- 投稿日:2019-11-25T23:10:17+09:00
cometchatの日本語対応について
みなさん、cometchatってご存知でしょうか?
cometchatとはチャットAPI&メッセージSDKで、自分のWebサイトに簡単にチャット機能が設置できます。
私はこのcometchat pro(cometchatのもっと柔軟に扱えるサービス)のAPIを使って自分のサイトにチャット機能をつけました。
(こちらを元にpython(Django)で実装しています。)
しかし完成後、悲劇が起こります。
cometchatで日本語のテキストが送れない。。。。
私のサイトは日本語
サイトがインターナショナルになってしまった訳です。
公式ドキュメントには「日本語も対応しているよ!」と書いてありますが、
実際日本語でメッセージ送ろうとすると以下のエラーが出ます。UnicodeEncodeError: 'latin-1' codec can't encode characters in position 90-92: Body ('あああ') is not valid Latin-1. Use body.encode('utf-8') if you want to send it encoded in UTF-8.Use body.encode('utf-8')←上記のエラーでこれ試せばいいって教えてくれてますが、
試すとERR_BAD_REQUESTが返ってきます。{"error":{"code":"ERR_BAD_REQUEST","details":{"receiver":["The receiver field is required."],"receiverType":["The receiver type field is required."]},"message":"Failed to validate the data sent with the request."}}解決方法
メッセージを送る時。
byteにして16進数文字列に変換する。text = "送りたいメッセージ" text.encode().hex() # 'e98081e3828ae3819fe38184e383a1e38383e382bbe383bce382b8'メッセージを受け取る時。
16進数文字列をbyteに変換、byteをstrに変換する。bytes.fromhex(text).decode() # "送りたいメッセージ"
※一応公式サイトには日本語も対応していると書いているので、
もしかしたら普通に送っても問題ない可能性があります。

- 投稿日:2019-11-25T22:49:34+09:00
Python Scikit-learn 線形回帰分析 非線形単回帰分析 機械学習
Pythonでcsvデータを読み込んで線形回帰と非線形回帰を実施する方法について書きます。
windows10環境でPythonのverは3.7.3です.コードは以下になります.
◆csvデータを読み込んで線形単回帰分析
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.dates as mdates #変数 fig = plt.figure() ax = fig.add_subplot(1,1,1) #y軸csvデータ読み込み data = pd.read_csv('cp.csv') y = np.array(data)#配列化 y = y.reshape(-1,)#次元変更(2から1次元) #日付のx軸を作成 x = pd.date_range('2019-08-30 00:00:00', periods=16, freq='d') x1=np.arange(16) x2 = [[x1] for x1 in x1] #線形単回帰 from sklearn import linear_model clf = linear_model.LinearRegression() clf.fit(x2,y) # 予測モデルを作成 print("回帰係数= ", clf.coef_) print("切片= ", clf.intercept_) print("決定係数= ", clf.score(x2,y)) #グラフ作成 ax.plot(x2,y,'b') ax.plot(x2, clf.predict(x2),'k') #グラフフォーマットの指定 plt.xlabel("Days elapsed")#横軸ラベル plt.ylabel("plice")#縦軸ラベル plt.grid(True)#目盛表示 plt.tight_layout()#全てのプロットをボックス内に plt.show()◆csvデータを読み込んで非線形単回帰分析
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.dates as mdates #変数 fig = plt.figure() ax = fig.add_subplot(1,1,1) #y軸csvデータ読み込み data = pd.read_csv('cp.csv') y = np.array(data)#配列化 y = y.reshape(-1,)#次元変更(2から1次元) #日付のx軸を作成 x = pd.date_range('2019-08-30 00:00:00', periods=16, freq='d') #非線形回帰次数 x1=np.arange(16) fit = np.polyfit(x1,y,5) y2 = np.poly1d(fit)(x1) #決定係数 from sklearn.metrics import r2_score print(r2_score(y,y2)) #予測 x_30 = np.poly1d(fit)(30) print(x_30) #グラフ作成 ax.plot(x,y,'bo') ax.plot(x,y2,'--k') #グラフフォーマットの指定 days = mdates.DayLocator() daysFmt = mdates.DateFormatter('%m-%d') ax.xaxis.set_major_locator(days) ax.xaxis.set_major_formatter(daysFmt) plt.xlabel("date")#横軸ラベル plt.ylabel("price")#縦軸ラベル plt.grid(True)#目盛表示 plt.tight_layout()#全てのプロットをボックス内に plt.show()回帰分析の技術説明と各コードの詳細な解説はこちら(´・ω・`)☟☟☟
https://kgrneer.com/python-numpy-scikit-kaiki/重回帰についても勉強中です。
- 投稿日:2019-11-25T22:16:55+09:00
matplotlibでscatterの点をクリックすると色を変えたい
初めに
scatterでプロットしたところまでは良かったのですが、その後データの更新しようとすると難しかったので共有しておきます。
コード
scatter.pyimport matplotlib.pyplot as plt import itertools #デカルト積 import numpy as np if __name__ == '__main__': x_max = 10 y_max = 10 fig = plt.figure(figsize=(5,5)) ax = fig.add_subplot(111) ax.set_xlim(-x_max*0.05,(x_max-1)*1.05) ax.set_ylim(-y_max*0.05,(y_max-1)*1.05) x_data = [i for i in range(x_max)] y_data = [i for i in range(y_max)] tmp_data = list(itertools.product(x_data,y_data)) t_x = [i[0] for i in tmp_data] t_y = [i[1] for i in tmp_data] data = [t_x,t_y] colors = [(0,0,0,1) for i in range(x_max*y_max)] art = ax.scatter(data[0],data[1],c=colors) def onclick(event): x = round(event.xdata,0) y = round(event.ydata,0) tmp = int(x*(y_max) + y) if colors[tmp] == (0,0,0,1): colors[tmp] = (0.5,0.5,0.5,1) elif colors[tmp] == (0.5,0.5,0.5,1): colors[tmp] = (0,0,0,1) art.set_facecolor(colors) plt.draw() plt.connect('button_press_event', onclick) plt.show()
- 投稿日:2019-11-25T20:30:35+09:00
"You have multiple authentication backends configured ..." への対処法(Django)
この記事について
日本語で書かれている対処法がなかったので、書き残しておきます。
問題の発生
Djangoで作成していたアプリケーションにて、Userを作成してそのユーザーでログインした場合に以下のエラーが発生。
You have multiple authentication backends configured and therefore must provide the `backend` argument or set the `backend` attribute on the user.原因
複数のAUTHENTICATION_BACKENDSを使用していたにも関わらず、ログインさせる処理でbackendの指定をしなかったため。
views.py# ユーザー登録画面 # ログイン処理 login(self.request, user) # ここでエラー※ソーシャルログイン機能を実装するために
django-allauthを使用していました。settings.pyAUTHENTICATION_BACKENDS = ( 'django.contrib.auth.backends.ModelBackend', # ID/pass 'allauth.account.auth_backends.AuthenticationBackend', # ソーシャル )対処法
backendを指定した。
views.py# ユーザー登録画面 # ログイン処理 login(self.request, user, backend='django.contrib.auth.backends.ModelBackend')結果
解決しました。
backendを指定する必要があったんですね。
- 投稿日:2019-11-25T18:53:40+09:00
Pythonで二面体群を作ってみる
以前、Pythonで自由群$F_2$を作ってみました。
今回はその続きで、二面体群$D_4$を作ってみます。
二面体群とは?
平らな正n角形を思い浮かべてください。今回は、$D_4$を作るので、正方形を思い浮かべます。
この正方形について、
- 操作r: 正方形を時計回りに360/n度回転する
- 操作t: 正方形を裏表ひっくり返す
- 操作e: なにもしない
の3つの操作を考えます。
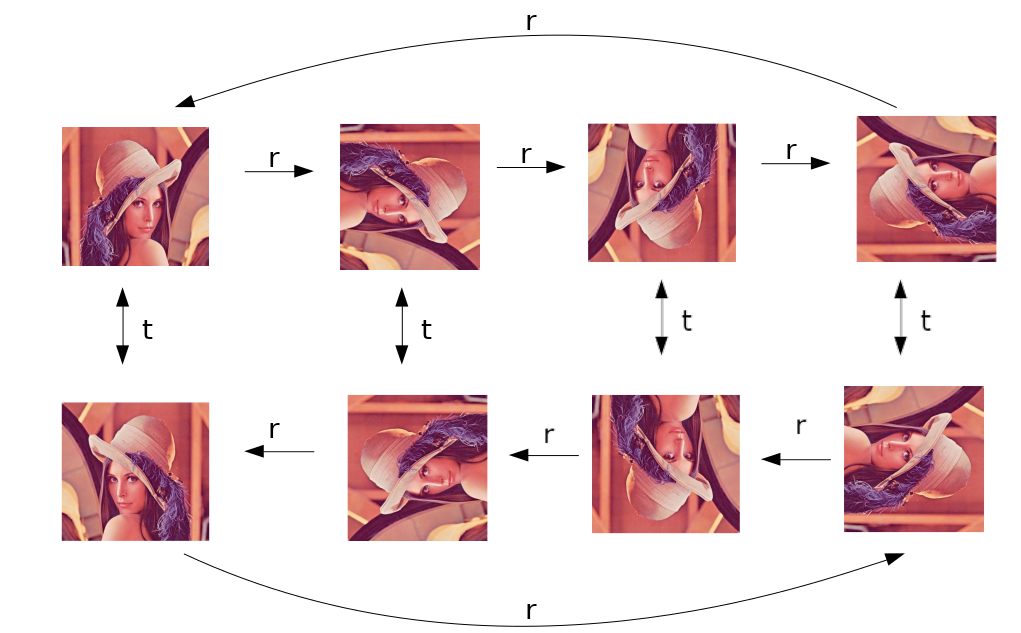
また、これらの積(複数の操作を順に行う)や、逆元(rの逆元は、反時計回りに回転する, tの逆元はt)を考えることもできます。また、「なにもしない」操作eは単位元に相当します。$r^{-1}$を書くのをサボっていますが、図にすると、次のようになります。
2つの元r, tから生成される、という点では、自由群$F_2$と似ているのですが、自由群になかった特徴として、
$r^4 = e$, $t^2 = e$ や、さらには $trt = r^{-1}$ という性質があります。(3つ目の性質に気づかれていましたでしょうか? 裏返して時計回りに回転して、再び裏返すと、反時計回りに回転したことになっている、ということを言っています)実は、どんな群でも、自由群にこういった関係式を付け加えることで作ることができる、というのは知っておいて損はないかもしれません。
実装していきましょう
簡単な形にしたい
自由群のときと同じように、文字列で保持するのですが、関係式を考慮しながら、できるだけ簡単な形にしておきたいです。
まず、$t^{-1}$は$t$に、$r^{-1}$は$r^3$に置き換えることができます。($r\cdot r^{3} = e$なので$r^{-1} = r^{3}$です)
