- 投稿日:2020-02-11T23:56:50+09:00
【Python】Blueprintを使って大きなFlaskファイルを分割する
はじめに
pythonのwebフレームワークであるFlaskを使ってWEBアプリをつくっていると、Flaskのファイルの行数が多くなってしまいがちなのでファイル分割を検討した。FlaskではBrueprintを使ったファイル分割が一般的なようで、今回Blueprintを使用してファイルを分割した。
ディレクトリ構成
├── main.py ├── COMP_A │ └── func_A.py ├── COMP_B │ └── func_B.py └── templates ├── COMP_A │ ├── index_A_1.html │ └── index_A_2.html └── COMP_B ├── index_B_1.html └── index_B_2.htmlメインプログラムはmain.pyとする。またこの他にコンポーネントA、Bがあるものと想定。
各コンポーネント内のfunc_A.py、func_B.pyはそれぞれFlaskを使用するファイル。flaskでは、template配下にはhtmlファイルを格納するが、今回はtemplate配下にコンポーネントごとのディレクトリを準備して、htmlファイルを格納した。
ソースコード
func_A.py
from flask import render_template from flask import Blueprint bpa = Blueprint('bpa', __name__, url_prefix='/A') @bpa.route('/a1') def app_a1(): return render_template('COMP_A/index_A_1.html') #return "hello A a1" @bpa.route('/a2') def app_a2(): return render_template('COMP_A/index_A_2.html') #return "hello A a2"func_B.py
from flask import render_template from flask import Blueprint bpb = Blueprint('bpb', __name__, url_prefix='/B') @bpb.route('/b1') def app_b1(): return render_template('COMP_B/index_B_1.html') #return "hello B b1" @bpb.route('/b2') def app_b2(): return render_template('COMP_B/index_B_2.html') #return "hello B b2"main.py
from flask import Flask app = Flask(__name__) from COMP_A.func_A import bpa from COMP_B.func_B import bpb @app.route('/') def index(): return 'Hello main' app.register_blueprint(bpa) app.register_blueprint(bpb) if __name__ == '__main__': app.debug = True app.run(host='127.0.0.1',port=60000)本来、Flask(name)で生成したappに対し、関数を登録していくが、別ファイルの関数の場合には、register_blueprintを使って Brueprintをappに登録していく。
この際、事前に別関数のBrueprintをimportするのを忘れないこと。呼び出し
URLに以下を指定
127.0.0.1:60000/ #main.py index()
127.0.0.1:60000/A/a1 #func_A.py app_a1()
127.0.0.1:60000/A/a2 #func_A.py app_a2()
127.0.0.1:60000/B/b1 #func_B.py app_b1()
127.0.0.1:60000/B/b2 #func_B.py app_b2()
URLはBrueprint指定時のPrefixと@xxx.route定義時のパスの組み合わせになる点に注意その他
moduleを使ったファイル分割
flask.moduleを使ってファイル分割を行う方法もある様子。次回検討。redirect
redirectを行うときにはapp名を指定する必要がある。例えばb2にredirectするには以下のように書く。return redirect(url_for('bpb.b2'))
- 投稿日:2020-02-11T23:50:44+09:00
Pythonで画像表示、お絵描き用のアプリケーション作りの仕組み解説
前説
AI (Deep Learning)の流行とともにPythonの人気が上がっていますね。
Pythonで画像を表示・描き込み・保存するGUIアプリケーションを以前から作っていたもコードなどを整理して作ってみました。自分の理解を整理するためにも、その仕組みを書いてみます。
使ったものはQt for Python(PySide2)というライブラリです。
Qtは元々C++で開発されており、同一のソースコードからWindows, Mac, Linuxなどの様々なOSで動作するクロスプラットフォームなアプリケーションが開発できます。
PythonからQtを利用するにはQt for PythonかPyQtがありますが、作成したアプリのライセンスの縛りがそれほどないQt for Pythonを使いました。
GUIアプリケーション作りではオブジェクト指向について把握していると理解しやすいです。画像を描画するときにいくつもオブジェクトが出てきて、それぞれの役割や関係がわかりづらいところが初心者に辛く感じるところですが、きれいな形でなくても動くものができてくると理解が進みます。(経験談)
なので、作りたいイメージがあったら諦めずに色々試行錯誤してみてください。この記事がそのときの一助にでもなれば幸いです。アプリの全体像
アプリの全体像は下図のようになります。
Layoutというウィンドウなどのサイズに合わせて自動的に置いた部品(Widget)を整列する機能を持つもので画面構成を管理しています。
メインウィンドウの作成
メインウィンドウとしてQMainWindowを継承したclass MainWindow(QMainWIndow)を作ります。この中に様々な機能を持たせた部品(Widget)を配置し、それを押したときなどの動作を記述していきます。
ここで初期化のなかで、self.mainWidget = QWidget(self)のように宣言しておかないとLayoutを設定していけませんでした。アプリケーションの起動は、下のように実行します。
class MainWindow(QMainWindow): def __init__(self): # 以下、色々な処理を記述 if __name__ == '__main__': app = QApplication(sys.argv) window = MainWindow() window.show() sys.exit(app.exec_())メニューバーの作成
編集中
部品へのアクションを受け取る仕組み
編集中
Signal, Slotについて
画像表示の仕組み
画像表示にはいくつかのWidgetを連携させます。
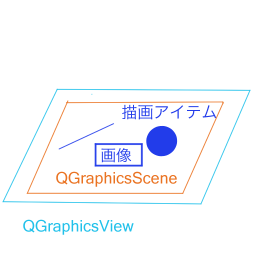
下図のような関係になっており、MainWindowに描画領域オブジェクトであるQGraphicsViewを用意し、その中に描画オブジェクトを保持・管理するQGraphicsSceneを配置し、QGraphicsSceneにラインや円などの描画や画像を加えていきます。
メインの描画領域に設定するQGraphicsSceneにはカーソルのツールを選んでいるときは表示されている画像の画素情報をステータスバーに表示し、ペンや消しゴムのツールを選んでいるときは画像の上のレイヤーにお絵描きをするようにします。そのような自分で設定した機能を追加するためQGraphicSceneを継承したGraphicsSceneを以下のように作成します。
初期化init関数において、親である描画領域のQGraphicsViewとそのさらに親であるMainWindowを設定することで、このGraphicsSceneの各アイテムで得た情報を描画領域やウィンドウに渡せるようにします。正直、最初はQGraphicsViewとQGraphicsSceneがよく分からないけど分かれていてなんか複雑でコンテンツへのアクセスや制御が面倒!と思いました。
これは描画する対象コンテンツは変わらなくても、視点を変えて見える範囲(描画できる範囲)で描画するという複雑な要求にも応えられる設計にしているためと思われます。例えば、描画するコンテンツが描画エリアより大きいときにスクロールバーで視点を変えながら表示する、3Dオブジェクトを視点を変えながら表示するといったことが考えられます。class GraphicsSceneForMainView(QGraphicsScene): def __init__(self, parent=None, window=None, mode='cursor'): QGraphicsScene.__init__(self, parent) # Set parent view area self.parent = parent # Set grand parent window self.window = window # Set action mode self.mode = mode # mouse move pixels self.points = [] # added line items self.line_items = [] self.lines = [] # added line's pen attribute self.pens = [] def set_mode(self, mode): self.mode = mode def set_img_contents(self, img_contents): # image data of Graphics Scene's contents self.img_contents = img_contents def clear_contents(self): self.points.clear() self.line_items.clear() self.lines.clear() self.pens.clear() self.img_contents = None def mousePressEvent(self, event): # For check program action pos = event.scenePos() x = pos.x() y = pos.y() if self.mode == 'cursor': # Get items on cursor message = '(x, y)=({x}, {y}) '.format(x=int(x), y=int(y)) for img in self.img_contents: # Get pixel value pix_val = img.pixel(x, y) pix_rgb = QColor(pix_val).getRgb() message += '(R, G, B) = {RGB} '.format(RGB=pix_rgb[:3]) # show scene status on parent's widgets status bar self.window.statusBar().showMessage(message) if self.mode == 'pen' or self.mode == 'eraser': if x >= 0 and x < self.width() and y >= 0 and y < self.height(): if len(self.points) != 0: draw_color = self.window.draw_color # Set transparenc value画像オブジェクト
QGraphicsSceneに画像を配置するには、QPixmapという形式にして、QGraphicsScene.addItem(QPixmap)とします。ただし、QPixmap形式だと各画素の情報を取得したり、書き換えたりすることができないため、QImage形式で保持しておいて、それをQPixmapに変換して描画させます。画像ファイルからQImageを作成し、それをQPixmapにして、QGraphicsSceneに加えるには以下のようなコードとなります。
# selfはMainWindowをさす self.scene = GraphicsSceneForMainView(self.graphics_view, self) self.org_qimg = QImage(self.org_img_file_path) self.org_pixmap = QPixmap.fromImage(self.org_qimg) scene.addItem(self.org_pixmap)空の各8bit(256階調)RGBA(Aは透過度)のQImageを作るには、以下のようなコードとなります。
self.layer_qimg = QImage(self.org_img_width, self.org_img_height, QImage.Format_RGBA8888)カラーバーの設定
編集中
描画した内容を反映して、ファイルとして保存
編集中
ソースコード
作成したアプリのソースコードを以下の場所に掲載します。
アプリのソースコードのページ
- 投稿日:2020-02-11T23:50:44+09:00
Pythonで画像表示、お絵描き用のアプリケーション作りの解説
前説
AI (Deep Learning)の流行とともにPythonの人気が上がっていますね。
Pythonで画像を表示・描き込み・保存するGUIアプリケーションを以前から作っていたもコードなどを整理して作ってみました。自分の理解を整理するためにも、その仕組みを書いてみます。
使ったものはQt for Python(PySide2)というライブラリです。
Qtは元々C++で開発されており、同一のソースコードからWindows, Mac, Linuxなどの様々なOSで動作するクロスプラットフォームなアプリケーションが開発できます。
PythonからQtを利用するにはQt for PythonかPyQtがありますが、作成したアプリのライセンスの縛りがそれほどないQt for Pythonを使いました。
GUIアプリケーション作りではオブジェクト指向について把握していると理解しやすいです。画像を描画するときにいくつもオブジェクトが出てきて、それぞれの役割や関係がわかりづらいところが初心者に辛く感じるところですが、きれいな形でなくても動くものができてくると理解が進みます。(経験談)
なので、作りたいイメージがあったら諦めずに色々試行錯誤してみてください。この記事がそのときの一助にでもなれば幸いです。アプリの全体像
アプリの全体像は下図のようになります。
Layoutというウィンドウなどのサイズに合わせて自動的に置いた部品(Widget)を整列する機能を持つもので画面構成を管理しています。
メインウィンドウの作成
メインウィンドウとしてQMainWindowを継承したclass MainWindow(QMainWIndow)を作ります。この中に様々な機能を持たせた部品(Widget)を配置し、それを押したときなどの動作を記述していきます。
ここで初期化のなかで、self.mainWidget = QWidget(self)のように宣言しておかないとLayoutを設定していけませんでした。アプリケーションの起動は、下のように実行します。
class MainWindow(QMainWindow): def __init__(self): # 以下、色々な処理を記述 if __name__ == '__main__': app = QApplication(sys.argv) window = MainWindow() window.show() sys.exit(app.exec_())メニューバーの作成
編集中
部品へのアクションを受け取る仕組み
編集中
Signal, Slotについて
画像表示の仕組み
画像表示にはいくつかのWidgetを連携させます。
下図のような関係になっており、MainWindowに描画領域オブジェクトであるQGraphicsViewを用意し、その中に描画オブジェクトを保持・管理するQGraphicsSceneを配置し、QGraphicsSceneにラインや円などの描画や画像を加えていきます。
メインの描画領域に設定するQGraphicsSceneにはカーソルのツールを選んでいるときは表示されている画像の画素情報をステータスバーに表示し、ペンや消しゴムのツールを選んでいるときは画像の上のレイヤーにお絵描きをするようにします。そのような自分で設定した機能を追加するためQGraphicSceneを継承したGraphicsSceneを以下のように作成します。
初期化init関数において、親である描画領域のQGraphicsViewとそのさらに親であるMainWindowを設定することで、このGraphicsSceneの各アイテムで得た情報を描画領域やウィンドウに渡せるようにします。正直、最初はQGraphicsViewとQGraphicsSceneがよく分からないけど分かれていてなんか複雑でコンテンツへのアクセスや制御が面倒!と思いました。
これは描画する対象コンテンツは変わらなくても、視点を変えて見える範囲(描画できる範囲)で描画するという複雑な要求にも応えられる設計にしているためと思われます。例えば、描画するコンテンツが描画エリアより大きいときにスクロールバーで視点を変えながら表示する、3Dオブジェクトを視点を変えながら表示するといったことが考えられます。class GraphicsSceneForMainView(QGraphicsScene): def __init__(self, parent=None, window=None, mode='cursor'): QGraphicsScene.__init__(self, parent) # Set parent view area self.parent = parent # Set grand parent window self.window = window # Set action mode self.mode = mode # mouse move pixels self.points = [] # added line items self.line_items = [] self.lines = [] # added line's pen attribute self.pens = [] def set_mode(self, mode): self.mode = mode def set_img_contents(self, img_contents): # image data of Graphics Scene's contents self.img_contents = img_contents def clear_contents(self): self.points.clear() self.line_items.clear() self.lines.clear() self.pens.clear() self.img_contents = None def mousePressEvent(self, event): # For check program action pos = event.scenePos() x = pos.x() y = pos.y() if self.mode == 'cursor': # Get items on cursor message = '(x, y)=({x}, {y}) '.format(x=int(x), y=int(y)) for img in self.img_contents: # Get pixel value pix_val = img.pixel(x, y) pix_rgb = QColor(pix_val).getRgb() message += '(R, G, B) = {RGB} '.format(RGB=pix_rgb[:3]) # show scene status on parent's widgets status bar self.window.statusBar().showMessage(message) if self.mode == 'pen' or self.mode == 'eraser': if x >= 0 and x < self.width() and y >= 0 and y < self.height(): if len(self.points) != 0: draw_color = self.window.draw_color # Set transparenc valueQGraphicsViewのドキュメントへのリンク
QGraphicsSceneのドキュメントへのリンク画像オブジェクト
QGraphicsSceneに画像を配置するには、QPixmapという形式にして、QGraphicsScene.addItem(QPixmap)とします。ただし、QPixmap形式だと各画素の情報を取得したり、書き換えたりすることができないため、QImage形式で保持しておいて、それをQPixmapに変換して描画させます。画像ファイルからQImageを作成し、それをQPixmapにして、QGraphicsSceneに加えるには以下のようなコードとなります。
# selfはMainWindowをさす self.scene = GraphicsSceneForMainView(self.graphics_view, self) self.org_qimg = QImage(self.org_img_file_path) self.org_pixmap = QPixmap.fromImage(self.org_qimg) scene.addItem(self.org_pixmap)空の各8bit(256階調)RGBA(Aは透過度)のQImageを作るには、以下のようなコードとなります。
self.layer_qimg = QImage(self.org_img_width, self.org_img_height, QImage.Format_RGBA8888)QImageのドキュメントへのリンク
QPixmapのドキュメントへのリンクカラーバーの設定
編集中
描画した内容を反映して、ファイルとして保存
編集中
GUIでのWidget(部品)配置
QtにはQt DesignerというGUI画面上でボタンなどのパーツを配置するツールも付いています。
慣れないうちはどんなWidgetがあるかなどイメージしやすいため、これを使って外観を作ってみてるととわかりやすいかもしれません。ソースコード
作成したアプリのソースコードを以下の場所に掲載します。
アプリのソースコードのページ
- 投稿日:2020-02-11T23:26:13+09:00
機械学習のアルゴリズム(単回帰分析)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
今回は基本の「単回帰分析」。参考にしたのは次のページです。
基本
$ x $軸、$ y $軸からなる平面上の直線は$$ y=Ax+B $$として表される。$ A $は傾きで$ B $は切片とも言いますね。
多数の$ x $、$ y $の組み合わせに、いい感じの直線を引くための$ A $と$ B $を求めるのが単回帰です。人間ならなんとなく「こんな感じかな?」という直線を引くことができるが、これをコンピュータに引かせようというアプローチですね。お題
pythonのscikit-learnにはいくつかのテスト用のデータセットがある。今回はその中からdiabetes(糖尿病データ)を使う。コードはGoogle Colaboratoryなんかで試すことができます。
前準備
まずはテストデータを眺める。
詳しい説明はAPIドキュメントに記載があるが、10個のデータに対してターゲット(1年後の進行状況)が用意されている。
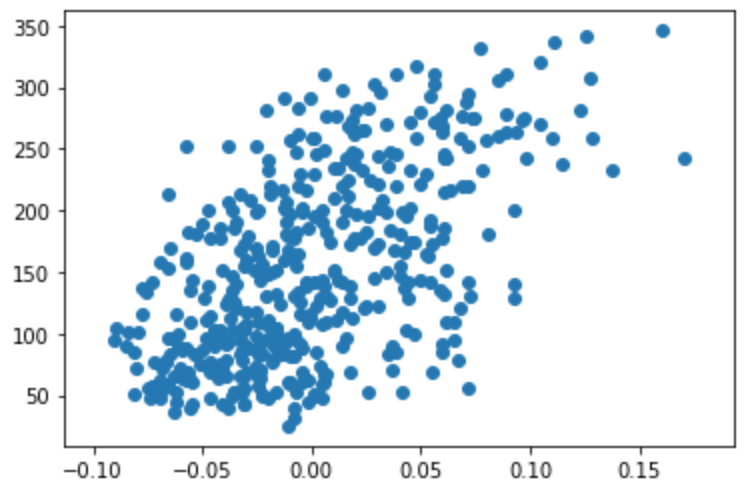
10個の要素のうち、BMIのデータがどう影響するかを散布図で見て見たい。なぜBMIかはいずれ触れる。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets diabetes = datasets.load_diabetes() df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names) x = df['bmi'] y = diabetes.target plt.scatter(x, y)横軸がBMI、縦軸が進行状況です。図で見るとなんとなく右肩上がりの直線を引けそうですね。
単回帰の解き方
与えられた$ N $個の$ (x, y) $列に対し、いい感じの直線を引くためのパラメータ$ A $と$ B $は、直線$ y = Ax + B $と$ i $番目の $(x_i, y_i) $との差の二乗の和を最小にする$ A $と$ B $を探せばいいことになる。つまり、$$ \sum_{i=1}^{N} (y_i-(Ax+B))^2 $$が最小となるような$ A $と$ B $を求めていく。
具体的には、上式を$ A $と$ B $で偏微分し、連立方程式を解くことになるのだが、割愛する。是非紙と鉛筆で書いてみるといいと思います。$ \sum_{i=1}^{N}x_i $が$ n\bar{x} $、$ \sum_{i=1}^{N}y_i $が$ n\bar{y} $で表すと$ A $と$ B $はそれぞれ$$ A = \frac{\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^{n}(x_i-\bar{x})^2} $$ $$ B= \bar{y}-A\bar{x}$$となる。ここまでくれば与えられた$ (x_i, y_i) $を上式にぶち込めば$ A $、$ B $は簡単に求まる。
pythonで愚直に実装してみる。
$ A $、$ B $を素直にコーディングしてもいいのだが、numpyに便利な関数がすでにあるのでそれを使う。$A$の分母は$x$列の分散(の$1/n$)、分子は$x$列と$y$列の共分散(の$1/n$)である。
S_xx = np.var(x, ddof=1) S_xy = np.cov(np.array([x, y]))[0][1] A = S_xy / S_xx B = np.mean(y) - A * np.mean(x) print("S_xx: ", S_xx) print("S_xy: ", S_xy) print("A: ", A) print("B: ", B)結果は以下である。なお、分散(var)は、標本分散と不偏分散というのがあり、あとで説明するscikit-learnは不偏分散であるため、不偏分散で計算する。標本分散と不偏分散については別で説明する。
<追記>ありました
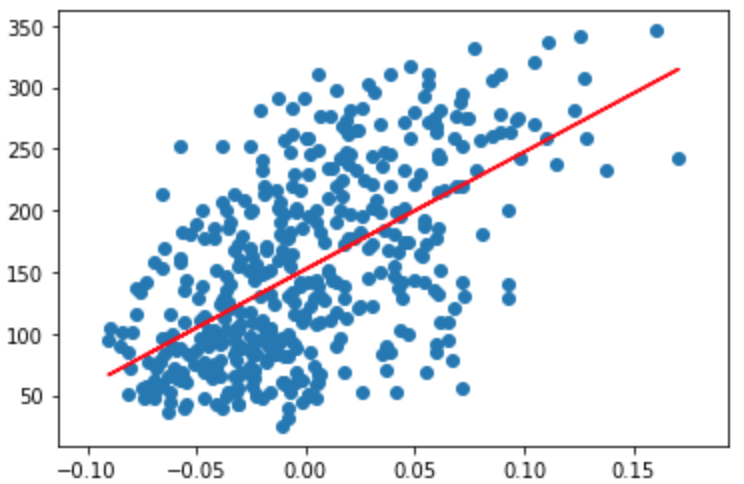
* 統計学4 - 標本分散と不偏分散S_xx: 0.0022675736961455507 S_xy: 2.1529144226397467 A: 949.43526038395 B: 152.1334841628967実はnp.cov[0][0]はxの分散なので計算する必要は無いのだが理解のために上記のようにしている。ここで求めた直線をさきほどの散布図にプロットしてみる。
plt.scatter(df['bmi'], diabetes.target) plt.plot(df['bmi'], A*df['bmi']+B, color='red')結果のグラフを見るとなんとなくいい感じの直線が引けていることがわかる。
同じことをscikit-learnでやってみる
同じことをscikit-learnでやるともっと簡単になる。なんとなく使えてしまうのがわかると思うが理論的なところをわかった上で使うと全然腹落ちがちがうというのも理解いただけるだろうか。
from sklearn.linear_model import LinearRegression model_lr = LinearRegression() model_lr.fit(x.to_frame(), y)これだけです。fitメソッドの第一引数はpandas.DataFrameしか受け付けないらしいのでto_frameで強制的にDataFrameにする必要がある(参考)。
傾きと切片はそれぞれ、coef_とintercept_なので(API参照)、先ほどの結果と比較してみる。
print("coef_: ", model_lr.coef_[0]) print("intercept: ", model_lr.intercept_) coef_: 949.4352603839491 intercept: 152.1334841628967同じ結果になりましたね。
さらなる理解(相関係数Rと決定係数R2)
相関係数
相関係数(correlation coefficient)Rは、2つの変数間にどれくらいの関連性があるか(どれくらい影響を及ぼしあっているか)を表す係数で、-1〜1の数字をとる。
相関係数$r$は$x$と$y$の共分散をそれぞれの標準偏差で割った値で、numpyではcorrcoefメソッドで求められる。r = S_xy/(x.std(ddof=1)*y.std(ddof=1)) rr = np.corrcoef(x, y)[0][1] 0.5864501344746891 0.5864501344746891こちらも同じ値ですね。値が大きいほど、それぞれの関連性が強いということになります。
決定係数
決定係数は、求めた直線と実際のデータがどれくらい合致しているかの指標で、1に近いほどもとのデータに近いということになる。
決定係数は、全変動と残差変動という値をもとに求めることができ、相関係数の二乗と等しくなる。くわしくはこちらを参照。
決定係数はLinearRegressionクラスのscoreメソッドで求められる。
R = model_lr.score(x.to_frame(), y) print("R: ", R) print("r^2: ", r**2) R: 0.3439237602253803 r^2: 0.3439237602253809等しくなりますね。
まとめ
単回帰分析について、理論を確認しながらpythonの実装を試してみた。回帰直線を引く方法と、求めた直線がどれくらいもとのデータを表現しているかがわかることを理解できたと思う。
ちなみにターゲットに対してBMIを選んだのは、相関係数がもっとも高かったからである。そのあたりの確認方法についてもいずれ書いていきたいと思っている。
- 投稿日:2020-02-11T23:17:35+09:00
【RasPi4入門】環境構築;自然言語処理系mecabなどなど。。。♪
会話アプリを動かすために、自然言語処理系のLibをインストールします。
-nanoとほぼ同様ですがそれなりに苦労したので、丁寧に記載したいと思います。
ほぼ参考のとおりですが、一部ディレクトリが異なるので、対応します。
【参考】
・ubuntu 18.10 に mecab をインストールmecabのインストール
mecabのインストール
$ sudo apt install mecab $ sudo apt install libmecab-dev $ sudo apt install mecab-ipadic-utf8ここまではまんま出来ました。
$ mecab 特急はくたか 特急 名詞,一般,*,*,*,*,特急,トッキュウ,トッキュー は 助詞,係助詞,*,*,*,*,は,ハ,ワ く 動詞,自立,*,*,カ変・クル,体言接続特殊2,くる,ク,ク た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ EOS上記の出力が得られます。
neologd をインストール
$ git clone https://github.com/neologd/mecab-ipadic-neologd.git $ cd mecab-ipadic-neologd $ sudo bin/install-mecab-ipadic-neologdここまで問題なくインストールできます。
辞書のダウンロードに時間(約30分)がかかりました。/etc/mecabrc を編集する
ここで問題発生。ubuntuでは、辞書は以下のディレクトリにインストールされますが、Raspbianでは異なるようです。
dicdir = /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologdということで、ファイルの存在するディレクトリを検索します。
【参考】
ファイルを探す[findとlocate]$ sudo find / -name '*mecab-ipadic-neologd*' /usr/lib/arm-linux-gnueabihf/mecab/dic/mecab-ipadic-neologdこれで以下のコマンドで書き換えできました。
ちなみに、viのコマンドは参考見てください。
【参考】
viの基本操作$ sudo vi /etc/mecabrcということで、以下のように書き換えました.
