- 投稿日:2019-12-01T23:55:25+09:00
【AWS EC2】自動デプロイ設定後に、修正ファイルを再デプロイする手順
①まずデスクトップアプリでgithubのmasterに編集ファイルをpushしてマージする。
②EC2でログインして該当ディレクトリまで移動
EC2にログイン
$ cd .ssh $ ssh -i chat-space.pem ec2-user@[生成したElastic IP]アプリまで移動
$ cd /var/www/app/③②の位置でマスターをpull
$ git pull origin masterこれで変更がEC2サーバー上にきたか確認
④念の為プロセスを切る
$ ps aux | grep unicorn $ kill プロセス番号⑤ローカルで自動デプロイする。
$ bundle exec cap production deploy⑥デプロイしたIPで確認
- 投稿日:2019-12-01T23:47:52+09:00
ハッカソン で勝つためのノウハウ
導入
初めてのAdventCalender企画も残りあと2日です。
読んだ方も、書き手として参加した方も、楽しんでいただけたでしょうか。
今回は、箸休め的にハッカソン参加&運営の経験者としてノウハウを伝えたいと思います。自己紹介
前提として、自分自身の経験値としてはこんな素性になります。
- システム業界経験 →10年以上
- 社内のハッカソン参加 →2回
- ハッカソン、アイデアソン運営 →4回
- デザインシンキング研修講師 →多数
- オープンなハッカソンイベントは参加経験無し
- エンジニアスキル的にはオンプレのインフラ歴が長くフルスタックには至らず、ローコード使えば何とか
- AIスピーカーなどIoT機器や新しいWebサービスは一通り手を出す方
- 最近のマイブームは家の光回線を解約し、遊んでた格安SIM+据え置きLTEルーター でスマートホームの回線を確保しつつ、クラウドSIMを採用したどんなときもWiFiのモバイルWiFiで通信費削減&アウトドアのネット環境を強化したこと
どうすれば勝つか
まず、ハッカソンで勝利するための条件を確認します。
多くのイベントでは、オーディエンスや複数の審査員による投票方式を採ります。
なので得票数で1位になったら勝ちです。
どういう作品に票が集まるかと言えば、審査基準はいろいろ書いてるかもしれませんが、要は
- 欲しいね(実用性がある)
- 楽しいね(ネタ感がいい)
と思わせることです。
更に、票を投じる人の属性によっては違った観点も必要です。
例えば企業が自社のサービス、製品を使ってというレギュレーションの元に開催している場合は、企業が審査員を立てることになるでしょう。
その場合は製品が主役になる、「お手本のような使い方」が出来ているかもファクターになります。何が難しいか
次に、勝利へ近づくために障壁となるポイントを纏めてみます。
この辺りをリスクマネジメントできるのが強いチームです。
時限
- 与えられる時間は、非常に短時間であることが多いです。(Yahoo! HackDayは24時間)
- 限られた時間内にサービスを形にすることが求められます。
実装スキル
- 作るものが決まってから技術を習得し始めては遅れを取ってしまいます。
- あまり背伸びして技術を入れ込みすぎても未完成になるリスクもあります。
- 作りあげるのがゴールの状況においては、広く/浅くより、狭く/深く攻めた方が成功するでしょう。技術の数よりも、使い込みで魅せるということです。
- 勝負はイベントの前から始まっていると心得て、日頃から使える武器(技術)を集めておくと強いでしょう。
基盤スキル
- 基本的にIaaSはお金、構築の手間もかかるので、SaaSを中心にサーバレスで構築出来ると低負荷です。
- また、IaaS,PaaSを使うとしても、AWSよりもIBM Cloud、Microsoft Azureの方が無償で使える範囲が広いです。
- AWSは無償枠超えても青天井ですが、Azureは打ち止めの仕組みもあって親切です。
- 他にもIFTTTやGoogleドキュメント、SNSのAPIなど既存のSaaSを活用するとサービスに厚みが出たりコード量が削減できて生産性が格段に上がります。
アイデア
- 「それ、既にあります」なサービスを自信満々に紹介されても、がっかりですね。開発した側からしてみれば、SanSanのCMよろしく、「それ、早く言ってよぉ〜」かもしれませんが、後の祭りです。
- がっかりだけでなく、既存のサービスの方がクオリティ高いです。
- これを「車輪の再発明」と言います:「重いものめっちゃ簡単に運ぶ方法思いついた」 →「それ車輪だよね」
- 新しいITサービスについて、日頃から情報収集はしておきましょう。何かネットサーフィンしてる時に情報をキャッチしたらどんなサービスなのか確認するとか、例えば直近だとYhoo!とLINEが統合してどんなサービス始めようとしてるかなど、メジャーどころだけでも十分です。
- 練っている間に、意図せず既存のサービスに寄っていってしまう場合もあります。時々立ち止まってチェックしましょう。
- Googleドキュメントの機能など、思わぬメジャーどころに強力なライバルが潜んでいます。こんな機能ないの?に対して、思わぬ方法で実現できてないかググりましょう。もし既にあるけど少し足りてないなら、それを利用して新しい価値を生み出すというのもアリかもしれません。
- 例:コメント弾幕
- PCでプレゼンテーションのスライド再生中、聴講者が質問やコメントを投げて、同一スクリーン上に重ねて表示する、ニコニコ動画の弾幕みたいなものが欲しいケース。順当に考えるとクライアントアプリとして動作して表示させるところ、スライドをWebアプリであるGoogleスライドを使用する前提で、ChromeブラウザのChrome拡張機能でHTMLを改変できることを確認。拡張ツールとしてスライドのHTMLにコメントの情報を追加してWebアプリとして持ち合わせのスキルセットで簡単に実装する事に成功。
何をすべきか
各ステップごと、何に気をつけて進めるべきか纏めてみます。
1. チームビルディング
通常は複数人で臨む場合が多いと思います。
チームを組んでから申し込む場合、申し込んでからその場で決める場合、まちまちと思いますが一般的な話として考えてみます。
Oneチーム
目標、価値観のすり合わせをすることが重要です。
技術に長けた人がどれだけいるか、よりもチームワークを発揮することの方が、遥かに生産性に寄与します。作れる人がたくさんいたところで同じ目標を共有できていなければ、船頭多くして船は山に登ります。
そのためには、「否定しないこと」、「ポジティブなムード」が、特にアイデアのブレスト段階で重要です。
「なぜ出来ないか」でなく「どうしたらできるか」を考えましょう。人が挙げたアイデアに乗っかり、捻り、新しいアイデアを生み出しましょう。
良いサービスは、良い雰囲気の中で生まれます。多様性
仲良しグループで構成する事によるメリットもありますが、初めましての人同士で組んでも、大きなメリットがあります。まず、旧知の仲でなければお互い敬意を持って接するはずなので、お互い肯定してポジティブな雰囲気が作りやすいです。
また、アイデアは色々な所に転がっているので、異なるクラスタの人の方が、自分が持っていない知見を持っている可能性が高く、よりアイデアの幅が広がります。案外、固定概念のない素人から新しいアイデアが出てきたりするものです。2. サービス設計
ここのアウトプットが、優勝できる可能性の大部分を左右します。
「唯一無二」を目指すこと
安直に勝つためのアプローチを考えるならば、ナンバー1でなくオンリー1を目指すことです。既存の仕組みを置き換えるようなサービスの場合、まず先駆者、挑戦者が居ます。
かの洞窟探検家は、「山に未踏の地は殆ど無い、海も空も同じ、だから僕は地中に潜る」と言ってました。
先駆者がお金と時間、スキルや情熱をつぎ込み、改良を重ねたものを超越するのは、簡単なことではありません。
ブルーオーシャンを作り出し、最初の開拓者になりましょう。そこにライバルは居ません。
そして目指すのはIT化ではなく、DXです。例えばUberは、タクシーのデジタル化に留まらない新しいユーザー体験を実現しています。サービスのデザイン、哲学
軸となるビジョン、ポリシーを明確にし、チーム内で認識を合わせましょう。
ユーザーにとって、サービスを使うことが目的ではなく、どれだけ満足できるかが重要なのです。
そうすると後続の設計や、時間の使い方など、あらゆる場面で迷わず優先順位づけが出来るはずです。
例1:「気持ちよく募金するサービスを作る」
例2:「システムの目的は、特定の技術を使用することでもなく、プログラミングの良い成果を出すことでもなく、ユーザーにサービスを提供することである。」ドン・ノーマンSoEの追求
上とも重なりますが、なぜ、そのサービスを使う必要があるか、明確に打ち出せていますか?
更に、それが細かく説明して初めてわかる、ではなくアプリ触ったら分かるレベルで明確に伝わらないとダメです。
インセンティブ設計も、最近のPayアプリを中心に現金なメリットが多いですが、原資となる収入源やフィージビリティもきちんと説明出来るようにしましょう。
ただ、ハッカソン的には説明しなくても伝わるもの、お金よりもエモーショナルさがウケる傾向にあります。人はお金に惹かれつつも、それを面に出すことは恥ずかしがるのです。デートで割引クーポンに拘る男が小さく見られるのと同じでしょうか。(私はクーポン拘る派です)
ネタに走れとは言いませんが、せっかくハッカソンというお祭りで開発するなら、収益性よりも感動を追求した方が作っても、見ても楽しいんじゃないかと思います。
- AnycaとCREW
個人的に使ったことのある2つの対極的なサービスを紹介します。どちらもMaaSですが、Anycaは個人間カーシェアのサービスで、ユーザー同士のコミュニティやオーナーズブログなどSNSのような役割を果たし、レンタカーと差別化しています。一方CREWは国内版Uberと言えるライドシェアサービスですが、合法的に運用することばかりに注力しており、本来ライドシェアで得られる、ヒッチハイクのようなドライバーとライダーの関係性は構築できません。ペルソナの設定
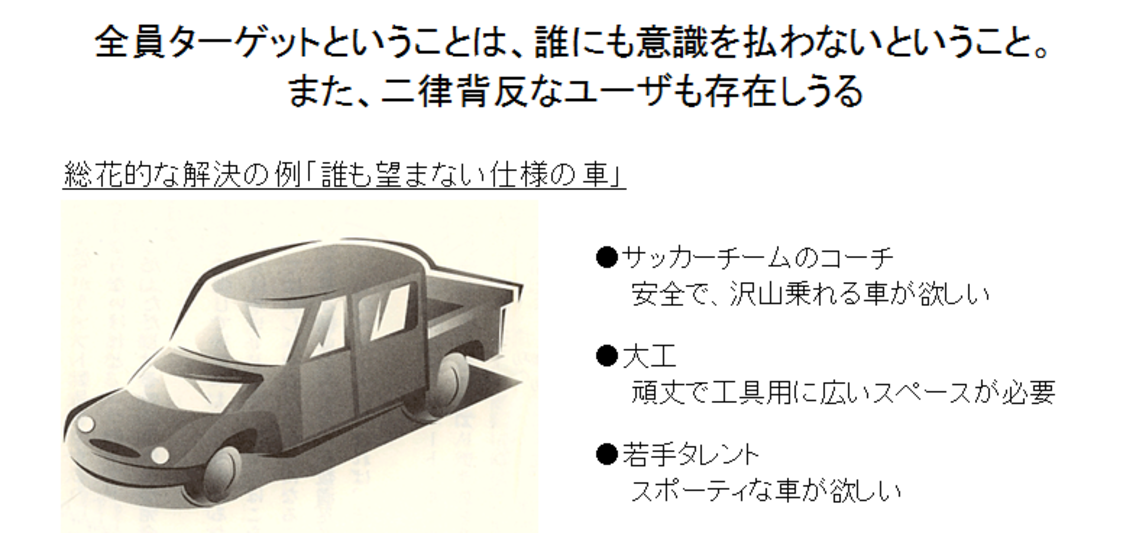
上記をうまく纏める手法として、ペルソナを設定します。
やるべき事を明確にして、こんな車が出来上がらないように進めます。
誰も望まない仕様の車
そんな事になる訳ないだろ、と思うなかれ、「リリースされたサービスの機能のうち、80%はほとんど、もしくは全く使われていない」という統計データもあります。ご参考
堀江貴文のゲームチェンジャー論3. システム設計・実装
さあ、どのようにユーザーを満足させるか決まったら、形にしていきましょう。
技術選定
上に挙げたように、スキルエリアについて力量と相談して適切に選択し、必要以上に手を広げないように狭く/深く、を意識して進めてみてください。プロジェクト管理
ここでは開発の進捗管理や問題の解決能力が勝敗を左右します。
ここがハッカソンのソン(マラソンのソン)たる所以で、ユーザー満足度への欲求、言い換えると勝利への欲求を原動力としてスタミナを維持しましょう。そして、チームワークを発揮して駆動力を推進力に換え、効率的に進めたいところです。Gitでソースを共有したり、NetlifyやGitHub Actionsでデプロイの負担を軽減したり、Tarelloでタスク管理したり、便利なツールを活用しましょう。MVP
「必要最小限の構成」です。
サービスのメリットを感じてもらうため、ユーザーの満足を得るために、最低限どのユースケースが必要か見極め、何よりもまずそれを実現させましょう。あれもこれも中途半端に手を出した挙句、何も完成してないでは、サービスの価値を評価しようがありません。UIへの偏り
良くある落とし穴が、UIばかり綺麗に作り上げて、裏側の処理は空っぽ、という事態です。UIが出来ると華があり作った感が出ますが、UI部分だけで新鮮味を出せるのはIoTやAR、ゲームなど限られたケースだけです。一般的なWebアプリやモバイルアプリの場合は、綺麗なUIはMVPに含まれないので程々にして、まずはビジネスロジックを組み立てましょう。
俳優、阿部寛のWebページは高速にロードされることで有名です。最近は動画コンテンツなどで重いサイトも多いですが、シンプルな構成で圧倒的なユーザビリティを提供しています。UIに拘り始めてしまったら、阿部寛を思い出しましょう。ちなみに阿部寛のサイトをPageSpeed Insightsで分析すると、「計測不能」になります。変化への対応
メンバーで議論を重ねる中、サービス設計に影響するような変更が出てきて、いつの間にか変な方向に走ってしまうケースがあります。サービスの哲学はブレていないか、都度チェックしましょう。技術を活かして新しい価値を生み出す
色気を出して新しい技術を取り込みたくなるギークな気持ち、わかりますが、ほどほどにしましょう。技術オリエンテッドでなく、サービスオリエンテッドで考えることです。技術に踊らされることなく、技術を使いこなしましょう。4. 発表
デモは難しい
過去に発表の場でデモをしようとしたことがありました。見事に動かず大コケした痛い思い出です。非常に短い時間で発表を纏めるため、発表者がリアルタイムでデモすべきでありません。
大抵は細かいレスポンスの悪さであったり粗が目立ちやすい上、発表のテンポも崩れ、伝えるべきことも伝えそびれてしまいます。
発表者は、アプリケーションの画面は動画に撮っておき、適宜ステージ上でデモンストレーションも交えて伝えましょう。
リアルに、使えるもの作った感じを伝えるにはアプリを聴講者に公開して触ってもらうのが良いでしょう。目的に忠実に、シンプルに
プレゼンテーションの目的を意識して、シンプルに纏めましょう。
あなたがプレゼンする目的は、サービスを紹介することではないはずです。そのサービスが欲しいと思わせ、投票させる必要があります。サービスの世界観を丁寧に作り上げ、聴衆を引き込み、共感させます。
その為にも、サービスの哲学が明確で、それを叶える機能が整っていることが重要です。
この記事を書いていたら、PDD/プレゼン駆動開発という言葉を見つけました。
開発者として押し出したいポイントを強調するのではなく、プレゼンのストーリーを重視しましょう。発表がゴールのハッカソンにおいては、ストーリーを組み立てる為に必要なもの、プレゼンウケするものに注力して開発を進めます。ヒラメキの源泉
短期間でそれっぽい新たなビジネスモデルを考え出すのは、そう簡単なことではありません。日頃の鍛錬が実を結びます。
例えば私が新しいサービスを目にした時、こんなことを考えます。
- どういうビジネスモデルか
- 何が新しいか、二番煎じならどう差別化してるか
- なぜ、今リリースしたか、背後に法改正があるのか、技術が成熟してきたからか
- 自分の組織に応用できないか
- 世の中はどういうトレンドにあるのか
ブルーオーシャンを作り出すことをアドバイスしましたが、Facebookは世界初のSNSではありません。Googleも、Youtubeも同じくその業界の第一号ではありません。
ちょっとしたことで差別化し、他の追従を許さない圧倒的なサービス品質で登り詰めたわけです。
スティーブ・ジョブズやイーロン・マスクみたいに、自己流のセンスを押し出して世に受け入れられたケースもありますが、そんな芸当は一部の天才にしかできません。
一般人はとにかく他のサービスを分析して、真似しながら、新しいサービスを練っていきましょう。きっと他のサービスも似たような経緯を辿っていると思います。締め
如何だったでしょうか。
どうこう言っても、参加してやってみるのが一番です。
参加して初めて、このサービスを作る為にはこんなスキルが必要だ、とか、
触ったことがある技術を使ってみたけど、使いこなせるレベルになくて苦労した、とか、色々気づきがあります。そろそろ来年の抱負を決める時期ですが、来年はハッカソン参戦、で決まりですね。
そして終わった後に、チームで美味い酒を飲みましょう。それでは神のご加護を。
Merry Christmas?
- 投稿日:2019-12-01T23:40:39+09:00
「Cloud functions VS AWS Lambda」を「お金」と「始めやすさ」で勝手に比較してみた
この記事は「Google Cloud Platform Advent Calendar 2019」1日目の記事です。
▶ 対決条件
今回は最近流行りのサーバーレスの中でも「Cloud functions」と「AWS Lambda」の2つがどう違うのかを個人的な観点で勝手に比較してみることにしました!
とはいえ漠然と比較するとしても比較のしようもないので、今回は「 お金 」と「 始めやすさ 」という2つの軸で調べて比較することにしてみました!
お金
- 関数に 512 MB のメモリを割り当て、3,000,000 回実行し、毎回の実行時間が1秒間だった場合にかかるお金
- 実行回数が1,000万の月
- 実行時間が100msecの月
始めやすさ
- ドキュメントやチュートリアルなどの充実度に限定
▶ まずは前哨戦、各種サービスの謳い文句を比較
Cloud Functions
イベント ドリブンなサーバーレス コンピューティング プラットフォーム
* クラウドで簡単にコードを実行、スケーリング
* 自動スケーリングによって実現される高い可用性と耐障害性
* プロビジョニング、管理、パッチ適用、アップデートのためのサーバーが不要
* お支払いはコードを実行した時間分だけ
* クラウド サービスを連携、拡張AWS Lambda
サーバーについて検討することなくコードを実行できます。お支払いいただくのは、実際に使用したコンピューティング時間に対する料金のみです。
AWS Lambda を使用することで、サーバーのプロビジョニングや管理をすることなく、コードを実行できます。課金は実際に使用したコンピューティング時間に対してのみ発生し、コードが実行されていないときには料金も発生しません。
Lambda を使用すれば、実質どのようなタイプのアプリケーションやバックエンドサービスでも管理を必要とせずに実行できます。コードさえアップロードすれば、高可用性を実現しながらコードを実行およびスケーリングするために必要なことは、すべて Lambda により行われます。コードは、他の AWS サービスから自動的にトリガーされるよう設定することも、ウェブまたはモバイルアプリから直接呼び出すよう設定することもできます。
所感としては、↓のようにこの時点で既に思想の違いが出ていて面白いですね。
* GCP: Developer向け? シンプルに特筆すべき要点だけを整理
* AWS: ベンダー向け? このサービスはどんなサービスかという観点で解説のように説明▶ 比較してみた
▽ お金
なんと言っても重要なのは「いくらかかるか」だと私は思っています。
どんなに使いやすいものでも一回のデバッグに数千円とかかかったり、1アカウント数千円〜万円とかかかるのであればよほど需要があって即座にお金が回収できる宛があるか懐に余裕がなければ気軽に試すことは難しいでしょう。
実際の運用に載せるとしてもやりたいことに対して最適なコストなのかも重要な項目ですのでまずはこちらの項目から比較して行きたいと思います。
さて、比較するとしても簡単な設定があったほうが計算もしやすいので今回は↓の3つのケースで考えてみたいと思います。
- 関数に 512 MB のメモリを割り当て、3,000,000 回実行し、毎回の実行時間が1秒間だった場合にかかるお金
- 実行回数が1,000万の月
- 実行時間が100msecの月
では早速「 月に100万アクセスが来るアプリケーションを作ると想定した時にかかるお金 」をベースとして計算していきます。
各サービスに掛かる料金は↓の公式で求められます。
- 関数の呼び出し料金 = (呼び出し回数 - 2,000,000(※1)) x $0.0000004
- コンピューティング時間(※2) = メモリ利用料金 + CPU利用料金
- メモリ利用料金 = (利用した時間(秒) x メモリ(GB) - 400,000) x $0.0000025
- CPU利用料金 = (利用した時間(秒) x CPU(GHz) - 200,000) x $0.0000100
- ネットワーキング(※34) = (送信データ転送(GB) - 5GB) x $0.12
- 合計/月 = 関数の呼び出し料金 + コンピューティング時間 + ネットワーキング
- コンピューティング料金(月) = (合計コンピューティング時間 (GB-秒) – 400,000(※1) ) x 0.00001667 USD
- 合計コンピューティング時間 (GB-秒) = 実行回数 x 実行時間(秒) x メモリ(GB)
- リクエスト料金(月) = (リクエスト件数 - 1,000,000(※1) ) x 0.20 USD / 1,000,000
- 合計料金 = コンピューティング料金(月) + リクエスト料金(月)
※1 無料枠
※2 100 ミリ秒単位で測定され、最も近い増分値に切り上げられる
※3 上り(受信)データは無料
※4 同じリージョン内の他の Google API に送信されるデータは、受信データと同様に無料
※5 米国東部 (バージニア北部) 料金の場合計算式自体はAWSの方がシンプルに見えますが、実際にお得なのはどちらなのかでしょうか。
例題に当てはめて計算して見てみましょう。
今回は前提としてどちらも無料枠が生きている前提で行っていきます。なお、気づいた方もいるかも知れませんが、この問題はAWSの公式で例題として出している料金プラン例を拝借しております。
○ 関数に 512 MB のメモリを割り当て、3,000,000 回実行し、毎回の実行時間が1秒間だった場合にかかるお金
Cloud functions
式に当てはめて計算していきますが、今回この関数はバックグラウンド関数として請求対象となる下りデータもないこととしておきます。
関数の呼び出し料金 = (呼び出し回数 - 2,000,000) x $0.0000004
- = (3,000,000 - 2,000,000) x $0.0000004
- = $0.4
コンピューティング時間(※2) = メモリ利用料金 + CPU利用料金
- メモリ利用料金 = (利用した時間(秒) x メモリ(GB) - 400,000) x $0.0000025
- = (3,000,000 x 1 x 512 / 1024 - 400,000) x $0.0000025
- = (1,500,000 - 400,000) x $0.0000025
- = $2.75
- CPU利用料金 = (利用した時間(秒) x CPU(GHz) - 200,000) x $0.0000100
- = (3,000,000 x 1 x 800 / 1000 - 200,000) x $0.0000100
- = (2,400,000 - 200,000) x $0.0000100
- = $22
ネットワーキング(※34) = (送信データ転送(GB) - 5GB) x $0.12
- = $0
合計/月 = 関数の呼び出し料金 + コンピューティング時間 + ネットワーキング
- = 0.4 + 2.75 + 22 + 0
- = $25.15
Cloud functionsでは「 $25.15/月 」掛かることがわかりました。
AWS Lambda
では次にAWS Lambdaで見てみましょう
合計コンピューティング時間 (GB-秒) = 実行回数 x 実行時間(秒) x メモリ(GB)
- = 3,000,000 x 1 x 512 ÷ 1024
- = 1,500,000 GB-秒
コンピューティング料金(月) = (合計コンピューティング時間 (GB-秒) – 400,000(※1) ) x 0.00001667 USD
- = 1,500,000 - 400,000 x 0.00001667
- = 18.34 USD
リクエスト料金(月) = (リクエスト件数 - 1,000,000(※1) ) x 0.20 USD / 1,000,000
- = (3,000,000 - 1,000,000) x 0.20 USD / 1,000,000
- = 0.40 USD
合計料金 = コンピューティング料金(月) + リクエスト料金(月)
- = 18.34 USD + 0.40 USD
- = 18.74 USD/月
AWS Lambdaでは「 $18.74/月 」掛かることがわかりました。
○ 実行回数が1,000万の月
さて、ベースとなる基準では「AWS」の方に軍配があがりました。
では次はそれぞれの条件が変わったらどうなるかで検証していきましょう。まずは「実行回数」が単純に増えた場合で比較してみましょう。
他の条件は一緒としてみます。Cloud functions
関数の呼び出し料金 = (呼び出し回数 - 2,000,000) x $0.0000004
- = (10,000,000 - 2,000,000) x $0.0000004
- = $3.2
コンピューティング時間(※2) = メモリ利用料金 + CPU利用料金
- メモリ利用料金 = (利用した時間(秒) x メモリ(GB) - 400,000) x $0.0000025
- = (10,000,000 x 1 x 512 / 1024 - 400,000) x $0.0000025
- = $11.5
- CPU利用料金 = (利用した時間(秒) x CPU(GHz) - 200,000) x $0.0000100
- = (10,000,000 x 1 x 800 / 1000 - 200,000) x $0.0000100
- = $78
ネットワーキング(※34) = (送信データ転送(GB) - 5GB) x $0.12
- = $0
合計/月 = 関数の呼び出し料金 + コンピューティング時間 + ネットワーキング
- = 3.2 + 11.5 + 78 + 0
- = $92.7
Cloud functionsでは「 $92.7/月 」掛かることがわかりました。
AWS Lambda
では次にAWS Lambdaで見てみましょう
合計コンピューティング時間 (GB-秒) = 実行回数 x 実行時間(秒) x メモリ(GB)
- = 10,000,000 x 1 x 512 ÷ 1024
- = 5,000,000 GB-秒
コンピューティング料金(月) = (合計コンピューティング時間 (GB-秒) – 400,000(※1) ) x 0.00001667 USD
- = 5,000,000 - 400,000 x 0.00001667
- = 76.682 USD
リクエスト料金(月) = (リクエスト件数 - 1,000,000(※1) ) x 0.20 USD / 1,000,000
- = (10,000,000 - 1,000,000) x 0.20 USD / 1,000,000
- = 1.8 USD
合計料金 = コンピューティング料金(月) + リクエスト料金(月)
- = 76.682 USD +1.8 USD
- = 78.482 USD/月
AWS Lambdaでは「 $78.482/月 」掛かることがわかりました。
○ 実行時間が100msecの月
ここまではAWS優勢と言ったところでしょうか。
しかし、アプリケーションがちゃんとチューニングをして実行時間が早くなったケースではどうでしょう?次に実行時間が「100msec = 0.1秒」となったケースで比較してみましょう。
今回も他の条件は一緒としてみます。Cloud functions
関数の呼び出し料金 = (呼び出し回数 - 2,000,000) x $0.0000004
- = (3,000,000 - 2,000,000) x $0.0000004
- = $0.4
コンピューティング時間(※2) = メモリ利用料金 + CPU利用料金
- メモリ利用料金 = (利用した時間(秒) x メモリ(GB) - 400,000) x $0.0000025
- = (3,000,000 x 0.1 x 512 / 1024 - 400,000) x $0.0000025
- = $0
- CPU利用料金 = (利用した時間(秒) x CPU(GHz) - 200,000) x $0.0000100
- = (3,000,000 x 0.1 x 800 / 1000 - 200,000) x $0.0000100
- = (2,400,000 - 200,000) x $0.0000100
- = $0.4
ネットワーキング(※34) = (送信データ転送(GB) - 5GB) x $0.12
- = $0
合計/月 = 関数の呼び出し料金 + コンピューティング時間 + ネットワーキング
- = 0.4 + 0 + 0.4 + 0
- = $0.8
Cloud functionsでは「 $0.8/月 」掛かることがわかりました。
AWS Lambda
では次にAWS Lambdaで見てみましょう
合計コンピューティング時間 (GB-秒) = 実行回数 x 実行時間(秒) x メモリ(GB)
- = 3,000,000 x 0.1 x 512 ÷ 1024
- = 150,000 GB-秒
コンピューティング料金(月) = (合計コンピューティング時間 (GB-秒) – 400,000(※1) ) x 0.00001667 USD
- = (150,000 - 400,000) x 0.00001667
- = 0 USD
リクエスト料金(月) = (リクエスト件数 - 1,000,000(※1) ) x 0.20 USD / 1,000,000
- = (3,000,000 - 1,000,000) x 0.20 USD / 1,000,000
- = 0.40 USD
合計料金 = コンピューティング料金(月) + リクエスト料金(月)
- = 0 USD + 0.40 USD
- = 0.4 USD/月
AWS Lambdaでは「 $0.4/月 」掛かることがわかりました。
お金の対決結果
残念ながらCloud FunctionsはAWS Lambdaに価格面では少し割高になってしまうという結果となってしまいました。
しかし、アプリケーションのチューニング次第ではAWS Lambdaと同じくらいのお値段になることは分かりましたので、利用する際には是非ともアプリケーションの実行時間には気をつけて実装していきましょう。▽ 始めやすさ
次の比較は「始めやすさ」です。
こちらではドキュメントやチュートリアルなどの充実度を比較していこうと思います。1.公式ドキュメント
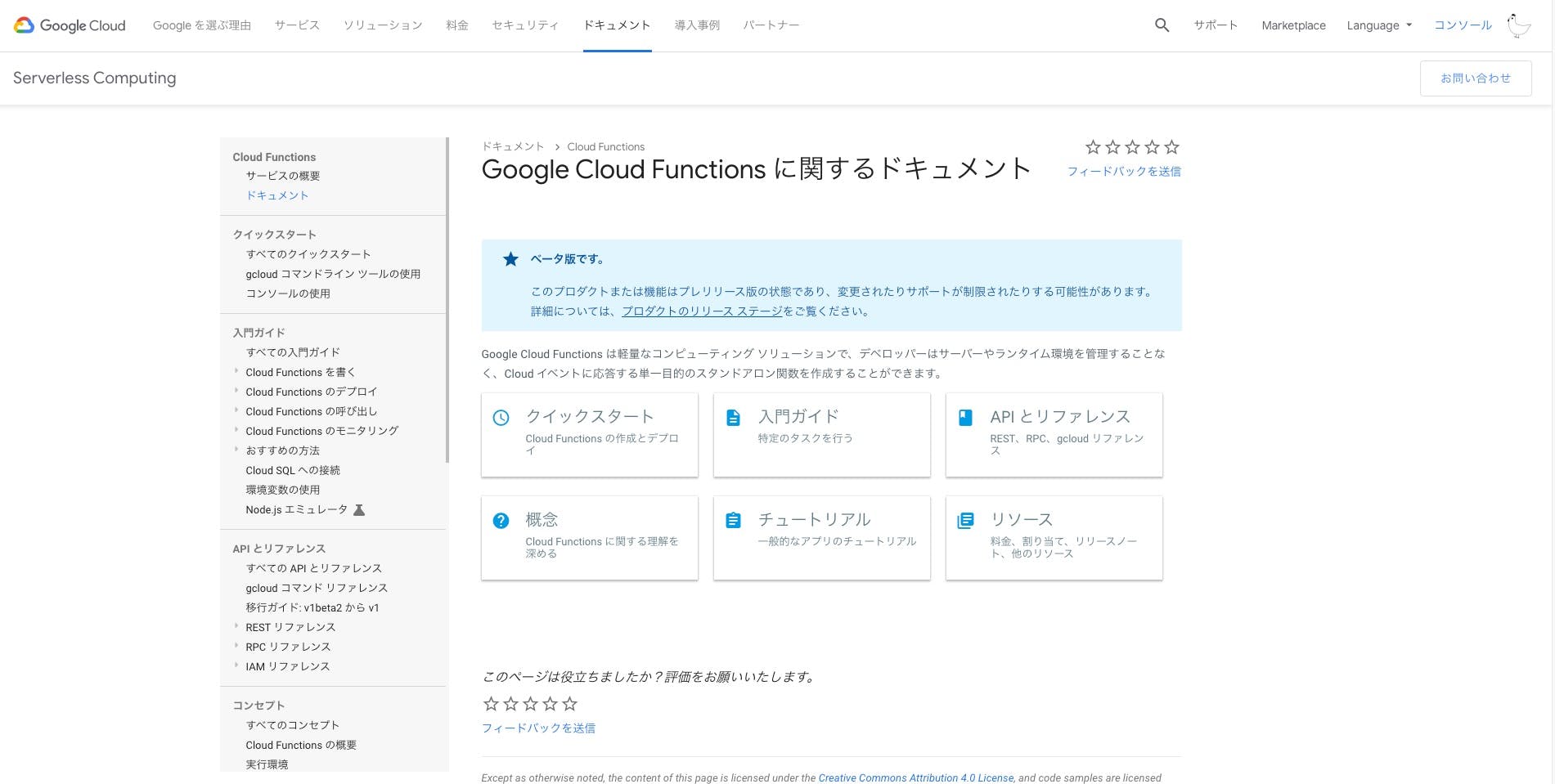
Cloud functions
- ドキュメント見やすい
- LPからもすぐ飛べる
- サイドメニューは目的別となっているが見出しが他のものと共通なのでパット見で戸惑う人もいるかも
- https://cloud.google.com/functions/docs/?hl=ja
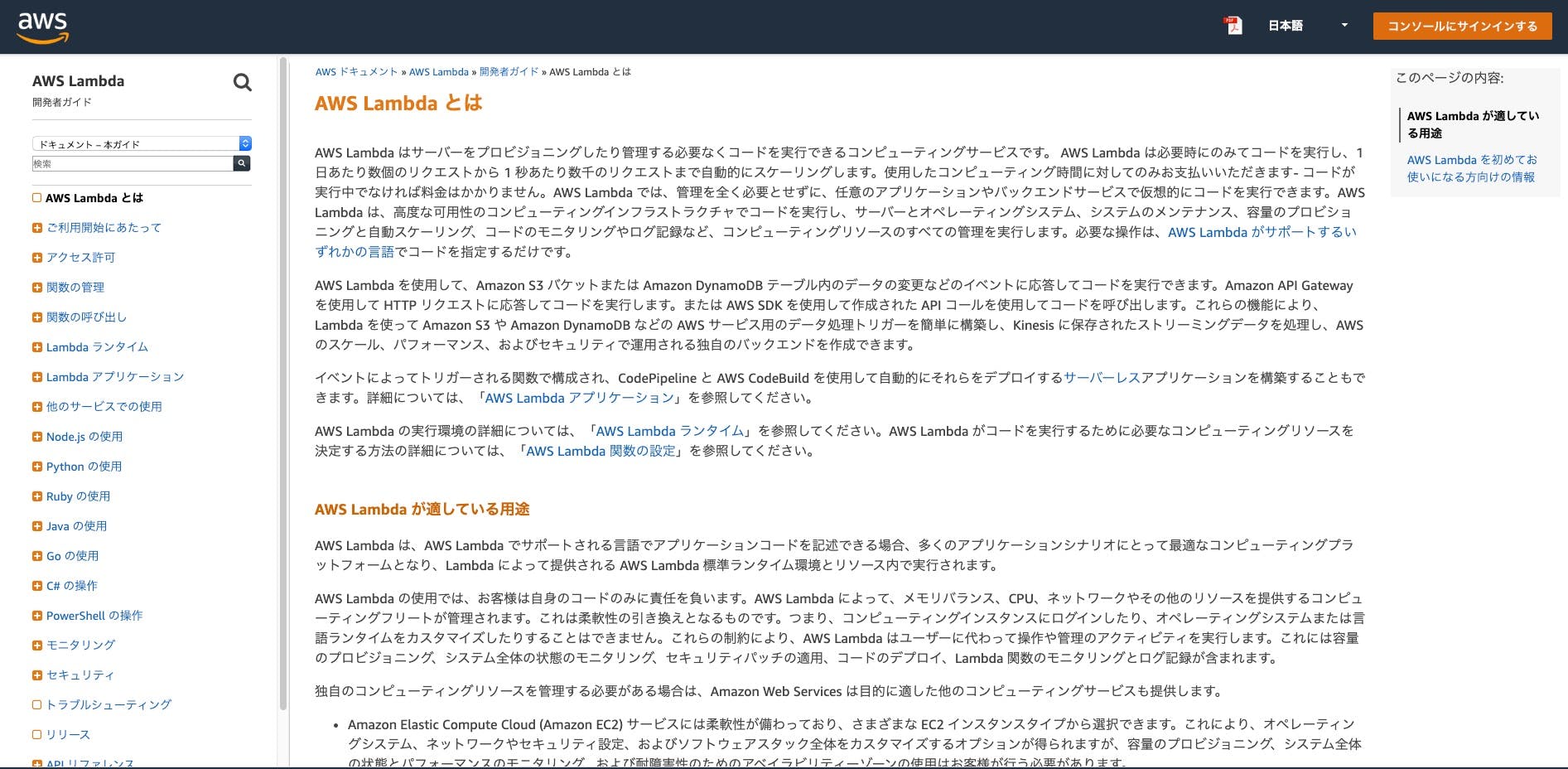
AWS Lambda
- https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/welcome.html
- 文字が多いのとUI的に硬い印象
- サービスとしてどういうシチュエーションに適しているかがわかるように最初から説明を用意している
- サイドメニューにはAWS Lambdaの情報だけがまとまっているとわかりやすい
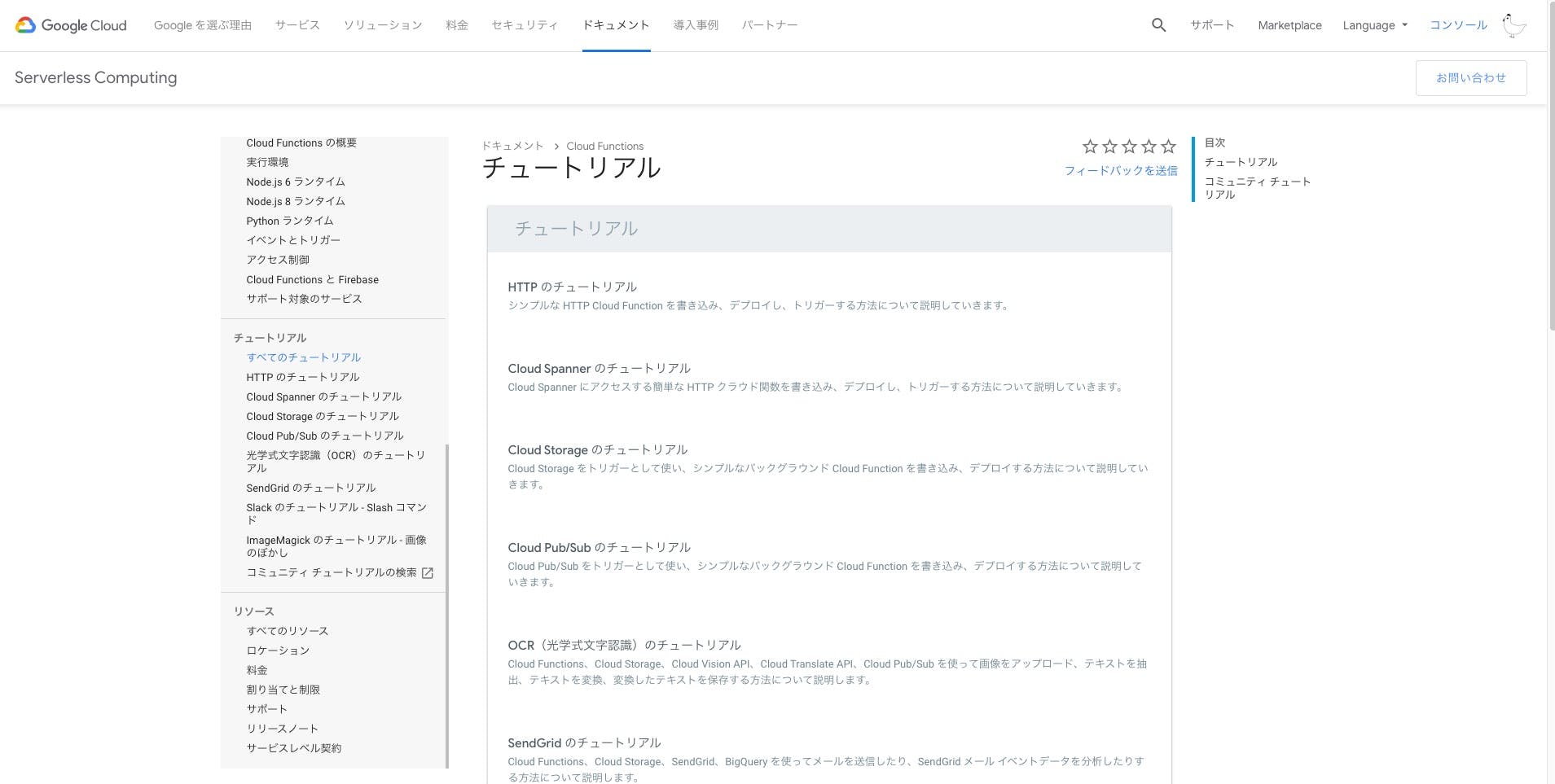
2.公式のチュートリアル
Cloud functions
- シンプルにまとまっている
- 「とりあえず動かしてみよう」という感じで使うことができる
AWS Lambda
- チュートリアルはあるにはあるが、色々なところに点在している
- 他のサービスとの関連、という形では詳しく書いてある
3.検索結果の数
- Cloud functions
→ 約 274,000,000 件
- AWS Lambda
→ 約 15,400,000 件
使いやすさの結果
所感ではありますが、こちらはGCPの方がドキュメントが充実&見やすいかと思います。
AWSも丁寧ではありますが少し文字が多いので最初のイメージを掴むのは大変かもしれません。▶ 結論
何も知らない状態でまずは始めてみよう!というのには公式のドキュメントのわかりやすさや試しやすさからもCloud Functionsの方が簡単そうな感じがします。
しかし、サービスの規模が大きくなってきた場合は単純にはAWSの方が安くなります。ただ、どちらのサービスでもチューニングをしっかりとしないと大きなコストとなってきてしまうので、使う際はしっかりと運用する必要がありそうです。
- 投稿日:2019-12-01T23:11:25+09:00
素人がAWSに手を出してみた様子-3
素人がAWSに手を出してみた様子-3
どうもはじめまして。
前回
【素人がAWSに手を出してみた様子-2】
ではEC2でインスタンス作成→とりあえずindex.htmlを表示してみよう
を行いました。そして第3回はlambda
バタバタして前回から更新が大幅に遅くなった。。。だめだなぁ
lambdaを使ってみよう
まずはサービスから【コンピューティング】→【Lambda】を選択します。
オプションを選択しますが、今回は【一から作成】を選択します。
ランタイムは【Node.js】を選択しました。
Lambdaが作成完了したら【API Gateway】との連携を行います。
今回はLINE BOTのためのAPIを作成したので【LINE Developers】も手を出してみました。
言語はpythonを使用されていますが参考になると思います
https://qiita.com/yoshidev523/items/4090653578b788acb540他にもググったりすれば沢山参考にできる良いまとめがあると思うので頑張って探してください!
ヤマビコBOTを作りました
「あああ」と打ったら「あああ」と返ってくるだけ
それでも良かったのです。
とりあえずまず動くものを作ってみたい(一からとは言っていない)そこから色を自分なりにつけていけばいいじゃない
「勉強なんだし」と軽い感じで考えていますLambda+API Gatewayは楽しい
今回はLINE BOTでしたがこれからまた触ってみたいと思う技術でした
次回
次回はここまで駆け抜けてバタバタととりあえず記事にしてしまったので
おさらいでまとめ記事など書いてみるつもりです(復習も兼ねて)
- 投稿日:2019-12-01T23:05:43+09:00
【Win10】AWS CLIでS3にファイルをアップロード & バックアップ用のバッチファイルを作成する
概要
本書ではWindows10にAWS CLIをインストールし、S3にローカルのファイルをアップロードします。またAWS CLIとS3を利用したバックアップ用のバッチファイルを作成します。
0. 前提条件
- AWS S3のバケットを作成していること。
- IAMユーザーを作成し、AWS S3のIAMロールを適用していること。
- 作成したIAMユーザーのアクセスキーID,シークレットアクセスキーを生成していること。
- <注意>AWSを不正に利用されないために、アクセスキーIDとシークレットアクセスキーの取り扱いに十分気を付けてください。
- 本書ではWindows10 Proを使用します。
1. AWS CLIのインストール
https://aws.amazon.com/jp/cli/ に移動し、Windows用のAWS CLIをダウンロードする。
ダウンロードした「AWSCLI64PY3.msi」を起動する。
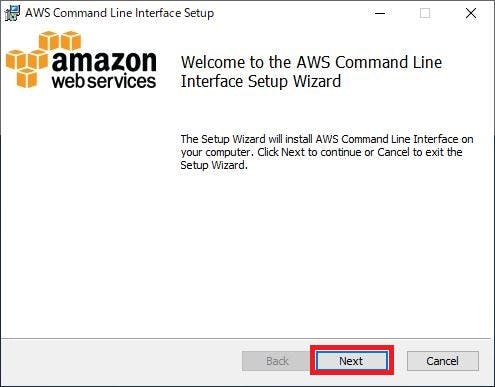
「Next」をクリックする。
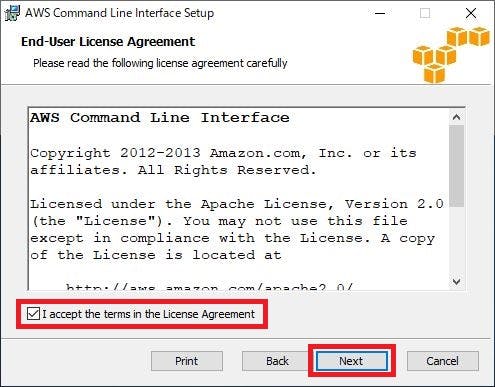
「I accept terms in the License Agreement」にチェックを入れ、「Next」をクリックする。
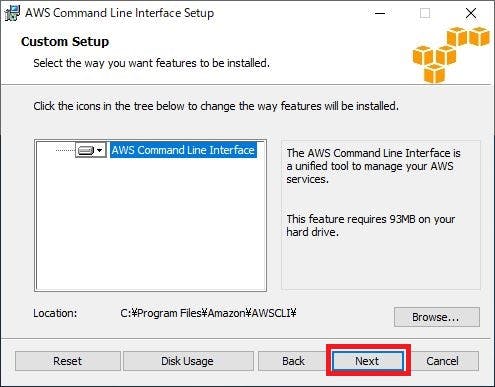
インストール先を指定し、「Next」をクリックする。
「Install」をクリックする。
インストールが完了するまで待機する。
「Completed the AWS Command Line Interface Setup Wizard」と表示されることを確認し、「Finish」をクリックする。
2. AWS CLIの初期設定
コマンドプロンプトを起動する。
AWS CLIのインストール確認のため、AWS CLIのバージョンを表示する。
> aws --version aws-cli/1.16.292 Python/3.6.0 Windows/10 botocore/1.13.28AWS CLIに作成したIAMユーザーを紐づける。
> aws configure AWS Access Key ID [None]: アクセスキーID AWS Secret Access Key [None]: シークレットアクセスキー Default region name [None]: リージョン(東京の場合はap-northeast-1) Default output format [None]: jsonAWS CLIにIAMユーザーが紐づいたことを確認する。
> aws sts get-caller-identity { "UserId": "xxxxxxxxxxxxxxxxxxxxx", "Account": "xxxxxxxxxxxx", "Arn": "arn:aws:iam::xxxxxxxxxxxx:user/xxxxxxx" }3. S3にローカルのファイルをアップロード
作成したAWS S3のバケットを表示する。
> aws s3 ls 2019-12-01 19:44:02 バケット名ローカルのファイルを作成したバケットにコピーする。
> aws s3 cp "C:\tmp\test_windows10.txt" s3://バケット名
※ファイルをバケットに移動する際はaws s3 mv "ローカルのファイル" s3://バケット名を実行する。バケットにファイルがコピーされたことを確認する。
> aws s3 ls s3://バケット名 2019-12-01 20:27:23 8 test_windows10.txt4. バックアップ用のバッチファイルを作成する
作成例
〇バッチファイル
@echo off rem Declaring the folder to be backed up. set backup_folder="C:\tmp\ rem Generate the backup date (YYMMDD format) when the batch file was executed. set datefile=%date% set datefile=%datefile:/=% rem Harden the folder to be backed up into a zip file. powershell Compress-Archive -Path %backup_folder% -DestinationPath D:\backup-%datefile%.zip rem Upload backup target zip folder to AWS S3 bucket. aws s3 mv "D:\backup-%datefile%.zip" s3://バケット名/ rem View files in an AWS S3 bucket. aws s3 ls s3://バケット名 pause exit 0〇実行結果
move: D:\backup-20191201.zip to s3://バケット名/backup-20191201.zip 2019-12-01 21:19:35 349 backup-20191201.zip 続行するには何かキーを押してください . . .作成例の流れ
本書で作成しましたバックアップ用のバッチファイルの流れを下記に記載します。
「backup_folder」変数にバックアップ対象のフォルダを指定する。
set backup_folder="C:\tmp\「datefile」変数にバックアップ日(YYMMDD形式)を生成する。
set datefile=%date% set datefile=%datefile:/=%バックアップ対象のフォルダをzipファイルに固める。
powershell Compress-Archive -Path %backup_folder% -DestinationPath D:\backup-%datefile%.zipバックアップ対象のzipファイルをS3バケットに移動する。
aws s3 mv "D:\backup-%datefile%.zip" s3://バケット名/バケットに保存されているファイルを表示する。
aws s3 ls s3://バケット名バックアップ結果を確認するため、一時停止する。
pause最後に
AWS CLIを利用することでAWSマネジメントコンソールを開かずにS3にファイルをアップロードすることができます。またS3を利用したバックアップ用のバッチファイルを作成することで、AWSマネジメントコンソールを経由せずにバックアップ対象のファイルをS3にアップロードすることができます。
- 投稿日:2019-12-01T23:02:47+09:00
lambdaを勉強した①
今更ながらlambdaについて勉強しました。
今回は概要についてです。lambdaとは
- サーバーの管理を気にすることなくコードを実行できるサービス
- ほかのAWSのサービスをトリガーにコードを実行できる
- APIのように使うことができる
- 課金されるのはコードを実行した時間と、回数によって課金(月に100万リクエストまで無料)
- デフォルトで使える言語はJava、Node.js、C#、Python、Go、PowerShell、Ruby
- Javaは実行時にコンパイルが行われる関係で速度が遅い
- lambda layerを利用することでほかの言語も使用可能
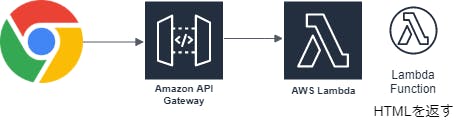
下記はlambdaのイメージ
API GateWay
S3
lambda functionとは
- 実際に実行されるコード
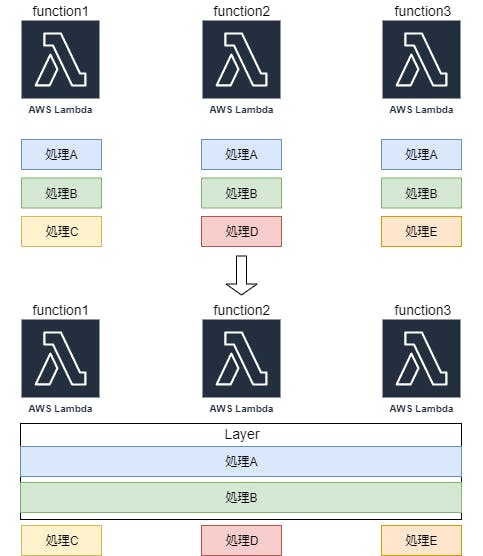
lambda layerとは
- 複数のlambda functionで共通する処理や、使用するライブラリを一つにまとめたもの
- ひとつのlambda functionに使用できるレイヤーは最大5つまで、ただし、容量制限もある(公式サイト)
下記はイメージ
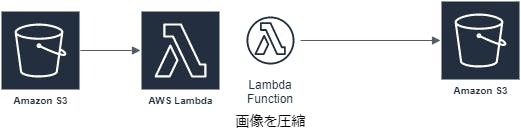
今回、lambdaについて概要をまとめてみました。
次回は実際にlambda functionを実際に使ってみたいと思います。
- 投稿日:2019-12-01T23:02:17+09:00
AWS認定の模擬試験を受けてみる流れ
AWS認定の模擬試験を受けてみたのですが、思い立ってから実際に受けるところまでの事務的なところがわかりにくかったため記録に残そうと思います。
事務的なところではなく、勉強という意味での準備や事前の心構えなどにであれば調べればいくらでもブログ記事があるので、本記事では特に触れません。1
アカウントを用意する
AWS認定には、模擬試験でも本試験でも同様にアカウント登録が必要になります。
前提としてAWSアカウント(amazon.comのアカウント)が必要になる2のですが、そのAWSアカウントにて進めるのではなくそのAmazonアカウントからシングルサインオンで認定用アカウント登録をするという流れとなります。
その認定アカウントにログインし、そこから試験の申し込み・支払い・実施などを行うかたちです。
https://www.aws.training/Certification にアクセスし、サインインより進むとアカウント作成ができます。
本試験と模擬試験の構造関係
試験には本試験と模擬試験がありますが、とくに構造上分離しているわけではなく、試験一覧の中に本試験があったり模擬試験があったりします。
試験リストにアソシエイトレベル、プロフェッショナルレベル、とグルーピングされている中に模擬試験(Practice)が並んでいます。そのため、模擬試験のみを受けたい場合であってもアカウント作成~試験申し込みまでのかなり長いパートが本試験と共通になっており、途中から「模擬試験はこちらから」のようになっていたりはしません。
PSI / ピアソンVUEについて
認定用アカウントでログインし申し込みに進もうとすると「PSIで申し込み」「ピアソンVUEで申し込み」などと選択肢があります。
これらは何かというと、試験を実施(開催)するベンダーの名前です。
イメージとしては、試験の作問はAWSが行い、試験費用の支払い受付や試験場所・環境の提供など実施の部分をベンダーが行うという構造です。会場にいって行う場合でも(模擬試験のように)ブラウザ上で行う場合でも差はないので、模擬試験の場合はどちらを選んでも良いと思います。
申し込み・受験の流れ
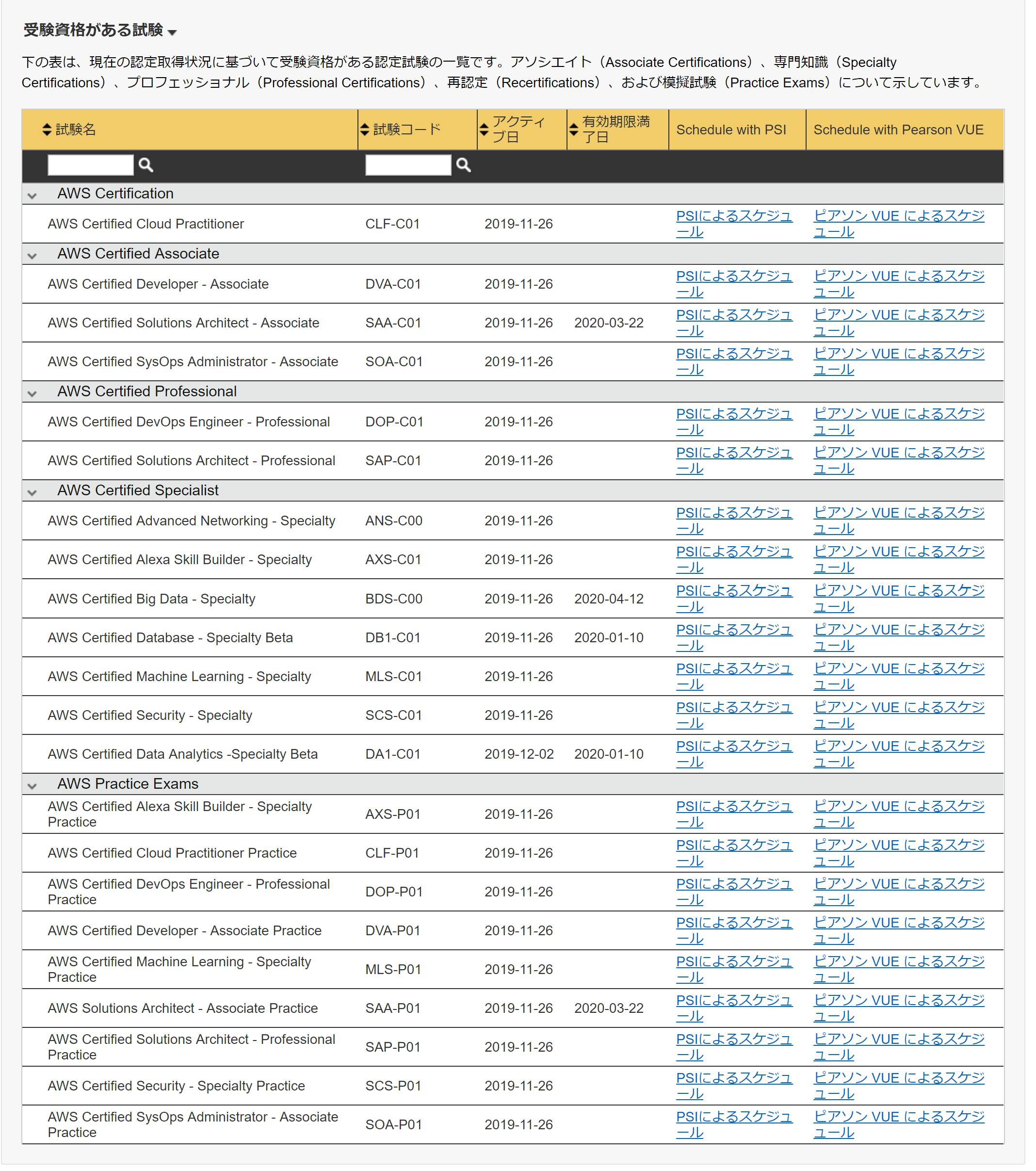
どのタイプの試験を受けるかを決めたとして、実際に申し込み・支払い・受験するまでの流れです。
まず認定アカウントにログインし、申し込み画面まで遷移します。
ページ下部の一覧のAWS Practice Examsのグループから目的のものを選び、PSI / Piasonの受験リンクを押します。
その後選んだほうのベンダーの手続きページに遷移するため、言われるまま言語や支払い情報(クレジットカード情報)を入力します。
住所入力欄がとてもアメリカ式で分かりづらいのですが、そこは適当に調べて入力します。なおここで試験言語として日本語を選んだ場合でも、(少なくともPSIでは)試験中に英語の文章を出すことが可能でした。34
支払いが完了すると「試験に進むか?」となるので、OKすると試験画面になります。
試験自体は(操作的な意味で)特にわかりにくい部分は無くサクサク進めていきます。UIとしてはWEBで4択アンケートをするよくあるフォームのようなイメージです。
縦に全問並んでるタイプではなく、1問ごとにページ遷移するタイプ。なお問題文・回答は試験後に確認することはできないので注意しましょう。
結果確認
試験が完了すると、1~2分程度で結果がメールで送られてきます。結果部分だけ抜粋すると以下のようになります:
総合スコア: 80% トピックレベルスコア: 1.0 Design Resilient Architectures: 88% 2.0 Define Performant Architectures: 57% 3.0 Specify Secure Applications and Architectures: 100% 4.0 Design Cost-Optimized Architectures: 50% 5.0 Define Operationally-Excellent Architectures: 100%ちなみにどの問題がどのトピックかは推測する他無く、かなり目安的な情報になります。
パーセンテージの数値からそのトピックが何問あったかは推測できなくもないですが...まとめ
必要なアカウント登録はAWSアカウントがあればポチポチすればすぐ終わるし、申し込み・実施も手順さえ迷わなければサクッと完了します。
試験自体も最大30分しかなく(実際には時間余るので20分もかからなかった)結果も即時確認できるため、割と思い立ったらすぐできます。
試験費用2,000円+税が気にならないのであれば、寝る前に1時間あれば余裕でできてしまうので気になる方はやってみるといいと思います。
- 投稿日:2019-12-01T22:39:47+09:00
Android 端末上で開発環境を整えてみた
本記事は、サムザップ Advent Calendar 2019 #2 の初日の記事です。
前書き
普段は SRE として既存タイトルの保守運用・改善を行いつつ、新規プロジェクトへ向けた標準化、構築運用がメインタスクです。他にもエンジニア採用と育成など、幅広く業務を行なっています!
この記事は出張前の6時間(移動時間含む)を使ってどこまで Android端末に開発環境を整備できるかトライした記事になります。(スクリーンショットは後から取得したものです。)
やりたいこと
- PCを持ち歩くのが辛いので、普段使いのAndroid端末を開発作業環境にする
- 個人の開発環境は、AWS と python に依存しているので使えるようにする
- ssh (4G回線なので固定IPが使えないので、SSMで代用できないか検証)
- python (できれば anyenv 経由の pyenv でインストールしたい)
- pip で aws-cli を使えるようにする
- bash / zsh のスクリプトが書けること
やったこと
さあ、残り5時間半で頑張っていきます!
Andoird で Terminal が使えるようにする
2019年12月現在、terminal emulator は数多く Goole PlayStore に登録されてる。
Termux を見つけた。
基本的なシステムコマンド or ssh のみ使えるものが多いが、Termux はaptやpkg を用いてパッケージの追加が可能だ。
https://github.com/termux/termux-packagesインストール完了後の起動画面
ここで、ls や df などのコマンドが使えることを確認した。
かなり便利だ。スマホでの作業環境構築が一気に捗った気がする。(さぁ、移動しなくては。)
python のインストール
package リストに python があるのは確認済みなので何も考えずに実行してみる。
Termux上で実行apt install pythonpip を含めて使えるようになった。
同じ要領で以下のパッケージもインストール
Termux上で実行apt install git apt install openssh(ここで残り3時間程度。スクリーンショットの共有ができないくらいに空港のWi-Fiが弱い...)
ここまでで、python, pip, ssh, git のコマンドが実行できることは確認した。
さあ、搭乗時間が迫ってきた。anyenv化は将来的に対応するとして、aws-cli はめちゃめちゃ大事だ。これがなければ、何もできない....
Termux上で実行pip install awscli
意外にさっくりできてしまった!
(搭乗手続きのため、中断。)
(気がつけば残り2時間程度。)Termux上で実行aws s3 ls 2019-02-01 18:20:37 ********************************** 2019-01-01 20:13:29 ********************************** 2018-12-01 16:31:29 ********************************** 2018-11-01 16:36:22 ********************************** 2018-10-01 11:06:09 **********************************実行確認をした。(モザイクが面倒だったので、テキストをコピペしました。)
ssm が使えるようにセッティング
Termux実行mkdir ~/.ssh touch ~/.ssh/config vim ~/.ssh/configここで気が付いた... vimが標準インストールされていない...
Termux実行apt install vim(残り1時間20分)
Termux実行vim ~/.ssh/config Host i-* mi-* ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"これはインスタンス名を指定した時に、自動で ssm を経由してポート解放せずログインできるようにするおまじない。ただし、対象のEC2にはインスタンスロールなどで、ssmによるログインを許可しておく必要がある。
その辺りは、AWS Systems Manager のセットアップを参照してくだされ。aws コマンドが使えるように credential をセット
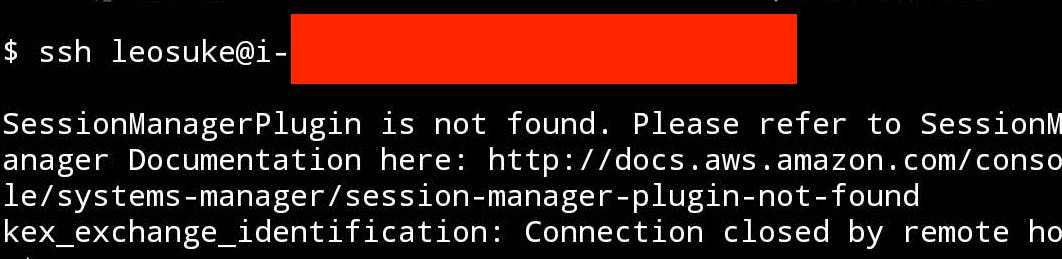
Termux実行vim ~/.bashrc AWS_SECRET_ACCESS_KEY=**************************************** AWS_DEFAULT_REGION=ap-northeast-1 AWS_ACCESS_KEY_ID=********************Termux上で実行ssh leosuke@i-**************
セッションマネージャのプラグインがインストールされていない!
ということでインストールしようとしたが... windows用のexe, amd用のrpm と deb しかなく....
alienコマンドで変換してファイル共有してみたが... イントールできなかった。さらに
aws helpを利用しようとしたら、groff がなく... groffもインストールできなかった。
(ここで時間が終了。作業時間は3時間弱くらい。)まとめ
Android 端末で実現できなかったことがあるものの、割と使える環境が整った!
(記事に書いていない部分の後悔としては、bluetooth キーボード。トラックパッドがないものを買ってしまったのがよくなかった)改善したい点は、termux で aws session-manager-plugin と groff がインストールできなかった。Groffはアウトプットフォーマッタだが、こんなに影響範囲があるとは思わなかった。session-manager-plugin の rpm や deb ファイルのアーキテクチャを amd64 から aarch64 に変換する方法も検討したが、無理だった。
ひと昔前なら root 化しなくてはできなかったことが、端末スペックの向上とアプリケーションによって割と簡単に導入できるようになった。少ない時間でゴリゴリと進められて良かったので、Termux の disabled-packages を使えるように コミットしていこうと思った。
明日は @hiroki_shimada さんの記事です。
ーーーーーー後日談
mac の bundle用 Python スクリプトでインストールしてみた。
kex_exchange_identification というエラーが出て結局 ssm 経由では接続できなかった。
- 投稿日:2019-12-01T21:56:07+09:00
AWS amplify Reactでログイン画面作成
amplifyとやらが便利そうなので入門として、TODOリストでも作ってみようかなと思った、第一弾です。
次は、Cognito認証付きAPIを作ろうと思います。0. 環境
$ node -v v10.16.3 $ npm -v 6.9.01. Amplify CLIインストール(準備)
公式: https://aws-amplify.github.io/docs/
$ sudo npm install -g @aws-amplify/cli$ amplify configure Scanning for plugins... Plugin scan successful Follow these steps to set up access to your AWS account: Sign in to your AWS administrator account: https://console.aws.amazon.com/ Press Enter to continue ## ここでブラウザが開き、ログイン画面が出るのでログインする。 ## すでにログインしている場合は、AWSマネジメントコンソールが開く。 ## ログインできたら、エンターを押す。 Specify the AWS Region ? region: eu-west-1 eu-west-2 eu-central-1 ❯ ap-northeast-1 ## 上・下カーソルで選択できるので、入力。 ? user name: [任意の名前を入れる] Complete the user creation using the AWS console https://console.aws.amazon.com/iam/home?region=undefined#/users$new?step=final&accessKey&userNames=************************************ Press Enter to continue ## ブラウザが開くのでそのまま登録(プログラムによるアクセスだけチェック入っていればOKです) Enter the access key of the newly created user: ? accessKeyId: ****************** ? secretAccessKey: ******************************* This would update/create the AWS Profile in your local machine ? Profile Name: default ## ~/.aws/credentials が更新されるので、すでにdefault登録ずみの場合は注意。 Successfully set up the new user.2. ReactJS生成
マニュアル: https://aws-amplify.github.io/docs/js/start?platform=react
今回はReactでマニュアルに則って作ってみます。
$ npx create-react-app mytodo $ cd mytodo $ npm install aws-amplify $ npm install aws-amplify-react $ npm startここまでで一旦Reactのデフォルト画面が表示されます。
3. バックエンドのセットアップ
3-1. 初期設定
★★のところが自分で入力できる箇所です。
★★★のところはそのままenterでOKです。$ amplify init Scanning for plugins... Plugin scan successful Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project mytodo ★★ ? Enter a name for the environment dev ★★ ? Choose your default editor: Visual Studio Code ★★ ? Choose the type of app that you're building javascript ★★ Please tell us about your project ? What javascript framework are you using react ★★ ? Source Directory Path: src ★★★ ? Distribution Directory Path: build ★★★ ? Build Command: npm run-script build ★★★ ? Start Command: npm run-script start ★★★ Using default provider awscloudformation For more information on AWS Profiles, see: https://docs.aws.amazon.com/cli/latest/userguide/cli-multiple-profiles.html ? Do you want to use an AWS profile? Yes ★★ ? Please choose the profile you want to use default ★★←ここはamplify configureで設定したProfile Nameを入力. ⠼ Initializing project in the cloud... ~~~~~ ✔ Successfully created initial AWS cloud resources for deployments. ✔ Initialized provider successfully. Initialized your environment successfully. Your project has been successfully initialized and connected to the cloud! Some next steps: "amplify status" will show you what you've added already and if it's locally configured or deployed "amplify <category> add" will allow you to add features like user login or a backend API "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloud Pro tip: Try "amplify add api" to create a backend API and then "amplify publish" to deploy everything3-2. auth(Cognito)の設定
3-2-1. Cognito作成
Emailでのログインを設定しました。
$ amplify add auth Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Default configuration ★★ Warning: you will not be able to edit these selections. How do you want users to be able to sign in? Email ★★ Do you want to configure advanced settings? No, I am done. ★★ Successfully added resource mytodo locally Some next steps: "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloud以下コマンドでCloudFormation Stackが作成されます。
一度作ってみて、ログイン機能の確認をしてみます。$ amplify push3-2-2. ログイン機能の実装
公式: https://aws-amplify.github.io/docs/js/authentication
SignUp/Inページ自体は、以下をのコードをApp.jsに追加するだけでできます。
ログイン後、先ほどのデフォルトページが表示さるようになります。App.jsimport Amplify, { Auth } from 'aws-amplify'; import { withAuthenticator } from 'aws-amplify-react'; import awsconfig from './aws-exports'; Amplify.configure(awsconfig); const signUpConfig = { header: 'MyTodo SignUp', hideAllDefaults: true, defaultCountryCode: 1, signUpFields: [ { label: 'email', key: 'username', required: true, displayOrder: 1, type: 'email' }, { label: 'password', key: 'password', required: true, displayOrder: 2, type: 'password' }, ] }うまくいかないときは、src/aws-wxports.jsの設定が正しいか確認してください。
自分は、この設定が別プロジェクトのものになっていて詰まりました(´-`)また、
<button onClick={() => Auth.signOut()}>Sign Out</button>を追加してあげるとログアウトできます。
4. おわり
おそらく、この通りにやれば10分~30分程度でログイン画面ができてしまいます。便利な世の中になりましたね。
今回は以上です。
- 投稿日:2019-12-01T21:07:08+09:00
【Go】S3のファイルを取得する方法
環境
- Go -
1.13事前準備
aws-sdk-goパッケージを使用するため、go getする。$ go get -u github.com/aws/aws-sdk-goサンプルコード
package main import ( "bytes" "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3" ) func main() { bucket := "bucket" // バケット名 path := "path/to/file" // ファイルパス /* * アクセスキーID・シークレットアクセスキーを直接指定する場合 */ // svc := s3.New(session.New(), &aws.Config{ // Region: aws.String("ap-northeast-1"), // Credentials: credentials.NewStaticCredentialsFromCreds(credentials.Value{ // // NOTE: GitHub等で公開する場合は環境変数に入れましょう // AccessKeyID: "xxxxxxxxxxxx", // SecretAccessKey: "xxxxxxxxxxxx", // }), // }) /* * ~.aws/credentialsに認証情報が設定済の場合、 * または、環境変数`AWS_ACCESS_KEY_ID`と`AWS_SECRET_ACCESS_KEY`に値が設定されている場合は、 * ここではアクセスキーID・シークレットアクセスキーを指定しなくても大丈夫 */ svc := s3.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) obj, _ := svc.GetObject(&s3.GetObjectInput{ Bucket: aws.String(bucket), Key: aws.String(path), }) defer obj.Body.Close() buf := new(bytes.Buffer) buf.ReadFrom(obj.Body) rslt := buf.String() fmt.Println(rslt) // => "ファイルの内容" }参考
- 投稿日:2019-12-01T20:02:12+09:00
ECS Fargateでブランチ毎にQA環境を作れるようにする
目次
前書き
概要
ECSでブランチごとの動作確認用の環境を準備したので、そのノウハウを共有します。
作った環境はこんな感じです。
動機
ディレクターが、エンジニアが開発中のブランチの挙動確認をするのに「
git pullしてdocker-compose upして、メモリが足りなくてビルド終わらなくて…」というのを見て「大変だなー」と思い、パッと動作確認できる環境を作ろうと思いました。本文
利用した主なツール
- aws-cli
- ecs-cli
- docker
- docker-compose
コンテナの構成
fargateで起動するコンテナ群はこんな感じです
コンテナ名 内容 app Nginx+プロダクションコード mysql DB redis バッチジョブ用のキュー 今回は、これを一つのタスクとして起動させています。
docker-compose.ymlで80番ポートを空けてインターネット → nginx → プロダクションコードという流れで通信が行われます。またfargate特有の事情としては、コンテナ間通信の名前解決がコンテナ名でなくlocalhostとなることなので、それは注意が必要です。
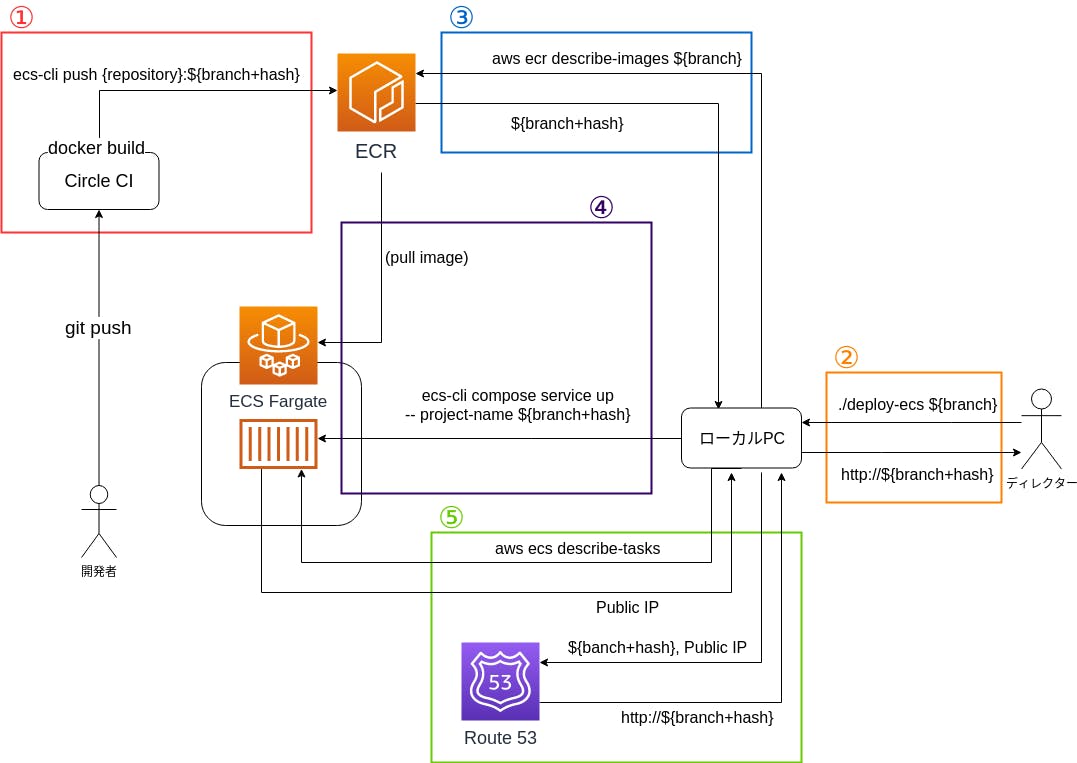
(自分はここで結構ハマりました…)1の解説
現在、ブランチがプッシュされたらCircleCIでphpunitを実行させています。
その工程に、docker imageのビルドとECRへのプッシュを追加します。
実際のコードはこんな感じです。config.yml- run: name: Install Docker client command: | set -x VER="19.03.5" curl -L -o /tmp/docker-$VER.tgz https://download.docker.com/linux/static/stable/x86_64/docker-$VER.tgz tar -xz -C /tmp -f /tmp/docker-$VER.tgz mv /tmp/docker/* /usr/bin - run: name: Install ecs-cli command: | set -x curl -o /usr/bin/ecs-cli https://amazon-ecs-cli.s3.amazonaws.com/ecs-cli-linux-amd64-latest chmod +x /usr/bin/ecs-cli - run: name: push docker image to AWS ECR command: | BRANCH_HASH=`echo $CIRCLE_BRANCH | sed 's:/:_:g'`-`git rev-parse HEAD` docker build -f Dockerfile_Ecs -t {{registory_id}}.dkr.ecr.ap-northeast-1.amazonaws.com/{{repository}}:${BRANCH_HASH} . ecs-cli push {{registry_id}}.dkr.ecr.ap-northeast-1.amazonaws.com/{{repository}}:${BRANCH_HASH}ECRの運用としては、一つのレポジトリに対して、「ブランチ名+コミットハッシュ」でタグ付けをしたイメージをプッシュすることにしています。
これでレポジトリにライフサイクルポリシーを設定することで、ECRの容量が肥大化することが防げます。
ただ、イメージのタグに/が使えないので_で置換しています。Dockerfile_Ecsの内容としては、ビルド済みのプロダクションコードを
COPYして、nginxの設定ファイル等を 適切な場所に配置って感じです。2の解説
ユーザーがブランチ名を引数としてスクリプトを実行したら、URLが出力されるようにします。
このURLからECSで起動したサービスにアクセスすることができれば、ユーザーはビルドやgit操作が不要となります。3の解説
今回の肝となるのは、4の
ecs-cli compose --project-name ${branch+hash} service upとなります。
しかし、そのためには入力された、ブランチ名から${branch+hash}を取得する必要があります。
そのために ECRでイメージ一覧を取得し、ブランチ名の前方一致でフィルターし、そのイメージのタグを取得することで${branch+hash}を取得します。4の解説
今回で一番重要なのが、この処理となります。
図ではスペースの都合でコマンドを省略しましたが、省略しないと下記になります。BRANCH_HASH=${branch+hash} ecs-cli compose \ -c {{cluster_name}} \ -f docker-compose-ecs-base.yml -f docker-compose-ecs.yml \ --ecs-params docker/ecs/ecs-params.yml \ --project-name ${branch+hash} \ service up \ --launch-type FARGATE環境変数
BRANCH_HASHに値を渡して、それを下記の docker-compose.yml で取得しています。services: app: build: context: . dockerfile: Dockerfile_Ecs image: "{{registry_id}}.dkr.ecr.ap-northeast-1.amazonaws.com/{{repository}}:${BRANCH_HASH}" ports: - "80:80" command: docker/ecs/entrypoint-app.shこれによって
ecs-cli compose service upの実行時に、どのタグのイメージをECSで立てるかを決定しています。
ECSはこのコマンドを受けて、タスク定義の作成、ECRからimageの取得、サービス+タスクの起動を行ってくれます。
そして、最後にentrypoint-app.shで、migration、シードデータの作成、nginx起動などのコンテナ起動に必要な処理を行っています。5の解説
今回は、4でECSのサービス+タスクがパブリックサブネットで作成されています。
そのため、そのタスクにはパブリックIPが付与されています。
そのパブリックIPをaws ecs describe-tasks等を利用して取得して、そのIPと${branch+hash}を紐付けて、 Route53でAレコードを作成します。ユーザーは、このAコードのURLを使うことで、ECSのサービスにアクセスできるようになります。
(パブリックIPが自動的に変更されて、URLとIPの紐付けが変わる可能性が高いような気はしますが、サービスは毎晩に削除しようと思ってるので、まぁ大丈夫かな?という予想です)
終わりに
続きの作業としては
- slackopsにする
- ECSのサービスを自動的に削除する
- Route53のレコードを自動的に削除する
をやりたいなーと思います。
ただslackops対応が意外と難しい…
参考
下記を参考にさせていただきました。
ありがとうございました
- 投稿日:2019-12-01T20:01:11+09:00
【LINE Notify API,AWS】LINE Notify APIとAWSを使って、バズってるツイートをグループLINEに定期送信
今回作るもの
友達とのグループLINEに対して、
定刻になるとバズってるツイートを送信する仕組みをつくります。LINE Notify API
LINE Notifyと連携を行うことで、LINEユーザーが簡単にサービスの通知を受信できるようになります。
【引用元】:LINE Notify
らしいです。
実際に使うとこんな感じで
LINE Notifyというアカウントからメッセージが届きます。
LINE Notifyの下準備
下記リンクの手順通り、
LINE Notifyが使える状態にします。
[超簡単]LINE notify を使ってみるバズってるツイートの取得
バズってるツイートも
Twitter API使って頑張ろうか迷いましたが、
辛そうだったので既存のランキングサイトからスクレイピングしてくることにしました。Twitter人気ランキングサイト →【TwTimez】
コード(Python)
import requests from bs4 import BeautifulSoup #一番勢いのあるツイートを取得 def bazz_get(): # アクセスするURL url = "http://www.twtimez.net/index.html" # URLにアクセスする html = requests.get(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html.text, "html.parser") try: for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href")) except: return "なんかしらのエラー" #Lineにメッセージを送る def send_line(Bazz): notify_url = "https://notify-api.line.me/api/notify" token = "アクセストークン" headers = {"Authorization": "Bearer " + token} message = "\r\n" + Bazz payload = {"message": message} requests.post(notify_url, headers=headers, params=payload) if __name__ == "__main__": send_line(bazz_get())スクレイピング
何気にちゃんとやる?の初めてです。
BeautifulSoupってのを使えばちょちょいのちょいでした。下記の箇所でhtmlの中から欲しい情報を持つクラスやタグを引っ張ってきてます。
for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href"))欲しい情報を持つクラスやタグはGIFでやっているような手順で突き止めます。
F12 Keyを押せばページのhtmlを見れます。
ここまで問題なければ、実行後にLINEへメッセージが送られます。
AWS
AWSのサービスを利用して定刻になるとメッセージを自動で送る仕組みを作ります。
多分無料です。後で請求書来たら勉強料を支払って速攻で止めます。
AWS Lambda
サーバーについて検討することなくコードを実行できます。お支払いいただくのは、実際に使用したコンピューティング時間に対する料金のみです。
らしいです。ここに今回書いたコードをぶち込みます。
Amazon CloudWatch
AWS とオンプレミスにおける AWS のリソースとアプリケーションのオブザーバビリティ
らしいです。なるほどわからん。
要するに自分で作った何かしらを簡単に監視していろいろできますってことだと思います。
設定した時刻にLambda上で作成した関数を定期的に実行可能です。実際の手順
Lambdaのコンソールにサインインして関数の作成を選択し、
適当に名前をつけて次に進みます。
Zipでフォルダ毎アップすることもできるみたいですが、
そこまで大したものを作ってないので、関数に先程のコードをコピペして貼り付けます。モジュールを利用しているのでダメでした。
さらに言うと、コードを追加、もしくは修正する必要があります。また、
コードをインラインで編集ではなく、.zipファイルでアップロードします。AWS用に変更したコード
import requests from bs4 import BeautifulSoup def bazz_get(): # アクセスするURL url = "http://www.twtimez.net/index.html" # URLにアクセスする html = requests.get(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html.text, "html.parser") try: for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href")) except: return "なんかしらのエラー" def send_line(Bazz): notify_url = "https://notify-api.line.me/api/notify" token = "アクセストークン" headers = {"Authorization": "Bearer " + token} message = "\r\n" + Bazz payload = {"message": message} requests.post(notify_url, headers=headers, params=payload) def bot(event, lambda_context): send_line(bazz_get())下記がLambdaで実際に呼び出される関数です。
実行だけを担うScriptを別途用意しても良かったのですが、
問題なく動いてくれて、今後拡張する予定もないので下記のようにしました。
Lambdaで呼び出すためには引数が必要です。def bot(event, lambda_context): send_line(bazz_get())アップロード先のハンドラにPython Script名と呼び出したいメソッド名を
.で繋いで書いておきます。
モジュール入りのZipファイルをLambdaにアップロード
まずは、モジュールを任意のディレクトリに保存します。
今回で言うと下記のような処理です。まずは保存したいディレクトリまで移動します。
コマンドプロンプトで実行cd 任意のディレクトリをD&Dあとは、カレントディレクトリにPython Script内で使用したモジュールを保存します。
コマンドプロンプトで実行pip install beautifulsoup4 -t . pip install requests -t .次はZip圧縮です。
アップロードしたいPython Scriptとモジュールを圧縮します。
全てを格納したフォルダに対してZip圧縮行うと一階層分余計なフォルダができてしまうので
GIF画像のように全選択して圧縮します。
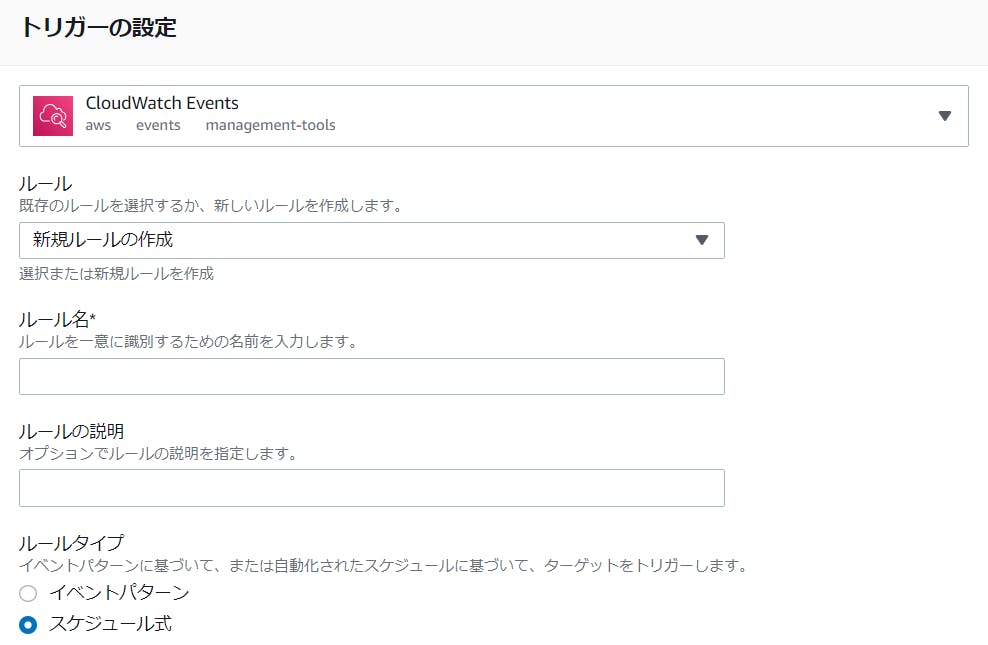
CloudWatch Events
次は
トリガーを追加を選択してCloudWatchと連携します。
(CloudWatchのコンソールにサインインして別途設定を行うアプローチでも可能です。)
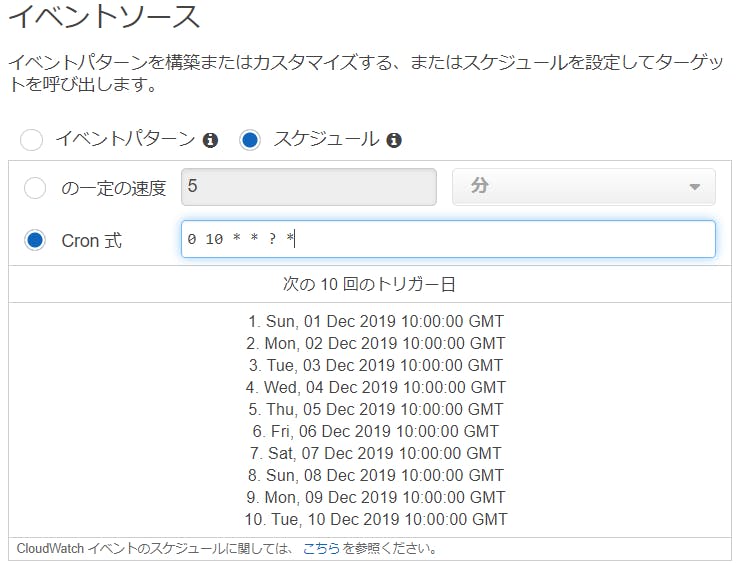
スケジュールの設定
スケジュールの設定方法(いつコードを実行するか)は下記リンクが参考になります。
Schedule Expressions for RulesCloudWatchにコンソールからサインインして
ルールの新規作成をした場合は下記画像のように
どのタイミングで実行するか表示されるのでわかりやすいです。
UTC(GMT)とJST
先程の画像を見ればわかりますが、GMTという文字が実行時間の後ろに書かれています。
日本の時間と9時間差があるそうなので、その時差を考慮した時間で設定しないとダメなようです。
【参考リンク】:【AWS】CloudWatch cron 式 または rate 式の書式について解説
グループLINE内のみんなの感想
全員フルシカトでした。なんで?
参考リンク
朝イチで知りたいことをLINEで教えてくれるプログラム(Python)
【Python】BeautifulSoupの使い方・基本メソッド一覧|スクレイピング
AWS LambdaをPythonで使ってみた ライブラリの読み込みや環境変数の注意点について解説


