- 投稿日:2020-01-21T23:57:17+09:00
capistranoとは?から�インストール、自動デプロイまで(rails)【AWSを無料で独学勉強】
自動でデプロイさせて負担を軽減する
デプロイの作業は非常に手間です。
いちいちその作業をすれば、随分な時間が取られてしまいます。
煩わしいので、自動化させましょうこれまでのデプロイまでの流れを振り返る
ここまでデプロイするための作業をしましたが、簡単に流れを振り返りましょう
1. git push
2. git pull
3. SSH接続
4. アセットコンパイル
5. Unicorn再起動この一連の流れをすれば、デプロイが完了されます。
なお、この一連の流れをまだしたことがない、自信がないという人は
詳しく解説している下記の記事を閲覧してください。EC2インスタンスを立ち上げるまでの記事はシリーズ化しているので、こちらをどうぞ
独学ではじめてAWSのEC2にデプロイする方法①~⑩(インスタンスの作成)capistranoとは
この一連のデプロイ作業を自動化させる、様々のツールの一つにcapistranoがあります。
capistranoを利用することでサーバーにログインしなくても"" コマンド一つで ””デプロイできちゃうのですから、非常に楽です。一度Capistranoにデプロイが成功すれば、簡略してエラーなしにデプロイができます。
Capistranoの導入
Gemのインストール
ローカルのwebappにCapistranoのgemを追加しましょう
Gemfile(ローカル)group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' end続いて、インストールします
$ bundle installgemがインストールできたところで、Capistranoの下記のコマンドを実施
$ bundle exec cap installするとファイルが作成されます。
railsルート ├─ Capfile ├─ config │ ├─ deploy │ │ ├─production.rb │ │ └─staging.rb │ └─deploy.rb └─ lib └─capistrano └─tasksこれらのファイル説明は作業しながら学びましょう
Capfileを編集
一度ファイルの中身を全部消して、下記のように編集しましょう
Capfilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }production.rbを編集
production.rbですが2つファイルがあります
❌ config/environment/production.rb
⭕️ config/deploy/production.rb今回作業はするのはconfig/deploy/production.rbです
実際に開くと下記の画面が出ます。
このファイルを下記に編集しましょう!
config/deploy/production.rbserver '18.○○○.○○.○○○(Elastic IP)', user: 'ec2-user', roles: %w{app db web}deploy.rbを編集
config/deploy.rbを開くと下記の画面が出ます
deploy.rbの記述をすべて削除
下記を追加します
config/deploy.rb# config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '○.○○.○(Capistranoのバージョン)' # Capistranoのログの表示に利用する set :application, '○○○(自身のアプリケーション名)' set :deploy_to, '/var/○○○(アプリを入れているディレクトリ)/○○○(アプリ名)' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:○○○(Githubのユーザー名)/○○○(レポジトリ名.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '○.○.○(rubyのバージョン)' #カリキュラム通りに進めた場合、2.5.1か2.3.1です # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/○○○○○.pem(ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス 例:~/.ssh/key_pem.pem))'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end貼り付けたテンプレートの一部を修正しましょう
config/deploy.rblock '<Capistranoのバージョン>'Capistranoのバージョンを確認するために、Gemfile.lockを開きましょう
Gemfile.lockcapistrano (3.11.1) airbrussh (>= 1.0.0) i18n rake (>= 10.0.0) sshkit (>= 1.9.0)これでCapistranoのバージョンが(3.11.1)とわかりました。
ではdeploy.rbを修正しましょうconfig/deploy.rblock '3.11.1'rubyのバージョン確認
set :rbenv_ruby, '○.○.○(rubyのバージョン)'ターミナルで下記を実行しましょう
$ ruby -v > ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-darwin18]○○○のところは、アプリ名などを入れる必要があるので、穴埋めしてください
deproy.rbset :application, '○○○(自身のアプリケーション名)' set :repo_url, 'git@github.com:○○○(Githubのユーザー名)/○○○(レポジトリ名.git' keys: ['~/.ssh/○○○○○.pem(ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス 例:~/.ssh/key_pem.pem))']unicorn.rbを編集
unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen "#{app_path}/tmp/sockets/unicorn.sock" stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log"上記のunicorn.rbの記述を下記に変更
unicorn.rb# ../が一つ増えている app_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"Nginxの設定ファイルを編集
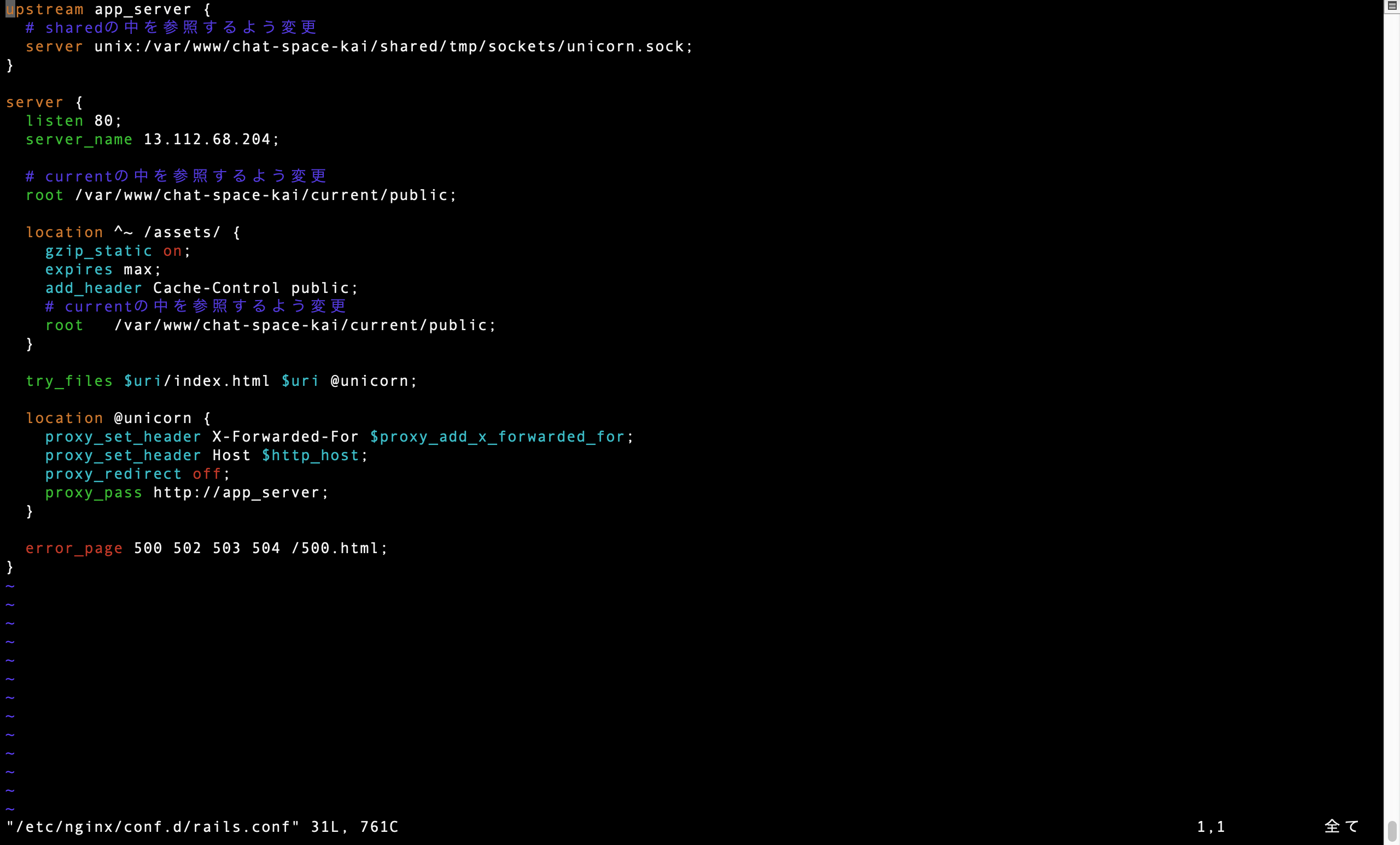
ターミナル(EC2)$ sudo vim /etc/nginx/conf.d/rails.confするとrails.confが表示されるので、一旦すべて削除します
rails.confupstream app_server { server unix:/var/○○○(ディレクトリ)/○○○(アプリケーション名)/tmp/sockets/unicorn.sock; } server { listen 80; server_name 18.○○.○○○.○○(Elastic IP); root /var/○○○(ディレクトリ/○○○○○○(アプリケーション名)/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }そして、下記にを貼り付けて〇〇〇〇を埋めてください
rails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/○○○(アプリをまとめているディレクトリ)/○○○○○(アプリケーション名)/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name 18.○○○.○○(Elastic IP); # currentの中を参照するよう変更 root /var/○○○(アプリをまとめているディレクトリ)/○○○○○(アプリケーション名)/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/○○○/○○○○○○(アプリケーション名)/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }Nginxの設定を変更したら、忘れずに再読込・再起動
[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx reload [ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restartMySQLの起動を確認
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld restartunicornのプロセスをkillしよう
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn一番上のunicorn_rails masterをkillしたいので、下記を実施
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill 17877ローカルでの修正を全てmasterにpushしてください
自動デプロイの実施
# アプリケーションのディレクトリで実行する $ bundle exec cap production deployすると下記ん画像のように、徐々に処理が進み出す。
エラーが発生する場合
ディレクトリ `/var/www' を作成できません: 許可がありません
mkdir stdout: Nothing written mkdir stderr: mkdir: ディレクトリ `/var/www' を作成できません: 許可がありません mkdir: ディレクトリ `/var/www' を作成できません: 許可がありませんヒヤリング:手動デプロイはできていたか?
・YES:Capistranoの設定の問題(ここまで進めている以上、できているはず)
・NO:もう一度手動デプロイを確認する必要があるかもしれません。設定の見直し
rails.confとdeploy.rbのパスの確認をしてください。 var/www/アプリ名で設定しているか? ・ディレクトリはwwwの場合、入力間違いがないか??? ・ディレクトリは"wwwでない"場合、capistranoのデフォルト設定を変更する必要がある。EC2でのアプリの保存場所が『 var/www/アプリ名 』でない場合、、
[参考](https://capistranorb.com/documentation/getting-started/configuration/)
deplory.rbに下記を追加してください。
deploy.rbset :deploy_to, '/var/○○○/アプリ名'capistranoのデフォルト設定では、/var/www/アプリ名が設定されているため、これを変更する必要がある。
そのオプション設定がset :deploy_to, '/var/○○○/アプリ名'である。Master.keyがないエラー( Missing encryption key to decrypt file with. Ask your team for your master key and write it to )
このエラーが表示されたということは、『 本番環境にあるmaster.keyをうまく読み込めていない 』ことを意味します。
rake stdout: Nothing written rake stderr: Missing encryption key to decrypt file with. Ask your team for your master key and write it to /var/○○○(アプリを格納しているディレクトリ名)/○○○(アプリ名)/releases/20200121124714/config/master.key or put it in the ENV['RAILS_MASTER_KEY'].なので現状として可能性は二つです。
- master.keyを作成していない。
- master.keyを作成する場所が間違っている。
ここまで作業を進めている人は,master.keyを作成しているはずです。
>つまり、master.keyの作成場所をまちがている可能性が高いです。# 誤解が生まれやすいmaster.keyの作成場所 ✖︎ アプリ名>config>master.key ○ アプリ名>shared>config>master.keyおそらく、上記のようにmaster.keyの作成場所に誤りがある可能性が高いです。
ですから、ターミナル(EC2)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ cd shared [ec2-user@ip-172-31-23-189 shared ]$ cd config [ec2-user@ip-172-31-23-189 config ]$ ls >ここでmaster.keyがない場合、 master.keyを作成してください。master.keyを作成する場合、、、
ターミナル(ローカル)アプリ名 $ vi config/master.key >master.keyを中身がわかります。 >間違っても編集しないようにしましょうローカル環境のmaster.keyをコピーしたら、EC2にmaster.keyを作成しましょう
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ cd shared/config [ec2-user@ip-172-31-23-189 config ]$ vi master.key >編集画面が出るので >ローカルのmaster.keyをコピペします。 >:wpで保存しましょうmaster.keyを読み込ませるために、deploy.rbに
下記を追加してくださいdeploy.rbset :linked_files, fetch(:linked_files, []).push("config/master.key")再度自動デプロイしましょう
# アプリケーションのディレクトリで実行する $ bundle exec cap production deploy今度はうまくいくはずです。
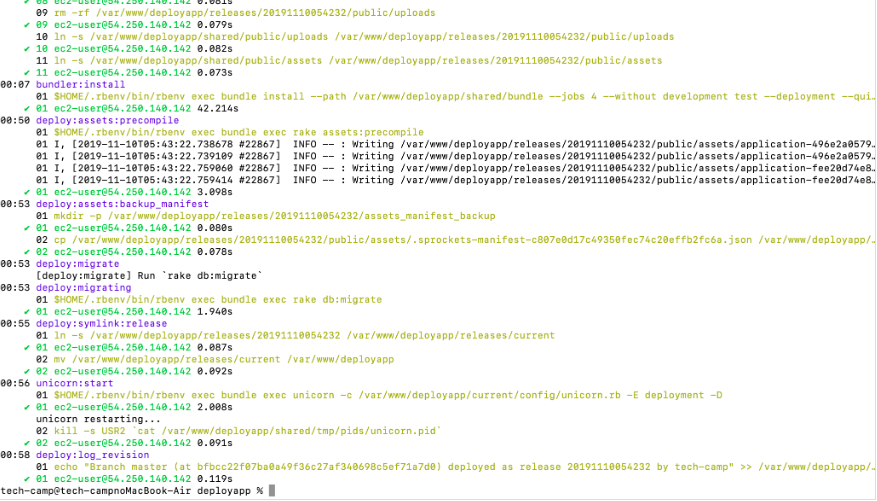
- 投稿日:2020-01-21T23:32:34+09:00
無から素数列挙 on Athena (Presto)
動機
Athenaを扱うスクリプトを書いていたときに、クエリキャンセル時のテストを行う必要がありました。
ただ、Athenaは検索が早いため、処理に時間かかるクエリを実データに対して投げると、それなりにデータスキャンが行われ、それなりに課金が発生する可能性があります。この理由から、
Data scanned: 0 KBで任意の長さの時間がかかりそうな処理を書けるようになろうと考えました。
ついでに自分の理解度や表現力でどのような処理ができるか試すため、プログラミングの定番の素数列挙をテーマにしました。完成形
WITH seq AS ( SELECT * FROM UNNEST ( sequence(2,5) ) AS _(num) ), lower_set AS ( SELECT * FROM seq CROSS JOIN UNNEST ( sequence(1, num) ) AS _(lower_num) ), cnt AS ( SELECT num, COUNT(*) AS divisible_count FROM lower_set WHERE num % lower_num = 0 GROUP BY num ), answer AS ( SELECT num AS prime FROM cnt WHERE divisible_count = 2 ORDER BY num ASC ) SELECT * FROM answer解説
seqテーブルWITH seq AS ( SELECT * FROM UNNEST ( sequence(2,5) ) AS _(num) ),
sequence関数を使って連番の配列を生成します。
生成した配列をUNNEST句を使って展開し、numカラムに格納したテーブルのように扱います。
num 2 3 4 5
lower_setテーブルlower_set AS ( SELECT * FROM seq CROSS JOIN UNNEST ( sequence(1, num) ) AS _(lower_num) ),
seqテーブルで生成した数字に対して、それより小さい値を全て組み合わせたテーブルを作ります。
UNNEST句はJOINとセットで使うことで、行ごとの値を参照した配列を作ることができます。
今回はsequence(1, num)なので、num=2の行にはARRAY[1,2]をUNNESTしたものが、num=3の行にはARRAY[1,2,3]をUNNESTしたものがCROSS JOINされることになります。
num lower_num 2 1 2 2 3 1 3 2 3 3 4 1 4 2 4 3 4 4 5 1 5 2 5 3 5 4 5 5
cntテーブルcnt AS ( SELECT num, COUNT(*) AS divisible_count FROM lower_set WHERE num % lower_num = 0 GROUP BY num ),
lower_setテーブルで生成したnum >= lower_num, lower_num >= 1となる(num,lower_num)の全組について、
numがlower_numで割り切れる行の数をnumごとに集計します。
num divisible_count 2 2 3 2 4 3 5 2
answerテーブルanswer AS ( SELECT num AS prime FROM cnt WHERE divisible_count = 2 ORDER BY num ASC )
cntテーブルから素数を抽出します。
素数であればその数字自体と1でのみ割り切れるので、divisible_count = 2になっているはずです。
prime 2 3 5 これで列挙完了です。
WITHの使いどころ
この例のように
WITHを使って数珠繋ぎに処理を進めていくことで、行数やメモリ消費と引き換えに複数の処理をシンプルに保つことができます。計算量の改善
n以下の素数を列挙するとき、
lower_setテーブルにて(num,lower_num)の組がnum^2通りあるのでO(n^2)の計算量になってしまいます。
sqrt(num) < lower_numとなる組が割り切れる場合、必ずsqrt(num) > lower_numとなる割り切れる組が存在するので、
この対称性を利用してクエリを一部見直すことでO(n^(3/2))に減らせます。lower_set AS ( SELECT * FROM seq CROSS JOIN UNNEST ( sequence(1, cast( sqrt(num) AS integer ) ) ) AS _(lower_num) ),answer AS ( SELECT num AS prime FROM cnt WHERE divisible_count = 1 ORDER BY num ASC )素数列挙の計算量はもう少し少なくできるはずですが、現状良い実装が思いつかなかったので、
これより少ない計算量の実装が出来た人がいればお知らせください。時間計測
O(n^(3/2))の方のクエリを使って、nまでの素数を列挙する処理時間を計測しました。
n 平均(s) 1回目(s) 2回目(s) 3回目(s) 1000 0.30 0.5 0.21 0.19 5000 0.62 0.56 0.71 0.59 10000 0.79 0.83 0.79 0.74 50000 1.52 1.58 1.5 1.49 100000 2.91 2.78 3.02 2.92 500000 22.62 23.79 23 21.06 1000000 57.41 54.56 51.67 66 少しRUNNINGにさせる目的ならnを6桁前半くらいにするのが良さそうです。
感想
意外にも列挙できることがわかった。
いい教材になりそう。注意
もし素数列を使用する場合は、ソートされているとは限らないので必要があればソートしましょう。
SELECT * FROM answer ORDER BY num ASC
- 投稿日:2020-01-21T22:38:40+09:00
[Welcome to nginx on the Amazon Linux AMI!]nginxサーバにアプリケーションをアップロードした時に起こるルーティングエラーの解決例
1.エラーの様子
まずエラーまでの流れですが、ローカル環境でエラーもなく、GitHubへのcommit,pushをし、EC2サーバー(nginx)上に自動デプロイが終わった後にElastic id(個人のipアドレスに紐付け済みの公開用ipアドレス)に接続したところ下記のような画面が表示されました。
<出てきたエラー文>
<出て欲しい画面>
2.どんなエラー?
自分が設定したアプリケーションのアドレスではなく、nginxのホームに接続してしまうというエラーになっています。
3.エラーの原因
ネットサーバーまでのルーティングの設定エラーです
見つけ方としては、エラーまでの流れで説明した通り、ローカル環境でエラーを出していないため、ルーティングの設定ミスだとわかります。
4.解決方法
ルーティングに関する箇所を調べて打ち忘れ打ち間違いを修正します。
具体的には下記の原因が考えられます①開発したファイルの中のconfig/locals/unicorn.rbの記載ミス
②config/deploy/production.rbの記載ミス
③config/deploy/deploy.rbの記載ミス
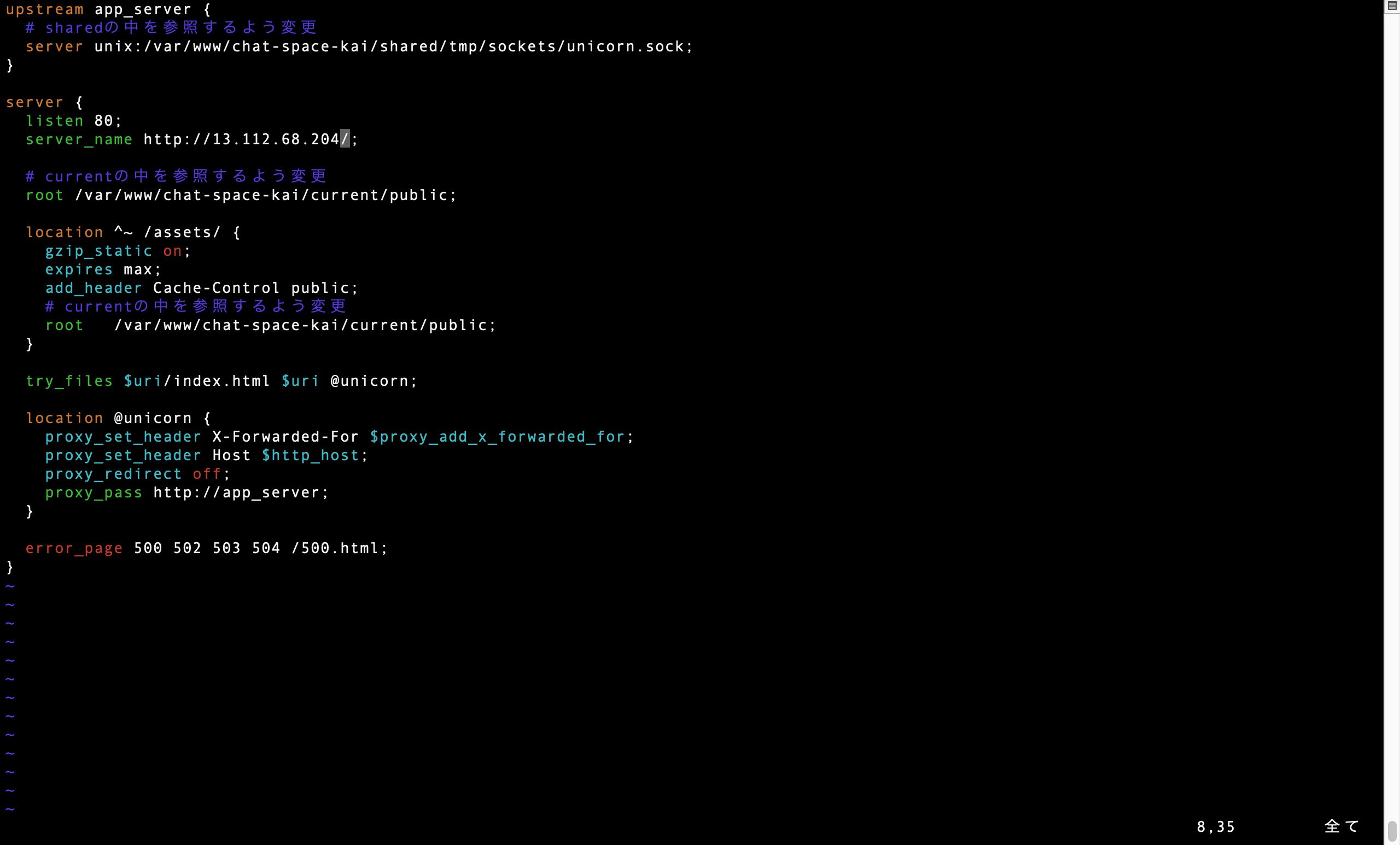
④nginxの設定の記載ミス(EC2サーバにログインして[ec2-user@ip-172-xx-xx-xxx ~]$ sudo vim /etc/nginx/conf.d/rails.confとコマンドを打つことで確認できます)そして今回筆者は④で下記のように設定していました。
<間違った設定>
よくよく見るとこの中の'sever_name'に余計な文字が入っており間違っています。
設定にはElastic idだけで良いので正しくは下記の通りとなるべきでした。
<正しい設定>
こちらを修正したところ、検索の箇所にElastic id(13.112.68.204)を打つことで正しいアプリケーションのサイトに飛ぶよう設定することができました。
※ここまでのルーティングのチェックでローカルのファイルに変更などが生じている可能性があるため、GitHubのcommit忘れの確認と、自動deploy(またはpull origine masterコマンド)を行っておきましょう。更新忘れてるかもと思ったら、この更新作業は何度コマンドしても大丈夫なのでとりあえず行ってみましょう。
何かの参考にしてください。
- 投稿日:2020-01-21T22:15:05+09:00
AWS SES メール送信サーバのセキュリティを解剖する (2020年版)
はじめに
Amazon SES (以下SES) を使えば、Linuxを立ててPostfixを入れて設定して・・・などという面倒なことをしなくても、サーバレスで簡単にメール送信サーバを構築できます。
SESを使ってメールを送るには、AWS側で以下の3ステップを踏む必要があります。
- サンドボックスの解除
- SMTP Credentialの発行
- セキュリティ (認証・アクセス許可等) の設定
今回、以下の「目指したい姿」を満たすため、セキュリテイの設定をどうすれば良いのか、検証によって導いてみました。
目指したい姿
今回、SESでやりたかったことは以下です。
- メール送信用途で使う。
- 送信を許可する唯一のドメインを「test1.com」とすること。
- 「test1.com」以外のドメインは全て拒否されること。
- Eメールアドレスは、個人につき1つ割り当てられ、個人は自分のメールアドレスだけを使用できること。
- 全ての利用者は、管理者が払い出したEメールアドレス以外を名乗って使用できないこと。
- SESから送信されていることを隠蔽すること。
SESのセキュリティ
SESのマネジメントコンソールを開くと「Identity Management」という項目があります。
この項目で、SESのセキュリティ (アクセス許可) を設定できます。設定できるアクセス許可項目
「Domains」と「Email Addresses」の2項目を設定できます。
後述の検証結果でも分かりますが、これらはホワイトリスト形式です。Domains
ここに登録したドメインをFromとするメールの送信を許可します。
ドメインは、DNSのゾーンに所定のTXTレコードを追加し、SESで承認される必要があります。
このため、他人が持っているドメインを勝手に登録してFromに使うことはできません。Email Addresses
ここに登録したメールアドレスをFromとするメールの送信を許可します。
メールアドレスは、SESから送信される確認メールのリンクを押すことで、SESで承認される必要があります。
このため、他人が持っているメールアドレスを勝手に登録してFromに使うことはできません。デフォルトの状態
まずはデフォルトの状態を見てみました。
サンドボックスを解除し、SMTP Credentialを発行しただけの状態では、DomainsとEmail Addressには何も登録されていません。「Domains」
「Email Addresses」
この状態でSESのSMTP Endpointに対してメールを送信しても、以下のようなエラーが返り、送信に失敗します。
Message rejected: Email address is not verified. The following identities failed the check in region US-EAST-1: yamada.taro@test1.com, Taro Yamada <yamada.taro@test1.com>
つまり「Domains」と「Email Addresses」に何も入っていない状態では、SMTP Endpoint宛にメールを送信してもRejectされますので、何も送信できないと言えます。
この検証から、SESのセキュリティはホワイトリスト方式であり、Fromのドメインやメールアドレスは必要なものだけを許可するというポリシーであることが分かります。
検証パターン
「目指したい姿」を実現するにはどう設定を投入すれば良いのかを、検証によって導くことを考えました。
今回、SESのセキュリティの設定の入れ方のパターンを全9パターン定義し、検証しました。検証表と、検証の結果は以下の通りとなりました。
No. Domains DKIM Email Addresses ses:FromAddress P1 P2 P3 P4 Memo 1 - - - - F F F F デフォルト状態 2 test1.com F - - T T F F amazonses.com経由と表示。Domainsのドメインは全通。 3 test1.com T - - T T F F 2と同じだが、amazonses.com経由の表示が消える。 4 test1.com F yamada.taro@test1.com - T T F F amazonses.com経由。Domainsの設定が強くP2も通る。 5 test1.com T yamada.taro@test1.com - T T F F 4と同じだが、amazonses.com経由の表示が消える。 6 test1.com F - yamada.taro@test1.com T F F F amazonses.com経由。ses:FromAddressでP2をブロック。 7 test1.com T - yamada.taro@test1.com T F F F 6と同じだが、amazonses.com経由の表示が消える。 8 test1.com F yamada.taro@test1.com yamada.taro@test1.com T F F F amazonses.com経由。ses:FromAddressでP2をブロック。 9 test1.com T yamada.taro@test1.com yamada.taro@test1.com T F F F 8と同じだが、amazonses.com経由の表示が消える。 表の各項目については、以下の通りです。
- Domains : Domainsに登録した唯一の許可ドメイン名 (From)
- DKIM : 上記の許可ドメイン名において、DKIMを有効にしたかどうか (T/F)
- Email Addresses : Email Addressesに登録した、許可メールアドレス (From)
- ses:FromAddress : SMTP Credentialに紐づいているIAMポリシーで、ses:FromAddressに書くメールアドレス (From)
- ses:FromAddressではFromのメールアドレスを制限可能。ses:FromAddressに書かれているメールアドレス以外がFromに指定されている場合、メールを送信できなくなります。
- P1~P4 : 以下P1~P4のメール送信成否 (T/F)
- Memo : メモ/備考
上の表では、上記の7パターンにおいて、Fromを次の順で変更してメールを送信 (P1~P4) し、成否を確認し、結果を記入しました。
No. From Email Address P1 yamada.taro@test1.com P2 sato.jiro@test1.com P3 yamada.taro@test2.com P4 sato.jiro@test2.com 検証結果から分かること
検証により、Case 7の組み合わせで各設定を投入すれば、「目指したい姿」が満たせると分かりました。
以下に、各設定について分かったことをまとめました。1. DomainsはEmail Addressesよりも強い
Case 2とCase 4の結果から分かるように、Domainsで許可したドメインの具体的なFromメールアドレスをEmail Addressesに書いたとしても、許可はDomainsの範囲のままで、Email Addressesの範囲に絞られません。
これらの比較から、Domainsの設定はEmail Addressesの設定よりも強いことが分かります。
DomainsとEmail Addressesの和集合が、SESで送信を許可されるFromメールアドレスの範囲となります。2. Domainsでドメインを許可すれば、Email Addressesのメールアドレス単位の許可は不要
1.で示したように、Domainsで許可したドメインのメールアドレスを、Email Addressesに書いたとしても、意味がありません。
例えば、Email Addressesの有無でケースが分かれるCase 7とCase 9は、結果が同じです。Domainsでドメインを許可した場合は、Email Addressesでそのドメインのメールアドレスを改めて許可する必要がないと言えます。
3. Domainsはホワイトリストである
Fromにtest2.comを指定し、ローカル部を変えて送信を検証 (P3とP4) しましたが、Domainsでtest1.comしか許可していない状況では、どちらも送信できません。
つまりDomainsでドメインを絞った時点で、他のドメインからの送信は全て遮断できると言えます。4. amazonses.com経由を隠蔽するにはDKIMを設定する
検証結果から分かるように、DKIMのT/Fによってamazonses.com経由の表示の有無が変わりました。
amazonses.com経由であることを隠すために、DKIMを入れるべきだと言えます。5. 「1人あたり1メールアドレス」にはses:FromAddressが必須
SMTP CredentialのIAMポリシーで「ses:FromAddress」を設定すると、Domainsで許可したドメインの中で、Fromのメールアドレスを限定できます。
この仕様を利用し、個人ごとにSMTP Credentialを与え、各SMTP CredentialのIAMポリシーでメールアドレスを限定すれば、「1人あたり1メールアドレス」を配って利用してもらうことができます。設定例は以下となります。
policy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "ses:SendRawEmail", "Resource": "*", "Condition": { "ForAnyValue:StringLike": { "ses:FromAddress": [ "yamada.taro@test1.com" ] } } } ] }SESを使う時に押さえておきたい特徴や対策
分析結果から総合すると、以下のようにまとまりそうです。
- ドメイン、メールアドレスのなりすましは基本的にできない
- SESでホワイトリストに追加する時に必ず所有を確認されるため
- ただしドメインやメールアドレスそのものが乗っ取られないように注意
- DNSのセキュリティ、メールの認証情報 (SMTP Credential含む) の管理は厳重に
- SESのアクセス許可はホワイトリスト
- Fromのドメインやメールアドレスを追加しない限りは、何もできない
- SMTP Credentialの発行も必要
- 個人ごとにメールアドレスを発行するには、SMTP CredentialのIAMポリシーを設定
- Credentialごとにses:FromAddressでメールアドレスを縛る
- 個人ごとにSMTP Credentialを払い出して配布する
- 個人の不正なメール利用を疑ったら、まずSMTP Credentialの無効化で対処
- 個人ごとにSMTP Credentialを分けていれば、この対処が可能
- 上記で止まらない場合にDomainsやEmail Addressesを無効化
- SMTP Credentialの使用状況はIAM Access Analyzerで追跡
- DKIMでSES経由を隠蔽する
- 署名による信頼度アップ
- DKIM自体がアクセス許可を左右するわけではない (検証結果からも分かる)
終わりに
ハードルが高そうなイメージがあるSESのセキュリティですが、それほど複雑なものではありません。
アクセス許可の観点でDomains/Email AddressesとSMTP CredentialのIAMポリシーを押さえ、メール送信の信頼度の観点でDKIMとSPF等を押さえれば、頭の中でも整理できると思います。
本記事が、SESを使ってメール送信サーバを立てようと考えている皆様のお役に立てば幸いです。


- 投稿日:2020-01-21T21:37:55+09:00
EC2のマウント先をAmazon S3にする方法
目的
EC2インスタンスのマウントをEBSではなく、S3にする方法について調査してまとめました。
S3にとマウントする方法について
S3にマウントする方法について、インターネットで調査しましたが、ネットユーザーの意見から以下3つの方法が有力候補となるらしいです。
AWS純正のサービスを利用する方法
- AWS StorageApacheライセンス/GPLライセンスで公開されているフリーソフトウェアを利用する方法
- Googfy
- S3fsAWS Storage Gatewayは、標準的なストレージプロトコルを利用してAWSのストレージサービスへの アクセスを可能にするAWS標準サービスです。標準的なプロトコル(NFSなど)を用いて、S3をバックエンドとしたファイルストレージとして利用することができます。
Goofyと、S3fsは、S3バケットをLinuxのファイルシステムにマウントするためのソフトウェアであり、これを用いることでユーザーはS3 バケットをファイルシステムのように使用することができます。 Googyは、Apache Liscense 2.0ライセンスであり、S3fsはGNU GPL version 2のライセンスであります。基本的には使用や配布に伴うトラブルは自己責任となっております。
Githubの公開情報(copyright情報)によりますと、Goofyは、Ka-Hing Cheung氏によって、S3fsはRandy Rizun氏によって作成されました。
Storage Gatewayに関するネット情報
Goofyに関するネット情報
S3FSに関するネット情報
で、どれが良いのか?
