- 投稿日:2020-02-16T23:34:51+09:00
AWSの既存のリソースをterraformで管理する
1. 概要
マネジメントコンソールから作成した既存のセキュリティグループをterraformで管理するようにしたので、その手順を記載します。
今回はterraformerを使ってimportしています。
tfstateファイルはS3に置くようにしています。2. 前提条件
terraform、terraformer、aws configの設定は済んでいることとします。
※ terraformerのインストール方法や使い方は下記を参照して下さい。
https://github.com/GoogleCloudPlatform/terraformer3. 手順
3.1 terraformのmain.tfファイルを作成する
$ vi main.tf設定例)
terraform { required_version = "0.12.20" } provider "aws" { region = "ap-northeast-1" version = "2.49.0" } terraform { backend "s3" { bucket = "hogehoge" key = "hogehoge/terraform.tfstate" region = "ap-northeast-1" } }3.2 terraform initする
$ terraform initリソースを定義していないため、tfstateは作成されません。
3.3 terraformer importする
$ terraformer import aws --resources=sg --filter=aws_security_group=sg-093ffc7be63295434 --regions=ap-northeast-1→コマンドを実行したディレクトリ配下に「generated/aws/sg/ap-northeast-1」ディレクトリが作成されます。
sg-093ffc7be63295434は、terraformで管理したいセキュリティグループのグループIDです。3.4 作成されたterraform.tfstateのterraform_version を main.tfで指定しているバージョンに合わせる
$ vi generated/aws/sg/ap-northeast-1/terraform.tfstategenerated/aws/sg/ap-northeast-1/terraform.tfstateのterraform_versionは、terraformerのバージョンによって変わるようです。
こちらはterraformのバージョンと合わせる必要があります。3.5 ディレクトリを移動する
$ cd generated/aws/sg/ap-northeast-1/3.6 terraform state mv する
$ terraform state mv -state-out=../../../../terraform.tfstate 'aws_security_group.tfer--qiita_sg-002D-093ffc7be63295434' 'aws_security_group.qiita'aws_security_group.tfer--qiita_sg-002D-093ffc7be63295434 → terrafomerでimportしたリソース名
aws_security_group.qiita → terrafomのリソース名3.7 ディレクトリを移動する
$ cd ../../../../terraform.tfstateが作成されているはずです。
3.8 terraform planで差分が出なくなるようにリソースを定義する
$ vi security_group.tfgenerated/aws/sg/ap-northeast-1/security_group.tf を参考にすると良いです。
3.9 terraform planで差分が出ないことを確認する
$ terraform plan差分が出なくなっていればterraformで管理出来ています。
4. まとめ
既にtfstateが存在しているscopeに既存のリソースをimportする場合は少し手順が変わります。
terraformerが対応していないリソースをimportしたい場合は、terraform importすれば良いと思います。
- 投稿日:2020-02-16T23:15:38+09:00
インフラ/AWS 基礎知識①プロトコル IPアドレス サブネット Ping
はじめに
エンジニアとしての最低限のインフラ基礎知識をわかりやすくメモ用として記録する。
自分自身苦労した部分でもありますので参考になれば...OSI基本参照モデル(Open System Interconnection)
ネットワークの各装置が「どの層に属するか」「何を中継するのか」、ISO(国際標準機構)が7階層(レイヤー)にまとめたもの。
階層 階層名 概要 7 アプリケーション層 アプリケーション間でのやりとりするデータ形式や内容を提供する 6 プレゼンテーション層 データの表現形式の制御や変換を行う 5 セッション層 プログラム間の会話単位の制御を行う 4 トランスポート層 伝送するデータの順序やデータの紛失に対する誤り検出や回復処理等を規定する 3 ネットワーク層 ルーティングや中継機能、コネクションの確立と解放などの規定する 2 データリンク層 隣接するノード間での伝送制御手順を提供する 1 物理層 コネクタの形状やケーブルの材質、データを電気信号に変換する方法等規定する *ノードとは
節点という意味があり、ネットワークに接続された機器やネットワークとネットワークを接続する機器のこと!
Pingとは
通信相手との接続性を確認するコマンド
ネットワークやサーバーがつながらない時、つながりにくくなった時の問題切り分けで使用する。
プロトコル
ネットワークではコンピュータ同士が通信する時の手順や約束事のことを言います
TCP/IP階層モデル
名称 役割 プロトコル 4層 アプリケーション層 アプリケーション間のやり取り HTTP、POP3、SMTP、FTP、DHCP, DNS, TFTP, IMAP4 3層 トランスポート層 プログラム間の通信、通信の制御 TCP、UDP 2層 インターネット層 インターネットワークでの通信 IP、IPsec 1層 ネットワークインターフェイス層 同一ネットワーク上での通信、ハードウェア仕様など Ethernet、PPP IPアドレス
インターネットに接続された装置間で通信を行うために必要な住所のようなもの
「通信したい相手」「通信してきた相手」の判別に利用される192.168.1.1(10進数)
↓
11000000.10101000.00000001.00000001(2進数) <-- 8ビットずつ区切るDNS(Domain Name System)
インターネット上でドメイン名(IPアドレスに文字で別名付けたもの)を管理・運用するために開発されたシステム
DNSサーバーはドメイン名やホスト名などとIPアドレスを対応付けする。
例
①www. ②hogehoge. ③co. ④jp
①コンピュータの名前 ②組織の名前 ③組織の種類 ④国の名前クラスとサブネット
IPアドレスのクラス
IPアドレスの32ビットは、ネットワーク部とホスト部で構成されます。端末やネットワーク機器を「どのネットワークに属するのか」「どのホスト(コンピュータ)か」を示す。
クラス
クラスA:/8 => 255.0.0.0((2^24) = 16777216ー2台) =>大規模
クラスB:/16 => 255.255.0.0((2^16) = 65536ー2台) =>中規模
クラスC:/24 => 255.255.255.0((2^8) = 256−2台) =>小規模サブネットとは...
大きなネットワークの中にある小さなネットワーク。
これにより、インターネットからのアクセス制限をかける。利点
・余計な通信を発生させない
・ある程度のセキュリティ向上につながる
サブネットマスクとは
簡単にいうとサブネットを柔軟に決定できること!
ネットワーク部(サブネット部含む)に1、 ホスト部に0を入れて区切りを設定する
例えば...
ある会社が300台のパソコンのIPアドレスを用意したいが...
下のクラスCだと足りないのでクラスBに上げないといけない...クラスC:/24 => 255.255.255.0((2^8) = 256−2台) =>小規模
クラスB:/16 => 255.255.0.0((2^16) = 65536ー2台) =>中規模クラスBにあげた場合65000以上ものをIPアドレスが余ってしまって無駄..
そこでサブネットマスク!!
/23, /28,など10.0.0.0/23:10.0.0.0 ~ 10.0.1.254 (512台に付与)
10.0.0.0/28:10.0.0.0 ~ 10.0.0.254 (14台に付与)
とできる
補足① CIDR(サイダー)/Classless inter-Domain Routingとは
サブネットマスクを使ったIPアドレスの管理方法
サブネット導入でネットワーク部とホスト部の境界を、下位ビット側に柔軟に移動できるようになりました。さらに進めたものがCIDRで、8ビット単位で区切るクラスの枠を取り払い、最上位ビットから1ビット単位でネットワーク部とホスト部の境界を設定できる考え。
CIDR表記とは
IPアドレスとサブネットマスクを一緒に表記する方法
補足の補足② プレフィックス表記とは
まとめると「198.51.100.xxx/24」のような形でIPアドレスとサブネットマスクを表現する表記方法が「プレフィックス表記」です。
つまり「CIDR表記」と同じ意味。
最後に
至らない部分がありましたら、よろしくお願いします。
今度はネットワークを構成する装置をまとめたいと思います!
- 投稿日:2020-02-16T21:32:44+09:00
AWSの10分間チュートリアルをやってみる 10.Deploy and host a ReactJS app
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は、「Docker コンテナのデプロイ」をやりました。
今までにない数のいいねをいただいて、トレンドにも載ってびっくりしています。今回は「Deploy and host a ReactJS app」をやっていきます。
Deploy and host a ReactJS app
(https://aws.amazon.com/jp/getting-started/tutorials/deploy-react-app-cicd-amplify/)
[AWS Amplify Console]はGitベースでSingle Page Applicationや静的サイトを開発・デプロイ・ホスティングするためのサービスです。
このチュートリアルではReactのアプリケーションをデプロイしていきます。1. Sign up for AWS
AWSのアカウントはすでに作成しているので、サインインしておきます。
2. Confirm environmental setup
ターミナルを開き、以下のコマンドで
nodeのバージョンを確認します。node -v;
command not foundが出る場合はチュートリアルのリンク先からダウンロードします。
また、バージョンが8以下のときは更新します。3. Create a new React application
npx create-react-app amplifyappで
amplifyappという名前のReactアプリケーションを作成します。npxについては、下記が詳しそうでした。
https://dev.classmethod.jp/node-js/node-npm-npx-getting-started/ちなみに、実行したところ下記のようなエラーが発生しました。
npm ERR! code ECONNRESET npm ERR! errno ECONNRESET npm ERR! network request to https://registry.npmjs.org/create-react-app failed, reason: read ECONNRESET npm ERR! network This is a problem related to network connectivity. npm ERR! network In most cases you are behind a proxy or have bad network settings. npm ERR! network npm ERR! network If you are behind a proxy, please make sure that the npm ERR! network proxy' config is set properly. See: 'npm help config' npm ERR! A complete log of this run can be found in: npm ERR! /Users/xxx/.npm/_logs/2020-02-16T10_41_14_3742-debug.log ] コード [ 'create-react-app@latest' ]でのインストールに失敗しました以前の記事でネットワーク関係のエラーが出たときにカスペルスキーが関連しているという話があったので、もしかしてと思いカスペルスキーを再起動をしたところ無事作成できました。
作成できたら、
cd amplifyapp npm startで起動してみます。
4. Initialize GitHub repository
a./b.
チュートリアルに従ってGitHubでリポジトリを作成し、3.で作成したアプリケーションをpushします。
5. Log in to the AWS Amplify Console
AWSコンソールから[サービス]->[モバイル]にある[AWS Amplify]を開きます。
チュートリアルの通り、検索したほうが早いです。6. Deploy your app to AWS Amplify
作成したアプリケーションをデプロイします。
a./b.
チュートリアルに従って、[Deploy]の下にある[Get Start]を押し、次の画面で[GiftHub]を選択して[Continue]を押します。
c.
GitHubの認証画面が表示されるので、認証します。
認証が完了したら、4.で作成したリポジトリとブランチを選択し[次へ]を押します。d./e.
チュートリアルの通り、[ビルド設定の構成]はデフォルト設定で次へ進み、確認画面で[保存してデプロイ]を押します。
f.
作成が開始すると次のような画面が表示されます。
[検証]まですべて緑のチェックになるとデプロイ完了です。g.
デプロイが完了すると、サムネイルまたはその下のURLからアクセスすることができます。
アクセスすると、3.で起動したアプリケーションと同じように起動しているのが確認できます。7. Automatically deploy code changes
a.
チュートリアルの通り、ソースを編集した上でGitの
masterブランチに変更をpushします。pushすると、自動的にAmplify Console上の最終コミットが更新され、デプロイが実行されます。
b.
デプロイ完了後に再度URLにアクセスすると変更点が反映されています。
8. Clean up your resources
最後にアプリケーションを削除します。
チュートリアルの通り、アプリケーションの詳細から[アクション]ー>[アプリの削除]をクリックします。
下記の通り、確認のダイアログが表示されるので、削除して問題なければdeleteを入力した上で[Delete]ボタンを押します。
削除されるとメッセージが表示された上で、Amplify Consoleのトップに戻ります。
まとめ
GitHubと接続して、ブランチを更新したら自動的にデプロイしてくれるAmplifyConsoleはとても便利でした。
ちなみに、手元にあったRailsのリポジトリをデプロイしようとしたところビルドでエラーになりました。
今後SPAで開発するときがあったら使用してみたいと思います。次は「コンテンツを迅速に配信する」をやっていきます
残りの[ウェブサイトとアプリケーション]のチュートリアルがサーバーレス関係ばかりになったのでここで一区切りとし、次回でこの形でチュートリアルをやるの最後にする予定です。




- 投稿日:2020-02-16T19:07:49+09:00
LambdaでEKS Worker Nodeの夜間・休日停止を行う
はじめに
検証環境やステージング環境でEKSを使用するときには夜間・休日には停止させて料金を抑えたいことがあると思います。
しかしながらEKSのWorker Nodeの数は宣言的であるがために停止させても新たに立ち上がります。
Masterを消すにしても元の状態に戻すためのアプリケーションのバックアップ・リストア作業を全て自動化しておかないと相当面倒です。今回はAutoscaling Groupのパラメータを変更することでWorker Nodeをシャットダウンさせ擬似的な夜間・休日停止をLambda関数で実行させます。
前半ではLambdaの設定内容を説明し、後半では実際にPulumiで構築していきます。
環境情報
macOS Mojave 10.14.1
Pulumi: 1.10.1
EKS: 1.14Lambda設定内容
Lambdaで設定する関数、IAM Policy、トリガーについて説明します。
関数
ランタイムは
Python 3.7を使用します。lambda_function.pyimport boto3 autoscaling = boto3.client("autoscaling") def lambda_handler(event, context): args = dict(AutoScalingGroupName=event["AutoSaclingGroupName"], MinSize=event["MinSize"], MaxSize=event["MaxSize"], DesiredCapacity=event["DesiredCapacity"]) autoscaling.update_auto_scaling_group(**args)IAM Policy
IAM RoleにはLambdaのIAM Policyの他にAutoscaling Groupを編集するためのIAM Policyをアタッチする必要があります。
これはAWSで用意されている
arn:aws:iam::aws:policy/AutoScalingFullAccessを選択すれば問題ないです。トリガー
今回はEKS Worker Node起動時間を平日07:00-23:00(JST)とします。
CloudWatch Eventsでスケジュール式のルールを2種類(停止用、起動用)作成しましょう。
スケジュール式はUTCで記述する必要があることに注意します。停止ルール
- スケジュール式
cron(0 14 ? * MON-FRI *)
- 入力(定数Jsonテキスト)
{ "AutoSaclingGroupName": <NODEGROUP_NAME>, "MinSize": 0, "MaxSize": 0, "DesiredCapacity": 0 }起動ルール
- スケジュール式
cron(0 22 ? * SUN-THU *)
- 入力(定数Jsonテキスト)
{ "AutoSaclingGroupName": <NODEGROUP_NAME>, "MinSize": 1, "MaxSize": 2, "DesiredCapacity": 2 }以上が夜間・休日にWorker Nodeを落とすための設定内容となります。
構築
手動でコンソールから設定するとNodeGroup名を調べるのがいちいち面倒です。
コード化しておけばその部分を柔軟に行えます。今回はPulumiを採用します。
スタック作成
下記コマンドでpulumiスタックを作成します。
$ pulumi new aws-typescript $ pulumi config set aws:region ap-northeast-1実装
ディレクトリ構造は下記となります。
編集するのはupdate_node_size.pyとindex.tsのみです。
他のファイルはスタック作成時のままで問題ありません。├── Pulumi.eks.yaml ├── Pulumi.yaml ├── node_modules/ ├── package-lock.json ├── package.json ├── tsconfig.json ├── lambda_functions │ └── update_node_size.py * └── index.ts *
update_node_size.pylambda関数として使用されるものです。
こちらは説明は不要かと思います。update_node_size.pyimport boto3 autoscaling = boto3.client("autoscaling") def handler(event, context): args = dict(AutoScalingGroupName=event["AutoSaclingGroupName"], MinSize=event["MinSize"], MaxSize=event["MaxSize"], DesiredCapacity=event["DesiredCapacity"]) autoscaling.update_auto_scaling_group(**args)
index.tsこちらは生成するAWSリソースを定義したものです。
順に説明していきます。index.tsimport * as aws from "@pulumi/aws"; import * as awsx from "@pulumi/awsx"; import * as eks from "@pulumi/eks"; import * as pulumi from "@pulumi/pulumi"; const minSize = 1, maxSize = 2, desiredCapacity = 2; const vpc = new awsx.ec2.Vpc("custom", { cidrBlock: "10.0.0.0/16", numberOfAvailabilityZones: 3, }); const cluster = new eks.Cluster("pulumi-eks-cluster", { vpcId: vpc.id, subnetIds: vpc.publicSubnetIds, minSize: minSize, maxSize: maxSize, desiredCapacity: desiredCapacity }); const handlerRole = new aws.iam.Role("handlerRole", { assumeRolePolicy: { Version: "2012-10-17", Statement: [{ Action: "sts:AssumeRole", Principal: { Service: "lambda.amazonaws.com", }, Effect: "Allow", Sid: "", }], }, }); new aws.iam.RolePolicyAttachment("handlerRoleAttachmentLambda", { role: handlerRole, policyArn: aws.iam.AWSLambdaFullAccess, }); new aws.iam.RolePolicyAttachment("handlerRoleAttachmentAutoscaling", { role: handlerRole, policyArn: aws.iam.AutoScalingFullAccess, }); const updateNodeSizeFunc = new aws.lambda.Function("updateNodeSizeFunc", { runtime: aws.lambda.Python3d7Runtime, handler: "update_node_size.handler", code: new pulumi.asset.AssetArchive({ ".": new pulumi.asset.FileArchive("./lambda_functions"), }), role: handlerRole.arn }); const stopInstancesEventRule = new aws.cloudwatch.EventRule("stopInstances", { description: "stop instances at night", scheduleExpression: "cron(0 14 ? * MON-FRI *)", }); const startInstancesEventRule = new aws.cloudwatch.EventRule("startInstances", { description: "start instances in the morning", scheduleExpression: "cron(0 22 ? * SUN-THU *)", }); new aws.lambda.Permission("stopInstances", { action: "lambda:InvokeFunction", function: updateNodeSizeFunc, principal: "events.amazonaws.com", sourceArn: stopInstancesEventRule.arn, }); new aws.lambda.Permission("startInstances", { action: "lambda:InvokeFunction", function: updateNodeSizeFunc, principal: "events.amazonaws.com", sourceArn: startInstancesEventRule.arn, }); if (cluster.defaultNodeGroup != undefined) { new aws.cloudwatch.EventTarget("stopInstances", { arn: updateNodeSizeFunc.arn, rule: stopInstancesEventRule.name, input: cluster.defaultNodeGroup.cfnStack.outputs.apply(outputs => { return JSON.stringify({ "AutoSaclingGroupName": outputs["NodeGroup"], "MinSize": 0, "MaxSize": 0, "DesiredCapacity": 0 }) }) }); new aws.cloudwatch.EventTarget("startInstances", { arn: updateNodeSizeFunc.arn, rule: startInstancesEventRule.name, input: cluster.defaultNodeGroup.cfnStack.outputs.apply(outputs => { return JSON.stringify({ "AutoSaclingGroupName": outputs["NodeGroup"], "MinSize": minSize, "MaxSize": maxSize, "DesiredCapacity": desiredCapacity }) }) }); }まず最初にネットワークとEKSの構築を行います。
必須パラメータは少なく、定義していないパラメータは補完してくれます。const vpc = new awsx.ec2.Vpc("custom", { cidrBlock: "10.0.0.0/16", numberOfAvailabilityZones: 3, }); const cluster = new eks.Cluster("pulumi-eks-cluster", { vpcId: vpc.id, subnetIds: vpc.publicSubnetIds, minSize: minSize, maxSize: maxSize, desiredCapacity: desiredCapacity });次にIAM Roleの設定です。
LambdaとAutoscaling GroupのIAM Policyをアタッチさせています。const handlerRole = new aws.iam.Role("handlerRole", { assumeRolePolicy: { Version: "2012-10-17", Statement: [{ Action: "sts:AssumeRole", Principal: { Service: "lambda.amazonaws.com", }, Effect: "Allow", Sid: "", }], }, }); new aws.iam.RolePolicyAttachment("handlerRoleAttachmentLambda", { role: handlerRole, policyArn: aws.iam.AWSLambdaFullAccess, }); new aws.iam.RolePolicyAttachment("handlerRoleAttachmentAutoscaling", { role: handlerRole, policyArn: aws.iam.AutoScalingFullAccess, });次に関数を定義します。
./lambda_functions配下に定義しているupdate_node_size.pyのhandler関数を読み込むようにしています。const updateNodeSizeFunc = new aws.lambda.Function("updateNodeSizeFunc", { runtime: aws.lambda.Python3d7Runtime, handler: "update_node_size.handler", code: new pulumi.asset.AssetArchive({ ".": new pulumi.asset.FileArchive("./lambda_functions"), }), role: handlerRole.arn });次にCloudWatch Eventsのルールを作成します。
Worker Nodeの停止と起動のスケジュール式を定義します。const stopInstancesEventRule = new aws.cloudwatch.EventRule("stopInstances", { description: "stop instances at night", scheduleExpression: "cron(0 14 ? * MON-FRI *)", }); const startInstancesEventRule = new aws.cloudwatch.EventRule("startInstances", { description: "start instances in the morning", scheduleExpression: "cron(0 22 ? * SUN-THU *)", });先ほど作成したCloudWatch EventsのルールをLambdaのトリガーとして設定します。
new aws.lambda.Permission("stopInstances", { action: "lambda:InvokeFunction", function: updateNodeSizeFunc, principal: "events.amazonaws.com", sourceArn: stopInstancesEventRule.arn, }); new aws.lambda.Permission("startInstances", { action: "lambda:InvokeFunction", function: updateNodeSizeFunc, principal: "events.amazonaws.com", sourceArn: startInstancesEventRule.arn, });最後にLambda関数実行時の引数に入れる値をJsonとして定義します。
EKS構築時に作成したNodeGroup名がAutoscalingGroupNameのvalueとして入るようにしています。
これでわざわざ自分でNodeGroup名を調べる必要がなくなります。if (cluster.defaultNodeGroup != undefined) { new aws.cloudwatch.EventTarget("stopInstances", { arn: updateNodeSizeFunc.arn, rule: stopInstancesEventRule.name, input: cluster.defaultNodeGroup.cfnStack.outputs.apply(outputs => { return JSON.stringify({ "AutoSaclingGroupName": outputs["NodeGroup"], "MinSize": 0, "MaxSize": 0, "DesiredCapacity": 0 }) }) }); new aws.cloudwatch.EventTarget("startInstances", { arn: updateNodeSizeFunc.arn, rule: startInstancesEventRule.name, input: cluster.defaultNodeGroup.cfnStack.outputs.apply(outputs => { return JSON.stringify({ "AutoSaclingGroupName": outputs["NodeGroup"], "MinSize": minSize, "MaxSize": maxSize, "DesiredCapacity": desiredCapacity }) }) }); }実行
下記コマンドで実行します。
$ pulumi up以上でpulumiを使用したときの手順は終わりです。
おわりに
LambdaでEKS Worker Nodeに紐付くAutoscaling GroupのNode数を変更し夜間・休日に停止させる手順を説明しました。
本当に料金を抑えるなら下記3つの設定を全てコード化しておき毎日削除・作成を行うことが理想だと思います。
- AWSリソース
- Kubernetesリソース
- アプリケーション
コード化する時間が取れない場合はとりあえず今回の手順に沿ってWorker Nodeだけ落とすだけでも料金は抑えられます。
- 投稿日:2020-02-16T19:00:46+09:00
【AWS認定試験対策】VPC、Route53のポイントまとめ
はじめに
AWSの認定試験を受験するにあたって、各AWSのサービスを幅広く理解する必要があったためサービスごとに抑えるべきポイント等をまとめてみました。
今回はVPC、Route53についてです。※情報は2019年12月31日時点のものになります。ご了承ください。
ちなみにAWS認定試験での勉強方法についてはこちらの記事で紹介しています。
VPC
Amazon VPC(Virtual Private Cloud)とは、AWS上での仮想ネットワーク環境になります。
以下が簡単な特徴になります。
- 料金は発生しない
- リージョンごとに作成可能
- 以下の制限がある
- リージョンあたりのVPCは5まで(制限緩和で100まで引き上げ可能)
- VPCあたりのサブネットの数は200まで
- VPC 当たりの IPv4 CIDR ブロックは5まで(最大50まで引き上げ可能)
- VPC 当たりの IPv6 CIDR ブロックは1まで
- IPアドレスの範囲を/16 〜 /28 のブロックサイズでCIDRブロック形式で指定する必要がある (例:10.0.0.0/16)
- 10.0.0.0 〜 10.255.255.255
- 172.16.0.0 〜 172.31.255.255
- 192.168.0.0 〜 192.168.255.255
サブネットについての参考
- VPCのIPアドレスの範囲でサブネットを作成する
- サブネットで使用できないホストアドレス
- .0:ネットワークアドレス
- .1:VPCの仮想ルーター
- .2:DNSサービス
- .3:AWSが予約済み(将来何かに使われる?)
