- 投稿日:2020-01-21T20:36:50+09:00
Cassandra×SpringBoot 奮闘記録
この記事の概要
- Cassandraに触れたことがなかったので、構築〜SpringBootのアプリケーションから参照・更新をすることろまでをやってみたときの記録
- 環境はローカルPC(Mac)
参考
Cassandra: http://cassandra.apache.org/doc/latest/
SpringDataCassandra: https://spring.io/projects/spring-data-cassandraCassandraの構築
インストール
# Cassandra本体 brew install cassandra # CQL(Cassandra Query Language) brew install cql起動
cassandra -fConnection error: ('Unable to connect to any servers', {'127.0.0.1': error(61, "Tried connecting to [('127.0.0.1', 9042)]. Last error: Connection refused")})
動かん。。。
僕の場合はJAVA_HOMEがJava11のディレクトリを指しているのがいけなかったようです。。。
定義し直したら無事起動!export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home/ cassandra -fどうせならHomebrewで起動!
vi /usr/local/etc/cassandra/cassandra-env.sh # 末尾に「export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home/」を追記 brew services start cassandra接続!
cqlshcqlsh localhost 9042
これと一緒ちょっとCassandra単体で遊んでみる
cqlshここから再開
こまかいオプションの説明はここでは省略。。。KeySpaceの追加
MySQLやOracleでいうDatabaseに当たる概念
-- # keyspace追加前 DESCRIBE keyspaces -- system_traces system_schema system_auth system system_distributed -- # 「sample」 keyspace追加 CREATE KEYSPACE sample WITH REPLICATION = {'class':'SimpleStrategy','replication_factor':1}; -- # keyspace追加前 DESCRIBE keyspaces -- system_schema system_auth system sample system_distributed system_tracesちなみに削除は
DROP KEYSPACE sample;Databaseの移動
USE sampleテーブルの作成
ここではシンプルにKeyとValueを持つデータを想定
-- 作成 CREATE TABLE t_sample (key text PRIMARY KEY, value text); -- 一覧確認 DESCRIBE tables; -- テーブル定義の確認 DESCRIBE table t_sample;ちなみに削除は
DROP TABLE t_sample;データ操作
先ほど作成したt_sampleテーブルを使って一通り
-- 参照(空っぽ) select * from t_sample; -- 参照(上と同等) select key, value from t_sample; -- 登録 INSERT INTO t_sample (key, value) VALUES ('key1', 'value1'); -- 登録(重複) -- クエリは成功して、updateのような動きになっている INSERT INTO t_sample (key, value) VALUES ('key1', 'value2'); -- 更新 UPDATE t_sample SET value = 'value3' WHERE key = 'key1'; -- 削除 DELETE FROM t_sample WHERE key = 'key1';primary違反したら弾かれるんじゃなくてupdateされるのは初体験
Springアプリケーションの構築
project作成
build.gradleplugins { id 'org.springframework.boot' version '2.2.4.RELEASE' id 'io.spring.dependency-management' version '1.0.9.RELEASE' id 'java' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '11' repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-cassandra' // webfluxは動作確認用です implementation 'org.springframework.boot:spring-boot-starter-webflux' compileOnly('org.projectlombok:lombok') annotationProcessor('org.projectlombok:lombok') }application.ymlspring: data: cassandra: keyspace-name: sampleテーブルのモデルクラスを作成
Sample.javaimport lombok.Value; import org.springframework.data.cassandra.core.mapping.PrimaryKey; import org.springframework.data.cassandra.core.mapping.Table; @Data @Table("t_sample") public class Sample { @PrimaryKey private String key; private String value; }登録・参照・削除をしてみる
Application.java@Slf4j @SpringBootApplication public class Application { public static void main(String[] args) { //SpringApplication.run(Application.class); Cluster cluster = Cluster.builder() .addContactPoints("localhost") .withoutJMXReporting() // 付けないとエラー .build(); Session session = cluster.connect("sample"); var template = new CassandraTemplate(session); var data = new Sample("key1", "value1"); template.insert(data); // 全件検索 var selected = template.select("SELECT * from t_sample", Sample.class); log.info("selected: {}", selected); // 更新 data = new Sample("key1", "value2"); template.update(data); // 条件付き検索 selected = template.select(Query.query(Criteria.where("key").is("key1")), Sample.class); log.info("selected: {}", selected); // 削除(PK指定) template.deleteById("key1", Sample.class); // 件数取得 var count = template.count(Sample.class); log.info("count: {}", count); // 接続クローズ session.close(); cluster.close(); } }
.withoutJMXReporting()については記述しておかないと以下のエラーが発生したException in thread "main" java.lang.NoClassDefFoundError: com/codahale/metrics/JmxReporter
Webアプリケーションっぽくしてみる
まずは「spring-boot-starter-data-cassandra」がどこまでBean登録してくれるのか調査
Cluster
org.springframework.boot.autoconfigure.cassandra.CassandraAutoConfigurationがBean登録しているspring.data.cassandra配下のpropertiesを設定すれば良さそうspring.data.cassandra.keyspace-name=sampleとかSession
- SessionというかSessionFactoryなのかな?
org.springframework.boot.autoconfigure.data.cassandra.CassandraDataAutoConfigurationがBean登録している- こちらも同様に
spring.data.cassandra配下の設定が反映されそうCassandraTemplate
- Session同様、
org.springframework.boot.autoconfigure.data.cassandra.CassandraDataAutoConfigurationがBean登録している結論、、、
いきなりCassandraTemplate使うでOK!CassandraController.java@RequiredArgsConstructor @RestController public class CassandraController { private final CassandraTemplate template; // curl localhost:8080 @GetMapping("") public List<Sample> all() { return template.select("SELECT * FROM t_sample", Sample.class); } // curl localhost:8080/key1 @GetMapping("/{key}") public Sample getByKey(@PathVariable String key) { return template.selectOneById(key, Sample.class); } // curl localhost:8080/insert -d '{"key":"key1","value":"value1"}' -X PATCH -H 'Content-Type: application/json' @PatchMapping("/**") public Sample patch(@RequestBody Sample sample) { return template.insert(sample); } // curl localhost:8080/key1 -X DELETE @DeleteMapping("/{key}") public Boolean delete(@PathVariable String key) { return template.deleteById(key, Sample.class); } }Reactive対応
ReactiveCassandraTemplateを使うだけ!
返り値の型をFlux or Monoにするもの忘れずに!(一括でPublisherとしてもOK)ReactiveCassandraController.java@RequiredArgsConstructor @RestController @RequestMapping("/reactive") public class ReactiveCassandraController { private final ReactiveCassandraTemplate template; // curl localhost:8080/reactive @GetMapping("") public Flux<Sample> all() { return template.select("SELECT * FROM t_sample", Sample.class); } // curl localhost:8080/reactive/key1 @GetMapping("/{key}") public Mono<Sample> getByKey(@PathVariable String key) { return template.selectOneById(key, Sample.class); } // curl localhost:8080/reactive/insert -d '{"key":"key1","value":"value1"}' -X PATCH -H 'Content-Type: application/json' @PatchMapping("/**") public Mono<Sample> patch(@RequestBody Sample sample) { return template.insert(sample); } // curl localhost:8080/reactive/key1 -X DELETE @DeleteMapping("/{key}") public Mono<Boolean> delete(@PathVariable String key) { return template.deleteById(key, Sample.class); } }
- 投稿日:2020-01-21T18:16:29+09:00
[Java] GlassFish 5トラブルシュート記録
GlassFish 5を動かそうとして、意外にすんなりいかなかったのでトラブルシュートの記録です。
環境
OS: Azure上のWindows Server 2008 R2
JDK: Zuluトラブルシュート記録
[解決]
asadminコマンドを実行するとNullPointerExceptionJDK 11 (Zulu 11.31.11)ではだめでした。
JDK 8 (Zulu 8.44.0.9)を使うとOKでした。[解決]
asadmin start-domainするとNoClassDefFoundError例外
asadmin start-domainとすると、こんなエラーになりました。Exception in thread "main" MultiException stack 1 of 2 java.lang.NoClassDefFoundError: com/sun/enterprise/admin/launcher/GFLauncherException at java.lang.Class.getDeclaredConstructors0(Native Method) (略)すみません。GlassFish 5.0使ってました。
Eclipseに移管したGlassFish 5.1を使いましょう。https://projects.eclipse.org/projects/ee4j.glassfish
[未解決] デプロイするとIllegalStateException
warファイルをデプロイすると、このようなエラーが出ました。
remote failure: Error occurred during deployment: Exception while loading the app : java.lang.IllegalStateException: ContainerBase.addChild: start: org.apache.catalina.LifecycleException: org.apache.catalina.LifecycleException: org.glassfish.jersey.server.model.ModelValidationException: Validation of the application resource model has failed during application initialization. [[FATAL] No injection source found for a parameter of type public java.lang.String service.AddonFacadeREST.create(java.io.File,java.io.File,java.lang.String,javax.ws.rs.core.SecurityContext) at index 0.; source='ResourceMethod{httpMethod=PO (略)GlassFish 5あきらめました。
4.1.2を使うことにしました。快調です。
- 投稿日:2020-01-21T13:34:04+09:00
SpringBoot で起動引数による環境切替を行う
はじめに
SpringBoot でバックエンドを開発しているときにある話。
昨今、Dockerが出てきてから結合から本番までワンモジュール、ワンソースで最後まで管理する傾向にある。
各環境の区別は、環境引数を外から渡すだけ、という設計方針にした際に、
では、中身のSpringBootで作ったアプリケーションのモジュールはどういう風にすればよいのかをまとめる環境の数が少ないなら
SpringBootのProfileで切替すればよい。
下記に公式情報があるため、こちらで実現できます。
公式起動引数に下記を含めれば、
-Dspring.profiles.active=dev1
下記ファイルが読み込まれる仕様である。
src/main/resource/application-dev1.properties」
ビルドでプロパティファイルを切替
mavenのprofile切替が簡単。
モジュールを固める、jar やwar などにするときに、maven の機能で設定ファイルの切り替えを行う。
ビルド時にファイル移送を実施するため、設定ファイルの切替で最も簡単な方法。
mvn package -P dev01
pom.xml
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-war-plugin</artifactId> <configuration> <webappDirectory>${project.build.directory}/${project.build.finalName}</webappDirectory> <webResources> <resource> <directory>${basedir}/release/${project.stage}</directory> </resource> </webResources> <useCache>false</useCache> <!-- 警告エラーが発生するため追加--> <failOnMissingWebXml>false</failOnMissingWebXml> <archive> <manifest> <!-- main クラス指定(必要に応じて)--> <mainClass>jp.co.●●.●●.Main</mainClass> </manifest> </archive> </configuration> </plugin> <profiles> <profile> <id>dev1</id> <activation> <activeByDefault>true</activeByDefault> </activation> <properties> <project.stage>dev01</project.stage> </properties> </profile> <profile> <id>dev02</id> <activation> <activeByDefault>false</activeByDefault> </activation> <properties> <project.stage>dev02</project.stage> </properties> </profile> </profiles>シェルコマンドを内部に組み込むことも可能なため、
maven に慣れている人にとっては、なじみ深い。ワンモジュールで環境切替したい
今までの問題点
1つ目、springboot のprofile 切替方法は、プロパティファイルの形式が固定されており、複数のファイルの読み込みなどの設定が非常にやりづらい。特に環境が増えた場合に柔軟性に欠ける。
2つ目、maven のprofile 切替方法は、複数ファイルの読み込みは、特定の環境には特定のモジュールしか動かない設定のため、デプロイシェル等に誤りや手順ミスがあった場合に、障害が発生する可能性が高い。
spring bootのprofile 機能拡張を利用する。
ApplicationContextInitializerを利用して起動時にprofileを設定するようにする。
Javaの起動引数指定 → ApplicationContextInitializerでprofileに指定
この方法の場合、profile 指定するときに、グルーピングできるようになり、
dev01で実行すると、dev とdev01の二つの情報を含めることができる。java -Dproject.stage=dev01 hoge.war
public class SpringActiveProfileInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> { /** ロガー */ private static final Logger LOG = LoggerFactory.getLogger(SpringActiveProfileInitializer.class); @Override public void initialize(final ConfigurableApplicationContext applicationContext) { // 起動引数を取得(dev01) String projectStage = System.getProperty("project.stage"); // 起動グループを取得(dev) String prjectStageGroup = projectStage.replaceAll("[0-9]+", ""); ConfigurableEnvironment env = applicationContext.getEnvironment(); if (StringUtils.equals(projectStage, prjectStageGroup)) { env.setActiveProfiles(projectStage); } else { env.setActiveProfiles(prjectStageGroup); env.addActiveProfile(projectStage); } if (LOG.isDebugEnabled()) { // setting spring.profiles.active = [dev, dev01] LOG.debug("setting spring.profiles.active = {}", Arrays.asList(env.getActiveProfiles())); } } }web-fragment.xml
<?xml version="1.0" encoding="UTF-8"?> <web-fragment xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:webfragment="http://xmlns.jcp.org/xml/ns/javaee/web-fragment_3_0.xsd" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-fragment_3_0.xsd" version="3.0"> <!-- JVMシステムパラメータで設定したProjectStageをSpringActiveProfileへ設定 --> <context-param> <param-name>contextInitializerClasses</param-name> <param-value>jp.co.future.project.palette.common.context.SpringActiveProfileInitializer</param-value> </context-param> </xml>spring bootのprofile はxml でも利用可能
xml 内部でもprofile を記載でき、
環境ごとに定義ファイルの切り分けられるサンプルで記載しているが、共通化や外部ファイルの読み込みなどの設定も可能。
<beans profile="dev"> <!-- データソース --> <bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource" destroy-method="close"> <property name="jdbcUrl" value=""/> </bean> </beans> <beans profile="stg"> <!-- データソース --> <bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource" destroy-method="close"> <property name="jdbcUrl" value=""/> </bean> </beans> <!-- カンマ区切りで複数ステージの指定も可能 --> <beans profile="dev,stg"> <bean id="redis" > </bean> </beans> <beans profile="dev01"> <!-- xmlからプロパティファイルの読み込みも可能 --> <bean class="org.springframework.context.support.PropertySourcesPlaceholderConfigurer"> <property name="location" value="classpath:config/connect-config-dev01.properties" /> </bean> </beans> <!-- xmlそのものをインポートすることも可能 --> <import resource="classpath:META-INF/common-context.xml" />おわりに
以上、spring boot で環境切替を行う方法でした。
ワンモジュール、ワンソース!
