- 投稿日:2019-11-26T22:40:05+09:00
NNablaでtensorboardを使う
tensorboard は学習時にロスカーブを書いたり、ヒストグラムや画像を描画したりするのがとても便利なツールです。私は最近ソニー製のニューラルネットワークフレーム NNabla (https://nnabla.org/) を使っていますが、可視化ツールがなかったので、NNabla でも tensorboard を使えるように、python のパッケージを作りました。
https://github.com/naibo-code/nnabla_tensorboard
基本は "tensorboardX for pytorch" をベースに作りました。
使い方
基本的には
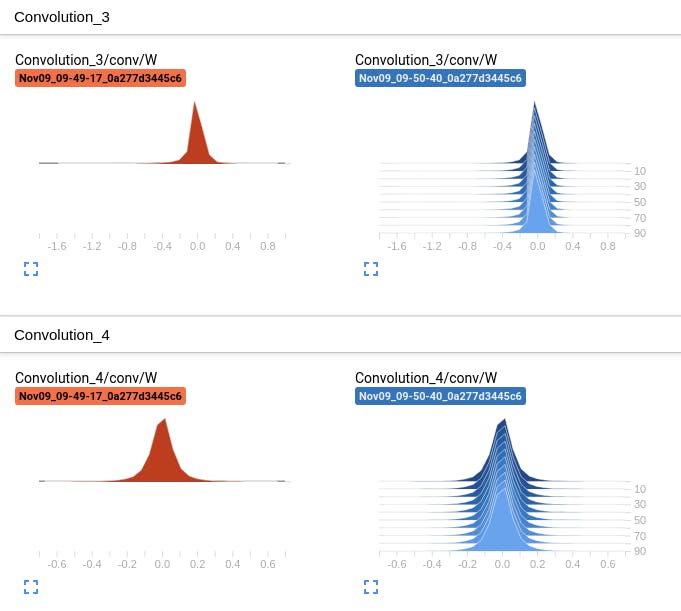
demp.pyを実行してもらうとどんな感じか分かるかと思います。スカラ、ヒストグラム、画像などの描画に対応しています。# Install pip install 'git+https://github.com/naibo-code/nnabla_tensorboard.git' # Demo python examples/demo.pyスカラ
ヒストグラム
文字出力
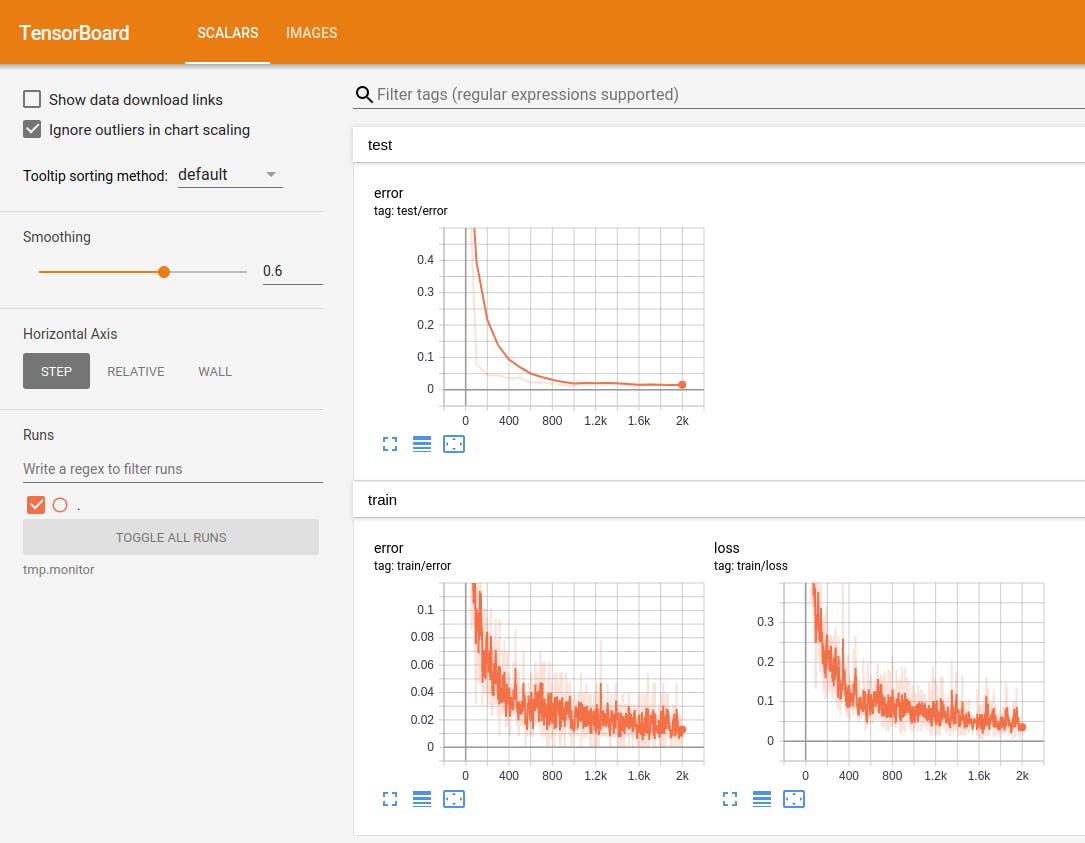
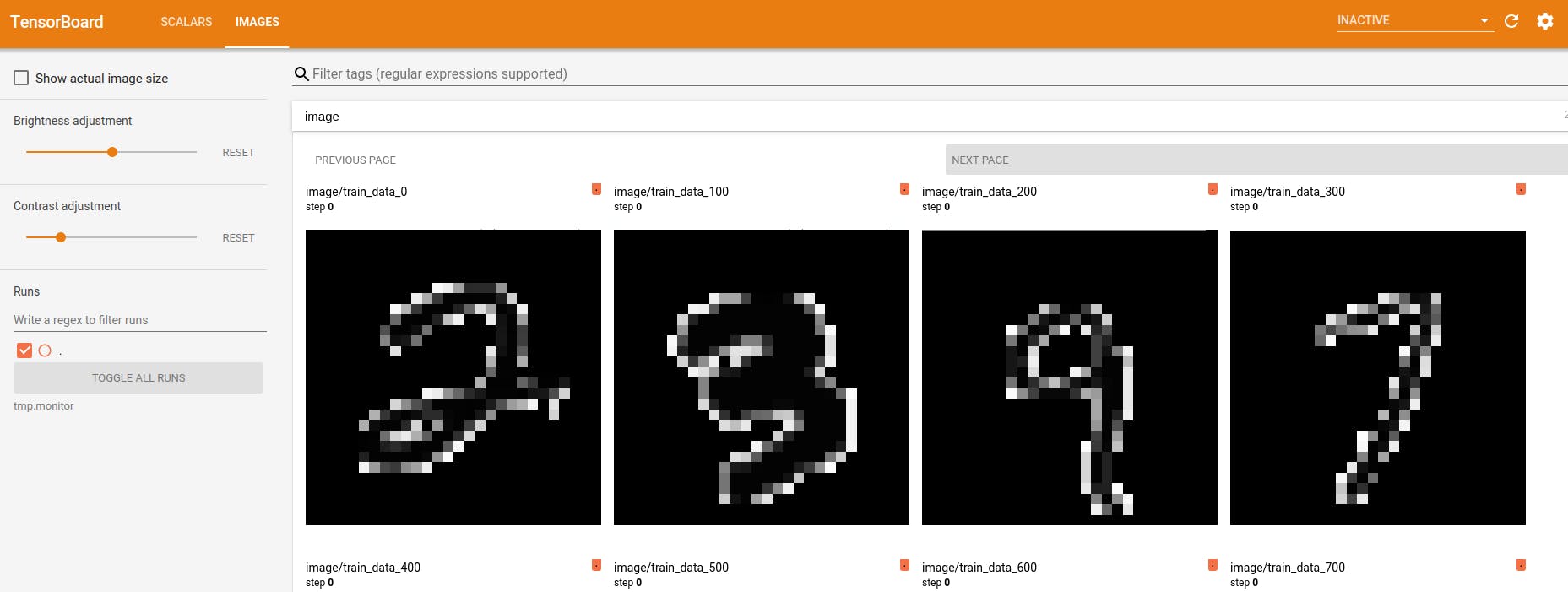
NNabla + tensorboard で MNIST の学習を可視化
NNabla はこちらのリポジトリ https://github.com/sony/nnabla-examples/ で幾つかの examples を提供しています。今回はその中から MNIST の学習コード を使って、リアルタイムに学習結果を tensorboard で可視化してみました。
変更すべきのはこちらの2つの関数だけです(
NEWと書かれた部分だけ。)。あとファイルの先頭にfrom nnabla_tensorboard import SummaryWriterでパッケージをインポートします。from nnabla_tensorboard import SummaryWriter def train(): """ Main script. Steps: * Parse command line arguments. * Specify a context for computation. * Initialize DataIterator for MNIST. * Construct a computation graph for training and validation. * Initialize a solver and set parameter variables to it. * Create monitor instances for saving and displaying training stats. * Training loop * Computate error rate for validation data (periodically) * Get a next minibatch. * Execute forwardprop on the training graph. * Compute training error * Set parameter gradients zero * Execute backprop. * Solver updates parameters by using gradients computed by backprop. """ args = get_args() from numpy.random import seed seed(0) # Get context. from nnabla.ext_utils import get_extension_context logger.info("Running in %s" % args.context) ctx = get_extension_context( args.context, device_id=args.device_id, type_config=args.type_config) nn.set_default_context(ctx) # Create CNN network for both training and testing. if args.net == 'lenet': mnist_cnn_prediction = mnist_lenet_prediction elif args.net == 'resnet': mnist_cnn_prediction = mnist_resnet_prediction else: raise ValueError("Unknown network type {}".format(args.net)) # TRAIN # Create input variables. image = nn.Variable([args.batch_size, 1, 28, 28]) label = nn.Variable([args.batch_size, 1]) # Create prediction graph. pred = mnist_cnn_prediction(image, test=False, aug=args.augment_train) pred.persistent = True # Create loss function. loss = F.mean(F.softmax_cross_entropy(pred, label)) # TEST # Create input variables. vimage = nn.Variable([args.batch_size, 1, 28, 28]) vlabel = nn.Variable([args.batch_size, 1]) # Create prediction graph. vpred = mnist_cnn_prediction(vimage, test=True, aug=args.augment_test) # Create Solver. solver = S.Adam(args.learning_rate) solver.set_parameters(nn.get_parameters()) # Create monitor. from nnabla.monitor import Monitor, MonitorTimeElapsed monitor = Monitor(args.monitor_path) monitor_time = MonitorTimeElapsed("Training time", monitor, interval=100) # For tensorboard (NEW) tb_writer = SummaryWriter(args.monitor_path) # Initialize DataIterator for MNIST. from numpy.random import RandomState data = data_iterator_mnist(args.batch_size, True, rng=RandomState(1223)) vdata = data_iterator_mnist(args.batch_size, False) # Training loop. for i in range(args.max_iter): if i % args.val_interval == 0: # Validation (NEW) validation(args, ctx, vdata, vimage, vlabel, vpred, i, tb_writer) if i % args.model_save_interval == 0: nn.save_parameters(os.path.join( args.model_save_path, 'params_%06d.h5' % i)) # Training forward image.d, label.d = data.next() solver.zero_grad() loss.forward(clear_no_need_grad=True) loss.backward(clear_buffer=True) solver.weight_decay(args.weight_decay) solver.update() loss.data.cast(np.float32, ctx) pred.data.cast(np.float32, ctx) e = categorical_error(pred.d, label.d) # Instead of using nnabla.monitor, use nnabla_tensorboard. (NEW) if i % args.val_interval == 0: tb_writer.add_image('image/train_data_{}'.format(i), image.d[0]) tb_writer.add_scalar('train/loss', loss.d.copy(), global_step=i) tb_writer.add_scalar('train/error', e, global_step=i) monitor_time.add(i) validation(args, ctx, vdata, vimage, vlabel, vpred, i, tb_writer) parameter_file = os.path.join( args.model_save_path, '{}_params_{:06}.h5'.format(args.net, args.max_iter)) nn.save_parameters(parameter_file) # append F.Softmax to the prediction graph so users see intuitive outputs runtime_contents = { 'networks': [ {'name': 'Validation', 'batch_size': args.batch_size, 'outputs': {'y': F.softmax(vpred)}, 'names': {'x': vimage}}], 'executors': [ {'name': 'Runtime', 'network': 'Validation', 'data': ['x'], 'output': ['y']}]} save.save(os.path.join(args.model_save_path, '{}_result.nnp'.format(args.net)), runtime_contents) tb_writer.close()def validation(args, ctx, vdata, vimage, vlabel, vpred, i, tb_writer): ve = 0.0 for j in range(args.val_iter): vimage.d, vlabel.d = vdata.next() vpred.forward(clear_buffer=True) vpred.data.cast(np.float32, ctx) ve += categorical_error(vpred.d, vlabel.d) tb_writer.add_scalar('test/error', ve / args.val_iter, i)NNabla + tensorboard : MNIST の実行結果
学習カーブ
入力イメージもplotしてみた。
自作スクリプトで描画したりする必要がなく、やっぱり tensorboard は便利ですね。
追加したい機能
- Network graph を tensorboard に表示する機能。
- NNabla をうまく使えば、中間層のデータの可視化も tensorboard でできちゃうかもしれません。(まだ色々調べ中・・・)

- 投稿日:2019-11-26T22:37:10+09:00
tf.data.Dataset apiでテキスト (自然言語処理) の前処理をする方法をまとめる
TensorFlow2.0 Advent Calendar 2019の11日目です。
tf.data.Dataset APIを用いてテキストの前処理を行う方法をまとめたいと思います。
本記事では以下の順に説明します。
- tf.data.Dataset APIとは何か、また、その有効性は何かを説明
- 実際にテキストの前処理の手続きを説明
- performance向上のtipsのまとめ
説明が長いので(コードも長いですが。。。)コードだけ見て俯瞰したい場合はこちらから参照できます。
(注意として、本記事の内容は十分な検証ができているとは言えないです。コードは動きますが、パフォーマンスの向上に寄与しているのかいまいち把握しきれていないところがいくつかあります。随時更新していきますが、参考程度に留めておいていただけたらと思います。)
同アドベントカレンダーでは以下の記事が関連します。こちらも参考にされるといいかなと思います。
- 3日目: tf.data.Dataset APIの基本的な紹介がされています(TensorFlowで使えるデータセット機能が強かった話)
7日目: tf.data.Dataset APIで、Mecabを使った分かち書きの手順が紹介されています(Mecabとtf.dataを使ってlivedoorニュースコーパスを分かち書きする)
10日目: joblibで並列化してmapの高速化を図っています。本記事ではtf.dataの.map自体がもっている並列化機能を紹介しますが、どちらが速いのか追って検証したいです。(というか、組み合わせれそうです)(【TF2.0応用編】TFの例の強いデータセット機能で汎用的なDataAugmentationを並列化しハイスピードで実現した件)
1. tf.data.Dataset API
典型的な学習プロセスは、以下のような流れになると思います。
- データの読み込み: ローカルストレージ、インメモリ、クラウドストレージから読込
- 前処理: CPUで処理
- 学習用のデバイスにデータを渡す: GPU, TPUに渡す
- 学習: GPU, TPUで処理
データセットが大きくなってくると1~4の処理を一つずつやっていくと、リソースが足りなくなってきます。
(特に画像だと数GBであることがざらにあるので1. データの読み込みだけでも一度には処理できなくなります)
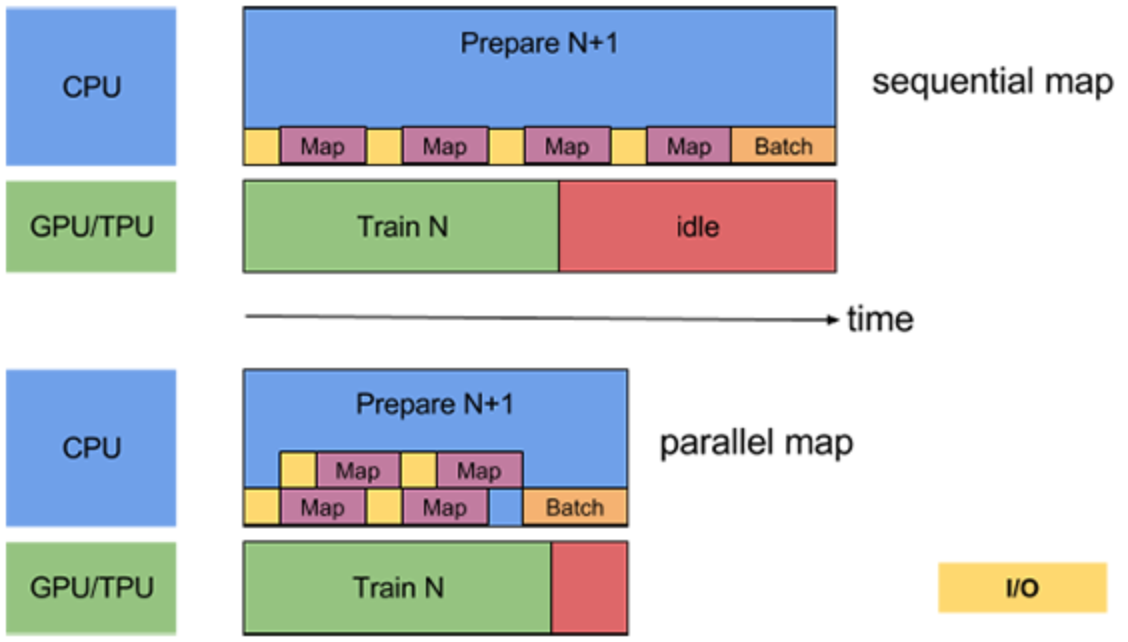
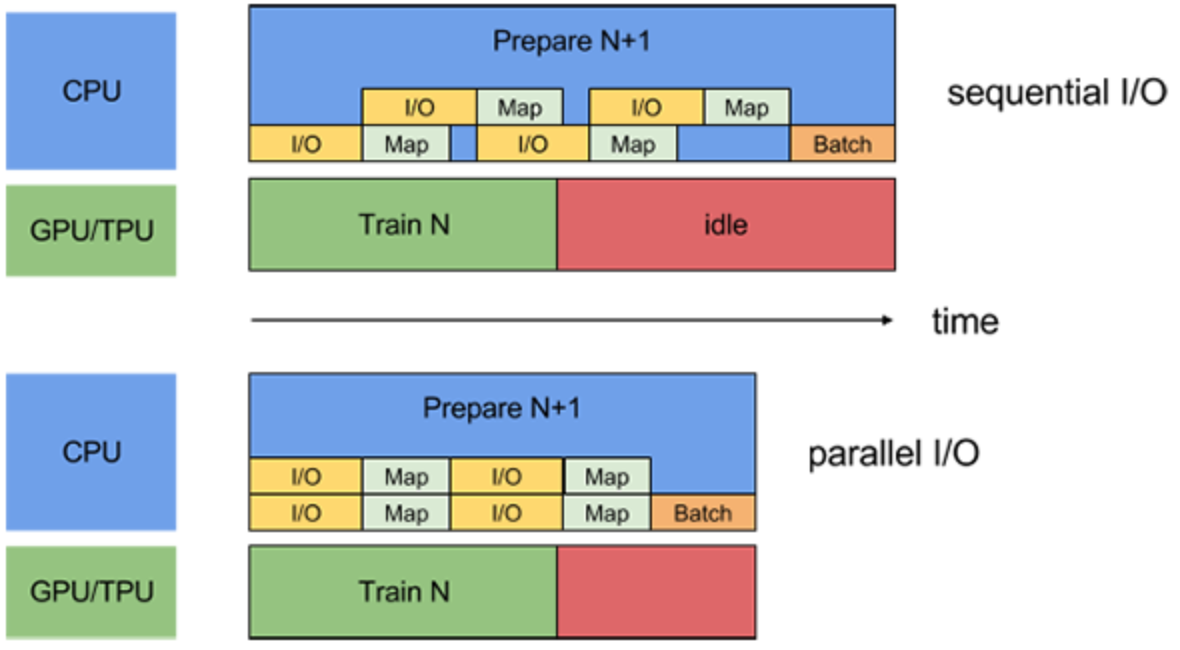
なので、バッチに分けて(例えば、数枚の画像毎に)1 ~ 4までの処理を一気通貫で行う。ということを繰り返すことが推奨されます。これはパイプライン処理と言います。愚直なパイプラインをしくと、この一連のプロセスは、以下のようにオーバーヘッド部分に無駄な待ち時間が発生し得えます。
https://www.tensorflow.org/guide/data_performancetf.data.Dataset APIでは以下のようにオーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
- prefetch: CPUとGPU/TPUでそれぞれ並列に処理
- map: 前処理の並列処理
- read_file: 読み込みの並列処理
これらについては後述します。まず、先にtf.data.Dataset APIの使い方を知るためにもテキストの前処理について書きます。
2. テキストの前処理の流れ
では、tf.data.Dataest APIを使ってテキストの前処理をやってみます。
順番は前後すると思いますが、標準的なテキストの前処理の流れは以下のようなものだと思います。
1. load: テキストの読み込み・シャッフル
2. standarize: ストップワード削除、置換、小文字に統一、など
3. tokenize: 分かち書き(日本語の場合)
4. encode: idに置き換え
5. split: trainとtest用にデータ分割
6. padding: ゼロ埋め
7. batch: バッチデータとして取得2.1. load
まずはじめに、dataset loaderをつくります。処理の流れは以下の様になります。
1. local discにデータをダウンロード
2. local discのデータを指定
3. ラベルづけ
4. データのシャッフルlocal discにデータをダウンロード
昨今扱うデータセットのサイズがでかくなっているので、最初からlocal discにデータがあるケースはそこまで多くないと思います。なので、以下のようなケースが考えられます。
- 外部ストレージからダウンロード
- クラウドストレージからダウンロード
- Databaseから取得
ここでは、単に(認証の必要のない)外部ストレージからデータを取得する例を紹介します。
以下で、cowper.txt, derby.txt, butler.txtというテキストファイルをlocal discにダウンロードできます。 (ダウンロードが簡単なため、こちらの英語のテキストデータを使いますが、実際には日本語に対する前処理を想定しています)
なお、ダウンロードしたlocal discのpathのリストを返す関数になっています。適宜ダウンロードの仕方を置き換えた上で、アウトプットを揃えれば、以下同様な手続きが流用できると思います。def download_file(directory_url: List[str], file_names: List[str]) -> List[str]: file_paths = [ tf.keras.utils.get_file(file_name, directory_url + file_name) for file_name in file_names ] return file_paths # download dataset in local disk directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/' file_names = ['cowper.txt', 'derby.txt', 'butler.txt'] file_paths = download_file(directory_url, file_names)local discのデータを指定 & ラベルづけ & データのシャッフル