- .255:ブロードキャストアドレス
- サブネットはアベイラリティーゾーン単位で作成する
■インターネットゲートウェイ
VPC内のインスタンスとインターネット通信を可能にするもの
■ルートテーブル
VPC内でルーティング設定を行うもの
インターネットゲートウェイへのルーティング設定がされたルートテーブルをアタッチされたサブネットをパブリックサブネット(インターネット通信できるから)そうでないサブネットをプライベートサブネットという(インターネット通信できないから)
■サブネット内のインスタンスがインターネットに接続するためのステップ
- サブネットAを作成する
- 作成したサブネットAでインスタンスを起動する
- ルートテーブルBを作成する (転送先をインターネットゲートウェイに、宛先を0.0.0.0/0 にする。この設定だとすべてのIPアドレスの宛先がインターネットゲートウェイに転送される)
- サブネットAとルートテーブルBを関連付けする。つまり、インターネットゲートウェイをアタッチする
■NACL(Network ACL)
サブネットのインバウンド、アウトバウンドの通信をコントロールをするもの
(セキュリティグループのサブネット版みたいなもの)
- インバウンドもしくはアウトバウンドの許可、禁止を設定できる
- デフォルトでは、インバウンドもアウトバウンドもすべて許可された状態
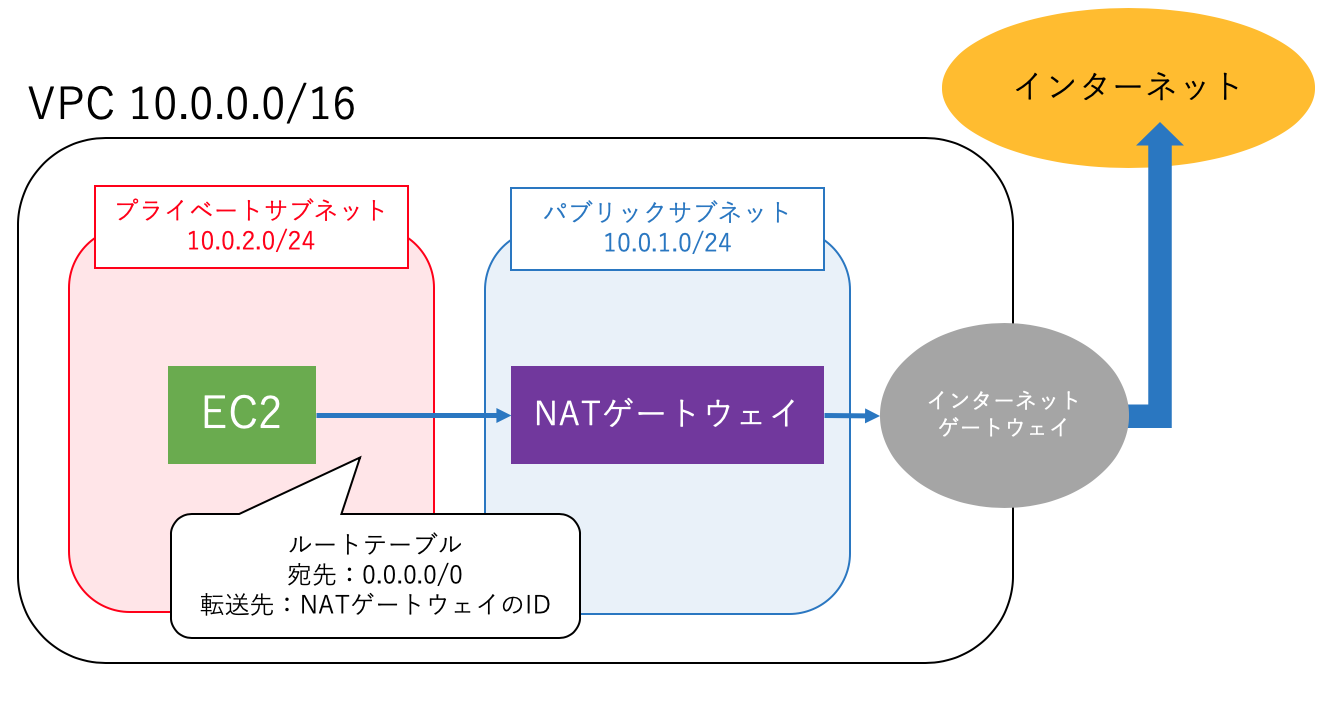
■NATゲートウェイ
プライベートサブネット内のインスタンスがインターネットにアクセスしたい場合、NATゲートウェイをプライベートサブネットに配置してNATゲートウェイ経由でインターネットへアクセスを行う。
具体的には、プライベートサブネットに関連づけられているルートテーブルに「転送先をNATゲートウェイに、宛先を0.0.0.0/0 」などとする。この設定だとすべてのIPアドレスの宛先がNATゲートウェイに転送されNATゲートウェイがその先のルーティングを引き受ける。
※NATゲートウェイはアベイラリティーゾーンごとに作成
■【頻出】VPCのプライベートサブネット内のインスタンスがインターネットへのアクセスを有効にする手順
10.0.1.0/24がパブリックサブネット、10.0.2.0/24がプライベートサブネットとする
- VPCにインターネットゲートウェイをアタッチする
- パブリックサブネットのルートテーブルにおいて、通信をインターネットゲートウェイへ接続するように設定する
- パブリックサブネットNATゲートウェイ(またはNATインスタンス)を配置する
- NATのインスタンスに、グローバルに一意なIPアドレス(IPv4アドレス、IPv6アドレス、Elastic IPアドレスのいずれか)が割り当てる
- プライベートサブネットのルートテーブルにおいて「宛先を0.0.0.0/0(すべてのIP)、転送先をNATゲートウェイ」に設定する
- ネットワークアクセスコントロール(NACL)とインスタンスのセキュリティグループルールをインスタンス間の通信を許可するように設定する
■VPCエンドポイント
プライベートサブネット内のインスタンスがAWSのAPI(S3など)にアクセスするときにはVPCエンドポイントを利用する。したがって、同一リージョンならばインターネットを経由せずに通信が完結する。
※VPCエンドポイントを追加するとルートテーブルにAWS APIへのルーティング設定が自動で追加される
VPCエンドポイントには2つの種類があり、すべてのAWSサービスをサポートしているわけではない
- Gateway型 S3、DynamoDB
- Interface型 EC2、SNS、Cloud Watchなど
■VPCピアリング
異なるVPC間で通信する仕組み
- 異なるアカウントのVPCでも通信できる
- 異なるリージョンのVPCでも通信できる
■VPC Flow Logs
VPC内の通信ログをCloudWatchに流す仕組み
■Direct Connect
オンプレ環境とAWSを接続する専用回線
仮想インターフェースと一緒に用いることが多い
- パブリック仮想インターフェース:S3などのパブリックサービスにアクセス
- プライベート仮想インターフェース:VPCへのアクセス
■VPNコネクション
オンプレ環境とAWSを接続する手法の一つ。
ハードウェアVPNを使われることが多いがDirect Connctほどは安定しない
■その他 覚えておくといいこと
- IPv4とIPv6が混在する場合はVPCのデュアルスタックモードを用いる
- プライベートサブネット内のインスタンスからインターネットへのアウトバウンド接続を行う場合、NAT インスタンス上の送信元/送信先チェック属性を無効にする必要性がある
- NATゲートウェイはIPv4のみ
- プライベートサブネットはNATに対してIPv4トラフィックルーティングしていたが、IPv6はルーティングできないので別途Egress-Only インターネットゲートウェイを作って、そこに対してルーティングをする必要がある
Route 53
グローバルに配置されているAWSのDNSサービスになります。
■料金
以下で料金が発生します。
- ホストゾーンの管理:Route 53 で管理した各ホストゾーンに対する月額料金が発生
- DNS クエリへの応答:DNS クエリに対する Amazon Route 53 サービスからの応答に対して料金が発生 ただし、クエリの対象がエイリアスAレコードかつ以下の場合は無料
- Elastic Load Balancing インスタンス
- CloudFront ディストリビューション
- AWS Elastic Beanstalk 環境
- API Gateway
- VPC エンドポイント
- Amazon S3 ウェブサイトバケットにマッピング
- ドメイン名の管理:Route 53 経由で登録された各ドメイン名または Route 53 に転送された各ドメイン名に対して年間料金が発生
■サポートしているDNSレコードタイプ
- A:アドレスレコード ドメインをIPアドレスにする
inu-is-kawaii.jp. IN A 192.168.0.1 www.neko-ha-kami.jp. IN A 192.168.0.1
AAAA:IPv6アドレスコード
CNAME:正規名レコード
ドメインを異なるドメインにするinu-is-kawaii.jp.jp. IN A 192.168.0.1 www.neko-ha-kami.jp. IN CNAME neko.jp.
MX:メール交換レコード
NS:ネームサーバーレコード
PTR:ポインターレコード
SOA:管理情報の始点レコード
SPF:センダーポリシーフレームワーク
SRV:サービスロケーター
TXT:テキストレコード
エイリアスレコード
■ルーティングポリシー
Route 53ではトラフィックルーティングのルーティングポリシーを定めることができます。
シンプルルーティングポリシー
通常のDNSサーバーと同じ挙動加重ルーティングポリシー
ルーティングする宛先の重み付けをすることができるレイテンシールーティングポリシー
レイテンシーが最も低いリージョンのリソースにルーティングする
フェイルオーバールーティングポリシー
正常なリソースに対してトラフィックをルーティングする複数値回答ルーティングポリシー
DNS クエリに対する応答として複数の値 (ウェブサーバーの IP アドレスなど) を返すように設定できる。
また、各リソースが正常であるかどうかも確認し、その結果を返却することもできる
- 地理的近接性ルーティングポリシー
トラフィックを最も近いアベイラリティーゾーンのリソースにルーティングする(トラフィックフローのみ)
- 位置情報ルーティングポリシー ユーザーの位置に基づいてトラフィックをルーティングする
■その他 覚えておくといいこと
- Route53は、ELBやCloudFrontに対して、 ZoneApexレコードをAレコード で指定することができる
- 投稿日:2020-02-16T18:08:59+09:00
AWS CloudWatch メモリ使用率を出す際でのエラー Can't locate Sys/Syslog.pm in
CloudWatchはデフォルトではメモリ、ディスク使用率が監視できない。
その方法は、AWSの公式ページがよくまとまっている。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/mon-scripts.html#mon-scripts-perl_prereq注意が必要な点
- モニタリングスクリプトのインストール後、
cp awscreds.template awscreds.confしてからvi awscreds.confで、キーを入力する。エラー
CloudWatchのテストの際(
./mon-put-instance-data.pl --mem-util --verify --verbose)、以下のエラーが発生。Can't locate Sys/Syslog.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at ./mon-put-instance-data.pl line 77.
BEGIN failed--compilation aborted at ./mon-put-instance-data.pl line 77.解決策
aws-scripts-monをディレクトリ毎削除して、もう一度最初の手順を行う。細かい原因等ご存知の方居たら教えてください!
- 投稿日:2020-02-16T16:06:03+09:00
EC2にSSH接続できる環境を、CloudFormationを利用して作ってみた
はじめに
今回の目標は、以下のとおりです。
パブリックサブネットに配置されたEC2にSSH接続できる環境を、CloudFormationで作成する。 また、そのテンプレートをローカルからAWSCLIを利用してデプロイする。以降では、本記事で利用したテンプレートを記載し、またそれらのパラメータについて説明しようと思います。
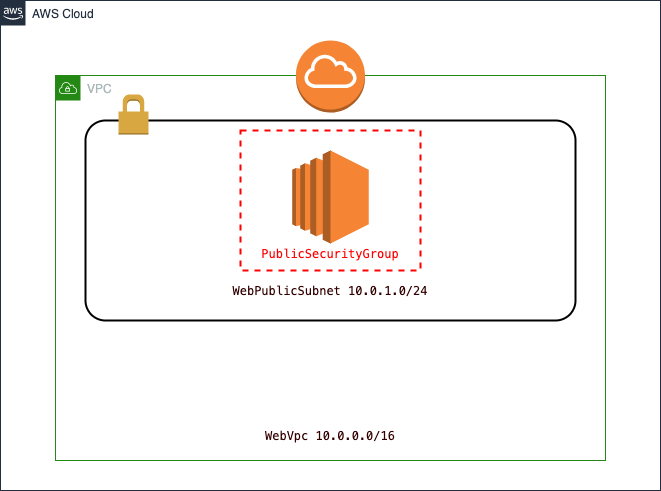
最後に、実際にテンプレートをCLIを利用してローカルからデプロイし、実際にSSHしてみます。構成内容
- VPC
- InternetGateway
- EC2(Public)
やったこと
CloudFormationで利用するテンプレートの作成- テンプレートのデプロイ
- 作成したインスタンスへの、SSH接続
※事前にデプロイ用のIAMユーザ、SSH接続用のキーペアは作成済み
CloudFormationで利用するテンプレートの作成今回利用したテンプレート
AWSTemplateFormatVersion: "2010-09-09" Description: A sample template Mappings: RegionMap: ap-northeast-1a: Name: "ap-northeast-1a" ap-northeast-1c: Name: "ap-northeast-1c" Resources: # ____ # ___ ___|___ \ # / _ \/ __| __) | # | __/ (__ / __/ # \___|\___|_____| WebInstance: Type: AWS::EC2::Instance Properties: ImageId: ami-011facbea5ec0363b InstanceType: t2.micro KeyName: "keypair" SubnetId: Ref: WebPublicSubnet SecurityGroupIds: [Ref: PublicSecurityGroup] Tags: - Key: "Name" Value: "web" # __ ___ __ ___ # \ \ / / '_ \ / __| # \ V /| |_) | (__ # \_/ | .