$ cat /etc/mecabrc ; ; Configuration file of MeCab ; ; $Id: mecabrc.in,v 1.3 2006/05/29 15:36:08 taku-ku Exp $; ; ;dicdir = /var/lib/mecab/dic/debian dicdir =/usr/lib/arm-linux-gnueabihf/mecab/dic/mecab-ipadic-neologd ; userdic = /home/foo/bar/user.dic ; output-format-type = wakati ; input-buffer-size = 8192 ; node-format = %m\n ; bos-format = %S\n ; eos-format = EOS\nそして、辞書が変わったことを確認します。
ちゃんと「はくたか」として、まとまった形で分離できました。$ mecab 特急はくたか 特急 名詞,一般,*,*,*,*,特急,トッキュウ,トッキュー はくたか 名詞,固有名詞,一般,*,*,*,はくたか,ハクタカ,ハクタカ EOSpython3 で使えるようにする
sudo apt install swig sudo apt install python3-pip sudo pip3 install mecab-python3これで以下のように参考にあるサンプルが動きます。
$ python3 mecab_sample.py 名詞,固有名詞,一般,*,*,*,はくたか,ハクタカ,ハクタカ はくたか 名詞,固有名詞,地域,一般,*,*,富山,トヤマ,トヤマ 富山 名詞,固有名詞,地域,一般,*,*,金沢,カナザワ,カナザワ 金沢 名詞,固有名詞,地域,一般,*,*,兼六園,ケンロクエン,ケンロクエン 兼六園pyaudioのインストール
会話アプリは一応、音声会話出力をしているので、pyaudioを利用しています。
【参考】
PyAudioのインストール| Python備忘録$ sudo apt-get install python3-pyaudio無事にインストールできました。
Pykakasiをインストール
これは録音音声発生(ファイル名がアルファベット)や発生音声のTextへの変換に使います。
$ pip3 install pykakasi --user以下のコードで確認します
# coding: utf-8 from pykakasi import kakasi kakasi = kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() filename = '本日は晴天なり.jpg' print(filename) # 本日は晴天なり.jpg print(type(filename)) print(conv.do(filename))出力例.$ python3 pykakasi_ex.py 本日は晴天なり.jpg <class 'str'> honjitsuhaseitennari.jpg環境
$ uname -a Linux raspberrypi 4.19.97-v7l+ #1294 SMP Thu Jan 30 13:21:14 GMT 2020 armv7l GNU/Linux $ cat /etc/os-release PRETTY_NAME="Raspbian GNU/Linux 10 (buster)" NAME="Raspbian GNU/Linux" VERSION_ID="10" VERSION="10 (buster)" VERSION_CODENAME=buster ID=raspbian ID_LIKE=debian HOME_URL="http://www.raspbian.org/" SUPPORT_URL="http://www.raspbian.org/RaspbianForums" BUG_REPORT_URL="http://www.raspbian.org/RaspbianBugs"会話アプリの実行
$ python3 gensm_ex1.py 訓練開始 Epoch: 1 gensm_ex1.py:16: DeprecationWarning: Call to deprecated `iter` (Attribute will be removed in 4.0.0, use self.epochs instead). model.train(sentences, epochs=model.iter, total_examples=model.corpus_count) Epoch: 2 Epoch: 3 Epoch: 4 Epoch: 5 Epoch: 6 Epoch: 7 Epoch: 8 Epoch: 9 Epoch: 10 Epoch: 11 Epoch: 12 Epoch: 13 Epoch: 14 Epoch: 15 Epoch: 16 Epoch: 17 Epoch: 18 Epoch: 19 Epoch: 20 SENT_0 [('SENT_2', 0.08270145207643509), ('SENT_3', 0.0347767099738121), ('SENT_1', -0.08307887613773346)] SENT_3 [('SENT_0', 0.0347767099738121), ('SENT_1', 0.02076556906104088), ('SENT_2', -0.003991239238530397)] SENT_1 [('SENT_3', 0.02076556347310543), ('SENT_2', 0.010350690223276615), ('SENT_0', -0.08307889103889465)] gensm_ex1.py:33: DeprecationWarning: Call to deprecated `similar_by_word` (Method will be removed in 4.0.0, use self.wv.similar_by_word() instead). print (model.similar_by_word(u"魚")) [('今', 0.15166150033473969), ('海', 0.09887286275625229), ('明日', 0.03284810855984688), ('猫', 0.019402338191866875), ('吠えた', -0.0008345211390405893), ('泳ぐ', -0.02624458074569702), ('今日', -0.05557712912559509), ('犬', -0.0900348424911499)]RaspberryPi4_conversation/model_skl.py /
$ python3 model_skl.py TfidfVectorizer(analyzer='word', binary=False, decode_error='strict', dtype=<class 'numpy.float64'>, encoding='utf-8', input='content', lowercase=True, max_df=1.0, max_features=None, min_df=1, ngram_range=(1, 1), norm='l2', preprocessor=None, smooth_idf=True, stop_words=None, strip_accents=None, sublinear_tf=False, token_pattern='(?u)\\b\\w\\w+\\b', tokenizer=None, use_idf=True, vocabulary=None) {'私は': 5, '醤油': 6, 'ラーメン': 2, 'とんこつ': 1, '好き': 4, 'です': 0, '味噌': 3} {'醤油': 4, 'ラーメン': 1, 'とんこつ': 0, '好き': 3, '味噌': 2} 醤油 4 ラーメン 1 とんこつ 0 好き 3 味噌 2 ['とんこつ', 'ラーメン', '味噌', '好き', '醤油'] (0, 4) 0.4976748316029239 (0, 1) 0.7081994831914716 (0, 0) 0.3540997415957358 (0, 3) 0.3540997415957358 (1, 1) 0.7081994831914716 (1, 0) 0.3540997415957358 (1, 3) 0.3540997415957358 (1, 2) 0.4976748316029239 {'醤油': 6, 'ラーメン': 3, 'とんこつ': 2, '好き': 5, '味噌': 4, 'かつ丼': 1, 'お好み焼き': 0} (0, 6) 0.5486117771118656 (0, 3) 0.6480379064629606 (0, 2) 0.4172333972107692 (0, 5) 0.3240189532314803 (1, 3) 0.6480379064629607 (1, 2) 0.41723339721076924 (1, 5) 0.32401895323148033 (1, 4) 0.5486117771118657 (2, 3) 0.35959372325985667 (2, 5) 0.35959372325985667 (2, 1) 0.6088450986844796 (2, 0) 0.6088450986844796 [[1. 0.69902512 0.34954555] [0.69902512 1. 0.34954555] [0.34954555 0.34954555 1. ]]こうして、無事に会話アプリにたどりつきました.
RaspberryPi4_conversation/auto_conversation_.py$ python3 auto_conversation_.py -i data/conversation_n.txt -s data/stop_words.txt data/conversation_n.txt > 今日は良い天気だね (0.41): あれ ね 。 > あれってなに (0.55): ワンちゃん って 何 > ワンちゃんは犬だろ (0.41): どこ で ワンちゃん に あっ た の > あそこの路地だよ (0.46): * * * って 何 よ > 公園の近く (0.00): """「 どー し て 私 だけ やら なく ちゃ いけ ない の ? 少し は 手伝っ て よ 。 」 ,""" > 何を手伝えばいいの (0.46): ( そう 、 いい ね ) > なんとなく津っ つっかっているでしょ (0.38): 誰 の 話 を し て いる の > ほ ら (0.00): あ ワン ちゃーん とか 言っ て なで て 、 ほ い で 、 この 人 たち は こっち 行っ て 、 あたし ら こっち 行っ た じゃん 。 > そんあなの覚えてないよ (0.35): ばか に なんか し て ない よ > やはりばかだとおもってるんだ (0.33): 格好 は しっかり し てる ん だ 。 >以下、必要なもののインストールです。
【参考】
How to install scipy and numpy on Ubuntu 16.04?
$ sudo apt update $ sudo apt upgrade$ sudo apt install python3-numpy python3-scipy$ sudo pip3 install numpy scipy Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple Requirement already satisfied: numpy in /usr/lib/python3/dist-packages (1.16.2) Requirement already satisfied: scipy in /usr/lib/python3/dist-packages (1.1.0)$ pip3 install --user gensim Successfully installed boto-2.49.0 boto3-1.11.14 botocore-1.14.14 gensim-3.8.1 jmespath-0.9.4 s3transfer-0.3.3 smart-open-1.9.0【参考】
scikit-learnのインストール in Ubuntu$ sudo pip3 install scikit-learn ... Requirement already satisfied: scipy>=0.17.0 in /usr/lib/python3/dist-packages (from scikit-learn) (1.1.0) Requirement already satisfied: numpy>=1.11.0 in /usr/lib/python3/dist-packages (from scikit-learn) (1.16.2) Installing collected packages: joblib, scikit-learn Successfully installed joblib-0.14.1 scikit-learn-0.22.1まとめ
・RasPi4に自然言語系中心に必要なLibをインストールした
・一応、自然言語系のアプリが動かせた・もう少し、会話アプリをまともにしたいと思う
おまけ
これでだいたい入った。
【参考】
・pipのlistとfreezeの違い$ pip3 freeze > requirements.txt・RaspberryPi4_conversation/requirements.txt
$ pip3 freeze absl-py==0.9.0 arrow==0.15.5 asn1crypto==0.24.0 astor==0.8.1 astroid==2.1.0 asttokens==1.1.13 attrs==19.3.0 automationhat==0.2.0 backcall==0.1.0 beautifulsoup4==4.7.1 bleach==3.1.0 blinker==1.4 blinkt==0.1.2 boto==2.49.0 boto3==1.11.14 botocore==1.14.14 buttonshim==0.0.2 Cap1xxx==0.1.3 certifi==2018.8.24 chardet==3.0.4 Click==7.0 colorama==0.3.7 colorzero==1.1 cookies==2.2.1 cryptography==2.6.1 cycler==0.10.0 Cython==0.29.14 decorator==4.4.1 defusedxml==0.6.0 dill==0.3.1.1 docutils==0.14 drumhat==0.1.0 entrypoints==0.3 envirophat==1.0.0 ExplorerHAT==0.4.2 Flask==1.0.2 fourletterphat==0.1.0 gast==0.3.3 gensim==3.8.1 google-pasta==0.1.8 gpiozero==1.5.1 grpcio==1.27.1 h5py==2.10.0 html5lib==1.0.1 idna==2.6 importlib-metadata==1.5.0 ipykernel==5.1.4 ipython==7.12.0 ipython-genutils==0.2.0 ipywidgets==7.5.1 isort==4.3.4 itsdangerous==0.24 jedi==0.13.2 jinja2-time==0.2.0 jmespath==0.9.4 joblib==0.14.1 jsonschema==3.2.0 jupyter==1.0.0 jupyter-client==5.3.4 jupyter-console==6.1.0 jupyter-core==4.6.1 Keras==2.3.1 Keras-Applications==1.0.8 Keras-Preprocessing==1.1.0 keyring==17.1.1 keyrings.alt==3.1.1 kiwisolver==1.1.0 klepto==0.1.8 lazy-object-proxy==1.3.1 logilab-common==1.4.2 lxml==4.3.2 make==0.1.6.post1 Markdown==3.2 MarkupSafe==1.1.0 matplotlib==3.1.3 mccabe==0.6.1 mecab-python3==0.996.3 microdotphat==0.2.1 mistune==0.8.4 mote==0.0.4 motephat==0.0.2 mypy==0.670 mypy-extensions==0.4.1 nbconvert==5.6.1 nbformat==5.0.4 notebook==6.0.3 numpy==1.16.2 oauthlib==2.1.0 olefile==0.46 opencv-python==3.4.6.27 pandocfilters==1.4.2 pantilthat==0.0.7 parso==0.3.1 pexpect==4.8.0 pgzero==1.2 phatbeat==0.1.1 pianohat==0.1.0 picamera==1.13 pickleshare==0.7.5 piglow==1.2.5 pigpio==1.44 pox==0.2.7 prometheus-client==0.7.1 prompt-toolkit==3.0.3 protobuf==3.11.3 psutil==5.5.1 ptyprocess==0.6.0 PyAudio==0.2.11 pygame==1.9.4.post1 Pygments==2.3.1 PyGObject==3.30.4 pyinotify==0.9.6 PyJWT==1.7.0 pykakasi==1.2 pylint==2.2.2 pyOpenSSL==19.0.0 pyparsing==2.4.6 pyrsistent==0.15.7 pyserial==3.4 python-apt==1.8.4.1 python-dateutil==2.8.1 PyYAML==5.3 pyzmq==18.1.1 qtconsole==4.6.0 rainbowhat==0.1.0 requests==2.21.0 requests-oauthlib==1.0.0 responses==0.9.0 roman==2.0.0 RPi.GPIO==0.7.0 RTIMULib==7.2.1 s3transfer==0.3.3 scikit-learn==0.22.1 scipy==1.1.0 scrollphat==0.0.7 scrollphathd==1.2.1 SecretStorage==2.3.1 Send2Trash==1.5.0 sense-hat==2.2.0 simplejson==3.16.0 six==1.12.0 skywriter==0.0.7 smart-open==1.9.0 sn3218==1.2.7 soupsieve==1.8 spidev==3.4 ssh-import-id==5.7 tensorboard==1.13.1 tensorflow-estimator==1.14.0 termcolor==1.1.0 terminado==0.8.3 testpath==0.4.4 thonny==3.2.6 tornado==6.0.3 touchphat==0.0.1 traitlets==4.3.3 twython==3.7.0 unicornhathd==0.0.4 wcwidth==0.1.8 webencodings==0.5.1 widgetsnbextension==3.5.1 wrapt==1.11.2 zipp==2.2.0
- 投稿日:2020-02-11T22:14:09+09:00
WEBマンガのコメントでワードクラウドを作ってみたら、どんな漫画なのかが視覚的にわかっておもしろい
はじめに
WEBマンガ、たまに読むんですが、いっぱいありすぎてどれを読めばいいのかわからなくなります。
どのマンガを読むかを選ぶひとつの指標として、コメントが使えないかというの考えました。
人気のある漫画はコメントが多いですし、コメントが少なくても面白いマンガも多い。
それで、いろいろとコメントを解析してみようと思っているんですが、その第一弾として、コメントをワードクラウド化してみたところ、コメントが視覚的に把握できて、興味をそそるマンガかどうかを直感的に見ることができました。ワードクラウドをもとに新たな切り口でマンガを選ぶことで、作家さんが一生懸命書いたマンガの入り口になって、マンガ界の活性化に貢献できればという思いもこもってます。ちょっと大げさですかね。
環境
python 3.7.6
selenium 3.141.0
ChromeDriver 80.0.3987.16
wordcloud 1.6.0
BeautifulSoup 4.8.2
mecab-python-windows 0.996.3対象
WEBマンガワードクラウド参照サイト
結果を参照できるサイトを下記に作成しました。ワードクラウドをクリックするとそのマンガに遷移します。
ワードクラウド出力結果
以下が出力結果です。どんなマンガなのか気になってきませんか?
「美人」「好き」などのコメントで、ちょっと読んでみたいなぁなんて考えてしまいます。
規約を確認
スクレイピングを行うので、規約を確認します。
<niconico利用規約より抜粋>
5 禁止事項
利用者による「niconico」の利用に関して、以下の行為が禁止されています。
- ニコニコ活動ガイドライン第3項及び第4項に掲げる行為又はこれらの行為に準じる行為(コメントの書き込みや動画等の投稿以外の手段を通じて行われる行為を含みます)
- 本利用規約の条項に違反する行為
- 公職選挙法に抵触する行為
- 「niconico」のサーバーに過度の負担を及ぼす行為
- 「niconico」の運営を妨害する行為
- 児童買春・ポルノ、無修正ビデオ動画のダウンロードサイト等へのリンク掲載
- 運営会社の許諾を得ない売買行為、オークション行為、金銭支払やその他の類似行為
- 運営会社の許諾を得ない商品の広告、宣伝を目的としたプロフィール内容の公開、その他スパムメール、チェーンメール等の勧誘を目的とする行為
- 13歳以上の未成年者が法定代理人(親権者)の同意を得ずに、「niconico」を利用する行為
- 運営会社が不適切であると考える行為
- その他上記に準じる行為
ということで、過度な負荷をかけないよう注意して実施します。
連続走行させない、スリープを挟むなどを実施しながら実行してます。処理の流れ
以下の流れで処理を実行します。
- ニコニコにログイン
- ニコニコ静画を更新順で表示しマンガ一覧からURLリストを取得
- 漫画の詳細に遷移
- コメントを取得
- コメントをWordCloudで処理
ニコニコにログイン
ニコニコ静画を参照するにはログインが必要です。
ここでは、seleniumを使って、バックグラウンドでニコニコにログインします。seleniumとChromeDriverはインストールしてある前提です。
ChromeDriverライブラリインポート
下記で必要ライブラリをインポートします。
from selenium import webdriver from selenium.webdriver.common.by import By from bs4 import BeautifulSoup import urllib.parseWebDriver構築
オプションを設定して、ドライバーを構築します。
バックグラウンドで動作させるため、--headlessオプションを指定しています。
また、set_page_load_timeoutでタイムアウトを30秒に設定しています。options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--disable-gpu') options.add_argument('--window-size=1024,768') driver = webdriver.Chrome(options=options) driver.set_page_load_timeout(30)ログイン
まず、
https://account.nicovideo.jp/login?site=seiga&next_url=%2Fにアクセスします。
つぎに、メールアドレスとパスワードの項目をIDで取得して、それぞれを設定しています。
最後に、ログインボタンをクリックしています。
[メールアドレス]、[パスワード]はご自身のに変更してください。driver.get('https://account.nicovideo.jp/login?site=seiga&next_url=%2F') e = driver.find_element(By.ID, "input__mailtel") e.send_keys('[メールアドレス]') e = driver.find_element(By.ID, "input__password") e.send_keys('[パスワード]') e = driver.find_element(By.ID, 'login__submit') e.click()requestsのpostを使ってもログインできるのですが、その場合は、ログイン画面から
auth_idを取得してそれもポストする必要があります。そのあたりの処理がseleniumでは不要です。
また、画面表示後にJavaScript等で画面が更新される場合にもrequestsではいろいろと手間がかかりますが、seleniumだとそのあたりも気にせずに処理ができるのが便利です。ニコニコ静画を更新順で表示しマンガ一覧からURLリストを取得
更新順でマンガの一覧を取得
下記の状態の時の静画の一覧を取得していきます。
ページ遷移をしながら各ページのマンガ一覧のマンガのURLを一覧で取得します。負荷のことを考え、ここでは1~3ページまでを取得します。url_root = 'https://seiga.nicovideo.jp' desc_urls = [] for n in range(1, 4): target_url = urllib.parse.urljoin(url_root, 'manga/list?page=%d&sort=manga_updated' % n) try: driver.get(target_url) html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html, 'html.parser') # change to loop for desc in soup.select('.mg_description'): title = desc.select('.title') desc_urls.append(urllib.parse.urljoin(url_root, title[0].find('a').get('href'))) except Exception as e: print(e) continue
desc_urlsリストにマンガへのURLを保存します。
target_urlに各ページへのURLを設定します。QueryString のpage=に数字を設定することでページ制御されていますので、そこに取得したいページの数字を設定します。
driver.getでページを取得します。取得したら、driver.page_source.encode('utf-8')で中身のHTMLを取得し、扱いやすいようにBeautifulSoupに設定しています。
BeautifulSoupに設定しなくても扱えますが、こっちのほうが慣れているのでこっちにしたという程度です。WebDriverはXPathとかも使えるので、そのままでも十分大丈夫だと思います。
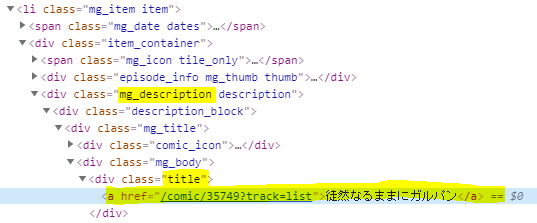
BeautifulSoupのselectはCSSセレクターなので、.mg_descriptionを取得して、その中の.titleとそこに設定されているaタグのhrefを取得しています。
これで、ページ上のマンガのタイトルとURLの一覧が取得できました。
漫画の詳細に遷移
リスト内のURLでページを取得
desc_urlsに保持したURLでページを取得します。取得は、driver.get(desc_url)でやってます。
取得したら同様にHTMLを取得してBeautifulSoupに設定します。for desc_url in desc_urls: try: driver.get(desc_url) html = driver.page_source.encode('utf-8') soupdesc = BeautifulSoup(html, 'html.parser')タイトルと著者を取得して確認
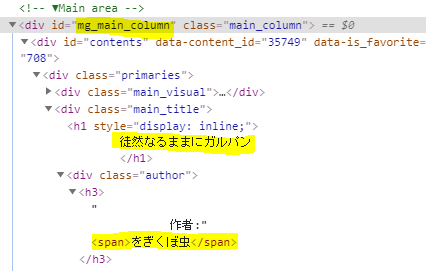
div タグで id が
ng_main_columnのエレメントを取得します。
その中の、`.main_title'クラスのエレメントを取得し、タイトルと著者を取得します。
print してみて、きちんと取得できているかを確認してみます。maindesc = soupdesc.find('div', id = 'mg_main_column') titlediv = maindesc.select('.main_title')[0] title = titlediv.find('h1').text.strip() author = titlediv.find('span').text.strip() print(title) print(author)HTMLの構造は以下のようになっています。
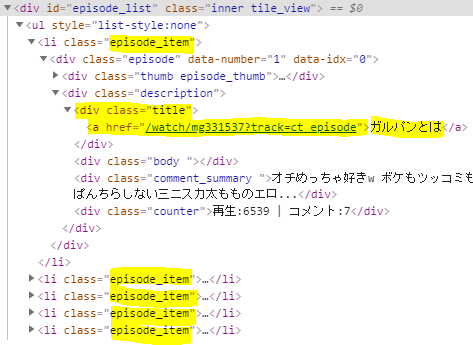
エピソード一覧からサブタイトルと詳細へのURLを取得して遷移
クラスが
.episode_itemのエレメントに各エピソードがあるので、そのリストを CSSセレクタのselectで取得します。
複数のエレメントが取得されるので、それぞれのエレメントから、サブタイトルと詳細へのURLを取得します。for eps in soupdesc.select('.episode_item'): eps_ttl_div = eps.select('.title') eps_title = eps_ttl_div[0].find('a') eps_url = urllib.parse.urljoin(url_root, eps_title.get('href')) eps_t = eps_title.text print(eps_t) try: driver.get(eps_url) html = driver.page_source.encode('utf-8') soupeps = BeautifulSoup(html, 'html.parser')タイトルは、
.titleクラス、URLは a タグのhrefから取得しています。
driver.get(eps_url)で詳細画面を取得しています。
取得したら、BeautifulSoupに設定します。コメントを取得
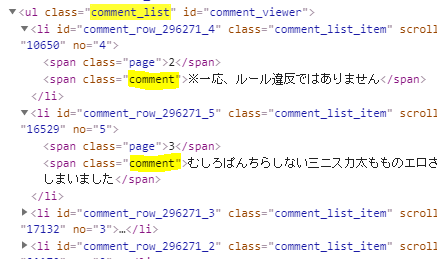
コメントのリストを取得し、その中のテキストを配列に設定
クラスが
.comment_listのエレメントを取得し、その中の.commentをすべて取得しています。
その中の文字列をc.textで取得し、配列comments_textに設定しています。
配列への設定は、リスト内包表記を使っています。pythonの内包表記はチューリング完全だそうです。crlist = soupeps.select('.comment_list') comments = crlist[0].select('.comment') comments_text = [c.text for c in comments]コメント部分のHTML構成は以下のようになっています。
comment_viewerの find でもできそうですね。この辺りはいい感じに指定していきましょう。
コメントをWordCloudで処理
MeCabで形態素解析
取得したコメントの文字列は、MeCabで形態素解析します。
インポート分を付け加えましょう。import MeCabMeCab の
parseで形態素解析をします。m = MeCab.Tagger('') parsed = m.parse('。'.join(comments_text))形態素解析した結果は、以下のようになります。
'流石\t名詞,形容動詞語幹,*,*,*,*,流石,サスガ,サスガ\nに\t助詞,副詞化,*,*,*,*,に,ニ,ニ\nなかっ\t形容詞,自立,*,*,形容詞・アウオ段,連用タ接続,ない,ナカッ,ナカッ\nた\t助動詞,*,*,*,特殊・タ,基本形,た,タ,タ\nwww\t名詞,一般,*,*,*,*,*\n。\t記号,句点,*,*,*,*,。,。,。\nそれ\t名詞,代名詞,一般,*,*,*,それ,ソレ,ソレ\nは\t助詞,係助詞,*,*,*,*,は,ハ,ワ\n筆記具\t名詞,一般,*,*,*,*,筆記具,ヒッキグ,ヒッキグ\nで\t助詞,格助詞,一般,*,*,*,で,デ,デ\nは\t助詞,係助詞,*,*,*,*,は,ハ,ワ\nあり\t動詞,自立,*,*,五段・ラ行,連用形,ある,アリ,アリ\nませ\t助動詞,*,*,*,特殊・マス,未然形,ます,マセ,マセ\nん\t助動詞,*,*,*,不変化型,基本形,ん,ン,ン\n…\t記号,一般,*,*,*,*,…,…,…\n。\t記号,句点,*,*,*,*,。,。,。\nキシガイ\t名詞,一般,*,*,*,*,*\n。\t記号,...
