- 投稿日:2019-02-09T23:23:31+09:00
【Python】特定のインスタンスにメソッドを追加
types.MethodTypeを使うtypes.MethodType(function, instance) Create a bound instance method object.バウンドされたインスタンスメソッドを作成します
動作環境
Python 3.7.1特定のインスタンスにだけメソッドを追加する
class MyClass: def __init__(self, name): self._name = name a = MyClass('tamago') b = MyClass('taro')
bのインスタンスにだけメソッドを追加したい場合、types.MethodType()でbに紐づくインスタンスメソッド(get_name)を生成し、b.get_nameに設定する# 関数を定義 >>> def get_name(self): ... return self._name >>> import types # bのインスタンスメソッドを生成し、設定する >>> b.get_name = types.MethodType(get_name, b) >>> b.get_name() 'taro'また、
aにはget_nameというメソッドは無いため、エラーになる>>> a.get_name() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'MyClass' object has no attribute 'get_name' 'MyClass' object has no attribute 'get_name'面白い
参考文献
- 投稿日:2019-02-09T23:14:00+09:00
数字と文字
前回:https://qiita.com/New_enpitsu_15/items/b71c7da6387b315d6f7e
次回:
目次:https://qiita.com/New_enpitsu_15/private/479c69897780cabd01f4Pythonには、というか、ほとんどのプログラム言語には数字と文字の区別があります。
数字と文字の区別?
前回、
文字列という単語が出てきたのを覚えていますか?
文字列は、その名の通り文字の集合です。文字は文字じゃん…と言われれば、文字は文字なのですが
たとえば
1+1
は2ですよね?
ところがどっこい。"1"+"1"
は"11"なのです。
そんな小学生のひっかけみたいなこと…と思うかもしれませんが、実際にprint(1+1) #2 print("1"+"1") #11と実行してあげるとそうなるのです。
これは
1は数値を表していて、
"1"は文字を表しているから。だいたいイメージはつくとは思いますが、
文字列("1"とか)同士の足し算は結合ってことになります。
なので"1"と"1"を結合したら"11"なんですね。1+1はそのまま数値の計算ですから2です。
数字と文字の区別は、そういったところから必要となってくるんですね。
ちょっとまって!"や'を文字として使いたいんだけど!
普通では、
"と'は文字を区別するための記号なので使うことはできません。でも
"+"と表示したかったりするときはどうすればいいの?大丈夫。そんな時は、
'"+"'と、周りを違う引用符で囲ってあげましょう。print('"+"') #"+"せんせー!だったら'"+"'は表示できないんですかー?
できます。
でもこれは少し厄介。普通に"で囲っても、''と表示されるだけでしょう。print("'"+"'")#"'"と"'"を結合している #''だったらどうするの。そんな時はバックスラッシュ(えんまーく)を文字として表示したい
"の前につけてあげましょう。print("'\"+\"'") #'"+"'すると、
'"+"'と表示されましたね。
この、文字の前につけるバックスラッシュのことを、エスケープシークエンスといったりします。エスケープ
エスケープは
"の前に\と書きましたが、他にもいろいろあります。
例えば、\'は'を文字として。\\は\自体を文字として表示してくれます。print("\"") #" print('\'') #' print("\\") #\ほかにも、
\nで改行。print("ここで日記は途切れている\n\n\nとでも思っていたのか") #日記はここで途切れている # # # #とでも思っていたのかなどなど、ほかにもいろいろな種類があります。
(調べるときは「Python エスケープ」等で)
次回は
変数についてやりますよ~
なんでprint(aaa)だとaaaと表示されずにエラーなの?
そんな謎を解明。
- 投稿日:2019-02-09T23:09:43+09:00
Pythonでe-statにAPIアクセスしてSQLServerに突っ込むときにJSONとPandasで格闘したメモ
はじめに
興味深いAPI
[2019] 公開されているAPI一覧まとめ
Netflix API | ProgrammableWeb
BloombergのAPIから価格取得をするジェイソンとデータフレーム
最初に e-stat からデータを取ろうとしたときに、jsonでの取得まではすんなりいったけど、データフレームの入れ方が悪かった(JSONとデータフレームの関係がわかってなかった)ということがあった。
Syntax(構文)
pandas.read_json
Convert a JSON string to pandas object.構文についてpandas.read_json(path_or_buf=None, orient=None)引数についてpath_or_buf : a valid JSON string or file-like, default: None orient : string, 'records' : list like [{column -> value}, ... , {column -> value}]返り値についてresult : Series or DataFrame, depending on the value of typ.JSON試行錯誤
こんな感じに書いて...import urllib import urllib.request import pandas as pd # Read appId with open('api_setting/appid.txt', mode='r', encoding='utf-8') as f: appId = f.read() # stat url url = r'http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?' # Query param setting keys = { "appId" : appId, "lang" : "J" , "statsDataId" : "0003143513" , "metaGetFlg" : "Y" , "cntGetFlg" : "N", "sectionHeaderFlg" : "1" } # Get json data query_param = urllib.parse.urlencode(keys) df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records') print(df)Pythonコンソール(こんなふうに出てきたので)>>> df GET_STATS_DATA PARAMETER {'LANG': 'J', 'STATS_DATA_ID': '0003143513', '... RESULT {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE... STATISTICAL_DATA {'RESULT_INF': {'TOTAL_NUMBER': 13142278, 'FRO...Pythonコンソール(データを取る練習してたんだけど)------------- データフレームてっぺんから最下層のリテラルを取るぞ! ------------- >>> print(df.columns) Index(['GET_STATS_DATA'], dtype='object') >>> print(df['GET_STATS_DATA']) PARAMETER {'LANG': 'J', 'STATS_DATA_ID': '0003143513', '... RESULT {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE... STATISTICAL_DATA {'RESULT_INF': {'TOTAL_NUMBER': 13142278, 'FRO... >>> print(df['GET_STATS_DATA']['RESULT']) {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE': '2019-02-07T22:35:18.179+09:00'} # ここまでで、1つの固有値を取得できた >>> print(df['GET_STATS_DATA']['RESULT']['ERROR_MSG']) 正常に終了しました。Pythonコンソール(データフレームのまま、APIデータまでたどり着けない!)------------- Pandasで集計するぞ! ------------- # あれ、一段下がっただけでシリーズになっちまうのか...まぁそうか >>> print(type(df['GET_STATS_DATA'])) <class 'pandas.core.series.Series'> # ここから下は辞書になっちまうのか... >>> print(type(df['GET_STATS_DATA']['STATISTICAL_DATA'])) <class 'dict'> >>> print(df['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF'].keys()) dict_keys(['NOTE', 'VALUE']) ???? >>> print(df['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) (・3・)アルェー?とにかくデータフレームのまま操作したいのにできない。というハマりポイントがあった。ただこれ整理してみると、JSONデータであればデータフレームの入れ物にはスポッと入ってくれる。ただ、jsonの最初には大概ヘッダが入っている。つまり、データフレームに入れる時点で十分に階層を降りていないといけないということがわかった。
https://dev.classmethod.jp/etc/concrete-example-of-json/JSONデータの例(あーなるほど、たしかにヘッダが入ってるわ...)[ { "InstanceId": "i-XXXXXXXX", "ImageId": "ami-YYYYYYYY", "LaunchTime": "2015-05-28T08:30:10.000Z", "Tags": [ { "Value": "portnoydev-emr", "Key": "Name" }, { "Value": "j-ZZZZZZZZZZZZ", "Key": "aws:elasticmapreduce:job-flow-id" }, { "Value": "CORE", "Key": "aws:elasticmapreduce:instance-group-role" } ] }, (略) ]Pythonコンソール(なのでデータフレームに入れるのはJSONナマじゃなくて...)>>> df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')Pythonコンソール(こうなんやな!)>>> df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')['GET_STATS_DATA']['STATISTICAL_DATA'] >>> print(type(df)) <class 'dict'> (・3・)アルェー?Pythonコンソール(オライリーを見てみると、辞書をデータフレームに変換してた)>>> print(type(result['GET_STATS_DATA']['STATISTICAL_DATA'])) <class 'dict'> >>> stats = pd.DataFrame(result['GET_STATS_DATA']['STATISTICAL_DATA']) >>> print(type(stats)) <class 'pandas.core.frame.DataFrame'> >>> stats RESULT_INF ... DATA_INF @id NaN ... NaN CLASS_OBJ NaN ... NaN CYCLE NaN ... NaN FROM_NUMBER 1.0 ... NaN GOV_ORG NaN ... NaN MAIN_CATEGORY NaN ... NaN NEXT_KEY 100001.0 ... NaN NOTE NaN ... {'@char': '***', '$': '該当データがない場合を示す。'} OPEN_DATE NaN ... NaN OVERALL_TOTAL_NUMBER NaN ... NaN SMALL_AREA NaN ... NaN STATISTICS_NAME NaN ... NaN STATISTICS_NAME_SPEC NaN ... NaN STAT_NAME NaN ... NaN SUB_CATEGORY NaN ... NaN SURVEY_DATE NaN ... NaN TITLE NaN ... NaN TITLE_SPEC NaN ... NaN TOTAL_NUMBER 13142278.0 ... NaN TO_NUMBER 100000.0 ... NaN UPDATED_DATE NaN ... NaN VALUE NaN ... [{'@tab': '1', '@cat01': '0001', '@area': '13A... [22 rows x 4 columns]Pythonコンソール(VALUEまで取りに行けばいいじゃん?...ダメらしい...)>>> stats = pd.DataFrame(result['GET_STATS_DATA']['STATISTICAL_DATA']['VALUE']) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'VALUE'たしかにそこにいるはずなんだが...
なんかもう昔のゲームやってるみたいだわ、3次元以上の配列って...(この感じわかるひといる?)
ん?
Pythonコンソール(なるほど?いままでの単純な表形式の見方を発展させないといけないか)>>> stats.columns Index(['RESULT_INF', 'TABLE_INF', 'CLASS_INF', 'DATA_INF'], dtype='object') >>> stats['DATA_INF'] @id NaN CLASS_OBJ NaN CYCLE NaN FROM_NUMBER NaN GOV_ORG NaN MAIN_CATEGORY NaN NEXT_KEY NaN NOTE {'@char': '***', '$': '該当データがない場合を示す。'} OPEN_DATE NaN OVERALL_TOTAL_NUMBER NaN SMALL_AREA NaN STATISTICS_NAME NaN STATISTICS_NAME_SPEC NaN STAT_NAME NaN SUB_CATEGORY NaN SURVEY_DATE NaN TITLE NaN TITLE_SPEC NaN TOTAL_NUMBER NaN TO_NUMBER NaN UPDATED_DATE NaN VALUE [{'@tab': '1', '@cat01': '0001', '@area': '13A... Name: DATA_INF, dtype: object # これやるとデータがずばーっと出てくるので >>> stats['DATA_INF']['VALUE'] # 5レコードにおさえる >>> stats['DATA_INF']['VALUE'][0:5] [{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2019000101', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001212', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001111', '$': '101.4'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001010', '$': '101.7'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018000909', '$': '101.4'}]5レコードのJSONを整理する>>> stats['DATA_INF']['VALUE'][0:5] [ {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2019000101', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001212', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001111', '$': '101.4'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001010', '$': '101.7'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018000909', '$': '101.4'} ]Pythonコンソール(listかぁ...これもういっちょデータフレームにキャストしてみるか)>>> print(type(stats['DATA_INF']['VALUE'])) <class 'list'> # あっ!なんかキタぞ!めっちゃ試行錯誤いるなぁ...JSON... >>> df = pd.DataFrame(stats['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101 1 101.2 13A01 0001 1 2018001212 2 101.4 13A01 0001 1 2018001111 3 101.7 13A01 0001 1 2018001010 4 101.4 13A01 0001 1 2018000909 ... ... ... ... ... ... 99995 100.9 00049 0003 1 2011000808 99996 100.8 00049 0003 1 2011000707 99997 99.6 00049 0003 1 2011000606 99998 99.9 00049 0003 1 2011000505 99999 99.4 00049 0003 1 2011000404 [100000 rows x 5 columns] >>> df['$'] 0 101.2 1 101.2 2 101.4 3 101.7 4 101.4 ... 99995 100.9 99996 100.8 99997 99.6 99998 99.9 99999 99.4 Name: $, Length: 100000, dtype: object >>> df['@time'] 0 2019000101 1 2018001212 2 2018001111 3 2018001010 4 2018000909 ... 99995 2011000808 99996 2011000707 99997 2011000606 99998 2011000505 99999 2011000404 Name: @time, Length: 100000, dtype: object補足:見てるオライリーはこれ
オライリーって無骨だけど読みやすいよね
JSONコンソール操作まとめ
res(=Full JSON) が返ってきてから、dfに入れる直前までの間に、単純なタテヨコの一般的な(?)2元配列になるところまで十分にJSON配列(?)を潜ってからデータフレームに渡すんや。...というよりは、dfに代入してデータフレーム手に入ったー!って思ってたのはただのナマJSONだった(pd.DataFrame(...)の漏れ)
Pythonコンソール>>> import urllib >>> import urllib.request >>> import pandas as pd >>> appId = '****************************' >>> url = r'http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?' >>> keys = { "appId" : appId, "lang" : "J" , "statsDataId" : "0003143513" , "metaGetFlg" : "Y" , "cntGetFlg" : "N", "sectionHeaderFlg" : "1" } >>> query_param = urllib.parse.urlencode(keys) >>> res = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records') >>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101 1 101.2 13A01 0001 1 2018001212 2 101.4 13A01 0001 1 2018001111 3 101.7 13A01 0001 1 2018001010 4 101.4 13A01 0001 1 2018000909 ... ... ... ... ... ... 99995 100.9 00049 0003 1 2011000808 99996 100.8 00049 0003 1 2011000707 99997 99.6 00049 0003 1 2011000606 99998 99.9 00049 0003 1 2011000505 99999 99.4 00049 0003 1 2011000404 [100000 rows x 5 columns] >>> df['$'] 0 101.2 1 101.2 2 101.4 3 101.7 4 101.4 ... 99995 100.9 99996 100.8 99997 99.6 99998 99.9 99999 99.4 Name: $, Length: 100000, dtype: object >>> df['@time'] 0 2019000101 1 2018001212 2 2018001111 3 2018001010 4 2018000909 ... 99995 2011000808 99996 2011000707 99997 2011000606 99998 2011000505 99999 2011000404 Name: @time, Length: 100000, dtype: object
ようやく僕が知ってるデータフレームまできたぁ~
いっかい寝よ...つべこべいわずにJSON整形サイトに流し込め!
http://tm-webtools.com/Tools/JsonBeauty
元のデータを知らない(作ってない)んだから試行錯誤になるのはあたりまえ!あっ!階層一撃で追えるわ...トホホ{ "GET_STATS_DATA": { "RESULT": { "STATUS": 0, "ERROR_MSG": "正常に終了しました。", "DATE": "2019-02-08T21:16:05.801+09:00" }, "PARAMETER": { "LANG": "J", "STATS_DATA_ID": "0003143513", "DATA_FORMAT": "J", "START_POSITION": 1, "METAGET_FLG": "Y", "CNT_GET_FLG": "N", "SECTION_HEADER_FLG": 1 }, "STATISTICAL_DATA": { "RESULT_INF": { "TOTAL_NUMBER": 13142278, "FROM_NUMBER": 1, "TO_NUMBER": 100000, "NEXT_KEY": 100001 }, "TABLE_INF": { "@id": "0003143513", "STAT_NAME": { "@code": "00200573", "$": "消費者物価指数" }, "GOV_ORG": { "@code": "00200", "$": "総務省" }, "STATISTICS_NAME": "2015年基準消費者物価指数", "TITLE": { "@no": "1", "$": "消費者物価指数(2015年基準)" }, "CYCLE": "-", "SURVEY_DATE": 0, "OPEN_DATE": "2019-01-25", "SMALL_AREA": 0, "MAIN_CATEGORY": { "@code": "07", "$": "企業・家計・経済" }, "SUB_CATEGORY": { "@code": "03", "$": "物価" }, "OVERALL_TOTAL_NUMBER": 13142278, "UPDATED_DATE": "2019-01-24", "STATISTICS_NAME_SPEC": { "TABULATION_CATEGORY": "2015年基準消費者物価指数" }, "TITLE_SPEC": { "TABLE_NAME": "消費者物価指数(2015年基準)" } }, "CLASS_INF": { "CLASS_OBJ": [ { "@id": "tab", "@name": "表章項目", "CLASS": [ { "@code": "1", "@name": "指数", "@level": "" }, { "@code": "2", "@name": "前月比・前年比・前年度比", "@level": "", "@unit": "%" }, { "@code": "3", "@name": "前年同月比", "@level": "", "@unit": "%" }, { "@code": "4", "@name": "ウエイト(実数)", "@level": "" }, { "@code": "5", "@name": "ウエイト(万分比)", "@level": "" } ] }, { "@id": "cat01", "@name": "2015年基準品目", "CLASS": [ { "@code": "0001", "@name": "0001 総合", "@level": "1" }, { "@code": "0002", "@name": "0002 食料", "@level": "1" }, { "@code": "0003", "@name": "0003 穀類", "@level": "3", "@parentCode": "0002" }, (略) ] } ] }, "DATA_INF": { "NOTE": { "@char": "***", "$": "該当データがない場合を示す。" }, "VALUE": [ { "@tab": "1", "@cat01": "0001", "@area": "13A01", "@time": "2019000101", "$": "101.2" }, { "@tab": "1", "@cat01": "0001", "@area": "13A01", "@time": "2018001212", "$": "101.2" }, { "@tab": "1", "@cat01": "0001", "@area": "13A01", "@time": "2018001111", "$": "101.4" }, (略) ] } } } }e-Stat
(JSONの試行錯誤は上のセクションにまとめたので、それ以外を書きます)
参考ページ
e-Stat(政府統計)のAPI機能をつかってpythonでグラフを書いたりしてみる
APIの使い方 how_to_use前準備情報等
・ユーザー登録
・ログインしてマイページ→API機能(アプリケーションID発行)
・名称は「開発用」
・URLは「ttp://localhost/」(※Qiitaだとリンクになっちゃうから先頭の h は削除)
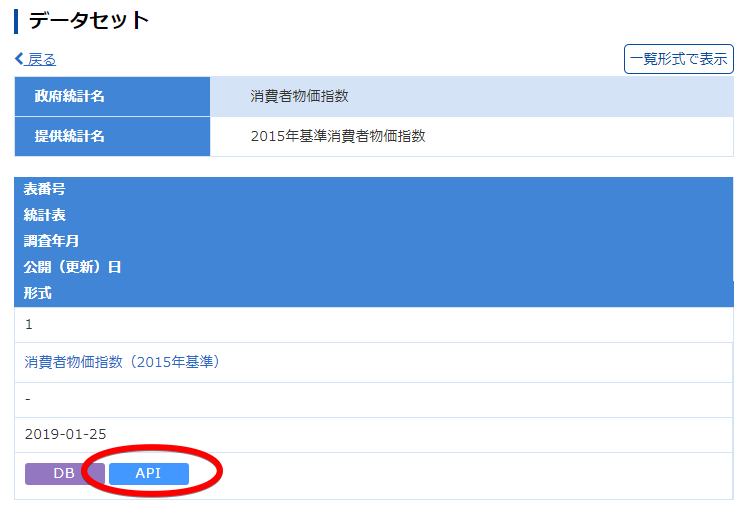
消費者物価指数 2015年基準消費者物価指数(公開日:2019-01-25)
消費者物価指数(URLをよく見ると「appId」に何も入っていない)(使い方を見て、jsonで表示するように加工してある)http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?appId=&lang=J&statsDataId=0003143513&metaGetFlg=Y&cntGetFlg=N§ionHeaderFlg=1データについて
db形式で表示されるページがあるなら先に構造を見ておけってのは、まぁあたりまえっちゃあたりまえだったね
このへんかな?
https://www.e-stat.go.jp/api/api-info/e-stat-manual#api_3_4うーん?cdArea 地域事項? lvCat01 分類事項01? cdTab 表章事項? lvTime 時間軸事項?VALUE 統計数値(セル)の情報です。データ件数分だけ出力されます。
属性として表章事項コード(tab)、分類事項コード(cat01 ~ cat15)、地域事項コード(area)、時間軸事項コード(time)、単位(unit)を保持します。全ての属性はデータがある場合のみ出力されます。単語:表章 https://www.stat.go.jp/data/kokusei/2010/users-g/pdf/mikata.pdf
うーん、例えば地域コード 13A01 はどこだよ!?マスタは?みたいな感じになるよなぁ~??
Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101 1 101.2 13A01 0001 1 2018001212 2 101.4 13A01 0001 1 2018001111 3 101.7 13A01 0001 1 2018001010 4 101.4 13A01 0001 1 2018000909 ... ... ... ... ... ... 99995 100.9 00049 0003 1 2011000808 99996 100.8 00049 0003 1 2011000707 99997 99.6 00049 0003 1 2011000606 99998 99.9 00049 0003 1 2011000505 99999 99.4 00049 0003 1 2011000404 [100000 rows x 5 columns]Pythonコンソール(あっ!わかった!同じJSONに入ってるぞ!CLASS_INFだ)>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']) >>> df @id @name CLASS 0 tab 表章項目 [{'@code': '1', '@name': '指数', '@level': ''}, ... 1 cat01 2015年基準品目 [{'@code': '0001', '@name': '0001 総合', '@level... 2 area 地域(2015年基準) [{'@code': '13A01', '@name': '13100 東京都区部', '@... 3 time 時間軸(年・月) [{'@code': '2019000101', '@name': '2019年1月', '...整形サイト http://tm-webtools.com/Tools/JsonBeauty でJSONとにらめっこだな。
わかってきたのは...Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS']) >>> df @code @level @name @unit 0 1 指数 NaN 1 2 前月比・前年比・前年度比 % 2 3 前年同月比 % 3 4 ウエイト(実数) NaN 4 5 ウエイト(万分比) NaNPythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS']) >>> df @code @level @name @parentCode 0 0001 1 0001 総合 NaN 1 0002 1 0002 食料 NaN 2 0003 3 0003 穀類 0002 3 0004 5 0004 米類 0003 4 1000 6 1000 うるち米 0004 .. ... ... ... ... 793 0905 1 0905 食料(酒類を除く)及びエネルギーを除く総合(季節調整済) NaN 794 0921 1 0921 財(季節調整済) NaN 795 0922 1 0922 半耐久消費財(季節調整済) NaN 796 0923 1 0923 生鮮食品を除く財(季節調整済) NaN 797 0906 1 0906 生鮮食品及びエネルギーを除く総合(季節調整済) NaN [798 rows x 4 columns]Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS']) >>> df @code @level @name 0 13A01 1 13100 東京都区部 1 00000 1 全国 2 00011 1 人口5万以上の市 3 00012 1 大都市 4 00013 1 中都市 .. ... ... ... 67 14A02 1 14130 川崎市 68 14A03 1 14150 相模原市 69 22A02 1 22130 浜松市 70 27A02 1 27140 堺市 71 40A01 1 40100 北九州市 [72 rows x 3 columns]Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS']) >>> df @code @level @name @parentCode 0 2019000101 4 2019年1月 2019000103 1 2018001212 4 2018年12月 2018001012 2 2018001111 4 2018年11月 2018001012 3 2018001010 4 2018年10月 2018001012 4 2018000909 4 2018年9月 2018000709 .. ... ... ... ... 681 1970000404 4 1970年4月 1970000000 682 1970000303 4 1970年3月 1970000000 683 1970000202 4 1970年2月 1970000000 684 1970000101 4 1970年1月 1970000000 685 1970000000 1 1970年 NaN [686 rows x 4 columns]つまり...どういうことだってばよ
データフレームに SQL:Where を適用する
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.where.html
まぁ4つのマスタはそれぞれ違うデータフレームに受け取るのがわかりやすいとは思うけどPythonコンソール(この明細を例にとったときに...)>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101Pythonコンソール:地域コード>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS']) >>> df['@name'].where(df['@code'] == '13A01')[0] '13100 東京都区部'Pythonコンソール:カテゴリー>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS']) >>> df['@name'].where(df['@code'] == '0001')[0] '0001 総合'Pythonコンソール:表彰事項>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS']) >>> df['@name'].where(df['@code'] == '1')[0] '指数'Pythonコンソール:時間軸(年・月)>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS']) >>> df['@name'].where(df['@code'] == '2019000101')[0] '2019年1月'つまりソースはこうなるな?# translation to dataframe from json-data data = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) area = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS']) category = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS']) tab = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS']) time = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS'])複数のデータフレームをInnerJoinする
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.join.html
If we want to join using the key columns, we need to set key to be the index in both df and other. The joined DataFrame will have key as its index.
キー列を使って結合したい場合は、keyをdfとotherの両方のインデックスになるように設定する必要があります。結合されたDataFrameはそのインデックスとしてキーを持ちます。公式ドキュメントのお手本>>> df.set_index('key').join(other.set_index('key')) A B key K0 A0 B0 K1 A1 B1 K2 A2 B2 K3 A3 NaN K4 A4 NaN K5 A5 NaNここから先は結合するにあたって項目名がカブってくるので列名を変更する。
data以外のデータフレームの「@name」だけでいいんじゃないかな
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.rename.html#pandas.DataFrame.renamePythonコンソール:列構成の確認と調整、結合# 確認: >>> data.columns Index(['$', '@area', '@cat01', '@tab', '@time'], dtype='object') >>> area.columns Index(['@code', '@level', '@name'], dtype='object') >>> category.columns Index(['@code', '@level', '@name', '@parentCode'], dtype='object') >>> tab.columns Index(['@code', '@level', '@name', '@unit'], dtype='object') # 調整1: 列名変更 >>> area = area.rename(columns={'@name': 'area_name'}) >>> category = category.rename(columns={'@name': 'category_name'}) >>> tab = tab.rename(columns={'@name': 'tab_name'}) # 調整2: くっつけるとカブる列とか不要列の削除(レベルは、「全国」と「都道府県」を分けるみたいな深さ情報みたい) # エラーを出しながら判断 >>> area = area.drop(columns=['@level']) >>> category = category.drop(columns=['@level','@parentCode']) >>> tab = tab.drop(columns=['@level','@unit']) # 結合: Inner Join >>> joined = data.set_index('@area').join(area.set_index('@code')) >>> joined = joined.set_index('@cat01').join(category.set_index('@code')) >>> joined = joined.set_index('@tab').join(tab.set_index('@code')) # 確認: たぶんこれ「指数」以外もあるんだよね(「:10」で、10件だけ表示) >>> joined[:10] $ area_name category_name tab_name time_name 1970000000 31.5 全国 0001 総合 指数 1970年 1970000000 31.7 人口5万以上の市 0001 総合 指数 1970年 1970000000 31.7 大都市 0001 総合 指数 1970年 1970000000 31.8 中都市 0001 総合 指数 1970年 1970000000 31.2 小都市A 0001 総合 指数 1970年 1970000000 33.2 北海道地方 0001 総合 指数 1970年 1970000000 30.6 東北地方 0001 総合 指数 1970年 1970000000 31.5 関東地方 0001 総合 指数 1970年 1970000000 31.5 北陸地方 0001 総合 指数 1970年 1970000000 31.5 東海地方 0001 総合 指数 1970年データの加工
これ最初さー、「2019年1月」とか日本語入ってるとあとから取り回し悪くて仕方ないから int で年月項目にしようとしたんだけど13行目と14行目見て?
年度!?いらないよー。かんべんしてくださいよこれ。で、@levelって 1 と 4 以外にあるのかな?って思ってみるも、Pythonコンソールってデータを省略して見せてくるので、しかたなくcsv出力をして確認。 1 と 4 しかないことを確認できたので 1 のレコードを消しましょう。そうすれば ym にできるはず。Pythonコンソール:年どまりとか年度とかが混ざってる>>> time @code @level @name @parentCode 0 2019000101 4 2019年1月 2019000103 1 2018001212 4 2018年12月 2018001012 2 2018001111 4 2018年11月 2018001012 3 2018001010 4 2018年10月 2018001012 4 2018000909 4 2018年9月 2018000709 5 2018000808 4 2018年8月 2018000709 6 2018000707 4 2018年7月 2018000709 7 2018000606 4 2018年6月 2018000406 8 2018000505 4 2018年5月 2018000406 9 2018000404 4 2018年4月 2018000406 10 2018000303 4 2018年3月 2018000103 11 2018000202 4 2018年2月 2018000103 12 2018000101 4 2018年1月 2018000103 13 2018000000 1 2018年 NaN 14 2017100000 1 2017年度 NaN 15 2017001212 4 2017年12月 2017001012 16 2017001111 4 2017年11月 2017001012 17 2017001010 4 2017年10月 2017001012main.py:いろいろ加工しました。文字加工のエッセンスが詰まっているね# edit text to '201901' from '2019年1月' time['yyyy'] = time['time'].str.split('年', expand=True)[0] time['mm'] = time['time'].str.split('年', expand=True)[1].str.strip('月').str.zfill(2) time['yyyymm'] = time['yyyy'] + time['mm'] # If there is 'A' in the middle, it means 'city' area['city_flag'] = area['@code'].str.contains('..A..') area['area'] = area['area'].str.split(' ', expand=True)[1]
API取得制限に注意な
なんかデータ足りなくない??って思って、例えばカテゴリーが「総合」か「食料」か「穀物」までしかないんだよなぁ~、くっつけかた間違えたかなぁ~??とか思ってたけどこれだったか。data の時点のデータフレームでは100,000レコードであることを確認できました。URLをクエリパラメータ作ってひっぱるときにレコード減らす工夫するしかないね。
Q7 : 【統計データ取得機能】10万件を超えるデータを取得できません。
A7 : API機能は、一度に最大で10万件のデータを返却します。そのため、統計データが一度に取得できない場合には、継続データの取得開始位置をレスポンスのタグの値として出力します。継続データを要求する場合は、データ取得開始位置パラメータ(startPosition)にこの値を指定することで、取得できます。SQLServerでテーブルを作る
テーブル作成クエリCREATE TABLE e_Stat ( yyyymm INT NOT NULL , category NVARCHAR(50) NULL , area NVARCHAR(50) NULL , amount NUMERIC(5,1) NULL );プログラムを流してみる
あーできたー... 解散!解散ー!おつかれー
うまいもんくって寝ましょ
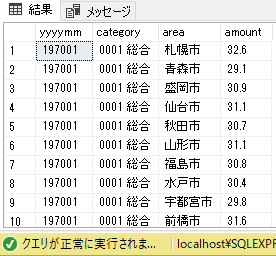
Pythonコンソール:上位30件のみbasic_connect-api-e_stat> python main.py 197002,0002 食料,岡山市,30.4 197004,0002 食料,福井市,29.6 197006,0002 食料,盛岡市,30.0 197008,0001 総合,山口市,32.9 197010,0001 総合,長野市,32.7 197012,0001 総合,秋田市,32.2 197101,0002 食料,松山市,33.0 197103,0002 食料,名古屋市,33.3 197105,0002 食料,水戸市,31.7 197107,0001 総合,北九州市,32.6 197109,0001 総合,大津市,34.9 197112,0001 総合,奈良市,35.4 197202,0001 総合,横浜市,34.4 197205,0002 食料,松江市,31.1 197209,0002 食料,青森市,32.8 197301,0001 総合,甲府市,35.5 197304,0002 食料,高松市,38.9 197308,0002 食料,福島市,37.7 197312,0001 総合,津市,41.6 197402,0002 食料,富山市,45.1 197402,0002 食料,金沢市,46.3 197402,0002 食料,福井市,44.7 197402,0002 食料,甲府市,46.1 197402,0002 食料,長野市,48.4 197402,0002 食料,岐阜市,45.0 197402,0002 食料,静岡市,44.6 197402,0002 食料,名古屋市,48.0 197402,0002 食料,津市,44.2 197402,0002 食料,大津市,51.6 197402,0002 食料,京都市,49.9ソースコード
ソースをgithubにしとくとあとがラクねぇ~
https://github.com/duri0214/Python/tree/master/basic_connect-api-e_stat



- 投稿日:2019-02-09T23:09:43+09:00
Pythonでe-statにAPIアクセスしてSQLServerに突っ込むときにJSONと格闘したメモ
はじめに
興味深いAPI
[2019] 公開されているAPI一覧まとめ
Netflix API | ProgrammableWeb
BloombergのAPIから価格取得をするジェイソンとデータフレーム
最初に e-stat からデータを取ろうとしたときに、jsonでの取得まではすんなりいったけど、データフレームの入れ方が悪かった(JSONとデータフレームの関係がわかってなかった)ということがあった。
Syntax(構文)
pandas.read_json
Convert a JSON string to pandas object.構文についてpandas.read_json(path_or_buf=None, orient=None)引数についてpath_or_buf : a valid JSON string or file-like, default: None orient : string, 'records' : list like [{column -> value}, ... , {column -> value}]返り値についてresult : Series or DataFrame, depending on the value of typ.JSON試行錯誤
こんな感じに書いて...import urllib import urllib.request import pandas as pd # Read appId with open('api_setting/appid.txt', mode='r', encoding='utf-8') as f: appId = f.read() # stat url url = r'http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?' # Query param setting keys = { "appId" : appId, "lang" : "J" , "statsDataId" : "0003143513" , "metaGetFlg" : "Y" , "cntGetFlg" : "N", "sectionHeaderFlg" : "1" } # Get json data query_param = urllib.parse.urlencode(keys) df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records') print(df)Pythonコンソール(こんなふうに出てきたので)>>> df GET_STATS_DATA PARAMETER {'LANG': 'J', 'STATS_DATA_ID': '0003143513', '... RESULT {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE... STATISTICAL_DATA {'RESULT_INF': {'TOTAL_NUMBER': 13142278, 'FRO...Pythonコンソール(データを取る練習してたんだけど)------------- データフレームてっぺんから最下層のリテラルを取るぞ! ------------- >>> print(df.columns) Index(['GET_STATS_DATA'], dtype='object') >>> print(df['GET_STATS_DATA']) PARAMETER {'LANG': 'J', 'STATS_DATA_ID': '0003143513', '... RESULT {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE... STATISTICAL_DATA {'RESULT_INF': {'TOTAL_NUMBER': 13142278, 'FRO... >>> print(df['GET_STATS_DATA']['RESULT']) {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE': '2019-02-07T22:35:18.179+09:00'} # ここまでで、1つの固有値を取得できた >>> print(df['GET_STATS_DATA']['RESULT']['ERROR_MSG']) 正常に終了しました。Pythonコンソール(データフレームのまま、APIデータまでたどり着けない!)------------- Pandasで集計するぞ! ------------- # あれ、一段下がっただけでシリーズになっちまうのか...まぁそうか >>> print(type(df['GET_STATS_DATA'])) <class 'pandas.core.series.Series'> # ここから下は辞書になっちまうのか... >>> print(type(df['GET_STATS_DATA']['STATISTICAL_DATA'])) <class 'dict'> >>> print(df['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF'].keys()) dict_keys(['NOTE', 'VALUE']) ???? >>> print(df['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) (・3・)アルェー?とにかくデータフレームのまま操作したいのにできない。というハマりポイントがあった。ただこれ整理してみると、JSONデータであればデータフレームの入れ物にはスポッと入ってくれる。ただ、jsonの最初には大概ヘッダが入っている。つまり、データフレームに入れる時点で十分に階層を降りていないといけないということがわかった。
https://dev.classmethod.jp/etc/concrete-example-of-json/JSONデータの例(あーなるほど、たしかにヘッダが入ってるわ...)[ { "InstanceId": "i-XXXXXXXX", "ImageId": "ami-YYYYYYYY", "LaunchTime": "2015-05-28T08:30:10.000Z", "Tags": [ { "Value": "portnoydev-emr", "Key": "Name" }, { "Value": "j-ZZZZZZZZZZZZ", "Key": "aws:elasticmapreduce:job-flow-id" }, { "Value": "CORE", "Key": "aws:elasticmapreduce:instance-group-role" } ] }, (略) ]Pythonコンソール(なのでデータフレームに入れるのはJSONナマじゃなくて...)>>> df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')Pythonコンソール(こうなんやな!)>>> df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')['GET_STATS_DATA']['STATISTICAL_DATA'] >>> print(type(df)) <class 'dict'> (・3・)アルェー?Pythonコンソール(オライリーを見てみると、辞書をデータフレームに変換してた)>>> print(type(result['GET_STATS_DATA']['STATISTICAL_DATA'])) <class 'dict'> >>> stats = pd.DataFrame(result['GET_STATS_DATA']['STATISTICAL_DATA']) >>> print(type(stats)) <class 'pandas.core.frame.DataFrame'> >>> stats RESULT_INF ... DATA_INF @id NaN ... NaN CLASS_OBJ NaN ... NaN CYCLE NaN ... NaN FROM_NUMBER 1.0 ... NaN GOV_ORG NaN ... NaN MAIN_CATEGORY NaN ... NaN NEXT_KEY 100001.0 ... NaN NOTE NaN ... {'@char': '***', '$': '該当データがない場合を示す。'} OPEN_DATE NaN ... NaN OVERALL_TOTAL_NUMBER NaN ... NaN SMALL_AREA NaN ... NaN STATISTICS_NAME NaN ... NaN STATISTICS_NAME_SPEC NaN ... NaN STAT_NAME NaN ... NaN SUB_CATEGORY NaN ... NaN SURVEY_DATE NaN ... NaN TITLE NaN ... NaN TITLE_SPEC NaN ... NaN TOTAL_NUMBER 13142278.0 ... NaN TO_NUMBER 100000.0 ... NaN UPDATED_DATE NaN ... NaN VALUE NaN ... [{'@tab': '1', '@cat01': '0001', '@area': '13A... [22 rows x 4 columns]Pythonコンソール(VALUEまで取りに行けばいいじゃん?...ダメらしい...)>>> stats = pd.DataFrame(result['GET_STATS_DATA']['STATISTICAL_DATA']['VALUE']) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'VALUE'たしかにそこにいるはずなんだが...