__/ \___| # |_| WebVpc: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 EnableDnsSupport: true EnableDnsHostnames: true Tags: - Key: Name Value: PublicVpc WebPublicSubnet: Type: AWS::EC2::Subnet Properties: AvailabilityZone: !FindInMap [RegionMap, ap-northeast-1a, Name] VpcId: Ref: WebVpc CidrBlock: 10.0.1.0/24 MapPublicIpOnLaunch: true Tags: - Key: Name Value: WebPublicSubnet # ___ _ _ # |_ _|_ __ | |_ ___ _ __ _ __ ___| |_ # | || '_ \| __/ _ \ '__| '_ \ / _ \ __| # | || | | | || __/ | | | | | __/ |_ # |___|_| |_|\__\___|_| |_| |_|\___|\__| # ____ _ # / ___| __ _| |_ _____ ____ _ _ _ # | | _ / _` | __/ _ \ \ /\ / / _` | | | | # | |_| | (_| | || __/\ V V / (_| | |_| | # \____|\__,_|\__\___| \_/\_/ \__,_|\__, | # |___/ InternetGateway: Type: AWS::EC2::InternetGateway InternetGatewayAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: InternetGatewayId: !Ref InternetGateway VpcId: !Ref WebVpc # ____ _ _____ _ _ # | _ \ ___ _ _| |_ __|_ _|_ _| |__ | | ___ # | |_) / _ \| | | | __/ _ \| |/ _` | '_ \| |/ _ \ # | _ < (_) | |_| | || __/| | (_| | |_) | | __/ # |_| \_\___/ \__,_|\__\___||_|\__,_|_.__/|_|\___| RouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref WebVpc DefaultRoute: Type: AWS::EC2::Route Properties: RouteTableId: Ref: RouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: Ref: InternetGateway DependsOn: - SubnetRouteTableAssociation SubnetRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: RouteTableId: !Ref RouteTable SubnetId: !Ref WebPublicSubnet # _ _ _ # ___ ___ ___ _ _| |_(_) |_ _ _ __ _ _ __ ___ _ _ _ __ # / __|/ _ \/ __| | | | __| | __| | | | / _` | '__/ _ \| | | | '_ \ # \__ \ __/ (__| |_| | |_| | |_| |_| | | (_| | | | (_) | |_| | |_) | # |___/\___|\___|\__,_|\__|_|\__|\__, | \__, |_| \___/ \__,_| .__/ # |___/ |___/ |_| PublicSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: "sg for public" GroupName: "public sg" VpcId: !Ref WebVpc SecurityGroupIngress: - CidrIp: 0.0.0.0/0 IpProtocol: tcp FromPort: 22 ToPort: 22各設定値について(カッコ内は本記事での論理ID)
AWS::EC2::Instance(
WebInstance)ImageId
どのAMIでインスタンスを作成するかを設定する。今回はAWSが提供している標準的なAMIを利用した。ここを動的に指定すれば、常に起動インスタンスのバージョンを最新にする、的なことができる、はず。
InstanceType
起動するインスタンスのタイプを設定する(そのまんま)。
KeyName
作成したインスタンスにSSHする際に利用するキーペアを設定する。ここで設定しておかないと、SSHできなるなるので注意(セッションマネージャを利用しての接続があるので、できないこともない。むしろ、そっちを利用したほうがわざわざセキュリティグループのSSH用の穴を開けなくて済むので、安全かも)。
SubnetId
インスタンスが、どのサブネットに属するかを設定する。
SecurityGroupIds
インスタンスが、どのセキュリティグループに属するかを設定する。
Id「s」とあるように、リストで書く必要がある。Tags
タグです(そのまんま)。
KeyとValueを設定し、リソースに情報を与えることができる。「特定のインスタンスだけ操作したいぜ」等なときに便利。これ以降のTagsも同様。なので以降は割愛。AWS::EC2::VPC(
WebVpc)CidrBlock
利用するIPアドレスの範囲(CIDR表記)。
EnableDnsHostnames
パブリック IP アドレスを持つインスタンスが、対応するパブリック DNS ホスト名を取得するかどうか。これと
EnableDnsSupportの両方がtrueじゃないと、インスタンスにパブリックDNSが割り当てられない。EnableDnsSupport
DNS 解決がサポートされているかどうか。これと
EnableDnsHostnamesの両方がtrueじゃないと、インスタンスにパブリックDNSが割り当てられない。参考:
AWS公式ドキュメント
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-dns.htmlAWSでPublic DNS(パブリックDNS)が割り当てられない時の解決法
https://qiita.com/sunadoridotnet/items/4ea689ce9f206e78a523AWS::EC2::Subnet(
WebPublicSubnet)AvailabilityZone
作成するサブネットがどの
AvailabilityZoneに属するかを設定する。VpcId
作成するサブネットがどの
VPCに属するかを設定する。CidrBlock
利用するIPアドレス範囲(CIDR表記)。
MapPublicIpOnLaunch
このサブネットで起動するインスタンスが、パブリックIPを取得するかどうかを設定する。
AWS::EC2::InternetGateway(
InternetGateway)設定値は特にないです(そもそもタグしかつけられない)。
ただ、これがないとインタネットゲートウェイが作成できない。
「どのVPCにアタッチするか」を設定するために、
後述するAWS::EC2::VPCGatewayAttachmentと一緒に使いましょう。AWS::EC2::VPCGatewayAttachment(
InternetGatewayAttachment)InternetGatewayId 及び VpcId
インタネットゲートウェイと
VPCの関係を設定する。
「このインタネットゲートウェイ(=InternetGatewayId)を、このVPC(=VpcId)にアタッチする」というように使う。AWS::EC2::RouteTable(
RouteTable)VpcId
このルートテーブルを使用する
VPCを指定。AWS::EC2::Route(
DefaultRoute)RouteTableId
ここで作成するルーティング情報を、どのルートテーブルに適用するかを設定する。
DestinationCidrBlock
転送するIPアドレスの範囲を設定する。今回は、これをデフォルトゲートウェイとして扱いたいので、
0.0.0.0/0を指定。GatewayId
転送先のインタネットゲートウェイのIDを設定する。他にも転送先としてインスタンス等があり、どれか一つのみを指定する必要がある。
DependsOn
これを記述すると、
「このリソースは、DependsOnで指定したリソースを作成したあとに作成してね」
というように、リソースの作成順序を明示的に指定できる。
基本、AWSがよしなにやってくれるが、たまに明示的に指示しないとスタックの作成に失敗する。
ルーティング設定のリソース絡みは要注意?らしい。主な例外:
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-attribute-dependson.htmlAWS::EC2::SubnetRouteTableAssociation(
SubnetRouteTableAssociation)RouteTableId 及び SubnetId
AWS::EC2::VPCGatewayAttachmentみたいなもの。「どのルートテーブルをどのサブネットにアタッチするか」を設定する。AWS::EC2::SecurityGroup(
PublicSecurityGroup)GroupDescription
このセキュリティグループの説明を記述する。
Descriptionなのだが、必須なので注意。GroupName
このセキュリティグループの名前をつける。こっちは任意。
VpcId
このセキュリティグループを適用する
VPCのIDを設定する。SecurityGroupIngress
所謂インバウンドルールを設定する。以下の4つが必要。
- CidrIp
所謂ソース。SourceSecurityGroupId等、何でもいいからソースは必要- IpProtocol
どのプロトコルを利用するかを設定する- FromPort, ToPort
ポートの利用範囲を設定するテンプレートのデプロイ
作成したテンプレートを、実際にデプロイします。冒頭で述べたとおり、今回は
AWSCLIを利用します。
といっても、下記コマンドを入力するだけですが…aws cloudformation deploy --template ./template.yaml --stack-name standard-vpc --profile admin一応コマンドの簡単な説明は以下のとおりです。
aws cloudformation deploy
変更セットを作成し、その変更セットを実行してから停止する。今回の実行結果の予測が既についており、とっとと反映させたい場合deployコマンドを利用するのが便利そう。--template ./template.yaml
「どのテンプレートを利用して、変更セットを作成するか」を指定する。--stack-name standard-vpc
今回作成するスタックの名称を指定する。--profile admin
利用するプロファイル情報を指定する。デフォルト以外のプロファイル情報を利用する場合はこのオプションを利用して切り替える。ベストプラクティス的には最小権限で行うべきなんでしょうが、今回は個人的な遊びだからってことで…デプロイが完了したら、コンソールでスタックが作成され、変更セットの実行が成功しているのを確認。
作成したインスタンスへの、SSH接続
最後に今回作成したインスタンスへちゃんと接続できるかを検証します。SSH接続のコマンドは以下の通り。
ssh -i keypair.pem ec2-user@{dns_name}
終わりに
今回は「インスタンスへのSSH接続ができる環境」を
CloudFormationで作成してみました。
必要なリソース自体はコンソールで作成する場合と同じなのですが、「インタネットゲートウェイのVPCへのアタッチ」等リソースに対する操作をどうCloudFormationで表現すればいいかにすごく悩みました。ただ、これで簡単に一つの環境をいつでも作れるようになったことを考えると、やっぱり
CloudFormationは必須なんですねぇ…今後はこれをベースに継ぎ足していきたいと思います。
※タグがあったりなかったり、組み込み関数を利用したりしなかったり等、纏まりがなくすいません…

- 投稿日:2020-02-16T14:52:55+09:00
Embulkでローカルディスクを使わずにクラウドストレージにアップロードする
embulk-output-commandからgsutilコマンドにデータを渡してストリーミングアップロードしてディスクレスにしてみた話。
embulkってなにって方はこちらから。
なんでやったの
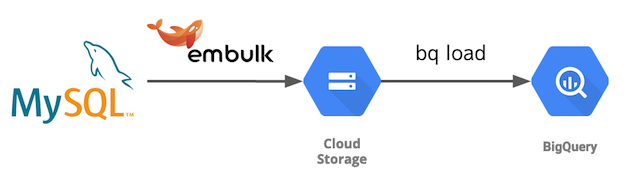
EmbulkでMySQLやOracleからデータをBigQueryにデータ連携する際、データレイクとしてひとまずGoogle Cloud Storage(GCS)にファイルをアップロードしています。
最初はembulk-output-gcsを使ってたんですけど、1TBのテーブルとか出てきてマシンのストレージが枯渇しちゃったんですよね。