- 投稿日:2019-12-01T20:01:11+09:00
【LINE Notify API,AWS】バズってるツイートをグループLINEに定期送信
今回作るもの
友達とのグループLINEに対して、
定刻になるとバズってるツイートを送信する仕組みをつくります。LINE Notify API
LINE Notifyと連携を行うことで、LINEユーザーが簡単にサービスの通知を受信できるようになります。
【引用元】:LINE Notify
らしいです。
実際に使うとこんな感じで
LINE Notifyというアカウントからメッセージが届きます。
LINE Notifyの下準備
下記リンクの手順通り、
LINE Notifyが使える状態にします。
[超簡単]LINE notify を使ってみるバズってるツイートの取得
バズってるツイートも
Twitter API使って頑張ろうか迷いましたが、
辛そうだったので既存のランキングサイトからスクレイピングしてくることにしました。Twitter人気ランキングサイト →【TwTimez】
コード(Python)
import requests from bs4 import BeautifulSoup #一番勢いのあるツイートを取得 def bazz_get(): # アクセスするURL url = "http://www.twtimez.net/index.html" # URLにアクセスする html = requests.get(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html.text, "html.parser") try: for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href")) except: return "なんかしらのエラー" #Lineにメッセージを送る def send_line(Bazz): notify_url = "https://notify-api.line.me/api/notify" token = "アクセストークン" headers = {"Authorization": "Bearer " + token} message = "\r\n" + Bazz payload = {"message": message} requests.post(notify_url, headers=headers, params=payload) if __name__ == "__main__": send_line(bazz_get())スクレイピング
何気にちゃんとやる?の初めてです。
BeautifulSoupってのを使えばちょちょいのちょいでした。下記の箇所でhtmlの中から欲しい情報を持つクラスやタグを引っ張ってきてます。
for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href"))欲しい情報を持つクラスやタグはGIFでやっているような手順で突き止めます。
F12 Keyを押せばページのhtmlを見れます。
ここまで問題なければ、実行後にLINEへメッセージが送られます。
AWS
AWSのサービスを利用して定刻になるとメッセージを自動で送る仕組みを作ります。
多分無料です。後で請求書来たら勉強料を支払って速攻で止めます。
AWS Lambda
サーバーについて検討することなくコードを実行できます。お支払いいただくのは、実際に使用したコンピューティング時間に対する料金のみです。
らしいです。ここに今回書いたコードをぶち込みます。
Amazon CloudWatch
AWS とオンプレミスにおける AWS のリソースとアプリケーションのオブザーバビリティ
らしいです。なるほどわからん。
要するに自分で作った何かしらを簡単に監視していろいろできますってことだと思います。
設定した時刻にLambda上で作成した関数を定期的に実行可能です。実際の手順
Lambdaのコンソールにサインインして関数の作成を選択し、
適当に名前をつけて次に進みます。
Zipでフォルダ毎アップすることもできるみたいですが、
そこまで大したものを作ってないので、関数に先程のコードをコピペして貼り付けます。モジュールを利用しているのでダメでした。
さらに言うと、コードを追加、もしくは修正する必要があります。また、
コードをインラインで編集ではなく、.zipファイルでアップロードします。AWS用に変更したコード
import requests from bs4 import BeautifulSoup def bazz_get(): # アクセスするURL url = "http://www.twtimez.net/index.html" # URLにアクセスする html = requests.get(url) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(html.text, "html.parser") try: for detalis in soup.find(class_="details details2"): print(detalis.get("href")) return str(detalis.get("href")) except: return "なんかしらのエラー" def send_line(Bazz): notify_url = "https://notify-api.line.me/api/notify" token = "アクセストークン" headers = {"Authorization": "Bearer " + token} message = "\r\n" + Bazz payload = {"message": message} requests.post(notify_url, headers=headers, params=payload) def bot(event, lambda_context): send_line(bazz_get())下記がLambdaで実際に呼び出される関数です。
実行だけを担うScriptを別途用意しても良かったのですが、
問題なく動いてくれて、今後拡張する予定もないので下記のようにしました。
Lambdaで呼び出すためには引数が必要です。def bot(event, lambda_context): send_line(bazz_get())アップロード先のハンドラにPython Script名と呼び出したいメソッド名を
.で繋いで書いておきます。
モジュール入りのZipファイルをLambdaにアップロード
まずは、モジュールを任意のディレクトリに保存します。
まずは保存したいディレクトリまで移動します。
コマンドプロンプトで実行cd 任意のディレクトリあとは、カレントディレクトリにPython Script内で使用したモジュールを保存します。
コマンドプロンプトで実行pip install beautifulsoup4 -t . pip install requests -t .次はZip圧縮です。
アップロードしたいPython Scriptとモジュールを圧縮します。
全てを格納したフォルダに対してZip圧縮行うと一階層分余計なフォルダができてしまうので
GIF画像のように全選択して圧縮します。
CloudWatch Events
次は
トリガーを追加を選択してCloudWatchと連携します。
(CloudWatchのコンソールにサインインして別途設定を行うアプローチでも可能です。)
スケジュールの設定
スケジュールの設定方法(いつコードを実行するか)は下記リンクが参考になります。
Schedule Expressions for RulesCloudWatchにコンソールからサインインして
ルールの新規作成をした場合は下記画像のように
どのタイミングで実行するか表示されるのでわかりやすいです。
UTC(GMT)とJST
先程の画像を見ればわかりますが、GMTという文字が実行時間の後ろに書かれています。
日本の時間と9時間差があるそうなので、その時差を考慮した時間で設定しないとダメなようです。
【参考リンク】:【AWS】CloudWatch cron 式 または rate 式の書式について解説
グループLINE内のみんなの感想
全員フルシカトでした。なんで?
参考リンク
朝イチで知りたいことをLINEで教えてくれるプログラム(Python)
【Python】BeautifulSoupの使い方・基本メソッド一覧|スクレイピング
AWS LambdaをPythonで使ってみた ライブラリの読み込みや環境変数の注意点について解説
- 投稿日:2019-12-01T19:12:05+09:00
AWS Configを駆使して使っていないSecurity Groupをお掃除する
この記事はSpeee Advent Calendar 2019 1日目の記事です。
あらすじ
長い間AWSアカウントを運用していると、様々な理由で不要なリソースというものが生まれます。
- 長く運用されているアカウントで昔のリソースがIaCされていなくて使われなくなったリソースが残り続けていたり
- dev兼用だったりして不意に誰かの検証リソースが残っていたり
- などなど理由は様々です
使ってないリソースは消すに限ります。
本記事では、使ってないSecurityGroupをAWS Configを使って洗い出す方法をご紹介します。AWS Config
AWS Configには様々な機能がありますが、機能の一つにAWSリソース間の依存関係をSQLライクなクエリで抽出する機能があります。
https://docs.aws.amazon.com/ja_jp/config/latest/developerguide/querying-AWS-resources.html使ったことがない方向けに雰囲気を共有するためにAWS Configのサンプルクエリを一つ紹介します。
下記は使っていないEBSボリュームを抽出するクエリです。SELECT resourceId, resourceType, configuration.volumeType, configuration.size, resourceCreationTime, tags, configuration.encrypted, configuration.availabilityZone, configuration.state.value WHERE resourceType = 'AWS::EC2::Volume' AND configuration.state.value <> 'in-use'AWS ConfigのクエリはAWS Config用のデータのみを参照するのでFROM句は使いません。
基本的にSELECTとWHEREで欲しい情報の列と行を絞る感じになります。
JOINはサポートしていないけどGROUP BYはあります。HAVING BYはないです。実際に使っていないSecurityGroupを抽出する方法
では実際に使っていないSecurityGroupを抽出していきます。
紹介するクエリはコンソールかCLIかSDKかなんらか方法で実行して下さい。
得られた結果を加工したりするので得意な言語のSDKがおすすめです。Step1:他のAWSリソースから参照されているSecurityGroupを出す
まずは以下のクエリを実行します。
SELECT relationships.resourceId WHERE resourceType != 'AWS::EC2::VPC' AND relationships.resourceType = 'AWS::EC2::SecurityGroup' GROUP BY relationships.resourceIdこのクエリを実行するとセキュリティグループを参照しているリソース(例えばELB)が参照しているリソース(例えばELBが参照しているVPC,SecurityGroup,Subnet)のID一覧を得ることができます。
ややこしいですね。クエリを少し解説すると、WHERE句の
relationships.resourceType = 'AWS::EC2::SecurityGroup'はSecurityGroupを参照しているAWSリソースを抽出しています。relationshipsというカラムにそのリソースが参照している依存関係の情報があります。
VPCを除いているのは、全てのSecurityGroupはVPCに紐付けられるのでVPCにしか参照されていない(つまり他から使われていない)SecurityGroupもクエリに含められてしまうからです。GROUP BYは参照先のリソースIDで集約しています。
このクエリを実行するとSecurityGroup以外にもVPCやSubnetのIDも含まれてしまうので、得られた結果のうちを
sg-から始まるidだけをスクリプトか何かで抽出します。
本当はHavingが使えればそこで絞れて良いのですが...最終的にここで抽出されたSecurityGroupのIdは、何かのawsリソースから参照されているSecurityGroupの一覧になります。
Step2:他のAWSリソースから参照されていないSecurityGroupを出す
全SecurityGroup - 他のAWSリソースから参照されているSecurityGroup = 他のAWSリソースから参照されていないSecurityGroupです。以下のクエリを実行します。
SELECT resourceId, resourceName WHERE resourceType = 'AWS::EC2::SecurityGroup' AND resourceId NOT IN ( 'sg-xxxxxx', 'sg-yyyyyy', 'sg-zzzzzz', ... )IN句に入れるIDはstep1で抽出したIDになります。サブクエリとか使えると良いんですがね..
これで晴れて他のAWSリソースから参照されていないSecurityGroupの一覧が出せました。
Step3:SecurityGroupのルールで参照されているSecurityGroupを除く
もう一つ考慮するケースがあって他のSecurityGroupのsrcやdestに指定されているSecurityGroupは消すことができません。
なのでSecurityGroupのルールとして使われているSecurityGroupを除きます。
Step2:で得られたSecurityGroupIdに対して何らスクリプトでループを回して各SecurityGroupIdに対して以下のクエリを実行します。
(この辺もうちょいいい感じでクエリ書けるかもしれません)SELECT * WHERE resourceType = 'AWS::EC2::SecurityGroup' AND ( configuration.ipPermissions.userIdGroupPairs.groupId = 'sg-xxxxxx' OR configuration.ipPermissionsEgress.userIdGroupPairs.groupId = 'sg-xxxxxx' )SELECTの結果が0ならどのSecurityGroupにも参照されていません。消せる候補です。
終わりに
以上のステップで使っていないSecurityGroupを洗い出すことができました。あとは一覧をチェックして消すのみです。一応消す前は人の目を挟んだ方がいいと思います。
不要なゴミは消して快適なAWS運用を実現しましょう!!
- 投稿日:2019-12-01T19:12:05+09:00
Hinemos ver.6.2.1 をAWS上にインストールして監視するまで(初期設定編)
初投稿です。
仕事で使っている監視・ジョブツールであるHinemosのインストールと、やっておいた方が良い(と、思う)最低限の初期設定をまとめます。
他の方の参考になれば嬉しいです。前提知識
このページでは、以下の内容をある程度理解されていることを前提に
(説明すると長くなって面倒なので)記載をしています。
- Linuxの基本的な操作
- AWSの設定(セキュリティグループの設定とか)
viエディタの使い方Hinemosとは?
Javaで動作するオープンソースの監視・ジョブツールです。基本機能は無料で利用できます。
Hinemos1つで監視とジョブを行うことができます(ただし、一部の監視とジョブを利用するには、対象マシンにHinemosエージェントをインストールする必要があります)。
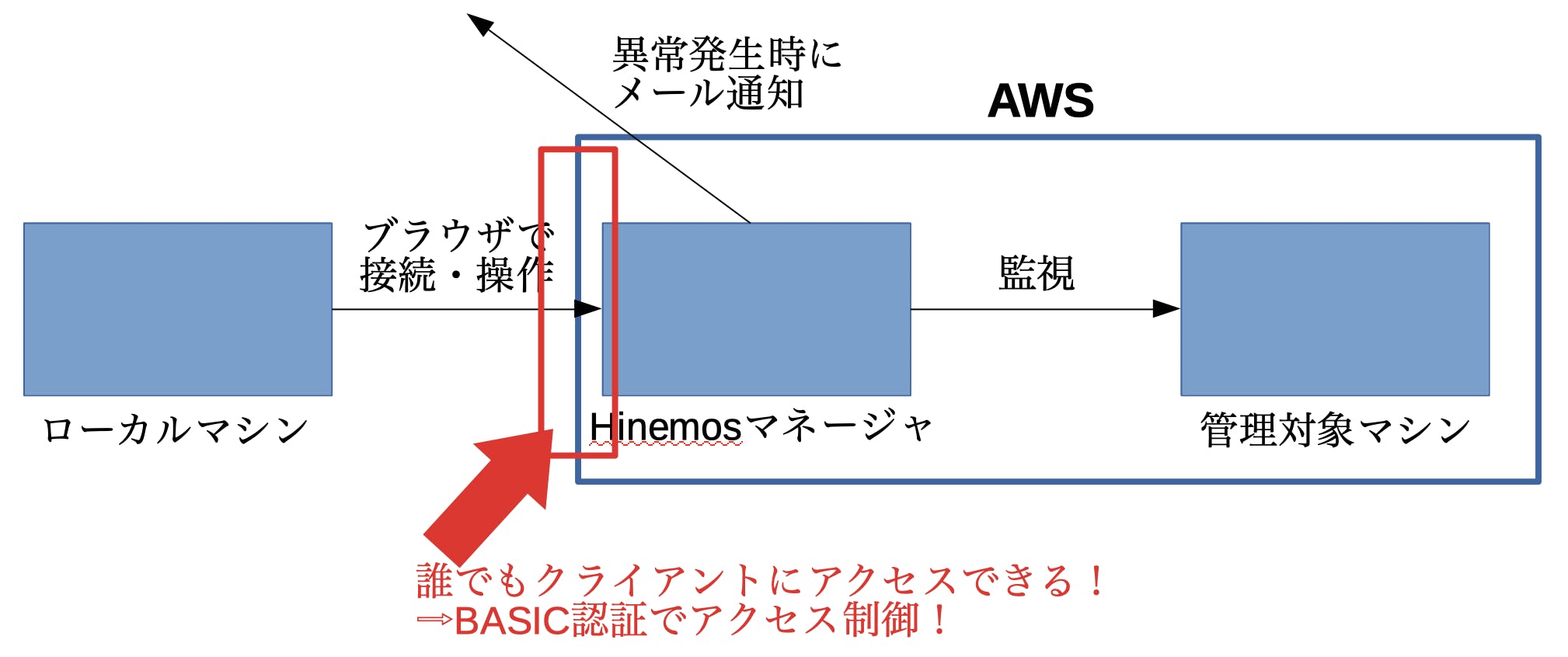
詳細は製品サイトへ作るもの
執筆時点で最新のver.6.2.1を利用します。
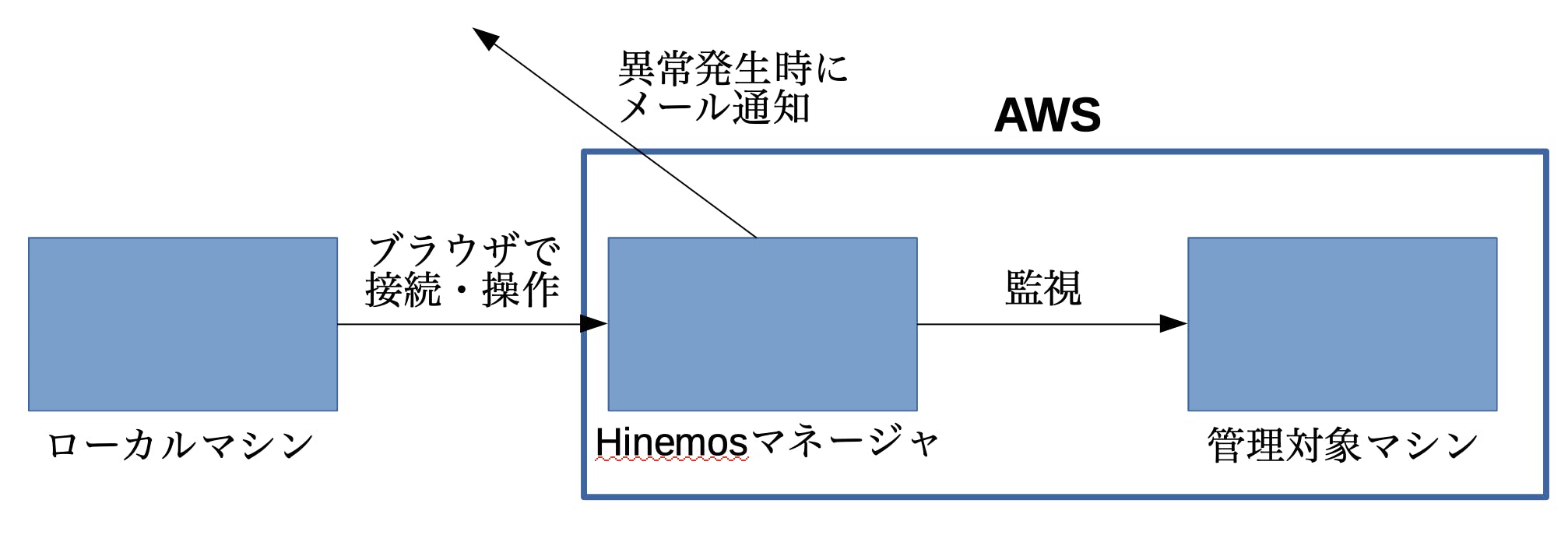
なお、本記事では下図を実現するためのHinemosマネージャ(下図の真ん中の青い四角)の設定を行います。
監視対象側の設定、監視の設定方法などは別の記事でまとめようと思います。必要なもの
- Hinemosマネージャ用のRHEL系マシン1台(RHEL7系) ※RHEL7であればマイナーバージョンはなんでもOK
- Gmailアカウント(通知メールをリレーさせるため)
このページでは、下のような図の構成で示す通り、AWS上で動く管理対象マシンを監視するため、Hinemosマネージャを構築します。異常を検知した場合は、メールで異常の内容を通知するよう設定をしたいと思います。
メールはHinemosマネージャからGmailをリレーして送信されるように設定します。
Hinemosはマネージャと監視・ジョブの実行対象となるマシン、そしてクライアント(上の図では「ローカルマシン」と記載)の3つで構成されています。
なお、少し前で触れましたが、一部の監視とジョブを実行するには、対象のマシンにHinemosエージェントをインストールする必要があります。また、HinemosはJavaで動作するので、対象のマシンにJavaをインストールする必要があります(ここ地味に重要)。
が、(一部を除いて)監視を行うだけであれば、監視対象にHinemosエージェントは必要ありません。
今回はエージェントを必要としない監視だけ行うので、管理対象マシンにHinemosエージェントはインストールしません。Hinemosクライアントについて
Hinemosマネージャに対して監視やジョブの設定などを行うためには、Hinemosクライアントが必要です。
Hinemosクライアントは、ローカルマシン(Windows)にインストールするタイプ(リッチクライアント)と、RHEL系マシンにインストールして、Webブラウザで接続して操作するタイプ(Webクライアント)の2種類があります。
サーバリソースに余裕があれば、HinemosマネージャとWebクライアントを同居させることができます。WebクライアントはHTML5対応のWebブラウザさえあればOSに関係なく操作できるので、こっちがオススメです。今回は、HinemosクライアントとしてWebクライアントを利用します。
Hinemosに必要なパッケージ
Hinemosの動作環境については、こちらを見てください。ここでは、Hinemosの動作環境を満たした上で、最低限必要なものをまとめます。より詳しい情報は、Hinemosインストールマニュアル(リンクのja_Install_Linux_6.2_rev2.pdf)を見てください。
Hinemosマネージャ
- Java: OpenJDK 1.8
- vim-common
Hinemos Webクライアント
- Java: OpenJDK 1.8
- unzip
Hinemos環境の準備
Hinemosインストーラの入手
GitHubでインストーラを入手します。具体的には、下記の2つをダウンロードします。
- hinemos-6.2-manager-6.2.1-1.el7.x86_64.rpm
- hinemos-6.2-web-6.2.1-1.el7.x86_64.rpm
Hinemosマネージャ用インスタンスの作成
AWS上でHinemosマネージャ用のインスタンスを作成します。今回は以下の内容でインスタンスを作成します。
ちなみに後述しますが、t2.microインスタンスではHinemosマネージャ、Webクライアントの2つを同時に動かすにはリソース(メモリ)が足りません。
お金に余裕があればt2.small以上を用意してください。
- OS: CentOS7(x86_64)
- インスタンスタイプ: t2.micro
Hinemosマネージャとwebクライアントのインストール・・・のための準備
Hinemosマネージャをインストールするために必要な作業は、下記の通りです。
- SELinuxの無効化
- OpenJDKのインストール
- スワップ領域の拡張(t2.small以上のインスタンスの場合は不要)
1. SELinuxの無効化
HinemosはSELinuxが有効化されているとインストールできないので、SELinuxを無効化します。
エディタで/etc/selinux/configを下記の通り変更します。
今後、rootユーザでないと実行できないコマンドが多く出てくるので、rootユーザでbashを開き直して実施するのが楽だと思います。# rootユーザでbashを開く sudo bash# SELinuxの設定ファイルを編集 vi /etc/selinux/config/etc/selinux/config# 変更前 SELINUX=enforced # 変更後 SELINUX=disabled変更後、再起動をして設定を反映させましょう。
reboot2.OpenJDKのインストール
Hinemosに必要なパッケージでも述べましたが、Hinemosマネージャ、Hinemos WebクライアントはOpenJDK8以上が必要です。
下記コマンドでOpenJDK 1.8をインストールします。sudo bash # OpenJDK 1.8をインストール yum -y install java-1.8.0-openjdk-devel3. スワップ領域の拡張(t2.small以上のインスタンスの場合は不要)
Hinemosマネージャ用インスタンスの作成の部分で説明した通り、このページで作成するインスタンス(t2.micro)ではメモリが足りません。インストールマニュアルによると、HinemosマネージャとHinemos Webクライアントを1台のマシンで運用するには、最低でも1.5GB必要なので、t2.micro(メモリ:1GB)では500MB不足しています。なので、根本的な解決方法ではないですが、スワップ領域を広げて無理やり動かす、、という荒技で解決します。
次は、スワップ領域を2GB増やすための設定例です。
# スワップファイルを作成 dd if=/dev/zero of=/var/swpfile bs=1M count=2048 mkswap /var/swpfile # スワップ領域として使用する swapon /var/swpfile最後にfreeコマンドでスワップ領域が増えているか確認してみましょう。
[centos@hinemos-manager ~]$ free total used free shared buff/cache available Mem: 1013192 674312 65804 44920 273076 136804 Swap: 2097148 256 2096892Hinemosマネージャ、Hinemos Webクライアントのインストール
インストールのための準備ができたので、早速インストールをしましょう。
scpコマンドやWinSCPを利用してインストーラをインスタンスに転送し、インストールを実行します。# scpでrpmファイルをCentOSサーバに転送するコマンド例 scp -i <秘密鍵のパス> hinemos-6.2-manager-6.2.1-1.el7.x86_64.rpm centos@<IPアドレス>:/home/centos/ scp -i <秘密鍵のパス> hinemos-6.2-web-6.2.1-1.el7.x86_64.rpm centos@<IPアドレス>:/home/centos/AWS上で利用するCentOSの場合、sshのログインユーザは「centos」になります。sshコマンドでログインする場合は下記のようなコマンドになります。
ssh -i <秘密鍵のパス> -l centos <IPアドレス>インストーラを転送した先のファイルパスに移動し、下記のコマンドを実行します。
# Hinemosマネージャのインストール rpm -ivh hinemos-6.2.1-manager-6.2.1-1.el7.x86_64.rpm # Hinemos Webクライアントのインストール rpm -ivh hinemos-6.2-web-6.2.1-1.el7.x86_64.rpmインストールがうまくいくと、/opt配下にhinemosディレクトリ(Hinemosマネージャのインストールディレクトリ)と、hinemos_webディレクトリ(Hinemos Webクライアントのインストールディレクトリ)の2つが作成されます。
インストールマニュアルを見ると、上記のrpmコマンドを実行する際にオプションをつけることでインストールディレクトリを変更することができるようです。詳しくはインストールマニュアルを参照してください。
前置きが長くなりましたが、以上がHinemosマネージャとWebクライアントのインストール方法についてでした。次からは、Hinemosマネージャ、Hinemos Webクライアントを利用するにあたって、必要な設定をしていきます。
AWS上でHinemosを利用する前の設定
インストールが終わったので、これからHinemosを利用する前にしておくべき設定をします。
具体的には、下記の設定をします。
- Hinemosマネージャ内部DB(PostgreSQL)のパスワード変更
- Hinemos Webクライアントの設定
- AWSのセキュリティグループ設定
Hinemosマネージャ内部DBのパスワード変更
Hinemosマネージャは、監視対象などの設定や監視結果のデータを記録するため、PostgreSQLが同梱されています。このPostgreSQLには、インストール直後だとユーザ名もパスワードも「hinemos」でログインできてしまいます。
このままにしていると万が一の時、セキュリティ的に問題があると思うので、最低限パスワードは変更をした方が良いでしょう。PostgreSQLのパスワードを変更するには、次のステップを行います。
- PostgreSQLに直接ログインしてパスワードを直接変更する
- Hinemosマネージャの設定ファイルを変更する
PostgreSQLのパスワードを変更する
PostgreSQLを起動/ログインし、ALTER USER文を実行してログインパスワードを変更します。
# Hinemosに同梱されているPostgreSQLを起動する systemctl start hinemos_pg # PostgreSQLにログインする /opt/hinemos/postgresql/bin/psql -U hinemos -p 24001-- パスワードを変更 ALTER USER hinemos PASSWORD '(新しいパスワード)';以上でPostgreSQLのパスワード変更ができたので、ログアウトします
# PostgreSQLからログアウト \q以上が完了したら、PostgreSQL側の作業は終了なので、PostgreSQLを一旦停止させましょう。
systemctl stop hinemos_pgHinemosマネージャの設定ファイルを変更する
PostgreSQL側のパスワードの変更をしたので、今度はHinemos側のパスワードを変更します。
vi /opt/hinemos/etc/META-INF/persistence.xmlpersistence.xmlの次の行をPostgreSQLのパスワードを変更するで設定したのとパスワードに変更しましょう。
/opt/hinemos/etc/META-INF/persistence.xml#変更前 <property name="javax.persistence.jdbc.password" value="hinemos"/> #変更後 <property name="javax.persistence.jdbc.password" value="(新しいパスワード)"/>同様に、次のファイルに対しても、PostgreSQLのパスワードを変更するで設定したのと同じパスワードを指定します。
vi /opt/hinemos/etc/db_account.properties/opt/hinemos/etc/META-INF/persistence.xml#変更前 hinemos_pass=hinemos #変更後 hinemos_pass=(新しいパスワード)これで、Hinemosの内部DBに対する設定は完了です。
Hinemos Webクライアントの設定
Hinemos Webクライアントの設定をしていきます。このページでは、大きく下記の2点を実施します。
- アクセス制御設定
- HTTPS化設定
Hinemos Webクライアントのアクセス制御
Hinemos Webクライアント側の設定として、アクセス制御の設定をしようと思います。
AWSのセキュリティグループでIPアドレスフィルタを設定するでも良いのですが、そうすると外出先で急遽サーバの状態を確認したい、などの場合に対応できない状況が想定されます。
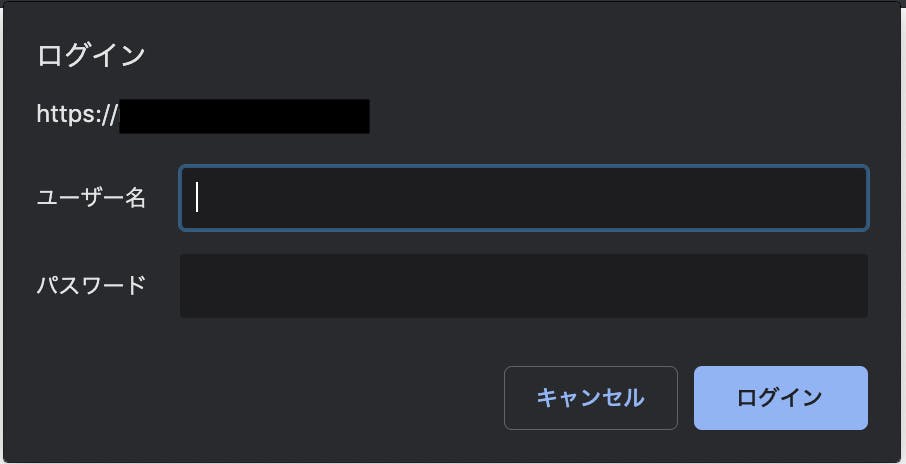
かといって、セキュリティグループを設定せずに、どこからでもアクセスできる状態にしてしまうと、最悪Hinemosマネージャに不正アクセスされてしまうリスクがあります。ジレンマですね。
そんなジレンマ解決方法の1例として、Hinemos Webクライアントで設定可能なBASIC認証によるアクセス制御を実施します。これをすることで、下のようなダイアログが表示されるようになり、認証をクリアしないとアクセスすることができなくなります。
これで、少なくとも不特定多数の人間がHinemosマネージャにアクセスできないように制限することができますね。
では、アクセス制御設定をするためにHinemosマネージャの下のファイルを編集します。
vi /opt/hinemos_web/conf/basic-auth-users.xml下記のコメントアウト(<!-- ~~ -->)を外して、usernameとpasswordの値を変更します。
/opt/hinemos_web/conf/basic-auth-users.xml<!-- 変更前 --> <!-- <role rolename="hinemos"/> <user username="user" password="<must-be-changed>" roles="hinemos"/> --> <!-- 変更後 --> <role rolename="hinemos"/> <user username="<任意のユーザ名>" password="<任意のパスワード>" roles="hinemos"/>BASIC認証を利用するよう、web.xmlの設定内容を変更します。
具体的には、下記の該当部分のコメントアウトを外します。/opt/hinemos_web/conf/web.xml<!-- 変更前 --> <!-- BASIC Auth --> <!-- <security-constraint> <web-resource-collection> <web-resource-name> Authentication of BasicAuth </web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>hinemos</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <realm-name>Hinemos WebClient</realm-name> </login-config> --> <!-- 変更後 --> <!-- BASIC Auth --> <security-constraint> <web-resource-collection> <web-resource-name> Authentication of BasicAuth </web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>hinemos</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <realm-name>Hinemos WebClient</realm-name> </login-config>Hinemos WebクライアントのHTTPS化
ローカルマシンからHinemos Webクライアントへの接続はデフォルトではHTTP通信となっています。このままでは盗聴の恐れがあり、セキュリティ的に問題があるので、HTTPS通信になるよう設定します。
なお、Hinemos Webクライアントとマネージャの間もデフォルトではHTTP通信となっていますが、今回構築する環境の場合は、Hinemos WebクライアントとHinemosマネージャは同じマシンなので、Hinemosマネージャ・Hinemos Webクライアント間のHTTPS通信化はしないものとします。興味がある方はマニュアルを参照してください。ローカルマシンとWebクライアント間でHTTPS通信をするには、下記の作業を行います。
- オレオレ証明書の発行
- server.xmlの設定変更
オレオレ証明書の発行
まずはオレオレ証明書を発行し、/opt/hineos_web/.keystoreに配置します。
keytool -genkey -alias tomcat -keyalg RSA -keystore /opt/hinemos_web/.keystore キーストアのパスワードを入力してください:(1でコメントを外したパラメータ「keystorePass」に設定した値を入力) 新規パスワードを再入力してください: 姓名を入力してください。 [Unknown]: (何も入力せずENTER) 織単位名を入力してください。 [Unknown]: (何も入力せずENTER) 組織名を入力してください。 [Unknown]: (何も入力せずENTER) 都市名または地域名を入力してください。 [Unknown]: (何も入力せずENTER) 州名または地方名を入力してください。 [Unknown]: (何も入力せずENTER) この単位に該当する 2 文字の国番号を入力してください。 [Unknown]: (何も入力せずENTER) CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown でよろしいですか? [いいえ]: (はいを入力) <tomcat> の鍵パスワードを入力してください。 (オレオレ証明書用のパスワードを入力してください)server.xmlの設定変更
そして、/opt/hinemos_web/conf/server.xmlを編集し、先ほど発行したオレオレ証明書を利用してHTTPS通信ができるよう設定を変更します。
vi /opt/hinemos_web/conf/server.xml/opt/hinemos_web/conf/server.xml<!-- 変更前 --> <Connector port="80" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="443" maxThreads="32" /> <!-- Define a SSL HTTP/1.1 Connector on port 8443 This connector uses the NIO implementation that requires the JSSE style configuration. When using the APR/native implementation, the OpenSSL style configuration is required as described in the APR/native documentation --> <!-- <Connector port="443" protocol="org.apache.coyote.http11.Http11NioProtocol" maxThreads="32" SSLEnabled="true" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" keystoreFile="/opt/hinemos_web/.keystore" keystorePass="changeit" /> --> <!-- 変更後 --> <!-- <Connector port="80" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="443" maxThreads="32" /> --> <!-- Define a SSL HTTP/1.1 Connector on port 8443 This connector uses the NIO implementation that requires the JSSE style configuration. When using the APR/native implementation, the OpenSSL style configuration is required as described in the APR/native documentation --> <Connector port="443" protocol="org.apache.coyote.http11.Http11NioProtocol" maxThreads="32" SSLEnabled="true" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" keystoreFile="/opt/hinemos_web/.keystore" keystorePass="<オレオレ証明書のパスワード>" />AWSのセキュリティグループ設定
Hinemosマネージャは管理対象と色々な通信をするので、必要に応じてセキュリティグループを変更しておく必要があります。
下記の表では、HinemosマネージャとHinemos WebクライアントをAWS上に構成するにあたって、最低限必要なインバウンドの設定を記載します。ソース部分は状況によって全然違うと思うので記載を省略します。
ポート番号 TCP or UDP 用途 備考 443 TCP Webクライアントへの接続のため(HTTPS通信の場合) 80 TCP Webクライアントへの接続のため(HTTP通信の場合) 161 UDP リソース監視、プロセス監視、SNMP監視のため 162 UDP SNMPTRAP監視のため 8080 TCP HinemosクライアントとHinemosマネージャ通信のため 8081 TCP HinemosエージェントとHinemosマネージャ通信のため 514 TCP or UDP システムログ監視のため システムログ監視でTCP、UDPどちらを利用するか決めて設定する必要がある 今回の場合は、443、161、8080のインバウンド許可だけ追加します。
以上で、Hinemosを利用する前の設定は完了です。
早速、HinemosマネージャとHinemos Webクライアントを起動してみましょう。# Hinemosマネージャを起動 systemctl start hinemos_manager # Hinemos Webクライアントを起動 systemctl start hinemos_web # Hinemosマネージャ、Hinemos Webクライアントの起動状態確認 systemctl status hinemos_manager systemctl status hinemos_web # Active: active (running) となっていればOKでは、ブラウザで
https://Hinemos WebクライアントのIPアドレスにアクセスしてみましょう。BASIC認証で設定したユーザ名、パスワードを入力してHinemos Webクライアントにアクセスします。
ログインダイアログが表示されるので、初期パスワード(ユーザ名:hinemos、パスワード:hinemos)でログインしましょう。
※ここでのパスワードは、Hinemosマネージャ内部DBのパスワード変更で設定したパスワードとは違います。Hinemosの設定
では次に、Hinemosにログインして以下の設定をしていきましょう。
- ログインユーザのパスワード変更
- SMTPサーバの設定
ログインユーザのパスワード変更
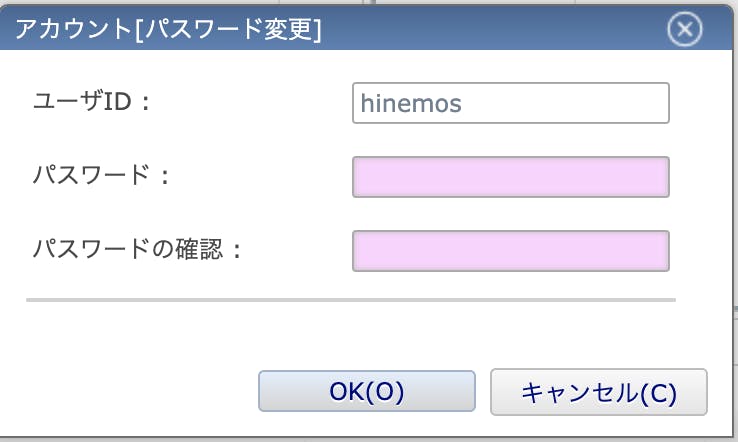
インストール時に用意されているログインユーザとパスワードは両方とも「hinemos」になっています。この「hinemos」ユーザは管理者権限を持っているので、このまま万が一不正ログインされると色々とマズいので、パスワードを変更しましょう。
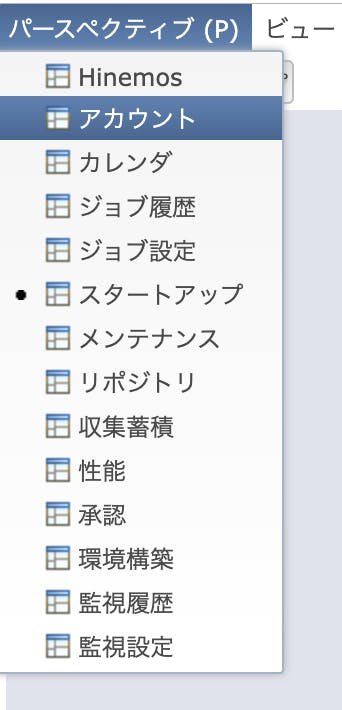
まずは左上のメニューから「パースペクティブ(P)→アカウント」の順番でアカウント画面を開きます。
右上にある「アカウント[ユーザ]」画面でhinemosユーザを選択して南京錠のアイコンをクリックします。
新しいパスワードの入力を求められるので、パスワードを2回入力してログインパスワードを変更します。
Gmailのリレー設定
Hinemosでメールでの通知を実現するために、Gmailのリレー設定を行います。
Gmailへのリレー設定をするためには、前提として2段階認証を設定する必要がありますので、まずは2段階認証設定を行ってください。
ここでは、HinemosからGmailへリレーするための設定方法を簡単に解説したいと思います。1, Googleアカウントのページ に行く
2, 左のタブから「セキュリティ」を選択し、「Googleへのログイン」内の「アプリ パスワード」を選択
3, 「アプリを選択」からメール、「デバイスを選択」から任意の名前を入力し、生成をクリック
4, 表示されたパスワードをメモする
SMTPサーバの設定(Hinemos側の転送設定)
転送予定のGmail側の設定が終わったので、次にHinemos側の転送設定を行います。
まず左上のメニューから「パースペクティブ(P)→メンテナンス」の順番でメンテナンス画面を開きます。
「メンテナンス[Hinemosプロパティ]画面」から、次の行を見つけて編集します。
キー 概要 設定値 mail.smtp.auth SMTPサーバとの通信時に認証が必要か true mail.smtp.host SMTPサーバのホスト smtp.gmail.com mail.smtp.port SMTPサーバのポート番号 587 mail.smtp.starttls.enable SMTPとの通信時にTLSを利用するか true mail.transport.password SMTPサーバの認証パスワード Gmailのリレー設定で取得したパスワード mail.transport.user SMTPサーバの認証ユーザ Gmailのリレー設定でパスワード取得に使用したアカウント(メールアドレス)
これで、HinemosからGmailをリレーしてメールを通知する設定ができました。
・・・ここまで書いていたら長くなってしまったので、監視結果をメールで送信する方法は別の記事でまとめようと思います。まとめ
本記事では、AWS上でHinemosをインストールし、下記の必要最低限の設定を行いました。
- Hinemosの内部DB(PostgreSQL)のパスワード変更
- Basic認証を利用したWebクライアントへのアクセス制限
- Webクライアントとの通信のHTTPS化
- 管理者アカウントのパスワード変更
- メール通知をするためのGmailへのリレー設定
次の記事では、本記事でまとめた環境をもとに監視を行い、監視結果をメールで任意アドレスに通知する方法をまとめたいと思います。


