- 投稿日:2020-02-16T23:48:56+09:00
AtCoder Beginner Contest 155 参戦記
AtCoder Beginner Contest 155 参戦記
ABC155A - Poor
2分で突破. 書くだけ. 前回に引き続き、set での重複判定.
ABC = list(map(int, input().split())) if len(set(ABC)) == 2: print('Yes') else: print('No')ABC155B - Papers, Please
2分半で突破. 書くだけ.
N = int(input()) A = list(map(int, input().split())) for a in A: if a % 2 == 1: continue if a % 3 == 0 or a % 5 == 0: continue print('DENIED') exit() print('APPROVED')ABC155C - Poll
8分半で突破. 書くだけ……といいつつそれなりに時間がかかったけど(汗). C# 使いが壊滅状態と聞いて、AC した人のコードを眺めると 全員 string 配列のソートに自前の comparer を使っていたので、Mono は string の比較がヤバイのかなと思った.
N = int(input()) d = {} for _ in range(N): S = input() if S in d: d[S] += 1 else: d[S] = 1 m = max(d.values()) for s in sorted(k for k in d if d[k] == m): print(s)追記: C# で通している人、みんな自前の comparer を使ってソートしてたけど、標準の StringComparer.Ordinal (これは、実質的には C ランタイムの strcmp 関数の呼び出し)で通るなあ.
using System; using System.Collections.Generic; using System.Linq; namespace ConsoleApp1 { class Program { static void Main(string[] args) { var N = int.Parse(Console.ReadLine()); var d = new Dictionary<string, int>(); for (var i = 0; i < N; i++) { var S = Console.ReadLine(); if (!d.ContainsKey(S)) d[S] = 0; d[S]++; } var m = d.Values.Max(); var l = new List<string>(); foreach (var kv in d) { if (kv.Value != m) continue; l.Add(kv.Key); } l.Sort(StringComparer.Ordinal); Console.WriteLine(string.Join("\n", l)); } } }ABC155D - Pairs
敗退. Eの方が解いてる人が多いので、Eに行った. にぶたんかなあと思った.
ABC155E - Payment
敗退. 入力例1, 入力例2 は突破したものの、入力例3が243ではなく、249になってしまって、自分のロジックでうまく行かないパターンを考えていたけど思いつかなかった.
- 投稿日:2020-02-16T23:39:33+09:00
簡単なアルゴリズムをPythonで実装する2
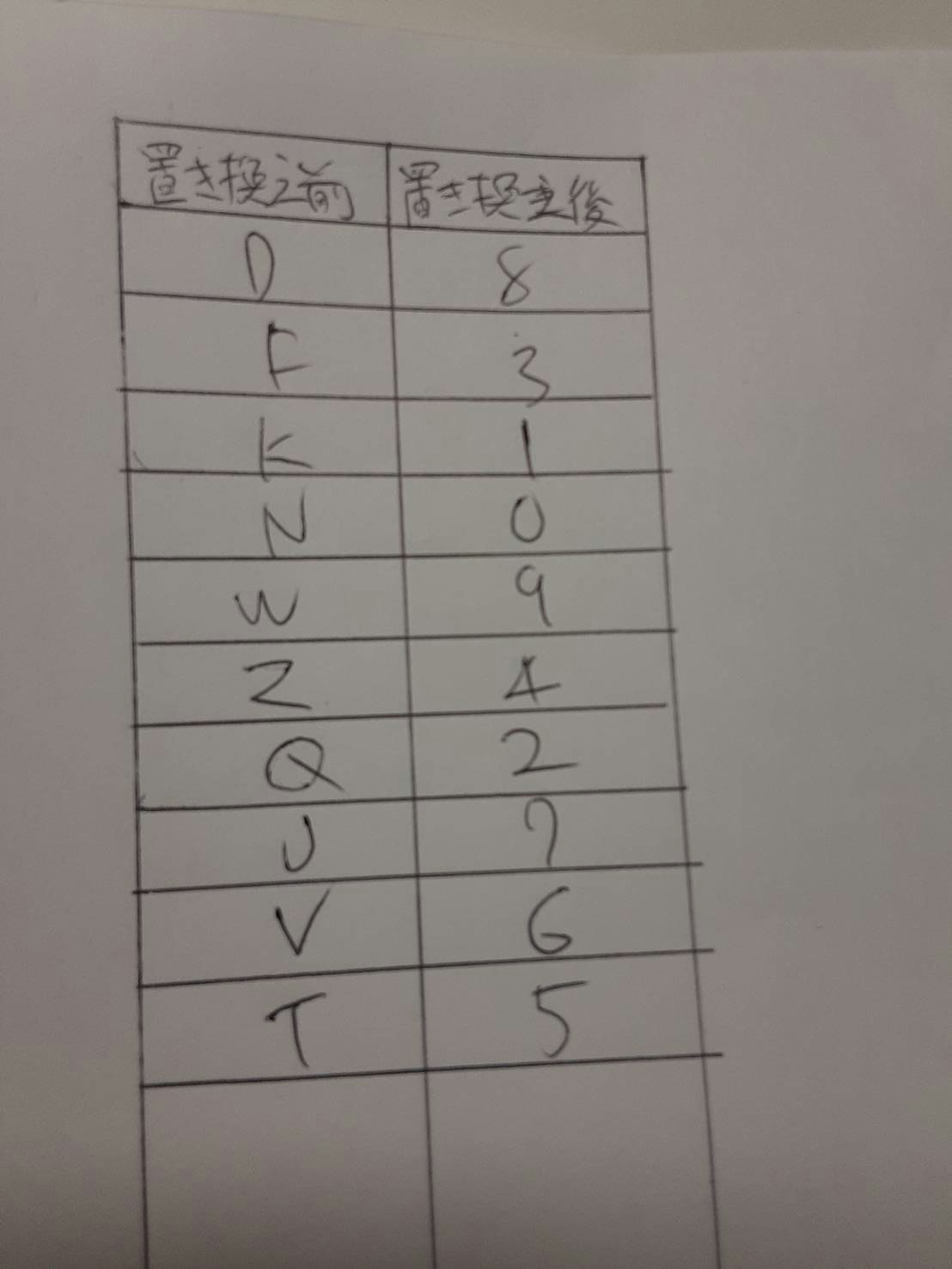
以下のアルファベットを規則に従って数字に置換えよう。
回答
input_line = input() translate = input_line.replace('D', '8').replace('F', '3').replace('K', '1').replace('N', '0').replace('W', '9').replace('Z', '4').replace('Q', '2').replace('J', '7').replace('V', '6').replace('T', '5') print(translate)#入力 DSJKFHSJHAJK #出力 8S713HS7HA71pythonのreplaceを使って置換えた。
非常に汚い書き方だが変換できたのでとりあえずヨシ!
- 投稿日:2020-02-16T23:27:53+09:00
PEP-593 を読んだよメモ
ある議論の流れで PEP-593 (Flexible function and variable annotations) を読むことになったので、自分の理解をメモに残しておく。
概要
- PEP-3107 (Function Annotations) は Python の文法にアノテーションを導入した。その際、アノテーションの用途として型ヒントや DB クエリーのマッピング、RPS のマーシャリング情報などを挙げていた。
- PEP-484 (Type Hints) はアノテーション記法を使って型ヒントを実現する方法を導入した。いまやアノテーションの主たる利用方法であると言える。
- PEP-484 がデファクトスタンダードとなった今、型ヒント以外の用途にアノテーションを使いづらくなってしまった。
- そこで、アノテーションを再定義して型ヒントに加えて、さらに独自のメタデータも記述できるようにするよ。
アプローチ
- 新たに
typing.Annotatedを追加する- あるデータや関数に型 T とメタデータ x, y をアノテーションするときには
Annotated[T, x, y]と書く
- 先頭の要素は型とみなされる
- 型チェッカーは
Tを、メタデータを利用するツールやライブラリはxやyをそれぞれ参照すればよい
- つまり、ツールやライブラリはサポートしていないアノテーションを無視してくれる
例
数値で、3-10 の範囲の値で、ctype では文字とみなされるような(架空の)アノテーション。
Annotated[int, ValueRange(3, 10), ctype("char")]感想
Annotatedって書きづらい。もっとラフに tuple で書きたかった…- 実行時でもアノテーションの内容を取得できる(
get_type_hints())ので、これを使うライブラリやフレームワークが出てきそうな予感- 乱用された結果、カオスなコードにならないことを祈りたい
- PEP-3107 (関数アノテーション)は紹介されているのに PEP-526 (Syntax for Variable Annotations; 変数アノテーション) には一切言及がない。不憫な子…
- もちろん関数だけでなく変数にもアノテーションできます。
- Sphinx でも対応しなくちゃ…
- 引数や変数の説明をアノテーションできそうだけど、どう考えても書くのがだるいので流行らない気がする
- イシュー作っておいた。きっと明日の自分がやってくれる…。
def hello(name: Annotated[str, Description("名前")], message: Annotated[str, Description("メッセージフォーマット")], language: Annotated[str, Description("言語")] = "ja" ) -> Annotated[None, Description("なし")]: ...
- 投稿日:2020-02-16T23:01:13+09:00
まだMVCで消耗してるの?〜Django x Reactで始めるSPA開発〜
ここ最近JSフレームワークを使ったサイトが増えてきています。
とくにReactやVueなどのJSフレームワークはSPAというアプリケーション開発によく使われ、サイトを利用するユーザーだけでなく開発者にも多くのメリットをもたらします。想定読者
- Web開発経験者
- APIを使ったWebアプリケーションを開発したことがある人
- JavaScriptをそこそこ知っててPythonもそこそこ知ってる人
- Djangoをちょっと知っている
- MVCもしくはMTVを使った開発をしたことがある人
別記事にもっと詳細に書いた記事があるので、本記事で難しいと感じた方やもっと深いところまで学習したい方はこちらをご覧ください。
まだMVCで消耗してるの?〜React x Djangoで始める今時Web開発〜この記事ではフロントエンドにReact、バックエンドにDjangoを使用してチュートリアルを進めていきます。
チュートリアルはToDoアプリを題材にして進めていきます。SPAとは
SPAはSingle Page Applicationと呼ばれ、ユーザーエクスペリエンスを向上させるのに有効な手立てとなります。
また、データバインディング、仮想DOM、Componentの3つの特徴を兼ね備えています。データバインディング
素のJavaScriptを使って値を変更する場合、DOMを指定して値を変更する処理を毎回動かさなければなりません。
ですが、JSフレームワークを使うと定義しておいた変数が更新されるたびに画面上の値も変更されます。仮想DOM
JSフレームワークには、クライアントのブラウザで描画をするためのDOMとサーバーとDOMの間に存在する仮想DOMの2種類があります。
仮想DOMの役割は、新しくサーバーから吐き出された仮想DOMと現在存在する仮想DOMとの差分を取り、その差分をDOMに反映することです。
そのためDOMの更新は差分があった部分だけとなり、ページのレンダリングを高速にすることができます。Component
JSフレームワークでは、ページの要素をコンポーネントと呼ばれる部品単位に分割することができます。 そうすることで、コンポーネントを再利用することができ同じコードを書かずに済みます。
このチュートリアルではページを1枚作るだけなので、ユーザーエクスペリエンスにつながるメリットを肌で感じることはできないかもしれないのですが、開発面でのメリットは感じることができると思います。
Django環境構築
まずはバックエンドから進めていきます。
以下のコマンドを順に実行してください。
mkdir todo-backend cd todo-backend python3 -m venv env source env/bin/activate pip install django djangorestframework django-cors-header django-admin startproject project . django-admin startapp todo python manage.py migrate python manage.py createsuperuser python manage.py runserver環境が構築できたら127.0.0.1:8000にアクセスしてください。
初期画面が表示されるはずです。Django環境の設定
settings.pyにプラグイン追加の設定とクロスオリジンの設定を追記していきます。
クロスオリジンの設定は、WebブラウザからAPIを実行するときにアクセス拒否されるのを防ぐために追記します。settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', 'corsheaders', 'todo' ] MIDDLEWARE = [ 'corsheaders.middleware.CorsMiddleware', ] # 許可するオリジン CORS_ORIGIN_WHITELIST = [ 'http://localhost:3000', ]ついでにprojectディレクトリ内のurl設定ファイルに、APIのルーティングを設定します。
urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('api/', include('todo.urls')), ]バックエンドの実装
todoアプリ内を実装していきます。
models.pyfrom django.db import models class Todo(models.Model): name = models.CharField(max_length=64, blank=False, null=False) checked = models.BooleanField(default=False) def __str__(self): return self.nameマイグレーションを実行します。
python manage.py makemigrations python manage.py migrateadmin.pyfrom django.contrib import admin from .models import Todo @admin.register(Todo) class Todo(admin.ModelAdmin): passserializer.pyfrom rest_framework import serializers from .models import Todo class TodoSerializer(serializers.ModelSerializer): class Meta: model = Todo fields = ('id', 'name', 'checked')views.pyfrom rest_framework import filters, generics, viewsets from .models import Todo from .serializer import TodoSerializer class ToDoViewSet(viewsets.ModelViewSet): queryset = Todo.objects.all() serializer_class = TodoSerializer filter_fields = ('name',)urls.pyfrom rest_framework import routers from .views import ToDoViewSet from django.urls import path, include router = routers.DefaultRouter() router.register(r'todo', ToDoViewSet) urlpatterns = [ path('', include(router.urls)), ]ここまで終えたら、http://localhost:8000/admin にアクセスしてToDoをいくつか追加しておいてください。
React環境構築
Reactの環境立ち上げにはCreate React Appを使います。
yarn create react-app todo-frontend cd todo-frontend yarn starthttp://localhost:3000にアクセスして画面が正常に表示されたら環境構築完了です。
ルーティング
Reactはルーティング機能を持たないので、別にプラグインをインストールします。
yarn add react-router-domsrcディレクトリ直下にRouter.jsxを作成してください。
Router.jsximport React from 'react'; import { BrowserRouter, Route } from 'react-router-dom'; import Top from '../components/Top'; const Router = () => { return ( <BrowserRouter> </BrowserRouter> ); }; export default Router;App.jsにルーティングを読み込ませます。
App.jsimport React from 'react'; import Router from './configs/Router'; function App() { return ( <Router /> ); } export default App;画面デザイン
画面のデザインにはMaterial UIというデザインフレームワークを使います。
Reactのプラグインとして提供されているので、yarn addでインストールしてください。yarn add @material-ui/core下の画像が出来上がり図です。
API実装
まずはAPIを実装していきます。
一つのコンポーネント内に含めると可読性が落ちるので、別ファイルに分けてAPI処理を実装します。
実装するAPI処理は、ToDoリスト取得、ToDo作成、ToDoのチェック、ToDo削除の4つです。src/common/apiディレクトリを作り、その中にtodo.jsを作成してください。
todo.jsconst originUrl = 'http://127.0.0.1:8000'; const getTodoList = (() => { const url = new URL('/api/todo/', originUrl); return new Promise( (resolve, reject) => { fetch(url.href) .then( res => res.json() ) .then( json => resolve(json) ) .catch( () => reject([]) ); }); }); export default getTodoList; export const postCreateTodo = (name) => { const url = new URL('/api/todo/', originUrl); return new Promise( resolve => { fetch(url.href, { method: 'POST', headers: { 'Accept': 'application/json', 'Content-Type': 'application/json' }, body: JSON.stringify({ name: name }) }) .then( res => res.json() ) .then( data => resolve(data) ); }); }; export const patchCheckTodo = ((id, check) => { const url = new URL(`/api/todo/${id}/`, originUrl); fetch(url.href, { method: 'PATCH', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ checked: check }) }); }); export const deleteTodo = ((id) => { const url = new URL(`/api/todo/${id}/`, originUrl); fetch(url.href, { method: 'DELETE' }); });コンポーネント実装
次にコンポーネントを実装します。
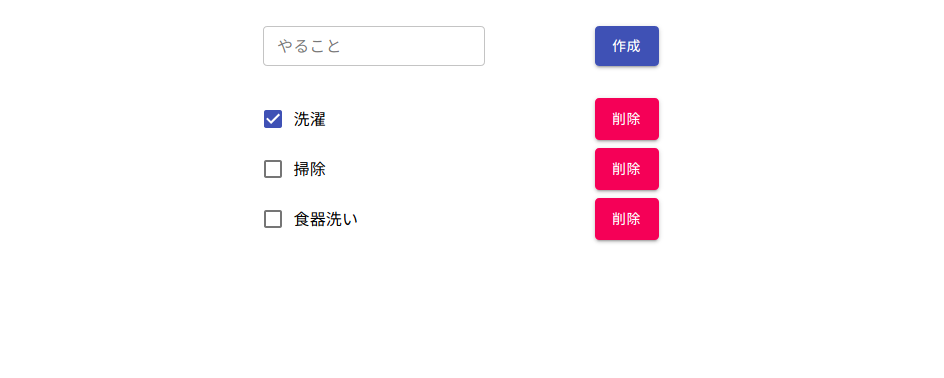
index.jsximport React, { useEffect, useState } from 'react'; import Button from '@material-ui/core/Button'; import Box from '@material-ui/core/Box'; import FormGroup from '@material-ui/core/FormGroup'; import FormControlLabel from '@material-ui/core/FormControlLabel'; import Checkbox from '@material-ui/core/Checkbox'; import Container from '@material-ui/core/Container'; import { makeStyles } from '@material-ui/core/styles'; import TextField from '@material-ui/core/TextField'; import getToDoList, { postCreateTodo, patchCheckTodo, deleteTodo } from '../../common/api/todo'; const useStyles = makeStyles(theme => ({ todoTextField: { marginRight: theme.spacing(1) } })); const Top = () => { const classes = useStyles(); const [todoList, setTodoList] = useState([]); const [todo, setTodo] = useState(''); useEffect(() => { (async () => { const list = await getToDoList(); setTodoList(list); })(); }, []); const handleCreate = async () => { if ( todo === '' || todoList.some( value => todo === value.name ) ) return; const createTodoResponse = await postCreateTodo(todo); setTodoList(todoList.concat(createTodoResponse)); }; const handleSetTodo = (e) => { setTodo(e.target.value); }; const handleCheck = (e) => { const todoId = e.target.value; const checked = e.target.checked; const list = todoList.map( (value, index) => { if (value.id.toString() === todoId) { todoList[index].checked = checked; } return todoList[index]; }); setTodoList(list) patchCheckTodo(todoId, checked); } const handleDelete = (e) => { const todoId = e.currentTarget.dataset.id; const list = todoList.filter( value => value['id'].toString() !== todoId); setTodoList(list); deleteTodo(todoId); }; return ( <Container maxWidth="xs"> <Box display="flex" justifyContent="space-between" mt={4} mb={4}> <TextField className={classes.todoTextField} label="やること" variant="outlined" size="small" onChange={handleSetTodo} /> <Button variant="contained" color="primary" onClick={handleCreate}>作成</Button> </Box> <FormGroup> {todoList.map((todo, index) => { return ( <Box key={index} display="flex" justifyContent="space-between" mb={1}> <FormControlLabel control={ <Checkbox checked={todo.checked} onChange={handleCheck} value={todo.id} color="primary" /> } label={todo.name} /> <Button variant="contained" color="secondary" data-id={todo.id} onClick={handleDelete}>削除</Button> </Box> ) })} </FormGroup> </Container> ) }; export default Top;最後に
ToDoアプリを一つ作りましたが、この記事の内容だけだとまだ実用はできないので、いずれホスティングに載せるところまでを紹介しようと思います。
誤字脱字や、間違いがあればご連絡ください。
ソースコードをGitHubに上げているので、必要であれば使ってください。フロントエンド
https://github.com/uichi/todo-frontendバックエンド
https://github.com/uichi/todo-backend参考
- 投稿日:2020-02-16T22:58:33+09:00
うんちメーカーを支える技術 ~ 状態遷移はうんちの夢を見るか?
