- 投稿日:2019-12-01T23:19:13+09:00
【SLAYER】スラッシュメタルの歌詞を可視化して、鋼鉄魂を確認してみた【WordCloud】
はじめに
私が愛するスラッシュメタル(Thrash Metal)、その中でもSLAYERは一番のお気に入りだ。
長年活躍してきた彼らだが、メンバーの死を乗り越えながらも、ついにファイナルワールドツアーを迎えた。
そして2019年11月30日、LAでの最終講演をもって有終の美を飾った。https://www.youtube.com/watch?v=OwsdbuxRc_s
これを記念して、彼らが伝えたかったことを確認しておきたいと思う。
環境
- Windows10
- Python 3.7.5
可視化結果
もはや何も言うことはない。
俺は満足だ!!素晴らしい音楽とメッセージをありがとう!!!!!
ソースコード
import requests from bs4 import BeautifulSoup import pandas as pd import time #アルバムごとのURLリスト urls = ['http://www.darklyrics.com/lyrics/slayer/shownomercy.html', 'http://www.darklyrics.com/lyrics/slayer/hauntingthechapel.html', 'http://www.darklyrics.com/lyrics/slayer/hellawaits.html', 'http://www.darklyrics.com/lyrics/slayer/reigninblood.html', 'http://www.darklyrics.com/lyrics/slayer/southofheaven.html', 'http://www.darklyrics.com/lyrics/slayer/seasonsintheabyss.html', 'http://www.darklyrics.com/lyrics/slayer/divineintervention.html', 'http://www.darklyrics.com/lyrics/slayer/undisputedattitude.html', 'http://www.darklyrics.com/lyrics/slayer/diabolusinmusica.html', 'http://www.darklyrics.com/lyrics/slayer/godhatesusall.html', 'http://www.darklyrics.com/lyrics/slayer/christillusion.html', 'http://www.darklyrics.com/lyrics/slayer/worldpaintedblood.html', 'http://www.darklyrics.com/lyrics/slayer/repentless.html'] #リリックのデータフレーム準備 list_df = pd.DataFrame(columns=['lyrics']) for url in urls: #取得 response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') song_lyrics = soup.find('div', class_='lyrics') song_lyric = song_lyrics.text song_lyric = song_lyric.replace('\n','') #1秒待機(サーバー負荷の考慮) time.sleep(1) #取得した歌詞を表に追加 tmp_se = pd.DataFrame([song_lyric], index=list_df.columns).T list_df = list_df.append(tmp_se) print(list_df) #csv保存 list_df.to_csv('list.csv', mode = 'a', encoding='utf-8')from janome.tokenizer import Tokenizer import pandas as pd import re #list.csvファイルを読み込み df_file = pd.read_csv('list.csv') song_lyrics = df_file['lyrics'].tolist() t = Tokenizer() results = [] for s in song_lyrics: tokens = t.tokenize(s) r = [] for tok in tokens: if tok.base_form == '*': word = tok.surface else: word = tok.base_form ps = tok.part_of_speech hinshi = ps.split(',')[0] if hinshi in ['名詞', '形容詞', '動詞', '副詞']: r.append(word) rl = (' '.join(r)).strip() results.append(rl) #余計な文字コードの置き換え result = [i.replace('\u3000','') for i in results] print(result) text_file = 'wakati_list.txt' with open(text_file, 'w', encoding='utf-8') as fp: fp.write("\n".join(result))from wordcloud import WordCloud text_file = open('wakati_list.txt', encoding='utf-8') text = text_file.read() print(text) #無意味そうな単語除去 stop_words = ['the', 'of', 'to', 'is', 'in', 'for', 'with', 'that', 'my', 'all', 'will', 'from', 'can', 'your', 'on', 'me', 'it', 'and', 'this', 'be', 'are', '=', 're', 'll', 'am', 'their', 'lyrics', 'king', 'hanneman', 'chorus', 'music', 'Lead', 'bonus', 'Araya', 'thanks', 'darklyrics', 'track', 'do', 'there', 'submits', 'comments', 'Richard Hung Himself', 'at', 'webmaster', 'corrections', 'welcomed', 'or', 'its', 'don', 'correcting', 'before', 'without', 'an', 'they', 'one', 'you', 'com', 'slayer'] wordcloud = WordCloud(background_color='black', colormap='autumn', font_path=fpath, width=800, height=600, stopwords=set(stop_words)).generate(text) #画像はwordcloud.pyファイルと同じディレクトリにpng保存 wordcloud.to_file('./wordcloud.png')※参考ページから雑に拝借しているので、そのうち見直します・・・。(とにかく作りたかった・・・)
おわりに
1983年「Show No Mercy」から、1986年の伝説的アルバム「Reign in Blood」。
そして、最後のオリジナルアルバムとなる2015年「Repentless」。生涯をかけて、これだけ音楽性を貫き通したバンドは他にいないだろう。
彼らはとても希有な存在だった。彼らの音を、そして鋼鉄魂を、俺は一生この胸に抱き続ける。
あ・・・ここブログじゃなかった。
参考
https://qiita.com/yuuuusuke1997/items/122ca7597c909e73aad5
https://qiita.com/itkr/items/513318a9b5b92bd56185
https://qiita.com/TkrUdagawa/items/aa483630b5ec7d337c9e
https://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html#wordcloud.WordCloud

- 投稿日:2019-12-01T23:11:44+09:00
ちょっと条件を緩和してoptunaに数独を解かせてみた
はじめに
これは、前回(optunaに数独を解かせてみた)の続編です。
前回は数独のルールすら知らない状態で、optunaを使って最適化することで正解にたどり着けるか試してみました。
今回は、縦・横・3x3のブロックで数字の重複がないというルールを知ったうえでoptunaに最適化させてみました。もっと早くに投稿するつもりだったのですが、前回の投稿後に始めたリングフィット アドベンチャーがハードすぎて気力・体力がともになくなって、遅くなってしまいました。
方法
今回は、焼き鈍し法で解きます。
焼き鈍し法は、現在の値を少しランダムに変化させて次の値を作ります。(初回は元の値がないので、完全にランダムに作ります。)
作った新しい値から計算されるコストが減少するなら新しい値に移動します。
減少しない場合でも確率で移動したり、しなかったりします。
徐々にその確率を小さくしていくことで、局所解に収束します。実装
optunaで焼き鈍しをする方法は公式ドキュメントにあります。
新しい値をサンプリングする部分を変更しただけで、後は公式ドキュメントのとおりです。
サンプラーを変更した以外は前回のコードのままです。ここでは、新しい値をサンプリングする部分のみを示します。
コード全体は最後に示します。params = {} # サンプリングの順序をランダムにする name_list = shuffle(list(search_space)) for param_name in name_list: # 2次元の座標(i, j) i, j = int(param_name[1]), int(param_name[2]) # 予め(i, j)がある縦・横・3x3のブロックの要素を取り出すマスクを作っておいた # ただし、(i, j)の要素はマスクでは取り出さない mask = self._mask_array[i, j] tmp = self._state * mask # 1~9の各要素がそれぞれいくつあるかを数える cost = np.asarray([np.count_nonzero(tmp == v) for v in range(1, 10)]) probability = softmax(-cost * 5) # 新しい値をサンプリング new_value = np.random.choice(9, p=probability) + 1 # 新しい値を記録 params[param_name] = new_value self._state[i, j] = new_value return params新しい値は、縦・横・3x3のブロックで数字の重複がないというルールに基づいてサンプリングされる確率が高くなるようにしています。
ここでルールについての知識を利用しています。
実験結果
左に*がある数字は元からヒントとして与えられているものです。
*5*3 2 4*7 6 9 1 8 *6 7 4*1*9*5 3 5 2 1*9*8 2 3 8 4*6 7 *8 1 9 5*6 4 7 2*3 *4 2 6*8 7*3 5 9*1 *7 5 3 9*2 1 8 4*6 9*6 1 3 5 7*2*8 4 2 8 7*4*1*9 6 3*5 3 4 5 6*8 2 1*7*9 loss: 4.0惜しい。
トライアル数が115回目にこの答えに辿り着きました。
この後も、200回まで行いましたがダメでした。一目ではどこが間違っているかわからないですが、中央で縦方向に7が重複しています。
中央の7が縦方向では間違っていますが、横方向では条件を満たしています。
そのため、複数の要素が同時に変わらないと正解に辿り着けないので、かなり深い局所解になっています。(コストがかなり高い状態を経由しないと正解に辿り着かない)まとめ
局所解になってしまいました。
正解にたどり着くためには、複数の要素が同時に変わらないといけないので、現在の方法では難しいようです。
初期値を変えて何度もやり直せば、正解できるはずです。今後の予定
今回は中央で縦方向に7が重複していましたが、7は元から与えられているものがあるので、サンプリングされるべきでないはずです。
(ルールに関する知識をどこまで利用するかという条件に関係してくる)
また、右から3列目、上から3行目の様に元から与えられている数字から値が確定するものもあります。これらが今回の方法では全く考慮されていなかったので、次回はこれを解決したいと思います。
(もうoputunaは関係ない気がする)コード
from itertools import product import numpy as np import optuna import click from scipy.special import softmax from sklearn.utils import shuffle # https://optuna.readthedocs.io/en/stable/tutorial/sampler.html class SimulatedAnnealingSampler(optuna.samplers.BaseSampler): def __init__(self, temperature=100): self._rng = np.random.RandomState() self._temperature = temperature self._current_trial = None self._state = None self._mask_array = make_mask_array() def sample_relative(self, study, trial, search_space): if search_space == {}: return {} # 現在のtrialはstudy.trials[-1] previous_trial = study.trials[-2] if self._current_trial is None or previous_trial.value <= self._current_trial.value: probability = 1.0 else: probability = np.exp((self._current_trial.value - previous_trial.value) / self._temperature) self._temperature *= 0.99 if self._rng.uniform(0, 1) < probability: self._current_trial = previous_trial if self._state is None: self._state = np.empty([9, 9], dtype=np.int32) for i, j in product(range(9), repeat=2): name = 'p{}{}'.format(i, j) if name in preset: self._state[i, j] = preset[name] for i, j in product(range(9), repeat=2): name = 'p{}{}'.format(i, j) if name in self._current_trial.params: self._state[i, j] = self._current_trial.params[name] params = {} name_list = shuffle(list(search_space)) for param_name in name_list: i, j = int(param_name[1]), int(param_name[2]) mask = self._mask_array[i, j] tmp = self._state * mask cost = np.asarray([np.count_nonzero(tmp == v) for v in range(1, 10)]) probability = softmax(-cost * 5) new_value = np.random.choice(9, p=probability) + 1 params[param_name] = new_value self._state[i, j] = new_value return params def infer_relative_search_space(self, study, trial): return optuna.samplers.intersection_search_space(study) def sample_independent(self, study, trial, param_name, param_distribution): independent_sampler = optuna.samplers.RandomSampler() return independent_sampler.sample_independent(study, trial, param_name, param_distribution) def make_mask_array(): mask_array = np.zeros([9, 9, 9, 9]) for i, j in product(range(9), repeat=2): mask = mask_array[i, j] mask[i] = 1 mask[:, j] = 1 s, t = i // 3 * 3, j // 3 * 3 mask[s:s + 3, t:t + 3] = 1 # 自分自身を取り除く mask[i, j] = 0 return mask_array """ ----------------- |5|3| | |7| | | | | |-+-+-+-+-+-+-+-+-| |6| | |1|9|5| | | | |-+-+-+-+-+-+-+-+-| | |9|8| | | | |6| | |-+-+-+-+-+-+-+-+-| |8| | | |6| | | |3| |-+-+-+-+-+-+-+-+-| |4| | |8| |3| | |1| |-+-+-+-+-+-+-+-+-| |7| | | |2| | | |6| |-+-+-+-+-+-+-+-+-| | |6| | | | |2|8| | |-+-+-+-+-+-+-+-+-| | | | |4|1|9| | |5| |-+-+-+-+-+-+-+-+-| | | | | |8| | |7|9| ----------------- """ preset = {'p00': 5, 'p01': 3, 'p04': 7, 'p10': 6, 'p13': 1, 'p14': 9, 'p15': 5, 'p21': 9, 'p22': 8, 'p27': 6, 'p30': 8, 'p34': 6, 'p38': 3, 'p40': 4, 'p43': 8, 'p45': 3, 'p48': 1, 'p50': 7, 'p54': 2, 'p58': 6, 'p61': 6, 'p66': 2, 'p67': 8, 'p73': 4, 'p74': 1, 'p75': 9, 'p78': 5, 'p84': 8, 'p87': 7, 'p88': 9} def evaluate(answer): tmp = np.reshape(answer, [3, 3, 3, 3]) loss = np.sum(( np.sum([np.count_nonzero(np.logical_not(np.any(answer == i, axis=0))) for i in range(1, 10)]), np.sum([np.count_nonzero(np.logical_not(np.any(answer == i, axis=1))) for i in range(1, 10)]), np.sum([np.count_nonzero(np.logical_not(np.any(tmp == i, axis=(1, 3)))) for i in range(1, 10)]), )) return loss def objective(trial): candidate = (1, 2, 3, 4, 5, 6, 7, 8, 9) answer = np.empty([9, 9], dtype=np.uint8) for i, j in product(range(9), repeat=2): key = 'p{}{}'.format(i, j) if key in preset: answer[i, j] = preset[key] else: answer[i, j] = trial.suggest_categorical(key, candidate) return evaluate(answer) def run(n_trials): study_name = 'sudoku' sampler = SimulatedAnnealingSampler() study = optuna.create_study(study_name=study_name, storage='sqlite:///sudoku.db', load_if_exists=True, sampler=sampler) study.optimize(objective, n_trials=n_trials) show_result(study.best_params, study.best_value) df = study.trials_dataframe() df.to_csv('tpe_result.csv') def show_result(best_params, best_value): for i in range(9): for j in range(9): key = 'p{}{}'.format(i, j) if key in preset: print('*{:1d}'.format(preset[key]), end='') else: print('{:2d}'.format(best_params[key]), end='') print('') print('loss: {}'.format(best_value)) @click.command() @click.option('--n-trials', type=int, default=1000) def cmd(n_trials): run(n_trials) def main(): cmd() if __name__ == '__main__': main()
- 投稿日:2019-12-01T23:02:09+09:00
PEP557 dataclassは内部で何を行っているのか
TL;DR
- dataclassすごくいいよ

- 手書きで書いたclassと遜色ないよ
- これからdataclassをベースにしたライブラリが出てきそう
dataclassとは?dataclassはpython 3.7で追加された新しい標準ライブラリ。簡単に説明するとclassに宣言に
@dataclassデコレータを付けると、__init__,__repr__,__eq__,__hash__といった所謂dunder(double underscoreの略。日本語だとダンダーと読むのかな)メソッドを生成してくるライブラリ。これを使うと面倒なクラスの定義を大幅に短縮できたり、下手な実装より高速だったりする。ここで紹介した以外にもdataclassには色々な機能があるので、詳しくは公式ドキュメントやPython3.7からは「Data Classes」がクラス定義のスタンダードになるかもしれないを参照してほしい。python3.7がまだ使えないよ、という人にもPyPIに3.6用のbackportが用意されています。
dataclassの使い方from dataclasses import dataclass, field from typing import ClassVar, List, Dict, Tuple import copy @dataclass class Foo: i: int s: str f: float t: Tuple[int, str, float, bool] d: Dict[int, str] b: bool = False # デフォルト値 l: List[str] = field(default_factory=list) # listのデフォルトを[]にする c: ClassVar[int] = 10 # クラス変数 # 生成された`__init__`でインスタンス化 f = Foo(i=10, s='hoge', f=100.0, b=True, l=['a', 'b', 'c'], d={'a': 10, 'b': 20}, t=(10, 'hoge', 100.0, False)) # 生成された`__repr__`でhの文字列表現をプリントアウトする print(f) # コピーを作って書き換えてみる ff = copy.deepcopy(f) ff.l.append('d') # 生成された`__eq__`で比較する assert f != ffパフォーマンス
dataclassを使って作ったDataclassFooと手書きで書いたManualFooの
__init__,__repr__,__eq__の実行時間を計測してみた。
- macOS 10.14 Mojave
- Intel 2.3GHz 8-core Intel Core i9
- DDR4 32GB RAM
- Python 3.6.3
計測に使ったソースコードimport timeit from dataclasses import dataclass @dataclass class DataclassFoo: i: int s: str f: float b: bool class ManualFoo: def __init__(self, i, s, f, b): self.i = i self.s = s self.f = f self.b = b def __repr__(self): return f'ManualFoo(i={self.i}, s={self.s}, f={self.f}, b={self.b})' def __eq__(self, b): a = self return a.i == b.i and a.s == b.s and a.f == b.f and a.b == b.b def bench(name, f): times = timeit.repeat(f, number=100000, repeat=5) print(name + ':\t' + f'{sum(t)/5:.5f}') bench('dataclass __init__', lambda: DataclassFoo(10, 'foo', 100.0, True)) bench('manual class __init__', lambda: ManualFoo(10, 'foo', 100.0, True)) df = DataclassFoo(10, 'foo', 100.0, True) mf = ManualFoo(10, 'foo', 100.0, True) bench('dataclass __repr__', lambda: str(df)) bench('manual class __repr__', lambda: str(mf)) df2 = DataclassFoo(10, 'foo', 100.0, True) mf2 = ManualFoo(10, 'foo', 100.0, True) bench('dataclass __eq__', lambda: df == df2) bench('manual class __eq__', lambda: mf == mf2)各10万回を5セット実行した平均
計測結果(sec) dataclass __init__ 0.04382 手書きclass __init__ 0.04003 dataclass __repr__ 0.07527 手書きclass __repr__ 0.08414 dataclass __eq__ 0.04755 手書きclass __eq__ 0.04593 50万回実行してこれならほぼ差はないと言っていいでしょう。
また、バイトコードも一致した。
dataclassの__init__
>>> import dis >>> dis.dis(DataclassFoo.__init__) 2 0 LOAD_FAST 1 (i) 2 LOAD_FAST 0 (self) 4 STORE_ATTR 0 (i) 3 6 LOAD_FAST 2 (s) 8 LOAD_FAST 0 (self) 10 STORE_ATTR 1 (s) 4 12 LOAD_FAST 3 (f) 14 LOAD_FAST 0 (self) 16 STORE_ATTR 2 (f) 5 18 LOAD_FAST 4 (b) 20 LOAD_FAST 0 (self) 22 STORE_ATTR 3 (b) 24 LOAD_CONST 0 (None) 26 RETURN_VALUE
手書きclassの__init__
>>> dis.dis(ManualFoo.__init__) 13 0 LOAD_FAST 1 (i) 2 LOAD_FAST 0 (self) 4 STORE_ATTR 0 (i) 14 6 LOAD_FAST 2 (s) 8 LOAD_FAST 0 (self) 10 STORE_ATTR 1 (s) 15 12 LOAD_FAST 3 (f) 14 LOAD_FAST 0 (self) 16 STORE_ATTR 2 (f) 16 18 LOAD_FAST 4 (b) 20 LOAD_FAST 0 (self) 22 STORE_ATTR 3 (b) 24 LOAD_CONST 0 (None) 26 RETURN_VALUEdataclassの内部の解説に入る前に
dataclassを説明するにあたり重要なパーツを説明しておきたい。
PEP526: Syntax for Variable Annotations
PEP526は型宣言の方法を記述してあるんだけど、この仕様追加によってclassに宣言された変数の型情報をプログラム実行時に取得することが可能になった。
from typing import Dict class Player: players: Dict[str, Player] __points: int print(Player.__annotations__) # {'players': typing.Dict[str, __main__.Player], # '_Player__points': <class 'int'>}組み込み
exec関数evalは知ってる人が多いと思う。ざっくりevalとの違いをいうと、
eval: 引数の文字列を式として評価する
exec: 引数の文字列を文として評価するこれだけじゃ意味不明なので次の例を見てみよう。
これを実行すると"typing rocks!"を出力されるのは簡単に想像できる。
>>> exec('print("typing rocks!")') "typing rocks!"ではこれは?
exec(''' def func(): print("typing rocks!") ''')次にこれを実行してみる
>>> func() "typing rocks!"そう。実はexecは文字列を式として評価するので、pythonの関数でさえも動的に定義することができる。すげぇ。
で、dataclassは内部で何を行っているのか?
dataclassデコレータをつけたclassがimportされると、上で説明したtype annotationsやexecを使ってコード生成を行っている。超ざっくりだが、以下のような流れになる。詳しく知りたい人はcpythonのソースのこの辺を読んでみよう。
- dataclassデコレータがクラスに対して呼ばれる
- 各フィールドの型情報(型名、型クラス、デフォルト値等)をtype annotationsから取得する
- 型情報を使って
__init__関数定義の文字列を作る- 文字列を
execに渡して動的に関数を生成する- クラスに
__init__関数をセットする3, 4, 5を単純化したコードはこんな感じ。
nl = '\n' # f-string内でエスケープ使えないので外で定義する # 関数定義の文字列作成 s = f""" def func(self, {', '.join([f.name for f in fields(Hoge)])}): {nl.join(' self.'+f.name+'='+f.name for f in fields(Hoge))} """ # 関数定義の文字列をコンソール出力してみる print(s) # def func(self, i, s, f, t, d, b, l): # self.i=i # self.s=s # self.f=f # self.t=t # self.d=d # self.b=b # self.l=l # execでコード生成。`func`関数がスコープ内に定義された exec(s) setattr(Foo, 'func', func) # クラスに生成した関数をクラスにセットする以上は単純化された例だけど、実際には
- フィールドに設定されたデフォルト値
- List等に使うデフォルトファクトリ関数
- クラス変数(ClassVar)
- プログラマが定義済みだったら生成しない
- 他のdunder関数の生成
- dataclassのclassの継承
等を全て考慮して、どんな場合も正しく動作するように丁寧に丁寧に関数定義文字列作成、コード生成が行われているのです。
さらに、もう一つ押さえておきたいことが、このコード生成が行われるのはモジュールがロードされた瞬間のみということ。一度classがimportされたら、手書きで書いたclassと何の変わりもなく使えるということだ。
Rustの
#[derive]Rustにはstructを定義する時につけるDerive attribute(
#[derive])というものがある。これ、dataclassとほぼ同等かそれ以上のことができる。例えば以下をみてもらえると、#[derive(Debug, Clone, Eq, PartialEq, Hash)] struct Foo { i: i32, s: String, b: bool, }
#[derive(Debug, Clone, Eq, PartialEq, Hash)]をつけるだけで、これだけのメソッドを生成してくれる。
- Debug用文字列生成のメソッド生成 (Pythonでいう
__repr__)- オブジェクトをクローンするメソッド生成
- 比較メソッド生成(Pythonでいう
__eq__や__gt__)- ハッシャーメソッド生成(Pythonでいう
__hash__)またRustはさらにすごくて、自分のCustom driveを実装する機能が公式でサポートされていて、割とカジュアルに型ベースのメタプログラミングができる。
こういったプログラマを楽にする機能がRustには他にもたくさんあるので、型制約や所有権が難しくてもRustが生産性が高い理由だと筆者は思っている。Rustは本当に素晴らしい言語なのでPythonistaの方々もぜひぜひ触ってみてほしい。
メタプログラミングとしてのdataclassの可能性
dataclassは型ベースのメタプログラミングの有用性と可能性を示したいい例だと個人的には思っている。
筆者も二つほどdataclassをベースにしたライブラリを作ってみたので、興味がある人はみてみてほしい。
- envclasses
- 環境変数の値をdataclassのフィールドにマッピングするライブラリ。コンテナ使ってて、Pythonのコンフィグclassを環境変数でオーバーライドしたい時とかに便利
- pyserde
- dataclassベースのシリアライズライブラリ
RustでそうであるようにPythonでもこの分野が盛り上がって良いライブラリがたくさん出てきてほしい。
- 投稿日:2019-12-01T23:01:14+09:00
文字化けで出てきた漢字ランキングBEST20(UTF8→SJIS)
動機
(要約)ただ僕が知りたくなったからです。それ以上の理由はありません。
もっと詳しく
文字化けには何種類ものパターンがあります。
UTF8のファイルをSJISで表示した時に起こる文字化け、
UTF8をEUCで表示した時に起こる文字化け、
EUCをUTF8で表示した時に起こる文字化け……。
それぞれがどんな見た目になるかはこのページなどで確認できます。
正直最近はUTF8で作業をするため、文字化けはあまり見ていません。
けれども私が新卒で入った職場ではテキストファイルの作成はSJISが基本でした。そして、UTF8のファイルをSJISで開いて文字化けを起こすことが、わりと頻繁に起きていました。
UTF8→SJISへの文字化けだとよく縺ォ蜈育函縺ィ蜻シ繧薙〒縺�縺溘€ゅ□縺……のような文字化けが発生するのですが、これを見ていると、同じ漢字が何度も何度も登場していることが分かると思います。
文字化けで出てくる漢字には偏りがある。
そのよく出てくる漢字とその意味を、ただ知りたかった……。
でも意外とそういう内容の記事って見つからないし、しょうがないから自分で書くか……。
という、私の特に何の役にも立たない些細な好奇心がこの記事を書く原動力でした。
同じ漢字ばかり出てくる理由
同じ文字ばかり出てくる理由については、去年に素晴らしい記事が書かれていたため、ここでは割愛させて頂きます。
UTF-8からSJISに文字化けすると糸偏の漢字がよく出てくる集計方法
適当な長文をもとに、元UTF8 → SJIS表示での文字化けを発生させてファイルに保存しておき、その漢字をPythonで数え上げます。
どんなに輝かしい名文でも、一旦SJISで表示させてからUTF8として保存し直せば、見るも無残な姿に早変わりできます。この世の無常を感じずにはいられません。
長文には何をチョイスするかですが、ここではおそらくみんなが知っているであろうものを題材にしてみます。
高校の教科書に載っている夏目漱石の『こころ』と、中学校の教科書に載っている太宰治の『走れメロス』でそれぞれカウントしてみましょう。メインは『こころ』の方で、短編の『走れメロス』のランキングはオマケ程度に紹介します。文章は青空文庫に載っているため、そこからコピペしてデータを作らせて頂きました。
プログラムは、特に何の面白みもないpythonのコードを書きました。
import re with open('./source.txt', encoding="utf-8") as f: s: str = f.read() # 出てくる文字を数え上げて、その結果を辞書にする # このとき、漢字以外の文字を除外する。つまり「ョ」とか「ケ」とかをはじく。 count_dic = {} for char in s: result = re.search('[一-鿐]', char) if result is None: # 漢字じゃないので飛ばす continue if char in count_dic: count_dic[char] += 1 else: count_dic[char] = 1 # 少ない順に出力 for k, v in sorted(count_dic.items(), key=lambda x: x[1]): print(str(k) + ": " + str(v))結果発表『こころ』部門
※漢検の級判定はgoo辞書で出てきたものをそのまま使っています。
第20位
出現数1049回
$\huge{遘}$
漢検1級トップバッターからいきなり心を折ってくる難しい漢字が出ました。『こころ』のランキングの自覚はあるのでしょうか。
あう。であう。めぐりあう、という漢字です。
めぐりあうは「めぐり遘う」とも書くことができ、邂逅は邂遘とも書けるようです。
現代でこんな字を書いたら多分嫌われてしまいますね。第19位
出現数1112回
$\huge{代}$
漢検8級「田代まさし」の「代」。覚醒剤はだめだぞ。
第18位
出現数1190回
$\huge{荳}$
漢検1級植物のマメ、を表す字です。確かに豆が難しくなったような見た目です。
荳角皇女(ささげのおうじょ)という継体天皇の皇女様が6世紀頃にいらっしゃったようです。
それと関係あるかは不明ですが、大角豆(ささげ)という豆は日本で古くから食べられているササゲ属の一年草です。お祝い用の赤飯には、ササゲが使われます。時は江戸時代、小豆(あずき)は煮ると皮が破れやすく、「腹切れする豆は切腹に通じる」として、武士の間で嫌われていました。そのため、赤飯にはササゲを使ったんですって。……これはプログラミングの記事です。大丈夫です。上にPythonのコードをちゃんと書いておきました。なので消されないはずです。第17位
出現数1201回
$\huge{莠}$
漢検1級訓読みで「はぐさ」と読みます。稲に似ているけれども、葉ばかり伸びて実らない雑草のことだそうです。例えば、猫じゃらしとして有名なエノコログサがこれに当たります。稲っぽいけど、実らない。転じて、悪いものの例えとしても使われるようです。なので莠言(ゆうげん)というのは、有害で醜悪な言葉を指します。まぁ使いませんよねこんな熟語……。
第16位
出現数1401回
$\huge{昴}$
漢検1級紛らわしいですが「激昂」の「昂」ではありません。「昴」は「すばる」と読みます。星です。
平安時代の清少納言は、「星はすばる。ひこぼし。ゆふづつ。よばひ星、すこしをかし」とすばるを讃えました。
風の中のすばる 砂の中の銀河 みんな何処へ行った 見送られることもなく……第15位
出現数1493回
$\huge{峨}$
漢検準1級文系で日本史選択だった場合は、後嵯峨天皇(ごさがてんのう)という文字を見たことがあるはずです。そうでなくても、この漢字は人名で目にするかもしれません。峨という字は、山が高くけわしいさまを表します。
第14位
出現数1512回
$\huge{翫}$
漢検準1級翫ぶ(もてあそぶ)、翫る(むさぼる)、翫る(あなどる)と読めます。
芝翫縞(しかんじま)というのは、江戸時代に流行した着物の柄です。四本の縦縞と鐶(かん。金属の輪)をつないだ形を合わせた柄のことで、「四鐶縞」と書くのが意味的には正しかったのですが、歌舞伎役者の3代目中村歌右衛門(うたえもん)の俳号「芝翫」にちなんでこの漢字があてられたようです。
第13位
出現数1553回
$\huge{医}$
漢検8級お客様の中にお医者様はいませんか!?
第12位
出現数1555回
$\huge{上}$
漢検10級領収書の宛名、上様でいいよって会社ってあるんでしょうか……?
第11位
出現数1625回
$\huge{輔}$
漢検準1級人名でよく出てくるけど意外と漢検準1級扱い。
漢検準1級の読み問題で出てくる「輔弼」は、「ほひつ」と読みます。
輔弼は天皇の行為としてなされるべき、あるいは、なされざるべきことについて進言することです。第10位
出現数1794回
$\huge{阪}$
漢検2級サカには「坂」と「阪」の2種類があります。理由は諸説あるようですが、文化5年(1808)刊行の『摂陽落穂集』によると、坂は分解すると「土」と「反」に分けられ「土に返る」と読めることから、縁起がよくないと忌み嫌って「阪」を用いる人がいたとされています。せやから大坂って書いたらアカンで。知らんけど。
第9位
出現数2215回
$\huge{吶}$
漢検1級たまに小説で出てくる漢字です。吶(ども)る、と書いたりします。
彼は訥々(とつとつ)と語りだした――。訥々と語るというのは、口ごもりながら語るということです。
飾りけがなく無口なことを朴訥(ぼくとつ)と言います。
言偏の「訥」と口偏の「吶」がありますが、同じ意味のようです。第8位
出現数2282回
$\huge{薙}$
漢検準1級漢検準1級扱いですが、説明は不要ですね。
三種の神器「八咫鏡」「天叢雲剣(別名:草薙剣)」「八尺瓊勾玉」はオタクの義務教育です。第7位
出現数3147回
$\huge{後}$
漢検9級ここから後ろは出現数が跳ね上がっていきます。
第6位
出現数4078回
$\huge{溘}$
漢検1級「溘」という字はたちまち、にわかにという意味です。
「溘焉(こうえん)として逝く」というのは、雑に言うと「突然の死!!!」です。第5位
出現数4718回
$\huge{励}$
漢検3級Qiitaのいいねって励みになりますよね。押してください。
第4位
出現数5831回
$\huge{九}$
漢検10級九なのに4位。
次からは文字化けで本当によく目にする糸偏三銃士です。第3位
出現数6656回
$\huge{縲}$
漢検1級螺旋丸!!! ではありません。虫偏ではなく糸偏です。
「縲」は罪人をしばる縄を表す、かなりニッチな漢字です。
「縲絏(るいせつ)の辱を受けんより、寧ろ只今潔く自殺せん」〈竜渓・経国美談〉とあるように、主に「絏(せつ)」とセットで使われるようです。絏は、しばるという意味があるようです。昭和よりも前の時代には金属の手錠なんてものはありませんから、縄で罪人を縛るわけです。江戸時代には捕手術(とりてじゅつ。素手で敵を殺さずに捕り抑える武術)の一環として捕縄術(ほじょうじゅつ/とりなわじゅつ)が盛んに用いられていました。取り押さえた敵を素早く拘束する『早縄』、形式・儀式的に用いる『本縄』、緊縛による拷問を加えるための『拷問縄』などがあり、縛る相手の身分や職業、性別、用途によってそれぞれ異なる縛り方が用意されていたらしいです。捕縄術はれっきとした武術であり、江戸時代には150もの流派があったとか……。すごい。
第2位
出現数12928回
$\huge{繧}$
漢検1級出現回数を3位から大きく引き離して倍近くを稼ぎ出しました。
エンジニアでなくとも文字化けで何度も何度も目にしたであろうこの憎き漢字……。繧繝(うんげん。暈繝)という言葉があります。
繧繝というのは簡単にいうと、古のグラデーションです。中国西域から伝わり、奈良・平安時代の仏画、寺院の装飾や染織などに用いられました。
そして繧繝彩色(うんげんさいしき)という色彩用語があります。具体的な絵を見た方が分かると思います。色彩検定などで出てくるらしいので、もしかしたらWebデザイナーの方の中には知っている方もいるかもしれません。参考:暈繝彩色の意味とは
正倉院の宝物、漆金薄絵盤(うるしきんぱくえのばん)というものがあるのですが、ここにわかりやすい繧繝彩色があります。
(出典:宮内庁のHP http://shosoin.kunaicho.go.jp/ja-JP/Treasure?id=0000014245 )
よく見ると、ぼかして色を重ねるのではなく、層をなすように同系統の色が重なっているでしょう? これが繧繝彩色です。
身近な例でいうと、Vueのロゴも繧繝彩色であると言えるかもしれませんね。
第1位
出現数60693回
$\huge{縺}$
漢検1級6万回という圧倒的な出現数で他の追随を許さないスコアを稼ぎ出しました。
UTF8→SJISの文字化け界の王者に輝いたのは、糸偏三銃士最強の漢字「縺」です!よく聞くのは「痴情の縺(もつ)れ」というように、「もつれ」を表す漢字です。
もつれは、絡み合うことです。「糸の縺れを解く」というふうに言います。
紛らわしいことに、「ほつれ」と「もつれ」の2つの言葉があります。
「解れ(ほつれ)」と「縺れ(もつれ)」というそれぞれの漢字が指すように、
解れはほどけること、縺れは絡まることなので、意味的には真逆です。注意しましょう。舌縺れ(したもつれ)というのは、舌がからんですらすらと物が言えないことです。
具体的に言うと初対面の方と会話する時に僕のような引きこもりエンジニアはよく舌縺れします。
縺れ髪(もつれがみ)というのは、もつれた髪。乱れ髪のことです。
具体的に言うと一般的エンジニアの髪型のことです。
エンジニアにふさわしい漢字が第1位に輝きましたね!!!(やかましいわ)結果発表『走れメロス』部門
『こころ』だけで終わらせてしまうと、上の結果は『こころ』でしか通用しないんじゃないの??? 他の文章だと全然違う結果になるんじゃないの??? と思われがちなので、念のため、他の文章でもランキングをつけてみました。ちょっと順位は変動していますが、一部を除いて概ね似たような結果になっています。
メロスは短編小説なので、テキストの量は少なめです。41位 遘: 20回(ランク外)
32位 昴: 24回(ランク外)
22位 莠: 48回(ランク外)
―――――――――――――――
20位 譚: 54回 new!(冒険譚の譚)
19位 吶: 56回
18位 偵: 57回 new!(偵察の偵)
17位 輔: 59回
16位 荳: 63回
15位 代: 76回
14位 峨: 80回
13位 翫: 92回
12位 上: 98回
11位 阪: 98回
10位 医: 111回
9位 薙: 117回
8位 励: 149回
7位 繝: 156回 new!(繧繝(うんげん)の繝の方)
6位 溘: 222回
5位 後: 224回
4位 九: 290回
3位 縲: 753回
2位 繧: 933回
1位 縺: 2944回2位「繧」のパートナーである「繝」が7位にランクインしているところが注目の点ですね。
実は「繝」は『こころ』では172回出現の78位という不完全燃焼な結果となっていましたが、メロスではその実力を遺憾なく発揮してくれました。パートナーの飛躍に「繧」も喜びの表情を浮かべています。実は「繝」の字は上にも貼った別の方の記事「UTF-8からSJISに文字化けすると糸偏の漢字がよく出てくる」でも紹介されているのですが、「ダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴヵヶ」の文字が文字化けすると出てきます。なので、「メロス」を文字化けさせると「繝。繝ュ繧ケ」みたいに「繝」の字が2回も出てきてくれるのですが、『こころ』はカタカナの割合が現在の文章に比べるとかなり少ないので、「繝」選手にとってはやや不利な戦いを強いられてしまった感は否めません。糸偏三銃士がもし糸偏四天王になるとしたら、その最弱ポジションは間違いなく「繝」選手になるでしょう。
おわりに
こ、これはぷろぐらみんぐのきじです……。ぱいそんかいてるもんね……。
文字化けした結果出てくる、なんだか恐ろしげな漢字も、調べてみたら意外と面白かったよということが伝わったら幸いです。憎き謎の漢字も、文学やら歴史やらの背景があって生きている(いた)漢字なので、あまり繧繝ちゃんのことをいじめないであげてください。



