- 投稿日:2020-02-11T16:52:45+09:00
Unity 宴 別のシーンから「宴」のラベルを呼び出す
はじめに
「宴」とはビジュアルノベルや会話シーンを手軽に作成するためのUnityアセットです。
この記事ではUnityの別シーン上のC#スクリプトから宴のシナリオの中の特定のラベルを呼び出す方法を記述します。具体的にどのようなことに応用できるかというと…
・キャラクターセレクト
・画像によるチャプターセレクト
・購入済みのシナリオのみを選択できるようにする
など応用範囲の広いテクニックです。開発環境
・Windows 10
・Unity 2019.3.0f6
・「宴」3.8.0手順
ここでは最初に上げた「キャラクターセレクト」をイメージした手順を記述します。
1.「宴」のセットアップ(プロジェクトの作成)を行ってください。
ここでは「Main」という名前のプロジェクトの作成を行ったと仮定します。
セットアップ(プロジェクトの作成)方法は「宴」の公式サイトのチュートリアルを参照してください。2.「宴」用シナリオスクリプト(Excelファイル)を用意する
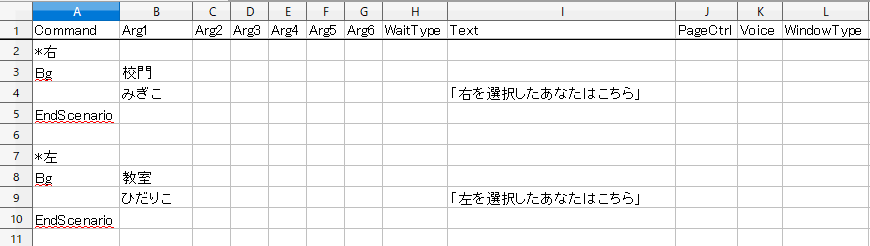
今回は以下のようなテスト用シナリオスクリプトを用意しました。
シナリオスクリプトの詳細な記述方法は「宴」の公式サイトを参照してください。
3.以下の3つのC#スクリプトを用意してください。
C#スクリプトを置く場所はどこでもいいです。ExecuteUtage.csusing System.Collections; using UnityEngine; using UnityEngine.SceneManagement; public class ExecuteUtage : MonoBehaviour { // 他シーンのUtage呼び出し public void Execute(string utageSceneName, string label) { // 実行するラベル名を保存 ExecuteScenario.Label = label; StartCoroutine(ExecuteScenarioCoroutine(utageSceneName)); } // シーン読み込みが完了したか private bool IsSceneLoaded; private void Start() { SceneManager.sceneLoaded += OnSceneLoaded; } // シーン読み込み完了イベント private void OnSceneLoaded(Scene scene, LoadSceneMode mode) { IsSceneLoaded = true; } // シナリオの呼び出しCorotine private IEnumerator ExecuteScenarioCoroutine(string utageSceneName) { IsSceneLoaded = false; SceneManager.LoadScene(utageSceneName); yield return new WaitUntil(() => IsSceneLoaded); } }SelectScenario.csusing System.Collections; using UnityEngine; using Utage; public class SelectScenario : MonoBehaviour { [SerializeField] public AdvEngine Engine; [SerializeField] public UtageUguiTitle Title; [SerializeField] public UtageUguiMainGame MainGame; private void Start() { StartCoroutine(Execute()); } // シナリオを呼び出す private IEnumerator Execute() { // Utage Engine の起動を待つ yield return new WaitUntil(() => !Engine.IsLoading); // 機能呼び出し yield return StartCoroutine(ExecuteLabel()); } // 機能呼び出し private IEnumerator ExecuteLabel() { // 起動ラベルのラベル名を取得 string label = ExecuteScenario.Label; // 機能呼び出し Title.Close(); MainGame.OpenStartLabel(label); yield return null; } }ExecuteScenario.cspublic class ExecuteScenario { // 呼び出すラベル public static string Label; }4.Mainシーンのヒエラルキーの中に「SelectScenario」という名前の空のオブジェクトを作成して「SelectScenario.cs」スクリプトをアタッチします。
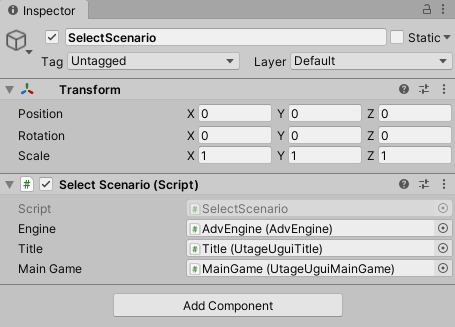
5. 作成した「SelectScenario」コンポーネントのプロパティに以下のオブジェクトを設定します。
プロパティー名 オブジェクト名 オブジェクトの位置 Engine AdvEngine ヒエラルキー直下 Title Title Canvas-AdvUI/Title Main Game MainGame Canvas-AdvUI/MainGame 6.「Main」シーンを保存してください。
7.Unityでキャラクターセレクトを行うシーンを作成してください。
ここでは「Title」という名前のシーンを作ったと仮定します。8.今回はキャラクターセレクトということでキャラクターの画像が載ったButtonUIを設置しました。
このボタンに「ExecuteUtage.cs」スクリプトをアタッチします。
これで「宴」のラベルを呼び出す準備ができました。9.この「ExecuteUtage」コンポーネントの...