\nが一行ごとなので、splitlinesで一行ずつ取り出し、\tで区切られている右側の7番目から、形態素の基本形を取得します。
その際、助詞と助動詞、代名詞、そして「する」や「てる」などのいくつかの文字列を除外しています。
除外しないと、ワードクラウドを作ったときに、そればっかりが大きな文字れ表示されてしまいます。words = ' '.join([x.split('\t')[1].split(',')[6] for x in parsed.splitlines()[:-1] if x.split('\t')[1].split(',')[0] not in ['助詞', '助動詞'] and x.split('\t')[1].split(',')[1] not in ['代名詞'] and x.split('\t')[1].split(',')[6] not in ['する', 'てる', 'なる', 'さん', 'そう', 'この', 'ある']])WordCloudでワードクラウドを作成
WordCloudの
to_fileで、ワードクラウドを作成します。
comic_titlescomic_subtitlescomic_imagescomic_urlsは配列で宣言してある変数で、後ほどHTMLを作成するときに使用します。それぞれ、タイトル、サブタイトル、画像名、URLを保持しています。WordCloud構築時は、フォント、背景色、サイズを指定しています。フォントは、YouTubeでよく使われているらしい「ラノベPOP」というものを使っています。この辺りはお好みで指定してください。
wordcloud.to_fileでファイルに出力しています。if len(words) > 0: try: comic_titles.append(title) comic_subtitles.append(eps_t) comic_images.append('%d.png' % (comic_index)) comic_urls.append(eps_url) wordcloud = WordCloud(font_path=r"C:\\WINDOWS\\Fonts\\ラノベPOP.otf", background_color="white", width=800,height=800).generate(words) wordcloud.to_file("[保存したいパス]/wordcloud/%d.png" % (comic_index)) comic_index += 1 except Exception as e: print(e)出力結果は、最初にお見せしたものです。
これらでHTMLをつくってサイトに公開します。公開したサイト
上記URLにアクセスすると、下記のようなワードクラウドの一覧が表示されます。
ワードクラウドをクリックすると、そのマンガが開きます。
おわりに
ジャンプ+とかマンガワンとかのコメントって、結構辛辣なコメントが多いですが、ニコニコはみんな優しいコメントが多いです。やはり、コメント慣れしているんでしょうね。
ワードクラウドを作るだけではなくいろいろな分析をして、今まで出会うことが難しかった名作への扉を開くことができたらいいなと思います。



- 投稿日:2020-02-11T21:57:28+09:00
APLpyでcontour mapが描けないとき
APLpy(version 2.0.3) でcontour mapを書こうとしてBeginner Tutorialにあるようにやったらgc.show_contourのところで
ValueError: The output dimension of 'a' must be equal to the input dimensions of 'b'って怒られてなんだそれはって感じ。
ググったらここに、バージョンを1.1.1まで落とせと書いてあったので
pip install APLpy=1.1.1でダウングレードしたら普通に動いた。
- 投稿日:2020-02-11T21:46:59+09:00
Pythonで全探索により部分和問題を解く
問題(蟻本 P.34)
整数a1, a2, ...., anが与えられます。その中からいくつか選び、その和をちょうどkにすることができるかどうかを判定しなさい。
#入力 n = int(input()) a = list(map(int, input().split())) k = int(input()) #判定用の変数 cnt = 0 #全探索 for i in range(1<<len(a)): l = [] for j in range(len(a)): if (i>>j & 1) == 1: l.append(a[j]) if sum(l) == k: cnt += 1 print('Yes' if cnt>=1 else 'No')
- 投稿日:2020-02-11T21:46:59+09:00
Pythonで部分和問題を解く
問題(蟻本 P.34)
整数a1, a2, ...., anが与えられます。その中からいくつか選び、その和をちょうどkにすることができるかどうかを判定しなさい。
#入力 n = int(input()) a = list(map(int, input().split())) k = int(input()) #判定用の変数 cnt = 0 #全探索 for i in range(1<<len(a)): l = [] for j in range(len(a)): if (i>>j & 1) == 1: l.append(a[j]) if sum(l) == k: cnt += 1 print('Yes' if cnt>=1 else 'No')
- 投稿日:2020-02-11T21:17:15+09:00
Kubeflow v0.71でcustom imageのnotebookで遊ぶ
ある種ナイスタイミング
- 本記事を書いているまさにその時、Kubeflow v1.0RCがリリースされました。
- 私の環境のv0.71では、PipelineやKalibなど、いつくかの機能が動かないので、なる早でv1.0RCを試したいと思います…
- が、v0.71の記事を書いちゃったので、供養を兼ねて(ほとんどの手順はv1.0に転用できるし)。
この記事は何?
- Kubeflow v0.71のインストール方法
- 自前のNotebookコンテナイメージを使ってみた&Notebook環境にノードのデータ(KaggleのTitanic)をマウントしてみた
の2本立てです。
当初期待していたPipelinesやKalibはうまく動かせず、v1.0RC今度使ってみよう、で終わります
(KaggleのTitanicデータで前処理Pipeline作成&パラメータチューニング、までやりたかった)Kubeflowを使おうとした背景
筆者はいつくか機械学習系のプロジェクトを回しているのですが、
- 実戦投入中の機械学習モデル精度管理
- データ処理の自動化
- アドホックなデータ分析の成果物管理
等に課題を感じていました。
最初のうちは自前でツールを整備して対処していたものの、データ分析業務(本業)に時間を取られるようになり、やがてツールは放置。陳腐化したツールは誰も使えず、精度検証や学習用のデータ前処理が他人にはできない…という状況になっていました。MLOpsの文脈でよく耳にする「Kubeflow」を使えば上記の状態を改善できるのでは? とKubeflow試用を決意しました。
手順
本記事ではUbuntu18.04環境に、kubernetes、Kubeflow環境を整えます。
また、Dockerは別途セットアップ済みとします。microk8sでk8sインストール
Kubeflowの前に、kubernetes(k8s)環境を整備します。
構築方法はいろいろありますが、今回は最も簡単なmicrok8sを使って構築しました。(余談ですが、Kubeflow v1.0RCからはmicrok8sのアドオンとしてkubeflowが提供されるようになっています。microk8s選んで良かった。)
インストールは下記サイトを参考にすすめます。
https://v0-7.kubeflow.org/docs/other-guides/virtual-dev/getting-started-multipass/スクリプト化されており、たった6行で終わります。
git clone https://github.com/canonical-labs/kubernetes-tools cd kubernetes-tools git checkout eb91df0 # v1.0向けに更新されるかもしれないのでcheckout sudo ./setup-microk8s.sh microk8s.enable registry # 自前Notebookイメージ使用に必要 microk8s.enable gpu # GPUを搭載している場合このスクリプトでは、microk8sの
v1.15がインストールされます
snap installで入る最新のmicrok8sのバージョンはv.1.17でKubeflow v0.7が非対応ですので注意。インストール後は、
kubectl get pod --all-namespacesですべてのPodが
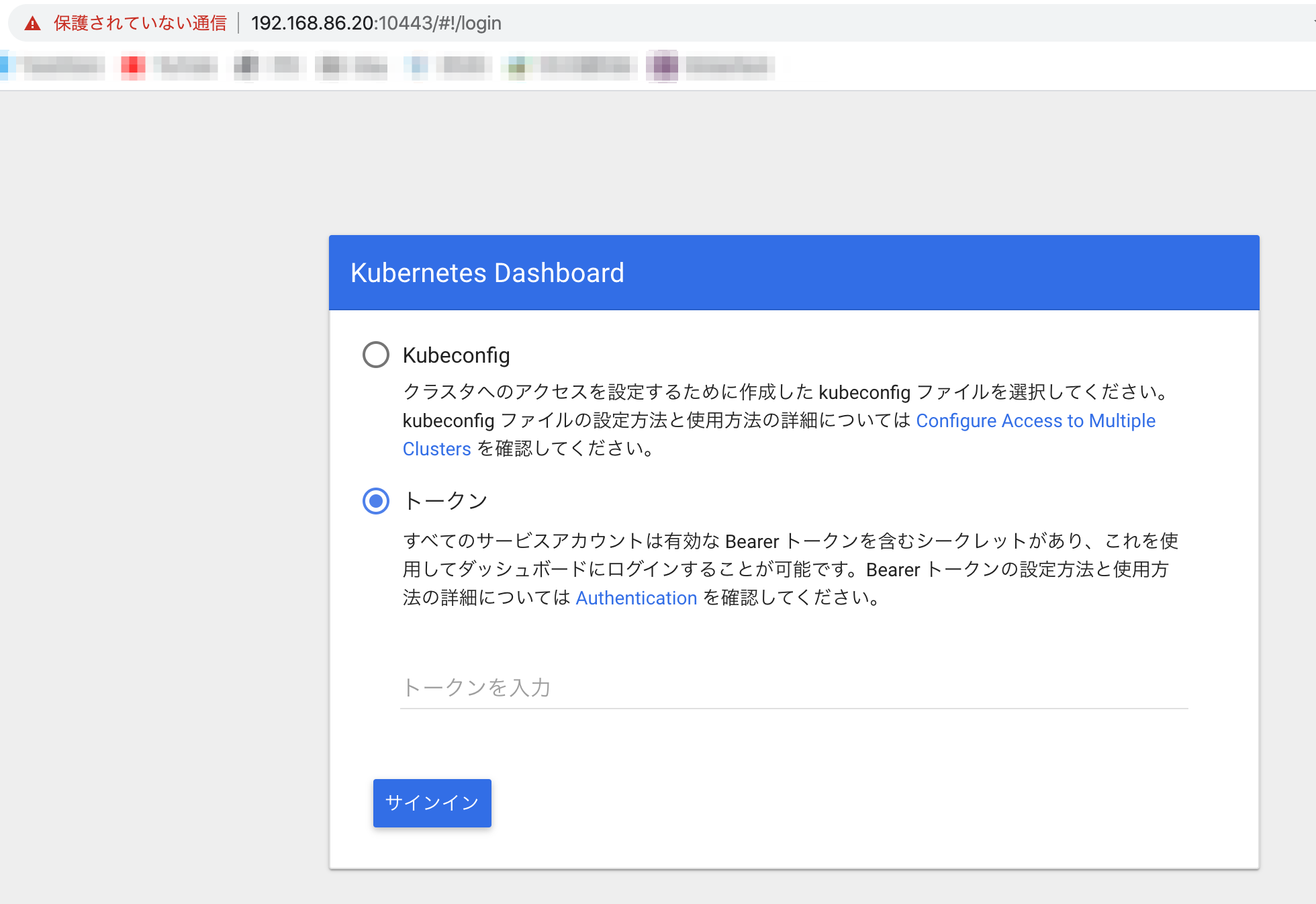
Runningになっていることを確認します。(Optional) Kubernetes Dashboradへのアクセス
デバッグ時に役立つ、k8sのダッシュボードには次のようにアクセスします。
次のコマンドを打ち、出力されたTOKENを記録
token=$(microk8s.kubectl -n kube-system get secret | grep default-token | cut -d " " -f1) microk8s.kubectl -n kube-system describe secret $tokenポートフォワーディング
microk8s.kubectl port-forward -n kube-system service/kubernetes-dashboard 10443:443 --address=0.0.0.0
https://<hostname>:10443にアクセスし、先のTOKENでサインインします。
Dashboardが表示されたらOKです。
kubeflowインストール
https://v0-7.kubeflow.org/docs/started/k8s/kfctl-k8s-istio/
の手順に従って進めます。(先に使用した
kubernetes-toolsのようにkubeflow-toolsというスクリプトも用意されているのですが、インストールされるkubeflowのバージョンが古いため使用しませんでした。)kfctl バイナリダウンロード
wget https://github.com/kubeflow/kubeflow/releases/download/v0.7.1/kfctl_v0.7.1-2-g55f9b2a_linux.tar.gz tar -xvf kfctl_v0.7.1-2-g55f9b2a_linux.tar.gz環境変数を設定
# kfctlの実行ファイルにPATHを通す export PATH=$PATH:"<path-to-kfctl>" # deploymentの名前を適当につける (筆者は’kf-yums') export KF_NAME=<your choice of name for the Kubeflow deployment> # yamlファイル等を配置するディレクトリ(筆者は`~/.local/`) export BASE_DIR=<path to a base directory> export KF_DIR=${BASE_DIR}/${KF_NAME} export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v0.7-branch/kfdef/kfctl_k8s_istio.0.7.1.yaml"インストール
mkdir -p ${KF_DIR} cd ${KF_DIR} # 一度で成功しないことがある。何度かリトライ。 kfctl apply -V -f ${CONFIG_URI}
kubectl get pod --all-namespacesを実行すると、多数のコンテナが作成されていることが判る。すべてがRunningになるまで、しばらく待機。kubeflow Dashboardにアクセス
ポートフォワーディング
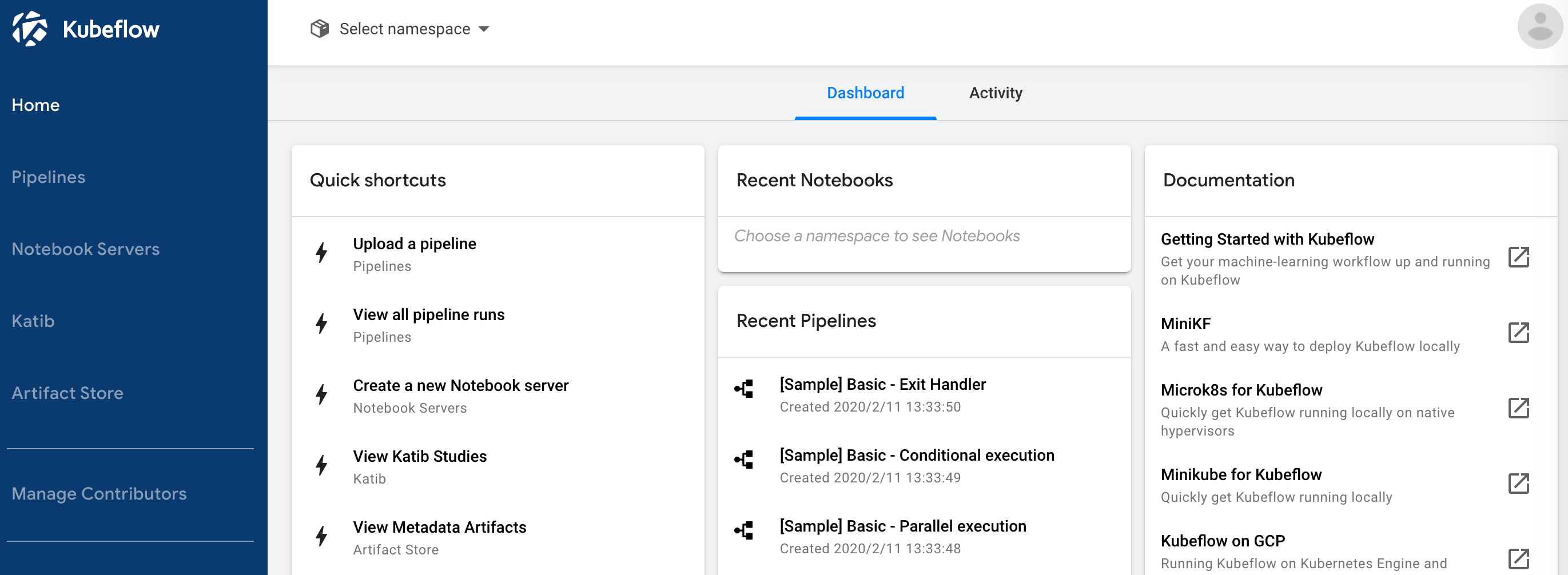
# 誰でもアクセスできてしまうため、適宜アクセス制限をかけたほうがよい kubectl port-forward -n istio-system svc/istio-ingressgateway 10080:80 --address 0.0.0.0httpで10080番ポートにアクセスすると、Dashboard(のWelcome画面)が現れます。
なお、この構成ではURLを知っていれば誰でもアクセスできるため、セキュリティ上の懸念があります。 社内で使用する場合
Dex等を使用してパスワード保護したり、ポートフォワーディングでのアクセス制限を検討したほうが良いかもしれません。
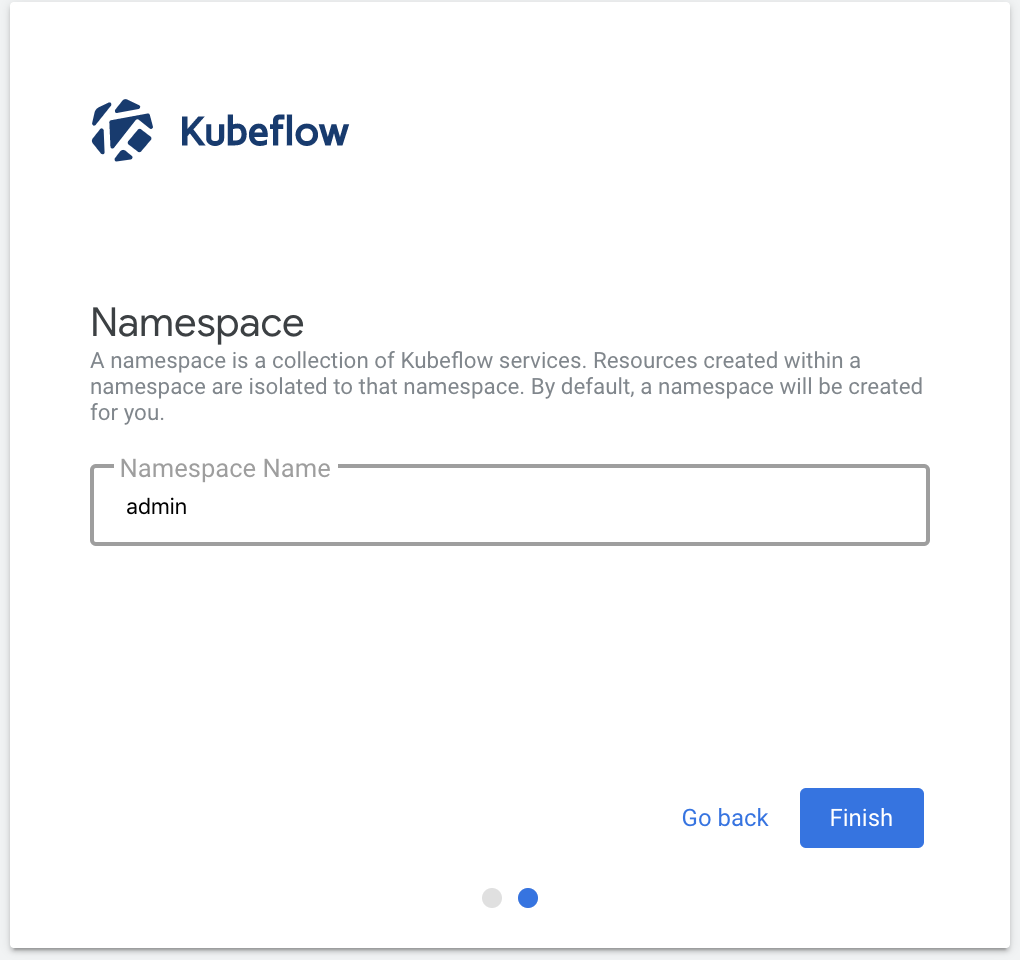
進むと
Namespaceの作成画面に遷移するため、適当に設定します (筆者はkf-yumsとしました)
Finish、でKubeflowのDashboardにアクセスできます。
自前イメージでNotebook Serverを立てる
Kubeflowの機能の一つに、Jupyter Notebookのホスティング機能があります。
メモリ、CPU、(GPU)等必要なリソースと環境(Dockerイメージ)を指定するだけで、誰でも簡単にオレオレNotebook環境を作成可能。分析基盤構築の時間を削減できます。本機能を使用して、自前のJupyter Notebook入りDockerイメージのホスティングを行ってみます。
また、k8sが動いている端末上のデータを、Notebookから参照可能にします。自前イメージのビルドとPush
https://www.kubeflow.org/docs/notebooks/custom-notebook/
を参考にすすめます。とりあえずは、RandomForestとか使えれば良いか…と下記のようなDockerfileを作成。
FROM python:3.8-buster RUN pip --no-cache-dir install pandas numpy scikit-learn jupyter ENV NB_PREFIX / EXPOSE 8888 CMD ["sh","-c", "jupyter notebook --notebook-dir=/home/jovyan --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX}"]ビルドします。
docker build -t myimage .microk8sのコンテナレジストリ(
localhost:32000)に本イメージをPushするため、daemon.jsonを次のように編集します。> sudo vim /etc/docker/daemon.json下記を追記
{ "insecure-registries" : ["localhost:32000"] }追記したらDockerを再起動し、microk8sのレジストリにPushします。
sudo systemctl restart docker docker tag myimage:latest localhost:32000/myimage:latest docker push localhost:32000/myimage:latestレジストリPushされたイメージは次のように確認できます。
microk8s.ctr -n k8s.io images ls | grep myimageNotebookから端末のデータを参照可能にする
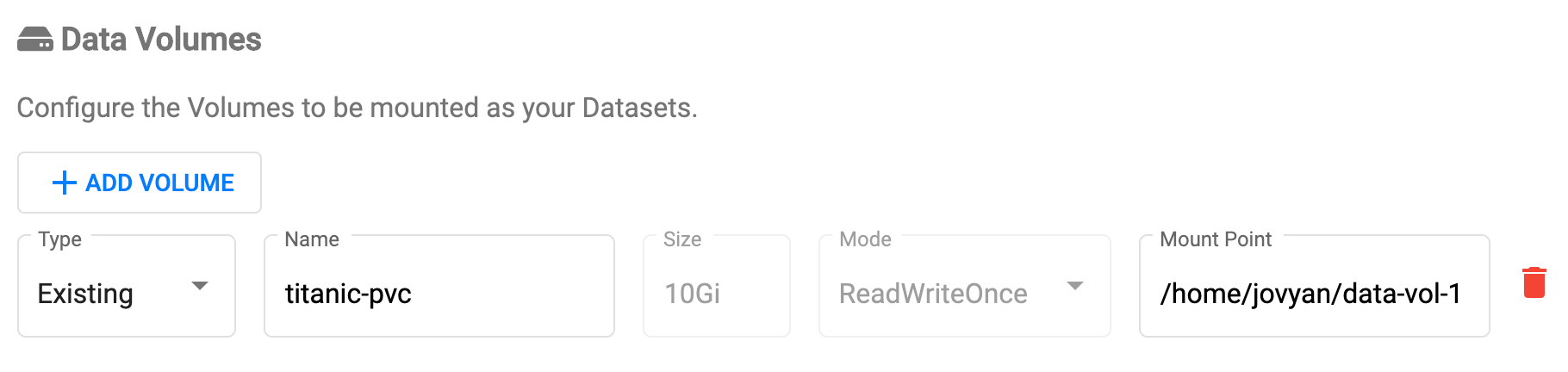
上で作成したNotebookイメージには、入力データは含めていません(普通、含められません。)
ノード上の入力データをNotebook内から参照できるよう、事前にPV、PVCを作成しておきます。ここでは、
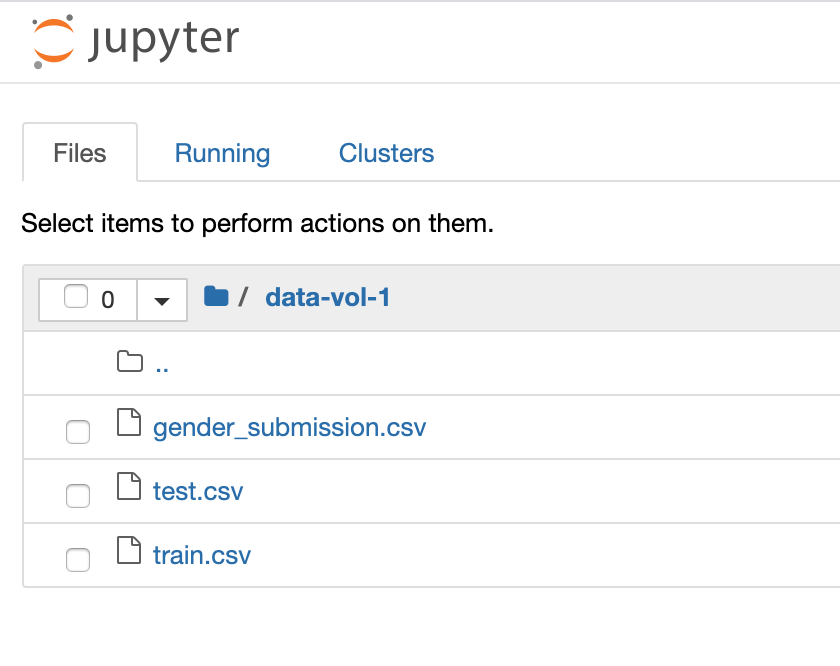
/data/titanic/に配置したKaggleのTitanicデータセットを、Notebookから参照できるようにしてみます。# kaggleから事前にダウンロードしたデータが配置されているものとする > find /data/titanic titanic/gender_submission.csv titanic/train.csv titanic/test.csv