- 投稿日:2019-12-01T22:38:33+09:00
Python/C API で Awaitable を作る
はじめに
今年も年末が近づいてきたので無駄に Python C/API を使ってみます。目的と手段の逆転。今回は Awaitable を、次の coroutine function spam を実行して得られる Coroutine のようなものをめざします。
import asyncio async def spam(): print('do something') ret = await asyncio.sleep(1, 'RETURN VALUE') return ret.lower() async def main(): ret = await spam() print(ret) if __name__ == '__main__': asyncio.run(main())なにか print して、 await sleep して結果を得て、それの lower メソッドを呼んで結果を返します。 3 動作。 Awaitable はもっていないが Coroutine や Generator ならばもっている send, throw, close メソッドは今回は再現しません。
await と yield from
async def, await と書かれたコードを模倣する前に。そもそもこれはなんなのかを復習します。これらの言語機能が Python に追加提案されたときの文章が PEP 492 です。
これを読んで await とは実質 yield from だったな、と雑に思い出しました。これが用意された経緯は次のようなものだったのではないでしょうか。「Generator の仕様はもともと Coroutine として使われることを視野に入れて設計されていました。一時停止・再開ができるという特性は Iterator そのものでしたし、値を送り込むことができるという特性も PEP 342 にて追加しました。そして Python 3.4 以前まで順調に実績を積んできました。しかし Generator や Iterator と Coroutine の区別がつかないことによる問題が報告され始めたので区別がつくように Python 3.5 の言語仕様に手を入れます。 __iter__ ではなく __await__ という別のメソッドを新設します。 Generator Function 用である yield from 文も流用はせず、 Coroutine Function の中で使うための別の文 await 文を新設して区別します。」 、と。 __await__ と __iter__ という別の名前が用意されてはいますが動作としては異なるものではないのでした。 CPython の PyTypeObject 構造体上でも tp_iter と tp_as_sync.am_await が用意され別のメンバ扱いとなっています。__await__
Awaitable に対する理解が進んだので。さっそく coroutine function spam を class 文で書き下します。 Iteratable との違いは __iter__ の代わりに __await__ を持っているところですね。とはいえ名前が違うだけで、ここから Iterator を返すという点はかわりません。
class Spam: def __await__(self): ... # TODO: どのような Itarator を返せば spam コルーチンを模倣できる?__iter__ と __next__
分解をつづけます。 Iterator とは __iter__ で自身を返し、 __next__ で処理を再開し次の値を作り処理を中断しつつ値を返すものです。
class _Spam: def __iter__(self): return self def __next__(self): ... # TODO: どうすれば spam コルーチンを模倣できる? class Spam: def __await__(self): return _Spam()さて、「coroutine function spam を実行して得られる Coroutine と似た Awaitable」を実装するためには何が必要でしょうか。「なにか print して、 await sleep して結果を得て、それの lower メソッドを呼んで結果を返す」の 3 動作のうちどこまで処理したかの状態の保持ですね。オブジェクトに _state 属性を持たせるようにします。今回はとりあえず 0, 1, 2 の int で表現しましたが、きれいに書くのであれば Enum をもちいるのがよいでしょう。
そして状態別に処理を行う __next__ を実装します。ここで問題となるのが yield from 。 yield from とは別の Iterator に処理を委譲するものです。別の Iterator が停止するまで繰り返し処理をしつづけて得られた値をそのまま返し続けます。これと同等の処理を実装するために動作中の別の Iterator を保持する必要があります。このため _it 属性をもたせました。この Iterator が停止したら StopIteration 例外が送られてくるので value 属性をみます。これが coroutine function や generator function の return 文に、 yield from の値に対応しています。
逆に値を返すときには StopIteration 例外に値を持たせます。
一度停止した Iterator は StopIteration 例外を返し続けないといけないという制約がありますのでその対策をします。 __next__ の末尾は raise StopIteration にします。状態を保持する属性は外部から書き換えて欲しくないものであることを示すため名前を _ で始めるようにします。この _state の初期化は、 __init__ の複数回の呼び出しへの耐性をもたせるため __new__ でおこないます。class _Spam: def __new__(cls): obj = super().__new__(cls) obj._state = 0 obj._it = None return obj def __iter__(self): return self def __next__(self): if self._state == 0: print('do something') self._it = asyncio.sleep(1, 'RETURN VALUE').__await__() self._state = 1 if self._state == 1: try: v = next(self._it) except StopIteration as e: ret = e.value self._it = None self._state = 2 raise StopIteration(ret.lower()) else: return v raise StopIteration class Spam: def __await__(self): return _Spam()Python C/API でクラスを書こう
分解が終わったので。これを Python C/API でかきます。ここから C 言語。クラスをつくるには PyTypeObject 構造体を直接書くか PyType_Spec を定義して PyType_FromSpec を呼びます。今回は PyType_FromSpec を使う方向で。
まずは _Spam よりは簡単な Spam から。 __await__ をつくるには tp_as_sync.am_await に関数を登録します。このメソッドからは _Spam のインスタンスを返す必要があるので Spam クラスの属性に _Spam クラスを持たせるようにすることにします。クラス属性追加処理は Py_mod_exec として登録するモジュールの初期化処理にて PyType_FromSpec でのクラス作成後に行います。typedef struct { PyObject_HEAD } SpamObject; static PyObject * advent2019_Spam_await(SpamObject *self) { PyObject *_Spam_Type = PyObject_GetAttrString((PyObject *)Py_TYPE(self), "_Spam"); if (_Spam_Type == NULL) { return NULL; } PyObject *it = PyObject_CallFunction(_Spam_Type, ""); Py_DECREF(_Spam_Type); return it; } static PyType_Slot advent2019_Spam_slots[] = { {Py_am_await, (unaryfunc)advent2019_Spam_await}, {0, 0}, }; static PyType_Spec advent2019_Spam_spec = { .name = "advent2019.Spam", .basicsize = sizeof(SpamObject), .flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE, .slots = advent2019_Spam_slots, }; static int advent2019_exec(PyObject *module) { int ret = -1; PyObject *_Spam_Type = NULL; // TODO PyObject *Spam_Type = NULL; if (!(Spam_Type = PyType_FromSpec(&advent2019_Spam_spec))) { goto cleanup; } // Spam._Spam = _Spam if (PyObject_SetAttrString(Spam_Type, "_Spam", _Spam_Type)) { goto cleanup; } if (PyObject_SetAttrString(module, "Spam", Spam_Type)) { goto cleanup; } if (PyObject_SetAttrString(module, "_Spam", _Spam_Type)) { goto cleanup; } ret = 0; cleanup: Py_XDECREF(_Spam_Type); Py_XDECREF(Spam_Type); if (ret) { Py_XDECREF(module); } return ret; }C/API で書く Iterator
さて、後回しにした Iterator _Spam の実装ですね。まずは _SpamObject 構造体と __new__ から。状態を保持するための何らかの値 state と asyncio.sleep().__await__ イテレータを保持する it を用意。他の PyObject* を保持することになるのでガベージコレクション機構に対応する PyObject_GC_New でメモリを確保するようにします。また、初期化が終わったら PyObject_GC_Track を呼び、ガベージコレクタに自身を登録します。
typedef struct { PyObject_HEAD unsigned char state; PyObject *it; } _SpamObject; static PyObject * advent2019__Spam_new(PyTypeObject *type, PyObject *args, PyObject *kwargs) { static char *kwlist[] = {NULL}; if (!PyArg_ParseTupleAndKeywords(args, kwargs, "", kwlist)) { return NULL; } _SpamObject *obj = PyObject_GC_New(_SpamObject, type); if (!obj) { return NULL; } obj->state = 0; obj->it = NULL; PyObject_GC_Track(obj); return (PyObject *)obj; }ガベージコレクションが動いた時用の関数が必要になります。抱えているオブジェクトを手繰れるようにする traverse と、参照を破棄する clear 、自身を破棄する dealloc の 3 つです。 Py_VISIT マクロ は traverse を書くのに便利。 PyObject_GC_Track と対になる PyObject_GC_UnTrack は dealloc の開始時に呼び出すようにします。
static int advent2019__Spam_traverse(_SpamObject *self, visitproc visit, void *arg) { Py_VISIT(self->it); return 0; } static int advent2019__Spam_clear(_SpamObject *self) { Py_CLEAR(self->it); return 0; } static void advent2019__Spam_dealloc(_SpamObject *self) { PyObject_GC_UnTrack(self); advent2019__Spam_clear(self); PyObject_GC_Del(self); }__iter__ は自身を返すだけなので簡単ですね。参照カウントの操作を忘れないようにしつつ。
static PyObject * advent2019__Spam_iter(_SpamObject *self) { Py_INCREF(self); return (PyObject *)self; }最後に __next__ 。 Python C/API 上では iternext という名前になります。組み込み関数 print と asyncio モジュールの sleep はクラス作成時に _print と _sleep という名前でクラス属性に持たせるようにしておきます、 Spam._Spam と同じ要領で。
あとは Python で書いたコードを PyObject_GetAttrString, PyObject_CallFunction らを用いて地道に移植していく作業です。呼ぶたびに戻り値が NULL になっていないかを確認します。不必要となったオブジェクトの参照カウントを減らす処理がしんどい。
try 文の移植には PyErr_Fetch, PyErr_GivenExceptionMatches, PyErr_Restore を使います。static PyObject * advent2019__Spam_iternext(_SpamObject *self) { if (self->state == 0) { // print('do something') PyObject *printfunc = PyObject_GetAttrString((PyObject *)Py_TYPE(self), "_print"); if (!printfunc) { return NULL; } PyObject *ret = PyObject_CallFunction(printfunc, "s", "do something"); Py_DECREF(printfunc); if (!ret) { return NULL; } Py_DECREF(ret); // self._it = asyncio.sleep(1, 'RETURN VALUE').__await__() PyObject *sleep_cofunc = PyObject_GetAttrString((PyObject *)Py_TYPE(self), "_sleep"); if (!sleep_cofunc) { return NULL; } PyObject *sleep_co = PyObject_CallFunction(sleep_cofunc, "is", 1, "RETURN VALUE"); Py_DECREF(sleep_cofunc); if (!sleep_co) { return NULL; } if (!(Py_TYPE(sleep_co)->tp_as_async)) { Py_DECREF(sleep_co); return NULL; } if (!(Py_TYPE(sleep_co)->tp_as_async->am_await)) { Py_DECREF(sleep_co); return NULL; } PyObject *temp = self->it; self->it = Py_TYPE(sleep_co)->tp_as_async->am_await(sleep_co); Py_DECREF(sleep_co); Py_XDECREF(temp); if (self->it == NULL) { return NULL; } self->state = 1; } if (self->state == 1) { // next(self.it) if (Py_TYPE(self->it)->tp_iternext == NULL) { PyErr_SetString(PyExc_TypeError, "no iternext"); return NULL; } PyObject *ret = Py_TYPE(self->it)->tp_iternext(self->it); if (!ret) { // except StopIteration as e PyObject *type, *value, *traceback; PyErr_Fetch(&type, &value, &traceback); if (PyErr_GivenExceptionMatches(type, PyExc_StopIteration)) { Py_XDECREF(type); Py_XDECREF(traceback); if (!value) { PyErr_SetString(PyExc_ValueError, "no StopIteration value"); return NULL; } // ret = e.value.lower() PyObject *value2 = PyObject_CallMethod(value, "lower", NULL); Py_DECREF(value); if (!value2) { return NULL; } // raise StopIteration(ret) PyErr_SetObject(PyExc_StopIteration, value2); Py_DECREF(value2); Py_CLEAR(self->it); self->state = 2; } else { // except: // raise PyErr_Restore(type, value, traceback); } } return ret; } // raise StopIteration(None) PyErr_SetNone(PyExc_StopIteration); return NULL; }これで _Spam クラスのメソッドがそろったので PyType_Spec を定義します。ガベージコレクションで管理されるべきクラスであることををしめすフラグ Py_TPFLAGS_HAVE_GC を設定するようにします。
static PyType_Slot advent2019__Spam_slots[] = { {Py_tp_new, advent2019__Spam_new}, {Py_tp_iter, advent2019__Spam_iter}, {Py_tp_iternext, advent2019__Spam_iternext}, {Py_tp_traverse, advent2019__Spam_traverse}, {Py_tp_clear, advent2019__Spam_clear}, {Py_tp_dealloc, advent2019__Spam_dealloc}, {0, 0}, }; static PyType_Spec advent2019__Spam_spec = { .name = "advent2019._Spam", .basicsize = sizeof(_SpamObject), .flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_GC, .slots = advent2019__Spam_slots, };おわりに
Python C/API で Awaitable を実装してみました。また、これをおこなうにあたって必要な情報がまとまっている公式ドキュメントへのリンクを集めることができました。
ところで。これは役に立つのでしょうか? たったこれだけのことのためのコードがずいぶんと長く、 async def, await 構文の便利さを思い知っただけのような、いや CPython への理解を深めるのには役立つかもしれない………。setup.cfg[metadata] name = advent2019 version = 0.0.0 [options] python_requires = >=3.5.0setup.pyfrom setuptools import Extension, setup extensions = [Extension('advent2019', sources=['advent2019.c'])] setup(ext_modules=extensions)advent2019.c#define PY_SSIZE_T_CLEAN #include <Python.h> typedef struct { PyObject_HEAD unsigned char state; PyObject *it; } _SpamObject; static PyObject * advent2019__Spam_new(PyTypeObject *type, PyObject *args, PyObject *kwargs) { static char *kwlist[] = {NULL}; if (!PyArg_ParseTupleAndKeywords(args, kwargs, "", kwlist)) { return NULL; } _SpamObject *obj = PyObject_GC_New(_SpamObject, type); if (!obj) { return NULL; } obj->state = 0; obj->it = NULL; PyObject_GC_Track(obj); return (PyObject *)obj; } static PyObject * advent2019__Spam_iter(_SpamObject *self) { Py_INCREF(self); return (PyObject *)self; } static PyObject * advent2019__Spam_iternext(_SpamObject *self) { if (self->state == 0) { // print('do something') PyObject *printfunc = PyObject_GetAttrString((PyObject *)Py_TYPE(self), "_print"); if (!printfunc) { return NULL; } PyObject *ret = PyObject_CallFunction(printfunc, "s", "do something"); Py_DECREF(printfunc); if (!ret) { return NULL; } Py_DECREF(ret); // self._it = asyncio.sleep(1, 'RETURN VALUE').__await__() PyObject *sleep_cofunc = PyObject_GetAttrString((PyObject *)Py_TYPE(self), "_sleep"); if (!sleep_cofunc) { return NULL; } PyObject *sleep_co = PyObject_CallFunction(sleep_cofunc, "is", 1, "RETURN VALUE"); Py_DECREF(sleep_cofunc); if (!sleep_co) { return NULL; } if (!(Py_TYPE(sleep_co)->tp_as_async)) { Py_DECREF(sleep_co); return NULL; } if (!(Py_TYPE(sleep_co)->tp_as_async->am_await)) { Py_DECREF(sleep_co); return NULL; } PyObject *temp = self->it; self->it = Py_TYPE(sleep_co)->tp_as_async->am_await(sleep_co); Py_DECREF(sleep_co); Py_XDECREF(temp); if (self->it == NULL) { return NULL; } self->state = 1; } if (self->state == 1) { // next(self.it) if (Py_TYPE(self->it)->tp_iternext == NULL) { PyErr_SetString(PyExc_TypeError, "no iternext"); return NULL; } PyObject *ret = Py_TYPE(self->it)->tp_iternext(self->it); if (!ret) { // except StopIteration as e PyObject *type, *value, *traceback; PyErr_Fetch(&type, &value, &traceback); if (PyErr_GivenExceptionMatches(type, PyExc_StopIteration)) { Py_XDECREF(type); Py_XDECREF(traceback); if (!value) { PyErr_SetString(PyExc_ValueError, "no StopIteration value"); return NULL; } // ret = e.value.lower() PyObject *value2 = PyObject_CallMethod(value, "lower", NULL); Py_DECREF(value); if (!value2) { return NULL; } // raise StopIteration(ret) PyErr_SetObject(PyExc_StopIteration, value2); Py_DECREF(value2); Py_CLEAR(self->it); self->state = 2; } else { // except: // raise PyErr_Restore(type, value, traceback); } } return ret; } // raise StopIteration(None) PyErr_SetNone(PyExc_StopIteration); return NULL; } static int advent2019__Spam_traverse(_SpamObject *self, visitproc visit, void *arg) { Py_VISIT(self->it); return 0; } static int advent2019__Spam_clear(_SpamObject *self) { Py_CLEAR(self->it); return 0; } static void advent2019__Spam_dealloc(_SpamObject *self) { PyObject_GC_UnTrack(self); advent2019__Spam_clear(self); PyObject_GC_Del(self); } static PyType_Slot advent2019__Spam_slots[] = { {Py_tp_new, advent2019__Spam_new}, {Py_tp_iter, advent2019__Spam_iter}, {Py_tp_iternext, advent2019__Spam_iternext}, {Py_tp_traverse, advent2019__Spam_traverse}, {Py_tp_clear, advent2019__Spam_clear}, {Py_tp_dealloc, advent2019__Spam_dealloc}, {0, 0}, }; static PyType_Spec advent2019__Spam_spec = { .name = "advent2019._Spam", .basicsize = sizeof(_SpamObject), .flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_GC, .slots = advent2019__Spam_slots, }; typedef struct { PyObject_HEAD } SpamObject; static PyObject * advent2019_Spam_await(SpamObject *self) { PyObject *_Spam_Type = PyObject_GetAttrString((PyObject *)Py_TYPE(self), "_Spam"); if (_Spam_Type == NULL) { return NULL; } PyObject *it = PyObject_CallFunction(_Spam_Type, ""); Py_DECREF(_Spam_Type); return it; } static PyType_Slot advent2019_Spam_slots[] = { {Py_am_await, (unaryfunc)advent2019_Spam_await}, {0, 0}, }; static PyType_Spec advent2019_Spam_spec = { .name = "advent2019.Spam", .basicsize = sizeof(SpamObject), .flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE, .slots = advent2019_Spam_slots, }; static int advent2019_exec(PyObject *module) { int ret = -1; PyObject *builtins = NULL; PyObject *printfunc = NULL; PyObject *asyncio_module = NULL; PyObject *sleep = NULL; PyObject *_Spam_Type = NULL; PyObject *Spam_Type = NULL; if (!(builtins = PyEval_GetBuiltins())) { goto cleanup; } /* borrowed */ // fetch the builtin function print if (!(printfunc = PyMapping_GetItemString(builtins, "print"))) { goto cleanup; } // import asyncio if (!(asyncio_module = PyImport_ImportModule("asyncio"))) { goto cleanup; } if (!(sleep = PyObject_GetAttrString(asyncio_module, "sleep"))) { goto cleanup; }; if (!(_Spam_Type = PyType_FromSpec(&advent2019__Spam_spec))) { goto cleanup; } // _Spam._print = print if (PyObject_SetAttrString(_Spam_Type, "_print", printfunc)) { goto cleanup; } // _Spam._sleep = asyncio.sleep if (PyObject_SetAttrString(_Spam_Type, "_sleep", sleep)) { goto cleanup; } if (!(Spam_Type = PyType_FromSpec(&advent2019_Spam_spec))) { goto cleanup; } // Spam._Spam = _Spam if (PyObject_SetAttrString(Spam_Type, "_Spam", _Spam_Type)) { goto cleanup; } if (PyObject_SetAttrString(module, "Spam", Spam_Type)) { goto cleanup; } if (PyObject_SetAttrString(module, "_Spam", _Spam_Type)) { goto cleanup; } ret = 0; cleanup: Py_XDECREF(printfunc); Py_XDECREF(asyncio_module); Py_XDECREF(sleep); Py_XDECREF(_Spam_Type); Py_XDECREF(Spam_Type); if (ret) { Py_XDECREF(module); } return ret; } static PyModuleDef_Slot advent2019_slots[] = { {Py_mod_exec, advent2019_exec}, {0, NULL} }; static struct PyModuleDef advent2019_moduledef = { PyModuleDef_HEAD_INIT, .m_name = "advent2019", .m_slots = advent2019_slots, }; PyMODINIT_FUNC PyInit_advent2019(void) { return PyModuleDef_Init(&advent2019_moduledef); }これをつかってみるコードの例
import sys import asyncio import advent2019 async def main(): v = await advent2019.Spam() print(v) if __name__ == '__main__': if sys.version_info < (3, 7): loop = asyncio.get_event_loop() loop.run_until_complete(main()) loop.close() else: asyncio.run(main())
- 投稿日:2019-12-01T22:27:25+09:00
[Python]dataclassesを使ってValueObjectを完全コンストラクタで生成する
はじめに
最近、無謀にもDDDの勉強を始めたのですが、Pythonの例が少ない・・・!
ということで、
・DDDに関する自分の考えを整理する
・Pythonによる記述方法の一例を提案する
という目的で記事を書いてみることにしました。
とりあえず今回は一番とっつきやすそうなValueObjectについて書いています。ValueObjectと完全コンストラクタとは・・・
ちゃんとした説明は他の方々のとても分かりやすい記事がたくさんあるのでそちらに譲るとして、簡単に書くと、
ValueObjectは「値をintなどのプリミティブ型ではなく、期待している振る舞い、在り方をクラスを使って表現したもの」、
完全コンストラクタは「期待している振る舞い」や、逆に「期待しない振る舞いをさせない」を実現するための手法と言えます。
(私はこう理解しています・・・合ってる・・・?)例えば、「金額」を表現するのであれば「負の値にはならない」など、表現する対象物に対して
本来あるべき振る舞いなどをクラスで定義したものがValueObjectです。
上記の「負の値にはならない」というのをコンストラクタの中で記述して、
「存在してはならない値を存在させない」ということを実現するのが完全コンストラクタです。dataclassesでValueObjectを表現してみる
前節で金額の話をしたので、金額を例に簡単に書いてみます。
import dataclasses @dataclasses.dataclass class Money: # 詳細は省きますが、ここに挙げた変数が通常のクラスの __init__ に記述するインスタンス変数となります amount: int # __post_init__ は __init__ の後に実行される処理です。 # 完全コンストラクタの表現をここに記述します。 def __post__init__(self): if self.amount < 0: raise ValueError()これで負の値を持ったMoneyオブジェクトは存在できず、
正しい値を持っていることが保証されたMoneyオブジェクトだけが存在することになります。
(他にも課すべき制限はあるかと思いますが、今回はこの程度にして話を先に進めます)イミュータブルにする
dataclassesを使うと、クラスをイミュータブルにすることもできます。
イミュータブルにすることで再代入が不可となり、コードの安全性が向上します。
(ValueObjectは基本的にイミュータブルにするべきもののようです)
Pythonはインスタンス変数への再代入を防ぐ方法が乏しいため、重要な機能です。import dataclasses # frozen=Trueとするとイミュータブルになる @dataclasses.dataclass(frozen=True) class Money: amount: int def __post__init__(self): if amount < 0: raise ValueError()金額の変化をどう表現するか
イミュータブルにしたことで一度インスタンス化すると、その金額の増減が発生しても値を変更できなくなりました。
では、金額の増減はどう表現するか、増減後の金額の値を持った新しいインスタンスを生成します。
メソッドは通常のクラスと同様に記述できます。import dataclasses @dataclasses.dataclass(frozen=True) class Money: amount: int def __post__init__(self): if amount < 0: raise ValueError() def lost(self, loss): return Money(self.amount - loss.amount) # 例えばこんな感じに書きます money1 = Money(1000) money2 = Money(100) left_money = money1.lost(money2)dataclassesを使うべきか
従来の記述方法でも同様のことは可能なので必須ではありません。
ただ、
・イミュータブルにできる
・コンストラクタの記述量が減らせる
・インスタンス変数の記述と完全コンストラクタにするためのロジックの記述を分離でき、見やすくなる
という点でdataclassesを使ったほうがいいかなぁという印象です。
dataclassesは他にも様々な機能があるのでValueObjectに限らず使ってみたいですね。最後に
このように書けばPythonでもValueObjectを表現できる、ということを今回紹介させていただきました。
まだ勉強し始めたばかりのためValueObjectそのものについての説明は薄いですが、理解が深まれば
補足の記事を書いたり、エンティティなどについても記事にできればと思っています。参考
dataclassesの用法はこちらを参考にしています。
https://docs.python.org/ja/3.7/library/dataclasses.html
- 投稿日:2019-12-01T22:21:52+09:00
OpenCVやPILで画像を表示させる(だけ)の話
はじめに
OpenCVやPILの話。
Qiitaに限らずウェブ上にいくらでもある情報ではあるが、記事が細切れになっているものが多く比較するには適していないのでその点に注意してまとめてみた。
その過程で先人が触れていない事項にたどり着いた(ように思える)ので、お読みいただけると幸いです。OpenCV
CVはComputer Visionの略で、単に画像を加工するだけでなくさまざまな機能を持つ。
まあ、今回は画像加工どころか画像を表示するだけの話なのだが。画像を読み込む imread()
cv2.imread(filename, flags)という使い方をする。
filenameはファイル名。これが適切でない場合でもエラーにならずNoneを返す。
flagsについては後述する。画像読み込みimport cv2 filename = "hoge.png" imgCV = cv2.imread(filename) # flagsは省略(デフォ値=1)画像を表示する imshow()
cv2.imshow(winname, mat) という使い方をする。
winnameはウィンドウの名前。ヌルストリングでもいいが指定は必須。
matはマトリックス、すなわち行列。要するに画像データ。
デフォではサイズ変更ができないが、imshowする前にnamedWindowで「これこれこういう名前でサイズ変更可能なウィンドウを作るよ」としてやればサイズ変更できるようになる。
imreadを失敗してNoneが返ってきた場合、ここでエラーになる。サイズ変更不可のウィンドウで画像表示cv2.namedWindow("image", cv2.WINDOW_AUTOSIZE) # この一文、なくてもよい cv2.imshow("image", imgCV)サイズ変更可のウィンドウで画像表示cv2.namedWindow("image", cv2.WINDOW_NORMAL) # cv2.WINDOW_NORMALの値は0なので0を指定してもよい cv2.imshow("image", imgCV)OpenCVの画像データについて
画像データはnumpy.ndarrayの型で構成されている。シェイプで次元を調べることができるし内容を確認するのも容易だ。
カラーはBGRの順で格納されていることに注意。画像のシェイプ
flagsを指定して画像を読み込んだとき、画像データがどのようなカタチになっているか確認してみよう。
flags cv2.IMREAD_COLOR cv2.IMREAD_GRAYSCALE cv2.IMREAD_UNCHANGED 値 1
(デフォルト値)0 -1 処理 カラー画像として読み込む グレースケールで読み込む そのままの仕様で読み込む 例1
RGBA画像
実際の背景は市松模様ではなく透明
shape=(200, 182, 3)
shape=(200, 182)
shape=(200, 182, 4)例2
グレースケール画像
shape=(192, 144, 3)
shape=(192, 144)
shape=(192, 144)カラーチャンネル数は、cv2.IMREAD_COLORでは透明度があってもグレースケール画像であっても一律で3チャンネルの配列になる。cv2.IMREAD_GRAYSCALEの場合はチャンネル数が1になるのではなく、チャンネル数の指定のない(h, w)という二次元配列になる。
cv2.IMREAD_UNCHANGEDは、OpenCV-Pythonチュートリアル「画像を扱う」には「アルファチャンネルも含めた画像として読み込む」とあるが、一律4チャンネルになるわけではなく、元の画像から変更なく読み込むというのが正しい。RGBA画像なら4チャンネル、RGB画像なら3チャンネル。グレースケール画像なら1チャンネルなので(h, w, 1)ではなく(h, w)を返す。
ややこしい? いや、最初からそう言ってるでしょ、cv2.IMREAD_UNCHANGEDって。サイズを取得する
元画像のタイプによって配列のカタチが異なるOpenCVの画像データ。高さや幅を取得するにはif文を使って場合分けしなくてはいけない…ということはない。
(高さ, 幅)で得られるグレースケール画像のシェイプも、(高さ, 幅, チャンネル数)となるカラー画像も、0番目に高さがあって1番目に幅があることは同じ。だから0や1で決め打ちしてやればいいのだ。# どちらでも可 def getSize1(imgCV): h = imgCV.shape[0] w = imgCV.shape[1] return h, w def getSize2(imgCV): h, w = imgCV.shape[:2] return h, wGoogle Colabの場合
Google Colabではcv2.imshow()は使えないようになっている。Jupyterのセッションがクラッシュしてしまうらしい。
代わりにcv2_imshow()というGoogle Colab独自のメソッドを使うよう代替案を提示してくる。
cv2_imshow()にウィンドウ名は不要で画像データのみを指定する。これによりColabのセル内に画像が表示される。Google Colab# 1セル1文でも全部まとめても可 import cv2 from google.colab.patches import cv2_imshow filename = "hoge.png" imgCV = cv2.imread(filename) cv2_imshow(imgCV)Jupyter Notebookの場合
Jupyter Notebookではcv2.imshow()は禁止されているわけではないが、クラッシュすることがあるのは変わらない。
実は、Jupyter Notebookでは、正しい処理をすることで正しく表示させることができる。
先程のサイトにあるようにcv2.imshow()で表示した後、キー入力を待ってウィンドウを破棄するようにすればいいのだ。
この場合でも右上バッテンで画像ウィンドウを閉じようとしてはいけない。やはりクラッシュしてしまう。
正しく表示できるといってもミスったら死だなんて嫌すぎる。そんなのはゲームの世界だけで十分だ。Jupyter Notebookimport cv2 filename = "hoge.png" imgCV = cv2.imread(filename) # 以下を一つのセルで実行する cv2.imshow("image",imgCV) cv2.waitKey(0) cv2.destroyAllWindows()正しい処理とはどういうことか
画像表示するにはcv2.imshow()だぞと書いたが、この段階ですでにつまづいている人もいるかもしれない。
Pythonをインストールしたときに一緒に付いてくる開発環境IDLE上で実行するとうまくいく。だがpyファイルをダブルクリックすると期待通りの動きにならない。VS Codeでもダメ。
これは、IDLEではプログラムが終了してもシェルが生き続けているのに対し、python.exeを実行する場合はそれが終了した瞬間に画像のウィンドウも閉じてしまうから。だと思われる。
cv2で作成したウィンドウはcv2で破棄する。これがこの世界のジャスティスなのだ。PIL(Pillow)
PIL(Python Image Library)という画像処理ライブラリがあって、その後継がPillow。OpenCVとの得手不得手の差はまた今度。
Pillowをインストールしても、実際に使う際にインポートするのはPIL。画像を読み込む Image.open()
Image.open(filename)という使い方をする。
filenameが適切でない場合はエラーになる。
厳密にはmodeという引数もありデフォ値が"r"なのだが、これが何を意味しそれ以外にどんな値が使えるのかよくわからない。画像を表示する show()
読み込んだ画像データをshow()することで画像が表示される。
画像はOSごとに異なる画像ビューアが起動して表示される。ちょいと不便だな。
引数にはtitleやcommandがあるがいずれも省略可能。言うまでもないことだが、引数がなくてもカッコは必須。ソースfrom PIL import Image filename = "hoge.png" imgPIL = Image.open(filename) # 画像読み込み imgPIL.show() # 画像表示PILの画像データについて
画像データは、たとえばpng画像ならばPIL.PngImagePlugin.PngImageFileという形式になっており、中身を確認するのは容易ではない。
その代わり、これは画像データであると自覚しているのでさまざまな属性を持っている。サイズを取得する
print (imgPIL.mode) # RGBA # ほかに RGB L(グレースケール)などがある。 # Image.open()のmodeとの関係は不明。 print (imgPIL.size) # (182, 200) # タプルで、幅,高さ の順 print (imgPIL.width) # 182 print (imgPIL.height) # 200matplotlibのグラフとして表示
画像をmatplotlibのグラフとして表示することも多い。
matplotlib.pyplotの詳しい使い方はここでは説明しない。python上で実行すると、インタラクティブなmatplotlibのグラフがあらわれる。拡大したり表示エリアを変えたりできる。
Google ColabやJupyter Notebook上では単なる画像としてグラフが表示される。
Jupyter Notebookでは%matplotlib inlineというおまじないを唱えるといいらしい。
え? 普通に画像を表示する場合との違いがわからない?
では、こんな画像ならばどうする?
← ここにいる
これは6×8の画像。matplotlibのグラフはこんな小さい画像もいい感じに拡大してくれるのがありがたい。
PIL画像の場合
PIL画像はそのままではグラフ化できないのでnumpy.asarray()でnumpy.ndarrayにしてやる必要がある。
ソースimport numpy as np from PIL import Image from matplotlib import pyplot as plt %matplotlib inline # Jupyter Notebookでインライン表示する filename = "hoge.png" imgPIL = Image.open(filename) arrPIL = np.asarray(imgPIL) plt.imshow(arrPIL) plt.show()OpenCVの場合
ここのみ諸事情によりサンプル画像がいらすとやでなくスキマナースになっています。
これが元画像。
OpenCの画像データはもとよりnumpy.ndarray。ならばそのままplt.imshowすればいい?
とやってみると。
はいダメー。OpenCVの画像はBGRだって言ったでしょ。matplotlib.pyplotは普通にRGBなのでOpenCVの画像をmatplotlibでグラフ表示する際は色を変換してやる必要があるのだ。
カラーをコンバートするにはcv2.cvtColorを使う。cv2.cvtColor(src, code)という使い方をする。
srcはソース。元の画像データ。
codeは色変換の組み込み定数。BGRをRGBにするとか、その逆とか、RGBをグレーにするとか、RGBをRGBAにするとか、いろいろある。BGRをRGBにコンバートするのはcv2.COLOR_BGR2RGB。
このひと手間によってOpenCVの画像もmatplotlibのグラフとして表示できる。
BGR→RGBは、(高さ, 幅, BGR値)というシェイプの配列の2番目の並びをRGBと逆順にすることにほかならない。
前回学んだスライスを活用することもできる。ソースimport numpy as np import cv2 from matplotlib import pyplot as plt filename = "nurse.jpg" imgCV = cv2.imread(filename) # cv2.cvtColorを使う方法 imgCV_RGB = cv2.cvtColor(imgCV,cv2.COLOR_BGR2RGB) # スライスを使う方法 # imgCV_RGB = imgCV[:, :, ::-1] plt.imshow(imgCV_RGB) plt.show()ここで透過を持つpng画像を使わなかったのは、今後詳しく調べていくため。
で、できなかったからじゃないんだからね、勘違いしないでよね。
証拠として、グラフ画像として透過が正しく表現できた例を示す。
次回予告
画像と画像を合成する、その際に手前の画像の透明部分は背後の画像が透けて見えるようにする。そんな80年代のゲーマーなら「ああ、スプライトね」と言いたくなるようなマスク処理を手作業でおこなっていきます。
最後に、もう一度透過画像をさまざまなflagsで表示する表をもう一度見てみよう。
がんばって作ったので予習として。
元画像 cv2.IMREAD_COLOR cv2.IMREAD_GRAYSCALE cv2.IMREAD_UNCHANGED