public void Execute(string utageSceneName, string label)関数を呼び出せば「宴」シナリオスクリプト内のラベルが呼び出せます。
引数名 設定する値 string utageSceneName 宴のあるシーン名 string label 呼び出すラベル名 10.今回はサンプルとして以下のC#スクリプトを用意しました。
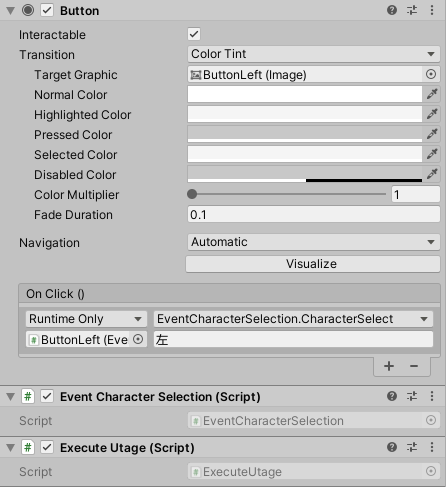
このC#スクリプトを各ボタンにアタッチしてください。EventCharacterSelection.csusing UnityEngine; [RequireComponent(typeof(ExecuteUtage))] public class EventCharacterSelection : MonoBehaviour { private ExecuteUtage ExecuteUtageComponent; private void Start() { ExecuteUtageComponent = gameObject.GetComponent<ExecuteUtage>(); } public void CharacterSelect(string label) { ExecuteUtageComponent.Execute("Main", label); } }11.各ボタンの「On Click ()」を以下の画像のように設定してください。
これでボタンを押すと「宴」のラベルが呼び出されます。
13.以上で完了です。
シーンが変わる際に「メニュー」画面がちらっと見えることがありますが「宴」のシーンの「Canvas-AdvUI/Title」にUIが配置されていますので非表示にするなりローディング画面を出すなり好きにしてください。

- 投稿日:2020-02-11T16:41:12+09:00
週報作成が面倒くさく、文字を指定幅で改行する作業を自動化した
コードだけ手っ取り早く見たい方はここを参照。
https://github.com/anareta/TextWrapper/blob/master/TextWrapper/TextUtility.cs
- インデントと折り返し幅を指定すると文章を折り返してくれる
- wordwrapに対応
- 禁則文字にも対応
- サロゲートペアや結合文字にも対応
- フォントによってはキレイに折り返されずにガタつくかも
- 分かっているだけでも半角カナが含まれると正しく動かない、他にもあるかも
導入部
週報を書くのが面倒くさい
【C#】会社への反骨精神からツールを完成させた話
https://qiita.com/yukibacho/items/0265926f607ccf5489b8このフォーマットではまず書く意味があるのかと疑問を抱きます。
また最初のうちはOJT指導者などが週報を閲覧している形跡がありましたが入社して1年が過ぎたころには誰も閲覧しなくなりました。週報を書きたくないと理由をつけて説明しても「OJT期間はやろう」の一点張りで、要求を受け入れてくれませんでした。
これが会社か。。。
と思いながらもOJT期間中は渋々週報を書くことにしました。あるあるwwwと思いながら読んでました。自分もだいたい同じような状況で、実際の効果はともかくとして、とにかく儀式として毎週「週報」を提出することを求められています。ちなみにわたしのところはOJT期間限定じゃないです。つらみ。
この記事の方の場合は
- 週報を所定のフォーマットでテキストデータで作成
- そのテキストをファイルにしてファイルサーバーに配置
という形で運用されていました。
ところが、自分のところの週報の運用には他にも要件があって、
- テキストをファイルにしてサーバーに配置した上で上司にメールで送信
というのがあります。なんでサーバーに配置した上でメールまで送らないといけないのか理解に苦しみますが。
で、別に週報のテキストをペッと貼り付けて送信するだけなら楽でいいのですが、もうひとつ、
- 週報は適切な位置で改行を入れないと上司が怒る
というのがあります。
…いや文字の折返しなんかお使いのツールでなんとかしろよと思わなくもないですが、過去に改行を入れないテキストデータを提出したところ「このような読みにくい週報を出してくるとは、この無礼者が!」と詰られたのでこれは動かせない要件なのです。わたしのような下っ端無礼者エンジニアは上司(いわゆるゴッド)の言うことには逆らえないのです。長く書きましたが最終的には以下のようなテキストを作る必要があります(中身はダミーテキスト)。
○○様 お疲れ様です。○○部○○課のAzothです。 今週の週報をお収めください。 2020年 1月 17日 【XXXの開発】 ■xxxxをxxxxする ASCIIは、7桁の2進数で表すことのできる整数の数値のそれぞれに、大小のラテン文字 や数字、英文でよく使われる約物などを割り当てた文字コードである。1963年6月17日 に、American Standards Association(ASA、後のANSI)によって制定された。当時 の規格番号は ASA X3.4 、現在の規格番号は ANSI INCITS 4 である。 https://www.jisc.go.jp/app/jis/general/GnrJISNumberNameSearchList?show&jisStdNo=X0201 ■xxxxにxxxのxxxxxをやる ASCIIはISO標準7ビット文字コードISO/IEC 646の元となり、後に8ビット文字コード であるISO/IEC 8859が主流となって以降、世界中で使用されている様々な文字の符号 化方式の多くは、ASCIIで使用されていない128番以降の部分に、その他の文字を割り 当てたものである。 ■xxxxの準備 他の文字コードと同じく、ASCIIは整数で表されるデジタルデータと文字集合とが対応 づけられたコードである。このコードに従い、文字等を整数に変換することで、通信、 文字情報の処理や保存を行うのが容易になる。ASCIIやASCII互換コードは、ほとんど 全てのコンピュータ(特にパーソナルコンピュータやワークステーション)で扱うこと ができる。MIMEでは、「US-ASCII」とするのが望ましい。 以上、よろしくお願いいたします。手作業で週報を作る場合、エディタに週報の中身を書いてから、このテキストの折り返し位置に改行を入れていく作業をひたすらやっていくわけです。ちなみに改行を入れたあとで誤字脱字に気づいて修正すると、周囲の行の折り返しが全部ずれるので改行を入れ直して調整しないといけません。これが地獄か。
さすがにやっていられないので自動化を考えた、というのがこの記事の趣旨になります。
折り返しの要件を整理
折り返しの要件を整理します。
- テキストは、折り返された位置が縦に揃っているように見える位置で折り返される
- テキストの各行の先頭に固定幅のインデント(空白)を入れる必要がある
ちょっと考えてみると最初の要件はそもそも実現不可能であるということがわかります。なぜなら文字(グリフ)の幅はフォントによって違うからです。提出はテキストデータなので、そのデータを開くツールがどんなフォントでそれを表示するかはコントロールできません。
…とはいえ、弊社の上司がエディタやメーラーのフォント設定をデフォルトのMSゴシックから変えているとは思えないので、もう割り切って「ASCII範囲の文字は幅1」「ASCII範囲外の文字は幅2」として考えます。半角カナ? 知らんなあ。ちゃんとやるならMSゴシックのグリフ幅を取得して幅計算すべきですが、まあ大丈夫でしょう多分。
ちなみに弊社にmacOSを使っている上司はいないのでツールのデフォルトフォントはたいていMSゴシックです。そもそも業務にmacOS使わせてもらえないし。ところで実際に折り返しをやってみて気づいたのですが、文章に英単語が入っていたときにその途中で折り返されるのは見栄えがかなり悪いです。英単語以外にもURLとかが含まれる行もあるのでその場合は折り返してほしくない。いわゆるwordwrapと呼ばれるやつです。
もうひとつ、文章に含まれる句読点("。、")が折り返しの結果行頭に来てしまうのも気になります。あと逆に行末に"「"や"("が来てしまうパターンもあります。いわゆる禁則文字への対応も必要になります。
- 半角英数字が連続している部分では折り返さない(いわゆるwordwrap)
- 行頭に"」)、。"などの文字が来ないように折り返す(行頭禁則)
- 行末に"「("などの文字が来ないように折り返す(行末禁則)
指定文字の折り返し
というわけで、頑張って作りました。
TextWrapper