なんかもう昔のゲームやってるみたいだわ、3次元以上の配列って...(この感じわかるひといる?)
ん?
Pythonコンソール(なるほど?いままでの単純な表形式の見方を発展させないといけないか)>>> stats.columns Index(['RESULT_INF', 'TABLE_INF', 'CLASS_INF', 'DATA_INF'], dtype='object') >>> stats['DATA_INF'] @id NaN CLASS_OBJ NaN CYCLE NaN FROM_NUMBER NaN GOV_ORG NaN MAIN_CATEGORY NaN NEXT_KEY NaN NOTE {'@char': '***', '$': '該当データがない場合を示す。'} OPEN_DATE NaN OVERALL_TOTAL_NUMBER NaN SMALL_AREA NaN STATISTICS_NAME NaN STATISTICS_NAME_SPEC NaN STAT_NAME NaN SUB_CATEGORY NaN SURVEY_DATE NaN TITLE NaN TITLE_SPEC NaN TOTAL_NUMBER NaN TO_NUMBER NaN UPDATED_DATE NaN VALUE [{'@tab': '1', '@cat01': '0001', '@area': '13A... Name: DATA_INF, dtype: object # これやるとデータがずばーっと出てくるので >>> stats['DATA_INF']['VALUE'] # 5レコードにおさえる >>> stats['DATA_INF']['VALUE'][0:5] [{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2019000101', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001212', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001111', '$': '101.4'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001010', '$': '101.7'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018000909', '$': '101.4'}]5レコードのJSONを整理する>>> stats['DATA_INF']['VALUE'][0:5] [ {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2019000101', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001212', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001111', '$': '101.4'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001010', '$': '101.7'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018000909', '$': '101.4'} ]Pythonコンソール(listかぁ...これもういっちょデータフレームにキャストしてみるか)>>> print(type(stats['DATA_INF']['VALUE'])) <class 'list'> # あっ!なんかキタぞ!めっちゃ試行錯誤いるなぁ...JSON... >>> df = pd.DataFrame(stats['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101 1 101.2 13A01 0001 1 2018001212 2 101.4 13A01 0001 1 2018001111 3 101.7 13A01 0001 1 2018001010 4 101.4 13A01 0001 1 2018000909 ... ... ... ... ... ... 99995 100.9 00049 0003 1 2011000808 99996 100.8 00049 0003 1 2011000707 99997 99.6 00049 0003 1 2011000606 99998 99.9 00049 0003 1 2011000505 99999 99.4 00049 0003 1 2011000404 [100000 rows x 5 columns] >>> df['$'] 0 101.2 1 101.2 2 101.4 3 101.7 4 101.4 ... 99995 100.9 99996 100.8 99997 99.6 99998 99.9 99999 99.4 Name: $, Length: 100000, dtype: object >>> df['@time'] 0 2019000101 1 2018001212 2 2018001111 3 2018001010 4 2018000909 ... 99995 2011000808 99996 2011000707 99997 2011000606 99998 2011000505 99999 2011000404 Name: @time, Length: 100000, dtype: object補足:見てるオライリーはこれ
オライリーって無骨だけど読みやすいよね
JSONコンソール操作まとめ
res(=Full JSON) が返ってきてから、dfに入れる直前までの間に、単純なタテヨコの一般的な(?)2元配列になるところまで十分にJSON配列(?)を潜ってからデータフレームに渡すんや。...というよりは、dfに代入してデータフレーム手に入ったー!って思ってたのはただのナマJSONだった(pd.DataFrame(...)の漏れ)
Pythonコンソール>>> import urllib >>> import urllib.request >>> import pandas as pd >>> appId = '****************************' >>> url = r'http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?' >>> keys = { "appId" : appId, "lang" : "J" , "statsDataId" : "0003143513" , "metaGetFlg" : "Y" , "cntGetFlg" : "N", "sectionHeaderFlg" : "1" } >>> query_param = urllib.parse.urlencode(keys) >>> res = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records') >>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101 1 101.2 13A01 0001 1 2018001212 2 101.4 13A01 0001 1 2018001111 3 101.7 13A01 0001 1 2018001010 4 101.4 13A01 0001 1 2018000909 ... ... ... ... ... ... 99995 100.9 00049 0003 1 2011000808 99996 100.8 00049 0003 1 2011000707 99997 99.6 00049 0003 1 2011000606 99998 99.9 00049 0003 1 2011000505 99999 99.4 00049 0003 1 2011000404 [100000 rows x 5 columns] >>> df['$'] 0 101.2 1 101.2 2 101.4 3 101.7 4 101.4 ... 99995 100.9 99996 100.8 99997 99.6 99998 99.9 99999 99.4 Name: $, Length: 100000, dtype: object >>> df['@time'] 0 2019000101 1 2018001212 2 2018001111 3 2018001010 4 2018000909 ... 99995 2011000808 99996 2011000707 99997 2011000606 99998 2011000505 99999 2011000404 Name: @time, Length: 100000, dtype: object
ようやく僕が知ってるデータフレームまできたぁ~
いっかい寝よ...つべこべいわずにJSON整形サイトに流し込め!
http://tm-webtools.com/Tools/JsonBeauty
元のデータを知らない(作ってない)んだから試行錯誤になるのはあたりまえ!あっ!階層一撃で追えるわ...トホホ{ "GET_STATS_DATA": { "RESULT": { "STATUS": 0, "ERROR_MSG": "正常に終了しました。", "DATE": "2019-02-08T21:16:05.801+09:00" }, "PARAMETER": { "LANG": "J", "STATS_DATA_ID": "0003143513", "DATA_FORMAT": "J", "START_POSITION": 1, "METAGET_FLG": "Y", "CNT_GET_FLG": "N", "SECTION_HEADER_FLG": 1 }, "STATISTICAL_DATA": { "RESULT_INF": { "TOTAL_NUMBER": 13142278, "FROM_NUMBER": 1, "TO_NUMBER": 100000, "NEXT_KEY": 100001 }, "TABLE_INF": { "@id": "0003143513", "STAT_NAME": { "@code": "00200573", "$": "消費者物価指数" }, "GOV_ORG": { "@code": "00200", "$": "総務省" }, "STATISTICS_NAME": "2015年基準消費者物価指数", "TITLE": { "@no": "1", "$": "消費者物価指数(2015年基準)" }, "CYCLE": "-", "SURVEY_DATE": 0, "OPEN_DATE": "2019-01-25", "SMALL_AREA": 0, "MAIN_CATEGORY": { "@code": "07", "$": "企業・家計・経済" }, "SUB_CATEGORY": { "@code": "03", "$": "物価" }, "OVERALL_TOTAL_NUMBER": 13142278, "UPDATED_DATE": "2019-01-24", "STATISTICS_NAME_SPEC": { "TABULATION_CATEGORY": "2015年基準消費者物価指数" }, "TITLE_SPEC": { "TABLE_NAME": "消費者物価指数(2015年基準)" } }, "CLASS_INF": { "CLASS_OBJ": [ { "@id": "tab", "@name": "表章項目", "CLASS": [ { "@code": "1", "@name": "指数", "@level": "" }, { "@code": "2", "@name": "前月比・前年比・前年度比", "@level": "", "@unit": "%" }, { "@code": "3", "@name": "前年同月比", "@level": "", "@unit": "%" }, { "@code": "4", "@name": "ウエイト(実数)", "@level": "" }, { "@code": "5", "@name": "ウエイト(万分比)", "@level": "" } ] }, { "@id": "cat01", "@name": "2015年基準品目", "CLASS": [ { "@code": "0001", "@name": "0001 総合", "@level": "1" }, { "@code": "0002", "@name": "0002 食料", "@level": "1" }, { "@code": "0003", "@name": "0003 穀類", "@level": "3", "@parentCode": "0002" }, (略) ] } ] }, "DATA_INF": { "NOTE": { "@char": "***", "$": "該当データがない場合を示す。" }, "VALUE": [ { "@tab": "1", "@cat01": "0001", "@area": "13A01", "@time": "2019000101", "$": "101.2" }, { "@tab": "1", "@cat01": "0001", "@area": "13A01", "@time": "2018001212", "$": "101.2" }, { "@tab": "1", "@cat01": "0001", "@area": "13A01", "@time": "2018001111", "$": "101.4" }, (略) ] } } } }e-Stat
(JSONの試行錯誤は上のセクションにまとめたので、それ以外を書きます)
参考ページ
e-Stat(政府統計)のAPI機能をつかってpythonでグラフを書いたりしてみる
APIの使い方 how_to_use前準備情報等
・ユーザー登録
・ログインしてマイページ→API機能(アプリケーションID発行)
・名称は「開発用」
・URLは「ttp://localhost/」(※Qiitaだとリンクになっちゃうから先頭の h は削除)
消費者物価指数 2015年基準消費者物価指数(公開日:2019-01-25)
消費者物価指数(URLをよく見ると「appId」に何も入っていない)(使い方を見て、jsonで表示するように加工してある)http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?appId=&lang=J&statsDataId=0003143513&metaGetFlg=Y&cntGetFlg=N§ionHeaderFlg=1データについて
db形式で表示されるページがあるなら先に構造を見ておけってのは、まぁあたりまえっちゃあたりまえだったね
このへんかな?
https://www.e-stat.go.jp/api/api-info/e-stat-manual#api_3_4うーん?cdArea 地域事項? lvCat01 分類事項01? cdTab 表章事項? lvTime 時間軸事項?VALUE 統計数値(セル)の情報です。データ件数分だけ出力されます。
属性として表章事項コード(tab)、分類事項コード(cat01 ~ cat15)、地域事項コード(area)、時間軸事項コード(time)、単位(unit)を保持します。全ての属性はデータがある場合のみ出力されます。単語:表章 https://www.stat.go.jp/data/kokusei/2010/users-g/pdf/mikata.pdf
うーん、例えば地域コード 13A01 はどこだよ!?マスタは?みたいな感じになるよなぁ~??
Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101 1 101.2 13A01 0001 1 2018001212 2 101.4 13A01 0001 1 2018001111 3 101.7 13A01 0001 1 2018001010 4 101.4 13A01 0001 1 2018000909 ... ... ... ... ... ... 99995 100.9 00049 0003 1 2011000808 99996 100.8 00049 0003 1 2011000707 99997 99.6 00049 0003 1 2011000606 99998 99.9 00049 0003 1 2011000505 99999 99.4 00049 0003 1 2011000404 [100000 rows x 5 columns]Pythonコンソール(あっ!わかった!同じJSONに入ってるぞ!CLASS_INFだ)>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ']) >>> df @id @name CLASS 0 tab 表章項目 [{'@code': '1', '@name': '指数', '@level': ''}, ... 1 cat01 2015年基準品目 [{'@code': '0001', '@name': '0001 総合', '@level... 2 area 地域(2015年基準) [{'@code': '13A01', '@name': '13100 東京都区部', '@... 3 time 時間軸(年・月) [{'@code': '2019000101', '@name': '2019年1月', '...整形サイト http://tm-webtools.com/Tools/JsonBeauty でJSONとにらめっこだな。
わかってきたのは...Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS']) >>> df @code @level @name @unit 0 1 指数 NaN 1 2 前月比・前年比・前年度比 % 2 3 前年同月比 % 3 4 ウエイト(実数) NaN 4 5 ウエイト(万分比) NaNPythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS']) >>> df @code @level @name @parentCode 0 0001 1 0001 総合 NaN 1 0002 1 0002 食料 NaN 2 0003 3 0003 穀類 0002 3 0004 5 0004 米類 0003 4 1000 6 1000 うるち米 0004 .. ... ... ... ... 793 0905 1 0905 食料(酒類を除く)及びエネルギーを除く総合(季節調整済) NaN 794 0921 1 0921 財(季節調整済) NaN 795 0922 1 0922 半耐久消費財(季節調整済) NaN 796 0923 1 0923 生鮮食品を除く財(季節調整済) NaN 797 0906 1 0906 生鮮食品及びエネルギーを除く総合(季節調整済) NaN [798 rows x 4 columns]Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS']) >>> df @code @level @name 0 13A01 1 13100 東京都区部 1 00000 1 全国 2 00011 1 人口5万以上の市 3 00012 1 大都市 4 00013 1 中都市 .. ... ... ... 67 14A02 1 14130 川崎市 68 14A03 1 14150 相模原市 69 22A02 1 22130 浜松市 70 27A02 1 27140 堺市 71 40A01 1 40100 北九州市 [72 rows x 3 columns]Pythonコンソール>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS']) >>> df @code @level @name @parentCode 0 2019000101 4 2019年1月 2019000103 1 2018001212 4 2018年12月 2018001012 2 2018001111 4 2018年11月 2018001012 3 2018001010 4 2018年10月 2018001012 4 2018000909 4 2018年9月 2018000709 .. ... ... ... ... 681 1970000404 4 1970年4月 1970000000 682 1970000303 4 1970年3月 1970000000 683 1970000202 4 1970年2月 1970000000 684 1970000101 4 1970年1月 1970000000 685 1970000000 1 1970年 NaN [686 rows x 4 columns]つまり...どういうことだってばよ
データフレームに SQL:Where を適用する
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.where.html
まぁ4つのマスタはそれぞれ違うデータフレームに受け取るのがわかりやすいとは思うけどPythonコンソール(この明細を例にとったときに...)>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) >>> df $ @area @cat01 @tab @time 0 101.2 13A01 0001 1 2019000101Pythonコンソール:地域コード>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS']) >>> df['@name'].where(df['@code'] == '13A01')[0] '13100 東京都区部'Pythonコンソール:カテゴリー>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS']) >>> df['@name'].where(df['@code'] == '0001')[0] '0001 総合'Pythonコンソール:表彰事項>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS']) >>> df['@name'].where(df['@code'] == '1')[0] '指数'Pythonコンソール:時間軸(年・月)>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS']) >>> df['@name'].where(df['@code'] == '2019000101')[0] '2019年1月'つまりソースはこうなるな?# translation to dataframe from json-data data = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']) area = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS']) category = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS']) tab = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS']) time = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS'])複数のデータフレームをInnerJoinする
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.join.html
If we want to join using the key columns, we need to set key to be the index in both df and other. The joined DataFrame will have key as its index.
キー列を使って結合したい場合は、keyをdfとotherの両方のインデックスになるように設定する必要があります。結合されたDataFrameはそのインデックスとしてキーを持ちます。公式ドキュメントのお手本>>> df.set_index('key').join(other.set_index('key')) A B key K0 A0 B0 K1 A1 B1 K2 A2 B2 K3 A3 NaN K4 A4 NaN K5 A5 NaNここから先は結合するにあたって項目名がカブってくるので列名を変更する。
data以外のデータフレームの「@name」だけでいいんじゃないかな
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.rename.html#pandas.DataFrame.renamePythonコンソール:列構成の確認と調整、結合# 確認: >>> data.columns Index(['$', '@area', '@cat01', '@tab', '@time'], dtype='object') >>> area.columns Index(['@code', '@level', '@name'], dtype='object') >>> category.columns Index(['@code', '@level', '@name', '@parentCode'], dtype='object') >>> tab.columns Index(['@code', '@level', '@name', '@unit'], dtype='object') # 調整1: 列名変更 >>> area = area.rename(columns={'@name': 'area_name'}) >>> category = category.rename(columns={'@name': 'category_name'}) >>> tab = tab.rename(columns={'@name': 'tab_name'}) # 調整2: くっつけるとカブる列とか不要列の削除(レベルは、「全国」と「都道府県」を分けるみたいな深さ情報みたい) # エラーを出しながら判断 >>> area = area.drop(columns=['@level']) >>> category = category.drop(columns=['@level','@parentCode']) >>> tab = tab.drop(columns=['@level','@unit']) # 結合: Inner Join >>> joined = data.set_index('@area').join(area.set_index('@code')) >>> joined = joined.set_index('@cat01').join(category.set_index('@code')) >>> joined = joined.set_index('@tab').join(tab.set_index('@code')) # 確認: たぶんこれ「指数」以外もあるんだよね(「:10」で、10件だけ表示) >>> joined[:10] $ area_name category_name tab_name time_name 1970000000 31.5 全国 0001 総合 指数 1970年 1970000000 31.7 人口5万以上の市 0001 総合 指数 1970年 1970000000 31.7 大都市 0001 総合 指数 1970年 1970000000 31.8 中都市 0001 総合 指数 1970年 1970000000 31.2 小都市A 0001 総合 指数 1970年 1970000000 33.2 北海道地方 0001 総合 指数 1970年 1970000000 30.6 東北地方 0001 総合 指数 1970年 1970000000 31.5 関東地方 0001 総合 指数 1970年 1970000000 31.5 北陸地方 0001 総合 指数 1970年 1970000000 31.5 東海地方 0001 総合 指数 1970年データの加工
これ最初さー、「2019年1月」とか日本語入ってるとあとから取り回し悪くて仕方ないから int で年月項目にしようとしたんだけど13行目と14行目見て?
年度!?いらないよー。かんべんしてくださいよこれ。で、@levelって 1 と 4 以外にあるのかな?って思ってみるも、Pythonコンソールってデータを省略して見せてくるので、しかたなくcsv出力をして確認。 1 と 4 しかないことを確認できたので 1 のレコードを消しましょう。そうすれば ym にできるはず。Pythonコンソール:年どまりとか年度とかが混ざってる>>> time @code @level @name @parentCode 0 2019000101 4 2019年1月 2019000103 1 2018001212 4 2018年12月 2018001012 2 2018001111 4 2018年11月 2018001012 3 2018001010 4 2018年10月 2018001012 4 2018000909 4 2018年9月 2018000709 5 2018000808 4 2018年8月 2018000709 6 2018000707 4 2018年7月 2018000709 7 2018000606 4 2018年6月 2018000406 8 2018000505 4 2018年5月 2018000406 9 2018000404 4 2018年4月 2018000406 10 2018000303 4 2018年3月 2018000103 11 2018000202 4 2018年2月 2018000103 12 2018000101 4 2018年1月 2018000103 13 2018000000 1 2018年 NaN 14 2017100000 1 2017年度 NaN 15 2017001212 4 2017年12月 2017001012 16 2017001111 4 2017年11月 2017001012 17 2017001010 4 2017年10月 2017001012main.py:いろいろ加工しました。文字加工のエッセンスが詰まっているね# edit text to '201901' from '2019年1月' time['yyyy'] = time['time'].str.split('年', expand=True)[0] time['mm'] = time['time'].str.split('年', expand=True)[1].str.strip('月').str.zfill(2) time['yyyymm'] = time['yyyy'] + time['mm'] # If there is 'A' in the middle, it means 'city' area['city_flag'] = area['@code'].str.contains('..A..') area['area'] = area['area'].str.split(' ', expand=True)[1]
API取得制限に注意な
なんかデータ足りなくない??って思って、例えばカテゴリーが「総合」か「食料」か「穀物」までしかないんだよなぁ~、くっつけかた間違えたかなぁ~??とか思ってたけどこれだったか。data の時点のデータフレームでは100,000レコードであることを確認できました。URLをクエリパラメータ作ってひっぱるときにレコード減らす工夫するしかないね。
Q7 : 【統計データ取得機能】10万件を超えるデータを取得できません。
A7 : API機能は、一度に最大で10万件のデータを返却します。そのため、統計データが一度に取得できない場合には、継続データの取得開始位置をレスポンスのタグの値として出力します。継続データを要求する場合は、データ取得開始位置パラメータ(startPosition)にこの値を指定することで、取得できます。SQLServerでテーブルを作る
テーブル作成クエリCREATE TABLE e_Stat ( yyyymm INT NOT NULL , category NVARCHAR(50) NULL , area NVARCHAR(50) NULL , amount NUMERIC(5,1) NULL );プログラムを流してみる
あーできたー... 解散!解散ー!おつかれー
うまいもんくって寝ましょ
Pythonコンソール:上位30件のみbasic_connect-api-e_stat> python main.py 197002,0002 食料,岡山市,30.4 197004,0002 食料,福井市,29.6 197006,0002 食料,盛岡市,30.0 197008,0001 総合,山口市,32.9 197010,0001 総合,長野市,32.7 197012,0001 総合,秋田市,32.2 197101,0002 食料,松山市,33.0 197103,0002 食料,名古屋市,33.3 197105,0002 食料,水戸市,31.7 197107,0001 総合,北九州市,32.6 197109,0001 総合,大津市,34.9 197112,0001 総合,奈良市,35.4 197202,0001 総合,横浜市,34.4 197205,0002 食料,松江市,31.1 197209,0002 食料,青森市,32.8 197301,0001 総合,甲府市,35.5 197304,0002 食料,高松市,38.9 197308,0002 食料,福島市,37.7 197312,0001 総合,津市,41.6 197402,0002 食料,富山市,45.1 197402,0002 食料,金沢市,46.3 197402,0002 食料,福井市,44.7 197402,0002 食料,甲府市,46.1 197402,0002 食料,長野市,48.4 197402,0002 食料,岐阜市,45.0 197402,0002 食料,静岡市,44.6 197402,0002 食料,名古屋市,48.0 197402,0002 食料,津市,44.2 197402,0002 食料,大津市,51.6 197402,0002 食料,京都市,49.9ソースコード
ソースをgithubにしとくとあとがラクねぇ~
https://github.com/duri0214/Python/tree/master/basic_connect-api-e_stat
- 投稿日:2019-02-09T23:04:30+09:00
pandasで全要素が条件を満たすSeriesを抽出
はじめに
pandasの
DataFrameに対し条件を指定し、全要素がそれを満たすSeries(行または列)のみを抽出します。例えば、以下のようなデータがあるとします。
行は生徒、列は教科で、各要素はテストの点数を格納しています。
English Math Science Arts Tim 48 54 82 50 David 68 58 50 72 Alex 61 58 68 48 Abdi 61 82 60 66 Lisa 58 51 34 73 このとき、例えば、全てのテストで50点以上を獲得した生徒(DavidとAbdi)のみを取得、
もしくは全生徒が50点以上を取った教科(Math)のみを取得することが目的です。以下、環境。
- OS:Ubuntu 16.04 LTS
- python 3.5.2
- pandas 0.24.1
また、本記事は公式Documentationを参照しています。
結論
上記のデータが
data.csvに保存されているとき、以下のように1行で取得可能です。import numpy as np import pandas as pd # データの読み込み df = pd.read_csv('data.csv', index_col=0, header=0) print(df) # English Math Science Arts # Tim 48 54 82 50 # David 68 58 53 72 # Alex 61 58 68 48 # Abdi 61 82 60 66 # Lisa 58 51 34 73 # 全てのテストで50点以上を取った生徒(行)の取得 print(df[df >= 50].dropna(how='any')) # English Math Science Arts # David 68.0 58 53.0 72.0 # Abdi 61.0 82 60.0 66.0 # 全生徒が50点以上取得した教科(列)の取得 print(df[df >= 50].dropna(how='any', axis=1)) # Math # Tim 54 # David 58 # Alex 58 # Abdi 82 # Lisa 51解説
使っているpandasの機能は以下の2つです。
1.boolen indexingによる要素のTrue False判定
2.dropna()によるNaN要素を持つ行(列)の削除まずpandasのboolen indexingを使って、要素の判定を行います。
同じデータを使って、何をやっているか見ていきましょう。
DataFrameに対し、比較演算子>,>=,<,<=や、等価演算==で要素の評価を行います。
その結果をDataFrameに大括弧[]で渡してあげることで、Falseの要素がNaNになります。import numpy as np import pandas as pd # データの読み込み df = pd.read_csv('data.csv', index_col=0, header=0) # 要素が50以上の要素Trueに、 # 条件を満たさない要素をFalseに df_bool = df >= 50 print(df_bool) # English Math Science Arts # Tim False True True True # David True True True True # Alex True True True False # Abdi True True True True # Lisa True True False True # Falseの要素をNaNに df_nan = df[df_bool] print(df_nan) # English Math Science Arts # Tim NaN 54 82.0 50.0 # David 68.0 58 53.0 72.0 # Alex 61.0 58 68.0 NaN # Abdi 61.0 82 60.0 66.0 # Lisa 58.0 51 NaN 73.0
DataFrame.dropnaは要素にNaNを持つSeriesに対する操作を行うAPIです。
オプションとして、
axis:行か列のどちらに対する操作かを決定。axis=0(デフォルト)で行に対する操作、axis=1で列に対する操作。how:how='any'で要素に1つでもNaNがあればdrop、how='all'で全ての要素がNaNのとき削除などがあります。他のオプションは今回使わないので割愛。詳細は公式Documentationを参照。
# 先ほどのスクリプトの続き print(df_nan) # English Math Science Arts # Tim NaN 54 82.0 50.0 # David 68.0 58 53.0 72.0 # Alex 61.0 58 68.0 NaN # Abdi 61.0 82 60.0 66.0 # Lisa 58.0 51 NaN 73.0 # NaNを1つでも持つ行を削除 df_rows = df_nan.dropna(how='any') print(df_rows) # English Math Science Arts # David 68.0 58 50.0 72.0 # Abdi 61.0 82 60.0 66.0 # NaNを1つでも持つ列を削除 df_cols = df_nan.dropna(how='any', axis=1) print(df_cols) # Math # Tim 54 # David 58 # Alex 58 # Abdi 82 # Lisa 51以上です。
pandas本当に便利ですね!
