- 投稿日:2019-11-25T20:57:07+09:00
【Rails】flashの使い方
flashを利用して、アクション実行後に簡単なメッセージを表示させることができます。
ログイン周りの処理において特に重宝されます。
(Sessionはモデルを持たない→ActiveRecordがエラーメッセージを吐かないから)使い方
flash[:<キー>] = <メッセージ>で登録し、flash.each do |message_type, message|...で出力します。
flashとflash.nowflashの仲間に
flash.nowがあり、
flash→次のアクションまでデータを保持する→redirect_toと一緒に使う
flash.now→次のアクションに移行した時点でデータが消える→renderと一緒に使う
という使い分けが必要です。TODOアプリにflashを実装する
簡単なTODOアプリにflashを実装していきます。
・Ruby on Railsで簡単なアプリを作成
・RailsアプリをHerokuにデプロイする手順
・【Rails】バリデーションを実装する
・【Rails】ログイン機能を実装する
application.html.erbにflash表示領域を確保する/app/views/layouts/application.html.erb<!DOCTYPE html> . . <body> <% flash.each do |message_type, message| %> <%= message %> <% end %> . .tasksコントローラーを修正する
redirect_toの前にflashを、renderの前にflash.nowをそれぞれ追加します。/app/controllers/tasks_controller.rbclass TasksController < ApplicationController before_action :logged_in_user, only:[:create, :edit, :update, :destroy] def index @tasks = Task.all end def new @task = Task.new end def create @task = Task.new(task_params) if @task.save flash[:success] = "タスクを追加しました。" redirect_to tasks_url else flash.now[:danger] = "登録に失敗しました。" render 'tasks/new' end end def edit @task = Task.find(params[:id]) end def update @task = Task.find(params[:id]) if @task.update(task_params) flash[:success] = "タスクを修正しました。" redirect_to tasks_url else flash.now[:danger] = "更新に失敗しました。" render 'tasks/edit' end end def destroy @task = Task.find(params[:id]) @task.destroy flash[:success] = "タスクを削除しました。" redirect_to tasks_url end private def task_params params.require(:task).permit(:title) end endsessionsコントローラーを修正する
tasksコントローラー同様、
redirect_toの前にflashを、renderの前にflash.nowを追加します。/app/controllers/tasks_controller.rbclass SessionsController < ApplicationController def new end def create user = User.find_by(email: params[:session][:email].downcase) if user && user.authenticate(params[:session][:password]) log_in user flash[:success] = "ログインしました。" redirect_to root_url else flash.now[:danger] = "ログインに失敗しました。" render 'new' end end def destroy log_out if logged_in? flash[:success] = "ログアウトしました。" redirect_to root_url end end
- 投稿日:2019-11-25T20:12:34+09:00
Rails/アンチパターン: 一見すると存在しないアクション
何の変哲も無い(?)コントローラー。これはエクスポート処理関連の各種コントローラーの親クラス
controllers/export_controller.rbclass ExportController < ApplicationController def some_method やりたい処理 end endそして、何もないHogeController。よく見るとExportControllerを継承している。これを見落とすとやばい
controllers/hoge_controller.rbclass HogeController < ExportController end最後にrouting。HogeControllerのsome_methodアクションにroutingしている
routes.rbget '/hoge', to: 'hoge#some_method'何が問題か
- アクション=そのcontrollerに定義するという設計スタイルの慣れていると、ExportControllerを継承しているのを見落としガチで、その場合 「some_methodアクションなど定義されていない。routing自体が意味のないものになっている」という判断をしてしまいがち
どうあるべきか
controllers/export_controller.rbclass ExportController < ApplicationController def common_some_method やりたい処理 end endcontrollers/hoge_controller.rbclass HogeController < ExportController def some_method common_some_method end end
あるいはConcernを使う
controllers/concerns/export_concern.rbmodule ExportConsern extend ActiveSupport::Concern module ClassMethods def common_some_method やりたい処理 end end endcontrollers/hoge_controller.rbclass HogeController < ApplicationController include ExportConcern def some_method common_some_method end endなど。何れにしても重要なのはHogeControllerには明示的にアクションを定義し、親クラスのメソッドが暗黙的にアクションとして呼ばれることがないようにするべき
まとめとか補足とか
- 実際には気付ける方法は幾つかあるので、そこまで問題かというまあまあなところ
- とにかく親クラスのメソッドをアクションとして使用するのは良くない
- と思っていますが、実際どうなんでしょう
宣伝のようなもの
都内でRailsエンジニアでアンチパターンや失敗談を共有する会をやりたいと考えています。
conpassとかで見かけたらよろしくです。
- 投稿日:2019-11-25T18:53:21+09:00
何も分からないのに始めた。
はじめまして、ほやっとです。
何も分からないのにプログラミングの勉強をはじめました。印刷物やWEBの仕事をしていました。
プログラミングってもっと遠いところにあると思ってたんです。ぼんやり、
あんなシステムを作るのってどうやるんだろ~~??って思ってたけど、
WEBに最後繋がるんだ!というのに純粋に驚いた。そりゃそうか・・・;笑
そう思ったら急に身近に感じてきた。
そしていつかスキルとして身につけたいと思って
何だか分からないけど、やってみよう精神で始めました。Qiitaもなんだかよくわかってません!ごめんね!
- 投稿日:2019-11-25T18:49:55+09:00
[Ruby] 継承可能なクラス属性を定義する
やりたいこと
継承可能なクラス属性を定義したい。
class A self.x = :hoge end class B < A end class C < B self.x = :fuga end A.x #=> :hoge B.x #=> :hoge (親の x を継承する。) C.x #=> :fuga (再定義した場合はその値を使う。)たったひとつの冴えたやり方
Active Support コア拡張の Class#class_attribute を使う。
require 'active_support/core_ext/class/attribute' class A class_attribute :x self.x = :hoge end class B < A end class C < B self.x = :fuga end A.x #=> :hoge B.x #=> :hoge C.x #=> :fuga他に考えた方法
クラス変数を使う (失敗)
クラス変数はサブクラスとも共有され、サブクラスで代入できるためこの用途に使えない。
class A @@x = :hoge end class B < A end class C < B @@x = :fuga end A.class_variable_get(:@@x) #=> :fuga ? B.class_variable_get(:@@x) #=> :fuga ? C.class_variable_get(:@@x) #=> :fuga
クラスインスタンス変数はサブクラスとは共有されず、各クラスで独立している。しかし継承もしない。
class A @x = :hoge end class B < A end class C < B @x = :fuga end A.instance_variable_get(:@x) #=> :hoge B.instance_variable_get(:@x) #=> nil ? C.instance_variable_get(:@x) #=> :fuga
