- 投稿日:2020-03-17T23:19:04+09:00
Ruby on RailsでWebAPIの作成
Ruby on RailsでWebAPIの作成
はじめに
この記事では、Ruby on RailsにおけるAPIの作り方を簡単に紹介します。
データベースへのユーザ登録、参照、消去、更新ができるAPIを作成し、いじりながら解説します。前提知識
- API
- JSON
- HTTPリクエスト、レスポンス
- GET, POST, DELETE, etc
環境
- ruby 2.6.5
- Rails 6.0.2
作り方
なにはともあれAPIの基盤の作成。
[tmp]$ rails new RailsApi --apiご存知
rails new [アプリ名]とすることでアプリの基盤を作成することができるが、 --apiのオプションをつけることでAPIに必要なものだけに絞って作ってくれる。[tmp]$ cd RailsApiRailsApiフォルダに移動。
[RailsApi]$ rails g scaffold user user_id:string password:string
rails g (generate) scaffold [モデル名(単数形)] カラム名:データ型 (カラム名:データ型)
今回はユーザテーブルにIDとパスワードを持たせようと思うのでこの様に指定しました。IDのカラム名をidとしない様に注意。(自動生成されるカラム名のidと被るため)[RailsApi]$ rails db:create [RailsApi]$ rails db:migrateデータベースの作成とテーブルの作成を行います。
そしてなんと、、、
これでAPIの完成です。(マジ)詳しくはあとで解説するとしてこのAPIを試してみましょう。
作成したAPIを試す
まず、APIをいじるならhttpリクエスト送信とレスポンス受信ができるツールが必要なので、chromeの拡張機能であるAdvanced REST clientをダウンロードしておきましょう。
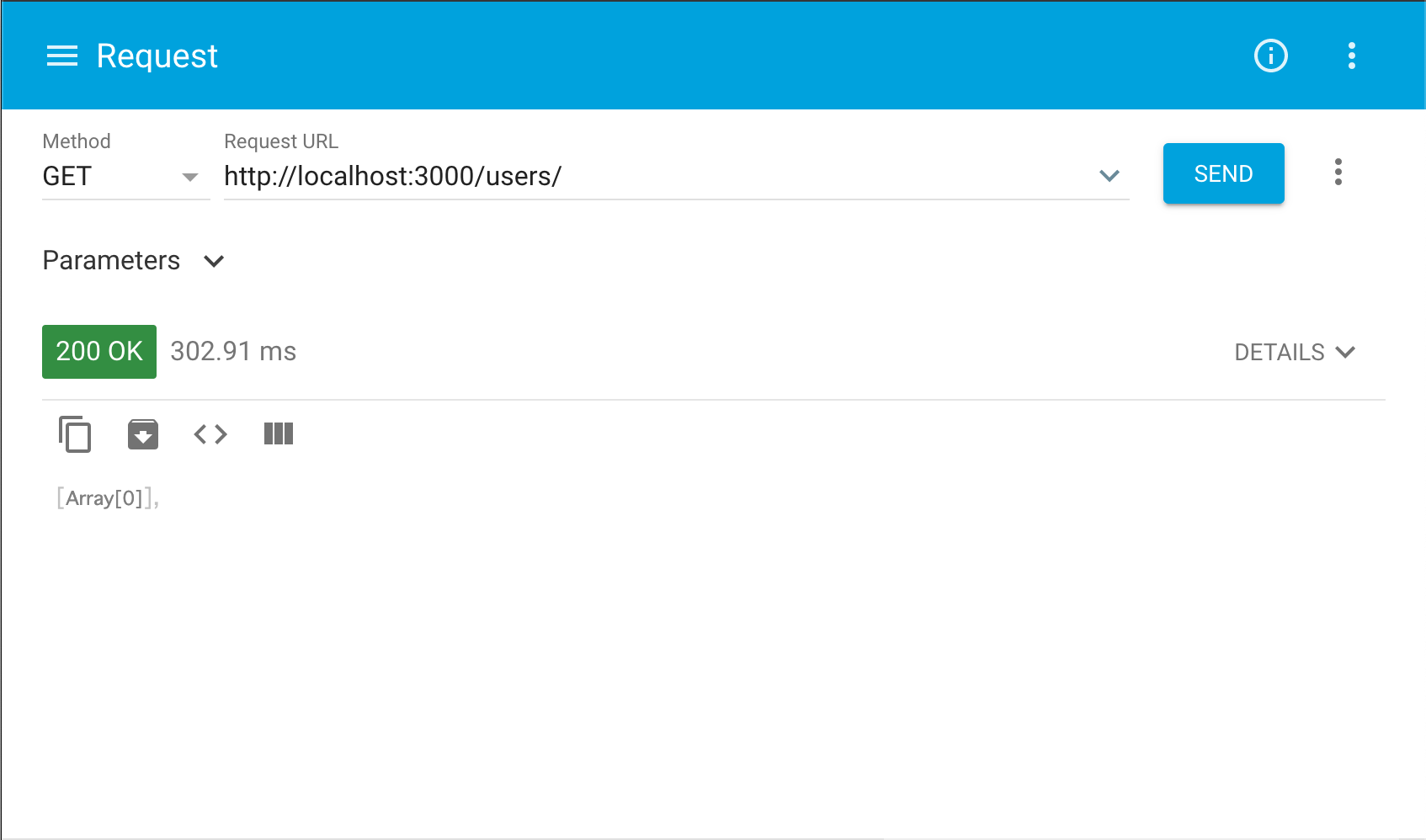
全件取得
[AppName]$ rails s上記コマンドでローカルサーバを起動し、
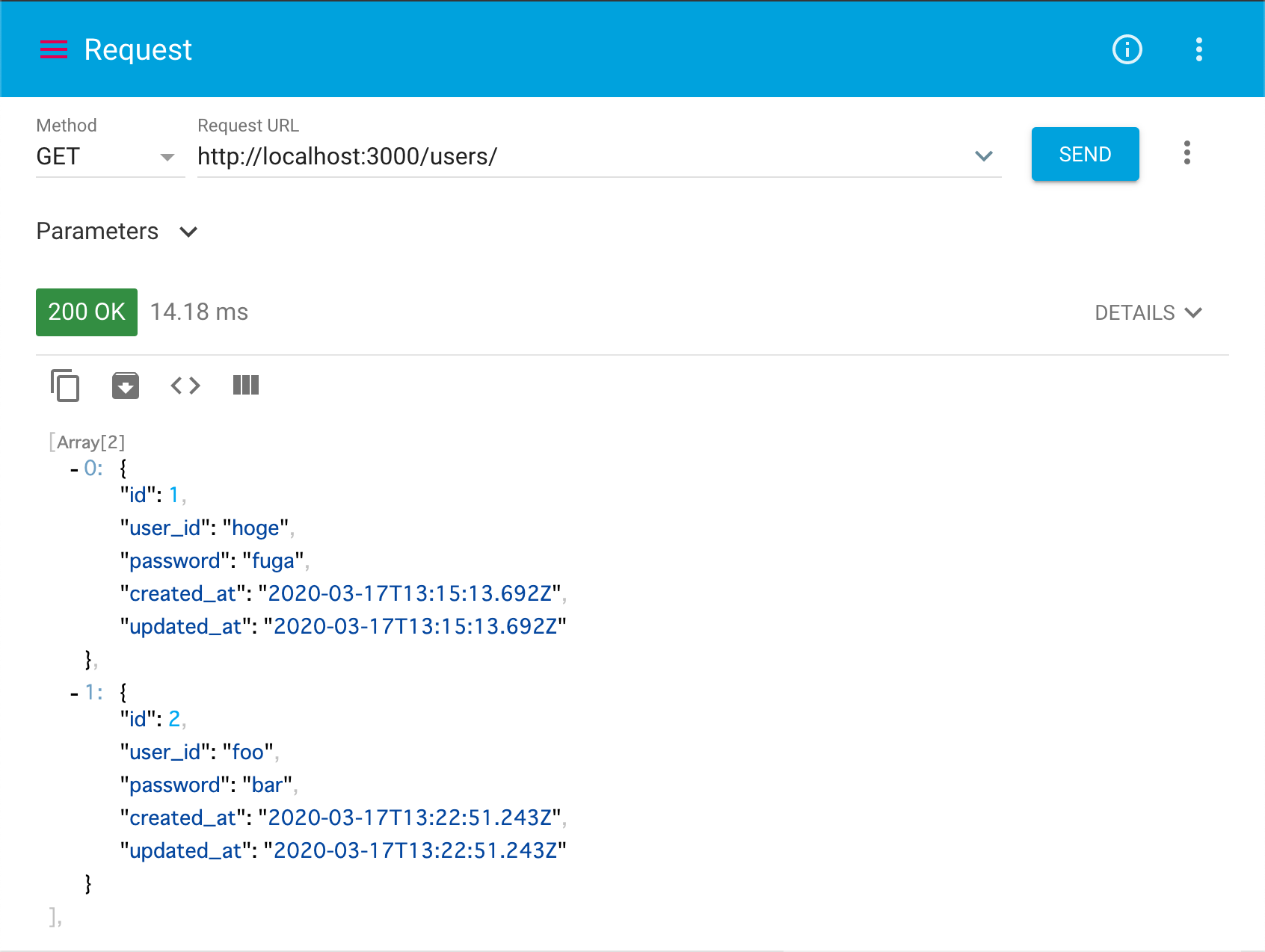
http://localhost:3000/users/へGETリクエストを送ってみましょう。これは「データの全件取得」を意味します。
(rails g scaffold user ~でuserのモデルを作成したためその複数形をパスに指定。)すると以下の様な空のレスポンスが返ってきます。これはまだデータ投入していないからです。
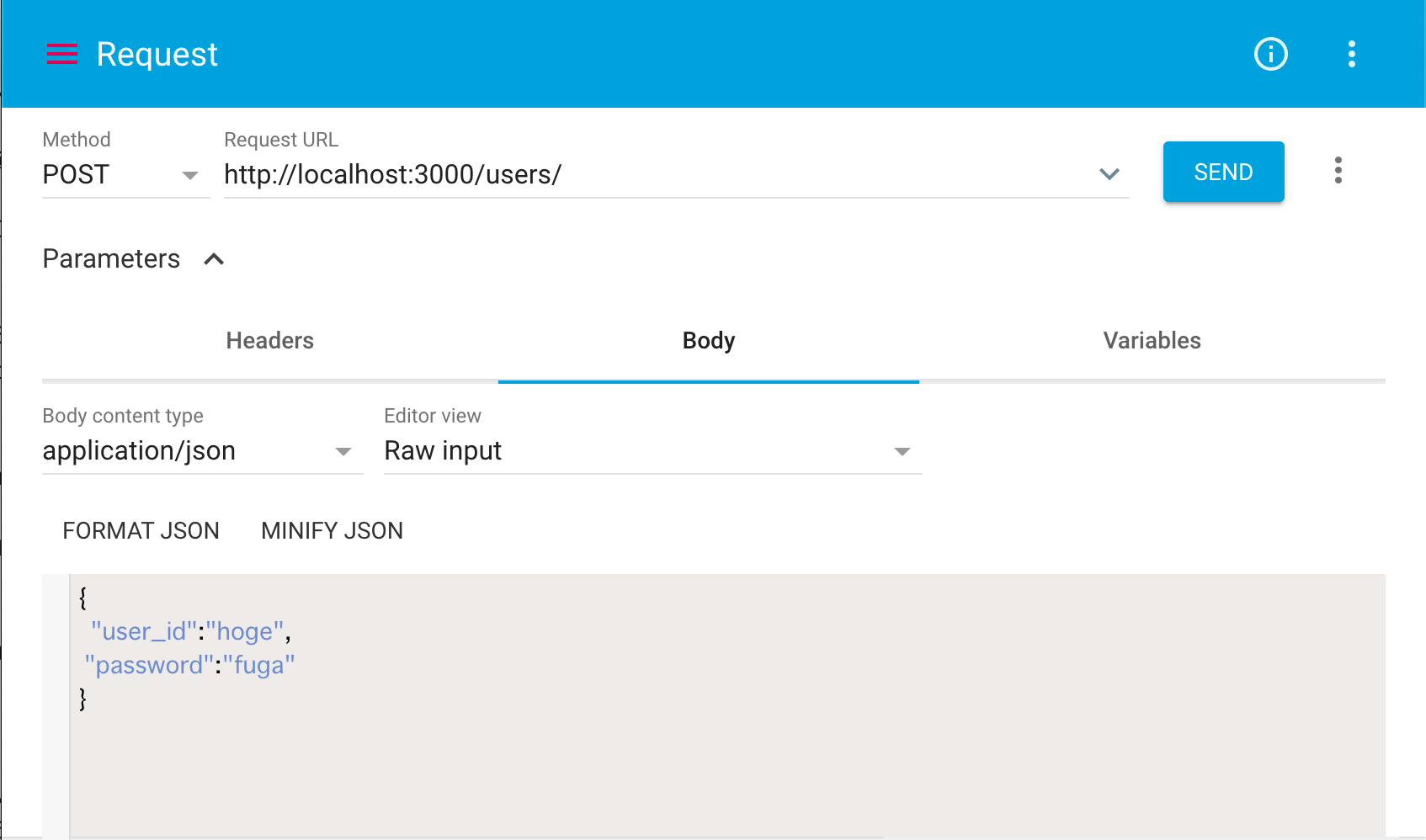
データ投入
ではデータ投入しましょう。
~/users/へPOSTリクエストを送ります。これは「bodyのjsonを元にデータを作成する」ことを意味します。その際に、リクエストのBodyを以下の様に指定しましょう。
Body content type : application/json
Body : {"user_id":"hoge","password":"fuga"}
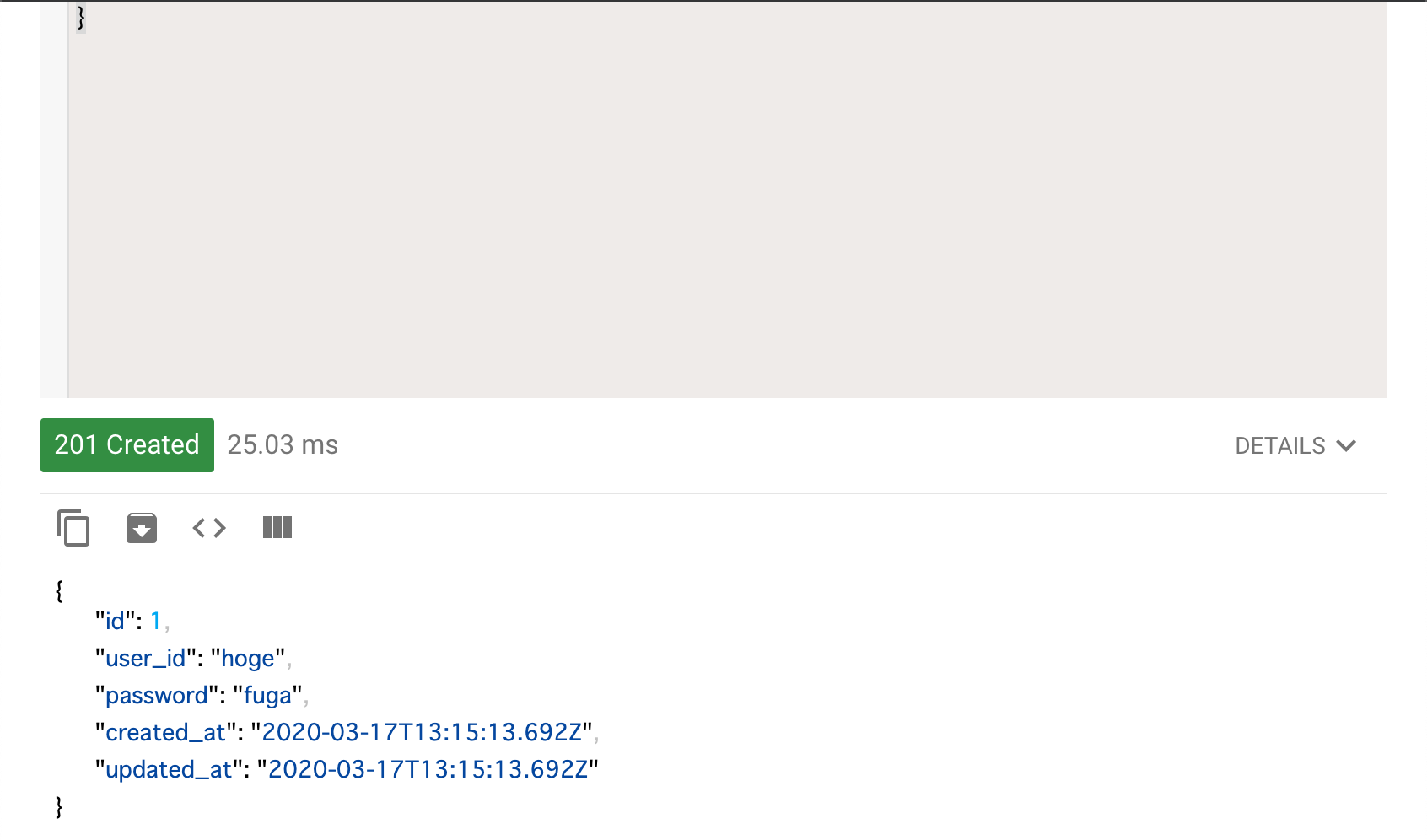
すると以下の様なレスポンスが返ってきてユーザが作られたことが分かります。
ついでにもう1つデータ投入しておきましょう。
この状態で
~/users/へGETリクエストを送ると、、、
先ほど入れた2件のデータが両方取れます。
1件取得
次は、
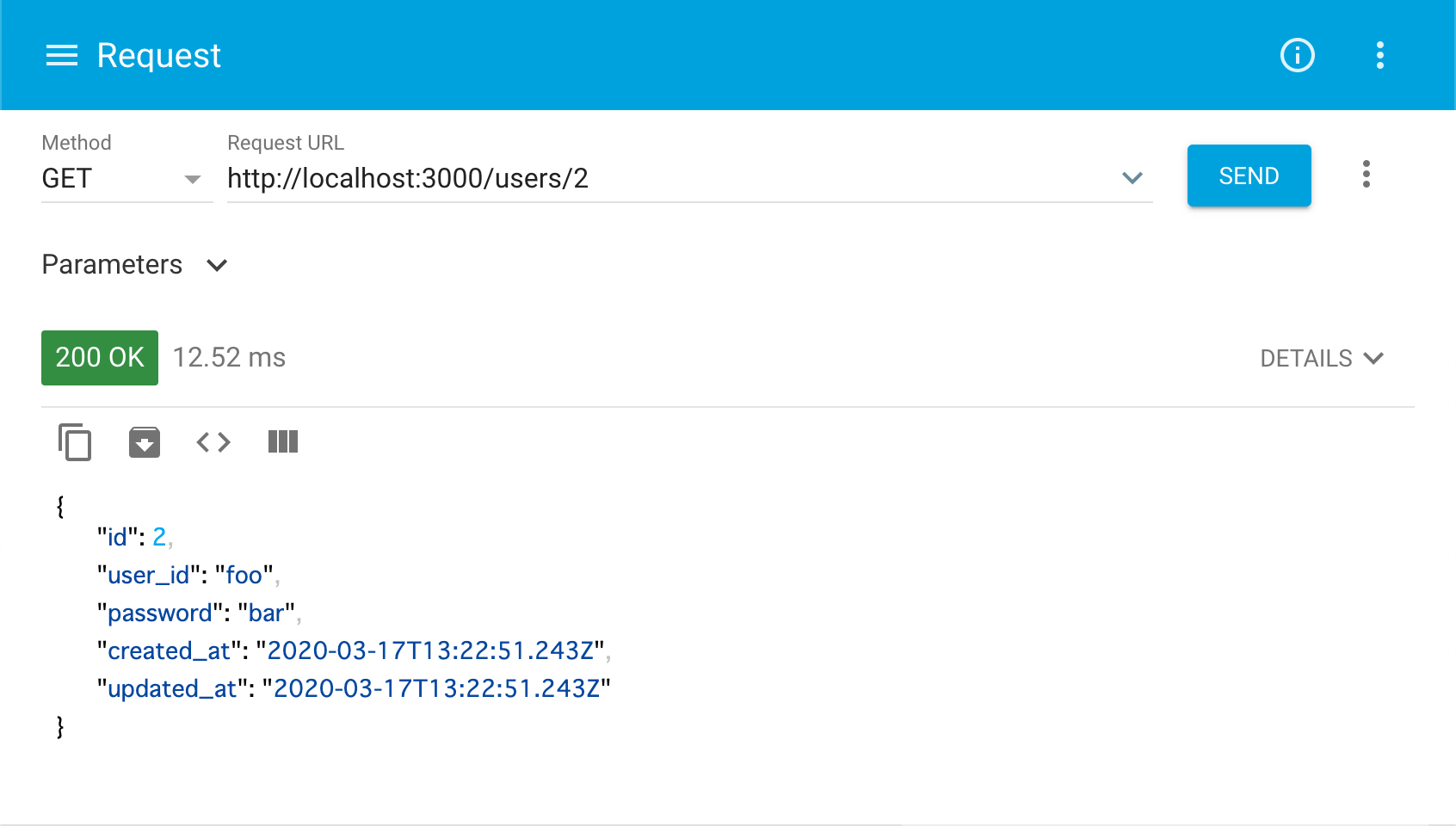
~/users/2へGETリクエストを送ってみましょう。これは「idが2である人のデータを取得する」ことを意味しており、以下の様なレスポンスが返ってきます。
削除
次は、
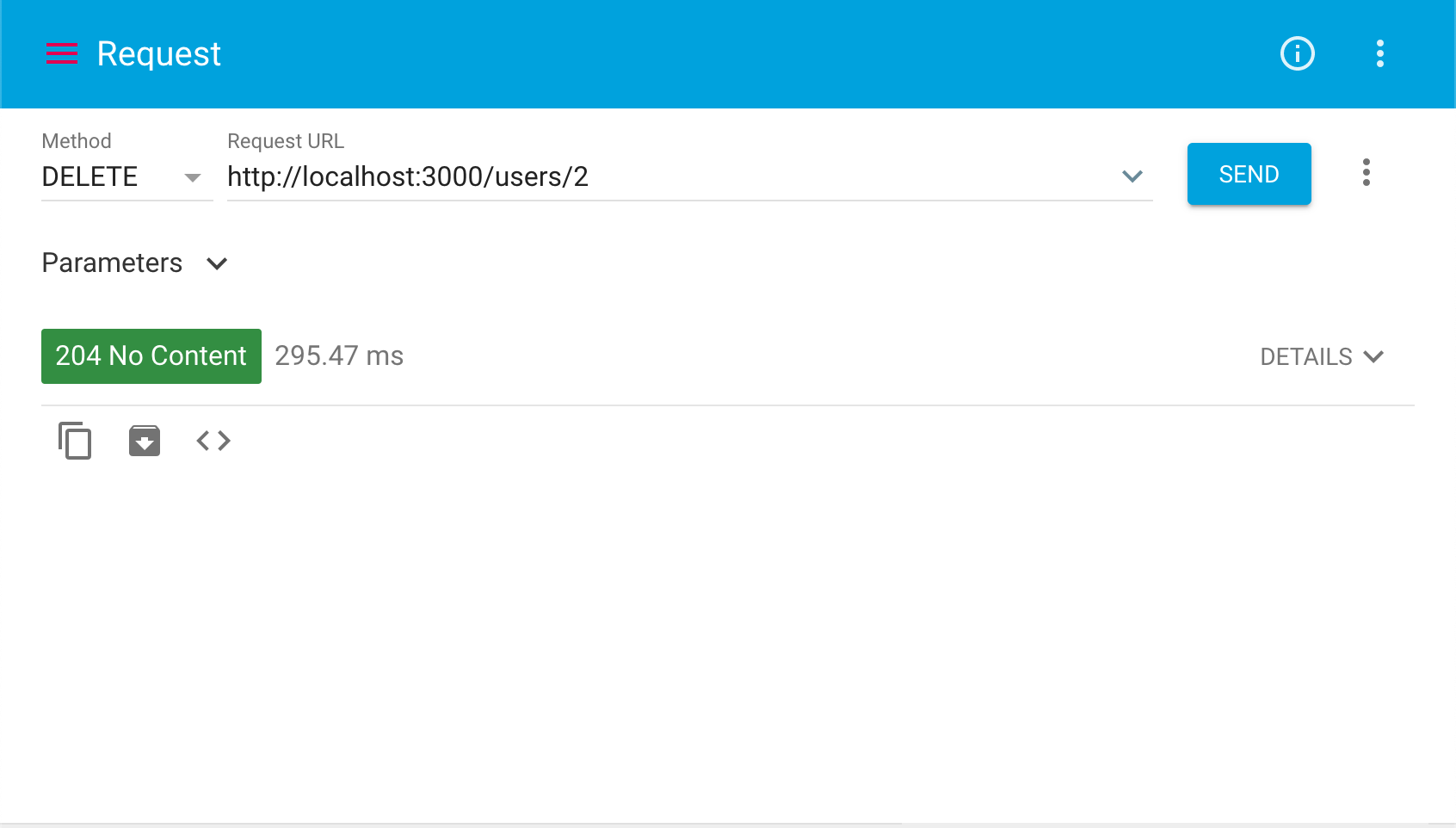
~/users/2へDELETEリクエストを送ってみましょう。これは「idが2である人のデータを削除する」ことを意味しており、以下の様なレスポンスが返ってきます。
この状態で
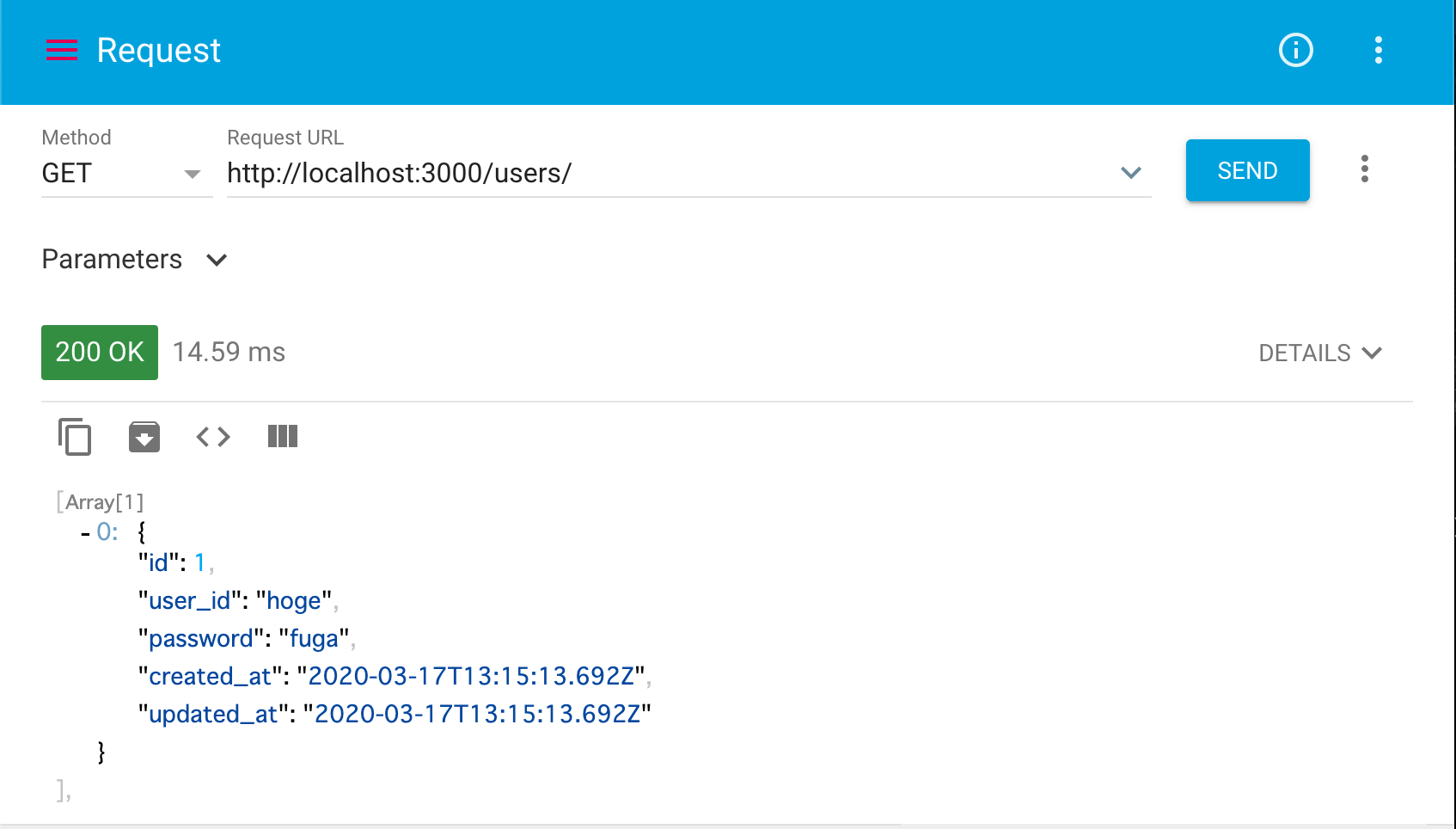
~/users/へGETリクエストを送ると、、、
idが2のデータがなくなっていることがわかります。
更新
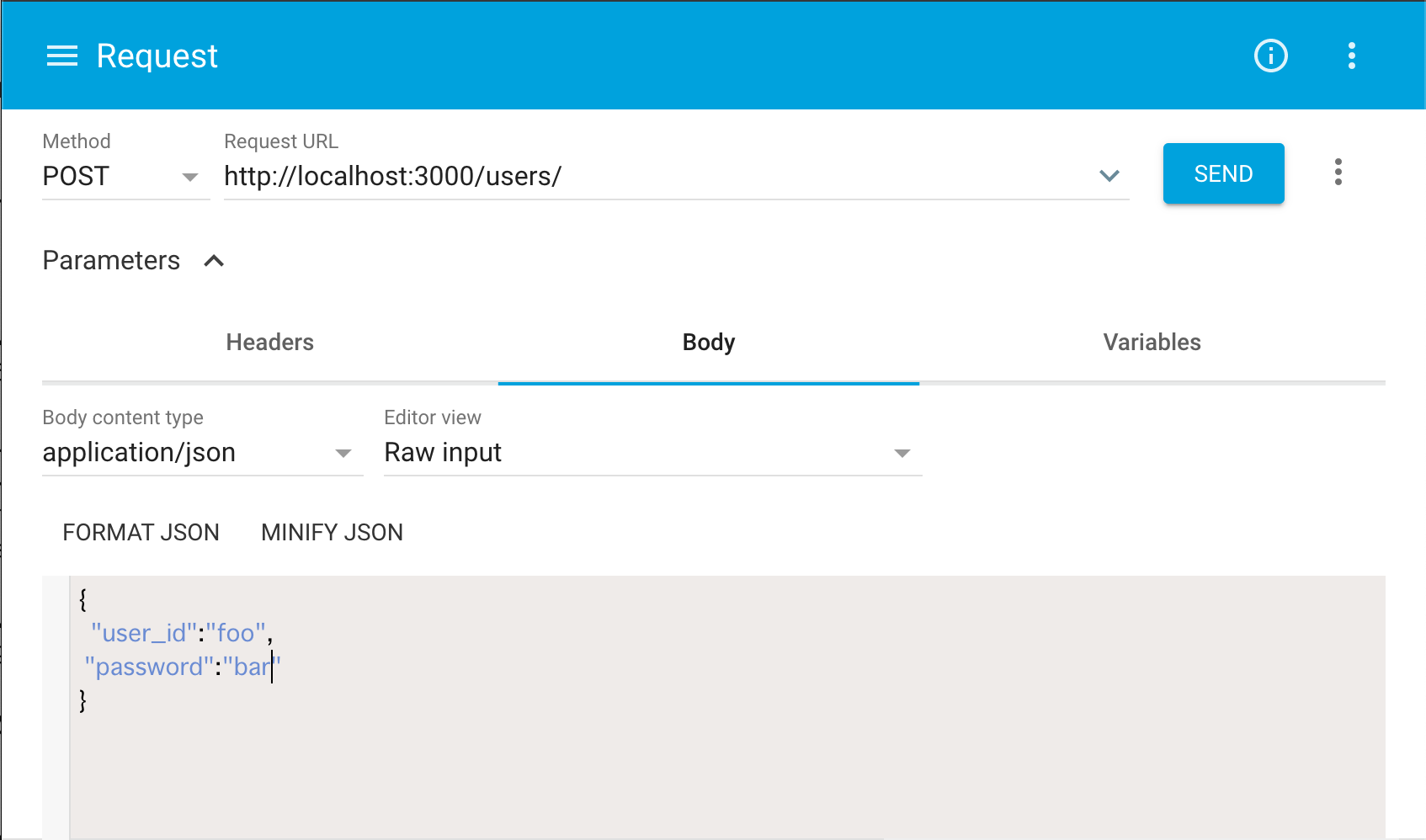
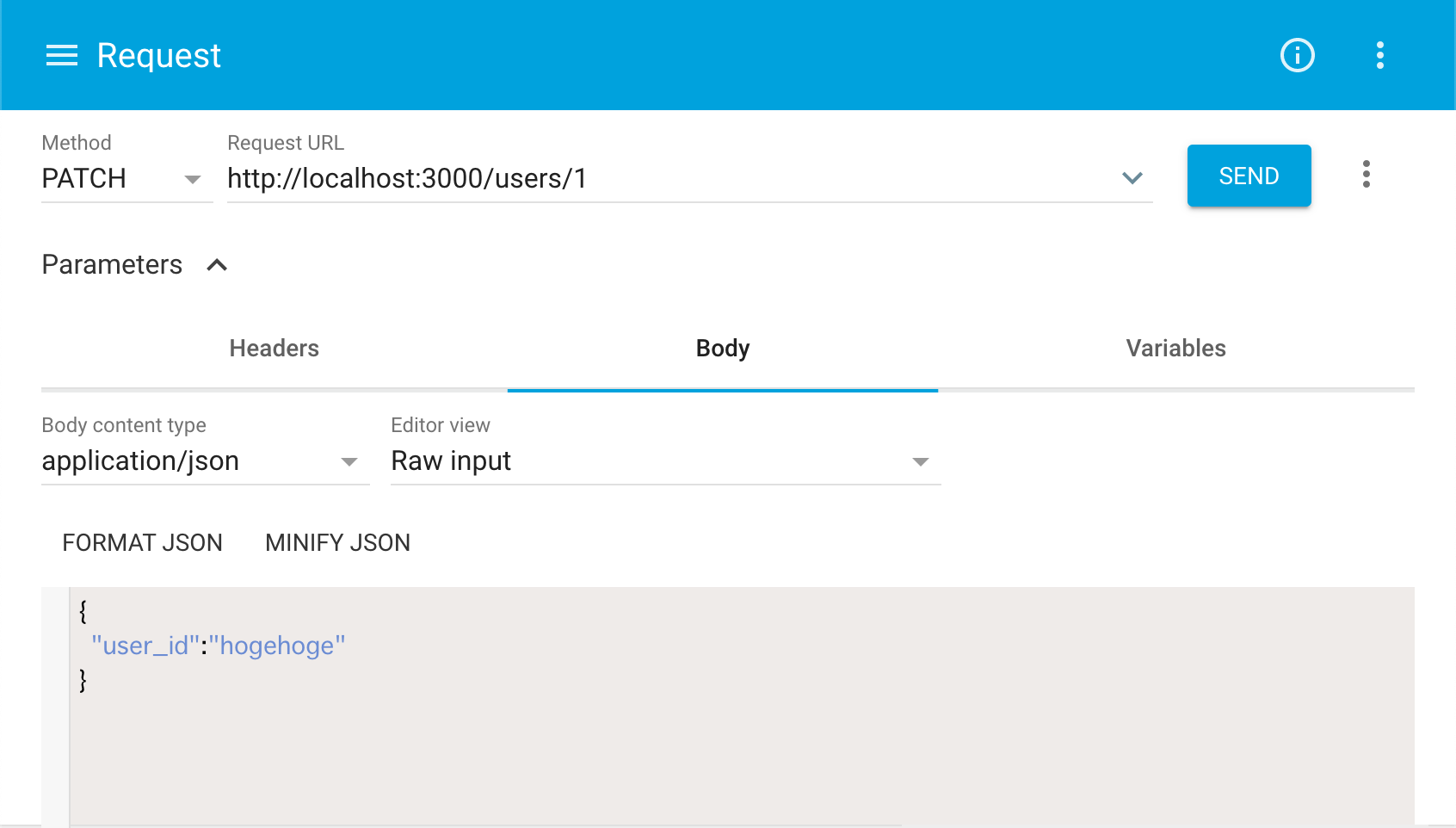
最後に、
~/users/1へPATCHリクエスト(PUTでも可)を送ってみましょう。これは「bodyのjsonを元にidが1であるデータを更新する」ことを意味します。その際に、リクエストのBodyを以下の様に指定しましょう。
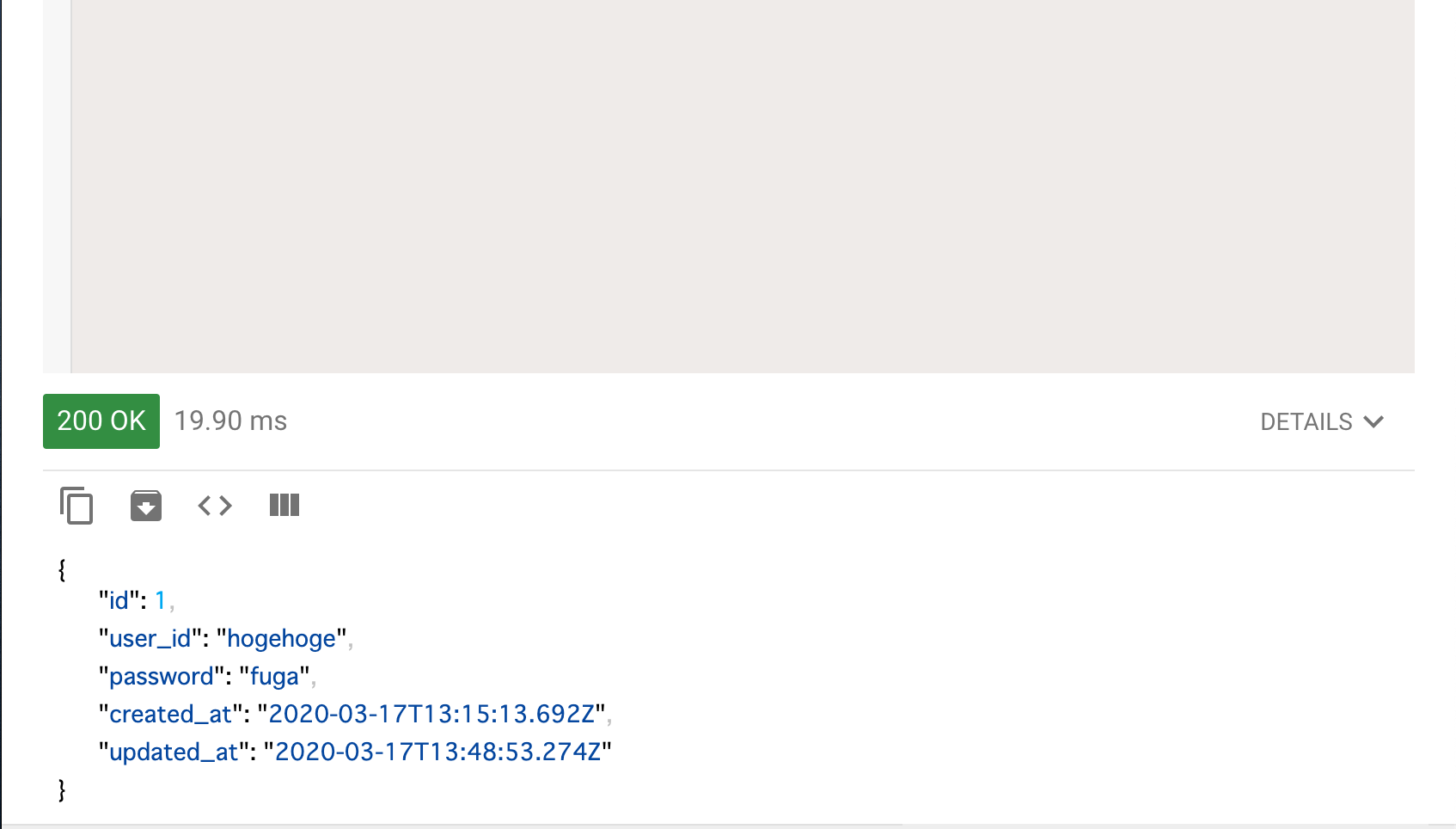
すると以下の様なレスポンスが返ってきます。
idが1のデータのuser_idがhogehogeに変更されているのがわかると思います。
メソッドとパスその効果をまとめると以下の様になります。
メソッド パス 効果 GET /users/ 全件取得 POST /users/ bodyのjsonでデータ投入 GET /users/:id/ 該当idのデータを取得 PATCH /users/:id/ 該当idのデータをbodyのjsonで更新 PUT /users/:id/ 該当idのデータをbodyのjson更新 DELETE /users/:id/ 該当idのデータを削除 さいごに
- なぜ
rails g scaffold ~するだけでこの様なAPIが作成できるのか- ソースコードの中身
- 自分好みの仕様に作り替えるには
は別の記事で解説したいと思います。
ご質問などあれば気軽にどうぞ。
@ruemura3
- 投稿日:2020-03-17T23:19:04+09:00
【5分で出来る】Ruby on RailsでWebAPIの作成
1. はじめに
この記事では、Ruby on RailsにおけるAPIの作り方を簡単に紹介します。
Rails が非常に優秀なので作成は5分もあればできるでしょう。(Rails を使う環境が整っている前提)
データベースへのユーザ登録、参照、消去、更新ができるAPIを作成し、いじりながら解説します。前提知識
- API
- JSON
- HTTPリクエスト、レスポンス
- GET, POST, DELETE, etc
環境
- ruby 2.6.5
- Rails 6.0.2
2. 作り方
なにはともあれAPIの基盤の作成。
[tmp]$ rails new RailsApi --apiご存知
rails new [アプリ名]とすることでアプリの基盤を作成することができるが、 --apiのオプションをつけることでAPIに必要なものだけに絞って作ってくれる。[tmp]$ cd RailsApiRailsApiフォルダに移動。
[RailsApi]$ rails g scaffold user user_id:string password:string
rails g( or generate) scaffold [モデル名(単数形)] カラム名:データ型 (カラム名:データ型)
今回はユーザテーブルにIDとパスワードを持たせようと思うのでこの様に指定しました。IDのカラム名をidとしない様に注意。(自動生成されるカラム名のidと被るため)[RailsApi]$ rails db:create [RailsApi]$ rails db:migrateデータベースの作成とテーブルの作成を行います。
そしてなんと、、、
これでAPIの完成です。(マジ)詳しくはあとで解説するとしてこのAPIを試してみましょう。
3. 作成したAPIを試す
まず、APIをいじるならhttpリクエスト送信とレスポンス受信ができるツールが必要なので、chromeの拡張機能であるAdvanced REST clientをダウンロードしておきましょう。
全件取得
[AppName]$ rails s上記コマンドでローカルサーバを起動し、
http://localhost:3000/users/へGETリクエストを送ってみましょう。これは「データの全件取得」を意味します。
(rails g scaffold user ~でuserのモデルを作成したためその複数形をパスに指定。)すると以下の様な空のレスポンスが返ってきます。これはまだデータ投入していないからです。
データ投入
ではデータ投入しましょう。
~/users/へPOSTリクエストを送ります。これは「bodyのjsonを元にデータを作成する」ことを意味します。その際に、リクエストのBodyを以下の様に指定しましょう。
Body content type : application/json
Body : {"user_id":"hoge","password":"fuga"}
すると以下の様なレスポンスが返ってきてユーザが作られたことが分かります。
ついでにもう1つデータ投入しておきましょう。
この状態で
~/users/へGETリクエストを送ると、、、
先ほど入れた2件のデータが両方取れます。
1件取得
次は、
~/users/2へGETリクエストを送ってみましょう。これは「idが2である人のデータを取得する」ことを意味しており、以下の様なレスポンスが返ってきます。
削除
次は、
~/users/2へDELETEリクエストを送ってみましょう。これは「idが2である人のデータを削除する」ことを意味しており、以下の様なレスポンスが返ってきます。
この状態で
~/users/へGETリクエストを送ると、、、
idが2のデータがなくなっていることがわかります。
更新
最後に、
~/users/1へPATCHリクエスト(PUTでも可)を送ってみましょう。これは「bodyのjsonを元にidが1であるデータを更新する」ことを意味します。その際に、リクエストのBodyを以下の様に指定しましょう。
すると以下の様なレスポンスが返ってきます。
idが1のデータのuser_idがhogehogeに変更されているのがわかると思います。
メソッドとパスその効果をまとめると以下の様になります。
メソッド パス 効果 GET /users/ 全件取得 POST /users/ bodyのjsonでデータ投入 GET /users/:id/ 該当idのデータを取得 PATCH /users/:id/ 該当idのデータをbodyのjsonで更新 PUT /users/:id/ 該当idのデータをbodyのjson更新 DELETE /users/:id/ 該当idのデータを削除 4. さいごに
理解するには自分でやってみるのが一番なので自分で作ってみてください。ユーザのAPIができたら投稿記事のAPIなんかも作ってみるといいと思います。
- なぜ
rails g scaffold ~するだけでこの様なAPIが作成できるのか- ソースコードの中身
- 自分好みのAPIに作り替えるには
は別の記事で解説したいと思います。
ご質問などあれば気軽にどうぞ。
@ruemura3
- 投稿日:2020-03-17T23:11:34+09:00
【AWS】DynamoDBとRDSの違いについて
AWSのデータベースサービスについて
AWSが提供するデータベースは下記の5つ
DynamoDBとRDSの違いについて
データベースサービスの中で「DynamoDB」と「RDS」の違いがよく理解できなかったため色々な記事や資料をあさりました。
RDSの各種操作にはSQLを使用し、業務ではOracleやPostgresを用いておりかつRDSは用いていたためすぐに理解できました。ただし、DynamoDBについてはSQLを使わないデータベースアーキテクチャ(NoSQL)となります。RDBと比較したときのNoSQLの特徴としては「柔軟でスキーマレスなデータモデル」「水平スケーラビリティ」「分散アーキテクチャ」「高速な処理」が挙げられ、RDSが抱えるパフォーマンスとデータモデルの問題に対処することを目的に作られたアーキテクチャとなっています。参考URL
タイトルにある通り、具体的にDynamoDBとRDSの違いについてわかりやすく説明されている記事を下記に記載します。
最後に
何が違う?DynamoDBとRDS
に記載があるように、DynamoDBとRDSの気を付けポイントや使いどころがそれぞれあり、メリットデメリットがそれぞれ存在します。
- DynamoDBの使いどころ
読み込み/書き込みの多いシステム
テーブル結合が不要なシステム
- RDSの使いどころ
更新が頻繁なシステム
テーブル結合が必要となるテーブル設計のシステム特徴に合った使い方をして、その効果を存分に得られるように使い分けできるようにしていく必要があるようです。
- 投稿日:2020-03-17T23:03:59+09:00
メモリ不足でLaravelインストール、composer update失敗
なにがおきたか
Laravelを5.8から6にしようと
composer updateしたら下記のようなエラーがたくさん出た
mmap() failed: [12] Cannot allocate memory mmap() failed: [12] Cannot allocate memory PHP Fatal error: Out of memory (allocated 448884736) (tried to allocate 20480 bytes) in phar:///usr/local/bin/composer/src/Composer/Json/JsonFile.php on line 275 Fatal error: Out of memory (allocated 448884736) (tried to allocate 20480 bytes) in phar:///usr/local/bin/composer/src/Composer/Json/JsonFile.php on line 275 mmap() failed: [12] Cannot allocate memory PHP Fatal error: Out of memory (allocated 448884736) (tried to allocate 20480 bytes) in phar:///usr/local/bin/composer/src/Composer/Console/Application.php on line 82思い出せばLaravelを入れたときもメモリが足りないとかなったなと思い備忘録
対処法
swapの設定をすればいいらしい
そもそもswap何やねんレベルだったので勉強になった
Swap とは、簡単に言うと物理メモリを使い切った場合に、物理メモリの代わりに使われる領域のことで、パーティション、またはファイルを使って作成できますが、推奨されるのは、パーティションです。
https://wa3.i-3-i.info/word1718.html
https://server.etutsplus.com/allocate-swap-space/
設定する
確認
free -mreeコマンドは空きメモリと使用しているメモリの容量を表示するコマンドです。
結果こんな感じで、swapは0
