- 投稿日:2019-12-01T23:25:22+09:00
【Heroku】デプロイ時の"Missing encryption key to decrypt file with."を乗り越える
はじめてのHerokuデプロイ。
下記のQiita記事にならって進めていました。【初心者向け】railsアプリをherokuを使って確実にデプロイする方法【決定版】
(丁寧にまとめていただき、本当にありがとうございます。)おかげさまで順調に進み、デプロイ間近でわくわくしていたところ以下のエラーと遭遇しました。
Missing encryption key to decrypt file with. Ask your team for your master key and write it to ~~~~~~/config/master.key or put it in the ENV['RAILS_MASTER_KEY'].要するに、"復号するためのキーが見つからない"ということです。
なぜ?
と、思いましたが、たしかにそうですね。
GitHubと連携してデプロイを試みていましたが、リモートリポジトリに
master.keyはありません。通常はgitignoreの監視下なのでGitHubにはあがっていないはずです。そのため、これを別途読み取らせる工程が必要です。解決策
ということで、ちょっと迷いましたが一手で解決することができました。
heroku config:set RAILS_MASTER_KEY=`rake secret`以上のコマンドを実行したあとで、ようやくデプロイが通るようになりました。
参考
stackoverflow:Ask your team for your master key and put it in ENV[“RAILS_MASTER_KEY”] on heroku deploy
上の質問と回答をもとに解決することができました。ありがとうございます。さいごに
初心者らしく「なぜ?」からはじまり、その解決策もシンプルすぎるがゆえいろいろ戸惑ったので残しておきます。今後はじめてデプロイに臨まれる方の参考になれば幸いです。
万が一、誤りや解釈が十分でないところがあれば、ご指摘いただけると嬉しいです。
- 投稿日:2019-12-01T22:55:23+09:00
【Rails】Rails側で定義した変数をJavaScriptに簡単に渡せるgem 「gon」を使ってみた
はじめに
Railsアプリケーションを作成中、JavaScriptにRails側で定義した変数を渡したくなり、調べたところ
gonというかなり使い勝手のいいgemがあったので導入してみました。この記事が役に立つ方
- Rails側で定義した変数をJavaScript側でも使いたい方
この記事のメリット
gonを使ってRailsで定義した変数をJavascriptに渡せるようになる環境
- macOS Catalina 10.15.1
- zsh: 5.7.1
- Ruby: 2.6.5
- Rails: 5.2.3
- Docker: 19.03.5
- docker-compose: 1.24.1
- gon: 6.3.2
gem
gonとは?シンプルにRailsアプリ内でJavaScriptに変数を渡すことが出来るgemです。
RSpecにも変数を渡せたりと、便利。
GitHub - gazay/gon: Your Rails variables in your JSIf you need to send some data to your js files and you don't want to do this with long way through views and parsing - use this force!
(ざっくり)JavaScriptに何かデータを送る必要があるなら、面倒くさいビューとかパースとかやめてこれを使っちゃいなよ!
と紹介されています。インストール
Gemfilegem 'gon'↓
bundle install使用方法
Usage example · gazay/gon Wiki · GitHub
1. Viewで読み込み
app/views/layouts/application.html.erb<head> <title>some title</title> <%= include_gon %> <!-- include your action js code -->
titleタグの下で、javascript_include_tagよりは上。※公式Wikiであった、以下方法ではうまくいきませんでした。
app/views/layouts/application.html.erb<head> <title>some title</title> <%= Gon::Base.render_data %> <!-- include your action js code -->
2. Controllerで使っている変数をgonにセット。
any_controller.rb@your_int = 123 @your_array = [1,2] @your_hash = {'a' => 1, 'b' => 2} # 上記の変数をJavaScriptで呼び出したいなら # 以下のように頭に`gon`をつけて変数定義する gon.your_int = @your_int gon.your_array = @your_array gon.your_hash = @your_hash # `gon`をつけた後に別の変数定義に活用することも可能。 gon.your_other_int = 345 + gon.your_int # `gon`をつけたもの同士で配列に追加も可能。 gon.your_array << gon.your_int gon.your_array # > [1, 2, 123] # `all_variables`で`gon`をつけた全ての変数がハッシュで取り出せる gon.all_variables # > {:your_int => 123, :your_other_int => 468, :your_array => [1, 2, 123], :your_hash => {'a' => 1, 'b' => 2}} # `clear`で全変数をクリアできる gon.clear # gon.all_variables now is {}
gonをつけるだけでいいのでシンプルですね。
3. JavaScriptで呼び出し
any.jsalert(gon.your_int) alert(gon.your_other_int) alert(gon.your_array) alert(gon.your_hash)先程コントローラー側で定義したものがそのまま使えます。
※aleatはテキトーです。当然ですが、例えば
current_userを渡していた場合は、current_user.jsalert(gon.current_user.name) alert(gon.current_user.email) alert(gon.current_user.id)のようにすると名前やメールアドレスなど、欲しいキーを指定すれば値が取り出せます。
非常に分かりやすくて便利です。
おわりに
最後まで読んで頂きありがとうございました
他にも
inputタグ経由で変数を渡したり、JSONを使ったりして変数を渡している記事を見つけましたが、gonの方がシンプルに変数を渡せるので楽ですね参考にさせて頂いたサイト(いつもありがとうございます)

- 投稿日:2019-12-01T22:49:22+09:00
RubyでDBMSを実装 (導入編)
この記事は RubyでDBMS Advent Calendar 2019 の1日目の記事です。
全体の概要
ブラックボックスなデータベースの内部実装を少しでも理解したいと思った筆者が、
25日かけてオレオレDBMSをスクラッチで実装していくAdvent Calendar 2019の企画となります。言語はRuby使います。
このようなミドルウェアを書くとなると、最近だとパフォーマンスや並行処理の書きやすさの観点からGoやRustなどが多いのかもしれませんが、
- 第一の目的はDBMSの内部実装を理解することであり、パフォーマンスは特に考慮しない
- 筆者の現在の業務でのメイン言語がRuby(余計な部分で詰まらないようにしたい)
- あまり例がないと思うので、弊社内の人間を始めとして多くのRubyistに読んでもらえたら嬉しい
などの理由でRubyで書いていくことにしました。
(Rust勉強したいのでいつかRustで書き直したりもしたい)参考資料
CMU(カーネギーメロン大学)のDATABASE SYSTEMSという講義をメインに参考にしていきます。
非常に質の高い講義のスライド、ノート、動画がすべて無料で見れるためオススメです。また、今年話題のO'Reillyのデータ指向アプリケーションデザインも適宜参考にするかもしれません。
成果物
こちらのGitHubリポジトリに
day01のように日付でディレクトリを切ってその日実装したコードを上げていく予定です。本日の概要
初回なので、
サーバコマンド(MySQLのmysqldに相当)と、
クライアントコマンド(MySQLのmysqlに相当)を用意します。
また、RubyのRDBといいうことでRBDBと名付けました。サーバコマンド
サーバはHTTPサーバとして立てます。
/exec?query=hogeというパスにクエリパラメータとしてクエリを渡すことで実行される仕様です。
Rubyの標準ライブラリに含まれるWEBrickを使ってチャチャっと作っていきます。
./rbdbdと実行ファイルを実行することで、以下のServerクラスのstartメソッドが呼ばれるようになっています。
(詳しくはソースを参照)
ひとまずqueryに渡された値をechoするだけにしておきます。# frozen_string_literal: true require 'webrick' module Rbdb class Server def initialize(host: 'localhost', port: 40219) @host = host @port = port end def start server.mount_proc '/exec' do |req, res| query = req.query['query'] # TODO: res.body = query end trap('INT') do |_| terminate end server.start terminate rescue Interrupt terminate end private def terminate server.shutdown puts "\ngood bye!" end def server @server ||= WEBrick::HTTPServer.new({ DocumentRoot: '/', BindAddress: @host, Port: @port, }) end end end実行してみます。
% ./bin/rbdbd [2019-12-01 22:07:43] INFO WEBrick 1.4.2 [2019-12-01 22:07:43] INFO ruby 2.6.5 (2019-10-01) [x86_64-darwin18] [2019-12-01 22:07:43] INFO WEBrick::HTTPServer#start: pid=28968 port=40219% curl "http://localhost:40219/exec?query=hoge" hoge%クライアントコマンド
次にクライアント側です。
./rbdbと実行すると、プロンプトを表示して入力を待ちます。
(遊び心で最初にアスキーアートを表示してみました)
exit,quit、あるいはCtrl+cで終了します。
こちらもひとまず、サーバからのレスポンスボディをそのまま表示するだけです。# frozen_string_literal: true require 'cgi' require 'net/http' module Rbdb class Client def initialize(host: 'localhost', port: 40219) @host = host @port = port end def start show_title show_prompt while query = gets.chomp do break if terminate_query?(query) res = exec_query(query) # TODO: puts res show_prompt end terminate rescue Interrupt terminate end private def show_title puts <<~'EOS' _ _ _ _ __| |__ __| | |__ | '__| '_ \ / _` | '_ \ | | | |_) | (_| | |_) | |_| |_.__/ \__,_|_.__/ EOS end def show_prompt print '>> ' end def terminate_query?(query) query == 'exit' || query == 'quit' end def exec_query(query) Net::HTTP.get(@host, "/exec?query=#{CGI.escape(query)}", @port) end def terminate puts "\ngood bye!" end end end実行してみます。
% ./bin/rbdb _ _ _ _ __| |__ __| | |__ | '__| '_ \ / _` | '_ \ | | | |_) | (_| | |_) | |_| |_.__/ \__,_|_.__/ >> SELECT * FROM users; SELECT * FROM users; >> ^C good bye!まとめ
初日ということで、特にDBに関係ない内容となってしまいましたが、
明日からはサーバが受け取ったクエリを解析していく部分から実装していく予定です。
- 投稿日:2019-12-01T21:46:48+09:00
プログラミング初学者が2ヶ月半で630時間勉強した話
はじめに
Qiita初投稿です。記事を書くのは初めてなので、上手く書けるかわかりませんが、どうか温かい目で閲覧いただけると幸いです。また、まだまだ勉強中で下記の説明の中で理解が及んでおらず、間違っているところもあるかと思いますので、あらかじめご容赦下さい。
これからプログラミングを学習しようと考えている方や、プログラミングを学習中の方の励みになればと思ってこの記事を投稿させていただきます。プログラミングに出会うまで
私は、沖縄の大学を卒業後、地元の鹿児島に戻り実業団選手として陸上競技をしていました。その後、工業機械の製造・メンテナンス、建設業・設備業の仕事をしてきました。しかし、年齢を重ねるにつれて肉体的にしんどくなり、何かいい仕事はないかと考えていたところ、学生時代の先輩がSNSでプログラミングスクールの告知をしていたため、スクールを受講してみようと思いました。
スクールについて
概要
スクールは沖縄のCODEBASEに通いました。こちらのスクールでは、自習ベースで学習し、毎週月曜と木曜(祝日を除く)の19:00〜22:00の週に2回、全18回の講義を実施し、自習した内容の確認や不明点や補足を講義で質問・説明する形式です。
また、スクール卒業までにSinatraでwebアプリケーションを制作し発表するというものでした。スクール面談
早速申し込みをして、面談をすることになりました。スクールは定員が決まっており、面談ではどうして受講しようと思ったか、勉強時間は確保できるか、最後まで通い続ける自身はあるか、スクール卒業後はどうなりたいか等の話をしました。私は鹿児島にいましたが、skypeでオンライン面談をさせていただき、自分の気持ちを話させていただきました。
スクールに通い始めるまでにやったこと
無事受講させていただくことになり、受講までにprogateで学習を進めてほしいというメールが届きました。progateはスクール側でアカウントを用意してくれました。
受講まで2週間ほど期間があったので、HTML、CSS、Javascript、jQuery、Rubyを1周しました。
HTML、CSSは、学生時代に講義で学んだことがあったため、思い出しながら学習しました。その他に関しては、あまり理解できませんでしたが、とりあえず触っておこうと思い、進めた感じです。スクール初回
講義内容
ついにスクールが始まりました。私は沖縄へ移動し、宿泊しながらスクールに通いました。仕事はフリーランスだったため、スクールに通っている間は、プログラミングに集中しようと思い一時休業しました。
スクール初日はslackという業務用のLINEみたいなアプリの紹介、使い方等を学びスクールのカリキュラム説明を聞きました。また、初日は台風でした笑次回講義までの予習内容
HTMLとCSSの学習をする指示があったため、再度progateで学習しました。また、実際に簡単なWebページを作成し、CSSでスタイルを適用させるまでやってみました。
ここまでの学習時間
5時間
スクール2回目
講義内容
ChromeとVisual Studio Codeを使用するため、これらをインストールし、簡単な使い方の説明を聞きました。
その後、Webの仕組みやHTML、CSSについて学習しました。それぞれバージョンがあり、現在はHTML5とCSS3を使って開発するということを学びました。講義では具体的には、ブラウザに文字を表示させる方法、文字の色を変更する方法、画像を挿入する方法等でした。
その後、実際に簡単なWebページを制作しました。私は、2回目の講義までに制作していたWebページがあったため、さらにそのページを作り込みました。具体的には、CSSのメディアクエリを使い、レスポンシブに対応するようにデザインしました。制作していると講師の方から発表してほしいと声をかけられたため、みんなの前で発表させていただきました。
ブラウザ、Webがどのように進化したかを視覚的に見ることができるこちらのサイトが面白いと思いました。次回講義までの予習内容
CSSフレームワークのBootstrap4の使い方を調べる、Javascript、jQueryの勉強をするという指示があったので、progateでの学習、Bootstrapについては、googleで検索し、どのようなものなのかを調べました。
また制作していたWebページにBootstrap4を導入して制作し直したり、公式のドキュメントを見て使い方を勉強しました。ここまでの学習時間
40時間
スクール3回目
講義内容
実際にBootstrapを導入してwebサイトをきれいにデザインする方法を学習しました。私は、予習していたので、すんなり使うことができました。Bootstrapでレスポンシブ対応させたり、カルーセルで画像をスライド表示させたり、モーダルを実装したりしました。
Bootstrapを使うことで、デザイン時間を短縮でき、かつデザインが苦手でも、それっぽいサイトを作れるのはすごくいいなと思いました。次回講義までの予習内容
引き続きJavascript、jQueryの学習を進める、Rubyの学習を進めるとの指示だったため、それぞれprogateで学習しました。
ここまでの学習時間
62時間
スクール4回目
講義内容
Javascript、jQueryを使って、Webサイトに動きをつける学習をしました。私個人の感想としては、このあたりから少し難しくなっていったと思います。
具体的には、Javascriptのバージョンについてや、記述方法、Javascriptライブラリの種類等を学びました。ライブラリの中でも、初心者が学習しやすいjQueryを使ってボタンを押すとスクロールしたり、クリックするとメニューが開くアコーディオンを作ったり、タブパネルを作ったりして実際にサイトに動きをつけてみました。次回講義までの予習内容
引き続きJavascript、jQueryの学習を進める、Rubyの学習を進めるとの指示だったため、それぞれprogateで学習しました。
ここまでの学習時間
114時間
スクール5回目
講義内容
前回の続きで、Javascript、jQueryの学習をしました。また、非同期通信のAjaxについても学習しました。Ajaxについては、具体的な例を出してくれて、twitterのいいねボタンやgoogleマップの拡大縮小、チャット機能等がそれに当たるということを知りました。
Javascriptのデバッグ方法(ブラウザのコンソールを使う)についても学習しました。次回講義までの予習内容
中間発表のWebページ制作を進められる人は進めておいてほしいという指示もあったので、私は制作を進めました。
ここまでの学習時間
170時間
スクール6回目
講義内容
この日は各自オリジナルサイトの制作を進めました。わからないところがあったら講師の方に質問したり、アドバイスを貰ったりして、制作しました。これまで学んだことが結構盛りだくさんだったので、どんなデザインでどんなアニメーションを実装するかを考え、制作を進めました。
次回講義までの予習内容
中間発表オリジナルサイト制作の指示があったため、これまで学習した内容を生かして制作を進めました。
ここまでの学習時間
196時間
スクール7回目
講義内容
学習のハマる仕掛けや、2回目の講義よりさらに詳しくWebのしくみについて学習しました。具体的には、Webページが表示されるまでに、サーバーとクライアントでどのようなことが行われているのか、サーバーにはどのような種類があるのか等を学びました。
またWebサイト(静的)とWebアプリケーション(動的)の違いについても学習しました。このあたりから、Webアプリケーションを制作するにあたっての導入編だったのかなと思います。次回講義までの予習内容
前回同様、中間発表のオリジナルサイト制作の指示があったため、引き続き制作を続けました。また、gitの学習をする指示されたのでprogateのgitを学習しました。
ここまでの学習時間
213時間
スクール8回目
講義内容
前半はWebサイト制作をしてわからないところを質問し、残りの1時間で制作したオリジナルサイトを発表しました。私は、知人がラーメン屋をやっているため、宣伝用のオリジナルサイトを制作しました。
CSSフレームワークはmaterializeというマテリアルデザインベースのフレームワークを使い、jQueryのライブラリbx-sliderを使って要素をカルーセルスライダーにしたり、ウィンドウをスクロールすることで要素をふわっと表示させるアニメーションを付けたりしました。
また、制作したサイトをgitにpushして実際に公開するところまで行いました。また、gitを使うことで、バージョン管理したり、チーム開発で使用したりできるということだったので、すごい便利な機能だと思いました。次回講義までの予習内容
次回の講義からRubyに入るとのことだったので、再度progateのRubyを学習しました。私はトータルで5周くらいしたと思います。
ここまでの学習時間
247時間
スクール9回目
講義内容
この回からWebアプリケーションを制作するための学習が始まりました。こちらのスクールではRubyを使って制作するということでした。
なぜRubyを使ってWebアプリケーションを制作するのか理由として、
- Rubyは世界で使われている開発言語の1つであるため
- 日本語の記事が多いため
- 記法がシンプルで書きやすいため
という理由のようです。
日本語の記事が多いためというのが一番の理由みたいです。なぜ、日本語の記事が多いのか、それはRuby言語の開発者が日本人だからということでした。また、公式のドキュメントも非常に充実しており、卒業後に学習を進めていくにあたり、Railsチュートリアルというものもあるということから、Rubyを学習するカリキュラムを組んでいるようです。Ruby初回の講義は、計算・演算、変数、条件分岐、関数、ループ文について学習しました。計算・演算では演算子(+ - * / %)を使って計算したり、計算式を変数に代入したりしました。
条件分岐はif文を使って表示させる内容を分岐させたり、条件によって計算方法を変えたりしました。
関数は、何度も使う処理を定義して呼び出すだけで結果を表示することができるので便利な機能だと思いました。
ループ文は1から100までの数字を出力する時に、putsを100回書くのではなく、eachやtimesを使って同じ処理を繰り返すことで楽にプログラムが書けることを知りました。
またプログラムをデバッグするgemのpryを使って、変数の値がどうなっているか実際に値を取り出して説明してくれたりしたので、少しはイメージしやすかったです。
これまで学習してきたHTML、CSS、JS等のフロントエンドと違ってサーバーサイドの学習はこれまで以上に難しかったです。次回講義までの予習内容
FizzBuzz問題というプログラムを学習する上で、一番最初に練習問題として作るプログラムを作ってくるようにとの課題が出たので、そのプログラムを制作しました。
前回までにかなりprogateで学習していたので、Sinatraについても予習しておこうと思い、paizaラーニングを個人的に登録し、Sinatraの学習も同時に進めました。また、Sinatraでの投稿、編集・更新、削除できる簡易的な掲示板のようなものを実際に作ってみようと思い、paizaラーニングを参考にしながら制作を進めました。ここまでの学習時間
265時間
スクール10回目
講義内容
クラスとインスタンスについて学習しました。クラスで抽象的なものを定義して、インスタンスでより具体的なものを作成するということを学びました。クラス内で変数を呼び出すにはインスタンス変数を作ること、@をつけることでインスタンス変数にできること等を教わりました。インスタンスを作成する際にはnew,newしたときに自動的にinitializeメソッドが呼び出される等も教わりました。
また、モジュールやライブラリ、フレームワークについての説明もありました。
最後にSinatraを導入してHello Worldを表示させるところまで講義で説明があり、このあたりの理解度としてはまだまだ低いですが、最初はとにかく難しかったです。次回講義までの予習内容
次回からSinatraを使ってWebアプリケーションを制作していくため、Sinatraについて学習する指示があったので公式ドキュメントやpaizaラーニングを使って学習しました。また、個人的に掲示板を作ってみて、なんとなく理解できてきたので早めに卒業制作を始めました。また、データベースについても学習しようと思い、progateのSQLを学習しました。