残りの処理は以下の様にまとめられます。これでtextとlabelをiterationしてくれるDatasetができます。
def load_dataset(file_paths: List[str], file_names: List[str], BUFFER_SIZE=1000): # loadする複数ファイルを指定 files = tf.data.Dataset.list_files(file_paths) # 各ファイル毎にmap関数を適用 (labeling_map_fnは後述(dataの読み込み & ラベルづけ)) datasets = files.interleave( labeling_map_fn(file_names), ) # dataのshuffle all_labeled_data = datasets.shuffle( BUFFER_SIZE, reshuffle_each_iteration=False ) return all_labeled_data datasets = load_dataset(file_paths, file_names) text, label = next(iter(datasets)) print(text) # <tf.Tensor: id=99928, shape=(), dtype=string, numpy=b'Comes furious on, but speeds not, kept aloof'> print(label) # <tf.Tensor: id=99929, shape=(), dtype=int64, numpy=0>細かく処理をみていきます。
tf.data.Dataset.list_files(): loadする複数ファイルを指定
tf.data.Dataset.list_filesでつくったfilesは、以下のようにlocal discのpathを値としてもつDatasetインスタンスになっています。面倒ですが、Datasetインスタンスはイテレーションして中身を確認する必要があります。さらに面倒ですが、
.numpy()メソッドを使うと値が取得できます。print(files) # <DatasetV1Adapter shapes: (), types: tf.string> next(iter(files)) # <tf.Tensor: id=99804, shape=(), dtype=string, numpy=b'/Users/username/.keras/datasets/cowper.txt'> next(iter(files)).numpy() # b'/Users/username/.keras/datasets/cowper.txt'.interleave(): 各ファイル毎にmap関数を適用してflatなDatasetを返す
datasetにmap functionを適用した後に、結果をflatにして結合します。今回の使い方でいうと、まずテキストファイルを読みこみ、1行ずつiterationするようなDatasetを返すmap funcitonを定義します。そしてそれを、
.interleave()にわたすと、ファイルごとに別々のDatasetが作られるのではなく、全ファイルの中から一行ずつiterationされるflatなDatasetがつくられます。参考: 公式ドキュメント
.shuffle(): dataのshuffle
名前からもわかるようにDatasetをシャッフルしてくれます。iteration時にbuffer_sizeの中からrandomにデータを抽出します。繰り返しiterationを行い、buffer_sizeをこえると、次のbuffer_size分のデータの中から抽出します。なので、大きいbuffer_sizeにしたほうが乱雑さは保証されます。しかし、buffer_sizeが大きいとその分リソースを食うのでトレードオフになります。
また、
reshuffle_each_iteration=Falseとすると、iterationを何度開始しても同じ順番でシャッフルしてくれます。defaultではTrueなので単に.shuffle()を呼んだ後は、next(iter(dataset))や、for data in dataset:と書く度に異なる順番でiterationされてしまいます。良いか悪いかはさておき、要注意です。labeling_map_fn: dataの読み込み & ラベルづけ
ファイル名がラベルになっていて、各行が1つのテキストデータである.txt ファイルを読み込む方法を紹介します。
標準的な処理だと思いますが、データの形式によって、適宜置き換えて頂ければと思います。ここでは、以下のmap functionを
.interleave()にわたすことでflatなテキストとラベルをもつDatasetを得ます。
1. ファイルごとにtf.data.TextLineDataset()でファイルを読み込みこんでDataset instanceを生成。
2..map(labeler)でファイル名と一体一のラベルidをわりふります。def labeling_map_fn(file_names): def _get_label(datasets): """ datasetの値(file path)からfile名をパースし、 file_namesのインデックス番号をlabel IDとする """ filename = datasets.numpy().decode().rsplit('/', 1)[-1] label = file_names.index(filename) return label def _labeler(example, label): """datasetにlabelを追加する""" return tf.cast(example, tf.string), tf.cast(label, tf.int64) def _labeling_map_fn(file_path: str): """main map function""" # テキストファイルから1行ずつ読み込み datasets = tf.data.TextLineDataset(file_path) # file pathをlabel IDに変換 label = tf.py_function(_get_label, inp=[file_path], Tout=tf.int64) # label IDをDatasetに追加 labeled_dataset = datasets.map(lambda ex: _labeler(ex, label)) return labeled_dataset return _labeling_map_fn途中、
tf.py_functionという関数を使っています(doc)。 これは、Dataset APIのmap functionの引数はTensor objectが渡されるためです。Tensor objectはpythonでは直接値を参照できませんが、tf.py_functionでwrapしてあげると引数にnext(iter(dataset))としたときと同じ型の値が渡ります。なので、.numpy()で値を参照でき、馴染みのあるpythonの処理を書くことができます。
ただし、パフォーマンスに若干難があるようなので極力使わないようにしたいです。2.2. standarize & 2.3. tokenize
ここではいろいろな処理を一気に行います。pythonのライブラリや、ベタ書きしたものを使う想定です。
tensorflowにもテキストに対する処理はたくさんありますが、結構大変なのでpythonで書いたものをそのまま使うことを想定します。少なくとも分かち書きはtensorflowではできないので、日本語だと必須の行程になると思います。例 (janome使用)
janomeはpythonで実装されている形態素解析でpip installだけで使えるので便利です。以下の様にanalyzerという標準化のパイプラインを柔軟に構築できます。
from janome.tokenizer import Tokenizer from janome.analyzer import Analyzer from janome.charfilter import ( RegexReplaceCharFilter # 文字列置換 ) from janome.tokenfilter import ( CompoundNounFilter, # 複合名詞化 POSStopFilter, # 特定の品詞を除去 LowerCaseFilter # lowercaseに変換 ) def janome_tokenizer(): # standarize texts char_filters = [RegexReplaceCharFilter(u'蛇の目', u'janome')] tokenizer = Tokenizer() token_filters = [CompoundNounFilter(), POSStopFilter(['記号','助詞']), LowerCaseFilter()] analyze = Analyzer(char_filters, tokenizer, token_filters).analyze def _tokenizer(text, label): tokenized_text = " ".join([wakati.surface for wakati in analyze(text.numpy().decode())]) return tokenized_text, label return _tokenizerこれだけで、以下の様に標準化・分かち書きされます。
text, _ = janome_tokenizer()('蛇の目は形態素解析器です。Easy to Use.', 0) print(text) # 'janome 形態素解析器 です easy to use.'tf.py_functionでラップ
上記関数をDatset apiから呼びます。
そのためには、ここでもtf.py_functionを使って変換します。outputの型を指定する必要があります。そして、その関数を.map()でdatasetにわたすことで呼び出せます。def tokenize_map_fn(tokenizer): """ convert python function for tf.data map """ def _tokenize_map_fn(text: str, label: int): return tf.py_function(tokenizer, inp=[text, label], Tout=(tf.string, tf.int64)) return _tokenize_map_fn datasets = datasets.map(tokenize_map_fn(janome_tokenizer()))2.4. encode
encode (stringをIDに変換)するためにtensorflow_datasets.text APIを使います。
とくに、encodeには、tfds.features.text.Tokenizer()とtfds.features.text.TokenTextEncoderが便利です。vocabulary作成
まずは、vocabularyを作成する必要があります。先に作っておく場合は以下は省略できます。
ここでは、学習データからvocabularyを作成します。tfds.features.text.Tokenizer()を使ってtokenを取得し、set()で重複を削除します。import tensorflow_datasets as tfds def get_vocabulary(datasets) -> Set[str]: tokenizer = tfds.features.text.Tokenizer().tokenize def _tokenize_map_fn(text, label): def _tokenize(text, label): return tokenizer(text.numpy()), label return tf.py_function(_tokenize, inp=[text, label], Tout=(tf.string, tf.int64)) dataset = datasets.map(_tokenize_map_fn) vocab = {g.decode() for f, _ in dataset for g in f.numpy()} return vocab vocab_set = get_vocabulary(datasets) print(vocab_set) # {'indomitable', 'suspicion', 'wer', ... }encode
ここでは、
tfds.features.text.TokenTextEncoder()を使って、vocabularyに含まれるtokenをIDに変換します。以下のencode_map_fn()をdatasets.map()にわたして使います。def encoder(vocabulary_set: Set[str]): """ encode text to numbers. must set vocabulary_set """ encoder = tfds.features.text.TokenTextEncoder(vocabulary_set).encode def _encode(text: str, label: int): encoded_text = encoder(text.numpy()) return encoded_text, label return _encode def encode_map_fn(encoder): """ convert python function for tf.data map """ def _encode_map_fn(text: str, label: int): return tf.py_function(encoder, inp=[text, label], Tout=(tf.int64, tf.int64)) return _encode_map_fn datasets = datasets.map(encode_map_fn(encoder(vocab_set))) print(next(iter(datasets))[0].numpy()) # [111, 1211, 4, 10101]2.5. split
datasetをtrainとtestに分割します。最初からわかれている場合は以下は省略できます。
Dataset APIではdatasetの分割は以下の様にすごく簡単に実装できます。def split_train_test(data, TEST_SIZE: int, BUFFER_SIZE: int, SEED=123): """ TEST_SIZE = test dataの数 note: because of reshuffle_each_iteration = True (default), train_data is reshuffled if you reuse train_data. """ train_data = data.skip(TEST_SIZE).shuffle(BUFFER_SIZE, seed=SEED) test_data = data.take(TEST_SIZE) return train_data, test_data2.6. padding & 2.7. batch
tf.data.Dataset apiではpaddingとbatch化は同時に行えます。
そのままですが、epochsはエポック数、BATCH_SIZEはバッチサイズです。
注意すべきことは以下です。
drop_remainder=Trueにするとデータをbatch化したときに、きりよくバッチサイズに達しなかったiterationの最後のデータを使用しなくなります。- padded_shapesでpaddingするサイズ (=最大長)を指定できます。この引数を指定しなければ、バッチごとの最大長にpaddingされます。
train_data = train_data.padded_batch(BATCH_SIZE, padded_shapes=([max_len], []), drop_remainder=True) test_data = test_data.padded_batch(BATCH_SIZE, padded_shapes=([max_len], []), drop_remainder=False)ここで、max_lenは以下の様にdatasetから求めてもいいですし、決め打ちで入力してもいいと思います。
文書最大長の取得
ほとんどのモデルではtokenの最大長が必要になります。ここでデータセットから取得します。決めで入力する場合は以下の処理は飛ばせます。
def get_max_len(datasets) -> int: tokenizer = tfds.features.text.Tokenizer().tokenize def _get_len_map_fn(text: str, label: int): def _get_len(text: str): return len(tokenizer(text.numpy())) return tf.py_function(_get_len, inp=[text, ], Tout=tf.int32) dataset = datasets.map(_get_len_map_fn) max_len = max({f.numpy() for f in dataset}) return max_lenテキストの前処理の流れのまとめ
以下のような流れでtf.data.Dataset APIを使った実装を見ていきました。
1. load: テキストの読み込み・シャッフル
2. standarize: ストップワード削除、置換、小文字に統一、など
3. tokenize: 分かち書き(日本語の場合)
4. encode: idに置き換え
5. split: trainとtest用にデータ分割
