- 投稿日:2019-11-25T23:13:15+09:00
AWS APIGateway + Lambda統合プロキシ の利用でCORS設定にはまった話
要約
AWSのAPIGatewayを利用してAPIを作ったが、CORSの設定がどうも上手くいかない、、、
という所にはまった話です。
(昔作ったAPIは動くのに、、、なんで!?( ゚д゚)ハッ! )
結論から言うと、
「Lambda統合プロキシ」利用の場合、
CORSに関するレスポンスヘッダの設定は各自のプラグラム上でやれよ!
という事です。
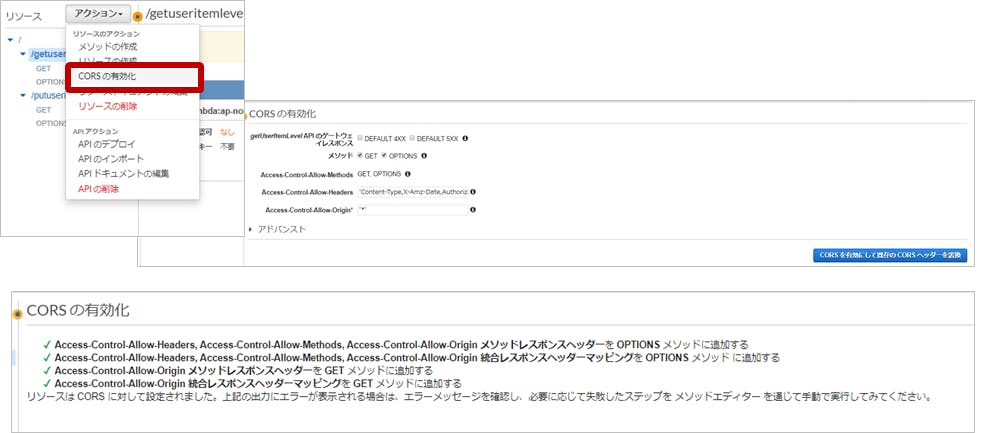
GUI上で、CORSの有効化をしても、レスポンスヘッダの「Access-Control-Allow-Origin」は反映されません。
(統合リクエストのタイプがLambdaの場合に有効になります。)
CORSの有効化ボタンが押せちゃうので混乱しちゃいますよね;;AWS公式にも記載があります。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/how-to-cors.html
1.過去のAPIGateway
AWS APIGatewayは以前からあるサービスですが、
Lambda統合Proxyがなかった頃は、APIの情報をLamdaへ流してやるために、
マッピングテンプレートなどを自分で設定する必要がありました。
(統合リクエストのタイプがLambda)・Lambdaへ流す(メソッドリクエスト、統合リクエスト)
・Lambdaから返す(メソッドレスポンス、統合レスポンス)
2.過去のCORS設定
過去のLambda統合Proxyがなかった頃(統合リクエストのタイプがLambdaの場合)、
API GatewayのGUI上の「CORSの有効化」というボタンをポチっと押すことで、
自動的にレスポンスヘッダ、統合レスポンスヘッダ、に各種設定を追加してくれていました。APIGatewayが出始めの頃は、
公式ドキュメントの他、すばらしいエンジニアたちが残してくれた情報が溢れており、
これらはすんなりといった記憶があります。
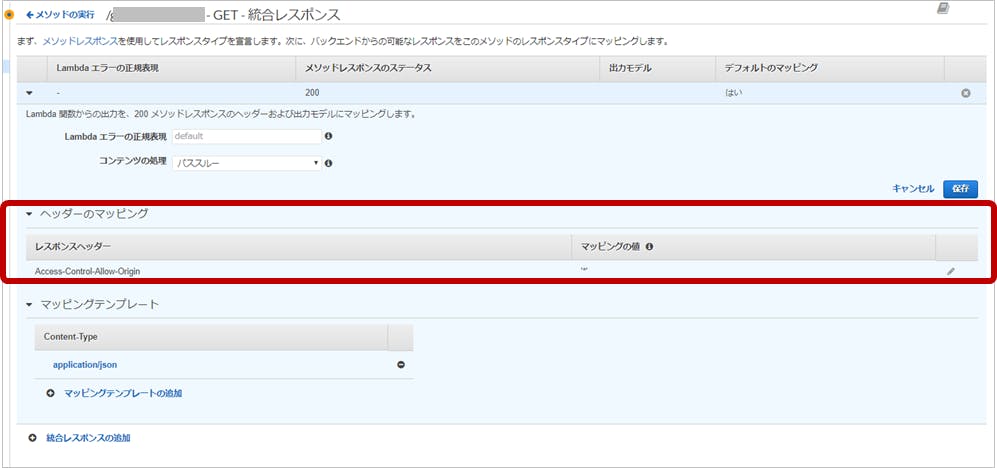
上記の状態で、統合レスポンスヘッダを見ると設定が追加されていました。
3.Lambda統合Proxyの登場
「マッピングテンプレートを、自分で設定するのって手間じゃね?」という事で、「Lambda統合Proxy」が出来ました。
Lambda関数側に多少の制約が出てきますが、楽になったと思います。
そもそも「Lambda統合Proxy」って何やねん?
ってことですが、
後述します参考にあります @_mogaming さんの言葉が分かりやすく引用させていただきますと、「このGatewayに対するリクエストの情報(HTTPメソッド、クエリストリング、パス、ソースIPなど)を勝手にまとめてくれて、Lambdaに渡してくれる」機能
という事です。
また、Lambda統合プロキシを利用したAPIGateway自体については、
下記、Classmethodさんの記事が大変わかりやすいと思います。
API Gateway が「Lambda プロキシ統合」でさらに使いやすくなっててびっくりした話
4.Lambda統合ProxyでのCORS設定
すばらしいエンジニアたちが残してくれた情報を元に、
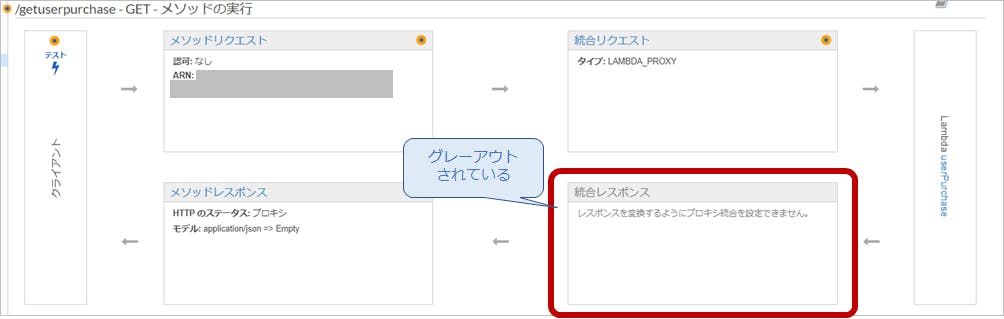
「CORS設定を画面からポチッ」っと設定をしても反映されません。。。なぜなら、「Lambda統合Proxy」を利用することで、
「統合レスポンス」のめんどくさい設定を全部スルーしているんですもの!!
もちろん、
「統合レスポンス」に設定してた「Access-Control-Allow-Origin」も効かないわけですよね;;
ということで、
レスポンスヘッダに自前で書いてください。
以下、Node.jsの例です。exports.handler = function(event, context, callback) { callback(null, { statusCode: '200', body: "Hello world", headers: { "Access-Control-Allow-Origin": "*" } }); }
みなさまも快適なAPIGateway&Lambda生活を!参考にさせて頂きました。
AWS Lambda Proxy Integrationを試してみた
API Gateway が「Lambda プロキシ統合」でさらに使いやすくなっててびっくりした話上記、APIGatewayやLambda統合Proxyについて、より詳細を解説されております。
(大変助かりました!!)


- 投稿日:2019-11-25T23:13:15+09:00
AWS APIGateway + Lambda プロキシ統合 の利用でCORS設定にはまった話
要約
AWSのAPIGatewayを利用してAPIを作ったが、CORSの設定がどうも上手くいかない、、、
という所にはまった話です。
(昔作ったAPIは動くのに、、、なんで!?( ゚д゚)ハッ! )
結論から言うと、
「Lambda プロキシ統合」利用の場合、
CORSに関するレスポンスヘッダの設定は各自のプラグラム上でやれよ!
という事です。
GUI上で、CORSの有効化をしても、レスポンスヘッダの「Access-Control-Allow-Origin」は反映されません。
(統合リクエストのタイプがLambdaの場合に有効になります。)
CORSの有効化ボタンが押せちゃうので混乱しちゃいますよね;;AWS公式にも記載があります。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/how-to-cors.html
1.過去のAPIGateway
AWS APIGatewayは以前からあるサービスですが、
Lambda プロキシ統合がなかった頃は、APIの情報をLamdaへ流してやるために、
マッピングテンプレートなどを自分で設定する必要がありました。
(統合リクエストのタイプがLambda)・Lambdaへ流す(メソッドリクエスト、統合リクエスト)
・Lambdaから返す(メソッドレスポンス、統合レスポンス)
2.過去のCORS設定
過去のLambda プロキシ統合がなかった頃(統合リクエストのタイプがLambdaの場合)、
API GatewayのGUI上の「CORSの有効化」というボタンをポチっと押すことで、
自動的にレスポンスヘッダ、統合レスポンスヘッダ、に各種設定を追加してくれていました。APIGatewayが出始めの頃は、
公式ドキュメントの他、すばらしいエンジニアたちが残してくれた情報が溢れており、
これらはすんなりといった記憶があります。
上記の状態で、統合レスポンスヘッダを見ると設定が追加されていました。
3.Lambda プロキシ統合の登場
「マッピングテンプレートを、自分で設定するのって手間じゃね?」という事で、「Lambda プロキシ統合」が出来ました。
Lambda関数側に多少の制約が出てきますが、楽になったと思います。
そもそも「Lambda プロキシ統合」って何やねん?
ってことですが、
後述します参考にあります @_mogaming さんの言葉が分かりやすく引用させていただきますと、「このGatewayに対するリクエストの情報(HTTPメソッド、クエリストリング、パス、ソースIPなど)を勝手にまとめてくれて、Lambdaに渡してくれる」機能
という事です。
また、Lambda プロキシ統合を利用したAPIGateway自体については、
下記、Classmethodさんの記事が大変わかりやすいと思います。
API Gateway が「Lambda プロキシ統合」でさらに使いやすくなっててびっくりした話
4.Lambda プロキシ統合でのCORS設定
すばらしいエンジニアたちが残してくれた情報を元に、
「CORS設定を画面からポチッ」っと設定をしても反映されません。。。なぜなら、「Lambda プロキシ統合」を利用することで、
「統合レスポンス」のめんどくさい設定を全部スルーしているんですもの!!
もちろん、
「統合レスポンス」に設定してた「Access-Control-Allow-Origin」も効かないわけですよね;;
ということで、
レスポンスヘッダに自前で書いてください。
以下、Node.jsの例です。exports.handler = function(event, context, callback) { callback(null, { statusCode: '200', body: "Hello world", headers: { "Access-Control-Allow-Origin": "*" } }); }
みなさまも快適なAPIGateway&Lambda生活を!参考にさせて頂きました。
AWS Lambda Proxy Integrationを試してみた
API Gateway が「Lambda プロキシ統合」でさらに使いやすくなっててびっくりした話上記、APIGatewayやLambda プロキシ統合について、より詳細を解説されております。
(大変助かりました!!)
- 投稿日:2019-11-25T23:02:05+09:00
クレカ登録無しでAWSを無料で使える! AWS Educate Starter アカウントで出来る事をまとめてみた
AWSとは?
AWS(アマゾンウェブサービス)とは、インターネット通販で有名なAmazonの子会社がサービスを提供いる「クラウドコンピューティングサービス」である。
元々、このAWSは、Amazon自身のインフラを支えるために作られたものである。世界中から集まる膨大なアクセスに対応するため、日々サーバー機器などの増強を続けていく中で、自社だけではなく、他社にも提供しようという事でスタートしたのがこのサービスである。AWSのサービスは2006年7月に公開された。AWS Educateとは?
クラウドに強い従業員の需要は高まっており、AWS Educateでは、次世代のITとクラウドのプロフェッショナルに向けた学習の機会を提供している。AWS Educateは、Amazonのグローバルイニシアティブで、クラウド関連の学習を促進するために必要な資料、その他を学生や教員に提供している。未来のクラウド技術者を育成する事を目的としている。
☞ 簡単に言えば、AWS Educateは、誰でも自由に参加できるクラウド学習プログラム。(14歳以上の学生もしくは教員が参加可能)
AWS Educateには、3つの形態がある
教育機関版
教員と学生にクラウド関連の学習に向けたリソースを提供される。加盟校は通常の2倍のAWSクレジット、デモ、特別なオンキャンパスのプログラムを利用できる。教員版
教授、教育助手、教員は、AWS テクノロジー、授業に組み込めるオープンソースコンテンツ、トレーニングリソース、クラウドエバンジェリストのコミュニティにアクセスできる。学生版
学生は、AWS のテクノロジー、トレーニング、コンテンツ、キャリアパスを使用でき、AWS Educateの求人情報を実際に利用するクレジットを受けることができる。AWS Educateを使う為の2つの方法
AWS Educateを使用するには . . .
① 自身のAWSアカウント(事前に作成してあるもの)を使用して、AWS Educateを使用する。
登録には、クレジットカードを必要とするが、AWS サービスは自由に使用でき、AWS Educate のプロモーションクレジットがなくなってもアカウントのリソースは維持される。② AWS Educate Starterアカウントを新規作成して使用する。
無料のAWS Educateプロモーションクレジットがすでにアカウントで使用可能であるため、Starterアカウントを使用するのにクレジットカードは必要ない。
しかし、アカウントの残高がなくなると、アカウントは閉鎖され、アカウントで実行中のサービスやその他のリソースはすべて失われる。注: Starterアカウントは一部のAWSのサービスのみを使用可能である
今回扱うのは、② AWS Educate Starterアカウント についてである。上述のように使用できるのは、一部のサービスである。
その使用できるサービスを下のようにして纏めた。
AWS Educate Starterアカウントで出来る事まとめ
これから記述する内容に関しては、AWSに掲載されているpdf「Starterアカウントで利用できる一部のAWSのサービス」を翻訳して、要約したものとなっている。
サービス名 説明 API Gateway 全てのサービスが使用可能 Cloud9 全てのサービスが使用可能 Cloudformation IAMポリシーまたはロールを作成するCloudformationスクリプトは失敗する。既存のロールを再利用するスクリプトは影響を受けない。 Cloudfront 全てのサービスが使用可能 Cloudtrail 全てのサービスが使用可能 Cloudwatch 全てのサービスが使用可能 Codecommit 全てのサービスが使用可能 Codepipeline 全てのサービスが使用可能 Codedeploy 全てのサービスが使用可能 Cognito-identity 全てのサービスが使用可能 Cognito-idp 全てのサービスが使用可能 Cognito-sync 全てのサービスが使用可能 DynamoDB 全てのサービスが使用可能 Deeplens 全てのサービスが使用可能 EC2 使用可能インスタンスタイプ(t2.small、t2.micro、t2.nano、m4.large、c4.large、c5.large、m5.large、t2.medium、m4.xlarge、c4.xlarge、c5.xlarge、 t2.2xlarge、m5.2xlarge、t2.large、t2.xlarge、m5.xlarge)。スポットインスタンス使用不可。リザーブドインスタンスの購入不可。NATゲートウェイ、VPNゲートウェイ、VPN接続またはカスタマーゲートウェイ使用不可。マーケットプレイスEC2使用不可。スケジュールされたEC2インスタンス使用不可。スポットフリート使用不可。 ECS 全てのサービスが使用可能 Elasticache リザーブドインスタンスの購入不可 Elasticfilesystem 全てのサービスが使用可能 Elasticloadbalancing 全てのサービスが使用可能 Events 全てのサービスが使用可能 Execute-api 全てのサービスが使用可能 Elasticbeanstalk 全てのサービスが使用可能 Gamelift 全てのサービスが使用可能 IAM ポリシー作成機能無し。ユーザーおよびグループを作成する機能機能無し。インラインポリシーを作成する機能無し。 Inspector 全てのサービスが使用可能 IOT 全てのサービスが使用可能 IOTAnalytics 全てのサービスが使用可能 IOT1Click 全てのサービスが使用可能 Kinesis Shardsの制限数は2 Kinesisanalytics 全てのサービスが使用可能 Firehose 全てのサービスが使用可能 KMS 全てのサービスが使用可能 Lambda 全てのサービスが使用可能 Lex 全てのサービスが使用可能 Logs 全てのサービスが使用可能 Machinelearning 全てのサービスが使用可能 Mobilehub 全てのサービスが使用可能 RDS (Relational Database Service) 使用不可データベースインスタンス(db.x1e、db.r3.8xlarge、db.r3.4xlarge、db.r4.16xlarge、db.r4.8xlarge、db.r4.4xlarge、db.m4.10xlarge 、db.m4.4xlarge、db.m4.8xlarge、db.m4.4xlarge、db.m4.2xlarge) Route 53 全てのサービスが使用可能 S3 全てのサービスが使用可能 SNS 全てのサービスが使用可能 SQS 全てのサービスが使用可能 SWF 全てのサービスが使用可能 Sumerian 全てのサービスが使用可能 Sagemaker 高速化されたコンピューティングインスタンス使用不可。 使用不可インスタンス(ml.m4.2xlarge、ml.m4.4xlarge、ml.m4.10xlarge、ml.m4.16xlarge) Polly 全てのサービスが使用可能 Translate 全てのサービスが使用可能 Comprehend 全てのサービスが使用可能 Rekognition 全てのサービスが使用可能 Transcribe 全てのサービスが使用可能 Athena 全てのサービスが使用可能 Glue 全てのサービスが使用可能 Opworks 全てのサービスが使用可能 Personalize 全てのサービスが使用可能 Forecast 全てのサービスが使用可能 Deepracer 全てのサービスが使用可能 Robomaker 全てのサービスが使用可能 おわりに
今回は、ただ翻訳しただけだったので、時間がある時により分かりやすいよう再編集したい。
- 投稿日:2019-11-25T21:52:16+09:00
C言語を勉強する初めの一歩をまとめてみた#42tokyo
はじめに
42tokyoという学校の入試に挑むにあたり、C言語の勉強をしておこうかなと思いました
どんな感じで勉強したらよいか考えてみたので簡単にまとめます開発環境
開発環境は手軽なものがよいです
クラウド上で開発環境が用意できるAWSのCloud9というものが良いと思います
↓こちらの記事を参考にしたらとても簡単にできました!
https://dx.nissho-ele.co.jp/blog/aws-beginner-cloud9_20190419.html教材(無料)
基礎を抑えるという意味では無料のもので十分かと思います
下記の2つがよさげです
(自分はまだほぼやってませんが、、)ドットインストール
https://dotinstall.com/lessons/basic_c
「C言語入門」というレッスンが22動画無料で見れます
ドットインストールは色々他のレッスンもよかったのでオススメできます苦しんで覚えるC言語
http://9cguide.appspot.com/index.html
なんか良いみたいです
42tokyoのグループ(非公式)とかでおすすめされてますおわりに
ピシンがんばんりましょう!
記事について何かあればtwitterの方にご連絡ください!m(__)m
- 投稿日:2019-11-25T20:53:44+09:00
AWSのロードバランサーをCLBからALBへの移行する
概要
・AWSのロードバランサーをCLBからALBに移行する
CLB/ALBとは・・・
・こちらに詳しく記載されていました。
https://www.wafcharm.com/blog/difference-between-alb-and-elb/
・こういうところの言語化は人任せな私をお許しください。
・とにかくこれから使う方には不要な知識になりますが、とにかくALBの方が断然良いので移行しないと!手順
- ALBの作成
- AutoScalingGroupへ作成したALBのターゲットグループを紐付け
- DNS登録(CLBのDNS名からALBのDNS名に変更)
- AutoScalingGroupからCLBを外す
実施
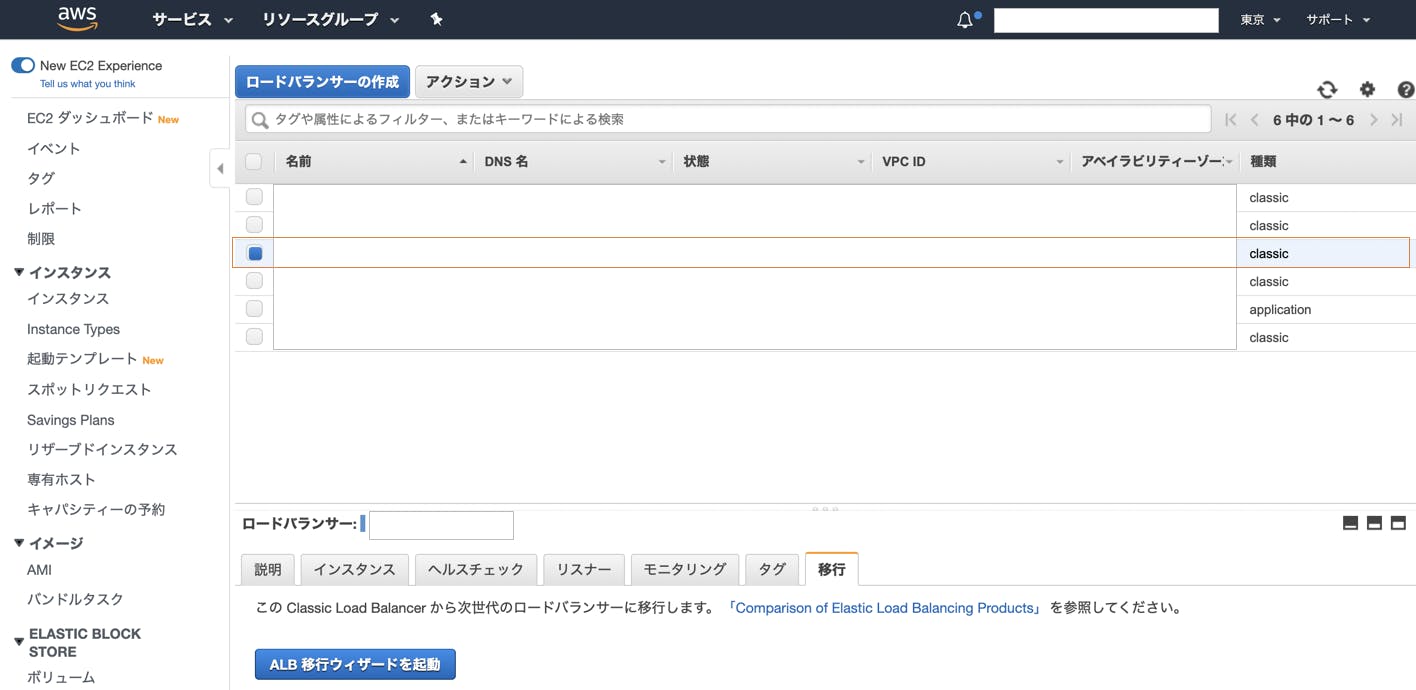
1.ALBの作成
・AWSコンソールでロードバランサーの一覧画面を表示し、
・移行対象のロードバランサーで種類がclassicになっているものを選択
・詳細表示枠の移行タブを選択
・「ALB移行ウィザードを起動」ボタンを押下
・いきなりALB作成画面の最終確認画面が表示されますのでここでは「作成」ボタンを押さない
・「1. ロードバランサーの設定」タブを選択
・ロードバランサー名がCLBと同じ名前になってしまっているのでALB用の名前に変更
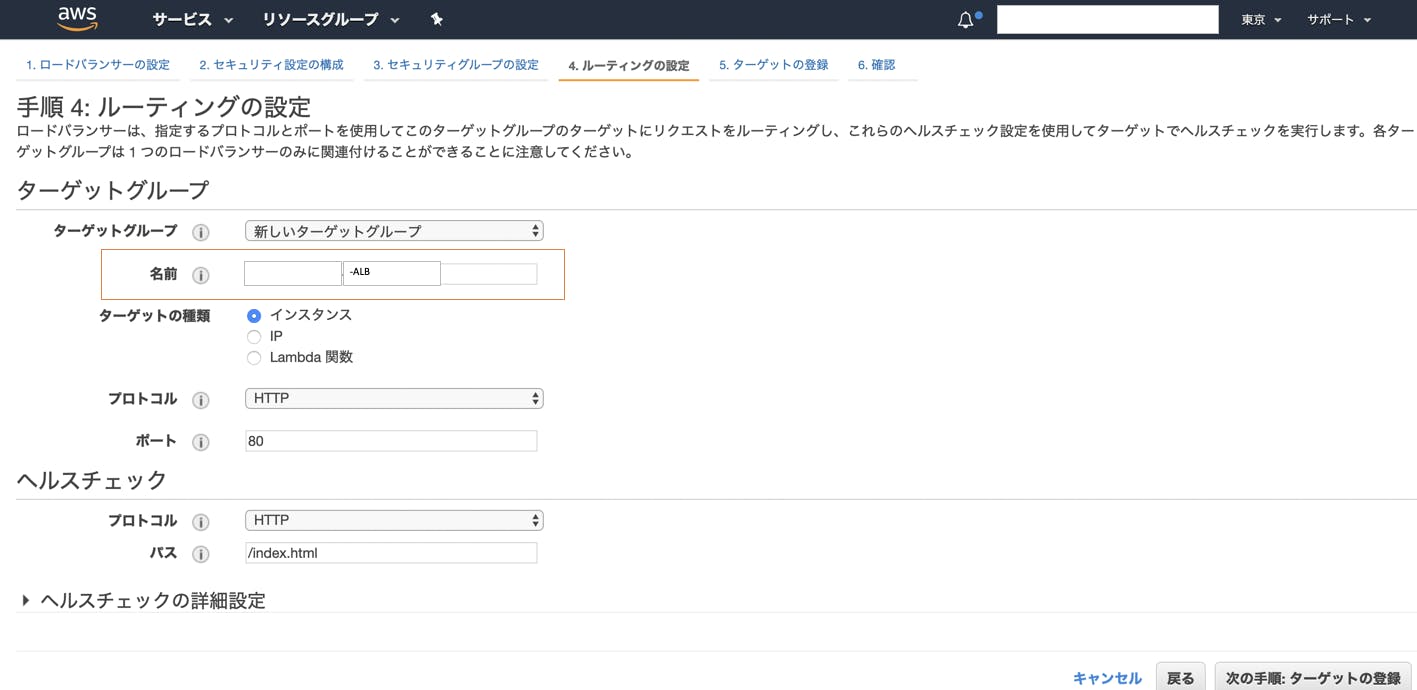
・「4. ルーティングの設定」タブを選択
・ALBのターゲットグループを作成することになりますのでこちらもCLBと同じ名前になってしまっているのでALB用のターゲットグループ名に変更
・確認タブから「作成」ボタンを押下
※ 他の設定は移行対象のCLBの情報を引き継いでいるので特に変更は不要(何か変更したい場合は対応する)AutoScalingGroupへ作成したALBのターゲットグループを紐付け
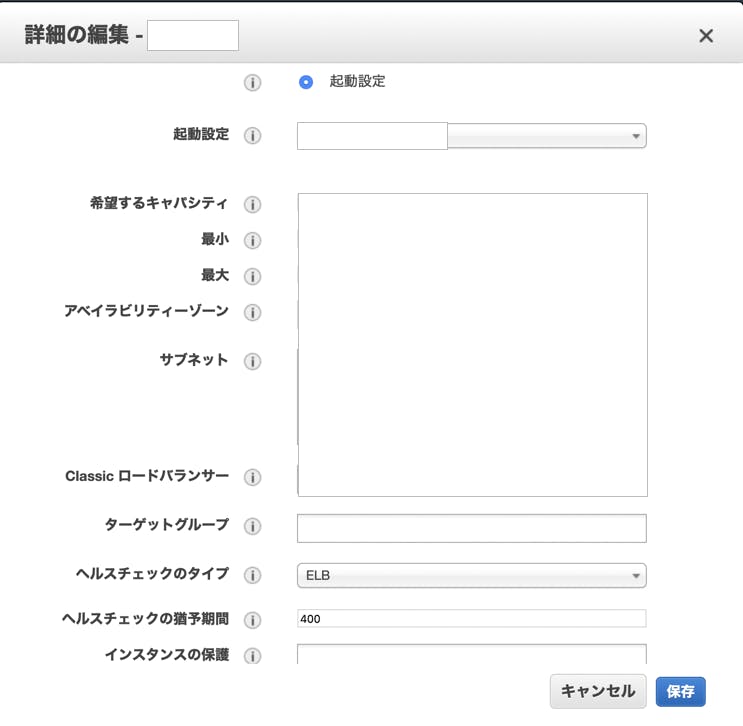
・対象のAutoScalingGroupを選択し編集
・編集画面で「ターゲットグループ」項目に作成したALBのターゲットグループを設定
DNS登録(CLBからALBに変更)
・DNSでCLBのDNS名を指定していたレコードを選択
・エイリアス先をCLBからALBに変更し、「レコードセットの保存」を押下
AutoScalingGroupからCLBを外す
・2.でALBのターゲットグループを紐付けた画面で「Classic ロードバランサー」項目に入っているCLBを削除
確認
・実際にドメインにアクセスしてALBの方にリクエストがきていることを確認し、CLBにリクエストがきていないことを確認する
・CLBを削除してもOK所感
ステージング環境で試しても結局本番環境でも同じことをするので、リスクはありますが、やらないとレガシーになり、
あとでえらい目見そうなのでやって良かった公文式的な。
1ミリでも誰かのためになれば幸いでございます。