クラスインスタンス変数を使い、継承時に親クラスの値を引き継ぐ (成功)
class A def self.inherited(subclass) subclass.instance_variable_set(:@x, @x) end @x = :hoge end class B < A end class C < B @x = :fuga end A.instance_variable_get(:@x) #=> :hoge B.instance_variable_get(:@x) #=> :hoge C.instance_variable_get(:@x) #=> :fuga参考
- 投稿日:2019-11-25T18:45:26+09:00
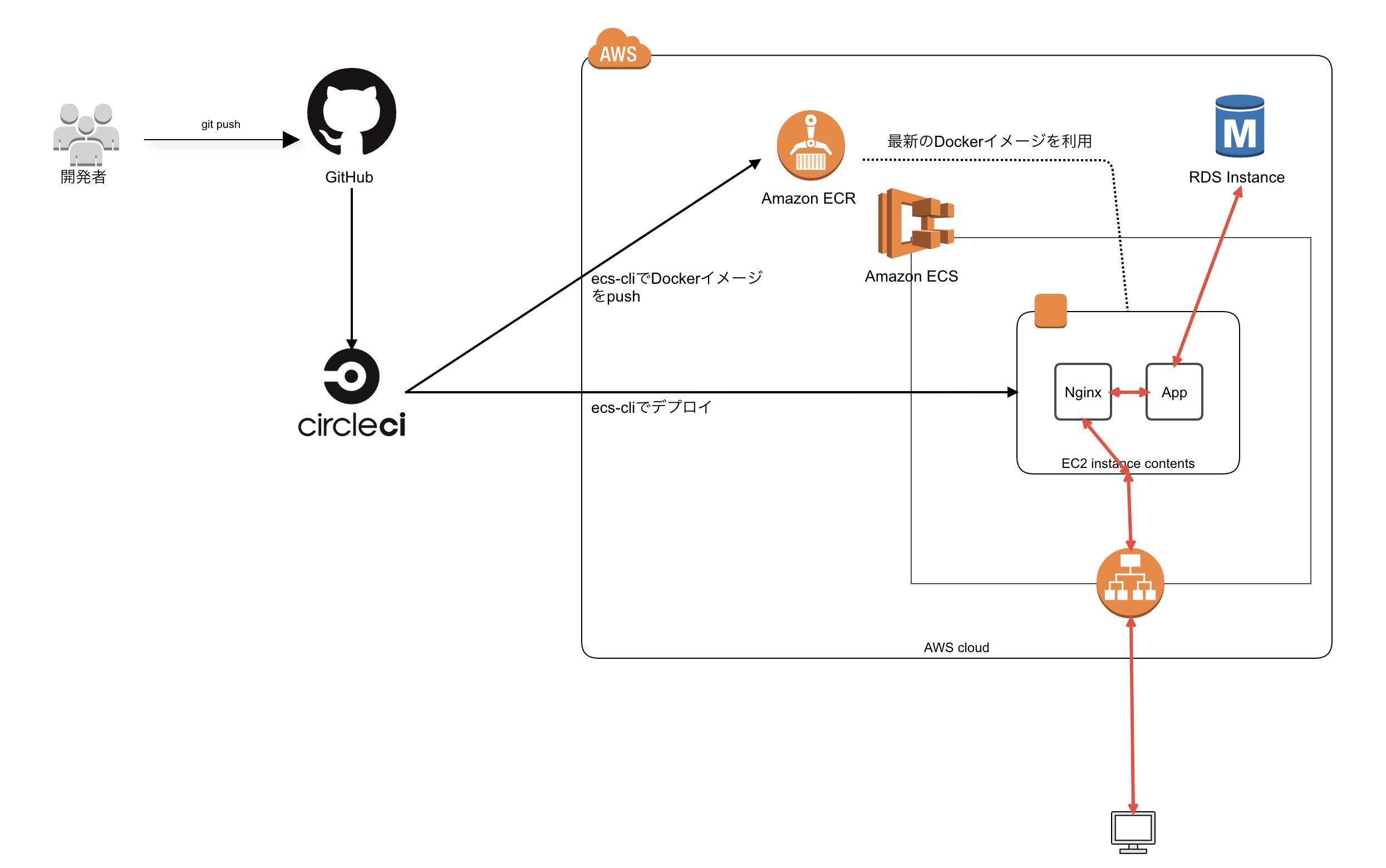
【WIP】Rails × CircleCI × ECSのインフラ構築
簡単なRailsデモアプリを本番環境に上げるまでのインフラ構成に関してのまとめ
* あくまで参考に(実務でそのまま利用できるほどしっかり構築しておりません)
前提知識
ECSとは?クラスターとは?サービスとは?タスクとは?って人は
ECSの概念を理解しよう
などを読んでください。Railsアプリ作成
まずはローカルでRailsアプリを作成しましょう。
機能は簡単なものでいいので、scaffoldを利用してとりあえずで作成してしまいましょう。
もちろんフルDocker化AWS上で利用するリソースの作成
コンソール上(or Terraformなど)からあらかじめ作成しておくべきものになります。
IAMロール・ポリシーの作成
ECSで運用するための必要なIAMロール・ポリシーを作成していきます。
ちなみにポリシーとは、ロールに付与される権限情報です。なのでポリシーのないロールは何も権限がない状態なのでまずはポリシーを作成してロールを作成していきましょう。(sandboxアカウントでは既に作成済みのため不要)ポリシーの作成
作成手順
- IAMページに行って、サイドバーの「ポリシー」選択
- 「ポリシーの作成」ボタン押下
- JSONタブを開いて下記に記載したJSON内容をコピペして、「ポリシーの確認」押下
- それぞれのポリシー名を入力する
下記の4つのポリシーを作成する。
- AmazonSSMReadAccess
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:GetParameters", "secretsmanager:GetSecretValue", "kms:Decrypt" ], "Resource": "*" } ] }
- AmazonECSTaskExecutionRolePolicy
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }
- AmazonEC2ContainerServiceforEC2Role
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeTags", "ecs:CreateCluster", "ecs:DeregisterContainerInstance", "ecs:DiscoverPollEndpoint", "ecs:Poll", "ecs:RegisterContainerInstance", "ecs:StartTelemetrySession", "ecs:UpdateContainerInstancesState", "ecs:Submit*", "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }
- AmazonECSServiceRolePolicy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ECSTaskManagement", "Effect": "Allow", "Action": [ "ec2:AttachNetworkInterface", "ec2:CreateNetworkInterface", "ec2:CreateNetworkInterfacePermission", "ec2:DeleteNetworkInterface", "ec2:DeleteNetworkInterfacePermission", "ec2:Describe*", "ec2:DetachNetworkInterface", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:DeregisterTargets", "elasticloadbalancing:Describe*", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:RegisterTargets", "route53:ChangeResourceRecordSets", "route53:CreateHealthCheck", "route53:DeleteHealthCheck", "route53:Get*", "route53:List*", "route53:UpdateHealthCheck", "servicediscovery:DeregisterInstance", "servicediscovery:Get*", "servicediscovery:List*", "servicediscovery:RegisterInstance", "servicediscovery:UpdateInstanceCustomHealthStatus" ], "Resource": "*" }, { "Sid": "ECSTagging", "Effect": "Allow", "Action": [ "ec2:CreateTags" ], "Resource": "arn:aws:ec2:*:*:network-interface/*" }, { "Sid": "CWLogGroupManagement", "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:DescribeLogGroups", "logs:PutRetentionPolicy" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/ecs/*" }, { "Sid": "CWLogStreamManagement", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:DescribeLogStreams", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/ecs/*:log-stream:*" } ] }ロールの作成
- ecsInstanceRole
- AWSServiceRoleForECS
- ecsTaskExecutionRole
ecsInstanceRoleの場合は一番簡単で、テンプレートがあるので
IAMページに行って、サイドバーの「ロール」→「ロールの作成」より
ecsTaskExecutionRole
Amazon ECS タスク実行 IAM ロールにある{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }をコピペして貼り付けましょう。
ちなみに上記のやつは公式ドキュメントにもあるので確認してください。
例: Amazon ECS タスク実行 IAM ロールALBの作成
ECSのサービス作成時にALBを登録しておけば、コンテナに動的にポートマッピングをしてくれるようになるので楽になります。
クラスターの作成
ECSのサイドバーにある「クラスター」から「クラスターの作成」ボタンを押下
「クラスターテンプレートの選択」は「EC2 Linux + ネットワーキング」を選択
1. クラスター名記載
2. EC2インスタンスタイプの選択(お好み)
3. キーペア(お好み。ただし、デバッグ時にSSHできた方がいいので設定しておくことをおすすめ)
4. コンテナインスタンスの IAM ロールに「ecsInstanceRole」を選択CircleCIの設定
circleci/config.ymlversion: 2.1 orbs: aws-cli: circleci/aws-cli@0.1.13 executors: builder: docker: - image: circleci/buildpack-deps commands: init: steps: - checkout - aws-cli/install - install_ecs-cli - setup_remote_docker install_ecs-cli: steps: - run: name: Install ECS-CLI command: | sudo curl -o /usr/local/bin/ecs-cli https://amazon-ecs-cli.s3.amazonaws.com/ecs-cli-linux-amd64-latest sudo chmod +x /usr/local/bin/ecs-cli jobs: build: executor: builder steps: - init - run: name: Build application Docker image command: | docker build -f build.Dockerfile --rm=false -t rails-sample-app-build:latest . - run: name: Save image command: | mkdir -p /tmp/docker docker save rails-sample-app-build:latest -o /tmp/docker/image - persist_to_workspace: root: /tmp/docker paths: - image deploy: executor: builder steps: - init - attach_workspace: at: /tmp/docker - run: docker load -i /tmp/docker/image - run: name: Assets precompile and Push Docker image command: | docker build -f assets.Dockerfile --build-arg