- 投稿日:2020-01-21T22:32:26+09:00
LinuxでプロセスのRunキュー待ち時間を測定してみた
Linuxでスケジューリングポリシーを指定してプロセスを起動する で起動したCPUバウンドなSCHED_FIFOプロセスのRunキュー待ち時間を測定してみます。
Runキュー待ち時間の取得にあたり、以下のページを参考にしました。
https://yohei-a.hatenablog.jp/entry/20150806/1438869775CPUバウンドなFIFOプロセスの/proc/PID/schedstat を1秒空けて取得した結果。
2列目がRunキュー待ち時間。単位ナノ秒。
- time spent on the cpu
- time spent waiting on a runqueue
- # of timeslices run on this cpu
( https://www.kernel.org/doc/html/latest/scheduler/sched-stats.html より)
[ec2-user@ip-172-21-0-185 ~]$ sudo cat /proc/27629/schedstat ; sleep 1; sudo cat /proc/27629/schedstat 1585551572096 83397623426 1669 1586504089039 83449107507 167051ミリ秒ほどですね。
3列目、タイムスライスが1というところから、Context Switchが1回しか起きていない?ようで、まさにリアルタイムプロセス。下は、同時に走らせていたCPUバウンドなSCHED_OTHERプロセスの/proc/PID/schedstat を1秒空けて取得した結果。
[ec2-user@ip-172-21-0-185 ~]$ sudo cat /proc/28585/schedstat ; sleep 1; sudo cat /proc/28585/schedstat 28229659566 570788962732 8601 28291651447 571746971282 8620約958ミリ秒。SCHED_FIFOのプロセスが走っていた時間ほぼずっとRunキューにいたことが分かります。
SCHED_OTHER のプロセスをkillして測定
SCHED_OTHER のプロセスをkillして、他にCPUを大量に使うプロセスがない状態でSCHED_FIFOのRunキュー待ち時間を測定した見たところ、約50ミリ秒という結果になりました。(コマンド出力結果はありません)
ということは、SCHED_FIFOのyesプロセスがCPUを使っていない時間でのみSCHED_OTHERのyesプロセスが走れていたんですね。
- 投稿日:2020-01-21T22:31:09+09:00
systemd で httpd.conf を指定して Apache を起動する方法(CentOS7、CentOS8編)
CentOS7やCentOS8のsystemdで、httpd.confを指定してApacheを起動する方法を紹介します。
動作確認環境
- CentOS Linux release 7.7.1908
- CentOS Linux release 8.0.1905
httpd.conf の代わりに myhttpd.conf を指定して起動
/etc/httpd/confディレクトリ配下に、Apacheの起動時に使用したい設定ファイルmyhttpd.confがあるものとします。1. httpd.service を修正
Apacheのsystemdのユニット定義ファイル
/usr/lib/systemd/system/httpd.serviceを修正します。修正前の
httpd.serviceは以下となります。/usr/lib/systemd/system/httpd.service(修正前)[Unit] Description=The Apache HTTP Server After=network.target remote-fs.target nss-lookup.target Documentation=man:httpd(8) Documentation=man:apachectl(8) [Service] Type=notify EnvironmentFile=/etc/sysconfig/httpd ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND ExecReload=/usr/sbin/httpd $OPTIONS -k graceful ExecStop=/bin/kill -WINCH ${MAINPID} # We want systemd to give httpd some time to finish gracefully, but still want # it to kill httpd after TimeoutStopSec if something went wrong during the # graceful stop. Normally, Systemd sends SIGTERM signal right after the # ExecStop, which would kill httpd. We are sending useless SIGCONT here to give # httpd time to finish. KillSignal=SIGCONT PrivateTmp=true [Install] WantedBy=multi-user.target
修正後のhttpd.serviceは以下となります。/usr/lib/systemd/system/httpd.service(修正後)[Unit] Description=The Apache HTTP Server After=network.target remote-fs.target nss-lookup.target Documentation=man:httpd(8) Documentation=man:apachectl(8) [Service] Type=notify EnvironmentFile=/etc/sysconfig/httpd ExecStart=/usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf $OPTIONS -DFOREGROUND ExecReload=/usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf $OPTIONS -k graceful ExecStop=/bin/kill -WINCH ${MAINPID} # We want systemd to give httpd some time to finish gracefully, but still want # it to kill httpd after TimeoutStopSec if something went wrong during the # graceful stop. Normally, Systemd sends SIGTERM signal right after the # ExecStop, which would kill httpd. We are sending useless SIGCONT here to give # httpd time to finish. KillSignal=SIGCONT PrivateTmp=true [Install] WantedBy=multi-user.target
