- 投稿日:2019-11-26T23:58:28+09:00
Serverless Frameworkでevent scheduleをステージ毎に切り替える
環境
- Serverless Framework
やりたいこと
CloudWatch Eventの定期実行をステージングでは手動実行、本番では定期実行させたいということがあったので、備忘録として残しておきます。
serverless.yml
至って簡単です。
service: hoge provider: name: aws runtime: nodejs8.10 stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 custom: defaultStage: dev schedule_active: dev: false prod: true default: false functions: hello: handler: handler.hello events: - schedule: rate: rate(30 minutes) enabled: ${self:custom.schedule_active.${opt:stage, self:custom.defaultStage}, self:custom.schedule_active.default}上記で通常はscheduleを実行しないで、prod環境の時だけ、定期実行を行うように出来ます。
sls deploy --stage prodでデプロイすればOK
- 投稿日:2019-11-26T23:49:54+09:00
【初心者】AWS CloudFormation を使ってみる
目的
- CloudFormation のテンプレートがある程度読めるようになりたい。ハンズオン等で「このテンプレートをデプロイして下さい」と言われることがあるが、中身がよく分からないテンプレートを実行して、想定外のリソースができてしまったりするのが嫌なので。
やったこと
- 以下を実現するシンプルな CloudFormation テンプレートを作成する。
- VPC, IGW, Subnetを作成する。
- SubnetにIGW向けのルーティングを入れる。
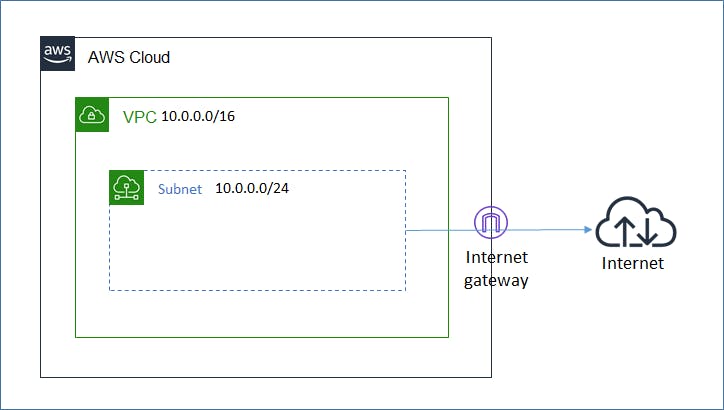
構成図
作業手順
- AWS公式のテンプレート「DNS およびパブリック IP アドレスを持つ Amazon VPC」 を見て、必要な設定のみ残す。
- 「Resources」で設定している内容は以下の通り。
- VPC: VPCを作成する。IPレンジ(10.0.0.0/16)は固定。
- Subnet: Subnetを作成する。IPレンジ(10.0.0.0/24)は固定。
- InternetGateway: IGWを作成する。
- AttachGateway: VPCにIGWをアタッチする。
- PublicRouteTable: RouteTableを作成する。
- Route: RouteTableにRoute(0.0.0.0/0をIGWへ)を追加する。
- PublicSubnetRouteTableAssociation: RouteTableとSubnetを紐づける。
sampletemplate.json{ "AWSTemplateFormatVersion" : "2010-09-09", "Description" : "Test template", "Parameters" : { "StackName": { "Description" : "Please input StackName.", "Type": "String", "Default" : "SampleStack", "AllowedPattern" : "[-a-zA-Z0-9]*", "ConstraintDescription" : "" }, }, "Resources" : { "VPC" : { "Type" : "AWS::EC2::VPC", "Properties" : { "CidrBlock" : "10.0.0.0/16", "Tags" : [{"Key" : "Name", "Value" : { "Ref" : "AWS::StackName" }}] } }, "Subnet" : { "Type" : "AWS::EC2::Subnet", "Properties" : { "VpcId" : { "Ref" : "VPC" }, "CidrBlock" : "10.0.0.0/24", "Tags" : [ {"Key" : "Name", "Value" : { "Ref" : "AWS::StackName" }} ] } }, "InternetGateway" : { "Type" : "AWS::EC2::InternetGateway", "Properties" : { "Tags" : [ {"Key" : "Name", "Value" : { "Ref" : "AWS::StackName" } } ] } }, "AttachGateway" : { "Type" : "AWS::EC2::VPCGatewayAttachment", "Properties" : { "VpcId" : { "Ref" : "VPC" }, "InternetGatewayId" : { "Ref" : "InternetGateway" } } }, "PublicRouteTable" : { "Type" : "AWS::EC2::RouteTable", "Properties" : { "VpcId" : {"Ref" : "VPC"}, "Tags" : [ {"Key" : "Name", "Value" : { "Ref" : "AWS::StackName" } } ] } }, "Route" : { "Type" : "AWS::EC2::Route", "DependsOn" : "AttachGateway", "Properties" : { "RouteTableId" : { "Ref" : "PublicRouteTable" }, "DestinationCidrBlock" : "0.0.0.0/0", "GatewayId" : { "Ref" : "InternetGateway" } } }, "PublicSubnetRouteTableAssociation" : { "Type" : "AWS::EC2::SubnetRouteTableAssociation", "Properties" : { "SubnetId" : { "Ref" : "Subnet" }, "RouteTableId" : { "Ref" : "PublicRouteTable" } } }, } }
- マネージメントコンソールからjsonファイルを読み込んでstackを作成する。Parametersで「StackName」を入力させるようにしており、ここで入力した値がVPC等のリソースのNameに反映される。
所感
- 変なリソースが作られないように、他人のテンプレートの実行前にはきちんと内容をチェックするようにし、あわせて読解力を高めていきたい。
- 投稿日:2019-11-26T23:45:47+09:00
Node.jsでGlobal Secondary Indexを使用して特定条件のレコードを抽出する
環境
- Nodejs
- AWS Lambda
- AWS DynamoDB
はじめに
DynamoDBではパーティションキーもしくはレンジキーを使用してしか基本的には抽出が出来ないのですが、任意のキーを元に抽出を行いたいという時は、Global Secondary Index(以下GSI)を使用する事で任意のキーでレコードを抽出することが出来ます。
注意点
以下の点に気をつける必要があります。
* GSIは1テーブルにつき20件までしか作成出来ない
* GSIのキーに指定出来るカラムのデータ型は文字列、数値、バイナリのいずれかである必要があります
* Serverless Frameworkではまだそこまで自由なGSIは作成出来ないようなので、DynamoDBコンソールからGSIを作成する必要がある(ハッシュキー or レンジキー以外でのGSIの作成がうまくいかなかった)例えばboolean型のカラムをキーにGSIは作成出来ません(私がやろうとしていました...)
参考情報:
* DynamoDB での制限前提
適当ですが、以下のような
Usersテーブルがあるとします。
カラム名 データ型 キー username string hash age integer range isPremier integer
isPremierカラムは0か1が整数で入るとします。
そしてisPremierが0のレコードを全件取得したいというのが実現したいことです。動作サンプルの手順
- AWS DynamoDB ConsoleからGSIを作成
- queryを行うLambdaを作成
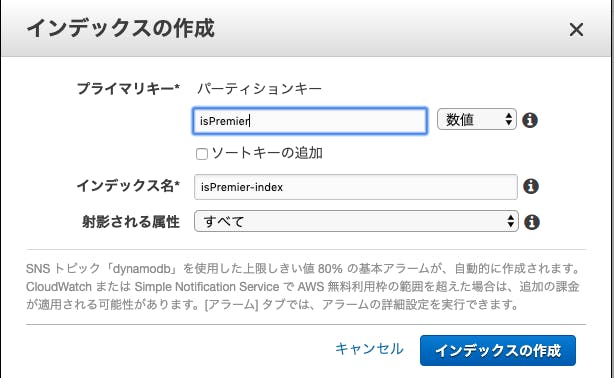
AWS DynamoDB ConsoleからGSIを作成
AWSのDynamoDB Consoleページ > テーブル > インデックス にアクセスします
そして
インデックスの作成ボタンから新規のGSIを以下のように作成します。
queryを行うLambdaを作成
NodejsでLambda関数を作成します。
先ほど作成したGSIの以下の情報を使用します。
* テーブル名:Users
* インデックス名:isPremier-index
抽出条件はisPremierが0のレコードを全件取得const AWS = require('aws-sdk') const DynamoDB = new AWS.DynamoDB.DocumentClient({region: "ap-northeast-1"}) module.exports.hello = async (event, context) => { try { const params = { TableName: 'Users', // テーブル名 IndexName: 'isPremier-index', // 作成したGSI名 KeyConditionExpression: '#indexKey = :indexValue', // 条件を指定 ExpressionAttributeNames : { "#indexKey" : 'isPremier' // GSIの作成時に指定したキー名を設定 }, ExpressionAttributeValues: { ':indexValue': 0 // isPremierの0を抽出 } } let items = [] // 抽出したレコードを格納するための空の配列を定義 const query = async () => { console.log('start query') let result = await DynamoDB.query(params).promise() items.push(...result.Items) // LastEvaluatedKeyが存在していたら再帰的にqueryを実行 if(result.LastEvaluatedKey){ params.ExclusiveStartKey = result.LastEvaluatedKey await query() } } await query() console.log(`Execution result: ${items.length}`) } catch (err) { console.error(`[Error]: ${JSON.stringify(err)}`) return err } }以上で条件にあったレコードを全件取得出来ます。
- 投稿日:2019-11-26T19:31:04+09:00
CloudFormationテンプレートのセキュリティ的な問題を開発プロセスの初期段階から警告しよう
CloudFormation を使用することで、AWS のリソースを素早くプロビジョニングできます。また、yaml 形式のテンプレートファイルで記述することにより、インフラ開発者はどのリソースが作成されるのかを宣言的に管理できます。
開発者は AWS リソースをすばやく簡単に作成できますが、安全でないリソースもすばやく作成できてしまいます。「安全でない」とは、TCP ポートを世界中に公開したり、特定の IAM ユーザーにフル権限を与えてしまうことでセキュリティ的に問題があるリソースを作り出してしまうことを意味しています。以前、CircleCI MeetUp で CloudFormation を静的構文解析する話をしました。
CloudFormation を静的構文解析することにより、セキュリティ的に問題があったり、命名規則に従っていないリソースに対して警告できます。このようにポリシー違反を検知する仕組みを作ることで、AWS リソースを構築する前にセキュリティ的な問題を対応できるようになります。
ただしルールを全て自作したり、セキュリティ的に問題がある箇所を洗い出す作業は非常に面倒です。
今回はそんなケースに有効な cfn-nag というツールを紹介します。
cfn-nag はセキュリティ的に問題がある CloudFormation のテンプレートを警告できるツールです。cfn-Python-lint と並んで CI のプロセスに組み込むことができます。
cfn-nag のインストール
cfn-nag は Ruby 製のツールです。Gem としてインストールしましょう。
gem install cfn-nagcfn-nag の使用方法
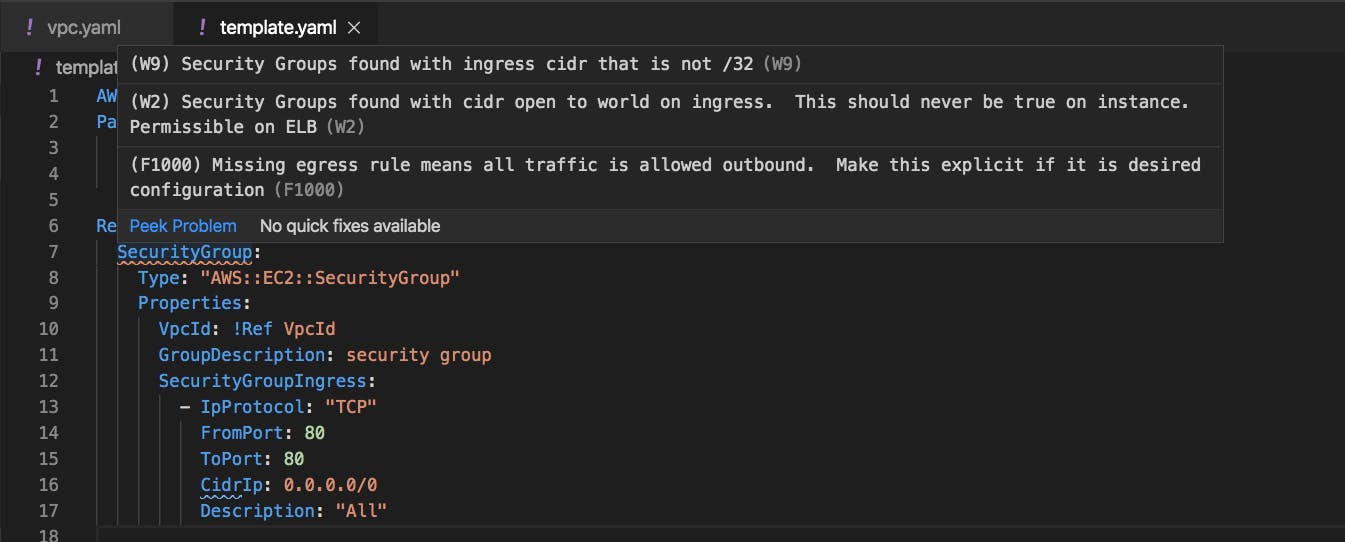
以下のようなテンプレートを例に取り上げます。
外部から 80 番ポートで TCP 通信することを許可するセキュリティグループを作成しようとしています。template.yamlSecurityGroup: Type: 'AWS::EC2::SecurityGroup' Properties: VpcId: !Ref VpcId GroupDescription: security group SecurityGroupIngress: - IpProtocol: "TCP" FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 Description: "All"このテンプレートに対して cfn-nag を実行してみましょう。
$ cfn_nag template.yaml ------------------------------------------------------------ template.yaml ------------------------------------------------------------------------------------------------------------------------ | WARN W9 | | Resources: ["SecurityGroup"] | Line Numbers: [9] | | Security Groups found with ingress cidr that is not /32 ------------------------------------------------------------ | WARN W2 | | Resources: ["SecurityGroup"] | Line Numbers: [9] | | Security Groups found with cidr open to world on ingress. This should never be true on instance. Permissible on ELB ------------------------------------------------------------ | FAIL F1000 | | Resources: ["SecurityGroup"] | Line Numbers: [9] | | Missing egress rule means all traffic is allowed outbound. Make this explicit if it is desired configuration Failures count: 1 Warnings count: 22つの Warnings, 1 つの Failure, 合計 3 つの警告がでました。
- Warnings: ingress ルールで/32 からのアクセスを許可していること
- Warnings: ingress ルールが全世界に向けて全開放していること
- Failures: egress ルールがついていないこと
cfn-nag のルールを許容する
cfn-nag の警告を確認すると確かにセキュリティ的にはあまりよくないルールになっていますね。
ただし、実際にこのようなセキュリティグループを使用することはよくあります。たとえばチームとして egress ルールは全許可にしていても良いなどのルールを決めている。あるいはパブリックユーザ向けの Web サービスの場合、特定のポート番号(例えば 443)で ingress ルールを全世界に向けて全開放することは一般的です。
このような場合は、許容するルールを
Metadataに記載しておきましょう。template.yamlSecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: VpcId: !Ref VpcId GroupDescription: security group SecurityGroupIngress: - IpProtocol: "TCP" FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 Description: "All" Metadata: cfn_nag: rules_to_suppress: - id: W9 reason: "このセキュリティグループはEC2には付与しない。ELBに付与して使用する" - id: W2 reason: "このセキュリティグループはEC2には付与しない。ELBに付与して使用する" - id: F1000 reason: "egressルールには制限を課しません"このようにしておくことで警告を無視できます。
$ cfn_nag template.yaml ------------------------------------------------------------ template.yaml ------------------------------------------------------------ Failures count: 0 Warnings count: 0開発環境に組み込む(VSCode の場合)
VSCode には cfn-nag の拡張機能(プラグイン)が提供されています。
こちらからインストールしておきましょう。
Format On Saveの項目にチェックを入れておくと、ファイルを保存した時に自動的に cfn-nag が実行されます。
このようにすることで早い段階でセキュリティ的に問題があるテンプレートを見つけることができるようになりました。
CI に組み込む(CircleCI の場合)
さらにCIのプロセスにも組み込んでおくと安心です。CircleCI の場合は以下のような感じでしょうか。
実際のユースケースに合わせてbundlerで管理することもあるかと思います。circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/ruby:2.6.0-node-browsers-legacy working_directory: ~/repo steps: - checkout - run: gem install cfn-nag - run: cfn_nag template.yaml


- 投稿日:2019-11-26T18:58:48+09:00
AWSの利用料金をGoで積み上げ棒グラフ化した
はじめに
- 最近いろんな所でDevOpsって言葉を聞きますね。
- DevOpsの影響を受けてFinOpsと呼ばれるテクノロジー、ビジネス、財務を融合させたクラウドの運用モデルも提唱されています。
- もしかしたら、数年後にはDevOpsと同じくらいメジャーな概念となっているかもしれません。
- FinOpsを始めるための第一歩としてクラウドの利用料金の可視化、通知が挙げられています。
- というわけで、今回はAWSの利用料金を手っ取り早くグラフ化してslackに通知するツールについて紹介します。
TL;DR
- CostExplorer APIからサービスごとの利用料金を取得
- gonum/plotでStackedBarChartを生成
- nlopes/slackでslackに通知
AWS料金の可視化方法いろいろ
- メリット: AWS公式ツール(APIもあるよ)
- デメリット: AWSアカウントがないと閲覧できない。外部サービスへの通知機能がない。
BIツール(re:dash, metabaseなど)
- メリット: 既存のOSSを利用できて開発コストを下げられる。すでに別用途で使っていれば同じサーバを流用できる。
- デメリット: データストア、BIサーバを構築・運用しなければならない。サーバのコストがかかる。
Datadog等の監視ツール
- メリット:SaaSを利用できて開発コストを下げられる。すでに別用途で使っていれば同じアカウントを流用できる。
- デメリット: Datadogのアカウントを持っていないと閲覧できない。Datadogのコストがかかる。
今回はなるべく運用コストかけたくなかったので、シンプルにCostExplorerAPIを使って料金を取得して、slack通知は別途実装することにしました。
CostExplorer APIからサービスごとの利用料金を取得
func fetchAWSDailyCost(f Flags) ([]*costexplorer.ResultByTime, error) { results := []*costexplorer.ResultByTime{} err := retry(5, time.Second, func() error { svc := costexplorer.New(session.Must(session.NewSessionWithOptions(session.Options{ AssumeRoleTokenProvider: stscreds.StdinTokenProvider, }))) results = []*costexplorer.ResultByTime{} input := &costexplorer.GetCostAndUsageInput{ Granularity: aws.String("DAILY"), GroupBy: []*costexplorer.GroupDefinition{ { Key: aws.String("SERVICE"), Type: aws.String("DIMENSION"), }, }, Metrics: []*string{ aws.String("BlendedCost"), }, TimePeriod: &costexplorer.DateInterval{ Start: aws.String(f.Start), End: aws.String(f.End), }, } for { res, err := svc.GetCostAndUsage(input) if err != nil { return err } results = append(results, res.ResultsByTime...) input.NextPageToken = res.NextPageToken if res.NextPageToken == nil { break } // Avoid LimitExceededException time.Sleep(time.Second) } return nil }) return results, err }
- CostExplorerAPIは他のAWSのAPIと比べてRate limitが厳しいので、ちゃんとsleepしたほうが良いです。
gonum/plotでStackedBarChartを生成
// Draw AWS cost chart func drawAWSDailyCostsChart(f Flags, costs []*costexplorer.ResultByTime) error { services := []string{} dates := []string{} pm := make(map[string]map[string]float64) for _, cost := range costs { date := *cost.TimePeriod.Start dates = append(dates, date) cm := make(map[string]float64) for _, group := range cost.Groups { service := strings.TrimPrefix(*group.Keys[0], "Amazon ") bc, err := strconv.ParseFloat(*group.Metrics["BlendedCost"].Amount, 64) if err != nil { return err } if bc > f.IgnoreCost { cm[service] = bc if !contains(services, service) { services = append(services, service) } } } pm[date] = cm } sort.Strings(services) scs := []serviceCost{} for _, service := range services { var sc serviceCost sc.service = service for _, date := range dates { v, exists := pm[date][service] if exists { sc.costs = append(sc.costs, v) } else { sc.costs = append(sc.costs, 0) } } scs = append(scs, sc) } return drawStackedBarChart(dates, scs, "price (USD)", f.File) } // Draw stacked bar chart func drawStackedBarChart(dates []string, serviceCosts []serviceCost, ylabel string, file string) error { plotutil.DefaultColors = append(plotutil.DefaultColors, plotutil.DarkColors...) p, err := plot.New() if err != nil { return err } p.Title.Text = "AWS Daily Costs" p.Y.Label.Text = ylabel p.Legend.Top = true p.Legend.Font.Size = vg.Points(8) p.X.Tick.Label.Font.Size = vg.Points(6) p.NominalX(dates...) bars := []*plotter.BarChart{} for i, sc := range serviceCosts { bar, err := plotter.NewBarChart(sc.costs, vg.Points(20)) if err != nil { return err } bar.Color = plotutil.Color(i) bar.LineStyle.Width = vg.Length(0) bars = append(bars, bar) p.Legend.Add(sc.service, bar) } for i := range bars { bar := bars[len(bars)-i-1] if i > 0 { bar.StackOn(bars[len(bars)-i]) } p.Add(bar) } p.Add(plotter.NewGlyphBoxes()) return p.Save(vg.Points(36*float64(len(dates))), 6*vg.Inch, file) }
- 何も考えずに
bar.StackOnでグラフを積み上げていくとグラフ本体の順序と右上の凡例の順序が逆になってしまうため、逆順でfor文を回しています。- フォントの大きさは自分で微調整する必要があります。
- godocにとても助けられました!!
nlopes/slackでslackに通知
// Post file and message to slack func postFileMessageToSlack(f Flags, account string) error { client := slack.New(f.Token) file, err := client.UploadFile(slack.FileUploadParameters{ File: f.File, }) if err != nil { log.Errorf("failed to upload file error:%+v", err) return err } file, _, _, err = client.ShareFilePublicURL(file.ID) if err != nil { return err } emoji := slack.MsgOptionIconEmoji(f.Emoji) username := slack.MsgOptionUsername(AppName) attachment := slack.MsgOptionAttachments(slack.Attachment{ Color: "FFBF00", // Amber Title: "AWS Cost Management", TitleLink: "https://console.aws.amazon.com/cost-reports/home#/dashboard", ImageURL: file.PermalinkPublic, Fields: []slack.AttachmentField{ { Title: "StartDate", Value: f.Start, Short: true, }, { Title: "EndDate", Value: f.End, Short: true, }, { Title: "Account", Value: account, }, }, }) _, _, err = client.PostMessage(f.Channel, emoji, username, attachment) return err }
- slackに投稿した画像をPublicにしないとAttachmentのImageURLに設定できないのがちょっと残念でした。どなたか良い方法ご存じの方ご教示ください

