- 投稿日:2020-01-21T23:51:05+09:00
Djangoのチュートリアルやってみた。Part4
今回はフォームについて解説してあります。
1 フォームの作成
polls/index.htmlを更新します。
polls/templates/polls/detail.html<h1>{{ question.question_text }}</h1> {% if error_message %}<p><strong>{{ error_message }}</strong></p>{% endif %} <form action="{% url 'polls:vote' question.id %}" method="post"> {% csrf_token %} {% for choice in question.choice_set.all %} <input type="radio" name="choice" id="choice{{ forloop.counter }}" value="{{ choice.id }}"> <label for="choice{{ forloop.counter }}">{{ choice.choice_text }}</label><br> {% endfor %} <input type="submit" value="Vote"> </form>2 フォームからデータが送られてきた時の処理を記述する
polls/views.pyfrom django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from .models import Choice, Question # ... def vote(request, question_id): question = get_object_or_404(Question, pk=question_id) try: selected_choice = question.choice_set.get(pk=request.POST['choice']) except (KeyError, Choice.DoesNotExist): # Redisplay the question voting form. return render(request, 'polls/detail.html', { 'question': question, 'error_message': "You didn't select a choice.", }) else: selected_choice.votes += 1 selected_choice.save() # Always return an HttpResponseRedirect after successfully dealing # with POST data. This prevents data from being posted twice if a # user hits the Back button. return HttpResponseRedirect(reverse('polls:results', args=(question.id,)))3 リダイレクト先の処理を書く
polls/views.pyfrom django.shortcuts import get_object_or_404, render def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/results.html', {'question': question})4 リダイレクト先のテンプレート作成
polls/templates/polls/results.html<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li>{{ choice.choice_text }} -- {{ choice.votes }} vote{{ choice.votes|pluralize }}</li> {% endfor %} </ul> <a href="{% url 'polls:detail' question.id %}">Vote again?</a>汎用テンプレートを使う
5 URLconfを修正する
polls/urls.pyfrom django.urls import path from . import views app_name = 'polls' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('<int:pk>/', views.DetailView.as_view(), name='detail'), path('<int:pk>/results/', views.ResultsView.as_view(), name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]Viewを変更する
polls/views.pyfrom django.http import HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from django.views import generic from .models import Choice, Question class IndexView(generic.ListView): template_name = 'polls/index.html' context_object_name = 'latest_question_list' def get_queryset(self): """Return the last five published questions.""" return Question.objects.order_by('-pub_date')[:5] class DetailView(generic.DetailView): model = Question template_name = 'polls/detail.html' class ResultsView(generic.DetailView): model = Question template_name = 'polls/results.html' def vote(request, question_id): ... # same as above, no changes needed.Part 4 おしまい
- 投稿日:2020-01-21T23:25:12+09:00
[GCP]Cloud Functionsでお手軽Webアプリ作成(Flask)
はじめに
Flaskをさわれる人向けに、Cloud Functionsを用いた超単純なWebアプリの作成・公開・削除方法をまとめています。
手順
1. Cloud Shell起動
https://console.cloud.google.com にアクセスし、画面右上にあるプロンプトのアイコン(下図でいう左から2番目)をクリックしてください。
その後、Cloud Shellが表示されますので以下のコマンドを実行してください。
gcloud config set project <プロジェクト名>するとプロンプトにプロジェクト名が追加されます。
username@cloudshell:~ (プロジェクト名)$プロジェクトについて不明な方は以下をご覧ください。
https://cloud.google.com/resource-manager/docs/creating-managing-projects?hl=ja2. ファイル構成
Cloud Shellで以下のようなファイル構成で作成します。
root/ |--main.py |--templates/ |--index.html3. main.pyの作成
main.pyを作成してください。
port=80の部分を変更しても80番ポートでしか接続できませんでした。main.pyfrom flask import render_template, Flask app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def webapp(request): return render_template('index.html') if __name__ == "__main__": app.run(debug=False, host='0.0.0.0', port=80)4. index.htmlの作成
index.htmlを作成してください。<html> <head> </head> <body> hello </body> </html>5. デプロイ
Cloud Shellで
main.pyと同じフォルダに移動したのち、以下のコマンドを実行してください。
deployの後ろにはmain.pyに記載した最初に呼び出したい関数名を記載してください。
今回は関数名をwebappにしたので以下のようなコマンドになります。gcloud beta functions deploy webapp --runtime python37 --trigger-httpデプロイコマンドの詳細は以下に記載されています。
https://cloud.google.com/functions/docs/deploying/filesystem?hl=ja6. 公開したWebアプリの表示
デプロイ完了するとCloud Shellにメッセージが表示されますが、その中に
httpsTriggerという記載があります。
ここに公開されたWebアプリのURLが表示されますのでブラウザで接続してください。httpsTrigger: url: https://us-central1-<プロジェクト名>.cloudfunctions.net/webappすると今回の場合は「hello」と表示されたページが見えます。
7. 公開したWebアプリの削除
https://console.cloud.google.com にアクセスし、[Cloud Functions]をクリックしてください。
すると先ほど公開したWebアプリが表示されますので、左側のチェックボックスにチェックを入れ、画面上部の[削除]をクリックしてください。
これで削除完了です。


- 投稿日:2020-01-21T22:37:07+09:00
Djangoのチュートリアルやってみた。Part3
今回は、ビュー(view) の作成を焦点に解説します。
1 Viewの追加
question_idはURLのパラメータ部分。
polls/views.pydef detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)2 URLとViewの紐付け
question_idを定義している。
polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ # ex: /polls/ path('', views.index, name='index'), # ex: /polls/5/ path('<int:question_id>/', views.detail, name='detail'), # ex: /polls/5/results/ path('<int:question_id>/results/', views.results, name='results'), # ex: /polls/5/vote/ path('<int:question_id>/vote/', views.vote, name='vote'), ]3 ページのテンプレートを作成。
まず、polls ディレクトリの中に、 templates ディレクトリを作成します
次にpolls/templates/polls/index.htmlを作成し下記を写します。polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="/polls/{{ question.id }}/">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}4 Viewとテンプレートを紐付ける
polls/views.pyfrom django.http import HttpResponse from django.template import loader from .models import Question def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] template = loader.get_template('polls/index.html') context = { 'latest_question_list': latest_question_list, } return HttpResponse(template.render(context, request))よく使うのでショートカット用の関数も存在する。
polls/views.pyfrom django.shortcuts import render from .models import Question def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'polls/index.html', context)5 404エラーを発生させる
登録されていない質問を取得しようとしたらエラーを発生させる必要があります。
polls/views.pyfrom django.http import Http404 from django.shortcuts import render from .models import Question # ... def detail(request, question_id): try: question = Question.objects.get(pk=question_id) except Question.DoesNotExist: raise Http404("Question does not exist") return render(request, 'polls/detail.html', {'question': question})polls/templates/polls/detail.html{{ question }}これも頻繁に書くので簡単にかけるようにしてあります。
polls/views.pyfrom django.shortcuts import get_object_or_404, render from .models import Question # ... def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/detail.html', {'question': question})6 テンプレートに動的にデータを代入する
polls/templates/polls/detail.html<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li>{{ choice.choice_text }}</li> {% endfor %} </ul>7 テンプレート内で直接URLを使用しないで動的に値が入るようにする
<li><a href="/polls/{{ question.id }}/">{{ question.question_text }}</a></li>上記を下記に変更する。
<li><a href="{% url 'detail' question.id %}">{{ question.question_text }}</a></li>8 URLの名前空間の定義
上記の url 'detail'では他にアプリを作った時にどのアプリのdetailに飛べばいいかわからなくなってしまうので名前空間を宣言してあげる。
polls/urls.pyfrom django.urls import path from . import views app_name = 'polls' urlpatterns = [ path('', views.index, name='index'), path('<int:question_id>/', views.detail, name='detail'), path('<int:question_id>/results/', views.results, name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]polls/templates/polls/index.html<li><a href="{% url 'detail' question.id %}">{{ question.question_text }}</a></li>上記を下記に変更します。
polls/templates/polls/index.html<li><a href="{% url 'polls:detail' question.id %}">{{ question.question_text }}</a></li>Part3おしまい
- 投稿日:2020-01-21T22:30:18+09:00
0.1は浮動小数点で正確に表せないのに、printしたときに0.1と表示されるのはなぜか
xに0.1を代入し、コンソールに表示すると0.1と表示されます。x = 0.1 print(x) # => 0.1当たり前のことに感じますが、
0.1は浮動小数点(IEEE 754)では正確に表現できません。
なのに0.1と表示されるのは不思議です。
このことについて分かったことを書いておきます。環境
この記事ではPython 3.7を使用しています。
【前提】浮動小数点
この記事で、以降"浮動小数点"という場合は、"IEEE 754 倍精度"のことを指します。
浮動小数点のフォーマットは、数を以下の形式に変換し、