ここまでの学習時間
329時間
スクール11回目
講義内容
この回から、Sinatraを使ったWebアプリケーションの制作について学習しました。講義では前回の終わりに少し触った程度だったのでまずは、Sinatraのインストールから説明があり、Hello Worldを表示させるまでを実行しました。Sinatraはファイルを編集するたびにサーバーを再起動し直さないといけないので、reloaderを追加する説明があったので、快適に開発できるようにしました。
講義の中では、GETリクエストでエンドポイントを作成したり、テンプレートエンジンのerbファイルを作ったり、layout.erbに共通部分をまとめたり、画像やCSS等の静的ファイルをpublicフォルダにまとめたりしました。
実際に手を動かしてWebアプリケーションを制作していくと、Rubyで学んだことがだいぶ理解できるようになっていきました。次回講義までの予習内容
今回の講義で学んだことをしっかり復習しておくことと、私は卒業制作を始めていたので、いろんなサイトを参考にしながら制作を進めていきました。この頃にはGET、POSTについてだいぶ理解できていました。また、実際にPostgreSQLでデータベースを作成して、接続し、データの投稿・更新等ができるようになりました。
ここまでの学習時間
383時間
スクール12回目
講義内容
前回の復習をして、続きを学習しました。GETとPOSTの違いや使い分けについて聞き、URLにどう影響するかを実際に見せてくれました。
また、実際に入力した内容を受け取るためにparamsを使うことや、ファイルアップロードの方法、ログイン機能を実装するためにクッキーやセッションの説明等、この回の講義はSinatraでアプリケーションを作る上で一番大事な回だったと思います。次回講義までの予習内容
今回の内容を理解できるように復習をしっかり復習しておく、SQLについての学習をする指示があったので、それぞれ復習とprogate、paizaラーニングでSQLを学習しました。
個人的には、卒業制作を進めて、8割方できていました。このあたりからgemを使っていろんな機能を追加してみようと思い、どんなgemがあるのかをrubygemsで見てみたり、調べたりして、実装していきました。
また、講義以外でも学んでみたいと思い、講師の方のコミュニティ勉強会に参加してみました。そちらは、Vue.jsについての勉強会でした。ここまでの学習時間
408時間
スクール13回目
講義内容
データベースのPostgreSQLを使ってデータベースを作る講義でした。データベースにアクセスしてSQL文でデータを追加、更新、削除、検索する学習がメインでした。SQLインジェクションやXSS等セキュリティに関することにも触れました。
またgemのpgを使ってSinatraでデータベース接続をしてデータを保存する方法についても学習しました。
SQLに関しては、学生の時に少し触ったことがあったので、簡単に学習することができたかなと思います。次回講義までの予習内容
簡単な掲示板を作成する、写真を投稿する掲示板を作成するとの指示があったので、そちらの課題を進めました。
個人的には、SQLインジェクションが気になったので、実際にSQLインジェクションできる掲示板を作ってどのような動きをするのか確認してみました。実際に攻撃を仕掛けてみると、データが全部削除されたり、ユーザー情報を盗むことができたりしたので、対策は大事だなと思いました。
実際に作った掲示板ここまでの学習時間
433時間
スクール14回目
講義内容
引き続きデータベースの講義でした。データベースの種類や条件等を学びました。
データベースには主に、
- PostgreSQL
- MySQL
- MariaDB
- OracleDB
- SQL Server
- SQLite3
- Access
これらの種類があることを知り、たくさんあるんだなと思いました。またテーブル同士の関係性には1対1、1対多、多対多があり、設計をどれだけ上手くできるかが重要ということを学びました。
講義の後半では、複数のチームを作って、ワークショップ形式で実際に提供されているサービスのテーブル構成やリレーションについて受講生同士で話し合い、ER図を書き出して発表しました。次回講義までの予習内容
データベースの復習と卒業制作のアイデアを考えてくる指示でした。
個人的には、卒業制作が終わっていたので、progateとpaizaラーニングのRuby on Railsを学習しました。Sinatraで学習した内容がMVCに分かれたという認識を持つことができたので、制作の基礎は比較的簡単に理解することができたかなと思います。ここまでの学習時間
506時間
スクール15回目
講義内容
Webアプリケーションの開発手法について学習しました。開発手法は主に
- ウォーターフォール型モデル
- アジャイル開発型モデル
があるということを学びました。また、開発していく中で便利な設計ツールを紹介してくれたり、実際にサンプルを見せてくれたりしました。
後半は、前回と同様ワークショップ形式で、ページ遷移図やER図を書き出しました。私は講義の中で紹介されたMySQLWorkbenchを使って実際にER図を書いてみることにもチャレンジしてみました。次回講義までの予習内容
次回から卒業制作を各自進めるとのことだったので、アイディアを考えてくるようにとのことでした。
個人的には、以前外部のVue.js勉強会に行った際に、話している内容が全くわからず、悔しかったのでVue.jsを学習しました。ここまでの学習時間
540時間
スクール16回目、17回目
講義内容
各自卒業制作を進めました。また、自信がない方向けに別室で講義形式でWebアプリケーションを制作する手順を解説してくれたので、かなり手厚いサポートだなと感じました。
私が制作したWebアプリケーションは、ActionMailerを使いお問合せフォームを設置しており、rbファイルに直接重要な情報を書き込んでいたため、環境変数について講師の方に個別で教えていただきました。
また、最後の発表はみんなを驚かせようと思い、もう一つ卒業制作をしました。ここまでの学習時間
568時間(16回目)、605時間(17回目)
スクール18回目
講義内容
卒業制作発表を行いました。私はスポーツポータルサイトを制作しました。具体的には、管理者が様々なスポーツ情報を掲載して公開するサイトです。
実装した機能としては、
- 画像を投稿するとカルーセルスライダーに追加される
- 大会情報を投稿・編集・更新・削除(CRUD)できる
- 絞り込み検索
- キーワードあいまい検索
- 管理者と編集者でアクセスできるページの権限を与える
- フラッシュメッセージ
- メールフォーム(ActionMailer使用)
- パスワード暗号化(bcrypt使用)
- カテゴリー分け
- 年別月集計
- リッチテキストエディタ設置(ckeditor)
- バリデーション設定
- エラーメッセージ表示
- その他多数またもう一つ制作したアプリケーションはフロントをNuxt.js、サーバーサイドをRuby on Railsで制作し、axiosでデータを取得させるということにもチャレンジしました。
講師やサポートで入ってくれていた方々はすごく驚いてくれました。
総学習時間
632時間
最後に
この2ヶ月半で632時間学習し、1日の学習平均時間は約8時間半でした。
今回、プログラミングについてほとんど分からなかった私が、ここまでできるようになったことは、かなり自信になりました。
私は、性格的に何においてもやり込む、極めることが好きで、これまでの職業が職人向けの仕事だったため、プログラミングは向いていたのかなと思います。
もし、プログラミングを学習してみたいと考えている。でも、学生の頃にプログラミングの勉強をしていなかったから無理等と決めつけないで、一度勉強してみて下さい。
プログラミングは、どれだけ学習をやったかで知識として身についていくので、我らが講師@saboyutakaさんの未経験からRuby on Railsを学んで仕事につなげるまでの1000時間メニューの記事を参考にしながら、学習習慣をつけてエンジニアとして働くことができるように日々精進していきたいと思います。卒業制作リンク
- 投稿日:2019-12-01T20:28:47+09:00
GraphQLのmutationでargumentにオブジェクトを渡す
graphql-ruby で Mutation を書いていて、 argument にスカラ型ではなくオブジェクトを渡す時に variables を併用する場合の書き方で詰まったのでメモを残しておく。
環境
- Rails 6.0.0
- graphql-ruby 1.9.14
目標
- createUser という mutation の argument にオブジェクトを渡す
- クライアント側のクエリでは variables を用いる
手順
MutationType にフィールドを追加する
app/graphql/types/mutation_type.rbmodule Types class MutationType < Types::BaseObject field :createUser, mutation: Mutations::CreateUserMutation end end
- mutation_type.rb に
createUserというフィールドを追加し、 Mutations::CreateUserMutation を紐付けるCreateUserMutation を実装する
app/graphql/mutations/create_user_mutation.rbmodule Mutations class CreateUserMutation < GraphQL::Schema::RelayClassicMutation graphql_name "CreateUser" field :user, Types::UserType, null: false argument :user, Types::Attributes::UserInput, required: true def resolve(user:) created_user = User.create(user.to_h.transform_keys {|key| key.to_s.underscore }) { user: created_user } end end end
field :userは、この mutation 実行後のレスポンスとして取得できるフィールド。Types::UserTypeは普段 query で使用する BaseObject なので内容は割愛。argument :userが本題。 user というリクエストパラメータを受け取ることを宣言。そのオブジェクトの方をTypes::Attributes::UserInputというクラスで定義している(詳細は後述)。- 上記で宣言したリクエストパラメータを
resolveメソッドのキーワード引数で受け取る。ちなみに user の中身はハッシュではなく
Types::Attributes::UserInputのインスタンスになっている。
そのため中のプロパティにアクセスするには下記の二通りある。user.postal_code # インスタンスメソッドを通してアクセス user[:postalCode] # ハッシュのキーを通してアクセス(この時、プロパティ名はキャメルケースにする)単純に
to_hするだけだとキーがキャメルケースのままなので、to_h.transform_keys {|key| key.to_s.underscore }という長ったらしい変換処理が必要になる(他に良い方法は無いものだろうか?)Types::Attributes::UserInput を実装する
app/graphql/types/attributes/user_input.rbclass Types::Attributes::UserInput < Types::BaseInputObject argument :name, String, required: true argument :gender, Integer, required: true argument :profile, String, required: true argument :postal_code, String, required: true end
- 先述した resolve メソッドで受け取るキーワード引数の型を下記のように定義する。型の書き方などは query_types 等と同様。
- さらにオブジェクトをネストしたい時は Types::BaseInputObject を継承する別のクラスを指定するのかな?(試してない)
以上でサーバー側の実装は完了。
クライアント側から送信する query を書く
mutation registerUser( $user: UserInput! ) { createUser(input: { user: $user }) { user { id postalCode profile } } }
- 1行目の
registerUserはこのクエリに付けた適当な名前なので変えても動く。- 2行目の
UserInput!の!がキモ。Mutations::CreateUserMutationのargumentでrequired: trueを指定した場合、この!を付けないとNullability mismatch on variable $userというエラーが出る(ここで1時間くらいハマった)。- 4行目の
createUserが Types::MutationType で定義した mutation 名。- 5行目の
user { id postalCode profile }が mutation 実行後のレスポンスボディに入れてほしいオブジェクトとフィールドの指定。クエリを実行
query = <<-QUERY mutation registerUser( $user: UserInput! ) { createUser(input: { user: $user }) { user { id postalCode profile } } } QUERY variables = { karte: { name: "midwhite", gender: 1, profile: "I am a software engineer." postalCode: "000-0000" } } AppSchema.execute(query, variables: variables).to_h
- variables に user オブジェクトとして渡したいパラメータをハッシュで記述する。
実際にはフロントから Apollo とか使って query や variables を送信するんだと思うけど、 query の形式さえ分かっていれば特に迷わないだろうと思うのでその部分は割愛。
ここまで分かれば mutation を実用レベルで書けそう。そろそろエンドポイントを GraphQL のみで実装したアプリケーションを書いてみたい気持ち。
- 投稿日:2019-12-01T18:47:52+09:00
メーリングリスト風サービスを作ってみた
長年利用させていただいていたメーリングリストサービスの
freeml byGMOが 2019.12.2 を持ってサービス終了ということで、ちょっと困ったので作ってみました。メーリングリスト
メーリングリストは、町内会の情報共有で利用していて、そんなに頻度は多くないのですが、祭りの準備とかイベントがある時などに、回覧板では情報共有に時差が出るので(もちろん回覧板でも情報は町内を回りますが)簡単に共有できるメーリングリストは重宝しています。
最近なら
LINEグループとかSlackとかで情報共有ってのは普通なのですが、これはコンピュータやネットワークなどについてある程度知識や技術がある人たちには使えますが、そうでない場合はなかなか敷居が高いものです。特に地方では高齢の方も多く、携帯電話(ガラケー)は使えてもスマホは使えない、というのはよくあります。ガラケーであれば、メールアドレスを持っているので、送信はできなくても受信ができるので、回覧板よりも早く情報共有することも可能です。
なので、こういう幅広い年代間での情報共有にはまだまだメーリングリストは有効なのです。GMO、freeml やめるってよ
前項でも書きましたが、メーリングリストは便利ですが 'メール' 自体が今となっては少しリアルタイム性の遅い、そして送受信に多少手間がかかるツールとなってしまい、メンバー間のコミュニケーションツールとしては下火になっています。なので、無料でメーリングリストのサービスを続けていくのも難しくなってきたのだと思います。
しかしながら、前項でも書いた通り、ネットやコンピュータに対する知識や技術が少ない人でも簡単に情報共有できるツールとしては、メーリングリストはまだまだ有効なコミュニケーションツールです。
メーリングリストを自前で用意する
というわけで、代わりの無料のメーリングリストを探してみたのですが、なかなか良さげなのが見つからなかったのと、おそらくいずれ同じ運命をたどるのだろうと想像したので、自前で用意できないか考えてみました。
有名どころでは
majordomoとか、GNU Mailmanとかありますが、いずれもちょっと面倒(インストールとか設定とか)だったので、一から作ることにしました。メーリングリスト風サービスを作ってみる
メーリングリストとは、ある一つの代表メールアドレスへ参加者の一人がメールを送信すると、登録されているメンバー全員へ、そのメールが配信される、というものです。
単純に言えば、この機能を実装できれば良い、ということになります。
というわけで、既存のメールアカウントを利用してメーリングリスト風サービスを作ってみました。
用意するもの
- メーリングリスト用のアドレス(アカウント)
- サービスを動かすサーバ (Linux とか Mac とか)
- Ruby2.5.x 以上(sinatra + unicorn で動きます)
ソースはここにあるので、git clone してください。
https://github.com/ysomei/mllikeserviceインストール方法
ruby や nginx などはすでにインストールされているものとします。
ちなみに ruby は rbenv でインストールします。
#ruby のバージョンは 2.5.5 で確認しています。
#bundler もインストールしておきましょう。$ rbenv install 2.5.5 $ rbenv local 2.5.5 $ gem install bundler$ git clone https://github.com/ysomei/mllikeservice.git $ cd mllikeservice $ bundle install --path vendor/bundler $ ./script/unicorn_mllikeservice startサービスのポート番号は 8286 ですので、nginx で reverse proxy するなり、そのままのポートで使用するなりしてください。
#nginx で reverse proxy する場合は config/application.rb の root_path のところを修正して、nginx の設定で、 proxy 設定の location を /mllikeservice/ { ... としてください。
基本的にインストール先は自宅サーバ等を想定しているので、外部に出すことは想定していません。サービス設定画面
起動したらブラウザでページにアクセスします。
http://localhost:8286
config/application.rbにBasic認証設定がしてあるので、設定してあるIDとパスワードでログインします。
メーリングリストを追加
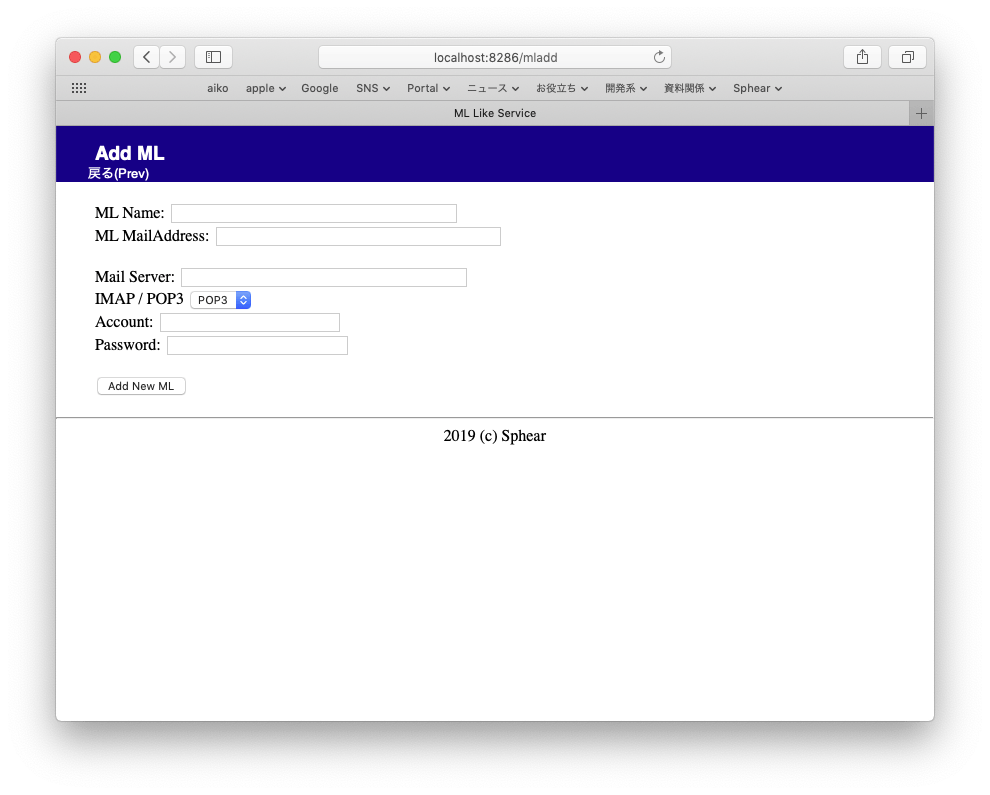
Add ML リンクをクリックするとML追加画面になります。ここでメーリングリストに使いたいメールアドレスとアカウント設定をします。
ML Nameはメーリングリスト名です。例)美術部ML
ML MailAddressはメーリングリストの宛先アドレス。 例)bijutsubu@ml.example.com
Mail Server、IMAP/POP3、Account、Passwordはアカウント設定です。上の ML Mailaddress にアクセスできる設定を記述します。ML一覧
Show ML List は登録されているメーリングリストの一覧を表示します。
クリックすると詳細が見れます。
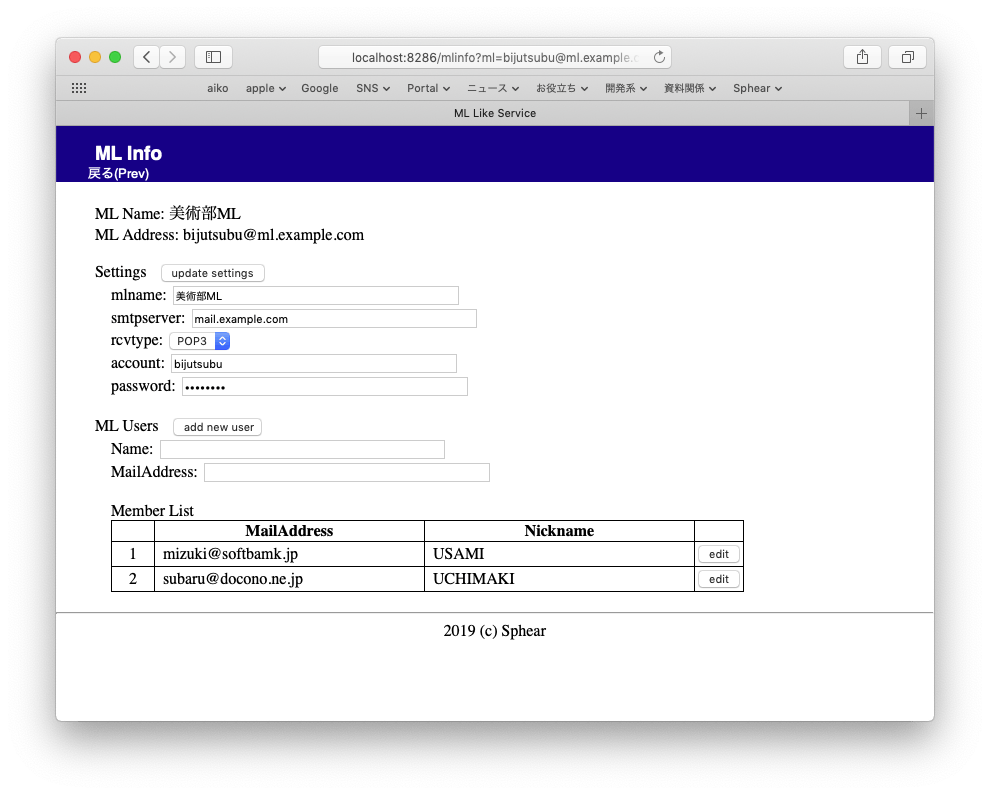
メンバー追加、情報修正
選択したMLの情報修正とメンバーの追加修正ができます。
#現在はとりあえず修正と追加のみです。削除したい場合は直接ファイルを編集してください。。。
# アカウント設定:data/mailinglist-address/settings.yml
# ユーザー設定:data/mailinglist-address/users.yml
メーリングリスト風サービスの動作
メーリングリスト追加で追加したサーバへ1分毎にアクセスして新しいメールがきているかどうか確認しています。
新しいメールが到着していれば、それがメンバーから送信されたものかを確認して、そうであれば登録されているメンバー全員へメールを送信します。
登録メンバー以外からのメールは無視します。メールは削除しないので、放っておくとメールボックスのサイズがいっぱいになって受信できなくなるかもしれないので、定期的に Thunderbird のようなメーラーで適切に処理をしましょう。
メールサーバが IMAP の場合は
既読にするとメーリングリストに反映されないので、注意しましょう。
#サービスは未読のもののみ処理するようになっています。処理後にサービスが既読にします。
#とは言え、一応 data/mailinglist-address/mailhashlist.csv で連番管理と一緒に送信済み管理をしています。
#POP3の場合は既読/未読がないので、 data/mailinglist-address/pop3readed.dat で既読管理をしています。まとめ
あまり難しいこと(たとえばメールサーバをインストールしたり、majordomo のようなサービスをインストールして連携させたり、コマンドラインでメンバー管理とか)をして運用したくなかったので、既存のメールアカウントを利用してメーリングリスト風サービスができるものを作りました。
#自前でそういうサービスを用意しなくてもできるようにしました。
#とは言ってもやっぱり専用のメールアカウントは用意するのですが。。。まだまだバグとか不具合とかあるかもしれませんが、ぼちぼち修正しながら使っていこうと思います。#町内会で利用するという需要があるので。。。
将来的には、LINEグループに配信したり、Slackに流したりもできればなぁと思っています。#逆は今の所考えてませんが。。。
同じように?困っている人の参考になれば幸いです。
以上。

- 投稿日:2019-12-01T17:47:09+09:00
ABC086C - Traveling
問題
https://atcoder.jp/contests/abs/tasks/arc089_a
1回目
回答
N = gets.to_i T,A,B = N.times.map{gets.split.map(&:to_i)}.transpose can = true t, x, y = T[0], A[0], B[0] for i in 0..N-1 if i > 0 t = T[i] - T[i-1] x = A[i] - A[i-1] y = B[i] - B[i-1] end if x + y > t || ( t - x - y ) % 2 != 0 can = false break end end puts can ? "Yes" : "No"結果
感想
他の人の回答を見た所、t,x,yの差を見ていなかったのが不思議だ。
もうちょい考えます。
奇数チェックはodd?にした方が良い。

- 投稿日:2019-12-01T16:34:37+09:00
自分の書いたコードの処理速度について考えさせられた話
近況
AtCoderの問題を解いて、コーディングの練習をしていますが、
最近はC問題にも手を出し始めました。
それに伴い、A・B問題ではあまり気にしなくてよかったことを気にしなくては行けなくなってきました。処理速度について
そう、それはプログラミングの処理速度です。
分岐や繰り返し文を必要以上に書いてしまうと、
入力値の桁が大きすぎて、制限時間以内に処理が終わらず不正解となってしまいます。プログラミングの勉強のため読んだ本でも、仕事でも、
「分岐や繰り返しは多くなるとよくない」と散々聞いてきましたが、
「ネストが深くなって読みにくくなるくらいでしょ?」
「別に何億とかの処理繰り返すわけでもないし、for文の中でさらにfor文回しても問題ないでしょ?」
くらいに思って、処理を最小限にする・無駄な計算はしない、ということはとりあえず二の次に考えていました。何で躓いたか
それを考えなければ行けなくなったのが、以下の問題
こちらの問題
N M
L1 R1(例:1..3)
L2 R2(例:2..4)
⋮
LM RMという入力値が与えられるので、M 行存在するL..Rの数字の中に、
いくつ重複が存在するかを数える問題です。例えば、上の例だと、{1,2,3}と{2,3,4}の中には、
重複している数字は3なので、答えは1となります。最初どうやって解いたか
では、この問題に私が最初どう解いたかというと、
以下のようなコードです。sample.rb_n,m = gets.split(' ').map(&:to_i) can_pass = [] existed = [] (m).times do |a| l,r = gets.split(' ').map(&:to_i) if a == 0 existed = (l..r).to_a else can_pass = (l..r).to_a existed = can_pass & existed end end puts existed.length変数existedとcan_passの中身を比較して、
重複している部分をexistedに残していって、
最後まで残った数字の数を数えるという方法です。sampleでも全部期待している値が出たから、
これは正解だろうと思って提出しましたが、
結果がこちら。
見事に制限時間をオーバーしております....