total used free shared buff/cache available Mem: 983 474 416 0 92 392 Swap: 0 0 0sudo dd if=/dev/zero of=/swapfile bs=1M count=2048 chmod 600 /swapfile mkswap /swapfile swapon /swapfileddコマンドで指定サイズの空のファイルを作成
mkswapで、作成したファイルをスワップ領域として使用できるようにする
swaponでスワップ領域を有効化dd」コマンドはファイルをブロック単位で読み出し、指定通り変換して出力します ※1。入力と出力にデバイスを指定できるため、HDDのパーティションをコピーする、USBメモリやCD-ROMのバックアップを取る、といった使い方が可能です。
処理するブロック数を指定でき、任意のサイズのファイルを作成するといった用途にも役立ちます。勉強になった....
- 投稿日:2020-03-17T21:16:33+09:00
CloudFormationに日本語コメントを含めるとエラーになる場合の解決方法
テンプレートに日本語コメントを含めるとエラーになる
# これは日本語だ AWSTemplateFormatVersion: '2010-09-09' Parameters: Parameter: Type: Number Resources: # 日本語だ、これは Lambda: Type: 'AWS::Lambda::Function'こういうテンプレートファイルを
aws cloudformation deploy --template-file hoge.yml --stack-name fooないしaws cloudformation create-stack --template-body file://hoge.yml --stack-name fooを実行するとテンプレートはバイナリだからfileb://~を指定しろといったエラーが出ることがある。もちろんテンプレートはバイナリではない。AWS CLI実行時に--debugをつけるとこのようなエラーが見える。UnicodeDecodeError: 'cp932' codec can't decode byte 0xef in position 89: illegal multibyte sequence文字コード関連のエラーらしい
VS Codeで記述したので、テンプレートファイルはUTF8である。根本的解決にならないが、cp(code page)932はShift_JISなので、テンプレートファイルをShift_JISに変換してAWS CLIを実行すれば問題ない。ただ、JISのままだと、GithubにPushすると文字化けする等、いろいろと面倒。というかつい先日にMicrosoftからUnicodeを使ってくれとお触れが出たばっかりである。
AWS CLIが食っている文字コードをUTF8にする
調べたところ、AWS CLIは後ろでboto(Python)が動いているらしい。
C:\> aws --version aws-cli/2.0.3 Python/3.7.5 Windows/10 botocore/2.0.0dev7管理者権限を持つCMDなりPowershellで環境変数を付加してやる。参考にしたのはこの記事。
setx /m PYTHONUTF8 1何も変わらん( ^ω^)…
'cp932' codec can't decode byte 0xef in position 89: illegal multibyte sequenceCLIが使っているPythonは環境変数を読んでないらしい
インストーラから入れたAWS CLIをアンインストールする。
参考にした記事はこの記事、要するにPythonが環境変数を読んでないなら、環境変数を読ませたいPythonのパッケージマネージャであるpipから、botoとAWS CLIをインストールしてやればいい。pip install https://github.com/boto/botocore/archive/v2.tar.gz pip install https://github.com/aws/aws-cli/archive/v2.tar.gz解決した
aws cloudformation deploy --template-file hoge.yml --stack-name foo Waiting for changeset to be created.. No changes to deploy. Stack foo is up to date環境構築でハマるのもストレスマッハだけど、文字コード関連もそれに準ずるくらいイラつくよね。
参考記事
WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話
https://qiita.com/Yuu94/items/9ffdfcb2c26d6b33792e
Windows 上の Python で UTF-8 をデフォルトにする
https://qiita.com/methane/items/9a19ddf615089b071e71
AWS CLI v2をpipからインストールしてみた
https://dev.classmethod.jp/cloud/aws/install-aws-cli-v2-from-sourcecode/
- 投稿日:2020-03-17T21:01:19+09:00
AWS Amazon Linux2 で Django 2.2以降の環境を構築する
概要
この記事は初心者の自分がRESTful なAPIとswiftでiPhone向けのクーポン配信サービスを開発した手順を順番に記事にしています。技術要素を1つずつ調べながら実装したため、とても遠回りな実装となっています。
前回の Djangoで画像を配信できるwebAPIを作る で実装したAPIを外部のサーバへデプロイし、パグリックな環境からAPIを利用できる状態にします。
作業は
- クラウドのインスタンスを立てて必要なソフトやパッケージをインストール
- RestAPIのアプリをデプロイ
になります。この記事では「1. クラウドのインスタンスを立てて必要なソフトやパッケージをインストール」を纏めます。
構成
今回はAmazonのEC2を使うことにしました。OSはAmazon Linux 2 を選びました。構築に失敗したり環境が合わなかったらインスタンスごと作り直せば良いと考えたので、docker等のコンテナは使わず、OSに直接インストールをする事にしました。
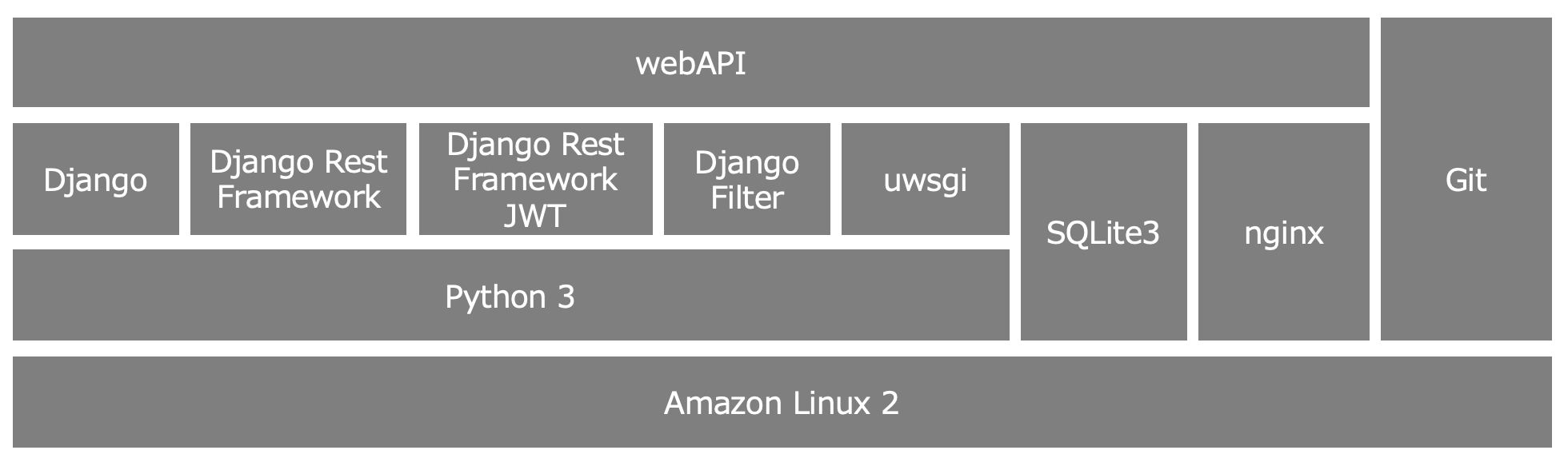
djangoで開発したwebAPIは nginx、uwsgi、djangoの構成で動かします。
構成図
こんな感じになるイメージです
参考
Amazon Linux 2でSQLite3を最新バージョンにする
Django2.2で開発サーバー起動時にSQLite3のエラーが出た場合の対応
Django + uWSGI + nginx (uWSGIチュートリアルの和訳)
【django】SQLiteバージョンエラー
Linuxやってみる! (6) ldconfigでライブラリパスを更新
Amazon Linux 2 ExtrasレポジトリのNginx、トピック名が「nginx1」になりました環境
Amazon Linux 2
Python 3.7.4
Django 3.0.3
SQLite 3.31.1手順
- AWSのアカウントを作成して(無料枠で)インスタンスを作成
- 必要なソフトをインストール
- python 3
- python のパッケージ
- django
- Django-filter
- djangorestframework
- djangorestframework-jwt
- wheel
- uwsgi
- Development Tools
- python3-devel
- git
- nginx
- SQLite3 のアップデート
AWSのアカウントを作成して(無料枠で)インスタンスを作成
クラウドサービスでよく使われている AWS、Azure、GCP の中から、今回は自分にとって操作経験があり且つその経験がまだ中途半端なAWSを選びました。無料枠を使ってAPIを公開させようと思います。
AWSのWebページにアクセスしてアカウントを登録するか、Googleで 「aws 無料枠」と入力すると “AWS クラウド無料利用枠 | AWS - Amazon Web Services” というリンクが出てくると思います(2020/1/5 時点)ので、そのページの「まずは無料で始める」からアカウントを登録をします。
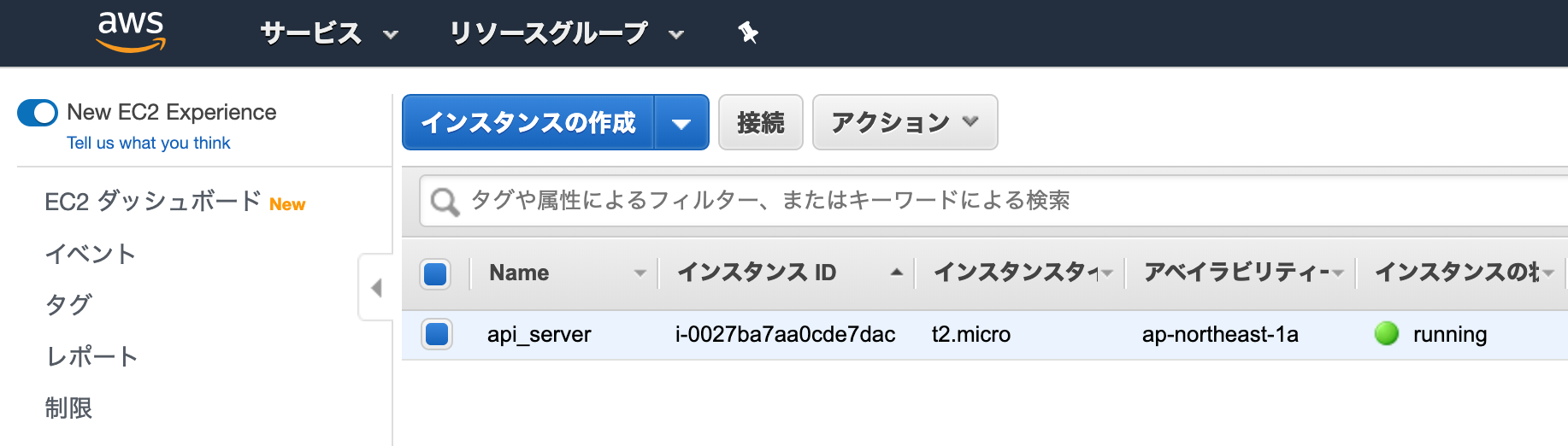
アカウントの登録が完了したらインスタンスを作成します。自分はOSをAmazon Linux、インスタンスタイプは無料枠のt2.micro を選びました。インスタンスの作り方はAWSのチュートリアルがわかりやすいので、そちらをご覧ください。途中で作成するキーペアのキーはアクセス時に使うことになるので、保存場所に気をつけてください。
インスタンスが一つ立ち上がりました。用途が分かり易いように api_server という名前を付けました。
インスタンスが立ち上がったのでSSHでの接続を試します。今後インスタンスに設定を加えたり必要なソフトをインストールするのにSSHでの操作が必要になるからです。(デフォルトでSSH接続ができるセキュリティ設定になっています。)
Macの場合はターミナルを使ってSSH接続ができます。Windowsの場合はエディタのコンソールから操作するか、TeraTarmのようなツールを使います。
ここからはキーペアによる認証で接続する場合の方法を記載します。Macからキーペアでアクセスする場合、事前にキー( XXX.pem )のアクセス権限を変更しておかないとエラーになりました。所有者のみ参照できるように権限を変更します。下記のコマンドで変更します。(AWSのチュートリアルにも出てきます)
chmod 400 [キー( XXX.pem )を格納したフォルダのパス]/[キーのファイル名].pemSSH接続します。Macの場合コマンドはこちらです。
ec2-userの部分はログインユーザの指定で、デフォルトはec2-userです。ssh -i [インスタンスを作成する際に作ったキーペアのキー( XXX.pem )の絶対パス] ec2-user@[インスタンスのグローバルIP]自分の場合はこんなコマンドになりました。
ssh -i ~/xxxxxx/yyyyy/MyKeyPair.pem ec2-user@zz.zzz.zz.zzz以下のように接続を続けるか確認される事があるので、
yesを入力してEnterします。The authenticity of host '13.230.91.101 (13.230.91.101)' can't be established. ECDSA key fingerprint is SHA256:ldQ3z2WraZy3xCGfL1taOnixN9baFpgnN3qYXfZLah0. Are you sure you want to continue connecting (yes/no)? yesこちらの表示が出たら接続が成功です。
__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 8 package(s) needed for security, out of 17 available Run "sudo yum update" to apply all updates.必要なソフトをインストール
ここからはインスタンスにSSH接続した状態でコマンドを使ってインストール作業を進めます。また開発したローカル環境とできる限り同じバージョンをインストールします。
最初にyum(パッケージの統合管理システム)をアップデートしておきます。
$ sudo yum update途中で
Is this ok [y/d/N]:と聞かれたらyを入力してEnter。なおyumの後ろに-yを付けると自動的にyesと答えてくれるので聞かれなくなります。この後、yumでインストールする際に頻繁に出てきます。Python3 のインストール
Amazon Linux 2 はデフォルトで Python がインストールされていますが、2系なので 3系のPythonを別途インストールします。なお、インストールされているpythonのバージョンを確認するコマンドは
$ Python -Vです。インストールする際のパッケージ名(バージョンの指定)がMacOSやCentOSの場合と異なったので、最初に少し困りました。今回のAmazon Linux 2 のケースでは
Python3になります。Python 3 のインストール。
$ sudo yum install python3Development Tools と python3のdevパッケージのインストール
uwsgiをインストールする際に必要なのでインストールしておきます。なお、python3のdevパッケージのパッケージ名は、CentOSやUbuntuでは
python 3.x-devのようになりますが、Amazon Linux 2ではpython3-develとなります。ネットの情報を頼りにインストールのコマンドを実行したらパッケージを引けず、小ハマりしました。パッケージ名を確認してからインストールを実行する習慣が大切です。Development Tools のインストール
$ sudo yum groupinstall "Development Tools"python3のdevパッケージのインストール
$ sudo yum install python3-develPython3 のパッケージのインストール
djangoなど必要なパッケージをpythonの環境にインストールします。Python3のインストールが成功していれば pip3 コマンドが使えます。現在インストールされているパッケージを確認します。まだ何もインストールしていないので何も表示されないはずです。
$ pip3 freezedjangoのインストール
$ sudo pip3 install django
$ pip3 freezeを実行するとdjangoも含めいくつかのパッケージがインストールされています。$ pip3 freeze asgiref==3.2.3 Django==3.0.3 pytz==2019.3 sqlparse==0.3.0この調子で他のパッケージもインストールしていきます。
Django Filter のインストール
$ sudo pip3 install django-filterDjango Restframework のインストール
$ sudo pip3 install djangorestframeworkDjango Restframework JWT のインストール
Json Web Token(JWT)を使ったAPIの認証機能を実装している場合に必要です。
$ sudo pip3 install djangorestframework-jwtwheel のインストール
uwisgi のインストールに必要です。
$ sudo pip3 install wheeluwisgi のインストール
$ sudo pip3 install uwsgigit のインストール
ソースコードからデプロイする際に必要です。
$ sudo yum install gitnginx のインストール
Amazon Linux 2 の場合 nginx は yum では無く