- 投稿日:2020-01-21T11:33:33+09:00
【#1】PythonでMinecraftを作る。【下調べと設計】
Part of pictures, articles, images on this page are copyrighted by Mojang AB.
概要
世界的に超有名なサンドボックスゲーム「Minecraft」をプログラミング言語「Python」で再現するプロジェクトです。
きっかけ
僕がプログラミングに初めて触れたのは、「Minecraft」がきっかけでした。
4年以上前の事です。
Minecraftにおける「MOD」と呼ばれる所謂改造コンテンツに興味があり、「自分でも作ってみたい!」とプログラミングの世界に足を踏み入れました。
総プレイ時間は数万時間を超えており、色々と思い出深いゲームの一つです。小学校低学年の頃からウェブサイトを制作したりと、多少はクリエイティブな活動をしておりました。
プログラミング言語を使用して実際に"モノ"をプログラミングし、それが実際に動いた時の感動は凄まじいものです。また、僕の"プログラミング"に対する物事の考え方や組み立て方、それを実現するにあたっての知識
全てにおいて相性抜群でした。そういった経緯もあり、4年経った今、"MOD"ではなく「Minecraft」そのものを実際に再現してみよう!
と立ち上がりました。心構え
しかしながら、あの規模のゲームの再現は簡単なものではありません。
今でこそ、「Unity」や「Unreal Engine」といったゲームエンジンと呼ばれるもので、
コーディングを一切せずとも簡単にハイクオリティなゲームが作れてしまう時代です。コーディングでさえも、ブループリントと呼ばれるものでビジュアライズし、GUIで組み立てる。
ということが可能であるほどです。これは驚くべきことです。しかしながら、当プロジェクトではそういったゲームエンジンは使用しません。
本当の意味で"イチから"作り上げます。下調べ
実際に制作する上で、先ずは敵を知らねばなりません。
Minecraftにおける描画
コンピュータグラフィックスライブラリと呼ばれる所謂「描画系」のライブラリは有名なものであれば
「DirectX」や「OpenGL」があります。本題です。MinecraftはJavaでどうやって描画しているのでしょうか?
Minecraftは、Javaにおけるゲームライブラリの一つである「LWJGL(Lightweight Java Game Library)」と呼ばれるものを使用しています。
OpenGLのWrapperの様です。Pythonにこの様なライブラリは存在するのでしょうか。
最悪無くてもいいんです。無ければ作りゃいい。足りなくなったら足すだけや。LWJGLに触れてみる
統合開発環境「Eclipse」を使用して、少しだけLWJGLに触れてみます。
公式サイトよりダウンロード。
懐かしい。この画面。
とりあえず、目が疲れるのでダークテーマに。
Window▶Preferences▶Appearance
適当にプロジェクトを作ります。
適当にクラスを作成。
main.javapublic class main { //コンストラクタ public main() {} public static void main(String[] args) { System.out.println("Hello LWJGL!"); } }とりあえず動作確認完了。
LWJGLの環境構築
LWJGLを使うには、「JDK(Java Development Kit)」が必要です。
参考記事: WindowsへのJDKインストール方法
javac -versionで通ればOK。
LWJGL環境構築にあたって、
Mavenをインストール。参考記事: WindowsへのMavenインストール方法
mvn -vで通ればOK。
今回は
Maven 3をインストールしました。
次に、
mvn archetype:generate -DgroupId=test -DartifactId=test
で適当にプロジェクトの作成
今回はEclipseのワーキングスペースに作成しました。参考記事: Maven3のメモ
Choose org.apache.maven.archetypes:maven-archetype-quickstart version: 1: 1.0-alpha-1 2: 1.0-alpha-2 3: 1.0-alpha-3 4: 1.0-alpha-4 5: 1.0 6: 1.1 7: 1.3 8: 1.4 Choose a number: 8: 8 [INFO] Using property: groupId = test [INFO] Using property: artifactId = test Define value for property 'version' 1.0-SNAPSHOT: : 1.0-SNAPSHOT [INFO] Using property: package = test Confirm properties configuration: groupId: test artifactId: test version: 1.0-SNAPSHOT package: test Y: : Y [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 06:21 min [INFO] Finished at: 2020-01-21T08:58:05+09:00 [INFO] ------------------------------------------------------------------------
次に、
作成したプロジェクトの中のpom.xmlにLWJGLをリンクmvn nativedependencies:copyでダイナミックリンクライブラリをダウンロード
mvn clean eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=trueでEclipseでプロジェクトを読み込めるようにします。
Eclipseを開いて、Import existing projectsからインポート。
ライブラリが構築されています。
実行
ソースコードは以下の通りです。
Main.javapackage test; import org.lwjgl.LWJGLException; import org.lwjgl.opengl.Display; import org.lwjgl.opengl.DisplayMode; import static org.lwjgl.opengl.GL11.*; public class Main { public static final int screen_width = 800; public static final int screen_height = 500; public static void Initialize() { try { Display.setDisplayMode(new DisplayMode(screen_width, screen_height)); Display.setTitle("Hello LWJGL!"); Display.create(); } catch(LWJGLException e) { e.printStackTrace(); return; } try { glOrtho(0, screen_width, 0, screen_height, 0, depth); glMatrixMode(GL_MODELVIEW); while (!Display.isCloseRequested()) { glClear(GL_COLOR_BUFFER_BIT); Render(); Display.update(); } } catch(Exception e) { e.printStackTrace(); } finally { Display.destroy(); } } public static void Render() { glBegin(GL_QUADS); glEnd(); } public static void main(String[] args) { Initialize(); } }とりあえず何も描画されていませんが、いけました。
線を描画
画面右上から右下まで赤い線を描画します。
Main.javapublic static void Render() { glBegin(GL_LINES); glColor3f(1.0f, 0f, 0f); glVertex2f(0, 0); glVertex2f(screen_width, screen_height); glEnd(); }線が描画されていることが確認できます。
Pythonでの描画
ここまでで、MinecraftにはOpenGLが使われていることがわかりました。
PythonでもOpenGLは使えるようです。環境構築
「PyCharm」と呼ばれるIDEを使用します。
File▶Setting▶Project:<プロジェクト名>▶Project Interpreter
より、必要なライブラリを追加します。
参考サイトにある画像読込のPillowはPython3.8サポート外らしいので、インストールできませんでした。
PythonでOpenGLに触れてみる
main.pyを作成して実行。
ソースコードは以下の通りです。
このPythonのスカスカ記法、慣れるのに時間がかかりそうです。main.pyfrom OpenGL.GL import * import glfw def main(): if not glfw.init(): return window = glfw.create_window(640, 480, 'Hello World', None, None) if not window: glfw.terminate() print('Failed to create window') return glfw.make_context_current(window) print('Vendor :', glGetString(GL_VENDOR)) print('GPU :', glGetString(GL_RENDERER)) print('OpenGL version :', glGetString(GL_VERSION)) glfw.destroy_window(window) glfw.terminate() if __name__ == "__main__": main()出力結果:
Vendor : b'NVIDIA Corporation' GPU : b'GeForce GTX 1080/PCIe/SSE2' OpenGL version : b'4.6.0 NVIDIA 441.08' Process finished with exit code 0順調です。
ウィンドウに実際に描画してみる
ソースコードは以下の通りです。
glClearColorの引数はRGBAです。
それぞれfloatで指定します。
(r / 255.f, g / 255.f, b / 255.f, a / 255.f)
※Red Green Blue Alpha(透明度)main.pyglfw.make_context_current(window) glfw.window_hint(glfw.CONTEXT_VERSION_MAJOR, 4) glfw.window_hint(glfw.CONTEXT_VERSION_MINOR, 0) glfw.window_hint(glfw.OPENGL_PROFILE, glfw.OPENGL_CORE_PROFILE) while not glfw.window_should_close(window): glClearColor(0, 1, 0, 1) glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT) glfw.swap_buffers(window) glfw.poll_events()▼この様な感じで描画されます。
Python凄いですね。こんなに簡単にできてしまうのか。
C# .NET WinFormでやっていたら、今頃地獄を見ていたことでしょう。
豆知識:フロントバッファとバックバッファ
フロントバッファ1枚だと、更新する度にチカチカしてしまったり、問題が生じます。
そこでバックバッファと呼ばれるものを用意し、更新はバックバッファに対して行います。
SwapBuffer()でバックバッファをフロントバッファに送ることで、画面に表示します。
設計
ここまでで、OpenGLでどの様に描画しているのか踏まえつつ、実際に触れてみました。
ここからが本題です。
ゲームを制作していく上で、あてずっぽうにプログラミングしていては、プログラムの保守性やメンテナンス性に支障をきたします。
そこで、大まかでも良いので、実際にプログラムの設計図を作成します。ワールドの管理
Minecraftでは、Worldのマネジメント手段のひとつとして、「チャンク」と呼ばれるものがあります。
これは、広大なワールドを16(x)×16(z)×256(y)のチャンクに分割し、必要な範囲のみ読み込み/描画を行うことで負荷を最小限に抑えるものです。不思議に思ったこと
通常、3Dゲームのワールドにおける3次元ベクトルの概念では
Zが高さとして定義されていると認識していますが、MinecraftではYが高さなんです。
理由は分かりません。謎です。。▼下記画像の3次元における
ZがMinecraftではYと定義されています。
画像出典: 第8回 基礎数学Ⅰ
ブロックの管理
次に、ブロックについてです。
Minecraftでは、内部的にはブロックには2種類あります。
- "土"ブロックといった、何の機能も持たない普通のブロックを
Block- "かまど"ブロックといった、GUIや機能を持つ特殊なブロックを
TileEntityとして定義されています。
"かまど"等の機能を持ったブロックの実体はBlockであり、TileEntityのオブジェクトを持ちます。
これも負荷軽減やリソース節約のワールドマネジメントの一つです。Block
Blockはインターフェースを継承します。
インターフェースにはWorldのインスタンスも含まれており、ブロックからWorldへ設置された/破壊された...等のイベントを送受信します。例えば、こんな感じです。
public boolean onBlockActivated(World world, int x, int y, int z, EntityPlayer player)TileEntity
TileEntityの実体はBlockですから、BlockとTileEntityの紐付けが必要です。
そこで、Minecraftではこの様に特定のブロックのインターフェース関数からTileEntityのオブジェクトを生成します。
MyTileEntityClassはインターフェースTileEntityを継承します。public TileEntity createNewTileEntity(World world) { return new MyTileEntityClass(); }設計
ここまでの情報を基に、軽く設計図を組み立ててみます。
あまりにも規模が大きいので、とりあえず細かい所は何も考えず、現状でわかっていること・実装したいことを基に設計を行います。▼この様な感じになりました。
ワールドとの情報のやり取り等のイベントはインターフェースに定義します。
悩みどころ
Minecraftのソースコードを実際に見たわけではないので、これまでMOD開発で培った経験や知識を基に大まかな設計はできましたが、細かい所までは自分で考えて実装しなければなりません。
なかなか厳しい戦いになりそうです。特に、悩みどころは描画です。
Worldからの描画を実際にどうやってレンダリングしようか。と。
特に3次元空間なので、2次元空間と違ってややこしそうです。
テクスチャの読み込み..etc問題は山積みです。とりあえず、メニュー画面の制作でしょうか。
次回に続く
規模が大きいので、プロジェクトはパート毎に分けることにしました。
プロジェクト名は...「PyCraft」でいいかな?
それっぽいロゴを制作して下さる方募集中です。宜しくお願い致します。次回はメニュー画面の制作と、レンダリング問題の解決を目標とします。
最後までご覧頂きありがとうございました。

















- 投稿日:2020-01-21T11:33:33+09:00
【#1】PythonでMinecraftを作る。~下調べと設計~
Part of pictures, articles, images on this page are copyrighted by Mojang AB.
概要
世界的に超有名なサンドボックスゲーム「Minecraft」をプログラミング言語「Python」で再現するプロジェクトです。
きっかけ
僕がプログラミングに初めて触れたのは、「Minecraft」がきっかけでした。
4年以上前の事です。
Minecraftにおける「MOD」と呼ばれる所謂改造コンテンツに興味があり、「自分でも作ってみたい!」とプログラミングの世界に足を踏み入れました。
総プレイ時間は数万時間を超えており、色々と思い出深いゲームの一つです。小学校低学年の頃からウェブサイトを制作したりと、多少はクリエイティブな活動をしておりました。
プログラミング言語を使用して実際に"モノ"をプログラミングし、それが実際に動いた時の感動は凄まじいものです。また、僕の"プログラミング"に対する物事の考え方や組み立て方、それを実現するにあたっての知識
全てにおいて相性抜群でした。そういった経緯もあり、4年経った今、"MOD"ではなく「Minecraft」そのものを実際に再現してみよう!