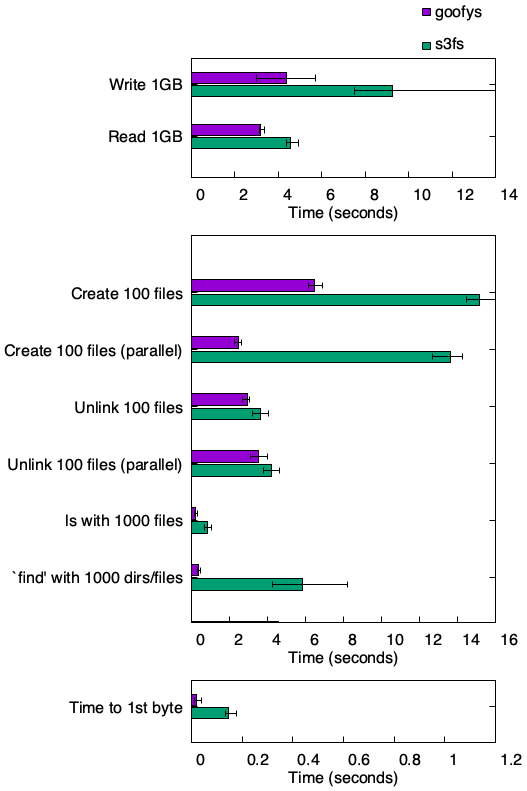
Goofy vs. S3FS
様々なサイトを比較したところ、ベンチマークの結果はgoofyが圧勝でした。著作者側のGithubのコメント(README)を確認したところ、S3FSを開発したRandy Rizun氏のコメントでは、Goofyを
similar to s3fs but has better performance and less POSIX compatibilityと表現しており、Goofyを開発したKa-Hing Cheung氏は以下のような検証結果をのせていました。
(とてもスポーツマンシップに則っていると少し感動してしまいました。プログラム開発の世界ではこれが普通なんですかね・・・)。著作者同士のコメントを信頼するに、どうやらフリーソフトを持ちいた場合は、Goofyの方が良さそうです。
Googy vs. Storage Gateway
ちょっと待ってて
- 投稿日:2020-01-21T20:32:50+09:00
Datadogでdockerコンテナを監視を始めたときのメモ
この記事について
AWSのEC2(なお、OSはAmazon Linux2)上に配置しているairflowのログ収集をdatadogに任せたく、チュートリアルに従って設定を行ったら本当に一瞬で終わってしまったので、メモがてら残しておく。datadog agentは参考記事1にならいdockerイメージ版を利用した。
設定にあたっては、公式ドキュメント2にある一番シンプルなスクリプトに環境変数をいくつか追加している。やったこと
下記のシェルスクリプトを実行しただけ。本当にそれだけ。
init_dd-agent.sh#!/bin/bash -eu DOCKER_CONTENT_TRUST=1 \ docker run -d --name dd-agent -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /proc/:/host/proc/:ro \ -v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro \ -e DD_API_KEY=$MY_DD_API_KEY \ -e DD_TAGS="<your-tag1> <your-tag2>" \ -e DD_LOGS_ENABLED=true \ -e DD_LOGS_CONFIG_CONTAINER_COLLECT_ALL=true \ -e DD_AC_EXCLUDE="name:datadog-agent" \ -e SD_BACKEND="docker" \ -e NON_LOCAL_TRAFFIC=false \ datadog/agent:latest正常に実行されていれば、datadog agentのコンテナが起動しているはずなので、
docker psコマンドを実行して確認しよう。
また、プロセスが実行されたあとにdatadog上にサーバのメトリクスやログが飛んできているか確認しましょう。設定のポイント
個人的には公式ドキュメントの他、datadog-agentのgithubリポジトリ3にも色々説明が乗っているので、監視したい対象に合わせて最適なオプションを探しましょう。
DD_API_KEYは当然ながら必須の設定。datadogの管理画面から取得し、環境変数にでも入れておきましょう。DD_TAGSにはスペース区切りでタグを入れることでdatadogの画面上での検索性が上がる。部署名などお好きなものをどうぞ。DD_LOGS_ENABLEDをtrueに設定することにより、DatadogのLogs配下にログが飛んでくるようになる。これを設定しないとサーバのメトリクスのみが連携される。DD_LOGS_CONFIG_CONTAINER_COLLECT_ALLこれをtrueにすることで、全てのコンテナの実行ログを取ることができる。airflow自体もdocker-composeで実行している他、airflowから複数のコンテナが起動おとび実行される想定のため設定した。DD_AC_EXCLUDEを設定することでログを収集しないコンテナを指定できる。今回の場合はdatadog-agent自体のログを収集しないため設定。参考記事
- 投稿日:2020-01-21T20:29:26+09:00
【Laravel - AWS】composer install が mbstring のエラーで失敗するとき
結論だけ知りたい
$ sudo yum install php{$ver}-mbstring.x86_64
$verはインストールしたPHPのバージョンに合わせる。PHPバージョン7.2系をインストールしている場合は
$ sudo yum install php72-mbstring.x86_64とすればOK。心配な人はPHPのバージョンを確認しましょう。
前提
Amazon Linuxの公式ガイドに沿ってLAMP環境を構築。
基本は記事に忠実に。ただ途中、phpのバージョンを70→72に指定した。
バージョン情報
Laravel : 6.9
PHP : 7.2.24
AWS : EC2 - AmazonLinux▼上記の記事に書かれているコマンド▼
[ec2-user ~]$ sudo yum install -y httpd24 php70 mysql56-server php70-mysqlnd▼実際に打ち込んだコマンド▼
[ec2-user ~]$ sudo yum install -y httpd24 php72 mysql56-server php72-mysqlnd起きたこと
ローカルのLaravelを本番でgit経由でpullし、
composer installしようとしたタイミングでエラー。エラー内容
[ec2-user@ip-XXX src]$ composer install Loading composer repositories with package information Installing dependencies (including require-dev) from lock file Your requirements could not be resolved to an installable set of packages. Problem 1 - Installation request for erusev/parsedown 1.7.3 -> satisfiable by erusev/parsedown[1.7.3]. - erusev/parsedown 1.7.3 requires ext-mbstring * -> the requested PHP extension mbstring is missing from your system. Problem 2 - Installation request for laravel/framework v6.9.0 -> satisfiable by laravel/framework[v6.9.0]. - laravel/framework v6.9.0 requires ext-mbstring * -> the requested PHP extension mbstring is missing from your system. Problem 3 - Installation request for facade/ignition 1.13.0 -> satisfiable by facade/ignition[1.13.0]. - facade/ignition 1.13.0 requires ext-mbstring * -> the requested PHP extension mbstring is missing from your system. Problem 4 - Installation request for phpunit/phpunit 8.5.1 -> satisfiable by phpunit/phpunit[8.5.1]. - phpunit/phpunit 8.5.1 requires ext-mbstring * -> the requested PHP extension mbstring is missing from your system. Problem 5 - Installation request for scrivo/highlight.php v9.17.1.0 -> satisfiable by scrivo/highlight.php[v9.17.1.0]. - scrivo/highlight.php v9.17.1.0 requires ext-mbstring * -> the requested PHP extension mbstring is missing from your system. Problem 6 - laravel/framework v6.9.0 requires ext-mbstring * -> the requested PHP extension mbstring is missing from your system. - facade/flare-client-php 1.3.1 requires illuminate/pipeline ~5.5|~5.6|~5.7|~5.8|^6.0 -> satisfiable by laravel/framework[v6.9.0]. - Installation request for facade/flare-client-php 1.3.1 -> satisfiable by facade/flare-client-php[1.3.1].何やら長々とエラーが出ているが、全部のエラーで php-extensionの
mbstringが無いということなのでそれをインストールすれば良さそう。調べてみると
yum install --enablerepo=remi-php72 php-mbstringでインストールできるとのこと。しかしコマンドを打ち込んだらまた怒られる。
[ec2-user@ip-XXX src]$ sudo yum install --enablerepo=remi-php72 php-mbstring 読み込んだプラグイン:priorities, update-motd, upgrade-helper Error getting repository data for remi-php72, repository not foundリポジトリが見つからないということなのでリポジトリのコマンドを外す。
[ec2-user@ip-XXX src]$ sudo yum install php-mbstring 読み込んだプラグイン:priorities, update-motd, upgrade-helper 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ php-mbstring.x86_64 0:5.3.29-1.8.amzn1 を インストール --> 依存性の処理をしています: php-common(x86-64) = 5.3.29-1.8.amzn1 のパッケージ: php-mbstring-5.3.29-1.8.amzn1.x86_64 --> トランザクションの確認を実行しています。 ---> パッケージ php-common.x86_64 0:5.3.29-1.8.amzn1 を インストール --> 衝突を処理しています: php72-common-7.2.24-1.18.amzn1.x86_64 は php-common < 5.5.22-1.98 と衝突しています --> 依存性解決を終了しました。 エラー: php72-common conflicts with php-common-5.3.29-1.8.amzn1.x86_64 問題を回避するために --skip-broken を用いることができます。 これらを試行できます: rpm -Va --nofiles --nodigestバージョンがコンフリクトしたらしい。どうやらインストールしているパッケージ自体がおかしい気がする。
よくよく調べると、AmazonLinuxはデフォルトで自前のリポジトリを最優先で探すことがわかった。
これを回避する方法は
- 対応するパッケージをAmazonLinux公式のリポジトリから落とす。
- リポジトリ優先度の設定をする。
の2つと考えられる。
今回は
mbstringがインストールできれば良いので1の方法で行くことにした。2の方法についてはこちらの記事がわかりやすい。
Amazon LinuxでYUMを使う時に気をつけるポイント | Developers.IO対応パッケージを探す
Amazon公式のリポジトリは
php72-cli.x86_64
のように、バージョンとパッケージ名を同時に指定する方式になっている。今回は72に対応するパッケージが欲しいのでgrepを使って探す
[ec2-user@ip-XXX src]$ yum list | grep php72 php72.x86_64 7.2.24-1.18.amzn1 @amzn-updates php72-cli.x86_64 7.2.24-1.18.amzn1 @amzn-updates php72-common.x86_64 7.2.24-1.18.amzn1 @amzn-updates php72-json.x86_64 7.2.24-1.18.amzn1 @amzn-updates php72-mbstring.x86_64 7.2.24-1.18.amzn1 @amzn-updates php72-mysqlnd.x86_64 7.2.24-1.18.amzn1 @amzn-updates ...mbstringも発見したので、これをインストールしてみる。
[ec2-user@ip-XXX src]$ sudo yum install php72-mbstring.x86_64 読み込んだプラグイン:priorities, update-motd, upgrade-helper 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ php72-mbstring.x86_64 0:7.2.24-1.18.amzn1 を インストール --> 依存性解決を終了しました。 依存性を解決しました ================================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ================================================================================================================= インストール中: php72-mbstring x86_64 7.2.24-1.18.amzn1 amzn-updates 1.4 M トランザクションの要約 ================================================================================================================= インストール 1 パッケージ 総ダウンロード容量: 1.4 M インストール容量: 3.2 M Is this ok [y/d/N]: y Downloading packages: php72-mbstring-7.2.24-1.18.amzn1.x86_64.rpm | 1.4 MB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : php72-mbstring-7.2.24-1.18.amzn1.x86_64 1/1 検証中 : php72-mbstring-7.2.24-1.18.amzn1.x86_64 1/1 インストール: php72-mbstring.x86_64 0:7.2.24-1.18.amzn1 完了しました!無事インストールできたので、改めて
composer installしてみる[ec2-user@ip-XXX src]$ composer install Loading composer repositories with package information Installing dependencies (including require-dev) from lock file Package operations: 85 installs, 0 updates, 0 removals ... Package manifest generated successfully.無事通った。
- 投稿日:2020-01-21T20:20:22+09:00
CodeCommit + CodeDeploy + CodePipelineでEC2にデプロイ~CodePipelineの設定・デプロイ実行~
目次 1. CodeCommitの設定 2. CodeDeployの設定 3. CodePipelineの設定・デプロイ実行(この記事) AWSのCodeCommit、CodeDeploy、CodePipelineを組み合わせてEC2にデプロイするまでをまとめました。
この記事ではCodePipelineでデプロイを自動実行するパイプラインを作成する手順を説明します。前提
- 前回、前々回の記事でCodeCommitのリポジトリ、CodeDeployのアプリケーションを作成済みとします。
CodePipeline
CI/CD のパイプラインを提供するサービスです。
パイプラインを作成することで、アプリケーションのビルド・テスト・デプロイを自動化することができます。
パイプラインの実行中ステータスはCodePipelineコンソールから視覚的に監視できます。用語
- ステージ : パイプラインの実行中に通過する「アプリケーションに何らかのアクションを実行する」各種フェーズの単位。
今回作るパイプライン
先に作成したCodeCommitのリポジトリのmasterブランチが変更されたら、EC2インスタンスにデプロイするパイプラインを作成します。
パイプラインにはリポジトリからソースコードを取得する「ソースステージ」と、デプロイを実行する「デプロイステージ」の2つのステージがあります。
ソースプロバイダはCodeCommit、デプロイプロバイダはCodeDeployを使用します。それぞれ、GithubやAmazon ECSなど他のサービスを代わりに使う事も可能です。CodePipelineに統合できるツール・サービスのリストはこちらを参照してください。パイプライン作成
- CodePipelineコンソール(http://console.aws.amazon.com/codesuite/codepipeline/home)にアクセスします。
- [パイプラインの作成]を選択します。
- パイプラインの設定を選択します。
- パイプライン名 : SampleAppPipeline
- サービスロール : 新しいサービスロール(CodePipelineに新規サービスロール作成を許可する)
- [高度な設定]の[アーティファクトストア]で[カスタムロケーション]を選択し、CodeDeployの設定時に作成したS3バケットを選択します。
- [次に]を選択し、ソースステージを追加します。
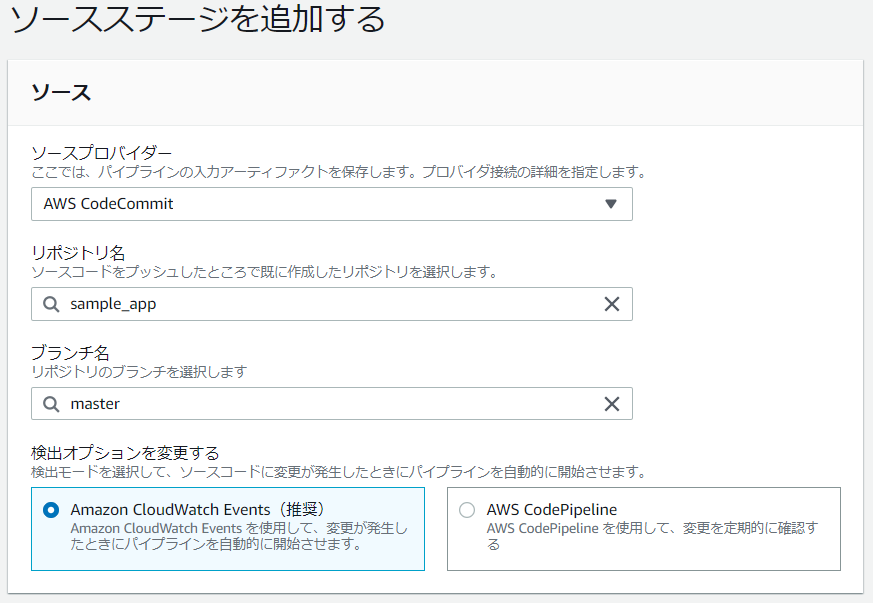
- ソースプロバイダー : AWS CodeCommit
- リポジトリ名 : ソースコードのリポジトリ名
- ブランチ名 : master
- 検出オプション : Amazon CloudWatch Events
- [次に]を選択するとビルドステージの追加画面が表示されます。今回ビルドステージは不要なので、[ビルドステージをスキップ]を選択します。
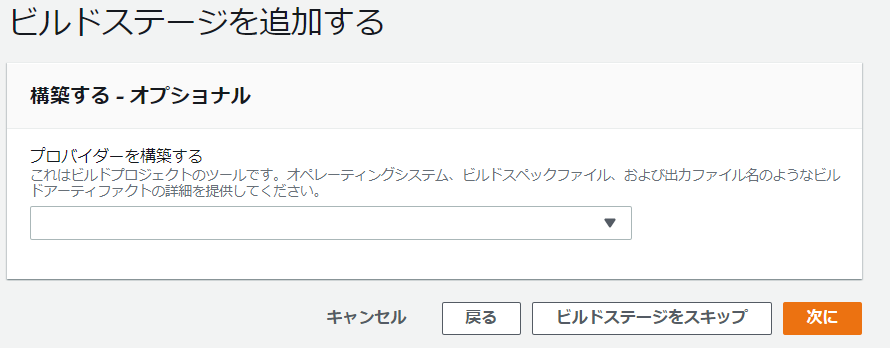
- デプロイステージの追加画面が表示されるので、設定を入力して[次に]を選択します。
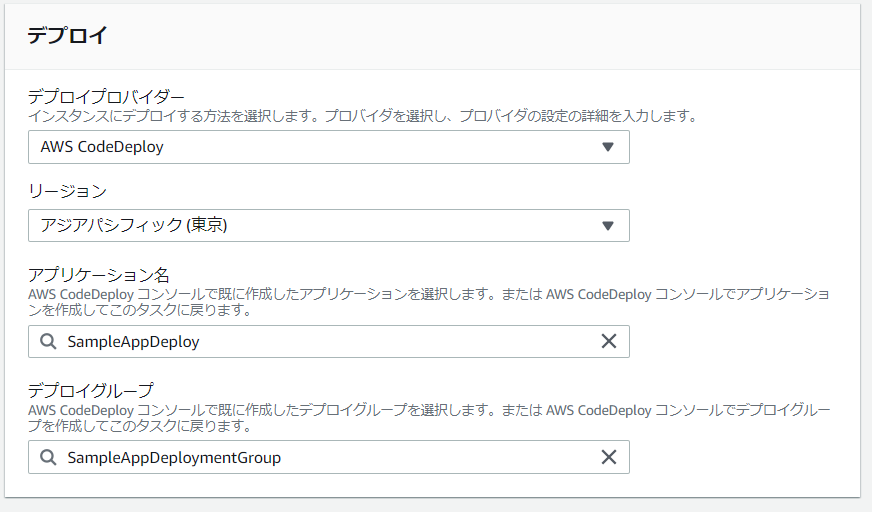
- デプロイプロバイダー : AWS CodeDeploy
- アプリケーション名 : CodeDeployアプリケーション名
- デプロイグループ : デプロイするデプロイグループ
- [パイプラインの作成]を選択します。
pushしてデプロイの実行
これでmasterブランチにpushするとデプロイを自動実行するパイプラインを作成できました。
「ソースステージ」と「デプロイステージ」があることを確認できると思います。
試しにmasterブランチに対してgit pushするとソースステージのアクションが開始します。
しばらくしてソースコードの取得が終わるとデプロイステージのアクションが開始します。
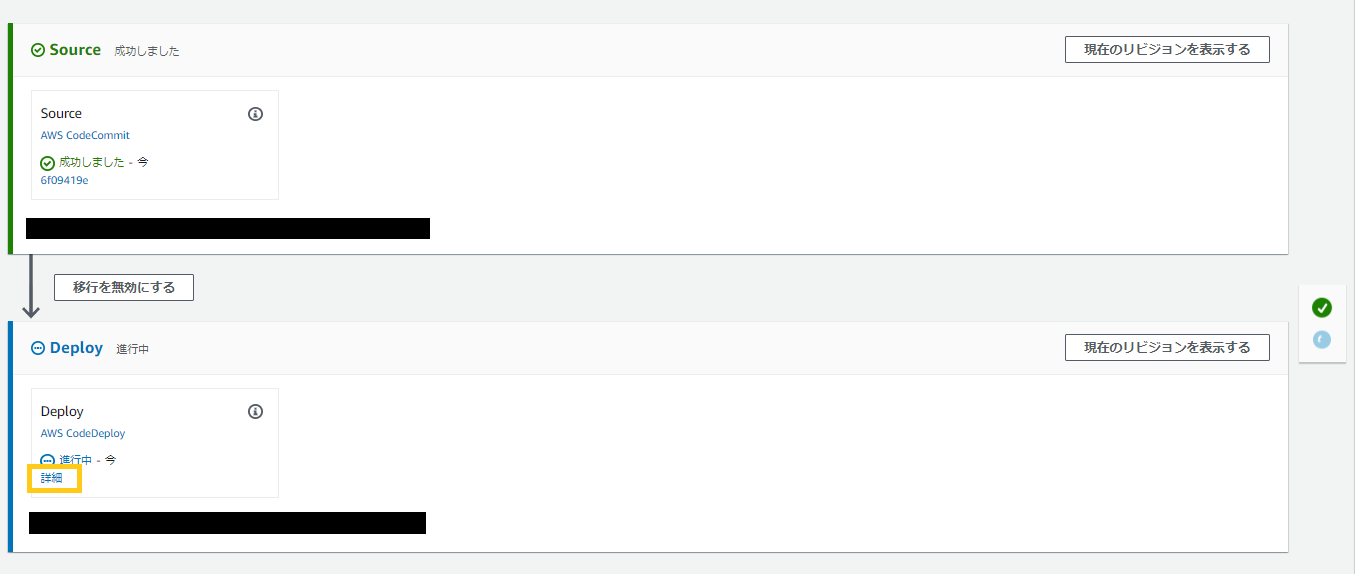
進行中のデプロイアクションの[詳細]を選択すると、CodeDeployコンソールが開きます。
上のスクリーンショットでは2つのEC2インスタンスにデプロイを実行しています。
デプロイ中インスタンスの[View events]を選択すると、CodeDeployライフライクルの進捗状況を監視できます。
デプロイでエラー発生時のログ
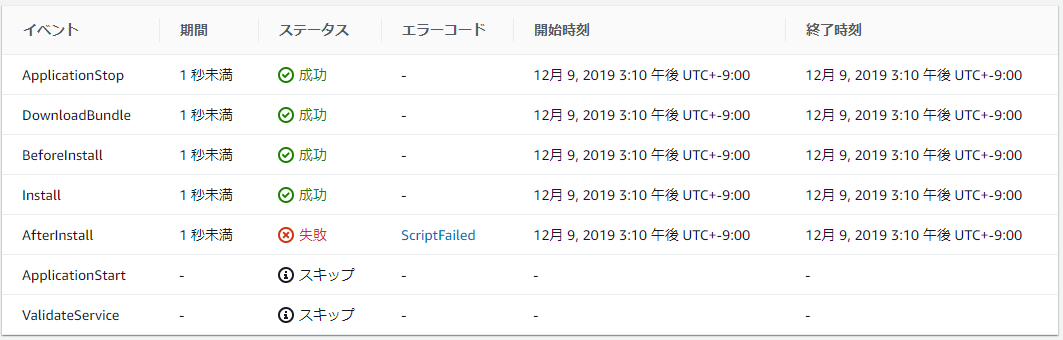
CodeDeployのライフライクルでエラーが発生した場合、先程のCodeDeployコンソールからエラー発生個所を特定できます。
エラーコード[ScriptFailed]はデプロイスクリプトの実行でエラーになったことを意味します。
[ScriptFailed]を選択すると下のようにエラー発生時のログを確認できるのですが、エラー発生個所の周辺数行しか見れません。
これだけで解決できる場合もありますが、より詳細なログが見たい場合はEC2インスタンスにログインしてデプロイのログを確認する必要があります。デプロイに関連するログは下記の場所にあるので、lessコマンド等で確認できます。
CodeDeployAgentのログ
/var/log/aws/codedeploy-agent/codedeploy-agent.log
CodeDeployスクリプトのログ
/opt/codedeploy-agent/deployment-root/{deployment-group-ID}/{deployment-ID}/logs/scripts.logまとめ
以上で「CodeCommit + CodeDeploy + CodePipelineでEC2にデプロイ」する事ができました。
今回は「ビルドステージ」を追加しませんでしたが、CodeBuildを使用すればDockerイメージを使用したアプリケーションのビルド・テスト実行をパイプラインに組み込むこともできます。
他にも、デプロイが成功したらAmazon SNSで通知を送るなども可能です。
コンソールでポチポチしていくだけで簡単にサービスを連携できる所がAWSの魅力だと思います。参考記事




- 投稿日:2020-01-21T20:19:27+09:00
CodeCommit + CodeDeploy + CodePipelineでEC2にデプロイ~CodeDeployの設定~
目次 1. CodeCommitの設定 2. CodeDeployの設定(この記事) 3. CodePipelineの設定・デプロイ実行 AWSのCodeCommit、CodeDeploy、CodePipelineを組み合わせてEC2にデプロイするまでをまとめました。
この記事ではCodeDeployでデプロイアプリケーションを作成する手順を説明します。前提
- デプロイ先のEC2インスタンスは作成済みとします。
- ELB(ロードバランサー)はApplication Load Balancerを使用する想定とします。
- Ruby on Railsアプリケーションをデプロイする想定とします。
- EC2 : Amazon Linux2
CodeDeploy
EC2インスタンスやオンプレミスインスタンス、AWS Lambda、Amazon ECSに対するアプリケーションのデプロイを自動化するデプロイメントサービスです。
EC2に対するデプロイは無課金で実行できます。用語
- AppSpec file : デプロイの内容を定義したファイル。YAMLもしくはJSONで記述する。
- リビジョン : S3もしくはGithubにアップロードした、アプリケーションコードとAppSpec fileをバンドルしたアーカイブファイル。
デプロイ要件
CodeDeployのデプロイタイプは「インプレースデプロイ」と「Blue/Greenデプロイ」が選択でき、今回は「インプレースデプロイ」を選択します(デプロイタイプについては後ほど説明します)。
デプロイ作業中にロードバランサーのトラフィック制御は行いません。EC2へのインプレースデプロイは以下のフローで行われます。
- アプリケーションにAppSpec fileを含めたアーカイブファイルをAmazon S3、もしくはGithubにアップロード。
- アップロードしたリビジョンの情報を次のデプロイ対象としてCodeDeployに提供。
- デプロイ先EC2に常駐しているCodeDeployAgentプロセスがCodeDeployをポーリングして、デプロイ対象リビジョンの置き場所・デプロイ実施時期などの情報を取得する。
- 3で取得した情報に基づいて、EC2のCodeDoployAgentがS3やGithubからデプロイ対象リビジョンをpullして、AppSpec fileの手順に従ってデプロイを実行する。
準備
S3にリビジョンを置くバケットを作成
- Amazon S3コンソール(https://console.aws.amazon.com/s3/)を開きます。
- [バケットを作成する]を選択します。
- [バケット名]を入力して[バケットの作成]を選択します。
CodeDeployからEC2にアクセスためのサービスロールを作成
- IAMコンソール(https://console.aws.amazon.com/iam/)を開きます。
- ナビゲーションペインの[ロール]を選択し、[作成]を選択します。
- [ロールの作成]ページで[AWSサービス]を選択し、[このロールを使用するサービスを選択]リストからCodeDeployを選択します。
- [ユースケースの選択]でCodeDeployを選択し、[次へ]を選択します。
- アクセス権限ポリシーのを確認して[次へ]を選択します。
- [ロールの名前]にサービスロール名(例:AWSCodeDeployRole)を入力し、[作成]を選択します。
EC2からS3にアクセスするためのインスタンスプロファイルを作成
- IAMコンソール(https://console.aws.amazon.com/iam/)を開きます。
- ナビゲーションペインの[ポリシー]を選択し、[作成]を選択します。
- [JSON]タブに以下を貼り付けて[確認]を選択します。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:Get*", "s3:List*" ], "Effect": "Allow", "Resource": "*" } ] }- [ポリシー名]に適当な名前を入力して[作成]を選択します。
- ナビゲーションペインで[ロール]を選択し、[作成]を選択します。
- [AWSサービス]を選択し、[このロールを使用するサービスを選択]リストからEC2を選択します。
- [ユースケースを選択]でEC2を選択し[次へ]を選択します。
- 先ほど作成したポリシーを選択し、[次へ]を選択します。
- [タグの追加]は何もせずに[次へ]を選択します。
- [ロールの名前]に適当なロール名を入力して[作成]を選択します。
EC2にCodeDeployAgentをインストール・起動
EC2にSSH接続して、下記コマンドを実行します。
$ sudo yum update # CodeDeployAgentはRubyで動作するので、Rubyをインストール $ sudo yum install ruby $ sudo yum install wget $ cd /home/ec2-user # このURLは東京リージョンのCodeDeployリソースキットファイルが置いてある場所です $ wget https://aws-codedeploy-ap-northeast-1.s3.ap-northeast-1.amazonaws.com/latest/install $ chmod +x ./install $ sudo ./install auto下のコマンドを叩いてCodeDeployAgentが起動していればOKです。
$ sudo systemctl status codedeploy-agentCodeDeployのデプロイアプリケーション作成・設定
デプロイアプリケーション作成
- CodeDeploy コンソール (https://console.aws.amazon.com/codedeploy) を開きます。
- ナビゲーションペインから[アプリケーション]を選択し、[アプリケーションの作成]を選択します。
- [アプリケーション名]を入力し、[コンピューティングプラットフォーム]で[EC2/オンプレミス]を選択します。
- [アプリケーションの作成]を選択します。
デプロイグループの作成
- 作成したデプロイアプリケーションのページの[デプロイグループ]タブを選択し、[デプロイグループの作成]を選択します。
- 必要項目を入力します。
- デプロイグループ名 : 任意の名前(例:SampleAppDeploymentGroup)
- サービスロール : 先に作成したAWSCodeDeployRole
- デプロイタイプ : インプレース
- 環境設定 : Amazon EC2 インスタンス(タググループでEC2インスタンスに使用したタグのキーと値を指定)
- デプロイ設定 : CodeDeployDefault.OneAtATime
- ロードバランサー : [ロードバランシングを有効にする]チェックボックスを外す
- 詳細-オプション : 任意で自動ロールバックの設定、アラームの設定が可能
- [デプロイグループの作成]を選択します。
デプロイタイプとデプロイ設定の選択肢と内容は下の通りです。
デプロイタイプ
インプレース Blue/Green 既存EC2インスタンスのアプリケーションを上書きする。 新規のEC2インスタンスを作成し、そちらにアプリケーションをデプロイする。アプリケーションが稼働したらロードバランサーのルーティングを新環境向けに切り替える。 デプロイ設定
OneAtATime HalfAtATime AllAtOnce 1度に可能な限り多くのインスタンスに対してデプロイを実施します。 1度に全体の半数のインスタンスに対してデプロイを実施します。 1度に1つのインスタンスに対してデプロイを実施します。 AppSpec file作成
AppSpec fileはデプロイの内容を定義するファイルです。
アプリケーションの配置先、パーミッション、デプロイのライフサイクルイベントで実行する処理を定義できます。
EC2へのインプレースデプロイで使用可能なライフサイクルイベントは5つあります。
- ApplicationStop
- アプリケーションの停止などで使用する。
- BeforeInstall
- ファイルの暗号化、現在のバージョンのバックアップ作成などで使用する。
- AfterInstall
- アプリケーションの設定、ファイルの許可の変更などに使用する。
- ApplicationStart
- アプリケーションの起動などで使用する。
- ValidateService
- デプロイが正常に完了したことの検証に使用する。
ApplicationStopイベントは注意が必要で、新しくデプロイするアプリケーションのAppSpec fileではなく、最後に正常にデプロイされたアプリケーションのAppSpec fileの内容で実施されます。従って初回デプロイ時には何も実行されません。
appspec.ymlを作成
appspec.ymlをアプリケーションソースコードのルートに作成し、デプロイの定義を書いてきます。
Railsアプリケーションのappspec.ymlの内容はこちらの記事が参考になります。appcpec.ymlversion: 0.0 # 0.0固定 os: linux # デプロイ先サーバーのOS files: # アプリケーションの配置場所 - source: / destination: /var/www/sample_app/current permissions: # 配置ディレクトリのパーミッション - object: /var/www/sample_app/current owner: {ユーザー名} group: {ユーザーグループ名} pattern: "**" mode: 775 type: - file - directory hooks: # デプロイのライフサイクルイベント ApplicationStop: - location: deployment_scripts/stop_application.sh runas: {シェルスクリプトの実行ユーザー名} AfterInstall: - location: deployment_scripts/install_gems.sh runas: {シェルスクリプトの実行ユーザー名} - location: deployment_scripts/compile_assets.sh runas: {シェルスクリプトの実行ユーザー名} - location: deployment_scripts/run_db_migrations.sh runas: {シェルスクリプトの実行ユーザー名} ApplicationStart: - location: deployment_scripts/start_application.sh runas: {シェルスクリプトの実行ユーザー名}デプロイタスクを作成
アプリケーションルートにdeployment_scriptsディレクトリを作成し、デプロイタスクのスクリプトを配置します。
デプロイタスクは任意のスクリプト言語で記述可能です。deployment_scripts/stop_application.sh#!/bin/bash source /home/{ユーザー名}/.bash_profile cd /var/www/sample_app/current # Pumaを停止 RAILS_ENV=production bundle exec pumactl -F config/puma.rb stopまとめ
これでCodeDeployを使用したデプロイの準備ができました。
今のままでもAWS CLIを使ってリビジョンをS3にアップロード → デプロイ実行を行うことはできますが、
デプロイの度に毎回手動でコマンドを叩くのは面倒です。次回で、CodePipelineを使用してCodeCommitのリポジトリが変更されたタイミングでデプロイを自動実行する仕組みを作っていきます。
参考記事
- 投稿日:2020-01-21T20:17:02+09:00
CodeCommit + CodeDeploy + CodePipelineでEC2にデプロイ~CodeCommitの設定~
目次 1. CodeCommitの設定(この記事) 2. CodeDeployの設定 3. CodePipelineの設定・デプロイ実行 AWSのCodeCommit、CodeDeploy、CodePipelineを組み合わせてEC2にデプロイするまでをまとめました。
この記事ではCodeCommitにリポジトリを作成してgit cloneするまでを説明します。前提
- 既にAWSアカウント、IAMユーザーは作成済みとします。
- ローカル環境 : CentOS 7
CodeCommit
AWSのGitホスティングサービスです。
競合サービス : GitHub、GitLab、etc..