RAILS_MASTER_KEY=${RAILS_MASTER_KEY} --rm=false -t rails-sample-app-build:latest . - run: name: Push Docker image command: | ecs-cli push rails-sample-app-build:latest - run: name: ECS Config command: | ecs-cli configure \ --cluster rails-sample-${CIRCLE_BRANCH} \ --region ${AWS_DEFAULT_REGION} \ --config-name rails-sample-${CIRCLE_BRANCH} - run: name: migrate deploy command: | ecs-cli compose \ --file ecs/${CIRCLE_BRANCH}/migrate/docker-compose.yml \ --ecs-params ecs/${CIRCLE_BRANCH}/migrate/ecs-params.yml \ --project-name rails-sample-${CIRCLE_BRANCH}-migrate \ up \ --launch-type EC2 \ --create-log-groups \ --cluster-config rails-sample-${CIRCLE_BRANCH} - run: name: Unicorn + Nginx deploy command: | ecs-cli compose \ --file ecs/${CIRCLE_BRANCH}/app/docker-compose.yml \ --ecs-params ecs/${CIRCLE_BRANCH}/app/ecs-params.yml \ --project-name rails-sample-${CIRCLE_BRANCH}-app \ service up \ --container-name nginx \ --container-port 80 \ --target-group-arn ${TARGET_GROUP_ARN} \ --timeout 0 \ --launch-type EC2 \ --create-log-groups \ --cluster-config rails-sample-${CIRCLE_BRANCH} workflows: version: 2 build-deploy: jobs: - build - deploy: requires: - build filters: branches: only: - masterCircleCIに設定する環境変数
CircleCIのプロジェクトの設定ページ(Settings→[アカウント名or組織名]→[プロジェクト名])に行き、下記の画像の箇所から設定する
https://circleci.com/gh/[アカウント名or組織名]/[プロジェクト名]/edit#env-vars
環境変数名 値 AWS_ACCESS_KEY_ID [AWSのアクセスキーID] AWS_ACCOUNT_ID [AWSのアカウントID] AWS_DEFAULT_REGION [AWSのデフォルトリージョン] AWS_ECR_REPOSITORY_URL [AWSのECRリポジトリURL] AWS_SECRET_ACCESS_KEY [AWSのシークレットアクセスキー] RAILS_MASTER_KEY [config/master.keyの値] TARGET_GROUP_ARN [ターゲットグループのarn] Task definitionの作成
docker-compose.yml
rails-sample/ecs/production/app/docker-compose.ymlversion: "3" services: app: image: [ECRのリポジトリURI] entrypoint: bundle exec unicorn -c config/unicorn.rb env_file: - ../env working_dir: /projects/rails-sample logging: driver: "awslogs" options: awslogs-region: "ap-northeast-1" awslogs-group: "rails-sample-production/app" awslogs-stream-prefix: "rails-sample-app" nginx: image: [ECRのリポジトリURI] entrypoint: /bin/bash /etc/nginx/start.sh ports: - 0:80 links: - "app:app" env_file: - ../env working_dir: /projects/rails-sample logging: driver: "awslogs" options: awslogs-region: "ap-northeast-1" awslogs-group: "rails-sample-production/nginx" awslogs-stream-prefix: "rails-sample-nginx"ecs-params.yml
タスク実行時に実行ロールの指定やコンテナに注入する環境変数をAWS Systems Managerから取得するして設定するためのファイル
rails-sample/ecs/production/app/ecs-params.ymlversion: 1 task_definition: # タスク実行時のロールを指定 task_execution_role: ecsTaskExecutionRole services: 起動するコンテナを記載(app, nginx) app: # 何らかの理由で失敗・停止した際に、タスクに含まれる他のすべてのコンテナを停止するかどうか(デフォルトはtrue) essential: true # AWS Systems Managerから秘匿情報を取得してコンテナに環境変数を注入 secrets: - value_from: /production/database_username name: DATABASE_USERNAME - value_from: /production/database_password name: DATABASE_PASSWORD - value_from: /production/database_host name: DATABASE_HOST nginx: essential: true # あまりわかってない run_params: network_configuration: awsvpc_configuration: assign_public_ip: ENABLEDAWS Systems Managerの設定
AWS Systems Managerは、タスク実行時にコンテナに注入する秘匿情報(環境変数)の管理に使えるAWSサービスです。
初めての人は設定の仕方を含め、
ECSでごっつ簡単に機密情報を環境変数に展開できるようになりました!
を見れば大体分かると思います。AWS Systems Managerの左側メニューから「パラメータストア」→「パラメータの作成」をクリック。パラメータの詳細画面が表示されるので、パラメータのキー名と値を入力します。タイプには「安全な文字列」を選択します。
パラメータのキー名と値一覧
キー名 値 /production/database_username [RDSに設定したusername] /production/database_password [RDSに設定したpassword] /production/database_host [RDSインスタンスのエンドポイント] RDSインスタンスのエンドポイント(RDS→データベース→[インスタンス名])
コンテナ全体に注入する環境変数の設定
各環境(production, stagingなど)ごとのディレクトリ以下に
envファイルを用意してそこに記載する# ここのファイルに追加した環境変数は全てのコンテナに展開されます # Rails APP_HOST=54.238.241.230 RAILS_ENV=production RAILS_LOG_TO_STDOUT=1 RAILS_SERVE_STATIC_FILES=1 # RDS DATABASE_NAME=rails-sample_production DATABASE_PORT=3306 DATABASE_POOL=10 # Unicorn UNICORN_PORT=23380 UNICORN_TIMEOUT=180 UNICORN_WORKER_PROSESSES=2 # Nginx専用 NGINX_APP_SERVER_NAME=app NGINX_APP_SERVER_PORT=23380 NGINX_DOCUMENT_ROOT=/projects/rails-sample/public NGINX_FRONT_SERVER_NAME=54.238.241.230構築の際に詰まる可能性のあるポイント
ECSコンテナインスタンスの作成
- インスタンスへのIAMロールを付与すること
- ecs-agentのインストール ( Amazon ECS コンテナエージェントのインストール - Amazon Elastic Container Service )
- EC2インスタンスの
/etc/ecs/ecs.configにCLUSTER_NAME=クラスター名の登録- 所属するクラスターを変更する場合、
/var/lib/ecs/data/ecs_agent_data.jsonを削除してからecs-agentを再起動するDefaultクラスター作成しているし、IAMロールにecs:CreateClusterの権限付与されているから自動で作成なんかもしてくれるのかと思ったら作成してくれなかった。
なので、クラスター作成→インスタンス作成の方が良い(ちな、クラスター作成時にインスタンスも作成するようにはできるっぽい)
→カスタマイズされてるAMI利用時のみ初期スクリプトによってDefaultクラスターを作成しているのかもしれない
参考
Amazon ECS コンテナインスタンスの起動 - Amazon Elastic Container Service
Amazon ECS-optimized AMI - Amazon Elastic Container Serviceインスタンスタイプについて
ある程度余裕持たないとタスク実行するための容量を持たなくて死ぬ