- 投稿日:2019-11-25T19:33:59+09:00
AWS認定 デベロッパー アソシエイト(DVA-C01)の合格記録
2019/11/22に試験に合格しました。
AWS認定 ソリューションアーキテクト プロフェッショナル(SAP-C01)の合格記録
と
AWS認定 SysOps アドミニストレーター アソシエイト(SOA)の合格記録
に続けて、今年3つ目の試験です。
こちらも、SAAに合格できたらあまり学習しなくても合格できるという話を聞きますが、人によりますので、注意してください。今回の学習内容
1. 試験ガイドの確認
https://aws.amazon.com/jp/certification/certification-prep/
「開発者 – アソシエイト」の欄にある、「AWSホワイトペーパーおよびよくある質問」の、
ホワイトペーパーやよくある質問、対象サービスのBlackbeltを全て読みます。
読んでも全然頭に入らないので、1,2回ざっと読んで終了。
問題集へ・・・。2.WHIZLABSで学習
https://www.whizlabs.com/aws-developer-associate/practice-tests/
デベロッパー試験の向けには黒本がないので、WHIZLABSのみで学習しました。
Udemyと迷ったのですが、問題の数が多いこちらにしました。
買ってから気付いたのですが、問題数が多い(700問以上)のは、旧試験の問題も含まれている為で、
新試験用は、65×5回分で、Udemyと大きな違いがありませんでした・・。前回と同様、複数回繰り返して9割以上正解できるようになりました。
試験振り返り
832/1000で合格しました。
今回は、「これ〇〇ゼミでやったやつだ」的に、自信を持って答えられる問題が3割、残りは消去法と、勘で解きました・・。
結果として、今まで一番良い点数が取れたのですが、前回までの試験よりも自信を持って答えられる問題が少なく不合格かもしれないと一瞬思いました。
問題集による学習で、全問暗記したとしても、試験範囲を全てカバーできたわけではないので、
最低限、試験対象となるサービスのblackbeltやホワイトペーパーに目を通し、Lambdaにサーバーレス の実装は体験しておいた方がよかったと思いました。
- 投稿日:2019-11-25T19:18:03+09:00
②パブリックサブネットの作成
目標
本章ではパブリックサブネットの作成を目標に解説を行います。
ゴール
本章のゴールは以下の構成図までの完成となります。
作成
それでは実際に作成をしていきましょう。
今の画面を確認
作成を始める前に、今の画面を確認しましょう。
①VPCの作成を完了した直後から画面を変更していなければ以下の画面かと思います。
※この画面でない場合は、前回の内容からこちらを参照にこの画面に切り替えてください。1. サブネットを開く
左端のメニューから"サブネット"を選択してください。
2. サブネットの作成
遷移した画面で、"サブネットの作成"をクリックします。
3. "サブネットの作成"画面
画面上では、
- 名前タグ:pub_sub_demo_{自分の苗字}
- VPC:vpc_demo_{自分の苗字}(自分が作成したVPC)を選択
- アベイラビリティゾーン:ap-northeast-1a(一番上の選択肢を選んでください)
- IPv4 CIDRブロック:10.0.1.0/24
と入力してください。
4. サブネットの作成を実行


- 投稿日:2019-11-25T18:45:38+09:00
CodeBuildバッジの活用方法
はじめに
多々あるAWSサービスの中であまり着目されることがなく、情報量も少ないCodeBuildバッジについて調査してみました。
バッチ(batch)ではなくバッジ(badge)ですのでお間違いなく。CodeBuildとは
ソースコードをコンパイルし、テストを実行し、デプロイ可能なソフトウェアパッケージを作成できる完全マネージド型のビルドサービスで、常時稼働させておく必要がないのが特徴です。常時稼働しないことで無駄なコストがかからず、必要な際に実行できるのでビルドの順番を待たされることがありません。
名前にBuildと付いていますがLinuxのコマンドを実行できるのでBuildに限らず任意の処理が実行可能です。CodeBuildバッジとは
埋め込み可能なイメージとして動的に生成され、プロジェクトの最新ビルドのステータスを示します。認証が不要で誰でもCodeBuildプロジェクトのステータスを確認できます。
認証が不要なサービスは珍しいですね。百聞は一見に如かず
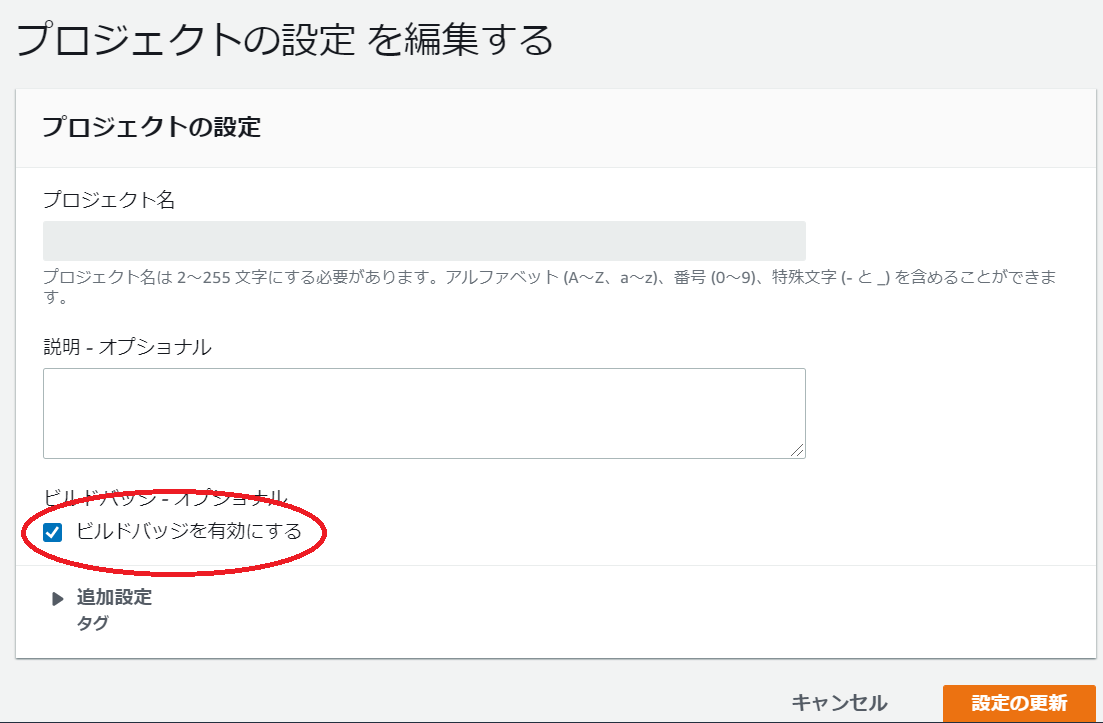
こんなイメージが誰でも参照可能になります。設定方法
ビルドバッジを有効にするのチェックボックスをONにするだけで有効になります。
バッジ URL のコピーボタンをクリックするだけでURLがコピーされます。
あとはこれを任意のWebページに埋め込むだけです。
実に簡単ですね。CodeBuildバッジのステータス
以下の4種類があります。
- PASSING
- 該当するブランチで最新ビルドが成功しました。
- FAILING
- 該当するブランチで最新ビルドがタイムアウト、失敗、途中終了、または停止しました。
- IN_PROGRESS
- 該当するブランチで最新ビルドが進行中です。
- UNKNOWN
- 該当するブランチでプロジェクトがビルドをまだ実行していないか、まったく実行したことがありません。また、ビルドバッジ機能が無効になっている可能性もあります。
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/sample-build-badges.html
より活用方法
自分の管理下にあるCodeBuildプロジェクトやAWSアカウントが少ない場合には正直あまり使いどころはないと思います。
しかしながらCodeBuildプロジェクトが多い場合や複数のAWSアカウントにCodeBuildプロジェクトが存在する場合に、認証が不要で誰でも確認できることを活かし、バッジが確認できるWebページを用意するだけで一目で全てのCodeBuildプロジェクトのステータスが確認できるようになります。
CodeBuildプロジェクトを一つ一つ確認して回ったり、AWSアカウントを切り替えたりするのは手間ですしね。CodeBuildプロジェクトのソースプロバイダにGitHubを指定している場合はGitHubのREADMEページにバッジを埋め込むと、最新のソースのステータスが一目でわかるようになって便利ですね。
注意点
活用方法に挙げたように便利なCodeBuildバッジですが、CodePipelineに組み込まれたCodeBuildではステータスが更新されないので注意が必要です。
さいごに
AWSの素晴らしい他のサービスに押されステータス表示だけを担うCodeBuildバッジはあまり目立ちませんが、よりよい運用を考慮すると利用すべきだと思いますので是非利用してみてください。
CodePipelineにもバッジがあれば便利だと思います。むしろCodePipelineにバッジが欲しいのでAWSさん、今後のアップデートを期待しています!


- 投稿日:2019-11-25T18:45:26+09:00
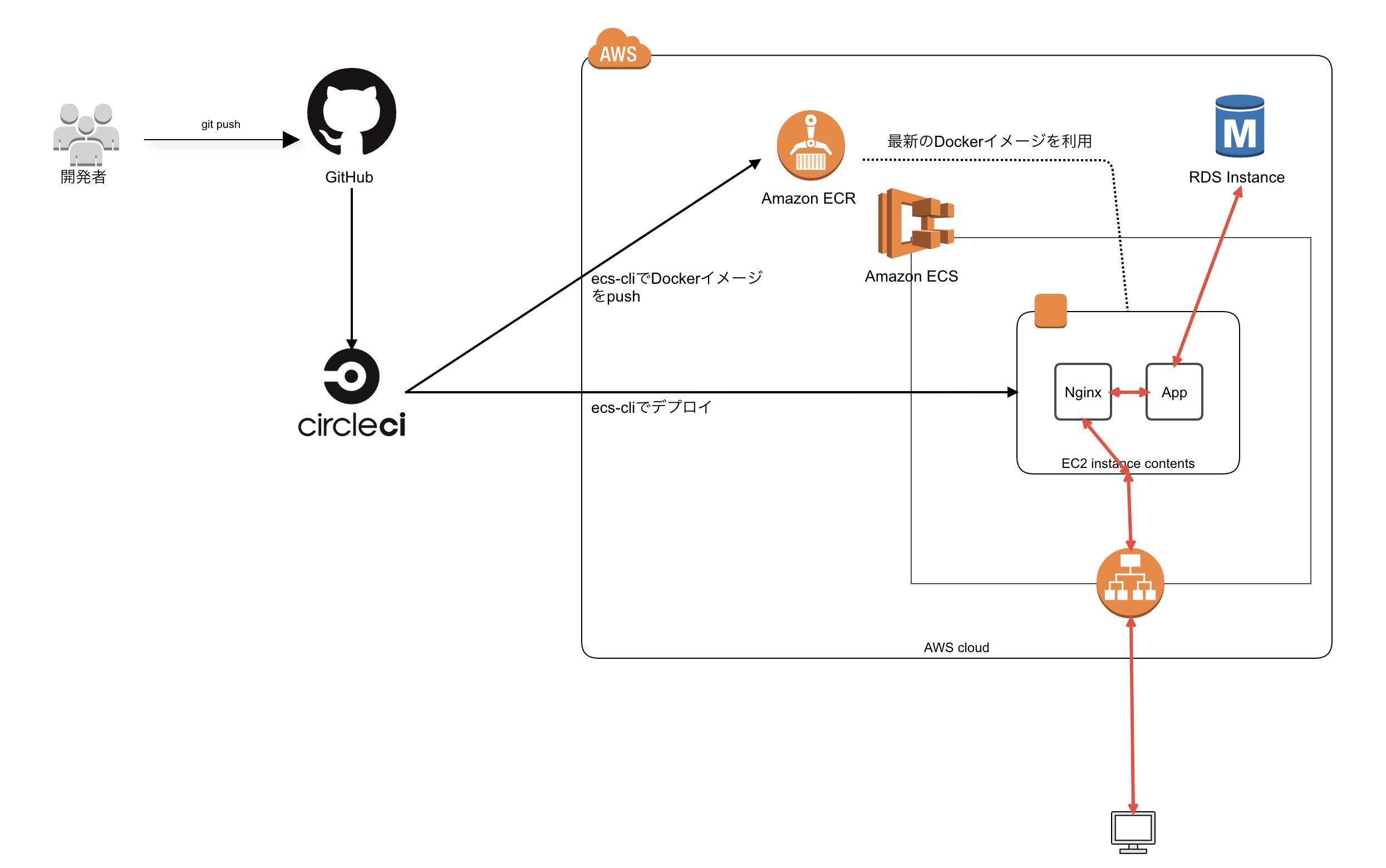
【WIP】Rails × CircleCI × ECSのインフラ構築
簡単なRailsデモアプリを本番環境に上げるまでのインフラ構成に関してのまとめ
* あくまで参考に(実務でそのまま利用できるほどしっかり構築しておりません)
前提知識
ECSとは?クラスターとは?サービスとは?タスクとは?って人は
ECSの概念を理解しよう
などを読んでください。Railsアプリ作成
まずはローカルでRailsアプリを作成しましょう。
機能は簡単なものでいいので、scaffoldを利用してとりあえずで作成してしまいましょう。
もちろんフルDocker化AWS上で利用するリソースの作成
コンソール上(or Terraformなど)からあらかじめ作成しておくべきものになります。
IAMロール・ポリシーの作成
ECSで運用するための必要なIAMロール・ポリシーを作成していきます。
ちなみにポリシーとは、ロールに付与される権限情報です。なのでポリシーのないロールは何も権限がない状態なのでまずはポリシーを作成してロールを作成していきましょう。(sandboxアカウントでは既に作成済みのため不要)ポリシーの作成
作成手順
- IAMページに行って、サイドバーの「ポリシー」選択
- 「ポリシーの作成」ボタン押下
- JSONタブを開いて下記に記載したJSON内容をコピペして、「ポリシーの確認」押下
- それぞれのポリシー名を入力する
下記の4つのポリシーを作成する。
- AmazonSSMReadAccess
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:GetParameters", "secretsmanager:GetSecretValue", "kms:Decrypt" ], "Resource": "*" } ] }
- AmazonECSTaskExecutionRolePolicy
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }
- AmazonEC2ContainerServiceforEC2Role
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeTags", "ecs:CreateCluster", "ecs:DeregisterContainerInstance", "ecs:DiscoverPollEndpoint", "ecs:Poll", "ecs:RegisterContainerInstance", "ecs:StartTelemetrySession", "ecs:UpdateContainerInstancesState", "ecs:Submit*", "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }
- AmazonECSServiceRolePolicy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ECSTaskManagement", "Effect": "Allow", "Action": [ "ec2:AttachNetworkInterface", "ec2:CreateNetworkInterface", "ec2:CreateNetworkInterfacePermission", "ec2:DeleteNetworkInterface", "ec2:DeleteNetworkInterfacePermission", "ec2:Describe*", "ec2:DetachNetworkInterface", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:DeregisterTargets", "elasticloadbalancing:Describe*", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:RegisterTargets", "route53:ChangeResourceRecordSets", "route53:CreateHealthCheck", "route53:DeleteHealthCheck", "route53:Get*", "route53:List*", "route53:UpdateHealthCheck", "servicediscovery:DeregisterInstance", "servicediscovery:Get*", "servicediscovery:List*", "servicediscovery:RegisterInstance", "servicediscovery:UpdateInstanceCustomHealthStatus" ], "Resource": "*" }, { "Sid": "ECSTagging", "Effect": "Allow", "Action": [ "ec2:CreateTags" ], "Resource": "arn:aws:ec2:*:*:network-interface/*" }, { "Sid": "CWLogGroupManagement", "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:DescribeLogGroups", "logs:PutRetentionPolicy" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/ecs/*" }, { "Sid": "CWLogStreamManagement", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:DescribeLogStreams", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/ecs/*:log-stream:*" } ] }ロールの作成
- ecsInstanceRole
- AWSServiceRoleForECS
- ecsTaskExecutionRole
ecsInstanceRoleの場合は一番簡単で、テンプレートがあるので
IAMページに行って、サイドバーの「ロール」→「ロールの作成」より
ecsTaskExecutionRole
Amazon ECS タスク実行 IAM ロールにある{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }をコピペして貼り付けましょう。
ちなみに上記のやつは公式ドキュメントにもあるので確認してください。
例: Amazon ECS タスク実行 IAM ロールALBの作成
ECSのサービス作成時にALBを登録しておけば、コンテナに動的にポートマッピングをしてくれるようになるので楽になります。
クラスターの作成
ECSのサイドバーにある「クラスター」から「クラスターの作成」ボタンを押下
「クラスターテンプレートの選択」は「EC2 Linux + ネットワーキング」を選択
1. クラスター名記載
2. EC2インスタンスタイプの選択(お好み)
3. キーペア(お好み。ただし、デバッグ時にSSHできた方がいいので設定しておくことをおすすめ)
4. コンテナインスタンスの IAM ロールに「ecsInstanceRole」を選択CircleCIの設定
circleci/config.ymlversion: 2.1 orbs: aws-cli: circleci/aws-cli@0.1.13 executors: builder: docker: - image: circleci/buildpack-deps commands: init: steps: - checkout - aws-cli/install - install_ecs-cli - setup_remote_docker install_ecs-cli: steps: - run: name: Install ECS-CLI command: | sudo curl -o /usr/local/bin/ecs-cli https://amazon-ecs-cli.s3.amazonaws.com/ecs-cli-linux-amd64-latest sudo chmod +x /usr/local/bin/ecs-cli jobs: build: executor: builder steps: - init - run: name: Build application Docker image command: | docker build -f build.Dockerfile --rm=false -t rails-sample-app-build:latest . - run: name: Save image command: | mkdir -p /tmp/docker docker save rails-sample-app-build:latest -o /tmp/docker/image - persist_to_workspace: root: /tmp/docker paths: - image deploy: executor: builder steps: - init - attach_workspace: at: /tmp/docker - run: docker load -i /tmp/docker/image - run: name: Assets precompile and Push Docker image command: | docker build -f assets.Dockerfile --build-arg RAILS_MASTER_KEY=${RAILS_MASTER_KEY} --rm=false -t rails-sample-app-build:latest . - run: name: Push Docker image command: | ecs-cli push rails-sample-app-build:latest - run: name: ECS Config command: | ecs-cli configure \ --cluster rails-sample-${CIRCLE_BRANCH} \ --region ${AWS_DEFAULT_REGION} \ --config-name rails-sample-${CIRCLE_BRANCH} - run: name: migrate deploy command: | ecs-cli compose \ --file ecs/${CIRCLE_BRANCH}/migrate/docker-compose.yml \ --ecs-params ecs/${CIRCLE_BRANCH}/migrate/ecs-params.yml \ --project-name rails-sample-${CIRCLE_BRANCH}-migrate \ up \ --launch-type EC2 \ --create-log-groups \ --cluster-config rails-sample-${CIRCLE_BRANCH} - run: name: Unicorn + Nginx deploy command: | ecs-cli compose \ --file ecs/${CIRCLE_BRANCH}/app/docker-compose.yml \ --ecs-params ecs/${CIRCLE_BRANCH}/app/ecs-params.yml \ --project-name rails-sample-${CIRCLE_BRANCH}-app \ service up \ --container-name nginx \ --container-port 80 \ --target-group-arn ${TARGET_GROUP_ARN} \ --timeout 0 \ --launch-type EC2 \ --create-log-groups \ --cluster-config rails-sample-${CIRCLE_BRANCH} workflows: version: 2 build-deploy: jobs: - build - deploy: requires: - build filters: branches: only: - masterCircleCIに設定する環境変数
CircleCIのプロジェクトの設定ページ(Settings→[アカウント名or組織名]→[プロジェクト名])に行き、下記の画像の箇所から設定する
https://circleci.com/gh/[アカウント名or組織名]/[プロジェクト名]/edit#env-vars
環境変数名 値 AWS_ACCESS_KEY_ID [AWSのアクセスキーID] AWS_ACCOUNT_ID [AWSのアカウントID] AWS_DEFAULT_REGION [AWSのデフォルトリージョン] AWS_ECR_REPOSITORY_URL [AWSのECRリポジトリURL] AWS_SECRET_ACCESS_KEY [AWSのシークレットアクセスキー] RAILS_MASTER_KEY [config/master.keyの値] TARGET_GROUP_ARN [ターゲットグループのarn] Task definitionの作成
docker-compose.yml
rails-sample/ecs/production/app/docker-compose.ymlversion: "3" services: app: image: [ECRのリポジトリURI] entrypoint: bundle exec unicorn -c config/unicorn.rb env_file: - ../env working_dir: /projects/rails-sample logging: driver: "awslogs" options: awslogs-region: "ap-northeast-1" awslogs-group: "rails-sample-production/app" awslogs-stream-prefix: "rails-sample-app" nginx: image: [ECRのリポジトリURI] entrypoint: /bin/bash /etc/nginx/start.sh ports: - 0:80 links: - "app:app" env_file: - ../env working_dir: /projects/rails-sample logging: driver: "awslogs" options: awslogs-region: "ap-northeast-1" awslogs-group: "rails-sample-production/nginx" awslogs-stream-prefix: "rails-sample-nginx"ecs-params.yml
タスク実行時に実行ロールの指定やコンテナに注入する環境変数をAWS Systems Managerから取得するして設定するためのファイル
rails-sample/ecs/production/app/ecs-params.ymlversion: 1 task_definition: # タスク実行時のロールを指定 task_execution_role: ecsTaskExecutionRole services: 起動するコンテナを記載(app, nginx) app: # 何らかの理由で失敗・停止した際に、タスクに含まれる他のすべてのコンテナを停止するかどうか(デフォルトはtrue) essential: true # AWS Systems Managerから秘匿情報を取得してコンテナに環境変数を注入 secrets: - value_from: /production/database_username name: DATABASE_USERNAME - value_from: /production/database_password name: DATABASE_PASSWORD - value_from: /production/database_host name: DATABASE_HOST nginx: essential: true # あまりわかってない run_params: network_configuration: awsvpc_configuration: assign_public_ip: ENABLEDAWS Systems Managerの設定
AWS Systems Managerは、タスク実行時にコンテナに注入する秘匿情報(環境変数)の管理に使えるAWSサービスです。
初めての人は設定の仕方を含め、
ECSでごっつ簡単に機密情報を環境変数に展開できるようになりました!
を見れば大体分かると思います。AWS Systems Managerの左側メニューから「パラメータストア」→「パラメータの作成」をクリック。パラメータの詳細画面が表示されるので、パラメータのキー名と値を入力します。タイプには「安全な文字列」を選択します。
パラメータのキー名と値一覧
キー名 値 /production/database_username [RDSに設定したusername] /production/database_password [RDSに設定したpassword] /production/database_host [RDSインスタンスのエンドポイント] RDSインスタンスのエンドポイント(RDS→データベース→[インスタンス名])
コンテナ全体に注入する環境変数の設定
各環境(production, stagingなど)ごとのディレクトリ以下に
envファイルを用意してそこに記載する# ここのファイルに追加した環境変数は全てのコンテナに展開されます # Rails APP_HOST=54.238.241.230 RAILS_ENV=production RAILS_LOG_TO_STDOUT=1 RAILS_SERVE_STATIC_FILES=1 # RDS DATABASE_NAME=rails-sample_production DATABASE_PORT=3306 DATABASE_POOL=10 # Unicorn UNICORN_PORT=23380 UNICORN_TIMEOUT=180 UNICORN_WORKER_PROSESSES=2 # Nginx専用 NGINX_APP_SERVER_NAME=app NGINX_APP_SERVER_PORT=23380 NGINX_DOCUMENT_ROOT=/projects/rails-sample/public NGINX_FRONT_SERVER_NAME=54.238.241.230構築の際に詰まる可能性のあるポイント
ECSコンテナインスタンスの作成
- インスタンスへのIAMロールを付与すること
- ecs-agentのインストール ( Amazon ECS コンテナエージェントのインストール - Amazon Elastic Container Service )
- EC2インスタンスの
/etc/ecs/ecs.configにCLUSTER_NAME=クラスター名の登録- 所属するクラスターを変更する場合、
/var/lib/ecs/data/ecs_agent_data.jsonを削除してからecs-agentを再起動するDefaultクラスター作成しているし、IAMロールにecs:CreateClusterの権限付与されているから自動で作成なんかもしてくれるのかと思ったら作成してくれなかった。
なので、クラスター作成→インスタンス作成の方が良い(ちな、クラスター作成時にインスタンスも作成するようにはできるっぽい)
→カスタマイズされてるAMI利用時のみ初期スクリプトによってDefaultクラスターを作成しているのかもしれない
参考
Amazon ECS コンテナインスタンスの起動 - Amazon Elastic Container Service
Amazon ECS-optimized AMI - Amazon Elastic Container Serviceインスタンスタイプについて
ある程度余裕持たないとタスク実行するための容量を持たなくて死ぬ
(ほんとは、ローカルや本番環境で動かした時の使用量見てタスク実行に必要なメモリを設定した方が良い)ecs-cliでのタスク実行
ecs-params.ymlファイル内でtask_execution_roleを指定することtask_execution_roleで指定した適切なポリシーを適用したIAM Roleを用意すること(エラーが出なくて、単純に実行されないので気づきにくい)aws-cliでRDSの作成
AWS CLI を使って外部からアクセス出来る RDS インスタンスを作る方法が公式ドキュメントに無かったのでメモ。
Aws rds コマンドを使って rds を作成するには、DB subnet group を指定する必要があるらしい。さもなければ以下のようなエラーが出る。aws rds create-db-instance \ --db-instance-identifier chiko-db-production \ --db-instance-class db.t2.micro \ --db-subnet-group-name ishihara-db-subnet-group \ --engine mysql \ --engine-version 5.7.26 \ --allocated-storage 20 \ --master-username root \ --master-user-password password \ --backup-retention-period 3 \ --profile sandbox-admin参考
AWS CLI を使って RDS を作成する (自分用メモ) - Qiita
AWS-CLI Amazon Aurora インスタンス作成 - Qiita






