- 投稿日:2020-02-11T23:51:07+09:00
IntelliJでJavaをKotlinへ変換する 〜その1〜
はじめに
過去の記事で作ったものをkotlinへ変換してみました。(まだ途中)
この記事では、java(spirng-boot)からkotlinへ変換するステップやちょっとしたテクニックを紹介します。なぜkotlin?
ぼくはjavaが結構好きですし、kotlinに精通しているわけではないです。
そして、javaは不滅だと思っています。不滅と言うと言い過ぎですが、今javaで作られているアプリケーションは多く、javaのスキルを求められるケースも多いです。
そのため、javaエンジニアも多く、今後も使われ続ける言語だと思っています。しかし、より生産性、安全性を高めるために「ラムダ式や関数型プログラミングの機能」や「non null/nullable」を搭載し、よりシンプルにかけるkotlinを学んでみようと思いました。
Source
こちらにコミットしています。
比較の際には、kotlinへ変換したリポジトリの履歴を見てもいいですし、kotlinとjavaのリポジトリを比較してもいいです。
(kotlinへ変換しているだけでロジックに手は入れていないです)kotlin: https://github.com/ken-araki/line_bot_kotlin
java: https://github.com/ken-araki/line_botjava to kotlin
変換機能が優秀なIntelliJを利用する前提で進めます。
変換後に少し手修正をしたので、その修正内容を紹介します。1. build.gradleを直してkotlinプラグインを導入
build.gradleを以下のように直して、kotlinのプラグインを導入します。
(Main classも含まれていますが、あとで少し直しているのでbuild.gradleだけ見てください)https://github.com/ken-araki/line_bot_kotlin/commit/ff8e2d9169633141ef0b0b3466711bb186460c04
2. MainClass(LineApiApplication)をkotlinへ変換
最終形はこんな感じです。
LineApiApplication.kt@SpringBootApplication @EnableScheduling open class LineApiApplication { companion object { @JvmStatic fun main(args: Array<String>) { SpringApplication.run(LineApiApplication::class.java, *args) } } }
companion objectと@JvmStaticでjavaびstaticに該当します。(kotlinは、デフォルトでfinal classとなるため、)
open修飾子をつけて継承可能にしています。
というのも、openをつけないと以下エラーが発生しました。
@Configuration class 'LineApiApplication' may not be final. Remove the final modifier to continue.どうやら、ConfigurationClassがjava(finalではない)で、MainClassがkotlin(finalである)と起きている模様です。
全てkotlinへ変換したら、openを消してあげましょう。3. Lombokを使わないようにする
kotlinを利用しているかぎり、Lombokは不要になります。(kotlinに同じ機能が実装されている)
IntelliJの変換では、Lombokが残ってしまうので、手で直していきましょう。AllArgsConstructorアノテーションはプライマリコンストラクタへ
このプロジェクトでは、基本的に
Constructor Injectionを利用しています。
なので、kotlin変換後に、メンバー変数をプライマリコンストラクタへ移動させてください。QiitaController.kt@RestController @RequestMapping(path = ["/test/qiita"]) @Profile("local") class QiitaController( private val client: QiitaClient, private val qiitaService: QiitaService ) { // 省略...あと、nullableで変換されますが、コンストラクタであればnon-nullにできます。
なので、Filed Injectionを利用していても、このタイミングでConstructor Injectionにしてしまう方がいいと思います。Dataアノテーションはdata classへ
Dataアノテーションを利用しなくても、以下のようにdata classに利用することで同じことができます。
TrainDelay.ktdata class TrainDelay( var name: String? = null, var company: String? = null, var lastupdate_gmt: String? = null, var source: String? = null )privateにすると、getter/setterもprivateになるので除外してください。
valにするとfinalになるので、getterのみ提供されます。Dataアノテーションを利用している場合はvarを設定するのが良いと思います。
(Valueアノテーションなら、valで良いと思います。)Builderを自作する
javaからの見え方を同じにしたい(javaを修正したくない)ので、kotlinに変換してもBuilderを提供する必要があります。
以下のように、data classにbuilerを実装しました。