何が問題か
処理速度についてあまり今まで考えたことがなかったので、正直困りました。
「そんなポンポン解放思いつくわけないだろう...」と。この解き方の何が悪いかと考えてみると、
M回(最大10^5回)繰り返して、1≤Li≤Ri≤N(最大10^5個)の数字を検索して、いるため、
M*N回文処理が行われていることが問題でした。どのように解決したか
そこで私がどのように解いたか、というのが
以下のような方法です。sample.rb_n,m = gets.split(' ').map(&:to_i) l = [] r = [] m.times do |a| single_l,single_r = gets.split(' ').map(&:to_i) l << single_l r << single_r end array = (l.max..r.min).to_a puts array.lengthまずLとRをそれぞれの配列に格納し、
Lの最大値とRの最小値、つまり、M行存在するL..Rの数字に重複している数字を、
数えて来るという方法にしました。
これにより、処理を行う回数は、M回となるので、
無事、制限時間内に回答が出力されるようになりました。学び
解説を見てみると、他の解放もあるようでしたが、
すっと頭の中に入ってこなかったため、自分の解法しか理解できていないのですが、
別のやり方でもM回の処理で回答を出力することが可能なようです。問題文を見て、頭の中で回答を考えて、コードを書くとなると、
どうしても原始的に1から10まで、
問題に書かれている処理を実装しようとしがちです。ですが、そのまま処理すると必要以上に計算に処理がかかってしまったりすることがあるため、
出来るだけ無駄をなくすためにできる処理の方法がないかということを、
常々考えながら、コーディングしていくことが大事だと感じました。他にもっと良い解法があるのか、他の人の回答を見て勉強しようと思います。
- 投稿日:2019-12-01T16:33:11+09:00
enumの実装と、日本語化について
enumの実装と日本語化
某プログラミングスクールの課題で、
enumの実装と、対応する日本語化の機能を実装しましたので、
そのやり方を投稿させていただきます。
<railsでの開発、haml記法を想定しています。>※本記事が初投稿です
わかりにくい点が見受けられるかと思いますが、ご容赦ください。。。enum実装の経緯
productsテーブル:statusカラム(integer型)の場合
statusカラムに保存されている情報(1、2など)を、変数を用いて表示させたかったが、→ DBに格納されている数字で表示されてしまう
例)viewで「@product.status」と記載 → 1 が表示される・・・
これを、「@product.status」 → ”新品、未使用” などの日本語へ変換したい実装方法
<前提として>
ruby 2.5.1
rails 5.2.3
なお、enum実装のメリットとしては、下記の2点が大きいと思います
・コードが読みやすくなる
・データの管理がやりやすいそれでは、段階を踏んで実装をしていきます。
1. gem の導入
gem 'rails-i18n' gem 'enum_help'bundle install の実行
2.モデル(product)にenumを記載
product.rbenum status:{ '---': 0, #--- unused: 1, #新品、未使用 nearly_unused: 2, #未使用に近い not_injured: 3, #目立った傷や汚れなし bit_injured: 4, #やや傷や汚れあり injured: 5, #傷や汚れあり bad: 6, #全体的に状態が悪い }今回はselectboxを作成するため、1~6の選択肢として記載。
選択されたstatusは、DBには1~6として格納される。
(記載した英語は、自由で大丈夫です)3. ja.ymlに変換したい日本語を記載
※ ja.yml がない場合は、 config>localsの下に作成してください。
ja.ymlja: enums: product: status: '---': "---" unused: "新品、未使用" nearly_unused: "未使用に近い" not_injured: "目立った傷や汚れなし" bit_injured: "やや傷や汚れあり" injured: '傷や汚れあり' bad: '全体的に状態が悪い'階層が綺麗になっていないと、日本語化出来ないので要注意
4. viewに記載
new.html.haml= f.select :status, Product.statuses.keys.map {|k| [I18n.t("enums.product.status.#{k}"), k]}Product : モデル名
statsues : カラム名(複数形にしてください)
keys.map {|k| [I18n.t("enums.product.status.#{k}"), k]}
→ 選択肢を1つ1つ取り出して、日本語に変換して並び替えるイメージです。5. 変数を表示する場合
statusに1が格納されている前提で、最後に'_i18n'を記載する
ruby.sample.haml(enum 実装ナシ) @product.status → " 1 " (enum実装アリ:日本語変換ナシ) 〃 → ”unused” (enum実装アリ:日本語変換アリ) @product.status_i18n → ”新品、未使用”最後に
DB設計の段階で、どのようにデータを管理するか、しっかり確認・詰めておくべきでした。。。
最初は、statusカラムの型をstringにしてしまったため、苦戦しました。
チーム開発半ばで、DBからデータを取って来た時に数字で表示されてしまって、
これは何とかしないといけないなと思ったことがスタートでした。皆様のお役に立てれば幸いです
- 投稿日:2019-12-01T16:33:11+09:00
rails での enumと、日本語化のやり方
enumの実装と日本語化
某プログラミングスクールの課題で、
enumの実装と、対応する日本語化の機能を実装しましたので、
そのやり方を投稿させていただきます。
<railsでの開発、haml記法を想定しています。>※本記事が初投稿です
わかりにくい点が見受けられるかと思いますが、ご容赦ください。。。enum実装の経緯
productsテーブル:statusカラム(integer型)の場合
statusカラムに保存されている情報(1、2など)を、変数を用いて表示させたかったが、→ DBに格納されている数字で表示されてしまう
例)viewで「@product.status」と記載 → 1 が表示される・・・
これを、「@product.status」 → ”新品、未使用” などの日本語へ変換したい実装方法
<前提として>
ruby 2.5.1
rails 5.2.3
なお、enum実装のメリットとしては、下記の2点が大きいと思います
・コードが読みやすくなる
・データの管理がやりやすいそれでは、段階を踏んで実装をしていきます。
1. gem の導入
gem 'rails-i18n' gem 'enum_help'bundle install の実行
2.モデル(product)にenumを記載
product.rbenum status:{ '---': 0, #--- unused: 1, #新品、未使用 nearly_unused: 2, #未使用に近い not_injured: 3, #目立った傷や汚れなし bit_injured: 4, #やや傷や汚れあり injured: 5, #傷や汚れあり bad: 6, #全体的に状態が悪い }今回はselectboxを作成するため、1~6の選択肢として記載。
選択されたstatusは、DBには1~6として格納される。
(記載した英語は、自由で大丈夫です)3. ja.ymlに変換したい日本語を記載
※ ja.yml がない場合は、 config>localsの下に作成してください。
ja.ymlja: enums: product: status: '---': "---" unused: "新品、未使用" nearly_unused: "未使用に近い" not_injured: "目立った傷や汚れなし" bit_injured: "やや傷や汚れあり" injured: '傷や汚れあり' bad: '全体的に状態が悪い'階層が綺麗になっていないと、日本語化出来ないので要注意
4. viewに記載
new.html.haml= f.select :status, Product.statuses.keys.map {|k| [I18n.t("enums.product.status.#{k}"), k]}Product : モデル名
statsues : カラム名(複数形にしてください)
keys.map {|k| [I18n.t("enums.product.status.#{k}"), k]}
→ 選択肢を1つ1つ取り出して、日本語に変換して並び替えるイメージです。5. 変数を表示する場合
statusに1が格納されている前提で、最後に'_i18n'を記載する
ruby.sample.haml(enum 実装ナシ) @product.status → " 1 " (enum実装アリ:日本語変換ナシ) 〃 → ”unused” (enum実装アリ:日本語変換アリ) @product.status_i18n → ”新品、未使用”最後に
DB設計の段階で、どのようにデータを管理するか、しっかり確認・詰めておくべきでした。。。
最初は、statusカラムの型をstringにしてしまったため、苦戦しました。
チーム開発半ばで、DBからデータを取って来た時に数字で表示されてしまって、
これは何とかしないといけないなと思ったことがスタートでした。皆様のお役に立てれば幸いです
- 投稿日:2019-12-01T16:26:00+09:00
ABC049C - 白昼夢 / Daydream
問題
https://atcoder.jp/contests/abs/tasks/arc065_a
1回目
回答
str = gets.chomp DREAM = "dream" DREAMER = "dreamer" ERASE = "erase" ERASER = "eraser" equal_flag = "NO" while true str_size = str.size if str_size >= 5 sliced_str = str.slice( ( str_size - 5 )..( str_size - 1 ) ) if sliced_str == DREAM || sliced_str == ERASE if str == sliced_str equal_flag ="YES" break end str = str.slice( 0..( str_size - 6 ) ) next end end if str_size >= 6 sliced_str = str.slice( ( str_size - 6 )..( str_size - 1 ) ) if sliced_str == ERASER if str == sliced_str equal_flag ="YES" break end str = str.slice( 0..( str_size - 7 ) ) next end end if str_size >= 7 sliced_str = str.slice( ( str_size - 7 )..( str_size - 1 ) ) if sliced_str == DREAMER if str == sliced_str equal_flag ="YES" break end str = str.slice( 0..( str_size - 8 ) ) next end end break end puts equal_flag結果
2回目
回答
S=gets.chomp s = S.gsub("eraser","").gsub("erase","").gsub("dreamer","").gsub("dream","") puts s.size==0?"YES":"NO"結果
感想
自分の知っている知識だけでも解けてしまうので他の人の回答がめっちゃ参考になる。
今回はパフォーマンスめちゃくちゃ影響したし、
実際の業務でこれに気付かなかったらこのパフォーマンスのままリリースされてしまっていたかと思うと怖い。
正規表現も今度触ってみよう。


- 投稿日:2019-12-01T15:58:47+09:00
rails-tutorial第6章
そもそもなんでmodelが必要なの?
・永続的な情報を保存したいけど普通の変数だと実現できない。
・永続的な情報の保存にはDBを使わないといけない。
・ActiveRecordを使うと変数のようにDBに保存をすることができる。
・モデルはActiveRecordを継承したApplicationRecordを継承している。
・つまり、RubyとDBの橋渡しをしてくれるから。Userモデルの作成
$ rails generate model User name:string email:stringモデルの作成時はUserのように単数形で書く。
name:string はnameカラムでデータ形式はstringだよーって意味。ちなみに id:integer created_at:datetime updated_at:datetimeはデフォルトで入っている。
このコマンドにより、テストファイルやマイグレーションファイルが作成される。
以下は作成されたマイグレーションファイルdb/migrate/[timestamp]_create_users.rbclass CreateUsers < ActiveRecord::Migration[5.0] def change create_table :users do |t| t.string :name t.string :email t.timestamps end end endこれで $ rails db:migrateをすると、Userリソースを保存するためのテーブルが作成される。
rails g modelコマンドだけではテーブルは作成されないから注意が必要。$ rails db:rollback
このコマンドによってrails db:migrateの更新を戻すことができる。
modelファイルを見てみよう
app/models/user.rbclass User < ApplicationRecord endUserクラスがApplicationRecordを継承していることがわかる。
この継承によって、Userクラスのインスタンスにsaveメソッドが使えるようになり、DBに保存することができる。(findメソッドとかallメソッドとか色々使える。)またマジックカラム(id ,created_at, updated_at)はDBに保存されて初めて値が埋まる。User.create
User.create(name: "A Nother", email: "another@example.org")
user.new, user.saveなどが面倒なときは、User.createでいきなりDBベースに保存することができる。
また、u = User.create(name: "A Nother", email: "another@example.org")createメソッドはUserインスタンスを返すので、上記でDBに保存し、かつローカル変数uに代入することができる。
findメソッドとfind_byメソッドの違い
findメソッドは見つからなかったときに例外を出すのに対して、find_byは見つからなかったときにnilを返す。
update_attributes
update_attributesはcreateと似ていて、更新のショートカットを可能にする。
>> user.update_attributes(name: "The Dude", email: "dude@abides.org") => trueこのように1行で書ける。
update_attribute
update_attributeは二つの引数を使って更新する。
>> user.update_attribute(:name, "El Duderino") => trueupdate_attributeはvalidationを介さずにDBに登録をすることができるという特徴がある。
ユーザーを検証する
モデルの場合、テストコードを先に書いて、あとでvalidationを書いていったほうが早い
モデルのテストを見ていこう
test/models/user_test.rbrequire 'test_helper' class UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com") end test "should be valid" do assert @user.valid? end end上記のsetupメソッドはその下の test do endが実行される直前に実行されるという特徴がある。
また、modelだけテストをしたいときは、
$ rails test:models
とすると良い。
このテストの場合、バリデーションが設定されてないのでテストは通る。では次のテストはどうだろうか?
test/models/user_test.rbrequire 'test_helper' class UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com") end test "should be valid" do assert @user.valid? end test "name should be present" do @user.name = " " assert_not @user.valid? end endこの場合、user.nameが空文字の際に、@userはnot validじゃなきゃいけないよね?っていうテスト。
この場合、バリデーションが設定されていないので、テストは失敗する。validationを設定しよう
app/models/user.rbclass User < ApplicationRecord validates :name, presence: true endvalidationはmodelのファイルに書く。
次は長さを検証してみよう
test/models/user_test.rbrequire 'test_helper' class UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com") end . . . test "name should not be too long" do @user.name = "a" * 51 assert_not @user.valid? end test "email should not be too long" do @user.email = "a" * 244 + "@example.com" assert_not @user.valid? end end@user.nameはsetupメソッドでテスト直前に定義されるから問題ない。
"a" * 51とすることで、aを50回打つなどの面倒を避ける。この場合、バリデーションを定義していないのでテストは失敗してしまう。
なので、app/models/user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } validates :email, presence: true, length: { maximum: 255 } endとすることで、文字数のバリデーションを定義できる。
適切なメールアドレスかチェックする
test/models/user_test.rbclass UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com") end . . . test "email validation should accept valid addresses" do valid_addresses = %w[user@example.com USER@foo.COM A_US-ER@foo.bar.org first.last@foo.jp alice+bob@baz.cn] valid_addresses.each do |valid_address| @user.email = valid_address assert @user.valid?, "#{valid_address.inspect} should be valid" end end test "email validation should reject invalid addresses" do invalid_addresses = %w[user@example,com user_at_foo.org user.name@example. foo@bar_baz.com foo@bar+baz.com] invalid_addresses.each do |invalid_address| @user.email = invalid_address assert_not @user.valid?, "#{invalid_address.inspect} should be invalid" end end end現在、メールアドレスは存在性と長さしかバリデーションを設定してないので、2つ目のテストで失敗してしまう。
なので、正規表現でバリデーションを設定しよう。
app/models/user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i validates :email, presence: true, length: { maximum: 255 }, format: { with: VALID_EMAIL_REGEX } endformatオプションで設定すると、その型通りじゃないとvalidにならないようになる。
ちなみにVALID_EMAIL_REGEXは定数である。一意性を知ろう。
同じメールアドレスがDB内に複数あると困る。
テストを見てみよう
test/models/user_test.rbclass UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com") end . . . test "email addresses should be unique" do duplicate_user = @user.dup @user.save assert_not duplicate_user.valid? end enddupは複製するメソッド。
@userがDBに保存された状態で、duplicate_userという複製されたインスタンスはvalidですか?というテストである。このテストは落ちる。じゃあ、一意性を担保するには?
app/models/user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i validates :email, presence: true, length: { maximum: 255 }, format: { with: VALID_EMAIL_REGEX }, uniqueness: true endこのようにuniqueness: trueとすると一意性が担保される確率が上がる。
まだ、このままだとメールアドレスの大文字小文字を区別できない。
そのため、test/models/user_test.rbrequire 'test_helper' class UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com") end . . . test "email addresses should be unique" do duplicate_user = @user.dup duplicate_user.email = @user.email.upcase @user.save assert_not duplicate_user.valid? end end最後のテスト、@userがDBに登録され、またメールアドレスが大文字になったインスタンスはnot validになるか?というテストなのだが、落ちてしまう。これはuniqueness: trueがデフォルトで大文字小文字を区別するようになっているためだ。
そこで
app/models/user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i validates :email, presence: true, length: { maximum: 255 }, format: { with: VALID_EMAIL_REGEX }, uniqueness: { case_sensitive: false } enduniqueness: trueからuniqueness: { case_sensitive: false }に変えてあげる。
case_sensitive: falseは大文字小文字を区別しなくてもいいよーって意味。
これで大文字小文字関係なく、スペルが同じアドレスは登録できなくなり、一意性が担保されるようになる?いや、まだだ。
全く同じメールアドレスが全く同じ時間に登録されたらどうなるか?
なんと、どちらも登録されてしまう。。。なので、DBにも一意性を担保してもらうようにお願いをしなければいけない。
具体的には片方のアドレスが登録されるまで次の登録を待ってもらう。その際はマイグレーションファイルを使う
$ rails generate migration add_index_to_users_emailできたマイグレーションファイルに
db/migrate/[timestamp]_add_index_to_users_email.rbclass AddIndexToUsersEmail < ActiveRecord::Migration[5.0] def change add_index :users, :email, unique: true end endこのように書く。
unique: trueは一意性をDB側でも担保してくださいねーってお願い。で、 rails db:migrateをする。
これでOKか?
