- 投稿日:2019-11-26T23:51:01+09:00
Goのポインタのポインタ
この記事は Go7 Advent Calendar 2019 の 6 日目の記事です。
はじめに
Go ではポインタ型としてポインタを扱うことができます。Go のポインタのポインタの Tips を共有します。Devquizです。
Q: 以下はの標準出力はいずれも
**Num型の値を表示しますが、1,2,3それぞれで何がどのように表示されるでしょうか??package main import ( "fmt" ) type Num struct { i int } func main() { np := &Num{i: 3} // 1: main 関数での出力 fmt.Printf("%p\n", &np) // 2: pointer 関数での出力 pointer(np) // 3: pointerpointer 関数での出力 pointerpointer(&np) } func pointer(np *Num) { fmt.Printf("%p\n", &np) } func pointerpointer(npp **Num) { fmt.Printf("%p\n", npp) }
答え
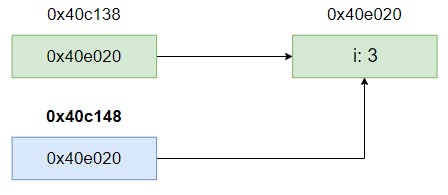
0x40c138 0x40c148 0x40c138https://play.golang.org/p/lJdJAX9fpEp
**Num型だけど全部同じアドレスではないです。(それはそうなのですが)何を表示しているのか
何を表示しているのか順番に確認していきましょう。
1: main 関数での出力
まず
np := &Num{i: 3}についてです。これは無名変数Num{i: 3}へのポインタです。コンパイラによって最適化されない限り、仮想メモリ上に確保されます、メモリ構造を簡易的に図にすると以下になっています。
Num{i: 3}もメモリ上に確保されています。Go Playground でfmt.Printf("%p\n", np)としてポインタのアドレスを確認してみます。func main() { np := &Num{i: 3} fmt.Printf("%p\n", &np) + fmt.Printf("%p\n", np) // 0x40e020 pointer(np) pointerpointer(&np) }すると
0x40e020であることが分かります。https://play.golang.org/p/qweDeErKUFR
よって以下では
**Num型の変数0x40c138が出力されることになります。fmt.Printf("%p\n", &np)2: pointer 関数での出力
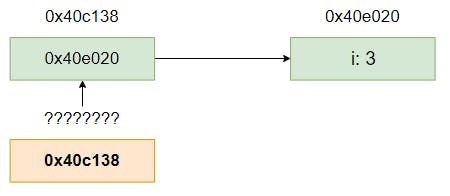
以下の関数について考えてみます。ここでは
*Numを引数として渡しています。*Numは何だったかというとNumのアドレスを保持している変数でした。ポインターで示している アドレスは値で渡されます。よってアドレスの値を格納する変数は、元の変数を格納しているアドレスとは別にメモリ上に確保されます。よって以下では
0x40c138ではなく別のアドレス値0x40c148が出力されています。func pointer(np *Num) { fmt.Printf("%p\n", &np) }
3: pointerpointer 関数での出力
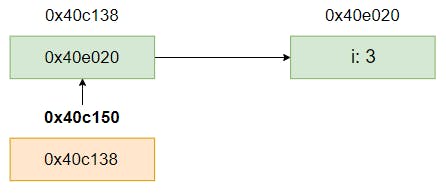
以下は
Numのポインターへのポインターでした。図にするとわかりやすいです。func pointerpointer(npp **Num) { fmt.Printf("%p\n", npp) }
この
**Numの値を格納する変数もメモリ上に確保されているので、そのアドレスを表示することができます。これも Go Playground に追加して確認しておきます。func pointerpointer(npp **Num) { fmt.Printf("%p\n", npp) + fmt.Printf("%p\n", &npp) // 0x40c150 }https://play.golang.org/p/9Ygqrowzylr
すると
0x40c150であることが分かります。つまり以下です。こちらも 2 の場合と同様にもとのアドレス0x40c138とは別のアドレス0x40c150が割り当てられていることがわかります。
まとめ
- ポインタ値は値
参考


- 投稿日:2019-11-26T19:26:16+09:00
[おすすめ]ターミナルでの作業効率が爆上げするTUIツール5選
こんにちわ、ゴリラです。
普段、筆者は主にターミナルで仕事をしています。そこで作業効率化のためいくつかTUIツールを使っています。
今日は、個人的におすすめのTUIツールを5つ紹介していきます。これらを導入することで、ターミナルでの作業効率が上がると思いますので、ぜひ導入して試してみてください。
また、こんな便利なツールがあるよって方いましたら、ぜひコメントをくださいー
- 2019/11/28 追記
- ffのブックマーク機能
Git
lazygitというTUIツールを使っています。
lazygit機能が豊富なので紹介しようとすると長くになってしまうため、筆者が普段使っていて便利だなと思う機能を紹介します。
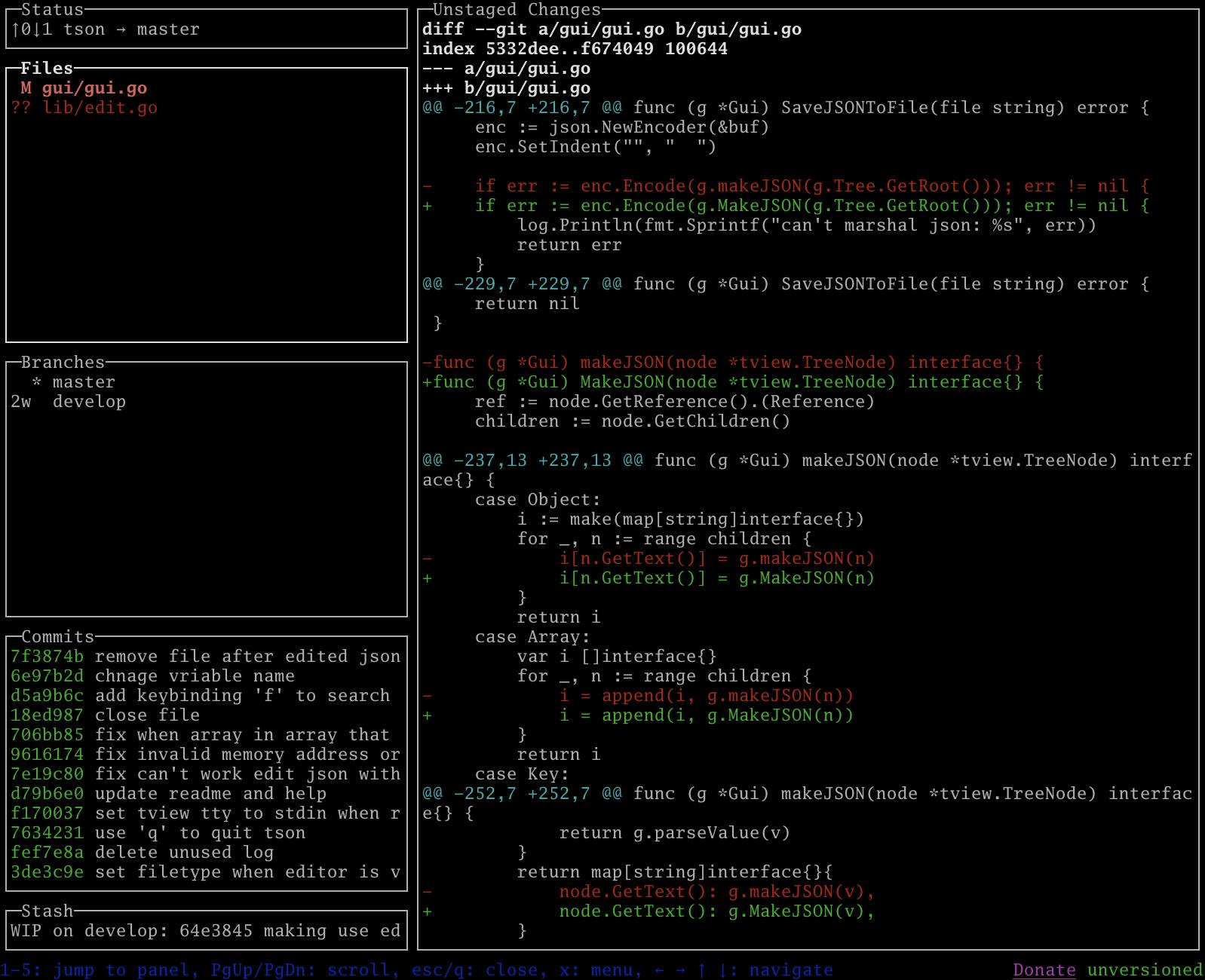
