- 投稿日:2019-11-26T23:26:46+09:00
Raspberry Pi ZeroのGPIOを使ってブラシレスモーターを制御する
Raspberry Pi Zeroでブラシレスモーターを制御する
概要
ちょっと思うところがあって、市販のブラシレスモーターをRPi Zeroを使って制御してみました。
構成
- Raspberry Pi Zero W (https://www.amazon.co.jp/gp/product/B0799FCCWS/)
- 適当なブラシレスモーターとESC(スピードコントローラー)セット (参考: https://www.amazon.co.jp/gp/product/B01MTCBO7D/)
- 適当なバッテリー
接続
- モーターとESCを繋ぐ。3本線があるが、適当に繋いでも回転が逆になるだけなので大丈夫。
- ESCとRPiを繋ぐ。コネクターに3本入っているが、真ん中の線は使わない。黒い線と反対側の何色かのもう一本を使う。黒い方を適当なGNDに、色がついている方を適当なGPIOに繋ぐ。GPIOは後でプログラムで指定するので、何番かをメモっておく。 ピンアサイン参考: https://www.raspberrypi.org/documentation/usage/gpio/
- いざ動作確認する段階でバッテリーを繋ぐ。何が起こるかわからないので、安全なバッテリーを推奨。例ではそのへんに転がっていたウナギ型のLiFeを利用。普通はウナギリフェなんて転がってはいないので注意。
プログラミング
とりあえずパルス幅を指定してやり、少しずつ回すのを繰り返す。
サンプルソースコード
import pigpio import time motor_pin = 27 #メモしたGPIO番号 pi = pigpio.pi() for i in range(3): pi.set_servo_pulsewidth(motor_pin, 1500) time.sleep(1) pi.set_servo_pulsewidth(motor_pin, 1600) time.sleep(1) pi.set_servo_pulsewidth(motor_pin, 1700) time.sleep(1) pi.set_servo_pulsewidth(motor_pin, 1800) time.sleep(1) pi.set_servo_pulsewidth(motor_pin, 1900) time.sleep(1) pi.set_servo_pulsewidth(motor_pin, 2000) time.sleep(1) pi.set_servo_pulsewidth(motor_pin, 0) pi.stop()解説
pi.set_servo_pulsewidth(motor_pin, 1500) time.sleep(1)motor_pinでGPIO番号を指定し、パルス幅を数値で指定する。
指定できる値範囲がどこからどこまでかは、ESCの仕様による。
ESCの仕様がわからない場合は手探りで探すしかない。
このESCでは、1500ぐらいから2000ぐらいまで指定できた。
sleepで、次の状態までの持続時間を指定する。pi.set_servo_pulsewidth(motor_pin, 0)止める場合は、こんな記述をしないとうまくいかなかった気がする。
いらなかったかも。まあおまじない的な。ESCによっては、動かす前におまじないが必要なものもあるらしい。
それはESCの仕様を調べるしかない。まとめ
という感じで、めちゃくちゃ簡単にブラシレスモーターを制御できた。
ただし、既存のESCを使ってのパルスと時間の制御になるので、厳密なブラシレスモーターの制御とは言えないかも。本来は、ESCの機能をそのものをRPiで制御したい。ちなみにこのブラシレスモーターは、中身が回るのではなく、外側のガワが回るので、固定しないとめっちゃ暴れる(笑)中央のローターが回るモーターを使ったほうが安全だと思う。
RPiを使ってモーターを制御すると、目に見えて制御できてる!!という達成感が得られるので、プログラミングの勉強にもおススメ。このブラシレスモーターとESCのセットは1000円ぐらいで買えるので、下手な電子工作キットなどを買うより安価に楽しめると思う。

- 投稿日:2019-11-26T23:24:31+09:00
緯度,経度,GPS高度を三次元直交座標に変換する
緯度経度を直交座標系における位置に変換したり,緯度経度から直線距離を出したりしたいシチュエーションって結構ありますよね(ない).
実際この手の記事はほかの方も多く書かれていると思います.ただこう,用途によって使いたい座標系が違ったりすると思うんですね.ということで,僕はこのたび地球の重心を原点にした移動しない三次元直交座標系に変換する方法を学んだので備忘録の意味も込めてここにまとめておきたいと思います.
ややアバウトですのでその道の方でご指摘があればお願いいたします.
緯度経度の表現について
まず前提というか,前置きとして緯度経度の表現について触れておきます.
緯度経度の記述には主に以下の2種類の表現が使われています.混同しないように注意が必要です.度分秒による表記
60進法による
135° 12' 34.56"というような形式.
よく耳にするやつですね.「135度12分34秒56」などと読みます.
135° 12' 34" 56と表記したり,「135度12分34.56秒」と読んだりすることもあります.それから1351234.56とか135.12.34.56と書くこともあるようです.
個人的には本当に紛らわしいのでやめてくれの一言ですが,ピリオドの付き方で次の十進法表記と区別することが出来ます.十進法表記
こちらはその名の通り10進法による表記で,
135.2096というようなもの.「分」「秒」の部分を「度」の少数で表しています.
上の例の135° 12' 34.56"は,135 + (12 / 60) + (34.56 / 3600)という計算をして
135.2096という十進数表記に変換されます.読み方は「135.2096度」です.一部の度分秒表記はとても十進数表記に似た姿をしていますが,小数点の付き方を見ればどちらで表現しているか見分けられることがお分かりいただけると思います.
ここで求める座標について
この記事ではGPSで測位された緯度経度の情報を,絶対的な三次元座標系における位置に変換する方法について解説しています.重要なポイントはただの三次元座標を得る手順を説明しているということです.
つまり何が言いたいかというと実際に地球がそこにあるかは関係ないってこと.
たとえこの方法で2つの任意の点の座標を得たとして,それらの2点間の距離を求めても地球を貫通した直線距離になります.だから飛行機とか宇宙機のことを考えるときにこの記事の方法は有用です(地表に沿って移動しないからね).地上の建造物や自動車とかのことを考えるときは,たとえば任意の点を原点としてある地点の二次元座標を得る(しかも地球の局面を考慮する)方法などが有用でしょう.こちらの記事がすごく参考になります.
緯度経度と平面直角座標の相互変換をPythonで実装する - Qiita
WGS-84座標系とは
今回計算に用いるのは,GPSの衛星たちが使っているWGS-84という三次元直交座標系です.
地球の重心を原点とする地球固定直交座標系の一種です.ようするに地球と一緒にぐるぐる回るってこと.
WGS-84準拠楕円体のパラメータを以下に示...そうと思ったけど必要なら各自おググりください.求めかた
まず以下の図のように変数を置きます.こういうの思いつく人ってすごいよね.
緯度Latitude φ,経度Longitude λ,楕円体高altitude h, あと点Pの座標x,y,zです.中央の楕円体が地球ですね.この楕円体にGPSはWGS-84を使っているというわけです.補足:楕円体高とは
その名の通り,地球に見立てた楕円体の表面から測った高度です.GPSから返される高度はこの楕円体高.
ここで注意が必要なのは,楕円体高はよく言う標高(elevation)とは別物だということ.標高は平均海面から測った高度です.平均海面を陸まで伸ばしたラインをジオイドといい,標高は目標物とジオイドの間の距離だといえます.そんで楕円体とジオイドの間の距離をジオイド高っていうんですね.つまり楕円体高は標高とジオイド高の和で表せるってこと.ややこしいね.
図解したらものすごい色遣いになりました.
ジオイド高は地球上の地点によって異なり,気象庁の計算サイトなどから得ることが出来ます.
https://vldb.gsi.go.jp/sokuchi/surveycalc/geoid/calcgh/calc_f.html式は
導出過程を全部書くのは大変なので全部端折りますと,点Pの座標は次のように表すことが出来ます.
ここでaは長半径,eは離心率で,WGS-84準拠楕円体の場合は以下の定数を用います(ほんとはeは扁平率から計算します).
- a = 6378137 [m]
- e = 0.0818191908426 [-]
以上の式はその道の方の間では有名(?)なものだそうで,探せば導出はいろいろ出てくると思います.必要に応じておググりください.この記事を参考文献にしたらだめだよ.
Pythonで実装すると
僕はこんな感じで関数にしておくことにしたよ.
引数 :緯度φ[deg],経度λ[deg],楕円体高h[m]
返り値 :x座標[m],y座標[m],z座標[m]import numpy as np def xyz(phi, lamb, h): #引数の緯度経度は10進数表記 # 緯度経度をラジアンに直す phi = np.deg2rad(phi) lamb = np.deg2rad(lamb) #定数(WGS-84準拠楕円体の場合) a = 6378137 #長半径 [m] e = 0.0818191908426 #離心率 [-] N = a / np.sqrt(1 - (e ** 2 * np.sin(phi) ** 2)) x = (N + h) * np.cos(phi) * np.cos(lamb) y = (N + h) * np.cos(phi) * np.sin(lamb) z = (N * (1 - e ** 2) + h) * np.sin(phi) return x, y, z #[m]以上です.駄文失礼しました.



- 投稿日:2019-11-26T23:05:07+09:00
wordcloudで遊んでみた!
はじめに
wordcloudを使用することになったので備忘録として投稿
mecabを使用するので、「mecabってなんぞや?」という方はこちらをどうぞ!
wordcloudのインストールから画像出力までをまとめてみた
お品書きは下記の通り
- これは何の物語でしょう?
- wordcloud とは
- 実際に動かしてみた
- 設定いろいろ
- 日本語でやりがちな失敗
- おわりに
これは何の物語でしょう?
せっかくなので wordcloud で出力した問題を出します(笑)
答えはおわりにで書いておきます!
wordcloud とは
文章中で出現頻度が高い単語を複数選び出し、その頻度に応じた大きさで図示する手法のこと
公式はこちら
インストールは pip などでインストールすればすぐ使える
pip install wordcloud
実際に動かしてみた
画像を用いて説明したほうが早いと思うので早速動かしてみた
ここで使用した物語は「赤ずきん」プログラム
import MeCab from wordcloud import WordCloud FILE_NAME = "sample.txt" with open(FILE_NAME, "r", encoding="utf-8") as f: CONTENT = f.read() tagger = MeCab.Tagger("-Owakati") parse = tagger.parse(CONTENT) wordcloud = WordCloud() wordcloud.generate(CONTENT) wordcloud.to_file("wordcloud.png")wordcloud = WordCloud()
生成および描画用のワードクラウドオブジェクト
wordcloud.generate("文字列")
テキスト(文字列)から wordcloud を作成
wordcloud.to_file("写真名")
画像ファイルにエクスポート
以上の手順により wordcloud の画像が作成されます
画像
wordcloud では多く使用している単語は大きく表示する
ただし、A, 俺 など1文字の単語は表示されないので注意!
「赤ずきん」の中では、grandmother, Little Red, Red Riding が多く使用されていることが分かる
設定いろいろ
背景や文字制限など、 WordCloud の中で設定を追加することができる
その中で、よく使うであろう設定をいくつか紹介
parameter デフォルト 説明 width 400 横幅 height 200 縦幅 background_color "black" 背景色 colormap None 文字色 collocations True 連語 stopwords None 除外する単語(リスト) max_words 200 表示する最大単語数 regexp r"\w[\w']+" 表示される文字の正規表現 画像の大きさを変えたい
先ほどの画像は少し小さい(Qiita用なので)
Desktopのサイズでもある 縦1080, 横1920に設定しようとすると以下のようになる
wordcloud = WordCloud(width=1920, height=1080)
色を変えたい
背景や文字の色が見づらい…
背景色は指定したい色を宣言する
文字の色は文字のイメージカラーがいくつかあるためそちらを宣言する今回は、背景色を白,文字のイメージカラーを summer とする
wordcloud = WordCloud(background_color="white", colormap="summer")
Red Riding みたいな連語を分解したい
Red Riding や Little Red のように、 「Red」が画面上に多発することが多々ある
そこで、下記のように設定をしてみる
連語を別々の単語として判断することができるのでとても便利wordcloud = WordCloud(background_color="white", colormap="summer", collocations=False)
ある文字を表示したくない
「the、and、to」のような言葉を wordcloud 上に出してもあまり意味がない
それらの言葉を表示させたくない場合は以下のように配列を使用して宣言してあげるとよい
(今回はわかりやすいように、["Little", "grandmother"]を表示させないようにしてみる)wordcloud = WordCloud(background_color="white", colormap="summer", collocations=False, stopwords=["Little", "grandmother"])
表示する文字数制限したい
wordcloud では、デフォルトで200個の文字を出力するように設定されている
以下のように設定すれば、何個の文字を出力するか設定することができるwordcloud = WordCloud(background_color="white", colormap="summer", collocations=False, stopwords=["Little", "grandmother"], max_words=10])
これを見ると、[the, and, to] あたりを消したらよさそうなデータが取れそう??
1文字の単語も表示したい
上のほうでも記述した通り、 wordcloudでは1文字の単語は出力できないようになっている
regexpで制限することで、1文字以上の単語でも対応することができるwordcloud = WordCloud(background_color="white", colormap="summmer", collocations=False, stopwords=["the", "and", "to"], max_words=20, regexp=r"[\w']+")
a が一番多くなるのは納得ですね…
ほかのも教えてよ!という方は公式さんから
日本語でやりがちな失敗
上記のプログラムで日本語文を流すと以下のような画像に…
これは wordcloud 内で使用しているフォントが日本語対応していないから
なので、フォントを設定してあげればよい
フォントの設定は、以下のようにしてあげる
FONT_FILE = "C:\Windows\Fonts\MSGOTHIC.TTC"
wordcloud = WordCloud(font_path=FONT_FILE, background_color="white", colormap="summer",
collocations=False, regexp=r"[\w']+")え? なんでMS ゴシックなのかって?
元コボラー だからだよ!(わかる人にはわかる…と思う)※ フォントは何でもいいので自分が一番好きなフォントにしてあげてください(^-^)
そんなこんなでこんな出力になった
おわりに
ざっくりと wordcloud についてまとめてみました
ちなみに先ほどの問題の答えは…
三匹の子豚です!
wordcloud は大きい文字がよく出てくる単語
画像を見るとlittle
pig
house上記の三つがよく出てくる単語になっています!
こんな風に wordcloud 化することによって、
その文字列が何を表しているかなどの指標にも使うことができますねー( ˘ω˘ )









- 投稿日:2019-11-26T22:40:05+09:00
NNablaでtensorboardを使う
tensorboard は学習時にロスカーブを書いたり、ヒストグラムや画像を描画したりするのがとても便利なツールです。私は最近ソニー製のニューラルネットワークフレーム NNabla (https://nnabla.org/) を使っていますが、可視化ツールがなかったので、NNabla でも tensorboard を使えるように、python のパッケージを作りました。
https://github.com/naibo-code/nnabla_tensorboard
基本は "tensorboardX for pytorch" をベースに作りました。
使い方
基本的には
demp.pyを実行してもらうとどんな感じか分かるかと思います。スカラ、ヒストグラム、画像などの描画に対応しています。# Install pip install 'git+https://github.com/naibo-code/nnabla_tensorboard.git' # Demo python examples/demo.pyスカラ
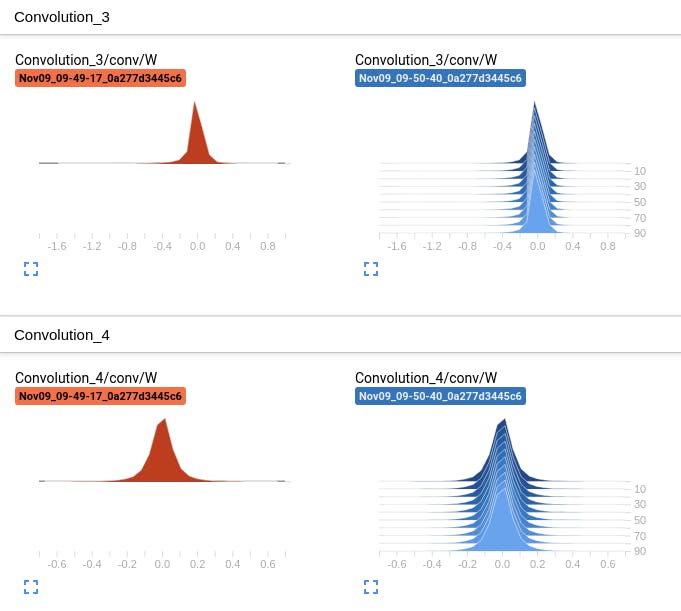
ヒストグラム
文字出力
NNabla + tensorboard で MNIST の学習を可視化
NNabla はこちらのリポジトリ https://github.com/sony/nnabla-examples/ で幾つかの examples を提供しています。今回はその中から MNIST の学習コード を使って、リアルタイムに学習結果を tensorboard で可視化してみました。
変更すべきのはこちらの2つの関数だけです(
NEWと書かれた部分だけ。)。あとファイルの先頭にfrom nnabla_tensorboard import SummaryWriterでパッケージをインポートします。from nnabla_tensorboard import SummaryWriter def train(): """ Main script. Steps: * Parse command line arguments. * Specify a context for computation. * Initialize DataIterator for MNIST. * Construct a computation graph for training and validation. * Initialize a solver and set parameter variables to it. * Create monitor instances for saving and displaying training stats. * Training loop * Computate error rate for validation data (periodically) * Get a next minibatch. * Execute forwardprop on the training graph. * Compute training error * Set parameter gradients zero * Execute backprop. * Solver updates parameters by using gradients computed by backprop. """ args = get_args() from numpy.random import seed seed(0) # Get context. from nnabla.ext_utils import get_extension_context logger.info("Running in %s" % args.context) ctx = get_extension_context( args.context, device_id=args.device_id, type_config=args.type_config) nn.set_default_context(ctx) # Create CNN network for both training and testing. if args.net == 'lenet': mnist_cnn_prediction = mnist_lenet_prediction elif args.net == 'resnet': mnist_cnn_prediction = mnist_resnet_prediction else: raise ValueError("Unknown network type {}".format(args.net)) # TRAIN # Create input variables. image = nn.Variable([args.batch_size, 1, 28, 28]) label = nn.Variable([args.batch_size, 1]) # Create prediction graph. pred = mnist_cnn_prediction(image, test=False, aug=args.augment_train) pred.persistent = True # Create loss function. loss = F.mean(F.softmax_cross_entropy(pred, label)) # TEST # Create input variables. vimage = nn.Variable([args.batch_size, 1, 28, 28]) vlabel = nn.Variable([args.batch_size, 1]) # Create prediction graph. vpred = mnist_cnn_prediction(vimage, test=True, aug=args.augment_test) # Create Solver. solver = S.Adam(args.learning_rate) solver.set_parameters(nn.get_parameters()) # Create monitor. from nnabla.monitor import Monitor, MonitorTimeElapsed monitor = Monitor(args.monitor_path) monitor_time = MonitorTimeElapsed("Training time", monitor, interval=100) # For tensorboard (NEW) tb_writer = SummaryWriter(args.monitor_path) # Initialize DataIterator for MNIST. from numpy.random import RandomState data = data_iterator_mnist(args.batch_size, True, rng=RandomState(1223)) vdata = data_iterator_mnist(args.batch_size, False) # Training loop. for i in range(args.max_iter): if i % args.val_interval == 0: # Validation (NEW) validation(args, ctx, vdata, vimage, vlabel, vpred, i, tb_writer) if i % args.model_save_interval == 0: nn.save_parameters(os.path.join( args.model_save_path, 'params_%06d.h5' % i)) # Training forward image.d, label.d = data.next() solver.zero_grad() loss.forward(clear_no_need_grad=True) loss.backward(clear_buffer=True) solver.weight_decay(args.weight_decay) solver.update() loss.data.cast(np.float32, ctx) pred.data.cast(np.float32, ctx) e = categorical_error(pred.d, label.d) # Instead of using nnabla.monitor, use nnabla_tensorboard. (NEW) if i % args.val_interval == 0: tb_writer.add_image('image/train_data_{}'.format(i), image.d[0]) tb_writer.add_scalar('train/loss', loss.d.copy(), global_step=i) tb_writer.add_scalar('train/error', e, global_step=i) monitor_time.add(i) validation(args, ctx, vdata, vimage, vlabel, vpred, i, tb_writer) parameter_file = os.path.join( args.model_save_path, '{}_params_{:06}.h5'.format(args.net, args.max_iter)) nn.save_parameters(parameter_file) # append F.Softmax to the prediction graph so users see intuitive outputs runtime_contents = { 'networks': [ {'name': 'Validation', 'batch_size': args.batch_size, 'outputs': {'y': F.softmax(vpred)}, 'names': {'x': vimage}}], 'executors': [ {'name': 'Runtime', 'network': 'Validation', 'data': ['x'], 'output': ['y']}]} save.save(os.path.join(args.model_save_path, '{}_result.nnp'.format(args.net)), runtime_contents) tb_writer.close()def validation(args, ctx, vdata, vimage, vlabel, vpred, i, tb_writer): ve = 0.0 for j in range(args.val_iter): vimage.d, vlabel.d = vdata.next() vpred.forward(clear_buffer=True) vpred.data.cast(np.float32, ctx) ve += categorical_error(vpred.d, vlabel.d) tb_writer.add_scalar('test/error', ve / args.val_iter, i)NNabla + tensorboard : MNIST の実行結果
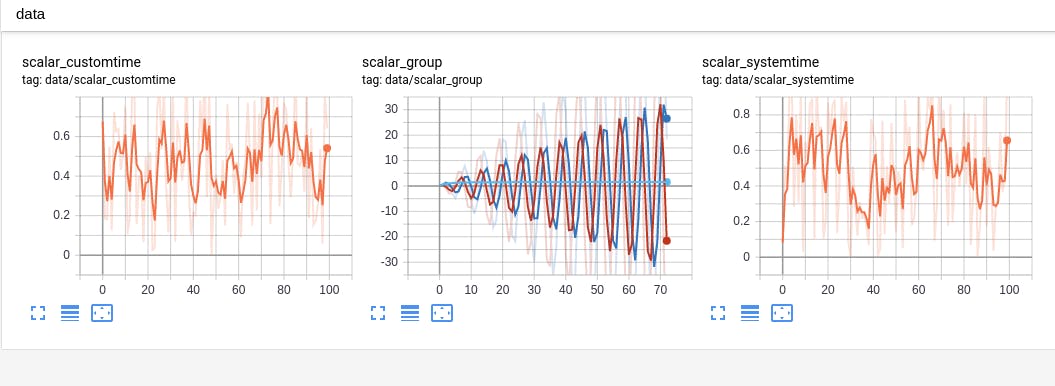
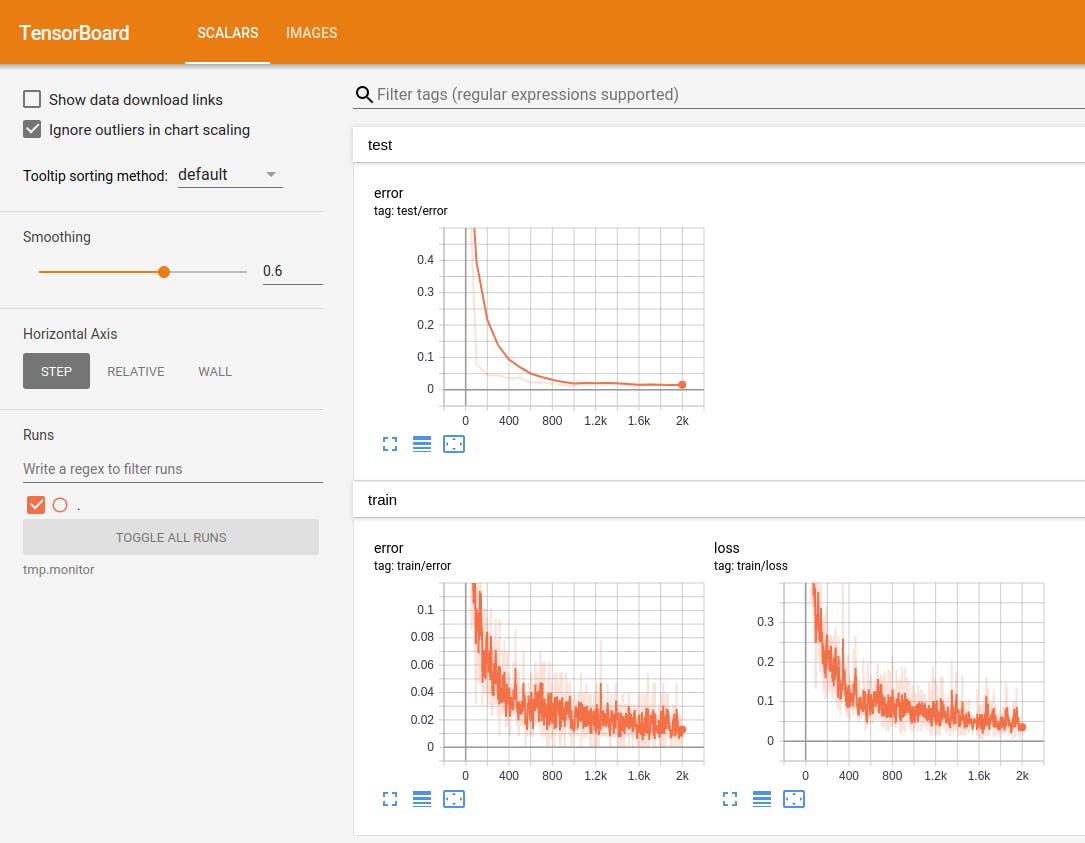
学習カーブ
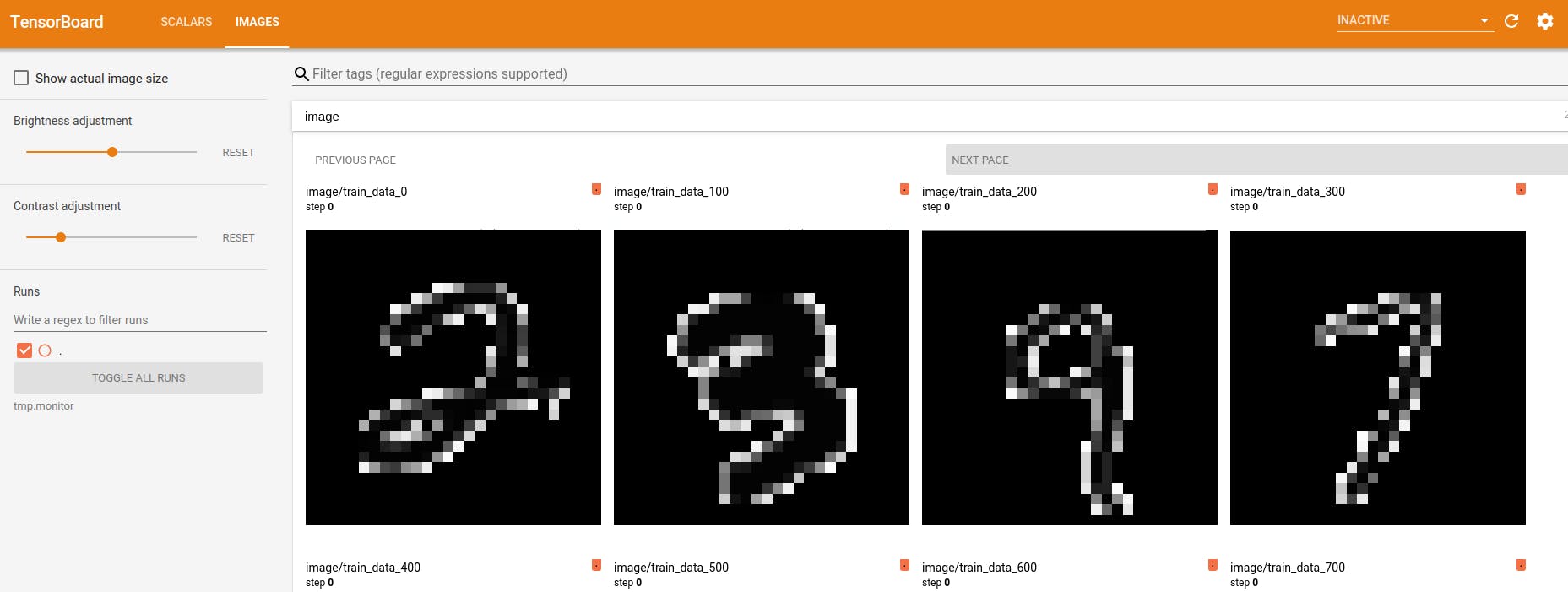
入力イメージもplotしてみた。
自作スクリプトで描画したりする必要がなく、やっぱり tensorboard は便利ですね。
追加したい機能
- Network graph を tensorboard に表示する機能。
- NNabla をうまく使えば、中間層のデータの可視化も tensorboard でできちゃうかもしれません。(まだ色々調べ中・・・)

- 投稿日:2019-11-26T22:37:10+09:00
tf.data.Dataset apiでテキスト (自然言語処理) の前処理をする方法をまとめる
TensorFlow2.0 Advent Calendar 2019の11日目です。
tf.data.Dataset APIを用いてテキストの前処理を行う方法をまとめたいと思います。
本記事では以下の順に説明します。
- tf.data.Dataset APIとは何か、また、その有効性は何かを説明
- 実際にテキストの前処理の手続きを説明
- performance向上のtipsのまとめ
説明が長いので(コードも長いですが。。。)コードだけ見て俯瞰したい場合はこちらから参照できます。
(注意として、本記事の内容は十分な検証ができているとは言えないです。コードは動きますが、パフォーマンスの向上に寄与しているのかいまいち把握しきれていないところがいくつかあります。随時更新していきますが、参考程度に留めておいていただけたらと思います。)
同アドベントカレンダーでは以下の記事が関連します。こちらも参考にされるといいかなと思います。
- 3日目: tf.data.Dataset APIの基本的な紹介がされています(TensorFlowで使えるデータセット機能が強かった話)
7日目: tf.data.Dataset APIで、Mecabを使った分かち書きの手順が紹介されています(Mecabとtf.dataを使ってlivedoorニュースコーパスを分かち書きする)
10日目: joblibで並列化してmapの高速化を図っています。本記事ではtf.dataの.map自体がもっている並列化機能を紹介しますが、どちらが速いのか追って検証したいです。(というか、組み合わせれそうです)(【TF2.0応用編】TFの例の強いデータセット機能で汎用的なDataAugmentationを並列化しハイスピードで実現した件)
1. tf.data.Dataset API
典型的な学習プロセスは、以下のような流れになると思います。
- データの読み込み: ローカルストレージ、インメモリ、クラウドストレージから読込
- 前処理: CPUで処理
- 学習用のデバイスにデータを渡す: GPU, TPUに渡す
- 学習: GPU, TPUで処理
データセットが大きくなってくると1~4の処理を一つずつやっていくと、リソースが足りなくなってきます。
(特に画像だと数GBであることがざらにあるので1. データの読み込みだけでも一度には処理できなくなります)
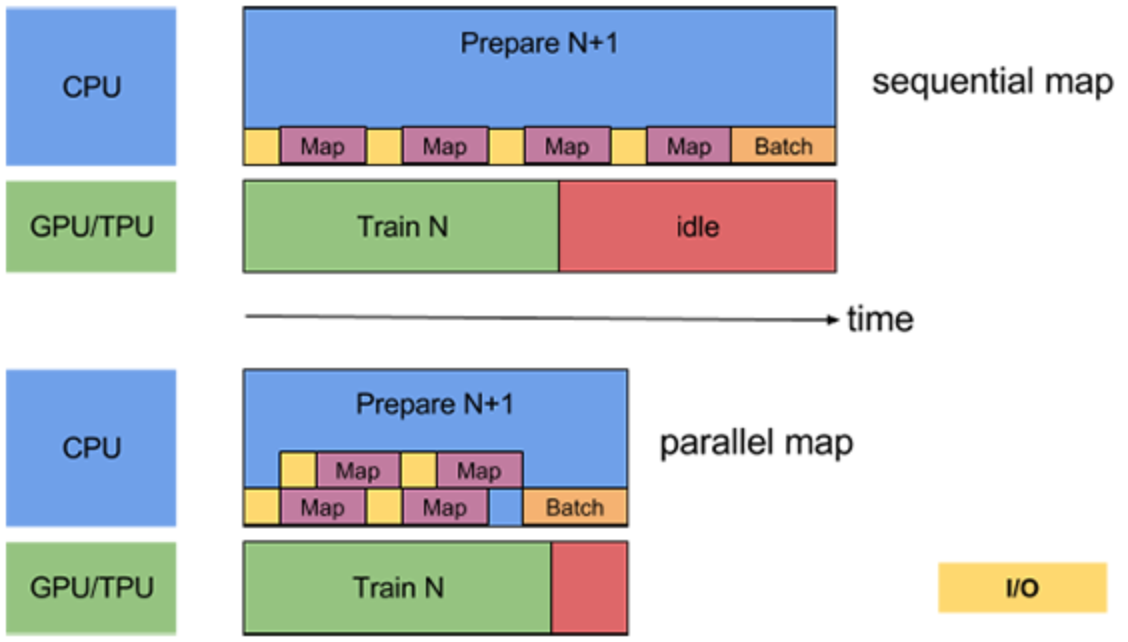
なので、バッチに分けて(例えば、数枚の画像毎に)1 ~ 4までの処理を一気通貫で行う。ということを繰り返すことが推奨されます。これはパイプライン処理と言います。愚直なパイプラインをしくと、この一連のプロセスは、以下のようにオーバーヘッド部分に無駄な待ち時間が発生し得えます。
https://www.tensorflow.org/guide/data_performancetf.data.Dataset APIでは以下のようにオーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
- prefetch: CPUとGPU/TPUでそれぞれ並列に処理
- map: 前処理の並列処理
- read_file: 読み込みの並列処理
これらについては後述します。まず、先にtf.data.Dataset APIの使い方を知るためにもテキストの前処理について書きます。
2. テキストの前処理の流れ
では、tf.data.Dataest APIを使ってテキストの前処理をやってみます。
順番は前後すると思いますが、標準的なテキストの前処理の流れは以下のようなものだと思います。
1. load: テキストの読み込み・シャッフル
2. standarize: ストップワード削除、置換、小文字に統一、など