- 投稿日:2019-12-01T19:03:53+09:00
Elasticsearch/Kibana on AWS ECSをTerraformで サクッと構築
はじめに
こんにちわ!Wano株式会社のnariと申します。
Wanoグループアドベントカレンダー初日の担当として書かせていただきます。今回は、少し前まで着手していた共通検索基盤の構築(WIP)の際に、この記事を参考にElasticsearch/Kibana on AWS ECSを構築しましたが、
- ECSはGUIでの操作がやっぱりしんどい(設定部分が散らばりすぎている)ので、TerraformでIaCした話
- ElasticSearch/Kibana 5,6系を対象とした記事だったので、7系で構築する場合のトラブルシューティング
をまとめていこうと思います。
TL;DR
- ECSでお手軽にELK(Logstashは今回なし。Elasticsearchとkibanaのみ)を動かせるサンプルを作ったのでその構築方法と概要をまとめた
- その際に5、6系 -> 7系の差異で少し詰まったので、その際の解決法をまとめた
- Elasticserachをシングルノードで設定したいなら、
discovery.type: single-node- kibanaは
ELASTICSEARCH_URLでElasticsearchのURLを設定するシステム全体像
- とりあえず、HA(高可用性)な構成を取らずにシングルノードでやっていく形を取っています
- 弊グループサービス(Tuncore)のアーティスト/リリース/曲名の全文検索機能のデータソースとして想定
設定環境
- kibana:7.4.0
- elasticsearch:7.4.0
- terraform:0.12.6
なぜ Elasticsearch/Kibana on AWS ECS なのか
今回の要件では、逐次登録されていくアーティスト/曲名をユーザー定義辞書として管理し、検索精度を担保してあげる必要がある.
(ex: 「きゃ」 と検索して、「きゃりーぱみゅぱみゅ」がヒットして欲しくない。)
- Amazon Elasticsearch Serviceがユーザー定義辞書の設定ができない
- これ、だいぶ前からユーザー待望のアップデートだと思うので、re:inventで発表されたりしないかな
- Elastic Cloud(ELASTICSEARCH SERVICE)のユーザー定義辞書の更新も、GUIを通してしかできない
- 問い合わせたが、APIやプログラマブルなハックができる仕組みは存在しないという回答があった
上記によって、フルマネージのサービスを使用できなさそうなので、自前でクラスター管理をする必要が出てきたが、直近のプロジェクトでECSを使っていたのもあって、ECSで構築することにした
Terraformの設定ファイル全容/構築方法/ハマりどころとその解決方法
Terraformの設定ファイル全容
分量が非常に多いので、 GitHub - fukubaka0825/terraform-elasticsearch-and-kibana-on-ecs: terraform-elasticsearch-and-kibana-on-ecsに置いておきました。詳しくはそちらを参照ください。
-> % tree -L 2 . ├── README.md ├── elasticsearch │ ├── Dockerfile │ ├── dummy.pub │ ├── elasticsearch.yml │ ├── es_task_container_definitions.json │ ├── kibana_task_container_definitions.json │ ├── main.tf │ ├── outputs.tf │ ├── userData.sh │ └── variables.tf └── modules ├── ecr ├── ecs ├── iam_role └── sgどう構築し、使用するか
1. 上記のサンプルのcloneしてくる
2. AWSクレデンシャルを自分のアカウントのものをセットし、variables.tfのnetwork周りの変数を、自身のアカウントのものに変更する(vpc,subnet)
variables.tfvariable "vpc_id" { default = "YOUR_VPC_ID" } variable "subnet_id" { default = "YOUR_SUBNET_ID" }3. ecrリソースのみをデプロイする
- terraform init - terraform apply --target=module.hoge_test_es_app_ecr4. Dockerfileのelasticsearchイメージをbuildし、2でデプロイしたecrにpushする
- cd ./elasticsearch - docker build -t es-test:latest . - docker tag es-test:latest ${YOUR_AWS_ACCOUNT_ID}.dkr.ecr.${YOUR_REGION}.amazonaws.com/es-test:latest - (aws ecr get-login --region ap-northeast-1) - docker push ${YOUR_AWS_ACCOUNT_ID}.dkr.ecr.${YOUR_REGION}.amazonaws.com/es-test:latest5. es_task_container_definitions.jsonのimageを、ecrのimageへの参照に変更し、その他のリソースをデプロイする
es_task_container_definitions.json[ { "name": "ec-test", "image": "${YOUR_AWS_ACCOUNT_ID}.dkr.ecr.${YOUR_REGION}.amazonaws.com/es-test:latest", "cpu": 0, "memory": 60000, "memoryReservation": 60000, "portMappings": [ { "containerPort": 9200, "hostPort": 9200, "protocol": "tcp" }, { "containerPort": 9300, "hostPort": 9300, "protocol": "tcp" } ], "essential": true, "environment": [ { "name": "ES_JAVA_OPTS ", "value": "-Xms8g -Xmx8g " }, { "name": "REGION", "value": "ap-northeast-1" } ], "mountPoints": [ { "sourceVolume": "esdata", "containerPath": "/usr/share/elasticsearch/data/" } ], "volumesFrom": [], "disableNetworking": false, "readonlyRootFilesystem": false, "ulimits": [ { "name": "nofile", "softLimit": 65536, "hardLimit": 65536 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/es-test", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } } } ]- terraform deploy6. http://${CONTAINER_INSTANCE_PUBLIC_IP}:5601 にアクセス
kibanaのdev-toolでElasticsearchのデータをいじっていく(いちいちCurlせずに、クエリを実行できるのでとても便利)
私のハマりどころとその解決方法
1. Elasticsearch 7系からの必須設定項目の変更
自分が参考にした、ELK on ecsの記事は5、6系対応の記事だったので、今回の設定バージョンの7.4.0でその通りの設定でやると以下のようなエラーが出ます。
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configuredそこで、今回はシングルノードでやりたかったので次のようにelasticsearch.ymlの、discovery.type設定を追加した
elasticsearch.ymlcluster.name: "es-test" bootstrap.memory_lock: false network.host: 0.0.0.0 //以下を追加 discovery.type: single-node xpack.security.enabled: false2. kibana 7系からの必須パラメタの変更
6.7系までは、kibanaにelasticsearchのurlをenvで設定するのに、
ELASTICSEARCH_URLを使用していましたが、7系以降はELASTICSEARCH_HOSTSを使用して設定します。kibana_task_container_definitions.json[ { "name": "kibana-test", "image": "docker.elastic.co/kibana/kibana:7.4.0", "cpu": 0, "memoryReservation": 1024, "portMappings": [ { "containerPort": 5601, "hostPort": 5601, "protocol": "tcp" } ], "essential": true, "environment": [ { "name": "ELASTICSEARCH_HOSTS", "value": "http://localhost:9200/" } ], "mountPoints": [], "volumesFrom": [] } ]終わりに
現在、大きめなの海外プロジェクトのプライオリティが高まり、こちらのタスクはpendingの状況ですが、少し余裕ができたらまた再開して行きたいです。(ESとマスターデータのsync周り,辞書更新+index再構築の自動化,検索精度/速度改善まとめ、などなどやって行きたいトピックが盛りだくさん)
明日の担当は @fujitayy さんの「自作キーボードを組み立てた話」です!自作キーボード僕も作ってみたいので読むの楽しみ!!
今回のアドベントカレンダーは、非常に多くの人に記事執筆協力をしていただけるので、多種多様で魅力的なカレンダーになっていて今から読むのが非常に楽しみです。
また、今回の弊社アドベントカレンダーの参加者は、打ち上げで焼肉が食べられる事になっています??
恵比寿で焼肉をリサーチしよっと。安定のトラジかな??
みんなで無事完走して、美味しいお肉食べましょう!!参考文献
- Deploying the ELK stack on AWS ECS, Part 1: Introduction & First Steps
- Elasticsearchのkuromojiの検索で重要な辞書(dictionary)と類義語(synonym)の設定 - デベロッパー・コラボ
- Elasticsearch 7.0.0 がリリースされるもアップグレードでハマる – papalagi.org
- Running Kibana on Docker | Kibana Guide [7.4] | Elastic
- elasticsearch.hosts or elasticsearch.url are not picked up at all in version 6.7.0 · Issue #140 · elastic/kibana-docker · GitHub
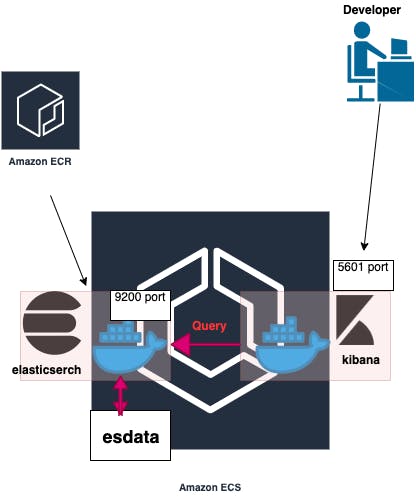
- 投稿日:2019-12-01T18:50:34+09:00
カフェの注文でいつも焦るので、Reactアプリを作って解決した
アプリ概要
スタバやドトールなどの主要カフェチェーンのドリンク・フードメニューを店ごとに一覧できるアプリを作りました。
商品名と各サイズの値段が表示され、行をタップすれば公式の詳細ページに飛びます。
なぜ作ったか
いわゆる「喫茶店」だと席についてからゆっくりとメニューを見られますが、スタバなんかだとレジの目の前で即断しないといけないこともあります。
後ろに人が並んでるし、目の前には店員さんもいる・・・。
この状況ではメニューをくまなく見れないし、結局前と同じ無難な注文をしがちです。
並んでいる最中にゆっくりと吟味できたらいいのにと思ったので作りました。
URL
技術
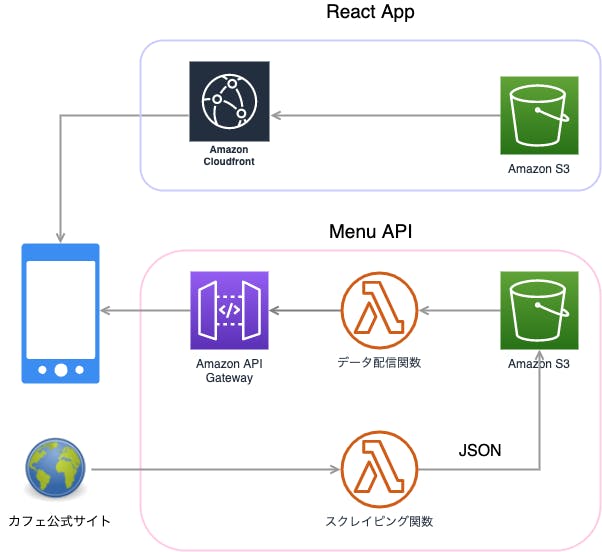
すべてAWS上で構成しました。
(矢印はユーザーが求めるデータの流れです)
フロントエンド
ReactによるSPAで、S3上にホスティングしました。
S3の静的サイトホスティング機能でも十分かなと思いますが、httpsに対応するためにCloudfrontを通しています。
UIフレームワークにはMaterial-UIを使わせてもらいました。
バックエンド
ReactからAPI Gateway -> Lambda関数を通して、S3上に保存されているメニューデータをjsonを返しています。
そのデータは各カフェチェーンの公式サイトから毎日一度だけスクレイピングさせてもらっています。
スクレイピング
言語はPythonで、 requests-htmlというライブラリを使用しました。
PythonといえばrequestsやBeautiful soupなんかが有名ですが、requests-htmlはそのあたりのライブラリをまとめて使いやすくしたもののようです。
実際、かなり直感的に使えるのでオススメです。
課題
Reactにまだ慣れない
初めて作ったReactアプリなのでいろいろと戸惑うことも多かったです。
各コンポーネントの依存関係や責任範囲などは、reduxも含めてもっと勉強したいと思います。
プロダクトとしての価値
適当な理想を掲げればwebサービスなんていくらでもデッチ上げられますが、多くの人に使ってもらえるようなプロダクトは稀です。
このアプリは「ショボくても、ダサくても、確実に誰かのニーズを満たせること」を目指してアイデアを練った結果生まれました。
ただ、どれだけ考えても確実なアイデアなんて出ないのはしょうがないと思います。
とにかくフットワークを軽くして、小さな検証を積み重ねていくつもりです。