https://github.com/anareta/TextWrapperpublic static class TextUtility { /// <summary> /// テキストを折り返す /// </summary> /// <param name="text">元テキスト</param> /// <param name="indent">テキスト全体に適用するインデント</param> /// <param name="maxWidth">インデントの分を含んだ折り返し幅(ASCII範囲の文字を1、それ以外の文字を2とカウント)</param> public static string Wrap(string text, string indent, int maxWidth) { var result = new StringBuilder(); var lineWidth = maxWidth; if (maxWidth - indent.Width() < maxWidth / 2) { // インデントが長すぎて文章がmaxWidthの半分にも満たない場合は最低限の長さを確保する lineWidth = indent.Width() + maxWidth / 2; } var index = 0; // 改行コードが2文字だと都合が悪いので一時的に置き換え var content = text.Trim(Environment.NewLine.ToCharArray()).Replace(Environment.NewLine, "\r"); while (index < content.Length) { if (result.Length > 0) { result.LineBreak(); } // コンテンツのすべての文字を処理しきるまで行ごとにループ var hasNewLine = false; var line = new StringBuilder(indent); while (true) { // 1文字ずつlineバッファに追加する var currentChar = content.SafeSubstring(index, 1); if (currentChar == "\r") { // 次に追加する文字が改行コードならループを抜ける(折り返す) hasNewLine = true; ++index; // "\r"は追加せずにスキップ break; } // 1文字分だけ追加 line.Append(currentChar); ++index; if (currentChar == "<") { // この記号があったときは終端記号までまとめて追加する var close = content.SafeSubstring(index).IndexOf('>'); if (close != -1) { line.Append(content.SafeSubstring(index, close + 1)); index += close + 1; } } var nextChar = content.SafeSubstring(index, 1); if (nextChar == "\r") { // 次に追加する文字が改行コードならループを抜ける(折り返す) hasNewLine = true; ++index; // "\r"は追加せずにスキップ break; } if ((line.Width() >= lineWidth || index >= content.Length) && CanLineBreak(currentChar, nextChar)) { break; } } if (!hasNewLine) { // 行頭禁則の対応 while (content.SafeSubstring(index, 1).IsStart行頭禁則文字()) { line.Append(content.SafeSubstring(index, 1)); ++index; } // 行末禁則の対応 if (line.ToString().SafeSubstring(line.Length - 1, 1).IsEnd行末禁則文字()) { line = new StringBuilder(line.ToString().SafeSubstring(0, line.Length - 1)); --index; } } if (!string.IsNullOrWhiteSpace(line.ToString())) { result.Append(line); } } return result.ToString(); } /// <summary> /// 前後の文字から折り返しが可能か判定する /// </summary> /// <param name="prevChar">判定したい位置の1つ前の文字</param> /// <param name="nextChar">判定したい位置の1つ後の文字</param> private static bool CanLineBreak(string prevChar, string nextChar) { if (string.IsNullOrWhiteSpace(nextChar)) { // 後続に文字がないか、半角スペースの場合は折り返し可能 return true; } // 最後に追加した文字が1バイト文字 if (prevChar == "\r") { // 改行コード return true; } if (prevChar.Width() == 1) { if (nextChar.Width() == 1) { // 1バイト文字が連続している場合 return false; } // 1バイト文字と2バイト文字の境界 return true; } // 最後に追加した文字がマルチバイト文字 return true; } } internal static class StringEx { /// <summary> /// ASCII範囲の文字を1、ASCII範囲外の文字を2とカウントする /// </summary> internal static int Width(this string s) { if (string.IsNullOrEmpty(s)) { return 0; } var enumerator = StringInfo.GetTextElementEnumerator(s); var enc = Encoding.UTF8; int count = 0; while (enumerator.MoveNext()) { // UTF-8で1バイトならASCII範囲の文字 count += (enc.GetByteCount(enumerator.GetTextElement()) > 1 ? 2 : 1); } return count; } /// <summary> /// ASCII範囲の文字を1、ASCII範囲外の文字を2とカウントする /// </summary> internal static int Width(this StringBuilder s) { return s.ToString().Width(); } /// <summary> ///サロゲートペアや結合文字に対応したLength /// </summary> public static int LengthInTextElements(this string str) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .LengthInTextElements; } /// <summary> ///サロゲートペアや結合文字に対応したElementAt /// </summary> public static string ElementAtInTextElements(this string str, int index) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(index, 1); } /// <summary> ///サロゲートペアや結合文字に対応したSubstring /// </summary> public static string SubstringByTextElements(this string str, int startingTextElement, int lengthInTextElements) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(startingTextElement, lengthInTextElements); } /// <summary> ///サロゲートペアや結合文字に対応したSubstring /// </summary> public static string SubstringByTextElements(this string str, int startingTextElement) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(startingTextElement); } /// <summary> /// 末尾に改行を追加する /// </summary> internal static StringBuilder LineBreak(this StringBuilder s, int times = 1) { for (int i = 0; i < times; i++) { s.Append(Environment.NewLine); } return s; } /// <summary> /// 例外を出さないSubstring(例外を出すケースでは空文字を返す) /// </summary> internal static string SafeSubstring(this string s, int startIndex) { if (startIndex < 0) { startIndex = 0; } if (startIndex > s.LengthInTextElements() - 1) { return ""; } return s.SubstringByTextElements(startIndex); } /// <summary> /// 例外を出さないSubstring(例外を出すケースでは空文字を返す) /// </summary> internal static string SafeSubstring(this string s, int startIndex, int length) { if (startIndex < 0) { startIndex = 0; } if (length < 1) { return ""; } if (startIndex > s.LengthInTextElements() - 1) { return ""; } if (startIndex + length > s.LengthInTextElements()) { return s; } return s.SubstringByTextElements(startIndex, length); } /// <summary> /// 文字列が行頭禁則文字から始まっていればtrue /// </summary> internal static bool IsStart行頭禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行頭禁則.Any(forbidden => s.ElementAtInTextElements(0) == new string(forbidden, 1)); } /// <summary> /// 文字列が行末禁則文字で終わっていればtrue /// </summary> internal static bool IsEnd行末禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行末禁則.Any(forbidden => s.ElementAtInTextElements(s.LengthInTextElements() - 1) == new string(forbidden, 1)); } private static readonly string 行頭禁則 = "。.?!‼⁇⁈⁉,))]}、〕〉》」』】〙〗〟’”⦆»ゝゞ\"ーァィゥェォッャュョヮヵヶぁぃぅぇぉっゃゅょゎゕゖㇰㇱㇲㇳㇴㇵㇶㇷㇸㇹㇷ゚ㇺㇻㇼㇽㇾㇿ々〻"; private static readonly string 行末禁則 = "(([{〔〈《「『【〘〖〝‘“⦅«\""; }長い。構造化されてなくてごめん。
解説
基本的な処理としては与えられたテキストを折り返しまでの幅だけとってきてStringBuilderに追加していきます。
文字列の操作
文字列を操作する機能はstringクラスに備わっていますが、サロゲートペア等の複数のUTF-16文字で構成される文字に対しては無力です。
英語圏の文字しか使わないのであればあまり考慮する必要はないと思いますが、日本語の文章だとたまにそういう文字が含まれる場合があって考慮しておくほうがいいです。これで絵文字も使える。
/// <summary> ///サロゲートペアや結合文字に対応したSubstring /// </summary> public static string SubstringByTextElements(this string str, int startingTextElement) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(startingTextElement); }文字の幅
文字の幅は以下で計算しています。
/// <summary> /// ASCII範囲の文字を1、ASCII範囲外の文字を2とカウントする /// </summary> internal static int Width(this string s) { if (string.IsNullOrEmpty(s)) { return 0; } var enumerator = StringInfo.GetTextElementEnumerator(s); var enc = Encoding.UTF8; int count = 0; while (enumerator.MoveNext()) { // UTF-8で1バイトならASCII範囲の文字 count += (enc.GetByteCount(enumerator.GetTextElement()) > 1 ? 2 : 1); } return count; }中身は、ASCII範囲だったら1、ASCII範囲外だったら2として、文字列の合計幅数を計算します。
文字コードの判別ロジックってけっこう難しかったので、諦めて「UTF-8にして何バイトの領域か」を取得して判定しています。厳密じゃないです。これ書いてるときに「そういえば半角カナってどうなるんだ?」って気づきました。半角カナはUTF-8だと3バイト。
前述しましたが真面目にやるならMSゴシックのグリフ幅を取得して計算するのが確実です。禁則文字
禁則文字の判定はクールな方法が見つからなかったので力技です。
/// <summary> /// 文字列が行頭禁則文字から始まっていればtrue /// </summary> internal static bool IsStart行頭禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行頭禁則.Any(forbidden => s.ElementAtInTextElements(0) == new string(forbidden, 1)); } /// <summary> /// 文字列が行末禁則文字で終わっていればtrue /// </summary> internal static bool IsEnd行末禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行末禁則.Any(forbidden => s.ElementAtInTextElements(s.LengthInTextElements() - 1) == new string(forbidden, 1)); } private static readonly string 行頭禁則 = "。.?!‼⁇⁈⁉,))]}、〕〉》」』】〙〗〟’”⦆»ゝゞ\"ーァィゥェォッャュョヮヵヶぁぃぅぇぉっゃゅょゎゕゖㇰㇱㇲㇳㇴㇵㇶㇷㇸㇹㇷ゚ㇺㇻㇼㇽㇾㇿ々〻"; private static readonly string 行末禁則 = "(([{〔〈《「『【〘〖〝‘“⦅«\"";
IsStart行頭禁則文字というメソッド名がわたしの投げやりな気持ちを表現している…。その他
どういう動きを想定しているかは、プロジェクトに単体テストも含まれてるのでそっちを見てください。
https://github.com/anareta/TextWrapper/blob/master/TextWrapperTest/TextUtilityTest.cs