(Builderアノテーションをつけてもダメです。)BotUserQiita.kt@Entity @Table(name = "bot_user_qiita") data class BotUserQiita( @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id") val id: Int? = null, @Column(name = "user_id") var userId: String? = null, @Column(name = "qiita_user_id") var qiitaUserId: String? = null, @Column(name = "deleted") var deleted: String = "0", @Column(name = "created_date") var createdDate: Date? = null ) { companion object { @JvmStatic fun builder(): BotUserQiitaBuilder = BotUserQiitaBuilder() } class BotUserQiitaBuilder { private var userId: String? = null private var qiitaUserId: String? = null private var deleted: String? = null private var createdDate: Date? = null fun build(): BotUserQiita = BotUserQiita( userId = userId, qiitaUserId = qiitaUserId, deleted = deleted ?: "0", createdDate = createdDate ) fun userId(userId: String) = apply { this.userId = userId } fun qiitaUserId(qiitaUserId: String) = apply { this.qiitaUserId = qiitaUserId } fun deleted(deleted: String) = apply { this.deleted = deleted } fun createdDate(createdDate: Date) = apply { this.createdDate = createdDate } } }staticメソッドで
builder()を提供し、各プロパティ名のメソッドで値を設定するBuilder Classを作成しました。
Builderは関係ないですが、デフォルト引数でオーバーロードができたり、nullだったら別の値を返すエルビス演算子(?:)だったり、applyだったり、kotlinはかなりいい感じにかけますね。ちなみに、javaのBuilderも、kotlinからは見えません。
調べた感じ、delombokをしてあげれば良さげですが、model,entityをすべてkotlinへ変換したので今回は特別対応していません。Functionを使わない
javaだとFunction Interfaceを実装したclassがあり、結構使います。
ただ、いつも覚えられず調べながら実装しています。(僕だけではないはず・・・)kotlinでは、それをいい感じにかけます。
Utils.kt@JvmStatic fun uncheck(runnable: () -> Void) { try { runnable() } catch (e: Exception) { throw RuntimeException(e) } } @JvmStatic fun <T> uncheck(supplier: () -> T): T { try { return supplier() } catch (e: Exception) { throw RuntimeException(e) } } @JvmStatic fun <T, R> uncheck(t: T, function: (T) -> R): R { try { return function(t) } catch (e: Exception) { throw RuntimeException(e) } }どうでしょうか。
runnable: () -> Voidは引数なし、戻り値なしの関数で、
supplier: () -> Tは引数なし、戻り値Tの関数で、
function: (T) -> Rは引数Tの1つで、戻り値Rの関数です。すべて、
変数名()で実行できます。ちなみに、これらはJavaから実行できません。
と言うと少し語弊がありますが、今回の使い方的にNGという意味です。Utils.ktのコメントにも記載していますが、このメソッドの目的はチェックを例外をチェック例外として扱わない仕組みです。
kotlinにはチェック例外の仕組みがない(明示的にアノテーションをつける必要がある)ためチェック例外を明示的に拾っていません。
そのため、javaから見ると「メソッドの引数はチェック例外を起こさないのに、渡す引数はチェック例外を出す可能性がある」ため、コンパイルエラーが起きてしまいます。なので、今回は↑の実装を新規作成しkotlinからは新しいほうを利用し、javaからは元々のメソッドを参照するようにしました。
(ジェネリクスを指定することで明示的に呼び出す必要があります。)おわりに
どうでしょうか。
まだ、ロジック部分を直していないですが、個人的にはkotlinにするといい感じにかけそうな感じがしています。次は、残りのモジュールたちをkotlinへ変換するのと、もっといい感じにかける方法を模索しようと思っています。
もっと、いい感じの書き方あるよ!というのがあれば、是非教えてください。
- 投稿日:2020-02-11T23:15:15+09:00
ColdFusionにCA証明書をインストールする