と立ち上がりました。心構え
しかしながら、あの規模のゲームの再現は簡単なものではありません。
今でこそ、「Unity」や「Unreal Engine」といったゲームエンジンと呼ばれるもので、
コーディングを一切せずとも簡単にハイクオリティなゲームが作れてしまう時代です。コーディングでさえも、ブループリントと呼ばれるものでビジュアライズし、GUIで組み立てる。
ということが可能であるほどです。これは驚くべきことです。しかしながら、当プロジェクトではそういったゲームエンジンは使用しません。
本当の意味で"イチから"作り上げます。下調べ
実際に制作する上で、先ずは敵を知らねばなりません。
Minecraftにおける描画
コンピュータグラフィックスライブラリと呼ばれる所謂「描画系」のライブラリは有名なものであれば
「DirectX」や「OpenGL」があります。本題です。MinecraftはJavaでどうやって描画しているのでしょうか?
Minecraftは、Javaにおけるゲームライブラリの一つである「LWJGL(Lightweight Java Game Library)」と呼ばれるものを使用しています。
OpenGLのWrapperの様です。Pythonにこの様なライブラリは存在するのでしょうか。
最悪無くてもいいんです。無ければ作りゃいい。足りなくなったら足すだけや。LWJGLに触れてみる
統合開発環境「Eclipse」を使用して、少しだけLWJGLに触れてみます。
公式サイトよりダウンロード。
懐かしい。この画面。
とりあえず、目が疲れるのでダークテーマに。
Window▶Preferences▶Appearance
適当にプロジェクトを作ります。
適当にクラスを作成。
main.javapublic class main { //コンストラクタ public main() {} public static void main(String[] args) { System.out.println("Hello LWJGL!"); } }とりあえず動作確認完了。
LWJGLの環境構築
LWJGLを使うには、「JDK(Java Development Kit)」が必要です。
参考記事: WindowsへのJDKインストール方法
javac -versionで通ればOK。
LWJGL環境構築にあたって、
Mavenをインストール。参考記事: WindowsへのMavenインストール方法
mvn -vで通ればOK。
今回は
Maven 3をインストールしました。
次に、
mvn archetype:generate -DgroupId=test -DartifactId=test
で適当にプロジェクトの作成
今回はEclipseのワーキングスペースに作成しました。参考記事: Maven3のメモ
Choose org.apache.maven.archetypes:maven-archetype-quickstart version: 1: 1.0-alpha-1 2: 1.0-alpha-2 3: 1.0-alpha-3 4: 1.0-alpha-4 5: 1.0 6: 1.1 7: 1.3 8: 1.4 Choose a number: 8: 8 [INFO] Using property: groupId = test [INFO] Using property: artifactId = test Define value for property 'version' 1.0-SNAPSHOT: : 1.0-SNAPSHOT [INFO] Using property: package = test Confirm properties configuration: groupId: test artifactId: test version: 1.0-SNAPSHOT package: test Y: : Y [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 06:21 min [INFO] Finished at: 2020-01-21T08:58:05+09:00 [INFO] ------------------------------------------------------------------------
次に、
作成したプロジェクトの中のpom.xmlにLWJGLをリンクmvn nativedependencies:copyでダイナミックリンクライブラリをダウンロード
mvn clean eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=trueでEclipseでプロジェクトを読み込めるようにします。
Eclipseを開いて、Import existing projectsからインポート。
ライブラリが構築されています。
実行
ソースコードは以下の通りです。
Main.javapackage test; import org.lwjgl.LWJGLException; import org.lwjgl.opengl.Display; import org.lwjgl.opengl.DisplayMode; import static org.lwjgl.opengl.GL11.*; public class Main { public static final int screen_width = 800; public static final int screen_height = 500; public static void Initialize() { try { Display.setDisplayMode(new DisplayMode(screen_width, screen_height)); Display.setTitle("Hello LWJGL!"); Display.create(); } catch(LWJGLException e) { e.printStackTrace(); return; } try { glOrtho(0, screen_width, 0, screen_height, 0, depth); glMatrixMode(GL_MODELVIEW); while (!Display.isCloseRequested()) { glClear(GL_COLOR_BUFFER_BIT); Render(); Display.update(); } } catch(Exception e) { e.printStackTrace(); } finally { Display.destroy(); } } public static void Render() { glBegin(GL_QUADS); glEnd(); } public static void main(String[] args) { Initialize(); } }とりあえず何も描画されていませんが、いけました。
線を描画
画面右上から右下まで赤い線を描画します。
Main.javapublic static void Render() { glBegin(GL_LINES); glColor3f(1.0f, 0f, 0f); glVertex2f(0, 0); glVertex2f(screen_width, screen_height); glEnd(); }線が描画されていることが確認できます。
Pythonでの描画
ここまでで、MinecraftにはOpenGLが使われていることがわかりました。
PythonでもOpenGLは使えるようです。環境構築
「PyCharm」と呼ばれるIDEを使用します。
File▶Setting▶Project:<プロジェクト名>▶Project Interpreter
より、必要なライブラリを追加します。
参考サイトにある画像読込のPillowはPython3.8サポート外らしいので、インストールできませんでした。
PythonでOpenGLに触れてみる
main.pyを作成して実行。
ソースコードは以下の通りです。
このPythonのスカスカ記法、慣れるのに時間がかかりそうです。main.pyfrom OpenGL.GL import * import glfw def main(): if not glfw.init(): return window = glfw.create_window(640, 480, 'Hello World', None, None) if not window: glfw.terminate() print('Failed to create window') return glfw.make_context_current(window) print('Vendor :', glGetString(GL_VENDOR)) print('GPU :', glGetString(GL_RENDERER)) print('OpenGL version :', glGetString(GL_VERSION)) glfw.destroy_window(window) glfw.terminate() if __name__ == "__main__": main()出力結果:
Vendor : b'NVIDIA Corporation' GPU : b'GeForce GTX 1080/PCIe/SSE2' OpenGL version : b'4.6.0 NVIDIA 441.08' Process finished with exit code 0順調です。
ウィンドウに実際に描画してみる
ソースコードは以下の通りです。
glClearColorの引数はRGBAです。
それぞれfloatで指定します。
(r / 255.f, g / 255.f, b / 255.f, a / 255.f)
※Red Green Blue Alpha(透明度)main.pyglfw.make_context_current(window) glfw.window_hint(glfw.CONTEXT_VERSION_MAJOR, 4) glfw.window_hint(glfw.CONTEXT_VERSION_MINOR, 0) glfw.window_hint(glfw.OPENGL_PROFILE, glfw.OPENGL_CORE_PROFILE) while not glfw.window_should_close(window): glClearColor(0, 1, 0, 1) glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT) glfw.swap_buffers(window) glfw.poll_events()▼この様な感じで描画されます。
Python凄いですね。こんなに簡単にできてしまうのか。
C# .NET WinFormでやっていたら、今頃地獄を見ていたことでしょう。
豆知識:フロントバッファとバックバッファ
フロントバッファ1枚だと、更新する度にチカチカしてしまったり、問題が生じます。
そこでバックバッファと呼ばれるものを用意し、更新はバックバッファに対して行います。
SwapBuffer()でバックバッファをフロントバッファに送ることで、画面に表示します。
設計
ここまでで、OpenGLでどの様に描画しているのか踏まえつつ、実際に触れてみました。
ここからが本題です。
ゲームを制作していく上で、あてずっぽうにプログラミングしていては、プログラムの保守性やメンテナンス性に支障をきたします。
そこで、大まかでも良いので、実際にプログラムの設計図を作成します。ワールドの管理
Minecraftでは、Worldのマネジメント手段のひとつとして、「チャンク」と呼ばれるものがあります。
これは、広大なワールドを16(x)×16(z)×256(y)のチャンクに分割し、必要な範囲のみ読み込み/描画を行うことで負荷を最小限に抑えるものです。不思議に思ったこと
通常、3Dゲームのワールドにおける3次元ベクトルの概念では
Zが高さとして定義されていると認識していますが、MinecraftではYが高さなんです。
理由は分かりません。謎です。。▼下記画像の3次元における
ZがMinecraftではYと定義されています。
画像出典: 第8回 基礎数学Ⅰ
ブロックの管理
次に、ブロックについてです。
Minecraftでは、内部的にはブロックには2種類あります。
- "土"ブロックといった、何の機能も持たない普通のブロックを
Block- "かまど"ブロックといった、GUIや機能を持つ特殊なブロックを
TileEntityとして定義されています。
"かまど"等の機能を持ったブロックの実体はBlockであり、TileEntityのオブジェクトを持ちます。
これも負荷軽減やリソース節約のワールドマネジメントの一つです。Block
Blockはインターフェースを継承します。
インターフェースにはWorldのインスタンスも含まれており、ブロックからWorldへ設置された/破壊された...等のイベントを送受信します。例えば、こんな感じです。
public boolean onBlockActivated(World world, int x, int y, int z, EntityPlayer player)TileEntity
TileEntityの実体はBlockですから、BlockとTileEntityの紐付けが必要です。
そこで、Minecraftではこの様に特定のブロックのインターフェース関数からTileEntityのオブジェクトを生成します。
MyTileEntityClassはインターフェースTileEntityを継承します。public TileEntity createNewTileEntity(World world) { return new MyTileEntityClass(); }設計
ここまでの情報を基に、軽く設計図を組み立ててみます。
あまりにも規模が大きいので、とりあえず細かい所は何も考えず、現状でわかっていること・実装したいことを基に設計を行います。▼この様な感じになりました。
ワールドとの情報のやり取り等のイベントはインターフェースに定義します。
悩みどころ
Minecraftのソースコードを実際に見たわけではないので、これまでMOD開発で培った経験や知識を基に大まかな設計はできましたが、細かい所までは自分で考えて実装しなければなりません。
なかなか厳しい戦いになりそうです。特に、悩みどころは描画です。
Worldからの描画を実際にどうやってレンダリングしようか。と。
特に3次元空間なので、2次元空間と違ってややこしそうです。
テクスチャの読み込み..etc問題は山積みです。とりあえず、メニュー画面の制作でしょうか。
次回に続く
規模が大きいので、プロジェクトはパート毎に分けることにしました。
プロジェクト名は...「PyCraft」でいいかな?
それっぽいロゴを制作して下さる方募集中です。宜しくお願い致します。次回はメニュー画面の制作と、レンダリング問題の解決を目標とします。
最後までご覧頂きありがとうございました。
- 投稿日:2020-01-21T10:50:39+09:00
良いコードの書き方
概要
チームによる継続的開発を前提としたコーディングのガイドライン。
特定の言語を対象としたものではないが、主に静的型付けのオブジェクト指向言語を想定している。
サンプルコードは別段の定めがなければSwiftで記載。ガイドラインの目的
- 生産性を高め、メンテナンスコストを下げる
- バグが生まれづらくする
- 開発メンバー(特に新規参加者)がコードを理解しやすくする
- 初心者プログラマーの教育
内容の説明
タイトルの頭についた【
数字】は重要度。
高いほどシステムに与える影響が大きいが、低いものの方が影響が小さく改修しやすいものが多い。
【
変わり得る値は複雑さを生み誤解やバグに繋がるため、プログラムは変数が少ないほど問題が生まれづらい。
プログラミングの大原則として、変数は必要最低限を心がけ、むやみに増やさないようにする。また、変数はスコープや寿命が大きいほど悪影響が大きいため、変数を使う場合はスコープと寿命を最小にするよう心がける。
基本的には以下の上のもの程スコープが広くなるので使用を避けるよう心がける。
- グローバル変数
- インスタンス変数(クラスのメンバー変数)
- ローカル変数
グローバル変数
前述のとおり変数はスコープが大きいほど害が大きいため、一番スコープが大きいグローバル変数は極力使用を避ける。
グローバル変数とは何か
どこからでも読み書きできる変数をグローバル変数と言う。
C言語などのいわゆるグローバル変数に加えて、Javaなどのstatic変数(クラス変数)もグローバル変数と呼ばれることが多い。
さらにここではもう少し意味を広げて、どこからでもアクセス可能なシングルトンや共有オブジェクトなどもグローバル変数として話を進める。また、データベースやファイルなどのストレージも、どこからでも読み書きできるという性質は同じなため、若干イレギュラーだがここではグローバル変数の一種として扱う。
グローバル変数はなぜダメなのか
グローバル変数はどこからでも値を読み書きできる特性上、以下のような問題を生み出す可能性が高い。
- 色々なところから値が変更されてプログラムが複雑になり、処理の流れを追いづらくなる
- 問題があったときに原因が何なのか特定しづらくなる
- 想定外のところで値が変更されてしまう
加えて、グローバル変数が存在すると、本来無関係なはずのクラスやモジュールが、グローバル変数を通して互いに影響を与え合ってしまう可能性がある(いわゆる密結合な状態になる)
その結果、クラスやモジュールを再利用しづらくなったり、問題の切り分けや、ユニットテストがしづらくなるのも大きな弊害である。全く使ってはいけないのか
では、グローバル変数を全く使ってはいけないのかと言うと、そんなことはない。
ここでは前述のとおり、シングルトンや共有オブジェクト、DBもグローバル変数の一種と定義しているが、それらを全く使わずアプリケーションを作るのは難しい。アプリケーションには設定やセッション情報など、全体で共通的に必要になるコンテキストのような情報がある場合が多い。
そういった情報は関数の引数などでバケツリレーのように別のオブジェクトに渡していくより、グローバル変数のようにどこからでもアクセスできる方法を用意した方が実装が簡単になる。ただし、極力グローバル変数の使用を避けるという方針は変わらない。
全体の設計を慎重に検討した上で、どうしても必要な最低限のものだけグローバルなアクセス方法を用意するようにする。バックエンドのグローバル変数
HTMLをサーバー側で生成するタイプのWEBアプリ(PHP、Rails、SpringMVC、ASPなど)では、DBやセッションなどがグローバル変数の役割を担うため、厳密な意味でのいわゆるグローバル変数(PHPのグローバル変数やJavaのstatic変数など)が必要になることはほとんどない。
WEBアプリでいわゆるグローバル変数を使っている場合、設計に問題がある可能性が高い。また、バッチ処理のような短期のプロセスも、DBを除いたいわゆるグローバル変数が必要になることはあまりないように思われる。
フロントエンドのグローバル変数
対して、スマホやデスクトップアプリ、SPAなどのフロントエンドアプリケーションでは、グローバル変数を自前で用意して使う場合が多い。
そのような場合は、以下のような使い方を避ける。
- 一時的なデータの受け渡しのためにグローバル変数を使う
- アプリケーションの一部の機能でしか使わないデータをグローバル変数にする
- グローバル変数にアクセスするクラスを制限せず、無差別にどこからでもアクセスする
裏を返すとグローバル変数は、一時的ではなく永続的に存在し、アプリケーションの様々な機能で共通して利用される情報のために用意され、アクセスするクラスが一部に制限されるなら使って良いということになる。
グローバル変数を使う際のポイント
グローバル変数やstatic変数を作る場合は、IntやStringのような単純なデータ型をそのまま変数に保持するのではなく、関連のあるデータをオブジェクトにして、シングルトンや共有オブジェクトの形にして保持するのが良い。
Badvar userName: String = "" var loginPassword: String = ""Goodclass AccountInfo { static var accountInfo = AccountInfo() var userName: String = "" var loginPassword: String = "" }また、このような共有オブジェクトを誰もが無制限に追加できると収拾がつかなくなるため、共有オブジェクトの設計はチーム内の一部の有識者で行うのが好ましい。
さらに、グローバル変数を作っても、むやみに色々なクラスから参照してはならない。
グローバル変数にアクセスしても良いレイヤーを決めて、それ以外のレイヤーからはアクセスしない。シングルトンより共有オブジェクト
グローバル変数はシングルトンや共有オブジェクトの形にするのが良いと書いたが、実際にはシングルトンより差し替え可能な共有オブジェクトの方が良い。
Badclass Sample { // 再代入できないシングルトン static let shared = Sample() }Goodclass Sample { // 再代入可能な共有オブジェクト static var shared = Sample() }シングルトンはインスタンスが一つしかないため以下のデメリットがある。これらのデメリットは特にUnitTestで障害になる上、アプリケーションの実装上問題になるケースもある。
- インスタンスを複数作りたい場合に作れない
- 保持する情報をクリアしたい場合にオブジェクトを破棄して作り直すことができない
- インスタンスの動作をカスタマイズしたい場合に継承ができない
共有オブジェクトならシングルトン的な機能を持たせつつ、上記のデメリットを解消できる。
共有オブジェクトはシングルトンと異なり、インスタンスが一つであることが機械的に保証されるわけではないが、インスタンスを一つにしたいのであれば開発チーム内でそのような設計方針を共有すれば良い。関連記事
シングルトンパターンの誘惑に負けないグローバル変数はデータベースとしてとらえる
- 関連のあるデータをまとめてオブジェクトとして保存する
- 一時的ではなく永続的に存在するデータを保存する
- アプリケーションの様々な機能で共通して利用されるデータを保存する
- グローバル変数にアクセスするクラスは一部に制限する
- 誰もが自由に追加するのではなく、チーム内の一部の有識者が設計する
共有オブジェクトを用いたグローバル変数について、これまでの項で書いた上記のことを振り返ると、これはDBの位置づけとよく似ている。
グローバル変数はデータベースやMVCパターンで語られるRepositoryのようなものととらえて設計するとイメージしやすい。DIコンテナ
DIコンテナがあるプラットフォーム(SpringやAngularなど)では、DIコンテナで共有オブジェクトを管理するのが良い。
DIコンテナのある環境ではアプリケーション全体がDIコンテナにべったり依存した設計になりがちだ。
それが良いか悪いかはさて置き、そのような環境では自前で共有オブジェクトを管理するのではなく、DIコンテナに管理を任せた方が統一感があって分かりやすい。グローバル変数を全く使わない設計は可能か?