- 投稿日:2019-12-01T17:22:19+09:00
【俺得】EBS暗号化の正体
前提知識
EC2作成時等に表示されるEBS暗号化について、深く理解してこなかったので整理したいと思う。
今迄での認識では、ストレージ自体の暗号化を行っておりあまり意味なさそう。。。位しか知らなかった。
EBS暗号化を有効にする事で提供される機能
1. AWSのデータセンターに侵入してHDDを盗まれた場合に、EBS暗号化を行っておけば盗人からデータを守る事が可能
2. EBS~EC2インスタンス間の通信経路上も暗号化される。
総評
確認した感じだと、EBS暗号化はいらなそう。
現実的にAWSデータセンター内への侵入が起こることが考えられない。
・・・通信経路上の暗号化も不要な気がする。(多分専用線を利用して通信していると考えられる。)参考
- 投稿日:2019-12-01T17:07:28+09:00
FargateとSSMでssh(ぽい)環境を構築してみた
自己紹介
SRE歴2年目、普段はAWS/GCPなどのインフラとrailsでサーバサイドをやっています。
たまに、GolangとDart書いてます。
基本的になんでも屋さん。やりたいこと
みなさん、AWS環境でsshはどうしていますか??

ほとんどの方はEC2で作って、そこにsshの公開鍵を置いたりしているはずです。
最近だと、Instance ConnectやSession Managerなど公開鍵を登録せずにシェルに入れる仕組みが増えてきました。
ただ、ほとんどの人がssh用にサーバは立ち上げた状態のはずです。
セキュリティグループなどを適切に設定していれば問題ありませんが、なんか怖い。
そんな人のために、必要なときだけ立ち上げて接続できるコンテナ環境を今回は作っていきます
やること
今回は、Fargateを使ってssh環境を作ってみます。
Fargateを使ってsshする場合、以下が候補になると思います。
- sshのpublic keyをコンテナに埋め込みssh接続
- パスワードとユーザ名でssh接続
- aws systems manager(session manager)で接続
この記事ではsession managerを使って接続してみたいと思います。
参考URLと使うサービス
今回はこの記事を参考にさせて頂いています!
ちなみに使うものは以下になります。
- クラウド環境
- AWS ECS Fargate
- AWS ECR
- AWS SSM Session Manager
- AWS SSM Managed Instances
- AWS SSM Hybrid Activations
- AWS Secrets Manager
- AWS VPC
- AWS CloudWatch Logs
- その他ツール
- Terraform 0.12.7
- fargatecli
- https://github.com/awslabs/fargatecli
ソースコード
ソースコードはGithubに公開しているので参考にしてみてください。
ポイント
コンテナ
ssmへの登録はdocker buildのタイミングで行います
- コンテナ起動時に登録すると、再起動のたびにssmに登録されるのであまりオススメしません

- 今回は登録数の上限を10個にしています
Fargateで使うDockerコンテナはamazonlinux2を使用しています
- yumでamazon-ssm-agentをインストールするために使っています
terraform/test/docker/fargate_ssh/DockerfileFROM amazonlinux:2 ARG SSM_AGENT_CODE ARG SSM_AGENT_ID ARG AWS_REGION ARG ACCESS_KEY_ID ARG SECRET_ACCESS_KEY RUN yum update -y && \ yum install -y amazon-ssm-agent RUN amazon-ssm-agent \ -register \ -code ${SSM_AGENT_CODE} \ -id ${SSM_AGENT_ID} \ -region ${AWS_REGION} COPY entrypoint.sh . CMD ["./entrypoint.sh"]
- Entrypointではシェルを実行しています
- ここでagentを起動しています
- 起動から一時間後に再起動するようにしています
terraform/test/docker/fargate_ssh/entrypoint.sh#!/bin/sh amazon-ssm-agent & sleep 3600task definition (container definition)
- ログはCloudWatch Logsに保存
- 環境変数はterraformで読み込む際にrenderで置き換えています
terraform/test/task-definitions/fargate_ssh.json[ { "essential": true, "image": "${DOCKER_IMAGE_URL}", "name": "fargate_ssh", "network_mode": "awsvpc", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "${AWS_LOGS_GROUP}", "awslogs-region": "${AWS_LOGS_REGION}", "awslogs-stream-prefix": "logs" } } } ]ECS Fargate
サブネットはPrivateにして、Internet Gatewayをつけないようにしています
- session managerはVPC Endpointを使って接続するようです
セキュリティグループのingressは開放せず、トラフィックを遮断しています
- session managerは厳密にはsshではないので、インターネット接続とポートの開放が必要ありません
パブリックIPアドレスも付与しないようにしています
terraform/test/main.tfmodule "fargate_ssh" { source = "../modules/fargate" name = "${local.name}-fargate_ssh" subnets = module.subnet.private_subnet_ids security_groups = [module.sg_deny_ingress.id] assign_public_ip = false task_cpu = 256 task_memory = 512 log_group_name = "/aws/ecs/${var.project}/${local.ws}/fargate_ssh" tags = local.tags container_definitions = file("task-definitions/fargate_ssh.json") container_definitions_vars = { DOCKER_IMAGE_URL = module.ecr_ssh.repository_url AWS_LOGS_GROUP = "/aws/ecs/${var.project}/${local.ws}/fargate_ssh" AWS_LOGS_REGION = var.region } }terraform/modules/fargate/main.tf# ECS Cluster resource "aws_ecs_cluster" "fargate" { name = var.name } ## ECS Service resource "aws_ecs_service" "fargate" { name = var.name cluster = aws_ecs_cluster.fargate.id task_definition = aws_ecs_task_definition.fargate.arn desired_count = var.desired_count launch_type = "FARGATE" network_configuration { subnets = var.subnets security_groups = var.security_groups assign_public_ip = var.assign_public_ip } lifecycle { ignore_changes = [desired_count] } } ## ECS Task resource "aws_ecs_task_definition" "fargate" { family = var.name container_definitions = data.template_file.fargate.rendered task_role_arn = aws_iam_role.fargate.arn execution_role_arn = aws_iam_role.fargate.arn network_mode = "awsvpc" cpu = var.task_cpu memory = var.task_memory requires_compatibilities = ["FARGATE"] tags = var.tags } data "template_file" "fargate" { template = var.container_definitions vars = var.container_definitions_vars } ## CloudWatch logs resource "aws_cloudwatch_log_group" "fargate" { name = var.log_group_name tags = var.tags } ## IAM resource "aws_iam_role" "fargate" { name = var.name assume_role_policy = data.aws_iam_policy_document.assume_policy.json tags = var.tags } data "aws_iam_policy_document" "assume_policy" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["ecs-tasks.amazonaws.com"] } } } resource "aws_iam_role_policy_attachment" "task_execution_role_policy" { role = aws_iam_role.fargate.name policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" } resource "aws_iam_role_policy_attachment" "fargate" { role = aws_iam_role.fargate.name policy_arn = aws_iam_policy.fargate.arn } resource "aws_iam_policy" "fargate" { name = "${var.name}_fargate" policy = data.aws_iam_policy_document.fargate.json } data "aws_iam_policy_document" "fargate" { statement { actions = [ "kms:Decrypt", "secretsmanager:GetSecretValue", "ssm:*", "iam:PassRole", ] resources = [ "*", ] } }
- IAMの権限ではSecrets Managerから秘匿情報を取得できるようにしています
- エージェント経由でコンテナを登録するため
ssm:*の権限も付与していますVPC Endpoint
- コンテナイメージはVPC Endpoint経由で取得します
- FargateはPrivateサブネットで動かすので、インターネット経由でECRからコンテナを取得できません
- s3を追加しているのは、ECRの裏でS3が使われているためです
- CloudWatch Logsも同様でPrivateサブネットからアクセス可能にします
terraform/modules/vpc_endpoint/main.tfresource "aws_vpc_endpoint" "ecr_api" { service_name = "com.amazonaws.${var.region}.ecr.api" vpc_endpoint_type = "Interface" vpc_id = var.vpc_id subnet_ids = var.subnet_ids security_group_ids = var.security_group_ids private_dns_enabled = true tags = var.tags } resource "aws_vpc_endpoint" "ecr_dkr" { service_name = "com.amazonaws.${var.region}.ecr.dkr" vpc_endpoint_type = "Interface" vpc_id = var.vpc_id subnet_ids = var.subnet_ids security_group_ids = var.security_group_ids private_dns_enabled = true tags = var.tags } resource "aws_vpc_endpoint" "logs" { service_name = "com.amazonaws.${var.region}.logs" vpc_endpoint_type = "Interface" vpc_id = var.vpc_id subnet_ids = var.subnet_ids security_group_ids = var.security_group_ids private_dns_enabled = true tags = var.tags } resource "aws_vpc_endpoint" "s3" { service_name = "com.amazonaws.${var.region}.s3" vpc_endpoint_type = "Gateway" vpc_id = var.vpc_id route_table_ids = var.private_route_table_ids tags = var.tags }環境作成と動作確認
- 今回の場合、ECSサービスの
desired_coutは0にしているので初期状態ではコンテナは動いていません。terraformでAWS環境を作成
- インストールなどは飛ばします
terraform/test$ cd terraform/test $ terraform init $ terraform plan $ terraform apply # outputの結果はメモしておきますコンテナイメージの作成
- ローカル環境でBUILDして、ECRにPUSHします
terraform/test/docker/fargate_ssh/docker# aws profileの設定 $ aws configure --profile test $ export AWS_PROFILE=test # push_ecr.shを修正して、環境変数を入力 $ vi push_ecr.shterraform/test/docker/fargate_ssh/docker/push_ecr.sh## ここを修正 export ECR_URL="" export SSM_AGENT_CODE="" export SSM_AGENT_ID="" export AWS_REGION="ap-northeast-1" export ACCESS_KEY_ID="" export SECRET_ACCESS_KEY=""terraform/test/docker/fargate_ssh/docker$ ./push_ecr.shコンテナ起動
- コンテナの起動にはfargatecliを使います
# インストール $ go get -u github.com/awslabs/fargatecli $ export PATH=$HOME/go/bin:$PATH $ export AWS_PROFILE=test $ export AWS_REGION=ap-northeast-1 $ fargatecli --version fargate version 0.3.2 # ECSサービスの確認 $ fargatecli service list \ --cluster aws-sample-test-fargate_ssh # コンテナを1個だけ起動 $ fargatecli service scale aws-sample-test-fargate_ssh 1 \ --cluster aws-sample-test-fargate_ssh # 起動確認 $ fargatecli service info aws-sample-test-fargate_ssh \ --cluster aws-sample-test-fargate_ssh Service Name: aws-sample-test-fargate_ssh Status: Desired: 1 Running: 0 #ここが1になればOK Pending: 1session managerからコンテナに接続
# 登録したインスタンスIDを確認 $ aws ssm describe-instance-information --query 'InstanceInformationList[0].InstanceId' "mi-XXXXXXXX" # コンテナに接続 $ aws ssm start-session --target mi-XXXXXXXXコンテナを停止
$ fargatecli service scale aws-sample-test-fargate_ssh 0 \ --cluster aws-sample-test-fargate_ssh利点と欠点
- 利点
- パブリックIPアドレスを付与せずにsshぽいことが可能
- 必要なときに立ち上げて接続可能
- こまめに止めればお得
- 欠点
- sshではないので、ポートフォワードなどができない
- 設定次第ではできるみたい
- /var/log/secureにログが残らない
- セッションのログはSSMに残っている
- 止め忘れると利用料がお高くなる
- ssmのagentがインストールできるコンテナのみ利用可能
まとめ
便利な半面、利用料が高かったり、sshの便利機能を使えなかったりします。
今後、Fargateのサービスが増えてくれば、標準でこういう機能もでてくると思います。
今後に期待!!!
- 投稿日:2019-12-01T17:07:26+09:00
PlantUMLによってコードベースでAWSのアーキテクチャー図を作る方法
AWS上にサービスを構築するうえで、アーキテクチャー図を作る機会はままあるかと思います。
その際、draw.ioやCacooなどのウェブサービスで作っている人も多いのではないでしょうか。
今回は別のアプローチとして、PlantUMLによってコードベースでAWSのアーキテクチャー図を作る方法をご紹介します。PlantUMLの実行環境を用意
まずは、PlantUMLの実行環境を用意します。
ローカル環境にインストールするのもいいですが、素早く試したい場合はPlantUML Web Serverを使うのが便利です。AWSのアイコンセットを用意
PlantUMLでは、ファイルパスやURLを指定してリソースをインポートすることができます。
これにより自作の画像を組み込むことができるわけですが、ありがたいことにAWSが公式にPlantUMLのためのアイコンセットを配布しています。記事執筆時点でスター数が57と、まだ世の中にはあまり知られていないようです。
PlantUMLのコードを書く
さっそくですが、次のようなコードを書いてみましょう。
@startuml Two Modes - Technical View !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !include AWSPuml/AWSCommon.puml !include AWSPuml/General/Users.puml !include AWSPuml/Mobile/APIGateway.puml !include AWSPuml/SecurityIdentityAndCompliance/Cognito.puml !include AWSPuml/Compute/Lambda.puml !include AWSPuml/Database/DynamoDB.puml left to right direction Users(sources, "Events", "millions of users") APIGateway(votingAPI, "Voting API", "user votes") Cognito(userAuth, "User Authentication", "jwt to submit votes") Lambda(generateToken, "User Credentials", "return jwt") Lambda(recordVote, "Record Vote", "enter or update vote per user") DynamoDB(voteDb, "Vote Database", "one entry per user") sources --> userAuth sources --> votingAPI userAuth <--> generateToken votingAPI --> recordVote recordVote --> voteDb @enduml出典:https://github.com/awslabs/aws-icons-for-plantuml/blob/master/README.md
すると、このような図が生成されます。
それぞれのコードの意味を紐解いていきます。
AWSのアイコンをインポート
!define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !include AWSPuml/AWSCommon.puml !include AWSPuml/General/Users.puml !include AWSPuml/Mobile/APIGateway.puml !include AWSPuml/SecurityIdentityAndCompliance/Cognito.puml !include AWSPuml/Compute/Lambda.puml !include AWSPuml/Database/DynamoDB.puml使用するAWSのアイコンをインポートしています。
ここではGitHub上のURLを指定していますが、ローカルにダウンロードしてファイルパスを指定してもかまいません。!define AWSPuml path/to/AWSPuml描画方向を指定
left to right direction図の描画方向を左から右に指定しています。
デフォルトでは上から下なので、この行を書かなければ次のようになります。
AWSのリソースを定義
Users(sources, "Events", "millions of users") APIGateway(votingAPI, "Voting API", "user votes") Cognito(userAuth, "User Authentication", "jwt to submit votes") Lambda(generateToken, "User Credentials", "return jwt") Lambda(recordVote, "Record Vote", "enter or update vote per user") DynamoDB(voteDb, "Vote Database", "one entry per user")配置するAWSのリソースを定義しています。
名前の部分は、実際のリソース名にすると分かりやすいでしょう。各リソースの関係を定義
sources --> userAuth sources --> votingAPI userAuth <--> generateToken votingAPI --> recordVote recordVote --> voteDbそれぞれのリソースの関係を定義しています。
リソース間を-->や<--で繋ぐと一方向、<-->で繋ぐと双方向の矢印が描画されます。生成した図を埋め込む
Qiitaの記事中にPlantUMLの図を埋め込む場合、UML anywhereというChrome拡張を使用すると便利です。1
なお、Qiita:TeamではPlantUMLの埋め込みに対応しているので、コードブロックの言語にplantumlを指定することで図が生成されます。2
おわりに
CloudFormationのテンプレートを読み込んで、PlantUML用のコードを出力してくれるようなツールがあれば最高ですね。3


