- 投稿日:2020-02-16T23:10:29+09:00
はじめてのクエリチューニング(MySQL) vol.4 インデックス以外のチューニング例
インデックス作成はクエリチューニングにおいて、劇的な改善が期待できる重要なものですが
それ以外にもチューニングする方法はあり〼
その一例
目次
1.データ型の見直し
2.必要なカラムのみ指定
3.サブクエリの見直し
4.IN を EXISTSに
5.DISTINCTをEXISTSに
6.ALLを使う
データ型の見直し
テーブルに設定したデータ型と入力したデータのデータ型が異なっていた場合、
変更可能であればエラーにならず暗黙の型変換が行われ、その分時間がかかる
必要なカラムのみ指定
SELECT時に *(ワイルドカード) を使っていると不要なカラムまで取得することになる
全てのカラムを取得したい場合も、カラム名に置き換える処理が内部で行われているので書いた方が良い
サブクエリの見直し
・テーブル結合で書き換えられる場合もある
・EXISTSを使用したサブクエリの場合はテーブル結合よりEXSISTの方が早い場合もある
IN を EXISTSに
・書き換えられる場合は、ワークテーブルが作られない分INより速い
・該当する値があった場合検索をストップ
・WHERE(結合キー)にインデックスが貼られていれば実テーブルを見にいかなくてよい
ただOracle、PostgreはINでも同じパフォーマンスを発揮できるようになってきている
DISTINCTをEXISTSに
・ソートを回避できる分速くなる
ALLを使う
・集合演算子(UNION INTERSECT EXCEPT)は必ず重複削除が行われる
・重複が発生しない(重複削除が不要な)場合はUNION ALL のようにALLを使う
- 投稿日:2020-02-16T15:39:13+09:00
MYSQL 全テーブル、データベース(schema)から特定のカラムを検索
このカラムを持つテーブルって何だっけ??って時に使える
information_schemaから取得する方法SELECT TABLE_SCHEMA,TABLE_NAME,COLUMN_NAME FROM information_schema.columns WHERE column_name = '特定のカラム名' ;見やすく複数行で
SELECT TABLE_SCHEMA ,TABLE_NAME ,COLUMN_NAME FROM information_schema.columns WHERE column_name = '特定のカラム名' ;*補足 WHERE句にスキーマ名(TABLE_SCHEMA)を指定しても良いかも
- 投稿日:2020-02-16T14:58:55+09:00
MySQLコマンド(テーブル作成関連)
はじめに
前回MySQLコマンド(基本)について紹介しました。
今回は実際にテーブル作成に必要なコマンドを紹介していきます。テーブル作成関連のMySQLコマンド