いや、このままだと、テストが全て通らなくなってしまう。これは以下が原因となっている。
test/fixtures/users.ymlone: name: MyString email: MyString two: name: MyString email: MyStringテスト用データベースの中に、MyStringというメールアドレスが2つあり、一意性に引っかかってしまったのだ。
解決策としては、このファイルの内容を全て消してあげれば良い。
セキュアなパスワードを設定する。
まずは散らばった文字列のパスワードのハッシュ値を入れる場所を作る。
$ rails generate migration add_password_digest_to_users password_digest:string
ちなみにマイグレーションファイル名を add_カラム名toテーブル名とするとRailsが勝手に判断して以下のようにコーディングしてくれる。
db/migrate/[timestamp]_add_password_digest_to_users.rbclass AddPasswordDigestToUsers < ActiveRecord::Migration[5.0] def change add_column :users, :password_digest, :string end endあとは、上のファイルが自分のやりたいことと一致するか確認して、
$ rails db:migrateを実行する。これでパスワードのハッシュ値を保存する場所ができた。
bcrypt
次に、パスワードをハッシュ化するためのgem bcryptをインストールする。
gem 'bcrypt', '3.1.12'
bundleそして、モデルファイルに has_secure_passwordと書けば完了。以下
app/models/user.rbclass User < ApplicationRecord before_save { self.email = email.downcase } validates :name, presence: true, length: { maximum: 50 } VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i validates :email, presence: true, length: { maximum: 255 }, format: { with: VALID_EMAIL_REGEX }, uniqueness: { case_sensitive: false } has_secure_password endただ、この状態だとテストが落ちてしまう。
理由はtestファイルのsetupメソッドにpassword属性とpassword_confirmation属性の値を指定していないためらしい。ちなみにpasswordとpassword_confirmationは仮想的な属性で、実際にDBに保存されるのはpassword_digestだけ。
そこで、
test/models/user_test.rbrequire 'test_helper' class UserTest < ActiveSupport::TestCase def setup @user = User.new(name: "Example User", email: "user@example.com", password: "foobar", password_confirmation: "foobar") end . . . endというように、仮想的な属性を指定してあげる。これで一応テストは通る。
あとは、パスワードの文字数を6文字以上とかにするバリデーションを設定してあげる。
app/models/user.rbclass User < ApplicationRecord before_save { self.email = email.downcase } validates :name, presence: true, length: { maximum: 50 } VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i validates :email, presence: true, length: { maximum: 255 }, format: { with: VALID_EMAIL_REGEX }, uniqueness: { case_sensitive: false } has_secure_password validates :password, presence: true, length: { minimum: 6 } endパスワードの存在性と長さ6文字以上を指定。
これで一応セキュアなパスワードは実装完了。
パスワードの認証について
has_secure_passwordをUserモデルに追加したことで、そのオブジェクト内でauthenticate()メソッドが使えるようになっています。このメソッドは、引数に渡された文字列 (パスワード) をハッシュ化した値と、データベース内にあるpassword_digestカラムの値を比較します。
マイグレーションファイルを色々設定したあとは、
$ heroku run rails db:migrate
を忘れずに!!!
- 投稿日:2019-12-01T15:57:23+09:00
RailsとVue.js(SPA)を「いいとこ取り」。API連携で開発するハンズオン。(その1:Rails編)
はじめに
DBの操作と管理画面はRailsで作成しつつ、一般ユーザ向けの画面はSPAとかPWAにしたいというシーンは結構あるかと思います。既存アプリがRailsで動いているのを活かしながら、フロント側はSPA化するとか。基本はSPAなんだけど、管理画面はscaffoldでサクッと作って済ませたいとか。
今回はそんなことを考えながら、
Rails(管理画面&API)+Vue.js&Nuxt.js(SPA)という構成のアプリを作ってみました。題材は、ちょうど作り直したいと考えていた自分のポートフォリオサイトです。1以下の役割分担で作っていきます。
Rails(View) Rails(API) Vue&Nuxt コンテンツの表示(一般公開) ○ ○ ○ コンテンツの編集(管理者限定) ○ - - この記事では、Rails側で画面とAPIを作成するところまで掲載します。
SPA側の作成と、本番環境へのデプロイは、別途記事化します。Rails側の準備
Railsに持たせる機能がAPIだけだったら
rails new projectname --apiで良いのですが、これだとview関連のコードが作成されません。
今回は、管理画面は「Railsのいいとこ」を活かして作りつつ、SPA向けのAPIも作るので、このオプションは使わずに進めていきます。以下、Rails5.2の環境が作成済みである前提です。2
rails new
まずは普通に rails new
$ rails new portfolio-rails $ cd portfolio-railsdeviseを導入
ユーザ管理にはdeviseを使います。こういった「よく使う機能を手軽に実現できるgem」が充実しているのも「Railsのいいとこ」と思います。
Gemfilegem 'devise'console$ bundle install $ rails g devise:install続けて、
rails g devise:installをした時に表示されるSome setup you must do manually if you haven't yet:の下に書かれている1〜3を実施します。config/environments/development.rbconfig.action_mailer.default_url_options = { host: 'localhost', port: 3000 }config/routes.rbroot to: "home#index"app/views/layouts/application.html.erb<p class="notice"><%= notice %></p> <p class="alert"><%= alert %></p>console$ rails g devise user $ rails db:migrate $ rails g devise:views $ rails g devise:controllers usersこの時点で、usersテーブルには以下の列が生成されています。
- encrypted_password
- reset_password_token
- reset_password_sent_at
- remenber_created_at
ここで一度
rails sして最低限の動作を確認しました。
大丈夫ですね。
すでにdeviseを入れてあるので、http://localhost:3000/users/sign_in からログイン画面にアクセスできます。
この時点では、サインアップしようとしても roots.rb に記述した root to: "home#index" をまだ作成していないので、Routing Errorになります。
routes.rbを書き換えます。
routes.rbRails.application.routes.draw do devise_for :users, controllers: { sessions: 'users/sessions' } endこれで、サインアップしようとした際のRouting Errorはなくなりました。
ユーザ管理(認証・認可)周りはまだやることがありますが、一旦置いておき、他の作業に進みます。
Githubへ初期コミット
生成されたコードや設定への変更点が増える前に、Githubへの初期コミットをしておきます。
Github側でリポジトリを作成し、そこの指示通りに作業します。
今回は「portfolio-rails」というリポジトリにしました。
https://github.com/shozzy/portfolio-rails$ git init $ git add README.md $ git commit -m "first commit" $ git remote add origin https://github.com/shozzy/portfolio-rails.git $ git push -u origin masterこれだけだとREADME.mdだけがpushされた状態なので、続けてここまでに生成されたコードや設定ファイルもpushしようと思いますが、その前に
.gitignoreの内容を見直しておきます。
正直詳しくないので、 gitignore.io で取得した内容をそのまま適用します。
https://www.gitignore.io/api/railsこれで公開してはいけないファイルを誤って公開してしまう可能性は低減できたでしょう。
それでは、コミットを実施します。3
$ git add . $ git commit -m "second commit" $ git pushコンテンツ用のmodel, view, controllerを作成
ここからは、ポートフォリオのコンテンツ用のmodel, view, controllerを作成します。
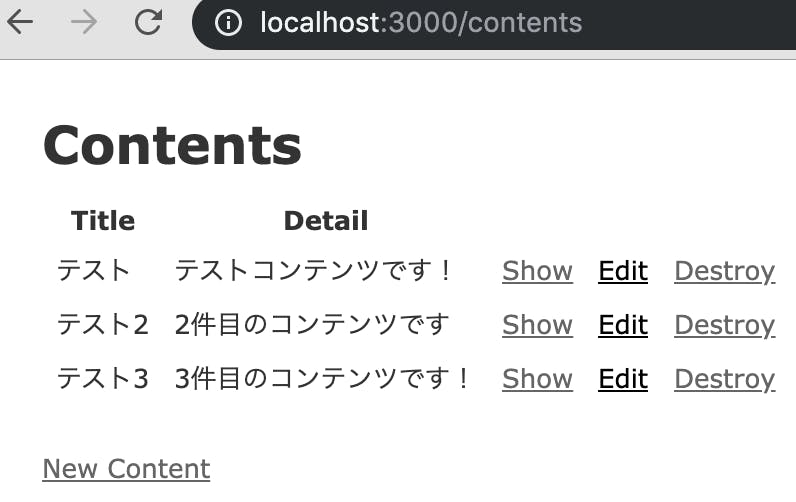
今回は、scaffoldを使って、最低限のCRUDをざっくり作成してしまいます。$ rails g scaffold Content title:String detail:String $ rails db:migrate
rails sして確認すると、エラーになりました。
マイグレーションはしたのですが、、、
と思ってコンソールを見直したら、マイグレーションファイルの中にtypoがありました。フィールドの型を
stringと書くべきところ、うっかりキャメルケースでStringと書いていました。NoMethodError: private method `String'マイグレーションに失敗した状態なので、マイグレーションファイル4を修正してから再度マイグレーションします。
$ rails db:migrate == 20190923152109 CreateContents: migrating =================================== -- create_table(:contents) -> 0.0015s == 20190923152109 CreateContents: migrated (0.0016s) ==========================成功しました。
rails sまだ中身のデータは入っていませんが、scaffoldで作成した画面が表示できました。
新機能を作成したので、featureブランチを作成して、そこにpushしておきます。
$ git checkout -b create-contents $ git add . $ git commit -m "create contents scaffold" $ git push origin create-contents試しに動かしてみる
一応動くものができているはずなので、試しに動かしてみましょう。ここでは、データを3件登録してみました。
scaffoldのままなのでドシンプルですが、正しく画面表示できています。
最低限のテスト(RSpec)
APIを作る前に、ここまでの内容に対して最低限のテストを書いておきます。
RSpecとFactoryBotを導入します。
Gemfilegroup :test do # 中略 gem 'rspec-rails', '~> 3.8' gem 'factory_bot_rails', '~> 5.1.0' endconsole$ bundle install $ rails g rspec:installこれにより、specフォルダが作成されます。
minitest用のフォルダを削除します。
$ rm -r ./testHeadless Chromeを使用するように設定を入れます。
spec/spec_helper.rbrequire 'capybara/rspec' RSpec.configure do |config| config.before(:each, type: :system) do driven_by :selenium_chrome_headless end end下記設定がデフォルトではコメントアウトされていますが、コメントを外しておきます。
rails_driver.rbDir[Rails.root.join('spec', 'support', '**', '*.rb')].each { |f| require f }console$ mkdir ./spec/factories./spec/factories/contents.rb を作成します。
./spec/factories/contents.rbFactoryBot.define do factory :content do title { 'テストタイトル' } detail { 'テストコンテンツの明細です。' } end endconsole$ mkdir ./spec/system./spec/system/contents_spec.rb を作成します。
./spec/system/contents_spec.rbrequire 'rails_helper' describe 'コンテンツ管理機能', type: :system do describe '一覧表示機能' do context '1件だけデータがある場合' do before do # コンテンツを1件作成 FactoryBot.create(:content, title:"テストコンテンツ1", detail:"コンテンツ1の明細") visit contents_path end it '1件のコンテンツが表示される' do # 表示内容を確認 expect(page).to have_content 'テストコンテンツ1' end end end endconsole$ bundle exec rspec spec/system/contents_spec.rb Capybara starting Puma... * Version 3.12.1 , codename: Llamas in Pajamas * Min threads: 0, max threads: 4 * Listening on tcp://127.0.0.1:55559 2019-09-28 15:15:03 WARN Webdrivers Driver caching is turned off in this version, but will be enabled by default in 4.x. Set the value with `Webdrivers#cache_time=` in seconds . Finished in 5.84 seconds (files took 2.37 seconds to load) 1 example, 0 failuresテストは無事にパスしました。
Set the value with `Webdrivers#cache_time=` in secondsのWARNが気になるので、下記対処をしておきます。console$ mkdir ./spec/supportspec/support/javascript_driver.rb# During the cache time, Webdrivers won't check to update Chrome. Webdrivers.cache_time = 1.month.to_iWARNが出なくなりました✨
console$ bundle exec rspec spec/system/contents_spec.rb Capybara starting Puma... * Version 3.12.1 , codename: Llamas in Pajamas * Min threads: 0, max threads: 4 * Listening on tcp://127.0.0.1:55767 . Finished in 2.39 seconds (files took 2.34 seconds to load) 1 example, 0 failuresAPIを生やす
さて、ここからようやく本題です。APIを生やして行きます。
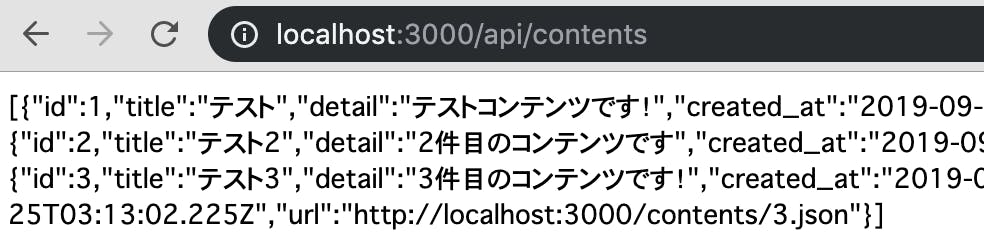
元々
http://localhost:3000/contents.json
へアクセスしたらJSONで結果が返ってきますが5、ここではせっかくなのでもう少しAPIっぽく、
http://localhost:3000/api/contents
でアクセスしたらJSONで結果が返ってくるようにしてみます。routes.rbに以下の設定を追加します。APIからはindexとshowのアクションだけを呼べるようにしたいので、resouresは使わず、個別に設定しています。
routes.rbscope '/api' do get '/contents', to: 'contents#index', defaults: { format: :json } get '/contents/:id', to: 'contents#show', defaults: { format: :json } endscope を設定することで、URLに
/apiが入っていても/api/contentsではなく/contentsにアクセスしたかのような動きになり、
各ルーティングの defaults に format の設定を入れることで、/contents.jsonではなく/contentsと書くだけでJSONが自動的にフォーマットとして指定されるようになります。
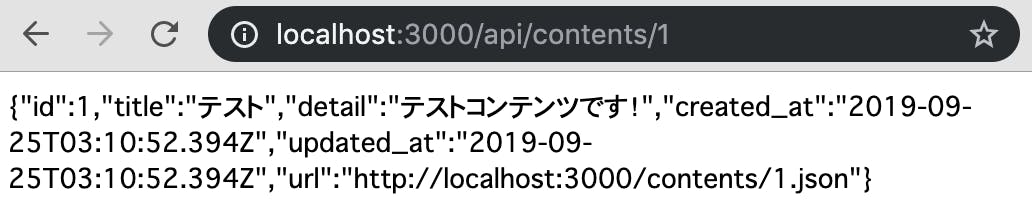
同様に、特定のコンテンツの明細も以下のように取得できます。6
たったこれだけで、APIを作ることができました。
なお、今回は一般公開する機能だけをAPI化したので、APIキーによるアクセス制限は実施していません。
編集機能や特定ユーザだけに公開する情報をAPI化する時は、何らか7のアクセス制御を組み込む必要があります。編集系の機能をログイン必須にする
今回は自分以外は編集できないようにする計画ですが、ここまでの内容のままでは誰でもコンテンツを編集できてしまいます。
最初にdeviseを入れてありますので、それを利用してログイン状態でなければ追加・編集・削除を実施できないようにします。controllerの
before_actionを使って、ログイン済みの場合だけ表示を認可します。
現時点では複雑な権限設定は持たせていないので、単純に「ログイン済みであれば誰でもOK」という仕組みです。8contentsは、indexアクションは誰でもOKなので、それ以外のアクションに認可をかけています。
contents_controller.rbbefore_action :authenticate_user!, only: [:show, :new, :edit, :create, :update, :destroy]認可されていないアクションを実行しようとすると、ログイン画面にリダイレクトされます。
masterブランチへマージする
最低限ではありますが、作りたかった機能が出来上がったので、自分にプルリクを出してmasterブランチへマージします。
まず、テストを流して問題が発生していないことを確認。
$ bundle exec rspec spec/system/contents_spec.rb (中略) Finished in 4.7 seconds (files took 1.95 seconds to load) 1 example, 0 failuresfeatureブランチにcommit&push。9
$ git add . $ git commit -m "add auth to contents" $ git pushGitHub側で、プルリクエストを出します。
マージします。
これで、masterブランチに開発内容を入れることができました。
最後にローカル側で、今後の作業に備えてmasterブランチをcheckoutしておきます。うっかりfeatureブランチからさらに別のfeatureブランチを派生させないために。個人開発なので、master+feature1本ずつで運用する方針です。
$ git fetch $ git checkout master Switched to branch 'master' Your branch is behind 'origin/master' by 8 commits, and can be fast-forwarded. (use "git pull" to update your local branch) $ git pullまとめ
この記事では、contentsの編集画面をRailsのscaffold機能でサクッと作った上で、contentsの一覧と詳細をREST API経由でJSONとして取得できるところまでを作りました。
次の記事(鋭意制作&執筆中)では、Vue.js&Nuxt.jsで作成したSPAから、このAPIを叩いて取得した情報をいい感じに表示するところを作ります。
自己最長記事なので推敲にかなり時間をかけましたが、おかしいところがありましたら教えて頂けますと幸いです。
参考にした書籍・Webサイト
執筆者の皆様、本当にありがとうございます!
- 「現場で使える Ruby on Rails 5 速習実践ガイド」https://www.amazon.co.jp/dp/4839962227
- https://www.gitignore.io/api/rails
- https://railsguides.jp/routing.html
- https://bokunonikki.net/post/2018/0804_rails5_devise/
- https://qiita.com/Hal_mai/items/350c400e8763ce0487a3
- https://qiita.com/tatsurou313/items/c923338d2e3c07dfd9ee
- https://bloggie.io/@kinopyo/migrate-from-chromedriver-helper-to-webdrivers
- https://qiita.com/Kokudori/items/d2bcb6fd24c662e73a33
- https://qiita.com/ttiger55/items/d144b8094d61b70955bf
- https://qiita.com/ebi_death/items/3912630e32268c9cce46
- https://qiita.com/tobita0000/items/866de191635e6d74e392
- https://solodev.io/git-flow/
初代は静的サイトとして構築したので、コンテンツを更新するときにサイト自体をデプロイし直す必要がありました。今度はDBと連携させて、コンテンツの更新を容易にしようと考えています。ちなみに初代を構築した時の記事はこちら。https://qiita.com/shozzy/items/dadea4181d6219d2d326 ↩
少し前にRails6がリリースされていますが、Rails5.xで開発を進めてきたのでまだバージョンアップしていません。 ↩
ここまではmasterに直接コミットしていますが、この先はそういうことはしません。 ↩
ここでは db/migrate/20190923152109_create_contents.rb でした。 ↩
https://qiita.com/ttiger55/items/d144b8094d61b70955bf にあるように、デフォルトのJSON生成機構では速度が遅いようですが、それは今後の課題としてここでは触れません。 ↩
このサンプルでは、一覧に全ての情報が含まれているので、明細を取得しても意味がありません。むしろ、URLなど不要な情報も含んでいるので、必要なデータだけ返すように改善が必要ですね。 ↩
APIキーとリファラの組み合わせをチェックするとか。 ↩
自分用のアカウントだけ発行する想定なのでこれで十分という判断です。アカウントごとに権限レベルによる画面制御を細かく掛けるなら、もっとしっかり作り込む必要があります。 ↩
実際には、featureブランチにはもう少しこまめにコミット&プッシュしていました。1機能分の進捗があった時と、作業が途切れるタイミングで。 ↩

- 投稿日:2019-12-01T15:25:37+09:00
SORACOMの使用状況をLagoonで可視化してみた
2019/11/23に開催されたSORACOM UG Explorer 2019にてLTした「SORACOMの使用状況をLagoonで可視化してみた」をやってみるための記事をまとめました。技術ブログ初投稿です。
経緯
皆様SORACOM使ってますか?