そこで、embulk-output-commandからgsutilコマンドにデータを渡して、ストリーミングアップロードしてディスクレスにしてみました。
GCSのストリーミングアップロードに関してはこちら。
https://cloud.google.com/storage/docs/streamingどうやったの
環境
- ubuntu:bionic
- openjdk-8-jdk
- Embulk v0.9.17
- embulk-input-mysql v0.10.1
- embulk-output-gcs v0.4.4
- embulk-output-command v0.1.4
- gsutil 4.47
embulkはGKEでコンテナ実行
Before (embulk-outout-gcs)
embulk-output-gcsを使うとこんな感じ。
ローカルの/tmpにファイルがに書き込まれて、GCSアップロード後に削除されているのが分かります。job.yamlin: type: mysql host: localhost port: 3306 database: test user: mysql_user password: xxxxxxx query: select * from test_table out: type: gcs auth_method: compute_engine bucket: bucket_name path_prefix: mysql/test/test_table file_ext: .csv formatter: type: csv... 2020-02-15 13:11:17.756 +0000 [INFO] (0001:transaction): Using local thread executor with max_threads=8 / output tasks 4 = input tasks 1 * 4 2020-02-15 13:11:17.790 +0000 [INFO] (0001:transaction): {done: 0 / 1, running: 0} 2020-02-15 13:11:19.186 +0000 [INFO] (0016:task-0000): Fetch size is 10000. Using server-side prepared statement. 2020-02-15 13:11:19.187 +0000 [INFO] (0016:task-0000): Connecting to jdbc:mysql://localhost:3306/test options {useCompression=true, socketTimeout=1800000, useSSL=false, user=admin, useLegacyDatetimeCode=false, tcpKeepAlive=true, useCursorFetch=true, connectTimeout=300000, password=***, zeroDateTimeBehavior=convertToNull} 2020-02-15 13:11:19.289 +0000 [INFO] (0016:task-0000): SQL: select * from test 2020-02-15 13:11:19.311 +0000 [INFO] (0016:task-0000): > 0.01 seconds 2020-02-15 13:11:20.679 +0000 [INFO] (0016:task-0000): Local Hash(MD5): XTIT3ANlo6QqZnwNBdzGCA== / Remote Hash(MD5): XTIT3ANlo6QqZnwNBdzGCA== 2020-02-15 13:11:20.679 +0000 [INFO] (0016:task-0000): Delete generated file: /tmp/embulk/2020-02-15 13-11-16.996 UTC/0016_task-0000_5418765600230876857.tmp > true 2020-02-15 13:11:20.679 +0000 [INFO] (0016:task-0000): Uploaded 'bucket_name/mysql/test/test_table.000.01.csv' to 930bytes ...After (embulk-output-command + gsutil)
embulk-output-commandからgsutilでストリーミングアップロードするとこんな感じ。
inputの設定は同じなので省略してます。
gsutilが標準入力からデータを受け取ってアップロードしているログが出てます。job.yamlout: command: "gsutil cp - gs://bucket_name/mysql/test/test_table/data.$INDEX.$SEQID.csv" formatter: type: csv type: command... 2020-02-15 13:09:59.514 +0000 [INFO] (0001:transaction): Using local thread executor with max_threads=8 / output tasks 4 = input tasks 1 * 4 2020-02-15 13:09:59.543 +0000 [INFO] (0001:transaction): {done: 0 / 1, running: 0} 2020-02-15 13:09:59.559 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.634 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.638 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.643 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.700 +0000 [INFO] (0016:task-0000): Fetch size is 10000. Using server-side prepared statement. 2020-02-15 13:09:59.701 +0000 [INFO] (0016:task-0000): Connecting to jdbc:mysql://localhost:3306/test options {useCompression=true, socketTimeout=1800000, useSSL=false, user=admin, useLegacyDatetimeCode=false, tcpKeepAlive=true, useCursorFetch=true, connectTimeout=300000, password=***, zeroDateTimeBehavior=convertToNull} 2020-02-15 13:09:59.814 +0000 [INFO] (0016:task-0000): SQL: select * from test_table 2020-02-15 13:09:59.838 +0000 [INFO] (0016:task-0000): > 0.01 seconds Copying from <STDIN>... Copying from <STDIN>... 0.0 B] Copying from <STDIN>... 0.0 B] Copying from <STDIN>... 0.0 B] / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. ...Pros / Cons
Pros
- ディスクレスでembulkでクラウドストレージにアップロードできる
- SSDって値段高いよね。
- コンテナ on k8sで動かそうとした日にはPersistent Volumeがでてきて管理が面倒です。
- ステートレス最高。
Cons
- gsutilのストリーミングアップロードはチェックサム計算をしてくれない
- なので自分でデータの検証を書く必要がります。もはやローカルにファイル持ってないので、チェックサムによる検証はできません。いまはBigQueryにロードできるかどうか(CSVファイルとして正しいか)と、MySQLとBigQueryのレコード数が一致しているかを見ています。
性能
OracleからGCSに入れる処理で比較。
- ネットワーク経路:
Oracle---(DedicatedIntterConnect)---GKE--(PrivateAccess)---GCS- コンピュート: 8 vCPU / 7.5GB Mem / 50GB SSD
- データ量: 2,000,000レコード / 7ファイル / 5.2GB / CSV
処理 時間 コマンド embulk-output-gcs 6m18.374s embulk run job.yamlembulk-output-command + gsutil cp(streaming) 3m5.471s embulk run job.yamlembulk-output-file + gsutil cp(bulk) 3m15.211s embulk run job.yaml && gsutil -m cp -r /tmp/embulk gs://bucket_name/tmp/embulkembulk-output-gcsは内部で使ってるGCSのAPIバージョンが古いので、結構遅かった。
なので、embulkでファイル化したあとに普通にgsutil cp(bulk upload)した処理も計測。
コンピュートリソースやネットワーク構成、input側も影響するので一概には言えませんが、5.2GBくらいだったらストリーミングアップロードにしても問題なさそうでした。ちなみに2TBのテーブルでやったときは50時間ほどかかったので、時間は線形増加にはならなさそう。
メモ
embulk-output-commandは、ScatterExecutorの恩恵を受ける。
outputタスク数(デフォルトだとCPUコア数、設定で指定可能)の分だけ並列に処理してくれる。
Embulk の LocalExecutor プラグインの振る舞いについて整理あときっとembulk-output-s3もawscli使えば同じようにストリーミングアップロードができると思う。
検証中にgsutilコマンドがうまく動かないと思ったらこれだった。
https://github.com/googleapis/google-api-python-client/issues/803
httplib2をダウングレードして解決。$ pip install httplib2==0.15.0
- 投稿日:2020-02-16T14:52:55+09:00
Embulkでクラウドストレージにストリーミングアップロードする
embulk-output-commandからgsutilコマンドにデータを渡してストリーミングアップロードしてディスクレスにしてみた話。
embulkってなにって方はこちらから。
なんでやったの
EmbulkでMySQLやOracleからデータをBigQueryにデータ連携する際、データレイクとしてひとまずGoogle Cloud Storage(GCS)にファイルをアップロードしています。
最初はembulk-output-gcsを使ってたんですけど、1TBのテーブルとか出てきてマシンのストレージが枯渇しちゃったんですよね。
そこで、embulk-output-commandからgsutilコマンドにデータを渡して、ストリーミングアップロードしてディスクレスにしてみました。
GCSのストリーミングアップロードに関してはこちら。
https://cloud.google.com/storage/docs/streamingどうやったの
環境
- ubuntu:bionic
- openjdk-8-jdk
- Embulk v0.9.17
- embulk-input-mysql v0.10.1
- embulk-output-gcs v0.4.4
- embulk-output-command v0.1.4
- gsutil 4.47
embulkはGKEでコンテナ実行
Before (embulk-outout-gcs)
embulk-output-gcsを使うとこんな感じ。