3. tokenize: 分かち書き(日本語の場合)
4. encode: idに置き換え
5. split: trainとtest用にデータ分割
6. padding: ゼロ埋め
7. batch: バッチデータとして取得2.1. load
まずはじめに、dataset loaderをつくります。処理の流れは以下の様になります。
1. local discにデータをダウンロード
2. local discのデータを指定
3. ラベルづけ
4. データのシャッフルlocal discにデータをダウンロード
昨今扱うデータセットのサイズがでかくなっているので、最初からlocal discにデータがあるケースはそこまで多くないと思います。なので、以下のようなケースが考えられます。
- 外部ストレージからダウンロード
- クラウドストレージからダウンロード
- Databaseから取得
ここでは、単に(認証の必要のない)外部ストレージからデータを取得する例を紹介します。
以下で、cowper.txt, derby.txt, butler.txtというテキストファイルをlocal discにダウンロードできます。 (ダウンロードが簡単なため、こちらの英語のテキストデータを使いますが、実際には日本語に対する前処理を想定しています)
なお、ダウンロードしたlocal discのpathのリストを返す関数になっています。適宜ダウンロードの仕方を置き換えた上で、アウトプットを揃えれば、以下同様な手続きが流用できると思います。def download_file(directory_url: List[str], file_names: List[str]) -> List[str]: file_paths = [ tf.keras.utils.get_file(file_name, directory_url + file_name) for file_name in file_names ] return file_paths # download dataset in local disk directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/' file_names = ['cowper.txt', 'derby.txt', 'butler.txt'] file_paths = download_file(directory_url, file_names)local discのデータを指定 & ラベルづけ & データのシャッフル
残りの処理は以下の様にまとめられます。これでtextとlabelをiterationしてくれるDatasetができます。
def load_dataset(file_paths: List[str], file_names: List[str], BUFFER_SIZE=1000): # loadする複数ファイルを指定 files = tf.data.Dataset.list_files(file_paths) # 各ファイル毎にmap関数を適用 (labeling_map_fnは後述(dataの読み込み & ラベルづけ)) datasets = files.interleave( labeling_map_fn(file_names), ) # dataのshuffle all_labeled_data = datasets.shuffle( BUFFER_SIZE, reshuffle_each_iteration=False ) return all_labeled_data datasets = load_dataset(file_paths, file_names) text, label = next(iter(datasets)) print(text) # <tf.Tensor: id=99928, shape=(), dtype=string, numpy=b'Comes furious on, but speeds not, kept aloof'> print(label) # <tf.Tensor: id=99929, shape=(), dtype=int64, numpy=0>細かく処理をみていきます。
tf.data.Dataset.list_files(): loadする複数ファイルを指定
tf.data.Dataset.list_filesでつくったfilesは、以下のようにlocal discのpathを値としてもつDatasetインスタンスになっています。面倒ですが、Datasetインスタンスはイテレーションして中身を確認する必要があります。さらに面倒ですが、
.numpy()メソッドを使うと値が取得できます。print(files) # <DatasetV1Adapter shapes: (), types: tf.string> next(iter(files)) # <tf.Tensor: id=99804, shape=(), dtype=string, numpy=b'/Users/username/.keras/datasets/cowper.txt'> next(iter(files)).numpy() # b'/Users/username/.keras/datasets/cowper.txt'.interleave(): 各ファイル毎にmap関数を適用してflatなDatasetを返す
datasetにmap functionを適用した後に、結果をflatにして結合します。今回の使い方でいうと、まずテキストファイルを読みこみ、1行ずつiterationするようなDatasetを返すmap funcitonを定義します。そしてそれを、
.interleave()にわたすと、ファイルごとに別々のDatasetが作られるのではなく、全ファイルの中から一行ずつiterationされるflatなDatasetがつくられます。参考: 公式ドキュメント
.shuffle(): dataのshuffle
名前からもわかるようにDatasetをシャッフルしてくれます。iteration時にbuffer_sizeの中からrandomにデータを抽出します。繰り返しiterationを行い、buffer_sizeをこえると、次のbuffer_size分のデータの中から抽出します。なので、大きいbuffer_sizeにしたほうが乱雑さは保証されます。しかし、buffer_sizeが大きいとその分リソースを食うのでトレードオフになります。
また、
reshuffle_each_iteration=Falseとすると、iterationを何度開始しても同じ順番でシャッフルしてくれます。defaultではTrueなので単に.shuffle()を呼んだ後は、next(iter(dataset))や、for data in dataset:と書く度に異なる順番でiterationされてしまいます。良いか悪いかはさておき、要注意です。labeling_map_fn: dataの読み込み & ラベルづけ
ファイル名がラベルになっていて、各行が1つのテキストデータである.txt ファイルを読み込む方法を紹介します。
標準的な処理だと思いますが、データの形式によって、適宜置き換えて頂ければと思います。ここでは、以下のmap functionを
.interleave()にわたすことでflatなテキストとラベルをもつDatasetを得ます。
1. ファイルごとにtf.data.TextLineDataset()でファイルを読み込みこんでDataset instanceを生成。
2..map(labeler)でファイル名と一体一のラベルidをわりふります。def labeling_map_fn(file_names): def _get_label(datasets): """ datasetの値(file path)からfile名をパースし、 file_namesのインデックス番号をlabel IDとする """ filename = datasets.numpy().decode().rsplit('/', 1)[-1] label = file_names.index(filename) return label def _labeler(example, label): """datasetにlabelを追加する""" return tf.cast(example, tf.string), tf.cast(label, tf.int64) def _labeling_map_fn(file_path: str): """main map function""" # テキストファイルから1行ずつ読み込み datasets = tf.data.TextLineDataset(file_path) # file pathをlabel IDに変換 label = tf.py_function(_get_label, inp=[file_path], Tout=tf.int64) # label IDをDatasetに追加 labeled_dataset = datasets.map(lambda ex: _labeler(ex, label)) return labeled_dataset return _labeling_map_fn途中、
tf.py_functionという関数を使っています(doc)。 これは、Dataset APIのmap functionの引数はTensor objectが渡されるためです。Tensor objectはpythonでは直接値を参照できませんが、tf.py_functionでwrapしてあげると引数にnext(iter(dataset))としたときと同じ型の値が渡ります。なので、.numpy()で値を参照でき、馴染みのあるpythonの処理を書くことができます。
ただし、パフォーマンスに若干難があるようなので極力使わないようにしたいです。2.2. standarize & 2.3. tokenize
ここではいろいろな処理を一気に行います。pythonのライブラリや、ベタ書きしたものを使う想定です。
tensorflowにもテキストに対する処理はたくさんありますが、結構大変なのでpythonで書いたものをそのまま使うことを想定します。少なくとも分かち書きはtensorflowではできないので、日本語だと必須の行程になると思います。例 (janome使用)
janomeはpythonで実装されている形態素解析でpip installだけで使えるので便利です。以下の様にanalyzerという標準化のパイプラインを柔軟に構築できます。
from janome.tokenizer import Tokenizer from janome.analyzer import Analyzer from janome.charfilter import ( RegexReplaceCharFilter # 文字列置換 ) from janome.tokenfilter import ( CompoundNounFilter, # 複合名詞化 POSStopFilter, # 特定の品詞を除去 LowerCaseFilter # lowercaseに変換 ) def janome_tokenizer(): # standarize texts char_filters = [RegexReplaceCharFilter(u'蛇の目', u'janome')] tokenizer = Tokenizer() token_filters = [CompoundNounFilter(), POSStopFilter(['記号','助詞']), LowerCaseFilter()] analyze = Analyzer(char_filters, tokenizer, token_filters).analyze def _tokenizer(text, label): tokenized_text = " ".join([wakati.surface for wakati in analyze(text.numpy().decode())]) return tokenized_text, label return _tokenizerこれだけで、以下の様に標準化・分かち書きされます。
text, _ = janome_tokenizer()('蛇の目は形態素解析器です。Easy to Use.', 0) print(text) # 'janome 形態素解析器 です easy to use.'tf.py_functionでラップ
上記関数をDatset apiから呼びます。
そのためには、ここでもtf.py_functionを使って変換します。outputの型を指定する必要があります。そして、その関数を.map()でdatasetにわたすことで呼び出せます。def tokenize_map_fn(tokenizer): """ convert python function for tf.data map """ def _tokenize_map_fn(text: str, label: int): return tf.py_function(tokenizer, inp=[text, label], Tout=(tf.string, tf.int64)) return _tokenize_map_fn datasets = datasets.map(tokenize_map_fn(janome_tokenizer()))2.4. encode
encode (stringをIDに変換)するためにtensorflow_datasets.text APIを使います。
とくに、encodeには、tfds.features.text.Tokenizer()とtfds.features.text.TokenTextEncoderが便利です。vocabulary作成
まずは、vocabularyを作成する必要があります。先に作っておく場合は以下は省略できます。
ここでは、学習データからvocabularyを作成します。tfds.features.text.Tokenizer()を使ってtokenを取得し、set()で重複を削除します。import tensorflow_datasets as tfds def get_vocabulary(datasets) -> Set[str]: tokenizer = tfds.features.text.Tokenizer().tokenize def _tokenize_map_fn(text, label): def _tokenize(text, label): return tokenizer(text.numpy()), label return tf.py_function(_tokenize, inp=[text, label], Tout=(tf.string, tf.int64)) dataset = datasets.map(_tokenize_map_fn) vocab = {g.decode() for f, _ in dataset for g in f.numpy()} return vocab vocab_set = get_vocabulary(datasets) print(vocab_set) # {'indomitable', 'suspicion', 'wer', ... }encode
ここでは、
tfds.features.text.TokenTextEncoder()を使って、vocabularyに含まれるtokenをIDに変換します。以下のencode_map_fn()をdatasets.map()にわたして使います。def encoder(vocabulary_set: Set[str]): """ encode text to numbers. must set vocabulary_set """ encoder = tfds.features.text.TokenTextEncoder(vocabulary_set).encode def _encode(text: str, label: int): encoded_text = encoder(text.numpy()) return encoded_text, label return _encode def encode_map_fn(encoder): """ convert python function for tf.data map """ def _encode_map_fn(text: str, label: int): return tf.py_function(encoder, inp=[text, label], Tout=(tf.int64, tf.int64)) return _encode_map_fn datasets = datasets.map(encode_map_fn) print(next(iter(datasets))[0].numpy()) # [111, 1211, 4, 10101]2.5. split
datasetをtrainとtestに分割します。最初からわかれている場合は以下は省略できます。
Dataset APIではdatasetの分割は以下の様にすごく簡単に実装できます。def split_train_test(data, TEST_SIZE: int, BUFFER_SIZE: int, SEED=123): """ TEST_SIZE = test dataの数 note: because of reshuffle_each_iteration = True (default), train_data is reshuffled if you reuse train_data. """ train_data = data.skip(TEST_SIZE).shuffle(BUFFER_SIZE, seed=SEED) test_data = data.take(TEST_SIZE) return train_data, test_data2.6. padding & 2.7. batch
tf.data.Dataset apiではpaddingとbatch化は同時に行えます。
そのままですが、epochsはエポック数、BATCH_SIZEはバッチサイズです。
注意すべきことは以下です。
drop_remainder=Trueにするとデータをbatch化したときに、きりよくバッチサイズに達しなかったiterationの最後のデータを使用しなくなります。- padded_shapesでpaddingするサイズ (=最大長)を指定できます。この引数を指定しなければ、バッチごとの最大長にpaddingされます。
train_data = train_data.padded_batch(BATCH_SIZE, padded_shapes=([max_len], []), drop_remainder=True) test_data = test_data.padded_batch(BATCH_SIZE, padded_shapes=([max_len], []), drop_remainder=False)ここで、max_lenは以下の様にdatasetから求めてもいいですし、決め打ちで入力してもいいと思います。
文書最大長の取得
ほとんどのモデルではtokenの最大長が必要になります。ここでデータセットから取得します。決めで入力する場合は以下の処理は飛ばせます。
def get_max_len(datasets) -> int: tokenizer = tfds.features.text.Tokenizer().tokenize def _get_len_map_fn(text: str, label: int): def _get_len(text: str): return len(tokenizer(text.numpy())) return tf.py_function(_get_len, inp=[text, ], Tout=tf.int32) dataset = datasets.map(_get_len_map_fn) max_len = max({f.numpy() for f in dataset}) return max_lenテキストの前処理の流れのまとめ
以下のような流れでtf.data.Dataset APIを使った実装を見ていきました。
1. load: テキストの読み込み・シャッフル
2. standarize: ストップワード削除、置換、小文字に統一、など
3. tokenize: 分かち書き(日本語の場合)
4. encode: idに置き換え
5. split: trainとtest用にデータ分割
6. padding: ゼロ埋め
7. batch: バッチデータとして取得学習時には、以下の様に、
.fit()メソッドにわたすだけです。model.fit(train_data, epochs=epochs, validation_data=test_data )3. performance向上のtips
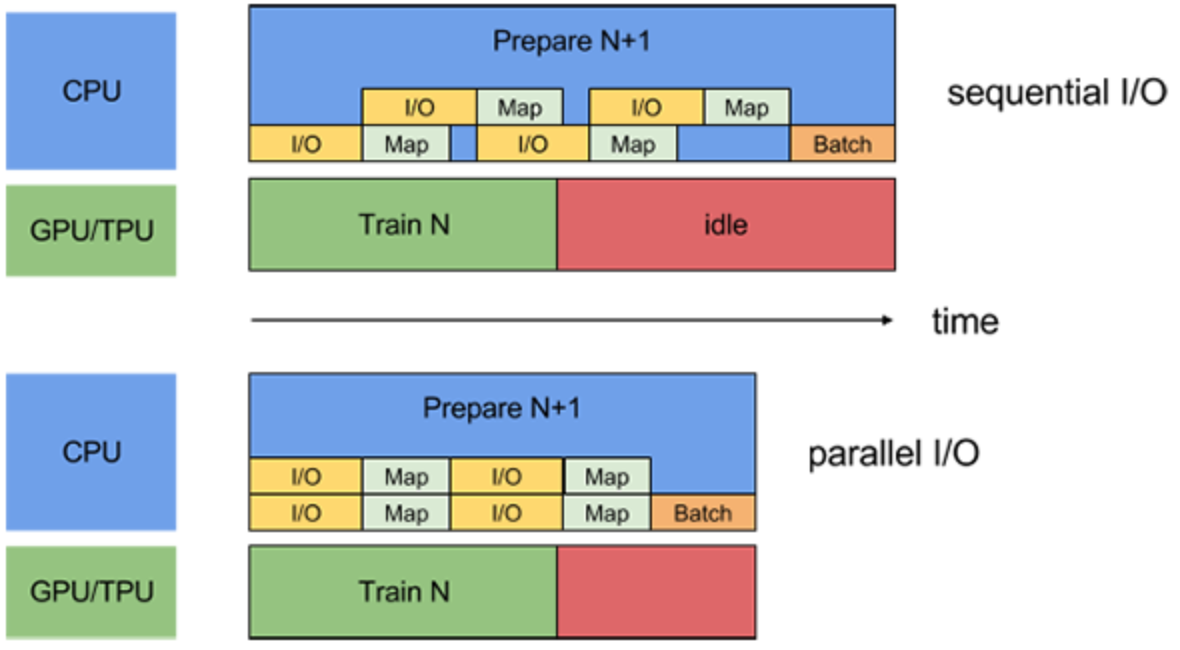
冒頭で説明したように、前処理の一連のプロセスは、以下のようにオーバーヘッド部分に無駄な待ち時間が発生し得えます。
https://www.tensorflow.org/guide/data_performancetf.data.Dataset APIでは以下のようにオーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
- prefetch: CPUとGPU/TPUでそれぞれ並列に処理
- map: 前処理の並列処理
- read_file: 読み込みの並列処理
参考: Optimizing input pipelines with tf.data
prefetch
CPUとGPU/TPUでそれぞれ並列に処理を実行させます。
tf.experiments.AUTOTUNEで自動的に調節されます。
https://www.tensorflow.org/guide/data_performance面倒なことは必要ありません。以下の処理を最後に加えるだけです。(本記事ではtrain_dataとtest_dataに対して行う)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)map
map関数も分散処理をさせられます。
こちらもtf.experiments.AUTOTUNEで自動的に調節してくれます。
また、あまり遅くなるようであれば先に.batch()メソッドを使ってから渡すという手もあります。
https://www.tensorflow.org/guide/data_performance以下の様に、
.map()メソッドに引数を加えるだけです。dataset = dataset.map(map_func, num_parallel_calls=tf.data.experimental.AUTOTUNE)read file
複数ファイルを読み込むときも、処理を分散させて同時にreadできます。
特にremote storageからdataを読み込むときはI/Oがボトルネックになる可能性が高いです。
(本記事ではlocal discから読み込んでいるのであまり効果はないかもしれません。)
https://www.tensorflow.org/guide/data_performance以下の様に、
.interleave()メソッドに引数を加える必要があります。dataset = files.interleave( tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_reads, num_parallel_calls=tf.data.experimental.AUTOTUNE)cache
文脈はかわりますが、performance向上のためには、
.cache()が有効です。
以下の様に書くと、in memoryにcacheされます。dataset = dataset.cache()以下の様に引数にstringをわたすとin memoryではなく、ファイルに保存されます。
dataset = dataset.cache('tfdata')まとめ
長くなりましたが、tf.data.Dataset APIを用いたテキストの前処理を行う方法を紹介しました。まとまったコードはこちらから参照できます。
特に、tf.data.Dataset APIの紹介、テキストの前処理の手続き、performance向上のtipsをまとめました。
説明が長くなってしまいましたが、最後まで読んでくださってありがとうございました!
何かの参考になれば嬉しいです!refs


- 投稿日:2019-11-26T22:19:00+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2018年度夏 プログラミング試験
2018年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- キャッシュミス
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
配布ファイル
※ 公開されていないので以下は筆者が適当に作ったものです
mat1_sample.txt
0 1 2 3,4 5 6 7,8 9 10 11.mat2_sample.txt
0 1 2,3 4 5,6 7 8,9 10 11.(1)
A: m^2n
B: m^2n(2)
file_path = 'mat1_sample.txt' def solve(): with open(file_path, 'r') as f: text = f.read() text = text.split('.')[0] text_array = text.split(',') mat = [] for text in text_array: row = text.split(' ') for index, strnum in enumerate(row): row[index] = int(strnum) mat.append(row) row_num = len(mat) col_num = len(mat[0]) print(row_num, col_num)(3)
file_path1 = 'mat1_sample.txt' file_path2 = 'mat2_sample.txt' import numpy as np def parse_file(file_path): with open(file_path, 'r') as f: text = f.read() text = text.split('.')[0] text_array = text.split(',') mat = [] for text in text_array: row = text.split(' ') for index, strnum in enumerate(row): row[index] = int(strnum) mat.append(row) return np.array(mat) def solve(file_path1, file_path2): mat1 = parse_file(file_path1) mat2 = parse_file(file_path2) mat = np.dot(mat1, mat2) ans = 0 for i in range(0, len(mat)): ans += mat[i, i] return ans(4)
class Ele(object): def __init__(self, mat_name:str, row:int, col:int): self.mat_name = mat_name self.row = row self.col = col def __repr(self): return 'mat_name: {0}, row_idx: {1}, col_idx: {2}'.fromat(self.mat_name, self.row, self.col) def solve(m, n, s): # 次にpushするcacheのidx next_cache_idx = 0 # cacheでidxに入っているものを指定 cache = np.empty(s, dtype=Ele) # memmoryでmem_a[i, j] ai,jの入っているキャッシュのインデックスを返すキャッシュに入ってない場合-1 mem_a = -1*np.ones((m, n), dtype=np.int) mem_b = -1*np.ones((n, m), dtype=np.int) a_num = 0 b_num = 0 for i in range(0, m): for j in range(0, m): for k in range(0, n): # ai,k if (mem_a[i, k] < 0): # キャッシュにない a_num += 1 if (cache[next_cache_idx] != None): # 入れるキャッシュの場所が空でない # 追い出す ele = cache[next_cache_idx] # memを更新 if (ele.mat_name == 'A'): mem_a[ele.row][ele.col] = -1 elif (ele.mat_name == 'B'): mem_b[ele.row][ele.col] = -1 ele = Ele('A', i, k) cache[next_cache_idx] = ele # cacheに入れる mem_a[i, k] = 1 # cacheにある next_cache_idx += 1 if (next_cache_idx >= s): next_cache_idx = 0 # bk,j if (mem_b[k, j] < 0): # キャッシュにない b_num += 1 if (cache[next_cache_idx] != None): # 入れるキャッシュの場所が空でない # 追い出す ele = cache[next_cache_idx] # memを更新 if (ele.mat_name == 'A'): mem_a[ele.row][ele.col] = -1 elif (ele.mat_name == 'B'): mem_b[ele.row][ele.col] = -1 ele = Ele('B', k, j) cache[next_cache_idx] = ele # cacheに入れる next_cache_idx += 1 mem_b[k, j] = 1 # cacheにある if (next_cache_idx >= s): next_cache_idx = 0 return a_num, b_num(5)
順番にu p v p w p
(6)
def solve(m, n, p, s): # cacheでidxに入っているものを指定 cache = np.empty(s, dtype=Ele) # memmoryでmem_a[i, j] ai,jの入っているキャッシュのインデックスを返すキャッシュに入ってない場合-1 mem_a = -1*np.ones((m, n), dtype=np.int) mem_b = -1*np.ones((n, m), dtype=np.int) data = { 'a_num': 0, 'b_num': 0, 'next_cache_idx': 0 } def check_cache(): if (cache[data['next_cache_idx']] != None): # 入れるキャッシュの場所が空でない ele = cache[data['next_cache_idx']] # memを更新 if (ele.mat_name == 'A'): mem_a[ele.row][ele.col] = -1 elif (ele.mat_name == 'B'): mem_b[ele.row][ele.col] = -1 def check_A(i, k): if (mem_a[i, k] < 0): # キャッシュにない data['a_num'] += 1 check_cache() ele = Ele('A', i, k) cache[data['next_cache_idx']] = ele # cacheに入れる data['next_cache_idx'] += 1 mem_a[i, k] = 1 if (data['next_cache_idx'] >= s): data['next_cache_idx'] = 0 def check_B(k, j): if (mem_b[k, j] < 0): # キャッシュにない data['b_num'] += 1 check_cache() ele = Ele('B', k, j) cache[data['next_cache_idx']] = ele # cacheに入れる data['next_cache_idx'] += 1 mem_b[k, j] = 1 if (data['next_cache_idx'] >= s): data['next_cache_idx'] = 0 u = 0 while (u < m): v = 0 while (v < m): w = 0 while (w < n): i = u while (i < u + p): j = v while (j < v + p): k = w while (k < w + p): # ai,k check_A(i,k) # bk,j check_B(k,j) k += 1 j += 1 i += 1 w += p v += p u += p return data(7)
すみません、解けなかったです...