ColdFusionで接続先のWebサーバーやメールサーバー、LDAPサーバー(OpenLDAP、Active Directoryなど)が利用している証明書がプライベートCAから発行された証明書や自己証明書だと通信できないので、それを解決する方法です。
※この記事はColdFusion 2018をデフォルトの設定でインストールしている場合を前提としています。ColdFusion 2016でもパスを読み替えれば使えると思います。
ぱぱっと知りたい
ColdFusionはJVMで動作しているので、keytoolコマンドを利用してcacertsキーストアに証明書をインポートするJavaの方法がそのまま使えます。付属のJavaランタイム(JRE)にもkeytoolが同梱されています。
- JREは
C:\ColdFusion2018\jreにあります。- cacertsキーストアのパスワードは
changeitがデフォルトです。基本これだけ分かればあとはググればいろいろと出てきますが、私が良く利用しているWindows環境での方法をまとめてみました。
手順
1. 証明書を準備
インポートする証明書ファイルを用意します。
- サーバー自身が自己証明書を使用しているならその証明書ファイル
- サーバーがプライベートCAから発行されている証明書を利用しているなら、CAの証明書ファイル(サーバーの証明書ではない)
ファイル形式はDER(バイナリ形式)、PEM(BASE64形式)、P7B(PKCS #7形式)のどれでも出来るようですが、よく利用されているPEM形式で準備ます。
ファイル名は
example-ca.cerとして保存した例ですすめます。2. バッチ
運用するときやテスト等で毎回手打ちは手間がかかるのでWindowsバッチ化しておきます。
example-ca.cerを保存したフォルダと同じ場所に以下の内容をコピペした
register-cert.batファイルを作ります。register-cert.bat@echo off setlocal set JRE_HOME=C:\ColdFusion2018\jre set CERT_FILE=%~dp0example-ca.cer set CERT_ALIAS=example-ca echo %CERT_FILE% を別名 %CERT_ALIAS% として登録中... "%JRE_HOME%\bin\keytool.exe" -importcert -alias "%CERT_ALIAS%" -file "%CERT_FILE%" -keystore "%JRE_HOME%\lib\security\cacerts" -storepass changeit -noprompt echo. pause不要になった時に削除用のバッチファイルも用意しておきます。
remove-cert.bat@echo off setlocal set JRE_HOME=C:\ColdFusion2018\jre set CERT_ALIAS=example-ca echo 別名 %CERT_ALIAS% を削除中... "%JRE_HOME%\bin\keytool.exe" -delete -alias "%CERT_ALIAS%" -keystore "%JRE_HOME%\lib\security\cacerts" -storepass changeit -noprompt echo. pause
CERT_FILEのexample-ca.cer部分がファイル名なので、適宜変えます。
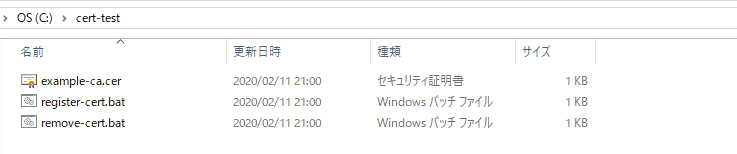
CERT_ALIASの指定が証明書のエイリアス名として登録されます。削除時にこの名前を使います。3. フォルダの内容
こんな感じになっていればOKです。
4. 登録する
register-cert.batをダブルクリックして実行します。実行結果:
C:\cert-test\example-ca.cer を別名 example-ca として登録中... 警告: cacertsキーストアにアクセスするには-cacertsオプションを使用してください 証明書がキーストアに追加されました 続行するには何かキーを押してください . . .「証明書がキーストアに追加されました」と表示されれば登録成功です。
ちなみに既に登録済みだと以下のように失敗します。
C:\cert-test\example-ca.cer を登録中... 警告: cacertsキーストアにアクセスするには-cacertsオプションを使用してください keytoolエラー: java.lang.Exception: 証明書はインポートされませんでした。別名<example-ca>はすでに存在します 続行するには何かキーを押してください . . .5. 削除する
remove-cert.batをダブルクリックして実行します。実行結果:
別名 example-ca を削除中... 警告: cacertsキーストアにアクセスするには-cacertsオプションを使用してください 続行するには何かキーを押してください . . .成功メッセージは出ないようです。未登録だと以下のように失敗します。
別名 example-ca を削除中... 警告: cacertsキーストアにアクセスするには-cacertsオプションを使用してください keytoolエラー: java.lang.Exception: 別名<example-ca>は存在しません 続行するには何かキーを押してください . . .補足
ColdFusion 2018のインストール時期によってJVMが「Java 8ベース」と「Java 11ベース」の2パターンあるようです。
今回の環境ではJava 11で、keytoolで
-cacertsオプションを使うよう警告がでていますが、追加・削除自体はできました。
-cacertsオプションは-keystoreと排他となっていてcacertsファイルまでのパスを指定しなくても良くなったみたいです。ただ、Java 8ではこのオプションが無いので、複数の環境でバッチを流用させるなら記載したようにkeystoreでパス指定した方が現状では良いように思います。Java 11で警告出さないようにするには