・テーブルの作成
mysql > CREATE TABLE [テーブル名] ( [カラム名] [データ型] [オプション] ); //例 mysql > CREATE TABLE `users` ( `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT "ID", `name` VARCHAR(50) NOT NULL COMMENT "名前", `mail` VARCHAR(100) NOT NULL COMMENT "メールアドレス", `created_at` datetime DEFAULT NULL COMMENT "登録日", );・テーブル一覧の表示
mysql > show tables;・テーブル名の変更
mysql > ALTER TABLE [旧テーブル名] RENAME [新テーブル名];・テーブルの削除
mysql > DROP TABLE [テーブル名];・テーブルにカラムの追加作成
mysql > ALTER TABLE [テーブル名] ADD [カラム名] [型] [必要であればオプション];・テーブル設計の確認
mysql > show columns from [テーブル名]; //もしくは mysql > desc [テーブル名];・カラムの変更
mysql > ALTER TABLE テーブル名 ALTER COLUMN [カラム名] [型];・カラムの削除
mysql > ALTER TABLE テーブル名 DROP COLUMN [カラム名];・レコードの追加作成
mysql > INSERT INTO [テーブル名] [カラム名] VALUES [値]; //例 mysql > INSERT INTO users (name, mail, created_at,) VALUES ("Yamada Takumi", "takumi@hoge.com", now());・レコードの更新
mysql > UPDATE [テーブル名] SET [カラム名]=[値] [条件式];・レコードの削除
//全レコード削除 mysql > DELETE FROM [テーブル名]; //一部レコード削除 mysql > DELETE FROM [テーブル名] WHERE [条件式];おわりに
ここまで使えれば一通りのMySQLコマンドは困らないと思います。
- 投稿日:2020-02-16T14:13:35+09:00
RubymineでDB接続するための方法
Rubymine上でDBを見れるようにする方法を紹介します。
似たような記事は多いですが、備忘録のためメモ。環境
・Rails
・MySQLゴール
RubymineでDB接続
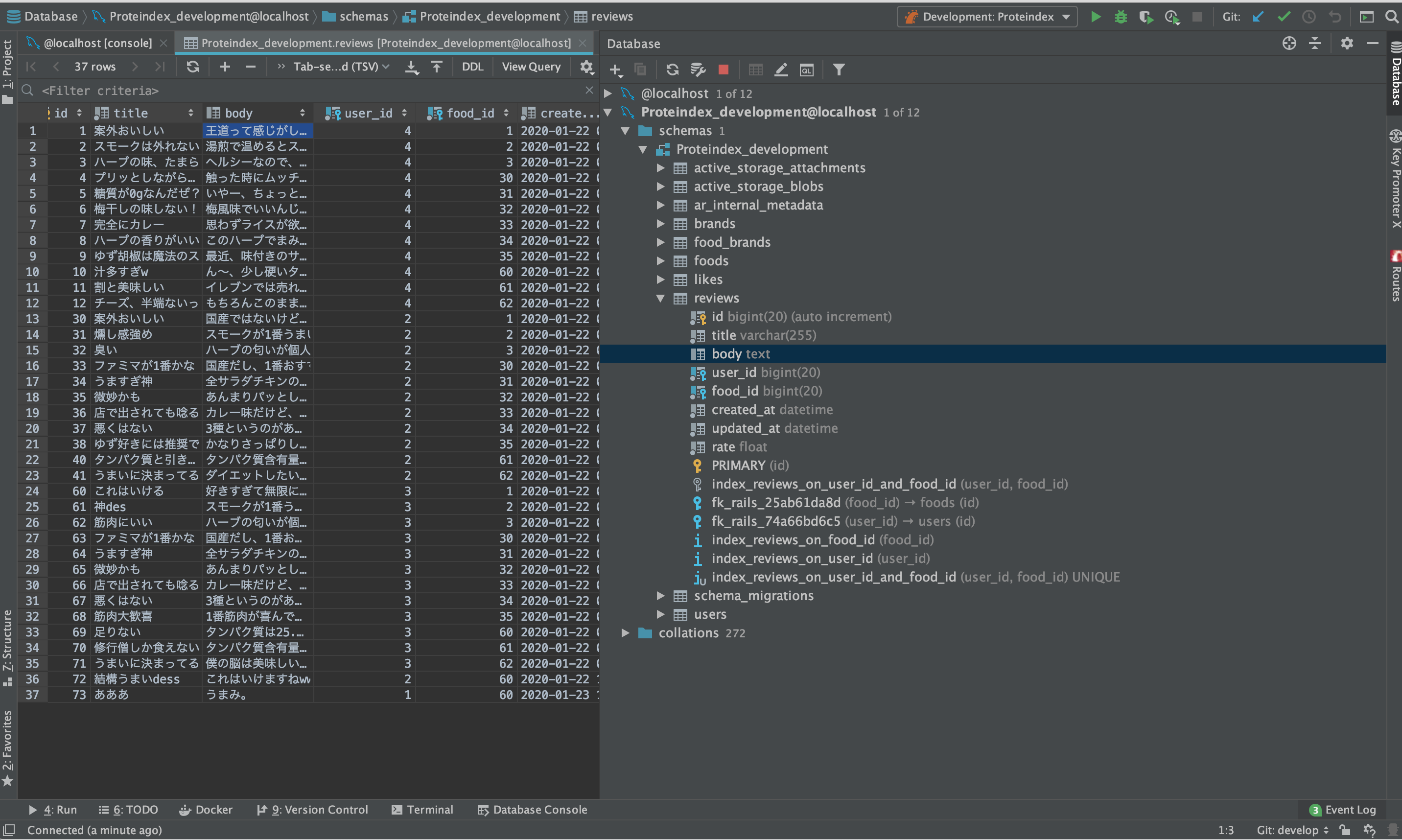
こんな感じに中身を見れるようします。可視化出来ると見やすく、ちゃんと保存されたか、更新されたかなどが分かるのでいいですよね!