さらに$t^2 = e$, $r^4 = e$も考慮すると、rとtの数を数えて、4で割った余り、2で割った余りを取ればいいことが分かります。もっと簡単にならないでしょうか。
$trt = r^{-1}$ がありましたが、右から$t$をかけると、$t^2 = e$を考慮すると$tr = r^{-1}t$となります。$trrt = trttrt = r^{-1}r^{-1}$となります。これを繰り返すと$tr^nt = tr^{-n}t$が分かります。
上と同様に、$tr^n = r^{-n}t$となります。
これを繰り返すことで、r...rtr...rtr...rtとなっているのを、r...rtの形に、tを右にずらせることが分かります。結果、どんな元でも、正規表現で書くと 'r{,3}t?' の形 (0〜3個のrと、0個または1個のt)で書けることが分かります。
積を考える
tの有無で場合分けして考えます。
- $(r^n t)\cdot(r^m t)$のとき⇒$r^{n-m}$になります
- $(r^n t)\cdot(r^m)$のとき⇒$r^{n-m}t$になります
- $(r^n)\cdot(r^m t)$のとき⇒$r^{n+m}t$になります
- $(r^n)\cdot(r^m)$のとき⇒$r^{n+m}$になります
つまり、左側にtがあればrの数がn-mに、なければn+mになります。
また、最後にtがつくかどうかは、tの個数が奇数か偶数かで決まります。逆元を考える
自由群のときと同じように、文字列を逆転して、また、すべてを逆元にするといいのですが、簡単な形式に直すことを考えると、次のように場合分けできます。
- $(r^n)^{-1} = r^{-n}$
- $t^{-1} = t$
- $(r^n t)^{-1} = t r^{-n} = r^n t$
なんと、tがついていたら、自分自身が逆元になるんですね。面白い。
コード
前回作った
FreeGroupBaseを親クラスにしていきます。from collections import namedtuple FreeGroupBase = namedtuple('FreeGroupBase', 's')さらに、先ほど考察したことをコードに書き起こします。
import re class DihedralGroup(FreeGroupBase): '''rとtの2つの元からなる群で、r^n = e, t^2 = e, trt = r^-1を満たす。 ここでは、n=4 (D_4)とした。 ''' check = re.compile('r{,3}t?') def __init__(self, s: str): if not self.check.fullmatch(s): raise ValueError('Unexpected format') def __mul__(self, other: 'DihedralGroup') -> 'DihedralGroup': return DihedralGroup(self._reduction(self.s, other.s)) def __invert__(self) -> 'DihedralGroup': # ~(r^n) = r^{-n} # ~t = t # ~(r^n t) = t r^{-n} = r^n t if not self.s or self.s[-1] == 't': return self return DihedralGroup('r' * (4 - len(self.s))) @staticmethod def _reduction(lhs: str, rhs: str) -> str: # r^4 = e, t^2 = t, trt = r^-1 の関係式がある。 # trt = r^-1は、tr = r^-1 tと読み替えられるので、これを使って、tを右に寄せていく # また、r^-k (k>0)のような形が残った場合、r^{n-k}に置き換える # 結果的に、正規表現で書くと r{,4}t? の形にまとめられる。 # lhs, rhsは、既にこの処理が済んでいると考える def count(s): '"r{,3}t?" で表された文字列のrの数とtの数を返す' if not s: return 0, 0 if s[-1] == 't': return len(s) - 1, 1 return len(s), 0 r1, t1 = count(lhs) r2, t2 = count(rhs) if t1: r2 = -r2 return 'r' * ((r1 + r2) % 4) + 't' * ((t1 + t2) % 2) def __repr__(self) -> str: if not self.s: return 'e' return ' * '.join(self.s)やってみる
print(t * r * t) print(t * r * t * r) print(t * r * r * r * t) print(e * e * t * r * e * r * e * e * e * r * t) print(r * r * t * r) print(~(r*r*r) * (r*r*r)) print(~(r*r*r*t) * (r*r*r*t))r * r * r e r r r * t e eなんかできてそう。
まとめ
今回、二面体群をPythonで作ってみました。
二面体群は、簡単ながらも、化学計算などで分子の対称性を考えるときなどにも使われる有用な群です。
- 投稿日:2019-11-25T13:50:32+09:00
pythonでNoneをjson.dumpするとnullという文字列が変える
こんな感じ
>>> import json >>> outputs = None >>> json.dumps(outputs) 'null' >>> type(json.dumps(outputs)) <class 'str'>配列の場合はこんな感じ
>>> list = ["hoge", None] >>> json.dumps(list) '["hoge", null]' >>> type(json.dumps(list)) <class 'str'>
- 投稿日:2019-11-25T13:50:32+09:00
pythonでNoneをjson.dumpするとnullという文字列が返却される
こんな感じ
>>> import json >>> outputs = None >>> json.dumps(outputs) 'null' >>> type(json.dumps(outputs)) <class 'str'>配列の場合はこんな感じ
>>> list = ["hoge", None] >>> json.dumps(list) '["hoge", null]' >>> type(json.dumps(list)) <class 'str'>
- 投稿日:2019-11-25T13:42:54+09:00
【機械学習】決定木
決定木(Decision Tree)
決定木とは教師あり学習に使われるアルゴリズムです。与えられたデータを木のように枝分けしていくことで、予測やデータの要約を行います。回帰と分類両方に使用できる学習モデルです。
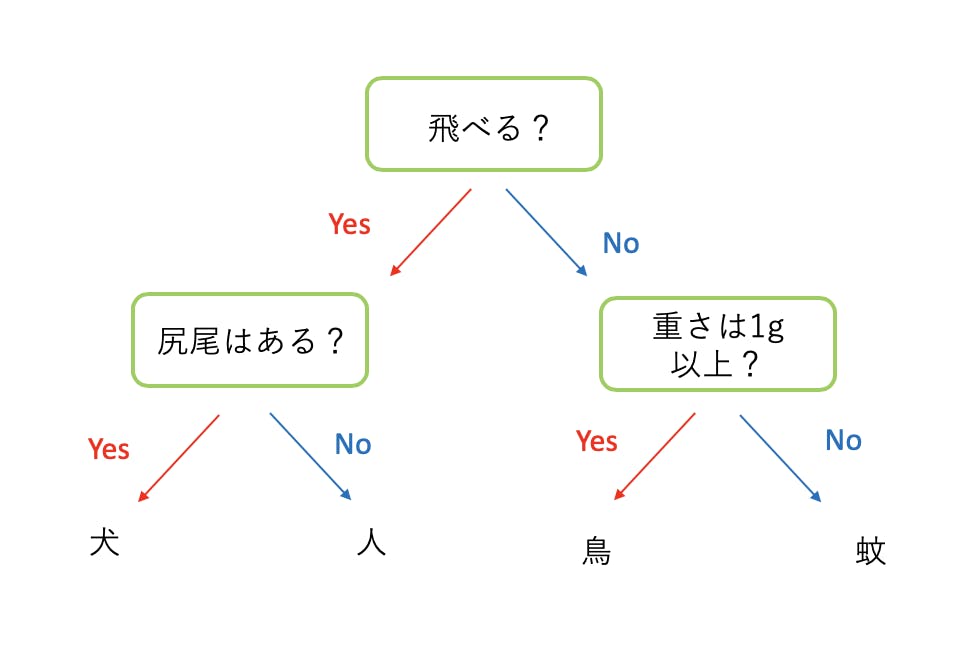
下の図は、データを「犬」「人」「鳥」「蚊」に分類するための決定木を表しています。
各枝では特徴量を利用してデータを分類してきます。最後の葉になる部分で、分類結果が決まります。
ここで、各枝を伸ばす際に考えるポイントとして
- どの特徴量をどのくらい使うか
- どこまで深く木を伸ばすか
が重要となってきます。
まず1を判断する基準に情報利得 (Information Gain)という基準が利用されます。
情報利得 (Information Gain)
情報利得は簡単に言うと、子ノードが親ノードと比べてどれくらい綺麗にデータを分類できたかを示す値です。もしくは、各ノードで標準偏差がどのくらい減るかを表した値です。どれくらいこの情報利得を計算するのに、不純度と呼ばれる値が使われます。不純度にはいくつか種類がありますが、今回は最も代表的なGiniとEntropyを紹介します。
Gini
Gini は次の式で表されます。
G = 1 - \sum_{n = 1}^{classes}P(i|t)^2各ノードで、データがあるクラスに分類される確率が高いほどGiniは0に近ずくことがわかります。仮にクラスが1つしかない場合、Giniは0となります。逆に、全てのサンプルが異なるクラスに属す時、Giniは1に近似します。
更に、各ノードでGiniからInformation Gain (IG)を計算します。IG = G(parent) - \sum_{children}\frac{N_j}{N}G(child_j)ここでは、親枝のGiniと子枝のGiniの加重平均(各クラスに含まれるデータの数の割合)の差を情報利得として取得します。
Entropy
Entropyは次の式で表されます。
E = - \sum_{i = 1}^{N}P(i|t)*log(P(i|t))ここで、P(i|t)が0.5に近いほど(1か0か分からない;分類できない)ほどエントロピーは高くなることがわかります。反対にP(i|t)が0か1の時、エントロピーは0となります。
IG = E(parent) - \sum_{children}\frac{N_j}{N}E(child_j)先程と同様、親枝の交差Entropyと子枝の交差Entropyの加重平均の差を情報利得として取得します。
この情報利得が大きい分割方法が各ノードで選択されます。
Gini と Entropy の使い分け
Gigiは回帰問題に向いており、Entropyは分類問題に向いています。
木の深さ
決定木の木の深さが深いほど、学習データにフィットしたモデルが選択されます。実際、最後の子ノードのデータ数が1の時、全てのデータを完璧にクラス分けすることができます。しかし、これではサンプルデータに過学習してしまい、モデルの意味がなくなってしまいます。なので、学習モデルを作る際には、木の深さに制限をつける必要があります。skitlearnでは、木の深さはパラメターで設定されます。
Scikit-learn 決定木
回帰
from sklearn.tree import DecisionTreeRegressor clf = DecisionTreeRegressor(criterion="entropy", max_depth=3) clf = clf.fit(X_train,y_train) y_pred = clf.predict(X_test)分類
from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier(criterion="entropy", max_depth=3) clf = clf.fit(X_train,y_train) y_pred = clf.predict(X_test)決定木のパラメター
パラメタ- 概要 オプション デフォルト criterion 分割基準 "gini", "entropy" "gini" splitter 分割選択の戦略 "best", "random" "best" max_depth 木の最深深さ int None min_samples_split 分割後ノードの最小サンプルサイズ(小さいと過学習傾向になる) int(サンプル数)/float(全サンプルに対する割合) 2 min_samples_leaf 葉(最終ノード)に必要な最小サンプルサイズ(小さいと過学習傾向になる) int/float 2 max_features 分割する上で使う特徴量の数(大きいほど過学習の傾向) int/float, auto, log2 None class_weight クラスの重み "balanced", none none presort データの事前の並べ替え(データサイズによって計算速度が変わる) bool False min_impurity_decrease 不純度にリミットをかけノードの伸びを制御する float 0. 決定木の長所と短所
長所
- 容易に可視化と要約ができる。
- データが線形パターンでない場合にも利用できる。
- 正規化の前処理が不要。
短所
- 外れ値の影響を受けやすい。
- 小さい分散でも、結果が大きく変わってしまう。
- 計算が複雑性、時間計算量が多くなる。
- 投稿日:2019-11-25T12:49:40+09:00
コード可視化ツール「SOURCETRAIL」でPythonで書いた自作簡易検索エンジンのソースコード解析をする