各バッチファイルの
-keystore "%JRE_HOME%\lib\security\cacerts"の部分を-cacertsに書き換えるだけでOKでした。参考文献
- 投稿日:2020-02-11T22:26:40+09:00
[Java] TreeMap successor method and entrySet complexity
Succcessor Method
As we know
TreeMapis implemented by Binary Search Tree. So I am very curious about theentrySetorsubMapmethod implementation and complexity.It turns out java do it very straight forward. For entrySet, it start from the first node and by finding successor to move to next node.
It has a successor method to find next node by the following steps.
- if current node is null, then no next, return null
- if current node has right child
- find the most left one of right child as next node
- if current node does not have right child, check current node is left or right child
- if it is left child, the parent is next code
- if it is right child, then go back to parent
/** * Returns the successor of the specified Entry, or null if no such. */ static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { if (t == null) return null; else if (t.right != null) { Entry<K,V> p = t.right; while (p.left != null) p = p.left; return p; } else { Entry<K,V> p = t.parent; Entry<K,V> ch = t; while (p != null && ch == p.right) { ch = p; p = p.parent; } return p; } }Complexity
About the complexity, here has a good explain.
Assume we go through a balanced BST. We can separate it as two parts.
- The leaf nodes
- All other nodes
The average steps is 2 according to the explain here. so the average complexity of successor is
O(1)and the complexity of going through all elements with entrySet isO(n).
- 投稿日:2020-02-11T16:32:37+09:00
で、結局パスパラメータ、クエリパラメータ、リクエストボディってどう違ってどう作るのが正しいの?
事の発端
基本フロントのお仕事をしているのですが、RESTfulAPIの設計をしてね、と言われてRESTfulAPIについて色々調べることがありました。
パスパラメータ、クエリパラメータ、リクエストボディの使い分けについてヘ〜〜〜と思ったので、その結果を備忘として残したいと思います。
(かなり基礎的な情報なので、初心者向けです。)この記事で書くこと
- パスパラメータ、クエリパラメータ、リクエストボディってHTTPリクエストで言うどれのこと?
- パスパラメータ、クエリパラメータ、リクエストボディにはどういう情報を持たせればいいの?
この記事で書かないこと(この記事を読む上での前提知識)
- HTTPリクエストとは何か? これを読めば大体OKです。→ 「HTTPリクエスト」と「HTTPレスポンス」 / ITSakuraさん
- RESTful APIとは何か? これを読めば大体OKです。→ RESTful APIとは何なのか / @NagaokaKenichi さん
ここでいう大体OKとは、この記事を読むにあたって大体OKという意味であり、
アーキテクチャ理解を指しているわけではないので悪しからず。パスパラメータ、クエリパラメータ、リクエストボディってどれのこと?
まずパスパラメータ、クエリパラメータ、リクエストボディとは何かについて書いていきます。
パスパラメータ(Pathparameter),クエリパラメータ(queryparameter)
URIで送るものがパスパラメータとクエリパラメータです。
https://example.com/pathparameter/{pathparameter}?queryparameter1=hogehoge&queryparameter2=fugafuga例を見て貰えばわかるのですが、
URIでドメインの後、?の前に来るものがパスパラメータです。
そして、?の後に来るのがクエリパラメータです。リクエストボディ(requestBody)
URIではなく、JSONで送るものです。
{ hoge_name: fugafuga, description: hogefugahoge, }例えば、こんな感じになります。
パスパラメータ、クエリパラメータ、リクエストボディにはどういう情報を持たせればいいの?