httpd.serviceの差分は以下となります。/usr/lib/systemd/system/httpd.service(差分)-ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND -ExecReload=/usr/sbin/httpd $OPTIONS -k graceful +ExecStart=/usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf $OPTIONS -DFOREGROUND +ExecReload=/usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf $OPTIONS -k graceful2. Apache を起動
以下のコマンドで修正したユニット定義ファイル(
httpd.service)でApacheを起動します。
systemctl start httpd実行結果[root@CENTOS7 ~]# systemctl start httpd [root@CENTOS7 ~]#以下のコマンドでApache(httpd)のプロセスを確認し、
/etc/httpd/conf/myhttpd.confで起動されていることを確認します。
ps -ef | grep httpd実行結果[root@CENTOS7 ~]# ps -ef | grep httpd root 1332 1 0 22:20 ? 00:00:00 /usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf -DFOREGROUND apache 1333 1332 0 22:20 ? 00:00:00 /usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf -DFOREGROUND apache 1334 1332 0 22:20 ? 00:00:00 /usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf -DFOREGROUND apache 1335 1332 0 22:20 ? 00:00:00 /usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf -DFOREGROUND apache 1336 1332 0 22:20 ? 00:00:00 /usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf -DFOREGROUND apache 1337 1332 0 22:20 ? 00:00:00 /usr/sbin/httpd -f /etc/httpd/conf/myhttpd.conf -DFOREGROUND root 1341 1295 0 22:21 pts/0 00:00:00 grep --color=auto httpd [root@CENTOS7 ~]#その他
今回は
/usr/lib/systemd/system/httpd.serviceのExecStart及びExecReloadに直接-f /etc/httpd/conf/myhttpd.confを追加しましたが、変数にすることもできます。
ユニット定義ファイルでの変数の使用方法は以下を参考にしてください。以上
- 投稿日:2020-01-21T21:17:57+09:00
Linuxでスケジューリングポリシーを指定してプロセスを起動する
スケジューリングポリシーの種類とその説明はこの記事では扱いません。(後日追記する可能性はあるかもしれません)
スケジューリングポリシーを指定してプロセスを起動する方法
chrtコマンドを使います。-f でFIFOを指定。
$ sudo chrt -f 38 yes > /dev/null &ポリシー確認。
$ sudo chrt -p 32407 pid 32407's current scheduling policy: SCHED_OTHER pid 32407's current scheduling priority: 0すると、SCHED_OTHERですね。なぜだ・・・
追加調査
$ sudo chrt -f 1 yes > /dev/null &chrt -p で表示されるスケジューリングポリシーと、psコマンドのclsで表示されるスケジューリングポリシーが異なりますね。(FFがSCHED_FIFOのはず)
$ ps -C yes -o comm,pid,ppid,cls,rtprio,%cpu COMMAND PID PPID CLS RTPRIO %CPU yes 27629 27628 FF 1 94.2 $ $ chrt -p 27629 pid 27629's current scheduling policy: SCHED_OTHER pid 27629's current scheduling priority: 0なぜだ・・・
閑話
同じプログラムを実行している以下の二つのプロセス
(1) SCHED_FIFOのプロセスをchrtでSCHED_OTHERにしたプロセス
(2) SCHED_OTHERのプロセスtopの出力を見るとどちらも同じくらいのCPU使用率になるのだが
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 626 ec2-user 20 0 132m 7088 4304 R 49.8 0.7 7:53.42 cpu_bound.py 722 ec2-user 20 0 132m 6980 4196 R 49.8 0.7 3:45.94 cpu_bound.pypsコマンドで確認すると、以下のような感じでCPU使用率に偏りが出ている。
[ec2-user@ip-172-21-0-185 experiment]$ ps -C cpu_bound.py -o comm,pid,ppid,cls,rtprio,pri,ni,%cpu COMMAND PID PPID CLS RTPRIO PRI NI %CPU cpu_bound.py 626 26292 TS - 19 0 69.1 cpu_bound.py 722 26292 TS - 19 0 35.4なぜだ・・・
さらに、%CPUの合計が100を超えるのもなぞ。
