- 投稿日:2020-01-21T23:32:58+09:00
SpringBootでグループウェアの開発②〜DB接続〜
DB接続
前回は環境構築をして、HelloWorldを表示するところまで実施しました。今回はDB接続をして、新規登録機能を完成させることを目標に取り組もうと思います。
DB関連の設定
MySQL8.0を起動
前回作成したMySQLのコンテナを起動する。
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES be628a63358d mysql:8.0 "docker-entrypoint.s…" 22 hours ago Exited (0) 16 seconds ago mygroupware_db_1 $ docker start be628a63358d be628a63358d $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES be628a63358d mysql:8.0 "docker-entrypoint.s…" 22 hours ago Up 9 seconds 33060/tcp, 0.0.0.0:3304->3306/tcp mygroupware_db_1ユーザーテーブル作成
SQLクライアントツールでMySQLに接続して、以下のデータベースとテーブルを作成。自分はworkbenchを使ってる。
--データベース作成 CREATE DATABASE mygroupwere; --testユーザにmygroupwere内での権限付与。次回からはテストユーザで作業する。 GRANT ALL ON mygroupwere.* TO test; --ユーザーテーブルを作成する。idとupdated_atは自動で設定。 USE mygroupwere; CREATE TABLE users ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, name TEXT NOT NULL, password TEXT NOT NULL, role TEXT NOT NULL, updated_at datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP )DEFAULT CHARACTER SET=utf8;application.propertiesの編集
application.propertiesspring.datasource.url=jdbc:mysql://localhost:3304/mygroupwere spring.datasource.username=test spring.datasource.password=test spring.datasource.driverClassName=com.mysql.jdbc.Driverbuild.gradleを編集
mvnrepositoryから、mysqlを検索して、以下のように依存関係を追加。
build.gradleplugins { id 'org.springframework.boot' version '2.2.3.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'rsrepo.groupware' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { developmentOnly runtimeClasspath { extendsFrom developmentOnly } compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok' developmentOnly 'org.springframework.boot:spring-boot-devtools' annotationProcessor 'org.projectlombok:lombok' implementation 'mysql:mysql-connector-java' // 追加 testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } } test { useJUnitPlatform() }ユーザーモデルを作成
User.javapackage パッケージ名.プロジェクト名.domain.model; import java.util.Date; import lombok.Data; @Data public class User { private String id; // ID private String name; // ユーザー名 private String password; // パスワード private String role; // ロール private Date updated_at; // 更新日時 }いい時間になってしまったので、今日はここまでで終了!
次回はDB接続の続きから始めます。
SpringBootでグループウェアの開発①〜環境構築〜
SpringBootでグループウェアの開発③〜DB接続の続き〜
GitHub:MyGroupware
- 投稿日:2020-01-21T22:01:08+09:00
docker環境で db:migrate:resetしたいとき( seed_fuも)
dbをリセットしたいとき
dockerを触り始めたばかりのときは停止させたdockerを再起動するのにも手こずりますので初歩的な手順。
大体rails のコマンド前にdocker-composeをつけるだけですが。docker-compose exec コンテナ名 bin/rails db:migrate:resetコンテナは停止させなくて良いです
なぜならそのコンテナに対してmigrateリセットするからですdocker-compose exec コンテナ名 bin/rails db:migratedocker-compose exec コンテナ名 bin/rails db:seed_fudocker-composeのときはymlファイルを参照するのでコンテナIDではなくコンテナ名を記述してください。
- 投稿日:2020-01-21T21:03:15+09:00
DockerでINTERNAL ERROR: cannot create temporary directory!となるときの対処法
環境 : Dockerコンテナ(mysql, Wordpress, nginx)
WordPressのブログの記事を執筆していると次のようなエラーが表示されました.
どうしてこのエラーが表示されたのかわかりませんが,おそらく画像をアップロードするときに失敗していたのでそれが原因ではないかと思います.
早速サーバー内に入ってDBのDockerコンテナを再起動しようとしましたが,
INTERNAL ERROR: cannot create temporary directory!とエラーが表示されました.違うコンテナで試してみても同じエラーだったので,どうやらDBのDockerコンテナに問題があるのではなく,サーバーかDocker自体に問題があるようです.とりあえず,
$ free -mで今のメモリの状況を確認し,$ echo 1 > /proc/sys/vm/drop_cachesでキャッシュの解放をして空きを増やしました.
再度,コンテナを起動しようとしましたが,同じエラーのままでした.解決方法
色々調べてこちらのstack overflowにたどり着きました.
どうやらコンテナとイメージを削除すればよさそうです.
(20/01/23追記)下記のコマンドでコンテナとイメージを全て削除できますが,まずはDockerに残ってしまている不要なものを削除しましょう(ahsgw様にコメントでご教授いただいたリンクが参考になります).ちなみに僕は,それでもできなかったので,下記コマンドを実行しました.
$ docker rm -f $(docker ps -a -q) $ docker rmi $(docker images -q)その後,
$ docker-compose up -dすると動きました.DBのコンテナはマウントしていましたが,サーバから操作しないだろうと思いwordpressのコンテナをマウントしていませんでした.
イメージ消したら中身のデータ消えちまうんじゃねぇか!?
と恐る恐る実行しました.
結果は,記事などのデータはDBに保存しているので,しっかり残っていましたが,Wordpressプラグインなどがやはり消えてしまっていました.全部消えなかっただけよかったですが,マウントしておこう.....
- 投稿日:2020-01-21T20:32:50+09:00
Datadogでdockerコンテナを監視を始めたときのメモ
この記事について
AWSのEC2(なお、OSはAmazon Linux2)上に配置しているairflowのログ収集をdatadogに任せたく、チュートリアルに従って設定を行ったら本当に一瞬で終わってしまったので、メモがてら残しておく。datadog agentは参考記事1にならいdockerイメージ版を利用した。
設定にあたっては、公式ドキュメント2にある一番シンプルなスクリプトに環境変数をいくつか追加している。やったこと
下記のシェルスクリプトを実行しただけ。本当にそれだけ。
init_dd-agent.sh#!/bin/bash -eu DOCKER_CONTENT_TRUST=1 \ docker run -d --name dd-agent -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /proc/:/host/proc/:ro \ -v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro \ -e DD_API_KEY=$MY_DD_API_KEY \ -e DD_TAGS="<your-tag1> <your-tag2>" \ -e DD_LOGS_ENABLED=true \ -e DD_LOGS_CONFIG_CONTAINER_COLLECT_ALL=true \ -e DD_AC_EXCLUDE="name:datadog-agent" \ -e SD_BACKEND="docker" \ -e NON_LOCAL_TRAFFIC=false \ datadog/agent:latest正常に実行されていれば、datadog agentのコンテナが起動しているはずなので、
docker psコマンドを実行して確認しよう。
また、プロセスが実行されたあとにdatadog上にサーバのメトリクスやログが飛んできているか確認しましょう。設定のポイント
個人的には公式ドキュメントの他、datadog-agentのgithubリポジトリ3にも色々説明が乗っているので、監視したい対象に合わせて最適なオプションを探しましょう。
DD_API_KEYは当然ながら必須の設定。datadogの管理画面から取得し、環境変数にでも入れておきましょう。DD_TAGSにはスペース区切りでタグを入れることでdatadogの画面上での検索性が上がる。部署名などお好きなものをどうぞ。DD_LOGS_ENABLEDをtrueに設定することにより、DatadogのLogs配下にログが飛んでくるようになる。これを設定しないとサーバのメトリクスのみが連携される。DD_LOGS_CONFIG_CONTAINER_COLLECT_ALLこれをtrueにすることで、全てのコンテナの実行ログを取ることができる。airflow自体もdocker-composeで実行している他、airflowから複数のコンテナが起動おとび実行される想定のため設定した。DD_AC_EXCLUDEを設定することでログを収集しないコンテナを指定できる。今回の場合はdatadog-agent自体のログを収集しないため設定。参考記事
- 投稿日:2020-01-21T16:46:08+09:00
今日のdocker error: ERRO[11840] error waiting for container: EOF
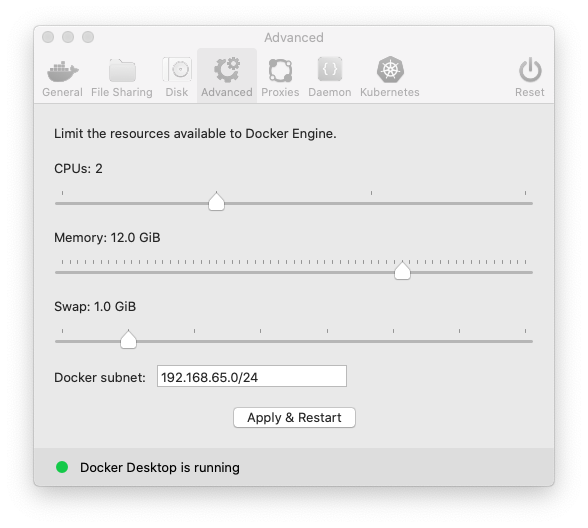
docker 動かしたまま、メモリの割り当てを変更した。
Docker for Macが路頭に迷わないようにたくさんメモリを食べられるようにする
https://blog.pinkumohikan.com/entry/increase-memory-limit-of-docker-for-macdockerメニューでpreferenceを選択
]12GBにした。
各 docker起動している窓で、
docker/ubuntu/bashERRO[11840] error waiting for container: EOF
- 投稿日:2020-01-21T16:20:02+09:00
Docker上のFlask + Nginxでコンソールにログを出力する
前提
本来であればflask、nginxに加えuwsgiサーバを立てるのが良いのは認識しているが、現状の構成からできることを行なった結果である。
背景
Docker上のFlask + Nginxのサーバを立てたのだが、Flaskのログがファイル出力のみされており、docker runを行なったプロンプトやdocker logsで確認ができない。どうにかしてできるようにしたい。
現状の構成
かなり省略するが、次の通り。
DockerfileFROM centos:centos7 CMD ["/bin/bash", "./start.sh"]start.sh# !/bin/bash uwsgi --ini=uwsgi.ini nginx -g "daemon off;"uwsgi.inidaemonize = /var/log/uwsgi/uwsgi.log上記の状態だとuwsgiプロセスがデーモン化して動作し、フォアグラウンドジョブとしてNginxが動作する。
そして、ログはdaemonizeで指定した/var/log/uwsgi/uwsgi.logに全て出力されてしまう。対応
いくつか対応を試みたがうまくいかず、結果的に3番目の対応方法でうまくいった。
flask上でコンソール出力を明示的に追加
すでにコンソール出力はされているとは思いながら、追加でコンソール出力のストリームを追加することでできないか確認。
logger.addHandler(logging.StreamHandler())しかし、daemonizeは標準出力されるものをファイルに流すようで、追加したストリームの内容もファイルに出力されてしまった。
daemonizeの設定を/dev/stdout に設定
daemonizeは指定したファイルに標準出力・エラー出力を出力してくれるのだが、あえて/dev/stdoutに出力することで標準出力にできないかと試みた。
コンソール出力へはうまく出力ができたが、flaskのログローテーション機能が当該ファイルをチェックにいき、絶えずエラーメッセージが出てしまう。
ログローテーション機能を抑止する方法を探したが、見つからずに断念。uwsgi_check_logrotate()/lseek(): Illegal seek [core/logging.c line 494]ログファイルをtailで監視
起動シェル上でtailによる監視を追加。
ファイルにもコンソールにもログが出力できることを確認。start.shとuwsgi.ini両方で出力ファイルを合わせる必要があるが、とりあえずできた。start.sh# 追加部分 touch /var/log/uwsgi/uwsgi.log tail -F /var/log/uwsgi/uwsgi.log > /dev/stdout & uwsgi --ini=uwsgi.ini nginx -g "daemon off;"
- 投稿日:2020-01-21T13:19:23+09:00
Autoware Docker環境の構築
ここでは以下の書籍に従い、Autoware Dockerを動作させていきます。
加藤 真平、藤居 祐輔、大里 章人 監修
安積 卓也、福富 大輔、徳永 翔太、橘川 雄樹、清谷 竣也 著
Autoware :自動運転ソフトウェア入門以降「Autoware :自動運転ソフトウェア入門」を本書と記述します。
同じような投稿が他にもありますが、ここでは初心者を対象として、できるだけ丁寧に書いていきたいと思います。
また、私が行った内容をトレースていますので、最終的に不要な事をやっている場合もありますので、ご注意下さい。本書の3.2章にAurowareのDocker環境を構築する方法が記載されていますが、情報が既に古くなっています。
例えば本書ではAutowareはGitHubで開発されていると記載されていますが、現在はGitLabへ移行しています。GitLab上のドキュメントに載っている手順ですが、新しい部分と古い部分が混在していて、少なくとも私にはわかりずらいです(2019年時点)。
環境
今回実施したのは以下の環境です。
- OS:Ubuntu 16.04
- GPU:GeForce GTX 960Autowareバージョンの決定
動作させるAutowareのバージョンを決定します。
3.2章を読み進めていくとどうもUbuntu 16.04ではAutoware1.8を使っているようです。しかしここを見るとUbuntu16.04では1.9.0〜1.12.0を使うように書かれています。
1.8.0についての記述はありません。よってここでは1.8.0に近い1.9.0を使うこととします。Nvidia GPUドライバのセットアップ
GPUドライバのセットアップについては3.2章には詳しい記述がありません。
UbuntuでNvidiaドライバのインストール方法をググってみると、リポジトリを登録してaptでインストールする方法が良く出てきます。
しかしドライバのバージョンは、使用するGPUに依存するだけでなく、CUDAのバージョンにも依存があるので、単独のインストールは避けたいところです。本書の3.3章を見るとCUDAのインストールを行うとGPUドライバがインストールできることがわかります。
CUDAのバージョンはAutowareのバージョンに依存しているらしいです。Autoware1.8に対応するCUDAのバージョンは8.0と本書に書かれていますが、AutowareとCUDAの対応バージョンの一覧は載っていないです。本書はココらへんは割と載っていないので、ちょと違うことをやろうとすると判断に困ります。以下をみるとUbuntu16.04ではCUDA9.0を使うように書かれています。
https://gitlab.com/autowarefoundation/autoware.ai/autoware/-/wikis/Source-Build
ちょっと不安ですがCUDA9.0を使うようにします。以下からダウンロードします。
https://developer.nvidia.com/cuda-90-download-archive?target_os=Linux
※画像はNVIDIA公式サイトから引用Installer Typeは"dev(local)"を選択しました。
パッチがあるようですが目的はGPUドライバのみなのでBase Installerだけでいいでしょう。
画像の赤マルのところをクリックしてダウンロードします。ファイルをダウンロードしたら四つのコマンドを実行しろと書かれています(上の画像の青シカク)ので、1つずつ実行していきます。