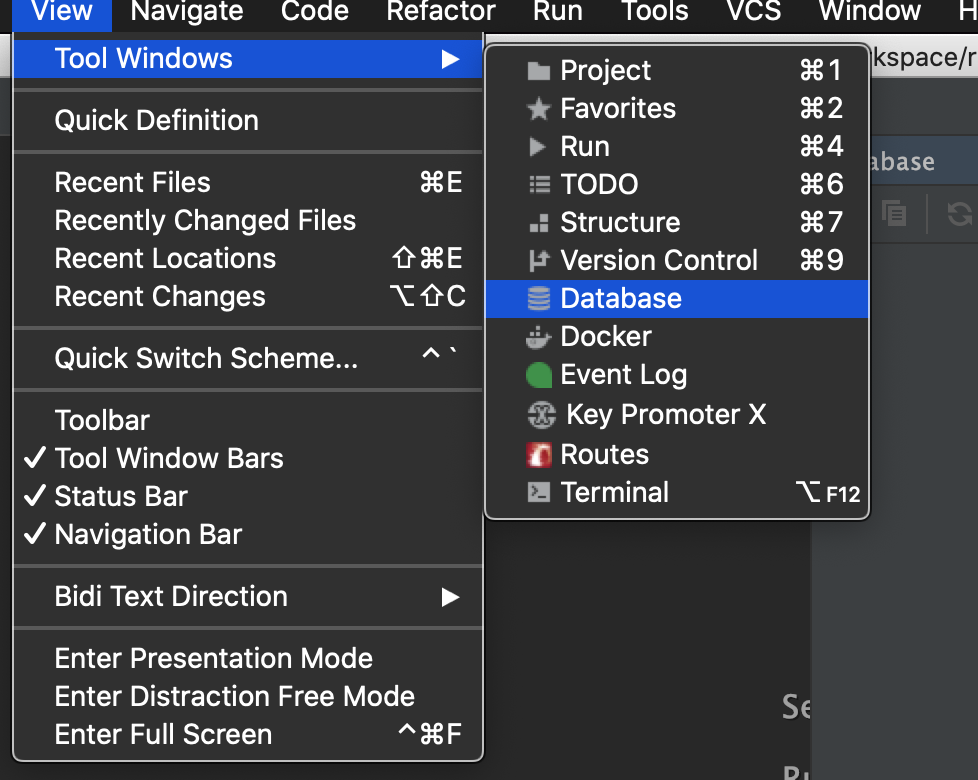
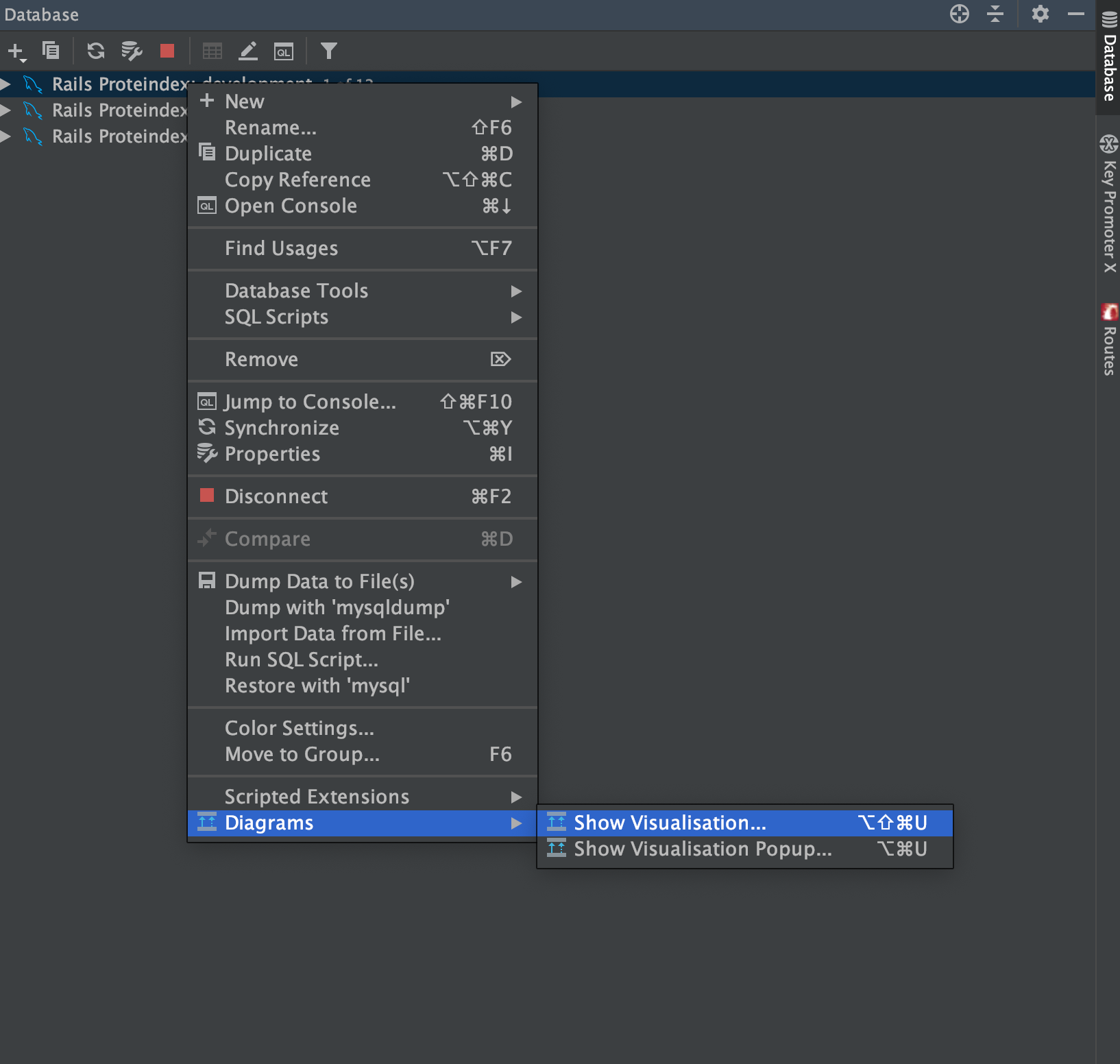
ViewからToolwindowを開き、Databaseを選択
画像のとおりに
View → Toolwindows → Databaseと選択します。
(もし仮にここでDatabaseが追加されない場合は、ググってみてください)
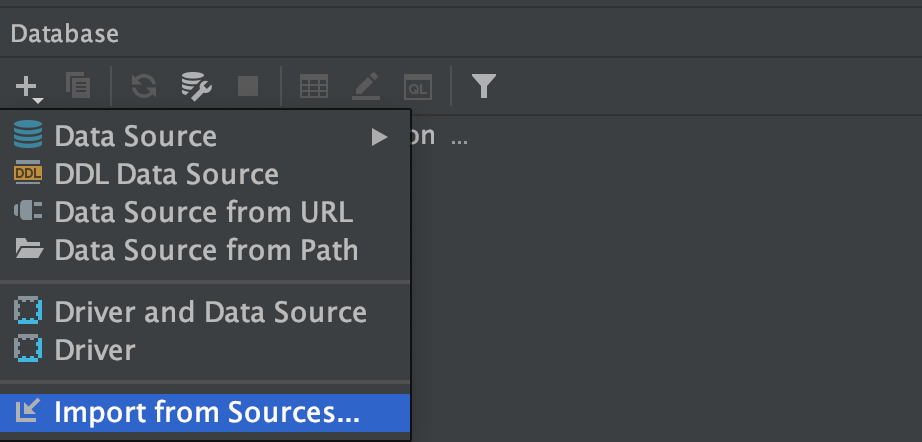
Import from Sourcesを押す
これだけでRubyMineがあとは自動設定してくれます。
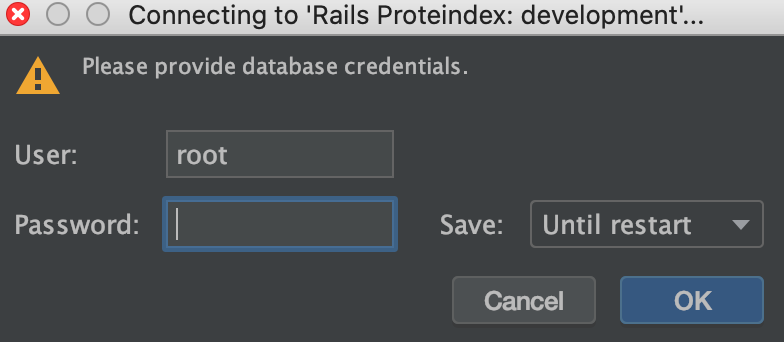
Test Connectionして OKを押す
databaseにつなぐ設定をテストします。
Railsなら。database.ymlに記載されてますよね。パスワードが空欄の場合はそのままでOKです。
そしたら成功し、OKを押せば完了です!
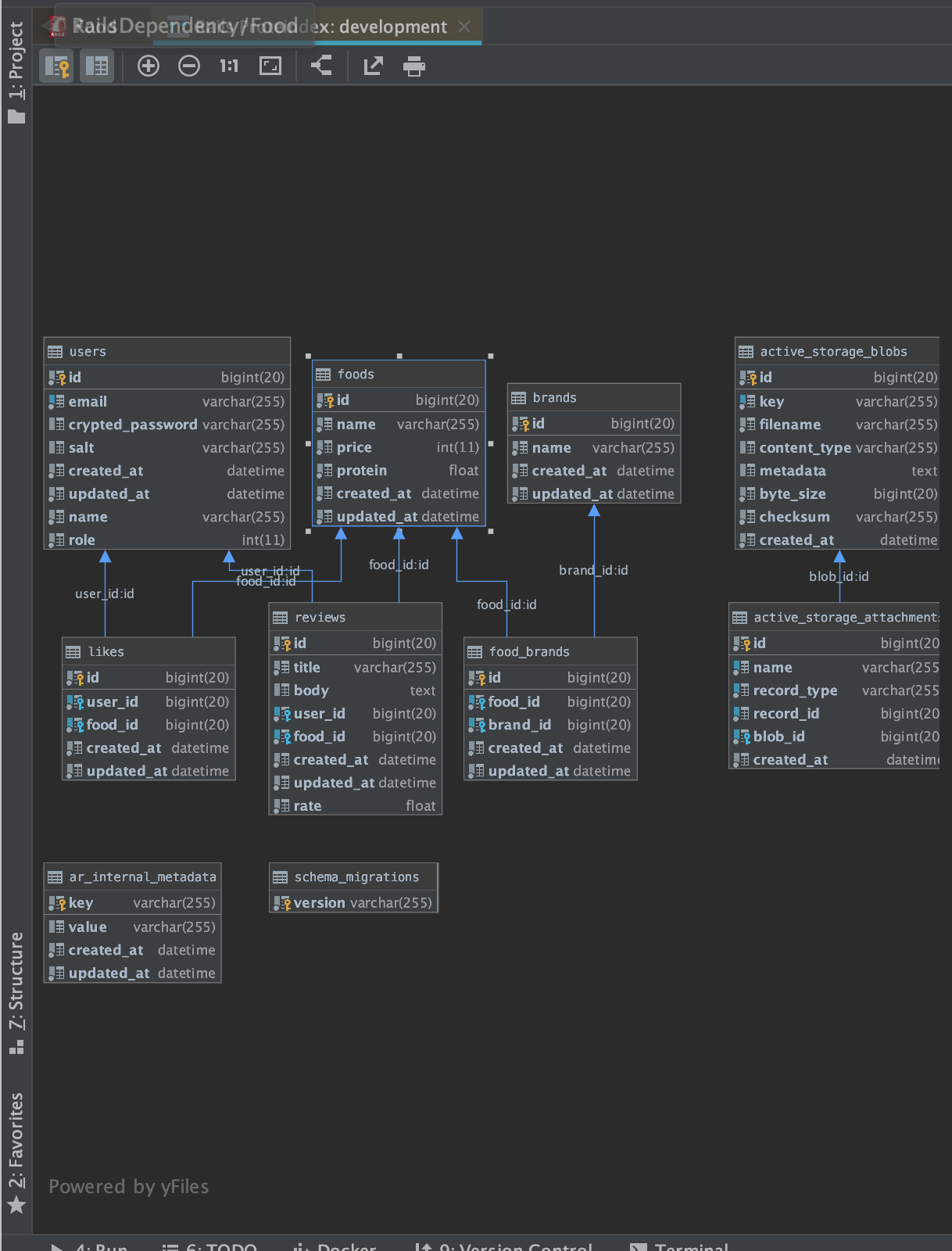
おまけ DBのDiagramを見る
右クリック → Diagrams → Show VisualisationでDB図を見れます。
こんな感じです。便利ですね。
他にもDB関係で便利な機能があるはずですが、まだ発掘中です。
これ便利だよってのがあれば教えてください!
私も分かり次第追加します。
- 投稿日:2020-02-16T07:17:11+09:00
MySQL 8 のWindow関数を試してみた(集約関数以外)
こちらの参考を元に試してみました。間違っていたら指摘いただけるとありがたいです
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
また、
sum()やcount()といった集約関数でもウィンドウ関数として使えますが、今回はそれ以外の関数を試したという内容です。
関数 説明 google翻訳 CUME_DIST() Cumulative distribution value 累積分布値 DENSE_RANK() Rank of current row within its partition, without gaps パーティション内のギャップのない現在の行のランク FIRST_VALUE() Value of argument from first row of window frame ウィンドウフレームの最初の行からの引数の値 LAG() Value of argument from row lagging current row within partition パーティション内の現在の行よりも遅い行の引数の値 LAST_VALUE() Value of argument from last row of window frame ウィンドウフレームの最後の行からの引数の値 LEAD() Value of argument from row leading current row within partition パーティション内の現在の行に先行する行の引数の値 NTH_VALUE() Value of argument from N-th row of window frame ウィンドウフレームのN番目の行からの引数の値 NTILE() Bucket number of current row within its partition. パーティション内の現在の行のバケット番号 PERCENT_RANK() Percentage rank value 割合ランク値 RANK() Rank of current row within its partition, with gaps ギャップ内のパーティション内の現在の行のランク ROW_NUMBER() Number of current row within its partition パーティション内の現在の行の数
CUME_DIST()
- 0 より大きく 1 以下の値の範囲を返す
- 累積分布を返す
- 累積分布で個人的にわかりやすかった説明です 【12-1. 累積分布関数とは | 統計学の時間 | 統計WEB】
https://www.db-fiddle.com/f/2kQsqvBDY2nPKD2txdYwP7/0
create table hoge(n int); insert into hoge values (1),(2),(2),(4),(5); select n ,cume_dist() over(order by n) from hoge;結果mysql> select n -> ,cume_dist() over(order by n) -> from hoge; +------+------------------------------+ | n | cume_dist() over(order by n) | +------+------------------------------+ | 1 | 0.2 | /* 5つの値の中で nが1以下 の割合20% */ | 2 | 0.6 | /* 5つの値の中で nが2以下 の割合60% */ | 2 | 0.6 | /* 5つの値の中で nが2以下 の割合60% */ | 4 | 0.8 | /* 5つの値の中で nが4以下 の割合80% */ | 5 | 1 | /* 5つの値の中で nが5以下 の割合100% */ +------+------------------------------+ 5 rows in set (0.01 sec)