amazon-linux-extrasでインストールします。なお、2020年2月現在でトピック名の指定は「nginx1」だそうです。(以前は「nginx1.12」)$ sudo amazon-linux-extras install nginx1インストールが完了したら起動してみます。
# nginxの起動 $ systemctl start nginx # active (running) と表示されていれば起動しています ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled) Active: active (running)nginxの操作を纏めました。(CentOS7と同じです)
# 起動 $ systemctl start nginx # 再起動 $ systemctl restart nginx # 停止 $ systemctl stop nginxSQLite3 のアップデート
Djangoを使うのにSQLite3が必要になります。
python3をインストールした際にSQLite3もインストールされるようですが、デフォルトでインストールされるSQLite3のバージョンが古く、Django2.2以降ではサーバ起動時などにバージョンチェックでエラーとなってしまいます。そこでSQLite3のアップデートが必要です。バージョンは
$ sqlite3 ―versionで確認できます。デフォルトは3.7.17でした。# SQLite 3.8.3 より新しいバージョンを要求される File "/home/ec2-user/.local/share/virtualenvs/ami-folvMrTj/lib/python3.7/site-packages/django/db/backends/sqlite3/base.py", line 65, in check_sqlite_version raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17).2020年1月時点でyum でのアップデートに対応していないようで、ファイルをダウンロードするところから手動でアップデートが必要です。
SQLite3 のファイルをダウンロードして解答する
SQLiteの公式サイト(https://www.sqlite.org/download.html)で最新版を確認して、そのバージョンのgzファイルのパスを取得します。2020年1月時点の最新版は
https://www.sqlite.org/2020/sqlite-autoconf-3310100.tar.gzでした。# ファイルをダウンロード $ wget https://www.sqlite.org/2020/sqlite-autoconf-3310100.tar.gz # ファイルを解凍 $ tar xvfz sqlite-autoconf-3310100.tar.gz # ダウンロードしたファイルと、解凍したファイルが入ったフォルダができています。 $ ls sqlite-autoconf-3310100 sqlite-autoconf-3310100.tar.gzビルドをしてインストールする
# 解凍したフォルダへ移動します。 $ cd sqlite-autoconf-3310100/ # ビルドしてインストール # ./configure → make → make install の流れは定番らしいです $ ./configure --prefix=/usr/local $ sudo make $ sudo make install新しくインストールしたSQLite3のパスを通す
最新版のインストールは出来ましたがパスが通っていないので、実行時に古いバージョンのSQLite3の方が参照/実行されてしまいます。不要なファイルを削除したり新しいSQLite3にパスを通す作業をします。
# SQLite3のインストールに使ったファイルを削除 $ rm sqlite-autoconf-3310100.tar.gz $ rm -rf sqlite-autoconf-3310100次にSQLiteがインストールされたか確認します。
# sqlite3で検索 $ sudo find / -name sqlite3 /usr/bin/sqlite3 /usr/lib64/python2.7/sqlite3 /usr/lib64/python3.7/sqlite3 /usr/local/bin/sqlite3 /usr/local/lib64/python3.7/site-packages/django/db/backends/sqlite3 # /usr/lib64/python2.7/sqlite3、/usr/lib64/python3.7/sqlite3、~django/db/backends/sqlite3 はディレクトリ # /usr/bin/sqlite3 と /usr/local/bin/sqlite3 のバージョンを確認 $ /usr/bin/sqlite3 --version 3.7.17 2013-05-20 $ /usr/local/bin/sqlite3 --version 3.31.1
/usr/local/bin/sqlite3の方が新しくインストールしたSQLite3 なので、古い/usr/bin/sqlite3が参照されないようにします。# 古い方のsqlite3のファイル名を変更 $ sudo mv /usr/bin/sqlite3 /usr/bin/sqlite3_old # ディレクトリに新しいsqlite3へのシンボリックリンクを作成 $ sudo ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 # sqlite3のバージョンを参照。新しい方が参照される事を確認 $ sqlite3 --version 3.31.1次に、共通ライブラリ(
ld.so.conf)へパスを通します。# ld.so.conf があるディレクトリへ移動 $ cd /etc # ls か ll でld.so.confファイルの存在を確認 $ ls # ld.so.confをVimで開いてパスを追加 # 追加するパスは /usr/local/lib $ sudo vi ld.so.conf # 編集を反映 $ sudo ldconfig # パスが通ったか確認する # /usr/local/lib/~のパスが表示されれば通っている $ ldconfig -p | grep sqlite libsqlite3.so.0 (libc6,x86-64) => /usr/local/lib/libsqlite3.so.0 libsqlite3.so.0 (libc6,x86-64) => /lib64/libsqlite3.so.0 libsqlite3.so (libc6,x86-64) => /usr/local/lib/libsqlite3.soさて、参考にさせて頂いた方の情報によるとこれでSQLite3のアップデートは完了のはずですが、何故かdjangoのサーバ起動時のバージョンチェックのエラーが消えず、3日ほどハマりました。
アップデートをして共通ライブラリにパスも通したはずなのに、バージョン3.7.17 が参照されるのです。
いろいろと試した結果(インスタンスごと作り直しました)、元から存在したライブラリ(
/lib64/libsqlite3.so.0)が優先的に読み込まれているのが原因らしいと分かりました。# SQLite 3.8.3 より新しいバージョンを要求される File "/home/ec2-user/.local/share/virtualenvs/ami-folvMrTj/lib/python3.7/site-packages/django/db/backends/sqlite3/base.py", line 65, in check_sqlite_version raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17).そこで、
/lib64/libsqlite3.so.0を削除すると、問題無く起動しました。
(他の箇所に影響を及ぼす可能性があるため自己責任でお願いいたします)# 該当するファイルを探す $ cd /lib64 $ ls # リンクとディレクトリを削除 $ sudo rm libsqlite3.so.0 $ sudo rm -rf libsqlite3.so.0.8.6 # 削除を反映 $ sudo ldconfig # 古いライブラリが参照されないか確認 $ ldconfig -p | grep sqlite libsqlite3.so.0 (libc6,x86-64) => /usr/local/lib/libsqlite3.so.0 libsqlite3.so (libc6,x86-64) => /usr/local/lib/libsqlite3.soここまでで環境の準備は出来ました。
次はnginxのインストールと、APIのデプロイをします。
- 投稿日:2020-03-17T20:58:03+09:00
Pythonを使ったDigest認証の設定@Lambda
はじめに
Digest認証について検索してもほとんど情報がなかったので Pythonを使ったBasic認証の設定@Lambda の続編として書いてみた。
Digest認証自体ほとんど触ったことがなく、その仕組みを勉強するのも兼ねて。コード
import os import ctypes import json import base64 import time import hashlib import copy from Crypto.Cipher import AES accounts = [ { "user": "user1", "pass": "pass1" }, { "user": "user2", "pass": "pass2" } ] realm = "sample@test.com" qop = "auth" # Basic認証と違って、認証後のタイムアウトを設定できるので入れてみた timeout = 30 * (10 ** 9) # 30 seconds # AES暗号化で使うための情報の準備 raw_key = "password1234567890" raw_iv = "12345678" key = hashlib.sha256(raw_key.encode()).digest() iv = hashlib.md5(raw_iv.encode()).digest() def lambda_handler(event, context): request = event.get("Records")[0].get("cf").get("request") if not check_authorization_header(request): return { 'headers': { 'www-authenticate': [ { 'key': 'WWW-Authenticate', 'value': create_digest_header() } ] }, 'status': 401, 'body': 'Unauthorized' } return request def check_authorization_header(request: dict) -> bool: headers = request.get("headers") authorization_header = headers.get("authorization") if not authorization_header: return False data = { "method": request.get("method"), "uri": request.get("uri") } header_value = authorization_header[0].get("value") # Digest認証のデータは、「Digest 〜」と言う形式で来るので、まずは不要な部分を削除する header_value = header_value[len("Digest "):] # 各値がカンマで区切られてるので、分割する values = header_value.split(",") data = { "method": request.get("method"), "uri": request.get("uri") } # 各値を扱いやすいようにまたまた分割 for v in values: # nonceをBase64エンコードしているので、単純に`=`で分割するとおかしくなるので、このような対応をしている idx = v.find("=") vv = [v[0:idx], v[idx+1:]] # 前後に半角スペースが入るので削除する vv[0] = vv[0].strip() vv[1] = vv[1].strip() # 値によってはダブルクォーテーションで括られているので、削除する if vv[1].startswith("\""): vv[1] = vv[1][1:] if vv[1].endswith("\""): vv[1] = vv[1][:len(vv[1])-1] data[vv[0]] = vv[1] for account in accounts: if account.get("user") != data.get("username"): continue d = copy.deepcopy(data) d["user"] = account.get("user") d["pass"] = account.get("pass") encoded_value = create_validation_data(d) if d.get("response") == encoded_value: if check_timeout(data.get("nonce")): return True return False def check_timeout(nonce: str) -> bool: aes = AES.new(key, AES.MODE_CBC, iv) value = aes.decrypt(base64.b64decode(nonce.encode())).decode() # AESで暗号化する時にpaddingで`_`を追加しているので、その分を削除する while value.endswith("_"): value = value[:len(value)-1] return int(value) + timeout > time.time_ns() def create_validation_data(data: dict) -> str: v1 = "{}:{}:{}".format(data.get("user"), realm, data.get("pass")) vv1 = hashlib.md5(v1.encode()).hexdigest() v2 = "{}:{}".format(data.get("method"), data.get("uri")) vv2 = hashlib.md5(v2.encode()).hexdigest() v3 = "{}:{}:{}:{}:{}:{}".format(vv1, data.get("nonce"), data.get("nc"), data.get("cnonce"), qop, vv2) return hashlib.md5(v3.encode()).hexdigest() def create_digest_header() -> str: aes = AES.new(key, AES.MODE_CBC, iv) timestamp = "{}".format(time.time_ns()).encode() # 暗号化する時に長さが16の倍数じゃないとダメなので、paddingで詰めている while len(timestamp) % 16 != 0: timestamp += "_".encode() header = "Digest " values = { "realm": '"' + realm + '"', "qop": '"auth,auth-int"', "algorithm": 'MD5', "nonce": '"' + base64.b64encode(aes.encrypt(timestamp)).decode() + '"' } idx = 0 for k, v in values.items(): if idx != 0: header += "," header += '{}={}'.format(k, v) idx += 1 return header動かすための準備