データ分析には欠かせません。おまけ
以下、関連してよく使いそうな使い方をまとめます。
複数の条件を満たすSeriesの取得
論理積
&、論理和|で複数の条件を指定可能です。
ちなみに否定~も使えます。
また、等価演算子==では文字の評価も行えます。df = pd.read_csv('data.csv', index_col=0, header=0) print(df) # English Math Science Arts # Tim 48 54 82 50 # David 68 58 50 72 # Alex 61 58 68 48 # Abdi 61 82 60 66 # Lisa 58 51 34 73 # 50点以上、かつ80点より小さい行 print(df[(df >= 50) & ~(df >= 80)].dropna(how='any')) # English Math Science Arts # David 68.0 58.0 50.0 72.0 # ちなみに文字の評価も可能 df2 = pd.DataFrame([list('abc'), list('def')]) print(df2) # 0 1 2 # 0 a b c # 1 d e f # 'a'または'e'をTrue print((df2 == 'a') | (df2 == 'e')) # 0 1 2 # 0 True False False # 1 False True False条件を満たす行(または列)の要素数をカウント
DataFrame.sumは要素の合計値(もしくは文字列を連結したもの)を取得するAPIです。
Trueは1、Falseは0と判断されるため、条件に合う要素数をカウントする使い方も可能です。
axis=0(デフォルト)で列方向に合計、axis=1で行方向に合計します。
詳しいオプションは公式を参照。# 先ほどの生徒とテストの結果のデータを使います print(df) # English Math Science Arts # Tim 48 54 82 50 # David 68 58 50 72 # Alex 61 58 68 48 # Abdi 61 82 60 66 # Lisa 58 51 34 73 # 要素が50以上の要素Trueに、条件を満たさない要素をFalseに df_bool = df >= 50 print(df_bool) # English Math Science Arts # Tim False True True True # David True True True True # Alex True True True False # Abdi True True True True # Lisa True True False True # 列方向に合計 print(df_bool.sum()) # English 4 # Math 5 # Science 4 # Arts 4 # dtype: int64 # 行方向に合計 print(df_bool.sum(axis=1)) # Tim 3 # David 4 # Alex 3 # Abdi 4 # Lisa 3 # dtype: int64
- 投稿日:2019-02-09T22:51:51+09:00
【Django】Djangoで開発環境の構築から、facebookAPIを使いfacebookでユーザー認証を行うところまでのTips②
Django-Facebookを使ってFacebook認証を実装
Djangoが用意しているSNSアカウント認証のパッケージはいくつもありますが(https://djangopackages.org/grids/g/facebook-authentication/ )、
一般的にDjango-Allauthが広く使われています。$pip install django-allauth .... Installing collected packages: defusedxml, python3-openid, oauthlib, urllib3, certifi, chardet, idna, requests, requests-oauthlib, django-allauth Running setup.py install for django-allauth ... done Successfully installed certifi-2018.11.29 chardet-3.0.4 defusedxml-0.5.0 django-allauth-0.38.0 idna-2.8 oauthlib-3.0.1 python3-openid-3.1.0 requests-2.21.0 requests-oauthlib-1.2.0 urllib3-1.24.1
config/settings.pyに下の最後の4行を追加しますconfig/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'django.contrib.sites', 'allauth', 'allauth.account', 'allauth.socialaccount', 'allauth.socialaccount.providers.facebook', ]django-allauthはsitesフレームワークの利用が必要になります。
そこでDjangoサイトを識別する為に、以下の設定を付け加えます。config/settings.pySITE_ID = 1config/urls.pyurlpatterns = [ path('admin/', admin.site.urls), path('', TemplateView.as_view(template_name='home.html'), name='home'), path('accounts/', include('allauth.urls')), ] #<=変更するFacebookディベロッパーに登録
まずはこちらのリンクから、Facebookディベロッパー登録します。
https://developers.facebook.com/アプリIDとSecret keyを取得できます。これは後ほど使います。
もし登録はしたことがあるけど自分のアプリIDとSecret keyがわからないという方は、ログイン後トップ画面の
左側のツールバーから[設定]=>[ベーシック]から調べることが可能です。
続いてmigrate、runserverします。
$python manage.py migrate $python manage.py createsuperuser #管理者のユーザー名、メールアドレス、Passwordを求められる $python manage.py runserverhttp://localhost:8000/admin/ に先ほどcreatesuperuserして作成した管理者アカウントでログイン。
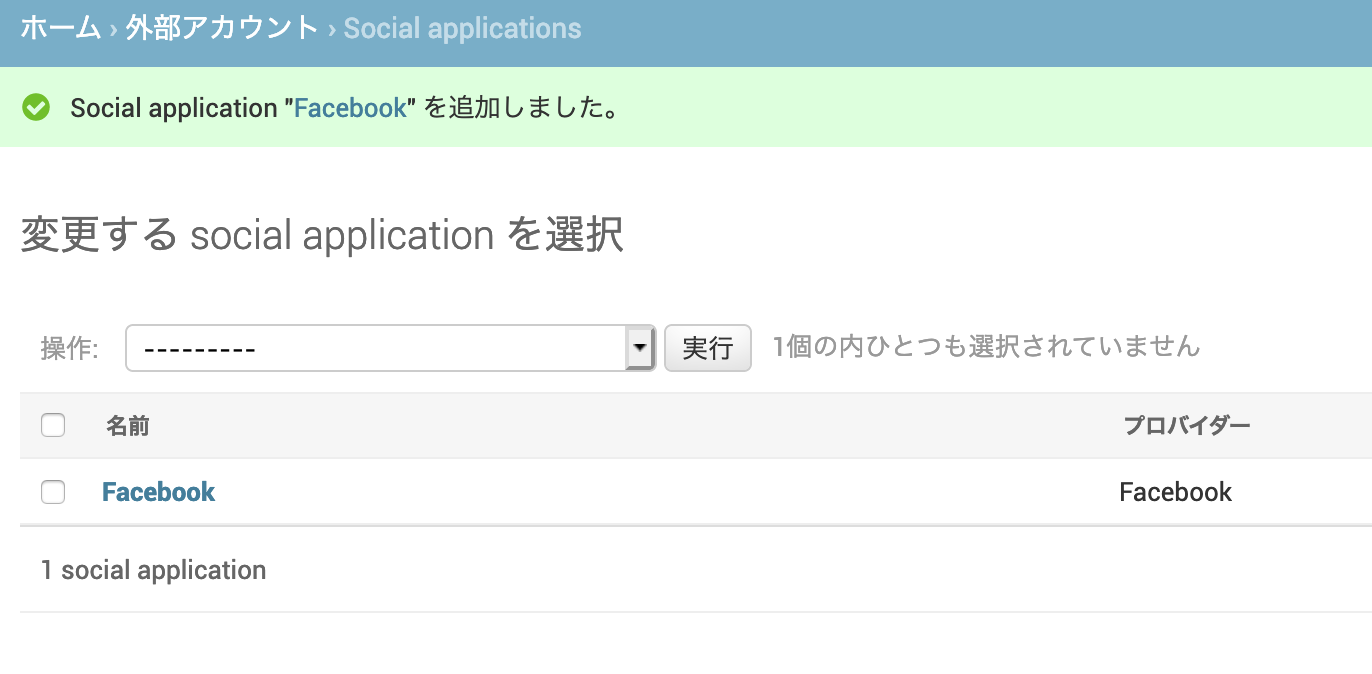
そしてログイン後、「サイト」にアクセスすると,
example.com というサイトができていることがわかります。管理画面トップに戻り、
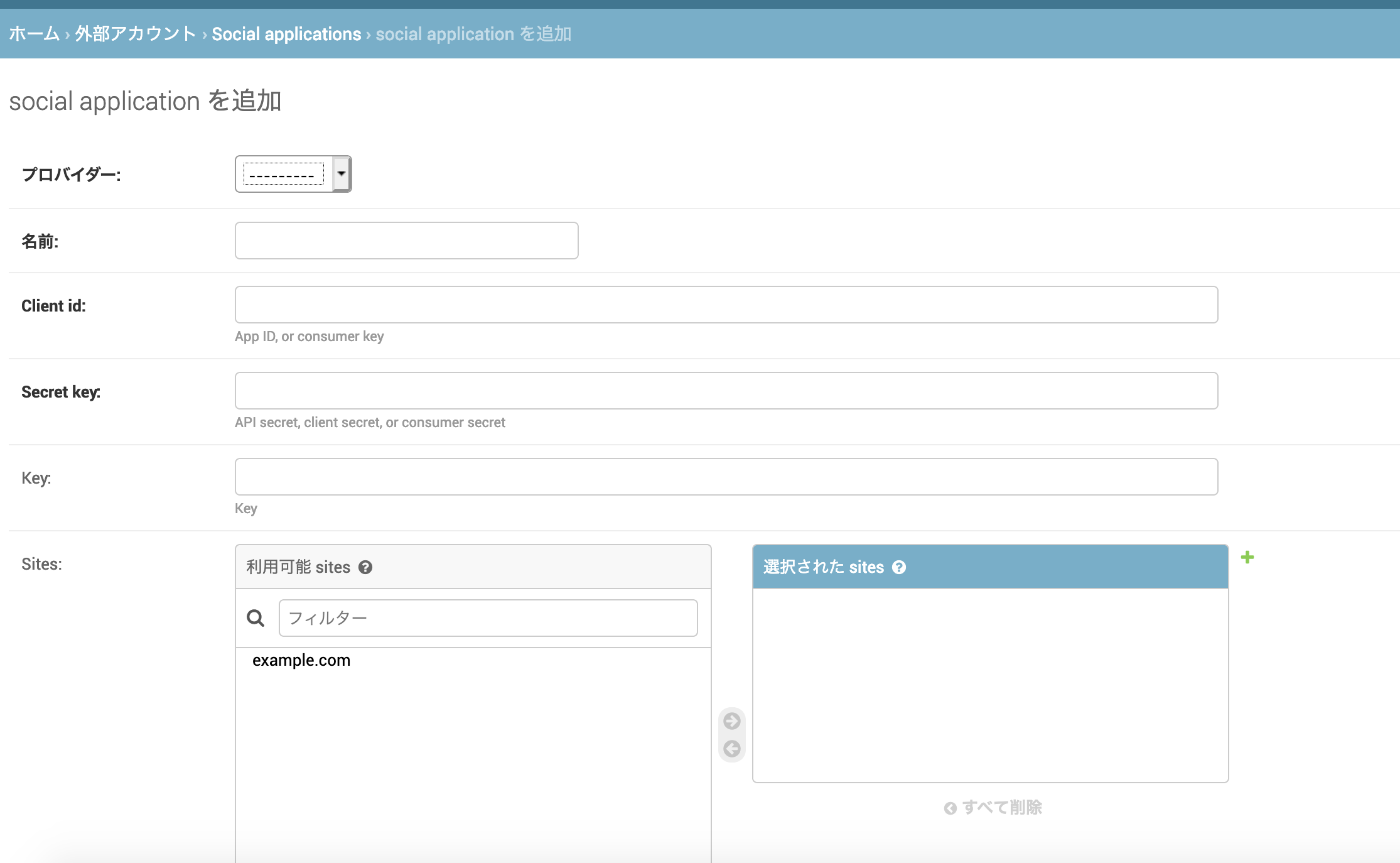
[外部アカウント]=>[Social applications]=>[social applicationを追加]を選択していくと、入力画面が現れます。
プロバイダーを選択、名前(Facebookなど)、Client ID、Secret keyを入力し(Client IdとSecret keyはFacebookディベロッパーから取得)、保存します。
早速ログインを試してみる
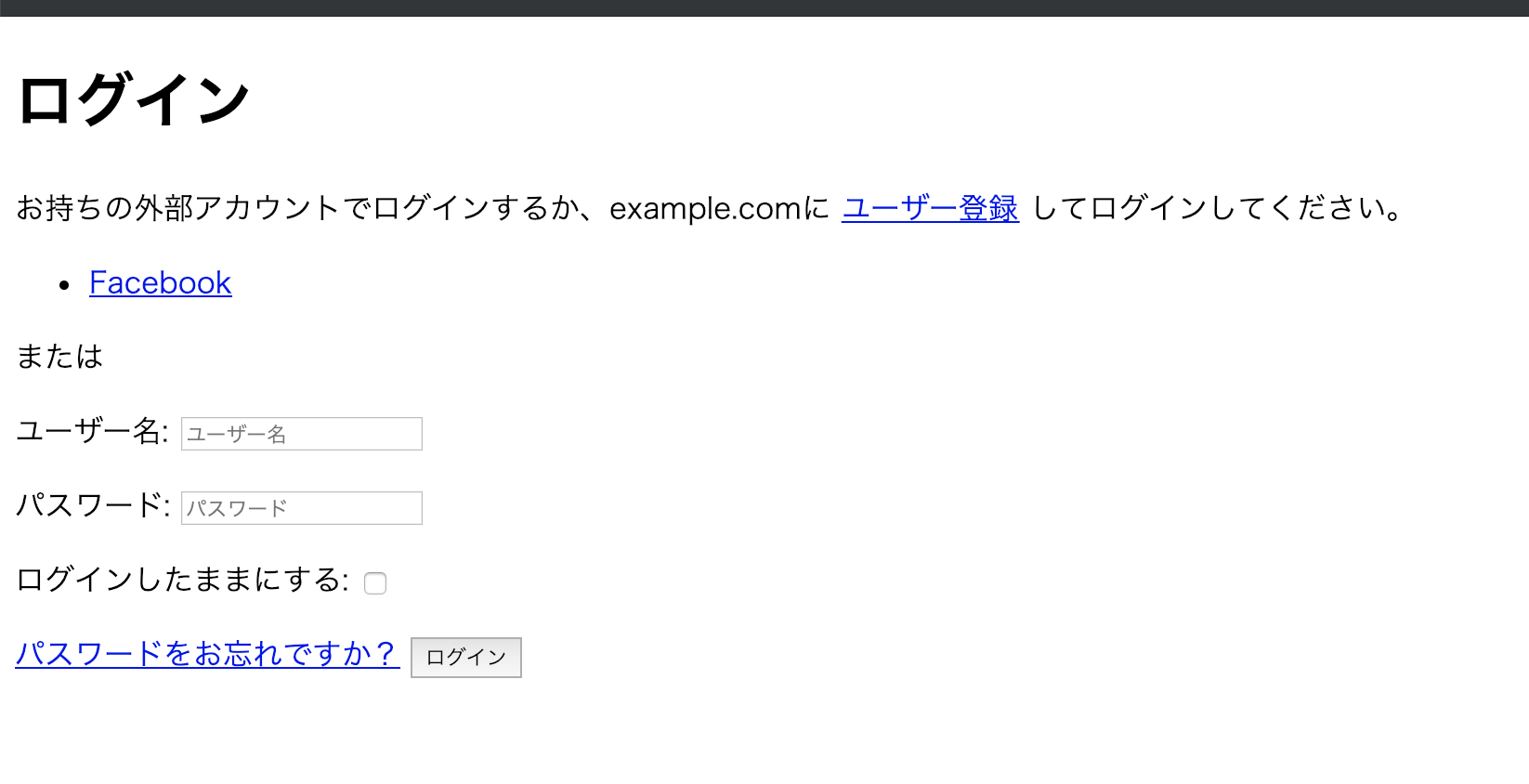
管理サイトからログアウトし、http://localhost:8000/accounts/login/ にアクセス。
ここはもちろんFacebookリンクにアクセスしましょう。
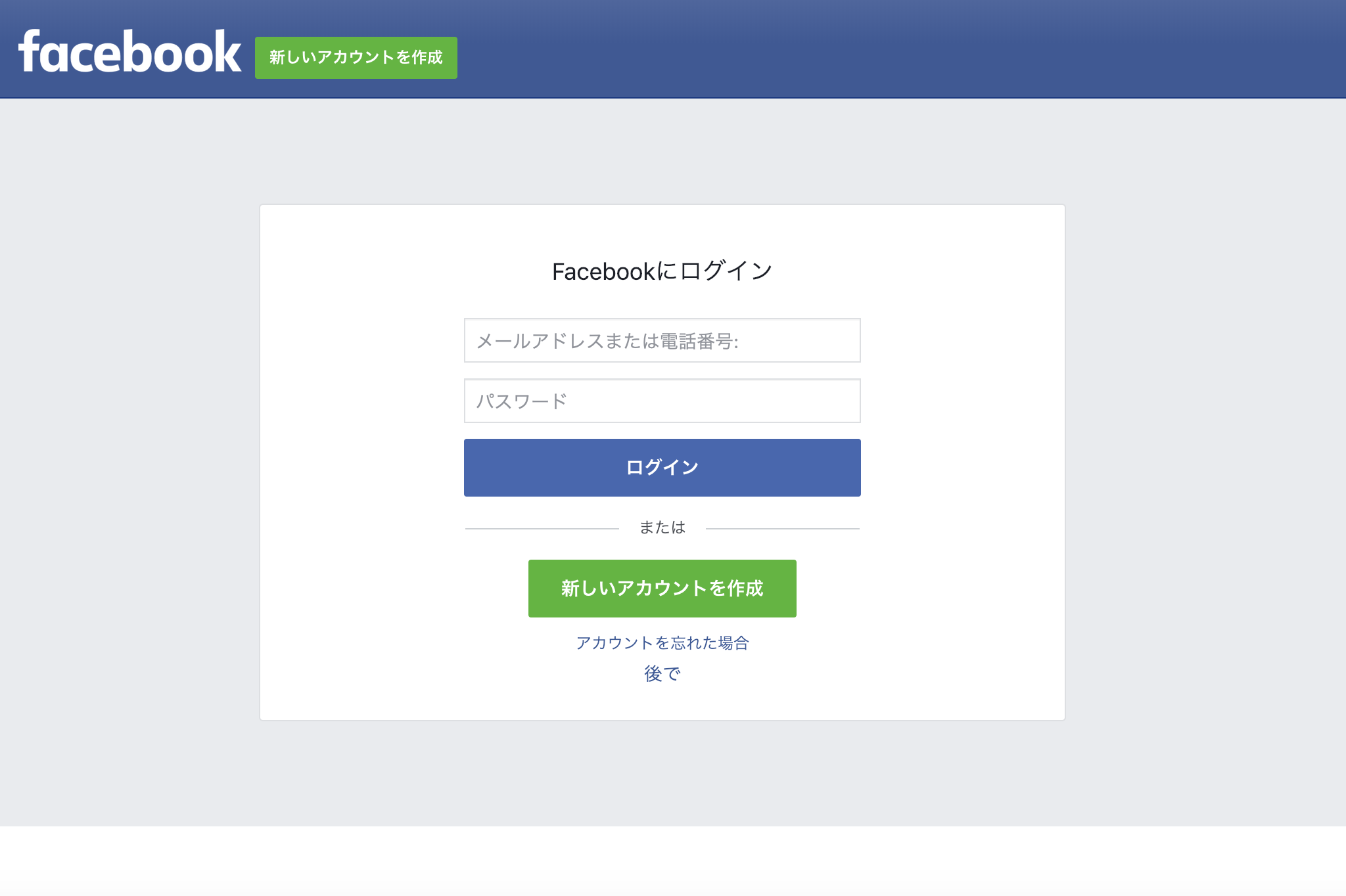
Facebook認証画面の登場です。
良い感じですね。
自分のFacebookアカウントでログインしてみましょう。
自身のFacebookの名前が入り、ログインされていることができましたか?
facebookユーザー認証までは以上の流れになります。その先
実際はログアウト、パスワードリセット、アカウント削除、ユーザーモデルのアレンジや認証方法のアレンジ(メール認証など)、リダイレクト先やサイトのUIなどやることは山積みですが、これでDjangoでのfacebook認証というとっつきづらそうな課題に風穴を開けたことに間違いはありません。
ちなみに今回はfacebook認証を行いましたが、django-allauthを使えば様々なソーシャルアカウントでの認証ができます。例えば...# ... include the providers you want to enable: 'allauth.socialaccount.providers.agave', 'allauth.socialaccount.providers.amazon', 'allauth.socialaccount.providers.angellist', 'allauth.socialaccount.providers.asana', 'allauth.socialaccount.providers.auth0', 'allauth.socialaccount.providers.authentiq', 'allauth.socialaccount.providers.baidu', 'allauth.socialaccount.providers.basecamp', 'allauth.socialaccount.providers.bitbucket', 'allauth.socialaccount.providers.bitbucket_oauth2', 'allauth.socialaccount.providers.bitly', 'allauth.socialaccount.providers.cern', 'allauth.socialaccount.providers.coinbase', 'allauth.socialaccount.providers.dataporten', 'allauth.socialaccount.providers.daum', 'allauth.socialaccount.providers.digitalocean', 'allauth.socialaccount.providers.discord', 'allauth.socialaccount.providers.disqus', 'allauth.socialaccount.providers.douban', 'allauth.socialaccount.providers.draugiem', 'allauth.socialaccount.providers.dropbox', 'allauth.socialaccount.providers.dwolla', 'allauth.socialaccount.providers.edmodo', 'allauth.socialaccount.providers.eveonline', 'allauth.socialaccount.providers.evernote', 'allauth.socialaccount.providers.facebook', 'allauth.socialaccount.providers.feedly', 'allauth.socialaccount.providers.fivehundredpx', 'allauth.socialaccount.providers.flickr', 'allauth.socialaccount.providers.foursquare', 'allauth.socialaccount.providers.fxa', 'allauth.socialaccount.providers.github', 'allauth.socialaccount.providers.gitlab', 'allauth.socialaccount.providers.google', 'allauth.socialaccount.providers.hubic', 'allauth.socialaccount.providers.instagram', 'allauth.socialaccount.providers.jupyterhub', 'allauth.socialaccount.providers.kakao', 'allauth.socialaccount.providers.line', 'allauth.socialaccount.providers.linkedin', 'allauth.socialaccount.providers.linkedin_oauth2', 'allauth.socialaccount.providers.mailru', 'allauth.socialaccount.providers.mailchimp', 'allauth.socialaccount.providers.meetup', 'allauth.socialaccount.providers.naver', 'allauth.socialaccount.providers.odnoklassniki', 'allauth.socialaccount.providers.openid', 'allauth.socialaccount.providers.orcid', 'allauth.socialaccount.providers.paypal', 'allauth.socialaccount.providers.persona', 'allauth.socialaccount.providers.pinterest', 'allauth.socialaccount.providers.reddit', 'allauth.socialaccount.providers.robinhood', 'allauth.socialaccount.providers.shopify', 'allauth.socialaccount.providers.slack', 'allauth.socialaccount.providers.soundcloud', 'allauth.socialaccount.providers.spotify', 'allauth.socialaccount.providers.stackexchange', 'allauth.socialaccount.providers.steam', 'allauth.socialaccount.providers.stripe', 'allauth.socialaccount.providers.trello', 'allauth.socialaccount.providers.tumblr', 'allauth.socialaccount.providers.twentythreeandme', 'allauth.socialaccount.providers.twitch', 'allauth.socialaccount.providers.twitter', 'allauth.socialaccount.providers.untappd', 'allauth.socialaccount.providers.vimeo', 'allauth.socialaccount.providers.vimeo_oauth2', 'allauth.socialaccount.providers.vk', 'allauth.socialaccount.providers.weibo', 'allauth.socialaccount.providers.weixin', 'allauth.socialaccount.providers.windowslive', 'allauth.socialaccount.providers.xing', ... )https://django-allauth.readthedocs.io/en/latest/installation.html
(ドキュメントより)個人的にFBはあまり信頼していないので、一つのパッケージにこうした多くの他の手段が用意されているのは非常にありがたいなと思います。
ただし難点も...
https://djangopackages.org/grids/g/facebook-authentication/
これをみると
django-allauthはdevelopment statusがBetaのようです。
本番環境で使うには心許ないか。
しかしUpdatedの頻度やStars、Repo Forksの数などをみると、他に比べるとdjango-allauthは圧倒的人気を誇っているようですね。開発にかけられる工数もそれぞれだと思いますので、用途に合わせて使えるよう色々と今後勉強してみたいと思います!


- 投稿日:2019-02-09T22:51:51+09:00
【Django】Djangoで開発環境の構築から、django-allauthを使いfacebookでユーザー認証を行うところまでのTips②
Django-Facebookを使ってFacebook認証を実装
Djangoが用意しているSNSアカウント認証のパッケージはいくつもありますが(https://djangopackages.org/grids/g/facebook-authentication/ )、
一般的にDjango-Allauthが広く使われています。$pip install django-allauth .... Installing collected packages: defusedxml, python3-openid, oauthlib, urllib3, certifi, chardet, idna, requests, requests-oauthlib, django-allauth Running setup.py install for django-allauth ... done Successfully installed certifi-2018.11.29 chardet-3.0.4 defusedxml-0.5.0 django-allauth-0.38.0 idna-2.8 oauthlib-3.0.1 python3-openid-3.1.0 requests-2.21.0 requests-oauthlib-1.2.0 urllib3-1.24.1
config/settings.pyに下の最後の4行を追加しますconfig/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'django.contrib.sites', 'allauth', 'allauth.account', 'allauth.socialaccount', 'allauth.socialaccount.providers.facebook', ]django-allauthはsitesフレームワークの利用が必要になります。
そこでDjangoサイトを識別する為に、以下の設定を付け加えます。config/settings.pySITE_ID = 1config/urls.pyurlpatterns = [ path('admin/', admin.site.urls), path('', TemplateView.as_view(template_name='home.html'), name='home'), path('accounts/', include('allauth.urls')), ] #<=変更するFacebookディベロッパーに登録
まずはこちらのリンクから、Facebookディベロッパー登録します。
https://developers.facebook.com/アプリIDとSecret keyを取得できます。これは後ほど使います。
もし登録はしたことがあるけど自分のアプリIDとSecret keyがわからないという方は、ログイン後トップ画面の
左側のツールバーから[設定]=>[ベーシック]から調べることが可能です。
続いてmigrate、runserverします。
$python manage.py migrate $python manage.py createsuperuser #管理者のユーザー名、メールアドレス、Passwordを求められる $python manage.py runserverhttp://localhost:8000/admin/ に先ほどcreatesuperuserして作成した管理者アカウントでログイン。
そしてログイン後、「サイト」にアクセスすると,
example.com というサイトができていることがわかります。管理画面トップに戻り、
[外部アカウント]=>[Social applications]=>[social applicationを追加]を選択していくと、入力画面が現れます。
プロバイダーを選択、名前(Facebookなど)、Client ID、Secret keyを入力し(Client IdとSecret keyはFacebookディベロッパーから取得)、保存します。
早速ログインを試してみる
管理サイトからログアウトし、http://localhost:8000/accounts/login/ にアクセス。
ここはもちろんFacebookリンクにアクセスしましょう。
Facebook認証画面の登場です。
良い感じですね。
自分のFacebookアカウントでログインしてみましょう。
自身のFacebookの名前が入り、ログインされていることができましたか?
facebookユーザー認証までは以上の流れになります。その先
実際はログアウト、パスワードリセット、アカウント削除、ユーザーモデルのアレンジや認証方法のアレンジ(メール認証など)、リダイレクト先やサイトのUIなどやることは山積みですが、これでDjangoでのfacebook認証というとっつきづらそうな課題に風穴を開けたことに間違いはありません。
ちなみに今回はfacebook認証を行いましたが、django-allauthを使えば様々なソーシャルアカウントでの認証ができます。例えば...# ... include the providers you want to enable: 'allauth.socialaccount.providers.agave', 'allauth.socialaccount.providers.amazon', 'allauth.socialaccount.providers.angellist', 'allauth.socialaccount.providers.asana', 'allauth.socialaccount.providers.auth0', 'allauth.socialaccount.providers.authentiq', 'allauth.socialaccount.providers.baidu', 'allauth.socialaccount.providers.basecamp', 'allauth.socialaccount.providers.bitbucket', 'allauth.socialaccount.providers.bitbucket_oauth2', 'allauth.socialaccount.providers.bitly', 'allauth.socialaccount.providers.cern', 'allauth.socialaccount.providers.coinbase', 'allauth.socialaccount.providers.dataporten', 'allauth.socialaccount.providers.daum', 'allauth.socialaccount.providers.digitalocean', 'allauth.socialaccount.providers.discord', 'allauth.socialaccount.providers.disqus', 'allauth.socialaccount.providers.douban', 'allauth.socialaccount.providers.draugiem', 'allauth.socialaccount.providers.dropbox', 'allauth.socialaccount.providers.dwolla', 'allauth.socialaccount.providers.edmodo', 'allauth.socialaccount.providers.eveonline', 'allauth.socialaccount.providers.evernote', 'allauth.socialaccount.providers.facebook', 'allauth.socialaccount.providers.feedly', 'allauth.socialaccount.providers.fivehundredpx', 'allauth.socialaccount.providers.flickr', 'allauth.socialaccount.providers.foursquare', 'allauth.socialaccount.providers.fxa', 'allauth.socialaccount.providers.github', 'allauth.socialaccount.providers.gitlab', 'allauth.socialaccount.providers.google', 'allauth.socialaccount.providers.hubic', 'allauth.socialaccount.providers.instagram', 'allauth.socialaccount.providers.jupyterhub', 'allauth.socialaccount.providers.kakao', 'allauth.socialaccount.providers.line', 'allauth.socialaccount.providers.linkedin', 'allauth.socialaccount.providers.linkedin_oauth2', 'allauth.socialaccount.providers.mailru', 'allauth.socialaccount.providers.mailchimp', 'allauth.socialaccount.providers.meetup', 'allauth.socialaccount.providers.naver', 'allauth.socialaccount.providers.odnoklassniki', 'allauth.socialaccount.providers.openid', 'allauth.socialaccount.providers.orcid', 'allauth.socialaccount.providers.paypal', 'allauth.socialaccount.providers.persona', 'allauth.socialaccount.providers.pinterest', 'allauth.socialaccount.providers.reddit', 'allauth.socialaccount.providers.robinhood', 'allauth.socialaccount.providers.shopify', 'allauth.socialaccount.providers.slack', 'allauth.socialaccount.providers.soundcloud', 'allauth.socialaccount.providers.spotify', 'allauth.socialaccount.providers.stackexchange', 'allauth.socialaccount.providers.steam', 'allauth.socialaccount.providers.stripe', 'allauth.socialaccount.providers.trello', 'allauth.socialaccount.providers.tumblr', 'allauth.socialaccount.providers.twentythreeandme', 'allauth.socialaccount.providers.twitch', 'allauth.socialaccount.providers.twitter', 'allauth.socialaccount.providers.untappd', 'allauth.socialaccount.providers.vimeo', 'allauth.socialaccount.providers.vimeo_oauth2', 'allauth.socialaccount.providers.vk', 'allauth.socialaccount.providers.weibo', 'allauth.socialaccount.providers.weixin', 'allauth.socialaccount.providers.windowslive', 'allauth.socialaccount.providers.xing', ... )https://django-allauth.readthedocs.io/en/latest/installation.html
(ドキュメントより)個人的にFBはあまり信頼していないので、一つのパッケージにこうした多くの他の手段が用意されているのは非常にありがたいなと思います。
ただし難点も...
https://djangopackages.org/grids/g/facebook-authentication/
これをみると
django-allauthはdevelopment statusがBetaのようです。
本番環境で使うには心許ないか。
しかしUpdatedの頻度やStars、Repo Forksの数などをみると、他に比べるとdjango-allauthは圧倒的人気を誇っているようですね。開発にかけられる工数もそれぞれだと思いますので、用途に合わせて使えるよう色々と今後勉強してみたいと思います!
- 投稿日:2019-02-09T22:41:58+09:00
Jupyterで使える自作のプロットライブラリを作ってみたい。
Jupyter上で使えるプロットを自分で作って遊べないか試してみました。
ゴミでもなんでもアウトプットしていくべきとのことで、大したことのないものですが進めていきます。
plotlyとか既に色々選択肢がありますが、勉強目的と、自分でカスタマイズなどもできるように、車輪の再発明をしていきます。使うjsライブラリ
インタラクティブ且つ色々アニメーションさせたりも考えて、D3.jsをPython側から扱っていく方向で進めます。後は作業中は個別のモジュール単位などで実施し、定期的に全体のテストを流していく等すればテスト時間はそこまで気にならなくなりそうです。
(D3.js自体は以前記事にしているのでそちらも良ければ : SVGとD3.jsの入門まとめ)
jsライブラリの読み込みはどうやるの?