- 投稿日:2020-01-21T21:02:30+09:00
Ubuntu 19.10 Eoan Ermine に Apache 2.4 をインストールして CGI を動かす
概要
- Ubuntu に apache2 パッケージをインストール
- a2enmod コマンドで mod_cgid を有効化
- CGI スクリプトを設置
- a2ensite コマンドで設定を有効化
Apache 2 のインストール
apache2 パッケージをインストール。
$ sudo apt install apache2バージョンを確認。
$ /usr/sbin/apachectl -V Server version: Apache/2.4.41 (Ubuntu) Server built: 2019-08-14T14:36:32 Server's Module Magic Number: 20120211:88 Server loaded: APR 1.6.5, APR-UTIL 1.6.1 Compiled using: APR 1.6.5, APR-UTIL 1.6.1 Architecture: 64-bit Server MPM: event threaded: yes (fixed thread count) forked: yes (variable process count) Server compiled with.... -D APR_HAS_SENDFILE -D APR_HAS_MMAP -D APR_HAVE_IPV6 (IPv4-mapped addresses enabled) -D APR_USE_SYSVSEM_SERIALIZE -D APR_USE_PTHREAD_SERIALIZE -D SINGLE_LISTEN_UNSERIALIZED_ACCEPT -D APR_HAS_OTHER_CHILD -D AP_HAVE_RELIABLE_PIPED_LOGS -D DYNAMIC_MODULE_LIMIT=256 -D HTTPD_ROOT="/etc/apache2" -D SUEXEC_BIN="/usr/lib/apache2/suexec" -D DEFAULT_PIDLOG="/var/run/apache2.pid" -D DEFAULT_SCOREBOARD="logs/apache_runtime_status" -D DEFAULT_ERRORLOG="logs/error_log" -D AP_TYPES_CONFIG_FILE="mime.types" -D SERVER_CONFIG_FILE="apache2.conf"起動しているのを curl 等でアクセスして確認。
$ curl -I http://localhost/ HTTP/1.1 200 OK Date: Tue, 21 Jan 2020 10:47:37 GMT Server: Apache/2.4.41 (Ubuntu) Last-Modified: Tue, 21 Jan 2020 10:28:46 GMT ETag: "2aa6-59ca3df7ac2c0" Accept-Ranges: bytes Content-Length: 10918 Vary: Accept-Encoding Content-Type: text/htmlmod_cgid の有効化
a2enmod cgi または a2enmod cgid で cgid モジュールを有効化する。
$ sudo a2enmod cgi Your MPM seems to be threaded. Selecting cgid instead of cgi. Enabling module cgid. To activate the new configuration, you need to run: systemctl restart apache2mod_cgid - Apache HTTP サーバ バージョン 2.4
Unix オペレーティングシステムの中には、マルチスレッドのサーバから プロセスを fork するのが非常にコストの高い動作になっているものがあります。 理由は、新しいプロセスが親プロセスのスレッドすべてを複製するからです。 各 CGI 起動時にこのコストがかかるのを防ぐために、mod_cgid は子プロセスを fork して CGI スクリプトを実行するための 外部デーモンを実行します。 主サーバは unix ドメインソケットを使ってこのデーモンと通信します。
コンパイル時にマルチスレッド MPM が選ばれたときは mod_cgi の代わりに必ずこのモジュールが使用されます。 ユーザのレベルではこのモジュールの設定と動作は mod_cgi とまったく同じです。唯一の例外は ScriptSock ディレクティブの 追加で、このディレクティブは CGI デーモンとの通信用のソケットの名前を 指定します。
CGI スクリプトを設置
/var/www/hello ディレクトリを作成。
$ sudo mkdir /var/www/helloCGI スクリプトファイルを編集するユーザーに権限を与える。
$ sudo chown hoge:hoge /var/www/helloindex.cgi ファイルを設置する。
$ vim /var/www/hello/index.cgiindex.cgi の中身。今回はシェルスクリプトによる CGI とする。
#!/usr/bin/sh echo 'Status: 200 OK' echo 'Content-Type: text/html;charset=utf-8' echo '' echo '<html><body>Hello, world.</body></html>'index.cgi に実行権限を付与する。
$ chmod 755 /var/www/hello/index.cgi設定ファイルを設置
/etc/apache2/sites-available ディレクトリにある 000-default.conf ファイルをコピーして hello.conf というファイルを作成する。
$ sudo cp /etc/apache2/sites-available/000-default.conf /etc/apache2/sites-available/hello.confhello.conf ファイルの中身を修正する。
$ sudo vim /etc/apache2/sites-available/hello.confhello.conf ファイルは以下の内容に置き換える。
hello.conf<VirtualHost *:80> # /etc/apache2/sites-available/000-default.conf からコピーした内容 ServerAdmin webmaster@localhost DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined # CGI を動かす設定 ScriptAlias /hello/ /var/www/hello/ <Directory "/var/www/hello/"> Options ExecCGI AddHandler cgi-script .cgi DirectoryIndex index.cgi AllowOverride None Require all granted </Directory> </VirtualHost>hello.conf を有効化して 000-default.conf を無効化