sign、exp、fracを順に並べたものです。(-1)^{sign} \times 2^{exp - 1023} \times (1 + frac \times 2^{-52})それぞれの記号の名前と範囲は以下の通りになります。
記号 日本語名 英語名 範囲 sign 符号 sign 0か1 exp 指数 exponent 1から2,046 frac 仮数 fraction 0から4,503,599,627,370,495 10進数をこの形式に変換する方法は、こちらを参照してください。
http://www.picfun.com/mathlib02.html10進数の小数を2進数の小数にする方法はこちらがわかりやすいです。
https://mathwords.net/syosuu2sin多くの場合、10進数の小数は2進数では循環小数となります。
10進数の小数を2進数に変換する過程で、有限桁で操作を打ち切った場合、変換前の数と誤差を生じます(丸め誤差)。例えば0.1を浮動小数点で表現したとき
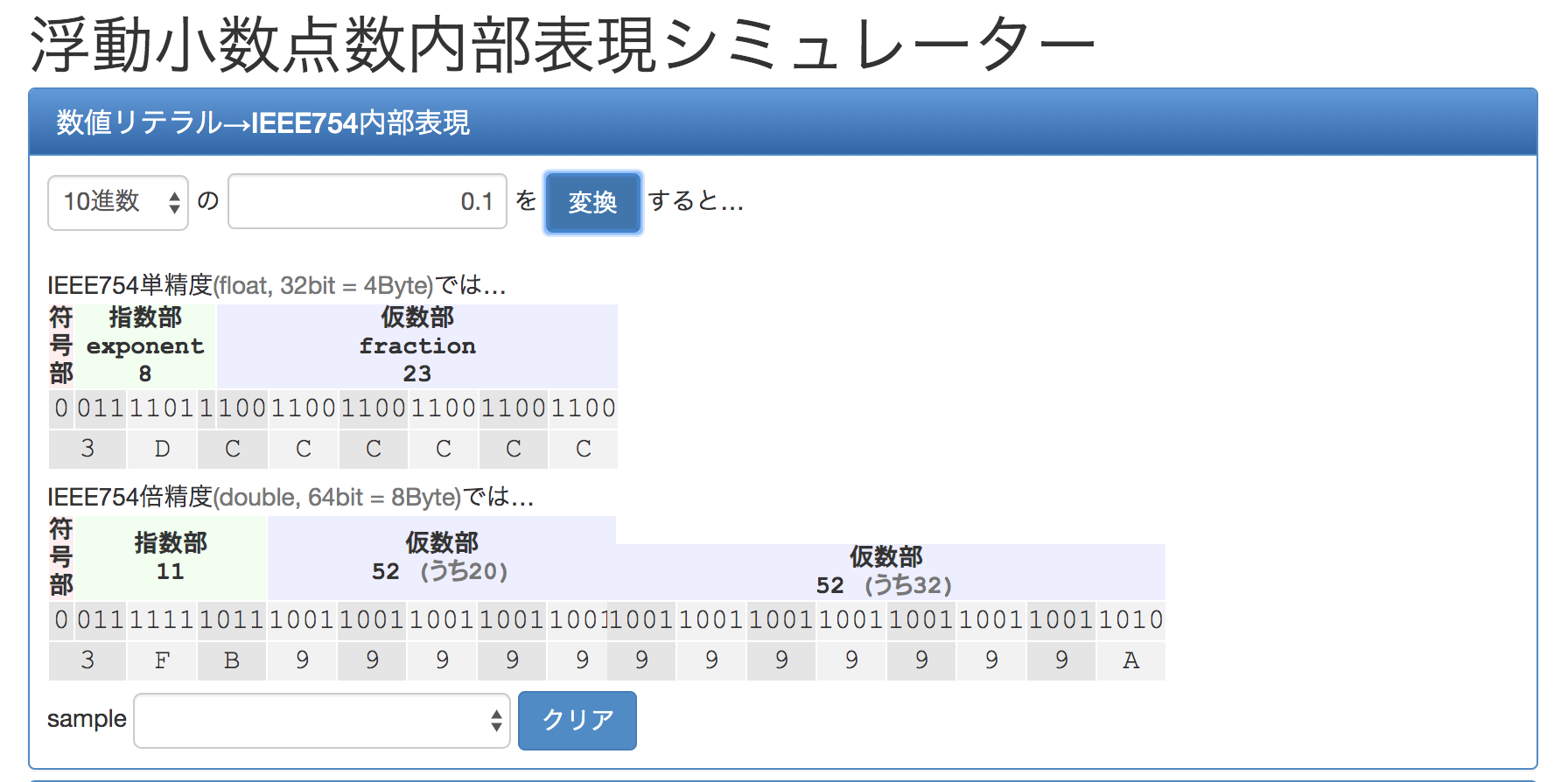
0.1を浮動小数点に変換します。
変換には、以下のツールを利用しました。
https://tools.m-bsys.com/calculators/ieee754.php
0.1は、浮動小数点の2進数表現では、符号 = 0 指数 = 01111111011 仮数 = 100110011001100110011001100110011001100110011001101010進数に変換すると、
符号 = 0 指数 = 1019 仮数 = 2702159776422298です。
上記の浮動小数点の式に当てはめると、
\begin{align} &(-1)^{0} \times 2^{1019-1023} \times (1 + 2702159776422298 \times 2^{-52})\\ &= 1 \times 2^{-4} \times (2^{52} \times 2^{-52} + 2702159776422298 \times 2^{-52})\\ &= 2^{-4} \times (4503599627370496 \times 2^{-52} + 2702159776422298 \times 2^{-52})\\ &= 2^{-4} \times 7205759403792794 \times 2^{-52}\\ &= 7205759403792794 \times 2^{-56}\\ &= \frac{7205759403792794}{72057594037927936}\\ &= 0.1000000000000000055511151231257827021181583404541015625 \end{align}となり、コンピュータ上で0.1は
0.1000000000000000055511151231257827021181583404541015625として扱われていることがわかります。
これが、例えば
0.1を3回足したときに0.3ぴったりにならない原因です(正確にいうと、"ならない"というより"表示されない")。print(0.1 + 0.1 + 0.1) # => 0.30000000000000004printした時の挙動
本題の、
0.1が浮動小数点で正確に表せないのに、0.1と表示されるのはなぜか、ですが、Pythonの公式ページに答えが書いてあります。昔の Python は、プロンプトと repr() ビルトイン関数は 17 桁の有効数字を持つ 0.10000000000000001 のような10進数の値を選んで表示していました。 Python 3.1 からは、ほとんどの場面で 0.1 のような最も短い桁数の10進数の値を選ぶようになりました。
https://docs.python.org/ja/3/tutorial/floatingpoint.htmlとのことです。
つまり、浮動小数点で、
0.1と同じ表現になる数のうち、一番短い表現が選択されるということです。Python以外の言語でも同じような理由で0.1が0.1と表示されるのだと思われます。
逆に言えば、例えば
0.1に非常に近い数であれば、0.1と表示されます。print(0.1000000000000000056) # => 0.1なお、調べた限りでは、
0.099999999999999998612221219218554324470460414886474609375 から 0.100000000000000012490009027033011079765856266021728515625までが、
0.1と表示される範囲です。1番短い表現が特にない場合は17桁の有効数字を持つ数値を表示するようです。
print(0.12345678901234567890) #=> 0.12345678901234568おまけ
Pythonで小数点以下の桁数を指定するには以下のようにします。入力した数値と出力に誤差があることが確認できます。
print(f'{0.1:.20f}') # => 0.10000000000000000555

- 投稿日:2020-01-21T21:02:46+09:00
Python ImageDataGeneratorで画像の水増し
Pythonで画像の水増し
pythonで画像を水増しする際に便利なImageDataGeneratorを紹介します。
関数内の詳細はhttps://keras.io/ja/preprocessing/image/ をご覧ください。以下ソースコード
data_augumentation.py# -*- coding: utf-8 -*- from keras.preprocessing.image import load_img, img_to_array from keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt import numpy as np import os import glob import argparse import cv2 from scipy import ndimage def data_augumentation(input, output, size, ex, ran): files = glob.glob(input + '/*.' + ex) if os.path.isdir(output) == False: os.mkdir(output) for i, file in enumerate(files): img = load_img(file) img = img.resize((size, size)) ksize = 13 x = img_to_array(img) x = np.expand_dims(x, axis=0) datagen = ImageDataGenerator( channel_shift_range=50, rotation_range=180, zoom_range=0.5, horizontal_flip=True, vertical_flip=True, width_shift_range=0.1, height_shift_range=0.1, ) g = datagen.flow(x, batch_size=1, save_to_dir=output, save_prefix='img', save_format='jpg') for i in range(ran): batch = g.next() def main(): parser = argparse.ArgumentParser(description='output mixed images') parser.add_argument('--size', '-s', type=int, default=256, help='size to resize images') parser.add_argument('--out', '-o', default='./', help='Path to the folder containing images') parser.add_argument('--input', '-i', default='./', help='Path to the folder containing images') parser.add_argument('--range', '-r', default=9,type = int, help='data_augumentation range') parser.add_argument('--extension', '-e', default='jpg', help='File extension to images') args = parser.parse_args() os.makedirs(args.out, exist_ok=True) data_augumentation(args.input, args.out, args.size, args.extension, args.range) if __name__ == '__main__': main()関数の使い方
> python data_augumentation.py --size 512 --out outdir --input inputdir --range 3 --e png
コマンドライン引数 内容 --size 出力画像の解像度を指定 --out 出力フォルダの指定 --input 入力フォルダの指定 --range 1枚の画像を何枚水増しするか --extension 入力フォルダ内の拡張子を指定
- 投稿日:2020-01-21T20:42:48+09:00
Djangoのチュートリアルやってみた。Part2
Part2では、
データベースをセットアップ
最初のモデルを作成
Django が自動的に生成してくれる管理 (admin) サイトについての簡単なイントロダクションをします。1 DataBaseの準備をする。
下記のコマンドを行います。
$ python manage.py migrate2 モデルの定義
モデル(データの構造のようなもの)を定義します。
polls/models.pyに下記のコードを写す。
これにより投票するための質問と選択肢が定義される。polls/models.pyfrom django.db import models class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0)3 アプリケーションの追加をプロジェクトに知らせる。
mysite/settings.pyのINSTALLED_APPSの部分に'polls.apps.PollsConfig'を追加します。
mysite/settings.pyINSTALLED_APPS = [ 'polls.apps.PollsConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]4 モデルの作成したことプロジェクトに知らせる。
モデルの作成や変更が通知される。
$ python manage.py makemigrations polls5 モデルに対応するテーブルを作成する。
下記のコマンドでテーブルが作成される。
$ python manage.py migrate6 モデルを使ってできること
# インポート from polls.models import Choice, Question # 全ての質問データを取得 Question.objects.all() # 新しいデータの作成 q = Question(question_text="What's new?", pub_date=timezone.now()) # データの保存 q.save() # データにアクセス q.id q.question_text q.pub_date # データの変更 q.question_text = "What's up?" q.save() # データを探す Question.objects.filter(id=1) Question.objects.filter(question_text__startswith='What') Question.objects.get(id=1) # データの削除 q.delete()7 管理用ユーザの作成
下記のコマンドで作成できます。このときにユーザ名、メールアドレス、パスワードが求められます。
python manage.py createsuperuser8 管理者用ページの確認
$ python manage.py runserverサーバを起動します。そして http://127.0.0.1:8000/admin/ アクセスします。
ログインすると管理者用ページが表示されます。9 管理用ページにpollsを追加する。
このままではpollsの情報が管理できません。
polls/admin.pyを下記のようにするとpollsを管理画面に追加できます。polls/admin.pyfrom django.contrib import admin from .models import Question admin.site.register(Question)これでブラウザからpollsのデータを編集できるようになりました。
- 投稿日:2020-01-21T20:09:20+09:00
自動でVtuberの配信予定を更新するカレンダーを作ってみた
はじめに
はじめまして。ほどよくエンジニアをがんばっているシュンといいます。
自動でVtuberの配信予定を更新するカレンダーを作ってみたので、その過程を書きたいと思います。
今回はYouTube Data APIを使ってYouTubeチャンネルの動画情報を取得します。環境
- Azure VM (Windows Server 2016)
- Python 3.7
用意するデータ
- YouTube チャンネルID
取得するデータ
- チャンネル情報
- 動画情報
方法
まずはじめに、YouTube Data APIを利用できるようにGoogleにアプリケーションを登録します。
詳しい方法はこちら。
(ちなみに、このページからAPIを試すこともできます。)
ここで手に入れたAPIキーを利用して、動画情報を取得していきます。取得の流れとしてはこんな感じになります。
- チャンネルIDからそのチャンネルの動画IDを取得
- 動画IDから動画情報を取得
1. チャンネルIDからそのチャンネルの動画IDを取得
チャンネルIDは知りたいチャンネルのホームを開いたときのURLから取得できます。
例えば僕のイチオシの湊あくあちゃんの場合は、
https://www.youtube.com/channel/UC1opHUrw8rvnsadT-iGp7Cg
これがYouTubeチャンネルのURLなので、チャンネルIDはUC1opHUrw8rvnsadT-iGp7Cgになります。このチャンネルIDを使って動画のリストを取得します。
import urllib.request import json import ssl context = ssl.SSLContext(ssl.PROTOCOL_TLSv1) def get_video_info(channel_id, page_token=None, published_after=None): url = 'https://www.googleapis.com/youtube/v3/search' params = { 'key': 'YOUTUBE_API_KEY', 'part': 'id', 'channelId': channel_id, 'maxResults': 50, 'order': 'date' } if page_token is not None: params['pageToken'] = page_token if published_after is not None: params['publishedAfter'] = published_after req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params))) with urllib.request.urlopen(req, context=context) as res: body = json.load(res) return bodyチャンネルID以外にもパラメータとして以下の値を指定します。
- key
- 最初に取得したAPIキー。
- part
- idとsnippetが指定できます。今回は動画IDが分かればいいのでidを指定。
- channelId
- チャンネルID。
- maxResults
- 返ってくるアイテムの最大数。最大で50なので50を指定。
- order
- いろいろ設定できます。日時順で欲しいのでdateを指定。
- pageToken
- 一度で指定した条件に当てはまる動画を取得しきれない場合、nextPageTokenとして次のページを示す値が得られるのでそれを指定することで続きを取得。
- publishedAfter
- 日時を指定して、その日時より後に作成された動画を取得。
- 日時形式例: 2020-01-01T00:00:00Z
2. 動画IDから動画情報を取得
取得した動画IDを使って今度は各動画の詳細情報を取得します。
def get_video_details(video_ids): url = 'https://www.googleapis.com/youtube/v3/videos' params = { 'key': 'YOUTUBE_API_KEY', 'part': 'snippet, liveStrea mingDetails', 'id': video_ids } req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params))) with urllib.request.urlopen(req, context=context) as res: body = json.load(res) return bodyパラメータは新たにidとして動画IDを指定しているほか、partにsnippetとliveStrea mingDetailsを指定しています。