6. padding: ゼロ埋め
7. batch: バッチデータとして取得学習時には、以下の様に、
.fit()メソッドにわたすだけです。model.fit(train_data, epochs=epochs, validation_data=test_data )3. performance向上のtips
冒頭で説明したように、前処理の一連のプロセスは、以下のようにオーバーヘッド部分に無駄な待ち時間が発生し得えます。
https://www.tensorflow.org/guide/data_performancetf.data.Dataset APIでは以下のようにオーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
- prefetch: CPUとGPU/TPUでそれぞれ並列に処理
- map: 前処理の並列処理
- read_file: 読み込みの並列処理
参考: Optimizing input pipelines with tf.data
prefetch
CPUとGPU/TPUでそれぞれ並列に処理を実行させます。
tf.experiments.AUTOTUNEで自動的に調節されます。
https://www.tensorflow.org/guide/data_performance面倒なことは必要ありません。以下の処理を最後に加えるだけです。(本記事ではtrain_dataとtest_dataに対して行う)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)map
map関数も分散処理をさせられます。
こちらもtf.experiments.AUTOTUNEで自動的に調節してくれます。
また、あまり遅くなるようであれば先に.batch()メソッドを使ってから渡すという手もあります。
https://www.tensorflow.org/guide/data_performance以下の様に、
.map()メソッドに引数を加えるだけです。dataset = dataset.map(map_func, num_parallel_calls=tf.data.experimental.AUTOTUNE)read file
複数ファイルを読み込むときも、処理を分散させて同時にreadできます。
特にremote storageからdataを読み込むときはI/Oがボトルネックになる可能性が高いです。
(本記事ではlocal discから読み込んでいるのであまり効果はないかもしれません。)
https://www.tensorflow.org/guide/data_performance以下の様に、
.interleave()メソッドに引数を加える必要があります。dataset = files.interleave( tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_reads, num_parallel_calls=tf.data.experimental.AUTOTUNE)cache
文脈はかわりますが、performance向上のためには、
.cache()が有効です。
以下の様に書くと、in memoryにcacheされます。dataset = dataset.cache()以下の様に引数にstringをわたすとin memoryではなく、ファイルに保存されます。
dataset = dataset.cache('tfdata')まとめ
長くなりましたが、tf.data.Dataset APIを用いたテキストの前処理を行う方法を紹介しました。まとまったコードはこちらから参照できます。
特に、tf.data.Dataset APIの紹介、テキストの前処理の手続き、performance向上のtipsをまとめました。
説明が長くなってしまいましたが、最後まで読んでくださってありがとうございました!
何かの参考になれば嬉しいです!refs


- 投稿日:2019-11-26T17:37:15+09:00
Pythonおよび機械学習勉強用のRaspberryPiの構築 (RaspberryPi4 & Buster版)
【内容】
ついにRaspberry Pi 4 model Bが日本で発売を開始しました。
早速使って見るべく、以前投稿した【Pythonおよび機械学習勉強用のRaspberryPiの構築】をラズパイ4版に書き直してみました。
ハードウェア以外にもRaspbianのバージョンを最新(Buster 20190926)にしてあります。なお、2019年11月26日現在、以下の問題があります。
- Edge TPUが正式には対応していない (← 非公式手順で対応)
- pip3でインストールできるTensorflowの最新版が1.14.0 (2019/12/02時点)
- pip3でインストールできるOpenCVの最新版4.1.1.26が動かない (← 4.1.0.25 なら動く)
- pip3でインストールできるOpenCVでUSBカメラが利用できない。 (← apt installで対応 3.2.0)
MicroHDMIケーブルを持ってないので画面がない^^;(← Headlessセットアップしてます)【本手順で作ったラズパイでできるようになること】
- Pythonの基礎学習
- データの可視化 (pandas, matplotlib)
- Computer Vision (OpenCV)
- 機械学習 (Scikit-Learn)
- DeepLearning (Tensorflow, Keras)
- Coral Edge TPUを使った推論
- 上記を使ったアプリの実装 (Flask)
【システム構成】
- Raspberry Pi 4 Model B
- Raspbian Buster 20190926
- Coral Edge TPU (オプション)
【0. OSイメージの準備】
Raspbian Buster 20190926を使うことを想定しています。
2019年11月26日時点では公式サイトからはDLできますが、念の為ミラーサイトを記しておきます。
【Raspbian Buster 20190926 ミラーサイト (ftp.jaist.ac.jp) 】【1. OSイメージの書き込み & 起動】
1-1. OSイメージの書き込み
上記で準備したOSイメージをSDカードに書き込みます。
SDカードへの書き込み手順は、以下の記事を参考にしてください。1-2. ssh起動用ファイルの作成
現行バージョンのRaspbianではデフォルトではsshサービスが無効化されています。
これを自動起動できるようにSDカードの「Boot」パティションにssh(拡張子なし)という空のファイルを作ってください。
windowsをご利用の方は、標準では拡張子が非表示になっているので、拡張子が付いていないか確認してください。なお、
sshファイルはRaspberry Pi起動時に読み込まれて削除されます。1-3. Wifi接続用の設定ファイルの作成
ssh同様、「Boot」パティションにWifi設定用のファイルを置いておくと、自動的に読み込まれて適切な場所に書き込まれます。
具体的には「Boot」パティションに
wpa_supplicant.confという名前のファイルを作り、設定を記述します。
Wifiに接続するためには下記の内容を記載してください。
設定内容は接続するアクセスポイントに応じて変更する必要があります。wpa_supplicant.confctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 country=JP network={ ssid="<SSID名>" psk="<パスワード>" }1-4. Raspberry Piの起動
上記の準備ができたらPCからSDカードを取り出し、ラズパイ本体に挿入して電源を投入します。
【2. システムアップデート & ネットワーク設定】
2-1. システムアップデート
ラズパイが起動したらsshで接続するかコンソールのターミナルで以下のコマンドを実行して、システムアップデートを行います。
(数分かかります)システムアップデートsudo apt update sudo apt upgrade -y sudo reboot2-2. ipv6 無効化
必須ではありませんが、場合によっては邪魔する場合があるので無効化しておきます。
ipv6運用の場合は本設定は必要ありません。ipv6無効化設定sudo vi /etc/sysctl.conf【設定内容】
/etc/sysctl.confnet.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1【設定の反映】
設定反映sudo sysctl -p または sudo reboot2-3. IPアドレスの固定
必要に応じてIPアドレスを固定します。
DHCP環境で利用する場合は本設定は必要ありません。
本手順では無線LANでの運用を想定しているため、無線LANアダプタもしくはSSIDに対してIPの固定設定をしています。
具体的には/etc/dhcpcd.confに以下の内容を追加します。
<IPアドレス>、<ルータアドレス>、<DNSアドレス>、<your_ssid>は環境に応じて変更してください。/etc/dhcpcd.confinterface wlan0 inform <IPアドレス> static routers=<ルータアドレス> static domain_name_servers=<DNSアドレス> noipv6 または SSID <your_ssid> inform <IPアドレス> static routers=<ルータアドレス> static domain_name_servers=<DNSアドレス> noipv6複数の無線AP環境で利用する場合はSSIDで固定するのが便利です。
2-4. 無線LANのPowerManagementをOFFにする
有線LAN環境で利用する場合は本設定は必要ありません。
デフォルトでは無線LANのPowerManagement機能がONになっていますが、この機能のせいでWifi通信が不安定になる場合があります。
起動時に実行されるrc.localにPowerManagementをOFFにするコマンドを追加します。rc.localの編集sudo vi /etc/rc.localrc.local# exit文の前に以下を追加して保存 sudo iwconfig wlan0 power off再起動sudo reboot【3. 必要モジュールのインストール】
以下の操作で必要になるモジュールをインストールします。
(主にOpenCVおよびNumpyで利用)必要モジュールインストールsudo apt install -y libhdf5-dev libqtwebkit4 libqt4-test libatlas-base-dev libjasper-dev【4. Python3 関連のインストール】
4-1. 基本モジュールのインストール
Python3&pip3インストールsudo apt install python3 python3-dev -y4-1-1. pip3の最新化 (オプション)
本手順は特に実行する必要はありません
過去の手順を踏襲してpip3コマンドを最新化すると、pip3実行時にエラーを吐いて機能しなくなります。
pip3のアップグレード【失敗】# 下記コマンドを実行するとpip3が実行できなくなります sudo pip3 install pip -U pip3 -V # 上記コマンドでpip3が動かせなくなったら、下記コマンドでリカバリ sudo python3 -m pip uninstall pip sudo apt install python3-pip --reinstall一応、下記の手順でpip3コマンドを最新化することは可能ですが、本手順では特に必要ありませんでした。
pip3のアップグレード# 既存のpip3コマンドをアンインストール sudo apt remove python3-pip # 最新のpip3コマンドをインストール wget https://bootstrap.pypa.io/get-pip.py sudo python3 get-pip.py # 一旦ログアウトして再ログイン後にバージョン確認 pip3 -V # setuptoolsの最新化 sudo pip3 install setuptools -U4-2. Python3の各種モジュールインストール
pipコマンドで各種のモジュールをインストールします。
numpyおよびpandasのバージョンを指定していますが、環境構築時点で最新のバイナリーパッケージが存在せずビルドが始まってインストールに時間がかかってしまうため、一つ前のバージョンを指定しています。
TensorFlowに関しては、環境構築時点で動作確認が取れている最新のものを指定しています。
それぞれ必要に応じて変更してください。Python3用各種モジュールインストール# numpy sudo pip3 install numpy # sklearn sudo pip3 install scipy sudo pip3 install sklearn # matplotlib sudo pip3 install matplotlib # pandas sudo pip3 install pandas # seaborn sudo pip3 install seaborn # Tensorflow (2019/12/02時点で最新は1.14.0) sudo pip3 install tensorflow # pip3を最新化した場合は `--ignore-installed` オプションを付けて対応 #sudo pip3 install tensorflow --ignore-installed # keras sudo pip3 install keras # flask sudo pip3 install flask flask_cors -U # OpenCV (2019/11/26時点で最新のRPi4では4.1.1.26は動かない) # また、pipでインストールしたものはUSBカメラが使えないので apt インストールで暫定対応 # sudo pip3 install opencv-python==4.1.0.25 sudo apt install python3-opencvなお、最近パッケージを管理している「https://www.piwheels.org/」の調子が悪いのか、pipがパッケージをダウンロードしている最中にセッションを切断され、結果インストールに失敗する場合が多々あります。
再実行すれば解決することが多いですが、scipyやtensorflowなどダウンロードサイズが大きいものはなかなか成功しません。
その際にはpip install実行時に表示されるダウンロード中のパッケージのURLをコピーして、wgetコマンドでそのファイルをローカルフォルダにダウンロードしてください。
wgetコマンドはダウンロードに失敗してもリジューム機能があるので、自動的にリトライしてなんとか目的のファイルをダウンロードしてくれます。
そのうえでpip3 install <ダウンロードしたファイル>を実行するとインストールできます。ミラーサイトがあればpipの参照先をそちらに向ければよいのですが、本記事を書いている時点ではわかりませんでしたので、ご存じの方がいらっしゃいましたら教えていただけると助かります。
【5. Edge TPU のインストール】
以下の記事を参考にしてください。
なお本項目は必須ではありません。
【RaspberryPi 4でCoral USB TPU Accelerator(EdgeTPU)をとりあえず使う (非公式手順)】【6. Jupyter Lab】
強力なNotebook環境が利用できるようになるJupyter Labをインストールします。
6-1. 基本インストール
【インストール】
下記のコマンドでインストールします。JupyterLabインストールsudo pip3 install jupyterlab【設定】
インストールが完了したら下記のコマンドで設定ファイルを作成した上で、作成された設定ファイルを編集します。
下記手順ではどの端末からも接続でき、接続時にパスワードを要求するように設定しています。設定ファイルの作成jupyter notebook --generate-config【設定ファイルの編集】
設定ファイルの編集vi ~/.jupyter/jupyter_notebook_config.py【設定内容】
jupyter_notebook_config.pyc.NotebookApp.ip = '*' c.NotebookApp.open_browser = False c.NotebookApp.password = 'sha1:<ハッシュ化されたパスワード>'なお、パスワードのハッシュ化は以下のコマンドで取得できます。
パスワードのハッシュ化python3 -c 'from notebook.auth import passwd;print(passwd())' (上記実行後、ハッシュ化したい文字を入力)6-2. Node jsのインストール
JupyterLabの拡張機能を利用するために、Node jsをインストールします。
NodeJsインストールsudo apt -y install nodejs npm6-3. Jputer Labの起動
Jupyter Labの起動は以下のコマンドで実行します。
JupyterLab起動jupyter lab6-4. ブラウザから接続
上記でJupyter Labを起動した状態で、ブラウザから以下のURLに接続してください。
上記手順では、他のPCからも接続できる設定になっていますので、ぜひご自分のPCからJupyterLabに接続して操作してみてください。http://<ip_address>:8888/labパスワードを要求されるので、上記で設定したパスワードを入力してください。
【最後に】
一部課題もありますが、ほぼ過去の手順を踏襲して環境を構築ができました。
まだ細かい動作確認は行っていなので、何かありましたらコメントください。【既知の不具合】
cv2.videoCapture でUSBカメラを使うとcv2.read()でエラーになる (暫定対応済み)
Buster20190926で現象発生?
