルによっても変わってくると思います。その点を善処いただくようJDLA事務局にメール送信したところ、「いただいたご意見は事務局長をはじめ協会内にて共有し、今後の参考とさせていただきます。」とのお返事をいただきました。E資格合格に向けての取り組み(2回目)
さて、趣味とはいえ、ここまで時間と労力と費用をかけてE資格が取れなかったままでいるのは、きっと後悔すると思い、再チャレンジすることを決めました。それには、以下のことが重なったことも重要でした。
・データ分析セミナーでお世話になった先生の勧め。
・まとまった額の還付金を入手。
・社内の異動で、時間に余裕ができた。
どれ一つ欠けても、ダメだったと思います。また、セミナー等で知り合った若い人たちが、みんなE資格を取得したことも、モチベーションを上げるきっかけとなりました。認定プログラムは、上記のお世話になった先生がおられるZ社にしました。費用は、前回の約1.5倍でした。しかし、講義内容は一変しました。
・「応用数学」の講義は無し
・配布された資料にそった講義動画を受講
・オンライン受講でも対面講義の動画を配信(復習用)
・講義内容の理解度チェックシート。随時質問対応可
・豊富なサンプルコードによる習得
・独自のE資格対策問題の配信
等々、さすがに額に見合った充実した内容でした。ある程度のベーススキルを有していないとついていけません。(僕は落ちこぼれ状態でした。)また、機械学習では、最適化の式の詳細な説明から実装まで。深層学習の内容では、一般的なCNN,RNN,GAN等から、最新の内容まで幅広く、難しい内容もポイントをおさえた講義であり、会社によってここまで違うのかと思いました。
修了認定を取得するには、
・動画を全て聴講する。
・「応用数学」、「機械学習」、「深層学習」のテストをクリアする。
・指定された課題をクリアするPythonコードを作成し提出する。
の3つが必要でした。コードを書きなれていない僕は、コードの提出は困難でした。結局、E資格認定の締め切り期日までにコード作成はクリアできませんでした。オンライン受講でしたが、希望すれば講師の方との面談が可能で、面談で相談したところ、修了認定書が発行可能な締め切りは先なので、コード作成を後回しにして、E資格対策を優先するアドバイスをいただき、その通りしました。
ちなみに、1回目の認定プログラムで修了認定を取得したので、2年間は受験資格がありますので。E資格、2回目の受験
受験3週間前から臨戦態勢。最後の追い込みと称して、時間があれば復習していました。時には、社内の会議室に籠って。時には遠距離出張の移動中に。さらには年休を取得して、コワーキングスペースに朝から行って。
とにかくなりふり構わず?対策しました。使ったのは、認定プログラムの資料とネット上の資料。参考書までは手が回りませんでした、
そして2020#1を受験。
普通なら「ここまでしたのだから余裕」ってことになりますが、これまた。。。。前回ほどではありませんが、新しい用語は???あと、コードのスキル不足は否めず。受験後、今回もダメだと思いました。お世話になった講師の先生にも、もう1回頑張りますの連絡をしてました。
同じ認定プログラムを受講した人は、8割以上できた等のSLACK投稿。
そして合否通知メールを見たところ、「合格」!
正解率を見た瞬間、恐らく最下位合格と思われました。
講師の先生からは、「追い込みが効きましたね」と言われました。確かにそうです。でも、合格は合格。1年越しで目標を達成し、ホッと一息つけました。E資格の認定プログラムについて思うこと
X社、Z社の異なる2つの認定プログラムを受講しました。知り合った学生に、どの会社のプログラムを受講したかを尋ねると、Y社とのこと。学生割引があって、超格安で受講できるからだそうです。しかし、選択の自由は無かったとも言ってました。全てを比較した訳ではありませんが、認定プログラムの内容は、
・すでに十分なスキルを保有している人向けのプログラム
・G検定合格レベルからE資格レベルに引き上げる為のプログラム
・全くの初心者レベルから合格させる為のプログラム
等、受講する人のスキルによって、その人に合ったプログラムがあるように思いました。だとすれば、ミスマッチした僕の1回目の受講は、運が悪かったとして気持ちを整理するしかありません。(高額だったけど)
ですが、これから受講する人は、その点を注意して、できるだけ情報収集して進んで欲しいと思います。E資格に合格してみて
「何事も合格してからが大事」ということで、まずは認定プログラムの残課題のコードを構築中。それ以前に、コードのお勉強を一からやり直し。
自称「趣味」で勉強しているので、気が楽です。会社に取得資格申請制度があるので申請しましたが、それを活かした職種に異動されるでもなく、ひっそりと続けています。E資格を取得したといっても、すぐにコードがバリバリ書ける訳ではないので、とにかく継続してコードの勉強をして、最新の情報を収集して、社外の人たちと繋がっていく、ということを目標にしていきたいと考えています。そういう意味では、機械学習、深層学習の世界の「運転免許証」といった感じです。この世界に慣れて、楽しくいろんな世界へ運転しに行きたいと考えています。
基本「趣味」ですから。。。(笑)
- 投稿日:2020-03-17T21:45:06+09:00
メルカリを python スクレイピングして出品した商品をバンバン売りたい
きっかけ
みなさん、メルカリ使って不要になったものを売っていますか?
私も不要になった本などをメルカリで出品していますが、どれも古めの参考書・勉強本のため、なかなか売れません。。。メルカリでは出品する際に、「売れやすい価格」を提案してくれます。
しかし高い金額に設定すると売れないし、逆に安くしすぎるとなんだか損をした気分になるしで苦悩しています。私は出品物の値段を設定する前に、一度検索をかけて本当の相場はどれくらいなんだろうと調査しています。
(きっと自分だけじゃないはず。。。)ただ、この作業がなかなか面倒くさく、何とか自動化できないかなと思っていました。
そこで python を使ってメルカリをスクレイピングし、いくらなら売れそうなのかを調査してみました!※ ページの最後に
githubへのリンクがありますので、ぜひ遊んでみてください!結果のイメージ図
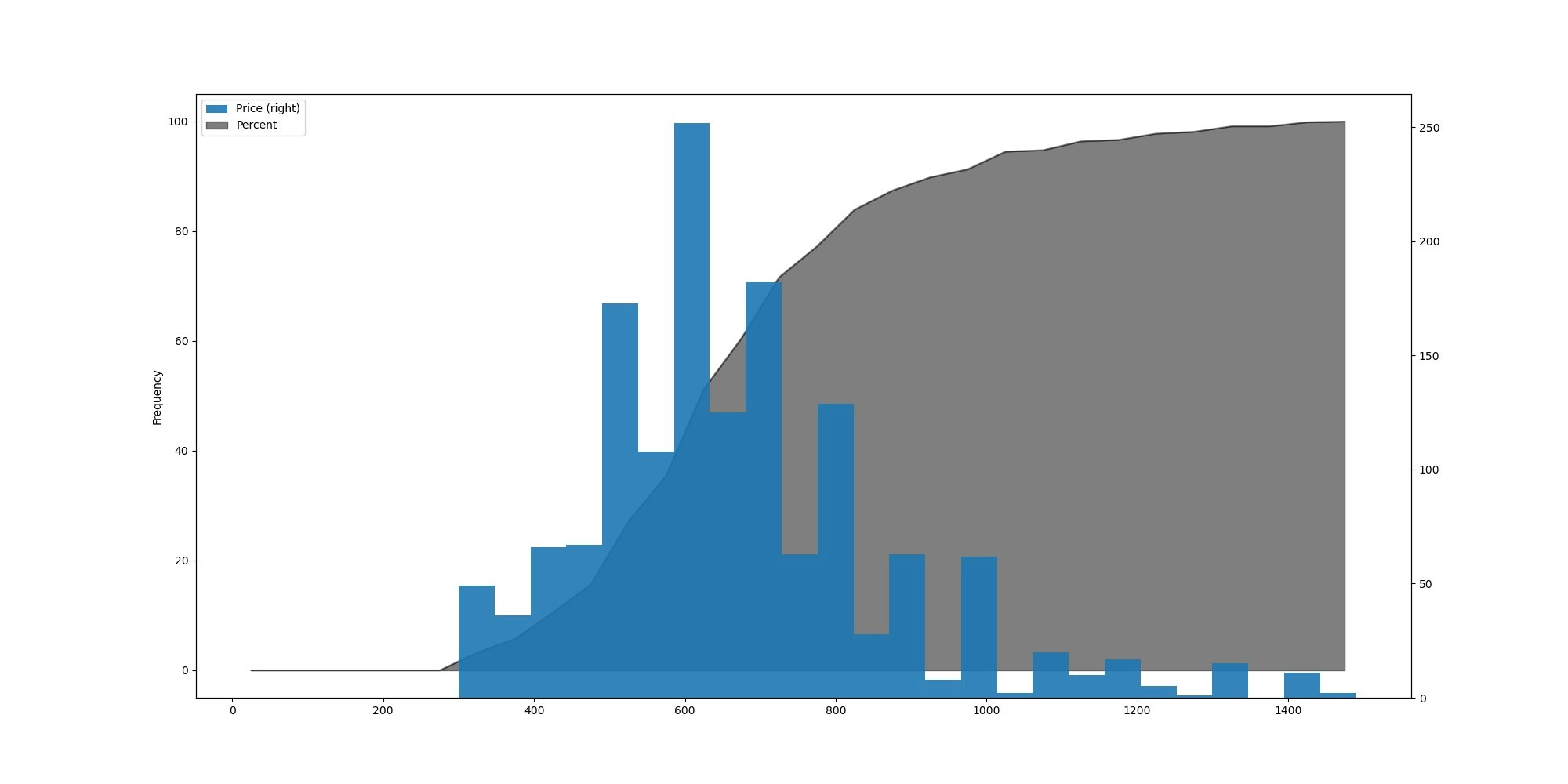
実際にメルカリでスクレイピングを行い、グラフ化した物が以下になります。
こんな感じで、ある商品を売る際には大体 600 円前後に価格を設定すると良いのでは?という結果を得られました。
以降では、メルカリでスクレイピングをする方法について記述します。環境
- Windows 10 Pro
- Python 3.8.2
- Selenium 3.141.0
- ChromeDriver 80.0.3987.106
環境準備
Python 仮想環境準備
自分のローカル環境が汚れるのが嫌だったので、自分は venv 仮想環境を作成しました。
なお、ローカルには Python 3.8.2 をインストール済みでパスも通してある状態です。python -m venv venv上記コマンドで、実行したディレクトリ内に
venvディレクトリが作成されます。仮想環境内での起動方法
venvディレクトリがある場所で以下のコマンドを入力してください。venv\Scripts\activateこれでターミナルの頭に
(venv)の文字がついていれば仮想環境内に入ることができました。※ ちなみに、仮想環境から抜け出すには以下のコマンドを入力してください。
deactivatepython のモジュール準備
本プログラムを実行するためには以下のモジュールが必要です。
事前に入れておきます。pip install pandas matplotlibSelenium 環境準備
python の仮想環境内で pip インストールしました。
pip install seleniumChrome Driver 環境準備
以下から、Selenium で利用する Chrome のドライバを用意します。
ChromeDriver - WebDriver for Chromeここでは、各自の Chrome のバージョンにあった物を選択します。
私の Chrome のバージョンは80.0.3987.132だったので、それに一番近いChromeDriver 80.0.3987.106の windows 版を選択しました。
(本当は 64bit 版が良かったですが、32bit 版しかなかったので仕方なくそれを使いました。)ちなみに、Chrome のバージョンは以下のようにして確認できます。
Google Chrome の設定 -> Chrome について(左の三本線をクリックした一番下の項目)ダウンロードし、解凍したら
chromedriver.exeを python ファイルと同じディレクトリに配置します。スクレイピング準備
メルカリ検索用 URL の解析
メルカリで商品を検索する際の URL は以下のようになります。
例 1:「パソコン」で検索。https://www.mercari.com/jp/search/?keyword=パソコン例 2:「パソコン」「中古」で検索。
https://www.mercari.com/jp/search/?keyword=パソコン+中古複数ワードで検索する際は、検索ワードとの間に
+が付く模様。HTML 解析
メルカリのページへ移動し、デベロッパーツールを使って HTML のソースを確認してみます。
デベロッパーツールは Web ページ上で「F12」キーで表示できます。商品情報
以下に、メルカリで検索をかけた時に表示される商品一つの参考情報を明記します。
この情報からスクレイピングでほしい情報を把握します。<section class="items-box"> <a href="https://item.mercari.com/jp/~~~~~~~~~~~~~~~~~~~~~~~~~~"> <figure class="items-box-photo"> <img class="lazyloaded" data-src="https://static.mercdn.net/c!/w=240/thumb/photos/~~~~~~~~~~~~" alt="パソコン" src="https://static.mercdn.cet/c!/w=240/thumb/photos/~~~~~~~~~~~~~~~~" /> <figcaption> <div class="item-sold-out-badge"> <div>SOLD</div> </div> </figcaption> </figure> <div class="itmes-box-body"> <h3 class="items-box-name font-2"> パソコン </h3> <div class="items-box-num"> <div class="items-box-price font-5">¥19,800</div> </div> </div> </a> </section>商品名
<h3 class="items-box-name font-2"> パソコン </h3>値段
<div class="items-box-price font-5">¥19,800</div>売却済み
売却済みの商品に関しては以下のタグが追加されています。
<figcaption> <div class="item-sold-out-badge"> <div>SOLD</div> </div> </figcaption>次ページ遷移ボタン
スクレイピングを行っていく中で、次のページボタンの情報も把握する必要があったので記載します。
<ul class="pager"> <li class="pager-num">{ページ番号1,2,3,4,5など}</li> <li class="pager-next visible-pc"> <ul> <li class="pager-cell"> <a href="/jp/search/?page=~~~~~~~~~~~~~~~~~~~~~"> <i class="icon-arrow-right"></i> </a> </li> <li class="pager-cell">{最後のページへ遷移するボタン}</li> </ul> </li> </ul>次ページボタン
<li class="pager-next visible-pc"> <ul> <li class="pager-cell"> <a href="/jp/search/?page=~~~~~~~~~~~~~~~~~~~~~"> <i class="icon-arrow-right"></i> </a> </li> </ul> </li>実装の前に
やりたかったこと
- メルカリで検索ワードに対する売却済み商品の価格を取得する(
スクレイピング)- スクレイピングしたデータを視覚的にわかりやすくする(
グラフ化)- 大量にある検索ワードに対して、上記 1 と 2 をぐるぐる回す(
バッチ処理化)設計概要
上記を実装するために行ったことを、以下に記述します。
ソースコードはそれを実現するようにただゴリゴリ書くだけです。
- メルカリで検索する商品リストを csv に上げておく
- python で 1 の csv ファイルを読み込む
- 読み込んだ検索ワードでスクレイピングを行う
- もし検索結果が複数ページにわたる場合は全ページでスクレイピングを行う
- スクレイピングが完了したら結果を別の csv ファイルに出力し保存する
- 5 で作成した csv ファイルを元にグラフを作成する
- グラフ作成用の csv ファイルとグラフ(.jpg)ファイルを保存する
- 以降、商品リスト csv を全てスクレイピングするまで 1~7 をループする
いざ実装
ディレクトリ構成
. ├── chromedriver.exe ├── mercari_search.csv ├── scraping_batch.py └── venv構成の説明
本ソースは大きく 3 つに分かれています。
search_mercari(search_words)
スクレイピングを行う関数です。
引数は検索ワードを入れます。make_graph(search_words, except_words, max_price, bins)
スクレイピングした情報を元に、グラフを描画する関数です。
引数にはそれぞれ検索ワード、除外するワード、検索商品の最大値、グラフ幅を入れます。read_csv()
事前に準備した検索用リストの csv ファイルを読み込みます。
実装
scraping_batch.pyimport pandas as pd from selenium import webdriver import matplotlib.pyplot as plt import time import csv import os def search_mercari(search_words): # 検索ワードをそのままディレクトリ名とするため、一時避難する org_search_words = search_words # 検索ワードが複数の場合、「+」で連結するよう整形する words = search_words.split("_") search_words = words[0] for i in range(1, len(words)): search_words = search_words + "+" + words[i] # メルカリで検索するためのURL url = "https://www.mercari.com/jp/search/?keyword=" + search_words # ブラウザを開く # 本pythonファイルと同じディレクトリにchromeriver.exeがある場合、 # 引数空でも良い browser = webdriver.Chrome() # 起動時に時間がかかるため、5秒スリープ time.sleep(5) # 表示ページ page = 1 # リストを作成 columns = ["Name", "Price", "Sold", "Url"] # 配列名を指定する df = pd.DataFrame(columns=columns) # 実行 try: while(True): # ブラウザで検索 browser.get(url) # 商品ごとのHTMLを全取得 posts = browser.find_elements_by_css_selector(".items-box") # 何ページ目を取得しているか表示 print(str(page) + "ページ取得中") # 商品ごとに名前と値段、購入済みかどうか、URLを取得 for post in posts: # 商品名 title = post.find_element_by_css_selector( "h3.items-box-name").text # 値段を取得 price = post.find_element_by_css_selector( ".items-box-price").text # 余計なものが取得されてしまうので削除 price = price.replace("¥", "") price = price.replace(",", "") # 購入済みであれば1、未購入であれば0になるように設定 sold = 0 if (len(post.find_elements_by_css_selector(".item-sold-out-badge")) > 0): sold = 1 # 商品のURLを取得 Url = post.find_element_by_css_selector( "a").get_attribute("href") # スクレイピングした情報をリストに追加 se = pd.Series([title, price, sold, Url], columns) df = df.append(se, columns) # ページ数をインクリメント page += 1 # 次のページに進むためのURLを取得 url = browser.find_element_by_css_selector( "li.pager-next .pager-cell a").get_attribute("href") print("Moving to next page ...") except: print("Next page is nothing.") # 最後に得たデータをCSVにして保存 filename = "mercari_scraping_" + org_search_words + ".csv" df.to_csv(org_search_words + "/" + filename, encoding="utf-8-sig") print("Finish!") def make_graph(search_words, except_words, max_price, bins): # CSV ファイルを開く df = pd.read_csv(search_words + "/" + "mercari_scraping_" + search_words + ".csv") # "Name"に"except_words"が入っているものを除く if(len(except_words) != 0): exc_words = except_words.split("_") for i in range(len(exc_words)): df = df[df["Name"].str.contains(exc_words[i]) == False] else: pass # 購入済み(sold=1)の商品だけを表示 dfSold = df[df["Sold"] == 1] # 価格(Price)が1500円以下の商品のみを表示 dfSold = dfSold[dfSold["Price"] < max_price] # カラム名を指定「値段」「その値段での個数」「パーセント」の3つ columns = ["Price", "Num", "Percent"] # 配列名を指定する all_num = len(dfSold) num = 0 dfPercent = pd.DataFrame(columns=columns) for i in range(int(max_price/bins)): MIN = i * bins - 1 MAX = (i + 1) * bins # MINとMAXの値の間にあるものだけをリストにして、len()を用いて個数を取得 df0 = dfSold[dfSold["Price"] > MIN] df0 = df0[df0["Price"] < MAX] sold = len(df0) # 累積にしたいので、numに今回の個数を足していく num += sold # ここでパーセントを計算する percent = num / all_num * 100 # 値段はMINとMAXの中央値とした price = (MIN + MAX + 1) / 2 se = pd.Series([price, num, percent], columns) dfPercent = dfPercent.append(se, columns) # CSVに保存 filename = "mercari_histgram_" + search_words + ".csv" dfPercent.to_csv(search_words + "/" + filename, encoding="utf-8-sig") # グラフの描画 """ :param kind: グラフの種類を指定 :param y: y 軸の値を指定 :param bins: グラフ幅を指定 :param alpha: グラフの透明度(0:透明 ~ 1:濃い) :param figsize: グラフの大きさを指定 :param color: グラフの色 :param secondary_y: 2 軸使用の指定(Trueの場合) """ ax1 = dfSold.plot(kind="hist", y="Price", bins=25, secondary_y=True, alpha=0.9) dfPercent.plot(kind="area", x="Price", y=[ "Percent"], alpha=0.5, ax=ax1, figsize=(20, 10), color="k") plt.savefig(search_words + "/" + "mercari_histgram_" + search_words + ".jpg") def read_csv(): # メルカリ検索用リストのcsvファイルを読み込む with open("mercari_search.csv", encoding="utf-8") as f: # 検索ワード格納用の空リストを準備 csv_lists = [] # csvファイルの何行目を読み込むかを確認するためのカウンター counter = 0 # csvファイルを1行ずつ読み込む reader = csv.reader(f) for row in reader: counter += 1 csv_lists.append(row) try: # 検索ワードチェック # 空の場合、エラーメッセージを表示して終了する if(len(row[0]) == 0): print("File Error: 検索ワードがありません-> " + "mercari_search.csv " + str(counter) + "行目") break except IndexError: # 行が空いている場合、エラーメッセージを表示して終了する print("File Error: CSVファイルに問題があります。行間を詰めるなどしてください。") break try: if(len(row[2]) == 0): # グラフ描画時の最高値チェック # 空の場合、エラーメッセージを表示して終了する print("File Error: 金額が設定されていません-> " + "mercari_search.csv " + str(counter) + "行目") break else: try: int(row[2]) except ValueError: # 値が数字出ない場合、エラーメッセージを表示して終了する print("File Error: 金額には数字を入力してください-> " + "mercari_search.csv " + str(counter) + "行目") break except IndexError: # そもそも金額自体が書かれていない場合、エラーメッセージを表示して終了する。 print("File Error: 金額が設定されていません-> " + "mercari_search.csv " + str(counter) + "行目") break try: if(len(row[3]) == 0): # グラフ描画時の最高値チェック # 空の場合、エラーメッセージを表示して終了する print("File Error: グラフ幅が設定されていません-> " + "mercari_search.csv " + str(counter) + "行目") break else: try: int(row[3]) except ValueError: # 値が数字出ない場合、エラーメッセージを表示して終了する print("File Error: グラフ幅には数字を入力してください->" + "mercari_search.csv " + str(counter) + "行目") break except IndexError: # そもそも金額自体が書かれていない場合、エラーメッセージを表示して終了する。 print("File Error: グラフ幅が設定されていません-> " + "mercari_search.csv " + str(counter) + "行目") break return csv_lists # ------------------------------------------------------ # # 0. メルカリ検索CSVファイルから読み取ったリストを格納する箱を用意 """ 検索用CSVファイルからリストを読み込む :param csv_lists[i][0]: 検索ワード :param csv_lists[i][1]: 検索結果から除外するワード :param csv_lists[i][2]: グラフ表示する際の最高金額 :param csv_lists[i][3]: グラフ幅(bin) """ csv_lists = read_csv() # バッチ処理 for i in range(len(csv_lists)): # 1. ディレクトリ作成 os.mkdir(csv_lists[i][0]) # 2. スクレイピング処理 search_mercari(csv_lists[i][0]) # 3. グラフ描画 make_graph(csv_lists[i][0], csv_lists[i][1], int(csv_lists[i][2]), int(csv_lists[i][3]))使い方
1. 検索ワードリストの準備
mercari_search.csv に検索したいワード、除外したいワード、最高金額、グラフ幅を入力します。
- 検索ワード(必須):メルカリで検索したいワードを入力してください
- 検索ワードが複数ある場合は
半角アンダーバー(_)で接続してください
- 例:ポケモン_ゲーム
- 検索ワードとの間にスペースは入れないよう注意してください(動作保証外です)。
- 除外ワード(任意):グラフ描画時、そのワードがある商品を除外したい場合に入力してください
- 除外ワードを入力しない場合は何も入れなくて結構です。
- 最高金額 (必須):グラフ描画時の横軸となる最高金額を入力してください
- 半角数字(整数)で入力してください。
- グラフ幅 (必須):グラフ描画時のグラフ幅を入力してください
- 半角数字(整数)で入力してください。
それぞれのワードを区切る際には csv ファイルですので、カンマ(,)で区切ります。
例:
時計,デジタル,10000,100 財布,牛,3000,100 ポケモン_ゲーム,カード_CD,3000,100 パソコン,,15000,5002. スクレイピングの実行
本ソース(
scraping_batch.py)ファイルと同じディレクトリにchromedriver.exe、mercari_search.py、があることを確認して、以下のコマンドを実行します。python scraping_batch.py3. 結果の確認
上記 2 で python を実行すると、検索ワードに応じたディレクトリが作成されます。
そのディレクトリ内に、メルカリでスクレイピングした結果としてグラフが作成されますので、結果を確認してください。結果に納得いかない場合は、csv ファイルの構成を見直して再度スクレイピングを実行しましょう!
注意
python ファイルと同じディレクトリに、検索ワードと同じディレクトリが作成されます(python ファイル存在ディレクトリに大量にファイルが作成されるのを防ぐためです)。
すでに検索ワードと同じディレクトリが存在する場合や、検索用 csv(mercari_search.csv)に同じ検索ワードがある場合、ディレクトリを作成する処理(os.mkdir())が正常に働かなくなり、スクレイピングが途中で止まってしまいます。
そのため、スクレイピングを開始する際は検索ワードと同じディレクトリが存在しないこと、csv ファイルに同じ検索ワードを入力しないように注意してください。作成してみて
実際に、現在出品中の商品「リンガメタリカ」(知る人ぞ知る英単語帳)で、スクレイピングしてみました。
検索時に使用したワードとパラメータは以下です。
(リンガメタリカの単語帳本体を売りたいため、検索ワードに「CD」という文字が入っている物を除外するようにしています)
リンガメタリカ,CD,1500,50
上記のソースを回した結果、以下のようなグラフが作成されます。
これを見てみると、
- 600 円程度でよく売れている
- 売れたものの約 80%が 800 円以下
という結果になっていました。
このグラフからは、もし「リンガメタリカ」を売りたければ 600 円程度が適正な価格であることがわかります。ちなみに
この記事を書いている時に「リンガメタリカ」を「目立った傷や汚れなし」で出品してみました。
その時にメルカリ側から提示された相場価格は「640 円」(売れやすい価格は 460 ~ 790 円)でした。もしかしたらスクレイピングをして自分で確かめなくても、妥当な金額をメルカリ側は提示していたのかもしれませんね。。。
今後
今考えていることは以下の 5 つです。
今後ゆっくり時間があるときにでも行いたいなと思ってます。
- ほかのフリマサイトにも商品を出品しているので、上記と同様なスクレイピングを使用して、商品の売上情報を獲得してみたい。
- 商品の価値は発売してからの月日と、季節ごとによって変わると思うので、今度は時系列ごとや季節ごとの価格分類をしてみたい。
- 商品の状態によっても価格が変わるので、今度は「商品の状態」も要素としてスクレイピングしたい。
- ソースが冗長になってしまった部分もあるので、リファクタリングしたい(python に詳しい人、レビューしていただけたら幸いです!)。
- スクレイピングした情報を元に値段を設定してみて、実際に売り上げは上がったのかなどを調査したい。
今回はここまでとなります。
最後までお読みいただき、ありがとうございました。Github へのリンク
kewpie134134/fleamarket_app_scraping
参考
- 投稿日:2020-03-17T21:20:49+09:00
Python初心者がエナジードリンクあるあるをコード化してみた
エナジードリンクは体への負担が大きいという事を伝えたい…
それだけのためにお題にしました。(クラスと呼び出しをファイル分けて書いていないのは許してください)import sys class Monena: def __init__(self): self.physical = 50 self.mental = 50 self.destruction = False self.physical_recovery = 0 self.mental_recovery = 0 def status_check(self): print('体力は' + str(self.physical)) print('気力は' + str(self.mental)) if self.physical < 0 or self.mental < 0: self.destruction = True print('アウトー!!!') sys.exit() def work(self, physical_damage, mental_damage): print('さあ今日も仕事するか…') self.physical = self.physical - physical_damage self.mental = self.mental - mental_damage self.physical_recovery = physical_damage self.mental_recovery = mental_damage if self.physical + self.mental < 50: self.monena() print('ようやく仕事終わった…') self.status_check() self.sleep() def monena(self): boost = 100 - (self.physical + self.mental) self.mental = self.mental + boost self.physical_recovery = self.physical_recovery - int(boost / 2) self.mental_recovery = self.mental_recovery - int(boost / 2) print('ヒャッハー!') self.status_check() def sleep(self): print('疲れた…寝よう…') if self.physical + self.physical_recovery > 50: self.physical = 50 else: self.physical = self.physical + self.physical_recovery if self.mental + self.mental_recovery > 50: self.mental = 50 else: self.mental = self.mental + self.mental_recovery self.get_up() def get_up(self): print('おはよう…もう朝か…') self.status_check() monena = Monena() monena.work(20, 20) monena.work(30, 30) monena.work(20, 20) monena.work(30, 30)
- 投稿日:2020-03-17T21:02:55+09:00
Pythonはじめから勉強 Hour3:関数
Python はじめから勉強 Hour3:関数
- Pythonで何かしようとしたときに、まずサンプルスクリプトを探してなんとなく実行してた私が、
- 自動実行でREST API叩いて、結果の確認、VM操作までやってみたいと思う7時間
- 今回は関数の使い方。用意されてる関数から、自分で作る関数までやってみる。
学習資料
- たった 1日で基本が身に付く! Python超入門
過去の投稿
環境
- Windows
- Python Ver3系
今回出てきた関数
- print()
- len()
- str() / int()
- sorted() ※ソート。昇順? タプル? ここでは置いておこう
- abs()
関数の命名規則
- 基本は変数と同じ
- 予約語(Pythonでの予約語 ifとかNG)
- 数字から始まる変数名(1a とかNG)
- 一般的に 「単語__単語」のルールが多い my _ function() とか。
関数の使いどころ
- 関数にしかできないこと。OSやハードウェアを叩くような、いわゆる 原始的な処理。print()なんてそうですね
- 複雑は処理を簡単に実現する。sorted()なんてそうですね。
- コードの重複を排除。同じようなコードを何度も書かないようにして、可読性メンテナンス性を上げるんですね
関数使ってみる:sorted
- リストをソートしてみる
org_list = [1, 20, 19, 4, 3] sort_list = sorted(org_list) print('org_list'+ str(org_list)) print('sort_list'+ str(sort_list))
- 実行してみる
>test09_function.py org_list[1, 20, 19, 4, 3] sort_list[1, 3, 4, 19, 20]
- 自力でもソートって書けると思うけど1行で済みますね。
オリジナル関数を作る
- 関数の使い方(定義・引数・戻り値)
def 関数名(引数1、引数2):
処理
処理
return 戻り値
先ほどの処理を関数化してみる
- リストを与えたら オリジナルのリストとソート後のリストを表示する (ここで初めて何も見ずにコーディングしてみる)
def my_sort(org_list): sort_list = sorted(org_list) print('org_list'+ str(org_list)) print('sort_list'+ str(sort_list)) return my_list = [1, 20, 19, 4, 3] my_sort(my_list)
- 実行してみる
>test10_myFunction.py org_list[1, 20, 19, 4, 3] sort_list[1, 3, 4, 19, 20]
- おお、一発で動いた。こりゃ嬉しい。
関数の注意事項
- 関数を先に定義する
- Pythonはファイルの先頭から処理するために関数を呼び出すには先に宣言しておく必要がある。メイン処理は後に。
関数:引数や戻り値の確認
先ほどは単純な引数を与えた関数をやってみました。戻り値は特に扱ってません。ここでは引数や戻り値をもう少し確認
戻り値について次のようなケースがあります
- returnを書かないケース >>戻り値:None
- 引数なしでreturnを扱うケース >>戻り値:None
- 引数ありでreturnを扱うケース>>戻り値:指定した引数
戻り値
- 戻り値の確認
def my_function1(a): print('in function1:'+ str(a)) def my_function2(b): print('in function1:'+ str(b)) return def my_function3(c): print('in function1:'+ str(c)) return 1 def my_function4(d): print('in function1:'+ str(d)) return 'aaa' aa = my_function1(5) print (aa) bb = my_function1(10) print (bb) cc = my_function1(15) print (cc) dd = my_function1(20) print (dd)
- 実行してみる
>test11_myFunction2.py in function1:5 None <<<returnなしの戻り値 in function2:10 None <<<引数なし return の戻り値 in function3:15 1 <<< return 1 の戻り値 in function4:20 aaa <<< return 'aaa' の戻り値
- 無駄に長いけど、確認したいことは確認できた。
- 数値だけでなく文字列も返せます
引数
関数での引数は次のような取り扱いができる
- 複数の引数を扱う
- 順不同で引数を指定できる「キーワード引数」
- 数が決まってない引数(可変長引数)
- print() など引数いくつでもOKのもの
複数の引数やキーワード引数
def my_function(arg1, arg2, arg3): print(str(arg1)+str(arg2)+str(arg3)) aa = arg1 * arg2 * arg3 print(aa) return my_function(2, 3, 4) my_function(arg2=2, arg1=3, arg3=4)
- 実行してみる
>test12_myFunction_arg.py 234 24 324 <<<順序入れ替えて引数を渡した 24 <<<当然結果は同じhelp 関数の使い方
- help(関数名)