create table fuga(category int, n int); insert into fuga values (1,3),(1,3),(1,5),(1,5),(1,1), (2,10),(2,10),(2,3),(2,3),(2,5); select category ,n ,cume_dist() over(partition by category order by n) from fuga;mysql> select category -> ,n -> ,cume_dist() over(partition by category order by n) cumedist -> from fuga; +----------+------+----------+ | category | n | cumedist | +----------+------+----------+ | 1 | 1 | 0.2 | /* category:1の値の中で nが5以下の割合20% */ | 1 | 3 | 0.6 | /* category:1の値の中で nが5以下の割合60% */ | 1 | 3 | 0.6 | /* category:1の値の中で nが5以下の割合60% */ | 1 | 5 | 1 | /* category:1の値の中で nが5以下の割合100% */ | 1 | 5 | 1 | /* category:1の値の中で nが5以下の割合100% */ | 2 | 3 | 0.4 | /* category:2の値の中で nが3以下の割合40% */ | 2 | 3 | 0.4 | /* category:2の値の中で nが3以下の割合40% */ | 2 | 5 | 0.6 | /* category:2の値の中で nが3以下の割合60% */ | 2 | 10 | 1 | /* category:2の値の中で nが3以下の割合100% */ | 2 | 10 | 1 | /* category:2の値の中で nが3以下の割合100% */ +----------+------+----------+ 10 rows in set (0.00 sec)
RANK()DENSE_RANK()
- 値に対するランクを返してくれる
RANK()は重複したランクの次のランクはその分飛んで次のランクにする、DENSE_RANK()重複したランクの次のランクも関係なく+1したランクにするhttps://www.db-fiddle.com/f/vSsqxv2jXisKaxwHRunoeq/2
create table hoge(n int); insert into hoge values (10),(20),(20),(100),(50),(60),(90),(20),(50),(70); create table fuga(category int, n int); insert into fuga values (1,10),(1,10),(1,10),(1,20),(1,30), (2,10),(2,10),(2,50),(2,50),(2,60);mysql> select n -> ,rank() over(order by n) r -> ,dense_rank() over(order by n) dr -> from hoge; +------+----+----+ | n | r | dr | +------+----+----+ | 10 | 1 | 1 | | 20 | 2 | 2 | | 20 | 2 | 2 | | 20 | 2 | 2 | | 50 | 5 | 3 | | 50 | 5 | 3 | | 60 | 7 | 4 | | 70 | 8 | 5 | | 90 | 9 | 6 | | 100 | 10 | 7 | +------+----+----+ 10 rows in set (0.00 sec) mysql> select category -> ,n -> ,rank() over(partition by category order by n) r -> ,dense_rank() over(partition by category order by n) dr -> from fuga; +----------+------+---+----+ | category | n | r | dr | +----------+------+---+----+ | 1 | 10 | 1 | 1 | | 1 | 10 | 1 | 1 | | 1 | 10 | 1 | 1 | | 1 | 20 | 4 | 2 | | 1 | 30 | 5 | 3 | | 2 | 10 | 1 | 1 | | 2 | 10 | 1 | 1 | | 2 | 50 | 3 | 2 | | 2 | 50 | 3 | 2 | | 2 | 60 | 5 | 3 | +----------+------+---+----+ 10 rows in set (0.00 sec)