まずは、dpkgによるインストールコマンドです。kameyama@u1604:~/ダウンロード$ ls cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb kameyama@u1604:~/ダウンロード$ sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb 以前に未選択のパッケージ cuda-repo-ubuntu1604-9-0-local を選択しています。 (データベースを読み込んでいます ... 現在 218236 個のファイルとディレクトリがインストールされています。) cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.deb を展開する準備をしています ... cuda-repo-ubuntu1604-9-0-local (9.0.176-1) を展開しています... cuda-repo-ubuntu1604-9-0-local (9.0.176-1) を設定しています ... The public CUDA GPG key does not appear to be installed. To install the key, run this command: sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub kameyama@u1604:~/ダウンロード$kameyama@u1604:~/ダウンロード$ sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub OK kameyama@u1604:~/ダウンロード$kameyama@u1604:~/ダウンロード$ sudo apt-get update 取得:1 file:/var/cuda-repo-9-0-local InRelease 無視:1 file:/var/cuda-repo-9-0-local InRelease 取得:2 file:/var/cuda-repo-9-0-local Release [574 B] ・・・・略・・・・ 取得:18 http://jp.archive.ubuntu.com/ubuntu xenial-backports/universe amd64 DEP-11 Metadata [5,320 B] ヒット:20 http://repo.steampowered.com/steam precise InRelease 取得:21 http://security.ubuntu.com/ubuntu xenial-security InRelease [109 kB] 1,589 kB を 1秒 で取得しました (979 kB/s) パッケージリストを読み込んでいます... 完了 kameyama@u1604:~/ダウンロード$kameyama@u1604:~/ダウンロード$ sudo apt-get install cuda パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libllvm5.0 snapd-login-service これを削除するには 'sudo apt autoremove' を利用してください。 以下の追加パッケージがインストールされます: bbswitch-dkms ca-certificates-java cuda-9-0 cuda-command-line-tools-9-0 cuda-core-9-0 cuda-cublas-9-0 cuda-cublas-dev-9-0 cuda-cudart-9-0 cuda-cudart-dev-9-0 cuda-cufft-9-0 cuda-cufft-dev-9-0 cuda-curand-9-0 cuda-curand-dev-9-0 cuda-cusolver-9-0 cuda-cusolver-dev-9-0 cuda-cusparse-9-0 cuda-cusparse-dev-9-0 cuda-demo-suite-9-0 cuda-documentation-9-0 cuda-driver-dev-9-0 cuda-drivers cuda-libraries-9-0 cuda-libraries-dev-9-0 cuda-license-9-0 cuda-misc-headers-9-0 cuda-npp-9-0 cuda-npp-dev-9-0 cuda-nvgraph-9-0 cuda-nvgraph-dev-9-0 cuda-nvml-dev-9-0 cuda-nvrtc-9-0 cuda-nvrtc-dev-9-0 cuda-runtime-9-0 cuda-samples-9-0 cuda-toolkit-9-0 cuda-visual-tools-9-0 default-jre default-jre-headless dkms fonts-dejavu-extra freeglut3 freeglut3-dev java-common lib32gcc1 libc6-i386 libcuda1-384 libdrm-dev libgif7 libgl1-mesa-dev libglu1-mesa-dev libice-dev libjansson4 libpthread-stubs0-dev libsm-dev libvdpau1 libx11-dev libx11-doc libx11-xcb-dev libxau-dev libxcb-dri2-0-dev libxcb-dri3-dev libxcb-glx0-dev libxcb-present-dev libxcb-randr0-dev libxcb-render0-dev libxcb-shape0-dev libxcb-sync-dev libxcb-xfixes0-dev libxcb1-dev libxdamage-dev libxdmcp-dev libxext-dev libxfixes-dev libxi-dev libxmu-dev libxmu-headers libxnvctrl0 libxshmfence-dev libxt-dev libxxf86vm-dev mesa-common-dev mesa-vdpau-drivers nvidia-384 nvidia-384-dev nvidia-modprobe nvidia-opencl-icd-384 nvidia-prime nvidia-settings ocl-icd-libopencl1 openjdk-8-jre openjdk-8-jre-headless screen-resolution-extra vdpau-driver-all x11proto-core-dev x11proto-damage-dev x11proto-dri2-dev x11proto-fixes-dev x11proto-gl-dev x11proto-input-dev x11proto-kb-dev x11proto-xext-dev x11proto-xf86vidmode-dev xorg-sgml-doctools xtrans-dev 提案パッケージ: bumblebee default-java-plugin libice-doc libsm-doc libxcb-doc libxext-doc libxt-doc icedtea-8-plugin fonts-ipafont-gothic fonts-ipafont-mincho fonts-wqy-microhei fonts-wqy-zenhei fonts-indic libvdpau-va-gl1 nvidia-vdpau-driver nvidia-legacy-340xx-vdpau-driver 以下のパッケージが新たにインストールされます: bbswitch-dkms ca-certificates-java cuda cuda-9-0 cuda-command-line-tools-9-0 cuda-core-9-0 cuda-cublas-9-0 cuda-cublas-dev-9-0 cuda-cudart-9-0 cuda-cudart-dev-9-0 cuda-cufft-9-0 cuda-cufft-dev-9-0 cuda-curand-9-0 cuda-curand-dev-9-0 cuda-cusolver-9-0 cuda-cusolver-dev-9-0 cuda-cusparse-9-0 cuda-cusparse-dev-9-0 cuda-demo-suite-9-0 cuda-documentation-9-0 cuda-driver-dev-9-0 cuda-drivers cuda-libraries-9-0 cuda-libraries-dev-9-0 cuda-license-9-0 cuda-misc-headers-9-0 cuda-npp-9-0 cuda-npp-dev-9-0 cuda-nvgraph-9-0 cuda-nvgraph-dev-9-0 cuda-nvml-dev-9-0 cuda-nvrtc-9-0 cuda-nvrtc-dev-9-0 cuda-runtime-9-0 cuda-samples-9-0 cuda-toolkit-9-0 cuda-visual-tools-9-0 default-jre default-jre-headless dkms fonts-dejavu-extra freeglut3 freeglut3-dev java-common lib32gcc1 libc6-i386 libcuda1-384 libdrm-dev libgif7 libgl1-mesa-dev libglu1-mesa-dev libice-dev libjansson4 libpthread-stubs0-dev libsm-dev libvdpau1 libx11-dev libx11-doc libx11-xcb-dev libxau-dev libxcb-dri2-0-dev libxcb-dri3-dev libxcb-glx0-dev libxcb-present-dev libxcb-randr0-dev libxcb-render0-dev libxcb-shape0-dev libxcb-sync-dev libxcb-xfixes0-dev libxcb1-dev libxdamage-dev libxdmcp-dev libxext-dev libxfixes-dev libxi-dev libxmu-dev libxmu-headers libxnvctrl0 libxshmfence-dev libxt-dev libxxf86vm-dev mesa-common-dev mesa-vdpau-drivers nvidia-384 nvidia-384-dev nvidia-modprobe nvidia-opencl-icd-384 nvidia-prime nvidia-settings ocl-icd-libopencl1 openjdk-8-jre openjdk-8-jre-headless screen-resolution-extra vdpau-driver-all x11proto-core-dev x11proto-damage-dev x11proto-dri2-dev x11proto-fixes-dev x11proto-gl-dev x11proto-input-dev x11proto-kb-dev x11proto-xext-dev x11proto-xf86vidmode-dev xorg-sgml-doctools xtrans-dev アップグレード: 0 個、新規インストール: 105 個、削除: 0 個、保留: 0 個。 1,217 MB 中 120 MB のアーカイブを取得する必要があります。 この操作後に追加で 2,852 MB のディスク容量が消費されます。 続行しますか? [Y/n] 取得:1 file:/var/cuda-repo-9-0-local cuda-license-9-0 9.0.176-1 [22.0 kB] 取得:2 file:/var/cuda-repo-9-0-local cuda-misc-headers-9-0 9.0.176-1 [684 kB] ・・・・略・・・・ Adding debian:Staat_der_Nederlanden_EV_Root_CA.pem done. libc-bin (2.23-0ubuntu11) のトリガを処理しています ... initramfs-tools (0.122ubuntu8.16) のトリガを処理しています ... update-initramfs: Generating /boot/initrd.img-4.15.0-72-generic W: Possible missing firmware /lib/firmware/i915/kbl_guc_ver9_14.bin for module i915 W: Possible missing firmware /lib/firmware/i915/bxt_guc_ver8_7.bin for module i915 dbus (1.10.6-1ubuntu3.5) のトリガを処理しています ... ureadahead (0.100.0-19.1) のトリガを処理しています ... ca-certificates (20170717~16.04.2) のトリガを処理しています ... Updating certificates in /etc/ssl/certs... 0 added, 0 removed; done. Running hooks in /etc/ca-certificates/update.d... done. done. kameyama@u1604:~/ダウンロード$インストールが完了したらUbuntuを再起動する必要があります。
nvidia-smiコマンドが実行できればOKです。
ここではバージョン384.130のドライバがインストールされていました。Dockerのインストール
本書の"3.2.2 Dockerのセットアップ"に従いDockerをインストールします。
ここら辺は以下に詳しく載ってます。
https://docs.docker.com/install/linux/docker-ce/ubuntu/まずは過去のバージョンのDockerを削除します。
kameyama@u1604:~$ sudo apt-get remove docker docker-engine docker.io containerd runc パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 パッケージ 'docker-engine' はインストールされていないため削除もされません パッケージ 'docker' はインストールされていないため削除もされません パッケージ 'containerd' はインストールされていないため削除もされません パッケージ 'docker.io' はインストールされていないため削除もされません パッケージ 'runc' はインストールされていないため削除もされません 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libllvm5.0 snapd-login-service これを削除するには 'sudo apt autoremove' を利用してください。 アップグレード: 0 個、新規インストール: 0 個、削除: 0 個、保留: 0 個。 kameyama@u1604:~$ kameyama@u1604:~$ sudo apt-get update ヒット:1 http://jp.archive.ubuntu.com/ubuntu xenial InRelease ヒット:2 http://jp.archive.ubuntu.com/ubuntu xenial-updates InRelease ヒット:3 http://jp.archive.ubuntu.com/ubuntu xenial-backports InRelease 無視:4 http://dl.google.com/linux/chrome/deb stable InRelease ヒット:5 http://repo.steampowered.com/steam precise InRelease ヒット:6 http://dl.google.com/linux/chrome/deb stable Release 取得:8 http://security.ubuntu.com/ubuntu xenial-security InRelease [109 kB] 109 kB を 1秒 で取得しました (97.2 kB/s) パッケージリストを読み込んでいます... 完了 kameyama@u1604:~$次にリポジトリをアップデートして、必要なパッケージをインストールします。
kameyama@u1604:~$ sudo apt-get update ヒット:1 http://jp.archive.ubuntu.com/ubuntu xenial InRelease ヒット:2 http://jp.archive.ubuntu.com/ubuntu xenial-updates InRelease ヒット:3 http://jp.archive.ubuntu.com/ubuntu xenial-backports InRelease 無視:4 http://dl.google.com/linux/chrome/deb stable InRelease ヒット:5 http://repo.steampowered.com/steam precise InRelease ヒット:6 http://dl.google.com/linux/chrome/deb stable Release 取得:8 http://security.ubuntu.com/ubuntu xenial-security InRelease [109 kB] 109 kB を 1秒 で取得しました (97.2 kB/s) パッケージリストを読み込んでいます... 完了 kameyama@u1604:~$ kameyama@u1604:~$ kameyama@u1604:~$ sudo apt-get install \ > apt-transport-https \ > ca-certificates \ > curl \ > gnupg2 \ > software-properties-common パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 apt-transport-https はすでに最新バージョン (1.2.32) です。 ca-certificates はすでに最新バージョン (20170717~16.04.2) です。 curl はすでに最新バージョン (7.47.0-1ubuntu2.14) です。 curl は手動でインストールしたと設定されました。 gnupg2 はすでに最新バージョン (2.1.11-6ubuntu2.1) です。 software-properties-common はすでに最新バージョン (0.96.20.9) です。 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libllvm5.0 snapd-login-service これを削除するには 'sudo apt autoremove' を利用してください。 アップグレード: 0 個、新規インストール: 0 個、削除: 0 個、保留: 0 個。 kameyama@u1604:~$次にDockerのofficial GPG keyを設定します。
kameyama@u1604:~$ curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - OK kameyama@u1604:~$ kameyama@u1604:~$ sudo apt-key fingerprint 0EBFCD88 pub 4096R/0EBFCD88 2017-02-22 フィンガー・プリント = 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid Docker Release (CE deb) <docker@docker.com> sub 4096R/F273FCD8 2017-02-22 kameyama@u1604:~$続けubuntu向けのstableリポジトリを登録します。
kameyama@u1604:~$ sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" kameyama@u1604:~$ kameyama@u1604:~$ sudo apt-get update ヒット:1 http://jp.archive.ubuntu.com/ubuntu xenial InRelease ヒット:2 http://jp.archive.ubuntu.com/ubuntu xenial-updates InRelease ヒット:3 http://jp.archive.ubuntu.com/ubuntu xenial-backports InRelease ヒット:4 https://download.docker.com/linux/ubuntu xenial InRelease 無視:5 http://dl.google.com/linux/chrome/deb stable InRelease ヒット:6 http://repo.steampowered.com/steam precise InRelease ヒット:7 http://dl.google.com/linux/chrome/deb stable Release 取得:9 http://security.ubuntu.com/ubuntu xenial-security InRelease [109 kB] 109 kB を 1秒 で取得しました (66.8 kB/s) パッケージリストを読み込んでいます... 完了 kameyama@u1604:~$updateも忘れずに実行します。