パスパラメータ
まず、パスパラメータなのですが、ここには 特定のリソースを識別するために必要な情報 を入れます。
例えば↓のようなuserを束ねるgroupというテーブルがあり、そこから特定のグループ(グループ1)に紐づくユーザーを取得したいとします。
groups_table
group_id group_name description 1 hoge hogeのグループです。 2 piyo piyoのグループです。 users_table
user_id user_name gruop_id description 1 hoge 1 hogeのグループに属しています。 2 fuga 1 hogeのグループに属しています。 3 piyo 1 hogeのグループに属しています。 4 inu 1 hogeのグループに属しています。 5 neko 2 piyoのグループに属しています。 この場合、groupId=1 は 特定のリソース識別するために必要な情報 なので設計と実際に叩くAPIは以下のようになります。
設計https://example.com/groups/{group_id}実際に叩くAPIhttps://example.com/groups/1(エンドポイントのgroupsについては好みです。)
クエリパラメータ
次に、クエリパラメータなのですが、ここには 特定のリソースを操作して取得する際に必要な情報 を入れます。
先ほどのテーブルから、特定のグループ(グループ1)に紐づくユーザーを3件、user_idの降順で取得したいとします。
この場合、3件 と user_idの降順 という条件は 特定のリソースを操作して取得する際に必要な情報 なので設計と実際に叩くAPIは以下のようになります。
設計https://example.com/groups/{group_id}?sort=boolean&limit=number実際に叩くAPIhttps://example.com/groups/1?sort=false&limit=3(sortは昇順がfalse,降順がtrueという設定です。)
その他では、 検索、フィルタ などに関する条件がクエリパラメータとして扱われるようです。リクエストボディ
最後に、リクエストボディなのですが、ここには 追加、更新する際の内容 を入れます。
先ほどのテーブルから、特定のグループ(グループ1)を更新したいとします。
この場合、更新する内容 という条件はまんま 追加、更新する際の内容 なので設計と実際に叩くAPIは以下のようになります。
設計(URI)https://example.com/groups/{group_id}設計(JSON){ group_name: "string", group_description: "string" }実際に叩くAPIhttps://example.com/groups/1リクエストするJSON{ group_name: "hogehogehoge", group_description: "hogehogehogeのグループです" }まとめ
- パスパラメータ
- URIでドメインの後、?の前に来るやつ
- 特定のリソースを識別するために必要な情報
- クエリパラメータ
- URIで?の後に来るやつ
- 特定のリソース操作して取得する際に必要な情報
- リクエストボディ
- URIではなく、JSONで送るやつ
- 追加、更新する際の内容
こんな感じで心がけるとわかりやすい設計ができるかもしれません。
オラーリージャパンのWebAPI theGoodPartsを読み中なので読破したらまた付け加えるかもしれません。読んでくださってありがとうございました。
認識違いなどありましたら教えてくださると嬉しいです!
- 投稿日:2020-02-11T16:32:37+09:00
で、結局APIのパスパラメータ、クエリパラメータ、リクエストボディってどう違ってどう設計するが正しいの?
事の発端
基本フロントのお仕事をしているのですが、RESTfulAPIの設計をしてね、と言われてRESTfulAPIについて色々調べることがありました。
パスパラメータ、クエリパラメータ、リクエストボディの使い分けについてヘ〜〜〜と思ったので、その結果を備忘として残したいと思います。
(かなり基礎的な情報なので、初心者向けです。)この記事で書くこと
- パスパラメータ、クエリパラメータ、リクエストボディってHTTPリクエストで言うどれのこと?
- パスパラメータ、クエリパラメータ、リクエストボディにはどういう情報を持たせればいいの?