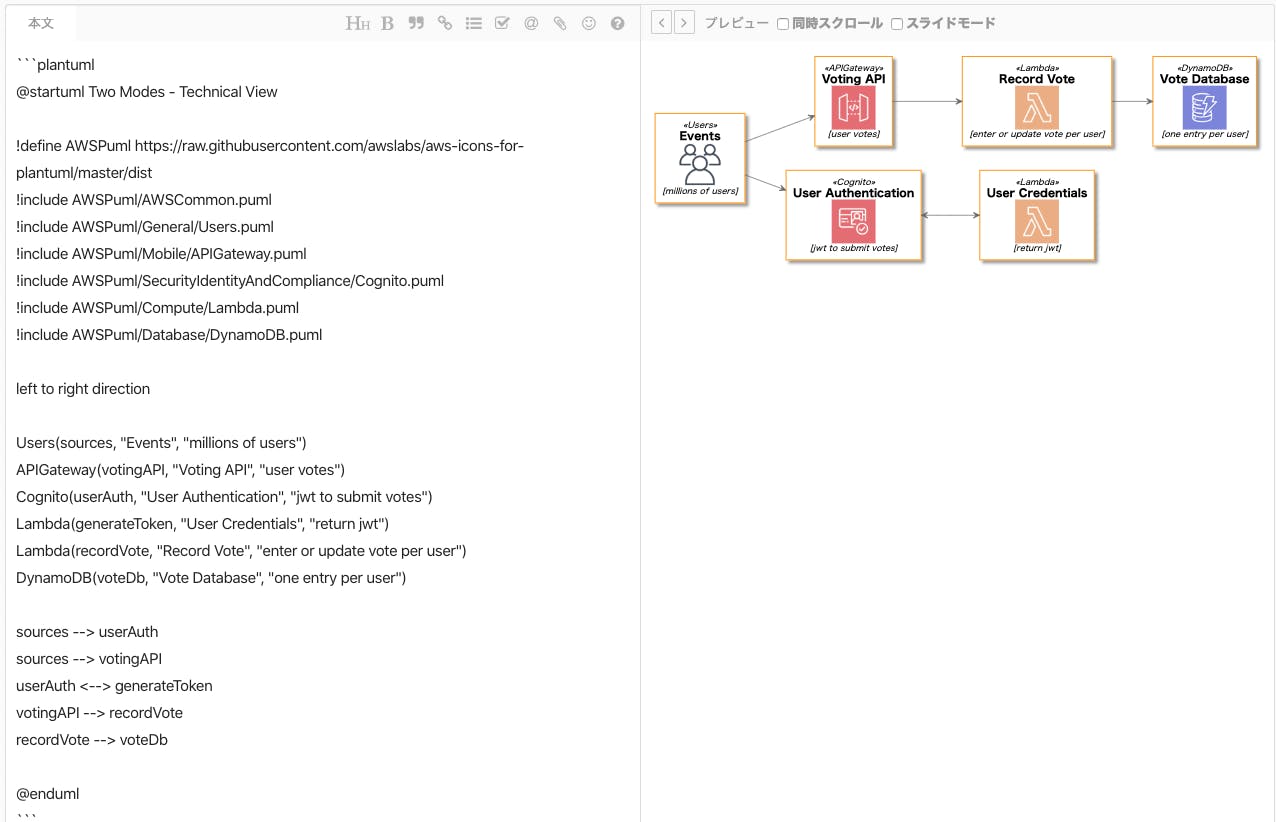
- 投稿日:2019-12-01T16:47:53+09:00
Amazon Connect のメリット、デメリット、使い方まとめ【2019年12月時点】
この記事はAteam Hikkoshi Samurai Inc. & Ateam Connect Inc.(エイチーム引越し侍、エイチームコネクト) Advent Calendar 2019 5日目の記事です。
エイチームコネクトでエンジニアのマネージャをしています @keki です。
最近、クラウドベースのコンタクトセンターシステム Amazon Connect を検討する機会がありましたので、メリット、デメリットと使い方を整理します。Amazon Connect とは
Amazon Connect を一言で表現すると「拡張が容易なクラウド型PBXをAWS内に構築できる機能」です。
従来のオンプレミス型PBXの場合、データセンター契約から、電話回線の手配、各種ネットワーク機器の配置と設定、PBX用のサーバを構築等々を行うことで初めて使えるものになりますが、Amazon Connect を活用することで、AWSにて用意しているネットワークインフラ内にPBXの構築が可能となります。
コンソール画面での操作で、簡単にPBXを構築することが出来ます。また、ACD(着信呼の自動分配)やIVR(自動音声案内)を実装することも可能です。
メリット/デメリット
メリット
初期費用無料
AWSその他サービスと同様、使った分だけ料金が発生する仕組みのため、初期費用無料で使うことができます。
月額料金が安い
Amazon Connect の料金は、
1日あたりの利用料(1番号あたりの利用料)+ 通話料金という構成になっています。
受電時の料金
発信時の料金
※ https://aws.amazon.com/jp/connect/pricing/ より引用(2019/12月時点)
通常、オンプレでPBXを構築、他社のクラウドPBXを利用して発着信を行う場合は、PBXの料金(オンプレの場合はデータセンター費用やハード費用等、クラウドの場合は月額利用料)と通話料がかかりますが、 Amazon Connect の場合は、番号使用料と通話料のみで利用することができるので、とても安価です。
- 料金例
以下、Amazon Connect 料金ページからの引用です。
料金の例
アジアパシフィック (東京) リージョンで、エンドカスタマーが Amazon Connect の ドイツ直通ダイヤルイン (DID) 番号を使用して電話をかけ、エージェントが Amazon Connect ソフトフォンを使用して応答します。通話は 7 分間続きます。
この通話には 3 種類の料金が適用されます。
1.エンドカスタマーの通話時間に応じて Amazon Connect のサービス利用料金が発生します。1 分あたり 0.018 USD * 7 分 = 0.126 USD
2.日本 DID 番号を使用したため、1 日単位の料金が発生します。1 日あたり 0.10 USD * 1 日= 0.10 USD
3.また、日本 DID 番号には、1 分単位の受信通話料金が発生します。1 分あたり 0.003 USD * 7 分 = 0.021 USD
この通話の合計は 0.25 USD です。 (税金、手数料および追加料金が適用される場合があります)
0.25ドル/7分 (1ドル=110円 とすると 27.5円/7分)は、圧倒的に安いです。
導入が楽
後ほど使い方を説明しますが、ACDやIVR等の設定を行わず、単に通話ができるようにするだけであれば、30分もあれば構築が可能です。構築の手間は、他のPBXと比較して圧倒的に楽です。
信頼性が高い(SLA99.99%)
AWSのネットワークインフラを活用しているので、他のAWSサービス同様の信頼性を確保することができます。
AWSの各サービスと連携ができる
深層学習チャットボットサービスである Amazon Lex や音声文字起こしサービスの Amazon Transcribe といったサービスとの連携が容易です。
また、録音された音声データを S3 にアップしたり、Lambda と組み合わせて受信した電話番号を元に処理を実行したりといった使い方も可能です。デメリット
取得できる電話番号に限りがある。0120番号が登録できないことも?
Amazon Connect の管理画面にてどの電話番号を使うか選択することができるのですが、
取得できる番号には限りがあるようです。
※ 今回検証した際には、0120番号を取得できましたが、数ヶ月前に試した際には0120で始まる番号を選択することはできませんでした。
既存の電話番号を移管出来ない
さらに、現在使っている電話番号を Amazon Connect に移管することはできないようです。
現在既にコールセンターシステムを導入しており、 Amazon Connect への移管を考えていらっしゃる方にとっては、致命的な課題かもしれません。今後のサービス成長に期待ですね!モニタリング機能が弱い
例えばSV(スーパーバイザー)がメンバーの通話状況をリアルタイムで確認したり、モニタリング(メンバーが話している内容を別端末で聞いたり)、通話中にメンバーにのみ音声を発信したり(アドバイスを出したり)といった機能は備わっていないようです。
こちらも今後のサービス成長に期待といったところですね。使い方
とりあえず電話ができるようにするまでの流れをまとめます。
※ 画面は2019/12時点のものです。URL
https://ap-northeast-1.console.aws.amazon.com/connect/home?region=ap-northeast-1
操作手順
- TOPページ
「今すぐ始める」をクリックします。
- ID管理画面
Amazon Connectで使用するユニークなIDを指定します。
ここでは、「sample-contact-center」としています。
- 管理者の作成
管理者ユーザを設定します。
なお、 Amazon Connect のユーザーは IAM とは別で管理されます。
- テレフォニーオプションの設定
そのままの設定で、次のステップに進みます。
- データストレージの設定
ここも特に設定変更する必要はないでしょう。
ストレージ管理を変更したい場合は、必要に応じて修正してください。
- 内容確認
内容確認し、問題なければ、インスタンスの作成ボタンをクリックします。
インスタンスが作成されるまでに1~2分程度かかるので、しばらく待ちましょう。
- 完了
完了したら、今すぐ始めるをクリックして Amazon Connect 管理画面に移動します。
※ インスタンス作成直後は403エラーが表示されます。15分ほど待てば、管理画面に移動できますので、403エラーが表示された時はしばらく待ちましょう。
- Amazon Connect管理画面ログイン
先ほど設定した管理者ユーザーのIDとパスワードを入力し、ダッシュボードにログインします。
- 管理画面TOP
管理画面TOPのダッシュボードより、電話番号の発番を行うことができます。
「1. コミュニケーションチャネルの調査」にある開始ボタンをクリックします。※ 画面の表示は日本語に変更しています。(デフォルトは英語)
- 電話番号取得画面
使用する電話番号を取得することができます。
2019/12時点では、0120番号を選択することもできました。※ 以前試した時は0800番号しか選択できませんでした。タイミングによっては取得できないかもしれません。
- 発信テスト
発信のテストを行います。画面右側に表示されたCCP(Contact Control Panel) の Number Pad をクリックし、ご自身のスマホ等に電話してみましょう。
- 着信テスト
デフォルトの設定のままでは、着信してもガイダンスが流れるだけで受信ができないので、問い合わせフローの設定が必要です。
左メニュー内の「ルーティング」から「電話番号」を選択します。
先ほど取得した番号が表示されるので、電話番号をクリックします。
電話番号の編集画面にて、「問い合わせフロー/IVR」のプルダウンを「Sample queue customer」に変更し、保存します。
着信を受けるためにはCCPを起動しておく必要があります。
画面右上の電話アイコンをクリックすると起動できます。
CCPを起動すると以下のような画面になります。
左上のステータスを「Available」にした状態で、取得した電話番号に電話をすると、電話に出ることができます。
着信中の画面はこちら。
電話をすると、英語のガイダンスが流れた後、軽快な保留音が流れてきます。
こちらは、問い合わせフロー設定やプロンプト設定にて変更することができます。まとめ
まだまだこれから発展していくと思われる Amazon Connect ですが、小規模なコールセンターを立ち上げる場合、0120番号にこだわりはなく、0800番号でも大丈夫という場合にはとても有用なサービスだと感じます。
逆に、既に大規模なコンタクトセンターを運用している状況の中で、コールシステムを移管するケースでは、 Amazon Connect を選択することは(現時点では)難しいですね。電話番号移管が出来ない点が、大きなボトルネックになってしまいます。今後に期待ですね。
お知らせ
エイチームグループでは一緒に活躍してくれる優秀な人材を募集中です。
興味のある方はぜひともエイチームグループ採用ページよりご応募ください!Qiita Jobsのエイチーム引越し侍社内システム企画 / 開発チーム、社内システム開発エンジニアを募集!からチャットでご質問いただくことも可能です!
明日
明日は私の直属の上長である @hironey さんの記事です。
どんな記事を書いてくださるか、私自信とても楽しみです♪
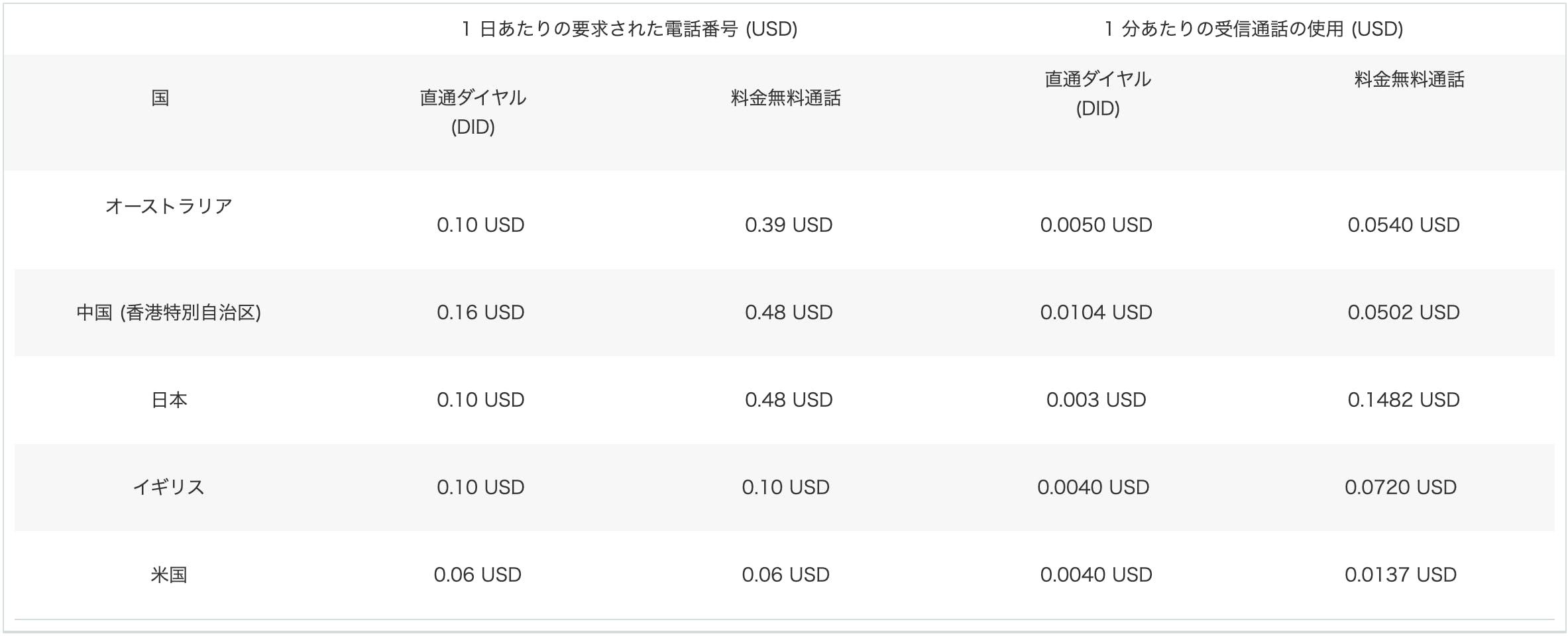


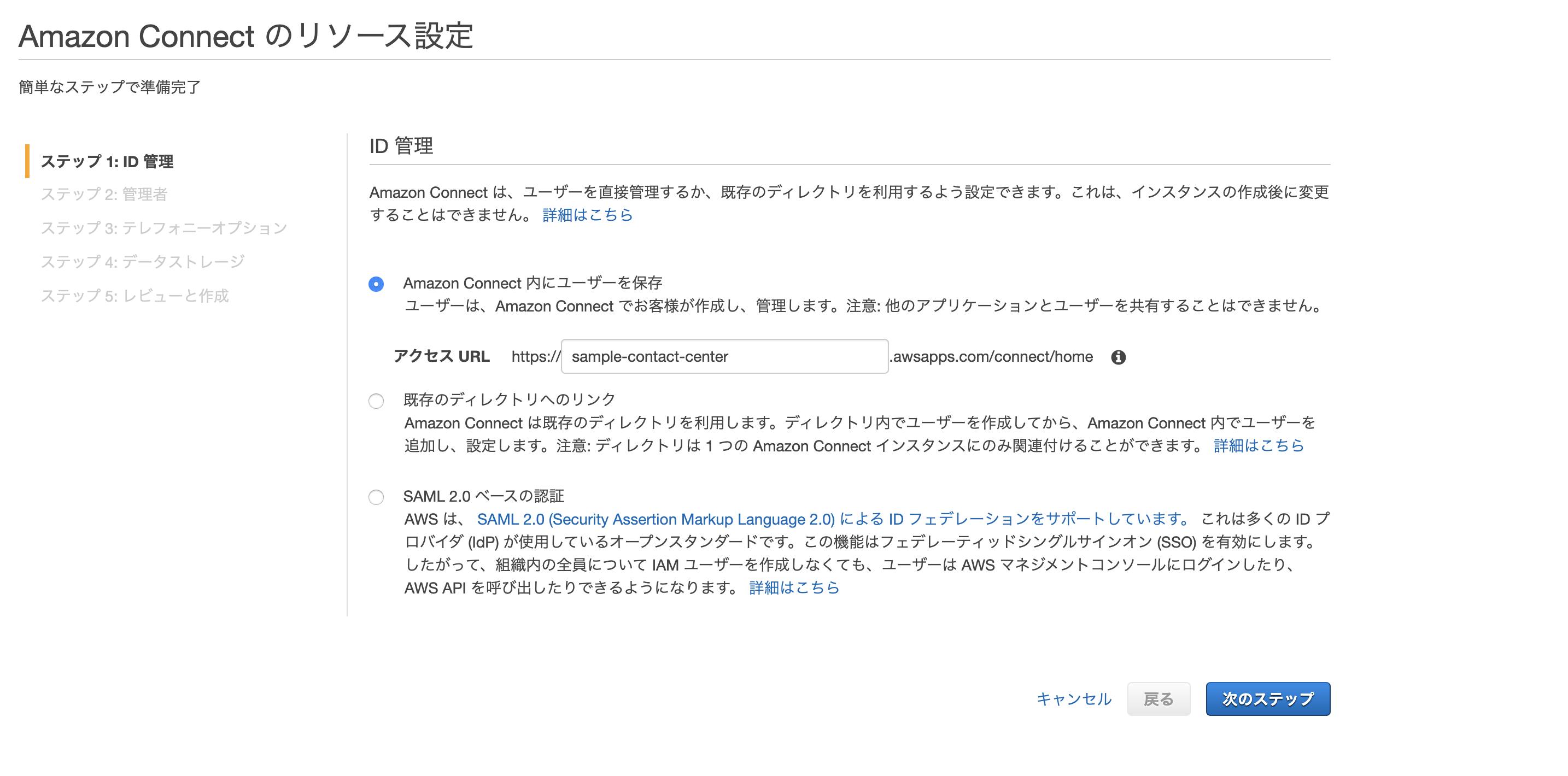
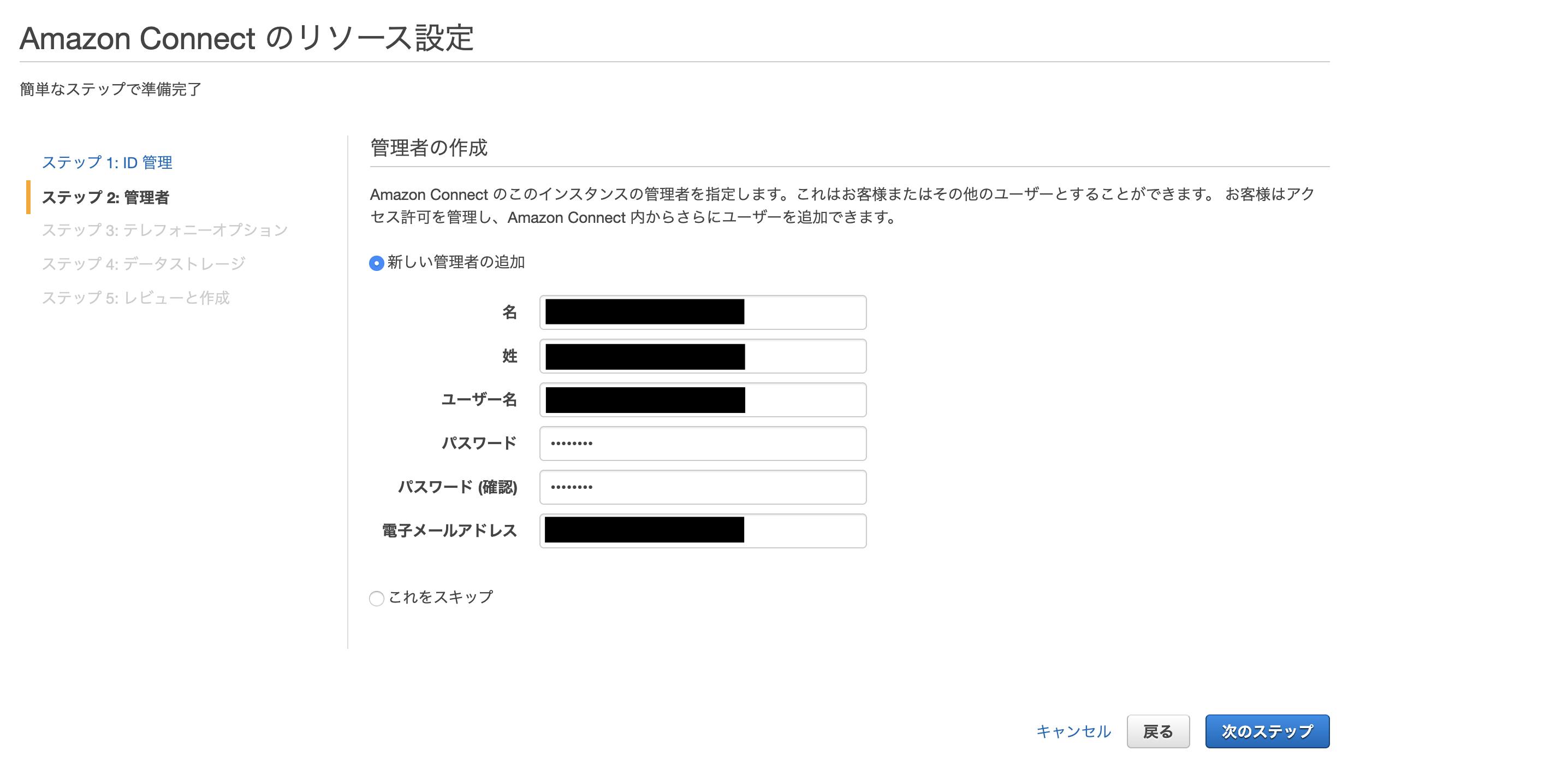
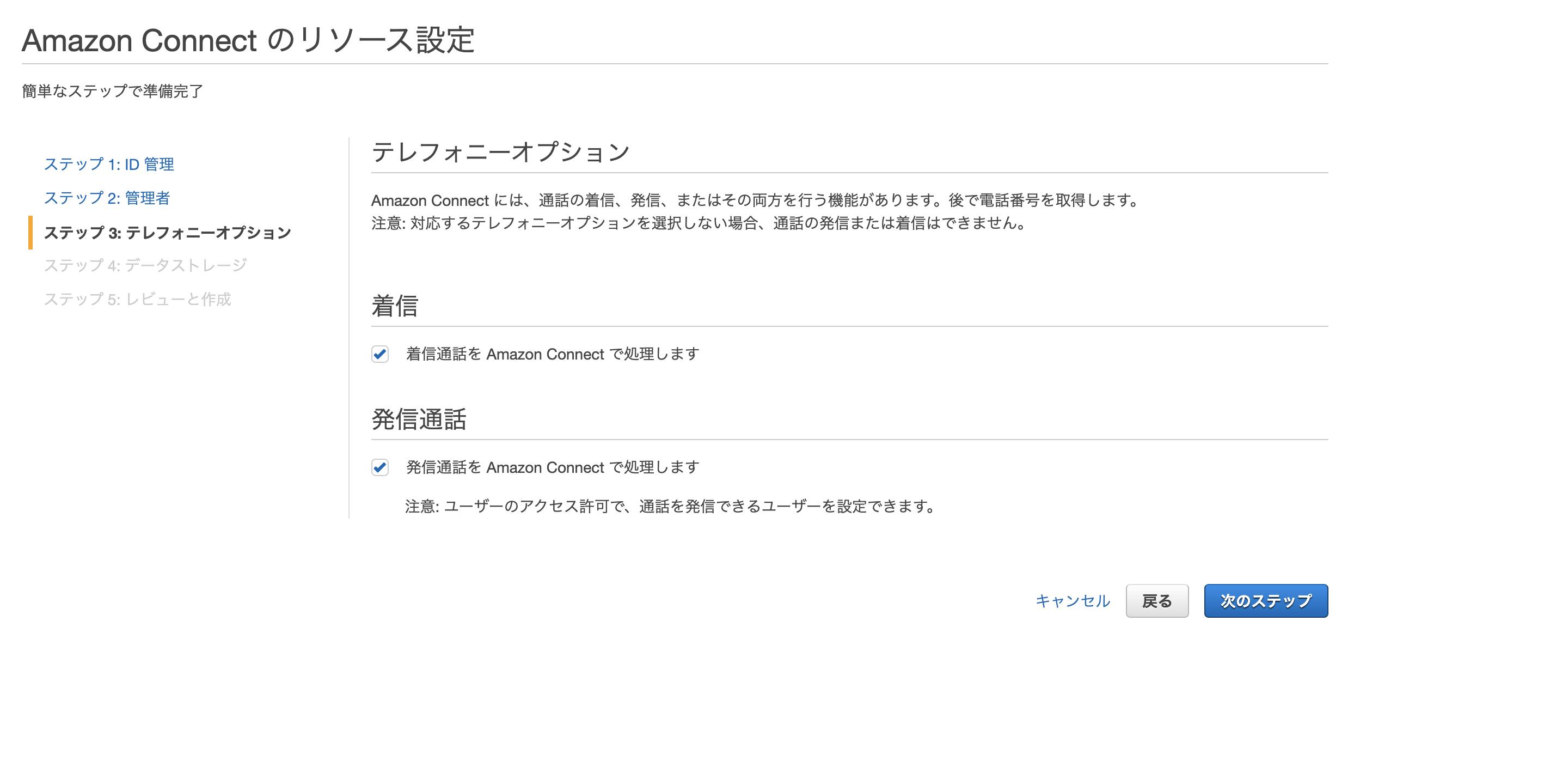
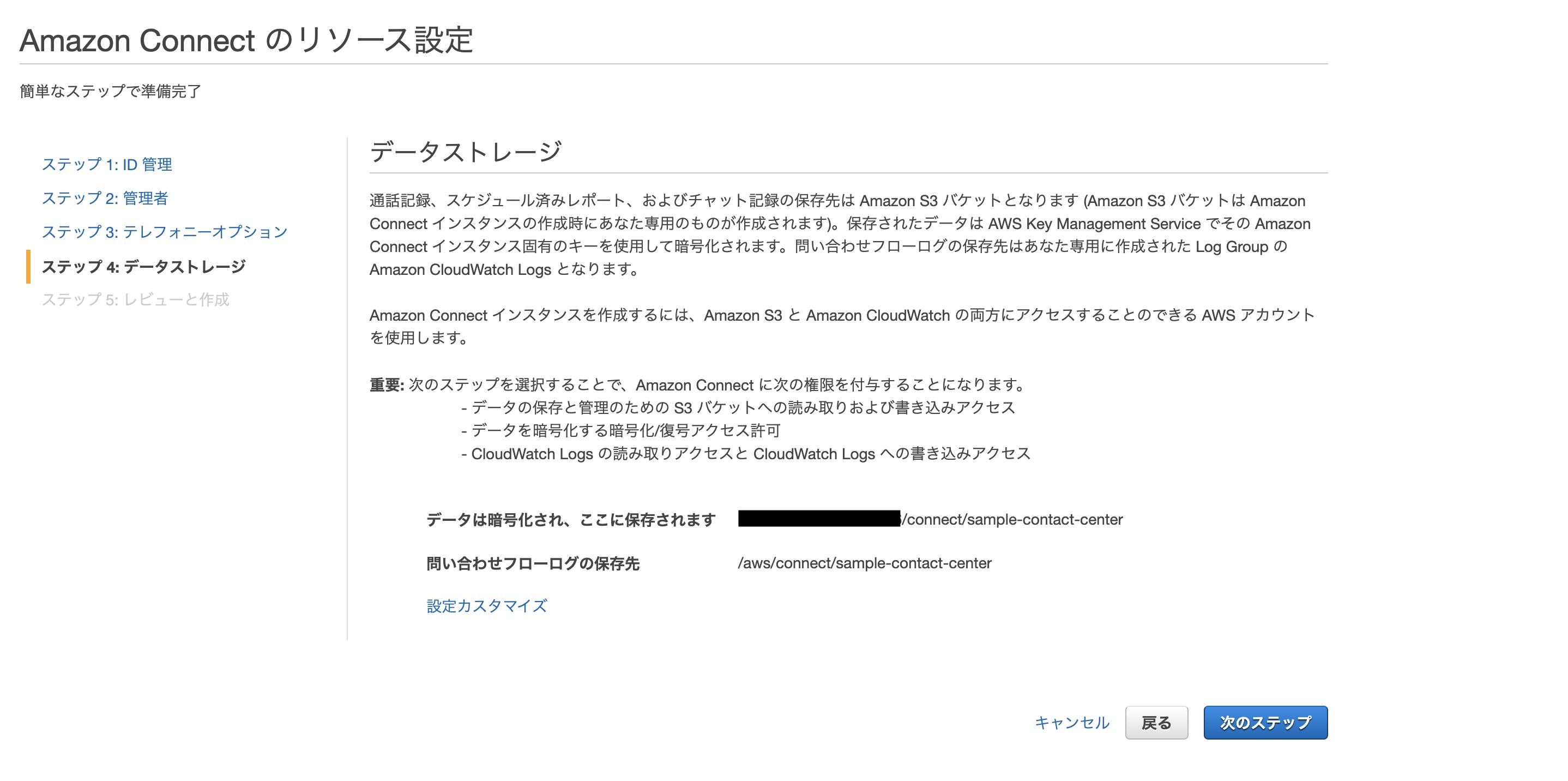