これで動画の基本的な情報に加えてライブ配信時の情報も取得できます。def get_videos(items): video_ids = '' for item in items: if 'videoId' in item['id']: video_ids += item['id']['videoId'] video_ids += ', ' video_details = get_video_details(video_ids[:-2]) for video_detail in video_details['items']: print(video_detail)最初に取得した動画IDのリストの中には再生リストのIDも含まれているので、videoIdを持っているものだけを集めてから動画情報を取得しています。
これらを合わせて実行するコードが↓になります。
video_info = get_video_info(channel_id='CHANNEL_ID', published_after='DATETIME') get_videos(video_info['items']) while 'nextPageToken' in video_info: page_token = video_info['nextPageToken'] video_info = get_video_info(channel_id='CHANNEL_ID', page_token=page_token) get_videos(video_info['items'])最初に日時を指定して取得、その後はnextPageTokenがある限り、取得を続けます。
湊あくあチャンネルの場合、チャンネル設立が2018/7/31なので、これより古い日時で取得を始めれば全動画の情報を取得できます。実際はこのあとカレンダーの更新等を続けて行いますが、それはまたの機会に......。
- 投稿日:2020-01-21T18:45:47+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 2章Step04メモ
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は2章Step04で、自分なりのポイントをメモります。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
これまでに作成した対話エージェントではBoWを用いて特徴抽出していたが、TF-IDF,BM25,N-gramといった様々な特徴抽出法について学び、文字列を適切な特徴ベクトルに変換することを目指す。
04.1 Bag of Words再訪
Bag of Wordsの性質
BoWは単語の出現頻度をベクトル化したもので、「私」や「好き」といった単語が含まれる「私の嗜好を表す」文意の類似性をある程度捉えられている。
一方、語順情報を含んでいないことからそれぞれメリデメがある。
次節以降の04.2と04.3では文全体の単語頻度や文の長さを考慮した改善、04.4と04.5では単語の分割方法を変えることによる改善を紹介する。
- メリット
- 日本語のような語順が自由な言語では、下記の2文は同じベクトルになる
- 明日友達と遊園地に遊びに行く
- 友達と遊園地に明日遊びに行く
- デメリット
- 主語と目的語が入れ替わったような文が、同じベクトルになってしまう
- 犬が人を噛んだ
- 人が犬を噛んだ
Bag of Wordsの名前由来は、文を単語(Word)に分解して、袋(Bag)にバラバラに放り込み、順序を無視して個数だけ数えるというイメージらしい。
未知語
CountVectorizerの.fitでの辞書作成と.transformのベクトル化する際、ベクトル化する際に会えて無視したい単語がある場合等は、対象とする文集合を分けることができる。
04.2 TF-IDF
BoWの問題点とTF-IDFによる解決
- BoWの問題点:文を特徴付ける単語と文を特徴付けない単語が同等に扱われてしまう
- TF-IDFによる解決:文を特徴付けない単語の寄与を小さく補正する
- いろいろな文に広く登場する単語は一般的な単語であるため、個々の文の意味を表現する上で重要でない
Scikit-learnによるTF-IDFの計算
CountVectorizer(BoW)の代わりにTfidfVectorizerを用いる。
TF-IDFの計算方法
最終的には、単語頻度のTF(TermFrequency)と文書頻度の逆数の対数IDF(InverseDocumentFrequency)を乗じた値になる。
TF-IDF(t,d) = TF(t,d)・IDF(t)
- TF:文中に頻繁に登場すると値が大きくなる
- IDF:多くの文に登場すると値が小さくなる
04.3 BM25
TF-IDFにさらに文の長さを考慮するよう修正を加えたものである。
04.4 単語N-gram
今まではわかち書きした結果、1単語を1次元として扱っていたので単語uni-gramの手法と言える。
これに対し、2単語をまとめて1次元として扱う手法を単語bi-gramと呼ぶ。
また3単語をまとめる場合は単語tri-gramで、これらをまとめて単語N-gramと呼ぶ。# わかち書き結果 東京 / から / 大阪 / に / 行く # uni-gramは5次元 1.東京 2.から 3.大阪 4.に 5.行く # bi-gramは4次元 1.東京から 2.から大阪 3.大阪に 4.に行く考慮すべき事項
単語N-gramを使うと、BoWでは無視していた語順情報を、ある程度考慮に入れた特徴抽出ができるようになる。
その一方で、Nを増やすほど次元は増えていくし、特徴がスパースになるので汎化性能はその文落ちてしまうことになるので、N-gramを使う際は上記のトレードオフを考慮する必要がある。Scikit-learnによるBoW、TF-IDFでの利用
CountVectorizerやTfidVectorizerのコンストラクタに
ngram_range=(最小値,最大値)引数を与える。
最小値と最大値を与えることによって、指定範囲内のN-gramを全て特徴ベクトルにすることができる。(例:uni-gramとbi-gramを両方使って辞書を生成することも可能)04.5 文字N-gram
単語ではなく、文字に対してN字をひとまとまりの語彙としてBoWを構成する考え方である。
文字N-gramの特徴(考慮すべき点)
単語の表記ゆれに強かったり、そもそも形態素解析(わかち書き)をしないので複合語や未知語にも強い。
その一方で、文字列としては似ていて意味が異なる単語・文を区別する能力が小さくなったり、日本語は文字の種類が多いため、次元数が大きくなる可能性がある。04.6 複数特徴量の結合
単語N-gramで複数のN-gramを結合して特徴ベクトルとして扱えたように、異なる特徴量を結合することができる。
# 特徴ベクトルをそれぞれ算出した後に結合する場合 bow1 = bow1_vectorizer.fit_transform(texts) bow2 = bow2_vectorizer.fit_transform(texts) feature = spicy.sparse.hstack((bow1, bow2)) # scikit-learn.pipeline.FeatureUnionを用いる場合 combined = FeatureUnion( [ ('bow', word_bow_vectorizer), ('char_bigram', char_bigram_vectorizer), ]) feature = combined.fit_transform(texts)複数の特徴量を連結する際の考慮事項
- 次元が大きくなる
- 性質の違う特徴量を連結すると精度が下がる可能性がある
- 値の範囲が大きく違う
- 疎性が大きく違う
04.7 その他アドホックな特徴量
下記のような特徴量も加えることができる。
- 文の長さ(下記の例)
- 句点で区切った場合の文の数(下記の例)
- 特定の単語の出現回数
Scikit-learnによるアドホックな特徴量の結合
途中経過を確認しておく。
test_sklearn_adhoc_union.py### メインソースは省略 import print print('# num_sentences - \'こんにちは。こんばんは。\':') print([sent for sent in rx_periods.split(texts[0]) if len(sent) > 0]) print('\n# [{} for .. in ..]') print([{text} for text in texts]) textStats = TextStats() print('\n# TextStats.fit():' + str(type(textStats.fit(texts)))) fitTransformTextStats = textStats.fit_transform(texts) print('\n# TextStats.fit_transform():'+ str(type(fitTransformTextStats))) pprint.pprint(fitTransformTextStats) dictVectorizer = DictVectorizer() print('\n# DictVectorizer.fit():' + str(type(dictVectorizer.fit(fitTransformTextStats)))) fitTransformDictVectorizer = dictVectorizer.fit_transform(textStats.transform(texts)) print('\n# DictVectorizer.fit_transform():' + str(type(fitTransformDictVectorizer))) pprint.pprint(fitTransformDictVectorizer.toarray()) countVectorizer = CountVectorizer(analyzer = 'char', ngram_range = (2, 2)) print('\n# CountVectorizer.fit():' + str(type(countVectorizer.fit(texts))))実行結果$ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python test_sklearn_adhoc_union.py # num_sentences - 'こんにちは。こんばんは。': ['こんにちは', 'こんばんは'] # [{} for .. in ..] [{'こんにちは。こんばんは。'}, {'焼肉が食べたい'}] # TextStats.fit():<class '__main__.TextStats'> # TextStats.fit_transform():<class 'list'> [{'length': 12, 'num_sentences': 2}, {'length': 7, 'num_sentences': 1}] # DictVectorizer.fit():<class 'sklearn.feature_extraction.dict_vectorizer.DictVectorizer'> # DictVectorizer.fit_transform():<class 'scipy.sparse.csr.csr_matrix'> array([[12., 2.], [ 7., 1.]]) # CountVectorizer.fit():<class 'sklearn.feature_extraction.text.CountVectorizer'>04.8 ベクトル空間モデル
線形代数の2次元/3次元ベクトル空間をイメージする。
識別器の役割
3次元ベクトル空間でかつ二値分類(どちらのクラスに属すか)の場合は、判断する際の境界を識別面・決定境界と呼ぶ。
- 学習:教師データの内容を満たすようにベクトル空間中に境界を引く処理
- 予測:新たに入力された特徴量が境界のどちら側にあるかを判断する処理
04.9 対話エージェントへの適用
前章からの追加・変更点
- 特徴量:BoW → TF-IDF
- 単語N-gramを追加(uni-gram、bi-gram、tri-gram)
~~ pipeline = Pipeline([ # ('vectorizer', CountVectorizer(tokenizer = tokenizer),↓ ('vectorizer', TfidVectorizer( tokenizer = tokenizer, ngram_range=(1,3))), ~~実行結果# evaluate_dialogue_agent.pyの読み込みモジュール名を修正 from dialogue_agent import DialogueAgent ↓ from dialogue_agent_with_preprocessing_and_tfidf import DialogueAgent $ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python evaluate_dialogue_agent.py 0.58510638
- 通常実装(Step01):37.2%
- 前処理追加(Step02):43.6%
- 前処理+特徴抽出変更(Step04):58.5%
- 投稿日:2020-01-21T18:25:45+09:00
文字を画像化してslackに投稿 (python slackbot)
前回(かなり前ですが)に書いたhubotの文字を画像化して投稿するスクリプトですが、
最近は、Pythonをさわる機会が多いのと、
python slackbot が使いやすいと思うので、pythonで書き直してみましたpythonだと、ImageMagicを入れなくていい代わりに、pip で Pillow を入れる必要があります
Pythonは3以降を使用しています、
環境によっては下記コマンドはpipではなく、pip3だったりしますPillowをインストール
pip install Pillow文字を画像化してslackに投稿するスクリプト
# -*- coding: utf-8 -* from slackbot.bot import respond_to from slackbot.bot import listen_to from slackbot.bot import default_reply from PIL import Image, ImageDraw, ImageFont import random @respond_to('str_img\s+(.*)') def mention_func1(message, arg1): spcolor = [ 'magenta', 'orange', 'LimeGreen', 'blue', 'purple', 'OrangeRed', 'SkyBlue', 'LightBlue', 'Turquoise', 'gold' ] im = Image.new("RGB",(50,50),"white") fnt = ImageFont.truetype('/slackbot/plugins/cp_font.ttf', 50) draw = ImageDraw.Draw(im) text_size = draw.textsize(arg1, fnt) im = im.resize(text_size) draw = ImageDraw.Draw(im) draw.text((0,0), arg1, fill=random.choice(spcolor), font=fnt) im.save("/tmp/str_img.png") message.channel.upload_file(fname="/tmp/str_img.png", fpath="/tmp/str_img.png")よくわかってないところ
- 文字を追加して、文字幅分のイメージを作成するために、ImageDraw.Draw を二回してます
- python(とくに画像関連)に詳しいわけじゃないので、他にいい書き方があれば修正します
その他
- 画像サイズを変えるオプションを前回はつけていましたが、 slack に表示されるときに同じ大きさにされてしまうので、今回は省きました
- 投稿日:2020-01-21T18:18:36+09:00
GCSのファイルをBigQueryにロードするジョブをPythonで実装したメモ
サンプルコード
# sevice account の設定しないと認証エラー出ます # export GOOGLE_APPLICATION_CREDENTIALS=/path/to/credential from google.cloud import bigquery client = bigquery.Client('project') table_ref = client.dataset('dataset').table('table$20200101') # partition指定する job_config = bigquery.LoadJobConfig() job_config.write_disposition = bigquery.WriteDisposition.WRITE_TRUNCATE # 上書き job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON # JSON # job_config.ignore_unknown_values = True #unknowsな値を許容するならコメント外す uri = 'gs://bucket/path/*.gz' # ディレクトリ以下全て指定 load_job = client.load_table_from_uri( uri, table_ref, job_config=job_config ) load_job.result() print("Job finished.")参考
CSV データをテーブルに読み込む