詳しく知りたい方はREADMEもしくは作者本人によるおすすめの15機能をまとめた動画を見てください。未コミットファイルの差分
lazygitを起動するとFilesに未コミットのファイルが表示されます。Unstaged Changesに選択したファイルの差分が表示されます。ファイルの選択はjとkもしくは↓と↑で、差分をスクロールする時はCTRL-d、CTRL-uを使用します。
ちなみに、変更を取り消すときは
dを使用します。未コミットなので消したら消えるのでご注意ください。コミットの差分
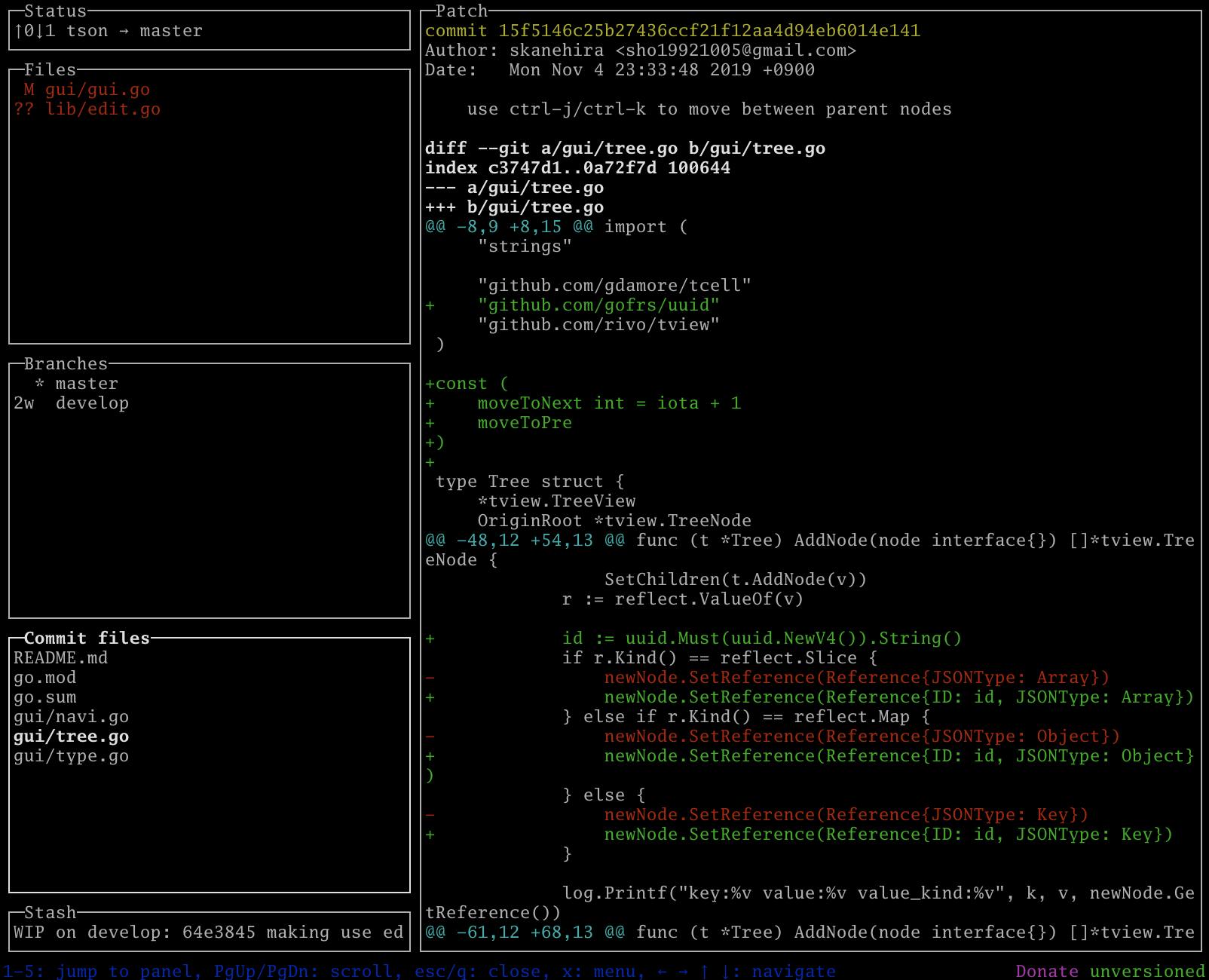
Commitでコミットを選択するとPatchにコミットの差分を確認できます。
コミット済みファイルの差分
CommitでEnterを押下するとCommit fiilesが表示されます。ファイルごとに差分を確認したい時に便利です。ちなみにこの機能は筆者が実装しました。便利だなと思いました。
ステージング
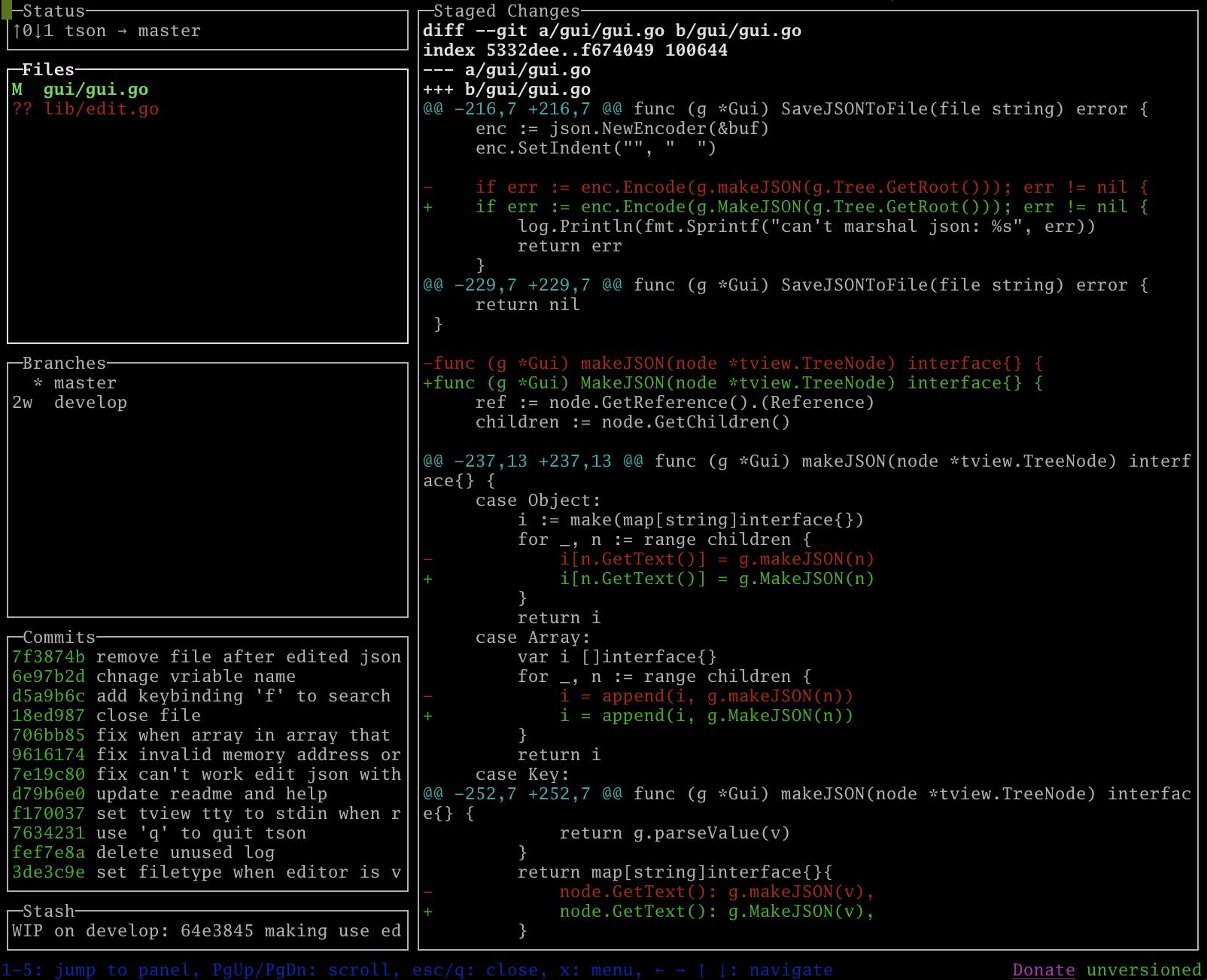
FilesでSpaceを押下すると選択したファイルをステージングできます。
aで全ファイルをステージングできます。ステージングしたら色が変わるのでわかりやすいですね。
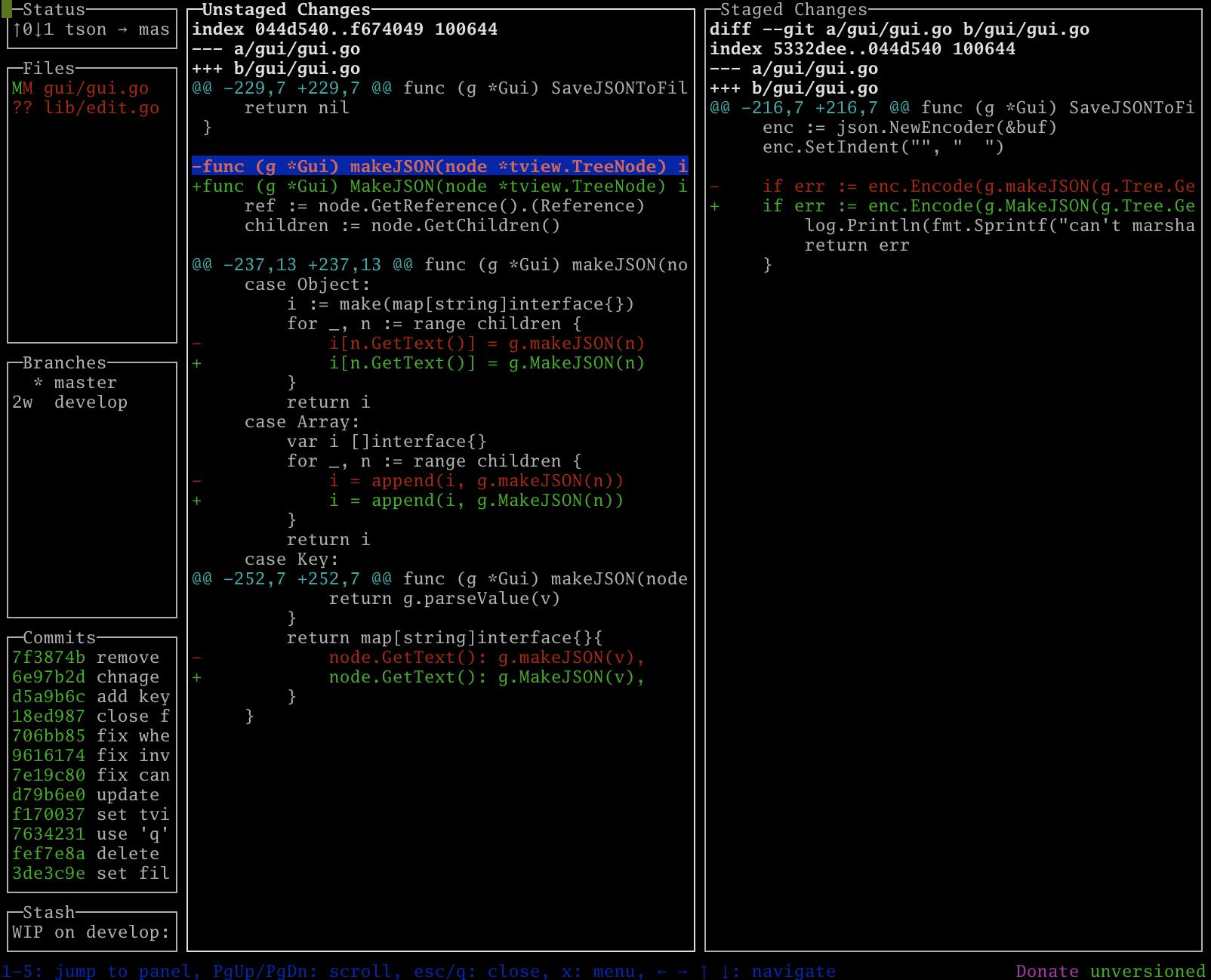
行単位のステージング
FilesでEnterを押下すると変更した行単位のステージングができます。選択肢た行でSpaceを押下するとStaged Changesに変更が追加されます。Tabを押下してStaged Changesに移動してdを押下するとステージングした変更を戻すことができます。とても便利です。
コミット
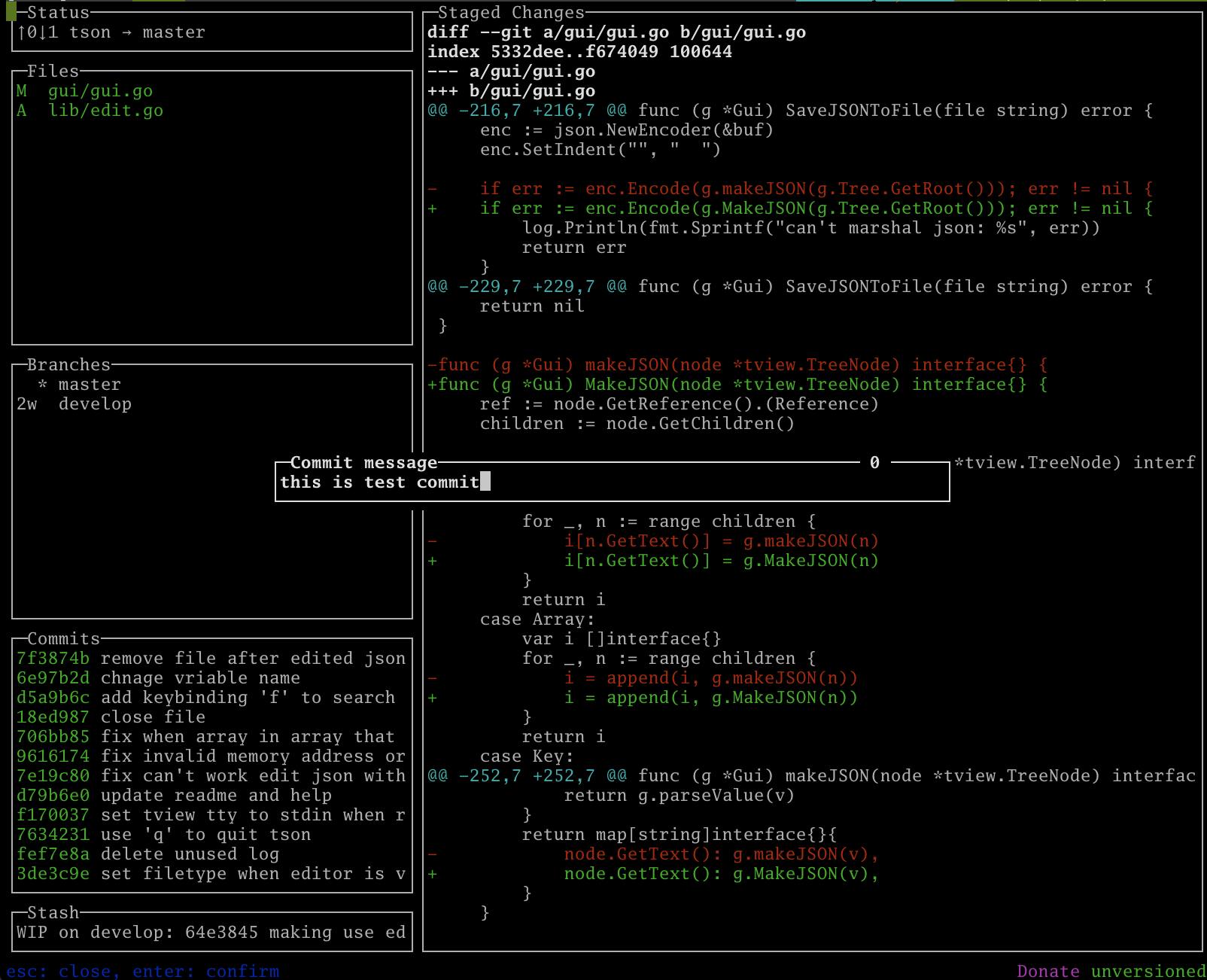
Filesでcを押下するとコミットメッセージを入力するパネルが表示されるのでそこでメッセージを入力したEnterを押下するとコミットできます。
より詳細なコミットメッセージを書きたいことが多いと思うので、Cを押下すると$EDITORに設定されているエディタを起動してコミットできます。
コミット間の差分
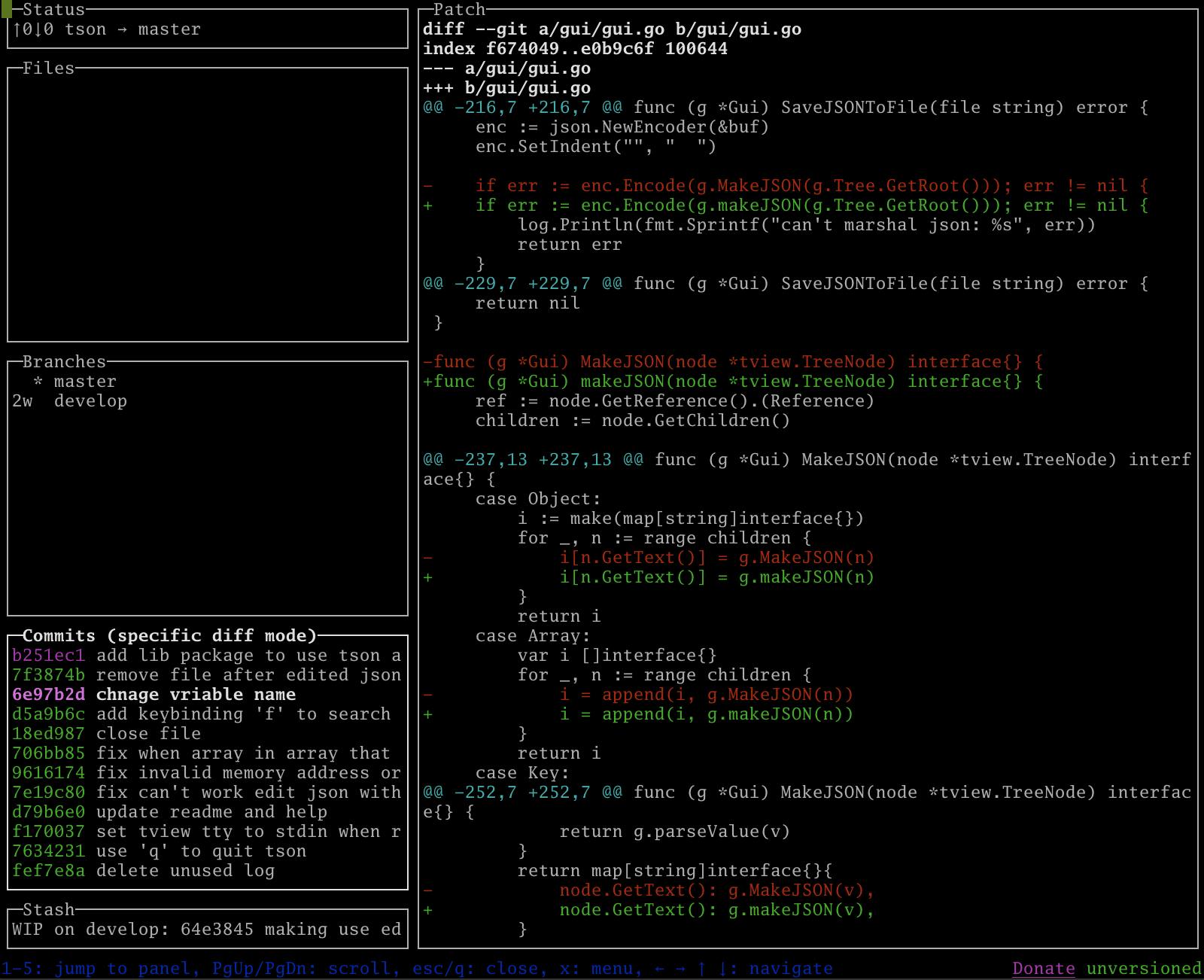
CommitsでSpaceを押下するとコミット差分モードに切り替わり、次に選択したコミットとの差分を確認することができます。ちなみにこれも筆者が実装しました。便利だなと思いました。
コミットにステージングファイルを追加
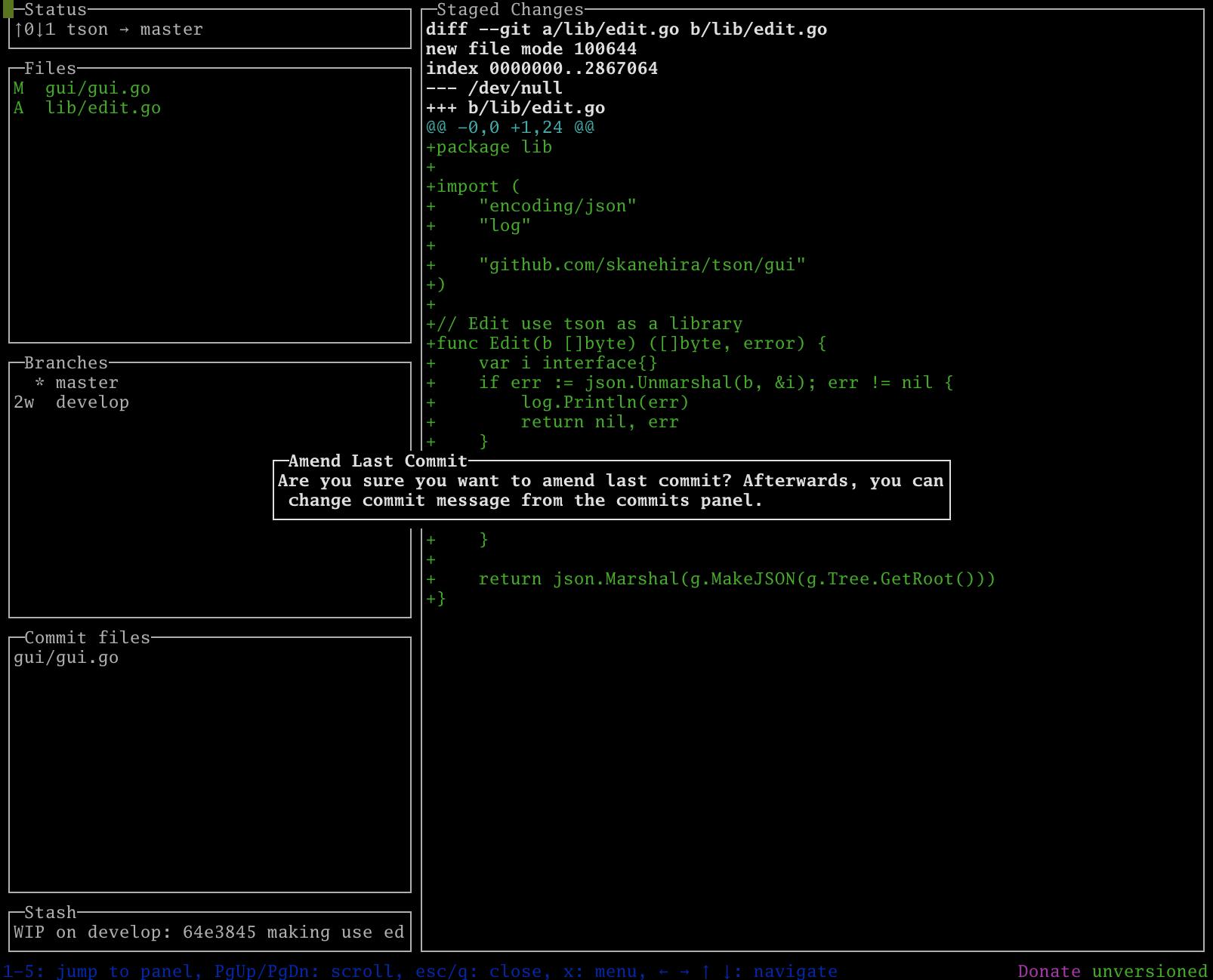
FilesでAを押下するとステージングしたファイルをコミットに追加することができます。
EscもしくはCTRL-[で操作をキャンセルできます。
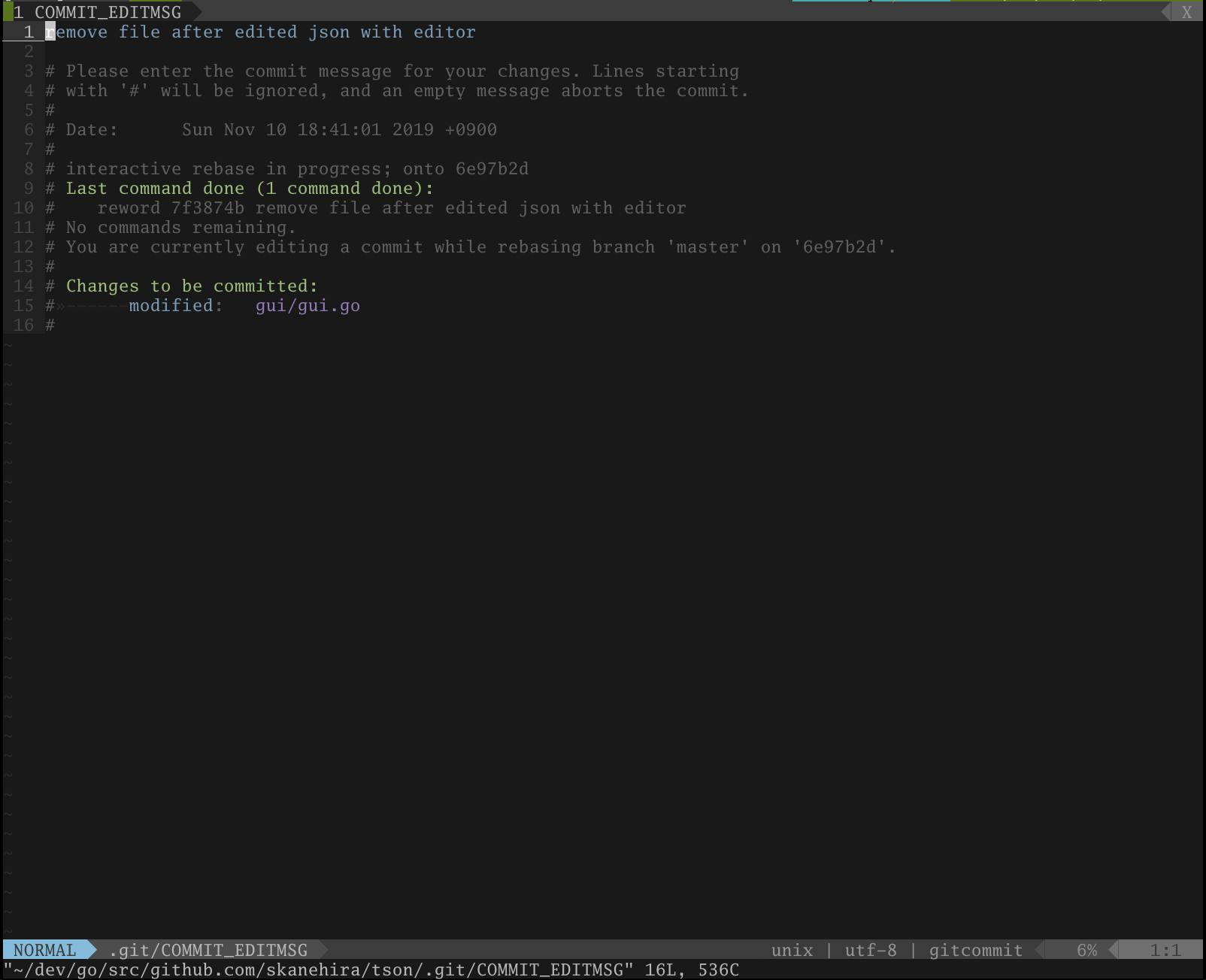
コミットメッセージの変更
CommitsでRでエディタを使ってコミットのメッセージを変更できます。
コミットの取り消し
Commitsでgで選択したコミットまでリセットできます。soft、mixed、hardを選択できます。
ブランチ作成
Branchesでnを押下すると新しいブランチを作成できます。
lazygitまとめ
ざっくりですが、いくつか機能を紹介しました。
他にもたくさんの機能がありますが、筆者もそこまで使いこなせているわけではないので、ぜひ読者自身で触ってみてください。Docker
最近開発ではdockerを使う方が多いのではないのでしょうか。筆者もその一人です。
dockerは基本コマンドで操作しますが、より簡単に操作できるTUIツールdocuiを以前作りました。より詳細な解説はこちらの記事を参考していただくとして、ここでは軽く紹介します。
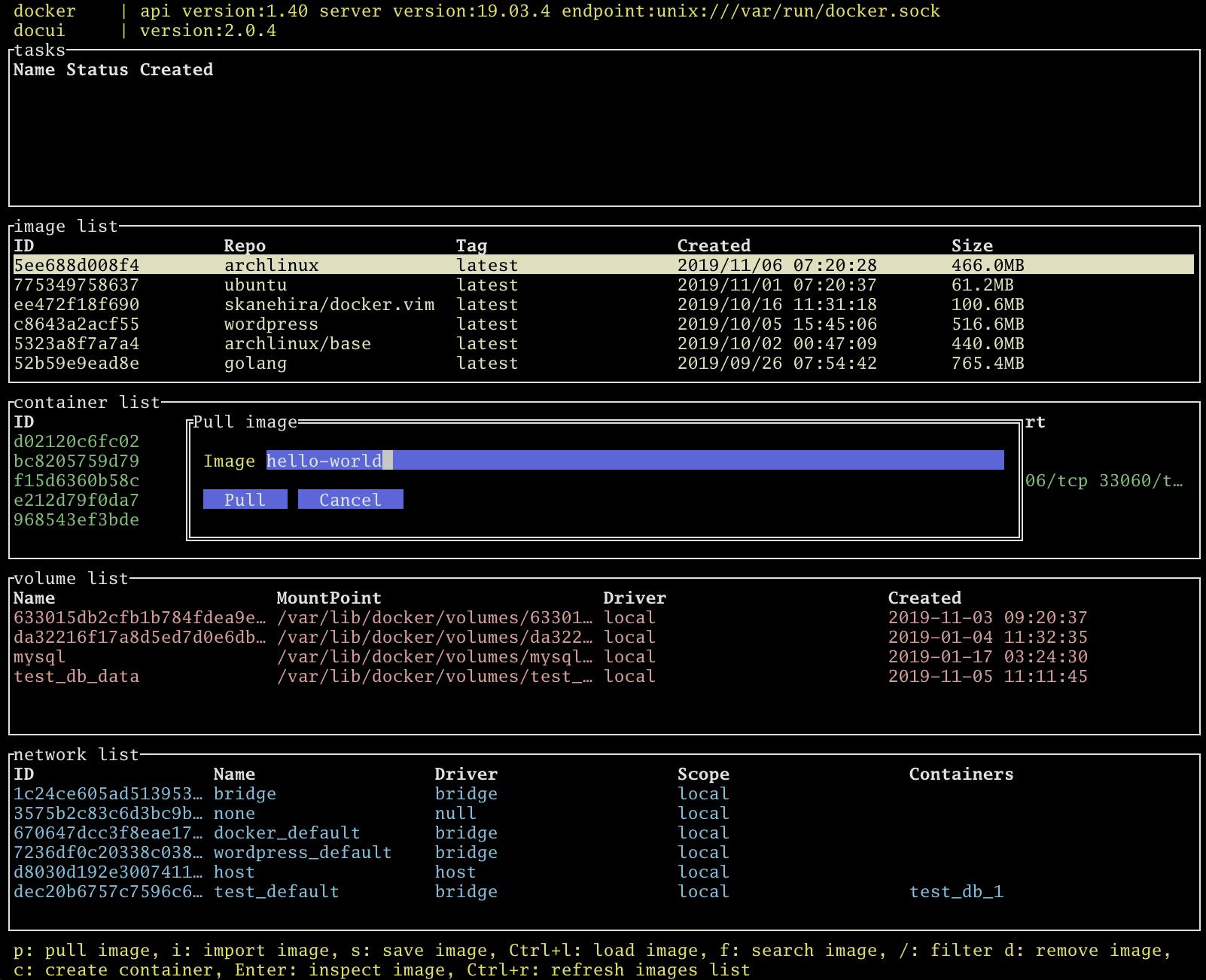
イメージ取得
image listでpでイメージをpullすることができます。これはdocker pullと同様な動きになります。基本操作は非同期で動くので、pullしている間にコンテナを起動したりすることもできます。便利ですね。
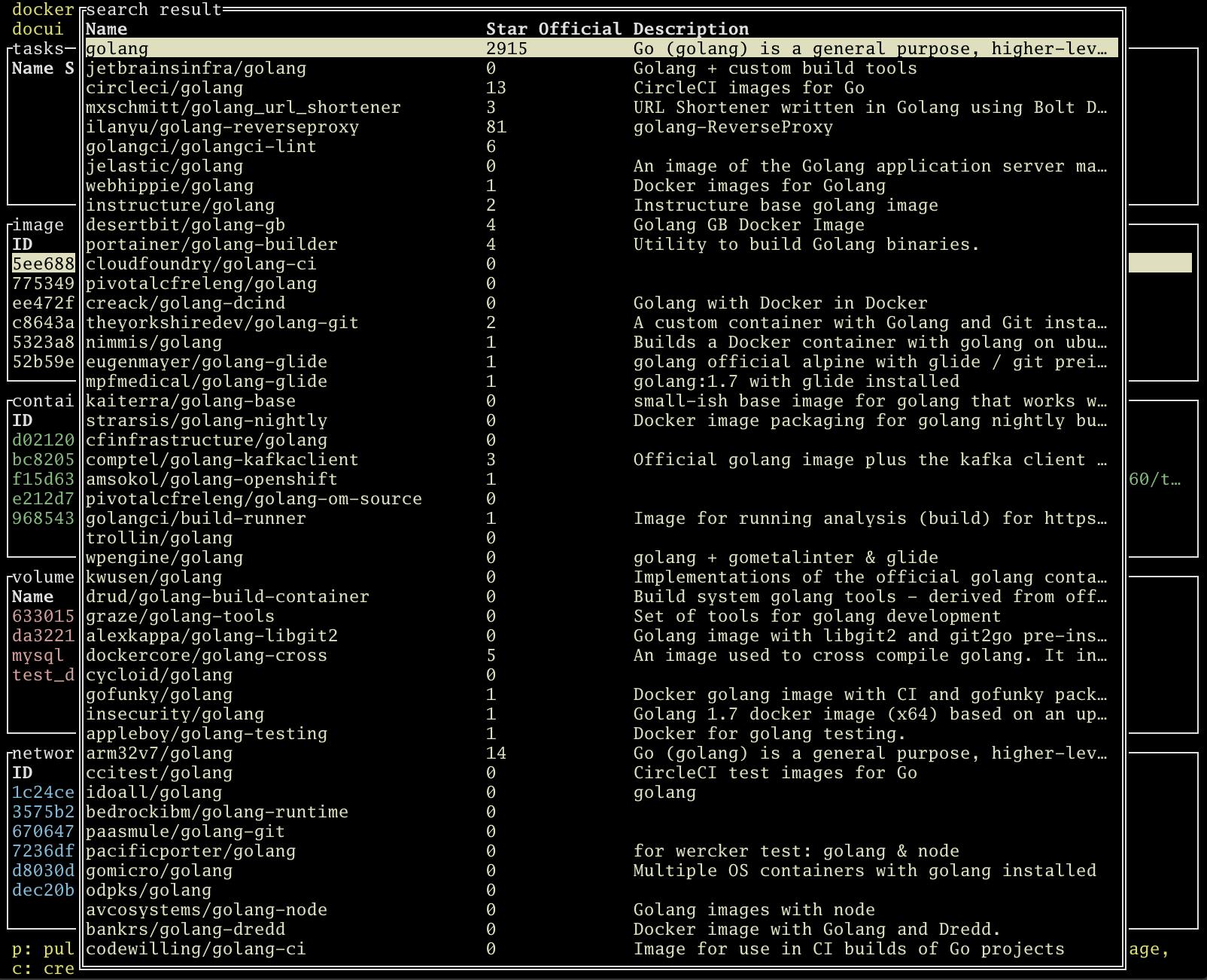
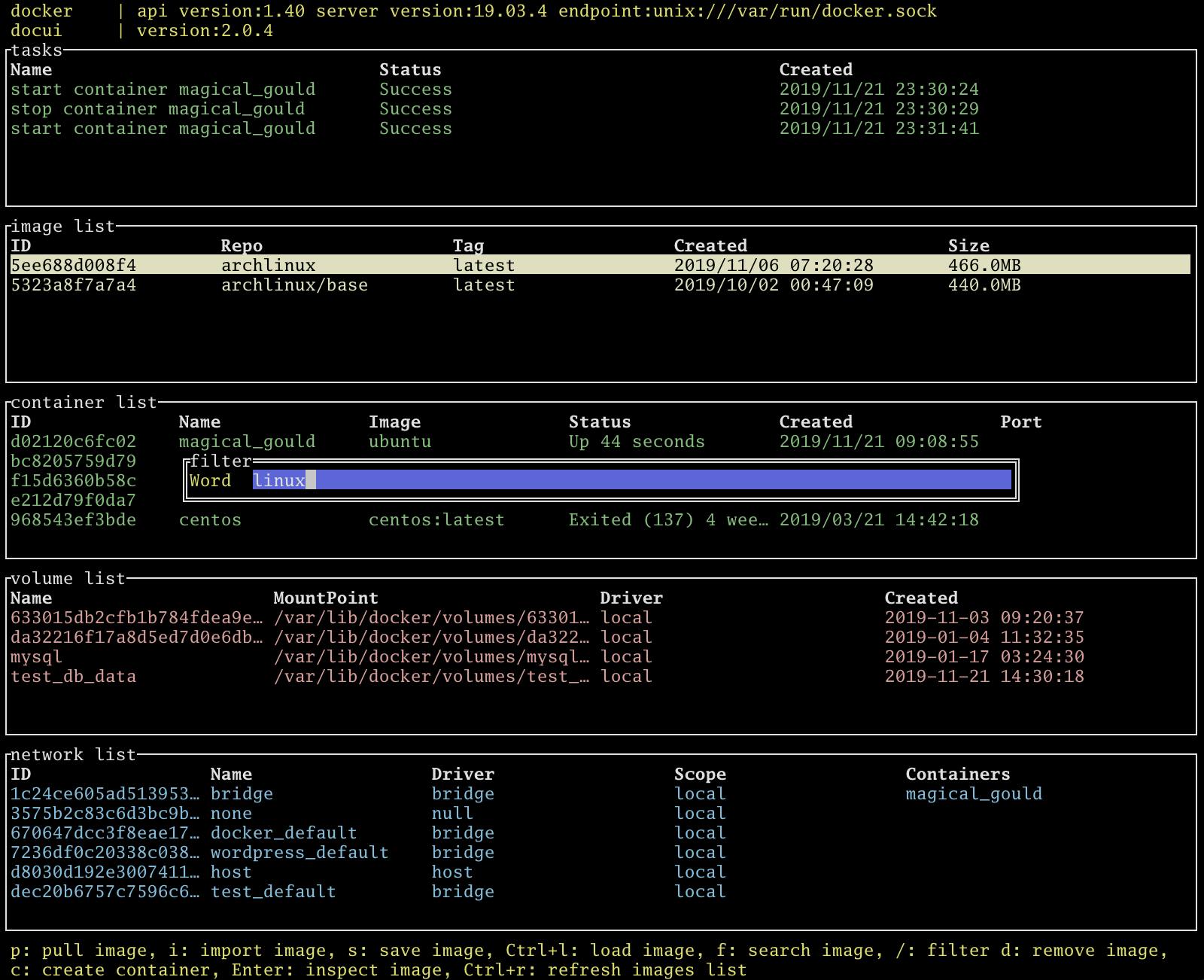
イメージの検索
image listでfでイメージをDockerHubから検索できます。search resultでpを押下すると選択したイメージをpullできます。
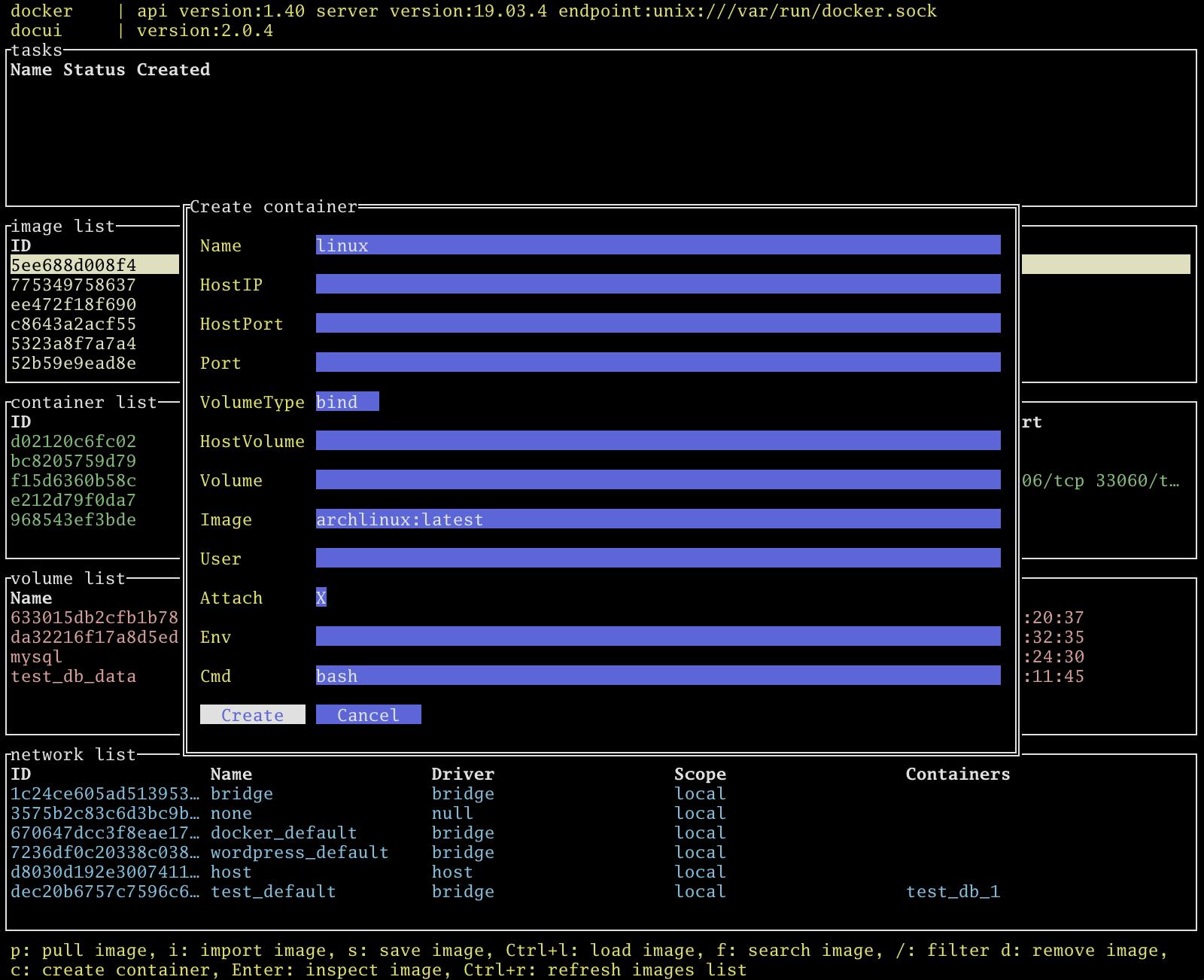
コンテナの作成
image listでcでイメージからコンテナを作成できます。docker createに相当します。
コンテナの起動・停止
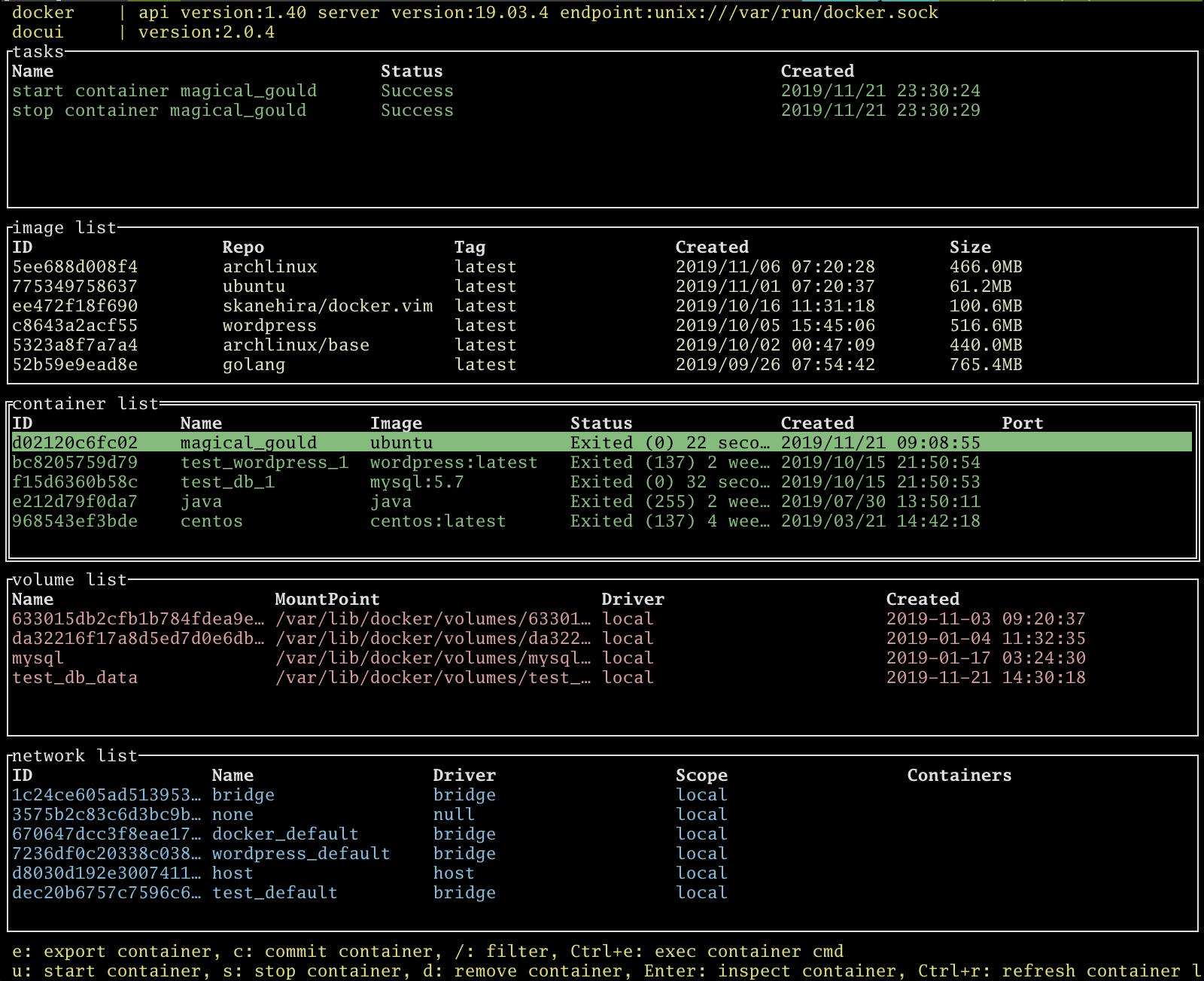
container listでuでコンテナを起動、sでコンテナを停止できます。
コンテナのアタッチ
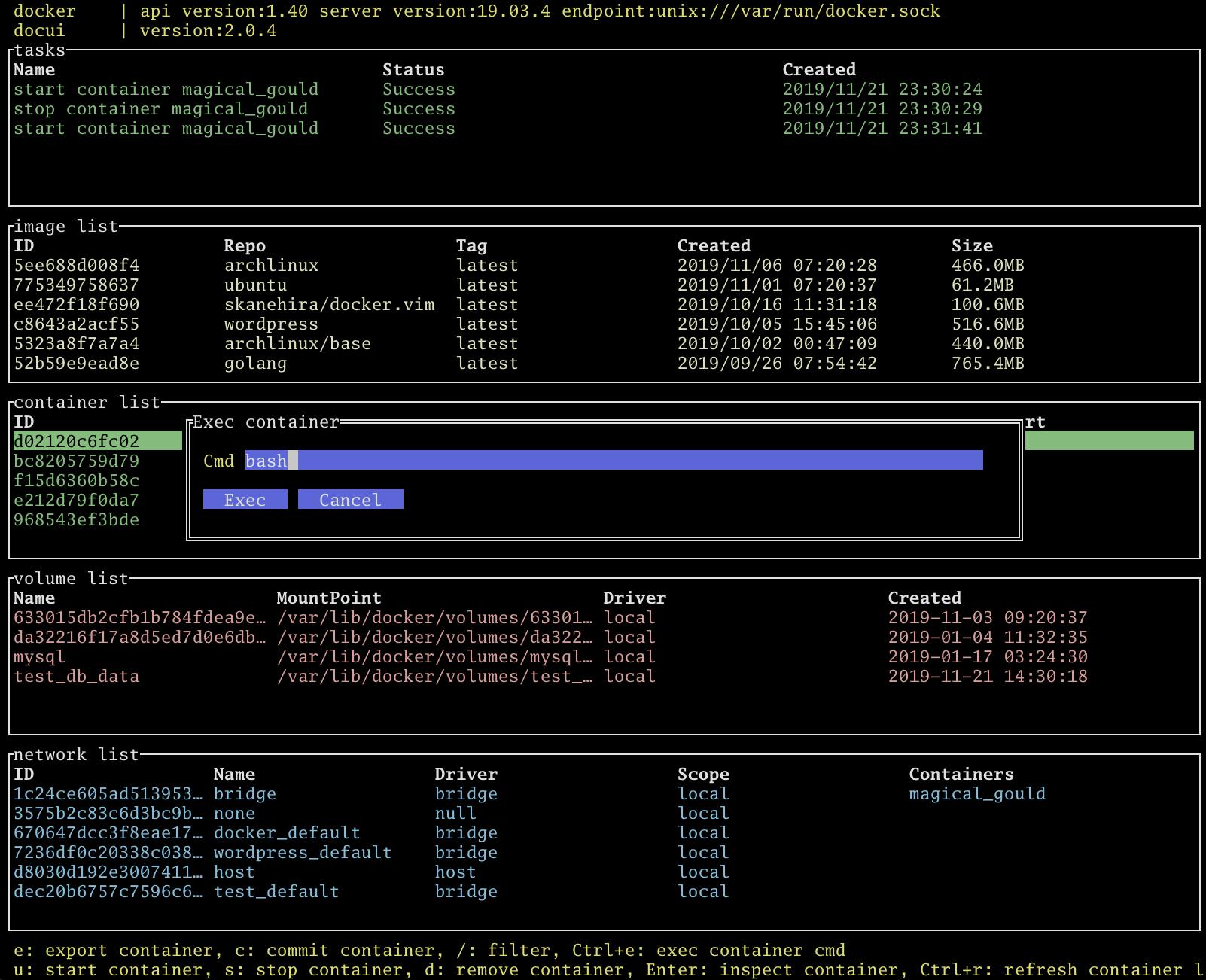
CTRL-eでコンテナにアタッチすることができます。これはdocker execと同様な動きになります。
フィルターリング
全パネル
/でフィルターリングできます。絞り込みしてコンテナ、イメージを操作するときに便利です。
docuiのまとめ
docuiを使用するとイメージ、コンテナの操作が楽になります。ぜひ使ってみてください。