LambdaやCloudFrontの設定はBasic認証の時と同じなので、記述することはない。
ただ、AESの暗号化するライブラリがpipでインストールする必要があるものなので、ちょっとだけ対応が必要。ライブラリをzipファイルにする
Lambda上で
pipを実行することができないので、ローカルPCなどでpip installしたものを zip ファイル化してアップする必要がある。
* 【Python】AWS Lambdaで外部モジュールを使用するこの際気をつけないといけないのが、AWS LambdaのOSは、Amazon Linuxだと言うこと。
「あ〜単純にzipしたら良いのね」ってローカルのMacでzipを作成しても動かないので注意。
* AWS Lambda ランタイムAmazon LinuxのEC2を作成してzipファイルを作成しても良いけど、高々zipファイル作成するだけなので、Dockerで十分。
と言うことで、Dockerを使って作成。# Amazon Linux2のイメージをpullして起動 $ docker run -it amazonlinux:2 bash # Dockerイメージ上で必要なパッケージをインストール $ yum install -y gcc python3 pip3 python3-devel.x86_64 # Lambda上で使うパッケージをインストール $ pip install pycrypto -t ./ # zipファイル作成 $ zip -r pycrypto.zip Crypto/lambda_handlerの作成
zipファイルをアップロードすると、
lambda_function.pyはなくなっているので改めてlambda_function.pyを作成し、lambda_handlerを記述するその他参考にしたサイト
- 投稿日:2020-03-17T19:08:02+09:00
AWS BackupのDefault vaultのリカバリーポイントをまとめて削除する。
概要
大分前にテストしていたAWS BackupでDefault vaultに大量のAMIとSnapshotがあり、
邪魔だったので消そうとしたところ、EC2のコンパネからはまとめて削除ができない。AWS Backupのコンパネからだと1個ずつしか消せず、vaultごと削除しようとしたところ
Defaultのvaultは削除できないことが判明。引用元:
AWS Backupを使い始める前に覚えておきたいこと解決策
50個程度のAMIとSnapshotなら1個1個手で消してもいいかもしれないが、どうせ同じ時間をかけるならまとめて削除できる方法を考えたい。
じゃあAWS CLIで一気にやってしまおう。環境
Amazon Linux2
aws-cli/1.16.300 Python/2.7.16 Linux/4.14.171-136.231.amzn2.x86_64 botocore/1.13.36組んだshell
budel.sh#!/bin/bash ##一覧作成CLI用変数 LIST="list-recovery-points-by-backup-vault --backup-vault-name" ##AWSBackupにやらせたいCLI用変数 CMD="delete-recovery-point --backup-vault-name" ##引数省略用 RPA="--recovery-point-arn" ##引っ張ってくる値 VAL="RecoveryPointArn" ##VAULTからリカバリーポイント一覧を取得&整理 aws backup $LIST $1 | grep $VAL | sed -e "s/[\"]//g" | awk '{print $2}' | awk -F ',' '{print $1}' | cat > vault.txt ##出力したファイルから一行ずつコマンド処理 while read line do aws backup $CMD $1 $RPA $line done < ./vault.txt ##立つ鳥跡を濁さず rm -f vault.txt結果
. budel.sh <vault名>で叩いてあげると、そのvault内にあるリカバリーポイント(EC2ならAMIとSnapshot)が全て消える。
※間違って他のvaultで削除しないように
CMDをlist-recovery-points-by-resource --resource-arnにして、
VALをResourceArnとかにすると、ResourceArn毎のリカバリーポイントの値を
リストで出してくれるので、そっちから試した方が良い(自分はそうした)まだ全部見てないけど、CLIによっては他にもっと便利な動きしてくれるかな。
AWS Backup CLI一覧悩み事
あと、vault一覧取得のところでどうしても以下じゃないと出力が出来なくて、
awkを二回挟んでるんだけど、どうにかならんものか。
awk '{print $2}' | awk -F ',' '{print $1}'こうすると何も出力されない。
awk -F ',' '{print $2}'

- 投稿日:2020-03-17T19:08:02+09:00
AWS BackupのDefault vaultをまとめて削除する。
概要
大分前にテストしていたAWS BackupでDefault vaultに大量のAMIとSnapshotがあり、
邪魔だったので消そうとしたところ、EC2のコンパネからはまとめて削除ができない。AWS Backupのコンパネからだと1個ずつしか消せず、vaultごと削除しようとしたところ
Defaultのvaultは削除できないことが判明。引用元:
AWS Backupを使い始める前に覚えておきたいこと解決策
50個程度のAMIとSnapshotなら1個1個手で消してもいいかもしれないが、どうせ同じ時間をかけるならまとめて削除できる方法を考えたい。
じゃあAWS CLIで一気にやってしまおう。環境
Amazon Linux2
aws-cli/1.16.300 Python/2.7.16 Linux/4.14.171-136.231.amzn2.x86_64 botocore/1.13.36組んだshell
budel.sh#!/bin/bash ##一覧作成CLI用変数 LIST="list-recovery-points-by-backup-vault --backup-vault-name" ##AWSBackupにやらせたいCLI用変数 CMD="delete-recovery-point --backup-vault-name" ##引数省略用 RPA="--recovery-point-arn" ##引っ張ってくる値 VAL="RecoveryPointArn" ##VAULTからリカバリーポイント一覧を取得&整理 aws backup $LIST $1 | grep $VAL | sed -e "s/[\"]//g" | awk '{print $2}' | awk -F ',' '{print $1}' | cat > vault.txt ##出力したファイルから一行ずつコマンド処理 while read line do aws backup $CMD $1 $RPA $line done < ./vault.txt ##立つ鳥跡を濁さず rm -f vault.txt結果
. budel.sh <vault名>で叩いてあげると、そのvault内にあるリカバリーポイント(EC2ならAMIとSnapshot)が全て消える。
※間違って他のvaultで削除しないように
CMDをlist-recovery-points-by-resource --resource-arnにして、
VALをResourceArnとかにすると、ResourceArn毎のリカバリーポイントの値を
リストで出してくれるので、そっちから試した方が良い(自分はそうした)まだ全部見てないけど、CLIによっては他にもっと便利な動きしてくれるかな。
AWS Backup CLI一覧悩み事
あと、vault一覧取得のところでどうしても以下じゃないと出力が出来なくて、
awkを二回挟んでるんだけど、どうにかならんものか。
awk '{print $2}' | awk -F ',' '{print $1}'こうすると何も出力されない。
awk -F ',' '{print $2}'
- 投稿日:2020-03-17T18:05:51+09:00
AWSのCloudFormationのテンプレートを作成中に依存循環のエラーが発生した。
cloudFormationを使っていたところ、依存循環のエラーが発生し少しハマってしまった。
AWS初学者です。エンジニアとして一年目なので、そこを考慮して見ていただけると幸いです。間違っている点などありましたら、教えてください。。環境
Amzon Linux2
エラーの内容
cloudformationのテンプレート作成中に以下のエラーが発生。調べると、依存循環のエラーとのことらしい。
[cfn-lint] E3004: Circular Dependencies for resource Ec2InstanceServer. Circular dependency with [WpLaunchTemplate, Ec2InstanceServer]以下、エラーが出たコード部分です。
---省略--- Parameters: DBPassword: NoEcho: true Description: The database admin account password Type: String MinLength: 8 MaxLength: 41 AllowedPattern: '[a-zA-Z0-9]*' ConstraintDescription: must contain only alphanumeric characters. ---省略--- Resources: WpLaunchTemplate: Type: AWS::EC2::LaunchTemplate Properties: LaunchTemplateName: wp-launch-template LaunchTemplateData: UserData: Fn::Base64: !Sub - | #!/bin/bash ---省略--- echo 'grant all on wpdb.* to wpadmin@${Ec2Ipaddress} identified by '${DBPassword}'' | mysql --defaults-extra-file=/etc/my.cnf.d/client.cnf - { Ec2Ipaddress: !GetAtt Ec2InstanceServer.PrivateIp, } ---省略---EC2のUserDataの中で自リソースを!GetAttで参照していたことがエラーの原因とのこと。
CloudFormationでは、組込関数(!Refや!GetAttなど)を使用すると、依存関係が自動的に作られる。
Aリソース内に!RefでBリソースを参照した場合、リソースが作成される順番は
Bリソース → Aリソース依存循環のエラーになる場合
Aリソース内に!RefでBリソースを参照しかつ、Bリソース内でも!Refなどの組込関数でAリソースを参照した時。
Bリソース ⇄ Aリソース
上のような状態になり、どちらから作成していいのか判断できなくなる。解決
EC2のパブリックIpアドレスをシェルスクリプト内で使用したかっただけなので、以下のようにコマンドを修正し、!GetAttを削除。
grant all on wpdb.* to 'wpadmin'@'hostname -i' identified by '${DBPassword}';
元々、シェルスクリプトやコマンドについての知識不足で、この書き方に気づけなかった。ちなみに複数のIPアドレスが振られている場合は以下のようにした。
// eth0 $ hostname -I | cut -f1 -d' ' // eth1 $ hostname -I | cut -f2 -d' '各コマンドについて
①cutコマンドについて
cut -f 項目数 -d 区切り文字 ファイル名
ex)
cut -f 2 -d ":" sample.txt
ファイルsample.txtを「:」の文字で区切り、その2項目目を表示するコマンド②hostnameコマンドについて
hostname -i
ホストのIPアドレスを表示するコマンド参考
組込関数について
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference.html
循環依存について
https://note.com/amakata/n/n914e5b87fbcd
cut・hosnameのコマンドについて
https://moomindani.wordpress.com/2014/09/17/linux-command-ip-address/
- 投稿日:2020-03-17T16:02:27+09:00
AWS-SDKを使いたくてAPIを叩いたらエラーが出た。
概要
aws-sdkを使用してRoute53の操作をしたかった。
エラー内容
Error executing "ListResourceRecordSets" on "https://route53.amazonaws.com/2013-04-01/hostedzone/XXXXXXXX/rrset"; AWS HTTP error: cURL error 60: SSL certificate problem: unable to get local issuer certificate (see https://curl.haxx.se/libcurl/c/libcurl-errors.html)原因
http://nanoappli.com/blog/archives/7992
このエラーは、SSL暗号化されているhttpsのサイトにアクセスしようとした際にそのサーバが信頼できるか否かの証明書(ca証明書)が取得できなかった時に発生します。
ライブラリ自体はあまり関係ない?
