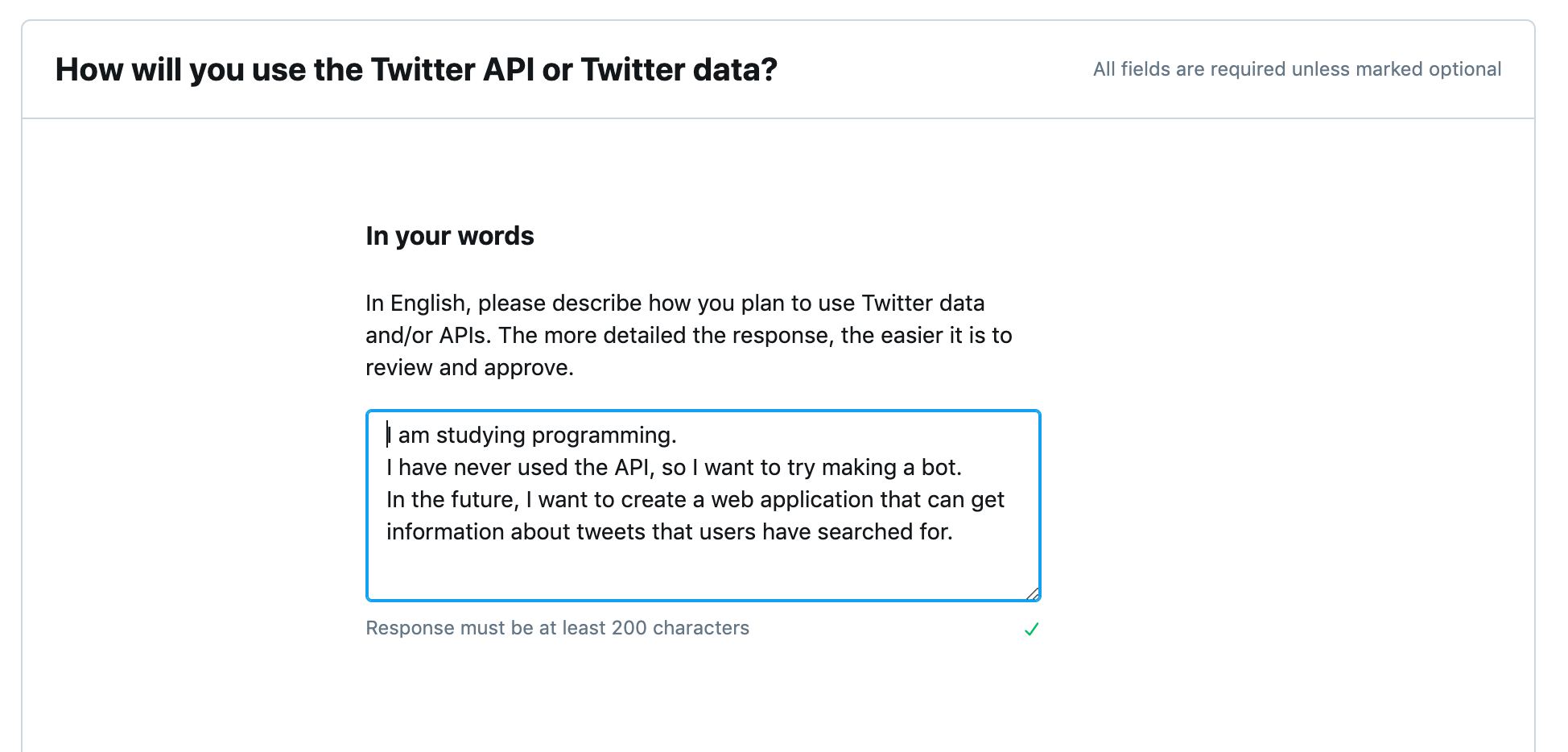
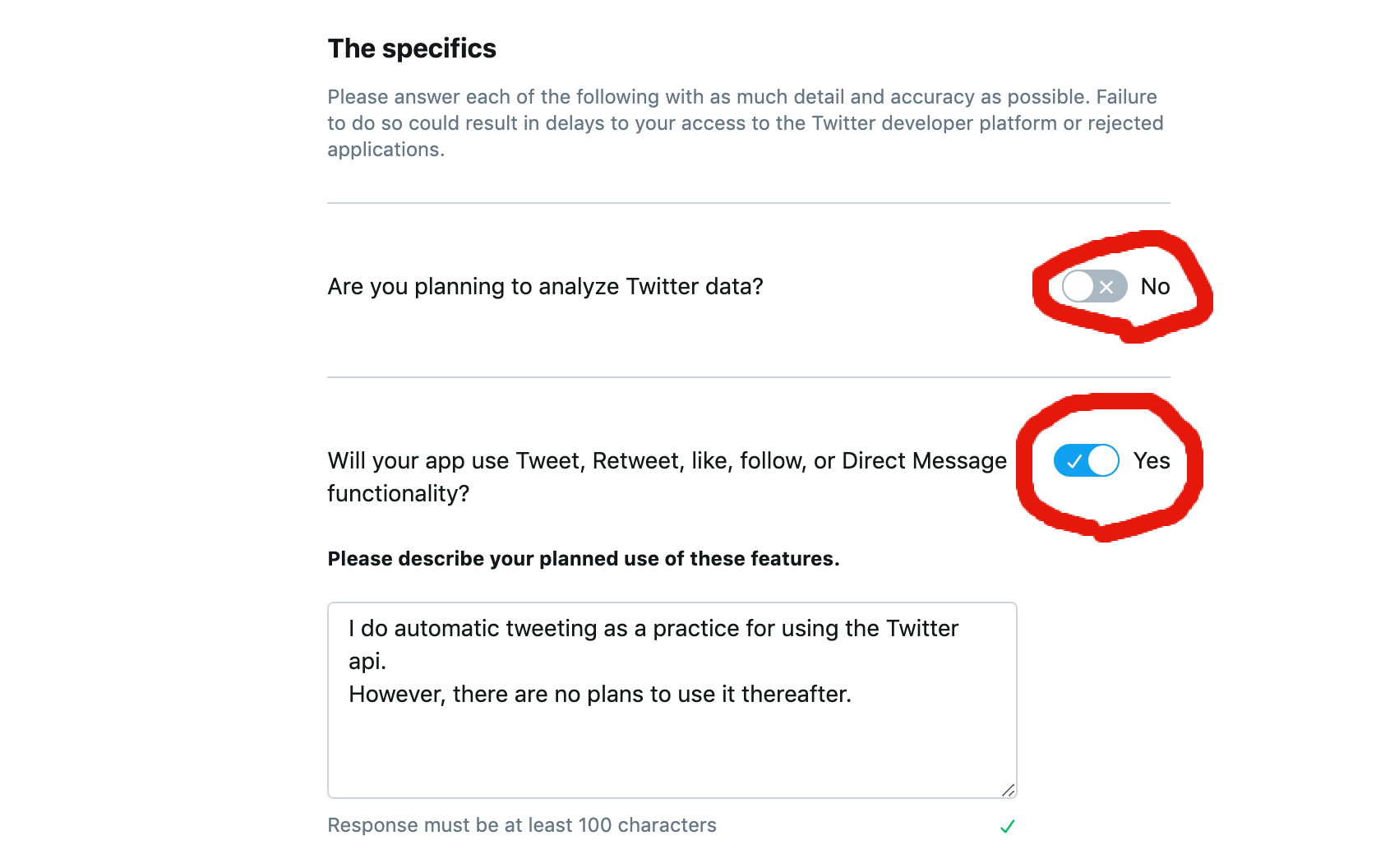
I am studying programing.
I have never used the API, so I want to try making a bot.
In the future, I want to create a web application that can get information about tweets that users have searched for.
Could not find gem 'pg (>= 0.18, < 2.0)' in any of the gem sources listed in your Gemfile.
Run `bundle install` to install missing gems.
言われてた通りbundle installを実行すると、
An error occurred while installing pg (1.2.2), and Bundler cannot continue.
Make sure that `gem install pg -v '1.2.2' --source 'https://rubygems.org/'` succeeds before bundling.
To see why this extension failed to compile, please check the mkmf.log which can be found here:
/home/username/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/extensions/x86_64-linux/2.5.0/pg-1.2.2/mkmf.log
extconf failed, exit code 1
Gem files will remain installed in /home/username/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/pg-1.2.2 for inspection.
Results logged to /home/username/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/extensions/x86_64-linux/2.5.0/pg-1.2.2/gem_make.out
FROM ruby:2.6
RUN apt-get update -qq && apt-get install -y nodejs postgresql-client
RUN mkdir /app
WORKDIR /app
COPY Gemfile /app/Gemfile
COPY Gemfile.lock /app/Gemfile.lock
RUN bundle install
COPY . /app
# Add a script to be executed every time the container starts.
COPY entrypoint.sh /usr/bin/
RUN chmod +x /usr/bin/entrypoint.sh
ENTRYPOINT ["entrypoint.sh"]