必要な情報を全てバケツリレーのように引数で渡していけば、グローバル変数を全く使わずにアプリケーションを作ることもできる。
必要な情報を使用者が取りに行くのではなく外から渡される形(以下これをDIと呼ぶ)である。ただし、DIの形をとっても、状態変更可能なオブジェクトを渡してしまうと、そのオブジェクトが複数の使用者に変更されてグローバル変数のように扱われてしまうため、DIで渡す情報は状態変更できない(書き込み不可の)値オブジェクトだけにする必要がある。
このように変更不可なオブジェクトをバケツリレーのように渡していくことを徹底すれば、グローバル変数のようなものを完全に排除でき、一見疎結合で綺麗な設計になると思われるが、この方針には実は落とし穴がある。
この方針の問題は、バケツリレーの末端のオブジェクトで必要な情報を、仲介する全てのオブジェクト(バケツリレーの渡し役)が一時的に持たなければいけなくなる点だ。
この問題により特定のクラスが一時的に無関係な情報を持つ必要がでてくるので、一概に疎結合になるとも言えない。結局のところ、グローバル変数の使用を避けろとは言うものの、全く使わないのも現実的ではなく、適切な方針のもとでグローバル変数を使用することが最善の設計なのかもしれない。
インスタンス変数(クラスのメンバー変数)
グローバル変数同様、インスタンス変数も可能な限り使用を避ける。
新たに変数を追加する場合は、気軽に追加するのではなくどうしても必要かをしっかり考える。
同じ機能を実装したクラスが2つあった場合、インスタンス変数が少ない方が良い設計だと言ってしまっていいくらい重要なポイントだ。初心者はインスタンス変数に値を保存して、パラメーターとして使いまわすということをやりがちだが、メソッド内でしか使わないデータは、インスタンス変数ではなくメソッドの引数にする。
関連記事
(あなたの周りでも見かけるかもしれない)インスタンス変数の間違った使い方ローカル変数
使ってもよいが、必要になったときに初めて定義して、スコープを最小にするよう心がける。
Badvar num = 0 for i in list { num = i print(num) }Goodfor i in list { let num = i print(num) }ただし、一部の言語(C言語やJavaScriptのvarの巻き上げへの対処など)ではスコープの先頭で変数を宣言する必要がある場合もある。
変数の寿命を短くする
何らかの状態を変数に保存する場合、値の存在期間はできる限り短くする。
必要になったタイミングで値を保存し、必要なくなったタイミングでなるべく早くクリアする。
変数に保存した値はその瞬間のスナップショットであり、時間が経つほど最新の状態とズレてしまう危険性があるため、変数に保存した値の寿命は極力短くする。【
同じ情報を重複して複数保持しない。
例えば以下の例では年齢を別の形で2つのフィールドに保持しており、情報が重複している。Badclass Person { var age = 17 var ageText = "17歳" }このような場合、以下のように保持する情報は一つにして、その値を加工して使うのが良い。
Goodclass Person { var age = 17 var ageText: String { return "\(age)歳" } }情報の重複はシステムに以下のような悪影響をもたらす。
- 複数ある情報のどれを使っていいか分からなくなる
- 複数ある情報の一部しか更新されないと、差異や矛盾ができる
- 誤った情報を参照、または更新してしまう可能性がある
- 情報を変更する場合、複数のフィールドを変更する必要がある
この例は単純で分かりやすい情報重複だが、他にも様々な形の情報重複がある。
キャッシュによる重複
以下の例ではDBのデータを読み込んでインスタンス変数に保持(キャッシュ)しているが、これによりインスタンス変数に保持した情報とDB内の情報が重複してしまう。
Badclass Foo { var records: [DBRecord]? func readDBRecord(dbTable: DBTable) { records = dbTable.selectAllRecords() } }DBから読み込んだデータを上記のようにインスタンス変数に保持するのはなるべく避けた方が良い。
Fooオブジェクトが長期間存在する場合、その間にDBが更新されるとFooが持つインスタンス変数の情報と、DBの情報に差異が出てしまう。分かりきった情報をコード化しない
以下の例ではDictionary(Map)のキーに0、1、2を使用しているが、Arrayにすればインデックスがあるので、順番をとりたいのであれば不要な情報だ。
Badfunc getName(index: Int) -> String? { let map = [0: "佐藤", 1: "品川", 2: "鈴木"] return map[index] }Arrayにすればインデックスでのアクセスが可能なので0〜2の情報は不要になる。
Goodfunc getName2(index: Int) -> String? { let names = ["佐藤", "品川", "鈴木"] if 0 <= index && index < names.count { return names[index] } return nil }プログラミング以外への適用
情報を重複させないという方針は、プログラミングに限らずドキュメント管理などでも役に立つ。
Badローカルマシンに仕様書をコピーして見ていたら、仕様書が更新されており、古い仕様書を元にコーディングしていた。諸々の事情によりローカルにコピーせざるを得ない場合もあるが、上記の例ではコピーして仕様書が重複したことにより問題が発生している。
Good仕様書は共有のサーバーに1つしかないので、常に最新の仕様が見れる。コードの重複を禁じるものではない
この項で問題にしているのはあくまで情報を重複して持たないことであり、同じようなロジックのコードを重複させないことではない。
「コードをコピペして似たようなコードを複数作る」ようなケースはここで言う重複とは異なるので誤解なきよう。
同じようなロジックのコードを共通化するのはまた別の話で、もっと優先度の低い方針になる。一つのフィールドに複数種類の情報を持たせない
逆に一つのフィールド(変数、DBカラム、テキストUIなど)に複数種類の情報を持たせるのも避ける。
一つのフィールドに複数種類の情報を入れると実装が複雑化し、様々なバグを生み出すリスクが発生する。【
クラス、プロパティ、関数、定数など、プログラムで定義する要素には適切な名前をつける。
特にクラスの名前は設計に大きく関わり重要性が高い。クラス名、プロパティ名、関数名を適切につけることができれば、それはクラス設計、データ設計、インターフェース設計が適切になされたのとほぼ同義である。
ある意味プログラミングとは名前を付ける作業だと言っても過言ではない。名前をつけるときは、以下を心がける。
- 他人が見ても名前から目的や意味がわかる
- 実際の用途や処理と名前が合っている
- 名前に書かれている以外の処理や役目を持たない
また、関数や変数はスコープの広いものほど丁寧な名前をつけるようにする。
名前に書かれていること以上の役割を持たせない
変数は名前に書かれた以上の役割を持たせない。関数は名前に書かれたこと以外の処理をしない。
例えば、
LoginViewControllerというクラスであれば、そこにはLoginのViewをControllする処理のみを記載し、それ以外の例えばログイン認証などの処理は原則として記載しない。
(ただし、短い処理であれば「関連するものは近くにおく」のルールに従い、同一ファイルに記載してもよい)Javaでいう
getHoge()のようなゲッターで何かの状態の更新をするなど、もってのほかである。名付けのアンチパターン
数字やIDをつける
Badvar code1 = "a" func func001() {} enum VieID { case vol_01, vol_02, vol_03 }上記のような数字やIDは、知らない人には何を意味するのか分からないため、プログラム内で名前に使用するのは避ける。
またコードにIDを使うと、IDが変わった場合にプログラムの修正が必要になってしまう。単語を省略する
Badfunc chkDispFlg(){}分かる人も多いと思うが上記は
checkDisplayFlagの略である。
このような単語の省略はプログラマーの伝統文化だが、現代ではIDEによるコード補完があることがほとんどなので、省略してもあまりメリットはない。
第三者に意味がわかりづらくなるため、単語は省略しないようにする。意味のない名付け
Badlet yen = "円"値の具体的な内容をそのまま名前にするのは、拡張性が無いので避ける。
例えば、上記の"円"は"ドル"に変わると変数名の "yen" が嘘になってしまう。
このような場合は、この定数が何であるかではなく、どういった役割・意味を持つかから名前をつける。
上記の例で言えば、例えば金額の接尾辞という役割から "priceSuffix" としたり、通貨単位を意味することから "currencyUnit" などが考えられる。Boolean変数の名付け方
Badvar loadFlag = falseflagという言葉はBooleanであることを表すだけで、用途や意味を何も表現できないため、Booleanの変数名にflagを使うのは避ける。
Boolean変数の命名は以下のようなお決まりパターンがあるので、この形に従うと良い。
- is + 形容詞 (isEmptyなど)
- is + 過去分詞 (isHiddenなど)
- is + 主語 + 過去分詞 (isViewLoadedなど)
- has + 名詞 (hasParentなど)
- can + 動詞 (canLoadなど)
- 動詞 (exists、containsなど)
- should + 動詞 (shouldLoadなど)
関連記事
boolean 値を返却するメソッド名、変数名の付け方英語が分からない問題
英名を知らないものに変数名をつける場合、まずはネットで調べるケースが多いと思うが、Google翻訳などの機械翻訳は単語が適切に翻訳されない場合が多いので気をつける。
英語を調べる場合は、Google翻訳だけでなく、辞書、Wikipediaなどで例文も含めて調べるのが良い。ただし、チームメンバーがみんな英語が苦手で、英語を調べるのに時間がかかるのなら、英語を諦めローマ字の日本語で書くのも一つの手である。
少し格好悪いが、大切なのはチームメンバー全員の可読性と生産性であると思う。また、ユニットテストの関数名は説明的な文章になる場合が多いので、関数名に日本語を使える環境であれば、日本語で書くのも良い。
Javaのユニットテストの関数名例public void 何々したときにこういう挙動をするか確認する試験() {}汎用的な名前を避ける
汎用的な名前はなるべく避ける。
よくあるのはなんとかManagerとなんとかController。
汎用的な名前は様々な処理を押しつけやすくクラスが肥大化しがち。辞書を作る
チームで開発をする場合は、アプリケーションで使う用語の辞書を作り、用語の認識をメンバーで合わせた上で開発を始めると良い。
辞書を作ることで、同じものが開発者によって別の名前で定義される不整合を防ぐことができるし、個々の開発者が同じものの名付けで別々に頭を悩ますという無駄を省くことができる。関連記事
モデルやメソッドに名前を付けるときは英語の品詞に気をつけよう
クラスの命名のアンチパターン【
関数にオブジェクトを渡す形
function(object)より、オブジェクトの関数を呼び出す形object.function()を好む。Badif StringUtils.isEmpty(string) {}Goodif string.isEmpty() {}これにはいくつかの理由があるので以下に説明する。
可読性のため
関数にオブジェクトを渡す形
function(object)は、複数の処理を重ねると括弧が入れ子になり読みづらくなるが、オブジェクトの関数を呼び出す形object.function()はドットで繋いで複数の処理を行えるため可読性がよい。BadStringUtils.convertC(StringUtils.convertB(StringUtils.convertA(string)))Goodstring.convertA().convertB().convertC()object.function()の方が再利用性が高い
一般的に
function(object)の場合、functionは何らかのクラスやモジュールに定義され、処理を行うにはfunctionが定義されたクラスやモジュールと引数のobjectの2つが必要になる。
対して、object.function()の場合はobject単体で処理を行うことができるため再利用性が高い。オブジェクト指向を身につける
object.function() の形はオブジェクト指向の真髄だ。
オブジェクト指向と言うと、クラス、継承、カプセル化などがまず説明されがちだが、実はそれらはオブジェクト指向に必須のものではなく、オブジェクト指向に唯一必要なものはオブジェクトに対してメソッドを呼び出す
object.function()の形だけだと思う。初心者にオブジェクト指向を教えるのは難しい。
オブジェクト指向について教えるべきことはたくさんありそうに思える。
しかし、継承やカプセル化やポリモーフィズムなどはいったん忘れて、まずobject.function()の形を体に染み込ませることが、オブジェクト指向を身につける最短ルートではないかと考える。関連記事
オブジェクト指向は、メソッドディスパッチの手法の1つComputed propertyを積極的に使う
言語によってはない場合もあるが、Computed propertyの機能により、functionをpropertyとして扱うことができる。
以下のようなfunctionは積極的にComputed propertyにしていこう。
- 引数が不要
- 値を返す
- 処理が重くない
当てはまらないケース
では、いついかなるときも
function(object)よりobject.function()の形がいいのかと言うと、そうではない場合もある。
object.function()の形をとるべきでないのは、この形をとることによってobjectのクラスに必要のない依存関係や、負うべきでない役割を持たせてしまう場合だ。以下の例は