Buster20190710では動いていたとの報告がありましたので試しましたがNGでした。
また、最新のOpenCVをビルドしてみましたが、解決しませんでした。なお下記コマンドでエラーは出なくなりますが、完全な映像が取得できませんでした。
# エラーは出なくなるがまだ不完全 sudo rmmod uvcvideo sudo modprobe uvcvideo nodrop=1 timeout=5000 quirks=0x80最終手段として、aptでインストールしたものはUSBカメラでも動作可能でした。
ただし、バージョンは 3.2.0 とかなり古いものになります。# pipでインストールしたものをアンインストール sudo pip3 uninstall opencv-python # aptでインストール (3.2.0) sudo apt install python3-opencvちょっとこれ以上時間をかけれないので、一旦ここでFIXします。
- 投稿日:2019-11-26T07:36:49+09:00
BERTの単語ベクトルを覗いてみる
Googleが2018年10月に発表し、大いに話題となった自然言語処理モデルBERT。このBERTのモデルから単語ベクトルが抽出できるようなので、色々と調べてみようと思います。
BERTの単語ベクトルの特徴
単語ベクトルといえばWord2Vecですが、Word2Vecの単語ベクトルは、異なる意味の単語でも字面が同じならば全て同じ値になってしまうという欠点があります。
例えば下のような文があった場合、この文の最初の「HP(ヒューレット・パッカード)」と2つ目の「HP(ホームページ)」は別の意味を持つ単語ですが、ベクトルとしては同じになります。HP社は、2019年11月18日に新製品をHPで発表した。
ところが、BERTの場合は、2つの「HP」のベクトルは異なる値になります。それだけではなく、下の例のような同じ意味の3つの「HP」も、すべて異なるベクトルになります。
HP社は、HP社と、HP社の競合会社であるXX社とが、業務提携すると発表した。
すなわち、BERTの場合には、全ての単語が出現ごとに文脈に依存して異なるベクトル表現を持ち、同じベクトルの値を持つ単語は一つもありません。
調べたいこと
BERTの単語ベクトルは全て異なる値を持ちますが、さすがに字面が同じで意味も同じ単語の場合は、似た(距離の近い)ベクトルになっているんじゃないかと思います。さらには、「HP」と「ヒューレット・パッカード」のように、字面は違っても意味の同じ単語どうしも、似たベクトルになっている気がします。
「思う」「気がする」のは勝手な期待なので、今回は「本当にそうなのか?」を調べてみたいと思います。本題
環境
- MacOS 10.15.1
- Python 3.6.5
- Tensorflow 1.14.0
- その他必要なものをpipでインストール
単語ベクトルの抽出
BERTの学習済モデルの準備
Googleが公開しているTensorflow版BERTのコードを使えば、BERTの学習、単語ベクトルの抽出ができますが、BERTの学習には非常に時間がかかってしまうため、今回はyoheikikutaさんが公開しているBERTの学習済モデルを使って実験を行います。このモデルは、日本語版Wikipediaを学習データとしており、トークナイズにはSentencePieceを使っています。
BERTの学習済モデルを適当なディレクトリ(以降、このディレクトリを<BERT_DIR>と記述します)に保存し、その中に下記の学習済モデル用のBERTの設定ファイルも保存します。bert_config.json{ "attention_probs_dropout_prob": 0.1, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "max_position_embeddings": 512, "num_attention_heads": 12, "num_hidden_layers": 12, "type_vocab_size": 2, "vocab_size": 32000 }データの準備
Wikipediaから、「GAFA」、「Google」、「Amazon.com」、「Facebook」、「アップル (企業)」、「アマゾン熱帯雨林」の先頭パラグラフを取得して、1行1センテンスとなるファイルsentence_gafa.txtを作成し、適当なディレクトリ(以降、このディレクトリを<INPUT_DIR>と記述します)に保存します(下記のテキスト先頭の[1]、[2]、…は、今回の記事用に追記した行番号で、実際のデータには含まれていません)。
sentence_gafa.txt[1]GAFA(ガーファ)またはGAFAMなどと往時には呼ばれ、最近はむしろビッグテックまたはビッグテク(Big Tech)と呼ばれているのは、米国の多国籍企業でコンピューターやソフトウェアを駆使してサイバースペースを2010年代に支配するに至った企業のことで、具体的にはグーグル・アマゾン・フェイスブック・アップル(およびマイクロソフト)の4/5つの主要IT企業である。 [2]最近、ヨーロッパから始まって、米国でも、独占禁止法を適用する声が上がり始めている。 [3]Google LLC(グーグル)は、インターネット関連のサービスと製品に特化した世界規模のアメリカの多国籍テクノロジー企業である。 [4]検索エンジン、オンライン広告、クラウドコンピューティング、ソフトウェア、ハードウェア関連の事業がある。 [5]アメリカ合衆国の主要なIT企業で、GAFA、FAANGの一つ。 [6]Amazon.com, Inc.(アマゾン・ドット・コム)は、アメリカ合衆国・ワシントン州シアトルに本拠を構えるECサイト、Webサービス会社である。 [7]アレクサ・インターネット、A9.com、Internet Movie Database(IMDb)などを保有している。 [8]アメリカ合衆国の主要なIT企業で、GAFA、またFAANGのひとつである。 [9]2019年現在、Amazon.comがアメリカ国外でサイトを運営している国はイギリス、フランス、ドイツ、カナダ、日本、中国、イタリア、スペイン、ブラジル、インド、メキシコ、オーストラリア、オランダ、トルコ、アラブ首長国連邦の15か国である。 [10]Facebook(フェイスブック、FB)は、アメリカ合衆国カリフォルニア州メンローパークに本社を置くFacebook, Inc.が運営する世界最大のソーシャル・ネットワーキング・サービス(SNS)である。 [11]Facebook, Inc.はアメリカ合衆国の主要なIT企業であり、GAFA、FAANGの一つで、FacebookのほかInstagramやMessenger、WhatsAppを提供している。 [12]Facebookという名前は、アメリカ合衆国の一部の大学が学生間の交流を促すために入学した年に提供している本の通称である「Face book(英語版)」に由来している。 [13]アップル(英: Apple Inc.)は、アメリカ合衆国カリフォルニア州に本社を置く、インターネット関連製品、デジタル家庭電化製品および同製品に関連するソフトウェア製品を開発、販売する多国籍企業である。 [14]2007年1月9日に、アップルコンピュータ(Apple Computer, Inc.)から改称した。アメリカ合衆国の主要なIT企業である。 [15]マイクロソフト(英: Microsoft Corporation)は、アメリカ合衆国ワシントン州に本社を置く、ソフトウェアを開発、販売する会社である。 [16]1975年にビル・ゲイツとポール・アレンによって創業された。 [17]アマゾン熱帯雨林(アマゾンねったいうりん、英: Amazon Rainforest、西: Selva Amazónica、葡: Floresta Amazônica)とは、南アメリカ大陸アマゾン川流域に大きく広がる、世界最大面積を誇る熱帯雨林である。 [18]2019年の大火事で10%の面積を焼失したとされる。 [19]森林破壊が原因と見られる、木が大量に枯死する等の現象が多発しており、焼き畑と合わせて二酸化炭素大量放出の原因になっており問題になっている。引用元:「GAFA」「Google」「Amazon.com」「Facebook」「アップル (企業)」「アマゾン熱帯雨林」『フリー百科事典 ウィキペディア日本語版』。2019年11月18日 (日) 6:00 UTC、URL: https://ja.wikipedia.org
ベクトル抽出プログラムの準備
Googleが公開しているTensorflow版BERTのextract_features.pyを使えば、BERTのモデルからベクトルが抽出できますが、このプログラムはトークナイザーにWordPieceを使っているため、そのままでは今回使用するモデルに対しては使えません(今回使用する学習済モデルはSentencePieceでトークナイズされているため)。
学習済モデルを公開しているyoheikikutaさんが、extract_features.pyをSentencePieceで使えるように修正したものを公開しているので、こちらを使うことにします(src/extract_features.py)。ベクトル抽出の実行
以下のコマンドを実行して、単語ベクトルを抽出します(<OUTPUT_DIR>は出力先のディレクトリ)。