(ほんとは、ローカルや本番環境で動かした時の使用量見てタスク実行に必要なメモリを設定した方が良い)ecs-cliでのタスク実行
ecs-params.ymlファイル内でtask_execution_roleを指定することtask_execution_roleで指定した適切なポリシーを適用したIAM Roleを用意すること(エラーが出なくて、単純に実行されないので気づきにくい)aws-cliでRDSの作成
AWS CLI を使って外部からアクセス出来る RDS インスタンスを作る方法が公式ドキュメントに無かったのでメモ。
Aws rds コマンドを使って rds を作成するには、DB subnet group を指定する必要があるらしい。さもなければ以下のようなエラーが出る。aws rds create-db-instance \ --db-instance-identifier chiko-db-production \ --db-instance-class db.t2.micro \ --db-subnet-group-name ishihara-db-subnet-group \ --engine mysql \ --engine-version 5.7.26 \ --allocated-storage 20 \ --master-username root \ --master-user-password password \ --backup-retention-period 3 \ --profile sandbox-admin参考
AWS CLI を使って RDS を作成する (自分用メモ) - Qiita
AWS-CLI Amazon Aurora インスタンス作成 - Qiita






- 投稿日:2019-11-25T18:39:42+09:00
インスタンス変数・ゲッターセッター・アクセスメソッド
今回はインスタンス変数、インスタンスメソッド、ゲッターとセッター、
attr_accessorについて書きます今回のコード
class MarsAlien #attr_reader :name →ゲッターの役割 #attr_writer :name →セッターの役割 attr_accessor :name #ゲッター・セッターの役割 def initialize(name) #初期化メソッド @name = name #@nameはインスタンス変数 end def greet #インスタンスメソッド puts '#{@name} says hello to earth' end end mars_bob = MarsAlien.new('Bob') mars_erich = MarsAlien.new('Erich') mars_bob.greet #=> Bob says hello to earth mars_bob.name #=> "Bob" mars_bob.name = "Johnny" #=> "Johnny"前回の復習
ざっくりと、前回の確認をします。
・クラス:〇〇製造工場
・インスタンス:工場で作られた固有の〇〇(オブジェクト、物体)
・メソッド:クラスやインスタンスが行える「動作・機能」
・initializeメソッド:作成されたインスタンスに、初期値(例:名前など)を設定するインスタンス変数
では、前回の最後で登場した「インスタンス変数」(例:
@name)とは何でしょうか?インスタンス変数とは、個々のインスタンス毎に特有のデータ(例:名前、年齢)を保持するための変数です。
(別の言い方をすると、インスタンス間で共有しないデータのためのものです)以下のように、
@変数名と記述します。class MarsAlien def initialize(name) @name = name #インスタンス変数 end end mars_bob = MarsAlien.new('Bob') mars_erich = MarsAlien.new('Erich')上記の例を見てみましょう。火星人クラス(
MarsAlien)から作成された、火星人ボブ(mars_bob)や火星人エリック(mars_erich)は、それぞれインスタンスです。そこで、彼らが(共有せず)固有に持っている名前を、初期値としてインスタンス変数で設定します。また、
@から始まるインスタンス変数は、同じクラス内であれば、メソッドを超えて参照することができます。その意味を次の節で見てみましょう。インスタンスメソッド
インスタンスメソッドとは、その名の通り、固有のインスタンスにのみ使用可能なメソッドです。
クラスが〇〇製造工場であることを思い出してみましょう。「挨拶をする」というメソッド(動作)があったさい、その主体者は、工場(クラス)ではなく、個々のオブジェクト(インスタンス)です。インスタンスメソッドは、そういった個々のオブジェクトが出来る動作を記述しています。
そのため、インスタンスメソッドを使用するためには、
newメソッドでインスタンスを作成する必要があります。class MarsAlien def initialize(name) #初期化メソッド @name = name #@nameはインスタンス変数 end def greet #インスタンスメソッド puts '#{@name} says hello to earth' #@nameを参照している end end mars_bob = MarsAlien.new('Bob') mars_erich = MarsAlien.new('Erich') mars_bob.greet #=> Bob says hello to earth mars_erich.greet #=> Erich says hello to earth最後の2行で、ボブとエリック(火星人クラスのインスタンス)に、インスタンスメソッドである
greetメソッドを使用して、地球に挨拶させています。
また、@name(インスタンス変数)を利用することで、メソッドをまたいで参照が可能になっています。ゲッターとは
ちなみに、
@で定義したインスタンス変数が知りたい場合は、どうすればよいのでしょうか?実は、作成したインスタンスから直接参照しようとすると、下記のようなエラーになってしまいます。class MarsAlien def initialize(name) @name = name #@nameはインスタンス変数 end end mars_bob = MarsAlien.new('Bob') mars_bob.name #=>undefined method `name'エラーとなり、参照できないこれは、インスタンス変数の値が、クラス内の範囲でしか参照できないためです。
そのため、クラス外からインスタンス変数を参照したい場合は、下記のように、ゲッター、つまり、クラス外からインスタンス変数を「ゲットする」ためだけのメソッドを定義する必要があります。class MarsAlien def initialize(name) @name = name #@nameはインスタンス変数 end def name #ゲッター @name end end mars_bob = MarsAlien.new('Bob') mars_bob.name #=> "Bob"(ゲッターがあるので、参照できるようになった)とはいえ、インスタンス変数が複数ある場合などは、↑のようにゲッターをいちいち書いていたら、とても手間ですね。なんとかならないでしょうか?
実はなんとかなるのですが、その前に、ゲッターと並んで紹介されることが多い「セッター」の概念についても確認しておきましょう。
セッターとは
ゲッターが(主に)インスタンス変数参照用であるのに対し、「セッター」はインスタンス変数を書き換える(更新する)場合に使用されます。
例を見てみましょう。class MarsAlien def initialize(name) @name = name #@nameはインスタンス変数 end end mars_bob = MarsAlien.new('Bob') mars_bob.name = "Johnny" #=>undefined method `name'エラーとなり、"Bob"から"Johnny"へ更新できない上記でエラーが出ているのは、インスタンス変数をクラス外から更新することはできないためです。そのため、インスタンス変数書き換え用メソッドのセッターを用意します。
class MarsAlien def initialize(name) @name = name #@nameはインスタンス変数 end def name=(name) #セッター @name = name end end mars_bob = MarsAlien.new('Bob') mars_bob.name = "Johnny" #=> "Johnny"(セッターがあるので、"Bob"から"Johnny"へ更新できる)このセッターくんも、ちょっと面倒ですよね。
それでは、セッター・ゲッターの記述を(体感)10倍ほど簡単にしてくれるのが
attr_accessor(アクセスメソッド)を見てみましょう!
attr_accessorとは
attr_accessorは、3種類あるうちのアクセスメソッドのひとつです。ゲッターとセッターの役割を持ち、インスタンス変数の値の参照・更新をともに可能にしてくれます。
メソッド 動作 attr_reader :変数名 ゲッターと同じ役割。インスタンス変数の値を参照する attr_writer :変数名 セッターと同じ役割。インスタンス変数の値を更新する attr_accessor :変数名 ゲッターとセッター、両方の役割を持つ。インスタンス変数の値が参照でき、かつ更新できる 最後に、
attr_accessorの定義方法を確認しましょう。
(ちなみに、:変数名(変数名にコロン)は「シンボル」という構文を使用しています。詳細は、シンボルに関するこちらの記事を参照してください)class MarsAlien #アクセスメソッド(@name変数をクラス外から参照・更新するのを可能にしてくれる) attr_accessor :name def initialize(name) @name = name #@nameはインスタンス変数 end end mars_bob = MarsAlien.new('Bob') mars_bob.name #=> "Bob"(attr_accessorがあるので、クラス外から値が参照できる) mars_bob.name = "Johnny" #=> "Johnny"(attr_accessorがあるので、クラス外から値が更新できる)参考記事
(英語)クラスメソッドとインスタンスメソッドについて
クラス変数とインスタンス変数について
Rubyリファレンスマニュアル(変数と定数)おつかれさまでした!
お付き合いくださり、ありがとうございました!!