object.function()の形をとることにより、enum APIResultに不要なViewクラスへの依存を作ってしまっている。Badclass LoginView: MyView { // ログイン結果を受け取って次の画面に遷移する func onReceivedLoginResult(result: APIResult) { let nextView = result.nextView() // object.function() の形 showNextView(nextView) } } enum APIResult { case success case warning case error func nextView() -> UIView { switch self { case .success: return HomeView() case .warning: return WarningView() case .error: return ErrorView() } // HomeView、WarningView、ErrorViewのクラスに依存してしまっている } }このような例では以下のように
function(object)の形をとった方が良いだろう。Goodclass LoginView: MyView { // ログイン結果を受け取って次の画面に遷移する func onReceivedLoginResult(result: APIResult) { let nextView = nextView(result: result) // function(object) の形 showNextView(nextView) } func nextView(result: APIResult) -> UIView { switch result { case .success: return HomeView() case .warning: return WarningView() case .error: return ErrorView() } } } enum APIResult { case success case warning case error }前者のような依存関係を作るべきでない理由は、下にある「依存の向きを意識する」の項で詳しく説明している。
【
クラスの継承には問題がある。
継承は強力な機能だが、その代りに多くのリスクもはらんでいる。
クラス継承は柔軟性がなく変更に弱い。修正により無関係な機能に影響を与えてしまう
例えばBaseクラスを継承したAとBのクラスがあったとして、Aの機能を改修するためにBaseを修正したら、無関係なBの機能がバグってしまうようなケース。
これはクラス設計に問題があると言えるが、継承を使うとこのような問題は起こり得る。複数の親を継承できない
C++など一部の言語を除き、複数のクラスを継承することはできない。
しかし、現実に存在するものには、複数の上位概念(親カテゴリー)が存在することが多い。例えば、唐突だが
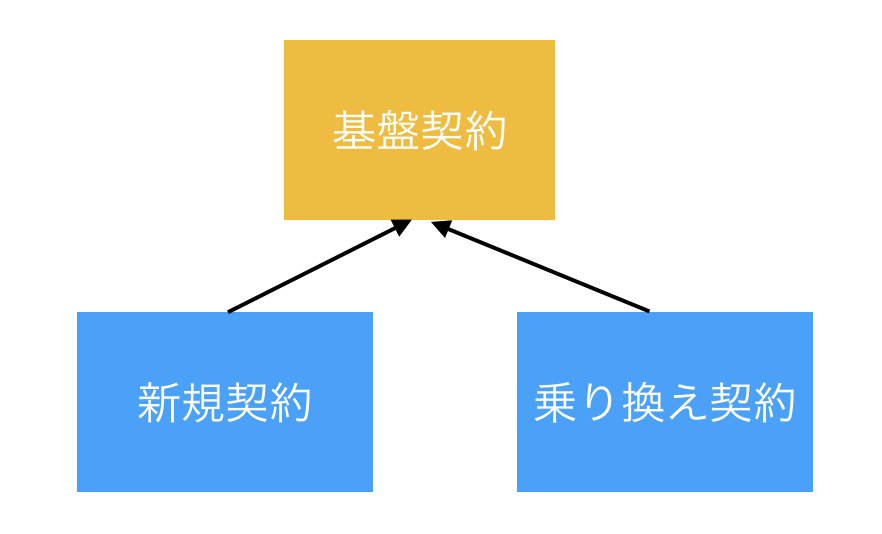
インドカレーについて考えてみると、その親はカレーとすることもできるし、インド料理とすることもできる。class インドカレー extends カレーclass インドカレー extends インド料理もう少し実装の流れにそった例をあげると、例えばWEBでスマホの契約ができるシステムがあったとする。
契約画面は新規契約と乗り換え(MNP)契約の2つに別れていて、それぞれに対応するクラスがある。
新規契約と乗り換え契約には共通する部分が多いので、共通の親クラスとして基盤契約クラスを作る。
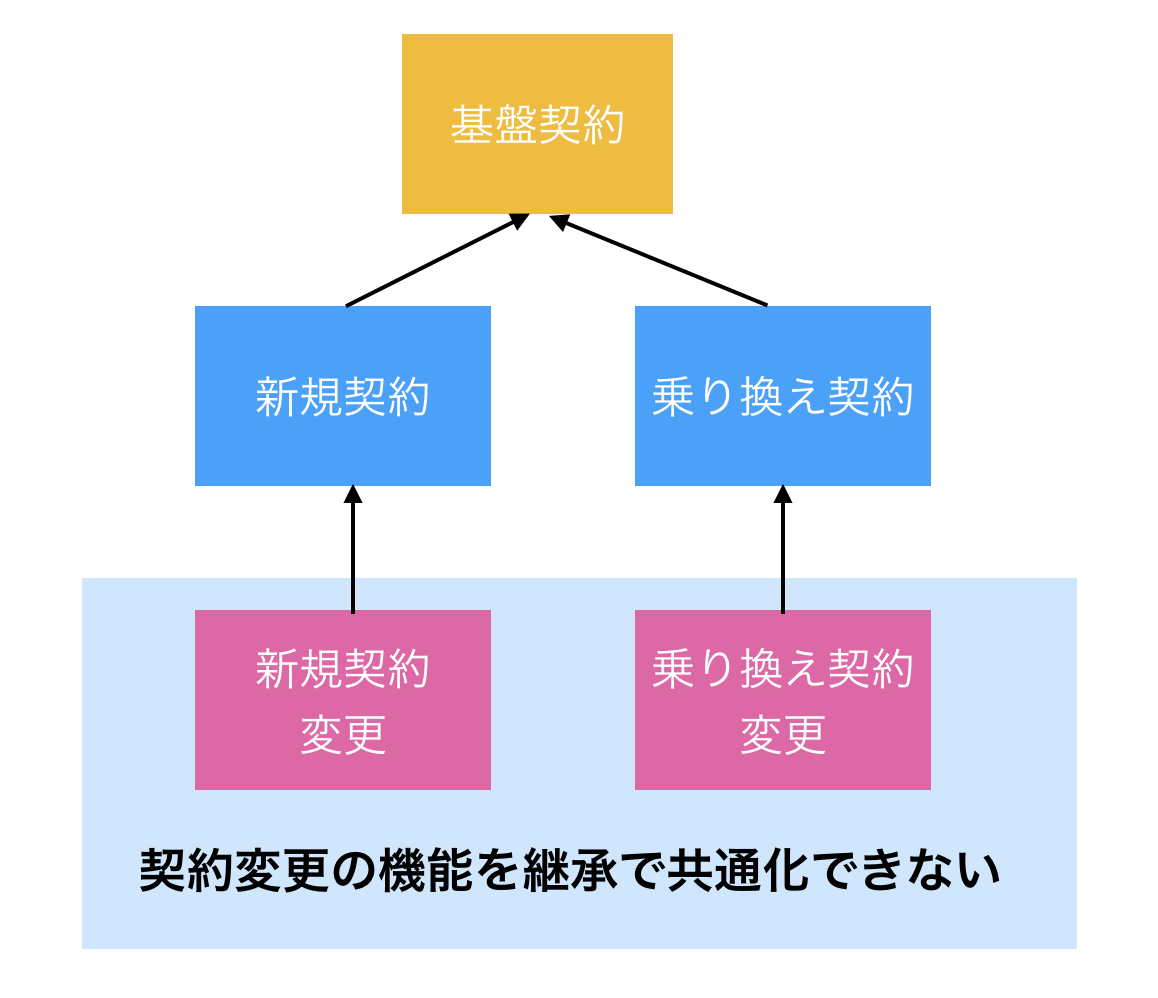
次に契約変更画面を実装することを考える。
契約変更用に新規契約クラスを継承した新規契約変更と乗り換え契約クラスを継承した乗り換え契約変更のクラスを作ったとすると、契約変更という観点では継承で処理を共通化できなくなってしまう。
共通の親クラスが肥大化しがち
例えば、全てのControllerクラスの親クラスになる
BaseControllerというクラスを作ったとすると、BaseControllerクラスは様々なControllerで使われる機能が盛り込まれ肥大化しがちだ。
必要最低限の機能であればよいが、基本的に共通の親クラスは機能を提供するのではなく、共通のインターフェースとして扱うために用意するのがよい。関連記事
継承のデメリット
iOSアプリの設計でBaseViewControllerのようなのは作りたくない
クラスの「継承」より「合成」がよい理由とは?ゲーム開発におけるコードのフレキシビリティと可読性の向上【
if文やswitch文によるロジックの分岐は、プログラムの可読性を損ないバグの原因になりやすいので、なるべくシンプルな形になるよう心がける。
ネストを深くしない
if文やfor文などのネスト(入れ子)が深くなるとコードが読みづらくなるため、なるべくネストを深くしない。ネストが深くなるのを防ぐには「早期return」と「ロジックの切り出し」を行うと良い。
以下のコードに「早期return」と「ロジックの切り出し」を適用するとどうなるか例を用いて説明する。
Beforeif text != nil { if text == "A" { // 処理1 } else { // 処理2 } }早期return
例外的なケースを先にreturnすることで、メインロジックのネストを浅くする。
以下のサンプルコードではtextがnilの場合を例外パターンとして先にreturnしている。After(早期return)if text == nil { return } if text == "A" { // 処理1 } else { // 処理2 }ただし、早期returnは名前のとおり早期にreturnする必要がある。
基本的に関数は末尾行まで処理が実行されることが期待されるため、長い関数の途中にreturnがあると、見落とされてバグを生んでしまうリスクがある。ロジックの切り出し
if文やfor文などのネストを含む処理をメソッドやプロパティに切り出して、メインロジックのネストを浅くする。
以下のサンプルコードではtextが”A”か判定して何らかの処理をする部分を、Textクラスのクラスメソッドとして切り出している。After(ロジックの切り出し)if text != nil { doSomething(text) } func doSomething(_ text: String?) { if text == "A" { // 処理1 } else { // 処理2 } }関連情報
ブロックネストの数を減らそう呼び出し元による場合分けをしない
様々なところから呼び出される関数には、呼び出し元による場合分けを入れてはいけない。
例えば以下のケースは、画面によって処理の場合分けをしているが、この書き方では画面が増えるほど際限なく関数が大きくなってしまう。Badclass BaseViewController: UIViewController { func doSomething() { if viewId == "home" { // ホーム画面の処理 } else if viewId == "login" { // ログイン画面の処理 } else if viewId == "setting" { // 設定画面の処理 } } }この書き方をすると一つの関数に様々な処理が詰め込まれ、読みづらく、バグりやすく、修正もしづらい巨大な関数になってしまう可能性が高い。
ポリモーフィズム
上記のような関数内の場合分けはポリモーフィズムを使って解消することができる。
ポリモーフィズムについての詳しい説明は長くなるので割愛するが、インターフェース(プロトコル)や継承によるメソッドのオーバーライドにより、場合分けされた各処理を子クラスにそれぞれ記載することができる。class BaseViewController { func doSomething() {} } class HomeViewController: BaseViewController { override func doSomething() { // ホーム画面の処理 } } class LoginViewController: BaseViewController { override func doSomething() { // ログイン画面の処理 } } class SettingViewController: BaseViewController { override func doSomething() { // 設定画面の処理 } }関数を引き渡す
また、関数を関数の引数にして渡すことによって、if文などの分岐を解消することもできる。
以下のように引数に関数を受け取るようにすれば、somethingの処理は呼び出し元で自由に設定できるので、分岐をなくすことができる。
この例では受け取った関数を実行するだけの意味のない関数になってしまっているが、呼び出し元によって異なる完了処理やエラー処理を引数として渡すようなことが多い。class BaseViewController: UIViewController { func doSomething(something: () -> Void) { something() } }Javaのような関数をオブジェクトとして扱えない言語でも、インターフェースを使って同じようなことが実現できる。
分岐ブロック内の行数を少なくする
分岐を見やすくするため、if文などの分岐ブロック内の行数はなるべく少なくなるよう心がける。
if conditionA { // ここに長い処理を書かない } else if conditionB { // ここに長い処理を書かない }コマンドとクエリを分離する
全てのメソッドは、アクションを実行するコマンドか、データを返すクエリかのどちらかであるべきで、両方を行ってはならない。
これはCQS(command query separation)と言われる考え方だ。
まず、データを返すメソッド(クエリ)の中でアクションを行ってはいけない。
ゲッターの中で更新処理をしないと言い換えると分かりやすいかもしれない。
これは当然のこととして心がけている人が多いと思う。次に、アクションを実行するメソッド(コマンド)の中にクエリをなるべく記載しない。
こちらは前者よりわかりづらく、もしかするとCQS本家の人が言ってることとはズレているかもしれないが、例をあげて説明する。例えば、ユーザーネームとセッションIDが両方ある場合にログイン済みとみなして次のページに進む関数を考える。
Badfunc nextAction() { if userName.isNotEmpty && sessionId.isNotEmpty { showNextPage() } }この関数は「次のページに進む」ことが主目的と考えると、「クエリ」 ではなく 「コマンド」 になるが、ログインしているかどうかを判定する部分はBoolの値を取得するクエリになるため、「コマンド」と「クエリ」が混在している。
この関数からログイン判定の部分をクエリとして別関数に切り出すと以下のようになる。
Good// コマンド func nextAction() { if isLoggedIn() { showNextPage() } } // クエリ func isLoggedIn() { return userName.isNotEmpty && sessionId.isNotEmpty }if文の条件式がごく短いものであれば、それを別関数に切り出すかは迷うところだが、ある程度の長さのクエリであれば別関数やプロパティとしてアクションから切り出すのがいいだろう。
【
クラスは50〜350行程度、ファンクションは5〜25行程度を目安とし、これを超える場合はクラスやファンクションの分割を検討する。
行数はあくまで目安で、これを超える行数でも同じクラスやファンクションに収めた方が良い場合もあるが、キリがいい上限として1000行を超えるクラスはヤバイと思っておこう。
言語や書き方や機能によって変わるので一概にこのサイズが正解とは言えないが、クラスの行数に対するざっくりしたサイズ感を記載する。
行数 サイズ感 50行未満 小さい 50〜350行 適正 350〜700行 大きい 700〜1000行 とても大きい 1000行超 ヤバイ とはいえ、基盤となる機能や、要素の多いUIクラスなどは上記のサイズ感を逸脱する場合もある。
例えば、AndroidのViewクラスは2万7千行あるし、極端な例だが異なる処理をするボタンが1000個ある画面は、簡潔に書いても1000行を超えてしまう。関連記事
プログラミング中級者に読んでほしい良いコードを書くための20箇条【
「変数のスコープを小さくする」の項に記載した、インスタンス変数をなるべく持たないという方針と近いが、Bool値についてはさらに厳しくインスタンス変数に保持しないよう心がける。
Badclass Foo: UIViewController { // フラグ var isHidden = false func hide() { isHidden = true view.isHidden = true } func show() { isHidden = false view.isHidden = false } }フラグ(Boolの変数)は判定済みの結果を保持するため、基本的に過去の情報になる。
対して、実際の状態はフラグとは独立して変わり続けるため、フラグに値を保存すると実際の状態とフラグが乖離してしまう危険性がある。他の状態を使って判定する
フラグをなくすため、まずはフラグの代わりに他の状態によって判断できないかを検討する。
フラグは何らかの状態を判定するためのものだが、フラグがなくても他のものを見て状態を判定できることは多い。以下の例では最初のサンプルコードからフラグをなくして(プロパティとしては存在するが)、代わりに
view.isHiddenの値を使うように変更している。Goodclass Foo: UIViewController { var isHidden: Bool { get { return view.isHidden } set(value) { view.isHidden = value } } }複数のフラグを1つの状態変数にまとめる