準備
IAM ユーザーに対してCodeCommit へのアクセスを許可
- AWSマネジメントコンソールにログインして、IAMコンソールを開きます。
- ナビゲーションから[ユーザー]を選択し、CodeCommitへのアクセスを許可するIAMユーザーを選択します。
- [アクセス権限]タブの[アクセス権限の追加]を選択します。※ここでPowerUserAccess等、CodeCommitにアクセス可能な権限が既に付与されている場合、4~5の作業は不要です。
- [既存のポリシーを直接アタッチ] を選択し、ポリシーのリストからCodeCommitにアクセス可能なポリシー(例. AWSCodeCommitFullAccess)を選択して[次のステップ:確認]。
- 追加するアクセス権限を確認して[アクセス権限の追加]を選択します。
CodeCommitへアクセスするためのGit認証情報を作成
- [IAMコンソール > ユーザー]で先にCodeCommitへのアクセス権限を追加したIAMユーザーを選択します。
- [認証情報]タブの[AWS CodeCommit の HTTPS Git 認証情報]で[認証情報を生成]を選択します。
- 生成された"ユーザー名"、"パスワード"が表示されるので控えておきます。[認証情報のダウンロード]からCSVでダウンロードすることも可能です。
- ローカルの
~/.netrcに先に控えた認証情報を書きます。.netrcmachine git-codecommit.ap-northeast-1.amazonaws.com login ユーザー名 password パスワードCodeCommitにリポジトリ作成
- CodeCommitのコンソール(https://console.aws.amazon.com/codesuite/codecommit/home)を開きます。
- [ソース]の[リポジトリ]を選択し、[リポジトリを作成]を選択します。
- リポジトリ名と作成(リポジトリの説明)を入力して[作成]を選択します。
- ローカル環境で、作成したリポジトリのHTTPSのURLを指定してgit cloneします。
まとめ
これでCodeCommitにリポジトリを作成してローカルにcloneできました。
次回はCodeDeployの設定方法を説明します。
- 投稿日:2020-01-21T19:22:28+09:00
S3のファイル(キー)一覧を取得する(AWS SDK for .NET)
概要
AWSの公式ドキュメントの通りにやると、バケット内のファイル一覧は取得できるけど、特定フォルダー内のファイル一覧の取得方法が分からなかったので調査。
ファイル一覧を取得するにはListObjectsV2Requestを使用する。コード
BucketName/Test/Template
└ file1.js
└ file2.jsというS3の構成で
file1.jsとfile2.jsを取得したい場合以下のようになるListObjectsTest.csstatic async Task ListingObjectsAsync() { ListObjectsV2Request request = new ListObjectsV2Request { BucketName = bucketName, Prefix = "Test/Template/", // ← 一覧を取得したいフォルダのキーをPrefixに指定する。 MaxKeys = 10 }; ListObjectsV2Response response; do { response = await client.ListObjectsV2Async(request); // Process the response. foreach (S3Object entry in response.S3Objects) { Console.WriteLine("key = {0} size = {1}", entry.Key, entry.Size); // 以下の内容が取得できる // [0] BucketName/Test/Template ←なぜかPrefixで設定したキーが取得される // [1] BucketName/Test/Template/file1.js // [2] BucketName/Test/Template/file2.js } Console.WriteLine("Next Continuation Token: {0}", response.NextContinuationToken); request.ContinuationToken = response.NextContinuationToken; } while (response.IsTruncated); }取得結果
// [0] BucketName/Test/Template // [1] BucketName/Test/Template/file1.js // [2] BucketName/Test/Template/file2.jsファイル一覧を取得できるが、
ListObjectsV2Request#Prefixで設定した内容が[0]に入る。
これが困る場合、値のSizeは0らしいので、Sizeを見て対応するのがよさそう。参考
- 投稿日:2020-01-21T19:22:28+09:00
【AWS SDK for .NET 】S3フォルダ内のファイル一覧を取得する
概要
AWSの公式ドキュメントの通りにやると、バケット内のファイル一覧は取得できるけど、特定フォルダー内のファイル一覧の取得方法が分からなかったので調査。
ファイル一覧を取得するにはListObjectsV2Requestを使用する。コード
BucketName/Test/Template
└ file1.js
└ file2.jsというS3の構成で
file1.jsとfile2.jsを取得したい場合以下のようになるListObjectsTest.csstatic async Task ListingObjectsAsync() { ListObjectsV2Request request = new ListObjectsV2Request { BucketName = bucketName, Prefix = "Test/Template/", // ← 一覧を取得したいフォルダのキーをPrefixに指定する。 MaxKeys = 10 }; ListObjectsV2Response response; do { response = await client.ListObjectsV2Async(request); // Process the response. foreach (S3Object entry in response.S3Objects) { Console.WriteLine("key = {0} size = {1}", entry.Key, entry.Size); // 以下の内容が取得できる // [0] BucketName/Test/Template ←なぜかPrefixで設定したキーが取得される // [1] BucketName/Test/Template/file1.js // [2] BucketName/Test/Template/file2.js } Console.WriteLine("Next Continuation Token: {0}", response.NextContinuationToken); request.ContinuationToken = response.NextContinuationToken; } while (response.IsTruncated); }取得結果
// [0] BucketName/Test/Template // [1] BucketName/Test/Template/file1.js // [2] BucketName/Test/Template/file2.jsファイル一覧を取得できるが、
ListObjectsV2Request#Prefixで設定した内容が[0]に入る。
これが困る場合、値のSizeは0らしいので、Sizeを見て対応するのがよさそう。参考
- 投稿日:2020-01-21T16:51:08+09:00
DynamoDBで一部の属性のみを取得する(プロジェクション式)--projection-expression
テーブルからデータを読み取るには、GetItem、Query や Scan などのオペレーションを使用します。Amazon DynamoDB は、デフォルトですべての項目属性を返します。すべての属性ではなく、一部の属性のみを取得するには、プロジェクション式を使用します。
key.json{ "Id": { "N": "123" } }まずは、
--projection-expressionなしですべての項目を呼び出してみる。$ aws dynamodb get-item \ --table-name testprojectionexpression \ --key file://key.json { "Item": { "Description": { "S": "test" }, "name": { "S": "sato" }, "Id": { "N": "123" } } }
--projection-expressionで Description のみを呼び出してみる。$ aws dynamodb get-item --table-name ProductCatalog \ --key file://key.json \ --projection-expression "Description" { "Item": { "Description": { "S": "test" } } }
- 投稿日:2020-01-21T16:26:35+09:00
Nginxのログが記録されなくなった
背景
- サーバの環境構築が終わってしばらくしてみると、Nginxのログが毎日は記録されておらず、ランダムに抜けている日がある。
- パブリックに公開していたため、攻撃のようなアクセスは毎日来るはず。なんかおかしい...
- 環境構築が終わってからも、開発やデプロイは何度か行なっていた。
- 今日のログはというと、アクセスログとエラーログともに0バイトで、今日の未明(2時から4時あたり)のタイムスタンプが付いていた。
- Nginxの再起動直後などは、特に問題がなくログが書き出される。
- Nginxはnginxユーザで実行しているが、なぜかログはログインしている一般ユーザが所有しており、グループのみnginxに設定されている状態だった。
環境
- Amazon Linux release 2 (Karoo)
- nginx version: nginx/1.12.2
AWSサポートに契約していたことを思い出す
ダメもとで問い合わせてみたところ...
ビジネス以上のプランにて、サードパーティ製ソフトウェアサポートをベストエフォートで行っているため、Nginxに関しては、本来サポート対象外との回答が、、(私のアカウントはデベロッパープランでした)
一方で、原因がnginxではない場合が考えられますので...と、他の可能性についてもご案内いただきました。(優しい)
その回答とは、以下のような内容でした。しばらく経つとログが出力されなくなる点から、ログのローテーションが行われた場合にファイルのパーミッションが書き換えられている可能性がございます。
なるほど...
ログのローテーション設定も確認してみたが...
以下のような設定になっていました。
(パーミッション設定については、一見問題ないように思える?)/etc/logrotate.d/nginx/var/log/nginx/*log { create 0644 nginx nginx daily rotate 10 missingok notifempty compress sharedscripts postrotate /bin/kill -USR1 `cat /run/nginx.pid 2>/dev/null` 2>/dev/null || true endscript }他に助けを求められる場所はないか
AWSのサポートプランをビジネスにする
サポートプランをアップグレードにすることに対する見返りとして、
- 必ずしも、それで解決できるとは限らない(ベストエフォート)点や、
- 実際に環境にログインして修正まで行なってもらえる訳ではない点
などから、こちらの選択肢は却下となりました。
Nginxのサポートに加入する
こちらも、費用に対する見返りとして、
- 必ずしも、それで解決できるとは限らない点と
- 現状で英語でしか問い合わせできない(日本語対応準備中とのことです)
などの理由で、こちらも却下となりました。
参考: https://www.nginx.co.jp/support/
teratailなど、他のコミュニティサイトで意見を求める
明確な回答は無かったのですが、
こちらに、手掛かりのようなものがあったように思います。対応方法
私の環境の場合、以下の修正でログがローテーションされた後も
引き続きログが書き出されるようになりました!/etc/logrotate.d/nginx/var/log/nginx/*log { create 0644 nginx nginx daily rotate 10 missingok notifempty compress sharedscripts postrotate - /bin/kill -USR1 `cat /run/nginx.pid 2>/dev/null` 2>/dev/null || true + /usr/sbin/nginx -s reload 2>/dev/null || true endscript }どちらの記述も、Nginxの設定ファイルを読み込み直す動作のようだ
といったところまでは調査できたのですが、明確な違いについては分からず...参考: https://nginx.org/en/docs/switches.html
動いたので、一旦はこれで良しとします。
(ご存知の方おられましたら、コメントいただけますと幸いです)
- 投稿日:2020-01-21T16:16:19+09:00
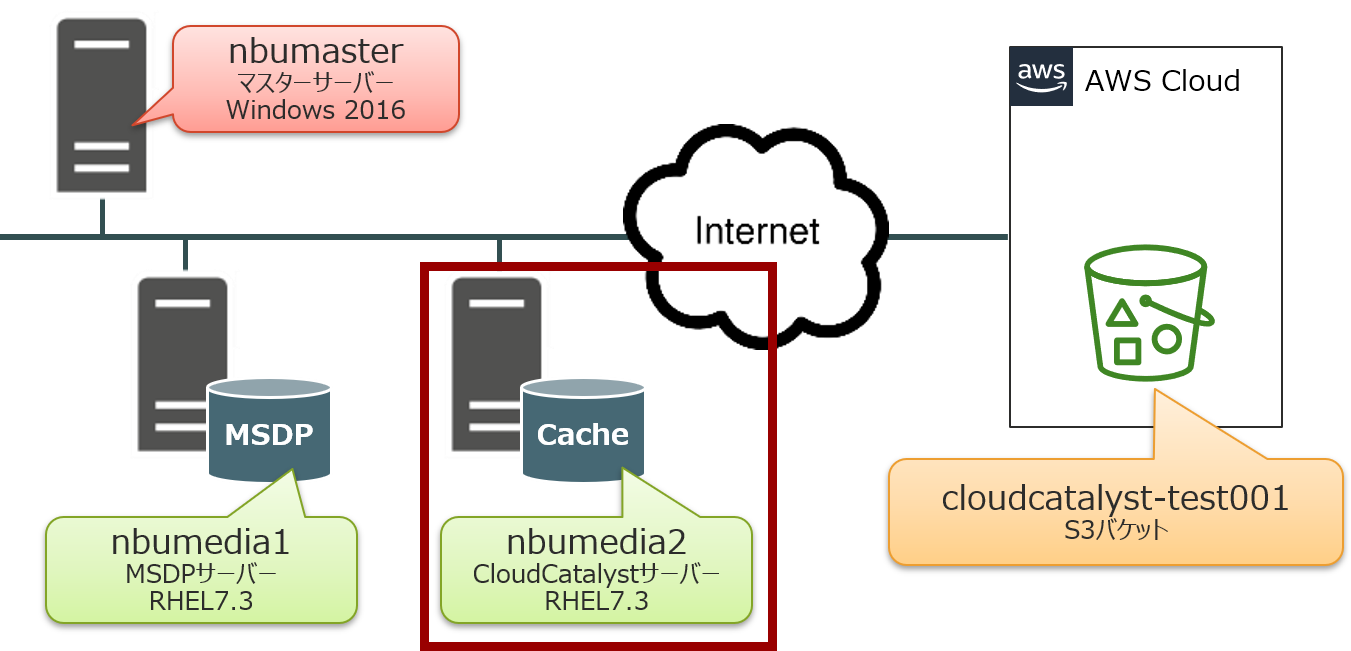
NetBackup CloudCatalyst for AWS入門 その3
NetBackup 8.1からの新機能であるCloudCatalystについて、3回に分けて解説を行います。
今回は3回目となり、オンプレ環境が全損し、Amazon S3にのみバックアップデータが残っている状態での復旧手順をお伝えします。障害復旧ということで長めの手順となりますが、最後までお付き合い下さい!
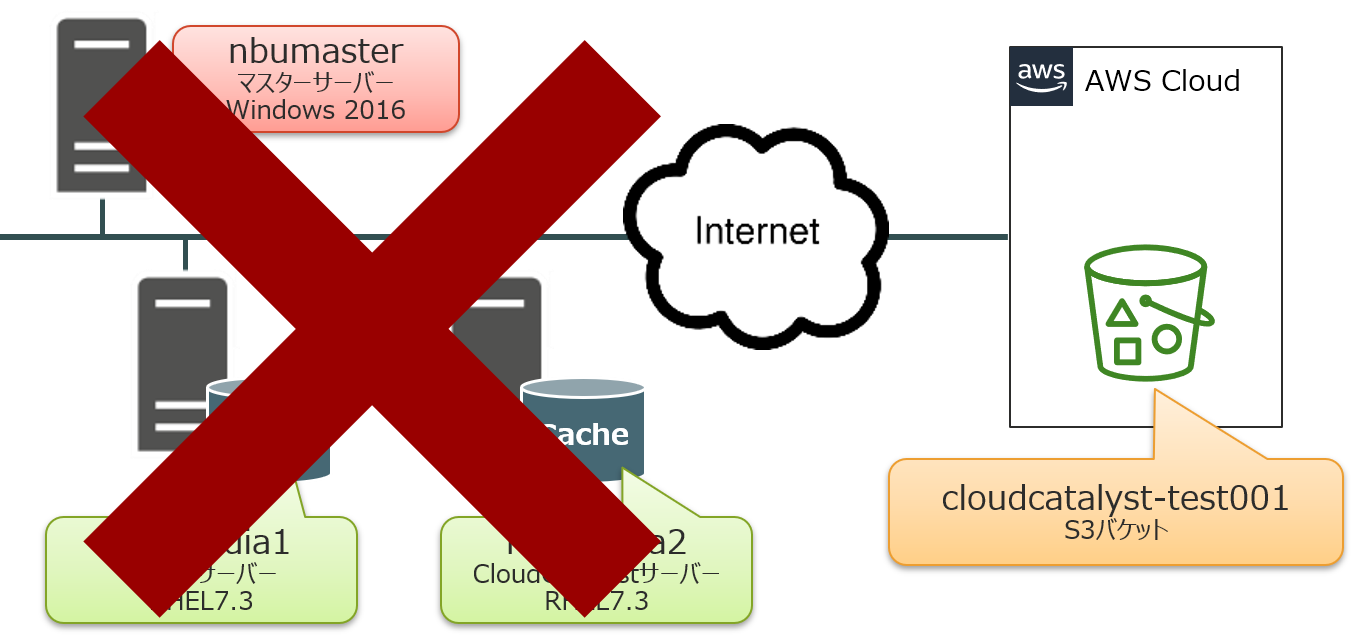
想定する災害シナリオについて
- 「NetBackup CloudCatalyst for AWS入門 その2」で構築したCloudCatalystのオンプレ環境が全損
- バックアップデータはAmazon S3にのみ残っている状態
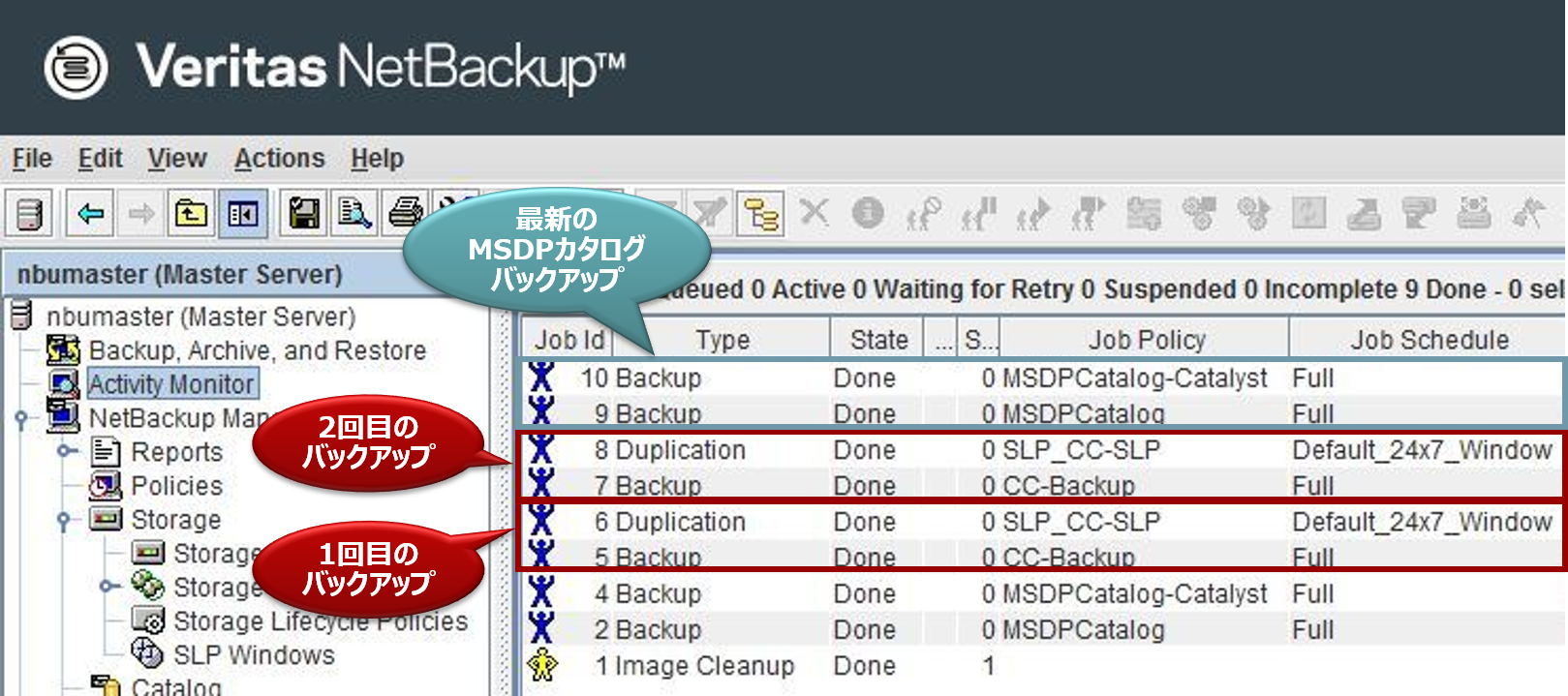
今回の環境では、事前に以下のバックアップデータをAmazon S3に保管しています。
バックアップを2回取得しており、この2つのバックアップデータを復旧するための手順を説明します。
復旧に当たっての前提条件
- 最新のMSDPカタログが残っていること
- Amazon S3からの復旧条件として、CloudCatalyst側の最新MSDPカタログが必須となります。
- そのため、通常運用時は、全てのバックアップ完了後に、MSDPカタログをバックアップする運用にして下さい。
- MSDPカタログは同一サーバー内ではなく、CloudCatalystとは別のバケットなどに保存するようにして下さい。
- 新たにOSを入れ直すなどした場合、サーバーのホスト名は以前と同じ名前に設定しておくこと
参考すべき資料
CloudCatalystの災害復旧手順書として以下が提供されています。
全損からの復旧については、この手順書にある「Recovering the master server (partial) and the MSDP cloud storage server when NetBackup CloudCatalyst is enabled」を参考にしながら進めます。■ Disaster Recovery for CloudCatalyst
https://www.veritas.com/support/en_US/article.100039183.htmlしかし、NetBackup 8.2環境では上記手順通りに進めても、エラーとなる箇所があるため、別途、Technoteが公開されています。
■ Disaster Recovery for CloudCatalyst in NetBackup 8.2
https://www.veritas.com/support/en_US/article.100046914今回の検証環境は、NetBackup 8.2を利用していますので、こちらのTechnoteを参考に復旧手順をご紹介致します。
復旧手順
以下の順番でCloudCatalystの復旧を行います。
①マスターサーバーの復旧
②MSDPサーバーの復旧
③CloudCatalystサーバーの復旧
④esfs_init.shファイルの編集
⑤MSDPカタログのインポート
⑥CloudCatalystストレージサーバーの構成
⑦環境変数の設定
⑧MSDPカタログのバックアップポリシー作成
⑨MSDPカタログのリカバリ準備
⑩CloudCatalystサーバーファイルとFSDB Databaseの復旧
⑪キャッシュディレクトリ以外のファイルとディレクトリを復元
⑫spadの起動
⑬カタログシャドウファイルからMSDPカタログを回復
⑭spooldの起動
⑮Amazon S3のバックアップデータをインポート
⑯リカバリ中に作成された一時ファイルを削除
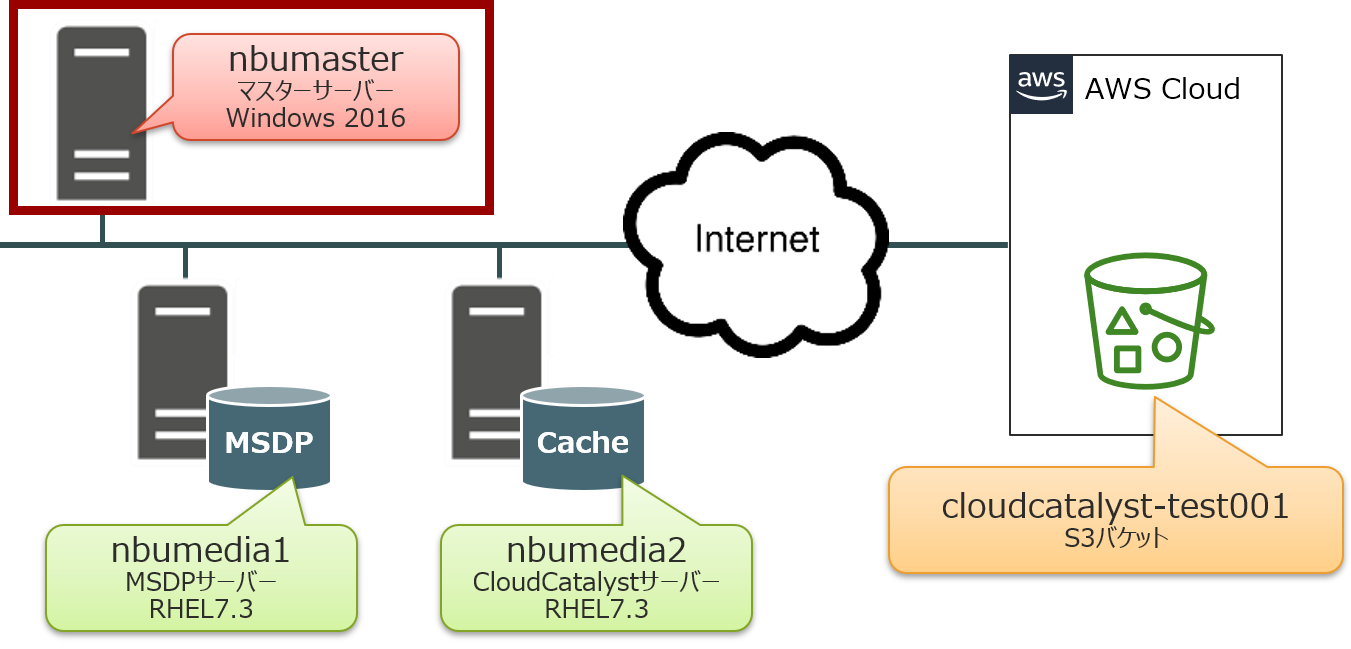
⑰「Backup, Archive, and Restore」を使って対象サーバーにデータをリストア①マスターサーバーの復旧