white, inc の ソフトウェアエンジニア r2en です。 自社では新規事業を中心としたコンサルタント業務を行なっており、普段エンジニアチームでは、新規事業を開発する無料のクラウド型ツール を開発したり、新規事業のコンサルティングからPoC開発まで携わったりしています
PoC開発フェーズから運用フェーズでの開発の引き継ぎや、既存のソフトウェアの運用などにおいて、インタラクティブにソースコードを理解できるツールがないか模索していたところ、SOURCETEAILを見つけたので今回は触ってみたので共有させてください
概要
SOURCETEAILは、開発者が他人の書いたソースコードを多大な時間を費やして理解しないように、ソースコードを解析し、可視化することで、生産的にコーディングを行えるよう支援するツール
TL;DR
実際に使って見ての感想は、操作が簡単でツールについて覚えることが少ないのに、割と見やすくて、割と使いやすい印象
完全に全容が理解できるわけではないにしろ、確実にソースコードを解読する手助けをしてくれると思うので、今後も使い続ける価値はあると思う
SOURCETEAIL インストール方法
https://www.sourcetrail.com/
sourcetrailのサイトへ飛び、ダウンロードボタンをクリック
sourcetrailのgithubのページに飛ぶため、自分のOS環境のイメージをダウンロードする
解凍してアプリケーションに移動させる
SOURCETEAIL 使用方法
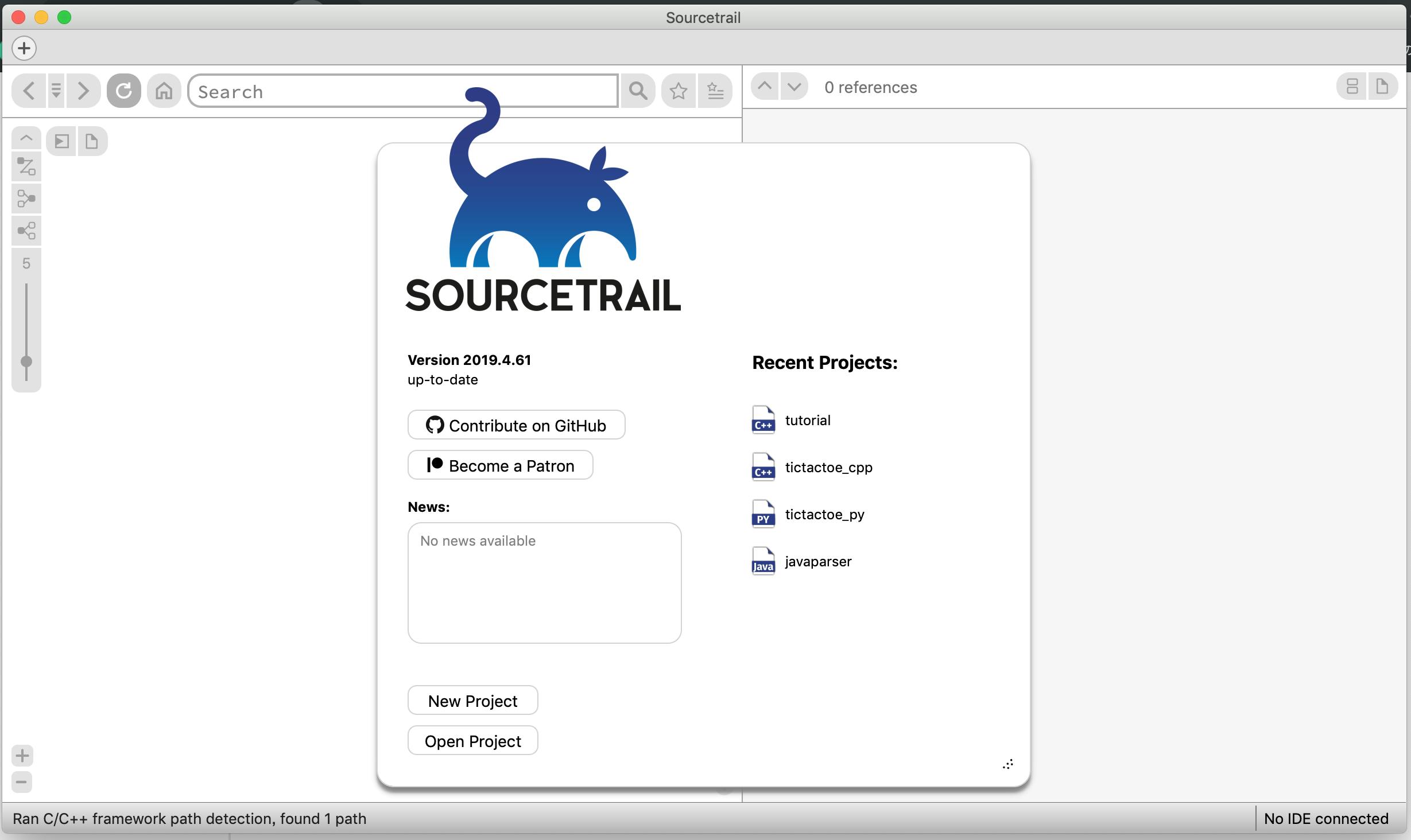
起動すると以下の画面になる。
New Projectを押す。
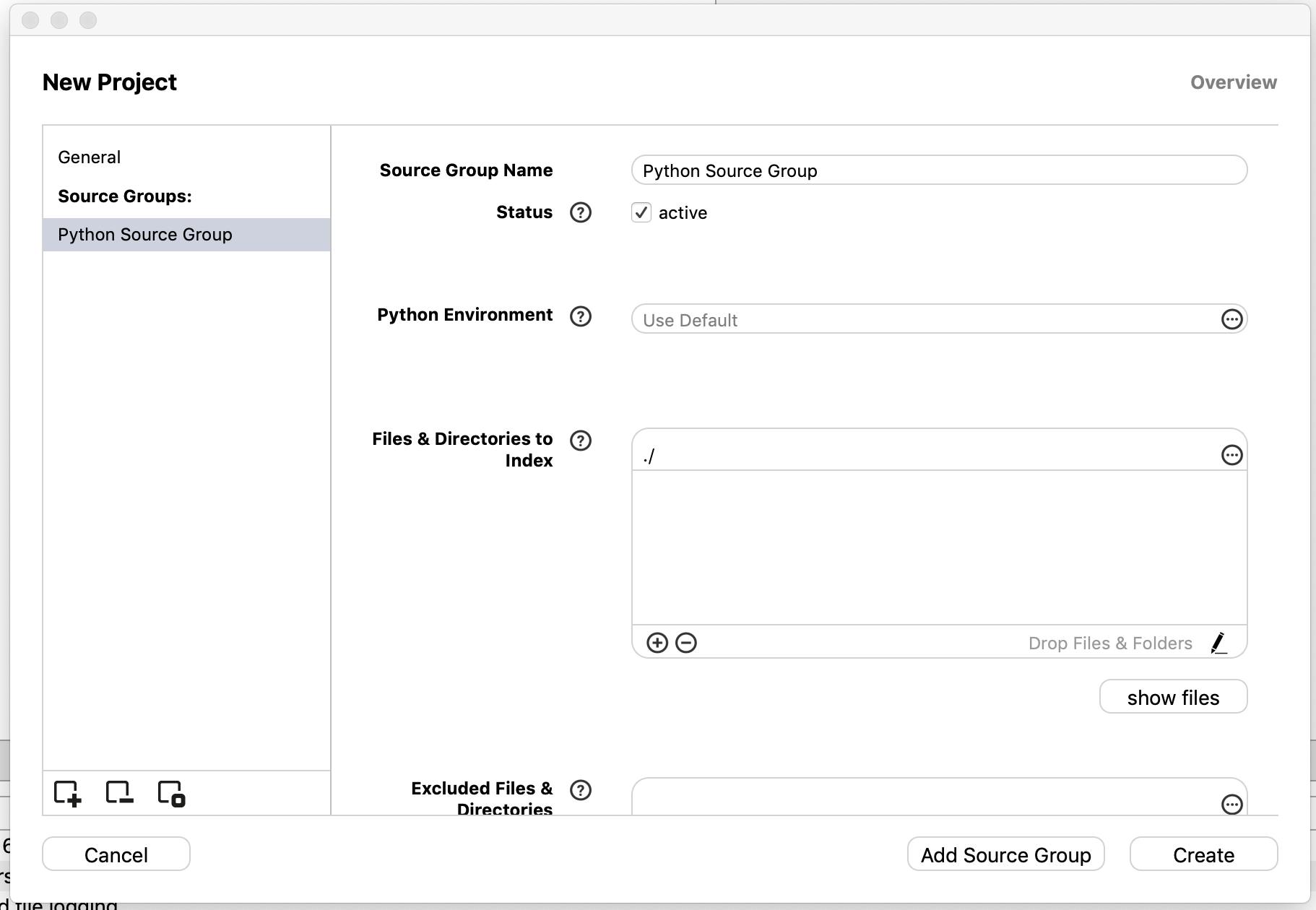
soucetailが静的解析した時に、解析したリポジトリ(ディレクトリ)に、ファイルが自動的に生成される。その時のために、project名とproject場所を選択する
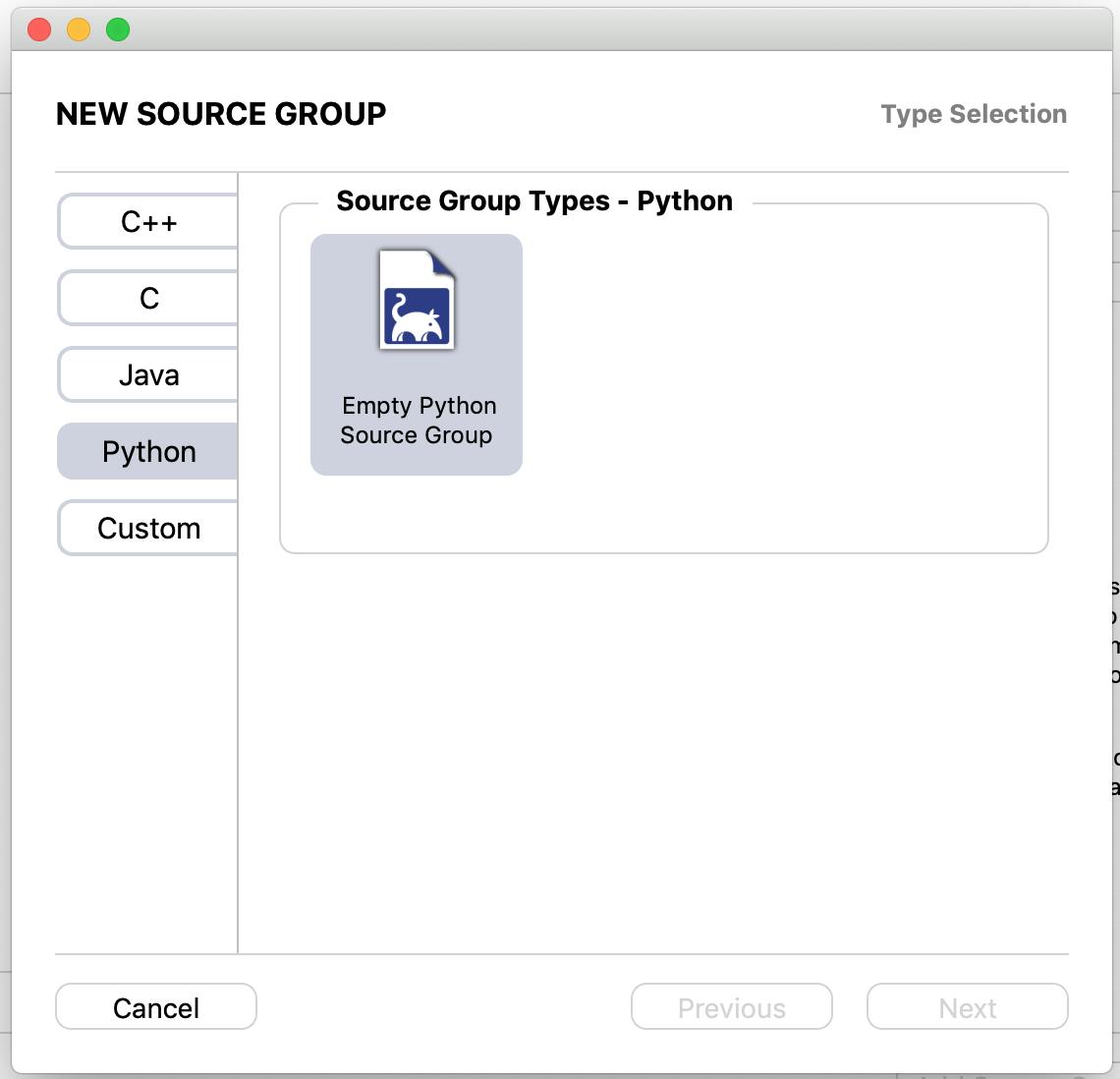
add source groupを選択する
自分が使うプログラミング言語を選択してnextを選択する
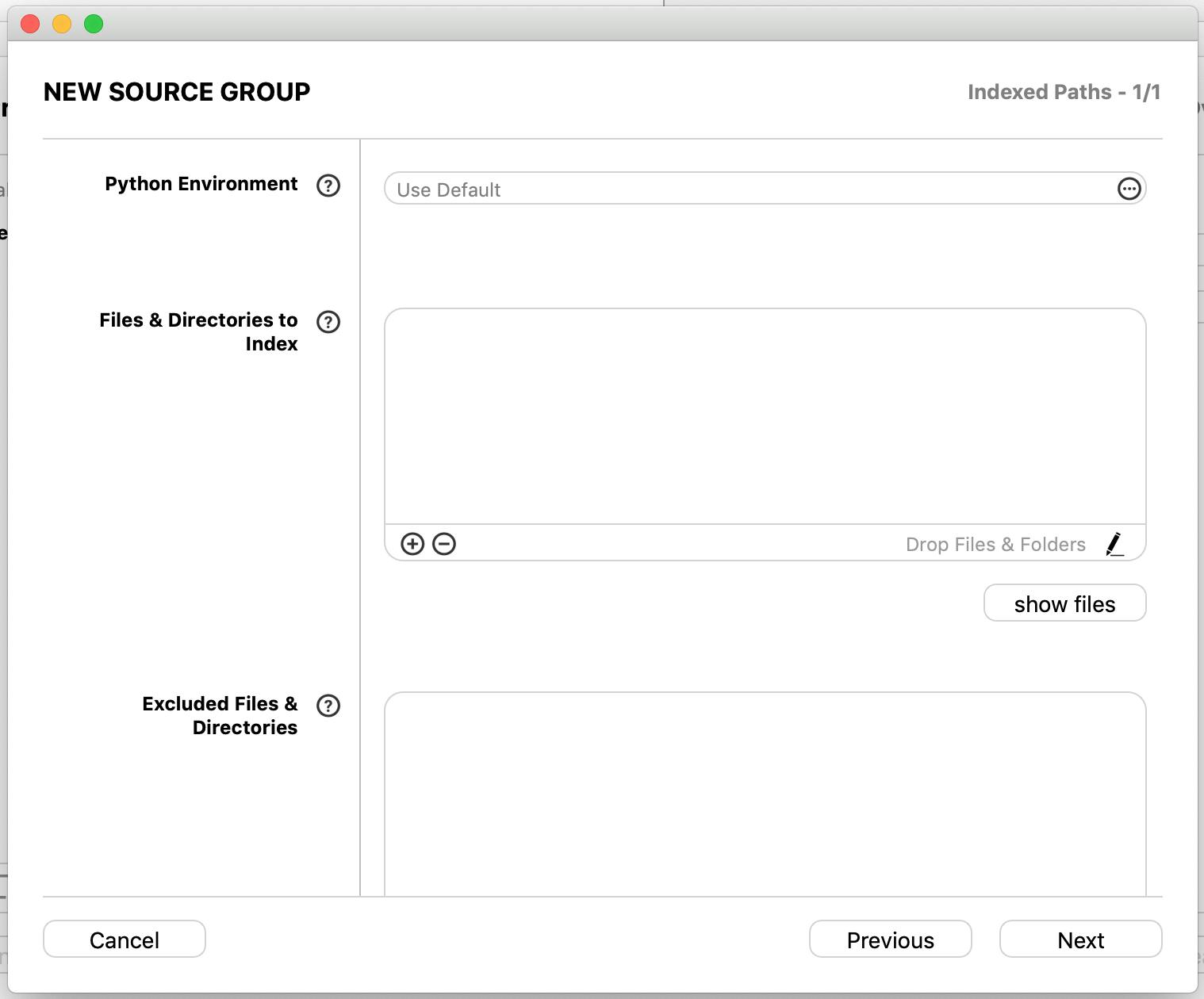
言語の環境や、外部モジュール、当該モジュールなどをここで入力する
ドラッグ&ドロップに対応しているため、当該リポジトリをそのままFiles & Directories to Indexに落とす※ 環境や外部モジュールを選択しないでも動作する
ドロップしたファイルを上記画面のshow filesで参照した画面
きちんとインポートされている
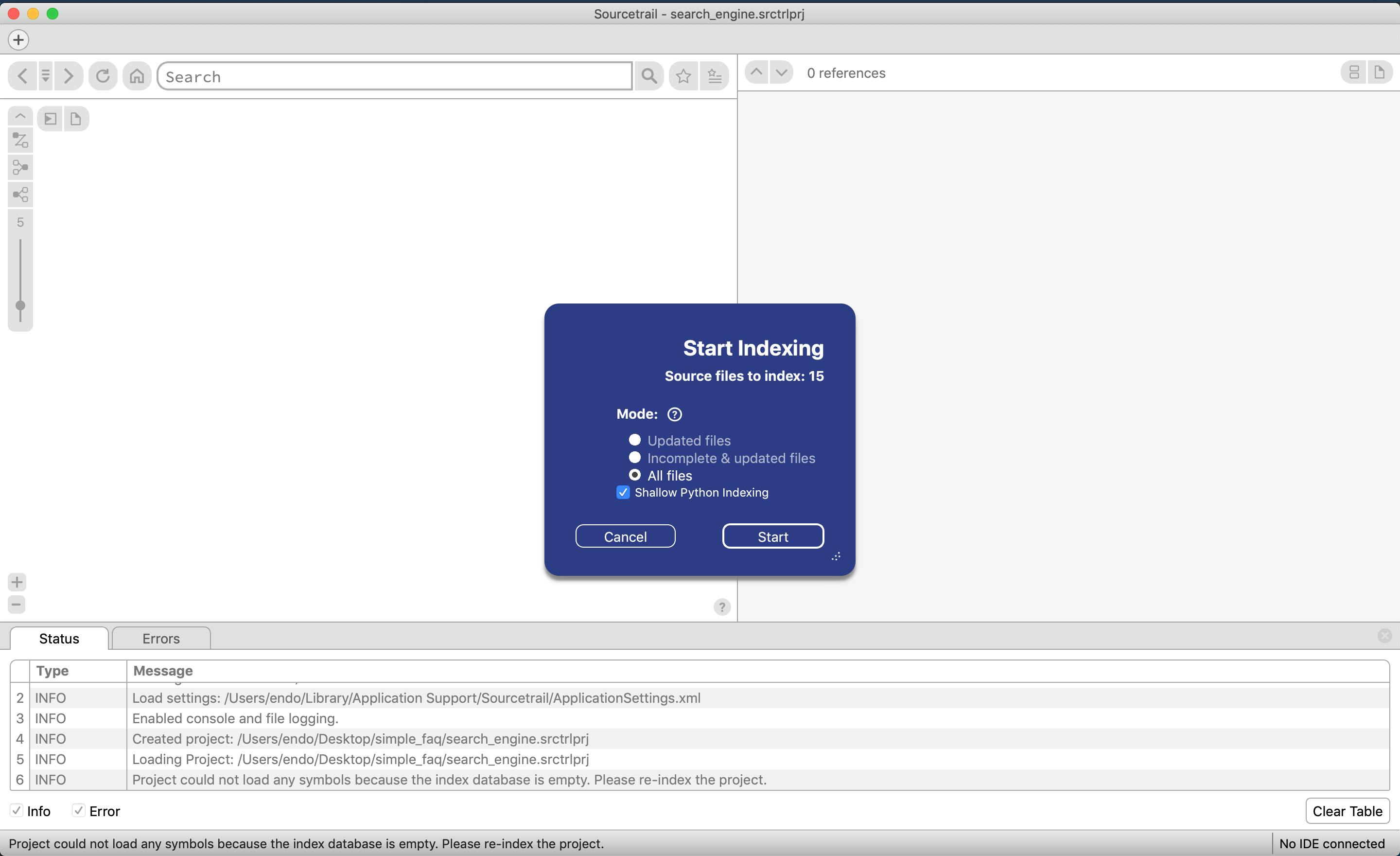
ある程度記入が終われば、createを選択する
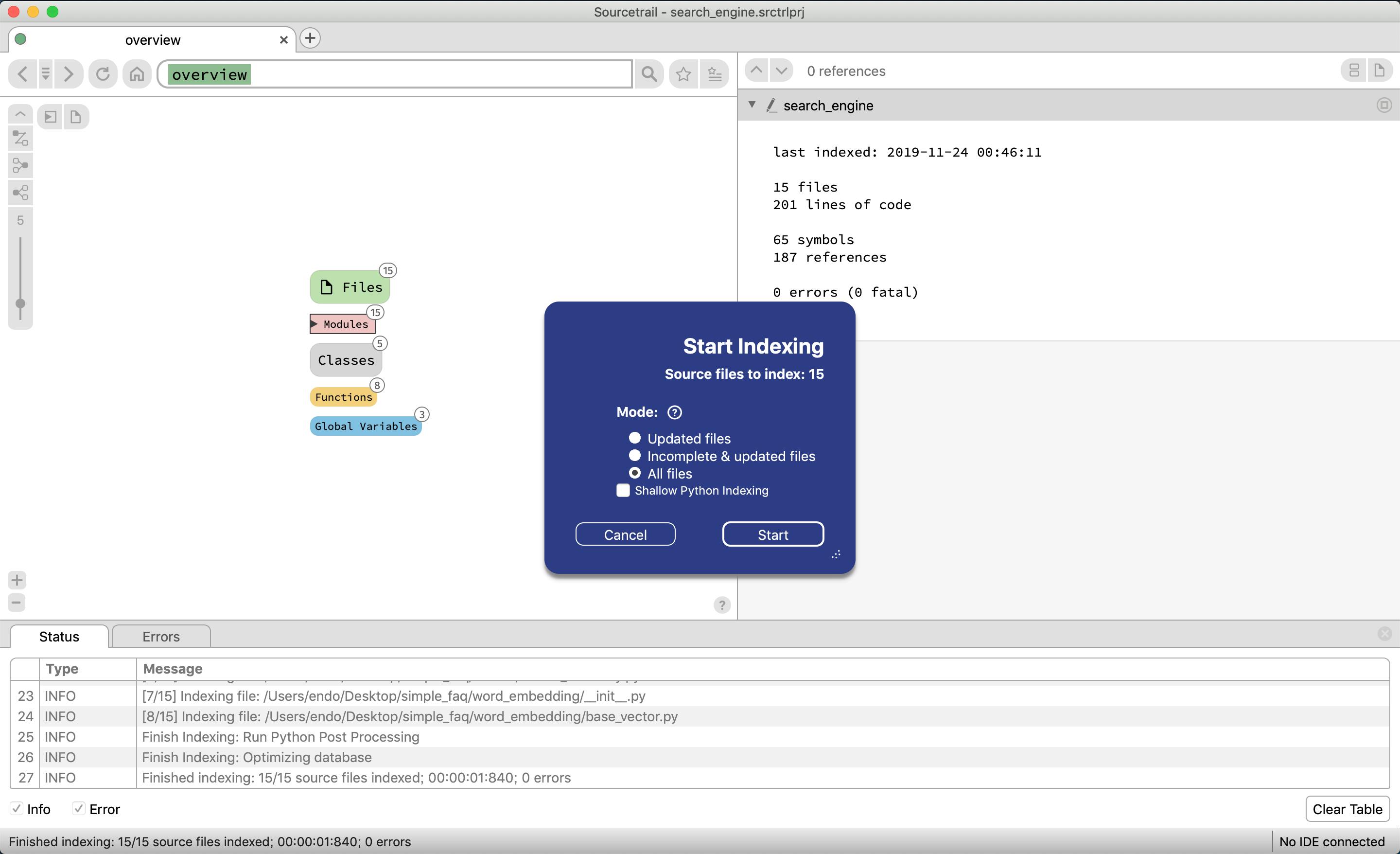
ソースコードの静的解析をする画面が表示されるため、startを選択する
下記フォルダのように、seach_engine.srctrlbm, seach_engine.srctrldb, seach_engine.srctrlprjが生成される
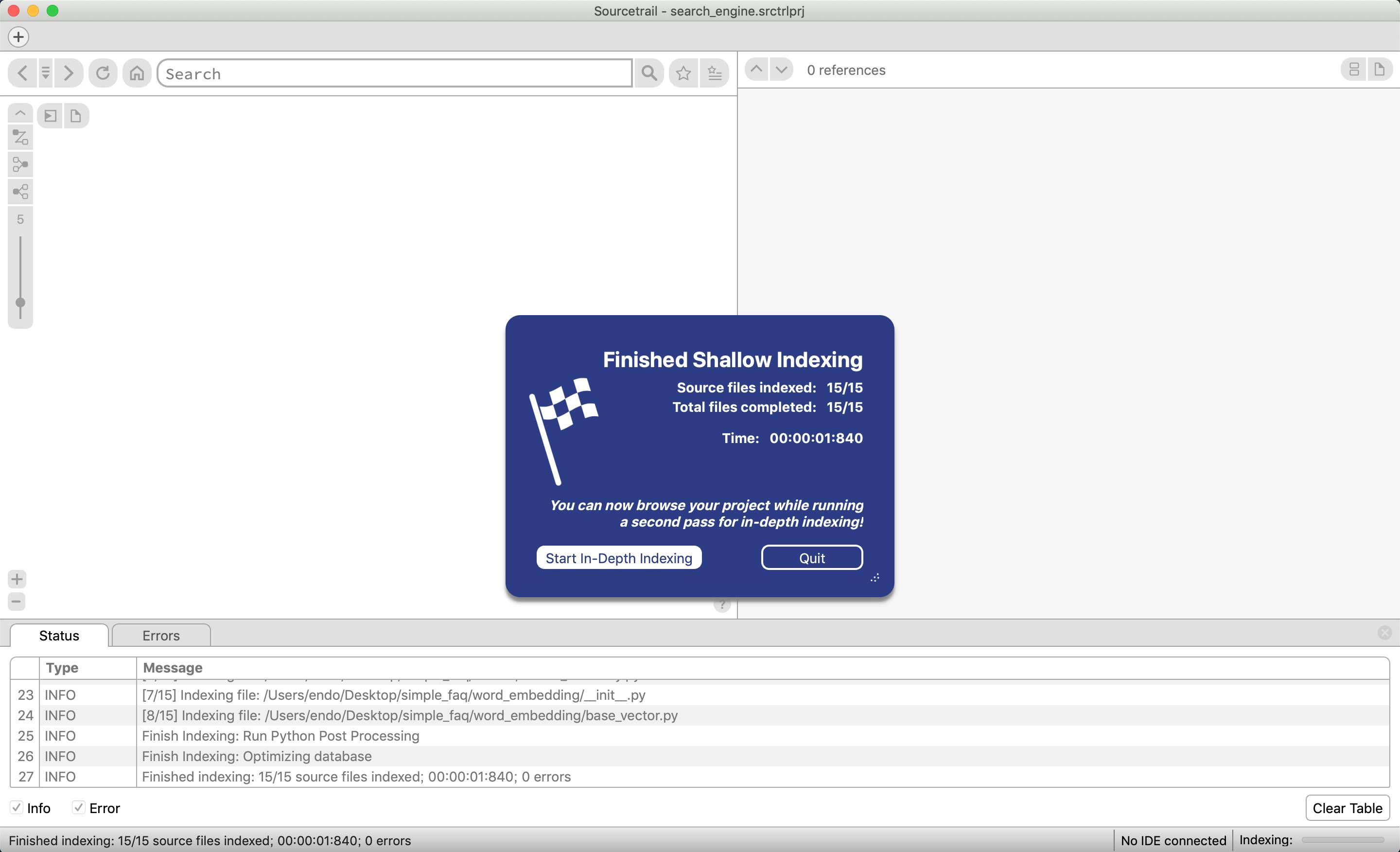
再度静的解析をより深くしてくれるらしいのでstart in-depth indexingを選択する
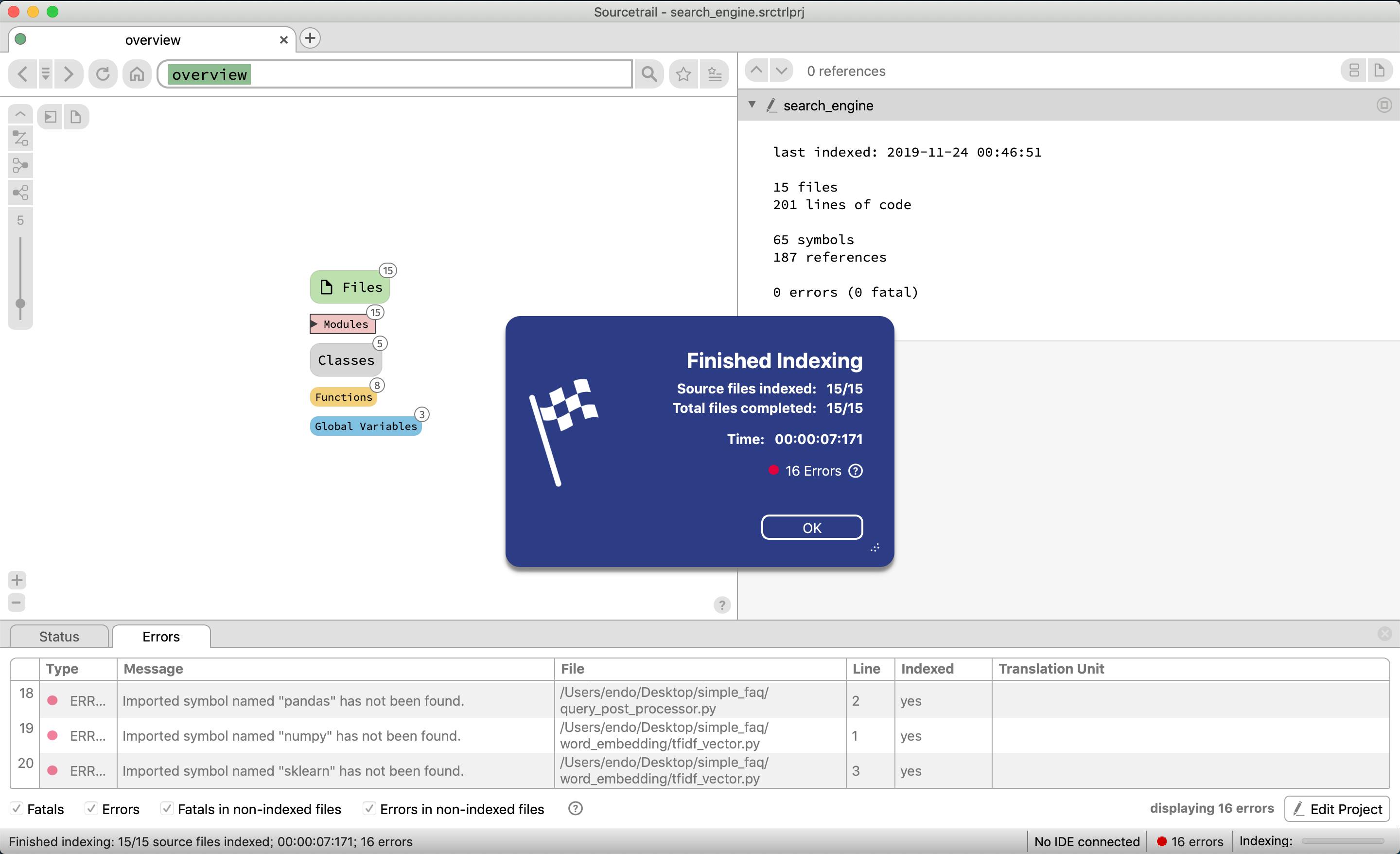
startを選択する
エラーが発生しているが、今回外部モジュール(numpy, pandas等々)を最初の設定の時に参照しなかったため。今回はそこまで差し支えないのでこのまま進める
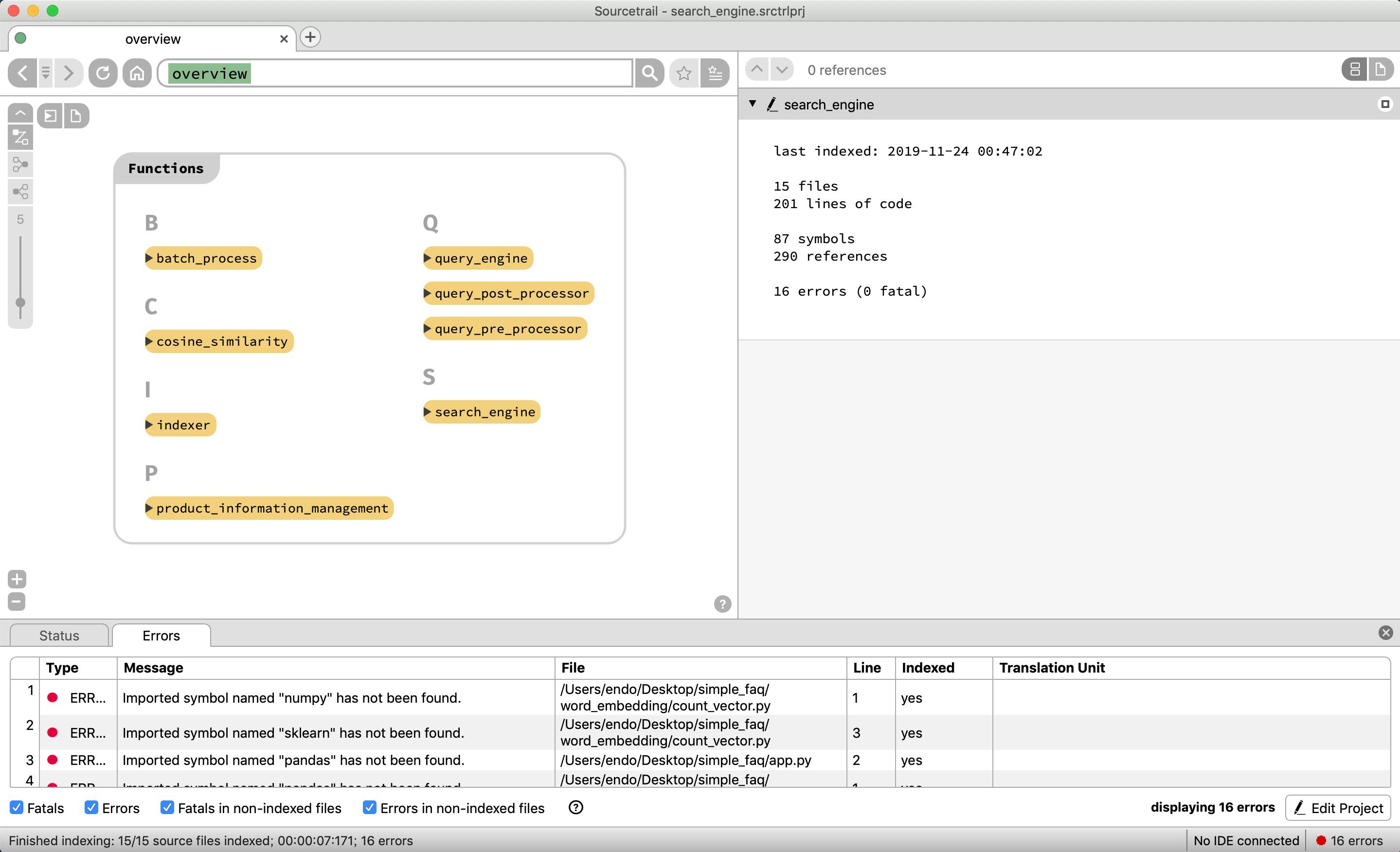
ソースコード概要(モジュール・クラス・関数・変数)
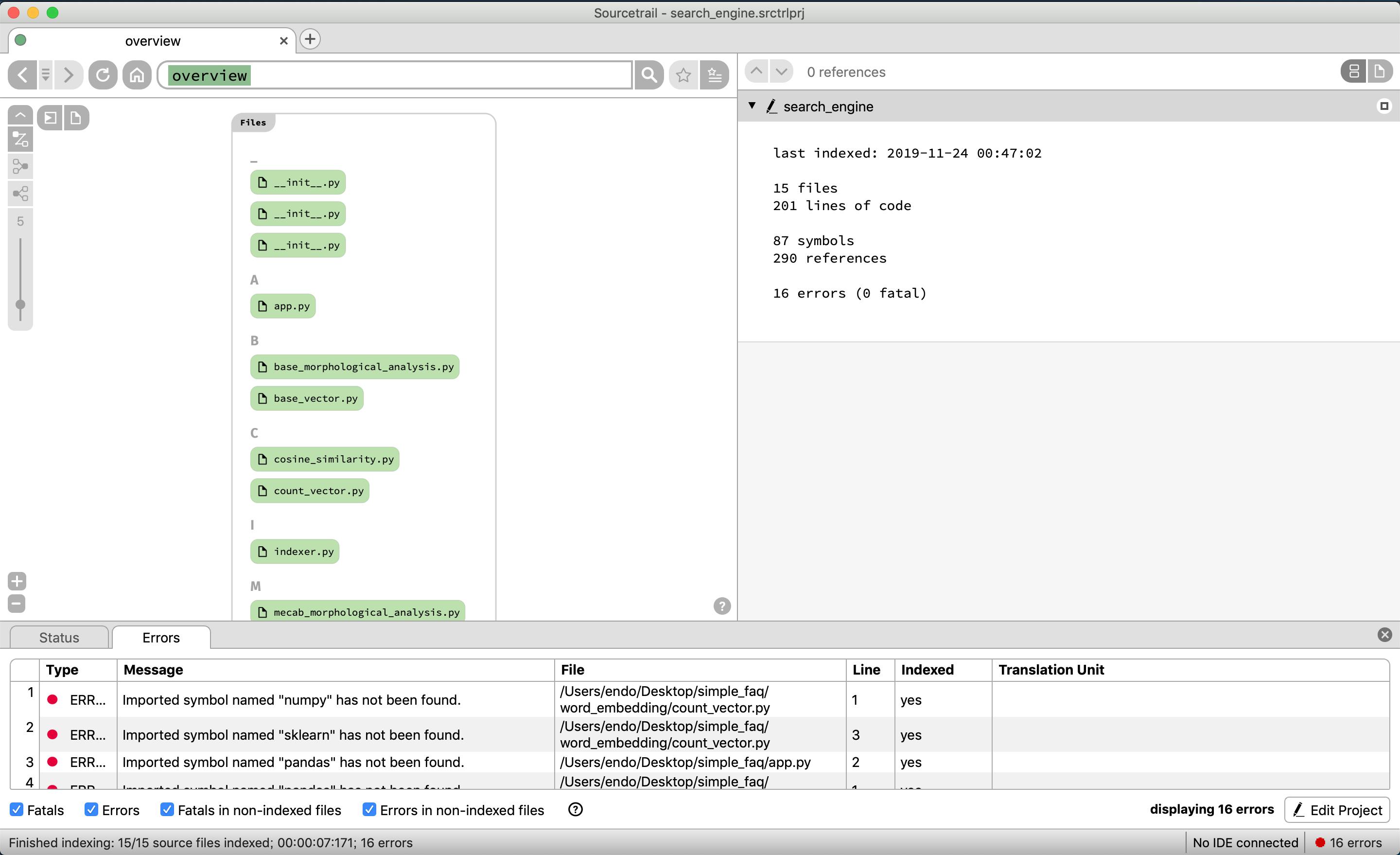
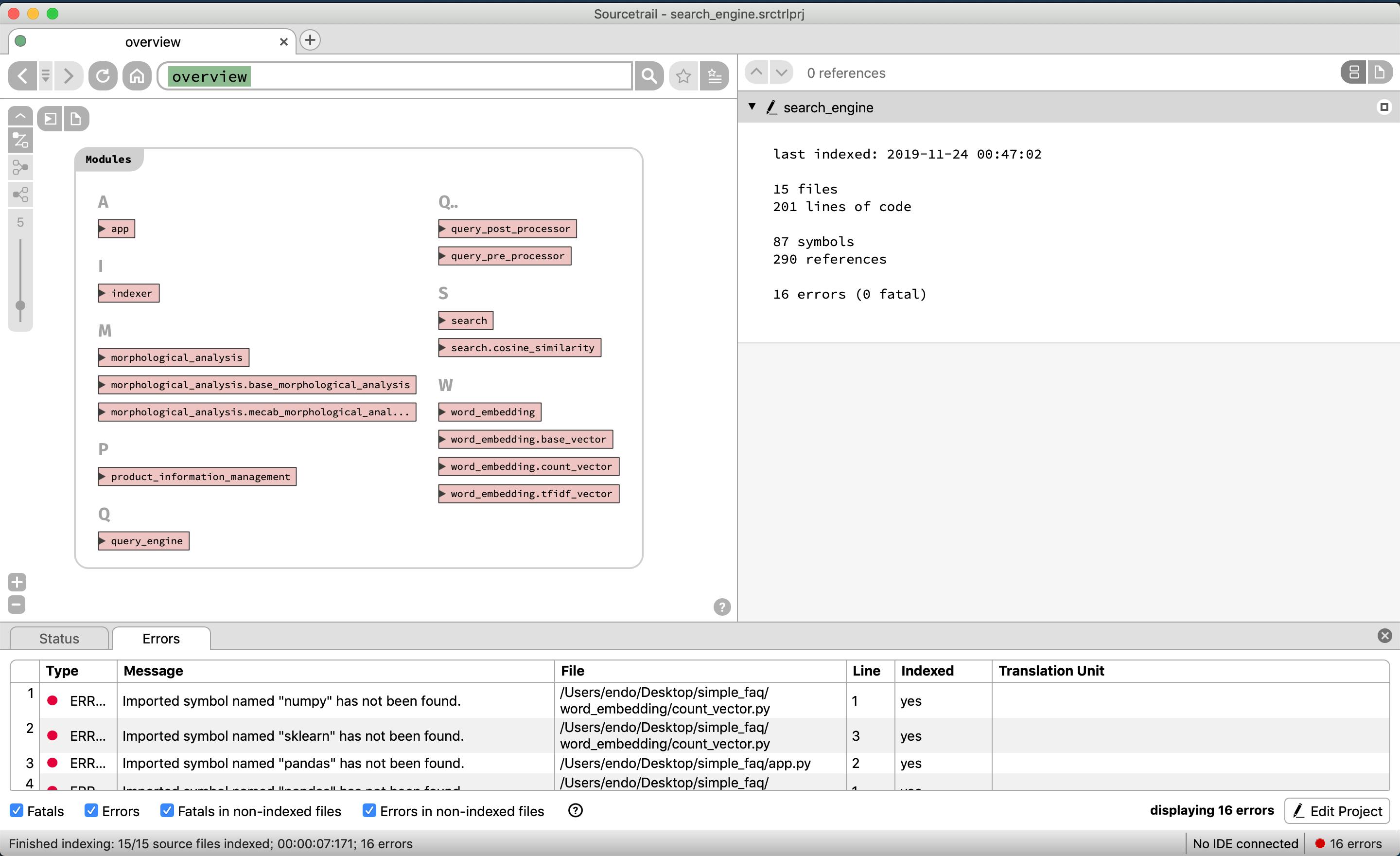
それではソースコードの構成要素を表示できているか見てみる
リポジトリに存在するファイル群がアルファベット順で表示される
リポジトリに存在するモジュール群がアルファベット順で表示される
リポジトリに存在するクラス群がアルファベット順で表示される
リポジトリに存在する関数群がアルファベット順で表示される
リポジトリに存在するグローバル変数群がアルファベット順で表示される
ソースコード解析(モジュール)
それではソースコードのより詳細な解析や依存関係が表示されているかどうか見ていく
まずはモジュールを見てみる
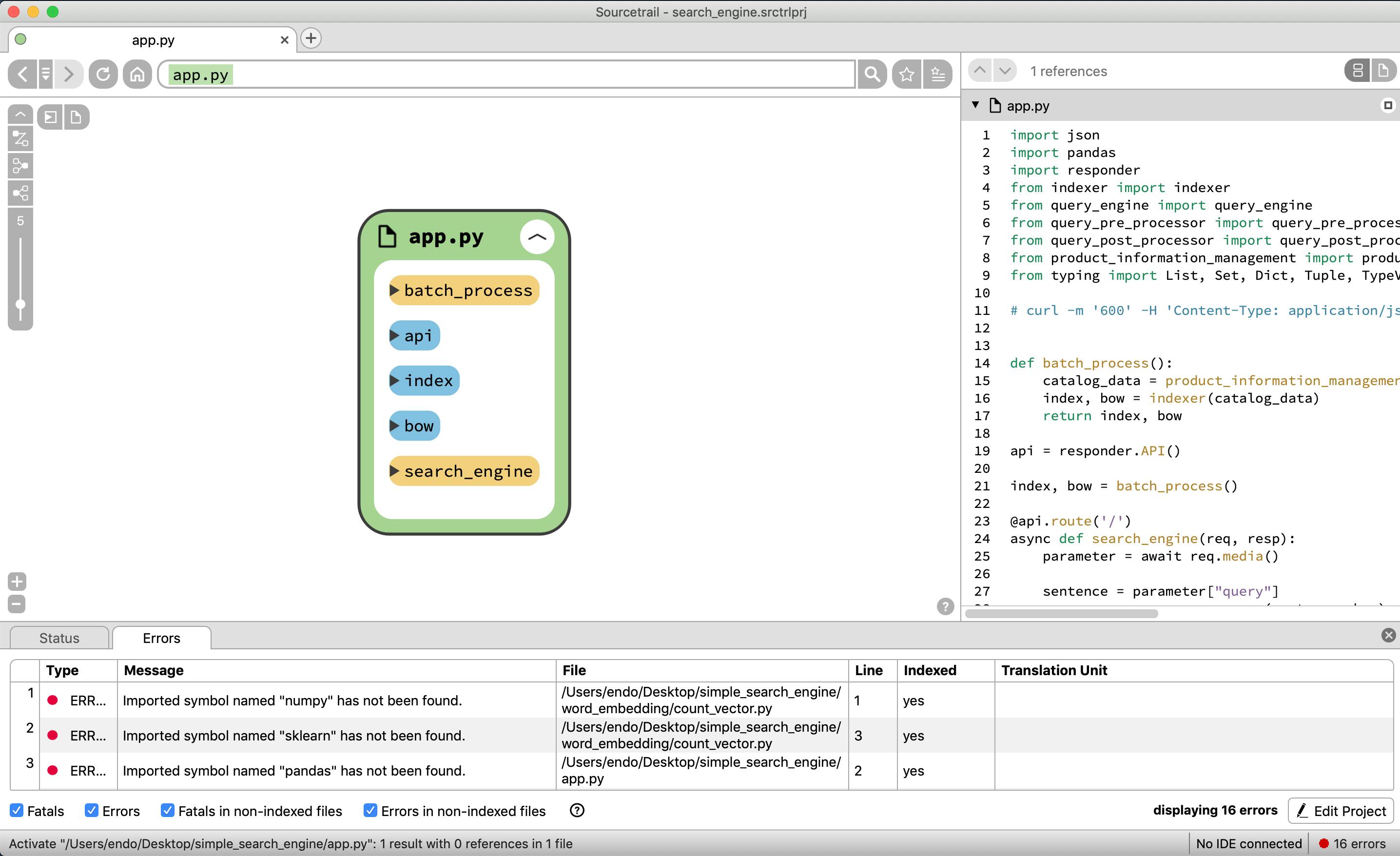
app.pyファイルには、responder serverを起動しているため、グローバル変数にapiを呼び、
本来リアルタイムAPiではなくバッチ処理しておくべきものであるが、今回簡易的な検索エンジンを作成しているため、データのインデックスを作成し、初回起動時のみに作成するため、グローバル変数に存在する
関数ではindexとbowを作成するためのbatch_process関数が存在していたり、検索エンジンAPIであるsearch_engineが存在する
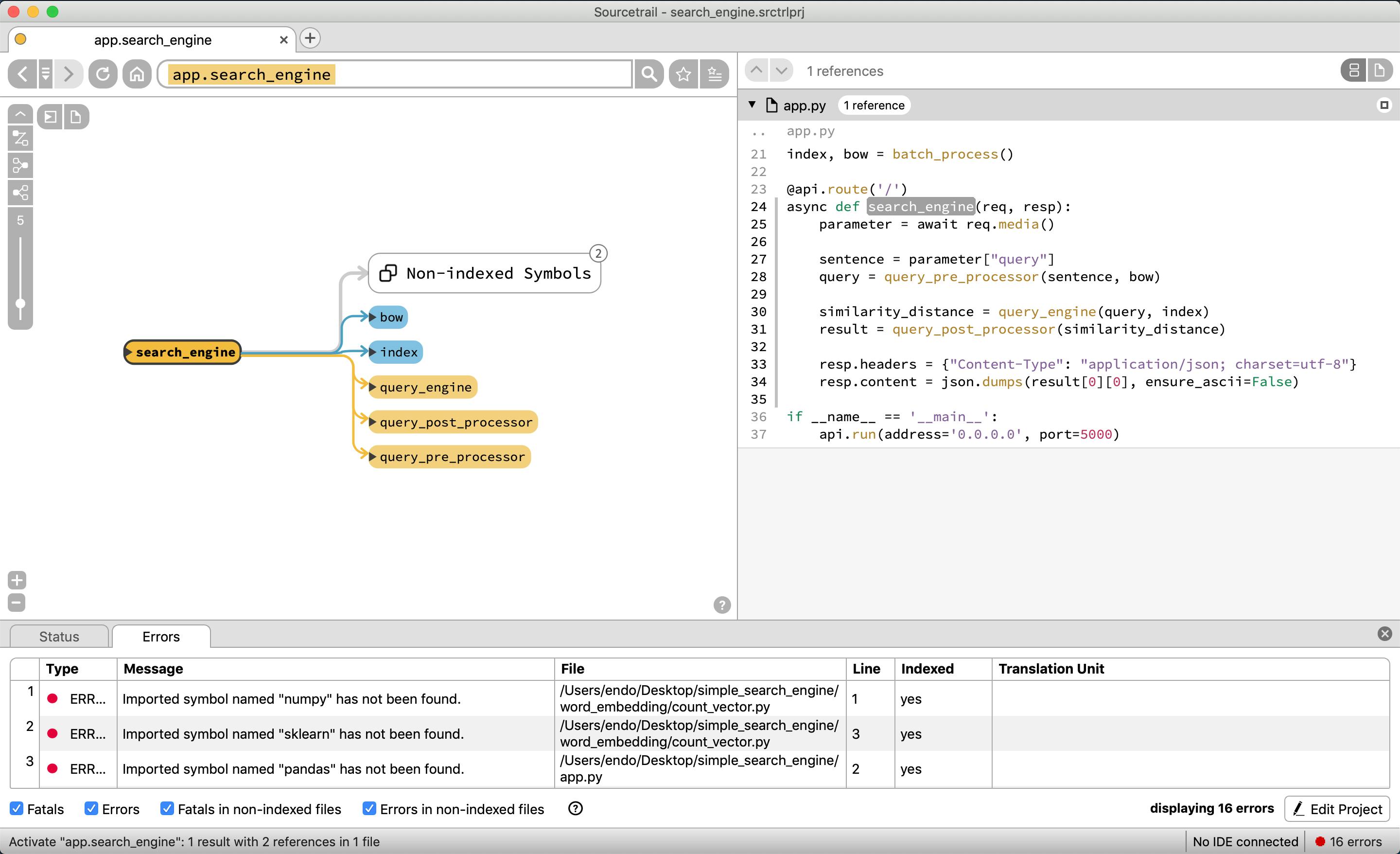
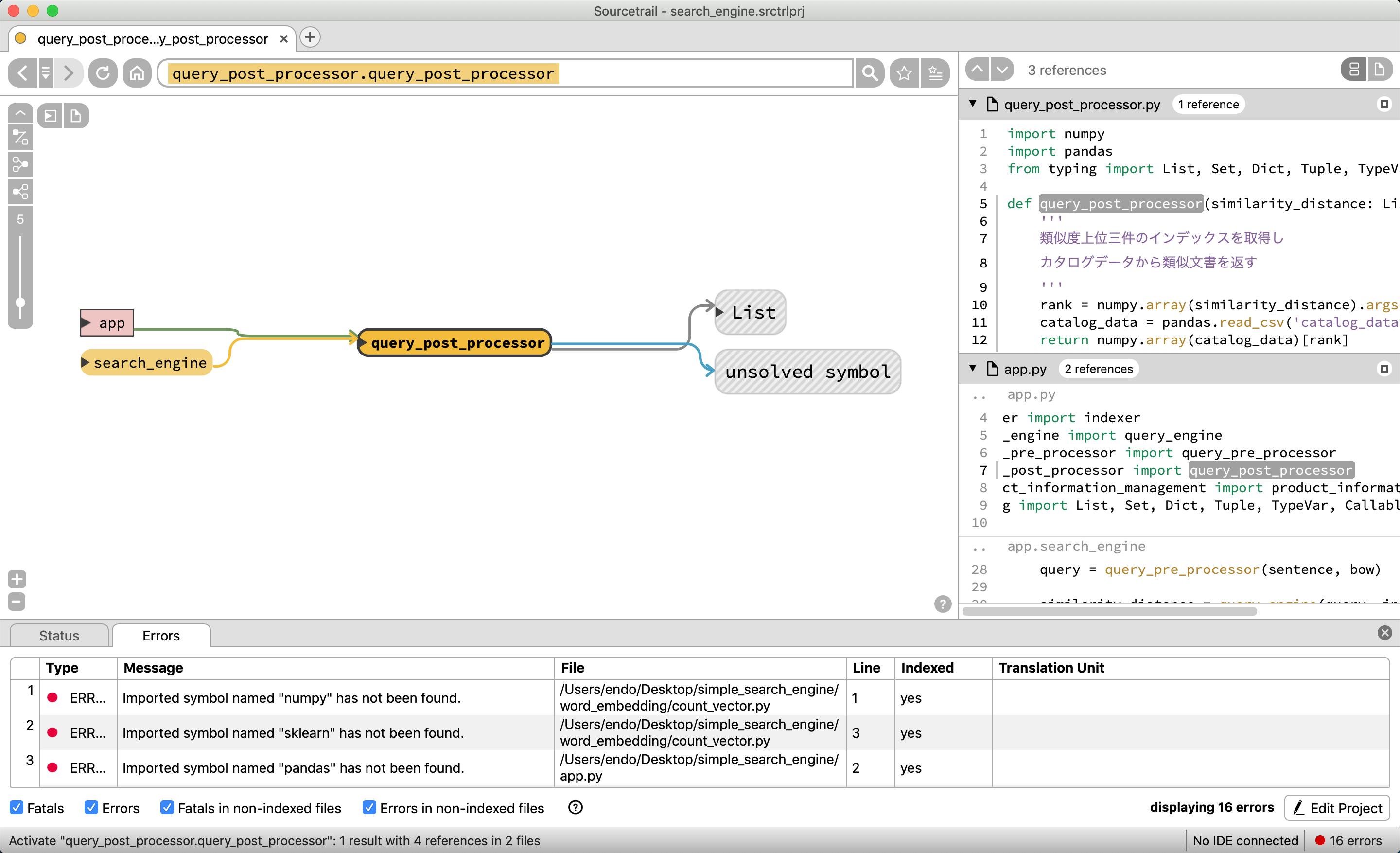
今回は、app.pyの中のsearch_engineが全ての処理のおおもとになるため、この関数を選択してみてみる。
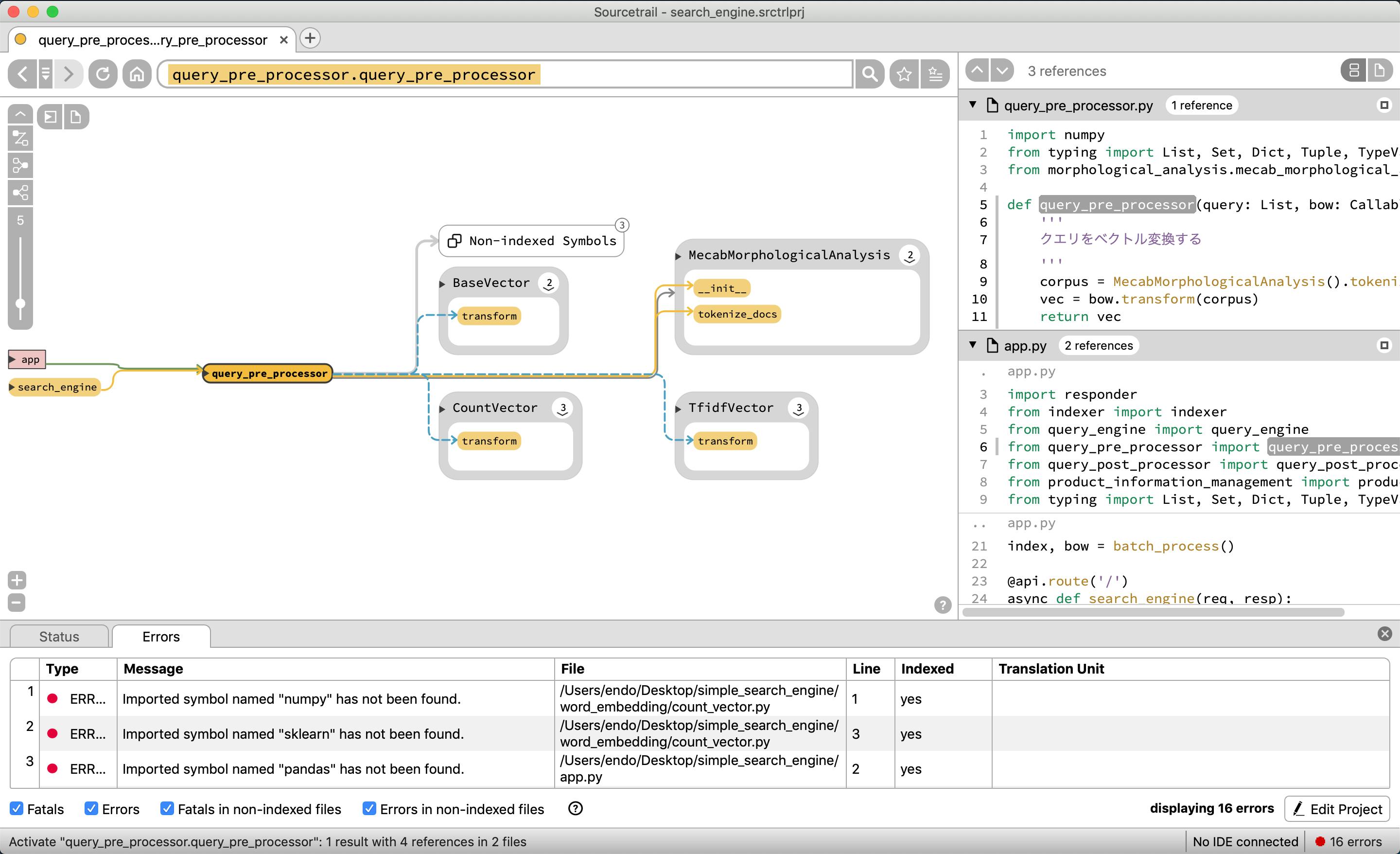
グローバル変数のbow, indexと、関数のquery_engine, query_post_processor, query_pre_processorで構成されていることがわかる。
もう少し深くみるために、query_pre_processorを選択する
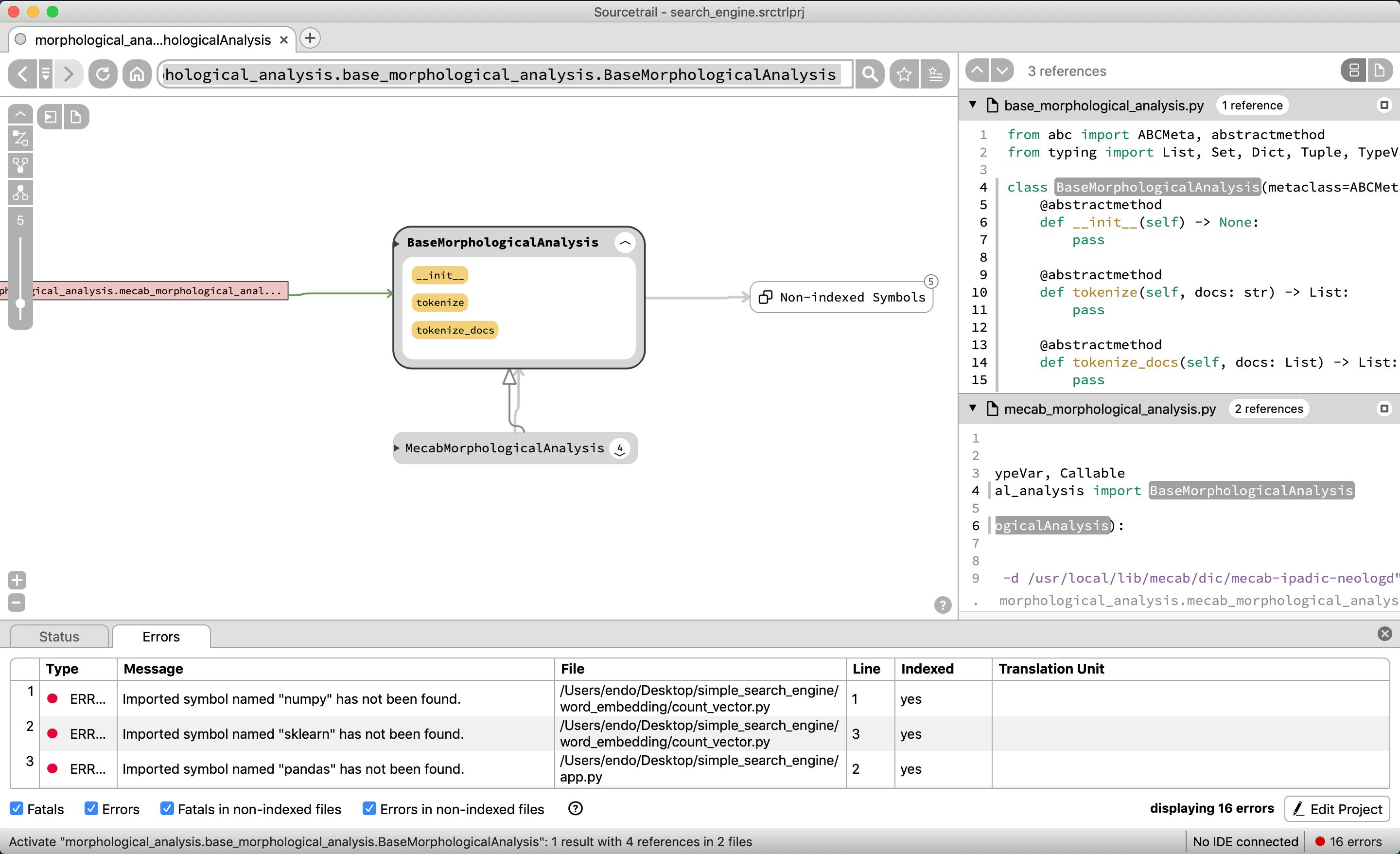
残念ながら、BaseVectorクラスを継承して、CountVectorやTfidfVectorのクラスが存在するが、この図表だと依存関係がわかりづらい。
MecabMorphologicalAnalysisも本来はBaseMorphologicalAnalysisクラスを継承しているのだが、それもぱっと見では表示されない。
他もそれぞれ見ていく
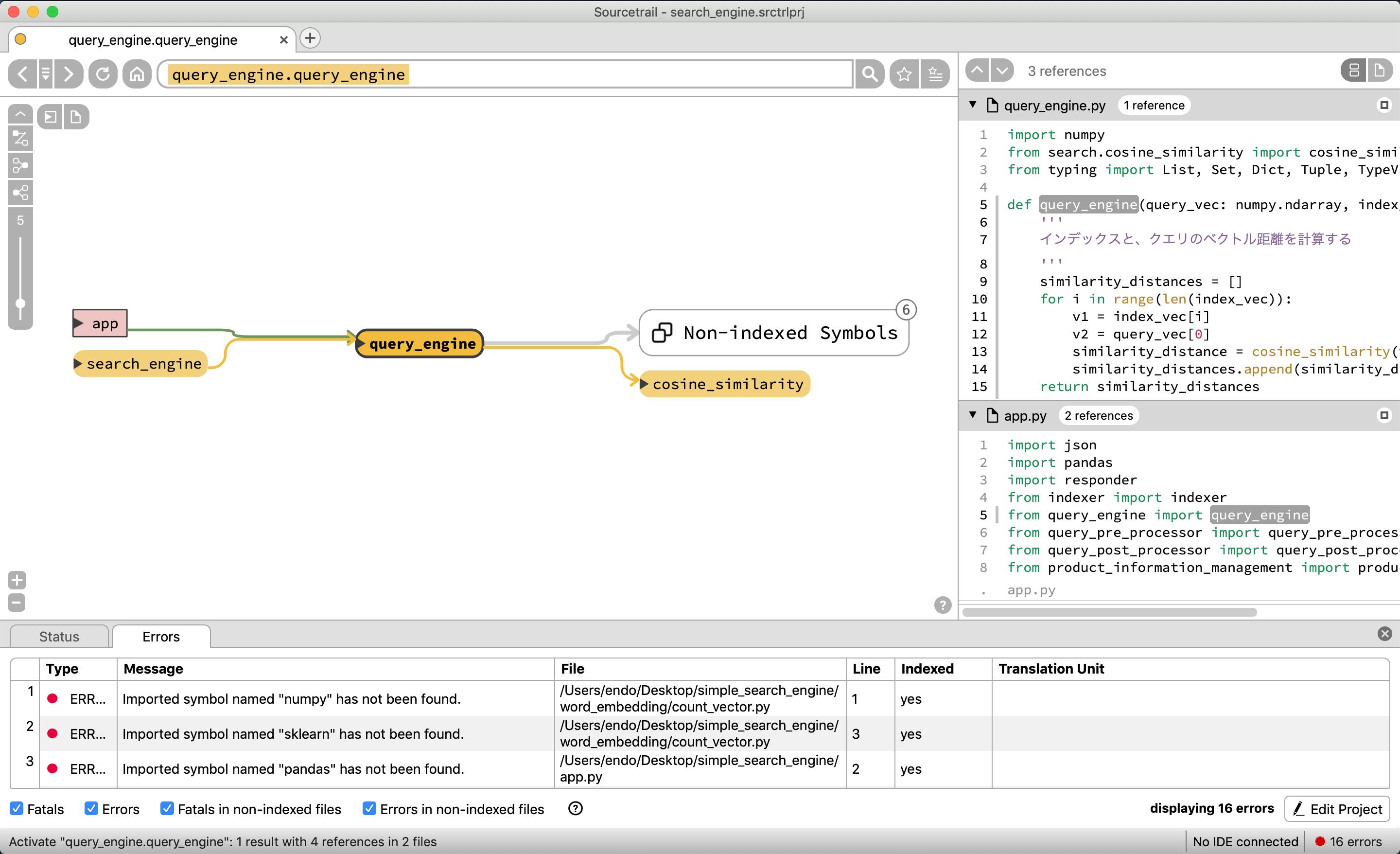
query_engineはcosine_similarityを使っていることがわかる
query_post_prosessorは他クラスや関数を使わずに閉じていることがわかる
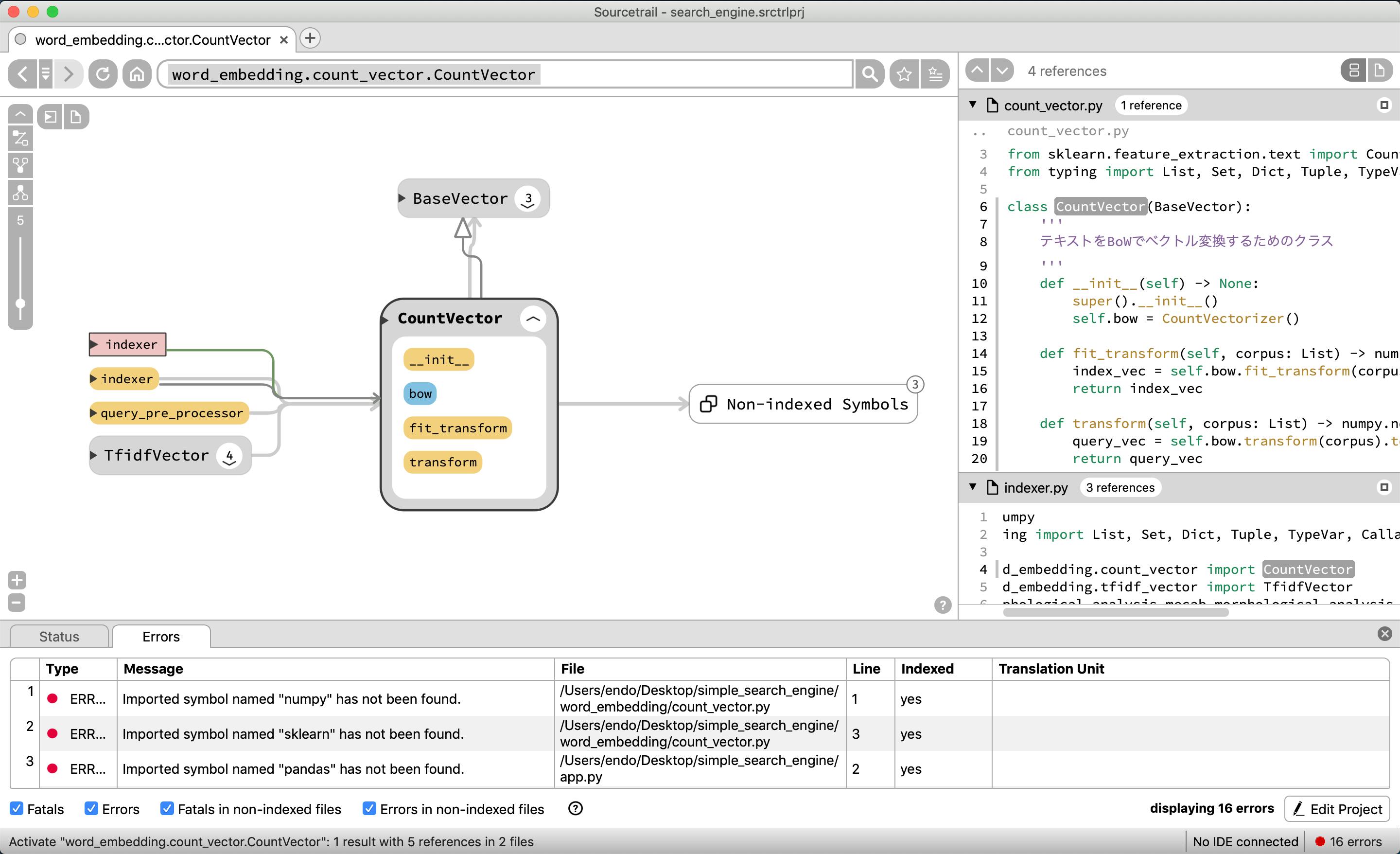
ソースコード依存関係(クラス)
CountVectorをみると、BaseVectorから継承していることがわかる
また、indexerモジュール、indexer関数、query_pre_processor関数から呼ばれていることがわかる
逆にBaseVectorを見てみると、count_vectorモジュールや、tfidf_vectorモジュールから呼ばれ、
CountVectorクラスや、TfidfVectorクラスの親であることがわかる
使用するソースコード
ここの部分はSOURCETEAILには関連がないので、何を解析しているのかをより深く理解したい場合に読んで欲しい
このソースコードを選んだ理由としては、複数ファイル(モジュール)あるシステムでかつ、ある程度依存関係があるコードでプロジェクト等でも使用できるかどうかを検証しつつ、理解がしやすいシンプルな構成のものを考えたときに該当するコードが簡易検索エンジンだった為
概要
ユーザがAPIに対して、「ワンワンって鳴き声の動物はなに?」というクエリを投げると、APIが内部にデータとして保持している以下の質問リスト「鼻の長い動物はなんですか?」、「首の長い動物はなんですか?」、「百獣の王って誰ですか?」、「にゃんにゃんって鳴き声の動物はなんですか?」、「ワンワンって鳴き声の動物はなんですか?」から、もっともクエリに近い質問文を選択肢、それに対となる答えの「犬」という答えをレスポンスとして返すシステムになっている
論理構成
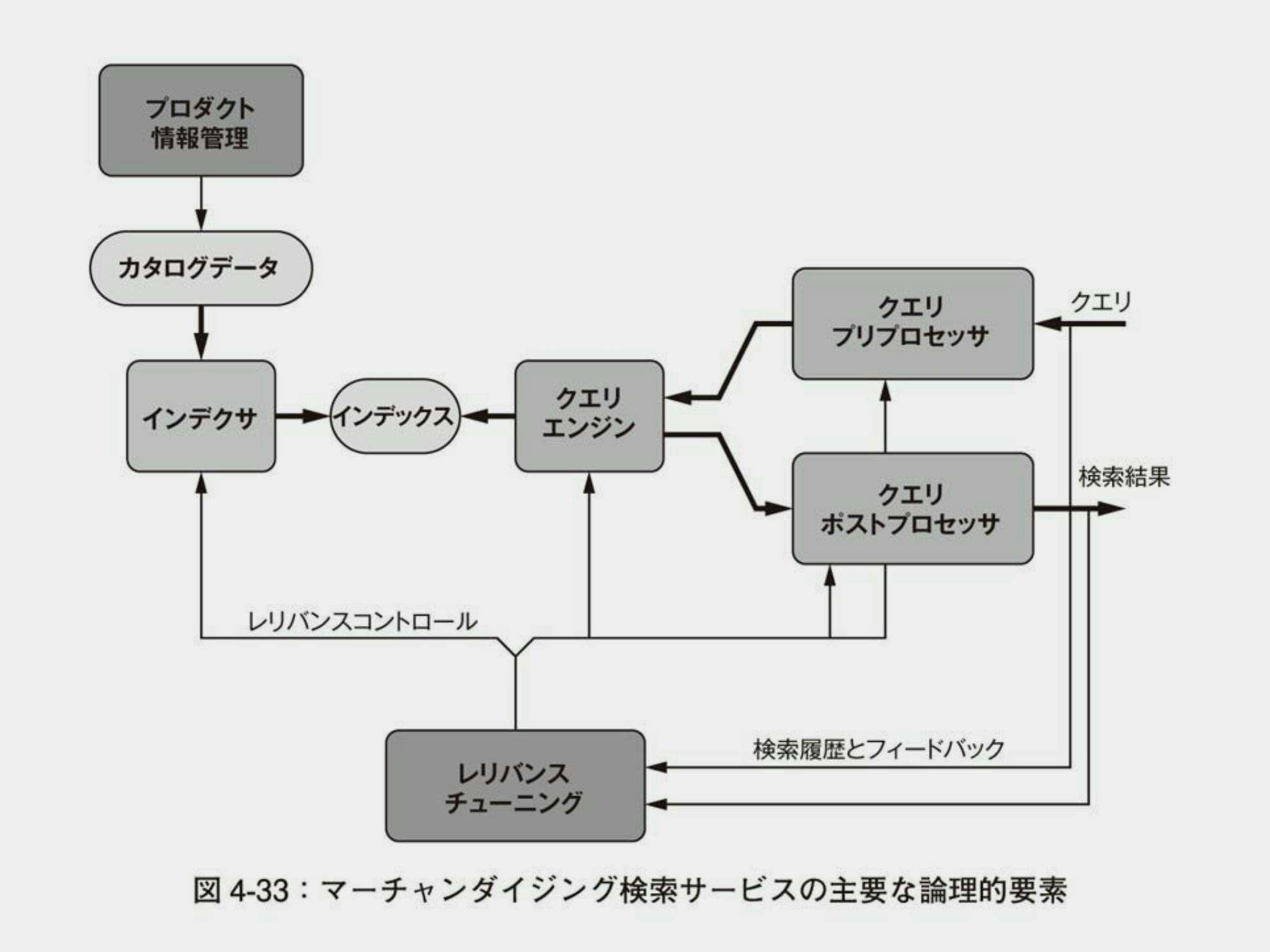
検索エンジンの理論的な構成要素は以下を参考にしている
検索したいデータをプロダクト情報管理を通して、前処理を行いインデックスとして生成しておき、ユーザからのリクエストで検索クエリが飛んできたら、同様の前処理をクエリプリプロセッサが行い、クエリエンジンで同質の要素を検索し、結果をクエリポストプロセッサで整形して、レスポンスとして検索結果を返すという至極シンプルで最低限の検索エンジンである
AIアルゴリズムマーケティング 自動化のための機械学習 の書籍から図表をお借りしました
あまり界隈で話題になってないような気がしますが、検索やレコメンドをやりたい人には、ものすごい学びが多い書籍なので是非みなさん読んで欲しいです
勝手に引用している為、著者や関係者からご連絡があった場合は即時削除させていただきます
ディレクトリ構成
具体的に落とし込むと以下の形になる
レリバンスチューニングの部分は今回はビジネス要件によって変動する部分なので、今回は割愛している
今回の記述したソースコードをgithub上にあげているので詳細に見たい場合は下記にアクセスしてください
https://github.com/r2en/simple_search_engine
├── app.py <- Responder APIサーバ 検索のリクエストを受けてつけて、検索結果を返す │ │ ├── indexer.py <- カタログデータ(文書)の前処理をして、インデックス(前処理済み文書のベクトル化)を生成する │ │ ├── query_engine.py <- クエリとカタログデータとのマッチングとスコアリングを行う │ │ ├── query_pre_processor.py <- クエリ(ユーザの検索のリクエスト)を、インデックス形式に処理をするindexerで行う前処理とほぼ同様のことを行う │ │ ├── query_post_processor.py <- クエリとカタログデータのマッチングの結果から検索結果を生成する │ │ ├── product_information_management.py <- 検索されるデータ群を操作する │ │ ├── catalog_data <- 検索されるデータを格納 │ │ │ │ │ ├── answer.csv <- クエリが求める回答のデータを格納 │ │ │ │ │ └── question.csv <- クエリと同質の質問のデータを格納 │ │ ├── morphological_analysis <- 自然言語を形態素解析器するツール群 │ │ │ ├── base_morphological_analysis.py <- ベースとなる形態素解析機の親クラス │ │ │ │ │ ├── mecab_morphological_analysis.py <- 形態素解析器のmecabが格納 │ │ │ │ │ └── __init__.py │ │ ├── search <- ベクトル化されたクエリと、カタログデータの類似性を検索する │ │ │ ├── cosine_similarity.py <- 類似性をコサイン類似度で検索する │ │ │ │ │ └── __init__.py │ │ └── word_embedding <- クエリとカタログデータの検索を可能にするデータ構造、インデックスを作成する │ │ ├── base_vector.py <- ベースとなるベクトル変換器の親クラス │ │ ├── count_vector.py <- BoWカウントベースのベクトル変換器 │ │ │ ├── tfidf_vector.py <- BoW Tf-Idfベースのベクトル変換器 │ │ └── __init__.py感想
実際に使って見ての感想は、操作が簡単でツールについて覚えることが少ないのに、割と見やすくて、割と使いやすい印象
完全に全容が理解できるわけではないにしろ、確実にソースコードを解読する手助けをしてくれると思うので、今後も使い続ける価値はあると思う






- 投稿日:2019-11-25T12:42:40+09:00
PySparkのTmeStampTypeに対してstringで演算するときの注意点
はじめに
PySparkのTimeStampTypeの演算時に、不用意に日付形式の文字列型を使うと意図しない挙動をするパターンがあるという話。
そのため、TimeStampTypeに対してstringで演算することもできるが、datetimeを使う方が無難。
例
具体例で説明する。
ここで示す例は、PySPark 2.4.4によるものである。