この記事で書かないこと(この記事を読む上での前提知識)
- HTTPリクエストとは何か? これを読めば大体OKです。→ 「HTTPリクエスト」と「HTTPレスポンス」 / ITSakuraさん
- RESTful APIとは何か? これを読めば大体OKです。→ RESTful APIとは何なのか / @NagaokaKenichi さん
ここでいう大体OKとは、この記事を読むにあたって大体OKという意味であり、
アーキテクチャ理解を指しているわけではないので悪しからず。パスパラメータ、クエリパラメータ、リクエストボディってどれのこと?
まずパスパラメータ、クエリパラメータ、リクエストボディとは何かについて書いていきます。
パスパラメータ(Pathparameter),クエリパラメータ(queryparameter)
URIで送るものがパスパラメータとクエリパラメータです。
https://example.com/pathparameter/{pathparameter}?queryparameter1=hogehoge&queryparameter2=fugafuga例を見て貰えばわかるのですが、
URIでドメインの後、?の前に来るものがパスパラメータです。
そして、?の後に来るのがクエリパラメータです。リクエストボディ(requestBody)
URIではなく、JSONで送るものです。
{ hoge_name: fugafuga, description: hogefugahoge, }例えば、こんな感じになります。
パスパラメータ、クエリパラメータ、リクエストボディにはどういう情報を持たせればいいの?
パスパラメータ
まず、パスパラメータなのですが、ここには 特定のリソースを識別するために必要な情報 を入れます。
例えば↓のようなuserを束ねるgroupというテーブルがあり、そこから特定のグループ(グループ1)に紐づくユーザーを取得したいとします。
groups_table
group_id group_name description 1 hoge hogeのグループです。 2 piyo piyoのグループです。 users_table
user_id user_name gruop_id description 1 hoge 1 hogeのグループに属しています。 2 fuga 1 hogeのグループに属しています。 3 piyo 1 hogeのグループに属しています。 4 inu 1 hogeのグループに属しています。 5 neko 2 piyoのグループに属しています。 この場合、groupId=1 は 特定のリソース識別するために必要な情報 なので設計と実際に叩くAPIは以下のようになります。
設計https://example.com/groups/{group_id}実際に叩くAPIhttps://example.com/groups/1(エンドポイントのgroupsについては好みです。)
クエリパラメータ
次に、クエリパラメータなのですが、ここには 特定のリソースを操作して取得する際に必要な情報 を入れます。
先ほどのテーブルから、特定のグループ(グループ1)に紐づくユーザーを3件、user_idの降順で取得したいとします。
この場合、3件 と user_idの降順 という条件は 特定のリソースを操作して取得する際に必要な情報 なので設計と実際に叩くAPIは以下のようになります。
設計https://example.com/groups/{group_id}?sort=boolean&limit=number実際に叩くAPIhttps://example.com/groups/1?sort=false&limit=3(sortは昇順がfalse,降順がtrueという設定です。)
その他では、 検索、フィルタ などに関する条件がクエリパラメータとして扱われるようです。リクエストボディ
最後に、リクエストボディなのですが、ここには 追加、更新する際の内容 を入れます。
先ほどのテーブルから、特定のグループ(グループ1)を更新したいとします。
この場合、更新する内容 という条件はまんま 追加、更新する際の内容 なので設計と実際に叩くAPIは以下のようになります。
設計(URI)https://example.com/groups/{group_id}設計(JSON){ group_name: "string", group_description: "string" }実際に叩くAPIhttps://example.com/groups/1リクエストするJSON{ group_name: "hogehogehoge", group_description: "hogehogehogeのグループです" }まとめ
- パスパラメータ
- URIでドメインの後、?の前に来るやつ
- 特定のリソースを識別するために必要な情報
- クエリパラメータ
- URIで?の後に来るやつ
- 特定のリソース操作して取得する際に必要な情報
- リクエストボディ
- URIではなく、JSONで送るやつ
- 追加、更新する際の内容
こんな感じで心がけるとわかりやすい設計ができるかもしれません。
オライリージャパンのWebAPI theGoodPartsを読み中なので読破したらまた付け加えるかもしれません。読んでくださってありがとうございました。
認識違いなどありましたら教えてくださると嬉しいです!