- 投稿日:2019-12-01T21:29:39+09:00
時系列分析 その1
目的
- 時系列データときたらとりあえずRNN!、LSTM!!っていう感じだったのですが、ARIMAとかSARIMAなるものを知り自分の引き出しに加えたいということで勉強。
- ライブラリ使ってそれにぶち込むのは簡単だろうけど、一応理論も知っておきたいということで、本を購入した。
- 沖本竜義先生の『経済・ファイナンスデータの計量時系列分析』という本。2010年の本です。
データ
読みながら手も動かしていこうということでとりあえずTOPIXのヒストリカルデータを使うことにした。
https://quotes.wsj.com/index/JP/TOKYO%20EXCHANGE%20(TOPIX)/180460/historical-prices
WSJのHPからダウンロードできた。とりあえず欠損値はない模様。
期間は2008年12月30日から2019年11月29日まで。
配当落ち調整なしの4本値のヒストリカルデータ。
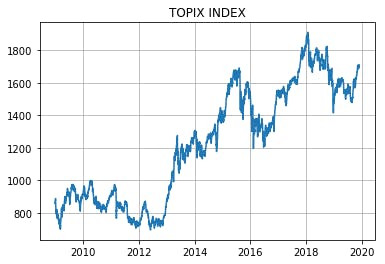
終値をプロットすると下図のような感じ。
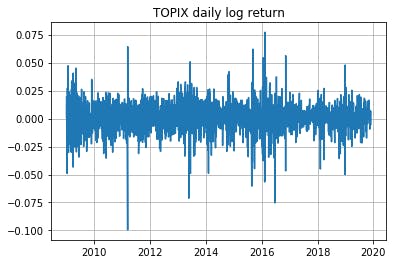
ちょうどリーマンショック直後の1,000pt割れの時期からアベノミクスを経てというような期間です。
日次リターンは以下の通り。日次なので大した差は出ないだろうが対数リターン($\Delta \log{y_t} = \log{(y_t)} - \log{(y_{t-1})}$)を使用した。
最大の下げを記録したのは2011年3月15日で、$\Delta \log{y_t} = -0.0995$となっている。前日引け前15分くらいのところで東北地方太平洋沖地震が起きたのが原因。各種統計量
平均
$\bar{y} = \frac{1}{T}\displaystyle{\sum_{t=1}^{T}y_t}$
tpx_return = np.log(tpx['close'].values)[1:] - np.log(tpx['close'].values)[:-1] tpx_return.mean()0.00025531962222667643自己共分散(auto-covariance)
$\hat{\gamma}_k = \frac{1}{T} \displaystyle{\sum_{t=k+1}^{T}}(y_t-\bar{y})(y_{t-k}-\bar{y}),\quad k = 0,1,2,...$import statsmodels.api as sm sm.tsa.stattools.acovf(tpx_return, fft=True, nlag=5)array([ 1.57113176e-04, 1.16917913e-06, 3.48846296e-06, -4.67502133e-06, -5.31500282e-06, -2.82855375e-06])statsmodelsのライブラリに慣れていないので一応手でも確認。
# k=0 ((tpx_return-tpx_return.mean())**2).sum() / len(tpx_return)0.00015711317609153836# k=4 ((tpx_return-tpx_return.mean())[4:]*(tpx_return-tpx_return.mean())[:-4]).sum() / len(tpx_return)-5.315002816332674e-06自己相関係数(auto-correlation)
$\hat{\rho}_k = \frac{\hat{\gamma}_k}{\hat{\gamma}_0},\quad k=1,2,3,...$sm.tsa.stattools.acf(tpx_return)[:5]array([ 1. , 0.00744164, 0.0222035 , -0.02975576, -0.03382913])先ほどの$k=0$と$k=4$の結果を使って確認すると、
-5.315002816332674e-06 / 0.00015711317609153836-0.03382913482212345ということでライブラリはイメージした通りの計算をしてくれている様子。
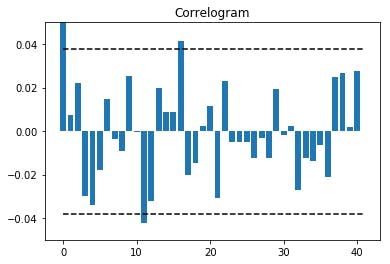
コレログラムも描いてみる。コレログラムとは自己相関係数をグラフにしたもののこと。
autocorr = sm.tsa.stattools.acf(tpx_return) ci = 1.96 / np.sqrt(len(tpx_return)) plt.bar(np.arange(len(autocorr)), autocorr) plt.hlines([ci,-ci],0,len(autocorr), linestyle='dashed') plt.title('Correlogram') plt.ylim(-0.05,0.05) plt.show()
CI(confidence interval)とは信頼区間のことで、データが互いに独立で同一の分布に従う時、$\hat{\rho}_k$が漸近的に平均$0$、分散$\frac{1}{T}$の正規分布に従うという性質を利用して両側95%を計算している。
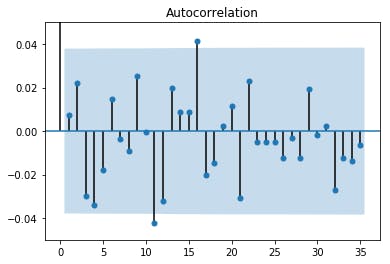
ライブラリを使うとこんな感じ。オシャレ。
sm.graphics.tsa.plot_acf(tpx_return) plt.ylim(-0.05,0.05) plt.show()
得られた数字について少し考えてみる。
$\hat{\rho}_{k=11}=-0.0421, \quad \hat{\rho}_{k=16}=0.0415$
の2回 $CI=0.0379$ をわずかながら上回っている。
特に $\hat{\rho}_{k=12}=-0.0323$ もマイナスの値となっており、1回相場が上昇・下落を始めても一旦そのモメンタムが2週間程度で終わることを示唆していると捉えることができるかもしれない。かばん検定(portmanteau test)
複数の自己相関係数がすべて0であるという帰無仮説を検定する手法。
$H_0 : \rho_1 = \rho_2 =\quad ... \quad= \rho_m = 0$
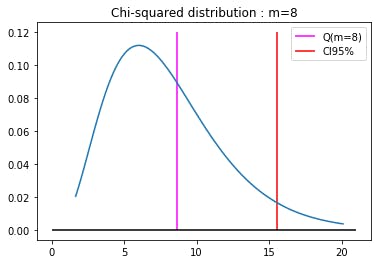
ここでは本で紹介されているLjung and Box(1978)の統計量を用いて検定を行ってみる。下の$Q(m)$とカイ2乗分布の95%点を比較するというアプローチである。
$Q(m) = T(T+2)\displaystyle{\sum_{k=1}^{m}}\frac{\hat{\rho}^2_k}{T-k} \sim \chi^2(m)$
また、P値という統計量も定義されており、カイ2乗分布に従う確率変数が$Q(m)$より大きな値をとる確率を示したものである。すなわち、有意水準5%とすれば、P値が0.05より小さいとき$H_0$は棄却される。
$m$の値については、$m \approx \log{(T)}$が目安とされるようだが、複数の$m$に対して検定を行い総合的に判断するのが一般的なようである。まずはstatsmodelsのライブラリを使うパターンから。
$m \approx \log{(T)} = 7.89$ ということで、とりあえずラグは16までの範囲で考えてみる。lvalue, pvalue = sm.stats.diagnostic.acorr_ljungbox(tpx_return)これだけで完了。非常に簡単。
$m$がどの値でもP値は0.05以下にはならず、TOPIXの日次変化率は自己相関を持つとは言えないという結果となった。まあ相場はそんなに単純なものではないってことですね。
最後に自分の理解を深めるためライブラリなしでも試してみる。
from scipy.stats import chi2 def Q_func(data, max_m): T = len(data) auto_corr = sm.tsa.stattools.acf(data)[1:] lvalue = T*(T+2)*((auto_corr**2/(T-np.arange(1,len(auto_corr)+1)))[:max_m]).cumsum() pvalue = 1 - chi2.cdf(lvalue, np.arange(1,len(lvalue)+1)) return lvalue, pvalue同じ結果が得られていることを確認。
l_Q_func, p_Q_func = Q_func(tpx_return,max_m=16) l_sm, p_sm = sm.stats.diagnostic.acorr_ljungbox(tpx_return, lags=16) ((l_Q_func-l_sm)**2).mean(), ((p_Q_func-p_sm)**2).mean()(0.0, 7.824090399073146e-34)$m=8$のケースを細かく見てみると、
T = len(tpx_return) auto_corr = sm.tsa.stattools.acf(tpx_return)[1:] lvalue = T*(T+2)*((auto_corr**2/(T-np.arange(1,len(auto_corr)+1)))[:8]).sum() print(lvalue)8.6047327785778531-chi2.cdf(lvalue,8)0.37672860496603844
ということで、帰無仮説を棄却することはかなり難しいことが分かった。
- 投稿日:2019-12-01T20:50:49+09:00
AWS lambda+scrapyで定期的にサーバレスなスクレイピング その1
初投稿!
本当はサーバレスまで一つの記事に入れたかったけど間に合わなかった・・・。
ということで今回はスクレイピング編になります。やりたいこと
定期的に情報が更新されるwebページを自動でスクレイピングしたい!
目標
Yahoo!天気(東京)のデータを6時間おきに取得。
方法
Python + Scrapy + AWSlambda + CroudWatchEventsあたりでいけそう・・・?
とりあえずやってみる
まずはスクレイピングから
以下手順でクローリング、スクレイピング部分を作成。
- Scrapyインストール
- Scrapy projectを作成
- spiderの作成
- 実行
1. Scrapyインストール
$ python3 -V Python 3.7.4 $ pip3 install scrapy ... Successfully installed $ scrapy version Scrapy 1.8.02. Scrapy projectを作成
コマンドを入力した階層にプロジェクトのフォルダが作成されます。
$ scrapy startproject yahoo_weather_crawl New Scrapy project 'yahoo_weather_crawl' $ ls yahoo_weather_crawl今回はyahoo天気のこの部分を取得してみます。
発表日時、日付、天気、気温、降水確率を拾ってみます。Scrapyはコマンドラインシェルがあり、コマンドを入力して取得対象がちゃんと取れているか確認することが可能なので、一旦それで確認しつつ進めてみます。
取得対象をxpathで指定します。
xpathはgoogle chromeのデベロッパーツール(F12押すと出るやつ)から簡単に取得することができます。
今回取得した発表日時のxpathは以下
//*[@id="week"]/pこれをresponceから抜いてみます。
# scrapy shellの起動 $ scrapy shell https://weather.yahoo.co.jp/weather/jp/13/4410.html >>> announcement_date = response.xpath('//*[@id="week"]/p/text()').extract_first() >>> announcement_date '2019年11月29日 18時00分発表'text()を指定すると、本文のみを取得することが可能です。
詳しくは、参考文献参照。とりあえず日時はとれたので、他も同様に取得していきましょう。
他の情報はtableタグの中にあるので、一度tableの中身を全て取得します。
>>> table = response.xpath('//*[@id="yjw_week"]/table')これで、
id="yjw_week"のテーブルタグ内の要素が取得できました。
ここから各要素を取得していきます。# 日付 >>> date = table.xpath('//tr[1]/td[2]/small/text()').extract_first() >>> date '12月1日' # 天気 >>> weather = table.xpath('//tr[2]/td[2]/small/text()').extract_first() >>> weather '曇時々晴' # 気温 >>> temperature = table.xpath('//tr[3]/td[2]/small/font/text()').extract() >>> temperature ['14', '5'] # 降水確率 >>> rainy_percent = table.xpath('//tr[4]/td[2]/small/text()').extract_first() >>> rainy_percent '20'これでそれぞれの取得方法がわかったので、
Spider(処理のメイン部分)を作成していきます。3. spiderの作成
先ほど作成したプロジェクトフォルダの構成は以下のようになっています。
. ├── scrapy.cfg └── yahoo_weather_crawl ├── __init__.py ├── __pycache__ ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.py └── __pycache__まずは取得するitemsを定義しておきます。
items.pyimport scrapy class YahooWeatherCrawlItem(scrapy.Item): announcement_date = scrapy.Field() # 発表日時 date = scrapy.Field() # 日付 weather = scrapy.Field() # 天気 temperature = scrapy.Field() # 気温 rainy_percent = scrapy.Field() # 降水確率次に、spiderの本体をspidersフォルダ内に作成します。
spider/weather_spider.py# -*- coding: utf-8 -*- import scrapy from yahoo_weather_crawl.items import YahooWeatherCrawlItem # spider class YahooWeatherSpider(scrapy.Spider): name = "yahoo_weather_crawler" allowed_domains = ['weather.yahoo.co.jp'] start_urls = ["https://weather.yahoo.co.jp/weather/jp/13/4410.html"] # レスポンスに対する抽出処理 def parse(self, response): # 発表日時 yield YahooWeatherCrawlItem(announcement_date = response.xpath('//*[@id="week"]/p/text()').extract_first()) table = response.xpath('//*[@id="yjw_week"]/table') # 日付ループ for day in range(2, 7): yield YahooWeatherCrawlItem( # データ抽出 date=table.xpath('//tr[1]/td[%d]/small/text()' % day).extract_first(), weather=table.xpath('//tr[2]/td[%d]/small/text()' % day).extract_first(), temperature=table.xpath('//tr[3]/td[%d]/small/font/text()' % day).extract(), rainy_percent=table.xpath('//tr[4]/td[%d]/small/text()' % day).extract_first(), )4. いざ実行!
scrapy crawl yahoo_weather_crawler 2019-12-01 20:17:21 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weather.yahoo.co.jp/weather/jp/13/4410.html> {'announcement_date': '2019年12月1日 17時00分発表'} 2019-12-01 20:17:21 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weather.yahoo.co.jp/weather/jp/13/4410.html> {'date': '12月3日', 'rainy_percent': '10', 'temperature': ['17', '10'], 'weather': '晴れ'} 2019-12-01 20:17:21 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weather.yahoo.co.jp/weather/jp/13/4410.html> {'date': '12月4日', 'rainy_percent': '0', 'temperature': ['15', '4'], 'weather': '晴れ'} 2019-12-01 20:17:21 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weather.yahoo.co.jp/weather/jp/13/4410.html> {'date': '12月5日', 'rainy_percent': '0', 'temperature': ['14', '4'], 'weather': '晴時々曇'} 2019-12-01 20:17:21 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weather.yahoo.co.jp/weather/jp/13/4410.html> {'date': '12月6日', 'rainy_percent': '10', 'temperature': ['11', '4'], 'weather': '曇り'} 2019-12-01 20:17:21 [scrapy.core.scraper] DEBUG: Scraped from <200 https://weather.yahoo.co.jp/weather/jp/13/4410.html> {'date': '12月7日', 'rainy_percent': '30', 'temperature': ['9', '3'], 'weather': '曇り'}上手く取れてそうですね!
せっかくなので、ファイルに出力してみましょう。ファイルに出力する際はデフォルトだと日本語が文字化けしてしまうため、
settings.pyにエンコードの設定を加えておきます。settings.pyFEED_EXPORT_ENCODING='utf-8'$ scrapy crawl yahoo_weather_crawler -o weather_data.json ...weather_data.json[ {"announcement_date": "2019年12月1日 17時00分発表"}, {"date": "12月3日", "weather": "晴れ", "temperature": ["17", "10"], "rainy_percent": "10"}, {"date": "12月4日", "weather": "晴れ", "temperature": ["15", "4"], "rainy_percent": "0"}, {"date": "12月5日", "weather": "晴時々曇", "temperature": ["14", "4"], "rainy_percent": "0"}, {"date": "12月6日", "weather": "曇り", "temperature": ["11", "4"], "rainy_percent": "10"}, {"date": "12月7日", "weather": "曇り", "temperature": ["9", "3"], "rainy_percent": "30"} ]出力できました!
次回はこの処理とAWSを組み合わせてサーバレスで動かしてみようと思います。
参考文献
Scrapy 1.8 documentation
https://doc.scrapy.org/en/latest/index.html
10分で理解する Scrapy
https://qiita.com/Chanmoro/items/f4df85eb73b18d902739
ScrapyによるWebスクレイピング
https://qiita.com/Amtkxa/items/4c1172c932264ae941b4