まず、マスターサーバー:「nbumaster」の復旧を行います。
マニュアルに従って、NetBackup 8.2のインストールを実施して下さい。
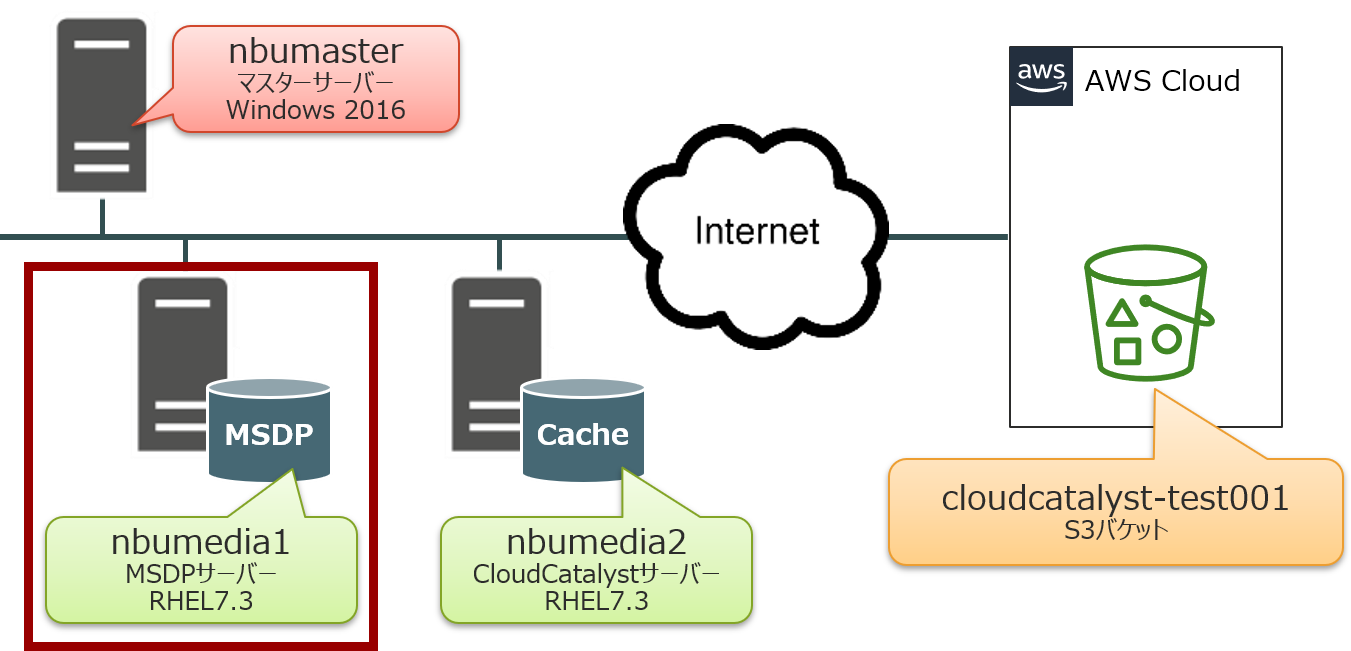
②MSDPサーバーの復旧
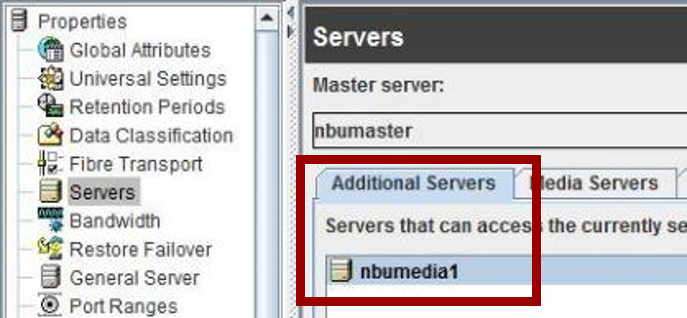
次に、MSDPサーバー:「nbumedia1」の復旧を行います。
マニュアルに従って、NetBackup 8.2のインストールを実施して下さい。
インストール後、マスターサーバーの「Host Properties - Additional Servers」に[nbumedia1]を追加します。
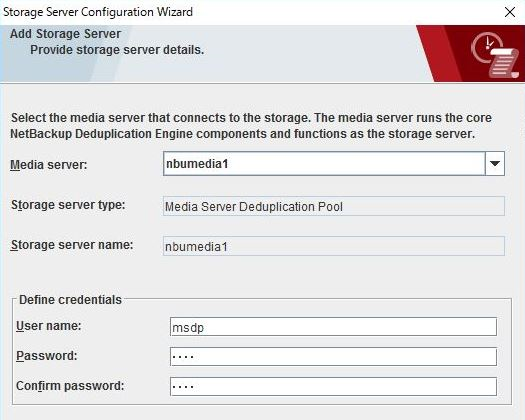
また、「Storage Server Configuration Wizard」を使って、MSDP領域を作成しておきます。
③CloudCatalystサーバーの復旧
続けて、CloudCatalystサーバー:「nbumedia2」の復旧を行います。
マニュアルに従って、NetBackup 8.2のインストールを実施して下さい。
インストール後、マスターサーバーの「Host Properties - Additional Servers」に[nbumedia2]を追加します。
④esfs_init.shファイルの編集
CloudCatalystサーバー:「nbumedia2」の「esfs_init.sh」ファイルに「readonly」オプションを付与します。
以下に編集例を記載します。(NetBackup 8.2の場合、197行目が該当行になります)【実行例】 [root@nbumedia2 /]# cd /usr/openv/esfs/scripts [root@nbumedia2 scripts]# cp -p esfs_init.sh esfs_init.sh.org [root@nbumedia2 scripts]# ls -l esfs_init.sh* -rwxr-xr-x 1 root bin 8260 Jun 4 2019 esfs_init.sh -rwxr-xr-x 1 root bin 8260 Jun 4 2019 esfs_init.sh.org [root@nbumedia2 scripts]# vi esfs_init.sh 【編集前】 MKESFS_OUTPUT=$( ${MKESFS} -o cache_dir="${CACHEDIR_AS_FUSEOPT}",storage_server=${CLDSRV}, 【編集後】 MKESFS_OUTPUT=$( ${MKESFS} -o readonly,cache_dir="${CACHEDIR_AS_FUSEOPT}",storage_server=${CLDSRV},⑤MSDPカタログのインポート
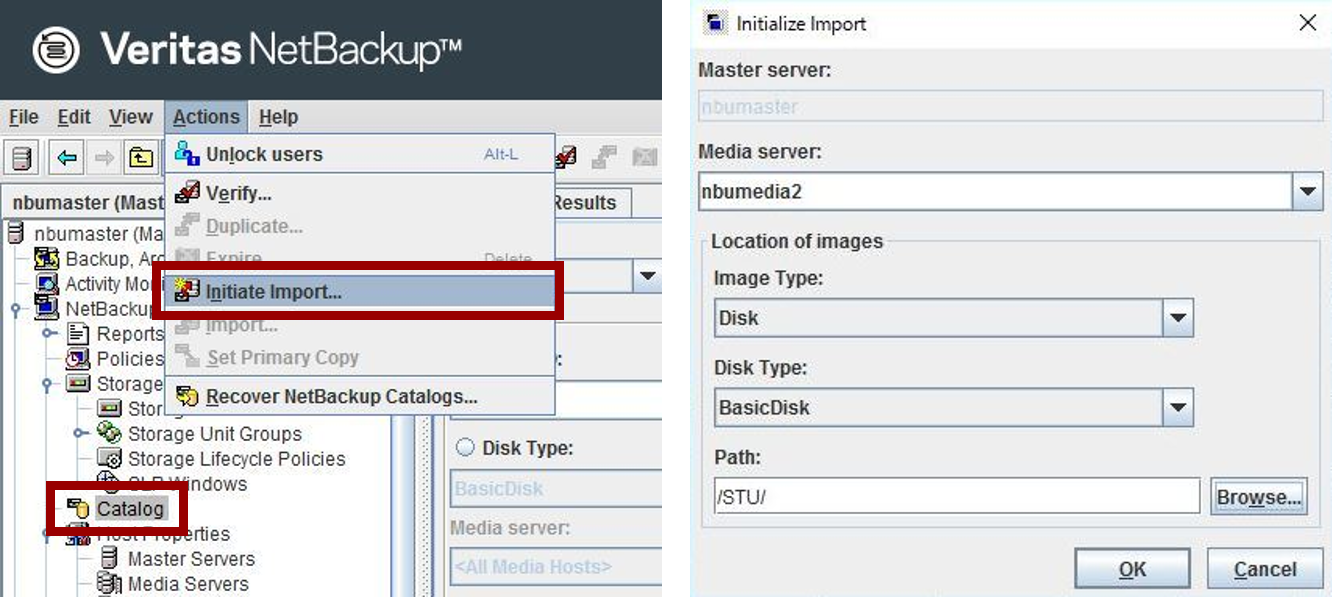
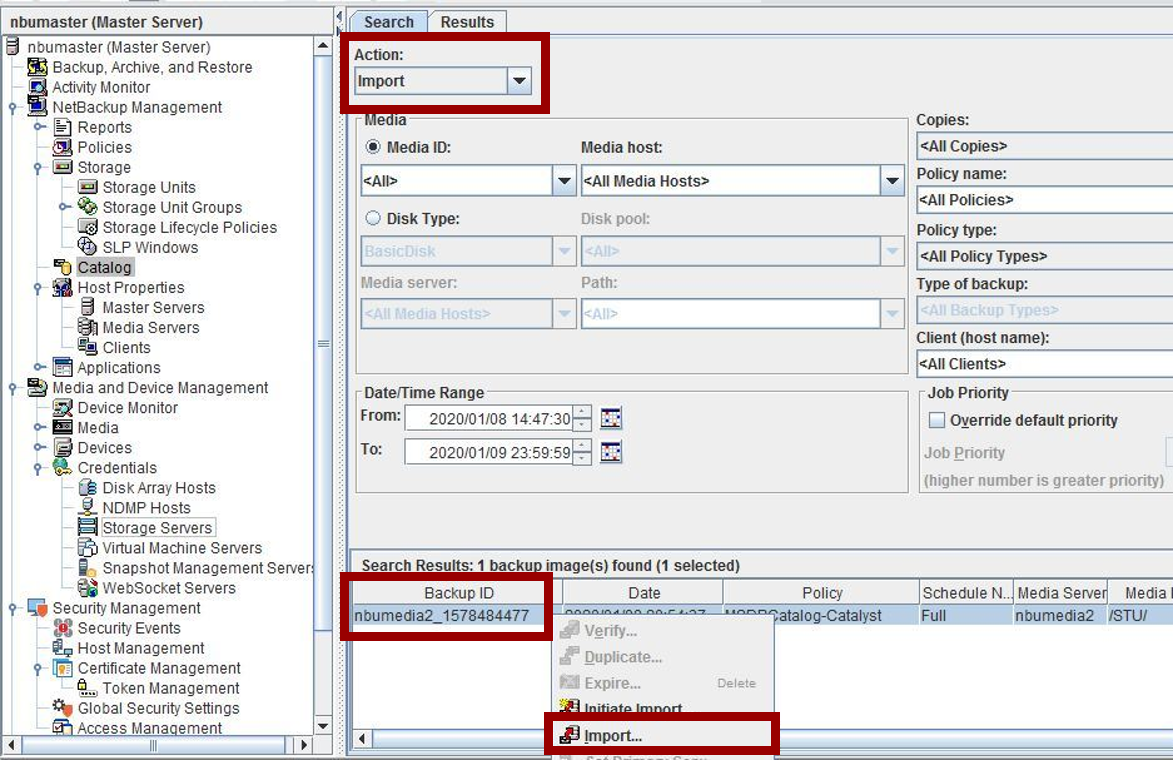
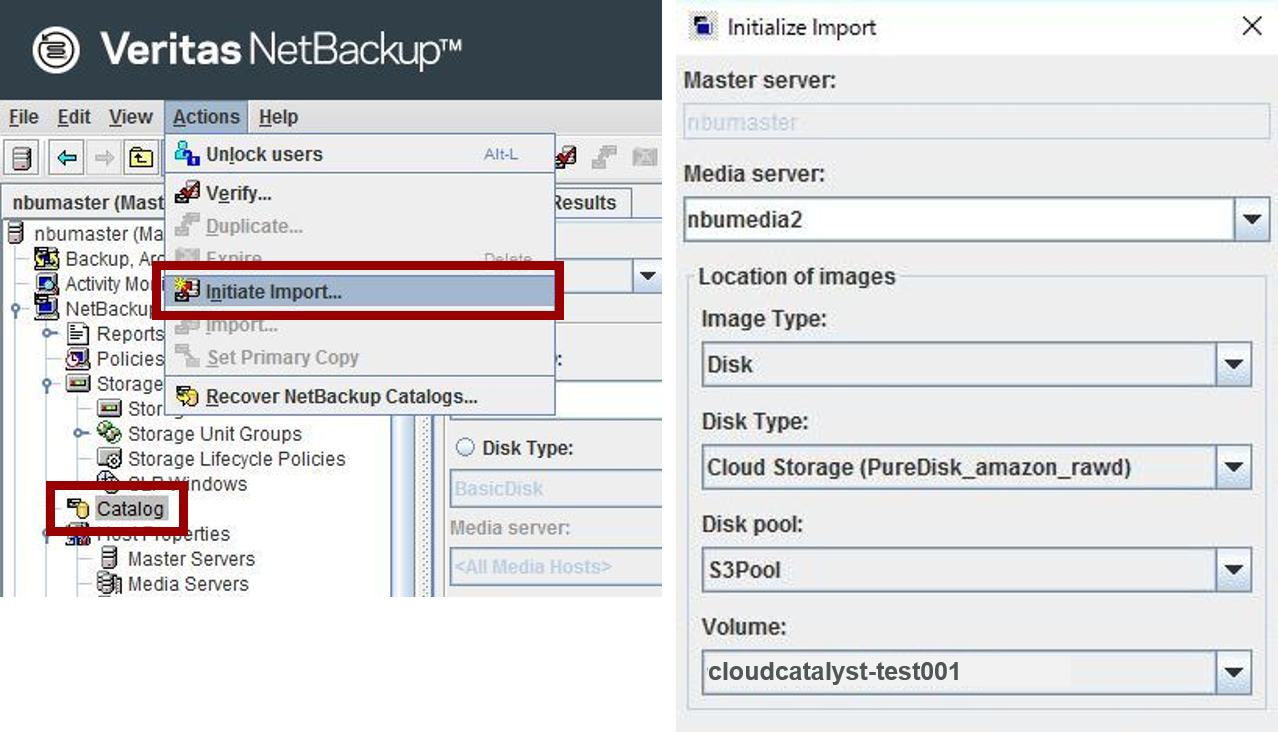
NetBackup管理コンソールのカタログユーティリティを使って、MSDPカタログをインポートします。
nbumedia2で取得した最新のMSDPカタログを指定して、インポートを実施して下さい。<Initiate Import>
<Import>
⑥CloudCatalystストレージサーバーの構成
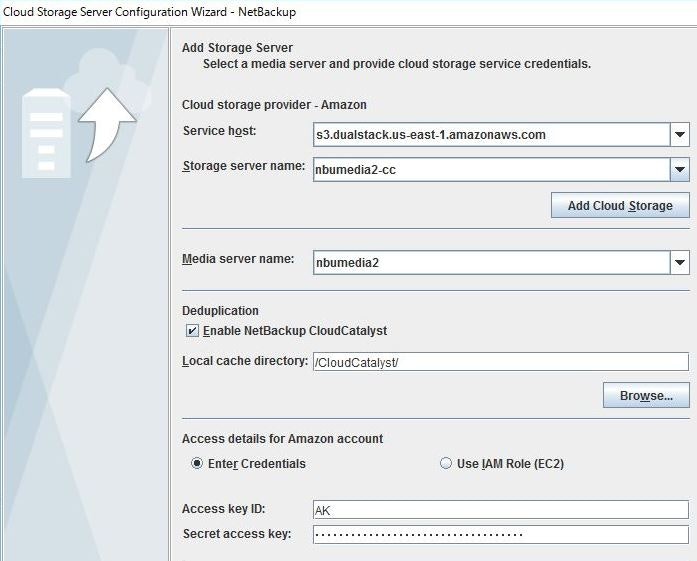
「Cloud Storage Server Configuration Wizard」を使って、nbumedia2でCloudCatalystストレージサーバーを構成します。
<CloudCatalystストレージサーバー作成画面>
<Amazon S3バケット選択画面>
⑦環境変数の設定
CloudCatalystサーバー:「nbumedia2」で環境変数の設定を行います。
# export CSSC_USERNAME={CLOUD_USERNAME}
# export CSSC_PASSWORD={CLOUD_PASSWORD}
※CLOUD_USERNAMEは「AWSアクセスキー」、CLOUD_PASSWORDは「AWSシークレットキー」になります。【実行例】 [root@nbumedia2 /]# export CSSC_USERNAME=AK************************************* [root@nbumedia2 /]# export CSSC_PASSWORD=***************************************⑧MSDPカタログのバックアップポリシー作成
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、MSDPカタログのバックアップポリシーを作成します。
ポリシー名は構築時と同じ名前を指定して下さい。【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdcr/bin/drcontrol --new_policy --policy MSDPCatalog-Catalyst no entity was found (227) The policy MSDPCatalog-Catalyst for host nbumedia2 has been successfully created. The log file may be found at: /var/log/puredisk/drcontrol/policy_admin/new_policy_1578551985.logNetBackup管理コンソールに、MSDPカタログのバックアップポリシーが作成されていることを確認します。
Deactivateの状態で作成されますが、その状態で問題ありません。
⑨MSDPカタログのリカバリ準備
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、MSDPカタログのリカバリ準備を行います。
途中の選択肢は「y」を入力して進めて下さい。【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdcr/bin/drcontrol --initialize_DR --policy MSDPCatalog-Catalyst You have requested to initialize NetBackup Deduplication Catalog Disaster Recovery This operation will recover the dedupe catalog to the point in time of the chosen dedupe catalog backup. All backup images on this deduplication storage server that were not successfully completed by the time of the chosen backup will be completely lost. Do you want to proceed? [y/n] (n) y Your NetBackup Deduplication Storage Server and Storage Unit will be offline during this process. Existing and new jobs that reference this storage server will end with an error like '(2074) Disk volume is down' or '(2106) Disk storage server is down'. You must ensure that no one will restart spoold on this system except for Online Check and CRQP (as part of the recovery process). Also, the status of spoold must be set as PUT=No and GET=No ASAP after starting spoold. Once you start this process, you must complete it before you can use this server. You will be unable to return the system to its current state. Upon successful completion of the NetBackup Deduplication Catalog Recovery process, the system will only be able to access those images that were completed by the time of the selected NetBackup Deduplication Catalog backup and that have not been expired from the NetBackup catalog. Do you want to proceed? [y/n] (n) y Terminating nbsvcmon. Stopping the deduplication service spad. Waiting 5 seconds for spad to stop Stopping the deduplication service spoold. Waiting 5 seconds for spoold to stop The log file may be found at: /var/log/puredisk/drcontrol/dedupe_catalog_DR/init_recovery_1578552433.log⑩CloudCatalystサーバーファイルとFSDB Databaseの復旧
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、CloudCatalystサーバーファイルとFSDB Databaseの復旧を行います。
途中の選択肢は「y」を入力して進めて下さい。【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdcr/bin/drcontrol --recover_last_cloud_catalyst_image --policy MSDPCatalog-Catalyst WARNING! this operation will use bprestore to restore the following paths "/CloudCatalyst/cache/etc" "/CloudCatalyst/cache/fsdb" "/CloudCatalyst/cache/userdata/proc/cloud.lsu" for the policy name [MSDPCatalog-Catalyst] and client name [nbumedia2]. The NetBackup Deduplication and NetBackup CloudCatalyst services will be shutdown. Do you want to proceed? [y/n] (n) y Stopping the NetBackup CloudCatalyst service. Restoring the last backup image for policy MSDPCatalog-Catalyst and client nbumedia2. Starting the NetBackup CloudCatalyst service. mount point /CloudCatalyst/storage Start new vxesfsd instance, pid 8598 for mount point /CloudCatalyst/storage The log file may be found at: /var/log/puredisk/drcontrol/dedupe_catalog_DR/recover_last_cloud_catalyst_image_1578552579.log⑪キャッシュディレクトリ以外のファイルとディレクトリを復元
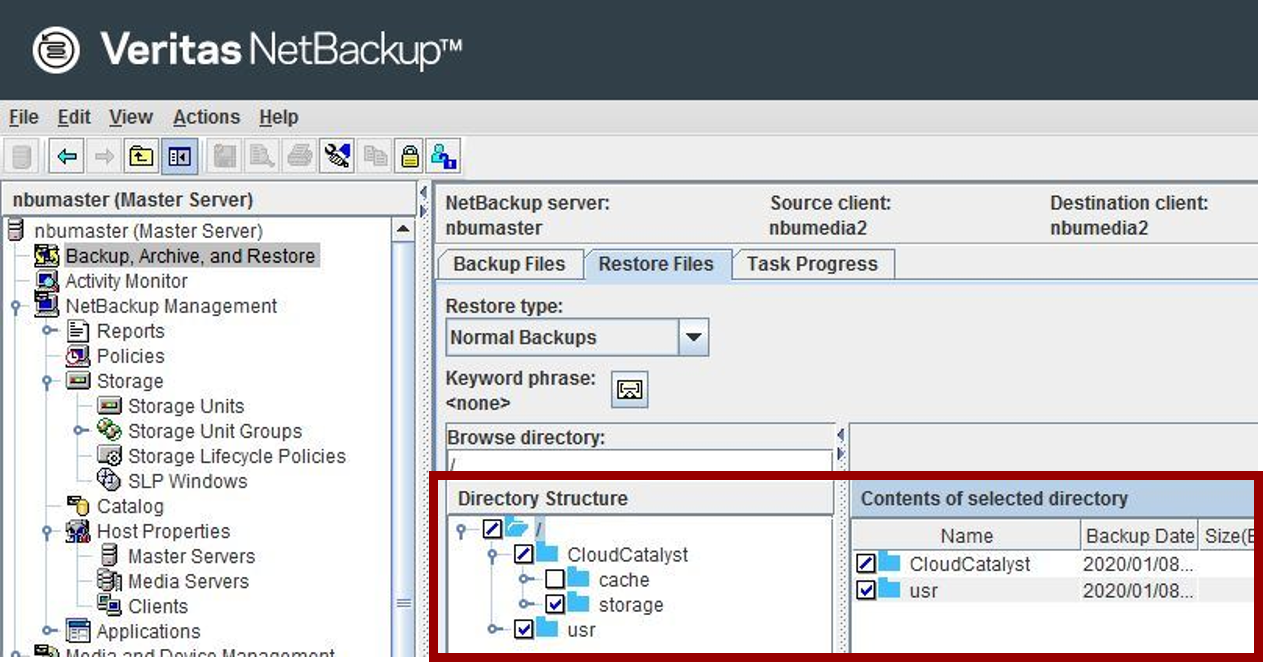
NetBackup管理コンソールの「Backup, Archive, and Restore」を使って、キャッシュディレクトリ以外のファイルとディレクトリを復元します。
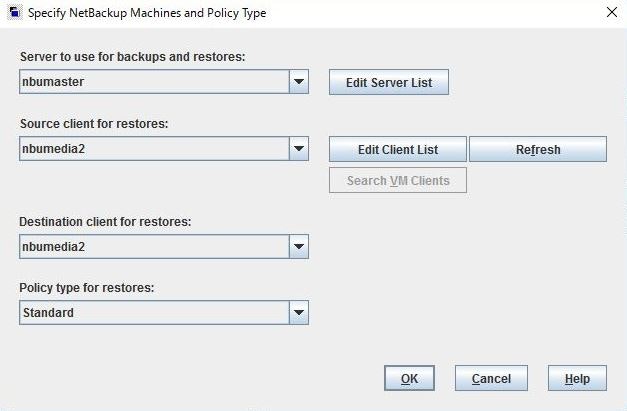
<Specify NetBackup Machines and Policy Type ウィンドウ>
<リストアの指定>
[/CloudCatalyst/storage]および[/usr]が対象で、この領域を上書きリストアして下さい。
[/CloudCatalyst/cache]は対象外ですので、注意して下さい。
⑫spadの起動
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、spadを起動します。
【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdconfigure/pdde spad start Starting spad Warning: manually modifying PureDisk services can cause unexpected behavior! Warning: press CTRL+C to abort. Checking for PDDE Mini SPA spad is stopped spad (pid 9440) is running... [ OK ]⑬カタログシャドウファイルからMSDPカタログを回復
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、カタログシャドウファイルからMSDPカタログを回復します。
【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdcr/bin/cacontrol --catalog disaster_recovery Successfully recovered as much as possible of the catalog. Please see the logs in <Storage>/log/spad/<MediaServerName>/cacontrol/spad/<date>.log for details.⑭spooldの起動
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、spooldを起動します。
【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdconfigure/pdde spoold start Starting spoold Warning: manually modifying PureDisk services can cause unexpected behavior! Warning: press CTRL+C to abort. Checking for PureDisk ContentRouter spoold is stopped spoold (pid 9685) is running... spoold [ OK ]⑮Amazon S3のバックアップデータをインポート
あと、もう一息です!
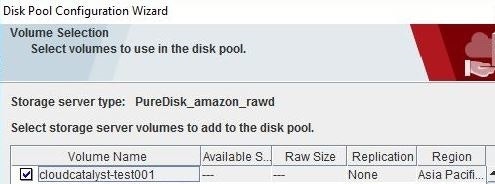
NetBackup管理コンソールのカタログユーティリティを使って、Amazon S3のバックアップデータをインポートします。<Initiate Import>
もし、Amazon S3のディスクプールが表示されない場合は、Refreshボタンで更新して下さい。
<Import>
事前に取得した2つのバックアップデータが出力されていることが確認出来ます!
この状態でインポートを実施すると、Amazon S3に保管されているバックアップデータが、CloudCatalystサーバー:「nbumedia2」にダウンロードされます。
⑯リカバリ中に作成された一時ファイルを削除
CloudCatalystサーバー:「nbumedia2」で以下のコマンドを実行し、リカバリ中に作成された一時ファイルを削除します。
途中の選択肢は「y」を入力して進めて下さい。【実行例】 [root@nbumedia2 /]# /usr/openv/pdde/pdcr/bin/drcontrol --cleanup Following file/folders will be deleted: /CloudCatalyst/cache/#corrupt_Cat_DR_save_1578552579_fsdb /CloudCatalyst/cache/#corrupt_Cat_DR_save_1578552579_userdata Do you want to proceed? [y/n] (n) y Cleanup of DR paths is completed The log file may be found at: /var/log/puredisk/drcontrol/dedupe_catalog_DR/cleanup_1578555880.log⑰「Backup, Archive, and Restore」を使って対象サーバーにデータをリストア
以上の作業が終了すれば、CloudCatalystサーバー:「nbumedia2」にバックアップデータが復元されていますので、対象サーバーにデータのリストアが可能です!
おわりに
いかがでしたでしょうか?