python extract_features.py --input_file=<INPUT_DIR>/sentences_gafa.txt --model_file=<BERT_DIR>/wiki-ja.model --vocab_file=<BERT_DIR>/wiki-ja.vocab --bert_config_file=<BERT_DIR>/bert_config.json --init_checkpoint=<BERT_DIR>/model.ckpt-1400000 --output_file=<OUTPUT_DIR>/features_gafa.txt --do_lower_case=false --layers=0,1,2,3,4,5,6,7,8,9,10,11出力されたファイルは以下のようなJSONっぽい形式になっています。
features_gafa.txt{ "linex_index": 0, // 入力ファイルの行番号(センテンスの番号) "features": [ { "token": "[CLS]", // センテンスを構成するトークン([CLS]はBERTでの行頭を表す特別なトークン) "layers": [ {"index": 0, "values": [0.48546, ...]}, // 中間層0の出力 {"index": 1, "values": [0.587065, ...]}, // 中間層1の出力 ... {"index": 11, "values": [0.48324, ...]} // 中間層11の出力 ] }, { "token": "▁", ... }, { "token": "GAFA", ... }, ... ] } { "linex_index": 1, ... } ... { "linex_index": 20, }今回使ったBERTのモデルは、12個の中間層、各中間層は768個のニューロンで構成されています。
上記出力の「layers」の各要素が中間層に該当し、「layers.values」が各中間層の768個のニューロンの出力に該当します。
各トークンに対して、768次元のベクトルが12個あり、これらがそのトークンのベクトル表現とみなすことができます。
これら12個のベクトルのうち、
- 12個のベクトルを連結した768×12次元のベクトル
- 12個のベクトルの平均
- 出力層に最も近い11番目のベクトル
など、そのトークンを表すベクトルを作る方法は色々ありますが、この記事によると、BiLSTMによる固有表現抽出タスクでは、出力に近い4つの層のベクトルを連結したベクトルを入力として使ったときに最も成績が良かったそうです。
連結をしてしまうと計算量が増えるため、今回は出力に近い4つの層のベクトルの平均をそのトークンのベクトルとすることにします。ちなみに、入力データの1番目のセンテンスをSentencePieceでトークナイズをすると、以下のようになります(「|」がトークンの区切り)。
[CLS]|▁|GAFA|(|ガー|ファ|)|または|GAFAM|などと|往|時には|呼ばれ|、|最近|は|むしろ|ビッグ|テック|または|ビッグ|テ|ク|(|B|ig|▁|T|e|ch|)|と呼ばれている|の|は|、|米国の|多|国籍|企業|で|コンピューター|や|ソフトウェア|を駆使して|サイバー|スペース|を|2010|年代に|支配|する|に至った|企業の|ことで|、|具体的に|は|グー|グル|・|アマゾン|・|フェイス|ブック|・|アップル|(|および|マイクロソフト|)|の|4|/|5|つの|主要|IT|企業である|。|[SEP]これをみて分かるように、トークン≠単語です。例えば「グーグル」という単語は、「グー」、「グル」という2個のトークンで構成されています。
BERTのモデルから取得できるのは単語のベクトルではなくトークンのベクトルです。今回は、複数のトークンで構成されている単語に対しては、この単語を構成する全てのトークンのベクトルを平均したものをその単語のベクトルとします(正しい方法かどうかはわかりませんが)。
例えば、「グー」のトークンベクトルが[1.0, 2.0, 3.0]、「グル」のトークンベクトルが[4.0, 5.0, 6.0]だった場合、「グーグル」の単語ベクトルは[(1.0+4.0)/2, (2.0+5.0)/2, (3.0+6.0)/2] = [2.5, 3.5, 4.5]となります。ベクトルの可視化
ベクトルの数字の並びを眺めていてもなんだかよくわからないので、可視化をしてみました。
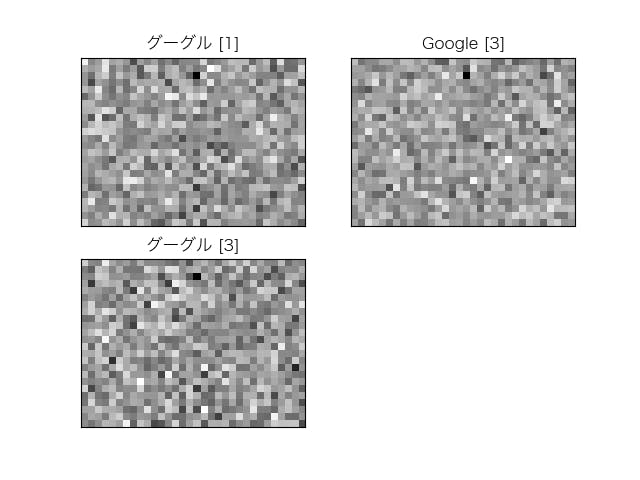
なぜか、どのベクトルも603次元目の値が他に比べて極めて小さいマイナスの値になっていて、可視化をしたときに特徴がつかみづらくなるため、0で補正をしました。全ての次元を可視化
入力データの1行目の「グーグル」(グーグル[1])、3行目の「グーグル」(グーグル[3])、「Google」(Google[3])のベクトルを取得し、グレースケールのマトリクス(ベクトルは768次元なので、24×32)で可視化しました([]内の数字は入力データの行番号です)。
目を細めてみると、「グーグル[1]」と「グーグル[3]」は似ているような気がしますが、多分気のせいです。当然、それらしい特徴はつかめません。
しかし、ここでは同じ「グーグル」という単語でも、異なったベクトル表現になっているということが重要です。2次元で可視化
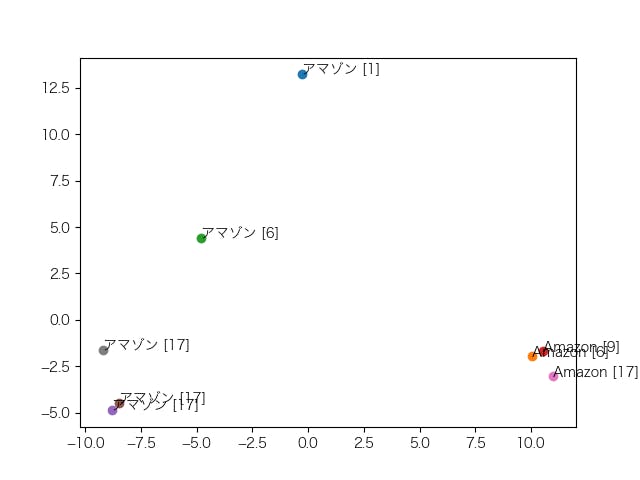
ベクトルの全ての次元を眺めてみてもよくわからないので、768次元のベクトルを、主成分分析で2次元に次元削減してみました([]内の数字は入力データの行番号です)。
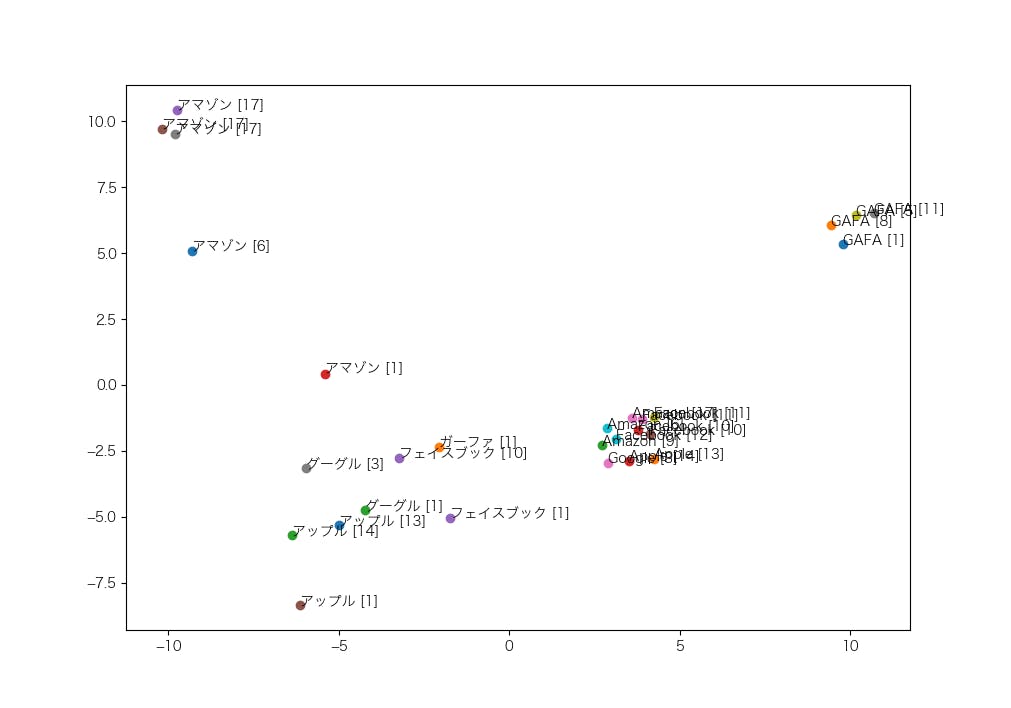
まずは、「GAFA」、「ガーファ」、「Google」、「グーグル」、「Amazon」、「アマゾン」、「Facebook」、「フェイスブック」、「Apple」、「アップル」のベクトルがどのように配置されているかを調べました。
次のような特徴が読み取れます。
- 地名の「アマゾン」(アマゾン[17])は、企業名の「アマゾン」(アマゾン[1]、アマゾン[6])とは区別されている
- アルファベットの単語に注目すると、企業名の「Google」、「Amazon」、「Facebook」、「Apple」は企業名ではない「GAFA」とは区別されている
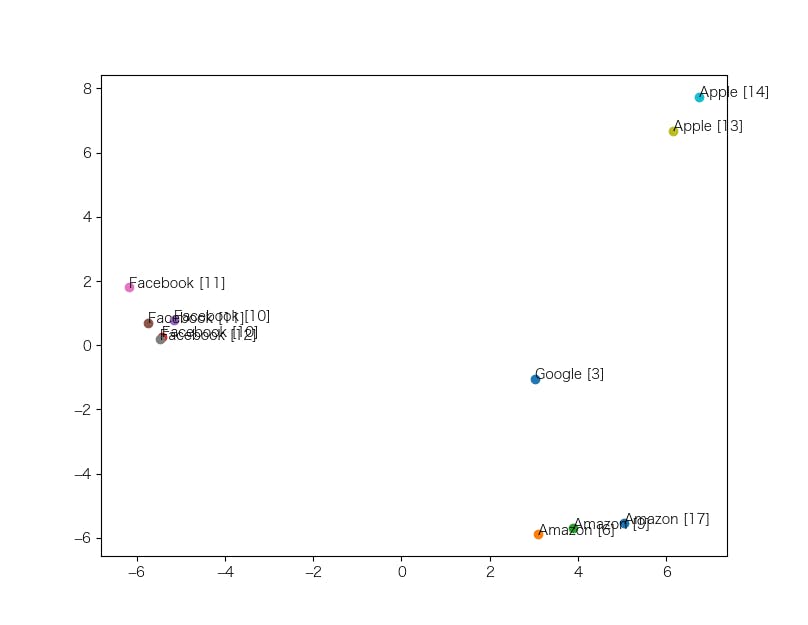
次に、ごちゃっとしている「GAFA」以外のアルファベットだけで次元削減を行い、ベクトルの配置を調べました。
おっ、いい感じに分かれているじゃないですか。と思いきや、右下のAmazonゾーンに、地名の「Amazon」(Amazon[17])が入り込んでしまっています。では、「Amazon」、「アマゾン」だけで次元削減をしたらどうなるか?企業名のグループ、地名のグループに分かれてくれたらうれしいですね。
ダメです。新たな特徴も見つかりませんでした。もう少し詳しく色々とみてみたいところですが、今回はここまでとさせていただきます。
まとめ
今回の実験はデータ数が少なく、定性的な結果でしかないですが、BERTのベクトルそのものでは、単語の意味を区別することは難しそうな感じがします。
BERTのベクトルには、おそらく単語の字面、前後の単語、品詞、意味、・・・など様々な要素が含まれているため、意味的な特徴を得たい場合には、ベクトルの中から意味を表現している成分を抽出する必要があるのかもしれません。
今後は、こういったことを深掘りしていきたいと考えています。
- 投稿日:2019-11-26T01:40:22+09:00
TensorBoardの使い方が若干変わっている件
概要
今更ですが、ちょっとTensorBoardを動かしてみました。その際に、TensorBoardの最も基本的な使い方というページが非常に参考になりました。サンプルが非常にシンプルで、簡単に試してみることができるのがもっとも良い点でした。
ただ、コメントにもあるようにバージョンが違うと色々と違いがあるようで、最新環境で動かしてみたという内容です。
ですので、大元のページをご覧になった上で、こちらも参考に見ていただければと思いますが、基本は大元のページのコピペに過ぎないので、こちらを参考にする必要もないかもしれません。
再掲:TensorBoardの最も基本的な使い方環境
$ pip list | grep tens tensorboard 1.14.0 tensorflow 1.14.0 tensorflow-estimator 1.14.0 と、 tensorboard 2.0.1 tensorflow 2.0.0 tensorflow-estimator 2.0.1v1系 (1.14)