>>> help(print) Help on built-in function print in module builtins: print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (stream); defaults to the current sys.stdout. sep: string inserted between values, default a space. end: string appended after the last value, default a newline. flush: whether to forcibly flush the stream. >>> help(print)
- printはただ表示するだけかと思ったら、区切り文字を指定できたり、ファイルに書き込んだりできるんですね。最後に改行したくないとき、たまにありますよね。
名前空間と関数の型について
- 名前空間とは変数の扱える範囲を言います
- 関数内で宣言した変数 か 関数外で宣言した変数か
- 関数の中で定義した変数は関数の外では使えません。
- 関数の外で定義した変数は関数の中で参照することができます。上書きはできないみたい
- global変数がどうのこうのありますが、推奨されてないとのことなので割愛
組み込み関数を使ってみる
range関数
- 数字の連番を作る関数
a = range(5) b = range(2, 5) print(a) print(list(a)) print(b) print(list(b)) for i in range(4, 7): print(i)
- 実行してみる
>test13_range.py range(0, 5) <<<0を省略しても range(0, 5)となる [0, 1, 2, 3, 4] range(2, 5) [2, 3, 4] 4 <<<< for文では使えそうですね 5 6今回のまとめ
- 単純な作業については関数を使ったり作ったりするように心がける
- メモしながら、考えながらすると2時間ぐらいかかった
名言・ライトニングトーク用
- Qiitaのmarkdownがうまく表示されないけど、Typoraからのコピペそのままで行きます
- 次の時間はオブジェクト指向.....理解できるかな
- 投稿日:2020-03-17T20:58:03+09:00
Pythonを使ったDigest認証の設定@Lambda
はじめに
Digest認証について検索してもほとんど情報がなかったので Pythonを使ったBasic認証の設定@Lambda の続編として書いてみた。
Digest認証自体ほとんど触ったことがなく、その仕組みを勉強するのも兼ねて。コード
import os import ctypes import json import base64 import time import hashlib import copy from Crypto.Cipher import AES accounts = [ { "user": "user1", "pass": "pass1" }, { "user": "user2", "pass": "pass2" } ] realm = "sample@test.com" qop = "auth" # Basic認証と違って、認証後のタイムアウトを設定できるので入れてみた timeout = 30 * (10 ** 9) # 30 seconds # AES暗号化で使うための情報の準備 raw_key = "password1234567890" raw_iv = "12345678" key = hashlib.sha256(raw_key.encode()).digest() iv = hashlib.md5(raw_iv.encode()).digest() def lambda_handler(event, context): request = event.get("Records")[0].get("cf").get("request") if not check_authorization_header(request): return { 'headers': { 'www-authenticate': [ { 'key': 'WWW-Authenticate', 'value': create_digest_header() } ] }, 'status': 401, 'body': 'Unauthorized' } return request def check_authorization_header(request: dict) -> bool: headers = request.get("headers") authorization_header = headers.get("authorization") if not authorization_header: return False data = { "method": request.get("method"), "uri": request.get("uri") } header_value = authorization_header[0].get("value") # Digest認証のデータは、「Digest 〜」と言う形式で来るので、まずは不要な部分を削除する header_value = header_value[len("Digest "):] # 各値がカンマで区切られてるので、分割する values = header_value.split(",") data = { "method": request.get("method"), "uri": request.get("uri") } # 各値を扱いやすいようにまたまた分割 for v in values: # nonceをBase64エンコードしているので、単純に`=`で分割するとおかしくなるので、このような対応をしている idx = v.find("=") vv = [v[0:idx], v[idx+1:]] # 前後に半角スペースが入るので削除する vv[0] = vv[0].strip() vv[1] = vv[1].strip() # 値によってはダブルクォーテーションで括られているので、削除する if vv[1].startswith("\""): vv[1] = vv[1][1:] if vv[1].endswith("\""): vv[1] = vv[1][:len(vv[1])-1] data[vv[0]] = vv[1] for account in accounts: if account.get("user") != data.get("username"): continue d = copy.deepcopy(data) d["user"] = account.get("user") d["pass"] = account.get("pass") encoded_value = create_validation_data(d) if d.get("response") == encoded_value: if check_timeout(data.get("nonce")): return True return False def check_timeout(nonce: str) -> bool: aes = AES.new(key, AES.MODE_CBC, iv) value = aes.decrypt(base64.b64decode(nonce.encode())).decode() # AESで暗号化する時にpaddingで`_`を追加しているので、その分を削除する while value.endswith("_"): value = value[:len(value)-1] return int(value) + timeout > time.time_ns() def create_validation_data(data: dict) -> str: v1 = "{}:{}:{}".format(data.get("user"), realm, data.get("pass")) vv1 = hashlib.md5(v1.encode()).hexdigest() v2 = "{}:{}".format(data.get("method"), data.get("uri")) vv2 = hashlib.md5(v2.encode()).hexdigest() v3 = "{}:{}:{}:{}:{}:{}".format(vv1, data.get("nonce"), data.get("nc"), data.get("cnonce"), qop, vv2) return hashlib.md5(v3.encode()).hexdigest() def create_digest_header() -> str: aes = AES.new(key, AES.MODE_CBC, iv) timestamp = "{}".format(time.time_ns()).encode() # 暗号化する時に長さが16の倍数じゃないとダメなので、paddingで詰めている while len(timestamp) % 16 != 0: timestamp += "_".encode() header = "Digest " values = { "realm": '"' + realm + '"', "qop": '"auth,auth-int"', "algorithm": 'MD5', "nonce": '"' + base64.b64encode(aes.encrypt(timestamp)).decode() + '"' } idx = 0 for k, v in values.items(): if idx != 0: header += "," header += '{}={}'.format(k, v) idx += 1 return header動かすための準備
LambdaやCloudFrontの設定はBasic認証の時と同じなので、記述することはない。
ただ、AESの暗号化するライブラリがpipでインストールする必要があるものなので、ちょっとだけ対応が必要。ライブラリをzipファイルにする
Lambda上で
pipを実行することができないので、ローカルPCなどでpip installしたものを zip ファイル化してアップする必要がある。
* 【Python】AWS Lambdaで外部モジュールを使用するこの際気をつけないといけないのが、AWS LambdaのOSは、Amazon Linuxだと言うこと。
「あ〜単純にzipしたら良いのね」ってローカルのMacでzipを作成しても動かないので注意。
* AWS Lambda ランタイムAmazon LinuxのEC2を作成してzipファイルを作成しても良いけど、高々zipファイル作成するだけなので、Dockerで十分。
と言うことで、Dockerを使って作成。# Amazon Linux2のイメージをpullして起動 $ docker run -it amazonlinux:2 bash # Dockerイメージ上で必要なパッケージをインストール $ yum install -y gcc python3 pip3 python3-devel.x86_64 # Lambda上で使うパッケージをインストール $ pip install pycrypto -t ./ # zipファイル作成 $ zip -r pycrypto.zip Crypto/lambda_handlerの作成
zipファイルをアップロードすると、
lambda_function.pyはなくなっているので改めてlambda_function.pyを作成し、lambda_handlerを記述するその他参考にしたサイト
- 投稿日:2020-03-17T20:24:16+09:00
Atcoder ABC60 D - Simple Knapsack 別解集
wの幅が小さいのが特徴的
なかなか見ない制約なので初見びびった動的計画法
だってナップザックなんでしょ?
じゃあdpやるしかねえだろ かかって来いぼけということでやってみた
wは10*9のままだとつらいのでw1を引いて扱おう
そうするとdpのリストは101301くらいなので全然間に合うdp.pyN,W=map(int,input().split()) dp=[[-1]*301 for i in range(N+1)] dp[0][0]=0 for i in range(N): w,v=map(int,input().split()) if i==0: base=w for i in range(N)[::-1]: for j in range(301)[::-1]: if dp[i][j]!=-1: dp[i+1][j+w-base]=max(dp[i][j]+v,dp[i+1][j+w-base]) ans=0 for index,item in enumerate(dp): if W-index*base+1<=0: break ans=max(max(item[:W-index*base+1]),ans) print(ans)貪欲
重さが4種類しかないので各wをまとめたリストからvの大きいものを取り出していけばいい
取り出す個数は総当たりで試せばヨシ!greedy.pydef saiki(value,HP,num): if num==0: value+=wa[0][min(HP//base,len(wa[0])-1)] ans.append(value) else: for i in range(len(wa[num])): if HP-(num+base)*i>=0: saiki(value+wa[num][i],HP-(num+base)*i,num-1) else: break return N,W=map(int,input().split()) lis=[[] for i in range(4)] for i in range(N): w,v=map(int,input().split()) if i==0: base=w lis[w-base].append(v) lis=list(map(lambda x:sorted(x, reverse=True),lis)) wa=[[0] for i in range(4)] for i in range(len(wa)): for item in lis[i]: wa[i].append(wa[i][-1]+item) ans=[] saiki(0,W,3) print(max(ans))なんでansを配列にしてるかっていうと
数字で扱った時の「まだ定義されてない」みたいなバグが苦手だから
- 投稿日:2020-03-17T20:20:03+09:00
matplotlibのarrowで'vertices' must be a 2D list ... と怒られる場合の対処法
問題設定
pythonのmatplotlibには矢印を表示する関数が用意されています.
import matplotlib.pyplot as plt dx = 0.3 dy = 0.3 params = { 'width':0.01, } plt.arrow(0, 0, dx, dy, **params) plt.xlim(-0.5, 0.5) plt.ylim(-0.5, 0.5) plt.show()
矢印の始点と終点を設定する際,矢印に鏃を含むか含まないかをlength_includes_headで設定できます.
デフォルトだと含まない設定です.import matplotlib.pyplot as plt dx = 0.0 dy = 0.2 params = { 'width':0.01, } plt.arrow(-0.1, 0, dx, dy, **params) params = { 'width':0.01, 'length_includes_head':True, } plt.arrow(0.1, 0, dx, dy, **params) plt.grid() plt.xlim(-0.5, 0.5) plt.ylim(-0.5, 0.5) plt.show()
長さ0の矢印を描画する場合,鏃を含むか含まないかで結果が変わり,鏃を含むとエラーが出ます.
鏃を含まない場合:
test1.pyimport matplotlib.pyplot as plt dx = 0.0 dy = 0.0 params = { 'width':0.01, } plt.arrow(0, 0, dx, dy, **params) plt.xlim(-0.5, 0.5) plt.ylim(-0.5, 0.5) plt.show()
鏃を含む場合:
test2.pyimport matplotlib.pyplot as plt dx = 0.0 dy = 0.0 params = { 'width':0.01, 'length_includes_head':True, } plt.arrow(0, 0, dx, dy, **params) plt.xlim(-0.5, 0.5) plt.ylim(-0.5, 0.5) plt.show()Traceback (most recent call last): File "test2.py", line 9, in <module> plt.arrow(0, 0, dx, dy, **params) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/pyplot.py", line 2411, in arrow return gca().arrow(x, y, dx, dy, **kwargs) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/axes/_axes.py", line 4822, in arrow a = mpatches.FancyArrow(x, y, dx, dy, **kwargs) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/patches.py", line 1269, in __init__ super().__init__(verts, closed=True, **kwargs) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/patches.py", line 938, in __init__ self.set_xy(xy) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/patches.py", line 1005, in set_xy self._path = Path(xy, closed=self._closed) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/path.py", line 130, in __init__ "'vertices' must be a 2D list or array with shape Nx2") ValueError: 'vertices' must be a 2D list or array with shape Nx2対処法
対処法1
矢印の長さと矢印の幅等をいい感じに変えればエラーが消えます.
import matplotlib.pyplot as plt dx = 1.0e-8 dy = 0.0 params = { 'width':1.0e-8, 'length_includes_head':True, } plt.arrow(0, 0, dx, dy, **params) plt.xlim(-0.5, 0.5) plt.ylim(-0.5, 0.5) plt.show()(何も表示されないので表示結果は略)
対処法2
元凶はmatplotlib/patches.py (私の環境では /Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/matplotlib/patches.py ) の1227行目付近の以下の文
if not length: verts = [] # display nothing if empty else: ...で,verts = [] が型違いで怒られています.