SORACOMは「IoTの民主化」を掲げる携帯回線(SORACOM Air)を軸としたIoTサービスで、
- 回線のステータスをコンソールやAPIで取得、操作できる
- SIMを認証デバイスとしてデバイス側に認証情報やSDKを持たずにクラウド連携できる
- データを可視化するLagoonや簡単・安全なデバイス遠隔操作を実現するNapterなど豊富なサービスが付随している
などにより高い人気を博しています。
そんなソラコムですが、使い始めてしばらく経ち、SIMの枚数が増えてくると、ある問題に直面します。それは、
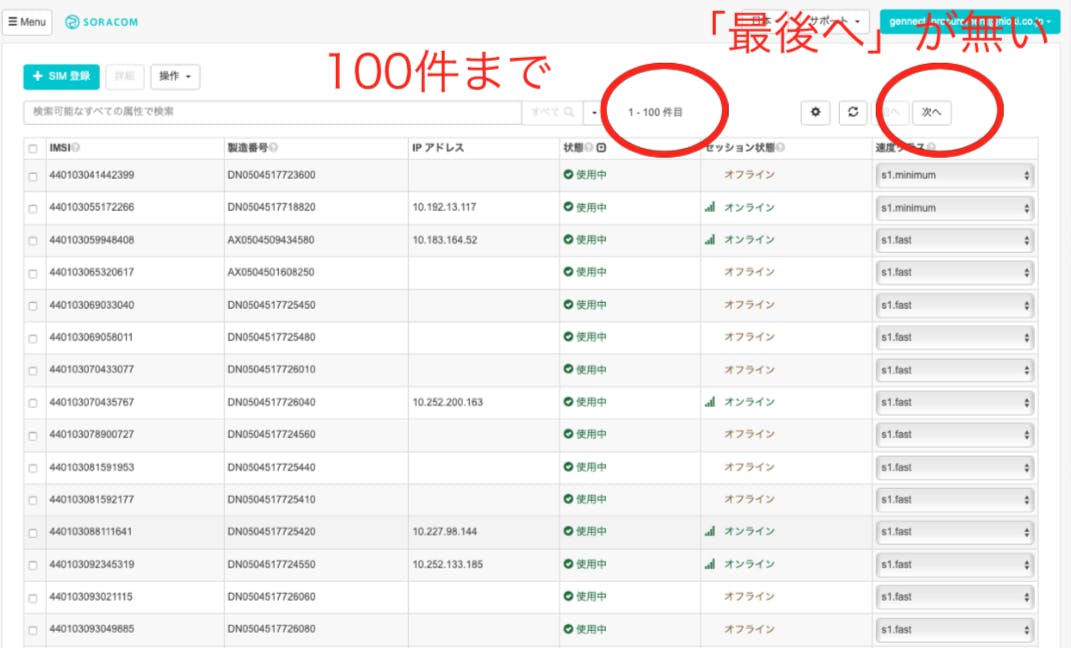
SIMが全部見れないという問題です。
同時に表示できるのが100までで、「最後へ」というリンクも無いので、アカウント内のSIMの枚数を確認しようと思ったら「次へ」をクリックしまくるしかないんですね。これは困った。
SORACOMのコンソールは特定条件のSIMを検索して、その詳細状況を確認したり操作したりする分にはとても便利なのですが、全体の状況を把握したり、推移を分析したりするのには向いていないんですね。SORACOM内でそのような可視化を担当するサービスはSORACOM Lagoonです。今回はSORACOM Lagoonを使ってSORACOMの使用状況を可視化したいと思います。
構成
以下の図のような構成で使用状況の可視化を実現します。
Web API
可視化の対象となるSORACOMの使用状況はWEB APIにて取得することが出来ます。仕様や使い方は以下に記載されています。
https://dev.soracom.io/jp/docs/api_guide/
https://dev.soracom.io/jp/docs/api/SIMの枚数だけでなく、通信量や接続イベント、課金状況など、可視化したくなる要素がいっぱいありますね。コンソールにて閲覧できるデータは全てWeb APIでも提供されているので、これを使って使用状況を収集出来そうです。
SORACOM Harvest
収集したデータはSORCOM Harvestに保存します。SORACOM HarvestはSORACOM Airの回線からデータをアップロードするのが基本的な使い方です。これはデバイスに認証情報を持つことなく、TCPやUDPでデータを送るだけでデータ保存ができる優れものなのですが、SIMと結びついているため、サーバーからデータを収集してアップロードする用途には使えません。
SORACOM Inventory
SORACOM Inventoryというデバイス管理サービスで作成したデバイスを用いて、インターネット経由でSORACOM Harvestにデータをアップロードすることもできるようになっているため、上の課題はこれで解決できます。
https://blog.soracom.jp/blog/2018/07/04/inventory-update/
これを知っているとSORACOMの使い方の幅が広がりそうですね。SORACOM Inventoryは発表された時にはLwM2Mというプロトコルを使ってデバイスの管理ができるサービスとして紹介されていて、LwM2M?よくわかんない、ということで使わなかった人も多いのではないかと思いますが、これは普通のHTTPSのWebAPIで使えます。
SORACOM Lagoon
SORACOM Harvestにデータが保存されたら、SORACOM Lagoonにて可視化できます。SORACOM LagoonはGrafanaをベースとしたダッシュボードツールで、SORACOMにアップロードされたデータをグラフや表、ヒートマップなど様々な形で表示する事が出来ます。グラフィカルな可視化の部分を自分で作るのは大変なのでとてもありがたい。
無料枠について
これらのサービスは無料枠があり、今回は基本構成だと全て無料で使用できます。
- WebAPI: 使用料金無し
- SORACOM Harvest: 1アカウントあたり毎月31日分の「Harvest利用オプション」が無料
- SORACOM Inventory: 初期費用(100円/台)、月額費用(50円/台)を含めて、月あたり 150円分が無料
- SORACOM Lagoon: Freeプラン(ダッシュボード、ユーザー、アラートが1つに制限)
(SIMごとの分布分析したい場合はデバイスが複数必要になり、Harvestが月150円、Inventoryが月50円追加されます)
準備
必要な準備は以下の2つです
- SAMユーザー
- SORACOM Inventoryデバイス
SAMユーザー
SAMユーザーは、SORACOM Access Managementのユーザーで、SORACOMにアクセスする権限が限定されたユーザーを作成、管理できる機能です。
いわゆるルートユーザーは権限が強く、自動処理のためにサーバーなどに置いておくことは基本的にはお勧めできません。最低限の権限を持ったユーザーを作って、そのユーザーで実行しましょう。
以下に作成手順がありますので、これに従って「認証キーID」「認証キーシークレット」を取得してください。
https://dev.soracom.io/jp/start/sam/SAMユーザーには適切な権限を設定する必要があります。今回のツールで使用する以下の権限を作成したSAMユーザーに設定します。
{ "statements": [ { "effect": "allow", "api": [ "Subscriber:listSubscribers", "Subscriber:listSessionEvents", "Log:getLogs", "Billing:exportBilling", "Stats:exportAirStats" ] } ] }SAMユーザーの準備はこれで終了です。
SORACOM Inventory デバイス
SORACOM Inventoryは「デバイス」を任意に作成する事ができ、そのデバイスを用いてHarvestにデータをアップロードしたり、LwM2Mにより制御を実行したりする事ができます。
以下に作成手順がありますので、これに従って「デバイスID」「シークレットキー」を取得してください。
https://dev.soracom.io/jp/start/inventory_harvest_with_keys/なお、上の記事にも微妙に書かれているのですが、デバイス作るだけじゃダメでHarvestが使えるデバイスグループを作ってデバイスをそのグループに所属させる必要があります。この記事の「ステップ3-1: デバイスのグループ設定」にグループ設定の方法が書いてあるので、これに従ってデバイスグループを作りましょう。
https://dev.soracom.io/jp/start/inventory-manage-device/#group
デバイスは最低1つは必要です。使用状況の全体を把握するためのデバイスで「soracom-summary」などと名前をつけると分かりやすいでしょう。
SIMごとの通信量、課金、セッション接続/切断数を分析したい場合は、それぞれ個別にデバイスを作成する必要があります。デバイスの準備はこれで終了です。
ツールの導入
Web APIからデータを収集し、SORACOM Harvestにアップロードするためにツールを作成し、GitHubおよびRubyGemsに公開しています。
https://github.com/1stship/soracom_summary
https://rubygems.org/gems/soracom_summaryPCにrubyがインストールされていれば、
gem install soracom_summaryでインストールでき、
soracom_summaryで実行できます。
(Rubyのインストールについては、申し訳ありませんが他の記事をあたってください)実行にはSAMユーザーとデバイスの認証情報を環境変数を設定しておく必要があります。
$ export SORACOM_AUTH_KEY_ID='SAMユーザーの認証キーID' $ export SORACOM_AUTH_KEY='SAMユーザーの認証キーシークレット' $ export SORACOM_SUMMARY_DEVICE_ID='デバイスのデバイスID' $ export SORACOM_SUMMARY_DEVICE_SECRET='デバイスのシークレットキー'にて環境変数を設定してから実行してください。
--sessionオプションを指定する事でセッションイベント(回線の接続/切断)の解析をする事ができますが、SIMの1枚1枚に対して情報を取得していくため、SIMの枚数が多いとかなり時間がかかります。面白い情報が取れるのでオプションにするのはもったいないんですけどね。(セッションイベントも課金情報や通信量と同じようにCSVでエクスポートできるようにならないだろうか)
また、そのうち改善しますが、現時点では実行中にはなにも表示されません。
$ SORACOM_SUMMARY_DEBUG=true soracom_summaryのようにデバッグ出力を有効にすると進捗がある程度わかりますので、必要に応じてご利用ください。
その他使い方の説明はGitHubのドキュメントをご覧いただければと思います。
またツールはMITライセンスで公開しているので、好きなように利用、改変してもらっていいです。ご意見はGitHubのIssueに上げればそのうち対応するかもしれません。(今回のLTを機にソラコムさんが公式で使用状況可視化サービス提供してくれるみたいな話もあるので、ソラコムさんに意見出した方がいいかもしれない)
可視化
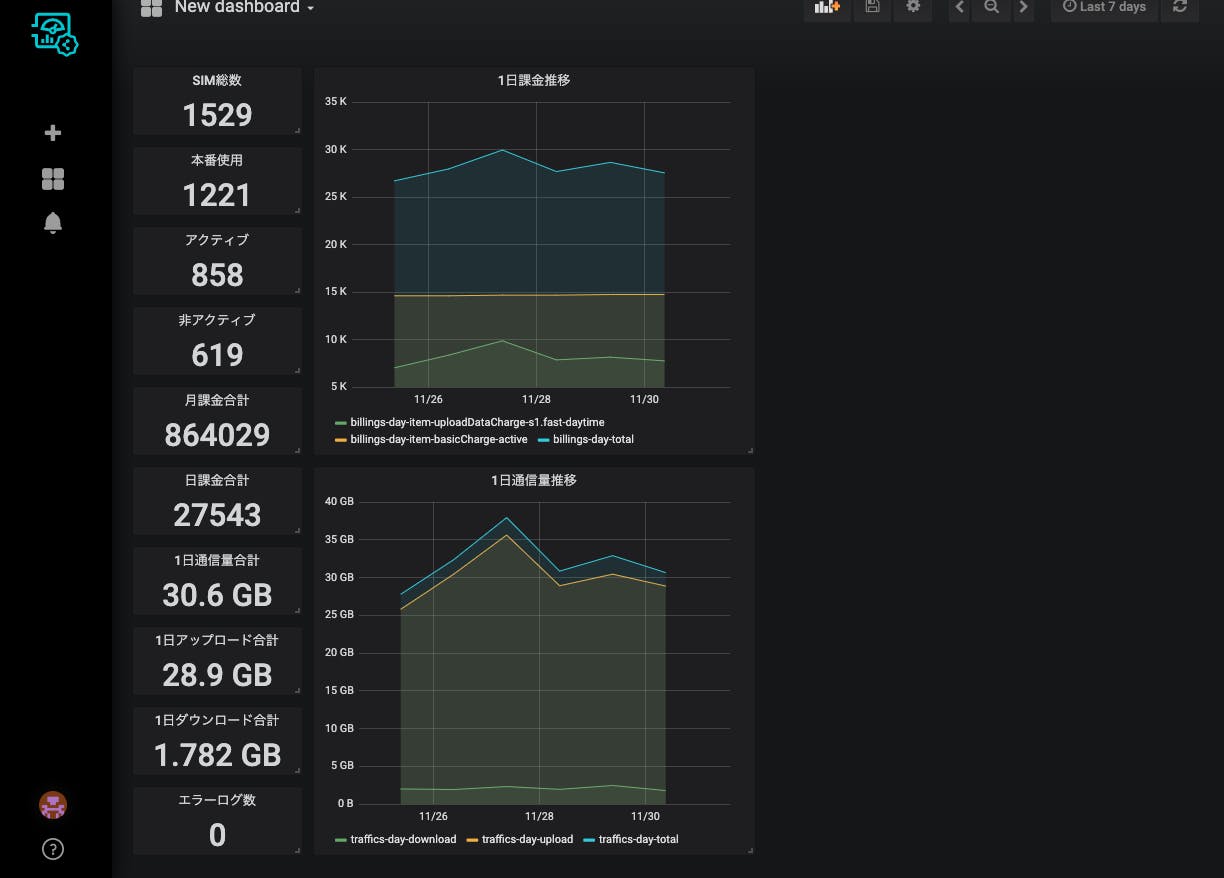
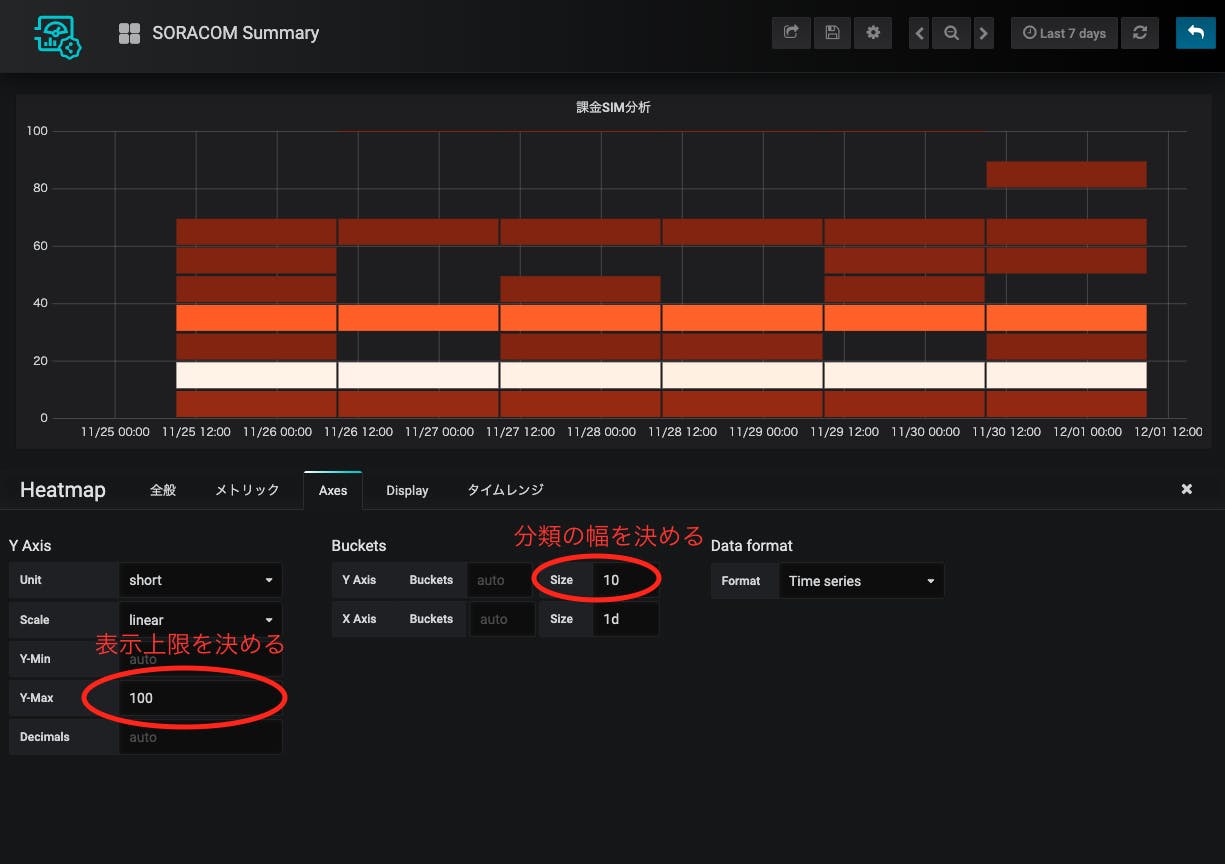
さて、ようやく準備ができたので可視化にいきましょう。まず以下の手順に従ってLagoonのFreeプランに登録してダッシュボードにログインします。
https://dev.soracom.io/jp/start/lagoon-dashboards/
最初はSinglestatで数値表示をしましょう。
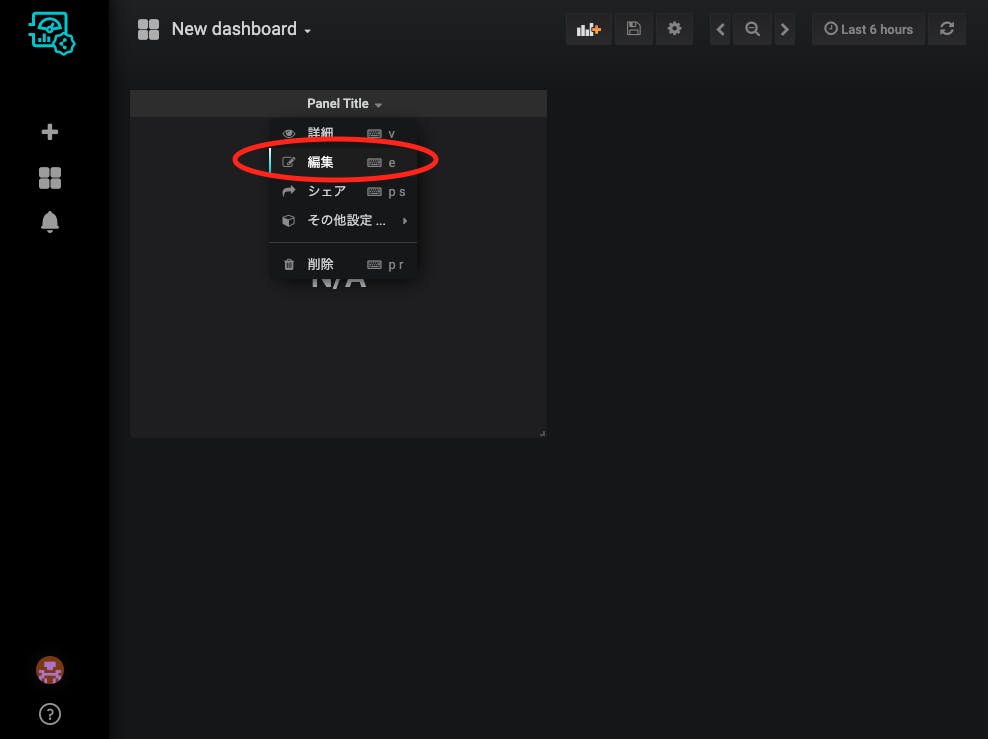
singlestatのパネルを追加して、
パネルの編集をクリックし、
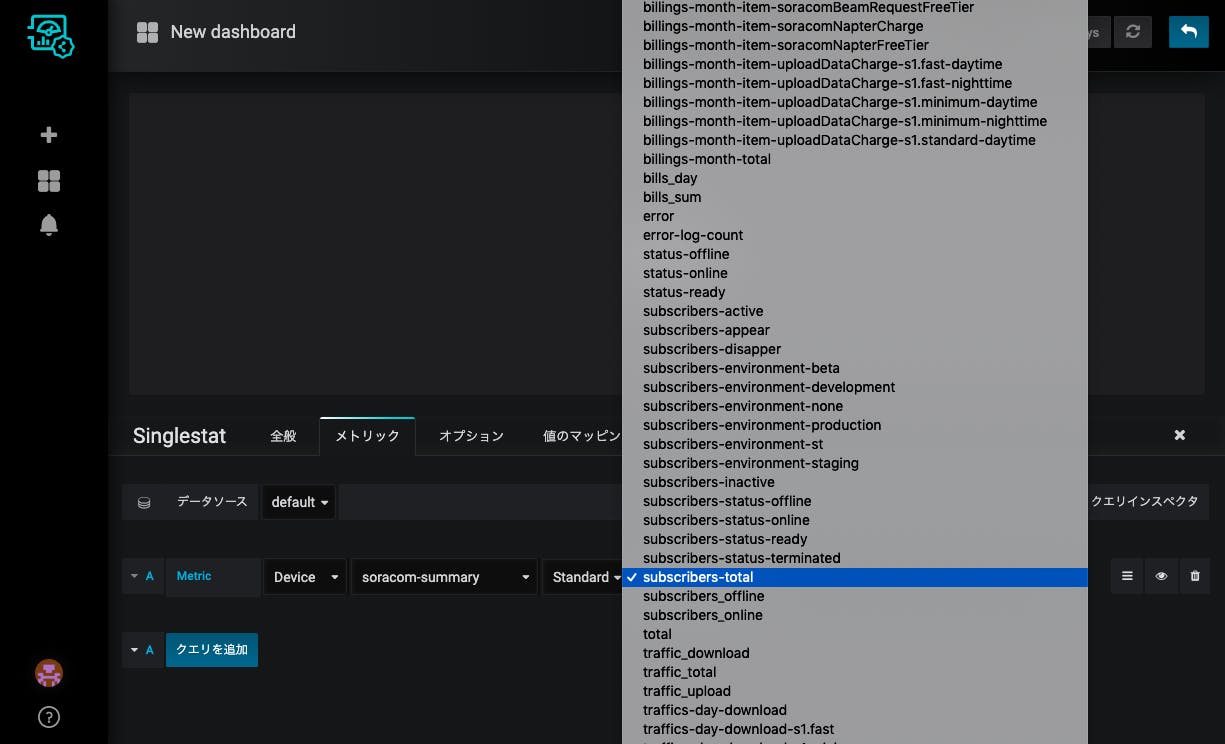
メトリックを、Device、soracom-summary(準備で作ったデバイスの名前)、Standard、subscribers-totalを選択します。
オプションで「表示」を「現在値」にしておきましょう。初期値は「平均値」なので、意図せず表示期間での平均が取られています。
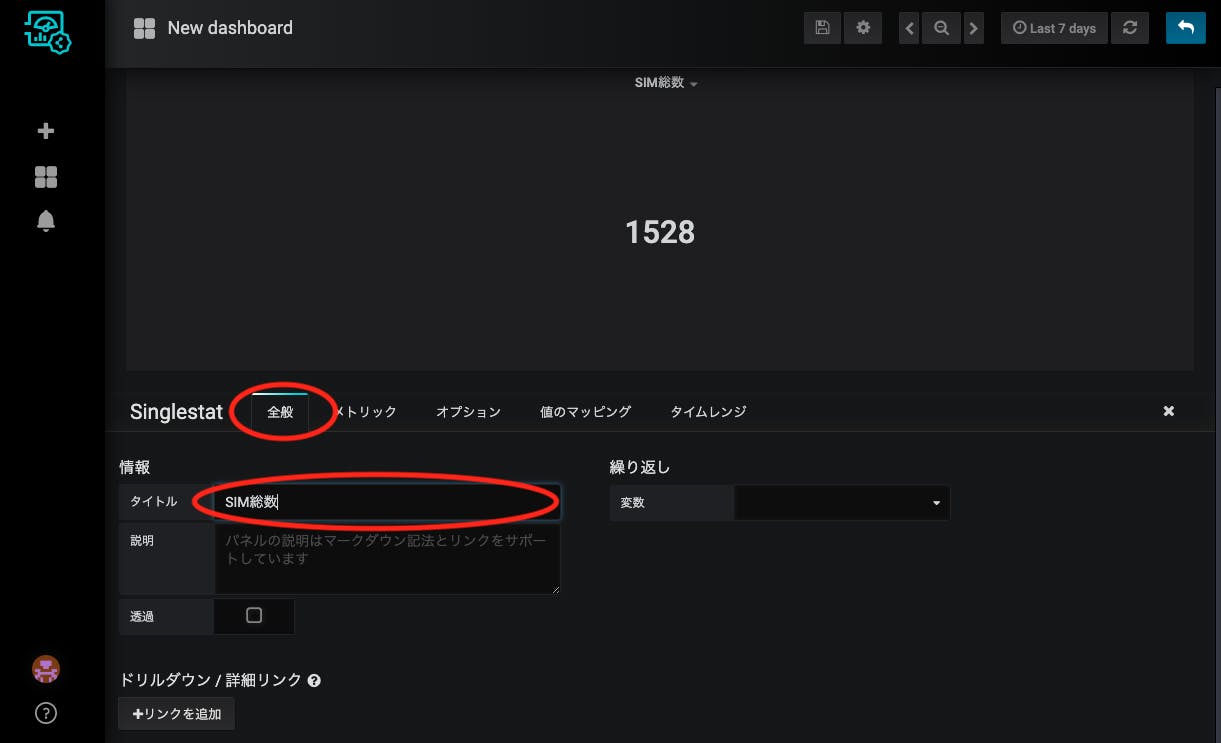
全般タブでタイトルを編集して完成です。
タイトル部分のドラッグで移動、パネル右下部分のドラッグでサイズ変更ができますので、いい感じに配置できます。