[TestMethod] public void Wrap_空白位置で改行() { string lineFeed = Environment.NewLine; var url1_1 = @"a aa aaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"; var url1_2 = @"bbbbbbbbbbbbbbbbb"; var url1 = url1_1 + " " + url1_2; var url2 = @"nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn"; var content = url1 + lineFeed + url2; var result = TextUtility.Wrap(content, " ", 30); var lines = result.Split(new[] { lineFeed }, StringSplitOptions.None); Assert.AreEqual(url1_1, lines[0].Trim()); Assert.AreEqual(url1_2, lines[1].Trim()); }英語力がpoorなので単体テストでは日本語を使う派。
終わりに
週報書くのがつらいので、週報書かなくてもいい会社を探しています。
- 投稿日:2020-02-11T16:41:12+09:00
【C#】wordwrapや禁則文字に対応しつつ文字を指定幅で折り返す
コードだけ手っ取り早く見たい方はここを参照。
https://github.com/anareta/TextWrapper/blob/master/TextWrapper/TextUtility.cs
- インデントと折り返し幅を指定すると文章を折り返してくれる
- wordwrapに対応
- 禁則文字にも対応
- サロゲートペアや結合文字にも対応
- フォントによってはキレイに折り返されずにガタつくかも
- 分かっているだけでも半角カナが含まれると正しく動かない、他にもあるかも
導入部
週報を書くのが面倒くさい
【C#】会社への反骨精神からツールを完成させた話
https://qiita.com/yukibacho/items/0265926f607ccf5489b8このフォーマットではまず書く意味があるのかと疑問を抱きます。
また最初のうちはOJT指導者などが週報を閲覧している形跡がありましたが入社して1年が過ぎたころには誰も閲覧しなくなりました。週報を書きたくないと理由をつけて説明しても「OJT期間はやろう」の一点張りで、要求を受け入れてくれませんでした。
これが会社か。。。
と思いながらもOJT期間中は渋々週報を書くことにしました。あるあるwwwと思いながら読んでました。自分もだいたい同じような状況で、実際の効果はともかくとして、とにかく儀式として毎週「週報」を提出することを求められています。ちなみにわたしのところはOJT期間限定じゃないです。つらみ。
この記事の方の場合は
- 週報を所定のフォーマットでテキストデータで作成
- そのテキストをファイルにしてファイルサーバーに配置
という形で運用されていました。
ところが、自分のところの週報の運用には他にも要件があって、
- テキストをファイルにしてサーバーに配置した上で上司にメールで送信
というのがあります。なんでサーバーに配置した上でメールまで送らないといけないのか理解に苦しみますが。
で、別に週報のテキストをペッと貼り付けて送信するだけなら楽でいいのですが、もうひとつ、
- 週報は適切な位置で改行を入れないと上司が怒る
というのがあります。
…いや文字の折返しなんかお使いのツールでなんとかしろよと思わなくもないですが、過去に改行を入れないテキストデータを提出したところ「このような読みにくい週報を出してくるとは、この無礼者が!」と詰られたのでこれは動かせない要件なのです。わたしのような下っ端無礼者エンジニアは上司(いわゆるゴッド)の言うことには逆らえないのです。長く書きましたが最終的には以下のようなテキストを作る必要があります(中身はダミーテキスト)。
○○様 お疲れ様です。○○部○○課のAzothです。 今週の週報をお収めください。 2020年 1月 17日 【XXXの開発】 ■xxxxをxxxxする ASCIIは、7桁の2進数で表すことのできる整数の数値のそれぞれに、大小のラテン文字 や数字、英文でよく使われる約物などを割り当てた文字コードである。1963年6月17日 に、American Standards Association(ASA、後のANSI)によって制定された。当時 の規格番号は ASA X3.4 、現在の規格番号は ANSI INCITS 4 である。 https://www.jisc.go.jp/app/jis/general/GnrJISNumberNameSearchList?show&jisStdNo=X0201 ■xxxxにxxxのxxxxxをやる ASCIIはISO標準7ビット文字コードISO/IEC 646の元となり、後に8ビット文字コード であるISO/IEC 8859が主流となって以降、世界中で使用されている様々な文字の符号 化方式の多くは、ASCIIで使用されていない128番以降の部分に、その他の文字を割り 当てたものである。 ■xxxxの準備 他の文字コードと同じく、ASCIIは整数で表されるデジタルデータと文字集合とが対応 づけられたコードである。このコードに従い、文字等を整数に変換することで、通信、 文字情報の処理や保存を行うのが容易になる。ASCIIやASCII互換コードは、ほとんど 全てのコンピュータ(特にパーソナルコンピュータやワークステーション)で扱うこと ができる。MIMEでは、「US-ASCII」とするのが望ましい。 以上、よろしくお願いいたします。手作業で週報を作る場合、エディタに週報の中身を書いてから、このテキストの折り返し位置に改行を入れていく作業をひたすらやっていくわけです。ちなみに改行を入れたあとで誤字脱字に気づいて修正すると、周囲の行の折り返しが全部ずれるので改行を入れ直して調整しないといけません。これが地獄か。
さすがにやっていられないので自動化を考えた、というのがこの記事の趣旨になります。
折り返しの要件を整理
折り返しの要件を整理します。
- テキストは、折り返された位置が縦に揃っているように見える位置で折り返される
- テキストの各行の先頭に固定幅のインデント(空白)を入れる必要がある
ちょっと考えてみると最初の要件はそもそも実現不可能であるということがわかります。なぜなら文字(グリフ)の幅はフォントによって違うからです。提出はテキストデータなので、そのデータを開くツールがどんなフォントでそれを表示するかはコントロールできません。
…とはいえ、弊社の上司がエディタやメーラーのフォント設定をデフォルトのMSゴシックから変えているとは思えないので、もう割り切って「ASCII範囲の文字は幅1」「ASCII範囲外の文字は幅2」として考えます。半角カナ? 知らんなあ。ちゃんとやるならMSゴシックのグリフ幅を取得して幅計算すべきですが、まあ大丈夫でしょう多分。
ちなみに弊社にmacOSを使っている上司はいないのでツールのデフォルトフォントはたいていMSゴシックです。そもそも業務にmacOS使わせてもらえないし。ところで実際に折り返しをやってみて気づいたのですが、文章に英単語が入っていたときにその途中で折り返されるのは見栄えがかなり悪いです。英単語以外にもURLとかが含まれる行もあるのでその場合は折り返してほしくない。いわゆるwordwrapと呼ばれるやつです。
もうひとつ、文章に含まれる句読点("。、")が折り返しの結果行頭に来てしまうのも気になります。あと逆に行末に"「"や"("が来てしまうパターンもあります。いわゆる禁則文字への対応も必要になります。
- 半角英数字が連続している部分では折り返さない(いわゆるwordwrap)
- 行頭に"」)、。"などの文字が来ないように折り返す(行頭禁則)
- 行末に"「("などの文字が来ないように折り返す(行末禁則)
指定文字の折り返し
というわけで、頑張って作りました。
TextWrapper