PersistentVolume(PV)、PersistentVolumeClaim(PVC)を次の通り定義。kind: PersistentVolume apiVersion: v1 metadata: name: titanic-pv namespace: <kubeflowで作成したnamespace> spec: storageClassName: standard capacity: storage: 1Gi claimRef: namespace: <kubeflowで作成したnamespace> name: titanic-pvc accessModes: - ReadWriteOnce hostPath: path: /data/titanic/ --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: titanic-pvc namespace: <kubeflowで作成したnamespace> spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Giこれを、
titanic_data.yamlとして保存し、kubectl apply -f titanic_data.yamlこれでVolumeが作成されました。Notebook Server作成時に本Volumeを指定することで、中のデータをNotebookから参照できます。
Notebook Server作成
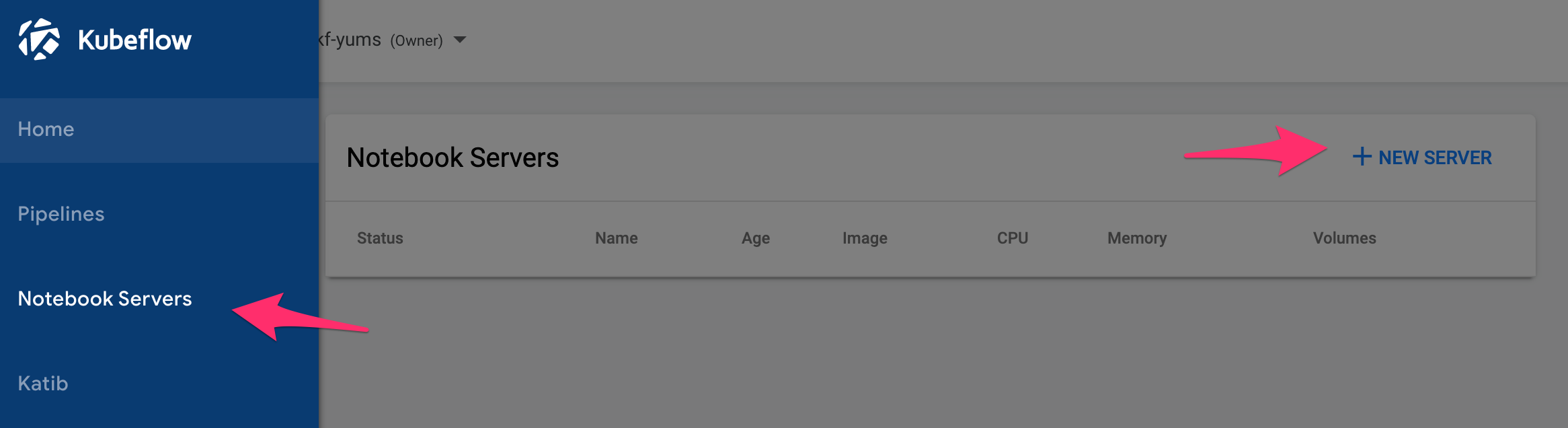
Kubeflow Dashboardから、
Notebook Servers->NEW SERVERと進みます。
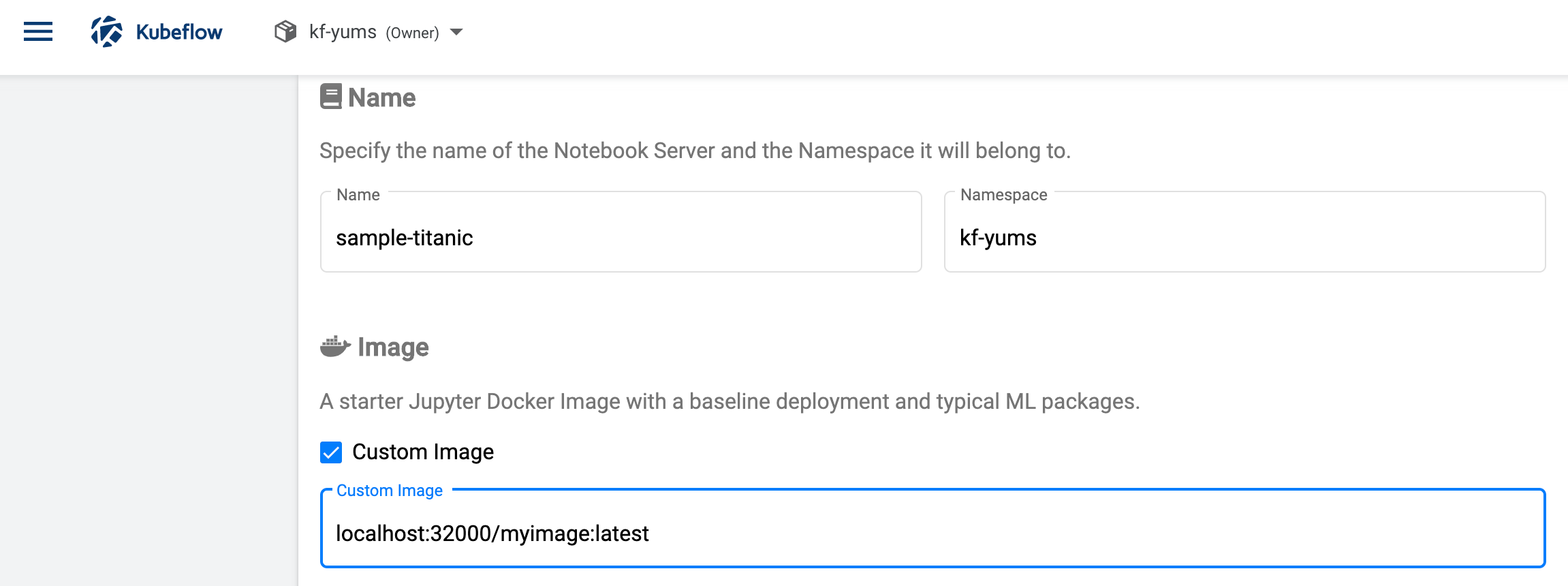
Notebook作成画面に進んだら、
Imageの項目のCustom Imageにチェックを入れ、先にPushしたイメージlocalhost:32000/myimage:latestを指定します。
- ノートブックサーバー名
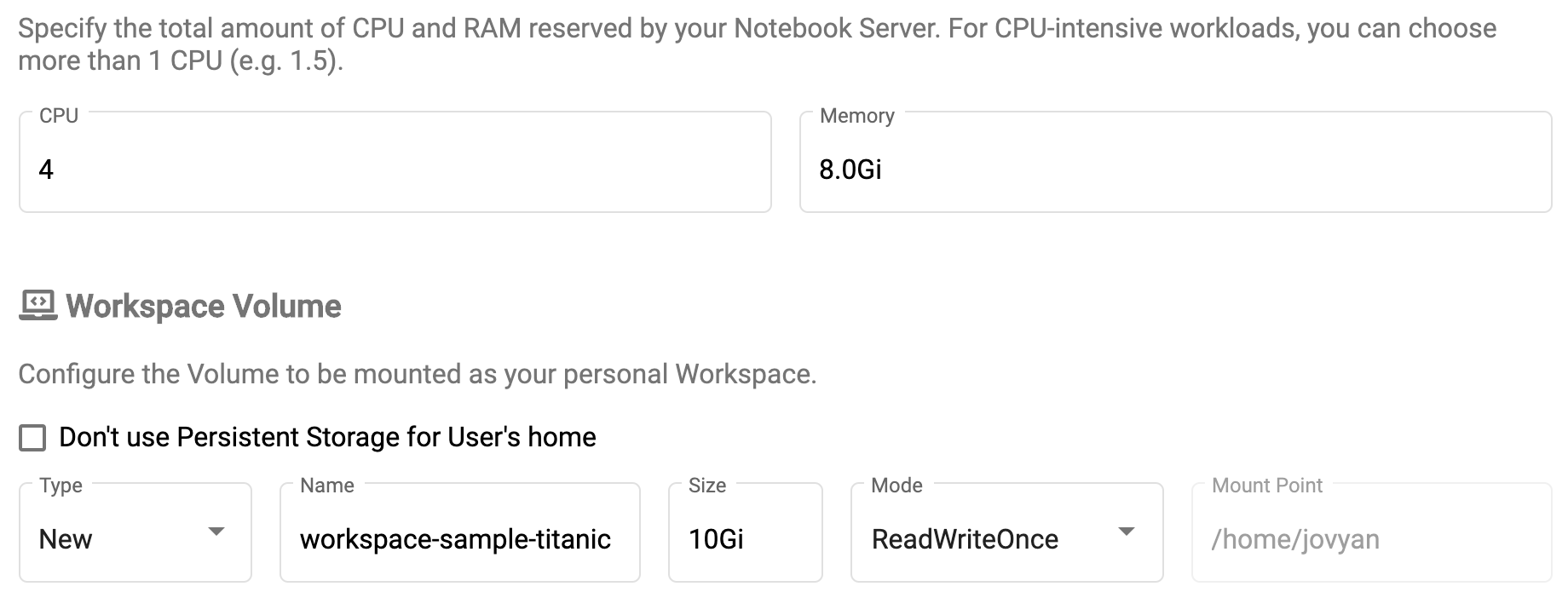
- CPU
- Memory
- Workspace Volume
は適当に設定します。
DataVolumesの項目では、先に作成した
PVCを指定します。
以上を設定したら、下段の
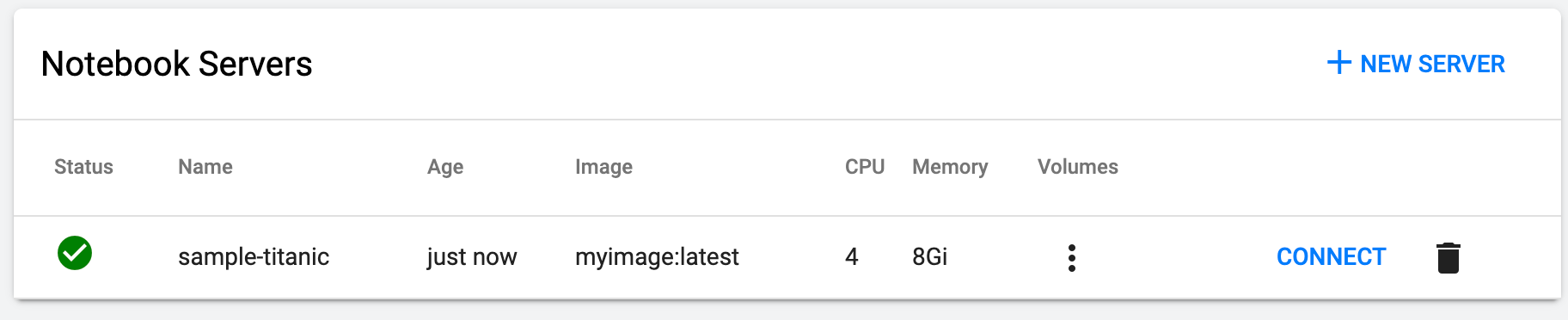
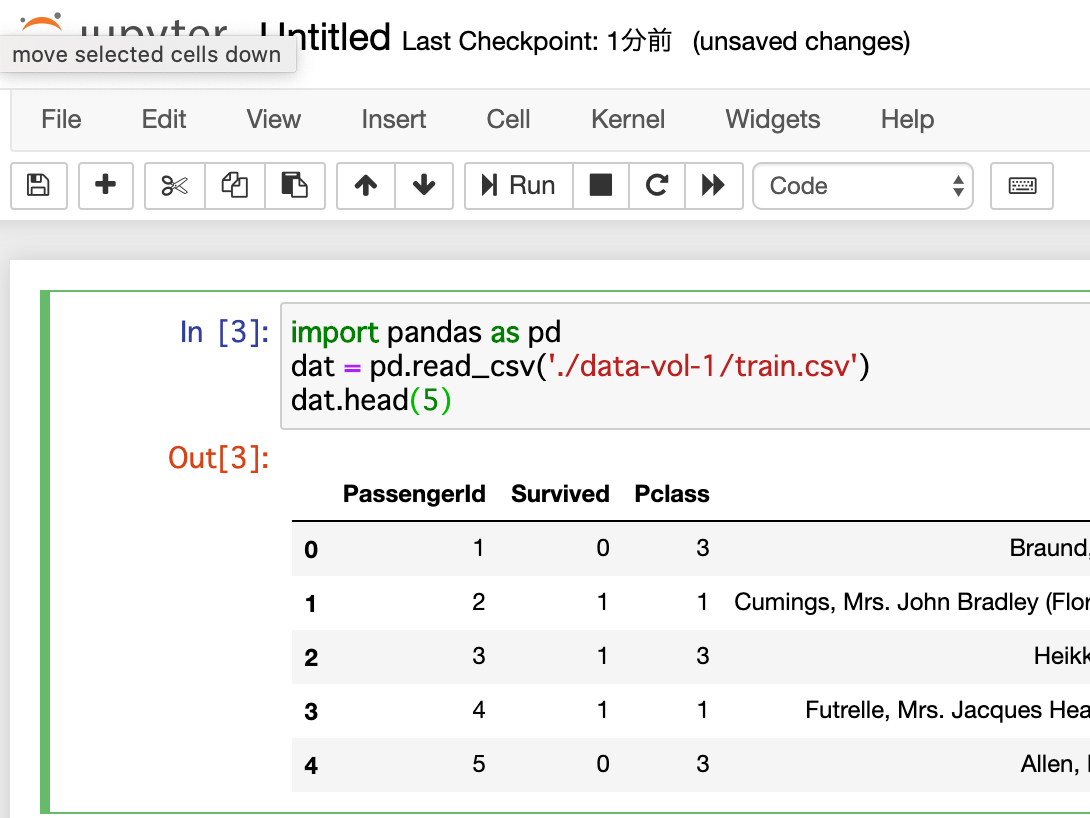
CREATEを押すと
わずか数秒で、Notebook Serverが立ち上がります。
(立ち上がらない場合、何かしらのエラーが裏で生じています。k8sのdashboardで確認できます。)
CONNECTを押すと、いつものJupyter Notebookの画面が現れます。
Titanicデータももちろん、マウントされています。
あとはいつものようにNotebookを作成し、色々データ分析しましょう。
Notebook Server以外の、動かせなかった機能たち
以上でNotebook Serverのホスティングができましたが、Kubeflowには他にも様々な機能があります。
特に注目しているのは、
- データ加工・学習・推論の処理実行と、各種KPIのトラッキングが行える
Pipeline- パラメータチューニングができる
Kalibの2機能。
ただこの2つ… 私の環境では動きませんでした。PipelineはJobを実行したら
Dockerがない、とエラー。
microk8sがコンテナの実行にDockerではなく、containerdを使用しているのが元凶でした。
issueも立ってた。KalibはもJobを実行すると、
INFO:hyperopt.utils:Failed to load dill, try installing dill via "pip install dill" for enhanced pickling support. INFO:hyperopt.fmin:Failed to load dill, try installing dill via "pip install dill" for enhanced pickling support.とメッセージを出して処理が進まず。
closedされていますが、一応issueがどちらもUpdateで解決しそうな匂いがあるので、Kubeflow v1.0RCを早速ためしてみます。

- 投稿日:2020-02-11T21:12:35+09:00
AESで暗号化されたWindows ChromeのCookieを復号する
概要
WindowsのChromeは v80以降、ブラウザcookieの暗号化にAESを使用するようになった。
(Linux、 macOSのChromeブラウザのcookieについてはここでは触れない。以下「cookie」は、Windows用 Chromeブラウザのcookieを指すものとする)
以前は、DPAPI Windows API(crypt32.dllのCryptUnprotectData)を使用して暗号化されていたが、新方式で暗号化されたcookieは旧方式では復号できない。
Windows Chromeのcookieファイルの中身を直接読み取ってWebサービスにログインするようなアプリは、今回の変更の影響を受けている。(例:ニコ生コメントビューア)
AESで暗号化されているcookieの復号手順の概要を下記に示す。
Windows ChromeのCookiesファイルの場所
デフォルトでは下記(以前と変わらない)
%userprofile%\AppData\Local\Google\Chrome\User Data\default\Cookies
(プロファイルの移動をしたり、Windowsの再インストールやgoogleアカウントの変更等をした場合は変わる)AESで暗号化されているcookieの識別
暗号化cookieデータの先頭が「0x01 00 00 00」→ DPAPIで暗号化されたcookie
暗号化cookieデータの先頭が「v10」 → AESで暗号化されたcookie
復号に必要なもの
復号には鍵(key)だけでなく、nonceと呼ばれるランダム値が必要になる。
nonceの位置・長さ
nonceは、各暗号化cookieデータの先頭からプレフィクス3バイト('v10')を除いた4バイト目以降12バイトをそのまま用いる。
encrypted_key(暗号化された鍵)の格納場所
デフォルトでは、keyはエンコード・暗号化されて下記の
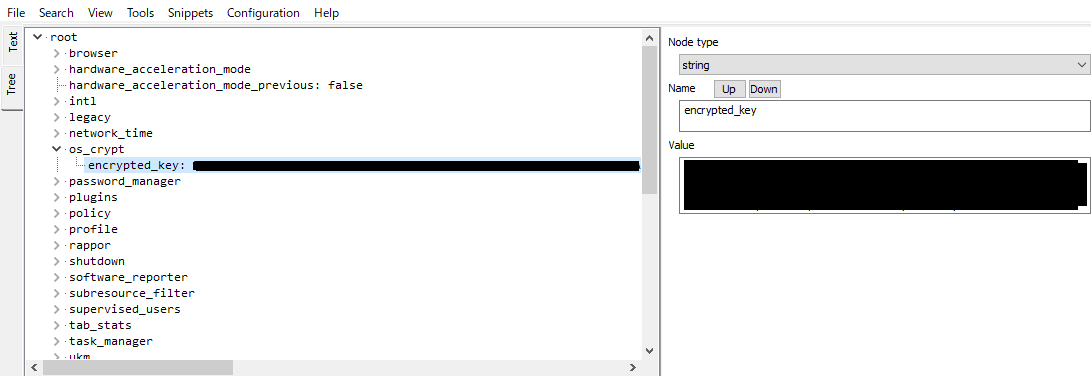
Local Stateファイル内に格納されている。
%userprofile%\AppData\Local\Google\Chrome\User Data\Local StateLocal Stateの中身はJSONフォーマットになっている。
この中の["os_crypt"]->["encrypted_key"] に暗号化された鍵データが格納されている。
keyの復号
- JSON(Local Stateファイル)から取り出したencrypted_keyの値をBASE64でデコードする。
- デコードしたデータの先頭5バイト(プレフィクス
'DPAPI')を除去する。- 2のデータをさらにDPAPIで復号する。 DPAPIによる復号は旧方式と同じcrypt32.dllのCryptUnprotectDataを用いればよい。
得られたkeyの長さは256bit(32バイト)のはずである。
これで、cookieの復号に必要となるkeyが復号できた。
cookieデータの復号
暗号化されたcookieデータの最初の15バイト('v10'+nonce 12bytes)を除いた部分を、上記で得られたnonceとkeyを用いて256bit AES-GCM で復号する。
さらに、復号されたデータの末尾16バイトを取り除く。
pythonによる実装
https://github.com/taizan-hokuto/chrome_cookie
AES-GCMのためにcryptographyライブラリを使用しています。
cryptographyが入っていない場合は、pip install cryptographyを行ってください。
python 3.7.4
Chrome バージョン: 80.0.3987.87(Official Build) (64 ビット)で動作確認。参考にしたもの
browsercookiejar (regen100)
https://github.com/regen100/browsercookiejarAES GCM example in python and go (sumanmukherjee03)
https://gist.github.com/sumanmukherjee03/dd16d6c732a1055b6af97daba484809dA little tool to play with Windows security (gentilkiwi)
https://github.com/gentilkiwi/mimikatz
- 投稿日:2020-02-11T21:12:35+09:00
AESで暗号化されたWindows ChromeのCookieを復号する【python】
概要
WindowsのChromeは v80以降、ブラウザcookieの暗号化にAESを使用するようになった。
(Linux、 macOSのChromeブラウザのcookieについてはここでは触れない。以下「cookie」は、Windows用 Chromeブラウザのcookieを指すものとする)
以前は、DPAPI Windows API(crypt32.dllのCryptUnprotectData)を使用して暗号化されていたが、新方式で暗号化されたcookieは旧方式では復号できない。
Windows Chromeのcookieファイルの中身を直接読み取ってWebサービスにログインするようなアプリは、今回の変更の影響を受けている。(例:ニコ生コメントビューア)
AESで暗号化されているcookieの復号手順の概要を下記に示す。
Windows ChromeのCookiesファイルの場所
デフォルトでは下記(以前と変わらない)
%userprofile%\AppData\Local\Google\Chrome\User Data\default\Cookies
(プロファイルの移動をしたり、Windowsの再インストールやgoogleアカウントの変更等をした場合は変わる)AESで暗号化されているcookieの識別
暗号化cookieデータの先頭が「0x01 00 00 00」→ DPAPIで暗号化されたcookie
暗号化cookieデータの先頭が「v10」 → AESで暗号化されたcookie
復号に必要なもの
復号には鍵(key)だけでなく、nonceと呼ばれる値が必要になる。
nonceの位置・長さ
nonceは、各暗号化cookieデータの先頭からプレフィクス3バイト('v10')を除いた4バイト目以降12バイトをそのまま用いる。
encrypted_key(暗号化された鍵)の格納場所
デフォルトでは、keyはエンコード・暗号化されて下記の
Local Stateファイル内に格納されている。
%userprofile%\AppData\Local\Google\Chrome\User Data\Local StateLocal Stateの中身はJSONフォーマットになっている。
この中の["os_crypt"]->["encrypted_key"] に暗号化された鍵データが格納されている。
keyの復号
- JSON(Local Stateファイル)から取り出したencrypted_keyの値をBASE64でデコードする。
- デコードしたデータの先頭5バイト(プレフィクス
'DPAPI')を除去する。- 2のデータをさらにDPAPIで復号する。 DPAPIによる復号は旧方式と同じcrypt32.dllのCryptUnprotectDataを用いればよい。
得られたkeyの長さは256bit(32バイト)のはずである。
これで、cookieの復号に必要となるkeyが復号できた。
cookieデータの復号
暗号化されたcookieデータの最初の15バイト('v10'+nonce 12bytes)を除いた部分を、上記で得られたnonceとkeyを用いて256bit AES-GCM で復号する。
さらに、復号されたデータの末尾16バイトを取り除く。
pythonによる実装
https://github.com/taizan-hokuto/chrome_cookie
AES-GCMのためにcryptographyライブラリを使用しています。
cryptographyが入っていない場合は、pip install cryptographyを行ってください。
python 3.7.4
Chrome バージョン: 80.0.3987.87(Official Build) (64 ビット)で動作確認。参考にしたもの
browsercookiejar (regen100)
https://github.com/regen100/browsercookiejarAES GCM example in python and go (sumanmukherjee03)
https://gist.github.com/sumanmukherjee03/dd16d6c732a1055b6af97daba484809dA little tool to play with Windows security (gentilkiwi)
https://github.com/gentilkiwi/mimikatz
- 投稿日:2020-02-11T21:01:50+09:00
[Pythonで遊ぼう] 文章自動生成をめざす ~.txtを読み込み一文単位にする~
はじめに
文章自動生成をめざす、二回目です。前回は文章の構造を調べる形態素解析というのをやりました。今回は、.txtを読み込んで一文ずつに分けるということをしていきます。
文章を読み込む
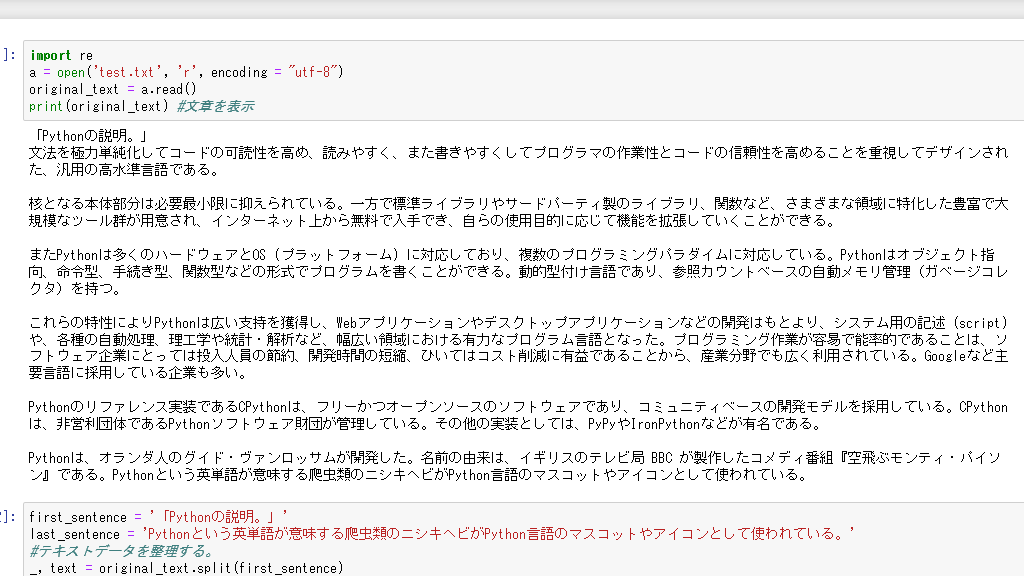
事前にメモ帳などで作成したテキストデータを用意しておきます。エンコーディング方法には注意しておきましょう。(例では'utf-8'です。)では、文章を読み込んで表示しましょう。
import re a = open('test.txt', 'r', encoding = "utf-8") original_text = a.read() print(original_text) #文章を表示こんな感じになります。
テキストデータを整理する
次にテキストデータを整理します。もととなるテキストの書き方次第で、各自調整が必要となります。コードは私のテキストデータの場合です。(例えば'文章(ぶんしょう)'などフリガナの場合は削除しなければならない。)
first_sentence = '「Pythonの説明。」' last_sentence = 'Pythonという英単語が意味する爬虫類のニシキヘビがPython言語のマスコットやアイコンとして使われている。' #テキストデータを整理する。 _, text = original_text.split(first_sentence) text, _ = text.split(last_sentence) text = first_sentence + text + last_sentence text = text.replace('!', '。') #!や?を。に変える。全角半角に気を付ける text = text.replace('?', '。') text = text.replace('(', '').replace(')', '') #()を削除する。 text = text.replace('\r', '').replace('\n', '') # テキストデータの改行で表示される\nを削除 text = re.sub('[、「」?]', '', text)sentences = text.split('。') #。で文章を一文単位に分割 print('文字数:', len(sentences)) sentences[:10] #10文を表示しますできたのがこれ
今回のコードはこれで以上です。これで一文単位のリストができましたね!これを形態素解析にかけて文章にしていく予定です。
雑談
個人的につまづいたところがいくつかあったので紹介。
- encoding = 'utf-8'を入れてなくてエラー。
- テキストデータの特徴がつかめてなくて'!'で一文が区切れない
といったところですかね。割と簡単なのに気づかなかったりして時間がかかりました。あと記事にする例文もどうしようか考えた末、無難なもの(WikipediaのPythonの説明文)となりました。
- 投稿日:2020-02-11T20:46:45+09:00
PythonでCloudWatchのデータを取得してみた
きっかけ
CloudWatchのダッシュボードでサーバーの状態を確認する日々。
出社したらまずダッシュボードを順番に確認してー・・・って、めんどくさい!