ローカルの/tmpにファイルがに書き込まれて、GCSアップロード後に削除されているのが分かります。job.yamlin: type: mysql host: localhost port: 3306 database: test user: mysql_user password: xxxxxxx query: select * from test_table out: type: gcs auth_method: compute_engine bucket: bucket_name path_prefix: mysql/test/test_table file_ext: .csv formatter: type: csv... 2020-02-15 13:11:17.756 +0000 [INFO] (0001:transaction): Using local thread executor with max_threads=8 / output tasks 4 = input tasks 1 * 4 2020-02-15 13:11:17.790 +0000 [INFO] (0001:transaction): {done: 0 / 1, running: 0} 2020-02-15 13:11:19.186 +0000 [INFO] (0016:task-0000): Fetch size is 10000. Using server-side prepared statement. 2020-02-15 13:11:19.187 +0000 [INFO] (0016:task-0000): Connecting to jdbc:mysql://localhost:3306/test options {useCompression=true, socketTimeout=1800000, useSSL=false, user=admin, useLegacyDatetimeCode=false, tcpKeepAlive=true, useCursorFetch=true, connectTimeout=300000, password=***, zeroDateTimeBehavior=convertToNull} 2020-02-15 13:11:19.289 +0000 [INFO] (0016:task-0000): SQL: select * from test 2020-02-15 13:11:19.311 +0000 [INFO] (0016:task-0000): > 0.01 seconds 2020-02-15 13:11:20.679 +0000 [INFO] (0016:task-0000): Local Hash(MD5): XTIT3ANlo6QqZnwNBdzGCA== / Remote Hash(MD5): XTIT3ANlo6QqZnwNBdzGCA== 2020-02-15 13:11:20.679 +0000 [INFO] (0016:task-0000): Delete generated file: /tmp/embulk/2020-02-15 13-11-16.996 UTC/0016_task-0000_5418765600230876857.tmp > true 2020-02-15 13:11:20.679 +0000 [INFO] (0016:task-0000): Uploaded 'bucket_name/mysql/test/test_table.000.01.csv' to 930bytes ...After (embulk-output-command + gsutil)
embulk-output-commandからgsutilでストリーミングアップロードするとこんな感じ。
inputの設定は同じなので省略してます。
gsutilが標準入力からデータを受け取ってアップロードしているログが出てます。job.yamlout: command: "gsutil cp - gs://bucket_name/mysql/test/test_table/data.$INDEX.$SEQID.csv" formatter: type: csv type: command... 2020-02-15 13:09:59.514 +0000 [INFO] (0001:transaction): Using local thread executor with max_threads=8 / output tasks 4 = input tasks 1 * 4 2020-02-15 13:09:59.543 +0000 [INFO] (0001:transaction): {done: 0 / 1, running: 0} 2020-02-15 13:09:59.559 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.634 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.638 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.643 +0000 [INFO] (0016:task-0000): Using command [sh, -c, gsutil cp - gs://bucket_name/mysql/test/test_table.$INDEX.$SEQID.csv] 2020-02-15 13:09:59.700 +0000 [INFO] (0016:task-0000): Fetch size is 10000. Using server-side prepared statement. 2020-02-15 13:09:59.701 +0000 [INFO] (0016:task-0000): Connecting to jdbc:mysql://localhost:3306/test options {useCompression=true, socketTimeout=1800000, useSSL=false, user=admin, useLegacyDatetimeCode=false, tcpKeepAlive=true, useCursorFetch=true, connectTimeout=300000, password=***, zeroDateTimeBehavior=convertToNull} 2020-02-15 13:09:59.814 +0000 [INFO] (0016:task-0000): SQL: select * from test_table 2020-02-15 13:09:59.838 +0000 [INFO] (0016:task-0000): > 0.01 seconds Copying from <STDIN>... Copying from <STDIN>... 0.0 B] Copying from <STDIN>... 0.0 B] Copying from <STDIN>... 0.0 B] / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. / [1 files][ 0.0 B/ 0.0 B] Operation completed over 1 objects. ...Pros / Cons
Pros
- ディスクレスでembulkでクラウドストレージにアップロードできる
- SSDって値段高いよね。
- コンテナ on k8sで動かそうとした日にはPersistent Volumeがでてきて管理が面倒です。
- ステートレス最高。
Cons
- gsutilのストリーミングアップロードはチェックサム計算をしてくれない
- なので自分でデータの検証を書く必要がります。もはやローカルにファイル持ってないので、チェックサムによる検証はできません。いまはBigQueryにロードできるかどうか(CSVファイルとして正しいか)と、MySQLとBigQueryのレコード数が一致しているかを見ています。
性能
OracleからGCSに入れる処理で比較。
- ネットワーク経路:
Oracle---(DedicatedIntterConnect)---GKE--(PrivateAccess)---GCS- コンピュート: 8 vCPU / 7.5GB Mem / 50GB SSD
- データ量: 2,000,000レコード / 7ファイル / 5.2GB / CSV
処理 時間 コマンド embulk-output-gcs 6m18.374s embulk run job.yamlembulk-output-command + gsutil cp(streaming) 3m5.471s embulk run job.yamlembulk-output-file + gsutil cp(bulk) 3m15.211s embulk run job.yaml && gsutil -m cp -r /tmp/embulk gs://bucket_name/tmp/embulkembulk-output-gcsは内部で使ってるGCSのAPIバージョンが古いので、結構遅かった。
なので、embulkでファイル化したあとに普通にgsutil cp(bulk upload)した処理も計測。
コンピュートリソースやネットワーク構成、input側も影響するので一概には言えませんが、5.2GBくらいだったらストリーミングアップロードにしても問題なさそうでした。ちなみに2TBのテーブルでやったときは50時間ほどかかったので、時間は線形増加にはならなさそう。
メモ
embulk-output-commandは、ScatterExecutorの恩恵を受ける。
outputタスク数(デフォルトだとCPUコア数、設定で指定可能)の分だけ並列に処理してくれる。
Embulk の LocalExecutor プラグインの振る舞いについて整理あときっとembulk-output-s3もawscli使えば同じようにストリーミングアップロードができると思う。
検証中にgsutilコマンドがうまく動かないと思ったらこれだった。
https://github.com/googleapis/google-api-python-client/issues/803
httplib2をダウングレードして解決。$ pip install httplib2==0.15.0
- 投稿日:2020-02-16T14:50:50+09:00
AWS技術簿 その2 - EBS -
EBSとは
AWSで提供されているサービスの一つ、正式名称は
Elastic Block Store
EC2と共に使用するために設計されている。
簡単に言ったらオンプレミスで言う所のHDDやSSDのようなもの。どのような利点があるか
・簡単に容量の拡張/縮小や、ストレージタイプをデータを保持したまま変更することが可能。
・AZ内で自動的に複製がされているため、もしもの際にすぐ復元できるという信頼性が高い。
・手動で定期的なバックアップを取ることも可能(S3を利用してスナップショットと呼ばれるバックアップを作成する)どのような種類があるのか
EBSボリュームを作成する際に、ボリュームタイプと容量を指定することができる。
ボリュームタイプは以下4種類から選択を行うことが可能なため、必要に応じて使い分ける。SSDタイプ
プロビジョンドIOPS SSD
4種類の中で一番最高速度とパフォーマンスを発揮するEBSストレージ。
1秒間の読み込み・書き込みををどれほど行えるかを示すIOPSが最大64000もあるため、
低レイテンシーを必要とする場面や読み書きを多用する場面に最適。
但し、使用料金も4種類の中で一番高い。
容量は4GB 〜 16TBまで選択が可能
汎用SSD
無料枠で使用できるEBSストレージのため、名前はよく聞くと思う。
先程のプロビジョンドIOPSよりは低速ではあるがSSDタイプのストレージなので、IOPSはかなり高く、最大16000を叩き出している。
価格も抑えつつ程々の性能で使いたい時にはオススメのストレージではある。
また、無料枠という強みもあるため、値段はかけたくないが少しだけ触りたいという場面、例えば開発やテスト環境を構築したい時にも便利。
容量は4GB 〜 16TBまで選択が可能HDDタイプ
スループット最適化 HDD
ビックデータやログの処理など、大きな容量を読み書きする状況に特化したHDD
また、データ等の処理も非常に高く設定されており、スループットパフォーマンスを利用時間の99%で発揮するように設計されている。
なお、HDDタイプのため起動ボリュームとしては使用できない。
容量は500GB 〜 16TBまで選択が可能
Cold HDD
IOPSなどが一番低速ではあるが、その代わりに値段も抑えられるHDD
アクセス頻度が低いデータを格納する際に便利。
なお、HDDタイプのため起動ボリュームとしては使用できない。
容量は500GB 〜 16TBまで選択が可能
- 投稿日:2020-02-16T12:31:46+09:00
分散した EC2 インスタンスのログの集約 - Nextcloud 環境の構築を通じて AWS での環境構築を体験する⑤