- 投稿日:2019-11-25T18:12:04+09:00
ABC087B - Coins
AtCoderやれ!!!!!って言われたので
問題はこれ↓
https://atcoder.jp/contests/abs/tasks/abc087_b問題
1回目
まずは自力で
回答
A = gets.to_i B = gets.to_i C = gets.to_i X = gets.to_i count = 0 for a in 0..A do for b in 0..B do for c in 0..C do if a * 500 + b * 100 + c * 50 == X then count += 1 end end end end puts count結果
2回目
他の人の回答を見て少し直す
回答
A = gets.to_i B = gets.to_i C = gets.to_i X = gets.to_i count = 0 for a in 0..A do for b in 0..B do x = X - a * 500 - b * 100 if x >= 0 && x % 50 == 0 for c in 0..C do if c * 50 == x then count += 1 break end end end end end puts count結果
まとめ
処理時間が 24 → 14 になった
思ったより楽しい


- 投稿日:2019-11-25T16:48:46+09:00
\(._. \)わっしょいって感じの正規表現と向き合う
はじめに
\(._. \)
正規表現がわからなすぎてちょっとイライラしていたところに友人からちょうどこの顔文字が送られてきたからイラッとした。
これも正規表現になりうるのだろうけど、読めない。。正規表現なんて使用する場面になったらその都度調べればよいだろう。
どこかでそんな心構えでやってきたのですが、いざ使う場面に出くわすと、前提知識が無さすぎて中々しんどい。とは言っても、一時的に大量に覚えたところですぐに忘れてしまうだろうから基礎の基礎から少しずつ試しに使っていくことにする。
超基本的な正規表現で電話番号を捉える
下記を例とする。電話番号の部分だけを抽出するにはどうするかを考えてみる。
会社名: 株式会社XXX 住所: 東京都港区南麻布1-1-1 本社: 03(2345)6789 携帯番号: 080-1234-5678 フリーダイヤル: 0120(000)000 緊急: 01234-5-6789共通点や異なる点の確認
① 3つに区切れる
② 2〜5桁、1〜4桁、3〜4桁の構成
③ 区切りはカッコ、またはハイフン
④ 1文字目は0、2文字目は0以外の半角数字文字数範囲の指定
・
\d... 1個の半角数字(0123456789)
・{n,m}... 直前の文字が n 個以上、m 個以下ゆえに、3〜4桁の数字は
\d{3,4}と表現する。AまたはB
・
[AB]... AまたはBのいずれか1文字ここまでの情報で、
\d{2,5}[-(]\d{1,4}[-)]\d{3,4}
とすれば、共通点や異なる点の①〜③をクリアできる。text = <<-TEXT 会社名: 株式会社XXX 住所: 東京都港区南麻布1-1-1 本社: 03(2345)6789 携帯番号: 080-1234-5678 フリーダイヤル: 0120(000)000 緊急: 01234-5-6789 TEXT text.scan /\d{2,5}[-(]\d{1,4}[-)]\d{3,4}/ => ["03(2345)6789", "080-1234-5678", "0120(000)000", "01234-5-6789"]例外に注意する
今のままだと以下のような例外も当てはまってしまう。
text = <<-TEXT 会社名: 株式会社XXX 住所: 東京都港区南麻布1-1-1 本社: 03(2345)6789 携帯番号: 080-1234-5678 フリーダイヤル: 0120(000)000 緊急: 01234-5-6789 例外1: 999-9999-999 例外2: 0120-000)000 TEXT text.scan /\d{2,5}[-(]\d{1,4}[-)]\d{3,4}/ => ["03(2345)6789", "080-1234-5678", "0120(000)000", "01234-5-6789", "999-9999-999", "0120-000)000"]まず、1文字目は0、2文字目は0以外の半角数字に対応させるには
0[1-9]\d{0,3}[-(]\d{1,4}[-)]\d{3,4}とすればよい。※ -(ハイフン)は位置によって意味が変わる。
・[1-9]... 1または2または3、、、、または9
・[19-]... 1または9または-grepメソッドを使用する
Rubyで使用できるものですが、grepメソッドを用いる。
・grep... 各要素に対して「引数obj === 要素」を試し、その結果が真だった要素を集めて配列にして返す
grepメソッドの引数を正規表現にすると、パターンにマッチする文字列を集められるので、これを利用する。使用する正規表現を確認
・|... or
・\... エスケープ
・+... 直前の1文字の1回以上の繰り返しを表す
()はグループ化を表現してしまうので、\でエスケープする必要がある。
\d+で数字が続くことを表現できる。
0120-000-000 または 0120(000)000を表現するには、
\(\d+\)|-\d+-となる。text = <<-TEXT 会社名: 株式会社XXX 住所: 東京都港区南麻布1-1-1 本社: 03(2345)6789 携帯番号: 080-1234-5678 フリーダイヤル: 0120(000)000 緊急: 01234-5-6789 例外1: 999-9999-999 例外2: 0120-000)000 TEXT before = text.scan /0[1-9]\d{0,3}[-(]\d{1,4}[-)]\d{3,4}/ => ["03(2345)6789", "080-1234-5678", "0120(000)000", "01234-5-6789", "0120-000)000"] after = before.grep(/\(\d+\)|-\d+-/) => ["03(2345)6789", "080-1234-5678", "0120(000)000", "01234-5-6789"]例外を出しだすときりがないですが、とりあえず正規表現を用いて目的のものを抽出できました。
おわりに
正規表現を勉強する前は、
0[1-9]\d{0,3}[-(]\d{1,4}[-)]\d{3,4},\(\d+\)|-\d+-
これらが暗号の羅列にしか見えなかったものが読めるようになりました。ついでに
\(._. \)こいつについて
.... 任意の文字
であるから(の_g )とかの 正規表現になるわけですね。顔文字か正規表現かを見破るアプリゲームとかいいかもしんないですね。
最低限の基礎があれば初見の正規表現に対しても少し調べれば読み解くことができそうなので、最低限を身につけるためにもう少し正規表現を勉強していく必要がありそうです。
参考
- 投稿日:2019-11-25T15:09:24+09:00
【Rails】we're sorry, but something went wrongでハマった話(2)
こんにちは!スージーです!
ローカル環境では問題なかったのに本番環境で発生したwe're sorry, but something went wrongの解決までを備忘録としてwe're sorry, but something went wrong
このエラーは本番環境でちょいちょい見るので