わかる方はぜひ教えてください感想
- (6)まで解いた時はこの年は簡単な方だなと思ってました...(簡単と言っても実装すべきポイントが少ないだけで(4)さえできれば後は使い回しという意味です。決してレベルが低い試験ではないと思います。)
- キャッシュミスの回数ですがAとBで別々にカウントしました。理由としては今回のように行列計算のキャッシュミスをテーマにする問題では、よくAとBでは実はキャッシュミスの回数が違うんだよと尋く問題が多いからです。(この問題ではあまり関係はなかったけど...)
- (4)なのですがcacheを全探索する実装の方法もありだと思いますし、実際そちらの方が実装するのは楽な気がします。でも筆者はあえてcacheの追い出しと更新を計算量O(1)でできるように複雑な実装をしました。理由としてはやっぱりキャッシュというのは速さのためにあると思ったからです。この問題のキャッシュを現実に落としこむと多分ダイレクトマップ型のキャッシュなので全探索の方が筋は通っていますが、やっぱり時間がかかるのはどうかなーと思いました。その代わり見ていただけばわかるのですが筆者の実装ではメモリを多くとります。
- さらに補足すると(7)では全探索だとm^2nsつまり200*200*150*600=3.6e10の計算量がかかり、おそらくpythonだと数分かかってしまいます
- だいたい1時間半ちょっとで(6)までは終わったのですが(7)はだいぶ悩んでも解けませんでした...分野としては離散数学な気がしますのでプロの方は教えてください!


- 投稿日:2019-11-26T21:52:59+09:00
Raspberry PiとSense Hatで漢字表示のコンパスを作る
Raspberry PiとSense Hatで漢字表示のコンパスを作る
概要
2年くらい前にラズパイとSense Hatで地磁気をどうにかする必要があって、ためしに作ったプログラムです。
今はWebのエミュレーターにしか残ってませんが、当時はちゃんと実機(RPi3+Sense Hat)で動いてました。
RPi + Sense Hat エミュレーター
https://trinket.io/library/trinkets/a50728f4da
RPiエミュレーターのtrinketです。
実機と比べても遜色ない動きをしてくれます。
これが無料で使える時代素晴しすぎます。解説
まったく大したことはしてません。
Pythonだとライブラリでいきなり方位角がとれるので、方位角の数値によって、何度から何度まではこの方位というのを決めてやり、表示しているだけです。漢字表示は、Sense Hatの液晶ディスプレイが8x8ドットなので、漢字っぽくドットを打った8x8のJPEG画像を作って表示するだけです。
他のOSだと、加速度センサーと磁気センサーの生の値しか取れなかったりするので、そこから端末の傾きを補正してセンサーの値から方位角を計算したりとか超面倒なのですが、Pythonは世界の有志が有用なライブラリを用意してくれているで超ラクチンです。
実機がなくても、Webのエミュレーターだけでも楽しめるのでおススメです。
やっぱプログラミングは、なにか動くものを作ると楽しいですからね。

- 投稿日:2019-11-26T21:30:26+09:00
機械学習未経験の大学生が1週間でツイートの類似度を評価するシステムを作った話
はじめまして
こんにちは。カトウです。この記事は、機械学習が気になるけど研究するほど詳しくない人が独学で成果物作るまで頑張った記録です。
そういえば、前に頭がおかしい時に書いたgo getの記事はおかげさまでSEO 4位(11/26)なので引き続き頑張ります。今回のテーマは
ツイートの類似度を評価するシステムを1週間で作ってみました!!
です!
というわけで、モデル選定から成果物を出すまでのフローを共有したいと思います。ツイートについて
ツイートは140字以内でテキストデータだけであると仮定しまっす。
ツイートを分解する
ツイート(文書)は単語によって構成されています。今回は、ツイートを単語単位で分解します。
ツイートをどうやって評価するか?
単語のベクトル(あとで説明する)を足し合わせて単語の数で割り、ベクトルの平均値をツイートのベクトルにします。
比較したい2つのツイートベクトルをコサイン類似度の式(あとで説明する)に当てはめて、ざっくり0~1の数値(たまに-0.0…や1.02…などの値も検出することもある)を得ます。
0に近ければ、ツイート間の類似度が低く、1に近ければツイート間の類似度が高いことになります。単語のベクトルとは?
単語のベクトルってなんだよ???
こんなやつ↓ 雑
ご飯=[0.22, 0.12, 0.21, 0.56],筋肉=[0.19, 0.63, 0.91, 0.37]
単語のベクトルを求めるために、word2vecというモデルを使います。
gensimというPythonのライブラリを使い、単語ベクトルの次元を引数として与えて、N次元のベクトルを得ます。word2vecとは?
word2vecは単語をベクトルで表現することで単語の意味みたいなものを表現するモデル。
word2vecの詳細を説明すると長くなりそうなので、学習済みのword2vecのインターフェイスだけ説明すると、インプットが単語(Ex: ご飯)で、アウトプットがベクトル(Ex: [0.22, 0.12, 0.21, 0.56])となりまっす。
このアウトプットの単語ベクトルを扱うことで、単語同士の意味の近さを比べたり、また王様ー男+女=王妃のような計算をすることができる。
すごーい٩( ᐛ )وどうやって単語ベクトルを求める?
まずは、膨大な日本語のテキストデータをGETします。
なぜなら、一度学習した単語ではないと単語ベクトルの値を求めることはできないからです。
では、この世の多くの言葉を偏りなく扱っている媒体はなんだろう。
広辞苑?新聞?
デジタルの媒体で一番扱いやすいものは、Wikipediaだと思います。
自然言語処理をやり始めて感じるWikipediaの有能さよ。
— 加藤ゆう (@yukato7777) May 22, 2019実際、多くの言語の学習済みのWikipediaのモデルがネット上に公開されてあります。
学習済みword2vecモデル一覧しかし、Wikipediaの学習済みモデルは、Python2系のみの対応であったり、最新の単語に対応していなかったり。。。
Twitterという最新の情報が飛びかうメディアには適していないと感じたので、Wikipediaの学習済みモデルを自分で作るという結論に至りました泣Wikipediaの全記事で学習する
日本語版Wikipediaの全記事を取得できるサイトがあるので、そこからxml形式のデータを取得します。(12GBぐらい)
xml形式のWikipediaのデータをテキストにするためにwikiextractorというツールを使います。
結果として、textディレクトリに大量のテキストデータが生成されます。
これをwiki.txtにまとめます。(やり方はGGR)
Word2vecにテキストデータを突っ込むには、テキストデータが単語ごとに、分割された状態でなければならないです。
分割するために、MeCabというオープンソースの形態素解析エンジンを使いまっす。
MeCabを使うと
(例文)目に見えるものが真実とは限らない。
(処理後)目 に 見える もの が 真実 と は 限ら ない。
このように、文章を分割することができます。
また、単語ごとの品詞を取得することもできます。(あとで使う)
MeCabでwiki.txt→wiki_wakati.txt(わかち書きされたテキストデータ)の変換を行います。
単語単位で分割したテキストデータ(wiki_wakati.txt)をgensimのword2vecの関数にぶち込みます。単語の次元数を300に設定します。そして数時間待つと、.modelというファイルが生成されます。
授業中にword2vecの学習し始めたら、pcのファンが爆音で音を立て始めて死にたい?
— 加藤ゆう (@yukato7777) May 23, 2019
https://twitter.com/yukato7777/status/1131422691741773824これを他のファイルで読み込み、単語を入力することで、あら不思議、単語ベクトルを求めることができます。
[-0.01494294 -0.1509463 0.06123272 ..., 0.01335443 0.03439184
0.05130962]MeCabを使ってツイートを分解する
ツイートの中で必要な情報とはなんでしょうか?
Go言語楽しい。Gopher最高!!いえええええええええええい!さいこおおおおおおおおお!
上のツイートで内容を表しているのは、Go言語とGopherでしょう。
いえ…い!さいこお…!はいらないです。
そこで、MeCabは単語ごとの品詞を取得することができるので、特定の品詞のみの単語(固有名詞と一般)を取得します。word2vecに単語をぶち込む
word2vecに特定の品詞の単語をインプットとして、単語ベクトルを取得します。そして、その和を単語の数で割ります。
以下コードword2vec-ave.py# coding: utf-8 import MeCab import numpy as np import glob from gensim.models.word2vec import Word2Vec from utils.cos_sim import cos_sim # load model model_path = 'model/wiki.model' model = Word2Vec.load(model_path) mecab = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd') test_folder = glob.glob('test/*') sentence_vectors = [] for test_file in test_folder: word_number = 0 sentence_vector = np.zeros(300) f = open(test_file, 'r') for line in f: node = mecab.parseToNode(line) while node: # get word word = node.surface # get part of speech(POS) pos = node.feature.split(',')[1] if pos == '固有名詞' or pos == '一般': try: vector_value = model.wv[word] word_number += 1 sentence_vector += vector_value except KeyError: pass # go to next word node = node.next sentence_vectors.append(sentence_vector/word_number) print(cos_sim(sentence_vectors[0], sentence_vectors[1]))コサイン類似度でTweet間の類似度を評価
コサイン類似度↓
今回はツイート1がベクトルq、ツイート2がベクトルdとして計算が行われるようなイメージ。
計算については、数式を書いたらいいので、具体例などは出しません。類似性を検証してみる
実験1
[Tweet1]
サカナクションが好き
[Tweet2]
Official髭男dismが好き
[結果]
0.33682251556012055
[メモ]
アーティストが異なるけど、’好き’とミュージシャンの名前が含まれているからそこそこの値がでた。実験2
[Tweet1]
AirPods無くした
[Tweet2]
忍者めし美味しい
[結果]
-0.06806525231440926
[メモ]
内容が全く違うので、-0.06..というかなり低い値が出た。実験3
[Tweet1]
清少納言は枕草子を書いたと見せかけて、紫式部に書かせた。さらに、居間で昼寝をしたと見せかけて、自分の部屋に戻ったところ少し疲れたのでゲームをした。
[Tweet2]
枕草子を書いたのは実は紫式部だ。枕草子は、清少納言の家の居間についての物語だ。
[結果]
0.6668826937397055
[メモ]
お世話になってるCTOが書いた名文たち(迷文)は0.666..とかなり高い数値が出た。考察
まだ実験のサンプリング数が少ないので肌感でしかないが、数値としては0.5~1.0の間だとツイートの類似性があることがわかりました。
まとめ(これからどうしよか)
今回は、ツイートを単語単位に分解して、単語ベクトルの平均値を評価することで、類似性を比較しました。
精度を上げるためには、単語の重要さを考慮することや、単語のクラスタリングが有効かもしれないです。
というわけで、現在、以下の2つのモデルを実装中です。
word2vecとTF-IDF(単語の重要さを加味するやつ)を組み合わせたモデル(現在実装中)
SCDV(単語のクラスタリングをするやつ)を使ったモデル
また、ツイートも今回はただTweetを単語単位で分解しただけですが、ツイートにリンクを含んでいたら、リンクのOGPの情報を取得をすることで、より正確にツイートを評価することができるかもしれません。
ソースコード
https://github.com/yukato7/vectrizing_tweet_system
まだまだビギナーなので、こんな工夫をしたら精度が上がったなど教えてもらえると嬉しいです!!!
https://twitter.com/yukato777


- 投稿日:2019-11-26T20:39:59+09:00
Pythonで一般相対性理論:導入編
Pythonを使って一般相対性理論で必要な
・計量 $g_{\mu \nu}$をはじめとするテンソルの計算
・Einstein方程式の計算
を行う。一般相対論におけるテンソル解析や代数計算に関するコンピューティングについては、
Heinicke, C., et.al.- Computer Algebra in Gravity
Korolkova, A., et.al.- Tensor computations in computer algebra systems
などの手頃なReview論文があるので、こちらも適宜参照されたい。
また、SageMathを用いた同様の研究に、
Gourgoulhon, E., et.al. - Symbolic tensor calculus on manifolds
などがある。GraviPy モジュールの導入
GraviPyはPython3上で動くテンソル計算用のモジュール。
代数計算の記号処理に特化したSymPyと協働することで、ストレスフリーなテンソル計算の環境をPython上で実現してくれる。
以下に従って、SymPy含むGraviPyモジュールダウンロードする
GraviPy, Tensor Calculus Package for General Relativity (Version 0.1.0) (2014)
(アクセス日:2019年11月26日)実際にはpipを使えば良く、
$ pip install GraviPyで問題なければインストールされる。SymPyはPython環境がver.3.7以上であれば同時にインストールされているはず。
シュバルツシルト計量を計算してみた
GraviPyを使ってシュバルツシルト計量からシュバルツシルト解を導出する。
シュバルツシルト計量の導入
計量の符号をMTWに従って$(+,-,-,-)$とし、線素を次のように決める。
$$ds^2=g_{\mu\nu}dx^\mu dx^\nu .$$
重力定数と光速度について、$G=c=1$をとれば、シュバルツシルト計量は次のように書かれる。g_{\mu\nu}=\left[\begin{array}{cccc} \Big( 1- \frac{2M}{r} \Big) & 0 & 0 & 0 \\ 0 & -\Big( 1- \frac{2M}{r} \Big)^{-1} & 0 & 0 \\ 0 & 0 & -r^2 & 0 \\ 0 & 0 & 0 & -r^2sin^2\theta \end{array}\right].ここで座標系として四次元座標$(t, r,\theta,\phi)$をとり、$M$をブラックホール質量とした。シュバルツシルト計量は動径方向について$r=2M$において特異点を示し、これがいわゆる「事象の地平」(Event Horizon)として知られる。
GraviPyを用いた導出の仕方
上記の$g_{\mu\nu}$からシュバルツシルト解を導出していこう。
GraviPyを用いて以下のプロセスに従って計算していけばよい。
- 時空の定義(計量の決定):$g_{\mu\nu}$
- クリストッフェル記号の計算:$\Gamma {}^\mu{}_{\nu\rho}$
- リッチテンソルの計算:$R_{\mu\nu}$
- アインシュタインテンソルの計算:$G_{\mu\nu}$
時空の定義
はじめに、時空を定義しよう。四次元時空座標として、$$x=x^\mu=(t,r,\theta,\phi)$$をとる。GraviPyでは次のように定義する。
GR.py#!/usr/bin/env python3 from gravipy import * from gravipy import tensorial as ten from sympy import * import inspect # Coordinates (\ chi is the four - vector of coordinates ) t, r, theta, phi, M = symbols('t , r , theta , phi , M ') x = ten.Coordinates('\chi',[t, r, theta, phi])ここで、
ten.Coordinates()の第一引数'\chi'は第二引数が四元ベクトルであることを指定している。また、ten.~としたのはこのCoordinates()が明示的にtensorialを参照してやらないと動かない為。以降、出現するテンソルは軒並み
ten.~で参照する。シュバルツシルト計量の定義
次に計量メトリック$g_{\mu \nu}$を定義しよう。先に述べたシュバルツシルト計量を次のようの記述してやればよい。
GR.py# 続き # Metric tensor Metric = diag((1 -2* M / r ) , -1/(1 -2* M / r ) , -r **2 , -r **2* sin( theta ) **2) g = ten.MetricTensor('g', x , Metric )ここで、
g = ten.MetricTensor('g',x,Metric)の出力結果はMetric # あるいは g(ten.All,ten.All)で表示することができ、次のようになる。
g_{\mu\nu}= \displaystyle \left[\begin{matrix}- 2M/r + 1 & 0 & 0 & 0\\0 & \displaystyle- \frac{1}{- 2M/r + 1} & 0 & 0\\0 & 0 & - r^{2} & 0\\0 & 0 & 0 & - r^{2} \sin^{2}{\left(\theta \right)}\end{matrix}\right]若干、表式に差異はあるが、先ほどの定義が正確に反映されている。
例えば、動径方向の成分$g_{rr}=g_{11}$を参照する場合にはg(1,1)とすればよく、次のように要素別で取得することができる。
g_{11}=- \frac{1}{\displaystyle- \frac{2M}{r} + 1}クリストッフェルの計算
続いて、$g_{\mu \nu}$をもとにして、クリストッフェル記号$\Gamma^\mu{}_{\nu\rho}$を計算してみよう。
GR.py# 続き # Christoffel symbol Ga = ten.Christoffel('Ga', g )
Gaが$g_{\mu\nu}$に対するクリストッフェル記号である。クリストッフェルは3階のテンソルであるから、$\mu=0$に制限してやると次のような2階のテンソルを得る。\Gamma^{ 0}{}_{\nu\rho}= \left[ \begin{matrix} 0 & \frac{M}{r^{2}} & 0 & 0 \\ \frac{M}{r^{2}} & 0 & 0 & 0 \\ 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 \end{matrix}\right]全成分を得るには
Ga(ten.All,ten.All,ten.All)としてやればよく、
\displaystyle \Gamma^\mu{}_{\nu\rho}= \left[\begin{matrix}\left[\begin{matrix}0 & \frac{M}{r^{2}} & 0 & 0\\\frac{M}{r^{2}} & 0 & 0 & 0\\0 & 0 & 0 & 0\\0 & 0 & 0 & 0\end{matrix}\right] & \left[\begin{matrix}- \frac{M}{r^{2}} & 0 & 0 & 0\\0 & \frac{M}{\left(2 M - r\right)^{2}} & 0 & 0\\0 & 0 & r & 0\\0 & 0 & 0 & r \sin^{2}{\left(\theta \right)}\end{matrix}\right] & \left[\begin{matrix}0 & 0 & 0 & 0\\0 & 0 & - r & 0\\0 & - r & 0 & 0\\0 & 0 & 0 & \frac{r^{2} \sin{\left(2 \theta \right)}}{2}\end{matrix}\right] & \left[\begin{matrix}0 & 0 & 0 & 0\\0 & 0 & 0 & - r \sin^{2}{\left(\theta \right)}\\0 & 0 & 0 & - \frac{r^{2} \sin{\left(2 \theta \right)}}{2}\\0 & - r \sin^{2}{\left(\theta \right)} & - \frac{r^{2} \sin{\left(2 \theta \right)}}{2} & 0\end{matrix}\right]\end{matrix}\right]となる。3階のテンソルなので、形式上「2次元配列の1次元配列」(=1次元配列の要素が2次元配列になっている形式)として得ることができる。
リッチテンソルの計算
次に、リッチテンソルを計算する。(この名称は数学者Ricciに由来する。)
# Ricci tensor Ri = ten.Ricci ('Ri ', g ) # Display all compon Ri(ten.All,ten.All)シュバルツシルト計量におけるRicciテンソルは全成分がゼロに落ちる。
R_{\mu\nu}= \displaystyle \left[\begin{matrix}0 & 0 & 0 & 0\\0 & 0 & 0 & 0\\0 & 0 & 0 & 0\\0 & 0 & 0 & 0\end{matrix}\right]もちろん、これは特殊なことであり、シュバルツシルト計量の表式で
$$r \longrightarrow r^{3.5}$$
などと置換してリッチテンソルを計算してみると、全く異なる値になるので実験してみるとよい。アインシュタインテンソルの計算
最後に、リッチテンソルを用いてアインシュタインテンソルを出力してみよう。
# Einstein tensor G = ten.Einstein ('G', Ri ) G(ten.All,ten.All)結果は、
G_{\mu\nu}= \displaystyle \left[\begin{matrix}0 & 0 & 0 & 0\\0 & 0 & 0 & 0\\0 & 0 & 0 & 0\\0 & 0 & 0 & 0\end{matrix}\right]となっている。この結果は、シュバルツシルト解の仮定である、真空条件
$$T_{\mu\nu}=0$$
にも適合しており、アインシュタイン方程式
$$G_{\mu\nu}=8\pi T_{\mu\nu}$$
を満たしている。参考文献
GraviPyのチュートリアルが公開されており、以下を参考にした。
https://github.com/wojciechczaja/GraviPy
また、SymPyのサポートページは以下にある。
- 投稿日:2019-11-26T20:12:36+09:00
Wantedlyの自社ストーリーをスクレイピング出来るように、レスポンスをパースする
まえがき
ニジボックスではキャリア採用向けにWantedlyを利用しています。 (興味があればこちらから)
で、ストーリーが更新されたときに、社内のSlackなんかにも通知できないかなと思ってソースを眺めてみたのですが、
RSSフィードが存在しません。1
となると、パーサーを駆使してデータ構造をうまいこと加工する必要が出てくる...そのために何をやったかを、この記事では残します。
本日のスタートとゴール
素材となるのは、ニジボックスのWantedlyにある、「ストーリー」です。
https://www.wantedly.com/companies/nijibox/feedここから、「別のアウトプットに耐えられるようなデータ構造」を抽出するコードを書いていきます。
答え(=出来上がったもの)
feed-from-wantedly.pyimport json import pprint import requests from bs4 import BeautifulSoup URL = 'https://www.wantedly.com/companies/nijibox/feed' resp = requests.get(URL) soup = BeautifulSoup(resp.content, 'html.parser') # <script data-placeholder-key="wtd-ssr-placeholder"> の中身を取ってきてる # このタグの中身はJSON文字列なのだが、先頭に'// 'があるため、読み込み用に除去 feed_raw = soup.find('script', {'data-placeholder-key': "wtd-ssr-placeholder"}).string[3:] feeds = json.loads(feed_raw) # JSON全体の中のbodyにいろいろ入っているのだが、body自体がdictで企業キーと思われるキーになってた # ただし、1個しか無いっぽいので、超雑に抽出 feed_body = feeds['body'][list(feeds['body'].keys())[0]] # 固定ポストと思われる項目 pprint.pprint(feed_body['latest_pinnable_posts'])これを実行すると、こんな感じになります。
$ python3 feed-from-wantedly.py [{'id': 188578, 'image': {'id': 4141479, 'url': 'https://d2v9k5u4v94ulw.cloudfront.net/assets/images/4141479/original/9064f3ba-9327-4fce-9724-c11bf1ea71e2?1569833471'}, 'post_path': '/companies/nijibox/post_articles/188578', 'title': 'まずは気軽にカジュアル面談から!ニジボックスが求職者の方に伝えたいこと、採用への思い'}, {'id': 185158, 'image': {'id': 4063780, 'url': 'https://d2v9k5u4v94ulw.cloudfront.net/assets/images/4063780/original/44109f75-6590-43cb-a631-cb8b719564d4?1567582305'}, 'post_path': '/companies/nijibox/post_articles/185158', 'title': '【初心者向け】デザインは「感覚」ではなく「理論」。今日からできる!UIデザイナーになるための作法'}, {'id': 185123, 'image': {'id': 4062946, 'url': 'https://d2v9k5u4v94ulw.cloudfront.net/assets/images/4062946/original/ff2169c7-568e-4992-b082-56f1e1be2780?1567573415'}, 'post_path': '/companies/nijibox/post_articles/185123', 'title': 'ICSの池田さんとReact勉強会を行いました!'}]準備
今回は、以下のような環境で作ってます。
- Python 3.7.3
- beautifulsoup4==4.8.1
- requests==2.20.0
順に見ていく
「
requestsでレスポンスを受け取り、BeautifulSoup4を使ってパースする」までは、いわゆるよくあることなので、今回はスキップします。よりパースするところはどこか
今回は「注目の投稿」のところを見つけてパースするわけなのですが、ここで2個ほど課題が出てきます。
id="posts"というわかりやすい領域はあるが、その中に結構な数のdivがあって面倒- レスポンスの時点では、
body部分はほぼ空っぽ特に後者が厄介で、タグを
soup.findで追いかける方式は通用しません。2じゃあ、どこをパースするかというと
ここです。
WantedlyのSSR考察(ソースのみ)
これは、上記の通り「ニジボックス」「Wantedly」でGoogle検索した結果なのですが、レスポンスの
bodyタグ内にはない概要などがちゃんと載っています。
WantedlyのサイトはコンテンツそのものはJS実行時の素材JSONとして持たせて、これをレンダリングする仕様のようです。BeautifulSoupで該当項目を抽出する
BeautifulSoupが仕事をするのは、実質この行のみです。feed_raw = soup.find('script', {'data-placeholder-key': "wtd-ssr-placeholder"}).string[3:]
BeautifulSoupのfind_allはタグだけでななく属性レベルでの絞り込みが効くので、一発で取りたい中身を取れました。便利ですね。
なお、string[3:]としているのは、この中身の先頭には//というJSONとしてパースするには邪魔な文字が入っているからです。3後はJSON文字列をオブジェクト化してパースのみ...と思いきや
ざっくり書くと、パース化したオブジェクトの中身は、こんな感じになってます。
{ "router":{"略"}, "page":"companies#feed", "auth":{"略"}, "body":{ "c29bc423-7f81-41c2-8786-313d0998988c":{ "company":{"略"} } } }謎のUUIDが。多分企業IDとは別に使う何かなんでしょう。
というわけで、この中身まで掘り進む必要があります。
feed_body = feeds['body'][list(feeds['body'].keys())[0]]幸いですが、
bodyの中身に使われているキーは1社分だけみたいなので、超雑に奥に分け入っていきます。最後に項目を抽出
今の所、便利そうな項目は次の2個です。
posts: これまでの全ストーリー?
latest_pinnable_posts: 「注目の投稿」に該当する部分今回は最小限だけ必要ということにして、
latest_pinnable_postsを出力してフィニッシュ。お疲れ様でした。pprint.pprint(feed_body['latest_pinnable_posts'])Slack通知は?