- 投稿日:2020-01-21T18:15:34+09:00
オンライン周波数解析アプリを作ってみた
背景
今回、周波数解析アプリを作ってみた経緯として、現在私が所属している大学の研究室では、脈波や心電図について研究している班が複数あるのですが、それらを解析するためのソフト(WaveLab有料ソフト)が入っているPCが1台しかないという現状です。
この現状により一つの班がソフトを使用している時に別の班は解析できないので、自分で作ってみようと思いました。
また、オンラインで周波数解析ができるようになると、ネットに繋がってさえいれば、わざわざソフトをインストールせずにどこでも解析ができるようになり、とても便利になると考えています。使用した言語について
このWebアプリケーションを作成するのにPythonを使用しました。理由として、Pythonで有名なライブラリのNumpyとScipyを使って作成しようと思ったからです。この2つのライブラリは、周波数解析をするための機能がたくさん入っているので、これらを使って作成していきます。
フレームワークでDjangoを使用した理由はPythonのFWと言えば、Djangoなのかなと思ったので使用しました。周波数解析モジュールの作成
脈波や心電図を解析するためのモジュールを作成します。
モジュール名はanalysis.pyにしています。analysis.pyimport io import pathlib import numpy as np from scipy import signal import matplotlib.pyplot as plt from .models import Pulse_Rate def setPlt(pk): # 対象データを取得 pulse_rate = Pulse_Rate.objects.get(pk=pk) path = pathlib.Path(pulse_rate.data.url) # データを読み込む f = open(path.resolve()) lines = f.read().split() # -----変数の準備----- N = 4096 lines_length = int(len(lines) / 2) if lines_length < N: N = 2048 dt = float(lines[2]) - float(lines[0]) pulse = [] for num in range(N - 1): pulse.append(float(lines[num * 2 + 1])) # ------------------- # -----サンプリング周波数計算----- t = np.arange(0, N * dt, dt) # time freq = np.linspace(0, 1.0 / dt, N) # frequency step # ----------------------------- # -----波形の生成----- y = 0 for pl in pulse: y += np.sin(2 * np.pi * pl * t) # ------------------- # -----フーリエ変換----- yf = np.fft.fft(y) # 高速フーリエ変換 # -------------------- # パワースペクトル算出 yf_abs = np.abs(yf) # -----グラフの生成----- plt.figure() plt.subplot(211) plt.plot(t, y) plt.xlabel("time") plt.ylabel("amplitude") plt.grid() plt.subplot(212) plt.plot(freq, yf_abs) plt.xlim(0, 10) plt.xlabel("frequency") plt.ylabel("amplitude") plt.grid() plt.tight_layout()こんな感じで脈波や心電図のグラフとパワースペクトルのグラフを生成します。
データはユーザーがアップロードしたテキストファイルから読み出します。Webページにグラフを表示する
上のモジュールではplotでグラフを作成しているので、これをsvg形式でWebページに表示したいと思います。
analysis.pydef pltToSvg(): buf = io.BytesIO() plt.savefig(buf, format='svg', bbox_inches='tight') s = buf.getvalue() buf.close() return sこれでplotをsvgに変換してWebページに表示することができます。
views.pyの設定
上記のモジュールを使用してviews.pyを書きます。
views.pydef get_svg(request, pk): setPlt(pk) # create the plot svg = pltToSvg() # convert plot to SVG response = HttpResponse(svg, content_type='image/svg+xml') return responseこれでHttpResponse(svg形式)でレスポンスを返します。
urls.pyの設定
URLの設定をします。
urls.pyurlpatterns = [ ... path('pulse_rate-detail/<int:pk>/plot/', views.get_svg, name="plot"), ]templatesの設定
今回グラフを表示するページは詳細画面にしたいと思います。
pulse_rate_detail.html<img src="{% url 'pulse_rate:plot' object.pk %}" width=600, height=300>これでグラフを表示することができます。
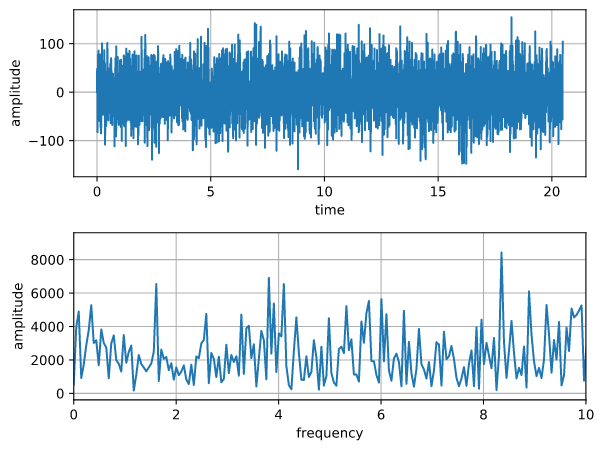
作成したグラフ
実際に作成できるグラフは以下のようになります。
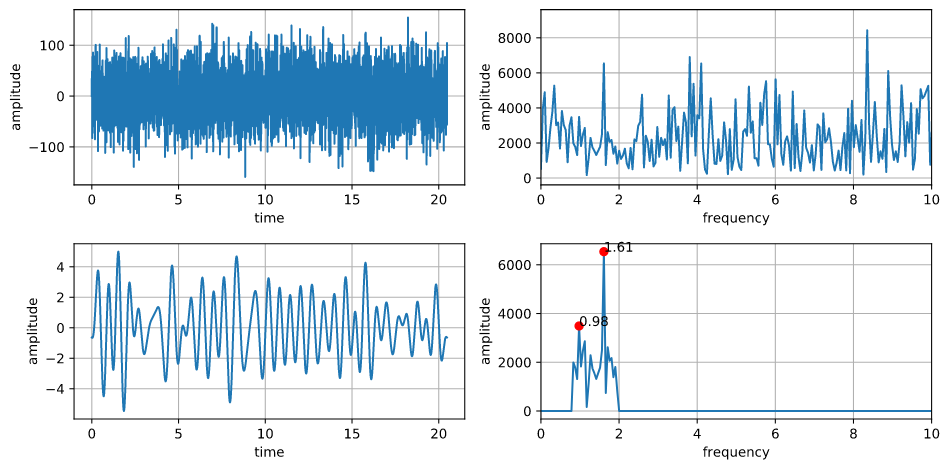
フィルタ処理をしたグラフの生成
上の図はフィルタ処理をしていないデータをグラフ化しているので、このままでは何もわかりません。
そこでフィルタ処理の機能を追加してグラフを生成しました。(コードについては省きます)
フィルタをかけるとなんとなく脈波っぽい波形がでます。(この脈波はカメラで撮影したRGB値のG成分を利用して出しているので、完璧な波形にはなりません)
フィルタの下限周波数と上限周波数はWebページから自分で調整することができるようにしています。まとめ
今回作成したアプリケーションは今後研究室で使用していく予定です。
また、私の所属している研究室では、心電図や脈波以外の研究をしている班もあるため、それらの班のためにも何か作成したいと考えています。
実際、私の研究テーマは人の鼻の温度からその人のストレス度を測定するというテーマをしております。私は自分の所属している研究室を大学内で一番イケてる研究室にしたいと考えているので4年生になってもこのようなアプリケーションを作成したいです!
- 投稿日:2020-01-21T18:13:31+09:00
[Python]メモ帳Twitterを作る(タイムライン表示編)
[Python]メモ帳Twitterを作る(ツイート編) - Qiitaの続編です。
上記の記事を投稿して1年以上経ってしまいました。
前回はツイートするところまで出来たので、今回はタイムラインを表示してみたよという備忘録。PythonでTkinterというGUI作れるライブラリ使ってメモ帳twitter作るよ!
前回のを少し修正
前回はツイート時に認証を通していたが、何度も認証通すのが面倒くさいので起動時に認証通すようにしてしまいました。
あとは可変があるキーはあとから修正しやすいように別ファイルに隔離しました。config.py#twitterの認証に必要なキー一覧 CONSUMER_KEY = "XXXXXXXXXXXXXXX" CONSUMER_SECRET = "XXXXXXXXXXXXXXX" ACCESS_TOKEN = "XXXXXXXXXXXXXXX" ACCESS_TOKEN_SECRET = "XXXXXXXXXXXXXXX"notepad.py# -*- coding: Shift_JIS -*- import tkinter import tkinter.font as font import json import config #config.pyの読み込み from requests_oauthlib import OAuth1Session #OAuthのライブラリの読み込み def tweet(): tweet = text_widget.get('1.0','end -1c') params = {"status": tweet} twitter.post("https://api.twitter.com/1.1/statuses/update.json",params = params) #認証部分を起動時に実行 #config.pyから各キーの取得 CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) root = tkinter.Tk() #以下前回と変わっていないため略タイムライン上のツイートを取得する
ここから本題です。
twitterのタイムラインを取得して表示していきます。
URLとパラメーター指定してtwitterからタイムラインの取得を行います。詳しい内容は公式ドキュメント参照
日本語翻訳されたのもあるよURLは
https://api.twitter.com/1.1/statuses/home_timeline.jsonらしい。パラメータはひとまず取得するツイート数のみ指定
Notepad.pydef getTimeLine(): url = "https://api.twitter.com/1.1/statuses/home_timeline.json" params ={'count' : 200} #取得ツイート数 req = twitter.get(url, params = params)取得したツイートを整形する
取得したツイートを良い感じに整形します。
Tkinterでは文字コードが基本多言語面?と呼ばれU+0000~U+FFFFの文字しか使えないらしい。
難しい文字とか使えないよーってやつですね。
なのでそれ以外の文字を出力しようとすると下記のようなエラーが表示される。
下記エラーは?(U+1f914)を表示しようとしてエラーが出ています。?????_tkinter.TclError: character U+1f914 is above the range (U+0000-U+FFFF) allowed by Tcltwitterはで顔文字が使われるなんてざらにあるのでそいつらは除外しつつ表示していきます。
なお今回は、ツイート内容、ユーザー名、投稿日時のみを対象としていますが、他にもいろいろな情報を持っています。
詳しくは公式ドキュメントを参照Notepad.pydef getTimeLine(): #~略~ #レスポンスステータスコードが200(成功)だった場合のみ実行 if req.status_code == 200: #取得されたツイートを1つづつリストに格納 timeline = json.loads(req.text) #ツイート1つ1つを整形して出力 for tweet in timeline: #tweetの対応外文字削除 #一文字ずつ精査し文字コードがU-FFFF(65535)以下の文字をリストに入れる。(ここもっとスマートな方法あったら教えてください) char_list = [tweet['text'][i] for i in range(len(tweet['text'])) if ord(tweet['text'][i]) in range(65535)] tweetstr = '' #リストに入っている文字をくっつけて文字列に for i in char_list: tweetstr=tweetstr+i #usernameの対応外文字削除 #usernameもツイート内容と同じく対応 char_list = [tweet['user']['name'][j] for j in range(len(tweet['user']['name'])) if ord(tweet['user']['name'][j]) in range(65535)] name = '' for j in char_list: name=name+j #レスポンスステータスコードが200(成功)以外の場合はステータスコードを表示 else: print("ERROR: %d" % req.status_code)ツイートを表示する
あとは内容をGUI上に表示するだけ、
前回作成したエディット上に表示させます。
表示にはinsertを使います
Tkinterのドキュメントより
https://docs.python.org/ja/3/library/tkinter.ttk.htmlinsert(pos, child, **kw)
指定された位置にペインを挿入します。pos は文字列の "end" か整数のインデックスか管理されている子ウィンドウの名前です。 child が既にノート>ブックの管理対象だった場合、指定された場所に移動させます。
ということらしいです。なるほど
基本的に一つ目の引数に'end'を入れておけばいいって感じだと思います。
ユーザー名とツイート内容、ツイート時間と見やすいように1ツイートごとに点線で区切ってます。
ここはいい感じに。あと何回も実行する場合に備えてはじめてにテキストボックスをクリアしておきます。
Notepad.pydef getTimeLine(): # テキストボックスをクリア text_widget.delete(1.0,tkinter.END) #~略~ text_widget.insert('end',name + '\n' + tweetstr+'\n') text_widget.insert('end',tweet['created_at']+'\n') text_widget.insert('end','----------------------------------------------------\n')これでタイムラインへの表示まで完了しました。
あとはコマンドの追加をして今回作成した関数を実行できるようにして終わりです。
今回は開く(O)ボタンでタイムライン表示することにします。Notepad.pyfilemenu.add_command(label="開く(O)...", command=getTimeLine)実行結果
今回作成したプログラム
[Python]メモ帳Twitterを作る(ツイート編) - Qiitaのを含め今回作成したプログラムを下記に置いています。
higuratujino/NotepadTwitter - GitHubさいごに
なるだけメモ帳っぽさを保ちたいためできるだけ違和感の内容に実装していきたいです
(色々詰め込めない言い訳)python初心者なので実装で至らない点等ありましたらアドバイスお願い致します。
今回の課題点はツイート時間がUTC時刻になっちゃってること。次回はツイートにたいしてリプライを返せるようなサムシングができたらいいなと妄想しております。
それかファボ&リツイート参考資料
tkinter.ttk --- Tk のテーマ付きウィジェット
12. Tk.Text の使い方 - 紫藤のページ
pythonでツイッターのタイムラインの取得 - Qiita
Get Tweet timelines - TwitterDeveloper
Twitter 開発者 ドキュメント日本語訳
- 投稿日:2020-01-21T17:13:27+09:00
MeCabのコスト計算について
はじめに
MeCabのコスト計算について勉強したのでまとめてみました。
どこか間違っていたらご指摘ください。MeCabの形態素解析の概要
MeCabは登録された辞書を使って形態素解析を行います。もし辞書に登録されていない単語(未知語)が出た場合、各単語のコストに基づいて分割します。そのなかで総コストが最小のものを結果として出力します。
実際にやってみる
今回はipadic-neologd辞書を用いて、架空の単語「アメリカドイツ村」がどのように形態素解析されるか確認します。
echo アメリカドイツ村|mecab -d C:\neologd -N2 アメリカ 名詞,固有名詞,地域,国,*,*,アメリカ,アメリカ,アメリカ ドイツ 名詞,固有名詞,地域,国,*,*,ドイツ,ドイツ,ドイツ 村 名詞,接尾,地域,*,*,*,村,ムラ,ムラ EOS アメリカ 名詞,固有名詞,地域,国,*,*,アメリカ,アメリカ,アメリカ ドイツ村 名詞,固有名詞,一般,*,*,*,ドイツ村,ドイツムラ,ドイツムラ EOS-dで辞書を指定し、NUMオプションで指定した数だけ候補を挙げます。
このように未知語に対して2種類の分け方が候補に挙がりました。この分け方は私たちにとっても、かなり納得のいくものではないでしょうか。MeCabの辞書
コストの計算に入る前に、MeCab辞書の登録方法について説明します。
辞書は、表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音という形でcsvファイルとして保存してから辞書をビルドします。これをみると、
・ 左文脈ID
・ 右文脈ID
・ コスト
という見慣れない言葉が含まれています。これらがMeCabの形態素解析に用いられる情報になります。生起コスト
生起コストとは、ある単語自体の現れにくさです。値が高いほどその単語は現れにくくなります。生起コストは先ほど登録した辞書のコストの値です。それでは「アメリカドイツ村」はどのような生起コストになったのでしょうか?