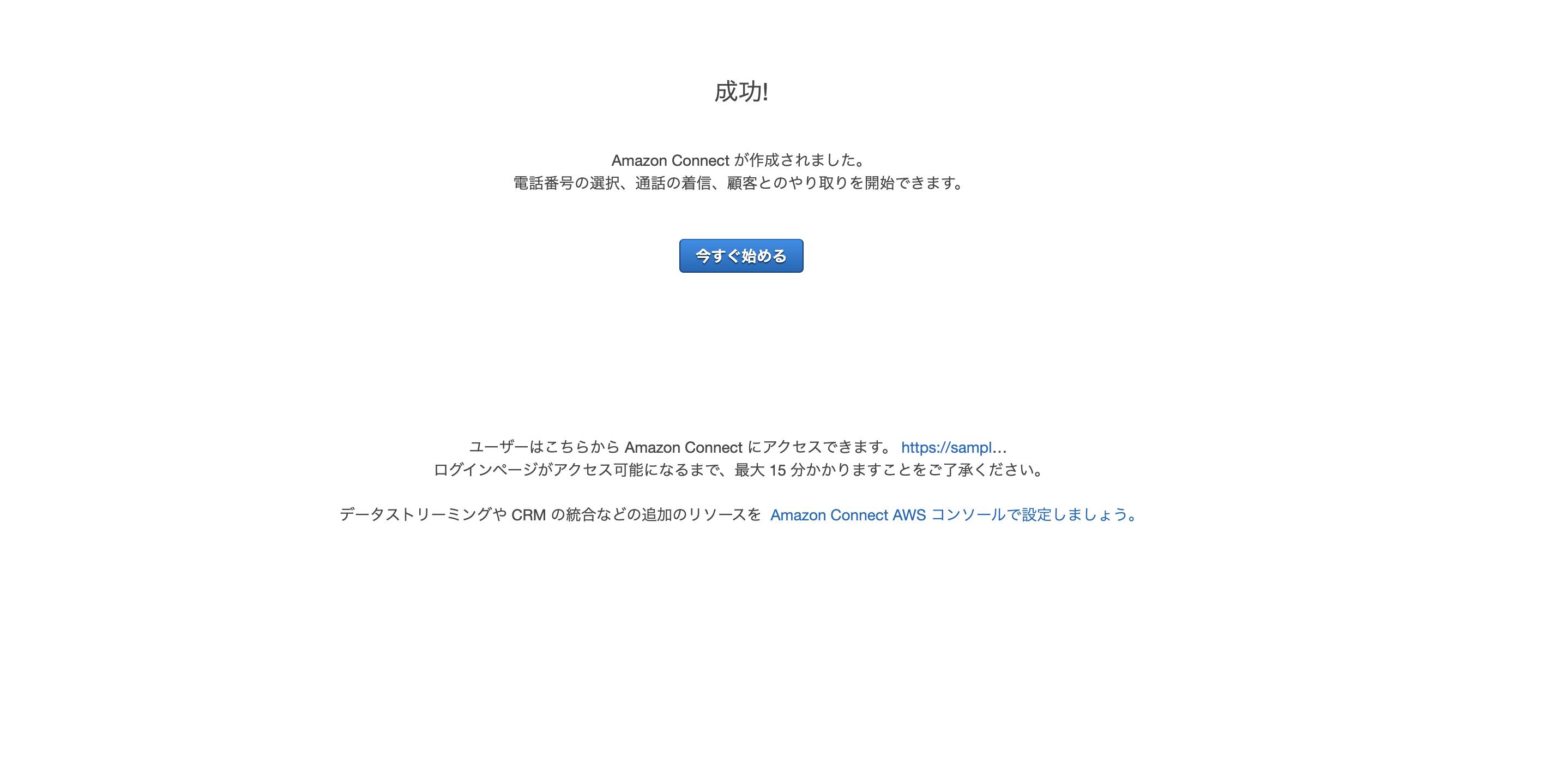

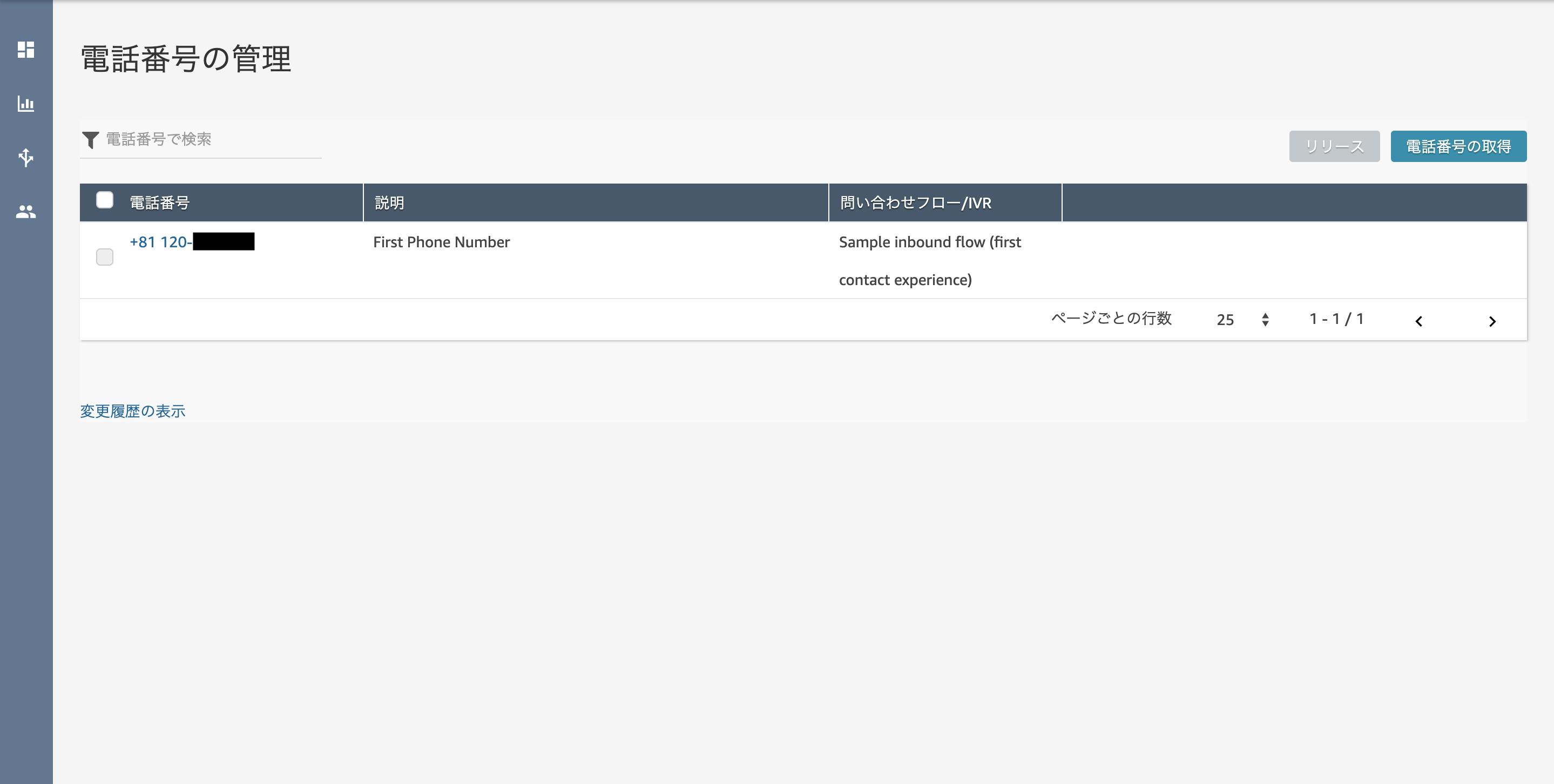
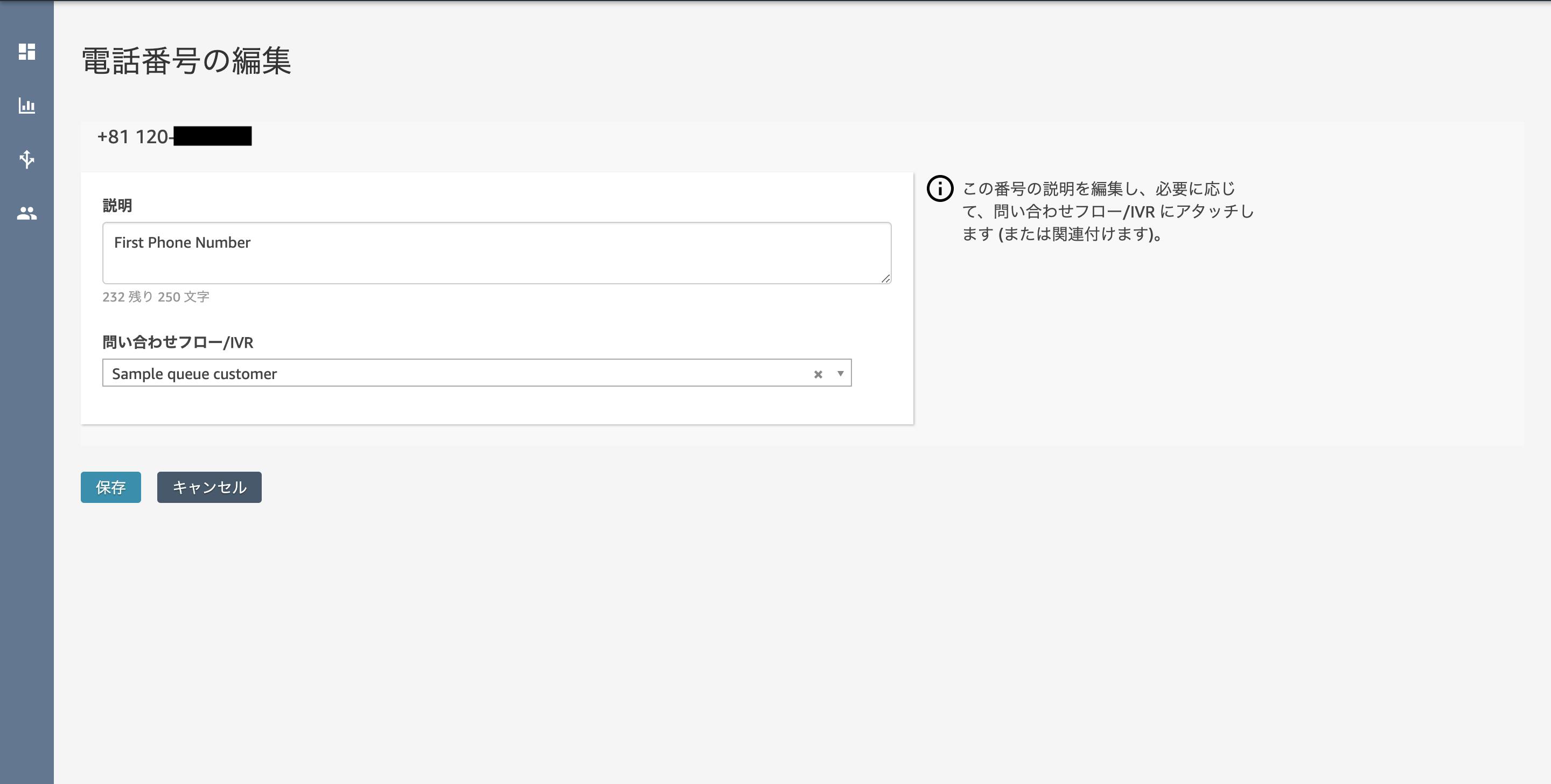

- 投稿日:2019-12-01T16:42:12+09:00
[AWS] 基本的な構成の VPC の構築メモ
0. 完成形
このようなネットワーク構成を作成していく
AWS の各サービスについての説明は今回は省略
1. VPC / Subnet の作成
1.1 VPC の作成
my-vpcという名前の VPC を作成
[AWS] > [VPC] > [VPC の作成] から以下のように作成
1.2 Subnet の作成
Public subnet と、Private subnet を以下のように作成
Name AZ my-public-subnet ap-northeast-1a my-private-subnet ap-northeast-1c [AWS] > [VPC] > [サブネット] > [サブネットの作成] から以下のように作成
それぞれの "VPC*" は、上で作成した
my-vpcを選択Public subnet
Private subnet
2. Internet Gateway / Route Tableの作成
2.1 Internet Gateway の作成
作成した VPC から、インターネットにアクセスするためには、ここで作成する Internet Gateway が必要となる。また、サブネットの作成手順からわかるように、Public subnet と Private subnet で、サブネット自体の作成に特に違いはない。ルートテーブルにこの Internet Gateway を設定したものが Public subnet になる。
[AWS] > [VPC] > [インターネットゲートウェイ] > [インターネットゲートウェイの作成] から以下のように作成
作成した Internet Gateway は、作成しただけでは VPC から使用することができないため、アタッチ
[my-igw] > [アクション] > [VPC にアタッチ] から、my-vpcを選択してアタッチする。
2.2 Route Table の作成
[AWS] > [VPC] > [ルートテーブル] > [ルートテーブルの作成] から以下のように作成
作成した Route Table で Internet Gateway が使えるように設定を行う
[my-route] > [ルート] > [ルートの編集] から以下のように設定0.0.0.0/0 のターゲットで、作成した
my-igwを選択
2.3 Public subnet と Route Table の関連付け
Route Table を作成したら、これをサブネットに関連付ければ、それが Public subnet になる
[my-route] > [サブネットの関連付け] > [サブネットの関連付けの編集] からmy-public-subnetを選択し、保存これで Public subnet で Internet Gateway が使えるようになったが、デフォルトだと Public IP Address がない状態
そのため、[my-public-subnet] > [アクション] > [自動割り当て IP 設定の変更] から、IPv4 の自動割り当てを有効化し保存3. EC2 インスタンスの作成
ここは本題ではないため詳細は省略
Public subnet と Private subnet に 1 つずつ、EC2 インスタンスを起動する
所属する VPC の設定を、それぞれ作成した、my-public-subnetとmy-private-subnetにするPublic subnet EC2
my-public-instanceを作成
Private subnet EC2
my-private-instanceを作成
4. Security Group の作成
EC2 インスタンスを起動すると、Security Group が設定される
Private subnet の EC2 インスタンスは、Public subnet からだけアクセスできるようにしたいため、新しく Security Group を作成
[AWS] > [EC2] > [セキュリティグループ] > [セキュリティグループの作成] で以下のように設定
作成した
my-private-sgを、my-private-instanceに設定する
[my-private-instance] > [アクション] > [ネットワーキング] > [セキュリティグループの変更] から、
作成したmy-private-sgを選択し、保存5. NAT Gateway の作成
Private subnet はインターネットに接続されていない
インターネットに接続するためには、Public subnet に NAT Gateway を作成し、Private subnet の Route table に追加する必要がある[AWS] > [VPC] > [NAT ゲートウェイ] > [NAT ゲートウェイの作成] で以下のように設定
サブネットは、
my-public-subnetを指定
Route table への追加は、
[my-private-subnet] > [ルート] > [ルートの編集] から以下のように設定0.0.0.0/0 のターゲットに、作成した NAT Gateway を指定
これで、
my-private-instanceからインターネット接続ができるようになる
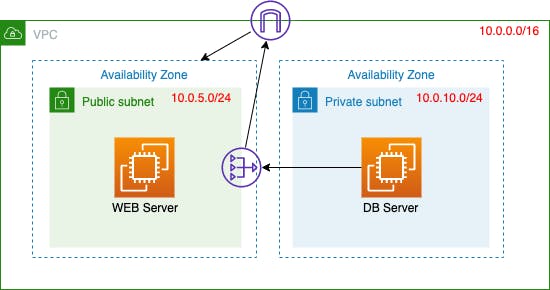

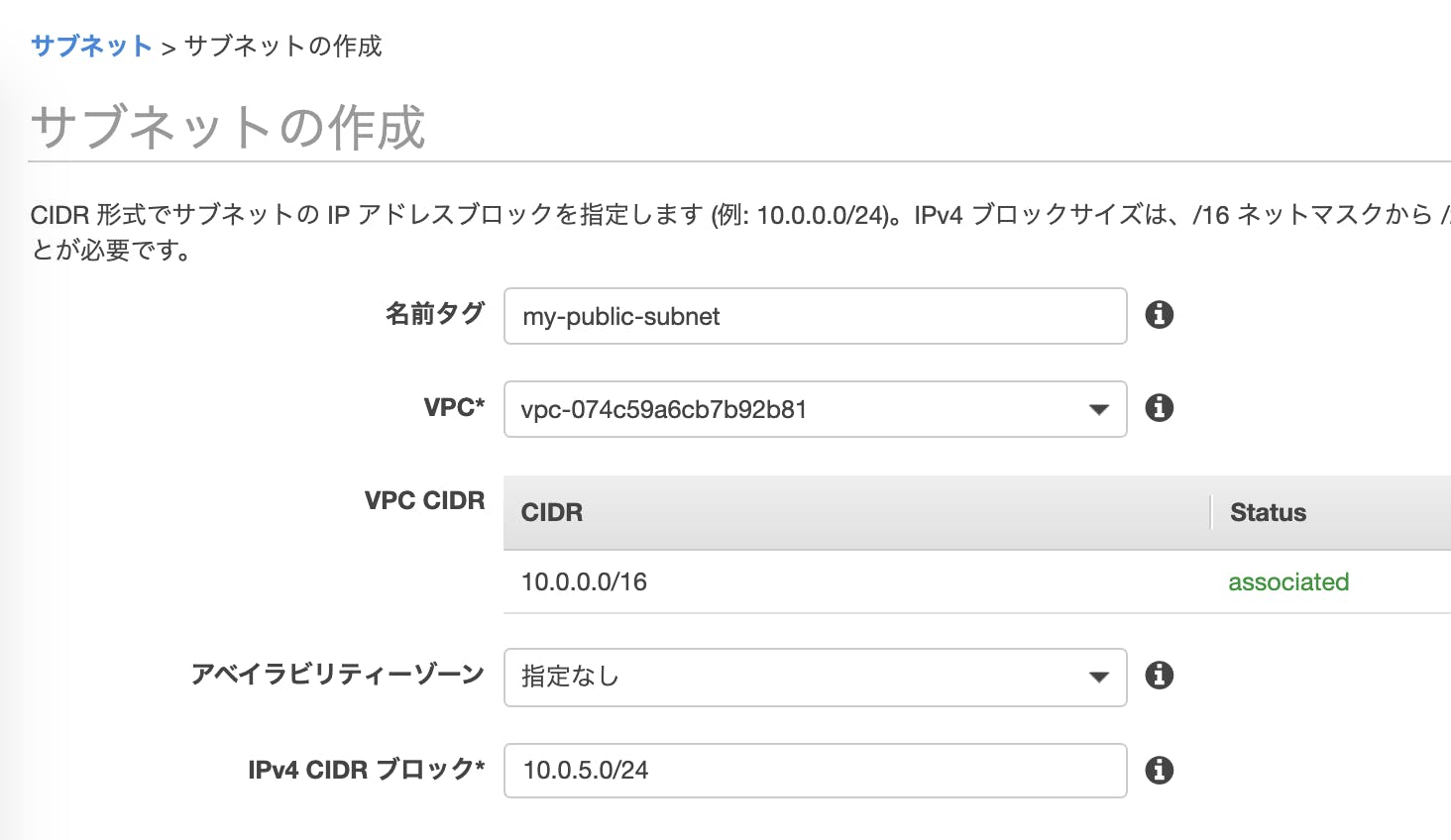
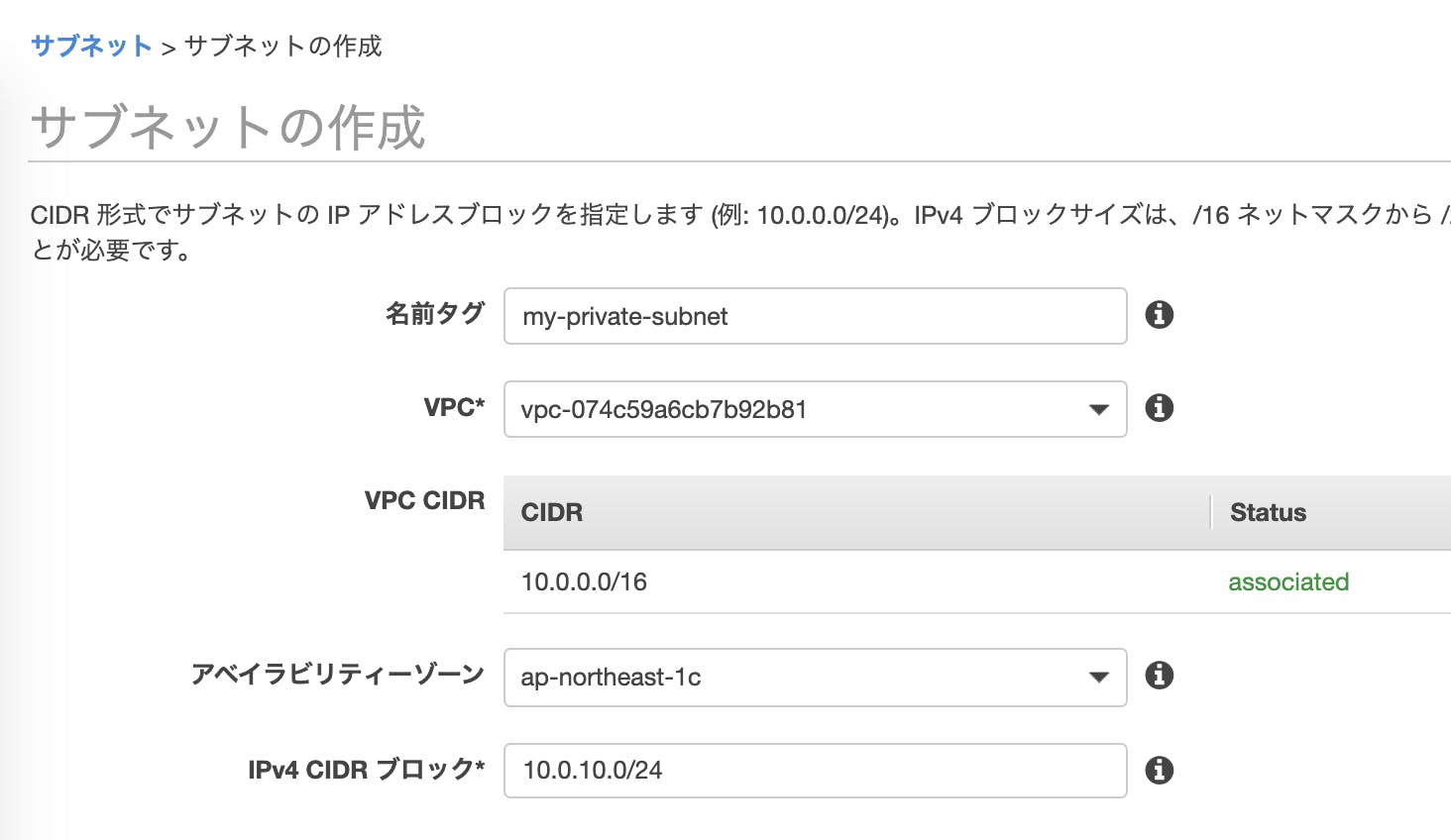