https://github.com/anareta/TextWrapperpublic static class TextUtility { /// <summary> /// テキストを折り返す /// </summary> /// <param name="text">元テキスト</param> /// <param name="indent">テキスト全体に適用するインデント</param> /// <param name="maxWidth">インデントの分を含んだ折り返し幅(ASCII範囲の文字を1、それ以外の文字を2とカウント)</param> public static string Wrap(string text, string indent, int maxWidth) { var result = new StringBuilder(); var lineWidth = maxWidth; if (maxWidth - indent.Width() < maxWidth / 2) { // インデントが長すぎて文章がmaxWidthの半分にも満たない場合は最低限の長さを確保する lineWidth = indent.Width() + maxWidth / 2; } var index = 0; // 改行コードが2文字だと都合が悪いので一時的に置き換え var content = text.Trim(Environment.NewLine.ToCharArray()).Replace(Environment.NewLine, "\r"); while (index < content.Length) { if (result.Length > 0) { result.LineBreak(); } // コンテンツのすべての文字を処理しきるまで行ごとにループ var hasNewLine = false; var line = new StringBuilder(indent); while (true) { // 1文字ずつlineバッファに追加する var currentChar = content.SafeSubstring(index, 1); if (currentChar == "\r") { // 次に追加する文字が改行コードならループを抜ける(折り返す) hasNewLine = true; ++index; // "\r"は追加せずにスキップ break; } // 1文字分だけ追加 line.Append(currentChar); ++index; if (currentChar == "<") { // この記号があったときは終端記号までまとめて追加する var close = content.SafeSubstring(index).IndexOf('>'); if (close != -1) { line.Append(content.SafeSubstring(index, close + 1)); index += close + 1; } } var nextChar = content.SafeSubstring(index, 1); if (nextChar == "\r") { // 次に追加する文字が改行コードならループを抜ける(折り返す) hasNewLine = true; ++index; // "\r"は追加せずにスキップ break; } if ((line.Width() >= lineWidth || index >= content.Length) && CanLineBreak(currentChar, nextChar)) { break; } } if (!hasNewLine) { // 行頭禁則の対応 while (content.SafeSubstring(index, 1).IsStart行頭禁則文字()) { line.Append(content.SafeSubstring(index, 1)); ++index; } // 行末禁則の対応 if (line.ToString().SafeSubstring(line.Length - 1, 1).IsEnd行末禁則文字()) { line = new StringBuilder(line.ToString().SafeSubstring(0, line.Length - 1)); --index; } } if (!string.IsNullOrWhiteSpace(line.ToString())) { result.Append(line); } } return result.ToString(); } /// <summary> /// 前後の文字から折り返しが可能か判定する /// </summary> /// <param name="prevChar">判定したい位置の1つ前の文字</param> /// <param name="nextChar">判定したい位置の1つ後の文字</param> private static bool CanLineBreak(string prevChar, string nextChar) { if (string.IsNullOrWhiteSpace(nextChar)) { // 後続に文字がないか、半角スペースの場合は折り返し可能 return true; } // 最後に追加した文字が1バイト文字 if (prevChar == "\r") { // 改行コード return true; } if (prevChar.Width() == 1) { if (nextChar.Width() == 1) { // 1バイト文字が連続している場合 return false; } // 1バイト文字と2バイト文字の境界 return true; } // 最後に追加した文字がマルチバイト文字 return true; } } internal static class StringEx { /// <summary> /// ASCII範囲の文字を1、ASCII範囲外の文字を2とカウントする /// </summary> internal static int Width(this string s) { if (string.IsNullOrEmpty(s)) { return 0; } var enumerator = StringInfo.GetTextElementEnumerator(s); var enc = Encoding.UTF8; int count = 0; while (enumerator.MoveNext()) { // UTF-8で1バイトならASCII範囲の文字 count += (enc.GetByteCount(enumerator.GetTextElement()) > 1 ? 2 : 1); } return count; } /// <summary> /// ASCII範囲の文字を1、ASCII範囲外の文字を2とカウントする /// </summary> internal static int Width(this StringBuilder s) { return s.ToString().Width(); } /// <summary> ///サロゲートペアや結合文字に対応したLength /// </summary> public static int LengthInTextElements(this string str) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .LengthInTextElements; } /// <summary> ///サロゲートペアや結合文字に対応したElementAt /// </summary> public static string ElementAtInTextElements(this string str, int index) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(index, 1); } /// <summary> ///サロゲートペアや結合文字に対応したSubstring /// </summary> public static string SubstringByTextElements(this string str, int startingTextElement, int lengthInTextElements) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(startingTextElement, lengthInTextElements); } /// <summary> ///サロゲートペアや結合文字に対応したSubstring /// </summary> public static string SubstringByTextElements(this string str, int startingTextElement) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(startingTextElement); } /// <summary> /// 