べたでjsやHTMLを書いたりする分にはIPython.displayパッケージ内の関数やクラスを使っていけばJupyter上で色々できますが、外部のjsファイルなどを対象としたい場合はどうすればいいのでしょう。
Jupyter上で、HTMLやdisplayメソッドを組み合わせてscriptタグでsrc指定したくらいだと、エラーで怒られるようです。
他の方のライブラリでマジックコマンドでJupyter上でD3.jsを扱えるようにするものがありましたが、今回はJupyter上で直接D3.jsを扱うのではなく、.pyファイルを経由する形でライブラリで色々やりたいところです。調べたところ、requirejsを使う形でJupyterで読み込めるとの記事があったため、そちらを利用する形にしました。
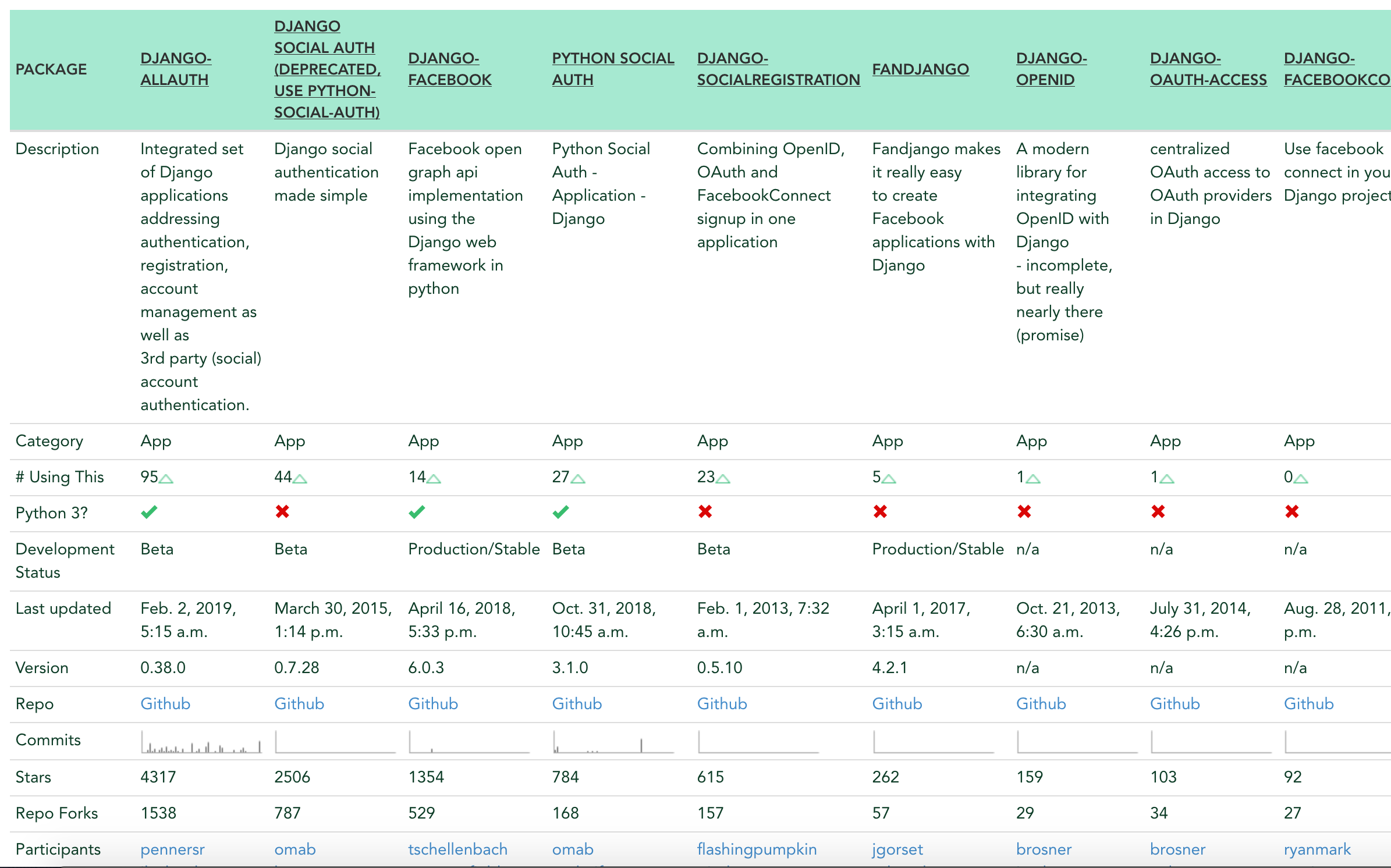
%%html <script> requirejs.config({ paths: { 'd3': ['https://d3js.org/d3.v4.min'], }, }); </script>※minの後に.jsといった拡張子は付けない形で指定します。
※v4のバージョンの個所は他のものを使う際には調整してください。後は、使いたいタイミングでrequire(['d3'], function(d3) {...といった記述をすることで、D3.jsがJupyter上で使えます。
%%html <svg id="test-svg" width="100" height="100"> </svg> <script> require(['d3'], function(d3) { d3.select("#test-svg") .append("rect") .attr("width", "100") .attr("height", "100") .attr("fill", "#ff0000"); }); </script>
※htmlのマジックコマンドで記述したましたが、IPython.display.display関数とIPython.display.HTMLを組み合わせて、.py上から実行してもちゃんとJupyter上で表示されます。
テストどうしようか問題
フロントのテストに近いような印象ですが、Jupyter上で動作することを目的とするため、普通のバックエンド側の単体テストなどと比べると少し厄介です。
手動でのテストに頼る形でもいいのかもしれませんが、50とか100とかにプロットの種類がなってくると少ししんどい気配があります。
細かいアニメーションなどは目に頼る必要がありますが、それ以外のあまりテストを書く負担が重くなく、且つ書いてあると安心感が出てくる費用対効果が高そうなところはJupyterなどが絡む個所でもテストを書く形で進めます。Jupyterの起動
まずは、Jupyterを起動させないといけないため、noseのテストランナーのラッパー的なモジュールを用意しました。
そのモジュール内で、別のプロセスでJupyterを起動するようにしました。
起動コマンドの--no-browserオプションで、ブラウザを起動せずにJupyterを起動できます。後で触れますが、selenium側で別途ブラウザを立ち上げるので、ここではブラウザの起動はしない形で設定しています。
また、--portでテスト用のJupyterのポートを指定しています。通常は8888が使われ、8888が使用済みであれば8889...といった具合にポート番号が割り振られていくので、それらとテスト用のJupyterで番号が被らないように設定しています。import os import multiprocessing as mp import subprocess as sp import time ... def run_jupyter_process(): """ Start Jupyter process for testing. """ os.system( 'jupyter notebook --no-browser --port={jupyter_test_port} &'.format( jupyter_test_port=JUPYTER_TEST_PORT )) ... jupyter_process = mp.Process(target=run_jupyter_process) jupyter_process.start()また、別のプロセスにしないとJupyter起動のコマンドで処理が止まってしまう(Ctrl + CなどでJupyterを止めないと次に進まない)のでmultiprocessingモジュールを利用しています。
ただ、いつ起動が終わるのかが見えないので、起動が終わったかどうかをチェックする必要があります。以下のようなコマンドで、起動が終わって動いているJupyterの一覧が表示できるので、そのリストの中に指定したテスト用のポートのJupyterが存在するかどうかをチェックし、存在する状態になったタイミングでnoseのテストに移るようにwhile文で制御します。$ jupyter notebook list以下のようにポートやトークンなどを含めたリストが表示されます。
Currently running servers: http://localhost:8888/?token=27fc5d92e60184655a145a6ef723ff5f6349571b3cd0cb1e :: C:\Users\def is_jupyter_started(): """ Get the boolean value as to whether Jupyter for testing has been started or not. Returns ------- result : bool If it is started this function will returns True. """ out = sp.check_output( ['jupyter', 'notebook', 'list']) out = str(out) is_in = str(JUPYTER_TEST_PORT) in out if is_in: return True return False ... while not is_jupyter_started(): time.sleep(1)また、テストが終わった後に、起動したJupyterを止めないと、ポート番号がどんどんずれていったり、メモリを無駄に消費したりと好ましくありません。
アクセス時にもポート番号がずれずに固定のものだと制御が楽なので、テスト前と終わったタイミングでテスト用のポートのJupyterが起動していれば止めるようにしておきます。
以下のようなフォーマットのコマンドで任意のJupyterを止めることができます。$ jupyter notebook stop {ポート番号}def stop_jupyter(): """ Stop Jupyter of the port number used in the test. """ os.system('jupyter notebook stop {jupyter_test_port}'.format( jupyter_test_port=JUPYTER_TEST_PORT )) ... stop_jupyter() jupyter_process.terminate()テスト長くない?問題
テスト時にJupyterを起動させる都合、ちょっとテストが終わるまで長くなります。
一部のモジュールだけテストしたい、といったケースでも1分かかったりします。
仕事だと部分的なテストは3秒くらいあれば起動から終わりまで通るのでそれらと比べると少し辛いところです。
基本的にテストを流している間もぼーっとしているのは非効率なので、作業しつつ終わったら通知が来るようにしておきます。Win10環境で作業しているので、Windows 10 Toast NotificationsというPythonライブラリを使わせていただきました。
これで、テストが終わった際に画面右下に通知が表示されます。
インストール :
$ pip install win10toast==0.9また、テストにはnoseライブラリを使っていますが、noseで引数に--with-xunitと--xunit-fileを指定することで、指定のパスにテストの実行結果をXMLで保存してくれるようになるようです。XML内に、テスト全体の実行件数や失敗件数、各テストの処理時間が保存されます。
XMLのパース用に、Pythonのxmlモジュールを使って値を取っていきます。import xml.etree.ElementTree as ET ... from win10toast import ToastNotifier import nose ... def run_nose_command(module_name): """ Execute the test command with the Nose library, and obtain the number of execution tests and the number of failure tests. Parameters ---------- module_name : str Name of the module to be tested. Specify in a form including a path. Omit extension specification. If an empty character is specified, all tests are targeted. Returns ------- test_num : int Number of tests executed. error_num : int Number of errors. failures_num : int Number of tests failed. """ xml_path = 'log_test.xml' nose_command = 'nosetests' if module_name != '': nose_command += ' %s' % module_name nose_command += ' --with-xunit --xunit-file={xml_path} -s -v'.format( xml_path=xml_path ) os.system(nose_command) with open(xml_path, 'r') as f: test_xml = f.read() xml_root_elem = ET.fromstring(text=test_xml) test_num = int(xml_root_elem.attrib['tests']) error_num = int(xml_root_elem.attrib['errors']) failures_num = int(xml_root_elem.attrib['failures']) return test_num, error_num, failures_num ... test_num, error_num, failures_num = run_nose_command( module_name=module_name) ... toast_msg = '----------------------------' toast_msg += '\ntest num: %s' % test_num toast_msg += '\nerror num: %s' % error_num toast_msg += '\nfailures num: %s' % failures_num toast_notifier = ToastNotifier() toast_notifier.show_toast( title='The test is completed.', msg=toast_msg, duration=5)これでテスト終了時に通知が飛んでくるようになります。音も鳴るのでよそ見していても安心。
お好みでSlackなどに調整するといいと思われます。というか、なんとなくお試しでこれ使ってみたけれど、普通にSlackでいいよね。
後は作業中は個別のモジュール単位などで実施し、定期的に全体のテストを流していく等すればテスト時間はそこまで気にならなくなりそうです。
また、テストのコマンドの引数で、Jupyterの起動をスキップするかどうかの指定を受け入れるようにも調整しました(1つの関数のみのテストなどで、Jupyterを使わない場合など)。遊びなので本格的なCI的なところまでは対応しませんが、ひとまずは個人で進めるにはこの程度で良さそうです。
(本当はPython用のlintを入れたり、Jupyterのプロセスを一度起動したら使いまわしたりした方がテストが早く終わったりで快適かと思われますが、それらは後日機会があれば少しずつ・・)seleniumでChromeのWebDriverを使う
テスト用のJupyterへのアクセスはseleniumとChromeのWebDriverを使わせていただきました。
過去、PhantomJSやらFireFoxは使ったことがありましたが、今回初のChromeです。前者二つよりも考えるべきことが少なく済んでなんだか快適です。参考にさせていただきました : Python + Selenium で Chrome の自動操作を一通り
import chromedriver_binaryとするだけでパスが通るのもシンプルでいいですね。
seleniumからJupyterのセルにスクリプトを入力できない問題
テスト時にJupyterやら起動させる点は問題がありませんでしたが、その後selenium経由でJupyterのセル内にスクリプトを入力していこうとしたところ、input周りの構造が大分複雑でうまくいきませんでした。クリックした後にseleniumのsend_keyなどだといまいちうまくいきません。どうやらtextarea関係がJupyter上では実は非表示になっているそうで・・
対策として、開く前にipynbファイルのセルの設定に直接値を設定して、それからノートのページを開くように調整しました。(テスト用であればこれだけでも十分かなと)
ただし、よく調べてみるとselenim経由でDOMを色々操作してしまえばいけそう、という情報が見つかりました。こちらの方がスマートな気がしないでもないので、後日気が向いたら調整しようと思います。
NOTE I have been successful when changing the DOM with javascript execution by making the textarea visible and then sending keys to it. (This was done by removing hidden; from the style attribute in the parent div element that it inherited from. However, I am looking for a solution which does not require altering the DOM.
python Selenium send_keys to a Jupyter notebook後は、seleniumからRUN ALLメニューなどを操作するスクリプトを書いて、アウトプットの内容を取得してテストするスクリプトを組んでひとまずはテストができそうな気配が出てきました。
アウトプットの要素のスクショがうまく取れない問題
How to take partial screenshot with Selenium WebDriver in python?
テストのためのJupyterやらseleniumなどの準備が整ったので、いざJupyter上でのD3.js経由のアウトプットの表示結果のスクショを取ってみよう・・と上記のstackoverflowの投稿を参考に進めてみたところ、なんだかスクショ領域がずれます。
なぜだろう・・と色々悩んだり調べていたところ、上記のstackoverflow内で以下のコメントを見つけました。
On MacOS (retina) there is problem that web element position in pixels dont match element position in screenshot, due to resize/ratio –
画面の比率の問題・・そういえば、タブレットで作業をしているので、150%(推奨値)に設定していたのを思い出しました。
ちょっと文字が小さい感が無きにしもですが、100%にしてみたところ正常に動作しました・・どうやら、selenium側での座標などの取得値が画面の解像度が100%ではない場合はずれてしまう模様。
てっきりJupyterのヘッダー部分などがある都合、座標がずれるのかとか考えて、非表示にする処理を追加したりしてしまいましたがそうではなかったようで・・。
環境変数的なもので、画面解像度設定のファイルを設置してもいいのですが、少し手間なので一旦100%で進めます。引数に渡したWebElement要素のスクショを取るコード(基本的にJupyter上のSVG要素を指定):
def save_target_elem_screenshot( target_elem, img_path=DEFAULT_TEST_IMG_PATH): """ Save screenshot of target element. Parameters ---------- target_elem : selenium.webdriver.remote.webelement.WebElement The WebElement for which screen shots are to be taken. img_path : str, default DEFAULT_TEST_IMG_PATH The destination path. """ driver.find_element_by_tag_name('body').send_keys( Keys.CONTROL + Keys.HOME) location_dict = target_elem.location size_dict = target_elem.size elem_x = location_dict['x'] left = location_dict['x'] top = location_dict['y'] right = location_dict['x'] + size_dict['width'] bottom = location_dict['y'] + size_dict['height'] screenshot_png = driver.get_screenshot_as_png() img = Image.open(BytesIO(screenshot_png)) img = img.crop((left, top, right, bottom)) img.save(img_path) img.close()※Jupyterの起動、seleniumの起動、Jupyterの入力のセルにテスト用のスクリプトを設定する処理、テスト用のノートを開く処理、Jupyter上のスクリプトの実行、ヘッダーと入力のセルを非表示にする処理(スクショが途切れないように)、アウトプットのSVG領域のスクショを保存する処理の流れのGIFアニメ:
一部以前使っていたJupyterの拡張機能の都合、通知の許可云々が出てきていますが、害は無いので放置します
スクショの保存結果:
ひとまずはD3.jsを経由しての四角を追加するだけのシンプルなものではありますが、このテストの流れでいけそうな気配があります。
OpenCVでの画像の比較
ヒストグラム比較
参考にさせていただきました。
スクショで取った画像のRGBのヒストグラムを比較して、ほぼ想定した通りの画像になっているのかをチェックするための処理を用意します。(将来、フォントなどの表示が少し変わっても分布の差はそこまで変わらずにテストが通る、といった状況を想定)
OpenCVのcalcHistでヒストグラムの計算、compareHistでヒストグラムの比較をします。
RGBの各チャンネルに対して実施し、それぞれの類似度の平均を取得するようにします。def compare_img_hist(img_path_1, img_path_2): """ Get the comparison result of the similarity by the histogram of the two images. This is suitable for checking whether the image is close in color. Conversely, it is not suitable for checking whether shapes are similar. Parameters ---------- img_path_1 : str The path of the first image for comparison. img_path_2 : str The path of the second image for comparison. Returns ------- similarity : float Similarity between two images. The maximum is set to 1.0, and the closer to 1.0, the higher the similarity. It is set by the mean value of the histogram of RGB channels. """ assert_img_exists(img_path=img_path_1) assert_img_exists(img_path=img_path_2) img_1 = cv2.imread(img_path_1) img_2 = cv2.imread(img_path_2) channels_list = [[0], [1], [2]] similarity_list = [] for channels in channels_list: img_1_hist = cv2.calcHist( images=[img_1], channels=channels, mask=None, histSize=[256], ranges=[0, 256] ) img_2_hist = cv2.calcHist( images=[img_2], channels=channels, mask=None, histSize=[256], ranges=[0, 256] ) similarity_unit = cv2.compareHist( H1=img_1_hist, H2=img_2_hist, method=cv2.HISTCMP_CORREL) similarity_list.append(similarity_unit) similarity = np.mean(similarity_list) return similarity試しにテストで真っ赤な画像2枚を指定して、類似度が1.0(最大)になっていることや、赤と緑の画像を比較して類似度が下がっていることを確認しました。
※注 赤と緑の画像の比較でも、青は両方とも0でそこは類似しているという判定になるので、類似度が0にはならない点に注意します。from nose.tools import assert_equal, assert_true, assert_raises, \ assert_less_equal from PIL import Image ... img = Image.new(mode='RGB', size=(50, 50), color='#ff0000') img.save(TEST_IMG_PATH_1) img.save(TEST_IMG_PATH_2) img.close() similarity = img_helper.compare_img_hist( img_path_1=TEST_IMG_PATH_1, img_path_2=TEST_IMG_PATH_2) assert_equal(similarity, 1.0) img = Image.new(mode='RGB', size=(50, 50), color='#00ff00') img.save(TEST_IMG_PATH_2) img.close() similarity = img_helper.compare_img_hist( img_path_1=TEST_IMG_PATH_1, img_path_2=TEST_IMG_PATH_2) assert_less_equal(similarity, 0.5)テストでのしきい値はそのうち様子を見て調整していくとして、これでとりあえずはエラーなんかで画像が表示されていない!とかデグレして全然違うように表示されてしまっている!といったことがチェックできます。
色ではなく形を重視して比較する方法(例えば、カラーセットの変更を加味して実装した場合のテストなど)もありますが、そちらは必要性を感じてきたら追加するようにします。実際にプロットの機能の実装を考える
ここまでが結構長かった感じですが、やっと本格的なプロットの機能を考えていきます。
最初にどういったものを作るか・・という点ですが、シンプルなプロットであればPythonで様々な選択肢があり、それを作るのでは面白みがありません。そのため、まだ他の方で作られてなさそうな、Storytelling with Data: A Data Visualization Guide for Business Professionalsの書籍に出てくるようなプロットのPythonでの実装を考えてみます。どういったプロットかというと、「極力シンプルに」「何を伝えたいのかを極力明確に」「なるべく短時間で使えたい内容を伝える」「より効果的にするためにデザインの知見を活かす」「色弱の方でも伝わる配色」といったような、スパゲッティコードならぬスパゲッティグラフを回避するためのプロットです。
プレゼンで聞いている方への説明で短時間で伝えないといけない際など、ビジネスで役立ちます。
詳細は著者の方のサイトのhow I storyboardなどもご確認ください。まずは一つのラインのみ目立たせる折れ線グラフから
ベーシックなものを作っていきます。
伝えたい内容が一つの数値だけで、他の要素はあまり重要ではないようなケースで使うようなプロットを考えます。
折れ線グラフで、目立たせるものを青色、他をグレーの配色にします。(色弱の方でも区別が付きやすく、青の部分があなたが伝えたいことということが瞬時に分かるプロット)その他、以下のような点を対応します。
- 凡例を端の方でまとめる形ではなく、折れ線グラフの右端に配置するのを想定します。
- タイトル・説明文をオプションとして設定できるようにします。
- X軸の値は日付(時系列のデータ)を想定します。
- 年の表記は毎回設定する必要がないのと、X軸の表示を回転させると可読性が下がるそうなので、回転させずに年と月日で2段の表示とします。
- Y軸のラベルをオプションで設定できるようにします。(何の値なのかのラベル)
- Y軸のラベルで、前後に文字列をオプションで設定できるようにします。(例 : $や円や%記号など)
Storytelling with data for grants managersの記事に、良くない例(Before)と修正後の良い例(After)が載っています。
モックを作る
最初からJupyterへの組み込みをしながらレイアウトなどの調整をするのはしんどいため、最初はHTML単体で書いてみます。こうすることで、色々D3.jsで試行錯誤がしやすかったり、最終的にPython側から渡さないといけないパラメーターの洗い出しなどを目的とします。
こんな感じになりました。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <script src="https://d3js.org/d3.v4.js"></script> <style> #test-svg { border: 1px solid #999999; } #test-svg .font { font-family: -apple-system, BlinkMacSystemFont, "Helvetica Neue", YuGothic, "ヒラギノ角ゴ ProN W3", Hiragino Kaku Gothic ProN, Arial, "メイリオ", Meiryo, sans-serif; } #test-svg .title { fill: #6bb2f8; font-size: 25px; } #test-svg .description { font-size: 14px; fill: #999999; } #test-svg .legend { font-size: 14px; fill: #999999; } #test-svg .stands-out-legend { font-size: 14px; fill: #6bb2f8; font-weight: bold; } #test-svg .x-axis path, #test-svg .y-axis path, #test-svg .x-axis line, #test-svg .y-axis line { stroke: #999999; shape-rendering: crispEdges; } #test-svg .x-axis text, #test-svg .x-axis-year, #test-svg .y-axis text, #test-svg .y-axis-label { font-family: -apple-system, BlinkMacSystemFont, "Helvetica Neue", YuGothic, "ヒラギノ角ゴ ProN W3", Hiragino Kaku Gothic ProN, Arial, "メイリオ", Meiryo, sans-serif; fill: #999999; font-size: 14px; } #test-svg .line { fill: none; stroke: #cccccc; stroke-width: 2.5; } #test-svg .stands-out-line { fill: none; stroke: #acd5ff; stroke-width: 4.0; } </style> </head> <body> <script> const SVG_ID = "test-svg"; const SVG_WIDTH = 600; const SVG_HEIGHT = 372; const OUTER_MARGIN = 20; const X_TICKS = 5; const Y_TICKS = 5; const Y_AXIS_PREFIX = ""; const Y_AXIS_SUFFIX = ""; const PLOT_TITLE_TXT = "Time series of fruit prices."; const PLOT_DESCRIPTION_TXT = "Orange price keeps stable value in the long term."; const DATASET = [{ date: new Date(2018, 0, 1), Apple: 100, Orange: 120, Melon: 250 }, { date: new Date(2018, 3, 12), Apple: 120, Orange: 150, Melon: 220 }, { date: new Date(2018, 10, 3), Apple: 110, Orange: 100, Melon: 330 }, { date: new Date(2019, 1, 10), Apple: 130, Orange: 160, Melon: 310 }] const COLUMN_LIST = ["Apple", "Melon"]; const STANDS_OUT_COLUMN_LIST = ["Orange"]; var MERGED_COLUMN_LIST = COLUMN_LIST.concat(STANDS_OUT_COLUMN_LIST); const LEGEND_DATASET = [ {key: "Apple", value: 130}, {key: "Orange", value: 160}, {key: "Melon", value: 310} ]; const LEGEND_KEY = function(d) { return d.key; } const YEAR_DATASET = [ new Date(2018, 0, 1), new Date(2019, 0, 1) ]; const Y_AXIS_MIN = 0; const Y_AXIS_MAX = 310 * 1.1; const Y_AXIS_LABEL = "Price of each fruit"; const X_AXIS_MIN = new Date(2018, 0, 1); const X_AXIS_MAX = new Date(2019, 1, 10); var svg = d3.select("body") .append("svg") .attr("width", SVG_WIDTH) .attr("height", SVG_HEIGHT) .attr("id", SVG_ID) var plotBaseLineY = 0; if (PLOT_TITLE_TXT !== "") { var plotTitle = svg.append("text") .attr("x", OUTER_MARGIN) .attr("y", OUTER_MARGIN) .attr("dominant-baseline", "hanging") .text(PLOT_TITLE_TXT) .classed("title font", true); var plotTitleBBox = plotTitle.node().getBBox(); plotBaseLineY += plotTitleBBox.y + plotTitleBBox.height; } if (PLOT_DESCRIPTION_TXT !== "") { var plotDescription = svg.append("text") .attr("x", OUTER_MARGIN) .attr("y", plotBaseLineY + 10) .attr("dominant-baseline", "hanging") .text(PLOT_DESCRIPTION_TXT) .classed("description font", true); var plotDesciptionBBox = plotDescription.node().getBBox(); plotBaseLineY += plotDesciptionBBox.height + 10; } var legend = svg.selectAll("legend") .data(LEGEND_DATASET, LEGEND_KEY) .enter() .append("text") .text(function(d) { return d.key; }) .attr("dominant-baseline", "central"); legend.each(function(d) { var className; if (STANDS_OUT_COLUMN_LIST.indexOf(d.key) >= 0) { className = "legend stands-out-legend font"; }else { className = "legend font"; } d3.select(this) .classed(className, true); }) var yLabelMarginAdjust = 0; if (Y_AXIS_LABEL !== "") { var yAxisLabel = svg.append("text") .text(Y_AXIS_LABEL) .attr("transform", "rotate(270)") .attr("text-anchor", "end") .attr("dominant-baseline", "text-before-edge") .classed("font y-axis-label", true); yAxisLabel.attr("x", -plotBaseLineY - OUTER_MARGIN + 1) .attr("y", OUTER_MARGIN - 3); var yAxisLabelBBox = yAxisLabel.node() .getBBox(); yLabelMarginAdjust = yAxisLabelBBox.height + 2; } var yAxisScale = d3.scaleLinear() .domain([Y_AXIS_MIN, Y_AXIS_MAX]) .range([SVG_HEIGHT - OUTER_MARGIN, plotBaseLineY + OUTER_MARGIN]); var yAxis = d3.axisLeft() .scale(yAxisScale) .ticks(Y_TICKS) .tickFormat(function (d) { var tickFormat = d; if (Y_AXIS_PREFIX !== "") { tickFormat = Y_AXIS_PREFIX + tickFormat; } if (Y_AXIS_SUFFIX !== "") { tickFormat += Y_AXIS_SUFFIX; } return tickFormat; }); var yAxisGroup = svg.append("g") .classed("y-axis font", true) .call(yAxis); var yAxisBBox = yAxisGroup .node() .getBBox(); var yAxisPositionX = OUTER_MARGIN + yAxisBBox.width + yLabelMarginAdjust; yAxisGroup.attr("transform", "translate(" + yAxisPositionX + ", 0)"); var xAxisScale = d3.scaleTime() .domain([X_AXIS_MIN, X_AXIS_MAX]) .range([yAxisPositionX, SVG_WIDTH - OUTER_MARGIN]); var yearFormat = d3.timeFormat("%Y"); var year = svg.selectAll("year") .data(YEAR_DATASET) .enter() .append("text") .text(function(d) { return yearFormat(d); }) .attr("text-anchor", "middle") .attr("x", function(d) { return xAxisScale(d); }) .attr("y", SVG_HEIGHT - OUTER_MARGIN) .classed("font x-axis-year", true); var yearBBox = year.node() .getBBox() var xAxis = d3.axisBottom() .scale(xAxisScale) .ticks(X_TICKS) .tickFormat(d3.timeFormat("%m/%d")); var xAxisGroup = svg.append("g") .classed("x-axis font", true) .call(xAxis) var xAxisBBox = xAxisGroup .node() .getBBox(); xAxisPositionY = SVG_HEIGHT - OUTER_MARGIN - xAxisBBox.height - yearBBox.height; xAxisGroup.attr( "transform", "translate(0, " + xAxisPositionY + ")"); yAxisScale.range([xAxisPositionY, plotBaseLineY + OUTER_MARGIN]); yAxis.scale(yAxisScale); yAxisGroup.call(yAxis); var legendMaxWidth = 0; svg.selectAll(".legend").each(function(d) { var width = d3.select(this) .node() .getBBox()["width"]; legendMaxWidth = Math.max(legendMaxWidth, width); }); svg.selectAll(".legend") .attr("x", function(d) { return SVG_WIDTH - OUTER_MARGIN - legendMaxWidth; }) .attr("y", function(d) { return yAxisScale(d.value); }); xAxisScale.range( [yAxisPositionX, SVG_WIDTH - OUTER_MARGIN - legendMaxWidth - 10]); xAxis.scale(xAxisScale); xAxisGroup.call(xAxis); year.attr("x", function(d) { return xAxisScale(d); }); for (var i = 0; i < MERGED_COLUMN_LIST.length; i++) { var columnName = MERGED_COLUMN_LIST[i]; var line = d3.line() .x(function (d) { return xAxisScale(d.date); }) .y(function (d) { return yAxisScale(d[columnName]); }); var line_class; if (STANDS_OUT_COLUMN_LIST.indexOf(columnName) >= 0) { className = "stands-out-line"; }else { className = "line"; } svg.append("path") .datum(DATASET) .classed(className, true) .attr("d", line); } </script> </body> </html>若干、複数回scaleを調整しているところとかはもうちょっとシンプルにできそうな気配かありますが、D3.jsのコードをもっとたくさん書いていれば段々洗練されていくのでしょう・・。
作業中、結構アンカーポイントやバウンディングボックス関係の設定で、合っているのか結構不安だったため、Chrome拡張のRuler関係のツールを多用していました。
また、色弱の方に対する表示も確認しておきます(水色と灰色の組み合わせは大丈夫だよ、と書籍に書かれていたものの一応)。
Chromatic Vision Simulatorというツールを利用させていただきました。
ちゃんと目立たせている場所とそうではない場所の区別が付くようで、大丈夫そうですね。
組み込んでJupyter上で表示できるようにする
作ったモックを組み込んでいきます。テンプレートとしてのjsとCSSのファイルを用意してそれらを文字列としてPythonで読み込み、パラメーターを置換して、最後にIPython.displayモジュール内のdisplay関数でJupyter上で表示します。
jsのテンプレートでは、以下のようにPythonの文字列のformat関数やDjangoのテンプレートのPython変数に近い感覚で、{変数名}のという形で記述しました。
... const SVG_WIDTH = {svg_width}; const SVG_HEIGHT = {svg_height}; const SVG_BACKGROUND_COLOR = "{svg_background_color}"; const SVG_MARGIN_LEFT = {svg_margin_left}; const OUTER_MARGIN = {outer_margin}; ...CSS側は、{}の括弧で書いてしまうとVS Code上でエラーになり、入力補完が効かなくなって辛い感じなので、--変数名--という形式で置換対象のパラメーターを設定しました。
... fill: --axis_text_color--; font-size: --axis_font_size--px; ...テンプレートのjsとCSS読み込み処理は以下のように対応してみました。
def read_template_str(template_file_path): """ Read string of template file. Parameters ---------- template_file_path : str The path of the template file under the template directory. e.g., storytelling/simple_line_date_series_plot.css Returns ------- template_str Loaded template string. The repr function is set. Raises ------ Exception If the file can not be found. """ file_path = os.path.join( settings.ROOT_DIR, 'plot_playground', 'template', template_file_path) if not os.path.exists(file_path): err_msg = 'Template file not found : %s' % file_path raise Exception(err_msg) with open(file_path, 'r') as f: template_str = f.read() template_str = re.sub(re.compile('/\*.*?\*/', re.DOTALL) , '', template_str) template_str = repr(template_str)[1:-1] template_str = template_str.replace('\\n', '\n') return template_strここで注意が必要な点として、Pythonの通常の文字列は{}の括弧や%などの記号が意味を持ちます。(%sなどと文字列内で記述したりなど)
{}内の記述がうまく表示されない一方で、jsなどだとこの括弧の記号が多用されます。
そのため、Python上で生の文字列として扱う必要があります。
Python上で定義する文字列であれば以下のようにクォーテーションの前にrを付けることで生(raw)の文字列として扱われます。sample_str = r'{your_variable}'一方で、今回はテンプレートのファイルを読み込んで生の文字列にする必要があります。
そういった場合にはrepr関数を使います。ただ、r記号を付けた場合と若干挙動が異なり、最初と最後に余分なクォーテーションが付与されてしまうのと、改行までエスケープされます。そのため、以下の記述で最初と最後の文字を取り除き、且つ改行を普通に改行させるために置換をしています。template_str = repr(template_str)[1:-1] template_str = template_str.replace('\\n', '\n')その他、正規表現でテンプレートの上部などに設けていたコメント部分を取り除いています。
template_str = re.sub(re.compile('/\*.*?\*/', re.DOTALL) , '', template_str)置換処理として以下のような関数を用意しました。
辞書のキーにテンプレート上のパラメーター名、値に置換するPythonのパラメーターを設定して、ループで回して置換しています。def apply_css_param_to_template(css_template_str, css_param): """ Apply the parameters to the CSS template. Parameters ---------- css_template_str : str String of CSS template. css_param : dict A dictionary that stores parameter name in key and parameter in value. Parameter name corresponds to string excluding hyphens in template. Returns ------- css_template_str : str Template string after parameters are reflected. """ for key, value in css_param.items(): key = '--%s--' % key css_template_str = css_template_str.replace(key, str(value)) return css_template_str def apply_js_param_to_template(js_template_str, js_param): """ Apply the parameters to the js template. Parameters ---------- js_template_str : str String of js template. js_param : dict A dictionary that stores parameter name in key and parameter in value. If the parameter is a list or dictionary, it is converted to Json format. Returns ------- js_template_str : str Template string after parameters are reflected. """ for key, value in js_param.items(): if isinstance(value, (dict, list)): value = data_helper.convert_dict_or_list_numpy_val_to_python_val( target_obj=value) value = json.dumps(value) key = r'{' + key + r'}' value = str(value) js_template_str = js_template_str.replace(key, value) return js_template_str一部、配列や辞書などもパラメーターで渡しているのですが、Pandasなどを経由している都合、NumPyの型の数値など(np.int64など)が紛れ込んでいるとjsonモジュールでJSON形式に変換できないので、NumPyの型の数値部分を置換する処理を挟みました。
def convert_numpy_val_to_python_val(value): """ Convert NumPy type value to Python type value. Parameters ---------- value : * The value to be converted. Returns ------- value : * The converted value. """ np_int_types = ( np.int, np.int8, np.int16, np.int32, np.int64, np.uint, np.uint8, np.uint16, np.uint32, np.uint64, ) if isinstance(value, np_int_types): return int(value) np_float_types = ( np.float, np.float16, np.float32, np.float64, ) if isinstance(value, np_float_types): return float(value) return value def convert_dict_or_list_numpy_val_to_python_val(target_obj): """ Converts the value of NumPy type in dictionary or list into Python type value. Parameters ---------- target_obj : dict or list Dictionary or list to be converted. Returns ------- target_obj : dict or list Dictionary or list after conversion. Raises ------ ValueError If dictionaries and lists are specified. """ if isinstance(target_obj, dict): for key, value in target_obj.items(): if isinstance(value, (dict, list)): target_obj[key] = convert_dict_or_list_numpy_val_to_python_val( target_obj=value ) continue target_obj[key] = convert_numpy_val_to_python_val( value=value) continue return target_obj if isinstance(target_obj, list): for i, value in enumerate(target_obj): if isinstance(value, (dict, list)): target_obj[i] = convert_dict_or_list_numpy_val_to_python_val( target_obj=value ) continue target_obj[i] = convert_numpy_val_to_python_val(value=value) continue return target_obj err_msg = 'A type that is not a dictionary or list is specified: %s' \ % type(target_obj) raise ValueError(err_msg)※若干、NumPy側で探せば関数が用意されている気配がしないでもないです・・。
表示してみる
実際にJupyter上で確認してみます。すごい適当なデータフレームを用意しました。
import pandas as pd from plot_playground.storytelling import simple_line_date_series_plot df = pd.DataFrame(data=[{ 'date': '2017-11-03', 'apple': 100, 'orange': 140, }, { 'date': '2017-12-03', 'apple': 90, 'orange': 85, }, { 'date': '2018-04-03', 'apple': 120, 'orange': 170, }, { 'date': '2018-09-03', 'apple': 110, 'orange': 180, }, { 'date': '2019-02-01', 'apple': 90, 'orange': 150, }])以下の関数内で、テンプレートの読み込みやら置換やらdisplay関数の呼び出しなどをしています。
simple_line_date_series_plot.display_plot( df=df, date_column='date', normal_columns=['apple'], stands_out_columns=['orange'], title='Time series of fruit prices.', description='Orange price keeps stable value in the long term.')