- 投稿日:2019-12-01T20:28:57+09:00
Pythonでお手軽にロジスティック回帰分析(理論なし)
とりあえず、pythonでロジスティック回帰を行いたい人向けです。パラメータはいじりません。
使用するデータはこちら(https://gist.github.com/tijptjik/9408623)
*一番下に、全てをまとめたコードがあります。ロジスティック回帰用のモジュールをインポート
sklearn.linear_modelの中から、LogisticRegressionだけをインポートします。
from sklearn.linear_model import LogisticRegressionデータを分割するモジュールをインポート
sklearn.model_selectionの中から、train_test_splitだけをインポートします。
from sklearn.model_selection import train_test_split行列を扱うモジュールをインポート
numpyをnpという名前で使用できる状態でインポートします。
import numpy as npcsvを扱うモジュールをインポート
pandasをpdという名前で使用できる状態でインポートします。
import pandas as pdグラフを描くモジュールをインポート
import matplotlib.pyplot as plt平均平方二乗誤差を求めるモジュールをインポート
from sklearn.metrics import mean_squared_errorcsvを読み込む
df(データフレーム)に、iris.csvを読み込む。
df=pd.read_csv('wine_type.csv')*('iris.csv')はカレントディレクトリからcsvファイルへのアクセスです。
pythonをデスクトップで実行し、Desktop>Documentsにcsvがある場合は、df=pd.read_csv('Desktop/Documents/wine.csv')などとなります。(Linux)
データを訓練用、テスト用に分ける
訓練:学習=6:4にします。
df_train, df_test = train_test_split(df, test_size=0.4)データを表示するとこんな感じです。
df_train= wine_type alcohol malic_acid ash alcalinity_of_ash magnesium total_phenols flavanoids nonflavanoid_phenols proanthocyanins color_intensity hue OD280/OD315_of_diluted_wines proline 106 2 12.25 1.73 2.12 19.0 80 1.65 2.03 0.37 1.63 3.40 1.00 3.17 510 157 3 12.45 3.03 2.64 27.0 97 1.90 0.58 0.63 1.14 7.50 0.67 1.73 880 75 2 11.66 1.88 1.92 16.0 97 1.61 1.57 0.34 1.15 3.80 1.23 2.14 428 142 3 13.52 3.17 2.72 23.5 97 1.55 0.52 0.50 0.55 4.35 0.89 2.06 520 83 2 13.05 3.86 2.32 22.5 85 1.65 1.59 0.61 1.62 4.80 0.84 2.01 515 .. ... ... ... ... ... ... ... ... ... ... ... ... ... ... 117 2 12.42 1.61 2.19 22.5 108 2.00 2.09 0.34 1.61 2.06 1.06 2.96 345 129 2 12.04 4.30 2.38 22.0 80 2.10 1.75 0.42 1.35 2.60 0.79 2.57 580 60 2 12.33 1.10 2.28 16.0 101 2.05 1.09 0.63 0.41 3.27 1.25 1.67 680 25 1 13.05 2.05 3.22 25.0 124 2.63 2.68 0.47 1.92 3.58 1.13 3.20 830 41 1 13.41 3.84 2.12 18.8 90 2.45 2.68 0.27 1.48 4.28 0.91 3.00 1035 [106 rows x 14 columns]説明変数と目的変数を分ける
xには分析に使いたい列を挿入します。(説明変数)
yには分析の結果の列を挿入します。(目的変数)
今回は、'color_intensity'と'alcohol'から'proline'を予測します。x_train = df_train[['color_intensity','alcohol']] x_test = df_test[['color_intensity','alcohol']] y_train = df_train[['proline']] y_test = df_test[['proline']]空モデルを作る
lr = LogisticRegression()回帰の学習を行う
fit(説明変数、目的変数)
で学習を行い、上で作ったモデルlrに学習した結果が保持されます。
lr.fit(x_train, y_train)回帰を行う
predict(回帰分析を行うデータ)
で回帰を行い、y_predに代入します。
y_pred = lr.predict(x_test)グラフに表示してみる
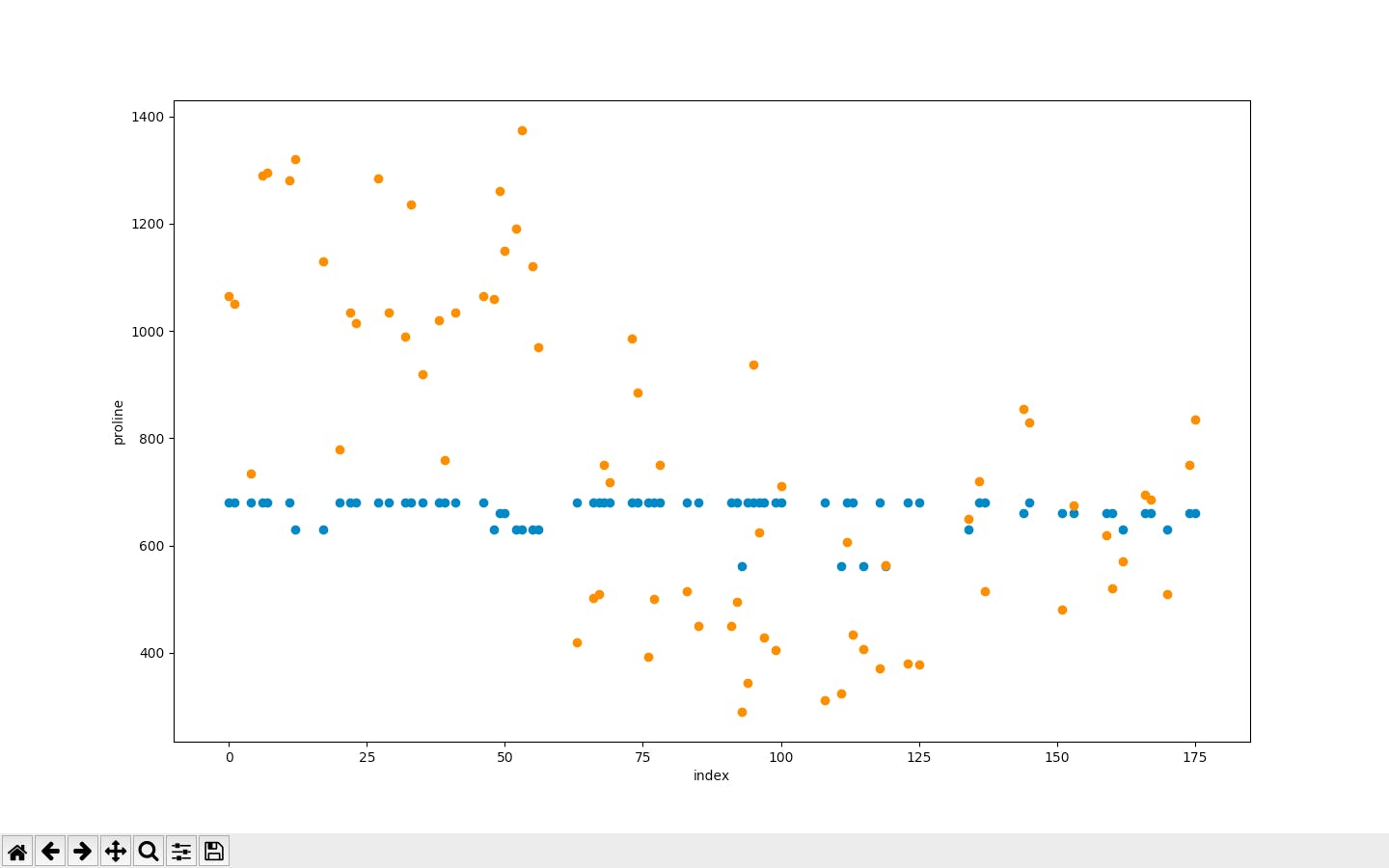
plt.scatter(x軸、y軸)で散布図を作ることができます。
今回は、データのインデックスと予測値、データのインデックスと実際の値をグラフに表示し比べてみます。plt.scatter(y_test.index, y_pred) plt.scatter(y_test.index, y_test) plt.xlabel("index") plt.ylabel("proline") plt.show()青色が実際の値、オレンジが予測値というわけです。
全然予測できてない笑
最後に、平均平方二乗誤差を求めます。
mean_squared_error(y_test,y_pred) #111299.75ですって笑パラメータをいじるともっと精度が上がると思います。
以下コピペ用コード
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error df=pd.read_csv('wine.csv') df_train, df_test = train_test_split(df, test_size=0.4) x_train = df_train[['color_intensity','alcohol']] x_test = df_test[['color_intensity','alcohol']] y_train = df_train[['proline']] y_test = df_test[['proline']] print(y_train) lr = LogisticRegression() lr.fit(x_train, y_train) y_pred = lr.predict(x_test) plt.scatter(y_test.index, y_pred) plt.scatter(y_test.index, y_test) plt.xlabel("index") plt.ylabel("proline") plt.show() print(mean_squared_error(y_test, y_pred))
- 投稿日:2019-12-01T20:28:57+09:00
Pythonでお手軽にLASSO回帰分析(理論なし)
とりあえず、pythonでLASSO回帰分析を行いたい人向けです。パラメータはいじりません。
使用するデータはこちら(https://gist.github.com/tijptjik/9408623)
*一番下に、全てをまとめたコードがあります。LASSO回帰用のモジュールをインポート
sklearn.linear_modelの中から、Lassoだけをインポートします。
from sklearn.linear_model import Lassoデータを分割するモジュールをインポート
sklearn.model_selectionの中から、train_test_splitだけをインポートします。
from sklearn.model_selection import train_test_split行列を扱うモジュールをインポート
numpyをnpという名前で使用できる状態でインポートします。
import numpy as npcsvを扱うモジュールをインポート
pandasをpdという名前で使用できる状態でインポートします。
import pandas as pdグラフを描くモジュールをインポート
import matplotlib.pyplot as plt平均平方二乗誤差を求めるモジュールをインポート
from sklearn.metrics import mean_squared_errorcsvを読み込む
df(データフレーム)に、iris.csvを読み込む。
df=pd.read_csv('wine_type.csv')*('iris.csv')はカレントディレクトリからcsvファイルへのアクセスです。
pythonをデスクトップで実行し、Desktop>Documentsにcsvがある場合は、df=pd.read_csv('Desktop/Documents/wine.csv')などとなります。(Linux)
データを訓練用、テスト用に分ける
訓練:学習=6:4にします。
df_train, df_test = train_test_split(df, test_size=0.4)データを表示するとこんな感じです。
df_train= wine_type alcohol malic_acid ash alcalinity_of_ash magnesium total_phenols flavanoids nonflavanoid_phenols proanthocyanins color_intensity hue OD280/OD315_of_diluted_wines proline 106 2 12.25 1.73 2.12 19.0 80 1.65 2.03 0.37 1.63 3.40 1.00 3.17 510 157 3 12.45 3.03 2.64 27.0 97 1.90 0.58 0.63 1.14 7.50 0.67 1.73 880 75 2 11.66 1.88 1.92 16.0 97 1.61 1.57 0.34 1.15 3.80 1.23 2.14 428 142 3 13.52 3.17 2.72 23.5 97 1.55 0.52 0.50 0.55 4.35 0.89 2.06 520 83 2 13.05 3.86 2.32 22.5 85 1.65 1.59 0.61 1.62 4.80 0.84 2.01 515 .. ... ... ... ... ... ... ... ... ... ... ... ... ... ... 117 2 12.42 1.61 2.19 22.5 108 2.00 2.09 0.34 1.61 2.06 1.06 2.96 345 129 2 12.04 4.30 2.38 22.0 80 2.10 1.75 0.42 1.35 2.60 0.79 2.57 580 60 2 12.33 1.10 2.28 16.0 101 2.05 1.09 0.63 0.41 3.27 1.25 1.67 680 25 1 13.05 2.05 3.22 25.0 124 2.63 2.68 0.47 1.92 3.58 1.13 3.20 830 41 1 13.41 3.84 2.12 18.8 90 2.45 2.68 0.27 1.48 4.28 0.91 3.00 1035 [106 rows x 14 columns]説明変数と目的変数を分ける
xには分析に使いたい列を挿入します。(説明変数)
yには分析の結果の列を挿入します。(目的変数)
今回は、'color_intensity'から'proline'を予測します。x_train = df_train[['color_intensity']] x_test = df_test[['color_intensity']] y_train = df_train['proline'] y_test = df_test['proline']空モデルを作る
lss = Lasso()回帰の学習を行う
fit(説明変数、目的変数)
で学習を行い、上で作ったモデルlrに学習した結果が保持されます。
lss.fit(x_train, y_train)回帰を行う
predict(回帰分析を行うデータ)
で回帰を行い、y_predに代入します。
y_pred = lss.predict(x_test)グラフに表示してみる
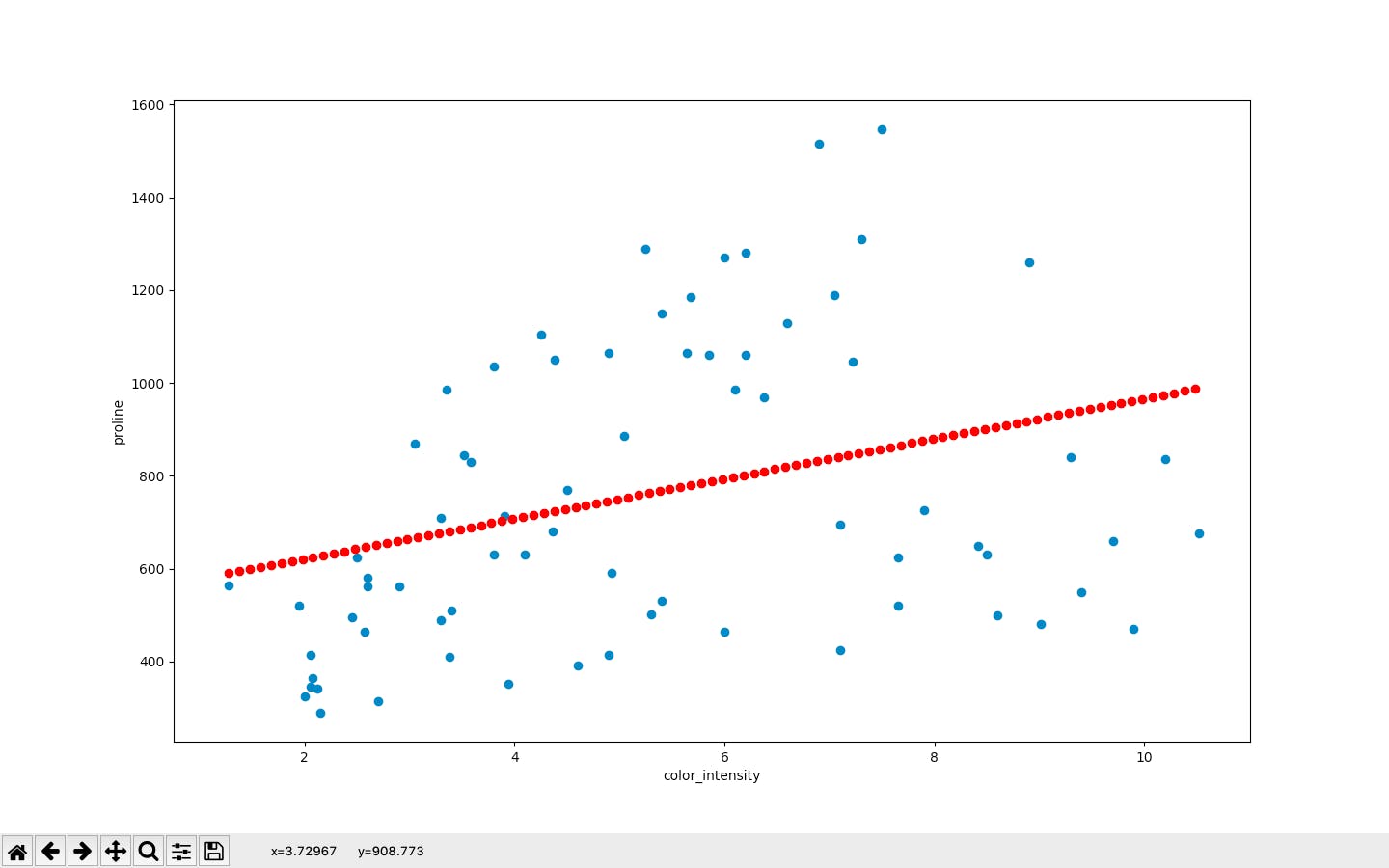
plt.scatter(x軸、y軸)で散布図を作ることができます。
正答を表示します。(青い点)plt.scatter(x_test, y_test)x_test["color_intensity"]の最小値から、最大値まで0.1刻みの配列を作り、行列にします。
そしてlss.predictにかけ、予測値を表示します。(赤い点)x_for_plot = np.arange(np.min(x_test["color_intensity"]) ,np.max(x_test["color_intensity"]),0.1).reshape(-1,1) plt.scatter(x_for_plot,lss.predict(x_for_plot),color="red")ラベルの設定
plt.xlabel("color_intensity") plt.ylabel("proline")表示
plt.show()青色が実際の値、赤が予測値というわけです。
最後に、平均平方二乗誤差を求めます。
print(mean_squared_error(y_test,y_pred)) #90027.41397601982ですって笑パラメータをいじるともっと精度が上がると思います。
以下コピペ用コード
from sklearn.linear_model import Lasso from sklearn.model_selection import train_test_split import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error df=pd.read_csv('wine.csv') df_train, df_test = train_test_split(df, test_size=0.4) x_train = df_train[['color_intensity']] x_test = df_test[['color_intensity']] y_train = df_train['proline'] y_test = df_test ['proline'] print(y_train) lss = Lasso() lss.fit(x_train, y_train) y_pred = lss.predict(x_test) plt.scatter(x_test, y_test) x_for_plot = np.arange(np.min(x_test["color_intensity"]),np.max(x_test["color_intensity"]),0.1).reshape(-1,1) plt.scatter(x_for_plot,lss.predict(x_for_plot),color="red") plt.xlabel("color_intensity") plt.ylabel("proline") plt.show() print(mean_squared_error(y_test,y_pred))
- 投稿日:2019-12-01T20:25:47+09:00
Pythonで勉強会の一覧を取得したら作ってみたいものが出てきた話
はじめに
この記事は「富士通ソーシアルサイエンスラボラトリ」アドベントカレンダー1日目の記事です。今年は全然カレンダーが埋まっていませんが、気楽にいきましょう!
みなさん「スキルを伸ばしたいけど、作りたいものがない」こんな経験はありませんか?
私はQiitaで個人開発の記事を読むたびに、開発したい気持ちが高まりますが、何を作りたいか分からないまま毎日が過ぎていきます。
もし、そんな状態から「どんどん作ってみたいものが出てくる」こんな状態が実現できたらいかがでしょうか?
そんなうまい話があるわけないと思いますよね?
もし「作りたいものがない」という同じような悩みを抱えている方は、この先を読む価値があるかもしれません。
今回はコードの実行手順などは書かず、最近よく使うYWTM(やったこと、わかったこと、次にやること、メリット)で書いてみたいと思います。
やったこと
やったことは何ですか?
- PythonでIT勉強会支援プラットフォーム「connpass」のイベントサーチAPIを呼び出し、キーワード「python」を含むイベントを検索し、Webページとして表示しました。
- 言語
- Python 3.6
- ライブラリ
- requests
- json2html
- flask
API
コード
connpass.pyimport requests from json2html import json2html from flask import Flask app = Flask(__name__) @app.route('/') def connpass(): return json2html.convert(requests.get('https://connpass.com/api/v1/event/?keyword=python').json()) if __name__ == "__main__": app.run()わかったこと
このやったことから、わかったことは何ですか?
- 身近なWebサービスのAPIを使ってみると、普段の生活を少し便利にできるものを手軽に実現することができ、作ってみたいものがどんどん出てくる。なぜならば、人は便利で手軽なものを使いたいと思うからです。
次にやること
このわかったことを活かして、次にやることは何ですか?
- Twitter、Facebook、LINE、Github、Qiita、はてなブログ、Slack、Office365、Yammerなど、身近なWebサービスのAPIを調べて使ってみる
メリット
この次にやることのメリットは何ですか?
- 身近なことは取り組みやすく続けられる
- 続けられると小さな成果が積み重なる
- 小さな成果が積み重なると目標を達成できる
- 目標を達成できると達成感が生まれる
- 達成感が生まれるとやる気が出る
- やる気が出ると更に続けたくなる
- 続けた結果としてスキルが伸びる
- スキルが仕事や人生に活かせる
まとめ
次にやることはやろうと思えばできますか?
これらのメリットがあるならば、次にやることに価値はありそうですか?「作りたいものがどんどん出てくる」こんな状態が実現できたらいかがでしょうか?
これから年末年始に向けて、身近なWebサービスのAPIを使って、自分の本当に作りたいものを見つけましょう!
People are good
- 投稿日:2019-12-01T20:07:59+09:00
プログラミング初心者(中学生)作ったアルゴリズムを最適化する
数学パズル
Python勉強中のK君数学パズル
を持ってきて、これやってみる。と言い出した。どんな問題かというと10進数、2進数、8進数のいずれでも回文数(12321のような数)で10以上で最小の値を求めるというもの。
皆さんも突っ込みどころ見つけて見てください。
D = list() E = list() F = list() def checker(num): a = str(num) b = list(reversed(a)) c = len(b) for j in range(c//2): if b[j] != b[-j-1]: return None return num for i in range(10,1000): d = checker(i) if d != None: D.append(d) for i in D: e = checker(str(oct(i))[2:]) if e != None: E.append(int(e,8)) for i in E: f = checker(str(bin(i))[2:]) if f != None: F.append(int(f,2)) print(F)正解も求まっているのでGood Jobです。
1パスではなくて、まず1000までの10進数の回文数を調べて、見つかった回文数に対して、8進数、2進数でどうかチェックしていく方式。
いろいろ思考錯誤して、付けたししながら作ったんだろうなぁ。K君のリファクタリングバージョン
でも1パスでできる事に気づいたK君直してきました。
number = 10 result_list = [] def checker(num): a = list(reversed(str(num))) for j in range(len(a)//2): if a[j] != a[-j-1]: return None return num while True: if checker(number) != None and checker(str(oct(number))[2:]) != None and checker(str(bin(number))[2:]) != None: result_list.append(number) print(number) break else: number += 1これはかなり素直な流れ
料理開始
2進数、8進数の文字列に直す方法はいろいろあり、K君の方法でも問題ないと思いますが、
"{:o}".format(number)こんな方法に変えてみました。
ここは、どちらの方法がよいというレベルではないと思います。一番、不思議なのは、checker関数の戻り値。単純に回文数かどうかを調べるという関数だとしたら、True/Falseを返せばいいと思うんだけどねぇ。
回文かしらべるのに、逆順にした文字を求めようとた名残の
reversed(str(num))結果的には、これいらないんじゃない?その当たりをザックリ直してみました。
def checker(num_str): for j in range(len(num_str)//2): if num_str[j] != num_str[-j-1]: return False return True number = 10 while True: if (checker(str(number)) and checker( "{:o}".format(number)) and checker( "{:b}".format(number))) : print(number) break number += 1
- 投稿日:2019-12-01T20:07:24+09:00
ABEJA Platform + LINE Botで機械学習アプリをつくる
この記事は ABEJA Advent Calendar 2019 の 2 日目の記事です。
昨年の ABEJA Platform Advent Calendar では「ABEJA Platform の認証についてまとめる」と題して、ABEJA Platform における API 呼び出しの認証について紹介しましたが、今年も ABEJA Platform ネタで書いてみました。
なお、まことに遺憾ながら ABEJA Platform は Elixir に対応していないため、コードはすべて Python で書いてあります。
概要
2019 年 7 月に投稿された、@yushin_n さんによる「ABEJA Platform + Cloud Functions + LINE Botで機械学習アプリをつくる」では、
- ABEJA Platform
- Google Cloud Functions
- LINE Bot
を組み合わせて、サーバーレスな機械学習アプリをつくるのがテーマでした。
今回は、この機械学習アプリを改良して、Google Cloud Functions を使わずに ABEJA Platform のみで LINE Bot を開発する手順について紹介します。
そのために、この記事では ABEJA Platform の以下の 3 つの機能を使います。
新しいコンテナイメージ
ABEJA Platform では大きく分けて 18.10 と 19.x 系の二種類のイメージを提供しています。19.x 系では、より新しいライブラリやフレームワークがインストールされているだけでなく、機械学習 API の実装方法が刷新され、より柔軟な処理を実装できるようになっています。
推論テンプレート
ABEJA Platform ではいくつかの機械学習タスクについて、学習と推論のテンプレートを提供しています。このテンプレートを使うことで、一行もコードを記述することなく機械学習モデルの学習と推論ができるだけでなく、コードを改変することで実装したいビジネスドメイン(今回は画像分類の LINE bot)に適したものに改良することができます。
API エンドポイントの認証方式
デプロイされた API の認証方式を選択可能です。組み込みのユーザー認証と API キーによる認証を選択可能なだけでなく、認証自体をオフにして独自の処理を実装することができます。LINE bot の実装では署名の検証による認証を実装するために、この機能を使います。
システム構成
- LINE Bot に画像を送信する
- LINE Messaging API からの HTTP リクエスト(webhook)を、ABEJA Platform の HTTP サービスで受け取る
- リクエストから画像データを取得し、推論を実行結果から画像のクラスの予測結果を取得する
- 予測結果を LINE に返す
推論コードの実装
「ABEJA Platformのテンプレートを使用して、ノンプログラミングで機械学習モデルを学習する」で、すでにネットワークの学習は完了し、結果のパラメータが ABEJA Platform の「モデル」として保存されているものとします。
最初のバージョンをテンプレートから作成
推論のコードをゼロから自分で書きたくはないので、ABEJA Platform の推論テンプレートのコードを改変することにします。推論のテンプレートでは、
- 画像分類の推論
- 推論結果を JSON で返す
処理が実装されているので、ここに LINE bot 特有の処理(詳細は後述)を追加すればいいはずです。
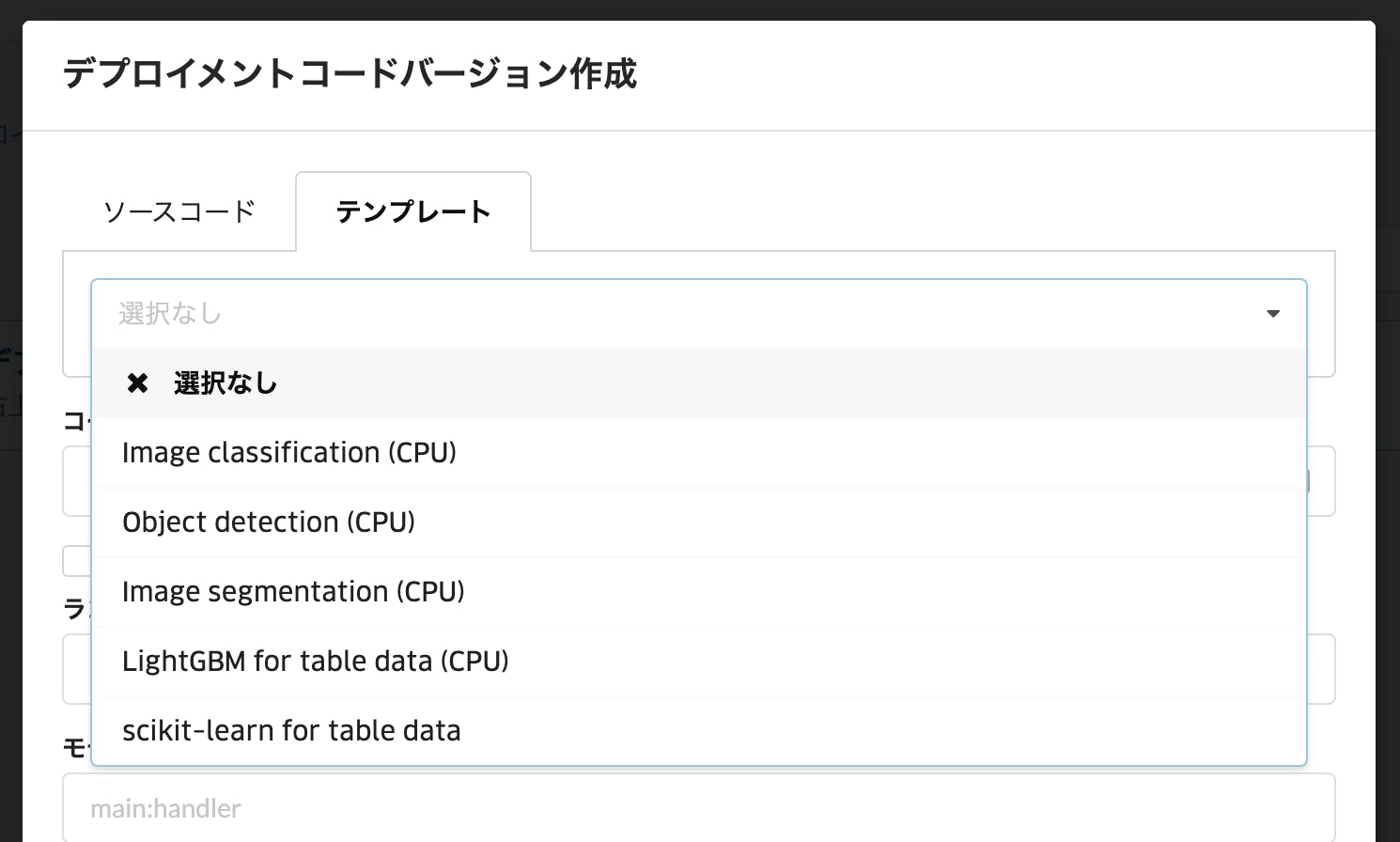
推論テンプレートのコードを生成するためには、コード(とデプロイされたサービス)を管理する容れ物となる「デプロイメント」を作成する必要があります。デプロイメント一覧画面の「デプロイメント作成」ボタンから新規デプロイメントを作成します。
新しく作成されたデプロイメントは、一覧では「0 モデルバージョン」となっているはずです。このリンクからコードの管理画面に移動します。
コードの管理画面では、このデプロイメントに属するコードをバージョン管理できます。早速、右上の「バージョン作成」から新規コードバージョンを作成します。
今回はテンプレートのコードを改変したいので、タブから「テンプレート」を選択し、「Image classification (CPU)」を選びます。
新しく作成されたコードバージョン「0.0.1」です。リンクをクリックして個別画面に移動します。
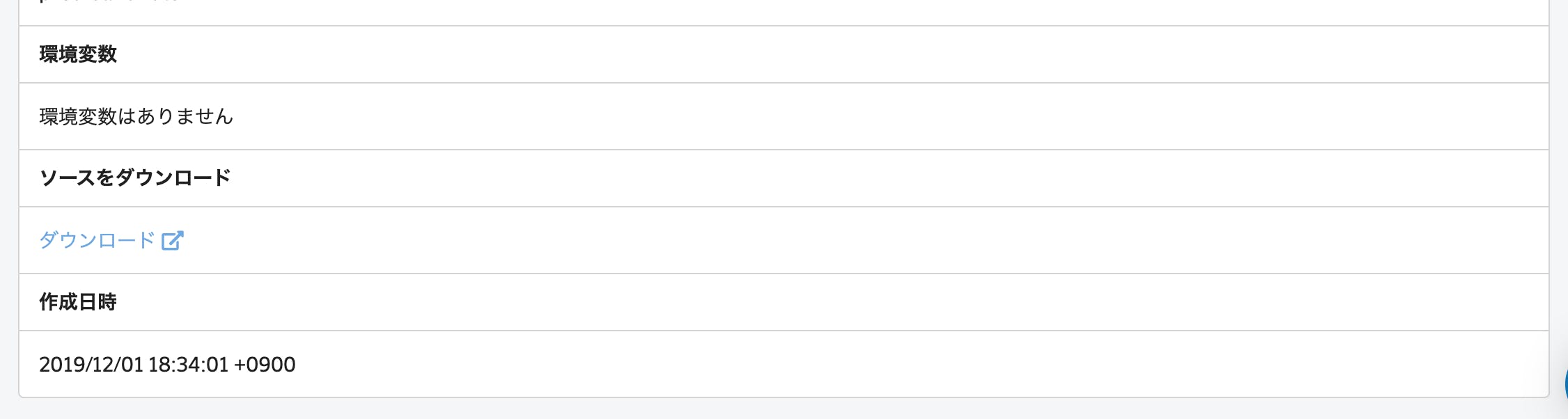
コードバージョンの個別画面では「ダウンロード」リンクからソースコードの zip をダウンロードできます。
テンプレートのコードを改良する
ダウンロードした zip ファイルを解凍すると、以下のようなディレクトリ構造になっているはずです。
$ ls -l total 96 -rw-r--r--@ 1 user staff 1068 10 30 01:31 LICENSE -rw-r--r--@ 1 user staff 4452 10 30 01:31 README.md -rw-r--r--@ 1 user staff 1909 10 30 01:31 predict.py -rw-r--r--@ 1 user staff 12823 10 30 01:31 preprocessor.py -rw-r--r--@ 1 user staff 82 10 30 01:31 requirements-local.txt -rw-r--r--@ 1 user staff 25 10 30 01:31 requirements.txt -rw-r--r--@ 1 user staff 4406 10 30 01:31 train.py drwxr-xr-x@ 6 user staff 192 10 30 01:31 utils元記事を参考に、必要なライブラリを
requirements.txtに追加します。line-bot-sdk googletrans ...そして、
predict.pyが推論処理を実装したファイルですが、ここに LINE bot に必要な処理である、
- ヘッダーで送られてくる署名の検証
- LINE メッセージから画像データの取得
- 結果を LINE で返信
を追加実装してやる必要があります。
まずは、これらの実装が完了した
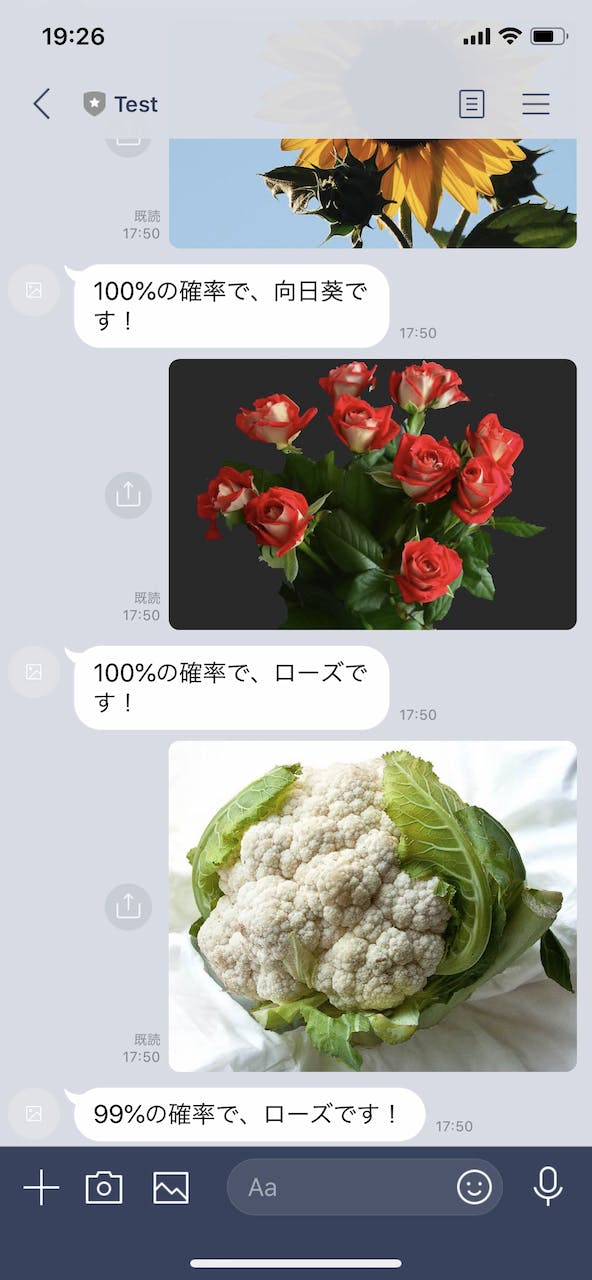
predict.pyを載せます。リクエストのエントリーポイントとなるhandler関数を修正しています。import os import io import linebot import linebot.exceptions import linebot.models import googletrans from keras.models import load_model import numpy as np from PIL import Image from preprocessor import preprocessor from utils import set_categories, IMG_ROWS, IMG_COLS # Initialize model model = load_model(os.path.join(os.environ.get( 'ABEJA_TRAINING_RESULT_DIR', '.'), 'model.h5')) _, index2label = set_categories(os.environ.get( 'TRAINING_JOB_DATASET_IDS', '').split()) # (1) Get channel_secret and channel_access_token from your environment variable channel_secret = os.environ['LINE_CHANNEL_SECRET'] channel_access_token = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] line_bot_api = linebot.LineBotApi(channel_access_token) parser = linebot.WebhookParser(channel_secret) def decode_predictions(result): result_with_labels = [{"label": index2label[i], "probability": score} for i, score in enumerate(result)] return sorted(result_with_labels, key=lambda x: x['probability'], reverse=True) def handler(request, context): headers = request['headers'] body = request.read().decode('utf-8') # (2) get X-Line-Signature header value signature = next(h['values'][0] for h in headers if h['key'] == 'x-line-signature') try: # parse webhook body events = parser.parse(body, signature) for event in events: # initialize reply message text = '' # if message is TextMessage, then ask for image if event.message.type == 'text': text = '画像を送ってください!' # (3) if message is ImageMessage, then predict if event.message.type == 'image': message_id = event.message.id message_content = line_bot_api.get_message_content(message_id) img_io = io.BytesIO(message_content.content) img = Image.open(img_io) img = img.resize((IMG_ROWS, IMG_COLS)) x = preprocessor(img) x = np.expand_dims(x, axis=0) result = model.predict(x)[0] sorted_result = decode_predictions(result.tolist()) # translate english label to japanese label_en = sorted_result[0]['label'] translator = googletrans.Translator() label_ja = translator.translate(label_en.lower(), dest='ja') prob = sorted_result[0]['probability'] # set reply message text = f'{int(prob*100)}%の確率で、{label_ja.text}です!' line_bot_api.reply_message( event.reply_token, linebot.models.TextSendMessage(text=text)) except linebot.exceptions.InvalidSignatureError: raise context.exceptions.ModelError('Invalid signature') return { 'status_code': 200, 'content_type': 'text/plain; charset=utf8', 'content': 'OK' }コードの解説
LINE bot 実装に関連した部分にコメントで番号を振ってあります。順を追って見ていきましょう。ここで解説している以外のコードは推論テンプレートおよび元記事そのままです。
1. LINE bot SDK の初期化
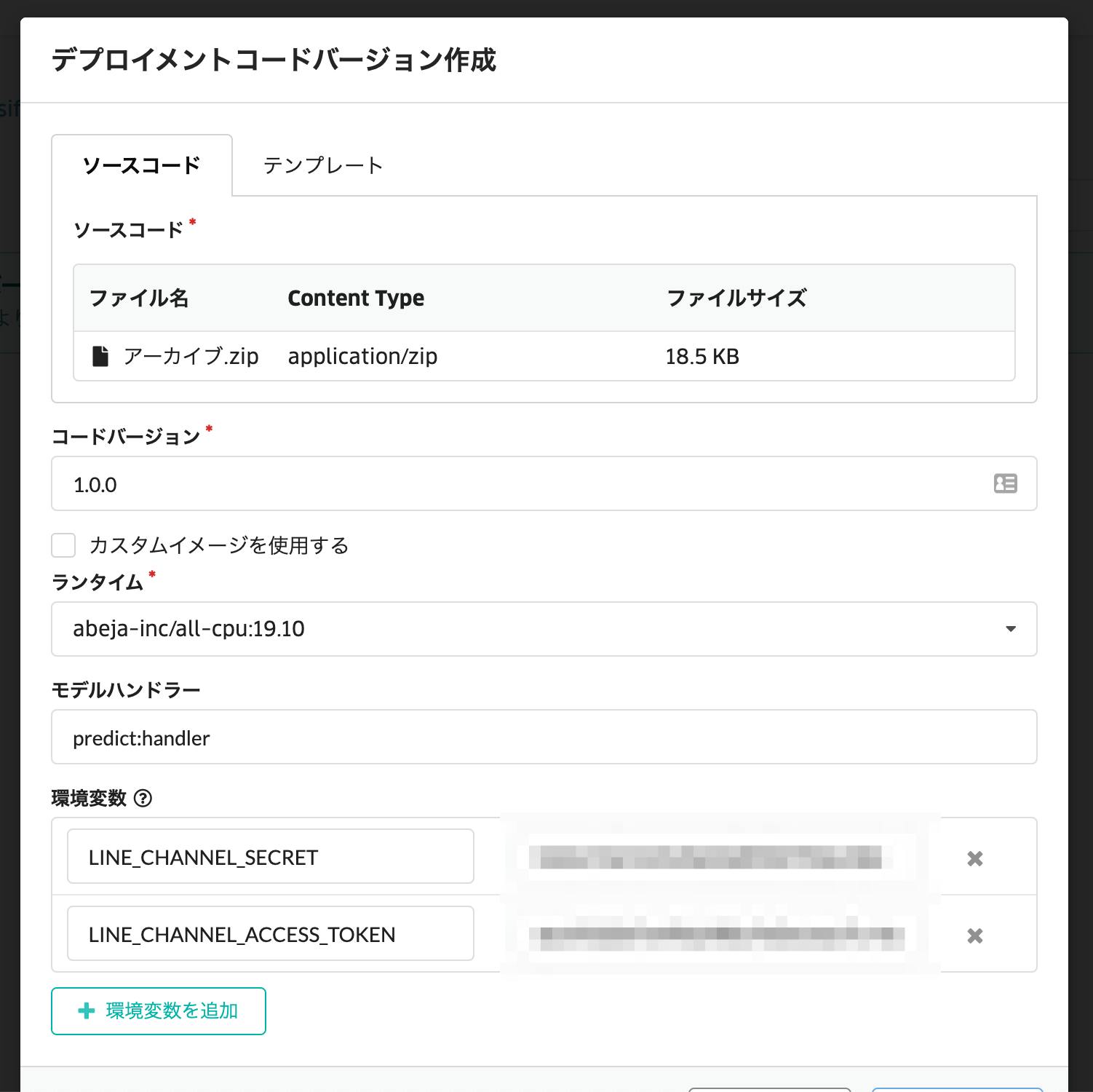
# (1) Get channel_secret and channel_access_token from your environment variable channel_secret = os.environ['LINE_CHANNEL_SECRET'] channel_access_token = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] line_bot_api = linebot.LineBotApi(channel_access_token) parser = linebot.WebhookParser(channel_secret)ここでは、LINE bot SDK を使って、API クライアントとメッセージの Parser を初期化しています。初期化に必要なパラメータ(秘密鍵とアクセストークン)は、環境変数で渡される想定です。
2. 署名の検証
# (2) get X-Line-Signature header value signature = next(h['values'][0] for h in headers if h['key'] == 'x-line-signature') try: # parse webhook body events = parser.parse(body, signature)HTTP のリクエスト・ヘッダーで渡される署名
X-Line-Signatureを SDK で検証します。HTTP のリクエスト・ヘッダーは handler 関数に渡されるrequestdict に格納されています。3. メッセージで送られてきた画像を取得
# (3) if message is ImageMessage, then predict if event.message.type == 'image': message_id = event.message.id message_content = line_bot_api.get_message_content(message_id) img_io = io.BytesIO(message_content.content) img = Image.open(img_io) img = img.resize((IMG_ROWS, IMG_COLS))メッセージの内容を取得し、PIL の Image オブジェクトに変換します。
機械学習モデルのデプロイ
では、出来上がったソースコードを zip に圧縮して、新しくコードバージョンを作りましょう。
新しいコードバージョン
さきほどのコード管理画面から新しくコードバージョン作成画面を表示し、zip をアップロードします。このとき、ランタイム(コンテナイメージ)を「abeja-inc/all-cpu:19.10」とし、必要な環境変数も設定します。
API のデプロイ
API のデプロイは「ABEJA Platformのテンプレートを使用して、ノンプログラミングで機械学習モデルをデプロイする」で解説されている通りなので繰り返しません。
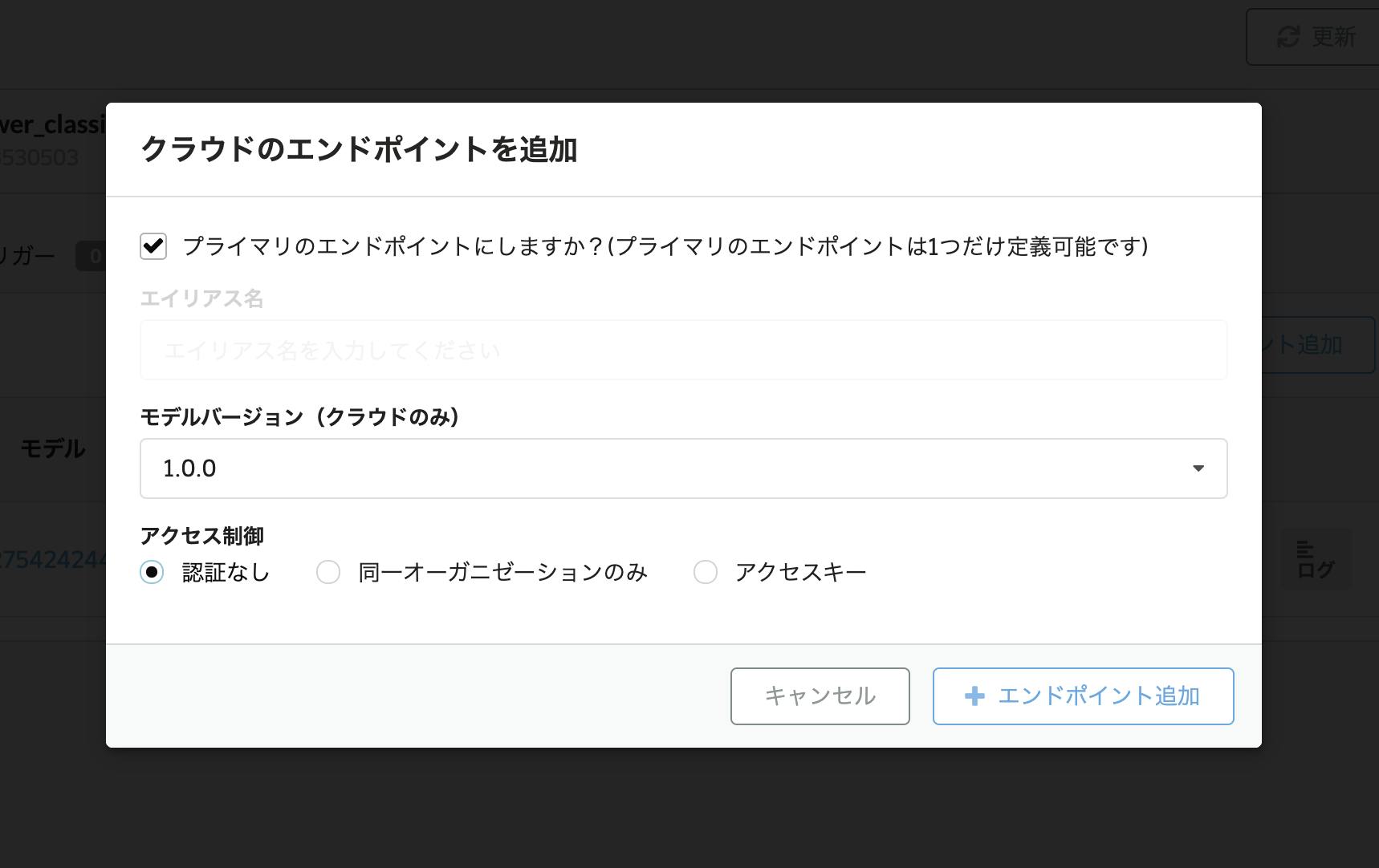
ただ、最初に説明したとおり、LINE bot からのリクエストを「認証なし」で通すために、新しいエンドポイントを作成し、
- プライマリのエンドポイントにする
- こうすることで、あとから HTTP サービスを切り替えても、API の URL を変更せずにすみます
- アクセス制御で「認証なし」を選択
新しく作成されたエンドポイントの URL は、サービス一覧の瞳のアイコンから確認できます。
https://{ORGANIZATION_NAME}.api.abeja.io/deployments/{DEPLOYMENT_ID}という形式になっているはずです。これを LINE bot の webhook として登録します。
LINE bot の動作確認
動作確認のために、今回作成した LINE bot にいくつか写真を投稿してみました。1
結果の真偽はともかく(?)LINE bot として動いているようです。
この投稿に使用させてもらった写真は次の通りです。 sunflower by Aiko, Thomas & Juliette+Isaac, rose by Waldemar Jan, cauliflower by liz west ↩