現時点ではまだ作ってません。
- 直前投稿のパース結果との差分を見て、新しい分だけ通知
- RSSフィード化して、SlackIntegrationに丸投げ 4
などのようなアプローチがありますね。ひとまず今回は対象外。
振り返り
久々に
BeautifulSoup4を触りましたが、やっぱり機能が揃ってて使いやすいですね。


- 投稿日:2019-11-26T20:10:51+09:00
python 継承について
継承
継承とはあるクラスを元にして新たなクラスを作ること
class 新しいクラス名(元となるクラス名):と書く事で他のクラスを継承して新しいクラスを定義することができる
このときの元となるクラスを親クラス、新たなクラスを子クラスと呼ぶ
継承すると、子クラスは親クラスのインスタンスメソッドを引き継ぐ
子クラスは「親クラス内に定義されているメソッド」と「独自に定義したメソッド」の両方が使える
親クラスと同名のメソッドを子クラスで定義するとメソッドを上書きできる。これをメソッドのオーバーライドという
オーバーライドすると子クラスで定義したメソッドが優先される
オーバーライドしたメソッドの中でsuper()とすることで、親クラスを呼び出すことができる
super().メソッド名()とすることで、親クラス内に定義されたインスタンスメソッドをそのまま利用することが可能
- 投稿日:2019-11-26T19:50:41+09:00
ABC146 感想
AtCoder Beginner Contest 146 に参加しました
普段はコンテストに参加→復習で終わってしまいますが、コンテスト中の考察を記録に残したいと思い、記事を書くことにしました。(いつまで続くかは不明)
問題A - Can't Wait for Holiday
愚直に実装しました。
A.pyS = input() if S == "SUN": print(7) elif S == "MON": print(6) elif S == "TUE": print(5) elif S == "WED": print(4) elif S == "THU": print(3) elif S == "FRI": print(2) else: print(1)問題B - ROT N
文字をアスキーコードに変換する方法を知らなかったので、
Google先生に聞いてord()とchr()を知りました。対象の文字を
0~25で表し、N回ずらすためNを加え、26で割った余りを求めます。
最後にord("A")を加えることで大文字のアルファベットのアスキーコードに戻します。
これを各文字に対して行うことで答えが求まりました。B.pyN = int(input()) S = input() new_s = [] for c in S: new_s.append(chr((ord(c) - ord("A") + N) % 26 + ord("A"))) print("".join(new_s))問題C - Buy an Integer
初めにNについて全探索を行いましたが、TLEでした。(そりゃそう)
PyPyなら通るのでは(?)と思いさらにTLEを重ねてしまいました。
途中で「条件を満たす中の最大値」を求めるには二分探索が使えると気づき、
通すことができました。1つの方法に固執し過ぎて二分探索に至るまでに30分を掛けてしまったのは反省。
C.pya,b,x = map(int, input().split()) left = 0 right = 10**9 + 1 while right > left + 1: n = (left + right) // 2 if a * n + b * len(str(n)) <= x: left = n else: right = n print(left)問題D - Coloring Edges on Tree
全くダメでした。
グラフ問題は見た瞬間に拒否反応が出てしまうので、どこかでしっかり勉強したいと思いつつ中々手を付けられていません...何か良い学習教材ありませんかね??
まとめ
早く緑になりたい!
- 投稿日:2019-11-26T19:49:31+09:00
文字が入った画像をpythonで作る(日本語)
背景
そんなにない
作業
- fontファイルの場所を調べる
$ fc-match -f "%{file}\n" FreeMono /System/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc
- 画像作る
from PIL import Image, ImageDraw, ImageFont font = ImageFont.truetype("/System/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc", size=60) def make_image(n): im = Image.new("RGB",(300,100),"blue") draw = ImageDraw.Draw(im)# im上のImageDrawインスタンスを作る draw.text((10,20), f"自由記述欄{n}", font=font) im.save(f"./freetext{n}.jpg") for i in range(0,50): make_image(i)
- jupyter notebookで表示したかったら
from IPython.display import Image, display_png display_png(Image('./name1.jpg'))成果物
参考


- 投稿日:2019-11-26T19:33:53+09:00
3分28秒でDjangoをデプロイ(docker-compose)
既に作成されたプロジェクトの場合でも対応可能な形のdocker-composeを作成しましたので、仕様を記事にまとめます。
GitHub上にHowtoUseを書いておりますのでどうぞ→GitHub
(DBをデフォルトのsqliteから変更してる場合はまた別の設定が必要になると思います・・・ごめんなさい)
デプロイ環境はDjango+Nginx+Gunicornとなります。
ちなみに3分28秒というのは、
①リポジトリのクローン
②GitHub上のDjangoプロジェクトをクローン
③設定ファイル編集
④docker-compose
⑤ブラウザでの動作チェックにかかった時間です。
概要
使い方は上記にリンクを用意しておりますGitHubのREADMEを参照ください。
簡単なデプロイを実現させるために、次のようなディレクトリ構成で動作するDjangoデプロイ用のdocker-composeを作りました。
django-nginx-gunicorn-docker/ ├ nginx/ │ └ project.conf ├ django/ │ ├ Dockerfile │ ├ requirements.txt │ └ [DJANGOPROJECT] │ ├ manage.py │ ├ … │ └ [PROJECTNAME] └ docker-compose.ymlコンテナでプロジェクトを丸ごとマウントして動作させます。
では設定ファイルをみていきます。docker-compose
利用するコンテナはDjangoアプリケーション用のもの(Gunicornもこの中で動作)と、リバースプロキシの役割を果たすNginxのコンテナです。
docker-compose.ymlversion: '3' services: django: build: ./django expose: - "8000" networks: - nginx_network volumes: - ./django:/code hostname: django-server restart: always nginx: image: nginx ports: - "80:80" networks: - nginx_network depends_on: - django volumes: - ./nginx/project.conf:/etc/nginx/conf.d/default.conf restart: always networks: nginx_network: driver: bridgedjangoのvolumesのところで、プロジェクト環境をマウントしています。もしコンテナ起動後に編集を行なっても、コンテナをrestartさせることで反映されます。
また、nginxコンテナの方では80:80でポートフォワーディングをしているので、ローカルホストの80番ポートにアクセスが来た際はnginxコンテナの方に受け渡されます。
特段トリッキーなことはしていませんので、composeの説明は終わりです。
Dockerfile
djangoディレクトリにあるDockerfileの説明です。
FROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code COPY requirements.txt /code/ RUN pip install -r requirements.txt COPY . /code/ WORKDIR /code/MYPROJECT CMD ["gunicorn", "--bind", "0.0.0.0:8000", "MYPROJECT.wsgi:application"]python3系のイメージを利用します。6行目のRUNでDjangoとGunicornをダウンロードしています。(あとついでにPostgres用のライブラリもダウンロードしていますが使っていません。ごめんなさい)
requirements.txtDjango==2.2.7 gunicorn==19.9.0 psycopg2ちなみにDjangoのバージョンですが、当初2.0を指定してGithubにあげた所くっそ怒られました。(セキュリティ警告がいっぱい来た。GitHubのBotから怒りのプルリクもきた。)
project.conf
nginxの設定ファイルです。ここで結構トリッキーな動きが必要でした。
project.confupstream django { server django:8000; } server { listen 80; server_name :localhost; location / { proxy_pass http://django; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; } }upstreamでリクエストの送信先を指定します。送信先はコンテナのlocalhostとなっています。また、ここで命名したものをプロキシパスの設定で用います。
serverのほうではlistenするポートとプロキシの設定を行なっています。
さいごに
ポートの設定でどはまりしました。。。
みなさんも気をつけましょう;;
- 投稿日:2019-11-26T19:33:53+09:00
docker-composeを使って3分28秒でDjangoをデプロイ
既に作成されたプロジェクトの場合でも対応可能な形のdocker-composeを作成しましたので、仕様を記事にまとめます。
GitHub上にHowtoUseを書いておりますのでどうぞ→GitHub
(DBをデフォルトのsqliteから変更してる場合はまた別の設定が必要になると思います・・・ごめんなさい)
デプロイ環境はDjango+Nginx+Gunicornとなります。
ちなみに3分28秒というのは、
①リポジトリのクローン
②GitHub上のDjangoプロジェクトをクローン
③設定ファイル編集
④docker-compose
⑤ブラウザでの動作チェックにかかった時間です。
概要
使い方は上記にリンクを用意しておりますGitHubのREADMEを参照ください。
簡単なデプロイを実現させるために、次のようなディレクトリ構成で動作するDjangoデプロイ用のdocker-composeを作りました。
django-nginx-gunicorn-docker/ ├ nginx/ │ └ project.conf ├ django/ │ ├ Dockerfile │ ├ requirements.txt │ └ [DJANGOPROJECT] │ ├ manage.py │ ├ … │ └ [PROJECTNAME] └ docker-compose.ymlコンテナでプロジェクトを丸ごとマウントして動作させます。
では設定ファイルをみていきます。docker-compose
利用するコンテナはDjangoアプリケーション用のもの(Gunicornもこの中で動作)と、リバースプロキシの役割を果たすNginxのコンテナです。
docker-compose.ymlversion: '3' services: django: build: ./django expose: - "8000" networks: - nginx_network volumes: - ./django:/code hostname: django-server restart: always nginx: image: nginx ports: - "80:80" networks: - nginx_network depends_on: - django volumes: - ./nginx/project.conf:/etc/nginx/conf.d/default.conf restart: always networks: nginx_network: driver: bridgedjangoのvolumesのところで、プロジェクト環境をマウントしています。もしコンテナ起動後に編集を行なっても、コンテナをrestartさせることで反映されます。
また、nginxコンテナの方では80:80でポートフォワーディングをしているので、ローカルホストの80番ポートにアクセスが来た際はnginxコンテナの方に受け渡されます。
特段トリッキーなことはしていませんので、composeの説明は終わりです。
Dockerfile
djangoディレクトリにあるDockerfileの説明です。
FROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code COPY requirements.txt /code/ RUN pip install -r requirements.txt COPY . /code/ WORKDIR /code/MYPROJECT CMD ["gunicorn", "--bind", "0.0.0.0:8000", "MYPROJECT.wsgi:application"]python3系のイメージを利用します。6行目のRUNでDjangoとGunicornをダウンロードしています。(あとついでにPostgres用のライブラリもダウンロードしていますが使っていません。ごめんなさい)
requirements.txtDjango==2.2.7 gunicorn==19.9.0 psycopg2ちなみにDjangoのバージョンですが、当初2.0を指定してGithubにあげた所くっそ怒られました。(セキュリティ警告がいっぱい来た。GitHubのBotから怒りのプルリクもきた。)
project.conf
nginxの設定ファイルです。ここでトリッキーな動きが必要でした。
project.confupstream django { server django:8000; } server { listen 80; server_name :localhost; location / { proxy_pass http://django; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; } }upstreamでリクエストの送信先を指定します。送信先はコンテナのlocalhostとなっています。また、ここで命名したものをプロキシパスの設定で用います。
serverのほうではlistenするポートとプロキシの設定を行なっています。
さいごに
ポートの設定でどはまりしました。。。
みなさんも気をつけましょう;;
- 投稿日:2019-11-26T18:57:46+09:00
比較演算でつまづいた話
ちょっとイキって比較演算子を使っていい感じに書いてコード量を減らそうとしたら、想定外のところでつまづいたので備忘録的に残しておこうと思います.
環境
- macOS Catalina 10.15.1
- Python 3.7.5
対象読者
自分
演算子一覧
pythonには以下のような比較演算子があり、分岐などの条件文に使用したりします。
演算子 結果 x < y x が y より小さければ True x <= y x が y より小さいか等しければ True x > y x が y より大きければ True x >= y x が y より大きいか等しければ True x == y x と y の値が等しければ True x != y x と y の値が等しくなければ True x is y x と y が同じオブジェクトであれば True x is not y x と y が同じオブジェクトでなければ True x in y x が y に含まれていれば True x not in y x が y に含まれていなければ True 他にも以下のような論理演算子が存在し、これらを組み合わせることで自由度の高い条件文を作成することが可能です。
演算子 結果 x and y x が True で y も True のとき y を返す。x が False のとき x を返す x or y x が True のとき x を返す。x が False のとき y を返す not x x が True であれば False、x が False であれば True を返す 論理演算子の結果が妥当か確認する方法
andやorの場合は、左辺がTrueになるかFalseになるかが重要になってきます。これについてはboolを使えば簡単に確認できます。bool
TrueやFalseは当然そのままの結果が返ってきます。
terminal>>> bool(True) True >>> bool(False) False数値
数値型の場合は0以外はTrueが返ってきます。
>>> bool(1) True >>> bool(0) False >>> bool(-1) True >>> bool(0.5) True >>> bool(1j) True >>> bool(0j) False >>> bool(-1j) True文字列
文字列型では文字が存在している場合にTrueになります。
>>> bool('') False >>> bool('hoge') True >>> bool(' ') Trueこれはstrのインスタンスが生成されているかを見ているわけではないので、注意が必要です。
>>> type('') <class 'str'>None
NoneもFalseとして扱われます。
>>> bool(None) False配列
配列は要素が1つ以上存在する時にTrueが返ってきます。
>>> bool([]) False >>> bool([""]) True >>> bool([None]) Trueつまづいた点
これまで見てきた通り非常に容易だとは思うのですが、注意するべき点は要素が存在している時にTrueが返ってくるとは限らないということです。
どういう意味かを説明する前に、一旦Falseになる条件を以下にまとめてみました。
>>> bool(False) False >>> bool(0) False >>> bool('') False >>> bool(None) False >>> bool([]) Falseこれを見る限り中身がなければFalseになりそうなところです。
そこで以下のようなコードを実行してみました。
>>> import numpy as np >>> hoge = None >>> fuga = True >>> if fuga: ... hoge = np.arange(10) >>> bazz = hoge if hoge else list(range(10)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()まさかのエラー!
個人的にやりたかったこととしては、条件式(fuga)がTrueのときndarrayを生成する関数が存在しており、別の関数ではhogeが生成されているかを判断し、新たに生成し直すかそのまま使用したいと考えていました。解決策としてはインスタンスを生成しているかの確認ではなく、Noneであるかを判断基準に用いました。
>>> import numpy as np >>> hoge = None >>> fuga = True >>> if fuga: ... hoge = np.arange(10) >>> bazz = hoge if hoge is not None else list(range(10)) >>> bazz array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])ただし、この場合だとhogeにndarray以外が生成されていてもhogeを返すので、ndarray限定にしたい場合は要検討という感じですね...
一案としては以下のようにするといいかと思います。
>>> import numpy as np >>> >>> hoge = np.array([]) >>> hoge array([], dtype=float64) >>> hoge.any() False >>> hoge = np.array([1]) >>> hoge array([1]) >>> hoge.any() Trueanyは配列内部に1つでも該当する要素が存在する時にTrueを返すので、何も指定しない場合は中身が存在しない時にFalseを返すようになります。
ただしこちらもいくつか注意が必要です。>>> hoge = np.array([None]) >>> hoge.any() >>> type(hoge.any()) <class 'NoneType'> >>> hoge = np.array(['']) >>> hoge.any() Traceback (most recent call last): ... TypeError: cannot perform reduce with flexible type >>> hoge = np.array(['',None]) >>> hoge.any() >>> type(hoge.any()) <class 'NoneType'> >>> hoge = np.array([None,'']) >>> hoge.any() ''配列内に何が入るのかを考えた上で使用する必要がありますね...
雑談
外部ライブラリをboolで判定するとFalseが返ってくることには驚きでした。まぁ、イキって変な書き方しようとした自分が悪いわけですが...
使いこなすにはまだまだ知識が足りてないことを痛感してしまいますが、めげずに日々精進していきたいものです(・∀・)参考
- 投稿日:2019-11-26T18:46:26+09:00
Blender2.80のスクリプトで恒星系を生み出す
みんな大好きBlenderスクリプトで恒星系(のように見える)配置を生み出そうという記事です。Blender2.80完全対応!
基本的にはイテレーションを回して物体に大量に配置する系のスクリプトですが、今回はマテリアルの設定などもしています。
1. 球体を大量に配置
とりあえず簡単なコードから。プリミティブの球体を自動的に並べてみます。
import bpy import numpy as np #現状をリセット for mat in bpy.data.materials: bpy.data.materials.remove(mat) for obj in bpy.data.objects: bpy.data.objects.remove(obj) for obj in bpy.context.scene.objects: bpy.data.objects.remove(obj) #球体を生み出す数 number = 10 for i in range(number): x = np.random.rand()*number*10-50 y = np.random.rand()*number*10-50 bpy.ops.mesh.primitive_uv_sphere_add(radius=np.random.rand()+1,location=(x,y,0))2. なんちゃって惑星軌道を追加
それぞれの球体に、原点を中心としてその球体を通るようなリングを設定したら、なんとなく恒星系のようになりそうです。元々
xとyで座標を指定していましたが、今後の計算の簡便のため、rとthetaの極座標で座標をします。
import bpy import numpy as np #現状をリセット for mat in bpy.data.materials: bpy.data.materials.remove(mat) for obj in bpy.data.objects: bpy.data.objects.remove(obj) for obj in bpy.context.scene.objects: bpy.data.objects.remove(obj) #球体を生み出す数 number = 10 bpy.data.materials.new(name = 'orbit') mat = bpy.data.materials['orbit'] mat.use_nodes = False mat.diffuse_color = (1,1,0,1) for i in range(number): #極座標で計算 r = np.random.rand()*number*10+10 theta = np.random.rand()*np.pi*2 x = r*np.cos(theta) y = r*np.sin(theta) #こっちは惑星 bpy.ops.mesh.primitive_uv_sphere_add(radius=np.random.rand()+1,location=(x,y,0)) #こっちは軌道 bpy.ops.mesh.primitive_torus_add(major_radius=100,minor_radius=.1) bpy.context.object.scale = (r/100,r/100,1)ここでは
bpy.ops.mesh.primitive_torus_addのAPIを用いています。リファレンスはここ。ドーナツの輪の半径をmajor_radius、ドーナツの断面の半径をminor_radiusで指定しています。ここでmajor_radiusを0としているのは、なぜかこのAPIでは100以上の値を指定できないというよくわからない仕様があるせいで(最初わからなくてハマった)、半径100のドーナツをbpy.context.object.scaleによって拡大縮小することでrに合わせるという風にしています。3. マテリアルの指定
今回はマテリアルも設定していきます。Blender2.80になってから、マテリアルを設定する場合はほぼシェーダ必須となってしまいましたが、そこまでスクリプトの勉強が追い付いていないので今回はシェーダ使わないモードで解説させていただきます。スクリプトでマテリアルを設定する場合、
bpy.data.materials.newでマテリアルのデータを作成した後、対象オブジェクトにbpy.ops.object.material_slot_add()でマテリアルスロットを追加し、そのスロットを対象にbpy.context.object.active_materialでそのマテリアルを設定する、という流れになります。マテリアルのリファレンスはここですが、ノードを使う場合これは序の口であって、更に細かいノードのAPIをいじる必要があります。とりあえず今回はノードを使わない設定でいくので(
mat.use_nodes = False)、この中のdiffuse_color、metallic、roughnessだけ乱数で指定していきます。
GUIで言うとこの表示になります。なおこの表示はレンダーエンジンによっても変わり、上の図は
Cyclesのものになります。import bpy import numpy as np #現状をリセット for mat in bpy.data.materials: bpy.data.materials.remove(mat) for obj in bpy.data.objects: bpy.data.objects.remove(obj) for obj in bpy.context.scene.objects: bpy.data.objects.remove(obj) #球体を生み出す数 number = 10 #軌道のマテリアルだけ先に設定 bpy.data.materials.new(name = 'orbit') mat = bpy.data.materials['orbit'] mat.use_nodes = False mat.diffuse_color = (1,1,0,1) for i in range(number): r = np.random.rand()*number*10+10 theta = np.random.rand()*np.pi*2 x = r*np.cos(theta) y = r*np.sin(theta) #こっちは惑星 bpy.ops.mesh.primitive_uv_sphere_add(radius=np.random.rand()+1,location=(x,y,0)) #惑星の個別のマテリアルを設定 mat_name = 'material' + str(i) bpy.data.materials.new(name = mat_name) mat = bpy.data.materials[mat_name] mat.use_nodes = False mat.diffuse_color = np.random.rand(4) mat.diffuse_color[3] = 1 mat.metallic = np.random.rand() mat.roughness = np.random.rand() bpy.ops.object.material_slot_add() bpy.context.object.active_material=mat #こっちは軌道 bpy.ops.mesh.primitive_torus_add(major_radius=100,minor_radius=.1) bpy.context.object.scale = (r/100,r/100,1) #前に設定した軌道マテリアルを適用 mat = bpy.data.materials['orbit'] bpy.ops.object.material_slot_add() bpy.context.object.active_material=mat4 太陽(っぽいもの)の作成&レンダリング
せっかくなので、中心に太陽(っぽいもの)を設定します。
上のコードに追記bpy.ops.mesh.primitive_uv_sphere_add(radius=4) bpy.data.materials.new(name = 'sun') mat = bpy.data.materials['sun'] mat.use_nodes = False mat.diffuse_color = (1,.5,0,1) bpy.ops.object.material_slot_add() bpy.context.object.active_material=mat惑星の半径や位置は乱数で指定しているので、スクリプトを回す度に違う恒星系らしきものが生成されます。Blenderのソリッド表示ではいい感じですが、この際レンダリングもしていきましょう。このままでは真っ暗なので中心にライトを設定してもよいですが、このニセ太陽のせいで光が遮られてしまいます。ここは手動でマテリアルを設定して、このニセ太陽自身が輝いているようにします。
シェーダノード。我々はこれに嫌でも慣れていかなければならない。
以下がカメラや背景等を設定してレンダリングしたもの。背景の星空はCGBeginner様よりお借りしました。








- 投稿日:2019-11-26T18:28:11+09:00
Python入門 1回目 Pythonの基礎
index
Jupyter Notebook使い方
以下を読んでインストールし、使い方を学ぶ。
データ分析で欠かせない!Jupyter Notebookの使い方【初心者向け】Pythonの基礎
変数
文字列を作成するときは、シングルクォーテーションまたはダブルクォーテーションで囲む。
またPythonには変数の型宣言が基本的に必要ない。値を代入するだけで使える。msg = 'test' print(msg) # 出力:test演算
data = 1 print(data) # 出力: 1 data = data + 10 print(data) # 出力: 11リスト
リストとは複数の値を人纏まりにして扱うためのもの。他の言語の配列と同じ。
data_list = [1,2,3,4,5,6,7,8,9,10] print(data_list) # 出力: [1,2,3,4,5,6,7,8,9,10] print('2番目の数:', data_list[1]) # 出力: 2番目の数:2 print('要素数:', len(data_list)) # 出力: 要素数:10 # リストに2を掛けても、リスト全体がもう一度繰り返されるだけ。2倍したい場合はfor文やNumpyを使う print(data_list * 2) # 出力: [1,2,3,4,5,6,7,8,9,10,1,2,3,4,5,6,7,8,9,10]リストの要素を追加したい場合は
append、削除したい場合はremoveやpop、delなどを使う。data_list2 = [1,2,3,4,5] print(data_list) # 出力: [1,2,3,4,5] # 括弧で指定した値と同じ要素を検索し、最初の要素を削除 data_list2.remove(1) print(data_list2) # 出力: [2,3,4,5]data_list3 = [1,2,3] data_list3.append(10) print(data_list3) # 出力: [1, 2, 3, 10]辞書型
辞書型では、キーと値をペアにして複数の要素を管理することができる。
Pythonで辞書を表現するには、{キー:値}のようにコンロ区切りで表記する。
次の例のように、「appleが100」「bananaが200」などのように、何か指定したキーに対して値を保持させたい時に使う。dic_data = {'apple':100, 'banana':200} print(dic_data['banana']) # 出力: 200 dic_data["banana"] # 出力: 200辞書の要素を追加したいときは
対象の辞書[キー] = 要素dic_data ["orange"] = 300 print(dic_data) # 出力: {'apple': 100, 'banana': 200, 'orange': 300}辞書の要素を削除したいときは
del 対象の辞書[キー]del dic_data["apple"] print(dic_data) # 出力: {'banana': 200, 'orange': 300}タプル
リストと同く複数の値を格納できる型であるが、変更できない点と実行速度が少し早い点が異なる。
タプルの使い方やリストとの違いについて解説list_sample = [1, 2, 3, 4, 5] tuple_sample = (1, 2, 3, 4, 5) #括弧がなくても良い tuple_sample2 = 1, 2, 3, 4, 5 print(list_sample) # 出力: [1, 2, 3, 4, 5] print(tuple_sample) # 出力: (1, 2, 3, 4, 5) print(tuple_sample2) # 出力: (1, 2, 3, 4, 5)集合
集合もリストと同く複数の値を格納できる型であるが、重複した要素は無視される点と要素に順番がない点が異なる。
【Python入門】すぐわかる!set型(集合型)の基本まとめset_data1 = set([1,2,3]) set_data2 = set([1,2,3,3,2,1]) print(set_data1) # 出力: {1, 2, 3} print(set_data2) # 出力: {1, 2, 3}if文
if [条件式]: [条件式がTrueのときに行う処理] else: [条件式がFalseのときに行う処理]
elifは他の言語で言うとelse ifif [条件式1]: [条件式がTrueのときに行う処理] elif [条件式2]: [elifの条件式2がTrueのときに行う処理] else: [if文の条件式1もelifの条件式2もどちらもFalseのときに行う処理]data_list4 = [1,2,3,4,5,6] findvalue = 10 if findvalue in data_list4: print('{0} は見つかりました。' .format(findvalue)) else: print('{0}は見つかりませんでした。' .format(findvalue)) # 出力: 10は見つかりませんでした。結果を表示するのに用いた
'文字列'.format(値,...)は文字列フォーマットと言い、上で指定している{0}は、formatの括弧の最初に指定した値を埋め込むための指定である。print('{0}と{1}を足すと{2}です。' .format(2,3,5)) # 出力: 2と3を足すと5です。for文