現時点では 000-default が有効になっている。
$ ls -l /etc/apache2/sites-enabled/ | grep conf lrwxrwxrwx 1 root root 35 1月 21 19:28 000-default.conf -> ../sites-available/000-default.confa2ensite コマンドで hello.conf を有効にする。
$ sudo a2ensite hello Enabling site hello. To activate the new configuration, you need to run: systemctl reload apache2a2dissite コマンドで 000-default.conf を無効にする。
$ sudo a2dissite 000-default Site 000-default disabled. To activate the new configuration, you need to run: systemctl reload apache2hello.conf が有効になっているのを確認できる。
$ ls -l /etc/apache2/sites-enabled/ | grep conf lrwxrwxrwx 1 root root 29 1月 21 20:03 hello.conf -> ../sites-available/hello.confApache を再起動して設定を反映
$ sudo systemctl restart apache2CGI が動作しているのを curl コマンド等で確認できる。
$ curl -i http://localhost/hello/ HTTP/1.1 200 OK Date: Tue, 21 Jan 2020 11:09:41 GMT Server: Apache/2.4.41 (Ubuntu) Content-Length: 40 Content-Type: text/html;charset=utf-8 <html><body>Hello, world.</body></html>参考資料
- Install and Configure Apache | Ubuntu tutorials
- Ubuntu 18.04 » Ubuntu Server Guide » Web Servers » HTTPD - Apache2 Web Server
- File: apache2.README.Debian | Debian Sources
- Ubuntu – eoan の apache2 パッケージに関する詳細
- Ubuntu Manpage: a2enmod, a2dismod - enable or disable an apache2 module
- Ubuntu Manpage: a2ensite, a2dissite - enable or disable an apache2 site / virtual host
- Apache Tutorial: CGI による動的コンテンツ - Apache HTTP サーバ バージョン 2.4
- RFC 3875 - The Common Gateway Interface (CGI) Version 1.1
- 投稿日:2020-01-21T19:20:49+09:00
Linux Mint でElixir = 快適
動機
GPUの性能をフルに活かしたいと思っていました。マイクロソフトも頑張っていてWSLはなかなか快適なのですが、一つ難点があります。GPUが扱えないことです。ElixirからGPUを活用するにはエミュレーターではなく、直にLinuxを扱う必要があります。覚悟を決めてインストールをしました。思い起こせば最初にLinuxにトライしたのは20世紀のころでした。当時はインターネットもまだまだ未発達であり、書籍と付録のCDを頼りに四苦八苦しつつインストールをした覚えがあります。
Linux MintはWindows10のよう
20世紀のころのLinux体験からすると今のLinux環境はまるで夢のようです。あれほど苦労したインストールもあっけなく終わりました。私の場合、インターネットはセキュリティーの関係上、かなり複雑なことになっています。有線LANでの固定IPの設定はUbuntuではどもうまくいきません。そこで最近人気のMintに切り替えました。こちらはとりあえずインストールをしてから固定IPの設定ができるのでなんとかネットに接続することができました。
Mintはとても軽快です。デスクトップはなんだかWindows10のようです。Windows感覚で扱えます。Ubuntuに次いでユーザーが多いそうですし、日本語による公式ページもあり安心です。Ubuntuがベースになっているそうで、Ubuntu用のものがそのまま使えるみたいです。さて、Elixirはどうかな?Elixirのインストール
まったく何も悩むところはありませんでした。Elixirの公式ページにあることをそのままやるだけです。
https://elixir-lang.org/install.htmlUbuntuでのインストール方法をそのまま実行するだけです。
以下、公式ページより引用
Ubuntu 14.04/16.04/17.04/18.04/19.04 or Debian 7/8/9/10 Add Erlang Solutions repo: wget https://packages.erlang-solutions.com/erlang-solutions_2.0_all.deb && sudo dpkg -i erlang-solutions_2.0_all.deb Run: sudo apt-get update Install the Erlang/OTP platform and all of its applications: sudo apt-get install esl-erlang Install Elixir: sudo apt-get install elixir引用終わり。
GPUの活用に向かって
これでGPU活用、CUDAを利用する準備が整いました。ElixirからNifs経由でcuBLASやcuFFTを呼び出すことにチャレンジです。
- 投稿日:2020-01-21T17:25:57+09:00
マルチコア対応したpigzでファイル圧縮・解凍を高速化させる
リモートにあるマシンとファイルをやり取りする…などで圧縮・解凍する場面が出てきますが、標準の
gzipやzipコマンドではマルチコアに対応していません?