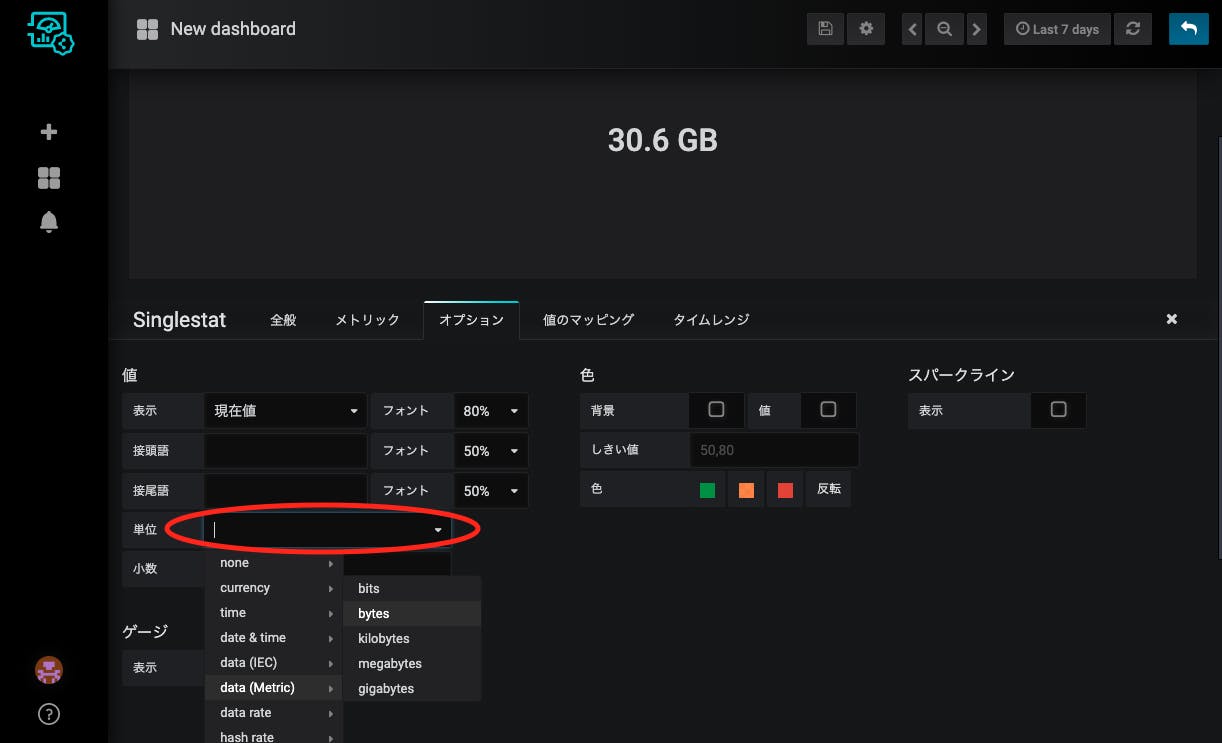
単位をつけたい場合はオプションタブの単位から、適切なものを選びます。補助単位(kとかMとか)も勝手につきます。
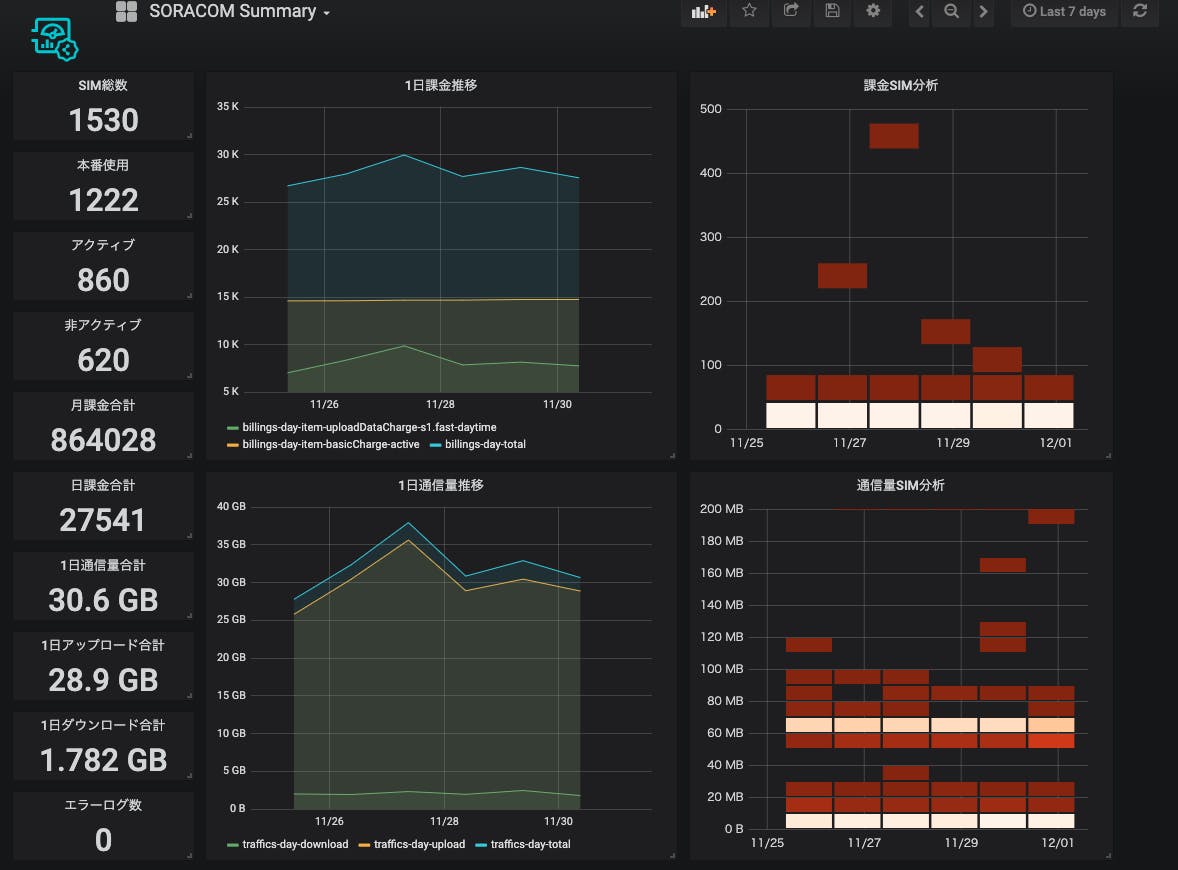
こんな感じで数字でパッとみて確認したい項目をSinglestatで置いていきます。SIM関係はsubscribers、請求関係はbillings、通信量関係はtrafficsがプレフィクスになっていますので、適当に選んで、適当に並べていきます。
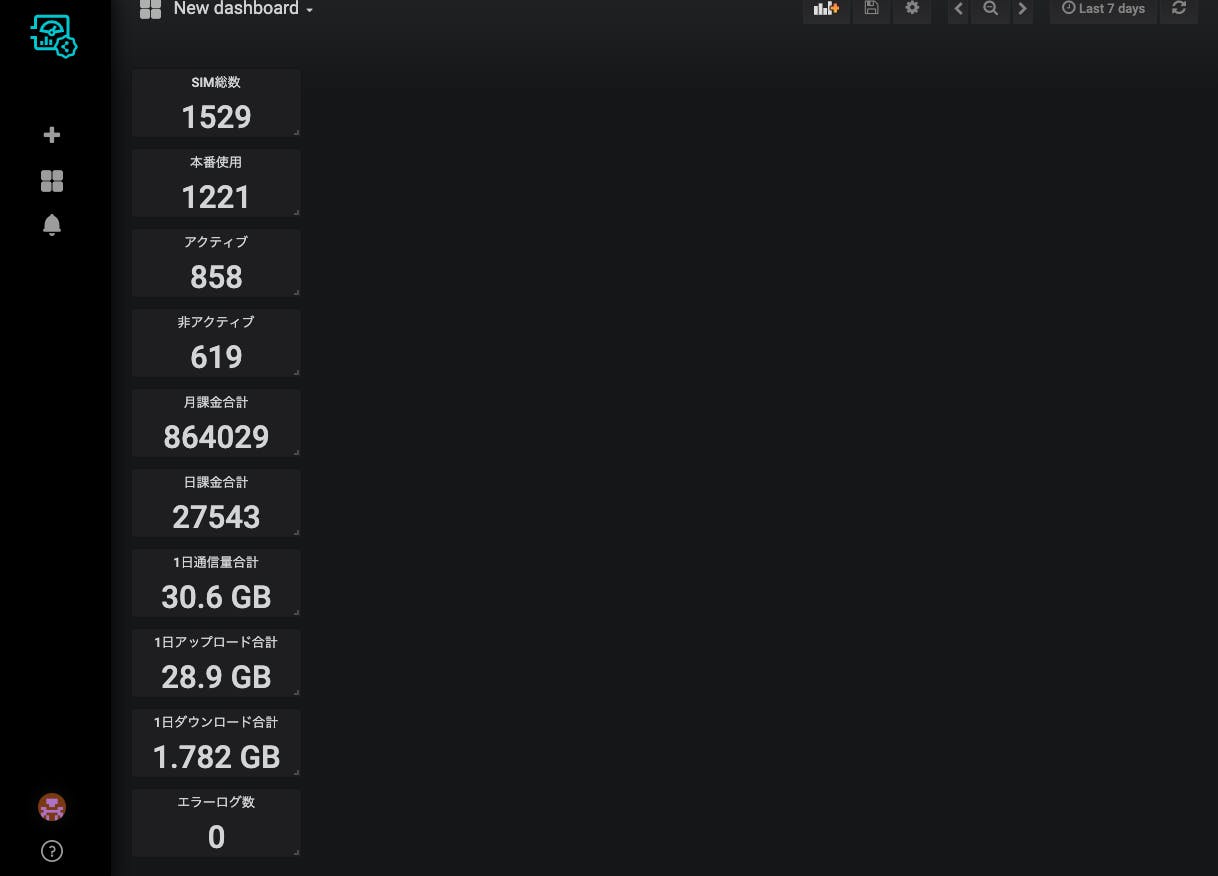
こんなもんですかね。おー、なんかどのくらい使ってるかが分かった気分になりますね。(ちなみにこの数字は実際のサービスの数字をもとに加工してアップロードしています。)
次はグラフを作っていきましょう。Graphのパネルを追加して、
タイトル、メトリックの選び方はSinglestatと同じです。メトリックは同じグラフ上に表示させる複数のメトリックを追加していきましょう。
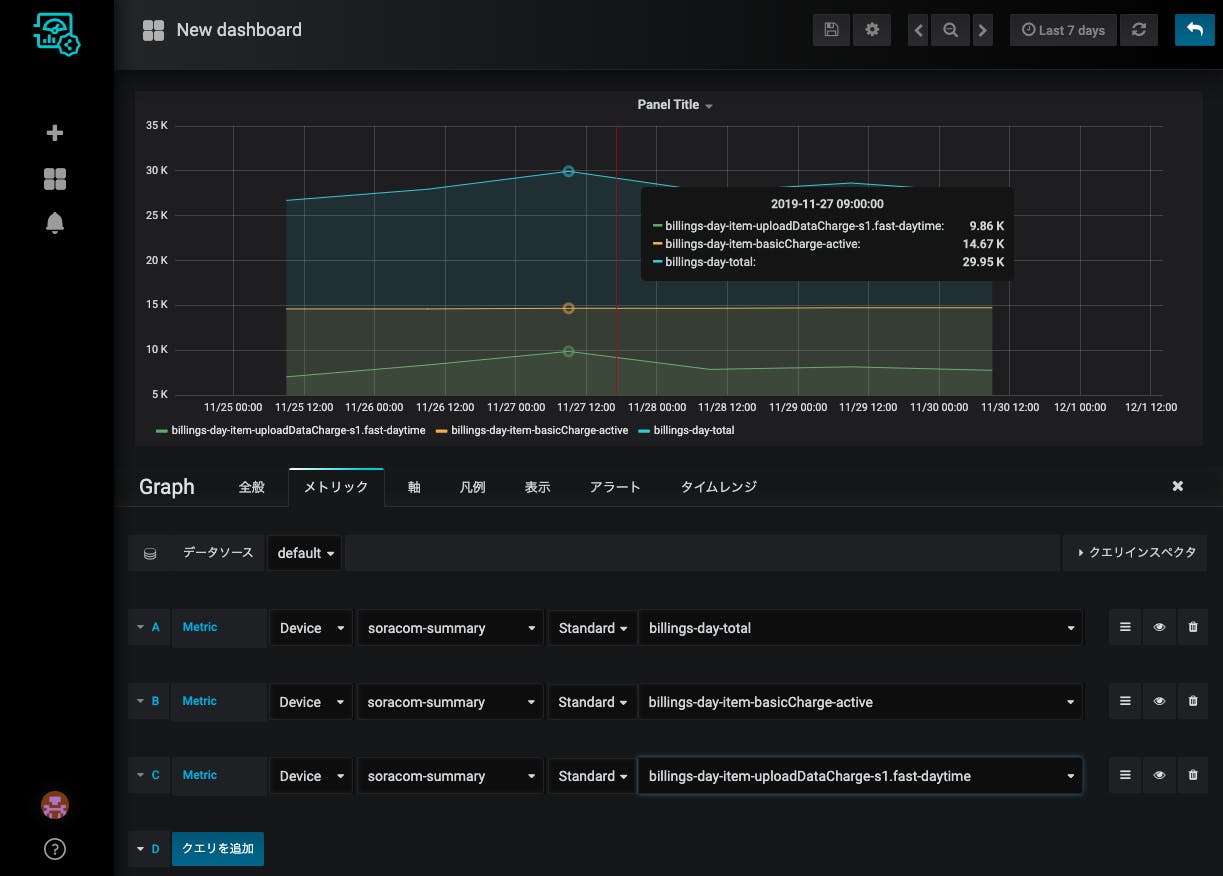
(メトリックをプレフィックス+ワイルドカード(billings-day-*とか)で指定できればな〜。1個1個選ぶのめんどくさい)
こんな感じでグラフを並べました。おー、推移と変動要素と割合が分かってきた感じがしますね。
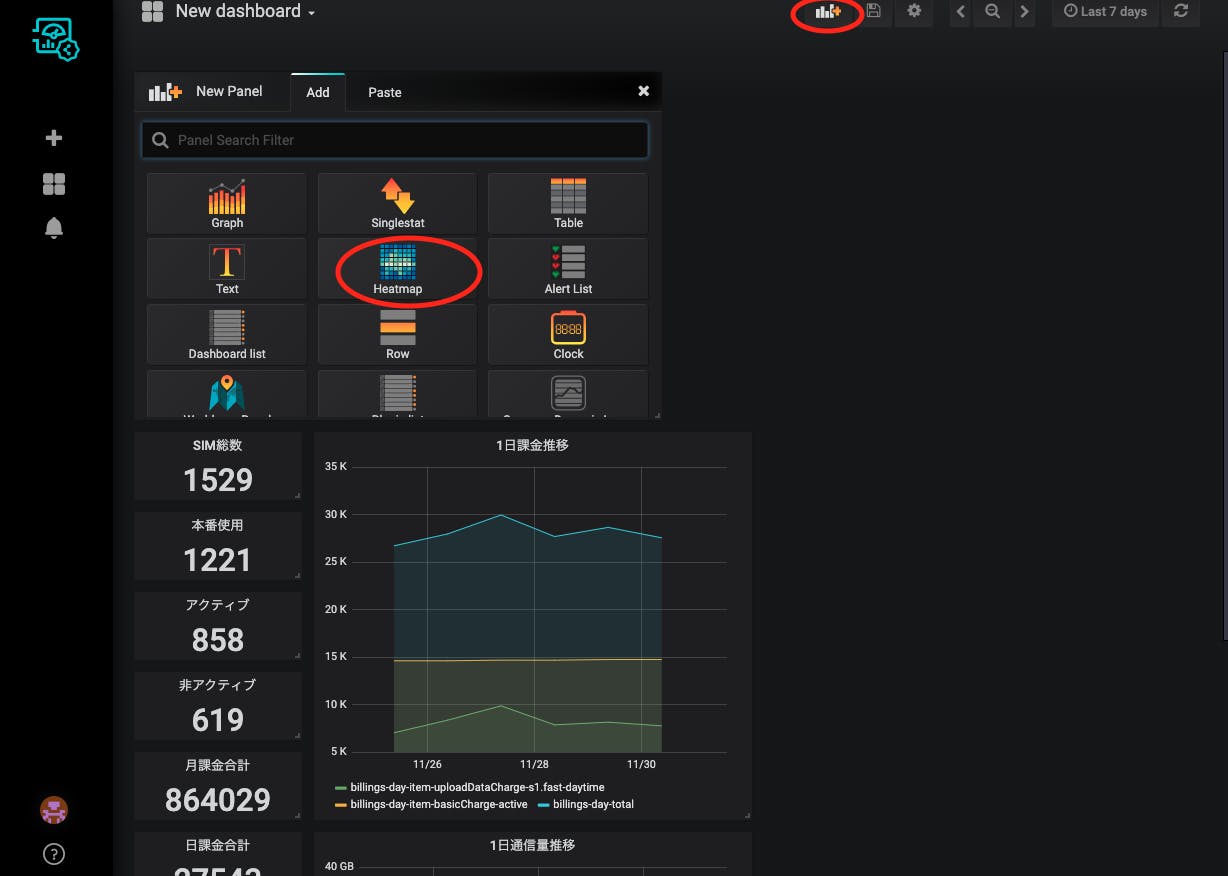
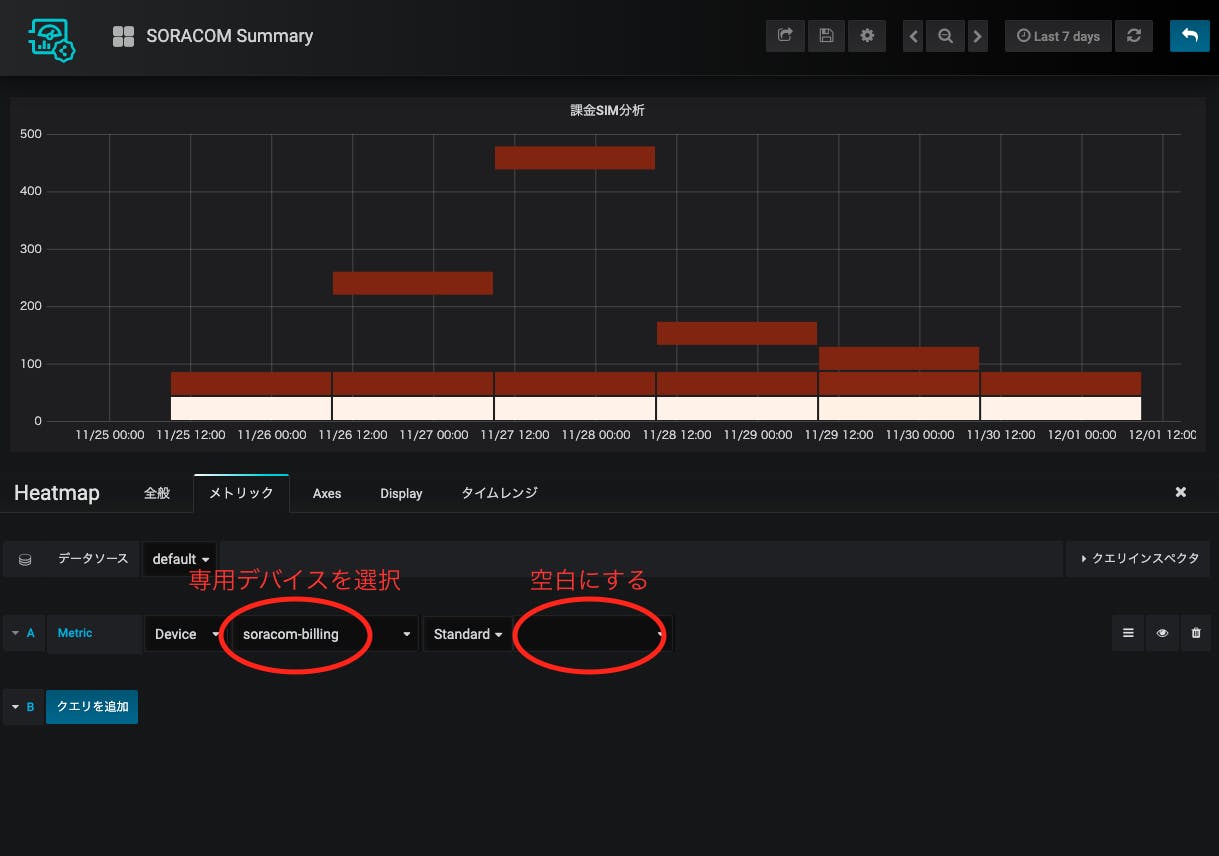
最後にHeatmapでSIMごとの分布を見たいと思います。これはsoracom-summaryとは別のデバイスからアップロードさせる必要があり、たとえばbillingだと
$ export SORACOM_BILLING_DEVICE_ID='請求分析用デバイスのデバイスID' $ export SORACOM_BILLING_DEVICE_SECRET='請求分析用デバイスのシークレットキー'を環境変数に上げた時のみアップロードされます。これは現在のところ動的に変動するメトリックを扱う方法が「デバイスを選択したら下の全部が選択される」という方法しかない(と思われる)からです。
ではHeatmapを作っていきましょう。これまでと同様Heatmapパネルを選択して、
メトリックはbilling専用のデバイスを選び、一番右の欄は空白のままにしておきます。これによりこのデバイスの下のメトリック(IMSI)が全て選択された状態になります。
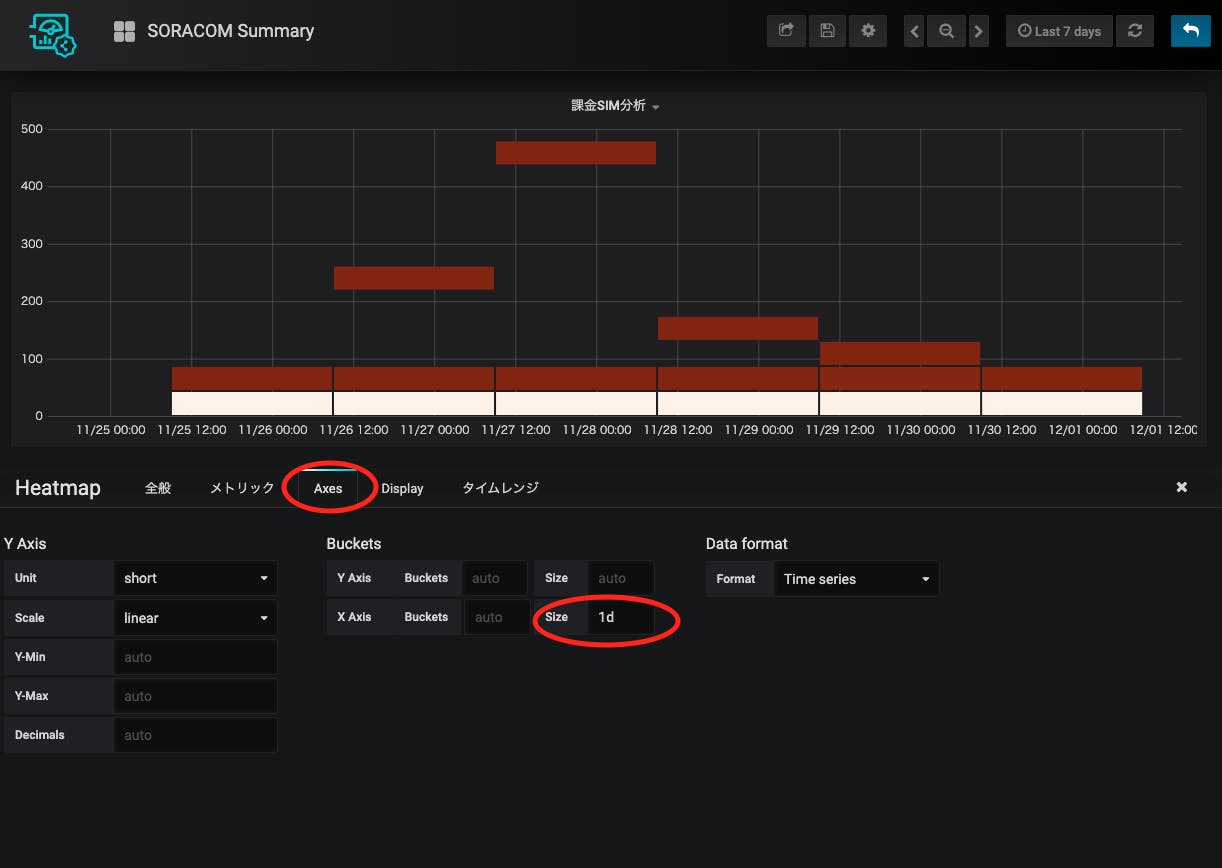
X軸のSizeを1d(1日)にしておきましょう。1日ごとの集計を取っているので、こうしておいた方が表示がぶれなくて良いです。
なんかすごく課金されてるSIMがいますね。。こうなると下の方の分布がわからなくなるので、必要に応じてY-MaxとY-AxisのSizeを変更して、下の方の分布がわかるようにします。
0-10に入っているのは、まだ開始されていないSIMですね。開始されて、あまりもしくは全く通信していないSIMは基本料金10円+通信料金やBeamの使用料金でちょっと増えるので、10-20に入ります。これが一番多い。そこそこ使われているSIMは30-40の範囲に入るものが多いみたいですね。そして何らかの通常使用ではないユースケース(Napterとか)があると、通常使用の範囲を超えて上に行く、という感じが見て取れます。
こういう、
- 普通はどういう使われ方をしているか
- 通常使用の範囲を超えた使われ方をしているSIMはないか
がパッと見てわかるのはHeatmapの面白いところですね。
そんな感じで通信量のSIM分析も入れてこんな感じのダッシュボードになりました。
皆さんもぜひ使用状況を可視化してみてください。いろんなものが見えてくるのではないかと思います。
最後に
今回のSORACOM UG Explorer 2019では、POCを終えてすでに実用段階に入っているIoTサービスの発表が多くあり、すでにIoTは普通になりつつあるのだなということを感じます。その中でソラコムが果たしている役割は大きいですね。
IoTサービスの実稼働に当たっては、このようなモニタリングやアラーム、遠隔制御による対処など運用面の課題が増えてくると思います。ソラコムが今後のIoTの課題にどのようなソリューションを提供してくるのか、今後も動向に注目していきたいと思います。



- 投稿日:2019-12-01T11:40:50+09:00
RubyonRails 環境構築 【Mac版】
はじめに
OCAではRailsを中心にプログラミングの学習を行っていただきますが、そもそもプログラミング初心者が最初に躓くことってなんだと思いますか?
アルゴリズムだとか、変数がわからないとか、それよりも前に『開発環境が作れない』ということが多々あります。
特にWeb系の言語は、初学者でも入りやすい言語だとは思いますが、環境を作るにはコマンドを使ったりしないといけなかったりで、導入のハードルは少し高く感じます。
そこでOCAでは、dockerを使って開発環境を用意することで、環境構築でつまずいてしまうという事態を回避しています。この記事では、一度回避した環境構築に立ち返り、より理解を深めようという内容です。
環境
今回作成する環境は次の通りです
- Homebrew 2.2.0
- ruby 2.6.3
- Rails 6.0.1
Homebrewのインストール
まずはHomebrewをインストールします。
HomebrewはMacOSのパッケージ管理ツールです。
Homebrewは色々なタイミングで使うことがあるので、入れていない人はこの機会にいれておきましょうまずは以下のコマンドを叩いてHomebrewがインストールされていないことを確認してください。
この記事に出るコマンドすべてに言えることですが、頭の$はコマンドであることを示しているため、打たなくて大丈夫です$ brew -vさて、まずはHomebrewのインストールと言いましたが、あれは嘘です
以下のコマンドを入力し、コマンドライン・デベロッパーツールをインストールします。
AppstoreからXCodeをインストールしてもOKな様子$ xcode-select --installダイアログが出たりすると思いますが気にせず進めましょう。
インストールが終わったら、今度こそHomebrewをインストールします
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"インストールが終わったら、正常にインストールが完了したか確認します。
$ brew dockerさて、ここで勘のいい方ならあることに気づくかと思います。
「あれ、rubyのコマンド使ってない?」
そうです。今からrubyを入れようとしているのに、rubyのコマンドを使用しました。
実はmacにはrubyが標準搭載されています。
ですが、バージョンが古かったり、別バージョンを使う上で管理が面倒なので、別の方法でrubyを入れ直すというわけです。rubyをインストール
次に、rubyをインストールするためのツールをインストールします。
以下のコマンドを実行します。
$ brew install rbenv ruby-build
rbenvはrubyをインストールするためのツールであり、rubyのバージョンを切り替えるためのツールでもあります。インストールが終わったら、rbenvのパスを通します。
簡単に説明すると、パスを通すと、ディレクトリのどの位置にいてもコマンドのフルパスを書かずともそのコマンドを実行できるというメリットがあります。$ echo 'export PATH="~/.rbenv/shims:/usr/local/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ source ~/.bash_profileパスを通し終わったら、以下のコマンドを実行してみます。
$ rbenv install --list今のコマンドは、rbenvを使ってインストールできるrubyのツールが表示されます。
ここでは最新版である2.6.3があるか確認しましょう。
他にインストールしたいバージョンが決まっていれば、そのバージョンを探してください。バージョンが決まれば、以下のコマンドを順番に実行してrubyをインストールします。
$ rbenv install 2.6.3 $ rbenv global 2.6.3 $ rbenv rehashインストールが完了したら、以下のコマンドで確認しましょう。
$ ruby -vここで表示されたrubyのバージョンが今インストールしたバージョンと同一か確認してください。
もし違う場合は、以下のコマンドを実行してインストールされているかを確認します。$ rbenv versions
rbenv globalコマンドを使えば指定のバージョンに切り替えることが可能です。Railsをインストール
まずは作業ディレクトリを決めましょう
今の場所を確認するときは、pwdコマンドを使います。
今の実行場所が嫌な人はcdコマンドを使って移動しましょう。作業ディレクトを決めたら、次のコマンドを実行します。
$ rbenv local 2.6.3このコマンドを使うと、今いるディレクトリで作業するときには、rubyのバージョンが
2.6.3に固定されます。
これにより、他のプロジェクトで違うrubyバージョンを扱うことになっても、影響がなくなります。次に、bundlerをインストールします。
すでにインストールされていないか、次のコマンドで確認してください。$ bundle -vbundlerはgemを管理するためのツールで、そのアプリケーションで使われるパッケージやバージョンを管理してくれます。
複数人で開発をするときは、他のPCでもバージョンは揃えないといけないので、その役割をbundlerが担っているというわけです。
https://qiita.com/jnchito/items/99b1dbea1767a5095d85逆にgemは、パッケージの形式だと考えてください。
bundlerもgemのひとつなので、次のコマンドを使ってインストールできます。
$ gem install bundler $ bundle -vbundlerにインストールが終わったら、次のコマンドでGemfileを作成します。
$ bundle init作成されたGemfileを編集します。
せっかくなのでvimを使って編集しましょう。
$ vi Gemfile最初はこの様になっていると思います。
# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } # gem "rails"この一番下にある
# gem "rails"のコメントアウトを解除します。矢印キーで一番下まで移動し、
xキーを二回押して#と余分なスペースを消しますこれで編集完了ですので、その状態で