もっとも簡単な修正方法は,その直前でlength等を適当に設定してしまうことです.if not length: length = distance = 1.0E-8 if not length: verts = [] # display nothing if empty else: ...(何も表示されないので表示結果は略)
おまけ
矢印の長さが鏃の大きさより小さいと表示が変になるので注意してください.
import matplotlib.pyplot as plt dx = 0.001 dy = 0.0 params = { 'width':0.01, 'length_includes_head':True, } plt.arrow(0, 0, dx, dy, **params) plt.xlim(-0.5, 0.5) plt.ylim(-0.5, 0.5) plt.show()
- 投稿日:2020-03-17T20:09:02+09:00
Basemapで位置情報を可視化する
Pythonを用いた地理空間情報の可視化方法は数多くありますが、今回はBasemap Matplotlib Toolkitを使って位置情報を可視化してみます。
例えば地理空間情報可視化に関して、過去に紹介されている記事はこちら
1. Basemapについて
Basemapは簡単に言うと、様々な地図投影法や地図タイル、あるいは海岸線や河川などを描きつつ、matplotlibのプロット機能を追加していくことができます。主に、地球科学者の間で使われています。
The matplotlib basemap toolkit is a library for plotting 2D data on maps in Python.
Basemap does not do any plotting on it’s own, but provides the facilities to transform coordinates to one of 25 different map projections (using the PROJ.4 C library). Matplotlib is then used to plot contours, images, vectors, lines or points in the transformed coordinates. Shoreline, river and political boundary datasets (from Generic Mapping Tools) are provided, along with methods for plotting them. The GEOS library is used internally to clip the coastline and polticial boundary features to the desired map projection region.
Basemap is geared toward the needs of earth scientists, particularly oceanographers and meteorologists.
(https://matplotlib.org/basemap/users/intro.htmlより引用)1–1. Basemapの基本
まずはcondaを使用して、basemapをインストールします。
$ conda install -c anaconda basemap $ conda install -c conda-forge basemap-data-hiresfrom mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt fig = plt.figure() # 地図を描く範囲を指定する。 m = Basemap(llcrnrlat=30, urcrnrlat=50, llcrnrlon=125, urcrnrlon=150) # Basemapインスタンス作成 # 緯度・経度を10度毎に引く。二つ目のオプションではラベルを上下左右どこに付けるかを設定している。 m.drawparallels(np.arange(-90, 90, 10), labels=[ True,False, True, False]) # 緯度線 m.drawmeridians(np.arange(0, 360, 10), labels=[True, False, False, True]) # 経度線 m.drawcoastlines() # 海岸線 plt.show()
1–2. 地図の詳細設定
地図の解像度や投影法なども柔軟に変更できます。(細かい設定はたくさんあります、、、)
class mpl_toolkits.basemap.Basemap(llcrnrlon=None, llcrnrlat=None, urcrnrlon=None, urcrnrlat=None, llcrnrx=None, llcrnry=None, urcrnrx=None, urcrnry=None, width=None, height=None, projection='cyl', resolution='c', area_thresh=None, rsphere=6370997.0, ellps=None, lat_ts=None, lat_1=None, lat_2=None, lat_0=None, lon_0=None, lon_1=None, lon_2=None, o_lon_p=None, o_lat_p=None, k_0=None, no_rot=False, suppress_ticks=True, satellite_height=35786000, boundinglat=None, fix_aspect=True, anchor='C', celestial=False, round=False, epsg=None, ax=None)
projection\resolution 低解像度 中解像度 高解像度 正距円筒図法 メルカトル図法 ランベルト図法 ちなみに何も設定しなかった場合のデフォルト値は
projection='cyl'(正距円筒図法)
resolution='c'(粗い解像度)2. 位置情報可視化方法
2–1. データソース
今回は無料公開されている擬似人流データをサンプルとして使わせてもらおうと思います。
2–2. データ構造
2013年9月16日の関西圏擬似人流データを読み込みんで、中身を確認します。