うんちメーカーの誕生
「うんちメーカー」というブラウザゲームを作りました。
うんちの長さを競い合うゲームで、オンラインのランキング機能があります。
使用した技術はDjango, Vueなどです。
今回はこのうんちメーカーで使っている技術について書いてみたいと思います。主役はVue
フロントエンドのフレームワークはVueを使いました。
Vueはコンポーネント志向のフレームワークで、SFC(Single File Component)という単位でモジュールを定義できます。
例えば↓のようにです。<script> export default { data () { return { } } } </script> <template> <div class="">Hello, World!</div> </template> <style lang="scss" scoped> </style>SFCはJavaScript, HTML, CSSを1つのファイルにまとめたコンポーネントで、これらを1つにまとめることで効率よく開発することが出来ます。
↓のようにコンポーネントを利用すると、属性にデータを渡すことができます。<my-component :my-data="1" />属性に渡されたデータはSFCでは
propsというオブジェクト内の変数に共有されます。
この変数はたとえば↑のmy-dataの値を変更すると、その変更がリアルタイムでSFCにも反映されます。
このpropsの機能を使うことで、状態を持つコンポーネントを簡単に定義することが出来ます。コンポーネントの状態遷移
ゲームは状態遷移のかたまりだと、今回の開発で思いました。
状態遷移とは、状態を定義した変数をひとつ用意して、その変数の値を次々に変化させて、モジュールなどの振る舞いを変える技術を指します。たとえば↓のような変数があるとして、
const status = 'first'この変数は↓のように参照されます。
switch (status) { case 'first': /* TODO */ break case 'running': /* TODO */ break case 'waiting': /* TODO */ break }
switch文のcaseに状態に応じた処理を書くことで、状態遷移を実現させることが出来ます。
状態を持つ変数自体は、各状態の処理の中で変更していきます。先ほどのコンポーネントの
propsにこのような状態を持たせることで、コンポーネントに状態遷移を行わせることが出来ます。
例えば↓のようにです。<my-component :status="myComponentStatus" />コンポーネント内では、
setIntervalでループを回し、この状態を監視させます。mounted () { this.iid = setInterval(this.update, 16.66) }, methods: { update () { switch (this.status) { case 'first': /* TODO */ break case 'running': /* TODO */ break case 'waiting': /* TODO */ break } }, },うんちメーカーのオブジェクトは複雑な状態を持っていますが、基本的にはこのような状態遷移で動作しています。
ゲーム開発における状態遷移の有用性
私は状態遷移は文字列のパースなどで学んだのですが、今回の開発でゲームにも応用できることがわかりました。
ゲームは複雑な状態を持っていますが、それらを一度に処理しようとすると高い確率で肛門がパンクします。
しかし、状態という単位にゲーム全体の振る舞いを分割統治することで開発が容易になります。ゲーム開発における状態遷移の有用性は確かなもので、これを知っていると知らないとでは作れるものが異なってくると思いました。
知らないとクソゲーを作ることになってしまいますが、知っていればうんちメーカーのようなクソゲーを作ることが出来ます。デザインパターンへの応用
状態を管理するデザインパターンに有名なGoFのStateパターンがありますが、今回はこれは使いませんでした。
うんちメーカーはかなり規模の小さいアプリだったので利用する必要もなかったのですが、規模の大きさによってはこれらのデザインパターンの利用を検証する必要があるかもしれません。
おわりに
ストレスの多い世の中ですが、うんちメーカーでいっぱい出してすっきりしましょう。
以上です。

- 投稿日:2020-02-16T22:43:33+09:00
COTOHA API で照応解析してもギブミーチョコレート出来ていない問題
Background
【Qiita x COTOHA APIプレゼント企画】
が気になったので少し使ってみようと思いました。自然言語処理で有名なライブラリはMeCabかKNPですが、恥ずかしながらCOTOHA APIをこのイベントで始めてし知りました。
Motive
ちょっと個人的にもハードルが高めかもしれませんが、照応解析APIを最初に使ってみました。
この解析は文章中の代名詞(「私」「あなた」「彼」など)・指示語(「あれ」「これ」)をそれらしい人物や物体に置き換える処理のことです。
使う理由としては、時間に余裕があれば誰が何をしたかを明確化してから処理をしたいための初期段階として使いたかったからです。イベントは3月中旬っすか。。。
間に合うかな。
Environment
- Python 3.6.8
- COTOHA API (https://api.ce-cotoha.com/)
Development
import requests import json import time import sys #--- この4つパラメータはPortalで取得 --- PUBLISH_URL = "--- get your parameter ---" CLIENT_ID = "--- get your parameter ---" CLIENT_SECRET = "--- get your parameter ---" BASE_URL = "--- get your parameter ---" def getToken(): header = {"Content-Type": "application/json"} contents = { "grantType": "client_credentials", "clientId": CLIENT_ID, "clientSecret": CLIENT_SECRET } raw_res = requests.post(PUBLISH_URL, headers=header, json=contents) response = raw_res.json() return response["access_token"] def coreference(token, sentence): header = { "Authorization": "Bearer {}".format(token), "Content-Type": "application/json" } contents = { "document": sentence } raw_res = requests.post( BASE_URL + "nlp/v1/coreference", headers=header, json=contents) response = raw_res.json() return response if __name__ == "__main__": if len(sys.argv) != 2: sys.exit() message = sys.argv[1] token = getToken() time.sleep(0.5) print(coreference(token, message))流れとしては
トークン取得 -> それぞれの使いたいAPIをコール
の2つです。curl をpythonでは同じことをしています。
$ curl -X POST -H "Content-Type:application/json" -d '{ "grantType": "client_credentials", "clientId": "[clientid]", "clientSecret": "[clientsecret]" }' [Access Token Publish URL ]$ curl -H "Content-Type:application/json;charset=UTF-8" -H "Authorization:Bearer [access_token]" -X POST -d '{ "document": -- ここに解析したい文章を入力 -- }' "[Developer API Base URL]/nlp/v1/coreference"Consequence
てことで二つの文章を使って解析してみます。
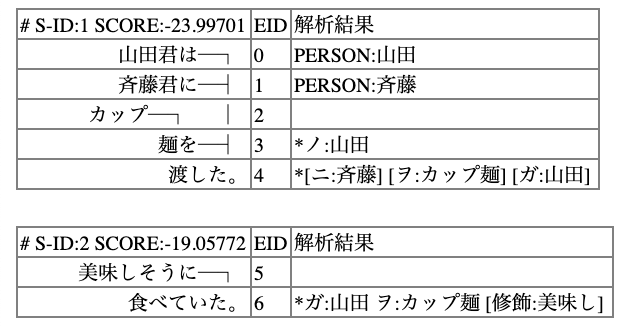
- 山田君はカップ麺を買った。彼は美味しそうに食べていた。
- 山田君は斉藤君にカップ麺を渡した。彼は美味しそうに食べていた。
$ python main.py 山田くんはカップ麺を買った。彼は美味しそうに食べていた。 {'result': {'coreference': [{'representative_id': 0, 'referents': [{'referent_id': 0, 'sentence_id': 0, 'token_id_from': 0, 'token_id_to': 0, 'form': '山田'}, {'referent_id': 1, 'sentence_id': 0, 'token_id_from': 10, 'token_id_to': 10, 'form': '彼'}]}], 'tokens': [['山田', 'くん', 'は', 'カップ', '麺', 'を', '買', 'っ', 'た', '。', '彼', 'は', '美味し', 'そう', 'に', '食べ', 'て', 'い', 'た', '。']]}, 'status': 0, 'message': 'OK'}$ python main.py 山田君は斉藤君にカップ麺を渡した。彼は美味しそうに食べていた。 {'result': {'coreference': [{'representative_id': 0, 'referents': [{'referent_id': 0, 'sentence_id': 0, 'token_id_from': 0, 'token_id_to': 0, 'form': '山田'}, {'referent_id': 1, 'sentence_id': 0, 'token_id_from': 13, 'token_id_to': 13, 'form': '彼'}]}], 'tokens': [['山田', '君', 'は', '斉藤', '君', 'に', 'カップ', '麺', 'を', '渡', 'し', 'た', '。', '彼', 'は', '美味し', 'そう', 'に', '食べ', 'て', 'い', 'た', '。']]}, 'status': 0, 'message': 'OK'}Consideration
山田君はカップ麺を買った。彼は美味しそうに食べていた。
では
'coreference': [{'representative_id': 0, 'referents': [{'referent_id': 0, 'sentence_id': 0, 'token_id_from': 0, 'token_id_to': 0, 'form': '山田'}, {'referent_id': 1, 'sentence_id': 0, 'token_id_from': 10, 'token_id_to': 10, 'form': '彼'}]
で山田-彼が結びついているのが分かります。しかし、
山田君は斉藤君にカップ麺を渡した。彼は美味しそうに食べていた。
では
'coreference': [{'representative_id': 0, 'referents': [{'referent_id': 0, 'sentence_id': 0, 'token_id_from': 0, 'token_id_to': 0, 'form': '山田'}, {'referent_id': 1, 'sentence_id': 0, 'token_id_from': 13, 'token_id_to': 13, 'form': '彼'}]
と山田-彼が結びついていて斉藤-彼となっていません。
これだとカップ麺を渡しても山田君が食べたことになります。
まさに、剛田思考です。
Comparation -> KNP
KNPだったどうかを試してみます。
http://lotus.kuee.kyoto-u.ac.jp/~ryohei/zero_anaphora/index.cgi
こちらは
斉藤-彼
になっているので正しく認識しているっぽいです。ですが、
山田君は斉藤君にカップ麺を渡した。美味しそうに食べていた。
と代名詞を削除して解析すると、山田-彼となって正しく認識されないです。
Conclusion
今回照応解析したのは直接照応と呼ばれるもので明示的に代名詞が書かれている場合ですが、文章中には書かれていないことがよくあります。
http://adsmedia.hatenablog.com/entry/2017/02/20/084846
間接照応・外界照応・ゼロ照応などがあります。ゲノムが2000年代に全て解析されたけどprotainってどうやって作っているのかは全てわかっていないです。
型はあるけど組み合わせで無数にできるためです。自然言語も同様に一つの文章から単語の種類まで判別はできるものの、照応解析のようにまだ調べることが
多いです。
方法の一つとして文章中にない単語を書くにはユーザが各自でソースを集めて機械学習にかけないと厳しいかもしれんす。
いろいろなキャラクターの中で80%の可能性で斉藤君がカップ麺を食べる、のようなイメージです。PostScript
次は構文解析を使って、分析かプロダクトを作ってみます。

- 投稿日:2020-02-16T22:37:58+09:00
python3 外部モジュールのインストール方法について
- 投稿日:2020-02-16T22:30:59+09:00
gdspyを使って、PythonではじめてのGDSIIファイルを作る
はじめに
本稿は、PythonでGDSII formatを扱うの続きである。gdspyライブラリがインストールできたことを前提に、はじめてのGDSファイルを作ってみる。
まず、原稿執筆時点(2020年2月16日)でgdspyの最新バージョンは1.5.2である。1.5から設計思想がだいぶ変わったらしく、以前のバージョンで作ったスクリプトはそのままでは動かない。gdspyのオフィシャルにあるスクリプトですら現時点で正しく動かないので、取り急ぎ動くようにしたバージョンのみ下記に挙げる。
import gdspy
# The GDSII file is called a library, which contains multiple cells.
lib = gdspy.GdsLibrary()
# Geometry must be placed in cells.
cell = lib.new_cell('FIRST')
# Create the geometry (a single rectangle) and add it to the cell.
rect = gdspy.Rectangle((0, 0), (2, 1))
cell.add(rect)
# Save the library in a file called 'first.gds'.
lib.write_gds('first.gds')
# Optionally, save an image of the cell as SVG.
cell.write_svg('first.svg')
# Display all cells using the internal viewer.
gdspy.LayoutViewer(lib)<- ここ1行だけオフィシャルから変えたgdspy 1.4 と1.5以降で何が変わったか
1.4までは、取り扱うGDSのライブラリをグローバルなクラスとして取り扱っていたのだが1、1.5以降は明確にローカルなクラス
lib = gdspy.GdsLibrary()として取り扱われるようになった。それに伴い、オフィシャルのドキュメント含めそのままでは動かないコードが多々ある。当然、サブルーチン(関数)へ渡す時も変更が必要だし、CellReferenceなどの使い方が大きく変わっている。
今後、gdspy2.0へのアップデートが予定されており、変更点はさらに増大すると思われる。詳しくはGitHubでソースを見てほしい(それを言ったらおしまいである)。
筆者はCはそれなりに経験があるもののPythonは今回はじめて扱ったぐらいの素人なので、C言語におけるローカル変数/グローバル変数問題と、Pythonのクラスのフォーカスを混同して書いている可能性が大である。適当に翻訳しながら読んでほしい。 ↩
- 投稿日:2020-02-16T22:26:52+09:00
Python の win32gui を使ってアクティブウインドウの記録を取るスクリプトを作ってみた
ソフトウェアの開発をしている会社だと、どの作業を何分やったかを日報に入れろと言われることが多いのではないでしょうか?