解決策
とりあえず動かしたいのであれば、Gitの証明書を使用せよ。みたいな記事を見たので
C:\PASS\etc\pki\ca-trust\extracted\openssl\ca-bundle.trust.crt上記パスをphp.iniのcurlの設定に適用
[curl] ; A default value for the CURLOPT_CAINFO option. This is required to be an ; absolute path. #curl.cainfo = ここ
- 投稿日:2020-03-17T15:46:37+09:00
New credentials encrypted and saved. の対処法
- 投稿日:2020-03-17T15:20:52+09:00
コンテナレジストリ(AWS ECR / AzureContainerRegistry)のスキャン機能を試してみた
はじめに
コンテナのベースイメージのスキャンがしたいなーと思いまして、Azure・AWS両方触ってみました。時間がない方は「AWSとAzureのコンテナレジストリの特徴」「両者の比較」「さいごに」という部分だけお読みください。
まずはそれぞれのスキャンの特徴から。
AWS ECR
2019年10月28日Amazon ECR のイメージスキャンの通知ということでAWSから発表されました。
- イメージスキャンにかかる料金は無料
- ECRにすでにプッシュしてあるイメージに対するスキャンが可能。
- pushをhookしてスキャンすることが可能
- スキャンが終わったら通知することが可能
サービスを組み合わせることですでにあるイメージに定期的にスキャンできるのでゼロデイの脆弱性にも有効ですね。
Azure Container Registry
ContainerRegistryについては以前書いたこちらの記事をどうぞ
これについに2019年11月にスキャンする機能がついたわけです。
AzureではQualysを使ったスキャン機能になります。
- イメージスキャンにかかる料金は有償
- SecurityCenterがStandardである必要があるのと、1イメージにつき16.24円(東日本 3/17現在)かかります。
- 参考:Security Centerの料金
- Pushされたタイミングでスキャンさせることが可能
- 1日に1回SecurityCenterの機能を使って設定したメールアドレスに重大な脆弱性については通知を行うことが可能。
Azure Container Registry と Security Center の統合に記載がありますが定期的なスキャンを行うにはCI/CDと組み合わせる必要がありそうですね。
準備
診断対象とするのは私が3年前に作ってdockerhubにpushしたイメージです。
何もメンテナンスしていないので大量に引っかかると予想されます。。。。
dockerデーモンを起動して、脆弱性たっぷりのイメージを落としておきます。docker pull uzresk/demo:ver1.0AWS ECRでのスキャン
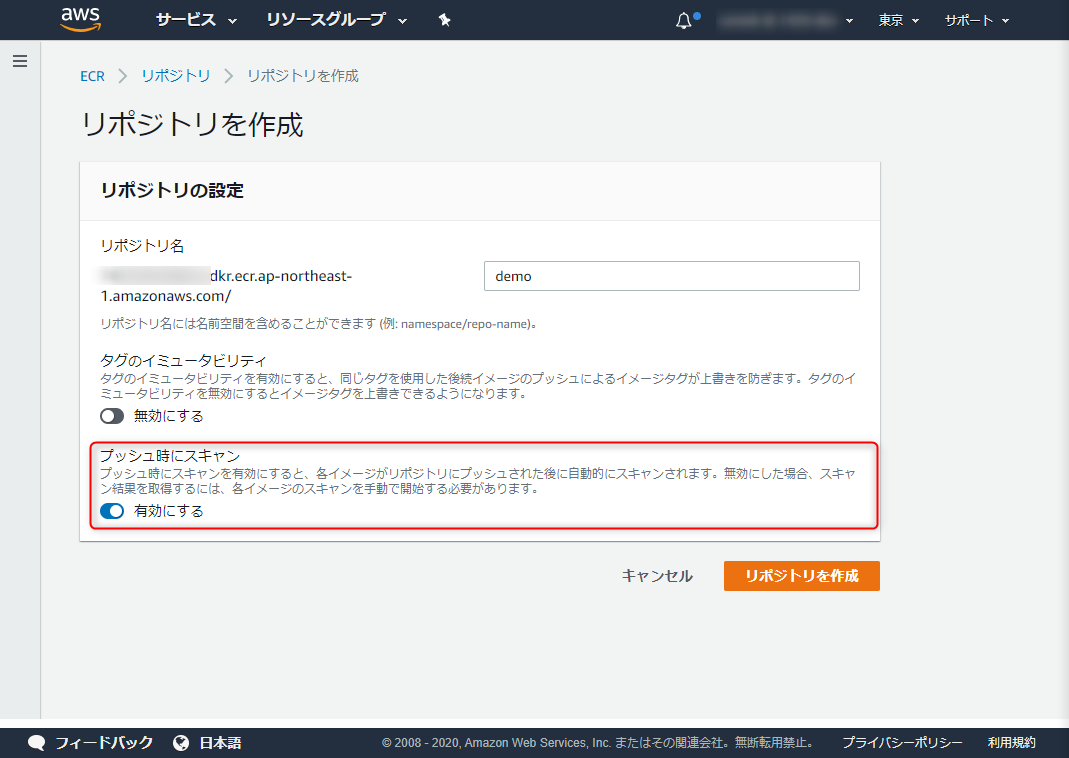
pushして即スキャンしてみようと思います。まずはリポジトリを作ってみましょう。プッシュ時にスキャンを選択しておきます。
docker loginします
`aws ecr get-login --region ap-northeast-1 --no-include-email`tagを付けてpushしましょう
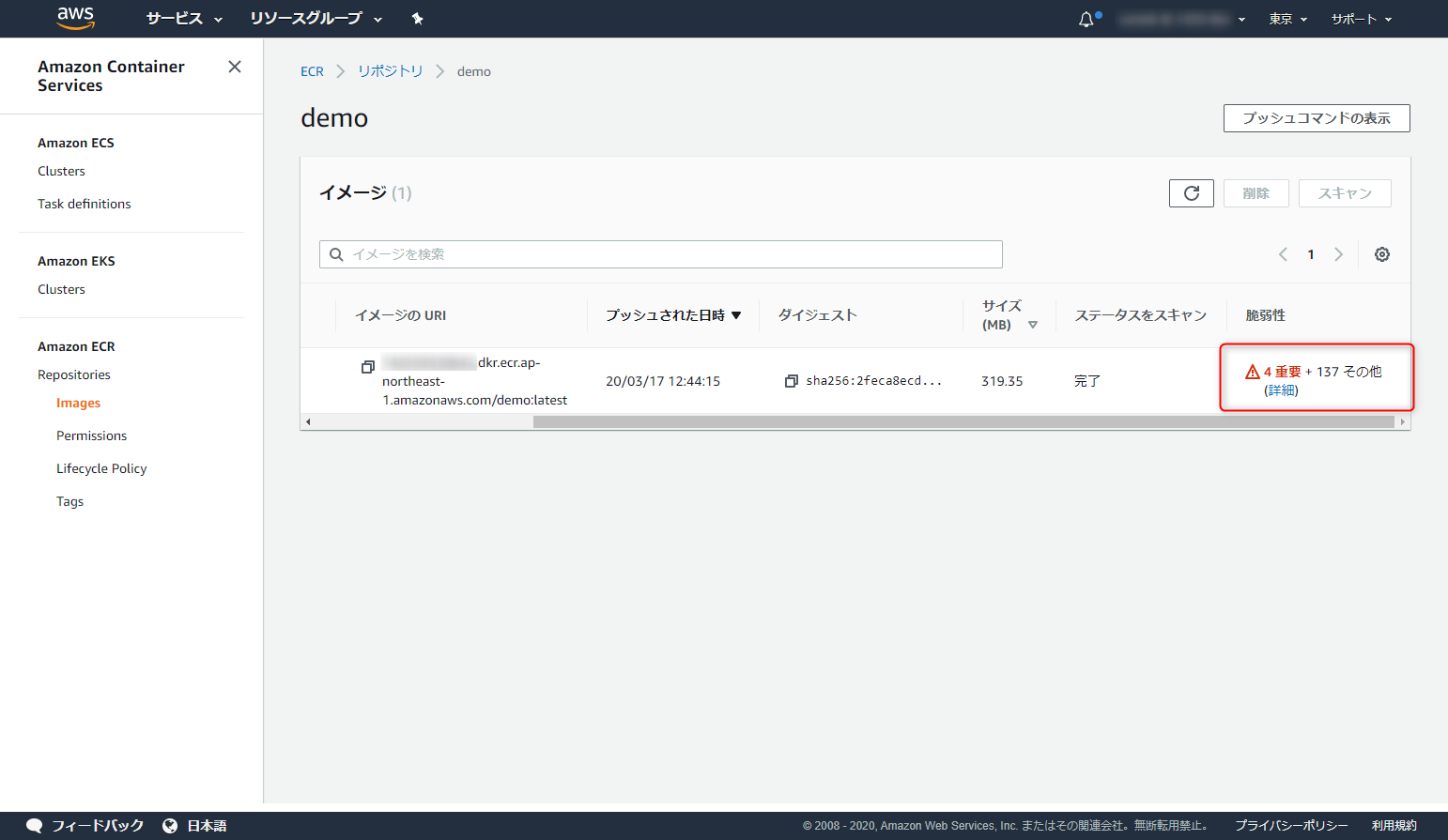
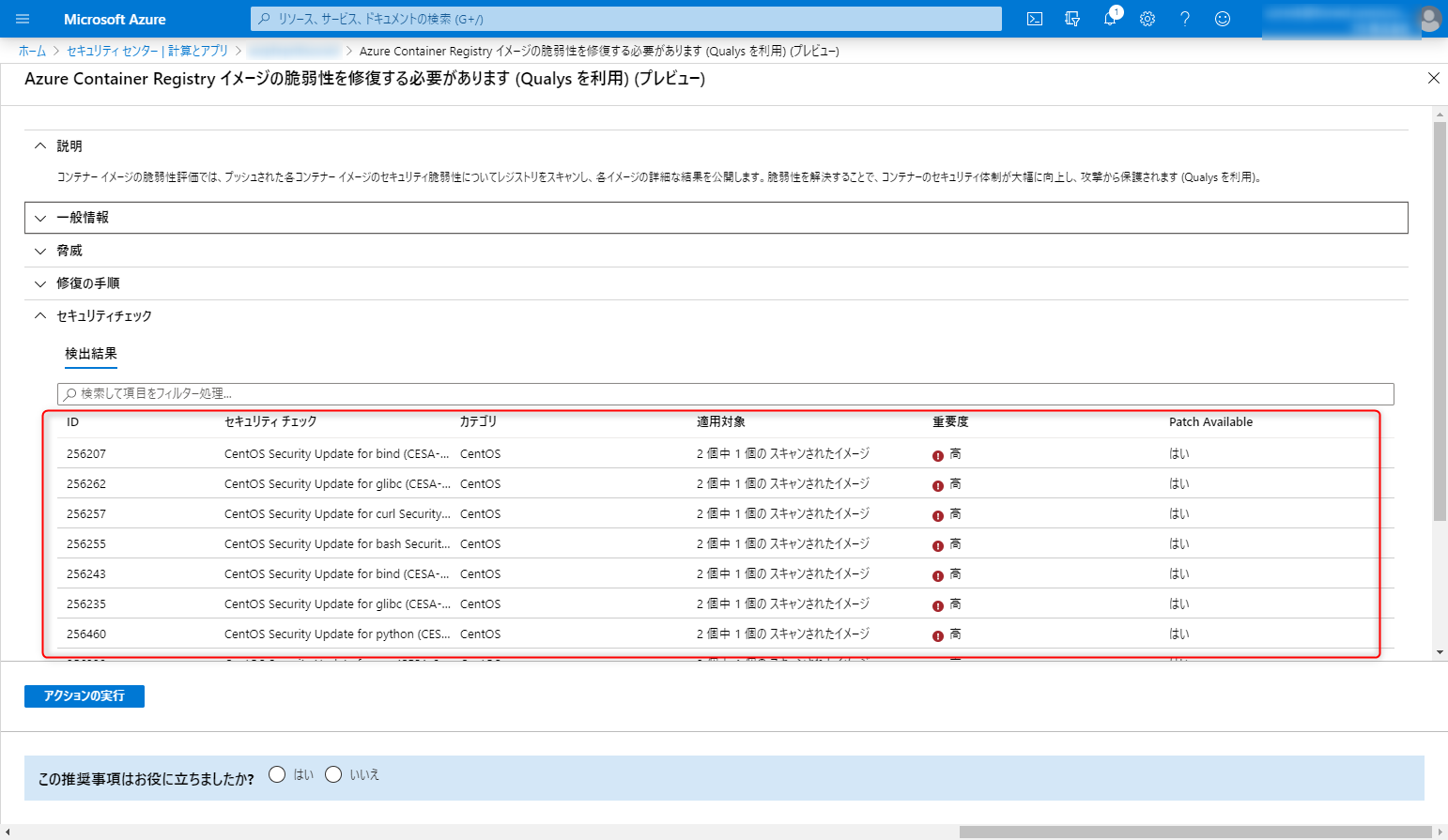
docker tag uzresk/demo:ver1.0 xxxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/demo:latest docker push xxxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/demo:latestpushするとなんと速攻スキャンが終わってました・・・その数なんと141個
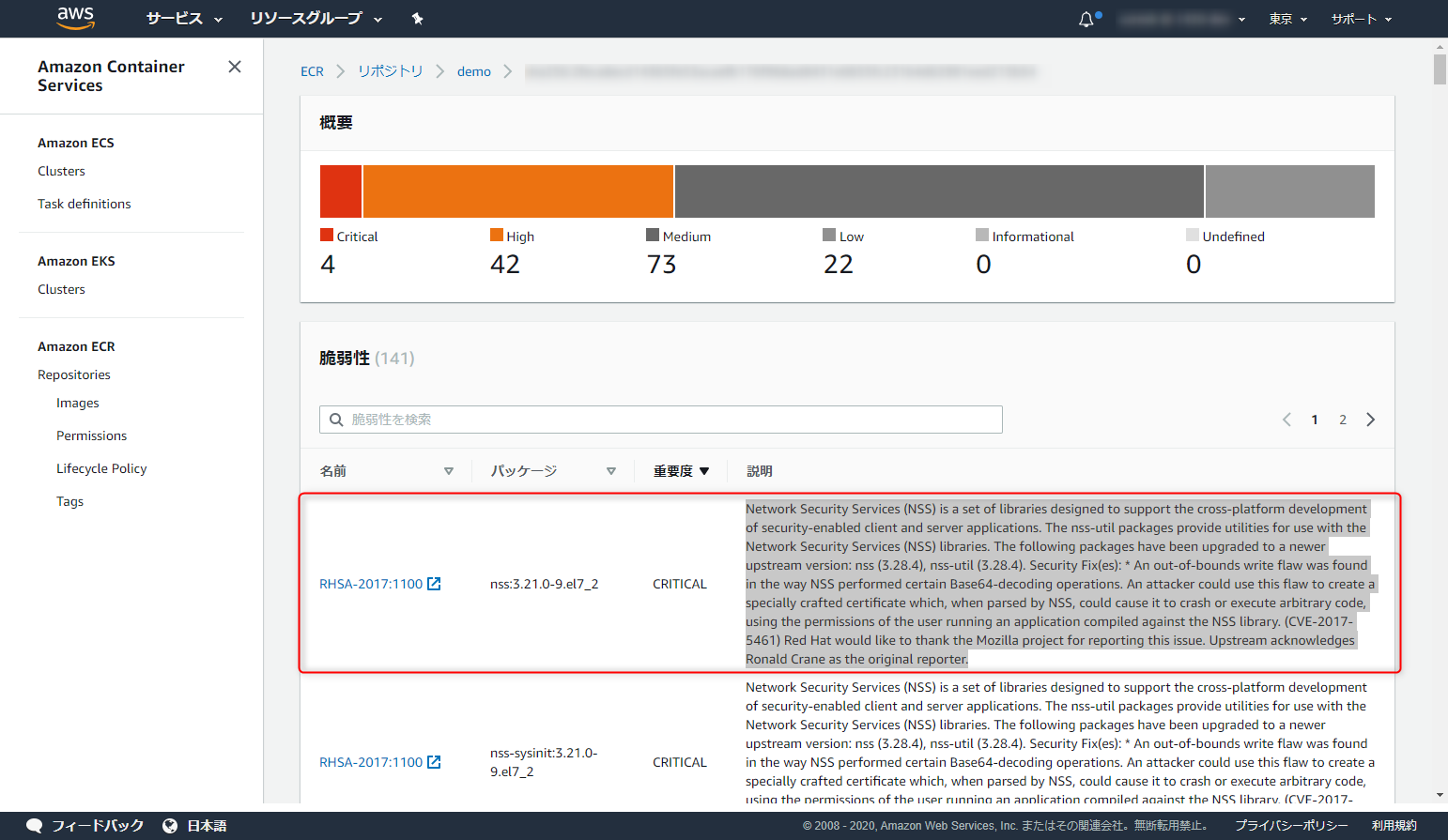
詳細も見てみましょう。リンク張っておくから読んどけよ。って感じですね
Azure Container Registryでのスキャン
Azure Cliを使ってログインし、タグをつけてpushします。
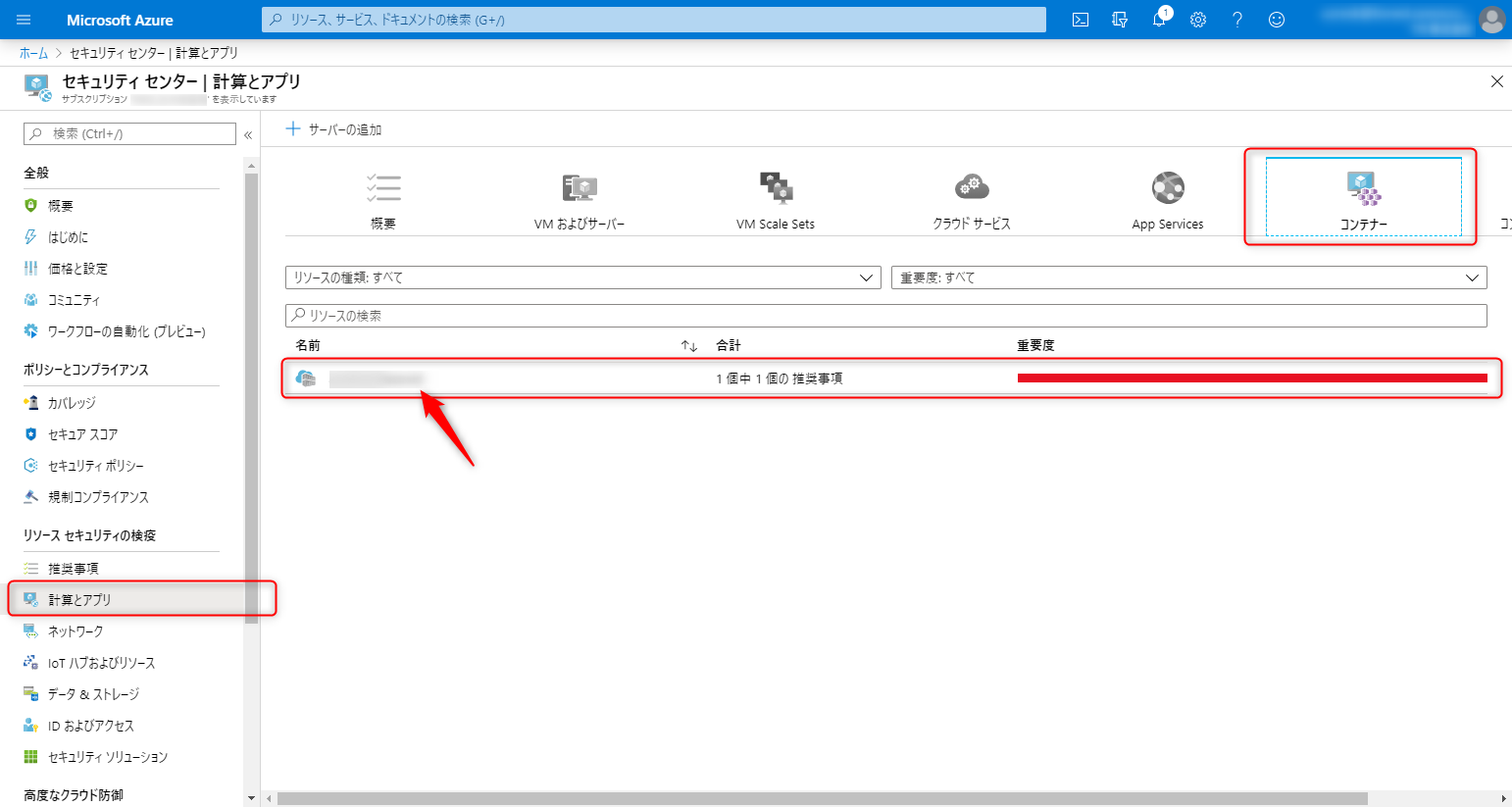
az login az acr login --name xxxxxxxxx docker tag docker.io/uzresk/demo:ver1.0 xxxxxxxxx.azurecr.io/demo:latest docker push xxxxxxxxx.azurecr.io/demo:latest10分後・・・・セキュリティセンターを開いてみます。
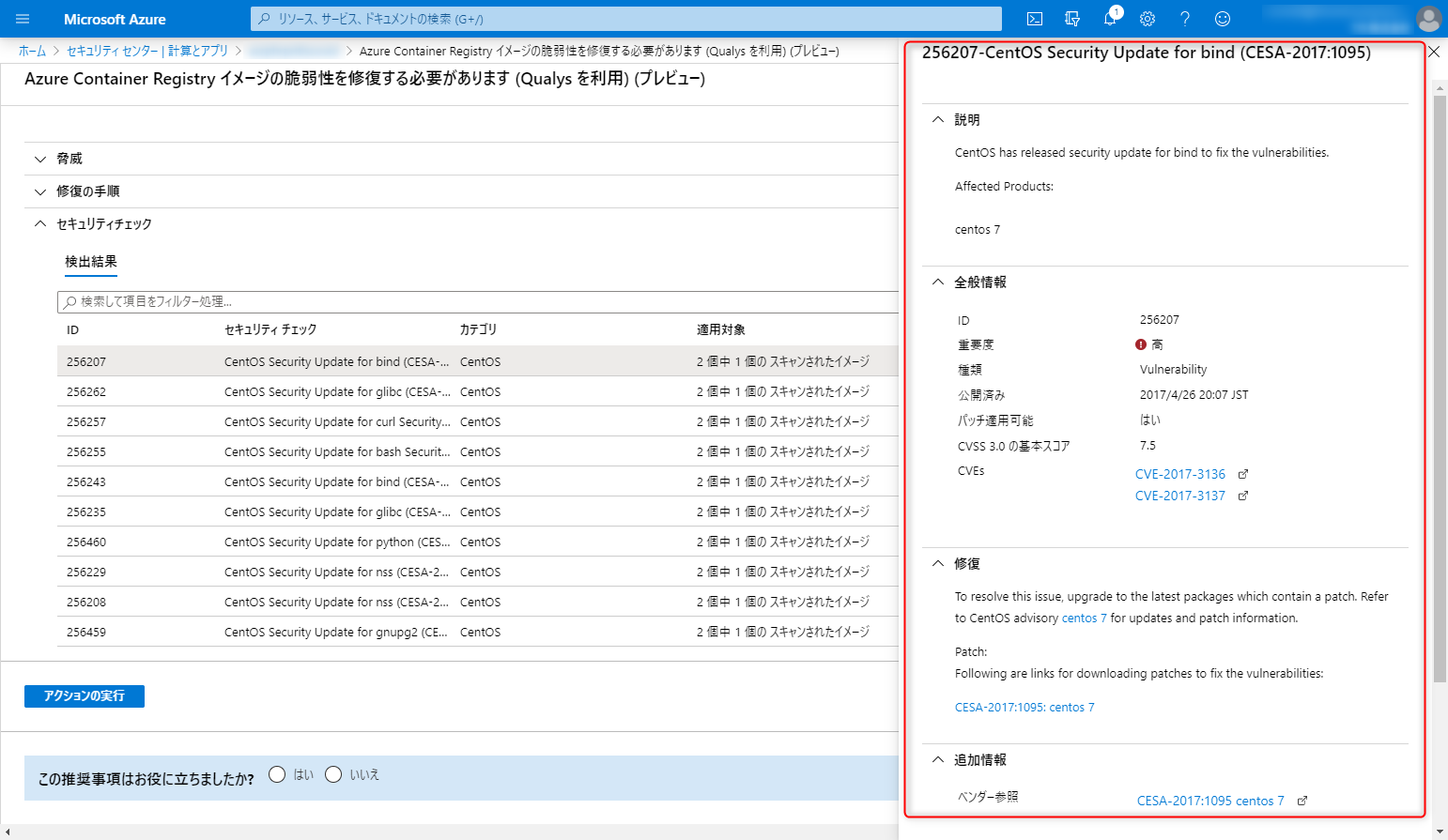
75件の脆弱性が検知できたみたいです。一覧を見るとパッチの有無なんかがでてて親切ですね。
詳細も見ることができます
両者を比べると・・・
料金が無料であったり、速攻スキャン結果が出てくるのはAWSの魅力ですね。
Azureのよい面はパッチあり・なしがわかったりする点でしょうか。
今回のイメージに関しては脆弱性が発見された数はAWSのほうが多かったのですが、それが常にそうかはわかりません。定期的なスキャンの仕組みはLambdaとかを組み合わせるとAWSのほうが簡単に作れるんじゃないかなという気がしました。CI/CDの仕組みがすでにあるのであればAzureでもAWSでも簡単に使えるのではないかと思います。
終わりに
ホストの脆弱性についてはAWS FargateやECSであれば自動で検知しホストを入れ替えたりすることができますし、これはAzureも同じでWebApp for Containerも自動でホストにパッチを当てたりしてくれます。
コンテナレイヤはこんなに簡単にスキャンができるとは思いませんでした。
定期的なスキャンの仕組みをいれてゼロデイに対する対策もしておきたいところですね。両者ともにOSの脆弱性までのようです。ですのでアプリケーションのレイヤに関してはこれまで通りWAFの導入や定期的なアプリケーション診断などの対策が必要になる点は勘違いしないようにしてください。
- 投稿日:2020-03-17T11:45:57+09:00
AWS ClientVPNエンドポイント接続時にAWS VPCを介さずインターネット・オンプレミスネットワークに接続する方法
1.概要
AWS ClientVPNの登場によって、VPC上に構築したプライベートサブネットに対して容易にVPN接続が行えるようになりました。便利になった一方で、デフォルト設定ではVPN接続中インターネットに接続できない・社内ネットワークに接続できない、といったことがあります。
本稿では、AWS ClientVPNにおけるVPN接続の仕組みを通じて、なぜインターネットに接続できないのか、そのとき何が起こっているのか、どのように設定すればよいかを解説します。2.AWS ClientVPNデフォルト設定におけるルーティング
2-1. 前提
- AWS ClientVPNでは、AWS ConsoleよりOpenVPNの接続設定ファイル(XX.ovpn)をダウンロードすることができる。ここでは本設定ファイルを用いOpenVPNよりVPN接続を行う。
- AWSクライアントVPNサービスでは「スプリットトンネル」を無効(既定値)に設定すると、VPN上の全ての通信がVPNトンネルにルーティングされる。本稿「2」章の解説は「スプリットトンネル」が無効であることを前提としている。
- 同様に、本稿「3」章は「スプリットトンネル」が有効であることを前提としている。
2-2. OpenVPN TUNインタフェースによるL3レベルのルーティング動作メカニズム
OpenVPNはVPN接続シーケンスにおいて、(1)「クライアント端末上に仮想NICデバイスを作成」し、(2)「仮想NICに対するルートテーブルのエントリを追加」するとともに(3)「VPNクライアントとClientVPNエンドポイント間のVPNトンネルを確立」する。
AWSクライアントVPNサービスでは、仮想NICはTAPインタフェース(L2=データリンク層におるブリッジ接続)でなくTUNインタフェース(L3=ネットワーク層におけるルーティング)として構成される。仮想NIC(TUN)があたかもルーターのように振る舞うことで、VPNクライアント上のパケットがAWS VPCへ送信されるのだ。
ここで、OSルートテーブルを見てみよう。OSシェル上でルート表示コマンドを発行しルートテーブルを表示する。ポイントは下記の通り。
- 「ネットワーク宛先」に「0.0.0.0 mask 128.0.0.0」「128.0.0.0 mask 128.0.0.0」が追加されている
- デフォルトルートがAWSに向けられている!⇒全ての通信がVPNトンネルにルーティングされる
- AWS宛・社内ネットワーク宛・インターネット宛も含め、全てのパケットがVPNトンネルに送信される。VPNトンネルのAWS側、クライアントVPNエンドポイントで受け入れていない、AWS側ルートテーブルで宛先が特定できない場合パケットは破棄される(例:社内ネットワーク宛・インターネット宛)。
- 「0.0.0.0 mask 128.0.0.0」はアドレスレンジ「0.0.0.0~127.255.255」を、「128.0.0.0 mask 128.0.0.0」はアドレスレンジ「128.0.0.0~255.255.255.255」をあらわし、2つのルートエントリをあわせてデフォルトルートを書き換えることを意味している。ルートテーブルではネットワーク部がより具体的であるものが優先適用されるため、上記2エントリは「0.0.0.0 mask 0.0.0.0」のような既存デフォルトルートエントリに優先して適用される。
- 「ネットワーク宛先」が「172.16.XX.XX」となっているものはVPNクライアント端末に割り当てられたIPアドレスであり、VPCアドレスブロックとは異なる。本稿の主旨とは関係ない。