他のコアは全く使っていないのに遅い…そこで、マルチコアに対応したpigzを用いてファイルの圧縮・解凍を高速化させましょう。インストール
yum,apt-getなどのパッケージマネージャーで導入できます。
ソースコードからのインストールが必要な場合は pigzのホームページ から入手できます。圧縮
1つのファイルを圧縮する
pigzにはファイル名を指定するオプションが無いため、-cオプションで圧縮結果を標準出力に出してからリダイレクトで指定したファイルに入れます。$ pigz --best -c db_dump.txt > single_file.gz実用的な最高圧縮率で圧縮したいため
--bestのオプションを付けています。--bestは-9と同じですが、時間を犠牲にしてでも最高の圧縮を求めたい場合は-11まで圧縮率を指定できます。$ man pigz ... -# --fast --best Regulate the speed of compression using the specified digit #, where -1 or --fast indicates the fastest compression method (less compres‐ sion) and -9 or --best indicates the slowest compression method (best compression). -0 is no compression. -11 gives a few percent better compression at a severe cost in execution time, using the zopfli algorithm by Jyrki Alakuijala. The default is -6.ディレクトリなど複数ファイルの圧縮は
tarでまとめてから圧縮する
pigzで圧縮する際にディレクトリを指定して-rで再帰的に圧縮しようとすると、 指定されたファイル一つずつつに対して圧縮ファイルを作成します。
zipコマンドの感覚でやってしまうとディレクトリ内にある元のファイルが一つずつzip置き換えられます?そこで、一度
tarで1ファイルにまとめてからそのファイルをpigzで圧縮します。$ tar c Directory | pigz --best > multiple_files.tar.gz解凍
pigzを用いた解凍について
pigzではマルチコアで解凍ができません。 …がファイルの読み書きなどは並列化されるため、結果として高速になる場合があります。$ man pigz ... Decompression can't be parallelized, at least not without specially prepared deflate streams for that purpose. As a result, pigz uses a single thread (the main thread) for decompression, but will create three other threads for reading, writing, and check calculation, which can speed up decompression under some circumstances. Parallel decompression can be turned off by specifying one process ( -dp 1 or -tp 1 ).1つのファイルを圧縮した場合は
-dオプションで解凍できます。$ pigz -d single_file.gzディレクトリなどを圧縮する前に
tarにまとめてしまった場合はtarコマンドの--use-compress-progオプションを使って解凍すると良いでしょう。
解凍にpigzを使いながらtarの展開まで自動で実行されます?$ tar -xvf multiple_files.tar.gz --use-compress-prog=pigzマルチコアで解凍できないというけど…?
ざっと解凍してみると、
pigzではすべて解凍し終わるまでの時間が短くなっていることがわかります(4-coreのCPU, テキストファイル534個を圧縮した434MBのtar.gzにて)$ time tar -xvf multiple_files.tar.gz ... real 0m18.233s user 0m16.780s sys 0m4.346s $ time tar -xvf multiple_files.tar.gz --use-compress-prog=pigz ... real 0m9.317s user 0m10.973s sys 0m4.556s参考
マルチコアでgzファイルの圧縮解凍ができるpigzの使い方 - Qiita
https://qiita.com/itukizora/items/10a9e7fffff857de374bpigzを使ったgzip並列圧縮 - Wolfeyes Bioinformatics beta
http://yagays.github.io/blog/2012/06/15/pigz/bzip2とgzipのParallel版、pbzip2とpigz - done is better than perfect
https://dibtp.hateblo.jp/entry/2014/07/06/004300
- 投稿日:2020-01-21T16:37:23+09:00
ubuntuパッケージアップデートスクリプト
#パッケージ更新、自動削除してキャッシュクリーンする sudo apt update && sudo apt full-upgrade -y && sudo apt autoremove -y && sudo apt autoclean -y
- 投稿日:2020-01-21T14:48:28+09:00
youtube download メモ
- 投稿日:2020-01-21T13:53:38+09:00
Ubuntu18.04にPython3とOpenCV環境を構築する
モチベーション
ラズパイとカメラでPythonを使って顔認識による顧客分析をやってみようと思い、VMでテスト環境を構築する。今回のゴールは、MacにUbuntuの仮想環境を作り、Ubuntu上でPython3とOpenCVを動作させるまでとする。
環境
- Ubuntu16.04が動作することが前提
- Python 3.6.9を導入
- OpenCV 4.2.0を導入
OpenCVと依存するライブラリのインストール
gitコマンドを使って、ソースコードを取得しています。
$ sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev $ sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libdc1394-22-devソースコードの入手
gitコマンドを使って、ソースコードを取得しています。
$ git clone https://github.com/opencv/opencv.git $ git clone https://github.com/opencv/opencv_contrib.gitwgetコマンドでダウンロードする場合はunzipコマンドでzipファイルを解凍してください。
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.2.0.zip $ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/master.zip $ unzip opencv.zip $ unzip opencv_contribソースが保存されたディレクトリを確認します。