# 必要なライブラリのインポート import tensorflow as tf import numpy as np # 変数の定義 dim = 5 LOGDIR = './logs' x = tf.compat.v1.placeholder(tf.float32, [None, dim + 1], name='X') w = tf.Variable(tf.zeros([dim+1,1]), name='weight') y = tf.matmul(x,w, name='Y') t = tf.compat.v1.placeholder(tf.float32, [None, 1], name='TEST') sess = tf.compat.v1.Session() # 損失関数と学習メソッドの定義 loss = tf.reduce_sum(tf.square(y - t)) train_step = tf.compat.v1.train.AdamOptimizer().minimize(loss) # TensorBoardで追跡する変数を定義 with tf.name_scope('summary'): # 戻りを利用する loss_summary = tf.compat.v1.summary.scalar('loss', loss) if tf.io.gfile.exists(LOGDIR): tf.io.gfile.rmtree(LOGDIR) # ./logdirが存在する場合削除 writer = tf.compat.v1.summary.FileWriter(LOGDIR, sess.graph) # セッションの初期化と入力データの準備 sess.run(tf.compat.v1.global_variables_initializer()) train_t = np.array([5.2, 5.7, 8.6, 14.9, 18.2, 20.4,25.5, 26.4, 22.8, 17.5, 11.1, 6.6]) train_t = train_t.reshape([12,1]) train_x = np.zeros([12, dim+1]) for row, month in enumerate(range(1, 13)): for col, n in enumerate(range(0, dim+1)): train_x[row][col] = month**n # 学習 i = 0 for _ in range(100000): i += 1 sess.run(train_step, feed_dict={x: train_x, t: train_t}) if i % 10000 == 0: # 上記で取得したloss_summeryを渡す s, loss_val = sess.run([loss_summary, loss] , feed_dict={x: train_x, t: train_t}) print('Step: %d, Loss: %f' % (i, loss_val)) # これによりSCALARSが出力される writer.add_summary(s, global_step=i)
- GRAPHSの画像
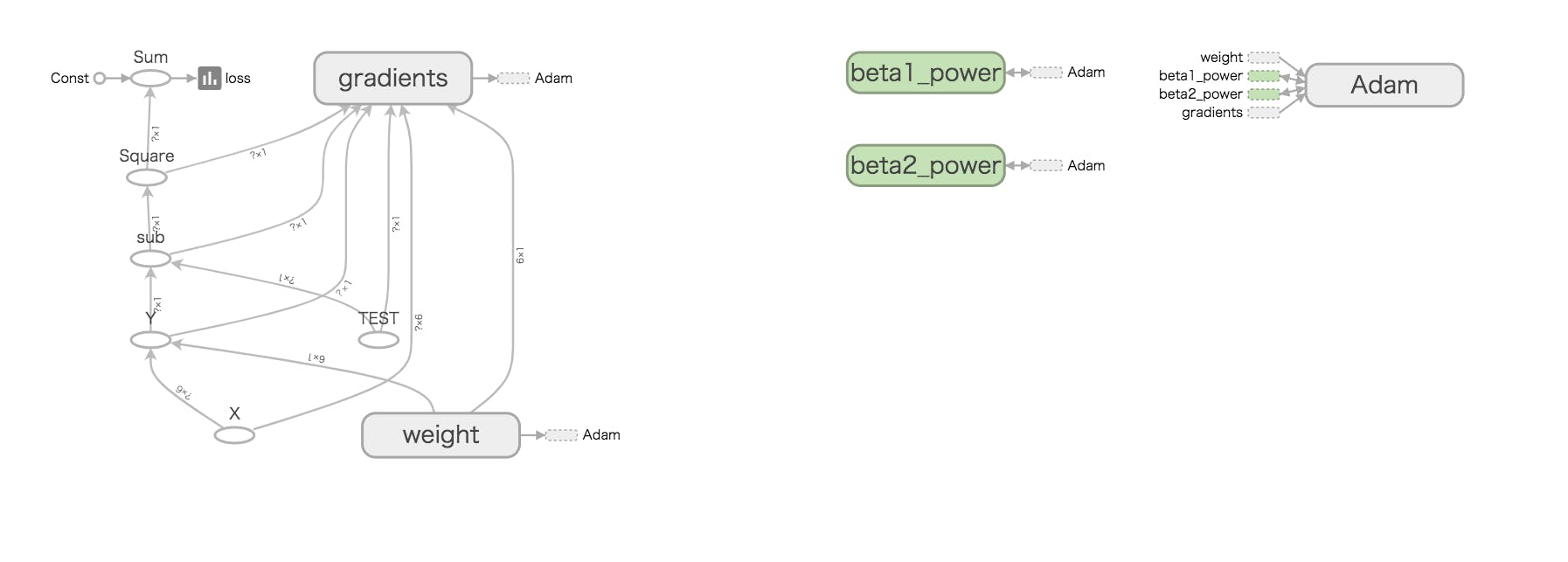
nameで名前をつけておくと、わかりやすくなります。
- SCALARSのグラフ
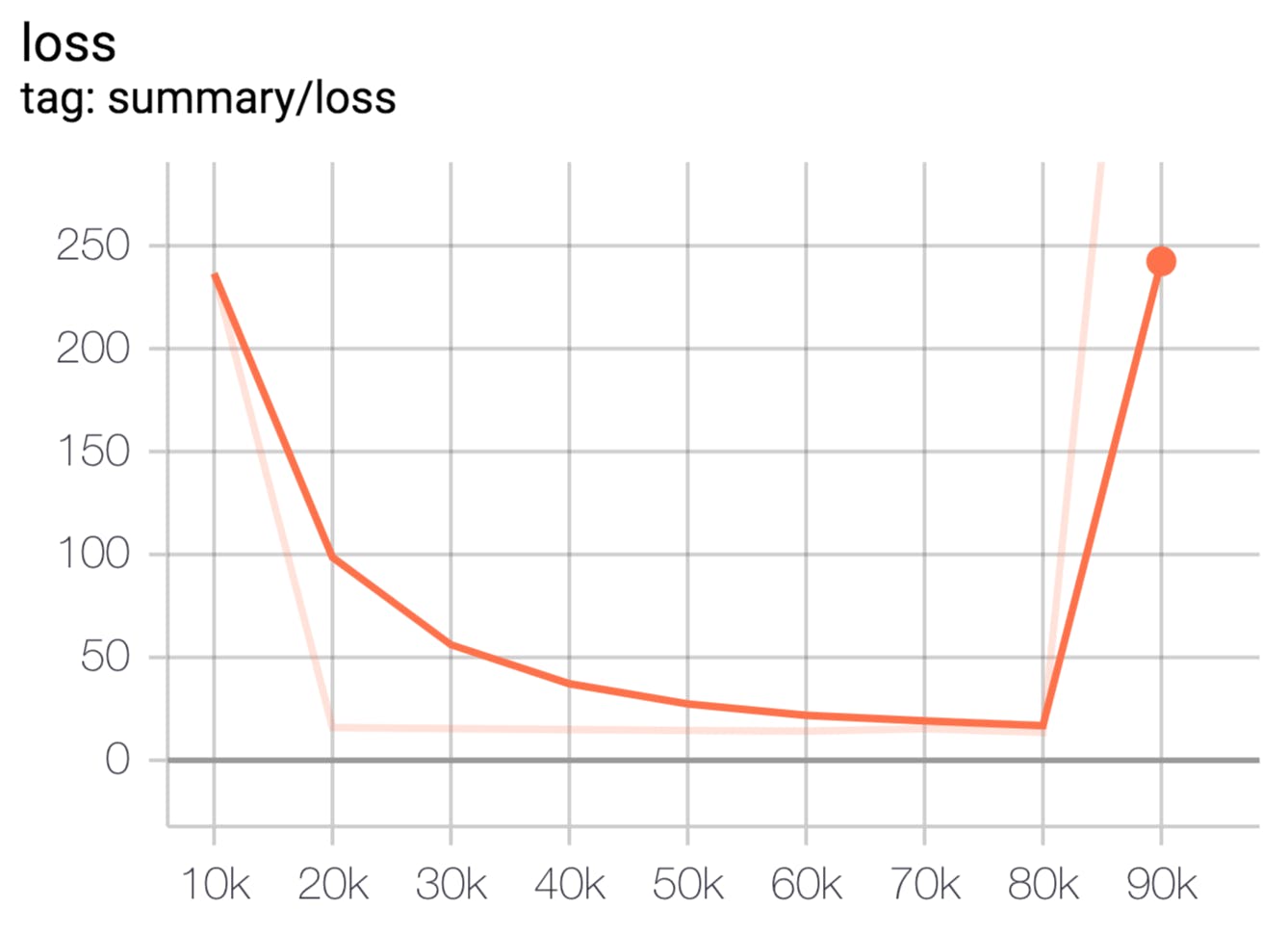
ちなみに、以下のような感じにすると、既存のコードをあまり変更しなくても済むっぽいです。
tensorflowのドキュメントに記載があるから、これが適切な記述方法かな。import tensorflow.compat.v1 as tfv2系 (2.00)
というわけで、こちらは書き方を変えてみる。
また、v2のポイントとしては、Variableの書き方が変わった点でしょうか。
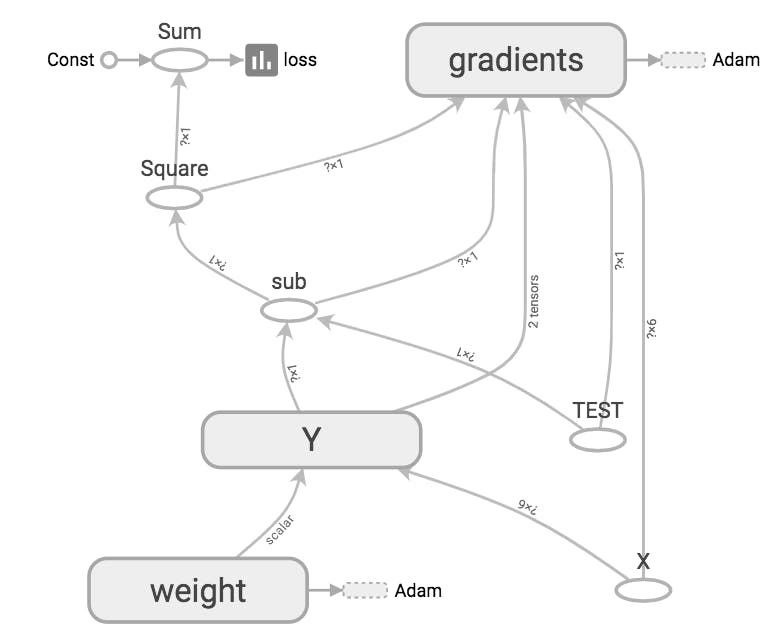
あと、良くわからないのが、EagerTensorsの部分でしょうか。とりあえず、sessionをwithで指定して見た。# 必要なライブラリのインポート import tensorflow.compat.v1 as tf import numpy as np # 変数の定義 dim = 5 LOGDIR = './logs' with tf.Session() as sess: x = tf.placeholder(tf.float32, [None, dim + 1], name='X') with tf.variable_scope('weight'): w = tf.get_variable("weight", shape=[dim+1,1], initializer=tf.zeros_initializer()) y = tf.matmul(x,w, name='Y') t = tf.placeholder(tf.float32, [None, 1], name='TEST') # 損失関数と学習メソッドの定義 loss = tf.reduce_sum(tf.square(y - t)) train_step = tf.train.AdamOptimizer().minimize(loss) # TensorBoardで追跡する変数を定義 with tf.name_scope('summary'): loss_summary = tf.summary.scalar('loss', loss) if tf.io.gfile.exists(LOGDIR): tf.io.gfile.rmtree(LOGDIR) # ./logdirが存在する場合削除 writer = tf.summary.FileWriter(LOGDIR, sess.graph) # セッションの初期化と入力データの準備 sess.run(tf.global_variables_initializer()) train_t = np.array([5.2, 5.7, 8.6, 14.9, 18.2, 20.4,25.5, 26.4, 22.8, 17.5, 11.1, 6.6]) train_t = train_t.reshape([12,1]) train_x = np.zeros([12, dim+1]) for row, month in enumerate(range(1, 13)): for col, n in enumerate(range(0, dim+1)): train_x[row][col] = month**n # 学習 i = 0 for _ in range(100000): i += 1 sess.run(train_step, feed_dict={x: train_x, t: train_t}) if i % 10000 == 0: s, loss_val = sess.run([loss_summary, loss] , feed_dict={x: train_x, t: train_t}) print('Step: %d, Loss: %f' % (i, loss_val)) writer.add_summary(s, global_step=i)
- SCALARSのグラフ
Yの部分が違っているようです。
- 投稿日:2019-11-26T01:13:36+09:00
KerasでInceptionとか色々な自作Modelを作ってみる話【Colab付き】
はじめに
今回の記事では、TF2.0付属のKerasModuleを用いて、様々な内容の
この記事はColabratoryで直接動かすことができます。
動かしながら確認したい方は是非利用してみてください。
Colabはこちら新しく統合されたKerasと3つのAPIについて
KerasはTF2.0からcontribレイヤーから正式なTFの仲間入りをしました。
代わりにTF1.xにあった共有レイヤー機能などは削除されています。(つまりKerasで書け。ということみたいです)
Kerasには色々なAPIがありますが、Model作成に関係するのは以下の3つのAPIです。
- Sequencial API
- Functional API
- SubClass API
これを使えば基本的に全てのモデルを作れるといってもいいくらい自由度が高いAPIになっています。
これらをCIFAR10モデルを例にチュートリアルしていこうと思います。最初に入れておいてほしいModule
チュートリアルでは以下のModuleを必要とします。
インストールされていない場合は各自pipなりで環境を構築するようにお願いします。importimport tensorflow as tf import tensorflow.keras as keras import matplotlib.pyplot as plt import numpy as np print("TensorFlow Version:",tf.__version__)TensorFlow Version: 2.0.0CIFAR10を扱う
今回チュートリアルで用いるのは皆さんお馴染みのCIFAR10データセットです。
データは(32,32,3)でのテンソルで表現されています。ダウンロードはtf.kerasから行うことができます。データセットをダウンロード
データセットをダウンロード(Train_X,Train_Y),(Test_X,Test_Y) = keras.datasets.cifar10.load_data() Train_X,Test_X = Train_X/255.0, Test_X/255.0データの表示
一度表示させてみましょう。
CIFAR10の画像をランダムで表示import random X = random.choice(Train_X) print(X.shape) plt.figure(facecolor="white") plt.imshow(X) plt.colorbar() plt.grid(False) plt.title("CIFAR10 sample") plt.show()結果(32,32,3)
次にランダムに沢山表示させてみましょう。
ランダムに表示labels = np.array([ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']) plt.figure(figsize=(10,30),facecolor="white") index=random.randint(0,Train_Y.shape[0]-25) for i in range(75): plt.subplot(15,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(Train_X[i+index]) plt.xlabel(labels[Train_Y[i+index][0]]) plt.show()
(ちょっと長すぎましたね?)