全体のコード (CLIにしました)
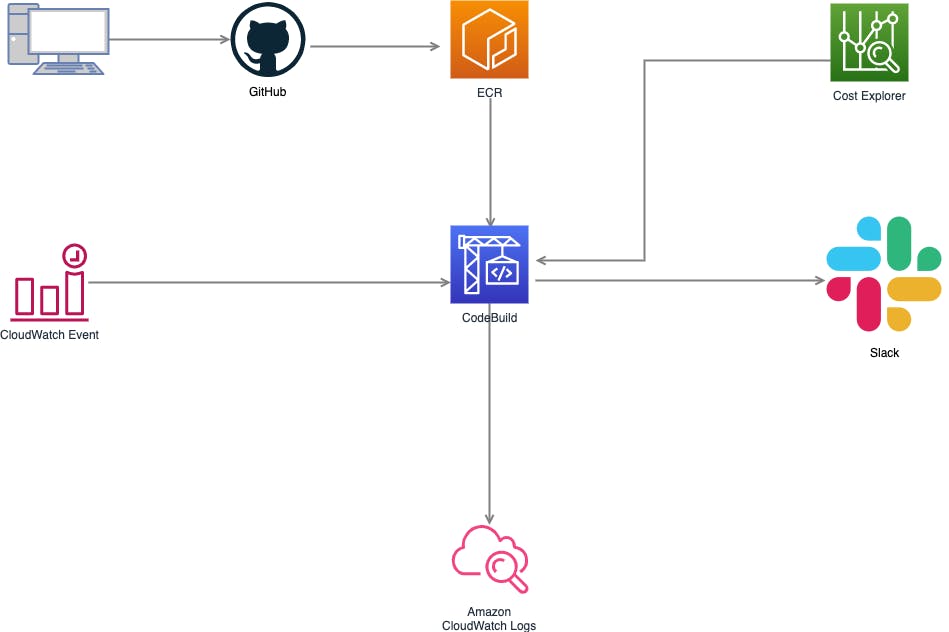
インフラの構築例
- CloudWatch EventとCodebuildで定期実行できるようにしておくと捗ります。
構成図
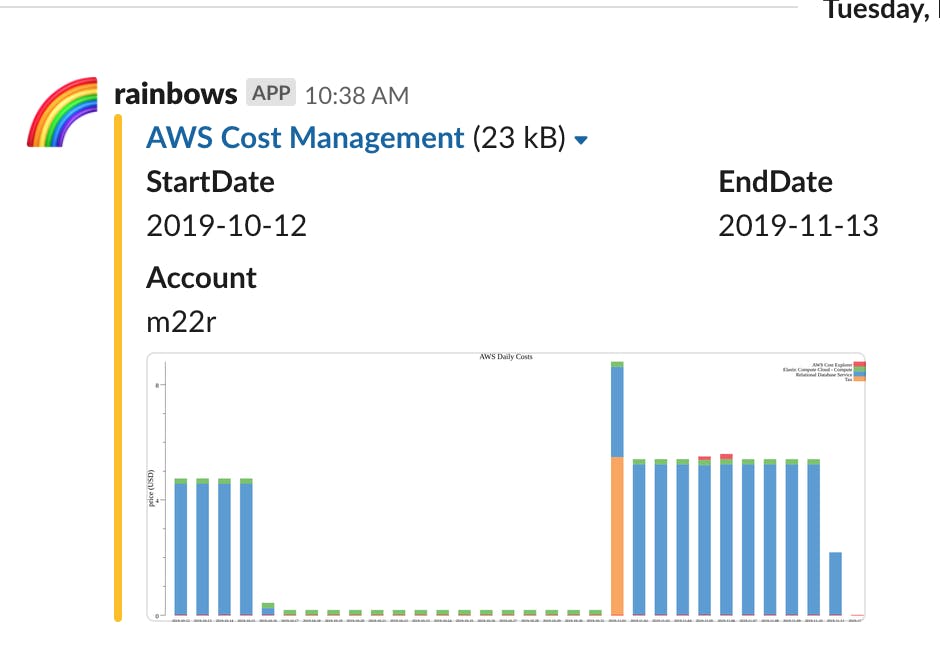
slackへの通知例
- こんな感じでグラフ化してslack通知できます!
運用してみた感想
- リリースして数カ月後に偉い人から「急にAWSの料金上がってるんだけど、なんなのこれ?」と聞かれて、とっさに思い出せなくて詰むことが少なくなった。
- 特定のサービスに想定以上のコストがかかっていることに早めに気づいて対策を打てるようになった。(例: cloudwatch logsに不要なログがたまりすぎる問題など)
- コストを絡めてリファクタリングの提案をやりやすくなった。
- 見積もりベースで行っていたコストの議論を実績ベースでできるようになった。
- 継続的な可視化/通知って大事ですね。
- 投稿日:2019-11-26T17:19:19+09:00
CDKでSlack botを作ろう
どうも!@ufoo68です。今回2回目の投稿になります。@keigo1450さんよりバトンパスをもらっての投稿となります。前日のものはかなり実用的で新卒の私はすごく勉強になりました。
そんな私の方は、また作ってみた系になります。はじめに
この記事が投稿されている頃、今頃私はラスベガスにいることでしょう。ということでAWS関係のことを書こうと思います(そのためにソリューションアーキテクト-アソシエイトとりました)。
あとこの記事は、自分がreinvent中にQiitaを書くというチャレンジで社内のアドベントカレンダーに登録しました。作ったものですが、Slack上で以下のコマンド/set_money hoge/check_moneyを叩いてカジノの勝ち金を見れるSlackBotを作りました。本当はカジノの戦略考えるBotとか考えましたが、時間と私の知識力により断念。。。
CDKとは
AWS CDKとは、ざっくりと説明すると、AWSのリソース関係のアーキテクチャの構築とか、デプロイとかをプログラム言語で記述できる便利なツールです。詳しい理解はこのチュートリアルを進めるとわかってくるかと思います。
また、このCDKを使ったIoT的なSlackBotを作る記事はすでに公開されています。今回はそれをベースに簡単なおうむ返しSlackBotを作ってみました。
ソースはここで公開しております。実装
まずは以下のコマンドでテンプレートを準備します
cdk init cdk-slack-bot --language typedあとはサンプルコードに以下を付け足したり修正したりします。
cdk-slack-bot/lib/cdk-slack-bot-stack.tsimport cdk = require('@aws-cdk/core') import lambda = require('@aws-cdk/aws-lambda') import apigw = require('@aws-cdk/aws-apigateway') import dynamodb = require('@aws-cdk/aws-dynamodb') export class CdkSlackBotStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props) const table = new dynamodb.Table(this, 'Money', { partitionKey: { name: 'path', type: dynamodb.AttributeType.STRING } }) const bot = new lambda.Function(this, 'BotHandler', { runtime: lambda.Runtime.NODEJS_8_10, code: lambda.Code.asset('lambda'), handler: 'bot.handler', environment: { HITS_TABLE_NAME: table.tableName } }) table.grantReadWriteData(bot); new apigw.LambdaRestApi(this, 'Endpoint', { handler: bot }) } }cdk-slack-bot/lambda/bot.tsimport * as QueryString from 'querystring' import { DynamoDB } from 'aws-sdk' exports.handler = async function (event: any) { const query = QueryString.parse(event.body) const dynamo = new DynamoDB() switch (query.command) { case '/set_money': if (query.user_name !== 'myname') return { statusCode: 200, headers: { "Content-Type": "text/plain" }, body: 'You are not me' } await dynamo.updateItem({ TableName: process.env.HITS_TABLE_NAME as string, Key: { path: { S: 'money' } }, UpdateExpression: 'SET money = :num', ExpressionAttributeValues: { ':num': { N: query.text as string } } }).promise() return { statusCode: 200, headers: { "Content-Type": "text/plain" }, body: 'Set your total money' } case '/check_money': const money = await dynamo.getItem({ TableName: process.env.HITS_TABLE_NAME as string, Key: { path: { S: 'money' } } }).promise() return { statusCode: 200, headers: { "Content-Type": "text/plain" }, body: `勝ち分は、${money.Item!.money.N}ドルです。` } default: return { statusCode: 200, headers: { "Content-Type": "text/plain" }, body: 'invalid command' } } }使ったのは
lambda,dynamodb,apigatewayの3つになります。かなり雑な実装ですが、一応私しかset_moneyできないようにガードをかけました(簡単にハックされるとは思いますが)。さいごに
一応このBotは社内Slackのワークスペースにこっそり入れたので
check_moneyで私の勝ち分を確認することができます。まあ、今の所マイナスですが。。。
さて、明日も@keigo1450さんの投稿です。お楽しみに!
- 投稿日:2019-11-26T17:18:33+09:00
Glueの使い方的な㊷(XMLで出力)
DataFrameでCSVをXMLで出力するジョブを作る
ジョブの内容
Glue、というか多分DynamicFrameが、
XMLの入力には対応していますが、出力には対応していません。https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-programming-etl-format.html
現在、AWS Glue は出力用に "xml" をサポートしていません。
DataFrameを使ってXML出力するにはdatabricksが作ったライブラリなどが必要です。DataFrameを使ってのXML出力をやってみます
※"Glueの使い方的な①(GUIでジョブ実行)"(以後①とだけ書きます)とほぼ同じ処理
"今回は出力をXML形式にします"
その際に以下のjarを使う
spark-xml_2.11-0.5.0.jarGlueのv0.9はSpark2.2、v1.0はSpark2.4
Glue Spark Python 0.9 2.2.1 2.7 1.0 2.4.3 3.6 https://github.com/databricks/spark-xml
今回はGlueのv0.9(Sparkバージョンは2.2.1)を使うので、requirement通りspark-xmlはv0.5.xを使いますRequirements
spark-xml Spark 0.6.x+ 2.3.x+ 0.5.x 2.2.x - 2.4.x 0.4.x 2.0.x - 2.1.x 0.3.x 1.x ジョブ名
se2_job26
全体の流れ
- 前準備
- ジョブ作成と修正
- ジョブ実行と確認
前準備
jarファイルダウンロード
このあたりからdatabricksのspark-xml_2.11-0.5.0.jarをダウンロードし、s3の s3://test-glue00/se2/lib/ にアップロードしておく。
ここにあるものを使いました。
https://repo1.maven.org/maven2/com/databricks/spark-xml_2.11/0.5.0/ソースデータ(19件)
※①と同じデータ
csvlog.csvdeviceid,uuid,appid,country,year,month,day,hour iphone,11111,001,JP,2017,12,14,12 android,11112,001,FR,2017,12,14,14 iphone,11113,009,FR,2017,12,16,21 iphone,11114,007,AUS,2017,12,17,18 other,11115,005,JP,2017,12,29,15 iphone,11116,001,JP,2017,12,15,11 pc,11118,001,FR,2017,12,01,01 pc,11117,009,FR,2017,12,02,18 iphone,11119,007,AUS,2017,11,21,14 other,11110,005,JP,2017,11,29,15 iphone,11121,001,JP,2017,11,11,12 android,11122,001,FR,2017,11,30,20 iphone,11123,009,FR,2017,11,14,14 iphone,11124,007,AUS,2017,12,17,14 iphone,11125,005,JP,2017,11,29,15 iphone,11126,001,JP,2017,12,19,08 android,11127,001,FR,2017,12,19,14 iphone,11128,009,FR,2017,12,09,04 iphone,11129,007,AUS,2017,11,30,14ジョブ作成と修正
ジョブ作成の細かい手順は②をご参照ください。以下の部分を修正します。
- 依存jarパス:s3://test-glue00/se2/lib/
処理内容は"S3の指定した場所に配置したcsvデータを、パーティション化し、指定した場所にXMLとして出力する"です。結果としてパーティション化はできませんでした(後述します)。
se2_job26import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) ###add sc._jsc.hadoopConfiguration().set("mapred.output.committer.class", "org.apache.hadoop.mapred.FileOutputCommitter") datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1") resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2") dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3") df = dropnullfields3.toDF() partitionby=['year','month','day','hour'] output='s3://test-glue00/se2/out19/' ###Add df.write.format('com.databricks.spark.xml').partitionBy(partitionby).option('rootTag', 'root').option('rowTag', 'item').mode("overwrite").save(output) job.commit()以下の部分を修正します。
Hadoopの設定を追加しています。
"mapred.output.committer.class"にFileOutputCommitterを使用するこれを入れないと"Class org.apache.hadoop.mapred.DirectOutputCommitter not found"というエラーが出ます。
####add sc._jsc.hadoopConfiguration().set("mapred.output.committer.class", "org.apache.hadoop.mapred.FileOutputCommitter")formatを'com.databricks.spark.xml'としています
optionでrootTagとrowTagを指定しています
partitionByでパーティション化しようとしましたができませんでした(後述します)df.write.format('com.databricks.spark.xml').partitionBy(partitionby).option('rootTag', 'root').option('rowTag', 'item').mode("overwrite").save(output)ジョブ実行と確認
ジョブ実行
対象ジョブにチェックを入れ、ActionからRun jobをクリックしジョブ実行します。
ファイルもXMLとして出力されていますが、パーティション分割はされませんでした。
以下のIssueにあるようにspark-xmlがパーティションには対応していないようです。(20191126,最新の0.7とかでもダメでした)
https://github.com/databricks/spark-xml/issues/327
ファイルをダウンロードしてエディタで開きXMLファイルとして出力はされています
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f

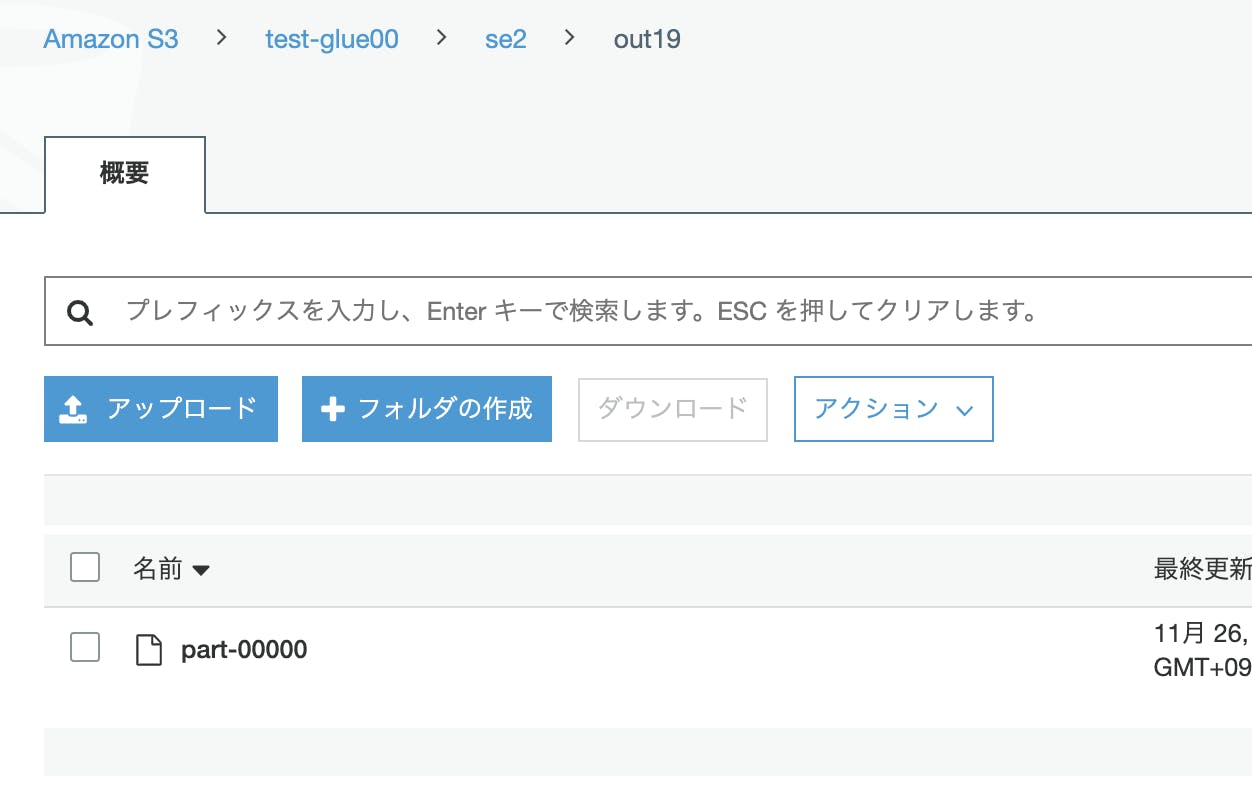
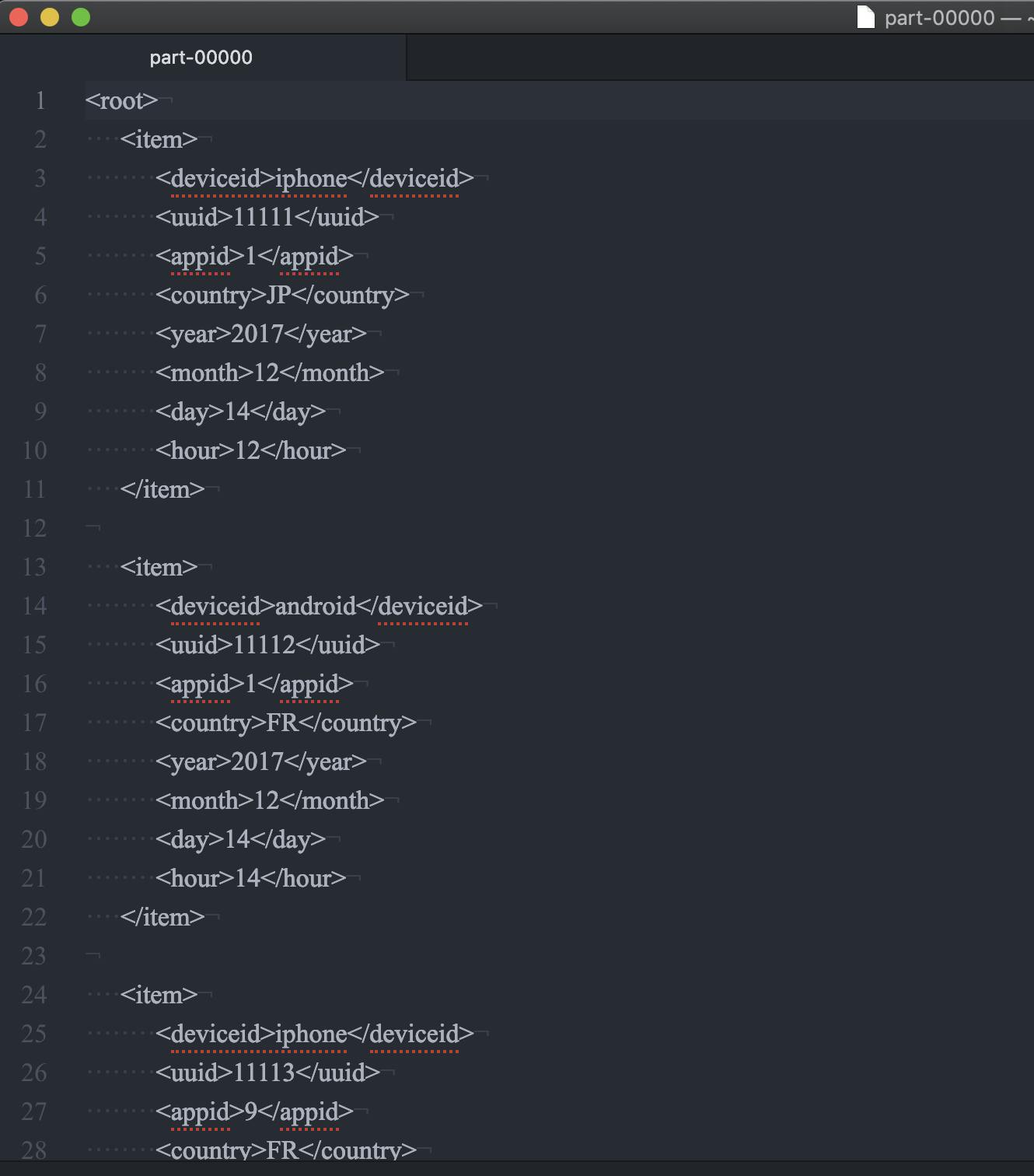
- 投稿日:2019-11-26T16:09:38+09:00
EC2のパブリックIPアドレスを意識せずにSSHログインする
やりたいこと
踏み台サーバーを構築した際などは、基本的にSSHでログインすることになる。
そのEC2のパブリックIPアドレスを知らない状態で、SSHログインをしたい。EC2を起動する度にパブリックIPアドレスは切り替わるので、ElasticIPを付与するケースが多かったりする。
しかし、ElasticIPは1AWSアカウントに対し、デフォルトではリージョン毎に5つしか設定できなかったりと何かと制約がある。
そのため、不必要にElasticIPを使うのも避けたい。解決策
下記の流れで解決できます。
- (事前準備) EC2インスタンスにタグを貼っておく
- (SSH接続時) SSH接続したいインスタンスのオブジェクトをタグで検索をかける
- (SSH接続時) ヒットしたEC2のパブリックIPアドレスを取得
- (SSH接続時) 取得したパブリックIPアドレスに対し、SSH接続
インスタンスへのタグ付
下記のように、Nameというキー名でタグを貼ると、コンソール画面のNameの場所にタグの値が表示されます。
今回は、Nameというタグをvrf-bastionという名前で貼りました。
SSH接続
AWS CLIを使ったスクリプトを書きます。
インスタンス情報を取得するには、aws ec2 describe-instancesを使用します。
追加で指定するオプションは下記の通りです。
--filters: 指定したインスタンス情報で検索するインスタンスを絞り込む--query: 取得したインスタンス情報から、抽出するフィールドを指定する作成したスクリプト
ssh-ec2.sh#!/bin/bash # ------------------------------------------ # 踏み台サーバーにSSHログイン # # 実行例: # $ sh ssh-ec2.sh # ------------------------------------------ KEY_PATH_LOCAL=~/.ssh/key-pair.pem PUBLIC_IP=$( aws ec2 describe-instances \ --filters \ "Name=tag:Name,Values=vrf-bastion" \ "Name=instance-state-name,Values=running" \ --query "Reservations[0].Instances[0].PublicIpAddress" \ | tr -d \" ) ssh -i ${KEY_PATH_LOCAL} ec2-user@${PUBLIC_IP}
--filtersでは、タグのName属性がvrf-bastionであるものを指定しており、さらに起動中のインスタンスの指定をしています。
検索に引っかかったインスタンスが1つであっても、リスト形式で情報が帰ってくるので--queryに、Instance[0]という形で先頭のインスタンスを取得し、パブリックIPアドレスのみを出力するよう指定しています。また、
"aaa.bbb.ccc.ddd"というダブルクオーテーション付きでパブリックIPが出力されるので、最後に両サイドのダブルクオーテーションを取り除いて変数に代入。最後にそれらの変数を用い、SSH接続。
あとは、下記のようスクリプトを実行するだけです。
$ sh ssh-ec2.shこれで動的にインスタンス名からIPアドレスを取得し、SSH接続できるようになりました。
- 投稿日:2019-11-26T15:04:19+09:00
AWS EC2でWordPressを構築する際に500エラーに悩まされた話
はじめに
今回、「ゼロからわかるAmazonWebServices入門」という書籍でAWSを学習しているものです。
こちらの書籍の第4章でエラーに遭遇し、多くの時間を浪費してしまったので備忘録として記します。
同じようなエラーに悩んでいらっしゃる方の一助となれれば幸いです。ブラウザからパブリックIPにアクセスすると500エラーになった
書籍の手順通り、デフォルトのVPC、サブネットにEC2インスタンスを作成、起動させ、そこへsshでログイン後、Apache、PHP、MARIADB、WordPressをインストールし終えたところでブラウザからパブリックIDを仕様してサーバーにアクセスすると、500エラーが表示されました。
原因と対処法
私の場合、インストールしたPHPとWordPressのバージョンが合わず、エラーを引き起こしていました。
そこでいったんインストールしたWordPressを削除してから、古いバージョンのものをバージョン指定してインストールする事で解決しました。1、インストール、展開したWordPressを削除
/home/wordpress
$ rm -rf *
/var/www/html/
$ rm -rf *
2、古いバージョンのWordPressをインストール(私の場合は5.0.7)
/home/wordpress
$ wget https://wordpress.org/wordpress-5.0.7.tar.gz
3、インストールした古いバージョンのWordPressを展開
/home/wordpress
$ tar wordpress-5.0.7.tar.gz
4、古いバージョンのWordPressをAppacheに移動
/home/wordpress
$ mv wordpress/* /var/www/html
500エラーとは何か
様々なステータスコードがある中で、500エラーは内部サーバーエラーと呼ばれるらしいです。
要するに、ソースコードや、プログラム自体に問題があるよ!という意味のエラーだと解釈しています。
今回のエラーに関しては、プログラム同士が互換性がなくエラーになっていたので、納得です。おわりに
このエラーに関しては、問題があることを知らせてくれるのみで具体的に何が悪いのかが分からず、半日ほど使ってしまいました。
Apacheを疑ってみたり、データベースを疑ってみたりと四苦八苦しました...。
WordPressをインストールし直す試みの途中で、いったんWordPressをアンインストールしたところ正常なapacheの画面が表示されたので、問題はWordPressにあるだろうというところまで来るものの、さらに時間を浪費するばかり...。
最終的には、書籍に記された
http://IPアドレス/wp-admin/install.php
ではなく、
http://IPアドレス/wp-admin/serup-config.php
にアクセスしてみたところ、「PHPとWordPressのバージョンに互換性がないよ」とエラーが表示されたので、なんとか解決。
まだまだ勉強することがたくさんありますね。
- 投稿日:2019-11-26T14:32:02+09:00
【クラウド初心者向け】Amazon Connectのリアルタイムモニタリング
概要
- ユーザー(エージェント)が受けている電話を管理者がリアルタイムに聞くことができる。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
【クラウド初心者向け】Amazon Connectのユーザー(エージェント)作成を参考に以下の設定でユーザーを作成します。
- 名:適当な名を入力します。
- 姓:適当な姓を入力します。
- ログイン名:適当なログイン名を入力します。
- パスワード、パスワード確認:適当なパスワードを入力します。
- ルーティングプロファイル:「Basic Routing Profile」(今回はルーティングされないものを選択しましたが適当に選択してください)
- セキュリティプロファイル:「CallCenterManager」 と「Agent」を選択します。
【クラウド初心者向け】Amazon Connectの着信確認を参考に、作成したユーザーでソフトフォンにサインインします。
- ステータス:Offline
作成したユーザーでAmazon Connectのインスタンスにサインインします。
- URL:https://インスタンス名.awsapps.com/connect/
ダッシュボードの左側のメニューから《リアルタイムメトリクス》をクリックします。
「リアルタイムメトリクス」画面が表示されるので《エージェント》をクリックします。
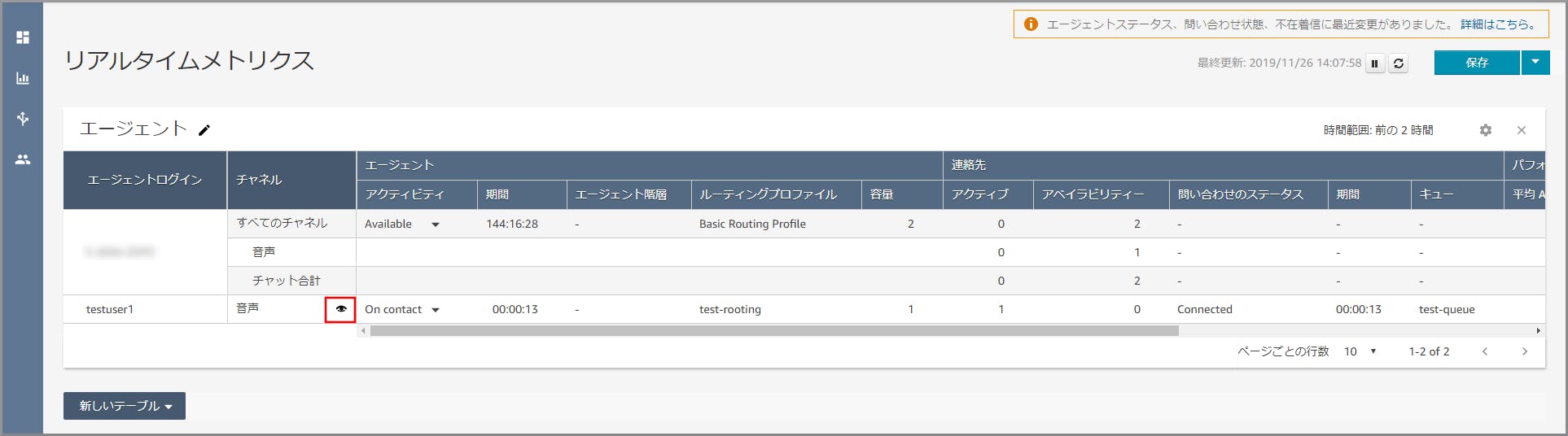
「エージェント毎のリアルタイムメトリクス」画面が表示されます。モニタリングしたいユーザーのチャネル欄にあるアイコンをクリックします。
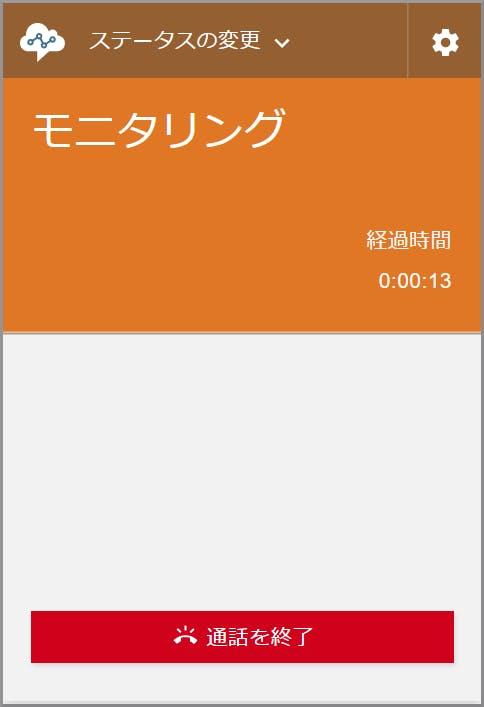
事前に起動しておいたソフトフォンがモニタリング状態になり通話内容を聴くことができます。
- モニタリング側の《通話を終了》をクリックするとモニタリング側だけ通話が終了します。(モニタリングのみ終了し、通話自体は継続しています)
参考サイト
目次に戻る