OpenCVのコンパイル・ビルド
OpenCVをビルドします。
cmakeのとき、-D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules をつけることでcontribの方もまとめてビルドされます。$ cd ~/opencv-4.2.0 $ mkdir build $ cd build $ cmake -D CMAKE_BUILD_TYPE=RELEASE \ -D CMAKE_INSTALL_PREFIX=/usr/local \ -D INSTALL_PYTHON_EXAMPLES=ON \ -D INSTALL_C_EXAMPLES=OFF \ -D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \ -D BUILD_EXAMPLES=ON ..OpenCVをコンパイルします。
$ make -j4 [100%] Build target opencv_python3 //この表示が出ればコンパイル成功私のMac Book ProのVM環境では、1時間ほどコンパイル・ビルドに時間がかかりました。
無事、コンパイル・ビルドに成功したら、OpenCVをインストールします。$ sudo make install $ sudo ldconfigOpenCVのバージョンを確認します。
$ opencv_version 4.2.0Python3と関連モジュールのインストール
まずは、Pythonパッケージを管理するpipをインストールします。次のモジュール(numpy, pandas, matplotlib, sklearn)が使えるようにします。
$ sudo install pip3 $ pip3 install numpy pandas matplotlib sklearn動作確認
pythonコンソールに入り、各種モジュールがimportできるかを確認する。
エラーが出なければ、無事モジュールがインストールされている。念のためopnecvのバージョンを確認する。$ python3 >>>import numpy >>>import pandas >>>import sklearn >>>import matplotlib >>>import cv2 //これがopencvのライブラリ >>>cv2.__version__ //opencvのバージョン確認 '4.2.0' >>>これで仮想マシンのUbuntuでPython3とOpenCVが利用できるようになりました。ディープラーニングをやりたい方はディープラーニング用のライブラリ(tensorflow, kerasなど)をpip3でインストールしてあげると利用できるはずです。それでは、次回、OpenCVを使った顔認識サンプルコードを実行してみたいと思います。
参考サイト
・こちらPython3.6とOpenCVのインストール (Ubuntu18.04LTS)の記事がとても参考になりました。
・こちらopencvをソースからビルドするの記事も参考になりました。
・OpenCV公式サイトはこちらです。
- 投稿日:2020-01-21T10:58:01+09:00
Linux OSのバージョンを確認する方法
カーネルのバージョンを調べる
$ cat /proc/version Linux version 5.0.0-37-genericDebian
$ cat /etc/debian_version 10.2Ubuntu
$ cat /etc/lsb-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=18.04 DISTRIB_CODENATE=bionic DISTRIB_DESCRIPTION="Ubuntu 18.04.3 LTS"Cent0S
$ cat /etc/redhad-release CentOS Linux release 7.7私のMacの仮想マシンは3つのLinuxしか入っていないので、今回はここまで。
他のLinuxを入れたときに更新します。
- 投稿日:2020-01-21T07:44:09+09:00
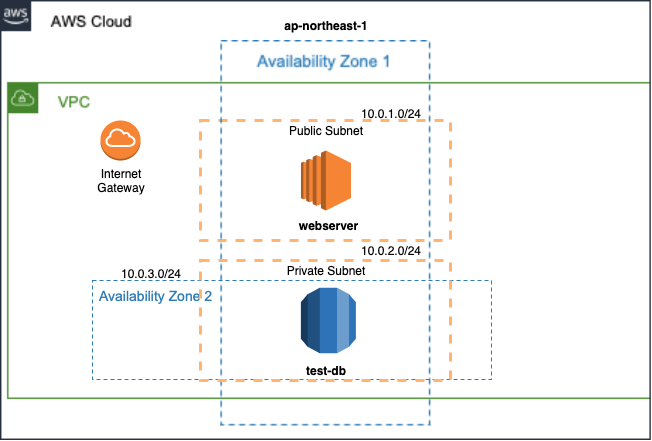
AWSのEC2とRDSをTerraformで構築する Terraform3分クッキング
はじめに
本記事はAWSのEC2とRDSをTerraformをで構築する方法について記載しています。
terraform applyで実行にかかる時間は、約3分程度です。カップラーメンの待ち時間で構築できます。デプロイするのは以下の環境(※)になります。また、あわせてEC2は最低限のOSセットアップも行います。
Terraformの基本から入りたい方は、以前書いたOracle Cloudで始めるTerraform 自動化の真骨頂を参照ください。
(※)本記事で記載しているtfファイルはGitHubで公開しています。
Terraform構築
AWS環境におけるTerraformによる構築を行うためには、IAMでユーザ作成を行い、必要なクレデンシャル情報を用意します。あとはTerraformをインストールし、Terraform実行に必要なtfファイルを用意します。
AWS環境の前提条件を以下に記載します。
- IAMでユーザの作成
- 必要な権限を付与していること
- SSHで使用するキーペアを作成していること
tfファイルの作成
tfファイルについて解説します。
はじめに任意の作業ディレクトリに移動します。
本記事では以下のディレクトリ構成になり、カレントディレクトリはcommonディレクトリとします。なお、sshのディレクトリの場所については他のディレクトリでも問題ありません。
- ディレクトリ構成
. |-- common | |-- userdata | |-- cloud-init.tpl | |-- ec2.tf | |-- env-vars | |-- network.tf | |-- provider.tf | |-- rds.tf `-- ssh |-- id_rsa |-- id_rsa.pub
- 各種ファイル説明
ファイル名 役割 cloud-init.tpl EC2用の初期構築スクリプト ec2.tf EC2のtfファイル env-vars プロパイダーで使用する変数のtfファイル network.tf ネットワークのtfファイル provider.tf プロパイダーのtfファイル rds.tf RDSのtfファイル id_rsa SSH秘密鍵 id_rsa.pub SSH公開鍵
- env-vars
### Authentication export TF_VAR_aws_access_key="<access_keyの中身をペースト>" export TF_VAR_aws_secret_key="<secret_keyの中身をペースト>"(※)引用符の中にはそれぞれaccess_keyとsecret_keyの中身ををペーストします。
- provider.tf
# Variable variable "aws_access_key" {} variable "aws_secret_key" {} variable "region" { default = "ap-northeast-1" } # Provider provider "aws" { access_key = var.aws_access_key secret_key = var.aws_secret_key region = "ap-northeast-1" }
- network.tf