:wqと順番に入力してエンターキーを押すとvimを終了させることが出来ます。ちなみにvimを使って何かを書き足したいときは、
iキーを押して挿入モードにします。
挿入モードを解除するときは、escキーを押します。もし万が一間違った操作をしてしまった場合は、
:q!と順番に入力してエンターキーを押せば、保存せずに終了することが出来ます。
https://qiita.com/hide/items/5bfe5b322872c61a6896Gemfileを編集したら、いよいよrailsのインストールです。
次のコマンドでrailsをインストールしましょう$ bundle install --path=vendor/bundle
bundle installは、Gemfileの中身を見て色々インストールしてくれます。
なので先程railsのコメントアウトを外しましたので、このコマンドでrailsがインストールされます。また、
--pathオプションでは、今インストールしたパッケージの保管場所を指定しています。
これをつけないとPC全体に影響が出るグローバルな位置にインストールされます。つけなくても問題ないとする声もありますが、同一サーバで複数のrailsを扱う場合はつけたほうがいいといった声もありますので、役割だけでも覚えておきましょう。
railsのインストールが完了したら、次にrailsプロジェクトを作成します。
$ bundle exec rails new samplesampleの部分はそのプロジェクトの名前に適宜変えてください。
プロジェクトの作成が終わったら、cdコマンドで移動し、railsサーバーを起動します$ cd sample $ rails sブラウザから
localhost:3000にアクセスしてWelcomeページが表示されたら成功です!
rails s が失敗する
Webpacker configuration file not foundといったメッセージで
rails sが失敗する場合があるようです。
下記コマンドを実行することで解消します。$ rails webpacker:install
yarnを入れろと怒られた場合はこちら$ brew install yarn私の場合はnode.jsのバージョンが低すぎると怒られたので下記の記事を参考に修正しました。
https://qiita.com/tonkotsuboy_com/items/5322d226b6783d25b5dfおわり
こうして文章にしてみると、結構やることあるんだなと再認識しました。
スムーズに行く場合もありますが、最後のように既存の環境が原因でうまく行かないなんてこともよくあります。エラーが起きたときは英語ばかりで何をかいてあるのかさっぱりでお手上げになりがちですが、よく読むとこうしてくださいと指示があったり、エラーの内容が書いてあったりするので、それを頼りにググればきちんと解決できます。
慌てず冷静に、素敵なコーディングライフを祈ってます
手順の参考はこちら
https://qiita.com/TAByasu/items/47c6cfbeeafad39eda07

- 投稿日:2019-12-01T10:48:37+09:00
rails-tutorial第5章
headタグの中身について
app/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title><%= full_title(yield(:title)) %></title> <%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> <!--[if lt IE 9]> <script src="//cdnjs.cloudflare.com/ajax/libs/html5shiv/r29/html5.min.js"> </script> <![endif]--> </head><%= csrf_meta_tags %>はcsrf対策のコードでクラッキングからサイトを守る。
<%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %>上記はcssに何か書かれていたら反映するよー。jsに何か書かれてたら反映するよーって意味。
<!--[if lt IE 9]> <script src="//cdnjs.cloudflare.com/ajax/libs/html5shiv/r29/html5.min.js"> </script> <![endif]-->上記はIEが9以下?の場合、HTML5のheaderタグなどが使えないため、JSでなんとかするよーってコード。
なんでaタグじゃなくてlink_toメソッドを使うの?
<header class="navbar navbar-fixed-top navbar-inverse"> <div class="container"> <%= link_to "sample app", '#', id: "logo" %> <nav> <ul class="nav navbar-nav navbar-right"> <li><%= link_to "Home", '#' %></li> <li><%= link_to "Help", '#' %></li> <li><%= link_to "Log in", '#' %></li> </ul> </nav> </div> </header>別に以下のコードでもよくね?って思うけど
<a href = # id = logo>sample app</a>aタグだとhelperメソッドや変数を呼び出すことができないという欠点がある。
<%= link_to #{example}, static_pages_url, id: "logo" %>そのため上記のようにurlや表示する文字にRubyのメソッドを使いたいがためにlink_toメソッドを使うのである。
id: logo はlink_toメソッドのオプションとしてハッシュの形で書かれている。
idは元から決められているがhogehoge: 'foobar'というオリジナルのオプションも与えられる。
オプション引数と呼ばれている。Bootstrap
先に書いたnavbar や containerはbootstrapでもともと決められたクラス名。
ちなみにbootstrapは公式サイトからダウンロードする必要はなく、gem 'bootstrap-sass', '3.3.7'$bundle installで準備ok。
$ touch app/assets/stylesheets/custom.scss
でファイルを作りapp/assets/stylesheets/custom.scss@import "bootstrap-sprockets"; @import "bootstrap";を記入する。
image_tagについて
<%= link_to image_tag("rails.png", alt: "Rails logo"), 'http://rubyonrails.org/' %>app/assets/images/に画像ファイルを置いておく(画像ファイルはここにダウンロードする)ことで、image_tagヘルパーによって画像を探してくれる。
ちなみにalt属性(オルト属性)とは、HTMLのimg要素の中に記述される画像の代替となるテキスト情報です。 ... 従って、そうした「画像が閲覧できない環境下でも、その情報が正しく理解される」ような代替テキスト情報がalt属性には記述されなければならないらしい。
パーシャルについて
yieldの時のように自分で自分のテンプレートを作りたい!そんなときに使うのがパーシャル。
app/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title><%= full_title(yield(:title)) %></title> <%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> <%= render 'layouts/shim' %> </head> <body> <%= render 'layouts/header' %> <div class="container"> <%= yield %> </div> </body> </html><%= render 'layouts/header' %>はヘッダーを別ファイルに分けて、「ヘッダーいじりたい人はlayouts/header見てねー」という感じになっている。これにより散らかったコードをdryにできる。
もちろん今までのコードを別ファイルにまとめる必要があるが、その際のファイル名はパーシャルとわかるように_から始まるファイル名にする。
app/views/layouts/_shim.html.erb<!--[if lt IE 9]> <script src="//cdnjs.cloudflare.com/ajax/libs/html5shiv/r29/html5.min.js"> </script> <![endif]-->つまり、<%= render 'layouts/shim' %>の場合は_shim.html.erbというファイル名にする。
逆に慣れてきたら最初からパーシャルを作ってコーディングしていけば早い。アセットパイプラインとは
CSS JS imageなどの管理機能。
1.アセットディレクトリ
静的ファイルを目的別に分類する。
2.マニフェストファイル
1つのファイルにまとめる方法をrailsに指示する。
app/assets/stylesheets/application.css*= require_tree . *= require_self1行目はマニフェストファイル(上記のファイル)内のcssの記述をまとめる。
2行目はマニフェストファイル以下のファイルもまとめるという意味。3.プリプロセッサエンジン
指示に従いブラウザに配信できるように結合する。
foobar.js.coffee
foobar.js.erb.coffee
1行目の場合、coffee.script → JavaScriptの順で外側からコンパイルされる。なぜアセットパイプライン?
パソコン的には複数のファイルを読み込むより、1つのファイルで改行や空白を無くしたものの方がレスポンスが早いから。また開発者的にも複数のファイルの方が開発がしやすく、それを一つにまとめてくれるなんて最高!ってこと。
名前付きルートについて
config/routes.rbRails.application.routes.draw do get 'static_pages/home' get 'static_pages/help' get 'static_pages/about' get 'static_pages/contact' root 'static_pages#home' endこの状態だと、urlにいちいちstatic_pagesが出てきて、わかりづらい.