- 投稿日:2019-11-26T13:23:14+09:00
AWSのサブアカウントを作る
今日はAWSのサブアカウント(支払いクレカが一緒の別アカウント)を作る方法をメモります
大した事ではないのだけど
割と「どっからやるんだぁ?これぇ」ってなるのでメモりますよ~メモメモ
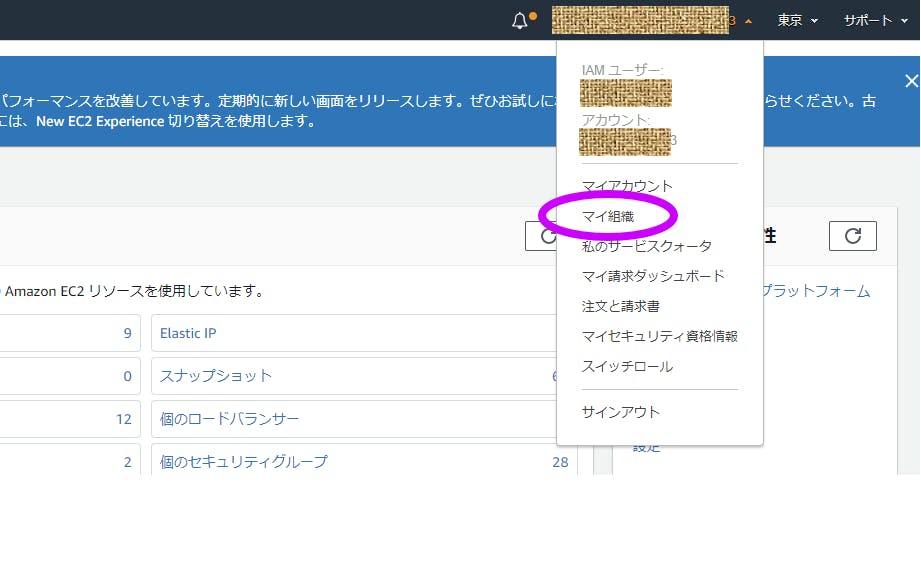
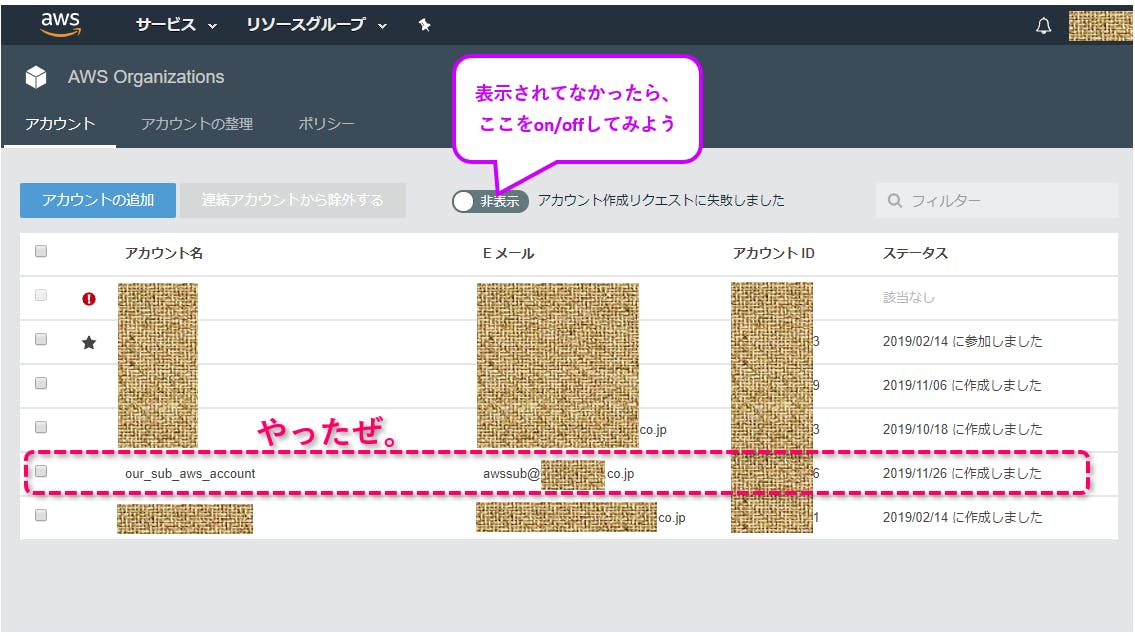
【マイ組織】にアクセス
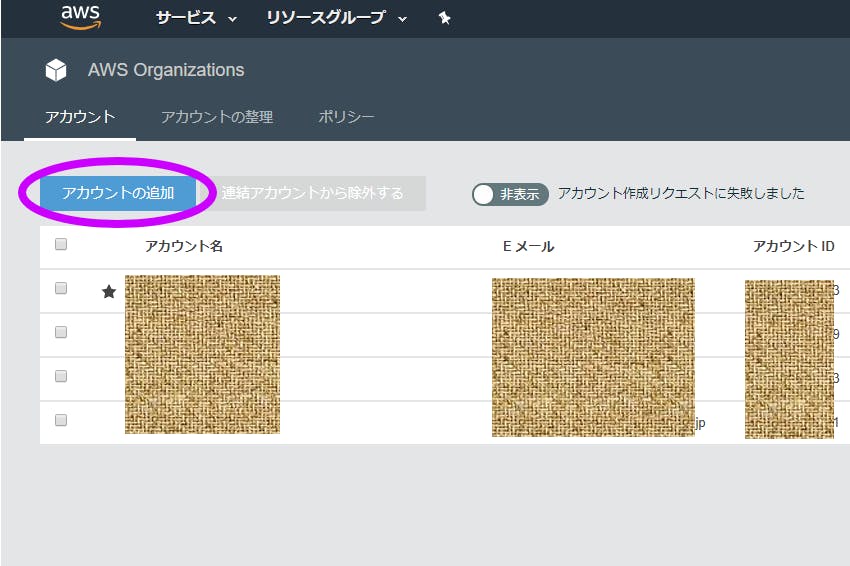
【アカウントの追加】を押す
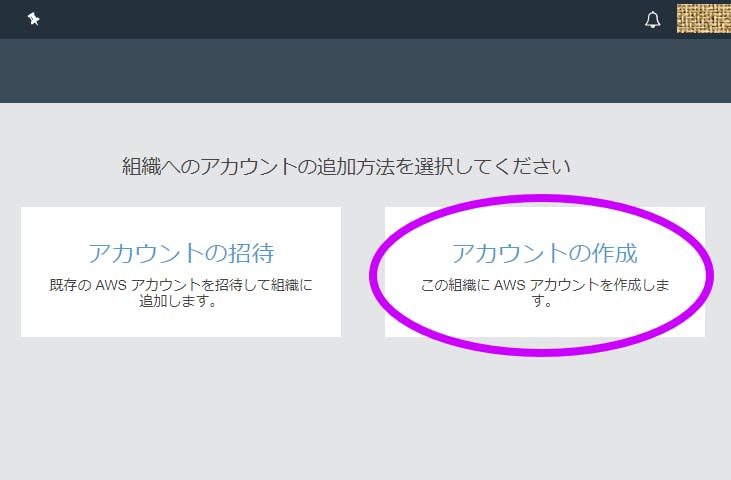
【アカウントの作成】を押す
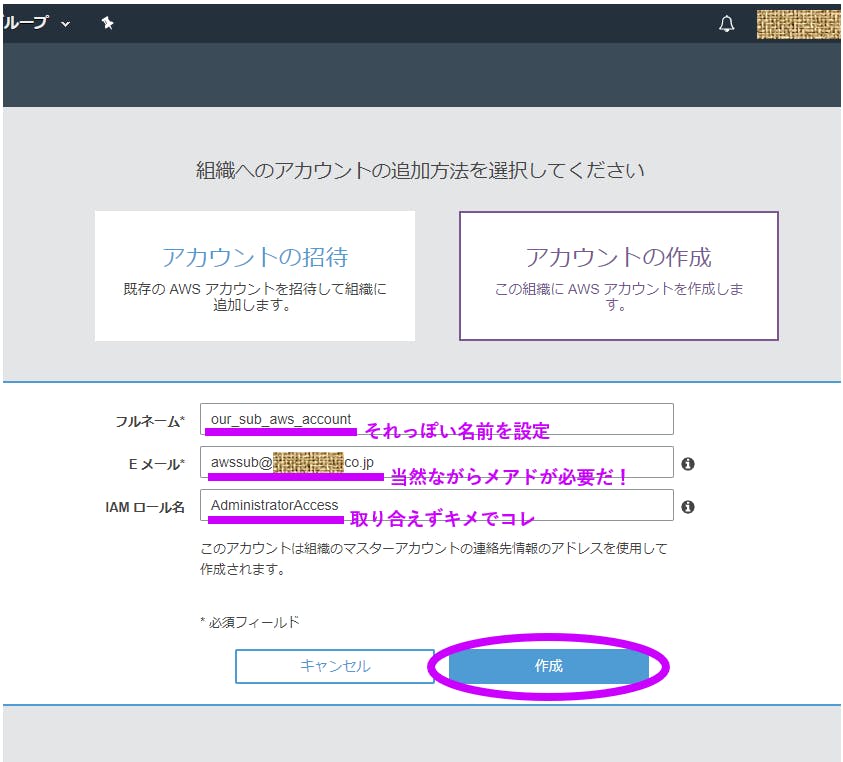
必要事項を記入して【作成】を押す
作成されるぜ
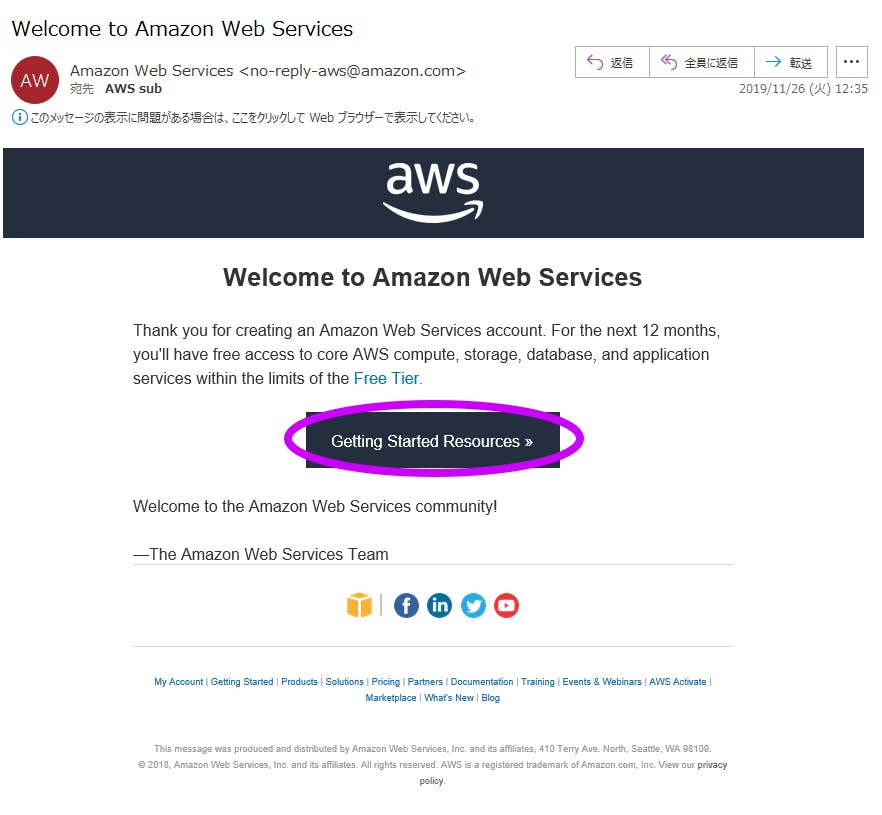
メアド宛に招待メールが来ているので、その中の【Getting Started Resources】を押す
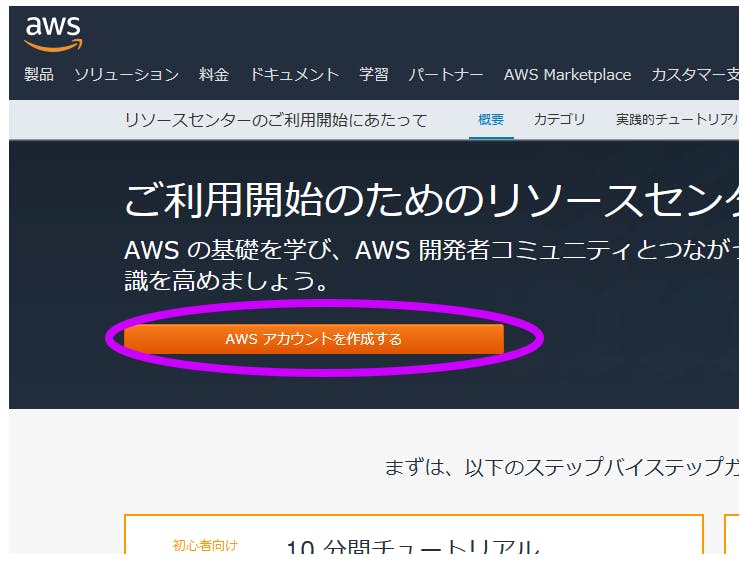
AWSサイトに飛ぶので【AWSアカウントを作成する】を押す
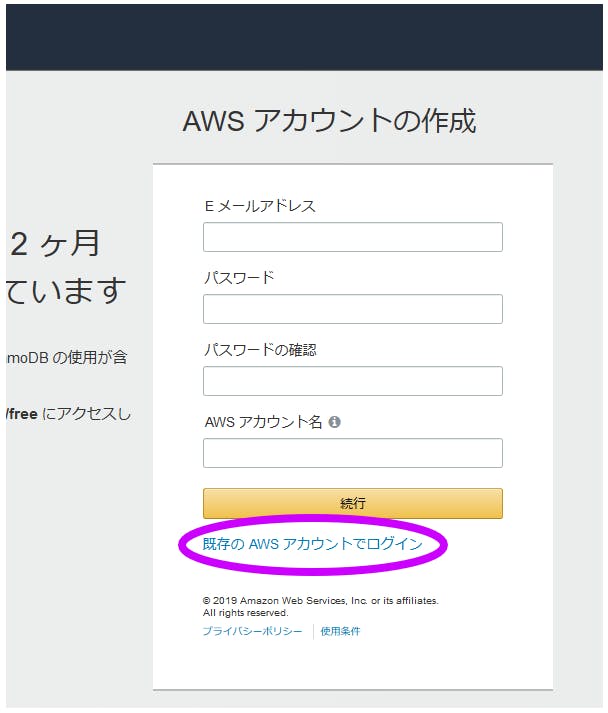
【既存のAWSアカウントでログイン】を押す
【ルートアカウント認証情報を使用してログイン】を押す
さっき設定したメアドを入力して【次へ】を押す
【パスワードをお忘れですか?】を押す
ん?
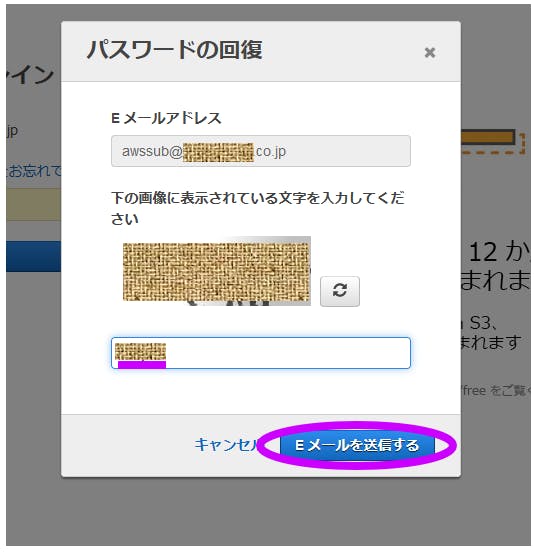
ここまでパスワード設定するとこあったっけ・・・?てことで、パスワードリセットを応用しちゃおう
他の正解フローあるんかいな…?
ママエアロ(適当)画像認証コードを入力して【Eメールを送信する】を押す
パスワードを設定
あとは分かるな?
ってことで成し遂げたぜ。


- 投稿日:2019-11-26T13:09:57+09:00
【クラウド初心者向け】Amazon Connectの録音確認
概要
- 問い合わせフローで「通話記録動作の設定」ボックスを置くことにより自動的に通話を録音する。
- 録音した通話は、通話終了後少し経つと聞けるようになる。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
ダッシュボードの左側のメニューから《問い合わせの検索》をクリックします。
「問い合わせの検索」画面が表示されるので以下の項目を設定して《検索》をクリックします。
- 開始日:音声を確認したい日付
- 終了日:音声を確認したい日付
- タイムゾーン:Japan または、Asia/Tokyo(タイムゾーンを選択すると検索後に表示される問い合わせ履歴の時間が現地時間に修正されます)
画面を下にスクロールして問い合わせ履歴一覧を表示し、再生ボタンをクリックします。
- 通話の有無に関係なく着信した履歴が全て表示されます。
- その中で通話したものだけ「録音/トランスクリプト」欄に記号が表示されます。
再生画面が表示され音声が再生されます。
目次に戻る


- 投稿日:2019-11-26T13:09:20+09:00
【クラウド初心者向け】Amazon Connectの着信確認までの振り返り
振り返り
- 概念図を見ながら、作成した順序と電話番号やルーティングプロファイルなどの関連を整理します。
概念図
- 赤い線:電話を架けた場合の流れ
- 青い線:関連付け
- 赤い数字:作成順序作成順序
- ①:電話番号の取得
- ②:キューの作成
- ③:ルーティングプロファイルの作成
- ④:ユーザー(エージェント)の作成
- ⑤:問い合わせフローの作成
関連付け
- 電話番号から問い合わせフローを指定
- 電話番号に関連づけられる問い合わせフローは一つのみ
- 問い合わせフロー内で呼び出すキューを指定
- 問い合わせフロー内で指定により呼び出すキューを変えられる
- ルーティングプロファイルが参加するキューを指定
- 複数のキューに参加可能
- ユーザー(エージェント)が所属するルーティングプロファイルを指定
- 一つのルーティングプロファイルにしか所属できない
まとめ
- 作成順序がわかりづらいのは、関連付けを手戻りなく進めるためこの順番で作成しています。
- キューが間に入る事によって、問い合わせフローとルーティングプロファイルが固定されずに色々と関連づける事ができる。 (データベースで言う所の多対多の関係をつないでいます)
- 基本はこれだけなので理解できると色々と何をすれば良いかが自然とわかるようになります。
目次に戻る