ダッシュボードの情報を一気に取得したい!
よし、Pythonで書こう!PythonでCloudWatch情報を取得
Boto3の
get_metric_statistics()を使ったら良さそう。
公式ドキュメント通りに、まずはBoto3でCloudWatchを読み込む準備をする。import boto3 client = boto3.client('cloudwatch')
get_metric_statistics()は以下のように使うようだ。response = client.get_metric_statistics( Namespace = 'string', MetricName = 'string', Dimensions = [ { 'Name': 'string', 'Value': 'string' }, ], StartTime = datetime(2020, 2, 11), EndTime = datetime(2020, 2, 11), Period = 123, Statistics = [ 'SampleCount'|'Average'|'Sum'|'Minimum'|'Maximum', ])Namespace
AWS/EC2とかAWS/ElastiCacheとかAWS/RDSとか。
CloudWatchのグラフ化したメトリクスタブの詳細情報にマウスカーソルを合わせると表示される情報の一番上に書かれたものです。
MetricName
CPUUtilizationとかMemoryUtilizationとかDiskSpaceAvailableとか。
CloudWatchのグラフ化したメトリクスタブの詳細情報にマウスカーソルを合わせると表示される情報の上から2番目、区切り線の上に書かれたものです。Dimensions
InstanceIdとかCacheClusterIdとかDBInstanceIdentifierとか。
CloudWatchのグラフ化したメトリクスタブの詳細情報にマウスカーソルを合わせると表示される情報の区切り線の下に書かれたものです。(区切り線の下は全てDimensions情報)
上の例のようにDimensionsは以下の形で書きます。
Dimensions=[{'Name': 'string', 'Value': 'string'}]
なので具体的には
Dimensions=[{'Name': 'InstanceId', 'Value': 'i-xxxxxxxxxxx'}]や
Dimensions=[{'Name': 'Role', 'Value': 'WRITER'}, {'Name': 'DBClusterIdentifier', 'Value': 'xxxxxxxxxxx'}]
のような形になります。Period
期間を秒数で書きます。なので
1分 → 60
5分 → 300
24時間 → 86400Statistics
統計を書きます。
レスポンス
get_metric_statistics()のレスポンスは以下のようになります。{'Label': 'CPUUtilization', 'Datapoints': [{'Timestamp': datetime.datetime(2020, 2, 10, 19, 8, tzinfo=tzutc()), 'Maximum': 6.66666666666667, 'Unit': 'Percent'}], 'ResponseMetadata': {'RequestId': 'xxxxxxxxxxx', 'HTTPStatusCode': 200, ...(省略)なので
値はresponse['Datapoints'][0][Statisticsで指定した値(上のレスポンスだとMaximum)]
値の単位はresponse['Datapoints'][0]['Unit']
あたりを使えばいい感じに出来そうです。実際に書いたもの(一部)
毎日CloudWatchで目視確認をしていたので、今回のスクリプトではスクリプト実行日時から過去24時間分を取得するようにします。
スクリプトが出来たらcronで定期実行してもいいかもしれません。import boto3 from datetime import datetime, timedelta client = boto3.client('cloudwatch') def get_metric_statistics(name_space, metric_name, dimensions_values, statistic): # CloudWatch情報の取得 response = client.get_metric_statistics( # CPU使用率の場合`AWS/EC2`が入る Namespace = name_space, # CPU使用率の場合`CPUUtilization`が入る MetricName = metric_name, # `[{'Name': 'InstanceId', 'Value': instance_id}]`が入る Dimensions = dimensions_values, # 開始日時を`スクリプト実行日時 - 1日`で指定 StartTime = datetime.now() + timedelta(days = -1), # 終了日時を`スクリプト実行日時`で指定 EndTime = datetime.now(), # 24時間を指定 Period = 86400, # `Maximum`が入る Statistics = [statistic] ) # 出力文作成 response_text = name_space + ' ' + metric_name + statistic + ': ' + str(response['Datapoints'][0][statistic]) + ' ' + response['Datapoints'][0]['Unit'] print(response_text) # 出力対象メトリクス instance_id = 'i-xxxxxxxxxxx' # CPU使用率 get_metric_statistics('AWS/EC2', 'CPUUtilization', [{'Name': 'InstanceId', 'Value': instance_id}], 'Maximum') # メモリ使用率 get_metric_statistics('System/Linux', 'MemoryUtilization', [{'Name': 'InstanceId', 'Value': instance_id}], 'Maximum')出力結果
AWS/EC2 CPUUtilizationMaximum: 6.66666666666667 Percent System/Linux MemoryUtilizationMaximum: 18.1909615159559 Percentまとめ
PythonスクリプトからCloudWatchの情報を取得してみました。
今回はDatapointsが一つしかないパターンで行いましたが、期間の指定によっては複数個の出力になります。
その場合はループ処理でいい感じに必要なデータを狙い撃ちしてください。We're hiring!
AIチャットボットを開発しています。
ご興味ある方は Wantedlyページ からお気軽にご連絡ください!参考記事

- 投稿日:2020-02-11T20:32:11+09:00
時間だけわかっているときのdatetimeへの埋め込み
概要
今回の記事は、スクレイピングしたときに時間は取得できたのでその時間に日時を足してdatetime型に変換したいときの解決策を載せたいと思います。
解決策1
datetimeから文字列への変換
dt_now = dt.now() time_str = dt_now.strftime('%Y/%m/%d')これによって以下のような変換が可能になります。
2018-02-02 18:31:13→18/02/02
この文字列に取得した値を組み合わせてからstrptimeを使って、datetime型に変換すればよいと思います。しかし、私の実行環境では%dがどうしてもエラーとなってしまうので別の方法を試してみました。
解決策2
datetimeの分割
dt_now = dt.now() year = int(dt_now.year) month = int(dt_now.month) day = int(dt_now.day)これらとスクレイピングで取得した値をint型に直したものを組み合わせます。
datetime_after = dt(year,month,day,hour,minute)まとめ
根本的には%dを直すのが先決ですが、はまりそうなら解決策2を試してみてもいいかもしれません。
- 投稿日:2020-02-11T20:04:59+09:00
Tkinterを使ってみる
PythonでGUIプログラムを書けるTkinterを使ってみる。
Tkinter
PythonでGUIアプリケーションを作成できるライブラリ。Pythonに標準で入っているため、特にインストールなどはせずに使用可能。
サンプルコード
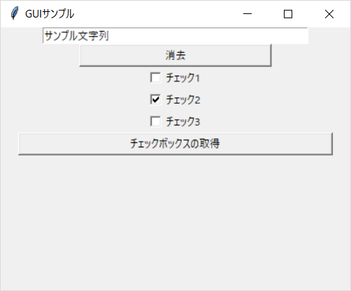
# -*- coding : utf-8 -*- u""" GUIプログラミングのサンプル """ import tkinter from tkinter import messagebox def button_push(event): u"ボタンをクリックされたときの動作" edit_box.delete(0, tkinter.END) def func_check(event): u"チェックボックスの状態を確認して、表示する" global val1 global val2 global val3 text = "" if val1.get() == True: text += "項目1はチェックされています\\n" else: text += "項目1はチェックされていません\\n" if val2.get() == True: text += "項目2はチェックされています\\n" else: text += "項目2はチェックされていません\\n" if val3.get() == True: text += "項目3はチェックされています\\n" else: text += "項目3はチェックされていません\\n" messagebox.showinfo("info", text) if __name__ == "__main__": root = tkinter.Tk() root.title(u"GUIサンプル") root.geometry("400x300") # テキストボックス edit_box = tkinter.Entry(width=50) edit_box.insert(tkinter.END, "サンプル文字列") edit_box.pack() # ボタン button = tkinter.Button(text=u"消去", width=30) button.bind("<Button-1>", button_push) button.pack() # button.place(x=105, y=30) # チェックボックス val1 = tkinter.BooleanVar() val2 = tkinter.BooleanVar() val3 = tkinter.BooleanVar() val1.set(False) val2.set(True) val3.set(False) checkbox1 = tkinter.Checkbutton(text=u"チェック1", variable=val1) checkbox1.pack() checkbox2 = tkinter.Checkbutton(text=u"チェック2", variable=val2) checkbox2.pack() checkbox3 = tkinter.Checkbutton(text=u"チェック3", variable=val3) checkbox3.pack() # ボタン button2 = tkinter.Button(root, text=u"チェックボックスの取得", width=50) button2.bind("<Button-1>", func_check) button2.pack() tkinter.mainloop()実行例
参照
- 投稿日:2020-02-11T19:57:08+09:00
Pythonで環境変数を扱う
- 投稿日:2020-02-11T19:52:02+09:00
Pythonでサウンドを扱う
Pythonでサウンドを扱う
Pythonでサウンドを扱う方法がいろいろあってよくわからなかったので、ざっくりまとめ
基本的にはこちらのサイト Playing and Recording Sound in Python を参考にした。
再生
オーディオ再生するライブラリの一例
- playsound WAVとMP3ファイルを再生するためだけの簡単なパッケージ
- simpleaudio WAVファイルとNumPyアレイを再生できるライブラリ
- winsound WAVファイルとビープ音を再生できる、Windows用ライブラリ
- python-sounddevice、pyaudio WAVファイルを再生するPortAudioライブラリの提供
- pydub pyaudioも必要になるが、ffmpegをインストールすることで数行のコードで幅広いオーディオ形式を再生できる
playsound
playsound関数のみが実装されており、WAVファイルもしくはMP3ファイルを指定して再生する。
install
pip install playsoundusage
from playsound import playsound playsound("sample.wav")simpleaudio
WAVファイルもしくはNumPyアレイを再生する。再生中かどうかの判別も可能。
install
pip install simpleaudiousage
import simpleaudio wav_obj = simpleaudio.WaveObject.from_wave_file("sample.wav") play_obj = wav_obj.play() play_obj.wait_done()# 再生中か確認する if play_obj.is_playing(): print("still playing")winsound
Windowsの場合、winsoundがデフォルトで使用可能? WAVファイルの再生およびビープ音の再生が可能。
usage
import winsound winsound.PlaySound("sample.wav", winsound.SND_FILENAME)# ビープ音の再生 import winsound winsound.Beep(1000, 100) # 1000Hzのビープを100ms再生python-sounddevice
PortAudioライブラリのバインドを提供。オーディオ信号、NumPyアレイを再生/録音するための機能を提供。
install
Anacondaを使用している場合、condaパッケージでインストールできる
conda install -c conda-forge python-sounddeviceusage
import sounddevice as sd import wave import numpy as np wf = wave.open("sample.wav") fs = wf.getframerate() data = wf.readframes(wf.getnframes()) data = np.frombuffer(data, dtype='int16') sd.play(data, fs) status = sd.wait()上記は一曲全体を一括で扱うが、リアルタイム処理などを行う場合はコールバック処理で短い単位ごとにオーディオ信号を扱う必要がある。
import sounddevice as sd duration = 5.5 def callback(indata, outdata, frames, time, status): if status: print(status) outdata[:] = indata with sd.Stream(channels=2, callback=callback): sd.sleep(int(duration * 1000))pydub
install
pip install pydubMP3等のWAV以外のファイルを使用する際には、ffmpegかlibavのインストールも必要。
さらに、オーディオの再生には以下のいずかれをインストールする必要あり(simpleaudioが推奨)
- simpleaudio
- pyaudio
- ffplay (ffmpegに同梱)
- avplay (libavに同梱)
usage
from pydub import AudioSegment from pydub.playback import play sound = AudioSegment.from_file("sample.wav", format="wav") play(sound)pyaudio
PortAudioライブラリのバインドを提供。クロスプラットフォーム上で簡単にオーディオ再生、録音が可能。
単純なオーディオの再生は他の方法に比べて複雑なため、単純にファイルを再生するだけであれば他の方法を選択した方がよい。
しかし、より低次元での制御を行うため入出力デバイスの設定やレイテンシの確認などが可能。また、callbackでも記述できるため、比較的複雑な処理を行う際に適している。
install
pip install pyaudio # condaでも可能 conda install pyaudiousage
import pyaudio import wave import sys chunk = 1024 wf = wave.open("sample.wav", "rb") p = pyaudio.PyAudio() stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) data = wf.readframes(chunk) while data != '': stream.write(data) data = wf.readframes(chunk) stream.stop_stream() stream.close() p.terminate()録音
オーディオ録音できるライブラリの一例
- python-sounddevice マイクから録音し、NumPyアレイとして保持する
- pyaudio マイクから録音し、バイナリとして保持する
python-sounddevice
usage
import sounddevice as sd from scipy.io.wavfile import write record_second = 3 fs = 44100 myrecording = sd.rec(int(record_second * fs), samplerate=fs, channels=2) write('output.wav', fs, myrecording)pyaudio
usage
import pyaudio import wave chunk = 1024 format = pyaudio.paInt16 channels = 2 fs = 44100 record_second = 3 p = pyaudio.PyAudio() stream = p.open(format=format, channels=channels, rate=fs, input=True, frames_per_buffer=chunk) print("* recording") frames = [] for i in range(int(fs / chunk * record_second)): data = stream.read(chunk) frames.append(data) print("* done recording") stream.stop_stream() stream.close() p.terminate() wf = wave.open("output.wav", "wb") wf.setnchannels(channels) wf.setsampwidth(p.get_sample_size(format)) wf.setframerate(fs) wf.writeframes(b''.join(frames)) wf.close()デバイス
再生/録音デバイスを指定したいことがあるので、各ライブラリでの変更方法を確認。
python-sounddevice
使用可能なデバイス、選択されているデバイスを表示
import sounddevice as sd sd.query_devices()実行例
ターミナル上で下記コマンドでも可能。
python -m sounddeviceデバイスIDを、
default.deviceに設定するか、play()やStream()に device引数 として割り当てることで、デバイスの選択が可能import sounddevice as sd sd.default.device = 1, 5

- 投稿日:2020-02-11T19:45:26+09:00
numpyとpandasの分散を求めるメソッドの違い
TL;DR
numpyとpandasの分散処理をしていて、両者が一致しないのでなんで?となったのでメモを残しておきます。
numpyとpandasのvarを求めるメソッドの結果はデフォルト値だと一致しない
簡単にrandomに生成した行列を用いてテストします。実際に一致しません。
import numpy as np import pandas as pd X = np.random.randn(10, 10) df = pd.DataFrame(data=X) np.allclose(X, df.values) # True X_var = np.var(X, axis=1) df_var = df.var(axis=1) np.allclose(X_var, df_var.values) # False実際にドキュメントを調べてみると、numpy.varではデフォルトが
ddof=0なんですが、pandas.DataFrame.varだとデフォルトがddof=1になっています。デフォルト値を揃えると結果は一致します。
X_var_ddof1 = np.var(X, ddof=1, axis=1) df_var_ddof1 = df.var(axis=1) np.allclose(X_var_ddof1, df_var_ddof1.values) # True計算結果がなんか合わないなーと思っていたら実はnumpyとpandasで微妙に違いがあったという罠。
統一してほしいものですが、もしかしたら誰かがはまっていたときのことを思ってメモを公開しておきます。
- 投稿日:2020-02-11T19:34:41+09:00
LINE botでディズニーの待ち時間を表示する
目次
- 概要
- 作成したLINE bot
- ディレクトリ構成
- 構成図
- 各ファイルの紹介
- 動作の流れ
- リッチメニューの作成
- パークの選択(ボタン)
- 開園チェック
- 開園中なら取得したい待ち時間のカテゴリを選択
- スクレイピング→Flex Messageのreciptで出力
- まとめと今後の課題
太字は特に苦労したところです
概要
以下のサイトを参考にnode.jsではなくPythonでbotを作ってみました。また、スクレイピングで取得した情報は上記に載っていたサイトと同じところからいただきました。
ディズニーの待ち時間を教えてくれるLINE botを作ってみた
このサイトでは手軽に使えることを前提としているので、文字列が多いのですが逆にリッチメニューやFlex Messageを使い、欲しいデータをユーザーに選んでもらえるようにしました。
リッチメニュー、Flex Messageなどはまとまっているところがなくリファレンスを見たり、様々なサイトを往復したのでそれもまとめられればと思っています。※この記事では初心者の私がつまずいた、初めて知ったことに重きを置いているため「LINE botでディズニーの待ち時間を表示する」こと自体はそこまで重要視していません。そのため初心者向けに細かく書いてあるので、中・上級者にとっては長すぎるかもしれませんがご了承ください。また、営利目的ではないことを先に記しておきます。
作成したLINE bot
先に完成版を貼っておきます。よければ登録して使ってください!