import pandas as pd df = pd.read_csv('./Kansai/2013_09_16.csv') df ''' 1列目:ユーザー ID 2列目:性別推定値(1:男性、2:女性、0・3:不明、NA:未推定) 3列目:日付・時刻(5分毎の24時間分) 4列目:緯度 5列目:経度 6列目:滞在者カテゴリ(大分類) ※文字列型 7列目:滞在者カテゴリ(小分類) ※文字列型 8列目:状態(滞在or移動) ※文字列型 9列目:滞在者カテゴリID(6、7行目に対応) '''
今回は移動しているユーザ(STAY_MOVE=='MOVE')を対象にします。
またtimestampを時分に分割しつつ、ユーザ毎・時間毎にランクを付与して扱いやすい形に整形しておきます。from dfply import * df = df >> filter_by(X.STAY_MOVE=='MOVE') >> select(columns_to(X.lon, inclusive=True)) df = df >> separate(X.timestamp, ['col1','hour','col2','minute','col3'], sep=[10,13,14,16],convert=True) >> select(~X.col1, ~X.col2, ~X.col3) df = df >> group_by(X.uid,X.hour) >> mutate(rk=row_number(X.minute)) df
2–3. Basemapの初期値設定と位置情報の可視化
ではこれから位置情報を可視化していこうと思いますが、先に今回ベースとして考えていく地図を設定します。
ArcGISの背景地図や県境・市町村境を描画できるメソッドもあるため、追加でそれらも適用させていこうと思います。県境や市町村境についてはこちらからShapefileをダウンロードしてください。
ファイル構造は以下の通り。-gadm -gadm36_JPN_1.cpg -gadm36_JPN_1.shp -gadm36_JPN_2.dbf -gadm36_JPN_2.shx -gadm36_JPN_1.dbf -gadm36_JPN_1.shx -gadm36_JPN_2.prj -gadm36_JPN_1.prj -gadm36_JPN_2.cpg -gadm36_JPN_2.shp
地図の初期値設定
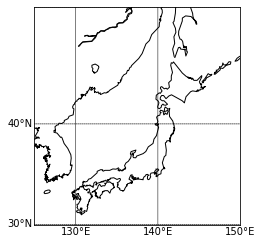
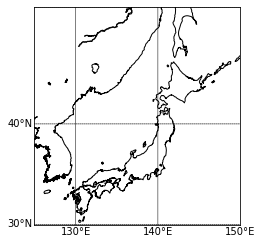
def basemap(): fig = plt.figure(dpi=300) m = Basemap(projection="cyl", resolution="i", llcrnrlat=33.5,urcrnrlat=36, llcrnrlon=134, urcrnrlon=137) m.drawparallels(np.arange(-90, 90, 0.5), labels=[True, False, True, False],linewidth=0.0, fontsize=8) m.drawmeridians(np.arange(0, 360, 0.5), labels=[True, False, False, True],linewidth=0.0, rotation=45, fontsize=8) m.drawcoastlines(color='k') m.readshapefile('./gadm/gadm36_JPN_1', 'prefectural_bound1', color='k', linewidth=.8) # 県境 m.readshapefile('./gadm/gadm36_JPN_2', 'prefectural_bound2', color='lightgray', linewidth=.5) # 市町村境 m.arcgisimage(service='World_Street_Map', verbose=True, xpixels=1000, dpi=300)
ここまでやれば、あとはmatplotlibの感覚でプロットできます。
scatter(x, y, *args, **kwargs)https://basemaptutorial.readthedocs.io/en/latest/plotting_data.html#scatter
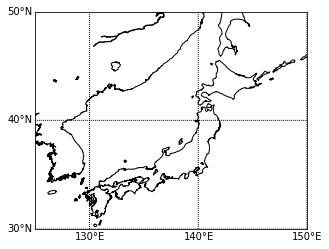
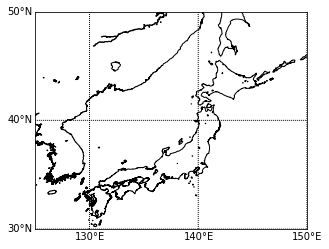
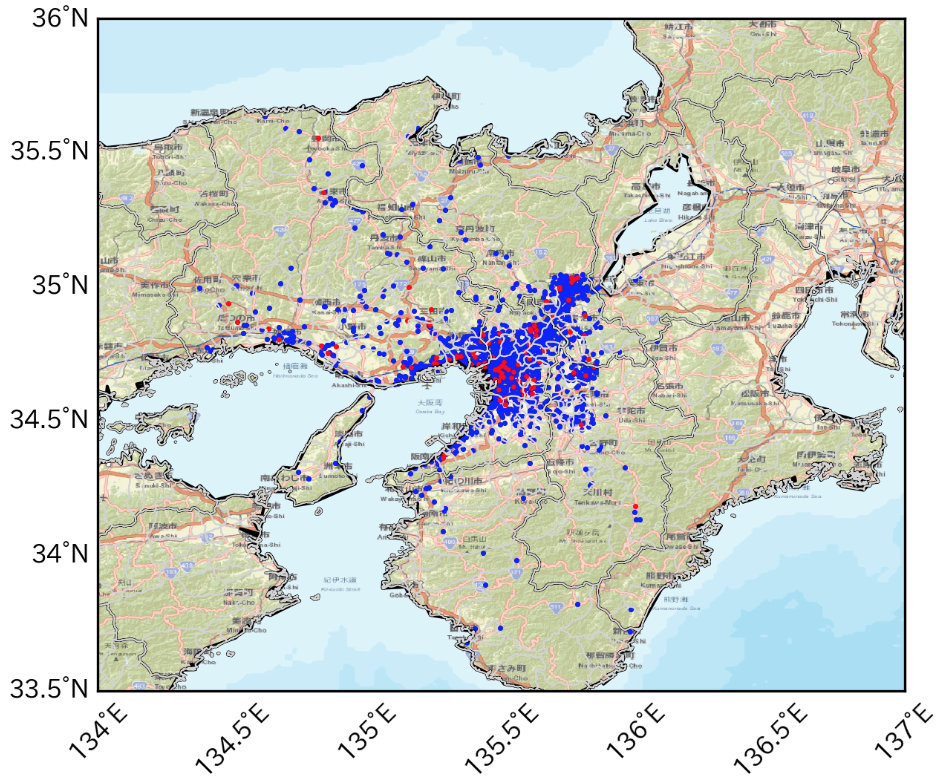
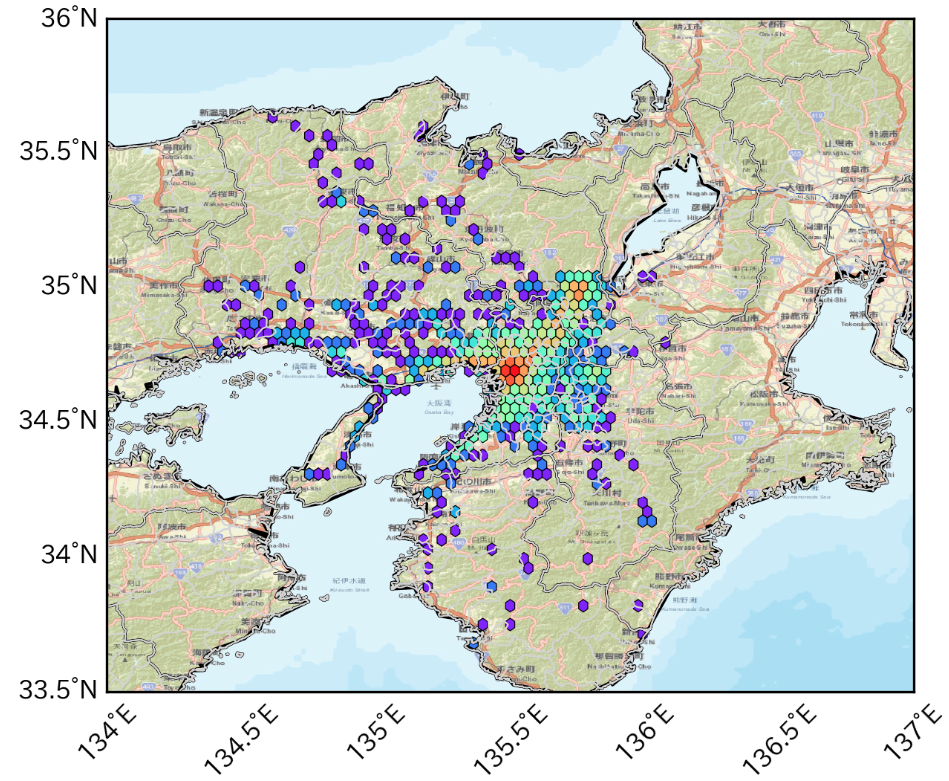
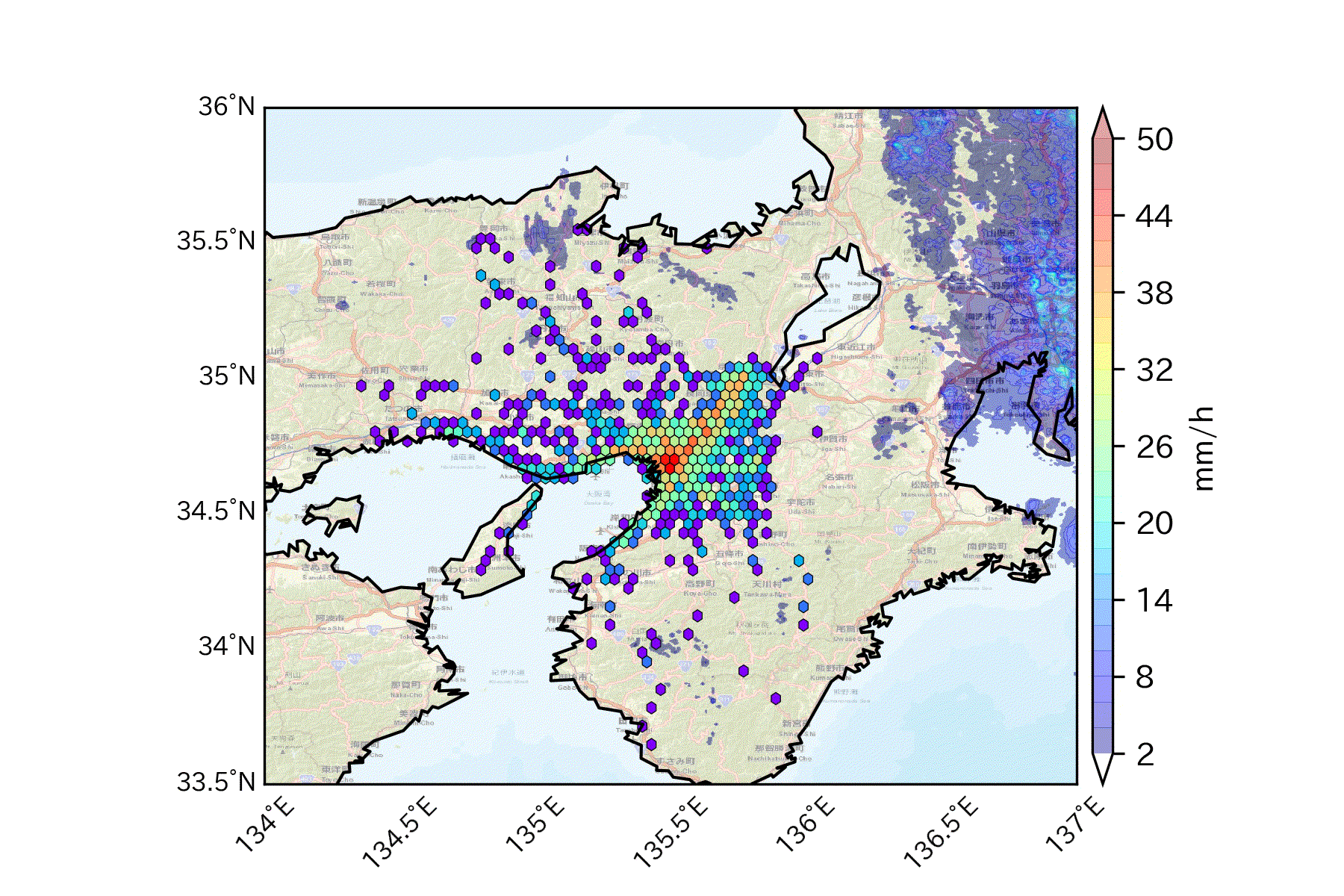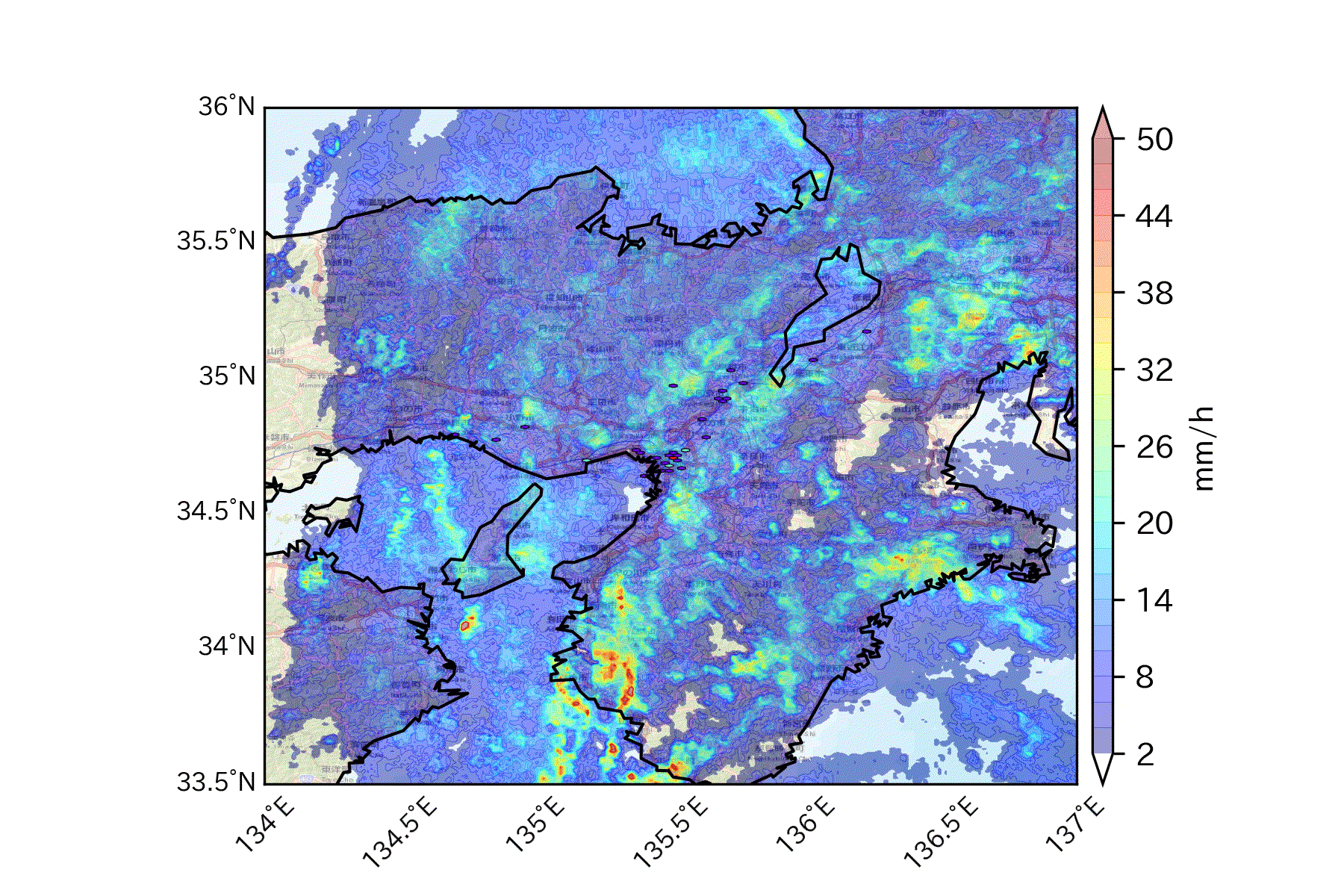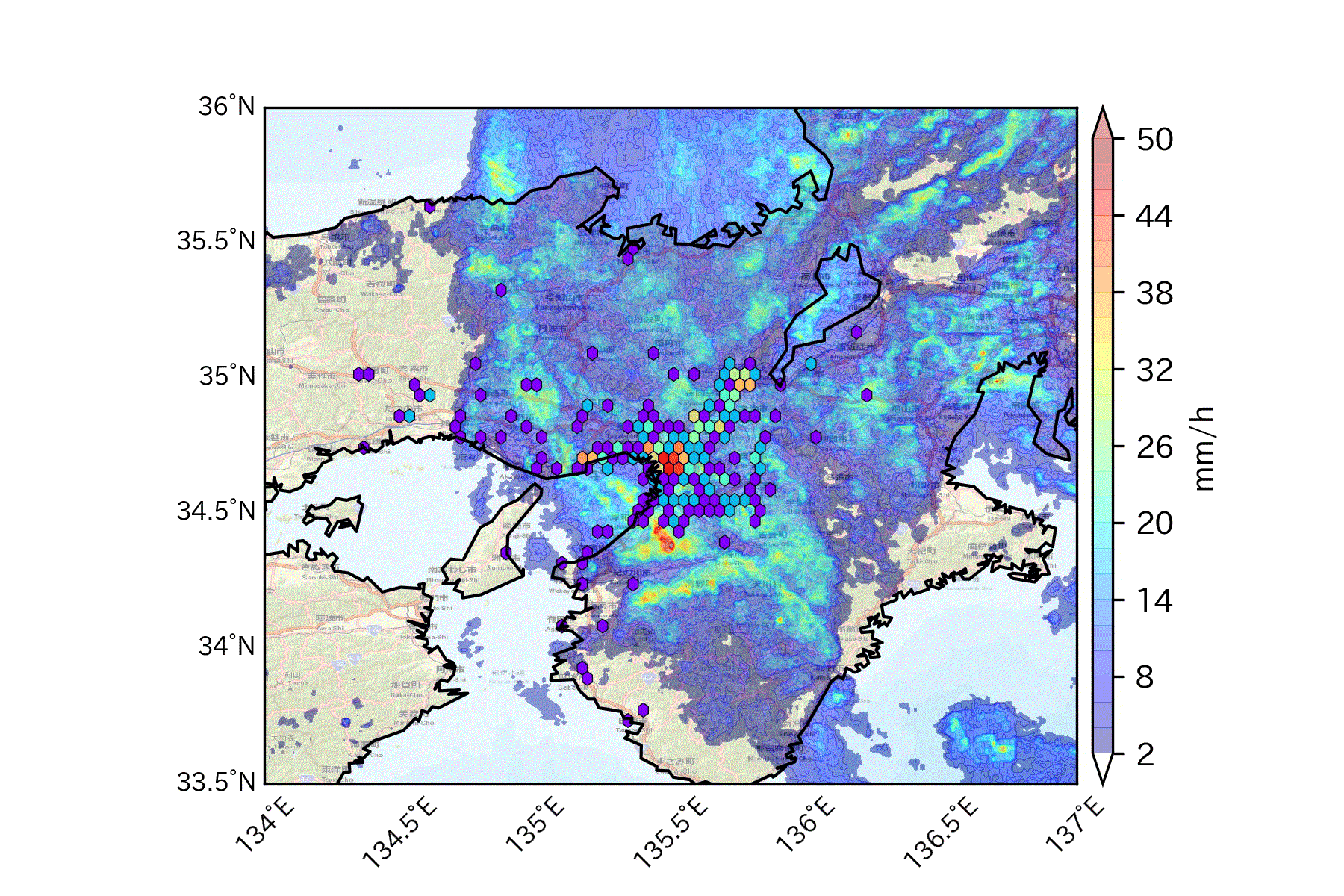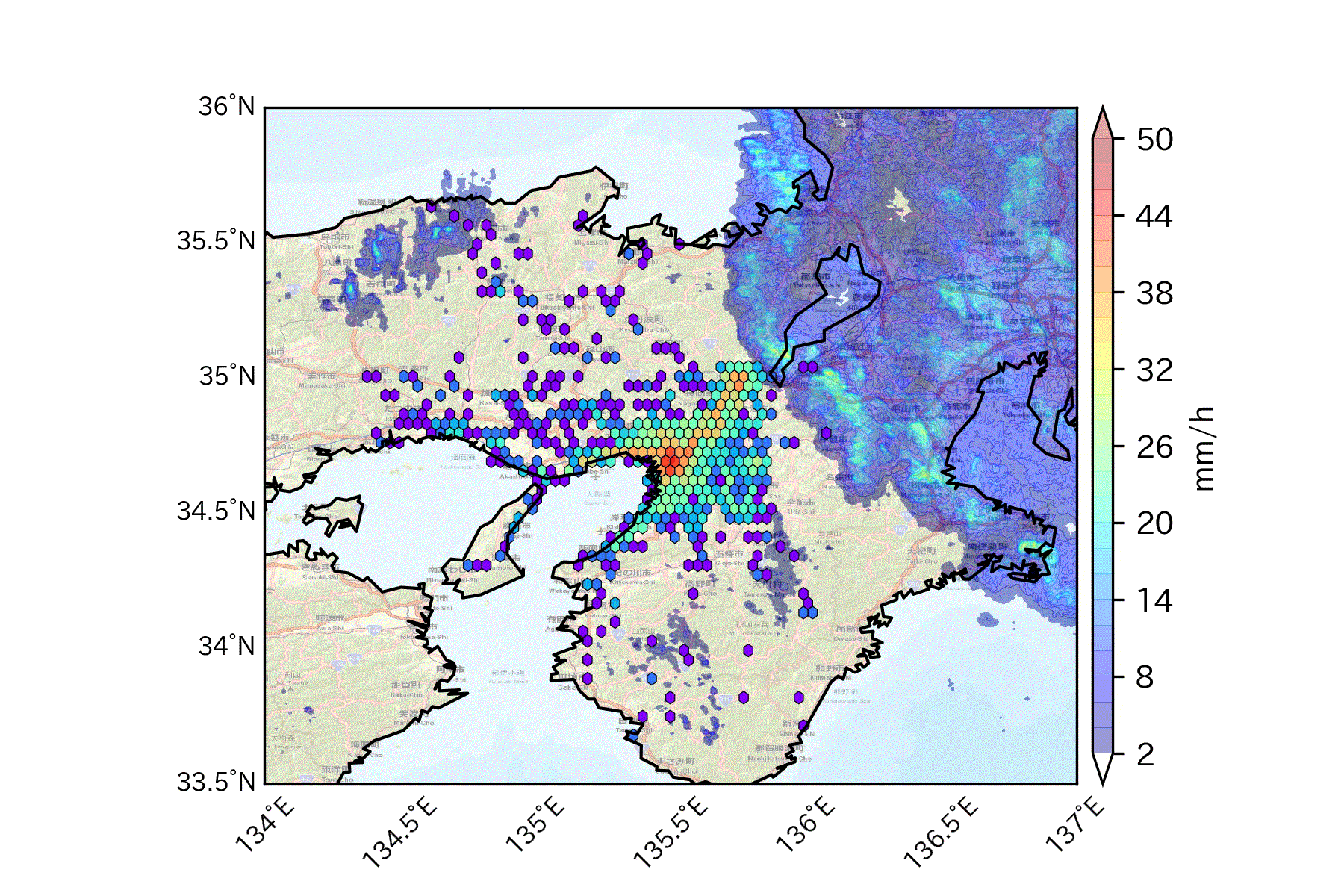
tmp1=df[(df['gender']==1) & (df['hour']==9) & (df['rk']==1)] tmp2=df[(df['gender']==2) & (df['hour']==9) & (df['rk']==1)] basemap() plt.scatter(tmp1['lon'],tmp1['lat'],color='b',s=0.5) # 男性を青で plt.scatter(tmp2['lon'],tmp2['lat'],color='r',s=0.5) # 女性を赤でここではユーザ毎に、9時台の最初のログだけをプロットしています。
hexbin(x, y, **kwargs)https://basemaptutorial.readthedocs.io/en/latest/plotting_data.html#hexbin
tmp=df[(df['hour']==9) & (df['rk']==1)] basemap() plt.hexbin(tmp['lon'],tmp['lat'], gridsize=50, cmap='rainbow', mincnt=1, bins='log',linewidths=0.3, edgecolors='k')gridsizeでヘキサグリッドの大きさも変えられます。
3. おまけ
頻度分布に降水分布を重ね合わせて可視化する例えば人の動きを左右しそうな気象データを掛け合わせることも可能。
ちなみに2013年9月16日は台風が通過した日でした。
気象庁より 1kmメッシュレーダーエコー
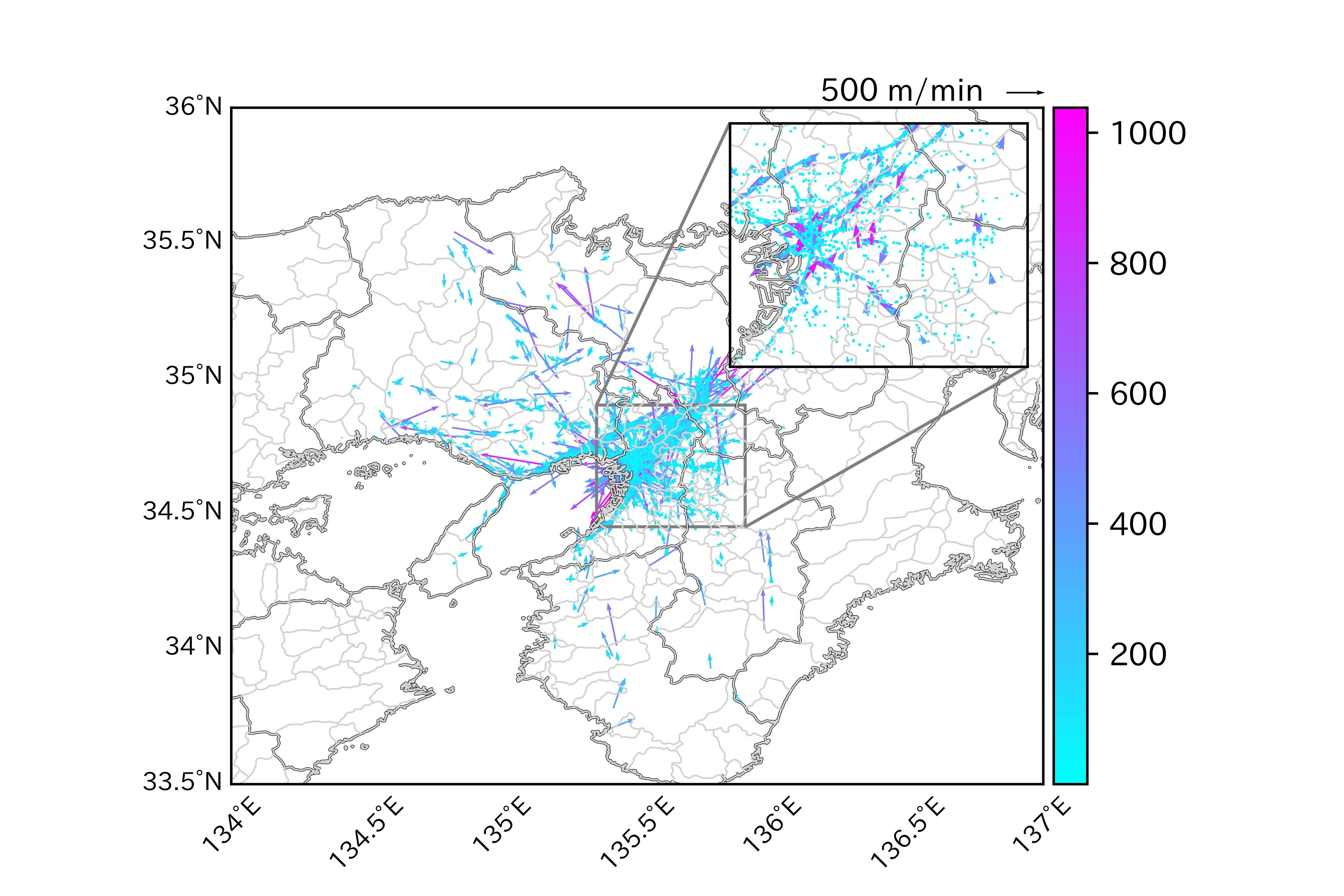
人の移動速度と移動方向を可視化する始点と終点の位置情報から速度と方位角を割り出してベクトル表示も可能。(使い道があるかは置いといて)
以上になります!