- 投稿日:2019-11-26T13:08:57+09:00
【クラウド初心者向け】Amazon Connectの顧客キューのフロー変更
設定していない音声と音楽が流れた理由
- 着信確認した際に設定していない音声と音楽が流れた理由を説明します。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
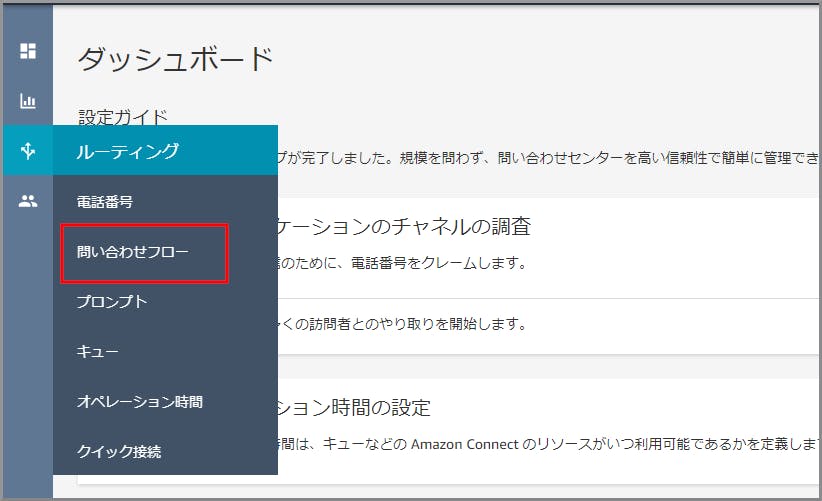
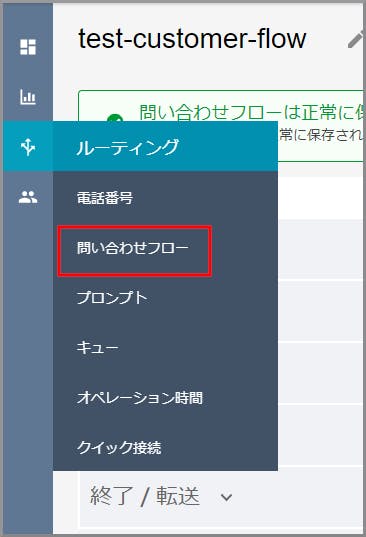
ダッシュボードの左側のメニューから《問い合わせフロー》をクリックします。
「Default customer queue」をクリックします。
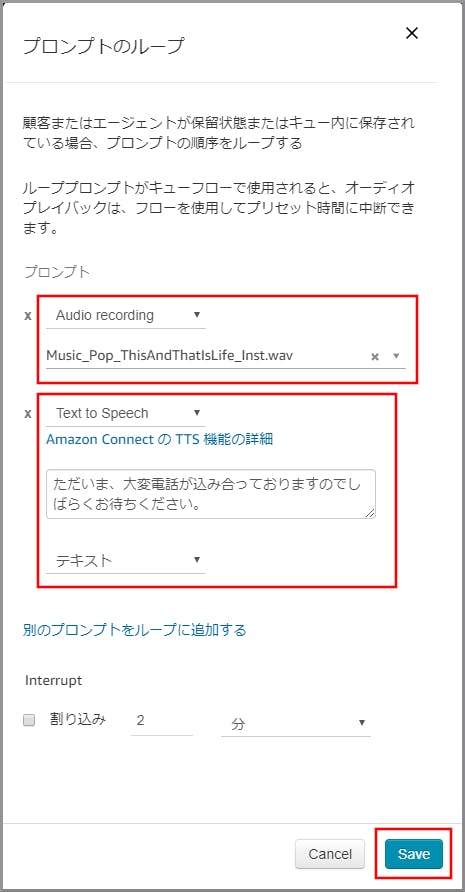
《プロンプトのループ》のタイトル部分をクリックします。
右側に「プロンプトのループ」画面がでるので内容を確認します。
設定していない音声と音楽が流れた理由
- 問い合わせフローで「キューへ転送」オブジェクトに制御が移った場合に、指定した顧客キューフローを実行する。
- 顧客キューフローを設定していない場合は、「Default customer queue」のフローが実行される。
- 今回は設定していなかったため謎の音声と音楽が流れました。
顧客キューのフロー変更
- 想定している顧客キューフローになるよう設定を行います。
- 問い合わせフローの「キューへ転送」に入った時点でユーザー(エージェント)に空きがあればソフトフォンのコールが始まります。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
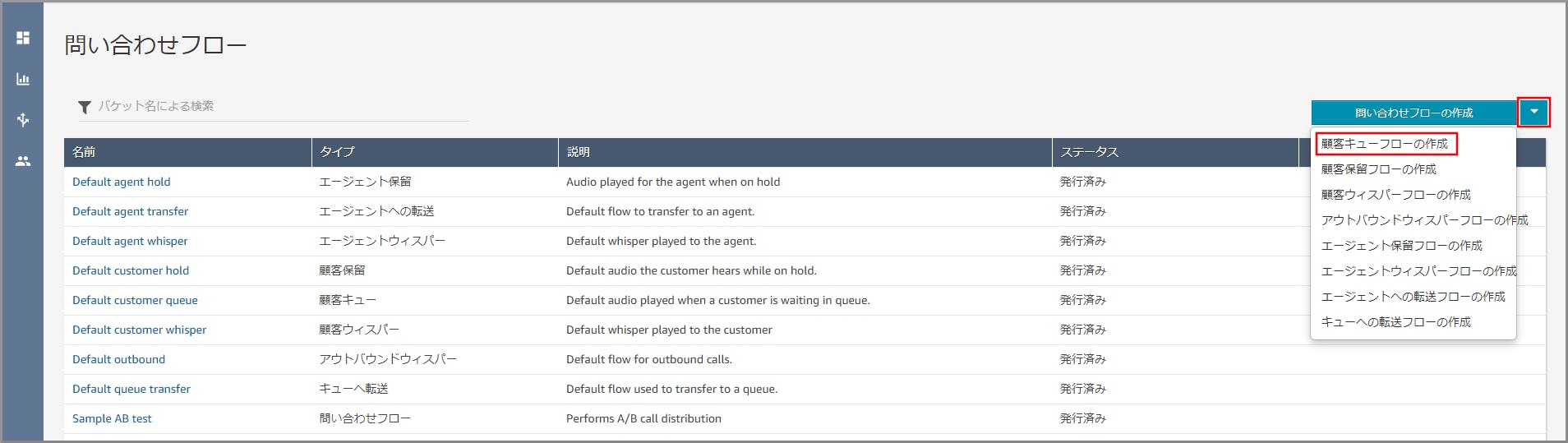
ダッシュボードの左側のメニューから《問い合わせフロー》をクリックします。
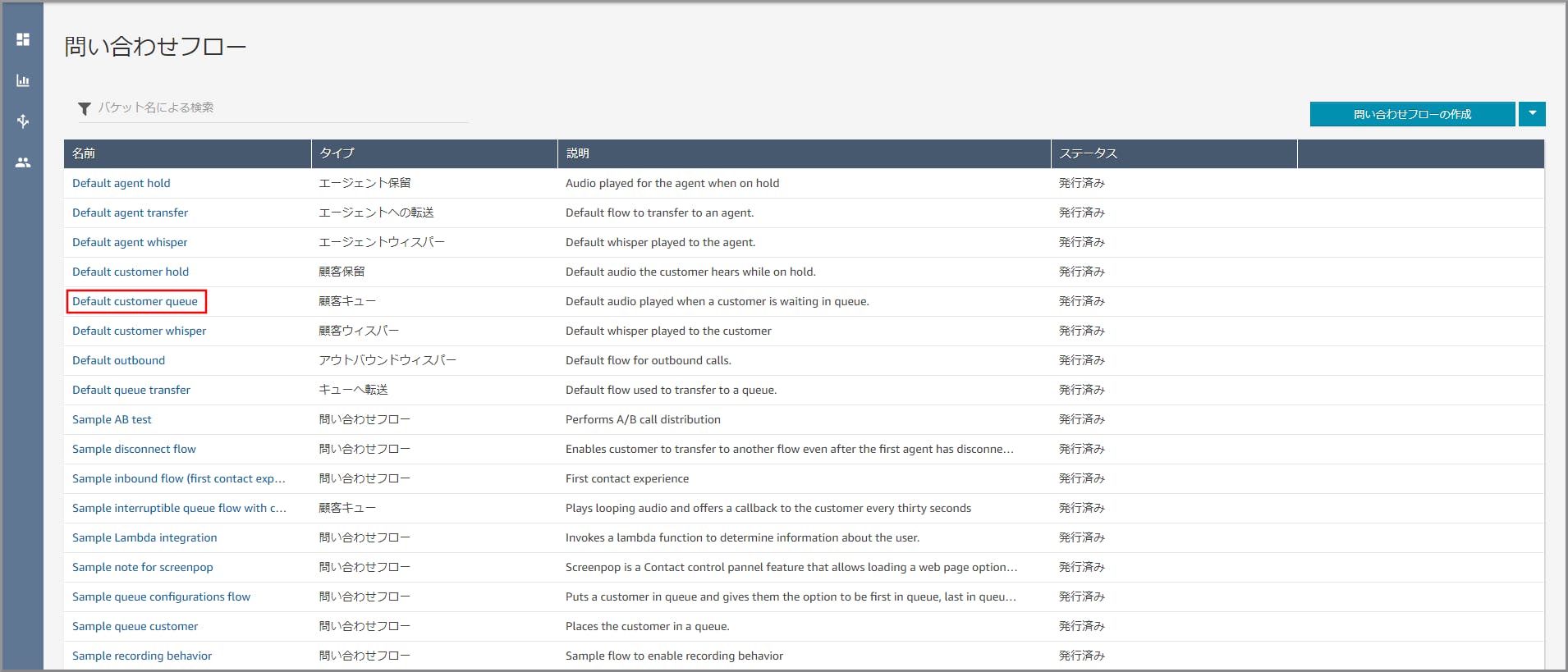
右側の《▼》をクリックし、《顧客キューフローの作成》をクリックします。
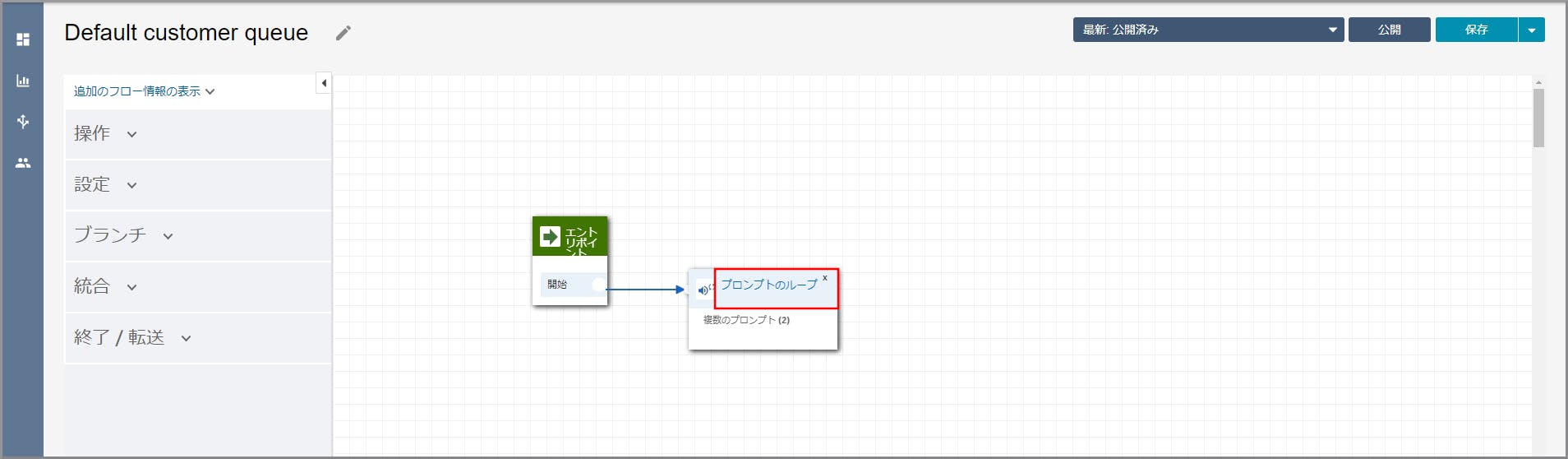
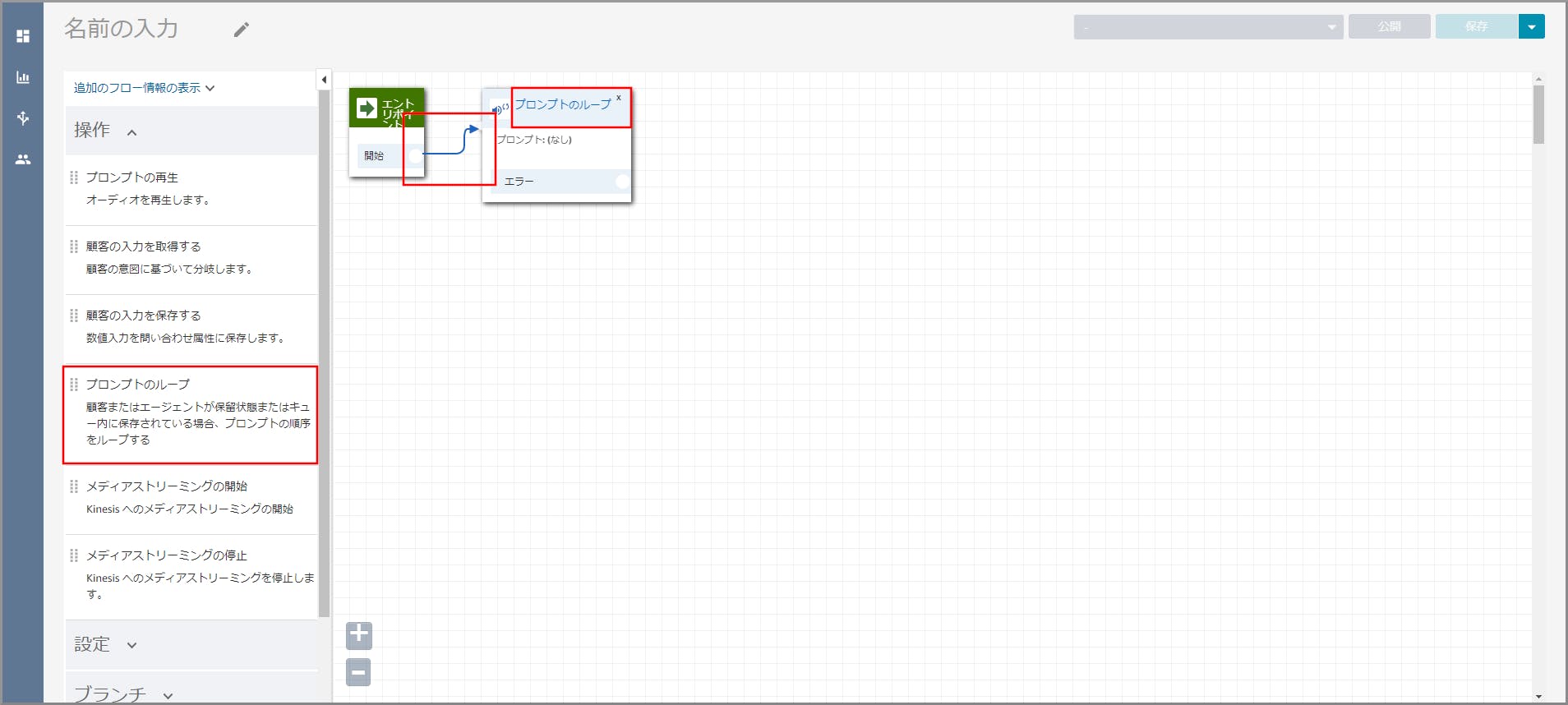
左側メニューの「操作」から《プロンプトのループ》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《プロンプトのループ》のタイトル部分をクリックします。
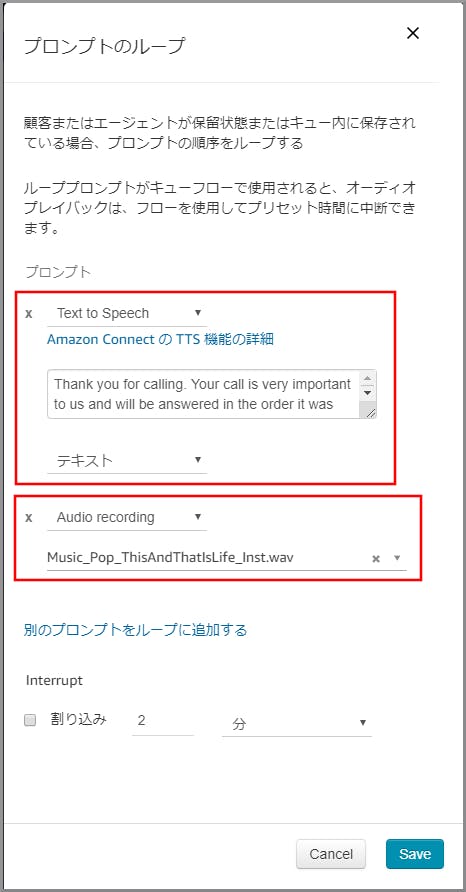
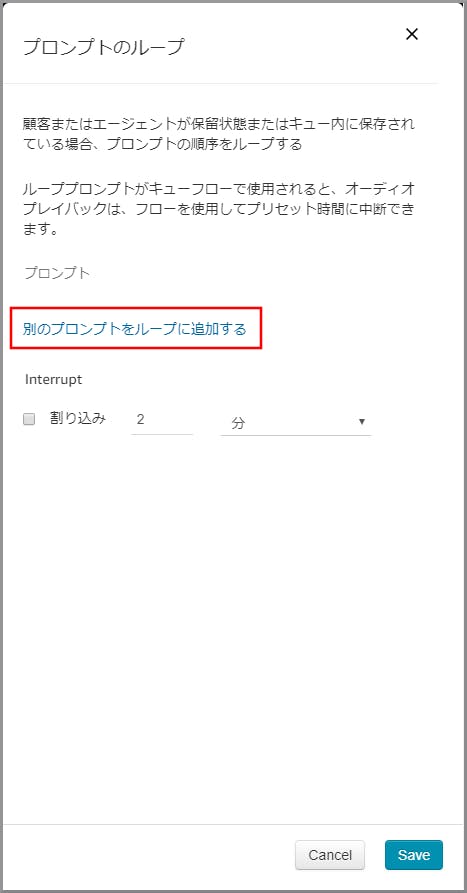
右側に「プロンプトのループ」画面が表示されるので、「別のプロンプトをループに追加する」を2回クリックします。
プロンプトが2つ表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- 1つめのプロンプト
- 動作:Audio Recording
- Audio:適当な音楽を選択します。
- 2つめのプロンプト
- 動作:Text to Speech
- Audio:音声案内する文言を入力します。
左側メニューの「終了/転送」から《切断/ハングアップ》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
左上の「名前の入力」に適当な名前を入力し、右上の《公開》をクリックします。
《公開》をクリックします。
左側のメニューから《問い合わせフロー》をクリックします。
【クラウド初心者向け】Amazon Connectの問い合わせフロー作成で作成した問い合わせフローをクリックします。
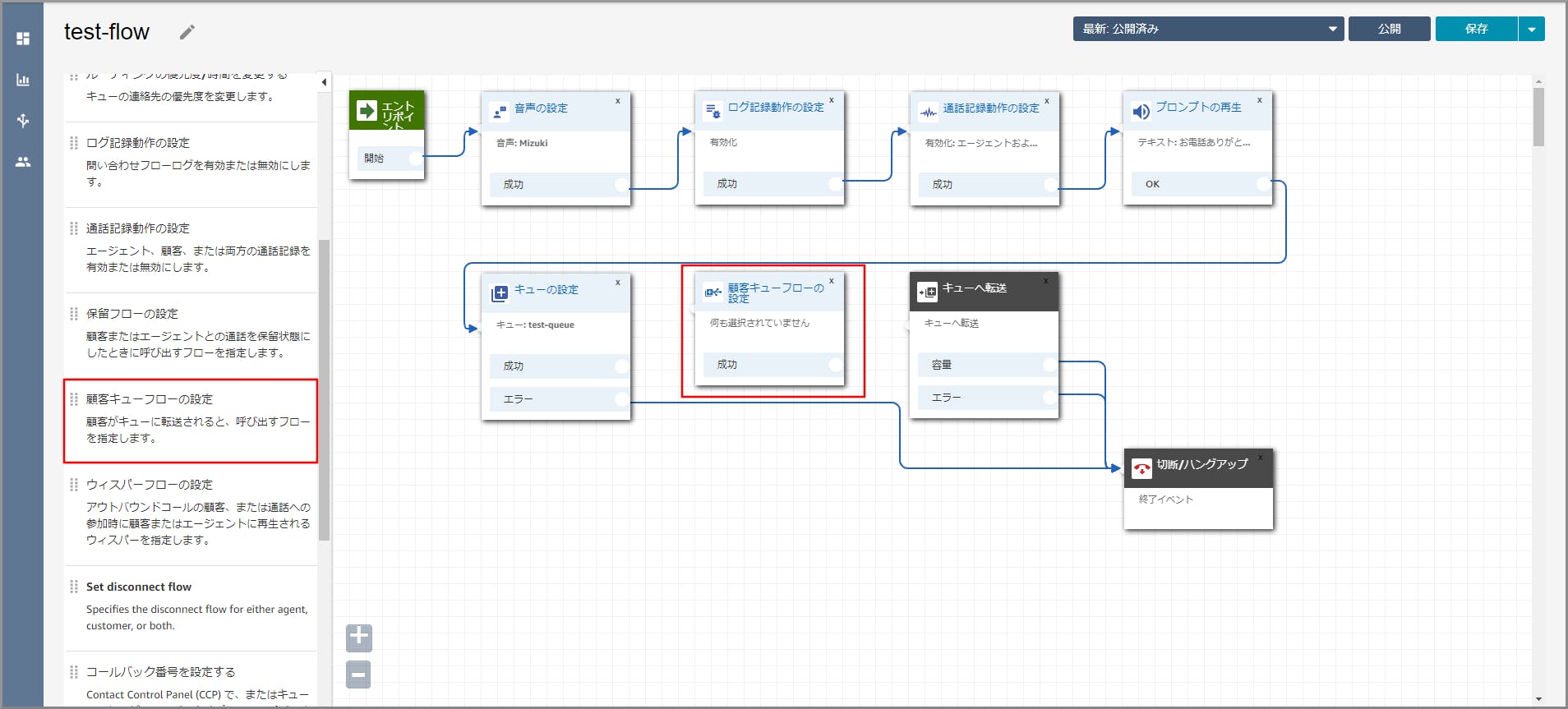
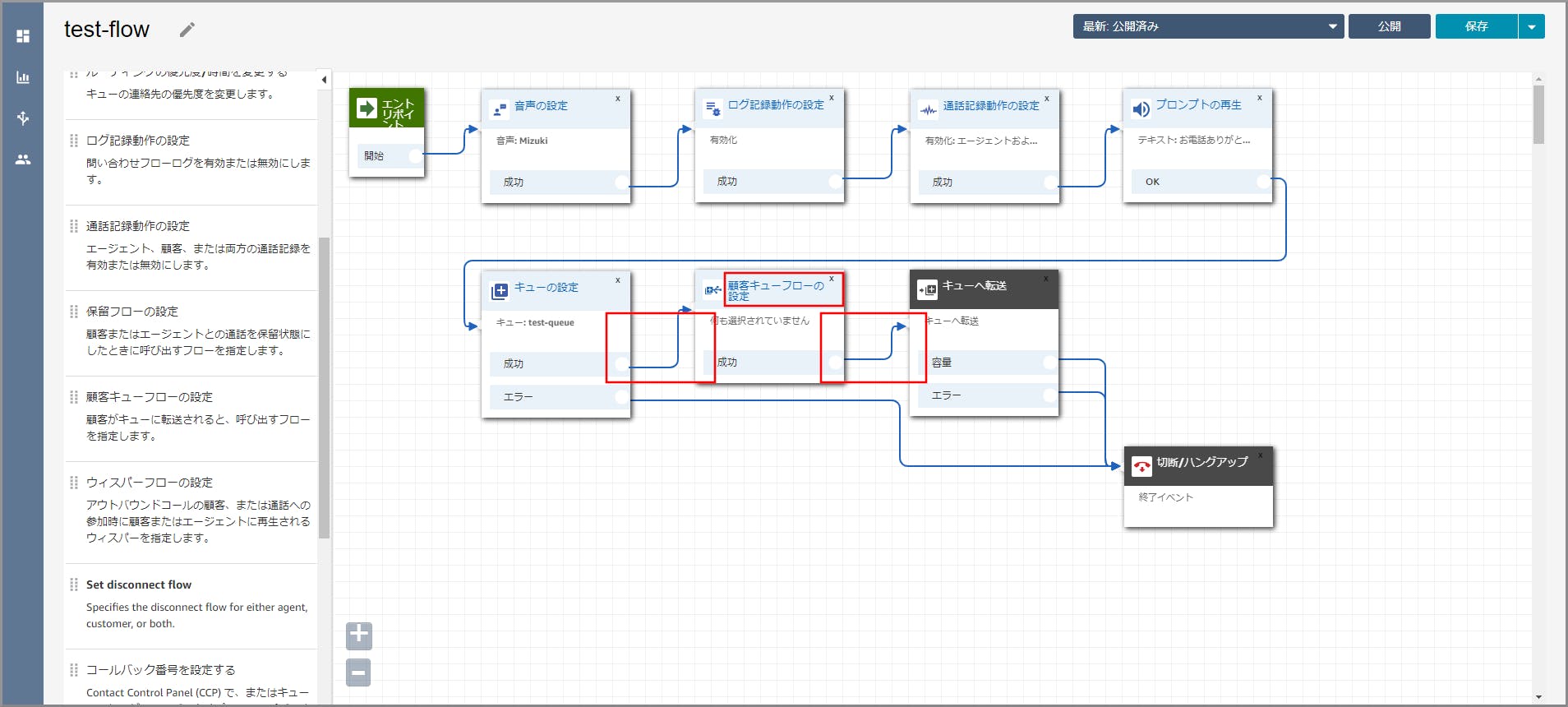
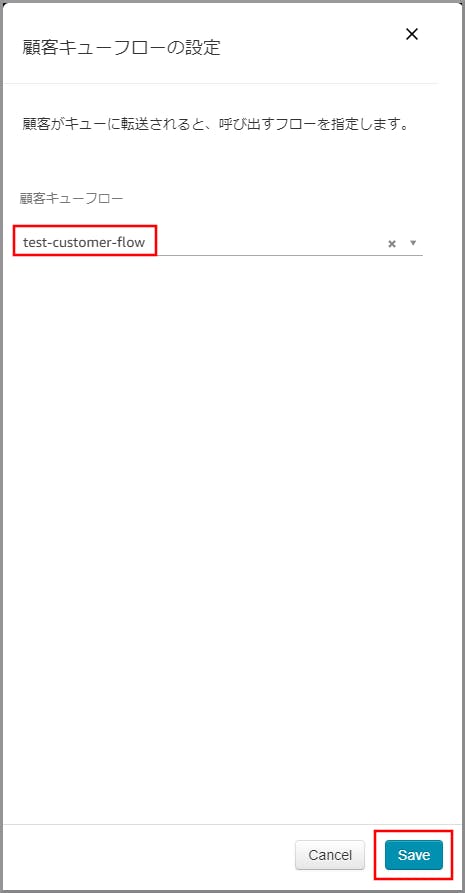
左側メニューの「設定」から《顧客キューフローの設定》を「キューの設定」と「キューへ転送」の間にドラッグ&ドロップします。
《顧客キューフローの設定》オブジェクト同志を矢印で接続して《顧客キューフローの設定》のタイトル部分をクリックします。
右側に「顧客キューフローの設定」画面が表示されるので、先ほど作成した顧客キューフローを選択して《Save》をクリックします。
右上の《公開》をクリックします。
《公開》をクリックします。
目次に戻る






- 投稿日:2019-11-26T13:05:43+09:00
【クラウド初心者向け】Amazon Connectの着信確認
概要
- 今まで作成した内容が正しく反映されているか確認します。
- ソフトフォン(CCP:Contact Control Panel)を起動して電話を受け会話します。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスの「アクセスURL」をクリックします。
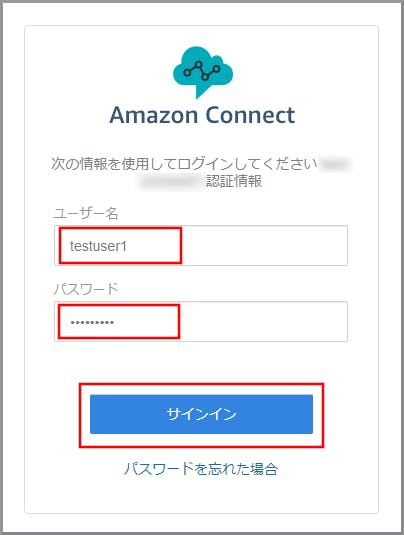
ソフトフォンのログイン画面が表示されるので、、以下の項目を選択、入力して《サインイン》をクリックします。
- ユーザー名:クラウド初心者向け】Amazon Connectのユーザー(エージェント)作成で作成したユーザーの「ログイン名」を入力します。
- パスワード:クラウド初心者向け】Amazon Connectのユーザー(エージェント)作成で作成したユーザーの「パスワード」を入力します。
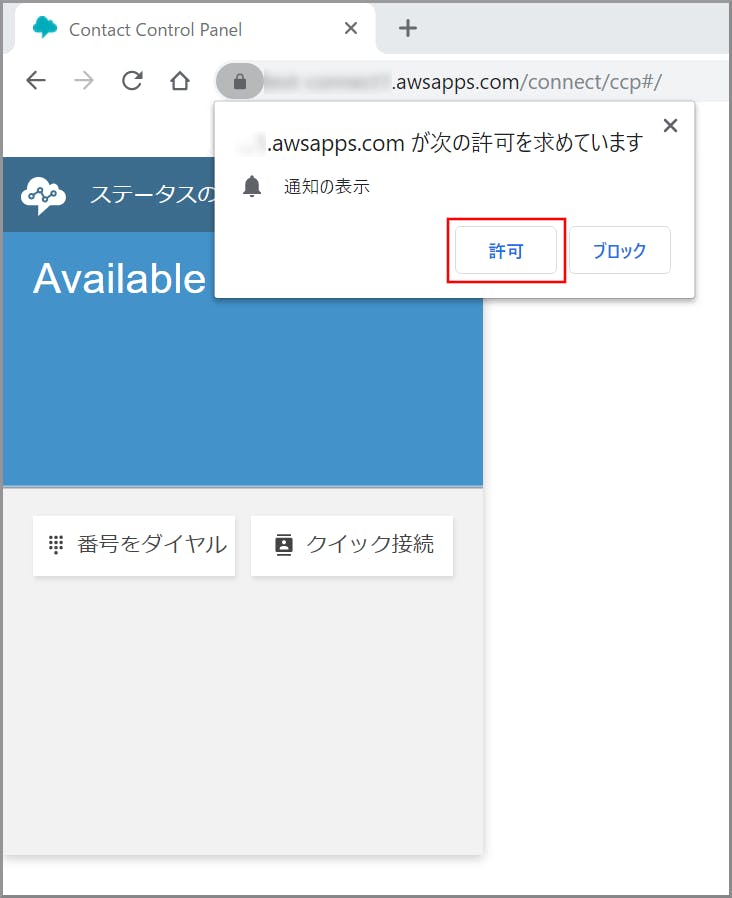
通知の表示の許可を求める画面が表示されるので、《許可》をクリックします。
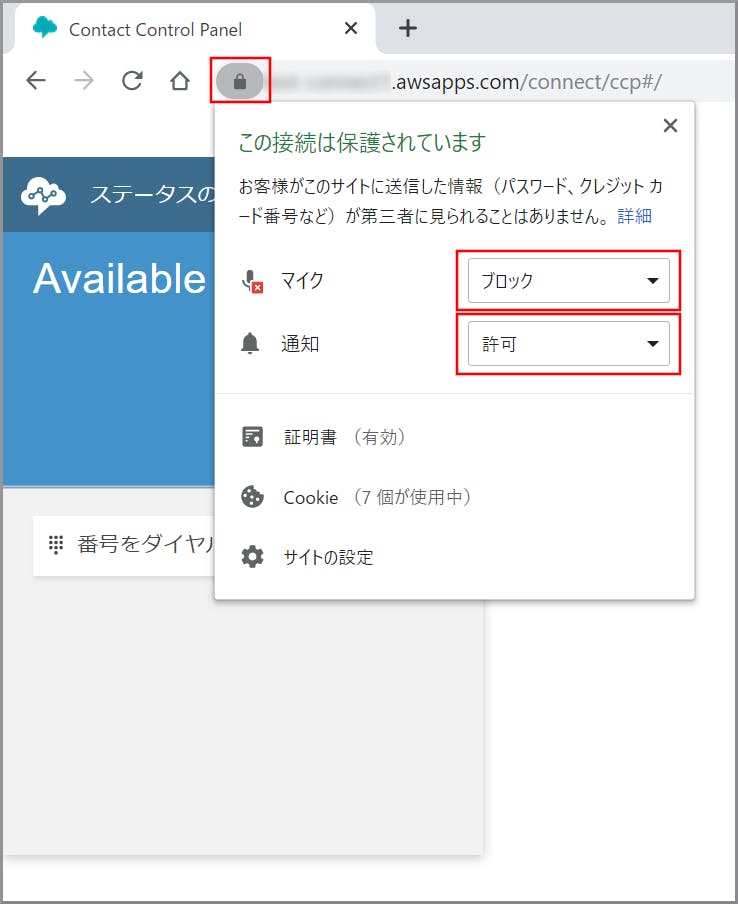
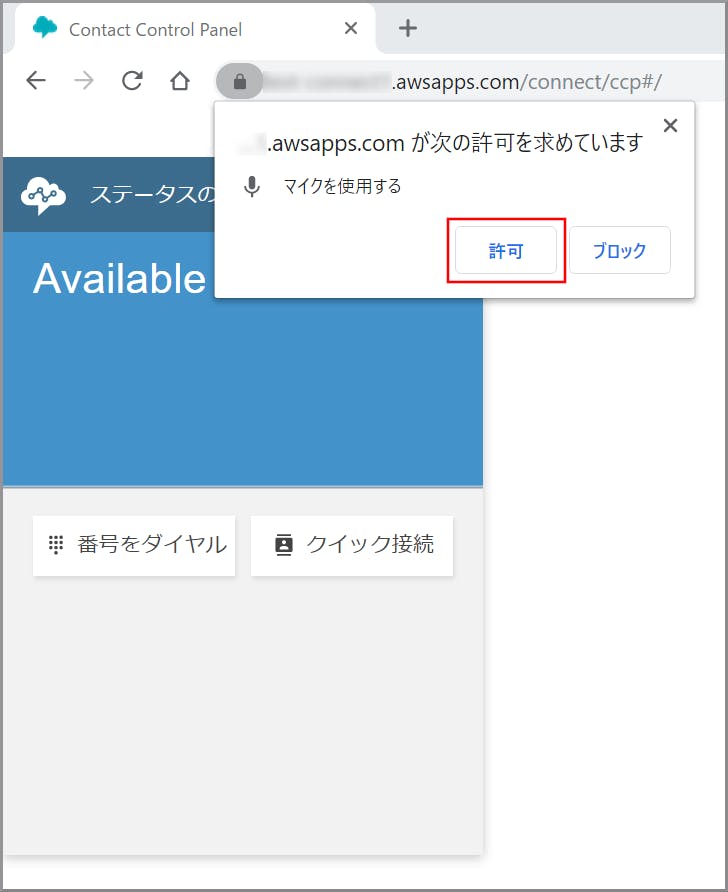
マイクを使用する許可を求める画面が表示されるので、《許可》をクリックします。
注意点まとめ
個別に許可を忘れた場合
- 鍵マークのアイコンをクリックして個別に許可が出せます。
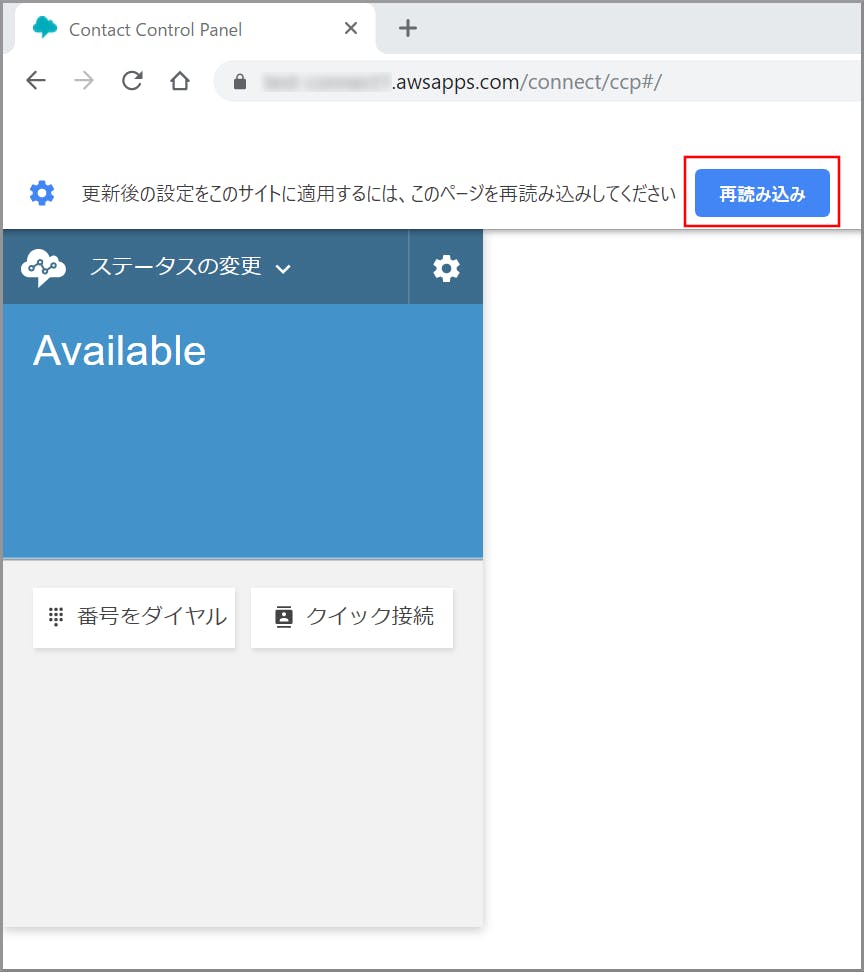
- 再読み込みをしてくださいと表示されるので《再読み込み》をクリックします。
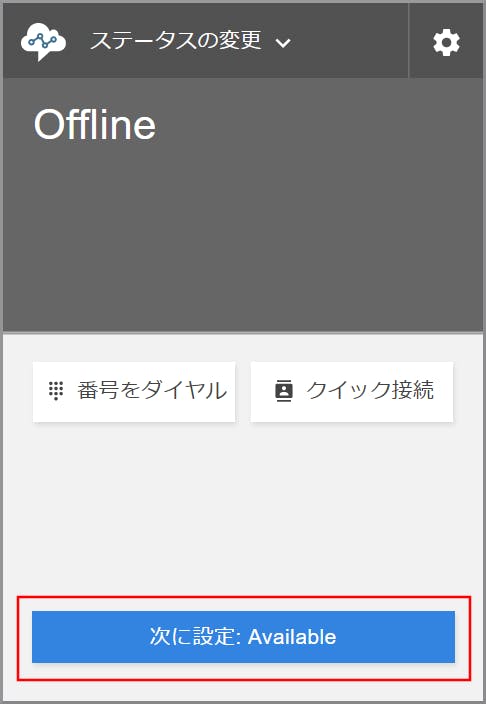
ステータスがAvailableになっていない場合
- 《次に設定:Available》をクリックします。
ソフトフォンサインイン後にAmazon Connectダッシュボード等の画面でエラーが発生する場合
- ダッシュボード、問い合わせフロー、キューなどの画面を表示すると以下の画面が表示されます。これはサインインしているユーザーがソフトフォンにサインインしたユーザーで表示しようとしているためです。