「Nextcloud 環境の構築を通じて AWS での環境構築を体験する」 の第 5 回となります。
これまでの記事は下記からどうぞ。
- 【第 1 回】EC2 と RDS を利用した Nextcloud 環境の構築
- 【第 2 回】ElastiCache サービスの導入
- 【第 3 回】EFS ファイルサーバーへの移行
- 【第 4 回】ALB を利用したサーバー負荷分散、可用性向上に向けた取り組み
はじめに
前回記事 で EC2 インスタンスを複数構成にすることにより可用性向上の構成としました。この状態でも運用することはできるのですが、ログを確認する際にそれぞれの EC2 インスタンスに保存されているログファイルを参照して合わせて・・・といったことが必要となり非常に面倒となります。
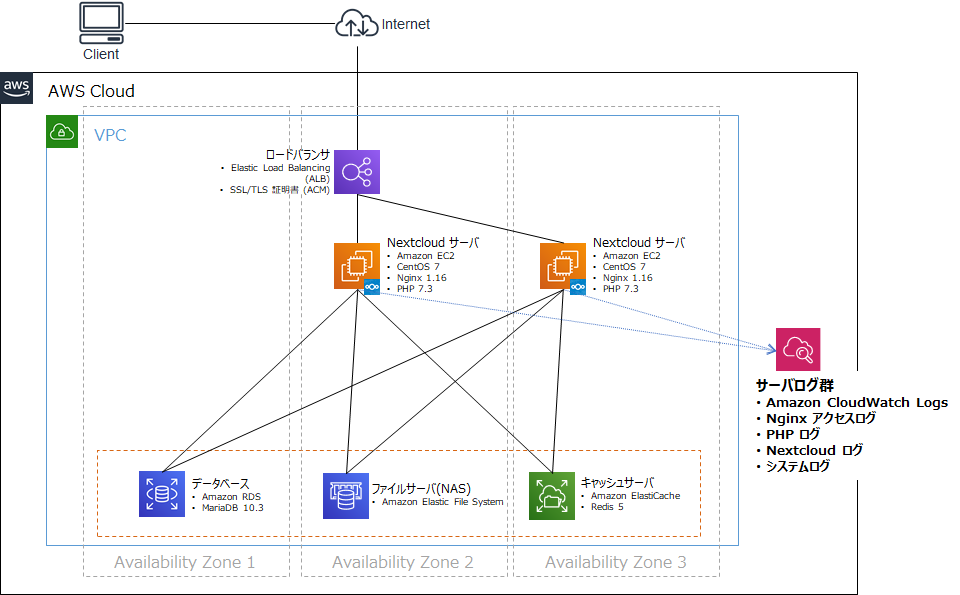
そこで、前回記事 までで構成したシステムに対して、今回はこれらログを AWS のログ保管サービスに集約して管理できるようにします。今回構築する Nextcloud on AWS 環境
次のような構成となります。今回は Nextcloud を動かす部分の構成自体には何も変更はありません。
今回追加で利用する AWS サービス
サービス名 役割 Amazon CloudWatch Logs EC2 等ソースのログファイルの監視、保存、アクセスができるサービス。ログ自体は S3 に保管されます。 設定手順
CloudWatch Logs エージェントの追加
CloudWatch Logs に EC2 に出力されるログを転送するエージェントを EC2 にインストール、設定します。2 つの EC2 インスタンスに同様に設定していきます。
Nextcloud の EC2 仮想サーバーに SSH 接続します。
CloudWatch Logs エージェントセットアッププログラムをダウンロードします。
wget https://s3.amazonaws.com/aws-cloudwatch/downloads/latest/awslogs-agent-setup.pyCloudWatch Logs エージェントのインストールを行います。ログを出力するリージョンは東京リージョン (ap-northeast-1) にします。
sudo python ./awslogs-agent-setup.py --region ap-northeast-1上記のスクリプト実施中に、あわせて設定も行います。まず CloudWatch Logs サービスを使うためのアクセス情報として AWS アクセスキーとシークレットアクセスキーを設定します。
Default region nameとDefault output formatは何も入力せず [Enter] キーを押下します。AWS Access Key ID [None]: xxxxxxxxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [ap-northeast-1]: Default output format [None]:引き続き CloudWatch Logs に集約するログの設定を行います。以下のように設定していきます。
"More log files to configure? [Y]:"で "Y" を入力することにより複数のログを繰り返して設定することができます。すべてのログを設定したら、この問い合わせで "N" を入力して終了します。【設定する内容】
問い合わせメッセージ 設定する内容 Path of log file to upload 集約するログファイル(フルパス) Destination Log Group name ロググループ名 → ここでは上と同じで OK です。 Choose Log Stream name ログがどの EC2 インスタンスから出ているかを区別する方法。ここでは "1. Use EC2 instance id." を指定します。 Choose Log Event timestamp format ログ日時フォーマット。好みのフォーマットを選んでください。 Choose initial position of upload ログをいつ出力するか。ログの種類にもよりますが、ここでは "1. From start of file." を指定します。 【設定対象のログ】
内容 ログファイルパス システムログ /var/log/messages Nginx アクセスログ /var/log/nginx/access.log Nginx エラーログ /var/log/nginx/error.log PHP-FPM ログ /var/log/php-fpm/error.log Nextcloud ログ /var/log/nextcloud/nextcloud.log Cron ログ /var/log/cron ※他に出力したいログがあったら適宜追加してかまいません。
以下のようなメッセージが出力されたら登録成功です。
------------------------------------------------------ - Configuration file successfully saved at: /var/awslogs/etc/awslogs.conf - You can begin accessing new log events after a few moments at https://console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logs: - You can use 'sudo service awslogs start|stop|status|restart' to control the daemon. - To see diagnostic information for the CloudWatch Logs Agent, see /var/log/awslogs.log - You can rerun interactive setup using 'sudo python ./awslogs-agent-setup.py --region ap-northeast-1 --only-generate-config' ------------------------------------------------------CloudWatch Logs へのログ出力状況の確認
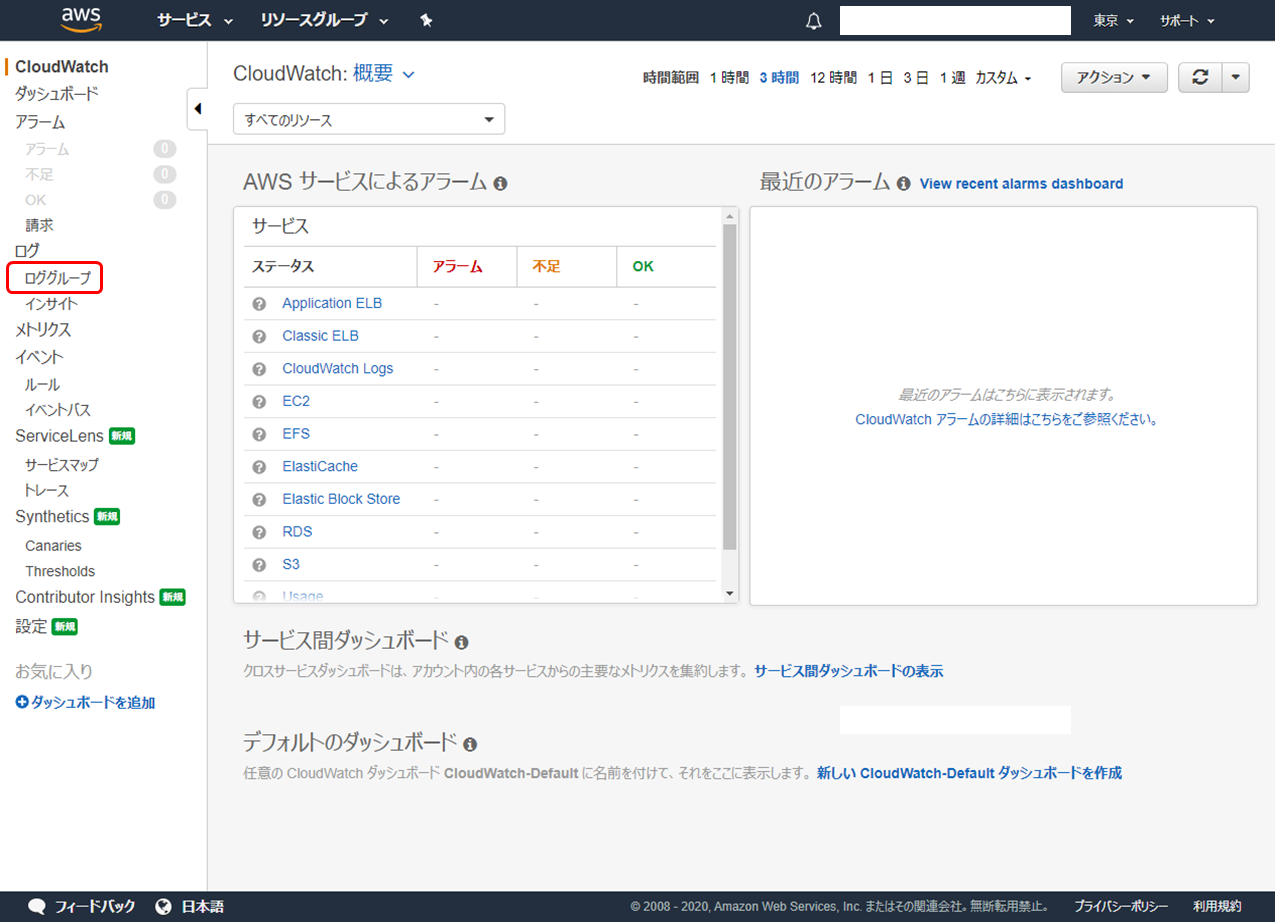
AWS マネジメントコンソールにログインし、CloudWatch サービスを選択します。左ペインで「ロググループ」をクリックします。
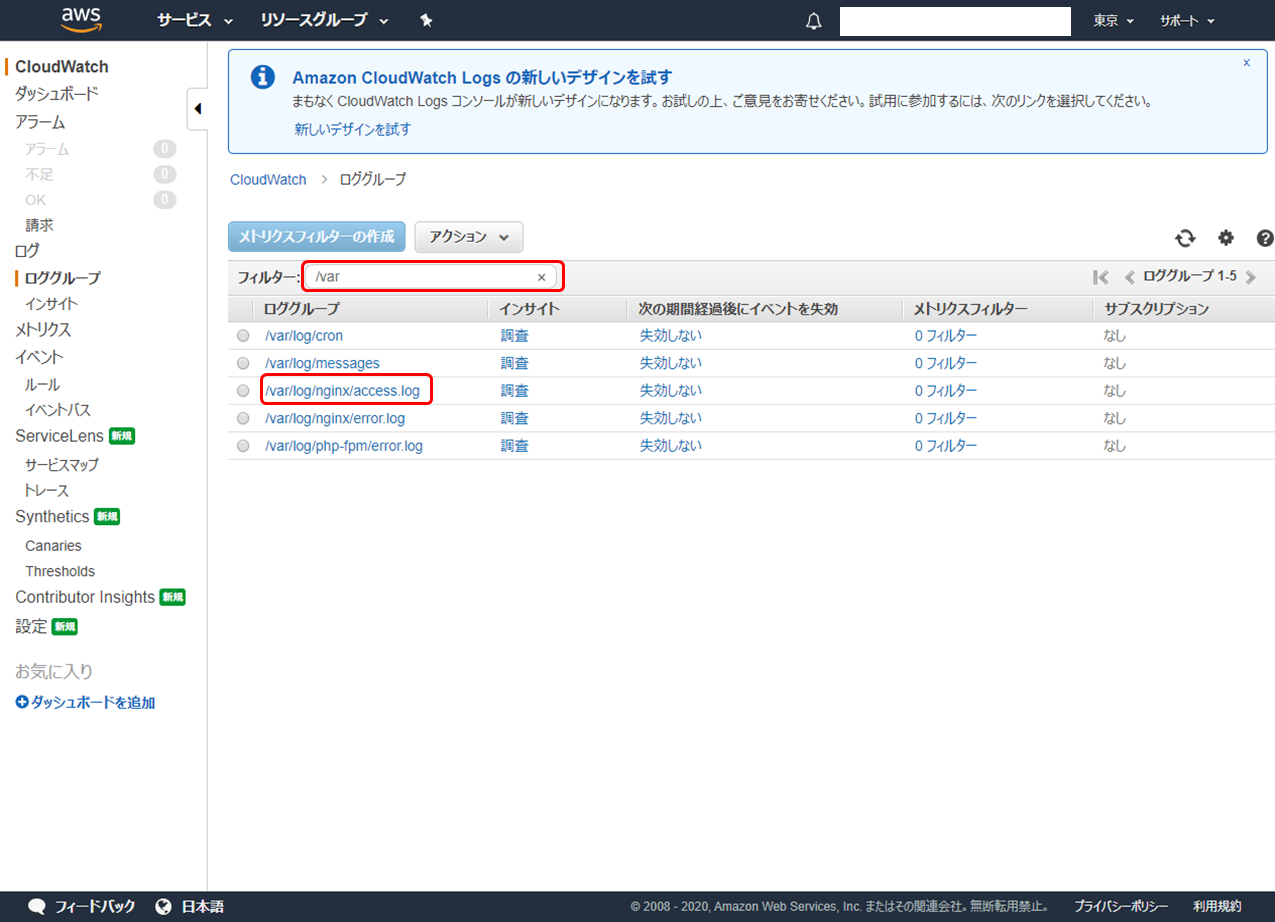
「フィルター:」に
"/var"と入力して Enter キーを押下すると設定したロググループが出てきます。確認したいログのリンクをクリックしてみます。
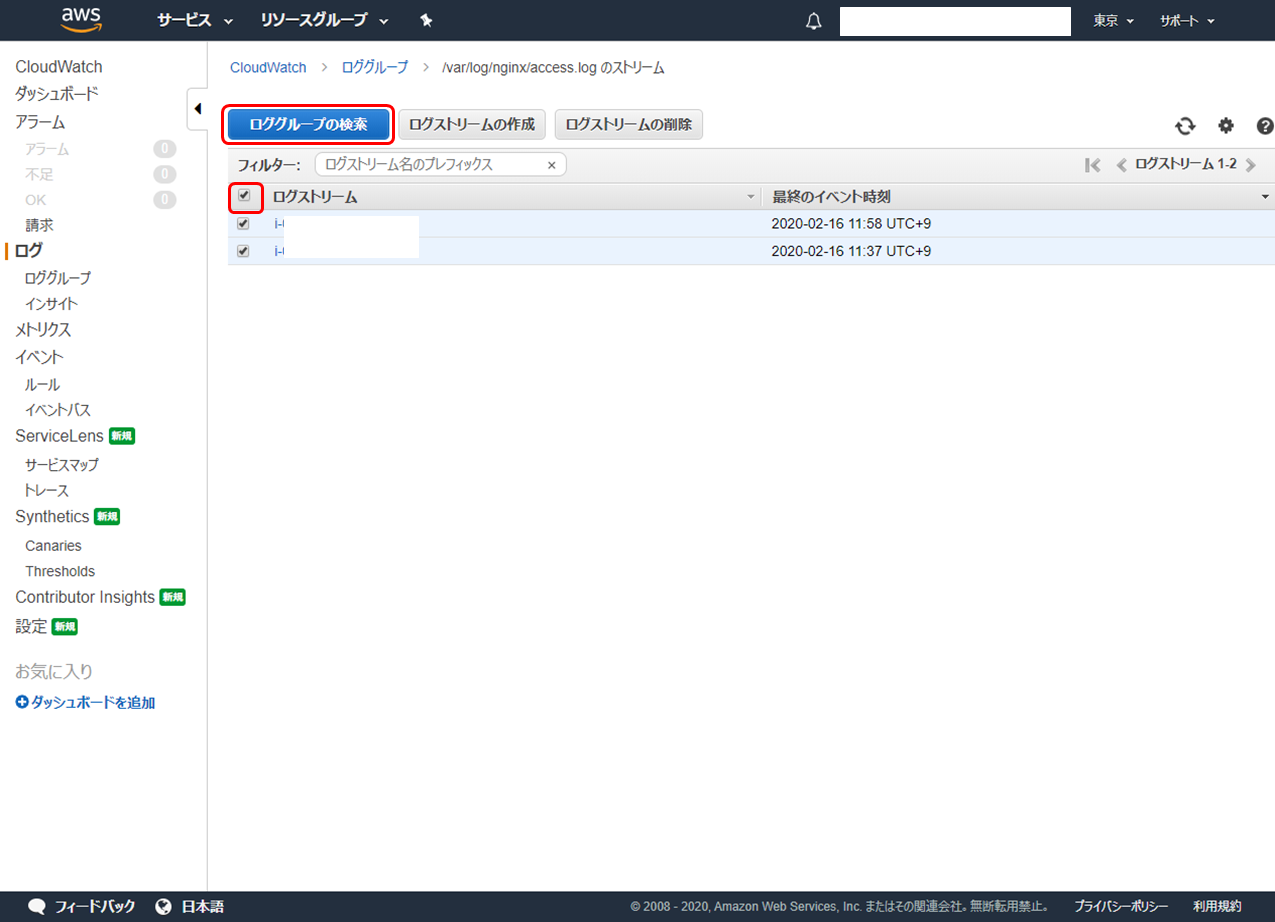
「ログストリーム」に EC2 インスタンスのインスタンス ID が表示されます。チェックボックスの一番上のものをチェックするとすべてのインスタンスを選択できます。引き続き「ロググループの検索」をクリックします。
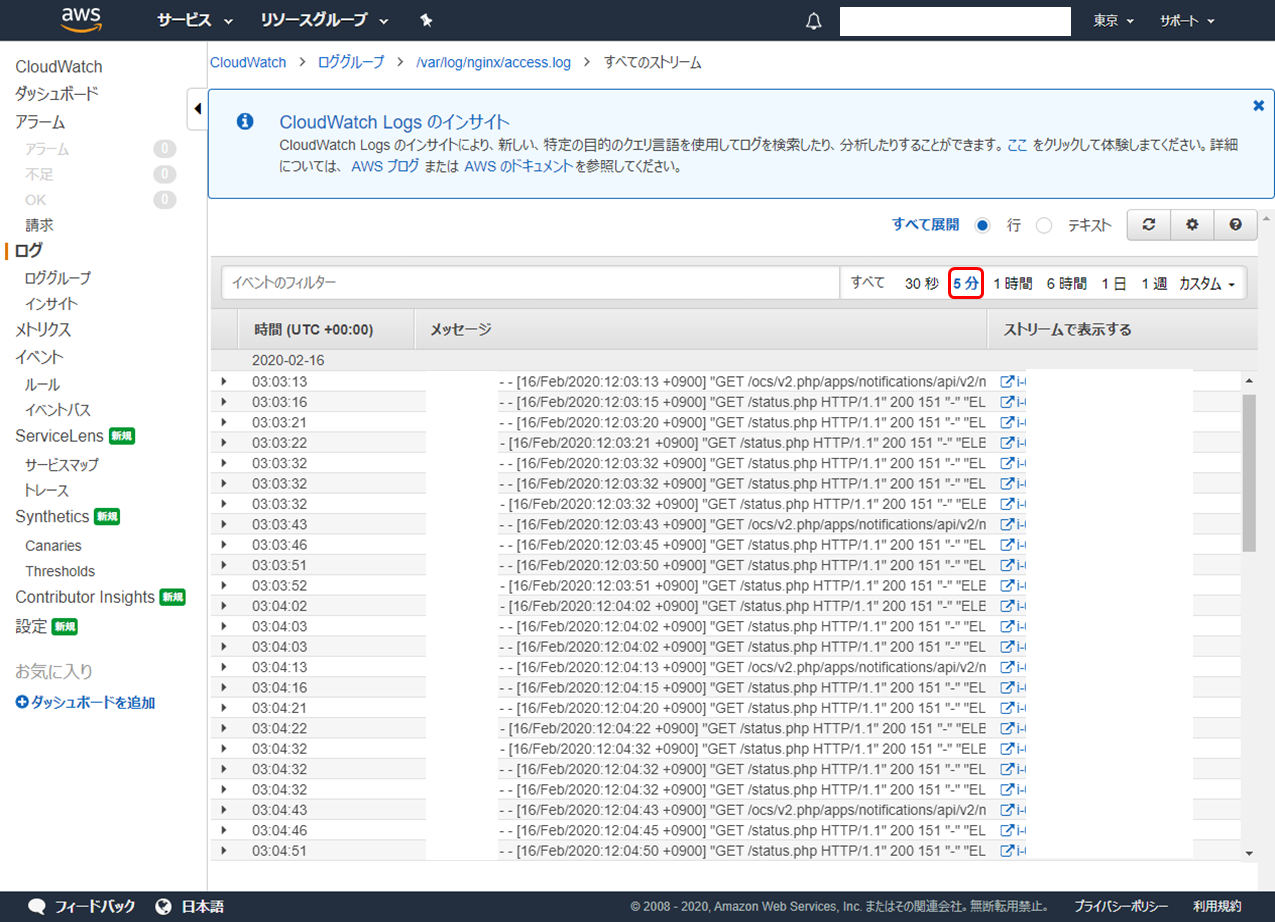
CloudWatch Logs に出力されたログが確認できます。フィルタリングも可能です。下の例では直近 5 分のログに絞り込んでいます。
お疲れさまでした! これで完了です。
あとがき
CloudWatch Logs はサーバーにログを保管しておく必要もなく、別途ログサーバーを準備する必要もなく、容量を気にせず半永久的にログを保管し続けることができます。また複数の EC2 サーバーにわたってログの確認ができるので、複数の EC2 インスタンスを運用する際には必須と言っても過言でないと思います。
また、ログを様々な視点で確認できる機能もありますので、活用してみてください。次回は、2 つの EC2 インスタンスの構成差分となっている Cron 設定への対策をして構成管理を単純化していきます。あわせて、 Nextcloud の通知メール機能を利用するためのメールサービスを AWS で構成します。
- 投稿日:2020-02-16T12:03:55+09:00
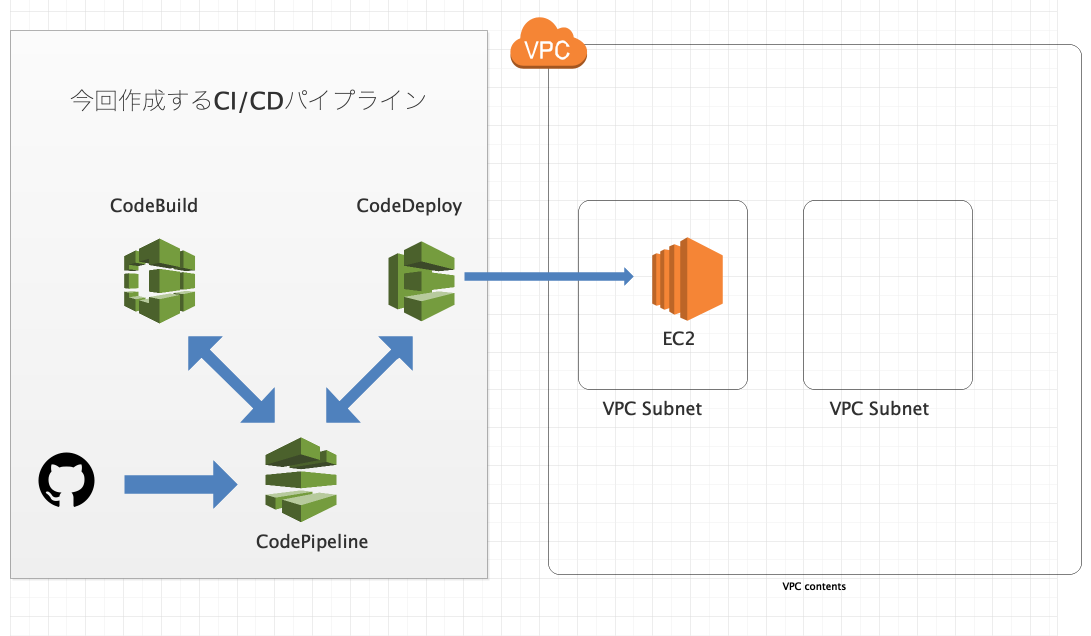
AWS CI/CDハンズオン
AWS CI/CDハンズオン
今回は細かな用語の説明などは飛ばして、基本的にCI/CDを体感するためのとりあえず手を動かすという内容となっておりますので、15分程度で実践することができると思います。
用語説明
継続的インテグレーション(CI)とは
開発者が自分のコード変更を定期的にセントラルリポジトリにマージし、その後に自動化されたビルドとテストを実行するDevOpsソフトウェア開発の手法のことです。
メリットとして、テストが頻繁に行われる。それによって、バグの発見にかかる時間が削減されます。また、機械的なチェックなどを自動化することができるので、開発者はアプリケーションの本質的なことに集中できるのです。継続的デリバリ(CD)とは
ソフトウェア開発手法の一つで、コード変更が発生すると、自動的に実稼働環境へのリリース準備が実行されるというものです。継続的デリバリーは継続的インテグレーションを拡張したものです。
メリットとして、デプロイまでのリリースが自動化されることです。それによって、コードの変更を素早くリリース可能となります。登場人物
CodePipeline
マネージドな継続的デリバリサービスです。
AWS環境にデプロイするパイプラインを容易に構築できます。
CodeBuild
マネージドなビルドを行うサービスです。
CodeDeploy
マネージドな自動デプロイサービスです。
全体の構成
『Githubのmasterブランチへのコミットをトリガーにソースコードを取得(CodePipelineでの処理を開始)→CodeBuildでのビルド開始→CodeDeployのデプロイ開始』という流れとなっております。
実践
Githubリポジトリの準備
デプロイするソースコード自体はなんでも良いのですが、今回はGolangのソースコードを用意しておきました。こちらのソースコードを使用して頂いても、独自のソースコードを使用して頂いても構いません。(独自ソースコードや異なる言語で作成する場合は、
buildspec.ymlファイルを修正する必要があります。)デプロイ対象となるEC2やVPCの準備
今回、EC2やVPCはハンズオンのメインではないので、
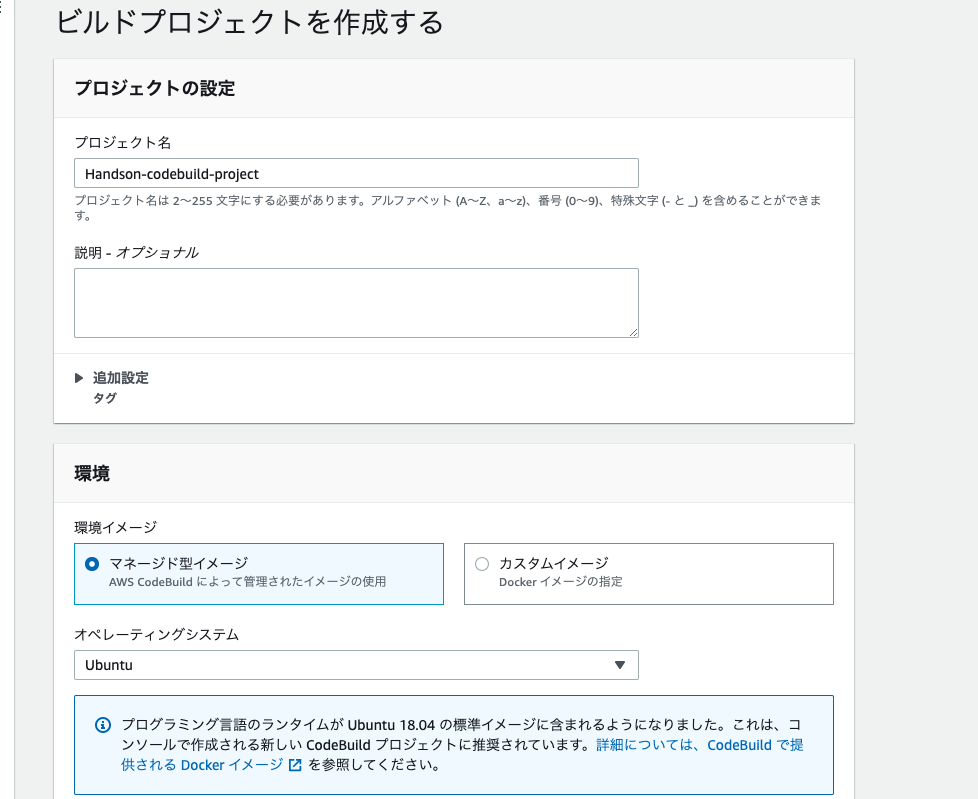
cloudformation.yamlというファイルを作成しておきました。こちらはAWSの infrastructure as codeにあたるもので、簡単に環境を構築できるようにしておきました。以下の手順に従ってCloudFormationを流してください。
- AWSマネジメントコンソールにログインし(東京リージョン)、EC2サービスを選択する。
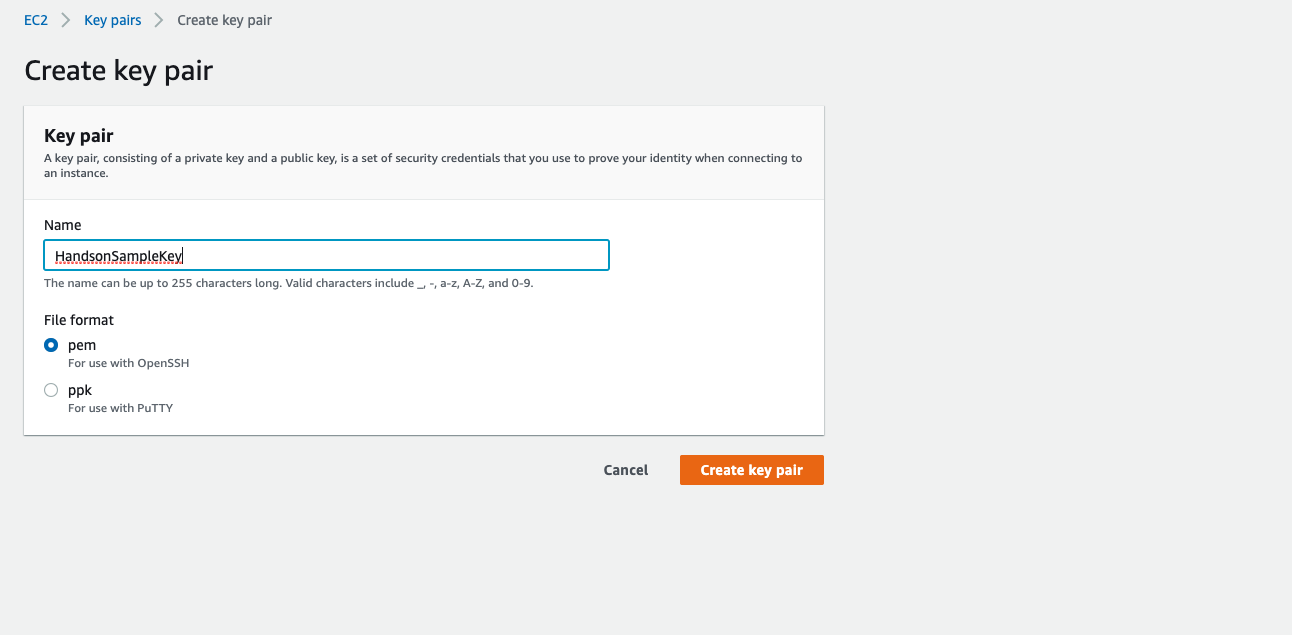
- 左側の一覧から、キーペアを選択する。
3. キーペアの作成から、Name: HandsonSampleKey,FileFormat: pemで作成する(CloudFormationの記述と結びついているので、違う名前にしたければ、CloudFormationでHandsonSampleKeyとなっている点を任意の名前に変更する)。
4. CloudFormationサービスを選択する。
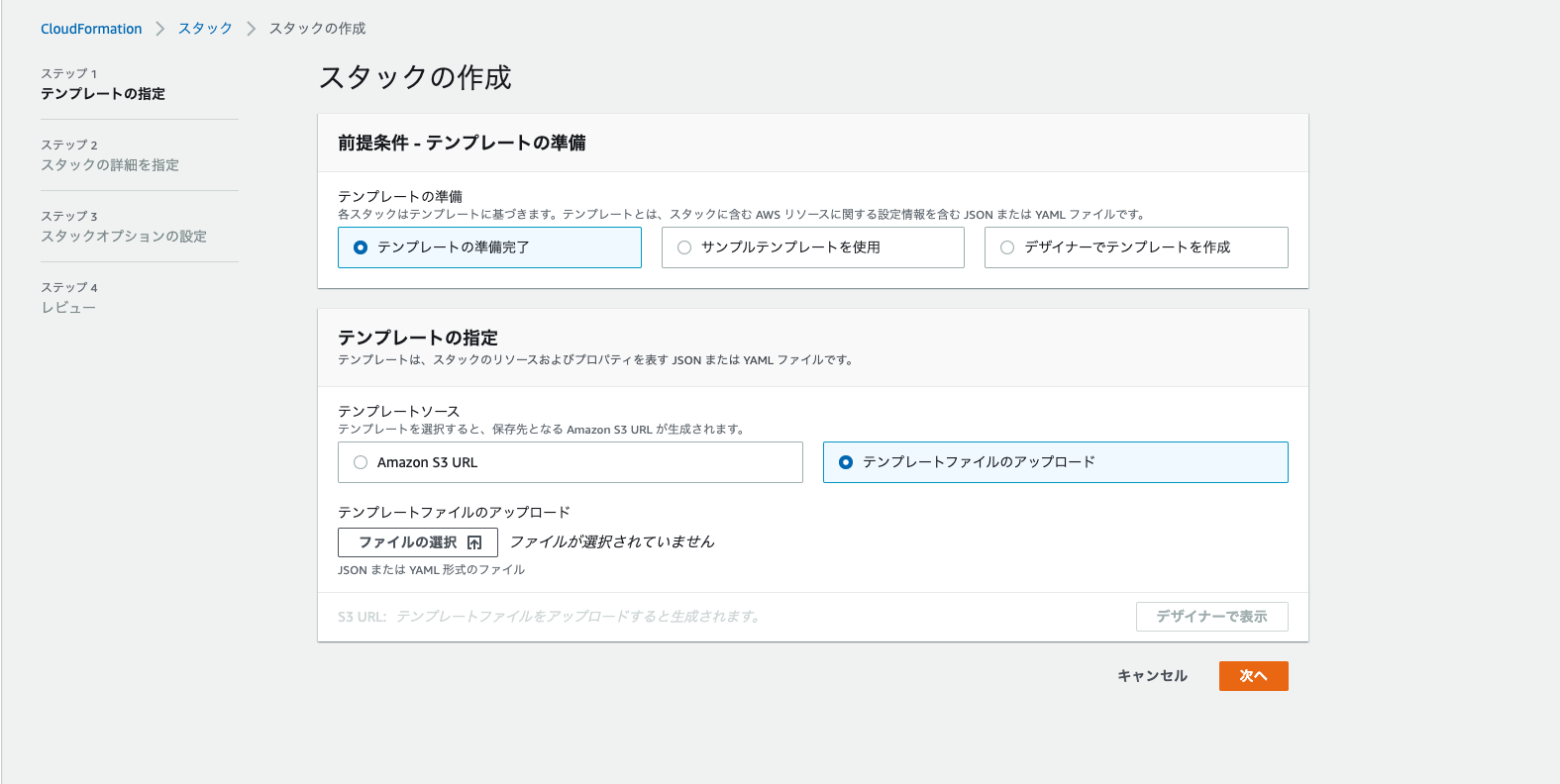
5. スタックの作成→新しいリソースを使用(標準)を選択する。
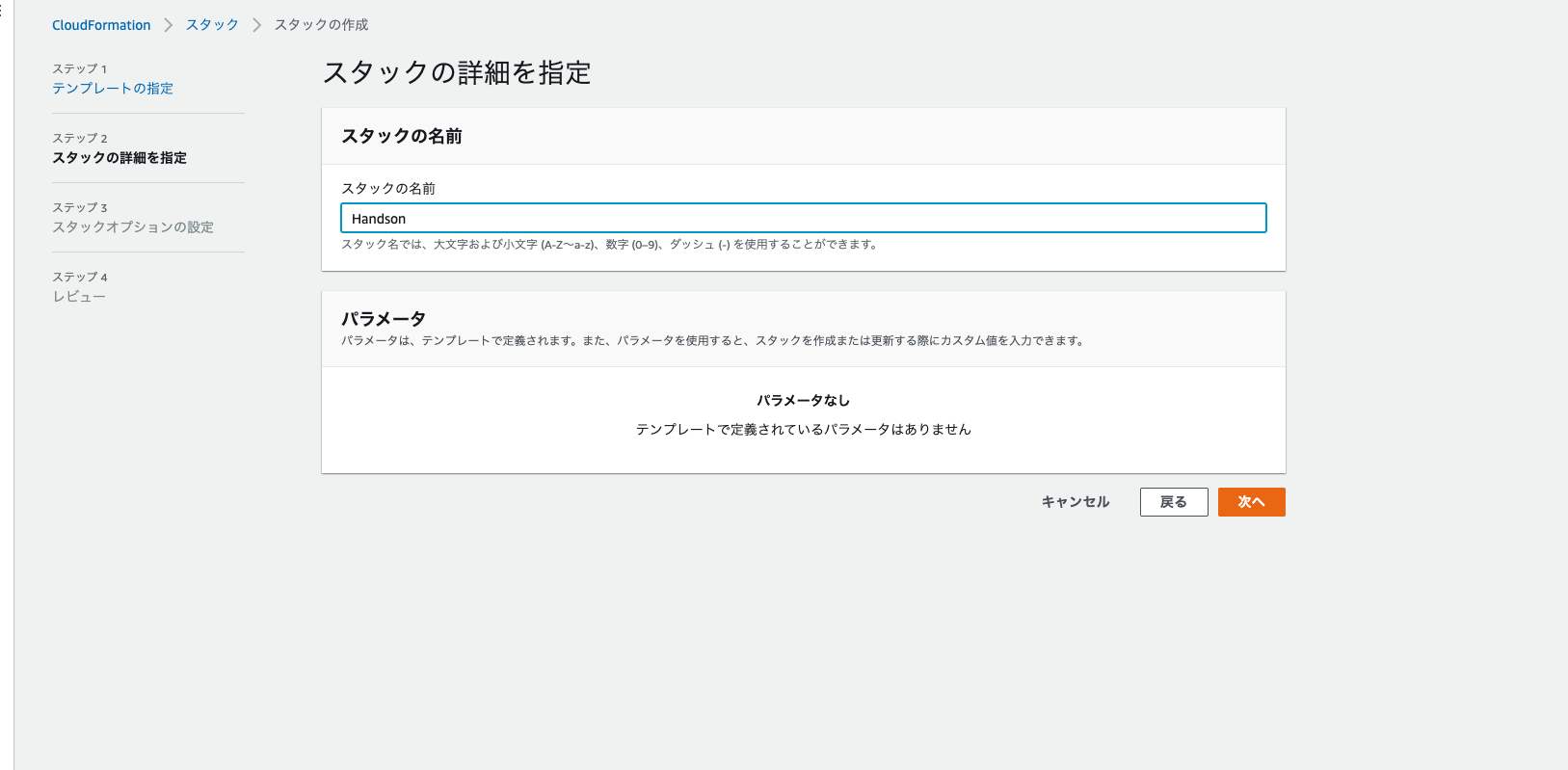
6. 以下の画像のように選択をし、Golangのソースコードのリポジトリに含まれるcloudformation.yamlファイルを選択する。
7. 以下の画像のようにスタックの名前: Handsonと入力し、次へ進む。
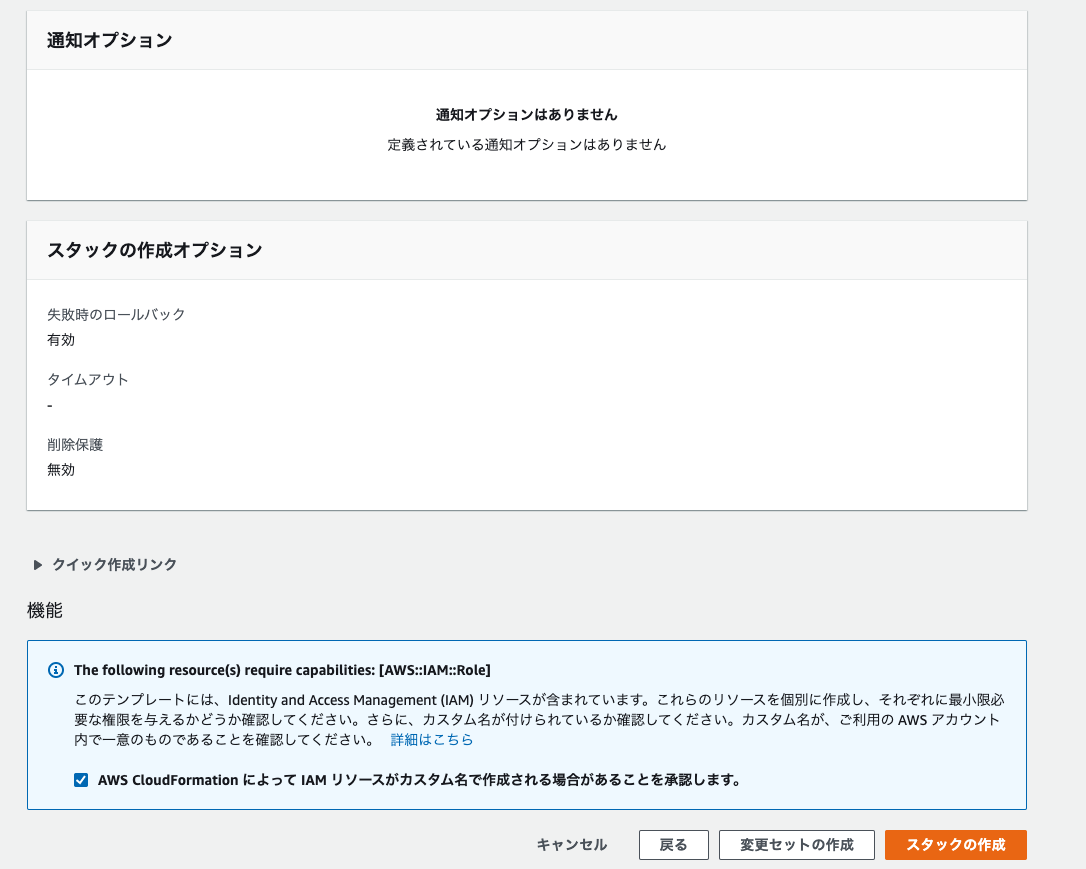
8. スタックオプションの設定とレビューは特に指定しなくて良いので、レビューまで進む。
9. 最後に以下の画像のようにチェックボックスのチェックを行い、スタックの作成を行う。
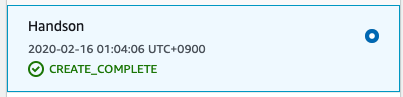
10. 以下の画像のようにCREATE_COMPLETEとなれば終了である。
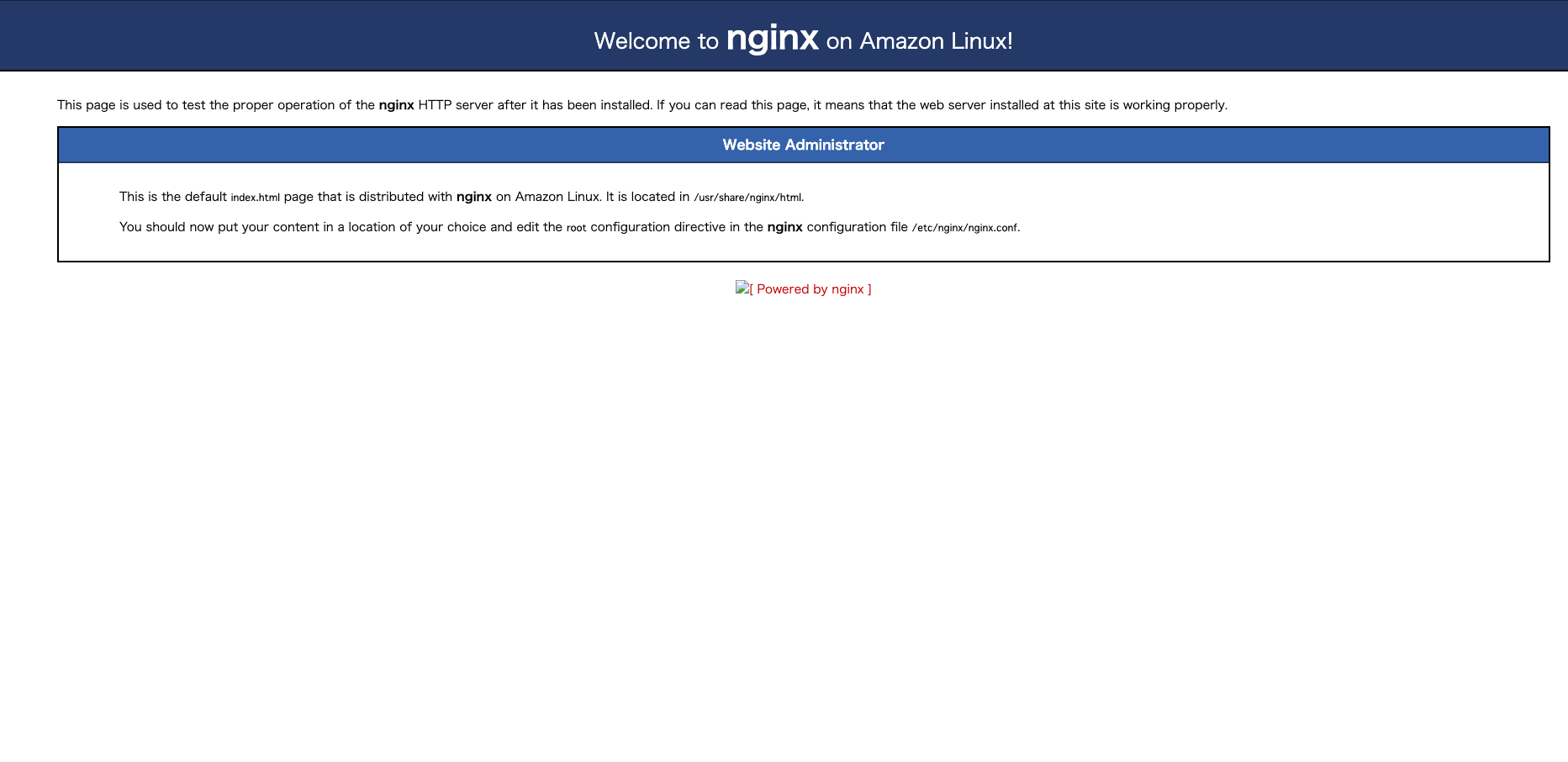
11. EC2のIPv4パブリックIPにアクセスし、Nginxが起動しているか確認する。