production.logでエラーログを確認するターミナル[ec2-user@ip-~~]$ cd /var/www/app-name [ec2-user@ip-~~]$ cd log [ec2-user@ip-~~]$ cat production.log D, [2019-11-18T07:06:44.834244 #5661] DEBUG -- : hogehoge~~ D, [2019-11-18T07:06:44.834597 #5661] DEBUG -- : hogehoge~~ ・ ・・ ・・・この時は
production.logにエラーログが無かったデバックを考える
タイポ→× 開発環境でもエラーが再現されているはずno method error→× 開発環境でもエラーが再現されているはずルーティングとアクション,コントローラの記述がおかしい→× 開発環境でもエラーが再現されているはず- エラー発生ページ
showアクションの:idが本番環境にないのではないか?(同期が教えてくれた)本番環境のMySQLにログインしてみる
同期の助言により、以前に本番環境下で
seedファイルのデータが投入できなかった事を思い出すターミナル[ec2-user@ip-~app-name]$ mysql -u root -p Enter password: ・ ・・ mysql > use app-name_production; ・ ・・ database changed mysql > describe meals; # <エラーが発生するテーブル> mysql > show * form meals; # <レコードを確認>mealsテーブル
Column Type Options name varchar null: false image text food_stuff text cooking_time integer null: false cooking_method integer post_id integer null: false user_id integer null: false エラー箇所特定
user_id:1で投稿したはずなのにmealsテーブルのuser_idカラムにはuser_id:17で保存されている...
開発環境では問題なくuser_idが保存されているから道理でエラーが再現されないはずだ...原因
この
user_idはデプロイ後に追加したカラム
開発環境でマイグレーションファイルを作成した後に以下の手順でdb:migrateしたターミナル[ec2-user@ip-~app-name]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop #<最新のDBにする為,一度drop> [ec2-user@ip-~app-name]$ rake db:create RAILS_ENV=production #<DBをcreateする> [ec2-user@ip-~app-name]$ rake db:migrate RAILS_ENV=production #<migrateする> [ec2-user@ip-~app-name]$ cd current #<currentディレクトリ下へ> [ec2-user@ip-~app-name]$ rake db:seed RAILS_ENV=production ・ ・・ ・・・ Mysql2::Error: Field 'user_id' doesn't have a default value上記エラーが最初出た時に
user_idカラムをMySQLにログインしてカラムを新規で作成し突っ込んでいたターミナルdatabase changed mysql > ALTER TABLE meals ADD user_id int; mysql > exit [ec2-user@ip-~app-name]$ cd current [ec2-user@ip-~app-name]$ rake db:seed RAILS_ENV=production ・ ・・ ・・・ Mysql2::Error: Field 'user_id' doesn't have a default valueまたエラーが出ている...アプリを動かして投稿してみると新規投稿はできていたので、その時は一旦保留にしていたが、やはりここが今回のエラーの原因であるのは間違いなさそう
解決方法
なぜ最新のマイグレーションファイルが本番環境に反映されないのか
参考
【Rails】本番環境デプロイでよく使うコマンド集!AWS/unicorn/nginx/Capistrano使用
https://qiita.com/15grmr/items/7ad36caa82a0fa27c4bdむむむ...db:migrateの手順が間違っていた...無理矢理に本番環境のDB構造を変えて正しく
user_idが保存されていないのが原因であれば正しくマイグレーションすればエラーは解決するはず。そうすればdb:seedでデータが投入されるはずであるターミナル[ec2-user@ip-~app-name]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop [ec2-user@ip-~app-name]$ rake db:create RAILS_ENV=production # ここで一度自動デプロイをかけて、db:migrateに当たる操作を完了 # ローカルにて app-name $ bundle exec cap production deploy # 無事作成されたら、再度EC2のcurrentディレクトリでseedを反映させる [ec2-user@ip-~app-name current]$ rake db:seed RAILS_ENV=production ・ ・・ ・・・ [ec2-user@ip-~app-name current]$無事にseedファイルが本番環境に投下され
we're sorry, but something went wrongのエラーは解決まとめ
今回、個人アプリで初めてデプロイ後のDB構造を変更・追加を行った。EC2内で
db:create→db:migrateまでしてから自動デプロイしても最新のマイグレーションファイルが本番環境へ反映されない事が原因だった。EC2内では古いDBをdropしcreateする所までを行い、capistranoを使った自動デプロイで最新マイグレーションをファイルの読み込みmigrateする今回のエラーはデプロイの手順の間違えで発生したものだったが、MySQLを触っているとRailsではマイグレーションファイルでバージョン管理してくれるし、ORMのお陰で生SQLを触る機会もほとんどないのでDB関連の知識が無くても動くアプリケーションが作れる。非常に便利だが、SQLの勉強は絶対にした方が良いと感じたエラーだった
- 投稿日:2019-11-25T15:01:22+09:00
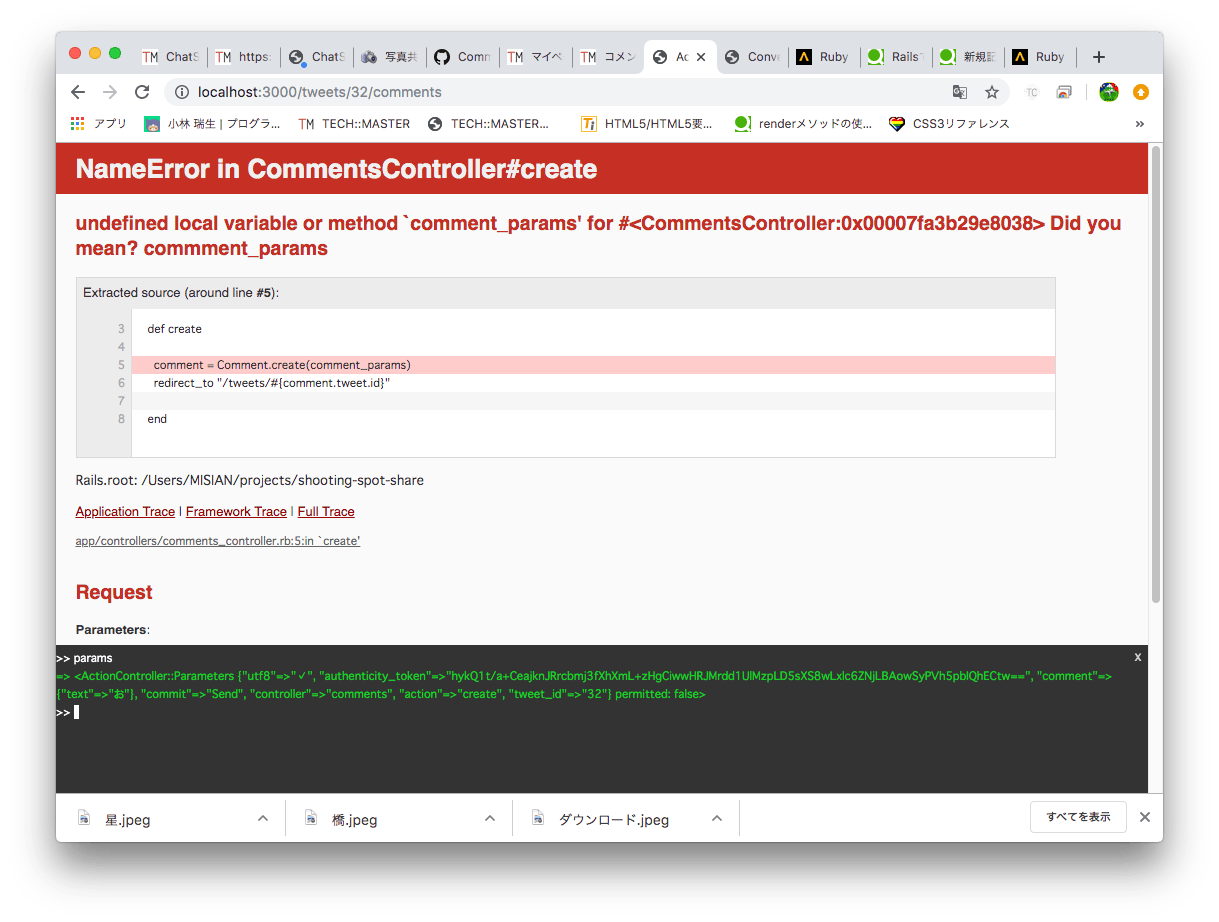
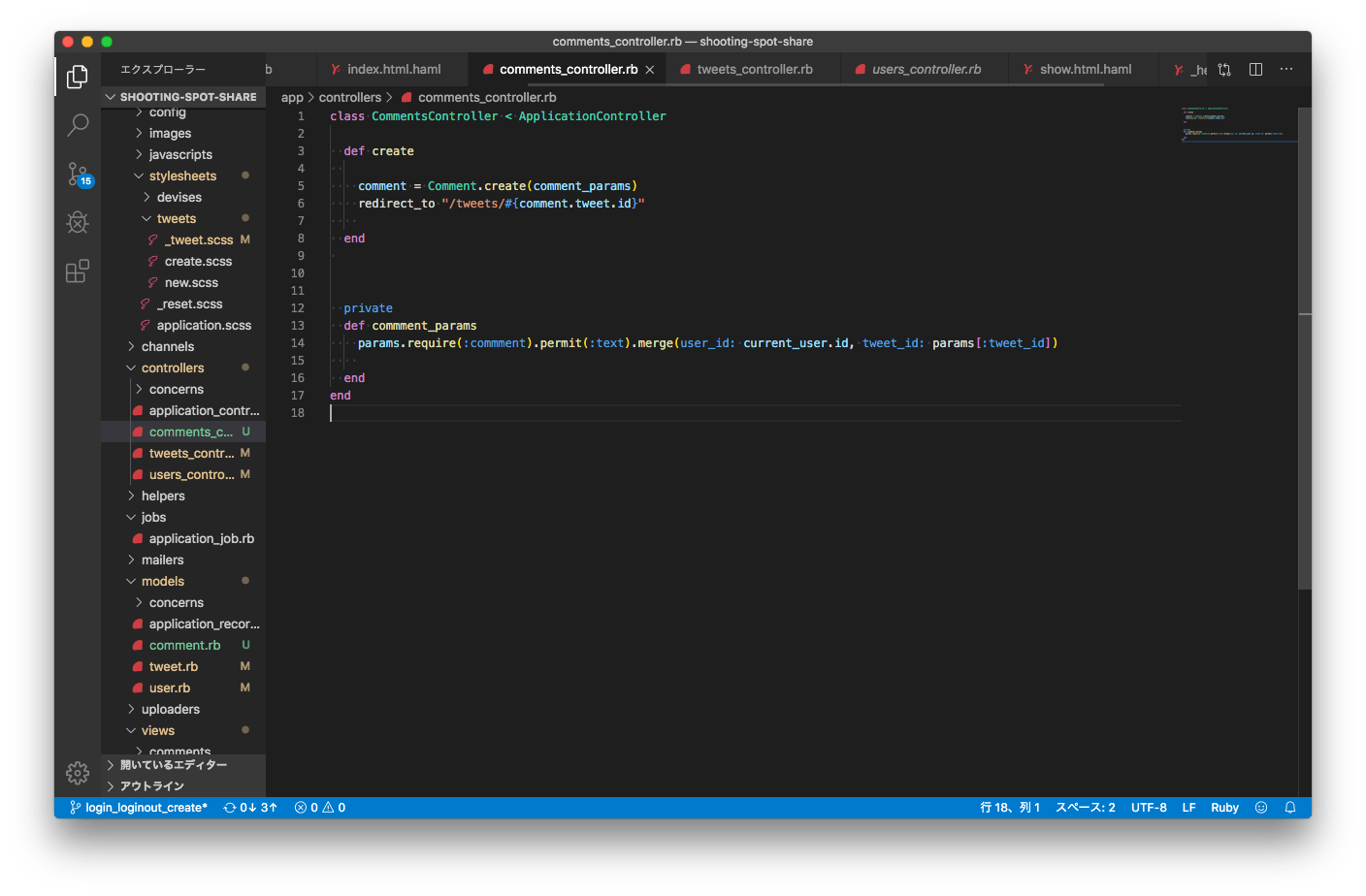
NameError in CommentsController#create undefined local variable or method `comment_params' for #<CommentsController:0x00007fa3b29e8038> Did you mean? commment_params
tweetに対してコメントできる機能の実装をしてて
commentsコントローラの
createアクションに記載したところ
写真のようなエラーが出て
困っています
原因は何でしょうか?