全損からの障害復旧ということで少々手順が複雑ですが、オンプレ環境が全損した場合でもキチンと復旧出来ることがお分かり頂けたかと思います。3回に分けてお伝えして来ました「NetBackup CloudCatalyst for AWS入門」ですが、今回で最後となります。
後日、CloudCatalyst構築および復旧手順書を公開致しますが、こちらにつきましては今暫くお待ち下さい。また、今までの内容で不明点などがございましたら、遠慮なくお問い合わせ下さい。
商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。





- 投稿日:2020-01-21T16:15:59+09:00
CloudFromation/samテンプレートでよく使う記法のメモ
本ページについて
- マニュアルなどにも記載されているCloudFormation/samのテンプレートの記法のうち、よく使うけれどもどうだったっけ?となりやすいものをメモします。最新の情報はマニュアルをご確認ください。
- 記述の方式は何通りか存在しますので、こちらに記載の内容”だけ”が唯一の書き方ではありません。
以下が前提です。
- yaml形式
ImportValueとSubの組み合わせ
Importしたいエクスポート名自体をパラメータで変えたい場合
{'Fn::ImportValue': !Sub "hogehoge-${Parameter}"}Importした値との文字列連結を行いたい場合。
- !Sub - ${hogehoge}/hugahuga - hogehoge: {'Fn::ImportValue': example-export-name}参考URL
- 投稿日:2020-01-21T15:37:20+09:00
【AWS】API GateWay + LambdaでSlakcアプリケーションの認証を行う方法
SlackのEventをAPI GateWayで処理し、Lambdaを起動しています。
APIのアドレスが漏れた場合、攻撃を受ける可能性が有る為、API GateWayで何かしらの対策ができないかと思い記事を書こうと思いました。Slackの認証方法について
以下の2種類があります。
- リクエストのBody内の文字列を利用した認証
- Signing Secretを用いた認証
リクエストのBody内の文字列を利用した認証
SlackのEvent APIについて
Eventが発生すると、下記のようなJSONが発行されます。
Slackのイベント{ "token": "XXYYZZ", "team_id": "TXXXXXXXX", "api_app_id": "AXXXXXXXXX", "event": { "type": "name_of_event", "event_ts": "1234567890.123456", "user": "UXXXXXXX1", ... }, "type": "event_callback", "authed_users": [ "UXXXXXXX1", "UXXXXXXX2" ], "event_id": "Ev08MFMKH6", "event_time": 1234567890 }
token、team、そしてapi_app_idフィールドでは、妥当性、起源、およびリクエストの送信先を識別するのに役立ちます。
と公式サイトに記載されています。tokenの内容で認証を行う方法
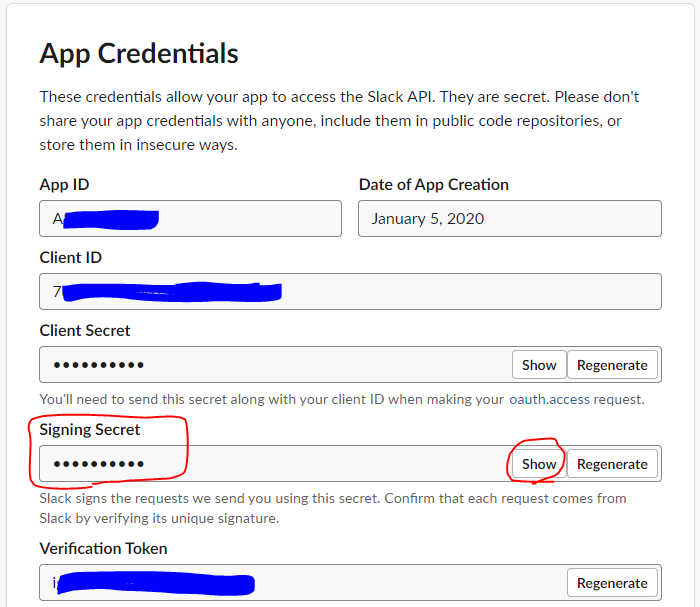
Slackアプリの「App Credentials」のページ内に記載されている、
Verification Tokenを用いて認証を行います。
Verification TokenをLambdaの環境変数「VERIFICATION_TOKEN_APPTEST_WS」に設定して利用します。
eventの内容は、Slackから来るPOSTのBodyが格納されています。確認用コード# TOKEN認証 if event['token'] != os.environ['VERIFICATION_TOKEN_APPTEST_WS']: return { 'statusCode': 200, 'body': json.dumps('Error'), 'text' : 'Token不整合' }※同様に、App_IDでも認証をする事が可能です。
Signing Secretを用いた認証を行う方法
Verifying requests from Slack の情報を参考に認証を設定していきます。
API GateWayの設定
SlackのBody以外の内容を受け取れるようにする為に、API GateWayの設定を行います。
下記の図の
統合リクエストをクリックします。
Lambda プロキシ統合の使用のチェックを有効にします。「Lambda プロキシ統合の使用」を有効化について
「Lambda プロキシ統合の使用」を有効化する事で、これまで、API GateWayが整形していたHTTPヘッダーの情報をきちんとLambda関数で受け取る事ができるようになります。
例)
・「Lambda プロキシ統合の使用」を無効化した状態
→ HTTPヘッダーの情報が切り捨てられ、Lambdaのeventに渡される内容は、Bodyの内容のみ無効時{ Message: 'Hello World!' }・「Lambda プロキシ統合の使用」を有効化した状態
→ HTTPヘッダーの情報も含めてLambdaのeventに渡される
※ 注意! eventの内容はJSONではなく、文字列で渡される為、注意が必要です。有効時{ resource: '/mook', path: '/mook', httpMethod: 'POST', headers: { Accept: ' application/json' }, queryStringParameters: { param1: 'value1' }, pathParameters: null, stageVariables: null, requestContext: { accountId: 'xxxxxxxxxxxx', resourceId: 'xxxxxx', stage: 'test-invoke-stage', requestId: 'test-invoke-request', identity: { cognitoIdentityPoolId: null, accountId: 'xxxxxxxxxxxx', cognitoIdentityId: null, caller: 'xxxxxxxxxxxx', apiKey: 'test-invoke-api-key', sourceIp: 'test-invoke-source-ip', cognitoAuthenticationType: null, cognitoAuthenticationProvider: null, userArn: 'arn:aws:iam::xxxxxxxxxxxx:root', userAgent: 'Apache-HttpClient/4.5.x (Java/1.8.0_102)', user: 'xxxxxxxxxxxx' }, resourcePath: '/mook', httpMethod: 'POST', apiId: 'xxxxxxxxxx' }, body: '{"Message": "Hello World"}' }Lambdaで認証の処理を作成
API GateWayでは認証の処理を実装する事ができないので、Lambdaに処理を実装します。
認証用の処理を記載したPythonファイル
slack_signing.pyを作成します。slack_signing.py# -*- coding: utf-8 -*- """ Slackの認証を行う処理 """ import hmac import hashlib import datetime import logging logger = logging.getLogger() logger.setLevel(logging.INFO) def __generate_hmac_signature(timestamp, body, secretkey): """ hmacの生成処理 """ secretkey_bytes = bytes(secretkey, 'UTF-8') message = "v0:{}:{}".format(timestamp, body) message_bytes = bytes(message, 'UTF-8') return hmac.new(secretkey_bytes, message_bytes, hashlib.sha256).hexdigest() def is_valid_event(event, secretkey): """ 認証処理 """ if "X-Slack-Request-Timestamp" not in event["headers"] \ or "X-Slack-Signature" not in event["headers"]: print('API GateWayで「Lambda プロキシ統合の使用」が選択されているかチェックしてください。') return False request_timestamp = int(event["headers"]["X-Slack-Request-Timestamp"]) now_timestamp = int(datetime.datetime.now().timestamp()) if abs(request_timestamp - now_timestamp) > (60 * 5): return False expected_hash = __generate_hmac_signature( event["headers"]["X-Slack-Request-Timestamp"], event["body"], secretkey ) expected = "v0={}".format(expected_hash) actual = event["headers"]["X-Slack-Signature"] logger.debug("Expected HMAC signature {} : {}".format(type(expected), expected)) logger.debug("Actual HMAC signature {} : {}".format(type(actual), actual)) return hmac.compare_digest(expected, actual)Lambdaのハンドラがあるソースで、
is_valid_eventを呼び出し、認証を行います。lambda_function.pyimport json import logging import os from slack_signing import is_valid_event logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event: dict, context): # EventのVerify用 logger.info(json.dumps(event)) if "challenge" in event: return event.get("challenge") # Signing処理の呼び出し secretkey = os.environ['SLACK_API_SIGNING_SECRET'] if is_valid_event(event, secretkey) is False: logger.error('×System Error!') return { 'statusCode': 200, 'body': json.dumps('OK') } # Bodyの内容は、文字列なので、ここでJSONに変換 body = json.loads(event['body']) # 処理をここに書く return { 'statusCode': 200, 'body': json.dumps('OK') }SLACK_API_SIGNING_SECRET を利用するために、環境変数に登録します。
下記の図のShowボタンを押して「Signing Secret」を表示し、Lambdaの環境変数に登録します。
まとめ
以上で認証については終了です。
今後、時間が有れば、API GateWayで、Tokenについて認証し、Lambdaで「Signing Secret」を利用し、認証する事ができるかも、試してみたいです。


- 投稿日:2020-01-21T12:25:50+09:00
【AWS】SQSで同一メッセージを同時に複数受信してしまうケース
SQSをポーリングする処理を実装していたところ、同一メッセージを同時に受信してしまう事象に遭遇した。
解説コードはPythonだが、事象は他の言語/SDKでも発生するものと考えられる。
何が起きたか
SQS対象のキューにはメッセージが1つだけ格納されている状態とする。
以下は、SQSキューからメッセージを最大10件取得するPythonコード。import boto3 # SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, MaxNumberOfMessages=10).get('Messages')受信したメッセージを表示する。
for i, message in enumerate(messages): print(i) print('MessageId: ' + message['MessageId']) print('MD5: ' + message['MD5OfBody']) # 0 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 1 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 2 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200*********このような感じでメッセージID、ボディが全く同じものを3件取得してしまった。
同時に取得する件数は1件だったり2件だったりする。原因と対処(推察)
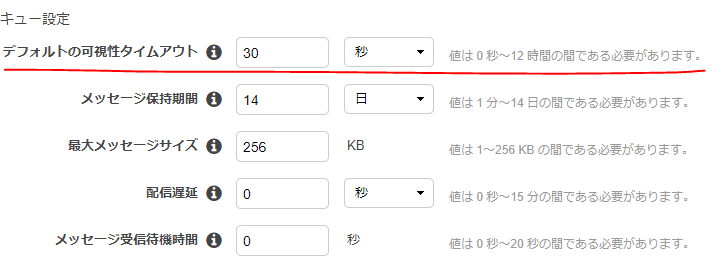
キューの設定で可視性タイムアウト(VisibilityTimeout)を0にしていると発生する。
これを0より大きな適当な値に変更すれば解消した。SQSはマネージドなメッセージキューイングサービスで、裏側でメッセージデータを分散保持して可用性を高めている。
この可視性タイムアウトが無効になっていると、ポーリングリクエストに対して全てのSQSサーバがレスポンスしてしまっていた可能性が高い。特にスケールを考えないシンプル構成だったため「ええい!こんなオプションは無効じゃ!」と適当に設定していた。。。
設定方法
コンソール画面から
[キュー操作]>[キューの設定]と進んで ↓ここ
(
)ポーリングリクエスト
オプションを付けてリクエストを送ることもできるが、キュー全体の設定を変えておいた方が無難だと思う。
Python SDK(boto3)の例
# SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, VisibilityTimeout=30)
- 投稿日:2020-01-21T12:25:50+09:00
【その設定値をゼロにするなんてとんでもない!】SQSで同じメッセージを複数件受信してしまう
SQSをポーリングする処理を実装していたところ、同一メッセージを同時に受信してしまう事象に遭遇した。
解説コードはPythonだが、事象は他の言語/SDKでも発生するものと考えられる。
何が起きたか
以下は、SQSキューからメッセージを最大10件取得するPythonコード。
なお、対象のキューにはメッセージが1つしか格納されていない状態とする。
import boto3 # SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, MaxNumberOfMessages=10).get('Messages')受信したメッセージを表示する。
for i, message in enumerate(messages): print(i) print('MessageId: ' + message['MessageId']) print('MD5: ' + message['MD5OfBody']) # 0 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 1 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 2 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200*********このような感じでメッセージID、ボディが全く同じものを3件取得してしまった。
同時に取得する件数は1件だったり2件だったりする。原因と対処(推察)
キューの設定で可視性タイムアウト(VisibilityTimeout)を0にしていると発生する。
これを0より大きな適当な値に変更すれば解消した。SQSはマネージドなメッセージキューイングサービスで、裏側でメッセージデータを分散保持して可用性を高めている。
この可視性タイムアウトが無効になっていると、ポーリングリクエストに対して全てのSQSサーバがレスポンスしてしまっていた可能性が高い。特にスケールを考えないシンプル構成だったため「ええい!こんなオプションは無効じゃ!」と適当に設定していた。。。
設定方法
コンソール画面から
[キュー操作]>[キューの設定]と進んで ↓ここ
(
)ポーリングリクエスト
オプションを付けてリクエストを送ることもできるが、キュー全体の設定を変えておいた方が無難だと思う。
Python SDK(boto3)の例
# SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, VisibilityTimeout=30)
- 投稿日:2020-01-21T12:02:13+09:00
Javascriptのシンプルな構成でAWS Cognitoを理解する
概要
いろいろと理解しなければならないことが多いですが、まずは、できるだけシンプルな構成でAWS Cognitoの基礎を理解します。
jQueryは使わずにJavascriptのみです。
ただし、アカウントの属性には標準属性とカスタム属性を設定します。
今回説明する内容を踏まえて、実用ではAmplifyを使うと良いかと思っています。画面遷移
まずはサインアップ画面
サインアップするとメールで検証リンクが配信されます。
Verify Emailリンクをクリックすると検証が完了します。
次にサインイン画面
最後に認証されたアカウントしか入ることのできない画面
Sign Outをクリックするとサインアウトしてサインイン画面に遷移します。ファイル構成
jsフォルダへ準備するライブラリ
それぞれのREAD.MEをしっかり確認してください。
AWS Cognitoの設定
- AWSへサインイン
- Cognitoのコンソールへ
- リージョンを東京へ変更

ユーザープールの管理をクリックユーザープールを作成するをクリック
プール名へお好きな名前を付けてください。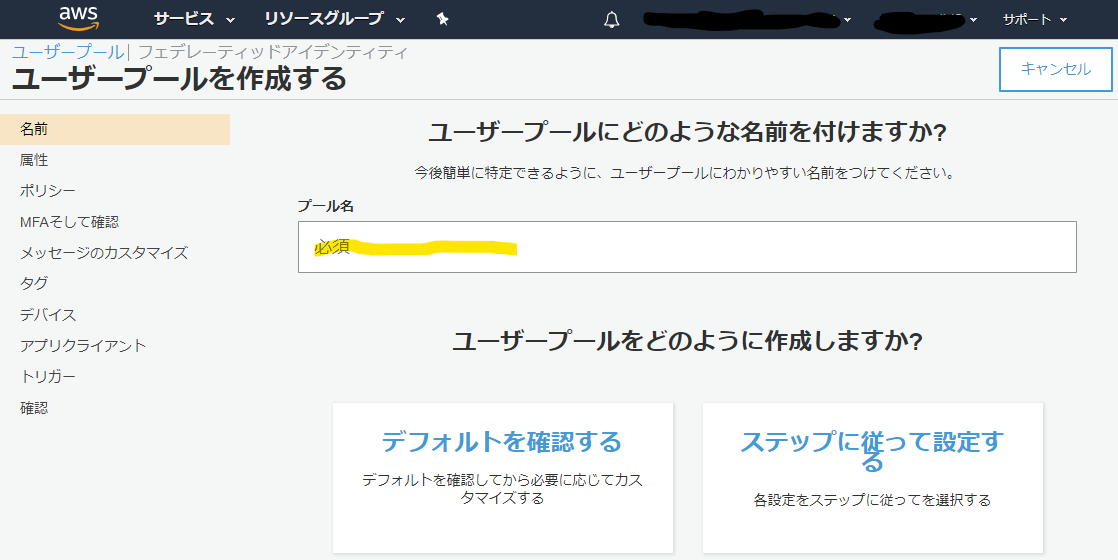
デフォルトを確認するをクリックすると↓の画面になります。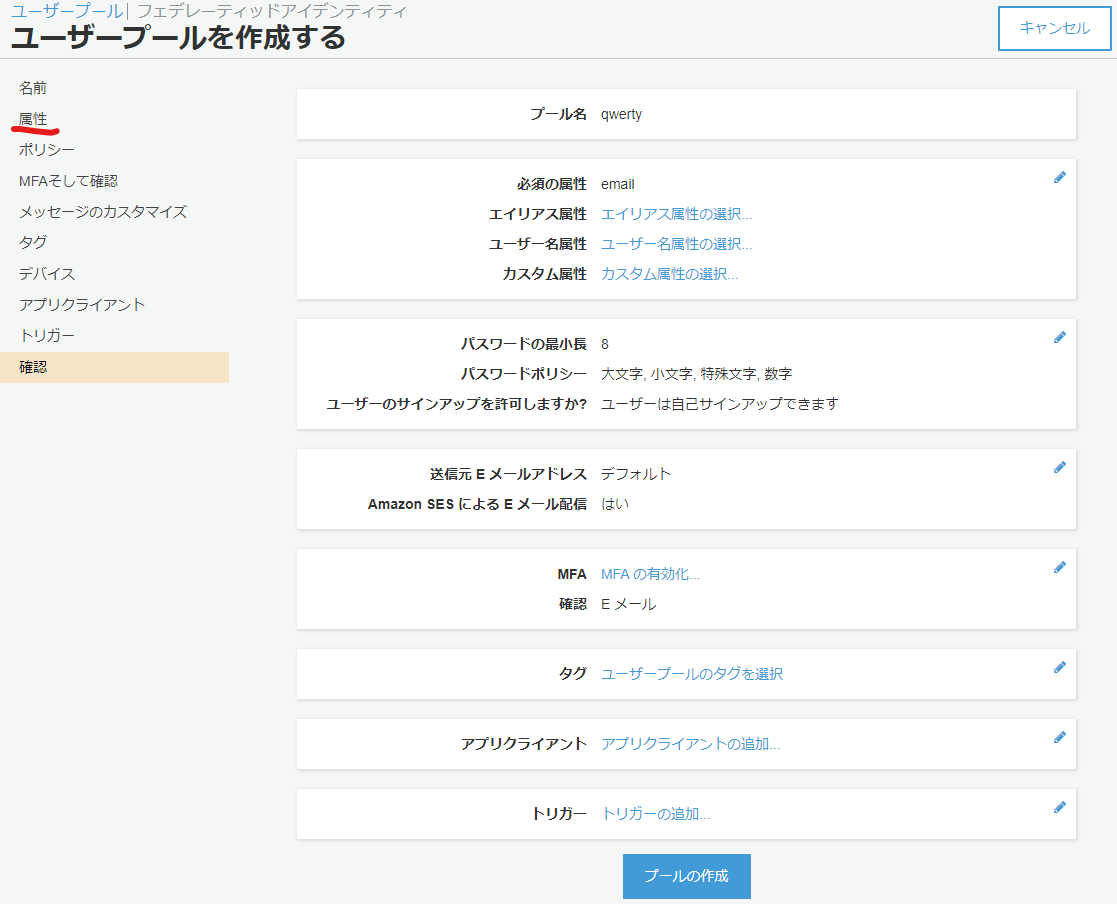
- サイドバーの
属性をクリック- 今回は↓のように設定します。
カスタム属性にはroleと入力しますが、自動でcustom:roleと変更されます。次のステップをクリック- 「ポリシー」の設定
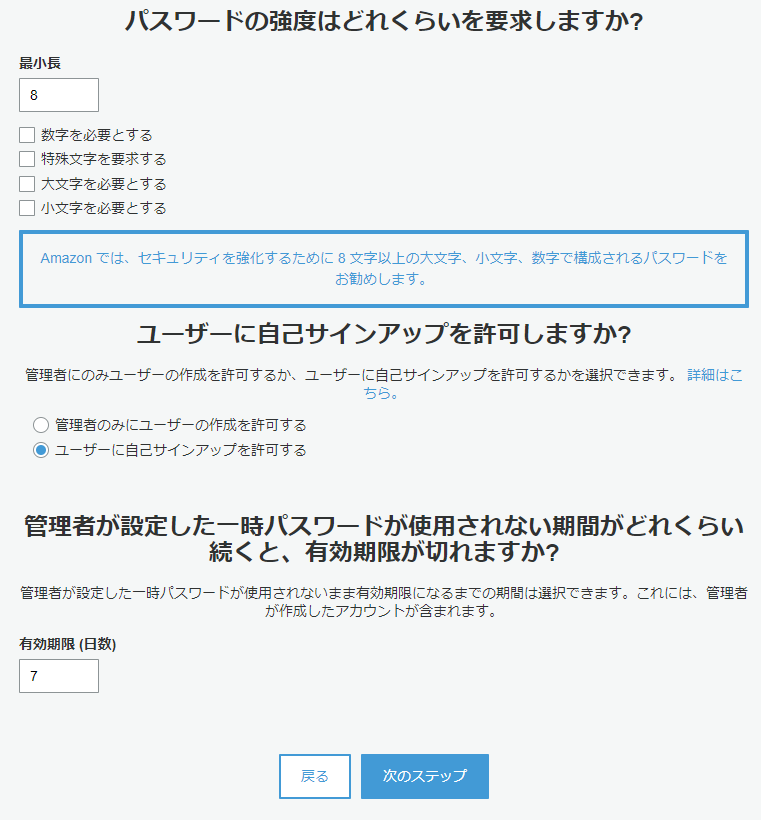
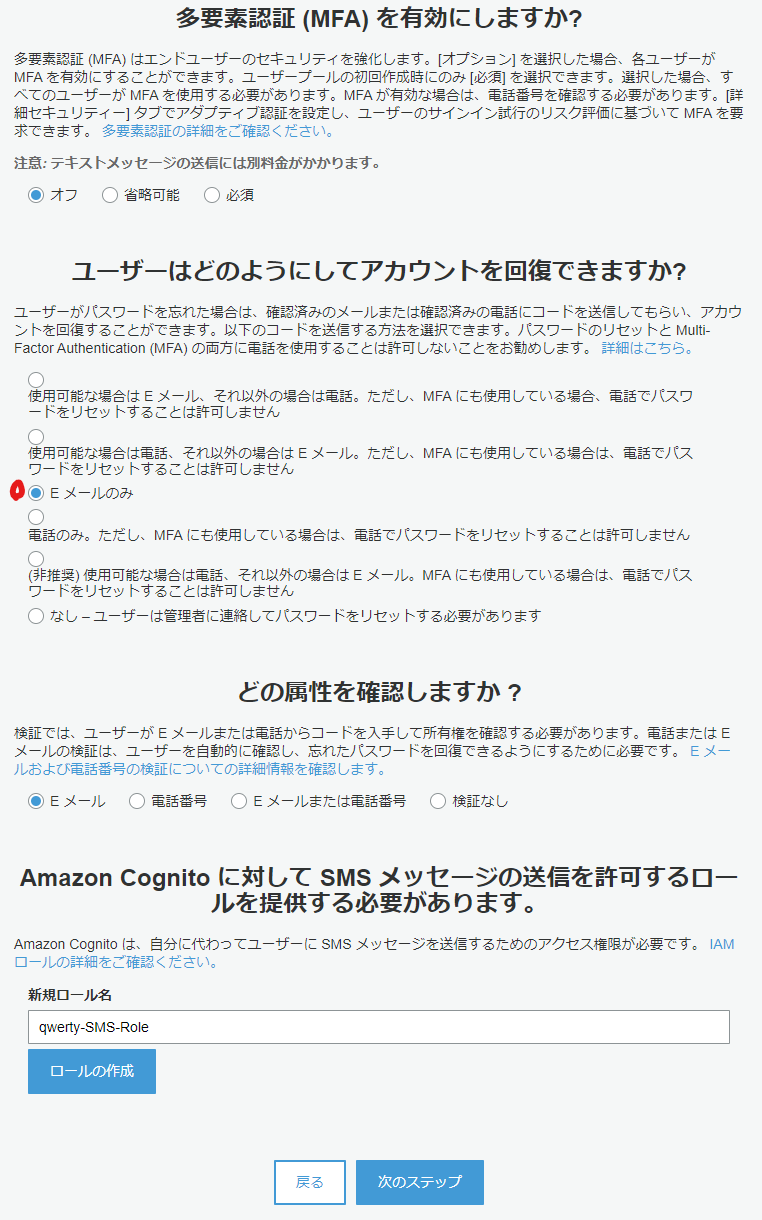
- 「MFAそして確認」の設定
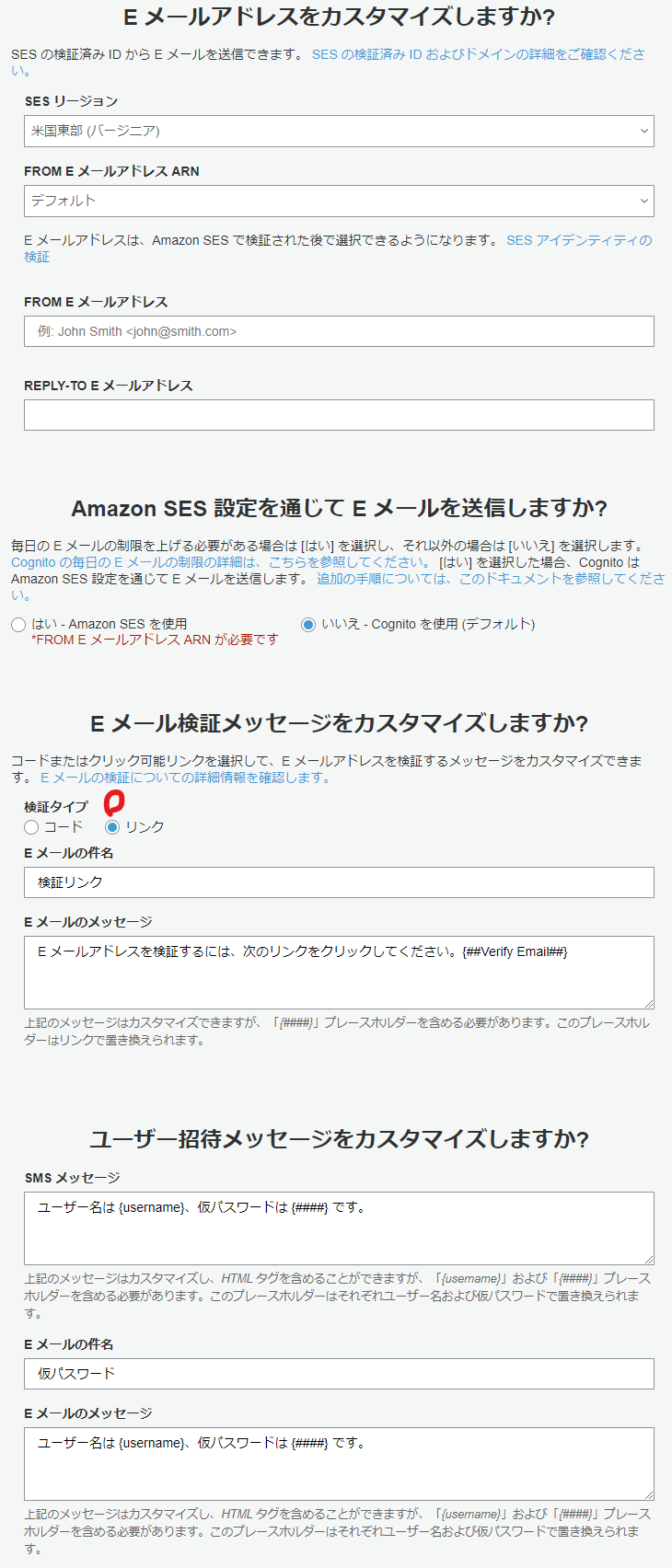
- 「メッセージのカスタマイズ」の設定
- 「アプリクライアント」の設定で
アプリクライアントの追加をクリック
- アプリクライアント名を入力し、
クライアントシークレットを作成のチェックを外す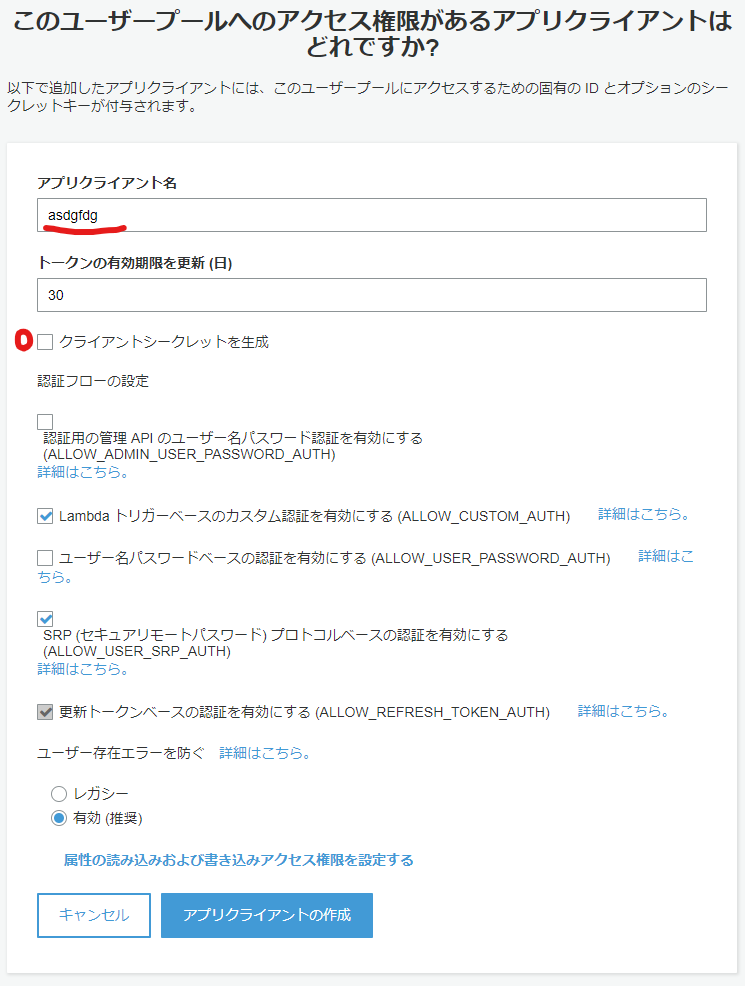
- サイドバーで「確認」をクリックすると↓が表示され、
プールの作成をクリック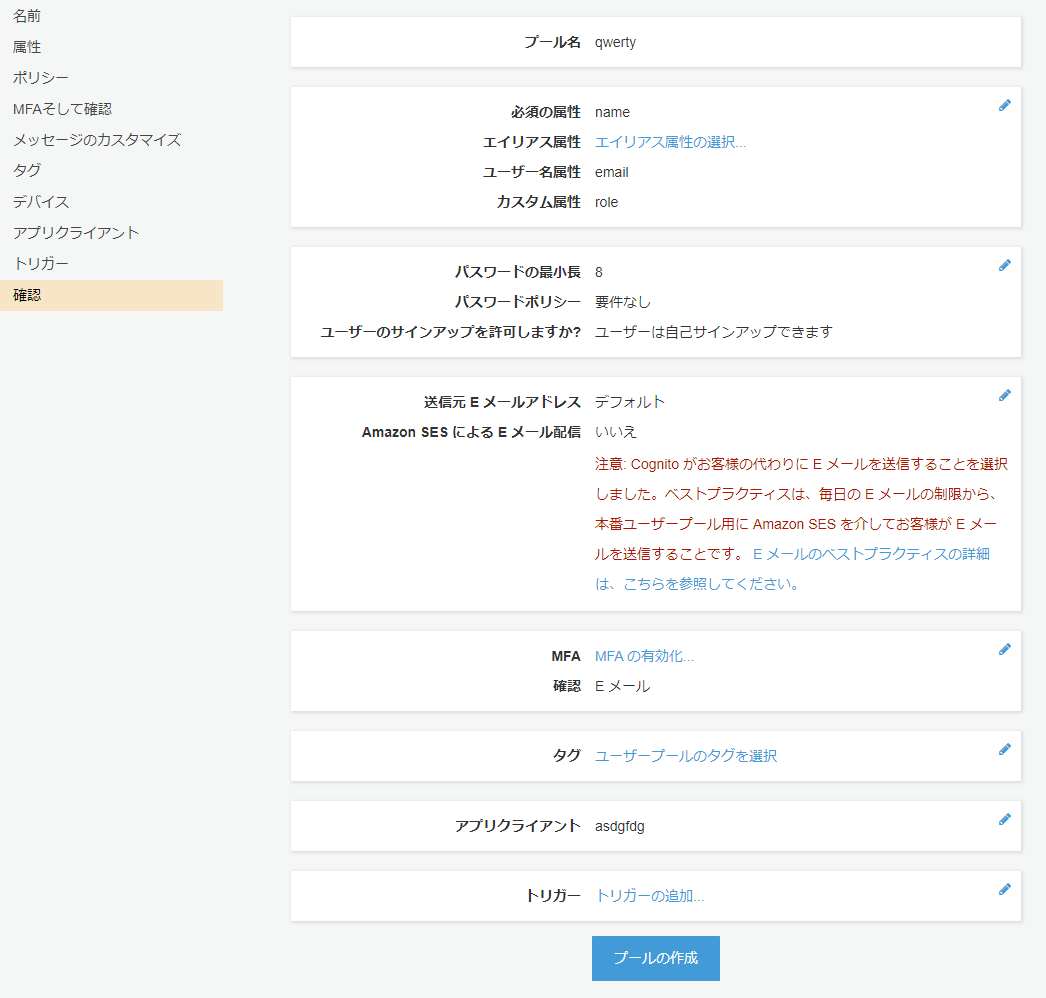
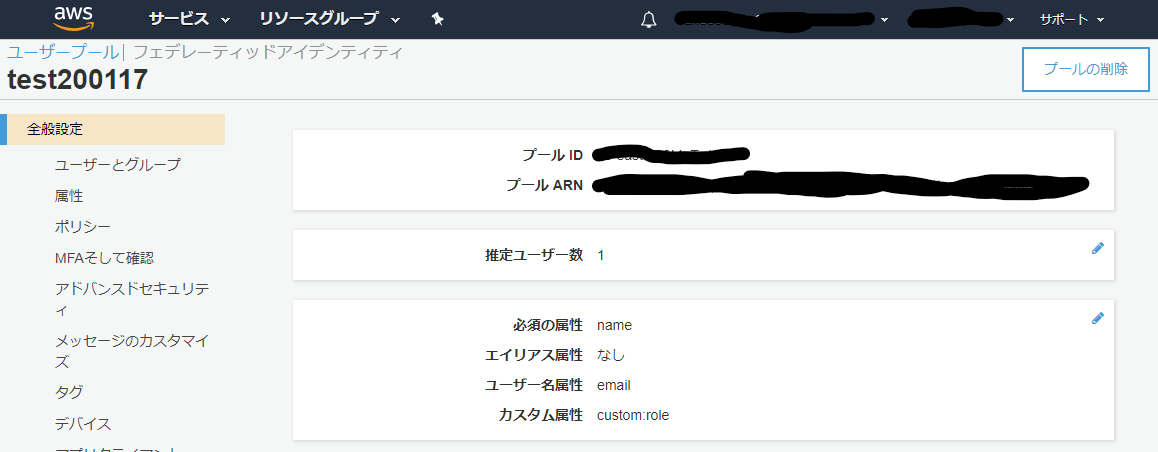
- プールIDが表示されるので、それをメモ
- サイドバーから「アプリクライアント」を選択すると
アプリクライアントIDが表示されるので、それをメモ
- サイドバーから「ドメイン名」を選択するとAmazon Cognito ドメインの作成ができるので好きな名前を入力してドメインを作成します。
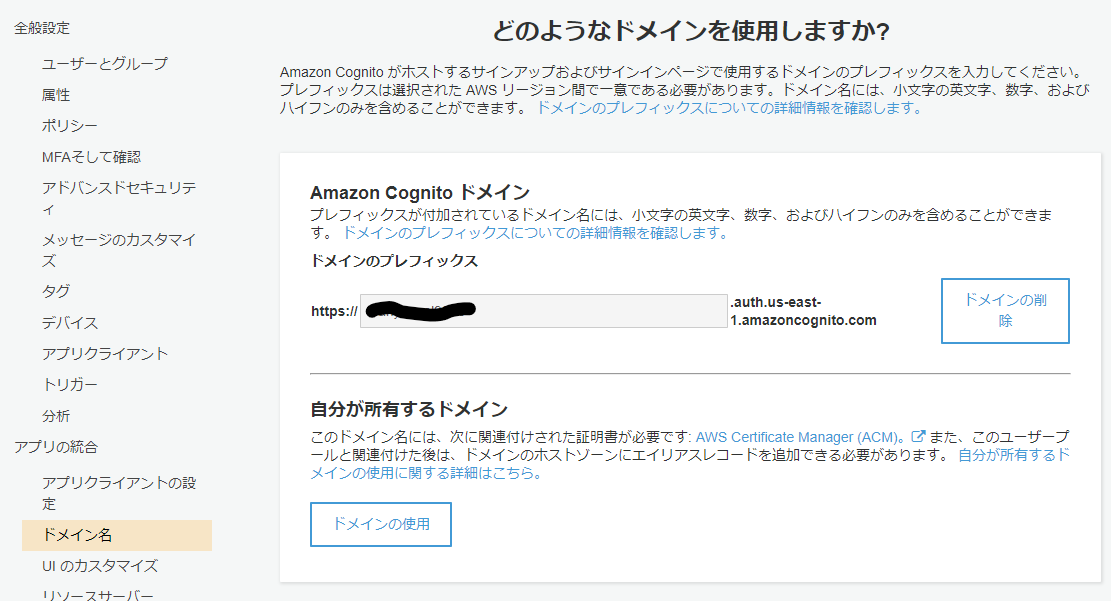
- これでユーザープールの設定が完了
フェデレーティッドアイデンティティの設定
- Cognitoコンソールの上部にある
フェデレーティッドアイデンティティをクリック
をクリック
- 使用開始ウィザードでIDプール名に好きな名前を入力
認証されていないIDに対してアクセスを有効にするをチェック- 認証プロバイダーを展開し、Cognitoを選択
- メモしたユーザープールIDとアプリクライアントIDを入力
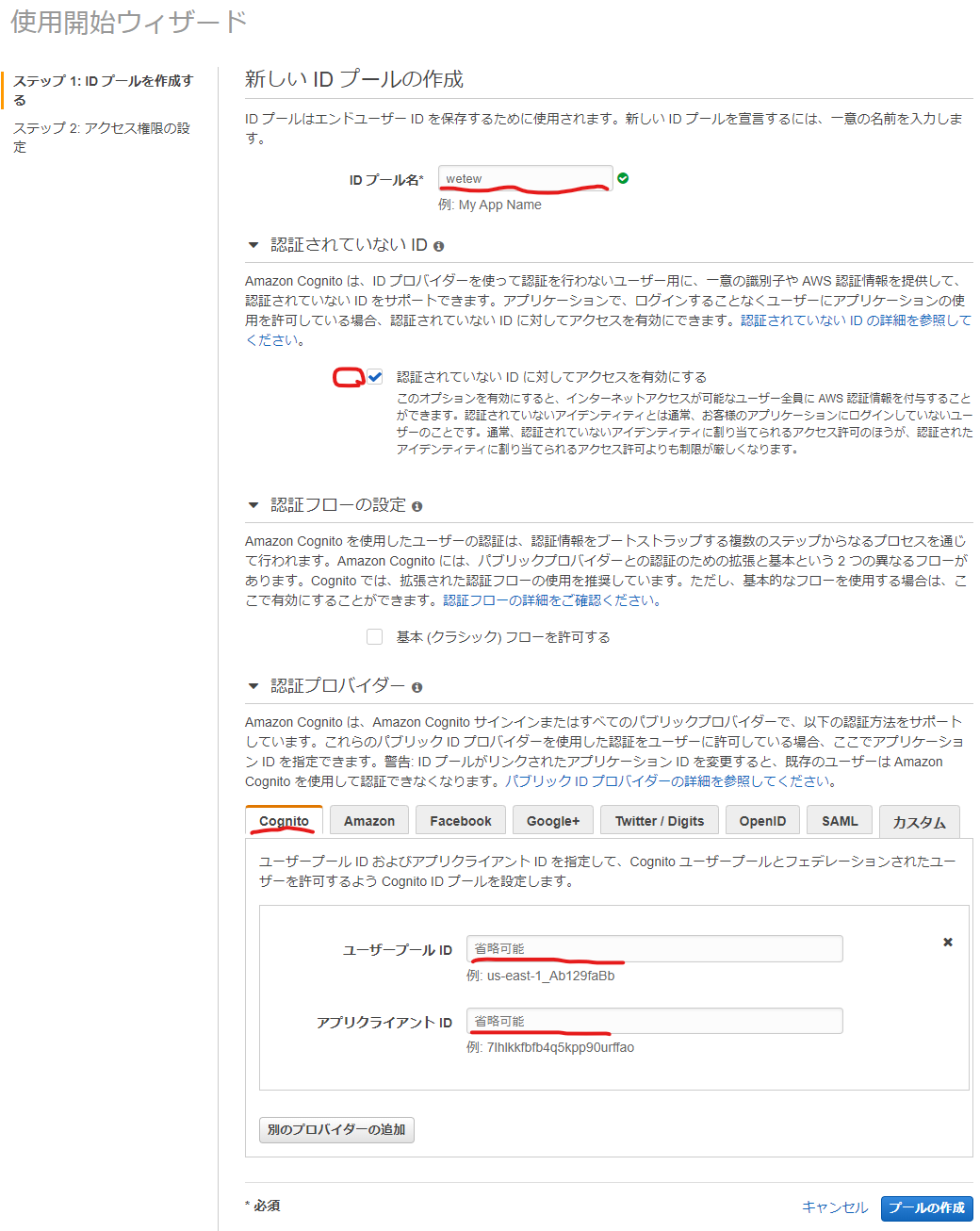
- プールの作成をクリック
- 次の画面ではデフォルトの内容を確認して、
許可をクリック- サイドバーでサンプルコードを選択し、プラットフォームを
Javascriptを選択。AWS認証情報の取得に表示されているコードをメモ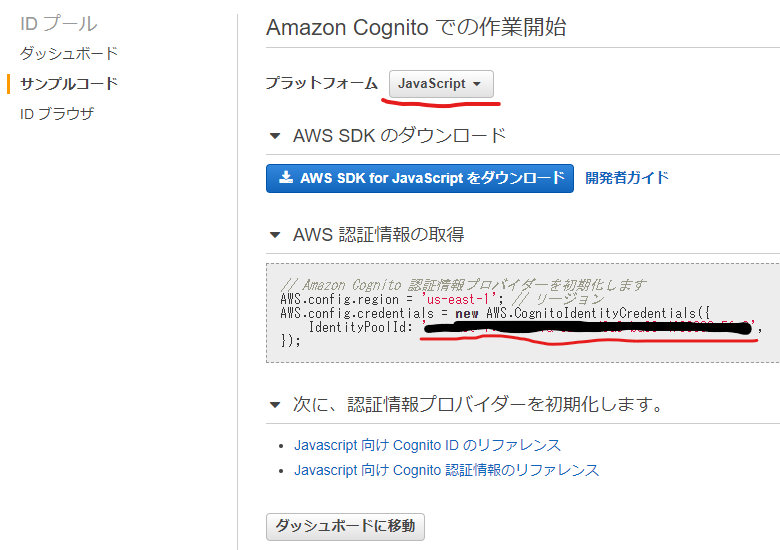
- これでCognitoの設定が完了
サインアップページの作成
signup.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Sign Up</title> <script src="./js/jsbn.js"></script> <script src="./js/jsbn2.js"></script> <script src="./js/sjcl.js"></script> <script src="./js/aws-sdk.min.js"></script> <script src="./js/aws-cognito-sdk.min.js"></script> <script src="./js/amazon-cognito-identity.min.js"></script> </head> <body> <div id="signup"> <h1>Sign Up</h1> <div id="message"><span id="message-span" style="color: red;"></span></div> <form name="form-signup"> <span style="display: inline-block; width: 150px;">User ID(Email)</span> <input type="text" id="email" placeholder="Email Address" /> <br /> <span style="display: inline-block; width: 150px;">Name</span> <input type="text" id="name" placeholder="Name" /> <br /> <span style="display: inline-block; width: 150px;">Password</span> <input type="password" id="password" placeholder="Password" /> <br /><br /> <input type="button" id="createAccount" value="Create Account" /> </form> </div> <br /> <a href="./signin.html">Sign In!</a> <script src="./js/signup.js" defer></script> </body> </html>サインアップの処理