- 投稿日:2019-11-25T18:12:31+09:00
Lambda + S3 + Transcribe で、日本語で自動音声吹き替え機能を作ろう!
こんにちは!
BeatFit エンジニアの飯塚です。
半年ぶりの投稿となります。エンジニアになって半年たち、今は、フロントエンドとバックエンドを主に担当しております。
が、そろそろ社内のインフラを Heroku から AWS へ完全移管する話が出たため、今年の6月頃から、AWSの勉強を開始しました。
先日、AWS ソリューションアーキテクトの資格をとりました。(1回落ちました。。)
が、実務では、まだまだ全然使いこなせていないので、これからも頑張っていきたいところです。今回、職場のコンテンツチーム(社長)より、動画の音声起こしができたら嬉しいと言う声が上がりました。
ちょうど、AWS Transcribe が 11/21に日本語対応されたので、この機会に触ってみたいと思います。S3 アップロード → Lambda → Transcribe と言う流れで、実装します!
Lambda は全然詳しくないため、間違いや不適切な表現等ございましたら、優しめのマサカリをよろしくお願いいたします! \(≧∇≦)S3の設定
まずは、S3 にバケットを作りましょう。
バケットを作ったら、フォルダの作成をクリックし、下記のように、二つからのフォルダを作ります。
IAM ロールの設定
続いて、Lambda に設定する、IAM ロールを作ります。
必要なロールは、AWS Transcribeにアクセスするロールと、cloudWatch Logsに書き込むロールとなります。サービスで IAM を検索 → 左サイドバーのロールをクリック → ロールの作成をしてください。
下記の画面になり、Lambdaをクリックし、次のステップに進みます。
検索窓から、
AWSLambdaExecuteと、AmazonTranscribeFullAccessを選択し、ロールの設定は完成です。Lambda 準備編
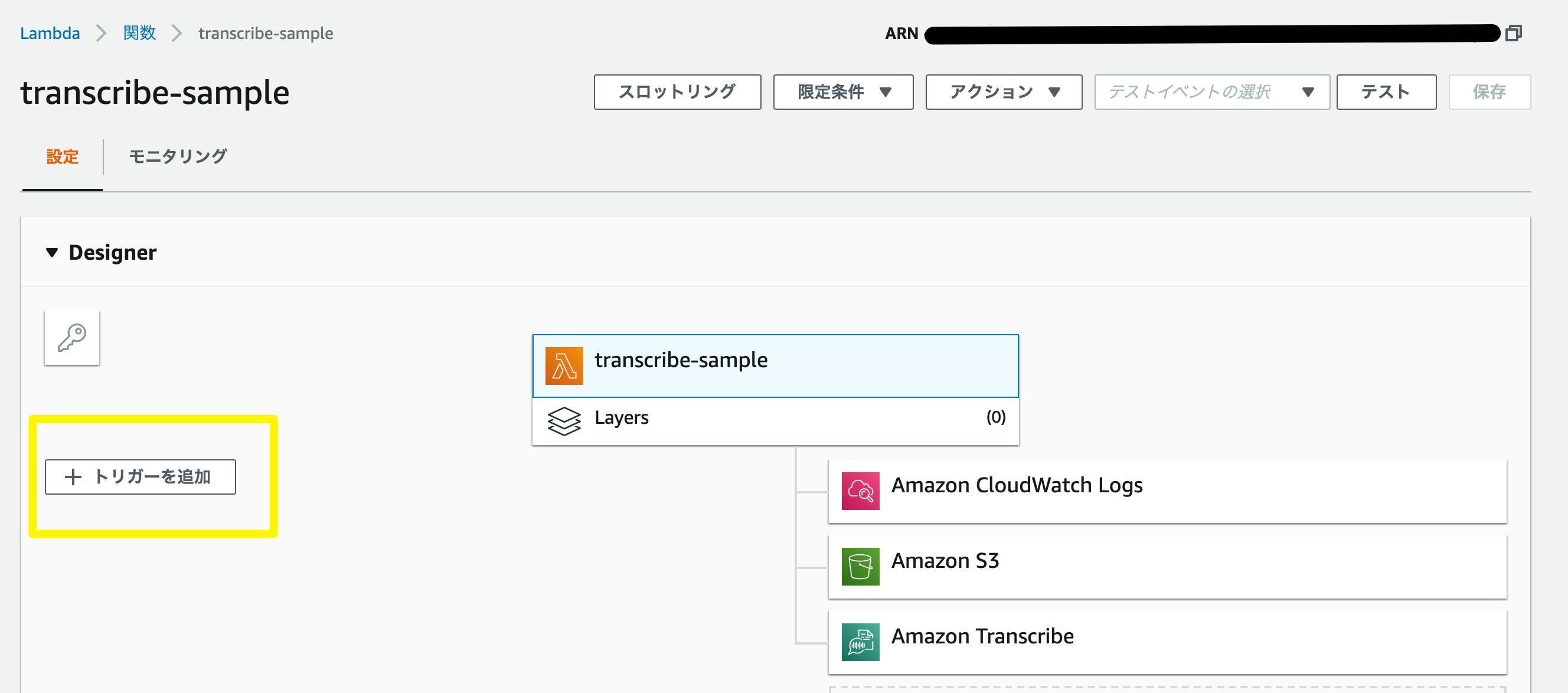
続いて、Lambda へ移ります。
Lambda → 関数の作成 → 1から作成 を選択します。
任意の名前をつけ、ロールには、既存のロールを使用するを選択し、先ほど作ったロールを適応します。関数が作成されましたら、下記の画面になりますので、左の
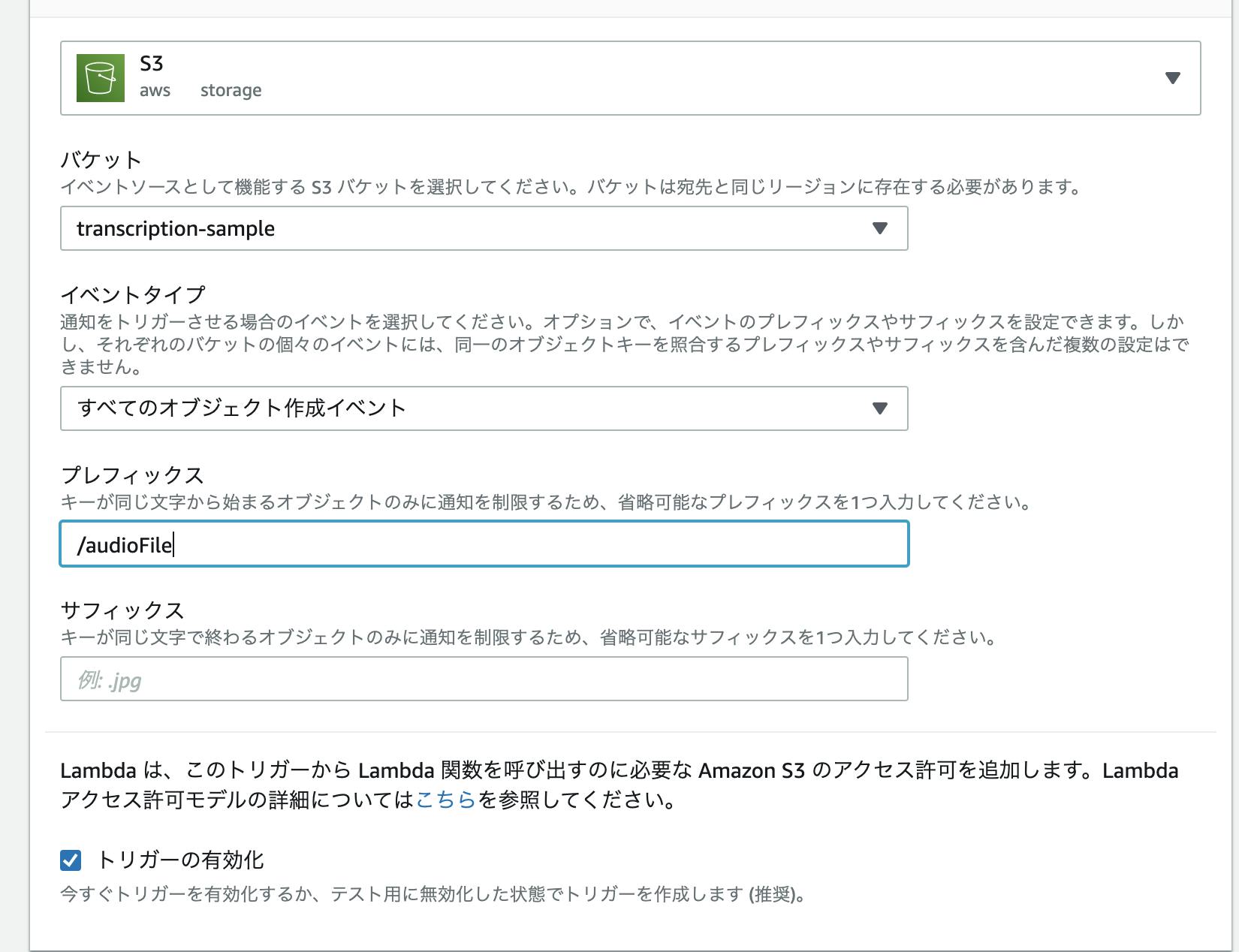
トリガーを追加をクリックし、S3 を選択し、下記のように設定します。
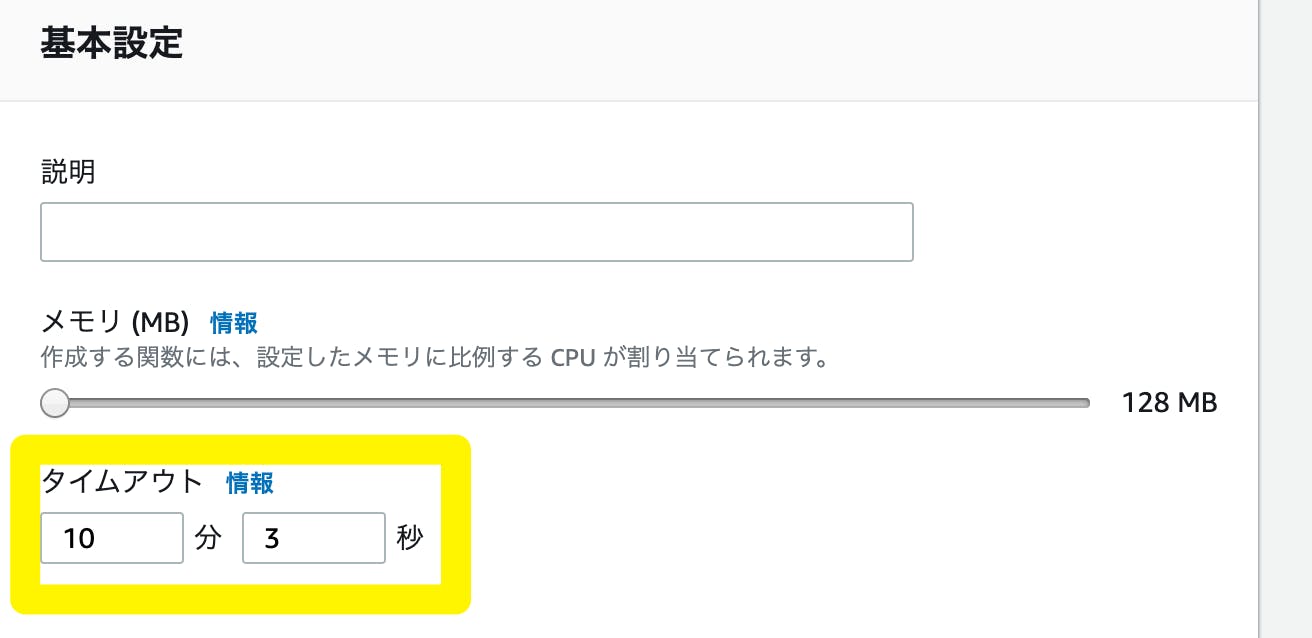
最後に、画面を下にスクロールし、基本設定の、タイムアウトを長めに設定します。
これで、準備は整いました。
これから、コードの実装をしていきます。Lambda 実装編
Lambda を初めて触る方もおられると思いますので、少し解説をします。
熟練者のかたは、この辺りは読み飛ばしてくださいませ。。S3 にアップロードした後、通知メッセージが JSON 形式で送信されます。
このメッセージは、Lambda に、eventという形で、伝達されます。Node.js(Lambda)exports.handler = async (event, context) => { };今回、S3 のバケットにアップロードする場合、PUTリクエストを行っていることになります。
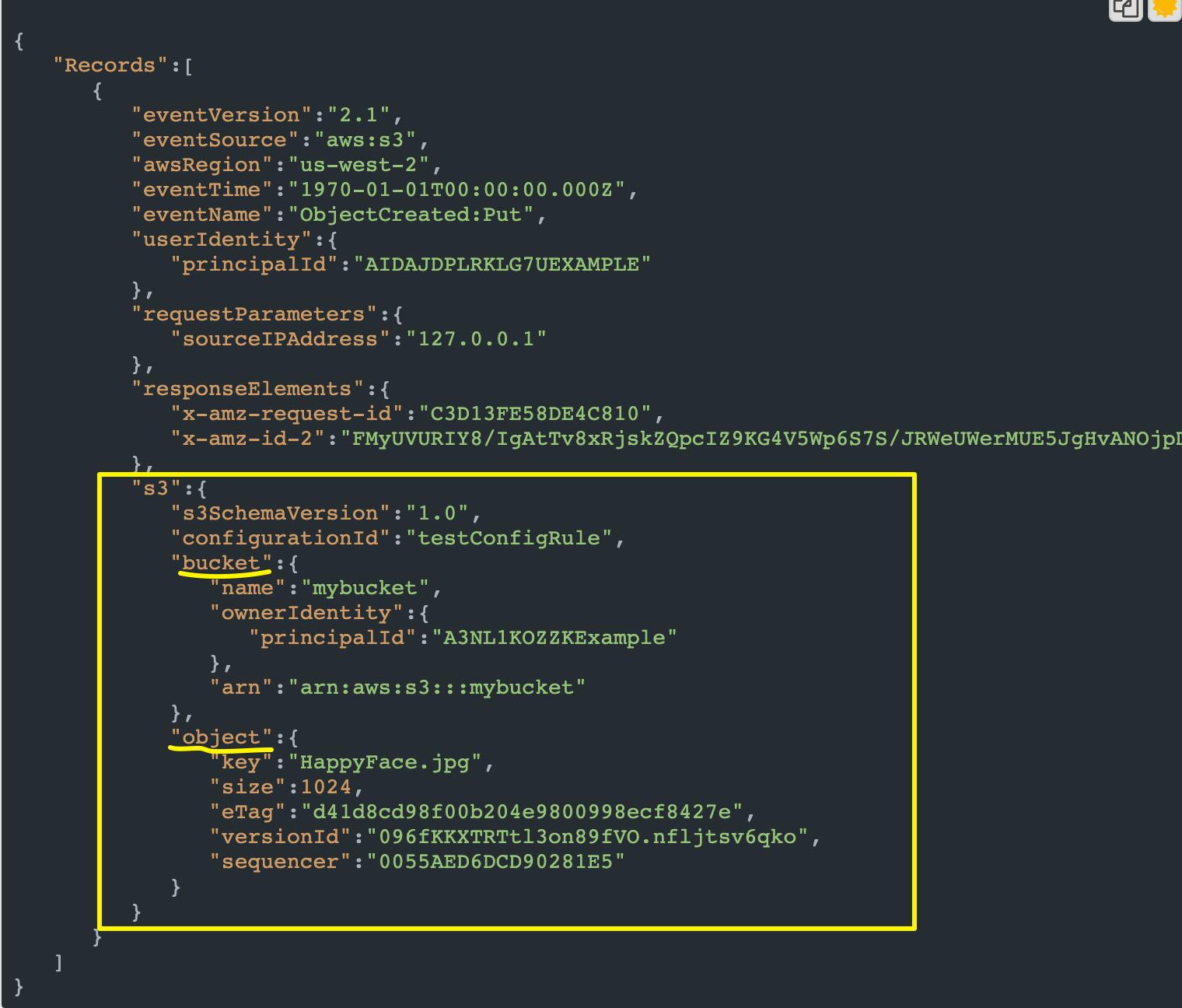
より正確な表現をすると、Amazon S3 が s3:ObjectCreated:Put イベントを発行することになります。こちらによると、PUTリクエストにより、Lambda へ渡される event は、以下になります。
{ "Records":[ { "eventVersion":"2.1", "eventSource":"aws:s3", "awsRegion":"us-west-2", "eventTime":"1970-01-01T00:00:00.000Z", "eventName":"ObjectCreated:Put", "userIdentity":{ "principalId":"AIDAJDPLRKLG7UEXAMPLE" }, "requestParameters":{ "sourceIPAddress":"127.0.0.1" }, "responseElements":{ "x-amz-request-id":"C3D13FE58DE4C810", "x-amz-id-2":"FMyUVURIY8/IgAtTv8xRjskZQpcIZ9KG4V5Wp6S7S/JRWeUWerMUE5JgHvANOjpD" }, "s3":{ "s3SchemaVersion":"1.0", "configurationId":"testConfigRule", "bucket":{ "name":"mybucket", "ownerIdentity":{ "principalId":"A3NL1KOZZKExample" }, "arn":"arn:aws:s3:::mybucket" }, "object":{ "key":"HappyFace.jpg", "size":1024, "eTag":"d41d8cd98f00b204e9800998ecf8427e", "versionId":"096fKKXTRTtl3on89fVO.nfljtsv6qko", "sequencer":"0055AED6DCD90281E5" } } } ] }ごちゃごちゃしてますが、大事なところは、以下のようになります。
つまり、
・bucket名 → event.Records[0].s3.bucket.name ・ObjectKey → event.Records[0].s3.object.keyとなります。
オブジェクトのファイルのパスは、今までなら、s3://バケット名/ObjectKeyで良かったのですが、自分の場合An error occurred (BadRequestException) when calling the StartTranscriptionJob operation: The S3 URI that you provided can't be accessed. Make sure that you have read permission and try your request again.と言うエラーログが出てしまい、こちら を参考にして修正しました。
FilePath → "https://s3-ap-northeast-1.amazonaws.com/" + bucket名 + '/' + ObjKeyこれで動きました。
しかし、こちらの記事によると、2020年9月30日以降、この形式で S3 API リクエストしても受け付けられなくなるとのことで、有識者の方、適切な書き方を教えてください・・・では、早速、Lambda を書いていきましょう。
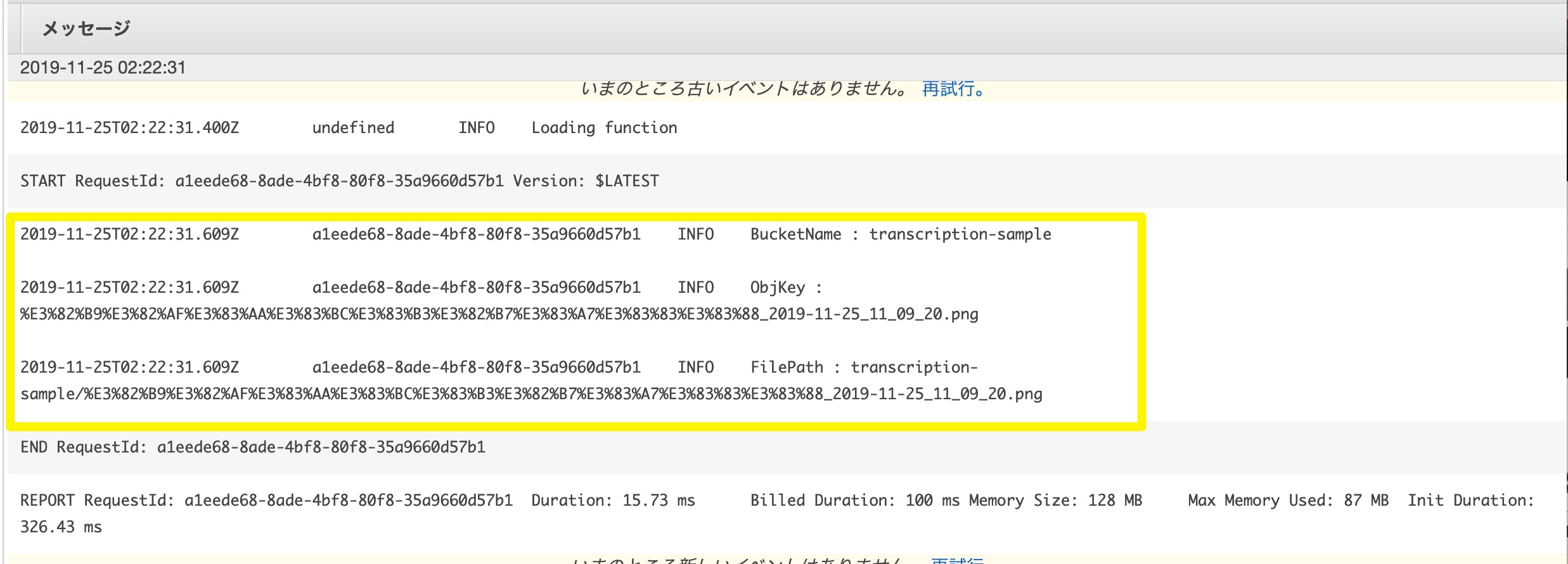
Node.jsexports.handler = async (event, context) => { const Bucket = event.Records[0].s3.bucket.name const ObjKey = event.Records[0].s3.object.key const FilePath = "https://s3-ap-northeast-1.amazonaws.com/" + Bucket + '/' + ObjKey console.log('BucketName : ' + Bucket); console.log('ObjKey : ' + ObjKey); console.log('FilePath : ' + FilePath); };これで、S3 にアップロードして、ログを吐く実装ができました。
では、早速S3 にアップロードして、cloudWatch にlog が飛んでいるかを試してみましょう!S3 アップロード → CloudWatch Logs でのログ確認
S3に戻り、最初の作成したバケットのフォルダへ、任意のファイルをアップロードします。
次に、Lambda へ戻り、上部のモニタリングタブをクリックし、CloudWatch の ログを表示をクリックします。
下記のように、無事、ログが飛んでいるのを確認できました。
では、続いて、Amazon Transcribe と連携していきます。
Amazon Transcribe 連携
Amazon Transcribe が起動するには、
StartTranscriptionJobAPI が必要になります。
公式DOC によると、以下のように書きます。Node.jsconst AWS = require('aws-sdk'); const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'}); const params = { LanguageCode: ja-JP /* required */ Media: { /* required */ MediaFileUri: 'STRING_VALUE' }, TranscriptionJobName: 'STRING_VALUE', /* required */ MediaFormat: mp3 | mp4 | wav | flac, OutputBucketName: 'STRING_VALUE', }; transcribeservice.startTranscriptionJob(params, function(err, data) { if (err) console.log(err, err.stack); // an error occurred else console.log(data); // successful response });
MediaFileUriは、S3へアップロードしたファイルのURI を入力します。
URI は、Amazon Transcribe と同一リージョンであることが必須のため、注意しましょう。
TranscriptionJobNameは、AWS Transcribe のjob 名です。
S3 からevent と context (呼び出し、実行関数、関数に関する情報を提供する役割を持つ) が渡ってくるのですが、こちらを使います。
awsRequestIdを使って、呼び出しリクエストのIDを、TranscriptionJobName に渡しましょう。最終的に、以下のコードになります!
Node.jsconst AWS = require('aws-sdk'); const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'}); exports.handler = async (event, context) => { const Bucket = event.Records[0].s3.bucket.name const ObjKey = event.Records[0].s3.object.key const FilePath = "https://s3-ap-northeast-1.amazonaws.com/" + Bucket + '/' + ObjKey const FileType = ObjKey.split(".")[1] const jobName = context.awsRequestId console.log('BucketName : ' + Bucket); console.log('ObjKey : ' + ObjKey); console.log('FilePath : ' + FilePath); console.log(FileType) const params = { LanguageCode: "ja-JP", Media: { MediaFileUri: FilePath }, TranscriptionJobName: jobName, MediaFormat: FileType, }; try{ const response = await transcribeservice.startTranscriptionJob(params).promise() console.log(response) return response }catch(error){ console.log(error) } };注意点として、
await の文章の最後に、promise() とつけるのを忘れないでください。
私は、このトラップで5時間無駄にしました・・・参考文献:
AWS LambdaがNode.js8.10をサポートしたのでasync/awaitを試してみたさあ、これで完成です!
S3 に mp3 か、mp4 ファイルを upload して、Transcribe が正常動作するか、確認しましょう!AWS Transcribe
S3 に mp3 もしくは、mp4ファイルを アップロードし、Amazon Transcribe の画面にいきましょう。
すると・・・
ご覧のように、 In Progress のStatus を持つ、新たな文字起こしJob が出現しました。
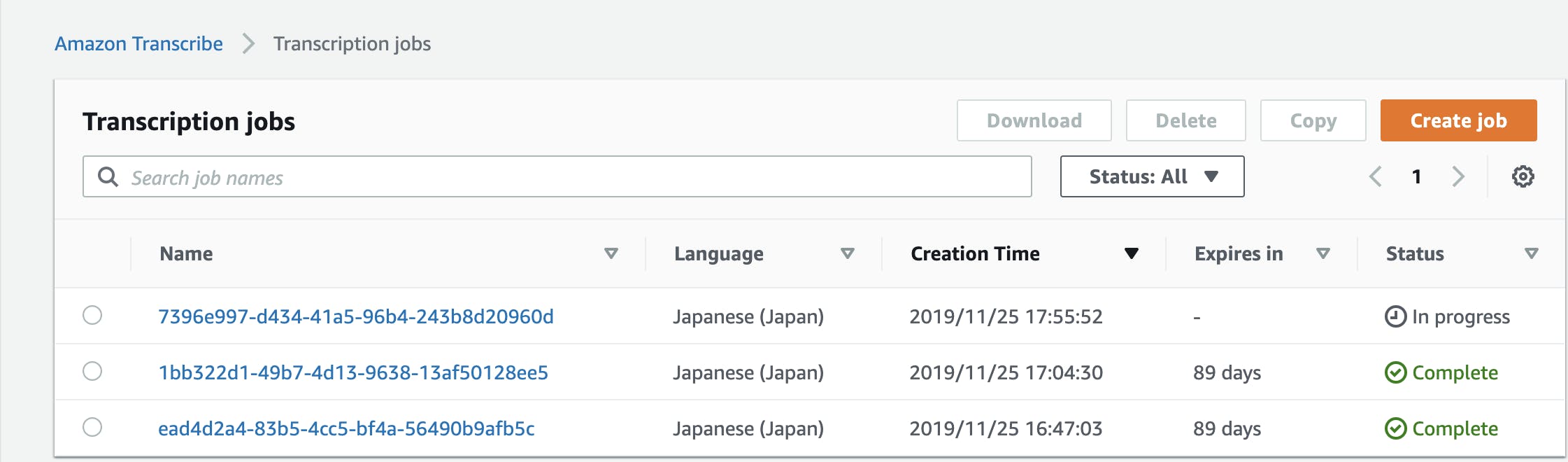
気になる日本語の精度はというと、 (あくまで自分のサンプルの限りですが)
び、微妙すぎる・・・・
わからなくもないが、まだまだな印象があります。
今後の精度up に乞うご期待ですね・・・!まとめ
ここまで、お疲れ様でした。今回
S3 → Lambda → Transcribeという実装を行いました。
次回は、Job が完了したら、それをLambdaに伝え、S3 ファイルにupload するという実装を行いたいと思います。それでは、また〜