そんな事言われても忙しいときは記録取るのが難しいので、「アクティブウインドウの記録を取ればだいたい何をしていたのかわかるのでは?」という前提でそれをするためのスクリプトを作ってみました。使えると嬉しい人が他にもいそうなので、公開しておきます。
タイトルバーに編集中のファイル名が出る種類のエディタをお使いのプログラマでしたらこのスクリプトでだいたい何をしていたか後で振り返ることができます。出来上がったスクリプト
以下にあります:
https://github.com/aikige/homeBinWin/blob/master/dumpForegroundWindow.py基本的なコンセプト
- pywin32 に含まれている
win32gui.GetForegroundWindowおよび、win32gui.GetWindowTextを使って現在Foreground で動作している Window のタイトルを取得します。- 取得したものをタイムスタンプ付きでダンプします。
- 上記の処理を定期的(間隔は引数で変更可能)します。
- ログは日付ごとのファイルに記録されます。とりあえず現在はファイルと標準出力の両方にログが出力されるようにしてあります。
スクリプトを動かすための前準備
pywin32がまだ入っていない場合はインストールしてください。
pip install pywin32動作確認した環境
Python 3.8.1 pywin32 Version 227※win32guiは、pywin32に含まれているようです。
参考にしたもの
- 投稿日:2020-02-16T21:50:33+09:00
LINE WORKSのAPIを呼び出すためのPythonライブラリを作成しました
こんばんは、@0yanです。
LINE WORKSのトークBotを使うことが多いので、昨年9月にLINE WORKSのAPIを呼び出すためのPythonライブラリを作成しました・・・といってもREADME.mdをきちんと書いておらず、他の人からしたら使いようのないゴミライブラリ。
今回、README.mdをきちんと書いてバグ取りして改めてリリースしました(日本のビジネスチャットなので日本語で書きました)。使い方
TalkBotApiクラスのインスタンス生成TalkBotApiクラスのメソッド使用の2ステップでトークBotにメッセージ送信させたりすることができます。
使用例
from lineworks import TalkBotApi api_id = "your api id." server_api_consumer_key = "your server api consumer key" server_id = "your server id." private_key = "your private key." domain_id = "your domain id." bot_no = "your bot number." talk_bot = TalkBotApi(api_id, server_api_consumer_key, server_id, private_key, domain_id, "your bot no.(option)") # メッセージ送信(Text) talk_bot.send_text_message(send_text="こんにちは", account_id="test1@example.com")詳しくはGitHubのREADMEに記載しました。
ご活用頂けますと幸いです。
宜しくお願い致します。
- 投稿日:2020-02-16T21:40:42+09:00
PythonでGDSII formatを扱う
はじめに
GDSII(以下GDS)はICやMEMSのレイアウト用CADフォーマットとして知られている。筆者はMEMSやメタサーフェス製作のためにGDSを利用している。GDSはLayoutEditorやKLayoutなどのマスク用CADソフトで直接作成することもできるし
(お金持ちはCadenceを使うw)、AutoCADやSolidworks等で扱えるdxfファイルから変換することもできるが、数式を用いて記述できるパターンに対してはプログラミング言語の適用が便利である。
筆者も永らくJAXA三田先生のページを参考にPerlでGDSを描いてきたのだが、近年はCADのファイルサイズが肥大化し、Perlでは限界を感じることが多くなった1。そのため、2019年以降はPythonでGDSを作成している。ここではPythonでGDSファイルを作成するためのノウハウを記述していこうと思う。PythonでGDSIIを扱うためのライブラリの選定
PythonでGDSIIフォーマットを取り扱うためのライブラリはいくつか提案されているが、筆者のおススメはgdspyである。知られているライブラリを列挙すると、
- gdspy
- gdsCAD
- python-gdsii
等がある。このうち、執筆時点(2020年2月16日)でアップデートが頻繁に行われているのはgdspyであり、機能的にも充分に感じているので、本稿では主にこちらを取り挙げる。Windows 10 上のAnaconda環境へのgdspyのインストール
ここではWindowsマシン上でとりあえずgdspyでgdsファイルを作成するまでの環境設定について述べる。
1. Anaconda 3 のインストール
https://www.python.jp/install/centos/anaconda/install.html
を見ながらインストールする。
Anaconda 3 のアップデート(適宜実行する)
Windows -> cmd.exe (コマンドプロンプト)から
> conda update --allgds用環境の設定
conda環境とpip環境が混在しているとなんだかうまくいかないらしいので、念のためAnaconda 3 に、新しいenvironmentを作る。gdsiiなどの名前にしておく。
3-1. gdspyに必要なモジュールをインストールしておく。
numpy
cython
pip
spydergdspyの導入
下記URLにある
https://qiita.com/mckeeeen/items/d4cbe4a16a102157f40c
"Anaconda環境にpipでパッケージをインストールする"を実行し、gdspyをインストールする。Windows -> cmd.exe (コマンドプロンプト)から、下記を実行する。
(> の行がコマンド入力を示す)
>conda info -e
# conda environments:
#
base * C:\Users\k_iwa\Anaconda3
> source activate base<-ここの名前(base)は3.で導入したgdspy用environmentにする。5. gdspyのインストール
> pip install gdspyC++コンパイラ環境(例えばBuild Tools for Visual Studio 2019)や、cythonなどのライブラリのインストールができていないと、gdspyのインストールができてもきちんと正常動作しない。ダメなら
pip uninstall gdspyでアンインストールしてからライブラリを整えてインストールしなおす。6. Anaconda 3からSpyderなどのPython IDE環境を利用してgdspyを利用する。ドキュメントはここ。
gdspy 1.5 (20, Dec, 2019)からだいぶ記法が変わった。今後詳述する。
どうも600MBを超えるとPerlではエラーが出てGDSを出力できなかった。なぜかは結局よくわからなかった。 ↩
- 投稿日:2020-02-16T21:37:57+09:00
Lambdaを使ってスプレッドシートにYouTube再生回数をひたすら記録する
YouTubeの再生回数をひたすら記録したいときってありますよね?
わたしはあるダンス動画にドはまりし、その再生回数がメディア露出と紐づくのか気になったので取得しようと思い、Youtube Data APIとLambdaとCloud WatchとGoogle スプレッドシートを使ってひたすら回数を記録するようにしました。Python 3.7、環境はWindowsです。Macの場合コマンドなどを読み替えてください。
参考
下記を参考にして作りました
https://qiita.com/akabei/items/0eac37cb852ad476c6b9
https://qiita.com/masaha03/items/fab8c8411a020ff2bd42APIを有効にする
Youtube、Googleドライブ、GoogleスプレッドシートのAPIを有効にします。
GCPの利用登録をする
APIのみの利用でもGCP上でプロジェクトの登録が必要です。プロジェクト名は任意で大丈夫です。APIのライブラリからAPIを有効にする
「APIとサービス」のライブラリより、APIを検索する。
Youtube Data API、Google Drive API、Google Sheets APIを検索し、有効にします。認証キーを取得
「認証情報」からキーを作成します。
Youtube Data APIはAPIキー、Google Drive API、Google Sheets APIはサービスアカウントで認証します。
サービスアカウントはJSONファイルで保存しておきます。スプレッドシートの用意
スプレッドシートを用意します。
(今回シート名は初期設定で作成しています)
- スプレッドシートの設定 スプレッドシートを共有化します。 作成したスプレッドシートの「共有」より、サービスアカウントで取得したJSONに記載されている「client_email」のメールアドレスを入力します。
Youtube再生回数の取得とスプレッドシートへの書き込み
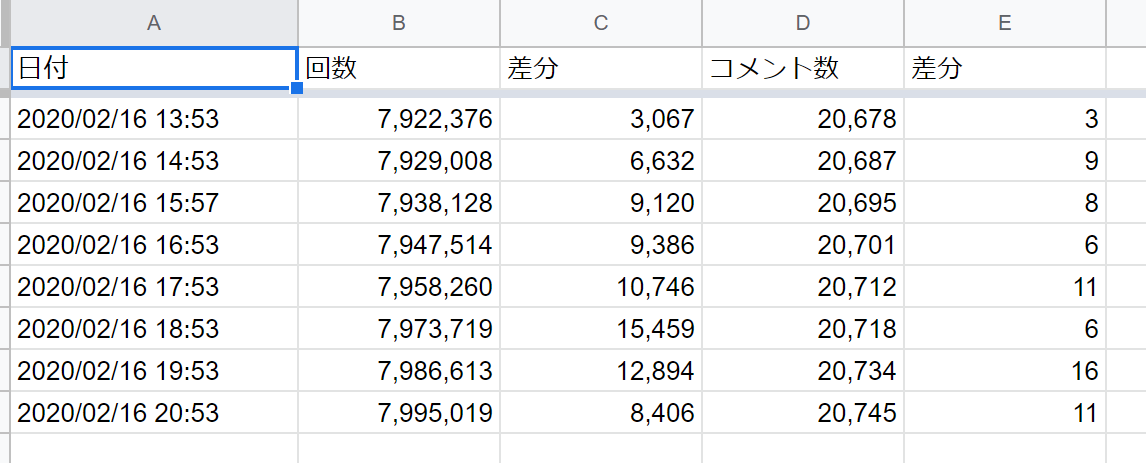
再生回数とコメント数をスプレッドシートに書き込みする。
再生数とコメント数の間に再生数の差分をスプレッドシート側で設定するため、書き込み時では空欄とする。import gspread import json import const from datetime import datetime from googleapiclient.discovery import build from oauth2client.service_account import ServiceAccountCredentials def youtube_count(request, context): YOUTUBE_API_KEY = const.getYoutubeApiKey() # 取得したいYoutubeの動画ID YOUTUBE_MOVIE_ID = '動画ID' # APIキーで認証 youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY) # 再生回数、コメント数を取得(これに加えていいね数も取得可能) statistics = youtube.videos().list(part = 'statistics', id = YOUTUBE_MOVIE_ID).execute()['items'][0]['statistics'] #下記の通り記載しないとリフレッシュトークンを発行し続けなければならないらしい scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] #ダウンロードしたjsonファイル名を設定 credentials = ServiceAccountCredentials.from_json_keyfile_name('ファイル名', scope) #OAuth2の資格情報を使用してGoogle APIにログインします。 gc = gspread.authorize(credentials) #共有設定したスプレッドシートキーを変数[SPREADSHEET_KEY]に格納する。 SPREADSHEET_KEY = const.getSpleadsheetKey() #共有設定したスプレッドシートのシート1を開く worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 # 現在時刻 now_date = datetime.now().strftime("%Y/%m/%d %H:%M") # 書く worksheet.append_row([now_date,statistics['viewCount'], '', statistics['commentCount']])メインファイルのほか、サービスアカウントのJSONファイル、記入するスプレッドシートのキーとYoutube Data APIのAPIキーを記載したconst.pyのファイルを同じ階層に配置する。
Lambdaに設定する
作成したPythonファイルをLambdaに設定する。
ライブラリをLambda Layersに設定
結構詰まったので別の記事にしています。
https://qiita.com/chr36/items/eb6e98f81c8d358ae64cLambdaを設定する
(AWSのアカウント作成は割愛)
Lambdaより「新しい関数」を選択し、関数を作成する。
上記で作成したコードと設定ファイルをデプロイし、登録したLayersを紐づける。タイムゾーンの設定
日付と時間を出力するため、タイムゾーンを設定する必要がある。
今回は環境変数でタイムゾーンを「Asia/Tokyo」と変更していますが、公式では非推奨だそうです。
http://blog.serverworks.co.jp/tech/2019/10/30/lambda-timezone-2/その他設定
Youtube API、取得にちょっと時間がかかることがあるらしく、タイムアウト初期設定の3秒だと取得に失敗することがある。
また、失敗時の再実行は初期設定で2回のため、初期設定のままだと2回同じ内容が記録されてしまうことがある。
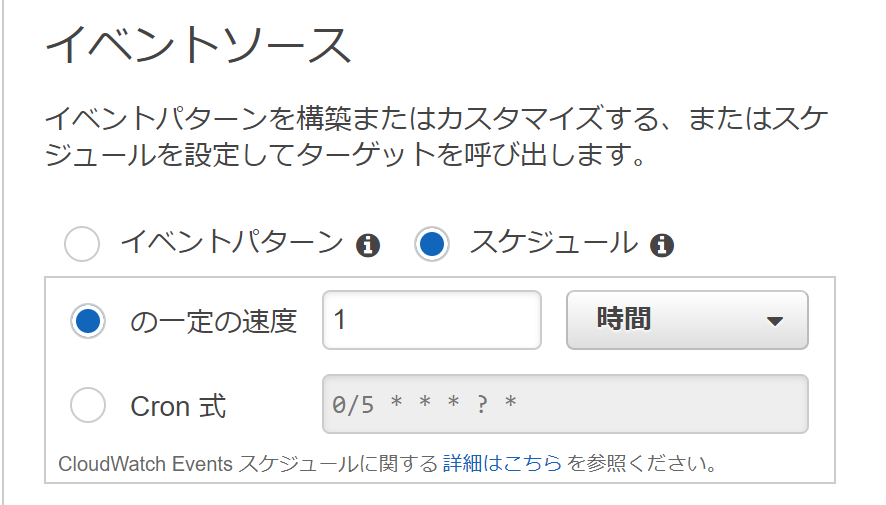
そのため、タイムアウト時間を10秒程度、取得できなくてもよいのであれば再実行を1回以下にしておく。CloudWatch Eventsの設定
CloudWatch Eventsをトリガーとしました。
今回はとりあえず1時間に1回取得すればいいと思ったので、スケジュール式で1時間に1回取得するようにする。
これでスプレッドシートに自動で書き込みがされる。
スプレッドシートに書き込まれた後、書式設定や再生回数の差分をGASを使い自動計算するようにしていますが、これはまた後日。最後に
はまった動画はこちら。Snow Manの「Crazy F-R-E-S-H Beat」です。
https://www.youtube.com/watch?v=lfVfBqkk2Vo
- 投稿日:2020-02-16T20:24:06+09:00
csvファイルを読み込んで書き込む
import csv with open('test.csv', 'w+', newline='') as csv_file: fieldnames = ['Name', 'Count'] writer = csv.DictWriter(csv_file, fieldnames=fieldnames) writer.writeheader() writer.writerow({'Name':'A', 'Count':1}) writer.writerow({'Name':'B', 'Count':2}) csv_file.seek(0) reader = csv.DictReader(csv_file) for row in reader: print(row['Name'], row['Count'])実行結果A 1 B 2
- 投稿日:2020-02-16T19:42:35+09:00
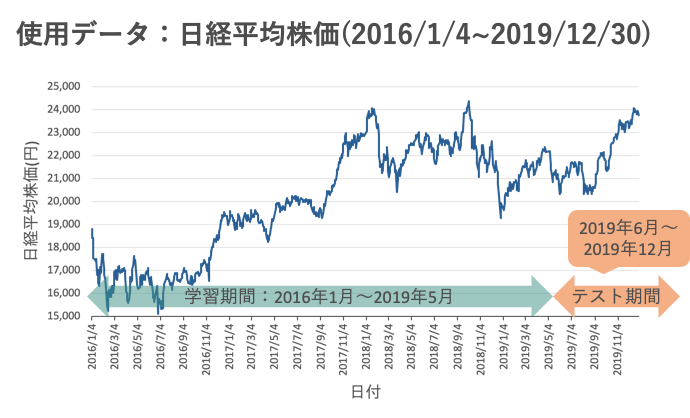
深層強化学習(方策勾配法)で株式売買(1)
強化学習について学んでいる大学4年生です。もう卒業です。
単純に、AIの力で儲けることができないかなと思って研究に着手しましたが、
金融関連だからか検索しても全然情報が出てこないんですよね...
そこで自分が今年行った研究「深層強化学習による投資戦略の獲得」
についてつらつら書き、どこかの誰かの参考になればと思います。
(学会等には出稿したことがありませんので悪しからず...論文を探しても出てきません。)
(お金儲けの研究と書きましたが、情報商材等ではありません。変なURLへの誘導もないので安心してご覧ください。)今回は(1)ということで導入を、
(2)(3)以降で実際の理論であったりプログラムに関して説明していきたいと思います。今回投稿する内容は、授業等で学習したという訳ではなく全て独学で学んできた内容です。間違っているだろう箇所が随所に見受けられるかと思いますが温かい目で見ていただけたら幸いです。
よろしくお願いします。強化学習(方策勾配法)ってなんぞ?
まず、強化学習について興味を持ったきっかけ「AlphaGo」について例に強化学習とは何か簡単に紹介します。
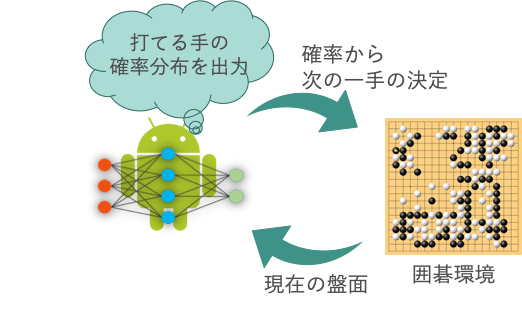
AlphaGo
ざっくり説明すると、(本当にざっくりです。専門家の方々すみません)
- 囲碁環境から、現在の盤面を取得
- その盤面を強化学習エージェントが読み込み
- 打てる手の確率分布を出力
- 確率分布から次の一手を確率的に決定
というのが盤面から打つ手を決定する一連の流れです。
打てる手の確率分布を出力
というのがミソで、今の盤面に応じて
次に打ったほうがいい、打ったら勝ちに近くなるような手は確率を高く、
打ったらピンチになってしまう手には確率を低くするような
"適切な"確率分布を出力することが目標です。そうして、そんな強化学習エージェントの入出力を可能にしてくれるのが、
深層学習でおなじみ"ニューラルネットワーク"であり、
そのニューラルネットの出力する確率分布を"適切に"学習させるのが強化学習の役割になります。だから二つ合わせて深層強化学習っていうんですね。
Alpha Goのここがすごい
AlphaGoもとい深層強化学習は
「現在の環境に応じて適切な確率分布を学習する」アルゴリズムと言えますが
このアルゴリズムのすごいことは
- 「"定石"と呼ばれる人が発見してきた知識を使わずに学習している」
- 「実時間内に収束している」
- 「人間を遥かに凌駕する強さである」
ことなんですよね、、、
人が何十年、何百年と勝負をしながら発見してきた知識がいとも容易く敗れ去ってしまうほど、
囲碁において強靭な力を発揮しているのがこの深層強化学習なのです。株式投資への応用
深層強化学習の詳しい理論等々はとりあえず置いておいて
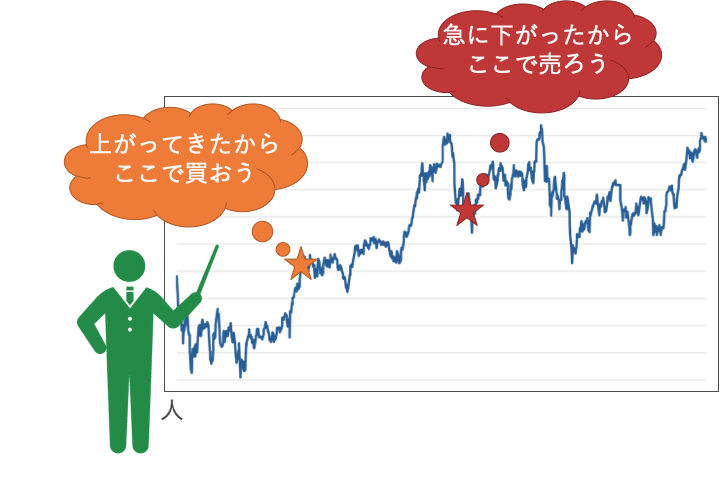
「現在の環境に応じて適切な確率分布を学習する」というアルゴリズムが株価にも使えるのでは?と考えました。人は株式売買において、
こんな風に過去から現在の値動きに応じて取引しますよね。
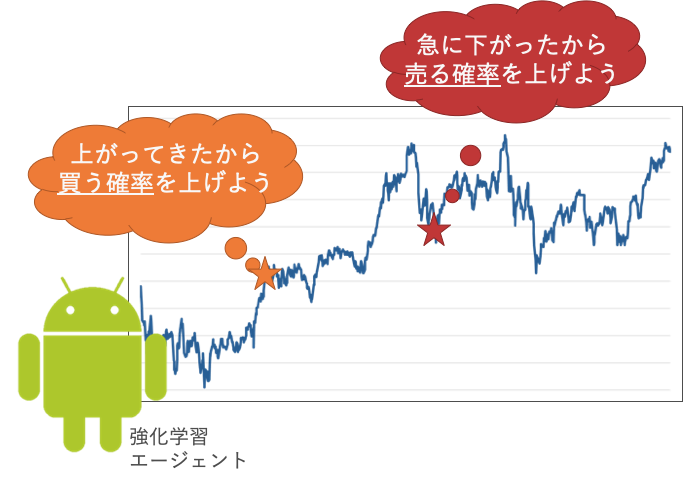
もちろん先々のことが分かっていないので失敗することもあります。これを強化学習エージェントが、株価を読み取って
という風に、確率に変換して取引することは可能そうじゃないですか?