これまでにメモした
ユーザープールID、クライアントID、AWS認証情報を張り付けます。js/signup.js(() => { // ユーザープールの設定 const poolData = { UserPoolId: "us-east-1_xxxxxxxx", ClientId: "xxxxxxxxxxxxxxxxxxxxx" }; const userPool = new AmazonCognitoIdentity.CognitoUserPool(poolData); const attributeList = []; // Amazon Cognito 認証情報プロバイダーを初期化します AWS.config.region = "us-east-1"; // リージョン AWS.config.credentials = new AWS.CognitoIdentityCredentials({ IdentityPoolId: "us-east-1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }); // 「Create Account」ボタン押下時 const createAccountBtn = document.getElementById("createAccount"); createAccountBtn.addEventListener("click", () => { /** * サインアップ処理。 */ const username = document.getElementById("email").value; const name = document.getElementById("name").value; const password = document.getElementById('password').value; // 何か1つでも未入力の項目がある場合、処理終了 const message = document.getElementById("message-span"); if (!username | !name | !password) { message.innerHTML = "未入力項目があります。"; return false; } // ユーザ属性リストの生成 const dataName = { Name: "name", Value: name }; const dataRole = { Name: "custom:role", Value: "5" }; const attributeName = new AmazonCognitoIdentity.CognitoUserAttribute( dataName ); const attributeRole = new AmazonCognitoIdentity.CognitoUserAttribute( dataRole ); attributeList.push(attributeName); attributeList.push(attributeRole); // サインアップ処理 userPool.signUp(username, password, attributeList, null, (err, result) => { if (err) { message.innerHTML = err.message; return; } else { // サインアップ成功の場合、アクティベーション画面に遷移する alert( "登録したメールアドレスへアクティベーション用のリンクを送付しました。" ); location.href = "signin.html"; } }); }); })();サインインページの作成
signin.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Sign In</title> <script src="./js/jsbn.js"></script> <script src="./js/jsbn2.js"></script> <script src="./js/sjcl.js"></script> <script src="./js/aws-sdk.min.js"></script> <script src="./js/aws-cognito-sdk.min.js"></script> <script src="./js/amazon-cognito-identity.min.js"></script> </head> <body> <div id="signin"> <h1>Sign In</h1> <div id="message"><span id="message-span" style="color: red;"></span></div> <form name="form-signin"> <span style="display: inline-block; width: 150px;">Email Address</span> <input type="text" id="email" placeholder="Email Address" /> <br /> <span style="display: inline-block; width: 150px;">Password</span> <input type="password" id="password" placeholder="Password" /> <br /><br /> <input type="button" id="signinButton" value="Sign In" /> </form> </div> <br /> <a href="./signup.html">Sign Up!</a> <script src="./js/signin.js" defer></script> </body> </html>サインインの処理
これまでにメモした
ユーザープールID、クライアントID、AWS認証情報を張り付けます。js/signin.js(() => { // ユーザープールの設定 const poolData = { UserPoolId: "us-east-1_xxxxxxxx", ClientId: "xxxxxxxxxxxxxxxxxxxxxxxxx" }; const userPool = new AmazonCognitoIdentity.CognitoUserPool(poolData); // Amazon Cognito 認証情報プロバイダーを初期化します AWS.config.region = "us-east-1"; // リージョン AWS.config.credentials = new AWS.CognitoIdentityCredentials({ IdentityPoolId: "us-east-1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }); /** * サインイン処理 */ document.getElementById("signinButton").addEventListener("click", () => { const email = document.getElementById('email').value; const password = document.getElementById('password').value; // 何か1つでも未入力の項目がある場合、メッセージを表示して処理を中断 const message = document.getElementById('message-span'); if (!email | !password) { message.innerHTML = "All fields are required."; return false; } // 認証データの作成 const authenticationData = { Username: email, Password: password }; const authenticationDetails = new AmazonCognitoIdentity.AuthenticationDetails( authenticationData ); const userData = { Username: email, Pool: userPool }; const cognitoUser = new AmazonCognitoIdentity.CognitoUser(userData); // 認証処理 cognitoUser.authenticateUser(authenticationDetails, { onSuccess: result => { const idToken = result.getIdToken().getJwtToken(); // IDトークン const accessToken = result.getAccessToken().getJwtToken(); // アクセストークン const refreshToken = result.getRefreshToken().getToken(); // 更新トークン console.log("idToken : " + idToken); console.log("accessToken : " + accessToken); console.log("refreshToken : " + refreshToken); // サインイン成功の場合、次の画面へ遷移 location.href = "index.html"; }, onFailure: err => { // サインイン失敗の場合、エラーメッセージを画面に表示 console.log(err); message.innerHTML = err.message; } }); }); })();認証完了で閲覧できるページの作成
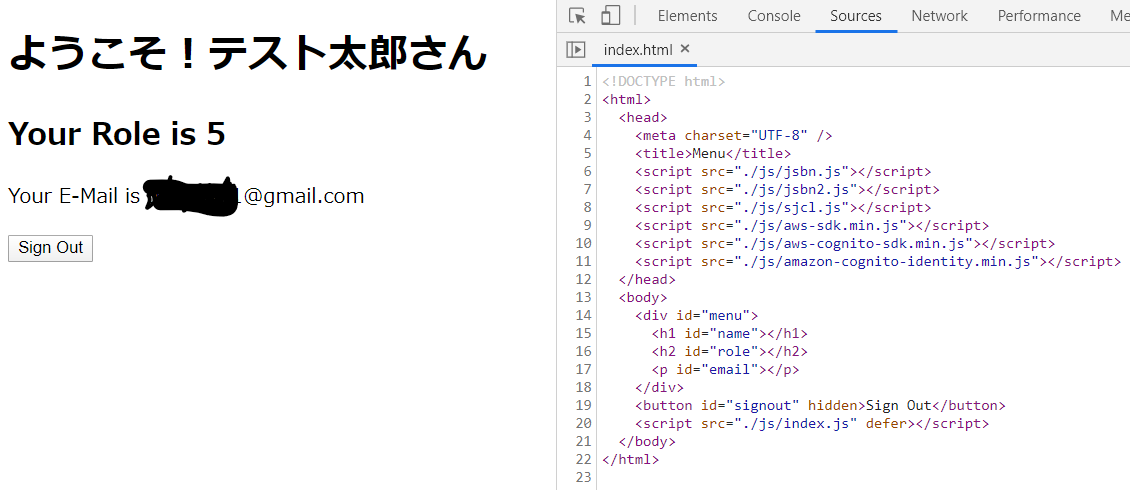
index.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Menu</title> <script src="./js/jsbn.js"></script> <script src="./js/jsbn2.js"></script> <script src="./js/sjcl.js"></script> <script src="./js/aws-sdk.min.js"></script> <script src="./js/aws-cognito-sdk.min.js"></script> <script src="./js/amazon-cognito-identity.min.js"></script> </head> <body> <div id="menu"> <h1 id="name"></h1> <h2 id="role"></h2> <p id="email"></p> </div> <button id="signout" hidden>Sign Out</button> <script src="./js/index.js" defer></script> </body> </html>認証済みかチェックする処理
これまでにメモした
ユーザープールID、クライアントID、AWS認証情報を張り付けます。js/index.js(() => { // ユーザープールの設定 const poolData = { UserPoolId: "us-east-1_xxxxxxxxxx", ClientId: "xxxxxxxxxxxxxxxxxxxxxxxxxx" }; const userPool = new AmazonCognitoIdentity.CognitoUserPool(poolData); const cognitoUser = userPool.getCurrentUser(); // 現在のユーザー const currentUserData = {}; // ユーザーの属性情報 // Amazon Cognito 認証情報プロバイダーを初期化します AWS.config.region = "us-east-1"; // リージョン AWS.config.credentials = new AWS.CognitoIdentityCredentials({ IdentityPoolId: "us-east-1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }); // 現在のユーザーの属性情報を取得・表示する // 現在のユーザー情報が取得できているか? if (cognitoUser != null) { cognitoUser.getSession((err, session) => { if (err) { console.log(err); location.href = "signin.html"; } else { // ユーザの属性を取得 cognitoUser.getUserAttributes((err, result) => { if (err) { location.href = "signin.html"; } // 取得した属性情報を連想配列に格納 for (i = 0; i < result.length; i++) { currentUserData[result[i].getName()] = result[i].getValue(); } document.getElementById("name").innerHTML = "ようこそ!" + currentUserData["name"] + "さん"; document.getElementById("role").innerHTML = "Your Role is " + currentUserData["custom:role"]; document.getElementById("email").innerHTML = "Your E-Mail is " + currentUserData["email"]; // サインアウト処理 const signoutButton = document.getElementById("signout"); signoutButton.addEventListener("click", event => { cognitoUser.signOut(); location.reload(); }); signoutButton.hidden = false; console.log(currentUserData); }); } }); } else { location.href = "signin.html"; } })();動作のテスト
一連の流れをブラウザでテスト
- サインアップ
- メールでアクティベート
- サインイン
- 認証情報の表示
- サインアウト
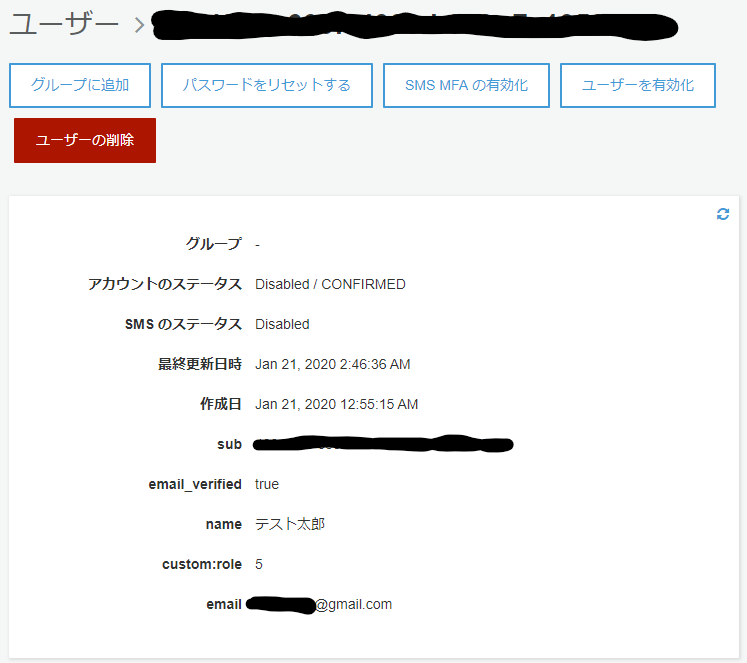
Cognitoのコンソールでユーザーの状況が確認できる
ユーザーを無効化したり、削除したり、詳細な操作ができる
最後に
他にもパスワードの変更や再設定など必要な機能があるかと思いますが、入門としてはシンプルに作成できたかと思います。
ここからJWTや認証・認可などへ広げていけば良いかと思います。





- 投稿日:2020-01-21T12:00:54+09:00
EFSをVPC PeeringしたLightsailのCentOSにマウントさせる
LightsailのVPC ピアリング接続って・・・
Amazon Lightsail では、Amazon RDS データベースや Amazon Aurora など、他の AWS リソースを表示して接続できます。
Lightsail Virtual Private Cloud (VPC) を同じリージョンの AWS VPC とピア接続できます。
たとえば、アプリからデータ層を分離することができます。ドキュメント
- 関連するドキュメントはこちらです。
手順(ごめんなさい、最低限の設定のみです。アクセス管理などは省略してます。)
Lightsail側でVPC Peeringを有効化する
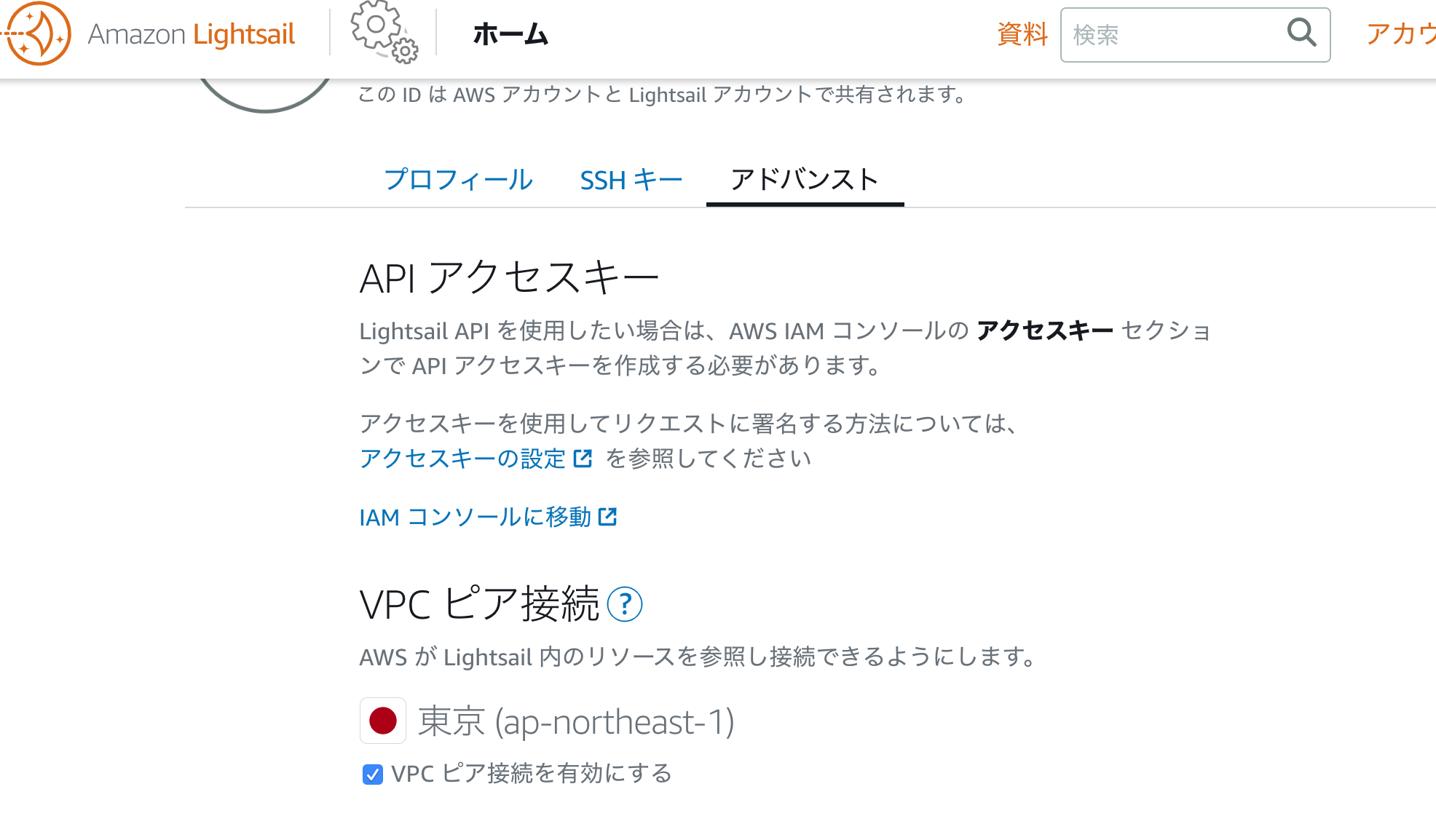
Lightsailのマネジメントコンソールからアカウントをクリックして設定画面を開く
「アドバンスト」の下の方に「VPC Peering」の設定項目があるのでクリックして有効化する
VPCのピアリング接続を確認すると、LightsailとデフォルトVPCでVPC Peeringが有効になっている
4.EFSファイルシステムの作成
ステップ 1: ネットワークアクセスを設定する
- VPC:デフォルトのVPCを指定しました(Lightsailとだとデフォルトでしかダメ)
- マウントターゲットの作成:アベイラビリティーゾーンとサブネット(デフォルト)、IPアドレス(自動)、セキュリティグループを選択
EFSのセキュリティグループは、事前に作成しておきます。
ステップ 2: ファイルシステムの設定を行う
- 特に何も変更せずデフォルトで設定しました。
ステップ 3: クライアントアクセスを設定
- 特に何も変更せずデフォルトで設定しました。
ステップ 4: 確認と作成
- ファイルシステムの作成ボタンをポチッとな
5.マウント
ansibleでやりたかったので、ansible-galaxyに、初めて公開してみました。
内部のIPアドレスで指定する方法を採用します。
main.yml- hosts: servers roles: - { role: kaihei777.ansible_role_efs_lightsail, mount_type: "vpc-peering", aws_efs_paths: [ { path: "/mnt/efs", ← マウントしたい場所 owner: "root", group: "root", mode: "0644", region: "ap-northeast-1", ← リージョン filesystem_id: "fs-xxxxx", ← 作成すると割当られるファイルシステムID mount_target_ip: "172.31.xx.xx", ← 作成すると割当られるマウントターゲットのIPアドレス state: "mounted", opts: "nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2", }, ], }このroleを実行すると・・・おー! すごい使用可能の領域w
fstabにも追加されてる![centos@hogehoge ~]$ ls -la /mnt/ 合計 12 drwxr-xr-x. 5 root root 59 1月 21 11:14 . dr-xr-xr-x. 17 root root 240 9月 12 18:06 .. drwxrwxrwx 2 root root 4096 1月 17 19:14 efs [centos@hogehoge ~]$ df ファイルシス 1K-ブロック 使用 使用可 使用% マウント位置 /dev/xvda1 20960236 4903012 16057224 24% / devtmpfs 225700 0 225700 0% /dev tmpfs 248556 0 248556 0% /dev/shm tmpfs 248556 33304 215252 14% /run tmpfs 248556 0 248556 0% /sys/fs/cgroup 172.31.xx.xx:/ 9007199254739968 0 9007199254739968 0% /mnt/efs [centos@hogehoge ~]$ cat /etc/fstab # # /etc/fstab # Created by anaconda on Mon Jan 28 20:51:49 2019 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # UUID=f41e390f-835b-4223-a9bb-9b45984ddf8d / xfs defaults 0 0 /swapfile none swap sw 0 0 172.31.xx.xx:/ /mnt/efs nfs4 nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 0 0書き込んでみる
[centos@hogehoge ~]$ sudo vi /mnt/jad_disk_efs/test.txt
[centos@hogehoge ~]$ sudo cat /mnt/jad_disk_efs/test.txt やったよー!最後に
もちろん、他のサーバーでマウントすれば、共有領域として使うことができます。
goofysでS3をマウントすることも可能ではありますが、そもそも用途が違うこともあり
頻繁に、I/Oを行う様なことをすると、goofys君メモリリークして、パンクします。
(プロセス落として、マウントし直すとかすると解放される・・・)無難に、EFSを使って、バックアップやアーカイブの保存先としてS3を使うのが良いかと





- 投稿日:2020-01-21T11:09:59+09:00
terraform で 同じスペックの EC2 を複数台作る
こんにちわ、 @ktoshi です!
2020年になり、そろそろ始める時期になってきたのではないでしょうか、そう新人研修です。
昔は余ったサーバを持ってきて一台一台セットアップして…と準備していましたが、
今や画面をポチポチすれば簡単にサーバが出来ちゃう時代。素晴らしい時代。しかし!やるからには徹底的に簡単にさせたい、ということで
同じようなサーバを簡単に作ってみよう!というのが今回の趣旨です。概要
AWSでいっぱいサーバ作ります!そして、作ったサーバを0にもできます!
構築ツールとしては terraform を用います。環境
- AWS
- Terraform v0.12.16
準備
事前に下記を準備ください。
- Terraform のインストール
- AWS アカウントの準備
- AMIアカウントを発行いただき、アクセスキーなどを入手ください。
- EC2に設定するSSH鍵の秘密鍵と公開鍵のセット
Let's try!!
それでは実践!