- 投稿日:2019-11-25T12:26:10+09:00
Rails6 のちょい足しな新機能を試す107(Digest::UUID編)
はじめに
Rails 6 に追加された新機能を試す第107段。 今回は、
Digest::UUID編です。
Rails 6 では、Digest::UUIDが require なしで使えるようになりました。Ruby 2.6.5, Rails 6.0.0, Rails 5.2.3 で確認しました。
$ rails --version Rails 6.0.0今回は、簡単なスクリプトを作って確認します。
Rails プロジェクトを作成する
$ rails new rails_sandbox $ cd rails_sandboxスクリプトを作成する
Digest::UUIDを使ったスクリプトを作成します。scripts/uuid.rbputs Digest::UUID.uuid_v3(Digest::UUID::DNS_NAMESPACE, 'rubyonrails.org') puts Digest::UUID.uuid_v4 puts Digest::UUID.uuid_v5(Digest::UUID::DNS_NAMESPACE, 'rubyonrails.org')スクリプトを実行する
rails runnerでスクリプトを実行します。$ bin/rails runner scripts/uuid.rb Running via Spring preloader in process 54 a063dfac-9c20-314f-8597-169d162b1e83 bd997739-d65c-4f56-ac56-81fc08775a79 4d446767-11df-526a-a2da-93799c90dee7Rails 5 では
Rails 5.2.3 では、
LoadErrorになります。$ bin/rails runner scripts/uuid.rb ... 1: from scripts/uuid.rb:1:in `<main>' /usr/local/lib/ruby/2.6.0/digest.rb:16:in `const_missing': library not found for class Digest::UUID -- digest/uuid (LoadError)`明示的に
requireすれば、LoadErrorは解消されます。scripts/uuid.rbrequire 'active_support/core_ext/digest/uuid' puts Digest::UUID.uuid_v3(Digest::UUID::DNS_NAMESPACE, 'rubyonrails.org') puts Digest::UUID.uuid_v4 puts Digest::UUID.uuid_v5(Digest::UUID::DNS_NAMESPACE, 'rubyonrails.org')試したソース
試したソースは以下にあります。
https://github.com/suketa/rails_sandbox/tree/try106_digest_uuid参考情報
- 投稿日:2019-11-25T12:25:46+09:00
Bulmaを使うためにRailsのフロント周りについて改めて調べてみた
個人開発で出くわした悩み事について書きます。
フロントエンドにあまりに疎いため、Bulmaを使おうとしたとき、Yarnで追加するのかbulma-rails gemを使うのか迷いました。
それぞれどういう違いがあるのか、改めて調べてみることにしました。bulma-railsは何をしているのか?
bluma-railsというgemがあります。
READMEにはこう書かれていますIntegrates Bulma with the rails asset pipeline.なるほど。asset pipelineを使うらしい。
asset pipelineという言葉に引っかかりを感じつつも、とりあえずgemの中身を見てみます。gemspecを見る
こちらがbluma-railsのgemspecです。
SassCというgemに依存していることがわかります。
SassCは、ffiという他言語の関数を呼んだりできるgemを使って、
C++で書かれたlibsassを使ってSassを扱っています。ffiというgem、初めて知りましたが面白そうなgemですね。
コードを見てみる
app/assets/stylesheetsというディレクトリの下にbulma.sassというファイルがあり、ここでapp/assets/stylesheets/sassをimportしているのがわかります。
@charset "utf-8" /*! bulma.io v0.8.0 | MIT License | github.com/jgthms/bulma */ @import "sass/utilities/_all" @import "sass/base/_all" @import "sass/elements/_all" @import "sass/form/_all" @import "sass/components/_all" @import "sass/grid/_all" @import "sass/layout/_all"あれ、これはつまりこれをapp/assets/stylesheets/bulma.sassに、app/assets/stylesheets/sassにこれを置いた、って感じですね。
続いて、libのbulma-rails.rbを見てみます。
こんな感じ。module Bulma class Engine < ::Rails::Engine end endRailsエンジンが出てきました。
エンジンも詳しくないのでRailsガイドのRailsエンジン入門を読んでみます。
エンジンの中にあるアセットは、通常のアプリケーションで使われるアセットとまったく同じように振る舞います。
エンジンのクラスはRails::Engineを継承しているので、アプリケーションはエンジンのapp/assetsディレクトリとlib/assetsディレクトリを探索対象として認識します。bulma-railsは、Railsが探索してくれるところにBulma使うのに必要なファイルを置いてくれるgemだということがわかりました。
置いたらあとはasset pipelineがよしなにやってくれるのでしょうね。asset pipeline
asset pipeline、随分ご無沙汰しており、どんな人なのか記憶にないので、改めてRailsガイドを読んでみます。
アセットパイプラインはsprockets-rails gemによって実装され、デフォルトで有効になっています。
なるほどsprocketsがアセットのコンパイル、圧縮を頑張る仕組みなのですね。
アセットパイプライン導入後は、app/assetsディレクトリがアセットの置き場所として推奨されています。このディレクトリに置かれたファイルはSprocketsミドルウェアによってサポートされます。
bulma-railsはapp/assets/stylesheets以下にscssファイルを置いてたので、sprocketsがサポートしてくれるというわけですね。
しかしファイル置くだけのgemって変だよな、と、調べていたところ以下の記事を見つけました。
新しいRailsフロントエンド開発(1)Asset PipelineからWebpackへ(翻訳)
依存関係についてはどうでしょうか。Asset Pipelineを常に最新に保つのは大仕事です。プロジェクトにJavaScriptライブラリを1つ追加する場合、CDNから読み込んだコードをコピペしてapp/assetsやlib/assetsやvendor/assetsに置くか、誰かがgem化してくれるまでぼんやり待つ方法があります。その間にも、JavaScriptコミュニティは同じことをnpm installコマンド、今ならyarn addコマンド一発で管理しています。アップデートも同様です。YarnはJavaScriptをBundlerのように便利に扱うことができます。
な、なるほど、、、それでgem化して固めてたのか。先人の苦悩が伝わってきました。Yarnありがとう。
webpacker + YarnでBulmaを追加するとどうなるのか?
Rails6ではwebpackerがデフォルトになっているので、webpacker + Yarnを使って同じことをやってみます。
ロゴが猫なのでYarnは好きです。コードがあるほうがよいかなとリポジトリ作りました。さて、雑にrails newしてみますとこんな出力が得られました。もりもりいろんなものがinstallされていることがわかります。
meowという気になる名前のモジュールがinstallされてますね。なんでしょうか。
├─ meow@3.7.0CLI app helperと書いてありました。
meowなページで癒やされたので続きをやっていきます。雑にアプリを作る
Yay! You’re on Rails! の画面が出ましたが、Bulmaの使い所がないので画面を増やすために雑にscaffoldしていきます。
rails generate scaffold cat name:string description:textmigrationしてrails sしてlocalhost:3000/catsを確認するとこんな画面が出ます。
殺風景ですね。Bulmaを導入していきます。Bulmaを使っていく
yarn add bulmaしてみると、こんな出力が出ます。
warningが出てますが、webpackerのissueで対策検討されているようなので今回はさらっと流していきます。yarn add bulmaしてみると、package.json、yarn.lockが更新され、node_modules以下にbulmaがinstallされます。node_modules以下は.gitignoreに書いてあるのでcommitに乗りません。これでBulmaが追加できました。
あとはRailsで使えるようにしていくだけ、なのですが、フロントエンド音痴ゆえここで大変苦戦しました。Rails6でwebpackを使ってbootstrapを導入する記事を見つけたので、これを参考にやっていきます。
- application.sassを app/javascript/stylesheetsに作って、Bulmaのcssをimport
- app/javascript/packs/application.jsで上記をimport
- app/views/layouts/application.html.erb の stylesheet_link_tag を stylesheet_pack_tag に
- app/views/cats/index.html.erbの適当な要素にclassを追加
これでBulmaのスタイルを適用できました。Bulmaが効いていることをチャッと確かめたかったので、New Catのリンクとh1にだけclassを振っております。まとめ
フロント開発から随分遠ざかっていたのでwebpackerについて調べる良い機会を得られました。しかしチャッとBulma使っていこう、というくらいのつもりだったのにwarningを追いかけてwebpackerのissueまで読むことになるとは思いませんでした。
asset pipelineを使っているbulma-railsは大変簡単に導入できたので、これはこれで良いなと思いました。ただ、長く開発していくアプリで使うならYarnで管理するのが良さそうですね。次はwebpackerではなく素のwebpackに挑戦してみようと思います。
この記事ではwebpackerの説明は省いてしまいました。webpackがどんなものなのかについては、24日に投稿する記事で紹介される予定です。お楽しみに。明日は、@mochikichi321さんの「投稿画像の彩度低下問題を解決した話」です。明日もよろしくおねがいします!