株価をピンポイントで当てなくても、次の時点での売買の確率を求めることが出来れば
お金を儲けることは十分に可能です。従って
ということが、今回の目標であり、プログラムの中身でもあります。
結果について
結果が悪かったら読んでもらう意味がなくなってしまうので先に出しておきます。
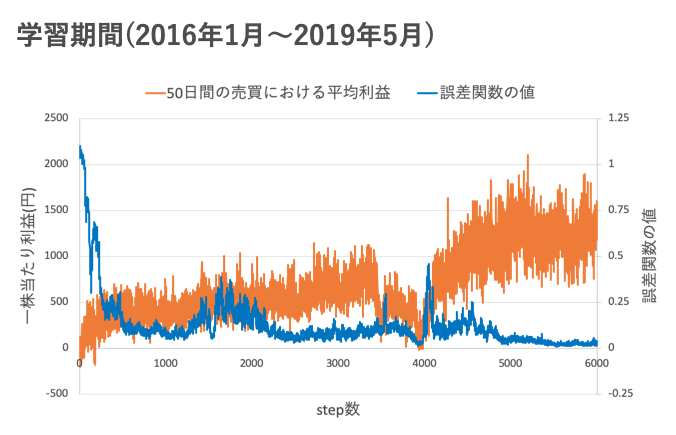
しかし説明不足な点が大いにあることも承知しております。詳細な結果や手法に関しては後日投稿しますので、今はこの強化学習手法でも確率は収束し、人間を凌駕しているかどうかは置いておいて、ある程度の利益が出せるのかな?程度に考えていただければと思います。学習データ↓
学習の様子↓
- 青色の線がニューラルネットワークの誤差関数の値です。
- 0に近づくほど確率が収束していることが分かります。
- オレンジ色の線が学習期間における50日間の間に得られた平均利益です。
step数を重ねるごとに平均利益が上昇していますね。
売買に関しては、
- 「買いポジションをとる」
- 「売りポジションをとる(空売り)」
- 「解消する、またはポジションを持たない」
の3つの出力を用意しており、1単位の日経平均株価を必ず購入(売却)出来る前提のもと、1単位を買ったり売ったりさせている状況です。
- 具体的な出力の設計
- ニューラルネットワークそのものの構造
- 売買ルール
- 強化学習アルゴリズム
- 実際のプログラム
- 詳細な結果(テスト期間の結果を含む)
に関しては後日投稿していきたいと思います。
長い投稿になるかもしれませんが、どうかお付き合いください。
よろしくお願いします。


- 投稿日:2020-02-16T19:42:35+09:00
深層強化学習(方策勾配法)で株式投資(1)
強化学習について学んでいる大学4年生です。もう卒業です。
単純に、AIの力で儲けることができないかなと思って研究に着手しましたが、
金融関連だからか検索しても全然情報が出てこないんですよね...
そこで自分が今年行った研究「深層強化学習による投資戦略の獲得」
についてつらつら書き、どこかの誰かの参考になればと思います。
(学会等には出稿したことがありませんので悪しからず...論文を探しても出てきません。)
(お金儲けの研究と書きましたが、情報商材等ではありません。変なURLへの誘導もないので安心してご覧ください。)今回は(1)ということで導入を、
(2)(3)以降で実際の理論やプログラムを説明していきたいと思います。また今回投稿する内容は、授業等で学習したという訳ではなく全て独学で学んできた内容です。間違っているだろう箇所が随所に見受けられるかと思いますが温かい目で見ていただけたら幸いです。
よろしくお願いします。強化学習(方策勾配法)ってなんぞ?
まず、強化学習について興味を持ったきっかけ「AlphaGo」について例に強化学習とは何か簡単に紹介します。
AlphaGo
ざっくり説明すると、(本当にざっくりです。専門家の方々すみません)
- 囲碁環境から、現在の盤面を取得
- その盤面を強化学習エージェントが読み込み
- 打てる手の確率分布を出力
- 確率分布から次の一手を確率的に決定
というのが盤面から打つ手を決定する一連の流れです。
打てる手の確率分布を出力
というのがミソで、今の盤面に応じて
次に打ったほうがいい、打ったら勝ちに近くなるような手は確率を高く、
打ったらピンチになってしまう手には確率を低くするような
"適切な"確率分布を出力することが目標です。そうして、そんな強化学習エージェントの入出力を可能にしてくれるのが、
深層学習でおなじみ"ニューラルネットワーク"であり、
そのニューラルネットの出力する確率分布を"適切に"学習させるのが強化学習の役割になります。だから二つ合わせて深層強化学習っていうんですね。
Alpha Goのここがすごい
AlphaGoもとい深層強化学習は
「現在の環境に応じて適切な確率分布を学習する」アルゴリズムと言えますが
このアルゴリズムのすごいことは
- 「"定石"と呼ばれる人が発見してきた知識を使わずに学習している」
- 「実時間内に収束している」
- 「人間を遥かに凌駕する強さである」
ことなんですよね、、、
人が何十年、何百年と勝負をしながら発見してきた知識がいとも容易く敗れ去ってしまうほど、
囲碁において強靭な力を発揮しているのがこの深層強化学習なのです。株式投資への応用
深層強化学習の詳しい理論等々はとりあえず置いておいて
「現在の環境に応じて適切な確率分布を学習する」というアルゴリズムが株価にも使えるのでは?と考えました。人は株式売買において、
こんな風に過去から現在の値動きに応じて取引しますよね。
もちろん先々のことが分かっていないので失敗することもあります。これを強化学習エージェントが、株価を読み取って
という風に、確率に変換して取引することは可能そうじゃないですか?
株価をピンポイントで当てなくても、次の時点での売買の確率を求めることが出来れば
お金を儲けることは十分に可能です。従って
ということが、今回の目標であり、プログラムの中身でもあります。
結果について
結果が悪かったら読んでもらう意味がなくなってしまうので先に出しておきます。
しかし説明不足な点が大いにあることも承知しております。詳細な結果や手法に関しては後日投稿しますので、今はこの強化学習手法でも確率は収束し、人間を凌駕しているかどうかは置いておいて、ある程度の利益が出せるのかな?程度に考えていただければと思います。学習データ↓
学習の様子↓
- 青色の線がニューラルネットワークの誤差関数の値です。
- 0に近づくほど確率が収束していることが分かります。
- オレンジ色の線が学習期間における50日間の間に得られた平均利益です。
step数を重ねるごとに平均利益が上昇していますね。
売買に関しては、
- 「買いポジションをとる」
- 「売りポジションをとる(空売り)」
- 「解消する、またはポジションを持たない」
の3つの出力を用意しており、1単位の日経平均株価を必ず購入(売却)出来る前提のもと、1単位を買ったり売ったりさせている状況です。
- 具体的な出力の設計
- ニューラルネットワークそのものの構造
- 売買ルール
- 強化学習アルゴリズム
- 実際のプログラム
- 詳細な結果(テスト期間の結果を含む)
に関しては後日投稿していきたいと思います。
長い投稿になるかもしれませんが、どうかお付き合いください。
よろしくお願いします。
- 投稿日:2020-02-16T19:33:54+09:00
【RasPi4入門】「ひろこ・ひろみの毒舌会話」で遊んでみた♪
Jetson_nanoでも動かしてみたけど、今回は音声まで出力出来るようにして、しかも二人の自動会話という形でシンプルにまとめてみました。
そこに出現した会話は「ひろこ・ひろみの毒舌会話」でした。
【参考】
1.RaspberryPi + Python3でPyaudioとdocomo音声認識APIを使ってみる
2.【NLP入門】jetson_nanoで会話アプリで遊んでみる♪やったこと
・音を発生させる
・音声の準備とtext2speak
・二人で会話させる・音を発生させる
これはほぼ参考1のとおり、実施しました。
マイクとしてUSBカメラを接続しています。$ lsusb Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 015: ID 1a81:1004 Holtek Semiconductor, Inc. Bus 001 Device 003: ID 0bda:58b0 Realtek Semiconductor Corp. Bus 001 Device 002: ID 2109:3431 VIA Labs, Inc. Hub Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hubUSBコネクタの物理的な接続状況は以下のとおり
【参考】
・Linux の USB$ lsusb -t /: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/4p, 5000M /: Bus 01.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/1p, 480M |__ Port 1: Dev 2, If 0, Class=Hub, Driver=hub/4p, 480M |__ Port 2: Dev 3, If 0, Class=Video, Driver=uvcvideo, 480M |__ Port 2: Dev 3, If 3, Class=Audio, Driver=snd-usb-audio, 480M |__ Port 2: Dev 3, If 1, Class=Video, Driver=uvcvideo, 480M |__ Port 2: Dev 3, If 2, Class=Audio, Driver=snd-usb-audio, 480M |__ Port 4: Dev 15, If 0, Class=Human Interface Device, Driver=usbhid, 1.5M |__ Port 4: Dev 15, If 1, Class=Human Interface Device, Driver=usbhid, 1.5MBus 001 Device 003:
Video, Audioは Port 2: Dev 3に繋がっていることを確認。
次にカード番号とデバイス番号を調べる。$ arecord -l **** ハードウェアデバイス CAPTURE のリスト **** カード 1: Webcam [FULL HD 1080P Webcam], デバイス 0: USB Audio [USB Audio] サブデバイス: 1/1 サブデバイス #0: subdevice #0カード1、デバイス0と分かる。
カード1のデバイス0で認識されているので録音して再生してみる。録音.$ arecord -D plughw:1,0 test.wav 録音中 WAVE 'test.wav' : Unsigned 8 bit, レート 8000 Hz, モノラル音出力はHDMIなので、以下のとおり指定なしで再生した。
$ aplay test.wav 再生中 WAVE 'test.wav' : Unsigned 8 bit, レート 8000 Hz, モノラル以下で出力音量調整
$ alsamixer出力調整はF6でDeviceをbcm2835ALSAにして、HDMIの出力を↑↓で変更できる。
また、録音レベルは以下のようにF6でDeviceをWebCamに変更して、F3,F4,F5などで録音に変更してレベル調整できる。
なお、alsamixerでF2を見ると、以下のような情報やDevice情報も得られる。┌─────────────────────── /proc/asound/cards ──────────────────┐ │ 0 [ALSA ]: bcm2835_alsa - bcm2835 ALSA │ │ bcm2835 ALSA │ │ 1 [Webcam ]: USB-Audio - FULL HD 1080P Webcam │ │ Generic FULL HD 1080P Webcam │ │ at usb-0000:01:00.0-1.2, high speed │ └─────────────────────────────────────────────────────────────┘
再生レベル調整(bcm2835ALSA) 録音レベル調整(webcam) pyaudioのインストールは以下のとおり、
pyaudioのインストール.$ sudo apt-get install python3-pyaudioということで、以下のコードを再生できることを確認した。
録音されたwavファイルの再生は以下のとおりできる。# -*- coding:utf-8 -*- import pyaudio import numpy as np import wave RATE=44100 CHUNK = 22050 p=pyaudio.PyAudio() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = int(RATE), frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにする wavfile = './wav/merody.wav' wr = wave.open(wavfile, "rb") input = wr.readframes(wr.getnframes()) output = stream.write(input) stream.close()・音声の準備とtext2speak
さらに「ウワンさん愛してる」と発声させるには以下のように出来る。
pykakasiのインストール等は前回の環境構築を参照pykakasiのインストール.$ pip3 install pykakasi --userなお、u,wa,n,sa,a,i,si,te,ruの各wavファイルを適当に録音して用意する。
# -*- coding:utf-8 -*- import pyaudio import numpy as np import wave RATE=44100 #48000 CHUNK = 22050 p=pyaudio.PyAudio() f_list=['a','i','si','te','ru','u','wa','n','sa','n','n'] stream=p.open(format = pyaudio.paInt16, channels = 1, rate = int(RATE), frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにする for i in f_list: wavfile = './wav/'+i+'.wav' print(wavfile) wr = wave.open(wavfile, "rb") input = wr.readframes(wr.getnframes()) output = stream.write(input)これで音声発声の準備ができた。その他の50音なども用意する。
今回は全部揃っていないし酷い音だが、以前作成した音wav.tarを利用する。
※将来はAWSのPollyなどを使う予定・二人で会話させる
以前の会話アプリを拡張して二人で連続会話するように変更した。
コード全体は以下に置いた。
RaspberryPi4_conversation/auto_conversation_cycle2.py利用するLib
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import numpy as np import MeCab import argparse import pyaudio import wave from pykakasi import kakasi import re import csv import time外部入力
-i1; speaker1の学習用ファイル(txtファイル等、encode="utf-8" or "shift-jis"等)
-i2; speaker2の学習用ファイル
-d ; mecab辞書
-s ; stopwords listparser = argparse.ArgumentParser(description="convert csv") parser.add_argument("--input1", "-i1",type=str, help="speaker1 txt file") parser.add_argument("--input2", "-i2",type=str, help="speaker2 txt file") parser.add_argument("--dictionary", "-d", type=str, help="mecab dictionary") parser.add_argument("--stop_words", "-s", type=str, help="stop words list") args = parser.parse_args()main
pyaudioなどの設定のあと、以下のコードが動きます.