なお、インスタンスが一瞬にして大量に作成できてしまうので、
費用には十分お気を付けください。Terraform の初期設定
Terraform で AWS を操作するための初期設定を行います。
provider の設定
provider.tfprovider "aws" {}今回、AWSのクレデンシャルは環境変数で設定します。
環境変数として下記を設定してください。
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- AWS_DEFAULT_REGION
上記の設定が終われば、Terraform の初期化及び設定の確認を行います。
# Terraform の初期化 $ terraform init # 認証情報の設定確認 $ terraform plan ※ エラー無く発行できればOK!!設定ファイルの準備
今回はとりあえず EC2 を起動させるための最低限の設定を記載します。
また、新人教育前提ということで秘密鍵も同じものを使いまわすようにします。terraform.tfvarspublic_key = <公開鍵> instance_number = <作成するEC2の数>ec2.tf# 定数の読み込み variable "public_key" {} variable "instance_number" {} # キーペアの作成 resource "aws_key_pair" "aws-key-pair" { key_name = "example-aws-key-pair" public_key = var.public_key } # EC2 の作成 resource "aws_instance" "ec2" { count = var.instance_number ami = "ami-0930de172e13fa059" # お好きなAMIを選択してください。 instance_type = "t2.micro" # 起動したいインスタンスタイプを選択してください。 disable_api_termination = false monitoring = true root_block_device { delete_on_termination = true volume_size = 20 volume_type = "standard" } credit_specification { cpu_credits = "standard" } key_name = aws_key_pair.aws-key-pair.key_name tags = { "Name" = "instance-${count.index}" } } # ElasticIP の作成 resource "aws_eip" "eip" { count = var.instance_name instance = aws_instance.ec2[count.index].id vpc = true tags = { "Name" = "instance-${count.index}-eip" } } # IPアドレスの出力 output "instance_ip" { value = join(", ", aws_eip.eip.*.public_ip) }設定の反映
下記コマンドを発行して、設定を反映させます。
Terraform では一般的に テスト実行 -> 実行 の流れになります。# Dry-Run $ terraform plan # Done!! $ terraform apply ~中略~ Outputs: instance_ip = XXX.XXX.XXX.XXX, YYY.YYY.YYY.YYY # 作成したインスタンスのIPアドレスこれでインスタンスが生成されました!!
instance_number の数字を変えれば、自由に作成するインスタンス数を変更できます。
「2」に設定すれば2つ作成され、同じ設定で実行すれば2つの状態が維持されます。
「2」から「100」に変えれば、追加で98個作成されて合計で100の状態になります。
「0」を設定すれば、作成されたインスタンスが全て削除されます。なので、当日新人が休み!とか新人追加で!とか研修キャンセルで!という
急な予定の変更にも柔軟に対応することができます。(インフラはね)まとめ
他の記事で秘密鍵の数に合わせて作成するインスタンス数を変更する、というのはありましたが、
研修用途で特に深く考えず、なるべく簡単に作成したかったのでインスタンス数を定数として渡すようにしました。
今回は研修用途であまり深い設定はしていません。(VPCとかセキュリティグループとか)
本番環境で作るのであれば、オートスケーリングなどを利用するのがベターかと思います!
研修用とかちょっとしたイベント用などにご利用いただければ幸いです。それでは皆様、素敵な研修ライフを。そして、素敵な2020年を。
- 投稿日:2020-01-21T07:44:09+09:00
AWSのEC2とRDSをTerraformで構築する Terraform3分クッキング
はじめに
本記事はAWSのEC2とRDSをTerraformをで構築する方法について記載しています。
terraform applyで実行にかかる時間は、約3分程度です。カップラーメンの待ち時間で構築できます。デプロイするのは以下の環境(※)になります。また、あわせてEC2は最低限のOSセットアップも行います。
Terraformの基本から入りたい方は、以前書いたOracle Cloudで始めるTerraform 自動化の真骨頂を参照ください。
(※)本記事で記載しているtfファイルはGitHubで公開しています。
Terraform構築
AWS環境におけるTerraformによる構築を行うためには、IAMでユーザ作成を行い、必要なクレデンシャル情報を用意します。あとはTerraformをインストールし、Terraform実行に必要なtfファイルを用意します。
AWS環境の前提条件を以下に記載します。
- IAMでユーザの作成
- 必要な権限を付与していること
- SSHで使用するキーペアを作成していること
tfファイルの作成
tfファイルについて解説します。
はじめに任意の作業ディレクトリに移動します。
本記事では以下のディレクトリ構成になり、カレントディレクトリはcommonディレクトリとします。なお、sshのディレクトリの場所については他のディレクトリでも問題ありません。
- ディレクトリ構成
. |-- common | |-- userdata | |-- cloud-init.tpl | |-- ec2.tf | |-- env-vars | |-- network.tf | |-- provider.tf | |-- rds.tf `-- ssh |-- id_rsa |-- id_rsa.pub
- 各種ファイル説明
ファイル名 役割 cloud-init.tpl EC2用の初期構築スクリプト ec2.tf EC2のtfファイル env-vars プロパイダーで使用する変数のtfファイル network.tf ネットワークのtfファイル provider.tf プロパイダーのtfファイル rds.tf RDSのtfファイル id_rsa SSH秘密鍵 id_rsa.pub SSH公開鍵
- env-vars
### Authentication export TF_VAR_aws_access_key="<access_keyの中身をペースト>" export TF_VAR_aws_secret_key="<secret_keyの中身をペースト>"(※)引用符の中にはそれぞれaccess_keyとsecret_keyの中身ををペーストします。
- provider.tf
# Variable variable "aws_access_key" {} variable "aws_secret_key" {} variable "region" { default = "ap-northeast-1" } # Provider provider "aws" { access_key = var.aws_access_key secret_key = var.aws_secret_key region = "ap-northeast-1" }
- network.tf
# vpc resource "aws_vpc" "dev-env" { cidr_block = "10.0.0.0/16" instance_tenancy = "default" enable_dns_support = "true" enable_dns_hostnames = "false" tags = { Name = "dev-env" } } # subnet ## public resource "aws_subnet" "public-web" { vpc_id = "${aws_vpc.dev-env.id}" cidr_block = "10.0.1.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "public-web" } } ## praivate resource "aws_subnet" "private-db1" { vpc_id = "${aws_vpc.dev-env.id}" cidr_block = "10.0.2.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "private-db1" } } resource "aws_subnet" "private-db2" { vpc_id = "${aws_vpc.dev-env.id}" cidr_block = "10.0.3.0/24" availability_zone = "ap-northeast-1c" tags = { Name = "private-db2" } } # route table resource "aws_route_table" "public-route" { vpc_id = "${aws_vpc.dev-env.id}" route { cidr_block = "0.0.0.0/0" gateway_id = "${aws_internet_gateway.dev-env-gw.id}" } tags = { Name = "public-route" } } resource "aws_route_table_association" "public-a" { subnet_id = "${aws_subnet.public-web.id}" route_table_id = "${aws_route_table.public-route.id}" } # internet gateway resource "aws_internet_gateway" "dev-env-gw" { vpc_id = "${aws_vpc.dev-env.id}" depends_on = [aws_vpc.dev-env] tags = { Name = "dev-env-gw" } }
- ec2.tf
# Security Group resource "aws_security_group" "public-web-sg" { name = "public-web-sg" vpc_id = "${aws_vpc.dev-env.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "public-web-sg" } } resource "aws_security_group" "praivate-db-sg" { name = "praivate-db-sg" vpc_id = "${aws_vpc.dev-env.id}" ingress { from_port = 5432 to_port = 5432 protocol = "tcp" cidr_blocks = ["10.0.1.0/24"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "public-db-sg" } } # EC2 Key Pairs resource "aws_key_pair" "common-ssh" { key_name = "common-ssh" public_key = "<公開鍵の中身をペースト>" } # EC2 resource "aws_instance" "webserver" { ami = "ami-011facbea5ec0363b" instance_type = "t2.micro" key_name = "common-ssh" vpc_security_group_ids = [ "${aws_security_group.public-web-sg.id}" ] subnet_id = "${aws_subnet.public-web.id}" associate_public_ip_address = "true" ebs_block_device { device_name = "/dev/xvda" volume_type = "gp2" volume_size = 30 } user_data = "${file("./userdata/cloud-init.tpl")}" tags = { Name = "webserver" } } # Output output "public_ip_of_webserver" { value = "${aws_instance.webserver.public_ip}" }(※)Security Groupで記載しているcidr_blocksは例になります。実際に使用する場合はセキュリティを充分に配慮し、特にSSHは送信元を制限しましょう。
- rds.tf
# RDS resource "aws_db_subnet_group" "praivate-db" { name = "praivate-db" subnet_ids = ["${aws_subnet.private-db1.id}", "${aws_subnet.private-db2.id}"] tags = { Name = "praivate-db" } } resource "aws_db_instance" "test-db" { identifier = "test-db" allocated_storage = 20 storage_type = "gp2" engine = "postgres" engine_version = "11.5" instance_class = "db.t3.micro" name = "testdb" username = "test" password = "test" vpc_security_group_ids = ["${aws_security_group.praivate-db-sg.id}"] db_subnet_group_name = "${aws_db_subnet_group.praivate-db.name}" skip_final_snapshot = true }(※)passwordの値は例として記載。使用不可な文字列もあります。
- cloud-init.tpl
#cloud-config runcmd: # ホスト名の変更 - hostnamectl set-hostname webserver # パッケージのインストール ## セキュリティ関連の更新のみがインストール - yum update --security -y ## PostgreSQL client programs - yum install -y postgresql.x86_64 # タイムゾーン変更 ## 設定ファイルのバックアップ - cp -p /etc/localtime /etc/localtime.org ## シンボリックリンク作成 - ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtimeTerraform構築
はじめに、以下の準備作業を行います。
- 環境変数の有効化
$ source env-vars- 環境変数の確認
$ env準備作業完了後、いよいよTerraform構築です。
Terraform構築作業は次の3Stepです!
terraform initで初期化terraform planで確認terraform applyで適用
terraformコマンドの説明については割愛します。
terraform apply実行後、Apply complete!のメッセージが出力されると各リソースが作成されます。
RDSへはEC2インスタンスからpsqlを実行して接続するか、SSH経由でDBeaverなどのSQLクライアントから接続することができます。terraform apply
plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_db_instance.test-db will be created + resource "aws_db_instance" "test-db" { + address = (known after apply) + allocated_storage = 20 + apply_immediately = (known after apply) + arn = (known after apply) + auto_minor_version_upgrade = true + availability_zone = (known after apply) + backup_retention_period = (known after apply) + backup_window = (known after apply) + ca_cert_identifier = (known after apply) + character_set_name = (known after apply) + copy_tags_to_snapshot = false + db_subnet_group_name = "praivate-db" + endpoint = (known after apply) + engine = "postgres" + engine_version = "11.5" + hosted_zone_id = (known after apply) + id = (known after apply) + identifier = "test-db" + identifier_prefix = (known after apply) + instance_class = "db.t3.micro" + kms_key_id = (known after apply) + license_model = (known after apply) + maintenance_window = (known after apply) + monitoring_interval = 0 + monitoring_role_arn = (known after apply) + multi_az = (known after apply) + name = "testdb" + option_group_name = (known after apply) + parameter_group_name = (known after apply) + password = (sensitive value) + performance_insights_enabled = false + performance_insights_kms_key_id = (known after apply) + performance_insights_retention_period = (known after apply) + port = (known after apply) + publicly_accessible = false + replicas = (known after apply) + resource_id = (known after apply) + skip_final_snapshot = true + status = (known after apply) + storage_type = "gp2" + timezone = (known after apply) + username = "test" + vpc_security_group_ids = (known after apply) } /*中略*/ aws_db_instance.test-db: Still creating... [3m0s elapsed] aws_db_instance.test-db: Creation complete after 3m5s [id=test-db] Apply complete! Resources: 13 added, 0 changed, 0 destroyed. Outputs: public_ip_of_webserver = <IPアドレス(※)>(※)EC2のパブリックIPが出力されます。
ナレッジ
AWS環境におけるリソース作成時の留意事項について以下に記載します。
- アベイラビリティゾーン
RDSの作成は複数のアベイラビリティゾーンの指定が必要です。単一では作成できません。本記事執筆時点で日本リュージョンの場合、以下から2つのアベイラビリティゾーンを指定する必要があります。zones: ap-northeast-1c, ap-northeast-1a, ap-northeast-1d.
terraform destroy実行時にRDSを削除したい場合
RDSはリソース削除時にデフォルトでスナップショットの作成が求められるため、terraform destroyを行うためにはtfファイルにskip_final_snapshotのオプションをtrueに指定する必要があります。デフォルトはfalse。本番環境で行う場合は注意しましょう。RDSのPostgreSQL仕様
RDSにおけるPostgreSQLの照合順序及びCtypeのデフォルトは、en_US.UTF-8になっています。性能を考慮する場合はpsqlで接続してdropして再作成した方が良さそうです。OpensshでSSHキーペアを作成した場合
OpensshでSSHキーペアを作成し、DBeaverなどのSQLクライアントを使用してSSH経由で接続する場合は、鍵の形式を変更する必要があります。おわりに
以上、Terraform3分クッキング
でした。
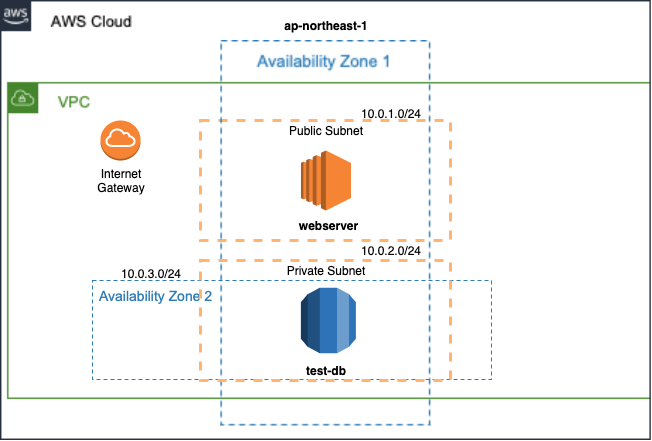
- 投稿日:2020-01-21T07:17:25+09:00
[bundler: command not found: unicorn_rails Install missing gem executables with `bundle install]AWSのEC2サーバ上でRailsに追加したgemfileが反映されない時の解決例
<エラー文>
このエラーの原因で考えられること
local環境でしかgemfileが反映されていないことが考えられます。
具体的には下記のことにより起こっていると考えられます。1.rbenvのrehashし忘れ
2.bundlerの入れ忘れ
3.githubへの反映し忘れ(commitとpushのし忘れ)解決方法
1.rbenvのrehashし忘れ
rbenv(rubyの環境構築)について更新をすれば解決します
EC2サーバー上で下記のコマンドを入力してください[ec2-user@ip-xxx-xx-xx-xxx chat-space$ gem install bundler -v 2.0.2]$rbenv rehash2.bundlerの入れ忘れ
EC2サーバー上にbundlerをインストールし、再度bundle installすることで解決します
バンドラーのバージョンはご自分のプロジェクトファイルのものと合わせるためローカルサーバー上でバージョンを調べたのち、EC2サーバー上で下記のコマンドを入力してくださいNeverland:chat-space kontatomoya$ bundler -v #プロジェクトのローカルディレクトリで bundler -v でbundleのバージョンを調べられます(筆者の場合は"Bundler version 2.0.2"が帰ってきたのでver2.0.2で以下を進めています) [ec2-user@ip-xxx-xx-xx-xxx chat-space]$ gem install bundler -v 2.0.2 [ec2-user@ip-xxx-xx-xx-xxx chat-space$ gem install bundler -v 2.0.2]$ bundle install #bundlerをインストールし、bundle installしてます3.GitHubへの反映し忘れ(commitとpushのし忘れ)
EC2サーバーにプロジェクトを保存するには、GitHub上のデータを受け取りコピーという流れとなるため、GitHub上のデータに反映した後のデータをgit cloneしないとEC2サーバー上でも反映されません。そのため下記の手順に従って最新ファイルを反映させましょう。
①GitHub Desktopでcommitとpushし、GitHub上のデータに反映させましょう。
やり方はここでは説明しませんが簡単です。わからない人は下記などでやり方を確認してみましょう。(公式の使用方法解説ページにリンクしてます。)
②EC2サーバーのファイルに反映させましょう
今はEC2のプロジェクトが更新されていない状態なので、pullコマンドで更新を行いましょう[ec2-user@ip-xxx-xx-xx-xxx chat-space$ gem install bundler -v 2.0.2]$ git pull origin master #EC2は表示だけが必要となるため反映させるのはmasterとしましょう③bundle installを行う
このプロジェクトのダウンロードができただけで、インストールはできていないので最後に忘れずbundle installしましょう[ec2-user@ip-xxx-xx-xx-xxx chat-space$ gem install bundler -v 2.0.2]$ bundle installこれでこのエラーは解消されます。

- 投稿日:2020-01-21T05:44:28+09:00
個人でやっている AWS IAM の運用
はじめに
私は個人開発でAWSを使っています。
クラウドサービスが出たおかげで、自宅サーバーやVPSを借りたりしなくても、手軽に色々なものが安価に試せるようになり、非常に便利になりました。
その反面、アカウントを乗っ取られた場合、高額な請求がくる危険性があります。
「AWS アカウント 乗っ取り」とかで調べれば事例がたくさん出てきます。心配性な私は、なるべく危険を排除して、セキュアにIAMを運用しようと努力しています。
その内容をまとめて見ようと思いこの記事を書きました。こういう風にしたらよりセキュアになるよ、とか、ここはこういった危険性があるかも、という点があれば、優しくコメントで指摘いただけると嬉しいです。
前提
- 個人レベルでの管理の話です。
- IAMのみを対象にしています。IAM以外のサービスを使ったセキュリティ(例: GuardDutyなど)や、AWS上に構築したサービスのセキュリティは、対象外とします。
- macOS での実行を前提にしています。
- 私はフロントエンドエンジニアをメインに仕事してます。
使用するツール
AWSマネジメントコンソール
AWSを使っているなら知らない人はいないと思いますが、AWSをブラウザ上から色々操作できるツールです。
aws-vault
AWSのアクセスキーをセキュアに管理し、便利に扱う機能があります。
macOSならHomebrewで簡単にインストールできます。
以下のコマンドでインストールできるはずです。# Homebrewのインストール $ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" # aws-vaultのインストール $ brew cask install aws-vault # インストールされたかの確認 $ aws-vault --version v5.1.2IAMベストプラクティス
AWSの公式ドキュメントにある、IAMでやっておくべき推奨事項です。
これを守ればひとまずOKという感じです。
この記事は、このIAMベストプラクティスを踏まえた上で、どう運用するか、という観点で書いています。
読んだことがない方は、こちらの記事を読む前にぜひ一読ください。ここから具体的な運用についての説明します。
ルートユーザーの保護
ルートユーザーは、アカウント内のリソースすべてにフルアクセスでき、非常に強い権限を持つ上、何も制限をかけることができないので、厳重に保護します。
ルートユーザーは、ミスなどで管理用のIAMユーザーが使用できなくなった場合などに使用する最終手段と私は位置づけおり、ほとんど使うことはありません。
強固なパスワードを使用する
言うまでもないことですが、他では使用していない、できる限りランダムな長い文字列でパスワードを設定します。
MFAを有効にする
こちらも当然ではありますが、多要素認証(MFA)を有効にして、よりルートアカウントをセキュアにしてください。
AWSマネジメントコンソールのIAMのトップ画面にも有効になっているかどうかがいつも表示されてます。
アクセスキーは作らない
非常に強い権限を持つルートユーザーのアクセスキーは作りません。
ないものは流出もしないので安全です。必要に応じて最小権限を持つIAMユーザーを作り、アクセスキーを発行します。
IAMユーザーの作成
使用する単位ごとにIAMユーザーを作成
私の場合は、使用する端末ごとにIAMユーザーを作成しています。
(個人の運用なので他の人はいませんが、組織なら当然各人にIAMユーザーを作りましょう)また、CIについてもリポジトリごとにユーザーを作成しています。
ちなみに GitHub Actions を使っています。IAMユーザーには権限を付与しない
IAMユーザーは個別に権限を 割り当てません。
IAMユーザーは、後述のIAMグループに所属させるためです。
IAMベストプラクティスにもありますが、グループの方が権限の管理が容易ですし、個別に権限を付与するのは抜け漏れが発生しやすいです。IAMユーザーのパスワードは作成しない
IAMユーザーはパスワードを作成作成しないようにします。
ないものは流出もしないので安全です。
パスワードがないとAWSマネジメントコンソール使えないじゃん、と思うかもしれませんが、STSの機能を使ってアクセスキーだけでAWSコンソールにアクセスすることが可能です。
詳細な仕組みまでは知らないのですが、aws-vault を使うと容易に実行できます。後述します。IAMグループの作成とIAMユーザーの追加
IAMグループの作成
必要なグループを定義して、そこにIAMユーザーを所属させます。
私の場合は、開発者グループとCI用グループを作成しています。開発者グループには、自身のIAMユーザーに対して、情報を閲覧する権限と、アクセスキーをローテーション(作成/削除)する権限しか付与していません。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:CreateAccessKey", "iam:DeleteAccessKey", "iam:GetUser" ], "Resource": [ "arn:aws:iam::123456789012:user/${aws:username}" ] } ] }ほとんど何もできないので、万一アクセスキーが流出したとしても安心ですね。
こんな権限じゃ何にも使えないじゃん、と思うかもしれませんが、IAMロールにAssumeRoleをすることで、その権限を実行することができるようになります。詳しくは後述します。CI用グループは、個別のケースでCIが使う権限を必要最小限にとどめて設定します。
渡しの場合は殆ど同じような用途で、権限も似ているので、1つのグループにしていますが、色々な用途がある場合は、用途に応じてCIも複数のグループにしたほうが良いかもしれません。
この辺はケースバイケースだと思います。IAMロールの作成
場面に応じて必要な権限を持つIAMロールを作成
私の場合は、普段使用する「閲覧権限+S3へのアップロードなど」の権限と、AdministratorAccessを付与した管理者権限の2つを作っています。
(管理者権限を持つIAMロールの例)信頼関係の設定
AssumeRoleを行うための設定を行います。
AssumeRoleはこのケースの場合、許可されたIAMユーザーがIAMロールの権限を一時的に使用することができるようになる、というイメージで一旦理解してもらえると良いかと思います。詳しくは、以下の記事が参考になります。
IAMロール徹底理解 〜 AssumeRoleの正体 | Developers.IO指定した状況だと、こういう表示になります。
この場合homeとworkというユーザーがAssumeRoleを許可されています。
JSONの指定はこんな感じです。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/work", "arn:aws:iam::123456789012:user/home" ] }, "Action": "sts:AssumeRole" } ] }ちなみに、万一AssumeRoleで取得したアクセスキーが流出したとしても、有効期限付きなので少しだけ安心感があります。
aws-vault
このツールを使うことでセキュアに色々なことができるようになります。
こちらの記事が詳細に書かれているので、正直こちらの記事を読めばだいたい分かると思います。ぜひ読んでみてください。
aws-vault でアクセスキーを安全に - Septeni Engineer's Blog以下、自分が使っている範囲で解説します。
環境変数の設定
そのままでも使えますが、私が設定している環境変数を紹介します。
~/.bash_profile# ログインKeyChainを使用するように変更 # パスワードを求められる頻度が格段に減る # (これを設定しない場合、15分経過するとサイドパスワードを求められる) export AWS_VAULT_KEYCHAIN_NAME="login" # AssumeRoleを1時間まで可能にする(1時間が最大、デフォルト15分) export AWS_ASSUME_ROLE_TTL="1h"リポジトリのドキュメントに他の環境変数も書かれています。
設定
初回はアクセスキーを設定する必要があるので、AWSマネジメントコンソールで対象のIAMユーザーのアクセスキーを発行します。
続いて以下のコマンドでアクセスキーを設定します。
myprofileはプロファイル名で任意の名前です。わかりやすい名前にしましょう。$ aws-vault add myprofile Enter Access Key ID: AKI****************** Enter Secret Access Key: XA1kev****************** Added credentials to profile "myprofile" in vaultこれで、アクセスキーを保存できました。
aws-vaultはmacOSの場合はKeyChainに保存されます。
平文でファイルに保存するよりも安心感がありますね。アクセスキーのローテーション
IAMベストプラクティスでも「認証情報を定期的にローテーションする」と書かれている通り、アクセスキーは頻繁に更新することをおすすめします。
とは言え普通にやるのは面倒なのでなかなかやりませんが、aws-vault ならコマンド一発でローテーションができます!
$ aws-vault rotate -n myprofile Rotating credentials stored for profile 'myprofile' using master credentials (takes 10-20 seconds) Creating a new access key Created new access key ****************B3K5 Deleting old access key ****************A53D Deleted old access key ****************A53D Finished rotating access keyこれだけで、アクセスキーをローテーションすることができました!
内部では、アクセスキーを新しく発行して、古いキーを削除しているだけですね。IAMユーザーは、制約としてアクセスキーは2つまでしか同時に発行できません。
なので、アクセスキーを2つ発行している場合はエラーになるので、どちらかを消しましょう。
上限が2つなのは、このようにローテーションするためのものだと思われます。余談:昔は
-nをつけなくても動作したんですがv5.1.2で実行するとエラーが出るんですよね。さしたる問題ではないですが。セッショントークンを含んだ一時的なアクセスキーの取得
$ aws-vault exec myprofile -- env | grep "AWS_" AWS_ACCESS_KEY_ID=ASIAxxxxxxxxxxxxCUVY AWS_SECRET_ACCESS_KEY=SBpcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxavRg AWS_SESSION_TOKEN=FwoGxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxkwpQF8=
aws-vault exec <profile_name> -- <コマンド>で実行すると、AWSの実行に必要な認証情報が環境変数に設定された状態でコマンドが実行できます。
このアクセスキーは有効期限があるので、少しだけ安心感があります。AssumeRoleの設定
IAMロールに対してAssumeRoleする設定を行います。
~/.aws/configに対して以下のように記述するとaws-vaultが自動的にAssumeRoleしてくれるようになります。~/.aws/config[profile admin] source_profile=myprofile role_arn=arn:aws:iam::123456789012:role/AdminRole
source_profileはAssumeRole対象のプロファイル名(この例だとmyprofile)を指定しrole_arnはAssumeRoleしたいIAMロールの ARN を指定します。
実行時は以下のように実行します。$ aws-vault exec admin -- <コマンド>これで、AdminRoleに設定されている権限でコマンドが実行できるようになります。
ちなみに、MFAの設定もできます。
自分も設定してみたのですが、個人で使っている分にはリスクより手間のほうが大きいと感じているので今は使っていません。
設定されたい方は公式ドキュメントのこの辺りを参考にされると良いかと思います。なお、AssumeRoleの設定は、アクセスキーと一緒に漏れるとIAMロールの権限内で諸々実行可能になってしまうので、なるべく流出しないようにしたほうが良いと思います。
個人的にはパスワードやアクセスキーよりはリスクは低いと思いますが。AWSマネジメントコンソールへのログイン
CLIからAWSマネジメントコンソールにログインできます。
$ aws-vault login myprofile # ブラウザでAWSマネジメントコンソールが開きます $ aws-vault login admin # IAMロールの権限でAWSマネジメントコンソールが開くことも可能ですいちいちパスワードを打つ必要がないので便利です!
ざっくりまとめ
- ルートユーザーはなるべくセキュリティを強固にして使わない
- IAMユーザーはパスワードがないので、そもそも流出しない
- aws-vaultを使用するとアクセスキーはKeyChainにあるので容易には盗まれない
- IAMユーザーのアクセスキーは流出しても権限がほとんどない
- aws-vaultで実行すると、通常は有効期限付きのアクセスキーで実行される
- 万一アクセスキーが流出しても、AssumeRoleの情報が分からない限り何もできない
おわりに
セキュリティに終わりはないので、ここに書いてある内容を実施しても100%安全と言うわけではないですが、私は大分安心できるようになりました。
アクセスキーはAWSを使う上で重要になってくるので、なるべくセキュアに扱いたいものです。今回は対象外としましたが、AWSの他のサービス(GuardDutyやConfigなど)も併用するとよりセキュアになるので、設定することをおすすめします。
Developers.IOはよくお世話になっています。【初心者向け】AWSの脅威検知サービスAmazon GuardDutyのよく分かる解説と情報まとめ | Developers.IO
AWS Configはとりあえず有効にしよう | Developers.IO冒頭にも書きましたが、こういう風にしたらよりセキュアになるよ、とか、ここはこういった危険性があるかも、という点があれば、優しくコメントで指摘いただけると嬉しいです。

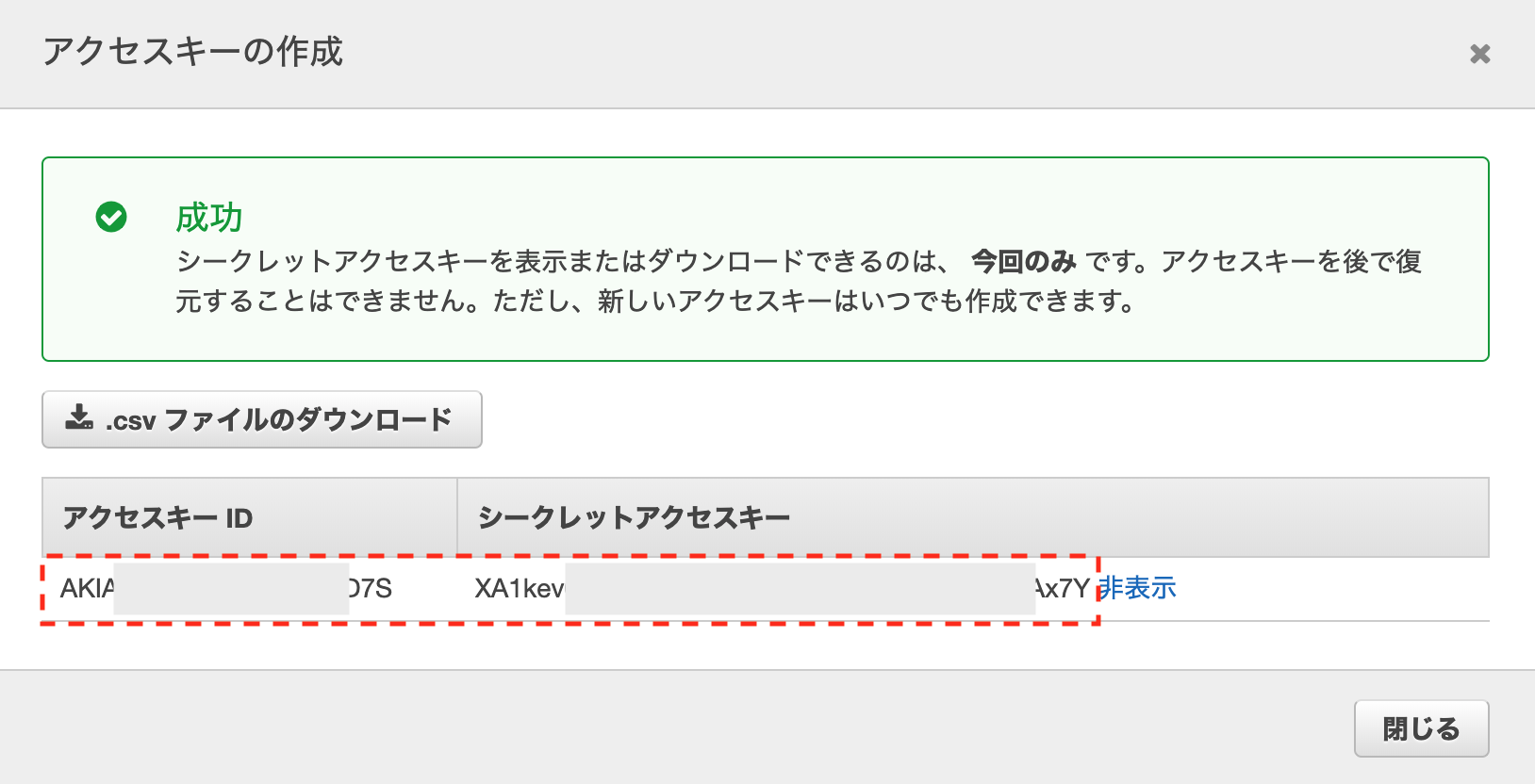
- 投稿日:2020-01-21T03:05:53+09:00
機械学習でひさ子のギターを自分のギターに持ち替えてもらう -実行編-
準備編(前回)
CycleGANでいい思いをしようと思って、まずはギターの画像を集めました。
画像をダウンロードしたりリサイズしたりした。
詳細はこちら実行編
私の環境
- macOS High Sierra 10.13.6
- Anaconda3
- Python3.7.2
- AWSは全然わかってなくて指示通りインスタンス作っただけ
- Deep Learning AMI (Ubuntu 16.04) Version 26.0 (?)