今回のハンズオンのメイン
CodeDeploy作成
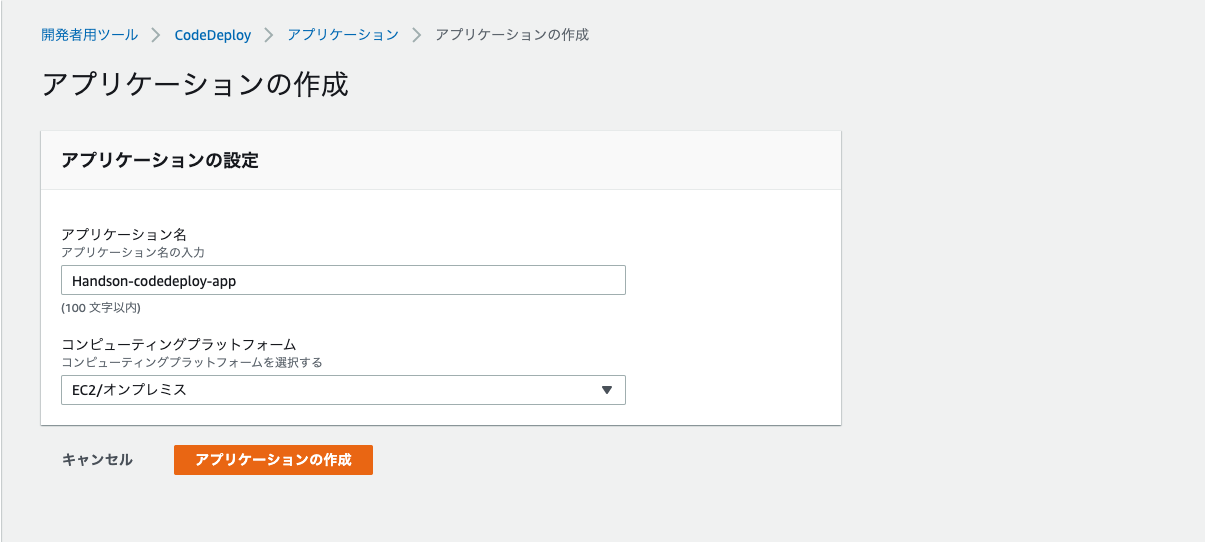
- CodeDeployサービスを選択し、アプリケーションの作成を選択する。
- 以下の画像のように入力し、作成を選択する。
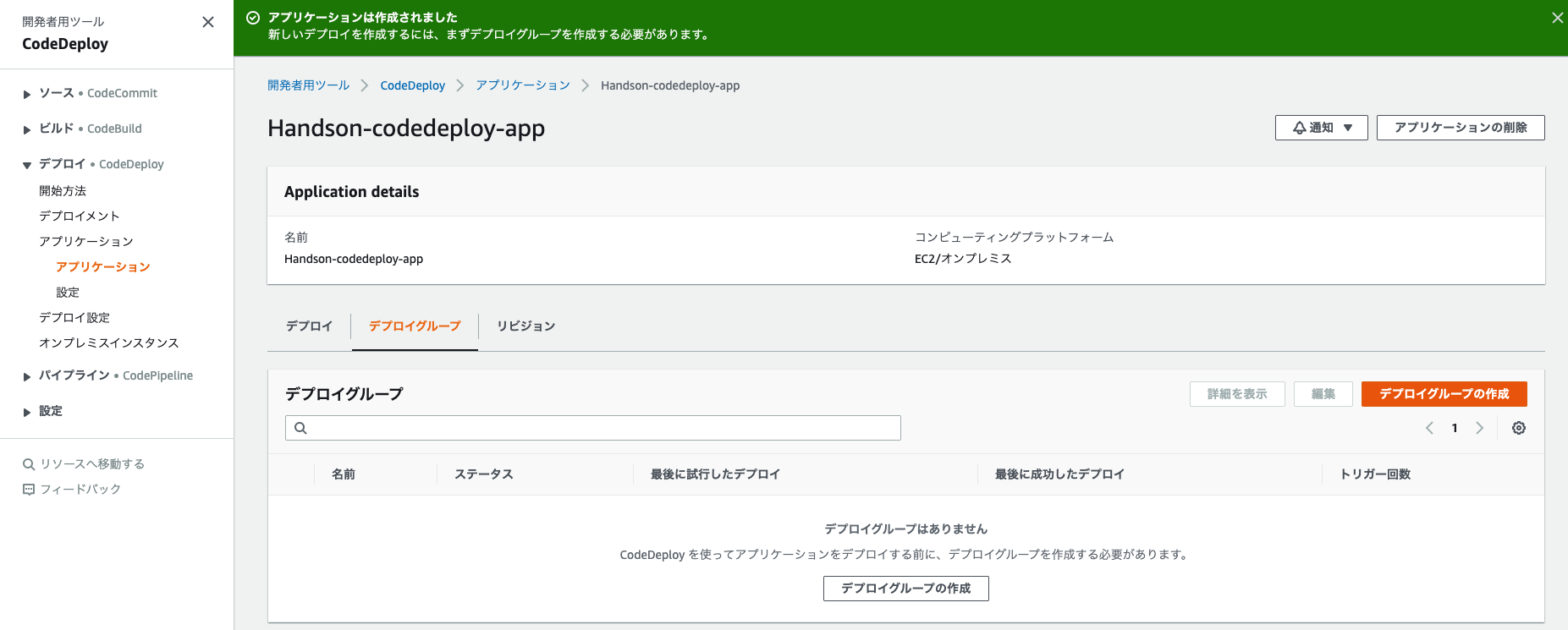
3. 成功画面が表示されると、そのままデプロイグループの作成を選択する。
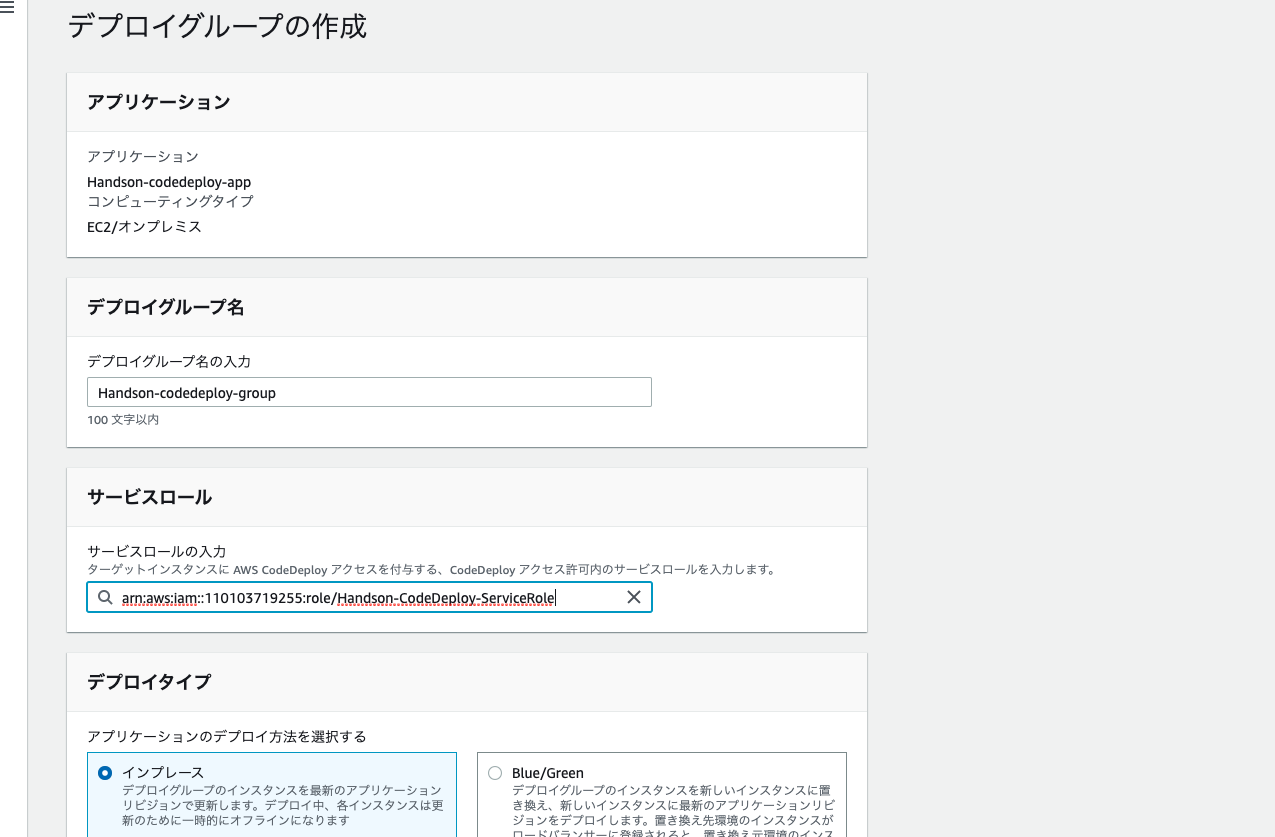
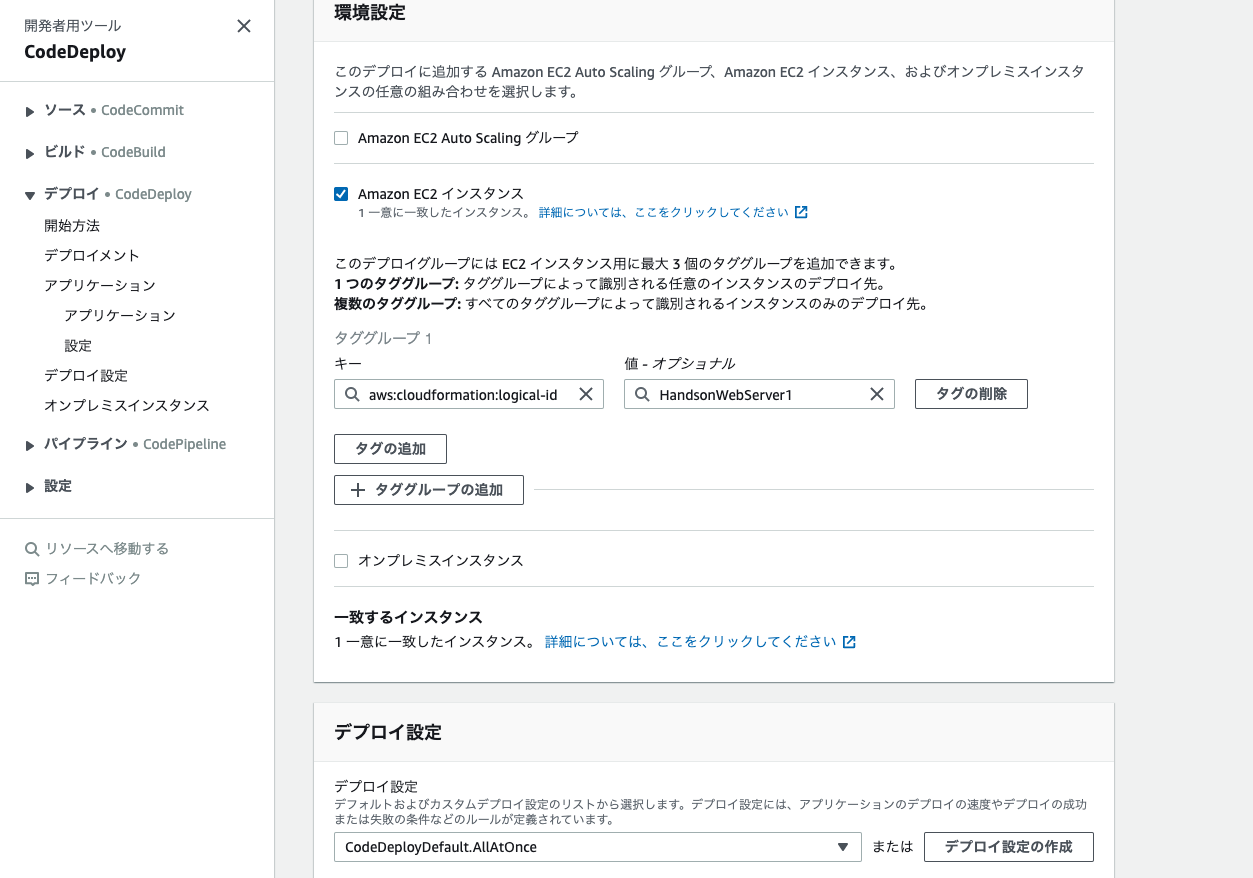
4. 以下の画像のように入力し、作成を選択する。
CodePipelineの作成
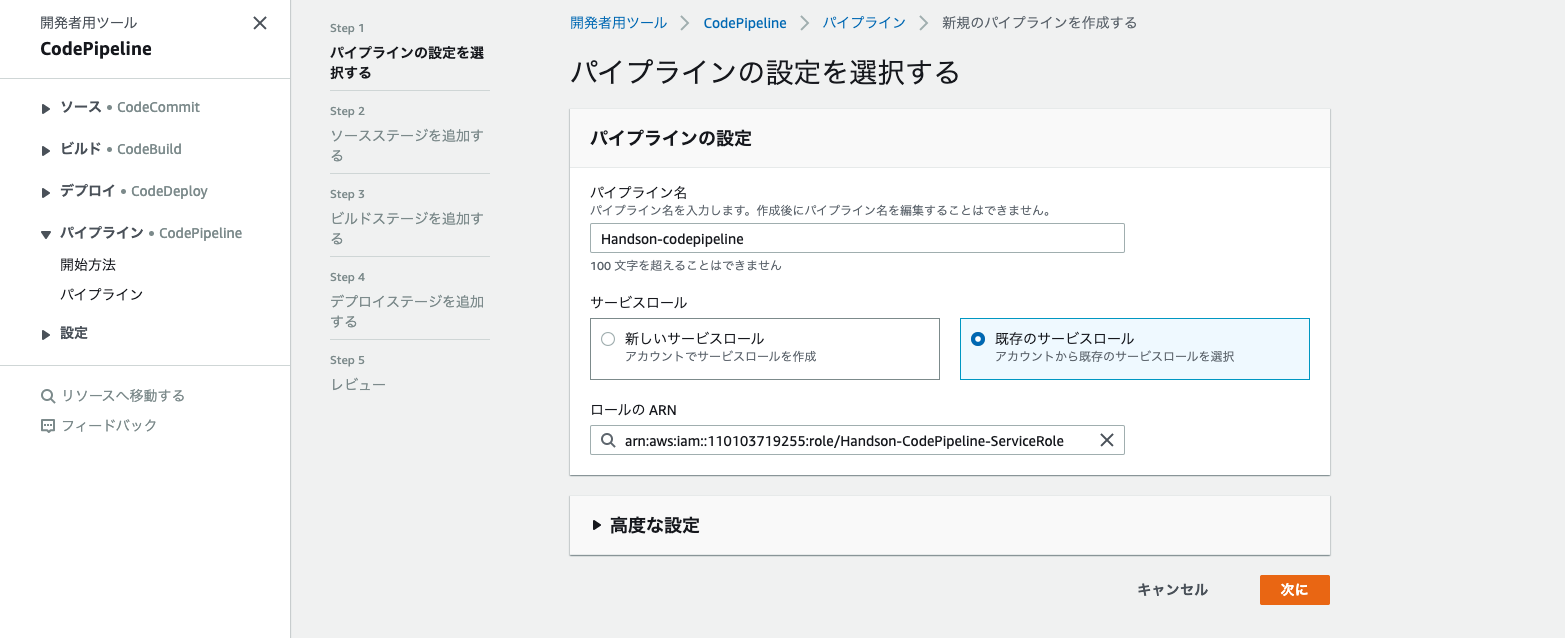
- CodePipelineサービスを選択し、パイプラインの作成を選択する。
- 以下の画像のように入力し、次にを選択する。
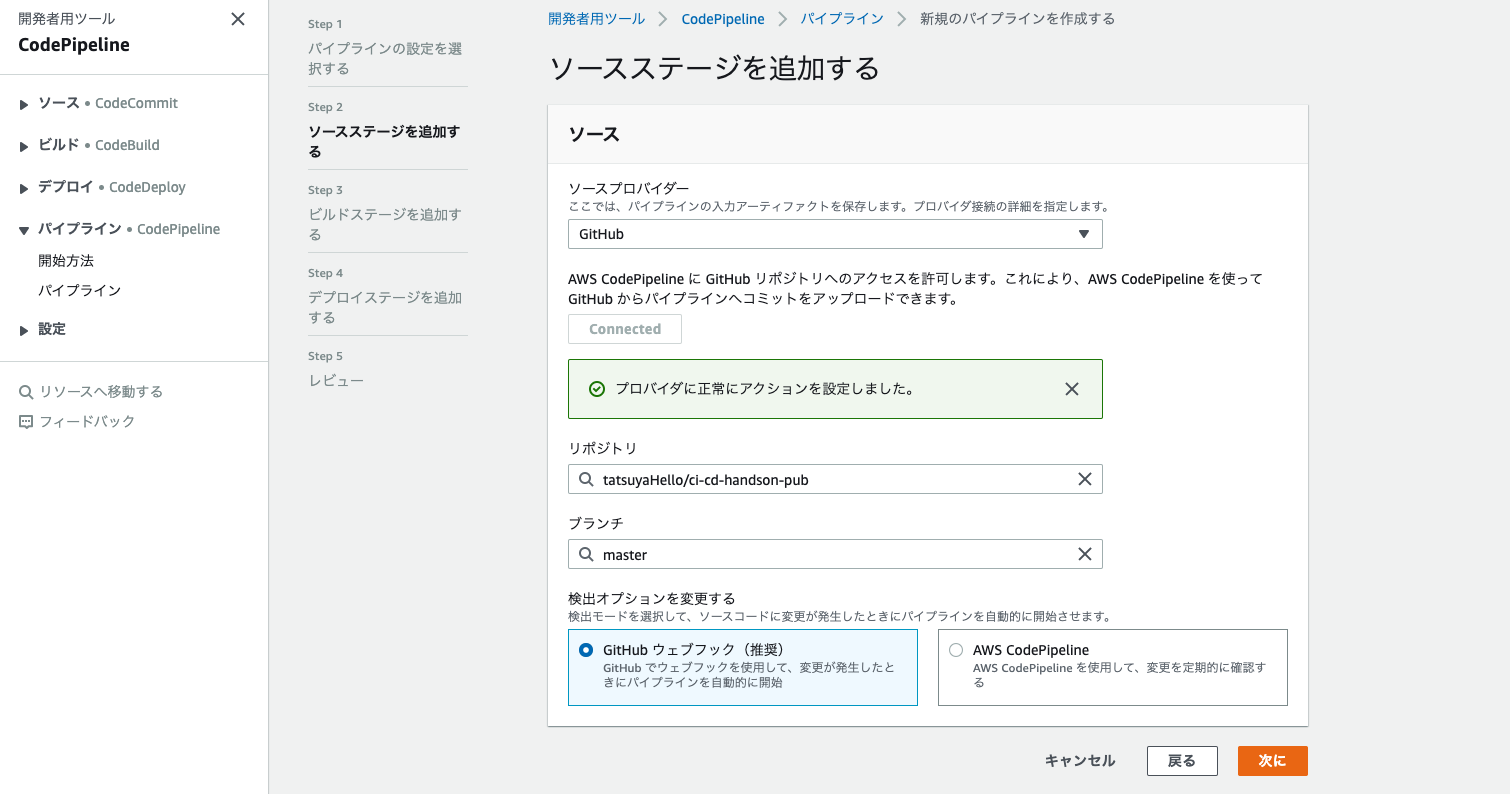
3. ソースプロバイダとして以下の画像のようにソースコード引っ張ってきたい場所を選択する。(リポジトリやブランチは自分のものを選択してください。この時、リポジトリやブランチに選択肢が表示されるまで少し時間がかかると思います。)
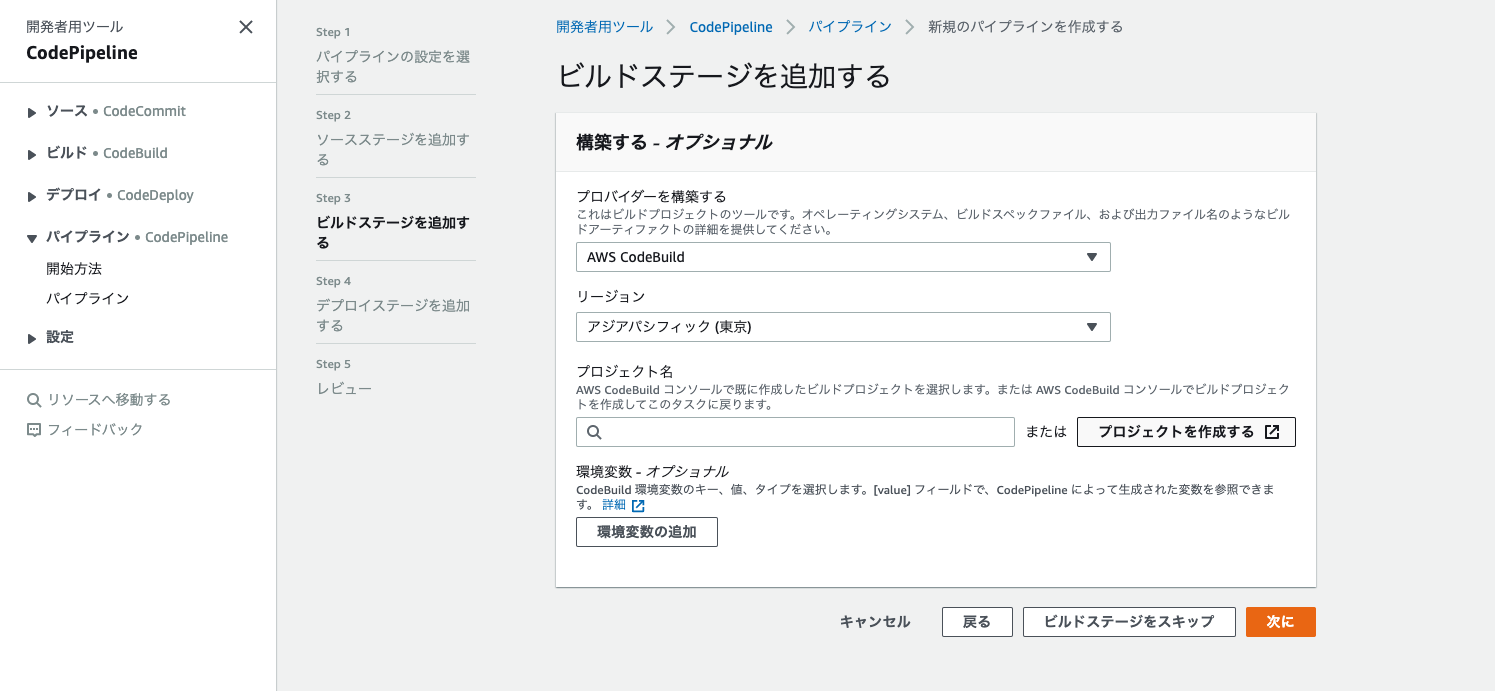
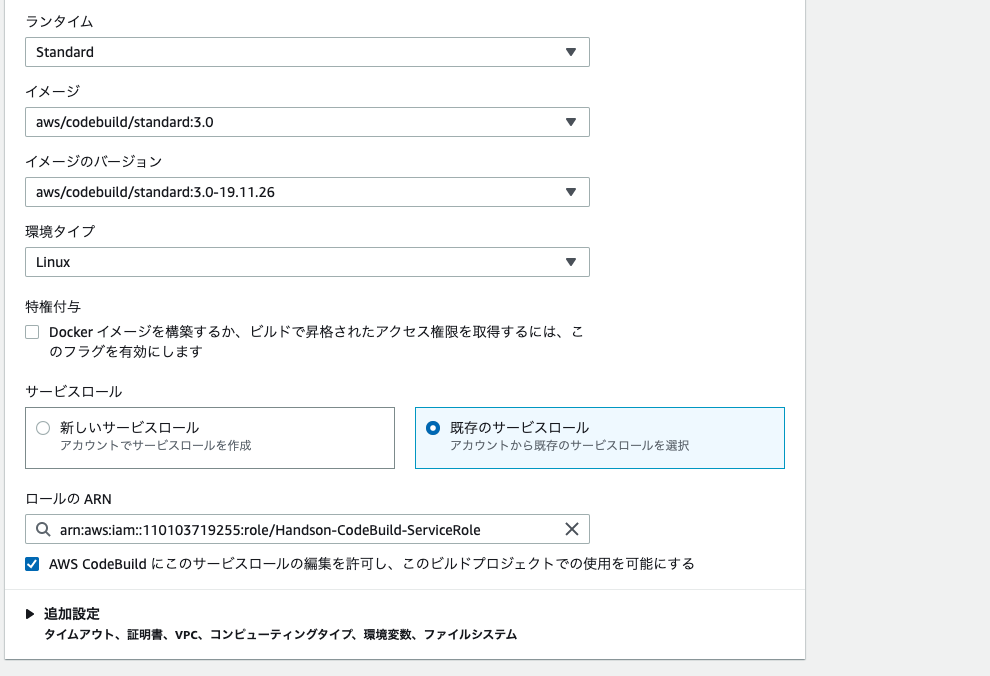
4. CodeBuildの設定を行います。以下の画像のように選択し、プロジェクトを作成するを選択します。
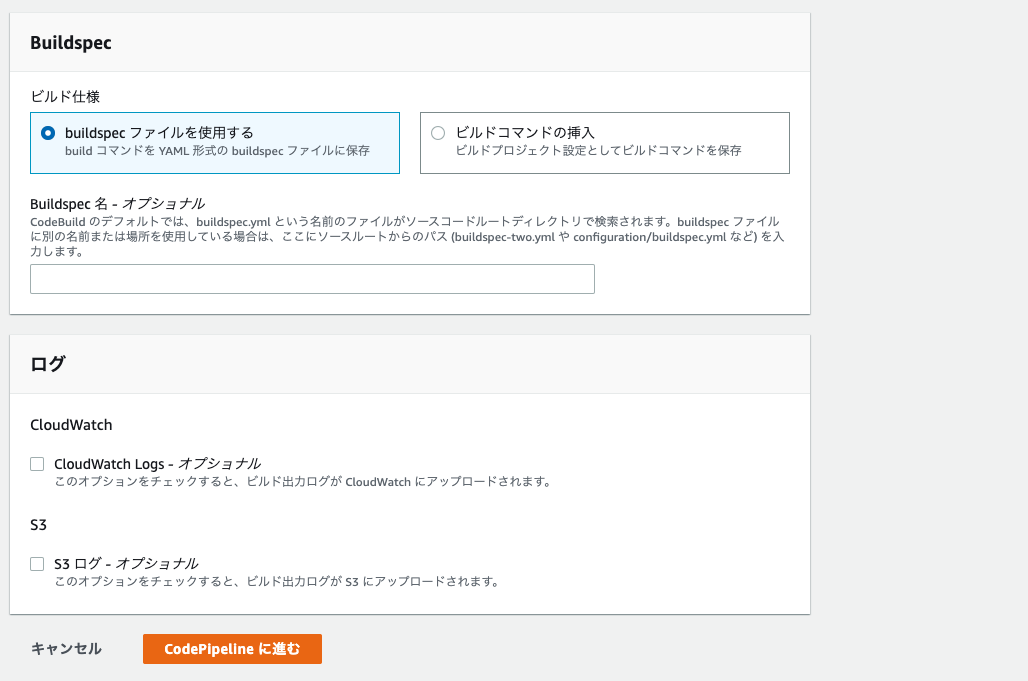
5. 以下の画像のように入力・選択を行い、CodePipelineに進むを選択する。
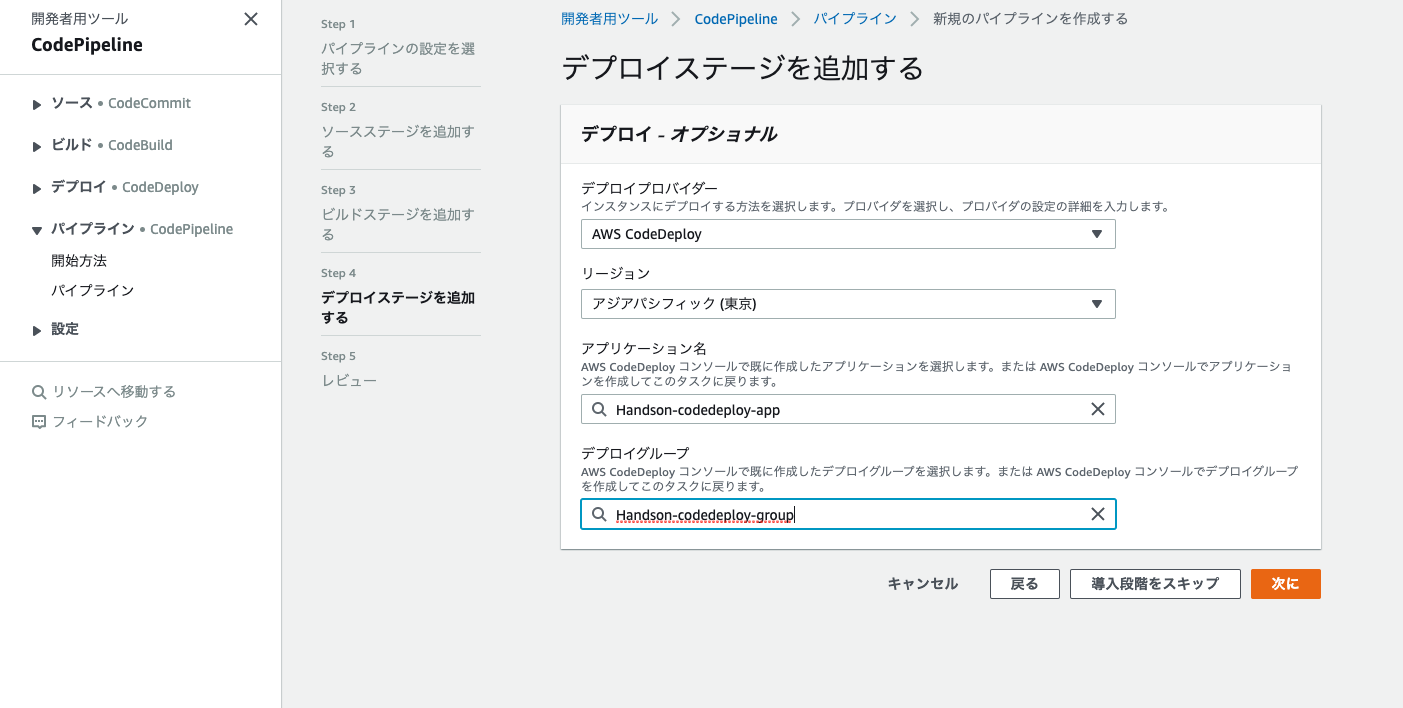
6. デプロイステージの追加では、前項で作成したCodeDeployを使用します。以下の画像のように入力・選択を行う。
7. 以上で全ての設定が終了したので、作成ボタンを押します。
8. 正常に終了していれば、以下の画像のようにCodePipelineが稼働します。
9. CodePipelineが全て終了後(5分程度)、EC2のエンドポイント(IP)に、IPアドレス:8080/ping/jsonとアクセスすると、以下の画像のようにレスポンスが返ってくると成功です。
まとめ
今回は、とりあえず手を動かしてCI/CDを体感したい人向けに、細かな用語等は説明しませんでしたが、少しでも作り込みたい(appspec.ymlやbuildspec.ymlなど)となった時に、必ず細かな知識等も必要になってきますので、そこは別記事等で学ぶことをお勧めします。





- 投稿日:2020-02-16T10:47:51+09:00
Pythonでゼロからでもサービス開発・公開できる学習ロードマップ
初めに
この記事は『プログラミング未経験からPythonでサービス開発できる』ことを目標に、
習得すべきスキルを学習ロードマップとして整理しました。毎日2~3時間(土日は+2時間)続ければ最短3ヵ月で完了できる内容に絞りました。
すでに習得済みのスキルは飛ばしつつ進めて大丈夫です。Rubyなど他の言語でも大筋は同じ流れなので、
Pythonと書いてある部分を、そのままRubyと読み替えれば大丈夫です。※なお、Twitter でもプログラミングに関する情報を発信しています。
もし良ければ Twitterアカウント「Saku731」 もフォロー頂けると嬉しいです。学習ロードマップの全体像
まず、サービス開発に必要なスキルは大きく分けて10種類あります。
各章で、それぞれのスキルが何の役に立つのか説明しつつ、
十分なスキルが習得できる参考記事・書籍を紹介して行きます。
学習方法と参考リンク集
①プログラミング環境の構築
まず、プログラミングに必要な「環境構築」を行います。
参考記事に沿ってエディター(Atom)とPythonをインストールしましょう。
- エディター(Atom)をインストール
- Pythonをインストール
②Webサイトの作り方
もしプログラミング未経験であれば最初はHTMLからスタートするのがおススメです。
私たちが普段見ている様々なWebサイトは『必ずHTMLが使用されている』点と、
多少は間違っても大丈夫なので気持ちよく学習を進められる点が理由です。
- HTML:Webサイトの骨組みを作る
- CSS:骨組みに装飾を加える
③デザイン(Bootstrap)
HTML/CSSに慣れてくると「もっと綺麗なWebサイトを作りたいな」と感じてきます。
相当に経験を積めばCSSでも綺麗なデザインを作ることは可能ですが、
皆さんは『サービスを作る』ために勉強しているので、1日でも早く先に進みましょう。そこで登場する便利なツールが、Twitter社が開発した Bootstrapです。
CSSのスキルや、デザイン経験が無くても洒落なサイトを作れる優れものです。色々なバージョンがありますが、
2020年2月時点で最新のBootstrap4を使用しましょう。
- Boobstrap基礎:Webサイトにデザインを加える
- Bootstrap応用:レスポンシブWebデザイン(スマホ対応)
④Python基礎
プログラミングにも慣れた頃なのでいよいよPythonの登場です。
一言でPythonといっても、いくら勉強しても足りないくらい色々な要素が存在します。そこで、本記事ではサービス開発だけにフォーカスして、
嫌でも使う必須スキルを紹介していきます。
- いろいろなデータ型に慣れる
- int型(整数)
- float型(小数を含む数)
- str型(文字列)
- list型(リスト)
- dict型(辞書)
- 制御構文に慣れる
- システムのパーツ(モジュール)を作る
⑤データベース
続いて、サービス開発には切っても切れないデータベース(以降 DB)です。
後ほど紹介するWebアプリケーションフレームワーク『Django』を使えば、
MySQLなどのDB言語が分からなくても大丈夫です。とは言っても、DBが内部でどういった処理を行っているのかについて
具体的なイメージを理解しておかないとサービス開発の段階で確実に苦労します。なので、最低限の要素に絞って効率よく勉強して行きましょう。
- 参考書籍
- DBの基本処理(CRUD処理)を理解する
- 外部キーの概念を理解する
- ER図の書き方を理解する(DBの設計図)
⑥開発環境(仮想環境)の構築
ここまでクリアすればサービス開発をスタートする基礎が身に付いています。
しかし焦らず、仮想環境の概念・使用方法を理解しておくと後々で役に立ちます。詳細は参考記事で確認いただければと思うのですが、
プログラミング環境がごちゃごちゃするのを防ぐことが目的です。⑦Webアプリ開発の手順を理解
いよいよサービス開発に入っていきましょう。
なお、正式にはWebアプリケーション開発と呼ぶので覚えておきましょう。
※以下、「Webアプリ開発」と呼びます。Webアプリ開発では『Webアプリケーション フレームワーク』を使用する事がほとんどです。
Webアプリフレームワークについて大まかに説明すると、自分で0からプログラミングしなくても
『開発に必要なパーツの大部分が完成した状態』で用意されている便利な開発補助ツールだと思って大丈夫です。とはいえ、『最後の表面的な部分』をコーディングするだけでも相当に骨が折れます。
ここが1番難しいので頑張って進めて行きましょう。Pythonで有名なWebアプリフレームワークは2種類あります。
勉強方法の好みに左右される部分もありますが、
せっかくFlaskで作ったのにDjangoで作り直しになるケースもあるので
最初からDjangoにチャレンジするのをおススメしています。なお、Djangoであれば私がオリジナルで書いたQiita記事があるので
最短で必要な要素が習得できる様に整理してあります。
- DjangoとFlaskの違い
- Django:
- 最初に覚える事が多い。入門としては難しめ
- オプション機能が豊富で、いったん覚えるともう手放せない
- Flask:
- 覚える事が少なく、比較的楽に開発できる
- オプションが少ないので、本格的な開発では逆に苦労する
- 実務ではDjangoを求められることが多い
- Python(Django)でシステム開発できる人材になれる記事_入門編
- Webアプリ開発の全体像を理解する
- 実際にWebアプリをコーディングする
⑧要件定義~システム設計
続いて、意外と見落とされがちな『要件定義~システム設計』です。
どれだけプログラミングが出来るようになっても、
『何を作ったら良いのか?』を決められないと何もスタートできません。過去に書いた記事を紹介するので、
『アイディアから設計図を描くプロセス』をしっかり習得しておきましょう。
- 要件定義~システム設計ができる人材になれる記事
- 要件定義のプロセス
- 画面設計
- 機能設計
- データ設計
⑨ソースコード管理(GitHub)
ここまで勉強すると、様々なソースコードが溜まってきます。
どれだけ几帳面な人でも管理するのが面倒になってくる時期です。「あのプログラムどこに保存したかな?」
「上書き保存してしまった。。以前の状態に戻したい。」
「他の人にプログラムを共有するのが面倒(Zip化してメール添付など)」こんな悩みを解決するツールがGitHubです。
実務でも使うので必ず習得しておきましょう。⑩サービス公開
最後に、開発したサービスを公開しましょう。
サービスを公開するための準備(サーバー準備)は大きく分けて5種類あります。本記事では「⑤:クラウドサーバー」について具体的な手順を紹介します。
※金融業界を除いて、実務では⑤が好まれるためです。また、クラウドサーバーを利用するには
Linuxコマンドを使いこなす必要があるので合わせて習得しておきましょう。
- 色々なサーバーサービスの特長・メリデメ
- ①自分でサーバーを購入する
- ②レンタルサーバーを借りる
- ③VPSを借りる
- ④専用サーバーを借りる
- ⑤クラウドサーバーを借りる
- AWS(EC2)を使ったサービス公開
- AWSと契約する
- サーバーを借りる
- サービスを公開する
- Linuxコマンドに慣れる
さいごに
自分ひとりでサービスを作るには多岐にわたるスキルが必要です。
それなりに苦労しますが、多くの方々が実際に乗り越えていく様子を見てきました。最近ではプログラミングを楽にする環境が整ってきたこともあり、
「ここだけ得意です」といった部分的なスキルでは良い仕事が獲得できない傾向が強まっています。いったん乗り越えてしまえば『他の誰にも負けない強力なスキル』となるので、
この記事を読んだ皆さんが3ヵ月を乗り切れるよう、応援しております。最後まで諦めず、頑張って良いサービスを創り上げて下さい。
【P.S.】
最後になりますが、Twitter でもプログラミングに関する情報を発信しています。
もし良ければ Twitterアカウント「Saku731」 もフォロー頂けると嬉しいです。

- 投稿日:2020-02-16T09:55:35+09:00
Forbidden You don't have permission to access this resource出た時の解決策
結論
公開ディレクトリ先のvar/www/htmlのhtmlディレクトリの所有者をapacheに変更した
まずは現在の所有者を確認してみる。
[root@ip-172-31-28-29 html]# cd .. [root@ip-172-31-28-29 www]# pwd /var/www [root@ip-172-31-28-29 www]# ls -l total 0 drwxr-xr-x 2 root root 6 Oct 22 22:59 cgi-bin drwxrw-rwx 3 ec2-user apache 51 Feb 15 09:43 html所有者がec2-userになっていたので今回のエラーが出ていました。
所有者をapacheに変更する
chown -R apache:apache 実行させるフォルダ
[root@ip-172-31-28-29 www]# chown -R apache:apache html [root@ip-172-31-28-29 www]# ls -l total 0 drwxr-xr-x 2 root root 6 Oct 22 22:59 cgi-bin drwxrw-rwx 3 apache apache 51 Feb 15 09:43 html [root@ip-172-31-28-29 www]# systemctl restart httpdこれで所有者がapacheに変更しました。
念のためsystemctl restart httpdを行い再起動させましょう。無事、表示することができました。
htmlディレクトリ先のファイルの所有者は?