- 投稿日:2019-12-01T20:02:51+09:00
Pythonでカラーフィルムを再現してみる
作りたいもの
今回作成しようと考えているのは,カメラに取り付けるような画像全体の色調を変えるフィルムです.Numpyモジュールを使えば3簡単に原色のフィルムを作れるのですが,汎用性を高めて全部の色に対応させようと考えました.
元画像
完成品
from PIL import Image import numpy as np def color_filter(img_source, rgb): #Imageクラスでの入力だった場合,ndarrayに変換 if isinstance(img_source, Image.Image): img_source=np.array(img_source) #フィルムRGBは0~255 if max(rgb)>255 or min(rgb)<0: return Image.fromarray(np.unit8(img_source)) #繰り返し用に幅,高さを取得 width,height,c = img_source.shape #出力用配列を初期化 img_out=np.empty((img_source.shape), dtype='uint8') #各ピクセルにRGBフィルムを適用 for i in range(width): for j in range(height): b,g,r=img_source[i][j] r*=rgb[0]/255 g*=rgb[1]/255 b*=rgb[2]/255 img_out[i][j]=b,g,r #Imageクラスに変換後出力 img_out=Image.fromarray(np.uint8(img_out)) return img_out仕組み
各ピクセルのRGBの値にフィルムのRGBの255(RGB最大値)に対する割合を掛けています.
色の範囲は元の画像から真っ黒まで変更可能です.真っ黒の時のフィルムは要は壁ですね.実行結果
フィルムカラー:RGB(100,255,100)
フィルムカラー:RGB(173,216,230)
失敗作
割合ではなく,フィルタの値との平均をとれば行けるかもと初めに思ったのでその結果も載せておきます.壁が再現できなかったので失敗作といたします.
from PIL import Image import numpy as np def color_filter2(img_source, rgb): #Imageクラスでの入力だった場合,ndarrayに変換 if isinstance(img_source, Image.Image): img_source=np.array(img_source) #フィルムRGBは0~255 if max(rgb)>255 or min(rgb)<0: return Image.fromarray(np.unit8(img_source)) #繰り返し用に幅,高さを取得 width,height,c = img_source.shape #出力用配列を初期化 img_out = np.empty((img_source.shape), dtype='uint8') #各ピクセルにRGBフィルムを適用 for i in range(width): for j in range(height): b,g,r=img_source[i][j] r=(r+rgb[0])//2 g=(g+rgb[1])//2 b=(b+rgb[2])//2 img_out[i][j]=b,g,r #Imageクラスに変換後出力 return Image.fromarray(np.uint8(img_out))実行結果
フィルムカラー:RGB(100,255,100)
フィルムカラー:RGB(173,216,230)
壁:RGB(0,0,0)
やはり全体的に白みがかってますね.まとめ
どちらとも需要はあると思うので,色々とお試しください.画像認識のデータ水増しにでも使用していただけると嬉しいです.






- 投稿日:2019-12-01T20:01:11+09:00
【LINE Notify API,AWS】バズってるツイートをグループLINEに定期送信
今回作るもの
友達とのグループLINEに対して、
定刻になるとバズってるツイートを送信する仕組みをつくります。LINE Notify API
LINE Notifyと連携を行うことで、LINEユーザーが簡単にサービスの通知を受信できるようになります。
【引用元】:LINE Notify
らしいです。
実際に使うとこんな感じで
LINE Notifyというアカウントからメッセージが届きます。
LINE Notifyの下準備
下記リンクの手順通り、
LINE Notifyが使える状態にします。
[超簡単]LINE notify を使ってみるバズってるツイートの取得
バズってるツイートも
Twitter API使って頑張ろうか迷いましたが、
辛そうだったので既存のランキングサイトからスクレイピングしてくることにしました。Twitter人気ランキングサイト →【TwTimez】
コード(Python)
import requests from bs4 import BeautifulSoup #一番勢いのあるツイートを取得 def bazz_get(): # アクセスするURL url = "http://www.twtimez.net/index.html" # URLにアクセスする html = requests.get(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html.text, "html.parser") try: for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href")) except: return "なんかしらのエラー" #Lineにメッセージを送る def send_line(Bazz): notify_url = "https://notify-api.line.me/api/notify" token = "アクセストークン" headers = {"Authorization": "Bearer " + token} message = "\r\n" + Bazz payload = {"message": message} requests.post(notify_url, headers=headers, params=payload) if __name__ == "__main__": send_line(bazz_get())スクレイピング
何気にちゃんとやる?の初めてです。
BeautifulSoupってのを使えばちょちょいのちょいでした。下記の箇所でhtmlの中から欲しい情報を持つクラスやタグを引っ張ってきてます。
for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href"))欲しい情報を持つクラスやタグはGIFでやっているような手順で突き止めます。
F12 Keyを押せばページのhtmlを見れます。
ここまで問題なければ、実行後にLINEへメッセージが送られます。
AWS
AWSのサービスを利用して定刻になるとメッセージを自動で送る仕組みを作ります。
多分無料です。後で請求書来たら勉強料を支払って速攻で止めます。
AWS Lambda
サーバーについて検討することなくコードを実行できます。お支払いいただくのは、実際に使用したコンピューティング時間に対する料金のみです。
らしいです。ここに今回書いたコードをぶち込みます。
Amazon CloudWatch
AWS とオンプレミスにおける AWS のリソースとアプリケーションのオブザーバビリティ
らしいです。なるほどわからん。
要するに自分で作った何かしらを簡単に監視していろいろできますってことだと思います。
設定した時刻にLambda上で作成した関数を定期的に実行可能です。実際の手順
Lambdaのコンソールにサインインして関数の作成を選択し、
適当に名前をつけて次に進みます。
Zipでフォルダ毎アップすることもできるみたいですが、
そこまで大したものを作ってないので、関数に先程のコードをコピペして貼り付けます。モジュールを利用しているのでダメでした。
さらに言うと、コードを追加、もしくは修正する必要があります。また、
コードをインラインで編集ではなく、.zipファイルでアップロードします。AWS用に変更したコード
import requests from bs4 import BeautifulSoup def bazz_get(): # アクセスするURL url = "http://www.twtimez.net/index.html" # URLにアクセスする html = requests.get(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html.text, "html.parser") try: for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href")) except: return "なんかしらのエラー" def send_line(Bazz): notify_url = "https://notify-api.line.me/api/notify" token = "アクセストークン" headers = {"Authorization": "Bearer " + token} message = "\r\n" + Bazz payload = {"message": message} requests.post(notify_url, headers=headers, params=payload) def bot(event, lambda_context): send_line(bazz_get())下記がLambdaで実際に呼び出される関数です。
実行だけを担うScriptを別途用意しても良かったのですが、
問題なく動いてくれて、今後拡張する予定もないので下記のようにしました。
Lambdaで呼び出すためには引数が必要です。def bot(event, lambda_context): send_line(bazz_get())アップロード先のハンドラにPython Script名と呼び出したいメソッド名を
.で繋いで書いておきます。
モジュール入りのZipファイルをLambdaにアップロード
まずは、モジュールを任意のディレクトリに保存します。
まずは保存したいディレクトリまで移動します。
コマンドプロンプトで実行cd 任意のディレクトリあとは、カレントディレクトリにPython Script内で使用したモジュールを保存します。
コマンドプロンプトで実行pip install beautifulsoup4 -t . pip install requests -t .次はZip圧縮です。
アップロードしたいPython Scriptとモジュールを圧縮します。
全てを格納したフォルダに対してZip圧縮行うと一階層分余計なフォルダができてしまうので
GIF画像のように全選択して圧縮します。
CloudWatch Events
次は
トリガーを追加を選択してCloudWatchと連携します。
(CloudWatchのコンソールにサインインして別途設定を行うアプローチでも可能です。)
スケジュールの設定
スケジュールの設定方法(いつコードを実行するか)は下記リンクが参考になります。
Schedule Expressions for RulesCloudWatchにコンソールからサインインして
ルールの新規作成をした場合は下記画像のように
どのタイミングで実行するか表示されるのでわかりやすいです。
UTC(GMT)とJST
先程の画像を見ればわかりますが、GMTという文字が実行時間の後ろに書かれています。
日本の時間と9時間差があるそうなので、その時差を考慮した時間で設定しないとダメなようです。
【参考リンク】:【AWS】CloudWatch cron 式 または rate 式の書式について解説
グループLINE内のみんなの感想
全員フルシカトでした。なんで?
参考リンク
朝イチで知りたいことをLINEで教えてくれるプログラム(Python)
【Python】BeautifulSoupの使い方・基本メソッド一覧|スクレイピング
AWS LambdaをPythonで使ってみた ライブラリの読み込みや環境変数の注意点について解説


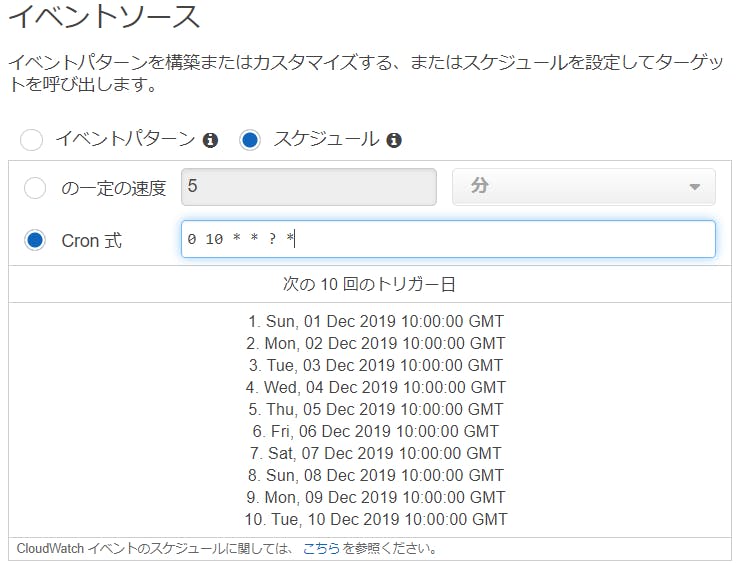
- 投稿日:2019-12-01T19:56:29+09:00
DjangoでSpotify APIを叩いてみる。
はじめに
この記事はDjango Advent Calendar 2019の記事です。
対象読者はこれからDjangoを初めて見ようと言う層向けです。前回の記事は@yuu-eguciさんの500エラーに関する内容でした。
https://qiita.com/yuu-eguci/items/a1e4b0a2f238d5ccc985今回の記事はDjangoでSpotifyのAPIを実行してみようといった内容です。
事前準備
Spotifyのユーザーアカウントを作成する必要があるのですが、以下のクラスメソッドさんの記事が大変参考になります。
https://dev.classmethod.jp/etc/about-using-of-spotify-api/記事のサンプルコードを実行したい方は、以下からチャートデータをCSV形式でダウンロードしてください。
https://spotifycharts.com/regional/jp/daily/latestサーバー側の実装
行儀が大変悪いですが、手軽に動作を確認してほしいのでviews.pyの中で全て纏めています。
違和感を与えてしまったら申し訳ありません。。。class SpotifySong: def __init__(self, song_name, uri): self.song_name = song_name self.uri = uri def spotify(request) : # SpotifyのClientID,Secretを使って認可を実施 client_id = '' client_secret = '' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) # Spotifyインスタンスを作成 spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager) # SpotifyからダウンロードしたCSVファイルを読み込む songs = pd.read_csv(BASE_DIR + '/regional-jp-daily-latest.csv', index_col=0, header=1) # Spotifyから曲情報を取得 spotify_songs_list = [] for url in songs['URL']: spotify_songs_list.extend(spotify.audio_features(url)) # 曲名をくっ付ける response_list = [] for i,spotify_song in enumerate(spotify_songs_list): response_list.append(SpotifySong(songs.iat[i,0],spotify_song['uri'])) # テンプレートを指定 template = loader.get_template('spotify/spotify_base.html') context = { 'response_list': response_list, } return HttpResponse(template.render(context, request))spotify.audio_featuresで返ってくるレスポンスは以下を参考にしてください。
演奏時間、キーはもちろんその曲がどれだけアコースティックなのか・どれだけ踊れるかといった指標も返ってきます。今回の記事では省きますが、季節によって好まれる曲の傾向を学習するサービスとか作れそうですね!!
https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/クライアント側の実装
{% if response_list %} <h1>デイリーランキング</h1> <ul> {% for response in response_list %} <li><a href="https://embed.spotify.com/?uri={{ response.uri }}"> {{response.song_name}} </a></li> {% endfor %} </ul> {% else %} <p>Spotifyからの楽曲取得に失敗しました。</p> {% endif %}簡素なHTMLですが、以下の様な感じでデイリーランキングが作れます。
クリックしたらSpotifyの曲ページに飛べるシンプルな画面ですが、初学者にとっては作れたら結構嬉しいのではないでしょうか?
サンプルコードを理解する上で知っておきたいこと
DjangoでTemplateを扱う際、いくつか注意する事があります。
マニュアルはこちら。
https://docs.djangoproject.com/en/2.2/ref/templates/language/#templates1.コレクションのサイズを取得したい時
{{ 変数|length }}という書き方で取得する必要があります。変数.lengthといった書き方は出来ません。
2.コレクションのインデックスを指定して取得したい時
{{変数.0}}といった様に、直接.インデックス番号を指定するという方法でしか取得出来ません。
{{変数[[0]]}}という書き方は出来ません。
上記理由から、今回のサンプルコードは曲名を取得するために独自クラスを定義しています。
SpotifyAPIの戻り値と、CSV読み込みの結果を2つ渡す案も考えられますが、インデックス番号を用いた取得が困難なため、オブジェクトが別れて状態でデータを取り扱うのが面倒になります。おまけのトラブルシューティング
以下コマンドを打つと、Portが使われていますエラーが起きる場合があります。
python3 manage.py runserver Django version 2.2.7, using settings 'mysite.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C. Error: That port is already in use.上記を解決するためには、以下手順でプロセスをkillする方法が一番簡単です。
1.ポートを調べる
lsof -i -P | grep 8000 Python 71504 user 4u IPv4 0x2cdb3e922e88888 0t0 TCP localhost:8000 (LISTEN)2.PIDを指定してkillコマンドを実行
kill -9 71504終わりに
Django 3.0のfinalリリースの日のハードルは超えられていませんが、誰かの参考になると幸いです。。。
明日の Django アドベント・カレンダーは @shimayu22 さんです。よろしくお願いします!!