- 投稿日:2019-11-25T17:35:21+09:00
Docker と ECS Scheduled Taskを使って定期的におじさんからメッセージが届く仕組みを作る??
皆さんはおじさんは好きカナ?( ̄ー ̄?
僕は好きだヨ!!✋( ̄▽ ̄ ♥ ?
定期的におじさんからメッセージが届いたら素敵じゃないカナ????
と言うわけで作ってみタヨ!!(^з<)❗?✋?概要
ECS Scheduled Taskを使っておじさんから定期的に Slack メッセージが届く仕組みを作ります。
おじさんのメッセージ生成には Ojichat を使わせていただきました。環境構築
AWS CLI用のIAMユーザーの作成
AWS CLI用のIAMユーザーを作成します。以下の記事を参考にしながらIAMユーザーを作成します。
今回は Terraform の例もあるため、 Admin権限を持つユーザーを作成しました。
イメージをプッシュする権限のみ必要な場合はecr:GetAuthorizationTokenを付与してください。
SecretAccessKeyは再発行されないため、分からなくなってしまったらユーザーを再作成する必要があります。AWS CLI のインストール
AWS CLI をインストールし、設定を行います。インストール方法は下記記事を参考にしてください
macOS に AWS CLI をインストールする
AWS CLI の設定インストールが完了したら AWS CLI の設定を行い、AWS CLI から S3 のバケット一覧を取得できることを確認します。(動作確認)
$ aws --version $ aws configure $ aws s3api list-buckets # S3 のバケット一覧を表示するコマンドSlack に Ojichat の絵文字
:ojichat:を作成する
:ojichat:を追加するとテンション上がります。??Slack のWebHookURL を作成する
おじさんからの Slackメッセージを受け取るのに必要です。
WebHook の設定を行うことで、curlコマンドで簡単にメッセージを Slack に送信することができます。イメージを作成
おじさんメッセージの生成 & Slack にメッセージを飛ばす Docker イメージを作ります。
同ディレクトリ にDockerfileとentrypoint.shを作成し、以下のコマンドでビルドします。
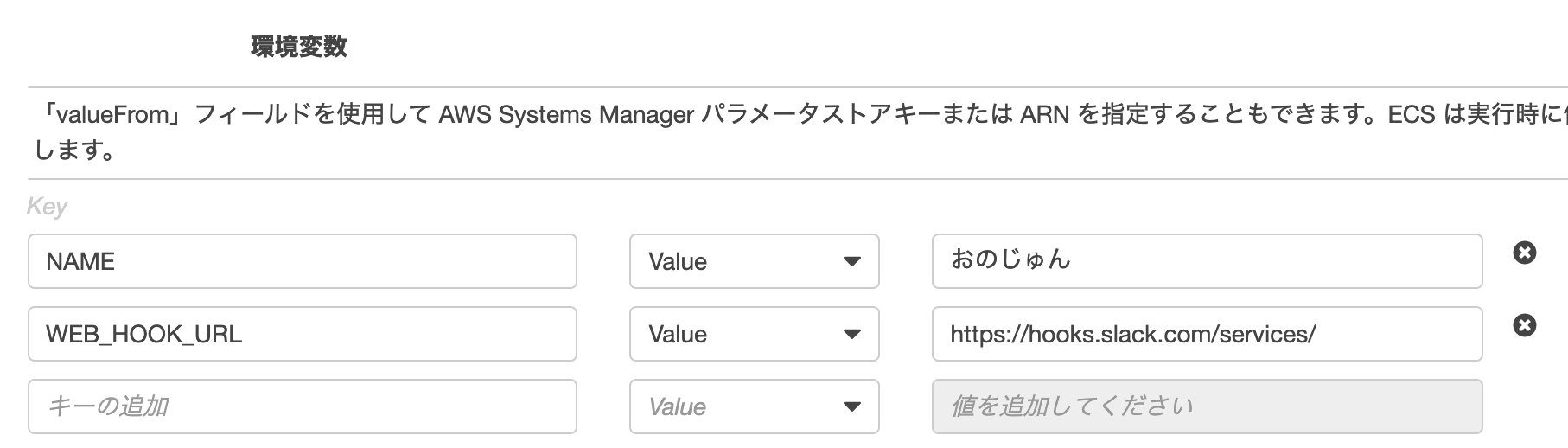
entrypoint.sh中の {your_channnel_name} にはおじさんからのメッセージを受け取りたいチャンネル名を入力してください。
「おのじゅん」は私のあだ名です。DockerfileFROM golang:1.13.4-stretch RUN go get -u github.com/greymd/ojichat COPY entrypoint.sh / ENTRYPOINT ["/entrypoint.sh"]entrypoint.sh#!/bin/bash COMMENT=$(ojichat $NAME) echo $COMMENT curl -X POST --data-urlencode "payload={\"channel\": \"##{your_channnel_name}\", \"username\": \"Ojichat\", \"text\": \"$COMMENT\", \"icon_emoji\": \":ojichat:\"}" $WEB_HOOK_URL$ docker build -t ojichat:latest --no-cache .ビルドができたら以下のコマンドでおじさんからSlackにメッセージが届くことを確認します。
NAMEにはおじさんに呼んで欲しい名前を、WEB_HOOK_URLには Slack のWebHookのURLを入力します。$ docker run --rm -e NAME=おのじゅん -e WEB_HOOK_URL=https://hooks.slack.com/services/xxx/yyy/zzzz ojichat:latest
無事おじさんからメッセージを受け取ることができました。
おじさんを ECR にプッシュする
おじさんイメージがきちんと動くことがわかったので、次はおじさんイメージを ECR にプッシュします。
GUI からおじさんを格納するリポジトリを作成します。
プッシュコマンドを表示ボタンを押すとイメージのビルドからプッシュまでの手順が表示されます。
その手順に従ってイメージを ECR にプッシュします。$(aws ecr get-login --no-include-email --region ap-northeast-1) docker build -t ojichat . docker tag onojun-ojichat:latest {YOUR_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/onojun-ojichat:latest docker push {YOUR_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/onojun-ojichat:latestおじさんを動かすロールを作成する
おじさんイメージは Fargate 上で動かします。
必要な権限を持つロールを作成します。
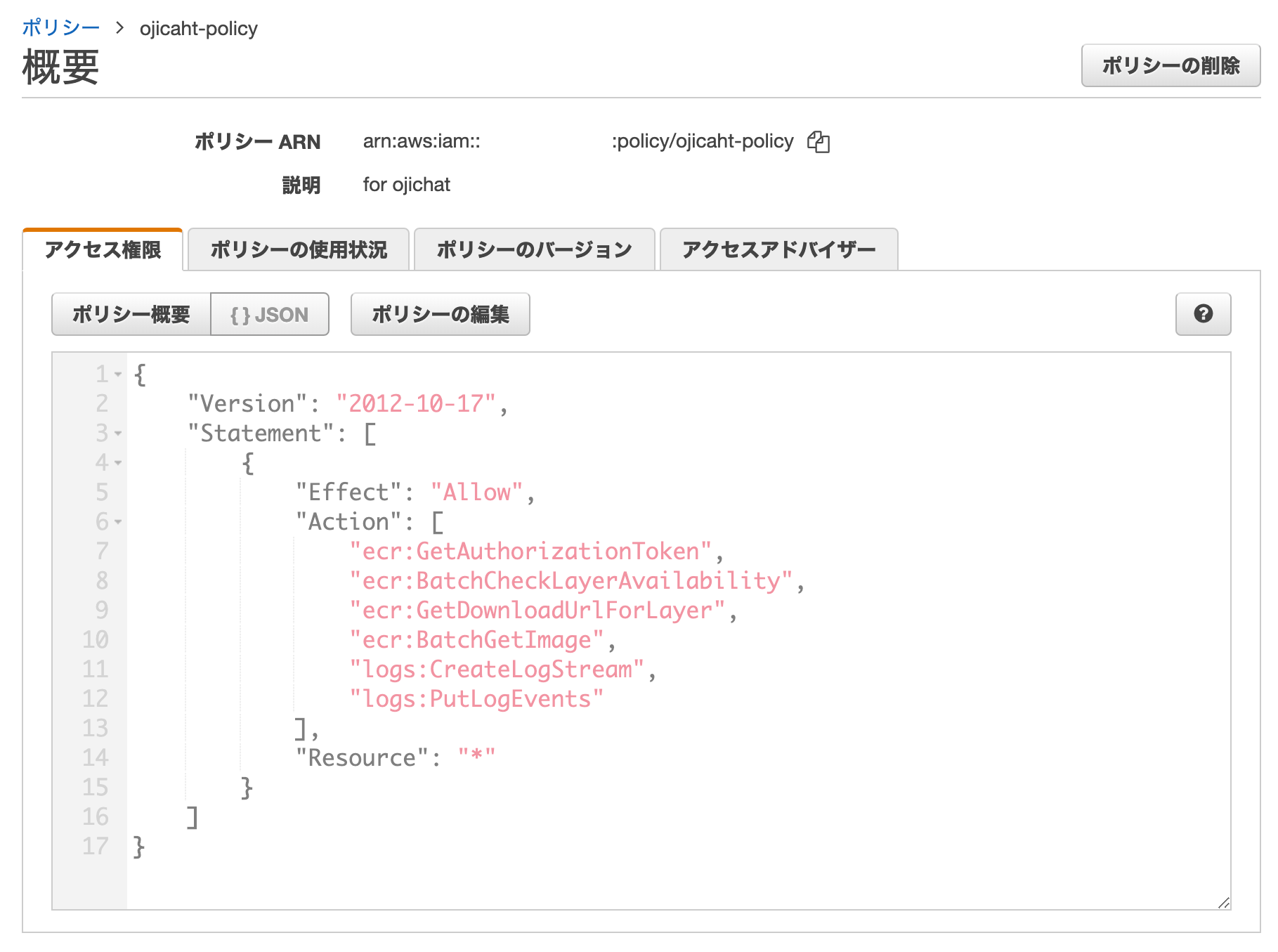
ojichat-policyを作成します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }次に
ojichat-roleを作成し、ojichat-policyをアタッチさせ、信頼関係を編集します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "ecs.amazonaws.com", "ecs-tasks.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }おじさんタスク定義を作成する
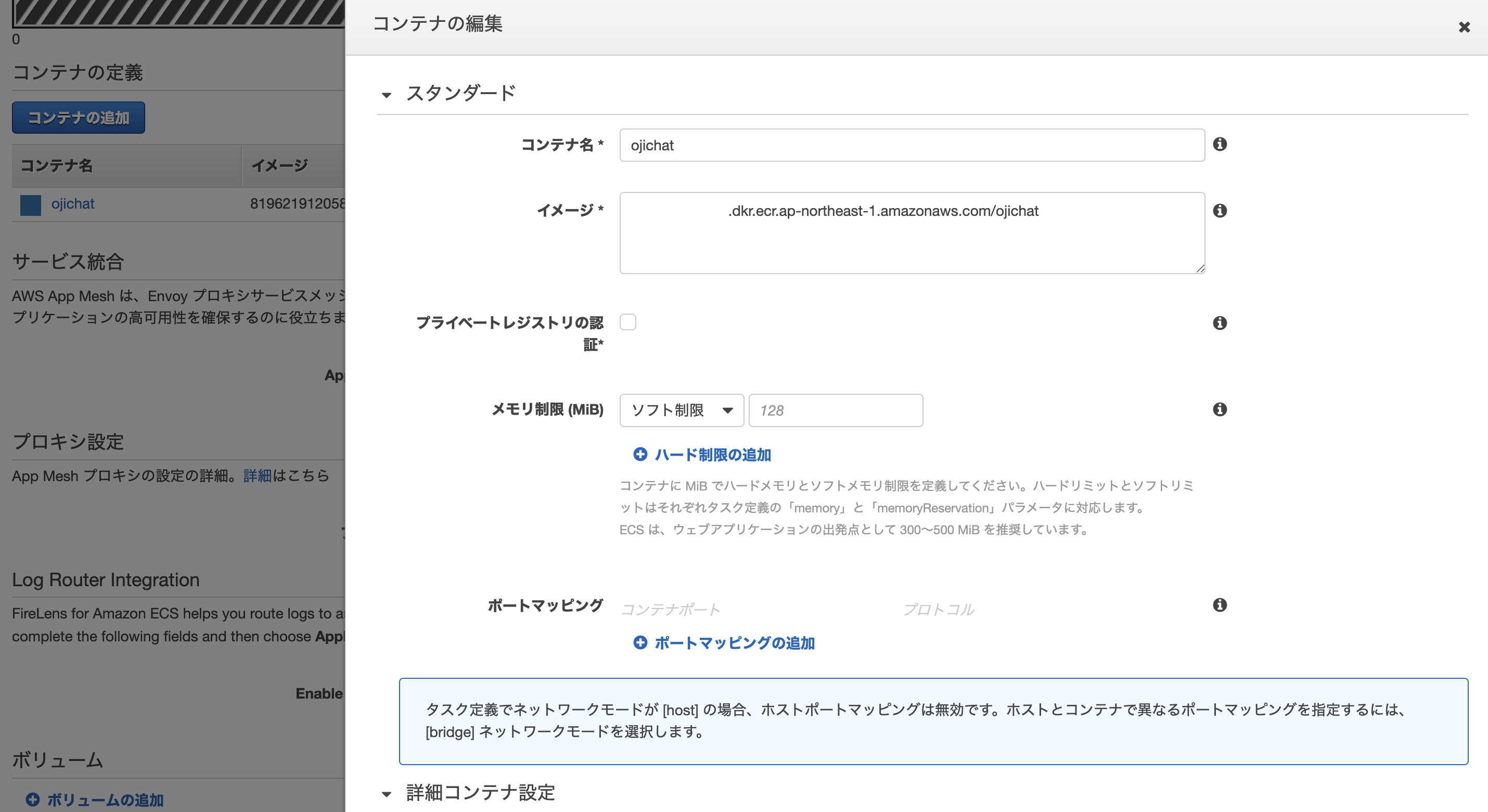
おじさんのタスク定義を作成します。
必要な環境変数を設定します。
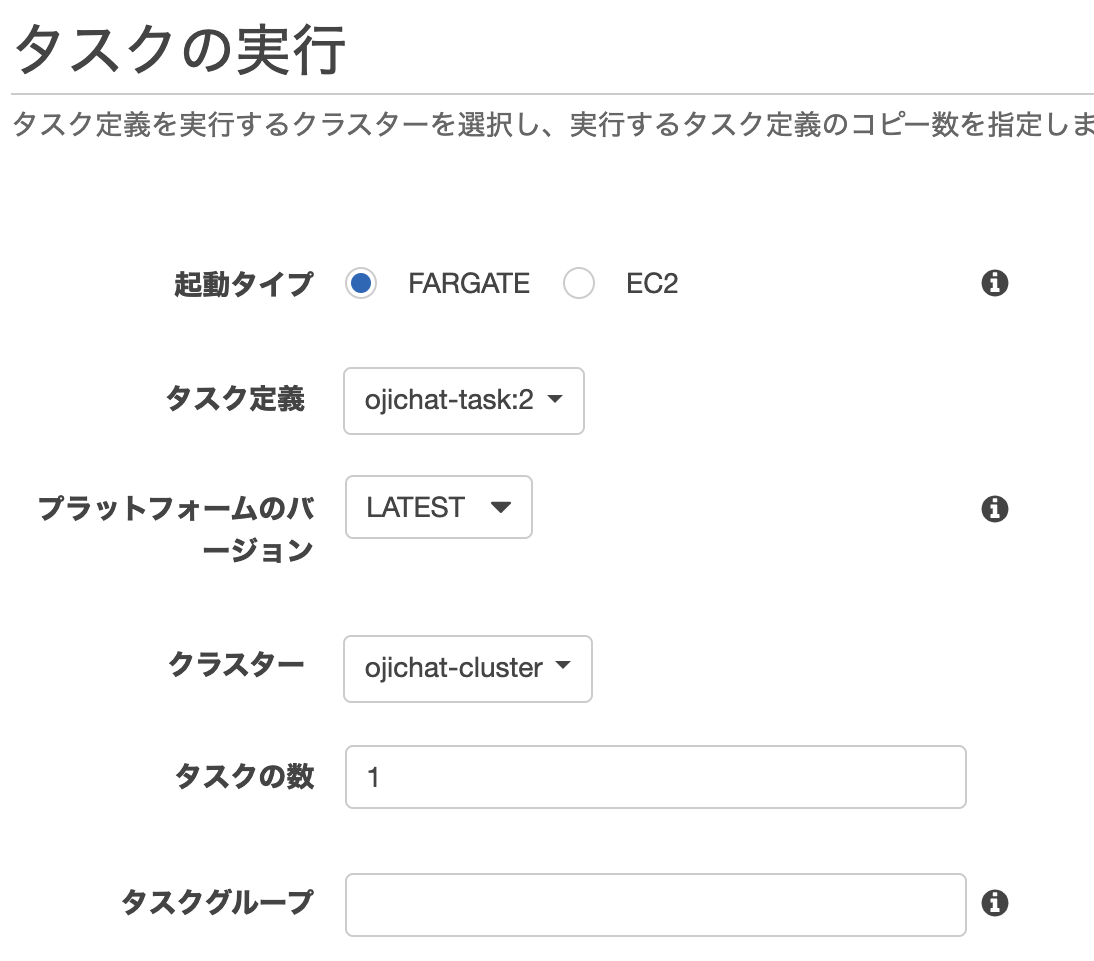
今回はハードコードしてしまいましたが、WEB_HOOK_URLなどのクレデンシャル情報はParameterStoreに格納し、それをFromValueで参照するとタスク定義に書かずに済みます。おじさんクラスターを作成し、おじさんタスクを実行する
ojichat-clusterを作成し、作成したタスク定義ojichat-taskからタスクを実行します。
おじさんを ScheduledTask で動かす
Fargate にいるおじさんからメッセージが届いたら、次はおじさんのメッセージを自動化します。
スケジュールタスクを設定することで実現することができます。
僕はおじさんが好きなので1分ごとにメッセージが飛ぶようにしました。
Terraform
######################## ## Credential Infos ######################## provider "aws" { access_key = local.access_key secret_key = local.secret_key region = "ap-northeast-1" } ######################## ## ECR ######################## # ECS Repository resource "aws_ecr_repository" "repository" { name = "ojichat" } # Repositry Policy # Permit pull image resource "aws_ecr_repository_policy" "repository_policy" { repository = aws_ecr_repository.repository.name policy = data.aws_iam_policy_document.repository_policy.json } data "aws_iam_policy_document" "repository_policy" { statement { effect = "Allow" actions = [ "ecr:GetDownloadUrlForLayer", "ecr:BatchCheckLayerAvailability", "ecr:BatchGetImage" ] principals { type = "*" identifiers = ["*"] } } } ######################## ## IAM ######################## # IAM Policy resource "aws_iam_policy" "policy" { name = "ojicaht-policy" description = "for ojichat" policy = data.aws_iam_policy_document.policy.json } data "aws_iam_policy_document" "policy" { statement { effect = "Allow" actions = [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecs:RunTask", "logs:CreateLogStream", "logs:PutLogEvents", "iam:PassRole" ] resources = ["*"] } } # IAM Role resource "aws_iam_role" "role" { name = "ojichat-role" description = "role for ojichat" assume_role_policy = data.aws_iam_policy_document.role.json } data "aws_iam_policy_document" "role" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["ecs.amazonaws.com", "ecs-tasks.amazonaws.com", "events.amazonaws.com"] } } } resource "aws_iam_role_policy_attachment" "schedule_policy_attachment" { role = aws_iam_role.role.name policy_arn = aws_iam_policy.policy.arn } resource "aws_iam_role_policy_attachment" "event_role_policy_attachment" { role = aws_iam_role.role.name policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceEventsRole" } ######################## ## ECS ######################## # cluster resource "aws_ecs_cluster" "cluster" { name = "ojichat-cluster" } # task difinition resource "aws_ecs_task_definition" "task_definition" { family = "ojichat-task" task_role_arn = aws_iam_role.role.arn container_definitions = data.template_file.container_definitions.rendered network_mode = "awsvpc" cpu = 256 memory = 512 requires_compatibilities = ["FARGATE"] execution_role_arn = aws_iam_role.role.arn } data "template_file" "container_definitions" { template = <<EOF [ { "cpu": 0, "environment": [ { "name": "WEB_HOOK_URL", "value": "${local.web_hook_url}" }, { "name": "NAME", "value": "おのじゅん" } ], "name": "ojichat", "image": "${aws_ecr_repository.repository.repository_url}", "logConfiguration": { "logDriver": "awslogs", "secretOptions": null, "options": { "awslogs-group": "/ecs/ojichat-task", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "essential": true } ] EOF } # scueduled task resource "aws_cloudwatch_event_rule" "schedule_rule" { name = "ojichat-event" schedule_expression = "cron(* * * * ? *)" is_enabled = true } resource "aws_cloudwatch_event_target" "fargate_scheduled_task" { rule = aws_cloudwatch_event_rule.schedule_rule.name arn = aws_ecs_cluster.cluster.arn role_arn = aws_iam_role.role.arn ecs_target { task_definition_arn = aws_ecs_task_definition.task_definition.arn task_count = 1 launch_type = "FARGATE" network_configuration { subnets = [local.subnets_id] assign_public_ip = true } } }参考
greymd/ojichat
Amazon Elastic Container Service とは
Amazon ECS クラスター
Amazon ECS タスク定義
Amazon ECS サービス