- インスタンスタイプ p2.xlarge (?)
FileZillaを使って画像をアップロード
READMEに書いてある手順と同じになるよう、フォルダ名を同じ名前にした
結局黒のジャズマスターが本当になくて、あと頑張る気力も足りなかったのでmaps ├── trainA(学習用sunburst:284枚) ├── trainB(学習用black:94枚) ├── testA(テスト用sunburst:151枚) └── testB(テスト用black:76枚)という非常にやる気がなくアンバランスな感じになりました。よくなさそうですがよろしくお願いします
大学の授業で使ったFileZillaが使いやすいかもと思ってつないでみる。
上の四角にそれらしいのを適当に打ち込むとかではダメで、ちゃんと「AWS FileZilla」とか調べた方がいいとわかった
- 左上の謎のアイコンからウィンドウを開き
- 「新しいサイト」を押して
- SFTPでなんか作るっぽい
- ホスト名は
IPv4 パブリック IPのことだったで接続して、これのいいところはドラッグ&ドロップでフォルダ、ファイルがアップロードできるとこ、というかこれでやる以外やり方がわからない
前編で作っておいたディレクトリ
mapsを丸ごとアップ、する前に、今AWS側にあるmapsをなかったことにする必要がある。私はFileZillaで削除しようとして1光年かかってしまいました。mv maps maps_realで解決。mvは名前を変えるのにも使えるんだなぁ。FileZilla上の操作でも2億分の1秒でできると思う
いざ実行
フォルダ名も揃えてあるので、本家のGitHubのREADMEに書いてある通りにいきます。まず学習。
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan時間かかる
学習後にcheck_pointにできた画像
コード本当によくできていて、webページにして結果を見せてくれるようになっているみたいだけど、なんか永久に読み込み続けていて見れない
あとなぜか元のmapsにあった画像(航空写真と地図の写真)も混ざっている なんでですか…かなしすそう
とりあえずAtomのPreviewで見てみたものの中でうまくいってそうなやつ
ふむ。
recとidtは再構築reconstructionとアイデンティティidentityという意味らしい
rec_A = F(G(A))
rec_B = G(F(B))
idt_A = G(B)
idt_B = F(A)
参考:different outputs (images) #326一旦、地図も混ざっているのは作成日時を見る限り結果だけ(学習用のものに混ざってるわけじゃない気がする)みたいなので、そのままテストも実行しちゃえ
python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan結果
うまくいったやつ
できなかったやつ
背景が黒だったり、ライブ映像だったりは難しかったみたい
背景透過させれば?とアドバイスされたけど人が弾いてるギターを頑張ってほしかったんだ…あのジャズマスがそれらしく変わったやつ
傷も残ってて結構それらしい
これは白黒になったのかな?くらい
これも白黒になっただけじゃんなまとめと反省
まとめ
- 楽器店の宣伝素材のギター画像は比較的うまくいく
- YouTubeの試奏系動画のスクショも結構うまくいく
- J Mascisや田渕ひさ子のライブ映像は全然ほとんどうまく行かなかった
反省
- 背景が黒の画像は、どこにギターがあるのかわからんみたい
- 自分で黒にした後recでバグってしまうのもあった
- ライブ映像、服装、置く場所など、ギターやバンドマンに関する画像はなんか黒が多くなりがちである
- 人間を入れずに背景透過させたギター画像ばっかりでやると綺麗にいったかも
- でもそれじゃ持ち替えてはくれない・・・
- 試奏系がなんでわりかしうまくいったのかは謎。似たような画像が多かったからか
- 人間込みを成功させたかったのに、人間込みの画像がえらい少なかった
実行編 ver.2
PycharmとAWSをつなぐことができるので、そっちでもやってみたい
つづく・・・









- 投稿日:2020-01-21T02:29:25+09:00
AuroraServerlessを操作するAPI(GET、PUT、POST)+lambdaを作る。
作るもの
今回、DBに入れるデータは以下のものとして進める。
id name age 1 Apigateway 12 2 lambda 34 3 Dynamodb 56 contents
- Aurora serverless、シークレットマネージャとは
- Aurora serverlessのDBの作り方。
- lambdaからAurora serverlessへアクセスする方法。
- APIでGET、PUT、POSTする方法
Aurora serverlessとは?
DBのインスタンス部分とストレージ部分が分離した構造を取っており、アクセスがない時にはインスタンス部分は起動しておらず、ストレージ部分のみが存在する。アクセスを受けると、負荷に応じてインスタンスがスケールアウトしクエリを実行する。アクセスがなくなると最終的にはインスタンスはゼロになるため、DBのランニングコストを抑えることが可能である。(RDSは停止させても7日で自動で起動する。)
クラスタとは?
まだよくわかっていないがAuroraのインスタンスやストレージの全体のことかと思われる。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.htmlAurora キャパシティーユニット (ACU) とは?
処理キャパシティーとメモリキャパシティーの組み合わせ。
最大と最小のACUを指定でき、それぞれDBクラスタをスケールダウン/アップできる最小/最大の値を示している。シークレットマネージャとは?
シークレットを一元的に管理するシステム。これまでは認証情報を用いる箇所にそれらをベタ書きしていたが、シークレットマネージャを用いることでセキュリティを高めることができる。
シークレットとは?
データベース認証情報、パスワード、サードパーティーのAPIキーなどの任意のテキスト。ローテーションとは?_
一定期間がたつと自動的にパスワードを変更する仕組み。ONにすると自動的にlambdaが生成され、対象の認証情報のパスワードを定期的にローテーションさせる。なお、この定期的な変更はユーザ側は気にすることなくアプリケーションを開発することができる。1. Aurora serverlessクラスター・データベースの作成。
RDSコンソールへ移動し、ナビゲーションペインのデータベースを選択→作成へ。
- データベース作成方法を選択 : 標準作成
- エンジンのオプション
- エンジンのタイプ : Aurora
- エディション : PostgreSQL
- データベースの機能 : サーバーレス
- 設定
DBクラスター識別子、マスターユーザー名、マスターパスワード- キャパシティーの設定
- 最小/最大キャパシティーユニット : 任意の値
- スケーリングの追加設定
- タイムアウトに達すると、容量を指定された値に強制的にスケーリングします
- 数分間アイドル状態のままの場合コンピューティング性能を一時停止する : 5 min
- 接続
- 追加の接続設定
- Data API
- 追加設定
最初のデータベース名→ 作成する。作成されるまでしばらくかかる。
なお、Data APIにチェックを入れていないと3で接続不可となる。
→その場合でもあとからクラスターの設定を変更できる。2. Secret Managerへの登録。
- シークレットの種類を選択 : RDSのデータベース認証情報
- ユーザー名 : 1で設定したマスターユーザー名
- パスワード : 1で設定したマスターパスワード
- 暗号化キーを選択してください : DefaultEncryptionKey (default)
- このシークレットがアクセスするRDSデータベースを選択してください : 1で設定したDBクラスター識別子
- シークレットの名前 :
シークレット名- 自動ローテーションを設定する : 自動ローテーションを無効にする
→ 保存
3. RDSコンソールからクエリ実行。
コンソールからDBにアクセスして疎通確認を行う。
対象のクラスターを選択し、[アクション]→[クエリ]
データベースユーザー名は直接入力不可のため、2で作成した「Secret Manager ARNと接続する」を指定する。
Secret Managerコンソールから対象のシークレットのARNを取得しペースト。
データベース名には1で設定した「最初のデータベース名」を指定。##### テーブル作成 ##### CREATE TABLE Staff (id CHAR(4) NOT NULL, name TEXT NOT NULL, age INTEGER , PRIMARY KEY (id)); # →実行 ##### データ挿入 ##### INSERT INTO Staff VALUES ('0001', 'Aurora', 12); INSERT INTO Staff VALUES ('0002', 'Lambda', 34); INSERT INTO Staff VALUES ('0003', 'Dynamo', 56); # →実行 ##### データ取得 ##### SELECT * FROM Staff # → 実行4. IAMロールの作成
4-1. SecretManagerからRDSにアクセスするIAMポリシー作成
クラメソさんの「Lambda で Aurora Serverless の Data API 使えました!そう、Lambda Layer があればね」に従います。
2020年1月現在でも"arn:aws:secretsmanager:*:*:secret:rds-db-credentials/*"だけでは不可でした。
公式ドキュメント:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/data-api.htmlIAMポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "SecretsManagerDbCredentialsAccess", "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:PutResourcePolicy", "secretsmanager:PutSecretValue", "secretsmanager:DeleteSecret", "secretsmanager:DescribeSecret", "secretsmanager:TagResource" ], "Resource": [ "arn:aws:secretsmanager:*:*:secret:rds-db-credentials/*", " ~~~ここにシークレットのARNを指定~~~ " ] }, { "Sid": "RDSDataServiceAccess", "Effect": "Allow", "Action": [ "dbqms:CreateFavoriteQuery", "dbqms:DescribeFavoriteQueries", "dbqms:UpdateFavoriteQuery", "dbqms:DeleteFavoriteQueries", "dbqms:GetQueryString", "dbqms:CreateQueryHistory", "dbqms:DescribeQueryHistory", "dbqms:UpdateQueryHistory", "dbqms:DeleteQueryHistory", "dbqms:DescribeQueryHistory", "rds-data:ExecuteSql", "rds-data:ExecuteStatement", "rds-data:BatchExecuteStatement", "rds-data:BeginTransaction", "rds-data:CommitTransaction", "rds-data:RollbackTransaction", "secretsmanager:CreateSecret", "secretsmanager:ListSecrets", "secretsmanager:GetRandomPassword", "tag:GetResources" ], "Resource": "*" } ] }4-2. lambdaに当てるIAMロールの作成
4-1で作成したIAMポリシーと、
AmazonRDSDataFullAccessを当てたIAMロールを作成する。
そのほかCloudWatchへのログ書き込みなど必要なものは適宜追加。5. Aurora serverlessに接続するlambda関数の作成
テーブル項目一覧取得のコード(同じくクラメソのコード)
lambda_function.pyimport json import boto3 def lambda_handler(event, context): rdsData = boto3.client('rds-data') print(boto3.__version__) # RDSクラスターのARN cluster_arn = 'arn:aws:rds:ap-northeast-1:xxxxxxxxxxxx:cluster:test' # シークレットのARN secret_arn = 'arn:aws:secretsmanager:ap-northeast-1:xxxxxxxxxxxx:secret:test' # ★ response1 = rdsData.execute_statement( resourceArn = cluster_arn, secretArn = secret_arn, database = '1で設定したデータベース名', sql = 'select * from table_name') # 3で作成したテーブル名 print (response1['records'])
- 初回のDBアクセスではインスタンス起動に時間がかかるためタイムアウトを1minに指定しておくこと。
- IAMロールは上記で作成済みのものを使用。
- RDSクラスターのARNはクラスターの[設定]タブから取得可能
- 参考としたクラメソさんのページではlambda layerを使用してboto3をzipしてレイヤに設定していましたが、layerを設定せずに
import boto3でもちゃんと取得できた。6. API Gatewayの作成
6-1. GET
クエリパラメータに指定したidのレコードを返すAPI+lambdaを作成する。
lambdaを一部変更。
# ★ sql_str = "select * from table_name where id = '" + event["id"] + "'" # 3で作成したテーブル名 response1 = rdsData.execute_statement( resourceArn = cluster_arn, secretArn = secret_arn, database = '1で設定したデータベース名', sql = sql_str) return response1["records"]メソッドリクエスト
1. [アクション]→[メソッドの作成]からGETを選択。
2. [メソッドリクエスト]→[URLクエリ文字列パラメータ]→「クエリ文字列を追加」にパラメータ名を入れる。ここでは名前
id、必須✔︎統合リクエスト
1. [統合リクエスト]→[マッピングテンプレート]→リクエスト本文のパススルーに「テンプレートが定義されていない場合(推奨)」を選択。
2. Content-Typeにはapplication/jsonを指定。
3. マッピングテンプレートに以下を指定。{ "id": "$input.params('id')" }この形式でlambdaのeventに渡される。クエリストリングは
$input.params('パラメータ名')で取得可能。最後に[アクション]→[APIのデプロイ]を選択してURIを発行する。
試しにブラウザから
id=0001を付してアクセスすると次の値が帰る。[ [ { "stringValue": "0001" }, { "stringValue": "Aurora" }, { "longValue": 12 } ] ]参考) https://qiita.com/Quantum/items/91ad6b6b788bf4051055
6-2. POST
リクエストボディに含めたjsonで新規にレコードを追加するAPI+lambdaを作成する。
lambdaを一部変更。
# ★ sql_str = "insert into table_name values ('" + event['id'] + "', '" + event['name'] + "', " + str(event['age']) + ");" response1 = rdsData.execute_statement( resourceArn = cluster_arn, secretArn = secret_arn, database = '1で設定したデータベース名', sql = sql_str, ) return response1同じく[アクション]から[メソッドの作成]でPOSTを選択し、[APIをデプロイ]で作成。
postmanから以下のjsonを投げるとレスポンスが得られる。リクエスト{ "id": "0004", "name": "Apigateway", "age": 78 }レスポンス{ "ResponseMetadata": { "RequestId": "fdc33f8d-2ace-4bd3-b3d6-3c0796068366", "HTTPStatusCode": 200, "HTTPHeaders": { "x-amzn-requestid": "fdc33f8d-2ace-4bd3-b3d6-3c0796068366", "content-type": "application/json", "content-length": "49", "date": "Mon, 20 Jan 2020 14:48:28 GMT" }, "RetryAttempts": 0 }, "generatedFields": [], "numberOfRecordsUpdated": 1 }参考) https://qiita.com/edg_aim/items/3989aca53d98e3cafc0f
6-3. PUT
指定したパスの
idの情報を更新するAPI+lambdaを作成する。lambdaを一部変更。
# ★ sql_str = "update table_name set name='" + event["name"] + "' where id = '" + str(event["id"]) + "';" response1 = rdsData.execute_statement( resourceArn = cluster_arn, secretArn = secret_arn, database = '1で設定したデータベース名', sql = sql_str, ) return response1まずはid毎のパスを切るため、[アクション]から[リソースmの作成]を選択。
ここで、リソース名にidとし、リソースパスに{id}とする。
これにより、{id}の部分はidの番号で置き換わったパス全てを指すことを意味する。続いて同じく[アクション]から[メソッドの作成]でPUTを選択し、[APIをデプロイ]で作成。
メソッドリクエスト
特に変更梨。リクエストパスを覗くと勝手にリソース名のidと書かれている。統合リクエスト
マッピングテンプレートの設定が少しややこしい。それまではGETと同じ手順。URI: https://〜〜〜/{id}
#set($test = '"' + $input.params("id") + '"') { "id": $test, "name": $input.json('name') }
#set()の中身では式を記述できる?と思われる。
"id": $input.params("id")と直接連結してもよいのだが、この場合にidに0001を指定するとクオーテーションで囲われないため以下のエラーが発生。Invalid numeric value: Leading zeroes not allowed
正しいテンプレートの下でpostmanから
context-typeを指定してput。URI: https://〜〜〜/0001
リクエスト{ "name": "Aurora" }200のレスポンスが得られ、テーブルが更新されていれば成功。
なお、マッピングテンプレートの記述は以下のドキュメントに書かれている。
参考) https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-mapping-template-reference.html#input-variable-reference

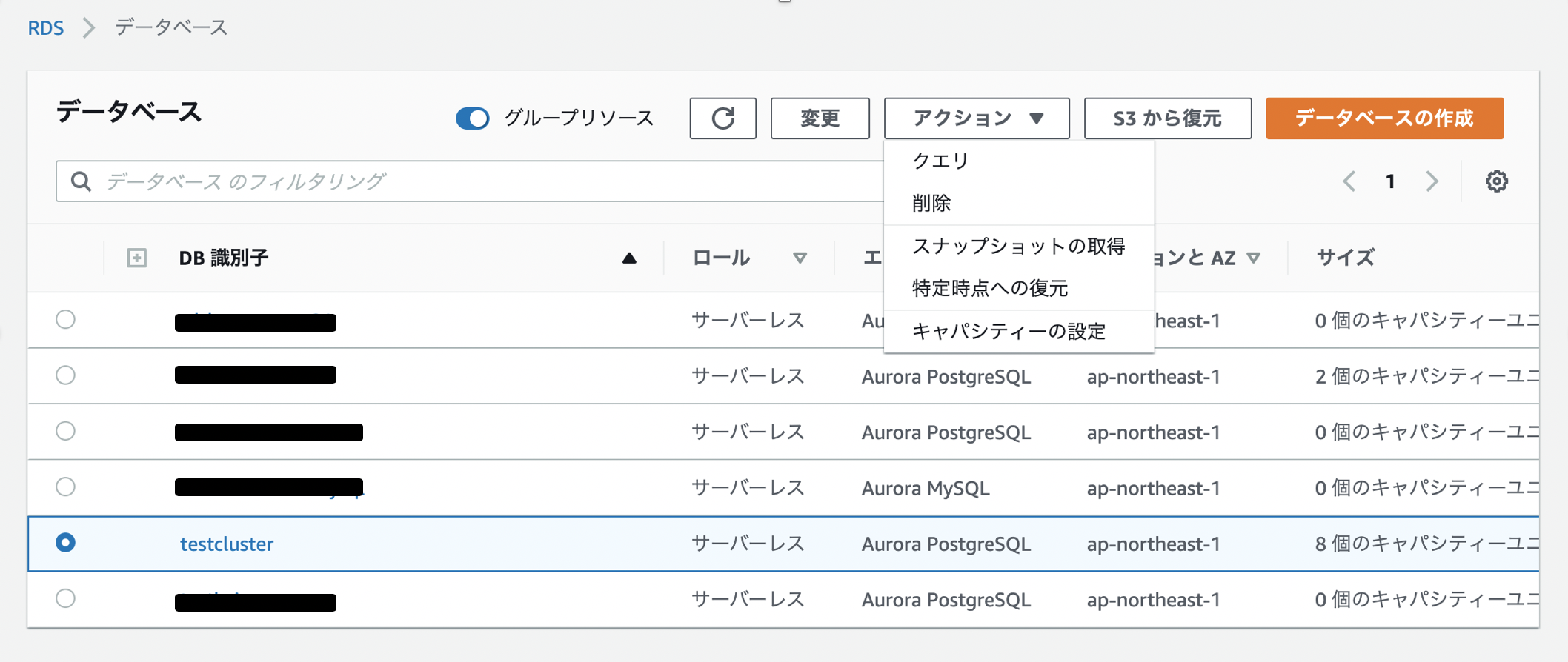
- 投稿日:2020-01-21T02:01:37+09:00
AWSが大阪リージョンを開設するに至った背景を推測する
AWSが大阪リージョンを2021年初頭に開設を発表
AWSは2020年1月20日にこれまで一部顧客向けの限定的なローカルリージョンとしての位置付けだった大阪リージョンを、東京やその他リージョンと同様なスタンダードなリージョンとして拡張を発表しました。
個人的にこの発表は、ここ最近のAWS関連ニュースの中でも上位に来るレベルなサプライズでした。というのも直近の案件でAWSでのDR構成についてアレやコレやと頭を悩ませていたからです。
官公庁システムのクラウド・バイ・デフォルトについて
日本政府は2018年より政府情報システムのクラウド利用における基本方針を打ち出して、「未来投資戦略2018」や「サイバーセキュリティ戦略」などにより諸外国の状況を調査したりと、クラウドサービス利用における安全性評価に関する検討を2019年まで行っておりました。
そして2020年秋から全省庁のシステムをクラウドに切り替えていくため、海外の企業に日本国内へのデータセンター設置などを求めていました。今後4~8年で原則、クラウドに切り替わっていきます。
制限付きの大阪ローカルリージョンは2018年に開設されておりましたが、2020年秋より本格化する官公庁システムのクラウド移行需要を取り込むための準備が整ったという感じなのかなと推測しています。
要件
堅めのシステムですと
データの海外持ち出しNG、国内裁判権、DRなどの要件を良く耳にすると思います。AWSで国内でDRを満たそうと既存の使い勝手が良いとは言えない大阪ローカルリージョンで構成しようとするとイケてない感じになってしまい、いっそ現状で東西リージョンのあるAzureにした方がいいのでは?ってパターンに遭遇することもありました。DR要件が局所的な被災を想定するのか広域的な被災を想定するかでまた変わって来ますが、広域想定とする場合は尚の事悩ましいものです。
今回の大阪リージョンのスタンダード化の発表によって、2021年から広域想定のDR構成が組みやすくなる為、シンプルにより顧客の要件に沿った提案が可能となるわけです。わ〜い。
あと純粋に西日本寄りに事業所がある場合、大阪リージョンにインスタンスを立てたほうがレスポンスがあがるのも嬉しいですよね。
まとめ
ざっくり簡単にまとめると
- 政府は2020年秋から順次システムをクラウドへ移行する為に準備してきた
- AWSは官公庁システムの移行需要に備えるため大阪リージョンの拡張を進めた(推測)
- これまでAWSでは満たし難かった要件を、将来満たせるようになるため提案の幅が増えた
以上、AWS大阪リージョンの拡張を祝したテンションで書いてみました。
- 投稿日:2020-01-21T02:01:37+09:00
AWSが大阪リージョンを開設するに至った背景(推測)とか書く
AWSが大阪リージョンを2021年初頭に開設を発表
AWSは2020年1月20日にこれまで一部顧客向けの限定的なローカルリージョンとしての位置付けだった大阪リージョンを、東京やその他リージョンと同様なスタンダードなリージョンとして拡張を発表しました。
個人的にこの発表は、ここ最近のAWS関連ニュースの中でも上位に来るレベルなサプライズでした。というのも直近の案件でAWSでのDR構成についてアレやコレやと頭を悩ませていたからです。
官公庁システムのクラウド・バイ・デフォルトについて
日本政府は2018年より政府情報システムのクラウド利用における基本方針を打ち出して、「未来投資戦略2018」や「サイバーセキュリティ戦略」などにより諸外国の状況を調査したりと、クラウドサービス利用における安全性評価に関する検討を2019年まで行っておりました。
そして2020年秋から全省庁のシステムをクラウドに切り替えていくため、海外の企業に日本国内へのデータセンター設置などを求めていました。今後4~8年で原則、クラウドに切り替わっていきます。
制限付きの大阪ローカルリージョンは2018年に開設されておりましたが、2020年秋より本格化する官公庁システムのクラウド移行需要を取り込むための準備が整ったという感じなのかなと推測しています。
要件
堅めのシステムですと
データの海外持ち出しNG、国内裁判権、DRなどの要件を良く耳にすると思います。AWSで国内でDRを満たそうと既存の使い勝手が良いとは言えない大阪ローカルリージョンで構成しようとするとイケてない感じになってしまい、いっそ現状で東西リージョンのあるAzureにした方がいいのでは?ってパターンに遭遇することもありました。DR要件が局所的な被災を想定するのか広域的な被災を想定するかでまた変わって来ますが、広域想定とする場合は尚の事悩ましいものです。
今回の大阪リージョンのスタンダード化の発表によって、2021年から広域想定のDR構成が組みやすくなる為、シンプルにより顧客の要件に沿った提案が可能となるわけです。わ〜い。
あと純粋に西日本寄りに事業所がある場合、大阪リージョンにインスタンスを立てたほうがレスポンスがあがるのも嬉しいですよね。
まとめ
ざっくり簡単にまとめると
- 政府は2020年秋から順次システムをクラウドへ移行する為に準備してきた
- AWSは官公庁システムの移行需要に備えるため大阪リージョンの拡張を進めた(推測)
- これまでAWSでは満たし難かった要件を、将来満たせるようになるため提案の幅が増えた
以上、AWS大阪リージョンの拡張を祝したテンションで書いてみました。
- 投稿日:2020-01-21T01:48:31+09:00
ServerlessFrameworkでスクレイピング用Lambda-Layerを作る
前書き
最近AWSの勉強をしていてLambda Layerの存在を知りました。
スクレイピングもLambdaで楽にできるのでは?と思いチュートリアル的な記事を色々やってみましたがハマったので備忘録を残します。チュートリアル?はこちらを参考にしました。
最終的にIaCにしたかったのでServerlessFrameworkも使ってみました。
作成したコードは→touka9029/selenium-lambda-layerDockerやAWS Cloud9、AWS CloudFormationなど周辺機能については解説しません。
環境やライブラリバージョン
- AWS Cloud9, AMI: ami-081330c4becd75920
- adieuadieu/serverless-chrome, v1.0.0-55, chromium 69.0.3497.81 (stable channel) for amazonlinux:2017.03
- ChromeDriver 2.41
- Lambda Runtime: python3.7
- selenium: 3.141.0
ハマったポイント
その1: Cloud9のpythonバージョンとpipバージョンが異なる
Cloud9のPreferencesからpythonのバージョンはpython3に変更できるのですが、pipのバージョンは2のままでした。
AWS Cloud9 でPython3を使うための設定を参考に、pipのバージョンもpython3を向くようにしました。その2: serverless-chromeとChromeDriverのバージョン
https://sites.google.com/a/chromium.org/chromedriver/downloads で確認しましょう。
chromium 69.0なのでSupports Chrome versionが69を含むバージョンにします。
いろいろ試した結果、ChromeDriver 2.41に落ち着きました。
メジャーバージョンなら2.44まで動くはずなのですが、タイムアウトしてしまいました。
Chromeとchromiumって違うのでしょうか?(しっかり把握していない)その3: chrome_optionsが足りていなかった
これが一番大きいハマりポイント。
チュートリアルのオプションだけでは(1年以上前ですが)最新バージョンでは動かず、最終的にはIssueで動いたと報告のあったオプションと見比べて解決しました。lambda_handler.py# このオプションが必要だった options.add_argument('--disable-dev-shm-usage')その4: Cloud9のEBS容量
ServerlessFrameworkでIaC化している最中にEBSの容量が足りなくなりました。
10GBしかない上、デフォルトでlambci/lambdaのDockerイメージが入っていたり(合計で2~3GBぐらい?)、seleniumのライブラリを作るために使ったlambci/lambda:build-python3.7イメージもそこそこ容量を食うのでほとんど消しました(使う際に再取得すればいいと思います)。
Lambdaのローカルデバッグに使うらしいですがLayerは現時点(2020/01/20)では対応していないみたいです。残念。
dockerhubのドキュメントを見たらを確認したらlayerをマウントできるみたいです。※後から確認したらCloud9とlambci/lambda:build-python3.7のOSは同じみたいなので直接
pip installでも良かったかも。とはいえCloud9以外でも使えるようにするならDockerでしょうか。実装
- IaC化にあたり、AWS Lambdaで動的サイトのwebスクレイピングをしてtwitterに投稿するbotを作った(続) の実装を参考にさせていただきました。
chrome driverを取得
- まずはheadless-chromiumとChromeDriverを取得します。
- 最後に容量節約のためDockerイメージを削除しています。
get-binaries.sh#!/bin/bash -x SERVERLESS_CHROME_URL=https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip CHROME_DRIVER_URL=https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip # get headless_chrome rm -r ./headless_chrome mkdir -p ./headless_chrome wget $SERVERLESS_CHROME_URL unzip stable-headless-chromium-amazonlinux-2017-03.zip -d ./headless_chrome/bin/ rm stable-headless-chromium-amazonlinux-2017-03.zip wget $CHROME_DRIVER_URL unzip chromedriver_linux64.zip -d ./headless_chrome/bin/ rm chromedriver_linux64.zip # get selenium # /opt/python, または /opt/python/lib/python3.7/site-packages に展開されるように配置する PYTHON_LIB=python/lib/python3.7/site-packages rm -r ./selenium mkdir -p ./selenium/${PYTHON_LIB} docker run --rm \ -u=`id -u ${USER}`:`id -g ${USER}` \ -v ${PWD}/selenium/${PYTHON_LIB}:/site-packages \ lambci/lambda:build-python3.7 \ pip install selenium -t /site-packages docker image rm lambci/lambda:build-python3.7Serverless FrameworkでLambda Layerを作成
npm install -g serverlessで Serverless Framework をインストール、以下のYAMLを作成してsls deployします。- 何度かAWS CloudFormationを触っていたのでとっつきやすかったです。裏でzipに固めてS3にアップロード、CloudFromationのjsonを自動生成してスタック作成しているようでした。
# template docs: https://serverless.com/framework/docs/providers/aws/guide/layers/ service: selenium-lambda-layer provider: name: aws stage: dev region: ap-northeast-1 layers: selenium: path: selenium description: selenium layer, Runtime python3.7 compatibleRuntimes: - python3.7 headlessChrome: path: headless_chrome description: serverless-chrome v1.0.0-55, ChromeDriver2.41 compatibleRuntimes: - python3.6 - python3.7 - python3.8 # docs: The name of your layer in the CloudFormation template will be your layer name TitleCased (without spaces) and have LambdaLayer appended to the end. # 別のCloudFormationスタックから参照させるためにエクスポートする。 resources: Outputs: SeleniumLambdaLayerArn: Description: The ARN for the SeleniumLambdaLayer Value: Ref: SeleniumLambdaLayer Export: Name: SeleniumLambdaLayer HeadlessChromeLambdaLayerArn: Description: The ARN for the HeadlessChromeLambdaLayer Value: Ref: HeadlessChromeLambdaLayer Export: Name: HeadlessChromeLambdaLayerマネジメントコンソールで試す
- ここからは結果だけ。
lambda_function.pyfrom selenium import webdriver class Chrome: def headless_lambda(self): options = webdriver.ChromeOptions() options.binary_location = "/opt/bin/headless-chromium" options.add_argument("--headless") options.add_argument("--no-sandbox") options.add_argument("--single-process") options.add_argument("--disable-gpu") options.add_argument("--window-size=1280x1696") options.add_argument("--disable-application-cache") options.add_argument("--disable-infobars") options.add_argument("--hide-scrollbars") options.add_argument("--enable-logging") options.add_argument("--log-level=0") options.add_argument("--ignore-certificate-errors") options.add_argument("--homedir=/tmp") # 参考に無かった以下のオプションが必要だった options.add_argument('--disable-dev-shm-usage') driver = webdriver.Chrome( executable_path="/opt/bin/chromedriver", chrome_options=options ) return driver def lambda_handler(event, context): chrome=Chrome() driver=chrome.headless_lambda() driver.get('https://www.google.com') return driver.title driver.quit()
- ロール(適当)とメモリ(320MB)、タイムアウト(30秒)を設定してCloudWatchテンプレートでテストしました。
- これだけでも12秒かかるんですね。
終わりに
ハマりポイントが誰かのためになれば幸いです。
完成してみれば Lambda Layer も Serverless Framework も便利ですね。
CloudWatchEventsで定期処理させたり通知飛ばしたりAPI Gatewayと連携させたり色々できそうです。その他参考記事