# vpc resource "aws_vpc" "dev-env" { cidr_block = "10.0.0.0/16" instance_tenancy = "default" enable_dns_support = "true" enable_dns_hostnames = "false" tags = { Name = "dev-env" } } # subnet ## public resource "aws_subnet" "public-web" { vpc_id = "${aws_vpc.dev-env.id}" cidr_block = "10.0.1.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "public-web" } } ## praivate resource "aws_subnet" "private-db1" { vpc_id = "${aws_vpc.dev-env.id}" cidr_block = "10.0.2.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "private-db1" } } resource "aws_subnet" "private-db2" { vpc_id = "${aws_vpc.dev-env.id}" cidr_block = "10.0.3.0/24" availability_zone = "ap-northeast-1c" tags = { Name = "private-db2" } } # route table resource "aws_route_table" "public-route" { vpc_id = "${aws_vpc.dev-env.id}" route { cidr_block = "0.0.0.0/0" gateway_id = "${aws_internet_gateway.dev-env-gw.id}" } tags = { Name = "public-route" } } resource "aws_route_table_association" "public-a" { subnet_id = "${aws_subnet.public-web.id}" route_table_id = "${aws_route_table.public-route.id}" } # internet gateway resource "aws_internet_gateway" "dev-env-gw" { vpc_id = "${aws_vpc.dev-env.id}" depends_on = [aws_vpc.dev-env] tags = { Name = "dev-env-gw" } }
- ec2.tf
# Security Group resource "aws_security_group" "public-web-sg" { name = "public-web-sg" vpc_id = "${aws_vpc.dev-env.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "public-web-sg" } } resource "aws_security_group" "praivate-db-sg" { name = "praivate-db-sg" vpc_id = "${aws_vpc.dev-env.id}" ingress { from_port = 5432 to_port = 5432 protocol = "tcp" cidr_blocks = ["10.0.1.0/24"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "public-db-sg" } } # EC2 Key Pairs resource "aws_key_pair" "common-ssh" { key_name = "common-ssh" public_key = "<公開鍵の中身をペースト>" } # EC2 resource "aws_instance" "webserver" { ami = "ami-011facbea5ec0363b" instance_type = "t2.micro" key_name = "common-ssh" vpc_security_group_ids = [ "${aws_security_group.public-web-sg.id}" ] subnet_id = "${aws_subnet.public-web.id}" associate_public_ip_address = "true" ebs_block_device { device_name = "/dev/xvda" volume_type = "gp2" volume_size = 30 } user_data = "${file("./userdata/cloud-init.tpl")}" tags = { Name = "webserver" } } # Output output "public_ip_of_webserver" { value = "${aws_instance.webserver.public_ip}" }(※)Security Groupで記載しているcidr_blocksは例になります。実際に使用する場合はセキュリティを充分に配慮し、特にSSHは送信元を制限しましょう。
- rds.tf
# RDS resource "aws_db_subnet_group" "praivate-db" { name = "praivate-db" subnet_ids = ["${aws_subnet.private-db1.id}", "${aws_subnet.private-db2.id}"] tags = { Name = "praivate-db" } } resource "aws_db_instance" "test-db" { identifier = "test-db" allocated_storage = 20 storage_type = "gp2" engine = "postgres" engine_version = "11.5" instance_class = "db.t3.micro" name = "testdb" username = "test" password = "test" vpc_security_group_ids = ["${aws_security_group.praivate-db-sg.id}"] db_subnet_group_name = "${aws_db_subnet_group.praivate-db.name}" skip_final_snapshot = true }(※)passwordの値は例として記載。使用不可な文字列もあります。
- cloud-init.tpl
#cloud-config runcmd: # ホスト名の変更 - hostnamectl set-hostname webserver # パッケージのインストール ## セキュリティ関連の更新のみがインストール - yum update --security -y ## PostgreSQL client programs - yum install -y postgresql.x86_64 # タイムゾーン変更 ## 設定ファイルのバックアップ - cp -p /etc/localtime /etc/localtime.org ## シンボリックリンク作成 - ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtimeTerraform構築
はじめに、以下の準備作業を行います。
- 環境変数の有効化
$ source env-vars- 環境変数の確認
$ env準備作業完了後、いよいよTerraform構築です。
Terraform構築作業は次の3Stepです!