複数のフラグがある場合、状態を表すEnumを作ることで複数のフラグを1つのEnum変数にまとめることができる。
Badclass User { var isAdmin = false var isSuperUser = false var isGeneralUser = false }Goodclass User { var userType: UserType = .admin } enum UserType { case admin case superUser case generalUser }【
数字を条件分岐の判定に使わない
0、1、2などの数字を条件分岐の判定に使うのは避ける。
代替方法はケースにより様々だが、配列やListを使うことで数字の使用を避けられることが多い。Badfunc title(index: Int) -> String { switch index { case 0: return "A" case 1: return "B" case 2: return "C" default: return "" } }Goodlet titles = ["A", "B", "C"] func title(index: Int) -> String { return titles.indices.contains(index) ? titles[index] : "" }ただし、0、1、-1は最初の要素を取得したり、APIのエラーや成功を表したりと、特殊な役目を持つ場合が多いため、環境によっては使わざるを得ない場合もある。
配列で複数種類のデータの受け渡しをしない
静的型付け言語では配列(Array、List)を使って複数種類のデータの受け渡しをしない。
以下の関数は数字を使ってListの1番目に名前、2番目に郵便番号、3番目に住所の情報を格納しているが、何番目に何の情報が入っているかはList型からは判別できないため、可読性が悪くなり間違いも起こりやすくなる。
Badfunc getUserData(): [String: String] { var userData: [String] = [] userData[0] = "山田 正男" userData[1] = "171-0001" userData[2] = "東京都豊島区" return userData }決まったデータ構造を受け渡す場合は、以下のようにstructやclassを作ってデータを受け渡す。
Goodstruct UserData { let name: String let postalCode: String let address: String } func getUserData(): UserData { return UserData(name: "山田 正男", postalCode: "171-0001", address: "東京都豊島区") }ただし、名前の一覧を受け渡したり、ファイルの一覧を受け渡したり、同じ種類のデータの一覧を受け渡す場合は配列やListを使って良い。
Mapで複数種類のデータの受け渡しをしない
全く同じ理由で、Map(Dictionary)で複数種類のデータを受け渡すのも避ける。
静的型付け言語であれば、配列の例と同様にデータ受け渡しのためのstructやclassを作成する。Badfunc getUserData(): [String: String] { var userData: [String: String] = [:] userData["name"] = "山田 正男" userData["postalCode"] = "171-0001" userData["address"] = "東京都豊島区" return userData }【
不要になったコードはコメントアウトせず削除する。
ローカルでの修正中に一時的にコメントアウトするのは構わないが、基本的にコメントアウトしたものはコミットしないようにしよう。コメントアウトした行が増えると、コードが読みづらくなる、検索時に使われていない箇所が引っかかるなど結構な害がある。
削除や変更の履歴はGitなどの管理ツールで分かるので、不要なコードは消すことを心がける。【
プログラム間の依存関係にはルールを設けて、無計画に依存をしないようにする。
抽象的な説明になってしまうが、以下の向きで依存して、この逆方向の依存を避ける。
- 具象から抽象に依存する
- 大きな機能から小さな機能に依存する
- 専用的な機能から汎用的な機能に依存する
依存とは何か?
あるプログラムが、何らかの別のクラスやモジュール、ライブラリなどを使っており、それがないとコンパイルできなかったり、動作できないことを依存していると言う。
また、コンパイルレベルの依存の他に、特定の仕様を前提として作られており、その仕様がなければ動かない場合なども、仕様に依存していると言える。専用的な機能から汎用的な機能に依存する
汎用的に使われるクラスは、専用的なクラスに依存しないようにする。
例えば極端な例だが、文字列を表す
Stringクラス(汎用的な機能)が、ログイン画面のクラスLoginView(専用的な機能)に依存していたとすると、Stringを使う全てのシステムはLoginViewも無駄に取り込む必要ができてしまい、Stringクラスが再利用しづらくなってしまう。もっとありがちな別の例を挙げると、通信処理を行うための
HTTPConnectionクラス(汎用的な機能)があったとして、このクラスの中でアプリ独自の画面クラス(専用的な機能)を処理や判定に使ってしまうと、HTTPConnectionクラスは別のアプリに移植することができなくなってしまう。汎用的な機能のクラス内で、アプリ独自の専用的な画面クラスやIDを判定に使うことは、汎用クラス内に過剰な分岐を生み出して複雑化させる弊害もあるので避ける。
ライブラリに依存するところは一箇所にまとめる
現代ではアプリの実装に何らかのオープンソースライブラリを使うのは当たり前だが、特定のライブラリを使った処理は一つのクラスやファイルにまとめて、様々なクラスがライブラリに依存するのは避ける。
面で依存するのではなく、点で依存するようなイメージだ。ライブラリを使ったコードを一箇所にまとめることにより、以下のような変更があった場合の影響や修正を最小限にすることができる。
- 使っているライブラリを別のライブラリに差し替えたい
- ライブラリに仕様変更が入り使い方が変わった
データクラスは具体的な機能や仕様に依存させない
「専用的な機能から汎用的な機能に依存する」の項に書いたことと若干被るが、DTOのようなデータの保持を目的としたクラスはなるべくシンプルにして、別の機能に依存したり、特定の仕様に依存させない方が良い。
// シンプルなデータクラスの例 struct UserInfo { let id: Int let name: String }このようなシンプルなデータクラスは多くのレイヤーをまたいで使われたり、ときには別のアプリケーションに移植されたりするが、その際に余計な依存があると色々と弊害が出ることがある。
インターフェースを使って具象への依存を断ち切る
多くの静的型付け言語ではインターフェース(プロトコル)を使って具体的な実装クラスへの依存をなくすことができる。(動的型付け言語ではインターフェースがない場合が多いのでこの項は当てはまらないケースが多い)
例えば、以下の例では
Exampleクラスが通信を行うHTTPConnectorクラスに依存している。Beforeclass Example { let httpConnector: HTTPConnector init(httpConnector: HTTPConnector) { self.httpConnector = httpConnector } func httpPost(url: String, body: Data) { httpConnector.post(url: url, body: body) } } class HTTPConnector { func post(url: String, body: Data) { // HTTP通信の実装 } }
HTTPConnectorクラスが何らかの通信ライブラリを使っていると、Exampleクラスは間接的にその通信ライブラリに依存することになってしまう。
だが、以下のようにHTTPConnectorをインターフェース(プロトコル)に変えれば、Exampleクラスが通信ライブラリに依存しないようにすることができる。Afterclass Example { let httpConnector: HTTPConnector init(httpConnector: HTTPConnector) { self.httpConnector = httpConnector } func httpPost(url: String, body: Data) { httpConnector.post(url: url, body: body) } } protocol HTTPConnector { func post(url: String, body: Data) }外部システムとの連携は一箇所にまとめる
アプリケーション外部のシステムとの連携やインターフェースに関わるコードは、なるべく一箇所にまとめる。
外部システムは色々なものが考えられるが、よくあるものとしてはHTTPのAPI、データベースなどがある。オープンソースライブラリへの依存について書いたことと同じだが、外部システムとの連携を一箇所にまとめることにより、外部システムの変更の影響や修正を最小限にすることができる。
こちらもまた、インターフェース(プロトコル)を使って具体的な実装クラスへの依存をなくせると良い。【
数値定数、文字列定数、コード値などで複数の値があるものはEnumを定義する。
※ Enumがない言語であれば定数にするBadfunc setStatus(status: String) { if status == "0" { // 成功時の処理 } }Goodenum Status: String { case success = "0" case error = "1" } func setStatus(status: Status) { if status == .success { // 成功時の処理 } }想定外の値を考慮する必要があるとき
Enumはあらかじめ定めた値しか取り扱うことができないが、APIのステータスコードなど想定外の値に対しても何らかの処理が必要な場合がある。
そのような場合は、以下のように生のコード値を保持して、ゲッターやcomputed propertyでEnumを取得できるようにするとよい。struct Response { var statusCode: String var status: Status? { return Status(rawValue: statusCode) } } func setResponse(response: Response) { if response.status == .success { // 成功時の処理 } else if response.status == .error { // エラー時の処理 } else { // 想定外のコード値がきた場合はコード値をログ出力 print("ステータスコード: \(response.statusCode)") } }【
分かりづらいコードを説明する
第三者が見て分かりづらいコードにはコメントを書く。
特殊な仕様を満たすためのコードや、バグ修正のためのトリッキーなコードなど、他人が読んだときすぐに意味が理解できないコードには、コメントでコードの説明を記載する。バグ修正のための特殊なコード
正攻法でバグを修正できず、仕方なく汚いコードをいれざるを得ないときはままある。
そのような場合は、後で見る人のためになぜそうしたのかコメントを記載しておく。例えば以下のようなケースは、コメントで説明を書いておいたほうが良い。
- 普通に実行すると上手く動かないので一瞬遅延して実行する
- なぜか上手く動かないので同じプロパティに2回値を代入する
- 特殊なケースに場合分けして処理をするため、Booleanのプロパティを作る
- 要件とは関係ないがシステム的に問題があったためif文で場合分けする
マジックナンバー
以下のコードは
3が何を意味するか第三者には分からないため、コメントが必要になる。Badif status == 3 { showErrorMessage() }Good// ステータス3は通信エラー if status == 3 { showErrorMessage() }コメントに適した文章の書き方
情報のない言葉や重複する言葉を削る
日本語はそれなりに回りくどく、何も考えずに文章を書くとたいてい情報量のない言葉がいくつか含まれる。
文章を書いたら一度見直して、重複する言葉や必要のない言葉がないか確認し、あれば削除して短くする。例えば、以下のような言葉は言い回しを簡潔にして、意味を変えずに短くすることができる。
- 「短くすることができる」→「短くできる」
- 「〜を調整するように修正」→「〜を調整する」
敬語や丁寧語を使わない
日本語は丁寧な言い回しになるほど文字数が増える。
「した」が2文字なのに対して「しました」は4文字になる。
好みの問題もあるが、必要なければ丁寧語や敬語を使わない方がコメントを短くできる。※お客さん向けのドキュメントなど、TPOに合わせて敬語が必要な場合も当然ある
小学生や外国人に言い聞かせるように
なるべく難しい言葉、言い回し、漢字、専門用語を使わず、簡単でより多くの人に伝わる文章を心がける。
カタカナの外来語も逆に英語圏の人に伝わりづらいことが多いので注意する。また、専門用語はなるべく使わない方がいいが、プログラムを説明するにあたり必要なものは使っても問題ない。
例えば「Socket通信」という言葉は専門用語だが、「Socket通信」関連のプログラムのコメントでは使わざるをえない場合もある。様々な国籍の人が参加するプロジェクトであれば、コメントを英語で統一するのも良い。
カッコつけなくていい
一番大切なのは、読む人が理解しやすいこと。
極端な話、読み手が理解できるなら、文法が間違っていても、英語が間違っていても問題ない。
改まって綺麗な文章を書くことに時間をかける必要はなく、フランクでもいいので読み手にとって役立つコメントを書くことが大切。無責任なコメントもないよりはマシ?