EXPOSE 3000
# Start the main process.
CMD ["rails", "server", "-b", "0.0.0.0"]
entrypoint.sh
#!/bin/bashset-e# Remove a potentially pre-existing server.pid for Rails.rm-f /app/tmp/pids/server.pid
# Then exec the container's main process (what's set as CMD in the Dockerfile).exec"$@"
FROM ruby:2.5RUN apt-get update -qq&& apt-get install-y nodejs postgresql-client
RUN mkdir /myapp
WORKDIR /myappCOPY Gemfile /myapp/GemfileCOPY Gemfile.lock /myapp/Gemfile.lockRUN bundle installCOPY . /myapp# Add a script to be executed every time the container starts.COPY entrypoint.sh /usr/bin/RUN chmod +x /usr/bin/entrypoint.sh
ENTRYPOINT ["entrypoint.sh"]EXPOSE 3000# Start the main process.CMD ["rails", "server", "-b", "0.0.0.0"]
#!/bin/bashset-e# Remove a potentially pre-existing server.pid for Rails.rm-f /myapp/tmp/pids/server.pid
# Then exec the container's main process (what's set as CMD in the Dockerfile).exec"$@"
docker-compose run web rails new . --force --no-deps --database=postgresql
# rails new . とすることで、カレントディレクトリ配下にrailsファイルが作成される
--forceで事前に作成したファイルを上書き、今回はGemfile等
[ec2-user@ip-000-00-00-00 ~]$ vim ~/.bash_profile
#.bash_profile(初期設定の隠しファイル)をviエディターで確認する
.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
eval "$(rbenv init -)"
export PATH="$HOME/.rbenv/bin:$PATH"
#↑環境構築のコマンドにより最下の行を追記しました。正しいコマンド通りだとした2行が逆転していなければなりません
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export PATH="$HOME/.rbenv/bin:$PATH"
eval "$(rbenv init -)"
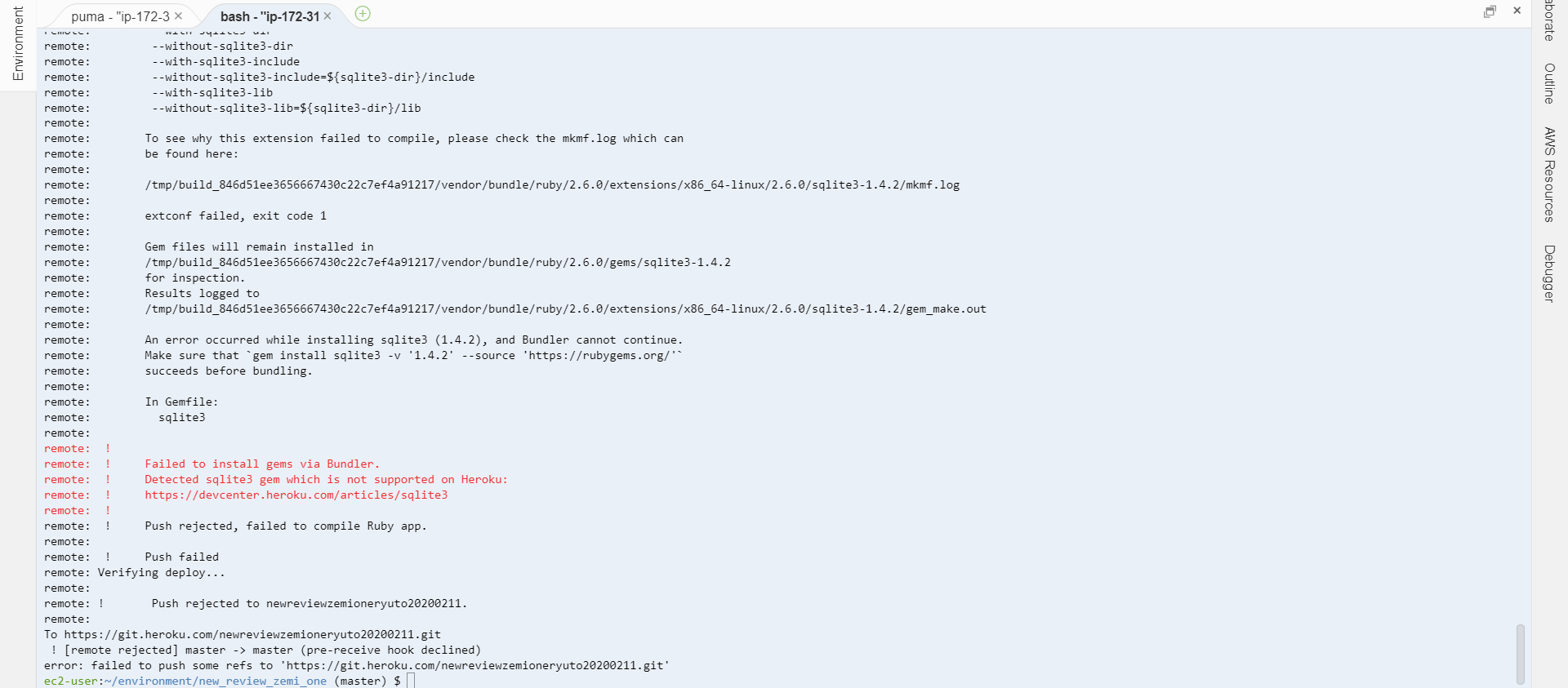
remote: !
remote: ! Failed to install gems via Bundler.
remote: ! Detected sqlite3 gem which is not supported on Heroku:
remote: ! https://devcenter.heroku.com/articles/sqlite3
remote: !
group :development, :test do
gem 'sqlite3', '1.3.13'
gem 'byebug', platforms: [:mri, :mingw, :x64_mingw]
end
group :production do
gem 'pg', '0.20.0'
end