他の言語と同様な動きをする。書き方は以下を参考。
data_list5 = [1,2,3,4,5] total = 0 for num in data_list5: total += num print('合計:',total) # 出力: 合計: 15辞書型でfor文を使って要素を取り出す際には、
key()メソッド:キーを取り出す
values()メソッド:値を取り出す。
items()メソッド:両方を取り出す。の3つがある。dic_data2 = {'apple':100, 'banana':200, 'orange':300} for all_data in dic_data2: print(all_data) # 出力: apple # banana # orange for all_data in dic_data2.keys(): print(all_data) # 出力: apple # banana # orange for all_data in dic_data2.values(): print(all_data) # 出力: 100 # 200 # 300 for all_data in dic_data2.items(): print(all_data) # 出力: ('apple', 100) # ('banana', 200) # ('orange', 300) for all_data1,all_data2 in dic_data2.items(): print(all_data1,all_data2) # 出力: apple 100 # banana 200 # orange 300range関数
連続した整数のリストを作りたい時に利用する関数。
range(N)とした時、0〜N-1までの整数が出力されることに注意する。for i in range(10): print(i)出力0 1 2 3 4 5 6 7 8 9さらにrange関数では括弧の中に
最初の値,最後の値-1,飛ばす値を指定できる。#1から9までの2個飛ばし for i in range(1,10,2): print(i)出力1 3 5 7 9内包表記
for文を使って取り出したデータを、さらに別のリストとして結果を作成する方法。
#dataから値を取り出して変数iに格納。これを2倍にしてdata1へ data = [1,2,3,4,5] data1 = [] data1 = [i * 2 for i in data] print(data1) # 出力: [2, 4, 6, 8, 10]条件を指定し、条件に合致するものだけを新しいリストの対象にすることも出来る。
先に条件に合うiだけを取り出して2倍していることがわかる。data = [1,2,3,4,5] [i * 2 for i in data if i % 2 ==0] # 出力: [4, 8]zip関数
それぞれ異なるリストを同時に取り出していく処理を実行する。
たとえば、[1,2,3]というリストと、[11,12,13]という2つのリストがあるとき、それぞれ同じインデックスで値を取って表示される。for x , y in zip([1,2,3], [11,12,13]): print(x, 'と', y)出力1 と 11 2 と 12 3 と 13while文
num = 1 #初期値 while num <= 10: print(num) num = num + 1出力1 2 3 4 5 6 7 8 9 10関数
一連の処理をひとまとめにする仕組み。
書き方としては、defの後に関数名、引数があれば、()の中に、引数名を記述。この引数が入力となって、returnで結果を返し(返り値)、これが出力となる。def calc_multi(a,b): return a*b calc_multi(3,10) # 出力: 30無名関数
関数には無名関数と呼ばれるものがあり、これを使うと、コードを簡素化出来る。
無名関数を書くには、lambda(ラムダ)というキーワードを使用する。
無名関数は、リストなどの要素に対して何か関数を実行したいときに、よく使う。(lambda a,b: a*b)(3,10) # 出力: 30ここで
lambda a, b:というのが、関数名(a, b)に相当する部分。
そして:で区切って、その関数の処理(ここではreturn a * b)を記述するというのが、無名関数の基本的な書き方となる。map
要素に対して、何か処理したいときは、map関数を使う。
関数を引数や戻り値として使う関数で、各要素に対して、何か処理や操作したいときに使う。def calc_double(x): return x * 2 #forを使う場合 for num in [1,2,3,4]: print(calc_double(num)) # 出力: ① #map関数を使う場合 list(map(calc_double, [1,2,3,4])) # 出力: ②出力①の出力 2 4 6 8 ②の出力 [2, 4, 6, 8]無名関数を使えば、別に関数を用意しなくても直接関数の処理を記述出来る。
list(map(lambda x : x * 2, [1,2,3,4])) # 出力: [2, 4, 6, 8]
- 投稿日:2019-11-26T18:17:29+09:00
Python を使った gRPC の辛み。2019年11月。(自分用メモ)
gRPC 界では普通なのかもしれませんが、初心者が Python で gRPC クライアントを書こうとして意外とハマったのでメモします。
Python Quick Start を元に作業を行います。まずサンプルコードのダウンロード。ここで、最新の v1.25.0 ではなくてちょっと古い v1.19.0 を使います。理由は後述します。
git clone -b v1.19.0 https://github.com/grpc/grpcドキュメントとは趣向を変えて、別のディレクトリに Python プロジェクトを作ってみます。ここでも v1.19.0 を使います。
mkdir python-grpc cd python-grpc pipenv --python 3.7 pipenv install grpcio~=1.19.0 pipenv install --dev grpcio-tools pipenv shell mkdir pb辛み1: grpc_tools.protoc のオプションが難しい。
grpc_tools.protoc コマンドを使って proto ファイルから py を作成して、
pbディレクトリに書き込みます。python -m grpc_tools.protoc \ -I../grpc/examples/protos/ \ --python_out=pb \ --grpc_python_out=pb \ ../grpc/examples/protos/helloworld.proto
-I: proto 中の include の他、このコマンドで処理する proto ファイルの位置も -I で指定しなければいけない。--python_out: xxx_pb2.py ファイルを出力するディレクトリを指定します。--grpc_python_out: xxx_pb2_grpc.py ファイルを出力するディレクトリを指定します。まず -I オプションは必須です。これが無いと
File does not reside within any path specified using --proto_path (or -I).というエラーになります。ちゃんと proto の位置を指定してるのになんで探せないのか理不尽です。また、-I オプションにはコツがあって、例えば
-I../grpc/examples/のように上位ディレクトリを指定するとpbではなくpb/protosにファイルが生成されます。知らないとファイルがどこに行ったのかわからず途方に暮れます。また、
--helpオプションの解説には--python_outと--grpc_python_outの違いに触れられていません。上記のように違いはあるのですが、別のディレクトリに入れても import に失敗するだけで良いことないので、わざわざ別のオプションがあるのは理不尽です。辛み2: 生成されたファイルに相対パスが通っていない。
出来たやつを試しに python から読んでみるとエラーが出ます。
$ python >>> import pb.helloworld_pb2_grpc Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/Users/tyamamiya/tmp/python-grpc/pb/helloworld_pb2_grpc.py", line 4, in <module> import helloworld_pb2 as helloworld__pb2 ModuleNotFoundError: No module named 'helloworld_pb2'なんと生成されたコードの相対パスが間違っている(Python2 風らしいです)。仕方がないので python: use relative imports in generated modules に従って
pb/__init__.pyを追加します。import sys from pathlib import Path sys.path.append(str(Path(__file__).parent))コツ: デバッグの仕方
エラーがそっけないのでうまく行かない時は環境変数を設定して実行すると良いです。ここでサーバとクライアントを起動して動作確認します。
$ python ../grpc/examples/python/helloworld/greeter_server.py & $ export GRPC_TRACE=all $ export GRPC_VERBOSITY=DEBUG $ python ../grpc/examples/python/helloworld/greeter_client.py ... 大量に色々出る。 Greeter client received: Hello, you! $ unset GRPC_TRACE $ unset GRPC_VERBOSITYよしよし。
辛み3: google.api
たまに google.api を include している proto ファイルがあります。proto ファイル自体は https://github.com/googleapis/googleapis/tree/master/google/api にあるのでダウンロードして
-Iで指定すればよいのですが、変換後のコードには include した proto の内容は含まれません。--include_importsというオプションで取り込んでくれるような気がしたのですがそんな事は無くて、別に変換済のやつをインストールする必要があります。pipenv install googleapis-common-protosまあこれはわかっていればどうってこと無いです。
辛み4:
missing selected ALPN property.最新の Python grpcio ライブラリで 既存の gRPC サーバに TLS で接続すると
missing selected ALPN property.が出る時があります。D1125 19:20:57.313482000 4619453888 security_handshaker.cc:186] Security handshake failed: {"created":"@1574677257.313465000","description":"Cannot check peer: missing selected ALPN property.","file":"src/core/lib/security/security_connector/ssl_utils.cc","file_line":118} I1125 19:20:57.313703000 4619453888 subchannel.cc:1000] Connect failed: {"created":"@1574677257.313465000","description":"Cannot check peer: missing selected ALPN property.","file":"src/core/lib/security/security_connector/ssl_utils.cc","file_line":118}このキーワードで検索すると色々興味深い事実が見つかるのですが、 https://github.com/grpc/grpc/issues/18710 から察するに、ALPN check という機能に対応していないサーバにアクセス出来ないようです。
仕方がないので古いバージョン v1.19.0 を使ってお茶を濁します。 https://stackoverflow.com/questions/57397723/grpc-client-failing-to-connect-to-server-with-tls-certificates
結論
Python と gRPC の組み合わせはこなれてない感がある。
- 投稿日:2019-11-26T17:53:23+09:00
Django基本
- 投稿日:2019-11-26T17:40:23+09:00
OpenSSLの鍵を使った暗号化/復号をPythonのpow関数でやってみる
OpenSSLの公開鍵/秘密鍵を使った暗号化/復号の操作を、
鍵の中にある整数n, e, d とPython3のpow関数を使って手作業でやってみます。
(ただし、元の値は1個だけ)OpenSSLの鍵の作成には、以下の2つの方法があります。
openssl genrsaコマンド
ブラウザでHTTPS通信を行う時に使うSSL用の秘密鍵と公開鍵を発行します。ssh-keygenコマンド
リモートマシンを操作する時に使うSSH用の秘密鍵と公開鍵を発行します。
鍵ファイルを開くためのパスフレーズを設定することができます。どちらの鍵でも、暗号化/復号の実験はできるのですが、
今回はSSL用の鍵で実験してみます。1. OpenSSLのバージョン
今回の実験で使用したOpenSSLのバージョンは、以下の通りです。
$ openssl version OpenSSL 1.1.1 11 Sep 20182. 秘密鍵ファイルの作成
openssl genrsaコマンドで秘密鍵ファイルを生成します。
デフォルトでは、鍵長は2048ビットになっています。$ openssl genrsa > key-private.pem Generating RSA private key, 2048 bit long modulus (2 primes) .....................................+++++ .............+++++ e is 65537 (0x010001)3. 秘密鍵ファイルの内容
3-1. catコマンドでの表示
catコマンドで鍵ファイルの中身を見てみます。
デフォルトでは、鍵ファイルはPEM 形式と呼ばれる固定のヘッダ・フッタの間に BASE64 でエンコードされて保存されています。
$ cat key-private.pem -----BEGIN RSA PRIVATE KEY----- MIIEowIBAAKCAQEAl+RPByBaEZjV2Lb8Z4VZ29XxNvRKn777wXHxEIIjJArgTXHS tRO2Yt15omy17YHt0vv0NYjMJoyV1nFaaGEsMdmmpqh4vbZGHNDgPwPe7IfOMujm UI9AmTtajnlEj/sxKdWlgQ9EVgSIUkTWxpad1DX7/gE2JfnxwgNXxCxkRD8XIcux ODCVeq53I/ZOOQcixCPYijD3p1X+H33q8AEtPLV1dakeYtg4O5TFsbo2/E7bent4 fVlZxb/pxB+nbv/QM0CP47lBpT1nXYG4o9C3GU48e1riuPGVgVJ7yjVBfIJXlt6s Xch+MID/iZPiNp7FbQlD1yfOqMLjkNsF+ZWI4wIDAQABAoIBAAoIebPlzi1FZDLJ e4i3BUWBL0rK/jbpHaYciajmf728vi4/a4SshaqoKIWzGp1SrMv3+pyiqaGOPcOJ f0hPyuSMFPcDP96AMMdsgLOI5OvI2LUCL1x46fJ1OjkZB49fL1MtGp6YzJHGAN82 Tt2VS12eJ0QS/mmpxe9j2yNJL2JWknpduzrWRluvIUvgtY6LSOHBrCjxsns30NWA kVES4R8SJihR9xKRWEaj3EX3BLheNrwQTByEEFYxAMlzv9mX1XRyK+KU1vZef11I MA/bxZLBZ7xx3tjt+/yBSgr8zMDOsrz69cwG98cv5Yw3tjar2OU9AF460GkoiZeO QsmNJ4kCgYEAxpUaHoCRtdnxXxh7Er/oqBpuqIvNa4oni/tJEArgxty0k8Ul6DoQ mcu79MhyKm3hOFPDNeZyZLuGeyODe3zTDXVLE8Qc9k1KA4B5V5XknDR0RCRvcxPQ Q51oME68n+nnHTUvi6Qyg4C7t2YWOzJjuQAKmHNPfoWeJpp9Qm2h3j8CgYEAw881 lrR04Bp4jm9NfpPboVXhEkVcTrxbro9HMqyUtYCDJROtLMjG+kauH/yK5DPlFglE o4ZGSxFcFk9xk2nxrlLTlI+wi7r5+E7WRUH4yzTdImTmJ92dc5GkAkForgO0+qbk IH04ytYcKxiYLdL3e00CH2a7W41a3MWlmAidNF0CgYAkivOPgWFO8Zg1Q7ACN0Z9 CMAsS+21SGsWm1tKlHXgomSofLMJFQZRBujDls9Ld4TmdKOLm6iZWNjaeCKN6t57 r4XtUT1zJa3lDxNFRtQW2qA6menYZ2D/0EuH+DVFyCk7eroRHFofUOU6TpLwuckY FiXc//s08Sm1OOCsBLiwyQKBgQCIVbrrPqRt8SBllAuyCUMP91qpvQ+DZtSzGuGo 387+/QbTBvs5xmX8lr/gV5dhQtzL1hIrhW9mDyU+B3x99nMnPFZDBzUWZU5s3H+G Y2PWIO2jZ/t0YHKjqBE43NAE8WHOb+tAz89+M0wTmaFDrrNP75N9x6rGGQrd0uP0 knLapQKBgBoxOwQM1LpaFrWvK8HmZHxfp9sRW+UAVFddJ40Eke3sHg8g2KzThigB 2Nfjafs92N2TJqm7xuy1wUMJA6AbYCXwKj0hfOooMleqkQZjdtpw2HUoPKD7UhGw NIPNEBzPVT3QFfhpEyQDpwF4nBWhGSvyoZxqPdyeo981twpehFX6 -----END RSA PRIVATE KEY-----3-2.
-textオプションでの展開ちなみに、鍵の中身ですが、以下のようなフォーマットになっています。
ITU-T X.690
https://www.itu.int/ITU-T/studygroups/com17/languages/X.690-0207.pdfRSAPrivateKey ::= SEQUENCE { version Version, modulus INTEGER, -- n publicExponent INTEGER, -- e privateExponent INTEGER, -- d prime1 INTEGER, -- p prime2 INTEGER, -- q exponent1 INTEGER, -- d mod (p-1) exponent2 INTEGER, -- d mod (q-1) coefficient INTEGER, -- (inverse of q) mod p otherPrimeInfos OtherPrimeInfos OPTIONAL }以下のコマンドで、鍵ファイルを展開することができます。
$ openssl rsa -in key-private.pem -text -noout RSA Private-Key: (2048 bit, 2 primes) modulus: 00:97:e4:4f:07:20:5a:11:98:d5:d8:b6:fc:67:85: 59:db:d5:f1:36:f4:4a:9f:be:fb:c1:71:f1:10:82: 23:24:0a:e0:4d:71:d2:b5:13:b6:62:dd:79:a2:6c: b5:ed:81:ed:d2:fb:f4:35:88:cc:26:8c:95:d6:71: 5a:68:61:2c:31:d9:a6:a6:a8:78:bd:b6:46:1c:d0: e0:3f:03:de:ec:87:ce:32:e8:e6:50:8f:40:99:3b: 5a:8e:79:44:8f:fb:31:29:d5:a5:81:0f:44:56:04: 88:52:44:d6:c6:96:9d:d4:35:fb:fe:01:36:25:f9: f1:c2:03:57:c4:2c:64:44:3f:17:21:cb:b1:38:30: 95:7a:ae:77:23:f6:4e:39:07:22:c4:23:d8:8a:30: f7:a7:55:fe:1f:7d:ea:f0:01:2d:3c:b5:75:75:a9: 1e:62:d8:38:3b:94:c5:b1:ba:36:fc:4e:db:7a:7b: 78:7d:59:59:c5:bf:e9:c4:1f:a7:6e:ff:d0:33:40: 8f:e3:b9:41:a5:3d:67:5d:81:b8:a3:d0:b7:19:4e: 3c:7b:5a:e2:b8:f1:95:81:52:7b:ca:35:41:7c:82: 57:96:de:ac:5d:c8:7e:30:80:ff:89:93:e2:36:9e: c5:6d:09:43:d7:27:ce:a8:c2:e3:90:db:05:f9:95: 88:e3 publicExponent: 65537 (0x10001) privateExponent: 0a:08:79:b3:e5:ce:2d:45:64:32:c9:7b:88:b7:05: 45:81:2f:4a:ca:fe:36:e9:1d:a6:1c:89:a8:e6:7f: bd:bc:be:2e:3f:6b:84:ac:85:aa:a8:28:85:b3:1a: 9d:52:ac:cb:f7:fa:9c:a2:a9:a1:8e:3d:c3:89:7f: 48:4f:ca:e4:8c:14:f7:03:3f:de:80:30:c7:6c:80: b3:88:e4:eb:c8:d8:b5:02:2f:5c:78:e9:f2:75:3a: 39:19:07:8f:5f:2f:53:2d:1a:9e:98:cc:91:c6:00: df:36:4e:dd:95:4b:5d:9e:27:44:12:fe:69:a9:c5: ef:63:db:23:49:2f:62:56:92:7a:5d:bb:3a:d6:46: 5b:af:21:4b:e0:b5:8e:8b:48:e1:c1:ac:28:f1:b2: 7b:37:d0:d5:80:91:51:12:e1:1f:12:26:28:51:f7: 12:91:58:46:a3:dc:45:f7:04:b8:5e:36:bc:10:4c: 1c:84:10:56:31:00:c9:73:bf:d9:97:d5:74:72:2b: e2:94:d6:f6:5e:7f:5d:48:30:0f:db:c5:92:c1:67: bc:71:de:d8:ed:fb:fc:81:4a:0a:fc:cc:c0:ce:b2: bc:fa:f5:cc:06:f7:c7:2f:e5:8c:37:b6:36:ab:d8: e5:3d:00:5e:3a:d0:69:28:89:97:8e:42:c9:8d:27: 89 prime1: 00:c6:95:1a:1e:80:91:b5:d9:f1:5f:18:7b:12:bf: e8:a8:1a:6e:a8:8b:cd:6b:8a:27:8b:fb:49:10:0a: e0:c6:dc:b4:93:c5:25:e8:3a:10:99:cb:bb:f4:c8: 72:2a:6d:e1:38:53:c3:35:e6:72:64:bb:86:7b:23: 83:7b:7c:d3:0d:75:4b:13:c4:1c:f6:4d:4a:03:80: 79:57:95:e4:9c:34:74:44:24:6f:73:13:d0:43:9d: 68:30:4e:bc:9f:e9:e7:1d:35:2f:8b:a4:32:83:80: bb:b7:66:16:3b:32:63:b9:00:0a:98:73:4f:7e:85: 9e:26:9a:7d:42:6d:a1:de:3f prime2: 00:c3:cf:35:96:b4:74:e0:1a:78:8e:6f:4d:7e:93: db:a1:55:e1:12:45:5c:4e:bc:5b:ae:8f:47:32:ac: 94:b5:80:83:25:13:ad:2c:c8:c6:fa:46:ae:1f:fc: 8a:e4:33:e5:16:09:44:a3:86:46:4b:11:5c:16:4f: 71:93:69:f1:ae:52:d3:94:8f:b0:8b:ba:f9:f8:4e: d6:45:41:f8:cb:34:dd:22:64:e6:27:dd:9d:73:91: a4:02:41:68:ae:03:b4:fa:a6:e4:20:7d:38:ca:d6: 1c:2b:18:98:2d:d2:f7:7b:4d:02:1f:66:bb:5b:8d: 5a:dc:c5:a5:98:08:9d:34:5d exponent1: 24:8a:f3:8f:81:61:4e:f1:98:35:43:b0:02:37:46: 7d:08:c0:2c:4b:ed:b5:48:6b:16:9b:5b:4a:94:75: e0:a2:64:a8:7c:b3:09:15:06:51:06:e8:c3:96:cf: 4b:77:84:e6:74:a3:8b:9b:a8:99:58:d8:da:78:22: 8d:ea:de:7b:af:85:ed:51:3d:73:25:ad:e5:0f:13: 45:46:d4:16:da:a0:3a:99:e9:d8:67:60:ff:d0:4b: 87:f8:35:45:c8:29:3b:7a:ba:11:1c:5a:1f:50:e5: 3a:4e:92:f0:b9:c9:18:16:25:dc:ff:fb:34:f1:29: b5:38:e0:ac:04:b8:b0:c9 exponent2: 00:88:55:ba:eb:3e:a4:6d:f1:20:65:94:0b:b2:09: 43:0f:f7:5a:a9:bd:0f:83:66:d4:b3:1a:e1:a8:df: ce:fe:fd:06:d3:06:fb:39:c6:65:fc:96:bf:e0:57: 97:61:42:dc:cb:d6:12:2b:85:6f:66:0f:25:3e:07: 7c:7d:f6:73:27:3c:56:43:07:35:16:65:4e:6c:dc: 7f:86:63:63:d6:20:ed:a3:67:fb:74:60:72:a3:a8: 11:38:dc:d0:04:f1:61:ce:6f:eb:40:cf:cf:7e:33: 4c:13:99:a1:43:ae:b3:4f:ef:93:7d:c7:aa:c6:19: 0a:dd:d2:e3:f4:92:72:da:a5 coefficient: 1a:31:3b:04:0c:d4:ba:5a:16:b5:af:2b:c1:e6:64: 7c:5f:a7:db:11:5b:e5:00:54:57:5d:27:8d:04:91: ed:ec:1e:0f:20:d8:ac:d3:86:28:01:d8:d7:e3:69: fb:3d:d8:dd:93:26:a9:bb:c6:ec:b5:c1:43:09:03: a0:1b:60:25:f0:2a:3d:21:7c:ea:28:32:57:aa:91: 06:63:76:da:70:d8:75:28:3c:a0:fb:52:11:b0:34: 83:cd:10:1c:cf:55:3d:d0:15:f8:69:13:24:03:a7: 01:78:9c:15:a1:19:2b:f2:a1:9c:6a:3d:dc:9e:a3: df:35:b7:0a:5e:84:55:fa3-3. asn1parseオプションでの展開
openssl asn1parseコマンドでも展開できます。$ openssl asn1parse -in key-private.pem 0:d=0 hl=4 l=1187 cons: SEQUENCE 4:d=1 hl=2 l= 1 prim: INTEGER :00 7:d=1 hl=4 l= 257 prim: INTEGER :97E44F07205A1198D5D8B6FC678559DBD5F136F44A9FBEFBC171F1108223240AE04D71D2B513B662DD79A26CB5ED81EDD2FBF43588CC268C95D6715A68612C31D9A6A6A878BDB6461CD0E03F03DEEC87CE32E8E6508F40993B5A8E79448FFB3129D5A5810F445604885244D6C6969DD435FBFE013625F9F1C20357C42C64443F1721CBB13830957AAE7723F64E390722C423D88A30F7A755FE1F7DEAF0012D3CB57575A91E62D8383B94C5B1BA36FC4EDB7A7B787D5959C5BFE9C41FA76EFFD033408FE3B941A53D675D81B8A3D0B7194E3C7B5AE2B8F19581527BCA35417C825796DEAC5DC87E3080FF8993E2369EC56D0943D727CEA8C2E390DB05F99588E3 268:d=1 hl=2 l= 3 prim: INTEGER :010001 273:d=1 hl=4 l= 256 prim: INTEGER :0A0879B3E5CE2D456432C97B88B70545812F4ACAFE36E91DA61C89A8E67FBDBCBE2E3F6B84AC85AAA82885B31A9D52ACCBF7FA9CA2A9A18E3DC3897F484FCAE48C14F7033FDE8030C76C80B388E4EBC8D8B5022F5C78E9F2753A3919078F5F2F532D1A9E98CC91C600DF364EDD954B5D9E274412FE69A9C5EF63DB23492F6256927A5DBB3AD6465BAF214BE0B58E8B48E1C1AC28F1B27B37D0D580915112E11F12262851F712915846A3DC45F704B85E36BC104C1C8410563100C973BFD997D574722BE294D6F65E7F5D48300FDBC592C167BC71DED8EDFBFC814A0AFCCCC0CEB2BCFAF5CC06F7C72FE58C37B636ABD8E53D005E3AD0692889978E42C98D2789 533:d=1 hl=3 l= 129 prim: INTEGER :C6951A1E8091B5D9F15F187B12BFE8A81A6EA88BCD6B8A278BFB49100AE0C6DCB493C525E83A1099CBBBF4C8722A6DE13853C335E67264BB867B23837B7CD30D754B13C41CF64D4A0380795795E49C347444246F7313D0439D68304EBC9FE9E71D352F8BA4328380BBB766163B3263B9000A98734F7E859E269A7D426DA1DE3F 665:d=1 hl=3 l= 129 prim: INTEGER :C3CF3596B474E01A788E6F4D7E93DBA155E112455C4EBC5BAE8F4732AC94B580832513AD2CC8C6FA46AE1FFC8AE433E5160944A386464B115C164F719369F1AE52D3948FB08BBAF9F84ED64541F8CB34DD2264E627DD9D7391A4024168AE03B4FAA6E4207D38CAD61C2B18982DD2F77B4D021F66BB5B8D5ADCC5A598089D345D 797:d=1 hl=3 l= 128 prim: INTEGER :248AF38F81614EF1983543B00237467D08C02C4BEDB5486B169B5B4A9475E0A264A87CB30915065106E8C396CF4B7784E674A38B9BA89958D8DA78228DEADE7BAF85ED513D7325ADE50F134546D416DAA03A99E9D86760FFD04B87F83545C8293B7ABA111C5A1F50E53A4E92F0B9C9181625DCFFFB34F129B538E0AC04B8B0C9 928:d=1 hl=3 l= 129 prim: INTEGER :8855BAEB3EA46DF12065940BB209430FF75AA9BD0F8366D4B31AE1A8DFCEFEFD06D306FB39C665FC96BFE057976142DCCBD6122B856F660F253E077C7DF673273C5643073516654E6CDC7F866363D620EDA367FB746072A3A81138DCD004F161CE6FEB40CFCF7E334C1399A143AEB34FEF937DC7AAC6190ADDD2E3F49272DAA5 1060:d=1 hl=3 l= 128 prim: INTEGER :1A313B040CD4BA5A16B5AF2BC1E6647C5FA7DB115BE50054575D278D0491EDEC1E0F20D8ACD3862801D8D7E369FB3DD8DD9326A9BBC6ECB5C1430903A01B6025F02A3D217CEA283257AA91066376DA70D875283CA0FB5211B03483CD101CCF553DD015F869132403A701789C15A1192BF2A19C6A3DDC9EA3DF35B70A5E8455FA4. 秘密鍵ファイルの生成
続いて、秘密鍵ファイルから、公開鍵ファイルを生成してみましょう。
デフォルトでは標準出力に出力されます。$ openssl rsa -in key-private.pem -pubout writing RSA key -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAl+RPByBaEZjV2Lb8Z4VZ 29XxNvRKn777wXHxEIIjJArgTXHStRO2Yt15omy17YHt0vv0NYjMJoyV1nFaaGEs Mdmmpqh4vbZGHNDgPwPe7IfOMujmUI9AmTtajnlEj/sxKdWlgQ9EVgSIUkTWxpad 1DX7/gE2JfnxwgNXxCxkRD8XIcuxODCVeq53I/ZOOQcixCPYijD3p1X+H33q8AEt PLV1dakeYtg4O5TFsbo2/E7bent4fVlZxb/pxB+nbv/QM0CP47lBpT1nXYG4o9C3 GU48e1riuPGVgVJ7yjVBfIJXlt6sXch+MID/iZPiNp7FbQlD1yfOqMLjkNsF+ZWI 4wIDAQAB -----END PUBLIC KEY-----ここでは、
key-public.pemというファイルに書き出しておきます。$ openssl rsa -in key-private.pem -pubout > key-public.pem writing RSA key5. 秘密鍵ファイルの内容
5-1. catコマンドでの表示
catコマンドで公開鍵ファイルの中身を確認してみます。
$ cat key-public.pem -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAl+RPByBaEZjV2Lb8Z4VZ 29XxNvRKn777wXHxEIIjJArgTXHStRO2Yt15omy17YHt0vv0NYjMJoyV1nFaaGEs Mdmmpqh4vbZGHNDgPwPe7IfOMujmUI9AmTtajnlEj/sxKdWlgQ9EVgSIUkTWxpad 1DX7/gE2JfnxwgNXxCxkRD8XIcuxODCVeq53I/ZOOQcixCPYijD3p1X+H33q8AEt PLV1dakeYtg4O5TFsbo2/E7bent4fVlZxb/pxB+nbv/QM0CP47lBpT1nXYG4o9C3 GU48e1riuPGVgVJ7yjVBfIJXlt6sXch+MID/iZPiNp7FbQlD1yfOqMLjkNsF+ZWI 4wIDAQAB -----END PUBLIC KEY-----5-2.