検証用データ
次のコードで、2000/1/1 ~ 2000/1/5の日付データをもつSpark DataFrameを作成し、この日付データに対する条件処理を行ってみる。
検証用データimport pandas as pd from pyspark.sql import functions as F pdf = pd.DataFrame(pd.date_range(start='1/1/2000', periods=5), columns=['date']) sdf = spark.createDataFrame(pdf, ['timestamp'])TimeStampTypeとdatetimeの演算
TimeStampTypeに対してdatetimeを用いた演算は、正常に動作する。
TimeStampTypeとdatetimeの演算target_datetime = datetime.strptime('2000-01-03', '%Y-%m-%d') print('== datetime(2000-01-03)') sdf.where(F.col('timestamp') == datetime.strptime('2000-01-03', '%Y-%m-%d')).show() print('> datetime(2000-01-03)') sdf.where(F.col('timestamp') > datetime.strptime('2000-01-03', '%Y-%m-%d')).show() print('>= datetime(2000-01-03)') sdf.where(F.col('timestamp') >= datetime.strptime('2000-01-03', '%Y-%m-%d')).show() print('< datetime(2000-01-03)') sdf.where(F.col('timestamp') < datetime.strptime('2000-01-03', '%Y-%m-%d')).show() print('<= datetime(2000-01-03)') sdf.where(F.col('timestamp') <= datetime.strptime('2000-01-03', '%Y-%m-%d')).show() print('between datetime(2000-01-02) and datetime(2000-01-04)') sdf.where(F.col('timestamp').between(datetime.strptime('2000-01-02', '%Y-%m-%d'), datetime.strptime('2000-01-04', '%Y-%m-%d'))).show()出力結果== datetime(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| +-------------------+ > datetime(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-04 00:00:00| |2000-01-05 00:00:00| +-------------------+ >= datetime(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| |2000-01-04 00:00:00| |2000-01-05 00:00:00| +-------------------+ < datetime(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-01 00:00:00| |2000-01-02 00:00:00| +-------------------+ <= datetime(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-01 00:00:00| |2000-01-02 00:00:00| |2000-01-03 00:00:00| +-------------------+ between datetime(2000-01-02) and datetime(2000-01-04) +-------------------+ | timestamp| +-------------------+ |2000-01-02 00:00:00| |2000-01-03 00:00:00| |2000-01-04 00:00:00| +-------------------+TimeStampTypeとstring(datetime形式)の演算
次に、datetime形式(yyyy-mm-dd hh
ss)でstringを与えたときの結果を示す。
stringは暗黙的にキャストされるらしく、問題なく演算が行える。TimeStampTypeとstring(datetime形式)の演算print('== string(2000-01-03 00:00:00)') sdf.where(F.col('timestamp') == '2000-01-03 00:00:00').show() print('> string(2000-01-03 00:00:00)') sdf.where(F.col('timestamp') > '2000-01-03 00:00:00').show() print('>= string(2000-01-03 00:00:00)') sdf.where(F.col('timestamp') >= '2000-01-03 00:00:00').show() print('< string(2000-01-03 00:00:00)') sdf.where(F.col('timestamp') < '2000-01-03 00:00:00').show() print('<= string(2000-01-03 00:00:00)') sdf.where(F.col('timestamp') <= '2000-01-03 00:00:00').show() print('between string(2000-01-02 00:00:00) and string(2000-01-04 00:00:00)') sdf.where(F.col('timestamp').between('2000-01-02 00:00:00', '2000-01-04 00:00:00')).show()出力結果== string(2000-01-03 00:00:00) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| +-------------------+ > string(2000-01-03 00:00:00) +-------------------+ | timestamp| +-------------------+ |2000-01-04 00:00:00| |2000-01-05 00:00:00| +-------------------+ >= string(2000-01-03 00:00:00) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| |2000-01-04 00:00:00| |2000-01-05 00:00:00| +-------------------+ < string(2000-01-03 00:00:00) +-------------------+ | timestamp| +-------------------+ |2000-01-01 00:00:00| |2000-01-02 00:00:00| +-------------------+ <= string(2000-01-03 00:00:00) +-------------------+ | timestamp| +-------------------+ |2000-01-01 00:00:00| |2000-01-02 00:00:00| |2000-01-03 00:00:00| +-------------------+ between string(2000-01-02 00:00:00) and string(2000-01-04 00:00:00) +-------------------+ | timestamp| +-------------------+ |2000-01-02 00:00:00| |2000-01-03 00:00:00| |2000-01-04 00:00:00| +-------------------+TimeStampTypeとstring(date形式)の演算
最後に、date形式(yyyy-mm-dd)でstringを与えたときの結果を示す。
この場合、直感的に意図する挙動とは異なる結果になるパターンがある。TimeStampTypeとstring(date形式)の演算print('== string(2000-01-03)') sdf.where(F.col('timestamp') == '2000-01-03').show() print('> string(2000-01-03)') # 意図しないパターン sdf.where(F.col('timestamp') > '2000-01-03').show() print('>= string(2000-01-03)') sdf.where(F.col('timestamp') >= '2000-01-03').show() print('< string(2000-01-03)') sdf.where(F.col('timestamp') < '2000-01-03').show() print('<= string(2000-01-03)') # 意図しないパターン sdf.where(F.col('timestamp') <= '2000-01-03').show() print('between string(2000-01-02) and string(2000-01-04)') # 意図しないパターン sdf.where(F.col('timestamp').between('2000-01-02', '2000-01-04')).show()出力結果== string(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| +-------------------+ > string(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| |2000-01-04 00:00:00| |2000-01-05 00:00:00| +-------------------+ >= string(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-03 00:00:00| |2000-01-04 00:00:00| |2000-01-05 00:00:00| +-------------------+ < string(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-01 00:00:00| |2000-01-02 00:00:00| +-------------------+ <= string(2000-01-03) +-------------------+ | timestamp| +-------------------+ |2000-01-01 00:00:00| |2000-01-02 00:00:00| +-------------------+ between string(2000-01-02) and string(2000-01-04) +-------------------+ | timestamp| +-------------------+ |2000-01-02 00:00:00| |2000-01-03 00:00:00| +-------------------+挙動について
演算時に暗黙的にstringがTimeStampへキャストされた結果、
TimeStamp(2000-01-01 00:00:00)とTimeStamp(string(2000-01-01 00:00:00))が等価であり、TimeStamp(2000-01-01 00:00:00) < TimeStamp(string(2000-01-01))のような結果となっている。このことから、時間分(上記の例における
00:00:00)の値が適切に処理されてないと想像できる。(厳密な仕様は、演算の詳細はScalaのソースを確認する必要がある)(番外編) StringTypeからTimeStampTypeへのキャスト