- 投稿日:2020-02-11T15:19:48+09:00
今月はJava強化月間と決めました
こんにちは、ヨースケです。以前投稿した記事でコメントしてくださった方ありがとうございます。大変勉強になりました!
アプリ開発する上での危機感
その記事でコメントにあったソースコードを見て「このままじゃダメだな」と感じ、もう一度勉強しなおそう!と思いました。こんな書き方があったんだ!という衝撃と自分の勉強不足さがあらわになって今月2月はJavaを隅から隅まで勉強し直そうと決めました。
次に作る予定があるアプリもありますが、いったんはお休みしてJavaを強化したいと思います。
まぁ、うつ病のせいで毎日がっつりはできないんですが少しずつでも進めていきます!
- 投稿日:2020-02-11T12:52:08+09:00
2020年オープンソースWebクローラー10選
Webクローラーとはインターネット上に公開されているテキスト・画像・動画などの情報を自動で収集し、データベースに保管するプログラムのことです。さまざまなウWebクローラーがビッグデータのブームで重要な役割を果たし、人々がデータを簡単にスクレイピングできるようにしています。
さまざまなWebクローラーの中には、オープンソースのWebクローラーフレームワークがたくさんあります。オープンソースのWebクローラーを使用すると、ユーザーはソースコードまたはフレームワークに基づいてプログラミングでき、スクレイピング支援のリソースも提供され、データ抽出が簡単になります。この記事では、おすすめのオープンソースWebクローラーを10選紹介します。
1. Scrapy
言語: Python
Scrapyは、Pythonで最も人気のあるオープンソースのWebクローラーフレームワークでです。Webサイトからデータを効率的に抽出し、必要に応じて処理し、好みの形式(JSON、XML、CSV)で保存するのに役立ちます。ツイスト非同期ネットワークフレームワーク上に構築されており、リクエストを受け入れてより速く処理できます。Scrapyプロジェクトを作って大規模なクローリング・スクレイピングを効率的かつ柔軟に作ることができます。
特徴:
- 高速、強力
- 詳細なドキュメントがある
- コアに触れることなく新しい機能を追加できる
- コミュニティと豊富なリソースがある
- クラウド環境で実行できる2. Heritrix
言語: JAVA
Heritrixは、拡張性が高く、JavaベースのオープンソースWebクローラーの一種で、Webアーカイブ用に設計されます。robot.txt除外ディレクティブとメタロボットタグを非常に尊重し、通常のWebサイトアクティビティを中断させる可能性のない、測定された適応ペースでデータを収集します。オペレータによるクローリングの制御と監視のために、Webブラウザでアクセス可能なWebベースのユーザーインターフェイスを提供します。
特徴:
- 交換可能なプラグ対応のモジュール
- Webベースのインターフェース
- robot.txtおよびメタロボットタグを尊重する
- 優れた拡張性3. Web-Harvest
言語: JAVA
Web-Harvestは、Javaで作られたオープンソースのWebクローラーです。指定されたページからデータを収集できます。そのために、主にXSLT、XQuery、正規表現などの技術と技術を活用して、HTML / XMLベースのWebサイトのコンテンツを操作またはフィルタリングします。抽出機能を強化するために、Javaライブラリをカスタマイズすることで簡単に補完できます。
特徴:
- データ処理および制御フローのための強力なテキストおよびXML操作プロセッサ
- 変数を保存および使用するための変数コンテキスト
- 実際のスクリプト言語をサポートし、Webクローラーに簡単に統合できる4. MechanicalSoup
言語: Python
MechanicalSoupは、Webサイトとのやりとりを自動化するためのPythonライブラリです。MechanicalSoupはPythonの巨人Requests (HTTPセッション用)とBeautifulSoup(ドキュメントナビゲーション用)で構築された同様のAPIを提供します。自動的Cookieを保存して送信し、リダイレクトに従い、リンクをたどり、フォームを送信することができます。データを単にスクレイピングするのではなく、人間の行動をシミュレートしようとする場合、MechanicalSoupは非常に便利です。
特徴:
- 人間の行動をシミュレートする機能
- かなり単純なWebサイトを高速でスクレイピングできる