最後までお読みいただきありがとうございました!
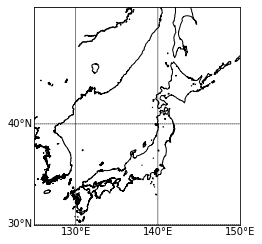
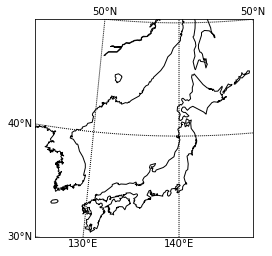
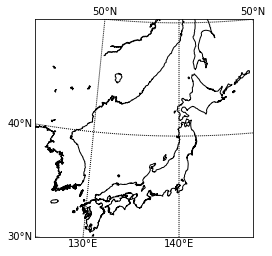
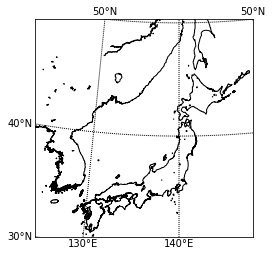
- 投稿日:2020-03-17T19:55:19+09:00
python-pptxで画像をセンタリングする
概要
python-pptxとPillow (PIL)を使って、PowerPointの中央に画像を挿入(センタリング)できるようにしました。
背景
python-pptxはpythonからPowerPointをつくることができるライブラリです。
非常に便利なのですが、スライドへ画像挿入するときの挿入位置は、画像左上の座標でしか指定しかできません。
センタリングをしたいなと思ったのですが、そのようなオプションがpython-pptxにあるのかよくわかりませんでした。
そこでPillowというライブラリで画像を別途読み込んで画像サイズを取得することで、センタリングを実現しました。環境
macOS Catalina バージョン 10.15.3
python3.7.0インストール
pip install python-pptx pip install Pillowコード
from pptx import Presentation from pptx.util import Inches from PIL import Image IMG_PATH = "/path/to/img_file" IMG_DISPLAY_HEIGHT = Inches(3) #スライドに表示するときの画像の高さ。とりあえず3インチとしておく。 SLIDE_OUTPUT_PATH = "test.pptx" #スライドの出力先パス #スライドオブジェクトの定義 prs = Presentation() #スライドサイズを取得 SLIDE_WIDTH = prs.slide_width # SLIDE_HEIGHT = prs.slide_height #白紙のスライドを追加 blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout) #画像サイズを取得してアスペクト比を得る im = Image.open(IMG_PATH) im_width, im_height = im.size aspect_ratio = im_width/im_height #表示された画像のサイズを計算 img_display_height = IMG_DISPLAY_HEIGHT img_display_width = aspect_ratio*img_display_height #センタリングする場合の画像の左上座標を計算 left = ( SLIDE_WIDTH - img_display_width ) / 2 top = ( SLIDE_HEIGHT - img_display_height ) / 2 #画像をスライドに追加 slide.shapes.add_picture(IMG_PATH, left, top, height = IMG_DISPLAY_HEIGHT) #スライドを出力 prs.save(SLIDE_OUTPUT_PATH)Pillowの部分は元の画像のアスペクト比が計算できれば何でも良いので、例えばopencvでも代用可能です。
ドキュメントによるとpython-pptxにはsizeのプロパティをもつImageというクラスがあって、そこからsizeを取得することもできそうなのですが、ちょっと具体的なやり方がわかりませんでした。
画像サイズ取得のためだけにPillowを使うのはスマートでない感じもするので、もしpython-pptx単体でのやり方をご存知な方がいたらご教授いただけると嬉しいです。本記事は以上です。
ここまで読んでいただきありがとうございました。
- 投稿日:2020-03-17T19:40:16+09:00
Pythonで毎日AtCoder #8
はじめに
8日目です。Mリーグ見ながら書いてます。#8
考えたこと
実はこの問題は、ぱっと問題見たときに解けなさそうだったので飛ばしていました。今回は、時間をたっぷり取って考えたので解けました。
チーム内の2番目に強い人がチームの強さになるので、どうやって二番目に強い人を残すかを考えなければいけません。メンバー3N人を大きい順でsortし、それをAとします。Aの後ろからN人は一人ずつチームに入れると、必ずチーム内で最小の値になります。
残ったA[:2*N]を連続した二個ずつ同じチームに入れると、それぞれのチームの強さが最大化されますn = int(input()) a = list(map(int,input().split())) a.sort(reverse=True) a = a[:2*n] ans = 0 for i in range(1,2*n,2): ans += a[i] print(ans)まとめ
次のAGCもAくらいは解けたらいいな。競プロとは関係ないけど、Mリーグおもしろいので見ましょう。
- 投稿日:2020-03-17T19:11:32+09:00
(Django) django-extra-viewsのUpdateWithInlinesViewで、条件によってInline Formを変える
Djangoでインラインフォームを簡単に実装できるdjango-extra-views。
ただたインラインフォームを使うだけだったら、view.pyに
from extra_views import UpdateWithInlinesView, InlineFormSetFactory class PostUpdateInlineFormSet(InlineFormSetFactory): model = Author fields = ('name',) factory_kwargs = {'extra': 0,'can_order': False, 'can_delete': False} class PostUpdate(UpdateWithInlinesView): model = Post fields = ('title',) template_name = 'post/post_detail.html' success_url = reverse_lazy('post:home')を書くだけで実装できてしまう。
また、インラインフォームクラスを複数作って、条件によって使うインラインフォームを変えたい時はget_inlines()をオーバーライドすれば可能になる。
class PostUpdate(UpdateWithInlinesView): model = Post fields = ('title',) template_name = 'post/post_detail.html' success_url = reverse_lazy('post:home') #ここではユーザーのタイプによって出し分け def get_inlines(self, **kwargs): inlines = super().get_inlines(**kwargs) user = self.request.user if user.user_type == 'admin': inlines = [AdminUpdateInlineFormSet, ] elif user.user_type == 'member': inlines = [PostUpdateInlineFormSet, ] return inlines
- 投稿日:2020-03-17T18:58:26+09:00
atcoder パナソニックプログラミングコンテスト2020の復習, E問まで(Python)
競プロ初心者の復習用記事です。
参加したコンテストはこちら↓。
https://atcoder.jp/contests/panasonic2020ここで書くコードは他の人の解答や解説を見ながら書いたものです。実際に提出したものではありません。
A - Kth Term
事前に決められた数列から与えられた入力n番目の項を出力する問題です。
li = [1, 1, 1, 2, 1, 2, 1, 5, 2, 2, 1, 5, 1, 2, 1, 14, 1, 5, 1, 5, 2, 2, 1, 15, 2, 2, 5, 4, 1, 4, 1, 51] i = int(input()) print(li[i-1])項の番号は1から数えていることだけ注意。
B - Bishop
$H\times W$マスの盤面で角が動ける範囲を答える問題です。
横か縦のサイズが1しかないとき角は一歩も動けないので注意しましょう(一敗)。
提出したコードはこんな感じです。
import math H, W = map(int, input().split()) if H == 1 or W == 1: print(1) else: w_odd = math.ceil(H/2) w_even = H // 2 N_odd = math.ceil(W/2) N_even = W // 2 print(w_odd * N_odd + w_even * N_even)横のマス目を左から数えて偶数番目の時と奇数番目の時で移動可能なマスの数は異なります。この二つの場合のマスの数と、それぞれが該当する列の数を別々に求めました。
実際にはもっと簡潔に書けます。
単純に全てのマスのうち半分は移動可能な範囲です。さらに2で割って余りが生じる場合、余りである右下のマスは必ず(奇数、奇数)の位置にあります。それは移動可能な位置なのでさらに一マス増えます。
H, W = map(int, input().split()) if H == 1 or W == 1: print(1) else: print((H * W + 1) // 2)あと、切り上げ処理にmathをインポートする必要もないですね。
C - Sqrt Inequality
入力A B Cに対して
$$\sqrt{A} + \sqrt{B} < \sqrt C \tag{1}$$
であるかを判定する問題。ダメだろうなーって思いつつ以下を提出しました。
a, b, c = map(int, input().split()) if a**0.5 + b**0.5 < c**0.5: print("Yes") else: print("No")ダメでした。mathを使う場合も駄目。
(1)式の両辺を2乗してみます。
$$A + 2\sqrt{AB} +B < C \tag{2}$$
これも駄目。諦めました。平方根の計算で何か誤差が出るんだろうなあとは思うんですが、その手の知識がありません。解説を見ました。(2)式をさらに変形させます。
$$ 2\sqrt{AB} < C - A - B$$
この両辺が正である時、両辺を二乗して
$$ 4AB < (C - A - B)^2 $$
が成立します。これで平方根の計算が消えました。というわけで答え。難しいことはないのでこれは気づくべきでした。
a, b, c = map(int, input().split()) if 0 < c - a - b and 4 * a * b < (c - a - b)**2: print("Yes") else: print("No")D - String Equivalence
N(≦10)の文字数で存在する文字列パターンを全て並べろ、という問題です。
いいやり方がわからなかったので、一度全パターンを並べてから消していくゴリ押しで解こうとしました。実際には書いてる途中で詰まって提出できてないですが、以下のようなコードを書きました。
import itertools N = int(input()) alp = [chr(ord('a') + i) for i in range(N)] allS = list(itertools.product(alp, repeat=N)) answers = [] PatternList = [] for s in allS: pattern = [] letters = [] for l in s: if not l in letters: letters.append(l) pattern.append(letters.index(l)) if not pattern in PatternList: PatternList.append(pattern) answers.append(s) for answer in answers: print(''.join(answer))N=10までならいけると思ったのですが、後半でTLEが出ました。
解説を見ました。標準形の条件は、以下の数式に置き換えられます。
$$ s_1 = a $$
$$ s_k \leq \max[ s_1, \cdots, s_{k - 1}] + 1$$この二つの条件を満たすようにDFSで探索すればいいようです。最大値の情報を保持する変数mxに最大値の情報を格納し、再帰関数で渡していきます。
サンプル通りに作ったのが以下です。
n = int(input()) def dfs(s, mx): if len(s) == n: print(s) else: for i in range(0, mx + 1): c = chr(ord('a') + i) if i == mx: dfs(s+c, mx+1) else: dfs(s+c, mx) dfs('', 0)E - Three Substrings
文字列sから取り出した部分文字列a, b, cの三つを与えられて、元の文字列sを推測する問題です。
文字列sとしてa+b+cの長さを持つ空の配列を用意して、a, b, cの三つを片っ端から当てはめていく方針で書き始めましたが、詰まる要素があったりどうせTLE出るのが見えてたりで諦めました。
解説を見ました。aとb、bとc、aとcの三つそれぞれについて存在しうる「相対位置」を配列として取得します。これを
ab[]、ac[]、bc[]として格納。そこからaとbの位置関係をi、aとcの位置関係をjで表すとbとcの位置関係はj-iで取得できます。これによって
iとjを回していき、ab[i]とac[j]、bc[j-i]の三つの条件を満たす場合の文字数を計算することによって求まります。a, b, cはそれぞれ$\pm 4000$まで離れうることに注意しましょう。ほとんど解説をPythonに書き換えただけですが、以下のコードで通りました。Pypy3でもこのアルゴリズムだとカツカツで、1991 msというギリギリの時間になります。例えば
ab[]に1と0ではなくTrueとFalseを入れるだけでTLEが出ます。数倍早い計算時間を出してる人やPythonでこれを通している人もいたので、もっと早い手法があるようです(まだちゃんと見てない)。a = input() b = input() c = input() A, B, C = len(a), len(b), len(c) ab, bc, ac = [1] * 16000, [1] * 16000, [1] * 16000 for i in range(A): if a[i] == '?': continue for j in range(B): if b[j] != '?' and a[i] != b[j]: ab[i-j+8000]= 0 for i in range(B): if b[i] == '?': continue for j in range(C): if c[j] != '?' and b[i] != c[j]: bc[i-j+8000]= 0 for i in range(A): if a[i] == '?': continue for j in range(C): if c[j] != '?' and a[i] != c[j]: ac[i-j+8000]= 0 ans = 6000 for i in range(-4000, 4000): for j in range(-4000, 4000): if ab[i+8000] and bc[j-i+8000] and ac[j+8000]: L = min(0, min(i, j)) R = max(A, max(B+i, C+j)) ans = min(ans, R-L) print(ans)この記事はここまでとします。できれば後にF問についても追記したい。
- 投稿日:2020-03-17T18:41:11+09:00
pythonでgithub apiを呼び出してPull Request 情報を取得する
背景
データ基盤のデータソースとなるサービスのレポジトリのスキーマ変更があった場合に自動で通知がくるような機能を作りたい。github api で Pull Request 情報を引っ張ってきて作ったのでその時のメモ。
認証は、個人アクセストークンを使用する↓コマンドライン用の個人アクセストークンを作成する
実装
import requests # closeされたPRのみ取得 URL = 'https://api.github.com/repos/owner/repo_name/pulls?&state=closed' headers = {'Authorization': 'token xxxxx'} # 取得したアクセストークン r = requests.get(URL.format(repo), headers=headers) return r.json()参考
- Github API 公式
- how to use github api token in python for requesting
- 公式ドキュメントだとtokenのheader定義方法がわかりづらかったので参考になった
- 投稿日:2020-03-17T18:03:44+09:00
機械学習に関する個人的なメモとリンク集②
はじめに
機械学習に関する個人的なメモとリンク集①に引き続き、先人の知恵をまとめていきます。
DeepLearningは、Tensorflowを中心に色々と勉強はする(した)のですが、構造化データを使うのが主な小売りではあまり使い道がなく。
結局、時間が掛かる割には機械学習(Scikit-learnでできるレベル)と精度が変わらない・勝てないレベルなんですよね。もちろん、もっと上手くニューラルネットワークを作ると違うのかもしれませんが。
ですので、Tensorflow2.xになってからは、情報が追えていません。今後勉強しないと。「お客様の声」とかで、自然言語処理を使ってみたりはしたいですね。。。
DeepLearning
機械学習(ニューラルネットワーク)モデル
CNN
RNN
- 再帰型ニューラルネットワーク: RNN入門
- TensorFlow の RNN チュートリアルやってみた
- 深層学習ライブラリKerasでRNNを使ってsin 波予測
- RNNの基礎だけじゃなく、Sequential Mnistにも実践!浅川先生の機械学習勉強会に参加してみた!