terraform initで初期化terraform planで確認terraform applyで適用
terraformコマンドの説明については割愛します。
terraform apply実行後、Apply complete!のメッセージが出力されると各リソースが作成されます。
RDSへはEC2インスタンスからpsqlを実行して接続するか、SSH経由でDBeaverなどのSQLクライアントから接続することができます。terraform apply
plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_db_instance.test-db will be created + resource "aws_db_instance" "test-db" { + address = (known after apply) + allocated_storage = 20 + apply_immediately = (known after apply) + arn = (known after apply) + auto_minor_version_upgrade = true + availability_zone = (known after apply) + backup_retention_period = (known after apply) + backup_window = (known after apply) + ca_cert_identifier = (known after apply) + character_set_name = (known after apply) + copy_tags_to_snapshot = false + db_subnet_group_name = "praivate-db" + endpoint = (known after apply) + engine = "postgres" + engine_version = "11.5" + hosted_zone_id = (known after apply) + id = (known after apply) + identifier = "test-db" + identifier_prefix = (known after apply) + instance_class = "db.t3.micro" + kms_key_id = (known after apply) + license_model = (known after apply) + maintenance_window = (known after apply) + monitoring_interval = 0 + monitoring_role_arn = (known after apply) + multi_az = (known after apply) + name = "testdb" + option_group_name = (known after apply) + parameter_group_name = (known after apply) + password = (sensitive value) + performance_insights_enabled = false + performance_insights_kms_key_id = (known after apply) + performance_insights_retention_period = (known after apply) + port = (known after apply) + publicly_accessible = false + replicas = (known after apply) + resource_id = (known after apply) + skip_final_snapshot = true + status = (known after apply) + storage_type = "gp2" + timezone = (known after apply) + username = "test" + vpc_security_group_ids = (known after apply) } /*中略*/ aws_db_instance.test-db: Still creating... [3m0s elapsed] aws_db_instance.test-db: Creation complete after 3m5s [id=test-db] Apply complete! Resources: 13 added, 0 changed, 0 destroyed. Outputs: public_ip_of_webserver = <IPアドレス(※)>(※)EC2のパブリックIPが出力されます。
ナレッジ
AWS環境におけるリソース作成時の留意事項について以下に記載します。
- アベイラビリティゾーン
RDSの作成は複数のアベイラビリティゾーンの指定が必要です。単一では作成できません。本記事執筆時点で日本リュージョンの場合、以下から2つのアベイラビリティゾーンを指定する必要があります。zones: ap-northeast-1c, ap-northeast-1a, ap-northeast-1d.
terraform destroy実行時にRDSを削除したい場合
RDSはリソース削除時にデフォルトでスナップショットの作成が求められるため、terraform destroyを行うためにはtfファイルにskip_final_snapshotのオプションをtrueに指定する必要があります。デフォルトはfalse。本番環境で行う場合は注意しましょう。RDSのPostgreSQL仕様
RDSにおけるPostgreSQLの照合順序及びCtypeのデフォルトは、en_US.UTF-8になっています。性能を考慮する場合はpsqlで接続してdropして再作成した方が良さそうです。OpensshでSSHキーペアを作成した場合
OpensshでSSHキーペアを作成し、DBeaverなどのSQLクライアントを使用してSSH経由で接続する場合は、鍵の形式を変更する必要があります。おわりに
以上、Terraform3分クッキング
でした。