末尾に改行を追加する /// </summary> internal static StringBuilder LineBreak(this StringBuilder s, int times = 1) { for (int i = 0; i < times; i++) { s.Append(Environment.NewLine); } return s; } /// <summary> /// 例外を出さないSubstring(例外を出すケースでは空文字を返す) /// </summary> internal static string SafeSubstring(this string s, int startIndex) { if (startIndex < 0) { startIndex = 0; } if (startIndex > s.LengthInTextElements() - 1) { return ""; } return s.SubstringByTextElements(startIndex); } /// <summary> /// 例外を出さないSubstring(例外を出すケースでは空文字を返す) /// </summary> internal static string SafeSubstring(this string s, int startIndex, int length) { if (startIndex < 0) { startIndex = 0; } if (length < 1) { return ""; } if (startIndex > s.LengthInTextElements() - 1) { return ""; } if (startIndex + length > s.LengthInTextElements()) { return s; } return s.SubstringByTextElements(startIndex, length); } /// <summary> /// 文字列が行頭禁則文字から始まっていればtrue /// </summary> internal static bool IsStart行頭禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行頭禁則.Any(forbidden => s.ElementAtInTextElements(0) == new string(forbidden, 1)); } /// <summary> /// 文字列が行末禁則文字で終わっていればtrue /// </summary> internal static bool IsEnd行末禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行末禁則.Any(forbidden => s.ElementAtInTextElements(s.LengthInTextElements() - 1) == new string(forbidden, 1)); } private static readonly string 行頭禁則 = "。.?!‼⁇⁈⁉,))]}、〕〉》」』】〙〗〟’”⦆»ゝゞ\"ーァィゥェォッャュョヮヵヶぁぃぅぇぉっゃゅょゎゕゖㇰㇱㇲㇳㇴㇵㇶㇷㇸㇹㇷ゚ㇺㇻㇼㇽㇾㇿ々〻"; private static readonly string 行末禁則 = "(([{〔〈《「『【〘〖〝‘“⦅«\""; }長い。構造化されてなくてごめん。
解説
基本的な処理としては与えられたテキストを折り返しまでの幅だけとってきてStringBuilderに追加していきます。
文字列の操作
文字列を操作する機能はstringクラスに備わっていますが、サロゲートペア等の複数のUTF-16文字で構成される文字に対しては無力です。
英語圏の文字しか使わないのであればあまり考慮する必要はないと思いますが、日本語の文章だとたまにそういう文字が含まれる場合があって考慮しておくほうがいいです。これで絵文字も使える。
/// <summary> ///サロゲートペアや結合文字に対応したSubstring /// </summary> public static string SubstringByTextElements(this string str, int startingTextElement) { return new StringInfo(string.IsNullOrEmpty(str) ? string.Empty : str) .SubstringByTextElements(startingTextElement); }文字の幅
文字の幅は以下で計算しています。
/// <summary> /// ASCII範囲の文字を1、ASCII範囲外の文字を2とカウントする /// </summary> internal static int Width(this string s) { if (string.IsNullOrEmpty(s)) { return 0; } var enumerator = StringInfo.GetTextElementEnumerator(s); var enc = Encoding.UTF8; int count = 0; while (enumerator.MoveNext()) { // UTF-8で1バイトならASCII範囲の文字 count += (enc.GetByteCount(enumerator.GetTextElement()) > 1 ? 2 : 1); } return count; }中身は、ASCII範囲だったら1、ASCII範囲外だったら2として、文字列の合計幅数を計算します。
文字コードの判別ロジックってけっこう難しかったので、諦めて「UTF-8にして何バイトの領域か」を取得して判定しています。厳密じゃないです。これ書いてるときに「そういえば半角カナってどうなるんだ?」って気づきました。半角カナはUTF-8だと3バイト。
前述しましたが真面目にやるならMSゴシックのグリフ幅を取得して計算するのが確実です。禁則文字
禁則文字の判定はクールな方法が見つからなかったので力技です。
/// <summary> /// 文字列が行頭禁則文字から始まっていればtrue /// </summary> internal static bool IsStart行頭禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行頭禁則.Any(forbidden => s.ElementAtInTextElements(0) == new string(forbidden, 1)); } /// <summary> /// 文字列が行末禁則文字で終わっていればtrue /// </summary> internal static bool IsEnd行末禁則文字(this string s) { if (string.IsNullOrEmpty(s)) { return false; } return 行末禁則.Any(forbidden => s.ElementAtInTextElements(s.LengthInTextElements() - 1) == new string(forbidden, 1)); } private static readonly string 行頭禁則 = "。.?!‼⁇⁈⁉,))]}、〕〉》」』】〙〗〟’”⦆»ゝゞ\"ーァィゥェォッャュョヮヵヶぁぃぅぇぉっゃゅょゎゕゖㇰㇱㇲㇳㇴㇵㇶㇷㇸㇹㇷ゚ㇺㇻㇼㇽㇾㇿ々〻"; private static readonly string 行末禁則 = "(([{〔〈《「『【〘〖〝‘“⦅«\"";
IsStart行頭禁則文字というメソッド名がわたしの投げやりな気持ちを表現している…。その他
どういう動きを想定しているかは、プロジェクトに単体テストも含まれてるのでそっちを見てください。
https://github.com/anareta/TextWrapper/blob/master/TextWrapperTest/TextUtilityTest.cs