バッチノーマライゼーション・バックプロパゲーション
半教師あり学習
強化学習
転移学習
Tensorflow
Tensorflow1.x関連
- 書籍転載:TensorFlowはじめました ― 実践!最新Googleマシンラーニング
- 中学生にも分かるTensorFlow入門
- TensorFlowチュートリアル - ML初心者のためのMNIST
- Tensorflow勉強会(1)、(2)、(3)、(4)
- 深層学習ライブラリKeras
- Kerasで深層学習を実践する
- KerasでMNIST
- GitHub
- KerasをTensorFlowバックエンドで試してみた
- DeepLearning4Jの問題点とKerasの使い勝手
- TF KerasからTensorboardを使用する方法
- jupyter上に、tensorBoardのグラフを表示させる
- Tensorflowの便利ライブラリTF-Slim
Tensorflowの活用事例
- Googleが提供する機械学習ライブラリ TensorFlow を1時間で試してみた
- 海外事例 マーケティング会社が Google BigQuery で天候データから顧客行動を分析
- BigQuery、パブリック データセット、TensorFlow で需要を予測する
- 【レポート】Recap of TensorFlow DEV SUMMIT 2017
自然言語
形態素解析
自然言語は、数値のような構造化されたデータでないために、構造化することが重要。
特に日本語の場合は、英語等と異なり単語の切れ目が明確でないため、どこまでを1つの単語と見做すのかといった問題を解決するために、形態素解析が行われる。JUMAN+;
形態素解析のライブラリは、JUMAN++を利用
他にMecabやJanomeといったライブラリもあるが、それらに比べてJUMAN++は遅いけど正確性が高い
- MeCabより高精度?RNNLMの形態素解析器JUMAN++
- MeCabよりも高精度なJUMAN++をUbuntuにインストールしたよ
- JUMAN++をPythonから使う
- GCEで立ち上げた機械学習環境で形態素解析を実行
Mecab
予測モデル構築
ナイーブベイズ
- http://aidiary.hatenablog.com/entry/20100613/1276389337
- https://qiita.com/kotaroito/items/76a505a88390c5593eba
- https://qiita.com/ynakayama/items/ca3f5e9d762bbd50ad1f
- https://pythondatascience.plavox.info/pythonとrの違い/ナイーブベイズ
RNN
- http://hytae.hatenablog.com/entry/2016/07/29/新たなRNNと自然言語処理
- https://www.slideshare.net/unnonouno/ss-43844132
- https://qiita.com/knok/items/26224c8489ad681769c0
- http://ksksksks2.hatenadiary.jp/entry/20160515/1463300078
Character-Level CNN
機械学習の世界で、画像等の分類で有名なCNN(畳み込みニューラルネットワーク)を、自然言語処理にも対応する様に用いた手法。
自然言語処理なら、前後の関係性が重要になるため、RNN(再帰型ニューラルネットワーク)だろうと言われているが、Twitterレベルの文字数制限であれば、CNNでも充分使い物になるらしい。
形態素解析→単語レベルでのCNN(Word-Level CNN)と、単純に文字で分けて行うCNN(Character-Level CNN)がある。
- character-level CNNでクリスマスを生き抜く
- 自然言語処理における畳み込みニューラルネットワークを用いたモデル
- CNNを利用した自然言語処理技術まとめ(2017年1月)
- KerasのCNNを使って文書分類する
- CNNを利用したセンチメント分析
- 艦これのセリフ分類をCNNでやる
その他
- MeCab, gensim, scikit-learnでニュース記事の分類
- Pythonでテキストマイニング ②Word Cloudで可視化
- KerasのサンプルでMLPを使って文の分類を試してみる
- テキスト分類器fastTextを用いた文章の感情極性判定
地理情報処理
地図作成
Open Street Map
- https://qiita.com/nyampire/items/423344fa75707dc138af
- https://qiita.com/duonys/items/c941bc2818abe5cc1da7
- https://qiita.com/k-ten/items/f7373e5e2fa709a97524
- https://qiita.com/k-ten/items/38160f10aee9ee904afc
- https://qiita.com/k-ten/items/ef4ddda743f1b0ad03eb
- https://qiita.com/k-ten/items/0ff819e35697f59203cc
ArcMap
BigQuery GIS
- 投稿日:2020-03-17T17:56:39+09:00
【機械学習】ランダムフォレストを理解する
1.目的
機械学習をやってみたいと思った場合、scikit-learn等を使えば誰でも比較的手軽に実装できるようになってきています。
但し、仕事で成果を出そうとしたり、より自分のレベルを上げていくためには
「背景はよくわからないけど何かこの結果になりました」の説明では明らかに弱いことが分かると思います。前回投稿させていただいた【機械学習】決定木をscikit-learnと数学の両方から理解するでは決定木の詳細について記載しましたが、今回は、より実務やkaggle等のコンペでも使われるランダムフォレストについてまとめていきます。
いつものような数学の話は今回はあまり出てきませんが、何となく「決定木を組み合わせたのがランダムフォレスト」くらいの理解しかできていなかったので、自分自身でも整理し、「ランダムフォレストとは何なのか」「パラメータチューニングは何を行っていけばいいのか」ということを、背景を押さえながら理解できるようにすることが今回の目的です。
また、今回はオライリーのPythonではじめる機械学習を参考にさせていただきました。
※「数学から理解する」シリーズとして、いくつか記事を投稿していますので、併せてお読みいただけますと幸いです。
【機械学習】決定木をscikit-learnと数学の両方から理解する
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する
【機械学習】線形重回帰をscikit-learnと数学の両方から理解する
【機械学習】ロジスティック回帰をscikit-learnと数学の両方から理解する
【機械学習】SVMをscikit-learnと数学の両方から理解する
【機械学習】相関係数はなぜ-1から1の範囲を取るのか、数学から理解する2.アンサンブル学習とランダムフォレスト
ランダムフォレストを理解するために、アンサンブル学習について触れていきます。
(1)アンサンブル学習とは
アンサンブル学習とは、複数の機械学習モデルを組み合わせることで、より強力なモデルを構築するやり方です。
機械学習のモデルには「ロジスティック回帰」「SVM」「決定木」等たくさんありますが、これらはそれぞれ単独でデータに対して予測を行います。
ただ、世間一般的にも、誰か1人の独断で答えを出すよりも、何人か集まって答えを導き出す、ある種の多数決がより良い結果を生むこともたくさんあると思います。
アンサンブル学習とはまさにこの考え方で、複数の機械学習モデルの判断結果から多数決で、最終的に判断を下す学習の仕方です。イメージは下記です。
(2)アンサンブル学習の種類
アンサンブル学習のやり方には主に2種類あり、「バギング」と「ブースティング」です。
ランダムフォレストはこの「バギング」をベースに予測を行います。◆バギングとは
ブーストラップというやり方を用いて複数のモデルを並列的に学習させていく方法です。
→新しいデータが入ってきた場合、分類であれば多数決、回帰であれば平均で予測を行います。<ブーストラップとは>
元データから一部のデータを復元抽出というやり方でサンプリングするやり方。
復元抽出は、1度取ったデータもまた元データに戻してサンプリングするため、同じデータが何回も選ばれるケースがあります。◆ブースティングとは
複数のモデルを用意して、学習を直列に進めていくやり方。前で作ったモデルの結果を参考にしながら、次のモデルを構築していきます。
ブースティングを元にしているモデルにはアダブーストがあります(今回は触れません)。
(3)ランダムフォレストとは
ランダムフォレストとは、アンサンブル学習のバギングをベースに、少しずつ異なる決定木をたくさん集めたものです。
決定木単体では過学習しやすいという欠点があり、ランダムフォレストはこの問題に対応する方法の1つです。
バギングでも触れましたが元のデータからランダムに何グループかサンプリングしているため、各決定木はそれぞれのデータを過学習している状態で構築されます。
それぞれ異なった方向に過学習している決定木をたくさん作れば、その結果の平均を取ることで過学習の度合いを減らすことができる、という考え方です。
この考え方を図示してみます。
STEP1:元データからランダムにデータをブーストラップでサンプリングし、Nグループ分データグループを作りますSTEP2:Nグループそれぞれで決定木モデルを作成します。
STEP3:Nグループそれぞれの決定木モデルで予測を一旦行います。
STEP4:Nグループの多数決(回帰は平均)を取り、最終予測を行います。
(4)ランダムフォレストをscikit-learnで実装する場合のパラメータ
具体的なscikit-learnでの実装は次から行いますが、各パラメータをどのように設定していくのかを先に説明しておきます。
但し前提として、ランダムフォレストはそれほどパラメータチューニングを行わなくてもそれなりに良い精度が出せることで知られています(データの標準化といったスケールを変換する必要もありません)。
ですので今回は紹介にとどめ、次の実装ではデフォルト設定でモデル構築を行います。ここでは、冒頭に紹介したPythonではじめる機械学習の87ページで「調整すべき重要なパラメータ」と触れられているn_estimators,max_featuresを紹介します。
◆n_estimators
いくつの決定木を用意するかを設定します。図示した「N個のデータ」のNをいくつにするかということです。
これは大きければ大きい方が良いです(たくさんの人から多数決を取れるというイメージ)が、増やしすぎると時間もメモリも食うので、このあたりとのバランスになるかと思います。◆max_features
ここで初めて記載するのですが、STEP1のデータのサンプリングの際に、実はもう1つ行われていることがあります。それは「特徴量の選択」です。すべての特徴量がモデル構築に使われるわけではなく、各グループでの決定木構築の際に特徴量もランダムに振り分けられます。
この各グループの特徴量の個数をmax_featuresで設定します。
※max_featuresを「n_features」とすると全特徴量を選択することになります。max_featuresを大きくすると、各決定木モデルは似たようなモデルになるはずで、逆に小さくすると各決定木モデルは大幅に異なるものができあがりますが、小さすぎるとデータにfitしない決定木ができてしまいます。
max_featuresは一般には、デフォルト値を使うと良いと”pythonではじめる機械学習”で述べられています。
3.scikit-learnでランダムフォレストを実装
それではここから、実際にscikit-learnでランダムフォレストを実装してみましょう。
(1)データセット
kaggleのKickstarter Projectsのデータセットを用います。
https://www.kaggle.com/kemical/kickstarter-projects(2)必要なもののインポート、データ読み込み
(ⅰ)インポート
import pandas as pd#pandasのインポート import datetime#元データの日付処理のためにインポート from sklearn.model_selection import train_test_split#データ分割用 from sklearn.ensemble import RandomForestClassifier#ランダムフォレスト(ⅱ)データ読み込み
df = pd.read_csv(r"C:~~\ks-projects-201801.csv")(ⅲ)データ外観
下記より、(378661, 15)のデータセットであることが分かります。
df.shapeまた、.headでデータをざっと確認しておきましょう。
df.head()(3)データ成形
(ⅰ)募集日数
今回はあくまでランダムフォレストに主軸を置くので詳細は割愛しますが、クラウドファンディングの募集開始時期と終了時期がデータの中にありますので、これを「募集日数」に変換します。
df['deadline'] = pd.to_datetime(df["deadline"]) df["launched"] = pd.to_datetime(df["launched"]) df["days"] = (df["deadline"] - df["launched"]).dt.days(ⅱ)目的変数について
こちらも詳細は割愛しますが、目的変数である「state」が成功("successful")と失敗("failed")以外にもカテゴリがありますが、今回は成功と失敗のみのデータにします。
df = df[(df["state"] == "successful") | (df["state"] == "failed")]この上で、成功を1、失敗を0に置き換えます。
df["state"] = df["state"].replace("failed",0) df["state"] = df["state"].replace("successful",1)(ⅲ)不要な行の削除
モデル構築の前に、不要だと思われるidやname(これは本来は残しておくべきかもしれないですが今回は消します)、そしてクラウドファンディングをしてからでないとわからない変数を削除します。
df = df.drop(["ID","name","deadline","launched","backers","pledged","usd pledged","usd_pledged_real","usd_goal_real"], axis=1)(ⅳ)カテゴリ変数処理
pd.get_dummiesでカテゴリ変数処理を行います。
df = pd.get_dummies(df,drop_first = True)(4)いよいよ本題~データ分割と、ランダムフォレスト~
(ⅰ)データ分割
訓練データとテストデータにまずは分割します。
train_data = df.drop("state", axis=1) y = df["state"].values X = train_data.values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1234)(ⅱ)ランダムフォレスト
clf = RandomForestClassifier(random_state=1234) clf.fit(X_train, y_train) print("score=", clf.score(X_test, y_test))上記を実行すると、精度が約0.638になると思います。
基本的なモデルであれば、これで終了です!4.結び
以上、いかがでしたでしょうか。
私の思いとして、「最初からものすごい複雑なコードなんて見せられても自分で解釈できないから、精度は一旦どうでもいいのでまずはscikit-learn等で基本的な一連の流れを実装してみる」ことは非常に重要だと思っています。ただ、慣れてきたらそれらを裏ではどのように動かしているのか、背景から理解していくことも非常に重要だと感じています。
もっと学習を進めていったら、このランダムフォレストもより深い内容に更新していきたいと思います。とっつきづらい内容も多いと思いますが、少しでも理解の深化の助けとなりましたら幸いです。
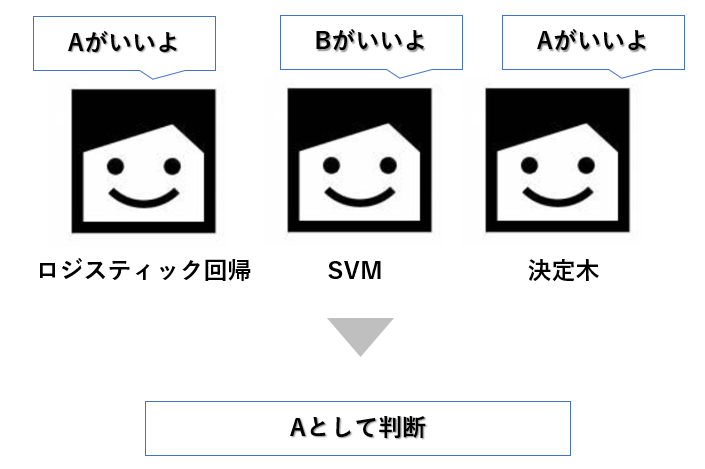
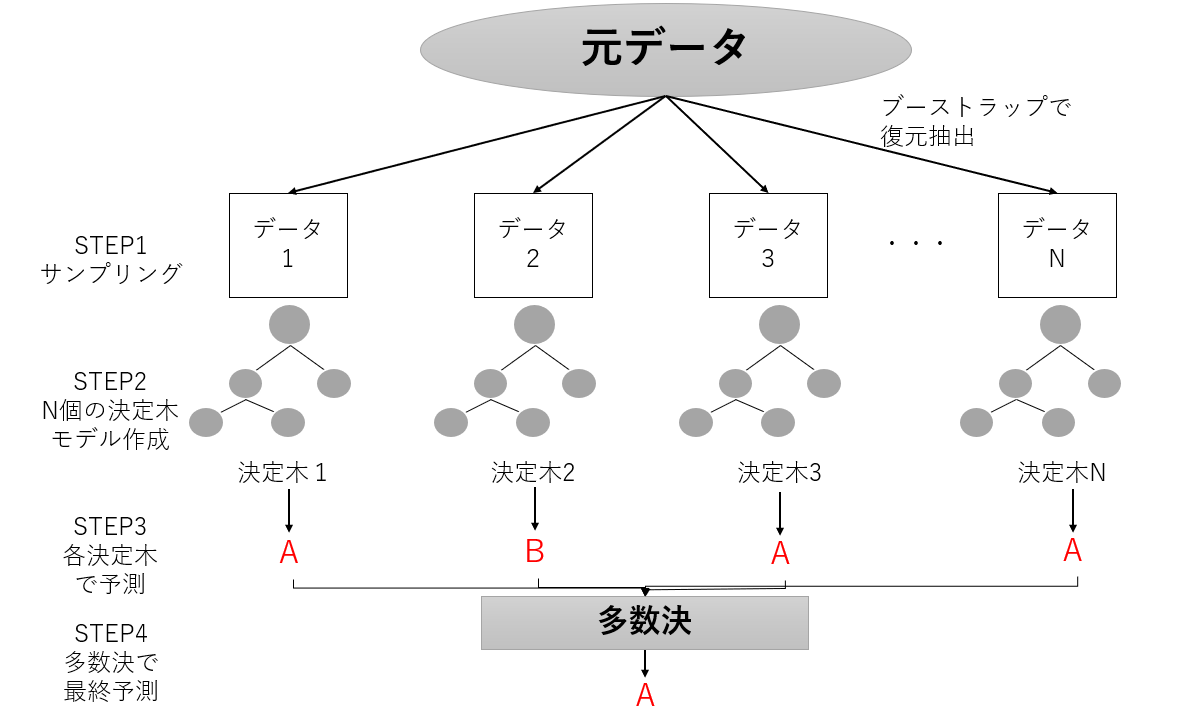
- 投稿日:2020-03-17T17:56:08+09:00
PyGithubを使って、GitHubの情報を取得する
こんにちは、@yshr10icです。
最近、アウトプットの目標として、GitHubに1日1コミット以上することを心掛けています。(もちろん、コミットすることが目的ではいけないことは重々承知しています。)
せっかく毎日コミットするのだから、どれくらいコミットしたのか可視化したいと思いました。そこで、GitHubのコミットログを取得する方法を調べていたところ、PyGithubの存在を知りました。
本記事では、PyGithubの使い方を簡単にまとめたいと思います。
PyGithubとは
PyGitHub is a Python library to access the GitHub API v3 and Github Enterprise API v3. This library enables you to manage GitHub resources such as repositories, user profiles, and organizations in your Python applications.