最後にdocker ceをインストールします。kameyama@u1604:~$ sudo apt-get install docker-ce docker-ce-cli containerd.io パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libllvm5.0 snapd-login-service これを削除するには 'sudo apt autoremove' を利用してください。 以下の追加パッケージがインストールされます: aufs-tools cgroupfs-mount git git-man liberror-perl pigz 提案パッケージ: git-daemon-run | git-daemon-sysvinit git-doc git-el git-email git-gui gitk gitweb git-arch git-cvs git-mediawiki git-svn 以下のパッケージが新たにインストールされます: aufs-tools cgroupfs-mount containerd.io docker-ce docker-ce-cli git git-man liberror-perl pigz アップグレード: 0 個、新規インストール: 9 個、削除: 0 個、保留: 0 個。 89.2 MB のアーカイブを取得する必要があります。 この操作後に追加で 409 MB のディスク容量が消費されます。 続行しますか? [Y/n] 取得:1 https://download.docker.com/linux/ubuntu xenial/stable amd64 containerd.io amd64 1.2.10-3 [19.9 MB] 取得:2 http://jp.archive.ubuntu.com/ubuntu xenial/universe amd64 pigz amd64 2.3.1-2 [61.1 kB] 取得:3 http://jp.archive.ubuntu.com/ubuntu xenial/universe amd64 aufs-tools amd64 1:3.2+20130722-1.1ubuntu1 [92.9 kB] 取得:4 http://jp.archive.ubuntu.com/ubuntu xenial/universe amd64 cgroupfs-mount all 1.2 [4,970 B] 取得:5 http://jp.archive.ubuntu.com/ubuntu xenial/main amd64 liberror-perl all 0.17-1.2 [19.6 kB] 取得:6 http://jp.archive.ubuntu.com/ubuntu xenial-updates/main amd64 git-man all 1:2.7.4-0ubuntu1.7 [736 kB] 取得:7 https://download.docker.com/linux/ubuntu xenial/stable amd64 docker-ce-cli amd64 5:19.03.5~3-0~ubuntu-xenial [42.4 MB] 取得:8 http://jp.archive.ubuntu.com/ubuntu xenial-updates/main amd64 git amd64 1:2.7.4-0ubuntu1.7 [3,160 kB] 取得:9 https://download.docker.com/linux/ubuntu xenial/stable amd64 docker-ce amd64 5:19.03.5~3-0~ubuntu-xenial [22.8 MB] 89.2 MB を 1秒 で取得しました (58.4 MB/s) 以前に未選択のパッケージ pigz を選択しています。 (データベースを読み込んでいます ... 現在 217124 個のファイルとディレクトリがインストールされています。) .../pigz_2.3.1-2_amd64.deb を展開する準備をしています ... pigz (2.3.1-2) を展開しています... 以前に未選択のパッケージ aufs-tools を選択しています。 .../aufs-tools_1%3a3.2+20130722-1.1ubuntu1_amd64.deb を展開する準備をしています ... aufs-tools (1:3.2+20130722-1.1ubuntu1) を展開しています... 以前に未選択のパッケージ cgroupfs-mount を選択しています。 .../cgroupfs-mount_1.2_all.deb を展開する準備をしています ... cgroupfs-mount (1.2) を展開しています... 以前に未選択のパッケージ containerd.io を選択しています。 .../containerd.io_1.2.10-3_amd64.deb を展開する準備をしています ... containerd.io (1.2.10-3) を展開しています... 以前に未選択のパッケージ docker-ce-cli を選択しています。 .../docker-ce-cli_5%3a19.03.5~3-0~ubuntu-xenial_amd64.deb を展開する準備をしています ... docker-ce-cli (5:19.03.5~3-0~ubuntu-xenial) を展開しています... 以前に未選択のパッケージ docker-ce を選択しています。 .../docker-ce_5%3a19.03.5~3-0~ubuntu-xenial_amd64.deb を展開する準備をしています ... docker-ce (5:19.03.5~3-0~ubuntu-xenial) を展開しています... 以前に未選択のパッケージ liberror-perl を選択しています。 .../liberror-perl_0.17-1.2_all.deb を展開する準備をしています ... liberror-perl (0.17-1.2) を展開しています... 以前に未選択のパッケージ git-man を選択しています。 .../git-man_1%3a2.7.4-0ubuntu1.7_all.deb を展開する準備をしています ... git-man (1:2.7.4-0ubuntu1.7) を展開しています... 以前に未選択のパッケージ git を選択しています。 .../git_1%3a2.7.4-0ubuntu1.7_amd64.deb を展開する準備をしています ... git (1:2.7.4-0ubuntu1.7) を展開しています... man-db (2.7.5-1) のトリガを処理しています ... libc-bin (2.23-0ubuntu11) のトリガを処理しています ... ureadahead (0.100.0-19.1) のトリガを処理しています ... ureadahead will be reprofiled on next reboot systemd (229-4ubuntu21.23) のトリガを処理しています ... pigz (2.3.1-2) を設定しています ... aufs-tools (1:3.2+20130722-1.1ubuntu1) を設定しています ... cgroupfs-mount (1.2) を設定しています ... containerd.io (1.2.10-3) を設定しています ... docker-ce-cli (5:19.03.5~3-0~ubuntu-xenial) を設定しています ... docker-ce (5:19.03.5~3-0~ubuntu-xenial) を設定しています ... liberror-perl (0.17-1.2) を設定しています ... git-man (1:2.7.4-0ubuntu1.7) を設定しています ... git (1:2.7.4-0ubuntu1.7) を設定しています ... libc-bin (2.23-0ubuntu11) のトリガを処理しています ... systemd (229-4ubuntu21.23) のトリガを処理しています ... ureadahead (0.100.0-19.1) のトリガを処理しています ... kameyama@u1604:~$hello-worldイメージを起動させて動作確認とします。
kameyama@u1604:~$ sudo docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:4fe721ccc2e8dc7362278a29dc660d833570ec2682f4e4194f4ee23e415e1064 Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/DockerからGPUを使う設定
DockerからGPUを使うためには、本書に従うとNVIDIA Dockerのセットアップを行う必要があります。
しかし、以下を見るとDocker のバージョン19.03以降の場合、DockerエンジンがGPUをサポートしているのでNVIDIA Dockerは不要とあります。
https://gitlab.com/autowarefoundation/autoware.ai/autoware/-/wikis/Generic-x86-DockerインストールしたDockerのバージョンを確認すると19.3.5でしたのでNVIDIA Dockerは不要のようです。
kameyama@u1604:~$ docker --version Docker version 19.03.5, build 633a0ea838 kameyama@u1604:~$DockerからGPUを使用する方法は以下に記載されています。
https://docs.docker.com/engine/reference/commandline/run/#access-an-nvidia-gpu
それによるとnvidia-container-runtimeをインストールする必要があります。インストール方法は以下にあります。
https://nvidia.github.io/nvidia-container-runtime/
このページに従って実行してみます。まずはGPGキーの設定から。
kameyama@u1604:~$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | \ > sudo apt-key add - OK次にリポジトリの登録
kameyama@u1604:~$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) kameyama@u1604:~$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | \ > sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list deb https://nvidia.github.io/libnvidia-container/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/$(ARCH) /アップデートしてインストールします。
kameyama@u1604:~$ sudo apt-get update 取得:1 file:/var/cuda-repo-9-0-local InRelease 無視:1 file:/var/cuda-repo-9-0-local InRelease 取得:2 file:/var/cuda-repo-9-0-local Release [574 B] 取得:2 file:/var/cuda-repo-9-0-local Release [574 B] 無視:4 http://dl.google.com/linux/chrome/deb stable InRelease ヒット:5 https://download.docker.com/linux/ubuntu xenial InRelease ヒット:6 http://jp.archive.ubuntu.com/ubuntu xenial InRelease 取得:7 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64 InRelease [1,106 B] 取得:8 https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 InRelease [1,103 B] ヒット:9 http://jp.archive.ubuntu.com/ubuntu xenial-updates InRelease ヒット:10 http://jp.archive.ubuntu.com/ubuntu xenial-backports InRelease ヒット:11 http://dl.google.com/linux/chrome/deb stable Release 取得:12 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64 Packages [8,576 B] 取得:13 https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages [9,212 B] ヒット:14 http://repo.steampowered.com/steam precise InRelease ヒット:16 http://security.ubuntu.com/ubuntu xenial-security InRelease 20.0 kB を 0秒 で取得しました (20.5 kB/s) パッケージリストを読み込んでいます... 完了 kameyama@u1604:~$ apt-get install nvidia-container-runtime E: ロックファイル /var/lib/dpkg/lock-frontend をオープンできません - open (13: 許可がありません) E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), are you root? kameyama@u1604:~$ sudo apt-get install nvidia-container-runtimeパッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libllvm5.0 snapd-login-service これを削除するには 'sudo apt autoremove' を利用してください。 以下の追加パッケージがインストールされます: libnvidia-container-tools libnvidia-container1 nvidia-container-toolkit 以下のパッケージが新たにインストールされます: libnvidia-container-tools libnvidia-container1 nvidia-container-runtime nvidia-container-toolkit アップグレード: 0 個、新規インストール: 4 個、削除: 0 個、保留: 0 個。 1,260 kB のアーカイブを取得する必要があります。 この操作後に追加で 4,136 kB のディスク容量が消費されます。 続行しますか? [Y/n] 取得:1 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64 libnvidia-container1 1.0.5-1 [57.9 kB] 取得:2 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64 libnvidia-container-tools 1.0.5-1 [15.6 kB] 取得:3 https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 nvidia-container-toolkit 1.0.5-1 [575 kB] 取得:4 https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 nvidia-container-runtime 3.1.4-1 [612 kB] 1,260 kB を 0秒 で取得しました (3,420 kB/s) 以前に未選択のパッケージ libnvidia-container1:amd64 を選択しています。 (データベースを読み込んでいます ... 現在 231201 個のファイルとディレクトリがインストールされています。) .../libnvidia-container1_1.0.5-1_amd64.deb を展開する準備をしています ... libnvidia-container1:amd64 (1.0.5-1) を展開しています... 以前に未選択のパッケージ libnvidia-container-tools を選択しています。 .../libnvidia-container-tools_1.0.5-1_amd64.deb を展開する準備をしています ... libnvidia-container-tools (1.0.5-1) を展開しています... 以前に未選択のパッケージ nvidia-container-toolkit を選択しています。 .../nvidia-container-toolkit_1.0.5-1_amd64.deb を展開する準備をしています ... nvidia-container-toolkit (1.0.5-1) を展開しています... 以前に未選択のパッケージ nvidia-container-runtime を選択しています。 .../nvidia-container-runtime_3.1.4-1_amd64.deb を展開する準備をしています ... nvidia-container-runtime (3.1.4-1) を展開しています... libc-bin (2.23-0ubuntu11) のトリガを処理しています ... libnvidia-container1:amd64 (1.0.5-1) を設定しています ... libnvidia-container-tools (1.0.5-1) を設定しています ... nvidia-container-toolkit (1.0.5-1) を設定しています ... nvidia-container-runtime (3.1.4-1) を設定しています ... libc-bin (2.23-0ubuntu11) のトリガを処理しています ... kameyama@u1604:~$インストールできたか確認します。
kameyama@u1604:~$ which nvidia-container-runtime-hook /usr/bin/nvidia-container-runtime-hook kameyama@u1604:~$インストールできたようです。インストール後はDockerデーモンを再起動する必要があります。
kameyama@u1604:~$ sudo systemctl | grep docker sys-devices-virtual-net-docker0.device loaded active plugged /sys/devices/virtual/net/docker0 sys-subsystem-net-devices-docker0.device loaded active plugged /sys/subsystem/net/devices/docker0 docker.service loaded active running Docker Application Container Engine docker.socket loaded active running Docker Socket for the API kameyama@u1604:~$ sudo systemctl restart docker kameyama@u1604:~$ここまで出来たらDockerイメージからGPUが使えるかを確認します。確認方法もhttps://docs.docker.com/engine/reference/commandline/run/#access-an-nvidia-gpu に従います。