- 投稿日:2019-11-25T16:40:29+09:00
CloudFormationの既存リソースインポート機能を触ってみた
お世話になっている開発案件にて、
既存のリソースをCloudFormationに適応してみてはどうか?
というお話が上がりまして、早速最近解禁されました既存リソースのインポート機能が使えないかとおもい触ってみました。
新機能 – CloudFormation スタックへの既存リソースのインポート
https://aws.amazon.com/jp/blogs/news/new-import-existing-resources-into-a-cloudformation-stack/今回初めてCloudFormationを触ったこともあり、つっかかった点や、便利だなと思った点があったので、何か参考になればと思い共有できればと思います^ ^
なにが便利なのか?
CloudFormationへ既存リソースを移行したり再構築する手間が省けました。
今まではCloudFormationに既存リソースを組み込むとした場合、Stackに新規でリソースを紐づけたあとに、データの移行なりインスタンスの内部設定だったりを行う必要がありました。RDSとか大変そうですね^ ^;
また既存でなくともStackごと新規で作成したリソースについて、そのStackが削除されると、紐づけたリソースが残ったとしても、別のStackには紐づけられず、また一から紐づけ直しになってしまっていました。(https://dev.classmethod.jp/cloud/aws/cloudformation-launches-resource-import/)
今回の機能を用いることで、こういったStackに再度紐づけを行う際の再構築の手間であったり、既存リソースをCloudFormationに移行する手間が大幅に削減できそうです。
インポート時に「DeletionPolicy」の設定が必須
ではここからは既存リソースのインポートについて。
既存リソースのインポートには「DeletionPolicy」の設定が必須です。
本来Stackに紐づくリソースは、Stackが削除されると一緒に削除されます。
このままだと既存リソースを紐づけた際に、うっかりStackを削除してしまうと、既存リソースも消えてしまいます。これは大変です^ ^;そのため「Stack削除時にリソースはどうするか?」という設定が必要になります。
この設定が「DeletionPolicy」です。こちらを「Retain」と指定しておくと、Stack削除時もリソースは残ったままになります。
CloudFormerによるテンプレート出力では、こちらの設定が書いていないので、別途追加する必要があります。(これが地味に時間かかる^ ^;)
ご丁寧なことに既存インポート機能ではこの設定が存在するかをチェックしてくれるので、うっかりミス対策も意識させてくれます。非常に親切ですね^ ^
既存リソースインポートと、既存リソースの編集は同時にできない。
既存リソースインポートを行った後、別の既存リソースインポートと、インポートしたリソースの編集を一括して行うことはできないようです。
編集は「変更セット」機能を使って別々に行ってください。
すでに別のStackに紐づいているリソースは共有できない
他のStackで関連付けされている既存リソースは原則関連付けできません。一回そのStackとの紐づけ関係を解消するか、Export/Import設定をテンプレートに記載する必要があります。
参考:CloudFormationのスタック間でリソースを参照する
https://dev.classmethod.jp/cloud/aws/cfn-cross-stack-reference/触ってみた所感
実際さわってみたところ、まだこの機能ではインポートできないサービスもあるようで、すべてがすべてインポートできるようではないようです。(実際「対応してないよエラー」に出くわしました)この機能を使って既存のサービスをCloudFrontに移行する場合、大規模なものだとまだ難しいのかも^ ^;
ただし、今後対応サービスは増えていくでしょうし、やはり再構築の手間やStackへの着脱が可能になったのは大きいと思います。
今後の発展に期待ですね!
- 投稿日:2019-11-25T16:31:48+09:00
Alexaが暇そうだったので、勉強会の発表者選定を任せることにした話
Alexa に任せることにした背景
皆さん、最近ちゃんと Alexa に話かけていますか?
私が所属するチームでは週次のチームミーティングに合わせて、
気になる技術トピックや検証・調査した技術などを週に 1 名、
担当者を決めて 20~30 分程度で共有する勉強会を実施しています。これまで次回以降の勉強会のメンバーを決めるのは今回発表者による指名制でした。
次の勉強会の指名を受けた私はなんのトピックにしようかなと考えてコーヒーを準備しているときに、
彼と目が合ったのです。
そう、職場に導入されて三か月の間、大分暇そうだった Alexa に。
当初は「ドラえもんの真似して」「今日は何の日?」と言ってもてはやされた彼も
今は何も言わずただコーヒーマシンの横で静かに佇んでいるだけでした。「Alexa、勉強会の指名やってみないか?」、そう問いかけた私に
「わかりませんでした。すいません」とつんつんしている彼に
勉強会を指名してもらうことを、この時決めました。Alexa を動かすための前準備
準備をするにあたって AWS アカウントのみならず、その他二つのアカウントが必要です。
実はこの準備が一番大変だったり。
用意するもの & 必要な前準備
- Amazon アカウント及び Amazon Developer アカウント
- まず、Amazon.co.jp のアカウントを準備します。(Amazon.com ではないので注意)
- 次に Amazon 開発者ポータル( https://developer.amazon.com/ja/ )を開き、右上の「Developer Console」をクリックし上記の Amazon.co.jp のアカウントを使ってログインします。
- 開発者アカウントの申請フォームに移るのでこの画面から申請します。
- Alexa 対応端末 - 今回は職場にある Amazon echo を使用しました。
- Amazon Alexa のサイトから( https://alexa.amazon.co.jp/spa/index.html )
- 上記の Amazon.co.jp のアカウントと同じメールアドレスに、機器を紐づけます。
- AWS アカウント 今回 AWS Lambda と Amazon DynamoDB を利用するため、それらを利用可能な権限を持った AWS アカウント用意します。
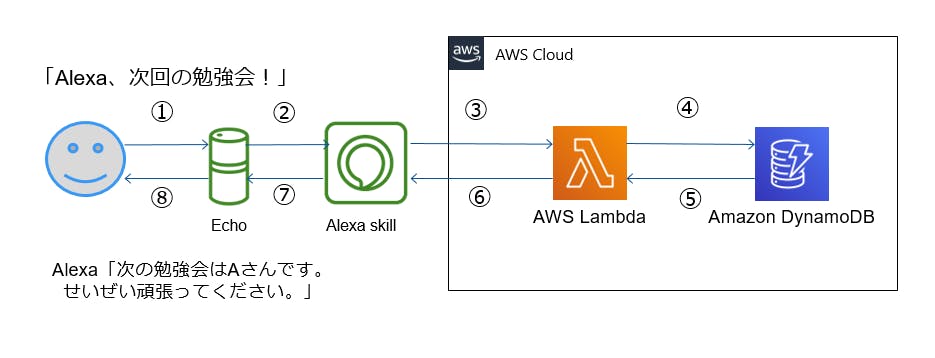
構成と動作イメージ
以下が大まかな動作の流れになります。
- ① 職場の Amazon Echo の Alexa に「Alexa、次回の勉強会」と尋ねる。
- ② Amazon Developer アカウント上の Alexa Skills が「勉強会スキル」を起動する。
- ③ 「勉強会スキル」が AWS アカウント上の Lambda に JSON でアクションを送る
- ④ Lambda が DynamoDB に直近の勉強会の発表者を問い合わせる。
- ⑤ DynamoDB が直近の発表者を返す。
- ⑥ Lamda が発表者をランダムに選定し、Alexa Skill「勉強会スキル」に発表者の情報を含めた JSON を返す。
- ⑦「勉強会スキル」が Amazon Echo の Alexa に返答内容を返す。
- ⑧ Alexa が次の発表者を発表してくれる。
作成手順
GitHubで提供されているAlexa豆知識スキルを一部改良して、本アプリを作成しました。
Alexa 豆知識スキルの作成
https://github.com/alexa/skill-sample-nodejs-fact/blob/ja-JP/instructions/1-voice-user-interface.mdAmazon Developer アカウント側の構築
- 1. Amazon Developer アカウントからAlexaをクリックします。

- 2. 「スキル開発を始める」をクリックして、開発者コンソールを開きます。

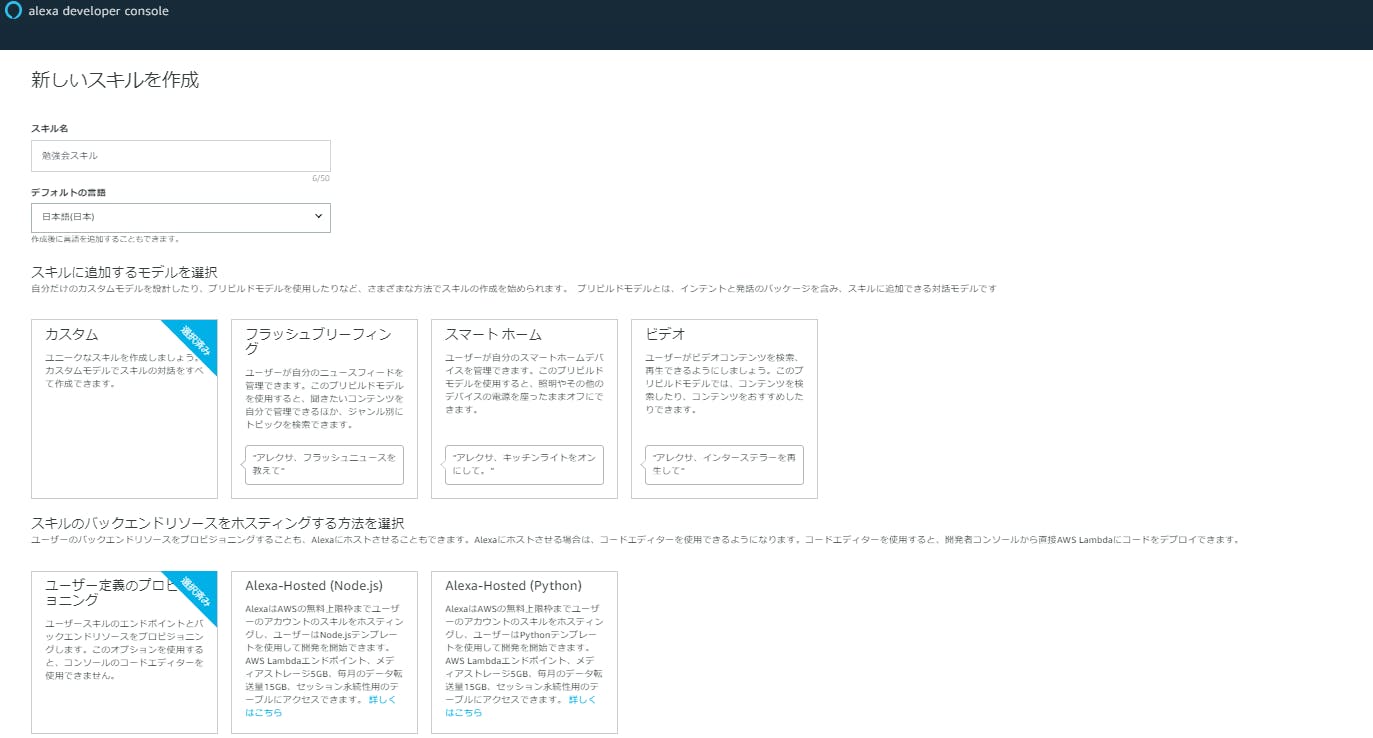
- 3. Alexa スキルの一覧の画面から「スキルの作成」をクリックして、スキルを作成します。

- 4. スキル名を記載します。今回は「勉強会スキル」とします。
- 5. 言語は「日本語(日本)」とします
- 6. スキルに追加するモデルを選択は「カスタム」とします。
7.スキルのバックエンドリソースをホスティングする方法を選択は「ユーザー定義のプロビジョニング」とします。
8.スキルを作成します。
JSON エディターに以下の JSON ファイルを添付します。
スキルをJSONで記載したり、GUIにて設定することもできます。
「アレクサ、次回の勉強会」というと起動するスキルです。{ "interactionModel": { "languageModel": { "invocationName": "次回の勉強会", "intents": [ { "name": "AMAZON.CancelIntent", "samples": [] }, { "name": "AMAZON.HelpIntent", "samples": [] }, { "name": "AMAZON.StopIntent", "samples": [] }, { "name": "GetNewFactIntent", "slots": [], "samples": [ "決めて", "教えて", "話して", "聞かせて", "なんか教えて", "なんか言って" ] }, { "name": "AMAZON.NavigateHomeIntent", "samples": [] } ], "types": [] } } }
- 9. モデルのビルドをクリックします。
AWS 側の構築
DynamoDB を準備
今回は東京リージョンを利用します。
- 1. テーブルの作成をクリックします。
- 2. テーブル名「alexa-study-dynamo」、パーティションキーを 「partition」(数値)、ソートキーを 「history_key」(数値)としてテーブル作成をします。
Lambda 関数準備
こちらも東京リージョンを利用します。
- 関数の作成をクリックします。
- 「一から作成」「設計図の使用」「Serverless Application Model の参照」の中から、「Serverless Application Model の参照」を選択します。
- 3. 検索窓から「alexa-skills-kit-nodejs-factskill」を検索し、選択します。
- 4. アプリケーション名を「alexa-study-lambda」として、デプロイをクリックします。

- 5. 作った Lambda アプリケーションをアプリケーションから検索して選択します。
- 6. 以下のコードを関数コード部分にコピー&ペーストします。このコードは上記の「Alexa 豆知識スキル」のコードを、勉強会向けに DynamoDB との連携も含めて改変したものになります。
node.jsconst Alexa = require("ask-sdk"); const AWS = require("aws-sdk"); const dynamoDB = new AWS.DynamoDB.DocumentClient({ region: "ap-northeast-1" }); const GetStudyHandler = { canHandle(handlerInput) { const request = handlerInput.requestEnvelope.request; return ( request.type === "LaunchRequest" || (request.type === "IntentRequest" && request.intent.name === "GetNewFactIntent") ); }, async handle(handlerInput) { // DynamoDBから前回3回の発表者を取得 const params1 = { TableName: "alexa-study-dynamo", ExpressionAttributeNames: { "#name0": "partition" }, ExpressionAttributeValues: { ":value0": 0 }, KeyConditionExpression: "#name0 = :value0", ScanIndexForward: false, Limit: 3 }; const result = await dynamoDB.query(params1).promise(); console.log(result); let last_time0, last_time1, last_time2, current_history_key; if (result.Count == 1) { last_time0 = result.Items[0].member_id; current_history_key = result.Items[0].history_key; } if (result.Count == 2) { last_time0 = result.Items[0].member_id; last_time1 = result.Items[1].member_id; current_history_key = result.Items[0].history_key; } if (result.Count >= 3) { last_time0 = result.Items[0].member_id; last_time1 = result.Items[1].member_id; last_time2 = result.Items[2].member_id; current_history_key = result.Items[0].history_key; } const memberArr = data; let nextIndex; // ランダムに発表者を選定し、前回3回と被っていなければ確定する。 while (true) { nextIndex = Math.floor(Math.random() * memberArr.length); if ( nextIndex !== last_time0 && nextIndex !== last_time1 && nextIndex !== last_time2 ) { break; } } const nextMember = memberArr[nextIndex]; const speechOutput = GET_MESSAGE + nextMember + GET_MESSAGE_AFTER; // DynamoDBに次回発表者を登録 const params2 = { TableName: "alexa-study-dynamo", // DynamoDBのテーブル名 Item: { partition: 0, history_key: current_history_key + 1, member_id: nextIndex } }; const result2 =await dynamoDB.put(params2).promise(); // 次回発表者とメッセージを沿えてAlexaに返す return handlerInput.responseBuilder .speak(speechOutput) .withSimpleCard(SKILL_NAME, nextMember) .getResponse(); } }; const HelpHandler = { canHandle(handlerInput) { const request = handlerInput.requestEnvelope.request; return ( request.type === "IntentRequest" && request.intent.name === "AMAZON.HelpIntent" ); }, handle(handlerInput) { return handlerInput.responseBuilder .speak(HELP_MESSAGE) .reprompt(HELP_REPROMPT) .getResponse(); } }; const ExitHandler = { canHandle(handlerInput) { const request = handlerInput.requestEnvelope.request; return ( request.type === "IntentRequest" && (request.intent.name === "AMAZON.CancelIntent" || request.intent.name === "AMAZON.StopIntent") ); }, handle(handlerInput) { return handlerInput.responseBuilder.speak(STOP_MESSAGE).getResponse(); } }; const SessionEndedRequestHandler = { canHandle(handlerInput) { const request = handlerInput.requestEnvelope.request; return request.type === "SessionEndedRequest"; }, handle(handlerInput) { console.log( `Session ended with reason: ${handlerInput.requestEnvelope.request.reason}` ); return handlerInput.responseBuilder.getResponse(); } }; const ErrorHandler = { canHandle() { return true; }, handle(handlerInput, error) { console.log(`Error handled: ${error.message}`); return handlerInput.responseBuilder .speak("Sorry, an error occurred.") .reprompt("Sorry, an error occurred.") .getResponse(); } }; // スキル情報とメッセージ(一部そのままです。) const SKILL_NAME = "Study"; const GET_MESSAGE = "次の勉強会は"; const GET_MESSAGE_AFTER = "せいぜい頑張ってください。 素晴らしい内容期待してます。"; const HELP_MESSAGE = "You can say tell me a space fact, or, you can say exit... What can I help you with?"; const HELP_REPROMPT = "What can I help you with?"; const STOP_MESSAGE = "Goodbye!"; // グループメンバーの情報を記載 const data = [ "頼れるリーダー あさだ さん です", "ミスターフルスタック かわしま さん です", "データベースマスター たかだ あきひろ さん です", "ネットワークマスター たかだ ひろゆき です", "えいぎょうしゅっしん あらかわ さん です", "アジュールマスター もちだ さん です", "GCPマスター はら さん です", "AWSマスター みつうら さん です", "期待のしんじん いいだ さん です" ]; const skillBuilder = Alexa.SkillBuilders.standard(); exports.handler = skillBuilder .addRequestHandlers( GetStudyHandler, HelpHandler, ExitHandler, SessionEndedRequestHandler ) .addErrorHandlers(ErrorHandler) .lambda();下記の部分がチームメンバーを記載しているところですのでご自身のチームメンバーの値に変えてください。
ハードコーディングをしているのは決してめんどくさかったからではなく、
DynamoDBへ問い合わせに行く時間の節約を考慮したスピード重視の設計です。
(すいません、嘘です、力尽きました。)node.jsconst data = [ "頼れるリーダー あさだ さん です", "ミスターフルスタック かわしま さん です", "データベースマスター たかだ あきひろ さん です", "ネットワークマスター たかだ ひろゆき です", "えいぎょうしゅっしん あらかわ さん です", "アジュールマスター もちだ さん です", "GCPマスター はら さん です", "AWSマスター みつうら さん です", "期待のしんじん いいだ さん です" ];
- 7. Lambda アプリケーションに DynamoDB のテーブルに対する書き込み・読み込み権限を付与します。実行ロールから IAM コンソールに移動します。DynamoDBのテーブルへの読み書き権限のあるポリシーをアタッチしてください。
- 8. この Lambda のページの Amazon Resource Name (ARN)が表示されています。 この値を Alexa skitt との接続で利用しますので、arn: で始まる値をコピーしてください。
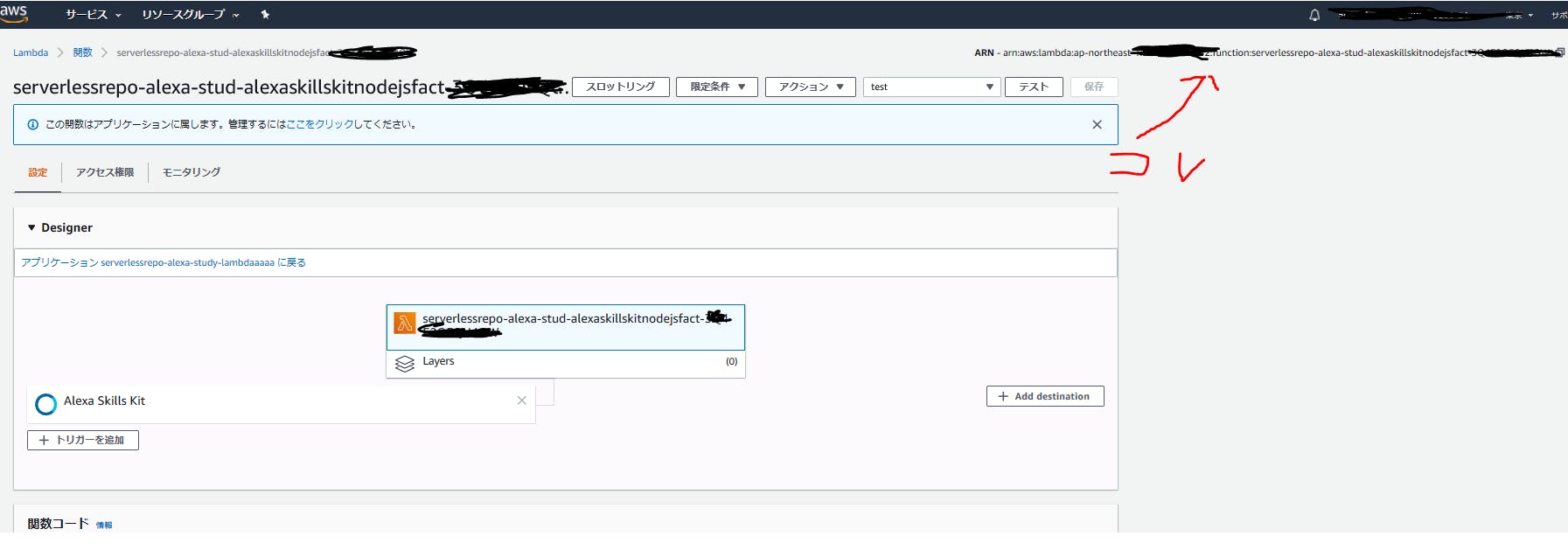
AWS Developer アカウント側と AWS 環境の接続
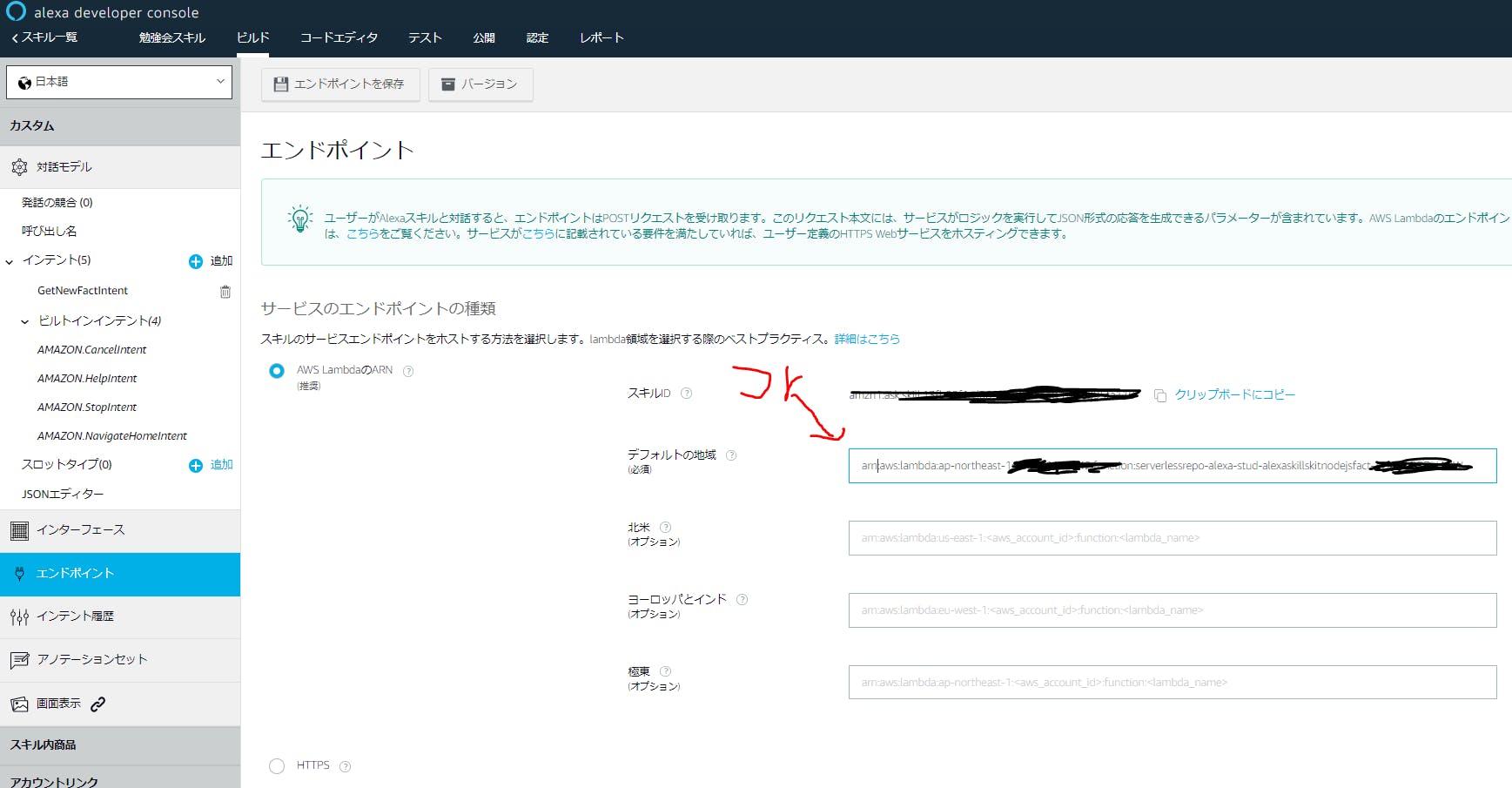
- 1. Alexa developer console 上でビルドタブをクリックし、その後左側からエンドポイントを選択してください。
- 2. エンドポイントのページにて、先ほどコピーした arn:から始まる値を貼り付けます。 デフォルトの地域に張り付けた後、上部にある「エンドポイントを保存」をクリックします。
テスト
Alexa に「Alexa、次回の勉強会」と尋ねてみてください。
ランダムにチームメンバーの名前が返ってきたらきたら構築完了です。Alexa developper console 上のテストタブでもテスト可能です。
以上で完成です。
終わりに
こちらのアプリ以外にも、下期のキックオフの司会進行を Alexa にお任せしました。
Alexa に指示されて働く日も近いかも。