-textオプションでの表示公開鍵ファイルを展開してみてみましょう。
秘密鍵ファイルを読み込ませる場合は、
-pubinのオプションを追加する必要があります。$ openssl rsa -in key-public.pem -pubin -text -noout RSA Public-Key: (2048 bit) Modulus: 00:97:e4:4f:07:20:5a:11:98:d5:d8:b6:fc:67:85: 59:db:d5:f1:36:f4:4a:9f:be:fb:c1:71:f1:10:82: 23:24:0a:e0:4d:71:d2:b5:13:b6:62:dd:79:a2:6c: b5:ed:81:ed:d2:fb:f4:35:88:cc:26:8c:95:d6:71: 5a:68:61:2c:31:d9:a6:a6:a8:78:bd:b6:46:1c:d0: e0:3f:03:de:ec:87:ce:32:e8:e6:50:8f:40:99:3b: 5a:8e:79:44:8f:fb:31:29:d5:a5:81:0f:44:56:04: 88:52:44:d6:c6:96:9d:d4:35:fb:fe:01:36:25:f9: f1:c2:03:57:c4:2c:64:44:3f:17:21:cb:b1:38:30: 95:7a:ae:77:23:f6:4e:39:07:22:c4:23:d8:8a:30: f7:a7:55:fe:1f:7d:ea:f0:01:2d:3c:b5:75:75:a9: 1e:62:d8:38:3b:94:c5:b1:ba:36:fc:4e:db:7a:7b: 78:7d:59:59:c5:bf:e9:c4:1f:a7:6e:ff:d0:33:40: 8f:e3:b9:41:a5:3d:67:5d:81:b8:a3:d0:b7:19:4e: 3c:7b:5a:e2:b8:f1:95:81:52:7b:ca:35:41:7c:82: 57:96:de:ac:5d:c8:7e:30:80:ff:89:93:e2:36:9e: c5:6d:09:43:d7:27:ce:a8:c2:e3:90:db:05:f9:95: 88:e3 Exponent: 65537 (0x10001)5-3.
asn1parseオプションでの表示秘密鍵ファイルと同様に、
openssl asn1parseコマンドで内容を展開することができます。$ openssl asn1parse -in key-public.pem 0:d=0 hl=4 l= 290 cons: SEQUENCE 4:d=1 hl=2 l= 13 cons: SEQUENCE 6:d=2 hl=2 l= 9 prim: OBJECT :rsaEncryption 17:d=2 hl=2 l= 0 prim: NULL 19:d=1 hl=4 l= 271 prim: BIT STRING最初に作った秘密鍵ファイルと公開鍵ファイルを見比べるとわかりますが、
公開鍵は、秘密鍵から(暗号化処理に必要となる)以下の項目を抽出した内容になっています。modulus INTEGER, -- n publicExponent INTEGER, -- e6. 整数e, d, n とpow関数を用いた暗号化/復号の実験
RSA公開鍵暗号化方式では、下記の手順で暗号化/復号を行うことができます。
暗号化
元の値をe乗してnで割った余りを得る復号
暗号化後の値をd乗してnで割った余りを得るさきほどの
openssl asn1parseの出力結果から、n, e, d に相当する部分を変数n, e, dに読み込ませます。
openssl asn1parseの出力結果は16進数ですので、int関数を使って16進数から10進数に変換すると良いでしょう。
int関数の第2引数に基数の16を指定すれば、10進数に変換して代入することができます。変数n
python>>> n = int('97E44F07205A1198D5D8B6FC678559DBD5F136F44A9FBEFBC171F1108223240AE04D71D2B513B662DD79A26CB5ED81EDD2FBF43588CC268C95D6715A68612C31D9A6A6A878BDB6461CD0E03F03DEEC87CE32E8E6508F40993B5A8E79448FFB3129D5A5810F445604885244D6C6969DD435FBFE013625F9F1C20357C42C64443F1721CBB13830957AAE7723F64E390722C423D88A30F7A755FE1F7DEAF0012D3CB57575A91E62D8383B94C5B1BA36FC4EDB7A7B787D5959C5BFE9C41FA76EFFD033408FE3B941A53D675D81B8A3D0B7194E3C7B5AE2B8F19581527BCA35417C825796DEAC5DC87E3080FF8993E2369EC56D0943D727CEA8C2E390DB05F99588E3', 16) >>> print(n) 19174567267106562614863777986013190733311720406517163236419798721057651041741132975692437635046772915985388744151381878391739010943167351904934011584525523379391186697776748275394847710370026168707668355363468298465929010753092617924044792285570698575811523066628303754919477816371556100017714944862167735437948517694796555955615103513053419306742815189247527511947589796524356990034768580398382078215058167355632932286761344674894465569796261922954597156699763620980072965273234707300569241109881200233991616854473630970425663335146366570862840409827825897729557509442076004084186075433324566154623231714988236572899変数e
>>> e = int('010001', 16) >>> print(e) 65537変数d
>>> d = int('0A0879B3E5CE2D456432C97B88B70545812F4ACAFE36E91DA61C89A8E67FBDBCBE2E3F6B84AC85AAA82885B31A9D52ACCBF7FA9CA2A9A18E3DC3897F484FCAE48C14F7033FDE8030C76C80B388E4EBC8D8B5022F5C78E9F2753A3919078F5F2F532D1A9E98CC91C600DF364EDD954B5D9E274412FE69A9C5EF63DB23492F6256927A5DBB3AD6465BAF214BE0B58E8B48E1C1AC28F1B27B37D0D580915112E11F12262851F712915846A3DC45F704B85E36BC104C1C8410563100C973BFD997D574722BE294D6F65E7F5D48300FDBC592C167BC71DED8EDFBFC814A0AFCCCC0CEB2BCFAF5CC06F7C72FE58C37B636ABD8E53D005E3AD0692889978E42C98D2789', 16) >>> print(d) 1266562425794655073618647403778798277072591629763535096975163780207494565813164542956994713247745242432530446517712622664416103550253619579725335858361093591549574243781002232085452427456121630290301605358323607489799757198988936676887710847372256193214338211322366403024954139906807854448276362914206083993922215094114776012124366236002371990952894667648628314166422099626061405451672662307764909200435879249013664134531240274310366361076547379589865534234754212903474203891892270277583495216595050906895706003102832662158785980707445928619686610586861592808732191214885213804349178521403558427718487767558413690761今回生成した鍵の鍵長は2048ビットなので、
元の値としては 0 ~ 2^2048-1 までの値を指定することができます。Python3のpow関数を使って暗号化/復号の処理を検証してみましょう。
とりあえず今回は、
暗号化したい元の値を999として、計算してみます。>>> res = pow(999, e, n) >>> print(res) 524543469488385391208649776185973445555945805700279654506952471132860336892462605649791076963494809100528555892416120164939727341582216996729091424255089000208944560774832745667292288852130261583027005786502988808264868095073383064006388838941814953270529661005557859554531440610634597104550314977758677359220270332738891641070581370988599952291373443267991140275169462890173229924742294722790318716574816586808362192527012499142400781383842103405401901384801647925304050154989496544788985011577610320345706511051127648308732239235134144620399441561198248345544962316221521339404384225995267012691211102015063665139 >>> pow(res, d, n) 999Lちゃんと元の値
999が取り戻せた様子が解ります。
(999Lの末尾のLは、長整数型であることを表します。)7. 整数d, e, n とpow関数を用いた電子署名/復号の実験
同様に、電子署名を生成する際の操作も確かめてみます。
電子署名の生成
元の値をd乗してnで割った余りを得る復号
生成した値をe乗してnで割った余りを得る元の値を
999として、計算してみましょう。>>> res = pow(999, d, n) >>> print(res) 12515145548924267994063078729711558694795939305875287590392530985593258425241072795063626446654873213977268021736112937973243180699117087520232129972712575525060239166094963345854149835308367216610630688466177263698932768887974675177666169711382251979967291763464839827987347286973550282470918001633660870333020695268293805924000830179825744511427332152587742208811697351651808682552483986509261284189871882421325531674159049062719085809968237649297132520093239037028418224856849358296300721149131689586359427295787997936203041546874958734266989850986012139160164407381286637028534638454642977487380551476319595646032 >>> pow(res, e, n) 999Lちゃんと元の値
999に戻った様子が解ります。8. 応用
ファイルの内容を読み込んで、上記の 7, 8 の処理を繰り返せば、
ファイル単位での暗号化/電子署名の生成/復号の処理が作れますね。当然ですが、OpenSSLにもファイル単位での暗号化/電子署名の生成/復号の機能が用意されています。
- 投稿日:2019-11-26T17:37:15+09:00
Pythonおよび機械学習勉強用のRaspberryPiの構築 (RaspberryPi4 & Buster版)
【内容】
ついにRaspberry Pi 4 model Bが日本で発売を開始しました。
早速使って見るべく、以前投稿した【Pythonおよび機械学習勉強用のRaspberryPiの構築】をラズパイ4版に書き直してみました。
ハードウェア以外にもRaspbianのバージョンを最新(Buster 20190926)にしてあります。なお、2019年11月26日現在、以下の問題があります。
- Edge TPUが正式には対応していない
- pip3でインストールできるTensorflowの最新版が1.13.1
- pip3でインストールできるOpenCVの最新版4.1.1.26が動かない (← 4.1.0.25 なら動く)
- MicroHDMIケーブルを持ってないので画面がない^^; (← Headlessセットアップしてます)
【本手順で作ったラズパイでできるようになること】
- Pythonの基礎学習
- データの可視化 (pandas, matplotlib)
- Computer Vision (OpenCV)
- 機械学習 (Scikit-Learn)
- DeepLearning (Tensorflow, Keras)
Coral Edge TPUを使った推論- 上記を使ったアプリの実装 (Flask)
【システム構成】
- Raspberry Pi Model 4B
- Raspbian Buster 20190926
Coral Edge TPU (オプション)【0. OSイメージの準備】
Raspbian Buster 20190926を使うことを想定しています。
2019年11月26日時点では公式サイトからはDLできますが、念の為ミラーサイトを記しておきます。
【Raspbian Buster 20190926 ミラーサイト (ftp.jaist.ac.jp) 】【1. OSイメージの書き込み & 起動】
1-1. OSイメージの書き込み
上記で準備したOSイメージをSDカードに書き込みます。
SDカードへの書き込み手順は、以下の記事を参考にしてください。1-2. ssh起動用ファイルの作成
現行バージョンのRaspbianではデフォルトではsshサービスが無効化されています。
これを自動起動できるようにSDカードの「Boot」パティションにssh(拡張子なし)という空のファイルを作ってください。
windowsをご利用の方は、標準では拡張子が非表示になっているので、拡張子が付いていないか確認してください。なお、
sshファイルはRaspberry Pi起動時に読み込まれて削除されます。1-3. Wifi接続用の設定ファイルの作成
ssh同様、「Boot」パティションにWifi設定用のファイルを置いておくと、自動的に読み込まれて適切な場所に書き込まれます。
具体的には「Boot」パティションに
wpa_supplicant.confという名前のファイルを作り、設定を記述します。
Wifiに接続するためには下記の内容を記載してください。
設定内容は接続するアクセスポイントに応じて変更する必要があります。wpa_supplicant.confctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 country=JP network={ ssid="<SSID名>" psk="<パスワード>" }1-4. Raspberry Piの起動
上記の準備ができたらPCからSDカードを取り出し、ラズパイ本体に挿入して電源を投入します。
【2. システムアップデート & ネットワーク設定】
2-1. システムアップデート
ラズパイが起動したらsshで接続するかコンソールのターミナルで以下のコマンドを実行して、システムアップデートを行います。
(数分かかります)システムアップデートsudo apt update sudo apt upgrade -y sudo reboot2-2. ipv6 無効化
必須ではありませんが、場合によっては邪魔する場合があるので無効化しておきます。
ipv6運用の場合は本設定は必要ありません。ipv6無効化設定sudo vi /etc/sysctl.conf【設定内容】
/etc/sysctl.confnet.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1【設定の反映】
設定反映sudo sysctl -p または sudo reboot2-3. IPアドレスの固定
必要に応じてIPアドレスを固定します。
DHCP環境で利用する場合は本設定は必要ありません。
本手順では無線LANでの運用を想定しているため、無線LANアダプタもしくはSSIDに対してIPの固定設定をしています。
具体的には/etc/dhcpcd.confに以下の内容を追加します。
<IPアドレス>、<ルータアドレス>、<DNSアドレス>、<your_ssid>は環境に応じて変更してください。/etc/dhcpcd.confinterface wlan0 inform <IPアドレス> static routers=<ルータアドレス> static domain_name_servers=<DNSアドレス> noipv6 または SSID <your_ssid> inform <IPアドレス> static routers=<ルータアドレス> static domain_name_servers=<DNSアドレス> noipv6複数の無線AP環境で利用する場合はSSIDで固定するのが便利です。
2-4. 無線LANのPowerManagementをOFFにする
優先LAN環境で利用する場合は本設定は必要ありません。
デフォルトでは無線LANのPowerManagement機能がONになっていますが、この機能のせいでWifi通信が不安定になる場合があります。
起動時に実行されるrc.localにPowerManagementをOFFにするコマンドを追加します。rc.localの編集sudo vi /etc/rc.localrc.local# exit文の前に以下を追加して保存 sudo iwconfig wlan0 power off再起動sudo reboot【3. 必要モジュールのインストール】
以下の操作で必要になるモジュールをインストールします。
(主にOpenCVおよびNumpyで利用)必要モジュールインストールsudo apt install -y libhdf5-dev libqtwebkit4 libqt4-test libatlas-base-dev libjasper-dev【4. Python3 関連のインストール】
4-1. 基本モジュールのインストール
Python3&pip3インストールsudo apt install python3 python3-dev -y4-1-1. pip3の最新化 (オプション)
本手順は特に実行する必要はありません
過去の手順を踏襲してpip3コマンドを最新化すると、pip3実行時にエラーを吐いて機能しなくなります。
# 下記コマンドを実行するとpip3が実行できなくなります sudo pip3 install pip -U pip3 -V # 上記コマンドでpip3が動かせなくなったら、下記コマンドでリカバリ sudo python3 -m pip uninstall pip sudo apt install python3-pip --reinstall一応、下記の手順でpip3コマンドを最新化することは可能ですが、本手順では特に必要ありませんでした。
# 既存のpip3コマンドをアンインストール sudo apt remove python3-pip # 最新のpip3コマンドをインストール wget https://bootstrap.pypa.io/get-pip.py sudo python3 get-pip.py # 一旦ログアウトして再ログイン後にバージョン確認 pip3 -V # setuptoolsの最新化 sudo pip3 install setuptools -U4-2. Python3の各種モジュールインストール
pipコマンドで各種のモジュールをインストールします。
numpyおよびpandasのバージョンを指定していますが、環境構築時点で最新のバイナリーパッケージが存在せずビルドが始まってインストールに時間がかかってしまうため、一つ前のバージョンを指定しています。
TensorFlowに関しては、環境構築時点で動作確認が取れている最新のものを指定しています。
それぞれ必要に応じて変更してください。Python3用各種モジュールインストール# numpy sudo pip3 install numpy # sklearn sudo pip3 install scipy sudo pip3 install sklearn # matplotlib sudo pip3 install matplotlib # pandas sudo pip3 install pandas # seaborn sudo pip3 install seaborn # Tensorflow (2019/11/26時点で最新は1.13.1) sudo pip3 install tensorflow # keras sudo pip3 install keras # flask sudo pip3 install flask flask_cors -U # OpenCV (2019/11/26時点で最新のRPi4では4.1.1.26は動かない) sudo pip3 install opencv-python==4.1.0.25なお、最近パッケージを管理している「https://www.piwheels.org/」の調子が悪いのか、pipがパッケージをダウンロードしている最中にセッションを切断され、結果インストールに失敗する場合が多々あります。
再実行すれば解決することが多いですが、scipyやtensorflowなどダウンロードサイズが大きいものはなかなか成功しません。
その際にはpip install実行時に表示されるダウンロード中のパッケージのURLをコピーして、wgetコマンドでそのファイルをローカルフォルダにダウンロードしてください。
wgetコマンドはダウンロードに失敗してもリジューム機能があるので、自動的にリトライしてなんとか目的のファイルをダウンロードしてくれます。
そのうえでpip3 install <ダウンロードしたファイル>を実行するとインストールできます。ミラーサイトがあればpipの参照先をそちらに向ければよいのですが、本記事を書いている時点ではわかりませんでしたので、ご存じの方がいらっしゃいましたら教えていただけると助かります。
【5. Edge TPU のインストール】
2019年11月26日時点で未対応です。
以下の記事を参考にしてください。
なお本項目は必須ではありません。
【Coral USB TPU Accelerator(EdgeTPU)をとりあえず使う (Quick Start)】【6. Jupyter Lab】
強力なNotebook環境が利用できるようになるJupyter Labをインストールします。
6-1. 基本インストール
【インストール】
下記のコマンドでインストールします。JupyterLabインストールsudo pip3 install jupyterlab【設定】
インストールが完了したら下記のコマンドで設定ファイルを作成した上で、作成された設定ファイルを編集します。
下記手順ではどの端末からも接続でき、接続時にパスワードを要求するように設定しています。設定ファイルの作成jupyter notebook --generate-config【設定ファイルの編集】
設定ファイルの編集vi ~/.jupyter/jupyter_notebook_config.py【設定内容】
jupyter_notebook_config.pyc.NotebookApp.ip = '*' c.NotebookApp.open_browser = False c.NotebookApp.password = 'sha1:<ハッシュ化されたパスワード>'なお、パスワードのハッシュ化は以下のコマンドで取得できます。
パスワードのハッシュ化python3 -c 'from notebook.auth import passwd;print(passwd())' (上記実行後、ハッシュ化したい文字を入力)6-2. Node jsのインストール
JupyterLabの拡張機能を利用するために、Node jsをインストールします。
NodeJsインストールsudo apt -y install nodejs npm6-3. Jputer Labの起動
Jupyter Labの起動は以下のコマンドで実行します。
JupyterLab起動jupyter lab6-4. ブラウザから接続
上記でJupyter Labを起動した状態で、ブラウザから以下のURLに接続してください。
上記手順では、他のPCからも接続できる設定になっていますので、ぜひご自分のPCからJupyterLabに接続して操作してみてください。http://<ip_address>:8888/labパスワードを要求されるので、上記で設定したパスワードを入力してください。
【最後に】
一部課題もありますが、ほぼ過去の手順を踏襲して環境を構築ができました。
まだ細かい動作確認は行っていなので、何かありましたらコメントください。また、今回はEdgeTPUには対応していませんが、EdgeTPUのサンプルプログラムが動くところまではいっていますので、近日中の公開します。
- 投稿日:2019-11-26T17:31:16+09:00
conda と pip でのパッケージ管理について
Anaconda は一言でいうと Python 本体に加え科学計算のライブラリ等が最初から付属されているものです。またパッケージ管理とデプロイを簡略化するための工夫がなされており conda というパッケージ管理コマンドが付属しています。
conda と pip について
Python の世界ではかなり昔からそれ自体にパッケージ管理ツールというのが付属していて、昔は EasyInstall なるものを使っており pip を使うためにはあとからセットアップしなければならなかった。いちいち面倒であった。最近の Python ではすっかりデフォルトで pip が付属していて最高の時代になっている。このコマンドを使うと PyPI というサイトに公開しているパッケージをコマンドによりインターネット経由でインストールできる。最高の時代である。
さて、よくある話が conda と pip を併用すると「壊れる」という言説。なにをもって壊れると主張しているのかよくわかりませんが、そもそも同じパッケージに対し conda で入れたり pip で入れたりしている状況が異常なわけです。壊れているのはパッケージ管理システムではなくむしろ支離滅裂なことをやろうとしているあなたの頭ではないかと。
誤解を招かないように言っておきますが Anaconda では基本 conda というコマンドを打ってパッケージを入れるが pip を使うこともできる。前者の conda は Anaconda 社のリポジトリから入れる。後者の pip は PyPI から入れる。当然、後者のほうがたくさんパッケージがある。また PyPI は審査とかあるわけではないので、誰でもパッケージ作者になれる。極端な話、変なソースコードを書いて PyPI で公開しても、誰もチェックしていないのが現状である。自分のプロジェクトにしか使わないようなソースコードをパッケージ化して PyPI に置いても誰にも何とも言われない。
一方 Anaconda 社のリポジトリは一応会社が管理しているものなので、それなりにはチェックしているとは思うが別に自分は中の人ではないので「チェックしてます!」と保証するつもりはない。
またコミュニティが運営する conda-forge というリポジトリもあり、こちらから conda で入れることもできる。でもそれを使う時点で結局コミュニティの成果物じゃないか、とまあそんな感じです。
ぶっちゃけて言えば、パッケージとパッケージ間の依存関係なんて、作者の都合で依存しているものなので、 Python の世界全体を見渡してそれらの関係性を厳密に検証している人間なんていない。使うあなた次第ってことですね。
こういう議論は Python に限らずたとえば Ruby のパッケージ管理システムでも昔から議論になっていて、結局みんな好き勝手にパッケージを作っているのだからフリーダム。オープンソースなんてそんなもの。使う人が検証すればよろしいみたいな雰囲気になっているものと思う。
パッケージ間の依存関係を徹底的に検証して品質を維持しているのって Debian 安定版くらいのものじゃないか、と個人的には思っている。
pip での依存情報の表示
パッケージメンテナや作者は知っていると思いますが PyPI に登録するときにはパッケージの配布ファイルに色々メタ情報を書きます。
で、依存情報はどうやって調べるかというと、以下のコマンドで表示できます。
pip install pipdeptree # pip で入れる pipdeptree -p <パッケージ名>例えば pandas というパッケージについてバージョンごとにいくつか例を挙げるとこんな感じ。
pandas==0.16.2 - numpy [required: >=1.7.0, installed: 1.11.2] - python-dateutil [required: >=2, installed: 2.6.0] - six [required: >=1.5, installed: 1.10.0] - pytz [required: >=2011k, installed: 2016.7] pandas==0.22.0 - numpy [required: >=1.9.0, installed: 1.13.3] - python-dateutil [required: >=2, installed: 2.6.1] - six [required: >=1.5, installed: 1.11.0] - pytz [required: >=2011k, installed: 2017.2]これを見ればどのパッケージがどのパッケージのどのバージョンに依存しているのか把握できる。
conda と pip の両方で重複しているパッケージの表示
よくあるのが conda で管理しているのに、意図せず pip でも入れてしまうという事故。というわけで重複しているパッケージは以下のワンライナーで表示できます。
conda list | cut -d ' ' -f 1 | sort | uniq -dたまにチェックして重複していないか確認しておくと良いです。
まとめ
というわけで長くなりましたが、まとめると
・Anaconda のパッケージ管理には conda と pip コマンドが付属している。
・基本は conda を利用して Anaconda のリポジトリを参照する。
・conda に無いものは pip で入れる。
・たまに重複していないかチェックして、重複しているなら conda を優先する。これらを参考に、目的となる環境を構築すればよろしい。
こんな感じかと思います。異論は認めるので各位ご意見をいただければと。雑ですが以上です。
- 投稿日:2019-11-26T17:19:02+09:00
強化学習20 Colaboratory+Pendulum+ChainerRL
強化学習19まで終了していることが前提です。
今までのをいじるのでは限界だったので、chainerrl/examples/gym/train_dqn_gym.py
をほぼそのままに、colaboratory notebookにしました。
工夫した点は、args = parser.parse_args('')くらいです。
50分くらいかかっていましたが、上々でしょう。