- CSSおよびXPathセレクターをサポート5. Apify SDK
言語: JavaScript
Apify SDKは、JavaScriptで構築された最高のWebクローラーの1つです。スケーラブルなスクレイピングライブラリにより、ヘッドレスChromeおよびPuppeteerでのデータ抽出およびWeb自動化ジョブの開発が可能になります。RequestQueueやAutoscaledPoolなどの独自の強力なツールを使用すると、複数のURLから開始して、他のページへのリンクを再帰的にたどり、それぞれシステムの最大容量でスクレイピングタスクを実行できます。
特徴:
- 大規模&高性能でスクレイピングできる
- 検出を回避するためのプロキシのプールがある
- CheerioやPuppeteerなどのNode.jsプラグインをサポート6. Apache Nutch
言語: JAVA
Apache NutchはJavaで作られたオープンソースのWebクローラフレームワークです。高度なモジュールアーキテクチャを備えており、開発者はメディアタイプの解析、データ取得、クエリ、クラスタリング用のプラグインを作成できます。プラグ可能なモジュラーであるNutchは、カスタムの実装に拡張可能なインターフェースも提供しています。
特徴:
- 高度な拡張性
- txtルールに従う
- 活気のあるコミュニティと積極的な発展
- プラグ可能な解析、プロトコル、ストレージ、およびインデックス付け7. Jaunt
言語: JAVA
JauntはJAVAに基づき、Webスクレイピング、Web自動化、およびJSONクエリ用に設計されています。Webスクレイピング機能、DOMへのアクセス、および各HTTP要求/応答の制御を提供する高速で超軽量のヘッドレスブラウザーを提供しますが、JavaScriptはサポートしていません。
特徴:
- 個々のHTTPリクエスト/レスポンスを処理する
- REST APIと簡単に接続できる
- HTTP、HTTPS、および基本認証をサポート
- DOMおよびJSONでのRegExクエリ対応8. Node-crawler
言語: JavaScript
Node-crawlerは、Node.jsに基づいた強力で人気のある実稼働Webクローラーです。 Node.jsで完全に記述されており、ノンブロッキングI / Oをサポートしているため、クローラーのパイプライン操作メカニズムに非常に便利です。同時に、DOMの迅速な選択をサポートし(正規表現を書く必要はありません)、クローラー開発の効率を向上させます。
特徴:
- レート制御
- URLリクエストに優先度がある
- 構成可能なプールサイズと再試行
- サーバー側DOMおよびCheerio(デフォルト)またはJSDOMによる自動jQuery挿入9. PySpider
言語: Python
PySpiderは、Python書かれた強力なWebクローラフレームワークです。使いやすいWeb UIと、スケジューラ、フェッチャー、プロセッサなどのコンポーネントを備えた分散アーキテクチャを備え、複数のクロールを簡単に追跡できるようになりました。MongoDBやMySQLなど、データストレージ用のさまざまなデータベースをサポートします。
特徴:
- ユーザーフレンドリーなインターフェイス
- RabbitMQ, Beanstalk, Redis, と Kombu のメッセージキュー
- 分散アーキテクチャ10. StormCrawler
言語: JAVA
StormCrawlerは、Apache Stormを使用して分散Webクローラーを構築するためのオープンソースSDKです。このプロジェクトはApacheライセンスv2の下にあり、ほとんどがJavaで書かれた再利用可能なリソースとコンポーネントのコレクションで構成されています。取得および解析するURLがストリームとして提供される場合の使用に最適ですが、特に低遅延が必要な大規模な再帰クロールにも適したソリューションです。 .
特徴:
- 拡張性が高く、大規模な再帰的クロールに使える
- 追加のライブラリが簡単に拡張できる
- クロールの待ち時間を短縮する優れたスレッド管理まとめ
オープンソースのWebクローラーは非常に強力で拡張可能ですが、開発者に限定されています。Octoparseのようなスクレイピングツールはたくさんあり、コードを書かなくてもデータを簡単に抽出できます。プログラミングに詳しくない場合は、これらのツールがより適切で、スクレイピングが簡単になります。
元記事:https://www.octoparse.jp/blog/10-best-open-source-web-crawler