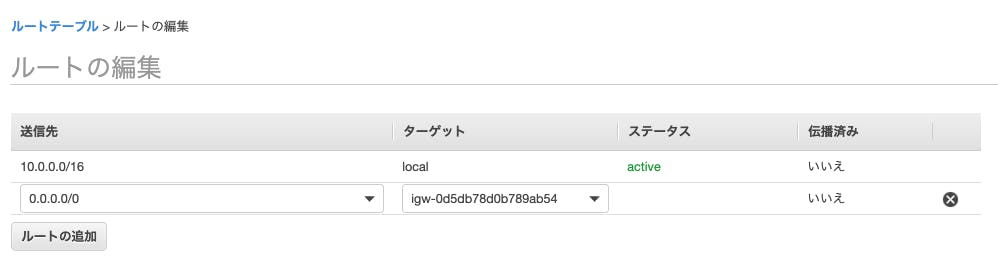


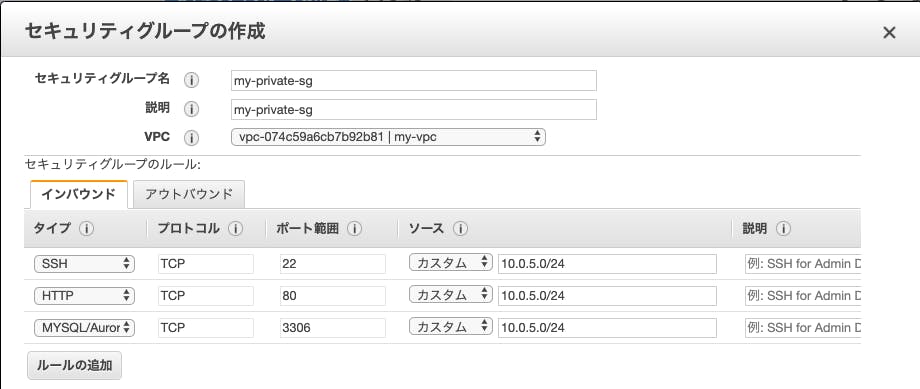

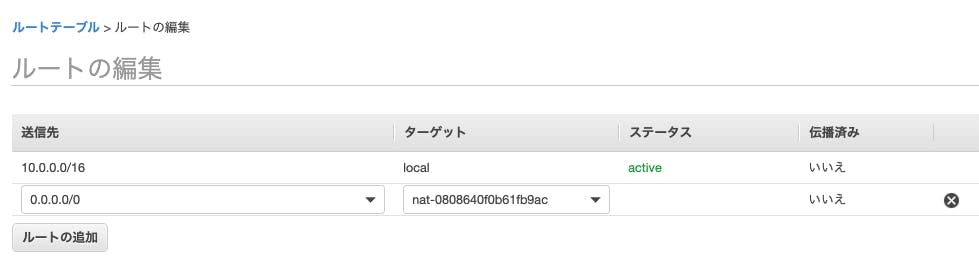
- 投稿日:2019-12-01T16:35:29+09:00
Rails Tutorialの知識から【ポートフォリオ】を作って勉強する話 #15 投稿機能, Active Storage編
こんな人におすすめ
- プログラミング初心者でポートフォリオの作り方が分からない
- Rails Tutorialをやってみたが理解することが難しい
前回:#14 ユーザ投稿表示, ページネーション編
次回:準備中今回の流れ
- ルーティングと各アクションを整える
- 投稿フォームをつくる
- 画像を投稿できるようにする
- 投稿編集・削除機能をつくる
- 投稿時の不具合を解消する
- テストをつくる
今回は投稿機能を実装します。
(投稿のためのモデルが必要なので未読の方は#14を参照下さい。)1. ルーティングと各アクションを整える
投稿フォームはshow.html.erbと同じビューを使用します。
投稿編集と削除の際には別途ビューを生成します。
以上から必要なアクションはcreate、edit、update、destroyとなります。
よって、ここでの手順は以下の通りです。
- ルーティングを行う
- 作成済みのメソッドを移動する
- 各アクションを整える
ルーティングを行う
まずはルーティングを行いましょう。
config/routes.rbRails.application.routes.draw do # 中略 resources :microposts, only: [:create, :edit, :update, :destroy] end作成済みのメソッドを移動する
各アクションを整える前に、1つ変更を加えます。
logged_in_userメソッドはMicropostsコントローラでも使用します。
先にこちらはApplicationコントローラに移動しましょう。app/controllers/application_controller.rbclass ApplicationController < ActionController::Base protect_from_forgery with: :exception include SessionsHelper private def logged_in_user unless logged_in? store_location flash[:warning] = 'ログインしてください' redirect_to login_url end end end各アクションを整える
create、edit、update、destroyといった4つのアクションを整えましょう。
app/controllers/microposts_controller.rbclass MicropostsController < ApplicationController before_action :logged_in_user, only: [:create, :edit, :update, :destroy] before_action :correct_user, only: :destroy def create @user = current_user @micropost = current_user.microposts.build(micropost_params) if logged_in? @microposts = @user.microposts.page(params[:page]).per(10) if @micropost.save redirect_to current_user else render 'users/show' end end def edit @micropost = current_user.microposts.find_by(id: params[:id]) || nil if @micropost.nil? flash[:warning] = "編集権限がありません" redirect_to root_url end end def update @micropost = current_user.microposts.find_by(id: params[:id]) @micropost.update_attributes(micropost_params) if @micropost.save flash[:success] = "編集が完了しました" redirect_to current_user else render 'microposts/edit' end end def destroy @micropost.destroy flash[:success] = "ログが削除されました" redirect_to current_user end private def micropost_params params.require(:micropost).permit(:memo, :time, :picture) end def correct_user @micropost = current_user.microposts.find_by(id: params[:id]) redirect_to root_url if @micropost.nil? end endこのポートフォリオはTutorialと異なり、user_pathにフォームを置いています。
この場合、フォーム入力失敗時のパスがmicroposts_pathとなります。その結果、フォーム入力失敗時に/user/show.html.erbをrenderするため、Micropostsコントローラのcreateアクションにuserとmicroposts変数を渡す必要があります。
2. 投稿フォームをつくる
投稿フォームをつくりましょう。
パーシャルを生成し、そこに投稿フォームを作ります。bash$ touch app/views/layouts/_micropost_form.html.erbapp/views/layouts/_micropost_form.html.erb<div class="container micropost-container"> <h1>Form</h1> <%= form_with(model: @micropost, url: microposts_path, local: true) do |form| %> <%= render 'shared/error_messages', object: form.object %> <div class="form-group"> <%= form.number_field :time, class: 'form-control', placeholder: "時間(分)を入力してください" %> </div> <div class="form-group"> <%= form.text_area :memo, class: 'form-control', placeholder: "メモを加えてください" %> </div> <div class="form-group"> <%= form.file_field :picture %> </div> <div class="form-group"> <%= form.submit "記録する", class: 'btn btn-info btn-lg form-submit' %> </div> <% end %> </div>
まず説明する点は、このような記述についてです。
<%= render 'shared/error_messages', object: form.object %>これによりerror_messages.html.erbで、userやmicropostなどを引き渡すオブジェクト名としてobjectを使用できます。
エラーを表示する他のビューに対しても、同様に記述しましょう。加えてerror_messages.html.erbはこのように変更しましょう。
app/views/shared/_error_messages.html.erb<% if object.errors.any? %> <div id="error_explanation"> <div class="alert alert-danger alert-form-extend" role="alert"> <%= object.errors.count %>個のエラーがあります </div> <ul> <% object.errors.full_messages.each do |msg| %> <li><%= msg %></li> <% end %> </ul> </div> <% end %>参考になりました↓
form_for の f.object って何だ?(Rails)続いてこの部分ですが、現状では動作しません。
<%= form.file_field :picture %>こちらは下記の画像投稿を可能にすることで動作します。
3. 画像を投稿できるようにする
画像投稿にはRails5.2から対応のActive Storageを使用します。
また画像をアップロードするストレージとしてS3を使用します。
まずはActive Storageについて理解しましょう。Active Storageを理解する
Active Storageとはファイルをアップロードする機能のことです。
以下の記事が分かりやすいですので一読してみましょう。
【Rails 5.2】Active Storageの使い方加えて今回はアップロード時の保存先にS3を使用します。
S3とはAWSが提供するストレージのことです。
S3の使用にはGemの追加と設定の編集が必要です。以上を踏まえてActive Storageを使用するにはこのような手順が必要です。
- S3(バケット)を作成する
- Active Storageを用意する
- Active StorageとS3を紐づける
S3(バケット)を作成する
まずはS3(バケット)を作成しましょう。
ここでの手順は以下の通りです。
- IAMユーザに権限を与える
- アクセスキーを作成する
- バケットを作成する
IAMユーザに権限を与える
ポートフォリオ用のユーザにS3を使用する権限を与えます。
以下の手順を行いましょう。
- ルートユーザでAWSにログインする
- IAMを開く
- ポートフォリオ用ユーザを選択する
- 「アクセス権限の追加」を押す
- 「既存のポリシーを直接アタッチ」からS3を検索する
- 「AmazonS3FullAccess」をチェックし確認する
分からない場合はこちらをご覧ください↓
【AWS】【S3】作成手順 & アップロード手順 & アクセス権限設定手順アクセスキーを作成する
続いて後述で必要になるアクセスキーを作成します。
このキーを作成することでRailsとS3を紐づけることが可能です。
以下の手順を行いましょう。
- ルートユーザでAWSにログインする
- IAMを開く
- ポートフォリオ用ユーザを選択する
- 「認証情報」タブから「アクセスキーの作成」を押す
- アクセスキーとシークレットアクセスキーをメモする (一度しか表示されないので注意)
バケットを作成する
最後にポートフォリオ用ストレージとなるバケットを作成します。
以下の手順を行いましょう。
- IAMユーザでAWSにログインする
- S3を開く
- 「バケットを作成する」を押す
- バケット名を入力し東京リージョンを選択する
- 「次へ」を押し続け「バケットを作成」を押す
分からない場合はこちらをご覧ください↓
【AWS】【S3】作成手順 & アップロード手順 & アクセス権限設定手順
以上でS3(バケット)の作成は完了です。Active Storageを用意する
次にActive Storageを用意しましょう。
ここでの手順は以下の通りです。
- Active Storageをインストールする
- モデル(今回はMicropostモデル)を編集する
Active Storageをインストールする
まずはインストールを行いDBをマイグレートします。
bash$ rails active_storage:install $ rails db:migrateモデル(今回はMicropostモデル)を編集する
モデルの編集はいたって簡単です。
app/models/micropost.rbに以下を加えるだけで成立します。app/models/micropost.rbhas_one_attached :pictureここで宣言した名前(今回はpicture)がモデルのカラムとして機能します。
以上でActive Storageの用意は完了です。Active StorageとS3を紐づける
最後にActive StorageとS3を紐づけましょう。
ここでの手順は以下の通りです。
- 必要なGemを追加する
- 設定を編集する
必要なGemを追加する
S3との紐づけにはaws-sdk-s3が必要です。
Gemfileに追加しましょう。gemfile+ gem 'aws-sdk-s3'設定を編集する
Active Storageの保存先をS3にするため:localから:amazonに変更します。
config/environments/development.rb# 中略 # Store uploaded files on the local file system (see config/storage.yml for options) config.active_storage.service = :amazonconfig/environments/production.rb# 中略 # Store uploaded files on the local file system (see config/storage.yml for options) config.active_storage.service = :amazon続いてstorage.ymlにてamazon:の部分をこのように変更します。
config/storage.yml# Use rails credentials:edit to set the AWS secrets (as aws:access_key_id|secret_access_key) amazon: service: S3 access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> region: ap-northeast-1 bucket: #S3で作成したバケット名(今回はlantern-lantern-s3)最後に、先ほどメモしたアクセスキーとシークレットアクセスキーを入力します。
この2つはセキュリティ上Rails Credentialsを使用します。
この機能により直接キーを入力することを回避し暗号化します。それではRails Credentialsを編集しましょう。
エディターにはVimを使用します。bash$ EDITOR=vim rails credentials:editVimは癖があるので、下記に簡単な操作を載せておきます。
- 入力開始:i
- 入力終了:esc
- 保存終了:ZZ
- 保存せず終了::q!
aws: access_key_id: # ここにアクセスキーを入力 secret_access_key: # ここにシークレットアクセスキーを入力以上で紐づけは完了です。
画像をリサイズする
このままではユーザが投稿する画像サイズに制限がありません。
画像のリサイズにはMiniMagickというGemを使用しましょう。
ここでの手順は以下の通りです。
- Gemを追加する
- ImageMagickをインストールする
- リサイズのメソッドを定義する
- ビューで表示する
Gemを追加する
gemfile+ gem 'mini_magick'bash$ bundle installImageMagickをインストールする
MiniMagickの使用にはImageMagickのインストールが必要です。
こちらも加えて行いましょう。bash$ sudo yum install -y ImageMagickリサイズのメソッドを定義する
画像のリサイズを行うよう、モデルにメソッドを定義します。
app/models/micropost.rbdef resize_picture return self.picture.variant(resize: '100x100').processed endビューで表示する
リサイズされた画像を表示するにはこのように記述します。
app/views/layouts/_log.html.erb<% @microposts.each do |micropost| %> <!-- 省略 --> <% if micropost.picture.attached? %> <div class="log-picture"> <%= image_tag micropost.resize_picture %> </div> <% end %> <!-- 省略 --> <% end %>フォーム入力↓
ログ表示↓
以上で画像のリサイズは完了です。4. 投稿編集・削除機能をつくる
編集と削除のためのアクションはすでに終えました。
よって、ここでの手順はビューをつくるのみです。bash$ touch app/views/microposts/edit.html.erbapp/views/microposts/edit.html.erb<% provide(:title, 'メモ編集') %> <div class="container micropost-edit-container"> <div class="edit-titles"> <%= image_tag 'edit_02.png', class: 'edit-img' %> <h1 class="title edit-micropost-title">メモ編集</h1> </div> <%= form_with(model: @micropost, url: micropost_path, local: true) do |form| %> <%= render 'shared/error_messages', object: form.object %> <div class="form-group"> <%= form.label :time, '時間' %> <%= form.number_field :time, class: 'form-control', placeholder: @micropost.time %> </div> <div class="form-group"> <%= form.label :memo, 'メモ' %> <%= form.text_area :memo, class: 'form-control', placeholder: @micropost.memo %> </div> <div class="form-group"> <%= form.label :picture, '画像' %> <%= form.file_field :picture, class: 'form-control-file', placeholder: @micropost.picture %> </div> <div class="row"> <div class="col"> <div class="form-group"> <%= link_to "削除", micropost_path, method: :delete, data: { confirm: "本当に削除しますか?" }, class: 'btn btn-lg btn-danger btn-edit-user' %> </div> </div> <div class="col"> <div class="form-group"> <%= form.submit "編集", class: 'btn btn-info btn-lg btn-edit-user' %> </div> </div> </div> <div class="form-group"> <%= link_to "戻る", current_user, class: 'btn btn-lg btn-edit-user btn-back' %> </div> <% end %> </div>メモ編集画面↓
5. 投稿時の不具合を解消する
このままではフォームの時間が空の時、ログが「分」のみで出力されてしまいます。
それを避けるために簡単な条件を書き、ログを正しく出力しましょう。app/views/layouts/_log.html.erb<!-- 省略 --> <% @microposts.each do |micropost| %> <li id ="micropost-<%= micropost.id %>"> <span class="row log-list"> <span class="col-2 log-timestamp d-none d-md-inline-block log-timestamp-block"> <span class="log-timestamp"><%= time_ago_in_words(micropost.created_at) %>前</span> </span> <span class="col-md-10 col-log-memos"> <div class="log-time-and-edit"> <div class="row"> <span class="log-time col-3"> <% if micropost.time.nil? %> 0分 <% else %> <%= micropost.time %>分 <% end %> </span> <span class="col-7 log-timestamp log-timestamp-inline"><%= time_ago_in_words(micropost.created_at) %>前</span> <span class="log-edit col-2"><%= link_to image_tag('edit.png', class: "log-edit-image"), edit_micropost_path(micropost) %></span> </div> </div> <% if micropost.memo.present? %> <div class="log-memo"><%= micropost.memo %></div> <% end %> <% if micropost.picture.attached? %> <div class="log-picture"><%= image_tag micropost.resize_picture %></div> <% end %> </span> </span> </li> <% end %> <!-- 省略 -->時間が空の場合「0分」と表示↓
(少々デザインも変更しています)
6. テストをつくる
残るはテストのみです。
ここではModel specとRequest specのテストを行います。Model specでのテスト
このテストでは以下を確認します。
- pictureのみ存在するMicropostモデルは有効か
- 5MBを超える画像は無効か
- 画像以外のファイルは無効か
その前に5MB以上の画像、画像以外のファイルを以下のフォルダに準備しましょう。
bash$ mkdir spec/fixtures/images# 実際にファイルを追加するその後、テストを記述します。
spec/models/micropost_spec.rbrequire 'rails_helper' RSpec.describe Micropost, type: :model do let(:user) { create(:user) } let(:micropost) { user.microposts.build(time: 240, memo: "Lorem ipsum", user_id: user.id) } # 中略 describe "picture" do it "should be valid if all columns are nil except picture" do micropost.update_attributes(time: nil, memo: nil, user_id: user.id) expect(micropost).to be_invalid micropost.picture.attach(io: File.open(Rails.root.join('spec', 'fixtures', 'images', 'test.jpg')), filename: 'test.jpg', content_type: 'image/jpg') expect(micropost).to be_valid end it "should not be over than 5MB" do micropost.picture.attach(io: File.open(Rails.root.join('spec', 'fixtures', 'images', 'test_5mb.jpg')), filename: 'test_5mb.jpg', content_type: 'image/jpg') expect(micropost).to be_invalid end it "should be only images file" do micropost.picture.attach(io: File.open(Rails.root.join('spec', 'fixtures', 'images', 'test.pdf')), filename: 'test.pdf', content_type: 'application/pdf') expect(micropost).to be_invalid end end end参考にさせていただきました↓
Active Storageの簡単なバリデーションの実装とテスト
ActiveStorageでattachできるものについて調べてみた
Ruby IOクラスについて学ぶ
Railsのファイルパスの操作のメモRequest specでのテスト
このテストでは以下を確認します。
- ログインしていないユーザの投稿が無効か
- フォームが全て空欄のユーザ投稿が無効か
- ログインしているユーザの投稿が有効か
- ログインしていないユーザの投稿削除が無効か
- 他ユーザの投稿削除が無効か
- ログインしているユーザの投稿削除が有効か
- ログインしていないユーザの投稿編集が無効か
- 他ユーザの投稿編集が無効か
- フォームが全て空欄の投稿編集が無効か
- ログインしているユーザの投稿編集が有効か
spec/requests/microposts_spec.rbrequire 'rails_helper' RSpec.describe "Microposts", type: :request do let(:user) { create(:user) } let(:other_user) { create(:other_user) } def post_valid_information post microposts_path, params: { micropost: { memo: "aaa" } } end def post_invalid_information post microposts_path, params: { micropost: { memo: nil } } end def patch_valid_information patch micropost_path, params: { micropost: { memo: "bbb" } } end def patch_invalid_information patch micropost_path, params: { micropost: { memo: nil } } end describe "POST /microposts" do it "does not add a micropost when not logged in" do expect{ post_valid_information }.not_to change(Micropost, :count) follow_redirect! expect(request.fullpath).to eq '/login' end it "does not add a micropost when the form has no information" do log_in_as(user) get user_path(user) expect{ post_invalid_information }.not_to change(Micropost, :count) end it "succeeds to add a micropost" do log_in_as(user) get user_path(user) expect(request.fullpath).to eq '/users/1' expect{ post_valid_information }.to change(Micropost, :count).by(1) follow_redirect! expect(request.fullpath).to eq '/users/1' end end describe "DELETE /micropost" do it "does not destroy a micropost when not logged in" do delete micropost_path(1) follow_redirect! expect(request.fullpath).to eq '/login' end it "does not destroy a micropost when other users logged in" do log_in_as(user) get user_path(user) post_valid_information follow_redirect! delete logout_path log_in_as(other_user) get user_path(other_user) expect(request.fullpath).to eq '/users/2' post_valid_information expect{ delete micropost_path(1) }.not_to change(Micropost, :count) expect{ delete micropost_path(2) }.to change(Micropost, :count).by(-1) end it "succeeds to destroy a micropost" do log_in_as(user) get user_path(user) expect{ post_valid_information }.to change(Micropost, :count).by(1) follow_redirect! expect{ delete micropost_path(1) }.to change(Micropost, :count).by(-1) follow_redirect! expect(request.fullpath).to eq '/users/1' expect(flash[:success]).to be_truthy end end describe "GET /microposts/:id/edit" do it "does not edit a micropost when not logged in" do log_in_as(user) get user_path(user) post_valid_information follow_redirect! delete logout_path follow_redirect! get edit_micropost_path(1) follow_redirect! expect(request.fullpath).to eq '/login' end it "does not edit a micropost when other users logged in" do log_in_as(user) get user_path(user) post_valid_information follow_redirect! delete logout_path follow_redirect! log_in_as(other_user) get edit_micropost_path(1) follow_redirect! expect(request.fullpath).to eq '/' end it "does not edit a micropost when the form has no information" do log_in_as(user) get user_path(user) post_valid_information follow_redirect! get edit_micropost_path(1) expect(request.fullpath).to eq '/microposts/1/edit' patch_invalid_information expect(request.fullpath).to eq '/microposts/1' end it "succeeds to edit a micropost" do log_in_as(user) get user_path(user) post_valid_information follow_redirect! get edit_micropost_path(1) expect(request.fullpath).to eq '/microposts/1/edit' patch_valid_information follow_redirect! expect(request.fullpath).to eq '/users/1' end end end以上でテストは終了です。
お疲れさまでした。備考:Active Storageを伴うテストにFactoryBotを使いたい
Micropostモデルを検証する際、FactoryBotを使ったテストを行いたかったのですが、断念しました。一応調べた分を共有します。
Active Storageを伴うFactoryBotを使う手順は以下の通りです。
- 環境設定を行う
- FactoryBotを整える
- テストを書く
環境設定を行う
まずは、ダミーでアップロードを行うfixture_file_uploadメソッドを使うために、環境設定をしましょう。
spec/rails_helper.rb# 中略 RSpec.configure do |config| # 中略 # ファイルアップロードのテストに使用する config.include ActionDispatch::TestProcess # factoryBot内での呼び出し FactoryBot::SyntaxRunner.class_eval do include ActionDispatch::TestProcess end # fixtureのパス指定(テスト時のパスをfixtures以下から省略できる) config.fixture_path = "#{::Rails.root}/spec/fixtures" # 中略 end参考にさせていただきました↓
parperclipでファイルアップロードをRspecでテスト w/ factory_girl
Factory Bot trait for attaching Active Storange has_attachedFactoryBotを整える
続いてFactoryBotを整えます。
spec/factories/microposts.rbFactoryBot.define do factory :micropost do trait :memo_1 do time { 240 } memo { "I just ate an orange!" } user_id { 1 } created_at { 10.minutes.ago } picture { fixture_file_upload('/images/test.jpg', 'image/jpg') } end # 中略 association :user end end参考にさせていただきました↓
Factory Bot trait for attaching Active Storange has_attachedテストを書く
残るはletでMicropostモデルを定義するだけです。
spec/models/micropost_spec.rbrequire 'rails_helper' RSpec.describe Micropost, type: :model do let(:micropost) { create(:micropost, :memo_1) } # 中略 endしかしテスト時に画像を追加・削除する際、Active Storageで生成される他の2つのモデルとの関連づけがないためエラーが発生します。
# どれもエラーが発生する micropost.picture = nil micropost.save! micropost.update_attribute(:picture, nil) micropost.picture.attach(nil)ActiveRecord::RecordNotSaved: Failed to save the new associated picture_attachment.強引に2つのクラスを生成するという方法もあるのですが、断念しました。
シンプルにテストを通す方法をご存知の方は、ご教示お願いします。参考にさせていただきました↓
ruby on rails 画像 fixture_file_uploadに{file}が存在しないというエラーがあります
ruby on rails rails_blob_path ActiveStorageでモデルテストを正しく行うには?
前回:#14 ユーザ投稿表示, ページネーション編
次回:準備中
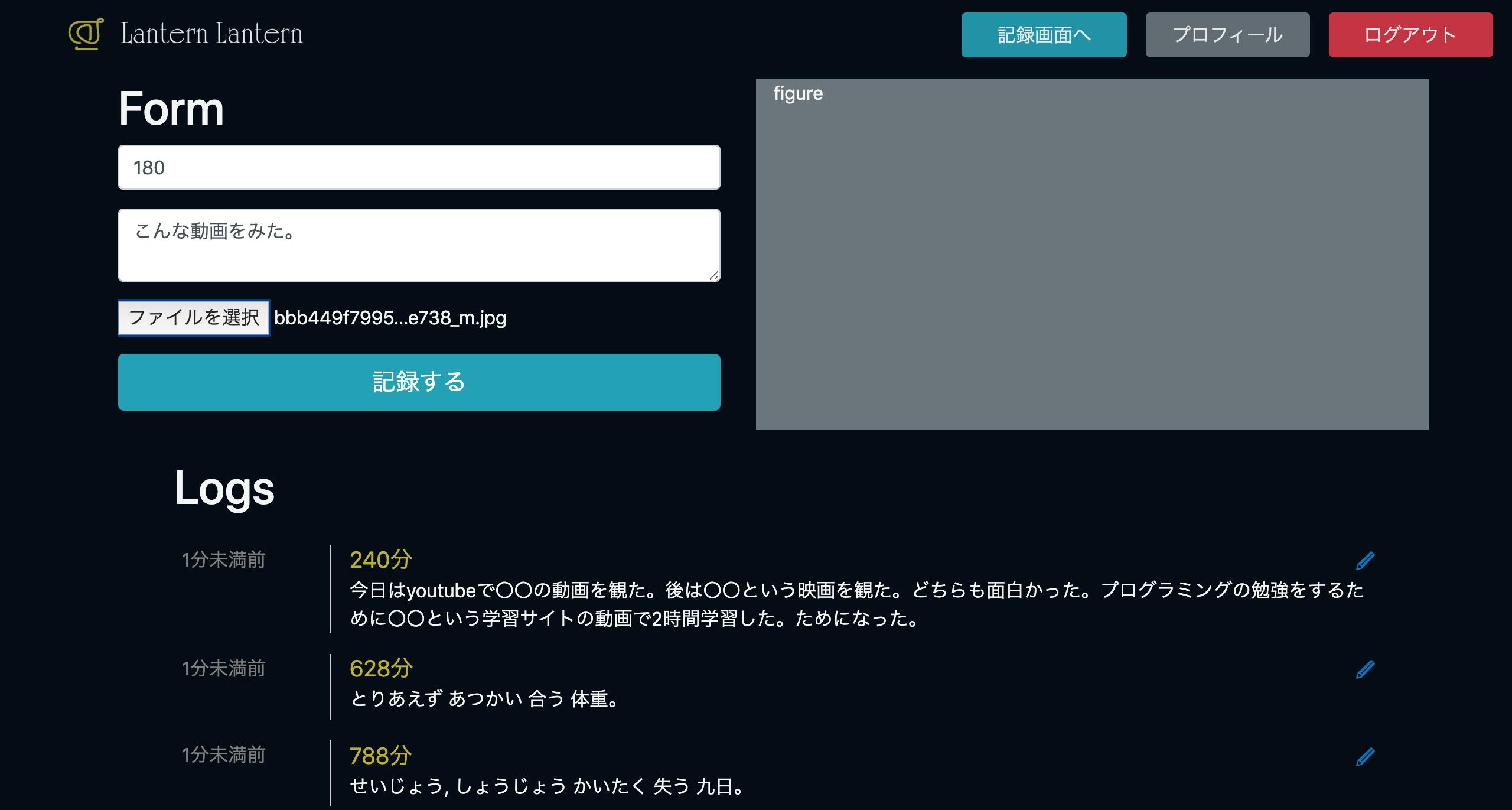
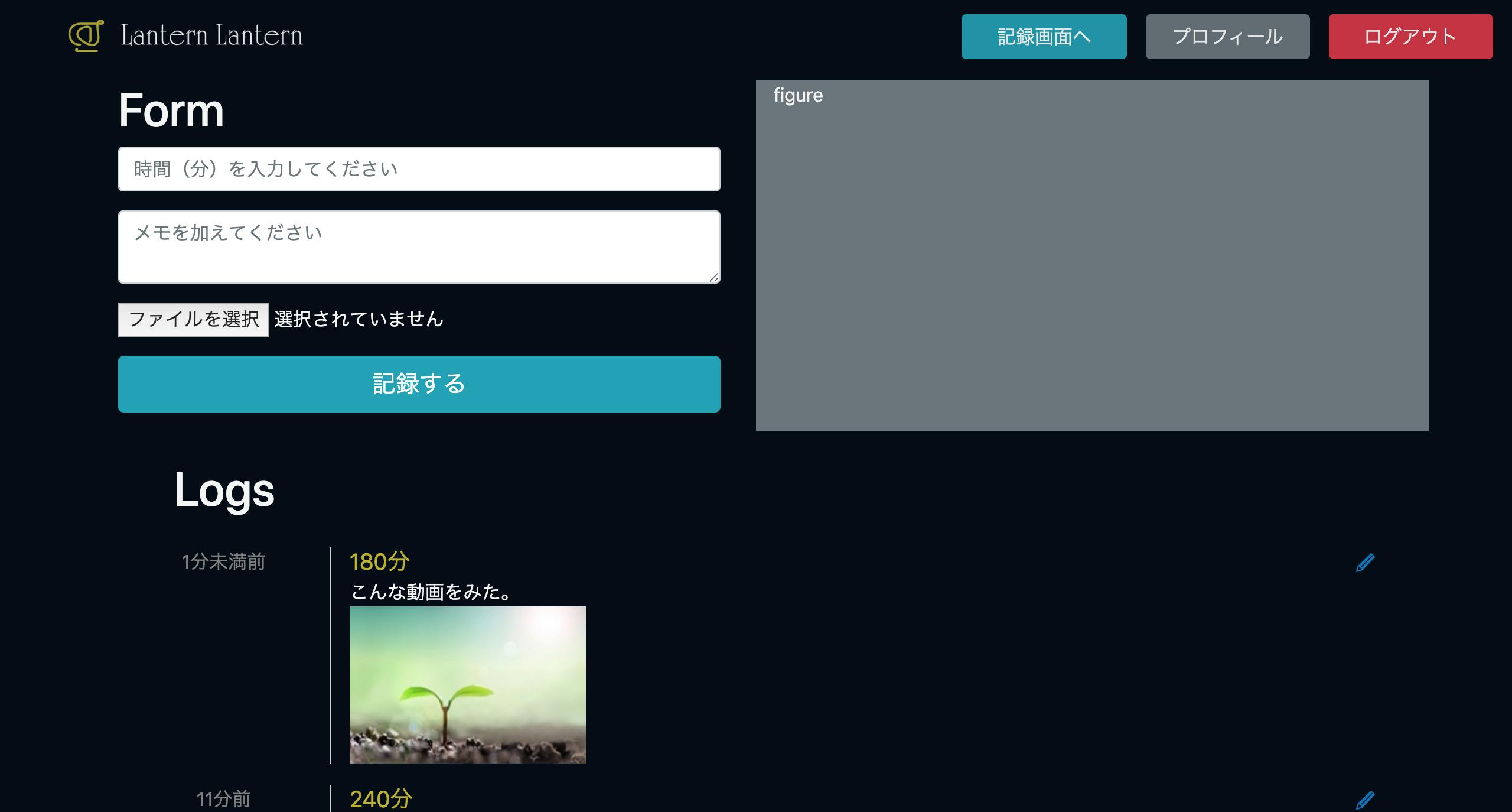
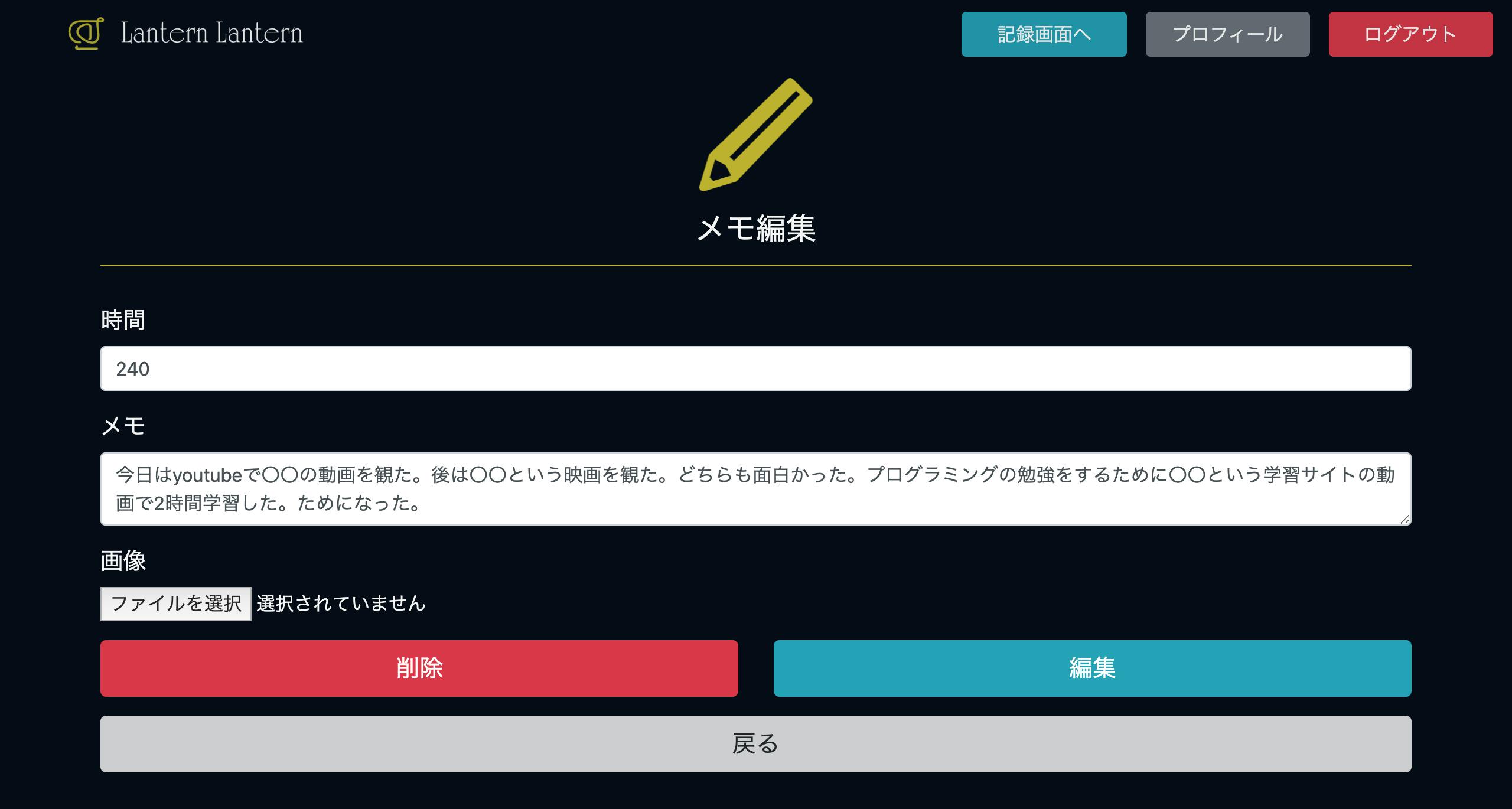
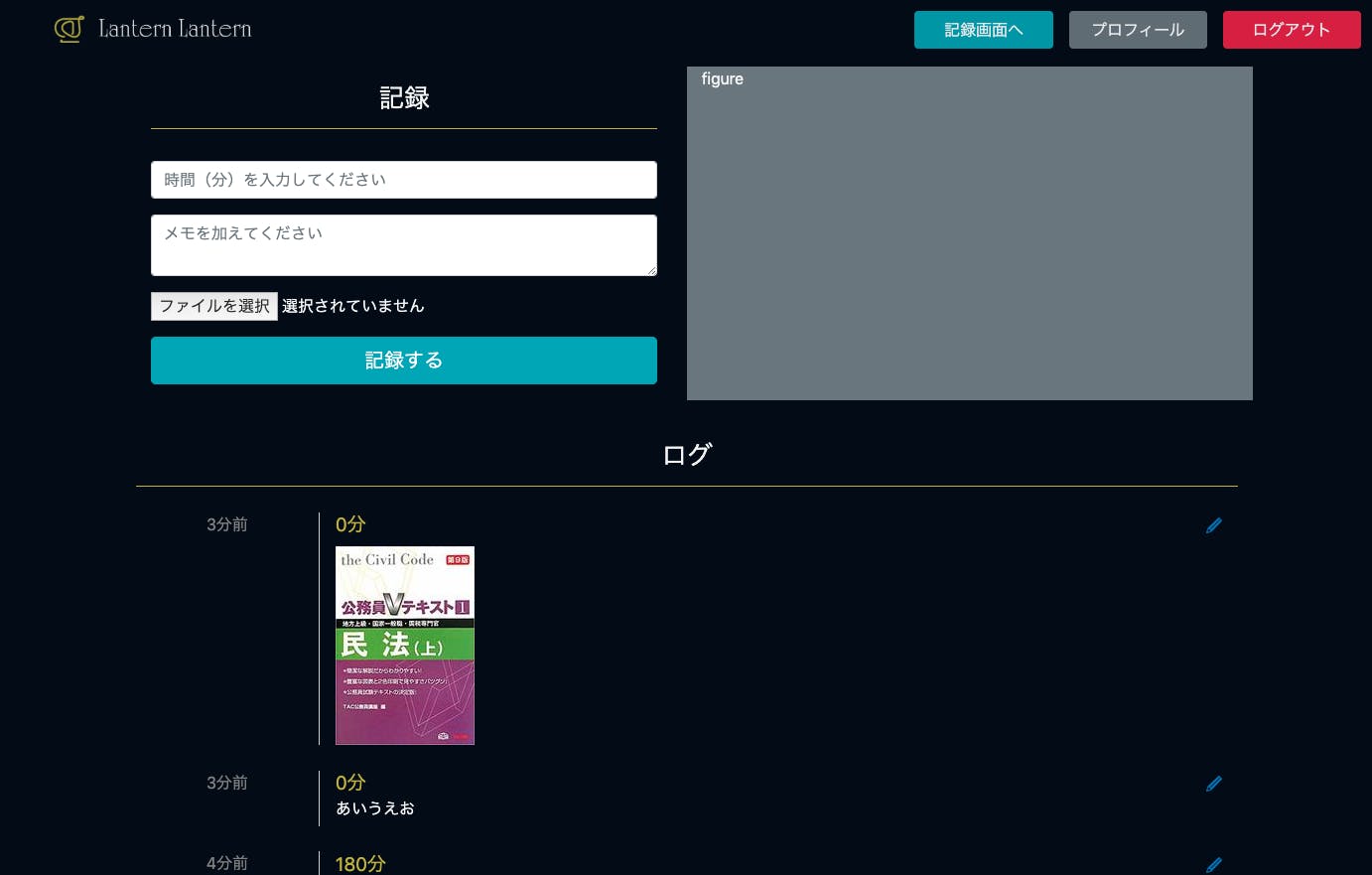
- 投稿日:2019-12-01T15:59:54+09:00
5年以上誰も手をつけていなかったAWS環境を改善した話
はじめに
昨年の12月から約10ヶ月ほど、とあるベンチャー企業のAWS環境を改善していました。今はその会社にいないのですが、会社の Jira と Confluence 以外にも知見をまとめておいたほうが良いかなと思ってアドベントカレンダーに書くことにしました。
組織の状況
以前にエンジニアが大量に退職したことにより、大量のメンテナンスできないソースコードがありました。それとともに、何の用途で動いているか分からないEC2サーバーもたくさんありました。 Technology & Infrastructure チーム(以下TIチーム)というのがあったのですが、障害対応をする人たちと数年がかりで新しい基盤を作っている人たち(たぶん目前の問題を諦めた人々)がいて、いわゆるサバイバルモードにありました。ちなみにアプリケーションのバグの量も半端なく、バグ修正チームが数年単位で存在しています。
このTIチームを解体することになり、私がAWSを触ってみたいというわりと個人的な理由と、直前にサービス系で使っていたElasticsearchの検索性能改善のタスクをやっていた時にインフラ周りに改善の余地がある、カネになりそうな仕事の匂いがしたのでチーム名を「SRE」として、実質1人で AWS環境を見直すことになりました。
成果
4万ドル/月ほどかかっていたAWSの費用を半年ほどで 2万ドル/月くらいにして、社長に褒められました。
最初にやったこと
SREのオライリーの青い本は分厚すぎて読む時間が十分にとれなかったのと、NewRelicを使っていたこともあって、SLI/SLOの章だけをまず熟読し、SLI/SLOを決めました。そもそもサービスの非機能要件はいままで定められておらず、それにより営業がお客様に説明する際にも言ってることがマチマチになっていた、ということもあり、部門ごとのリーダーを集めたミーティングでSLI/SLOについてディスカッションし、合意をとりました。障害対応基準・レスポンスタイムなど簡単な指標だけを整備してコンフルエンスにまとめました。そして、NewRelic で毎日監視したり、Cloudwatchのアラームを見直すようにしました。
AWSの営業に連絡
営業の方はとても親身にしてくれて改善点・改善方法をたくさん教えてくれるので仲良くしましょう。ここで Trusted Advisor や Business Support のお試しプランを教えてもらって、いろいろとはかどりました。
特に Trusted Advisor をBusiness Support で使うとSREで必要な業務が見えるようになったりするのでおすすめです。コスト削減
JAWS-UG 六本木一丁目支部に参加した時に知り合った方と、JAWS-UG南武線グループ(非公式)でお会いした際に会社のシステムについて相談したら、「チョット何言ってるかワカラナイんですが、運用コストがかかりすぎですねえ・・・」というリアクションをされたので、一般的に考えてヤバいんだな、と思いました。
AWS にはコストを分析してアドバイスしてくれるツールや、今では無駄遣いを指摘してくれる「Resource Optimization Recommendations」がありますが、当時はまず月額料金の高いサーバーからすべてリストアップして、用途・インスタンスタイプ・月額料金・今後どうするかを書き出しました。今後どうするかについては、だいたい以下の形に落ち着きました:
- 今すぐ停止・削除する(psとかでプロセス調べて、使ってないとわかればすぐ)
- 使ってるやつは年間契約する
- 別のマネージドサービスなどに置き換える(古いリアルタイム通信用nodejsのプロキシ用途のEC2はALBに、WordpressサーバーはLightsailに、など..)
- インスタンスタイプをスケールダウンする(スケールダウンについてもAWSのRecommendation である程度わかります。htopとかで見ながら使用状況を観察. NewRelic Infrastructureでも横断的に監視すると分かります)
- 5年以上塩漬けになってたEC2は paravirtual の仮想化方式のやつも多く、これらはちょっと苦労してスケールダウンしました EC2の t1.microをt2.microに変換する
あと、もちろんオートスケールするという選択肢もあったのですが、ちょっと難しそうだったので後回しにしました。
ことあるごとにやったこと
以前のTIチームにはなぜか AWSに関する権限が十分に与えられていなかったので、その都度グループチャットでCTOに連絡して権限付与をお願いしました。10回くらいやったら、だいたいのことができるようになりました。
やればよかったこと
在任中は、AWS Config / AWS GuardDuty / Business Support の1ヶ月お試し あたりを入れました。GuardDuty を入れたら、EC2がビットコイン採掘のbotとして使われていることがわかって焦りました。。
最後に
たぶん上記のような事例はあまりないと思うのですが、もし古い高コストAWS環境でお困りの方がいらっしゃいましたら、ご相談ください。
参考にしたページ
- 投稿日:2019-12-01T15:21:36+09:00
Alexaのアカウントリンクをデバッグする方法
自己紹介
こんにちは,ZOZOテクノロジーズの内定者さっとです.
最近、Alexaアプリの開発で遊んでいます!
意外と簡単に開発できるので、身の回りがもっと便利になるようなスキルを開発したいと思うこの頃です。※本記事はZOZOテクノロジーズ#5の4日目です.
昨日は@pakioさんが「v-for内のv-checkboxの値をwatchプロパティで検知したい」という記事を出しました.
他にもZOZOテクノロジーズでは5つのアドベントカレンダーを毎日更新しています!やること
アレクサアプリ開発でOAuth2.0を使った外部サービス(GoogleやFacebook,Slackなど)と連携したいことがあるかと思います.アレクサアプリでは,外部サービスとの連携を「アカウントリンク」と呼びますが,必要な項目を埋めるだけで簡単に設定することができます.
しかし,簡単に設定できるがゆえに,連携が失敗したり,上手くいかないとき調べる方法がありません.
そこで今回は,2016年にアレクサblogで紹介された下記の記事を元に,2019年版に刷新したデバック方法を紹介したいと思います.
How to Set up Amazon API Gateway as a Proxy to Debug Account Linking
API Gatewayを用いたプロキシ
先のブログでは,下記のようにAlexaと外部サービスの間にAWSのAPI Gatewayを利用したHTTPプロキシを構築しています.
How to Set up Amazon API Gateway as a Proxy to Debug Account Linking よりこのような構成にすることで,
Alexa Voice Serviceでアカウントリンクが実行されるときに発生するHTTPトラフィックはすべてCloudwatchに記録することができます.環境構築
前提条件
今回は,連携する外部サービスとしてAmazonを利用します.
そのため,Amazonのアカウントが必要です.また,AWSでHTTPプロキシを構築するため,AWSアカウントも別途必要です.
ここで注意したいのが,IAMを作成できる権限を持っていなければなりません.Login with Amazon
AmazonとAlexaを連携するためにLogin with AmazonにてOAuth2の証明書を作成しましょう.
作成した
- クライアントID
- クライアントシークレット
をメモしておきましょう.
Login with Amazonは下記からアクセスできます.
https://developer.amazon.com/loginwithamazon/console/site/lwa/overview.html作成方法は,下記のAlexa Developers JPチャンネルの動画が参考になります.
また,アカウントリンク方法も紹介しているので,普通に神動画です.
https://youtu.be/dnzZzc2sKBA?t=960AWS CloudFormation
AWS CloudFormationとは
HTTPプロキシはAWSのCloudFormationを利用して作成します.
CloudFormationとは,AWSが提供するリソースのモデル化およびセットアップをサポートしてくれるサービスです.
API Gateway,Cloudwatchなどのリソースの構築に必要な設定を記述したテンプレートファイルをインポートすることで簡単に環境を構築することができます.テンプレートのダウンロードと編集
今回は,本家サイトが提供するCloudFormationのテンプレートファイルを用いて構築するので事前にダウンロードしておきましょう.
https://alexademo.ninja/httpproxy/cloudformation-us-east-1.json
How to Set up Amazon API Gateway as a Proxy to Debug Account Linking よりまた,ブログは2016年のもので,テンプレートもその当時のままです.
このままでは,ビルド時に下記のようなエラーが発生してしまいます.The runtime parameter of nodejs4.3 is no longer supported for creating or updating AWS Lambda functions. We recommend you use the new runtime (nodejs8.10, nodejs10.x) while creating or updating functions. (Service: AWSLambdaInternal; Status Code: 400; Error Code: InvalidParameterValueException;)エラーは,Lambda構築時にnodejsのバージョンが対応していないため,怒られています.
ログを見ると,nodejs8.10やnodejs10.xにしてと言われているので,下記のようにファイルを編集します.65行目が
"Runtime": "nodejs4.3",となっているので,
これを下記のように"Runtime": "nodejs8.10",に変更し,保存しましょう."HostnameLambda": { "Type": "AWS::Lambda::Function", "Properties": { "Code": { "S3Bucket": "alexademo.ninja", "S3Key": "httpproxy/lambda/hostname_lambda_function.zip" }, "Handler": "index.handler", "Runtime": "nodejs8.10", "Timeout": "30", "Role": { "Fn::GetAtt": ["LambdaExecutionRole", "Arn"] } } },サービスの選択
まず,リージョンをバージニア北部に設定しましょう.
その後,サービスからCloudFormationを選択します.
スタックの作成
CloudFormationのスタックを作成します.
テンプレートの選択
次に,テンプレートファイルのアップロードを選択し,
ファイルの選択でテンプレートファイルをアップデートします.
最後に,次へを押します.
パラメータの設定
次に,スタックの名前を設定します.
これは,わかりやすい名前であれば何でも良いですが,今回はOAuthDebugとしました.
その後,外部サービスと連携するために必要なAccessTokenURLとAuthorizationURLを設定しましょう.
今回は,Login with Amazonを利用するのでデフォルトで入っているとおりにします.Login with Amazonの詳細なドキュメントは下記から確認してください.
https://developer.amazon.com/ja/docs/login-with-amazon/authorization-code-grant.html
スタックオプションの設定および詳細オプション
ここは,特に設定する項目は無いので,次へを選択します.
スタックの作成
最後に,IAMが作成されることを承認し,スタックを作成しましょう.
スタックの構築状況の確認
イベントログが流れ,環境が構築されている様子が見えると思います.
スタックの構築状況を確認するために,タブでスタックの情報を選択しましょう.
ステータスがCREATE_COMPLETEになるまで待ちます.
大体30秒~1分ぐらいかかります.
リンクのコピー
出力されたProxyAccessTokenURLとProxyAuthenticationURLはプロキシの入り口となるリンクになります.
Alexa開発者コンソールのアカウントリンクにこれらのURLを設定することで,HTTPプロキシ経由で外部サービスと通信を行うことが可能になります.
アレクサアプリの設定
Alexa開発者コンソールからリンクアカウントの設定を行います.
ProxyAuthenticationURLを認証画面のURIに貼り付けます
ProxyAuthenticationURLをアクセストークンのURI
実際に通信を発生させてみる
- スマホのアレクサアプリからデバックしたいスキルを選択しアカウントリンクをクリックします.
- これはおなじみのOauth2.0の認証画面ですね.
- 認証が成功すると次の画面が表示されます.
デバックログの確認
- AWSのコンソールからCloudWatchのサービスを選択
ロググループを見るとAPI-Gateway-Execution-Logsが表示されていることがわかります.
ログストリームが2つあり,それぞれコード発行およびトークン発行時に発生したログになります.
- ログを確認するとaccess_tokenもここで確認できます.
認証失敗時のログ
デバックが機能しているかを確認するためにクライアントシークレットをあえて間違えてみます.
認証しようとすると勿論「アカウントリンクを完了できませんでした」と表示されます.
このときのログを確認すると
コード発行は無事できていることがわかります.
Successfully completed executionしかし,アクセストークン取得時に失敗していることが確認できます.
{ "error_description": "Client authentication failed", "error": "invalid_client" }また,イベントフィルターでerrorと入れて検索するとエラーが起きているログだけ抽出できるので,
デバック作業の足がかりになると思います.
おわりに
今回は,Alexaアプリでアカウントリンク失敗した際のデバック方法を紹介しました.
Alexaに限らず,似たようなサービスでも利用できますので,ぜひ利用してみてください.
明日は,@ikeponsu さんで「Go言語の標準パッケージだけで画像処理をする その1 (入出力)」です!
お楽しみに!
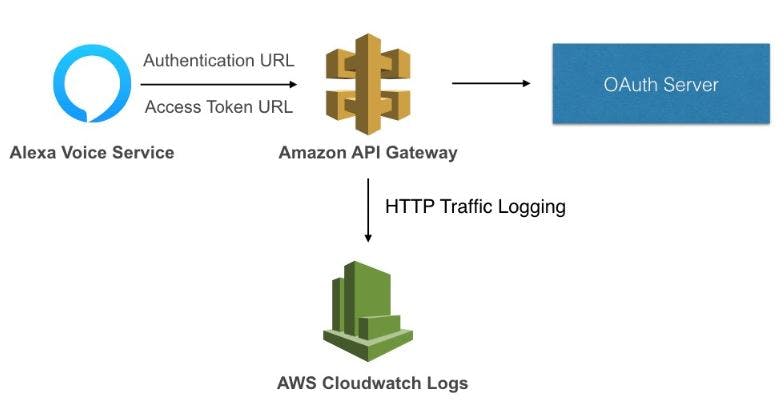
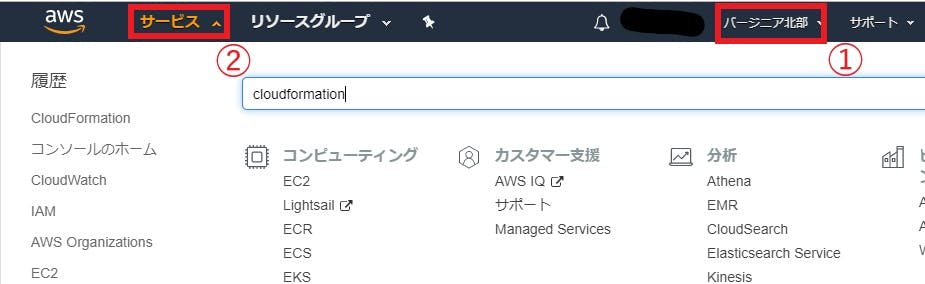
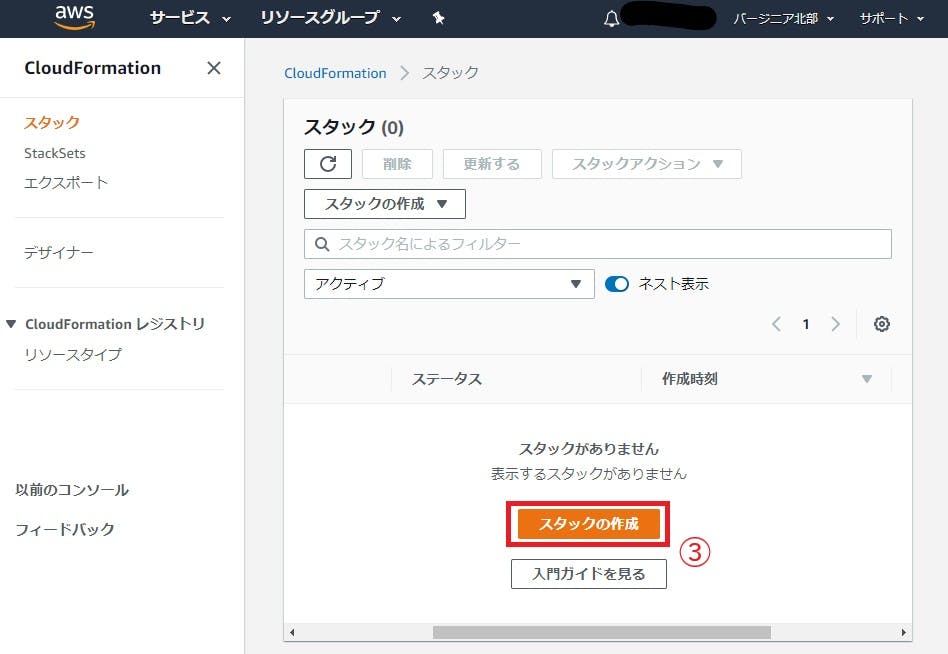
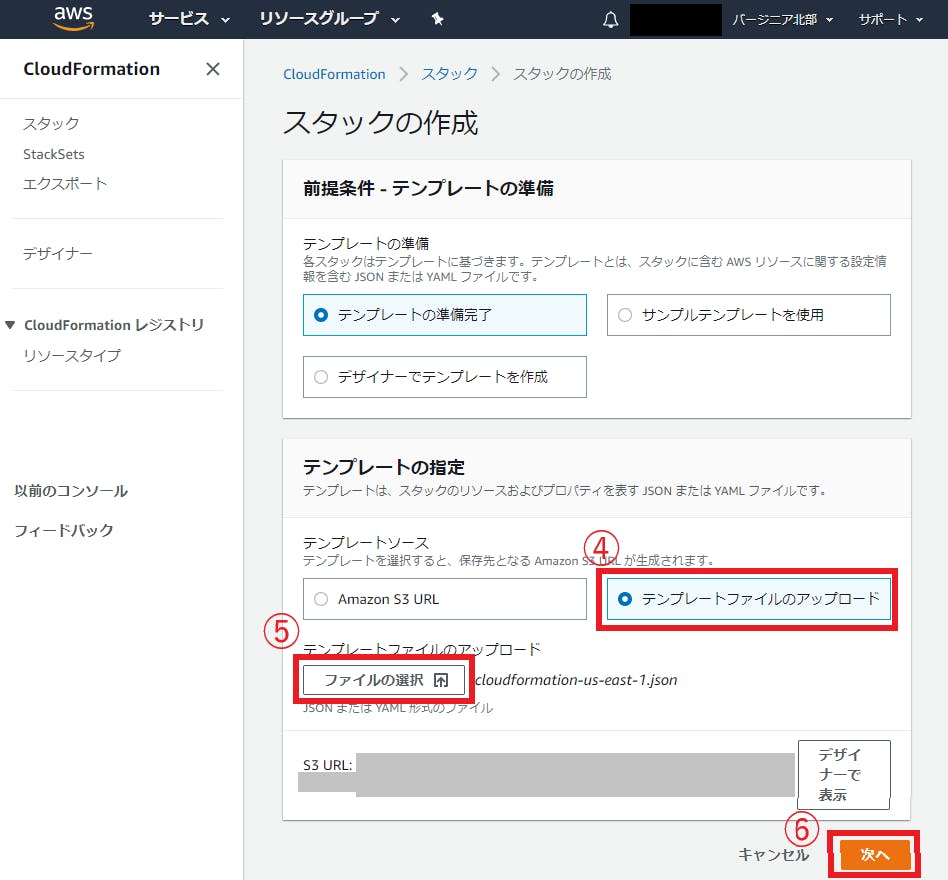
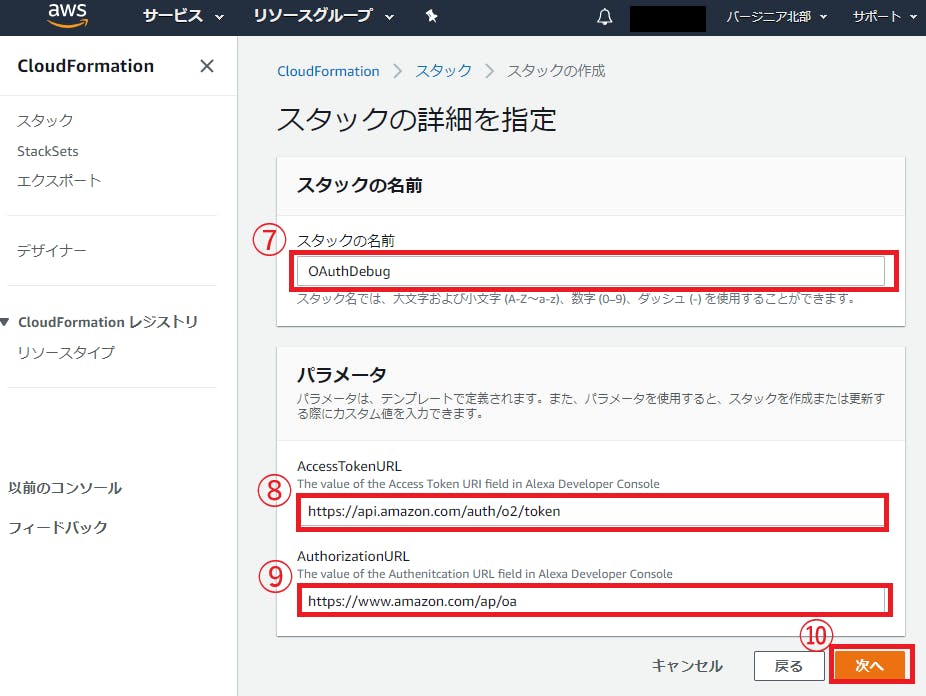
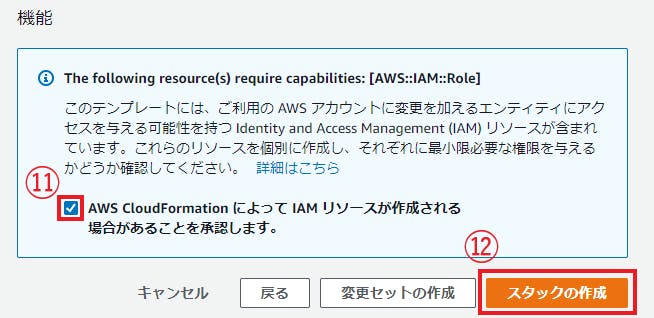
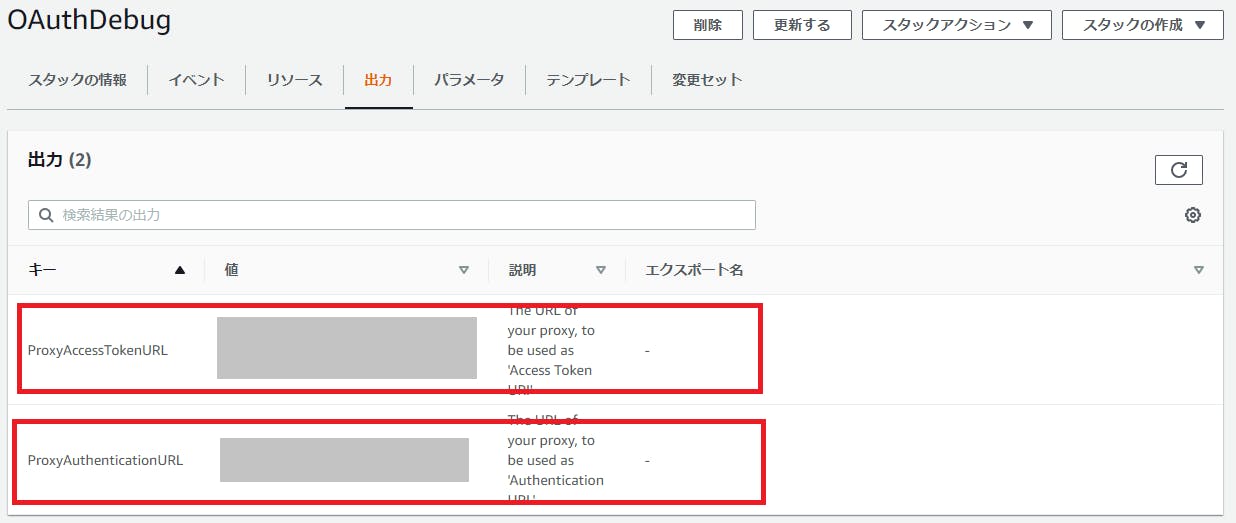
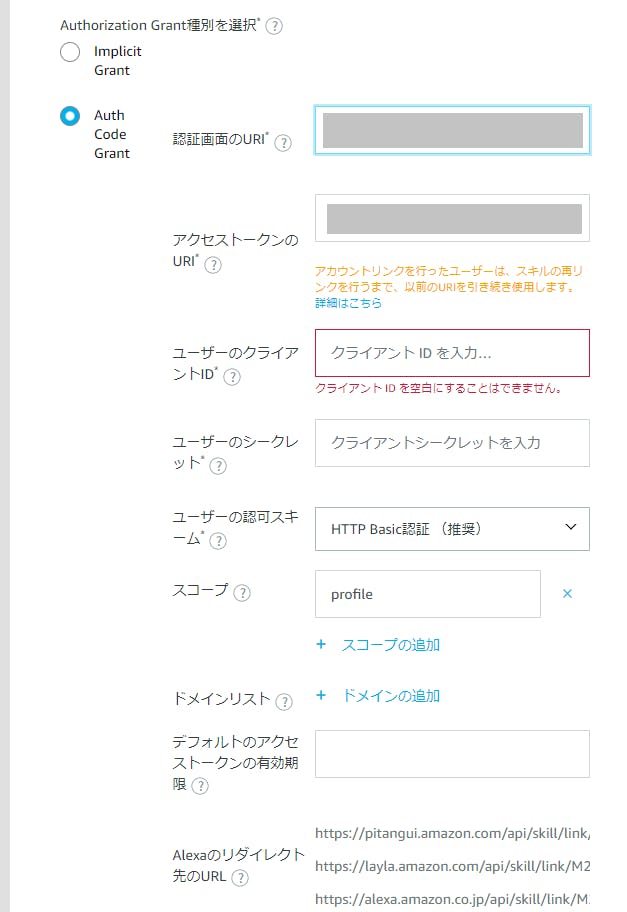