- 投稿日:2019-11-25T11:44:24+09:00
[メモ]Rails超基礎 勉強して個人的に違いが分からなくなったメソッド
redirect_toメソッド
「redirect_to(URL)」とすることで、そのページに転送することができます。
以下だとcreateアクションを実行すると「/posts/index」ページへ転送される。def create redirect_to("/posts/index") endrenderメソッド
別のアクションを経由せずに、直接ビューを表示することができます。
render("フォルダ名/ファイル名")のように表示したいビューを指定します。
renderメソッドを使うと、redirect_toメソッドを使った場合と違い、そのアクション内で定義した@変数をビューでそのまま使うことができます。
以下だとupdateアクションが実行された時、@postにid(例 id:1)を持つデータをデータベースから取り出す。
取り出したデータのcontentカラムデータだけ取り出し@post.contentに格納する。
最後に「posts/edit」というURLに@post.contentという変数をビューでそのまま使うことができる。def update @post = Post.find_by(id: params[:id]) @post.content = params[:content] render("posts/edit") endform_tagメソッド
「form_tag(送信先のURL) do」のように送信先のURLを指定します。
実行時に、指定されたURLにデータが送信されます。<%= form_tag("/posts/create") do %> <textarea></textarea> <input type="submit" value="投稿"> <% end %>
- 投稿日:2019-11-25T08:27:30+09:00
Rubyコーディング規約
コーディング規約
ルールではなくマナー
僕が気をつけているポイントを紹介するよ!インデントは2つ
if num > 0 ●●if num < 100 ●●●●puts "100より小さい正の数" ●●end endクラス内の各構成要素の区切りに空行を入れる
ただし、最初と最後は空けない。
tweets_controller.rbclass TweetsController < ApplicationController #最初は空けない before_action :move_to_index, except: :index #---ここ--- def index @tweets = Tweet.all end #---ここ--- def new @tweet = Tweet.new end #---ここ--- def create Tweet.create(tweet_params) end #---ここ--- private def tweet_params params.require(:tweet).permit(:text, :image) end #---ここ--- def move_to_index redirect_to root_path unless user_signed_in? end end #最後も空けないif文のthen
while文のdoは省略するif num < 100 puts "100より小さい" end while num < 100 puts num num += 1 end文字列リテラルはダブルクォーテーション
puts "ダブル!!"もちろん例外もあるよ!
三項演算子は簡単な条件の時のみ
puts score > 60 ? "合格":"不合格"少しでも複雑ならif文!
変数・メソッド名は小文字&スネークケース
#変数 num = 15 add_color = "yellow" #メソッド def index end def add_something end2単語繋げる場合は_を使う!
参考
ではまた!
- 投稿日:2019-11-25T07:01:29+09:00
【Rails】RSpecで`visit`が`undefined method`と怒られたときの解決法
はじめに
Rails+RSpec+Capybaraで書いたテストを実行しようとしたらタイトルのようなエラーが出た方に向けて解決法を残しておきます。
この記事が役に立つ方
- タイトルのようなエラーで困っている方
この記事のメリット
- エラー解決!
環境
- macOS Catalina 10.15.1
- zsh: 5.7.1
- Ruby: 2.6.5
- Rails: 5.2.3
- RSpec: 3.9.0
- Capybara: 3.29.0
エラー内容
NoMethodError: undefined method `visit' for #<RSpec::ExampleGroups::UsersIndex::IndexHtmlErb:...>なぜか
visitが定義されていないことになっている。原因
Capybaraが読み込まれていないことが原因です。
visitはCapybara内で定義されているため読み込む必要があります。解決法 その1
以下を追記します。
spec/spec_helper.rb...略 require 'capybara/rspec' # 追記 RSpec.configure do |config| ...略解決法 その2(1で解決しなかった場合)
もういっちょ追記します。
spec/spec_helper.rb...略 require 'capybara/rspec' RSpec.configure do |config| config.include Capybara::DSL # 追記 ...略なぜ解決したのか?
公式のREADMEに答えが書いています。(※以下はバージョン3.29対応版)
capybara/README.md at 3.29_stable · teamcapybara/capybara · GitHubLoad RSpec 3.5+ support by adding the following line (typically to your spec_helper.rb file):
RSpec3.5以上を使っているなら、
spec_helper.rbに以下を追記してねと書いてあります。require 'capybara/rspec'これで
Capybaraが読み込まれることになります。
ここまでが解決策1の範囲です。ただ、これで解決しない方はREADMEの次の文章に答えが書いてあります。
If you are using Rails, put your Capybara specs in spec/features or spec/system (only works if you have it configured in RSpec) and if you have your Capybara specs in a different directory, then tag the example groups with type: :feature or type: :system depending on which type of test you're writing.
書いたテストが以下ディレクトリにあるか、
spec/features
spec/systemタグが以下でないと
Capybaraが読み込まれません。
type: :feature
type: :systemそのため、それ以外のパターンに該当してしまう場合は
解決法 その2
で追記したように強制的にCapybara::DSLを読み込んでしまうことで解決出来ます。おわりに
自分は結構ここでハマってしまったので、同じような方の役に立てればと思います。
日本語の記事で楽をせず、困ったら公式を見ないといけませんね
参考にさせて頂いたサイト(いつもありがとうございます)
capybara/README.md at 3.29_stable · teamcapybara/capybara · GitHub
- 投稿日:2019-11-25T02:22:36+09:00
28歳から高卒未経験がWeb系エンジニアを目指す学習&就活の日記
どもども。初めまして、これが現在のおいらのスペックです。
・年齢:28歳
・仕事:離職中
・性格:自称コミュ障
・職歴:ほぼ工場。そしてほんの少しだけ音楽教室の運営を経験。
・学歴:高卒(工業系だんしーこう)
・英語力:グーグル翻訳最高!現在ちょびちょび勉強中。
・好物:天丼、とろサーモン(寿司)、家系ラーメン、徳用チョコ、うすしおポテチ、ダブルチーズバーガー、(見たらわかる全部太る奴やん)
・趣味:プログラミング(3日前から)、映画鑑賞(ほぼ洋画)、音楽鑑賞(オールジャンル)、昔はギターとかDTMとか。
・座右の銘:完璧より前進
・あこがれる人:レオナルド・ディカプリオ、
・最近気になる人:エドワード・スノーデン、
・悩み:プログラミングも覚えたい、英語も覚えたい、映画も見たい、ゲームもやりたい、仕事も探さなくちゃ、家事もしなくちゃ、などやる事が多すぎるので分身の術を使いたい昨今。
・現在のタスク:プログラミング学習、ポートフォリオ作成
・目の前の目標:Webエンジニアになる。
・ちょっと先の目標:リモートワークする。
・その先の目標:面白いWebサービスを作る。とにかく面白いものを作りたい。
・感化された本:サピエンス全史(ざっとしか読んでない(笑)でもオススメ!)
・プログラミング教材:Progate、ググりまくる、後日、参考書等も購入予定。・プログラミングを始めようと思ったきっかけ:
中学生の時にガラケーで、無料ホームページを利用して掲示板を作ったことがあり(i-mode時代)、学校の友達や他の学校の人達が利用してワイワイとコメントしてくれた。そして今頃になってその記憶を思い出し、またそんな風に色んな人達が楽しめるサービスを作りたい思った。(あの頃、ケータイ代が跳ね上がって親にガチで叱られたのは言うまでもない。。。)あとは、純粋にネットとかPCをいじっている時が一番楽しいため。ということで、以上がおいらの簡単なスペックでした。
なぜ投稿したのかって?
これからQiitaを、日々の学習内容の備忘録として活用しようと思ったから。
とりあえず今日で勉強をし始めて3日目です。
なので今日まで3日分の勉強内容をここに記そうと思います。この記事だけなんか長く書いてるのですが、この記事以降の日記は一言日記にしようと思ってます。
19/11/23
・ハローワークに行った。Web系エンジニアの未経験okの正社員求人を相談。結果→収穫無し(その他エンジニア求人情報はゲット)
・ためしにProgateに登録してみる。
・プログラミングおもしろいやんけ\(^o^)/
・HTML&CSSの基礎を学ぶ。11/24
・git hubに登録
・環境構築
・gitとgit hubについてググりまくってほぼ1日を使う(泣)
・progateのhtml&css中級編を半分まで修了。11/25
・html&css中級編を全部修了。
・Rubyの学習を始める。
・備忘録のために日記を書き始める。ということで引き続きプログラミング学習したいと思います。
ではでは。