ちなみに、StringTypeからTimeStampTypeへキャストする際は、正しくキャストできているようである。
ここでは例は示さないが、上記のパターンと同様に、TimeStampTypeとの演算処理を行っても、(TimeStampType型同士なので当然だが)正常に動作する。StringTypeからTimeStampTypeへのキャストdf = spark.createDataFrame([('2000',), ('2000-01-01',), ('2000-01-01 00:00:00',) ], ['str']) df = df.withColumn('timestamp', F.col('str').cast('timestamp')) df.show()出力結果+-------------------+-------------------+ | str| timestamp| +-------------------+-------------------+ | 2000|2000-01-01 00:00:00| | 2000-01-01|2000-01-01 00:00:00| |2000-01-01 00:00:00|2000-01-01 00:00:00| +-------------------+-------------------+
- 投稿日:2019-11-25T11:53:52+09:00
DockerでGeforceを使ってSpleeterを回す
Spleeter(https://github.com/deezer/spleeter) という、python+Tensorflowを使った、音声分離アプリケーションがあります。これを使うと楽曲のファイルからヴォーカルだけを抜き出したりできます。
使い方も上のサイトやこちらに書いてあったりするのですが、nvidia-dockerが古いだとか、GPU使ってないだとかで決め手に欠けています。ですので今まとも?な方法のメモ書きを残します。(本当は漏れのない手順書を書きたいとこでしたが、実施から時間が経って記憶から抜けている部分もあります・・)
自分で構築するのが面倒な人は、参考の1, 2を使うとよいでしょう。ただし録音に使ったデータがクラウド上に保存されるのかどうかは保証できません。
動作確認環境
- AMD Ryzen 3700X
- ASRock B450M Steel Regend
- メモリ: 32GB
- (ブランド不明)Geforce GTX 1080Ti
- Ubuntu 18.04 server
- nvidia公式driver
導入手順
nvidia driverを入れる
ホストマシン(Dockerを呼び出すマシン)にnvidiaの公式ドライバを入れます。おそらくCUDAドライバあたりも必要です。Docker ceを入れる
最新のnvidia-dockerがDocker ce 19.03を要求するので、入れます。Ubuntu標準dockerではダメです。
https://docs.docker.com/install/linux/docker-ce/ubuntu/nvidia-dockerを入れる
最近のはnvidia-docker2がdeprecatedされており、最新のnvidia-dockerではspleeterに書かれているコマンドでは実行出来ないので注意してください。
https://github.com/NVIDIA/nvidia-docker/wiki/Installation-(Native-GPU-Support)spleeterを入れて使う
https://github.com/deezer/spleeter/wiki/2.-Getting-started#using-docker-image
nvidia-dockerではなく、docker run --gpus all等を使う必要があります(allは手持ちのGPUによって変えてください)。
例: docker run --gpus all -v $(pwd)/output:/output deezer/spleeter:gpu separate -i audio_example.mp3 -o /output参考
- spleeter使って分離してくれるサービス https://moises.ai/
- Spleeterを簡単に使えるGoogle colaboratoryのノートを作成しました. https://qiita.com/Ryo0o0oOO/items/65acd38f4034800388c0
- 投稿日:2019-11-25T11:29:49+09:00
【Python】文字列と数値(asciiコード)の変換まとめ
はじめに
自分向けにPythonでの文字とasciiコードの計算方法をまとめました。
AtCoder上のPython3.4.3で動作確認済みです。変換方法
ord('文字')とchr(数値)で相互に変換できます。s = 'A' ord_s = ord(s) print(ord_s) # 65 chr_s = chr(ord_s) print(chr_s) # A変換表
まとめとしてasciiコードと文字の対応表を記載します。
なお、以下の表のasciiコードという項目は10進数での表記を表しています。重要な変換ピックアップ
asciiコード 16進数 文字 48 0x30 0 57 0x39 9 ... ... ... 65 0x41 A 90 0x5a Z ... ... ... 97 0x61 a 122 0x7a z 例えば、大文字と小文字は一度asciiコードに変換してから
+32することによって変換できます。(もちろん.replace()でも出来ます)s = 'A' small_s = chr(ord(s)+32) print(small_s) # a数字
ここでいう数字は文字としての数字なので注意してください。
asciiコード 16進数 文字 48 0x30 0 49 0x31 1 50 0x32 2 51 0x33 3 52 0x34 4 53 0x35 5 54 0x36 6 55 0x37 7 56 0x38 8 57 0x39 9 アルファベット大文字
asciiコード 16進数 文字 65 0x41 A 66 0x42 B 67 0x43 C 68 0x44 D 69 0x45 E 70 0x46 F 71 0x47 G 72 0x48 H 73 0x49 I 74 0x4a J 75 0x4b K 76 0x4c L 77 0x4d M 78 0x4e N 79 0x4f O 80 0x50 P 81 0x51 Q 82 0x52 R 83 0x53 S 84 0x54 T 85 0x55 U 86 0x56 V 87 0x57 W 88 0x58 X 89 0x59 Y 90 0x5a Z アルファベット小文字
asciiコード 16進数 文字 97 0x61 a 98 0x62 b 99 0x63 c 100 0x64 d 101 0x65 e 102 0x66 f 103 0x67 g 104 0x68 h 105 0x69 i 106 0x6a j 107 0x6b k 108 0x6c l 109 0x6d m 110 0x6e n 111 0x6f o 112 0x70 p 113 0x71 q 114 0x72 r 115 0x73 s 116 0x74 t 117 0x75 u 118 0x76 v 119 0x77 w 120 0x78 x 121 0x79 y 122 0x7a z さいごに
閲覧して頂きありがとうございました。間違い等があればご指摘お願いします。
- 投稿日:2019-11-25T09:28:19+09:00
【Python】Executore,Futureクラスについて
本稿について
Pythonバージョン3.2から追加された,concurrent.futuresモジュールの使い方を備忘録としてまとめる.
concurrent.futuresモジュールは結論から言ってしまえば,マルチスレッド,マルチプロセス両方のインターフェースを提供する.どんな場面で使われるか?
Q. 並行問題に対して,非同期アプリケーションに合わない場合やどうしていいかわからない場合には,どうするか?
A. 問題対象となる部分の処理をスレッドあるいはプロセスに委譲します.委譲した処理をコルーチンのように見せかけて,制御をイベントループに解放し,最終的な結果を処理します.
このAを実現するために用意されたのが
concurrent.futureモジュールです.なにができるのか?
concurrent.futureモジュールはasycioモジュールにも統合されており,この2つのモジュールを組み合わせることで,マルチスレッドやマルチプロセスで実行されるブロッキング関数を非同期のノンブロッキングコルーチンのように使用できます.どのように使うのか?
concurrent.futureモジュールには,ExecutorオブジェクトとFutureオブジェクトがあります.
Executorクラスについて
Executorは並列に作業項目を処理できるリソースのプールを表しています.multiprocessingモジュールのPoolクラスの目的と似ているようですが,インターフェスと設計が異なります.
Executorクラスはインスタンス化されていない基底クラスです.Executorクラスには,以下の2つのサブクラスが存在します.
ThreadPoolExecutor:スレッドプールを指定して,非同期処理を行いますProcessPollExecutor:プロセスプールを指定して,非同期処理を行います.これらのことから,
Executorクラスからマルチスレッドとマルチプロセスの両方のインターフェスを提供しているといえます.これらのクラスは3つメソッドを提供します.
submit(fn, *args, **kwargs):fn関数をリソースプールで実行するようにスケジュールし,Futureオブジェクトを返すmap(func, *iterables, timeout=None, chunksize=1):multiprocessing.Pool.map()メソッドと同様に,func関数をiterableなオブジェクトの要素をそれぞれに対して実行します.shutdown(wait=True):Executorをシャットダウンし,全てのリソースを解放します.以下,実装例.
geocoding_by_concurrentfutures.pyfrom gmaps import Geocoding from concurrent.futures import ThreadPoolExecutor api = Geocoding(api_key='maruhi') PLACES = ( 'Reykjavik', 'Vien', 'Zadar', 'Venice', 'Wrocow', 'Bolognia', 'Berlin', 'Dehil', 'New York', 'Osaka' ) POOL_SIZE = 4 def fetch_place(place): return api.geocode(place)[0] def present_result(geocoded): print("{:s}, {:6.2f}, {:6.2f}".format( geocoded['formatted_address'], geocoded['geometry']['location']['lat'], geocoded['geometry']['location']['lng'], )) def main(): with ThreadPoolExecutor(POOL_SIZE) as executor: results = executor.map(fetch_place, PLACES) print(type(results)) print(results) for result in results: present_result(result) if __name__ == "__main__": main()$python geocoding_by_concurrentfutures.py <class 'generator'> <generator object _chain_from_iterable_of_lists at 0x000001E2A3CED9C8> Reykjavík, Iceland, 64.15, -21.94 3110 Glendale Blvd, Los Angeles, CA 90039, USA, 34.12, -118.26 Zadar, Croatia, 44.12, 15.23 Venice, Metropolitan City of Venice, Italy, 45.44, 12.32 Wrocław, Poland, 51.11, 17.04 Bologna, Metropolitan City of Bologna, Italy, 44.49, 11.34 Berlin, Germany, 52.52, 13.40 Delhi, India, 28.70, 77.10 New York, NY, USA, 40.71, -74.01 Osaka, Japan, 34.69, 135.50