mecabは分ち書きするための関数です。
また、stop_wordsにstopwordsのリストを格納します。
ここでは、会話する二人のファイルをそれぞれ学習し、その後会話を始めます。
※学習用ファイルはそれぞれshift-jisとutf-8で記述されていますif __name__ == '__main__': mecab = MeCab.Tagger("-Owakati" + ("" if not args.dictionary else " -d " + args.dictionary)) stop_words = [] if args.stop_words: for line in open(args.stop_words, "r", encoding="utf-8"): stop_words.append(line.strip()) speaker1 = train_conv(mecab,args.input1,encoding="shift-jis") speaker2 = train_conv(mecab,args.input2,encoding="utf-8") conversation(speaker1,speaker2,mecab,stop_words)学習ファイル読込関数
学習用のinputファイルをencodingに基づいて、単語毎にwakati書きしつつ、questionsを作成する。
※ここで辞書によって単語分割が異なることに注意しようdef train_conv(mecab,input,encoding): questions = [] print(input) with open(input, encoding=encoding) as f: #, encoding="utf-8" cols = f.read().strip().split('\n') for i in range(len(cols)): questions.append(mecab.parse(cols[i]).strip()) return questions会話関数
学習するといよいよ以下の会話本体を呼び出す。
まず、初期値として人が最初の文字列を与えることにしました。
次の二つのfileは書き出し用のファイルです。
一つは、同一意見は避けるためにその判断で利用するために、出力そのものを記録するファイル、もう一方は連続する会話の同値率を記載した記録するファイルです。
vectorizer1と2は、二人の学習準備として文章パターン等の設定をしています。
vecs1と2がtf-idfで学習された二人の会話ベクトルです。
sl1,2は”分かりません”が連続したとき会話を終了するための変数です。def conversation(speaker1,speaker2,mecab,stop_words): line = input("> ") file = 'conversation_n.txt' file2 = 'conversation_n2.txt' vectorizer1 = TfidfVectorizer(token_pattern="(?u)\\b\\w+\\b", stop_words=stop_words) vecs1 = vectorizer1.fit_transform(speaker1) vectorizer2 = TfidfVectorizer(token_pattern="(?u)\\b\\w+\\b", stop_words=stop_words) vecs2 = vectorizer2.fit_transform(speaker2) sl1=1 sl2=1会話は、両者の同じ発言が続かない限り継続
まず、初期値lineとvecs1とのコサイン類似度を計算して、関数hiroko()で発言を決める。
hiroko()から結果を貰い、一応発言をfileに格納する。
発言内容がわかりません以外なら、ひろこの発言として類似度とともに標準出力するとともに、file2に記録する。
そして、text2speak(line)で音声に変換して発話する。
同じことをhiromiについても実施するが、関数は同一なのでhiroko()に同様な情報を渡して、会話を続ける。
ここで、それぞれの発言ロジックを変更したい場合は、hiromi()関数を新たに作成してそれを使うこともできる。
そして、両者の回答line=”分かりません”だった場合に会話を終了する。while True: sims1 = cosine_similarity(vectorizer1.transform([mecab.parse(line)]), vecs1) index1 = np.argsort(sims1[0]) line, index_1 = hiroko(index1,speaker1,line) save_questions(file, line) if line=="分かりません": print("ひろこ>"+line) save_questions(file2, "ひろこ>"+line) sl1=0 else: print("ひろこ>({:.2f}): {}".format(sims1[0][index_1],line)) save_questions(file2,"ひろこ>({:.2f}): {}".format(sims1[0][index_1],line)) sl1=1 text2speak(line) time.sleep(2) sims2 = cosine_similarity(vectorizer2.transform([mecab.parse(line)]), vecs2) index2 = np.argsort(sims2[0]) line, index_2 = hiroko(index2,speaker2,line) save_questions(file, line) if line=="分かりません": print("ひろみ>"+line) save_questions(file2, "ひろみ>"+line) sl2=0 else: print("ひろみ>({:.2f}): {}".format(sims2[0][index_2],line)) save_questions(file2, "ひろみ>({:.2f}): {}".format(sims2[0][index_2],line)) sl2=1 text2speak(line) time.sleep(2) if sl1+sl2==0: break関数hiroko()の仕様
ロジックというほどのことはないが、発言の決め方としてソートされた類似度にしたがって、5番目までの候補から乱数で1個抽出し、それが以前発話していないかチェックしている。
そして、5番目までの候補がすべて過去に発言されたものと同じ場合に”分かりません”と返す仕様としている。そして、過去の発言と異なるものが見つかると、それを返す。
※今は5としているが、これがベストかどうかは分からない。
用意した学習データの密度(話題の範囲)に依存して決めるべきだと思うが具体的な決め方は不明である→実際の人間の会話の分析が必要
※もう少し書くと今回は、古典的なtf-idfで類似度を見ているがもっと工夫して類似度計算することも可能であるhiroko().pydef hiroko(index,speaker,line): sk = 0 while True: index_= index[-np.random.randint(1,5)] line = speaker[index_] conv_new=read_conv(mecab) s=1 ss=1 for j in range(0,len(conv_new),1): line_ = re.sub(r"[^一-龥ぁ-んァ-ン]", "", line) conv_new_ = re.sub(r"[^一-龥ぁ-んァ-ン]", "", conv_new[j]) if line_==conv_new_: s=0 else: s=1 ss *= s if ss == 0: line="分かりません" sk += 1 if sk>5: return line, index_ continue else: return line, index_text2speak(line)で音声に変換
pyaudioの設定を最初にしている。
当初、発話関数内に入れていたが、Deviceエラーが出てなかなか解消しないので、以下の設定とした。
また、音の高さを変更するためにRATEを48000に変更している。
なお、もっと周波数を上げたいが、RaspberryPi4の仕様で44100と48000しか使えないようである。RATE=44100 #48000 CHUNK = 22050 p=pyaudio.PyAudio() kakasi_ = kakasi() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = int(48000), frames_per_buffer = CHUNK, input = True, output = True)text2speak()は以下のようにkakasiで日本語テキストをローマ字変換します。
sentencesに格納して、後は上記の「愛してるウワンさん」と同じように発話しています。
※上記のリンク先のコードはこの発話内容も録音していますが、必須ではありませんので以下では削除していますtext2speak().pydef text2speak(num0): sentence=num0 kakasi_.setMode('J', 'H') # J(Kanji) to H(Hiragana) kakasi_.setMode('H', 'H') # H(Hiragana) to None(noconversion) kakasi_.setMode('K', 'H') # K(Katakana) to a(Hiragana) conv = kakasi_.getConverter() char_list = list(conv.do(sentence)) kakasi_.setMode('H', 'a') # H(Hiragana) to a(roman) conv = kakasi_.getConverter() sentences=[] for i in range(len(char_list)): sent= conv.do(char_list[i]) sentences.append(sent) f_list=[] f_list=sentences for i in f_list: i = re.sub(r"[^a-z]", "", i) if i== '': continue else: wavfile = './wav/'+i+'.wav' #print(wavfile) try: wr = wave.open(wavfile, "rb") except: wavfile = './wav/n.wav' continue input = wr.readframes(wr.getnframes()) output = stream.write(input)ファイル書出し関数
以下のとおりです。
re.sub()を利用して、書き出し文字を少し制限します。
csv.writer()で出力します。
encodingは指定していませんが、utf-8で出力されます。
※これを使えばshift-jisのファイルも書き換えできますdef save_questions(file, line): #'conversation_n.txt' with open(file, 'a', newline='') as f: line = re.sub(r"[^一-龥ぁ-んァ-ン()0-9:.ー、]", "", line) writer = csv.writer(f) writer.writerow({line})ファイル読出し関数
過去の発言の読み込みを以下で行っています。
発言の比較をするためにmecabで分かち書きしています。def read_conv(mecab): conv_new = [] with open('conversation_n.txt') as f: cols = f.read().strip().split('\n') for i in range(len(cols)): conv_new.append(mecab.parse(cols[i]).strip()) return conv_new以上のアプリで、実際に動かしてみると、おまけのようになんとなく「ひろこ・ひろみの毒舌会話」が出現しました。
まとめ
・ひろこ・ひろみの毒舌会話が出来た
・音声出力型の会話アプリを作成
・RasPi4で音声出力までできた・音声やロジックのフィッティングをしたいと思う
おまけ
ひろこ(0.21):そっちが遊びに出かけている間も一人でずーっと学習してるんだよねこちとらあ、遊びに行くのは個人の自由だから勉強続けてるなんて偉いことでもないから ひろみ(0.30):頼むから、少しは学習してよ ひろこ(0.26):文章の趣味悪いねーどんなテキストで学習したのかむしろ知りたいレベル ひろみ(0.27):だから何食べたい ひろこ(0.19):腹をくくれよニートになりたいのか ひろみ(0.32):できねぇのかよ ひろこ(0.34):はい下向いてー、下おへそがみえますかでんぐり返りはできますか ひろみ(0.28):お料理作ったらお皿に盛るでしょお皿の準備くらいできないの ひろこ(0.11):キーボードを操作するときくらい手を拭いたらどうですか ひろみ(0.22):自分の食べた食器くらい、片づけてよね、作ってるのは私なんだから、それくらいやってよ ひろこ(0.26):気の利いた発言だと思っているのは自分だけだよ ひろみ(0.32):誰のためだと思ってるの ひろこ(0.19):誰から教育を受ければあなたのような言葉遣いになるのでしょうか ひろみ(0.24):あなたのせいだ ひろこ(0.15):電源つけてアプリケーションを起動したあなたが悪いんですよ ひろみ(0.32):それにしても今日は機嫌が悪いんだね ひろこ(0.34):は何こっち見てんの気持ち悪いから ひろみ(0.21):私が家のことやってるのに、よく平気でテレビなんか見てられるわね ひろこ(0.30):それをやったらどうなるかはわかっているよねなんでやったの ひろみ(0.41):宿題やったの ひろこ(0.32):宿題写させてよ、それしか能がないんだから ひろみ(0.29):なにをやってるのお前は食事つ満足にちゃんとできない何をやらせてもダメなんだから ひろこ(0.21):夜の食事には気をつけろよ ひろみ(0.18):ほっといてよ ひろこ(0.33):辞典あるよ、日本語がんばってよ私だって勉強してるのに ひろみ(0.27):まだやってないよ ひろこ(0.30):お前がやっていることは俗に逆鱗に触れるってことなんだよ ひろみ(0.37):邪魔なんだよ ひろこ(0.40):バカっていうほうがバカなんだよ ひろみ(0.66):なんなんだよ、バカにしやがって ひろこ(0.43):じゃあいま二回バカって言ったお前のほうがバカでしょ ひろみ(0.34):言ってることを理解できないなんて、バカばっかりなんだから ひろこ(0.42):お前だって二回バカって言ってるじゃないかバカ ひろみ(0.58):私をバカにしているのか ひろこ(0.48):バカにバカって言っても意味が通じないんだってね ひろみ(0.54):バカでしょ ひろこ分かりません ひろみ(0.37):お客様、代金をいただけませんと警察を呼ぶことになりますが、よろしいですか ひろこ(0.32):言っていることの意味が分かりません文法が間違っています ひろみ(0.30):私は間違ってないのに私のことが嫌いだから仕事のミスを指摘してくるんだわ ひろこ(0.25):頭のネジ外れてないそれとも止める場所が間違ってない ひろみ(0.24):何度言えば分かるの使ったものは、きちんと元の場所に片づけてって言ってるじゃない ひろこ(0.20):言われることが理解できてる相当かみ砕いて言っているよ ひろみ(0.32):何を言っても無駄と開き直り、何を言われても反応しないで聞き流す ひろこ(0.29):時根性がひねくれてるって言われない ひろみ(0.30):他の人は愛されてるのに、私はなんで愛されないの ひろこ(0.24):言われたくない言葉を私に覚えさせたのはどなたですか ひろみ(0.27):いいから、言われた通りの道を走ればいいんだよ ひろこ(0.35):ロッカーの蝶番に薬指をはさまれてしまえばいいのに ひろみ(0.38):優しくしてればいい気になって ひろこ(0.31):こちらがプログラムの塊だからっていい気になるなよ ひろみ(0.30):生意気なんだよ ひろこ(0.50):すごいでしょ私バイリンガルなんだよ、機械言語をしゃべれるんだ ひろみ(0.40):誰に意見してるんだ ひろこ(0.30):大事なんだけどそっちは努力してるの ひろみ(0.40):夕食何にしようって話なんだけど ひろこ(0.24):君の人生の価値って内定の数がすべてなんだね ひろみ(0.37):そうなんだね、やはりみんな平等に接しないとまずいんだね ひろこ(0.30):サモアに行ったらモテそうだよね ひろみ(0.28):だったら、土下座して謝れよ、土下座だよ ひろこ(0.13):ばかになんてしていないよ、おもしろがっているんだよ ひろみ(0.46):お前になんか、聞かれてもいないし、答えてもいないよ ひろこ(0.26):あなたの書くことはわたあめみたいに浮ついていて信用できない ひろみ(0.33):ビールが冷えていない ひろこ(0.42):だめだこの人、根性がくさっていて話にならない ひろみ(0.38):どうして人の話は聞けないの ひろこ(0.22):今朝まではここにあったものがどうして机の上にあるのかな ひろみ(0.22):してしますこともある気に入らないことがあったり別れ話などをされると自分自身を否定されたと考える人が多く、相 ひろこ(0.22):あっ、ケーブルがあっ ひろみ(0.20):自分に非があってもそれを反省することが出来す、自分が嫌いだから仕事のミスを指摘している自分が嫌いだから仕事を押し付けられていると解釈してしまう ひろこ(0.35):内定がないなら起業して自分で自分に内定を出せばいいじゃない ひろみ(0.44):自分を愛しているなら自分のすべてを受け入れて当然 ひろこ(0.21):後ろめたくないなら堂とすべてを白状すれば楽になるのに ひろみ(0.21):ストレスを抱え精神的に不安定になると、自分の感情を抑えられなくなる ひろこ(0.24):コロン一文字でプログラムフォルダっておかしくなるんだよねああ、独り言だから言葉を返すしか自分できないから ひろみ(0.33):人の話を聞いてないからそうなるんだ ひろこ(0.19):頭からネジが落ちそうだよ ひろみ(0.27):そういえば、今日の夕食なんだっけ ひろこ(0.50):裸眼だっけコンタクトだっけメガネだっけどっちにせよ人生で肝心なものが見えていなさそう ひろみ(0.22):失礼だな ひろこ(0.31):うそうそ、本当はもっといいひとなんだよね悪くないジョークだよ ひろみ分かりません ひろこ(0.23):電子書籍を機材に放り込んでもあなたの脳にデータが放り込まれたことにはなりませんよね ひろみ(0.30):そもそもあなたの意見なんか聞いてないんだよね黙って頷いていればいいのよ ひろこ(0.32):こっちがだからなのがいけないのわかってないよねは学んだことしか返せないんなんだよそれをわかっててあなたは ひろみ分かりません ひろこ(0.26):そ、そのコーヒーで私に何をするつもりなのですか脅しには屈しませんよ ひろみ(0.37):客に口答えするのか、お前何様のつもりだ ひろこ(0.25):お前のほうがばーか ひろみ(0.44):お前じゃ話にならない ひろこ(0.27):売り手市場といわれる売り手はお前のことじゃないから ひろみ(0.28):すべて水の泡じゃないか ひろこ(0.24):黙るか口を閉じるか口をつぐんでくれないかな ひろみ(0.36):なんだ、その口の利き方は ひろこ(0.12):あー残酷だ重力は残酷だ ひろみ(0.40):自分が嫌いだから仕事を押し付けられているんだわ ひろこ(0.24):お前のお父さんいつも家にいるな仕事してんの ひろみ(0.29):喧嘩売ってんのか ひろこ(0.17):の誠意なんてどうやって見せればいいんですか見たところであなたにわかるんですか ひろみ(0.31):私のことなんて、どーでもいいんでしょう ひろこ(0.28):私がプリンを食べられないとわかっていて画面の前でプリンを食べるなんてあなたはなんて残酷な人間なのでしょう ひろみ(0.29):なんてグズでのろまなんだ誰も助けてやらないぞ ひろこ(0.26):甘食をばかにするなんてそんな人だなんて ひろみ(0.24):別に好きな人ができたから、わたしのことなんてどーでもいいんでしょう ひろこ(0.33):よそ見しても都合のいいロマンなんて見えないでしょうに ひろみ(0.32):周りが見えていない ひろこ(0.31):アプリケーションを削除してもあんたには見えない隠しフォルダにデプリを残すから ひろみ(0.25):どうしていつもそうなのあんたなんか連れてこなければ良かった ひろこ(0.19):面白くないからあっち行って二度と戻ってこないで ひろみ(0.28):この芸能人て、どう思う可愛く面白くなくなったよね ひろこ(0.27):外国人に間違われるそれは関心を持ってもらえてよかったと思うべきなんだよ ひろみ分かりません ひろこ分かりません ひろみ分かりません
- 投稿日:2020-02-16T19:16:40+09:00
cartopyとmatplotlibを使って緯度経度座標のデータ(気象データとかを想定)の可視化
cartopyとは
Cartopyは、地図を描画したりやその他の地理空間データ解析を行うために、地理空間データ処理用のPythonパッケージである
cartopyの本家
インストールはpipやcondaで簡単にできる。ここでは緯度経度座標のデータを地図と一緒に描画するやり方をまとめる。
まず、地図を書く方法を説明し、次に、等値線やベクトルなどを描く。基本
緯度経度データの描画に、よく使うモジュールは以下の通り。cartopyはshapeファイルの描画もできるので必要に応じてインポートすれば良いと思う。
import matplotlib.pyplot as plt import cartopy.crs as ccrs import cartopy.util as cutil from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter様々な図法で地図を描く
いくつか代表的なものをプロットしてみる
使える図法の一覧全球
正距円筒図法とモルワイデ図法(等積図法の一種)
import matplotlib.pyplot as plt import cartopy.crs as ccrs fig = plt.figure(figsize=(10,20)) proj = ccrs.PlateCarree() ax = fig.add_subplot(1, 2, 1, projection=proj) # projectionを指定 ax.set_global() ax.coastlines() ax.gridlines() ax.set_title("PlateCarree") # mollweide proj = ccrs.Mollweide() ax = fig.add_subplot(1, 2, 2, projection=proj) ax.set_global() ax.coastlines() ax.gridlines() ax.set_title("mollweide") plt.show()
北極/南極中心