ちなみに、最近筆者はdocker.vimというVimのプラグインを作成してから、そちらを使うことが多くなりました。これはVim上でdocuiと同等なことができるプラグインです。Vimmerの方はぜひ試してみてください。JSON
JSONといえば、Web APIですね。システム間のデータ連携にJSONを使うことが一般的かと思います。そしてJSONといえば
jqというコマンドも有名かと思います。
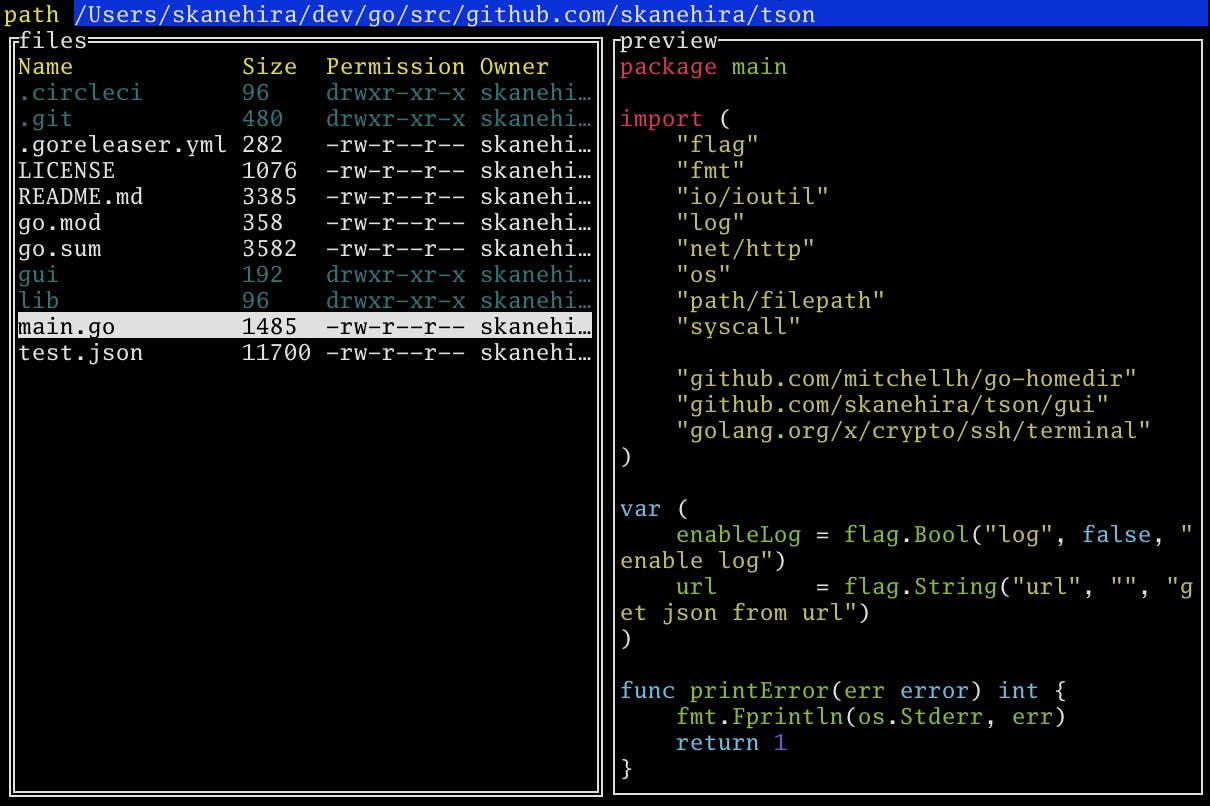
ただ、jqはインタラクティブにJSONを操作できないので、筆者はtsonというTUIツールを作りました。
tsonはJSONをツリー状にしてノードを操作することができます。主機能を紹介していきます。起動方法
3種類の起動方法があります。
1.tson < test.jsonでファイルから読み込む
2.curl https://jsonplaceholder.typicode.com/todos/1 | tsonでパイプラインから読み込む
3.tson -url https://jsonplaceholder.typicode.com/todos/1でURLから読み込む起動すると次の画面になります。
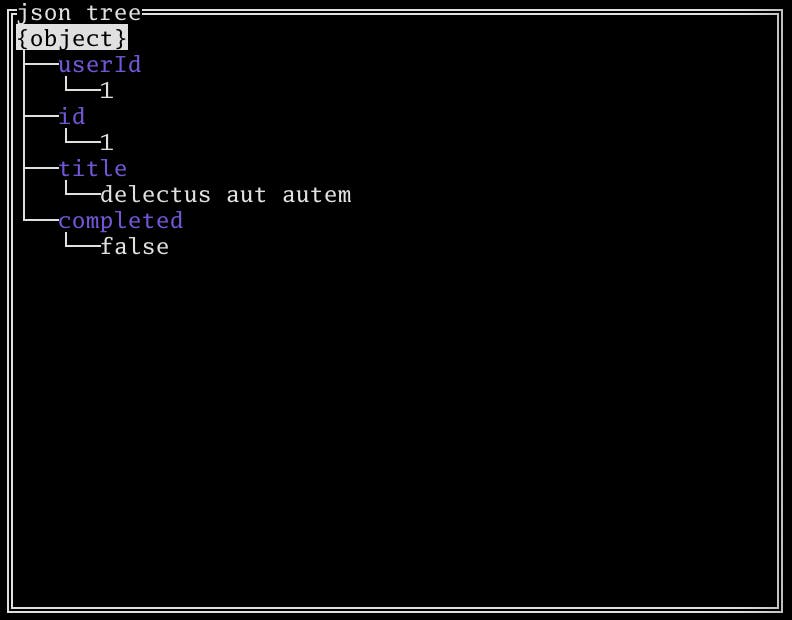
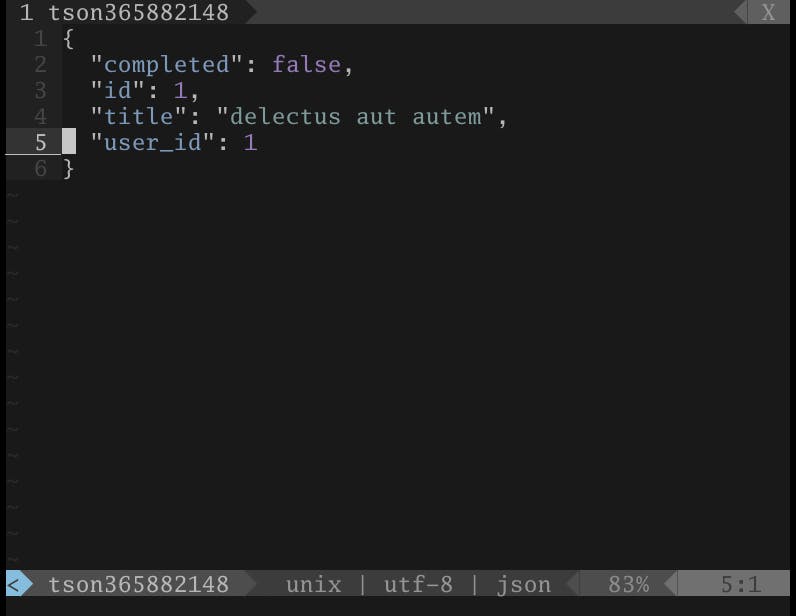
画像の場合のJSONは次になります。
{ "userId": 1, "id": 1, "title": "delectus aut autem", "completed": false }値を折りたたむ
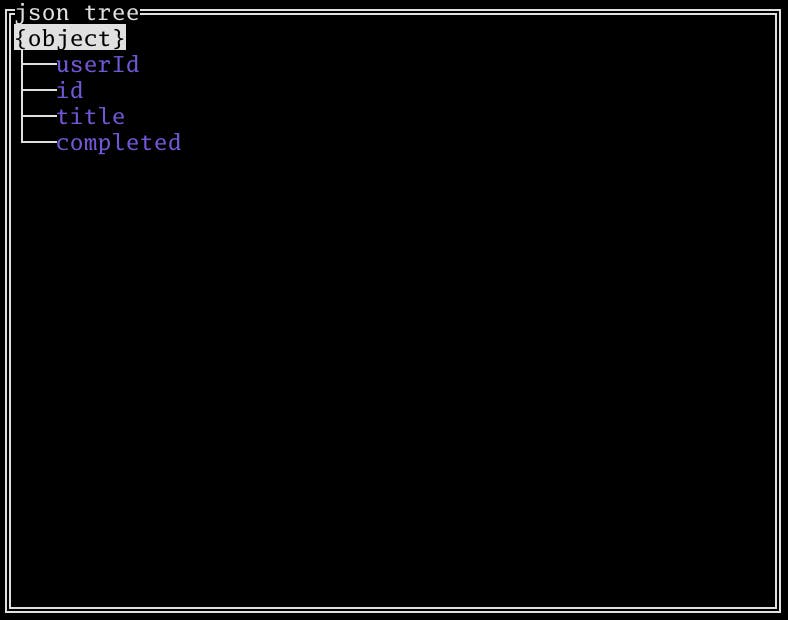
Hで値ノードを折りたたむことができます。どんなキーがあるのかぱっと確認する時に便利です。
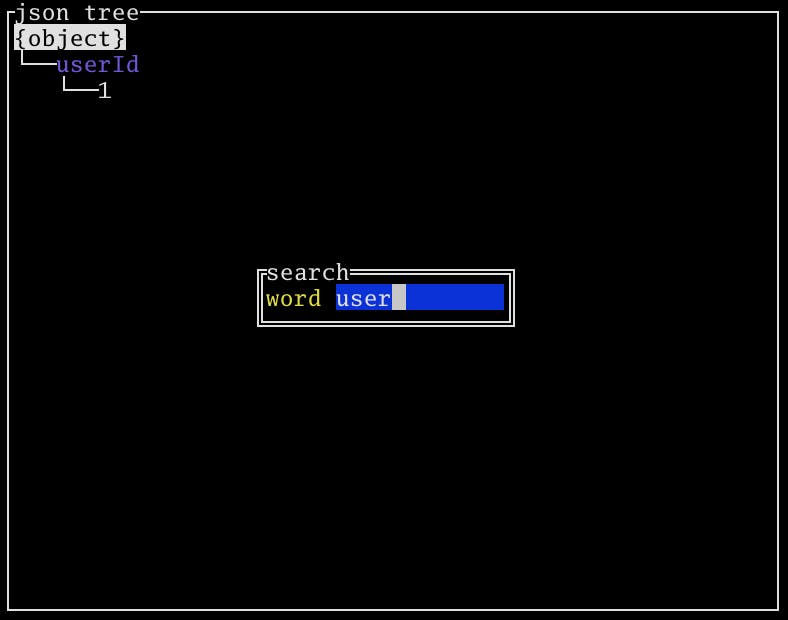
フィルターリング
fもしくは/でキーと値を絞り込むことができます。特定のキーの値を確認するときに便利です。
編集
Enterでノードの値を編集できます。
簡易的な編集の場合は
Enterで十分ですが、ガッツリ編集したいこともあると思うので、そういうときはeで$EDITORに設定されているエディタを使って編集できます。
エディタ終了後、
tsonに戻りその結果が反映されます。保存
現在のツリー状態をJSONファイルに出力できます。レスポンスの情報を保存するときに使えます。
組み込み
tsonを使用して、次のように既存アプリケーションに組み込むことができます。
ご自身のアプリケーションでtsonのインターフェイスを使用して編集などを行うことができます。そしてtsonを終了すると、その時点のJSONをバイト列で受け取ることができます。package main import ( "fmt" tson "github.com/skanehira/tson/lib" ) func main() { j := []byte(`{"name":"gorilla"}`) // tson.Edit([]byte) will return []byte, error res, err := tson.Edit(j) if err != nil { fmt.Println(err) return } fmt.Println(string(res)) }自分のツールで
tsonのインターフェイスを使いたい方いましたら、ぜひ試してみてください。tsonまとめ
シンプルなツールですが、大きなJSONを操作するときに特に便利かと思います。ぜひ使ってみてください。
ファイラー
筆者は普段
mkdirやcp、mvといった操作を行うことが多いのですが、ファイルパス入力が意外とめんどくさいなと感じています。補完があるとはいえ、もっとインタラクティブに操作できたらいいなぁと思ってffというTUIツールを作りました。
あ、某ゲームではないです。
プレビュー
-previewオプションをつけるとプレビューパネルで、ファイルの中身、ディレクトリの中身を見れます。
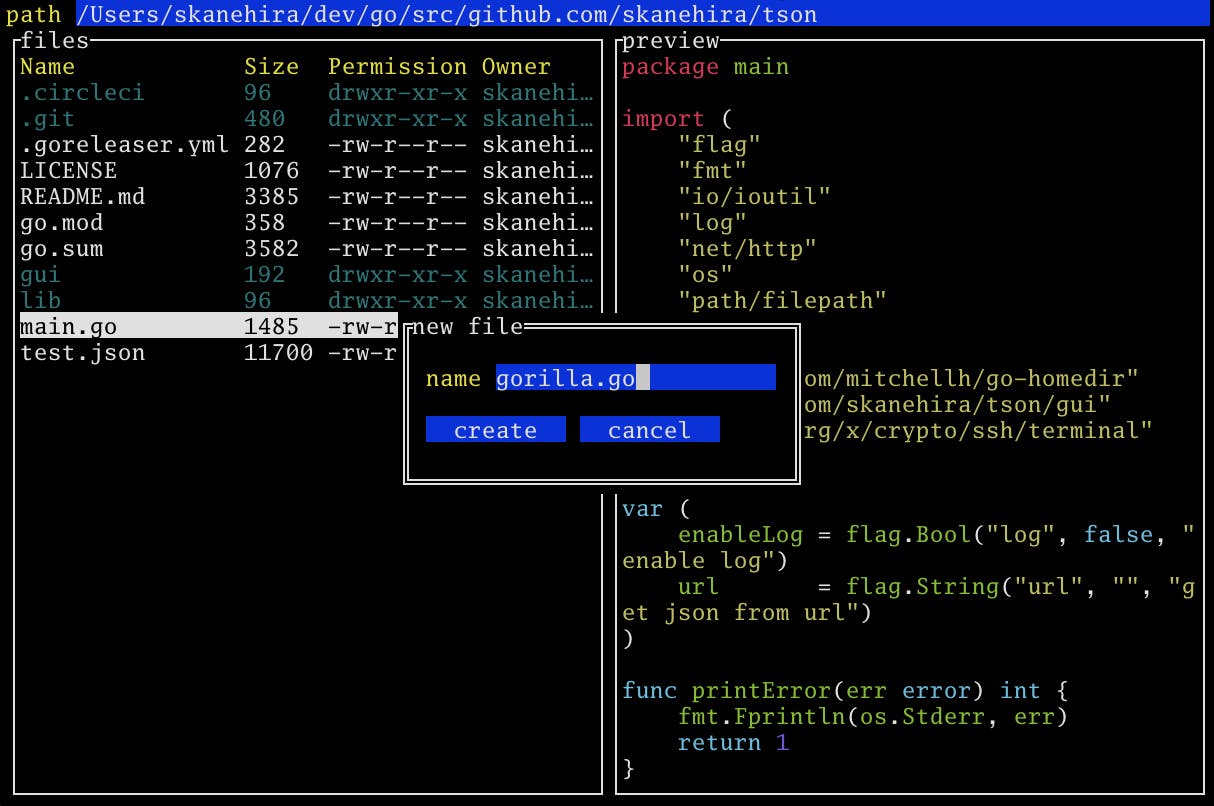
CTRL-j/CTRL-kでプレビューをスクロールできます。新規作成
nでファイル、mでディレクトリを新規作成できます。
コピー
yでファイル、ディレクトリをマーク(色が変わります)して、pでマークした対象をカレントディレクトリにコピーできます。
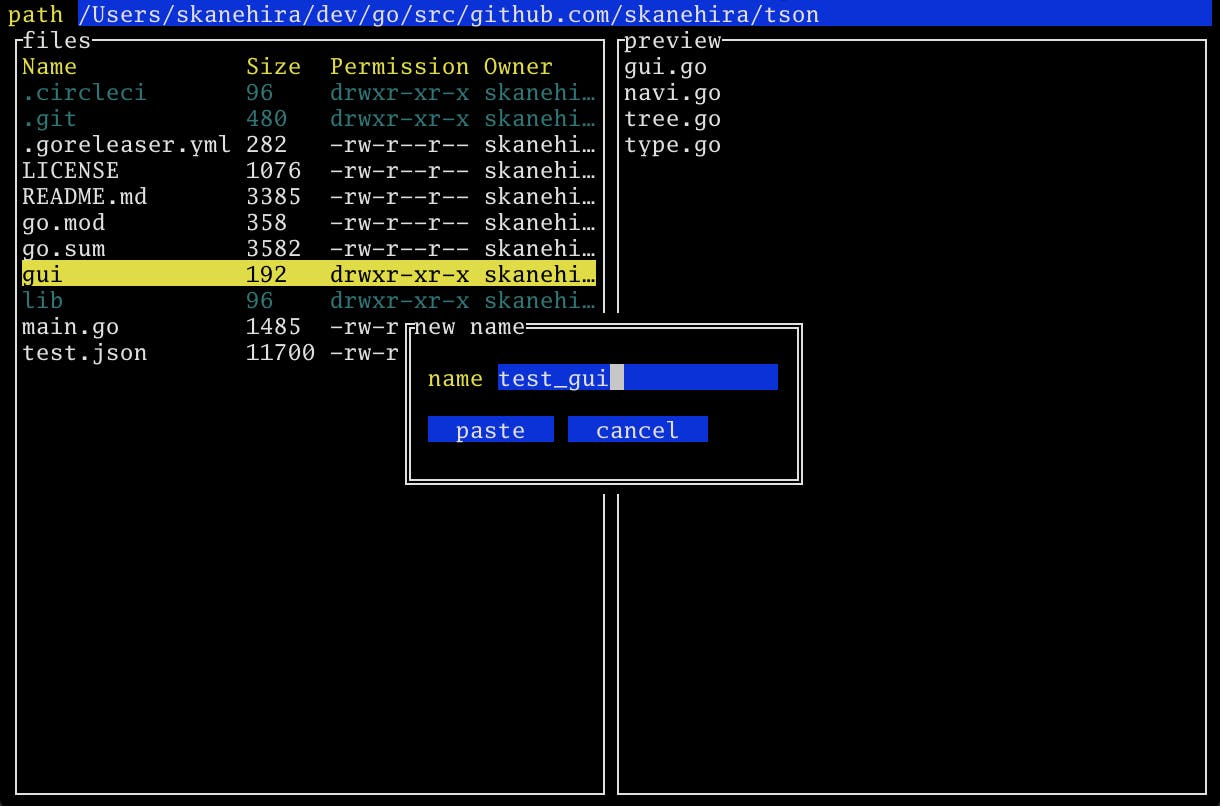
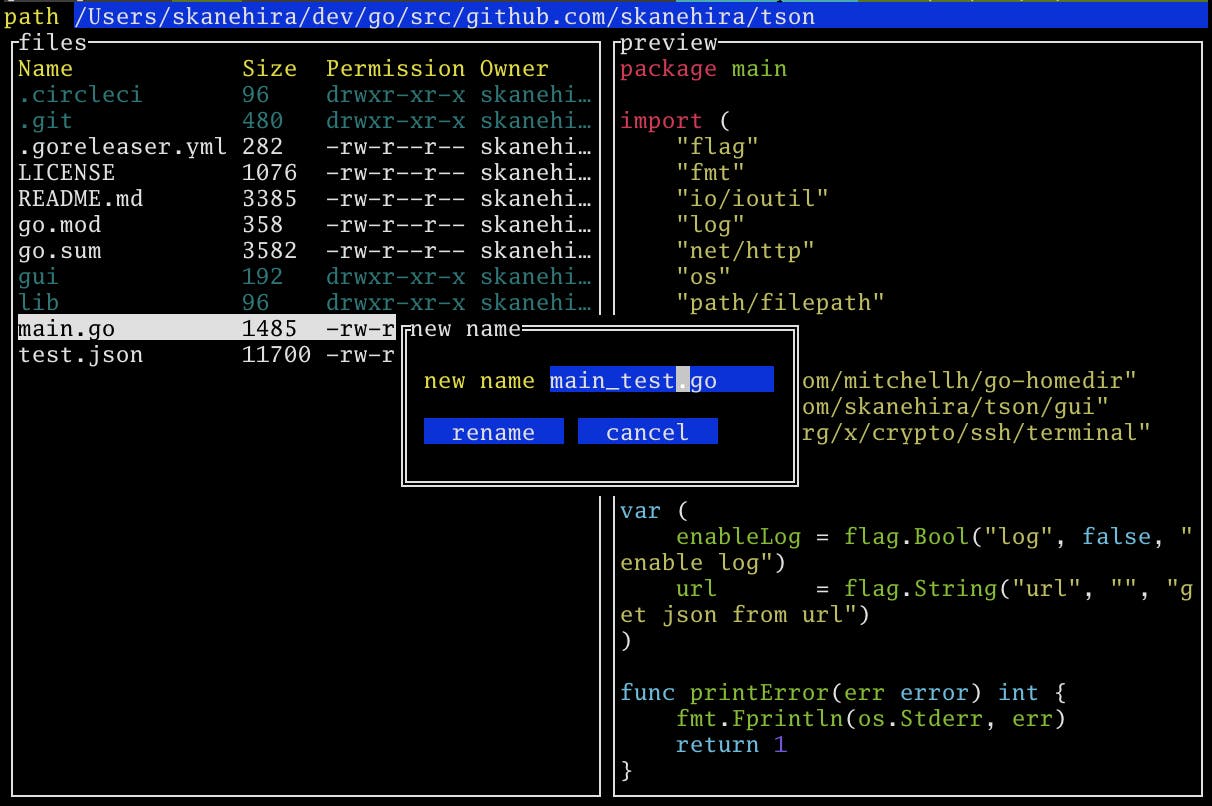
名前変更
rでファイル、ディレクトリの名前を変更できます。
編集
eで$EDITORに設定されているエディタを使ってファイルを編集できます。ブックマーク
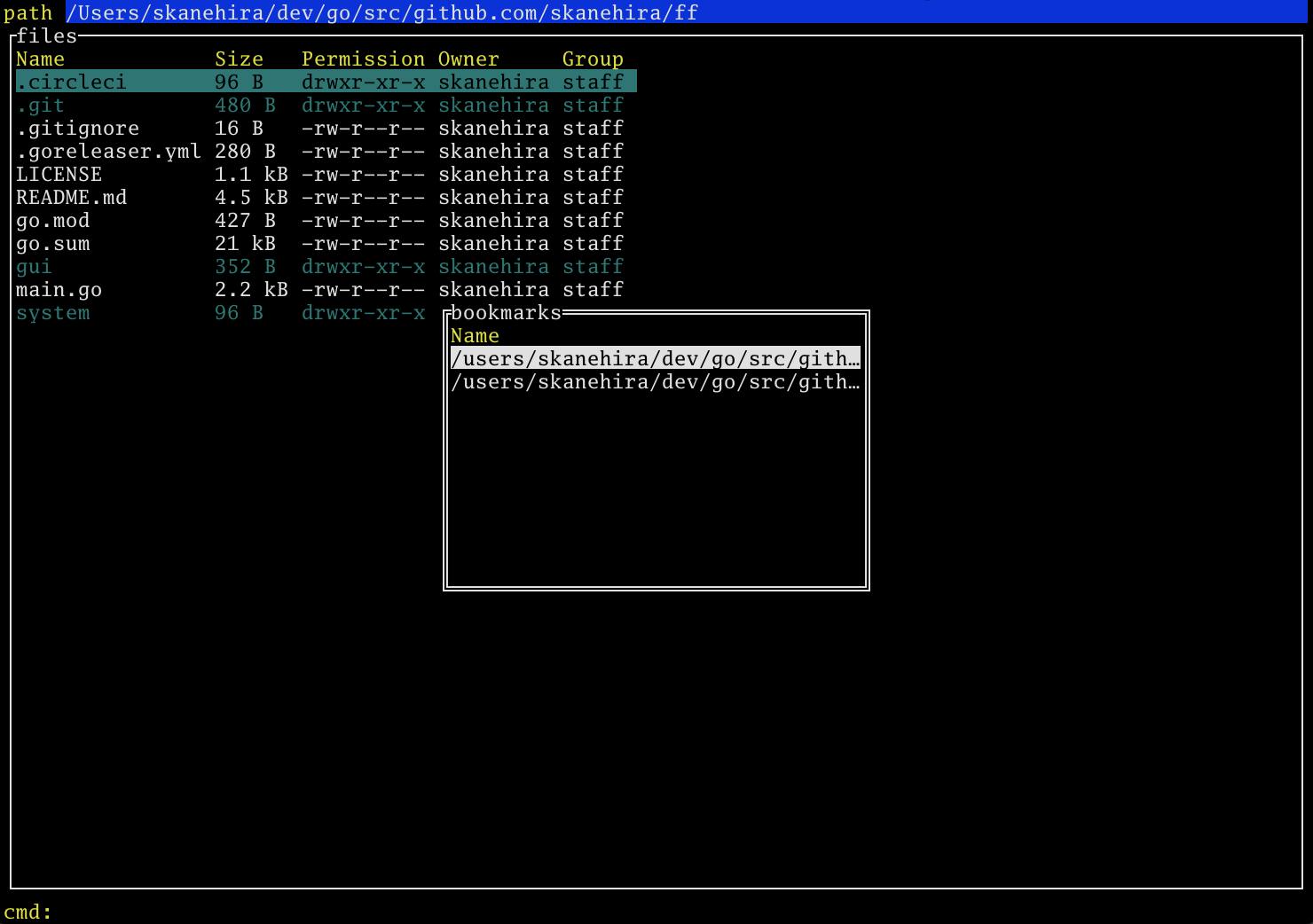
bで選択したディレクトリをブックマークする事ができます。
Bでブックマーク一覧を表示して、Ctrl-gでブックマークしたディレクトリに移動できます。
Vimで使う
Vimにはターミナル機能があるので、それを使用して
ffを動かすことができます。
Vimで:vert term ++close ffで次の画像のように使用することができます。プラグインを導入しなくてもVimを終了することなくファイル、ディレクトリの操作を行うこともできます。便利ですね。