無事Jupyter上で表示できました!大体完成ですが、scikit-learnなどみたくメタデータ的なものを返却したり、このプロットのテストを追加したり細かいところを対応しておきます。
PyPI登録
pipでインストールできるように、PyPI登録を進めます。
他の方が色々記事を書かれているのでここでは基本的なところは触れずに、躓いたところを中心に触れておきます。1. 同じバージョンのものは削除してももうアップできない
当たり前かもしれませんが、一度テストでTestのPyPI環境(ステージング的な環境)にアップして、後日web画面からそのバージョンを消して再度アップしようとしたら弾かれました。テスト環境でも、バージョンの番号を上げるしかなさそう?な印象です。(特に困ったりはしませんが・・)
2. ビルドの前に、過去のビルドで生成されたディレクトリを削除しておいた方が良さそう
前のものが含まれているとアップのときに弾かれたり、事故の元になりそうです。
この辺りのビルドのスクリプトは大した量ではないので後で書いておきたいところ・・。3. cssやjsをパッケージ内に含んでくれなかった
最初、.pyのモジュールしかビルド内に含んでくれませんでした。
調べたところ、setup.pyなどのビルド用のモジュールと同じフォルダにMANIFEST.inというファイルを設置して、含めるファイルを指定しないといけなかった模様です。
今回は以下のようにjsとCSSを含むように指定しました。recursive-include plot_playground *.js recursive-include plot_playground *.cssさらに、MANIFEST.inに書いただけでは含んでくれず、setup.pyのsetup関数内で以下の記述をしないと含
んでくれませんでした。他の記事でMANIFEST.inだけ触れられていたものを参考にしていたのでしばらく悩むことに・・
include_package_data=True,以下の記事に上記の点が書かれていました。助かりました
Pythonのパッケージングのベストプラクティスについて考える2018ここまでできたら、ステージング環境的なTestのPyPIにアップして動かしてみます。
Windows環境で作業していたので、ついでにLinuxでも念のため確認・・ということで、Azure Notebooksのクラウドのノートを利用しました。
ちょっと普通のpipコマンドと比べると、テスト環境なのでURLを指定したりで少し長いですが、無事インストールできました!
jsやCSSのテンプレートファイルも、問題なく読み込めているようです。
後は本番のPyPI環境にアップするだけですので、本番にアップします。
この段階で、お馴染みのpipコマンドでインストールできるようになります。
再び、Azure Notebooks上で試してみます。
既にテスト用のものがインストールされているので一旦アンインストールしてから実施します(ノートのカーネルも再起動しつつ)。
無事インストールできました。
長かったですがこれでやっと完了です!ちょっとドキュメントを書いたりは明日以降進めます。
また、まだプロットが1つだけで寂しいので、少しずつ作っていきたいところです。今回はテスト用のコードを書いたり、D3.jsとJupyterを繋いだり・・のところなども対応や検証が必要だったので、結構時間がかかりましたが、次回からは本質的なプロットの追加作業に注力できる・・はず。おまけ
※まだドキュメントなど全然書いていません。
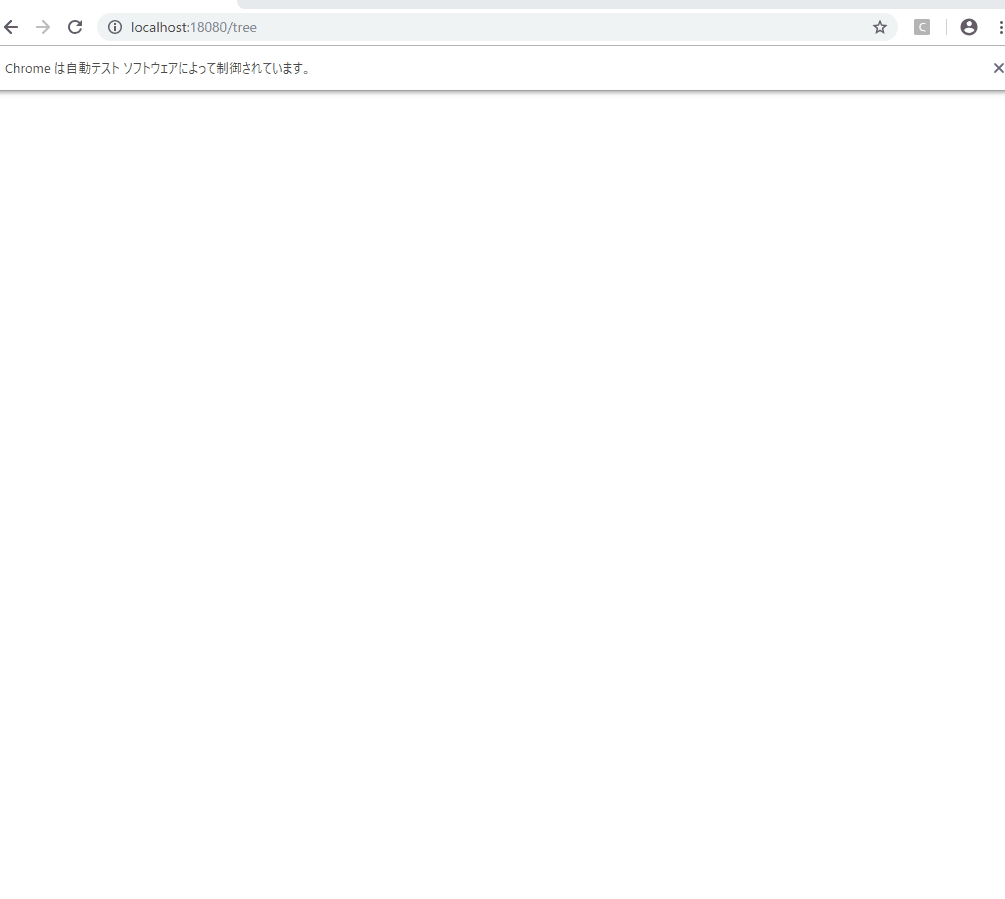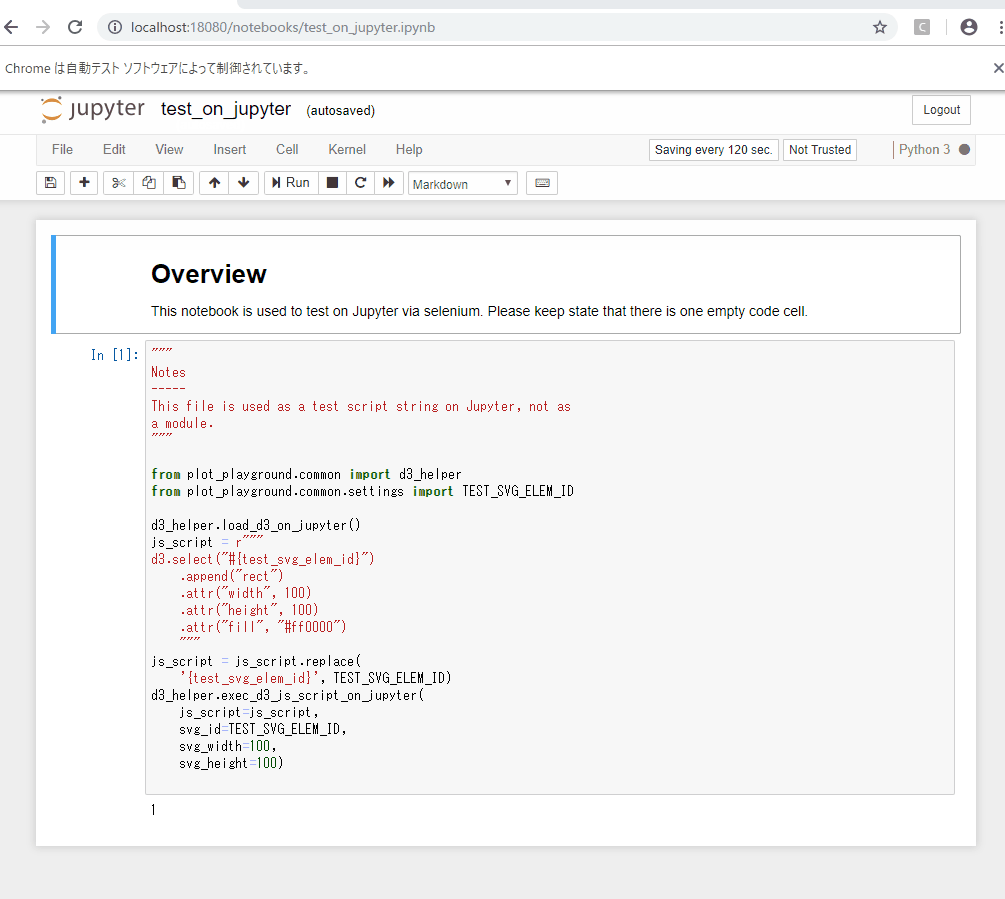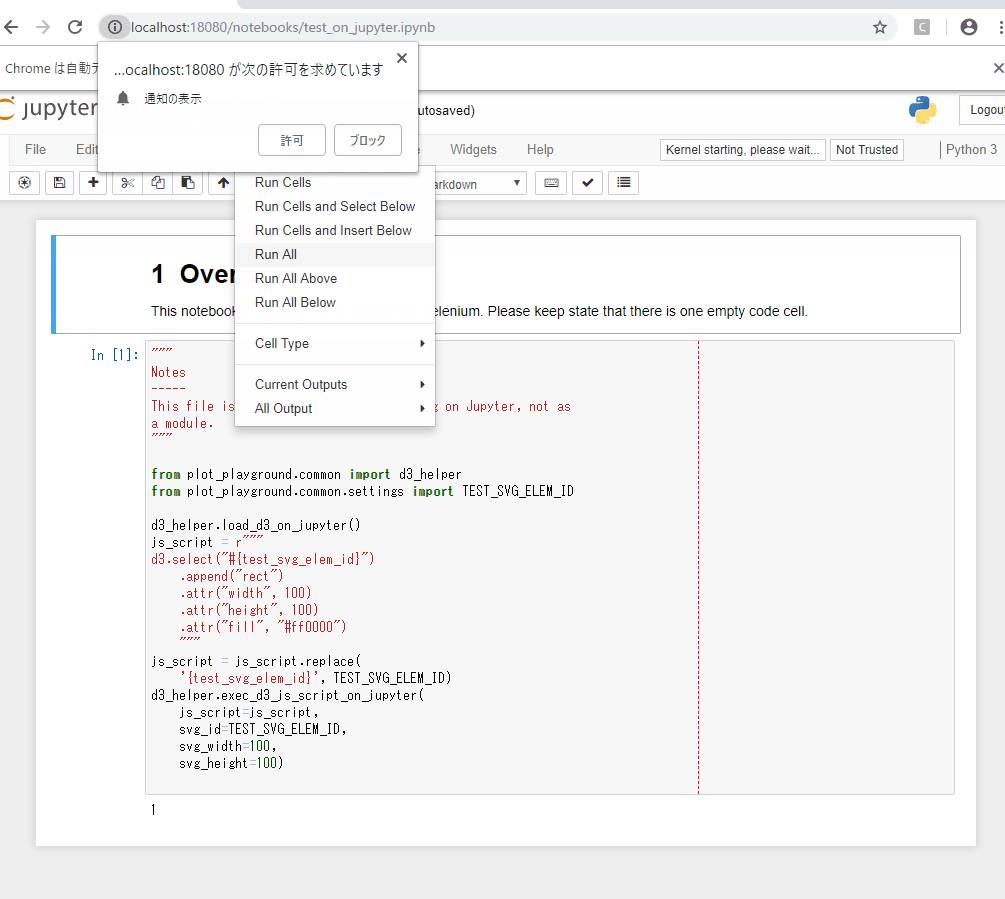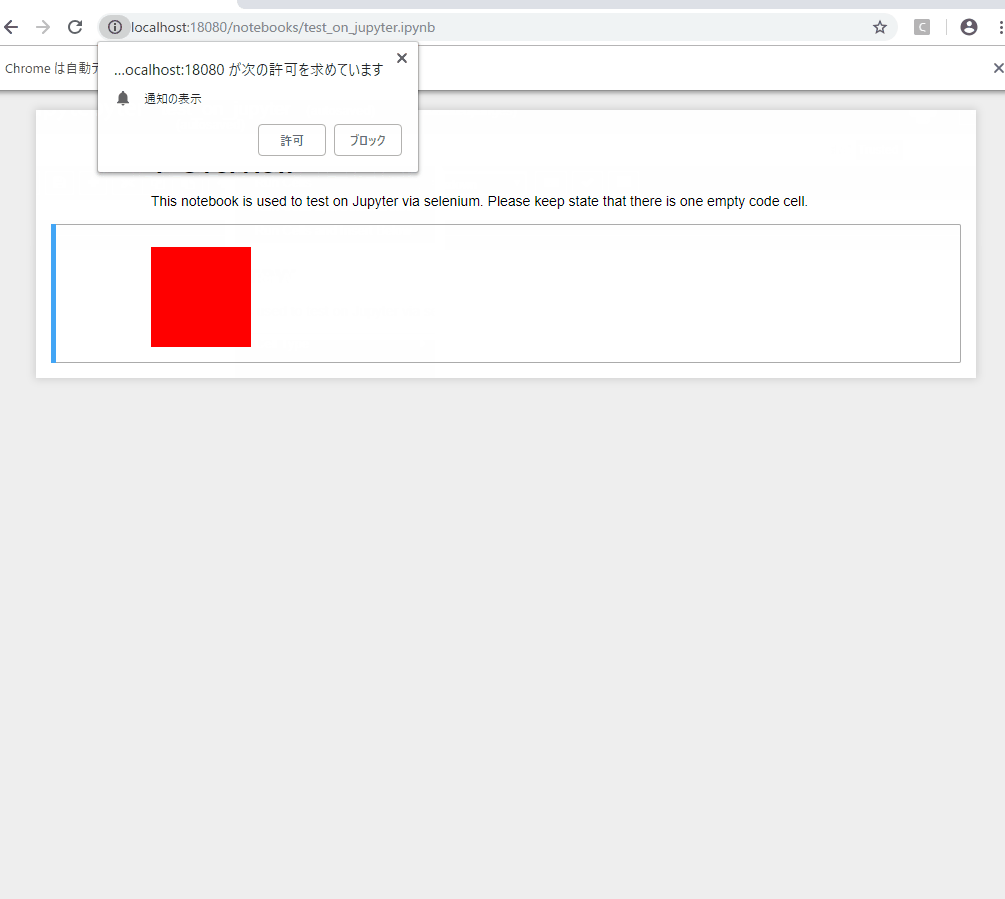

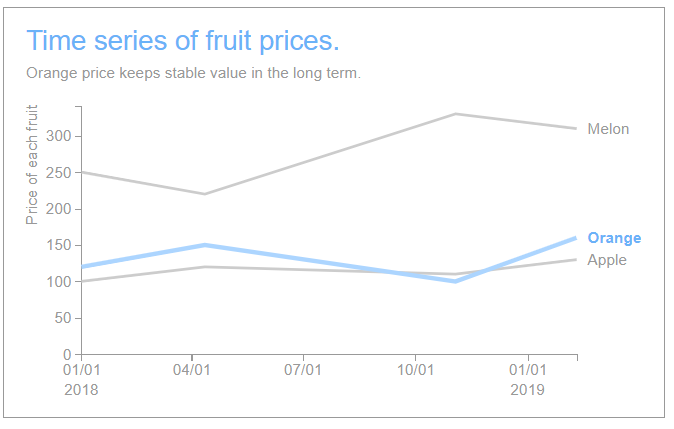
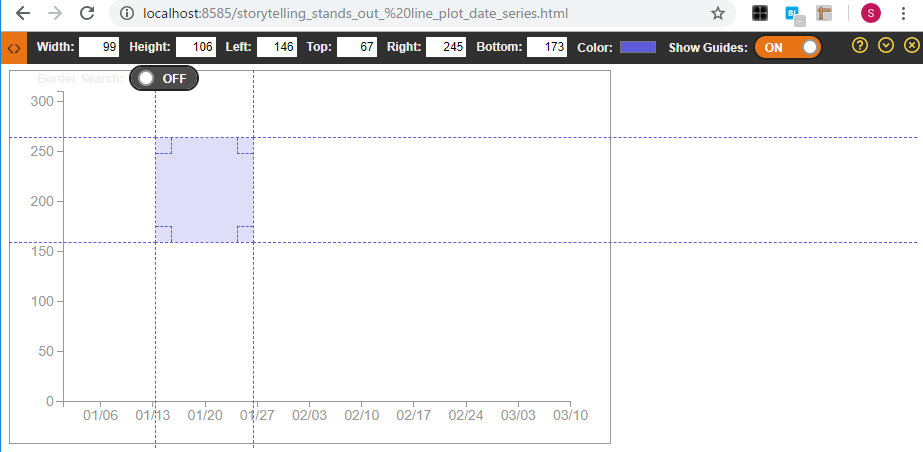
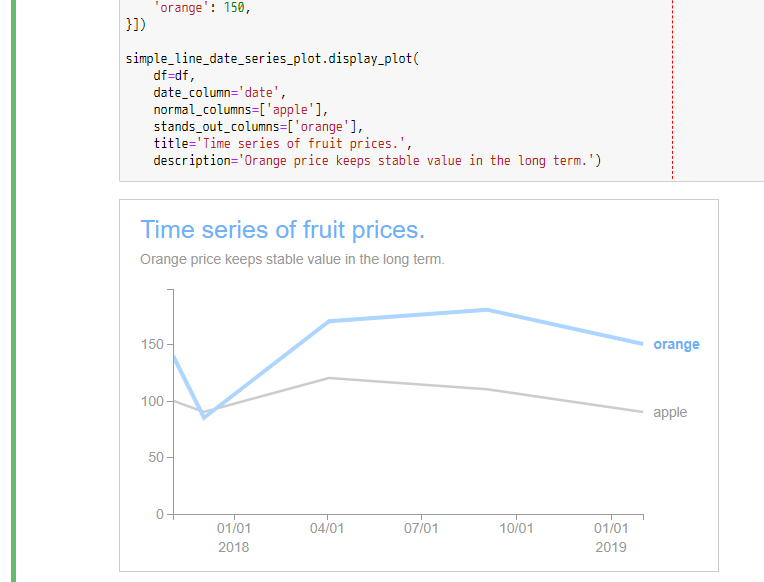
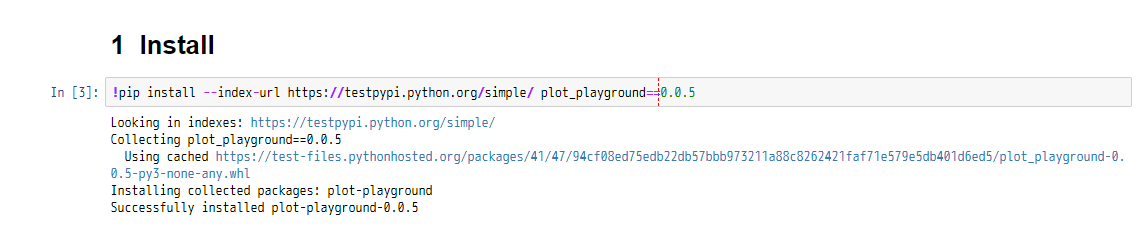
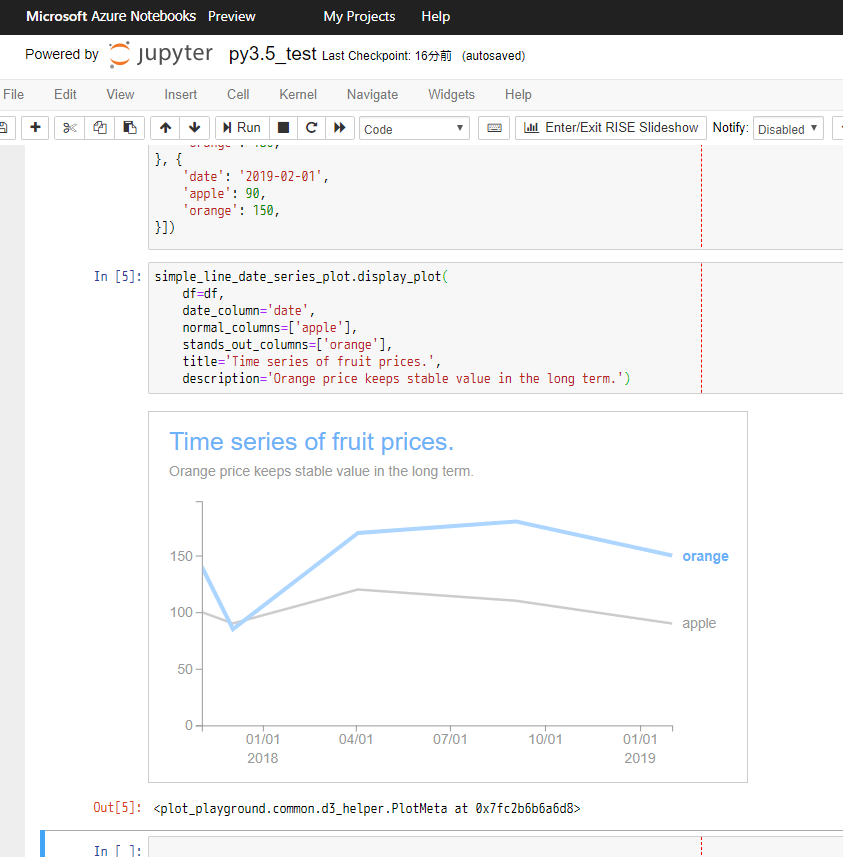
- 投稿日:2019-02-09T22:31:26+09:00
【Python】データ分析の序盤でよく使う手法メモ
Kaggleなどでデータ分析を行う際の探索的データ解析(EDA)の段階で、
自分自身がよく使う便利な関数やライブラリをまとめました。データはKaggleのTitanicのTrainデータを使用します
https://www.kaggle.com/c/titanic/data■ライブラリの読み込み
import numpy as np import pandas as pd■データの読み込み
df = pd.read_csv('titanic/train.csv')■データの基本情報、基本統計量の出力
- まずは最初の5行までを出力し、データを実際に見てみる
df.head() #()に行数を入力し出力行数を変更可能
- 要約統計量を出力
df.describe()
- オブジェクト型の要素数、ユニーク数、最頻値、最頻 値の出現回数を表示
df.describe(include = 'O')
- 全列の(データ数、nullの有無、データ型)を表示
df.info()
- その他便利なコマンド
df.tail() # 最後から5行表示 df.shape # (行数, 列数)を表示 df.size # データ数を表示 df.columns # 列一覧を表示 df.corr() #全列の相関係数表示■pandas-profilingでプロファイリング
2行のコードで、読み込むデータの様々な情報をグラフを含めて出力できます
import pandas_profiling #インポート pandas_profiling.ProfileReport(df) #実行別記事で詳しく解説しています
https://qiita.com/ryo111/items/705347799a984acd5d08■各列のユニーク値の種類数を表示
df.apply(lambda x: x.nunique())
■各列の欠損値の確認
df.isnull().sum()
■指定の列の他の列との相関関係を表示
df.corr()["Age"].sort_values(ascending = False)
目的変数を入力すれば、他の変数との相関関係をシンプルに出力できるので便利■数値データ(もしくはオブジェクトデータ)の列のみのインデックスを出力
#数値データのみ df.select_dtypes(include=[np.number]).columns
#オブジェクトデータのみ df.select_dtypes(include=[np.object]).columns
■指定したオブジェクトデータ列の項目を表示
df["Embarked"].unique()
■指定したオブジェクトデータ列の項目別の数量を表示
df['Embarked'].value_counts()
■グループバイによる集計
- 性別ごとに各変数の平均値を出力
df.groupby('Sex').mean()
■ピボットによる集計
- 性別('Sex')をインデックス、乗船場所('Embarked')をカラムとした、生存者('Survived')の合計(sum)の表を出力
df.pivot_table(values='Survived', index='Sex', columns='Embarked', aggfunc='sum')

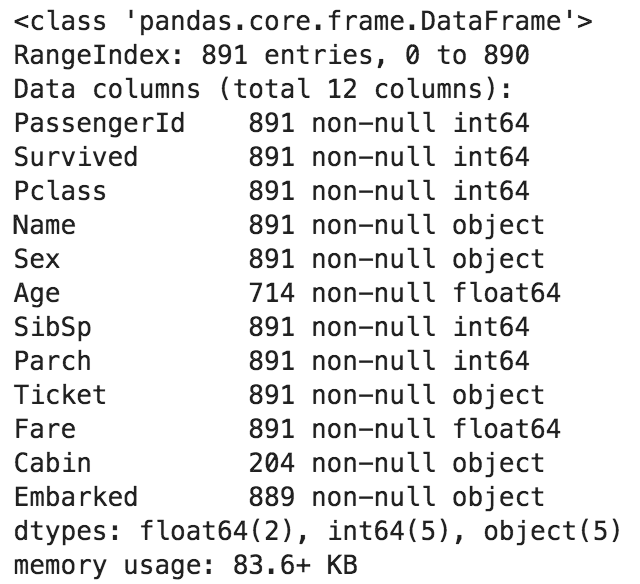
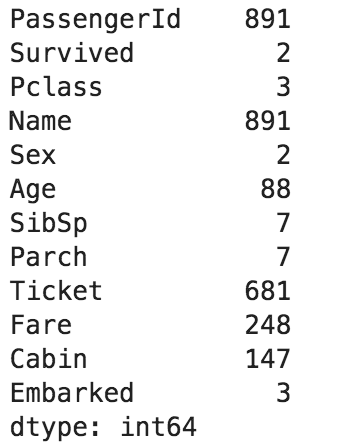
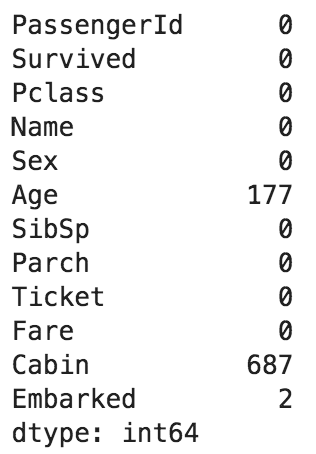



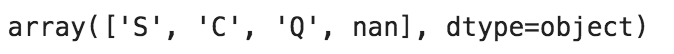


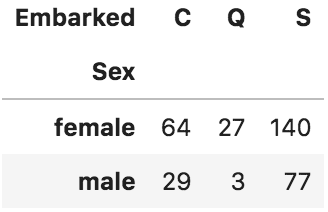
- 投稿日:2019-02-09T21:49:41+09:00
ColaboratoryでGPUを使った量子回路のシミュレーション
はじめに
今回は量子コンピュータそのものについてや,ゲート操作等の基本的な部分は書きません.
もし量子コンピュータ?ゲート?という方はこちらを参考になさってください.量子コンピュータと量子ゲートと私
ゲート式量子コンピュータの基本知識あと今回のコードはここにあります.実行したい場合はplaygroundモードで開いてください.(研究室の合宿用に簡単に作ったものなので,コードは汚いです...)
量子コンピューティングシミュレータ
最近ではQunasys社のQulacsなどのGPUによる量子コンピューティングのシミュレーションツールなどがあります.そもそも量子コンピュータは,言い換えれば超並列処理が得意なコンピュータで,そのシミュレーションをGPUにやらせようというのは自然な流れかなって感じがします.そこで今回は,GoogleのColaboratoryを用いて簡単にシミュレーションをしてみたいと思います.
環境
Google Colaboratory(Googleのアカウントを持っていれば,誰でも無料で使用可能です)
また,今回はpythonでgpuが簡単に使えるCuPyと呼ばれるモジュールを使用していきます.準備
ファイルからPython3の新しいノートブックを選択し,新しいノートブックを作成
ランタイムからランタイムのタイプを変更を選択し,ハードウェアアクセラレータをGPUにする.実験
今回は2量子ビット,10量子ビットの回路で実験を行なっていきます.
まず初期状態を$\mid{0}\rangle^{\otimes{n}}$とします.2量子ビットでの量子もつれ
回路図でいうとこんな感じ.(図はIBMQExperienceのComposer)
CPU
GPU
あれ,GPUの方が遅いですね...
では10量子ビットではどうでしょうか?10量子ビットでの量子フーリエ変換
回路図は大きくなってしまうので割愛しますが,アダマールゲートと,ある回転角の制御ユニタリ
ゲートの連続で実装されます.(詳しくは量子フーリエ変換 (Quantum Fourier Transform) とは)CPU
GPU
なんと約20倍にも早くなりました!ではどのくらいであればGPUを使うと有利なのか,今回は量子フーリエ変換で検証してみます.
以下のような結果になりました.
これを見ると,8量子ビットを境に実行時間の差が大きく開いていっていることがわかります.
まとめ
今回はgpuを用いたcupyによる量子回路のシミュレーションを行なっていきました.前述の通り量子コンピュータは非常に並列処理が得意なコンピュータです.現在シミュレーションできる量子ビットの数は約40~50程度とされていますが,もしかしたらこれがより大きくなっていくのかもしれません.
間違い等ありましたらご指摘いただけると幸いです!