GPUを使用する場合はオプション"--gpus"を使用します。このオプションにはどのGPUを使用するかを渡します。
ここではこだわりがないので"all"を指定しています。kameyama@u1604:~$ sudo docker run -it --rm --gpus all ubuntu nvidia-smi Fri Jan 3 02:50:00 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 384.130 Driver Version: 384.130 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 960 Off | 00000000:01:00.0 On | N/A | | 21% 38C P8 9W / 120W | 247MiB / 4036MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+ kameyama@u1604:~$Autoware Dockerのセットアップ
ここではPre-built Autoware Docker Imageを使用する方法を取ります。
3.2.4 章の流れに従いAutoware Dockerをセットアップします。
まずは適当にディレクトリを作って、リポジトリをCloneします。本書に記載されいているリポジトリは古い(GitHub)ので、
https://gitlab.com/autowarefoundation/autoware.ai/autoware/-/wikis/Generic-x86-Docker に従います。kameyama@u1604:~$ mkdir autoware kameyama@u1604:~$ cd autoware/ kameyama@u1604:~/autoware$ git clone https://gitlab.com/autowarefoundation/autoware.ai/docker.git Cloning into 'docker'... remote: Enumerating objects: 536, done. remote: Counting objects: 100% (536/536), done. remote: Compressing objects: 100% (319/319), done. remote: Total 536 (delta 237), reused 496 (delta 214), pack-reused 0 Receiving objects: 100% (536/536), 962.20 KiB | 719.00 KiB/s, done. Resolving deltas: 100% (237/237), done. Checking connectivity... done. kameyama@u1604:~/autoware$cloneした内容を確認します。
kameyama@u1604:~/autoware$ ls docker kameyama@u1604:~/autoware$ cd docker/ kameyama@u1604:~/autoware/docker$ ls -F CODE_OF_CONDUCT.md LICENSE SUPPORT.md dependencies nvidia/ CONTRIBUTING.md README.md crossbuild/ generic/ kameyama@u1604:~/autoware/docker$ cd generic/ kameyama@u1604:~/autoware/docker/generic$ ls -F Dockerfile Dockerfile.legacy.colcon hooks/ Dockerfile.base README.md run.sh* Dockerfile.cuda.kinetic build.sh* run_no_nvidia_docker.sh* Dockerfile.cuda.melodic dependencies Dockerfile.legacy.catkin entrypoint.sh*Pre-built Autoware Docker Imageを起動するにはrun.shスクリプトを実行しろと書かれているのですが、
既存のrun.shはDockerコンテナを使用しているため、NVIDIA Runtimeの指定方法が異なります。run.sh -hでオプションを確認すると、CUDAのon/offの切り替えができますので、これをoff指定にすることでNVIDIA Dockerの設定を無効にし、先の設定したDockerエンジンからNVIDIA Runtimeを指定するオプションをrun.shに追加します。具体的な変更は以下です。
kameyama@u1604:~/autoware/docker/generic$ git diff diff --git a/generic/run.sh b/generic/run.sh index c0a3d2b..e2857cb 100755 --- a/generic/run.sh +++ b/generic/run.sh @@ -117,7 +117,7 @@ echo -e "\tPre-release version: $PRE_RELEASE" echo -e "\tUID: <$USER_ID>" SUFFIX="" -RUNTIME="" +RUNTIME=" --gpus all " XSOCK=/tmp/.X11-unix XAUTH=$HOME/.Xauthority kameyama@u1604:~/autoware/docker/generic$run.shを実行します。先に記述した通りAutowareのバージョンは1.9.0、ROSはUbuntu16.04なのでROSはKineticです。
kameyama@u1604:~/autoware/docker/generic$ sudo ./run.sh -t 1.9.0 -r kinetic -c off Using options: ROS distro: kinetic Image name: autoware/autoware Tag prefix: 1.9.0 Cuda support: off Pre-release version: off UID: <0> Launching autoware/autoware:1.9.0-kinetic Unable to find image 'autoware/autoware:1.9.0-kinetic' locally 1.9.0-kinetic: Pulling from autoware/autoware 18d680d61657: Pulling fs layer 0addb6fece63: Pulling fs layer 78e58219b215: Pulling fs layer eb6959a66df2: Waiting 7a0b022c2633: Waiting 2536ccb3c0e4: Waiting 72568544e638: Waiting eb3c7a1fa7df: Waiting 89d000f1160c: Pull complete ab501f65d629: Pull complete d8ad9440c91b: Pull complete d2f04e964386: Pull complete adfe26dc1787: Pull complete 81077af92d65: Pull complete dba30169ab94: Pull complete a32d592f8e1d: Pull complete d9c260415685: Pull complete 428ae4963ce1: Pull complete 5fdd11ef6135: Pull complete 0d5bc3d196a5: Pull complete 6a5190daa6ee: Pull complete 765fb5730fbd: Pull complete bf41175d74f3: Pull complete cd90ad64d433: Pull complete 941205d3e9b6: Pull complete 9386e57c18b6: Pull complete 3bc1bcc4e918: Pull complete 774c00c9d22f: Pull complete 53efcdafd4a1: Pull complete ee426c8a1b38: Pull complete 55a185be5aac: Pull complete Digest: sha256:217efb995faa0ef058723b7e98620462aa2c30d72a37e186ca590aebdf8e50c3 Status: Downloaded newer image for autoware/autoware:1.9.0-kinetic autoware@u1604:~$ autoware@u1604:~$プロンプトが"kameyama@u1604:"から"autoware@u1604:"へ変わりました。無事Autoware Docker imageが起動しました。
Autowareの起動
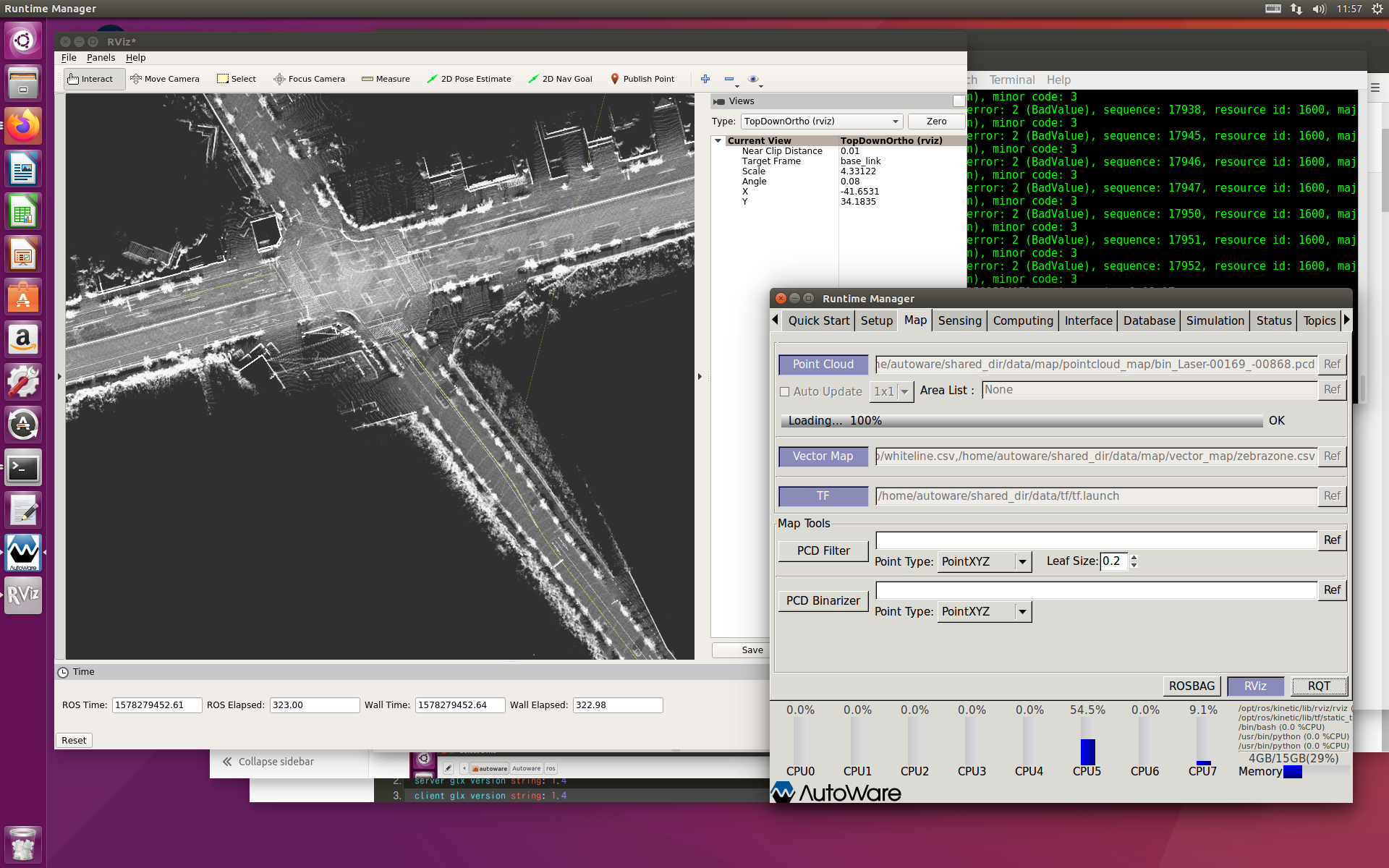
最後にAutowareを起動します。~/Autoware/ros配下の"run"を実行します。
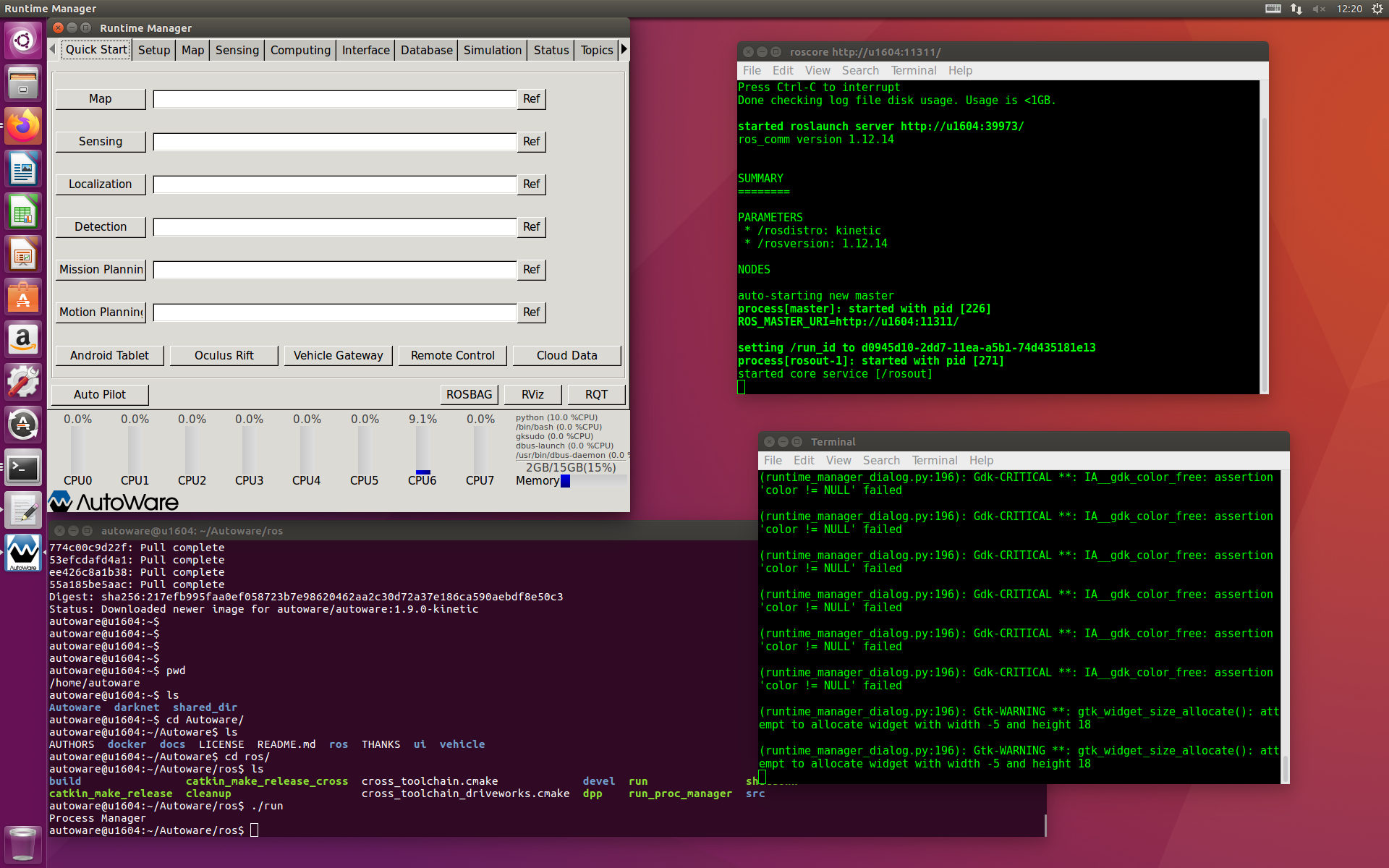
autoware@u1604:~$ pwd /home/autoware autoware@u1604:~$ ls Autoware darknet shared_dir autoware@u1604:~$ cd Autoware/ autoware@u1604:~/Autoware$ ls AUTHORS docker docs LICENSE README.md ros THANKS ui vehicle autoware@u1604:~/Autoware$ cd ros/ autoware@u1604:~/Autoware/ros$ ls build catkin_make_release_cross cross_toolchain.cmake devel run shutdown catkin_make_release cleanup cross_toolchain_driveworks.cmake dpp run_proc_manager src autoware@u1604:~/Autoware/ros$ ./run Process Managerこんな画面がでます。
しかし、、、
本書の"5章 Autowareの立ち上げ"に従いDEMOを実行したところ、Runtime ManagerからのROSツールの呼び出し("RViz"ボタンを押す)でエラーになりました。dockerコンテナからOpenGLが使えないようです。
やっぱりNVIDIA Dockerを使うべきか?※DEMOについてはここでは詳しく書きません。そのうち別に書くかも?
NVIDIA Dockerのインストール
pre-build Autoware docker imageはNVIDIA Dockerを使用するようになっているので、NVIDIA dockerをインストールします。
NVIDIA Dockerには1(無印)と2があります。本書の"3.2.3 NVIDIA Dockerのインストール"ではNVIDIA Docker 1を使用することになっていますが、Autoware 1.9.xのrun.shではNVIDIA Docker2を使っていましたので、そちらをインストールします。kameyama@u1604:~$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - OK kameyama@u1604:~$ curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list deb https://nvidia.github.io/libnvidia-container/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-docker/ubuntu16.04/$(ARCH) / kameyama@u1604:~$ sudo apt-get update 取得:1 file:/var/cuda-repo-9-0-local InRelease 無視:1 file:/var/cuda-repo-9-0-local InRelease 取得:2 file:/var/cuda-repo-9-0-local Release [574 B] 取得:2 file:/var/cuda-repo-9-0-local Release [574 B] ヒット:3 http://jp.archive.ubuntu.com/ubuntu xenial InRelease ヒット:4 http://jp.archive.ubuntu.com/ubuntu xenial-updates InRelease ヒット:6 http://jp.archive.ubuntu.com/ubuntu xenial-backports InRelease 無視:7 http://dl.google.com/linux/chrome/deb stable InRelease ヒット:8 https://download.docker.com/linux/ubuntu xenial InRelease ヒット:9 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64 InRelease ヒット:10 https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 InRelease 取得:11 https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 InRelease [1,096 B] ヒット:12 http://repo.steampowered.com/steam precise InRelease ヒット:13 http://dl.google.com/linux/chrome/deb stable Release 取得:14 https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages [8,796 B] 取得:15 http://security.ubuntu.com/ubuntu xenial-security InRelease [109 kB] 取得:17 http://security.ubuntu.com/ubuntu xenial-security/main amd64 DEP-11 Metadata [74.7 kB] 取得:18 http://security.ubuntu.com/ubuntu xenial-security/main DEP-11 64x64 Icons [79.5 kB] 取得:19 http://security.ubuntu.com/ubuntu xenial-security/universe amd64 DEP-11 Metadata [124 kB] 取得:20 http://security.ubuntu.com/ubuntu xenial-security/universe DEP-11 64x64 Icons [194 kB] 取得:21 http://security.ubuntu.com/ubuntu xenial-security/multiverse amd64 DEP-11 Metadata [2,464 B] 593 kB を 2秒 で取得しました (288 kB/s) パッケージリストを読み込んでいます... 完了 W: ターゲット Packages (Packages) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Translations (ja_JP) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Translations (ja) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Translations (en) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Packages (Packages) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Translations (ja_JP) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Translations (ja) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Translations (en) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Packages (Packages) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Translations (ja_JP) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Translations (ja) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Translations (en) は /etc/apt/sources.list.d/nvidia-container-runtime.list:1 と /etc/apt/sources.list.d/nvidia-docker.list:1 で複数回設定されています W: ターゲット Packages (Packages) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Translations (ja_JP) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Translations (ja) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています W: ターゲット Translations (en) は /etc/apt/sources.list.d/nvidia-container-runtime.list:2 と /etc/apt/sources.list.d/nvidia-docker.list:2 で複数回設定されています kameyama@u1604:~$ sudo apt-get install -y nvidia-docker2 パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libllvm5.0 snapd-login-service これを削除するには 'sudo apt autoremove' を利用してください。 以下のパッケージが新たにインストールされます: nvidia-docker2 アップグレード: 0 個、新規インストール: 1 個、削除: 0 個、保留: 0 個。 2,866 B のアーカイブを取得する必要があります。 この操作後に追加で 18.4 kB のディスク容量が消費されます。 取得:1 https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 nvidia-docker2 2.2.2-1 [2,866 B] 2,866 B を 0秒 で取得しました (9,939 B/s) 以前に未選択のパッケージ nvidia-docker2 を選択しています。 (データベースを読み込んでいます ... 現在 231230 個のファイルとディレクトリがインストールされています。) .../nvidia-docker2_2.2.2-1_all.deb を展開する準備をしています ... nvidia-docker2 (2.2.2-1) を展開しています... nvidia-docker2 (2.2.2-1) を設定しています ... kameyama@u1604:~$NVIDIA Docker 2を使ったAutoware Dockerの起動