- 投稿日:2019-11-25T15:09:24+09:00
【Rails】we're sorry, but something went wrongでハマった話(2)
こんにちは!スージーです!
ローカル環境では問題なかったのに本番環境で発生したwe're sorry, but something went wrongの解決までを備忘録としてwe're sorry, but something went wrong
このエラーは本番環境でちょいちょい見るので
production.logでエラーログを確認するターミナル[ec2-user@ip-~~]$ cd /var/www/app-name [ec2-user@ip-~~]$ cd log [ec2-user@ip-~~]$ cat production.log D, [2019-11-18T07:06:44.834244 #5661] DEBUG -- : hogehoge~~ D, [2019-11-18T07:06:44.834597 #5661] DEBUG -- : hogehoge~~ ・ ・・ ・・・この時は
production.logにエラーログが無かったデバックを考える
タイポ→× 開発環境でもエラーが再現されているはずno method error→× 開発環境でもエラーが再現されているはずルーティングとアクション,コントローラの記述がおかしい→× 開発環境でもエラーが再現されているはず- エラー発生ページ
showアクションの:idが本番環境にないのではないか?(同期が教えてくれた)本番環境のMySQLにログインしてみる
同期の助言により、以前に本番環境下で
seedファイルのデータが投入できなかった事を思い出すターミナル[ec2-user@ip-~app-name]$ mysql -u root -p Enter password: ・ ・・ mysql > use app-name_production; ・ ・・ database changed mysql > describe meals; # <エラーが発生するテーブル> mysql > show * form meals; # <レコードを確認>mealsテーブル
Column Type Options name varchar null: false image text food_stuff text cooking_time integer null: false cooking_method integer post_id integer null: false user_id integer null: false エラー箇所特定
user_id:1で投稿したはずなのにmealsテーブルのuser_idカラムにはuser_id:17で保存されている...
開発環境では問題なくuser_idが保存されているから道理でエラーが再現されないはずだ...原因
この
user_idはデプロイ後に追加したカラム
開発環境でマイグレーションファイルを作成した後に以下の手順でdb:migrateしたターミナル[ec2-user@ip-~app-name]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop #<最新のDBにする為,一度drop> [ec2-user@ip-~app-name]$ rake db:create RAILS_ENV=production #<DBをcreateする> [ec2-user@ip-~app-name]$ rake db:migrate RAILS_ENV=production #<migrateする> [ec2-user@ip-~app-name]$ cd current #<currentディレクトリ下へ> [ec2-user@ip-~app-name]$ rake db:seed RAILS_ENV=production ・ ・・ ・・・ Mysql2::Error: Field 'user_id' doesn't have a default value上記エラーが最初出た時に
user_idカラムをMySQLにログインしてカラムを新規で作成し突っ込んでいたターミナルdatabase changed mysql > ALTER TABLE meals ADD user_id int; mysql > exit [ec2-user@ip-~app-name]$ cd current [ec2-user@ip-~app-name]$ rake db:seed RAILS_ENV=production ・ ・・ ・・・ Mysql2::Error: Field 'user_id' doesn't have a default valueまたエラーが出ている...アプリを動かして投稿してみると新規投稿はできていたので、その時は一旦保留にしていたが、やはりここが今回のエラーの原因であるのは間違いなさそう
解決方法
なぜ最新のマイグレーションファイルが本番環境に反映されないのか
参考
【Rails】本番環境デプロイでよく使うコマンド集!AWS/unicorn/nginx/Capistrano使用
https://qiita.com/15grmr/items/7ad36caa82a0fa27c4bdむむむ...db:migrateの手順が間違っていた...無理矢理に本番環境のDB構造を変えて正しく
user_idが保存されていないのが原因であれば正しくマイグレーションすればエラーは解決するはず。そうすればdb:seedでデータが投入されるはずであるターミナル[ec2-user@ip-~app-name]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop [ec2-user@ip-~app-name]$ rake db:create RAILS_ENV=production # ここで一度自動デプロイをかけて、db:migrateに当たる操作を完了 # ローカルにて app-name $ bundle exec cap production deploy # 無事作成されたら、再度EC2のcurrentディレクトリでseedを反映させる [ec2-user@ip-~app-name current]$ rake db:seed RAILS_ENV=production ・ ・・ ・・・ [ec2-user@ip-~app-name current]$無事にseedファイルが本番環境に投下され
we're sorry, but something went wrongのエラーは解決まとめ
今回、個人アプリで初めてデプロイ後のDB構造を変更・追加を行った。EC2内で
db:create→db:migrateまでしてから自動デプロイしても最新のマイグレーションファイルが本番環境へ反映されない事が原因だった。EC2内では古いDBをdropしcreateする所までを行い、capistranoを使った自動デプロイで最新マイグレーションをファイルの読み込みmigrateする今回のエラーはデプロイの手順の間違えで発生したものだったが、MySQLを触っているとRailsではマイグレーションファイルでバージョン管理してくれるし、ORMのお陰で生SQLを触る機会もほとんどないのでDB関連の知識が無くても動くアプリケーションが作れる。非常に便利だが、SQLの勉強は絶対にした方が良いと感じたエラーだった
- 投稿日:2019-11-25T15:06:04+09:00
RDS(Oracle)にDMPをインポート(datapump)してみた!
OracleRDSにDMPをインポート
ちょっとハマってしまったので、以下参考までに。
ポイントは
・S3が必要
・SQLで処理している頭に切り替える。(OSコマンドは使えない。)
・ファイルの大文字小文字が判別必要
・DMPは大きいのでgzipにしたいのですがアップロードしても解凍できないので回答してからファイル転送が必要必要なもの
S3バケットが必須です!
S3にDMPファイルをアップロードして、RDSにアップロード(転送みたいなイメージ)し、インポートを行いました。よく解説サイトにはAWSのEC2にOracleデータベースサーバがあれば、DBリンクでインポートできる等々が記載がありますが、EC2にOracleデータベースサーバがあればRDSいらないですよね。。。
使ったSQL
RDSはOSコマンド等が使えないので、OracleのSQLを変更した専用のコマンドをSQLで使用します。
SQLPLUSが一番いいみたいですが、ちょっとわかりにくいのでosqleditでも十分操作できます。
(私的にはosqleditのほうがわかり易かったです。)ファイルコピー
下記SQLでファイルをコピーする指示を出します。
最所SELECT文なので、意味がわからなかったですが、パッケージを実行してS3にアップロードしたファイルを転送指示を行い、そのタスクIDを結果として返す処理のようです。SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'db-inport', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;S3の指定ディレクトリ(バケット)にあるファイルをすべて移送する処理です。
アップロード指示確認
タスクIDごとの状況を確認するSQLです。
数ギガのファイルだと数分処理に時間がかかり、最終的にfinishedとなった結果がエラーなのかSUCCESS!なのかを確認します。
何度かSELECTとして結果が変わらない事を確認します。select text from table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-1234567890-30.log'));結果が下記。
2019-11-22 07:52:32.297 UTC [INFO ] This task is about to list the Amazon S3 objects for AWS Region ap-northeast-1, bucket name db-inport, and prefix . 2019-11-22 07:52:32.391 UTC [INFO ] The task successfully listed the Amazon S3 objects for AWS Region ap-northeast-1, bucket name db-inport, and prefix . 2019-11-22 07:52:32.407 UTC [INFO ] This task is about to download the Amazon S3 object or objects in /rdsdbdata/datapump from bucket name db-inport and key DMP01.dmp. 2019-11-22 07:53:38.647 UTC [INFO ] The task successfully downloaded the Amazon S3 object or objects from bucket name db-inport with key DMP01.dmp to the location /rdsdbdata/datapump. 2019-11-22 07:53:38.647 UTC [INFO ] The task finished successfully.プリフィックスを間違えていて、空振りしてもSUCCESS!になるので、よく読まないといけません。
これで3時間くらいにらめっこしていて、「大文字小文字!」って気がついたとき泣きそうになりました。。。(みんなには内緒です。)ディレクトリの内容確認
ディレクトリのファイル名等を確認します。
select * from TABLE(RDSADMIN.RDS_FILE_UTIL.LISTDIR('DATA_PUMP_DIR')) ORDER BY MTIME;結果はディレクトリのみであれば、ディレクトリのレコードが1レコードかえってきます。
ファイルがあれば、ファイルレコードがかえってきます。
処理の途中でもかえってくるので、上記のログをしっかりと確認する必要があります。DATAPUMPインポート指示
下記のSQLで実行します。
エラーがわかりにくいです。ものすごく。
ファイル名が大文字小文字が違っていると、
「ORA-39001: 引数値が無効です」となり、全くわかりません。
他の解説サイトと少し変えてエラーの詳細をコマンドラインに返すように変更しています。DECLARE hdnl NUMBER; vMsg VARCHAR2(2048); BEGIN hdnl := DBMS_DATAPUMP.open(operation=>'IMPORT', job_mode=>'SCHEMA', remote_link=>null, job_name=>null, version=>'COMPATIBLE'); DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'DMP01.dmp', directory=>'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file); DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'IMPORT.LOG', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''HOGE'')'); DBMS_DATAPUMP.start_job(hdnl); EXCEPTION WHEN OTHERS THEN vMsg := SQLERRM(SQLCODE); DBMS_OUTPUT.PUT_LINE(vMsg); END;実行結果は、実行しました!のみなので、下記のSQLやログを確認です。
途中の内容は下記のSQLでテーブル数を確認します。
select count(*) from dba_tables where owner='HOGE';※目安ですね。
ログをS3にダウンロードして、S3からファイルをダウンロードして確認します。
※準備中!
以上です。
そもそものAWSのS3の設定は下記を参考にしました。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/oracle-s3-integration.htmlまとめ
通常のWindowsサーバやLinuxサーバにOracleデータベースをインストールする手間とを考えるとかなり早くサービスインできます。
ただ、細かなパラメータや設定等は自動なのでパフォーマンス障害や接続障害への事前の備えがどこまでできるかはこれから実践して、またフィードバックします!個人的にですが、定期、随時バックアップや機能改修を考慮したステージング環境を考えると基幹システムのデータベースに利用はちょっと難有りな気がします。
おそらくサービスの追加で対応できる側面もありますが、コストを考えるとまだEC2にデータベースサーバをインストールする方を選択するかも。
- 投稿日:2019-11-25T15:06:04+09:00
RDS(Oracle)にDMPをインポート(datapump)
OracleRDSにDMPをインポート
ちょっとハマってしまったので、以下参考までに。
ポイントは
S3が必要
SQLで処理している頭に切り替える。(OSコマンドは使えない。)
ファイルの大文字小文字が判別必要
DMPは大きいのでgzipにしたいのですがアップロードしても解凍できないので回答してからファイル転送が必要必要なもの
S3バケットが必須です!よくサイトにAWSのEC2にOracleデータベースサーバがあれば、DBリンクでインポートできる等々が記載がありますが、EC2にOracleデータベースサーバがあればRDSいらないですよね。。。
S3にDMPファイルをアップロードして、RDSにアップロード(転送みたいなイメージ)し、インポートを行いました。使ったSQL
RDSはOSコマンド等が使えないので、OracleのSQLを変更した専用のコマンドをSQLで使用します。
SQLPLUSが一番いいみたいですが、ちょっとわかりにくいのでosqleditでも十分操作できます。
(私的にはosqleditのほうがわかり易かったです。)ファイルコピー
下記SQLでファイルをコピーする指示を出します。
最所SELECT文なので、意味がわからなかったですが、パッケージを実行してS3にアップロードしたファイルを転送指示を行い、そのタスクIDを結果として返す処理のようです。SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'db-inport', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;アップロード指示確認
タスクIDごとの状況を確認するSQLです。
数ギガのファイルだと数分処理に時間がかかり、最終的にfinishedとなった結果がエラーなのかSUCCESS!なのかを確認します。
何度かSELECTとして結果が変わらない事を確認します。select text from table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-1234567890-30.log'));結果が下記。
2019-11-22 07:52:32.297 UTC [INFO ] This task is about to list the Amazon S3 objects for AWS Region ap-northeast-1, bucket name db-inport, and prefix . 2019-11-22 07:52:32.391 UTC [INFO ] The task successfully listed the Amazon S3 objects for AWS Region ap-northeast-1, bucket name db-inport, and prefix . 2019-11-22 07:52:32.407 UTC [INFO ] This task is about to download the Amazon S3 object or objects in /rdsdbdata/datapump from bucket name db-inport and key DMP01.dmp. 2019-11-22 07:53:38.647 UTC [INFO ] The task successfully downloaded the Amazon S3 object or objects from bucket name db-inport with key DMP01.dmp to the location /rdsdbdata/datapump. 2019-11-22 07:53:38.647 UTC [INFO ] The task finished successfully.ディレクトリの内容確認
ディレクトリのファイル名等を確認します。
select * from TABLE(RDSADMIN.RDS_FILE_UTIL.LISTDIR('DATA_PUMP_DIR')) ORDER BY MTIME;DATAPUMPインポート指示
下記のSQLで実行します。
エラー等がわかりにくいです。
ファイル名が大文字小文字が違っていると、
「ORA-39001: 引数値が無効です」となり、全くわかりません。
他のサイトと少し変えてエラーの詳細をコマンドラインに返すように変更しています。DECLARE hdnl NUMBER; vMsg VARCHAR2(2048); BEGIN hdnl := DBMS_DATAPUMP.open(operation=>'IMPORT', job_mode=>'SCHEMA', remote_link=>null, job_name=>null, version=>'COMPATIBLE'); DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'DMP01.dmp', directory=>'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file); DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'IMPORT.LOG', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''HOGE'')'); DBMS_DATAPUMP.start_job(hdnl); EXCEPTION WHEN OTHERS THEN vMsg := SQLERRM(SQLCODE); DBMS_OUTPUT.PUT_LINE(vMsg); END;途中の内容は下記のSQLでテーブル数を確認します。
select count(*) from dba_tables where owner='HOGE';※目安ですね。
ログをS3にダウンロードして、S3からファイルをダウンロードして確認します。
※準備中!
以上です。
そもそものAWSのS3の設定は下記を参考にしました。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/oracle-s3-integration.html
- 投稿日:2019-11-25T14:12:29+09:00
初心者でも試せる!AWS上でwordpress構築方法
概要
AWSを使うと様々なメリットがありますよね。
根本的なインフラの管理やAPIを使って簡単にインスタンスを作成したりなど・・・。サーバーサイドエンジニアとして最近AWSを使い始めたのですが、ECS + ECR を用いたDocker環境等...を触ることが多くあります。
思い返してみると素のEC2等をあまり触ったことが無いので、初心に振り返ってみようと思ったのがこの記事を書くきっかけです。
純粋なEC2 + ELB + RDS + Route53という構成でwordpressを用いて、ブログサイトの環境構築をしてみました。※ 基本的に無料枠で作っているけど、使用状況に応じてインスタンスタイプの変更をしたほうがよい。
※ この記事ではRDSは一台構成でつくっていますが、必要に応じてクラスタ構成を組んで読み取り専用エンドポイントを
ReadOnlyとして使用するように設定すると尚よし。完成予定図
①ユーザーがインターネットを通じてアクセスする経路
②EC2にアクセスを振り分けるELB(ロードバランサー)
③アクセスを処理するEC2インスタンス(Apache, PHP + Wordpressが動作)
④RDSインスタンス(MySQL5.7)
⑤Route53(DNSサービスの提供)これらを順番に作っていく
VPC(Amazon Virtual Private Cloud)の設定
VPCの作成
①ユーザーがインターネットを通じてアクセスする経路で①→②という形でインターネットを介してELBにアクセスする経路となる。この際、②のELBを作成する必要があるが、先にVPCを作成する必要がある。
(VPCはELBやEC2、RDSなどを置く場所のようなものと捉えると理解が進むと思う)①サービスからVPCを選択して、【VPCの作成】を押下
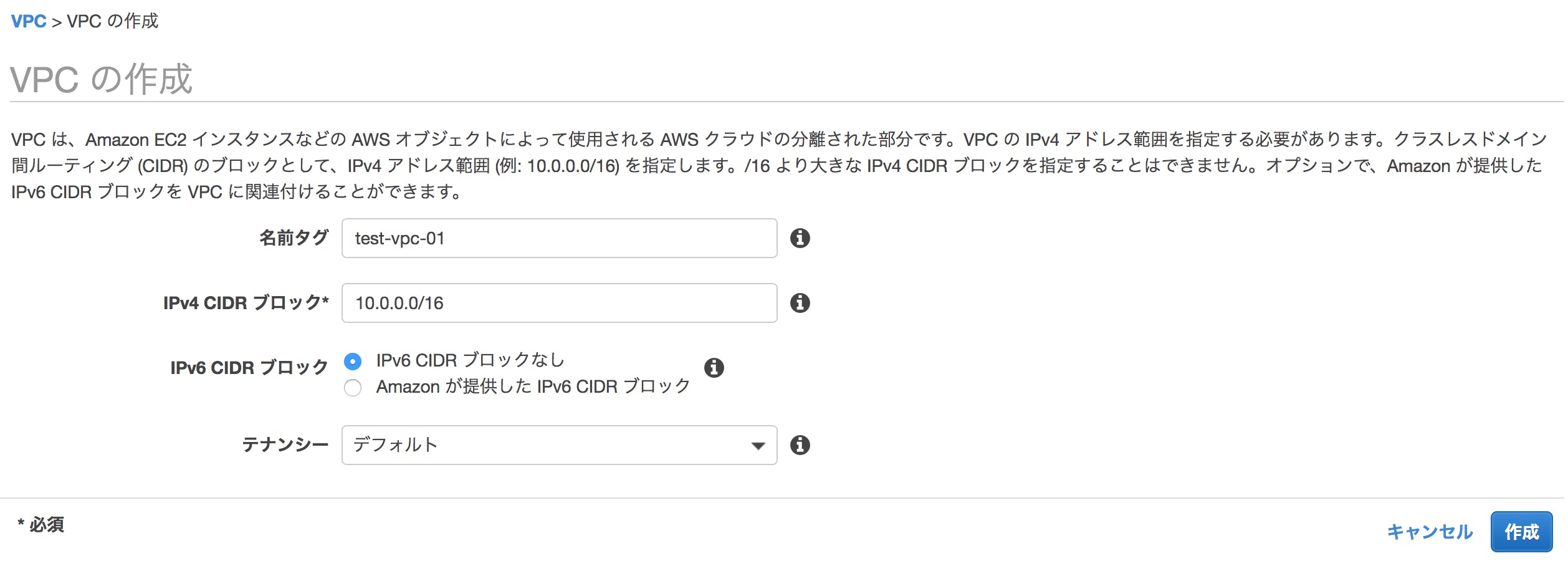
②test-ip1と記入する
③IPv4 CIDR ブロックに有効なIpv4 CDIRを入力(例:10.0.0.0/16で一旦設定)
④作成ボタンを押下
⑤IPv6 CIDR ブロック・テナンシーは必要がなければデフォルトのまま
IPv4 アドレスの範囲を Classless Inter-Domain Routing
(CIDR) ブロックの形式で指定する必要があります (例: 10.0.0.0/16)。
サブネットの作成
①サービスからVPCを選択して、メニューからサブネットを選択後、【サブネットの作成】を押下
②名前タグにtest-public-subnet-1aと入力
③VPCに先程作成したVPCを選択
④アベイラビリティーゾーンはap-notrtheast-1aを選択
⑤IPv4 CIDR ブロックに10.0.10.0/24を入力
⑥もう一度サブネット作成を押下し名前タグにtest-private-subnet-1aと入力。④は同じものを選択
⑦IPv4 CIDRに10.0.20.0/24を入力
⑧もう一度サブネット作成を押下し名前タグにtest-private-subnet-1cと入力
⑨アベイラビリティーゾーンはap-notrtheast-1cを入力
参考: https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/VPC_Subnets.html
ルーティングの設定
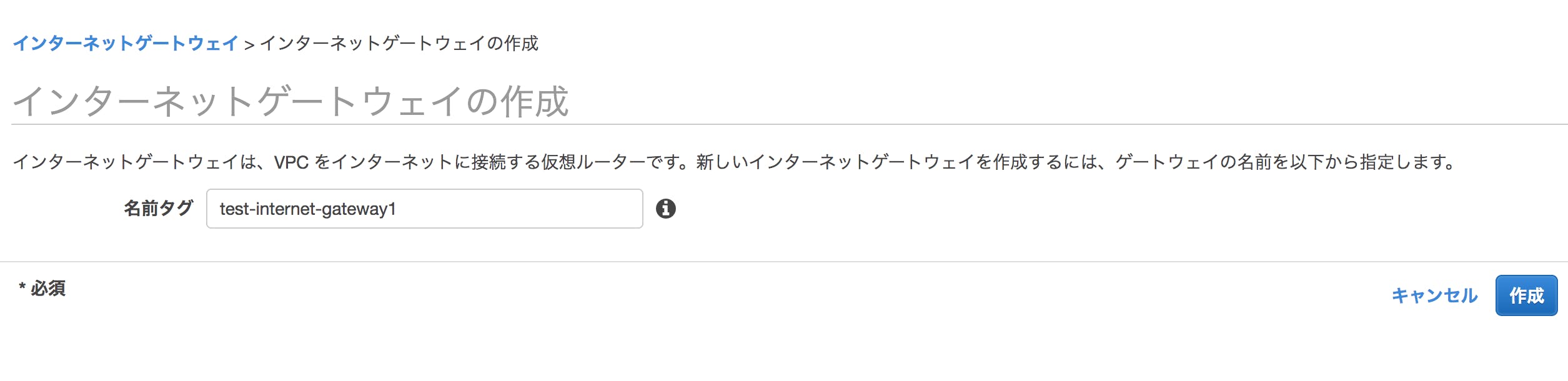
①サービスからVPCを選択し、メニューからインターネットゲートウェイを選択しインターネットゲートウェイの作成を押下
②名前タグにtest-internet-gateway1と入力し作成ボタンを押下
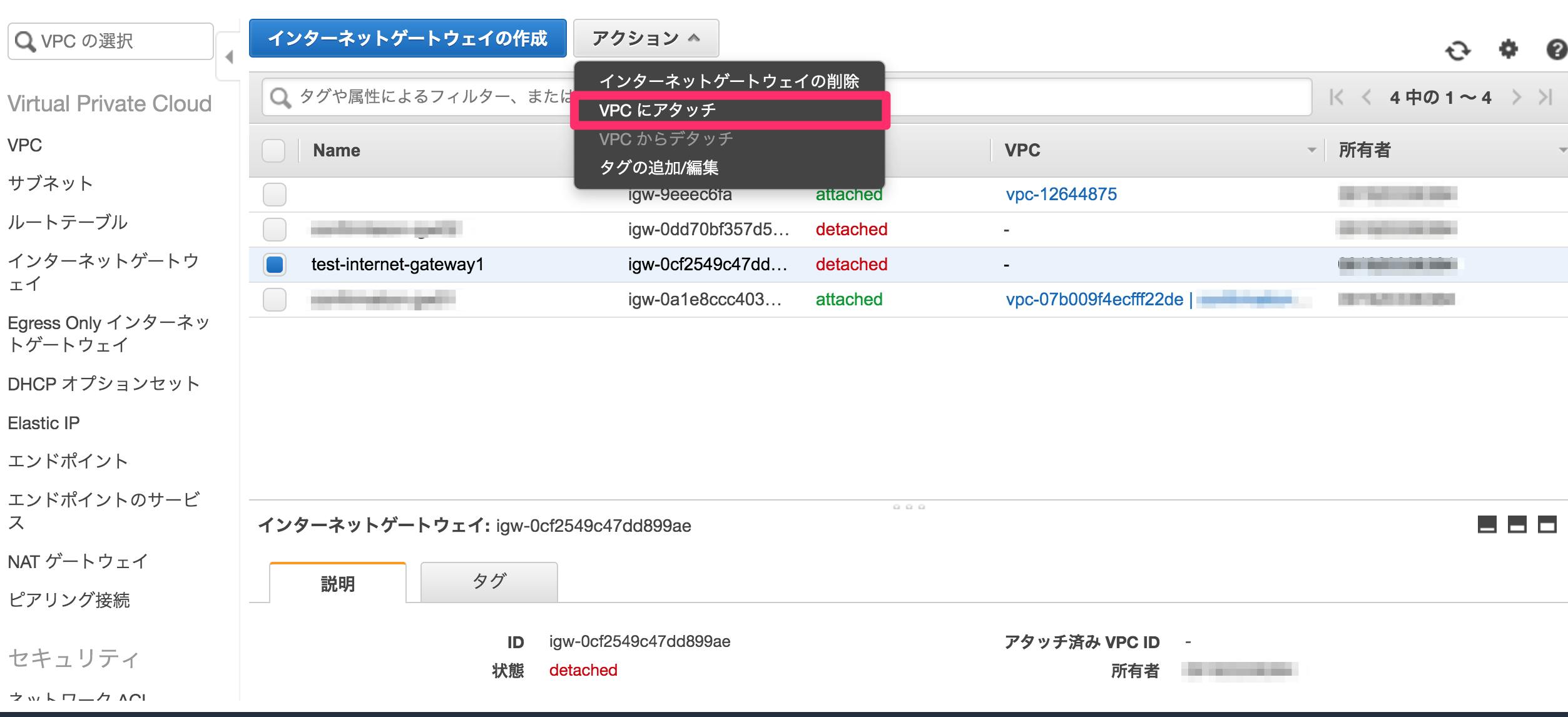
③作成されたインターネットゲートウェイのチェックボックスを押下する
④アクションからVPCにアタッチを選択し、先ほど作成したVPCのtest-ip1を選択し、アタッチボタンを押下
ルートテーブルの作成
①サービスからVPCを選択し、メニューからルートテーブルを選択
②ルートテーブルの作成を押下し、名前タグにtest-public-route-table1と入力
③VPCは作成したtest-ip1を選択
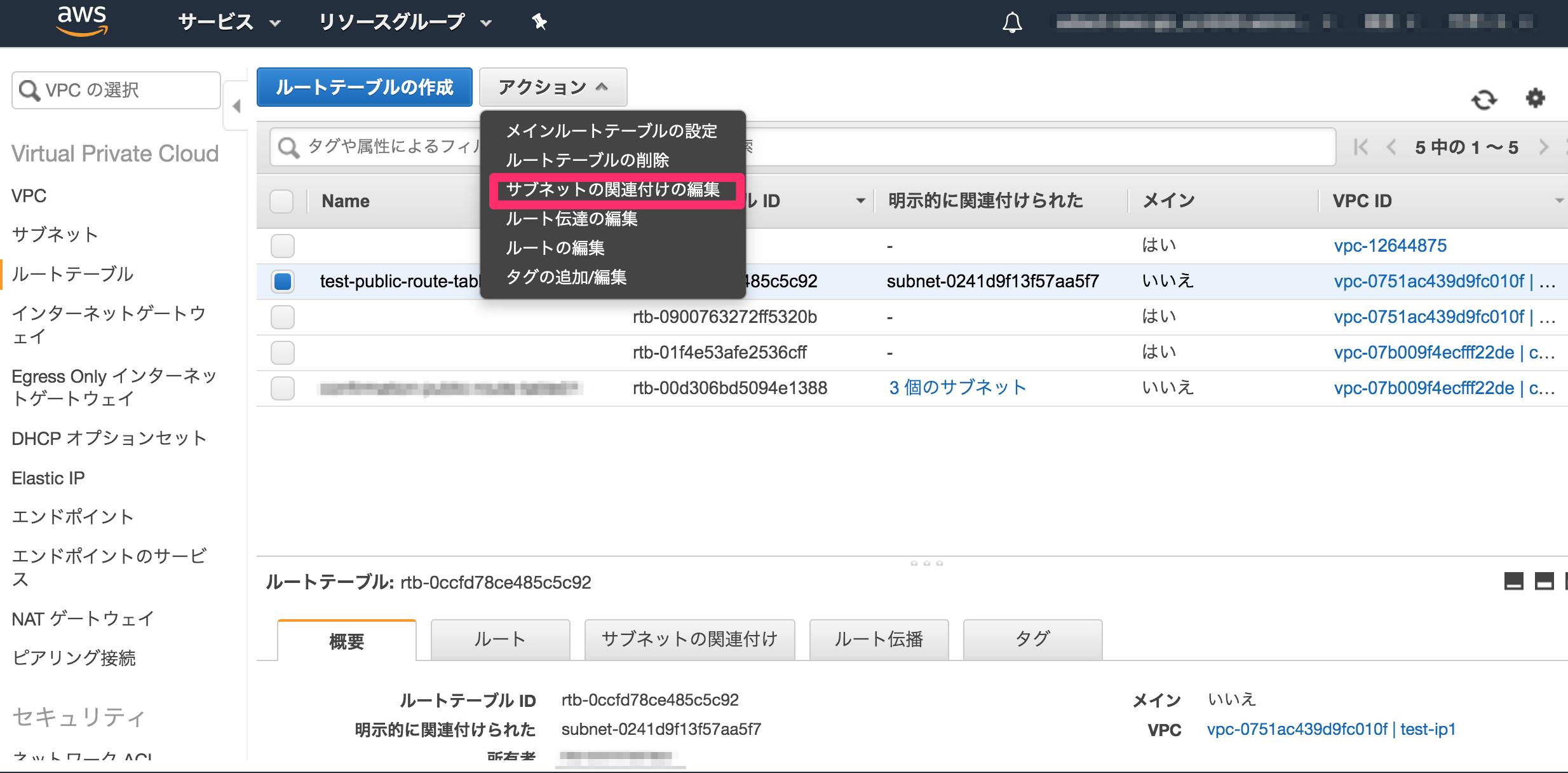
④作成された
test-public-route-table1のチェックボックスを押下し、サブネットの関連付けタブを押下しサブネット関連付けの編集を押下
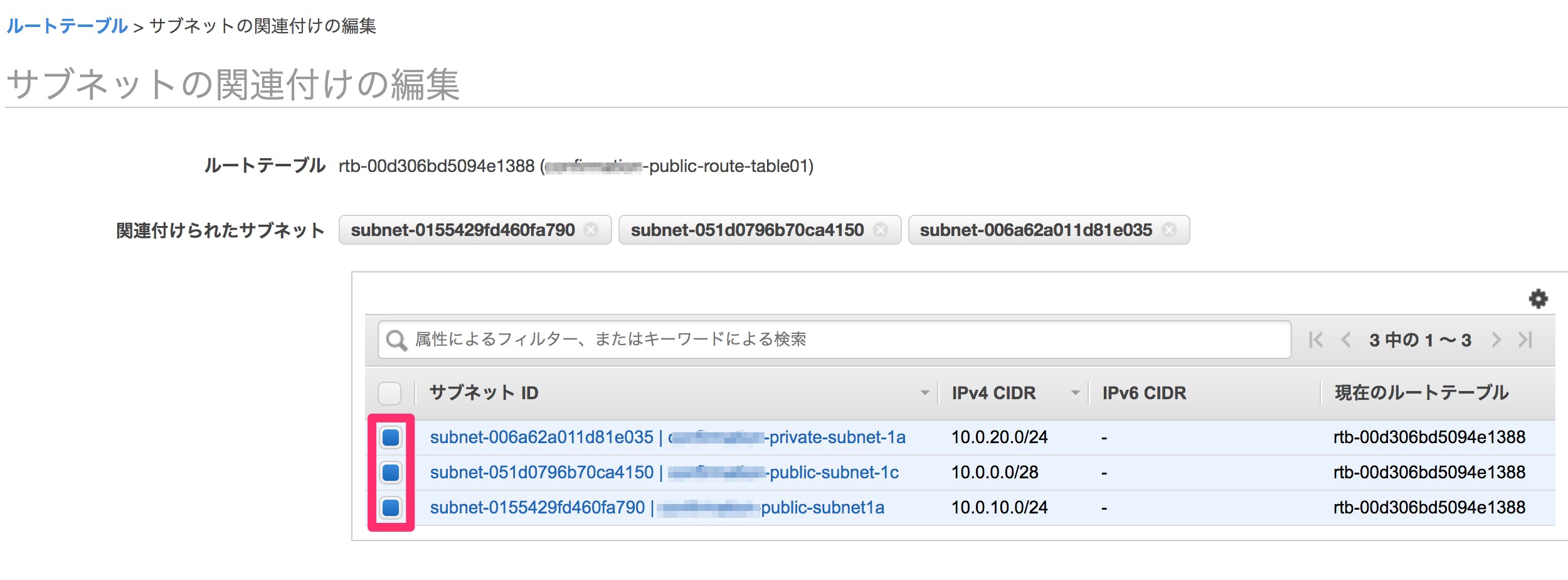
⑤作成した
test-public-subnet-1a,test-private-subnet-1a,test-public-subnet-1cを選択し、作成ボタンを押下する
⑥
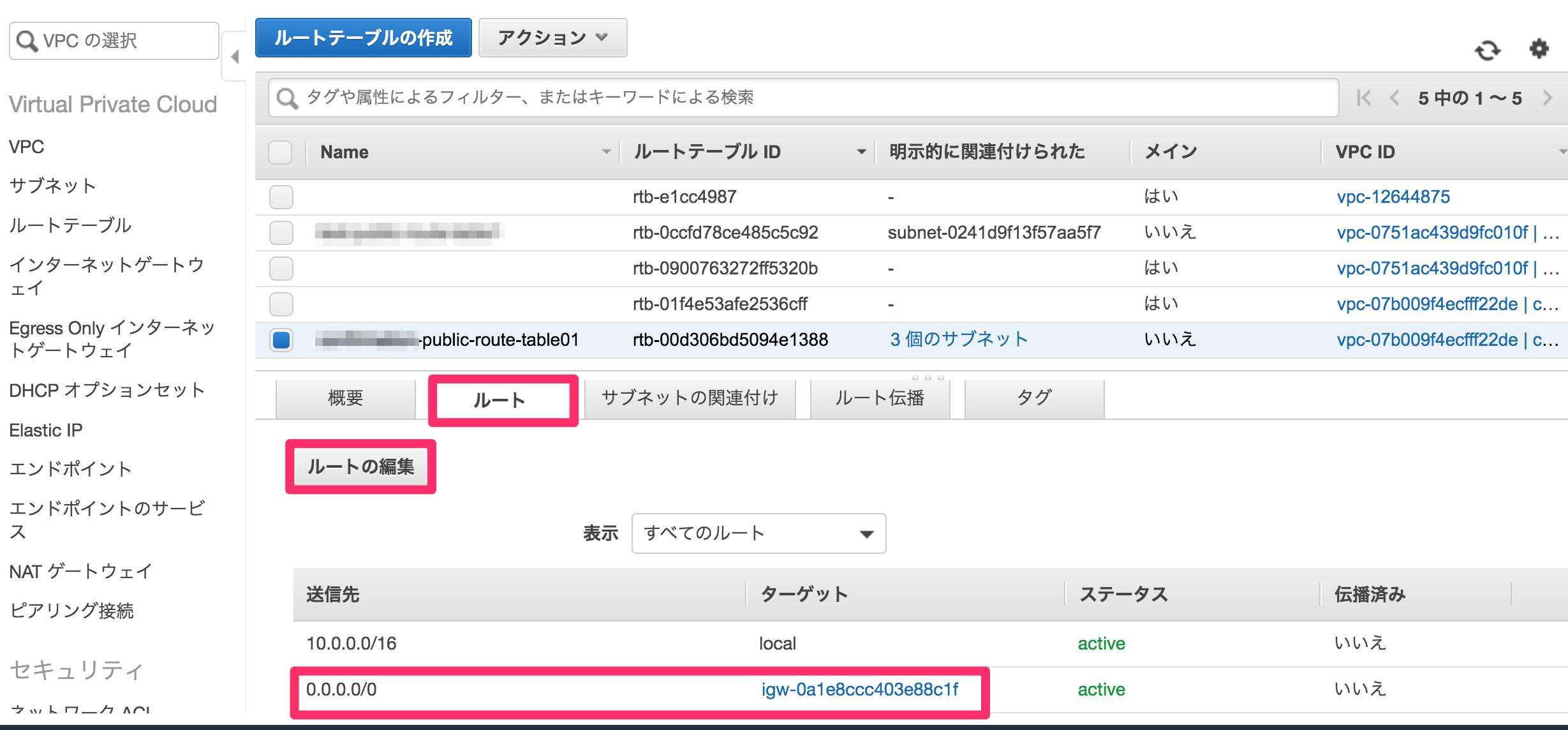
test-public-route-table1のチェックボックスを再度押下し、ルートタブからルートの編集を押下
⑦ルートの追加を押下
⑧送信先に0.0.0.0/0、ターゲットはInternet Gatewayを選びtest-internet-gateway1にする
EC2インスタンスのセットアップ
②→③の流れでユーザーはWordpressにアクセスする。
②のロードバランサーは、EC2インスタンスが無いと設定できないので、③のEC2インスタンスを先にセットアップする。①サービスからEC2を選択し、
インスタンス作成ボタンを押下
②AMI(Amazon Machine Image)は クイックスタートから無料枠のAmazonLinuxを選択
③インスタンスタイプは無料枠のt2.microを選択(動作確認くらいなのでこれで一旦進む※)
④インスタンスの詳細の設定を押下し、下記のテーブルの項目は変更する
項目 内容 ネットワーク VPCで作成したものを選択 サブネット VPCで作成したものを選択 ストレージサイズ 8Gb ボリュームタイプ: 汎用SSD Key: Name テストインスタンス01(作成するEC2インスタンスの名前)自動パブリック割り当てパブリック 有効 ⑤
ストレージの追加を押下
⑥タグの追加を押下し、タグの追加を押下し、下記のように入力
項目 内容 キー Name 値 テストインスタンス01 ⑦
セキュリティグループの設定を押下
⑧ 下記のように作成する。ルールの追加を押下して、ルールも追加する
項目 内容 セキュリティグループ名 wordpress-access 説明 wordpress-allow-access ⑨ ルールの追加 を押下し、下記のようなルールを作成する
タイプ プロトコル ポート範囲 ソース 説明 SSH TCP 22 0.0.0.0/0 HTTP TCP 80 0.0.0.0/0 ※IPアドレスは適切な範囲から絞り込んでください。今回は検証のためにセキュリティはあえて強固にしていません。
⑩
確認と作成を押下
⑪起動を押下
⑫新しいキーペアの作成を押下し、 キーペア名にwordpressと入力
⑬キーペアのダウンロードを押下 ※この時ダウンロードしたファイルは後で使います
⑭インスタンスの作成を押下ここまでで EC2インスタンスの起動が完了。
冗長構成にするためこちらをからもう一台インスタンスを設定するapacheのインストール
① EC2にログイン
console.bashssh -i ~/Downloads/wordpress.pem ec2-user@52.194.253.117➜ ~ ssh -i ~/Downloads/wordpress.pem ec2-user@52.194.253.117 Last login: Mon Nov 11 11:47:42 2019 from zz20194022436f572964.userreverse.dion.ne.jp __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 12 package(s) needed for security, out of 27 available Run "sudo yum update" to apply all updates. [ec2-user@ip-10-0-10-10 ~]$②EC2インスタンスのライブラリをアップデートしおく
sudo yum update -y③apacheをインストール
sudo yum install -y httpd④apacheを起動
sudo systemctl start httpd.serviceファイアーウォールの設定
①コンソール画面からEC2を選択し、インスタンスから
test-instance01を選択
②セキュリティグループに記載されているインスタンス名をクリックしインバウンドタブを押下
③編集ボタンを押下し、ルールの追加からHTTPを選択ポート番号は80のまま
ソースを任意の場所に変更し保存を押下EC2インスタンスにsshして
wordpress,apacheの起動sshで接続する
AWSコンソール上で、作成したEC2インスタンスを選択すると画面下部の詳細で下記のように表示される
この赤枠のIPアドレスに対して ssh接続を行う。
下記以降、EC2インスタンスに接続するIPアドレスは52.194.253.117としてアクセスするが、適宜自分自身のIPアドレスに置き換えてください。① sshで接続する ※1
console.bashssh -i ~/Downloads/wordpress.pem ec2-user@52.194.253.117※1:
~/Downloads/wordpress.pemの部分は、こちらの⑬で作成したファイルを指定する②下記のような画面となれば、 ssh接続は完了
➜ ~ ssh -i ~/Downloads/wordpress.pem ec2-user@52.194.253.117 Last login: Mon Nov 11 11:47:42 2019 from zz20194022436f572964.userreverse.dion.ne.jp __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 12 package(s) needed for security, out of 27 available Run "sudo yum update" to apply all updates. [ec2-user@ip-10-0-10-10 ~]$③ rootユーザーに切り替えておく
sudo su -PHPのインストール
①PHPのインストールコマンドをたたく
console.bashsudo amazon-linux-extras install -y php7.2console.bashsudo yum install -y php php-mbstringwordpressのインストール
① wgetコマンドでファイルを取得する
console.bashwget https://ja.wordpress.org/latest-ja.tar.gz② 次のように表示され、ダウンロードが完了する
[ec2-user@ip-10-0-10-10 ~]$ wget https://ja.wordpress.org/latest-ja.tar.gz --2019-11-11 11:57:07-- https://ja.wordpress.org/latest-ja.tar.gz ja.wordpress.org (ja.wordpress.org) をDNSに問いあわせています... 198.143.164.252 ja.wordpress.org (ja.wordpress.org)|198.143.164.252|:443 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 11838159 (11M) [application/octet-stream] `latest-ja.tar.gz.1' に保存中 100%[==================================================================================================================>] 11,838,159 5.51MB/s 時間 2.0s 2019-11-11 11:57:10 (5.51 MB/s) - `latest-ja.tar.gz' へ保存完了 [11838159/11838159]④ tarコマンドで解凍
tar xzvf latest-ja.tar.gz⑤
/var/www/htmlにファイルコピーcp -r wordpress/* /var/www/html/⑥ chown コマンドでファイルの所有権を変更
chown -R apache:apache /var/www/html/⑦ apache を起動させる
systemctl restart httpd.service※
restartだと、止まってても起動してても、再度起動がかかる⑧ ここまでで、WEBページにアクセスすると wordpressの設定画面が見れるようになる
著者の場合:
http://52.194.253.117/wp-admin/setup-config.phpwordpressで使用する RDSの設定
③→④の部分。
EC2インスタンスがRDSにSQLを送信してその結果を画面に返すような構成にしたい。
そのためにRDSの設定と、EC2インスタンスにRDSの接続先情報を設定する
①サービスからRDSを選択し、データベースの作成を押下
②データベース作成方法を選択で標準作成を選択
③エンジンのオプションでMySql、Mysqlバージョンは安定バージョン(筆者は5.7系を選択)
④テンプレートでは今回は無料利用枠を指定する
⑤DB インスタンス識別子にtest-database-01と記載
⑥認証情報の設定でDBにログインする際のユーザー名、パスワードを設定する
⑦接続はこちらで作成したVPCを選択
⑧追加の接続設定で
⑨その他はデフォルトのままでデータベース作成を押下wordpressを冗長構成にする
③の部分を見ると、EC2インスタンスが1台しか存在していない。
つまり、EC2インスタンスが1台障害等で使えなくなってしまった場合、このブログサイトはダウンしてしまう。
それを防ぐために複数のEC2インスタンスでwordpressを稼働させ、②のロードバランサーを使ってホットスタンバイかつ、ラウンドロビンを用いて冗長構成にする冗長構成
http://e-words.jp/w/%E5%86%97%E9%95%B7%E6%A7%8B%E6%88%90.htmlwordpressにログイン
①EC2で作成したインスタンスの
説明情報からIPv4 パブリック IPを確認し、新規タブでアクセスする
②Wordpressの画面が表示されるのでさあ始めましょうボタンを押下
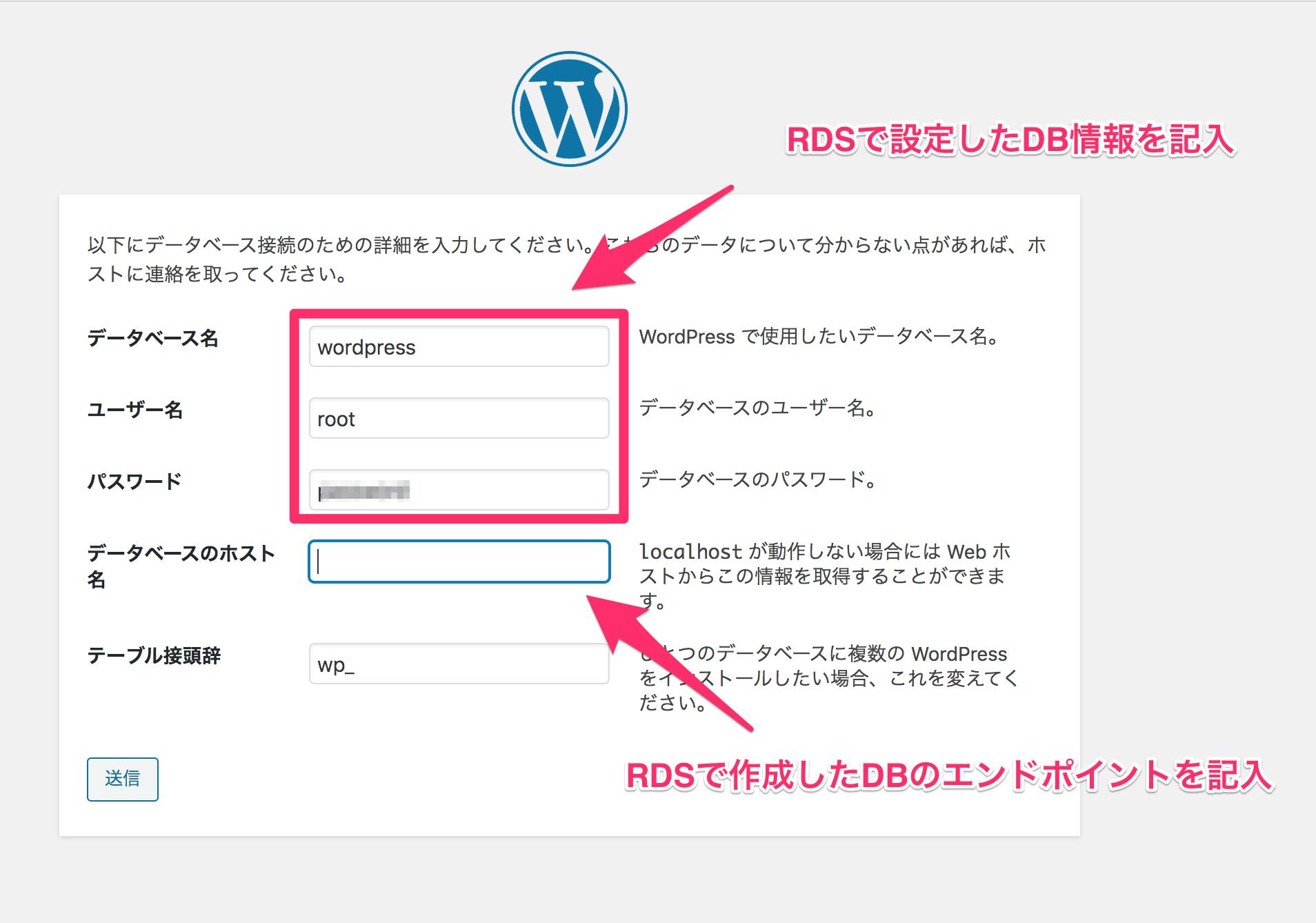
③下記画面が表示されるので情報を記載する
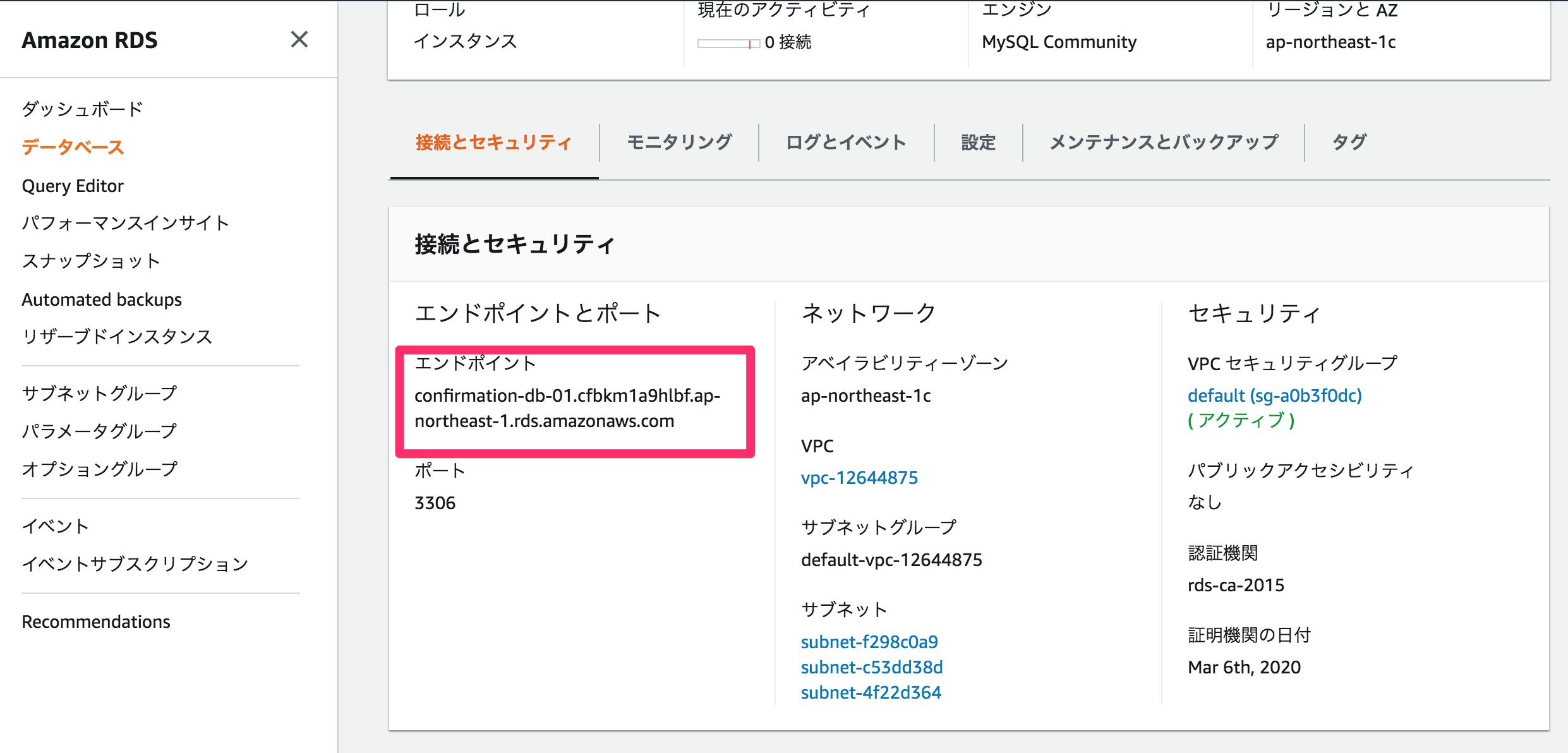
④データベースのホスト名には下記のRDS作成したDBのエンドポイントを記載する
DNSの設定を行う
現在wordpressにアクセスしようとすると、IPアドレスでのアクセスとなる。
著者の場合:http://52.194.253.117IPアドレスでアクセスするサイトは基本的に稀で、一般的にはドメインが使われます。
そのため、ドメインを用いてアクセスできるようにします。①サービスからRoute53をクリックし、メニューから
登録済みのドメインを選択
②ドメインの登録を押下
③取得したいドメインを入力し、トップレベルドメインを選び、チェックボタンをクリックし、使用できるドメインをカートに入れるを押下し、最下部の続行を押下。
④個人情報を入力し、続行を押下
⑤ドメインを自動的に更新しますか?は、お試しであれば無効化がおすすめ。
⑥規約に同意し、注文を完了を押下。※ ⑥を完了すると認証メールが登録したメールアドレスに届くのでメールを確認してリンクをクリックし認証しておく
ドメイン
https://ja.wikipedia.org/wiki/%E3%83%89%E3%83%A1%E3%82%A4%E3%83%B3%E5%90%8DDNS
https://ja.wikipedia.org/wiki/Domain_Name_SystemELBの設定
ELB作成ステップ1
①サービスからEC2を選択し、メニューから
ロードバランサーをクリック
②ロードバランサーの作成をクリックし、Application Load Balancerの作成を押下
③名前にtest-lb-01を入力する
④リスナーの追加をクリックし、以下をHTTPの設定を削除し追加する
ロードバランサーのプロトコル ロードバランサーのポート HTTPS 443 ⑤ 作成したVPCを選択しアベイラビリティゾーン最低2つ選択(作成したサブネットをそれぞれ選択)し、次の手順へすすむ
⑥ACM から新しい証明書をリクエストというリンクが出ているのでそのリンクをクリックACMでELB設定用の証明書作成
①ドメイン名にこちらで購入したドメインを入力し、
次へを押下
②DNS の検証を選択し確認を押下
③確定とリクエストを押下
④Route53でのレコード作成を押下する(Route53にCNAMEが登録される)
ELB作成ステップ2
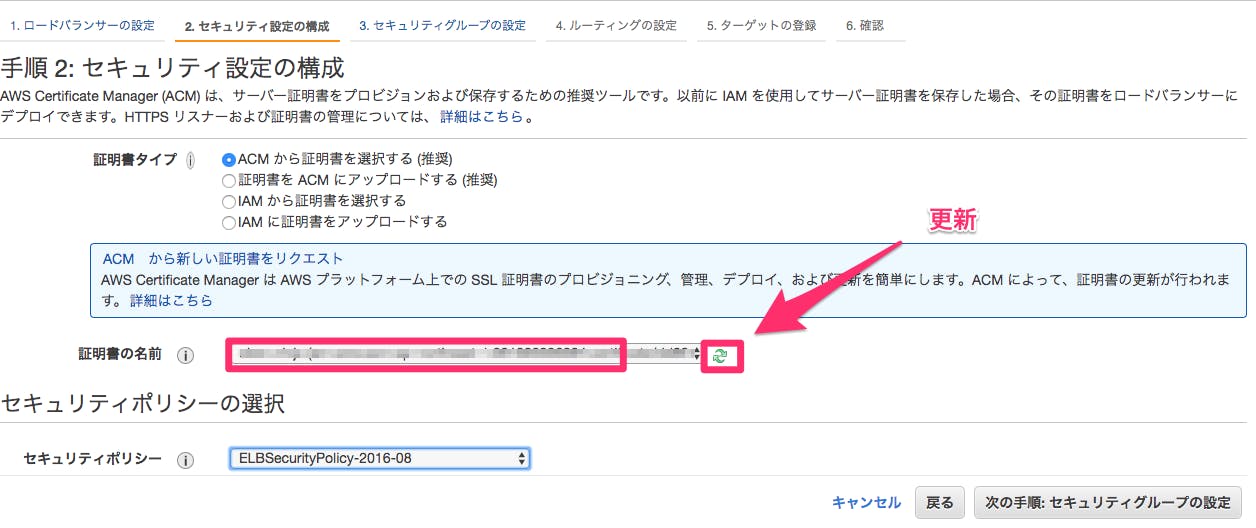
①下記にある
更新部分のボタンを押下し、作成したドメインの証明書が表示されたことを確認し、次の手順へ進む
②セキュリティグループの設定で
新しいセキュリティグループの作成するを選択
③セキュリティグループ名と説明を入力し次の手順へすすむ(他はデフォルトでOK)
④ルーティングの設定で名前にtest-target-group01と入力し、次へ
⑤下記の図を参照(EC2インスタンスを2台作成しているので2つのインスタンスを登録済みにする)
⑥
確認を押下し、作成を押下Route53でAレコードの設定
①
レコードセットの作成を押下し、タイプをA-IPv4アドレス、エイリアスをはいにする
②エイリアス先のターゲット名の入力欄をクリックし、ELB Application Load Balancerで作成したろーELBを選択する
③レコードセットの保存を押下
確認
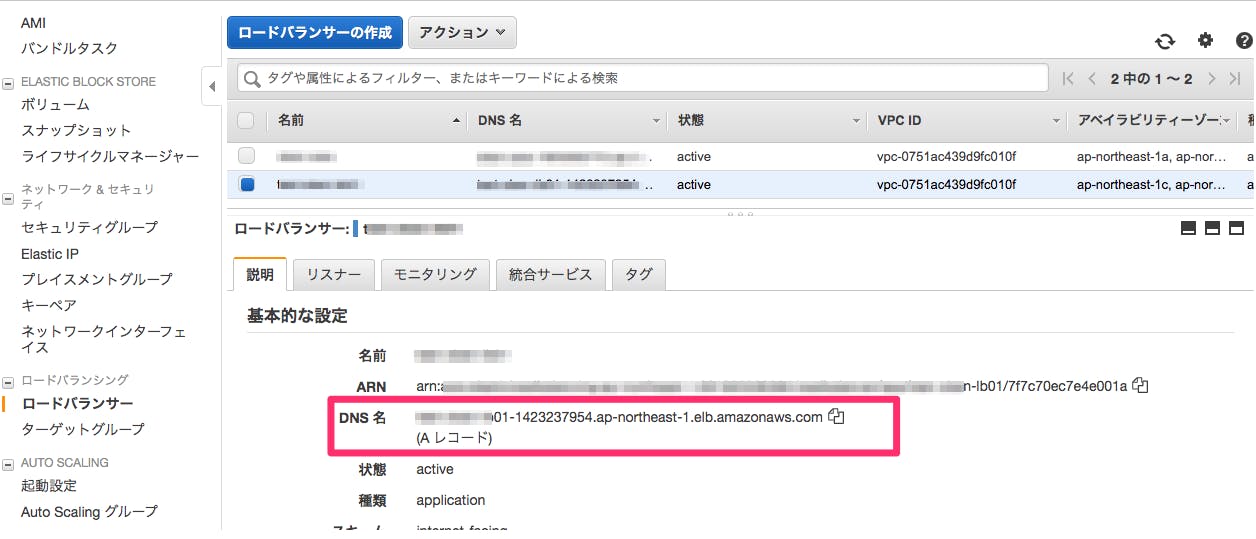
①ロードバランサーの一覧画面に遷移して、DNS名をコピー
②新しいタブを開き、DNS名をペーストしWordpressの画面がでてきたらOK
③購入したドメインでも接続を試してみてWordpressの画面が表示されればOKWordPressにCSSがあたらない
ELBを介すると、WordpressのCSSが上手く当たらないため対策を入れなければいけない
①以下のコードをfunctions.phpに追記する
/var/www/html/wp-includes/functions.phpclass relative_URI { function relative_URI() { add_action('get_header', array(&$this, 'get_header'), 1); add_action('wp_footer', array(&$this, 'wp_footer'), 99999); } function replace_relative_URI($content) { $home_url = trailingslashit(get_home_url('/')); return str_replace($home_url, '/', $content); } function get_header(){ ob_start(array(&$this, 'replace_relative_URI')); } function wp_footer(){ ob_end_flush(); } } new relative_URI(); //↑ここまでをコピペ require( ABSPATH . WPINC . '/option.php' );②apacheの再起動
console.bashsystemctl restart httpd.service③再度ドメインにアクセスし、表示が問題なければOK
参照: https://dogmap.jp/2011/03/18/wordpress-relative-url/
完成
ここまでで、ELBによってロードバランシングされ、冗長構成な wordpressの作成が完了です。
データベースはRDSが使用され、ドメインもRoute53で管理されている、全てAWSを使ってwordpressのインフラを構築してみました。完成図
感想
AWSの管理画面をポチポチするだけでサーバやロードバランサー、DBなどの設定を簡単にできる。
ただ、ネットワークの知識とか基礎的なものがないと操作わかっていてもあいまいなところがあるので勉強は必要だなと感じた。