参考
【秒速で無料GPUを使う】TensorFow(Keras)/PyTorch/Chainer環境構築 on Colaboratory
制御ゲートの作り方


- 投稿日:2019-02-09T21:43:51+09:00
PRML第9章の混合ガウスモデルに対するEMアルゴリズムをpythonで実装
この記事では、PRMLの第9章で述べられている、混合ガウスモデルに対するEMアルゴリズムをpythonで実装します。
対応するjupyter notebookは筆者のgithubリポジトリにあります。連載全体の方針や、PRMLの他のアルゴリズムの実装については、連載のまとめページをご覧いただければと思います。1 理論のおさらい
この節では、混合ガウスモデルに対するEMアルゴリズムの実装に必要な結果だけを、簡潔にまとめます。導出や、EMアルゴリズムの一般的な説明1などは、本の方をご参照ください。
なお、EMアルゴリズムの収束性の証明などはPRMLには記載はなく、私もフォローできていません2。1.1 設定
今回は教師なし学習を考えます。
- $N \in \mathbb{N}$ : データ点の個数
- $d \in \mathbb{N}$ : データの次元
- $x_0, x_1, \dots , x_{N-1} \in \mathbb{R}^d$ : データ点
- データ点をまとめて、行列$X$と表します。ただし、$X_{n,i}$は$x_n$の$i$番目の要素とします。
1.2 モデル
$K \in \mathbb{N}$に対し、$K$個の混合要素を持つ混合ガウスモデルは次のように表されます:
$$
\begin{align}
p\left(X,Z \middle| \mu, \Sigma, \pi \right) =
\prod_{n=0}^{N-1} \prod_{k=0}^{K-1}
\left[\pi_k \mathcal{N}\left(x_n \middle| \mu_k , \Sigma_k \right) \right]^{z_{n,k}}
\end{align}
$$
ただし、
- $Z = (z_{n,k})_{ n \in \{ 0, 1, \dots, N-1 \} k \in \{ 0,1, \dots, K-1 \} }, \ z_{n,k}\in \{0,1 \}, \sum_{k=0}^{K-1}z_{n,k}=1$であり、$Z$は潜在変数を表す。
- $\pi_k \geq 0, \sum_{k=0}^{K-1} \pi_k = 1$
- $\mathcal{N}\left(x \middle| \mu_k , \Sigma_k \right)$は、期待値$\mu_k \in \mathbb{R}^d$、共分散行列$\Sigma_k$のガウス分布の確率密度。
$Z$についての和をとると、$X$についての分布が次のように得られます。
$$
\begin{align}
p \left( X \middle| \mu, \Sigma, \pi \right) =
\prod_{n=0}^{N-1} \left[ \sum_{k=0}^{K-1} \pi_k \mathcal{N}\left(x_n \middle| \mu_k, \Sigma_k \right) \right]
\end{align}
$$このモデルに対して、対数尤度$\log p(X|\mu, \Sigma, \pi)$を「最大化」するパラメーター$(\mu, \Sigma, \pi)$を求めます。
ただし、PRML9.2.1でも散々述べられているように、この最大化問題はill-posedです。したがって、求めるのはあくまで、対数尤度を極大にするパラメーターです3。1.3 アルゴリズム
導出はPRMLにあるので全て省略しますが、EM algorithmでは次の計算を行い、対数尤度の「極大化」を行います。
- パラメーターの初期化を行う。
- E step : responsibility $\gamma_{n,k}$を次のように計算する: $$ \begin{align} \gamma_{n,k} := \frac{ \pi_{k} \mathcal{N}\left(x_n \middle| \mu_k , \Sigma_k \right) }{ \sum_{l=0}^{K-1} \pi_{l} \mathcal{N}\left(x_n \middle| \mu_l , \Sigma_l \right) } \end{align} $$
- M step : 上で計算したresponsibilityを用い、パラメーター$\mu, \Sigma, \pi$を次のように更新する $$ \begin{align} &{} N_k := \sum_{n=0}^{N-1} \gamma_{n,k} \\ &{} \pi_k = \frac{N_k}{N}\\ &{} \mu_k = \frac{1}{N_k} \sum_{n=0}^{N-1} \gamma_{n,k} x_n \\ &{} \Sigma_k = \frac{1}{N_k} \sum_{n=0}^{N-1} \gamma_{n,k} (x_n-\mu_k)(x_n-\mu_k)^T \end{align} $$
- 収束基準が満たされるまで、2と3を繰り返す。
収束基準としては、
- パラメーターの変化が十分小さくなったら停止
- 対数尤度の変化が十分小さくなったら停止
等の基準が考えられますが、ここでは後者の対数尤度の値を基にした基準を用いてみることにします。
なお、対数尤度の表式は次で表されます:
$$
\begin{align}
\log p \left( X \middle| \mu, \Sigma, \pi \right) =
\sum_{n=0}^{N-1} \log \left[ \sum_{k=0}^{K-1} \pi_k \mathcal{N}\left(x_n \middle| \mu_k, \Sigma_k \right) \right]
\end{align}
$$2 数式からコードへ
ここまでの理論をもとにして、実装を行います。
混合ガウスモデルを表す、
GaussianMixtureModelクラスを作成します。2.1 概要
GaussianMixtureModelクラスに、以下のデータ属性とメソッドを持たせることにします:
- データ属性
K: 混合要素の個数を表す整数($K$のこと)Pi: ($K$, ) array,Pi[k]= $\pi_k$Mu: ($K$, $d$) array,Mu[k,i]= $\mu_{k,i}$Sigma: ($K$, $d$, $d$) array,Sigma[k,i,j]= $\left( \Sigma_{k} \right)_{i,j}$- メソッド
_init_params: パラメーターPi,Mu, andSigmaの初期化を行うメソッド。入力データ点に依存させます。_calc_nmat: 次で定義される($N$, $K$) arrayNmatを計算して返すメソッド:Nmat[n,k]= $\mathcal{N}\left(x_n \middle| \mu_k, \Sigma_k \right)$。E-stepや対数尤度の計算などで用います。_Estep: 上記のE-stepの計算を行うメソッド。具体的にはresponsibility $\gamma$を計算して返します。_Mstep: 上記のM-stepの計算を行うメソッド。具体的には、$\gamma$を与えられたときに、Pi,Mu, andSigmaを計算して更新します。calc_prob_density: 与えられたデータ点$X$に対して、確率密度$p \left( X \middle| \mu, \Sigma, \pi \right) = \prod_{n=0}^{N-1} \left[ \sum_{k=0}^{K-1} \pi_k \mathcal{N}\left(x_n \middle| \mu_k, \Sigma_k \right) \right]$を計算して返すメソッド。確率密度をプロットするために使います。calc_log_likelihood: 与えられたデータ点$X$に対して、対数尤度$\log p \left( X \middle| \mu, \Sigma, \pi \right) = \sum_{n=0}^{N-1} \log \left[ \sum_{k=0}^{K-1} \pi_k \mathcal{N}\left(x_n \middle| \mu_k, \Sigma_k \right) \right]$を計算して返すメソッド。収束判定のために利用します。fit: fittingを行うメソッド。具体的には、_Estepと_Mstepを、収束基準が満たされるまで繰り返します。predict_proba: responsibility $\gamma$を計算して返すメソッド(_Estepと同じです)。predict: 与えられたデータ点たちに対し、各点がどのクラスタに属すかを計算して返すメソッド。以下に、各メソッドの詳細と対応するコードを書いていきます。
2.2 初期化:
_init_params
_init_paramsでは、次のように初期化を行うことにします:
Pi: 全ての要素が等しい値とします。Mu:K個の点を、入力データ点から一様ランダムに選びます。Sigma:Sigma[k]は、全て同一の共分散行列$\Sigma_0$とします。ただし、$\Sigma_0$は対角行列で、その$(i, i)$成分は、入力データの第$i$成分の分散にとります。対応するコードは、以下の通りです。なお、結果の再現性を持たせるために、
Muの初期化の際にはseedを指定できるようにしてあります。def _init_params(self, X, random_state=None): ''' Method for initializing model parameterse based on the size and variance of the input data array. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. ''' n_samples, n_features = np.shape(X) rnd = np.random.RandomState(seed=random_state) self.Pi = np.ones(self.K)/self.K self.Mu = X[rnd.choice(n_samples, size=self.K, replace=False)] self.Sigma = np.tile(np.diag(np.var(X, axis=0)), (self.K, 1, 1))2.3
Nmatの計算:_calc_nmat
_calc_nmatでは、Nmat[n,k]= $\mathcal{N}\left(x_n \middle| \mu_k, \Sigma_k \right)$で定義されるarrayを計算して返します。よりコードに直しやすいように書くと、次の計算を行います:
$$
\begin{align}
\verb| Nmat[n, k] | = \frac{1}{\sqrt{\det \verb|Sigma[k]|}} \exp\left( -\frac{1}{2} \sum_{i,j=1}^{d} \verb| Diff[n,k,i] L[k,i,j] Diff[n,k,j] | \right)
\end{align}
$$
ただし、
L: (K, d, d) array,L[k,i,j]= $\left( \Sigma_{k}^{-1} \right)_{i,j} $Diff: (N, K, d) array,Diff[n,k,i]= $x_{n,i} - \mu_{k,i}$対応するコードは次のように書けます。
ポイントとしては、
Diffの計算にあたっては、XとMuをreshapeすることにより、numpy broadcastingを利用しています。- 指数の部分の和には
numpy.einsumを利用します(詳細は公式ドキュメント参照)- 複数の行列の逆行列や行列式は、
numpy.linalg.invやnumpy.linalg.detを利用して一括して計算しています(こちらも詳細は公式ドキュメント参照。)。def _calc_nmat(self, X): ''' Method for calculating array corresponding $\mathcal{N}(x_n | \mu_k)$ Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- Nmat : 2D numpy array 2-D numpy array representing probability density for each sample and each component, where Nmat[n, k] = $\mathcal{N}(x_n | \mu_k)$. ''' n_samples, n_features = np.shape(X) Diff = np.reshape(X, (n_samples, 1, n_features) ) - np.reshape(self.Mu, (1, self.K, n_features) ) L = np.linalg.inv(self.Sigma) exponent = np.einsum("nkj,nkj->nk", np.einsum("nki,kij->nkj", Diff, L), Diff) Nmat = np.exp(-0.5*exponent)/np.sqrt(np.linalg.det(self.Sigma)) / (2*np.pi)**(n_features/2) return Nmat2.4 E-step :
_Estep(N, K) array
Gamを、responsibilityを表すarrayとします :Gam[n,k]= $\gamma_{n,k}$。_Estepでは、Nmatを用いて、次のようにGamを計算します。
$$
\begin{align}
\verb|Gam[n,k]| = \frac{\verb|Nmat[n,k] Pi[k] |}{ \sum_{l=1} \verb| Nmat[n,l] Pi[l] |}
\end{align}
$$これはシンプルですね。対応するコードも、そのまま翻訳するだけです。
def _Estep(self, X): ''' Method for calculating the array corresponding to responsibility. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- Gam : 2D numpy array 2-D numpy array representing responsibility of each component for each sample in X, where Gamt[n, k] = $\gamma_{n, k}$. ''' n_samples, n_features = np.shape(X) Nmat = self._calc_nmat(X) tmp = Nmat * self.Pi Gam = tmp/np.reshape(np.sum(tmp, axis=1), (n_samples, 1) ) return Gam2.5 M-step :
_MstepM-stepではいよいよ、パラメーターの更新を行います。arrayの表記で1節の数式を書き直すと、
$$
\begin{align}
\verb|Pi[k]| &= \frac{1}{N} \sum_{n=0}^{N-1} \verb| Gam[n,k] | \\
\verb| Mu[k,i]| &= \frac{1}{N_k} \sum_{n=0}^{N-1} \verb| Gam[n,k] X_[n,i] | \\
\verb| Sigma[k,i,j]| &= \frac{1}{N_k} \sum_{n=0}^{N-1} \verb| Gam[n,k] Diff[n,k,i] Diff[n,k,j]|
\end{align}
$$
となります。
Sigmaの計算は、numpy.einsumを用いて処理します。- $N_k$による割り算では、broadcastingを活用します。
def _Mstep(self, X, Gam): ''' Method for calculating the model parameters based on the responsibility gamma. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Gam : 2D numpy array 2-D numpy array representing responsibility of each component for each sample in X, where Gamt[n, k] = $\gamma_{n, k}$. ''' n_samples, n_features = np.shape(X) Diff = np.reshape(X, (n_samples, 1, n_features) ) - np.reshape(self.Mu, (1, self.K, n_features) ) Nk = np.sum(Gam, axis=0) self.Pi = Nk/n_samples self.Mu = Gam.T @ X / np.reshape(Nk, (self.K, 1)) self.Sigma = np.einsum("nki,nkj->kij", np.einsum("nk,nki->nki", Gam, Diff), Diff) / np.reshape(Nk, (self.K, 1, 1))2.6 確率密度
calc_prob_densityEMアルゴリズムの実行には不要ですが、後で確率密度の可視化をしたいので、実装しておきます。
def calc_prob_density(self, X): ''' Method for calculating the probablity density $\sum_k \pi_k \mathcal{N}(x_n | \mu_k)$ Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- prob_density : 2D numpy array ''' prob_density = self._calc_nmat(X) @ self.Pi return prob_density2.7 対数尤度の計算:
calc_log_likelihood対数尤度を計算して返します。収束判定に用いたり、異なる結果を比べたりするのに用います(実験の節で後述)。
これは、先ほどのcalc_prob_densityを用いると容易に書けます。def calc_log_likelihood(self, X): ''' Method for calculating the log-likelihood for the input X and current model parameters. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- loglikelihood : float The log-likelihood of the input data X with respect to current parameter set. ''' log_likelihood = np.sum(np.log(self.calc_prob_density(X))) return log_likelihood2.8
fitここまで書いてきたもろもろを組合せて、fittingを行うメソッドです。
_Estepと_Mstepを繰り返し実行します。- 繰り返し回数が
max_iterに達するか、対数尤度の変化がtol以下になったら停止します。- EMアルゴリズムの各ステップで対数尤度は非減少であることが理論的に示されているので、収束基準は「更新後の対数尤度 - 更新前の対数尤度 <
tol」としてあります。def fit(self, X, max_iter, tol, disp_message, random_state=None): ''' Method for performing learning. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. max_iter : int Maximum number of iteration tol : float, positive Precision. If the change of parameter is below this value, the iteration is stopped disp_message : Boolean Whether or not to show the message about the number of iteration ''' self._init_params(X, random_state=random_state) log_likelihood = - np.float("inf") for i in range(max_iter): Gam = self._Estep(X) self._Mstep(X, Gam) log_likelihood_old = log_likelihood log_likelihood = self.calc_log_likelihood(X) if log_likelihood - log_likelihood_old < tol: break if disp_message: print(f"n_iter : {i}") print(f"log_likelihood : {log_likelihood}")2.9
predict_proba与えられたデータに対してresponsibilityを求めるメソッドです。実態は
_Estepを呼び出すだけなのですが、良く用いられる名前のメソッドなので別個に作ってみました。コードはここでは省略します。
2.10
predict最後に、与えられたデータがどのクラスタに属するかを返すメソッドを書きます。
def predict(self, X): ''' Method for make prediction about which cluster input points are assigned to. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- pred : 1D numpy array 1D numpy array, with dtype=int, representing which class input points are assigned to. ''' pred = np.argmax(self.predict_proba(X), axis=1) return pred2.11 全体のコード
GaussianMixtureModelクラスのコードは、以下のようになります。class GaussianMixtureModel: def __init__(self, K): self.K = K self.Pi = None self.Mu = None self.Sigma = None def _init_params(self, X, random_state=None): ''' Method for initializing model parameterse based on the size and variance of the input data array. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. ''' n_samples, n_features = np.shape(X) rnd = np.random.RandomState(seed=random_state) self.Pi = np.ones(self.K)/self.K self.Mu = X[rnd.choice(n_samples, size=self.K, replace=False)] self.Sigma = np.tile(np.diag(np.var(X, axis=0)), (self.K, 1, 1)) def _calc_nmat(self, X): ''' Method for calculating array corresponding $\mathcal{N}(x_n | \mu_k)$ Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- Nmat : 2D numpy array 2-D numpy array representing probability density for each sample and each component, where Nmat[n, k] = $\mathcal{N}(x_n | \mu_k)$. ''' n_samples, n_features = np.shape(X) Diff = np.reshape(X, (n_samples, 1, n_features) ) - np.reshape(self.Mu, (1, self.K, n_features) ) L = np.linalg.inv(self.Sigma) exponent = np.einsum("nkj,nkj->nk", np.einsum("nki,kij->nkj", Diff, L), Diff) Nmat = np.exp(-0.5*exponent)/np.sqrt(np.linalg.det(self.Sigma)) / (2*np.pi)**(n_features/2) return Nmat def _Estep(self, X): ''' Method for calculating the array corresponding to responsibility. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- Gam : 2D numpy array 2-D numpy array representing responsibility of each component for each sample in X, where Gamt[n, k] = $\gamma_{n, k}$. ''' n_samples, n_features = np.shape(X) Nmat = self._calc_nmat(X) tmp = Nmat * self.Pi Gam = tmp/np.reshape(np.sum(tmp, axis=1), (n_samples, 1) ) return Gam def _Mstep(self, X, Gam): ''' Method for calculating the model parameters based on the responsibility gamma. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Gam : 2D numpy array 2-D numpy array representing responsibility of each component for each sample in X, where Gamt[n, k] = $\gamma_{n, k}$. ''' n_samples, n_features = np.shape(X) Diff = np.reshape(X, (n_samples, 1, n_features) ) - np.reshape(self.Mu, (1, self.K, n_features) ) Nk = np.sum(Gam, axis=0) self.Pi = Nk/n_samples self.Mu = Gam.T @ X / np.reshape(Nk, (self.K, 1)) self.Sigma = np.einsum("nki,nkj->kij", np.einsum("nk,nki->nki", Gam, Diff), Diff) / np.reshape(Nk, (self.K, 1, 1)) def calc_prob_density(self, X): ''' Method for calculating the probablity density $\sum_k \pi_k \mathcal{N}(x_n | \mu_k)$ Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- prob_density : 2D numpy array ''' prob_density = self._calc_nmat(X) @ self.Pi return prob_density def calc_log_likelihood(self, X): ''' Method for calculating the log-likelihood for the input X and current model parameters. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- loglikelihood : float The log-likelihood of the input data X with respect to current parameter set. ''' log_likelihood = np.sum(np.log(self.calc_prob_density(X))) return log_likelihood def fit(self, X, max_iter, tol, disp_message, random_state=None): ''' Method for performing learning. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. max_iter : int Maximum number of iteration tol : float, positive Precision. If the change of parameter is below this value, the iteration is stopped disp_message : Boolean Whether or not to show the message about the number of iteration ''' self._init_params(X, random_state=random_state) log_likelihood = - np.float("inf") for i in range(max_iter): Gam = self._Estep(X) self._Mstep(X, Gam) log_likelihood_old = log_likelihood log_likelihood = self.calc_log_likelihood(X) if log_likelihood - log_likelihood_old < tol: break if disp_message: print(f"n_iter : {i}") print(f"log_likelihood : {log_likelihood}") def predict_proba(self, X): ''' Method for calculating the array corresponding to responsibility. Just a different name for _Estep Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- Gam : 2D numpy array 2-D numpy array representing responsibility of each component for each sample in X, where Gamt[n, k] = $\gamma_{n, k}$. ''' Gam = self._Estep(X) return Gam def predict(self, X): ''' Method for make prediction about which cluster input points are assigned to. Parameters ---------- X : 2D numpy array 2-D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X. Returns ---------- pred : 1D numpy array 1D numpy array, with dtype=int, representing which class input points are assigned to. ''' pred = np.argmax(self.predict_proba(X), axis=1) return pred3 実験
それでは、ここまで書いてきたコードを実際に動かしてみます。
3.1 データ
使うデータは、
make_blobsで作った、次の2次元のtoy dataです。
3つのblobを生成しました。データ点の個数は100にしてあります。
3.2
K = 3の結果
K=3のモデルを用いて学習した結果は以下の通りです。tol = 1e-4としてあります。n_iter : 23 log_likelihood : -515.3221954638727
左側がクラスの予測値、右側が混合ガウスモデルが与える確率密度になっています。自然にクラスタリングできているのが見て取れるかと思います。
ただ、初期化の仕方によっては、次のように、大きく異なった結果が得られることもあります:n_iter : 29 log_likelihood : -533.6831531127243
対数尤度の値を比べてみると前者の方が大きいので、直感的にも数値的にも、前者の結果の方が尤もらしいのではないかと思われます4 。
3.3 様々な
Kについての結果ついでに、$K$の値を変えた場合の結果も見ておきましょう。
$K=1$
$K=2$
$K=4$
4 まとめ
この記事では、混合ガウスモデルに対する、EMアルゴリズムを実装しました。やや数式とコードが長かったですが、その対応は明確にできたのではないかと思います。
一方で、まだ私の理解の足りていないところも多々残っています:
- ill-posedな最尤推定をどう理解すべきか。
- 勾配法と比べたときの長所/短所が理解できていない。
- 収束性の理論的証明をきちんと理解していない。
これらは、今後の宿題としたいと思います。
次回は、同じモデルに対して、Bayes的な扱い(変分推論)を行う10章の内容を実装します!
特に、9.4節のKL divergenceを用いた導出 ↩
恐らく、次の文献に詳しいことが載っているかと思います: Wu, C. F. Jeff (Mar 1983). "On the Convergence Properties of the EM Algorithm". Annals of Statistics. 11 (1): 95-103. https://projecteuclid.org/euclid.aos/1176346060 ↩
「対数尤度を極大化するパラメーターを求める意義とは?」という疑問があるのですが、私はまだきちんと理解できていません。 ↩
ただ、対数尤度の最大化はill-posedな問題なので、値が大きいものが本当に「良い」のかどうかは、正直なところ判断がつかないです。 ↩
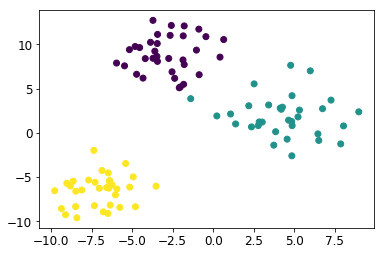
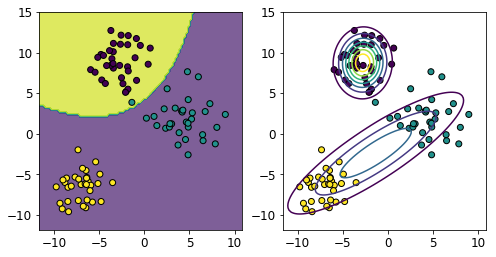
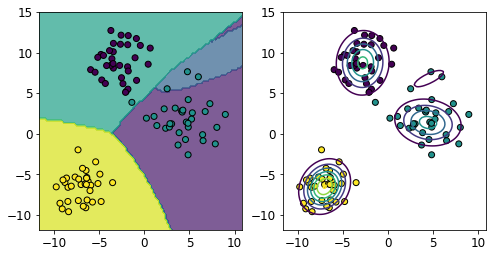
- 投稿日:2019-02-09T21:16:38+09:00
Python Twitter APIを使わずにツイートを収集
Twitterアフィリエイトを行うにあたって
ツイートのパクリは欠かせません。ただし、Twitter APIを使ってツイートの収集をしていると、アカウントが凍結されてしまいます。
複数のアカウントを切り替えてTwitter APIをコールしていてもそのうちすべて凍結されます。
Twitter APIを使わずにツイートが収集できればこの問題は解決します。ツイートにアクセス
こんな書式でアクセスすればJSONでツイートは得られます。
https://twitter.com/i/profiles/show/kabu01/timeline/tweets?include_available_features=1&include_entities=1&include_new_items_bar=true
解析が面倒。。。twitter-scraperの利用
上記の形式でTwitter APIを使わずにツイートを収集できる twitter-scraper ライブラリを使います。 python 3.6 以上で利用できます。
$ pip install twitter-scraperインストールしただけではエラーが出てしまいます。
File " path to /lib/python3.6/site-packages/twitter_scraper.py", line 42, in gen_tweets replies = int(interactions[0].split(" ")[0].replace(comma, "").replace(dot,"")) ValueError: invalid literal for int() with base 10: '\n'こんなエラーが出るので該当ファイルを次のように修正してください。
修正前replies = int(interactions[0].split(" ")[0].replace(comma, "").replace(dot,"")) retweets = int(interactions[1].split(" ")[0].replace(comma, "").replace(dot,""))修正後
try: replies = int(interactions[0].split(" ")[0].replace(comma, "").replace(dot, "")) except ValueError: replies = 0 try: retweets = int(interactions[1].split(" ")[0].replace(comma, "").replace(dot, "")) except ValueError: retweets = 0ツイート収集
こんな風に使います。
from twitter_scraper import get_tweets for tweet in get_tweets('kabu01', pages=1): print(tweet) print("\n")こんな風にリンクや画像も含めて取得できます。
{'tweetId': '1087597341912125440', 'time': datetime.datetime(2019, 1, 22, 15, 26, 27), 'text': '今日は長女の幼稚園で劇の発表会がありました。内容は何と「おおきなかぶ」(笑)\n劇のように今年は「大きな株」が抜けるでしょうか!?', 'replies': 0, 'retweets': 0, 'likes': 10, 'entries': {'hashtags': [], 'urls': [], 'photos': [], 'videos': []}} {'tweetId': '1085825146915479552', 'time': datetime.datetime(2019, 1, 17, 18, 4, 23), 'text': '直近、こちらの2つの投資勉強会を申し込んだ。\n忘れないように記録しています。\nいつもYouTubeで坂本さんの動画を見ている。\nとても勉強になります。\n本人に会うことができて楽しみにしています。( ◠‿◠ )pic.twitter.com/0KamlaDJG3', 'replies': 0, 'retweets': 0, 'likes': 4, 'entries': {'hashtags': [], 'urls': [], 'photos': ['https://pbs.twimg.com/media/DxGgNYpVAAANxGu.jpg', 'https://pbs.twimg.com/media/DxGgNYnU0AATgfm.jpg'], 'videos': []}} {'tweetId': '1087178896452141056', 'time': datetime.datetime(2019, 1, 21, 11, 43, 42), 'text': '今月発売のDIME、2019年3月号「株で人生を変えた人に学ぶ勝ちワザ」に掲載されました。\n\n私は50ページに載りましたが、その他、著名な方も掲載されておりました。pic.twitter.com/C8TC7ADBeG', 'replies': 0, 'retweets': 0, 'likes': 11, 'entries': {'hashtags': [], 'urls': [], 'photos': ['https://pbs.twimg.com/media/DxZvcNHUYAEv3E9.jpg'], 'videos': []}}
- 投稿日:2019-02-09T19:52:43+09:00
No.029【Python】文字列の連結と結合
「文字列の連結と結合」について書きます。
I'll write about "Link and Combination of strings in python" on this page.■ +演算子で連結 (Combination with "+ operator")
文字列リテラル(' ' or " ")および文字列の変数を連結することができる。
Combination between string literal abd string variable is possible.>>> w = 'aaa' + 'bbb' + 'ccc' >>> >>> print(w) aaabbbccc >>> >>> w1 = "aaa" >>> >>> w2 = "bbb" >>> >>> w3 = "ccc" >>> >>> w = w1 + w2 + w3 >>> >>> print(w) aaabbbccc >>> >>> w = w1 + w2 + w3 + "ddd" >>> >>> print(w) aaabbbcccddd■ +=演算子で連結
Combination with "+= operator"
>>> w = "aaa" >>> >>> w += "bbb" >>> >>> print(w) aaabbb■ 連続的に文字列リテラルで連結
Combination by consecutive string literal"
>>> w = 'aaa''bbb''ccc' >>> >>> print(w) aaabbbccc >>> >>> # スペースまたは\(バックスラッシュ)による改行も可能 >>> >>> w = "aaa" "bbb" "ccc" >>> w = "aaa" "bbb" "ccc" >>> >>> print(w) aaabbbccc >>> >>> w = "aaa"\ "bbb"\ "ccc" >>> >>> print(w) aaabbbccc■ 文字列の変数に対し、以下のコーディングは不可
It's not possible for variables of a string as below;
>>> w = w1 w2 w3 SyntaxError: invalid syntax■ 異なる型の+演算は不可
Calculating different types with "+ operator" returns an error
>>>> w1 = "aaa" >>> >>> w2 = "bbb" >>> >>> i = 50 >>> >>> f = 5.50 >>> >>> w = w1 + i Traceback (most recent call last): File "<pyshell#74>", line 1, in <module> w = w1 + i TypeError: can only concatenate str (not "int") to str■ 数値文字列の連結:数値を文字列変換し、+演算子で連結する
Combination between integers and strings:Integers convert to
strings,and it links with "+ operator">>> w1 = "aaa" >>> >>> w2 = "bbb" >>> >>> i = 50 >>> >>> f = 5.50 >>> >>> w = w1 + "_" + str(i) + "_" + w2 + "_" + str(f) >>> >>> print(w) aaa_50_bbb_5.5■ 数値書式の変換:format()関数または文字列メソッドformat()の使用
Format conversion:Use format()function or string method format()
>>> w1 = "aaa" >>> >>> w2 = "bbb" >>> >>> i = 50 >>> >>> f = 5.50 >>> >>> w = w1 + "_" + str(i) + "_" + w2 + "_" + str(f) >>> >>> print(w) aaa_50_bbb_5.5 >>> >>> w = w1 + "_" + format(i, "04") + "_" + w2 + "_" + format(f, ".4f") >>> >>> print(w) aaa_0050_bbb_5.5000 >>> >>> w = '{}_{:04}_{}_{:.4f}'.format(w1, i, w2, f) >>> >>> print(w) aaa_0050_bbb_5.5000■ 文字列のリストによる連結・結合: join( )
Link or combination by string list
"挿入する文字列".join([連結したい文字列リスト]) # join()メソッドの呼び出し:"挿入する文字列" # 渡す引数:[連結したい文字列リスト]>>> l = ['aaa', 'bbb', 'ccc'] >>> >>> w = ''.join(l) >>> >>> print(w) aaabbbccc >>> #↑上記は空文字列により、[連結したい文字列のリスト]を単純連結 >>> >>> w = ','.join(l) >>> >>> print(w) aaa,bbb,ccc >>> #↑上記はカンマにより、カンマ区切りの文字列となる >>> >>> w = '-'.join(l) >>> >>> print(w) aaa-bbb-ccc >>> #↑上記はハイフンによる、ハイフン区切り >>> >>> w = '\n'.join(l) >>> >>> print(w) aaa bbb ccc >>> # 上記は、改行文字"\n"による文字列要素ごとの改行いかがでしたでしょうか?
How was my post?本記事は、随時に更新していきますので、
定期的な購読をよろしくお願いします。
I'll update my blogs at all times.
So, please subscribe my blogs from now on.本記事について、
何か要望等ありましたら、気軽にメッセージをください!
If you have some requests, please leave some messages! by You-Tarinまた、「Qiita」へ投稿した内容は、随時ブログへ移動して行きたいと思いますので、よろしくお願いします。

- 投稿日:2019-02-09T18:57:31+09:00
[Cinema 4D] マテリアルアサインリスト
今回は各マテリアル側から,アサインしているオブジェクトにアクセスする方法を試してみます.
マテリアルがシーン内のオブジェクトに適用されている場合は,マテリアルのAssignmentを見ればわかります.ここにアクセスするには[c4d.ID_MATERIALASSIGNMENTS]を使います.
MatAssignDataのドキュメントはこちら
c4d.MatAssignDataクラスObjectFromIndex(doc, lIndex)
この戻り値はそのマテリアルが適用されているオブジェクトのテクスチャタグとなります.tag.GetObject()を使うことでオブジェクトにアクセスできます.
doc = c4d.documents.GetActiveDocument() mat = doc.GetFirstMaterial() while mat: objLink = mat[c4d.ID_MATERIALASSIGNMENTS] objCnt = objLink.GetObjectCount() if objCnt > 0: for i in xrange(objCnt): print "Material Name :", mat.GetName() tag = objLink.ObjectFromIndex(doc, i) print "Link index[", i, "] :", tag obj = tag.GetObject() print "Object name :", obj.GetName() mat = mat.GetNext()そのマテリアルがシーン内で使われているかの確認や,マテリアルが適用されているオブジェクトにアクセスすることができ,こちらのほうが都合がよいこともありそうです.