NDIVIA Dockerを使ったAutoware Dockerを起動してみます。
NVIDIA Dockerを使用しなかったときに変更した"run.sh"はもとに戻してください。
Autowareのバージョンは1.9.0、ROSはUbuntu16.04なのでROSはKineticです。kameyama@u1604:~/autoware/docker/generic$ sudo ./run.sh -t 1.9.0 -r kinetic -c on Using options: ROS distro: kinetic Image name: autoware/autoware Tag prefix: 1.9.0 Cuda support: on Pre-release version: off UID: <0> Launching autoware/autoware:1.9.0-kinetic-cuda Unable to find image 'autoware/autoware:1.9.0-kinetic-cuda' locally docker: Error response from daemon: manifest for autoware/autoware:1.9.0-kinetic-cuda not found: manifest unknown: manifest unknown. See 'docker run --help'. kameyama@u1604:~/autoware/docker/generic$エラーがでました。どうもautoware/autoware:1.9.0-kinetic-cudaというdocker imageが無いようです。
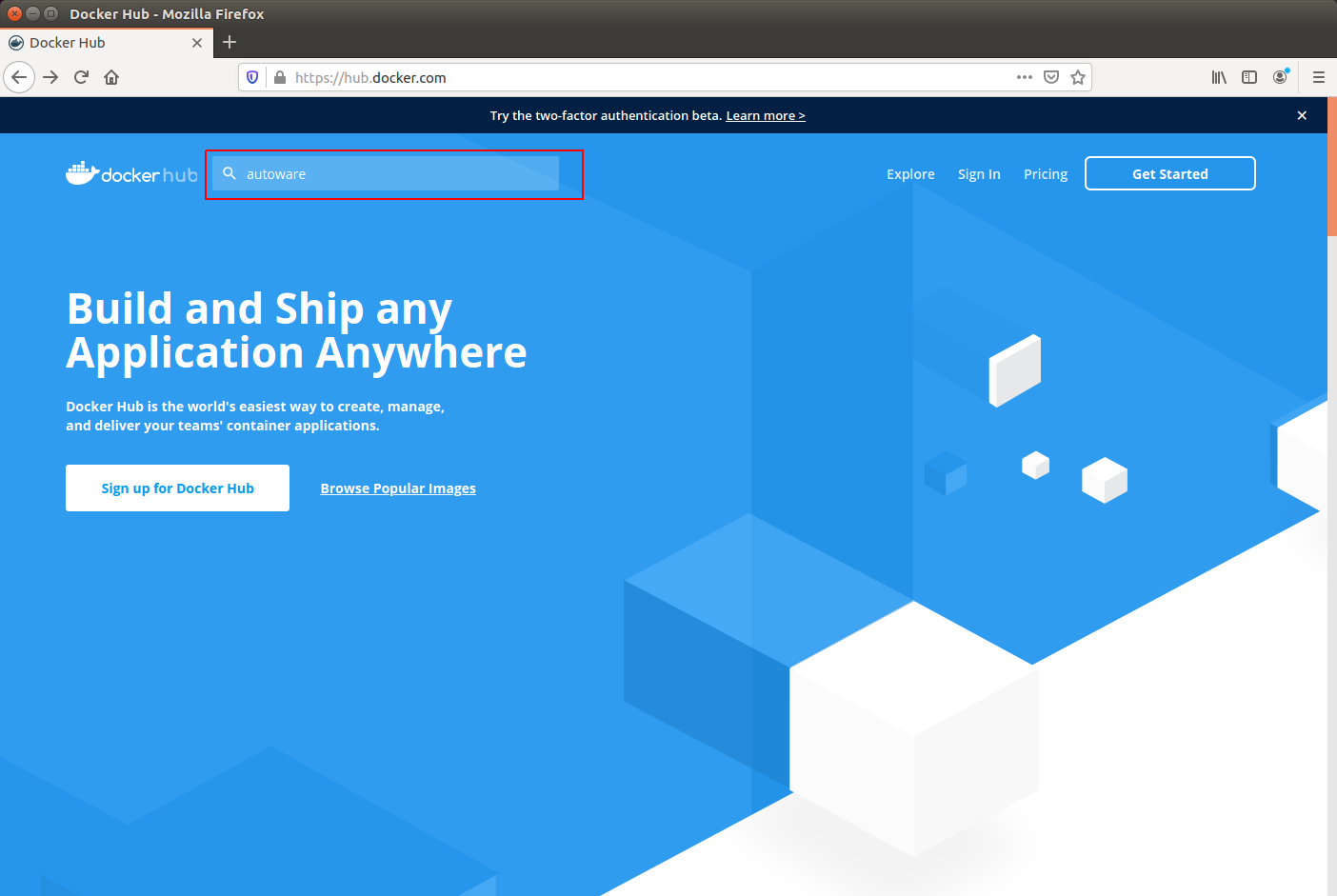
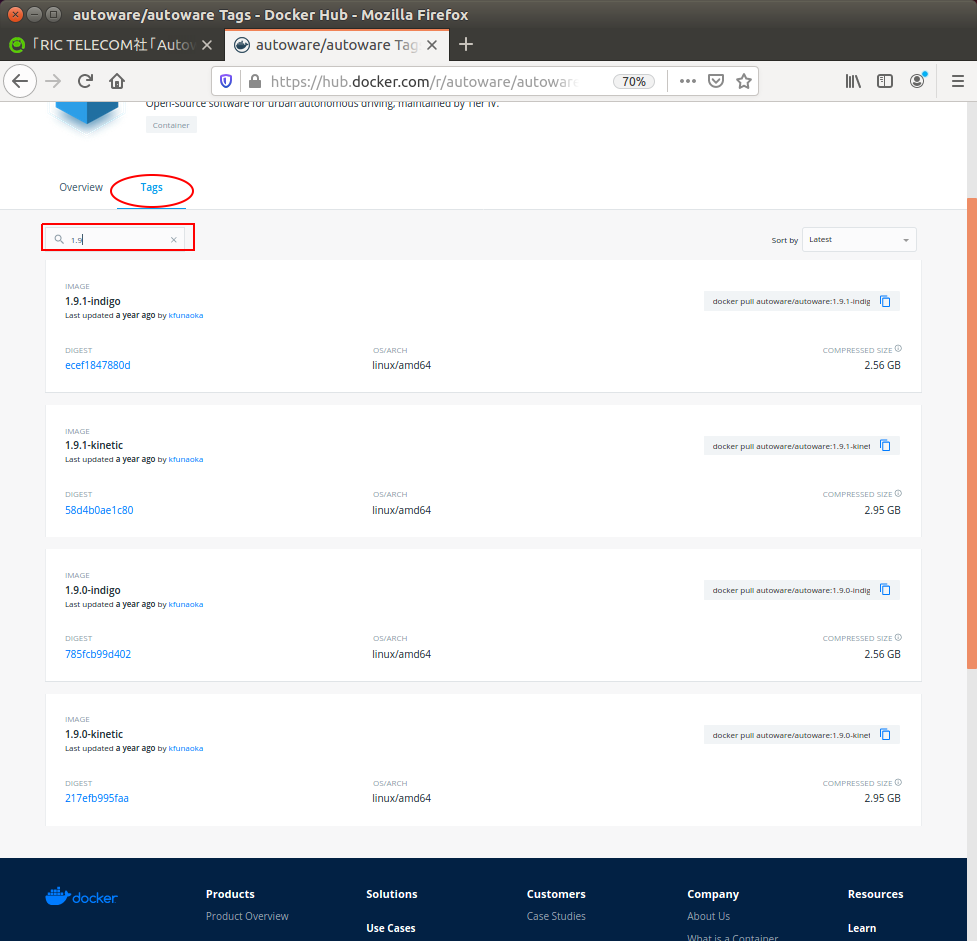
Docker-hubでイメージを探してみます。検索はDocker Hunの公式サイトから行います。
https://hub.docker.com/
以下、画像はDocker Hub公式サイトからの引用です。
"autoware"で検索します(赤四角部分)。
複数検索されますが、"Autoware/autoware"が正解です。
タブ"tag"を選択し、"1.9"で検索してみたところ、確かにありません。いっそのことUbuntu 16.04で使える最新の1.12.0にしてみます。
1.12.0を使用する場合、sudoで起動することができませんでした。自ユーザをdockerグループに追加します。
https://qiita.com/tifa2chan/items/9dc28a56efcfb50c7fbe
追加後はdockerサービス一式を再起動する必要があります。面倒なので装置再起動しました。
kameyama@u1604:~/autoware/docker/generic$ ./run.sh -t 1.12.0 -r kinetic Using options: ROS distro: kinetic Image name: autoware/autoware Tag prefix: 1.12.0 Cuda support: on Pre-release version: off UID: <1000> Launching autoware/autoware:1.12.0-kinetic-cuda Unable to find image 'autoware/autoware:1.12.0-kinetic-cuda' locally 1.12.0-kinetic-cuda: Pulling from autoware/autoware f7277927d38a: Pulling fs layer 8d3eac894db4: Pulling fs layer edf72af6d627: Pulling fs layer 3e4f86211d23: Waiting 043ed1e8467c: Pulling fs layer e012378676bb: Waiting b660a670cd96: Waiting 9d36c8c1d464: Pulling fs layer 9aa65fdb2ffc: Waiting 0d6158c90f97: Waiting d88a338206e9: Pull complete 9e53d5eaa46e: Pull complete bd1a8624b870: Pull complete feff03c28825: Pull complete e15ebf0d9f8f: Pull complete 3d758a5f8930: Pull complete 9144371c59ca: Pull complete 3fb4ac91b3db: Pull complete 88a50a258b75: Pull complete feb2fd5f57e3: Pull complete 5d2e178afc7d: Pull complete fc9d69c0c60a: Pull complete c2c4a7b696e8: Pull complete cd2510ba8834: Pull complete 3a95675ea1d8: Pull complete 49cb36c7682b: Pull complete ef1393e2650f: Pull complete 25eaca28f128: Pull complete 423a4e601079: Pull complete 5cdf53770173: Pull complete 42f136333de3: Pull complete 3f278d8fa51b: Pull complete ba80186b4625: Pull complete Digest: sha256:7c2fdb7974b8643230ac9275f0c647f49c602f91a6db8227b3e8ba1ff83ab253 Status: Downloaded newer image for autoware/autoware:1.12.0-kinetic-cuda To run a command as administrator (user "root"), use "sudo <command>". See "man sudo_root" for details. autoware@u1604:~$1.12.0のAutoware dockerイメージが起動しました。
1.12.0以降ではAutowareの起動方法も違っています。
https://gitlab.com/autowarefoundation/autoware.ai/autoware/-/wikis/ROSBAG-Demoautoware@u1604:~/Autoware$ source install/setup.bash autoware@u1604:~/Autoware$ ls autoware.ai.repos build install log src autoware@u1604:~/Autoware$ roslaunch runtime_manager runtime_manager.launch ... logging to /home/autoware/.ros/log/8f141552-302e-11ea-b922-74d435181e13/roslaunch-u1604-1043.log Checking log directory for disk usage. This may take awhile. Press Ctrl-C to interrupt Done checking log file disk usage. Usage is <1GB. started roslaunch server http://u1604:40423/ SUMMARY ======== PARAMETERS * /rosdistro: kinetic * /rosversion: 1.12.14 NODES / run (runtime_manager/run) auto-starting new master process[master]: started with pid [1053] ROS_MASTER_URI=http://localhost:11311 setting /run_id to 8f141552-302e-11ea-b922-74d435181e13 process[rosout-1]: started with pid [1066] started core service [/rosout] process[run-2]: started with pid [1069] [run-2] process has finished cleanly log file: /home/autoware/.ros/log/8f141552-302e-11ea-b922-74d435181e13/run-2*.logこれでROSツールの呼び出しにも成功しました。
以上です。
※各種製品名は、各社の製品名称、商標または登録商標です。本記事に記載されているシステム名、製品名には、必ずしも商標表示((R)、TM)を付記していません。



- 投稿日:2020-01-21T11:23:12+09:00
組み合わせ爆発の凄さ
組み合わせ爆発の凄さ
自分の好きなプログラミング言語で理解してもらおうと言語別の索引をつけてみました。私はプログラムを自分で書き換えて試さないと理論を理解できない傾向にあります。いろいろ書き換えてみようと思っています。たぶんpython。
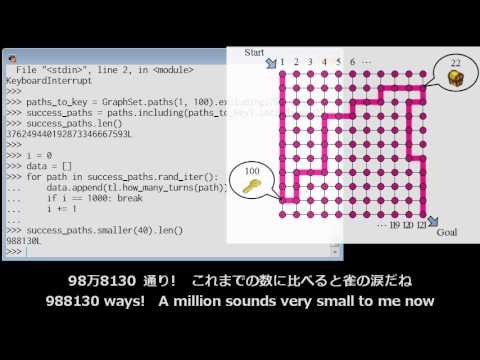
『フカシギの数え方』 おねえさんといっしょ! みんなで数えてみよう!
『フカシギの数え方』 おねえさんといっしょ! みんなで数えてみよう!
https://www.youtube.com/watch?v=Q4gTV4r0zRs
同じところを ? ??? ??2度通らない経路の数を数えるアルゴリズムについて 川原 純 湊 真一 JETRO 湊離散構造処理系プロジェクト/北海道大学 情報科学研究科
http://www-erato.ist.hokudai.ac.jp/docs/img/main3.pdf「フカシギの数え方」― 組合せ爆発に立ち向かう 最先端アルゴリズム技術 湊 真一 北海道大学 / JST ERATO
https://www.nii.ac.jp/userimg/openhouse/2013/lec_minato.pdfフカシギおねえさん問題の高速計算アルゴリズム 岩下 洋哲 JST ERATO 湊離散構造処理系プロジェクト 2013/7/26
http://www.edu.kobe-u.ac.jp/istc-tamlab/cspsat/pdf-open/cspsat2_mtg203_iwashita.pdfメディアラボ第11期展示「フカシギの数え方」展示解説
https://www.youtube.com/watch?v=TcjSu3_LMKY
「フカシギの数え方」 同じところを2度通らない道順の数
https://www.youtube.com/watch?v=ge8vy4tc_kQ
メディアラボ第11期展示「フカシギの数え方」インタビュー
https://www.youtube.com/watch?v=SfC0W1TQcVg
日本科学未来館第11期メディアラボ展示「フカシギの数え方」
http://www-erato.ist.hokudai.ac.jp/html/php/sub_html.php?id=19フロンティア法:BDD/ZDDを用いた 高速なグラフ列挙索引化アルゴリズム
湊 真一 北海道大学 情報科学研究科 / JST ERATO 2012年8月9日
https://www.ieice.org/~netsci/wp-content/uploads/2012/08/NetSci201208_Minato.pdf同じ所を2度通らない道順の数
http://shogo82148.github.io/letscount/おねぇさぁぁぁぁぁん! 日本科学未来館のアニメに狂気が宿っていると話題に
https://nlab.itmedia.co.jp/nl/articles/1209/11/news104.htmlおねえさんのコンピュータを作ってみた
https://shogo82148.github.io/blog/2012/09/22/letscount/vim
Vimおねえさんといっしょ!みんなで数えてみよう!: pla.log
http://pla.asablo.jp/blog/2012/09/30/6588034perl
「フカシギの数え方」をPerlで解く
http://hiratara.hatenadiary.jp/entry/20120916/1347796826VB(Visual Basic)
僕も組み合わせ爆発の凄さをみんなに伝えたくなりました^0^!
https://www.nicovideo.jp/watch/sm18920750
https://box.yahoo.co.jp/guest/viewer?sid=box-l-dohryx5swstii3sh27xxkh535i-1001&uniqid=476500bf-e1ff-4810-8ee6-0777e11a4c92&viewtype=detailPHP
『フカシギの数え方』 おねえさんといっしょ! PHPで数えてみよう!
https://sisidovski.hatenablog.com/entry/2012/09/13/023947
https://github.com/sisidovski/CombinationalExplosionjava
2012-10-19 おねえさんを組み合わせ爆発から救う:完結編おねえさんは星になった
https://nowokay.hatenablog.com/entry/20121019/1350607290python
ZDDを自作して数え上げお姉さんを救ってみた
https://qiita.com/cabernet_rock/items/01c48dd06178ba0768f9C++ + python
おねえさんのコンピュータを作ってみた
2012年9月15日土曜日「フカシギの数え方」の問題を解いてみた
http://handasse.blogspot.com/2012/09/blog-post.htmlGraphillion
Graphillion: 数え上げおねえさんを救え / Don't count naively
https://www.youtube.com/watch?v=R3Hp9k876Kk
「フカシギの数え方」から広がる世界 ~離散構造処理の現在と今後の展望~
湊 真一 北海道大学 大学院 情報科学研究科 教授
http://www.kecl.ntt.co.jp/openhouse/2014/talk/invite2/talk_minato.pdfオープンハウス2013:基調講演「フカシギの数え方― 組合せ爆発に立ち向かう最先端アルゴリズム技術」湊真一
https://www.youtube.com/watch?v=8xqEBQc1nTo
サイエンティスト・トーク「フカシギの不思議」
https://www.youtube.com/watch?v=QVVHEZCdY_k
参考資料(reference)
graphillionを使ってみた
https://qiita.com/cabernet_rock/items/50f955afc16287244154dockerで
zshdocker run -v /tmp/work:/tmp/work -it kaizenjapan/zdd /bin/bashソフトが導入済みの状態。プログラムは/home/pythonに入れてある。
プログラムは下記のようにprintを加えて出力するように。
gra.py# https://qiita.com/cabernet_rock/items/50f955afc16287244154 # https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3 # https://qiita.com/kaizen_nagoya/items/3a8d89f095489b6e1f56 # https://qiita.com/kaizen_nagoya/items/819f10124ec453b7ef27 # 必要なモジュールのインポート from graphillion import GraphSet import graphillion.tutorial as tl import time # 計算時間を調べる。 # グリッドのサイズを指定 universe = tl.grid(2, 2) GraphSet.set_universe(universe) tl.draw(universe) start = 1 # スタート位置 goal = 9 # ゴールの位置 paths = GraphSet.paths(start, goal) print (len(paths)) # key = 4 # 1箇所目 treasure = 2 # 2箇所目 paths_to_key = GraphSet.paths(start, key).excluding(treasure) treasure_paths = paths.including(paths_to_key).including(treasure) print (len(treasure_paths)) # universe = tl.grid(8, 8) # 9×9のグリッド GraphSet.set_universe(universe) start = 1 goal = 81 s = time.time() # 計算開始時刻 paths = GraphSet.paths(start, goal) print (time.time() - s )# 計算時間 print (len(paths))実行結果は
docker/ubuntu# python3 gra.py 12 2 0.25122714042663574 32665984869816429を12にしたらKilledで終わらなかった。
docker 作成と登録
なお、上記docker hubへ登録したものは次のように作成した。
zsh$ docker run -v /tmp/work:/tmp/work -it ubuntu /bin/bash起動したら
docker/ubuntu# apt update;apt -y upgrade # apt install -y python3 python3-pip vim wget curl sudo apt-utils # pip3 insatll networks matplotlib graphillionapt installでvim以降は個人的に利用するために入れたもの。
docker hub への登録は
zsh$ docker commit 04b268b5a441 kaizenjapan/zdd $ docker push kaizenjapan/zdd04b268b5a441 の値は、docker psでもわかるが、コマンドプロンプトにも値が出てる。
関連資料(related document)
今日のpython error:ModuleNotFoundError: No module named
https://qiita.com/kaizen_nagoya/items/3a8d89f095489b6e1f56今日のpython error: invalid keyword argument for this function
https://qiita.com/kaizen_nagoya/items/819f10124ec453b7ef27文書履歴(document history)
ver. 0.01 初稿 20200121 午前
ver. 0.02 プログラム追記 20200121 昼
ver. 0.03 docker登録 20200121 午後






- 投稿日:2020-01-21T11:23:12+09:00
『フカシギの数え方』 おねえさんといっしょ:組み合わせ爆発の凄さ
組み合わせ爆発の凄さ
自分の好きなプログラミング言語で理解してもらおうと言語別の索引をつけてみました。私はプログラムを自分で書き換えて試さないと理論を理解できない傾向にあります。いろいろ書き換えてみようと思っています。たぶんpython。
『フカシギの数え方』 おねえさんといっしょ! みんなで数えてみよう!