ffのまとめ
まだ作ったばかりのツールなので、これからもう少し機能を追加していきます。
例えば、複数の対象をマークする機能、シェルコマンドを実行する機能を実装する予定です。プロセスビュアー
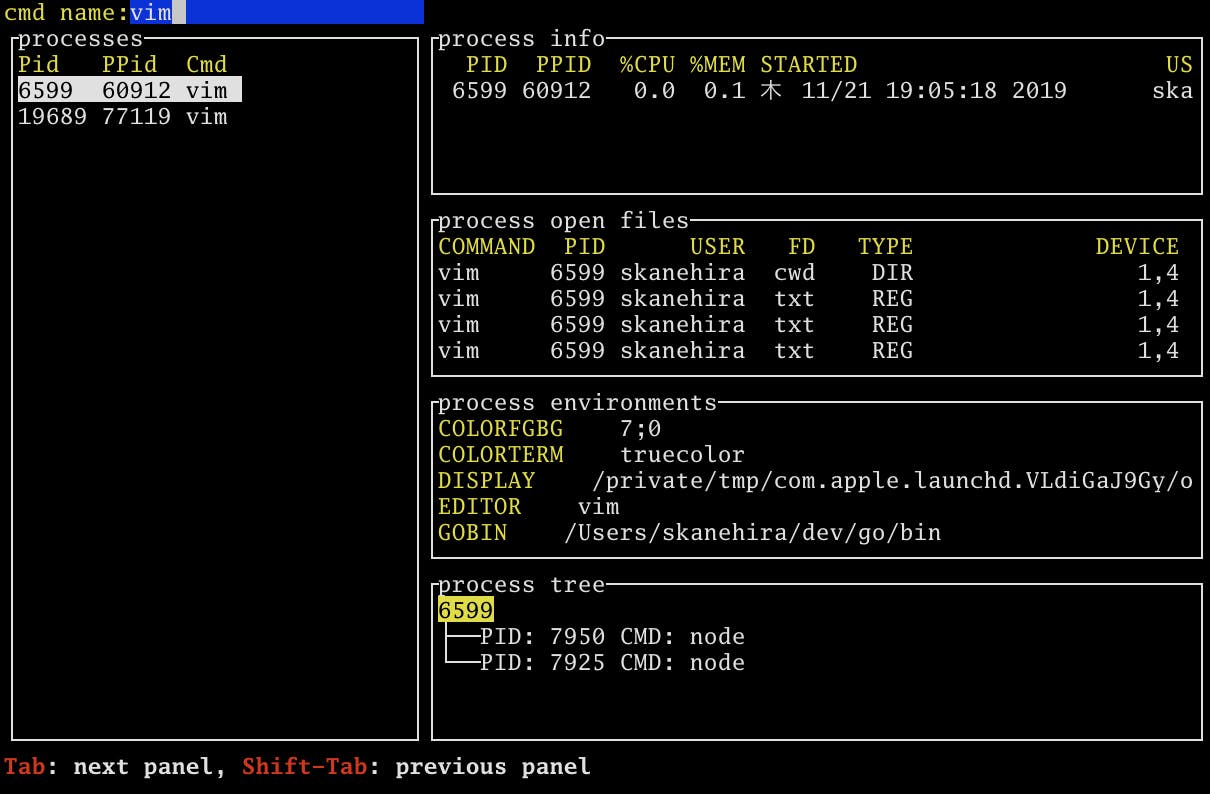
普段ツールを作ってると、バグって固まってしまうことがあり、プロセスを手軽にkillするツールほしいなと思ってpstというTUIツールを作りました。
どうせならプロセスの情報を色々見れたらいいなと思い、プロセス環境変数といった情報を表示できるようにしました。
プロセスの情報を取得するのにpsとlsofの外部コマンドを使用しています。フィルターリング
プロセス名をフィルターリングできます。
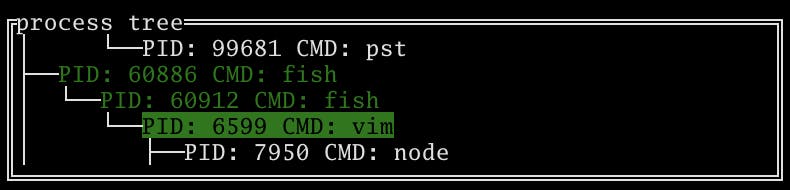
プロセスツリー
processesで選択したプロセスにぶら下がっている子プロセスをprocess treeで確認できます。
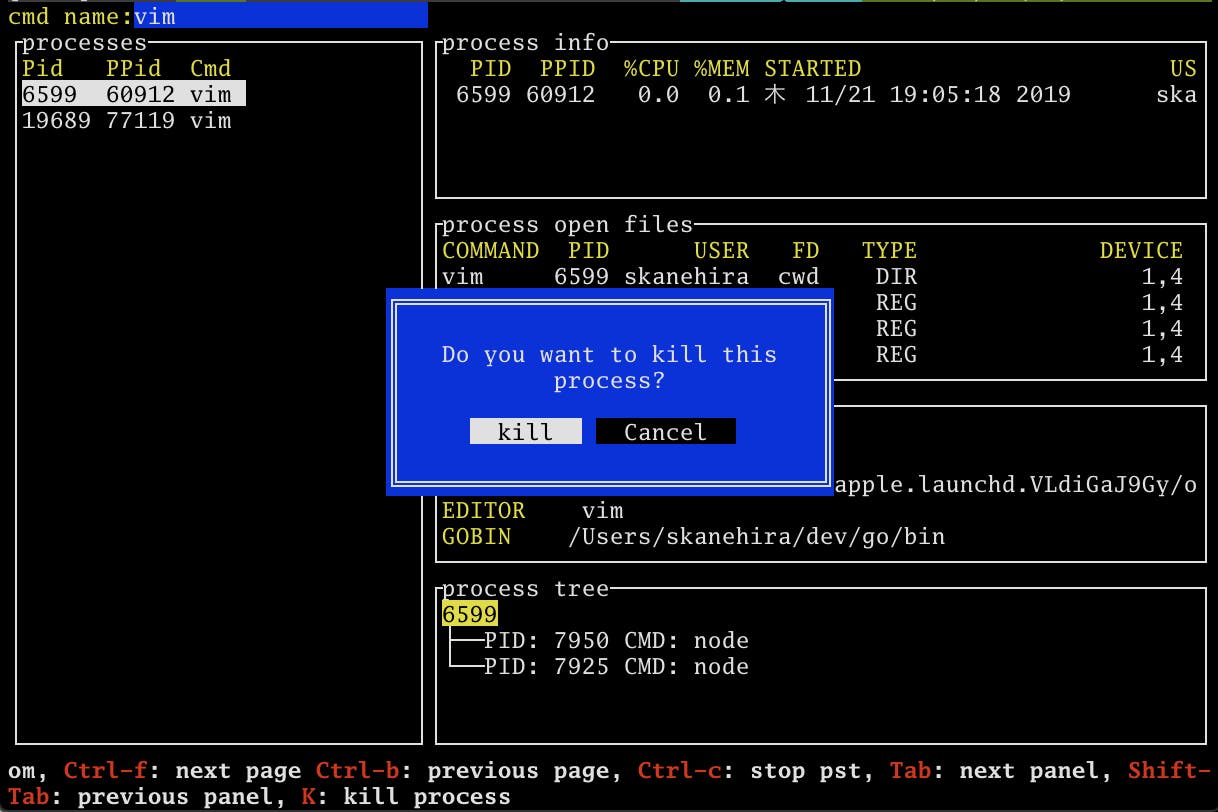
プロセスkill
processesもしくはprocess treeでKで選択したプロセスをkillできます。
pstまとめ
pstはプロセスモニターというより、プロセスビューアに近いです。なぜならプロセス情報を非同期で更新していないからです。理由はツール自体を重くしたくないし、killする対象を都度検索すればいいと考えているからです。
不便だと思ったら改善するかもしれません。まとめ
一通り、筆者が普段使っているTUIツールを紹介しました。いかがだったでしょうか。
少しでもみなさんの作業効率があがると嬉しいです。また、気が向いたらこうったTUIツールの記事を書こうと思います。
ではではー







- 投稿日:2019-11-26T18:58:48+09:00
AWSの利用料金をGoで積み上げ棒グラフ化した
はじめに
- 最近いろんな所でDevOpsって言葉を聞きますね。
- DevOpsの影響を受けてFinOpsと呼ばれるテクノロジー、ビジネス、財務を融合させたクラウドの運用モデルも提唱されています。
- もしかしたら、数年後にはDevOpsと同じくらいメジャーな概念となっているかもしれません。
- FinOpsを始めるための第一歩としてクラウドの利用料金の可視化、通知が挙げられています。
- というわけで、今回はAWSの利用料金を手っ取り早くグラフ化してslackに通知するツールについて紹介します。
TL;DR
- CostExplorer APIからサービスごとの利用料金を取得
- gonum/plotでStackedBarChartを生成
- nlopes/slackでslackに通知
AWS料金の可視化方法いろいろ
- メリット: AWS公式ツール(APIもあるよ)
- デメリット: AWSアカウントがないと閲覧できない。外部サービスへの通知機能がない。
BIツール(re:dash, metabaseなど)
- メリット: 既存のOSSを利用できて開発コストを下げられる。すでに別用途で使っていれば同じサーバを流用できる。
- デメリット: データストア、BIサーバを構築・運用しなければならない。サーバのコストがかかる。
Datadog等の監視ツール
- メリット:SaaSを利用できて開発コストを下げられる。すでに別用途で使っていれば同じアカウントを流用できる。
- デメリット: Datadogのアカウントを持っていないと閲覧できない。Datadogのコストがかかる。
今回はなるべく運用コストかけたくなかったので、シンプルにCostExplorerAPIを使って料金を取得して、slack通知は別途実装することにしました。
CostExplorer APIからサービスごとの利用料金を取得
func fetchAWSDailyCost(f Flags) ([]*costexplorer.ResultByTime, error) { results := []*costexplorer.ResultByTime{} err := retry(5, time.Second, func() error { svc := costexplorer.New(session.Must(session.NewSessionWithOptions(session.Options{ AssumeRoleTokenProvider: stscreds.StdinTokenProvider, }))) results = []*costexplorer.ResultByTime{} input := &costexplorer.GetCostAndUsageInput{ Granularity: aws.String("DAILY"), GroupBy: []*costexplorer.GroupDefinition{ { Key: aws.String("SERVICE"), Type: aws.String("DIMENSION"), }, }, Metrics: []*string{ aws.String("BlendedCost"), }, TimePeriod: &costexplorer.DateInterval{ Start: aws.String(f.Start), End: aws.String(f.End), }, } for { res, err := svc.GetCostAndUsage(input) if err != nil { return err } results = append(results, res.ResultsByTime...) input.NextPageToken = res.NextPageToken if res.NextPageToken == nil { break } // Avoid LimitExceededException time.Sleep(time.Second) } return nil }) return results, err }