- 投稿日:2019-02-09T18:26:06+09:00
【機械学習入門】「K-meansクラスタリング」というのをやってみる♬
参考の記事をちょっと試したら、少しはまったので備忘録で残しておく。
【参考】
・①K-meansクラスタリング少し古い記事らしくて、言語仕様やリンクがちょっとということで、その修正を以下の通り、実施しました。
やったこと
・urllib.urlretrieveをurllib.request.urlretrieveに変更する
・color=colorsをc=colorsに変更する・urllib.urlretrieveをurllib.request.urlretrieveに変更する
コード全体はおまけに載せておきます。
参考のとおり、「urlretrieveは、ネット上からファイルをダウンロードし保存するのに使う。しかし、2系と3系とで違いがありググラビリティが低い。なので、書き記す。」ということで、以下のとおり書き換えると動きました。import urllib.request # ウェブ上のリソースを指定する url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt' # 指定したURLからリソースをダウンロードし、名前をつける。 urllib.request.urlretrieve(url, 'SchoolScore.txt')【参考】
・②python3 urlretrieve・color=colorsをc=colorsに変更する
こちらは、少し英文読まないといけないのですが、つまりmatplotlibに渡すとき混乱するので、colorではなくcで渡しましょうということで、colorをcにするとカラーが反映しました。
原文引用「For the time been, as suggested, use c instead of color」
【参考】
・③ValueError: Supply a 'c' kwarg or a 'color' kwarg but not both; they differ but their functionalities overlap
まとめ
・k-meansクラスタリングと主成分分析をやってみた
・離散データには応用できそうだけど、残念ながら音声の分類には不適当なようだ
おまけ
以下のコードは上記記載の変更以外は前出の参考①のとおりです。
# URL によるリソースへのアクセスを提供するライブラリをインポートする。 import urllib.request import pandas as pd # データフレームワーク処理のライブラリをインポート # 図やグラフを図示するためのライブラリをインポートする。 import matplotlib.pyplot as plt from pandas.tools import plotting # 高度なプロットを行うツールのインポート from sklearn.cluster import KMeans # K-means クラスタリングをおこなう #import sklearn #機械学習のライブラリ from sklearn.decomposition import PCA #主成分分析器 # ウェブ上のリソースを指定する url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt' # 指定したURLからリソースをダウンロードし、名前をつける。 urllib.request.urlretrieve(url, 'SchoolScore.txt') #('SchoolScore.txt', <httplib.HTTPMessage instance at 0x104143e18>) df = pd.read_csv("SchoolScore.txt", sep='\t', na_values=".") # データの読み込み df.head() #データの確認 df.iloc[:, 1:].head() #解析に使うデータは2列目以降 plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6), alpha=0.8, diagonal='kde') #全体像を眺める plt.savefig('k-means/scatter_plot.jpg') plt.pause(1) plt.close()
# この例では 3 つのグループに分割 (メルセンヌツイスターの乱数の種を 10 とする) kmeans_model = KMeans(n_clusters=3, random_state=10).fit(df.iloc[:, 1:]) # 分類結果のラベルを取得する labels = kmeans_model.labels_ # 分類結果を確認 print(labels)以下が出力
[2 2 0 2 2 1 2 2 1 2 2 2 1 2 2 0 1 2 0 0 1 0 1 1 2 2 2 0 1 1 1 1 1 1 0 1 1]# それぞれに与える色を決める。 color_codes = {0:'#00FF00', 1:'#FF0000', 2:'#0000FF'} # サンプル毎に色を与える。 colors = [color_codes[x] for x in labels] # 色分けした Scatter Matrix を描く。 plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6),c=colors, diagonal='kde', alpha=0.8) #データのプロット plt.savefig('k-means/scatter_color_plot.jpg') plt.pause(1) plt.close()
#主成分分析の実行 pca = PCA() pca.fit(df.iloc[:, 1:]) PCA(copy=True, n_components=None, whiten=False) # データを主成分空間に写像 = 次元圧縮 feature = pca.transform(df.iloc[:, 1:]) # 第一主成分と第二主成分でプロットする plt.figure(figsize=(6, 6)) for x, y, name in zip(feature[:, 0], feature[:, 1], df.iloc[:, 0]): plt.text(x, y, name, alpha=0.8, size=10) plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, color=colors) plt.title("Principal Component Analysis") plt.xlabel("The first principal component score") plt.ylabel("The second principal component score") plt.savefig('k-means/PCA12_plot.jpg') plt.pause(1) plt.close()
最後にそもそものデータを掲載しておく
https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt
以下のデータでは上記で得られた分類(ラベル)を追加しています。
Student Japanese Math English Category 0 80 85 100 2 1 96 100 100 2 2 54 83 98 0 3 80 98 98 2 4 90 92 91 2 5 84 78 82 1 6 79 100 96 2 7 88 92 92 2 8 98 73 72 1 9 75 84 85 2 10 92 100 96 2 11 96 92 90 2 12 99 76 91 1 13 75 82 88 2 14 90 94 94 2 15 54 84 87 0 16 92 89 62 1 17 88 94 97 2 18 42 99 80 0 19 70 98 70 0 20 94 78 83 1 21 52 73 87 0 22 94 88 72 1 23 70 73 80 1 24 95 84 90 2 25 95 88 84 2 26 75 97 89 2 27 49 81 86 0 28 83 72 80 1 29 75 73 88 1 30 79 82 76 1 31 100 77 89 1 32 88 63 79 1 33 100 50 86 1 34 55 96 84 0 35 92 74 77 1 36 97 50 73 1
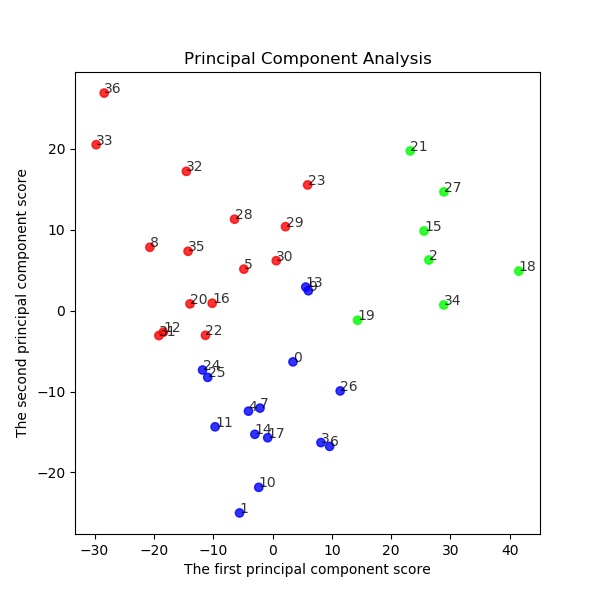
- 投稿日:2019-02-09T18:17:00+09:00
pythonちょい嵌り-'shift_jis' codec can't encode character '\uff5e' in position 1: illegal multibyte sequence
はじめに
Django2で動的にformを作る2-MultipleChoiceFieldに対応させる-で作成したものを加工して
CSV形式でZIPファイルに出力するものを作りました。クライアント端末であるWindows10から入力した「~」文字が
CSVで吐き出す際にUnicodeからShift-JISにマッピングできず困惑しました。
出力されるエラーはこんな感じ
'shift_jis' codec can't encode character '\uff5e' in position 1: illegal multibyte sequenceこれも嵌りポイントだと思うので記事にして行きます(^^♪
お試しコード
動的にformを作る2のソースにcsv,zip出力を組み込んだものとなります。
urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.dynamic, name='index'), ]forms.pyfrom django import forms class EnqForm(forms.Form): passviews.pyfrom django.shortcuts import render from .forms import EnqForm from django import forms from django.http import HttpResponse import io import os import csv, zipfile import tempfile # Create your views here. def dynamic(request): context = {} content = {} form_item = {} qs = [] # define enquete fields qs.append( {'title':'title1', 'description': 'note1', 'type': 'text' , 'required': False} ) qs.append( {'title':'title2', 'description': 'note2', 'type': 'text' , 'required': True} ) qs.append( {'title':'title3', 'description': 'note3', 'type': 'radio' , 'required': False} ) qs.append( {'title':'title4', 'description': 'note4', 'type': 'multi' , 'required': True} ) qs.append( {'title':'title5', 'description': 'note5', 'type': 'radio' , 'required': True} ) # create enquete form objects no = 0 for q in qs: if q['type'] == 'text': form_item.update( { ('ans%d' % no): forms.CharField(label=q['title'], label_suffix=q['description'], required=q['required'], max_length=256) } ) elif q['type'] == 'radio': form_item.update( { ('ans%d' % no): forms.ChoiceField(label=q['title'], label_suffix=q['description'], required=q['required'], choices=(('a','a'),('b','b'),('c','c'),('d','d')), widget=forms.RadioSelect) } ) elif q['type'] == 'multi': form_item.update( { ('ans%d' % no): forms.MultipleChoiceField(label=q['title'], label_suffix=q['description'], required=q['required'], choices=(('a','a'),('b','b'),('c','c'),('d','d')), widget=forms.CheckboxSelectMultiple) } ) no += 1 # create dynamic form DynamicEnqForm = type('DynamicEnqForm', (EnqForm,), form_item ) # get enquete answers if request.method == 'POST': formset = DynamicEnqForm(request.POST or None) if formset.is_valid(): for key in formset.cleaned_data: if key != 'csrfmiddlewaretoken' and key != 'method': content[key] = formset.cleaned_data[key] if 'method' in request.POST and request.POST['method'] == 'regist': # regist fp = tempfile.NamedTemporaryFile(mode='w', newline='', encoding='shift_jis', delete=False) fname = fp.name header=[] for key in content: header.append(key) writer = csv.DictWriter(fp, fieldnames=header) writer.writeheader() writer.writerow(content) fp.close() fp = open(fname, 'r') zip_io = io.BytesIO() with zipfile.ZipFile(zip_io, mode='w', compression=zipfile.ZIP_DEFLATED) as backup_zip: backup_zip.writestr('CSVファイル.csv', fp.read()) response = HttpResponse(zip_io.getvalue(), content_type='application/x-zip-compressed') response['Content-Disposition'] = 'attachment; filename=%s' % 'your_zipfilename' + ".zip" response['Content-Length'] = zip_io.tell() fp.close() os.unlink(fname) return response else: # confirm context['method'] = 'confirm' context['title'] = [] f_items = form_item['declared_fields'] for item in f_items: if type(content[item]) == type([]): context['title'].append({'title': f_items[item].label, 'description': f_items[item].label_suffix, 'answer': ','.join(content[item])}) else: context['title'].append({'title': f_items[item].label, 'description': f_items[item].label_suffix, 'answer': content[item]}) # draw enquete form DynamicForm = DynamicEnqForm(content) context['enq_form'] = DynamicForm return render(request, "dynamic.html", context)dynamic.html<form action="" method="POST"> {% csrf_token %} {% if method == 'confirm' %} <div> <div> {% for item in title %} <p>{{ item.title }}</p> <p>{{ item.description}}</p> <p>{{ item.answer}}</p> {% endfor %} {% for field in enq_form %} {{ field.as_hidden }} {% endfor %} <input type="hidden" name="method" value="regist" /> </div> </div> {% else %} {% for field in enq_form.visible_fields %} <div> <div> <label for="{{ field.id_for_label }}">{{ field.label }}</label> <p>{{ field.field.label_suffix }}</p> {{ field }} </div> </div> {% endfor %} {% endif %} <input type="submit"> </form>今回の主役はここのコード
views.pyfor key in formset.cleaned_data: if key != 'csrfmiddlewaretoken' and key != 'method': content[key] = formset.cleaned_data[key] if 'method' in request.POST and request.POST['method'] == 'regist': # regist fp = tempfile.NamedTemporaryFile(mode='w', newline='', encoding='shift_jis', delete=False) fname = fp.name header=[] for key in content: header.append(key) writer = csv.DictWriter(fp, fieldnames=header) writer.writeheader() writer.writerow(content) fp.close() fp = open(fname, 'r') zip_io = io.BytesIO() with zipfile.ZipFile(zip_io, mode='w', compression=zipfile.ZIP_DEFLATED) as backup_zip: backup_zip.writestr('CSVファイル.csv', fp.read()) response = HttpResponse(zip_io.getvalue(), content_type='application/x-zip-compressed') response['Content-Disposition'] = 'attachment; filename=%s' % 'your_zipfilename' + ".zip" response['Content-Length'] = zip_io.tell() fp.close() os.unlink(fname) return response実際に試してみる(成功パターン)
クライアントはWindows10でブラウザはChromeを使ってます。
まずは成功パターンである無難な文字列の入力
デスクトップが汚かったのでc:\TEMPに保存しましたが、Excelが真っ白だったのでデスクトップに保存するようにしたら問題なく表示されました。
実際に試してみる(失敗パターン)
クライアントはWindows10でブラウザはChromeを使ってます。
「~」をフォームに入力します。
とまぁこんな感じで怒られます"(-""-)"
原因は…
Windowsの文字コードはShift-JISではなくShift-JISの亜種であるCP932
「~」はPython上でUnicodeに変換されてますがそのコードはU+FF5E
Windows上のIMEパッドで確認すると…Shift-JIS(CP932)では0x8160Unicodeには、「波型」と「全角ティルダ」という二つの異なる「〜」が存在します。一般的には「波型」であるu'\u301c'が使われます。Shift_JISの「〜」'\x81\x60'はUnicodeの「波型」にマップされています。
詳しくはこちらの記事を参考にしてください。
Unicode波型問題 CP932とShift_JISは同じエンコーディングではない
文字化け対策コード
文字化けを防ぐため、
- クライアントから送信されてくる値についてはCP932でエンコードし、Shift_JISでデコードする。
- ファイルはShift_JISで作成
- ZIPに読み込ませる際はバイナリーモードで読み込む
を対策し無事にCSVが文字化けせずに出力されました。
views.pyfrom django.shortcuts import render from .forms import EnqForm from django import forms from django.http import HttpResponse import io import os import csv, zipfile import tempfile # Create your views here. def dynamic(request): context = {} content = {} form_item = {} qs = [] # define enquete fields qs.append( {'title':'title1', 'description': 'note1', 'type': 'text' , 'required': False} ) qs.append( {'title':'title2', 'description': 'note2', 'type': 'text' , 'required': True} ) qs.append( {'title':'title3', 'description': 'note3', 'type': 'radio' , 'required': False} ) qs.append( {'title':'title4', 'description': 'note4', 'type': 'multi' , 'required': True} ) qs.append( {'title':'title5', 'description': 'note5', 'type': 'radio' , 'required': True} ) # create enquete form objects no = 0 for q in qs: if q['type'] == 'text': form_item.update( { ('ans%d' % no): forms.CharField(label=q['title'], label_suffix=q['description'], required=q['required'], max_length=256) } ) elif q['type'] == 'radio': form_item.update( { ('ans%d' % no): forms.ChoiceField(label=q['title'], label_suffix=q['description'], required=q['required'], choices=(('a','a'),('b','b'),('c','c'),('d','d')), widget=forms.RadioSelect) } ) elif q['type'] == 'multi': form_item.update( { ('ans%d' % no): forms.MultipleChoiceField(label=q['title'], label_suffix=q['description'], required=q['required'], choices=(('a','a'),('b','b'),('c','c'),('d','d')), widget=forms.CheckboxSelectMultiple) } ) no += 1 # create dynamic form DynamicEnqForm = type('DynamicEnqForm', (EnqForm,), form_item ) # get enquete answers if request.method == 'POST': formset = DynamicEnqForm(request.POST or None) if formset.is_valid(): for key in formset.cleaned_data: if key != 'csrfmiddlewaretoken' and key != 'method': if type(formset.cleaned_data[key]) != type([]): content[key] = formset.cleaned_data[key].encode('cp932').decode('shift_jis') else: items = formset.cleaned_data[key] buf = [] for item in items: buf.append( item.encode('cp932').decode('shift_jis') ) content[key] = buf if 'method' in request.POST and request.POST['method'] == 'regist': # regist fp = tempfile.NamedTemporaryFile(mode='w', newline='', encoding='shift_jis', delete=False) fname = fp.name header=[] for key in content: header.append(key) writer = csv.DictWriter(fp, fieldnames=header) writer.writeheader() writer.writerow(content) fp.close() fp = open(fname, 'rb' ) zip_io = io.BytesIO() with zipfile.ZipFile(zip_io, mode='w', compression=zipfile.ZIP_DEFLATED) as backup_zip: backup_zip.writestr('CSVファイル.csv', fp.read()) response = HttpResponse(zip_io.getvalue(), content_type='application/x-zip-compressed') response['Content-Disposition'] = 'attachment; filename=%s' % 'your_zipfilename' + ".zip" response['Content-Length'] = zip_io.tell() fp.close() os.unlink(fname) return response else: # confirm context['method'] = 'confirm' context['title'] = [] f_items = form_item['declared_fields'] for item in f_items: if type(content[item]) == type([]): context['title'].append({'title': f_items[item].label, 'description': f_items[item].label_suffix, 'answer': ','.join(content[item])}) else: context['title'].append({'title': f_items[item].label, 'description': f_items[item].label_suffix, 'answer': content[item]}) # draw enquete form DynamicForm = DynamicEnqForm(content) context['enq_form'] = DynamicForm return render(request, "dynamic.html", context)解説
まずはクライアントから送信された値を綺麗にShift_JISに変換します。
一度CP932でエンコードした後に改めてShift_JISに変換します。
ちょっと処理が複雑になっているのはlist型の場合もあるのでその処理が入ってます。for key in formset.cleaned_data: if key != 'csrfmiddlewaretoken' and key != 'method': if type(formset.cleaned_data[key]) != type([]): content[key] = formset.cleaned_data[key].encode('cp932').decode('shift_jis') else: items = formset.cleaned_data[key] buf = [] for item in items: buf.append( item.encode('cp932').decode('shift_jis') ) content[key] = bufファイルの出力部分は変わっていません。Shift_JISとして書きだします。
fp = tempfile.NamedTemporaryFile(mode='w', newline='', encoding='shift_jis', delete=False) fname = fp.name header=[] for key in content: header.append(key) writer = csv.DictWriter(fp, fieldnames=header) writer.writeheader() writer.writerow(content) fp.close()あとはShift_JISで出力したファイルを読み込む際に、バイナリーモードで読み込みます。
そうしないとまたUnicodeになっちゃうので。fp = open(fname, 'rb' )
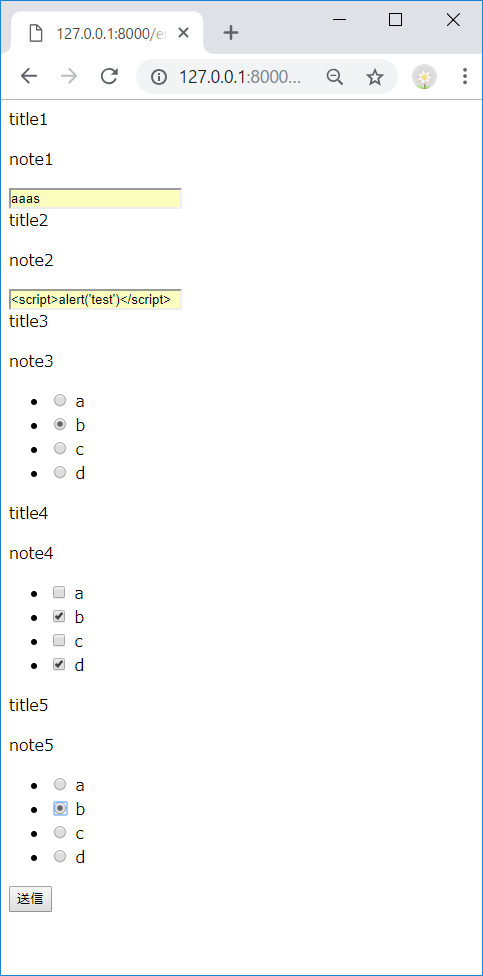
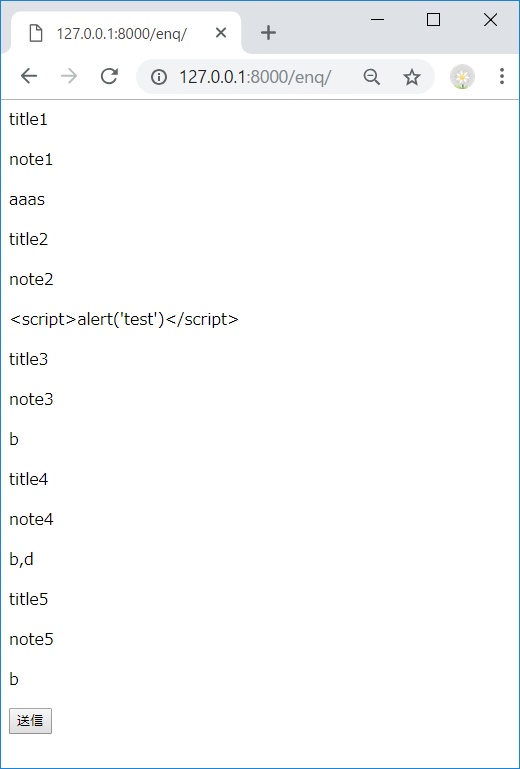
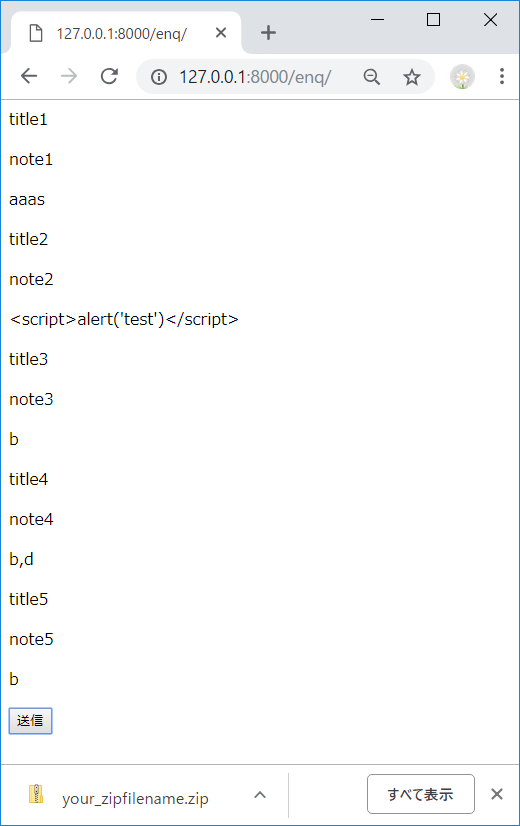
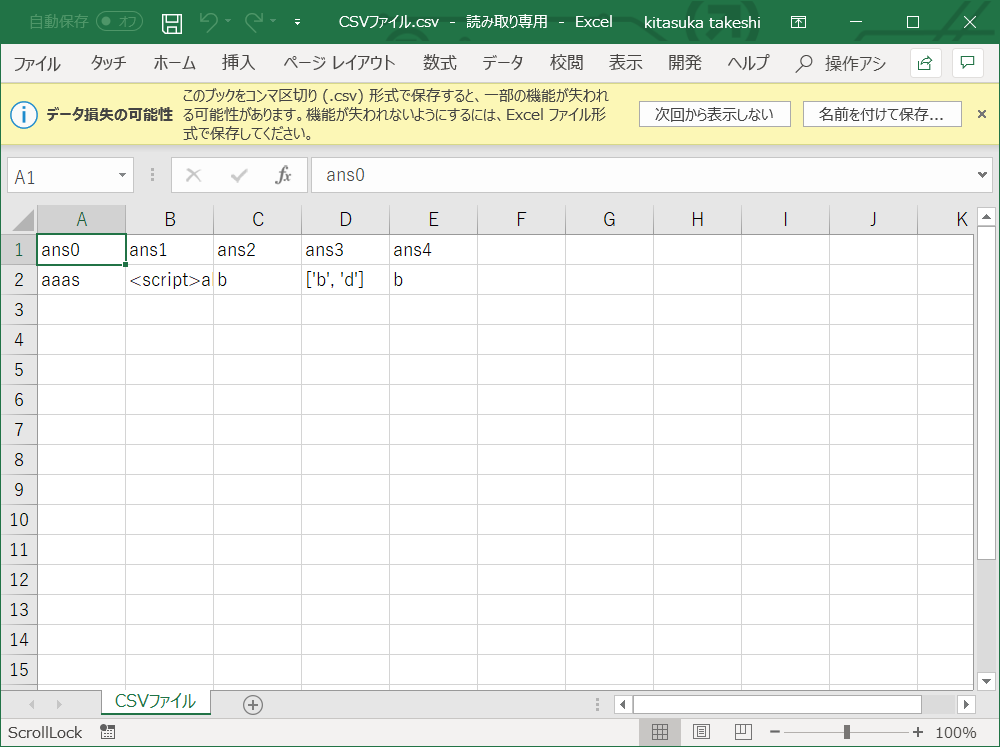
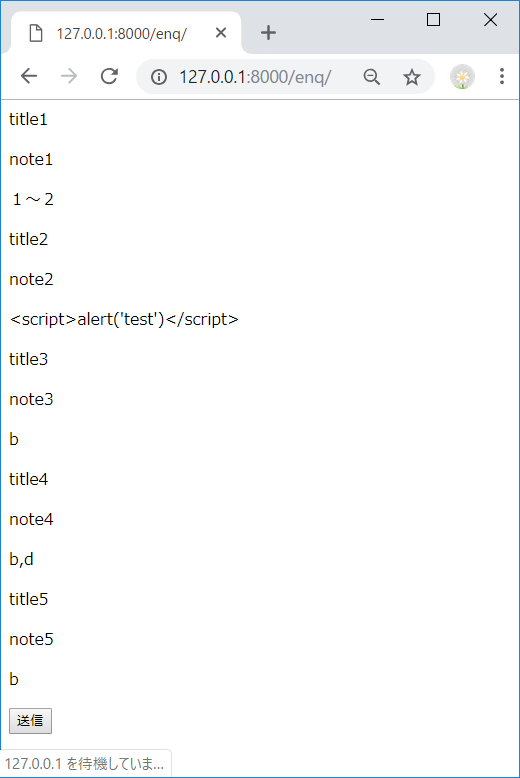
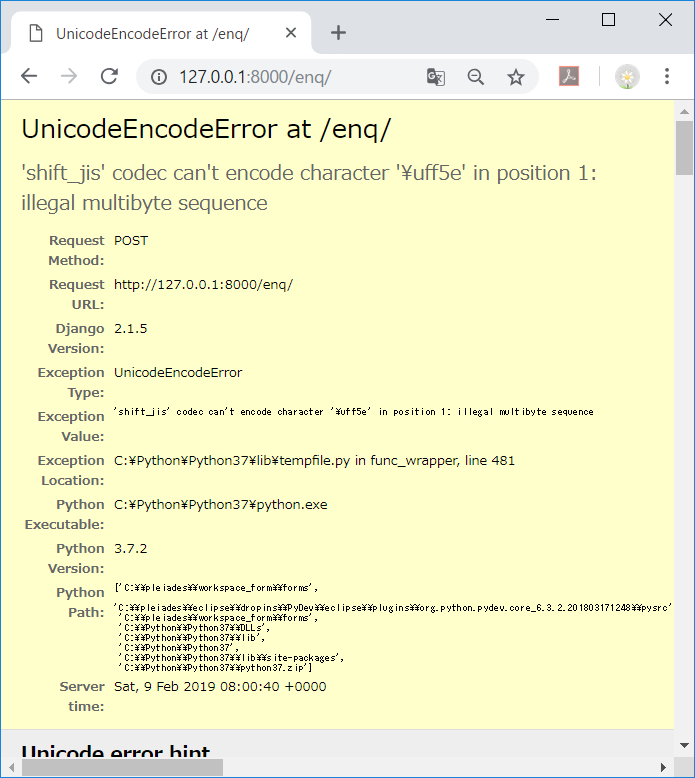
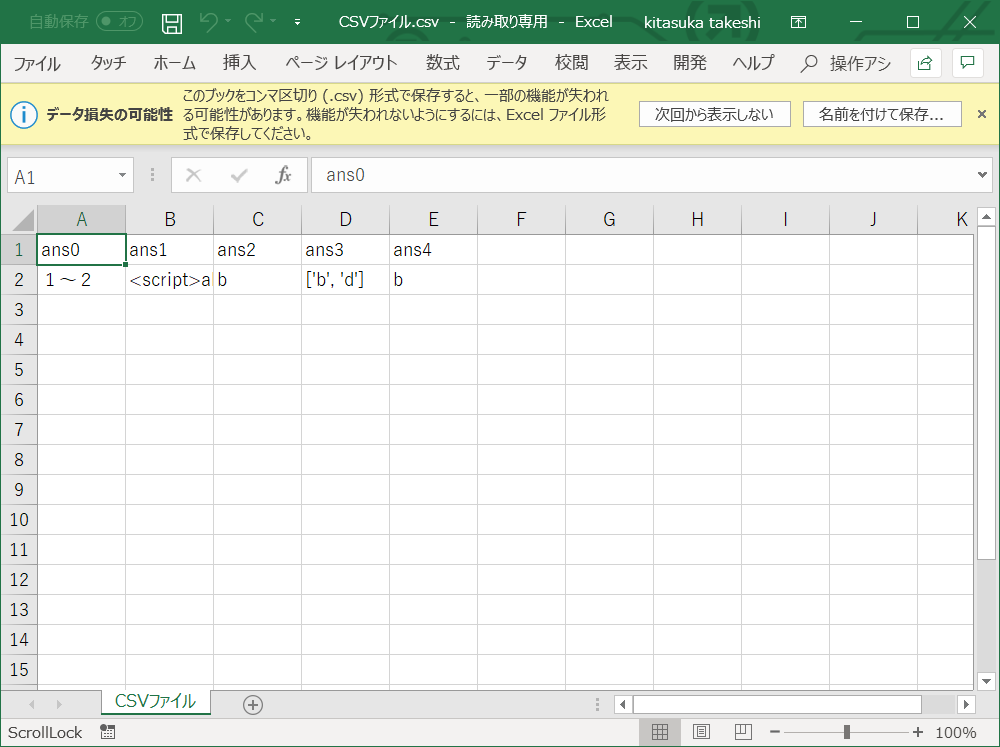
- 投稿日:2019-02-09T17:44:44+09:00
0から(numpyから)つくる量子フーリエ変換
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$趣旨
量子アルゴリズムって、割と基本的なものでも数式を追っていくと頭痛くなるほど難しくて、私は正直理解できてるのかよくわからなくなるんですよね。
あれだけAPIが充実した機械学習界隈でも代表的なアルゴリズムを一度は自分で書くべきと言われてるのだから、量子アルゴリズムもかくあるべきなのではないでしょうかと。
GUIはお手軽で楽しいですが、自分で実装したコードが狙い通りの出力をする快感には敵いません。というわけで、ふわっと量子フーリエ変換のnumpy実装にトライしました。
ほぼ確実に車輪の再発明ですけど、参考になればと思います。
素人実装な部分は大目に見てください...。数式
まずは https://whyitsso.net/physics/quantum_mechanics/QFT.html から抜粋させて頂きながら、量子フーリエ変換の数式を確認していきます。
入力n-qubit列$\ket{x}$が以下のように与えられるとしましょう。
$\ket{x} = \sum^{N-1}_{j=0} x_j \ket{j}$
$(N = 2^n)$ここで$\ket{x}, \ket{j}$はqubit列で表される2進数の10進表記で考えます。
どういうことかと言うと、例えば $\ket{j}$が2-qubits状態 $\ket{10}$の場合、$\ket{j} = \ket{2}$と書くものとします。
もう少し書くと、$$
\begin{align}
\sum^{3}_{j=0} x_j \ket{j} &= x_0 \ket{0}+x_1 \ket{1}+x_2 \ket{2}+x_3 \ket{3} \\
&= x_0 \ket{00}+x_1 \ket{01}+x_2 \ket{10}+x_3 \ket{11}
\end{align}
$$という感じです。
ここで各状態ベクトル $x_j \ket{j}$が離散フーリエ変換の入力データ点の1つとみなせるため、離散フーリエ変換の定式を用いて以下のように式展開できます。
(元々フーリエ変換が関数ベクトルの変換だったと考えると、量子フーリエ変換は量子状態ベクトルの変換をフーリエ変換と同じ作法で行っていると思えば良いと考えています)\begin{align} \ket{y} &= \sum^{N-1}_{k=0} y_k \ket{k} \\\ &= \sum^{N-1}_{k=0} [\frac{1}{\sqrt{N}} \sum^{N-1}_{j=0} \exp(i \frac{2\pi kj}{N})\ x_j] \ket{k}\\ &=\sum^{N-1}_{j=0}x_j\ [\frac{1}{\sqrt{N}} \sum^{N-1}_{k=0} \exp{(i\frac{2\pi kj}{N})}\ \ket{k} ] \end{align}ここでは変換後の状態ベクトル$\ket{y}$の係数$y_k$に、離散フーリエ変換の定式
$y_{k} = \frac{1}{\sqrt{N}} \sum^{N-1}_{j=0} \exp (i \frac{2 \pi kj}{N}) x_j$を代入しました。
すると、入力qubit列 $\ket{x} = \sum^{N-1}_{j=0} x_j \ket{j}$ の各$\ket{j}$について次のような変換が成り立つことがわかります。
$\ket{j}\ \to \frac{1}{\sqrt{N}} \sum^{N-1}_{k=0} \exp{(i\frac{2\pi kj}{N})}\ \ket{k} \tag{1}$これで、量子状態ベクトルに対してのフーリエ変換が定式化できました。
この変換ですが、実は次式のように書き換えることができます。$$
\begin{align}
\ket{j} &\to \frac{1}{\sqrt{2^n}}(|0>+e^{i2\pi 0.j_0}|1>)(|0>+e^{i2\pi 0.j_1 j_0}|1>)\cdots (|0>+e^{i2\pi 0.j_{n-1} j_{n-2} \cdots j_0}|1>) \tag{2}
\end{align}
$$すると、下図のような量子ゲート回路で実装が可能なようです。
(https://whyitsso.net/physics/quantum_mechanics/QFT.html より引用)
$H$ゲートはアダマールゲート
H= \begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix}$R_k$ゲートは下記のような量子ゲートです。
R_k = \begin{pmatrix} 1 & 0 \\ 0 & e^{i \pi/2^{k}} \end{pmatrix}bit数が増えても$H$ゲートと$R_k$ゲートを使った繰り返し処理で一般化できる形になっていますね。
実装
今回は式$(1)$と式$(2)$でそれぞれ量子フーリエ変換の出力を確認します。
(当然一致するはずです)
式(1)は解析的な計算、式(2)は量子ゲート回路を模倣した計算、と考えています。まずは式(1)の実装です(jupyter notebookで確認)。
入力状態は$\ket{10}$をリスト[1, 0]として与えています。import numpy as np def binToInt(inputState): out = 0 for i in range(len(inputState)): out += inputState[-1-i]* 2**i return out def QFT_calc(inputState): j = binToInt(inputState) N = 2 ** len(inputState) calc = [] for i in range(N): calc.append(1/np.sqrt(N) * np.exp(1j * 2*np.pi *i*j / N)) return calc inputState = [1,0] calc = QFT_calc(inputState) print(np.round(calc,3))以下のような出力になりました。
これくらいなら手計算でも簡単に確認できますね。[ 0.5+0.j -0.5+0.j 0.5-0.j -0.5+0.j]次に式(2)の実装です。
少し長いですが、本体は最下部の"QFT"関数です。import numpy as np class Qbits: def __init__(self, initial): self.states = [] for i in range(len(initial)): if initial[i]==1:# |1> self.states.append(np.array([0+0j,1+0j])) else: self.states.append(np.array([1+0j,0+0j])) def tensorProd(self, a, b): dim_a = len(a) dim_b = len(b) k = np.zeros(dim_a*dim_b) + 0j ite = 0 for i in range(dim_a): for j in range(dim_b): k[ite] = a[i]*b[j] ite += 1 return k def outputTensorProduct(self): out = self.states[0] for i in range(1, len(self.states)): out = self.tensorProd(out, self.states[i]) return out def Hadamard(self, i): H = np.array([[1,1],[1,-1]]) / np.sqrt(2) self.states[i] = np.dot(H, self.states[i]) def C_Hadamard(self, c, i): if self.states[c] == np.array([1,0]): self.Hadamard(i) def Rphase(self, i, k): R = np.array([[1,0],[0,np.exp(1j * np.pi / (2**k))]]) + 0j self.states[i] = np.dot(R, self.states[i]) def C_Rphase(self, c, i, k): if self.states[c][1] == 1+0j: self.Rphase(i, k) def flipState(self): self.states.reverse() def QFT(initial): A = Qbits(initial = initial) N = len(initial) for i in range(N): for j in range(i): A.C_Rphase(i, j, i-j) A.Hadamard(i) A.flipState() return A.outputTensorProduct() inputState = [1,0] a = QFT(initial = inputState) print(np.round(a,3))先程のコードと同じ入力状態を与えているため、出力も同じとなるはずです。
[ 0.5+0.j -0.5+0.j 0.5+0.j -0.5+0.j]inputStateは"0"または"1"のみを要素にもつリストであれば動くはずです。
例えばもっと長いqubit列を用意して、両実装の比較をするとinputState = [1,0,1,0] calc = QFT_calc(inputState) print(np.round(calc,3)) a = QFT(initial = inputState) print(np.round(a,3))出力は以下のように等しくなります。
[ 0.25 +0.j -0.177-0.177j 0. +0.25j 0.177-0.177j -0.25 +0.j 0.177+0.177j -0. -0.25j -0.177+0.177j 0.25 -0.j -0.177-0.177j -0. +0.25j 0.177-0.177j -0.25 +0.j 0.177+0.177j -0. -0.25j -0.177+0.177j] [ 0.25 +0.j -0.177-0.177j 0. +0.25j 0.177-0.177j -0.25 +0.j 0.177+0.177j -0. -0.25j -0.177+0.177j 0.25 +0.j -0.177-0.177j 0. +0.25j 0.177-0.177j -0.25 +0.j 0.177+0.177j -0. -0.25j -0.177+0.177j]計算誤差など考慮できていないため、状態列を長くしたらボロが出るかもしれないです。
複素数の扱いも、もっと良い方法がありそうですけどとりあえず気にしない。
2通りの計算方法で検算しているので合っている...はず...。まとめ
量子フーリエ変換をnumpyのみで実装できたと思います。
個人的には数式を読んで分かったと思っていても、実装して出力結果を突きつけられると理解が曖昧な部分があぶり出されたりして良かったです。
量子フーリエ変換はGrover's Algorithmなどで重要な役割を果たすのでぜひ理解しておきたいですよね。以上、読んで頂きありがとうございました。
参考にしたもの
- https://whyitsso.net/physics/quantum_mechanics/QFT.html
- "量子情報科学入門", 石坂 智 他, 共立出版

- 投稿日:2019-02-09T17:16:58+09:00
Jupyter Notebookのテーマカラーをかんたんに変更できる!