『フカシギの数え方』 おねえさんといっしょ! みんなで数えてみよう!
https://www.youtube.com/watch?v=Q4gTV4r0zRs
同じところを ? ??? ??2度通らない経路の数を数えるアルゴリズムについて 川原 純 湊 真一 JETRO 湊離散構造処理系プロジェクト/北海道大学 情報科学研究科
http://www-erato.ist.hokudai.ac.jp/docs/img/main3.pdf「フカシギの数え方」― 組合せ爆発に立ち向かう 最先端アルゴリズム技術 湊 真一 北海道大学 / JST ERATO
https://www.nii.ac.jp/userimg/openhouse/2013/lec_minato.pdfフカシギおねえさん問題の高速計算アルゴリズム 岩下 洋哲 JST ERATO 湊離散構造処理系プロジェクト 2013/7/26
http://www.edu.kobe-u.ac.jp/istc-tamlab/cspsat/pdf-open/cspsat2_mtg203_iwashita.pdfメディアラボ第11期展示「フカシギの数え方」展示解説
https://www.youtube.com/watch?v=TcjSu3_LMKY
「フカシギの数え方」 同じところを2度通らない道順の数
https://www.youtube.com/watch?v=ge8vy4tc_kQ
メディアラボ第11期展示「フカシギの数え方」インタビュー
https://www.youtube.com/watch?v=SfC0W1TQcVg
日本科学未来館第11期メディアラボ展示「フカシギの数え方」
http://www-erato.ist.hokudai.ac.jp/html/php/sub_html.php?id=19フロンティア法:BDD/ZDDを用いた 高速なグラフ列挙索引化アルゴリズム
湊 真一 北海道大学 情報科学研究科 / JST ERATO 2012年8月9日
https://www.ieice.org/~netsci/wp-content/uploads/2012/08/NetSci201208_Minato.pdf同じ所を2度通らない道順の数
http://shogo82148.github.io/letscount/おねぇさぁぁぁぁぁん! 日本科学未来館のアニメに狂気が宿っていると話題に
https://nlab.itmedia.co.jp/nl/articles/1209/11/news104.htmlおねえさんのコンピュータを作ってみた
https://shogo82148.github.io/blog/2012/09/22/letscount/vim
Vimおねえさんといっしょ!みんなで数えてみよう!: pla.log
http://pla.asablo.jp/blog/2012/09/30/6588034perl
「フカシギの数え方」をPerlで解く
http://hiratara.hatenadiary.jp/entry/20120916/1347796826VB(Visual Basic)
僕も組み合わせ爆発の凄さをみんなに伝えたくなりました^0^!
https://www.nicovideo.jp/watch/sm18920750
https://box.yahoo.co.jp/guest/viewer?sid=box-l-dohryx5swstii3sh27xxkh535i-1001&uniqid=476500bf-e1ff-4810-8ee6-0777e11a4c92&viewtype=detailPHP
『フカシギの数え方』 おねえさんといっしょ! PHPで数えてみよう!
https://sisidovski.hatenablog.com/entry/2012/09/13/023947
https://github.com/sisidovski/CombinationalExplosionjava
2012-10-19 おねえさんを組み合わせ爆発から救う:完結編おねえさんは星になった
https://nowokay.hatenablog.com/entry/20121019/1350607290python
ZDDを自作して数え上げお姉さんを救ってみた
https://qiita.com/cabernet_rock/items/01c48dd06178ba0768f9C++ + python
おねえさんのコンピュータを作ってみた
2012年9月15日土曜日「フカシギの数え方」の問題を解いてみた
http://handasse.blogspot.com/2012/09/blog-post.htmlGraphillion
Graphillion: 数え上げおねえさんを救え / Don't count naively
https://www.youtube.com/watch?v=R3Hp9k876Kk
「フカシギの数え方」から広がる世界 ~離散構造処理の現在と今後の展望~
湊 真一 北海道大学 大学院 情報科学研究科 教授
http://www.kecl.ntt.co.jp/openhouse/2014/talk/invite2/talk_minato.pdfオープンハウス2013:基調講演「フカシギの数え方― 組合せ爆発に立ち向かう最先端アルゴリズム技術」湊真一
https://www.youtube.com/watch?v=8xqEBQc1nTo
サイエンティスト・トーク「フカシギの不思議」
https://www.youtube.com/watch?v=QVVHEZCdY_k
参考資料(reference)
graphillionを使ってみた
https://qiita.com/cabernet_rock/items/50f955afc16287244154dockerで
zshdocker run -v /tmp/work:/tmp/work -it kaizenjapan/zdd /bin/bash/tmp/workはdockerを起動する前に存在するフォルダ。:/tmp/workは、docker上にできるが、docker終了後はdocker hubに登録してもdocker上には残らないので、docker hubに登録する場合は、必要なデータは/home/pythonのような入れ物を作って保存しておくと良い。
ソフトが導入済みの状態。プログラムは/home/pythonに入れてある。プログラムは下記のようにprintを加えて出力するように。
gra.py# https://qiita.com/cabernet_rock/items/50f955afc16287244154 # https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3 # https://qiita.com/kaizen_nagoya/items/3a8d89f095489b6e1f56 # https://qiita.com/kaizen_nagoya/items/819f10124ec453b7ef27 # 必要なモジュールのインポート from graphillion import GraphSet import graphillion.tutorial as tl import time # 計算時間を調べる。 # グリッドのサイズを指定 universe = tl.grid(2, 2) GraphSet.set_universe(universe) tl.draw(universe) start = 1 # スタート位置 goal = 9 # ゴールの位置 paths = GraphSet.paths(start, goal) print (len(paths)) # key = 4 # 1箇所目 treasure = 2 # 2箇所目 paths_to_key = GraphSet.paths(start, key).excluding(treasure) treasure_paths = paths.including(paths_to_key).including(treasure) print (len(treasure_paths)) # universe = tl.grid(8, 8) # 9×9のグリッド GraphSet.set_universe(universe) start = 1 goal = 81 s = time.time() # 計算開始時刻 paths = GraphSet.paths(start, goal) print (time.time() - s )# 計算時間 print (len(paths))実行結果は
docker/ubuntu# python3 gra.py 12 2 0.25122714042663574 32665984869816429を12にしたらKilledで終わらなかった。10,11でもkilled.メモリを使い果たしているかも。
主記憶16GBだがdockerに割り当てが少ないかも。
dockerに12GBに割り当てて10で実行したら、12時間たつがまだkilledにはなっていない。
docker 作成と登録
なお、上記docker hubへ登録したものは次のように作成した。
zsh$ docker run -v /tmp/work:/tmp/work -it ubuntu /bin/bash起動したら
docker/ubuntu# apt update;apt -y upgrade # apt install -y python3 python3-pip vim wget curl sudo apt-utils # pip3 insatll networks matplotlib graphillionapt installでvim以降は個人的に利用するために入れたもの。
docker hub への登録は
zsh$ docker commit 04b268b5a441 kaizenjapan/zdd $ docker push kaizenjapan/zdd04b268b5a441 の値は、docker psでもわかるが、コマンドプロンプトにも値が出てる。
関連資料(related document)
今日のpython error:ModuleNotFoundError: No module named
https://qiita.com/kaizen_nagoya/items/3a8d89f095489b6e1f56今日のpython error: invalid keyword argument for this function
https://qiita.com/kaizen_nagoya/items/819f10124ec453b7ef27後書き(post script)
この資料は、Knuthの著作に出てくる問題で、湊 真一 が考案したZDD方式をKnuthの著作の新版でも取り上げている題材です。
http://www.lab2.kuis.kyoto-u.ac.jp/minato/index-j.html
Knuthの名著"The Art of Computer Programming"(Vol.4, Fascicle 1, 2009年)において, 湊が考案したデータ構造「ZDD」 が項目として詳しく掲載された(日本人初)
https://www.amazon.co.jp/dp/4048930559/
日本のプログラマが、この題材をよりよくプログラミングすることにより、技術の伝搬速度を高めようとするための試みです。
ありとあらゆる言語で記述してみて、分かりやすく、応用しやすい記述を模索します。
文書履歴(document history)
ver. 0.01 初稿 20200121 午前
ver. 0.02 プログラム追記 20200121 昼
ver. 0.03 docker登録 20200121 午後
ver. 0.04 Knuth追記 20200122 午前
ver. 0.05 The Art of Computer Programming 表紙追記 20200122午後

- 投稿日:2020-01-21T01:53:03+09:00
docker-composeでMySQLのrootパスワードを忘れた場合
docker-composeでMySQLのrootパスワードを忘れた場合に自分が行った対処のメモです。
権限なしでmysqlコンテナを起動する
パスワードをリセットするためには権限テーブルを非参照で起動する必要があります。下記のオプションをdocker-compose.ymlに追加。
command: mysqld --skip-grant-tables --skip-networkingdocker-compose.ymlmysql: build: context: ./mysql args: - MYSQL_VERSION=${MYSQL_VERSION} environment: - MYSQL_DATABASE=${MYSQL_DATABASE} - MYSQL_USER=${MYSQL_USER} - MYSQL_PASSWORD=${MYSQL_PASSWORD} - MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASSWORD} - TZ=${WORKSPACE_TIMEZONE} command: mysqld --skip-grant-tables --skip-networking volumes: - ${DATA_PATH_HOST}/mysql:/var/lib/mysql - ${MYSQL_ENTRYPOINT_INITDB}:/docker-entrypoint-initdb.d ports: - "${MYSQL_PORT}:3306" networks: - backendコンテナを再起動し、変更を反映させます。
>docker-compose stop mysql >docker-compose up -d mysqlパスワード変更
mysqlコンテナに入る >docker-compose exec mysql bash パスワードなしでログインできるようになる mysql> mysql -u root ユーザ名、ホスト名を確認 mysql> use mysql; mysql> SELECT user, host FROM user; パスワードを変更 mysql> SET PASSWORD FOR ユーザ名@ホスト名 = 'パスワード';最後にcommand: mysqld --skip-grant-tables --skip-networkingをdocker-compose.ymlから削除し、再起動すれば完了。
- 投稿日:2020-01-21T01:17:23+09:00
【スターターキット】Scrapy&MariaDB&Django&Dockerでデータ自動収集ボットシステムを構築する
背景
世の中にあるWebサービスのデータベースを自動で同期して、本家にはない付加価値をつけることによって、手軽にニーズのあるWebサービスを作ることができます。
例えばECサイトのデータをスクレイピングして自前でデータベースとして持っておき、それに対して本家にはない検索方法を提供して、リンクを貼り、アフィリエイトで稼ぐみたいな軽量なビジネスモデルが個人事業のレベルで可能です。
このようなパターンはいくらでも考えられるのですが、とにかくまずはスクレイピングスクリプトを書いて、自動でデータ収集して、きちんと構造化して、それをなるべく最新の状態に保てるようなボットとインフラが必要になるわけです。今回はどのようなパターンであれ、アイデアを思いついてから、立ち上げまで作業を効率化できるようにサンプルテンプレートを作ってみました。
テンプレートといっても必要な以下のようなミドルウェアやフレームワーク込みでDockerで環境構築するところまでやってみようと思います。従ってDockerが使える人なら読み飛ばしてもこちらのコードさえあれば即実行できます。
- Scrapy
- MariaDB
- Django
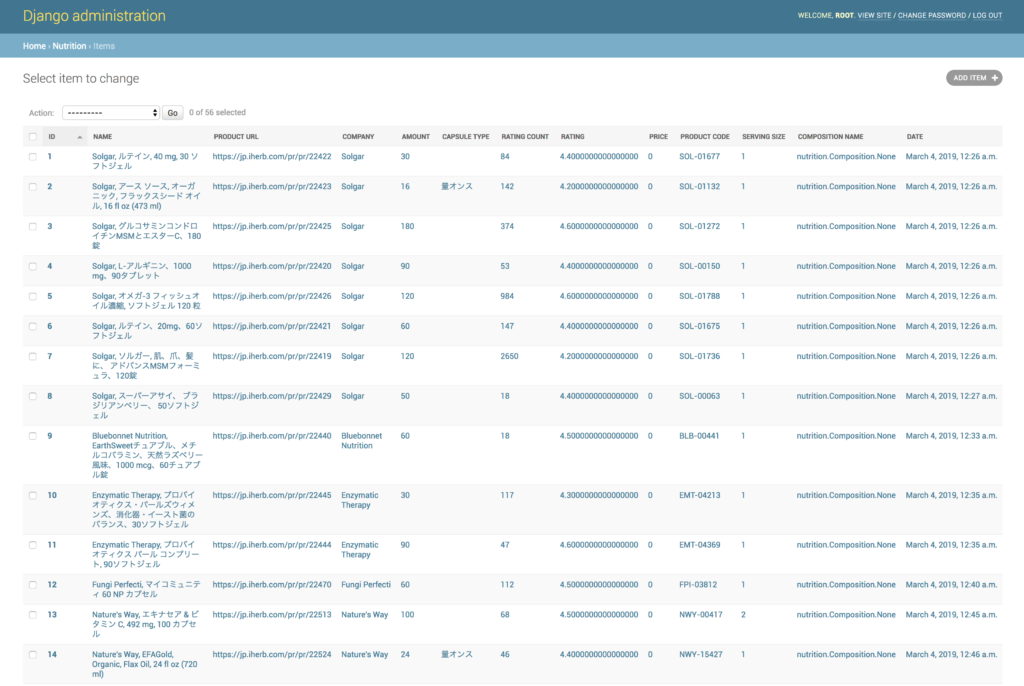
今回は、海外のサプリを輸入代行する大手ECサイトIHerbをターゲットにDBを構築し、Django Adminでデータの内容を閲覧できるところまで説明していきます。
とりあえず動かしたい人へ
git clone xxxx cd xxxx docker-compose up -d --build ./start.shGithubにソースコード置いてます。スターターキットとしてお使いください。
https://github.com/makotunes/scrapy-django-exampleDocker環境をローカルにフォワーディングしている場合は、http://localhost/admin にアクセスします。初期ユーザーはroot、パスワードはinitpassとなっています。ホスト名はDockerの依存する環境によって違うので注意してください。スクレイピングと同時並行で取得されたデータを確認することができます。
今回のサンプルとして、iHerbの商品の価格や栄養素を取得していくコードを書いていきます。第一段階として、サイトのHTML構造を観察し、必要なデータを取り出すスクレイピングについて見ていきます。まずiHerbの商品ページのルールは「 https://www.iherb.com/pr/pr/[ID] 」という規則に従っています。1からインクリメントで順番になめていけば良いはずです。IDが欠番になっていたり在庫切れの場合は取得できないですから、これもハンドリングしておく必要があるでしょう。以降、ざっくり主要なコンポーネントの実装について簡単に触れていきます。
Scrapyの基本的な使い方
ScrapyはPythonの多機能なスクレイピングライブラリです。まず基本的な作法として以下のようにscrapy.Spiderを継承したクラスを作っておきます。start_urlsにリスト型でスクレイピングするターゲットを入れておきます。そして、parseメソッドをオーバーライドして、responseを受け取りSelectorに変換します。
import os import scrapy from scrapy.selector import Selector class Spider(scrapy.Spider): name = 'items' start = int(os.getenv('SCRAPY_START_INDEX', 22419)) target_range = int(os.getenv('SCRAPY_NUM_ITEMS', 1000)) start_urls = ['https://www.iherb.com/pr/pr/' + str(x) for x in range(start, start + target_range) ] def parse(self, response): time.sleep(random.randint(2, 3)) product_url = response.url self.logger.info('url=%s', product_url) sel = Selector(response)selectorはHTMLの木構造を保持していて、任意のノードを取り出せるわけです。ここで、XPathは木構造の中から特定のノードを指定する文字列表現になります。
def get_product_name(sel): product_name = sel.xpath('//*[@id="name"]/text()').extract_first() self.logger.info('product_name = %s', product_name) return product_name必要な要素を表現するXPath文字列を取置します。難しく考える必要はありません。簡単な方法としては、Chromeで任意の要素で右クリックしたときに「検証」というメニューがあるのでそれを押してみてください。すると開発者コンソールを表示され、Elementsタブ内でHTML要素が青く選択されます。ここでさらに右クリックして、「Copy」 ⇛ 「Copy XPath」を押すとクリックボードに文字列がコピーされます。これをさきほどのクラスの中に書いていけばいいだけです。
Djangoについて
スクレイピングで値が取れれば、そのままファイルに書き出しで任務完了でも良いのですが、このデータを使ってアプリケーションを作ろうと考えているなら、最初からDBに保存して置いたほうが良いと思います。特に、一度取得して終わりではなく、定期的に取得して最新の状態を保つ必要のあるアプリケーションの場合は、取得・保管・利用のサイクルが効率的に回るように、スクレイピングモジュールの開発段階からしっかりRDBでモデルを定義していくことを私はおすすめします。
Djangoには中心的な概念を説簡単にご紹介しておきます。
ファイル 機能 settings.py アプリ全体の設定を定義します。 models.py データベースの構造を定義します。 views.py 機能そのものを記述します。 urls.py URLと機能のマッピングを担当します。 admin.py 管理者用サイトの機能を生成します。 permissions.py 機能に対する権限をユーザーごとに記述します。 serializers.py Rest API用にデータ構造を定義します。 Djangoの開発は上記のようなスクリプトを実装します。settings.py、models.py、views.py、urls.pyの4つが必須要素ですが、admin.pyはデータベースに簡単にアクセスするWebサイトを簡単に構築でき、大変便利なので私は使用しています。この役目はphpMyAdminのようなものを使用しても問題ないでしょう。permissions.py、serializers.pyはRest APIを生成するDjangoの拡張ライブラリであるdjangorestframeworkによって使用されます。