>route print =========================================================================== インターフェイス一覧 (省略) =========================================================================== IPv4 ルート テーブル =========================================================================== アクティブ ルート: ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック 0.0.0.0 0.0.0.0 192.168.128.1 192.168.128.102 25 0.0.0.0 128.0.0.0 172.16.1.1 172.16.1.2 281 18.182.134.236 255.255.255.255 192.168.128.1 192.168.128.102 281 127.0.0.0 255.0.0.0 リンク上 127.0.0.1 331 127.0.0.1 255.255.255.255 リンク上 127.0.0.1 331 127.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 128.0.0.0 128.0.0.0 172.16.1.1 172.16.1.2 281 172.16.1.0 255.255.255.224 リンク上 172.16.1.2 281 172.16.1.2 255.255.255.255 リンク上 172.16.1.2 281 172.16.1.31 255.255.255.255 リンク上 172.16.1.2 281 192.168.128.0 255.255.255.0 リンク上 192.168.128.102 281 192.168.128.102 255.255.255.255 リンク上 192.168.128.102 281 192.168.128.255 255.255.255.255 リンク上 192.168.128.102 281 224.0.0.0 240.0.0.0 リンク上 127.0.0.1 331 224.0.0.0 240.0.0.0 リンク上 172.16.1.2 281 224.0.0.0 240.0.0.0 リンク上 192.168.128.102 281 255.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 255.255.255.255 255.255.255.255 リンク上 172.16.1.2 281 255.255.255.255 255.255.255.255 リンク上 192.168.128.102 281 =========================================================================== 固定ルート: なし(参考)OpenVPN起動前のルートテーブル(VPNトンネル確立前)
>route print =========================================================================== インターフェイス一覧 (省略) =========================================================================== IPv4 ルート テーブル =========================================================================== アクティブ ルート: ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック 0.0.0.0 0.0.0.0 192.168.128.1 192.168.128.102 25 127.0.0.0 255.0.0.0 リンク上 127.0.0.1 331 127.0.0.1 255.255.255.255 リンク上 127.0.0.1 331 127.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 192.168.128.0 255.255.255.0 リンク上 192.168.128.102 281 192.168.128.102 255.255.255.255 リンク上 192.168.128.102 281 192.168.128.255 255.255.255.255 リンク上 192.168.128.102 281 224.0.0.0 240.0.0.0 リンク上 127.0.0.1 331 224.0.0.0 240.0.0.0 リンク上 192.168.128.102 281 255.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 255.255.255.255 255.255.255.255 リンク上 192.168.128.102 281 =========================================================================== 固定ルート: なし3.スプリット・トンネリングを有効にする
「スプリットトンネル」を有効にすることで、AWSクライアントVPNでAWS VPC宛のみVPNトンネルにルーティングし、それ以外のパケットはVPNクライアント上の通常NICにパケットを送信することができる。設定手順を説明する。
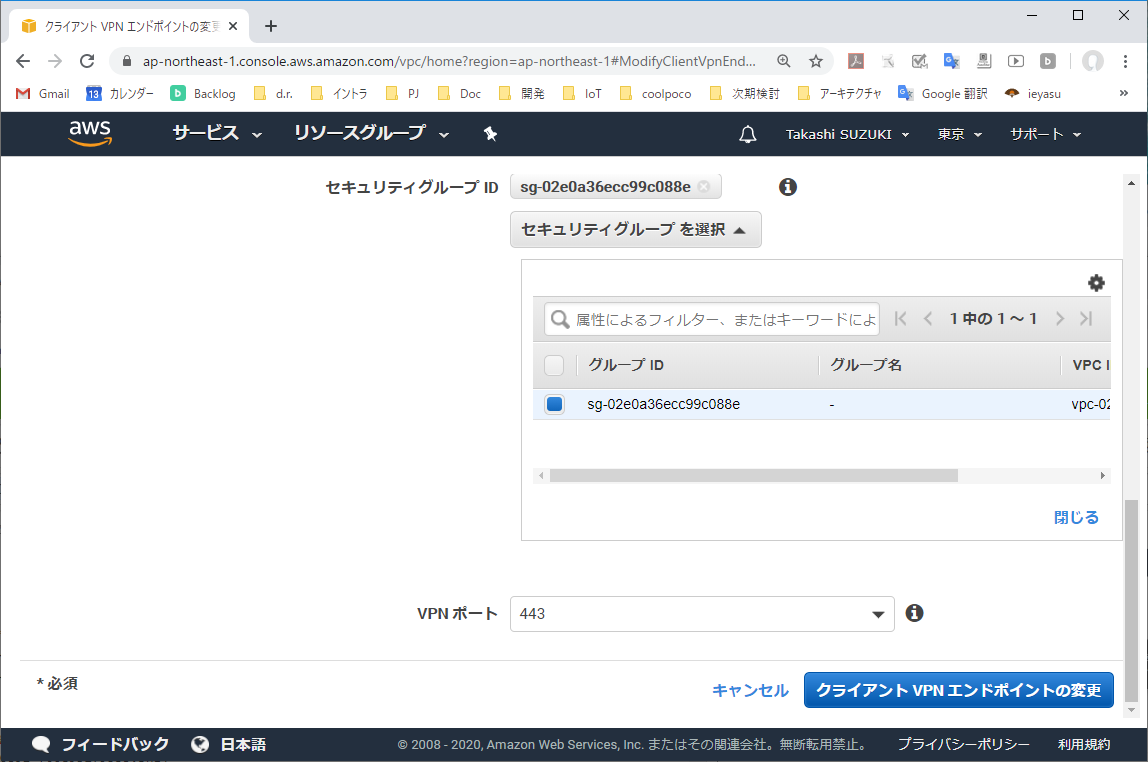
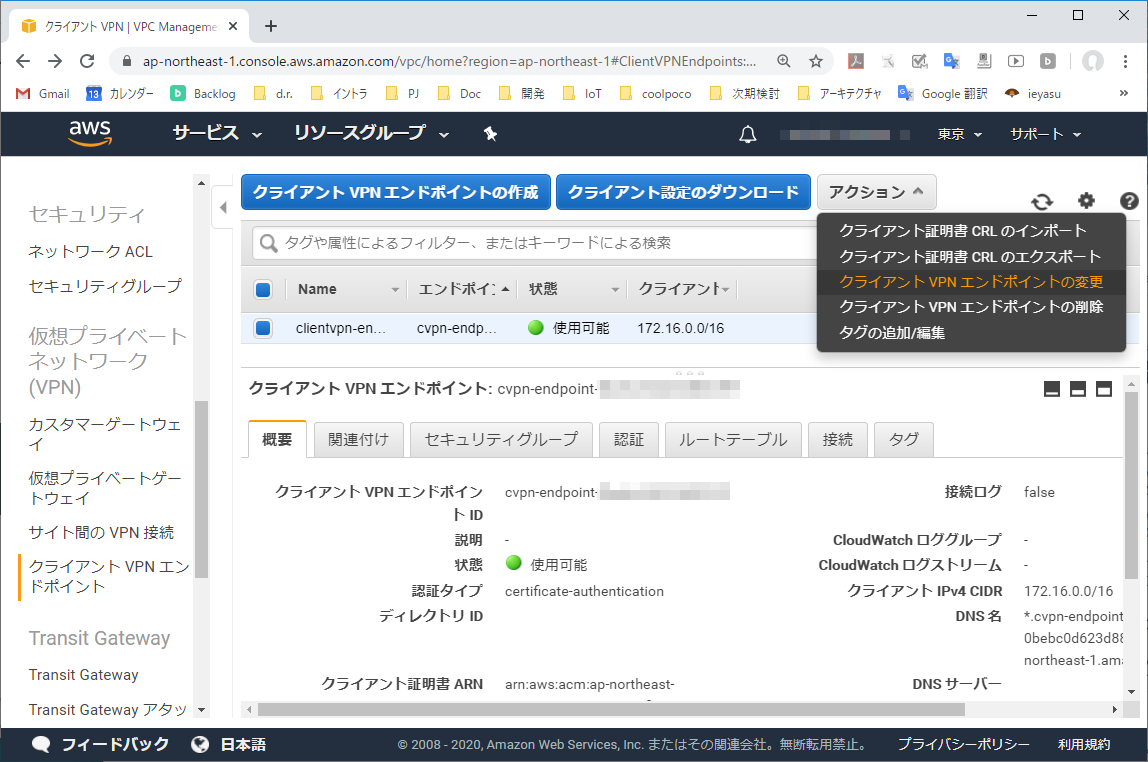
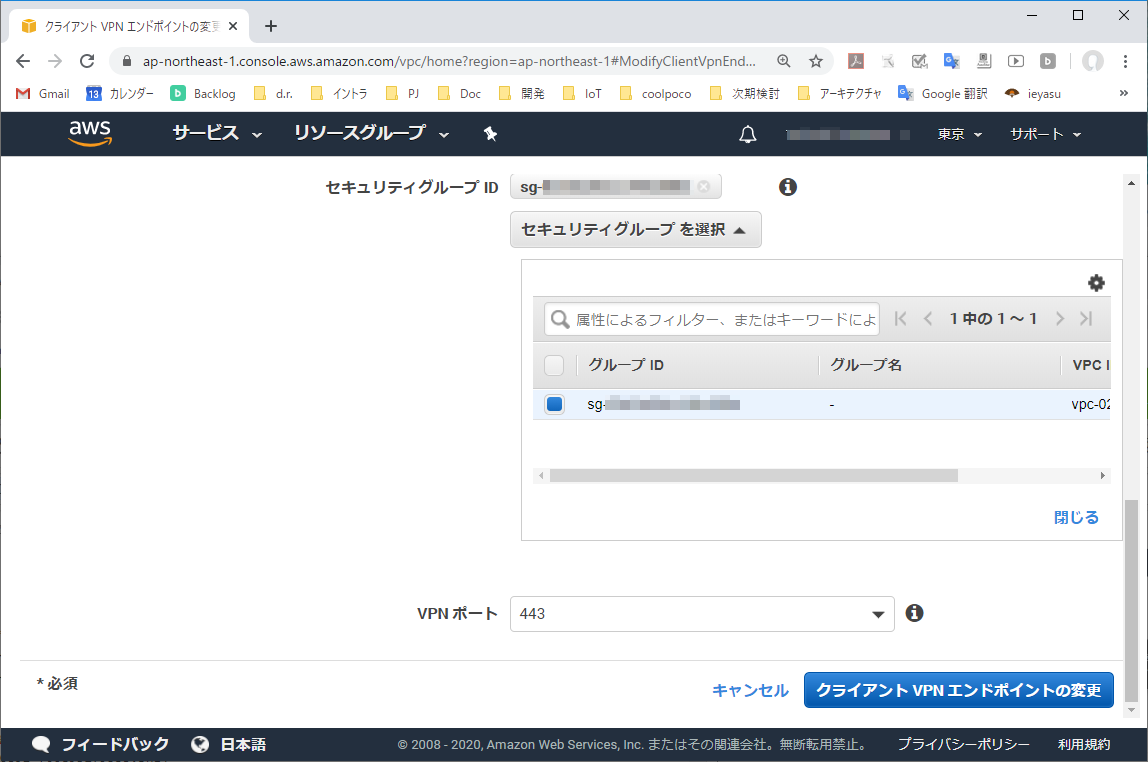
3-1. クライアントVPNエンドポイントの変更
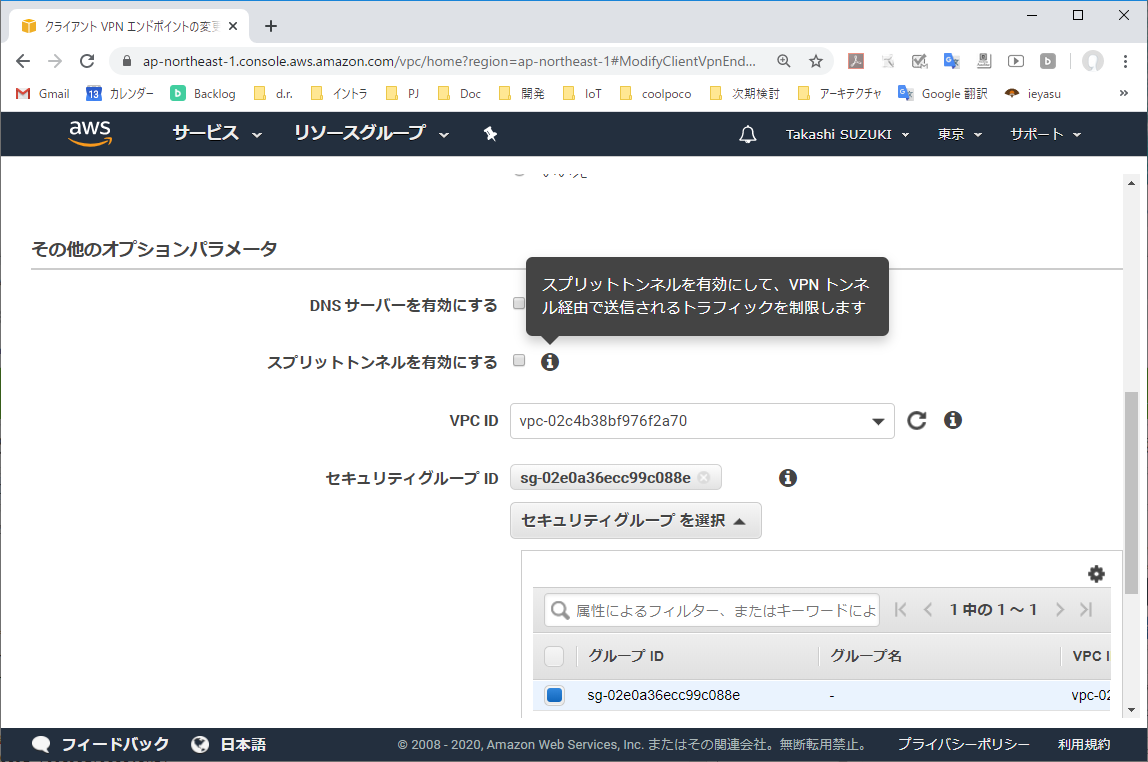
クライアントVPNエンドポイントを選択し、「アクション」より「クライアントVPNエンドポイントの変更」を実行する。
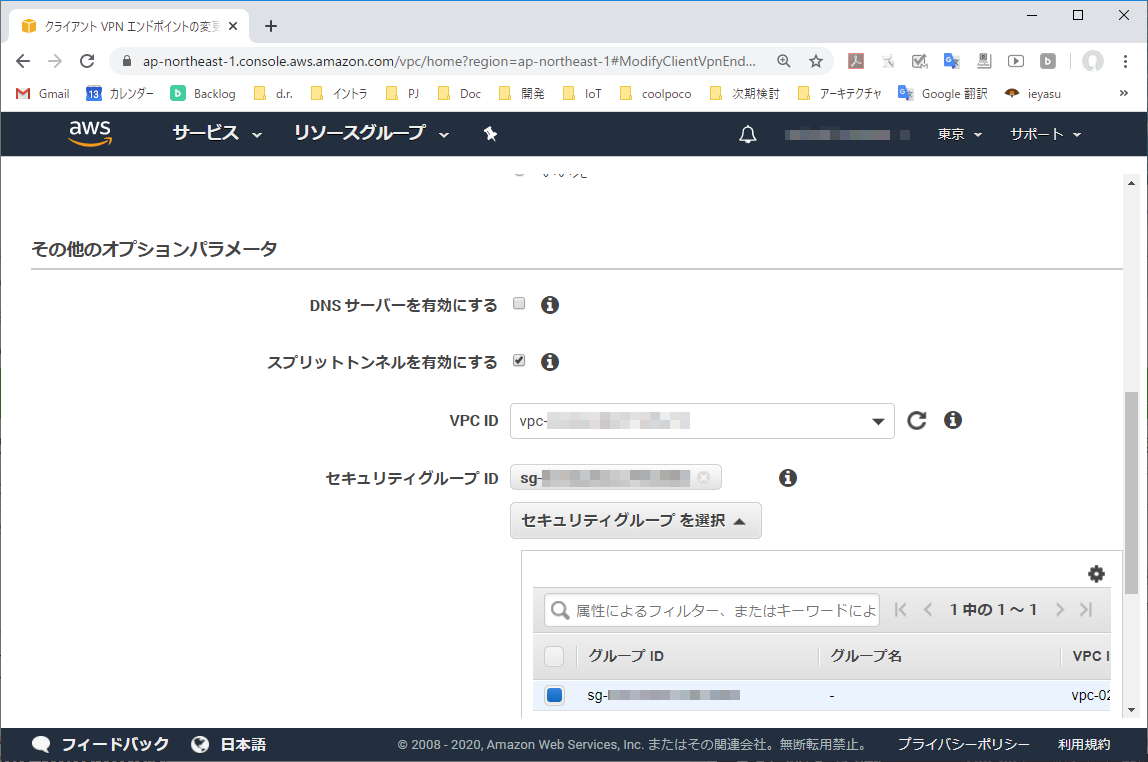
3-2. 「スプリットトンネル」設定を確認する
「スプリットトンネル」がオフの場合、VPNクライアント端末の全ての通信はクライアントVPNエンドポイントへ送信される。(「スプリットトンネル」はデフォルトオフになっている)
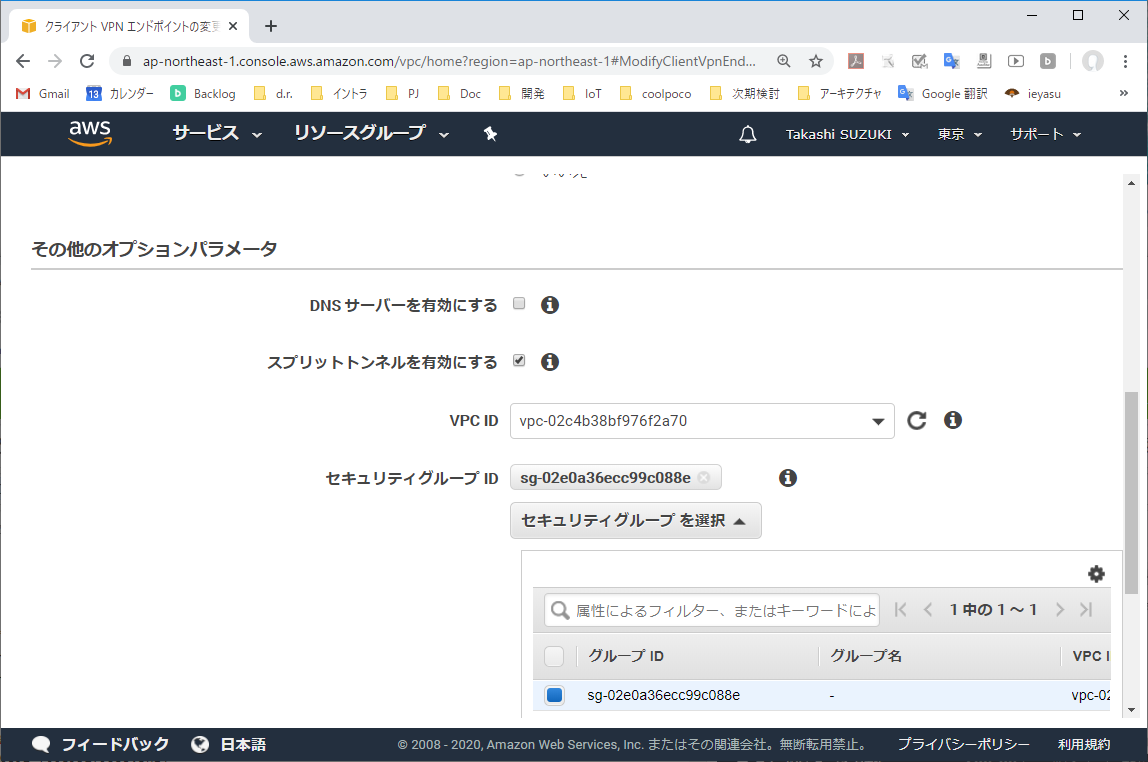
3-3. 「スプリットトンネル」をオンにする
「スプリットトンネル」チェックボックスをオンにする。オンにすることで、クライアントVPNエンドポイントに割り当てたルート宛のパケットのみVPNトンネルへ送られるようになる。それ以外のパケットはVPNクライアント端上の既定ルートテーブル設定でルーティングされる。
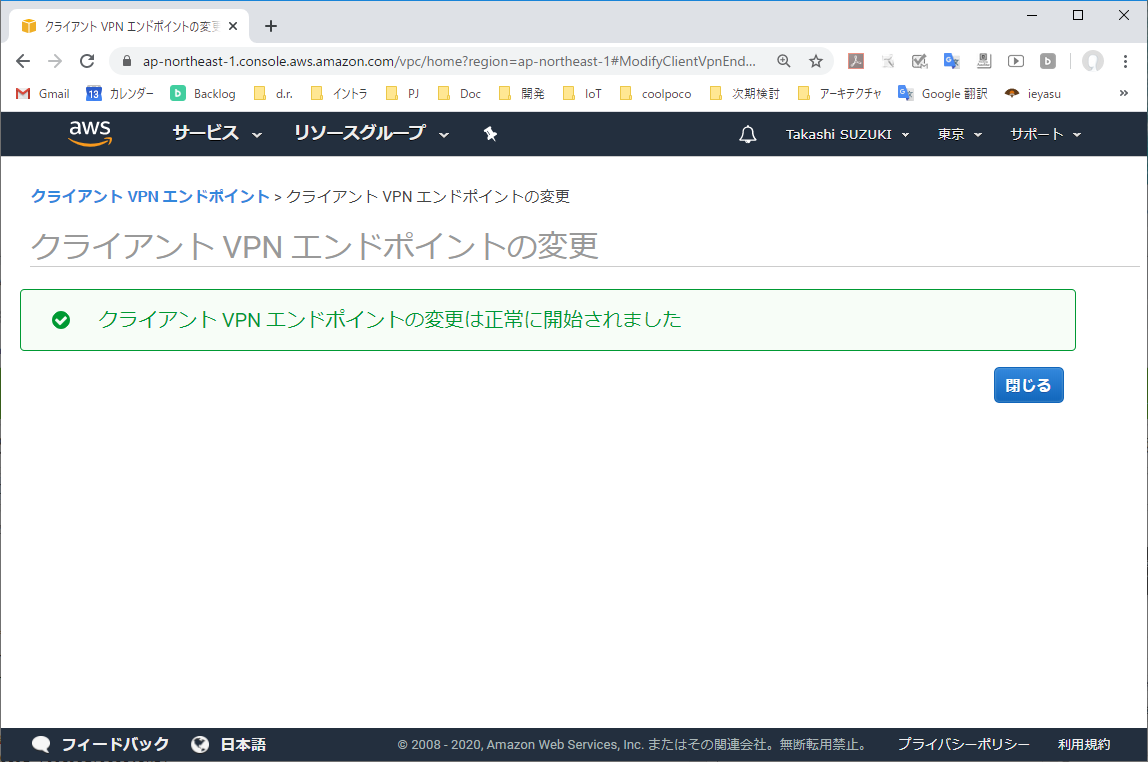
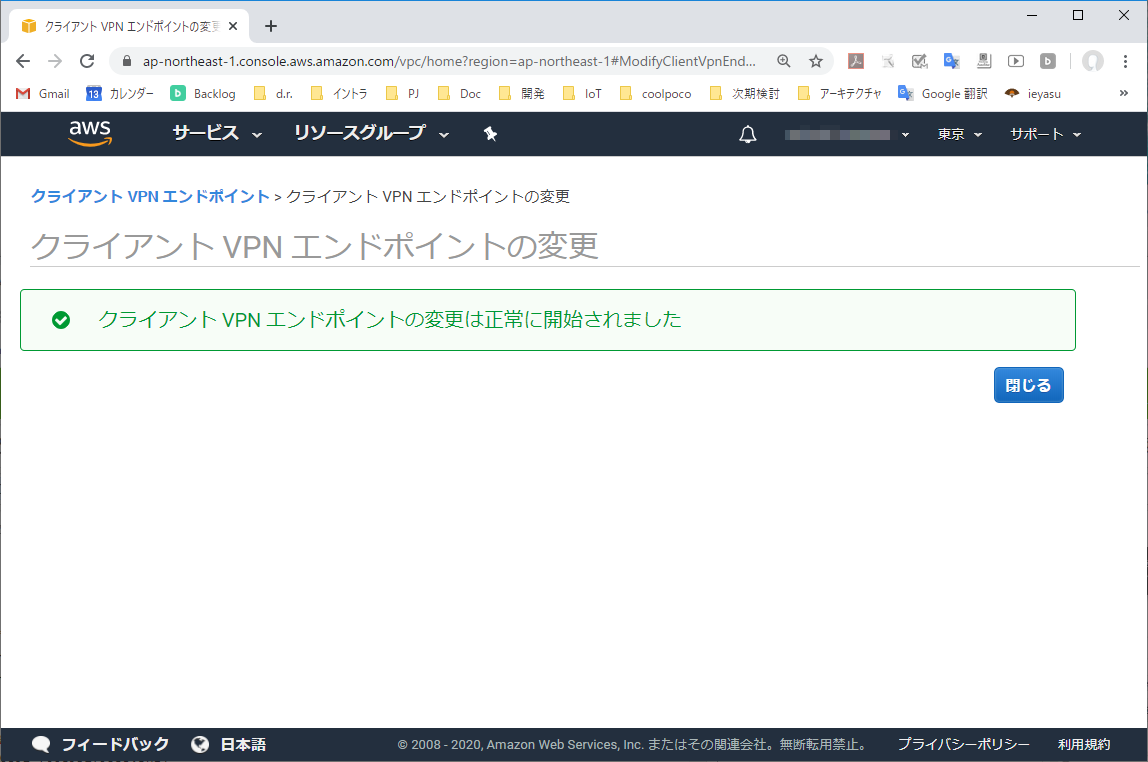
3-4. クライアントVPNエンドポイントの変更を適用する
「クライアントVPNエンドポイントの変更」より、変更を反映する。
3-5. クライアントVPNエンドポイントへの適用が完了
変更の適用が完了した。
適用が完了したら、VPNクライアント端末上でVPNトンネルを再接続する。
4. スプリット・トンネリング有効化の確認
OSルートテーブル表示コマンドを発行する。
確認のポイントは下記の通り。
- 「ネットワーク宛先」に「0.0.0.0」が追加されていない
- デフォルトルートがAWSに向いていない!
- これによって、AWS VPC以外のアドレスブロックがOS設定に則りルーティングされる。
- 「ネットワーク宛先」VPCのCIDRブロックが追加されている
- クライアントVPNエンドポイントに割り当てられた最小限のアドレスレンジのみVPNトンネルにルーティングされている(例:「ネットワーク宛先」が「10.1.0.0 mask 255.255.0.0」となっているものが該当)。
- 「ネットワーク宛先」が「172.16.XX.XX」となっているものはVPNクライアント端末に割り当てられたIPアドレスであり、VPCアドレスブロックとは異なる。本稿の主旨とは関係ない。
>route print =========================================================================== インターフェイス一覧 (省略) =========================================================================== IPv4 ルート テーブル =========================================================================== アクティブ ルート: ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック 0.0.0.0 0.0.0.0 192.168.128.1 192.168.128.102 25 10.1.0.0 255.255.0.0 172.16.0.129 172.16.0.130 281 127.0.0.0 255.0.0.0 リンク上 127.0.0.1 331 127.0.0.1 255.255.255.255 リンク上 127.0.0.1 331 127.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 172.16.0.128 255.255.255.224 リンク上 172.16.0.130 281 172.16.0.130 255.255.255.255 リンク上 172.16.0.130 281 172.16.0.159 255.255.255.255 リンク上 172.16.0.130 281 192.168.128.0 255.255.255.0 リンク上 192.168.128.102 281 192.168.128.102 255.255.255.255 リンク上 192.168.128.102 281 192.168.128.255 255.255.255.255 リンク上 192.168.128.102 281 224.0.0.0 240.0.0.0 リンク上 127.0.0.1 331 224.0.0.0 240.0.0.0 リンク上 172.16.0.130 281 224.0.0.0 240.0.0.0 リンク上 192.168.128.102 281 255.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 255.255.255.255 255.255.255.255 リンク上 172.16.0.130 281 255.255.255.255 255.255.255.255 リンク上 192.168.128.102 281 =========================================================================== 固定ルート: なし5. 参考
- https://superuser.com/questions/851462/understanding-routing-table-with-openvpn (Understanding Routing Table with OpenVPN)