PERCENT_RANK()
- ランクを相対的な値で出してくれる
- 0 〜 1 の値の範囲を返す
0が1位、1が最下位
0.25とかだと全体に対して上の方だな、というのがわかるhttps://www.db-fiddle.com/f/2NKvbDPsJo5kssVkE4rrg7/0
create table hoge(n int); insert into hoge values (1),(2),(2),(4),(5);mysql> select n -> ,rank() over (order by n) r -> ,percent_rank() over (order by n) pr -> ,(rank() over (order by n) - 1) / (count(*) over () - 1) tmp -- (rank - 1)/(rows - 1) の計算と percent_rankは同じ -> from hoge; +------+---+-------+--------+ | n | r | pr | tmp | +------+---+-------+--------+ | 1 | 1 | 0 | 0.0000 | | 2 | 2 | 0.25 | 0.2500 | | 2 | 2 | 0.25 | 0.2500 | | 4 | 4 | 0.75 | 0.7500 | | 5 | 5 | 1 | 1.0000 | +------+---+-------+--------+ 5 rows in set (0.01 sec)参考:SQL分析関数 PERCENT_RANK パーセントで順位を計算する:AABlog:So-netブログ
FIRST_VALUE()LAST_VALUE()
FIRST_VALUE()最初の行の値を返すLAST_VALUE()最後の行の値を返すhttps://www.db-fiddle.com/f/oxJwFDjsckyLfsyQxjMiEV/1
create table fuga(category int, n int); insert into fuga values (1,10),(1,10),(1,10),(1,20),(1,30), (2,20),(2,20),(2,50),(2,50),(2,60);mysql> select category -> ,n -> -> ,first_value(n) over(order by n) f1 -- 最初の値を返す -> ,last_value(n) over(order by n) l1 -- 最初の行から現在の行までで最後の値を返してしまう -> -> ,first_value(n) over(order by n range between unbounded preceding and unbounded following) f2 -- 最初の行の値を返す -> ,last_value(n) over(order by n range between unbounded preceding and unbounded following) l2 -- 全行で最後の値を返す -> -> ,first_value(n) over(partition by category order by n) fp1 -- categoryごとの最初の値を返す -> ,last_value(n) over(partition by category order by n) lp1 -- categoryごとの最初の行から現在の行までで最後の値を返してしまう -> -> ,first_value(n) over(partition by category order by n range between unbounded preceding and unbounded following) fp2-- categoryごとの最初の値を返す -> ,last_value(n) over(partition by category order by n range between unbounded preceding and unbounded following) lp2 -- categoryごとの最後の値を返す -> from fuga; +----------+------+------+-------+------+------+------+------+------+------+ | category | n | f1 | l1 | f2 | l2 | fp1 | lp1 | fp2 | lp2 | +----------+------+------+-------+------+------+------+------+------+------+ | 1 | 10 | 