- CostExplorerAPIは他のAWSのAPIと比べてRate limitが厳しいので、ちゃんとsleepしたほうが良いです。
gonum/plotでStackedBarChartを生成
// Draw AWS cost chart func drawAWSDailyCostsChart(f Flags, costs []*costexplorer.ResultByTime) error { services := []string{} dates := []string{} pm := make(map[string]map[string]float64) for _, cost := range costs { date := *cost.TimePeriod.Start dates = append(dates, date) cm := make(map[string]float64) for _, group := range cost.Groups { service := strings.TrimPrefix(*group.Keys[0], "Amazon ") bc, err := strconv.ParseFloat(*group.Metrics["BlendedCost"].Amount, 64) if err != nil { return err } if bc > f.IgnoreCost { cm[service] = bc if !contains(services, service) { services = append(services, service) } } } pm[date] = cm } sort.Strings(services) scs := []serviceCost{} for _, service := range services { var sc serviceCost sc.service = service for _, date := range dates { v, exists := pm[date][service] if exists { sc.costs = append(sc.costs, v) } else { sc.costs = append(sc.costs, 0) } } scs = append(scs, sc) } return drawStackedBarChart(dates, scs, "price (USD)", f.File) } // Draw stacked bar chart func drawStackedBarChart(dates []string, serviceCosts []serviceCost, ylabel string, file string) error { plotutil.DefaultColors = append(plotutil.DefaultColors, plotutil.DarkColors...) p, err := plot.New() if err != nil { return err } p.Title.Text = "AWS Daily Costs" p.Y.Label.Text = ylabel p.Legend.Top = true p.Legend.Font.Size = vg.Points(8) p.X.Tick.Label.Font.Size = vg.Points(6) p.NominalX(dates...) bars := []*plotter.BarChart{} for i, sc := range serviceCosts { bar, err := plotter.NewBarChart(sc.costs, vg.Points(20)) if err != nil { return err } bar.Color = plotutil.Color(i) bar.LineStyle.Width = vg.Length(0) bars = append(bars, bar) p.Legend.Add(sc.service, bar) } for i := range bars { bar := bars[len(bars)-i-1] if i > 0 { bar.StackOn(bars[len(bars)-i]) } p.Add(bar) } p.Add(plotter.NewGlyphBoxes()) return p.Save(vg.Points(36*float64(len(dates))), 6*vg.Inch, file) }
- 何も考えずに
bar.StackOnでグラフを積み上げていくとグラフ本体の順序と右上の凡例の順序が逆になってしまうため、逆順でfor文を回しています。- フォントの大きさは自分で微調整する必要があります。
- godocにとても助けられました!!