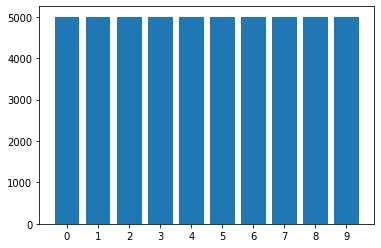
分布を表示させてみましょう。
データ分布を表示import collections c=collections.Counter(Train_Y.reshape(-1)) c=sorted(c.items(),key=lambda x:x[0]) left = [label for label,count in c] hight = [count for label,count in c] plt.figure(facecolor="white") plt.bar(left,hight,tick_label=left) plt.show()
各ラベル、5000枚均一のようですね。
チュートリアル1:KerasのSequentialAPIで問題を解く。
SequentialAPI
SequentialAPIは、Kerasの中ではもっとも簡単なDNNModelの書き方で、
その分直列一直線にしかModelを組めません。まずは複雑なモデルは組まず、単純なConv2Dモデルでやってみましょう。
SequentialAPIは基本的に以下のように記述します。
SequentialAPImodel=keras.Sequential() model.add(keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same",input_shape=(32,32,3))) model.add(keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same")) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding="same")) model.add(keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding="same")) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Conv2D(filters=256,kernel_size=(3,3),padding="same")) model.add(keras.layers.Conv2D(filters=256,kernel_size=(3,3),padding="same")) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(128,activation="relu")) model.add(keras.layers.Dense(10,activation="softmax")) model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=["accuracy"]) model.summary()結果Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 16) 448 _________________________________________________________________ conv2d_1 (Conv2D) (None, 32, 32, 16) 2320 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 16, 16, 16) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 16, 16, 64) 9280 _________________________________________________________________ conv2d_3 (Conv2D) (None, 16, 16, 64) 36928 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 8, 8, 64) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 8, 8, 256) 147712 _________________________________________________________________ conv2d_5 (Conv2D) (None, 8, 8, 256) 590080 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 4, 4, 256) 0 _________________________________________________________________ flatten (Flatten) (None, 4096) 0 _________________________________________________________________ dense (Dense) (None, 128) 524416 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 1,312,474 Trainable params: 1,312,474 Non-trainable params: 0 _________________________________________________________________このようにaddしていくことでDNNModelを構築することができます。
実際に学習させてみる
学習させてみましょう。やり方は簡単で、modelインスタンスの
.fitを使用すればいいだけです。学習history=model.fit(Train_X,Train_Y,validation_split=0.2,epochs=10,batch_size=128)結果Train on 40000 samples, validate on 10000 samples Epoch 1/10 40000/40000 [==============================] - 12s 293us/sample - loss: 1.4603 - accuracy: 0.4796 - val_loss: 1.1121 - val_accuracy: 0.6115 Epoch 2/10 40000/40000 [==============================] - 11s 271us/sample - loss: 0.9884 - accuracy: 0.6554 - val_loss: 0.9367 - val_accuracy: 0.6795 Epoch 3/10 40000/40000 [==============================] - 11s 271us/sample - loss: 0.7948 - accuracy: 0.7233 - val_loss: 0.8491 - val_accuracy: 0.7138 Epoch 4/10 40000/40000 [==============================] - 11s 270us/sample - loss: 0.6479 - accuracy: 0.7741 - val_loss: 0.8719 - val_accuracy: 0.7037 Epoch 5/10 40000/40000 [==============================] - 11s 268us/sample - loss: 0.5212 - accuracy: 0.8179 - val_loss: 0.8546 - val_accuracy: 0.7215 Epoch 6/10 40000/40000 [==============================] - 11s 269us/sample - loss: 0.4168 - accuracy: 0.8551 - val_loss: 0.9460 - val_accuracy: 0.7288 Epoch 7/10 40000/40000 [==============================] - 11s 271us/sample - loss: 0.3216 - accuracy: 0.8884 - val_loss: 1.0214 - val_accuracy: 0.7089 Epoch 8/10 40000/40000 [==============================] - 11s 271us/sample - loss: 0.2616 - accuracy: 0.9078 - val_loss: 1.1193 - val_accuracy: 0.7123 Epoch 9/10 40000/40000 [==============================] - 11s 269us/sample - loss: 0.2134 - accuracy: 0.9260 - val_loss: 1.2778 - val_accuracy: 0.7148 Epoch 10/10 40000/40000 [==============================] - 11s 270us/sample - loss: 0.1822 - accuracy: 0.9372 - val_loss: 1.2681 - val_accuracy: 0.7187ちなみに、ColabのようにGPUがあるような場合、自動的にGPUモードで学習してくれます。
評価は以下のように行うことができます。
モデル最終評価model.evaluate(Test_X,Test_Y,batch_size=128,verbose=0)結果[1.2933093170166015, 0.7155]左はloss、右はAccuracyを示しています。
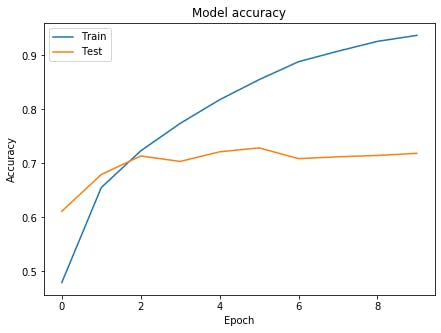
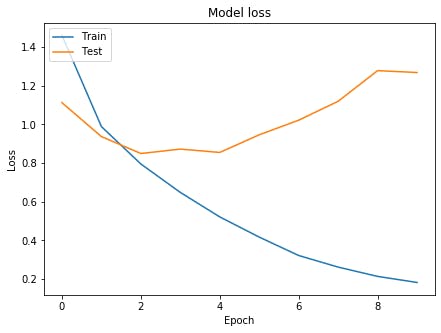
グラフの表示
グラフを表示させてみましょう。
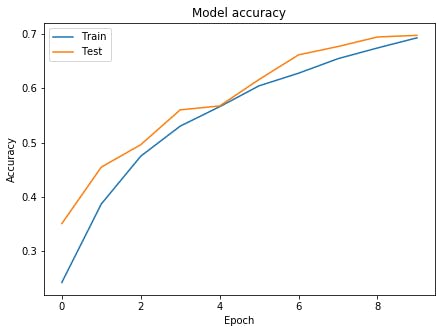
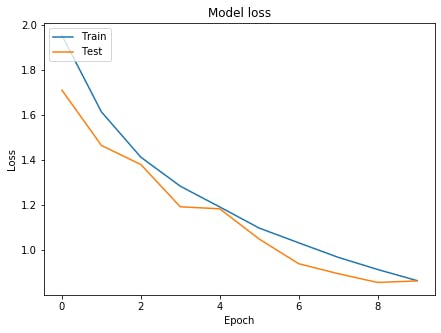
グラフを表示# Accuracyを表示 plt.figure(figsize=(7,5),facecolor="white") plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show() # lossを表示 plt.figure(figsize=(7,5),facecolor="white") plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show()
お手本のような過学習が起きています。
次こそはいいモデルを作るために、InceptionV3と呼ばれるモデルを作成してみましょう。チュートリアル2:Functional API
Inceptionを構成する
InceptionV3は非常に複雑なモデルですが、FunctionalAPIを用いれば簡単に構築できます。
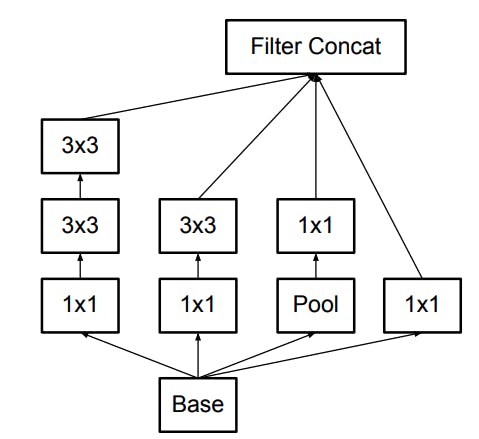
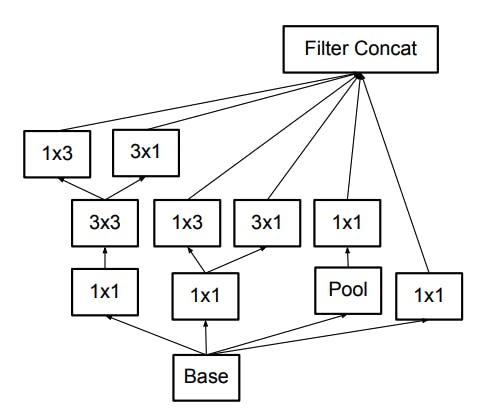
InceptionV3の名前はInceptionModuleから来ています。InceptionModuleは参考文献から引用すると、以下のように構成されています。(他にも様々なバリエーションがあります。)
CIFAR10と論文中のコンペとでは画像サイズが違うため、一部改造してInceptionModuleをFunctionalAPIで組んで行きましょう。
4つ伸びている線を左からCell1,Cell2,Cell3,Cell4と名前をつけます。
実際にInceptionModuleを組んでいくと以下のようなモデルになります。InceptionModuleinput_x=keras.Input((32,32,3)) x = keras.layers.Conv2D(32,3,padding="same")(input_x) out_x = keras.layers.Conv2D(64,3,strides=2,padding="same")(x) output_filter = 128 #--inceptionModuleStart---# cell1 = keras.layers.Conv2D(output_filter//4,1,padding="same")(out_x) cell1 = keras.layers.Conv2D(output_filter//4,3,padding="same")(cell1) cell1 = keras.layers.Conv2D(output_filter//4,3,padding="same")(cell1) cell2 = keras.layers.Conv2D(output_filter//4,1,padding="same")(out_x) cell2 = keras.layers.Conv2D(output_filter//4,3,padding="same")(cell2) cell3 = keras.layers.MaxPool2D(pool_size=(2,2),strides=1,padding="same")(out_x) cell3 = keras.layers.Conv2D(output_filter//4,1,padding="same")(cell3) cell4 = keras.layers.Conv2D(output_filter//4,1,padding="same")(out_x) x = keras.layers.Concatenate()([cell1,cell2,cell3,cell4]) #--inceptionModuleEnd---# x = keras.layers.Flatten()(x) x = keras.layers.Dense(128,activation="relu")(x) x = keras.layers.Dropout(0.4)(x) output_x = keras.layers.Dense(10,activation="softmax")(x) model=keras.Model(input_x,output_x) model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=["accuracy"]) model.summary()カッコが二つ!と驚かれると思いますが、これはコンストラクタの()と関数としての()という意味で別になります。
どちらかというと、tensorflowというよりも、Kerasの仕様に近いですね。こんな風にして数珠つなぎをすることができます。注目してほしいのは、どのCellのはじめには
out_xが入っています。
こうする事により、同じ入力を別の4つのNNに入力することがFunctionalAPIではできるのです。FunctionalAPIの解説
だだーっと解説しましたが、FunctionalAPIのポイントは、
解説input_x = keras.Input(shape) #バッチを除いた単一のデータ入力サイズを指定したInputLayer x = keras.layers.Dense(dense_size, activation="relu")(input_x) #NN中間層 output_x = keras.layers.Dense(1,activation="sigmoid")(x)#NN最終層 model = keras.Model(inputs=input_x, outputs=output_x)#入力と出力を設定してモデルインスタンスを作成となります。ちなみに複数のInput、Outputも設定できます。その場合はTupleでinputs/outputs引数に入れれば自動でfitしてくれます。
(詳細については後日カレンダーが空いていたらやろうかと思います。)さらに以下のことを加えます。
- GlovalAveragePoolingを使用
- Convolution後にReLUを使用
- DropOutを適用
そうすると最終形として、以下のようになります。
Inception_for_CIFAR10input_x=keras.Input((32,32,3)) x = keras.layers.Conv2D(32,3,padding="same",activation="relu")(input_x) x = keras.layers.Dropout(0.1)(x) x = keras.layers.Conv2D(32,3,padding="same",activation="relu")(x) x = keras.layers.Dropout(0.1)(x) x = keras.layers.Conv2D(64,3,padding="same",activation="relu")(x) x = keras.layers.Dropout(0.1)(x) out_x = keras.layers.MaxPool2D()(x) output_filter = 128 #--inceptionModule--# cell1 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(out_x) cell1 = keras.layers.Conv2D(output_filter//4,3,padding="same",activation="relu")(cell1) cell1 = keras.layers.Conv2D(output_filter//4,3,padding="same",activation="relu")(cell1) cell2 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(out_x) cell2 = keras.layers.Conv2D(output_filter//4,3,padding="same",activation="relu")(cell2) cell3 = keras.layers.MaxPool2D(pool_size=(2,2),strides=1,padding="same")(out_x) cell3 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(cell3) cell4 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(out_x) out_x = keras.layers.Concatenate()([cell1,cell2,cell3,cell4]) output_filter = 128 #--inceptionModule--# cell1 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(out_x) cell1 = keras.layers.Conv2D(output_filter//4,3,padding="same",activation="relu")(cell1) cell1 = keras.layers.Conv2D(output_filter//4,3,padding="same",activation="relu")(cell1) cell2 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(out_x) cell2 = keras.layers.Conv2D(output_filter//4,3,padding="same",activation="relu")(cell2) cell3 = keras.layers.MaxPool2D(pool_size=(2,2),strides=1,padding="same")(out_x) cell3 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(cell3) cell4 = keras.layers.Conv2D(output_filter//4,1,padding="same",activation="relu")(out_x) out_x = keras.layers.Concatenate()([cell1,cell2,cell3,cell4]) output_filter = 256 #--inception_reduction# cell1 = keras.layers.Conv2D(output_filter//2,1,padding="same",activation="relu")(out_x) cell1 = keras.layers.Conv2D(output_filter//2,3,padding="same",activation="relu")(cell1) cell1 = keras.layers.Conv2D(output_filter//2,3,strides=2,padding="same",activation="relu")(cell1) cell2 = keras.layers.Conv2D(output_filter//2,1,padding="same",activation="relu")(out_x) cell2 = keras.layers.Conv2D(output_filter//2,3,strides=2,padding="same",activation="relu")(cell2) cell3 = keras.layers.MaxPool2D(pool_size=(2,2),strides=2,padding="same")(out_x) x = keras.layers.Concatenate()([cell1,cell2,cell3]) x = keras.layers.GlobalAveragePooling2D()(x) x = keras.layers.Dense(200,activation="relu")(x) x = keras.layers.Dropout(0.4)(x) output_x = keras.layers.Dense(10,activation="softmax")(x) model=keras.Model(input_x,output_x) model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=["accuracy"]) model.summary()学習させてみる
学習させてみましょう。
モデルを学習history=model.fit(Train_X,Train_Y,validation_split=0.2,epochs=10,batch_size=128)結果Train on 40000 samples, validate on 10000 samples Epoch 1/10 40000/40000 [==============================] - 38s 947us/sample - loss: 1.9527 - accuracy: 0.2422 - val_loss: 1.7093 - val_accuracy: 0.3506 Epoch 2/10 40000/40000 [==============================] - 35s 871us/sample - loss: 1.6131 - accuracy: 0.3867 - val_loss: 1.4641 - val_accuracy: 0.4547 Epoch 3/10 40000/40000 [==============================] - 35s 870us/sample - loss: 1.4118 - accuracy: 0.4748 - val_loss: 1.3792 - val_accuracy: 0.4960 Epoch 4/10 40000/40000 [==============================] - 35s 871us/sample - loss: 1.2831 - accuracy: 0.5302 - val_loss: 1.1916 - val_accuracy: 0.5602 Epoch 5/10 40000/40000 [==============================] - 35s 874us/sample - loss: 1.1909 - accuracy: 0.5660 - val_loss: 1.1827 - val_accuracy: 0.5674 Epoch 6/10 40000/40000 [==============================] - 35s 871us/sample - loss: 1.0971 - accuracy: 0.6045 - val_loss: 1.0484 - val_accuracy: 0.6162 Epoch 7/10 40000/40000 [==============================] - 35s 871us/sample - loss: 1.0318 - accuracy: 0.6278 - val_loss: 0.9390 - val_accuracy: 0.6616 Epoch 8/10 40000/40000 [==============================] - 35s 872us/sample - loss: 0.9674 - accuracy: 0.6546 - val_loss: 0.8948 - val_accuracy: 0.6769 Epoch 9/10 40000/40000 [==============================] - 35s 868us/sample - loss: 0.9134 - accuracy: 0.6742 - val_loss: 0.8558 - val_accuracy: 0.6945 Epoch 10/10 40000/40000 [==============================] - 35s 870us/sample - loss: 0.8641 - accuracy: 0.6929 - val_loss: 0.8625 - val_accuracy: 0.6975評価model.evaluate(Test_X,Test_Y,batch_size=128,verbose=0)結果[0.8861876195907593, 0.6829]うーん、悪くなってしまったように思えます。 グラフをみてみましょう。
過学習が非常に抑えられていていいですね、もっとepoch数を伸ばしたらもっとよくなりそうですね。
epochを100にhistory=model.fit(Train_X,Train_Y,validation_split=0.2,epochs=100,batch_size=128) print(model.evaluate(Test_X,Test_Y,batch_size=128,verbose=0))結果Train on 40000 samples, validate on 10000 samples Epoch 1/100 40000/40000 [==============================] - 37s 934us/sample - loss: 1.9353 - accuracy: 0.2507 - val_loss: 1.6810 - val_accuracy: 0.3510 Epoch 2/100 40000/40000 [==============================] - 35s 871us/sample - loss: 1.5842 - accuracy: 0.4001 - val_loss: 1.4552 - val_accuracy: 0.4647 Epoch 3/100 40000/40000 [==============================] - 35s 870us/sample - loss: 1.3558 - accuracy: 0.4974 - val_loss: 1.3613 - val_accuracy: 0.5091 Epoch 4/100 40000/40000 [==============================] - 35s 868us/sample - loss: 1.2095 - accuracy: 0.5586 - val_loss: 1.0845 - val_accuracy: 0.6082 Epoch 5/100 40000/40000 [==============================] - 35s 869us/sample - loss: 1.1131 - accuracy: 0.5954 - val_loss: 1.0509 - val_accuracy: 0.6200 ...(中略) Epoch 97/100 40000/40000 [==============================] - 34s 859us/sample - loss: 0.0869 - accuracy: 0.9710 - val_loss: 1.0830 - val_accuracy: 0.8110 Epoch 98/100 40000/40000 [==============================] - 34s 860us/sample - loss: 0.0830 - accuracy: 0.9718 - val_loss: 1.1919 - val_accuracy: 0.8027 Epoch 99/100 40000/40000 [==============================] - 34s 858us/sample - loss: 0.0843 - accuracy: 0.9722 - val_loss: 1.0689 - val_accuracy: 0.8040 Epoch 100/100 40000/40000 [==============================] - 34s 858us/sample - loss: 0.0864 - accuracy: 0.9709 - val_loss: 1.1582 - val_accuracy: 0.8007 [1.1903886857509614, 0.8022]
いい感じに伸びましたね!