Futureクラスについて
FutureクラスはExecutor.submit()関数によって生成されます.
Futureオブジェクトは呼び出し可能なオブジェクトの非同期実行を管理し,処理結果を示します.登録した呼び出し可能オブジェクトの戻り値は,Future.result()メソッドで取得します.終了していない場合,結果が準備できるまでブロックします.result()メソッドによる結果の取得は,処理の終了後である必要はなく,result()は終了を待って,値を返します.[(公式)Futureオブジェクトについて]https://docs.python.org/ja/3/library/concurrent.futures.html#future-objects
sample_concurrent_futures.pyfrom concurrent.futures import ThreadPoolExecutor def loudy_return(): print("processing") return 42 with ThreadPoolExecutor(1) as executor: future = executor.submit(loudy_return) print(future) print(future.result())$python sample_concurrent_futures.py processing <Future at 0x27f17bd76c8 state=finished returned int> 42参考文献
- 投稿日:2019-11-25T09:28:19+09:00
【Python】Executor,Futureクラスについて
本稿について
Pythonバージョン3.2から追加された,concurrent.futuresモジュールの使い方を備忘録としてまとめる.
concurrent.futuresモジュールは結論から言ってしまえば,マルチスレッド,マルチプロセス両方のインターフェースを提供する.どんな場面で使われるか?
Q. 並行問題に対して,非同期アプリケーションに合わない場合やどうしていいかわからない場合には,どうするか?
A. 問題対象となる部分の処理をスレッドあるいはプロセスに委譲します.委譲した処理をコルーチンのように見せかけて,制御をイベントループに解放し,最終的な結果を処理します.
このAを実現するために用意されたのが
concurrent.futureモジュールです.なにができるのか?
concurrent.futureモジュールはasycioモジュールにも統合されており,この2つのモジュールを組み合わせることで,マルチスレッドやマルチプロセスで実行されるブロッキング関数を非同期のノンブロッキングコルーチンのように使用できます.どのように使うのか?
concurrent.futureモジュールには,ExecutorオブジェクトとFutureオブジェクトがあります.
Executorクラスについて
Executorは並列に作業項目を処理できるリソースのプールを表しています.multiprocessingモジュールのPoolクラスの目的と似ているようですが,インターフェスと設計が異なります.
Executorクラスはインスタンス化されていない基底クラスです.Executorクラスには,以下の2つのサブクラスが存在します.
ThreadPoolExecutor:スレッドプールを指定して,非同期処理を行いますProcessPollExecutor:プロセスプールを指定して,非同期処理を行います.これらのことから,
Executorクラスからマルチスレッドとマルチプロセスの両方のインターフェスを提供しているといえます.これらのクラスは3つメソッドを提供します.
submit(fn, *args, **kwargs):fn関数をリソースプールで実行するようにスケジュールし,Futureオブジェクトを返すmap(func, *iterables, timeout=None, chunksize=1):multiprocessing.Pool.map()メソッドと同様に,func関数をiterableなオブジェクトの要素をそれぞれに対して実行します.shutdown(wait=True):Executorをシャットダウンし,全てのリソースを解放します.以下,実装例.
geocoding_by_concurrentfutures.pyfrom gmaps import Geocoding from concurrent.futures import ThreadPoolExecutor api = Geocoding(api_key='maruhi') PLACES = ( 'Reykjavik', 'Vien', 'Zadar', 'Venice', 'Wrocow', 'Bolognia', 'Berlin', 'Dehil', 'New York', 'Osaka' ) POOL_SIZE = 4 def fetch_place(place): return api.geocode(place)[0] def present_result(geocoded): print("{:s}, {:6.2f}, {:6.2f}".format( geocoded['formatted_address'], geocoded['geometry']['location']['lat'], geocoded['geometry']['location']['lng'], )) def main(): with ThreadPoolExecutor(POOL_SIZE) as executor: results = executor.map(fetch_place, PLACES) print(type(results)) print(results) for result in results: present_result(result) if __name__ == "__main__": main()$python geocoding_by_concurrentfutures.py <class 'generator'> <generator object _chain_from_iterable_of_lists at 0x000001E2A3CED9C8> Reykjavík, Iceland, 64.15, -21.94 3110 Glendale Blvd, Los Angeles, CA 90039, USA, 34.12, -118.26 Zadar, Croatia, 44.12, 15.23 Venice, Metropolitan City of Venice, Italy, 45.44, 12.32 Wrocław, Poland, 51.11, 17.04 Bologna, Metropolitan City of Bologna, Italy, 44.49, 11.34 Berlin, Germany, 52.52, 13.40 Delhi, India, 28.70, 77.10 New York, NY, USA, 40.71, -74.01 Osaka, Japan, 34.69, 135.50
Futureクラスについて
FutureクラスはExecutor.submit()関数によって生成されます.
Futureオブジェクトは呼び出し可能なオブジェクトの非同期実行を管理し,処理結果を示します.登録した呼び出し可能オブジェクトの戻り値は,Future.result()メソッドで取得します.終了していない場合,結果が準備できるまでブロックします.result()メソッドによる結果の取得は,処理の終了後である必要はなく,result()は終了を待って,値を返します.[(公式)Futureオブジェクトについて]https://docs.python.org/ja/3/library/concurrent.futures.html#future-objects
sample_concurrent_futures.pyfrom concurrent.futures import ThreadPoolExecutor def loudy_return(): print("processing") return 42 with ThreadPoolExecutor(1) as executor: future = executor.submit(loudy_return) print(future) print(future.result())$python sample_concurrent_futures.py processing <Future at 0x27f17bd76c8 state=finished returned int> 42参考文献
- 投稿日:2019-11-25T09:16:39+09:00
Pythonプログラム用のショートカットをつくる(Windows10)
きっかけ
アカネチャンカワイイヤッターがしたくて,単純なタイマーをpythonで作った.
たまに茜ちゃんが応援してくれるタイマーできたー
— o_danny (@dannyso16) November 16, 2019
声はデフォルトのままやけど
ドット絵:マイラさん pic.twitter.com/2cLZYNZZojしかし実行するのに,いちいちコマンドから
cd working/directoryみたいに移動して実行するのもだるいので,デスクトップにショートカットを作りたくなった.最終的にこういうのができた.ダブルクリックで起動できる.
やったことたち
コマンドでやっている流れをそのまま.batファイルに書く
まず
AkaneTimer.txtのようにテキストファイルを作成して,コマンドでの操作をそのまま書く.cd your/repository python ./main.py pause最後に
pauseを入れとくといいらしい拡張子.batに変える
今回だと
AkaneTimer.batに変えるダブルクリックしてみると…
起動した!
けどコマンドプロンプトも一緒に立ち上がる.邪魔だし,間違えてコマンドプロンプトを消すと当然プログラムも落ちてしまう.やだ
黒画面をバックグラウンドで起動
これにはVBScriptを使った.
やることは簡単で,
no_cmd.txtをbatファイルと同じ階層に作って以下のように書く.Set ws = CreateObject("Wscript.Shell") ws.run "cmd /c AkaneTimer.bat", vbhide
vbhideで隠している.これを.vbsに変えて,ダブルクリックで実行すると,
黒画面消えた!!
ショートカットをデスクトップに置く
毎回二つもファイルいらないので,こいつらは
main.pyと同じファイルにでも入れておいて,.vbsファイルのショートカットだけデスクトップに置いた.アイコンがださい
変えよう.
Windows10でアイコンファイルを作成する方法を参考にした.簡単にまとめると
- ペイントで絵を描くか持ってくる(正方形で描こう)
- 32x32のbmpファイルで保存
- 拡張子を
.icoに変える- ショートカットのプロパティからアイコンを選択する
これで上のショートカットができた.やったね!
最後に
とりあえず目標は達成したけど,もっといいやり方あったら教えてください…
- 投稿日:2019-11-25T09:11:47+09:00
wordcloudでslackのみんなの発言をまとめてみた(Python)
これはjsys19AdventCalender(https://adventar.org/calendars/4301) の12/8の記事です。
jsysとは
筑波大学学園祭 雙峰祭実行委員会の局のうちの一つ、情報メディアシステム局の通称です。
主な活動としてはその年度の学祭Webや委員会で使用するシステムの作成、学祭の様子の生中継や、宣伝やダイジェストなどの映像作成などです。自己紹介
むらかみ(@ITF_village)です。ネ部門のやかましいやつです。
こうして自分のコードを文章とともに発信するのは初めてで、拙い文章、コードになりますが見守っていただけると、また「こここうした方がええで!」と思うところがあったら伝えていたけると幸いです。
slackのみんなの発言を解析してまとめてみた
突然ですがみなさんはワードクラウドというものをご存知でしょうか?