細かいところはよくわかりません。import google.colab.drive google.colab.drive.mount('gdrive') !ln -s gdrive/My\ Drive mydrive!apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1 !pip install pyvirtualdisplay > /dev/null 2>&1 !pip -q install JSAnimation !pip -q install chainerrlfrom __future__ import print_function from __future__ import unicode_literals from __future__ import division from __future__ import absolute_import from builtins import * # NOQA from future import standard_library standard_library.install_aliases() # NOQA import argparse import os import sys from chainer import optimizers import gym from gym import spaces import numpy as np import chainerrl from chainerrl.agents.dqn import DQN from chainerrl import experiments from chainerrl import explorers from chainerrl import links from chainerrl import misc from chainerrl import q_functions from chainerrl import replay_buffer import logging logging.basicConfig(level=logging.INFO, stream=sys.stdout, format='') parser = argparse.ArgumentParser() parser.add_argument('--outdir', type=str, default='mydrive/OpenAI/Pendulum/result') parser.add_argument('--env', type=str, default='Pendulum-v0') parser.add_argument('--seed', type=int, default=0), parser.add_argument('--gpu', type=int, default=0) parser.add_argument('--final-exploration-steps',type=int, default=10 ** 4) parser.add_argument('--start-epsilon', type=float, default=1.0) parser.add_argument('--end-epsilon', type=float, default=0.1) parser.add_argument('--noisy-net-sigma', type=float, default=None) parser.add_argument('--demo', action='store_true', default=False) parser.add_argument('--load', type=str, default=None) parser.add_argument('--steps', type=int, default=10 ** 5) parser.add_argument('--prioritized-replay', action='store_true') parser.add_argument('--replay-start-size', type=int, default=1000) parser.add_argument('--target-update-interval', type=int, default=10 ** 2) parser.add_argument('--target-update-method', type=str, default='hard') parser.add_argument('--soft-update-tau', type=float, default=1e-2) parser.add_argument('--update-interval', type=int, default=1) parser.add_argument('--eval-n-runs', type=int, default=100) parser.add_argument('--eval-interval', type=int, default=10 ** 4) parser.add_argument('--n-hidden-channels', type=int, default=100) parser.add_argument('--n-hidden-layers', type=int, default=2) parser.add_argument('--gamma', type=float, default=0.99) parser.add_argument('--minibatch-size', type=int, default=None) parser.add_argument('--render-train', action='store_true') parser.add_argument('--render-eval', action='store_true') parser.add_argument('--monitor', action='store_true') parser.add_argument('--reward-scale-factor', type=float, default=1e-3) args = parser.parse_args('') # Set a random seed used in ChainerRL misc.set_random_seed(args.seed, gpus=(args.gpu,)) if os.path.exists(args.outdir): raise RuntimeError('{} exists'.format(args.outdir)) else: os.makedirs(args.outdir) print('Output files are saved in {}'.format(args.outdir)) def clip_action_filter(a): return np.clip(a, action_space.low, action_space.high) def make_env(test): env = gym.make(args.env) # Use different random seeds for train and test envs env_seed = 2 ** 32 - 1 - args.seed if test else args.seed env.seed(env_seed) # Cast observations to float32 because our model uses float32 env = chainerrl.wrappers.CastObservationToFloat32(env) if args.monitor: env = chainerrl.wrappers.Monitor(env, args.outdir) if isinstance(env.action_space, spaces.Box): misc.env_modifiers.make_action_filtered(env, clip_action_filter) if not test: # Scale rewards (and thus returns) to a reasonable range so that # training is easier env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor) if ((args.render_eval and test) or (args.render_train and not test)): env = chainerrl.wrappers.Render(env) return env env = make_env(test=False) timestep_limit = env.spec.tags.get( 'wrapper_config.TimeLimit.max_episode_steps') obs_space = env.observation_space obs_size = obs_space.low.size action_space = env.action_space action_size = action_space.low.size # Use NAF to apply DQN to continuous action spaces q_func = q_functions.FCQuadraticStateQFunction( obs_size, action_size, n_hidden_channels=args.n_hidden_channels, n_hidden_layers=args.n_hidden_layers, action_space=action_space) # Use the Ornstein-Uhlenbeck process for exploration ou_sigma = (action_space.high - action_space.low) * 0.2 explorer = explorers.AdditiveOU(sigma=ou_sigma) if args.noisy_net_sigma is not None: links.to_factorized_noisy(q_func, sigma_scale=args.noisy_net_sigma) # Turn off explorer explorer = explorers.Greedy() # Draw the computational graph and save it in the output directory. chainerrl.misc.draw_computational_graph( [q_func(np.zeros_like(obs_space.low, dtype=np.float32)[None])], os.path.join(args.outdir, 'model')) opt = optimizers.Adam() opt.setup(q_func) rbuf_capacity = 5 * 10 ** 5 if args.minibatch_size is None: args.minibatch_size = 32 if args.prioritized_replay: betasteps = (args.steps - args.replay_start_size) \ // args.update_interval rbuf = replay_buffer.PrioritizedReplayBuffer( rbuf_capacity, betasteps=betasteps) else: rbuf = replay_buffer.ReplayBuffer(rbuf_capacity) agent = DQN(q_func, opt, rbuf, gpu=args.gpu, gamma=args.gamma, explorer=explorer, replay_start_size=args.replay_start_size, target_update_interval=args.target_update_interval, update_interval=args.update_interval, minibatch_size=args.minibatch_size, target_update_method=args.target_update_method, soft_update_tau=args.soft_update_tau, ) if args.load: agent.load(args.load) eval_env = make_env(test=True) experiments.train_agent_with_evaluation( agent=agent, env=env, steps=args.steps, eval_n_steps=None, eval_n_episodes=args.eval_n_runs, eval_interval=args.eval_interval, outdir=args.outdir, eval_env=eval_env, train_max_episode_len=timestep_limit) agent.save(args.outdir+'/agent')import pandas as pd import glob import os score_files = glob.glob(args.outdir+'/scores.txt') score_files.sort(key=os.path.getmtime) score_file = score_files[-1] df = pd.read_csv(score_file, delimiter='\t' ) dfdf.plot(x='steps',y='average_q')from pyvirtualdisplay import Display display = Display(visible=0, size=(1024, 768)) display.start()from JSAnimation.IPython_display import display_animation from matplotlib import animation import matplotlib.pyplot as plt %matplotlib inline frames = [] env = gym.make(args.env) # Use different random seeds for train and test envs env_seed = args.seed env.seed(env_seed) # Cast observations to float32 because our model uses float32 env = chainerrl.wrappers.CastObservationToFloat32(env) misc.env_modifiers.make_action_filtered(env, clip_action_filter) # Scale rewards (and thus returns) to a reasonable range so that # training is easier env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor) envw = gym.wrappers.Monitor(env, args.outdir, force=True) for i in range(3): obs = envw.reset() done = False R = 0 t = 0 while not done and t < 200: frames.append(envw.render(mode = 'rgb_array')) action = agent.act(obs) obs, r, done, _ = envw.step(action) R += r t += 1 print('test episode:', i, 'R:', R) agent.stop_episode() #envw.render() envw.close() from IPython.display import HTML plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),dpi=72) patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),interval=50) anim.save(args.outdir+'/test.mp4') HTML(anim.to_jshtml())
- 投稿日:2019-11-26T17:11:50+09:00
icrawlerを使用して画像を収集する
pip install icrawlermain.pyfrom icrawler.builtin import GoogleImageCrawler # 車の画像取得 crawler = GoogleImageCrawler(storage={"root_dir": "car"}) crawler.crawl(keyword="車", max_num=100) #100枚の画像を取得
- 投稿日:2019-11-26T16:24:36+09:00
Blueqatのバックエンドを作る 〜 その2
簡単に量子プログラミングが始められるBlueqatライブラリ
を開発しています。
https://github.com/Blueqat/Blueqat前回
Blueqatのバックエンドを作る 〜 その1では、OpenQASMの入力を受け入れられるシミュレータのバックエンドの作り方を説明しました。
今回は、そうでない一般の場合のバックエンドの作り方を説明します。全部自分で作る方法
最低限、
Backendを継承して、runメソッドを実装すれば、バックエンドが作れます。
また、バックエンドオブジェクト自体のコピーが、copy.deepcopyでは都合が悪い場合は、copyメソッドも再実装します。
runメソッドはrun(self, gates, n_qubits, *args, **kwargs)の形になっています。
gatesは、量子ゲートのオブジェクトのリスト、n_qubitsは、量子ビット数、*args,**kwargsには、ユーザがCircuit().run()を呼び出したときのrunの引数が渡されます。これさえ実装すれば、バックエンドはできるのですが、さすがに開発者に丸投げしすぎているので、次のようなフローを用意しています。
ややこしそうに思えますが、フローに乗っかれば、実装をやや楽にすることができます。
また、runメソッドを再実装する際も、用意しているものを流用してもいいかもしれません。用意しているフローに乗っかる方法
全体的な流れ
デフォルトでは、
runメソッドを呼ぶと、以下のコードが呼び出されます。def _run(self, gates, n_qubits, args, kwargs): gates, ctx = self._preprocess_run(gates, n_qubits, args, kwargs) self._run_gates(gates, n_qubits, ctx) return self._postprocess_run(ctx) def _run_gates(self, gates, n_qubits, ctx): """Iterate gates and call backend's action for each gates""" for gate in gates: action = self._get_action(gate) if action is not None: ctx = action(gate, ctx) else: ctx = self._run_gates(gate.fallback(n_qubits), n_qubits, ctx) return ctxバックエンド開発者が実装すべきものは
_preprocess_runメソッド- 各ゲートごとのaction
_postprocess_runメソッドです。
ctxについて
ここで
ctxと書かれている変数に注目してください。
この変数は、runが始まってから終わるまでの状態を保持するための変数です。(不要ならばNoneで構わないですが、全く不要となるケースは少ないと思います)
バックエンド自体も普通のオブジェクトなのでself.foo = ...などとすれば状態を持たせられますが、バグ等の原因になりますので、できるだけctxを使ってください。
ctxに保存するものの一例として、
- 量子ビット数
- 計算途中の状態ベクトル
runメソッドの入力オプションや、それをパースしたもの- その他、作るのに時間がかかるものや、状態を持っているもの
などがあります。
(量子ビット数をctxに残しておかないと、実行中には分からないことについては、注意が必要です)また、
ctxに注目して上のコードを見ると
_preprocess_runでctxオブジェクトを作る- 各ゲートごとのactionを呼び出す際、
ctxオブジェクトが渡される。また、actionはctxオブジェクトを返すよう実装することが期待されている_postprocess_runはctxを受け取りrunの結果を返すという流れになっています。
actionの定義
量子回路は、ゲートを並べることで作られています。
典型的なバックエンドの実装方法として、並んでいるゲートを順次適用していく、というものがあります。ゲートを適用する操作をここではactionと言っています。
actionを実装するには、単にメソッドを追加すればよく、def gate_{ゲート名}(self, gate, ctx): # なにか実装 return ctxのようにします。
Blueqatの特徴として、
Circuit().h[:]のようなスライス表記がありましたが、スライス表記をバラすためのメソッドも用意していて、for idx in gate.target_iter(量子ビット数)のようにすると1量子ビットゲートのインデックスがとれます。また、CNOTなどの2量子ビットゲートのインデックスはfor c, t in gate.control_target_iter(量子ビット数)のようにします。
ここで量子ビット数が必要なのはCircuit().h[:]などのようにしたとき、何量子ビット目まで適用するかを知るためです。定義が必要なaction
全部のゲートは実装する必要がありません。
例えば、TゲートやSゲートは、回転Zゲート(RZ)があれば作ることができるので、Blueqat側で、そういったゲートについては、実装されていなければ別のゲートを代わりに使うように面倒を見ています。また、代わりのゲートがないと、もし使われた場合はエラーになりますが、使われなかった場合はエラーにならないので、一部のゲートのみをサポートしたバックエンドを作っても構いません。(たとえばXゲート、CXゲート、CCXゲートのみを実装すると、古典の論理回路に特化したバックエンドを作れます。ただのビット演算で実装できるので高速に動作するものが作成できます)
実装が必要なゲートは今後整理するかもしれませんが、現状は
X, Y, Z, H, CZ, CX, RX, RY, RZ, CCZ, U3と測定です。(測定も、ゲートと同じようにactionを定義します)実装例を見る
やや変わり種のバックエンドに
QasmOutputBackendがあります。
これは、シミュレータではなく、Blueqatの量子回路をOpenQASMに変換するためのバックエンドです。
ctxには、OpenQASMの行のリストと量子ビット数を保持します。
また、各actionでは、リストに行を追加していきます。コード全体はこちら。
class QasmOutputBackend(Backend): """Backend for OpenQASM output.""" def _preprocess_run(self, gates, n_qubits, args, kwargs): def _parse_run_args(output_prologue=True, **_kwargs): return { 'output_prologue': output_prologue } args = _parse_run_args(*args, **kwargs) if args['output_prologue']: qasmlist = [ "OPENQASM 2.0;", 'include "qelib1.inc";', f"qreg q[{n_qubits}];", f"creg c[{n_qubits}];", ] else: qasmlist = [] return gates, (qasmlist, n_qubits) def _postprocess_run(self, ctx): return "\n".join(ctx[0]) def _one_qubit_gate_noargs(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"{gate.lowername} q[{idx}];") return ctx gate_x = _one_qubit_gate_noargs gate_y = _one_qubit_gate_noargs gate_z = _one_qubit_gate_noargs gate_h = _one_qubit_gate_noargs gate_t = _one_qubit_gate_noargs gate_s = _one_qubit_gate_noargs def _two_qubit_gate_noargs(self, gate, ctx): for control, target in gate.control_target_iter(ctx[1]): ctx[0].append(f"{gate.lowername} q[{control}],q[{target}];") return ctx gate_cz = _two_qubit_gate_noargs gate_cx = _two_qubit_gate_noargs gate_cy = _two_qubit_gate_noargs gate_ch = _two_qubit_gate_noargs gate_swap = _two_qubit_gate_noargs def _one_qubit_gate_args_theta(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.theta}) q[{idx}];") return ctx gate_rx = _one_qubit_gate_args_theta gate_ry = _one_qubit_gate_args_theta gate_rz = _one_qubit_gate_args_theta def gate_i(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"id q[{idx}];") return ctx def gate_u1(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.lambd}) q[{idx}];") return ctx def gate_u2(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.phi},{gate.lambd}) q[{idx}];") return ctx def gate_u3(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.theta},{gate.phi},{gate.lambd}) q[{idx}];") return ctx def gate_cu1(self, gate, ctx): for c, t in gate.control_target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.lambd}) q[{c}],q[{t}];") return ctx def gate_cu2(self, gate, ctx): for c, t in gate.control_target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.phi},{gate.lambd}) q[{c}],q[{t}];") return ctx def gate_cu3(self, gate, ctx): for c, t in gate.control_target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.theta},{gate.phi},{gate.lambd}) q[{c}],q[{t}];") return ctx def _three_qubit_gate_noargs(self, gate, ctx): c0, c1, t = gate.targets ctx[0].append(f"{gate.lowername} q[{c0}],q[{c1}],q[{t}];") return ctx gate_ccx = _three_qubit_gate_noargs gate_cswap = _three_qubit_gate_noargs def gate_measure(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"measure q[{idx}] -> c[{idx}];") return ctx
_preprocess_runを見るdef _preprocess_run(self, gates, n_qubits, args, kwargs): def _parse_run_args(output_prologue=True, **_kwargs): return { 'output_prologue': output_prologue } args = _parse_run_args(*args, **kwargs) if args['output_prologue']: qasmlist = [ "OPENQASM 2.0;", 'include "qelib1.inc";', f"qreg q[{n_qubits}];", f"creg c[{n_qubits}];", ] else: qasmlist = [] return gates, (qasmlist, n_qubits)まずやっていることは、オプションの解析です。
Circuit().run(backend='qasm_output', output_prologue=False)のようにoutput_prologueオプションを付けて実行される場合があるので、オプションの解析を行っています。
このオプションはデフォルトではTrueですが、Falseが指定された場合、OpenQASMの冒頭に付け加えられるOPENQASM 2.0; include "qelib1.inc"; qreg q[ビット数]; creg c[ビット数];を省略します。
続いて、ctxは、OpenQASMの行のリストと、量子ビット数のタプルとしています。
gatesとctxを返していますが、gatesは引数で渡されたものをそのまま返しています。
gatesを_preprocess_runで返すことにしているのは、最適化等でゲート列を操作したい場合などを考慮したためですが、特に行う必要がなければ、受け取った引数をそのまま返します。actionを見る
def _one_qubit_gate_noargs(self, gate, ctx): for idx in gate.target_iter(ctx[1]): ctx[0].append(f"{gate.lowername} q[{idx}];") return ctx gate_x = _one_qubit_gate_noargs gate_y = _one_qubit_gate_noargs gate_z = _one_qubit_gate_noargs # いっぱいあるので略 def gate_cu3(self, gate, ctx): for c, t in gate.control_target_iter(ctx[1]): ctx[0].append(f"{gate.lowername}({gate.theta},{gate.phi},{gate.lambd}) q[{c}],q[{t}];") return ctxこんな感じでやっていきます。x, y, zゲートなどは、一個一個作るのが面倒なので横着しています。
横着できない場合は、gate_cu3のように丁寧に実装します。
やっていることは、ctxが([行のリスト], 量子ビット数)でしたので、ctx[0].append(...)で行のリストに新たな行を追加しているだけです。
_postprocess_runを見るdef _postprocess_run(self, ctx): return "\n".join(ctx[0])単純に、行のリストを、改行区切りの文字列にして返しているだけです。
この結果が、runの結果になります。まとめ
前回は、OpenQASMを読み込める処理系のためのバックエンド実装方法を見ていきましたが、今回は、より汎用的なバックエンドの実装方法を見ていきました。
Blueqatでは、ライブラリ側でできるだけ多く面倒を見ることと、開発者やユーザがやりたいことをできるようにすることの両立を目指していて、Blueqatが用意した仕組みに乗っかってバックエンドを簡単に作ることもでき、乗っからずにフルで
runメソッドを実装することもできます。バックエンド自体は、誰でも作ることができ、みなさんの自作シミュレータをBlueqatのインタフェースで使うことも可能です。
ぜひ皆さん、バックエンドの実装をしてみてください。
- 投稿日:2019-11-26T16:05:40+09:00
Kaggleのタイタニック号のチュートリアルを試す
KaggleのTitanicのチュートリアルをやってみました。
Pandasやscikit-learnの使い方を覚えるためにJupyter NoteBook上でのコードをここに記録しておきます。Kaggleは実際のデータをもとに機械学習をしてそのスコアを競うサイトです。
コンペティションに参加しなくてもチュートリアルがいくつかあり、機械学習に使える実際のデータがそろっているので、機械学習を勉強するにはとても便利です。
Kaggleの使い方やタイタニック号のチュートリアルについては
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
を参考にしました。私のコードは、上記記事を参考にしつつ、自分でわかりやすいように変えています。
Kaggleにユーザ登録すると
Titanic: Machine Learning from Disaster | Kaggle
からデータをダウンロードできるようになります。アルゴリズムは決定木です。
これ以降は、
Jupyter NotebookをDockerを使って簡単にインストールし起動(nbextensions、Scalaにも対応) - Qiita
に従って準備したJupyter Notebookの環境で試しています。このJupyterの環境でブラウザで8888番ポートにアクセスして、Jupyter Notebookを使うことができます。右上のボタンのNew > Python3をたどると新しいノートを開けます。
データ準備
import numpy as np import pandas as pd train = pd.read_csv("train.csv") test = pd.read_csv("test.csv")
train、testはDataFrameのオブジェクトになります。
データの前処理を
train、testとで共通して行うためにいったんデータを連結します。あとで再度分割できるようにフラグを入れておきます。またSurvivedという列はtrainにしか含まれていませんので、これはいったん削除します。train["is_train"] = 1 test["is_train"] = 0 data = pd.concat([train.drop(columns=["Survived"]), test])
train.drop(columns=["Survived"])は列を削除した新しいDataFrameオブジェクトを返します。新しいオブジェクトを返すので、元のtrainには列は残ったままです。なお、train.drop(["Survived"], axis=1)と書いても同じです。axis=1は行ではなく列を削除というフラグです。が、前者のほうがわかりやすいです。
pd.concatは複数のDataFrameを連結した新しいDataFrameを返します。ちなみにpd.concatにaxis=1を渡すと横方向に連結します。連結した結果、こんなデータになります。1309行のデータです。
欠損データに対応
欠損データの状況を確認します。上のスクショで
NaNと表示されている箇所がもとのCSVファイルでは空になっていた箇所でデータが欠損しています。data.isnull().sum()
以下のコードでどんなデータがあるかや、中央値を確認できます。
data["Age"].unique() data["Age"].median()
Ageの項目の欠損箇所には中央値を入れることにします。data["Age"] = data["Age"].fillna(data["Age"].median())
Embarkedにはどんなデータがあるかを確認します。データごとにそのレコード数を確認できます。data["Embarked"].value_counts()
Embarkedは多くをSが占めているようですので、欠損箇所にはSを入れることにします。data["Embarked"] = data["Embarked"].fillna("S")data.isnull().sum()文字列データを数値に変換
次に、文字列になっている
SexとEmbarkedの項目を数値に変換します。
EmbarkedにはS, C, Qの3パターンしかありませんでしたので、こんな風に変換したいと思います。これをワンホットエンコーディング(one-hot encoding)といいます。
Embarked S S C Q ↓
Embarked_C Embarked_Q Embarked_S 0 0 1 0 0 1 1 0 0 0 1 0 one-hot encodingは
pd.get_dummiesという関数でできます。pd.get_dummies(data["Embarked"], prefix="Embarked")]というコードはEmbarked_S,Embarked_C,Embarked_Qという3列のDataFrameを生成します。3列のうちのどれかが1になっていて、それ以外が0になっています。これをもとのdataと横に連結して、もともとのEmbarked列を削除します。data = pd.concat([data, pd.get_dummies(data["Embarked"], prefix="Embarked")], axis=1).drop(columns=["Embarked"])
Sexはmaleとfemaleしかありませんでしたので、2列にする必要はなく、0, 1の1列で足ります。
Sex male female female ↓
Sex 1 0 0
pd.get_dummiesにdrop_first=Trueというオプションを付けると1列目を削除して、結果1列のみにしてくれるようです。data["Sex"] = pd.get_dummies(data["Sex"], drop_first=True)
pd.get_dummiesで生成した2列のうち1列目がたまたまfemaleだったからか、maleのほうが1でfemaleが0になりました。どっちになってもいいと思います。結果こういうデータになりました。
前処理をした
dataを再び訓練データと検証データに分割し、さらに今回使用する列のみに絞ります。feature_columns =["Pclass", "Sex", "Age", "Embarked_C", "Embarked_Q", "Embarked_S"] feature_train = data[data["is_train"] == 1].drop(columns=["is_train"])[feature_columns] feature_test = data[data["is_train"] == 0].drop(columns=["is_train"])[feature_columns]目的変数は
dataには含まれてませんでしたので、最初のtrainから抽出します。target_train = train["Survived"]学習
モデルを学習します。
from sklearn import tree model = tree.DecisionTreeClassifier() model.fit(feature_train, target_train)参考
sklearn.tree.DecisionTreeClassifier — scikit-learn 0.21.3 documentation訓練データで正解率を見てみます。
from sklearn import metrics pred_train = model.predict(feature_train) metrics.accuracy_score(target_train, pred_train)
0.9001122334455668と出ました。9割が正解のようです。評価
Kaggleに推論結果を登録して評価してみます。
まず
my_prediction.csvに検証データでの推測結果を保存します。pred_test = model.predict(feature_test) my_prediction = pd.DataFrame(pred_test, test["PassengerId"], columns=["Survived"]) my_prediction.to_csv("my_prediction.csv", index_label=["PassengerId"])CSVファイルの1行目はヘッダ行で、
PassengerId,Survivedになっています。このファイルをKaggleのサイトにアップすると、スコアを出してくれます。
0.74641でした。






- 投稿日:2019-11-26T16:04:03+09:00
タミヤ楽しい工作シリーズをDonkeyCar化する
AI RCカー Advent Calendar 2019 参加記事です。
タミヤの工作シリーズ「ブルドーザ」 をベースにAI自律走行カーDonkey Car をつくってみました。実際に走行会にて周回コースを次回学習モデルを使って走行させてみました。
今回使用したソースコードや作り方は、GitHub 側に詳しく書いていますので、この記事では概要と改変ポイントなどを紹介します。
1 Donkey Car とは
Donkeycar は、Raspberry Pi/Jetson Nano や市販のRCカーなど比較的入手しやすい部品を使って、自律走行を実現するためのMIT準拠のオープンソースおよび3Dプリンタ用設計図(Creative Commons)などを含むドキュメントのセットです。
2. Donkey Car をはじめるには
Donkey Carを始めるには、ドキュメントに従って、各自で部品を調達し、 Donkey Car を組み立て、ソフトウェアを導入・設定を行う必要があります。DIYが得意ではない方や、プログラミングやソフトウェアに詳しくない方でも参加できるように、コミュニティでは標準 Donkey Car キットを販売しているので、こちらをまず購入することをおすすめします。
私も最初のDonkey Carは香港の Robocar Store で購入して組み立てました。その際の組み立て方は こちら を参照してください。
香港の標準DonkeyCarのバッテリはタミヤのミニコネクタを使用しています。この形状のバッテリは国内だと入手が難しいかもしれません..