以下のような目を疑うようなコメントも、一応情報ではあるのでないよりマシかもしれない。
// ここでメモリリークします。 // ここの分岐はあまり意味ないかも。。 // なんで動作してるのかわかんないけど、とりあえずここの問題はこのコードで解決した【
アプリケーションをクラッシュさせない
大前提として、アプリは落ちない方がいい。
当たり前のことだと思われるかもしれないが、現代のプログラミング言語は簡単にクラッシュする。
例えば要素数3の配列の4番目にアクセスすれば多くの言語はクラッシュする。
この手のバグは容易に発生するし、ものによっては気づかれないままリリースされることも珍しくない。不正な状態ならExceptionを吐いてしかるべきという考えも一理あるが、それによりアプリケーション全体がクラッシュするのはよろしくない。
APIやバッチなどバックエンド系のプログラムでは、Exceptionがシステム全体を止めてしまうことはあまりないのでExceptionを積極的に活用するのも良いが、フロントエンドアプリケーションでは、一つのExceptionがアプリを完全停止させてしまうことが多いので、なるべくExceptionを吐かないようにした方が良い。
このようなクラッシュをできる限り防ぐには、以下のような工夫が必要になる。
適切なガードを実装する
クラッシュする可能性があるコードにif文などを加えて、クラッシュする場合は処理を行わなくする。
JavaのようなNULL安全でない言語でのNULLチェックなどがこれにあたる。JavaでのNULLチェックの例if (hoge != null) { hoge.fuga(); }しかし、このようなガードはバグを握りつぶして隠蔽してしまうリスクがあるため、開発環境でのみ不正時に処理を止めるassertの仕組みがあれば代わりにそれを用いるのが良い。
例えば、Swiftのassert関数はDEBUGビルドの場合のみ、条件チェックを行い不正な場合にクラッシュさせることができる。Swiftでのassertの例func hoge(text: String?) { assert(text != nil) // DEBUGビルドならtextがnilの場合ここでクラッシュする // 通常時の処理 }もしくは、if文でガードを入れるとしても、不正な状態が発生したら最低限ログ出力くらいはしておいた方が良いだろう。
そもそもクラッシュしないようにする
可能ならクラッシュするコードがそもそも書きづらい開発環境を作るのが良い。
これはガードを実装するより根本的な解決になる。
例えば、NullPointerExceptionに対する一つの根本解決として「JavaをやめてNULL安全なKotlinを使う」ことができる。また、言語を変えるまでいかなくても、NULL安全でない言語にOptionalクラスを追加するなど、安全にコードを書くための拡張を追加することはできる。
以下はSwiftのCollectionを拡張して、範囲外のインデックスを指定してもクラッシュせず
nilを返すgetter(subscript)を追加した例。extension Collection { subscript (safe index: Index) -> Element? { return indices.contains(index) ? self[index] : nil } } let list = [0, 1] print(list[safe: -1]) // クラッシュせずnilになるNULLアクセス、配列の範囲外アクセスなど一般的でよく起こるクラッシュについては、このような関数などを追加することで対策できる。
不正なデータがあってもできる限りのことはする
データの一部に不正な状態や想定外の状態があっても、問題のない部分についてはなるべく通常通り処理が行われるようにする。
例えば、銀行口座の明細が見れるシステムを考える。利用明細データの1つがおかしいと何も見れなくなるシステムと、利用明細データの1つがおかしくても他の明細と口座残高は見れるシステムを比べると、ユーザーにとっては当然後者の方が使い勝手が良い。
アプリケーションはユーザーをサポートする優秀な執事のように振る舞うのが理想だ(少なくとも私はそう思っている)
一つ予想外のことが起こっただけで全ての職務を放棄するようでは優秀な執事とは程遠い。ただし、この方針が当てはまるのは情報を見る機能に限定される。
後戻りのできない更新処理などの場合は、異常を検知したらただちに処理を取りやめるのが無難だ。【
複数箇所に書かれた同じ処理を一つにまとめることで、コード量を減らし可読性を高めるとともに、修正のコストを少なくすることができる。
汎用的な機能は共通クラスや関数に切り出す
ビジネス要件に左右されない汎用的な機能は、共通のクラスや関数として切り出して利用する。
例えば以下は、文字列をURLエンコードする機能を共通関数として定義している。
※厳密にはcomputed propertyextension String { var urlEncoded: String { var allowedCharacterSet = CharacterSet.alphanumerics allowedCharacterSet.insert(charactersIn: "-._~") return addingPercentEncoding(withAllowedCharacters: allowedCharacterSet) ?? "" } }if文やswitch文内の記述は最低限にする
if文やswitch文で処理を分岐させる場合、分岐内に同じ処理があるなら、重複部分はif文やswitch文の外に出すようにする。
例えば、以下はlabel.text =の部分がifブロックとelseブロックの両方にあり重複している。Badif flag { label.text = "aaa" } else { label.text = "bbb" }このケースでは重複部分を外に出すとif文自体を消すことができる。
Goodlabel.text = flag ? "aaa" : "bbb"共通化のデメリット
ロジックやデータ構造の共通化にはデメリットもある。
同じ処理をむやみやたらと共通化することは、むしろ保守性の低下を招くことも多い。処理を共通化することには以下のようなデメリットがある
- ロジックが複雑になり分かりづらくなる
- 仕様変更により共通化したロジックを場合分けしなくてはいけなくなった場合に修正がたいへん
- 共通化したロジックの修正が、意図しないところに影響を与えてしまう
特にクラス継承による共通化は強い密結合を生み出し、プログラムの柔軟性を失わせてしまうこともあるので十分注意する。
関連記事
「コードを共通化するために継承しよう」なんて寝言は寝て言えとゆ話
共通化という考え方はアンチパターンを生み出すだけ説共通化すべきものとするべきでないもの
では、どんなときに共通化するべきで、どんなときに共通化すべきでないか。
最初に挙げたように、ビジネス要件に左右されない汎用的な機能は積極的に共通化を目指す。
ビジネス要件に絡むロジックやデータの場合、共通化するかしないかはケースバイケースだが、以下を満たしていることが共通化の指針になる。
- 将来的な仕様変更によりロジックの分離が必要になる可能性が低い
- 分かりやすく実態にあったクラス名や関数名をつけられる
- クラス継承をする場合、特定のサブクラスでしか使わない関数やプロパティが親クラスに存在しない
- 呼び出し元や使い方によって、ロジックに場合分けがあまり発生しない
- 一部の呼び出し元だけに必要なライブラリやフレームワークがない
【
アプリケーションを作るとき最初にワイヤーフレームやラフスケッチを作るように、プログラムもコードを書き始める前にワイヤーフレームやラフスケッチを作ると効率良く進めることができる。
開発が始まると目に見えた進捗が欲しいため、とりあえずコードを書き始めてしまいがちだが、深く考えずに書いたコードは考慮漏れ、仕様不備、設計不備などにより手戻りが発生することが多い。
とりあえずコードを書けば一見進捗しているように見えるが、下手なコードは最終的に全くの無駄であったり、むしろ害悪であることすらよくある。そのため、最初はコードを書きたい気持ちを我慢して、 プログラムのラフスケッチを作る方がプロジェクト全体で見ると効率が良い。
プログラムのラフスケッチとは
ここで言うプログラムのラフスケッチはクラス図や概略のコードなどを想定している。
ただし、必ずそうある必要はなく、以下のことがわかれば別の形でもいい。
- どういうクラスがあるか。各クラスの役割と名前
- クラス間の包含関係と参照関係
- 各クラスが保持するデータ(プロパティなど)と、他のクラスから呼び出される関数のインターフェース
- 各クラスがどのようにインスタンス化され、どのように他のクラスと連携するか
- 各画面遷移やUIイベントで何をするか
クラス図を書く
最初はクラス間の包含関係と参照関係を考えるためにクラス図を作るとわかりやすい。
この段階のクラス図はルール無用、思うがままのスケッチでいい。
クラスのプロパティや関数を網羅する必要もなく、最低限クラスの名前、包含関係、参照関係と役割が分かればよい。試行錯誤しながら書き直すため手書きで作るのがおすすめだ。
一対NのN側を複数書いたり、包含を線で囲んで表したりして、UML図をもっと簡単で直感的にした形にするとわかりやすい。クラスの保持するデータとインターフェースを決める
クラスの構成が決まったら、次は各クラスが保持するデータと外部との連携に必要な関数のインターフェースを決める。
保持するデータというのは具体的にはインスタンス変数(メンバー変数)のことだ。
クラス図と異なり、この段階でインスタンス変数はなるべく網羅しておこう。最初の方の項に書いたが、クラスのインスタンス変数はなるべく少なくする必要がある。
どうしても必要なものだけをインスタンス変数にして、設計後はなるべく予定外のインスタンス変数を追加しないよう心がける。ラフコードを書く
クラスの構成が決まったら、詳細を省略したラフコードを書いていく。
ただし、ここでは大筋を決めることが目的なので、細かな文法にとらわれないようにする。
そのためコンパイルエラーがチェックされるIDEではなく、シンプルなエディターに書くのが良い。
上級者であれば言語の文法も自分で好きに決めて良い。細部は省略して以下の点をラフコードで記述する。
- UIイベントからの処理
- 他クラスの呼び出しと、情報の受け渡し
仕様書の不備を見つける
仕様書の不備を見つけることもラフスケッチを作る目的の一つだ。
仕様書や設計書をもとにプログラムを書く場合、仕様書や設計書には必ず間違いがある ということを念頭に置く必要がある。
仕様書の間違いに実装の後に気づくと、それまでの作業が無駄になってしまう。そのためラフスケッチを書く際には、仕様書に不備がないかを意識する。
【
関連するコードを同じディレクトリや同じファイルに配置すると、コードリーディングの際にファイルを探したり切り替えたりする手間を減らせる。
例えば、同じ機能で使うファイル群を同じディレクトリに置いたり、特定のクラス内でしか使わないクラスをインナークラスにしたりと、関連するコードは近くに配置してコードを探しやすくする。ディレクトリを機能で分けるか種類で分けるか
ディレクトリやパッケージにファイルをまとめる場合、大きく分けて機能単位でまとめる方法と、ファイルの種類でまとめる方法がある。
1.ファイルの種類でまとめる例
Storyboard ├ LoginViewController.storyboard └ TimeLineViewController.storyboard View ├ LoginView.swift └ TimeLineView.swift Controller ├ LoginViewController.swift └ TimeLineViewController.swift Presenter ├ LoginViewPresenter.swift └ TimeLineViewPresenter.swift UseCase ├ LoginViewUseCase.swift └ TimeLineViewUseCase.swift2.機能でまとめる例
Login ├ LoginViewController.storyboard ├ LoginView.swift ├ LoginViewController.swift ├ LoginViewPresenter.swift └ LoginViewUseCase.swift TimeLine ├ TimeLineView.swift ├ TimeLineViewController.storyboard ├ TimeLineViewController.swift ├ TimeLineViewPresenter.swift └ TimeLineViewUseCase.swift上記はどちらの例も同じファイルを持っているが、ディレクトリの分け方が異なっている。
ファイルの種類でまとめる方法はレイヤー設計がわかりやすく、複数機能で使われるファイルも矛盾なく配置できるが、1つの画面のコードを読むために5ディレクトリにまたがってファイルを探す必要があり煩雑になるというデメリットもある。
この2つの分け方はどちらが良いというものではなく状況に応じた使い分けが必要だが、他の機能から使われることのないファイル群であれば、機能によってディレクトリをまとめた方が開発は楽になるケースが多い。
疎結合と密結合のバランス
一般にプログラムは疎結合である方が汎用性やメンテナンス性に優れるが、本項の方針はそれに反してプログラムの結合度を高めるものだ。
結合度を高めすぎると、1つのファイルが肥大しすぎたり密結合により汎用性やメンテナンス性を損なってしまうが、不必要で過剰な疎結合もまたメリットよりコストが大きくなってしまうというデメリットがある。何がベストかはケースバイケースで正解のない課題ではあるが、適切なバランスでコードをまとめることは意識する必要がある。
【
ここで言うUnitTestは手動のものではなく、JUnitなどのプログラムテストを指す。
データを加工などの小さな機能に対して、開発初期からUnitTestを積極的に作成する。UnitTestの効能
事前確認をすることで全体コストを減らす
システムに問題が見つかった場合、規模が大きい機能ほど原因調査に時間がかかる。
また、後ろの工程になるほどプログラムの修正は他機能への影響や考慮しなければならない点が大きくなる。
小さな機能に対して早い段階でUnitTestによる動作確認をしておくことで、これらのコストを減らすことができる。実際に動かしてテストするのが難しい処理の動作確認をする
イレギュラーなデータや状態に対する処理は、実際にアプリケーションを動かしてテストするのが難しいケースも多い。
そのようなテストでも、UnitTestであればイレギュラーな状況をプログラムで作り出してテストをすることができる。クラスや関数の使い心地を確認する
UnitTestを書くことでプログラマーはテスト対象のクラスや関数を実際にプログラムで使うことになる。
このときにクラスや関数の使い心地を体験することで、クラスや関数のインターフェースをより使いやすい形にブラッシュアップすることができる。