- もう一度、インスタンスの概要表示の画面から《管理者としてログイン》をクリックします。
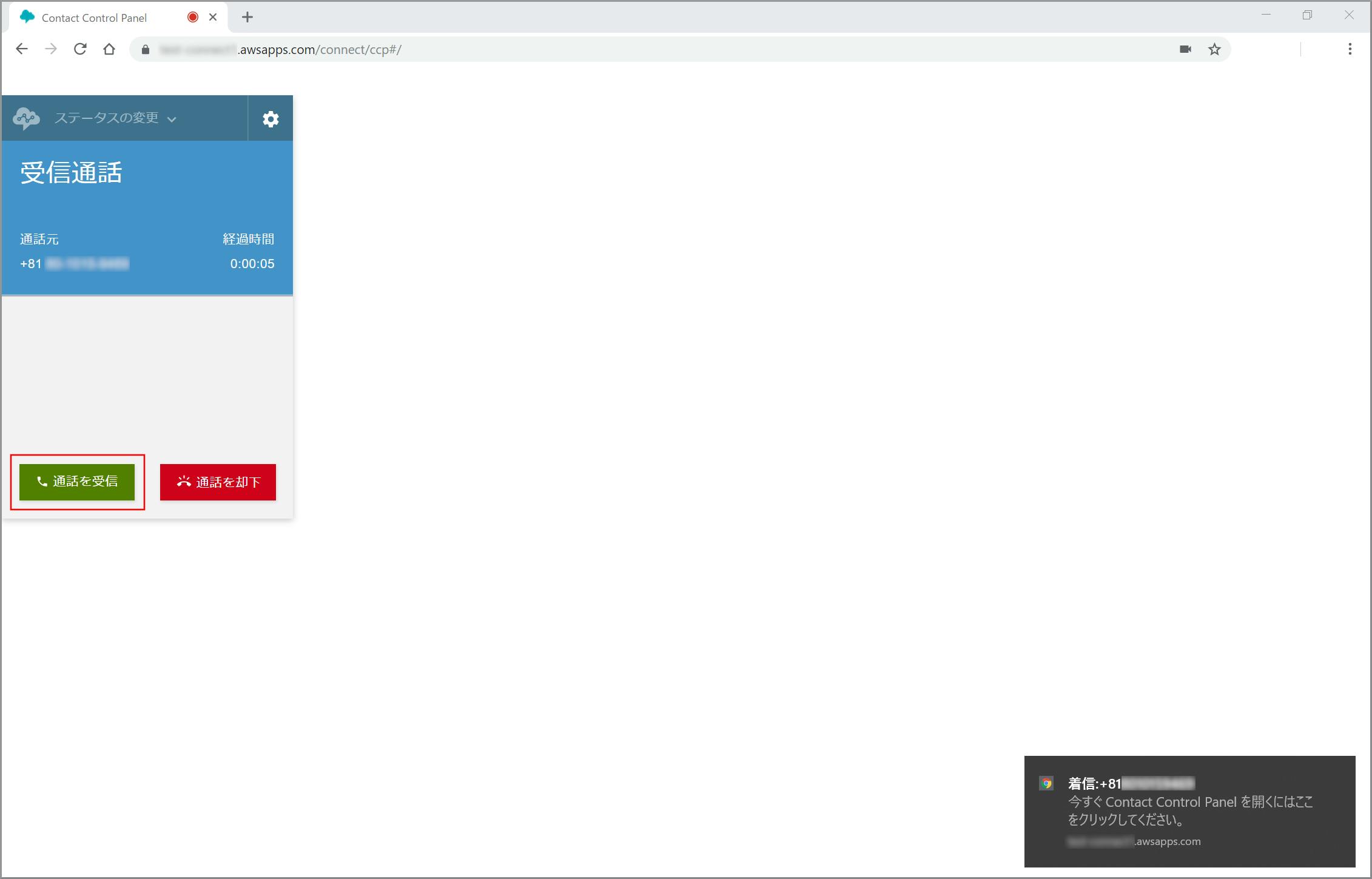
同時に利用する場合は、シークレットウィンドウを利用したり別のブラウザを利用すると便利です。ステータスがAvailableになっていることを確認し、【クラウド初心者向け】Amazon Connectの電話番号取得で取得した電話番号に電話を架けます。
ソフトフォンに着信しました。《通話を受信》をクリックして通話を開始します。
通話確認ができましたので《通話を終了》をクリックするか、電話の方を切ります。
通話が終わると、ソフトフォンはAfterCallWorkの状態になりますのでこのタイミングで電話対応後の後処理を行います。また、復帰する場合は《次に設定:Available》をクリックします。
目次に戻る