文章中で出現頻度が高い単語を複数選び出し、その頻度に応じた大きさで図示する手法。ウェブページやブログなどに頻出する単語を自動的に並べることなどを指す。文字の大きさだけでなく、色、字体、向きに変化をつけることで、文章の内容をひと目で印象づけることができる。
https://kotobank.jp/word/%E3%83%AF%E3%83%BC%E3%83%89%E3%82%AF%E3%83%A9%E3%82%A6%E3%83%89-674221こんな感じのもので、実際のものは以下の画像のようなものです
これはtypescript-eslintのgithubのページのりどみをワードクラウドにかけた画像です単語をちょっと面白く表現できるこの方法を以前にネットで見て、「slackのログでこれやったら面白くね?」と思い記事を書くまでに至りました。
wordcloudに渡す文章を作る
wordcloudはスペースごとに区切られたものしか受け取れません。みんなの発言はそんなことはないので、MeCabを利用してわかち書きをします。その前に全ての発言を一つにまとめる作業を入れました。
まずslackのみんなの発言のアーカイブをワークスペースのオーナーの局長よりいただき、文章の抜き出しを試みます。
ファイルを開くと各チャンネルごとにフォルダがあり、その中にjson形式で発言が送信者やリアクションなどの情報が保存されています。(この時点でbotの発言が多いようなチャンネルのフォルダは消しておくと楽です)ex-2020-6-31.json[ { "client_msg_id": "hoge", "type": "message", "text": "ハタチになりました", "user": "hogee", "ts": "hooge", "team": "foo", "user_team": "foo", "source_team": "foo", "user_profile": { "avatar_hash": "bar", "image_72": "https:\/\/avatars.slack-edge.com\/ore.png", "first_name": "Murakami", "real_name": "Murakami ore", "display_name": "むらかみ", "team": "piyo", "name": "s31051315", "is_restricted": false, "is_ultra_restricted": false }, } ]アーカイブフォルダ内の全てのjsonファイルを走査して、発言を示すtextプロパティの内容を一つの変数に収めるためのコードが以下になります。
from pathlib import Path import glob import json import re main_text = "" json_path=Path("src/jsys_archive") dirs=list(json_path.glob("**/*.json")) for i in dirs: json_open = open(i) json_text = json.load(json_open) json_dicts = len(json_text) for j in range(json_dicts): json_text_fixed = re.sub("<.*?>|:.*?:","",json_text[j]["text"]) main_text += json_text_fixed調べたいフォルダのパスをPath()にわたしてpathオブジェクト化し、glob()に任意のjsonファイルを探すように"**/*.json"を渡しています。
pa_th=Path("src/jsys_archive") dirs=list(pa_th.glob("**/*.json"))そして、みんなの発言には<>で囲われた色々なslack上で扱うであろうデータやメンション情報, ::で囲われたリアクション情報などの純粋なテキストではないノイズが混ざっています。
これらも含んでしまうと出力されるワードクラウドがシステムメッセージばかりになってしまうので、正規表現を用いて文字列操作をしています。json_text_fixed = re.sub("<.*?>|:.*?:","",json_text[j]["text"]) #<>、または::とその内部のテキストを消去これで変数main_textにみんなの発言が集まりました(膨大)。あとはMeCabにかけていきます。
wordcloudはスペースごとに区切られたものしか受け取れません。みんなの発言はそんなことはないので、MeCabを利用してわかち書きをします。
これをします。
import MeCab words = MeCab.Tagger("-Owakati") nodes = words.parseToNode(main_text) s = [] while nodes: if nodes.feature[:2] == "名詞": s.append(nodes.surface) nodes = nodes.nextそのためには
MeCab.Tagger()に"-Owakati"をわたして分かちます。Taggerオブジェクトは主に以下の四つの引数を取れます。1, "mecabrc" (引数なし)
2,"-Ochasen" (ChaSenの互換形式)
3,"-Owakati" (分かち書きを出力)←
4,"-Oyomi" (読みを出力)
今回は3の"お分かち"を利用します
(MeCabの引数日本語チックなのおもしろいけどお分かちとは言わないよね)次に
(Taggerインスタンス).parseToNode("文字列")でパースされて返されるNodeオブジェクトは.surfaceと.featureの二つのプロパティがあります。
surfaceにはNodeオブジェクトの文字列データが、featureには[品詞,品詞分類1,品詞分類2,品詞分類3,活用形,活用型,原形,読み,発音]が入っています。
下はプログラム例です。feature_exampleimport MeCab mecab = MeCab.Tagger() nodes = mecab.parseToNode("情報メディアシステム局") while nodes: print(nodes.feature) nodes = nodes.next↓実行結果
名詞,一般,*,*,*,*,情報,ジョウホウ,ジョーホー 名詞,一般,*,*,*,*,メディア,メディア,メディア 名詞,一般,*,*,*,*,システム,システム,システム 名詞,接尾,一般,*,*,*,局,キョク,キョク図に表示させるのは名詞だけで良いので、名詞であるものだけをifで通し、その文字列データを用意しておいた空リストに追加していきます。そして完成したリストを半角空白区切りで文字列化して、ようやく準備終了です。
s = [] while nodes: if nodes.feature[:2] == "名詞": s.append(nodes.surface) nodes = nodes.next parsed_main_text = " ".join(s)wordcloudで画像出力
やっと画像が作れます。
wc = WordCloud()に各種画像の設定をわたしてwordcloudオブジェクトを生成します。
画像の縦横を設定するheight,width、背景のbackground_colorなどはスタイルチックでわかりやすいかと思います。他には同じワードの出現を回避するcollocation,出現させたくないワードを設定するstopwordsなど様々ですが今回はここにあるだけのものだけ用います。
出力する画像の形を決めるmaskは後述します。import numpy from PIL import Image from wordcloud import WordCloud mask_jsys = numpy.array(Image.open("jsys.jpeg")) wc = WordCloud(width=1200, height=800, background_color="black", collocations = False, mask=mask_jsys, stopwords={"もの","これ","ため","それ","ところ", "よう","から","さん","けど","こと","そう"}, font_path="/System/Library/Fonts/ヒラギノ角ゴシック W6.ttc")一行目では画像の形を決めています。今回は下の画像を使いました。フォントは自分の好みですがImpactを使っています。
これでこの画像のjsysの文字の部分にのみワードクラウドの文字が配置されます。
wc.generate()に先ほど作ったparsed_main_textを渡して画像を生成し、wc.to_file("ファイル名")で保存されます。
wc.generate(parsed_main_text) wc.to_file('jsys_wordcloud.png')こうしてようやく完成です。長かった、、
完成!
良さげでは?(自画自賛)
こんなこと言ったっけ?と思うような発言も、確かに言ったなーこれーみたいな発言もあるんじゃないでしょうか?個人的には「お願い」とか「大丈夫」が大きくなるのが面白いですね。団体名のjsysも出てきてくれてよかったです。ちょっとポエム
なんとなく高校学祭委員の延長感覚と、四月当時に知っている先輩たちがいたからという理由だけで入った実委と情報メディアシステム局でしたが、自分がプログラミングを学べたこと、複数人での開発に携われたこと、たくさんの人に会えたこと、本当に本当に実委には感謝しかありません。今年自分がそうであったように、来年の一年生が楽しめるように今度は自分たちが努力していこうと思います。
さて来年はReactを使うらしいですね!(突然)記事書いたら欲しいものリストをのせるもんだと強い友人が言っていました。https://www.amazon.jp/hz/wishlist/ls/3I77JGCQC219C?ref_=wl_share
大変貴重な経験ができたと思います。本当にありがとうございました。
参考にしたWebページ
https://oku.edu.mie-u.ac.jp/~okumura/python/wordcloud.html
https://qiita.com/sea_ship/items/7c8811b5cf37d700adc4
https://www.pynote.info/entry/python-wordcloud#%E3%83%9E%E3%82%B9%E3%82%AF%E3%82%92%E4%BD%BF%E7%94%A8%E3%81%99%E3%82%8B
https://takaxtech.com/2018/11/03/article271/
https://qiita.com/amowwee/items/e63b3610ea750f7dba1b



- 投稿日:2019-11-25T01:59:16+09:00
Jupyter Notebook マジックコマンド自分的まとめ
前提条件
- macOS Catalina 10.15.1
- anaconda 4.17.12
- jupyter-notebook 5.0.0
- Python 3.6.9
マジックコマンドとは
マジックコマンド(Magic Commands)は、IPythonのカーネルから提供される仕組み。Notebookの動作に関連した機能のほか、ディレクトリ移動やファイル一覧を表示するなどのユーティリティ的な機能を提供する。
マジックコマンドの基本
先頭に
%を入力して続けてコマンドを入力する。現在のディレクトリを出力するコマンドは次のようになる。%pwdマジックコマンドの
%pwdは、シェルを利用した!pwdと違いがないようにも見えるが、!を利用したコマンド実行はOSのシェルに依存するのに対し、マジックコマンドはIPythonカーネルから提供される機能に依存。マジックコマンドが何らかの値を変える場合、Pythonの関数を呼び出した場合と同様、戻り値を変数に代入できる。
curr_dir = %pwd curr_dir使いがちなマジックコマンド
%timePythonの実行時間を計測するマジックコマンド。
%time sum(range(10000)) CPU times: user 226 μs, sys: 0 ns, total: 226 μs Wall time: 230 μs
出力 説明 Wall time プログラムの開始から終了までにかかった時間 CPU times: user user CPU time。プログラム自体の実行に要した時間 sys system CPU time。OSのシステムコールに要した時間
%timeit複数回試行した結果の計測値を要約して返すマジックコマンド。以下の場合、1000回の繰り返し処理を7回試行した場合の時間が出力されている。
%timeit sum(range(10000)) 224 µs ± 21.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)ループ回数と試行回数はオプションで指定可能。
# ループ回数2000回、試行回数5回 %timeit -n 2000 -r 5 sum(range(10000)) 215 µs ± 17.9 µs per loop (mean ± std. dev. of 5 runs, 2000 loops each)複数行のPythonコードに対して%timeitによる計測を行う場合、以下のように先頭の
%を2つ続け、%%にする。(Cell magics)%%timeit -n 1000 -r 3 for i in range(1000): i * 2 75.2 µs ± 9.58 µs per loop (mean ± std. dev. of 3 runs, 1000 loops each)
%historyコードセルの実行履歴を一覧で取得するマジックコマンド。
# 直近5つの履歴を取得 %history -l 5
%lsUNIXコマンドの
lsと同様の動作をするマジックコマンド。!lsとは違い、%lsはOSの種別を判断して、内部で実行するコマンドを使い分ける。(macOSの場合はlsコマンド、Windowsの場合はdirコマンド)
%autosaveAuto Saveの頻度を変更できる。(default120秒)
# Auto Saveを60秒に1回実行する。 %autosave 60
%matplotlibMatplotlibに関する設定を行うマジックコマンド。
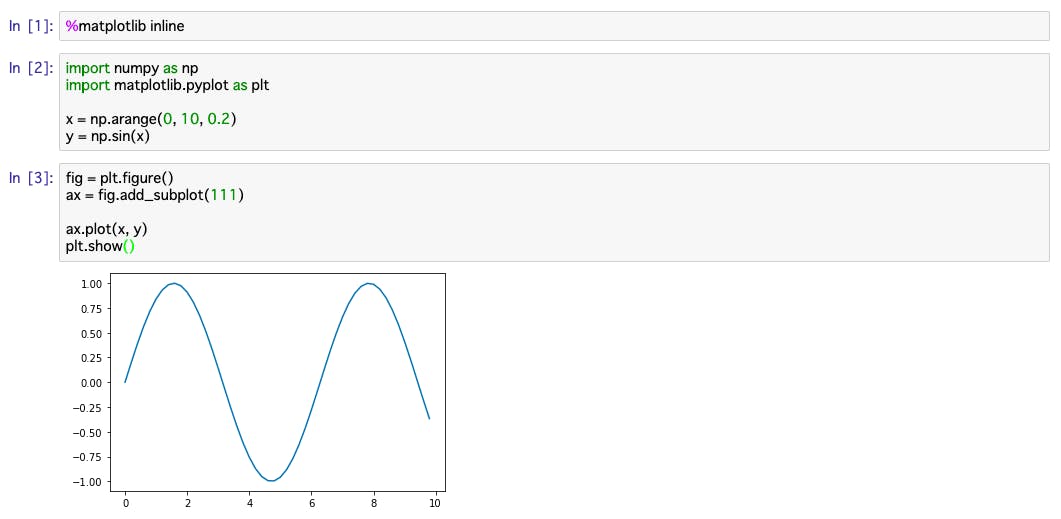
%matplotlib inlineinlineを指定した場合、コードセル直下にグラフが描画される。
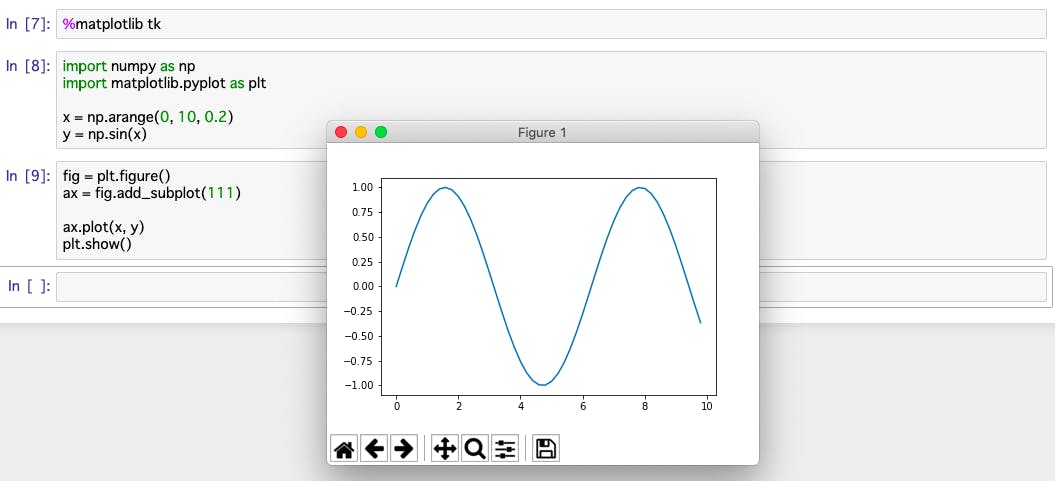
%matplotlib tktkを指定した場合、別ウィンドウにインタラクティブなグラフが出力される。
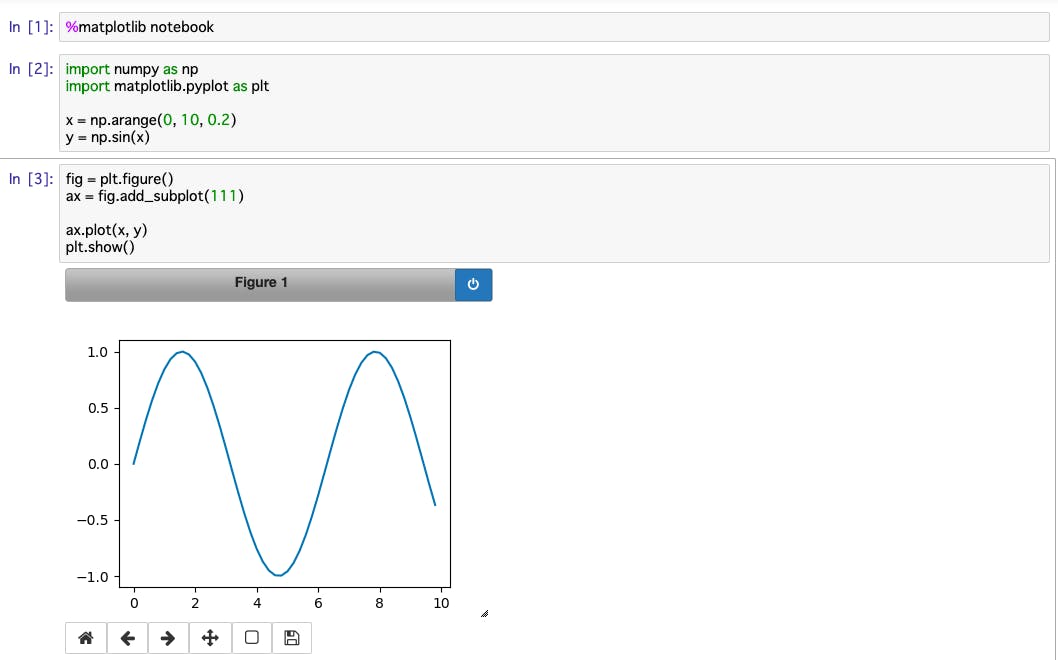
%matplotlib notebooknotebookを指定した場合、コードセルの直下にインタラクティブなグラフが出力される。
- 一度指定した出力方法を変更するには、カーネルのリスタートを行う。
- 投稿日:2019-11-25T01:18:27+09:00
気象×Python 〜気象データ取得からスペクトル解析まで〜
これまでの記事で気象庁のデータの扱い方をいくらか取り上げてきましたが、また違ったデータ取得方法(現状、この方法が一番効率的)を実践し、取得したデータの解析も軽くしていこうと思います。
<過去の記事>
・気象×Python 〜AMeDASの地点データ自動取得〜
https://qiita.com/OSAKO/items/264c77b70843045bc12b
・気象×Python 〜AMeDASの地点データ自動取得(番外編)〜
https://qiita.com/OSAKO/items/505ecee67df424963e53
・気象×Ruby 〜Mechanizeを使ってRubyスクレイピング〜
https://qiita.com/OSAKO/items/3c1cac0b5448be9ab2431. クローリング
▶以下のような表形式で埋め込まれている数値 or 文字列を一気に取得したい。(例:東京における2019年1月の1日データ)
https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=44&block_no=47662&year=2019&month=01&day=1&view=▶まずは1000以上にわたる地点のurlを全部取得して、リスト化するためのクローラを実装する。
https://www.data.jma.go.jp/obd/stats/etrn/index.php?prec_no=44&block_no=47662&year=&month=&day=&view=
↑取得したいurlの例(prec_noやblock_noのidが地点によって異なる)手順
①まずはこちらのurlから各地域にアクセスするためのurlが欲しいので、areaタグ配下のhref属性を検索してリスト化する。(下記コードのget_area_linkメソッド)
②上記でリスト化した各地域のurlをキーにして、同様に各地点のhref属性を検索すれば、prec_noとblock_noにidが含まれた目的のurlが取得できる。(下記コードのget_station_linkメソッド)
③あとは、リスト化したurlを少々整形してからcsvに保存する。(下記コードのdata_arangeメソッド)
プログラム
get_amedas_station_url.py# -*- coding: utf-8 -*- import pandas as pd import urllib.request from bs4 import BeautifulSoup class Get_amedas_station: def __init__(self): url = 'https://www.data.jma.go.jp/obd/stats/etrn/select/prefecture00.php?prec_no=&block_no=&year=&month=&day=&view=' html = urllib.request.urlopen(url) self.soup = BeautifulSoup(html, 'html.parser') def get_area_link(self): elements = self.soup.find_all('area') self.area_list = [element['alt'] for element in elements] self.area_link_list = [element['href'] for element in elements] def get_station_link(self): out = pd.DataFrame(columns=['station','url','area']) for area, area_link in zip(self.area_list, self.area_link_list): url = 'https://www.data.jma.go.jp/obd/stats/etrn/select/'+ area_link html = urllib.request.urlopen(url) soup = BeautifulSoup(html, 'html.parser') elements = soup.find_all('area') station_list = [element['alt'] for element in elements] station_link_list = [element['href'].strip('../') for element in elements] df1 = pd.DataFrame(station_list,columns=['station']) df2 = pd.DataFrame(station_link_list,columns=['url']) df = pd.concat([df1, df2],axis=1).assign(area=area) out = pd.concat([out,df]) print(area) self.out = out def data_arange(self): out = self.out[~self.out.duplicated()].assign(append='https://www.data.jma.go.jp/obd/stats/etrn/') out['amedas_url'] = out['append'] + out['url'] out = out.loc[:,['area','station','amedas_url']] out.to_csv('amedas_url_list.csv',index=None, encoding='SJIS') if __name__ == '__main__': amedas = Get_amedas_station() amedas.get_area_link() amedas.get_station_link() amedas.data_arange()2. スクレイピング
▶本題のAMeDASデータの取得に関してだが、今回は1日・1時間・10分データの異なる時間スケールに対応したプログラムを書いた(ただし、コード量は比較的多く、無駄が多いかもしれないので要改善)
▶注意点として、どのAMeDAS地点を選択するかで観測種目が違う。(選択された地点が気象台とそうでない場合で異なる)<例えば、各時間スケールで東京と八王子間で観測種目を比較してみる。>
・1日データ
東京
八王子
・1時間データ
東京
八王子
・10分データ
東京
八王子
プログラム
get_amedas_data.py# -*- coding: utf-8 -*- import re import time import numpy as np import pandas as pd import urllib.request from bs4 import BeautifulSoup from datetime import timedelta from datetime import datetime as dt from dateutil.relativedelta import relativedelta # 各AMeDAS地点のurlから取得対象データを検索し、リスト化するメソッド def search_data(url): html = urllib.request.urlopen(url) time.sleep(1) soup = BeautifulSoup(html, 'html.parser') element = soup.find_all('tr', attrs={'class':'mtx', 'style':'text-align:right;'}) out = [list(map(lambda x: x.text, ele)) for ele in element] return out class Get_amedas_data: def __init__(self,area_name,station_name): # 指定した地域と地点から対象のurlを参照する self.st_name = station_name self.a_name = area_name amedas_url_list = pd.read_csv('amedas_url_list.csv',encoding='SJIS') df = amedas_url_list[(amedas_url_list['area']==self.a_name) & (amedas_url_list['station']==self.st_name)] amedas_url = df.iat[0,2] # urlから正規表現で数字を取得する(prec_noとblock_noのidが必要) pattern=r'([+-]?[0-9]+\.?[0-9]*)' id_list=re.findall(pattern, amedas_url) self.pre_id = id_list[0] self.s_id = id_list[1] # 1日データは1月分のデータとしてまとめて取得できるため、開始月と終了月を指定する def set_date1(self, startmonth, endmonth): self.start = startmonth self.end = endmonth strdt = dt.strptime(self.start, '%Y%m') enddt = dt.strptime(self.end, '%Y%m') months_num = (enddt.year - strdt.year)*12 + enddt.month - strdt.month + 1 # 開始月〜終了月までの月をリスト化 self.datelist = map(lambda x, y=strdt: y + relativedelta(months=x), range(months_num)) # 1時間 or 10分データに関しては、開始日と終了日を指定する def set_date2(self,startdate,enddate): self.start = startdate self.end = enddate strdt = dt.strptime(self.start, '%Y%m%d') enddt = dt.strptime(self.end, '%Y%m%d') days_num = (enddt - strdt).days + 1 # 開始日〜終了日までの日付をリスト化 self.datelist = map(lambda x, y=strdt: y + timedelta(days=x), range(days_num)) # 予め空のデータフレームを作成しておく。気象台のある地点の方が取得できる要素が多い。 # 取得したい時間スケールを指定(type) def dl_data(self, type): # dailyデータに関する空のデータフレーム data1 = pd.DataFrame(columns=['年月','日','平均現地気圧','平均海面気圧','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均湿度','最小湿度','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','日照時間','降雪','最深積雪','天気概況(昼)','天気概況(夜)']) data1_ = pd.DataFrame(columns=['年月','日','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','最多風向','日照時間','降雪','最深積雪']) # hourlyデータに関する空のデータフレーム data2 = pd.DataFrame(columns=['日付','時','現地気圧','海面気圧','降水量','気温','露点温度','蒸気圧','湿度','風速','風向','日照時間','全天日射量','降雪','積雪','天気','雲量','視程']) data2_ = pd.DataFrame(columns=['日付','時','降水量','気温','風速','風向','日照時間','降雪','積雪']) # 10minデータに関する空のデータフレーム data3 = pd.DataFrame(columns=['日付','時分','現地気圧','海面気圧','降水量','気温','相対湿度','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間']) data3_ = pd.DataFrame(columns=['日付','時分','降水量','気温','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間']) # リスト化した月 or 日付リストを回しながらデータを取得しつつ、縦に結合しながらデータフレームを作成する for dt in self.datelist: d = dt.strftime("%Y%m%d") yyyy = d[0:4] mm = d[4:6] dd = d[6:8] if type=='daily': # 気象台のある地点のblock_noは5桁の番号 if len(self.s_id) == 5: pattern = 's1' url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1' out = search_data(url) df = (pd.DataFrame(out, columns=['日','平均現地気圧','平均海面気圧','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均湿度','最小湿度','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','日照時間','降雪','最深積雪','天気概況(昼)','天気概況(夜)'])).assign(年月=f'{yyyy}{mm}') df = df.loc[:,['年月','日','平均現地気圧','平均海面気圧','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均湿度','最小湿度','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','日照時間','降雪','最深積雪','天気概況(昼)','天気概況(夜)']] data1 = pd.concat([data1, df]) data1.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS') else: pattern = 'a1' url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1' out = search_data(url) df = (pd.DataFrame(out, columns=['日','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','最多風向','日照時間','降雪','最深積雪'])).assign(年月=f'{yyyy}{mm}') df = df.loc[:,['年月','日','日降水量','最大1時間降水量','最大10分間降水量','平均気温','最高気温','最低気温','平均風速','最大風速','最大風向','最大瞬間風速','最大瞬間風向','最多風向','日照時間','降雪','最深積雪']] data1_ = pd.concat([data1_, df]) data1_.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS') elif type=='hourly': if len(self.s_id) == 5: pattern = 's1' url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1' out = search_data(url) # 日付の列を追加(24個分) date = pd.DataFrame((np.full([24,1], f'{yyyy}{mm}{dd}')),columns=['日付']) df = pd.DataFrame(out, columns=['時','現地気圧','海面気圧','降水量','気温','露点温度','蒸気圧','湿度','風速','風向','日照時間','全天日射量','降雪','積雪','天気','雲量','視程']) df = pd.concat([date, df],axis=1) data2 = pd.concat([data2, df]) data2.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS') else: pattern = 'a1' url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1' out = search_data(url) date = pd.DataFrame((np.full([24,1], f'{yyyy}{mm}{dd}')),columns=['日付']) df = pd.DataFrame(out, columns=['時','降水量','気温','風速','風向','日照時間','降雪','積雪']) df = pd.concat([date, df],axis=1) data2_ = pd.concat([data2_, df]) data2_.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS') elif type=='10min': if len(self.s_id) == 5: pattern = 's1' url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1' out = search_data(url) # 日付の列を追加(6×24個分) date = pd.DataFrame((np.full([144,1], f'{yyyy}{mm}{dd}')),columns=['日付']) df = pd.DataFrame(out, columns=['時分','現地気圧','海面気圧','降水量','気温','相対湿度','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間']) df = pd.concat([date, df],axis=1) data3 = pd.concat([data3, df]) data3.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS') else: pattern = 'a1' url = f'https://www.data.jma.go.jp/obd/stats/etrn/view/{type}_{pattern}.php?prec_no={self.pre_id}&block_no={self.s_id}&year={yyyy}&month={mm}&day={dd}&view=p1' out = search_data(url) date = pd.DataFrame((np.full([144,1], f'{yyyy}{mm}{dd}')),columns=['日付']) df = pd.DataFrame(out, columns=['時分','降水量','気温','平均風速','平均風向','最大瞬間風速','最大瞬間風向','日照時間']) df = pd.concat([date, df],axis=1) data3_ = pd.concat([data3_, df]) data3_.to_csv(f'{self.a_name}_{self.st_name}_{self.start}-{self.end}_{type}.csv',index=None, encoding='SJIS') print(f'{self.a_name}_{self.st_name}_{yyyy}-{mm}-{dd}_{type}') print(f'{self.a_name}_{self.st_name}における{self.start}〜{self.end}の{type}データをダウンロードしました。') if __name__ == '__main__': a_name = input('ダウンロードしたい地域を入力してください:') st_name = input('ダウンロードしたい地点を入力してください:') amedas = Get_amedas_data(a_name,st_name) type = input('時間スケールを選択してください(daily or hourly or 10min):') if type == 'daily': start= input('取得したい開始月(yyyymm)を入力してください:') end = input('取得したい終了月(yyyymm)を入力してください:') amedas.set_date1(start,end) else: start= input('取得したい開始日(yyyymmddを入力してください:') end = input('取得したい終了日(yyyymmdd)を入力してください:') amedas.set_date2(start,end) amedas.dl_data(type)地域:東京都
地点:東京
時間スケール:10min
開始日:20190401
終了日:20190731という条件で試しにデータをダウンロードしてみる。
保存した"東京都_東京_20190401-20190731_10min.csv"ファイルの中身はこんな感じ
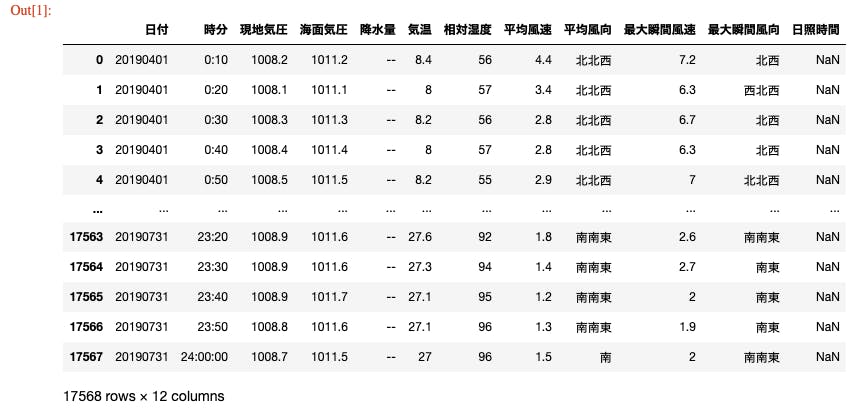
3. スペクトル解析
▶せっかく、10分という時間解像度の細かいデータを取得したので、軽く時系列データ解析をしてみる。
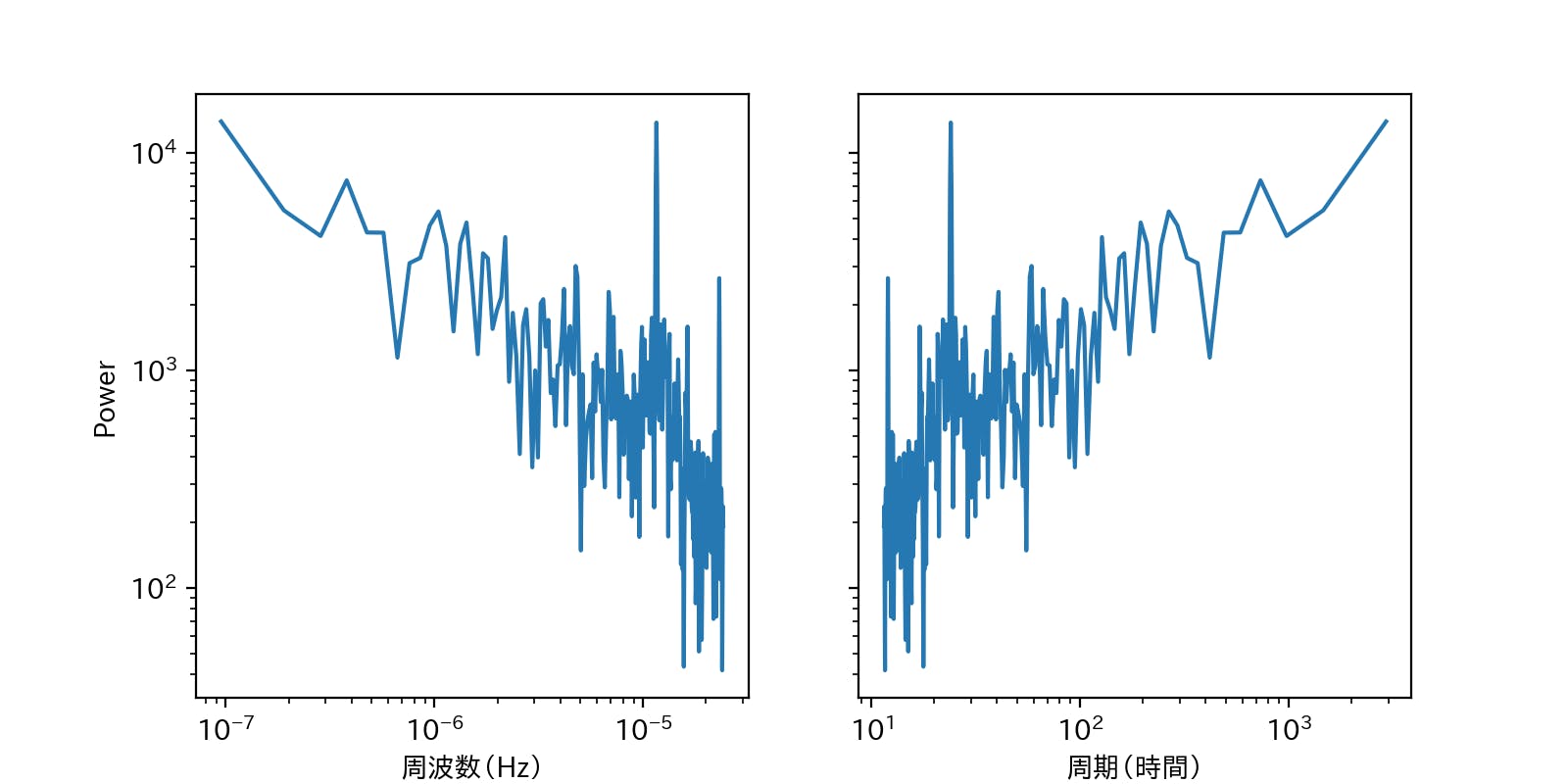
▶今回は、取得した期間における気温変動にスペクトル解析を適用し、パワースペクトルを算出した。
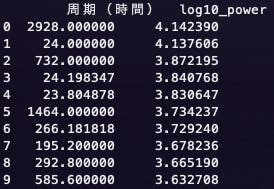
フーリエ変換の気持ちを理解したい人はこちらの動画がわかりやすいかも。fft_temp.py# -*- coding: utf-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt from numpy.fft import fftn, ifftn, fftfreq class FFT: def __init__(self): df = pd.read_csv('東京都_東京_20190401-20190731_10min.csv', encoding='SJIS').replace(['--','×'],-99) df['気温'] = df['気温'].astype(float) y = df['気温'].replace(-99, (df['気温'] > -99).mean()).values y = (y - np.mean(y)) * np.hamming(len(y)) ''' サンプリング周波数 fs → 1秒間にサンプリングされるデータ数 第二引数にはd=1.0/fs 今回のサンプリング周波数は10分間隔データなので1/600 ''' self.z = np.fft.fft(y) self.freq = fftfreq(len(y), d=1.0/(1/600)) def plot(self, n_samples): fig, axes = plt.subplots(figsize=(8, 4), ncols=2, sharey=True) ax = axes[0] ax.plot(self.freq[1:int(n_samples/2)], abs(self.z[1:int(n_samples/2)])) ax.set_yscale('log') ax.set_xscale('log') ax.set_ylabel('Power') ax.set_xlabel('周波数(Hz)') ax = axes[1] ax.plot((1 / self.freq[1:int(n_samples / 2)])/(60*60), abs(self.z[1:int(n_samples / 2)])) ax.set_yscale('log') ax.set_xscale('log') ax.set_xlabel('周期(時間)') plt.show() def periodic_characteristics(self, n_samples): fft_pow_df = pd.DataFrame([(1 / self.freq[1:int(n_samples / 2)])/(60*60), np.log10(abs(self.z[1:int(n_samples / 2)]))], index=['周期(時間)', 'log10_power']).T fft_pow_df = fft_pow_df.sort_values('log10_power', ascending=False).head(10).reset_index() print(fft_pow_df.loc[:, ['周期(時間)', 'log10_power']]) if __name__ == '__main__': fft = FFT() fft.periodic_characteristics(512) fft.plot(512)一番パワースペクトルの大きい122日周期はいまいちピンとは来ないが、想定通り、23,24時間の周期も卓越していたのでおそらく合っているのかと。(朝から昼にかけて気温が上がり、夜にかけてまた下がるという日周期の物理特性を持っているため)
何か間違いなどあればご指摘いただけるとありがたいです。以上!!!









- 投稿日:2019-11-25T00:57:01+09:00
TISさんが作成した企業分析用データセット「CoARiJ」で遊んでみる①
CoARiJとは
「CoARiJ」は、有価証券報告書やCSR報告書、統合報告書の記載内容(事業概要や財務情報等)と、数値情報(株価およびTOPIX等の指数)をまとめたデータセットです。
https://www.tis.co.jp/news/2019/tis_news/20191114_1.html
github
https://github.com/chakki-works/CoARiJ/blob/master/README.md
非財務情報の重要性
ESGをはじめとした非財務情報の活用がこれからの投資判断には必要
伊藤レポート
投資判断において企業の持続可能性(Sustainability)やリスクを評価するために「ESG (環境・社会・ガバナンス」等の非財務情報を組み込むことが大きな論点となっている。
MiFIFⅡ等により、アナリストのリサーチが激しく評価され、淘汰圧力が高まる中で、非財務情報をベースとして投資家が必要とする情報を提供するアナリストのみが生き残れるといった意見も示された。
https://www.meti.go.jp/press/2017/10/20171026001/20171026001-1.pdf
GPIFのESG投資への取り組み
ESGの要素に配慮した投資は長期的にリスク調整後のリターンを改善する効果があると期待できることから、公的年金など投資額の大きい機関投資家のあいだでESG投資に対する関心が高まっています。
https://www.gpif.go.jp/investment/esg/
投資家は企業の持続可能性を見ている
我々が適切なEDG評価基準を持ち、持続的な成長が見込める企業に投資を行うことで、長期的な投資パフォーマンスを向上させることができる可能性がある
www.amazon.co.jp/dp/4532134811
非財務諸表分析の問題点
上場企業の「財務情報」は有価証券報告書や決算短信による開示が義務付けられている。ユーザは企業情報開示サイトであるTDNETやEDINETへのアクセス、また各種APIの利用により、財務情報を容易に閲覧、収集ができる。
http://disclosure.edinet-fsa.go.jp/
https://ufocatch.com/一方で、「非財務情報」であるESG情報の収集は難しかった。そもそも開示義務がないため入手手段が限られているし、WEB上で公開されていたとしても手動でひとつひとつレポートをダウンロード、前処理する必要があったためである。
やること
- 動作確認
- part1ってことでご勘弁を
https://github.com/chakki-works/CoARiJ/blob/master/README.md
Environments
conda create -n coarij python=3.6 anaconda source activate coarijInstall
pip install coarij pip install janome # テキスト処理に使用 coarij -- # マニュアルが出てくるRun command sample
# Download raw file version dataset of 2014. coarij download --kind F --year 2014 # Extract business.overview_of_result part of TIS.Inc (sec code=3626). coarij parse business.overview_of_result --sec_code 3626 # Tokenize text by Janome (`janome` or `sudachi` is supported). pip install janome coarij tokenize --tokenizer janome # Show tokenized result (words are separated by \t). head -n 5 data/processed/2014/docs/S100552V_business_overview_of_result_tokenized.txt 1 【 業績 等 の 概要 】 ( 1 ) 業績 当 連結 会計 年度 における 我が国 経済 は 、 消費 税率 引上げ に 伴う 駆け込み 需要 の 反動 や 海外 景気 動向 に対する 先行き 懸念 等 から 弱い 動き も 見 られ まし た が 、 企業 収益 の 改善 等 により 全体 ...まとめ
- 素晴らしいデータセット
- 分析はまた今度実施
- 経年での業績・ESG書きっぷり変化
- 伊藤レポートの検証
- 業績との相関というよりESG投資の実際
- 懸念
- 「書きっぷり」への対応
- 辞書
- 投稿日:2019-11-25T00:04:00+09:00
GBDTライブラリ:CatBoostで燃費予測(回帰)をやってみた
GBDT(Gradient Boosting Decision Trees)なライブラリであるXGBoost, lightGBMと並んで使われることがあるCatBoostを最近まで知らなかったので、回帰タスクで動かしてみました。
CatBoost?
公式サイトの紹介文を貼ります。(Google翻訳したもの)
CatBoostは、決定木の勾配ブースティングのアルゴリズムです。 Yandexの研究者およびエンジニアによって開発され、 検索、推奨システム、パーソナルアシスタント、自動運転車、天気予報、およびYandexやCERN、Cloudflare、Careemタクシーなどの他社の多くのタスクに使用されます。参考にさせていただいた記事
今回使わせていただいたデータセット
- Auto MPG データセット
- こちらのTensorFlow Tutorialsで使われているデータセットです。
- 自動車の燃費を予測します。説明変数には、気筒数、排気量、馬力、重量などが含まれています。
内容
以下のコードはGoogle Colab上で実行しました。(CPU)
CatBoostをpipでインストール
!pip install catboost -Uデータセットをダウンロード
import urllib.request url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data' file_path = './auto-mpg.data' urllib.request.urlretrieve(url, file_path)データの前処理
import pandas as pd column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight', 'Acceleration', 'Model Year', 'Origin'] dataset = pd.read_csv(file_path, names=column_names, na_values = "?", comment='\t', sep=" ", skipinitialspace=True) # 今回は動かすことが目的なのでnanはdropする dataset = dataset.dropna().reset_index(drop=True) # カテゴリ変数: OriginはCatBoostにて取り扱うのでString型にしておく dataset['Origin'] = dataset['Origin'].astype(str) train_dataset = dataset.sample(frac=0.8,random_state=0) test_dataset = dataset.drop(train_dataset.index) train_labels = train_dataset.pop('MPG') test_labels = test_dataset.pop('MPG')CatBoostが使うためのデータセットを用意する
import numpy as np from catboost import CatBoostRegressor, FeaturesData, Pool def split_features(df): cfc = [] nfc = [] for column in df: if column == 'Origin': cfc.append(column) else: nfc.append(column) return df[cfc], df[nfc] cat_train, num_train = split_features(train_dataset) cat_test, num_test = split_features(test_dataset) train_pool = Pool( data = FeaturesData(num_feature_data = np.array(num_train.values, dtype=np.float32), cat_feature_data = np.array(cat_train.values, dtype=object), num_feature_names = list(num_train.columns.values), cat_feature_names = list(cat_train.columns.values)), label = np.array(train_labels, dtype=np.float32) ) test_pool = Pool( data = FeaturesData(num_feature_data = np.array(num_test.values, dtype=np.float32), cat_feature_data = np.array(cat_test.values, dtype=object), num_feature_names = list(num_test.columns.values), cat_feature_names = list(cat_test.columns.values)) )学習
model = CatBoostRegressor(iterations=2000, learning_rate=0.05, depth=5) model.fit(train_pool)上記のパラメータは参考記事のままの値としています。
ちなみに学習はtotal: 4.3 sで終わりました。推論・結果プロット
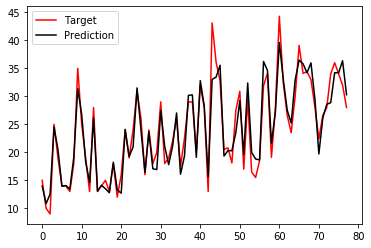
import matplotlib.pyplot as plt preds = model.predict(test_pool) xs = list(range(len(test_labels))) plt.plot(xs, test_labels.values, color = 'r') plt.plot(xs, preds, color = 'k'); plt.legend(['Target', 'Prediction'], loc = 'upper left'); plt.show()プロットすると以下のような結果となりました。
感想など
- 今回は参考記事ほぼそのままで動かしただけなのですが、回帰でのざっくりした使い方がわかってよかったです。
- 参考にしたKaggleのKernelへもコメントされている内容ですが、ハイパーパラメータチューニングでBayesSearchCVを使うのが良いようなので、次に試してみようかと思います。(こちらの資料が参考になりそうでした)