10 | 10 | 10 | 60 | 10 | 10 | 10 | 30 | | 1 | 10 | 10 | 10 | 10 | 60 | 10 | 10 | 10 | 30 | | 1 | 10 | 10 | 10 | 10 | 60 | 10 | 10 | 10 | 30 | | 1 | 20 | 10 | 20 | 10 | 60 | 10 | 20 | 10 | 30 | | 1 | 30 | 10 | 30 | 10 | 60 | 10 | 30 | 10 | 30 | | 2 | 20 | 10 | 20 | 10 | 60 | 20 | 20 | 20 | 60 | | 2 | 20 | 10 | 20 | 10 | 60 | 20 | 20 | 20 | 60 | | 2 | 50 | 10 | 50 | 10 | 60 | 20 | 50 | 20 | 60 | | 2 | 50 | 10 | 50 | 10 | 60 | 20 | 50 | 20 | 60 | | 2 | 60 | 10 | 60 | 10 | 60 | 20 | 60 | 20 | 60 | +----------+------+------+-------+------+------+------+------+------+------+ 10 rows in set (0.00 sec)https://dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html
こちらの参考にあるように、
order byだけを指定した場合、LAST_VALUE()が思った通りに動かないことがあります。With ORDER BY: The default frame includes rows from the partition start through the current row, including all peers of the current row (rows equal to the current row according to the ORDER BY clause). The default is equivalent to this frame specification:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
order byがあった場合で、範囲について何も指定がないとデフォルトで↑のような指定になってしまうため、
LAST_VALUE()は最初の行から現在の行の中の範囲から最後の値を返してしまいます。最初の行からpartitionで区切った最後までの値で
LAST_VALUE()を返したい場合は↓のように指定すると良いようでしたRANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING参考:【BigQuery】FIRST_VALUE関数,LAST_VALUE関数の使い方とその違い - Qiita
NTH_VALUE()
- N番目の行の値を返す
https://www.db-fiddle.com/f/xqaSnB3QwXRmuVRQt8GiBX/0
create table fuga(category int, n int); insert into fuga values (1,10),(1,20),(1,20),(1,30),(1,50), (2,30),(2,30),(2,50),(2,50),(2,70);mysql> select category -> ,n -> -> ,nth_value(n, 2) over(order by n) n1 -- 2つ目の値を返す -> ,nth_value(n, 5) over(order by n) n2 -- 5つ目の値を返す -> -> ,nth_value(n, 2) over(order by n range between unbounded preceding and unbounded following) n3 -> ,nth_value(n, 5) over(order by n range between unbounded preceding and unbounded following) n4 -> -> ,nth_value(n, 2) over(partition by category order by n) n5 -- カテゴリーごとの2つ目の値を返す -> ,nth_value(n, 5) over(partition by category order by n) n6 -- カテゴリーごとの5つ目の値を返す -> -> ,nth_value(n, 2) over(partition by category order by n range between unbounded preceding and unbounded following) n7 -> ,nth_value(n, 5) over(partition by category order by n range between unbounded