- 投稿日:2019-11-26T12:54:54+09:00
【クラウド初心者向け】Amazon Connectの問い合わせフロー作成
概要
- かかってきた電話をどう処理するか流れを決められます。
- 電話番号やお客様の選択によって処理を分ける事ができます。
- ログの取得ができます。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
ダッシュボードの左側のメニューから《問い合わせフロー》をクリックします。
《問い合わせフローの作成》をクリックします。
フローの作成画面が表示されます。ここにフローを作成していきます。
左側メニューから「設定」をクリックします。
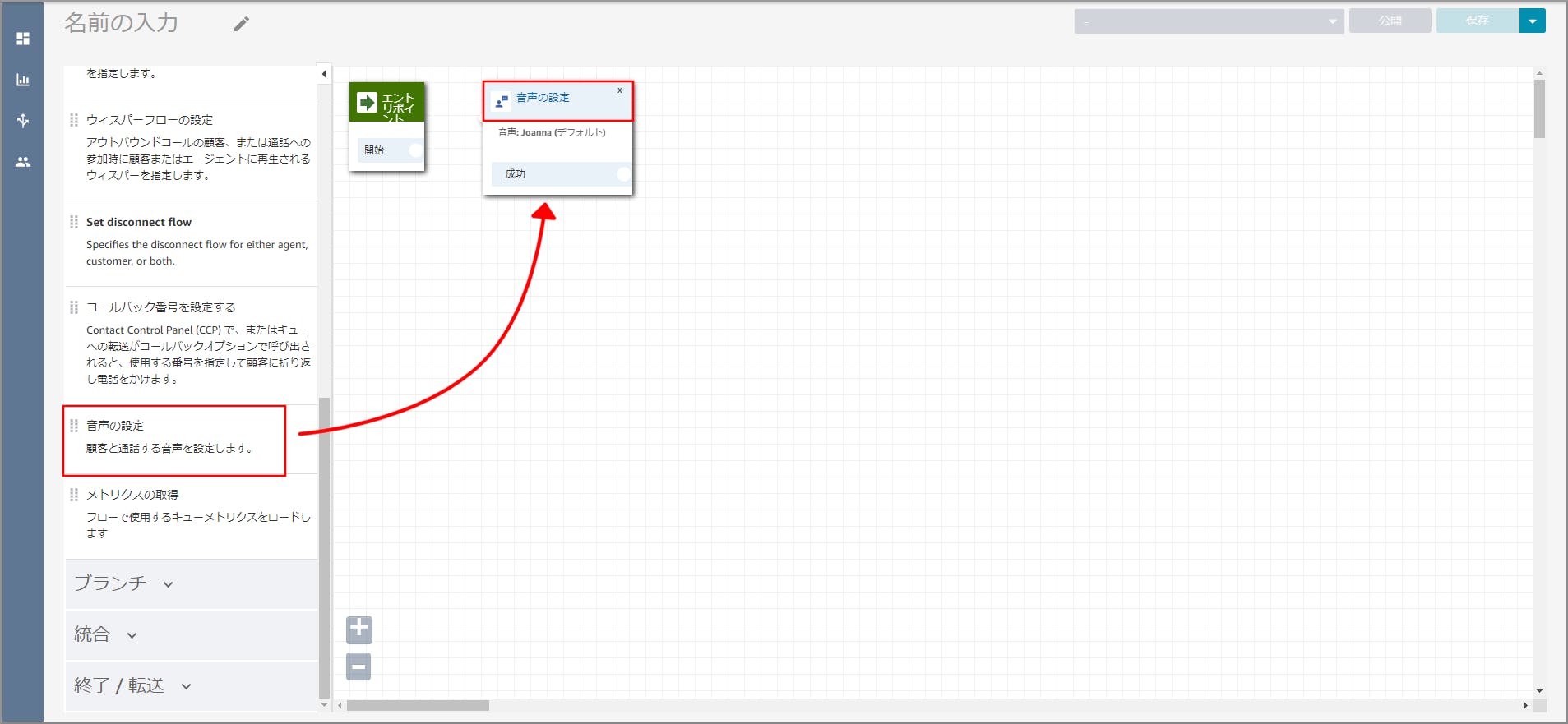
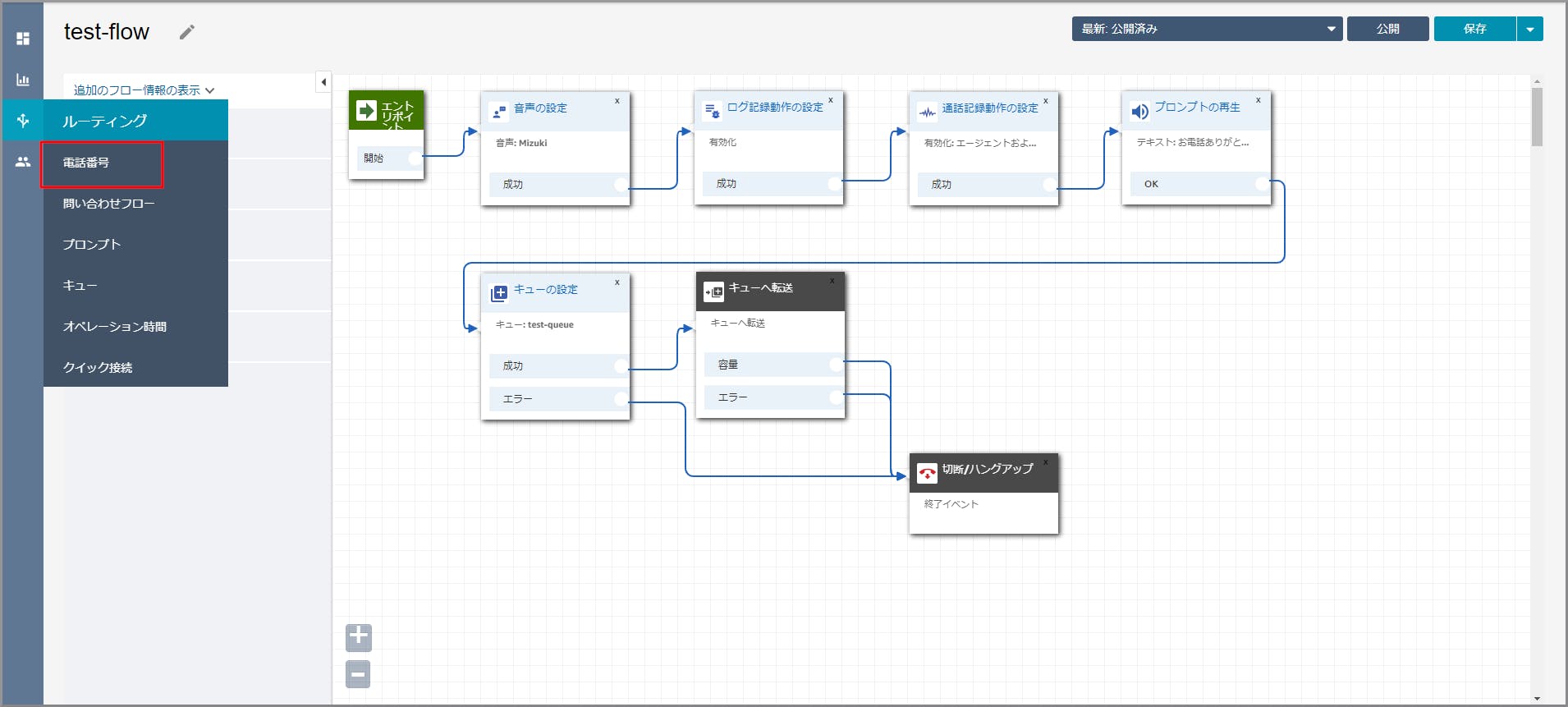
注:以降この説明の画面キャプチャーは省略します。フロー部分に《音声の設定》をドラッグ&ドロップし、タイトル部分をクリックします。
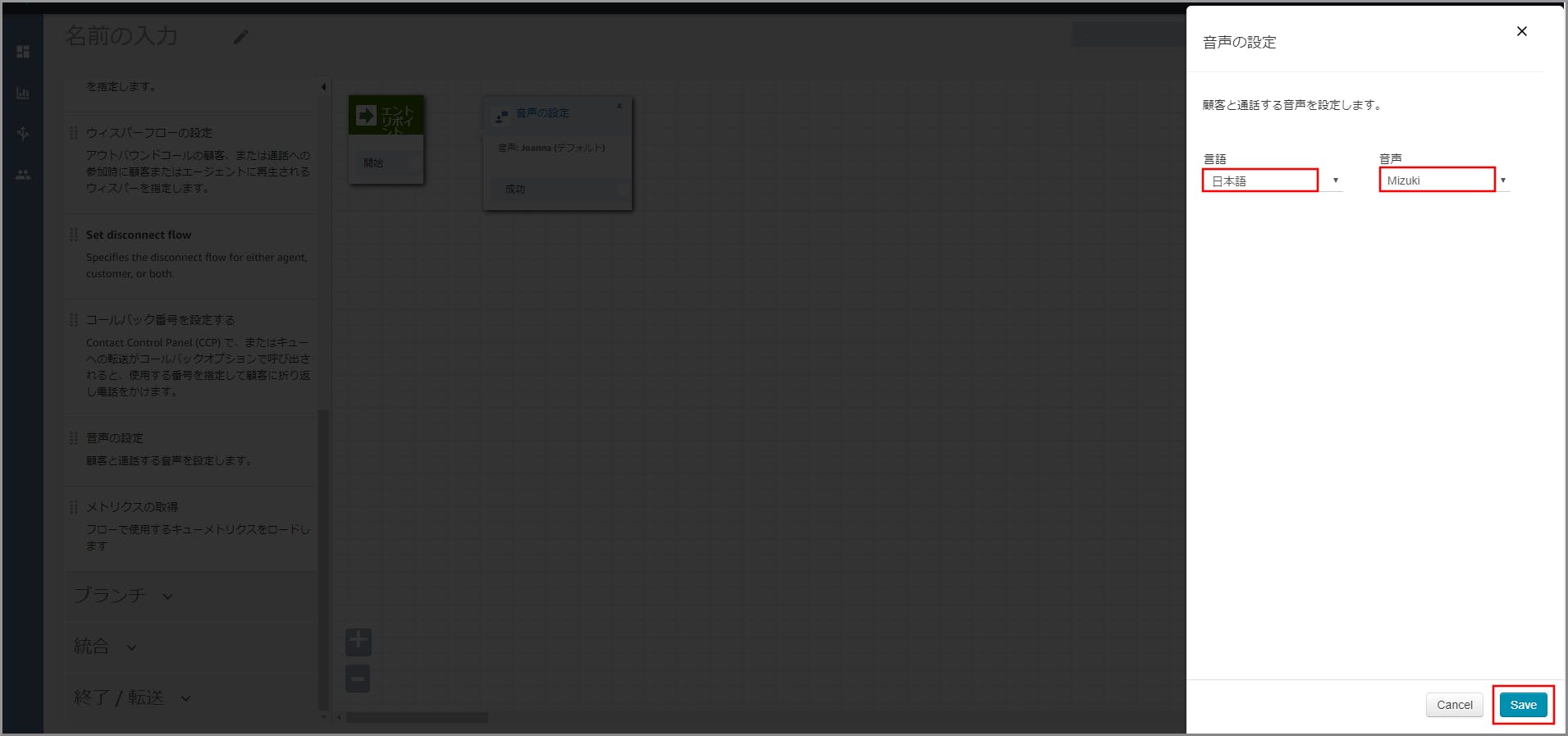
右側に「音声の設定」画面が表示されるので以下の設定をし、《Save》をクリックします。
主に「プロンプトの再生」で話す音声の設定になります。
- 言語:日本語を選択します。
- 音声:適当な音声を選択します。(男性か女性の分けになっています)
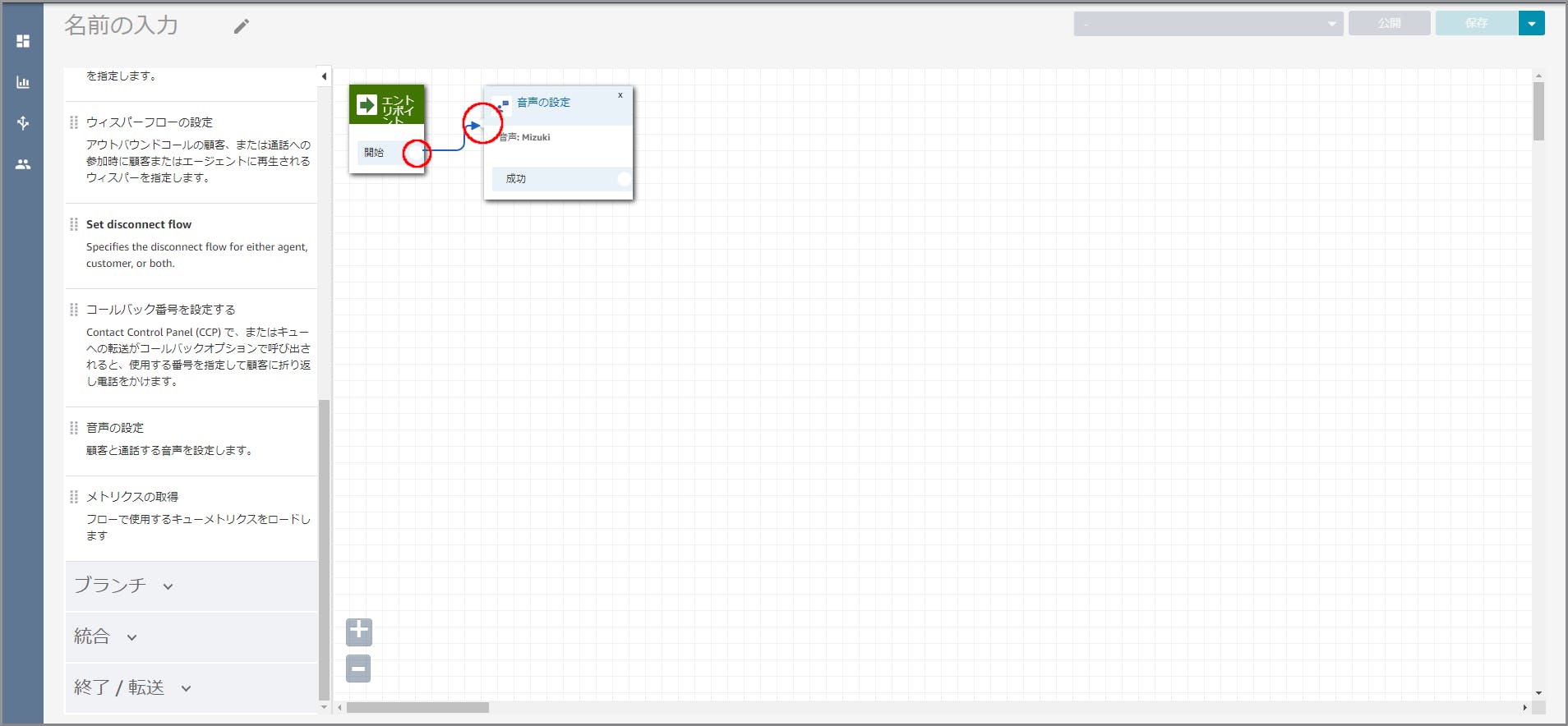
「エントリポイント」の成功(赤丸部分)から「音声の設定」(赤丸部分)までドラッグ&ドロップしオブジェクト同志を矢印で接続します。
矢印でつなぐことにより、前の処理が終わったら次の処理へという流れができます。
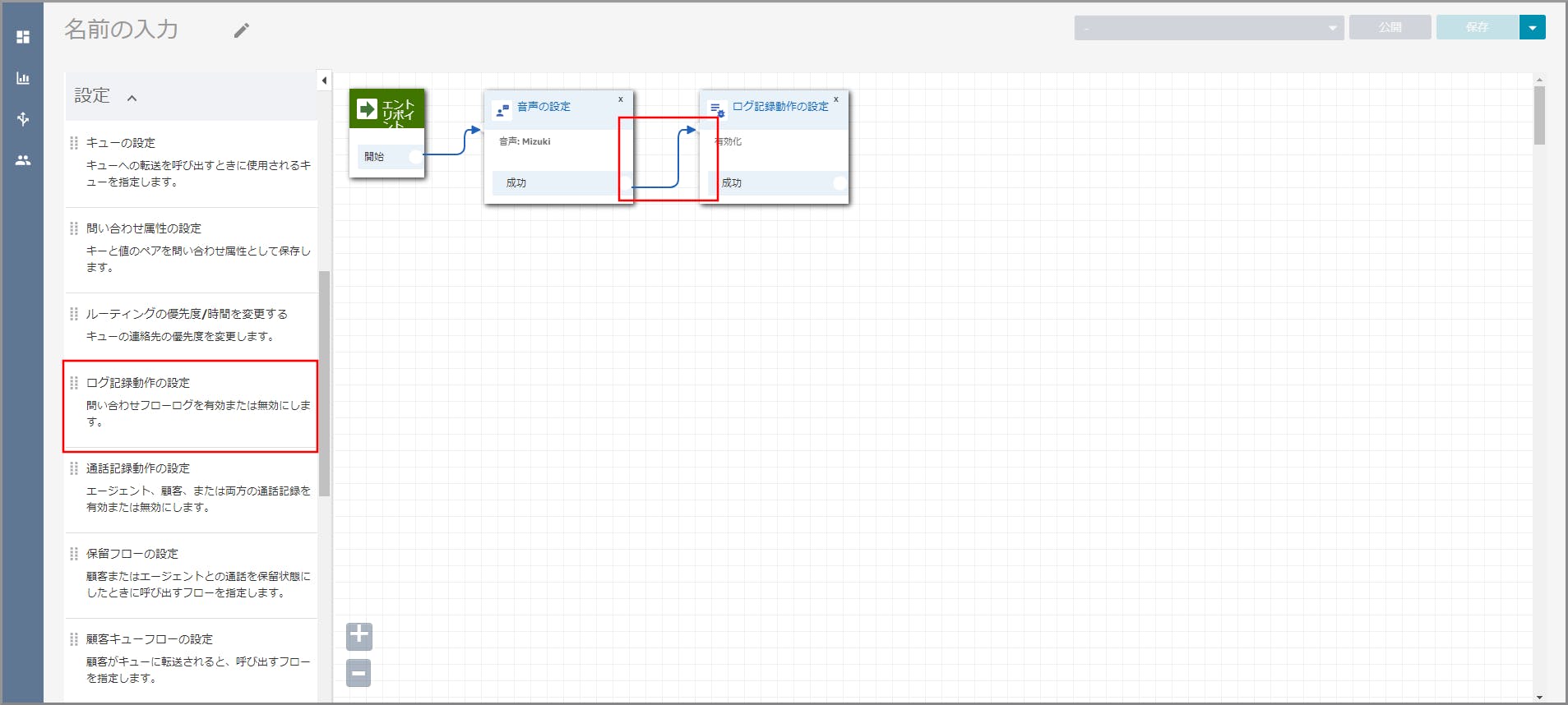
左側メニューの「設定」から《ログ記録動作の設定》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
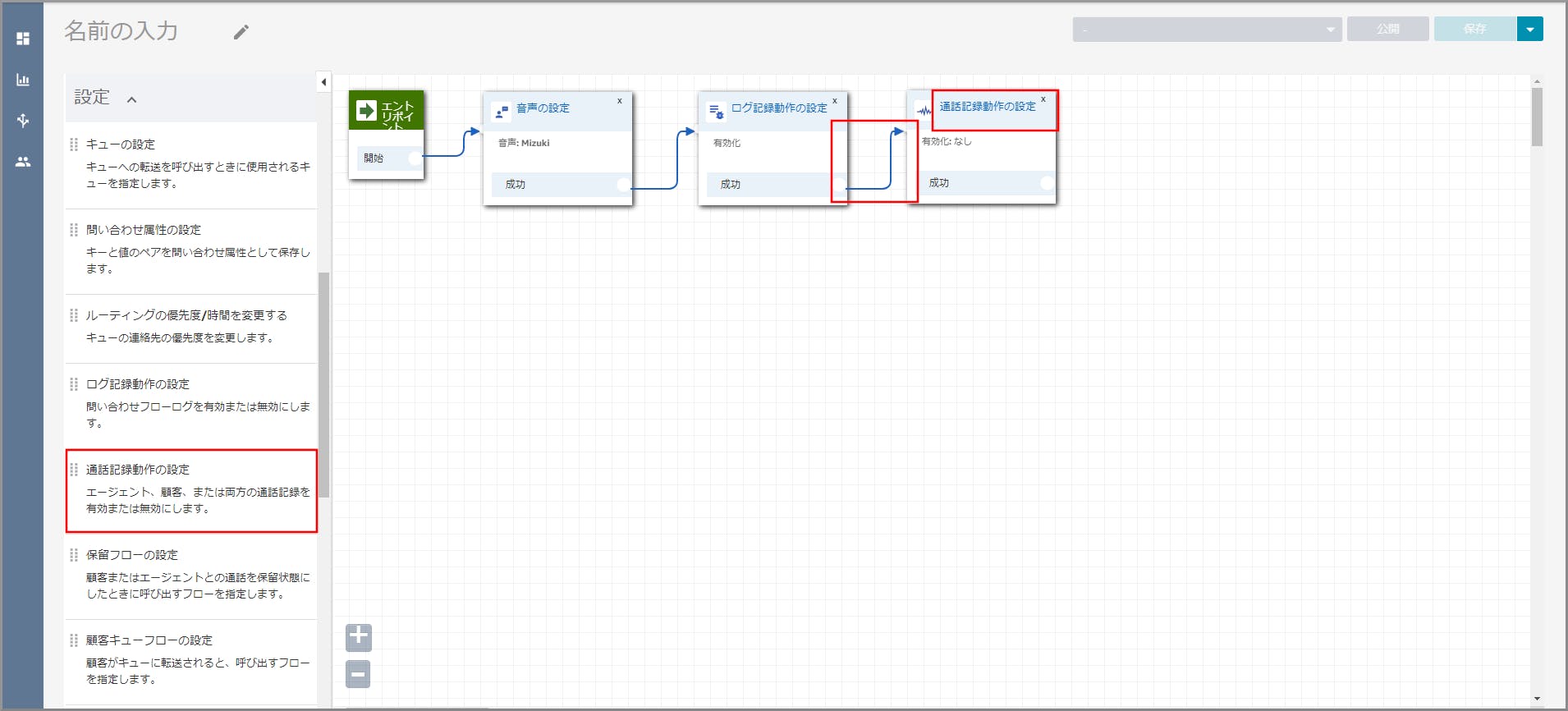
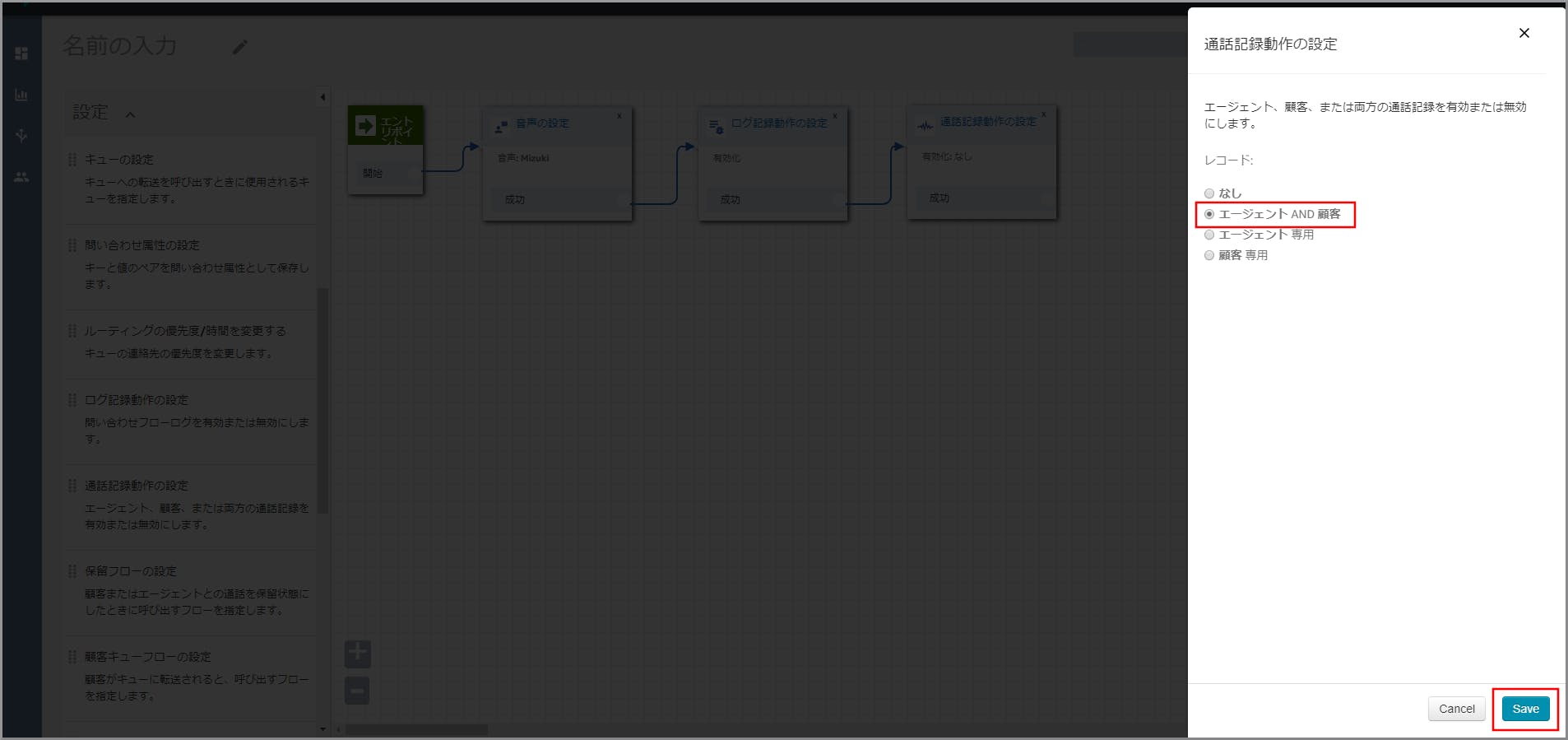
左側メニューの「設定」から《通話記録動作の設定》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《通話記録動作の設定》のタイトル部分をクリックします。
右側に「通話記録動作の設定」画面が表示されるので、「エージェントAND顧客」を選択して《Save》をクリックします。
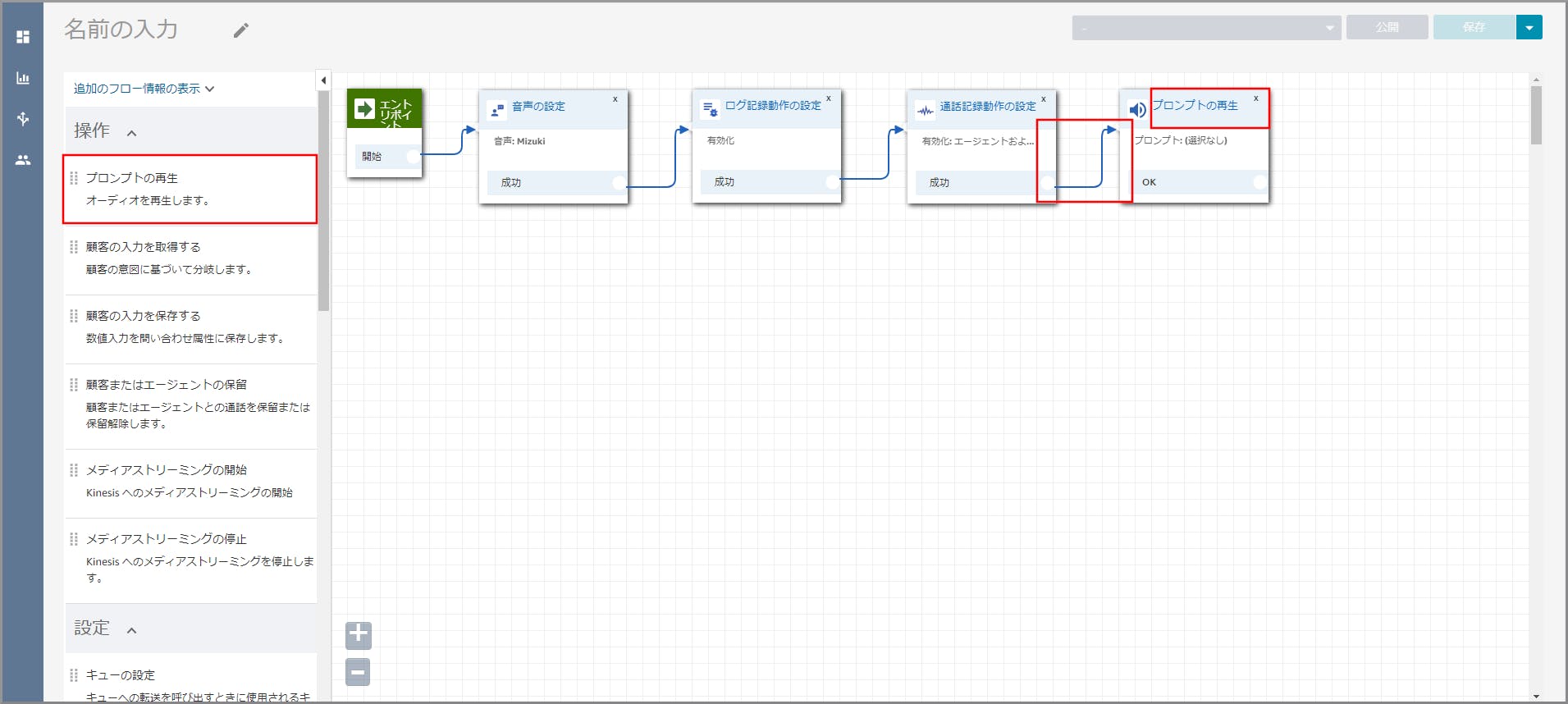
左側メニューの「操作」から《プロンプトの再生》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に
《プロンプトの再生》のタイトル部分をクリックします。
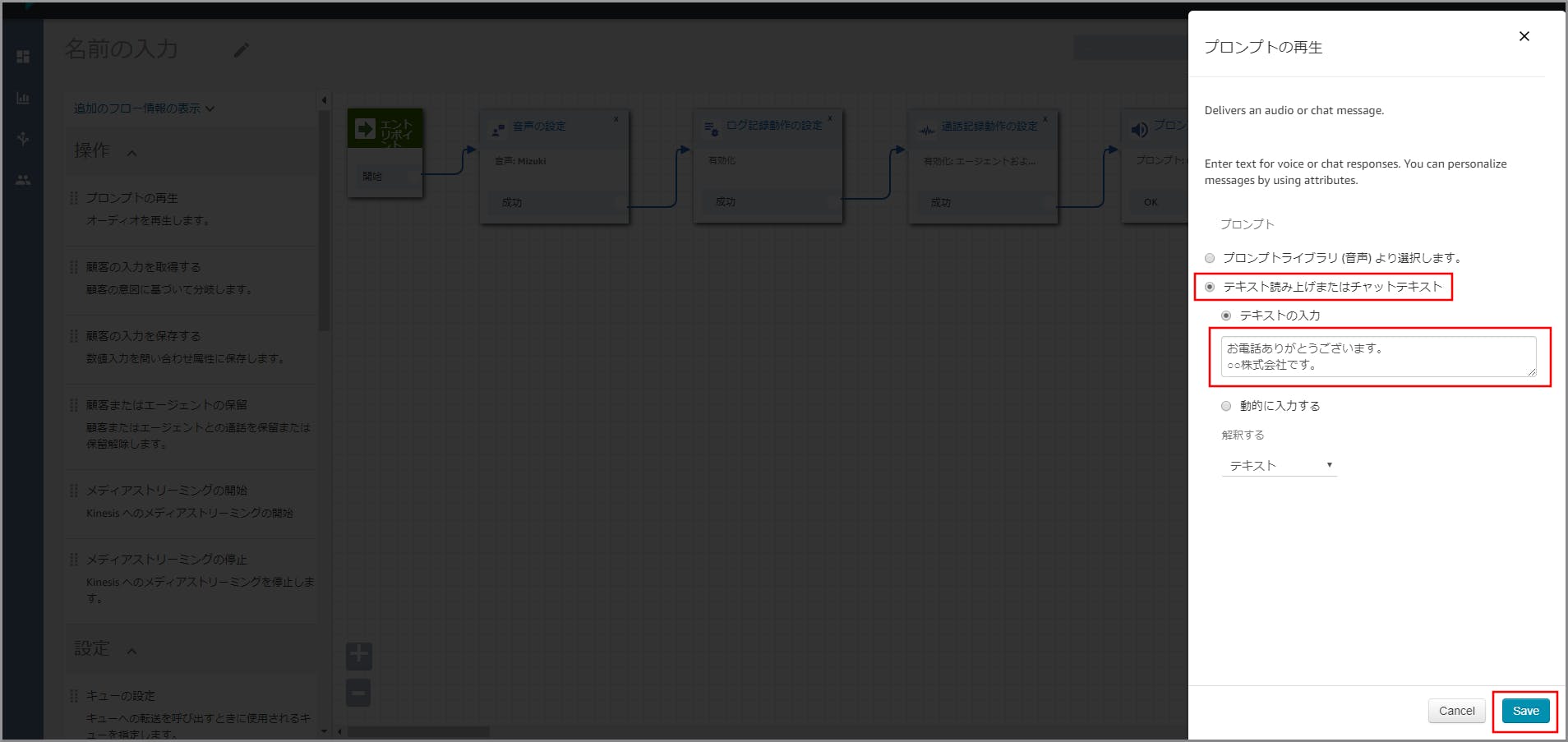
右側に「プロンプトの再生」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- テキスト読み上げまたはチャットテキスト:選択します。
- テキストの入力:選択し、音声案内する文言を入力します。
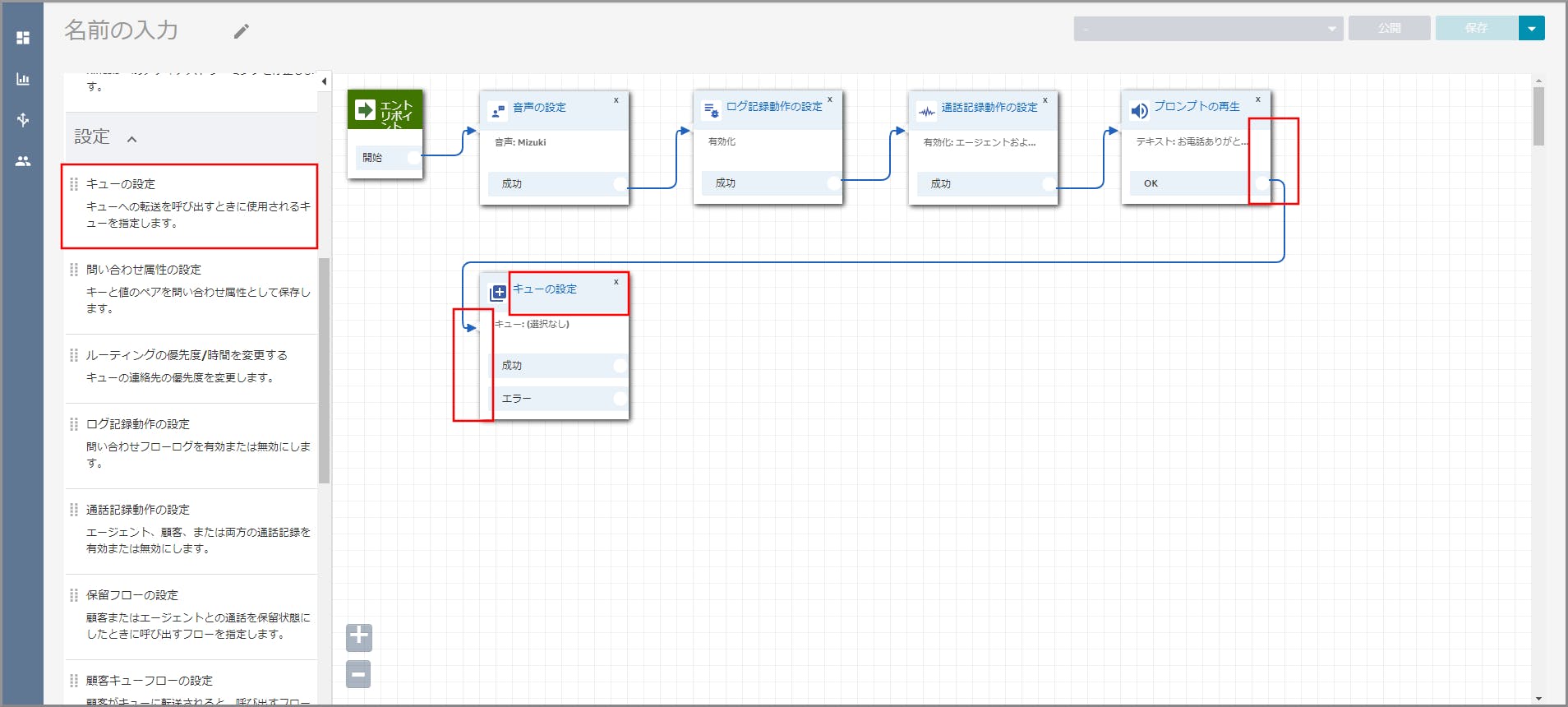
左側メニューの「設定」から《キューの設定》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に
《キューの設定》のタイトル部分をクリックします。
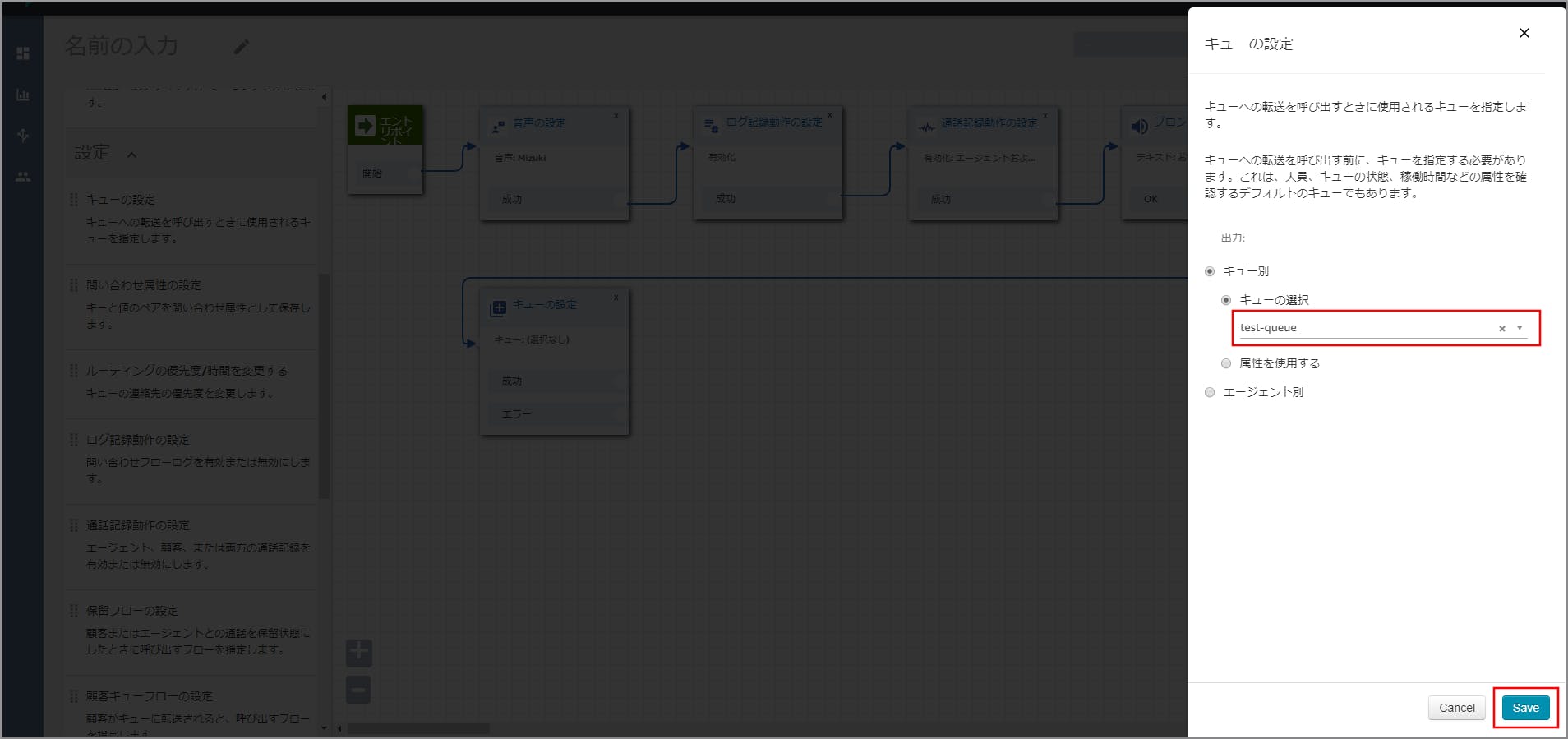
右側に「キューの設定」画面が表示されるので、、以下の項目を選択、入力して《Save》をクリックします。
- キュー別:選択します。
- キューの選択:選択し、【クラウド初心者向け】Amazon Connectのキュー作成で作成したキューを選択します。
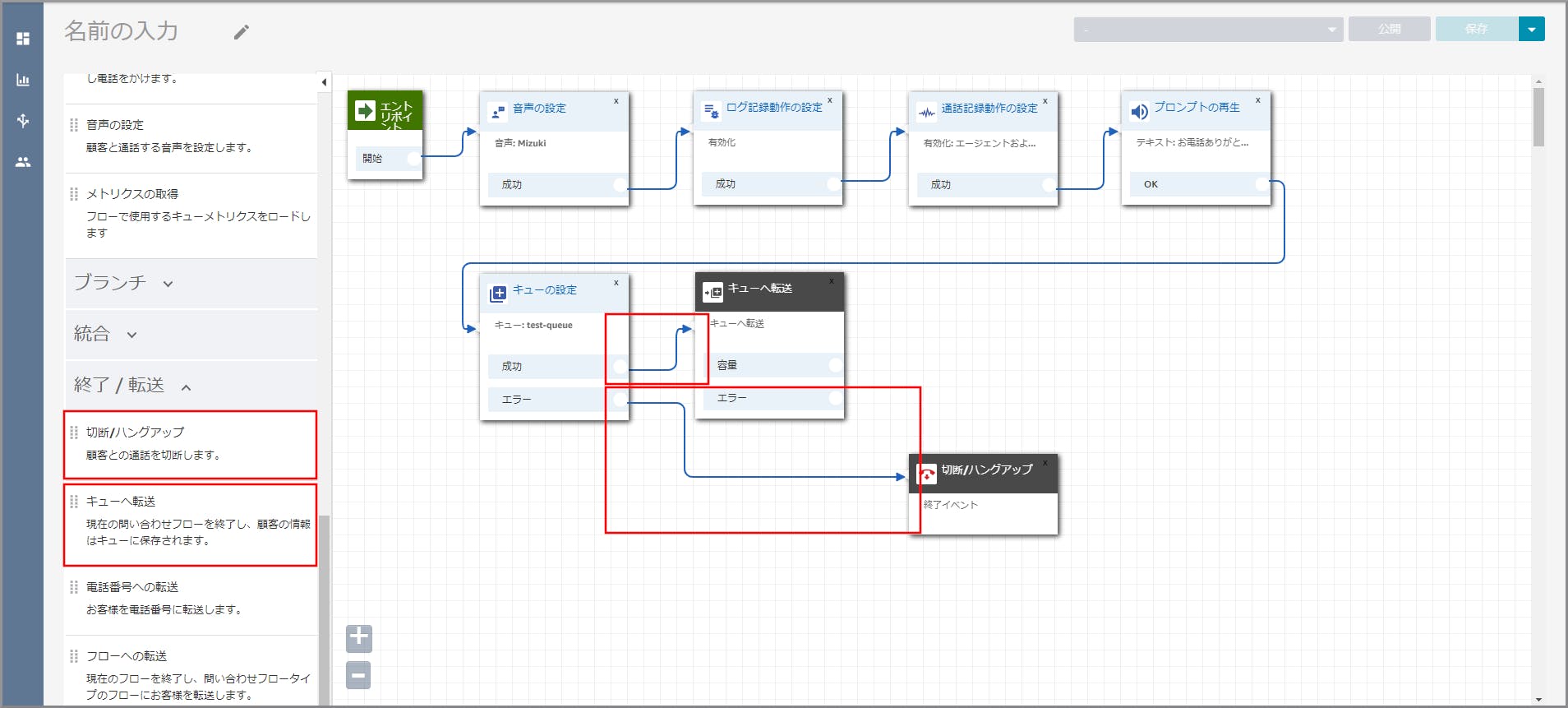
左側メニューの「終了/転送」から《キューへ転送》と《切断/ハングアップ》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
《キューへ転送》と《切断/ハングアップ》オブジェクト同志を矢印で接続します。
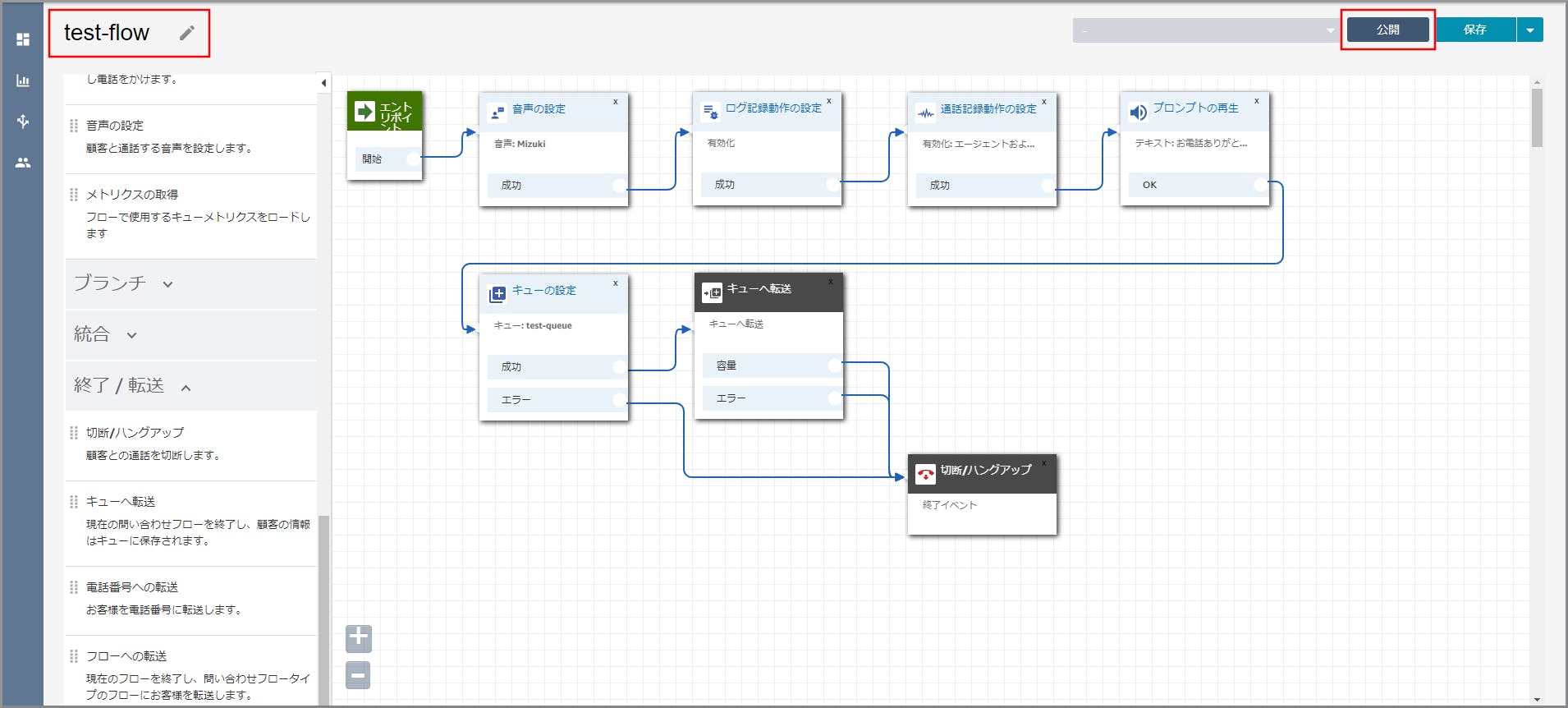
左上の「名前の入力」に適当な名前を入力し、右上の《公開》をクリックします。
《公開》をクリックします。
これで問い合わせフローが完成しました。最後に電話番号に関連づければ完成します。
左側のメニューから《電話番号》をクリックします。
【クラウド初心者向け】Amazon Connectの電話番号取得で取得した電話番号を選択します。
「問い合わせフロー/IVR」に先ほど作成した問い合わせフローを選択して《保存》をクリックします。
目次に戻る