直接読み込む場合は、こちらからどうぞソースコード類はGitHubで公開しています。スクレイピングのコードなど詳しいものが見たい場合はこちらからどうぞ
ディレクトリ構成
構成図
disneyというフォルダに全部入れる形にしました。.gitは隠しファイルとなっていたためここには出てきていませんがdeploy.batと同階層においてあります。
disney ├ deploy.bat ├ main.py ├ scrape_requests.py ├ makejsonfile.py ├ Procfile ├ runtime.txt ├ requirements.txt │ └─templates land_theme.json recipt.json sea_theme.json theme_select.json各ファイルの紹介
LINE botを動かす部分は後で説明するので、設定ファイルの中身を下に載せます。
deploy.bat:これは変更版をHerokuにデプライするときにいちいちコマンドを打たなくていいようにするものです。
deploy.batgit add . && git commit -m 'Improve' && git pushProcfile:Herokuにプログラムの起動方法を教えるための設定ファイル、Procfileを作成します。コマンドプロンプトでカレントディレクトリまで移動した後に、下のコマンドを入力してください。この時main.pyと書いてあるところに最初に起動するものを入れてください。名前はmain.pyでなくて大丈夫です。
Procfileecho web: python main.py > Procfileruntime.txt:使用するPythonのバージョンをここに記します。
runtime.txtpython-3.7.0requirements.txt:Pythonで使うモジュールの中でpip installしたものはここに書いておきます。これでHeroku側でもこれらのモジュールが使えるようになります。
requirements.txtFlask==1.1.1 line-bot-sdk==1.15.0 requests==2.21.0 bs4==0.0.1 lxml==4.4.2※余談になりますが、スクレイピングにselenium,chromedriverを使うときはHerokuのSettingにあるBuildpacksにこれらを追加する必要があります。add buildpacksを押した後に以下のURLを貼り付けてください。
https://github.com/heroku/heroku-buildpack-chromedriver.git https://github.com/heroku/heroku-buildpack-google-chrome.git動作の流れ
- ホームボタンを押してもらう(後述のリッチメニュー)
- パーク選択
- 開園チェック
- 開園中なら取得したい待ち時間のカテゴリを選択(後述のリッチメニュー)
- スクレイピング→Flex Messageのreciptで出力
リッチメニューの作成
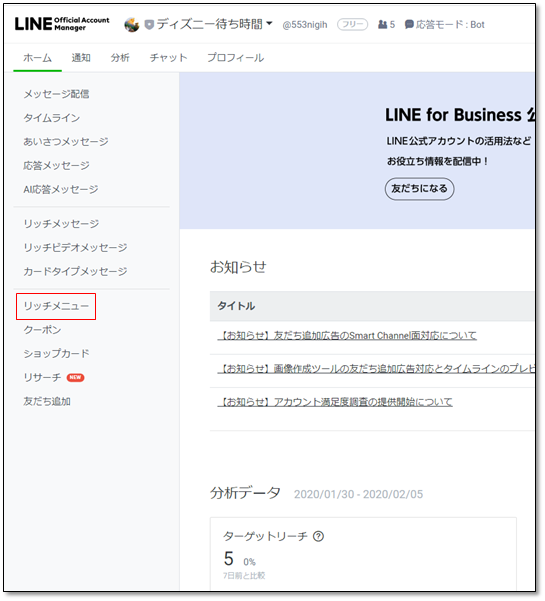
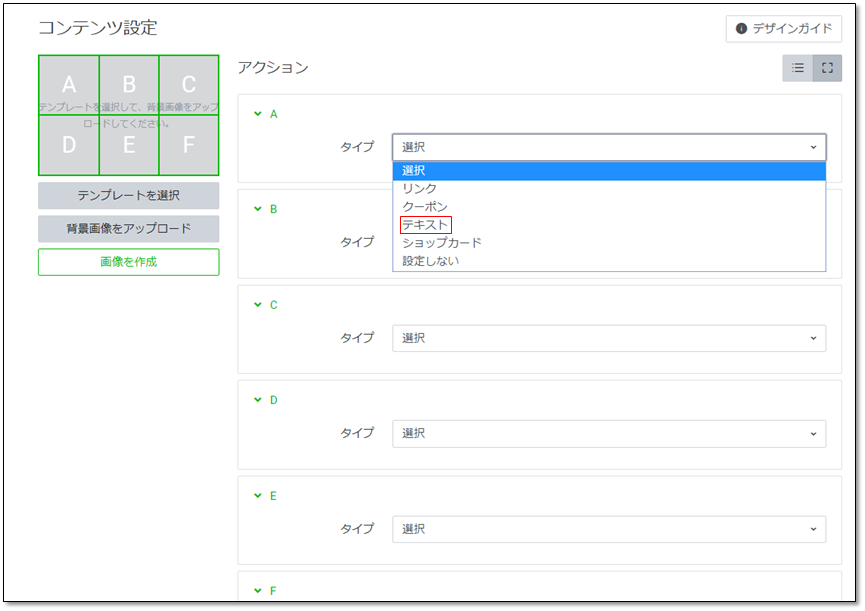
下の画像に出ている6分割の部分がリッチメニューです。今回は自分で組むのではなく、LINE Official Managerの機能を使って作ります。本当はポストバックを使いたかったので完全自作にしたかったのですが、リファレンスを読んでも実装方法がいまいちよくわからなかったので妥協しました。
LINE Official Manager
ログインした後は下の赤枠をクリックしてください。
そこで作成ボタンを押すと次のようなページが表示されます。
タイトルは何でもいいです。リッチメニューを複数作ったときに見分けるようです。(自作でないと同一アカウントでのリッチメニューの切り替えはできなさそうです)
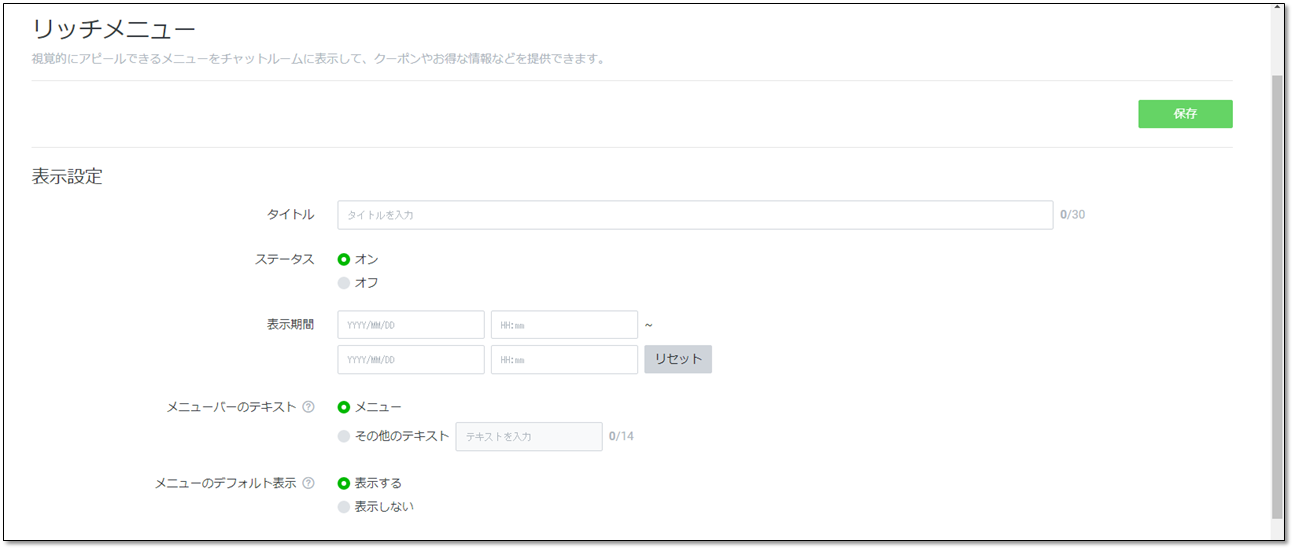
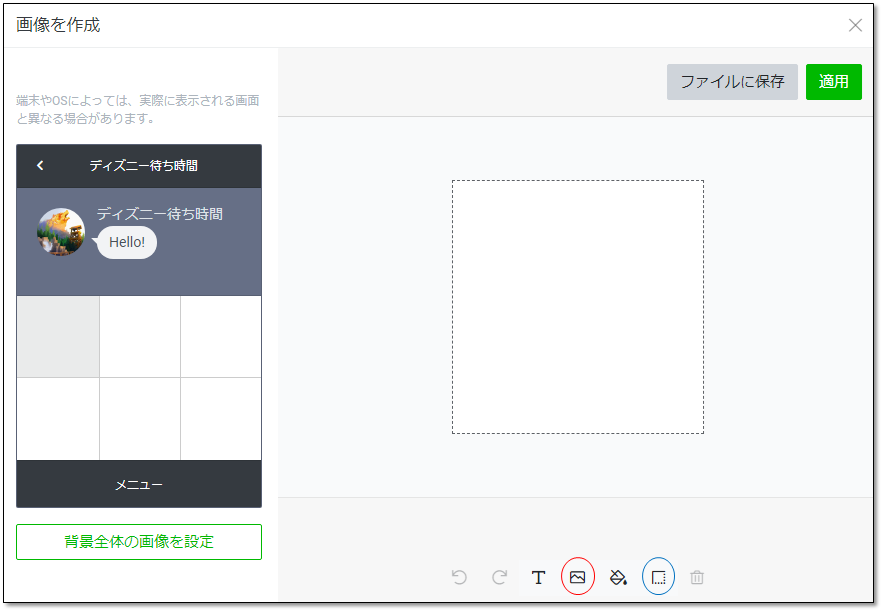
表示期間は長めに取っておけばよいとおもいます。開始日は実装する日より前にしないと出てきません。(当然ですが)下に行くとコンテンツの設定があります。テンプレートを選択を押すと分割数を選べます。ここでは6分割を選びました。背景画像をアップロードを選択すると一面の画像になってしまうので、6分割個々に画像をつけるなら下の画像を作成を押します。
また、アクションで押したときの反応を選べます。今回はそのあとのイベントにつながるのでテキストにします。(他を使う機会はあまりない気がします)
画像の作成時のポイントを述べます。まず赤丸のアイコンを押すと画像をアップロードできます。そして青丸のアイコンで外枠が縁どられます。これがないと境界がわからないのであったほうがいいと思います。デフォルトの太さだと隙間が空いたので、縁はmaxの5でちょうどよかったです。
また、右上の適用は全部終わってから押しましょう。途中で押すとそれで背景の1枚の画像として保存されてしまうので、個々の編集ができなくなります。
こうして出来上がったのがこのリッチメニューです。
動作の流れで書いたホームボタンが真ん中下のミッキーアイコンです。押したときに「ホーム」とテキストを返す役割を担っています。
その他の5つはすべてカテゴリを選択するためにあるので、ホームボタンとは機能が違います。パークの選択(ボタン)
ホームボタンを押した後はパークを選択してもらうために下のようなボタンが出るようにしました。
ホームボタンを押したときの処理をざっくり載せます。この後ポストバックのイベントもあり、どのパークを選択しているかなど保存しておきたい情報があるので、変数のスコープを考えてグローバル変数を使っています。ホームボタンを押した後の処理に関してはles = "les"というところから始まっています。大事な点は以下の2点です。
- jsonファイルの表示の仕方
- pushとreplyの違い
home_button.py@handler.add(MessageEvent, message=TextMessage) def handle_message(event): global park,genre,area,info_url,target_url,counter,situation text = event.message.text userid = event.source.user_id #最初とリセット時 if text == "ホーム": #初期化 park = "park" genre = "genre" area = "area" info_url = "" target_url = "" counter = 0 situation = "" les = "les" template = template_env.get_template('theme_select.json') data = template.render(dict(items=les)) select__theme_massage = FlexSendMessage( alt_text="テーマ選択", contents=BubbleContainer.new_from_json_dict(json.loads(data)) ) line_bot_api.push_message(userid, messages=select__theme_massage)まず最初に書いておきたいのは、TextMessageやFlexSendMessageについてです。これらはオウム返しでコピペしたソースコードの上のほうをいじる必要があります。下のようにEvent,Action,Message系はimportする必要があるようです。エラーが出た場合は、ここに記述しているか確認してみてください。
from linebot.models import ( MessageEvent, TextMessage, PostbackTemplateAction, PostbackEvent, PostbackAction, QuickReplyButton, QuickReply, FlexSendMessage, BubbleContainer, CarouselContainer, TextSendMessage )jsonファイルの表示
正直jinja2を使ってテンプレートに当て込むということしかわかっていないので、あまり理解をしていないです。なので、初心者の方はles = "les"以下をコピペしてもらうのが時短になると思います。
jsonファイルを作成する
Flex Message Simulatorを使って、完成しているものをいじってとりあえず形にしました。
theme_select.json{ "type": "bubble", "hero": { "type": "image", "url": "https://secured.disney.co.jp/content/disney/jp/secured/dcc/tokuten/bf-tdr-prk-tckt/_jcr_content/par/dcc_hero_panel_image/image1.img.jpg/1474355301452.jpg", "size": "full", "aspectRatio": "20:13", "aspectMode": "cover" }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "パークを選択してください", "weight": "bold", "size": "lg" } ] }, "footer": { "type": "box", "layout": "vertical", "spacing": "sm", "contents": [ { "type": "button", "style": "link", "height": "sm", "action": { "type": "postback", "label": "ランド", "data": "land" } }, { "type": "button", "style": "link", "height": "sm", "action": { "type": "postback", "label": "シー", "data": "sea" } }, { "type": "spacer", "size": "sm" } ], "flex": 0 } }"action"の中身は
- type
- label
- data
に分かれており、"type"がデータのやり取りの形、"label"はボタンに書いてあるもの(今回なら「ランド」、「シー」)、"data"は受け取るデータを指します。"data"には画像や音声も入るらしいです。詳しくはリファレンスを読んでください。
(補足)"action" : {}の"type"は用途のよって選んでください。相手が押したときにそれがメッセージとして出たほうが良ければ"type" : messageとするのが良いです。大事!
jsonファイルの保存は同階層にtemplatesというフォルダを作ってその中に保存してください!そこから読み込んでるらしいです。
下のコードに代入する
文字列の部分に代入してください。template = template_env.get_template('theme_select.json')カルーセルを実装する場合(横スライドのやつ)、下のコードに変更する
BubbleContainerからCarouselContainerに変更します。select__theme_massage = FlexSendMessage( alt_text="テーマ選択", contents=CarouselContainer.new_from_json_dict(json.loads(data)) )pushとreplyの違い
pushは一回のイベントに対して複数回可能ですが、replyは一回しかできなさそうです。なのでreplyをしてしまうとそのあとにはもうメッセージが送れなくなってしまいます。
例えばスクレイピングに多少の時間がかかると想定して、ユーザーからメッセージを受け取ったときに「処理中」と表示し、その後結果をjsonファイルで表示する場合は、「処理中」をpushしjsonファイルをreplyすることで解決します。
また、pushはuseridとmessageを用意しなくてはいけないです。上のbutton.pyを見て真似てください。push.pyline_bot_api.push_message(userid, messages=select__theme_massage)reply.pyline_bot_api.reply_message( event.reply_token, FlexSendMessage( alt_text="結果表示", contents=BubbleContainer.new_from_json_dict(json.loads(data)) ) )開園チェック
datetimeを用いて開園時間以外は「閉園中」と表示するようにしました。以下に2つのコードを載せます。
1つ目はパーク選択のデータをポストバックで受け取り、営業時間を確認し、戻り値でユーザーに返信をするものです。
2つ目は営業時間を確認するコードです。(おまけ)注意点:Herokuのタイムゾーン設定を日本にしていないとdatetimeがアメリカの時間帯になってしまいます。タイムゾーン設定については→こちらの記事
postback_park.py@handler.add(PostbackEvent) def handle_postback(event): global park,genre,area,info_url,target_url,counter,situation area = "" post_data = event.postback.data userid = event.source.user_id if post_data == "land" or post_data == "sea": park = post_data if park == "land": #開園時間や天気などのリンク info_url = "https://tokyodisneyresort.info/index.php?park=land" park_ja = "ランド" elif park == "sea": #開園時間や天気などのリンク info_url = "https://tokyodisneyresort.info/index.php?park=sea" park_ja ="シー" #開園時間をチェック business_hour = Scrape_day(info_url) situation = Check_park(business_hour) if situation == "close": print("close") line_bot_api.reply_message( event.reply_token, TextSendMessage(text="閉園中です") ) elif situation == "open": park_message = TextSendMessage(text= str(park_ja) + "を選択しています\nカテゴリを下のメニューから\n選択してください") line_bot_api.push_message(userid, messages=park_message)areaを空にしてるのはボタンを間違って複数回押してしまったときを想定したエラー回避です。
check_park.py#今が開園時間か確認 def Check_park(business_hour): #今の時間、日時を確認 dt_now = dt.now() #今日の日付 year = int(dt_now.year) month = int(dt_now.month) day = int(dt_now.day) #開園時間の分割 open_time = business_hour.split("~")[0] if open_time.split(":")[0] == "": return "close" else: open_hour = int(open_time.split(":")[0]) open_minute = int(open_time.split(":")[1]) #閉園時間の分割 close_time = business_hour.split("~")[1] close_hour = int(close_time.split(":")[0]) close_minute = int(close_time.split(":")[1]) #datetime化 open_datetime = dt(year,month,day,open_hour,open_minute) close_datetime = dt(year,month,day,close_hour,close_minute) if open_datetime < dt_now < close_datetime: return "open" else: return "close"引数のbusiness_hourはサイトからスクレイピングしてきた営業時間を文字列に変換したものです。
開園中なら取得したい待ち時間のカテゴリを選択
パークを選択した結果、開園中であったら次のステップに進みます。先ほど作成したリッチメニューを押し、どのカテゴリの待ち時間を表示したいかを選択します。このとき、選択したカテゴリはテキストで画面上に表示されます。これを回避するにはリッチメニューを自作するしかありません泣
スクレイピング→Flex Messageのreciptで出力
コード全体は上記の通りgithubで公開しているので、待ち時間のスクレイピングに関しては特に記述しません。ここでは取得してきた値を出力するときにFlex Messageのreciptを用いる方法について説明します。
出力する文字列が少ない場合や形にこだわらない場合は、上に記述したpushまたはreplyで十分なのでここは飛ばしていいと思います。今回もjsonファイルをいじっていきますが、大きく分けて3つのことをします。
- 一部に変数を埋め込む
- 出力する項目数がその時々で変わるものを埋め込む
- ファイルの初期化
Flex Message Simulatorのreciptを編集して以下のjsonファイルを作成しました。
recipt.json{ "type": "bubble", "styles": { "footer": { "separator": true } }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "待ち時間", "weight": "bold", "color": "#1DB446", "size": "sm" }, { "type": "text", "text": "テーマ", "weight": "bold", "size": "xl", "margin": "md" }, { "type": "separator", "margin": "xxl" }, { "type": "box", "layout": "vertical", "margin": "xxl", "spacing": "sm", "contents": [ ] } ] } }一部に変数を埋め込む
"text": "テーマ"と書いてある部分を"text": "取得した文字"に変更したいので、次のような処理を行います。
set_json.pydef Send_area(area): json_file = open('templates/recipt.json', 'r',encoding="utf-8-sig") json_object = json.load(json_file) json_object["body"]["contents"][1]["text"] = str(area) #書き込み new_json_file = open('templates/recipt.json', 'w',encoding="utf-8") json.dump(json_object, new_json_file, indent=2,ensure_ascii=False)手順としては
1. まず上のjsonファイルを書き込める形で読み込みます
2. 複雑なリストの要素を指定することによって"text": "テーマ"があるところまで行きます(エディターによっては簡単に見つけることができると思います)
3. そして"text"の中身に変数を代入すれば一部に変数を代入することができます
という感じです。出力する項目数がその時々で変わるものを埋め込む
これは形の決まったboxに変数を埋め込み、それを追加挿入していくことで解決しました。
new_json.pydef Make_jsonfile(attraction,info): json_file = open('templates/recipt.json', 'r',encoding="utf-8-sig") json_object = json.load(json_file) new = { "type": "box", "layout": "vertical", "margin": "xxl", "spacing": "sm", "contents": [ { "type": "box", "layout": "horizontal", "contents": [ { "type": "text", "text": str(attraction), "size": "sm", "color": "#555555", "flex": 0 }, { "type": "text", "text": str(info), "size": "md", "color": "#111111", "align": "end" } ] } ] } json_object["body"]["contents"][3]["contents"].append(new) new_json_file = open('templates/recipt.json', 'w',encoding="utf-8") json.dump(json_object, new_json_file, indent=2,ensure_ascii=False)複雑なため分かりにくいと思いますが、大事なのはappend(new)を行っているところです。上のrecipt.jsonにある一番下の空のcontentsはリスト形式であるため、そこにappendすることによって表示するデータ数があらかじめ分かっていなくても対応できます。
new_json.pyではアトラクション名と待ち時間を変数で埋め込み、それらをまとめたboxをcontentsに挿入しています。※ encodingをutf-8-sigで行なっているのは、エラー回避のためです。utf-8でエラーが出ている人はこのサイトをみてください→UnicodeDecodeError: 'cp932'が出たとき
※ Herokuのログ確認でemptyと書いてあるときは大体ここが原因だと思います。元のcontentsが空であるため、何も追加されていないと出力するときにエラーが出ます。まずはcontentsにboxが追加されているか確認しましょう。
ファイルの初期化
当然ながら、初期化せずにappendを繰り返すと今までの情報が残り続けてしまいます。reciptを作成する前に、上のrecipt.jsonを上書きすることで初期化しています。
まとめと今後の課題
初投稿ながらかなり長くなってしまいました。今回は私自身が苦労したリッチメニューとFlex Messageに重点をおき、まとめてみたので誰かの参考になれば幸いです。
挙げられる課題としては、
- 公式サイトから情報をとって来れればより表示できる項目が増える(セキュリティ的に厳しいと思うが)
- リッチメニューを自作して、リッチメニュー自体を動的に使いたい(リッチメニューを押すとボタンではなく、新しいリッチメニューが出てくるような)
があります。特に2つ目のリッチメニューに関するPythonの記事が少ないので、たまたまこの記事を読んだ人の中に詳しい方がいらっしゃったらぜひ投稿していただけると嬉しいです。




- 投稿日:2020-02-11T19:31:58+09:00
【PEP8】Pythonのソースコードを規約に乗っ取ってキレイに書く
始めに
プログラム言語の紹介サイトなどを見ると、Pythonは行儀のいい言語などと記載されているのを見かけます。Pythonは他言語に比べると書き方の制約が多い印象を受けますが、それでもやはり自由度は高く、実際開発を行ってみると各プログラマ固有のクセがソース内に大量に残存してしまいます。
これは個人の趣味程度であればさほど重要な問題ではありませんが、仕事、特にチーム開発の場合には由々しき問題です。一度開発したものは基本的に何年と保守せねばならず、その中で保守担当者が変わることもよくあることです。後々の保守を考え、プログラム規約をプロジェクト内で定義しておくことは非常に重要な事となります。
プロジェクトごとに規約を定義する場合には一から作成することも手としてありです。しかしながら時間およびコストが掛かってしまうため、PEP8をベースとしてコーディング規約を作成することが多々ありますのでご紹介させて頂きます。
PEP8とは
PEP8とは「コードは書くよりも読まれることの方が多い」という考えの元に作成されたPythonのコーディング規約です。この規約に乗っ取ることでコードを読みやすくするとともに、各プログラマによって作られたコードのスタイルを一貫させることを目的としています。
なおPEP8では必ずしも本規約に従う必要がないという姿勢を示しています。プロジェクトの特性に合わせて柔軟に規約を作成していくのが良いかと思います。
しかし、一貫性を崩すべき場合があることも知っておいてください つまり、このスタイルガイドが適用されない場合があります。 疑問に思ったときは、あなたの判断を優先してください。 他の例を調べ、一番良さそうなものを決めて下さい。使い方
PEP8自体は規約ですが、この規約に則ってコードを記載できているか簡単にチェックできる仕組みが提供されています。
- 環境設定
pipでインストールできます
pip install pep8
- 実行
引数に対象のソースコードを指定して、pep8コマンドを叩きますpep8 test.py
- 結果
test.py:16:1: E302 expected 2 blank lines, found 1 test.py:22:80: E501 line too long (95 > 79 characters) test.py:27:1: E302 expected 2 blank lines, found 1 test.py:39:1: E302 expected 2 blank lines, found 1 test.py:44:11: E225 missing whitespace around operator test.py:46:12: E225 missing whitespace around operator test.py:47:13: E225 missing whitespace around operator test.py:50:27: W291 trailing whitespace test.py:51:34: W291 trailing whitespace test.py:60:45: W291 trailing whitespace test.py:66:16: E231 missing whitespace after ':' test.py:74:80: E501 line too long (90 > 79 characters) test.py:90:10: E231 missing whitespace after ',' test.py:92:56: E231 missing whitespace after ',' test.py:101:1: W391 blank line at end of file規約内容について
規約について一部を紹介します。
インデント
1インデントはスペースを4つ使う。
行を継続する場合は、折り返された要素を縦に揃える。
開き括弧に揃える
foo = long_function_name(var_one, var_two, var_three, var_four)
- もしくは引数とそれ以外を区別するため、スペースを4つ加える
def long_function_name( var_one, var_two, var_three, var_four):タブorスペース
- スペースが好ましいインデントの方法。
行の長さ
- すべての行の長さを、最大79文字までに。
- 改行は括弧やブラケット、波括弧の中では暗黙のうちに行を継続させることを利用する
- バックスラッシュを使うことも可
with open('/path/to/some/file/you/want/to/read') as file_1, \ open('/path/to/some/file/being/written', 'w') as file_2: file_2.write(file_1.read())空行
- トップレベルの関数やクラスは、2行ずつ空けて定義。
- クラス内部では、1行ずつ空けてメソッドを定義。
ソースファイルのエンコーディング
- utf8を使用
import
- import文は、通常は行を分けるべき
#good: import os import sys #bad: import sys, os
- import文は、例外を除き絶対パスで指定
#good: import mypkg.sibling from mypkg import sibling from mypkg.sibling import example #bad: from . import sibling from .sibling import example
- importは以下でグループ化する。
- 標準ライブラリ
- サードパーティライブラリ
- ローカルな アプリケーション/ライブラリ に特有のもの
式や文中の空白文字
- 基本的に式や文の中に文字は入れない
#good: spam(ham[1], {eggs: 2}) #bad: spam( ham[ 1 ], { eggs: 2 } ) #good: foo = (0,) #bad: bar = (0, ) #good: spam(1) #bad: spam (1) #good: dct['key'] = lst[index] #bad: dct ['key'] = lst [index] #good: x = 1 y = 2 long_variable = 3 #bad: x = 1 y = 2 long_variable = 3末尾のカンマ
- 末尾にカンマを付けるかどうかは、通常は任意。
- 要素数がひとつのタプルを作るときは例外的に必須。
#good FILES = ('setup.cfg',)参考
- 投稿日:2020-02-11T19:00:41+09:00
特殊メソッド
class Word(object): def __init__(self, text): self.text = text def __str__(self): return 'texttxet' def __len__(self): return len(self.text) def __add__(self, word): return self.text.lower() + word.text.lower() def __eq__(self, word): return self.text.lower == word.text.lower() w = Word('aaaaaaaaaa') w2 = Word('bbbbbbbbbbbbb') print(w) print(len(w)) print(w + w2) print(w == w2)実行結果texttxet 10 aaaaaaaaaabbbbbbbbbbbbb False
- 投稿日:2020-02-11T18:58:07+09:00
pythonでterminal上にマインスイーパー実装してみた
きっかけ
terminal上にマインスイーパーを実装したくなったので,実装しました.実はプログラミング始めたての頃に,Cで一度実装したが完成してなかったこともあり,復習も兼ねて.
*備忘録用のブログのため,細かい話はありません!(え)マインスイーパー概要
マインスイーパは1980年代に発明された、一人用のコンピュータゲームである。ゲームの目的は地雷原から地雷を取り除くことである。
筆者も小学生くらいの頃に遊んでました.(歳がバレる)
ところで,今の小学生だとどれくらい知ってるんだろう.ちなみに,今だとChromeで遊べるので,ぜひ
実装概要
大枠は下記サイトと同じです(多分).
ターミナル上で遊べるマインスイーパ実装アプリ概要
ファイルと,マス目の大きさ,ボムの比率を指定し,実行.