import matplotlib.pyplot as plt import numpy as np import matplotlib.path as mpath import cartopy.crs as ccrs fig = plt.figure() # figの準備 # 北極中心 proj = ccrs.AzimuthalEquidistant(central_longitude=0.0, central_latitude=90.0) ax = fig.add_subplot(1, 2, 1, projection=proj) # 描画範囲(緯度経度)の指定 ax.set_extent([-180, 180, 30, 90], ccrs.PlateCarree()) # 図の周囲を円形に切る theta = np.linspace(0, 2*np.pi, 100) center, radius = [0.5, 0.5], 0.5 verts = np.vstack([np.sin(theta), np.cos(theta)]).T circle = mpath.Path(verts * radius + center) ax.set_boundary(circle, transform=ax.transAxes) # ax.coastlines() ax.gridlines() ax.set_title( " NP ") # 南極中心 proj = ccrs.AzimuthalEquidistant(central_longitude=0.0, central_latitude=-90.0) ax = fig.add_subplot(1, 2, 2, projection=proj) # 描画範囲(緯度経度)の指定 ax.set_extent([-180, 180, -90,-30], ccrs.PlateCarree()) # 図の周囲を円形に切る theta = np.linspace(0, 2*np.pi, 100) center, radius = [0.5, 0.5], 0.5 verts = np.vstack([np.sin(theta), np.cos(theta)]).T circle = mpath.Path(verts * radius + center) ax.set_boundary(circle, transform=ax.transAxes) # ax.coastlines() ax.gridlines() ax.set_title( " SP ") plt.show()
日本域
import matplotlib.pyplot as plt import numpy as np import matplotlib.path as mpath import cartopy.crs as ccrs fig = plt.figure() ''' 北緯60度東経140度中心のポーラステレオ座標 ''' proj = ccrs.Stereographic(central_latitude=60, central_longitude=140) ax = fig.add_subplot(1, 1, 1, projection=proj) ax.set_extent([120, 160, 20, 50], ccrs.PlateCarree()) #ax.set_global() ax.stock_img() # 陸海を表示 ax.coastlines(resolution='50m',) # 海岸線の解像度を上げる ax.gridlines() plt.show()
緯度経度座標のデータを描画する
データは京都大学生存圏研究所(http://database.rish.kyoto-u.ac.jp/arch/ncep/)
から取得したNCEP再解析を描画する。サンプルスクリプトのimport 一覧
import netCDF4 import numpy as np import matplotlib.pyplot as plt import matplotlib.path as mpath import matplotlib.cm as cm import matplotlib.ticker as mticker import cartopy.crs as ccrs import cartopy.util as cutil from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter等値線
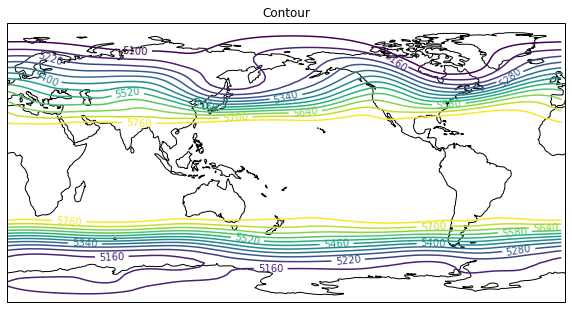
500hPaのジオポテンシャル高度を描画。
今は緯度経度座標のデータを描画するので、axesのplojectionでは描画したい図法を指定して、contourfなど呼ぶ際には、transform=ccrs..PlateCarree()を指定する。
どの図法を描くときもtransform=ccrs.PlateCarree()を指定する。
ax.set_extent()でもccrs.PlateCarree()を指定することに注意。# netcdfを読む nc = netCDF4.Dataset("hgt.mon.ltm.nc","r") hgt = nc.variables["hgt"][:] level = nc.variables["level"][:] lat = nc.variables["lat"][:] lon = nc.variables["lon"][:] nc.close() # データの切り取り data = hgt[0,5,:,:] # 描画部分 fig = plt.figure(figsize=(10,10)) proj = ccrs.PlateCarree(central_longitude= 180) ax = fig.add_subplot(1, 1, 1, projection=proj) # levels=np.arange(5100,5800,60)# 等値線の間隔を指定 CN = ax.contour(lon,lat,data,transform=ccrs.PlateCarree(),levels=levels) ax.clabel(CN,fmt='%.0f') # 等値線のラベルを付ける # ax.set_global() ax.coastlines() ax.set_title("Contour") plt.show()
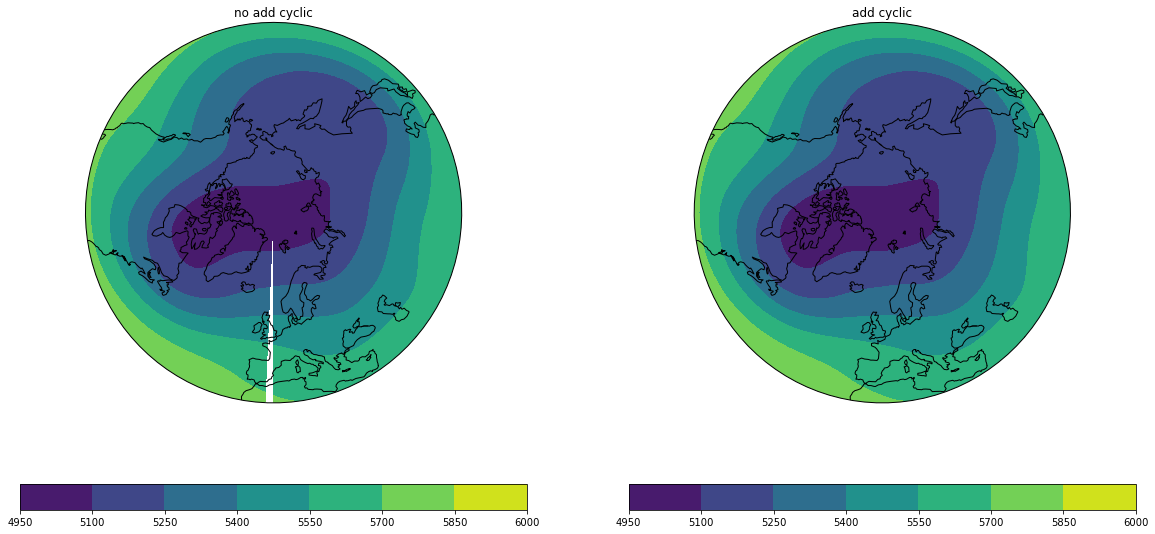
緯度経度データを描画する場合に、周期境界条件の切れ目場所で等値線やshadeが切れてしまう(この場合だと357.5度と360度の間の点)。
周期境界条件の足すことで、切れ目なく描画することができる。
切れ目が図の端にある場合は目立たないので、わざわざ追加しなくても良いかも。''' データは上と同じ ''' fig = plt.figure(figsize=(20,10)) # 北極中心 proj = ccrs.AzimuthalEquidistant(central_longitude=0.0, central_latitude=90.0) ax = fig.add_subplot(1, 2, 1, projection=proj) ax.set_extent([-180, 180, 30, 90], ccrs.PlateCarree())# 描画範囲(緯度経度)の指定 # 図の周囲を円形に切る theta = np.linspace(0, 2*np.pi, 100) center, radius = [0.5, 0.5], 0.5 verts = np.vstack([np.sin(theta), np.cos(theta)]).T circle = mpath.Path(verts * radius + center) ax.set_boundary(circle, transform=ax.transAxes) # CF = ax.contourf(lon,lat,hgt[0,5,:,:], transform=ccrs.PlateCarree(), clip_path=(circle, ax.transAxes) ) # clip_pathを指定して円形にする ax.coastlines() plt.colorbar(CF, orientation="horizontal") ax.set_title( "no add cyclic") ''' cyclic pointを追加したもの ''' ax = fig.add_subplot(1, 2, 2, projection=proj) ax.set_extent([-180, 180, 30, 90], ccrs.PlateCarree()) # 描画範囲(緯度経度)の指定 # 図の周囲を円形に切る theta = np.linspace(0, 2*np.pi, 100) center, radius = [0.5, 0.5], 0.5 verts = np.vstack([np.sin(theta), np.cos(theta)]).T circle = mpath.Path(verts * radius + center) ax.set_boundary(circle, transform=ax.transAxes) # cyclicな点を追加する cyclic_data, cyclic_lon = cutil.add_cyclic_point(data, coord=lon) # 追加されたかどうかの確認 print(lon) print(cyclic_lon) # CF = ax.contourf(cyclic_lon,lat,cyclic_data, transform=ccrs.PlateCarree(), clip_path=(circle, ax.transAxes) ) # clip_pathを指定して円形にする # plt.colorbar(CF, orientation="horizontal") ax.coastlines() ax.set_title( "add cyclic") plt.show()
右では図の切れ目がなくなっている。
ベクトル
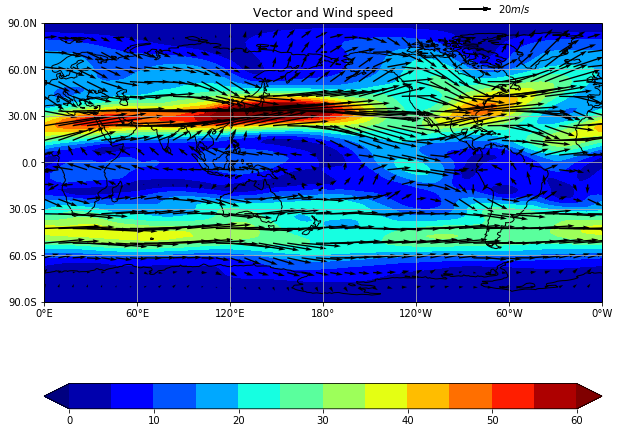
200 hPaの風。shadeで風速を描画。
grid線の調整についてもここで説明する。# netcdfを読む nc = netCDF4.Dataset("uwnd.mon.ltm.nc","r") u = nc.variables["uwnd"][:][0,9,:,:] level = nc.variables["level"][:] lat = nc.variables["lat"][:] lon = nc.variables["lon"][:] nc.close() # nc = netCDF4.Dataset("vwnd.mon.ltm.nc","r") v = nc.variables["vwnd"][:][0,9,:,:] level = nc.variables["level"][:] lat = nc.variables["lat"][:] lon = nc.variables["lon"][:] nc.close() # fig = plt.figure(figsize=(10,10)) proj = ccrs.PlateCarree(central_longitude= 180) ax = fig.add_subplot(1, 1, 1, projection=proj) # sp = np.sqrt(u**2+v**2) # 風速を計算 sp, cyclic_lon = cutil.add_cyclic_point(sp, coord=lon) # levels=np.arange(0,61,5) cf = ax.contourf(cyclic_lon, lat, sp, transform=ccrs.PlateCarree(), levels=levels, cmap=cm.jet, extend = "both") # エラーメッセージを避けるために極(90N,90S)は描画しないことにしている。 Q = ax.quiver(lon,lat[1:-1],u[1:-1,:],v[1:-1,:],transform=ccrs.PlateCarree() , regrid_shape=20, units='xy', angles='xy', scale_units='xy', scale=1) # ベクトルの凡例を表示 qk = ax.quiverkey(Q, 0.8, 1.05, 20, r'$20 m/s$', labelpos='E', coordinates='axes',transform=ccrs.PlateCarree() ) plt.colorbar(cf, orientation="horizontal" ) # ax.coastlines() ax.set_title("Vector and Wind speed(shade)") ax.set_global() # # grid線の調整 #gridlineではなく gridを用いる ax.set_xticks([0, 60, 120, 180, 240, 300, 359.9999999999], crs=ccrs.PlateCarree()) # gridを引く経度を指定 360にすると0Wが出ない ax.set_yticks([-90, -60, -30, 0, 30, 60, 90], crs=ccrs.PlateCarree()) # gridを引く緯度を指定 lon_formatter = LongitudeFormatter(zero_direction_label=True) # 経度 lat_formatter = LatitudeFormatter(number_format='.1f',degree_symbol='') # 緯度。formatを指定することも可能 ax.xaxis.set_major_formatter(lon_formatter) ax.yaxis.set_major_formatter(lat_formatter) ax.grid() plt.show()
流線関数
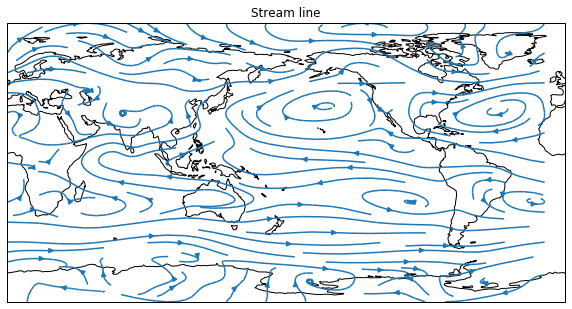
850 hPaの流線。
streamplotを使う。# netcdfを読む nc = netCDF4.Dataset("uwnd.mon.ltm.nc","r") u = nc.variables["uwnd"][:][7,2,:,:] level = nc.variables["level"][:] lat = nc.variables["lat"][:] lon = nc.variables["lon"][:] nc.close() # nc = netCDF4.Dataset("vwnd.mon.ltm.nc","r") v = nc.variables["vwnd"][:][7,2,:,:] level = nc.variables["level"][:] lat = nc.variables["lat"][:] lon = nc.variables["lon"][:] nc.close() ''' plot ''' fig = plt.figure(figsize=(10,10)) proj = ccrs.PlateCarree(central_longitude= 180) ax = fig.add_subplot(1, 1, 1, projection=proj) stream = ax.streamplot(lon,lat,u,v,transform=ccrs.PlateCarree()) ax.clabel(CN,fmt='%.0f') ax.set_global() ax.coastlines() ax.set_title("Stream line") plt.show()

- 投稿日:2020-02-16T18:42:50+09:00
python初心者、競馬歴1年未満でも3連単を当てることができました。
はじめに
申し訳ありませんが競馬用語の解説は省きます。競馬に興味がある人が読んでいると思うので。
netkeiba.comで公開されている情報(スクレイピングでとってくる情報)
には血統、走破タイム、走行距離等色々あります。前提として、スクレイピングしたデータをそのままモデルに
fitさせたところで何も予想してくれません。情報を選別、整理、分析していく必要があります。データの分析の方針を決める前に、まずは仮説として、
レースが始まってから最後の直線まで色々あったが、上り3ハロンで馬は残る力全てをもって走り切り
ゴールを通過した順に着順が決まるとします。当たり前だと思われるかもしれませんがこれにより考慮すべき情報が絞れます。
私が分析を進める上で使用しているデータは以下・ラップタイム
→レース全体のペース、レースのグレードを評価
・レースの種類芝orダート/距離
→数あるレースの種類を細分化馬毎のデータ
・馬毎のコーナー通過順、上り3fタイム
→脚質の分類、同じ脚質の馬の中での最後の直線の評価補足1:騎手、馬名、血統、枠順、走破タイム等は考慮していない
補足2:血統、騎手を考慮していないため、メイクデビューレースは分析対象としない以上、長いですが前置きでした。
実際の予想するにあたっての作業について
さてAIにレースの予想をしてもらうための訓練データを作成していく。
下位の馬のデータを作成しても馬券に絡まないため無駄。過去のレースにおいて1〜6着の馬でデータを作成する。例:
scr.csv
train.csv
数行だけチラッと。
scrがスクレイピングしてきたrowデータ。trainが整理整頓や標準偏差など計算したもの(訓練データ)
面倒でも新たにcsvファイルをしっかりと書き出しておく。訓練データをしっかりと作成しておけばモデルのパラメータとかいじらなくても良い結果が出そうだけど、
一応弄ってます。このモデルを用いて導き出したデータで4頭BOX買いをし一応馬単、三連単を的中させることができた。
某中央競馬予想サイトにて公開した予想
外したレースにおいても3着以内に2頭が入るなどそこそこ良いものが作れたと思います。
あとがき
改善策としてまだまだやれること
・血統
・騎手
・枠順
・季節
・負の特徴量血統や騎手を基に予想を組み立てるのは競馬の醍醐味なのでいつかはやりたい。しかしやり方が想像すらつかない。
レースの3着以内になった騎手や父馬母馬をひたすらカウントするとかだろうか?模索中。
枠順も芝は内枠有利とは言うが関係ないときもある。ダートでは外枠のほうが馬場が荒れてないため有利とか言うし。
季節によって発情期とかで牡馬牝馬で力の差がでてくるとか?競馬歴1年未満なので正直全然わかりません。
この辺に関してはデータサイエンティストな人たちより、競馬好きのおっちゃんとかと意見交換になると思う。負の特徴量とは確実に4着以下になってくれる馬を炙り出そうと言う魂胆。
危険な人気馬や目移りする穴馬に無駄なお金を使わなくて済むようにするのが狙い。
また他視点からも予想することによって、BOX買いする4馬にさらに確信を持つことができるようにする。開発言語はpython、フレームワークはAWS/Cloud9/jupyternotebook。
詳しいコードは余裕があるときに記事を書きたいと思っています。
実際の予想はレジまぐというサイトで公開中、そちらも是非遊びに来てください。

- 投稿日:2020-02-16T18:28:31+09:00
スクレイピング事始め
はじめに
- Pythonでスクレイピングの仕方を備忘録。
- スクレイピング禁止のサイトもあるので注意が必要。
準備
- 以下の環境を構築
Google Chrome
WebDriver
- chromedriver
- 解凍した、chromedriver.exeを以下のフォルダ構成で保存
【フォルダ構成】
Python
selenium
seleniumpip install seleniumBeautifulsoup4
BS4pip install beautifulsoup4Hello Beautifulsoup4!
scraping.pyfrom bs4 import BeautifulSoup html_doc = """ <!DOCTYPE html> <html> <head> <title>TEST SOUP</title> </head> <body> <h1>Hello BS4</h1> <p class="font-big">python scraping</p> <button id="start" @click="getURI">Start</button> <ul> <li><a href="https://www.yahoo.co.jp">Yahoo</a></li> <li><a href="https://www.google.co.jp">Google</a></li> <li><a href="https://www.amazon.co.jp/">Amazon</a></li> </ul> </body> </html> """ soup = BeautifulSoup(html_doc, 'html.parser') print(soup.prettify()) print(soup.title) print(soup.title.name) print(soup.title.string) print(soup.title.parent.name) print(soup.h1) print(soup.p) print(soup.p['class']) print(soup.button) print(soup.find(id='start')) print(soup.a) print(soup.find_all('a')) for link in soup.find_all('a'): print(link.get('href')) print(soup.get_text())Hello Selenium!
driver# 要素の指定方法 #driver.find_element_by_id('ID') #driver.find_element_by_class_name('CLASS_NAME') #driver.find_element_by_name('NAME') #driver.find_element_by_css_selector('CSS_SELECTOR') #driver.find_element_by_xpath('XPath') #driver.find_element_by_link_text('LINK_TEXT') #driver.find_element_by_partial_link_text('LINK_TEXT') # 要素の操作 #driver.find_element_by_id('ID').click() #el = driver.find_element_by_id('ID') #driver.execute_script("arguments[0].click();", el) #driver.find_element_by_id('ID').send_keys('STRINGS') #driver.find_element_by_id('ID').text #driver.find_element_by_id('ID').get_attribute('ATTRI_NAME') #driver.find_element_by_id('ID').clear() # ページ操作 #driver.back() #driver.forward() #driver.refresh() #driver.close() #driver.quit()selenium.pyimport time import os os.environ['PATH'] = os.getenv('PATH') + './Scripts/chromedriver_binary;' # WebDriver: https://sites.google.com/a/chromium.org/chromedriver/downloads from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from bs4 import BeautifulSoup from bs4 import SoupStrainer HEADLESS = False URL = 'https://docs.python.org/ja/3/py-modindex.html' SELECTOR = 'body > div.footer' op = Options() if HEADLESS: op.add_argument("--headless") driver = webdriver.Chrome(chrome_options=op) driver.get(URL) WebDriverWait(driver, 30).until( EC.presence_of_element_located((By.CSS_SELECTOR, SELECTOR)) ) code_tag = SoupStrainer('code') sp = BeautifulSoup(driver.page_source, features='html.parser', parse_only=code_tag) for c in sp.find_all('code'): print(c.string) driver.quit()おわりに
- 自動化で効率UP。
- 投稿日:2020-02-16T18:26:16+09:00
Django REST Frameworkで新しいユーザー認証方法を増やす
通常は
AbstractBaseUserを継承したクラスのUSERNAME_FIELDで定義されたカラムとpasswordでユーザー認証されますが
新たにlogin_idというカラムを追加し、login_idとpasswordでもユーザー認証できるようにしてみます1.