preceding and unbounded following) n8 -> from fuga; +----------+------+------+------+------+------+------+------+------+------+ | category | n | n1 | n2 | n3 | n4 | n5 | n6 | n7 | n8 | +----------+------+------+------+------+------+------+------+------+------+ | 1 | 10 | NULL | NULL | 20 | 30 | NULL | NULL | 20 | 50 | | 1 | 20 | 20 | NULL | 20 | 30 | 20 | NULL | 20 | 50 | | 1 | 20 | 20 | NULL | 20 | 30 | 20 | NULL | 20 | 50 | | 1 | 30 | 20 | 30 | 20 | 30 | 20 | NULL | 20 | 50 | | 1 | 50 | 20 | 30 | 20 | 30 | 20 | 50 | 20 | 50 | | 2 | 30 | 20 | 30 | 20 | 30 | 30 | NULL | 30 | 70 | | 2 | 30 | 20 | 30 | 20 | 30 | 30 | NULL | 30 | 70 | | 2 | 50 | 20 | 30 | 20 | 30 | 30 | NULL | 30 | 70 | | 2 | 50 | 20 | 30 | 20 | 30 | 30 | NULL | 30 | 70 | | 2 | 70 | 20 | 30 | 20 | 30 | 30 | 70 | 30 | 70 | +----------+------+------+------+------+------+------+------+------+------+ 10 rows in set (0.00 sec)例えば、5行目の値(
nth_value(n, 5))を出したいときに、1〜4行目がnullになってしまう場合があるため、LAST_VALUE()と同様に、range between unbounded preceding and unbounded followingをつけると良いと思いました。
LAG()LEAD()
LAG()現在の行からN行先行する行の値を返す
- 構文:
LAG(expr [, N[, default]])LEAD()現在の行からN行リードしている行を返す
- 構文:
LEAD(expr [, N[, default]])https://www.db-fiddle.com/f/nEeQyNMhFKR6zyVQ9DyAmD/0
create table hoge(n int); insert into hoge values (10),(20),(20),(100),(50),(60),(90),(20),(50),(70);mysql> select n -> ,lag(n) over(order by n) lag1 -- 1行前の値を返す -> ,lead(n) over(order by n) lead1 -- 1行後の値を返す -> ,lag(n, 3) over(order by n) lag3 -- 3行前の値を返す -> ,lead(n, 3) over(order by n) lead3 -- 3行後の値を返す -> ,lag(n, 3, 999) over(order by n) lagdefault -- 3行前の値を返す、取得できな かった場合のデフォルト値は999 -> ,lead(n, 3, 999) over(order by n) leaddefault -- 3行後の値を返す、取得でき なかった場合のデフォルト値は999 -> from hoge; +------+------+-------+------+-------+------------+-------------+ | n | lag1 | lead1 | lag3 | lead3 | lagdefault | leaddefault | +------+------+-------+------+-------+------------+-------------+ | 10 | NULL | 20 | NULL | 20 | 999 | 20 | | 20 | 10 | 20 | NULL | 50 | 999 | 50 | | 20 | 20 | 20 | NULL | 50 | 999 | 50 | | 20 | 20 | 50 | 10 | 60 | 10 | 60 | | 50 | 20 | 50 | 20 | 70 | 20 | 70 | | 50 | 50 | 60 | 20 | 90 | 20 | 90 | | 60 | 50 | 70 | 20 | 100 | 20 | 100 | | 70 | 60 | 90 | 50 | NULL | 50 | 999 | | 90 | 70 | 100 | 50 | NULL | 50 | 999 | | 100 | 90 | NULL | 60 | NULL | 60 | 999 | +------+------+-------+------+-------+------------+-------------+ 10 rows in set (0.00 sec)