そもそも、上記は「このurlにリクエストされたらこのコントローラのこのアクションを実行してください」という情報を1つにまとめてしまっている。
もうちょっとわかりやすくできないものかと。config/routes.rbRails.application.routes.draw do root 'static_pages#home' get '/help', to: 'static_pages#help' get '/about', to: 'static_pages#about' get '/contact', to: 'static_pages#contact' endこのように書き換えることによってヘルパーを使えるようになる。
例えば、/helpだったらhelp_path /aboutなら about_path
root なら root_pathという感じだ。これが名前付きルート。名前付きルートをテストで使うと以下のようになる。
test/controllers/static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do get root_path assert_response :success assert_select "title", "Ruby on Rails Tutorial Sample App" end test "should get help" do get help_path assert_response :success assert_select "title", "Help | Ruby on Rails Tutorial Sample App" end test "should get about" do get about_path assert_response :success assert_select "title", "About | Ruby on Rails Tutorial Sample App" end test "should get contact" do get contact_path assert_response :success assert_select "title", "Contact | Ruby on Rails Tutorial Sample App" end end名前付きルートを使う注意点としては、使うときに''をつけないこと。urlをそのまま入れるときは''必要だけど、名前付きルートはそのまま書かないと逆にエラーになってしまう。
統合テスト (Integration Test)
統合テストは、ページから別のページに飛ぶなどurlがちゃんと機能してるか?を確かめるときに使う。
アプリケーションの動作を端から端まで (end-to-end) シミュレートしてテストすることができる。$ rails generate integration_test site_layout
上記のコマンドでテストファイルができる。
test/integration/site_layout_test.rbrequire 'test_helper' class SiteLayoutTest < ActionDispatch::IntegrationTest test "layout links" do get root_path assert_template 'static_pages/home' assert_select "a[href=?]", root_path, count: 2 assert_select "a[href=?]", help_path assert_select "a[href=?]", about_path assert_select "a[href=?]", contact_path end endその中でも
assert_select "a[href=?]", about_path上記はRailsは自動的にはてなマーク "?" をabout_pathに置換しています (このとき "about_path" 内に特殊記号があればエスケープ処理されます)。これにより、次のようなHTMLがあるかどうかをチェックすることができます。
<a href="/about">...</a>一方で、ルートURLへのリンクは2つあることを思い出してください (1つはロゴに、もう1つはナビゲーションバーにあります)。このようなとき、
assert_select "a[href=?]", root_path, count: 2上記のようにそのページにいくつ指定したurlリンクが存在するかもテストすることができる。
Users controller作ってみる。
$ rails generate controller Users new
config/routes.rbRails.application.routes.draw do root 'static_pages#home' get '/help', to: 'static_pages#help' get '/about', to: 'static_pages#about' get '/contact', to: 'static_pages#contact' get '/signup', to: 'users#new' end/signupでアクセスできるようにして、signup_pathという名前ルートも使えるようにする。コントローラーを作成すると、テストも自動作成されるよね。でも上記で名前付きルート設定しちゃったからテストが通らない。なので、、
test/controllers/users_controller_test.rbrequire 'test_helper' class UsersControllerTest < ActionDispatch::IntegrationTest test "should get new" do get signup_path assert_response :success end end名前付きルートを設定したら、必ずテストコードも書き換えるようにする。
- 投稿日:2019-12-01T04:04:20+09:00
Rubyのattr_reader的なことをTypeScriptでやるならreadonly
はじめに
TypeScriptで「クラスにgetterは作るけどsetterを作らない」とき、Rubyの
attr_readerっぽくシンプルに書きたいなーと思って試したメモです。TL;DR
TypeScriptclass Hoge { constructor(readonly value: Type) { } }Rubyclass Hoge attr_reader :value def initialize(value) @value = value end endなんとTypeScriptの方が短く書ける!
やりたいこと
Itemクラスを、こんな風に使いたい。TypeScriptconst item = new Item('Apple') console.log(item.name) // Apple item.name = 'Orange' // エラーTypeScriptでのイマイチな例
冗長なprivate
検索するとよく見る例ですね。Javaにかなり近い雰囲気。
TypeScriptclass Item { private _name: string constructor(name: string) { this._name = name } get name(): string { return this._name } } const item = new Item('Apple') console.log(item.name) // Apple item.name = 'Orange' // Cannot assign to 'name' because it is a read-only property.うーん、、ちょっとつらい。
やりたいことは「コンストラクタの引数をそのまんまgetしたい」だけなのに、thisが必須だったり、名前が被るから_つけて区別したり。。無法地帯なpublic
コンストラクタの引数にアクセス指定子を追加すると、同じ名前でメンバ変数を作ってくれます。ここを
publicにしちゃえばコードはかなりシンプルになります。TypeScriptclass Item { constructor(public name: string) { } } const item = new Item('Apple') console.log(item.name) // Apple item.name = 'Orange' console.log(item.name) // Orangeこの書き方はとても好きなのですが、setter以前のメンバ変数直代入を認めるので、使う側はもう無法地帯。。ちょっとこれで妥協はしたくないですねぇ。
Rubyの素敵な例
Rubyには
attr_readerってのがあって、getterだけをシンプルに作ってくれます。Rubyはそもそもインスタンス変数に必ず@を付ける仕様なので、単純比較はできないけどこれはとっても素敵。Rubyclass Item attr_reader :name def initialize(name) @name = name end end item = Item.new('Apple') puts item.name #=> Apple item.name = 'Orange' #=> undefined method `name=' (NoMethodError)TypeScriptでもこんな風に書けないものか!?
TypeScriptの素敵な例
書けました!
readonlyを使います。TypeScriptclass Item { constructor(readonly name: string) { } } const item = new Item('Apple') console.log(item.name) // Apple item.name = 'Orange' // Cannot assign to 'name' because it is a read-only property.シンプルで安全で良いですね!
readonlyとは?
http://www.typescriptlang.org/docs/handbook/interfaces.html#readonly-properties
このreadonlyは、どんなアクセス指定子とも組み合わせて使えます。public readonly hoge: string protected readonly fuga: string private readonly piyo: stringたとえば
private readonlyの場合は、「クラス内のメソッドでも変更不可(コンストラクタでの初期化のみ)」となります。class Hoge private readonly hoge: string constructor(public _hoge: string) { this.hoge = _hoge // OK } setHoge(_hoge: string) { this.hoge = _hoge // Cannot assign to 'hoge' because it is a read-only property. } }コンストラクタの引数でも、もちろん同様に使えます。
constructor(public readonly hoge: string) { } constructor(protected readonly fuga: string) { } constructor(private readonly piyo: string) { }TSではアクセス指定子省略は
publicなので、この2つは等価ってことですね。constructor(public readonly hoge: string) { } constructor(readonly hoge: string) { }今知ったけど、C#にも
readonlyがありました。同じMicrosoftだし、これがTypeScriptにも導入されたのですねきっと。
https://docs.microsoft.com/ja-jp/dotnet/csharp/language-reference/keywords/readonlyおわりに
C#使いにとっては当たり前なんでしょうけど、Rubyの
attr_readerと比較する記事は見つからなかったので、これで世界のググラビリティが少し上がったのではないかと思います!型でキッチリ書くことと、コードが冗長にならないこと、ぜひとも両立をめざしたいものですねっ!TypeScriptでは
public readonlyを活用していきましょう
ではまた!
- 投稿日:2019-12-01T02:12:52+09:00
Crystalでk-d木を実装してRubyと実行速度を比べてみた
はじめに
こんにちは、Misocaの洋食(@yoshoku)です。この記事は、Misoca+弥生 Advent Calendar 2019の4日目の記事です。
Misocaは、WebフレームワークにRuby on Railsを採用しており、Rubyと関わりの深い会社です。そのRubyとよく似た文法で、静的型付けな言語にCrystalがあります。どの様な言語か試してみました。
インストールと動作確認
Crystalのインストール方法は、Macであればhomebrewでインストールするのが簡単です(公式ページに各OSでのインストール方法が掲載されています)。
$ brew install crystal挨拶するだけのコードを書いてみました。公式ページには「Crystal is statically type checked...Crystal has built-in type inference」とあり、型推論により型を明示的に書くことは少なそうですね。
class Greeting def hello puts "Hello, World." end end g = Greeting.new g.hello動かすだけの場合:
$ crystal hello.cr Hello, World.実行ファイルを作って動かす場合:
$ crystal build hoge.cr $ ./hoge Hello, World.buildでは、--releaseオプションをつけると、最適化した実行ファイルを得られます。ただし、コンパイルは遅くなります。
エディタの設定
公式Wikiに各エディタのプラグインなどが紹介されています。私はneovim+vim-plugな環境でプログラムを書いているので、以下のようなinit.vimを書いてPlugInstallしました。
call plug#begin() " ...省略 Plug 'rhysd/vim-crystal' call plug#end()k-d木を実装する
k-d木は、二分木による空間分割データ構造で、近傍探索に利用されます。k次元の空間に配置されるデータを、各軸の中央値で分割することを繰り返し、木構造で表現します。この記事の実装では、k次元のデータは、k個の要素からなるfloatの配列で表すとします。
# 4個の3次元なデータの例 data = [[1.2, 0.5, 3.0], [0.2, 0.3, 2.0], [2.3, 1.8, 1.7], [1.6, 1.4, 2.9]]Crystalでの実装
まず、木のノードを実装します。どの軸を分割の基準に用いたか、中央値の値、木の深さ、二分木なので左右のノード、そして、葉であった場合のデータ点を保持します。
class Node getter :axis, :threshold, :depth, :left, :right, :element def initialize(@axis : Int32, @threshold : Float32, @depth : Int32, @left : Node | Nil, @right : Node | Nil, @element : Array(Float32) | Nil) end endインスタンス変数を直接的にinitializeに書けるのがおもしろいですね。getterは、Rubyのattr_accessorに相当するものです。ただ値を保持するだけなので、Structでも良いのですが、後でRubyと比較したいのでClassにしました。
次にk-d木の構築と、最近傍探索を実装していきましょう。各ノードでの分割以外は、以下の様な感じになります。検索は、葉に到達するまで木をたどるだけです。
class KdTree @tree : Node | Nil = nil # 木の構築 def build(points) @tree = grow(points, 0) end # 最近傍データの探索 def search(point) apply(point, @tree) end private def grow(points, depth) # ...あとで実装する。 end private def apply(point, node) # 葉に到達したら、葉がもつデータを返す. return nil if node.nil? return node.element unless node.element.nil? # 基準となる軸と閾値で、次にたどる左右のノードを選択する. if point[node.axis] >= node.threshold apply(point, node.left) else apply(point, node.right) end end endk次元データの軸を分割することで、木を成長させていく部分を実装します。分割の基準となる軸の選択は、木の深さに応じて順番に選択されます。そして、選択された軸の中央値を閾値とします。閾値でデータを分割して、左右のノードに割り当てます。これをデータが1個になるまで繰り返します(葉に割り当てるデータの数は、1個と決まっているわけではありませんが、この記事では簡単のため1個としました)。
private def grow(points, depth) # データ数が0ならばNodeを作らない. n_points = points.size return nil if n_points.zero? # データ数が1ならば葉としてデータを割り当てたNodeを返す. if n_points == 1 return Node.new(-1, 0.0, depth, nil, nil, points[0]) end # 分割の基準となる軸を選択する. n_axes = points[0].size target_axis = depth % n_axes # その軸上の値の中央値を閾値とする. threshold = points.map { |e| e[target_axis] }.sort[(n_points / 2).to_i] # 閾値でデータを左右に分割する. Node.new( target_axis, threshold, depth + 1, grow(points.select { |e| e[target_axis] >= threshold }, depth + 1), grow(points.select { |e| e[target_axis] < threshold }, depth + 1), nil ) endCrystalは型推論を行うので、型を明示する必要がない場合は、上記のように、ほぼRubyと同じようなものになります。
Rubyでの実装
同じものをRubyで実装してみました。よく似てますね。
class Node attr_accessor :axis, :threshold, :depth, :left, :right, :element def initialize(axis, threshold, depth, left, right, element) @axis = axis @threshold = threshold @depth = depth @left = left @right = right @element = element end end class KdTree def initialize @tree = nil end def build(points) @tree = grow(points, 0) end def search(point) apply(point, @tree) end private def grow(points, depth) n_points = points.size return nil if n_points.zero? if n_points == 1 return Node.new(-1, 0.0, depth, nil, nil, points[0]) end n_axes = points[0].size target_axis = depth % n_axes threshold = points.map { |e| e[target_axis] }.sort[(n_points / 2).to_i] Node.new( target_axis, threshold, depth + 1, grow(points.select { |e| e[target_axis] >= threshold }, depth + 1), grow(points.select { |e| e[target_axis] < threshold }, depth + 1), nil ) end private def apply(point, node) return nil if node.nil? return node.element unless node.element.nil? if point[node.axis] >= node.threshold apply(point, node.left) else apply(point, node.right) end end end実験
準備
pendigitsという16次元のデータで検索を行ってみて、その実効速度を、CrystalとRubyで比較してみましょう。csvファイルのpendigitsデータセットを取得します。
$ wget https://datahub.io/machine-learning/pendigits/r/pendigits.csvこのpendigitsデータセットを読み込んで配列にするコードは、以下のようになります。
require "csv" points = Array(Array(Float32)).new skip_header = true CSV.each_row(File.open("pendigits.csv")) do |row| if skip_header skip_header = false next end pt = Array(Float32).new row[0...-1].each { |e| pt.push(e.to_f32) } points.push(pt) endさらにBenchmarkで実行速度を計測するコードは、以下のようになります。
require "benchmark" Benchmark.bm do |x| x.report("kd-tree") do tree = KdTree.new tree.build(points) points.each { |pt| tree.search(pt) } end end掲載しませんが、Rubyでも同様のコードを実装しました。
実験結果
実験環境は、MacBook Early 2016(Intel Core m3 1.1GHz, 8GB DDR3)
です。まずは、Crystalで実装したものから実行してみます。$ crystal -v Crystal 0.31.1 (2019-10-02) LLVM: 8.0.1 Default target: x86_64-apple-macosx $ crystal build --release kdtree.cr $ ./kdtree user system total real kd-tree 0.031911 0.002470 0.034381 ( 0.028745)次に、Rubyで実装したものを実行します。
$ ruby -v ruby 2.6.5p114 (2019-10-01 revision 67812) [x86_64-darwin19] $ ruby kdtree.rb user system total real kd-tree 0.164685 0.003777 0.168462 ( 0.170641)さすがにコンパイルした実行ファイルなだけあって、Crystalのほうが速いですね(コンパイルの時間を必要としますが)。
ただし、ちょっと例が良くなかったのか、例えば以下のようなk-d木の構築・検索では、Rubyでも遅くは感じませんでした。
tree = KdTree.new tree.build(points) p tree.search(points[0]) p tree.search(points[1]) p tree.search(points[2])$ time ruby kdtree.rb [47.0, 100.0, 27.0, 81.0, 57.0, 37.0, 26.0, 0.0, 0.0, 23.0, 56.0, 53.0, 100.0, 90.0, 40.0, 98.0] [0.0, 89.0, 27.0, 100.0, 42.0, 75.0, 29.0, 45.0, 15.0, 15.0, 37.0, 0.0, 69.0, 2.0, 100.0, 6.0] [0.0, 57.0, 31.0, 68.0, 72.0, 90.0, 100.0, 100.0, 76.0, 75.0, 50.0, 51.0, 28.0, 25.0, 16.0, 0.0] ruby kdtree.rb 0.44s user 0.10s system 95% cpu 0.562 totalおわりに
Crystalの書き味は、Rubyとよく似たものでした。Rubyで開発したもので、外部ライブラリに依存がなく、実行速度が欲しいものは、Crystalに書き換えるのを試しても良いかもしれません。
- 投稿日:2019-12-01T00:47:36+09:00
アウトプット重視の教材【Progate】【Techpit】【チェリー本】
はじめに
プログラミングの勉強には、アウトプットが重要って聞くけれど、何をしたら良いのかわからない…
そんな方に自分が実際に使ってみて、良いと思ったオススメの教材を紹介します。1.Progate(プロゲート)
プログラミング入門として有名な鉄板のサービスです。
この記事を見ている方なら、すでにご存知の方も多いかもしれませんね。
https://prog-8.com/良い点
・スライドごとに一つの課題をこなしていく形式となっていて、丁寧な解説で初学者でもサクサク勉強を進めることが出来る。
・プログラミングに必要な環境構築をしなくても、プロゲート内でコードを書きながら勉強することが出来る敷居の低さや、さらには、プロゲートのアプリもあるので移動中などの隙間時間でも勉強出来る。
・レベルが上がったり、カレンダーに自分の学習量が可視化されるなど、挫折防止の仕組みがたくさんある。
料金:月額980円注意点
簡単にプログラミングを始められる反面、あくまで入門教材なのでプロゲートだけで学べる技術力はそんなに高くはありません。2〜3周勉強してみて感覚を掴んだら、実際に自分で何か作ってみるという経験が重要です。
2.Techpit(テックピット)
テックピットは、比較的新しいサービスでTwitterで拡散され話題になりました。
Progateでプログラミングの基礎を勉強した後、次のステップに進むにはすごくちょうどいいサービスです。
https://www.techpit.jp良い点
・現役プログラマーが執筆した教材で、プログラムを作りながら実践的な力を身につけることが出来る。
・自分が作りたいサービスに近い教材を選ぶことで、学習したいことをピンポイントで学べる。実際に作りたいサービスを作ることが出来るのでそれがモチベーションにもなる。
・教材で不明点があったり、エラーが生じた際には質問欄から執筆者に対応してもらうことが出来る。ドラクエ風ゲームプログラムを作ってみよう!
テックピットの中から「自分の頭で考えてロジックを書く力を身に着ける」をテーマにしたアプリを紹介します。
https://www.techpit.jp/p/ruby-dragon-quest
当カリキュラムで作成するプログラムはとてもシンプルです。実装するのは以下の機能だけ。
・勇者とモンスターが攻撃し合う
・どちらかのHPが0になるまで戦いが続く
・勇者が勝ったら経験値やゴールドが得られる実装する機能はシンプルですが、現場で実際に使う知識に焦点を当てた実践形式でクラスの継承やリファクタリングなどRubyの色々な技術を学習することができます。
自分で程度考えてコードを書く必要があり、基礎知識やロジックを組むなどの実力が試されます。
内容的にもなかなかボリュームがあるので、実力を付けたい方は是非チャレンジしてみてください。料金:教材ごとに異なります
「ドラクエ風ゲームプログラムを作ってみよう!」は1280円。
教材の序盤までは購入しなくても見ることが出来るので、ある程度の教材の内容は購入する前に確認できます。注意点
サービスを作るので、プログラミングの基礎に関しては事前に学んでおく必要があります。
今回紹介した教材に関しても、後半に連れて難易度が上がってくるので、自分は次の教材を合わせて読んでいました。3.プロを目指す人のためのRuby入門
通称:チェリー本
解説が丁寧でわかりやすい、例題が豊富な手を動かすタイプの技術書です。
Amazon:プロを目指す人のためのRuby入門良い点
・章中に例題があるのが特徴で、例題コードと説明が分かりやすい
・例題が軸となって学習が進められるので、覚えるべきことが明確で覚えやすい。
・「Railsアプリを開発するなら、ここは必ず押さえておきたい」というRubyの基礎知識をカバーしているまず章の内容の基本を学び、例題はその基本的な内容を使ったものなので、理解が深まります。
そしてその後、深い内容は実際に手を動かしてから説明を読むため、理解しやすいです。
料金:定価2980円+税注意点
本書はプログラミング未経験者向けの本ではない点に注意してください。
本書にも書いてある通り、ある程度プログラミングの基礎を学習し終わっている方が対象の書籍になります。
この本を読んで「難しくて全然わからない」という方は、最初に紹介したProgateで基礎を勉強しましょう。さいごに
最後まで読んでいただきありがとうございます!
現在勉強中の方は教材を読んだり、視聴したりで終わりではなく実際に手と頭を動かしてアウトプットすることを大切にしてみてください。




- 投稿日:2019-12-01T00:34:25+09:00
ruby on rails 基本1
はじめに
この記事は、2019/11/1からプログラミング学習を始めた学生がプロのプログラマーになるまでのアウトプットする為の書き込みの場である。
Rails構造
railsは、ルーティング→コントローラー→モデル→ビューの順番に処理が行われます
MVC = モデル(model)とビュー(view)とコントローラー(controller)Rails ルーティング編
- ルーティング
- クライアントからリクエストがあった際に、リクエストに対応した行き先を定義します
- HTTPメソッド
- クライアントから送られたリクエストの種別を表すものです
- get = ページを表示する操作のみを行う時
- post = データを登録する操作をする時
- put = データを変更する操作をする時
- delete = データを削除する操作を行う時
今日の感想
今日は、今までやってきたがブログに投稿していなかったruby,ruby on railsについて復習しました
raiksの内容が多く、今日のブログに書ききる事ができなかったので、明日から引き続きrailsについてアウトプットしていこうと思います終わりに
もっとこうした方が良いよなどご指摘頂けると幸いです