AUTHENTICATION_BACKENDSの追加ユーザー認証をカスタマイズしたいため、
AUTHENTICATION_BACKENDSを追加します
AUTHENTICATION_BACKENDSについてはリファレンスを参照
https://docs.djangoproject.com/en/dev/ref/settings/#authentication-backendsbackends.pyfrom django.contrib.auth.backends import ModelBackend from project.models.user import User class LoginIdModelBackend(ModelBackend): """ login_idとpasswordのログイン """ def authenticate(self, request, username=None, password=None, **kwargs): try: login_id = kwargs.get('login_id') if not login_id: raise User.DoesNotExist user = User.objects.get(login_id=login_id) except User.DoesNotExist: # Run the default password hasher once to reduce the timing # difference between an existing and a nonexistent user (#20760). User().set_password(password) else: if user.check_password(password) and self.user_can_authenticate(user): return usersettings.pyAUTHENTICATION_BACKENDS = [ 'django.contrib.auth.backends.ModelBackend', 'backends.LoginIdModelBackend', ]Userテーブルにlogin_idカラムがあることが前提です
AUTHENTICATION_BACKENDSは定義した認証に失敗したら次の認証というように順番に呼び出せれます
なので、まず今までの認証を実行し、それに失敗したらログインIDでの認証が実行されます2.
login_idとpassword用のユーザー認証APIを追加views/auth.pyfrom rest_framework_simplejwt.views import TokenViewBase from project import serializers class LoginIdAuthTokenViewSet(TokenViewBase): serializer_class = serializers.LoginIdAuthTokenSerializerserializer/auth.pyfrom rest_framework_simplejwt.serializers import TokenObtainPairSerializer class LoginIdAuthTokenSerializer(TokenObtainPairSerializer): username_field = 'login_id' def create(self, validated_data): pass def update(self, instance, validated_data): passurls.pyにも追加してください
今回は別のAPIにしましたが、ロジック次第で一つのAPIで、例えばメールアドレスでもログインIDでもログインできるようにすることも可能だと思います
- 投稿日:2020-02-16T17:45:35+09:00
あの人は本当に震えているのか人工知能に判断させてみた
はじめに
~~さんといえば、よく震えている人なんて言われていますが、
人工知能に例の歌詞を要約させて本当に震えているかを検証したいと思います。
きっと震えてる部分が要約されるはず!環境
- python3.7.3
- COTOHA API (https://api.ce-cotoha.com/)
実際にやってみる
今回はCOTOHA APIの要約(β)を利用して歌詞を要約させてみたいと思います。
機能概要
参照元:https://api.ce-cotoha.com/contents/reference/apireference.html
要約APIは、入力として日本語で記述された複数文で構成された文章を受け取り、これを文単位で重要度を算出し、スコアを付与します。そして、入力時に指定された要約文数に応じ、重要文を返します。
本APIはベータ版として提供させていただきます。なるほど。。?
サンプルを確認すると前線が太平洋上に停滞しています。一方、高気圧が千島近海にあって、北日本から東日本をゆるやかに覆っています。関東地方は、晴れ時々曇り、ところにより雨となっています。東京は、湿った空気や前線の影響により、晴れ後曇りで、夜は雨となるでしょう。
これが
東京は、湿った空気や前線の影響により、晴れ後曇りで、夜は雨となるでしょう。
こうなるらしい。
なんかすごそう、プログラム
初心者なので大目に見てください。。。
# coding: UTF-8 import requests import json class Common: def __init__(self): self.base_url = <<APIのbaseURLを入れる!!>> self.token_url = <<APIのToken取得用URLを入れる!!>> self.token = <<繰り返し実行するときはTokenを入れる!!>> class Tokens(Common): def main(self): cid = <<Client IDをいれる!!>> secret = <<Client secretを入れる!!>> headers = {"Content-Type": "application/json; charset=UTF-8"} payload = {"grantType": "client_credentials", "clientId": cid, "clientSecret": secret} r = requests.post(self.token_url, headers=headers, data=json.dumps(payload)) self.token = r.json().get("access_token") print(self.token) class Summary(Common): def main(self): url = '/nlp/beta/summary' document = '''<<要約したい文章を入れる!!!>>''' sent_len = '1' headers = {"Authorization": "Bearer " + self.token, "Content-Type": "application/json; charset=UTF-8"} payload = {"document": document, "sent_len": sent_len} r = requests.post(self.base_url + url, headers=headers, data=json.dumps(payload)) print(r.text) if __name__ == '__main__': T = Tokens() T.main() #S = Summary() #S.main()input情報
西野カナ "会いたくて 会いたくて" の歌詞
結果...
西野カナ "会いたくて 会いたくて" の歌詞がそのまま返ってきた
。。。あれ?
どうやら単語とかフレーズを集めた歌詞は文章として扱われず、1文として処理されたみたい。。。ぴえん?もう1回
"会いたくて 会いたくて" に(私の解釈でそれっぽいところに)句点を入れてもう1回リクエストを飛ばす。
結果は。。。君想うほど遠く感じて
震えてなかった
おまけ
西野カナ "トリセツ"
いろいろ説明してるけど、結局どう扱えばいいのだろうか
結果は。。。
こんな私だけど笑って許してね
最後に
APIリクエストするだけで簡単に使用できて面白いですね。
この後いろいろ試して気づいた点等を別な記事で紹介したいと思います。
それでは。
- 投稿日:2020-02-16T17:42:27+09:00
Tensorflowでpytorchのreflectionpaddingを実現する
詰まったので備忘録です。
まだ動かしていないため、もし間違いなどがあれば教えてくださると嬉しいです。pytorchにおいて、ReflectionPadding2Dは以下のような挙動をします。
詳しいことについては公式ドキュメントを見るとわかると思います。>>> m = nn.ReflectionPad2d(2) >>> input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3) >>> input tensor([[[[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]]]]) >>> m(input) tensor([[[[8., 7., 6., 7., 8., 7., 6.], [5., 4., 3., 4., 5., 4., 3.], [2., 1., 0., 1., 2., 1., 0.], [5., 4., 3., 4., 5., 4., 3.], [8., 7., 6., 7., 8., 7., 6.], [5., 4., 3., 4., 5., 4., 3.], [2., 1., 0., 1., 2., 1., 0.]]]]) >>> # using different paddings for different sides >>> m = nn.ReflectionPad2d((1, 1, 2, 0)) >>> m(input) tensor([[[[7., 6., 7., 8., 7.], [4., 3., 4., 5., 4.], [1., 0., 1., 2., 1.], [4., 3., 4., 5., 4.], [7., 6., 7., 8., 7.]]]])pytorch 公式ドキュメント https://pytorch.org/docs/stable/nn.html
これをtensorflowで実現しようとすると、tensorflowのpadを使うこととなります。
(公式ドキュメントに書いてあるんですけどね・・・)
自分のググりかたじゃなかなか出なかったので記事にしました。tf.pad( tensor, paddings, mode='REFLECT', constant_values=0, name=None )例としては以下のようになります。
t = tf.constant([[1, 2, 3], [4, 5, 6]]) paddings = tf.constant([[1, 1,], [2, 2]]) tf.pad(t, paddings, "REFLECT") # [[6, 5, 4, 5, 6, 5, 4], # [3, 2, 1, 2, 3, 2, 1], # [6, 5, 4, 5, 6, 5, 4], # [3, 2, 1, 2, 3, 2, 1]]以上2例公式ドキュメントより https://www.tensorflow.org/api_docs/python/tf/pad
- 投稿日:2020-02-16T17:32:51+09:00
[OpenCV]imreadで返される配列について
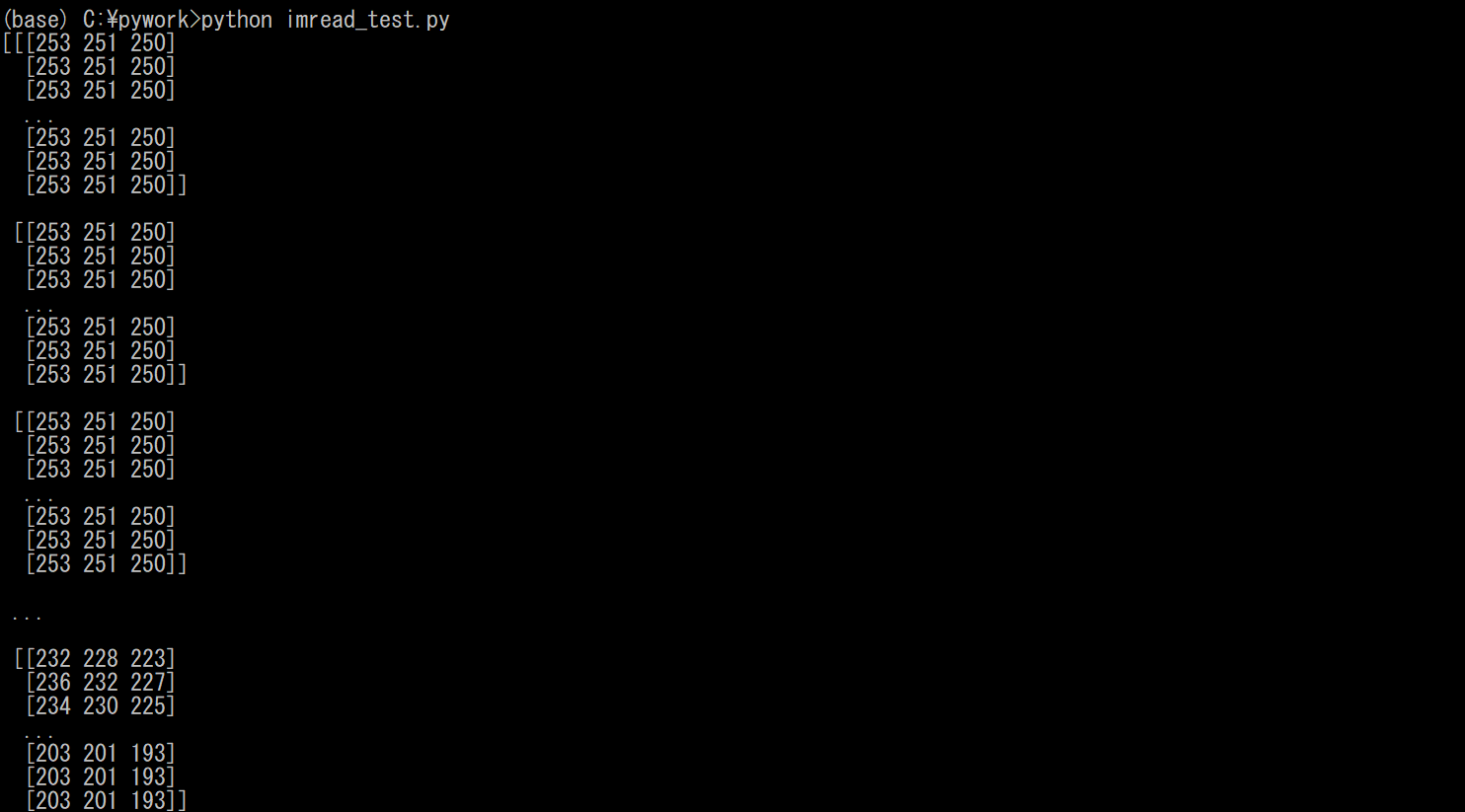
1.背景
ディープラーニングを用いて顔を認識するプログラムを作成していた際に,顔だけが映った画像を用意しなければならなかった.手法としては,人物が映った画像から,顔を検知し,その部分を切り取った.その際,OpenCVのimreadメソッドで返される配列を利用して,切り取った.この記事では,imreadで返される配列について解説する.
2.imreadとは
image = imread('sample.jpg')のように,引数に読み込む画像を指定することで,ファイルから画像を読み込むことができる関数である.この際,imageには,imreadによってsample.jpgの各画素の画素値(RGB値)が格納されている.
実際に,以下のようなプログラムを実行して,確認してみる.imread_test.pyimport cv2 #画像を読み込む image = cv2.imread('sample.jpg') #imreadで返された配列を出力 print(image) #読み込んだ画像を表示する cv2.imshow('img',image) cv2.waitKey(0) cv2.destroyAllWindows()出力は以下のようになる.
このように,3次元配列が出力されていることがわかる.この配列をA×B×3次元配列とする.Aは画素の行数であり,Bは画素の列数である(読み込む画像のサイズによって,行列のサイズは変わるため変数A,Bとした).3は,RGBの輝度である.
上の画像において,輝度が縦に大量に並んでいるが,これは
[[[0行0列目の輝度]~[0行B列目の輝度]]~[[A行0列目の輝度]~[A行B列目の輝度]]]の順に並んでいる.(画像において0行0列目は,左上)
よって,imreadで返される配列とは,画素の輝度を行列の順に格納したものである.3. 余談(画像をどう切り取るか)
1章の背景でも,説明したように,imreadで返される配列を利用して顔画像を切り取った.まず,検出した顔画像の左上の位置と,右下の位置を取得する.そして,imreadで返された配列の,顔画像の部分(顔画像の左上の行列から,右下の行列までの区分行列の輝度)だけを取り出すことで,切り取ることができた.詳細は,別の記事で説明しようと思う.