以上。

- 投稿日:2020-03-17T11:45:57+09:00
AWS ClientVPN接続時にAWS VPCを介さずインターネット・オンプレミスネットワークに接続する方法
1.概要
AWS ClientVPNの登場によって、VPC上に構築したプライベートサブネットに対して容易にVPN接続が行えるようになりました。便利になった一方で、デフォルト設定ではVPN接続中インターネットに接続できない・社内ネットワークに接続できない、といったことがあります。
本稿では、AWS ClientVPNにおけるVPN接続の仕組みを通じて、なぜインターネットに接続できないのか、そのとき何が起こっているのか、どのように設定すればよいかを解説します。2.AWS ClientVPNデフォルト設定におけるルーティング
2-1. 前提
- AWS ClientVPNでは、AWS ConsoleよりOpenVPNの接続設定ファイル(XX.ovpn)をダウンロードすることができる。ここでは本設定ファイルを用いOpenVPNよりVPN接続を行う。
- AWSクライアントVPNサービスでは「スプリットトンネル」を無効(既定値)に設定すると、VPN上の全ての通信がVPNトンネルにルーティングされる。本稿「2」章の解説は「スプリットトンネル」が無効であることを前提としている。
- 同様に、本稿「3」章は「スプリットトンネル」が有効であることを前提としている。
2-2. OpenVPN TUNインタフェースによるL3レベルのルーティング動作メカニズム
OpenVPNはVPN接続シーケンスにおいて、(1)「クライアント端末上に仮想NICデバイスを作成」し、(2)「仮想NICに対するルートテーブルのエントリを追加」するとともに(3)「VPNクライアントとClientVPNエンドポイント間のVPNトンネルを確立」する。
AWSクライアントVPNサービスでは、仮想NICはTAPインタフェース(L2=データリンク層におるブリッジ接続)でなくTUNインタフェース(L3=ネットワーク層におけるルーティング)として構成される。仮想NIC(TUN)があたかもルーターのように振る舞うことで、VPNクライアント上のパケットがAWS VPCへ送信されるのだ。
ここで、OSルートテーブルを見てみよう。OSシェル上でルート表示コマンドを発行しルートテーブルを表示する。ポイントは下記の通り。
- 「ネットワーク宛先」に「0.0.0.0 mask 128.0.0.0」「128.0.0.0 mask 128.0.0.0」が追加されている
- デフォルトルートがAWSに向けられている!⇒全ての通信がVPNトンネルにルーティングされる
- AWS宛・社内ネットワーク宛・インターネット宛も含め、全てのパケットがVPNトンネルに送信される。VPNトンネルのAWS側、クライアントVPNエンドポイントで受け入れていない、AWS側ルートテーブルで宛先が特定できない場合パケットは破棄される(例:社内ネットワーク宛・インターネット宛)。
- 「0.0.0.0 mask 128.0.0.0」はアドレスレンジ「0.0.0.0~127.255.255」を、「128.0.0.0 mask 128.0.0.0」はアドレスレンジ「128.0.0.0~255.255.255.255」をあらわし、2つのルートエントリをあわせてデフォルトルートを書き換えることを意味している。ルートテーブルではネットワーク部がより具体的であるものが優先適用されるため、上記2エントリは「0.0.0.0 mask 0.0.0.0」のような既存デフォルトルートエントリに優先して適用される。
- 「ネットワーク宛先」が「172.16.XX.XX」となっているものはVPNクライアント端末に割り当てられたIPアドレスであり、VPCアドレスブロックとは異なる。本稿の主旨とは関係ない。
>route print =========================================================================== インターフェイス一覧 (省略) =========================================================================== IPv4 ルート テーブル =========================================================================== アクティブ ルート: ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック 0.0.0.0 0.0.0.0 192.168.128.1 192.168.128.102 25 0.0.0.0 128.0.0.0 172.16.1.1 172.16.1.2 281 18.182.134.236 255.255.255.255 192.168.128.1 192.168.128.102 281 127.0.0.0 255.0.0.0 リンク上 127.0.0.1 331 127.0.0.1 255.255.255.255 リンク上 127.0.0.1 331 127.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 128.0.0.0 128.0.0.0 172.16.1.1 172.16.1.2 281 172.16.1.0 255.255.255.224 リンク上 172.16.1.2 281 172.16.1.2 255.255.255.255 リンク上 172.16.1.2 281 172.16.1.31 255.255.255.255 リンク上 172.16.1.2 281 192.168.128.0 255.255.255.0 リンク上 192.168.128.102 281 192.168.128.102 255.255.255.255 リンク上 192.168.128.102 281 192.168.128.255 255.255.255.255 リンク上 192.168.128.102 281 224.0.0.0 240.0.0.0 リンク上 127.0.0.1 331 224.0.0.0 240.0.0.0 リンク上 172.16.1.2 281 224.0.0.0 240.0.0.0 リンク上 192.168.128.102 281 255.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 255.255.255.255 255.255.255.255 リンク上 172.16.1.2 281 255.255.255.255 255.255.255.255 リンク上 192.168.128.102 281 =========================================================================== 固定ルート: なし(参考)OpenVPN起動前のルートテーブル(VPNトンネル確立前)
>route print =========================================================================== インターフェイス一覧 (省略) =========================================================================== IPv4 ルート テーブル =========================================================================== アクティブ ルート: ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック 0.0.0.0 0.0.0.0 192.168.128.1 192.168.128.102 25 127.0.0.0 255.0.0.0 リンク上 127.0.0.1 331 127.0.0.1 255.255.255.255 リンク上 127.0.0.1 331 127.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 192.168.128.0 255.255.255.0 リンク上 192.168.128.102 281 192.168.128.102 255.255.255.255 リンク上 192.168.128.102 281 192.168.128.255 255.255.255.255 リンク上 192.168.128.102 281 224.0.0.0 240.0.0.0 リンク上 127.0.0.1 331 224.0.0.0 240.0.0.0 リンク上 192.168.128.102 281 255.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 255.255.255.255 255.255.255.255 リンク上 192.168.128.102 281 =========================================================================== 固定ルート: なし3.スプリット・トンネリングを有効にする
「スプリットトンネル」を有効にすることで、AWSクライアントVPNでAWS VPC宛のみVPNトンネルにルーティングし、それ以外のパケットはVPNクライアント上の通常NICにパケットを送信することができる。設定手順を説明する。
3-1. クライアントVPNエンドポイントの変更
クライアントVPNエンドポイントを選択し、「アクション」より「クライアントVPNエンドポイントの変更」を実行する。
3-2. 「スプリットトンネル」設定を確認する
「スプリットトンネル」がオフの場合、VPNクライアント端末の全ての通信はクライアントVPNエンドポイントへ送信される。(「スプリットトンネル」はデフォルトオフになっている)
3-3. 「スプリットトンネル」をオンにする
「スプリットトンネル」チェックボックスをオンにする。オンにすることで、クライアントVPNエンドポイントに割り当てたルート宛のパケットのみVPNトンネルへ送られるようになる。それ以外のパケットはVPNクライアント端上の既定ルートテーブル設定でルーティングされる。
3-4. クライアントVPNエンドポイントの変更を適用する
「クライアントVPNエンドポイントの変更」より、変更を反映する。
3-5. クライアントVPNエンドポイントへの適用が完了
変更の適用が完了した。
適用が完了したら、VPNクライアント端末上でVPNトンネルを再接続する。
4. スプリット・トンネリング有効化の確認
OSルートテーブル表示コマンドを発行する。
確認のポイントは下記の通り。
- 「ネットワーク宛先」に「0.0.0.0」が追加されていない
- デフォルトルートがAWSに向いていない!