スクレイピングしたデータを保存して可視化するという点で重要なのはmodels.pyだけであり、ここさえしっかり書ければ、あとの実装はこの段階では問題ないです。この記事ではmodels.pyの部分だけご紹介しておきます。
データモデル
テーブル名 機能 Item 商品テーブル Composition 栄養素とその成分量のテーブル Nutrition 栄養素テーブル Item,Composition,Nutritionの3つのテーブルで構成されます。必要に応じて正規化していきます。この作業はデータ取得後になると難しくなってくるので、スクレイピング実装の段階でモデル実装もちゃんとやっておこうと思います。サンプルコードでは、第2正規化までやっておきました。
このモデルについてですが、DjangoにはDBのモデル構造を表現できるORマッパーが含まれています。従って、直接DBにSQL操作を行う必要はありません。ただし、データ構造が変更さびに、マイグレーションというテーブル構造の変更に対応するSQL操作を実行する必要がありますが、ORマッパーはこの点もスクリプトで表現されたモデルに従って自動でSQLを生成し、コマンドから一発で実行してくれます。この記事のサンプルコードでは、以下のスクリプトで、簡単に呼び出せるようにしてあります。
./migrate.shfrom django.db import models class Nutrition(models.Model): id = models.AutoField('ID', primary_key=True) name = models.CharField('Name', max_length=255, blank=True, null=True) description = models.TextField('Description', blank=True, null=True) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.name) class Composition(models.Model): id = models.AutoField('ID', primary_key=True) name = models.ForeignKey('Nutrition', related_name='composition_nutrition_id') amount = models.IntegerField('Amount', default=0, blank=False, null=False) unit = models.CharField('Unit', max_length=20,blank=True, null=True) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.name) + ':' + str(self.amount) + ' ' + str(self.unit) class Item(models.Model): id = models.AutoField('ID', primary_key=True) product_name = models.CharField('Name', max_length=100,blank=True, null=True) product_url = models.CharField('Product URL', max_length=999,blank=True, null=True) company = models.CharField('Company', max_length=100,blank=True, null=True) amount = models.IntegerField('Amount', default=0, blank=False, null=True) capsule_type = models.CharField('Capsule Type', max_length=20,blank=True, null=True) rating_count = models.IntegerField('Rating Count', default=0, blank=False, null=False) rating = models.DecimalField('Rating', max_digits=32, decimal_places=16, default=0.0) price = models.IntegerField('Price', default=0, blank=False, null=True) product_code = models.CharField('Product Code', max_length=100,blank=True, null=True) serving_size = models.IntegerField('Serving Size', default=1, blank=False, null=True) composition = models.ManyToManyField(Composition) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.product_name)データの保存
スクレイピングできた値、データ・セットを順番にMariaDBに保存していきます。簡略化して書くと以下ようになります。models.pyで定義したORマッパークラスのインスタンスに値を渡していき、save()メソッドでDBに反映します。以下のコードは簡略化して書いてあります。実際の実装についてはGit Hubで提供しているサンプルコードを見てください。
from nutrition.models import Item from scrapy.selector import Selector sel = Selector(response) product_name = get_product_name(sel) item = Item() item.product_name = product_name item.save()実際やってみると分かりますが、Webサイトのデータというのは完璧なものはなく、少なからず表記の不統一などがあり、一発で綺麗なデータ・セットにはならないことがほとんどです。従って表記の不統一を吸収するような実装が必要になってきます。モデルを厳密に定義しながら実装することはスクレイピングの精度を高めていく過程そのもと言えるでしょう。
ここまでできたら、次はアプリ側を実装していくフェイズになります。Djangoにはテンプレートエンジン、つまりサーバーサイドで動的にHTMLをレンダリングする機構がありますが、私はモバイル用途やSPA(Reactなど)などを想定して、Rest APIによる構成を中核に位置づけています。実はソースコードはサンプルコードにすでに含まれています。機会があればこの辺についても詳しく書いていきます。
おわりに
読んで頂きありがとうございました。
最後に開発中の個人アプリの紹介をさせて下さい。Mockers
https://mockers.io「Mockers」は、「危険すぎる」と話題の大規模教師なし機械学習技術「GPT-2」を搭載した多言語対応オンライン自動テキスト生成ツールです。 「Mockers」を使用すると、この素晴らしい技術をWeb上で簡単に使用できるだけでなく、Webサイトの記事やTwitterのツイートを学習して、そのスタイルやコンテキストを模倣して、関連性の高い文章を自動生成し、WordpressやTwitterに自動的に投稿することができます。
- 投稿日:2020-01-21T01:17:23+09:00
Scrapy&MariaDB&Djangoでデータ自動収集ボットをDockerで構築する
背景
世の中にあるWebサービスのデータベースを自動で同期して、本家にはない付加価値をつけることによって、手軽にニーズのあるWebサービスを作ることができます。
例えばECサイトのデータをスクレイピングして自前でデータベースとして持っておき、それに対して本家にはない検索方法を提供して、リンクを貼り、アフィリエイトで稼ぐみたいな軽量なビジネスモデルが個人事業のレベルで可能です。
このようなパターンはいくらでも考えられるのですが、とにかくまずはスクレイピングスクリプトを書いて、自動でデータ収集して、きちんと構造化して、それをなるべく最新の状態に保てるようなボットとインフラが必要になるわけです。今回はどのようなパターンであれ、アイデアを思いついてから、立ち上げまで作業を効率化できるようにサンプルテンプレートを作ってみました。
テンプレートといっても必要な以下のようなミドルウェアやフレームワーク込みでDockerで環境構築するところまでやってみようと思います。従ってDockerが使える人なら読み飛ばしてもこちらのコードさえあれば即実行できます。
- Scrapy
- MariaDB
- Django
今回は、海外のサプリを輸入代行する大手ECサイトIHerbをターゲットにDBを構築し、Django Adminでデータの内容を閲覧できるところまで説明していきます。
とりあえず動かしたい人へ
git clone xxxx cd xxxx docker-compose up -d --build ./start.shGithubにソースコード置いてます。
https://github.com/makotunes/scrapy-django-exampleDocker環境をローカルにフォワーディングしている場合は、http://localhost/admin にアクセスします。初期ユーザーはroot、パスワードはinitpassとなっています。ホスト名はDockerの依存する環境によって違うので注意してください。スクレイピングと同時並行で取得されたデータを確認することができます。
今回のサンプルとして、iHerbの商品の価格や栄養素を取得していくコードを書いていきます。第一段階として、サイトのHTML構造を観察し、必要なデータを取り出すスクレイピングについて見ていきます。まずiHerbの商品ページのルールは「 https://www.iherb.com/pr/pr/[ID] 」という規則に従っています。1からインクリメントで順番になめていけば良いはずです。IDが欠番になっていたり在庫切れの場合は取得できないですから、これもハンドリングしておく必要があるでしょう。以降、ざっくり主要なコンポーネントの実装について簡単に触れていきます。
Scrapyの基本的な使い方
ScrapyはPythonの多機能なスクレイピングライブラリです。まず基本的な作法として以下のようにscrapy.Spiderを継承したクラスを作っておきます。start_urlsにリスト型でスクレイピングするターゲットを入れておきます。そして、parseメソッドをオーバーライドして、responseを受け取りSelectorに変換します。
import os import scrapy from scrapy.selector import Selector class Spider(scrapy.Spider): name = 'items' start = int(os.getenv('SCRAPY_START_INDEX', 22419)) target_range = int(os.getenv('SCRAPY_NUM_ITEMS', 1000)) start_urls = ['https://www.iherb.com/pr/pr/' + str(x) for x in range(start, start + target_range) ] def parse(self, response): time.sleep(random.randint(2, 3)) product_url = response.url self.logger.info('url=%s', product_url) sel = Selector(response)selectorはHTMLの木構造を保持していて、任意のノードを取り出せるわけです。ここで、XPathは木構造の中から特定のノードを指定する文字列表現になります。
def get_product_name(sel): product_name = sel.xpath('//*[@id="name"]/text()').extract_first() self.logger.info('product_name = %s', product_name) return product_name必要な要素を表現するXPath文字列を取置します。難しく考える必要はありません。簡単な方法としては、Chromeで任意の要素で右クリックしたときに「検証」というメニューがあるのでそれを押してみてください。すると開発者コンソールを表示され、Elementsタブ内でHTML要素が青く選択されます。ここでさらに右クリックして、「Copy」 ⇛ 「Copy XPath」を押すとクリックボードに文字列がコピーされます。これをさきほどのクラスの中に書いていけばいいだけです。
Djangoについて
スクレイピングで値が取れれば、そのままファイルに書き出しで任務完了でも良いのですが、このデータを使ってアプリケーションを作ろうと考えているなら、最初からDBに保存して置いたほうが良いと思います。特に、一度取得して終わりではなく、定期的に取得して最新の状態を保つ必要のあるアプリケーションの場合は、取得・保管・利用のサイクルが効率的に回るように、スクレイピングモジュールの開発段階からしっかりRDBでモデルを定義していくことを私はおすすめします。
Djangoには中心的な概念を説簡単にご紹介しておきます。
ファイル 機能 settings.py アプリ全体の設定を定義します。 models.py データベースの構造を定義します。 views.py 機能そのものを記述します。 urls.py URLと機能のマッピングを担当します。 admin.py 管理者用サイトの機能を生成します。 permissions.py 機能に対する権限をユーザーごとに記述します。 serializers.py Rest API用にデータ構造を定義します。 Djangoの開発は上記のようなスクリプトを実装します。settings.py、models.py、views.py、urls.pyの4つが必須要素ですが、admin.pyはデータベースに簡単にアクセスするWebサイトを簡単に構築でき、大変便利なので私は使用しています。この役目はphpMyAdminのようなものを使用しても問題ないでしょう。permissions.py、serializers.pyはRest APIを生成するDjangoの拡張ライブラリであるdjangorestframeworkによって使用されます。
スクレイピングしたデータを保存して可視化するという点で重要なのはmodels.pyだけであり、ここさえしっかり書ければ、あとの実装はこの段階では問題ないです。この記事ではmodels.pyの部分だけご紹介しておきます。
データモデル
テーブル名 機能 Item 商品テーブル Composition 栄養素とその成分量のテーブル Nutrition 栄養素テーブル Item,Composition,Nutritionの3つのテーブルで構成されます。必要に応じて正規化していきます。この作業はデータ取得後になると難しくなってくるので、スクレイピング実装の段階でモデル実装もちゃんとやっておこうと思います。サンプルコードでは、第2正規化までやっておきました。
このモデルについてですが、DjangoにはDBのモデル構造を表現できるORマッパーが含まれています。従って、直接DBにSQL操作を行う必要はありません。ただし、データ構造が変更さびに、マイグレーションというテーブル構造の変更に対応するSQL操作を実行する必要がありますが、ORマッパーはこの点もスクリプトで表現されたモデルに従って自動でSQLを生成し、コマンドから一発で実行してくれます。この記事のサンプルコードでは、以下のスクリプトで、簡単に呼び出せるようにしてあります。
./migrate.shfrom django.db import models class Nutrition(models.Model): id = models.AutoField('ID', primary_key=True) name = models.CharField('Name', max_length=255, blank=True, null=True) description = models.TextField('Description', blank=True, null=True) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.name) class Composition(models.Model): id = models.AutoField('ID', primary_key=True) name = models.ForeignKey('Nutrition', related_name='composition_nutrition_id') amount = models.IntegerField('Amount', default=0, blank=False, null=False) unit = models.CharField('Unit', max_length=20,blank=True, null=True) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.name) + ':' + str(self.amount) + ' ' + str(self.unit) class Item(models.Model): id = models.AutoField('ID', primary_key=True) product_name = models.CharField('Name', max_length=100,blank=True, null=True) product_url = models.CharField('Product URL', max_length=999,blank=True, null=True) company = models.CharField('Company', max_length=100,blank=True, null=True) amount = models.IntegerField('Amount', default=0, blank=False, null=True) capsule_type = models.CharField('Capsule Type', max_length=20,blank=True, null=True) rating_count = models.IntegerField('Rating Count', default=0, blank=False, null=False) rating = models.DecimalField('Rating', max_digits=32, decimal_places=16, default=0.0) price = models.IntegerField('Price', default=0, blank=False, null=True) product_code = models.CharField('Product Code', max_length=100,blank=True, null=True) serving_size = models.IntegerField('Serving Size', default=1, blank=False, null=True) composition = models.ManyToManyField(Composition) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.product_name)データの保存
スクレイピングできた値、データ・セットを順番にMariaDBに保存していきます。簡略化して書くと以下ようになります。models.pyで定義したORマッパークラスのインスタンスに値を渡していき、save()メソッドでDBに反映します。以下のコードは簡略化して書いてあります。実際の実装についてはGit Hubで提供しているサンプルコードを見てください。
from nutrition.models import Item from scrapy.selector import Selector sel = Selector(response) product_name = get_product_name(sel) item = Item() item.product_name = product_name item.save()実際やってみると分かりますが、Webサイトのデータというのは完璧なものはなく、少なからず表記の不統一などがあり、一発で綺麗なデータ・セットにはならないことがほとんどです。従って表記の不統一を吸収するような実装が必要になってきます。モデルを厳密に定義しながら実装することはスクレイピングの精度を高めていく過程そのもと言えるでしょう。