echo アメリカドイツ村|mecab -F "%m,%c,\n" -d C:\neologd -N2 アメリカ, 4698, ドイツ, 2543, 村, 8707, EOS アメリカ, 4698, ドイツ村, 611, EOS%mで表層形、%cで生起コストを表示させます。
ここで一つの疑問が生まれます。総コストは明らかに2つ目の方が小さいはずなのに、出力第一候補は1つ目の結果になっています。その理由は新たなコスト、連接コストの存在にあります。連接コスト
連接コストとは、2つの単語の文脈IDの連続しにくさです。値が小さいほど連続する可能性が高くなります。文脈IDは辞書の左文脈IDと右文脈IDに当たります。基本的にこのIDは登録時には同じ値になっていると思われます。例えば「前後」という単語を考えます。
「前」の文脈IDは1314,「後」の文脈IDは1313です。連接コストは左文脈IDと右文脈IDの組み合わせで決められます。
組み合わせの一覧はMeCab\dic\ipadicにあるmatrix.def(またはmatrix.bin)にあります。これを見ると、1314 1313 -316 1313 1314 716前→後は連接コストが低い(-316)ため連続しやすく、後→前だと連接コストが高く(716)連続しにくいという結果が得られました。これも割と納得できるかと思います。
それでは「アメリカドイツ村」についても見てみましょう.echo アメリカドイツ村|mecab -F"%m,%phl,%phr,%c,%pc,%pn\n" -d C:\neologd -N2 アメリカ,1294,1294,4698,3746,3746 ドイツ,1294,1294,2543,-141,-3887 村,1303,1303,8707,881,1022 EOS アメリカ,1294,1294,4698,3746,3746 ドイツ村,1288,1288,611,2614,-1132 EOSMeCabコマンドをまとめると以下のようになります。
コマンド 説明 %m 表層形 %phl 左文脈ID %phr 右文脈ID %c(または%pw) 生起コスト %pc 連接コスト+単語生起コスト(文頭から累積) %pn 連接コスト+単語生起コスト(その形態素単独, %pw+%pC) 全てのコマンドはこちらに記載されています。
出力がわかりにくいのでこれも表にしてみます。
表層形 左文脈ID 右文脈ID 生起コスト 連接+生起(累積) 連接+生起(単独) アメリカ 1294 1294 4698 3746 3746 ドイツ 1294 1294 2543 -141 -3887 村 1303 1303 8707 881 1022 アメリカ 1294 1294 4698 3746 3746 ドイツ村 1288 1288 611 2614 -1132 ここで注意していただきたいのは、BOSとEOSにも文脈IDが付与されているということです。なので、1つ目の「アメリカ」の連接コストはmatrix.defより
0 1294 -952となります。そのため、累積コストは4698-952=3746となります。
次に「ドイツ」を見てみましょう。左右の文脈IDが1294で連接コストは-6430とかなり小さくなります。(確かに国名が連続して続くのは珍しい...)
累積コストは(3746+2543)-6430=-141で、単独の場合は2543-6430=-3887で、計算と一致しました。
また、出力はされていませんが、EOSにも文脈IDがあるため最終チェックを行います。
文脈ID1303→0の連接コストは5、文脈ID1288→0は-919で累積コストを比べると、886と1695で1つ目の方が最小コストなので、先ほどの謎が解明できました。参考
MeCabのコスト計算を理解する。
日本テレビ東京で学ぶMeCabのコスト計算
日本語形態素解析の裏側を覗く!MeCab はどのように形態素解析しているか
- 投稿日:2020-01-21T16:26:04+09:00
Pytorchでモデル構築するとき、torchsummaryがマジ使える件について
はじめに
自分でモデルを構築していて、私はいつも全結合層につなぐ前に「あれ、インプットの特徴量っていくつだ?」ってなります。よく
print(model)と打つとモデルの構造は理解できるが、FeatureMapのサイズまでは確認出来ません。そこで便利なのがtorchsummaryというものです。torchsummaryは何者か?
簡単に言うと、
特徴マップのサイズを確認できるものです。どのようにtorchsummaryを使うか
まずはモデルを作ります
今回は以下の簡単なモデルを作りました。
クラス分類するまでは書いていません。畳み込み➡︎BN➡︎ReLU➡︎pooling➡︎
畳み込み➡︎BN➡︎ReLU➡︎pooling➡︎
畳み込み➡︎GlobalAveragePoolingimport torch import torch.nn as nn class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN,self).__init__() self.conv1 = nn.Conv2d(3,16,kernel_size=3,stride=1) self.bn1 = nn.BatchNorm2d(16) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d((2,2)) self.conv2 = nn.Conv2d(16,32,kernel_size=3,stride=1) self.bn2 = nn.BatchNorm2d(32) self.conv3 = nn.Conv2d(32,64,kernel_size=3,stride=1) self.gap = nn.AdaptiveMaxPool2d(1) def forward(self,x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.conv2(x) x = self.bn2(x) x = self.relu(x) x = self.maxpool(x) x = self.conv3(x) x = self.gap(x) return xtorchsummaryのインストール
pip install torchsummarytorchsummary使い方
from torchsummary import summary model = SimpleCNN() summary(model,(3,224,224)) # summary(model,(channels,H,W))今回は、画像の入力サイズを224x224を想定して試しています。
他の解像度で試したいときは、HとWの値を変更してください。summaryの出力
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 16, 222, 222] 448 BatchNorm2d-2 [-1, 16, 222, 222] 32 ReLU-3 [-1, 16, 222, 222] 0 MaxPool2d-4 [-1, 16, 111, 111] 0 Conv2d-5 [-1, 32, 109, 109] 4,640 BatchNorm2d-6 [-1, 32, 109, 109] 64 ReLU-7 [-1, 32, 109, 109] 0 MaxPool2d-8 [-1, 32, 54, 54] 0 Conv2d-9 [-1, 64, 52, 52] 18,496 AdaptiveMaxPool2d-10 [-1, 64, 1, 1] 0 ================================================================ Total params: 23,680 Trainable params: 23,680 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.57 Forward/backward pass size (MB): 30.29 Params size (MB): 0.09 Estimated Total Size (MB): 30.95 ----------------------------------------------------------------OutputのShapeが確認で出来るのはかなり便利です。
パラメータの数もカウントしてくれるのもありがたいです。終わりに
torchsummary便利なので、ぜひ使って見てください。
- 投稿日:2020-01-21T16:21:10+09:00
PowershellからPythonの関数を実行(引数の渡し方)
やりたいこと
PowershellからPythonの関数を実行したい
ポイント
- 引数はコマンドライン引数を使用すること
- sys.argvは文字列なので数値を渡したい時はcastが必要
import sys #引数をsys.argv[n]を使用して定義する a = sys.argv[1]サンプルコード
calc.pydef add(a, b): return a + bmain.pyfrom calc import add import sys a = int(sys.argv[1]) b = int(sys.argv[2]) ret = add(a, b) print(ret)test.ps$a = 5 $b = 10 python.exe main.py $a $b結果6つまづいたところ
・引数を渡す時にPowershellの関数に渡すようなやり方をしたため
引数の定義エラーになったcalc.pydef add(a, b): return a + bmain.pyfrom calc import add ret = add(a, b) print(ret)test.ps$a = 5 $b = 10 python.exe main.py $a $b結果NameError: name 'a' is not defined
- 投稿日:2020-01-21T16:20:02+09:00
Docker上のFlask + Nginxでコンソールにログを出力する
前提
本来であればflask、nginxに加えuwsgiサーバを立てるのが良いのは認識しているが、現状の構成からできることを行なった結果である。
背景
Docker上のFlask + Nginxのサーバを立てたのだが、Flaskのログがファイル出力のみされており、docker runを行なったプロンプトやdocker logsで確認ができない。どうにかしてできるようにしたい。
現状の構成
かなり省略するが、次の通り。
DockerfileFROM centos:centos7 CMD ["/bin/bash", "./start.sh"]start.sh# !/bin/bash uwsgi --ini=uwsgi.ini nginx -g "daemon off;"uwsgi.inidaemonize = /var/log/uwsgi/uwsgi.log上記の状態だとuwsgiプロセスがデーモン化して動作し、フォアグラウンドジョブとしてNginxが動作する。
そして、ログはdaemonizeで指定した/var/log/uwsgi/uwsgi.logに全て出力されてしまう。対応
いくつか対応を試みたがうまくいかず、結果的に3番目の対応方法でうまくいった。
flask上でコンソール出力を明示的に追加
すでにコンソール出力はされているとは思いながら、追加でコンソール出力のストリームを追加することでできないか確認。
logger.addHandler(logging.StreamHandler())しかし、daemonizeは標準出力されるものをファイルに流すようで、追加したストリームの内容もファイルに出力されてしまった。
daemonizeの設定を/dev/stdout に設定
daemonizeは指定したファイルに標準出力・エラー出力を出力してくれるのだが、あえて/dev/stdoutに出力することで標準出力にできないかと試みた。
コンソール出力へはうまく出力ができたが、flaskのログローテーション機能が当該ファイルをチェックにいき、絶えずエラーメッセージが出てしまう。
ログローテーション機能を抑止する方法を探したが、見つからずに断念。uwsgi_check_logrotate()/lseek(): Illegal seek [core/logging.c line 494]ログファイルをtailで監視
起動シェル上でtailによる監視を追加。
ファイルにもコンソールにもログが出力できることを確認。start.shとuwsgi.ini両方で出力ファイルを合わせる必要があるが、とりあえずできた。start.sh# 追加部分 touch /var/log/uwsgi/uwsgi.log tail -F /var/log/uwsgi/uwsgi.log > /dev/stdout & uwsgi --ini=uwsgi.ini nginx -g "daemon off;"
- 投稿日:2020-01-21T16:05:11+09:00
Python命名規則(PEP8より)
Pythonには 「PEP8: Pythonコードのスタイルガイド」があって、変数名や関数名などの命名規則も書いてあります。