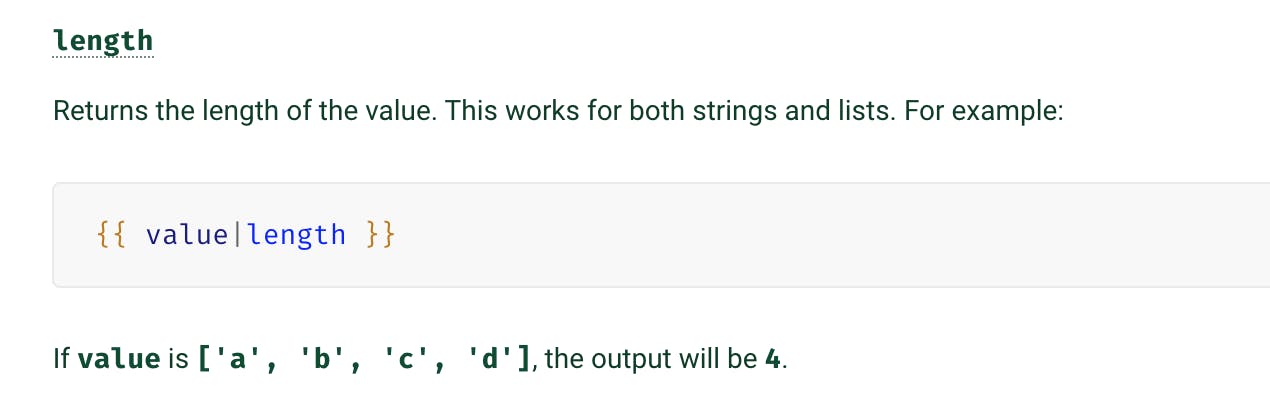

- 投稿日:2019-12-01T19:52:33+09:00
Flask-Migrateでflask db upgradeが終わらない
概要
Flask-Migrateを使用して
flask db upgradeを実行した際に下記のコンソール出力がされたまま処理が詰まってしまった場合の解決方法を説明します。
この状況だとCtrl+Cで処理を抜けることもできず、ターミナルを閉じてもDBスキーマの変更は反映されないままです。$ flask db upgrade INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.runtime.migration] Running upgrade 576e5f4a0fe7 -> 2b28fe44cc94, empty message原因は、おそらく処理が詰まっていることなので原因となるプロセスを強制終了します。
だいたい同じですが4パターン解決方法を紹介します。2~4については未検証なので、もしかしたら解決できないかもしれないです。方法1(ターミナルからプロセスを強制終了する)
ターミナル上で該当のプロセスを強制終了します。
psコマンドを実行すると実行中のプロセス一覧が表示されるので、その中から該当のプロセスを見つけkillコマンドで強制終了することができます。## postgresが実行しているプロセスを調べる ps aux | grep postgres ## 該当のプロセスを終了する kill <<プロセスID>> # ex) kill 12345方法2(PostgreSQLからプロセスを強制終了する)
※未検証です。
postgres上で行います。## ロックされている処理を調べます SELECT * FROM pg_locks; ## プロセスを終了します SELECT pg_cancel_backend(プロセスID);方法3(postgresqlを再起動する)
※未検証
postgresqlを再起動すればプロセスも終了されるはず。方法4(端末を再起動する)
※未検証
方法3とほぼ同じです。端末自体を再起動すればプロセスも終了されるはずです。
- 投稿日:2019-12-01T19:41:21+09:00
粒子群最適化を使って関数最小化問題を解いてみる
粒子群最適化
粒子群最適化(PSO:Particle Swarm Optimization)とは, 群知能の一種であり, 解探索手法として組合せ最適化問題に使用されます.
粒子の速度と位置という2つの情報の更新を繰り返して, 探索を進めていく流れになります.
下の図は粒子群最適化のイメージです.
アルゴリズム
粒子群最適化のアルゴリズムは以下のようになります.
更新式
以下の更新式より粒子の速度と位置を更新します.
簡単に説明すると, 速度は粒子を進化させる方向を表し, 位置は粒子自身のパラメータを表します.
実験
実際に最適化問題を解いていきましょう.
今回はx^2 + y^2の最小化問題を解いていきましょう.
ですので, (x,y)=(0,0)が最適解となります.
使用したコードは以下のようになります.# -*- coding: utf-8 -*- import numpy as np import random # 評価関数 def evaluate(particle): z = 0 for i in range(len(particle)): z += particle[i] ** 2 return z # 位置更新 def update_position(particle, velocity): new_particle = particle + velocity return new_particle # 速度更新 def update_velocity(particle, velocity, pbest, gbest, w=0.5, max=0.15): new_velocity = np.array([0.0 for i in range(len(particle))]) #new_velocity = [0.0 for i in range(len(particle))] r1 = random.uniform(0, max) r2 = random.uniform(0, max) for i in range(len(particle)): new_velocity[i] = (w * float(velocity[i]) + r1 * (float(pbest[i]) - float(particle[i])) + r2 * (float(gbest[0]) - float(particle[i]))) return new_velocity def main(): N = 100 # 粒子の数 length = 2 # 次元数 para_max = 100 #パラメータの最大値 # 粒子位置の初期化 ps = [[random.uniform(-para_max, para_max) for j in range(length)] for i in range(N)] vs = [[0.0 for j in range(length)] for i in range(N)] # パーソナルベスト personal_best_position = ps # パーソナルベストの評価 personal_best_scores = [evaluate(p) for p in ps] # 評価値が最も小さい粒子のインデックス best_particle = np.argmin(personal_best_scores) # グローバルベスト global_best_position = personal_best_position[best_particle] generation = 30 # 最大世代数 # 世代数分ループ for t in range(generation): file = open("data/pso/pso" + str(t+1) + ".txt", "w") # 粒子数分ループ for n in range(N): # ファイル書き込み file.write(str(ps[n][0]) + " " + str(ps[n][1]) + "\n") # 粒子の速度の更新 vs[n] = update_velocity(ps[n], vs[n], personal_best_position[n], global_best_position) # 粒子の位置の更新 ps[n] = update_position(ps[n], vs[n]) # 評価値計算をしてパーソナルベストを求める score = evaluate(ps[n]) if score < personal_best_scores[n]: personal_best_scores[n] = score personal_best_position[n] = ps[n] # グローバルベストの更新をする best_particle = np.argmin(personal_best_scores) global_best_position = personal_best_position[best_particle] file.close() print(global_best_position) print(min(personal_best_scores)) if __name__ == '__main__': main()実験結果
1,10,20,30世代目の個体を色分けして図にプロットしています.
世代が進むに連れて, 粒子が(0,0)に収束しているのが確認できますね.
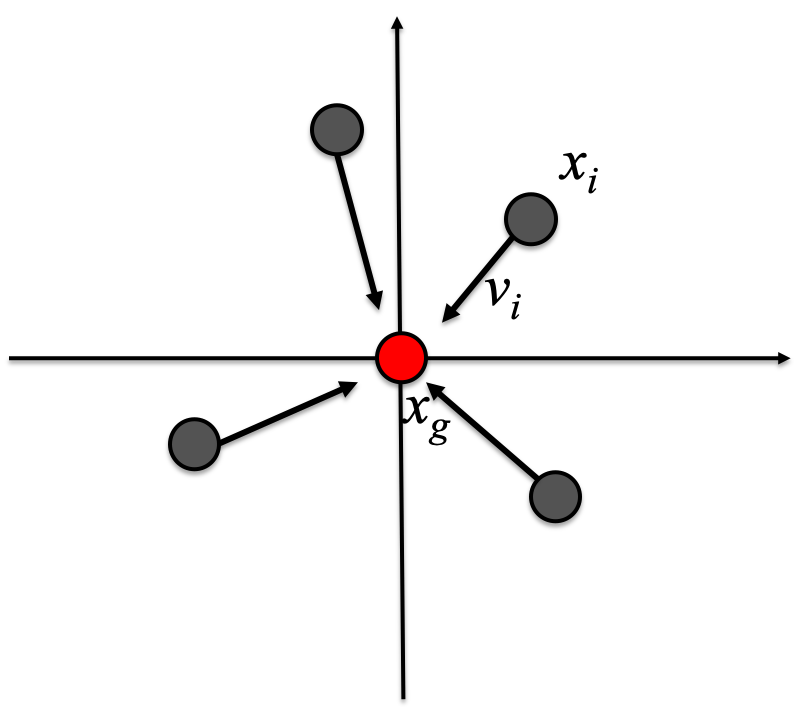


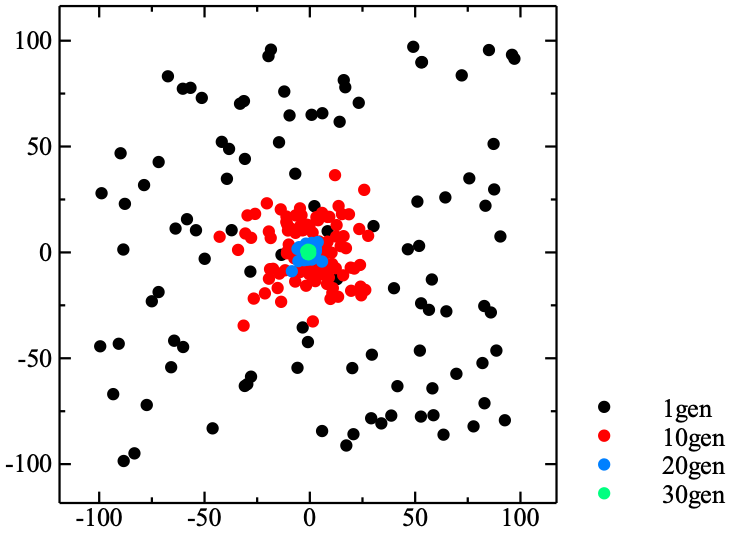
- 投稿日:2019-12-01T19:30:34+09:00
Pythonで大学の100円朝食LINEbotを作った話
この記事はTokyo City University Advent Calendar 2019 1日目の記事です。
https://adventar.org/calendars/4282はじめに
こんにちは!東京都市大学という大学で情報系の勉強をしています、おーじぇい( @920oj )と申します。
この度、都市大のアドベントカレンダーを建てましたので、自分は
「Pythonで大学の100円朝食を知らせてくれるLINEbotを作った話」を書きます!背景
弊学には朝食を100円で食べることができる非常にお得な制度があります。さらに自分は地方から上京して一人暮らしなので、金欠にはもってこいです。
これが100円なのだ
毎朝このメニューは食堂のWebサイトに掲示されるのですが、このWebサイトが曲者で、アクセスするためにアプリを通したり学校ポータルサイトを通さなければなりません。
そこで、毎朝自動で食堂Webサイトをスクレイピングし、その日の100円朝食をLINEに通知してくれる(LINE Notify)を作ることにしました。
筆者の環境
Python v3.7.1
pip 19.1.1
Windows 10 v1903できたもの
東京都市大横浜キャンパス学生食堂 100円朝食通知bot
https://github.com/920oj/TCU-YC-Breakfast-Notify-Bot
こんな感じに毎日朝7時30分に(100円朝食がある場合だけ)通知が飛んできます!
実装を考えていく
まずは学食のWebサイトをBeautifulSoupで取得します。学食Webサイトを閲覧するにはログインが必要なので、一度POSTを投げて認証してからセッションIDを使ってこねくり回そうという指針を建てていました。
しかし、よく見てみたら認証なんてものは存在せず、CookieにそのままIDとパスワードを平文で書き込んで認証、という感じになってました。(いいのか?)
(本来なら一度認証(POST)して、そのセッションIDに認証が通ったということが紐付かれていて、その後のリクエストが通る、ということだと思うのですが、何故かPOSTせずとも動いてしまってるので良しとします)(本来は良くないです)
セッション関係
とりあえず、ログインページに行くと「セッションキー」と「セッションID」というものが付与されるようなので、まずはこれを取得するところからはじまります。
def get_sessionid(): # 初期Cookieの取得処理 r = requests.get('https://livexnet.jp/local/default.asp') first_access_cookie = str(r.headers['Set-Cookie']) # "ASPSESSIONID+任意の8桁の英大文字"(英大文字24文字)の取得 asp_session = str(first_access_cookie[first_access_cookie.find("ASPSESSIONID"):first_access_cookie.find("; secure")]) asp_session_key = str(asp_session[0:asp_session.find("=")]) asp_session_id = str(asp_session[asp_session.find("="):].replace('=','')) return asp_session_key, asp_session_idフレームワークはASP.NETのようです。ASPSESSIONIDについては、末尾に8桁の英大文字が追加されるようなので、これも取得します。
この関数の返り値をasp_session_key, asp_session_idとして二種類を返します。Cookieを設定~スクレイピング
def get_breakfast_info(key,id): # Cookieを用意(今後情報が変更される可能性あり) site_cookies = { key: id, 'KCD': '02320', 'company_id': SITE_ID, 'company_pw': SITE_PASS, 'wrd': 'jp', 'dip': '0', 'ink': 'a', 'bcd': '02320', 'val': 'daily' } # メニュー・栄養表ページにアクセス url = 'https://reporting.livexnet.jp/eiyouka/menu.asp?val=daily&bcd=02320&ink=a&col=&str=' + today_data r = requests.get(url, cookies=site_cookies) r.encoding = r.apparent_encoding # HTML解析 all_html = r.text.replace('<br>','') souped_html = BeautifulSoup(all_html, 'lxml') try: breakfast = souped_html.find('p', class_="img_comment6").string return breakfast except: return FalseChromeの開発者ツールを使って、どんなCookieが設定されるかを確認します。
確認したら、それに沿ってcookieを用意してあげてbeautifulsoupに読み込ませるので、辞書を用意します。
keyはさっき取得したセッションキーと、idはセッションIDを読み込ませてます。(これは変数の名前がダメです。もっとわかりやすいものにしましょう)
先程も述べたとおり、SITE_IDとSITE_PASSで認証IDとパスワードを平文で読み込ませているようなので(?)この通りに指定します。
(これセッションIDを取得した意味無いのでは……?詳しい方いたら教えて下さい)
あとはHTML解析をしてくれるlxmlに読み込ませて、その中で「img_comment6」というクラス要素を抜き出してやればOKです!
LINEに飛ばす(LINE Notify)
def post_line(result): post_data = '本日(' + today_data + ')の100円朝食は、' + result + 'です。' line_api_headers = {"Authorization" : "Bearer "+ LINE_TOKEN} line_payload = {"message" : post_data} r = requests.post(LINE_API_URL ,headers = line_api_headers ,params=line_payload) return r.status_codeあとはLINE Notifyに飛ばすだけです。LINE Notifyではヘッダーに認証情報とメッセージ内容を乗っけて、APIのエンドポイントにPOSTを投げてやると予め設定しておいたトークに情報を流すことができます。
メイン処理を書く
def main(): print('東京都市大学100円朝食メニュー表示プログラム by 920OJ') print('今日は' + today_data + 'です。') session = get_sessionid() session_key = session[0] session_id = session[1] print('初期認証情報を取得しました。' + session_key + 'は' + session_id + 'です。3秒間待機します……') sleep(3) result = get_breakfast_info(session_key,session_id) if not result: print('情報を取得できませんでした。100円朝食が実施されていない可能性があります。') sys.exit() print('今日の100円朝食は、' + result + 'です。LINEに通知を送信します。') post_status = post_line(result) if post_status == 200: print('LINE通知に成功しました。プログラムを終了します。') else: print('LINE通知に失敗しました。レスポンスは' + str(post_status) + 'です。プログラムを終了します。') if __name__ == "__main__": main()あとは先程作った関数を組み立てていく要領でメインとなる処理を書いていきます。
最後に
if __name__ == "__main__":と書くのは、もしこのプログラムがどこかでimportされたときに処理が勝手に実行されるのを防ぐためです。実行中のファイルの名前が一致していたらmain()関数を呼び出す、という仕組みにするのは初めて知りました。運用する
借りているLightsail(VPS)にホストして、cronで定期実行しています。
実行すると即時にその日の朝食を取得しに行くので、毎朝7時30分にcron実行することで定期実行を実現しています。最後に
実を言うとこのコードは4月に作ったものなので、今みると変数名がよろしくなかったり実装があやふやなところがあります。もう少し暇になったらコードをリライトしてみたいです。
明日はケーさん(
@ke_odakyu9000)の記事です!よろしくおねがいします!
https://adventar.org/calendars/4282

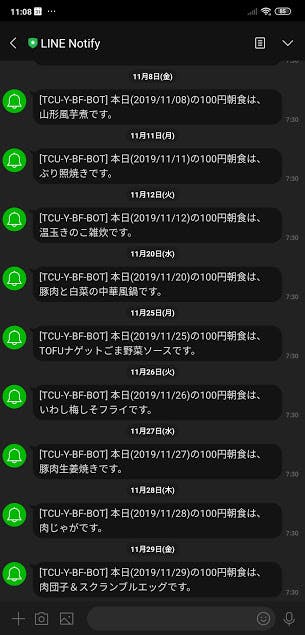
- 投稿日:2019-12-01T19:13:44+09:00
Docker + Flask(Python) + Jupyter notebookによる仮想環境構築
毎回構築の方法を忘れるため、備忘録として。
ファイル構成
project L DockerfileDockerfile
javaを利用するライブラリをインストールする可能性があるので、default-jdkを追加しています。
DockerfileFROM python:3.6 RUN apt-get update && apt-get install -y \ default-jdk \ build-essential \ gfortran \ libblas-dev \ liblapack-dev \ libxft-dev \ swig \ && rm -rf /var/lib/apt/lists/* RUN echo 'export LD_LIBRARY_PATH="/usr/local/lib:$LD_LIBRARY_PATH"' >> ~/.bash_profile && \ . ~/.bash_profile && \ cd ~ &&\ git clone https://github.com/taku910/mecab.git && \ cd mecab/mecab && \ ./configure --enable-utf8-only && \ make && \ make check && \ make install && \ cd ../mecab-ipadic && \ ./configure --with-charset=utf8 && \ make && \ make install &&\ cd ~ &&\ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git && \ cd mecab-ipadic-neologd && \ ./bin/install-mecab-ipadic-neologd -n -y RUN pip3 install --upgrade pyzmq --install-option="--zmq=bundled" && \ pip3 install --upgrade jupyter && \ pip3 install --upgrade \ pandas \ neologdn \ Flask \ numpy \ Pillow \ tensorflow \ ENV LD_LIBRARY_PATH "/usr/local/lib:$LD_LIBRARY_PATH" VOLUME /notebook WORKDIR /notebook EXPOSE 8888 ENTRYPOINT jupyter notebook --ip=0.0.0.0 --allow-root --no-browserDocker imageの作成
Dockerfileのディレクトリに移動して、docker buildコマンドを実行。構築に数分かかります。
$ cd project $ docker build -t image_name --force-rm=true . # (-t イメージ名) イメージ名を自分で決定 # (--force-rm=true) イメージのビルドに失敗したら、イメージを自動で削除するDocker containerの作成
描きコマンドを実行すると、自動でJupyter notebookが起動するので、表示されたURLにアクセスするとJupyter notebookが利用できる。
# 上と同じディレクトリで下記コマンド実行 $ docker run -v `pwd`:/notebook -p 8888:8888 -p 5000:5000 -it --name container_name image_id /bin/bash # http://127.0.0.0:8888/?token=#################### # こんな感じのアドレスが出てくるため、tokenごとコピペする。追加のライブラリをインストール
Jupyter notebookで作業している時に、足りないライブラリをインストールしたい場合は、コンテナの外から、下のコマンドでコンテナの中に入る。
$ cd project $ docker exec -it container_name /bin/bash # 上記コマンドでコンテナ内に入ると、ターミナルが下のように切り替わる。 root@ユーザー名:/notebook# ここにコマンドを入力できるようになる。 # インストールの例 root@ユーザー名:/notebook# pip install numpy
- 投稿日:2019-12-01T19:07:55+09:00
HeartRails Express APIでエリア情報/都道府県情報/路線情報/駅情報/最寄駅情報を取得した際の備忘録(python)
目的
HeartRails Express APIでエリア情報/都道府県情報/路線情報/駅情報/最寄駅情報を取得した際の備忘録(python)
準備
リクエスト送信モジュールをインストール
pip install requestsテスト
エリア情報取得 API
デフォルトのエリアを取得
sample.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import json import requests url = 'http://express.heartrails.com/api/json?method=getAreas' ret = requests.get(url) ret_json = json.loads(ret.text) print(ret_json)$ python sample1.py {'response': {'area': ['北海道', '東北', '関東', '中部', '近畿', '中国', '四国', '九州']}}都道府県情報取得 API
デフォルトの都道府県名を取得
sample.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import json import requests url = 'http://express.heartrails.com/api/json?method=getPrefectures' ret = requests.get(url) ret_json = json.loads(ret.text) print(ret_json)$ python sample.py {'response': {'prefecture': ['北海道', '青森県', '岩手県', '宮城県', '秋田県', '山形県', '福島県', '茨城県', '栃木県', '群馬県', '埼玉県', '千葉県', '東京都', '神奈川県', '新潟県', '富山県', '石川県', '福井県', '山梨県', '長野県', '岐阜県', '静岡県', '愛知県', '三重県', '滋賀県', '京都府', '大阪府', '兵庫県', '奈良県', '和歌山県', '鳥取県', '島根県', '岡山県', '広島県', '山口県', '徳島県', '香川県', '愛媛県', '高知県', '福岡県', '佐賀県', '長崎県', '熊本県', '大分県', '宮崎県', '鹿児島県', '沖縄県']}}路線情報取得 API
ex. prefecture=大阪府の路線情報を取得
sample.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import json import requests url = 'http://express.heartrails.com/api/json?method=getLines&prefecture=大阪府' ret = requests.get(url) ret_json = json.loads(ret.text) print(ret_json) print(ret_json["response"]["line"][0]) print(len(ret_json["response"]["line"]))$ python sample.py {'response': {'line': ['JR京都線', 'JR大和路線', 'JR大阪環状線', 'JR東西線', 'JR桜島線', 'JR片町線', 'JR神戸線', 'JR福知山線', 'JR関西空港線', 'JR阪和線', '京阪交野線', '京阪本線', '京阪中之島線', '北大阪急行', '南海多奈川線', '南海本線', '南海汐見橋線', '南海空港線', '南海高師浜線', '南海高野線', '大阪モノレール', '大阪モノレール彩都線', '大阪中央線', '大阪千日前線', '大阪南港ポートタウン線', '大阪四つ橋線', '大阪堺筋線', '大阪御堂筋線', '大阪谷町線', '大阪長堀鶴見緑地線', '山陽新幹線', '東海道新幹線', '水間鉄道', '泉北高速鉄道', '能勢電鉄妙見線', '近鉄けいはんな線', '近鉄信貴線', '近鉄南大阪線', '近鉄大阪線', '近鉄奈良線', '近鉄西信貴ケーブル線', '近鉄道明寺線', '近鉄長野線', '阪堺電軌上町線', '阪堺電軌阪堺線', '阪急京都本線', '阪急千里線', '阪急宝塚本線', '阪急神戸本線', '阪急箕面線', '阪神本線', '阪神なんば線', '大阪今里筋線', 'おおさか東線']}} JR京都線 54駅情報取得 API
ex.「name=大阪」を入力
sample.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import json import requests url = 'http://express.heartrails.com/api/json?method=getStations&name=大阪' ret = requests.get(url) ret_json = json.loads(ret.text) print(ret_json)$ python sample.py {'response': {'station': [{'name': '大阪', 'prefecture': '大阪府', 'line': 'JR京都線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'prev': '新大阪', 'next': None}, {'name': '大阪', 'prefecture': '大阪府', 'line': 'JR大阪環状線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'prev': None, 'next': '福島'}, {'name': '大阪', 'prefecture': '大阪府', 'line': 'JR神戸線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'prev': None, 'next': '塚本'}, {'name': '大阪', 'prefecture': '大阪府', 'line': 'JR福知山線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'prev': None, 'next': '尼崎'}]}}最寄駅情報取得 API
ex.大阪の緯度経度(x=135.495188, y=34.702398)を入力
sample.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import json import requests url = 'http://express.heartrails.com/api/json?method=getStations&x=135.495188&y=34.702398' ret = requests.get(url) ret_json = json.loads(ret.text) print(ret_json)$ python sample.py {'response': {'station': [{'name': '大阪', 'prefecture': '大阪府', 'line': 'JR京都線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'distance': '00m', 'prev': '新大阪', 'next': None}, {'name': '大阪', 'prefecture': '大阪府', 'line': 'JR大阪環状線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'distance': '00m', 'prev': None, 'next': '福島'}, {'name': '大阪', 'prefecture': '大阪府', 'line': 'JR神戸線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'distance': '00m', 'prev': None, 'next': '塚本'}, {'name': '大阪', 'prefecture': '大阪府', 'line': 'JR福知山線', 'x': 135.495188, 'y': 34.702398, 'postal': '5300001', 'distance': '00m', 'prev': None, 'next': '尼崎'}, {'name': '梅田', 'prefecture': '大阪府', 'line': '阪神本線', 'x': 135.496745, 'y': 34.701242, 'postal': '5300001', 'distance': '190m', 'prev': '福島', 'next': None}, {'name': '梅田', 'prefecture': '大阪府', 'line': '大阪御堂筋線', 'x': 135.497496, 'y': 34.703765, 'postal': '5300017', 'distance': '260m', 'prev': '中津', 'next': '淀屋橋'}, {'name': '西梅田', 'prefecture': '大阪府', 'line': '大阪四つ橋線', 'x': 135.495802, 'y': 34.699642, 'postal': '5300001', 'distance': '310m', 'prev': None, 'next': '肥後橋'}]}}Error対策
$ python sample3.py {'response': {'error': "Area '%E5%A4%A7%E9%98%AA%E5%BA%9C' not found."}}HTTPリクエストパラメータが間違っていると上記エラーが出る
参考
http://express.heartrails.com
路線図とかのAPIを使ってみた
乗換案内オープンAPIをアプリでも使う
駅すぱあとWebサービスでWebAPIを使ってみる
乗換案内オープンAPI仕様書
Google Maps APIで任意の住所から最寄り駅までの時間を取得する
公共機関や関連サービスが提供するAPI 20選
オープンデータのメモ書き
気象庁のデータをJSON化するAPIのようなものを作った
- 投稿日:2019-12-01T18:50:34+09:00
カフェの注文でいつも焦るので、Reactアプリを作って解決した
アプリ概要
スタバやドトールなどの主要カフェチェーンのドリンク・フードメニューを店ごとに一覧できるアプリを作りました。
商品名と各サイズの値段が表示され、行をタップすれば公式の詳細ページに飛びます。
なぜ作ったか
いわゆる「喫茶店」だと席についてからゆっくりとメニューを見られますが、スタバなんかだとレジの目の前で即断しないといけないこともあります。
後ろに人が並んでるし、目の前には店員さんもいる・・・。
この状況ではメニューをくまなく見れないし、結局前と同じ無難な注文をしがちです。
並んでいる最中にゆっくりと吟味できたらいいのにと思ったので作りました。
URL
技術
すべてAWS上で構成しました。
(矢印はユーザーが求めるデータの流れです)
フロントエンド
ReactによるSPAで、S3上にホスティングしました。
S3の静的サイトホスティング機能でも十分かなと思いますが、httpsに対応するためにCloudfrontを通しています。
UIフレームワークにはMaterial-UIを使わせてもらいました。
バックエンド
ReactからAPI Gateway -> Lambda関数を通して、S3上に保存されているメニューデータをjsonを返しています。
そのデータは各カフェチェーンの公式サイトから毎日一度だけスクレイピングさせてもらっています。
スクレイピング
言語はPythonで、 requests-htmlというライブラリを使用しました。
PythonといえばrequestsやBeautiful soupなんかが有名ですが、requests-htmlはそのあたりのライブラリをまとめて使いやすくしたもののようです。
実際、かなり直感的に使えるのでオススメです。
課題
Reactにまだ慣れない
初めて作ったReactアプリなのでいろいろと戸惑うことも多かったです。
各コンポーネントの依存関係や責任範囲などは、reduxも含めてもっと勉強したいと思います。
プロダクトとしての価値
適当な理想を掲げればwebサービスなんていくらでもデッチ上げられますが、多くの人に使ってもらえるようなプロダクトは稀です。
このアプリは「ショボくても、ダサくても、確実に誰かのニーズを満たせること」を目指してアイデアを練った結果生まれました。
ただ、どれだけ考えても確実なアイデアなんて出ないのはしょうがないと思います。
とにかくフットワークを軽くして、小さな検証を積み重ねていくつもりです。