海外のサイトでの購入はちょっと..という方は、国内で販売されている会社が何社かありますので、検索してみてください。
3. Donkey Carの自律走行
Donkey Car における自律走行は、 周回コースをできるだけ早く走行する ことを目的としています。このため、指定された場所で人やモノを乗せ、移動するといった、複雑な自律走行はできません。Donkey Carをコース上にのせて自動運転モードにすると、周回コースをずっと走り続けます。
Donkey Carのデフォルト自律走行モデルでは"教師あり機械学習"を採用しています。
詳細は説明しませんが、Donkey シミュレータを使った強化学習モデルを扱うことも可能です。
入力データは前方に搭載されたカメラの画像(120x160x3,nd.array型)、出力データはRCカーのステアリング・スロットルへの出力値(float×2)を使用します。ただしDonkey Carには いくつか別のモデル も用意されており、入力データや出力データが異なるものも存在します
Donkey Car 3.1 にて用意されているモデル群は こちら を参照してください。
デフォルトのモデルを使用する場合、"教師あり"ですので、まず学習データを収集しなくてはなりません。Donkey Carの構築が完了したら、
- リモコンを使って正しい運転走行を記録(手動運転による学習データ作成)
- 取得した記録を元にトレーニング処理をPC上で実行(機械学習モデルのトレーニング)
- 学習済みモデルに従って自動運転(学習済みモデルの推論結果で自動運転)
をおこないます。
学習に必要なデータ量ですが、公式ドキュメントには周回コース10周程度とあります。簡単なコースであれば、それほど必要ありませんが、コース周囲に人や動くものなどがある場合は、もう少し周回が必要になります。まずは10周以上をめどに走行させて、工夫してみてください。
4. Donkey Car のしくみ
4.1 RCカー
Donkey Car は比較的入手しやすい部品で、自律走行を実現するという思想のもとで設計されています。このため、車体のベースに RCカーを使用しています。
市販のRCカーには様々な種類がありますが、タミヤの1/10スケールなど一般的な ホビー用のRCカー を使用します。ホビー用RCカーの仕組みは、以下の図のような構成となっています。
プロポ とは操作用のコントローラのことで、車体に搭載する 受信機 とペアで販売されています(灰色の部分)。車体のみを購入した場合は、受信機を車体に組み付ける必要があります。
RCカーのステアリングは サーボモータ で動かしており、ステアリング用サーボからの3本ケーブル(電源、GND、PWM)を受信機にとりつけます。
強力な スロットル用モータ は、RCカーバッテリから宮殿を行いますが、直接接続されるのではなく スピードコントローラ(ESC) と呼ばれるマッチ箱より大きな箱に接続されます。スピードコントローラは、受信機から受けた指示に従って、調節された電気量をスロットル用モータへ送ります。なお、スピードコントローラはモータの種類によって違うので注意してください。
4.2 Donkey Car上の結線
当然自律走行にはRCカー用のプロポは不要です(ホビー用のRCカーショップでは、プロポを別売りしているので、RCカー本体のみを入手できます)。プロポに変わるものを代わりにつなぎます。
以下の図は、RCカーの構成図です。
受信機から見ると、2つのサーボモータを操作しているのとかわりません。
Donkey Car は、この受信機とプロポに当たる部分を、サーボコントローラで代替している構成になっています。
サーボコントローラは、Raspberry PiなどGPIOを搭載したマイクロコンピュータでサーボモータを操作できるようにした基板です。標準 Donkey Car では PCA9685 という16ch、つまり最大16個のサーボモータを操作が可能な基板を採用しています。
サーボモータは、GND(-)、Vcc(3.3V)、PWMの3つのケーブルで接続します。PWMとは、デジタル出力ピン(0か1)を短い時間で交互に出力して、擬似的なアナログ出力を実現する方法です。
しかし、Raspberry PiのGPIOにはPWMをハードウェアレベルで実装しているピンは4本、同時に複数の波形をだしたい場合は2本しかありません。
このような場合、Raspberry Piでは シリアル、I2C、SPIといった一定のピン数で複数のデバイスを操作する方法が用意されています。
標準DonkeyCarで2台以上のサーボモータを操作する場合、PCA9685(上図の青い基板)というモータドライバを使用しています。このPCA9685は I2C形式で Raspberry Piへ接続するため、複数台のサーボモータを少ないピン数(GND,Vcc含め4本)ですみます。
Raspberry Pi の弱点は、PWMピンが少ないことのほかに、 アナログピンがない ことがあげられます。アナログピンは、文字通り0と1の間の電圧を入出力できるピンのことです。とくにアナログ入力はセンサの接続などに用いられるため、ほかのたくさんのセンサ類を追加する場合には、 アナデジ変換器(ADC)やアナログピンを持つマイクロコンピュータとシリアルやI2C通信でつなぐなどの方法を取る必要があります。
4.3 ソフトウェア
Donkey Car はPythonで記述されています。Pythonがわからない人でも、標準Donkey Carを動かす場合は、知識は殆どなくてもかまいません。
しかし、今回のようなサーボモータドライバをDCモータドライバへ変更するなどの改変を行う場合は、プログラムの追加や書き換えが必要になります。
Donkey Car 上のマイクロコンピュータへ Donkey Car ソフトウェアをドキュメント通りにインストールした場合、
manage.pyというモジュールが起動のエントリポイントとなります。# Donkeycarをジョイスティックを使って手動運転するコマンド例 python manage.py drive --js第一引数に
driveを渡すと、手動・自動運転処理が実行されます。trainを渡すと、トレーニング処理が実行されます。
driveを指定した場合の手動・自動の切替はプロポにあたるゲームパッドやスマートフォンの操作で行います。今回は機械学習モデルの入力データ、出力データの変更は行わないので、
driveを指定した場合のみ、すなわちmanage.py内の関数drive()内が改変箇所になります。4.3.1 Vehicle フレームワーク
Donkey Car はPythonパッケージ donkeycar と、このパッケージを使って実際に(手動・自動)運転、トレーニングを行う実行プログラムで構成されています。
これらのプログラムは
donkeycar.vehicle上のVehicleクラスをつかったフレームワーク(ここでは vehicle フレームワークと呼称)ベースで実装されています。: import donkey as dk : # Veicleオブジェクトの生成 V = dk.vehicle.Veichle() : # パーツの追加 core_fighter = anaheim.core.Fighter() V.add(core_fighter, outputs=[ 'amuro/left/arm', 'amuro/right/arm', 'amuro/left/leg', 'amuro/right/leg'], threaded=True) a_part = anaheim.rx_78.APart() V.add(a_part, inputs=['amuro/left/arm', 'amuro/right_arm']) b_part = anaheim.rx_78.BPart() V.add(b_part, inputs=['amuro/left/leg', 'amuro/right/leg']) : # Veichleループの実行(1秒間20回、100,000回迄) V.start(start_hz=20, max_loop_count=100000)使い方は簡単で、
Vehicleオブジェクトを生成しパーツとよばれるクラスを追加(add)してから、最期にループをstartさせると、指定した引数に従ってパーツクラスがaddされた順番に実行されます。パーツクラス間の値のやりとりは、パーツを
addする際に指定したinputsおよびoutputsで指定したキーに格納されている辞書V.memの値を使います。
startする前に初期値を設定したい場合は、例えばV.mem['amuro/left/arm'] = 0.0と書くことで指定できます。4.3.2 パーツクラス
Veicleが
startすると、addされた順番で各クラスのrunメソッド(threaded=Trueの場合はrun_threadedメソッド)が呼び出されます。
runメソッドの引数は、addされた際のinputsに指定された値が格納されます。runメソッドの戻り値は、outputsに指定されたキーの値としてフレームワーク側V.memに格納されます。Veicleフレームワークは指定された周期(
rate_hz)でループが実行されますが、基本シングルスレッドで処理するため、runメソッドの処理時間が長くなると周期をまもることができません。そのため1回の処理が長くなりそうなパーツはマルチスレッドパーツとして実装します。マルチスレッドパーツは、
runメソッドの代わりにrun_threadedメソッドを実装します。マルチスレッドパーツが生成されると、別のスレッドが生成され定期的に引数なしのupdateメソッドが実行されます。Veicleフレームワーク側のメインスレッドはループの周回ごとにrun_threadedを呼び出します。このため、一般的な使い方はセンサなどの読み取りパーツに使用されます。updateメソッドは、新規スレッド内で実行されるメソッドです。普通はupdateメソッド内で無限ループをつくり、そのなかでセンサから読み取った値をクラス内インスタンス変数へ格納しtime.sleepメソッドを実行させます。そしてrun_threadedメソッドでは、updateメソッドが更新したインスタンス変数の値をVeicleフレームワーク側へ出力するといった実装を行います。# センサの値を読み取るthreadedパーツの例 class ThreadesSamplePart: def __init__(self): # センサの準備 self.sensor = HogehogeSensor() # センサ値を格納するインスタンス変数を初期化 self.value = 0 def update(self): while True: # センサからデータを読み取りインスタンス変数へ格納 self.value = self.sensor.read() time.sleep(0.1) def run_threaded(self): # インスタンス変数に格納されている最新値を返却 return self.value def shutdown(self): # センサの終了処理などを呼び出す self.sensor.close()Vehicleフレームワークに搭載し、実行するには以下の例のようにパーツを追加します。
# Vehicleオブジェクト生成 V = donkey.vehicle.Veicle() : # 戻り値を辞書V.memにキー'value'で格納 V.add(ThreadesSamplePart(), outputs=['value'], threaded=True) : # Vehicleループ開始(1秒間20回、全10000回) V.start(rate_hz=20, max_loop_count=10000)センサベンダ側がマルチスレッドを使ったデータ読み取りモジュールを提供している場合は、threaded
4.3.3 GPIO 操作
Python から Raspberry Pi の GPIO を操作する方法はいくつかあります。
パッケージ名 説明 RPi.GPIO 昔から使用されているGPIO操作ライブラリ。1つ1つのGPIOピン操作を記述していく。ハードをよく知っている人なら直感的にわかるコードの書き方となり、未だ多くの人が利用している。 WireingPi 一番事例が多くQitta上でも多数のサンプルコードが存在する。RPi.GPIOより後発で、それゆえ使いやすい。 pigpio この表の中では一番新しい。pigpiodデーモンが起動していることが前提となるが、デーモン間通信によりリモート操作も可能。ソフトウェアPWMの精度が高い。設計がソフト屋よりな気がする。 python-periphery GPIOキャラクタデバイスを操作するライブラリ。Coral Dev Board公式ドキュメント にはこのライブラリをつかった例で記述されている。 donkeycarパッケージで使用しているのは RPi.GPIO パッケージです。モータドライバは、Adafruit社の提供するライブラリ を使用しています。このドライバもソースをすべておいきってはいませんが RPi.GPIO パッケージを使用しています。
4.3.4 donkey コマンド
donkeycarパッケージをインストールすると、コマンドライン支援ツール
donkeyが使用可能になります。このコマンドで手動運転や自動運転するわけではありません。あくまで支援のためのツールで、Donkey Carの手動運転や自動運転を行うプログラム(DonkeyCarアプリケーション)はこの支援ツールを使って生成します。Donkey Car アプリケーション生成以外にもいくつか機能があります。以下の表は、第1引数に指定する値の一覧です。
第1引数 説明 createcarDonkey Car アプリケーションを生成する。 findcar同一セグメント上にてalive状態のDonkeyCarが存在する場合、IPアドレスを返却する。mac/Unix系OSのみ実行可能。 calibrateDonkey Carを走行させる前に、ステアリングやスロットルの調整を行うために使用する。 tubcleanWeb UIを使って不要なTubデータを削除する。が、削除後のTubデータは連番が飛び飛びになってしまう。 makemovieTubデータ上のイメージをつなげて動画にする。salientモードで実行すると動画の上にモデルが反応している箇所をオーバレイしてくれるが、処理に時間がかかる。 checktubTubデータの妥当性をチェックし、機械学習コーパスとして使えるかどうか確認する。 tubhistTubデータからヒストグラム作成し表示する。統計情報確認用。 tubplotTubデータからスロットル・アングル値を時系列のグラフとして表示する。 consyncDonkey CarからホストPCへ継続的にファイルをコピーする。Tubデータコピーに使用可能だが、rsyncを使うので設定が必要となる。 contrainトレーニング処理の1epochごとに新しいデータがないか継続的に調べ存在する場合はそれらも含め次のepochに使う。ホスト側のトレーニング処理でより良いloss値となったモデルができたらそれを差し替えることもできるらしい。 createjsサポートしていないジョイスティックを使いたい場合、ベースとなるPythonコードを生成させるウィザード。 cnnactivation画像1枚に対してどの箇所でモデルが発火しているかを可視化する。 makemovieは第1層目のConvのみ可視化するのに対し、このコマンドでは全部のConv層を可視化する。4.3.5 Donkey Car アプリケーション
donkey createcarコマンドを実行することで生成されるPython プログラム群をDonkey Car アプリケーションとよびます。このアプリケーションが、(手動・自動)運転やトレーニング処理を行います。パッケージ化されず、どうしていちいち生成している理由は、Donkey Car固有の設定を行う必要があります。
たとえば、Donkey Carのステアリングやスロットルは、使用するRCカーによって特性が異なります。この特性ごとの"調整"を行い、定義をDonkey Carアプリケーションへ反映させるためにDonkey Carアプリケーションを修正することで対応しています。
Donkey Carアプリケーションには以下の構成要素があります。
ファイル名 説明 config.pyDonkey Carへ渡しているデフォルトのパラメータ群が定義されたファイル。基本、このファイルは編集しない。 myconfig.py各自のDonkey Car固有の設定を行うためのファイル。生成時点では config.pyの構成がすべてコメントアウトされた状態となっており、ここに指定した値がconfig.pyの値をオーバライドされる。donkeyコマンドもこの設定を使用するものがある。manage.pyDonkey CarアプリケーションのEntry Point。このファイルを第1引数に driveを指定して実行すると(自動・手動)運転を、trainを指定して実行するとトレーニング処理を開始する。Donkey Carにセンサやサポート外のゲームパッドなどを使用する場合は、このファイルを修正する。train.pyトレーニング処理が実装されている。 manage.pyがtrainモードで実行されると、このファイルへ処理が移る。独自モデルを改変し入力層、出力層を変更する場合などがなければ、特に変更する必要はない。初期パラメータ変更は
myconfig.pyを、独自Donkey Car仕様変更があればmanage.pyを、独自モデル利用はtrain.pyをそれぞれ編集することとなります。先程説明したVehicleフレームワークは、
manage.py上に記述されています。トレーニング処理では使用していません。4.3.6 Tubデータ
Tubデータとは、Donkey Car の機械学習モデルのコーパスに相当するファイル群です。
Tubデータが格納されるディレクトリを指定せずに手動運転を開始した場合、Donkey Carアプリケーションディレクトリのサブディレクトリ
data/tub_N_YY-MM-DD/が作成され、以下の表にあるようなファイルが作成されます。
ファイル名形式 説明 NNN_cam-image_array_.jpg前方カメラ撮影画像ファイル。120x160のJPG形式。 record_NNN.json運転者の操作を数値化したJSON形式のファイル。デフォルトでは、スロットル値、アングル値、運転モード、対応するイメージファイル名、記録時刻が記録される。 meta.jsonTubデータを構成する要素の定義が格納されているJSON形式のファイル、各要素とそのタイプが記述されている。
NNNは1から始まる連番となっており、手動運転を開始すると、1/20秒ごとにイメージファイルとrecordファイルが作成されていきます。総件数を知りたい場合は、ファイル名でソートすることでわかります。MPU6050などのIMUセンサを搭載した場合(imuモデル)や、behaviorモデルなどを使用する場合、recordファイルの構成要素が増えます。独自センサ搭載などでrecordファイルへ要素を追加することが可能ですが、トレーニング処理時間が増えます。
5 タミヤ楽しい工作シリーズ「ブルドーザ」への改変
Donkey Car のどの部分を改変すればいいかを考える前に、まず「ブルドーザ」の構成を確認します。
5.1 タミヤ楽しい工作シリーズ「ブルドーザ」
タミヤの楽しい工作シリーズは、自作でなにかを作る場合のギアやプーリー、ユニバーサルプレート、タイヤ、キャタピラといった部品売りのものとは別に、DCモータやゴムを動力としたブルドーザやショベルカー、フォークリフト、船、車、ロープウェイなどのキット品があります。
今回は、そのキット品のなかでリモコンで操作可能な「ブルドーザ」を選択しました。
右左折が前・後進かのうであることと、Raspberry Piやバッテリが取り付けやすそうな構造であることと、なによりRCカーより値段が安いことが、選択した理由です。
RCカーをこのブルドーザに改変する場合、いくつかの問題点があります。
5.2 DCモータ
ブルドーザに使用しているDCモータは、ミニ四駆でおなじみの FA-130RA モータ (のバルク品)です。
これが2基搭載していますが、RCカーとの大きな違いは、左右別々の駆動であることです。Donkey Carの入力層はアングル値、スロットル値ですが、ブルドーザは左モータ入力値、右モータ入力値となり、場合によってはモデルを変更しなくてはなりません。
モデルの変更を行うと、修正が大きそうなので、入力層の構成はそのまま変更せず、DCモータへの出力直前にアングル値、スロットル値を左モータ入力値、右モータ入力値に変換しています。
なお、DCをモータはノイズ発生源となるので、0.1μFのコンデンサをはんだ付け しています。
5.3 モータドライバ
Donkey Car標準のモータドライバはPCA9685ですが、今回はDCモータなのでこの基板は使用できません。
そこで、秋月電子でDCモータ2基を操作可能なモータドライバを探してきました。「TB6612使用Dual DCモータドライブキット」です。
キット品なので、はんだ付けが必要ですがピンコネクタとターミナルブロックになっているので、配線がつないだりはずしたり自由になることと、1枚で2基のDCモータを個別に操作できるところがポイントです。
ただし、この基板はI2C接続ではなく、DCモータ1基あたり操作に3本のGPIOを使用します。うち1本はPWMピンである必要があります。
Raspberry Piには同時操作可能なハードウェアPWMピンは2本しか無いので、間に合うのですが、今回は技術的欲求もあって
pigpioパッケージをつかったソフトウェアPWMを試してみました。先程も書きましたがpigpioパッケージのソフトウェアPWM(通常のGPIOピンをPWMピンとして使用する)がどれくらいの性能なのか知りたかったのです。このため
pigpioパッケージをつかったラッパクラス を別途作成しました。上記以外にもTB6612自体への電源供給のため、Vccピン(5V)とGNDピン、そしてモータドライバの有効・無効を管理するSTBYピンの3本を使用するので、合計9本のピンをRaspberry Piとジャンパケーブルを使って結線しています。
STBYピンは、基板上のJP1をはんだ付けすることで、省略可能です。
5.4 バッテリ
Raspberry Pi は USB給電 ですので、5V電源が必要になることは明らかです。
1つのバッテリでRaspberry PiとDCモータ2基に給電する場合は、降圧回路が必要になり、電気回路への難易度が上がります。そこで、今回は別々にバッテリを用意しました。
まず、DCモータ2基のバッテリですが、これは3Vの単3電池で対応しました。電池ボックスは、本体への搭載のしやすさを考えて真四角のものを選んで使用しています。
そしてRaspberry Pi側のバッテリです。先程書いたとおりUSB給電ですので、手っ取り早いのは携帯などのモバイルバッテリの流用です。
Raspberry Piは、十分な電力が得られない場合はつないでも起動しません。起動しても、syslogにバッテリーエラーが頻発して勝手にshatdownしてしまうこともあるそうです。
そこでいくつか購入して試行錯誤した結果、マクセルのモバイルバッテリMPC-C2600 を選択しました。起動するモバイルバッテリの中で最軽量で、かつ薄い板のような形状なので、本体に取り付けやすかったためです。
5.5 カメラ取付台
先程のバッテリは、ヨドバシ.comで探してきたものですが、その際によさそうなものを見つけました。クリップ型カメラスタンドです。
一般のカメラを取り付けるためのものらしく、このクリップがなかなかに強力なので即採用しました。Raspberry Pi用カメラケースに一般のカメラ用のナットがついていたのもちょうどよかったです。
ただこのカメラケース、Wide Angle Piカメラはつけることができないため、標準カメラに変えています。
5.6 ジョイスティック
Donkey Car を手動運転する際、Web UIかジョイスティックのどちらかが選択できます。ただしこのWeb UIを使っている人はあまりいません。運転操作が難しいためです。
そこでジョイスティックを使用することになります。標準でサポートされているジョイスティックの種類は
myconfig.pyのCONTROLLER_TYPEのコメントにも書かれていますが、PS3/PS4コントローラ、XBoxコントローラ、Nimbus(AppleTVなど)コントローラ、WiiUコントローラ、Logicool F710コントローラなどがあります。RC3ChanJoystick というクラスも存在するのですが、これがどのジョイスティックなのかがわかりませんでした..
Raspberry PiにはBluetoothが搭載されているので、これを使ってPS3/PS4コントローラを..と考える方が多いと思いますが、Raspberry Pi Stretchでbluetoothを有効にするとデーモンがPermissionエラーをだしていたり、OSが不安定になってしまってイメージの再作成になったりと、なかなかうまく行かないことが多く、私は使用している人をみたことがありません。
国内のDonkey Carの多くはLogicool F710 ワイヤレスジョイスティックを使用しています。ドングルをUSBポートに刺してしまえばあとは
CONTROLL_TYPE値をf710にすれば操作するのでとても簡単です。ただMaker Fairなどの大きな走行会でDonkey Carを動かそうとすると、F710が混戦して運転操作ができなくなるという問題が発生しました。
そこで、自分はマイナーなジョイスティックである ELECOM製 JC-U3912T というマイナーなゲームパッドを使用しました。
独自のゲームパッドを使用する場合はコントローラパーツクラスを自作しなくてはなりませんが、先程紹介した
donkey createjsコマンドを使うとこのクラスを対話形式で作成することができます。5.7
manage.pyブルドーザをDonkey Car化するために作成したパーツは以下のとおりです。
- TB6612 を動かすためのpigpioラッパパーツおよびモータドライバパーツ
- JC-U3912Tを動かすためのパーツ
これを
manage.pyに組み込めば完成です。そこでmanage.pyがデフォルト状態でどのようなパーツが組み込まれているのかを理解する必要があります。以下の表は、デフォルト状態で実行した際にVeicleループで処理されるパーツクラスリストです。
パーツクラス inputsoutputsthreaded用途 PiCameraN/A ['cam/image_array']FalsePiカメラ撮影画像を取得 LocalWebController['cam/image_array']['user/angle', 'user/throttle', 'user/mode', 'recording']TrueWeb画面から入力された値を取得 ThrottleFilter['user/throttle']['user/throttle']False後進する際一旦スロットル値をゼロにする PilotCondition['user/mode']['run_pilot']False運転モード3値(文字列)をBoolean化 RecordTracker["tub/num_records"]['records/alert']False一定件数ごとにアラート表示 ImgPreProcess['cam/image_array']['cam/normalized/cropped']Falserun_conditionが真値の場合のみ画像を指定値だけ上下左右を削除してリシェイプFileWatcherN/A ['modelfile/modified']False指定ファイルの更新有無判定 FileWatcherN/A outputs=['modelfile/dirty']Falseai_runningが真の場合のみ指定ファイルの更新有無判定DelayedTrigger['modelfile/dirty']['modelfile/reload']Falseai_runningが真の場合指定件数ごとに真値を返却TriggeredCallback["modelfile/reload"],N/A Falseai_runningが真の場合指定メソッドを実行KerasLinear'cam/normalized/cropped']['pilot/angle', 'pilot/throttle']Falseai_runningが真の場合機械学習モデルの推論を実行DriveMode['user/mode', 'user/angle', 'user/throttle', 'pilot/angle', 'pilot/throttle']['angle', 'throttle']False運転モードに合わせて最終出力値を決定 AiLaunch['user/mode', 'throttle']['throttle']False機械学習モデル初期起動時から安定するまで一定スロットルを維持 AiRunCondition['user/mode']['ai_running']False自動運転中かどうかを判別 AiRecordingCondition['user/mode', 'recording']['recording']False自動運転中の場合常に記録モードを有効化 PWMSteering['angle']N/A False入力値をステアリングサーボへ伝達 PWMThrottle['throttle']N/A False入力値をスロットルモータ(ESC)へ伝達 TubWriter['cam/image_array','user/angle', 'user/throttle', 'user/mode']["tub/num_records"]Falseai_recordingが真値の場合、Tubデータを1件書き込み現在件数を取得上記のうちPCA9685を直接操作しているパーツクラスは、
PWMSteeringとPWMThottleの2つ。先の入力値を両輪駆動モータ値に変換する機能とこれらの変わりのTB6612へ出力するクラスを作成、追加しなくてはなりません。モータドライバの違いは
myconfig.pyのDRIVE_TRAIN_TYPE値で分岐しているので、TB6612用の分岐を増やして追加しました。: # DC2モータ pigpio制御、TB6612 ジャンパ設定無し elif cfg.DRIVE_TRAIN_TYPE == "DC_TWO_WHEEL_PIGPIO": try: import pigpio except: raise # pigpio 制御開始 pgio = pigpio.pi() from parts import PIGPIO_OUT, PIGPIO_PWM, CaterpillerMotorDriver # TB6612 STBY ピン初期化 stby = PIGPIO_OUT(pin=cfg.TB6612_STBY_GPIO, pgio=pgio, debug=use_debug) stby.run(1) # ジョイスティック出力値をDCモータ入力値に変換 driver = CaterpillerMotorDriver( left_balance=cfg.LEFT_PWM_BALANCE, right_balance=cfg.RIGHT_PWM_BALANCE, debug=use_debug) V.add(driver, inputs=['throttle', 'angle'], outputs=['left_motor_vref', 'left_motor_in1', 'left_motor_in2', 'right_motor_vref', 'right_motor_in1', 'right_motor_in2']) # 左モータ制御 left_in1 = PIGPIO_OUT(pin=cfg.LEFT_MOTOR_IN1_GPIO, pgio=pgio, debug=use_debug) left_in2 = PIGPIO_OUT(pin=cfg.LEFT_MOTOR_IN2_GPIO, pgio=pgio, debug=use_debug) left_vref = PIGPIO_PWM(pin=cfg.LEFT_MOTOR_PWM_GPIO, pgio=pgio, freq=cfg.PWM_FREQ, range=cfg.PWM_RANGE, debug=use_debug) V.add(left_in1, inputs=['left_motor_in1']) V.add(left_in2, inputs=['left_motor_in2']) V.add(left_vref, inputs=['left_motor_vref']) # 右モータ制御 right_in1 = PIGPIO_OUT(pin=cfg.RIGHT_MOTOR_IN1_GPIO, pgio=pgio, debug=use_debug) right_in2 = PIGPIO_OUT(pin=cfg.RIGHT_MOTOR_IN2_GPIO, pgio=pgio, debug=use_debug) right_vref = PIGPIO_PWM(pin=cfg.RIGHT_MOTOR_PWM_GPIO, pgio=pgio, freq=cfg.PWM_FREQ, range=cfg.PWM_RANGE, debug=use_debug) V.add(right_in1, inputs=['right_motor_in1']) V.add(right_in2, inputs=['right_motor_in2']) V.add(right_vref, inputs=['right_motor_vref'])デフォルト状態ではジョイスティックではなくWeb UIによる操作となっており、これは
LocalWebControllerが行っています。これをジョイスティックに変更する必要がありますが、ジョイスティックパーツクラスはmanage.pyでは直接生成していません。ファクトリ関数get_js_controller()を使ってインスタンス化しています。このため、今回は
get_js_controller()をラップした関数を作成して、manage.py上の該当する関数と差し替えています。: # 独自のファクトリ関数に変更 #from donkeycar.parts.controller import get_js_controller from parts import get_js_controller ctr = get_js_controller(cfg)なお、公開中のGitHubリポジトリ には、ブルドーザ用の
manage.pyをmanage_cat.pyという名前で保存しています。5.8
myconfig.py
manage_cat.pyに追加したいくつかのパーツ用に以下の変数を追加・変更しました。
変数名 値 説明 DRIVE_TRAIN_TYPEDC_TWO_WHEEL_PIGPIOpigpioパッケージをつかったDCモータ2基をTB6612で操作するパーツ群を組み込むLEFT_PWM_BALANCE1.0左右のバランスを調整するため左輪DCモータ出力に乗算される指標(0.0~1.0) RIGHT_PWM_BALANCE1.0左右のバランスを調整するため右輪DCモータ出力に乗算される指標(0.0~1.0) PWM_RANGE255PWM出力ピンのレンジ値 PWM_FREQ50PWMのタイムスライス(Hz) LEFT_MOTOR_PWM_GPIO13右輪駆動モータの電圧レベルを操作するPWM出力ピンのGPIO番号 LEFT_MOTOR_IN1_GPIO26左輪駆動モータの正逆転を操作する出力ピンのGPIO番号(2ピンで操作する) LEFT_MOTOR_IN2_GPIO19左輪駆動モータの正逆転を操作する出力ピンのGPIO番号(2ピンで操作する) RIGHT_MOTOR_PWM_GPIO16右輪駆動モータの電圧レベルを操作するPWM出力ピンのGPIO番号 RIGHT_MOTOR_IN1_GPIO21右輪駆動モータの正逆転を操作する出力ピンのGPIO番号(2ピンで操作する) RIGHT_MOTOR_IN2_GPIO20右輪駆動モータの正逆転を操作する出力ピンのGPIO番号(2ピンで操作する) TB6612_STBY_GPIO4TB6612を有効化・無効化を操作するスタンバイピンのGPIO番号 USE_JOYSTICK_AS_DEFAULTTrueデフォルトでジョイスティックを使用する AUTO_RECORD_ON_THROTTLETrue手動運転中スロットル値が0.0ではない場合、自動的にTubデータを記録する CONTROLLER_TYPEJCU3912TコントローラとしてELECOM製JC-U3912Tを使用する JOYSTICK_DEADZONE0.1ジョイスティックからのスロットルアナログ入力値の最小値、これより小さい値はスロットルゼロとする 6 問題点
実際に製作して、なんどか試走してみましたが、いくつか問題点が見つかりました。
6.1 履帯ゴム伸びる問題
ブルドーザ(というより楽しい工作シリーズで履帯を使うものすべて)の履帯を巻くとわかると思いますが、ややキツめになっています。このため走行せず長時間巻いたままにすると伸びてしまい、いざ走行すると履帯がポロポロ外れやすくなります。
このため、こまめに取り外しておく必要があります。
6.2 まっすぐ進まない問題
毎回履帯を巻き直していることもあるのですが、左右のモータ出力比を調整が毎回異なります。そして厄介なことに低速時は真っ直ぐ進むのに、高速になればなるほどどちらかによってしまいます。
このため、毎回のTubデータがその場のみ有効な学習データとなってしまい、再利用ができなくなってしまいます。
6.3 グリスつけると動きが変わる問題
グリスをつけるとなめらかに走行できるようになり、ドライバビリティが向上します。しかし、まっすぐ進まない問題同様、過去のTubデータの再利用ができません。
6.4 走行会では走るシケインになる問題
私の参加した走行会では、自分以外すべての自動走行車はRCカーベースなので、そもそもレースになりません..
7. さいごに
Donkey Car を始めようとされている方には、まず標準 Donkey Car のキット品で始めることをおすすめします。標準Donkey Carであれば、RCカーの知識やRaspberry Pi、Pythonの知識は不要です。
ただ、RCカーの知識のある方は、ブラシレスやエンジン(!)カーでやってみたくなるかもしれませんし、PythonやTensorflowの知識のある方は Tensorflow LiteやTensorflow Extentionを使ってみようかと思うかもしれません。IoTに詳しい人ならROSやMQTTブローカ、IoTゲートウェイによるEdge化などの拡張を考えるかもしれません。できるかはわかりませんがArduinoやM5、Corel Dev Board、Pi4Bに換装してみたいと思うかもしれません。あるいはLiDARや超音波センサ、IMUセンサなどを搭載させようと考えるかもしれません。
そして、できあがった自分独自の車を自慢させたくなるかもしれません。もしそうなっちゃった人は、ぜひ他の車も走っている走行会に参加して走らせてみましょう。
検索してみるとわかると思いますが、日本でも1~2ヶ月に1回位の頻度でどこかしらで走行会が開催されています。
そして、もしかしたらどこかで私と会うかもしれませんね。
p.s.
結束バンド、最強。
























- 投稿日:2019-11-26T15:15:05+09:00
SimpleITKで画像を読み込むときに、pathに日本語があるとダメな問題
はじめに
pythonの画像処理ライブラリとしてはopenCVやPILなどが有名だと思いますが、dicom画像を直接読み込みたいという理由からSimpleITKというものを使い始めました。
まずはSimpleITKを使って画像を読み込んで表示する、という単純なコードを書いたのですが、いきなりこれに躓いてしまった。。。
結論から言うと、入力画像のpathに日本語(恐らく英語以外ダメ?)が入っていると文字コードの問題でダメっぽい。
SimpleITK自体マイナーなライブラリなので使う人はほとんどいないかもしれませんが、一応共有します。PC環境
- OS : Windows 10 Professional
- 言語 : Python 3.7.3
- IDE : Eclipse 4.11.0
SimpleITKについて
ITK(https://itk.org/itkindex.html) というC++ベースで記述された画像処理ライブラリをpythonやJavaでも使えるようにしたものがSimpleITK(http://www.simpleitk.org/) らしい。
CTとかMRIといった医用画像を処理するのに稀によく使われます。医用画像はdicomと呼ばれる形式で保存されていることが多いため、SimpleITKはdicom画像を直接読み込めるようになっています。
ドキュメント(https://simpleitk.readthedocs.io/en/master/index.html) がある程度しっかりしているので、初心者にも始めやすい?
(まぁわたしはいきなり躓いたのですが)SimpleITKのインストール
pipで簡単にできる。
pip install SimpleITK画像の読み込み
公式ドキュメントの「Reading and Writing for Images and Transforms」(https://simpleitk.readthedocs.io/en/master/Documentation/docs/source/IO.html )に書いてある通りに画像を読み込みます。
ただし、入力画像のpathに日本語を含むようにします。
今回はdicom画像ではなくレナさん(png形式)を読み込むコードになっています。read_image.pyimport SimpleITK as sitk file_name="C:/日本語/Lenna_(test_image).png"#これだと動かない #file_name="C:/Lenna_(test_image).png"#正常に動く reader = sitk.ImageFileReader() reader.SetImageIO("PNGImageIO") reader.SetFileName(file_name) image = reader.Execute(); if ( not "SITK_NOSHOW" in os.environ ): sitk.Show( image, "image show" )#ImageJで画像を表示する。結果
以下のように、ファイルが見つかりませんっていうエラー文が出る。
RuntimeError: Exception thrown in SimpleITK ImageFileReader_Execute: D:\a\1\sitk-build\ITK\Modules\IO\PNG\src\itkPNGImageIO.cxx:149: itk::ERROR: PNGImageIO(000001A1C5886F00): PNGImageIO could not open file: E:/日本語/Lenna_(test_image).png for reading. Reason: Illegal byte sequence対策
画像のpathを変更して日本語を含まないようにすると正常に動作する。
※根本的な解決策がわかる人いたら教えてください・・・GithubのIssuesを見ると・・・
中国語がpathに含まれるとダメ!って悩んでいる人がいるっぽい。
(https://github.com/SimpleITK/SimpleITK/issues/795 )
pythonのstringは文字コードがunicodeだが、ITK側は文字コードがASCIIになっていることが問題とかなんとかと議論されています。ASCIIは日本語には対応していないため、ITK側がASCIIしか読めないという話になるとpathを全部アルファベットにしなきゃいけないかもですね。。。まとめ
SimpleITKを使うときは画像のpathに日本語を含まないようにすること。
根本的な解決策がわかったら更新します。
- 投稿日:2019-11-26T14:59:38+09:00