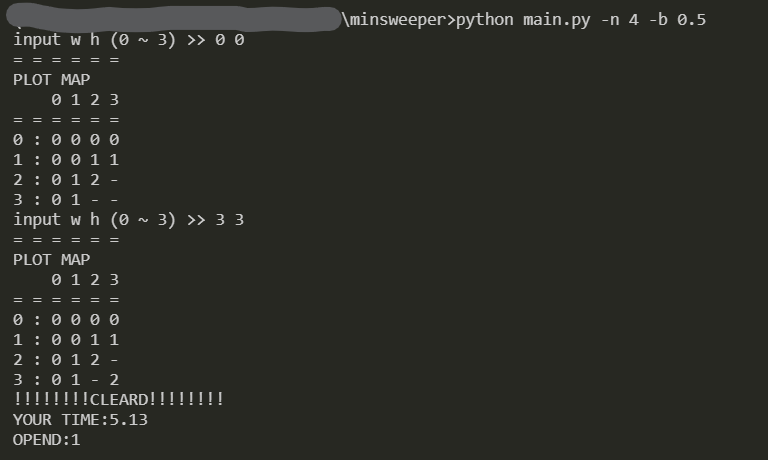
初期位置を指定.マスが表示される.
(*初期位置,および隣接マスには爆弾が配置されないように,設定しています.)以下,open位置を指定していく.
クリアすると,openマス数と経過時間を表示して終了
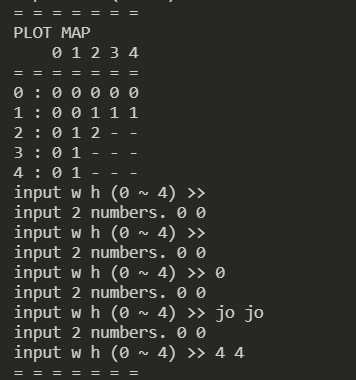
指定していない入力を受け取った際には,下図のように無限ループする.
ハマリポイント
二次元配列の生成
実装時に必要となった二次元配列を生成するときに,下記のコードでは,一つのリストを更新するとすべてのリストが更新されてしまうため注意.
失敗例#爆弾の位置,周囲の爆弾数を保持する二次元配列 mine_list = [["N"] * args.n] #マスがopen済みかどうかを保持する二次元配列 opened_ls = [[False] * args.n]下記のように,リスト内包表記で初期化して事なきを得た.
成功例#爆弾の位置,周囲の爆弾数を保持する二次元配列 mine_list = [["N"] * args.n for i in range(args.n)] #マスがopen済みかどうかを保持する二次元配列 opened_ls = [[False] * args.n for i in range(args.n)]感想
単純なゲームであるが,プログラムの基本を理解していないと実装できない.そのため,基礎復習の良いきっかけとなった.
課題,改善点
- 再帰処理が含まれるため,マスの大きさによっては最大再起回数を超える可能性あり.対応策
- フラグ設置機能の実装
Code
コードの全容は以下です.Githubでも公開しました.
import argparse import random import copy import itertools import time def main(args): def chk(): if args.n > 99: args.n = 99 if args.bomb_rate >= 1 or args.bomb_rate <= 0: args.bomb_rate = 0.5 return args def create_mine_map(init_w, init_h): def num_bomb(mine_list, iw, ih): num_bomb = 0 for i in range(-1, 2): for j in range(-1, 2): if iw+i < 0 or iw+i >= args.n or ih+j < 0 or ih+j >= args.n: continue elif mine_list[iw+i][ih+j] == "B": num_bomb += 1 return num_bomb mine_list = [["N"] * args.n for i in range(args.n)] # add bomb n_bomb = int((args.n ** 2) * args.bomb_rate) bomb_count = 0 for bomb_w in range(args.n): for bomb_h in range(args.n): # bomb設置 if bomb_count >= n_bomb: break if random.randint(0, 100) > 100 * (1 - args.bomb_rate): # 初期入力位置と周辺は除外 if bomb_w != init_w and bomb_h != init_h and \ bomb_w != init_w - 1 and bomb_h != init_h - 1 and \ bomb_w != init_w + 1 and bomb_h != init_h + 1: mine_list[bomb_w][bomb_h] = "B" bomb_count += 1 # increment around bomb for i in range(args.n): for j in range(args.n): if mine_list[i][j] == "N": mine_list[i][j] = num_bomb(mine_list, i, j) return mine_list, bomb_count def open_map(mine_list, open_w, open_h, opened_ls): if mine_list[open_w][open_h] == "B": opened_ls = [[True] * args.n for i in range(args.n)] return opened_ls opened_ls[open_w][open_h] = True if mine_list[open_w][open_h] == 0: for i in range(-1, 2): for j in range(-1, 2): if open_w + i < 0 or open_w + i >= args.n or open_h + j < 0 or open_h + j >= args.n: continue elif not opened_ls[open_w + i][open_h + j]: opened_ls = open_map(mine_list, open_w + i, open_h + j, opened_ls) return opened_ls def plt_mine(mine_list, opened_ls, play_mode=True): h = args.n mine_list_cp = copy.deepcopy(mine_list) print(*["="]*(args.n+2)) if play_mode: for i in range(h): for j in range(h): if not opened_ls[i][j]: mine_list_cp[i][j] = "-" print("PLOT MAP") else: print("PLOT MAP (All Opened)") print(" ", " ", *list(range(0, args.n))) print(*["="]*(args.n + 2)) for i in range(h): print(i, ":", *mine_list_cp[:][i]) "chk args" args = chk() "while wait input(w, h)" while True: try: init_w, init_h = map(int, input("input w h ({} ~ {}) >> ".format(0, args.n - 1)).split()) if init_w >= 0 and init_w < args.n and init_h >= 0 and init_h < args.n: break else: print("Over" + str(args.n)) except ValueError: print("input 2 numbers. 0 0") "create mine" opened_ls = [[False] * args.n for i in range(args.n)] mine_list, n_bomb = create_mine_map(init_w, init_h) opened_ls = open_map(mine_list, init_w, init_h, opened_ls) "plot mine" plt_mine(mine_list, opened_ls, play_mode=args.debug) "while wait input(w, h)" init_time = time.time() init_opend_num = sum(list(itertools.chain.from_iterable(opened_ls))) while True: if all(list(itertools.chain.from_iterable(opened_ls))): print("!!!!!!!!BOMBED!!!!!!!!") break elif sum(list(itertools.chain.from_iterable(opened_ls))) == args.n**2 - n_bomb: end_time = time.time() print("!!!!!!!!CLEARD!!!!!!!!") print("YOUR TIME:{:0=3.2f}".format(end_time - init_time)) print("OPEND:{}".format(args.n**2 - init_opend_num - n_bomb)) break try: open_w, open_h = map(int, input("input w h ({} ~ {}) >> ".format(0, args.n - 1)).split()) if open_w >= 0 and open_w < args.n and open_h >= 0 and open_h < args.n: "update mine" opened_ls = open_map(mine_list, open_w, open_h, opened_ls) "plot mine" plt_mine(mine_list, opened_ls, play_mode=args.debug) else: print("Over " + str(args.n)) except ValueError: print("input 2 numbers. 0 0") if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("-n", type=int, default=8, help="create (n, n) size") parser.add_argument("-b", "--bomb_rate", type=float, default=0.1, help="how many bomb in the mine.") parser.add_argument("-d", "--debug", action="store_false") args = parser.parse_args() main(args)参考
- 投稿日:2020-02-11T18:42:24+09:00
ユーザーフォロー機能の実装を通じて、djangoデフォルトUserとカスタムUserを比較
はじめに
プログラミング初心者です。
今年からDjango勉強中です。
この記事では、Twitterライクな短文投稿サイトを作成を前提とし、その中のユーザーフォロー機能の実装を通じて、デフォルトのUserモデルとAbstractBaseUserから継承したカスタムUserモデルの違いを比較していきます。
Userモデルの違い
djangoでUserモデルを使う方法は大きく2種類あります。以下に記載します。
①デフォルトで用意されているUserモデルを利用
②AbstractUserまたはAbstractBaseUserモデルを継承してUserモデルを自作
それぞれの特徴を簡単に記載します。
①デフォルトで用意されているUserモデルを利用
自分でモデルを作成する手間が掛からず便利だが、仕様が決まっているので欲しい機能を追加で実装することができない。
また、こちらを採用してしまうと、途中で②の方法に変えることは非常に困難。(②の公式リンクに記載あり)
②AbstractUserまたはAbstractBaseUserモデルを継承してUserモデルを自作
コード量は増えるが、自分の好きなようにカスタムができる。
django公式で推奨されている方法。
AbstractBaseUserの方が元からの機能が少ない分、こちらのカスタマイズを行った方がより自由度の高い仕様に変更できる。
今回は、①デフォルトUserモデルと、②AbstractBaseUserモデルを継承したUserモデルを使用していきます。
実装する機能
今回は以下の機能を実装します。
・トップページに自分の投稿した記事、およびフォローしているユーザーの記事が表示される
・ユーザーが他のユーザーをフォローできる
・フォロー一覧を確認できる
内容
デフォルトUserモデルを使用したパターンと、カスタムUserモデルを使用したパターンとで、上記の機能を実装するためのmodels.pyとviews.pyのコーディングにどのような違いがあるかを比較していきます。
前提条件
・Python 3.8.0
・Django 3.0.2
コード
Userモデル、Reportモデル
まずはmodels.pyから記載します。
①デフォルトUserモデル使用時
appというアプリを作成し、そのmodels.pyに以下を記載します。models.pyfrom django.db import models from django.contrib.auth.models import User class Report(models.Model): text = models.TextField(max_length=150) user = models.ForeignKey(User, on_delete=models.PROTECT) #中間テーブル class FollowRelation(models.Model): from_user = models.ForeignKey(User, on_delete=models.CASCADE) to_user = models.ForeignKey(User, on_delete=models.CASCADE)Reportテーブルには、userフィールドを持たせています。ReportとUserの関係は一対多なので、ForeignKeyを用いています。
また、本来ならばUserにフォロワーのフィールドを持たせたいところですが、デフォルトのUserモデルを使用した場合それが不可能であるため、FollowRelationという名の中間テーブルを作成しています。この中間テーブルではto_user、およびfrom_userというフィールドを持たせ、ForeignKeyでUserと一対多の関係を持たせています。誰かが誰かをフォローすると、from_user(フォローした人)とto_user(フォローされた人)の両方に値が入ったデータが追加されるような処理が行われることを想定しています。
②AbstractBaseUserモデルを継承したUserモデル使用時
こちらでは、usersというアプリを作成し、appとは別に管理します。users>models.pyfrom django.db import models from django.contrib.auth.models import PermissionsMixin from django.contrib.auth.base_user import AbstractBaseUser from django.contrib.auth.base_user import BaseUserManager from django.core.mail import send_mail from django.utils import timezone from app.models import Report class UserManager(BaseUserManager): """カスタムユーザーマネージャー""" use_in_migrations = True def _create_user(self, username, email, password, **extra_fields): if not username: raise ValueError('The given username must be set') email = self.normalize_email(email) username = self.model.normalize_username(username) user = self.model(username=username, email=email, **extra_fields) user.set_password(password) user.save(using=self.db) return user def create_user(self, username, email=None, password=None, **extra_fields): extra_fields.setdefault('is_staff', False) extra_fields.setdefault('is_superuser', False) return self._create_user(username, password, **extra_fields) def create_superuser(self, username, email, password, **extra_fields): extra_fields.setdefault('is_staff', True) extra_fields.setdefault('is_superuser', True) if extra_fields.get('is_staff') is not True: raise ValueError('Superuser must have is_staff=True') if extra_fields.get('is_superuser') is not True: raise ValueError('Superuser must have is_superuser=True') return self._create_user(username, password, **extra_fields) class User(AbstractBaseUser, PermissionsMixin): """カスタムユーザーモデル""" username = models.CharField(max_length=100) #フォロワーフィールドをUser自身に持たせる followers = models.ManyToManyField('self', blank=True, symmetrical=False) is_staff = models.BooleanField("is_staff", default=False) is_active = models.BooleanField("is_active", default=True) date_joined = models.DateTimeField("date_joined", default=timezone.now) objects = UserManager() USERNAME_FIELD = "username" EMAIL_FIELD = "email" REQUIRED_FIELDS = [] class Meta: verbose_name = "user" verbose_name_plural = "users"今回はAbstractBaseUserモデルを継承してカスタムUserを作成しているので、UserManagerクラスを記載する必要があります。デフォルトとは異なる機能を持たせたい場合、ここの内容を変更していきます。今回はほぼ変えずに使っています。
カスタムしたUserには、followersというManyToManyFieldを持たせています。①でデフォルトのUserモデルを使った際には、FollowRelationという中間テーブルを作成していましたが、今回はUserをカスタムすることができるので、ManyToManyFieldでUser自身に持たせています。
このfollowersフィールドで注意すべき点は2つあり、1つはManyToManyFieldの第一引数に'self'と記載している点です。ManyToManyFieldで結びつく相手が自分自身である際にはこのように記載します。
もう1つが、symmetrical=Falseという属性を持たせている点です。デフォルトではTrueになっていますが、この場合だと片方が片方をフォローをすると相互フォローとなり、片方が片方のフォローを外すと相互のフォローが外れます(Facebookの友達機能のようなイメージです)。今回は必ずしも相互フォローとはしたくないため、symmetrical=Falseとします。
続いてappのmodels.pyです。
app>models.pyfrom django.db import models class Report(models.Model): text = models.TextField(max_length=150) user = models.ForeignKey('users.User', on_delete=models.CASCADE)ReportテーブルではForeignKeyを用いて、Userと一対多の関係を持たせます。この際、第一引数にget_user_model()としてしまうと、相互に参照しあう関係となり、マイグレーションができません。そのため、'users.User'とString型で記載します。こうすることで参照タイミングがずれ、マイグレーションができるようになります。
省略していましたが、カスタムユーザーを使う場合、settings.pyにAUTH_USER_MODELの記載を行います。今回の場合、usersアプリのUserモデルを参照するという意味となるように記載します。上記のReportテーブルのuserフィールドの第一引数と同じ記載となります。settings.pyAUTH_USER_MODEL = 'users.User'
トップページ
続いてviews.pyを記載します。まずはトップページです。関数名はindexとします。
①デフォルトUserモデル使用時views.pyfrom django.db.models import Q from django.shortcuts import render from .models import Report from .models import FollowRelation #トップページ def index(request): if request.user.is_authenticated: user = request.user #自分がフォローしているユーザーをリスト化 to_relations = FollowRelation.objects.filter(from_user=user) followers = [to_relation.to_user for to_relation in to_relations] reports = Report.objects.filter( Q(user=user) | Q(user__in=followers) ).order_by('-id').distinct() else: reports = None context = { 'reports': reports, } return render(request, 'app/index.html', context)トップページは、自分の投稿した記事、およびフォローしているユーザーの記事が表示されるようにするため、Reportにフィルターをかけています。またフォローしているユーザーをイテラブルな形で持つため、FollowRelationテーブルから取り出したto_relationsをリスト化しています。
最後にreportsをtemplatesに渡すことで、要件通りに記事が表示されるようにします。
(要件は満たしていますが、ここのコードはあまり自信がありません。もっと簡潔にできる気がします。)
②AbstractBaseUserモデルを継承したUserモデル使用時app>views.pyfrom django.db.models import Q from django.shortcuts import render from .models import Report #トップページ def index(request): #ログイン時のみ投稿を表示 if request.user.is_authenticated: user = request.user followers = user.followers.all() reports = Report.objects.filter( Q(user=user) | Q(user__in=followers) ).order_by('-id').distinct() else: reports = None context = { 'reports': reports, } return render(request, 'app/index.html', context)User自身がfollowersフィールドを持っているため、①と比較して処理は少なめです。同様にまとめたreportsをtemplatesに渡しています。クエリの操作が多くないので、デフォルトUserを使用した①よりリーダブルなコードとなっています。
フォロー機能
続いてフォロー機能です。関数名はusers_followとします。
①デフォルトUserモデル使用時views.pyfrom django.contrib import messages from django.contrib.auth.models import User from django.shortcuts import get_object_or_404 from django.shortcuts import redirect from django.views.decorators.http import require_POST from .models import FollowRelation #フォロー機能 @require_POST def users_follow(request, pk): user = get_object_or_404(User, pk=pk) follow = FollowRelation.objects.filter(to_user=user, from_user=request.user) #既にフォローしていれば解除、していなければフォロー if follow.exists(): follow.delete() messages.success(request, 'フォローを解除しました') else: FollowRelation.objects.create(to_user=user, from_user=request.user) messages.success(request, 'フォローしました') return redirect('app:users_detail', pk=pk)既にフォローしているかしていないかを、FollowRelationテーブルにフィルターをかけ、データがあるかないかによって判断しています。データがあればdelete、なければcreateすることによって、フォロー解除およびフォローを行っています。
②AbstractBaseUserモデルを継承したUserモデル使用時
app>views.pyfrom django.contrib import messages from django.contrib.auth import get_user_model from django.shortcuts import get_object_or_404 from django.shortcuts import redirect from django.views.decorators.http import require_POST #フォロー機能 @require_POST def users_follow(request, pk): login_user = request.user user = get_object_or_404(get_user_model(), pk=pk) followers = login_user.followers.all() #既にフォローしていれば解除、していなければフォロー if user in followers: login_user.followers.remove(user) messages.success(request, 'フォローを解除しました') else: login_user.followers.add(user) messages.success(request, 'フォローしました') return redirect('app:users_detail', pk=pk)request.userとuserが混同するので、request.userをlogin_userとしています。
こちらも①と比較すると、クエリ操作が単純なため、わかりやすいコードとなっています。
フォロー一覧
最後にフォロー一覧です。関数名はusers_followlistとします。
①デフォルトUserモデル使用時views.pyfrom django.contrib.auth.decorators import login_required from django.contrib.auth.models import User from django.shortcuts import get_object_or_404 from django.shortcuts import render from .models import FollowRelation #フォロー一覧画面 @login_required def users_followlist(request, pk): user = get_object_or_404(User, pk=pk) #フォローしているユーザー follower =[to_relation.to_user for to_relation in FollowRelation.objects.filter(from_user=user)] #フォローされているユーザー followee =[from_relation.from_user for from_relation in FollowRelation.objects.filter(to_user=user)] context = { 'user': user, 'follower': follower, 'followee': followee, } return render(request, 'app/users_followlist.html', context)followerとfolloweeをtemplatesに渡すため、FollowRelationにフィルターをかけて取り出したクエリセットのto_userおよびfrom_userをリスト化しています。
ここで注意しないといけないのは、followerはuserがfrom_userのデータのto_user、followeeはuserがto_userのデータのfrom_userであることです。中間テーブルを利用しているので、ここは逆にならないように気をつける必要があります。
②AbstractBaseUserモデルを継承したUserモデル使用時
app>views.pyfrom django.contrib.auth import get_user_model from django.contrib.auth.decorators import login_required from django.shortcuts import get_object_or_404 #フォロー一覧画面 @login_required def users_followlist(request, pk): user = get_object_or_404(get_user_model(), pk=pk) #フォローしているユーザー followers = user.followers.all() #フォローされているユーザー followees = get_user_model().objects.filter(followers=user) context = { 'user': user, 'followers': followers, 'followees': followees, } return render(request, 'app/users_followlist.html', context)User自身がフォロワーフィールドを持っているため、①と比較して処理はとても単純です。フォロワーとフォロイーの違いさえ気を付けたら、簡単に実装することができます。
おわりに
フォロー機能程度ならデフォルトのUserモデルでも実装することはできましたが、それでもカスタムしたUserモデルと比較するとクエリ処理が複雑になります。Userモデルのカスタマイズは一見複雑に見えますが、便利な機能を実装しやすいので、基本的にはこちらを使用するようにした方が良いかと思います。
参考にしたサイト
ManyToManyFieldの学習は以下サイトを参考にさせていただきました。
ManyToMany フィルターなどのオブジェクト操作一覧
- 投稿日:2020-02-11T18:41:26+09:00
【dlib】AttributeError: module 'dlib' has no attribute ... とエラーがでたら
エラー概要
先日、dlibを使って顔特徴点を検出しようとしたらこんなエラーに遭遇しました
Traceback (most recent call last): File "dlib.py", line 33, in <module> detector = dlib.get_frontal_face_detector() AttributeError: module 'dlib' has no attribute 'get_frontal_face_detector'dlibをimportはできているのできちんと環境構築はできているようでしたが、実際dlibを使おうとするとなるとAttributeErrorが吐かれていました。
解決方法
いろいろ調べてみるとこちらのstackoverflowに解決方法が書かれていました。
Rename your file from dlib.py to something else, say dlib_project.py.