- 投稿日:2019-12-01T18:27:25+09:00
returnとprintの違い -Python
returnとprintの違いがよく分からなかったので、ここにまとめておきます。しかし、まだ完全に違いを掴めていないので、明確に違いを理解できたらなと思っております。
return = 関数において、値を呼び出し元に返す。勘違いしていたのだが、returnは値を返すものなので値を出力したい場合はprintを使わないといけない。
print = ただ文字列を出力するもの。関数の時だけでなく、様々な場面で利用する。returnで返した値を出力したい場合は、printで出力しないと表示できない。なんとなくは理解しましたが、returnの「値を返す」という部分がまだはっきり理解できていません。これから何度もコードを書いたり、他の方が書かれたコードを読んで明確に理解できたらなと思います。
- 投稿日:2019-12-01T18:03:43+09:00
Qiskitソースコードリーディング 〜 Terra: バックエンドの取得、呼び出し、結果の取得を読む
何をするの?
量子コンピューティングライブラリのBlueqatを作っている私が、量子コンピューティングライブラリのQiskitのソースコードを読んでみる、という企画です。
前回の続きで、今回はバックエンドの取得、呼び出し、結果の取得を読むの処理を読んでいきます。
シミュレータ自体のソースは読まずに、バックエンドまわりのインタフェースについて読んでいきます。Qiskit概要
QiskitはIBMが開発しているオープンソースの量子コンピューティングライブラリです。
Qiskitは以下のようにパッケージが分かれていますが、インストールする際はバラバラにやるよりも
pip install qiskitでまとめてインストールした方がトラブルが少ないです。
パッケージ 役割 Qiskit Terra メインとなるパッケージです。回路を作るクラスや、回路を実機向けにトランスパイルする機能、APIを叩いて実機に投げる機能などが含まれています Qiskit Aer 量子回路のシミュレータが含まれており、通常はQiskit Terraから呼び出します Qiskit Ignis 量子回路を実機で動かした際のノイズと戦いたい人のためのライブラリです。私は使ったことがありません Qiskit Aqua 量子アルゴリズムを簡単に使えるようにしたライブラリです 今回読むのはQiskit Terraの一部です。
https://github.com/Qiskit/qiskit-terra
具体的には、README.mdに書いてあるコード
from qiskit import * qc = QuantumCircuit(2, 2) qc.h(0) qc.cx(0, 1) qc.measure([0,1], [0,1]) backend_sim = BasicAer.get_backend('qasm_simulator') result = execute(qc, backend_sim).result() print(result.get_counts(qc))のうち、
backend_sim = BasicAer.get_backend('qasm_simulator')以降の流れを読んでいきます。
ただし、シミュレータの中味やトランスパイルの詳細は読みません。GitHub上のmasterブランチを読んでいきます。
現時点のコミットIDはe7be587ですが、結構頻繁に更新されているので、記事が書き終わる頃には変わる可能性もあります。ご了承ください。
BasicAer.get_backendの行を読むbackend_sim = BasicAer.get_backend('qasm_simulator')この行を読みます。
BasicAerはterraのqiskit/providers/basicaer/init.pyでBasicAer = BasicAerProvider()と定義されています。
BasicAerProviderを読むqiskit/providers/basicaer/basicaerprovider.pyの
BasicAerProviderを読んでいきます。SIMULATORS = [ QasmSimulatorPy, StatevectorSimulatorPy, UnitarySimulatorPy ] class BasicAerProvider(BaseProvider): """Provider for Basic Aer backends.""" def __init__(self, *args, **kwargs): super().__init__(args, kwargs) # Populate the list of Basic Aer backends. self._backends = self._verify_backends() # 略 def _verify_backends(self): """ Return the Basic Aer backends in `BACKENDS` that are effectively available (as some of them might depend on the presence of an optional dependency or on the existence of a binary). Returns: dict[str:BaseBackend]: a dict of Basic Aer backend instances for the backends that could be instantiated, keyed by backend name. """ ret = OrderedDict() for backend_cls in SIMULATORS: try: backend_instance = self._get_backend_instance(backend_cls) backend_name = backend_instance.name() ret[backend_name] = backend_instance except QiskitError as err: # Ignore backends that could not be initialized. logger.info('Basic Aer backend %s is not available: %s', backend_cls, str(err)) return ret一応、親クラスの
BaseProviderの__init__を読んでおきます。class BaseProvider(ABC): """Base class for a Backend Provider.""" def __init__(self, *args, **kwargs): pass何もしていません。
BasicAerProvider._verify_backendsを読む続いて
self._backends = self._verify_backends()の
_verify_backendsを読みます。コードは上に貼りましたが、verifyって名前で検証以外のことするの本当によくない……
それは置いといて。BasicAerはプロバイダーで、プロバイダーとはBackendを持っているものである、という構造が見えてきました。
SIMULATORSに定義されている[QasmSimulatorPy, StatevectorSimulatorPy, UnitarySimulatorPy]クラスを、それぞれ_get_backend_instanceして、(順序付き)辞書に詰め込んで返しているようです。
_get_backend_instanceを読んでみましょう。docstringは削って引用します。def _get_backend_instance(self, backend_cls): # Verify that the backend can be instantiated. try: backend_instance = backend_cls(provider=self) except Exception as err: raise QiskitError('Backend %s could not be instantiated: %s' % (backend_cls, err)) return backend_instance単にバックエンドクラスのインスタンスを作ってるだけですが、インスタンスにプロバイダー自身を渡しています。
プロバイダーとバックエンドとは相互参照の関係になっています。
QasmSimulatorPy.__init__を読むこれらのバックエンドクラス自体は
qiskit/providers/basicaer/qasm_simulator.py、qiskit/providers/basicaer/statevector_simulator.py、qiskit/providers/basicaer/unitary_simulator.pyに定義されています。QasmSimulatorPy.__init__だけ見てみましょう。class QasmSimulatorPy(BaseBackend): """Python implementation of a qasm simulator.""" MAX_QUBITS_MEMORY = int(log2(local_hardware_info()['memory'] * (1024 ** 3) / 16)) DEFAULT_CONFIGURATION = { 'backend_name': 'qasm_simulator', 'backend_version': '2.0.0', 'n_qubits': min(24, MAX_QUBITS_MEMORY), 'url': 'https://github.com/Qiskit/qiskit-terra', 'simulator': True, 'local': True, 'conditional': True, 'open_pulse': False, 'memory': True, 'max_shots': 65536, 'coupling_map': None, 'description': 'A python simulator for qasm experiments', 'basis_gates': ['u1', 'u2', 'u3', 'cx', 'id', 'unitary'], 'gates': [ { 'name': 'u1', 'parameters': ['lambda'], 'qasm_def': 'gate u1(lambda) q { U(0,0,lambda) q; }' }, { 'name': 'u2', 'parameters': ['phi', 'lambda'], 'qasm_def': 'gate u2(phi,lambda) q { U(pi/2,phi,lambda) q; }' }, { 'name': 'u3', 'parameters': ['theta', 'phi', 'lambda'], 'qasm_def': 'gate u3(theta,phi,lambda) q { U(theta,phi,lambda) q; }' }, { 'name': 'cx', 'parameters': ['c', 't'], 'qasm_def': 'gate cx c,t { CX c,t; }' }, { 'name': 'id', 'parameters': ['a'], 'qasm_def': 'gate id a { U(0,0,0) a; }' }, { 'name': 'unitary', 'parameters': ['matrix'], 'qasm_def': 'unitary(matrix) q1, q2,...' } ] } DEFAULT_OPTIONS = { "initial_statevector": None, "chop_threshold": 1e-15 } # Class level variable to return the final state at the end of simulation # This should be set to True for the statevector simulator SHOW_FINAL_STATE = False def __init__(self, configuration=None, provider=None): super().__init__(configuration=( configuration or QasmBackendConfiguration.from_dict(self.DEFAULT_CONFIGURATION)), provider=provider) # Define attributes in __init__. self._local_random = np.random.RandomState() self._classical_memory = 0 self._classical_register = 0 self._statevector = 0 self._number_of_cmembits = 0 self._number_of_qubits = 0 self._shots = 0 self._memory = False self._initial_statevector = self.DEFAULT_OPTIONS["initial_statevector"] self._chop_threshold = self.DEFAULT_OPTIONS["chop_threshold"] self._qobj_config = None # TEMP self._sample_measure = Falseいろいろ設定入れてるなー、という感じです。やってることは単に変数の初期化などで、大したことをやっているようには見えません。
最大で24量子ビットまでしかシミュレートできないんですね。知らなかったです。(結構少なめに設定してるな、という印象です。普通のパソコンでも、もう少し頑張れるはずです)バックエンド自体に、ショット数や、メモリなどの途中経過と思われる状態を持たせているように見えます。(Blueqatでは、そのような実装をあえて避けています)
このあたりの思想は、これからコードを読むうちにもう少し分かってくるかもしれません。
BasicAerとは何であったか
BasicAerはBasicAerProviderのインスタンス
BasicAerProviderのインスタンスはバックエンドのリストを持つが分かりました。続いて、
BasicAer.get_backendを見ていきます。
BasicAer.get_backendを読むdef get_backend(self, name=None, **kwargs): backends = self._backends.values() # Special handling of the `name` parameter, to support alias resolution # and deprecated names. if name: try: resolved_name = resolve_backend_name( name, backends, self._deprecated_backend_names(), {} ) name = resolved_name except LookupError: raise QiskitBackendNotFoundError( "The '{}' backend is not installed in your system.".format(name)) return super().get_backend(name=name, **kwargs)せっかく
self._backendsを辞書で持ってるのに、そのまま辞書を引かずにやっているのが気になりますね。
resolve_backend_nameを読んでみましょう。
resolve_backend_nameを読む
resolve_backend_nameはqiskit/providers/providerutils.pyに定義されています。def resolve_backend_name(name, backends, deprecated, aliased): """Resolve backend name from a deprecated name or an alias. A group will be resolved in order of member priorities, depending on availability. Args: name (str): name of backend to resolve backends (list[BaseBackend]): list of available backends. deprecated (dict[str: str]): dict of deprecated names. aliased (dict[str: list[str]]): dict of aliased names. Returns: str: resolved name (name of an available backend) Raises: LookupError: if name cannot be resolved through regular available names, nor deprecated, nor alias names. """ available = [backend.name() for backend in backends] resolved_name = deprecated.get(name, aliased.get(name, name)) if isinstance(resolved_name, list): resolved_name = next((b for b in resolved_name if b in available), "") if resolved_name not in available: raise LookupError("backend '{}' not found.".format(name)) if name in deprecated: logger.warning("Backend '%s' is deprecated. Use '%s'.", name, resolved_name) return resolved_name
availableで、バックエンド名のリストを作ります。
deprecatedは、BasicAerProvider._deprecated_backend_names()を見ると、前からQiskit使っていた人には分かるように@staticmethod def _deprecated_backend_names(): """Returns deprecated backend names.""" return { 'qasm_simulator_py': 'qasm_simulator', 'statevector_simulator_py': 'statevector_simulator', 'unitary_simulator_py': 'unitary_simulator', 'local_qasm_simulator_py': 'qasm_simulator', 'local_statevector_simulator_py': 'statevector_simulator', 'local_unitary_simulator_py': 'unitary_simulator', 'local_unitary_simulator': 'unitary_simulator', }
{'古いバックエンド名': '現役のバックエンド名'}の辞書になっています。
探したいバックエンド名がdeprecatedに入っていたら、現役のバックエンド名に変換します。
aliasedについては、qiskit-terraとqiskit-aerを探しましたが空でないものが渡されているのが見つかりませんでしたが、探したいバックエンド名がaliased辞書に入っていたら、別名のリストを取り出すようです。
別名がリストで複数あるので、一番最初のavailableなバックエンド名にして、もしどれもavailableでなけえれば空文字列にします。名前の変換が終わったら、変換された名前に対応するバックエンドを見て、あればその名前を返し、なければ例外を投げます。
親クラスの
get_backend()を読む名前の変換を行って、
availableな名前を得たら、return super().get_backend(name=name, **kwargs)としていました。なので、
BaseProvider.get_backend()を読みましょう。docstringは省略します。def get_backend(self, name=None, **kwargs): backends = self.backends(name, **kwargs) if len(backends) > 1: raise QiskitBackendNotFoundError('More than one backend matches the criteria') if not backends: raise QiskitBackendNotFoundError('No backend matches the criteria') return backends[0]
BasicAerProvider.backends(name)で返されるリストかなにかの最初の要素を返しています。
BasicAerProvider.backendsを読みます。def backends(self, name=None, filters=None, **kwargs): # pylint: disable=arguments-differ backends = self._backends.values() # Special handling of the `name` parameter, to support alias resolution # and deprecated names. if name: try: resolved_name = resolve_backend_name( name, backends, self._deprecated_backend_names(), {} ) backends = [backend for backend in backends if backend.name() == resolved_name] except LookupError: return [] return filter_backends(backends, filters=filters, **kwargs)また
resolve_backend_nameを呼び出しています。deprecatedが循環しているとか、そういう変なことがなければ、何度やっても同じ結果が返ってくるはずです。今度は名前ではなくバックエンド自身を取り出しています。
filter_backendsについては、さほど大したことやってないのに長いので、気になる方はqiskit/providers/providerutils.pyをご参照ください。docstringとコメントだけ引用します。
def filter_backends(backends, filters=None, **kwargs): """略 Args: backends (list[BaseBackend]): list of backends. filters (callable): filtering conditions as a callable. **kwargs: dict of criteria. Returns: list[BaseBackend]: a list of backend instances matching the conditions. """ # Inspect the backends to decide which filters belong to # backend.configuration and which ones to backend.status, as it does # not involve querying the API. # 1. Apply backend.configuration filtering. # 2. Apply backend.status filtering (it involves one API call for # each backend). # 3. Apply acceptor filter.
kwargsで、backend.configurationやbackend.statusに対する条件を与えます。
これらはまぜこぜで与えると、filter_backends側で振り分けてくれます。
さらに、関数をfilters引数に与えると、Python組み込みのfilter関数でフィルタした結果を返してくれます。ちなみに、思いっきり話が逸れますが。Python組み込みの
filter関数って、引数にNone渡してもいいんですね。知らなかった。Return an iterator yielding those items of iterable for which function(item)
is true. If function is None, return the items that are true.らしいです。
list(filter(None, [1, 2, 0, 3, "", "a"])) # => [1, 2, 3, 'a']ともかく、いろいろとたらい回しにされながらも、名前にマッチしたバックエンドを一つ得ることができました。
これでbackend_sim = BasicAer.get_backend('qasm_simulator')の行は読めたことになります。
executeを読む続いて
result = execute(qc, backend_sim).result()の行のうち、
executeを読んでいきます。
qiskit/execute.pyから、docstringを削って引用します。def execute(experiments, backend, basis_gates=None, coupling_map=None, # circuit transpile options backend_properties=None, initial_layout=None, seed_transpiler=None, optimization_level=None, pass_manager=None, qobj_id=None, qobj_header=None, shots=1024, # common run options memory=False, max_credits=10, seed_simulator=None, default_qubit_los=None, default_meas_los=None, # schedule run options schedule_los=None, meas_level=2, meas_return='avg', memory_slots=None, memory_slot_size=100, rep_time=None, parameter_binds=None, **run_config): # transpiling the circuits using given transpile options experiments = transpile(experiments, basis_gates=basis_gates, coupling_map=coupling_map, backend_properties=backend_properties, initial_layout=initial_layout, seed_transpiler=seed_transpiler, optimization_level=optimization_level, backend=backend, pass_manager=pass_manager, ) # assembling the circuits into a qobj to be run on the backend qobj = assemble(experiments, qobj_id=qobj_id, qobj_header=qobj_header, shots=shots, memory=memory, max_credits=max_credits, seed_simulator=seed_simulator, default_qubit_los=default_qubit_los, default_meas_los=default_meas_los, schedule_los=schedule_los, meas_level=meas_level, meas_return=meas_return, memory_slots=memory_slots, memory_slot_size=memory_slot_size, rep_time=rep_time, parameter_binds=parameter_binds, backend=backend, **run_config ) # executing the circuits on the backend and returning the job return backend.run(qobj, **run_config)
transpileを眺める今回、トランスパイルの詳細については立ち入りません。
本当に表面だけ眺めます。qiskit/compiler/transpile.pyにあります。
docstringがとても長いので省略しますが、興味深いので、読まれることをおすすめします。def transpile(circuits, backend=None, basis_gates=None, coupling_map=None, backend_properties=None, initial_layout=None, seed_transpiler=None, optimization_level=None, pass_manager=None, callback=None, output_name=None): # transpiling schedules is not supported yet. if isinstance(circuits, Schedule) or \ (isinstance(circuits, list) and all(isinstance(c, Schedule) for c in circuits)): return circuits if optimization_level is None: config = user_config.get_config() optimization_level = config.get('transpile_optimization_level', None) # Get TranspileConfig(s) to configure the circuit transpilation job(s) circuits = circuits if isinstance(circuits, list) else [circuits] transpile_configs = _parse_transpile_args(circuits, backend, basis_gates, coupling_map, backend_properties, initial_layout, seed_transpiler, optimization_level, pass_manager, callback, output_name) # Check circuit width against number of qubits in coupling_map(s) coupling_maps_list = list(config.coupling_map for config in transpile_configs) for circuit, parsed_coupling_map in zip(circuits, coupling_maps_list): # If coupling_map is not None if isinstance(parsed_coupling_map, CouplingMap): n_qubits = len(circuit.qubits) max_qubits = parsed_coupling_map.size() if n_qubits > max_qubits: raise TranspilerError('Number of qubits ({}) '.format(n_qubits) + 'in {} '.format(circuit.name) + 'is greater than maximum ({}) '.format(max_qubits) + 'in the coupling_map') # Transpile circuits in parallel circuits = parallel_map(_transpile_circuit, list(zip(circuits, transpile_configs))) if len(circuits) == 1: return circuits[0] return circuits実機などでは、CNOTなどがつながっていないゲートがありますので、それらを割付ながら回路を作っていく働きをしているようです。
さらに、その計算自体がしんどいので、並列化して計算しています。
引数を省略しても、バックエンドから適宜、設定を取ってきてくれるのは、バックエンドにいっぱい設定を付け加えたおかげと言えるでしょう。回路を変換して回路自身を返します。
assembleを眺めるqiskit/compiler/assemble.pyにある
assembleも、同様に眺めていきます。(docstringは省略)def assemble(experiments, backend=None, qobj_id=None, qobj_header=None, shots=1024, memory=False, max_credits=None, seed_simulator=None, qubit_lo_freq=None, meas_lo_freq=None, qubit_lo_range=None, meas_lo_range=None, schedule_los=None, meas_level=2, meas_return='avg', meas_map=None, memory_slot_size=100, rep_time=None, parameter_binds=None, **run_config): experiments = experiments if isinstance(experiments, list) else [experiments] qobj_id, qobj_header, run_config_common_dict = _parse_common_args(backend, qobj_id, qobj_header, shots, memory, max_credits, seed_simulator, **run_config) # assemble either circuits or schedules if all(isinstance(exp, QuantumCircuit) for exp in experiments): run_config = _parse_circuit_args(parameter_binds, **run_config_common_dict) # If circuits are parameterized, bind parameters and remove from run_config bound_experiments, run_config = _expand_parameters(circuits=experiments, run_config=run_config) return assemble_circuits(circuits=bound_experiments, qobj_id=qobj_id, qobj_header=qobj_header, run_config=run_config) elif all(isinstance(exp, ScheduleComponent) for exp in experiments): run_config = _parse_pulse_args(backend, qubit_lo_freq, meas_lo_freq, qubit_lo_range, meas_lo_range, schedule_los, meas_level, meas_return, meas_map, memory_slot_size, rep_time, **run_config_common_dict) return assemble_schedules(schedules=experiments, qobj_id=qobj_id, qobj_header=qobj_header, run_config=run_config) else: raise QiskitError("bad input to assemble() function; " "must be either circuits or schedules")回路に対するアセンブルと、パルスのスケジュールに関するアセンブルができるようです。
返す値の型はQObjで、回路の場合はQasmQObj型が返ってきます。
QasmQobj型がどういうデータ構造か分からないと、この後で困るので、from qiskit import * qc = QuantumCircuit(2, 2) qc.h(0) qc.cx(0, 1) qc.measure([0,1], [0,1]) backend_sim = BasicAer.get_backend('qasm_simulator') tran = transpile(qc, backend=backend_sim) asm = assemble(qc, backend=backend_sim)の
asmを見ると、以下のようになっていました。QasmQobj( config=QasmQobjConfig( memory=False, memory_slots=2, n_qubits=2, parameter_binds=[], shots=1024), experiments=[ QasmQobjExperiment( config=QasmQobjExperimentConfig(memory_slots=2, n_qubits=2), header=QobjExperimentHeader( clbit_labels=[['c', 0], ['c', 1]], creg_sizes=[['c', 2]], memory_slots=2, n_qubits=2, name='circuit0', qreg_sizes=[['q', 2]], qubit_labels=[['q', 0], ['q', 1]]), instructions=[ QasmQobjInstruction( name='u2', params=[0, 3.14159265358979], qubits=[0]), QasmQobjInstruction(name='cx', qubits=[0, 1]), QasmQobjInstruction(memory=[0], name='measure', qubits=[0]), QasmQobjInstruction(memory=[1], name='measure', qubits=[1]) ]) ], header=QobjHeader(backend_name='qasm_simulator', backend_version='2.0.0'), qobj_id='06682d2e-bfd8-4dba-ba8e-4e46492c1609', schema_version='1.1.0', type='QASM')特に問題なく読めるかと思います。ちなみにHゲートは
u2(0, π)に変換されています。これは等価な表現です。
backend.runを見る回路を
QasmQobjに変換したので、次はreturn backend.run(qobj, **run_config)を読んでいきます。qiskit/providers/basicaer/qasm_simulator.py
def run(self, qobj, backend_options=None): """Run qobj asynchronously. Args: qobj (Qobj): payload of the experiment backend_options (dict): backend options Returns: BasicAerJob: derived from BaseJob Additional Information: backend_options: Is a dict of options for the backend. It may contain * "initial_statevector": vector_like The "initial_statevector" option specifies a custom initial initial statevector for the simulator to be used instead of the all zero state. This size of this vector must be correct for the number of qubits in all experiments in the qobj. Example:: backend_options = { "initial_statevector": np.array([1, 0, 0, 1j]) / np.sqrt(2), } """ self._set_options(qobj_config=qobj.config, backend_options=backend_options) job_id = str(uuid.uuid4()) job = BasicAerJob(self, job_id, self._run_job, qobj) job.submit() return jobオプションに初期ベクトルを入れられるのはいいですね。完全にバックエンド依存になってしまいそうですが。
chop_thresholdオプションは、状態ベクトルをシミュレートする際に、この値以下だと値を0として扱うらしいです。
QasmSimulatorPy._set_optionsを読む
_set_options読んでいきます。def _set_options(self, qobj_config=None, backend_options=None): """Set the backend options for all experiments in a qobj""" # Reset default options self._initial_statevector = self.DEFAULT_OPTIONS["initial_statevector"] self._chop_threshold = self.DEFAULT_OPTIONS["chop_threshold"] if backend_options is None: backend_options = {} # Check for custom initial statevector in backend_options first, # then config second if 'initial_statevector' in backend_options: self._initial_statevector = np.array(backend_options['initial_statevector'], dtype=complex) elif hasattr(qobj_config, 'initial_statevector'): self._initial_statevector = np.array(qobj_config.initial_statevector, dtype=complex) if self._initial_statevector is not None: # Check the initial statevector is normalized norm = np.linalg.norm(self._initial_statevector) if round(norm, 12) != 1: raise BasicAerError('initial statevector is not normalized: ' + 'norm {} != 1'.format(norm)) # Check for custom chop threshold # Replace with custom options if 'chop_threshold' in backend_options: self._chop_threshold = backend_options['chop_threshold'] elif hasattr(qobj_config, 'chop_threshold'): self._chop_threshold = qobj_config.chop_thresholdバックエンド自身にオプションを持たせている都合上
# Reset default options self._initial_statevector = self.DEFAULT_OPTIONS["initial_statevector"] self._chop_threshold = self.DEFAULT_OPTIONS["chop_threshold"]がこんなところで出てきてしまっています。ともかく、ただ2つのオプションを解釈してqobjにセットしてるだけです。
BasicAerJob.__init__を読むjob_id = str(uuid.uuid4()) job = BasicAerJob(self, job_id, self._run_job, qobj)job_idとして適当なUUIDを降っています。
jobとしてBasicAerJobを作っています。self._run_jobはメソッドですが、メソッドをそのまま渡しています。後で呼び出されたときに見ましょう。qiskit/providers/basicaer/basicaerjob.py
class BasicAerJob(BaseJob): """BasicAerJob class. Attributes: _executor (futures.Executor): executor to handle asynchronous jobs """ if sys.platform in ['darwin', 'win32']: _executor = futures.ThreadPoolExecutor() else: _executor = futures.ProcessPoolExecutor() def __init__(self, backend, job_id, fn, qobj): super().__init__(backend, job_id) self._fn = fn self._qobj = qobj self._future = Noneデータ作っただけで、この時点では何もしていません。
Windows, Macではスレッドプールを、その他ではプロセスプールを使っていることは、若干気になりました。
PythonはマルチスレッドではCPUが複数あっても、1スレッドしか同時に動きません。
どう使われるのか気にしておきましょう。
BasicAerJob.submitを読むjob.submit() return jobjobをsubmitしてから、jobを返しています。
BasicAerJob.submitを読んでいきましょう。def submit(self): """Submit the job to the backend for execution. Raises: QobjValidationError: if the JSON serialization of the Qobj passed during construction does not validate against the Qobj schema. JobError: if trying to re-submit the job. """ if self._future is not None: raise JobError("We have already submitted the job!") validate_qobj_against_schema(self._qobj) self._future = self._executor.submit(self._fn, self._job_id, self._qobj)validate_qobj_against_schema(self._qobj)については、Qobjが、別ファイルに定義されているJSONスキーマの形式に合っているかを、外部ライブラリの
jsonschemaを使って検証しているだけでした。あまり面白くないので省略します。
_executorは、Python標準ライブラリconcurrent.futuresのThreadPoolExecutorまたはProcessPoolExecutorでした。そのsubmitメソッドを呼んでいます。公式ドキュメントを読んでみましょう。
submit(fn, *args, **kwargs)
呼び出し可能オブジェクトfnを、fn(*args **kwargs)として実行するようにスケジュールし、呼び出し可能オブジェクトの実行を表現する Future オブジェクトを返します。つまり、
self._fn(self._job_id, self._qobj)を実行するようにスケジュールするためのFutureオブジェクトを作っていることになります。この
Futureオブジェクトは非同期実行のためのもので、_executorによって裏で動かされながら、計算が終わってなくてもとりあえず処理は進みます。
(ハンバーガー屋さんでハンバーガーを注文したら、出来上がるまでカウンターの前で待っていても構いませんが、番号札をもらえば、先に席を取るとか、別のことができて時間が有意義に過ごせます。通常の関数呼び出しだと、結果が返ってくるまで待つ必要がありますが、非同期実行では、返ってくるまで待たずに別のことができます。Futureオブジェクトは、将来、ハンバーガーを受け取るための番号札のようなものです)
QasmSimulatorPy._run_jobを読む
_executorよって動かされるself._fn(self._job_id, self._qobj)って何だったかを思い出すと、job = BasicAerJob(self, job_id, self._run_job, qobj)で作ったself._run_job(job_id, qobj)でした。なので
QasmSimulatorPy._run_jobを読んでみましょう。def _run_job(self, job_id, qobj): """Run experiments in qobj Args: job_id (str): unique id for the job. qobj (Qobj): job description Returns: Result: Result object """ self._validate(qobj) result_list = [] self._shots = qobj.config.shots self._memory = getattr(qobj.config, 'memory', False) self._qobj_config = qobj.config start = time.time() for experiment in qobj.experiments: result_list.append(self.run_experiment(experiment)) end = time.time() result = {'backend_name': self.name(), 'backend_version': self._configuration.backend_version, 'qobj_id': qobj.qobj_id, 'job_id': job_id, 'results': result_list, 'status': 'COMPLETED', 'success': True, 'time_taken': (end - start), 'header': qobj.header.to_dict()} return Result.from_dict(result)
self._validate(後で読みます)- バックエンド自体に必要な情報をセット
- タイマー開始
qobj.experimentsからexperimentを1個ずつ取り出して
result_listに各experimentをrun_experiment(後で読みます)した結果を追加- タイマー終了
- 結果を辞書に詰めて、
Result型に変換して(後で読みます)返す
QasmSimulatorPy._validateを読むdef _validate(self, qobj): """Semantic validations of the qobj which cannot be done via schemas.""" n_qubits = qobj.config.n_qubits max_qubits = self.configuration().n_qubits if n_qubits > max_qubits: raise BasicAerError('Number of qubits {} '.format(n_qubits) + 'is greater than maximum ({}) '.format(max_qubits) + 'for "{}".'.format(self.name())) for experiment in qobj.experiments: name = experiment.header.name if experiment.config.memory_slots == 0: logger.warning('No classical registers in circuit "%s", ' 'counts will be empty.', name) elif 'measure' not in [op.name for op in experiment.instructions]: logger.warning('No measurements in circuit "%s", ' 'classical register will remain all zeros.', name)qubit数が最大値を越えていないことの確認と、古典レジスタがあるか、測定が行われているかの確認をしています。
(古典レジスタ無し、測定無しはエラーではなく警告扱い)
QasmSimulatorPy.run_experimentを眺めるその前に、
experimentsが何でできていたか思い出しておきましょう。experiments=[ QasmQobjExperiment( config=QasmQobjExperimentConfig(memory_slots=2, n_qubits=2), header=QobjExperimentHeader( clbit_labels=[['c', 0], ['c', 1]], creg_sizes=[['c', 2]], memory_slots=2, n_qubits=2, name='circuit0', qreg_sizes=[['q', 2]], qubit_labels=[['q', 0], ['q', 1]]), instructions=[ QasmQobjInstruction( name='u2', params=[0, 3.14159265358979], qubits=[0]), QasmQobjInstruction(name='cx', qubits=[0, 1]), QasmQobjInstruction(memory=[0], name='measure', qubits=[0]), QasmQobjInstruction(memory=[1], name='measure', qubits=[1]) ]) ],
QasmQobjExperimentがひとつの量子回路に対応しています。Qiskitでは、量子回路をいくつも詰めて実行できるんですが、今回はひとつだけのようです。
for experiment in qobj.experiments:のループを回していたので、各回路ごとにrun_experimentを呼び出していることになります。回路にはinstructionsがあり、これはゲートや測定に相当します。
run_experimentは本当に長いので省略します。ざっくりとは、shotsの回数だけゲートの計算、測定の計算を行って、return {'name': experiment.header.name, 'seed_simulator': seed_simulator, 'shots': self._shots, 'data': data, 'status': 'DONE', 'success': True, 'time_taken': (end - start), 'header': experiment.header.to_dict()}のような結果を返します。
なお、dataは# Add data data = {'counts': dict(Counter(memory))} # Optionally add memory list if self._memory: data['memory'] = memory # Optionally add final statevector if self.SHOW_FINAL_STATE: data['statevector'] = self._get_statevector() # Remove empty counts and memory for statevector simulator if not data['counts']: data.pop('counts') if 'memory' in data and not data['memory']のように、測定データなどをもたせています。
qiskit.result.Resultを読む辞書型を
return Result.from_dict(result)によってResult型にしています。
qiskit/result/result.py@bind_schema(ResultSchema) class Result(BaseModel): """Model for Results. Please note that this class only describes the required fields. For the full description of the model, please check ``ResultSchema``. Attributes: backend_name (str): backend name. backend_version (str): backend version, in the form X.Y.Z. qobj_id (str): user-generated Qobj id. job_id (str): unique execution id from the backend. success (bool): True if complete input qobj executed correctly. (Implies each experiment success) results (list[ExperimentResult]): corresponding results for array of experiments of the input qobj """ def __init__(self, backend_name, backend_version, qobj_id, job_id, success, results, **kwargs): self.backend_name = backend_name self.backend_version = backend_version self.qobj_id = qobj_id self.job_id = job_id self.success = success self.results = results本来は
from_dictを読みたいのですが、qiskit-terraの特徴のひとつとして、JSONスキーマ周りの処理をすごくがんばっています。from_dictは親クラスのBaseModelで定義されていて、その中味が@classmethod def from_dict(cls, dict_): """Deserialize a dict of simple types into an instance of this class. Note that this method requires that the model is bound with ``@bind_schema``. """ try: data = cls.schema.load(dict_) except ValidationError as ex: raise ModelValidationError( ex.messages, ex.field_name, ex.data, ex.valid_data, **ex.kwargs) from None return dataと、とてもシンプルになっています。
Resultクラスとは別にResultSchemaクラスを作ってclass ResultSchema(BaseSchema): """Schema for Result.""" # Required fields. backend_name = String(required=True) backend_version = String(required=True, validate=Regexp('[0-9]+.[0-9]+.[0-9]+$')) qobj_id = String(required=True) job_id = String(required=True) success = Boolean(required=True) results = Nested(ExperimentResultSchema, required=True, many=True) # Optional fields. date = DateTime() status = String() header = Nested(ObjSchema)とする、など、かなりちゃんとやっています。(/qiskit/result/models.pyで定義)
ちゃんとは読めてないんですが、これらのデータ型になっていることを確認しながら、ExperimentResultSchemaなどは再帰的にオブジェクトにしていくのではないかと思います。いずれにせよ、データの詰め替えなので、今回は省略させてください。
手元で動かして返ってきた
Resultは、次のようになっていました。Result( backend_name='qasm_simulator', backend_version='2.0.0', header=Obj(backend_name='qasm_simulator', backend_version='2.0.0'), job_id='65b162ae-fe6b-480a-85ba-8c890d8bbf3b', qobj_id='c75e9b2c-da7c-4dd6-96da-d132126e6dc0', results=[ ExperimentResult( data=ExperimentResultData(counts=Obj(0x0=493, 0x3=531)), header=Obj( clbit_labels=[['c', 0], ['c', 1]], creg_sizes=[['c', 2]], memory_slots=2, n_qubits=2, name='circuit0', qreg_sizes=[['q', 2]], qubit_labels=[['q', 0], ['q', 1]]), meas_level=2, name='circuit0', seed_simulator=1480888590, shots=1024, status='DONE', success=True, time_taken=0.12355875968933105) ], status='COMPLETED', success=True, time_taken=0.12369537353515625)
BasicAerJob.result()を読む相当、途中を飛ばしましたが、
result = execute(qc, backend_sim).result()の
execute(qc, backend_sim)が終わり、.result()を見ていきます。
executeはBasicAerJobを返すんでしたね。@requires_submit def result(self, timeout=None): # pylint: disable=arguments-differ """Get job result. The behavior is the same as the underlying concurrent Future objects, https://docs.python.org/3/library/concurrent.futures.html#future-objects Args: timeout (float): number of seconds to wait for results. Returns: qiskit.Result: Result object Raises: concurrent.futures.TimeoutError: if timeout occurred. concurrent.futures.CancelledError: if job cancelled before completed. """ return self._future.result(timeout=timeout)最初の
@requires_submitは、submitをしたかどうかを見ています。
submitしたかどうかは、BasicAerJobを作ったときにself._future = Noneとしていましたが、submitするとself._futureにFutureオブジェクトが入るので、Noneになっていないかチェックをしたら分かります。これは、普通に
Futureオブジェクトのresultメソッドを呼び出しています。
公式ドキュメントを見ましょう。
result(timeout=None)
呼び出しによって返された値を返します。呼び出しがまだ完了していない場合、このメソッドは timeout 秒の間待機します。呼び出しが timeout 秒間の間に完了しない場合、 concurrent.futures.TimeoutError が送出されます。 timeout にはintかfloatを指定できます。timeout が指定されていないか、 None である場合、待機時間に制限はありません。
future が完了する前にキャンセルされた場合 CancelledError が送出されます。
呼び出しが例外を送出した場合、このメソッドは同じ例外を送出します。終わっていたら結果を返して、終わってなかったら待ってから結果を返す、というメソッドです。
結果は、上で見たとおりResult型のオブジェクトです。
Result.get_countsを読むとうとう最後の行です。
print(result.get_counts(qc))を見ていきます。
def get_counts(self, experiment=None): """Get the histogram data of an experiment. Args: experiment (str or QuantumCircuit or Schedule or int or None): the index of the experiment, as specified by ``get_data()``. Returns: dict[str:int]: a dictionary with the counts for each qubit, with the keys containing a string in binary format and separated according to the registers in circuit (e.g. ``0100 1110``). The string is little-endian (cr[0] on the right hand side). Raises: QiskitError: if there are no counts for the experiment. """ exp = self._get_experiment(experiment) try: header = exp.header.to_dict() except (AttributeError, QiskitError): # header is not available header = None if 'counts' in self.data(experiment).keys(): return postprocess.format_counts(self.data(experiment)['counts'], header) elif 'statevector' in self.data(experiment).keys(): vec = postprocess.format_statevector(self.data(experiment)['statevector']) return state_to_counts(vec) else: raise QiskitError('No counts for experiment "{0}"'.format(experiment))
_get_experimentでは、回路名に対応したexperimentを取り出しています。今回のようにexperimentがひとつの場合は、experiment引数を省略しても構いません。
experimentからヘッダーが取り出せたら、古典レジスタの長さが分かるので、測定結果をいい感じにゼロ埋めできます。
format_countsではいい感じに文字列に変換して辞書に詰めるのをやっています。まとめ
今回、Qiskitで、量子計算に直接関わるところを除いた処理の流れを読んでいきました。
度重なる変更や、将来を見越した拡張性などから、とてもしんどい仕様になっている部分もありましたが、かなりいろんなことができるように作られていて、また、トランスパイルやJSONへの変換など、Blueqatでは扱っていない部分がかなり重厚で、大変勉強になる、という印象を受けました。全体の流れを読む、という目標は今回で終了ですが、今後もQiskitソースコードリーディングは続けていこうと思います。
- 投稿日:2019-12-01T17:27:38+09:00
(備忘)Pandas_購入ログっぽいサンプルデータ作成&groupbyとかassignとか
サンプルデータ作成
import numpy as np import pandas as pd from datetime import datetime, timedelta from math import ceil # create sample data --------------- ## function def repeat_copy_and_random_choice(values_list, sample_length): repeat_rate = 5 repeat_copied = values_list * ceil(sample_length / len(values_list) * repeat_rate) random_choiced = np.random.choice(repeat_copied, sample_length) return random_choiced ## parameters data_length = 100 users = [c for c in 'ABCDEFGHIJ'] items = [c for c in 'abcdefghijklmnopqrstuvwxyz'] order_dates = list(np.arange(datetime(2019,9,1), datetime(2019,9,30), timedelta(days=1)).astype(datetime)) item_price_master = pd.DataFrame() ## DataFrame df = pd.DataFrame() df['order_date'] = repeat_copy_and_random_choice(order_dates, data_length) df['user'] = repeat_copy_and_random_choice(users, data_length) df['item'] = repeat_copy_and_random_choice(items, data_length) df['quantity'] = np.random.randint(1,10, data_length) item_price_master['item'] = items item_price_master['unit_price'] = [np.ceil(x * 1000) for x in np.random.random(len(items))] df = df.merge(item_price_master, on='item', how='left') df = df.sort_values(by=['order_date', 'user', 'item']).reset_index(drop=True)こんなデータ
「購入日、ユーザー名、商品名、購入個数、単価」的なイメージ
※ランダム要素あるので、実行する度に変わる(シードは固定してない)計算例1:ユーザーごとの 購入額合計/購入日数合計
## purchase amount / (date & user) (df .assign(price=lambda xdf: xdf['unit_price'] * xdf['quantity']) .groupby('user') .agg({ 'order_date':pd.Series.nunique, 'price':pd.Series.sum, }) .assign(price_per_date=lambda xdf: (xdf['price'] / xdf['order_date']).astype(int)) .sort_values(by='price_per_date', ascending=False) ) ## purchase amount / (date & user):別の書き方(まどろっこしいが備忘) def tmp1(srs): x = int(srs['price'] / srs['order_date']) return pd.Series(data=[srs['order_date'], srs['price'], x], index=['order_date', 'price', 'price_per_date']) (df .assign(price=lambda xdf: xdf['unit_price'] * xdf['quantity']) .groupby('user') .agg({ 'order_date':pd.Series.nunique, 'price':pd.Series.sum, }) .apply(tmp1, axis=1) .sort_values(by='price_per_date', ascending=False) )結果はこんな感じ
※上のコードと下のコードで同じ計算してるが、表示フォーマットは若干変わるかも計算例2:ユーザーごとの 購入間隔日数の中央値
def calc_med_diff_date(xdf): # 日付が異なるところだけ残す flags = ( (xdf['order_date_prev'].notnull()) & (xdf['order_date']!=xdf['order_date_prev']) ) tmp = xdf.loc[flags, :] avg_diff_date = (tmp['order_date'] - tmp['order_date_prev']).median() return avg_diff_date (df .sort_values(by=['user', 'order_date'], ascending=True) .assign(order_date_prev=lambda xdf: xdf.groupby('user')['order_date'].shift(1)) [['user','order_date','order_date_prev']] # 別にこれはなくてもいい .groupby('user') .apply(calc_med_diff_date) .sort_values(ascending=True) )結果はこんな感じ
おわり