命名規則やコーディングスタイルを合わせることで、ソースコードを書くと、読んでくれる人たち、レビューしてくれる人たちの負担を下げることができます。
命名規則だけでなく「リーダブルコード」に書かれている命名方法も参考にしましょう。
用途 命名規則 非公開 先頭にアンダースコアを1個つける サブクラスで名前衝突回避 先頭にアンダースコアを2個つける 予約語や組込み関数と衝突 最後にアンダースコアを1個つける
用途 命名規則 パッケージ 全て小文字の短い名前、アンダースコアは使わない モジュール 全て小文字の短い名前、アンダースコアで接続してよい クラス、例外 CapWords方式 (先頭だけ大文字の単語を繋げる) 関数、メソッド 小文字のみ、必要に応じて単語をアンダースコアで区切る 変数 小文字のみ、必要に応じて単語をアンダースコアで区切る 1文字変数 l(小文字のエル)、O(大文字のオー)、I(大文字のアイ) は決して使わない定数 全て大文字、単語をアンダースコアで区切る リーダブルコード:
- 単語は省略しない (慣例的に省略して使われている名前はOK)
- 1文字変数は見える範囲 (25行以内)で使い終わる一時変数に使う
- 名前に情報・意味を込める (flag, check では何のフラグか、何をチェックしたどんな値か分からない)
- 名前で情報を伝えてコメント不要にする
など。
- 投稿日:2020-01-21T15:32:27+09:00
再帰関数
はじめに、 木情報源であったり、決定木アルゴリズムだったり、木構造の再帰を使う機会が多いので、再帰関数についてまとめたいと思います。
自分自身を実行する関数を再帰関数といい、再帰関数内の自分自身の実行箇所を再帰呼び出しと言います。recursive.ipynbdef recursive_f(depth): print("depth: "+ str(depth)) if depth == 10: return recursive_f(depth + 1) if __name__=="__main__": recursive_f(0)実行結果は次のようになります。
depth: 0
depth: 1
depth: 2
depth: 3
depth: 4
depth: 5
depth: 6
depth: 7
depth: 8
depth: 9
depth: 10自分自身を呼び出すので、どこかで条件分岐をしてあげなければ無限に実行が続きます。
決定木で実装する時は、ノードクラスを作ってやり、自分の子ノードを格納するメンバ変数を持たせ、自分を分割して子ノードを生成するメンバ関数を再帰関数化してやればいいです。自分の子ノードとなるメンバ変数が、更に孫ノードとなるメンバ変数を持ち、更に曽孫ノードとなるメンバ変数を持ち、、の様に永遠に子ノードを生成します。
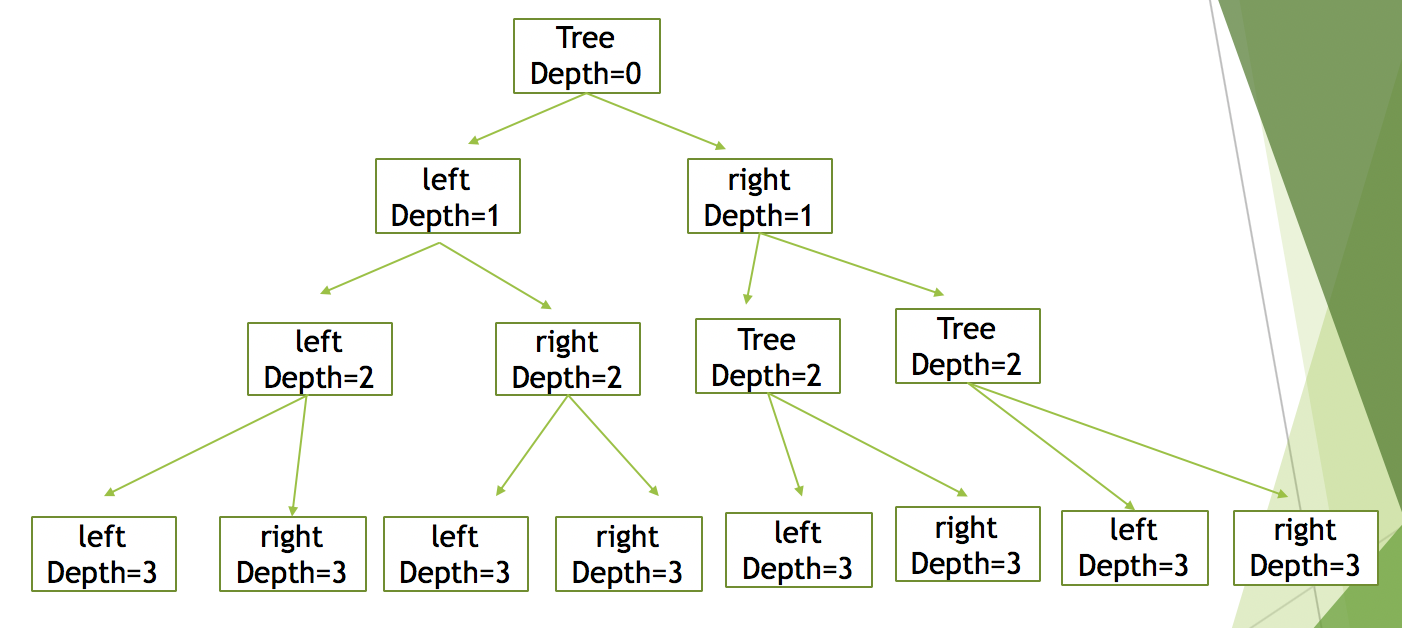
簡単のため、深さが3のときの図を表すと、
これをコード化してあげると
recursive_tree.ipynbclass Node: def __init__(self, max_depth): self.left = None self.right = None self.max_depth = max_depth self.depth = None def split_node(self, depth): self.depth = depth print("depth: " + str(self.depth)) if self.depth == self.max_depth: return self.left = Node(self.max_depth) self.right = Node(self.max_depth) self.left.split_node(depth + 1) # recursive call self.right.split_node(depth + 1) # recursive call if __name__ == "__main__": max_depth = 3 initial_depth = 0 tree = Node(max_depth) tree.split_node(initial_depth)実行結果
depth: 0
depth: 1
depth: 2
depth: 3
depth: 3
depth: 2
depth: 3
depth: 3
depth: 1
depth: 2
depth: 3
depth: 3
depth: 2
depth: 3
depth: 3
以上が、再帰関数の利用例です。この考え方を身につけると決定木アルゴリズムが実装しやすいのでぜひ試してみましょう。
- 投稿日:2020-01-21T15:30:35+09:00
Pythonの正規表現が覚えられない
使い方のかんたんなメモ
import re ptn = re.compile(r"hoge+") # 使い回すならcompileしたほうが速い ptn_with_capture = re.compile(r"(hoge)e*") # キャプチャはカッコを使う string = r"hogee_qwerty_hogeeeeee" # マッチする最初の部分を取得 first_matched_string = re.search(ptn, string).group() print(first_matched_string) # => hogee # キャプチャをつけるとgroup(番号)でその部分だけ取得 first_matched_string = re.search(ptn_with_capture, string).group(1) print(first_matched_string) # => hoge # マッチするすべての部分をリストで取得 matched_string_list = re.findall(ptn, string) print(matched_string_list) # => ['hogee', 'hogeeeeee'] # キャプチャをつけるとキャプチャ部分だけ取得 matched_string_list = re.findall(ptn_with_capture, string) print(matched_string_list) # => ['hoge', 'hoge'] # マッチするすべての部分をイテレータで取得 matched_string_iter = re.finditer(ptn, string) print([ s.group() for s in matched_string_iter]) # => ['hogee', 'hogeeeeee'] # マッチする部分で文字列を分割 split_strings = re.split(ptn, string) print(split_strings) # => ['', '_qwerty_', ''] # マッチする部分を別の文字列で置換 replace_with = r"→\1←" # バックスラッシュと番号でキャプチャしたものを使う。 substituted_string = re.sub(ptn_with_capture, replace_with, string) print(substituted_string) # => →hoge←_qwerty_→hoge← # 最小マッチ minimal_ptn = re.compile(r"h.*?e") # *や?、+など繰り返しを表す記号の後ろに?をつけて最小マッチ。 minimal_matched_string = re.search(minimal_ptn, string) print(minimal_matched_string.group()) # => hoge
- 投稿日:2020-01-21T15:27:37+09:00
numpy 1次元化の処理速度を調べてみた
ブログの動機
numpy配列の平坦化。処理方法により、どの程度速度差が出るのか調べてみました。コードはJupyterで動かしています。
reshape
まずは基本となる
reshapeです。10000×10000のアレイを生成し、平坦化する際の処理速度をみてみます。import numpy as np np.random.seed(0) a = np.random.randn(10**4, 10**4) print(a)出力
[[ 1.76405235e+00 4.00157208e-01 9.78737984e-01 ... 5.16872179e-01 -3.29206931e-02 1.29811143e+00] [-2.02117027e-01 -8.33231001e-01 1.73360025e+00 ... -5.72592527e-02 -1.05893126e+00 -3.26528442e-01] [ 3.30045889e-01 -4.79979434e-04 8.18115898e-01 ... -1.51127631e+00 9.76843833e-01 1.25550065e+00] ...
reshape実行%%time b = a.reshape(-1) b[0] = 100. print(b[:5], '\n') print(a[0, :5], '\n')出力
[100. 0.40015721 0.97873798 2.2408932 1.86755799] [100. 0.40015721 0.97873798 2.2408932 1.86755799] CPU times: user 2 ms, sys: 0 ns, total: 2 ms Wall time: 2.15 ms
reshapeメソッドはそのまま使うと、上記のように元のアレイaの参照渡しになります。新たなメモリ領域を確保する必要もなく高速です。ただaの値も変わってしまうので注意が必要flatten
%%time b = a.flatten() b[0] = 100. print(b[:5], '\n') print(a[0, :5], '\n')出力
[100. 0.40015721 0.97873798 2.2408932 1.86755799] [1.76405235 0.40015721 0.97873798 2.2408932 1.86755799] CPU times: user 152 ms, sys: 378 ms, total: 530 ms Wall time: 532 ms
flattenは上記のように、元のアレイのコピーを渡します。なのでbの値を変更しても、元々のaの値は変更されません。しかし、新たなメモリ領域の確保もあり、処理速度はかなり違います。一概には言えませんが上記の結果だけみるとreshapeの250倍近く処理速度がかかってしまっています。ravel
%%time b = a.ravel() b[0] = 100. print(b[:5], '\n') print(a[0, :5], '\n')出力
[100. 0.40015721 0.97873798 2.2408932 1.86755799] [100. 0.40015721 0.97873798 2.2408932 1.86755799] CPU times: user 2.75 ms, sys: 0 ns, total: 2.75 ms Wall time: 3.36 ms
ravelもreshape同様、参照渡しであり処理速度も高速です。resize
resizeメソッドは破壊的処理です。なのでaというオブジェクト自体を変更してしまいます。しかもreshapeメソッドと違って、shapeと値の数が合わない場合も、エラーにならず良しなに変えてくれます。下記の例ではどんどんaの値が更新されているのが分かります。a.resize(1, 10000*10000) print(a[:5], '\n') a.resize(2, 2) print(a, '\n') a.resize(3, 3) print(a, '\n') a.resize(1) print(a)出力
[[ 1.76405235 0.40015721 0.97873798 ... 0.32191089 0.25199669 -1.22612391]] [[1.76405235 0.40015721] [0.97873798 2.2408932 ]] [[1.76405235 0.40015721 0.97873798] [2.2408932 0. 0. ] [0. 0. 0. ]] [1.76405235]変換前の値を変えたくない場合、以下の様に記述します。
%%time b = np.resize(a, (-1, )) b[0] = 100. print(b[:5], '\n') print(a[0, :5], '\n') print(a.shape, '\n') print(b.shape, '\n')出力
[100. 0.40015721 0.97873798 2.2408932 1.86755799] [1.76405235 0.40015721 0.97873798 2.2408932 1.86755799] (10000, 10000) (99999999,) CPU times: user 235 ms, sys: 1.95 ms, total: 237 ms Wall time: 239 ms!?