nlopes/slackでslackに通知
// Post file and message to slack func postFileMessageToSlack(f Flags, account string) error { client := slack.New(f.Token) file, err := client.UploadFile(slack.FileUploadParameters{ File: f.File, }) if err != nil { log.Errorf("failed to upload file error:%+v", err) return err } file, _, _, err = client.ShareFilePublicURL(file.ID) if err != nil { return err } emoji := slack.MsgOptionIconEmoji(f.Emoji) username := slack.MsgOptionUsername(AppName) attachment := slack.MsgOptionAttachments(slack.Attachment{ Color: "FFBF00", // Amber Title: "AWS Cost Management", TitleLink: "https://console.aws.amazon.com/cost-reports/home#/dashboard", ImageURL: file.PermalinkPublic, Fields: []slack.AttachmentField{ { Title: "StartDate", Value: f.Start, Short: true, }, { Title: "EndDate", Value: f.End, Short: true, }, { Title: "Account", Value: account, }, }, }) _, _, err = client.PostMessage(f.Channel, emoji, username, attachment) return err }
- slackに投稿した画像をPublicにしないとAttachmentのImageURLに設定できないのがちょっと残念でした。どなたか良い方法ご存じの方ご教示ください

全体のコード (CLIにしました)
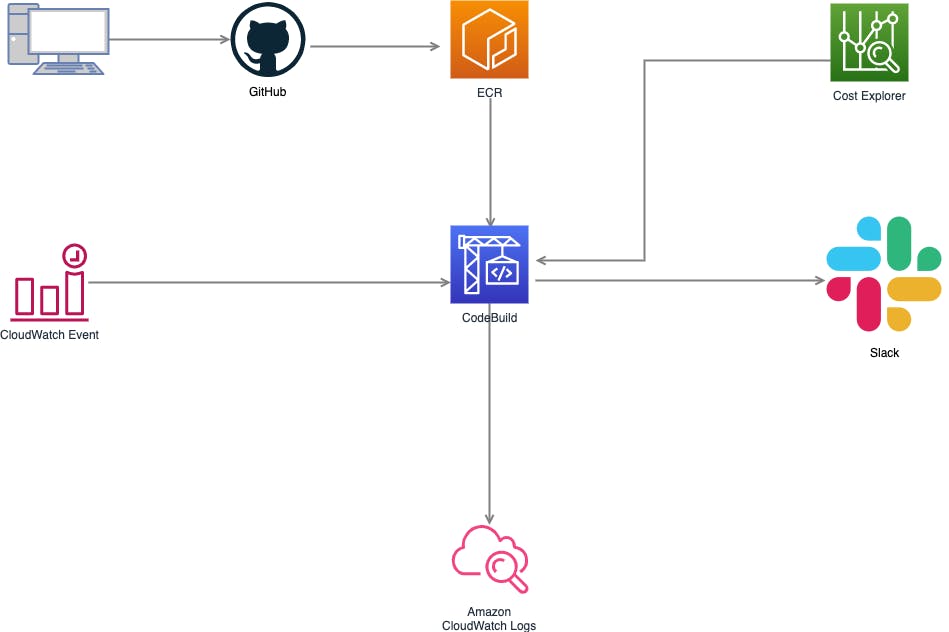
インフラの構築例
- CloudWatch EventとCodebuildで定期実行できるようにしておくと捗ります。
構成図
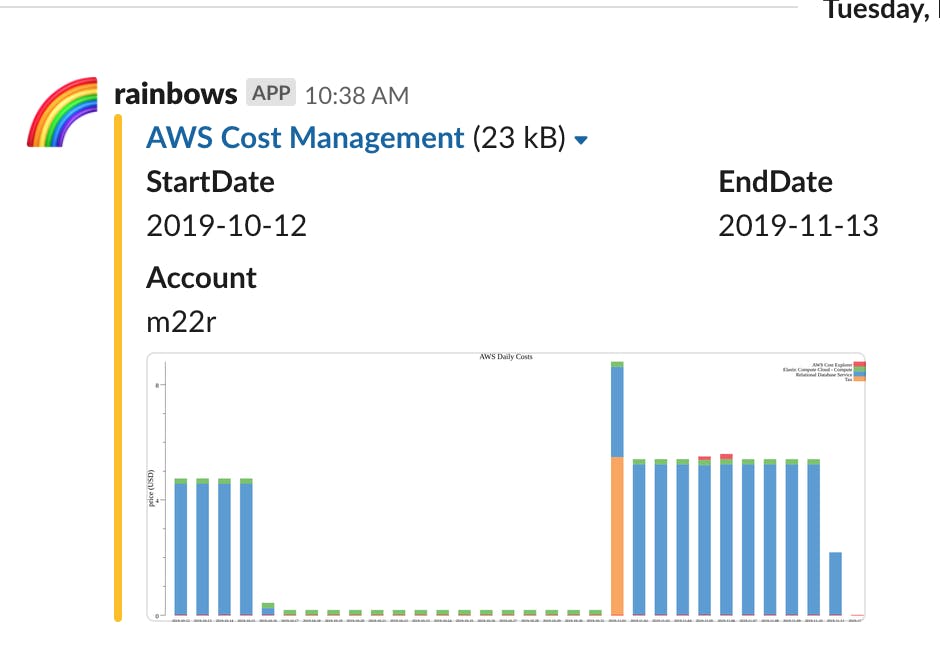
slackへの通知例
- こんな感じでグラフ化してslack通知できます!
運用してみた感想
- リリースして数カ月後に偉い人から「急にAWSの料金上がってるんだけど、なんなのこれ?」と聞かれて、とっさに思い出せなくて詰むことが少なくなった。
- 特定のサービスに想定以上のコストがかかっていることに早めに気づいて対策を打てるようになった。(例: cloudwatch logsに不要なログがたまりすぎる問題など)
- コストを絡めてリファクタリングの提案をやりやすくなった。
- 見積もりベースで行っていたコストの議論を実績ベースでできるようになった。
- 継続的な可視化/通知って大事ですね。
- 投稿日:2019-11-26T18:46:02+09:00
uber-go/fxを触りました。
はじめに
こんにちは、昨日に引き続きMedia Do Advent Calendar 3日目を担当するおかざわです。
uber-go/digの記事と同じく、ubar-go/fxを勉強を勉強する機会がありましたのでその時のまとめになります。
今回は短いですが、昨日と同じく暖かい目で見てやってください。概要
Package fxは、再利用可能で構成可能なモジュールからアプリケーションを簡単に構築できるフレームワークです。
Fxアプリケーションは依存関係注入を使用して、関数呼び出しを手動でつなぐ面倒な作業を行うことなくグローバルを排除します。依存性注入に対する他のアプローチとは異なり、Fxは単純なGo関数で動作します。構造体タグを使用したり、特殊な型を埋め込む必要がないため、FxはほとんどのGoパッケージで自動的に動作します。uber-go/fxのdocのgoogle翻訳より
やはり、ぱっと見では何をしてくれるものなのかよくわからないですが、以下の部分からuber-go/digと同じ様なことをすることが伺えます。(実際uber-go/fxはuber-go/digを内部で使用している)
Fxアプリケーションは依存関係注入を使用して、関数呼び出しを手動でつなぐ面倒な作業を行うことなくグローバルを排除します。
実際に使ってみて何をするのかを調べます。
インストール
go get go.uber.org/fx@v1go modulesをしている前提のインストールです。
それ以外はubar-go/fxを参照ください。使う
比較
uber-go/digを触りました。で使用したコードを使ってfxと見比べてみます。
package main // 通常とdigとfxの比較 import ( "fmt" "go.uber.org/dig" "go.uber.org/fx" ) type Usecase interface { Use() } type Repository interface { RepoPrint() } type usecase struct { repo Repository } func NewUsecase(r Repository) Usecase { return &usecase{ repo: r, } } func (u usecase) Use() { u.repo.RepoPrint() } type repository struct{} func NewRepository() Repository { return &repository{} } func (r repository) RepoPrint() { fmt.Println("1") } func main() { // 通常の依存関係注入 repo := NewRepository() usecase := NewUsecase(repo) usecase.Use() // uber-go/digを使った依存関係注入 c := dig.New() c.Provide(NewUsecase) c.Provide(NewRepository) c.Invoke(func(u Usecase) { u.Use() }) // uber-go/fxを使った依存関係注入 // 中身ではuber-go/digが使われている(なのでdigでできることはだいたいできる) app := fx.New( fx.Provide( NewUsecase, NewRepository, ), fx.Invoke(func(u Usecase) { u.Use() }), ) // 完了する app.Done() }main()の部分で通常のDI、digを使ったDI、fxを使ったDIを見比べることができます。
digではコンテナを生成し、コンテナに対して、Provide()やInvoke()をしますが、
fxではappを生成するタイミングでProvide()、Invoke()を行っています。
また、生成したappはapp.Done()を行って処理を終了しています。fxの機能
昨日のuber-go/digの説明をしていた時は
Invoke()で処理を実行して終了するものを扱うのが前提でした。
uber-go/fxも同じくInvoke()で処理を実行しますが、生成したappを「実行」することができます。これを説明するためにはhttpサーバ の様な「起動」と「終了」を明確に実行できるアプリケーションを作るのがわかりやすいです。
package main // Start&StopとRunの活用 import ( "context" "fmt" "log" "net/http" "go.uber.org/fx" ) func NewMux(lc fx.Lifecycle) *http.ServeMux { log.Print("Executing NewMux.") mux := http.NewServeMux() server := &http.Server{ Addr: ":8080", Handler: mux, } lc.Append(fx.Hook{ OnStart: func(context.Context) error { log.Print("Starting HTTP server.") go server.ListenAndServe() return nil }, OnStop: func(ctx context.Context) error { log.Print("Stopping HTTP server.") return server.Shutdown(ctx) }, }) return mux } func Register(mux *http.ServeMux) { // 「/」の設定 log.Println("Create Handler Default World") mux.HandleFunc("/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { w.WriteHeader(http.StatusOK) fmt.Fprintf(w, "Default World") log.Println("Passing Default World") })) // 「/hello」の設定 log.Println("Create Handler Hello World") mux.HandleFunc("/hello", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { w.WriteHeader(http.StatusOK) fmt.Fprintf(w, "Hello World") log.Println("Passing Hello World") })) } func main() { app := fx.New( fx.Provide( NewMux, ), fx.Invoke(Register), ) app.Run() }
Invoke()にはマルチプレクサの登録をする関数が指定されており、その関数を実行するために*http.ServeMuxを取得する必要がある。
(マルチプレクサ?ってなる人は → https://qiita.com/huji0327/items/c85affaf5b9dbf84c11e )
Provide()内で*http.ServeMuxを返す関数であるNewMuxが指定されているため実行される。
サーバ の設定をNewMuxから取得し、マルチプレクサの登録をする。上記が
Invoke()内でする処理である。
app.Run()はNewMuxの引数に設定されているfx.Lifecycleの処理を実行する。
(以降fx.Lifecycleをライフサイクルと呼びます)lc.Append(fx.Hook{ OnStart: func(context.Context) error { log.Print("Starting HTTP server.") go server.ListenAndServe() return nil }, OnStop: func(ctx context.Context) error { log.Print("Stopping HTTP server.") return server.Shutdown(ctx) }, })
OnStartはアプリケーション実行時に処理され、
OnStopはアプリケーション終了時に処理される。上記の処理によりサーバ の起動と終了処理を実行することができる。
もし、複数ライフサイクルに処理が紐付けされていた場合、
Invoke()するstructの順番がそのままライフサイクルのstartの順番、stopは逆の順番で処理されます。実行方法
appを実行する方法は大きく分けて3種類あります。
app.Done()はappで作成したアプリケーションを実行しない時に使用します。
終了のシグナルを出し、アプリケーションを終了します。app.Done()
app.Start()とapp.Stop()は明確にStartの処理とStopの処理を実行させたい時に使用します。
goのhttpサーバ だと、http.Get()などを用いて自動で通信させたりする時に重宝します。app.Start(/*コンテキスト*/) app.Stop(/*コンテキスト*/)
app.Run()は内部でrun(Done)しており、run()は上記のStart()+Stop()を持っています。
app.Run()実行時点でStart()の処理が走り、終了のシグナル(control + c)を受信後Stop()の処理を実行します。app.Run()fxはdigとは違いアプリケーションの実行周りも管理することができるライブラリです。
その他機能
dig.Inを活用したfxのサンプル
package main import ( "context" "log" "net/http" "os" "time" "go.uber.org/fx" ) func NewLogger() *log.Logger { logger := log.New(os.Stdout, "" /* prefix */, 0 /* flags */) logger.Print("Executing NewLogger.") return logger } func NewDefaultHandler(logger *log.Logger) (http.Handler, error) { logger.Print("Executing NewDefaultHandler.") return http.HandlerFunc(func(http.ResponseWriter, *http.Request) { logger.Print("Default World") }), nil } func NewHelloHandler(logger *log.Logger) (http.Handler, error) { logger.Print("Executing NewHelloHandler.") return http.HandlerFunc(func(http.ResponseWriter, *http.Request) { logger.Print("Hello World") }), nil } func NewMux(lc fx.Lifecycle, logger *log.Logger) *http.ServeMux { logger.Print("Executing NewMux.") mux := http.NewServeMux() server := &http.Server{ Addr: ":8080", Handler: mux, } lc.Append(fx.Hook{ OnStart: func(context.Context) error { logger.Print("Starting HTTP server.") go server.ListenAndServe() return nil }, OnStop: func(ctx context.Context) error { logger.Print("Stopping HTTP server.") return server.Shutdown(ctx) }, }) return mux } type inHandle struct { fx.In DefaultH http.Handler `name:"default"` HelloH http.Handler `name:"hello"` } type setHandle struct { defaultH http.Handler helloH http.Handler } func Register(mux *http.ServeMux, h *setHandle) { mux.Handle("/", h.defaultH) mux.Handle("/hello", h.helloH) } func main() { app := fx.New( fx.Provide( NewLogger, NewMux, // fx.Annotated{}は登録するfuncに対して名前をつけることができる // この挙動はfx.Outのstructを作成することでもできる fx.Annotated{ Name: "default", Target: NewDefaultHandler, }, fx.Annotated{ Name: "hello", Target: NewHelloHandler, }, func(h inHandle) *setHandle { return &setHandle{ defaultH: h.DefaultH, helloH: h.HelloH, } }, ), fx.Invoke(Register), ) // app.Run() startCtx, cancel := context.WithTimeout(context.Background(), 15*time.Second) defer cancel() if err := app.Start(startCtx); err != nil { log.Fatal(err) } http.Get("http://localhost:8080/") http.Get("http://localhost:8080/hello") stopCtx, cancel := context.WithTimeout(context.Background(), 15*time.Second) defer cancel() if err := app.Stop(stopCtx); err != nil { log.Fatal(err) } }
上記のサンプルのmain()のProvide()の様に
fx.Annotated{ Name: "default", Target: NewDefaultHandler, },と記述することでdig.Outを作らずともNameオプションやgroupオプションを設定することができます。
感想
uber-go/digを事前に勉強していたためそこまでつまずいたところはなかったですが、golangのhttpサーバの関連のstructについてやインターフェースの構造など、別のところの知識が不足していて躓くことが多かったです。
それと参考文献が本当にないのでサンプルを作るのが大変だった。
以上。参考文献
doc:https://godoc.org/go.uber.org/fx
github:https://github.com/uber-go/fx
https://journal.lampetty.net/entry/understanding-http-handler-in-go
https://qiita.com/huji0327/items/c85affaf5b9dbf84c11e
- 投稿日:2019-11-26T18:24:43+09:00
VScodeでGoをいい感じに設定する
Golangのインストール
まずは上記から、golangをインストールします。
VScodeの設定
VScodeをインストール
MacOSでVisual Studio Codeをインストールする手順VScodeを開きます。
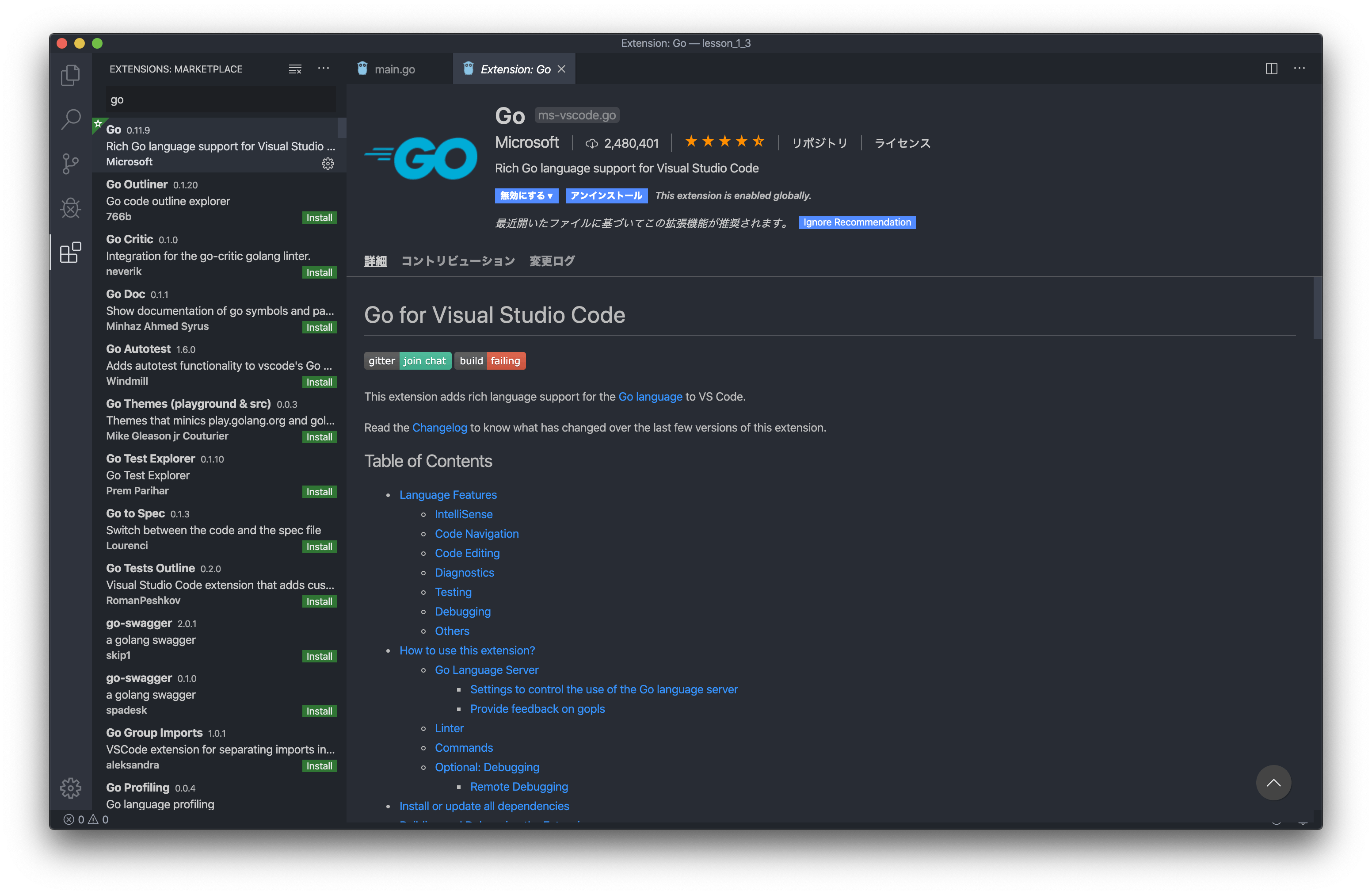
左側のタブの一番下、プラグインタブの検索窓に「go」と打ち”Go”をインストール
Command+Shift+Pでコマンドパレットを表示。
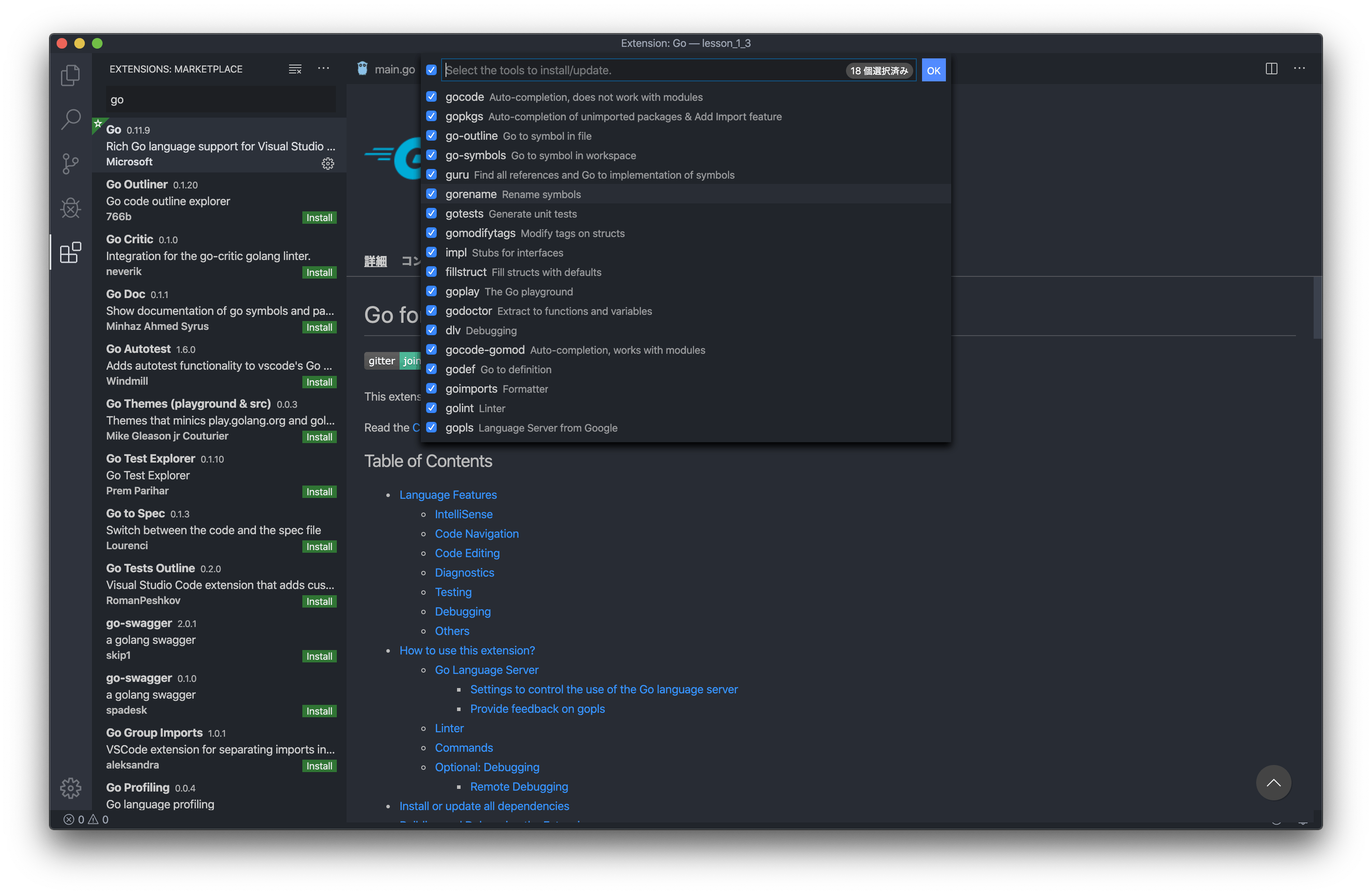
>Go:Install/Update Toolsと打って出てくるツール群を最新にします。
入力の左側のセレクターで全て選択肢、OKで自動インストールが始まります。
インストールが終わったら、
Command + ,で設定を開きます。'setting.json'に以下の設定を追加します。
setting.jsonsettings.json { "go.toolsEnvVars": {"GO111MODULE": "on"}, }まとめ
VScodeでGoを書いていたら、パッケージが見つからないとと出たので、備忘録として書きました。
Happy Hacking
!