関係無かったですが、htmlディレクトリ先のファイルの所有者も公開しておきます。
[root@ip-172-31-28-29 html]# pwd /var/www/html [root@ip-172-31-28-29 html]# ls -l total 8 drwxrwxrwx 2 ec2-user ec2-user 19 Feb 15 09:43 test -rwxrwxrwx 1 ec2-user root 11 Feb 12 23:17 test.html -rw-r--r-- 1 ec2-user root 22 Feb 14 14:45 test.php

- 投稿日:2020-02-16T03:41:15+09:00
VPC設定ついでにまとめてみた
概要
コンソールからVPC設定しているのでついでにVPC周辺の詳細を記述していきます。
VPC(Virtual Private Cloud)とは
- AWSアカウント専用の仮想ネットワーク空間のこと
- 社内ユーザのみアクセスが可能な仮想ネットワークの構築が可能(インターネットからはアクセスできない)
- アカウント作成時はデフォルトでVPC(Default VPC)が1つ作成されているが、ユーザ毎に個別で作成可能
リージョン
世界22ヶ所の分散されたデータセンター群で構成されている。
日本のリージョンは現在(2020年2月時点)は東京リージョン(ap-northeast-1)のみ※ 大阪ローカルリージョンが2021年初頭までに3つのアベイラビリティーゾーンを持つ完全なAWSリージョンに拡大するそうです。
アベイラビリティーゾーン(AZ)
各リージョンに存在するデータセンタの事
VPCはAZをまたいで作成できるがリージョンはまたげないIPアドレスの範囲
ユーザー毎に隔離されたネットワークを作成する為には、VCP領域に対してIPアドレスの範囲を与える必要がある。
CIDR(Classless Inter-Domain Routing)表記とは
例: 192.168.1.0〜192.168.1.255
上記のような256個のIPアドレスは通常IPアドレス範囲を表す時はサブネットマスク表記やCIDR表記を使用します。
サブネットマスク表記だと 192.168.1.0/255.255.255.0となり ネットワーク部が32ビット中24ビット使用されているのでCIDR表記では 192.168.1.0/24と記述することができます。 24の部分は「プレフィックス」とも言いVPCではプレフィックスは16ビットから28ビットで構成する必要があります。CIDRと利用可能なIPアドレス数
CIDRブロックでは最初の4IPと最後の1IPは利用できない為、利用可能なIPアドレス数から-5しています。
参考: https://aws.amazon.com/jp/premiumsupport/knowledge-center/change-subnet-mask/16ビットから28ビットのプレフィックスと利用可能なIPアドレス数を下記の表にまとめました。
プレフィックス 利用可能なIPアドレス数 16 65531 18 16379 20 4091 22 1019 24 251 26 59 28 11 例: プレフィックスが18の時 サブネットマスクが下記のようになり 11111111 11111111 11000000 00000000 => (64 * 256) -5 = 16,379となるサブネット
- VPC内に構成するネットワークを分割したもので1つのVPCに対して1つ以上のサブネットで構成される。
- サブネットを分けることで仮に片方のサブネットに障害が起きても、異なるサブネットに影響が生じにくくなることやそれぞれ別のネットワークの設定ができる為セキリティを高められる。
- VPCのIPアドレスの範囲内で設定
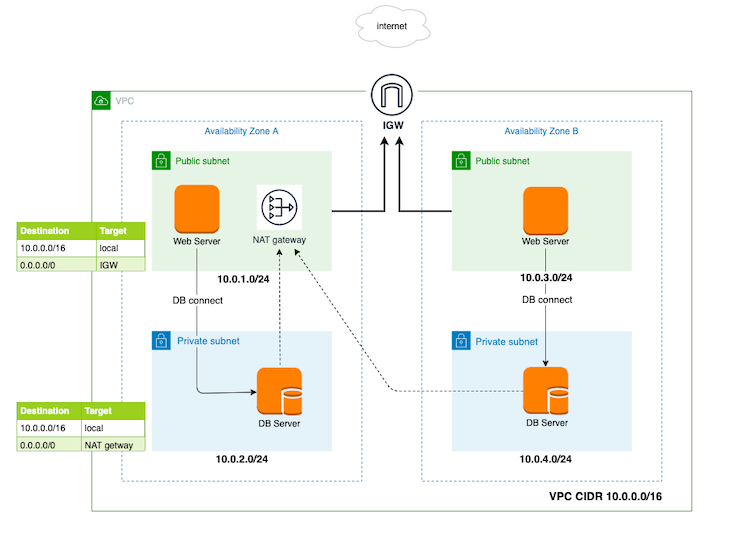
例: VPC CIDRが「10.0.0.0/16」の場合 サブネットは細分化された「10.0.1.0/24」や「10.0.2.0/24」などで作成パブリックサブネット
インターネットに直接接続し外部に公開される
インターネットゲートウェイを経由させることでインターネットとの接続を可能にするインターネットゲートウェイ
インターネットゲートウェイをVPCにアタッチすることで、アタッチしたVPC内のサブネットがインターネットへ接続できる。
ルートテーブル
どのネットワークに対する通信をどこのネットワークに流すかを定義するもの
ルートテーブルでデフォルトゲートウェイ(0.0.0.0/0)を設定して、インターネットゲートウェイを指定したものはパブリックサブネットになり、それ以外はプライベートサブネットになる
destination(送信先) target 10.0.0.0/16 local 0.0.0.0/0 インターネットゲートウェイ プライベートサブネット
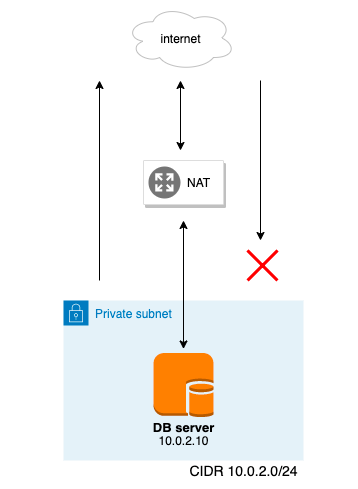
DBサーバーなどバック部分はインターネットに接続されたくない事やセキュリティーを高める必要があるので、プライベートサブネットでサーバーを隠す
サーバーからインタネットに接続することもできなくなるのでソフトのインストールやアップデート(yumの実行など)を可能にするにはNATを使用するNATゲートウェイ
NATはIPアドレスの置換を行う(送信元のプライベートIPアドレスをNAT上のパブリックIPアドレスに置換する)事でプライベートサブネットからインターネットへ接続が可能にする
インターネットからプライベートサブネットへの接続はできないちなみにIPアドレスとポート番号を置換する事で複数のホストを共有可能にしたものはNAPTという
NATを使用する為にNATゲートウェイ設置する必要があるが、作成時にはインターネット接続可能なパブリックサブネットとEIPを割り当てる必要がある
EIP(Elastic IP)
パブリックIPアドレスは起動/停止するたびに別のIPアドレスに割り当てられるのでEIPでIPアドレスを固定する
インスタンスにアタッチされている時は料金は発生しないが、どのインスタンスにもアタッチされていない場合は1時間当たり約0.5円の料金がかる公式(オンデマンド料金): https://aws.amazon.com/jp/ec2/pricing/on-demand/
セキュリティーグループとネットワークACL
ファイアウォール 範囲 初期インバウンド 初期アウトバウンド ルール セキュリテイーグループ EC2インスタンス毎 全て拒否 全て許可 累積的に許可 ネットワークACL サブネット毎 全て許可 全て許可 マッチした時点で許可、以降は拒否 最後に
今回はVPCを中心に内容を記述していきましたが、今回書いていないVPC周辺の知識やコンソール上では理解しにくいAWSの他のサービスの知識があるので設定しながらまたまとめていけたらなと思います。
- 投稿日:2020-02-16T00:15:00+09:00
EC2(AmazonLinux2)のログをKinesisFireHoseに流してS3へ蓄積する
まずはEC2からKinesisへのfullアクセスロールを用意。
ついでS3バケットとFireHoseのストリーム作成。FireHoseのIAMロールはここで作成できる。
以下、EC2の設定。
ここではApacheへのアクセスログを題材としている。$ sudo yum -y install httpd $ sudo systemctl enable httpd $ sudo systemctl start httpd $ sudo vi /etc/httpd/conf/httpd.conf
:set numberとすることで行数を表示できる。:197で197行目に飛べる。197行目に追記LogFormat "time:%t\tforwardedfor:%{X-Forwarded-For}i\thost:%h\treq:%r\tstatus:%>s\tsize:%b\treferer:%{Referer}i\tua:%{User-Agent}i\treqtime_microsec:%D\tcache:%{X-Cache}o\truntime:%{X-Runtime}o\tvhost:%{Host}i" ltsv219行目に追記LogFormat "time:%t\tforwardedfor:%{X-Forwarded-For}i\thost:%h\treq:%r\tstatus:%>s\tsize:%b\treferer:%{Referer}i\tua:%{User-Agent}i\treqtime_microsec:%D\tcache:%{X-Cache}o\truntime:%{X-Runtime}o\tvhost:%{Host}i" ltsv$ sudo systemctl restart httpd $ sudo chmod 755 /var/log/httpd $ sudo chmod 644 /var/log/httpd/access_log $ sudo yum install –y https://s3.amazonaws.com/streaming-data-agent/aws-kinesis-agent-latest.amzn1.noarch.rpm $ sudo vi /etc/aws-kinesis/agent.json/etc/aws-kinesis/agent.json{ "cloudwatch.emitMetrics": false, "firehose.endpoint": "https://firehose.ap-northeast-1.amazonaws.com", "flows": [ { "filePattern": "/var/log/httpd/access_log_ltsv", "deliveryStream": "作成したstream名" } ] }$ sudo systemctl restart aws-kinesis-agent $ sudo systemctl enable aws-kinesis-agent aws-kinesis-agent.service is not a native service, redirecting to /sbin/chkconfig. Executing /sbin/chkconfig aws-kinesis-agent on $ sudo tail -f /var/log/aws-kinesis-agent/aws-kinesis-agent.log 2020-02-15 13:48:42.192+0000 (FileTailer[fh:xxxx:/var/log/httpd/access_log_ltsv].MetricsEmitter RUNNING) com.amazon.kinesis.streaming.agent.tailing.FileTailer [INFO] FileTailer[fh:xxxx:/var/log/httpd/access_log_ltsv]: Tailer Progress: Tailer has parsed 3 records (985 bytes), transformed 0 records, skipped 0 records, and has successfully sent 0 records to destination. 2020-02-15 13:48:42.198+0000 (Agent.MetricsEmitter RUNNING) com.amazon.kinesis.streaming.agent.Agent [INFO] Agent: Progress: 3 records parsed (985 bytes), and 0 records sent successfully to destinations. Uptime: 120058ms 2020-02-15 13:48:51.186+0000 (sender-0) com.amazon.kinesis.streaming.agent.UserDefinedCredentialsProvider [INFO] No custom implementation of credentials provider present in the config file 2020-02-15 13:49:12.193+0000 (FileTailer[fh:xxxx:/var/log/httpd/access_log_ltsv].MetricsEmitter RUNNING) com.amazon.kinesis.streaming.agent.tailing.FileTailer [INFO] FileTailer[fh:xxxx:/var/log/httpd/access_log_ltsv]: Tailer Progress: Tailer has parsed 3 records (985 bytes), transformed 0 records, skipped 0 records, and has successfully sent 3 records to destination. 2020-02-15 13:49:12.198+0000 (Agent.MetricsEmitter RUNNING) com.amazon.kinesis.streaming.agent.Agent [INFO] Agent: Progress: 3 records parsed (985 bytes), and 3 records sent successfully to destinations. Uptime: 150058msしばらくすると
○ records sent successfully to destinationsとなりFireHose側に流れてきたことが確認できる。その後約5分してS3へデータが飛んだ。どうやらS3への送信は若干のラグがあるらしい。Monitoring
参考
- 投稿日:2020-02-16T00:14:08+09:00
EC2(AmazonLinux2)のログをCoudWatch Logsに流す
公式ドキュメント
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/QuickStartEC2Instance.html(1) IAMロールの準備→CloudWatchFullアクセスでおk。
(2) Agentのインストール$ sudo yum update -y $ sudo yum install -y awslogs $ sudo vi /etc/awslogs/awscli.conf # ここでregionをap-northeast-1に指定。 $ sudo vi /etc/awslogs/awslogs.conf # ここでCloudWatchに流したい対象のファイルを指定。 $ sudo systemctl start awslogsd $ sudo systemctl enable awslogsd.serviceawslogs.confの書き方
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/AgentReference.htmlリファレンス[logstream1] log_group_name = value log_stream_name = value datetime_format = value time_zone = [LOCAL|UTC] file = value file_fingerprint_lines = integer | integer-integer multi_line_start_pattern = regex | {datetime_format} initial_position = [start_of_file | end_of_file] encoding = [ascii|utf_8|..] buffer_duration = integer batch_count = integer batch_size = integerconfファイルには複数のログストリームの定義を書くことができる。それらの区別のために、括弧
[ ]にファイル内で一意な名前をつける。検証として以下のように記述。
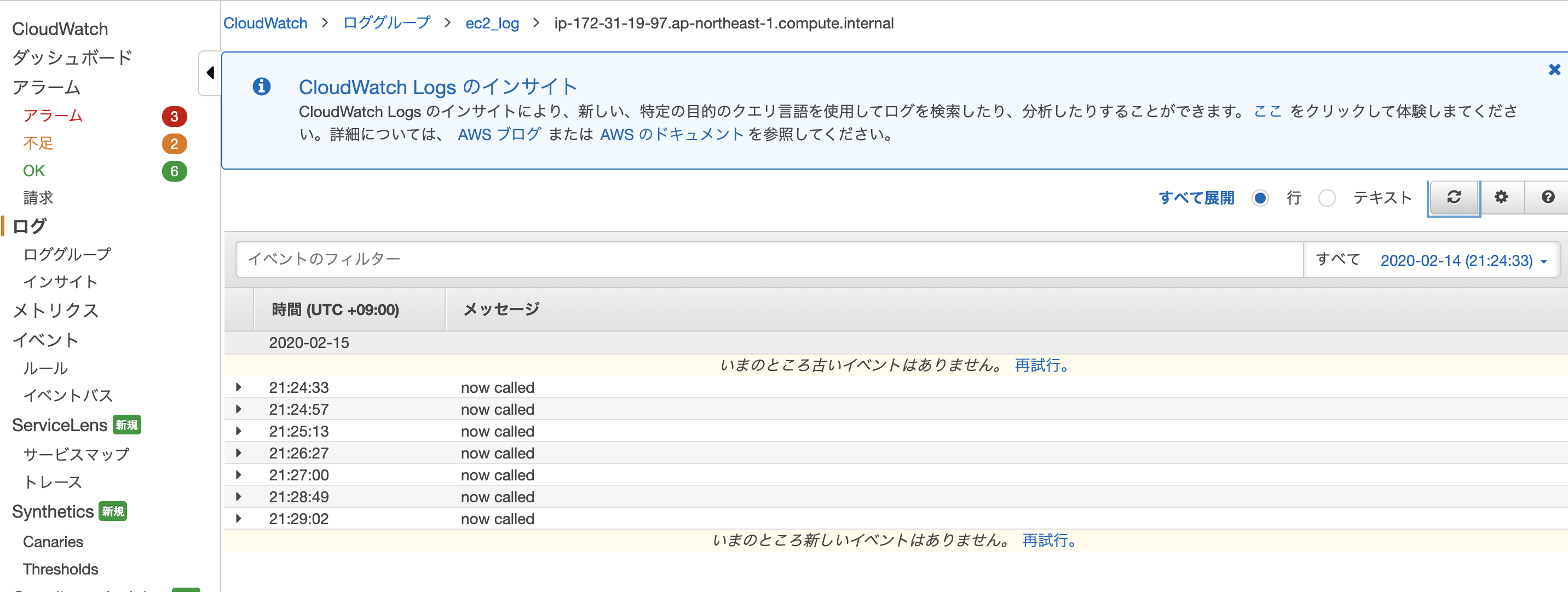
/etc/awslogs/awslogs.conf[/home/ec2-user/log.txt] datetime_format = %b %d %H:%M:%S file = /home/ec2-user/log.txt buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = ec2_logtest.sh#!/bin/sh echo "now called" >> ./log.txt
test.shを実行するたびにClowdWatchでログが見れるようになった。
なお、一度再起動した後もログが流れることが確認できた。