どうやらファイル名が
dlib.pyとなっていることが問題だったようです。
試しにgetFacialLandmarks.pyとファイル名を変更したら無事に動きました。
ライブラリ名と同じファイル名はつけないほうがいいみたいですね…
- 投稿日:2020-02-11T18:40:53+09:00
OpenPoseを使って、かめはめ波を撃ってみた
はじめに
かめはめ波を撃ちたくなったので作ってみました。
推定の線は非表示にすることもできます。
OpenPoseを用いて関節の座標を取得、そこから角度を算出して、そのポーズがそれっぽいかを判定しています。
OpenPoseについて
セットアップ方法
OpenPoseのTensorflow版であるtf pose estimationを使用しました。
私の環境はWindows10、GTX1070といったものだったので、セットアップに関しては下記のページを参考にしました。
Windowsで姿勢推定(tf pose estimation)はまったので注意書き
・長い、深いパスは避けた方が無難です。(swigが正しく動かないことがあるようです。)実行方法
下記コマンドで、自前のWebカメラを使って動作させることができます。
python run_webcam.pyEscで終了します。
関節の座標取得
各関節には下記のような番号が割り振られています。
例えば、右肩(2)を取得したい場合はこうなります。
複数人の取得もありうるため、humansをforで回しています。humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio) height,width = image.shape[0],image.shape[1] for human in humans: body_part = human.body_parts[2] x = int(body_part.x * width + 0.5) y = int(body_part.y * height + 0.5) debug_info = 'x:' + str(x) + ' y:' + str(y)実際のコード
実際のコードです。
kamehameha.pyとして保存し、run_webcam.py と同じフォルダに保存してください。import argparse import logging import time from pprint import pprint import cv2 import numpy as np import sys from tf_pose.estimator import TfPoseEstimator from tf_pose.networks import get_graph_path, model_wh import math logger = logging.getLogger('TfPoseEstimator-WebCam') logger.setLevel(logging.DEBUG) ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s') ch.setFormatter(formatter) logger.addHandler(ch) fps_time = 0 def find_point(pose, p): for point in pose: try: body_part = point.body_parts[p] return (int(body_part.x * width + 0.5), int(body_part.y * height + 0.5)) except: return (0,0) return (0,0) def euclidian( point1, point2): return math.sqrt((point1[0]-point2[0])**2 + (point1[1]-point2[1])**2 ) def angle_calc(p0, p1, p2 ): ''' p1 is center point from where we measured angle between p0 and ''' try: a = (p1[0]-p0[0])**2 + (p1[1]-p0[1])**2 b = (p1[0]-p2[0])**2 + (p1[1]-p2[1])**2 c = (p2[0]-p0[0])**2 + (p2[1]-p0[1])**2 angle = math.acos( (a+b-c) / math.sqrt(4*a*b) ) * 180/math.pi except: return 0 return int(angle) def accumulate_pose( a, b, c, d): ''' a and b are angle between neck, left shoulder and left wrist c and d are angle between neck, right shoulder and right wrist ''' if a in range(70,105) and b in range(100,140) and c in range(70,110) and d in range(120,180): return True return False def release_pose( a, b, c, d): ''' a and b are angle between neck, left shoulder and left wrist c and d are angle between neck, right shoulder and right wrist ''' if a in range(140,200) and b in range(80,150) and c in range(0,40) and d in range(160,200): return True return False def draw_str(dst, xxx_todo_changeme, s, color, scale): (x, y) = xxx_todo_changeme if (color[0]+color[1]+color[2]==255*3): cv2.putText(dst, s, (x+1, y+1), cv2.FONT_HERSHEY_PLAIN, scale, (0, 0, 0), thickness = 4, lineType=10) else: cv2.putText(dst, s, (x+1, y+1), cv2.FONT_HERSHEY_PLAIN, scale, color, thickness = 4, lineType=10) #cv2.line cv2.putText(dst, s, (x, y), cv2.FONT_HERSHEY_PLAIN, scale, (255, 255, 255), lineType=11) if __name__ == '__main__': parser = argparse.ArgumentParser(description='tf-pose-estimation realtime webcam') parser.add_argument('--camera', type=str, default=0) parser.add_argument('--resize', type=str, default='432x368', help='if provided, resize images before they are processed. default=432x368, Recommends : 432x368 or 656x368 or 1312x736 ') parser.add_argument('--resize-out-ratio', type=float, default=4.0, help='if provided, resize heatmaps before they are post-processed. default=1.0') parser.add_argument('--model', type=str, default='cmu', help='cmu / mobilenet_thin') parser.add_argument('--show-process', type=bool, default=False, help='for debug purpose, if enabled, speed for inference is dropped.') args = parser.parse_args() print("mode 0: Normal Mode \nmode 1: Debug Mode") mode = int(input("Enter a mode : ")) logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model))) w, h = model_wh(args.resize) if w > 0 and h > 0: e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h)) else: e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368)) logger.debug('cam read+') cam = cv2.VideoCapture(args.camera) ret_val, image = cam.read() logger.info('cam image=%dx%d' % (image.shape[1], image.shape[0])) count = 0 i = 0 frm = 0 y1 = [0,0] global height,width orange_color = (0,140,255) while True: ret_val, image = cam.read() i =1 humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio) pose = humans if mode == 1: image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False) height,width = image.shape[0],image.shape[1] debug_info = '' if len(pose) > 0: # angle calcucations angle_l1 = angle_calc(find_point(pose, 6), find_point(pose, 5), find_point(pose, 1)) angle_l2 = angle_calc(find_point(pose, 7), find_point(pose, 6), find_point(pose, 5)) angle_r1 = angle_calc(find_point(pose, 3), find_point(pose, 2), find_point(pose, 1)) angle_r2 = angle_calc(find_point(pose, 4), find_point(pose, 3), find_point(pose, 2)) debug_info = str(angle_l1) + ',' + str(angle_l2) + ' : ' + str(angle_r1) + ',' + str(angle_r2) if accumulate_pose(angle_l1, angle_l2, angle_r1, angle_r2): logger.debug("*** accumulate Pose ***") # (1) create a copy of the original: overlay = image.copy() # (2) draw shapes: cv2.circle(overlay, (find_point(pose, 4)[0] - 40, find_point(pose, 4)[1] + 40), 40, (255, 241, 0), -1) # (3) blend with the original: opacity = 0.4 cv2.addWeighted(overlay, opacity, image, 1 - opacity, 0, image) elif release_pose(angle_l1, angle_l2, angle_r1, angle_r2): logger.debug("*** release Pose ***") # (1) create a copy of the original: overlay = image.copy() # (2) draw shapes: cv2.circle(overlay, (find_point(pose, 7)[0] + 80 ,find_point(pose, 7)[1] - 40), 80, (255, 241, 0), -1) cv2.rectangle(overlay, (find_point(pose, 7)[0] + 80, find_point(pose, 7)[1] - 70), (image.shape[1], find_point(pose, 7)[1] - 10), (255, 241, 0), -1) # (3) blend with the original: opacity = 0.4 cv2.addWeighted(overlay, opacity, image, 1 - opacity, 0, image) image= cv2.flip(image, 1) if mode == 1: draw_str(image, (20, 50), debug_info, orange_color, 2) cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) #image = cv2.resize(image, (720,720)) if(frm==0): out = cv2.VideoWriter('outpy.avi',cv2.VideoWriter_fourcc('M','J','P','G'), 30, (image.shape[1],image.shape[0])) print("Initializing") frm+=1 cv2.imshow('tf-pose-estimation result', image) if i != 0: out.write(image) fps_time = time.time() if cv2.waitKey(1) == 27: break cv2.destroyAllWindows()実行・終了のさせ方
下記コマンドで実行させます。
python kamehameha.pyメニューがでてきます。「Debug Mode」を指定すると、推定の線や角度情報が表示されます。
初期処理が終わると、かめはめ波が撃てるようになります。
Escで終了します。注意事項
- 姿勢検知はおおざっぱなものです。カメラの位置・カメラに対してどう体を向けているかなどの条件によって正しく検知できないことがあります。
- 画面右から左に向けてしか放てません。
- OpenPoseの仕様の部分となりますが、背景と人物のコントラストがあった方が検知がよさそうです。(Debug Modeを併用して確認してください。)
姿勢検知の条件
「Debug Mode」の画面左上には、右肩、右ひじ、左肩、左ひじの角度が並んでいます。
それぞれの角度が条件に当てはまっている場合、その姿勢をしていると判断します。
「かめはめ」 「波~」 右肩 70 ~ 105 140 ~ 200 右ひじ 100 ~ 140 80 ~ 150 左肩 70 ~ 110 0 ~ 40 左ひじ 120 ~ 180 160 ~ 200 うまく反応しないようなときは、コードのaccumulate_pose関数、release_pose関数の判定の数値をいじっていただければと思います。
終わりに
OpenPoseを使ってなにかしたいと考えていたため、今回それができてよかったです。
筋トレが正しい姿勢で行えているかといったパーソナルトレーナー的役割とか、子供が喜ぶギミックめいたものなんかが作れそうですね。参考サイト




- 投稿日:2020-02-11T18:19:23+09:00
[備忘録]初めてのPython 開発環境を用意する
診療放射線技師、医学物理士をやっている者です。
プログラミングを学習していく過程を備忘録として記事に残していきます。
今後誰かの参考になれば幸いです。スキルとして漠然とプログラミングを始めたくて、最初に手をつけたのがProgateでした。
ホリエモンがオススメしていた影響です。
いろんな言語のチュートリアルを一通りクリアして、Pythonをメインに勉強することにしました。
Web、アプリ、データ分析など汎用的に使えそうで、人口も多そうだったのと、
仕事柄機械学習が研究テーマとしてホットだったことが決め手です。今回は、実際に自分のPCでPythonを動かしたはじめの一歩についてです。
全ては環境構築から
PCを用意
Pythonを扱っていくにあたり、まずは自分のPC上でPythonを動かす環境を用意する必要があります。
(※私はMacユーザーです。)<必要なもの>
・PC高いPCは(とりあえずは)必要ないようです。
PC一つでプログラミングを始められるのは、敷居が低くてありがたいです。Anacondaをインストール
手元にPCを用意できれば、次にPythonをインストールします。
と言っても、実はMacにはPythonが標準搭載されている、らしい。
インストールしなくても使えないことはないのですが、バージョンが古いもののようなので、最新のバージョンをインストールしたいところです。(やりたい処理によってはバージョン2.7(2系)の方が適切である場合もあります。初心者はとりあえずバージョン3.7(3系)をインストールしてしまって問題ないと考えています。)Pythonをインストールする方法がいくつかある中で、私は定番のAnacondaを使いました。
AnacondaにはPython本体の他に、機械学習においてよく使われるライブラリ等もセットで入っており、よく分からない初心者でもとりあえずこれさえあれば始められます。「Python欲張りセット」と言ったところでしょうか。
以下のURLから無料で簡単にAnacondaをダウンロードできます。
https://www.anaconda.com/distribution/
手順に従ってAnacondaのインストーラーのダウンロード、
Anacondaのインストールを行います。動作確認
インストールが完了すると、PATHも通り、すぐに使える状態だと思います。
(※Mac OSのバージョンによっては、自分でPATHを追加する必要があります!)Finderからターミナルを起動し、動作確認をしてみます。
ターミナルを起動できたら、以下を打ち込んでEnterを押します(コマンドを実行)。
python --version"Python 3.7.4" と表示されます。
次は、
conda --version"conda 4.7.11"と表示されます。
問題なく動作しています。さらに詳しいAnacondaのインストール方法は、ネット上で優しい方々がたくさん共有してくれています。
またターミナルの使い方も勉強しておくと後々困らないです。初めてのPythonファイルを実行
早速Pythonデビューしてみます。
標準ソフトでも構いませんので、適当なテキストエディタで次のコードを入力し、"hello.py"という名前でデスクトップに保存します。(私は"Atom"というテキストエディタを使っています)
".py"というのがPythonファイルの拡張子です。hello.pyprint("Hello")次にPythonファイルを実行してみます。実行にはターミナルを使用します。
ファイルを実行するには、ターミナル上でそのファイルが存在するディレクトリに移動する必要があります。
今回の場合はデスクトップに保存したので、デスクトップに移動すれば実行できます。
あるフォルダ内にファイルを保存したなら、そのフォルダに移動する必要があります。
ターミナルを起動すると、ホームディレクトリにいる状態からスタートです。
通常、デスクトップはホームディレクトリの直下にあるので、次のコマンドを実行してデスクトップに移動できるはずです。cd desktopデスクトップにある"Test"というフォルダに移動したい場合は
cd desktop/Testで移動できます。
ひとつ前のディレクトリ(親ディレクトリ)に戻りたいときは、cd ..で戻れます。"cd"の後ろのスペースを忘れないように。
正しくディレクトリに移動できたら、実行あるのみです。
次のコマンドを実行します。Python hello.pyターミナル上に"Hello"と表示されれば成功です。
"Python ファイル名"と打ち込んでEnterを押すことでPythonファイルを実行できます。
無事に自分のPCでPythonを動かす環境を構築できました。

- 投稿日:2020-02-11T17:56:54+09:00
【Python】初心者から抜け出すには、二次元配列を自在に操れ。
はじめに
Pythonを学ぶ上で避けては通れない二次元配列の操作(初期化・参照・抽出・計算・転置)をまとめました。
(※numpyモジュールのインストールが必要。macの場合は、terminalからpip3 install numpyでインストール可能。windowsの場合は、こちらを参考に、、WindowsでPython3, numpy, pandas, matplotlibなどインストール)
基本的に以下のようなコードでコードと出力結果を記載します。ex.pycode = 'コード' # 出力結果リストの初期化
例として、2行3列
[[0, 0, 0], [0, 0, 0]]の2次元配列を次の2通りの方法で作成する。1. リスト内包表記を使って二次元配列を作る
ex1.pya = [[0 for j in range(3)] for i in range(2)] print(a) # [[0, 0, 0], [0, 0, 0]] a[0][0] = 1 print(a) # [[1, 0, 0], [0, 0, 0]]2. numpyモジュールを使って二次元配列を作る
ex2.pyimport numpy as np a = np.zeros((2, 3)) print(a) # [[0, 0, 0], # [0, 0, 0]] print(a) a[0][0] = 1 # [[1, 0, 0], # [0, 0, 0]]一次元の配列を二次元に変換
例:0~5までの数字を2行3列の二次元配列に代入する場合
(※-1を使うとその次元のサイズは他の次元から自動的に算出される。)ex.pyimport numpy as np #0~5までの配列を自動生成 a = np.arange(6) print(a) # [0 1 2 3 4 5] #一次元配列aを二次元配列に変換 print(a.reshape(2, 3)) # [[0 1 2] # [3 4 5]] print(a.reshape(-1, 3)) # [[0 1 2] # [3 4 5]] print(a.reshape(2, -1)) # [[0 1 2] # [3 4 5]]範囲を指定してアクセスする
範囲を指定してアクセスする場合は、
X[start:end:step]のように指定する。
このときendは含まれないので注意が必要。(Matlabではendは含まれる。)
startを省略すると最初からになり、endを省略すると最後までになり、stepを省略するとstepが1になる。多次元の場合は、カンマ(,)で区切ってそれぞれを指定する。指定の仕方は一次元の時と同じ。
ex.pyimport numpy as np a = np.arange(12).reshape(3, 4) print(a) # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] #a[行の範囲, 列の範囲] print(a[:3, 1:3]) # [[1 2] # [5 6] # [9, 10] print(a[:, 1]) # [[1] # [5] # [9]]条件を満たすデータを取り出す
ex.pyimport numpy as np a = np.arange(12).reshape(3, 4) print(a) # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] #条件を満たす箇所がTrue,満たさない箇所がFalseとなるnumpy arrayが返される。 print(a > 5) # [[False False False False] # [False False True True] # [ True True True True]] #条件を満たす箇所の値が返される。 print( a[a > 5] ) # [ 6 7 8 9 10 11]各列・各行の最大値を求める
第二引数
axisを指定すると、各軸に沿って最大値となるインデックスが返される。
例えばaxis=0とすると各列ごとの最大値の行番号が返される。各列の最大値そのものはnp.max()でaxis=0とすると得られる。(axis=1とすると行ごとの最大値の列番号が返される。)ex.pyimport numpy as np a = np.array([[20, 50, 30], [60, 40, 10]]) print(a) # [[20 50 30] # [60 40 10]] #axis=1とすると列ごとの最大値の列番号が返される。 print(np.argmax(a, axis=0)) # [1 0 0] #列ごとの最大値 print(np.max(a, axis=0)) # [60 50 30] #同様にaxis=1とすると行ごとの最大値の列番号が返される。 print(np.argmax(a, axis=1)) # [1 0] #行ごとの最大値 print(np.max(a, axis=1)) # [50 60]同様に以下の応用が可能である。
・numpy.sum(): 合計
・numpy.mean(): 平均
・numpy.min(): 最小 /numpy.max(): 最大
・そのほか(numpy.std(): 標準偏差 /numpy.var(): 分散など)二次元配列(行列)の転置
T属性(.T)
T属性で元の二次元配列(行列)の転置行列を取得できる。ex1.pyimport numpy as np import numpy as np a = np.arange(6).reshape(2, 3) print(a) # [[0 1 2] # [3 4 5]] a_T = a.T print(a_T) # [[0 3] # [1 4] # [2 5]]・T属性が返すのは元の配列のビュー(参照)であり、いずれかの要素を変更するともう一方の要素も変更される。
・2つのndarrayが同じメモリのデータを参照している(片方がもう片方のビューである)かどうかはnp.shares_memory()で確認できる。ex2.pyprint(np.shares_memory(a, a_T)) # True a_T[0, 1] = 100 print(a_T) # [[ 0 100] # [ 1 4] # [ 2 5]] print(a) # [[ 0 1 2] # [100 4 5]]別々のデータとして処理したい場合はcopy()でコピーを作成する。
ex3.pya_T_copy = a.T.copy() print(a_T_copy) # [[0 3] # [1 4] # [2 5]] print(np.shares_memory(a, a_T_copy)) # False a_T_copy[0, 1] = 100 print(a_T_copy) # [[ 0 100] # [ 1 4] # [ 2 5]] print(a) # [[0 1 2] # [3 4 5]]最後に
他にも良い解法や知っておくと便利な情報があれば教えてもらえると嬉しいです。
- 投稿日:2020-02-11T17:56:54+09:00
【Python】二次元配列を自在に操れ。初心者から抜け出す一歩。
はじめに
Pythonを学ぶ上で避けては通れない二次元配列の操作(初期化・参照・抽出・計算・転置)をまとめました。
(※numpyモジュールのインストールが必要。macの場合は、terminalからpip3 install numpyでインストール可能。windowsの場合は、こちらを参考に、、WindowsでPython3, numpy, pandas, matplotlibなどインストール)
基本的に以下のようなコードでコードと出力結果を記載します。ex.pycode = 'コード' # 出力結果リストの初期化
例として、2行3列
[[0, 0, 0], [0, 0, 0]]の2次元配列を次の2通りの方法で作成する。1. リスト内包表記を使って二次元配列を作る
ex1.pya = [[0 for j in range(3)] for i in range(2)] print(a) # [[0, 0, 0], [0, 0, 0]] a[0][0] = 1 print(a) # [[1, 0, 0], [0, 0, 0]]2. numpyモジュールを使って二次元配列を作る
ex2.pyimport numpy as np a = np.zeros((2, 3)) print(a) # [[0, 0, 0], # [0, 0, 0]] print(a) a[0][0] = 1 # [[1, 0, 0], # [0, 0, 0]]一次元の配列を二次元に変換
例:0~5までの数字を2行3列の二次元配列に代入する場合
(※-1を使うとその次元のサイズは他の次元から自動的に算出される。)ex.pyimport numpy as np #0~5までの配列を自動生成 a = np.arange(6) print(a) # [0 1 2 3 4 5] #一次元配列aを二次元配列に変換 print(a.reshape(2, 3)) # [[0 1 2] # [3 4 5]] print(a.reshape(-1, 3)) # [[0 1 2] # [3 4 5]] print(a.reshape(2, -1)) # [[0 1 2] # [3 4 5]]範囲を指定してアクセスする
範囲を指定してアクセスする場合は、
X[start:end:step]のように指定する。
このときendは含まれないので注意が必要。(Matlabではendは含まれる。)
startを省略すると最初からになり、endを省略すると最後までになり、stepを省略するとstepが1になる。多次元の場合は、カンマ(,)で区切ってそれぞれを指定する。指定の仕方は一次元の時と同じ。
ex.pyimport numpy as np a = np.arange(12).reshape(3, 4) print(a) # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] #a[行の範囲, 列の範囲] print(a[:3, 1:3]) # [[1 2] # [5 6] # [9, 10] print(a[:, 1]) # [[1] # [5] # [9]]条件を満たすデータを取り出す
ex.pyimport numpy as np a = np.arange(12).reshape(3, 4) print(a) # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] #条件を満たす箇所がTrue,満たさない箇所がFalseとなるnumpy arrayが返される。 print(a > 5) # [[False False False False] # [False False True True] # [ True True True True]] #条件を満たす箇所の値が返される。 print( a[a > 5] ) # [ 6 7 8 9 10 11]各列・各行の最大値を求める
第二引数
axisを指定すると、各軸に沿って最大値となるインデックスが返される。
例えばaxis=0とすると各列ごとの最大値の行番号が返される。各列の最大値そのものはnp.max()でaxis=0とすると得られる。(axis=1とすると行ごとの最大値の列番号が返される。)ex.pyimport numpy as np a = np.array([[20, 50, 30], [60, 40, 10]]) print(a) # [[20 50 30] # [60 40 10]] #axis=1とすると列ごとの最大値の列番号が返される。 print(np.argmax(a, axis=0)) # [1 0 0] #列ごとの最大値 print(np.max(a, axis=0)) # [60 50 30] #同様にaxis=1とすると行ごとの最大値の列番号が返される。 print(np.argmax(a, axis=1)) # [1 0] #行ごとの最大値 print(np.max(a, axis=1)) # [50 60]同様に以下の応用が可能である。
・numpy.sum(): 合計
・numpy.mean(): 平均
・numpy.min(): 最小 /numpy.max(): 最大
・そのほか(numpy.std(): 標準偏差 /numpy.var(): 分散など)二次元配列(行列)の転置
T属性(.T)
T属性で元の二次元配列(行列)の転置行列を取得できる。ex1.pyimport numpy as np import numpy as np a = np.arange(6).reshape(2, 3) print(a) # [[0 1 2] # [3 4 5]] a_T = a.T print(a_T) # [[0 3] # [1 4] # [2 5]]・T属性が返すのは元の配列のビュー(参照)であり、いずれかの要素を変更するともう一方の要素も変更される。
・2つのndarrayが同じメモリのデータを参照している(片方がもう片方のビューである)かどうかはnp.shares_memory()で確認できる。ex2.pyprint(np.shares_memory(a, a_T)) # True a_T[0, 1] = 100 print(a_T) # [[ 0 100] # [ 1 4] # [ 2 5]] print(a) # [[ 0 1 2] # [100 4 5]]別々のデータとして処理したい場合はcopy()でコピーを作成する。
ex3.pya_T_copy = a.T.copy() print(a_T_copy) # [[0 3] # [1 4] # [2 5]] print(np.shares_memory(a, a_T_copy)) # False a_T_copy[0, 1] = 100 print(a_T_copy) # [[ 0 100] # [ 1 4] # [ 2 5]] print(a) # [[0 1 2] # [3 4 5]]最後に
他にも良い解法や知っておくと便利な情報があれば教えてもらえると嬉しいです。
- 投稿日:2020-02-11T17:56:54+09:00
【Python】二次元配列を自在に操れ。【初期化・参照・抽出・計算・転置】
はじめに
Pythonを学ぶ上で避けては通れない二次元配列の操作(初期化・参照・抽出・計算・転置)をまとめました。
(※numpyモジュールのインストールが必要。macの場合は、terminalからpip3 install numpyでインストール可能。windowsの場合は、こちらを参考に、、WindowsでPython3, numpy, pandas, matplotlibなどインストール)
基本的に以下のようなコードでコードと出力結果を記載します。ex.pycode = 'コード' # 出力結果リストの初期化
例として、2行3列
[[0, 0, 0], [0, 0, 0]]の2次元配列を次の2通りの方法で作成する。1. リスト内包表記を使って二次元配列を作る
ex1.pya = [[0 for j in range(3)] for i in range(2)] print(a) # [[0, 0, 0], [0, 0, 0]] a[0][0] = 1 print(a) # [[1, 0, 0], [0, 0, 0]]2. numpyモジュールを使って二次元配列を作る
ex2.pyimport numpy as np a = np.zeros((2, 3)) print(a) # [[0, 0, 0], # [0, 0, 0]] print(a) a[0][0] = 1 # [[1, 0, 0], # [0, 0, 0]]一次元の配列を二次元に変換
例:0~5までの数字を2行3列の二次元配列に代入する場合
(※-1を使うとその次元のサイズは他の次元から自動的に算出される。)ex.pyimport numpy as np #0~5までの配列を自動生成 a = np.arange(6) print(a) # [0 1 2 3 4 5] #一次元配列aを二次元配列に変換 print(a.reshape(2, 3)) # [[0 1 2] # [3 4 5]] print(a.reshape(-1, 3)) # [[0 1 2] # [3 4 5]] print(a.reshape(2, -1)) # [[0 1 2] # [3 4 5]]範囲を指定してアクセスする
範囲を指定してアクセスする場合は、
X[start:end:step]のように指定する。
このときendは含まれないので注意が必要。(Matlabではendは含まれる。)
startを省略すると最初からになり、endを省略すると最後までになり、stepを省略するとstepが1になる。多次元の場合は、カンマ(,)で区切ってそれぞれを指定する。指定の仕方は一次元の時と同じ。
ex.pyimport numpy as np a = np.arange(12).reshape(3, 4) print(a) # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] #a[行の範囲, 列の範囲] print(a[:3, 1:3]) # [[1 2] # [5 6] # [9, 10] print(a[:, 1]) # [[1] # [5] # [9]]条件を満たすデータを取り出す
ex.pyimport numpy as np a = np.arange(12).reshape(3, 4) print(a) # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] #条件を満たす箇所がTrue,満たさない箇所がFalseとなるnumpy arrayが返される。 print(a > 5) # [[False False False False] # [False False True True] # [ True True True True]] #条件を満たす箇所の値が返される。 print( a[a > 5] ) # [ 6 7 8 9 10 11]各列・各行の最大値を求める
第二引数
axisを指定すると、各軸に沿って最大値となるインデックスが返される。
例えばaxis=0とすると各列ごとの最大値の行番号が返される。各列の最大値そのものはnp.max()でaxis=0とすると得られる。(axis=1とすると行ごとの最大値の列番号が返される。)ex.pyimport numpy as np a = np.array([[20, 50, 30], [60, 40, 10]]) print(a) # [[20 50 30] # [60 40 10]] #axis=1とすると列ごとの最大値の列番号が返される。 print(np.argmax(a, axis=0)) # [1 0 0] #列ごとの最大値 print(np.max(a, axis=0)) # [60 50 30] #同様にaxis=1とすると行ごとの最大値の列番号が返される。 print(np.argmax(a, axis=1)) # [1 0] #行ごとの最大値 print(np.max(a, axis=1)) # [50 60]同様に以下の応用が可能である。
・numpy.sum(): 合計
・numpy.mean(): 平均
・numpy.min(): 最小 /numpy.max(): 最大
・そのほか(numpy.std(): 標準偏差 /numpy.var(): 分散など)二次元配列(行列)の転置
T属性(.T)
T属性で元の二次元配列(行列)の転置行列を取得できる。ex1.pyimport numpy as np import numpy as np a = np.arange(6).reshape(2, 3) print(a) # [[0 1 2] # [3 4 5]] a_T = a.T print(a_T) # [[0 3] # [1 4] # [2 5]]・T属性が返すのは元の配列のビュー(参照)であり、いずれかの要素を変更するともう一方の要素も変更される。
・2つのndarrayが同じメモリのデータを参照している(片方がもう片方のビューである)かどうかはnp.shares_memory()で確認できる。ex2.pyprint(np.shares_memory(a, a_T)) # True a_T[0, 1] = 100 print(a_T) # [[ 0 100] # [ 1 4] # [ 2 5]] print(a) # [[ 0 1 2] # [100 4 5]]別々のデータとして処理したい場合はcopy()でコピーを作成する。
ex3.pya_T_copy = a.T.copy() print(a_T_copy) # [[0 3] # [1 4] # [2 5]] print(np.shares_memory(a, a_T_copy)) # False a_T_copy[0, 1] = 100 print(a_T_copy) # [[ 0 100] # [ 1 4] # [ 2 5]] print(a) # [[0 1 2] # [3 4 5]]最後に
他にも良い解法や知っておくと便利な情報があれば教えてもらえると嬉しいです。