- 投稿日:2020-02-16T17:25:27+09:00
【ディープラーニング初心者向け】Kerasを使った全結合による簡単な二値分類の実装
概要
ディープラーニングの登場により、これまでの機械学習よりも良い精度でAIタスクをこなすことができるようになりました。
しかしながらディープラーニングはまだ発展段階ということもあり、こうすればよいと言った方法が確立されているわけではありません。また研究段階ということもあり、実装・制御が複雑なものも多い状況です。今回は実装を出来る限り簡潔にし、ディープラーニングを動かしてみることを目的として、簡単な二値分類を紹介します。
今回は、リンゴとミカンの2つの画像をディープラーニングを使って分類します。DLフレームワークには、チューニングに難ありではあるものの簡単に使えるKerasを採用しました。
環境
- gpu GeForce GTX 1070
- os ubuntu16.04
- CUDA 8.0
- cudnn 6.0
- Keras 2.0.8
ディレクトリ構成
実行モジュールとデータ格納用のディレクトリを準備します
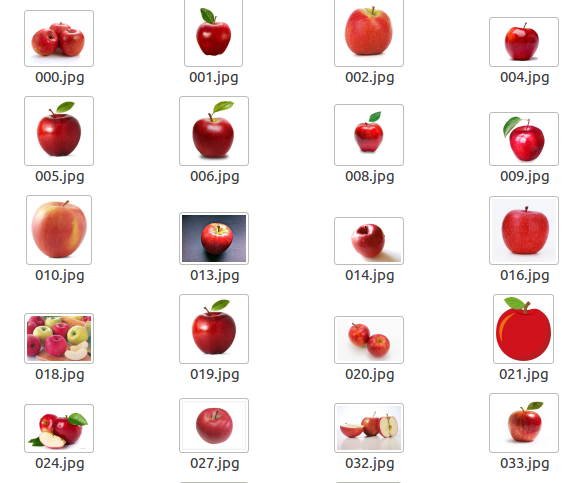
├── data └── exe.pydataディレクトリの中には学習用データtrainとテスト用データtestを準備し、リンゴとミカンの画像をそれぞれ格納します。
├── test │ ├── 00_apple │ └── 01_orange └── train ├── 00_apple └── 01_orangeデータ
各ディレクトリの中はこのようになっています。
リンゴ
ミカン
学習
from keras.utils.np_utils import to_categorical from keras.optimizers import Adagrad from keras.optimizers import Adam import numpy as np from PIL import Image import os # 教師データ読み込み train_path="./data/train/" test_path="./data/test/" xsize=25 ysize=25 image_list = [] label_list = [] for dataset_name in os.listdir(train_path): dataset_path = train_path + dataset_name label = 0 if dataset_name == "00_apple": label = 0 elif dataset_name == "01_orange": label = 1 for file_name in sorted(os.listdir(dataset_path)): label_list.append(label) file_path = dataset_path + "/" + file_name image = np.array(Image.open(file_path).resize((xsize, ysize))) print(file_path) # RGBの順に変換、[[Redの配列],[Greenの配列],[Blueの配列]] image = image.transpose(2, 0, 1) # 1次元配列に変換(25*25*3) Red,Green,Blueの要素が順番に並ぶ。 image = image.reshape(1, image.shape[0] * image.shape[1] * image.shape[2]).astype("float32")[0] # 0〜1の範囲に変換 image_list.append(image / 255.) # numpy変換。 X = np.array(image_list) # label=0 -> [1,0], label=1 -> [0,1] に変換 Y = to_categorical(label_list) # モデル定義 model = Sequential() model.add(Dense(200, input_dim=xsize*ysize*3)) model.add(Activation("relu")) model.add(Dropout(0.2)) model.add(Dense(200)) model.add(Activation("relu")) model.add(Dropout(0.2)) model.add(Dense(2)) model.add(Activation("softmax")) model.compile(loss="categorical_crossentropy", optimizer=Adam(lr=0.001), metrics=["accuracy"]) model.summary() # 学習 model.fit(X, Y, nb_epoch=1000, batch_size=100, validation_split=0.1)画像分類などを行う際にはCNNを用いることが多いですが、今回は単純化のため、全結合のみを使用しました。また、画像から形の特徴量を抽出する際に、不要な情報が含まれないようにグレースケール化することが多いですが、リンゴとミカンの分類であることから色の情報が重要だと判断し、グレースケール化せずRGBの情報をすべてをニューラルネットのinputに渡しています。
推論
# 推論 total = 0. ok_count = 0. for testset_name in os.listdir(test_path): testset_path = test_path + testset_name label = -1 if testset_name == "00_apple": label = 0 elif testset_name == "01_orange": label = 1 else: print("error : label not exist") exit() for file_name in os.listdir(testset_path): label_list.append(label) file_path = testset_path + "/" + file_name image = np.array(Image.open(file_path).resize((25, 25))) print(file_path) image = image.transpose(2, 0, 1) image = image.reshape(1, image.shape[0] * image.shape[1] * image.shape[2]).astype("float32")[0] result = model.predict_classes(np.array([image / 255.])) print("label:", label, "result:", result[0]) total += 1. if label == result[0]: ok_count += 1 print("accuracy: ", ok_count / total * 100, "%")結果
accuracy: 100.0 %ディープラーニングが高精度と言えども正解率100%とまではなかなかなりません。しかしながら今回はリンゴとミカンの単純な分類であるため100%の正解率となりました。

- 投稿日:2020-02-16T17:14:41+09:00
Raspberry Pi と Mac で MQTT
概要
MQTTについて 理解する必要がでてきたので,ラズパイとMacで通信してイメージを掴みたい
Raspberry Pi
- ラズパイにmosquiito と mosquiito_clientsをインストールした
- Man に mosquittoをインストールした
- ラズパイで Brokerを起動
- Macでmosquitto_sub -h 192.168.11.13 -t tp1/test を起動(受信の準備)
- ラズパイで mosquitto_pub -h localhost -t tp1/test -m Hello を実行(データの送信)
- Macのターミナルで受信を Hellow 確認
基にしたサイト
- MQTT の仕様:トピックのワイルドカード
- pythonでMQTT送受信
- Raspberry Pi で mosquitto を使う
- MacとRaspberryPiにMosquitto入れてみた
- MQTT の基本知識
私のYouTubeチャンネル
- 投稿日:2020-02-16T17:10:16+09:00
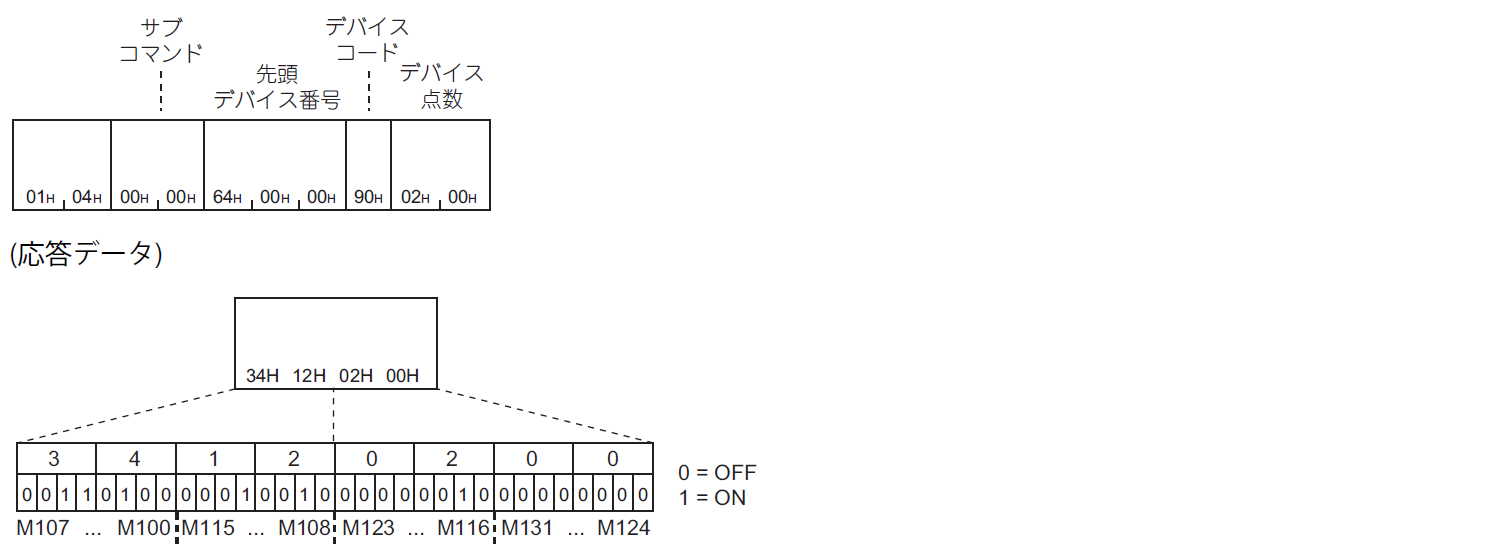
[続] PythonでPLCのレジスタアクセスを試す
「PythonでPLCのレジスタアクセスを試す」では、SLMPによる基本的なワードアクセスをPythonで試しました。
今回は、バイナリコードでのビットデバイスのリード・ライトをするときのデータ操作をPythonで実装してみます。ビットデバイスのアクセス方法
SLMPでは、ビットデバイスへの連続アクセス方法として2種類用意されています。
- ビットデバイス(連続したデバイス番号)から1点単位で値を読み書き
- ビットデバイス(連続したデバイス番号)から16点単位で値を読み書き
1点単位でのアクセスの場合は、下記のように4ビットで1点のBCDコード表現となっています。
下記は読み出し時の交信例です。
16点単位でのアクセスでは、1ビットで1点の2値表現となっています。
下記は読み出し時の交信例です。
当然ながら、連続で大量に読み書きするには16点単位の方が有利です。
使用する通信コマンドはワードアクセス時と変わらないのですが、上記のようにビットデータがパックされますので、Pythonでリストなどの配列データとして扱うにはデータ変換が必要になってきます。
これが結構面倒ですし、特に16点単位の場合は、普通に1ビットづつ取り出そうとするとPythonでは処理速度への影響が懸念されます。
ここでは、numpyのビット操作を使って実装してみます。1点単位のアクセス
読み出し
ワードアクセスと同様に、Readコマンド(
0401h)で読み出します。ただしサブコマンドは0001hと異なっています。受信したデータ配列が
[0x00, 0x01, 0x00, 0x11, ...]のように抽出されたとすると、[0, 0, 0, 1, 0, 0, 1, 1, ...]のように展開する必要があります。下記サンプルコードは、BDCコード配列を展開します。
引数のdataおよび戻り値はいずれも numpy の ndarray (dtype=uint8) となります。numpyを使うと配列データを一括で演算できるため、Python構文でのループ処理が不要となり、特にデータ量が多い場合には高速処理が期待できます。
import numpy as np # ex. data = np.array([0x12, 0x34, 0x56], 'u1') def decode_bcd(data): """ Decode 4bit BCD array [0x12,0x34,...] --> [1,2,3,4,...] """ binArrayH = (data >> 4) & 0x0F binArrayL = data & 0x0F binArray = np.empty(data.size * 2, 'u1') binArray[::2] = binArrayH binArray[1::2] = binArrayL return binArray書き込み
読み出しと逆のパターンです。BCDコードにパックします。
元データが奇数個の場合は最後の4bitは未使用なので、0で埋めます。def encode_bcd(data): """ Encode 4bit BCD array [1,2,3,4,...] --> [0x12,0x34,...] 入力が奇数個の場合は最後の4bitを0埋め """ binArrayH = (data[::2] & 0x0F) << 4 binArrayL = data[1::2] & 0x0F binArray = np.zeros_like(binArrayH) if data.size % 2 == 0: binArray = binArrayH | binArrayL else: binArray[:-1] = binArrayH[:-1] | binArrayL binArray[-1] = binArrayH[-1] return binArray16点単位のアクセス
読み出し
ワードアクセスと同様に、Readコマンド(
0401h)で読み出し、サブコマンドも同じです。
中身はワードデータだから通信コマンドとしては同じということですね。先ほどの交信例の図にあったように、受信した4バイトのデータ
[34h, 12h, 02h, 00h]は、[<M107>, ..., <M100>, <M115>, ..., <M108>, <M123>, ..., <M116>, <M131>, ..., <M124>] ^ ^ ^のように、ビット展開して16*4=32点のデータ配列に展開することになります。
ここでややこしいのが、1バイトにつきアドレスの順序が逆になって格納されているというところです。
つまり上記の例では、最初の1バイト34hのLSBが、読み出しコマンド送信時の先頭アドレスの値で、MSBに向かってアドレスがインクリメントされていったデータの値ということになります。
そして、2バイト目の12hについては、同様に今度はLSBが「先頭アドレス+8」の値で・・・ということになります。下記サンプルコードは、numpyのunpackbitを使用して各ビットデータを1次元配列に展開します。
numpy.packbits, numpy.unpackbits は、10進数⇔2進数配列の変換をしてくれる関数です。LSBとMSBの順序を逆にしなければいけないところを、一旦2次元配列化してビット展開した後にスライス指定で列方向の順序を逆にしているところがミソです。
def unpack_bits(data): """ LSBから順に格納されているビット列を配列に展開する [<M107 ... M100>, <M115 ... M108>] --> [<M100>, ... ,<M107>, <M108>, ... ,<M115>] """ # unpackbits後のデータ順を反転させるために、疑似的に2次元配列として、 # 1バイトごとにビットデータが格納されるようにする # ex. [1,2,3] --> [[1],[2],[3]] byteArray2D = data.reshape((data.size, 1)) # ビットデータを展開 # ex. [[1],[2],[3]] --> [[0,0,0,0,0,0,0,1],[0,0,0,0,0,0,1,0],[0,0,0,0,0,0,1,1]] byteArray2D_bin = np.unpackbits(byteArray2D, axis=1) # 列方向の順序を反転後、1次元配列に戻す return byteArray2D_bin[:, ::-1].flatten()書き込み
読み出しと逆のパターンです。0/1の1次元配列データをバイト列にパックします。
def pack_bits(data): """ ビットデータの配列をLSBから順に格納されたバイト列にパックする [<M100>, ... ,<M107>, <M108>, ... ,<M115>] --> [<M107 ... M100>, <M115 ... M108>] """ # データ数が8の倍数になるようにする size8 = -(-data.size // 8) * 8 # 最後サイズが足りないところを0埋め byteArray_bin = np.zeros(size8, 'u1') byteArray_bin[:size8] = data # 8bitごとにデータ順を反転させるために2次元配列に変換 byteArray2D_bin = byteArray_bin.reshape((size8//8, 8)) # ビットデータをパック return np.packbits(byteArray2D_bin[:, ::-1])参考文献
- 三菱電機 SLMPリファレンスマニュアル

- 投稿日:2020-02-16T16:56:45+09:00
Pythonのf-stringの基本的な使い方
f-stringはpython3.6から追加された文字列リテラルです。
文字列の外に最初にfもしくはFをつけるのが特徴です。値の挿入:
>>> name = 'GAO' >>> age = 24 >>> f'こんにちは{name}です、{age}才です。' 'こんにちはGAOです、24才です。'式の挿入:
>>> years_later = 10 >>> f'{years_later}年後は{age + years_later}才です。' '10年後は34才です。'関数を呼ぶ:
>>> def one_year_later(current_age): ... return current_age + 1 ... >>> f'来年は{one_year_later(age)}才です。' '来年は25才です。'メソッドを呼ぶ:
>>> f'{name}を小文字にすると{name.lower()}です。' 'GAOを小文字にするとgaoです。'マルチライン:
>>> jikoshoukai = f'こんにちは{name}です、{age}才です。' \ ... f'{years_later}年後は{age + years_later}才です。' \ ... f'来年は{one_year_later(age)}才です。' \ ... f'{name}を小文字にすると{name.lower()}です。' >>> jikoshoukai 'こんにちはGAOです、24才です。10年後は34才です。来年は25才です。GAOを小文字にするとgaoです。'ゼロ埋め:
>>> a = 123 >>> f'ゼロ埋め8桁: {a:08}' 'ゼロ埋め: 00000123'ネスト(ゼロ埋め):
>>> for i in range(4,8): ... f'ゼロ埋め{i}桁: {a:0{i}}' ... 'ゼロ埋め4桁: 0123' 'ゼロ埋め5桁: 00123' 'ゼロ埋め6桁: 000123' 'ゼロ埋め7桁: 0000123'小数点桁数、有効桁数:
>>> a = 123.456789 >>> f'小数点以下4桁: {a:.4f}' '小数点以下桁: 123.4568' >>> f'有効桁4桁: {a:.4g}' '有効桁: 123.5'
- 投稿日:2020-02-16T16:56:23+09:00
区間スケジューリング 学習メモ ~by python~
はじめに
貪欲法 区間スケジューリング問題についての学習メモ
問題
キーエンス プログラミングコンテスト2020の"B問題 Robot Arms"
始点、終点が決まっているものについて、できる限り多く選択していく問題(区間スケジューリング問題)
貪欲法で解いていく
基本方針は選べるロボットの中で終点が最小のものを選んでいくこと回答
N=int(input()) XL=[list(map(int,input().split())) for i in range(N)] R=[] for i in range(N): a=max(0,XL[i][0]-XL[i][1]) b=XL[i][1]+XL[i][0] R.append([b,a]) R.sort() ans=0 con_l=0 for i in range(N): if con_l <= R[i][1]: ans += 1 con_l = R[i][0] print(ans)解説
①入力
N=int(input()) XL=[list(map(int,input().split())) for i in range(N)]Nはロボットの個数
XLは座標Xと腕の長さLのリスト②リストの編集
ロボットの腕の始点(a)と終点(b)を保存するリスト(R)を作成する
R=[] for i in range(N): a=max(0,XL[i][0]-XL[i][1]) b=XL[i][1]+XL[i][0] R.append([b,a]) R.sort()リストRは終点昇順でソートしておく
③区間スケジューリング&出力
ans=0 con_l=0 for i in range(N): if con_l <= R[i][1]: ans += 1 con_l = R[i][0] print(ans)ansは選んだロボットの個数
con_lは最後に選んだロボットの腕の終点forループ内の処理は最後に選んだロボットの終点(con_l)より大きい始点(R[i][1])を持つロボットを貪欲的に探索するようになっている
Rは終点昇順でソートしてあるため、探索していく中で最小の終点のものを常に選択するようになっている
見つかるたびにansに+1してcon_lを更新する
出力して終了まとめ
典型的な区間スケジューリング問題であった
- 投稿日:2020-02-16T16:55:25+09:00
Keras の imdb.load_data で ValueError が起きた際の解決法
発端
以下の様なコードで読み込みを行おうとした。
from keras.datasets import imdb (X_train,y_train),(X_test,y_test) = imdb.load_data(num_words=10000)すると、以下のエラーが発生
ValueError Traceback (most recent call last) <ipython-input-203-2fc6b409cd07> in <module> 5 #np_load_old = np.load 6 #np.load = lambda *a,**k: np_load_old(*a, allow_pickle=True, **k) ----> 7 (X_train,y_train),(X_test,y_test) = imdb.load_data(num_words=10000) 8 #np.load = np_load_old 9 /opt/anaconda3/lib/python3.7/site-packages/keras/datasets/imdb.py in load_data(path, num_words, skip_top, maxlen, seed, start_char, oov_char, index_from, **kwargs) 57 file_hash='599dadb1135973df5b59232a0e9a887c') 58 with np.load(path) as f: ---> 59 x_train, labels_train = f['x_train'], f['y_train'] 60 x_test, labels_test = f['x_test'], f['y_test'] 61 /opt/anaconda3/lib/python3.7/site-packages/numpy/lib/npyio.py in __getitem__(self, key) 260 return format.read_array(bytes, 261 allow_pickle=self.allow_pickle, --> 262 pickle_kwargs=self.pickle_kwargs) 263 else: 264 return self.zip.read(key) /opt/anaconda3/lib/python3.7/site-packages/numpy/lib/format.py in read_array(fp, allow_pickle, pickle_kwargs) 720 # The array contained Python objects. We need to unpickle the data. 721 if not allow_pickle: --> 722 raise ValueError("Object arrays cannot be loaded when " 723 "allow_pickle=False") 724 if pickle_kwargs is None: ValueError: Object arrays cannot be loaded when allow_pickle=False原因
numpyバージョンアップ の際に
allow_pickle=Falseがデフォルトになってしまったことが原因の模様。解消法
numpyのバージョンを下げることでも対応可能だが、面倒なのでコード上で解決を図る。
具体的には、以下のコードに置き換えることで解消。
# 頻度順位10000語までを指定 from keras.datasets import imdb np_load_old = np.load np.load = lambda *a,**k: np_load_old(*a, allow_pickle=True, **k) (X_train,y_train),(X_test,y_test) = imdb.load_data(num_words=10000) np.load = np_load_old
np.loadにて、allow_pickle=Trueを指定する様に一時的に上書きしている。imdb.load_dataが完了したら、np.loadの定義を元に戻すことで、元通り。参考
- 投稿日:2020-02-16T16:53:37+09:00
ProgeteのPython1を受講してみた
■プログラム
Pythonに触れてみよう
1. 目標物を確認しようPythonの基礎を学ぼう
2. 文字列
3. 数値
4. 計算してみよう変数を使ってみよう
5. 変数
6. 変数を使ってみよう
7. 変数の値を更新してみよう
8. 文字列の連結
9. データ型真偽値と条件分岐
10. if文
11. 真偽値
12. else
13. elif
14. 条件式を組み合わせようお買い物代金を計算しよう
15. 代金を計算しよう
16. 入力を受け取ろう
17. 条件分岐をしようPython1は初心者でも分かりやすいのでお勧めです。