- 投稿日:2019-11-26T12:53:39+09:00
【クラウド初心者向け】Amazon Connectのユーザー(エージェント)作成
概要
- お客様の電話を受け取って対応する人。
- ソフトフォンを利用してお客様からの電話を受け取ります。
- ユーザー(エージェント)は複数のルーティングプロファイルを割り当てる事ができます。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
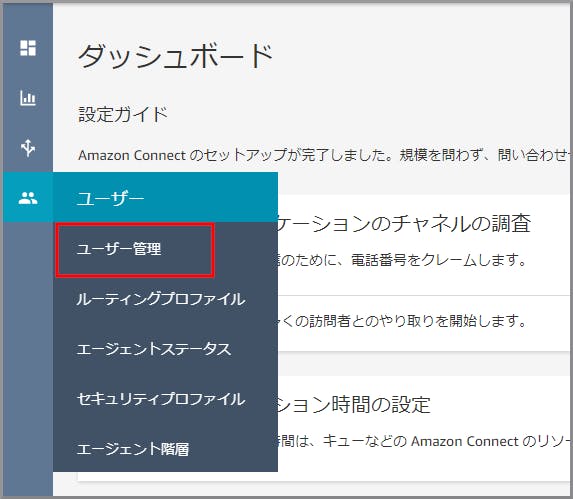
ダッシュボードの左側のメニューから《ユーザー管理》をクリックします。
《新しいユーザーの追加》をクリックします。
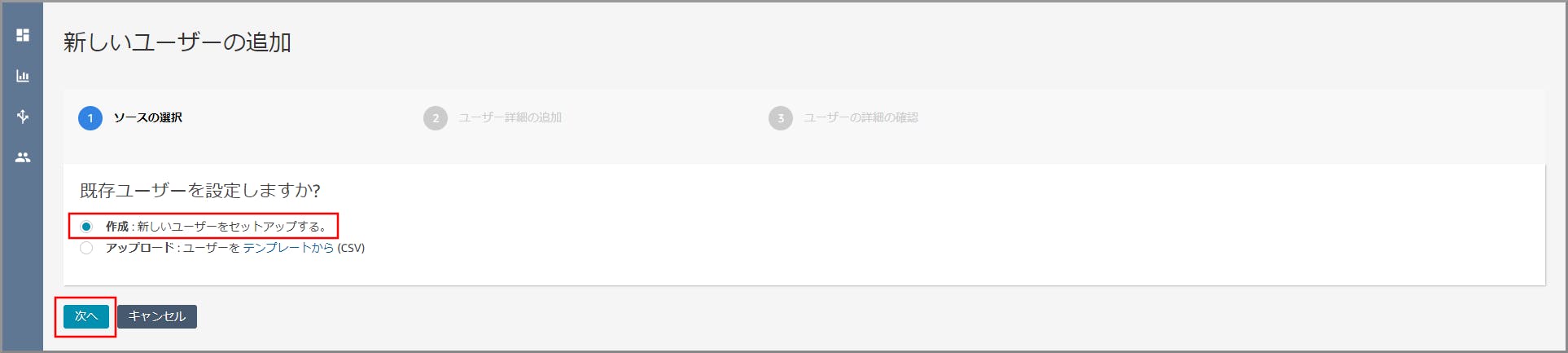
「作成」が選択されていることを確認し、《次へ》をクリックします。
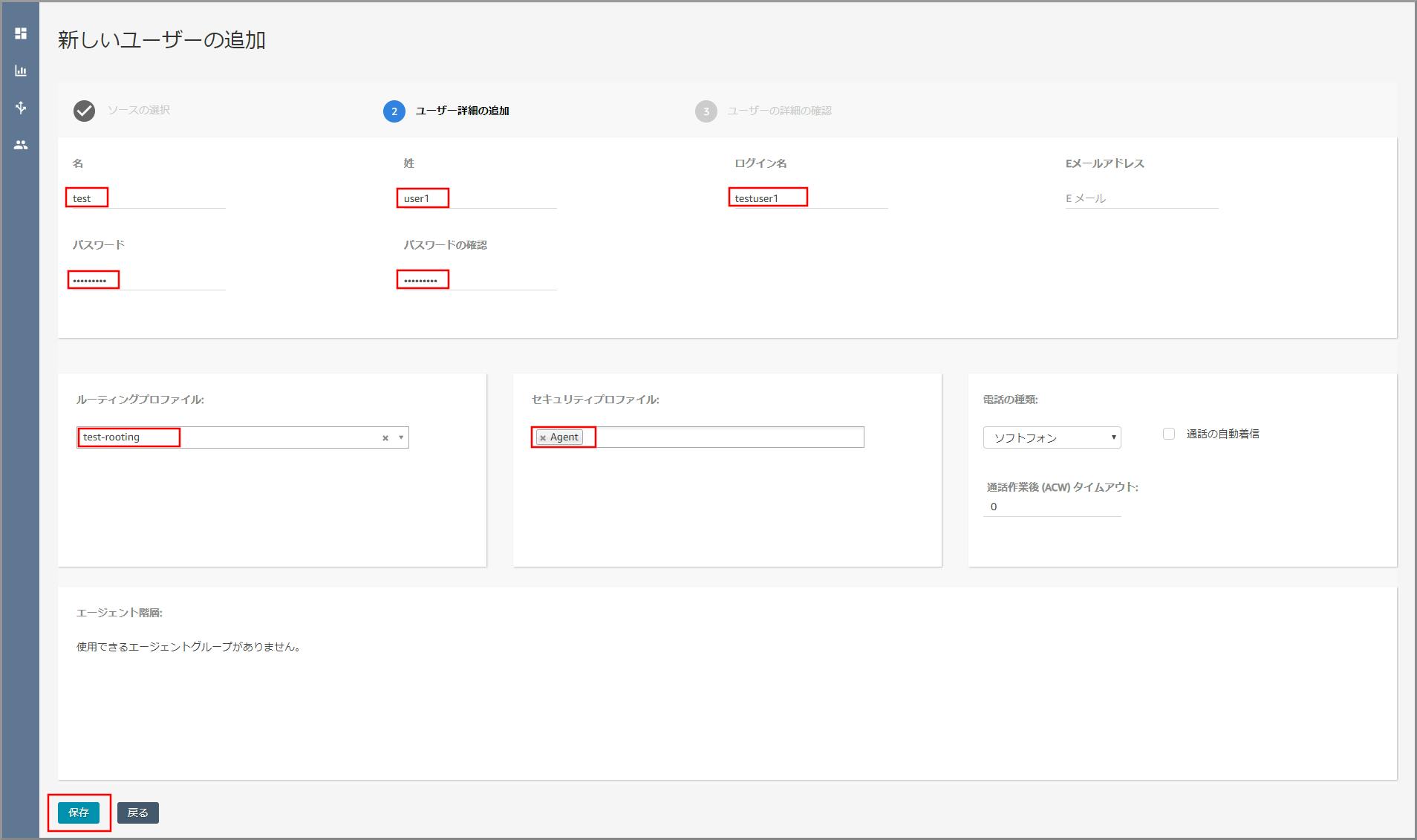
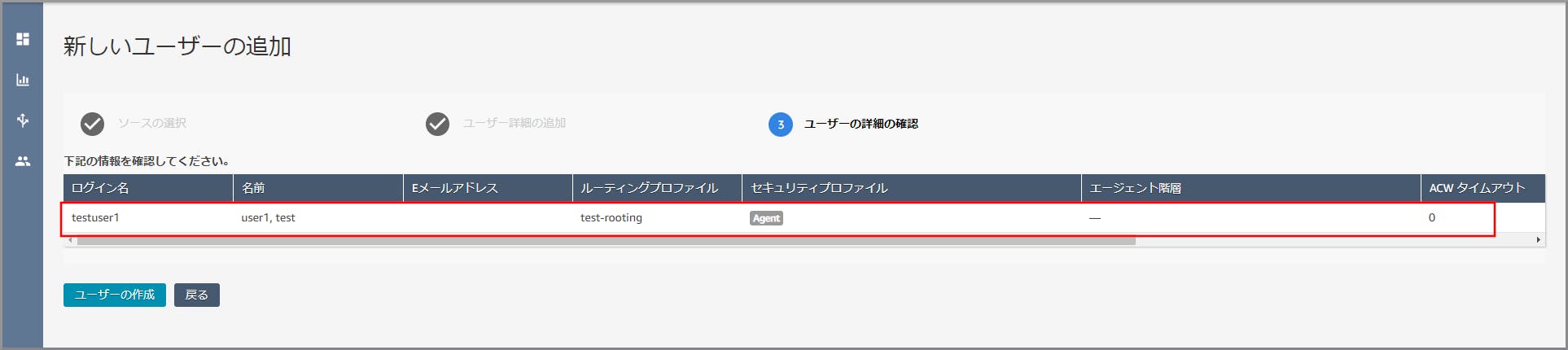
以下の項目を入力、選択し、《保存》をクリックします。
- 名:適当な名を入力します。
- 姓:適当な姓を入力します。
- ログイン名:適当なログイン名を入力します。
- パスワード、パスワード確認:適当なパスワードを入力します。
- ルーティングプロファイル:【クラウド初心者向け】Amazon Connectのルーティングプロファイル作成で作成したキューを選択します。
- セキュリティプロファイル:「Agent」を選択します。
(セキュリティプロファイルはAmazon Connect内ユーザーの権限設定です。)登録が完了し、ユーザー(エージェント)が一覧に表示されます。
参考サイト
目次に戻る

- 投稿日:2019-11-26T12:52:57+09:00
【クラウド初心者向け】Amazon Connectのルーティングプロファイル作成
概要
- この中から割り当てるユーザー(エージェント)が選択されます。
- ユーザー(エージェント)を束ねられます。
- ルーティングプロファイルには複数のキューを割り当てる事ができます。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
ダッシュボードの左側のメニューから《ルーティングプロファイル》をクリックします。
《新しいプロファイルを追加》をクリックします。
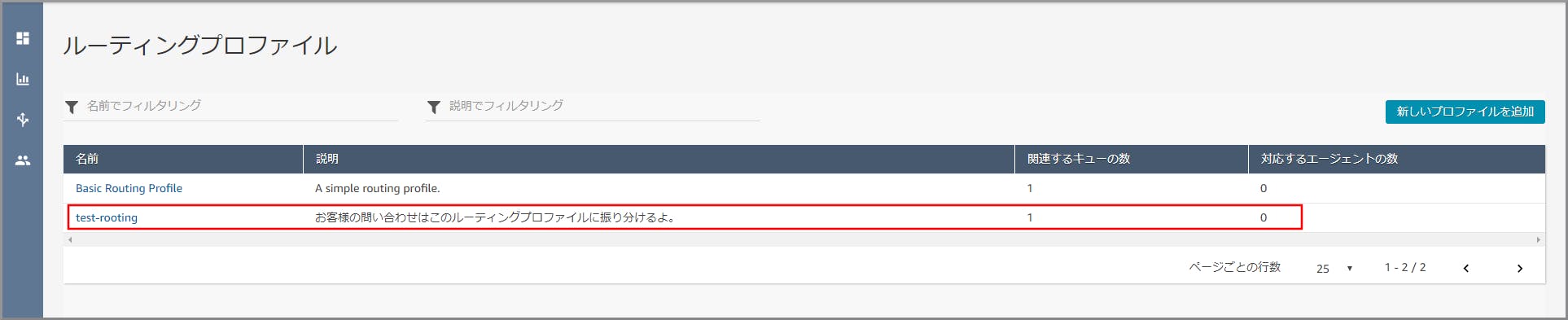
以下の項目を入力、選択し、《新しいプロファイルを追加》をクリックします。
- 名前:適当な名前を入力します。
- 説明:適当な説明を入力します。
- Set channels and concurrency:Voiceを選択します。
- ルーティングプロファイルのキュー:【クラウド初心者向け】Amazon Connectのキュー作成で作成したキューを選択します。
- デフォルトのアウトバウンドキュー:【クラウド初心者向け】Amazon Connectのキュー作成で作成したキューを選択します。
登録が完了し、ルーティングプロファイルが一覧に表示されます。


- 投稿日:2019-11-26T12:52:10+09:00
【クラウド初心者向け】Amazon Connectのキュー作成
概要
- お客様の電話がユーザー(エージェント)に接続されるまで待機している場所になります。
- キュー内の優先順位はキューに入ってきた順です。
- ルーティングプロファイルを割り当て、空いているユーザー(エージェント)に電話を転送します。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
ダッシュボードの左側のメニューから《キュー》をクリックします。
《新しいキューの追加》をクリックします。
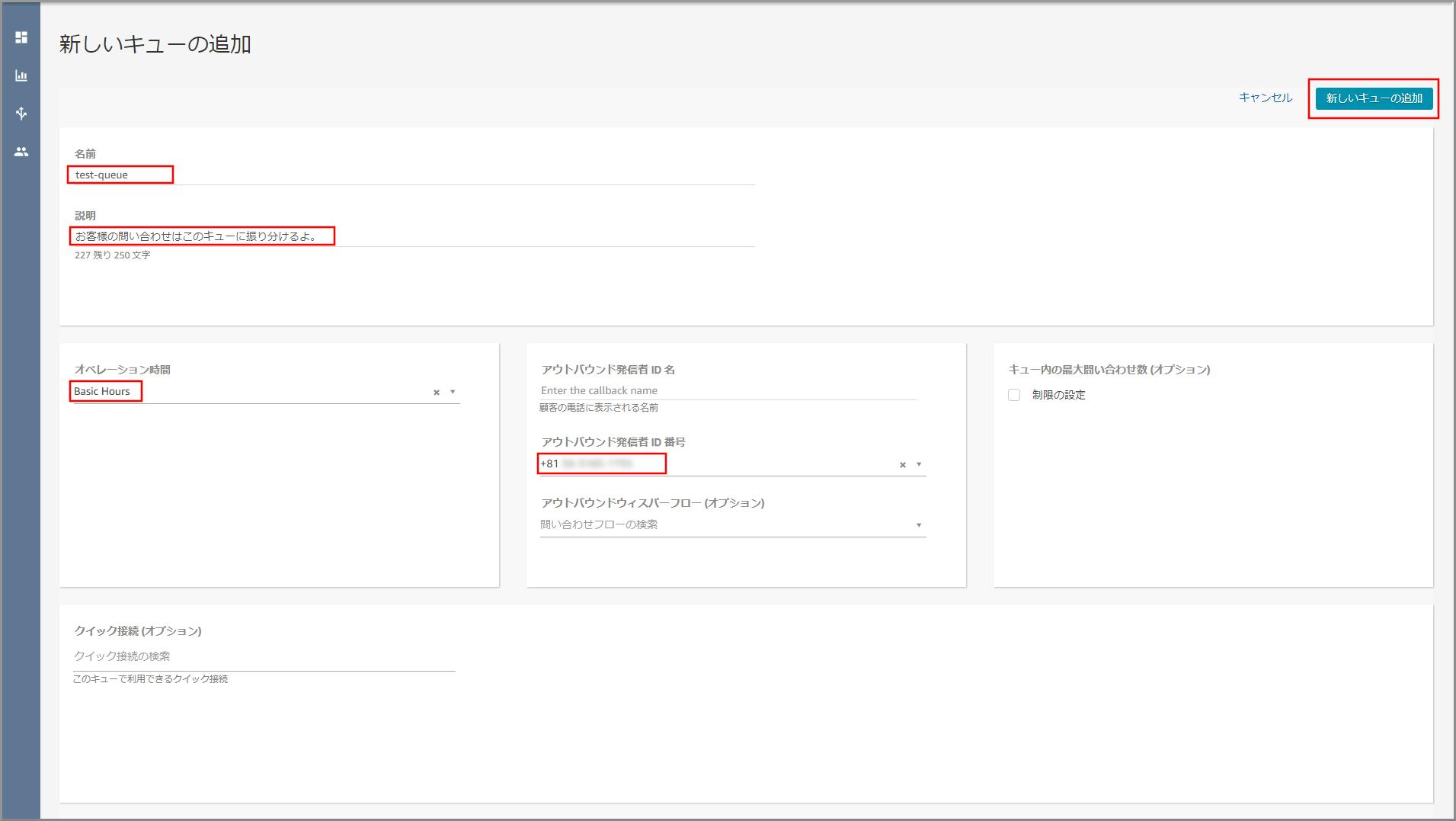
以下の項目を入力、選択し、《新しいキューの追加》をクリックします。
- 名前:適当な名前を入力します。
- 説明:適当な説明を入力します。
- オペレーション時間:デフォルトで用意されているBasic Hoursを選択します。
(利用しませんが何か指定しないといけないため指定する)- アウトバウンド発信者ID番号:【クラウド初心者向け】Amazon Connectの電話番号取得で取得した電話番号を選択します。
(外線転送した場合にこの番号が外線転送先に通知されます)登録が完了し、キューが一覧に表示されます。