GitHub API v3およびGithub Enterprise API v3にアクセスするためのライブラリ。リポジトリやユーザプロファイル、組織のようなGitHubのリソースをあなたのPythonアプリケーションで管理することができるようになります。PyGithubのインストール
$ pip install PyGithub私の環境では、バージョンは
1.47です。PyGithubの使い方
PyGithub - Examplesから一部抜粋。
GitHubインスタンスの作成
create_instance.pyfrom github import Github # ユーザ名、パスワードによるインスタンス生成 g = GitHub('username', 'password') # アクセストークンによるインスタンス生成 g = Github('access_token') # カスタムホストによるGitHubエンタープライズのインスタンス生成 g = Github(base_url='https://{hostname}/api/v3', login_or_token='access_token')リポジトリ一覧の取得
get_repos.pyfor repo in g.get_user().get_repos(): print(repo)出力
Repository(full_name="yshr10ic/deep-learning-from-scratch") Repository(full_name="yshr10ic/deep-learning-from-scratch-2") ...スター数の取得
get_count_of_stars.pyrepo = g.get_repo('yshr10ic/deep-learning-from-scratch-2') print(repo.stargazers_count)出力
1ブランチ一覧の取得
get_branches.pyrepo = g.get_repo('yshr10ic/deep-learning-from-scratch-2') for branch in repo.get_branches(): print(branch)出力
Branch(name="images") Branch(name="master")コミットしたファイル一覧の取得
get_committed_files.pyrepo = g.get_repo('yshr10ic/sample') for commit in repo.get_commits(): print(commit.files)出力
[File(sha="xxx", filename="django/djangorestframework/tutorial/tutorial/urls.py")] [File(sha="yyy", filename="django/djangorestframework/tutorial/tutorial/quickstart/views.py")] [File(sha="zzz", filename="django/djangorestframework/tutorial/tutorial/quickstart/serializers.py")] ...まとめ
今回は、既にあるGitHubリポジトリの情報を取得するだけでしたが、実際にはファイルの作成や、プルリク、イシューの作成などもできます。
GitHubインスタンスの生成から各種情報の取得までをやってみましたが、非常に簡単に情報を取得できて良かったですね。ただ、「どれくらいコミットしたのか可視化したい」という当初の目的を達成するには、コミットログを時間で検索できないといけません。PyGithubだと時間による検索ができそうもないので、他の手段も検討してみます。
- 投稿日:2020-03-17T17:02:23+09:00
[Python] 図の色を指定する方法まとめ
色の名前
color
Python でデータサイエンス: matplotlib で指定可能な色の名前と一覧
cmap
beizのノート: matplotlibのcmap(colormap)パラメータの一覧。
RGB値+透明度Aによる色の指定
- 文字列で指定: '#????????',上から2桁ずつRGBAの順.透明は末尾2桁を00.
- タプルで指定: (R,G,B,A)の順,各値は0-1.透明は0.0
ちなみに全くの透明で見えないという状態は「透明度0%」と呼ぶ.
一覧は以下.
原色大辞典
Qiita@konifar: ARGBのカラーコード透明度まとめ参考:
Python by Examples: Transparent colors例:
import numpy as np import matplotlib.pyplot as plt x = np.arange(0.0, 15.0, 0.1) y = np.sin(x) plt.plot(y , color='#ff4500' ) # orangered plt.plot(y - 1.0, color='#4169e1' ) # royalblue plt.plot(y - 2.0, color='#4169e199') # royalblue,透明度60% plt.plot(y - 3.0, color='#4169e133') # royalblue,透明度20% plt.plot(y - 4.0, color='#4169e100') # royalblue,透明度0%なので見えない
imshowの色を離散的に指定
from matplotlib import colors cmap = colors.ListedColormap(['white', 'red']) bounds=[0,5,10] norm = colors.BoundaryNorm(bounds, cmap.N) img = plt.imshow(zvals, interpolation='nearest', cmap=cmap, norm=norm) plt.colorbar(img, cmap=cmap, norm=norm, boundaries=bounds, ticks=[0, 5, 10])https://stackoverflow.com/questions/9707676/defining-a-discrete-colormap-for-imshow-in-matplotlib
1つのカラーマップから離散的に色を指定
複数の折れ線グラフを描くときなど.
cmap = plt.get_cmap("Blues") for i in xrange(len(y)): plt.plot(x, y[i], c=cmap(float(i)/N))Qiita@Tatejimaru137: Matplotlibのグラフの色を同系色で揃える(カラーマップ)
カラーマップの基準を調整
- 投稿日:2020-03-17T15:46:47+09:00
第5回 機械学習のための特徴量エンジニアリング - 特徴選択
はじめに
本記事では交互作用特徴量について解説しています。本記事は主に「機械学習のための特徴量エンジニアリング」を参考とさせて頂いておりますので、気になる方は是非チェックしてみてください。
※本記事で解説するプログラムは全てこちらにあります。
特徴選択とは
モデルの予測に有効ではない特徴量を削除する手法です。有効でない特徴量はモデルの学習時間を増大させ、精度も下げてしまいます。
フィルタ法
フィルタ法はモデルに関係なく、データセットのみを見て特徴量を削減する方法です。それぞれの特徴量がどれだけ予測に使えるかを指標をもとにして数値化し、実際に使う特徴量を選びます。この指標にはピアソンの相関係数, カイ二乗検定, ANOVAなどがあります。
具体的には、特徴量同士の相関が高すぎる特徴量を削除したり、目的変数との相関が低すぎる特徴量を削除したりします。しかしモデルを全く考慮しない手法なので、モデルによって有効になる可能性のあった特徴量を削除してしまうかもしれません。ラッパー法
ラッパー法はデータセットから一部の特徴量を取り出し、モデルに学習させます。この工程を複数回行い、有効である特徴量を決めるという手法です。実際にモデルに組み込みながら特徴量選択を行うので、フィルタ法のようにモデルに有効になる可能性のあった特徴量を事前に削除してしまうことはありません。ですが計算量が膨大になってしまいます。
組み込み法
組み込み法はモデルの学習時に特徴量選択が組み込まれていることを指します。決定木では特徴量の重要度を計算しながらモデルの学習を行うため、学習が終わったあとに特徴量の重要度が高いものを選択する手法となっています。組み込み法はラッパー方より品質は劣りますが、計算コストを抑えることができ、フィルタ法のよりモデルに有効な特徴量を選択できるので、バランスの取れた手法となっています。
最後に
YouTubeでITに関する動画を上げていこうと思っています。
YoutubeとQiita更新のモチベーションに繋がるため、いいね、チャンネル登録、高評価をよろしくお願い致します。
YouTube: https://www.youtube.com/channel/UCywlrxt0nEdJGYtDBPW-peg
Twitter: https://twitter.com/tatelabo参考
- 投稿日:2020-03-17T15:39:11+09:00
【Djnago】特定の日付(TimeField)で検索をする方法
Introduction
Pythonで特定の日付(TimeField)で検索する方法
備忘録的な形でお使いください。Code
# import from datetime import datetime, timedelta # 日時取得(今日の日付を取得) date = datetime.today() # 年検索 current_year = date.strftime('%y') Book.obhects.filter(target_date__month=current_year) # 月検索 current_month = date.strftime('%m') Book.obhects.filter(target_date__month=current_month) # 日付検索 today = date.strftime('%d') Book.obhects.filter(target_date__month=current_today)Conclus
色々検索してみましょう!!
参考文献
- DjangoでDateTimeFieldの日付をフィルタリングするにはどうすればよいですか? https://www.it-swarm.dev/ja/python/django%E3%81%A7datetimefield%E3%81%AE%E6%97%A5%E4%BB%98%E3%82%92%E3%83%95%E3%82%A3%E3%83%AB%E3%82%BF%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%99%E3%82%8B%E3%81%AB%E3%81%AF%E3%81%A9%E3%81%86%E3%81%99%E3%82%8C%E3%81%B0%E3%82%88%E3%81%84%E3%81%A7%E3%81%99%E3%81%8B%EF%BC%9F/966955482/
- 投稿日:2020-03-17T15:15:30+09:00
【備忘録】pythonのimportの種類と違い。from A import Bの意味
【備忘録】pythonのimportの種類と違い。from, asの使い方。
pythonでモジュールを使う呼び出し方に複数の方法がある。
それぞれの違いを確認しておく。
種類
- import A
- import A as B
- from A import C
それぞれの違い
1. import A
モジュールAを読み込む。
Aに定義されているすべてのクラスや関数を読み込む。例import datetime (datetimeモジュールを読み込む)※そもそもモジュールとは?
- pythonの定義や文章が入った「ファイル」のこと。
- そのファイルの中に、いろいろな関数(ツール)が記述されている。
- 関数定義や実行文を入れることができる。
- モジュール内で他のモジュールをimportできる
2. import A as B
モジュールAを名称B(任意)として読み込む。
コード記述を楽にするために省略語を設定することが多い。例import pandas as pd (pandasをpdとしてインポート)■import pandasのみの場合
df = pandas.DataFrame()■import pandas as pdの場合
df = pd.DataFrame()
3. from A import B
モジュールAの関数/クラスBを読み込む。
(関数/クラス = ツール)例from selenium import webdriver (seleiumのwebdriber)seleniumのファイルの中の、webdriverというツールを読み込む。
言葉の定義
モジュール、パッケージ、ライブラリの違い
①モジュール:.pyファイルのこと。
②パッケージ:こちらも.pyファイル。複数のモジュールをまとめたもの
③ライブラリ:モジュールやパッケージ。定義は曖昧。
└ jQueryのライブラリのように、便利な機能がたくさん集まったファイルの意参考サイト(言葉の違い、パッケージの作り方)
- 投稿日:2020-03-17T14:43:52+09:00
【Python】PyInstallerでExe化すると、No module named 'pyproj.datadir' が出るときの対処
背景
Pythonファイルをコマンドプロンプト等から起動すると問題なく動いていた。
しかし、PyInstallerでExe化したファイルを実行すると、pyprojをインポートするところで、以下のエラーが送出され、プログラムが落ちてしまった。ModuleNotFoundError: No module named 'pyproj.datadir'
環境
- Windows 10
- Python 3.7.4
- PyInstaller 3.6
- pyproj 2.4.0
対処法
specファイル内の、Analysis()のdatasにpyprojのパスを追加するとうまくいった。
.speca = Analysis(['hoge.py'], pathex=['C:\\workspace\\hoge\\src'], binaries=[], datas=[ ('C:\\Users\\grin\\Anaconda3\\envs\\py_37\\Lib\\site-packages\\pyproj\\*', '.\\pyproj\\'), ], hiddenimports=[], hookspath=[], runtime_hooks=[], excludes=[], win_no_prefer_redirects=False, win_private_assemblies=False, cipher=block_cipher)参考URL
- 投稿日:2020-03-17T14:37:08+09:00
Windows上のPythonタブ補間を有効化するためのメモ
概要:
・ Windows 上の Python インタラクティブ実行時のタブ補間(補完)を有効化しようとして
いつもつまづいてあきらめていましたが解決したのでメモ。「readline」ではなく「pyreadline」をインストールする。
環境:
・ Windows10
・ Python3.7.4結論として
C:\Python\python.exe -m pip install pyreadlineというように「pyreadline」をインスコすればよいということがわかりました。
※「readline」というパッケージもあってこれはインスコ時に「Windowsでは動かない」と吐いてエラーになる。
筆者はここでいつもあきらめてました。
※Linuxの場合は「readline」インストールで問題ないはず。pyreadlineインストール後は
無事タブ補間できるようになりました。場合によっては
import rlcompleter rlcompleter.readline.parse_and_bind('tab: complete')せよとかいう情報もあるようですが、ほんとに必要かどうかは不明(※「rlcompleter」 も pip で入れるひつようがあるかも)
日本語で気の利いた記事を見つけられなかったためメモとして残しときます。