ここまでできたら、次はアプリ側を実装していくフェイズになります。Djangoにはテンプレートエンジン、つまりサーバーサイドで動的にHTMLをレンダリングする機構がありますが、私はモバイル用途やSPA(Reactなど)などを想定して、Rest APIによる構成を中核に位置づけています。実はソースコードはサンプルコードにすでに含まれています。機会があればこの辺についても詳しく書いていきます。
- 投稿日:2020-01-21T01:17:23+09:00
Scrapy&MariaDB&Django&Dockerでデータ自動収集ボットシステムを構築する【スターターキット提供】
背景
世の中にあるWebサービスのデータベースを自動で同期して、本家にはない付加価値をつけることによって、手軽にニーズのあるWebサービスを作ることができます。
例えばECサイトのデータをスクレイピングして自前でデータベースとして持っておき、それに対して本家にはない検索方法を提供して、リンクを貼り、アフィリエイトで稼ぐみたいな軽量なビジネスモデルが個人事業のレベルで可能です。
このようなパターンはいくらでも考えられるのですが、とにかくまずはスクレイピングスクリプトを書いて、自動でデータ収集して、きちんと構造化して、それをなるべく最新の状態に保てるようなボットとインフラが必要になるわけです。今回はどのようなパターンであれ、アイデアを思いついてから、立ち上げまで作業を効率化できるようにサンプルテンプレートを作ってみました。
テンプレートといっても必要な以下のようなミドルウェアやフレームワーク込みでDockerで環境構築するところまでやってみようと思います。従ってDockerが使える人なら読み飛ばしてもこちらのコードさえあれば即実行できます。
- Scrapy
- MariaDB
- Django
今回は、海外のサプリを輸入代行する大手ECサイトIHerbをターゲットにDBを構築し、Django Adminでデータの内容を閲覧できるところまで説明していきます。
とりあえず動かしたい人へ
git clone xxxx cd xxxx docker-compose up -d --build ./start.shGithubにソースコード置いてます。スターターキットとしてお使いください。
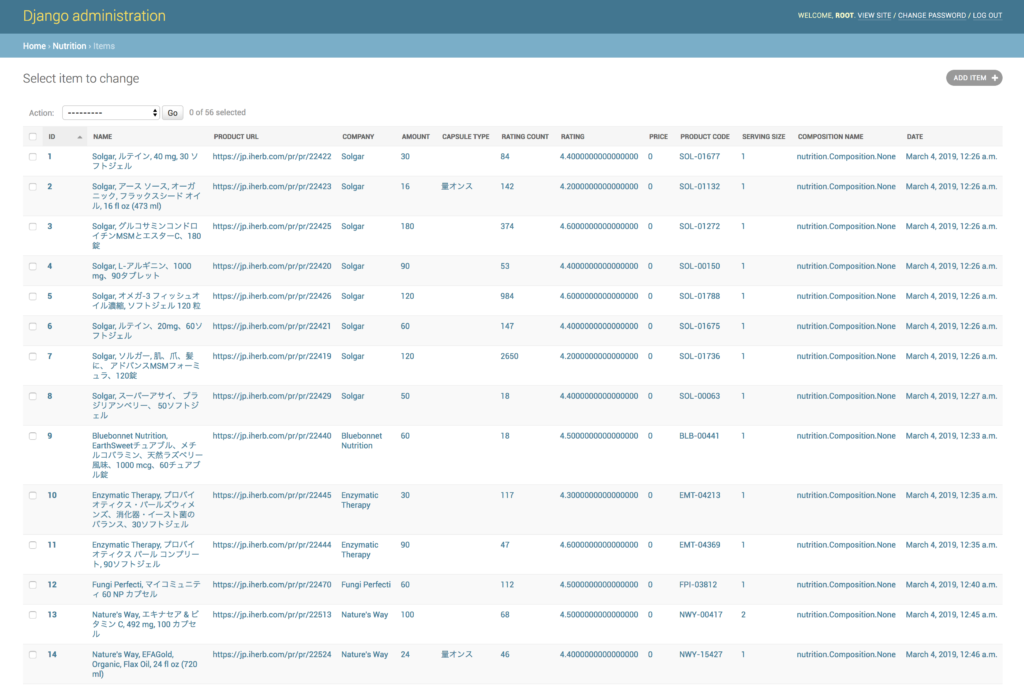
https://github.com/makotunes/scrapy-django-exampleDocker環境をローカルにフォワーディングしている場合は、http://localhost/admin にアクセスします。初期ユーザーはroot、パスワードはinitpassとなっています。ホスト名はDockerの依存する環境によって違うので注意してください。スクレイピングと同時並行で取得されたデータを確認することができます。
今回のサンプルとして、iHerbの商品の価格や栄養素を取得していくコードを書いていきます。第一段階として、サイトのHTML構造を観察し、必要なデータを取り出すスクレイピングについて見ていきます。まずiHerbの商品ページのルールは「 https://www.iherb.com/pr/pr/[ID] 」という規則に従っています。1からインクリメントで順番になめていけば良いはずです。IDが欠番になっていたり在庫切れの場合は取得できないですから、これもハンドリングしておく必要があるでしょう。以降、ざっくり主要なコンポーネントの実装について簡単に触れていきます。
Scrapyの基本的な使い方
ScrapyはPythonの多機能なスクレイピングライブラリです。まず基本的な作法として以下のようにscrapy.Spiderを継承したクラスを作っておきます。start_urlsにリスト型でスクレイピングするターゲットを入れておきます。そして、parseメソッドをオーバーライドして、responseを受け取りSelectorに変換します。
import os import scrapy from scrapy.selector import Selector class Spider(scrapy.Spider): name = 'items' start = int(os.getenv('SCRAPY_START_INDEX', 22419)) target_range = int(os.getenv('SCRAPY_NUM_ITEMS', 1000)) start_urls = ['https://www.iherb.com/pr/pr/' + str(x) for x in range(start, start + target_range) ] def parse(self, response): time.sleep(random.randint(2, 3)) product_url = response.url self.logger.info('url=%s', product_url) sel = Selector(response)selectorはHTMLの木構造を保持していて、任意のノードを取り出せるわけです。ここで、XPathは木構造の中から特定のノードを指定する文字列表現になります。
def get_product_name(sel): product_name = sel.xpath('//*[@id="name"]/text()').extract_first() self.logger.info('product_name = %s', product_name) return product_name必要な要素を表現するXPath文字列を取置します。難しく考える必要はありません。簡単な方法としては、Chromeで任意の要素で右クリックしたときに「検証」というメニューがあるのでそれを押してみてください。すると開発者コンソールを表示され、Elementsタブ内でHTML要素が青く選択されます。ここでさらに右クリックして、「Copy」 ⇛ 「Copy XPath」を押すとクリックボードに文字列がコピーされます。これをさきほどのクラスの中に書いていけばいいだけです。
Djangoについて
スクレイピングで値が取れれば、そのままファイルに書き出しで任務完了でも良いのですが、このデータを使ってアプリケーションを作ろうと考えているなら、最初からDBに保存して置いたほうが良いと思います。特に、一度取得して終わりではなく、定期的に取得して最新の状態を保つ必要のあるアプリケーションの場合は、取得・保管・利用のサイクルが効率的に回るように、スクレイピングモジュールの開発段階からしっかりRDBでモデルを定義していくことを私はおすすめします。
Djangoには中心的な概念を説簡単にご紹介しておきます。
ファイル 機能 settings.py アプリ全体の設定を定義します。 models.py データベースの構造を定義します。 views.py 機能そのものを記述します。 urls.py URLと機能のマッピングを担当します。 admin.py 管理者用サイトの機能を生成します。 permissions.py 機能に対する権限をユーザーごとに記述します。 serializers.py Rest API用にデータ構造を定義します。 Djangoの開発は上記のようなスクリプトを実装します。settings.py、models.py、views.py、urls.pyの4つが必須要素ですが、admin.pyはデータベースに簡単にアクセスするWebサイトを簡単に構築でき、大変便利なので私は使用しています。この役目はphpMyAdminのようなものを使用しても問題ないでしょう。permissions.py、serializers.pyはRest APIを生成するDjangoの拡張ライブラリであるdjangorestframeworkによって使用されます。
スクレイピングしたデータを保存して可視化するという点で重要なのはmodels.pyだけであり、ここさえしっかり書ければ、あとの実装はこの段階では問題ないです。この記事ではmodels.pyの部分だけご紹介しておきます。
データモデル
テーブル名 機能 Item 商品テーブル Composition 栄養素とその成分量のテーブル Nutrition 栄養素テーブル Item,Composition,Nutritionの3つのテーブルで構成されます。必要に応じて正規化していきます。この作業はデータ取得後になると難しくなってくるので、スクレイピング実装の段階でモデル実装もちゃんとやっておこうと思います。サンプルコードでは、第2正規化までやっておきました。
このモデルについてですが、DjangoにはDBのモデル構造を表現できるORマッパーが含まれています。従って、直接DBにSQL操作を行う必要はありません。ただし、データ構造が変更さびに、マイグレーションというテーブル構造の変更に対応するSQL操作を実行する必要がありますが、ORマッパーはこの点もスクリプトで表現されたモデルに従って自動でSQLを生成し、コマンドから一発で実行してくれます。この記事のサンプルコードでは、以下のスクリプトで、簡単に呼び出せるようにしてあります。
./migrate.shfrom django.db import models class Nutrition(models.Model): id = models.AutoField('ID', primary_key=True) name = models.CharField('Name', max_length=255, blank=True, null=True) description = models.TextField('Description', blank=True, null=True) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.name) class Composition(models.Model): id = models.AutoField('ID', primary_key=True) name = models.ForeignKey('Nutrition', related_name='composition_nutrition_id') amount = models.IntegerField('Amount', default=0, blank=False, null=False) unit = models.CharField('Unit', max_length=20,blank=True, null=True) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.name) + ':' + str(self.amount) + ' ' + str(self.unit) class Item(models.Model): id = models.AutoField('ID', primary_key=True) product_name = models.CharField('Name', max_length=100,blank=True, null=True) product_url = models.CharField('Product URL', max_length=999,blank=True, null=True) company = models.CharField('Company', max_length=100,blank=True, null=True) amount = models.IntegerField('Amount', default=0, blank=False, null=True) capsule_type = models.CharField('Capsule Type', max_length=20,blank=True, null=True) rating_count = models.IntegerField('Rating Count', default=0, blank=False, null=False) rating = models.DecimalField('Rating', max_digits=32, decimal_places=16, default=0.0) price = models.IntegerField('Price', default=0, blank=False, null=True) product_code = models.CharField('Product Code', max_length=100,blank=True, null=True) serving_size = models.IntegerField('Serving Size', default=1, blank=False, null=True) composition = models.ManyToManyField(Composition) create_date_time = models.DateTimeField('Date', auto_now=True) def __str__(self): return str(self.product_name)データの保存
スクレイピングできた値、データ・セットを順番にMariaDBに保存していきます。簡略化して書くと以下ようになります。models.pyで定義したORマッパークラスのインスタンスに値を渡していき、save()メソッドでDBに反映します。以下のコードは簡略化して書いてあります。実際の実装についてはGit Hubで提供しているサンプルコードを見てください。
from nutrition.models import Item from scrapy.selector import Selector sel = Selector(response) product_name = get_product_name(sel) item = Item() item.product_name = product_name item.save()実際やってみると分かりますが、Webサイトのデータというのは完璧なものはなく、少なからず表記の不統一などがあり、一発で綺麗なデータ・セットにはならないことがほとんどです。従って表記の不統一を吸収するような実装が必要になってきます。モデルを厳密に定義しながら実装することはスクレイピングの精度を高めていく過程そのもと言えるでしょう。
ここまでできたら、次はアプリ側を実装していくフェイズになります。Djangoにはテンプレートエンジン、つまりサーバーサイドで動的にHTMLをレンダリングする機構がありますが、私はモバイル用途やSPA(Reactなど)などを想定して、Rest APIによる構成を中核に位置づけています。実はソースコードはサンプルコードにすでに含まれています。機会があればこの辺についても詳しく書いていきます。
おわりに
読んで頂きありがとうございました。
最後に開発中の個人アプリの紹介をさせて下さい。Mockers
https://mockers.io「Mockers」は、「危険すぎる」と話題の大規模教師なし機械学習技術「GPT-2」を搭載した多言語対応オンライン自動テキスト生成ツールです。 「Mockers」を使用すると、この素晴らしい技術をWeb上で簡単に使用できるだけでなく、Webサイトの記事やTwitterのツイートを学習して、そのスタイルやコンテキストを模倣して、関連性の高い文章を自動生成し、WordpressやTwitterに自動的に投稿することができます。
- 投稿日:2020-01-21T01:02:48+09:00
pip3ベースでデータサイエンス環境を作るためのDockerfile
やること
データサイエンス用のDockerコンテナといえばjupyter公式が配布しているscipy-notebookがありますが、Dockerfileを見るとcondaベースで書かれています。
しかし、宗教上の理由でcondaを使いたくありません。
そこで、今回はpip3ベースでデータサイエンス用の環境を作るためのDockerfileを書きます。参考にした記事
Dockerを使って機械学習の環境を作ろうとした話方針
・ python公式のDocker imageをベースにする
・ pip3を使う
・ 必要なモジュールのみをrequirements.txtから読み込む
・google-cloud-bigqueryでBigQueryと繋ぎたいのでCloudSDKを入れる
・ jupyterlab+plotlyで可視化をしたいのでNode.jsを入れる出来たもの
Dockerfile
# Pythonの3.8をベースにする # 参考: https://qiita.com/penpenta/items/3b7a0f1e27bbab56a95f FROM python:latest USER root RUN apt-get update \ && apt-get upgrade -y \ && apt-get install -y sudo \ && apt-get install -y lsb-release \ # google-cloud-sdkのインストール時に必要 && pip3 install --upgrade pip # 作業するディレクトリを変更, なくてもいい # WORKDIR /home/{適当なユーザー名} # 予め作成してDockerfileと同じフォルダにあるrequirements.txtをインストール COPY requirements.txt ${PWD} RUN pip3 install -r requirements.txt # Cloud SDKをインストール # https://cloud.google.com/sdk/docs/downloads-apt-get RUN export CLOUD_SDK_REPO="cloud-sdk-$(lsb_release -c -s)" && \ echo "deb http://packages.cloud.google.com/apt $CLOUD_SDK_REPO main" | tee -a /etc/apt/sources.list.d/google-cloud-sdk.list && \ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - && \ apt-get update -y && apt-get install google-cloud-sdk -y # plotlyを使うため、Node.jsをインストール # https://github.com/nodesource/distributions/blob/master/README.md RUN curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash - \ && sudo apt-get install -y nodejs # JupyterLabでplotlyをサポートする ENV NODE_OPTIONS=--max-old-space-size=4096 RUN jupyter labextension install @jupyter-widgets/jupyterlab-manager@1.1 --no-build \ && jupyter labextension install jupyterlab-plotly@1.4.0 --no-buil \ && jupyter labextension install plotlywidget@1.4.0 --no-build \ && jupyter lab build ENV NODE_OPTIONS=今回インストールするモジュール群を
requirements.txtに書きます。
バージョン固定はお好みでrequirements.txtnumpy pandas matplotlib seaborn scikit-learn scrapy jupyter plotly google-cloud-bigquery jupyterlab使い方
適当なフォルダの中に上記2ファイルを入れて、そのディレクトリに移動します。
後は以下のコマンドを順に実行すればOK# Docker imageを作成 docker build --rm -t {Docker imageの名前} . # Docker Containerを作成 # Dockerの中と外を繋ぐためにポートフォワーディング(-p)する # Dockerコンテナを消してもファイルが消えないようにDocker外のフォルダをマウント(-v)する docker run -itp {コンテナ外のport}:{コンテナ内のport} -v {コンテナ外のフォルダの絶対パス,末尾に"/"はつけない}:{コンテナ内でフォルダをマウントしたい場所の絶対パス+マウントするフォルダのDocker内での名称} --name {コンテナの名前} {作成元のimageの名前} /bin/bash # jupyterの起動 jupyter lab --ip=0.0.0.0 --allow-root --port {コンテナ内のport}その他諸々
# cloud SDKの認証 gcloud init # google-cloud-bigqueryのAPI認証 hogehoge export GOOGLE_APPLICATION_CREDENTIALS={認証ファイルの絶対パス} export GOOGLE_CLOUD_PROJECT={繋げるプロジェクト名}