- 投稿日:2019-11-26T17:11:31+09:00
uber-go/digを触りました。
はじめに
こんにちは。今回Media Do Advent Calendar 2日目を担当する新卒2年目のおかざわです。
社内でubar-go/digを勉強する機会があったので、その時のまとめになります。
参考文献が少なく公式ドキュメントを読み漁りながら作りました。
分かりやすさ重視なので内容はそこまでですが、暖かい目で見てやってください。概要
パッケージdigは、オブジェクトの依存関係を解決するための意見に基づいた方法を提供します。
uber-go/digのdocのgoogle翻訳より
ぱっと見よくわからないですが、下記のコードの
func main()のように依存関係を構築するコードが、uber-go/digを使うことで少し楽に書くことができるようになります。package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { Use() } type Repository interface { RepoPrint() } type usecase struct { repo Repository } func NewUsecase(r Repository) Usecase { return &usecase{ repo: r, } } func (u usecase) Use() { u.repo.RepoPrint() } type repository struct{} func NewRepository() Repository { return &repository{} } func (r repository) RepoPrint() { fmt.Println("1") } func main() { // 通常の依存関係構築 repo := NewRepository() usecase := NewUsecase(repo) usecase.Use() }インストール
go get go.uber.org/dig@v1go modulesをしている前提のインストールです。
それ以外はubar-go/digを参照ください。使う
概要で軽く触れましたが例で挙げたコードのmainの部分(下記の部分)だけ変更します。
(importも勝手に追加されます)func main() { // 通常の依存関係構築 repo := NewRepository() usecase := NewUsecase(repo) usecase.Use() }uber-go/digを使うと下記になります。
func main() { c := dig.New() c.Provide(NewUsecase) c.Provide(NewRepository) c.Invoke(func(u Usecase) { u.Use() }) }一つずつ見ていきます。
コンテナ作成
c := dig.New()
dig.New()でコンテナを生成します。
uber-go/digでは「コンテナ」と言う依存関係になる構造体を入れる用のインスタンスを作成し処理します。オブジェクト登録
c.Provide(NewUsecase)
Provide()は先ほど作成したコンテナにオブジェクト(構造体)を登録します。
引数に指定しているものはファンクションで、上記のように既存のファンクションを指定するか、下記のようにファンクションをその場で作成する方法の2通りのの方法があります。c.Provide(func() Repository { return &repository{} })
Provide(func(引数)戻り値{処理})で構築できます。オブジェクト構築/実行
c.Invoke(func(usecase DogUsecase) { fmt.Println(usecase.All()) })
Invoke()は、コンテナに登録したオブジェクト達をよしなに解決して、指定したインターフェースの処理を実行することができます。
生成されるのはInvoke()内のみなのでInvoke()の外で実行することはできません。以上が例題をuber-go/digで処理してみた結果です。
美味しい?
uber-go/digで依存関係を構築することができることがわかりました。
ですが、上記の例ではあまりuber-go/digを使う美味しさがわからなかったと思います。もう少しuber-go/digについて掘り下げて行きます。
dig.In
下記の例を使って説明します。
最低限機能しか使っていないuber-go/digの例
package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooRepository interface { foo() } type BarRepository interface { bar() } type usecase struct { Foo FooRepository Bar BarRepository } func (u *usecase) use() { u.Foo.foo() u.Bar.bar() } type fooRepo struct { f string } func (u *fooRepo) foo() { fmt.Println(u.f) } type barRepo struct { b string } func (u *barRepo) bar() { fmt.Println(u.b) } func main() { c := dig.New() c.Provide(func() FooRepository { return &fooRepo{f: "Foo"} }) c.Provide(func() BarRepository { return &barRepo{b: "Bar"} }) c.Provide(func(f FooRepository, b BarRepository) Usecase { return &usecase{ Foo: f, Bar: b, } }) c.Invoke(func(u Usecase) { u.use() }) }
Invoke(func(u Usecase))を実行するとusecaseが生まれ、usecaseに定義されている
FooRepositoryとBarRepositoryを満たすfooRepoとbarRepoも自動的に生成/関連付けされます。下記部分はusecaseの生成方法の登録を行っています。
c.Provide(func(f FooRepository, b BarRepository) Usecase { return &usecase{ Foo: f, Bar: b, } })例では
FooRepositoryとBarRepositoryの2つしか引数に取っていないが、実装によっては何個も定義を書く必要があり、可読性を大きく損なう可能性があります。(引数4つ以上あると、もう見辛い)
uber-go/digではこの解決方法として「パラメータオブジェクト」を使用します。このような状況で読みやすくするために使用されるパターンは、関数のすべてのパラメーターをフィールドとしてリストする構造体を作成し、代わりにその構造体を受け入れるように関数を変更することです。これは、パラメータオブジェクトと呼ばれます。
uber-go/digのdocのgoogle翻訳より
上記の通り、パラメータ(引数とか)をフィールドとした構造体を定義し、関数にはその構造体を受け入れるように変更を加えることで可読性の低下を阻止します。
上記の例の中に下記の構造体を追加し、関数を下記の構造体を受け入れるように変更します。type inUsecase struct { dig.In Foo FooRepository Bar BarRepository }c.Provide(func(u inUsecase) Usecase { return &usecase{ Foo: u.Foo, Bar: u.Bar, } })
dig.Inを宣言することで「パラメータオブジェクト」になります。
パラメータが少ない場合は無理にdig.Inする必要は無いですが、複数パラメータを宣言しなければいけない時は便利だと思います。
dig.Inを追加した場合の全体像package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooRepository interface { foo() } type BarRepository interface { bar() } // dig.Inが定義されているオブジェクト type inUsecase struct { dig.In Foo FooRepository Bar BarRepository } type usecase struct { Foo FooRepository Bar BarRepository } func (u *usecase) use() { u.Foo.foo() u.Bar.bar() } type fooRepo struct { f string } func (u *fooRepo) foo() { fmt.Println(u.f) } type barRepo struct { b string } func (u *barRepo) bar() { fmt.Println(u.b) } func main() { // dig.Inを使った場合 c := dig.New() c.Provide(func() FooRepository { return &fooRepo{f: "Foo"} }) c.Provide(func() BarRepository { return &barRepo{b: "Bar"} }) // dig.Inが定義されている構造体を指定することにより可読性の低下を抑える c.Provide(func(u inUsecase) Usecase { return &usecase{ Foo: u.Foo, Bar: u.Bar, } }) c.Invoke(func(u Usecase) { u.use() }) }nameオプション
uber-go/digは依存関係を「よしな」にしてくれるすごいライブラリです。
ですが、下記の例の様にdig.Inに重複する型がある場合「よしな」が発動しません。
「よしな」にならない例
package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooBarRepository interface { foobar() } type inUsecase struct { dig.In FB1 FooBarRepository FB2 FooBarRepository } type usecase struct { FB1 FooBarRepository FB2 FooBarRepository } func (u *usecase) use() { u.FB1.foobar() u.FB2.foobar() } type foobarRepo struct { fb string } func (u *foobarRepo) foobar() { fmt.Println(u.fb) } func main() { c := dig.New() c.Provide(func() FooBarRepository { return &foobarRepo{fb: "Foo"} }) c.Provide(func() FooBarRepository { return &foobarRepo{fb: "Bar"} }) // inUsecaseは上記2つのFooBarRepositoryの内、先に宣言された"Foo"のみを取得する c.Provide(func(u inUsecase) Usecase { return &usecase{ FB1: u.FB1, // Foo FB2: u.FB2, // Foo } }) c.Invoke(func(u Usecase) { u.use() }) }コード内にも書いていますが、先に宣言された「
Foo」しか表示されません。
このように同じ型を宣言してしまった場合の回避方法としてnameオプションを使用することができます。
パラメータに対してnameを宣言することにより、登録時に同じnameのオブジェクトが関連付けされるようになります。type inUsecase struct { dig.In FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` }
dig.Name()を登録時に第二引数で指定することにより、オブジェクトにnameが付きます。c.Provide(func() FooBarRepository { return &foobarRepo{fb: "Foo"} }, dig.Name("Foo")) c.Provide(func() FooBarRepository { return &foobarRepo{fb: "Bar"} }, dig.Name("Bar"))実行すると
Foo
Bar
と表示され、期待通りの関連付けができます。
nameオプションを追加した場合の全体像package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooBarRepository interface { foobar() } type inUsecase struct { dig.In FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` } type usecase struct { FB1 FooBarRepository FB2 FooBarRepository } func (u *usecase) use() { u.FB1.foobar() u.FB2.foobar() } type foobarRepo struct { fb string } func (u *foobarRepo) foobar() { fmt.Println(u.fb) } func main() { c := dig.New() c.Provide(func() FooBarRepository { return &foobarRepo{fb: "Foo"} }, dig.Name("Foo")) c.Provide(func() FooBarRepository { return &foobarRepo{fb: "Bar"} }, dig.Name("Bar")) c.Provide(func(u inUsecase) Usecase { return &usecase{ FB1: u.FB1, FB2: u.FB2, } }) c.Invoke(func(u Usecase) { u.use() }) }dig.Out
goは複数戻り値を得ることができる言語です。
Provideでオブジェクトを登録するときも一つのProvide内で複数のオブジェクトを登録することができます。
あまり使用する機会は無いかもしれませんが、沢山オブジェクトを生成するコード = 戻り値が沢山あるコードとなり、可読性を損ないます。(引数と同じで戻り値も沢山あると見辛い)
戻り値もパラメータオブジェクト化することができます。上記にある「nameオプションを追加した場合の全体像」を例として使います。
例に下記の構造体を追加し、
FooBarRepositoryを登録している部分をパラメータオブジェクトを受け入れる様に変更します。type outUsecase struct { dig.Out FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` }c.Provide(func() outUsecase { return outUsecase{ FB1: &foobarRepo{fb: "Foo"}, FB2: &foobarRepo{fb: "Bar"}, } })
dig.Outを使うことにより複数オブジェクトを登録することができたり、nameオプションの宣言をdig.Out内で行うことができます。
nameオプションなどをmain内に書かなくてよくなるのは良いと思いました。
dig.Outを追加した場合の全体像
package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooBarRepository interface { foobar() } type inUsecase struct { dig.In FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` } // dig.Inの反対でdig.Outはオブジェクトの出力の形式を宣言する // dig.Outに`name:`を宣言することでProvide()の中で宣言しなくてよくなる type outUsecase struct { dig.Out FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` } type usecase struct { FB1 FooBarRepository FB2 FooBarRepository } func (u *usecase) use() { u.FB1.foobar() u.FB2.foobar() } type foobarRepo struct { fb string } func (u *foobarRepo) foobar() { fmt.Println(u.fb) } func main() { // dig.Outを使った場合 c := dig.New() // dig.Outを使うことにより複数オブジェクトを登録することができたり // nameオプションの宣言をdig.Out内で行うことができる c.Provide(func() outUsecase { return outUsecase{ FB1: &foobarRepo{fb: "Foo"}, FB2: &foobarRepo{fb: "Bar"}, } }) c.Provide(func(u inUsecase) Usecase { return &usecase{ FB1: u.FB1, FB2: u.FB2, } }) c.Invoke(func(u Usecase) { u.use() }) }optionalオプション
uber-goにはその構造体が「あっても無くてもOK」を実装することができます。
それがoptionalオプションです。
optionalオプションがついているパラメータは依存関係構築(Invoke)時に
対象となるオブジェクトがあれば使い、
対象となるオブジェクトがなければ「ゼロ値」を生成します。
optionalオプションの実装package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooBarRepository interface { foobar() } type inUsecase1 struct { dig.In FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` } // dig.Inに`optional:"true"`を宣言することにより // 取得できなかった時にその型のゼロ値を取得する type inUsecase2 struct { dig.In FB1 FooBarRepository `name:"Foo" optional:"true"` FB2 FooBarRepository `name:"Bar" optional:"true"` } // 今回は使用しない type outUsecase struct { dig.Out FB1 FooBarRepository `name:"Foo"` FB2 FooBarRepository `name:"Bar"` } type usecase struct { FB1 FooBarRepository FB2 FooBarRepository } func (u *usecase) use() { // optional:"true"が宣言されており、登録オブジェクトが無い場合はゼロ値で処理される if u.FB1 != nil { u.FB1.foobar() } else { fmt.Println("usecase FB1 is nil") } if u.FB2 != nil { u.FB2.foobar() } else { fmt.Println("usecase FB2 is nil") } } type foobarRepo struct { fb string } func (u *foobarRepo) foobar() { fmt.Println(u.fb) } func main() { // optionalを用いることで「あっても無くても良いオブジェクト」を宣言することができる // optional:"true"が宣言されていなかった場合 c1 := dig.New() // オブジェクトを登録しない c1.Provide(func(u inUsecase1) Usecase { return &usecase{ FB1: u.FB1, FB2: u.FB2, } }) // 実行時にエラーがでる err1 := c1.Invoke(func(u Usecase) { u.use() }) if err1 != nil { fmt.Printf("Invoke error :\n%s\n\n", err1) } // optional:"true"が宣言されていた場合 c2 := dig.New() // オブジェクトを登録しない c2.Provide(func(u inUsecase2) Usecase { return &usecase{ FB1: u.FB1, FB2: u.FB2, } }) // ゼロ値が登録されて実行される(構造体ならnil) err2 := c2.Invoke(func(u Usecase) { u.use() }) if err2 != nil { fmt.Printf("Invoke error :\n%s", err2) } }
optional:"true"を宣言していない方(inUsecase1)は依存関係構築時にエラーを吐きます。
optional:"true"を宣言している方(inUsecase2)は依存関係構築時にゼロ値のオブジェクトを生成し、u.use()を実行しています。(構造体のゼロ値はnil)
あらかじめoptionalのパラメータを受け取る関数内では、ゼロ値かどうかの判定を作る必要があります。むやみやたらに
optionalを使うとバグの原因になりそうですが、「あっても無くてもOK」を簡単に実装できるのは(あまり使わないと思いますが)便利です。groupオプション
groupオプションはuber-go/digのバージョン1.2から追加された機能です。
dig.Inとdig.Out両方に宣言する必要があるオプションで、dig.Outされたオブジェクトをdig.Inにスライスで渡します。(複数オブジェクトを渡すことができる)
groupオプションの実装package main import ( "fmt" "go.uber.org/dig" ) type Usecase interface { use() } type FooBarRepository interface { foobar() } // dig.Inのgroupオプションの宣言 type inUsecase struct { dig.In FB []FooBarRepository `group:"foobar"` } // dig.Outのgroupオプションの宣言 type outUsecase struct { dig.Out FB FooBarRepository `group:"foobar"` } // dig.Inから受け取る構造体もスライスにする必要がある type usecase struct { FB []FooBarRepository } // 値の取り出しはfor文で取り出すことができる // ただし取り出す順番をdigは保証しないらしい // 実際実行するたびに順番が変わる func (u *usecase) use() { for _, fb := range u.FB { fb.foobar() } } type foobarRepo struct { fb string } func (u *foobarRepo) foobar() { fmt.Println(u.fb) } func main() { // groupオプションがついているdig.Outを使用すると // dig.Inについているgroupのスライスで受け取ることができる // ただし、digライブラリはスライスに登録される順番を保証しない c := dig.New() c.Provide(func() outUsecase { return outUsecase{FB: &foobarRepo{fb: "Foo"}} }) c.Provide(func() outUsecase { return outUsecase{FB: &foobarRepo{fb: "Foo"}} }) c.Provide(func() outUsecase { return outUsecase{FB: &foobarRepo{fb: "Bar"}} }) c.Provide(func() outUsecase { return outUsecase{FB: &foobarRepo{fb: "Bar"}} }) c.Provide(func(u inUsecase) Usecase { return &usecase{ FB: u.FB, } }) c.Invoke(func(u Usecase) { u.use() }) }
dig.Outにgroupオプションを作成し、dig.Inにはdig.Outと同じ名前のgroupオプションをスライス型で定義します。
dig.Inを受け取るオブジェクト(usecase)もスライスで定義し、実行する時にfor文などでオブジェクトを取得します。
コード内にも書いていますが、digはgroupオプションで登録される順番を保証しません。
このプログラムを何度も動かしたらわかりますが、実行するたびに「Foo」「Bar」の順番が変わります。同じ型のオブジェクトをゴルーチンを用いて並列処理する時とかに使うと便利そうだ思いました。
その他
dig.IsIn() で対象の構造体が
dig.Inかどうか判定できる。dig.IsOut() で対象の構造体が
dig.Outかどうか判定できる。コンテナ.String()で コンテナに登録されている情報を確認する ことができる 。
↑結構重要コンテナ.Provide(),コンテナ.Invoke() は戻り値で エラー をとることができる。
↑結構重要感想
uber-go/digを使うことにより依存関係の構築を簡単にすることができる。
ただ、ドキュメントが少なかったし、ポインタ周りでかなりハマったりしたので疲れた。
良い勉強になったと思う。
あとマークダウンを書くときに
このパカパカ
パカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカ
<details> <summary>開閉オブジェクト</summary> <div> 中身 </div> </details>パカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカパカ
が便利だと思った。
以上。
参考文献
doc :https://godoc.org/go.uber.org/dig
github :https://github.com/uber-go/dig
https://int128.hatenablog.com/entry/2019/01/28/143158
https://tech.raksul.com/2019/06/21/golang-favorite-di-tool/
- 投稿日:2019-11-26T15:51:40+09:00
[Go言語] httpライブラリのHandler,Handlefuncとかをざっくり整理
はじめに
Go言語のhttpの標準ライブラリを利用すると、http.Handleとかhttp.Handlefuncとか似た名前が多い。
httpサーバを作るときによく使われるものについて、概念だけわかるようにかなりざっくり整理。Handler
リクエスト受信時の処理を持つインターフェースと思っておけばいい
定義されているServeHTTPは結局のところリクエスト受信時処理type Handler interface { ServeHTTP(ResponseWriter, *Request) }func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) { f(w, r) }http.Handle
URLと対応するHandlerをひもづける
URLに対してHandlerに定義されているリクエスト受信時処理が登録される
func Handle(pattern string, handler Handler)http.Handlefunc
URLと対応するリクエスト受信時処理を直接ひもづける
使い方はhttp.Handleと同じ
Handleとの違いは、Handler(の処理)とひもづけるか、Handlerとして実体化させていない処理そのものとひもづけるかの違いfunc HandleFunc(pattern string, handler func(ResponseWriter, *Request)) { DefaultServeMux.HandleFunc(pattern, handler) }実装時には
簡単なhttpサーバだと次の2ステップ
1.URLとURLリクエスト受信時の処理を登録する
http.Handleとかhttp.Handlefuncとか2.1.で登録した処理を指定のポートで待ち受け
http.ListenAndServehttp.HandleFunc("/test/", testHandler) log.Fatal(http.ListenAndServe(":8080", nil))参考
GoでHTTPサーバー入門 [Handler][HandleFunc][ServeMux]
https://noumenon-th.net/programming/2019/09/12/handler/Go 言語の http パッケージにある Handle とか
https://qiita.com/nirasan/items/2160be0a1d1c7ccb5e65
- 投稿日:2019-11-26T08:50:14+09:00
[Golang][競プロ]子ども達に大福を分け与える問題について解説してみた
はじめに
今日は、競技プログラミングをしてみたので、回答のロジックについて共有致します。
なお、競技プログラミングサービス側の規約もありますので、問題文は全く違うものを用意しておりますが、もし万が一コンプライアンスに問題があれば、ご連絡頂けると嬉しいです。問題
おばあさんは、大福を
N個持っています。
2人の孫が遊びに来たので、大福を分けてやることにしました。
標準入力で大福の数Nを与えられた場合、2人の孫はいくつずつもらえるでしょう?