チュートリアル3: SubClass API
SubClass APIとは?
SubClass APIとは、ざっくり言うとレイヤーやモデルを自作できる機能です。
先ほどのInceptionを一つのLayerとして自作してみましょう。Inceptionclass Inception(keras.layers.Layer): def __init__(self, output_filter=64, **kwargs): super(Inception, self).__init__(output_filter, **kwargs) self.c1_conv1 = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c1_conv1") self.c1_conv2 = keras.layers.Conv2D(output_filter//4,3,padding="same",name="c1_conv2") self.c1_conv3 = keras.layers.Conv2D(output_filter//4,3,padding="same",name="c1_conv3") self.c2_conv1 = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c2_conv1") self.c2_conv2 = keras.layers.Conv2D(output_filter//4,3,padding="same",name="c2_conv2") self.c3_MaxPool = keras.layers.MaxPool2D(pool_size=(2,2), strides=1, padding="same",name="c3_MaxPool") self.c3_conv = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c3_conv") self.c4_conv = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c4_conv") self.concat = keras.layers.Concatenate() def call(self, input_x, training=False): x1 = self.c1_conv1(input_x) x1 = self.c1_conv2(x1) cell1 = self.c1_conv3(x1) x2 = self.c2_conv1(input_x) cell2 = self.c2_conv2(x2) x2 = self.c3_MaxPool(input_x) cell3 = self.c3_conv(x2) cell4 = self.c4_conv(input_x) return self.concat([cell1,cell2,cell3,cell4])
これがひとかたまりになったInceptionModuleとなります。これだけではトレーニングできませんので、Modelを作る必要があります。
ModelでInceptionを使用したい場合は、Sequential APIでもFunctionalAPIでも、既存のレイヤーと同様にこのLayerClassは使うことができます。sequentialAPImodel = keras.models.Sequential() model.add(keras.layers.Conv2D(32, 3,padding="same",kernel_initializer="he_normal",name="conv_0",input_shape=(32,32,3))) model.add(Inception(64,name="inception1")) model.add(Inception(128,name="inception2")) model.add(Inception(256,name="inception3")) model.add(keras.layers.GlobalAvgPool2D()) model.add(keras.layers.Dense(10,activation="softmax",name="output_layer")) model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=["accuracy"]) model.summary()また、Model自体もLayerと同様にSubClassAPIで作成することができます。上のモデルを再現すると、
SubClassAPI_Modelclass InceptionNet(keras.models.Model): def __init__(self,**kwargs): super(InceptionNet, self).__init__(**kwargs) self.conv0 = keras.layers.Conv2D(32, 3,padding="same",kernel_initializer="he_normal",name="conv_0") self.inception1 = Inception(64,name="Inception1") self.inception2 = Inception(128,name="inception2") self.inception3 = Inception(256,name="inception3") self.GAP = keras.layers.GlobalAveragePooling2D() self.dense2 = keras.layers.Dense(10, activation="softmax",name="output_layer") def call(self, x, training=False):#trainingを引数に自動で選択してくれる x = self.conv0(x) x = self.inception1(x) x = self.inception2(x) x = self.inception3(x) x = self.GAP(x) x = self.dense2(x) return x def build_graph(self, input_shape): input_shape_nobatch = input_shape[1:] self.build(input_shape) inputs = tf.keras.Input(shape=input_shape_nobatch) if not hasattr(self, 'call'): raise AttributeError("User should define 'call' method in sub-class model!") _ = self.call(inputs) model = InceptionNet(name="InceptionNet") model.build_graph((None,32,32,3)) model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=["accuracy"]) model.summary()こういった書き方になります。つまり、ModelでもLayerでも、if文やprintといったことを適宜挟むことができます。
層を深くしてみる。
さらにGoingDeeperしてみましょう。
InceptionAclass InceptionA(keras.layers.Layer): def __init__(self, output_filter=64, **kwargs): super(InceptionA, self).__init__(output_filter, **kwargs) self.c1_conv1 = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c1_conv1") self.c1_conv2_1 = keras.layers.Conv2D(output_filter//4,(1,3),padding="same",name="c1_conv2_1") self.c1_conv2_2 = keras.layers.Conv2D(output_filter//4,(3,1),padding="same",name="c1_conv2_2") self.c1_conv3_1 = keras.layers.Conv2D(output_filter//4,(1,3),padding="same",name="c1_conv3_1") self.c1_conv3_2 = keras.layers.Conv2D(output_filter//4,(3,1),padding="same",name="c1_conv3_2") self.c2_conv1 = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c2_conv1") self.c2_conv2_1 = keras.layers.Conv2D(output_filter//4,(1,3),padding="same",name="c2_conv2_1") self.c2_conv2_2 = keras.layers.Conv2D(output_filter//4,(3,1),padding="same",name="c2_conv2_2") self.c3_MaxPool = keras.layers.MaxPool2D(pool_size=(2,2), strides=1, padding="same",name="c3_MaxPool") self.c3_conv = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c3_conv") self.c4_conv = keras.layers.Conv2D(output_filter//4,1,padding="same",name="c4_conv") self.concat = keras.layers.Concatenate() def call(self, input_x, training=False): x1 = self.c1_conv1(input_x) x1 = self.c1_conv2_1(x1) x1 = self.c1_conv2_2(x1) x1 = self.c1_conv3_1(x1) cell1 = self.c1_conv3_2(x1) x2 = self.c2_conv1(input_x) x2 = self.c2_conv2_1(x2) cell2 = self.c2_conv2_2(x2) x2 = self.c3_MaxPool(input_x) cell3 = self.c3_conv(x2) cell4 = self.c4_conv(input_x) return self.concat([cell1,cell2,cell3,cell4])
参考文献のFigure.6から引用(n=3とした)InceptionBclass InceptionB(keras.layers.Layer): def __init__(self, output_filter=64, **kwargs): super(InceptionB, self).__init__(output_filter, **kwargs) self.c1_conv1_1 = keras.layers.Conv2D(output_filter//6,1,padding="same",name="c1_conv1_1") self.c1_conv1_2 = keras.layers.Conv2D(output_filter//6,3,padding="same",name="c1_conv1_2") self.c1_conv2_1 = keras.layers.Conv2D(output_filter//6,(1,3),padding="same",name="c1_conv2_1") self.c1_conv2_2 = keras.layers.Conv2D(output_filter//6,(3,1),padding="same",name="c1_conv2_2") self.c2_conv1 = keras.layers.Conv2D(output_filter//6,1,padding="same",name="c2_conv1") self.c2_conv2_1 = keras.layers.Conv2D(output_filter//6,(1,3),padding="same",name="c2_conv2_1") self.c2_conv2_2 = keras.layers.Conv2D(output_filter//6,(3,1),padding="same",name="c2_conv2_2") self.c3_MaxPool = keras.layers.MaxPool2D(pool_size=(2,2), strides=1, padding="same",name="c3_MaxPool") self.c3_conv = keras.layers.Conv2D(output_filter//6,1,padding="same",name="c3_conv") self.c4_conv = keras.layers.Conv2D(output_filter//6,1,padding="same",name="c4_conv") self.concat = keras.layers.Concatenate() def call(self, input_x, training=False): x1 = self.c1_conv1_1(input_x) x1 = self.c1_conv1_2(x1) cell1_1 = self.c1_conv2_1(x1) cell1_2 = self.c1_conv2_2(x1) x2 = self.c2_conv1(input_x) cell2_1 = self.c2_conv2_1(x2) cell2_2 = self.c2_conv2_2(x2) x2 = self.c3_MaxPool(input_x) cell3 = self.c3_conv(x2) cell4 = self.c4_conv(input_x) return self.concat([cell1_1,cell1_2,cell2_1,cell2_2,cell3,cell4])
参考文献のFigure.7から引用Model作成はFunctionalAPIを使って書いてみましょう。
Modelinput_x=keras.Input((32,32,3)) x = keras.layers.Conv2D(32,3,padding="same",activation="relu")(input_x) x = keras.layers.Dropout(0.1)(x) x = keras.layers.Conv2D(32,3,padding="same",activation="relu")(x) x = keras.layers.Dropout(0.1)(x) x = keras.layers.Conv2D(64,3,padding="same",activation="relu")(x) x = keras.layers.Dropout(0.1)(x) x = keras.layers.MaxPool2D()(x) x = Inception(64,name="inception1")(x) x = Inception(64,name="inception2")(x) x = Inception(128,name="inception3")(x) x = keras.layers.MaxPool2D()(x) x = InceptionA(128,name="inceptionA1")(x) x = InceptionA(128,name="inceptionA2")(x) x = InceptionA(128,name="inceptionA3")(x) x = InceptionA(128,name="inceptionA4")(x) x = InceptionA(256,name="inceptionA5")(x) x = keras.layers.MaxPool2D()(x) x = InceptionB(256,name="inceptionB1")(x) x = InceptionB(512,name="inceptionB2")(x) x = keras.layers.GlobalAvgPool2D()(x) x = keras.layers.Dense(200,activation="relu")(x) x = keras.layers.Dropout(0.4)(x) output_x = keras.layers.Dense(10,activation="softmax")(x) model=keras.Model(input_x,output_x)学習してみる
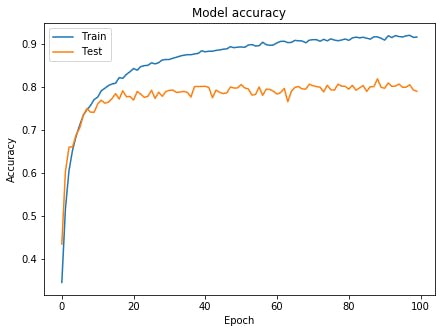
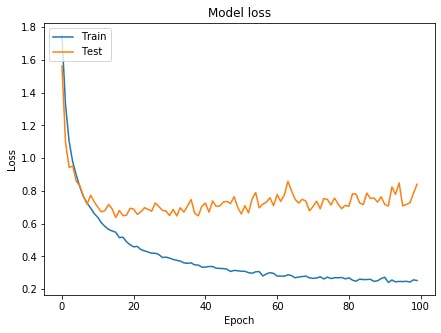
結果history=model.fit(Train_X,Train_Y,validation_split=0.2,epochs=100,batch_size=128) print(model.evaluate(Test_X,Test_Y,batch_size=128,verbose=0)) # Plot training & validation accuracy values plt.figure(figsize=(7,5),facecolor="white") plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show() # Plot training & validation loss values plt.figure(figsize=(7,5),facecolor="white") plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train', 'Test'], loc='upper left') plt.show()結果Train on 40000 samples, validate on 10000 samples Epoch 1/100 40000/40000 [==============================] - 21s 528us/sample - loss: 1.7499 - accuracy: 0.3451 - val_loss: 1.5629 - val_accuracy: 0.4344 Epoch 2/100 40000/40000 [==============================] - 14s 358us/sample - loss: 1.3234 - accuracy: 0.5164 - val_loss: 1.0947 - val_accuracy: 0.6033 Epoch 3/100 40000/40000 [==============================] - 14s 354us/sample - loss: 1.1026 - accuracy: 0.6058 - val_loss: 0.9439 - val_accuracy: 0.6604 Epoch 4/100 40000/40000 [==============================] - 14s 348us/sample - loss: 0.9771 - accuracy: 0.6535 - val_loss: 0.9520 - val_accuracy: 0.6610 Epoch 5/100 40000/40000 [==============================] - 14s 339us/sample - loss: 0.8966 - accuracy: 0.6862 - val_loss: 0.8594 - val_accuracy: 0.6891 Epoch 6/100 40000/40000 [==============================] - 13s 331us/sample - loss: 0.8242 - accuracy: 0.7118 - val_loss: 0.8313 - val_accuracy: 0.7049 Epoch 7/100 40000/40000 [==============================] - 13s 331us/sample - loss: 0.7646 - accuracy: 0.7346 - val_loss: 0.7673 - val_accuracy: 0.7348 ...(中略) Epoch 98/100 40000/40000 [==============================] - 13s 328us/sample - loss: 0.2433 - accuracy: 0.9205 - val_loss: 0.7278 - val_accuracy: 0.8055 Epoch 99/100 40000/40000 [==============================] - 13s 328us/sample - loss: 0.2573 - accuracy: 0.9159 - val_loss: 0.7851 - val_accuracy: 0.7935 Epoch 100/100 40000/40000 [==============================] - 13s 328us/sample - loss: 0.2532 - accuracy: 0.9165 - val_loss: 0.8414 - val_accuracy: 0.7903 [0.8851639811515808, 0.7773]
思うように精度向上とは行きませんでしたが、Lossは過学習が抑えられているとわかります。
おわりに
精度をもっとあげたい!という方は、パラメータチューニングを行うか、以下の記事を参考にされるとよろしいかと思われます。
CIFAR-10でaccuracy95%--CNNで精度を上げるテクニック--今回、DataAugmentationを行なわなかったりしている関係で、精度も過学習になっています。(次の日のTF2.0AdventCalendarにて紹介)
CNNで精度を上げるテクニックに関してはTF2.0アドベントカレンダーにも今後載せようかと考えています。ではまた明日!