- 投稿日:2019-12-01T15:17:41+09:00
Direct Connect(DX)入門&ネットワークの基礎
概要
仕事でDirect Connect(DX)を使って自社のオンプレサーバーとAWSを接続しています。しかし、いったいどういった仕組みになっているのか概念程度にしかわかっておりません。又、割と少なくない頻度で緊急メンテのお知らせメールがくるので、これはちゃんと仕組みを知っとかないとまずいぞと思い学び始めました。今回はDXの仕組みについて、さらにはDXを理解する上で前提になるネットワークの基礎について調べたことを書いていきます。
AWS Direct Connectとは
AWS Direct Connectロケーションにユーザーの内部ネットワークを接続するためのサービスです。(通信媒体としてイーサーネット光ファイバーケーブルを利用)。専用線を使うため、VPN接続よりも高速(Port Speedは10Gpbs又は1Gbps)に通信できます。また、他のISPなどを挟まないためセキュリティ要件が高いデータを扱う場合にも適しています。
https://docs.aws.amazon.com/ja_jp/directconnect/latest/UserGuide/Welcome.html
上の図のようにAWSは相互接続用のデータセンターを用意し、そのデータセンターに対して自社で要したデータセンターを接続することでAWSで接続できるような仕組みなっています。この相互接続データセンターとしてAWSはEquinix社などのデータセンターを利用して設置しています。
利用の流れ
1.DXローケーションのデータセンターに接続
AWS Direct Connectのローケーションで接続を作成し、自身のデータセンターから接続を確立します。
またはAPN(AWS Partner Network)というAWSが認定した事業者が提供するサービスを利用することでも接続を確立することができます。
https://aws.amazon.com/jp/directconnect/partners/
2.仮想インターフェース
AWSのサービスへのアクセスを有効にするために仮想インターフェースを作成する必要があります。パブリック仮想インターフェースにより、S3などパブリックサービスへのアクセスが有効になります(パブリックIPを利用)。プライベート仮想インターフェースは、VPCへのアクセスを有効にします(private IPを利用)。
仮想インターフェース作成の前提条件があるので詳細はこちらをご覧ください。
https://docs.aws.amazon.com/ja_jp/directconnect/latest/UserGuide/WorkingWithVirtualInterfaces.htmlさらにネットワークの要件も決められています。詳細はこちらをご覧ください。
https://docs.aws.amazon.com/ja_jp/directconnect/latest/UserGuide/Welcome.html実際の作業手順
AWSからのメンテメールがあった時
AWS Direct Connect Emergency Maintenance Notificationという内容でAWSからDXの緊急メンテがあるよという連絡がたまにきますが、上の図のようにDXの接続は基本2つの線で冗長化されていてメンテはその内一つに影響があるもので全体的には通常通り動作可能ということでした。なのでこちらについては内容を確認するだけで特別の対応は必要ありません。まとめ
普段はアプリケーション開発者の代わりにインフラエンジニアの方達がデータセンターを管理してくれているのでこういった仕組みについて理解しなくてもサービスを利用できるようになっていますが、AWSからの緊急メンテのお知らせだったり、また社内のサーバー移設の話や相乗りサーバーの分離の話がどういったことをやろうとしているのか見当をつけることができるようになりました。今後もAWSを触るだけでなくそれを実現している仮想環境の技術だったり今回のネットワークの内容をきちんと学んでいきたいと思います。
又、最後に今回Direct Connectの内容を理解するにあたって自分の知識が不足していて調べた内容について備忘録的にまとめておきます。調べたこと備忘録
L1/レイヤー1(OSI参照モデル)
通信媒体でのデータの送受信についての手順を定めています。通信媒体,インターフェース、データの3つから構成されます。
通信媒体
有線と無線の二つの形式があります。有線の場合は電気信号を使う銅線、光信号を使う光ファイバーがあります。
銅線
ex)UTPケーブル
http://www.takabun.co.jp/products/fuji_fs-tpcc5-patch/光ファイバー
ex)光ファイバーケーブル
https://direct.sanwa.co.jp/ItemPage/HKB-LCLC1-30Lインターフェース
通信媒体に信号を流し、受け取る機械。使用するケーブルや信号に応じてインターフェースを使い分けます。
Ethernet
有線LANの標準規格(有線LAN自体を指すように使われている場合が多いですが本来は規格のことです)。
OSI参照モデルのレイヤー1の物理層とレイヤー2のデータリンク層に関して規定しています。Ethernetで規定しているもの
通信媒体、データ送受信単位(Ethernetではデータをフレームと単位で送受信する)、接続形態、MACアドレスhttp://e-words.jp/w/Ethernet.html
ハブ
ネットワーク機器の一つで、複数のコンピュータ間の通信を実現します。
役割
- マルチアクセスネットワークを作る
- データ転送中の減衰によって崩れた信号を元の形に増幅、整形すること
ハブに繋がっている複数の機器が同時に送信することで衝突する可能性があります(衝突ドメイン)。
スイッチ
ハブと同様にマルチアクセスネットワークを作ることができるネットワーク機器です。ハブに同時にデータが届くと衝突が発生していますが、学習フィルタリングという機能を使うことで一度データを受け取ったportと宛先をセットで覚えておき、次に送信する時にその表を参照することでport別に送信できるようにすることでデータの衝突を防ぎます。又、同じポートに対してデータが送られてきた場合には後から送られてきたデータをバッファリングすることで送信を送らせ、衝突を防ぎます。
https://news.mynavi.jp/kikaku/switch-1/
全二重通信(Full-Duplex)
上のようにハブの代わりにスイッチを使うことで衝突が起こらなくなるため、データの送信と受信が同時にできるようになります。この通信のことを全二重通信と言います。
ARP
Address Resolution ProtocolでIPアドレスからMACアドレスを引くために利用される通信プロトコルです。
ドメインからIPアドレスを引くDNSと似てますね。ルーター
ハブやスイッチと同様にネットワーク機器の一つで、ネットワーク間同士の通信を行う機能を持ちます。ネットワーク同士を繋ぐことで広大な範囲での通信を実現することができます。ルータは所属するネットワークごとにインターフェースをもち、それぞれにネットワークのIPアドレスを持ちます。
後述するルーティングテーブルを元に、宛先IPとルーティングテーブルを比較して次の宛先を特定します。
デフォルトゲートウエイ
コンピューターはマルチキャストドメインでARPを行いデータ送信先のMACアドレスを取得します。しかし、宛先が別のネットワークにある場合、ルーターを超えた(マルチキャストドメイン外)ARPは届かないので宛先が特定できません。
そこでネットワーク間通信の最初の入り口にデータを送り、そこを起点としてネットワーク間でデータを通信してもらい目的地まで運んでもらいます。この宛先がデフォルトゲートウェイです。
ルーティングテーブル
ルータはルーティングテーブルを使って受け取ったパケットの宛先IPアドレスを確認して、Longet Matchのルールで次の宛先ネットワークを決めます。
宛先ネットワーク 次のルータ メトリック インターフェース 192.168.1.0 210.81.36.1 3 1 91.0.0.0 210.81.36.1 6 1 172.36.0.0 130.82.10.1 2 2 221.194.38.0 なし 0 3 Amazon Linux2でのルーティングテーブルの確認
$ route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface default ip-132-12-24-1. 0.0.0.0 UG 0 0 0 eth0 instance-data.a 0.0.0.0 255.255.255.255 UH 0 0 0 eth0 132.12.24.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0参考資料
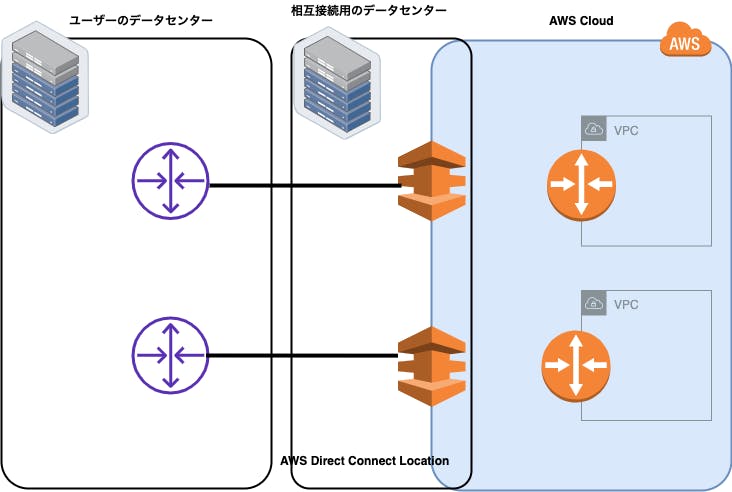
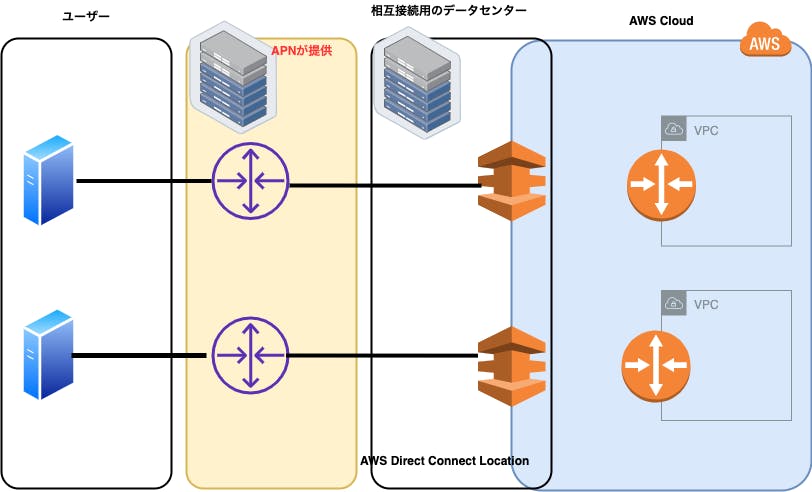
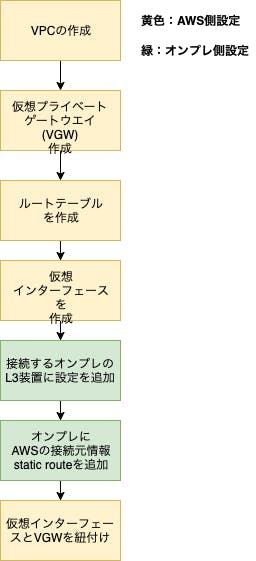




- 投稿日:2019-12-01T14:35:54+09:00
Aws の Ubuntu 18.04 を 19.10 にアップグレード
AWS の Ubuntu 18.04 を 19.10 にアップグレードする方法です。
設定ファイルの変更
sudo vi /etc/update-manager/release-upgrades次のように変更します。
/etc/update-manager/release-upgradesPrompt=normalリリースアップグレード
sudo do-release-upgrade再起動
sudo shutdown -r now更新できたことを確認するが、まだ 19.04 だった。
$ cat /etc/os-release NAME="Ubuntu" VERSION="19.04 (Disco Dingo)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 19.04" VERSION_ID="19.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=disco UBUNTU_CODENAME=discoもう一度、do-release-upgrade を行う
$ cat /etc/os-release NAME="Ubuntu" VERSION="19.10 (Eoan Ermine)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 19.10" VERSION_ID="19.10" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=eoan UBUNTU_CODENAME=eoan
- 投稿日:2019-12-01T14:15:21+09:00
2019年グッと来たAWSアップデートベスト5
はじめに
estie VPoEの青木と申します。
弊社ではインフラ基盤として主にAWSを利用しています。
AWSを利用していると、日々そのサービスがアップデートされ機能拡充されていくことに驚きますよね。
実際、AWSのリリースページによると、2019年だけで本日(12/02)までに1671ものアップデートリリースがあります!本日は、その中で特に個人的にグッと来たリリースをランキング形式でご紹介したいと思います。
(私自身がデータエンジニアとしてのキャリアが長いため、少し偏ったランキングとなっているかもしれませんがご容赦ください)なお、本日(12/2)から6日にかけてAWSのイベントであるre:Inventが開催され、
多くのアップデートが発表されるかと思いますが、本記事はそちらの発表前時点で選ばせていただいています。第5位: Glue・AthenaのprivateLink対応
できるようになったこと
Athena(S3内のファイルに対して直接クエリを実行できるサービス)とGlue(フルマネージドなETLサービス)がそれぞれ、VPCインターフェイスエンドポイントに対応しました。
これにより、インターネットを経由せずに各サービスに接続し利用することが可能となりました。どんなことが嬉しいのか
これまではインターネット経由のアクセスが厳しく制限されているプロダクトでは、AthenaやGlueを利用することができませんでした。
今回のリリースにより、セキュリテイ要件の厳しい案件など、より幅広いサービスで利用することが可能になりました!リリース記事
第4位: EC2 Instance Connect
できるようになったこと
IAM(Identity and Access Management)情報を用いて、一回限りのアクセスキーを発行してEC2へのSSH接続できます。
合わせて、マネジメントコンソール経由でブラウザからアクセスすることも可能になりました。どんなことが嬉しいのか
運用上作業が多くなりがちだがセキュリティ上重要なEC2へのアクセス権限の整理を全てIAMで管理することが可能に。
昨年発表された「AWS Systems Manager セッションマネージャー」と合わせ、EC2接続周りの利便性はかなり向上し、今後のアクセス情報管理のスタンダートが大きく変わる可能性を秘めてると感じました!リリース記事
第3位: Step Functionsで複雑なパターンを実行可能に(ネスト/外部コールバック/動的並列処理)
できるようになったこと
AWS Step Functions(AWS Lambdaなどのマイクロサービスのワークフローエンジン)がより様々なワークフローに対応しました。
- ステートマシンをネストして使用することが可能となり、より大規模なフローの構築が簡易に
- コールバックへの対応が可能となり、外部ユーザやAWS外のアプリケーションとの結合が可能に
- 動的に複数のLambdaを呼び出すような並列処理が可能に
どんなことが嬉しいのか
これまでであれば、他のワークフローエンジンを用いていたような複雑又は大規模な開発案件においても、
Lambda+Step Functionsだけでクイックにサーバレスかつ運用しやすい環境を構築することが可能となりました。
今後もStep Functionsがアップデートされていくと、かなりのパターンではこのような構成で完結していくようになるのかもしれませんね!リリース記事
第2位: savings Plans
できるようになったこと
将来一定期間(1年or3年)のEC2利用量を前もってコミットすることで、最大72%コスト削減できるようになりました。
どんなことが嬉しいのか
これまでもReserved Instanceという将来一定期間の利用を約束することでの割引機能は存在したのですが、購入時点でインスタンスタイプを指定する必要がありました。
本サービスでは合計の利用量だけをコミットすれば良いため、サービス拡大に伴うスケールアウトやスケールアップにも問題なく対応できます。
しかも割引率もReserved Instanceと比較しても遜色なさそうです。
サービス利用状況の予測が立てづらい弊社のようなスタートアップには、ありがたいサービスですね!リリース記事
第1位: Redshiftでの最適な分散キーの推奨
できるようになったこと
Redshift(DWH向け列志向のMPPデータベース)において、テーブル利用実績を元に最適な分散キー設定を推奨するようになった。
また、以前はテーブル作成後には変更できなかった分散キーがALTER TABLEコマンドにより変更可能となった。どんなことが嬉しいのか
Redshiftの高速なクエリパフォーマンスの鍵となるのは、複数のノードにデータを分散させるために用いられる分散キーの情報です。
以前までこのキー情報がテーブル作成後にはコマンドでは変更できず、どうしても処理時間が長すぎるクエリがある場合には、新しい分散キーの設定されたテーブルを作成した上で、古いテーブルからデータをINSERTする必要がありました。
その際、Redshiftのテーブルは多くの場合かなり多くの件数のデータが含まれるため、このINSERT処理はかなりの時間がかかるとともに、場合によっては圧縮を解凍した際にDB全体で容量不足となりクエリが失敗することもありました。今年こちらの仕様も変更され、ALTER TABLEコマンドでテーブルの分散キー、ソートキー(INTERLEAVED SORTKEYは未対応)を変更ができるようになりました。今回のリリースはさらに、この最善なソートキーを自動で推奨してくれる機能となります。
今回の一連の改善により、以前は初期構築時の大事な一発勝負の感があった分散キー設計が、恒常的に改善可能な設計内容へとだいぶハードルが下がったと感じました。
去年リリースされた短時間でのノード数変更を可能とするElasticResizeや、最近公開されたマテビューへの対応など、Redshift関連のアップデートはかなり高速で進んでいる印象があります。
今年のre:InventでもRedshiftについて大きなリリースがあるかもしれませんね!リリース記事
終わりに
リリース内容を振り返って
振り返ってみると、ランクインしていないものも含めて、たくさんのアップデートがありましたね。
やはりAWSのようなサービスを使うにあたっては、最新のアップデート情報を仕入れることが大切だと感じました。まだestieでは試せていないものもありますので、re:Inventで発表されるであろう分も含めて、
どんどん試してサービスに反映させていきたいと思います!estieについて
estieでは、新しい技術にアンテナを張っているエンジニア、フルスタックのエンジニアを常に募集しています!
https://www.wantedly.com/companies/company_6314859/projectsestie -> https://www.estie.jp
estiepro -> https://pro.estie.jp
会社サイト -> https://www.estie.co.jp
- 投稿日:2019-12-01T13:33:11+09:00
「Upgrading to Terraform v0.12」を実施した際の備忘録メモ
はじめに
主に公式ドキュメントを参考に、Terraform v0.11系からv0.12系へアップグレードした際の備忘録メモになります。
Upgrading to Terraform v0.12また、今回アップグレードを行なったのはこちらのリポジトリをforkしたリポジトリです。
https://github.com/collectivehealth/terraform-emr-spark-example手順
- tfenvでv0.11.14とv0.12系を用意
terraform 0.12checklistでアップグレード事前チェック- v0.12系にバージョンアップして
terraform initを実行terraform 0.12upgradeで構文置換各手順のメモ
tfenvでv0.11.14とv0.12系を用意
tfenvを使うとバージョンの切り替えが簡単に行えるため、これを使います。
https://github.com/tfutils/tfenv$ tfenv install 0.11.14 $ tfenv install 0.12.6 $ tfenv use 0.11.14 $ tfenv list 0.12.6 * 0.11.14 (set by /usr/local/Cellar/tfenv/1.0.1/version)また、tfファイルをv0.11.14に対応させておきます。
terraform 0.12checklistでアップグレード事前チェックv0.11.14には
0.12checklistというコマンドがあり、このコマンドを利用してv0.12系にアップグレードする前に事前チェックを行います。$ terraform 0.12checklist After analyzing this configuration and working directory, we have identified some necessary steps that we recommend you take before upgrading to Terraform v0.12: - [ ] Upgrade provider "aws" to version 2.40.0 or newer. No currently-installed version is compatible with Terraform 0.12. To upgrade, set the version constraint for this provider as follows and then run `terraform init`: version = "~> 2.40.0" - [ ] Upgrade provider "random" to version 2.2.1 or newer. No currently-installed version is compatible with Terraform 0.12. To upgrade, set the version constraint for this provider as follows and then run `terraform init`: version = "~> 2.2.1" - [ ] Upgrade provider "template" to version 2.1.2 or newer. No currently-installed version is compatible with Terraform 0.12. To upgrade, set the version constraint for this provider as follows and then run `terraform init`: version = "~> 2.1.2" - [ ] Upgrade provider "tls" to version 2.1.1 or newer. No currently-installed version is compatible with Terraform 0.12. To upgrade, set the version constraint for this provider as follows and then run `terraform init`: version = "~> 2.1.1" # Module `"bootstrap"` # Module `"emr"` # Module `"lb"` # Module `"s3"` # Module `"sec"` # Module `"sgs"` Taking these steps before upgrading to Terraform v0.12 will simplify the upgrade process by avoiding syntax errors and other compatibility problems.今回は4つのProviderがv0.12系と互換性がないとのことだったので、バージョン制約を指示通りに変更し、
terraform initを実施しました。
問題がなくなると以下のメッセージが表示されます。Looks good! We did not detect any problems that ought to be addressed before upgrading to Terraform v0.12. This tool is not perfect though, so please check the v0.12 upgrade guide for additional guidance, and for next steps: https://www.terraform.io/upgrade-guides/0-12.htmlv0.12系にバージョンアップして
terraform initを実行tfenvでバージョン切り替えて、
$ tfenv use 0.12.6 $ tfenv list * 0.12.6 (set by /usr/local/Cellar/tfenv/1.0.1/version) 0.11.14
terraform initを実行。$ terraform init There are some problems with the configuration, described below. The Terraform configuration must be valid before initialization so that Terraform can determine which modules and providers need to be installed. Error: Extraneous label for provider on config.tf line 5, in provider "aws" "aws": 5: provider "aws" "aws" { Only 1 labels (name) are expected for provider blocks. Error: Extraneous label for provider on config.tf line 10, in provider "random" "random": 10: provider "random" "random" { Only 1 labels (name) are expected for provider blocks. Error: Extraneous label for provider on config.tf line 14, in provider "template" "template": 14: provider "template" "template" { Only 1 labels (name) are expected for provider blocks. Error: Extraneous label for provider on config.tf line 18, in provider "archive" "archive": 18: provider "archive" "archive" { Only 1 labels (name) are expected for provider blocks. Error: Extraneous label for provider on config.tf line 22, in provider "tls" "tls": 22: provider "tls" "tls" { Only 1 labels (name) are expected for provider blocks. Error: Extraneous label for provider on config.tf line 26, in provider "http" "http": 26: provider "http" "http" { Only 1 labels (name) are expected for provider blocks. Error: Extraneous label for provider on config.tf line 30, in provider "local" "local": 30: provider "local" "local" { Only 1 labels (name) are expected for provider blocks.providerブロックが互換性のないコードとなっていたため、修正しました。
awsのprovider-provider "aws" "aws" { +provider "aws" {
terraform 0.12upgradeで構文置換v0.12系には
0.12upgradeというコマンドがあり、このコマンドを利用してv0.12系の構文への置換を行います。$ terraform 0.12upgrade This command will rewrite the configuration files in the given directory so that they use the new syntax features from Terraform v0.12, and will identify any constructs that may need to be adjusted for correct operation with Terraform v0.12. We recommend using this command in a clean version control work tree, so that you can easily see the proposed changes as a diff against the latest commit. If you have uncommited changes already present, we recommend aborting this command and dealing with them before running this command again. Would you like to upgrade the module in the current directory? Only 'yes' will be accepted to confirm. Enter a value:
yesと入力することで、書き換えが実行されます。
完了すると以下のメッセージが表示されます。Upgrade complete! The configuration files were upgraded successfully. Use your version control system to review the proposed changes, make any necessary adjustments, and then commit.アップグレードがすでに済んでいると以下のようなエラーが出ます。
$ terraform 0.12upgrade Error: Module already upgraded on versions.tf line 3, in terraform: 3: required_version = ">= 0.12" The module in directory . has a version constraint that suggests it has already been upgraded for v0.12. If this is incorrect, either remove this constraint or override this heuristic with the -force argument. Upgrading a module that was already upgraded may change the meaning of that module.今回はありませんでしたが、手動で変更しないといけない箇所があったりするとのことです。
また、0.12upgradeコマンドで不便な点としては、以下が挙げられます。
- ファイル末尾に空行が追加されてしまう
- カレントディレクトリのtfファイルしか変更してくれない
- 実行したディレクトリに
versions.tfが作成されるProviderのアップグレード
terraform initコマンドに-upgradeオプションを指定することで、バージョン制約を満たす最新のプロバイダにアップグレードすることができます。$ terraform init -upgrade Upgrading modules... - bootstrap in modules/bootstrap - emr in modules/emr - lb in modules/lb - s3 in modules/s3 - sec in modules/sec - sgs in modules/sgs Initializing the backend... Initializing provider plugins... - Checking for available provider plugins... - Downloading plugin for provider "archive" (hashicorp/archive) 1.3.0... - Downloading plugin for provider "tls" (hashicorp/tls) 2.1.1... - Downloading plugin for provider "http" (hashicorp/http) 1.1.1... - Downloading plugin for provider "local" (hashicorp/local) 1.4.0... - Downloading plugin for provider "aws" (hashicorp/aws) 2.40.0... - Downloading plugin for provider "random" (hashicorp/random) 2.2.1... - Downloading plugin for provider "template" (hashicorp/template) 2.1.2...参考
Terraform 0.12がリリースされたのでアップグレードしてみた
https://dev.classmethod.jp/tool/terraform-upgrade-from-0-11-to-0-12/Terraform職人入門: 日々の運用で学んだ知見を淡々とまとめる
https://qiita.com/minamijoyo/items/1f57c62bed781ab8f4d7
- 投稿日:2019-12-01T12:38:40+09:00
Chromeでの「応答時間が長すぎます」エラーにハマった時は.....
概要
メルカリのクローンサイトを作成する際にインフラ、デプロイ関係の担当をした者が沼にハマった部分を共有し、同じような状態から抜け出すための一助になればと思ったことが投稿するきっかけになります。
今回は、デプロイ完了後にIPアドレスでブラウザ(Chrome)からログインしようとしても「応答時間が長すぎます」エラーが頻発した際に、原因となった箇所について述べていきます。
AWSなどインフラ関係において、同じような状況で困っている方の一助に少しでもなれたら幸いです。環境
- Rails v5.2.3
- Ruby v2.5.1
- Unicorn
- capistrano
- nginx
- mysql
- AWS, EC2(本番環境)
①まずはじめにセキュリティグループとは
今回、メルカリのクローンサイトを作成する際に用いたインフラ環境はAWS、EC2です。
その設定の中で、セキュリティーグループについて何点か調べて理解した箇所があるので、少しまとめてみようと思います。
- ファイアーウォール機能として挙動する。
- インスタンスごとに1つ以上のセキュリティーグループを指定できる。
- インスタンスに関連したトラフィックを判断する機能を持つ。
* ファイアーウォールとは...
ファイアウォールとは防火壁のことだが、コンピュータネットワーク関連では、ネットワークの結節点となる場所に設けて、コンピュータセキュリティ上の理由、あるいはその他の理由により「通過させてはいけない通信」を阻止するシステムを指す。通過させてはいけない通信を火にたとえている。ルーターにその機能を実装したものは、そのルーターを指して言うこともあるし、そういったアプライアンス商品などもある。
上記でつらつらと述べましたが、簡単にまとめるならば
不正なアクセス、悪意ある攻撃を防ぐ機能です。
また、トラフィック(転送されるデータ量)も管理しているみたいです。②config.force_ssl = true を有効にしていたのが原因
私が直面した「応答時間が長すぎます」エラーの理由としては、テーマにある通りconfig.force_ssl = true のコメントアウトを外していたことが原因でした。
では、まずconfig.force_ssl = true とはどういう機能を表すのでしょうか...それは一言、全てのIPアドレスへのアクセスをhttpsに流す設定です。
はい。この設定の影響によって、上記で述べたセキュリティーグループをhttpでポート範囲設定しているのに常にhttpsとしてアクセスを流すために長々とアドレスには入れず、「応答時間が長すぎます」エラーが発生していたのです。
セキュリティーグループをhttpsで設定していればまだしも、httpだとこの機能を使っていれば入れるわけがなかったですね...
終わりに
今回の箇所で沼にハマって得た教訓としては、理解していない、なんとなく使っているコマンドほど要注意です。
当たり前ですが、なんとなく使って上手くいった経験がある人ほど要注意かなと...(自分もそうでした。)
ではまた沼った経験をまとめたいと思います。
長々と読んで頂きありがとうございました。