ただし、大福の数が奇数だった場合、孫のどちらかが多くなってしまいケンカになりかねないので、その場合はおばあさんが1つ食べるとします。回答
問題文の稚拙さは、ご容赦ください。笑
それでは、僕の回答について共有致します。コード
回答したコードpackage main import "fmt" func main(){ var i int fmt.Scanf("%d", &i) r := i / 2 fmt.Println(r) }解説
今回は、かなり初歩的な問題だったかと思います。
おそらく、標準入力の受け取りと出力の確認を兼ねた、ウォーミングアップといったところでしょうか。
では、簡単ではございますが、解説していきます。
fmt.Scanf関数で標準入力を取得以前書いた記事でも共有させて頂いた、この方法で行いました。
色々な方法がありますが、記述量も少なく直感的に使える関数で、個人的には好きな関数です。笑おばあちゃんが1つ食べるのはスルーしたロジック
今回は、
Nが奇数なら-1、偶数ならそのまま、2人に分けても良いかとも思いましたが、思い切ってスルーしました。
多くの言語で同じ挙動を見せるかと思いますが、いわゆる「除算の商」は整数のみになります。この特性を利用して、シンプルに割り算しただけにしました。
(奇数の場合は、商は少数にならずに切り捨てられるため。)さいごに
今回はこれで終わります。
何かあれば、ぜひお気軽にコメント頂けると嬉しいです。
最後までありがとうございました。
- 投稿日:2019-11-26T01:22:21+09:00
Ginのミドルウェアを使ったエラーハンドリング
はじめに
ginでAPIなんかを書いていると、エラーを返すとき、
if err != nil { log.Print(err) c.AbortWithJSON(http.StatusInternalServerError, gin.H{ "Error": "Request failed" }) }のようなコードが(気をつけないと)あちこちに散らばってしまいます。
このままだと、例えばログの表示方法や保存方法が変わることになったときなどに一つひとつ手直ししないといけません。
そこで、ミドルウェアを使ってエラー時の処理をまとめたいと思います。バージョン
Go : v1.12
gin : v1.5ミドルウェアについて
ginではミドルウェアを設定でき、通常のハンドラーの前後に任意の処理を入れることができます。
例えば、
func main() { r := gin.Default() r.Use(someMiddleware()) // ミドルウェアを登録 r.GET("/", func(c *gin.Context) { log.Println("2nd") c.JSON(200, gin.H{"Message": "Hello"}) }) r.Run() } func someMiddleware() gin.HandlerFunc { return func(c *gin.Context) { log.Println("1st") c.Next() // ハンドラーを実行 log.Println("3rd") } }とすると、ログは、
1st,2nd,3rdの順番で出てきます。
見ての通り、c.Nextの前に書いたものはハンドラーの前に、後に書いたものはハンドラーの後に実行されます。エラーハンドリング
エラーの投げ方
gin のコンテキストは、
Errorメソッドを使ってエラーが設定できます。
さらにこのメソッドは、元のエラーとTypeやMetaなどの追加情報を含むgin.Error型を返します。
Typeには、gin.ErrorTypePublic、ErrorTypePrivateなどがあり、デフォルトではErrorTypePrivateです。
Metaの方はinterface{}型なので任意のデータを設定できます。c.Error(err) // simple error c.Error(err).SetType(gin.ErrorTypePublic) c.Error(err).SetType(gin.ErrorTypePrivate).SetMeta("more data")リクエストの処理中に何かエラーが起きたときは、
AbortWithJSONなどとする代わりに、次のようにコンテキストにエラーを設定して一度ハンドラーから抜けます。if err != nil { c.Error(err).SetType(gin.ErrorTypePublic) return }エラーミドルウェア
エラーがセットされたコンテキストをミドルウェアで処理するようにします。
次のようなミドルウェアを作成して、
r.Use(errorMiddleware())というように登録してください。func errorMiddleware() gin.HandlerFunc { return func(c *gin.Context) { c.Next() err := c.Errors.ByType(gin.ErrorTypePublic).Last() if err != nil { log.Print(err.Err) c.AbortWithStatusJSON(http.StatusInternalServerError, gin.H{ "Error": err.Error() }) } } }ここでは、コンテキストにセットされたエラーの中でも、TypeがPublicで、最後のものを取得しています。
エラーを取得した後には、ログの出力やSentryへの送信などといった任意の処理を入れることができます。また、MetaにHTTPのステータスコードやレスポンスを入れたり、TypeのPrivateとPublicで処理を分けたりなどといったこともできます。
これで、エラーの処理をミドルウェアにまとめることができました!
参考リンク
- 投稿日:2019-11-26T01:04:50+09:00
Dependency Injection入門
はじめに
以下では、Dependency Injectionとは何なのか、またその意義について記述する。コード例にはPythonとGoを用いる。
まず、訳語について
Dependency Injectionという用語は、日本語の文脈では「依存性の注入」と訳されることが多い。たとえば、このWikipediaの項目も「依存性の注入」という名前になっている。
英語でDependency Injectionという言葉を考えると、明らかに日常的な状況では使用しない専門用語であるという印象を与えはするが、個別の単語に分解して考えれば、プログラマにとってはそれほど難解ではないだろう。
まず、プログラミングの文脈でDependencyといえば、あるソフトウェアが内部で使用している別のソフトウェアのことがすぐに頭に浮かぶはずだ。つまり、「あるプログラムが機能するために必要な別のプログラム」という意味で用いる、使用頻度の高い言葉であるといえる。
一方、Injectionについては、英語の文脈で最初に頭に浮かぶイメージは「注射」だろう。この言葉はプログラミングの文脈において頻繁に使用されるものとはいえないが、「外部に存在する物質を、何かの内部に取り込む」という感覚が、注射などの物理的な経験を通じて身体に染み付いている。
このように、英語を用いるプログラマにとっては、DependencyもInjectionも、個別の単語としてはそれほど珍奇な印象を与える言葉ではないのだ(もちろん、最初に述べたように、これらが合わされば、少なくとも初学者には奇妙に映るだろうが)。
これに対して、日本語訳である「依存性の注入」についてはどうだろうか。
「注入」については、「外部のものを、何かの内部に注ぎ入れる」という意味である。対応するInjectionとそれほど違いはないと考えられる。
だが、「依存性」という言葉については、普通の日本語の感覚からすると、「お酒も依存性のある薬物だ」といった言い方のように、薬物依存に関するものだという印象が強いのではないだろうか。あるいは、「依存性パーソナリティ障害」のような、こころの病気を思い浮かべる人もいるかも知れない。いずれにせよ、これらはプログラミングの文脈からはかけ離れた話題である。また、こうしたイメージがDependency Injectionという概念を理解するために有用であるかといえば、まったくそんなことはない。つまり、端的に言えば、「依存性」という訳語は不適切である。
後述するように、Dependency InjectionにおけるDependencyの意味は、「あるクラスや関数が機能するために必要な別のオブジェクト」のことである。したがって、Dependency Injectionの訳は、多少曖昧さを残すなら「依存対象の注入」、より具体的には「依存オブジェクトの注入」とでもするべきだったのだ。
残念ながら、日本語としては「依存性の注入」という訳語がすでに広く流通してしまっているが、上に述べたような意味で、この語は使用するべきではないと考えられる。そこで以下では、日本語訳は使用せず、Dependency Injectionの省略形であるDIによって、この語を表わすこととする。
DIとは何か
言葉による説明
ここではコードを用いずにDIについて説明する。ここでの説明をもとに、あとで具体的なコードを見ていく。
まず、少しフォーマルな定義から確認しよう。
In software engineering, dependency injection is a technique whereby one object supplies the dependencies of another object. A "dependency" is an object that can be used, for example as a service. Instead of a client specifying which service it will use, something tells the client what service to use. The "injection" refers to the passing of a dependency (a service) into the object (a client) that would use it.
これは英語版Wikipediaからの引用だ。DIについて何も知らずにこの定義を呼んだ場合、その意味と意義を理解することはかなり困難だと思うが、理解したあとに読むと実は上手くまとまっている。ポイントを抜き出そう:
- DIとは、あるオブジェクトが別のオブジェクトに、後者が依存しているものを与えること
- DIのDにあたるDependency「依存しているもの」とはオブジェクト
- DIのIにあたるInjectionとは、「依存している側のオブジェクト」に「依存対象のオブジェクト」をわたすこと
- 何かのサービスに依存しているオブジェクトはクライアントと呼ばれる
少し抽象的だが、登場人物は2つだ。図示すると、
Service (dependency) -> <Client>のようになる。非常に単純だ。
続いて、James Shoreの一行の定義を見てみよう:
Dependency injection means giving an object its instance variables. Really. That's it.
具体的かつ簡潔だ。先ほどの話を敷衍すれば、instance variablesがdependencyに対応する。つまり、
instance variables -> <Client>となる。Clientのインスタンス変数を外部から与えるということだ。
以上の説明では、「オブジェクト」や「インスタンス変数」という語が登場することからも明らかなように、オブジェクト指向プログラミング、すなわちOOPの思想が強く反映されている。しかし、たとえばGoなどのオブジェクト指向ではない言語においても、DIという語が用いられることはある。重要なことは、上で図示したような、Clientに依存対象を贈与するという共通構造だ。
まとめると、DIとは、あるクラスや関数が機能するために必要なコンポーネントを、その外部から提供するという構造のことだといえる。
コードを用いた説明
Python
ここまでの理解をもとに、ここからは具体的なプログラムで説明する。次のPythonの関数を見てほしい:
def greet(name): print(f'Hello, {name}')特に説明はいらないだろう。
nameという引数を使用して文字列を生成し、それを標準出力へと出力する関数だ。ところで、このような関数をテストするためにはどうすればいいだろうか。REPLで挙動を確認するというのは一つの方法だが、それでは自動化できない。
ここで問題となっているのは、
greet関数の出力先が標準出力へと固定されていることだといえる。標準出力へと送られた文字列が本当に期待通りになっていたかどうかを確認することが、不可能ではないが面倒なのだ。このことをDIの文脈で言い換えれば、greet関数の「出力先」という構成要素、すなわち依存対象が問題になっているといえる。そこで、出力先をテストの際に動的に変更し、そこに送信された文字列をキャプチャすることでテストをおこなうというアイデアが出てくる。つまり、依存している出力先を動的に「注入」するのだ:
import io import sys def greet(name, out=sys.stdout): print(f'Hello, {name}', file=out) def test_greet(): buffer = io.StringIO() greet('World', buffer) assert buffer.getvalue() == 'Hello, World\n'ここでのポイントは、
greet関数の出力先を一時的にメモリ上のバッファbufferへと変更していることだ。もともと関数内部に組み込まれていた出力先を、引数を経由して外部からコントロールできるようにすることで、容易にテストをおこなうことができるようになった。Go
Goを使用した別の例も見てみよう。次のような構造体があるとする。
type EmailSender struct { From string } func (sender *EmailSender) Send(to, subject, body string) error { // Eメールを送信する。失敗した場合はエラーを返す。 }Eメール送信を担う構造体だ。これを利用するコードを次に示す:
type Welcomer struct{} func (welcomer *Welcomer) Welcome(name, email string) error { subject := "Welcome" body := fmt.Sprintf("Hi, %s", name) sender := &EmailSender{ From: "welcomer@example.com", } return sender.Send(email, subject, body) }少し複雑になってはいるが、先ほどのPythonのコードと同様の問題が生じている。すなわち、ウェルカムメッセージをメール送信する
Welcomerは、Eメール送信サービスであるEmailSenderと密結合しており、使用するメール送信サービスを外部から選択できなくなってしまっている。これを解決するにはtype EmailSender interface { Send(to, subject, body string) error }のように
EmailSenderをinterfaceへと変更し、そしてWelcomerにEmailSenderを渡すようにする:type Welcomer struct { Sender EmailSender } func (welcomer *Welcomer) Welcome(name, email string) error { subject := "Welcome" body := fmt.Sprintf("Hi, %s", name) return welcomer.Sender.Send(email, subject, body) }
interfaceを定義し、それをフィールドとして外部から受け渡し可能にすることで、Welcomerの柔軟性が向上した。これでテストが書ける:type SpySender struct { SentTo string } func (spy *SpySender) Send(to, subject, body string) error { spy.SentTo = to return nil } func TestWelcome(t *testing.T) { sender := &SpySender{} welcomer := Welcomer{ Sender: sender, } name := "Foo" email := "foo@example.com" welcomer.Welcome(name, email) if sender.SentTo != email { t.Errorf("got %q want %q", sender.SentTo, email) } }
Welcomerは、依存対象として注入されたSpySenderのSendメソッドを利用してメール送信を試みる。SpySenderは、実際のEメール送信はおこなわずに、引数の情報を記録しておく。そして最後に、WelcomerがEmailSenderのSendメソッドを期待通り使用しているかどうかを、記録された値をもとにテストする。以上が大まかな流れだ。ここでは
WelcomeメソッドがSendの引数にSpySenderを拡張したり、他のMockライブラリを使用したりすれば、もっと多くのことをテストできる。DIの意義
以上のコード例から、DIの意義が垣間見えたのではないだろうか。上の例に即してまとめると、
- 関数の挙動の変更・設定が外部から可能となり、柔軟性が向上した
- その結果として、テストのしやすさが向上した
- 関数の責任が明確となった、つまり、「メッセージをどこに出力するか」という問題を外部に丸投げすることで、メッセージを作成するという単一の仕事に集中できるようになった(Single Responsibility Principle、単一責務の原則)
などがいえる。このように、DIによりオブジェクト同士が疎結合化することで、SRPやテスト容易性の向上などの利点が生まれてくる。
まとめ
以上、DIの意味を説明し、コードを交えつつその意義について述べてきた。DIの利点は他にも様々あるので、より詳しくは書籍やネット上の他の記事を参照してほしい。
なお、DIはいいことばかりではない。依存対象を注入する側の責務が増大するため、オブジェクトの依存対象が増加していけば、その管理の負担もまた増加する。そうした問題を解消するためのツールとして「DIコンテナ」というものがあるが、それは次のステップで学ぶといいだろう。
参考
- https://en.wikipedia.org/wiki/Dependency_injection#Advantages
- https://www.jamesshore.com/Blog/Dependency-Injection-Demystified.html
- https://stackoverflow.com/questions/130794/what-is-dependency-injection
- https://quii.gitbook.io/learn-go-with-tests/go-fundamentals/dependency-injection
- https://medium.com/@elliotchance/a-new-simpler-way-to-do-dependency-injection-in-go-9e191bef50d5