また、副次的な効果だがUnitTestを実行するにはプログラムが疎結合であることが求められるので、クリーンな設計の勉強にもなるかもしれない。仕様を明確にする
テストを作るには何が正しいかを定める必要がある。
テストを考えることにより、イレギュラーケースでどうあるべきかなどの仕様や課題がより明確になる。UnitTestは開発スピードを上げるためにやる
UnitTestは品質を担保するためではなく、全体の開発スピードを上げるために行う。
そのため、全てのコードを網羅する必要はないし、実装が難しいテストを無理に作る必要もない。
特にUI、通信、DBなどが絡むとUnitTestは様々な考慮が必要になるので、そのようなUnitTestを作成すると開発効率が下がるリスクがある。また、UnitTestをやったから品質が担保されるという考えもやめた方がいいだろう。
どれだけUnitTestをやろうが、最終的に人力でのテストは必要になる。小さな機能をテストする
UnitTestは基本的に小さくて独立した機能に対して行うようにする。
大きな一連の操作を自動で確認するプログラムを作る場合もあるが、そういうものはUnitTestとは目的が異なる。【
業務ロジックの計算にはInt、Float、Doubleなどの基本データ型を使わず、JavaならBigDecimal、SwiftならNSDecimalNumberやDecimalなどの数値クラスを使う。
Double、Floatなど浮動小数点数は基本的に業務ロジックに使わない
Double、Floatなどの浮動小数点数は、誤差が生じるので安易に使ってはいけない。
浮動小数点を使うのは、おおむね座標計算などの描画処理と、性能を重視する科学計算に限られる。
間違っても金額の計算にDoubleやFloatを使ってはいけない。金額の計算に32bitのIntを使用しない
例えばJavaのIntは32bitで最大値が約21億だが、これは金額を扱うには小さすぎる。
21億円というと大金だが、会社レベルの経理ならこれを超える金額は普通にあるし、個人資産でもあり得ない金額ではない。Intなどの組み込み整数型は桁数に上限があるため、なるべく業務ロジックでの使用は避け、使用する場合は桁あふれするケースがないかを十分考慮する。
金額であれば64bitの整数値(JavaならLong型)を使えばほぼ十分だろう。
64bit整数値の最大値は約900京なので、アメリカの国家予算(約400兆円)の100倍でも余裕でおさまる。関連記事
なぜBigDecimalを使わなければならないのか【
クラスは大きくなり過ぎないように心がけるべきだが、過剰にクラスを分割してクラスやインターフェースが増えすぎるのにも以下のようなデメリットがある。
- クラス結合のためのコードが必要になり全体のコード量が増える
- クラス同士の関係が複雑になりコードが難しくなる
- コードを読解・編集する際にファイル切り替が必要になり作業効率が落ちる
クラスやレイヤー構成を設計する際は、これらのデメリットを考慮した上で、メリットがデメリットを上回る設計をする必要がある。
クラスを切り出すポイント
何らかの機能をクラスに切り出す場合、その機能は以下のどれかである可能性が高い。
- 再利用性(汎用性)がある
- 単独でテストする必要がある
- 単独でデプロイ(リリース)する必要がある
逆に、再利用性がなく単独でテストもデプロイもしない機能群は、クラスを分けずに一つのクラスとして提供した方が良い可能性が高い。
機能を疎結合にすることはシステムの保守性を保つのに役立つ考え方だが、そこにはコストやデメリットもあり疎結合が常に密結合より優れているわけではない。例えばiOSアプリでは、特定の画面に対して
ViewControllerとカスタムのViewをそれぞれ作成する設計パターンがあるが、そのようなViewControllerとViewは必ず1対1で紐付き、再利用性がない上、単独でテストやデプロイもしないので、ViewとViewControllerに分けずに1つのクラスにした方が良いケースが多い。
※LoginViewControllerに対してLoginViewを作成するようなケース有名な設計パターンを機械的に模倣しない
過剰なクラスの細分化は、しばしばDDDやクリーンアーキテクチャーなど有名な設計パターンの機械的な模倣によって生まれる。
設計パターンを紹介する書籍や記事は、設計パターンの良いところばかりを強調し、悪いところや面倒な点には触れない傾向にある。
プロダクトやチームの規模によって最適な設計は変わってくるので、既存の設計パターンを機械的に模倣するのではなく、実際に自分たちのプロダクトに適用してメリットがデメリットに勝る形であるかを十分検討する。
とはいえ、特定の設計パターンがどのようなデメリットを秘めているかは一度試してみないと把握するのが難しい。
最適な設計パターンは、検討、実行、フィードバック、改良といったPDCAサイクルを回して徐々に洗練させていく必要がある。アプリケーション全体に画一的に同じレイヤー構成を適用しない
例えば、Hello Worldを出力するだけのプログラムにたくさんのクラスや複雑なアーキテクチャーを適用するのは無駄である。
やることがあまりないので、何もすることのないクラスやレイヤーが出てきてしまう。どういったクラスやレイヤーを用意するのが妥当かは、実装する機能の性質や複雑さによって変わる。
何にでもマッチする都合のいいクラス構成やアーキテクチャーはないのだ。一般的なアプリケーションには複数の画面や機能があり、性質や複雑さはそれぞれ異なるので、それら全てに同じレイヤー構成を当てはめれば、無駄やミスマッチが生じることになる。
そのため、すべての機能に同じ構成を適用するのでなく、もっと柔軟に、機能ごとに適切な設計を選択していく方が良いと思われる。また、同じ機能であっても、要件や仕様の変化にともない最善の構成は変わっていく。
良い設計を保つためには、大胆なリファクタリングや、既存のコードを完全に捨ててしまうこともときには必要になる。レイヤーのショートカット
クリーンアーキテクチャーなどレイヤーが細かく分かれたアーキテクチャーでファイル数を抑える1つの方法は、レイヤーのショートカットを許容することだ。
例えばプログラムが以下のようなレイヤー構成を持つ場合でも、UseCaseとPresenterでやることがなければ、Controllerが直接Entityを参照すれば良い。
- Entity
- UseCase
- Presenter
- Controller
- View
前項に記載したとおり、レイヤーの構成はアプリケーション内で統一する必要はなく、もっと自由に機能によって変えてしまって良いと思う。
ただし「依存の向きを意識する」の項に記載したとおり、EntityからViewを参照するような通常と逆向きの参照はしないようにしよう。インターフェース(プロトコル)をクロージャに置き換える
関数型言語など関数を引数として受け渡しできる言語であれば、メソッドが一つしかないような簡単なインターフェース(プロトコル)を関数渡しやクロージャに置き換えることができる。
以下はPresenterのOutputをprotocolから関数渡しに置き換えている。Beforeclass LoginPresenter { let output: LoginOutput init(output: LoginOutput) { self.output = output } func login() { output.loginCompleted() } } protocol LoginOutput { func loginCompleted() }Afterclass LoginPresenter { func login(onComplete: () -> Void) { onComplete() } }同じようなデータモデルを複数作らない
レイヤーの分離に執着し過ぎると、同じようなデータモデルが無意味に複数できてしまう場合がある。
例えば、ドメイン層にUserクラスがあり、その情報をUseCaseに渡すためのUserDTOがあり、さらにViewで使うためのUserViewModelがあるが、3つがほとんど同じコードになってしまうようなケースだ。
ほとんど同じでも分離しなければならないケースもあるが、分けずに使い回して良いケースもある。
以下の条件を満たすなら複数のレイヤーをまたいで上層のデータモデルを使っても良い。
- データモデルがDB、フレームワーク、ライブラリなど特定のアーキテクチャーに依存しない
- 上層のデータモデルが下層のクラスに依存しない(「依存の向きを意識する」の項に記載のとおり)
【
基本的にExceptionはcatchせず呼び出し元にthrowし、上層のレイヤーで一括してエラー処理をするようにする。
Exceptionをcatchする場合は以下を心がける。
- 適切なエラー処理をする
- エラー処理ができないのであれば、エラーログを出力する
- 明確な意図がありログすら出さずExceptionを隠蔽する場合は、その理由をコメントで記載する
この項に記載する内容は「サービスの可用性を意識する」の項に書いていることと少し矛盾するが、上層のレイヤーで適切にExceptionを処理できるならそれが一番良い。
「サービスの可用性を意識する」の項に記載した方針は、上層レイヤーでExceptionを適切に処理しきれない可能性があり、それがシステム全体のクラッシュにつながるなら、Exceptionを吐かないようにしようというものだ。
【
クラスの外から使われないプロパティや関数はprivateやprotectedにする。
クラスはコードやドキュメントを見なくてもコード補完で何となく使い方が分かるのが望ましいが、privateやprotectedにしないと外から使われる前提でないプロパティや関数もコード補完で候補として出てしまい、使いづらくなる。
ただし、privateなどのアクセス修飾子がないプログラミング言語もあり、その場合は特殊な実装でprivateを実現するより、シンプルで標準的なコードであることを優先して、privateを諦める方が良い。
どうしてもprivateを導入したいなら、そもそも言語を変えることをお勧めする(JavaScriptからTypeScriptにするなど)また、privateメソッドは別クラスのpublicメソッドに処理を切り出すことで実装がすっきりすることが多いので、汎用的な処理であったりクラスサイズが大きい場合はクラスの切り分けも検討する。
関連記事
privateメソッドは不要【
三項演算子のネストは分かりづらいので避ける。
Badflag ? subFlag ? a : b : cネストが必要になる場合は、途中の演算結果をローカル変数(説明変数)に入れてネストを解消すると良い。
Goodlet aOrB = subFlag ? a : b flag ? aOrB : cまた、三項演算子内に長い式や長い関数のチェインなどが含まれる場合も、それぞれの結果をローカル変数に入れてから、三項演算子で使う。
Badflag ? (1 + 2) * 3 - 4 : 5 % 6 * 7Goodlet a = (1 + 2) * 3 - 4 let b = 5 % 6 * 7 flag ? a : b関連記事
三項演算子?:は悪である。【
初心者は以下のように
truefalseをコード内にベタ書きしがちだ。Badvar isZero: Bool { if number == 0 { return true } else { return false } }しかし上記は
number == 0がBoolを返すのでtrue/falseを書く必要はなく、より簡潔に以下のように書ける。Goodvar isZero: Bool { return number == 0 }必ずtrueを返すケースや必ずfalseを返すケースではtrue/falseをべた書きする必要があるが、上記の例のように何らかの判定結果を返す場合は、true/falseをベタ書きするのは避ける。
ただ、この書き方は初心者には分かりづらい。チーム内に初心者がいる場合は説明してあげるのが良いだろう。
関連記事
読み手にやさしい if 文を書きたい【
SwiftのenumのrawValueのように、enumは何らかのコード値を保有することが多い。
しかし、このコード値を判定などに使ってしまうと、enumの存在意義が半減してしまう。Enumのサンプルenum Status: String { case success = "0" case error = "1" }例えば上記のようにコード値をもったEnumがある場合、コード値を判定などに使わず、Enumを直接使うようにする。
Badif status.rawValue == "0" { }Goodif status == .success { }引数で渡す場合もコード値は使わず、Enumを直接渡す。
BadcheckStatus(status.rawValue)GoodcheckStatus(status)そもそもenumにコード値を持たせるべきではない?
「コード値はenumにする」の項と矛盾するが、そもそもenumがコード値を持っていなければ、このような間違いは生まれない。
DBやAPIのコード値は外部仕様であり、アプリケーションの仕様とは分離すべきものと考えると、コード値は
Repositoryレイヤーでenumに変換してやりenumにはコード値をもたせない方が綺麗なプログラム設計になる。【
Lintなどの静的コードチェックを積極的に活用する。
静的コードチェックは人の手を使ずローコストでコードをチェックできるので、やっておいた方がお得である。
問題を検知するだけでなく、どのようなコードに問題があるかを知る勉強にもなる。ただし、静的コードチェックにもデメリットはあり、大量のワーニングが出たとき真面目に全てをチェックすると非常に時間がかかる場合がある。
ワーニングが出たからといって直ちに問題があるわけではないので、時間を使ってワーニングを潰してもアプリケーションのクオリティはさほど変わらないということもある。静的コードチェックはあくまで問題を見つける手助け程度に考えるのが良いかもしれない。
【
詳細な説明は省くが、その他雑多なプラクティスを列挙する。
- 関数の引数で渡す情報は必要最小限にする
- パフォーマンスの最適化を早期にしすぎない
- 大小比較には
<を使い>を使わない- 関数の引数を出力に使わない
- コードのインデントを揃える
求人情報
いかがでしたでしょうか?
この記事は私が代表を務める株式会社アルトノーツのコーディングガイドラインです。弊社は代表含め2名の会社ですが、現在iOS・Androidのエンジニアを募集中です。
興味を持たれた方は是非求人情報をのぞいてみて下さい!
- 投稿日:2020-01-21T02:43:59+09:00
Twitter4Jの使いかた
Twitter4Jを使ってみました。
流れは、
アカウント申請をする。3~4時間で許可出ます。(Botにするとか、簡単なものに使うとすれば。)
アクセスtokenをメモする。
mavenのpom.xmlにTwitter4Jに必要なビルドを統合する。
Javaでコード書いて、メモしたtokenを入力する。
実行してタイムラインを確認する。です!
コードやmavenの設定はGithubのreadme.mdにあります。
詳しくはGithubにあげています。