- 投稿日:2019-11-26T10:27:56+09:00
DynamoDBをJson形式でエクスポート・インポート
Amazon DynamoDBのデータをエクスポートする方法はいろいろとあります。
Pythonを使ったツールだとdynamodb-json、DynamoDBtoCSV あたりが星多めですね。本記事ではシェルスクリプトでJSON形式でデータをエクスポート・インポートする手軽な方法をまとめます。
使用ツール
実行前確認
下のコマンドでテーブル内容を取得できることを確認します(追加で指定が必要な環境もあります)。
aws dynamodb scan --table-name [テーブル名]エクスポート
AWS CLIを使ってJSON形式でエクスポートするシェルスクリプトです。
--queryを使って特定のデータのみを出力することも可能です。export-data.sh# 第一引数でテーブル名をセット table_name=${1:-null} if [ $table_name = "null" ]; then echo "export-data.sh [table_name]" exit fi # AWS CLIでエクスポート aws dynamodb scan \ --table-name ${table_name} \ --output json \ > ${table_name}.jsonテーブル構造が簡単で、Excelなどで編集したい場合は、下のように列名を指定してCSV形式で出力することもできます(Number列 「id」、String列「name」の例)。
CSV形式でエクスポートaws dynamodb scan \ --table-name ${table_name} \ --query "Items[*].[id.N,name.S]" \ --output json \ | jq -r '.[] | @csv' \ > ./${table_name}.csvインポート
インポートはひと手間かかり、ファイルを一行ずつ読み込んでアップサートすることになります。
import-data.sh# 第一引数でテーブル名をセット table_name=${1:-null} # テーブル名指定で1テーブルのみ処理 if [ $table_name != "null" ]; then while IFS= read -r item; do aws dynamodb put-item --table-name "${table_name}" --item "$item" done< <(jq -c '.Items[]' < "./${table_name}.json") exit fi参考
シェルスクリプトでテーブルスキーマごと複製したい場合は下の記事が参考になります。
- 投稿日:2019-11-26T10:08:33+09:00
AWS Windows サーバーがリモートデスクトップで手が滑りワンクリックで文鎮化?! 救済手段はあるのだろうか...
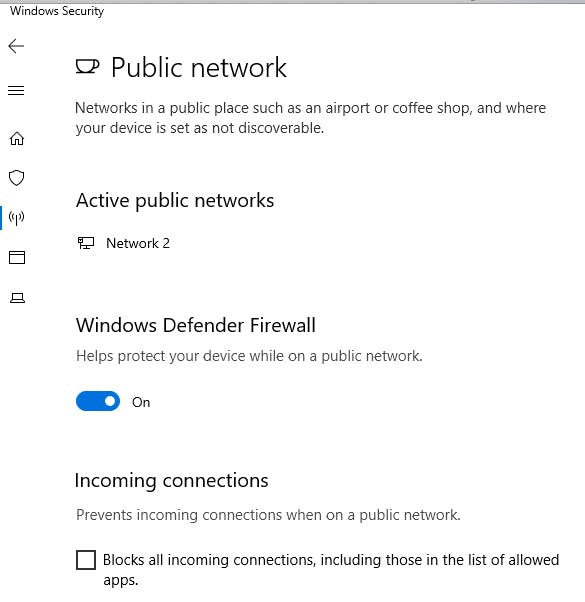
下図の場所(Windows Securityの"Incoming Connections"チェックボックス)を誤ってクリックしてリモートデスクトップが切断、再接続不能になり、文鎮化...
ドメインに参加しておらずグループポリシーによるスタートアップ時の強制配信もできず、他のリモートツールもインストールされておらず、クラウドから蒸発させるしか道は残されていないようでした。英語で検索すると他の人も困っているようで、
https://serverfault.com/questions/919736/windows-server-2012-unblock-windows-firewall-ec2
のようなリカバリー手段もなくもなさそうですが、現実的なのだろうか。
一つ可能性を考えたのは内部IPで別のWindows サーバーを構築し内部IPからリモートデスクトップを行う方法。ただし、画面の説明通り、"Public Network"としてしか元々認識されていなければ(初期のデフォルト値では)アウトですよね...
ドメインに参加しておらず内部ネットワークとしての認識もされておらず外部ネットワークのみで運用している場合は【危険】!
バックアップから戻しをできるようにしておく重要性を実感しました。
別のツールを入れていても通信自体がブロックされてしまうようなので、
バックアップからの戻しが一番現実的なのか。
とりあえず私物のAWSだったので文鎮化したサーバーを丸ごと消しました。
事象の再現ができるか試してみたところ見事に再現ができた
(再現させて画像のキャプチャをしたのですが・・・)。
恐るべしWindows Security!
パブリックネットワークの扱いでドメインにも参加させておらず、
Blocks all incoming connections... にチェック入れると終・わ・り!!
- 投稿日:2019-11-26T09:54:55+09:00
AWS WAF のアクセスログをとりあえず S3 で確認したい
今回は AWS WAF(Web アプリケーションファイアウォール)を利用するうえで、何かあったときに WAF のログを確認する方法を知っておきたい方という方へ、S3 Select でアクセスが拒否されたログを確認する方法をお送りします。
AWS WAF のログ出力先について
Web アプリケーションを保護する目的で AWS WAF を導入した場合、WAF のログを Kinesis Data Firehose 経由で S3 に保存することができます。
そして、S3 に保存された WAF ログを S3 の機能である S3 Select を利用して確認することができます。ちなみに、WAF のログの
出力先は Amazon S3、Amazon ElasticSearch、Amazon RedShift を指定できます。(2019年11月25日時点)
大量のログデータを確認する場合は、ElasticSearch と RedShift を選んでいきたいですね。WAFの設定方法
「WAF のアクセスログを Kinesis Data Firehose 経由で S3 に保存する」ために、今回は以下の流れで AWS を構築しました。
- Kinesis Data Firehose を構築し、ログ出力先を S3 に設定
- WAF を構築し、WAF のログ出力先を Kinesis に設定
※S3バケットは Kinesis の構築時に一緒に新規作成できます。
※Kinesis Data Firehoses は "aws-waf-logs-" で始まる名前にする必要があるので、注意が必要です。ウェブ ACL でログ記録を有効にするには
1. Amazon Kinesis Data Firehose を「aws-waf-logs-」で始まるプレフィックスを使用して作成します (たとえば、aws-waf-logs-us-east-2-analytics)
ウェブ ACL トラフィック情報のログ記録 - AWS WAF、AWS Firewall Manager、および AWS Shield アドバンスドWAF で XSS (クロスサイトスクリプティング) 攻撃をブロックする
WAF には、XSS 攻撃をブロックするルールを設定しています。
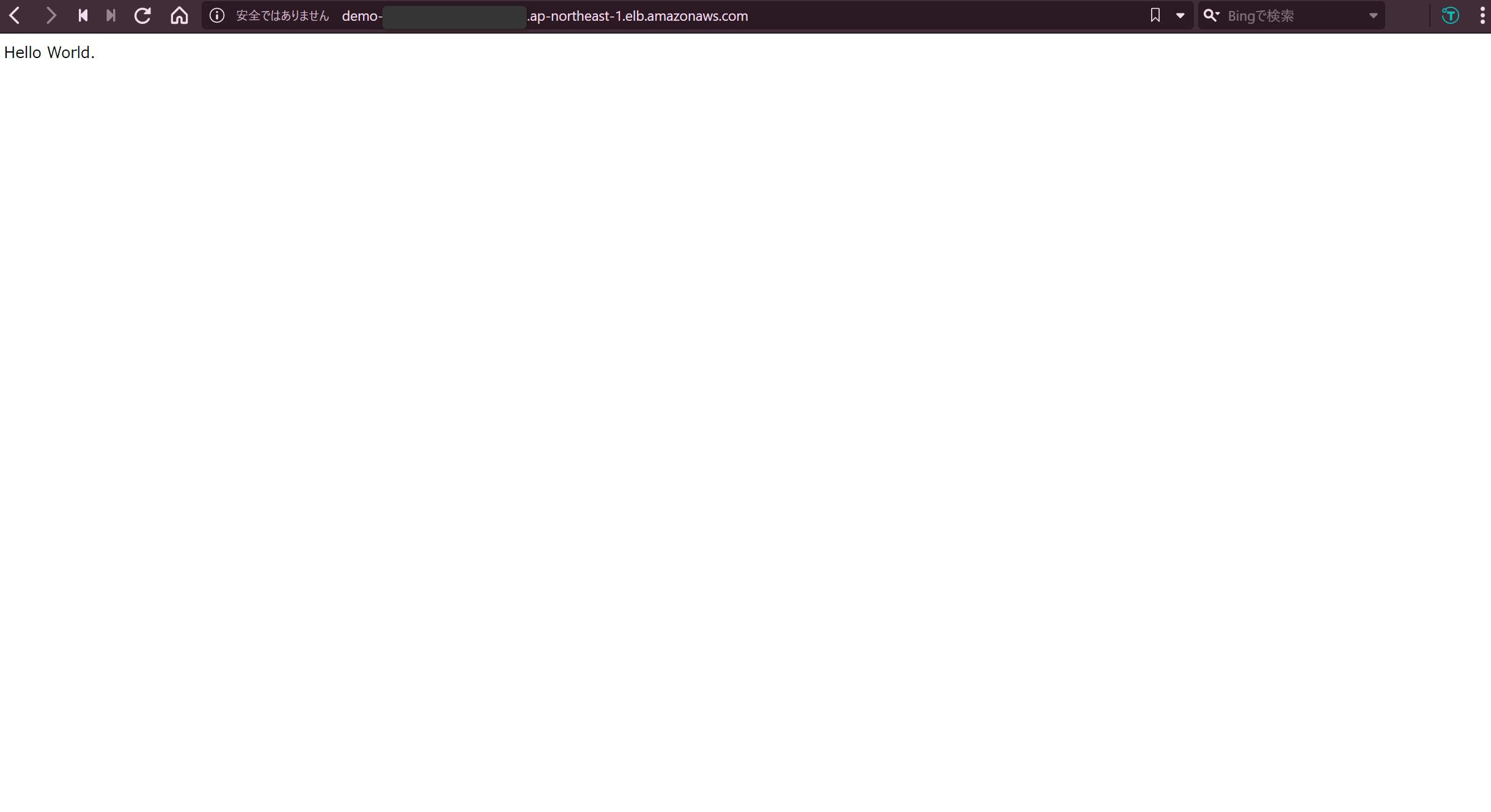
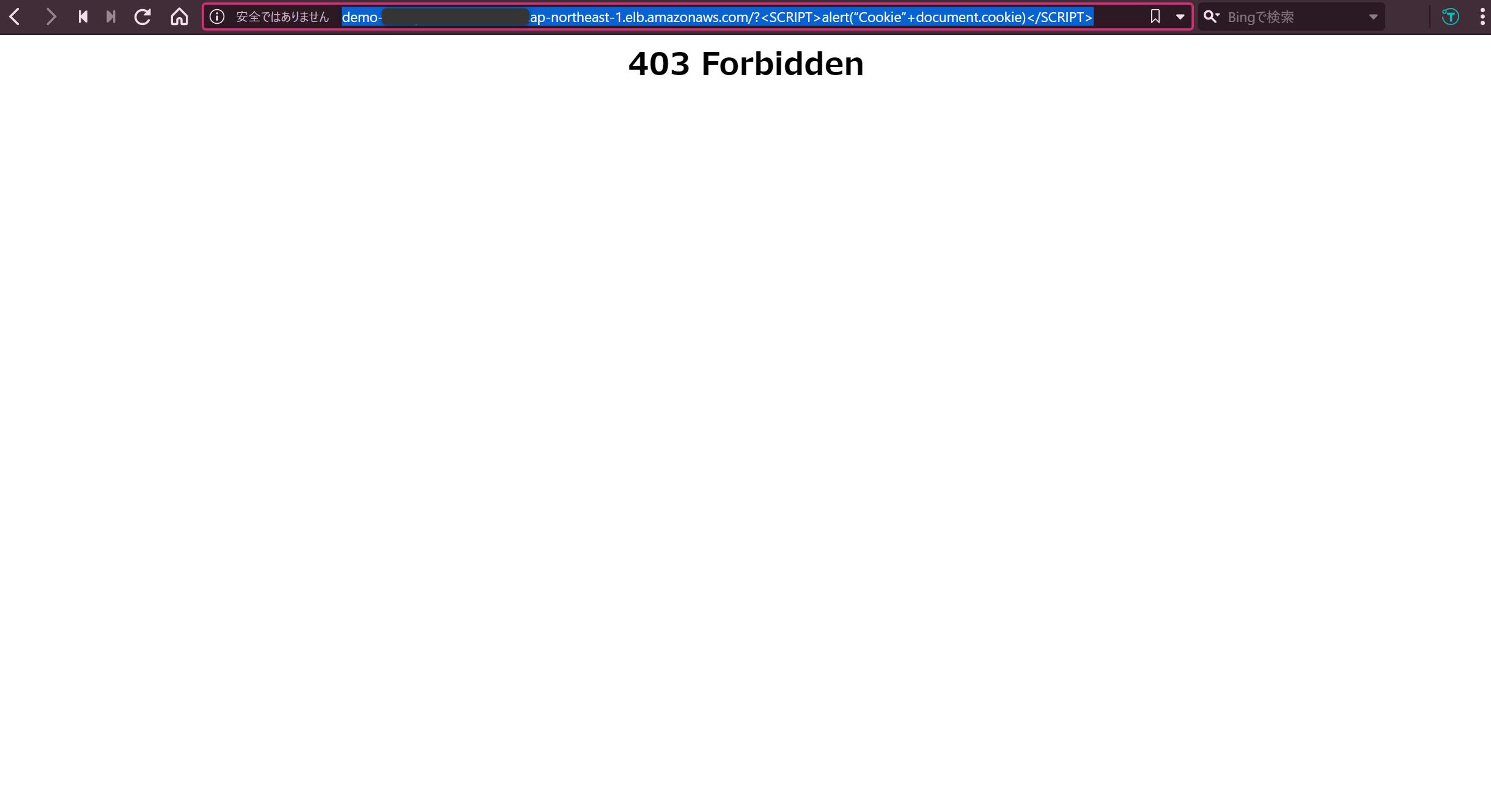
今回は EC2 上に構築した検証用の Web サイトの URL に以下を追記してアクセスし、XSS 攻撃を行います。
http://***.com/?%3CSCRIPT%3Ealert(%E2%80%9CCookie%E2%80%9D+document.cookie)%3C/SCRIPT%3E↓通常の URL だと問題なくアクセスできますが…
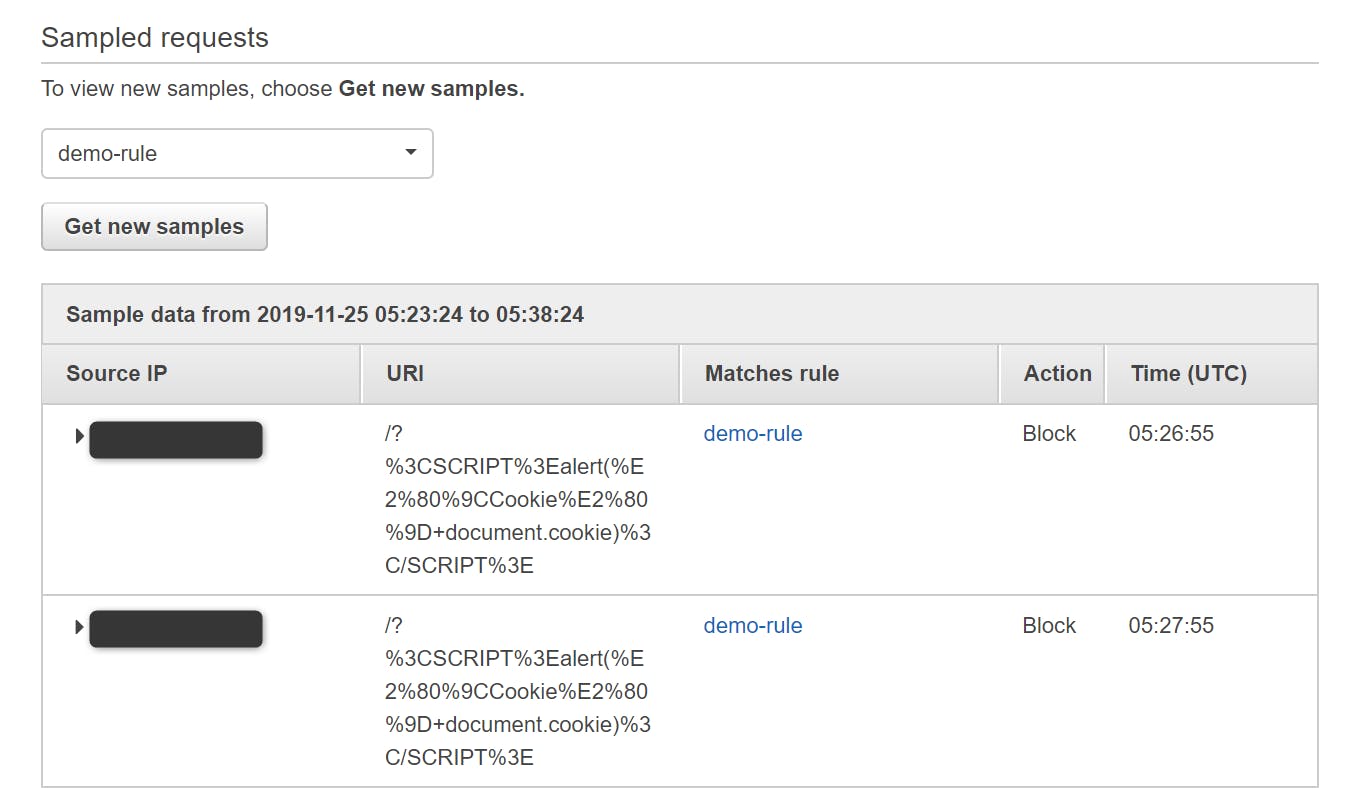
↓ "403 Forbidden" と表示されアクセスできませんでした。ちゃんと攻撃がブロックされていますね。
(WAF でアプリケーションを保護していない場合はアクセスできてしまいます。)
↓ WAF のコンソール上でも簡易的ですがブロックされた内容が確認できました。
WAF のログ確認方法
それでは、実際に S3 Select で WAF のログを確認してみましょう。
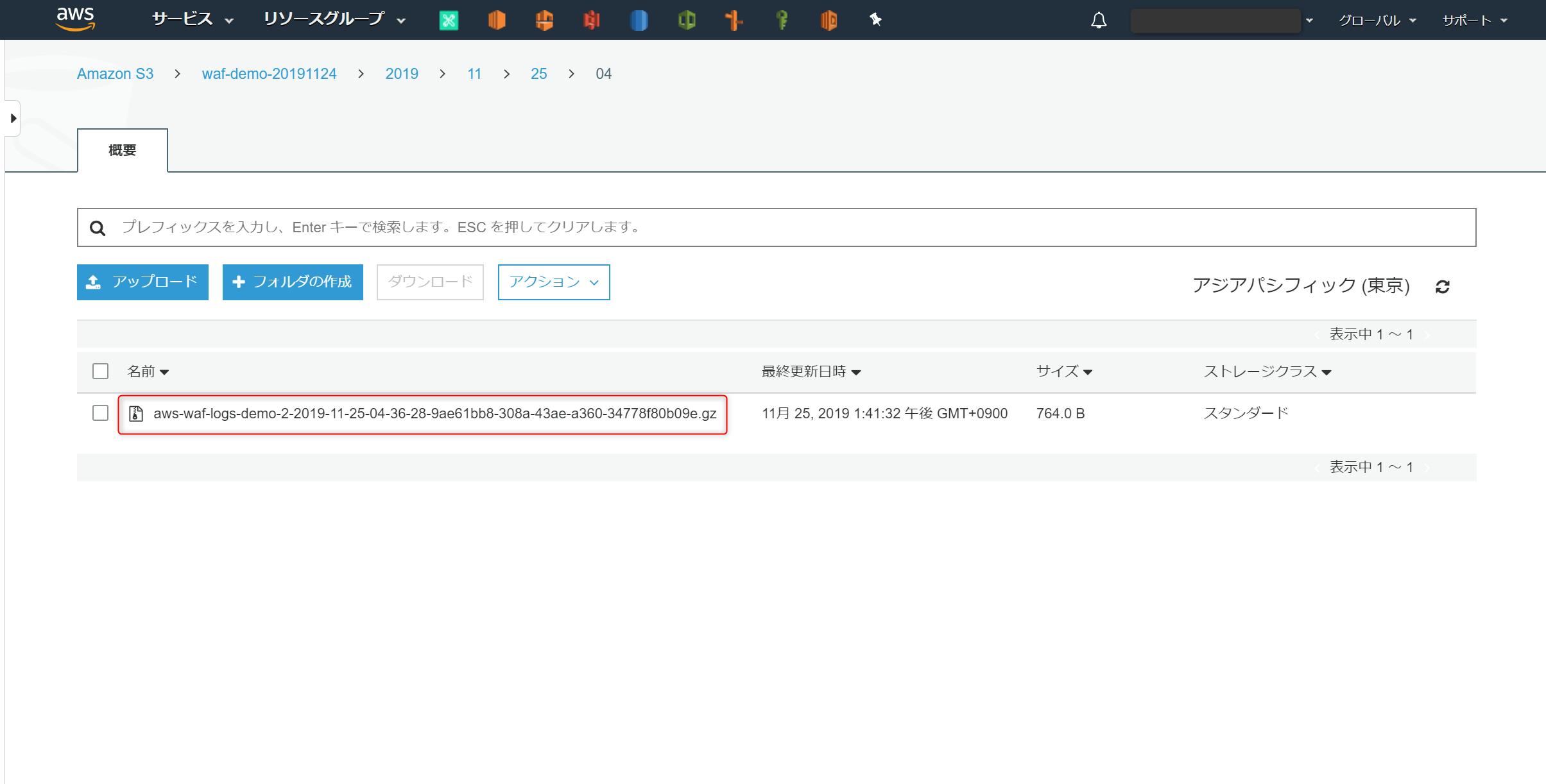
[サービス] > [S3] > [バケット] からログ出力先の S3 にアクセス
アクセスを確認したい日時のフォルダに移動して、対象のアクセスログファイルをクリックする
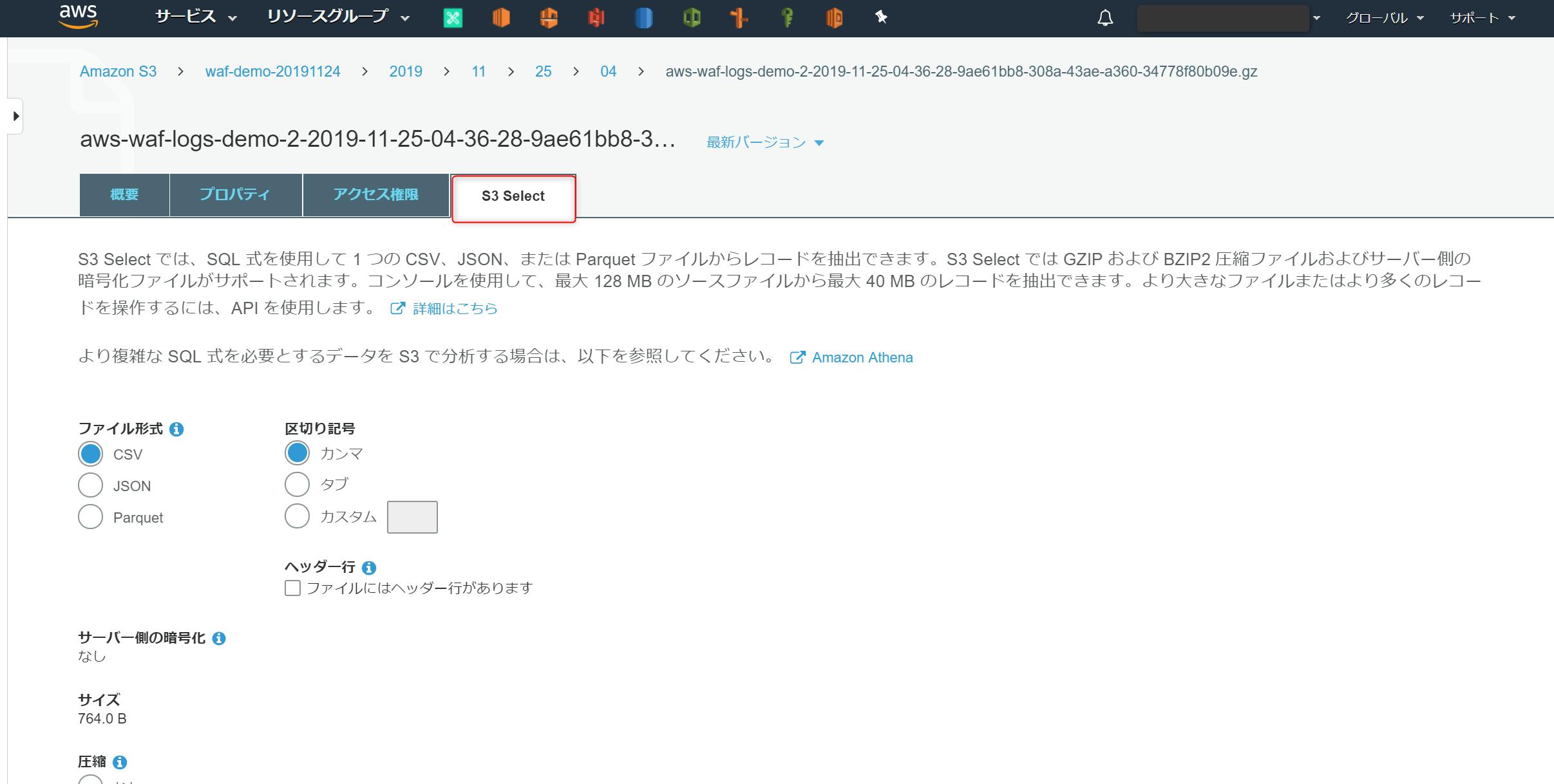
上部メニューの [アクション] > [S3 Select] を選択
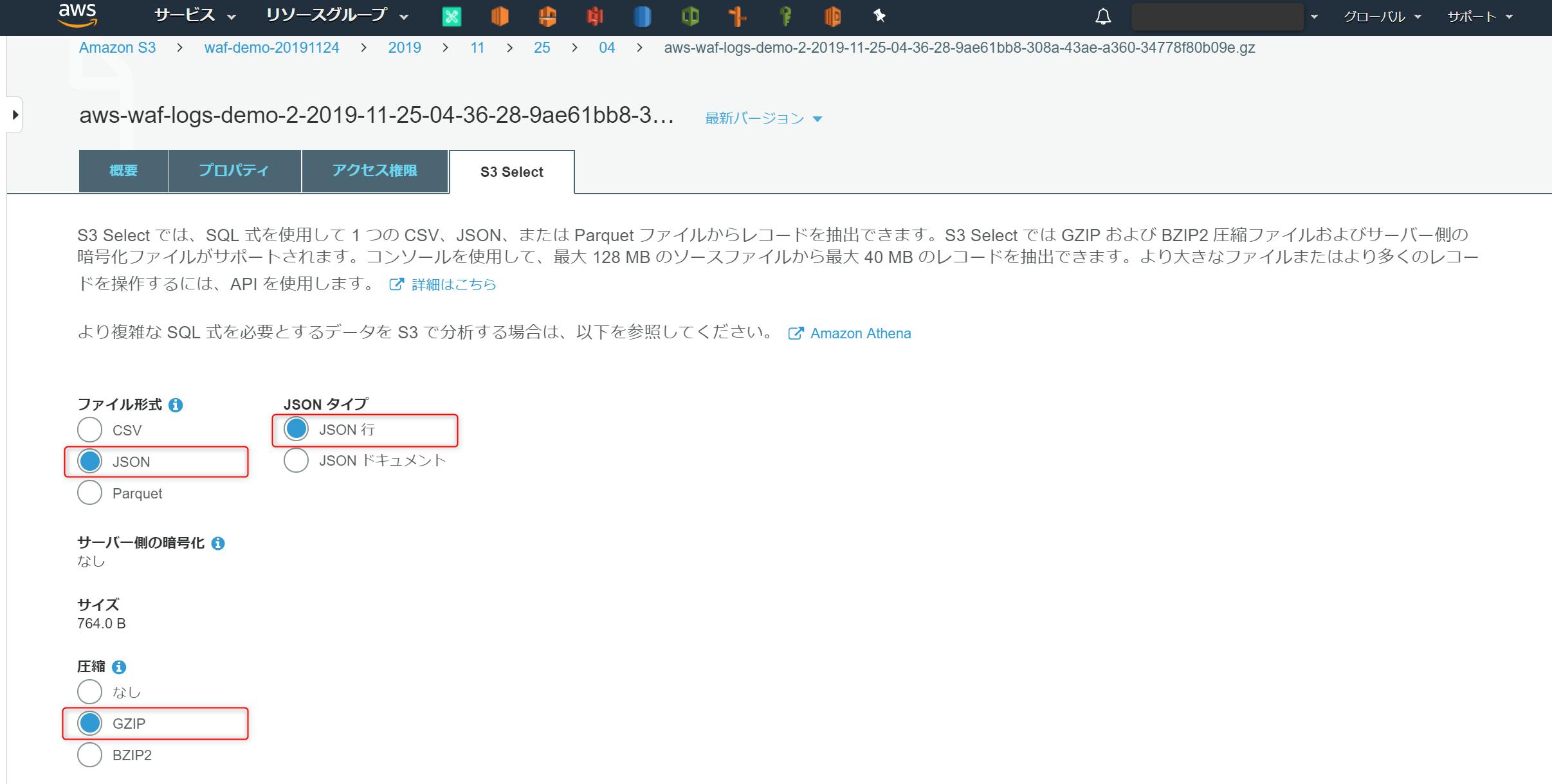
以下を選択し、[次へ] をクリック
ファイル形式 : JSON
JSONタイプ : JSON 行
圧縮 : GZIP (Kinesis 側の設定によって変わります)
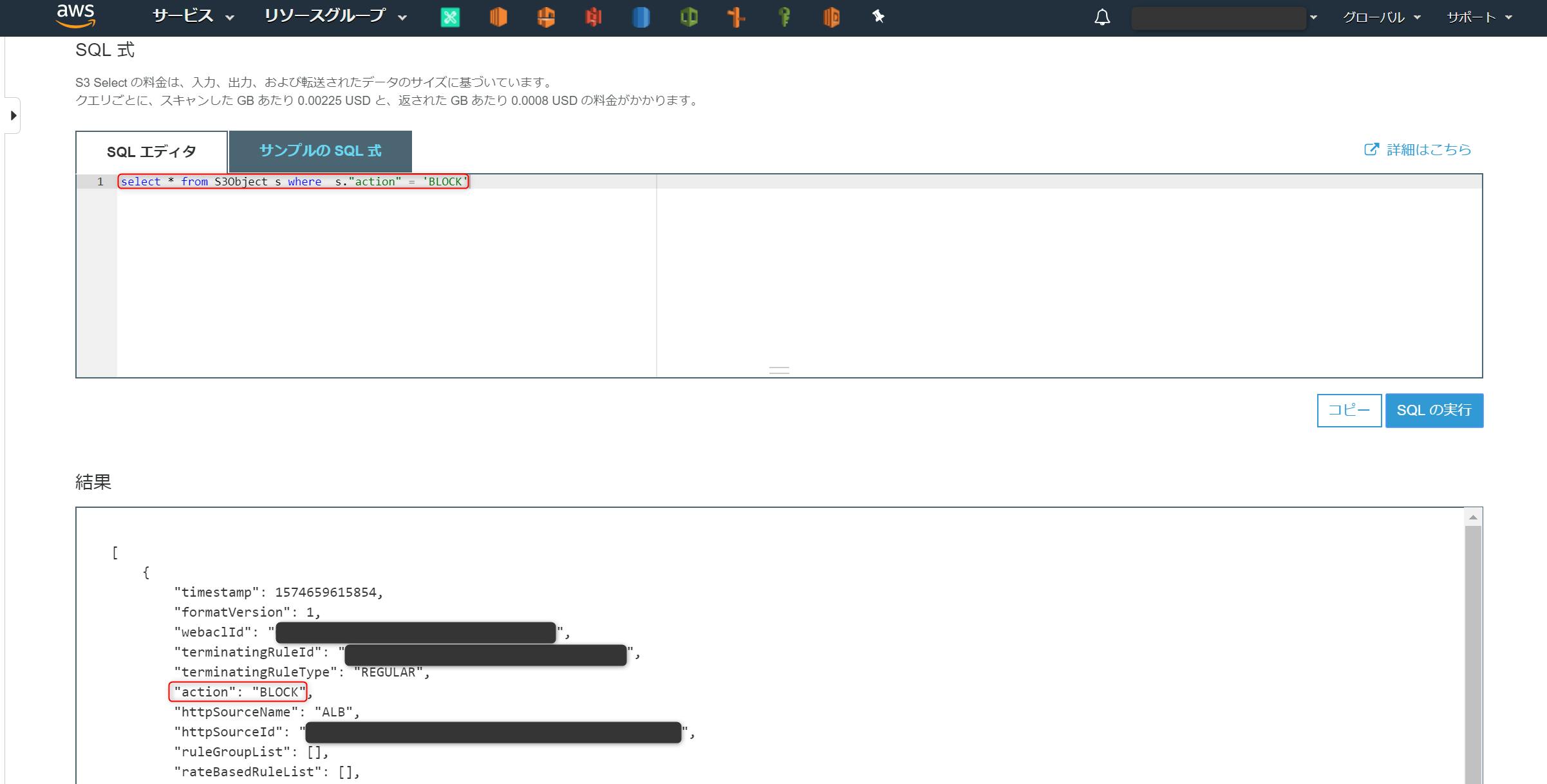
[SQL 式]のダイアログボックスに以下を入力し、[SQL の実行]を選択
- 許可されたアクセスログを確認
select * from S3Object s where s."action" = 'ALLOW'JSON データの
"action" : 'ALLOW'となっているログが表示される
- 拒否されたアクセスログを確認
select * from S3Object s where s."action" = 'BLOCK'
"action" : 'BLOCK'となっているログが表示される
WAF によってアクセスがブロックされたログが確認できました!
上記画像だとログが全部表示できていませんが、ログの例が AWS ドキュメントで記載されています。{ "timestamp":1533689070589, "formatVersion":1, "webaclId":"385cb038-3a6f-4f2f-ac64-09ab912af590", "terminatingRuleId":"Default_Action", "terminatingRuleType":"REGULAR", "action":"ALLOW", "httpSourceName":"CF", "httpSourceId":"i-123", "ruleGroupList":[ { "ruleGroupId":"41f4eb08-4e1b-2985-92b5-e8abf434fad3", "terminatingRule":null, "nonTerminatingMatchingRules":[ {"action" : "COUNT", "ruleId" : "4659b169-2083-4a91-bbd4-08851a9aaf74"} ] "excludedRules": [ {"exclusionType" : "EXCLUDED_AS_COUNT", "ruleId" : "5432a230-0113-5b83-bbb2-89375c5bfa98"} ] } ], "rateBasedRuleList":[ { "rateBasedRuleId":"7c968ef6-32ec-4fee-96cc-51198e412e7f", "limitKey":"IP", "maxRateAllowed":100 }, { "rateBasedRuleId":"462b169-2083-4a93-bbd4-08851a9aaf30", "limitKey":"IP", "maxRateAllowed":100 } ], "nonTerminatingMatchingRules":[ {"action" : "COUNT", "ruleId" : "4659b181-2011-4a91-bbd4-08851a9aaf52"} ], "httpRequest":{ "clientIp":"192.10.23.23", "country":"US", "headers":[ { "name":"Host", "value":"127.0.0.1:1989" }, { "name":"User-Agent", "value":"curl/7.51.2" }, { "name":"Accept", "value":"*/*" } ], "uri":"REDACTED", "args":"usernam=abc", "httpVersion":"HTTP/1.1", "httpMethod":"GET", "requestId":"cloud front Request id" } }ログの読み方についても、以下の AWS ドキュメントで説明されています。
以下ではこれらのログに示されている各項目について説明しています。
timestamp
タイムスタンプ (ミリ秒単位)。
formatVersion
ログの形式バージョン。
webaclId
ウェブ ACL の GUID。...
ウェブ ACL トラフィック情報のログ記録 - AWS WAF、AWS Firewall Manager、および AWS Shield アドバンスド補足
AWS ドキュメントを参考にしながらログの中身を見ていくと、WAFのどのルールでブロックされたか確認できる箇所があることが分かります。
ruleGroupList
このリクエストで動作したルールグループのリスト。前述のコード例では、1 つのみです。WAF で設定しているルールの中で、拒否されたアクセスがどのルールでブロックされたか確認する場合があると思いますが、その際は以下のように検索すればブロックされたルールの ID が確認できます。
select * from S3Object s where s."action" = 'BLOCK' select * from S3Object[*].ruleGroupList↓
terminatingRuleのruleIdにブロックされたルールの ID が表示されています。{ "_1": [ { "ruleGroupId": "7c968ef6-32ec-4fee-96cc-51198e412e7f", "terminatingRule": { "ruleId": "462b169-2083-4a93-bbd4-08851a9aaf30", "action": "BLOCK" }, "nonTerminatingMatchingRules": [], "excludedRules": null } ] }参考ドキュメント
- AWS WAF ドキュメント https://docs.aws.amazon.com/ja_jp/waf/index.html

- 投稿日:2019-11-26T00:18:50+09:00
AWS Coud9でphpMyAdmin画面へアクセスしたときに 404|not foud エラーを解決する方法
Cloud9で開発環境を整えて、時間がたってからなぜかphpMyAdminへアクセスできず、ログイン画面で見れなくなる症状に躓きました。
いくら調べても解決しなかったんですが、もしかしたら稀にいるかもしれないと思って記事を書くことにしました。
解決のために事前チェックその1
サーバーを起動しているか確認
サーバー起動コマンド$ ^Cec2-user:~/environment/project1 $ php -S $IP:$PORT PHP 7.3.11 Development Server started at Mon Nov 25 15:22:41 2019 Listening on http://127.0.0.1:8080 Document root is /home/ec2-user/environment/project1 Press Ctrl-C to quit.下記のコマンドで起動したサーバーは phpMyAdminのページへアクセスしても 404|not foudとなります。
サーバー起動コマンド(1)$ ec2-user:~/environment/project1 $ php artisan serve Laravel development server started: http://127.0.0.1:8000サーバー起動コマンド(2)$ ec2-user:~/environment/project1 $ php artisan serve --port=8080 Laravel development server started: http://127.0.0.1:8080事前チェックその2
Laravelのプロジェクト(ディレクトリ)内でmysqld を起動しているか確認
mysqld起動コマンド$ sudo service mysqld start ec2-user:~/environment/project1 $ sudo service mysqld start Starting mysqld: [ OK ]mysqldの状態確認コマンド$ ec2-user:~/environment/project1 $ sudo service mysqld status mysqld (pid 20873) is running... [ OK ]running...と表示されていれば、起動中です。
一応、mysqld 停止コマンドも明記しておきます。
mysqldの停止コマンド$ ec2-user:~/environment/project1 $ sudo service mysqld stop Stopping mysqld: [ OK ]事前チェックその3
phpMyAdminのURLを "https://~~.vfs.cloud9.~~.amazonaws.com/phpMyAdmin/index.php" まで指定している
それでも解決しなかった場合、Cloud9上で作成した他のプロジェクト内でmysqldが起動している可能性があるので、それを停止します。
(アクセス権限に関しても調べて変更してみましたが、結果的に関係ありませんでした。)
linuxコマンドに詳しい方はもうわかると思うので、読み進める必要はないです。念のためlinux初心者の方のために細かいコマンド実行の様子を記しておきます。
まずはディレクトリの移動
親ディレクトリ移動$ ec2-user:~/environment/project1 $ cd ../そこでlsコマンドを実行すると他にもプロジェクトがあることがわかります。
ec2-user:~/environment $ ls project1 project2 README.mdproject1 のディレクトリから project2 (別のプロジェクト)のディレクトリを移動します。
親ディレクトリ移動$ ec2-user:~/environment/ $ cd project2その中で再度、mysqldの状態を確認してみると、、、
mysqldの状態確認コマンド$ ec2-user:~/environment/project2 $ sudo service mysqld status mysqld (pid 20873) is running... [ OK ]動いてる。。。。(このプロジェクト、ずっと触ってなかったのに、、)
それで、もしかしたらと思い停止コマンドを実行して停止し、
project1 の方のディレクトリに移ってから、mysqldを起動してみるとmysqldの停止コマンド$ ec2-user:~/environment/project2 $ sudo service mysqld stop Stopping mysqld: [ OK ] $ ec2-user:~/environment/ $ cd ../project1 ec2-user:~/environment/project1 $ sudo service mysqld start Starting mysqld: [ OK ]無事表示されました!!
以上です。 うっかり他のプロジェクトでのmysqldを停止し損ねて、
別プロジェクトで使おうとしたときに起きた症状の対策方法でした。AWSはまだ触り始めたばかりなので、わからないことだらけで苦戦していますが、
上記の方法以外で解決方法をしっていたり、設定方法をご存知の方がいらっしゃいましたら
ぜひコメントいただけるとありがたいです。