aは変更されずに済みましたが、よくよく見ると肝心のbの値が1つ少なくなっています。どうやらresizeは上記の様に(-1,)を指定すると数が1つ少なくなってしまう?様です。なので、サイズを変更したい時は4つ上のセルのa.resize(1, 10000*10000)のように明示的にサイズを指定する必要があるようです。(追記)
resize(-1)はこのブログのコメントにもあるように指定された最後の値を除く仕様らしいです。c = np.arange(6).reshape(2, 3) d = np.resize(c, (-1,)) print(c, '\n') print(d)出力
[[0 1 2] [3 4 5]] [0 1 2 3 4]あとがき
速さを求めるなら
reshape。コピーを渡したいならflattenで今の所不便は感じないのかなと個人的に思っていますが、この辺り詳しい人にコメントもらえると嬉しいです。
- 投稿日:2020-01-21T14:22:43+09:00
teratailのダウンローダーを作った
はじめに
スクレイピングの練習に何か作ろうということで、teratailの記事の中にあるコードをダウンロードする「teratailer」というソフトを作りました。teratailerはhowdoiというソフトを参考にしました。
teratailerの説明
指定したURLのページからコードの部分を取得し、teratail1.txt(?には数字が入る)というファイル名で保存します。コードの箇所が複数ある場合は teratail1.txt teratail2.txt teratail3.txt ... という感じで複数のファイルに保存します。URLは複数指定できます。
また、-nで指定したURLに含まれるコードの数を表示、-tでファイルに保存せずターミナルに直接表示します。環境
Ubuntu 18.04 LTS
Python 3.6.9
Requests 2.22.0
lxml 4.4.2
cssselect 1.1.0ファイル構成
teratailer ├── README.md ├── setup.py (未完成) ├── teratailer │ ├── __init__.py │ └── teratailer.py └── test_teratailer.py (未完成)ソースコード
メインの部分のみ表示します。すべてのソースコードはこちら
teratailer.pyimport sys import argparse import time import requests from requests.exceptions import ConnectionError, HTTPError import lxml.html def get_parser(): parser = argparse.ArgumentParser(description='teratailにあるコードをダウンロードします') parser.add_argument('url', nargs='*', help='指定したURLのページのコードをダウンロード') parser.add_argument('-n', '--number', action='store_true', help='ダウンロードするファイルの数') parser.add_argument('-t', '--terminal', action='store_true', help='ダウンロードせず、ターミナルに表示する') return parser def get_text(url): try: r = requests.get(url) r.raise_for_status() return r.text except ConnectionError: print('ネットワークにエラーが発生しました') print('時間をおいて再度実行してください') sys.exit() except HTTPError: return 'None' def get_code(text): html = lxml.html.fromstring(text) code_list = [] for code in html.cssselect('code'): code_list.append(code.text_content()) return code_list def get_code_list(args): code_list = [] for url in args.url: print('{}を取得中'.format(url)) time.sleep(1) text = get_text(url) code_list += get_code(text) if not code_list: print('コードは見つかりませんでした') sys.exit() return code_list def save(code_list): for i, code in enumerate(code_list, 1): with open('teratail{}.txt'.format(i), 'w', encoding='utf-8') as f: f.write(code) def main(): parser = get_parser() args = parser.parse_args() if not args.url: parser.print_help() return code_list = get_code_list(args) if args.number: print(len(code_list)) return if args.terminal: for code in code_list: print(code) print('-' * 60) else: print('{}個のファイルを作成します'.format(len(code_list))) save(code_list) if __name__ == '__main__': main()
- 投稿日:2020-01-21T14:10:47+09:00
matplotlibの点の大きさについて
Pythonのmatplotlibは大変便利なのでいつもお世話になっています。とても足を向けて寝られませんが、今日は「点」の大きさについてちょっと試してみたいと思います。
%matplotlib inline import matplotlib.pyplot as plt点を描く
plt.scatter(0, 0, c='k')
大きい点を描く
plt.scatter(0, 0, c='k', s=1000)
点を増やす
ここで、点の大きさが少し変わったように見えますね。原点にある点の大きさは変えていないはずなんですが、この大きさは、あくまで表示サイズの大きさであって、座標の大きさとは対応していないようです。
plt.scatter(0, 0, c='k', s=1000) plt.scatter(0.1, 0.1, c='k', s=700) plt.scatter(-0.1, 0.1, c='k', s=700)
画像の表示域を変える
なので、画像を表示する座標域を変えると、全く違って見えます。水分子みたいになってしまいました。
plt.xlim([-1, 1]) plt.ylim([-1, 1]) plt.scatter(0, 0, c='k', s=1000) plt.scatter(0.1, 0.1, c='k', s=700) plt.scatter(-0.1, 0.1, c='k', s=700)
画像の縦横比を変える
画像の縦横比を変えても同様に、形が変わって見えます。ミッ...水分子...のように見えます。
plt.figure(figsize=(8,8)) plt.xlim([-1, 1]) plt.ylim([-1, 1]) plt.scatter(0, 0, c='k', s=1000) plt.scatter(0.1, 0.1, c='k', s=700) plt.scatter(-0.1, 0.1, c='k', s=700)
画像のサイズを変える
画像のサイズを変えても同様に、形が変わって見えます。ミッ...水分子...のように見えます。
plt.figure(figsize=(6,6)) plt.xlim([-1, 1]) plt.ylim([-1, 1]) plt.scatter(0, 0, c='k', s=1000) plt.scatter(0.1, 0.1, c='k', s=700) plt.scatter(-0.1, 0.1, c='k', s=700)
複製をたくさん作る
同じものを水平移動して、複製をたくさん描画してみましょう。あれ? 耳...じゃなくて...水素原子?みたいなのが見えなくなってしまいました。
plt.figure(figsize=(6,6)) plt.xlim([-10, 10]) plt.ylim([-10, 10]) for x in [-5, 0, 5]: for y in [-5, 0, 5]: plt.scatter(0 + x, 0 + y, c='k', s=1200) plt.scatter(0.1 + x, 0.1 + y, c='k', s=700) plt.scatter(-0.1 + x, 0.1 + y, c='k', s=700) plt.show()
ミッ...水分子みたいな形に戻すためには、位置関係を見直す必要があります。
plt.figure(figsize=(6,6)) plt.xlim([-10, 10]) plt.ylim([-10, 10]) for x in [-5, 0, 5]: for y in [-5, 0, 5]: plt.scatter(0 + x, 0 + y, c='k', s=1000) plt.scatter(1 + x, 1 + y, c='k', s=700) plt.scatter(-1 + x, 1 + y, c='k', s=700) plt.show()
まとめ
matplotlib は便利ですが、点の大きさをいい感じにするのは、ちょっと面倒です。








- 投稿日:2020-01-21T13:43:31+09:00
今日のpython error:
組み合わせ爆発の凄さ
https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3で、
graphillionを使ってみた
https://qiita.com/cabernet_rock/items/50f955afc16287244154をファイルにした。
実行しても何も出ない。
printを加えた。
gra.py# https://qiita.com/cabernet_rock/items/50f955afc16287244154 # 必要なモジュールのインポート from graphillion import GraphSet import graphillion.tutorial as tl import time # 計算時間を調べる。 # グリッドのサイズを指定 universe = tl.grid(2, 2) GraphSet.set_universe(universe) tl.draw(universe) start = 1 # スタート位置 goal = 9 # ゴールの位置 paths = GraphSet.paths(start, goal) print (len(paths)) # key = 4 # 1箇所目 treasure = 2 # 2箇所目 paths_to_key = GraphSet.paths(start, key).excluding(treasure) treasure_paths = paths.including(paths_to_key).including(treasure) print (len(treasure_paths)) # universe = tl.grid(8, 8) # 9×9のグリッド GraphSet.set_universe(universe) start = 1 goal = 81 s = time.time() # 計算開始時刻 print (paths = GraphSet.paths(start, goal)) time.time() - s # 計算時間 print (len(paths))docker/ubuntu# python3 gra.py 12 2 Traceback (most recent call last): File "gra.py", line 26, in <module> print (paths = GraphSet.paths(start, goal)) TypeError: 'paths' is an invalid keyword argument for this functionprint (paths = GraphSet.paths(start, goal))
を
paths = GraphSet.paths(start, goal)
print (paths)に変更。
- 投稿日:2020-01-21T13:43:31+09:00
今日のpython error: invalid keyword argument for this function
組み合わせ爆発の凄さ
https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3で、
graphillionを使ってみた
https://qiita.com/cabernet_rock/items/50f955afc16287244154をファイルにした。
実行しても何も出ない。
printを加えた。
gra.py# https://qiita.com/cabernet_rock/items/50f955afc16287244154 # 必要なモジュールのインポート from graphillion import GraphSet import graphillion.tutorial as tl import time # 計算時間を調べる。 # グリッドのサイズを指定 universe = tl.grid(2, 2) GraphSet.set_universe(universe) tl.draw(universe) start = 1 # スタート位置 goal = 9 # ゴールの位置 paths = GraphSet.paths(start, goal) print (len(paths)) # key = 4 # 1箇所目 treasure = 2 # 2箇所目 paths_to_key = GraphSet.paths(start, key).excluding(treasure) treasure_paths = paths.including(paths_to_key).including(treasure) print (len(treasure_paths)) # universe = tl.grid(8, 8) # 9×9のグリッド GraphSet.set_universe(universe) start = 1 goal = 81 s = time.time() # 計算開始時刻 print (paths = GraphSet.paths(start, goal)) time.time() - s # 計算時間 print (len(paths))docker/ubuntu# python3 gra.py 12 2 Traceback (most recent call last): File "gra.py", line 26, in <module> print (paths = GraphSet.paths(start, goal)) TypeError: 'paths' is an invalid keyword argument for this functionprint (paths = GraphSet.paths(start, goal))
を
paths = GraphSet.paths(start, goal)
print (paths)に変更。
- 投稿日:2020-01-21T13:39:54+09:00
pyautoguiで日本語入力
- 投稿日:2020-01-21T13:17:26+09:00
今日のpython error
graphillionを使ってみた
https://qiita.com/cabernet_rock/items/50f955afc16287244154組み合わせ爆発の凄さ
https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3dockerで実行しようとした。
# python3 gra.py Traceback (most recent call last): File "gra.py", line 7, in <module> universe = tl.grid(2, 2) File "/usr/local/lib/python3.6/dist-packages/graphillion/tutorial.py", line 28, in grid import networkx as nx ModuleNotFoundError: No module named 'networkx'# pip3 install networkxとすべきところを
# pip3 install networkとしていた。1文字違いはまぎらわしい。
- 投稿日:2020-01-21T13:17:26+09:00
今日のpython error:ModuleNotFoundError: No module named
graphillionを使ってみた
https://qiita.com/cabernet_rock/items/50f955afc16287244154組み合わせ爆発の凄さ
https://qiita.com/kaizen_nagoya/items/f309b0c2bb015bbc71c3dockerで実行しようとした。
# python3 gra.py Traceback (most recent call last): File "gra.py", line 7, in <module> universe = tl.grid(2, 2) File "/usr/local/lib/python3.6/dist-packages/graphillion/tutorial.py", line 28, in grid import networkx as nx ModuleNotFoundError: No module named 'networkx'docker 作る時に、
# pip3 install networkxとすべきところを
# pip3 install networkとしていた。1文字違いはまぎらわしい。
- 投稿日:2020-01-21T12:25:50+09:00
【AWS】SQSで同一メッセージを同時に複数受信してしまうケース
SQSをポーリングする処理を実装していたところ、同一メッセージを同時に受信してしまう事象に遭遇した。
解説コードはPythonだが、事象は他の言語/SDKでも発生するものと考えられる。
何が起きたか
SQS対象のキューにはメッセージが1つだけ格納されている状態とする。
以下は、SQSキューからメッセージを最大10件取得するPythonコード。import boto3 # SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, MaxNumberOfMessages=10).get('Messages')受信したメッセージを表示する。
for i, message in enumerate(messages): print(i) print('MessageId: ' + message['MessageId']) print('MD5: ' + message['MD5OfBody']) # 0 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 1 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 2 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200*********このような感じでメッセージID、ボディが全く同じものを3件取得してしまった。
同時に取得する件数は1件だったり2件だったりする。原因と対処(推察)
キューの設定で可視性タイムアウト(VisibilityTimeout)を0にしていると発生する。
これを0より大きな適当な値に変更すれば解消した。SQSはマネージドなメッセージキューイングサービスで、裏側でメッセージデータを分散保持して可用性を高めている。
この可視性タイムアウトが無効になっていると、ポーリングリクエストに対して全てのSQSサーバがレスポンスしてしまっていた可能性が高い。特にスケールを考えないシンプル構成だったため「ええい!こんなオプションは無効じゃ!」と適当に設定していた。。。
設定方法
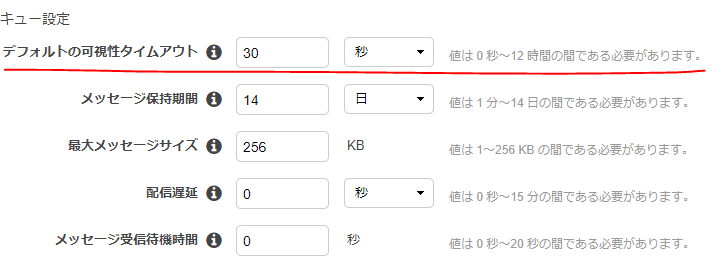
コンソール画面から
[キュー操作]>[キューの設定]と進んで ↓ここ
(
)ポーリングリクエスト
オプションを付けてリクエストを送ることもできるが、キュー全体の設定を変えておいた方が無難だと思う。
Python SDK(boto3)の例
# SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, VisibilityTimeout=30)
- 投稿日:2020-01-21T12:25:50+09:00
【その設定値をゼロにするなんてとんでもない!】SQSで同じメッセージを複数件受信してしまう
SQSをポーリングする処理を実装していたところ、同一メッセージを同時に受信してしまう事象に遭遇した。
解説コードはPythonだが、事象は他の言語/SDKでも発生するものと考えられる。
何が起きたか
以下は、SQSキューからメッセージを最大10件取得するPythonコード。
なお、対象のキューにはメッセージが1つしか格納されていない状態とする。
import boto3 # SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, MaxNumberOfMessages=10).get('Messages')受信したメッセージを表示する。
for i, message in enumerate(messages): print(i) print('MessageId: ' + message['MessageId']) print('MD5: ' + message['MD5OfBody']) # 0 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 1 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200********* # 2 # MessageId: 7d4f2923-****-4d86-87a6-85f20446086a # MD5: 38d2b0ed81e0200*********このような感じでメッセージID、ボディが全く同じものを3件取得してしまった。
同時に取得する件数は1件だったり2件だったりする。原因と対処(推察)
キューの設定で可視性タイムアウト(VisibilityTimeout)を0にしていると発生する。
これを0より大きな適当な値に変更すれば解消した。SQSはマネージドなメッセージキューイングサービスで、裏側でメッセージデータを分散保持して可用性を高めている。
この可視性タイムアウトが無効になっていると、ポーリングリクエストに対して全てのSQSサーバがレスポンスしてしまっていた可能性が高い。特にスケールを考えないシンプル構成だったため「ええい!こんなオプションは無効じゃ!」と適当に設定していた。。。
設定方法
コンソール画面から
[キュー操作]>[キューの設定]と進んで ↓ここ
(
)ポーリングリクエスト
オプションを付けてリクエストを送ることもできるが、キュー全体の設定を変えておいた方が無難だと思う。
Python SDK(boto3)の例
# SQSにリクエスト送信 client = boto3.client('sqs') messages = client.receive_messages(QueueUrl=my-url, VisibilityTimeout=30)
- 投稿日:2020-01-21T12:08:24+09:00
英語論文を読みたくない大学生
英語論文を楽して読みたい!!!