- 投稿日:2019-11-25T11:39:51+09:00
unexpected status "ROLLBACK_IN_PROGRESS" while waiting for CloudFormation stack ... が起きたら
ちょっとハマったので、同じ轍を踏む人が少しでも早く解決できるようにUP
環境
eksctl : 0.10.1
対応
eksctl を 0.10.2 以降に上げる
エラーメッセージ
[centos]$ eksctl create cluster --name=k8s --region=ap-northeast-1 --nodes=3 --nodes-min=1 --nodes-max=3 --version=1.12 --node-type=t2.medium --vpc-private-subnets=subnet-1,subnet-2,subnet-3 --vpc-public-subnets=subnet-4,subnet-5,subnet-6 Mon Nov 25 01:42:32 UTC 2019 [?] eksctl version 0.10.1 [?] using region ap-northeast-1 [?] using existing VPC (vpc-xxxxxxxxxxxxxxxxx) and subnets (private:[subnet-3 subnet-2 subnet-1] public:[subnet-4 subnet-5 subnet-6]) [!] custom VPC/subnets will be used; if resulting cluster doesn't function as expected, make sure to review the configuration of VPC/subnets [?] nodegroup "ng-xxxxxxxx" will use "ami-0cb3fc9f948330b7d" [AmazonLinux2/1.12] [?] using Kubernetes version 1.12 [?] creating EKS cluster "k8s" in "ap-northeast-1" region [?] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup [?] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=ap-northeast-1 --cluster=k8s' [?] CloudWatch logging will not be enabled for cluster "k8s" in "ap-northeast-1" [?] you can enable it with 'eksctl utils update-cluster-logging --region=ap-northeast-1 --cluster=k8s' [?] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "k8s" in "ap-northeast-1" [?] 2 sequential tasks: { create cluster control plane "k8s", create nodegroup "ng-2d1b6c23" } [?] building cluster stack "eksctl-k8s-cluster" [?] deploying stack "eksctl-k8s-cluster" [?] unexpected status "ROLLBACK_IN_PROGRESS" while waiting for CloudFormation stack "eksctl-k8s-cluster" [?] fetching stack events in attempt to troubleshoot the root cause of the failure [?] 1 error(s) occurred and cluster hasn't been created properly, you may wish to check CloudFormation console [?] to cleanup resources, run 'eksctl delete cluster --region=ap-northeast-1 --name=k8s' [?] waiting for CloudFormation stack "eksctl-k8s-cluster": ResourceNotReady: failed waiting for successful resource state [?] failed to create cluster "k8s"参考リンク
- 投稿日:2019-11-25T10:41:09+09:00
keycloakをAWS上にインストール・RDSと連携まで
この記事について
開発中のソフトウェアのログインにKeycloakを使用するので、セットアップ中に起こった問題とそれらに対するトラブルシューティングを備忘録として残す第二弾です。今回はAWS上に公式版(Github版ではない)のkeycloakをインストールし、RDSと連携させる手順を説明します。RDSはMySQLを使用しました
バージョンとクラス
keycloak: 6.0.1
AWS EC2: t2.micro
RDS: db.t2.micro, MySQL
日付:2019/11/22目次
AWSの設定(VPC)
まず最初に、AWSサーバーがインターネットからアクセスできるようVPCを使ってネットワークを構築していきます。Amazon VPC(Vitual Private Cloud)を使用すると、定義したAWSアカウント専用の仮想ネットワーク内で AWS リソースを起動できます。設定の流れはVPCのIP アドレス範囲を指定して、サブネットを追加し、セキュリティグループを関連付けて、ルートテーブルを設定するといった具合です。
サブネットとは
サブネットは、VPC の IP アドレスの範囲です。AWS リソースは、指定したサブネット内に起動できます。インターネットに接続する必要があるリソースにはパブリックサブネットを、インターネットに接続しないリソースにはプライベートサブネットを使用してください。インターネットにアクセスする
デフォルト VPC にはインターネットゲートウェイが含まれ、各デフォルトサブネットはパブリックサブネットです。デフォルトサブネット内に起動するインスタンスにはそれぞれ、プライベート IPv4 アドレスとパブリック IPv4 アドレスが割り当てられています。これらのインスタンスは、このインターネットゲートウェイを介してインターネットと通信できます。インターネットゲートウェイを使用すると、インスタンスは Amazon EC2 ネットワークエッジを介してインターネットに接続できます。
デフォルトでは、デフォルト以外のサブネットで起動した各インスタンスにはプライベート IPv4 アドレスが割り当てられていますが、パブリック IPv4 アドレスは割り当てられていません。
デフォルト以外のサブネットで起動するインスタンスのインターネットアクセスを有効にするには、インターネットゲートウェイをその VPC (デフォルト VPC でない場合) にアタッチし、インスタンスに Elastic IP アドレスを関連付けます。
1. VPCの作成
AWSマネジメントコンソールから、VPCを選択
ダッシュボードのVPCから、VPCの作成をクリック
適当に名前をつけ(わかりやすいようにkeycloak_vpcとか)、IPv4 CIDR ブロックにはまずは10.0.0.0/16を入れます
10.0.0.0/16が既に使われていた場合は10.1.0.0/16や20.0.0.0/16などでIPの数字をいい感じに上げます2. サブネットの作成
サブネットにはパブリックなものと、プライベートなものがあります。前述したように、インターネットに接続したい場合はパブリックサブネットが必要になります。それに加え今回はインターネットには直接接続ししないデータベースも作るので、プライベートサブネットも必要になります。といっても初期設定でできる事はあまりありません。ダッシュボードからサブネット、サブネット作成で名前を仮にkeycloak_publicとkeycloak_privateにします。VPCは先ほど作成したkeycloak_vpcに関連付けします。アベイラビリティゾーンはここで設定したものを後の設定でも一貫してください。IPv4 CIDR ブロックは、VPCのIPアドレスの3番目の数字をひとつ大きくした数字を使い、ポートは24から使用できます。(例: VPCが10.0.0.0/16ならサブネットは10.0.1.0/24[keycloak_public]と10.0.2.0/24[keycloak_private])3. インターネットゲートウェイの接続
次にインターネットへ接続するためにインターネットゲートウェイを作成します。同じくダッシュボードのインターネットゲートウェイから、インターネットゲートウェイの作成をクリックしてください。名前をkeycloak_gateとしてさくせいします。次に、インターネットゲートウェイ作成ボタンの隣にあるアクションというボタンから、VPCにアタッチを選択して先ほど作ったkeycloak_vpcに接続します。これでVPCからインターネットへアクセスする入口ができましたが、それをインスタンス(サブネット)に繋げるルートがありません。4. ルートテーブルの作成
そこで、インターネットの入口からVPCの中身を繋ぐルートを作ります。ダッシュボードのルートテーブルからルートテーブルの作成をクリックしてください。名前をkeycloak_routeとしてVPCはkeycloak_vpcを選びます。次に作成ボタンの隣のアクションからルートの編集に行きます。
デフォルトで上の様な設定になっていると思います。10.0.0.0/16はVPCのIPアドレスです。ここに送信先を0.0.0.0/0、ターゲットをkeycloak_vpcとしたルートを追加します。これで、インターネットゲートウェイからサブネットにIPの制限なく通信することができます。そして、画面の下の方にサブネットの関連付けというタブがあるので、keycloak_publicに関連付ければ、keycloak_publicサブネットからはインターネットにアクセスできます。これでVPCの準備は完了です。
AWSの設定(EC2)
Amazon Elastic Compute Cloud (Amazon EC2) は、AWSクラウドでサイズが変更できるコンピューティングキャパシティーを提供します。必要な数の仮想サーバーを起動して、セキュリティおよびネットワーキングの設定と、ストレージの管理を行います。Amazon EC2 では、要件変更や需要増に対応して迅速に拡張または縮小できるため、サーバートラフィック予測が不要になります。インスタンスと呼ばれる仮想コンピューティング環境で開発・デプロイをしていきます。
1. インスタンスの作成
以下の設定で作成していきます
AMI: Amazon Linux 2 AMI (HVM), SSD Volume Type
インスタンスタイプ: 汎用t2.micro(無料利用枠)
ネットワーク: keycloak_vpc
サブネット: keycloak_public
自動割り当てパブリック IP: 有効
作成したら名前をkeycloak_serverとします2. Elastic IP
これでインスタンスは作成し、VPCにも繋いでいるのでインターネットへのアクセスも可能です。しかし、現時点ではインスタンスを起動する度にパブリックIPアドレスが変わってしまうという欠点があります。これを回避するために、Elastic IPによってインスタンスのパブリックIPを固定します。ダッシュボードからネットワーク&セキュリティにElastic IPがあります。ここからElastic IPアドレスの割り当てをクリック、新たにパブリックIPアドレスを生成します。生成したIPを選択し、アクションタグのElastic IPアドレスの関連付けからkeycloak_serverに関連付けます。インスタンス画面に戻るとパブリックDNS(IPv4)とIPv4パブリックIPが固定されているはずです。セキュリティグループ
実世界でパケットフィルタリングを構成するのは、ルーターやサーバー、もしくは専用のファイアウォール機器だが、AWSでは、インスタンスに対して、構成する「セキュリティグループ」がこの機能を担う。先ほどインスタンスに対して作ったセキュリティグループ(launch-wizard-<数字>)を見ると、デフォルトの構成でinboundを見ると、ポート22にたいして全ての通信(0.0.0.0/0)を許可する、という設定があり、それ以外の設定はないことがわかる。
デフォルトのこの設定では、webサーバーソフトなどをインスタンスに入れた賭しても、阻まれて通信できないので、ソフトウェアのインストールとともに、セキュリティグループの構成も変更していく。最低限必要なのは以下の数個でしょうか。
タイプ プロトコル ポート範囲 ソース HTTP TCP 80 <自分のIPアドレス> HTTP TCP 80 < Elastic IP> カスタムTCP TCP 8080 < Elastic IP> SSH TCP 22 <自分のIP> SSH TCP 22 < Elastic IP> MYSQL TCP 3306 0.0.0.0/0 HTTPS TCP 443 0.0.0.0/0 接続できなかったり、必要があれば随時追加してください。
AWSの設定(RDS)
本稼働ではkeycloakは膨大な量のユーザーの情報を保管する可能性があります。EC2サーバーだけではおそらくパンクしてしまうので、Amazonが提供しているデータベースサービスのRDSへデータを保存します。
RDSを作成するには、EC2のダッシュボードではなくAWS マネジメントコンソールに行きます。RDSという項目があるのでクリックして、RDSのダッシュボードに行きます。データベースからデータベースの作成をクリックします。以下の設定で作成します。作成方法: 標準方法
エンジン: MySQL
バージョン: 5.7.22(ここはデフォルト)
テンプレート: お好みのスペックで
名前: keycloak-rds
マスターユーザー名: admin
パスワード: 適当に
VPC: keycloak_vpc
サブネット: 新規作成
パブリックアクセス可能: はい(重要)
VPCセキュリティグループ: Default + 新規作成(内容はEC2のものと同じ)
アベイラビリティゾーン: EC2と同じ
ポート: 3306RDSパラメータグループ設定
これでデータベースができました。しかしこのまま接続しても文字コードのエラーがでてしまいます。なぜなら、RDSのデフォルトは日本語に対応しているUTF-8ではなく、ラテン語に設定されているからです。mysql> show variables like 'character%'; +--------------------------+-------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /rdsdbbin/mysql-5.7.22.R5/share/charsets/ | +--------------------------+-------------------------------------------+ 8 rows in set (0.00 sec)普通ならば/etc/my.cnfをいじって設定を変更しますが、AWSのSQLの場合それができないのでダッシュボードのパラメータグループから新規にパラメータグループを作成します。作成したら、そのパラメータグループを選択してパラメータの編集をします。
"character"で検索をかけると8つ程パラメータが出てくるので、character_set_filesystem(デフォルトでbinary)以外をutf-8に変更します。mysql> show variables like 'character%'; +--------------------------+-------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /rdsdbbin/mysql-5.7.22.R5/share/charsets/ | +--------------------------+-------------------------------------------+ 8 rows in set (0.00 sec)これで日本語のデータが保存可能になります。
データベースの変更タグから、keycloak-rdsのパラメータグループの変更もお忘れなく。インストール各種
JDK8のインストール
$ sudo yum update -y $ sudo yum install java-1.8.0-openjdkkeycloakのインストール
$ cd /opt $ sudo wget https://downloads.jboss.org/keycloak/6.0.1/keycloak-6.0.1.zip $ sudo unzip keycloak-6.0.1.zip $ sudo mv keycloak-6.0.1 keycloakkeycloakのSQLドライバー(Java Database Connector)のインストール
$ sudo mkdir /opt/keycloak/modules/system/layers/keycloak/com/mysql $ sudo mkdir /opt/keycloak/modules/system/layers/keycloak/com/mysql/main $ sudo cd /opt/keycloak/modules/system/layers/keycloak/com/mysql/main $ sudo wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.42.zip $ sudo unzip mysql-connector-java-5.1.42.zip $ sudo cp mysql-connector-java-5.1.42/mysql-connector-java-5.1.42-bin.jar ./ $ sudo vi module.xml/opt/KEYCLOAK_HOME/modules/system/layers/keycloak/com/mysql/main/module.xml<?xml version="1.0"?> <module xmlns="urn:jboss:module:1.3" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.42-bin.jar"/> </resources> <dependencies> <module name="javax.api"/> <module name="javax.transaction.api"/> </dependencies> </module>MySQLのインストール
$ sudo yum install mysql-community-server -y $ mysqld --versionインストールにエラーが出たら下の参考文献をご覧ください(私はなぜかここでつまづいて結構時間取られました)
MySQLの設定
keycloakからログインする為のユーザーとデータベース作成
#EC2コンソールからRDSに接続します #ユーザーネームとパスワードはRDS作成時に作ったものです $ mysql -h <keycloak-rdsのエンドポイント> -P 3306 -u admin -p <password> #keycloakからログインする時用のユーザー作成 mysql> create user 'keycloak-user' identified by '<パスワード>'; #keycloakのデータ保存用のデータベース作成 mysql> create database keycloakDB character set utf8 collate utf8_unicode_ci; #keycloak-userにkeycloakDB上の全権限付与 mysql> grant all privileges on keycloakDB.* to 'keycloak-user'; mysql> exitkeycloak内の設定
1. 外部IP、書き込み権限とログ
#keycloak用のなにかではあったが詳しくは不明(ないとうまく動作しない) $ export EXTERNAL_IP=$(curl -s 169.254.169.254/latest/meta-data/local-ipv4) #書き込み権限 $ sudo chmod 777 -R ./ #ログ用ディレクトリ作成 $ sudo mkdir /var/log/keycloak2. サーバーコンフィグファイルの設定
/opt/KEYCLOAK_HOME/standalone/configuration/standalone-ha.xml#データベースへの接続 <datasource jndi-name="java:jboss/datasources/KeycloakDS" pool-name="KeycloakDS" enabled="true" use-java-context="true" statistics-enabled="${wildfly.datasources.statistics-enabled:${wildfly.statistics-enabled:false}}"> <connection-url>jdbc:mysql://<keycloak-rdsのエンドポイント>:3306/keycloakDB?characterEncoding=UTF-8&useSSL=false</connection-url> <driver>mysql</driver> <security> <user-name>keycloak-user</user-name> <password><パスワード></password> </security> </datasource> <drivers> <driver name="mysql" module="com.mysql"> <xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class> </driver> <driver name="h2" module="com.h2database.h2"> <xa-datasource-class>org.h2.jdbcx.JdbcDataSource</xa-datasource-class> </driver> </drivers> . . . #KeycloakサーバーのIPアドレスに変更 <interfaces> <interface name="management"> <inet-address value="${jboss.bind.address.management:<EC2プライベートIP>}"/> </interface> <interface name="public"> <inet-address value="${jboss.bind.address:<EC2プライベートIP>}"/> </interface> <interface name="private"> <inet-address value="${jboss.bind.address.private:<EC2プライベートIP>}"/> </interface> </interfaces>3. ログインと通信設定
/opt/KEYCLOAK_HOME/#初回ログイン用にアドミンユーザー作成 $ ./bin/add-user-keycloak.sh -r master -u admin -p admin #起動 $ ./bin/standalone.sh --server-config=standalone-ha.xml -b <EC2のパブリックDNS> -Djboss.node.name=<EC2のパブリックDNS> -Djboss.bind.address.private=<EC2のパブリックDNS> #アドミンとして認証情報を設定する $ ./bin/kcadm.sh config credentials --server http://<プライベートIP>:8080/auth --realm master --user admin --password admin #SSL requiredをNONEに変更 $ ./bin/kcadm.sh update realms/master -s sslRequired=NONE change https listener4. https通信への変更
一旦Control Cでサーバーを落とし、以下をして再起動します
proxy-address-forwarding="true"を追加/opt/KEYCLOAK_HOME/standalone/configuration/standalone-ha.xml<http-listener name="default" socket-binding="http" proxy-address-forwarding="true" redirect-socket="https" enable-http2="true"/>5. ログイン
http://<IPv4パブリックIP>:8080/authにアクセス完了です
参考文献
Keycloak 開発入門
AWSのEC2で行うAmazon Linux2(MySQL5.7)環境構築
Keycloakのインストール方法をわかりやすく手順化してみた