[TestMethod] public void Wrap_空白位置で改行() { string lineFeed = Environment.NewLine; var url1_1 = @"a aa aaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"; var url1_2 = @"bbbbbbbbbbbbbbbbb"; var url1 = url1_1 + " " + url1_2; var url2 = @"nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn"; var content = url1 + lineFeed + url2; var result = TextUtility.Wrap(content, " ", 30); var lines = result.Split(new[] { lineFeed }, StringSplitOptions.None); Assert.AreEqual(url1_1, lines[0].Trim()); Assert.AreEqual(url1_2, lines[1].Trim()); }英語力がpoorなので単体テストでは日本語を使う派。
終わりに
週報書くのがつらいので、週報書かなくてもいい会社を探しています。
- 投稿日:2020-02-11T10:17:39+09:00
シールド言語上でのusingとimportの違い
シールド言語上でのusingとimportの違い
using->既にリンクされているもの。
import->リンクされていないもの。ex.shieusing Sys using Os using Collection<-標準モジュールはusing
ex.shieimport WindowsAPI import ABC<-非標準モジュール(サードパーティー製や自作モジュール)はimport
ex.udml※Opening HTTP->MARK-UP->UDML Call Protocol->Start [module1](WindowsAPI.so) [module2](MyShield\ABC.a) [module3](MyShield\MyLib.so) define Entry EntryPoint eq ex->Start-Up->Main @exだとグローバル空間から開始。_だと任意の一文字に当たるため無効。_を書きたいときは-と書く必要がある。 define Link Linking eq (module1,module2,module3) out of !My-Shield-File.jcp where #Entry #Link open build 'ex.shie' T set call scan 出来上がりました。もう一度コンパイルしますか?'Yes'-or-'No' T eq yes get File->Open Me get Nil ecro 終了です。ありがとうございました。 sys set Call Protocol->Quit ※Closeing Call sys->Endex.shieusing WindowsAPI using ABC using MyLib from Sys using static Console cdef square(x): #コンパイル時定関数(メンバーにすることも可能) return x*x cpdef Fun(): #インライン関数get,setも実は中身はpub cpdef Get_XXX(value T),pub cpdef Set_XXX(): return float(Input("数字を入力")) static class Start_Up(Unit): def Main(): Output(square(6)) Output("数値は"+str(Fun())+"です") #処理<-この場合ex.udmlがないとコンパイル不可。
- 投稿日:2020-02-11T01:01:17+09:00
Utf8JsonのDeserialize
はじめに
Unity(C#)でJsonを使用したくてUtf8Jsonを導入したのですが、
Utf8JsonのDeserializeでつまづいた箇所がありましたので記事にしてみました。
つまづいたのはちゃんと私が調べられてないだけですが簡単な例
シンプルなJsonのDeserializeを実行してみます。
Unity上からなのでDebug.Logで出力しています。エスケープ前のJson(コード上はエスケープしている状態のため)
{"type": "Apple", "size": "small"}コード例
出力はUnityのDebug.Logを使用しています。
通常のC#ならDebug.LogをSystem.out.printlnに置き換えればいいかと思います。// テストデータ string json = "{\"type\": \"Apple\", \"size\": \"small\"}"; // Deserializeを実行 Dictionary<string, object> deserializeData = Utf8Json.JsonSerializer.Deserialize<dynamic>(json); // Key,Valueのデータとして取り出す foreach (KeyValuePair<string, object> pairData in deserializeData) { Debug.Log(string.Format("key={0} value={1}", pairData.Key, pairData.Value)); }出力結果(余計な部分は排除)
いたって普通に取り出せました。
key=type value=Apple key=size value=smallつまづいた例
シンプルなJsonですと使い勝手が悪いのでオブジェクトと配列を使いたかったのです。
ただ、配列の取り出し方がよくわからなかったのでつまづいてしまいました。フォーマットしたJson
stock_dataというオブジェクトの中に配列を持っています。{ "stock_data": [ { "type": "apple", "size": "small" }, { "type": "pear", "size": "large" } ] }コード例
// テストデータ string json = "{\"stock_data\":[{\"type\":\"apple\",\"size\":\"small\"},{\"type\":\"pear\",\"size\":\"large\"}]}"; // Deserializeを実行 var deserializeData = Utf8Json.JsonSerializer.Deserialize<dynamic>(json); // stock_dataオブジェクトからデータを取り出す List<object> stockData = deserializeData["stock_data"]; // List<object>として格納されているので取り出す foreach (object dictionaryData in stockData) { // objectをDictionary<string, object>に変換 Dictionary<string, object> dictionary = dictionaryData as Dictionary<string, object>; // Key,Valueのデータとして取り出す foreach (KeyValuePair<string, object> pairData in dictionary) { Debug.Log(string.Format("key={0} value={1}", pairData.Key, pairData.Value)); } }出力結果(余計な部分は排除)
無事に取り出す事ができました。
配列データはList<object>型で取り出すという事がポイントでした。key=type value=apple key=size value=small key=type value=pear key=size value=large余談
調査している時にC#は型が文字列で取得できるという事で
Debug.Log(deserializeData["stock_data"].GetType().FullName);というコードを追加したのですが、
System.Collections.Generic.List`1[[System.Object, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089]]という形で出力されてよくわかりませんでした。(今見ると丸わかりですが…)
習熟している人ならList<object>型で取り出すだろうという発想が出たと思いますが、
C#をたまにしか触らないのでずいぶん手間がかかってしまいました…