- 投稿日:2019-12-01T17:27:38+09:00
購入ログっぽいサンプルデータ作成&pandasでの加工・集計コード例
サンプルデータ作成
import numpy as np import pandas as pd from datetime import datetime, timedelta from math import ceil # create sample data --------------- ## function def repeat_copy_and_random_choice(values_list, sample_length): repeat_rate = 5 repeat_copied = values_list * ceil(sample_length / len(values_list) * repeat_rate) random_choiced = np.random.choice(repeat_copied, sample_length) return random_choiced ## parameters data_length = 100 users = [c for c in 'ABCDEFGHIJ'] items = [c for c in 'abcdefghijklmnopqrstuvwxyz'] order_dates = list(np.arange(datetime(2019,9,1), datetime(2019,9,30), timedelta(days=1)).astype(datetime)) item_price_master = pd.DataFrame() ## DataFrame df = pd.DataFrame() df['order_date'] = repeat_copy_and_random_choice(order_dates, data_length) df['user'] = repeat_copy_and_random_choice(users, data_length) df['item'] = repeat_copy_and_random_choice(items, data_length) df['quantity'] = np.random.randint(1,10, data_length) item_price_master['item'] = items item_price_master['unit_price'] = [np.ceil(x * 1000) for x in np.random.random(len(items))] df = df.merge(item_price_master, on='item', how='left') df = df.sort_values(by=['order_date', 'user', 'item']).reset_index(drop=True)こんなデータ
「購入日、ユーザー名、商品名、購入個数、単価」的なイメージ
※ランダム要素あるので、実行する度に変わる(シードは固定してない)計算例1:ユーザーごとの 購入額合計/購入日数合計
## purchase amount / (date & user) (df .assign(price=lambda xdf: xdf['unit_price'] * xdf['quantity']) .groupby('user') .agg({ 'order_date':pd.Series.nunique, 'price':pd.Series.sum, }) .assign(price_per_date=lambda xdf: (xdf['price'] / xdf['order_date']).astype(int)) .sort_values(by='price_per_date', ascending=False) ) ## purchase amount / (date & user):別の書き方(まどろっこしいが備忘) def tmp1(srs): x = int(srs['price'] / srs['order_date']) return pd.Series(data=[srs['order_date'], srs['price'], x], index=['order_date', 'price', 'price_per_date']) (df .assign(price=lambda xdf: xdf['unit_price'] * xdf['quantity']) .groupby('user') .agg({ 'order_date':pd.Series.nunique, 'price':pd.Series.sum, }) .apply(tmp1, axis=1) .sort_values(by='price_per_date', ascending=False) )結果はこんな感じ
※上のコードと下のコードで同じ計算してるが、表示フォーマットは若干変わるかも計算例2:ユーザーごとの 購入間隔日数の中央値
def calc_med_diff_date(xdf): # 日付が異なるところだけ残す flags = ( (xdf['order_date_prev'].notnull()) & (xdf['order_date']!=xdf['order_date_prev']) ) tmp = xdf.loc[flags, :] avg_diff_date = (tmp['order_date'] - tmp['order_date_prev']).median() return avg_diff_date (df .sort_values(by=['user', 'order_date'], ascending=True) .assign(order_date_prev=lambda xdf: xdf.groupby('user')['order_date'].shift(1)) [['user','order_date','order_date_prev']] # 別にこれはなくてもいい .groupby('user') .apply(calc_med_diff_date) .sort_values(ascending=True) )結果はこんな感じ
おわり
- 投稿日:2019-12-01T17:02:04+09:00
Word2Vec+RandomForestで笑点の回答者ともらえる座布団の枚数を予測する
動機
笑点がものすごく好きで、実家に帰省すると録画した笑点を延々と見ていたりする。
一時自然言語処理の研究から開放され、息抜きとして笑点を・・・ちゃっちゃら~ちゃらら
チャッ
チャッ!!!!!inside-head答えをどうぞ:(笑点っぽい答えを入力) 山田くん!三遊亭円楽さんの1枚持ってって!パフっ!(ひらめきのおと)
笑点って?
・昔からやっている演芸番組
・プロの落語家がお題に対して洒落た回答をする大喜利が有名
・面白い回答をすると座布団がもらえる。滑ったり失礼な回答をすると座布団を取られる
・座布団を10枚集めるとものすごい商品がもらえる目的
笑点っぽい答えを入力したら、
・誰の答えに一番近いか
・座布団を何枚もらえるのか
を予測して表示する。手順① 文章収集、前処理
日本テレビが公開している過去の放送内容http://www.ntv.co.jp/sho-ten/02_week/kako_2011.htmlから2011年分の
・回答
・回答者
・座布団の増減
を記録。主要6人以外の回答(アナウンサー大喜利、若手大喜利等)は対象外とした。収集した回答数は1773回答。
1人あたり大体330回答くらいで、あまり差がなかったのは驚き。この文章から記号や変な空白の削除、emojiで絵文字の排除、mojimojiで大文字小文字等の統一をした。
手順② Word2Vec
Word2Vecで文章を200次元のベクトルに変換した。
日本語Wikipediaエンティティベクトルを利用して文章中の単語をベクトル化する。
(口語的表現が多い笑点の回答でWikipedia使うのはどうかと思ったけど、気軽に使える学習済みモデルには勝てなかった)
回答中からとれた単語ベクトルの加算平均をその回答のベクトルとした。手順③ RandomForestで学習
ランダムフォレストで分類器を作成した。
ランダムフォレストは計算が軽いのがとても良いですね。
GridsearchCVでパラメータの最適化も行いました。
パラメータ探索範囲は
最大深さ:1~10
決定木数:1~1000
です。パラメータ探索後に最も正解率(accuracy)が高いやつを抜き出して、Pickleを使って分類器を保存します。
gridsearch.pygrid_mori_speaker = GridSearchCV(RandomForestClassifier() , grid_param_mori() , cv=10 ,scoring = 'accuracy', verbose = 3,n_jobs=-1) grid_mori_speaker.fit(kotae_vector,shoten.speaker) grid_mori_speaker_best = grid_mori_speaker.best_estimator_ with open('shoten_speaker_RF.pickle',mode = 'wb') as fp : pickle.dump(grid_mori_speaker_best,fp)これを回答者判別ともらえる座布団の枚数でそれぞれ計算して、pickleファイルで保存します。
ちなみに回答者判別での最高正解率は0.25、座布団枚数では0.50でした。
まだだいぶ低いので手順②~③を改良して精度よくしていきたいですね。手順④ 文章を入力させて分類するプログラムを作る
文章を手入力させて分類結果を表示させるプログラムを作ります。
やってることはpickleファイル化した分類機を解凍して文章ベクトルを突っ込んで分類結果を出力といった感じです。shoten.py#usr/bin/env python #coding:utf-8 import numpy as np import re import emoji import mojimoji import MeCab from gensim.models import KeyedVectors import pickle mecab = MeCab.Tagger("")#Neologd辞書を使う場合はパスを記載してください model_entity = KeyedVectors.load_word2vec_format("entity_vector.model.bin",binary = True) with open('shoten_speaker_RF.pickle', mode='rb') as f: speaker_clf = pickle.load(f) with open('shoten_zabuton_RF.pickle', mode='rb') as f: zabuton_clf = pickle.load(f) def text_to_vector(text , w2vmodel,num_features): kotae = text kotae = kotae.replace(',','、') kotae = kotae.replace('/n','') kotae = kotae.replace('\t','') kotae = re.sub(r'\s','',kotae) kotae = re.sub(r'^@.[\w]+','',kotae) kotae = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+','',kotae) kotae = re.sub(r'[!-/:-@[-`{-~ ]+','',kotae) kotae = re.sub(r'[:-@,【】★☆「」。、・]+','',kotae) kotae = mojimoji.zen_to_han(kotae,kana = False) kotae = kotae.lower() kotae = ''.join(['' if character in emoji.UNICODE_EMOJI else character for character in kotae]) kotae_node = mecab.parseToNode(kotae) kotae_line = [] while kotae_node: surface = kotae_node.surface meta = kotae_node.feature.split(",") if not meta[0] == '記号' and not meta[0] == 'BOS/EOS': kotae_line.append(kotae_node.surface) kotae_node = kotae_node.next feature_vec = np.zeros((num_features), dtype = "float32") word_count = 0 for word in kotae_line: try: feature_vec = np.add(feature_vec,w2vmodel[word]) word_count += 1 except KeyError : pass if len(word) > 0: if word_count == 0: feature_vec = np.divide(feature_vec,1) else: feature_vec = np.divide(feature_vec,word_count) feature_vec = feature_vec.tolist() return feature_vec def zabuton_challenge(insert_text): vector = np.array(text_to_vector(insert_text,model_entity,200)).reshape(1,-1) if(zabuton_clf.predict(vector)[0] == 0): print(str(speaker_clf.predict(vector)[0])+"さんに座布団は差し上げません") elif(zabuton_clf.predict(vector)[0] < 0): print("山田くん!"+str(speaker_clf.predict(vector)[0])+"さんに"+str(zabuton_clf.predict(vector)[0])+"枚差し上げて!") elif(zabuton_clf.predict(vector)[0] > 0): print("山田くん!"+str(speaker_clf.predict(vector)[0])+"さんの"+str(zabuton_clf.predict(vector)[0] * -1)+"枚持ってって!") else: print("山田くん!エラー出す分類器作った開発者の座布団全部持ってけ!") if __name__ == "__main__": while True: text = input("答えをどうぞ:") zabuton_challenge(text)コメントをほとんど書いていないのは今はお許しいただきたい。
関数text_to_vector()の内容はある方のブログ記事(ソース紛失しました。ごめんなさい)で書かれていたコードを改造したものです。動かす
テストデータとして、2012年12月29日放送の第2395回1問目の回答を入力してみる。
小遊三さんと円楽さんと木久扇さんしか出力されていないが、答えによっては他の3人も出力される。
正答率がよろしくないのは作成した分類器の精度が悪いのが原因ですね。
あと誰一人として座布団をもらえていないのは収集したデータの半数以上が座布団0枚だったことが足を引っ張っているのではないかと思ってます。改良案
・もっとデータ集める(収集元サイトでは2011年~2014年4月放送分までの回答が記載されている。もっとデータ集めてデータ数で殴って行きたい
ものっすごく面倒だけど)
・口語的表現に強いコーパスを使う(Wikipediaのコーパス以外見つけられなかったので口語的表現に強いものを知ってる方は教えていただきたい)
・分類アルゴリズムを変える(研究でBERT使う雰囲気になってきたのでBERTでやってみようかと考えている)

- 投稿日:2019-12-01T16:51:50+09:00
TouchDesignerでOpenCVを使った簡単な顔認識について
こんにちは
簡単に自己紹介をします。去年まで東京のデジハリで1年間デザインやプログラミングの勉強をしていました。8月から株式会社たき工房 でプログラマーをしています。個人ではTouchDesignerで映像制作やVJをしています。( Twitter )
入社してから初めて作ったコンテンツがこちらです!(動画は制作途中のものですが)
クスールさんと合同で
— komakinex (@komakinex) November 12, 2019
「ブロックに表示されている漢字を、ボードに書いてカメラに認識させると、そのままボードを動かしてブロックを引き抜くことができるゲーム」を作ってます!これは1週間前のデモ #dotFes #dotFes2019 #madewithunity #TouchDesigner pic.twitter.com/W3Q11eS3c611/17に大阪で行われたdotFes2019というイベントに出展しました。当日はたくさんの人に楽しんでもらえて大盛況でした!
自分はディスプレイ画面のシステムと、プレイヤーが持つホワイトボードの検出し、文字が書かれた部分を画像で保存するという部分を担当しました。その過程で初めてPythonやOpenCVを触り、TouchDesignerで実装しました。
同じような工程で顔認識できそうだなと思い、やってみました。出来上がり
こんな感じにできました。
顔認識!#TouchDesigner #OpenCV pic.twitter.com/q1XvTdZH1y
— komakinex (@komakinex) November 30, 2019顔認識した部分にモザイクをかける処理をしています。
サンプルファイル
↓ここにあります↓
https://github.com/komakinex/TD_AdventCalendar2019_facedetect動作環境
TouchDesigner 099 2019.19930
Windows10説明
OpenCVや顔認識についての詳細な説明は省きます!
参考にした記事
・PythonでOpenCVを使って顔を検出している記事
顔検出の基本的な部分を参考にしました。
https://note.nkmk.me/python-opencv-face-detection-haar-cascade/
https://qiita.com/FukuharaYohei/items/ec6dce7cc5ea21a51a82・TouchDesignerでOpenCVを使って特徴点抽出している記事
抽出した点にジオメトリを当てていること、レンダリング結果を元の画像とうまく合わせている部分を参考にしました。
http://satoruhiga.com/post/extending-touchdesigner/・TouchDesignerでOpenCVを使って動体追跡している記事
顔認識で使えるように、画像を配列に変換しているところを参考にしました。
https://www.velvet-number.com/atsushi/2019/06/21/150-touchdesigner%e3%81%aepython%e3%81%a7opencv%e3%82%92%e5%ae%9f%e8%a3%85%e3%81%97%e3%81%a6%e3%81%bf%e3%82%8b01/用意するもの
・TouchDesigner
・顔認識したい画像、webカメラなど
・顔認識の分類器↓
https://github.com/opencv/opencv/tree/master/data/haarcascades
正面を向いた顔を検出したいのでhaarcascade_frontalface_~を使います。自分はdefaultを使っています。altなどとは精度や顔認識の基準(判定の厳しさ?)の違いがあるみたいです。それぞれがしてること
TouchDesigner
・画像の受け取り
・解像度やアスペクト比の調整
・マスクの生成Python
・顔の検出
・検出した場所を四角で囲み、TouchDesignerに座標と大きさを渡す説明
・faces:顔認識したい画像や映像を受け取ります。
・res1:解像度を元の画像の1/4にして、処理の負荷を軽くしています。
・face_detect:face_preにCookが走った後にここに書いたPythonが動くようになっています。顔を検出する処理が書かれています。
・face_pos:検出された顔の位置と幅の情報をface_detectから受け取っています。maskのsizexやcenterxに直接値を入れてもいいです。見やすいようにface_posで受けています。
・mask:顔の部分を覆う用の四角形を生成しています。注意点
・
face_preのViewerをオフにすると顔認識が止まってしまいます。(Cookが走らなくなるから?ぽいです)
・解像度を小さくする処理をPythonの中でするとfpsがけっこう落ちます。Pythonに渡す前にTOPで処理したほうが良いです。
(arr = cv2.resize(arr, (int(frame.shape[1] / 4), int(frame.shape[0] / 4)))の部分)
まとめ
検出した座標を受け取るだけなので、TouchDesignerの部分は簡潔な仕組みになっています。画像を配列に変換したり、元の画像と合成する部分がややこしいと思うので、そのあたりを詳しく書き加えます(明日)。
最後に
12/11にたき工房でTouchDesignerのもくもく会を開催します!今後も月1でやっていくのと、次回はもっと参加できる人数を増やすつもりです。
また、今後はTouchDesignerで縛らず色々なツールでもくもくする会にしていきたいなと思っています。Twitterでアナウンスするので、チェックしてみてください!
https://techlab-tdmokumoku.peatix.com/おまけ
まったく関係ないですが、めちゃおもろかった動画を貼っておきます。
Aマッソのコント
https://youtu.be/ZxF3pdLJhiQ藤井健太郎が千原ジュニアの過去の映像と声で、舞台にいる千原ジュニアと会話する企画です。これはその紹介動画です。
https://youtu.be/WQdy70xoGMkぜひ見てみてください!
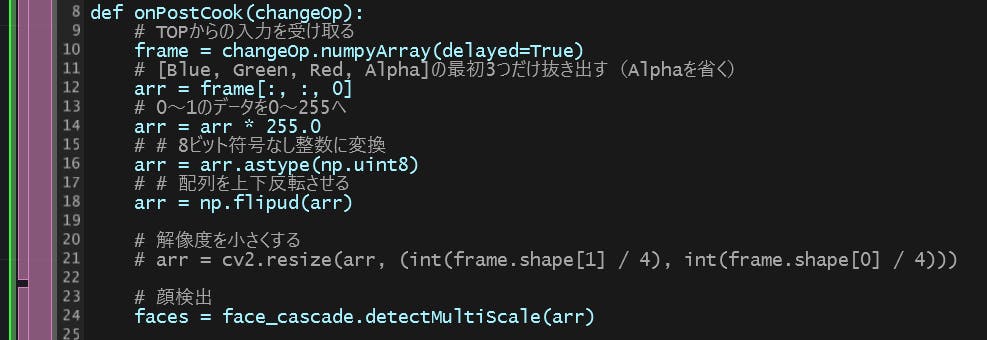
- 投稿日:2019-12-01T16:44:09+09:00
dlib, cv2のインストール
最近はコマンドさえ知っていれば一瞬でできるようになりました。
cv2
pip install opencv-pythondlib
Dockerfileに書くなら以下のようにする。
RUN apt-get update && apt-get upgrade -y && \ apt-get install -y --no-install-recommends \ curl \ cmake \ cmake-curses-gui \ cmake-gui \ git \ gobject-introspection \ libbz2-dev \ libcairo2-dev \ libgirepository1.0-dev \ libreadline-dev \ libsqlite3-dev \ lbssl-dev \ cmake \ RUN pip install dlib