NTILE()
- n個のグループに分割する
https://www.db-fiddle.com/f/kbecXN9k5MSTa8htiLFBFm/0
create table hoge(n int); insert into hoge values (10),(20),(20),(100),(50),(60),(90),(20),(50),(70);mysql> select n -> ,ntile(2) over(order by n) n2 -> ,ntile(3) over(order by n) n3 -> ,ntile(4) over(order by n) n4 -> ,ntile(5) over(order by n) n5 -> ,ntile(100) over(order by n) n100 -> from hoge; +------+------+------+------+------+------+ | n | n2 | n3 | n4 | n5 | n100 | +------+------+------+------+------+------+ | 10 | 1 | 1 | 1 | 1 | 1 | | 20 | 1 | 1 | 1 | 1 | 2 | | 20 | 1 | 1 | 1 | 2 | 3 | | 20 | 1 | 1 | 2 | 2 | 4 | | 50 | 1 | 2 | 2 | 3 | 5 | | 50 | 2 | 2 | 2 | 3 | 6 | | 60 | 2 | 2 | 3 | 4 | 7 | | 70 | 2 | 3 | 3 | 4 | 8 | | 90 | 2 | 3 | 4 | 5 | 9 | | 100 | 2 | 3 | 4 | 5 | 10 | +------+------+------+------+------+------+ 10 rows in set (0.01 sec)
ROW_NUMBER()
- 行の番号を返す
RANK()との違いは値が同じだった場合に重複した数値にするかしないかhttps://www.db-fiddle.com/f/21iEDwT8Dw8P8NwCgevNBa/0
create table hoge(n int); insert into hoge values (10),(20),(20),(100),(50),(60),(90),(20),(50),(70); create table fuga(category int, n int); insert into fuga values (1,10),(1,10),(1,10),(1,20),(1,30), (2,10),(2,10),(2,50),(2,50),(2,60);mysql> select n -> ,row_number() over(order by n) `row` -> ,rank() over(order by n) `rank` -> from hoge; +------+-----+------+ | n | row | rank | +------+-----+------+ | 10 | 1 | 1 | | 20 | 2 | 2 | | 20 | 3 | 2 | | 20 | 4 | 2 | | 50 | 5 | 5 | | 50 | 6 | 5 | | 60 | 7 | 7 | | 70 | 8 | 8 | | 90 | 9 | 9 | | 100 | 10 | 10 | +------+-----+------+ 10 rows in set (0.00 sec) mysql> select category -> ,n -> ,row_number() over(partition by category order by n) `row` -> ,rank() over(partition by category order by n) `rank` -> from fuga; +----------+------+-----+------+ | category | n | row | rank | +----------+------+-----+------+ | 1 | 10 | 1 | 1 | | 1 | 10 | 2 | 1 | | 1 | 10 | 3 | 1 | | 1 | 20 | 4 | 4 | | 1 | 30 | 5 | 5 | | 2 | 10 | 1 | 1 | | 2 | 10 | 2 | 1 | | 2 | 50 | 3 | 3 | | 2 | 50 | 4 | 3 | | 2 | 60 | 5 | 5 | +----------+------+-----+------+ 10 rows in set (0.00 sec)
最後まで見ていただいてありがとうございました。m(_ _)m