英語苦手すぎて輪講が進まないので、楽する方法がないかと考えました。
思いついたのが要約っぽいことをしてその英文を訳せばいいのでは…動作確認環境
- Windows10
- Powershell(cmdでもOK)
- Google Colaboratory
- Python 3.7.3
Colaboratoryとは
Colaboratory は、完全にクラウドで実行される Jupyter ノートブック環境である。設定不要で、無料で利用可能。
Colaboratory を使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティングリソースへのアクセスなどをブラウザからすべて無料で行うことが可能。
手順
- 論文から本文のみを抽出する(タイトル、章の名前、図表、参考文献を除去)
- 各章の文章に対してLexRankを適用し、キーとなる文章の抽出
- 各章のキーとなる文章を結合し、言語モデルを用いて要約に近い文章を作成する
※論文のabstractやconclusionより詳細な文章を生成するために、正解文を必要としないやり方を使ってます
LexRankについて
文章の要約は大きく分けて抽出型と生成型に分類されます。
LexRankは抽出型に分類される要約アルゴリズムです。
文書からグラフ構造を作り出して重要な文のランキングを作ることで要約と言える文を出力するというものです。
2004年にGunes Erkan, Dragomir R. Radevによって提案されています。文のグラフ表現における固有ベクトル中心性の概念に基づいて文の重要度を計算するための新しいアプローチ、LexRankを検討します。 このモデルでは、文内コサイン類似性に基づく接続性マトリックスが、文のグラフ表現の隣接性マトリックスとして使用されます。
We consider a new approach, LexRank, for computing sentence importance based on the concept of eigenvector centrality in a graph representation of sentences. In this model, a connectivity matrix based on intra-sentence cosine similarity is used as the adjacency matrix of the graph representation of sentences.
ohkeさんの記事で詳しく説明がされていました。LexRankのキーポイントは2つで、PageRankから着想を得たTextRank (提案論文PDF) の派生となります。文をノード、文間の類似度をエッジとした無方向グラフを作る。提案論文では、TF-IDFからコサイン類似度で計算 (現代的にはword2vecなども使えるはず)。上のグラフから得られた推移確率行列 (M) と確率ベクトル (P) が安定する状態 (MP=P) まで計算して、最終的な確率ベクトルの値が大きい文を要約文として選択する。
上の理論を視覚化したの上図 (提案論文Figure 2から抜粋) で、エッジ数が多く (=たくさんの文と類似している) かつエッジが太い (=類似度が高い) d5s1やd4s1などが要約文の候補となります。実装
ライブラリのインポートは以下の通りです。LexRankの実装や分かち書き、LSTM言語モデルの構築に必要なライブラリを使用しています。
from __future__ import absolute_import from __future__ import division, print_function, unicode_literals from sumy.parsers.html import HtmlParser from sumy.parsers.plaintext import PlaintextParser from sumy.nlp.tokenizers import Tokenizer from sumy.summarizers.lsa import LsaSummarizer as Summarizer from sumy.nlp.stemmers import Stemmer from sumy.utils import get_stop_words from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from keras.optimizers import RMSprop from keras.utils.data_utils import get_file from googletrans import Translator import nltk import numpy as np import random import sys import io import os import glob補足:nltkを使用するときは、punktパッケージごとアップデートすると使用できるようです。
!python -c "import nltk; nltk.download('punkt')"LexRank部分(sumyを用いた実装)
def sectionLex(): #言語は英語に設定 LANG = "english" #.txtファイル(各セクションの本文データ)を全て選択 file = glob.glob('*.txt') ex = [] for i in range(len(file)): parser = PlaintextParser.from_file(file[i], Tokenizer(LANG)) stemmer = Stemmer(LANG) summarizer = Summarizer(stemmer) summarizer.stop_words = get_stop_words(LANG) for sentence in summarizer(parser.document, [何文出力するか]): ex.append(str(sentence) + '\n') # utf-8エンコードで出力 with open('output.txt', mode='w', encoding='utf-8') as f: f.writelines(ex)辞書に使用する変数の宣言
#正順の辞書リスト chr_index = {} #逆順の辞書リスト rvs_index = {} #文のリスト sentences = [] #次の単語 next_word = []分かち書き
# utf-8エンコードで読み込み、textに格納 with io.open('output.txt', encoding='utf-8') as f: text = f.read().lower() #単語ごとに分解(分かち書き) text = nltk.word_tokenize(text) chars = text辞書の作成
#正順のリストを作成 count = 0 for c in chars: if not c in chr_index: chr_index[c] = count count += 1 print(count, c) #逆順のリストを作成 rvs_index = dict([(value, key) for (key, value) in chr_index.items()])部分文字列の作成
for i in range(0, len(text) - maxlen, step): #maxlen個の単語を部分文字列(1文)として格納 sentences.append(text[i: i + maxlen]) #格納した部分文字列の次の単語を格納 next_word.append(text[i + maxlen])単語のベクトル化
#np.bool型の3次元配列:(部分文字列の数、部分文字列の最大長、単語数) x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) #np.bool型の2次元配列:(部分文字列の数、単語数) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) #各部分文字列をベクトル化する for i, sentence in enumerate(sentences): for t, ch in enumerate(sentence): x[i, t, chr_index[ch]] = 1 y[i, chr_index[next_word[i]]] = 1モデルの作成
今回は、Sequentialモデルを使用しています。
softmaxについては、@rtokさんの記事が分かりやすかったです。#単純モデルを作る model = Sequential() #LSTMを使用。バッチサイズは128 model.add(LSTM(128, input_shape=(maxlen, len(chars)))) #単語ごとにsoftmaxで確率を出せるようにする model.add(Dense(len(chars), activation='softmax'))勾配法にはRMSpropを使用しました。
RMSpropは、@tokkumanさんの記事が分かりやすかったです。optimizer = RMSprop(learning_rate=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer)各単語の出現率を計算し、出力する単語を選ぶ
# preds :モデルからの出力。float32型。 # temperature :多様度。低いほど出現率の高いものが選ばれやすくなる。 #モデルから出力は多項分布の形のため、総和は1.0になる def selectWD(preds, temperature=1.0): #float64型へ変換 preds = np.asarray(preds).astype('float64') #確率の低い単語が選ばれやすくなるように、自然対数を多様度で割る preds = np.log(preds) / temperature #確率の自然対数を逆変換する(自然指数関数にする) exp_preds = np.exp(preds) #総和が1になるように、全値を総和で割る preds = exp_preds / np.sum(exp_preds) #多項分布に従って、ランダムに選ぶ probas = np.random.multinomial(1, preds, 1) return np.argmax(probas)各epochごとの処理
def on_epoch_end(epoch, _): print() print('----- Generating text after Epoch: %d' % epoch) #最初の4単語を入力文字列の一番最初にする start_index = 0 #diversity:多様性。selectWDのtemperatureと同じ。高いほど確率が低い文字も選ばれる。 for diversity in [0.2, 0.5, 0.8, 1.0]: print('----- diversity:', diversity) #出力用 generated = '' sentence = text[start_index: start_index + maxlen] generated += " ".join(sentence) print(" ".join(sentence)) print('----- Generating with seed: "' + " ".join(sentence)+ '"') sys.stdout.write(generated) #OUTSEN個の文を出力、あるいは1000単語出力で終了 flag = OUTSEN for i in range(1000): #現在の文中のどの位置に何の単語があるか x_pred = np.zeros((1, maxlen, len(chars))) for t, ch in enumerate(sentence): x_pred[0, t, chr_index[ch]] = 1. #次の単語を予測する preds = model.predict(x_pred, verbose=0)[0] next_index = selectWD(preds, diversity) next_char = rvs_index[next_index] #最初の単語を削り、後ろに予測された単語を追加 sentence = sentence[1:] sentence.append(next_char) #出力整理 if next_char == '.': flag -= 1 generated += next_char + "\n" sys.stdout.write(next_char+"\n") elif next_char == ',': generated += next_char sys.stdout.write(next_char) else: generated += " " + next_char sys.stdout.write(" "+next_char) sys.stdout.flush() if flag <= 0: break sys.stdout.flush() print()#各エポック時に上記処理を呼ぶように設定 print_callback = LambdaCallback(on_epoch_end=on_epoch_end)フィッティング処理
#バッチサイズ128、エポック数100、前記述の関数を呼び出す model.fit(x, y, batch_size=128, epochs=100, callbacks=[print_callback])結果
VandikasらのPerformance Evaluation of an IoT Platformをデータにした際の結果です。
----- Generating text after Epoch: 99 ----- diversity: 0.2 in general , iot ----- Generating with seed: "in general , iot" in general , iot can benefit from the virtually unlimited capabilities and resources of cloud to compensate its technological constraints ( e.g., storage, processing, communication ). being iot characterized by a very high heterogeneity of devices, technologies, and protocols, it lacks different important properties such as scalability, interoperability, flexibility, reliability, efficiency, availability, and security. as a consequence, analyses of unprecedented complexity are possible, and data-driven decision making and prediction algorithms can be employed at low cost, providing means for increasing revenues and reduced risks. the availability of high speed networks enables effective monitoring and control of remote things, their coordination, their communications, and real-time access to the produced data. this represents another important cloudiot driver : iot processing needs can be properly satisfied for performing real-time data analysis ( on-the-fly ), for implementing scalable, real-time, collaborative, sensor-centric applications, for managing complex events, and for supporting task offloading for energy saving.5文の出力をしていますが、google翻訳で日本語訳するとこんな感じ。
一般に、iotはクラウドの実質的に無制限の機能とリソースの恩恵を受けて、技術的な制約(ストレージ、処理、通信など)を補うことができます。 デバイス、テクノロジー、およびプロトコルの非常に高い不均一性が特徴であり、スケーラビリティ、相互運用性、柔軟性、信頼性、効率、可用性、セキュリティなどのさまざまな重要なプロパティがありません。 その結果、前例のない複雑さの分析が可能になり、データ駆動型の意思決定および予測アルゴリズムを低コストで採用できるため、収益の増加とリスクの削減を実現できます。 高速ネットワークの可用性により、リモートのもの、その調整、通信、および生成されたデータへのリアルタイムアクセスの効果的な監視と制御が可能になります。 これは別の重要なcloudiotドライバーを表します:リアルタイムデータ分析(オンザフライ)の実行、スケーラブルでリアルタイムのコラボレーション中心のセンサー中心のアプリケーションの実装、複雑なイベントの管理、および省エネのためにタスクのオフロードをサポートします。それっぽくまとまってるように感じます!
このソースコード全体はgithubで公開しています。
日本語的におかしいところも少し出ているので、改善していきます…