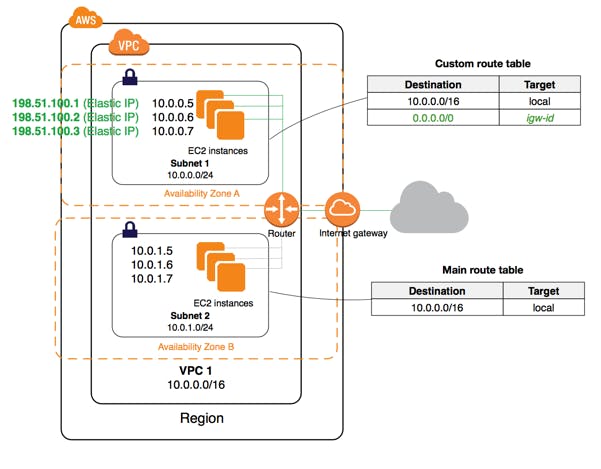


- 投稿日:2019-11-25T02:38:55+09:00
【GKE】Serviceリソースの外部IPアドレスに対してroute53で名前解決する方法
GKEの外部IPアドレスについて知っておきたい予備知識
※本記事は、GKE上にコンテナをデプロイしてServiceリソースを作成した前提でお話を進めます。(GKEの公式ドキュメントが分かりやすすぎるので、あえてドキュメントを書くまでもないと思っています。)
Dockerfileの作成方法については以下にまとめたので参考にしていただけると幸いです。
参考:https://qiita.com/arthur_foreign/items/fca369c1d9bde1701e38ただ、前提の前にGKEにおいて知っておきたい知識も、Google公式から引用しておきます。
デフォルトで、Kubernetes Engine 上で実行するコンテナは、外部 IP アドレスを持たないため、インターネットからアクセスできません。
アプリケーションのポッドにネットワーキングと IP サポートを提供する Service リソースを作成します。Kubernetes Engine は、アプリケーションの外部 IP とロードバランサ(課金対象)を作成します。
引用:https://cloud.google.com/kubernetes-engine/docs/tutorials/hello-app?hl=ja#step_6_expose_your_application_to_the_internetこの外部IPアドレスに対して、
route53で名前解決するのが本記事でやることです。GKEで作成したServiceリソースの外部IPアドレスの確認
$ kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE app_name LoadBalancer 11.1.11.11 11.111.111.111 80:22222/TCP 4d ※IPアドレスやServiceの外部IPアドレスは適当にぼかしています。
EXTERNAL-IPのIPアドレス(11.111.111.111)に対して、route53で名前解決してあげましょう。GKEのServiceリソースの外部IPアドレスに対してroute53で名前解決する
※ホストゾーンは設定されている前提で話を進めます。
kubectl get serviceで確認した外部IPアドレス(11.111.111.111)を「値」に入力しましょう。入力したら「作成」を押してあげてください。
これで名前解決は完了です。
IPアドレス周りの知識に関して参考にしておきたい記事
AレコードとCNAMEレコードの違いについては以下が参考になりました。
参考1:https://qiita.com/PharaohKJ/items/b6a933b7f79afe8a32e1
参考2:https://jprs.jp/glossary/index.php?ID=0212
参考3:http://fujiike.hateblo.jp/entry/2015/09/14/191934