- これによって、AWS VPC以外のアドレスブロックがOS設定に則りルーティングされる。
- 「ネットワーク宛先」VPCのCIDRブロックが追加されている
- クライアントVPNエンドポイントに割り当てられた最小限のアドレスレンジのみVPNトンネルにルーティングされている(例:「ネットワーク宛先」が「10.1.0.0 mask 255.255.0.0」となっているものが該当)。
- 「ネットワーク宛先」が「172.16.XX.XX」となっているものはVPNクライアント端末に割り当てられたIPアドレスであり、VPCアドレスブロックとは異なる。本稿の主旨とは関係ない。
>route print =========================================================================== インターフェイス一覧 (省略) =========================================================================== IPv4 ルート テーブル =========================================================================== アクティブ ルート: ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック 0.0.0.0 0.0.0.0 192.168.128.1 192.168.128.102 25 10.1.0.0 255.255.0.0 172.16.0.129 172.16.0.130 281 127.0.0.0 255.0.0.0 リンク上 127.0.0.1 331 127.0.0.1 255.255.255.255 リンク上 127.0.0.1 331 127.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 172.16.0.128 255.255.255.224 リンク上 172.16.0.130 281 172.16.0.130 255.255.255.255 リンク上 172.16.0.130 281 172.16.0.159 255.255.255.255 リンク上 172.16.0.130 281 192.168.128.0 255.255.255.0 リンク上 192.168.128.102 281 192.168.128.102 255.255.255.255 リンク上 192.168.128.102 281 192.168.128.255 255.255.255.255 リンク上 192.168.128.102 281 224.0.0.0 240.0.0.0 リンク上 127.0.0.1 331 224.0.0.0 240.0.0.0 リンク上 172.16.0.130 281 224.0.0.0 240.0.0.0 リンク上 192.168.128.102 281 255.255.255.255 255.255.255.255 リンク上 127.0.0.1 331 255.255.255.255 255.255.255.255 リンク上 172.16.0.130 281 255.255.255.255 255.255.255.255 リンク上 192.168.128.102 281 =========================================================================== 固定ルート: なし5. 参考
- https://superuser.com/questions/851462/understanding-routing-table-with-openvpn (Understanding Routing Table with OpenVPN)
以上。

- 投稿日:2020-03-17T08:54:47+09:00
.htaccessを使わず、S3から圧縮したJS,CSSを提供する
サーバーレスのアプリのため.htaccessを操作しづらい環境があったのでS3からこうやりました。
肝はアップロード時のcontent-encodingとcontent-typeの指定です。これがないとうまく読み込んでくれないです。gzip --best -f public/js/app.js # app.js.gzが生成される -fつけないと2回目から上書きしてくれない aws s3 cp public/js/app.js.gz s3://xxxx/ --content-encoding "gzip" --content-type "text/javascript"<script src="https://xxxx.s3-ap-northeast-1.amazonaws.com/app.js.gz"></script>参考
How to: Gzip compression of CSS and JS files on S3 with s3cmd
【Tips】S3 アップロード時に ContentType を指定する
- 投稿日:2020-03-17T08:19:43+09:00
NFCシールを活用して自動打刻ツールを(個人的に)作ってみた話
はじめに
今回はNFCシールを使用して会社の自動打刻システムを、完全に自分用で作ります!
要件定義
なぜつくるか?
現在、弊社の勤怠は、エクセルで管理されています。
実際の打刻フローとしては、
- 出社したら出社時刻をエクセル開いて手動で打刻
- 保存
- 退社するときに退社時刻をエクセル開いて手動で打刻
- 保存
。。。
毎日エクセルポチポチするの面倒すぎる!!!!!!!!!作業自体も面倒なのに、何日か打刻を忘れるとまあ面倒臭いことになります。
せっかくIT企業にいるんだからいろいろスマートにやりたい...
ということで、今回の自動打刻システムの開発を決意しました。どう作るか?
今回開発する自動打刻システムでは、NFCシールを活用していきます。
処理の流れとしては、
- NFCシールにスマホをかざして専用のWEBサイトを表示する
- WEBサイトから自動打刻システムにリクエストを投げる
- 打刻する
といった感じにしようかと思います。
NFCシールにスマホかざすのとリクエストを投げるところにWEBサイト表示をはさんでいるのは、
意図しない打刻を防ぐためです。クライアント側で打刻される時刻の確認、出社なのか退社なのかの選択できた方が、
手順は増えますが確実かなあということでワンクッションはさみました。また、現状では個人用なのでユーザーの識別は行いません。
どう使うか?
想定される使用フローは下記のとおりです。
- 出社したらデスクのどこかしらに貼ったNFCシールにスマホをかざす
- 表示されるWEBサイトで打刻時間を確認、出社ボタンを押す
- (退社時も同じ)
かなりスマート...!(な気がする)
使用技術
インフラはAWSの各サービスを利用します。
メイン処理の部分にはLambda、エクセルファイル(勤怠管理)はS3に保存します。
サーバーサイドにnode.js、WEBフロントエンドにはVue.jsを使用しつつ、HTTP通信はaxiosを使用します。
なぜNFCシールを使うか?
ただ使ってみたかった。
実は今回の開発、個人的にNFCシールを使ったアプリを作ってみたかったので、NFCシールありきで考えていました。
スマホかざすだけで打刻できるのステキじゃん...
なぜnode.jsか?
一番の理由は、Lambdaがnode.jsで書けるからです笑
他にも
java, ruby, pythonなどなど、いろんな言語で書くことができます。フロントエンド開発に興味があり、日頃からJavaScriptを勉強しているので、
サーバーサイドもJavaScriptで書こう!ということでnode.jsを選びました。なぜLambdaか?
Lambdaとは、AWSが提供するサーバレスアーキテクチャを構築するためのサービスです。
通常は、EC2インスタンスは常時存在し、アプリケーションも常時起動されているのですが、Lambdaはリクエストが送られてきたときのみインスタンスを生成→アプリケーションを実行→インスタンスを破棄という挙動をします。
今回作成するアプリは常時起動している必要もないので、コストを抑える意味でもLambdaが適しているのではないかと考えました。
なぜVue.jsか?
個人的に使い慣れているのでフロントはVue.jsで書きます。
と言っても、現在時刻を表示するのと、ボタンを二つ配置するだけなので全く難しいことはしません笑
強いて言えば、ローディングのアニメーションを作り込むくらいでしょうか...。
HTTP通信はaxiosを使用します。
設計
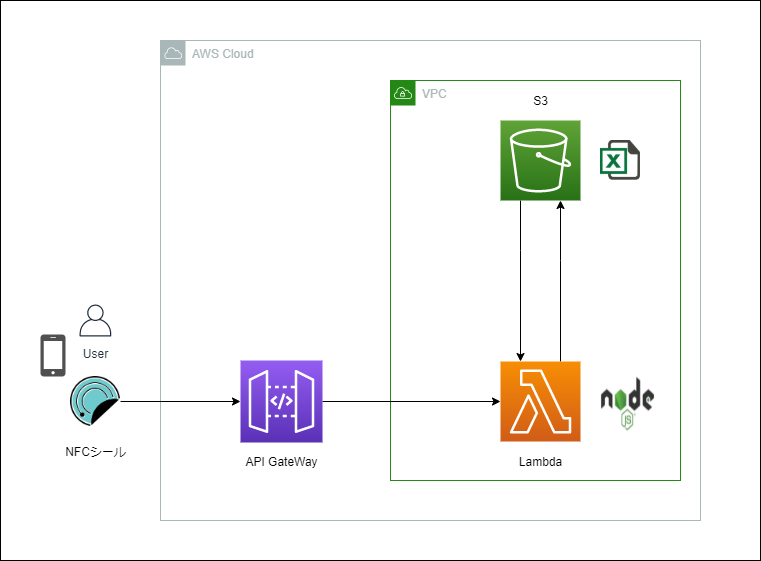
アーキテクチャ図
アーキテクチャの全体像としては、下記の通りです。
構成は至ってシンプルで、
HTTPリクエストをAPI Gatewayで受け付け、Lambdaに投げます。勤怠を管理しているエクセルはS3においておき、Lambdaからそのエクセルファイルに書き込みをしていく感じです。
処理が完了すると、処理結果をSuccessかFailでクライアントに通知します。
アプリケーションの実装
自動打刻システム(node.js)実装
コードの全貌は下記のGitHubリポジトリを御覧ください。
GitHub リポジトリ
エクセルファイルの操作には、「xlsx-populate」というライブラリを使用しました。
最初は「xlsx」というライブラリを使って実装していましたが、このライブラリだと処理をして、保存するとマクロや書式が無効化された状態になってしまうのでつかえず...。
個人的にはドキュメントも「xlsx-populate」のほうが読みやすかったです!
処理としてはファイルを読み込んで、シートを指定して、セルを指定して値を書き込み、保存しているだけです。弊社の勤怠表は月ごとにシートが分かれているので、処理の頭でDateオブジェクトを生成して、得られた各値でシートや記入するセルを判定しています。
また、弊社は30分ごとに勤務時間として打刻できるので、打刻する時刻を30分単位に変換する関数を用意しています。
今後もっと本格的に運用していくことになったら、このあたりで拡張の余地がありますね。
実装で苦労したのは非同期処理とAWS S3からファイルを取得して、書き込んだものをアップロードし直す処理のところ。
const params = { Bucket: 'バケット名', Key: 'キー' } s3.getObject(params, (err, data) => { }上記のように記述すれば、指定されたバケットのオブジェクト(ファイル)を取得できて、data変数に格納されます。
また、アップロードするときは、
const params = { Bucket: 'バケット名', Key: 'キー', Body: 'アップロードしたいファイル' } s3.putObject(params, (err, data) => { })でアップロードできます!
ここがnode.jsの情報がなかなか転がってなくて苦労しました。
取得も書き込みも注意点としては、取ってきたり送信するためには、データ形式に気をつけなければなりません。
今回僕は、これらの処理の前後にエクセルファイルをバッファーに変換する処理をはさみ、変換したものをparams変数のBodyとしています。
クライアントサイド(vue.js)実装
クライアントサイド(WEB)はVue.jsで作りました。
最終的には静的サイトとしてビルドして、Netlifyでホスティングします。
こちらは特に難しいことはしていません。
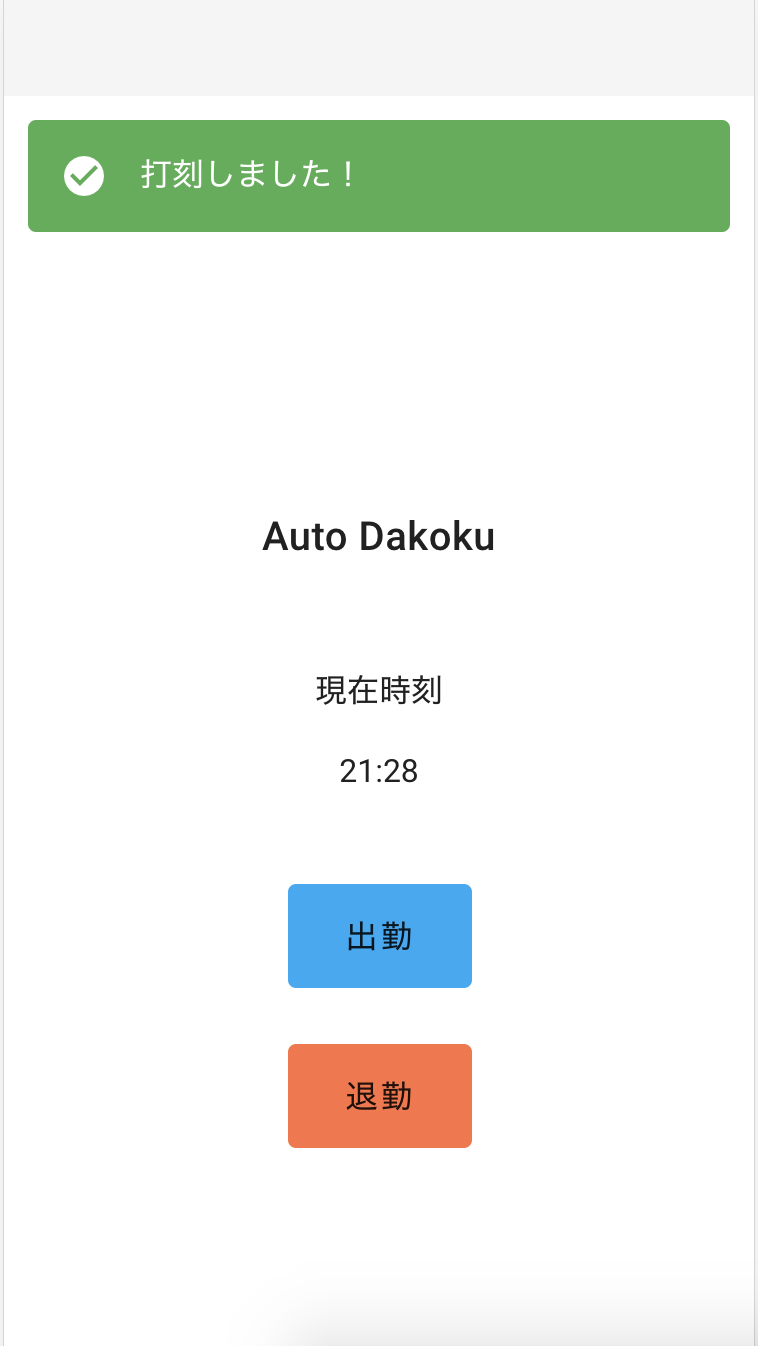
UIはVuetifyを使ったので適当に作った割には整っています。
スクショですが、下記のようになりました。
打刻すると、vue-loading-templateを使用したアニメーションが流れて、レスポンスが帰ってくるとアラートが表示されます。
(若干左によってるのはスクショが下手だからです...笑)
インフラ環境構築
構築したもの
いよいよインフラの構築に入ります。今回は、メインのAPIをLambdaで動かします。
勤怠表(エクセルファイル)はS3にアップロードしておき、Lambdaから読み取り、書き込みを行います。
HTTPリクエストの受け口として、APIGatewayを配置します。
ここに想定されるリクエストがとんできたら、それをトリガーにLambda関数が動く仕組みにしていきます。
また、クライアントサイド(WEBアプリ)はNetlifyという静的サイトのホスティングサービスを利用します。
Netlifyに関しては後日別記事で言及します。
ハマったポイント
私はインフラ超初心者なので、インフラ構築でかなりつまづきました...。
「LambdaからS3のファイルをとってこれない」
作成したLambdaに正しくロールを付与していなかったため、アクセス権限 is 何の状態が1時間くらい続きました...。
「Lambda関数(メインAPI)が非同期処理になっていて肝心の処理を行う前にLambdaが終了してしまっていた」今回使用した「xlsx-populate」は非同期処理をすることが前提のライブラリです。
恥ずかしながら、node.jsだけでなく非同期処理の知識も乏しく、Lambdaはエラーなく終了するのに肝心の処理が実行できてない...。
という状態で約5日間潰しました。
エラー箇所の切り出しが下手だったなあと反省しています。
いろんな記事や書籍を読み漁りつつ、async awaitを駆使してなんとか解決しました。
「CROS」
実際にクライアントサイドからリクエストを投げる時にはまりました。
今までなーんとなくしか理解してなかったですが、これを機にしっかり学べました。
CROSに関しては別記事でまとめます。
実際につかってみた
明日から出社と退社が楽しみになりそう。
(ちょっと処理は遅いですが)個人的にほぼノンストレスに打刻できるようになったので満足です。
ただ、本当にきちんと勤怠をつけるためには小難しい会社のルールがあるみたいなので、そのうちきちんとしたものも作りたいです。
今のところはほぼ毎日きっちり定時に退社しているので細かい調整はそんなに必要なさそう...だと思ってます笑
おわりに
NFCさいこう!!!!!たのしい!!!!!

- 投稿日:2020-03-17T01:41:19+09:00
AWSで配信をしてみる準備 (Cloud Frontを介してS3にアクセス)
自分用メモ。
以前書いたShaka Packagerを使った配信環境を構築してみるにあたって、CDNを介した環境を作ってみたいと思った。
Shaka Packagerを使った配信環境はEC2で構築してみようと思ったので、オリジンはS3で、EdgeとしてCloud Frontを使ってみることに。Cloud Frontを介したほうが安いのか、S3のみを使ったほうが安いかは調べてない。
やりたいこと
S3へのコンテンツへのアクセスをCloud Frontからのアクセスに限定して、S3のオブジェクトへの直接のアクセス (XXXX.s3-ap-northeast-1.amazonaws.com のURLでのアクセス) をさせないこともついでにやろうと思った、なぜか。
色々ドキュメントを探したところ、端的に書いていたのはこのページだった。
https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-restricting-access-to-s3.html以下のページから辿った。
https://docs.aws.amazon.com/AmazonS3/latest/dev/example-bucket-policies.htmlバケットの設定
バケットの「アクセス権限」 > 「ブロックパブリックアクセス」について。
今回、パブリックアクセスは許可しないので、全部ブロック(「パブリックアクセスを全てブロック」が「オン」の状態)で良い。Cloud Frontの設定
- 先にDistributionを作成していたので、作成済みのDistributionを選択し「Origins and Origin Groups」タブを選択。
- 「Origins」のセクションで「Create Origin」ボタンを押下
- 表示された画面で、「Origin Domain Name」にて作成済みのバケットのドメインを選択する。自動でOrigin IDが入るので、それは編集しない。
- 「Restrict Bucket Access」でYesを選択する。
- 後の項目はヘルプでも読みながら選択・入力すれば迷うことはない。
ちなみに、 「Grant Read Permissions on Bucket」で「Yes, Update Bucket Policy」を選んでおくと、バケットの「バケットポリシー」にOAIを使ったポリシーが勝手に更新されてくれた。
動作確認
バケットに適当なファイルを置いて、以下を確認した。
- S3のバケットのURLでファイルにアクセス → アクセスできないこと
- Cloud FrontのURLでファイルにアクセス → アクセスできること
- S3のバケットのURLでルートフォルダにアクセス → アクセスできないこと
- Cloud FrontのURLでルートフォルダにアクセス → アクセスできないこと
感想
EC2は以前から開発環境として使っていたけど、初めてそれ以外を使ってみた。
AWSを知っている人はすごいんだなと思った。