Jupyter Notebookのテーマカラーが変えられることに気づき(遅い…)、
さっそく、目にやさしくダークカラーに変えましたので、やり方をご共有まで。こちらのページをママ参考にしています、ありがとうございます!
STEP1
コマンドプロンプトで、以下を入力し。これでインストール完了。pip install jupyterthemesSTEP2
どんなテーマが選べるのかなー?テーマカラー一覧が以下で出せます。$ jt -lSTEP3
テーマカラーを以下で変更!(評判がよい「monokai」を今回はチョイス)jt -t monokaiSTEP4
テーマカラー以外にも、フォントやツールバー表示なども設定できます。
「-f ●●(フォント名)」:フォント名を変更
「-T」:ツールバー表示
「-N」:ノート名表示たとえば、こんな感じで
jt -t monokai -f inconsolata -N -TSTEP5
さいごに、ダークカラーにすると、グラフの縦軸横軸の表示が見えなくなってしまうので、これは都度でめんどうですが、Jupyter Notebook上で、以下をpandasとかのimportと同じタイミングで実行させておくと解消されます。custom_style = {'axes.labelcolor': 'white', 'xtick.color': 'white', 'ytick.color': 'white'} sns.set_style("darkgrid", rc=custom_style)どんどんJupyter Notebookの環境を使いやすくしていきたいなー
- 投稿日:2019-02-09T16:55:26+09:00
Jupyter Notebookのセル幅を広げたい!
初投稿です。
(記事作成の要領が分かっておらず、まずは備忘まで・・・)Jupyter Notebookのセル幅が妙に狭いので、
広げられないか?と思って以下のページにたどり着きました。結論、以下コードをJupyterのcodeに張り付け、実行するだけ。(とてもかんたん!!)
%%HTML <style> div#notebook-container { width: 95%; } div#menubar-container { width: 65%; } div#maintoolbar-container { width: 99%; } </style>デフォルト設定にできれば、もっといいんだけどなー
- 投稿日:2019-02-09T16:50:31+09:00
【python】思わぬ落とし穴~関数内で変数に代入されるされない~
背景
あれ?
なんか、再帰関数の中で配列の型だと代入されてint型だと代入されずに処理が終わってまう(´・ω・`)これってなんでだっけ?、、と思ったのがきっかけ。
変数が代入されないとき
個人的な経験上、変数が上手く代入されないときは
1. 関数の内側か外側かのスコープの問題
2. クラスなどで扱ってる中で変数(オブジェクト)が書き換え不可能になってる
3. その他バグ(その処理が行われる前に落ちてるとか)まぁ今回、ただの再帰関数を1つ書いてて起こった問題なので案の定スコープの問題でした。
みんなが知ってるスコープの話
- 約束事1. ローカル変数とグローバル変数を同じと思うべからず
>>> def i_to_1(): ... i = 1 ... >>> i_to_1() >>> print(i) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'i' is not definedあれ?関数内でiで変数使って代入もしてるのになんで??
これはもうそういうお約束なのです(´・ω・`)
(※雑になってすいません)
- 約束事2. グローバル変数はローカル変数に書き変わらないのである
>>> i = 100 >>> i_to_1() >>> i 100だけど変数を配列にしてみると?
>>> def ary_to_1(): ... ary[0] = 1 ... >>> ary_to_1() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in ary_to_1 NameError: name 'ary' is not defined配列で同じことをしようとすると、少し違う挙動をするみたいですね。
そこで、次が自分が最初に不思議に思ってた挙動です。>>> ary = [100] >>> >>> ary_to_1() >>> >>> ary [1]あら、変わってるではありませんか!?
まとめ
配列だとスコープの問題を回避して関数内で代入をできると言うことが分かった。
なんでかって?...(すいませんどなたかご教示ください)
また、用語の使い方に不備があったりするかも知れないのでご指摘いただけると幸いです(ぺこ
- 投稿日:2019-02-09T16:50:01+09:00
ResponderでModuleNotFoundError: No module named 'starlette.lifespan'が表示されてしまう
Responder実行時にエラーが出てしまう...
ModuleNotFoundError: No module named 'starlette.lifespan'
$ pip install starlette==0.8
をすればエラーが解決されるという記事を見ましたができませんでした。starletteのバージョンは現在
0.1.0, 0.1.1, 0.1.2, 0.1.3, 0.1.4, 0.1.5, 0.1.6, 0.1.7, 0.1.8, 0.1.9, 0.1.10, 0.1.11, 0.1.12, 0.1.13, 0.1.14, 0.1.15, 0.1.16, 0.1.17, 0.2.0, 0.2.1, 0.2.2, 0.2.3, 0.3.0, 0.3.1, 0.3.2, 0.3.3, 0.3.4, 0.3.5, 0.3.6, 0.3.7, 0.4.0, 0.4.1, 0.4.2, 0.5.0, 0.5.1, 0.5.2, 0.5.3, 0.5.4, 0.5.5, 0.6.0, 0.6.1, 0.6.2, 0.6.3, 0.7.0, 0.7.1, 0.7.2, 0.7.3, 0.7.4, 0.8.0, 0.8.1, 0.8.2, 0.8.3, 0.8.4, 0.8.5, 0.8.6, 0.8.7, 0.8.8, 0.9.0, 0.9.1, 0.9.2, 0.9.3, 0.9.4, 0.9.5, 0.9.6, 0.9.7, 0.9.8, 0.9.9, 0.9.10, 0.9.11, 0.10.0, 0.10.1試しに0.9バージョンの最新版である0.9.11に設定するとエラーが解決されました。
$ pip install starlette==0.9.11
- 投稿日:2019-02-09T16:32:48+09:00
k-NNで教授との色覚類似度を算出した
はじめに
大学院で受講していた講義で、k-NNを用いて教授と自分の色覚がどの程度似ているのかを算出するプログラムを作成するといった課題がありました。
本記事は、その課題の条件である
k-NNの仕組みを理解するために、機械学習ライブラリを用いることなく実装せよ。
というものにのっとり、進めていきます。よって、「こちとら時間がないんじゃあ!!」という場合(その様なケースが殆ど?)には、
あまり適していないのかもしれません。悪しからず。間違えている部分がございましたらご指摘のほどよろしくお願い致します!
また、今回Qiita初投稿なので、「わかりにくいんだよっ!こらっ!」ってことがあれば、ゴリゴリ指摘をいただきたいです。
環境
・python3.6
・macOS Mojavek-NNとは
k-NNとは、k近傍法のことで、機械学習アルゴリズムの一つです。
また、教師あり学習のクラス分類手法の一つです。
クラス分類時には、あらかじめ学習データが既知で、そのデータの各データ点と、新しく取得した未知のデータとの距離を、近い順にk個算出し、多数決でクラスを推定しています。以下のページがとても参考になりました。
- K近傍法(多クラス分類)
- k近傍法とk平均法の違いと詳細.k_NNでの距離とは
k-NNでは、前項でも述べた様にデータとデータの距離を算出して、クラスの推定を行います。
その距離の算出方法として、一般的にはユークリッド距離が用いられることが多い様です。ユークリッド距離とは以下の図の青色の線の部分です。ユークリッド距離
ユークリッド距離dは以下の式で表されます。
例として、以下の図のような、身長と体重をプロットした平面を考えます。各点は対象とした人々を表しています。平均的なデータとなるAから赤くプロットした点の距離を考えてみると、全て同じ距離を示します。ユークリッド距離は、変数間の相関を考慮しないので、データの集まりから遠く離れている点でも平等に扱います。
この様な、変数間に相関がある場合は、ユークリッド距離は良い距離とは言えません。
マハラノビス距離
マハラノビス距離を簡単に述べると、「変数間の相関を考慮した距離」です。
仮にデータがn次元でm個あったとすると、得られたデータ列を
として、i番目のデータは、
となります。この時の平均値ベクトルは
となり、分散共分散行列は、
となります。
そして、マハラノビス距離は、以下の式で表されます。
先ほどの例で考えると、以下の図の様になり、相関が強い方向の距離は、実際の距離よりも相対的に短くなります。
つまり、分散が大きいと、原点からの距離はあまり離れていないと解釈することができ、
分散が小さいと、原点からの距離は大きく離れているということになります。
使用したデータについて
- あらかじめ用意された、「乱数を用いて生成された緑と青の中間色を提示し、緑と青のどちらの色かを判断した結果をCSVファイルに保存する」という内容のプログラムを使用し、教授が生成したdata.csvを学習データとして用いる。
- テストデータとして、自らも先のプログラムを使用し、test.csvを生成する。
- 生成されたcsvファイルの中身は、提示された色のRGBの内、GとBの値と、判断されたクラスが各行にデータ毎に記されている。
test.csvG, B, Class 310,207,0 170,144,0 196,178,0 126,266,1 176,279,1 . . . 合計100個のデータ実装・前処理
データ読み込み
まずは、作成したdata.csvとtest.csvを読み込みます。
study_machine_learning_calc.pydef csv_read(csv_f): # データ読み込み df = pd.read_csv(csv_f,header=None) N = len(df) T = np.zeros((N,2)) X = np.zeros((N,2)) # for i in N: for k in range(2): # G&B X[:,k] = df[k] T[:,0] = df[2] T[:, 1] = [1 if i == 0 else 0 for i in T[:,0]] X = min_max(X) return X, T, Nこの関数ではXとTとNが返り値として設定されています。それぞれ、GとBの値が入った二次元配列、One hot表現で示されたクラスが入った二次元配列、データの総数となっています。
これを用いて、以下の様にデータを読み込みます。
knn_mah.py# 引数はdata.csv # X0 = 2つの変数のデータが入る2次元配列, T0 = X0のクラスが入る2次元配列 , N0 = 要素数 X0, T0, N0 = csv_read(csv_f[0]) # テストデータが指定されている場合に行う if len(csv_f) > 1: # 引数はtest.csv X1, T1, N1 = csv_read(csv_f[1]) else: X1, T1, N1 = X0, T0, N0メイン処理
次に、data.csvの分散共分散行列を求めます。
study_machine_learning_calc.pydef covariance_and_inverse(a, b): """a,bの異なる変数の共分散をして、逆行列を返す関数""" co = np.cov(a,b) return np.linalg.inv(co)以下の様にして求めます。
knn_mah.py# 引数の逆行列が返る g = covariance_and_inverse(X0[:,0],X0[:,1])次が、本プログラムの核となる部分です。
k=3~16とし、どのkが一番結果がよくなるのかを確認します。knn_mah.pyknn_mah_list = np.zeros((N0,N0)) knn_mah_result = [] TT = np.zeros((N0)) #最適なKを見つけるため for k in range(3,16): for i, t in enumerate(X1): for j, r in enumerate(X0): knn_mah_list[i,j] = mah(r - t, g) # 値が小さい順にk個のインデックスを取得 # それぞれのインデックスのクラスを取得し、合計をとる k_sum = sum(T0[np.argpartition(knn_mah_list[i,:], k)[:k],0]) # 多数決をし、クラスを決定する if k_sum / k >= 0.5 : TT[i] = 1 else: TT[i] = 0 knn_mah_result.append(np.sum(T1[:,0] == TT))プログラム中でマハラノビス距離を計算している関数は以下です。
study_machine_learning_calc.pydef mah(x, g): """マハラノビス距離を返す関数""" return np.dot(np.dot(np.transpose(x), g), x)結果の表示部分は以下となっています。
knn_mah.py"""結果表示部""" print("正解率は{0}%です。".format(max(knn_mah_result) / N0 *100)) print("最も正解率の高いkは{0}です。".format(knn_mah_result.index(max(knn_mah_result))+3)) print(knn_mah_result) x = [3,4,5,6,7,8,9,10,11,12,13,14,15] plt.plot(x,knn_mah_result) plt.xlabel('k') plt.ylabel('accuracy rate') plt.show()そして!たくさんの方が気になりまくりであろう(絶対なってない)、
私と教授の色覚の類似度は、
k=10の時に、95%となっております!!!
そして、本記事のはじめに表示されている画像は、一致しなかった色の一例です。
みなさんは、何色に見えましたか?コメントお待ちしております!
私は、左が青で、右が緑と判定していました。
プログラム全文
knn_mah.pyimport numpy as np import matplotlib.pyplot as plt import sys import os.path from study_machine_learning_calc import covariance_and_inverse, mah, csv_read def knn_mah(*csv_f): """マハラノビス距離を用いたk近傍法""" # X0 = 2つの変数のデータが入る2次元配列, T0 = X0のクラスが入る2次元配列 , N0 = 要素数 X0, T0, N0 = csv_read(csv_f[0]) # テストデータが指定されている場合に行う if len(csv_f) > 1: X1, T1, N1 = csv_read(csv_f[1]) else: X1, T1, N1 = X0, T0, N0 # 引数の逆行列が返る g = covariance_and_inverse(X0[:,0],X0[:,1]) knn_mah_list = np.zeros((N0,N0)) knn_mah_result = [] TT = np.zeros((N0)) #最適なKを見つけるため for k in range(3,16): for i, t in enumerate(X1): for j, r in enumerate(X0): knn_mah_list[i,j] = mah(r - t, g) # 値が小さい順にk個のインデックスを取得 # それぞれのインデックスのクラスを取得し、合計をとる k_sum = sum(T0[np.argpartition(knn_mah_list[i,:], k)[:k],0]) # 多数決をし、クラスを決定する if k_sum / k >= 0.5 : TT[i] = 1 else: TT[i] = 0 knn_mah_result.append(np.sum(T1[:,0] == TT)) """結果表示部""" print("正解率は{0}%です。".format(max(knn_mah_result) / N0 *100)) print("最も正解率の高いkは{0}です。".format(knn_mah_result.index(max(knn_mah_result))+3)) print(knn_mah_result) x = [3,4,5,6,7,8,9,10,11,12,13,14,15] plt.plot(x,knn_mah_result) plt.xlabel('k') plt.ylabel('accuracy rate') plt.show() if __name__ == "__main__": args = sys.argv # 学習データとテストデータが引数で設定されている場合 if len(args) == 3: if os.path.splitext(args[1])[1] == ".csv" or os.path.splitext(args[2])[1] == ".csv": knn_mah(args[1], args[2]) else: print("csvファイルでお願い申す。") # 学習データのみの場合 elif len(args) == 2: if os.path.splitext(args[1])[1] == ".csv": knn_mah(args[1]) else: print("csvファイルでお願い申す。") elif len(args) == 1: print("学習させたいデータのファイルを引数に設定してくだせえ。") else: print("学習させたいデータのファイルは1つにしてくだせえ。")study_machine_learning_calc.pydef csv_read(csv_f): # データ読み込み df = pd.read_csv(csv_f,header=None) N = len(df) T = np.zeros((N,2)) X = np.zeros((N,2)) # for i in N: for k in range(2): # G&B X[:,k] = df[k] T[:,0] = df[2] T[:, 1] = [1 if i == 0 else 0 for i in T[:,0]] X = min_max(X) return X, T, N def covariance_and_inverse(a, b): """a,bの異なる変数の共分散をして、逆行列を返す関数""" co = np.cov(a,b) return np.linalg.inv(co) def mah(x, g): """マハラノビス距離を返す関数""" return np.dot(np.dot(np.transpose(x), g), x)


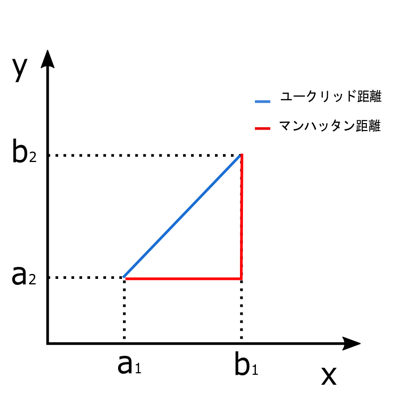
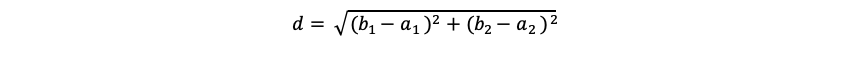
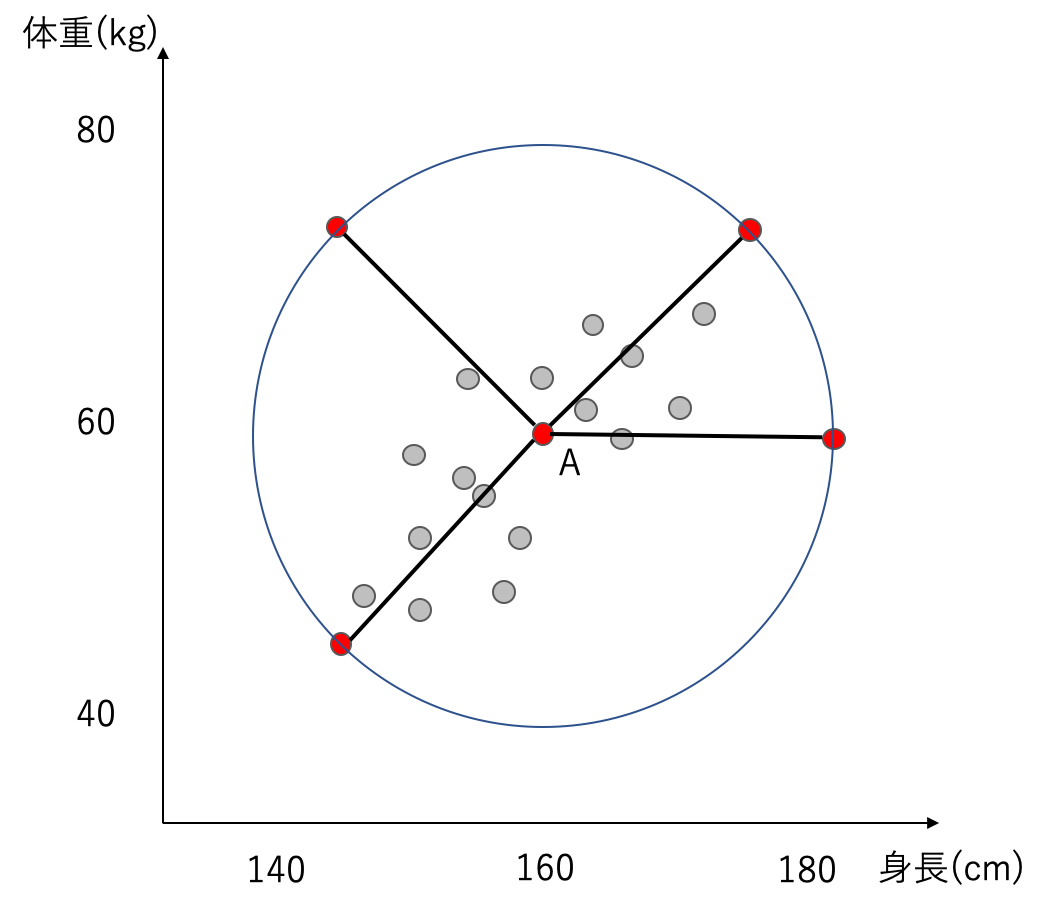
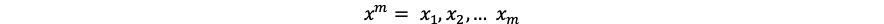
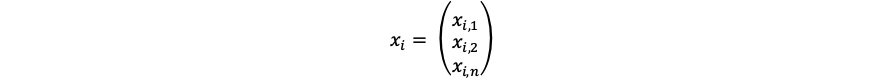
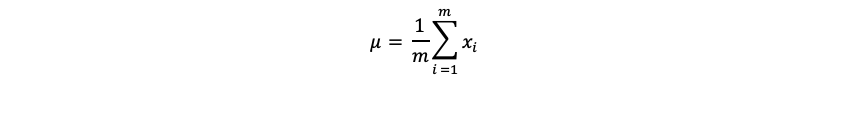
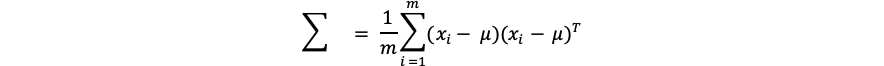
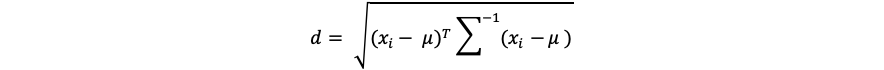
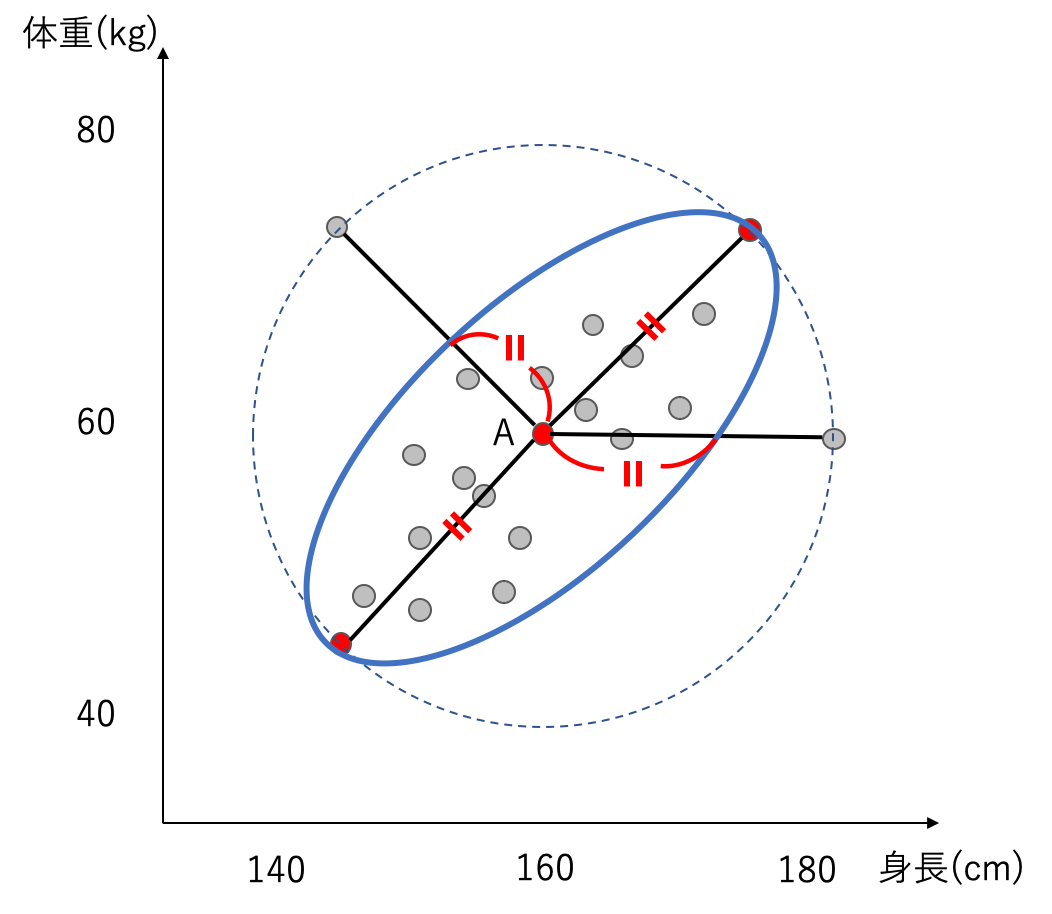
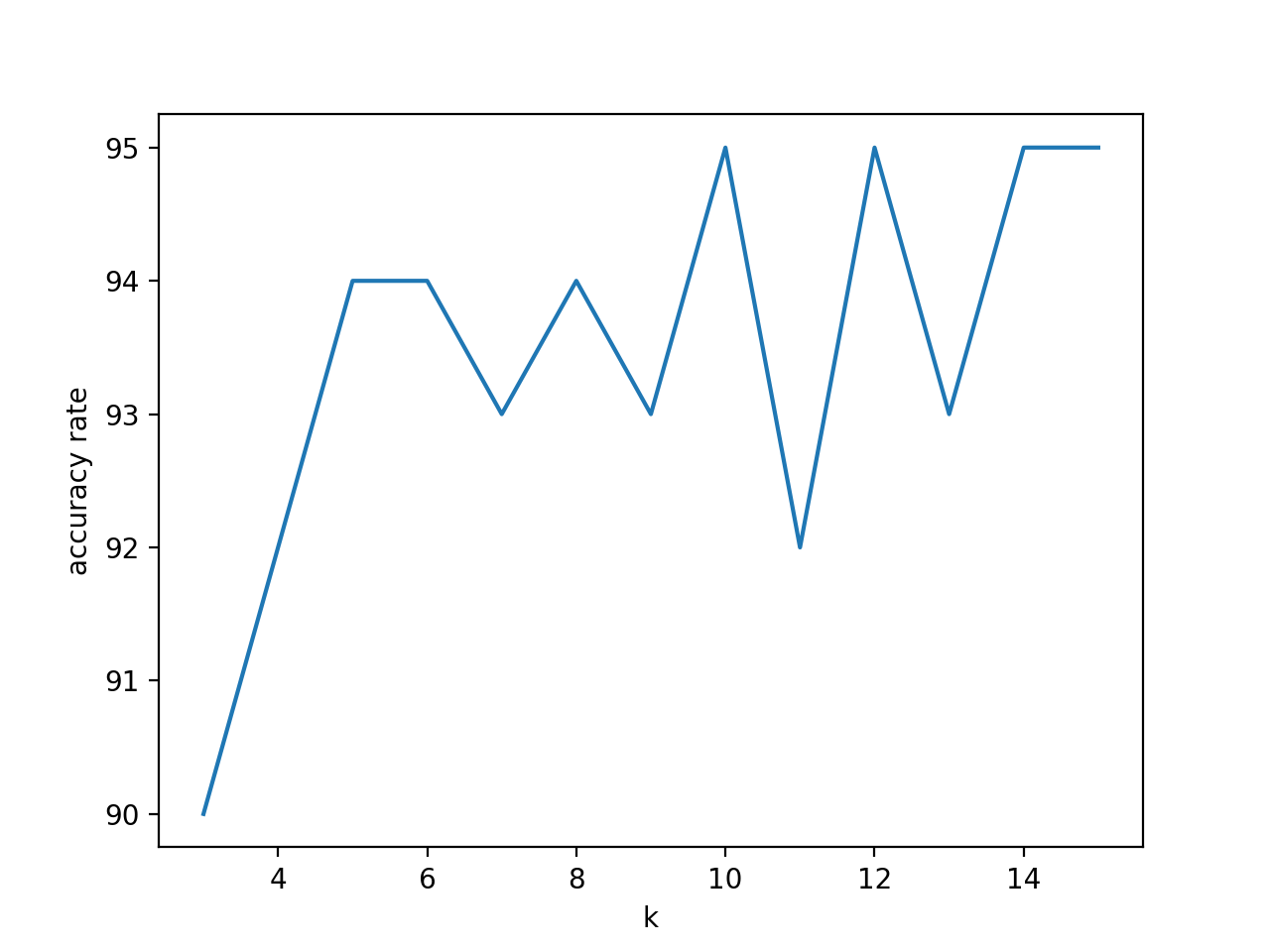
- 投稿日:2019-02-09T15:41:10+09:00
PythonによるMySQLの操作
PythonでMySQLを介してDBを操作してみました。
その際に引っかかった箇所や初歩的な箇所を簡単にですがまとめてみました。対象者
PythonでMySQLを操作してみたい方
大量データを素早くDBに書き込みたい方MySQLとは
オープンソースで公開されている関係データベース管理システム (RDBMS) の一つである。
GNU GPL(無料で使えるライセンス)と商用ライセンスのデュアルライセンスとなっている。
(ウィキペディアから一部抜粋)
ウィキペディア/MySQLメリット
- 運用経験者が多い
- 高いパフォーマンス
デメリット
- 脆弱性対応が遅い
↓その他のDBMSとの比較するときのご参考に
SQLの観点から「Oracle Database」「PostgreSQL」「MySQL」の特徴を整理しよう!MySQLを導入する際は下記を参考にすると良いと思います。
MySQLのダウンロード&インストールと初期設定方法Pythonの必要なパッケージ
pippip install MySQL-PythonMySQLと環境設定の説明はこの辺にして実際に書いたコードの内容に移ります。
実装概要
- MySQLに接続&文字のエンコード(utf-8)
- 指定DBのアクティブ化
- データテーブルの作成
- データの挿入(大量データに対応)
- データテーブルから指定データの取り出し
実装内容
今回はクラスが実装時に都合が良かったので下記で説明していく機能は全て1つのクラスのメソッドになります。
- MySQLに接続&文字のエンコード(utf-8)
DB_Manipulate/__init__def __init__(self): # Connect self.conn = MySQLdb.connect( user='root', passwd='password', host='localhost', db='mysql' ) # Encoding self.conn.set_character_set('utf8') self.cur = self.conn.cursor() self.cur.execute('SET NAMES utf8;') self.cur.execute('SET CHARACTER SET utf8;') self.cur.execute('SET character_set_connection=utf8;')自身のMySQL上で登録したユーザー名とパスワードをいれてください。
接続後に下の行でデータを入れる際に文字コードをエンコードするようにMySQLにSQL文で指示を送っています。
MySQLに何か操作をする際には基本的にconn.cur.execute('SQL文')で送ります。
- 今回使用するSQL文
SQLsql_DBactive = "use " sql_cretable = "CREATE TABLE IF NOT EXISTS " sql_insert = "INSERT INTO ""use"は指定したDBをアクティブにする
"CREATE TABLE IF NOT EXISTS "は既に指定したテーブル名が
存在するか確認して無い場合はテーブルを作成する
"INSERT INTO "データの挿入を行います
- 指定DBのアクティブ化
DB_Manipulate/DB_activatedef DB_activate(self, DBname): sql = self.sql_DBactive + DBname self.cur.execute(sql)実際にexcuteに入っているSQL文は'use DataBaseName'
これでどのデータベースを使用するか指定できます。
- データテーブルの作成
DB_Manipulate/CREATETABLE_City_ID_Namedef CREATETABLE_City_ID_Name(self, table_name): self.table_name = table_name sql = self.sql_cretable +\ self.table_name +\ " (ID INT," +\ "City CHAR(100)," +\ "Country CHAR(100))" self.cur.execute(sql)CREATE TABLEとそのテーブルの中に入れる列名とデータ型の指定をしています。
MySQLのデータ型の詳細は【MySQL】データ型一覧
扱えるデータ型がまとまっておりわかりやすいです。
また、一度テーブル作成後のカラムの変更は可能です詳細はカラムの名前と定義の変更
- データの挿入(大量データに対応)DB_Manipulate/INSERT_City_ID_Namedef INSERT_City_ID_Name(self, city_data): sql = self.sql_insert +\ self.table_name+\ " (ID, City, Country) VALUES (%s, %s, %s)" self.cur.executemany(sql, city_data) self.conn.commit()データを挿入する時はINSERT文で1つずつデータ挿入しますが大量データを挿入する際は一括で挿入する必要があります。
この目的を達成するにはSQL文とexcuteに工夫が必要で
"INSART INTO TABLENAME (カラム名*カラムの数だけ記入する) VALUES (%s*カラムの数だけ記入する)"
することで大量データを入力するSQL文にします
次にexecuteでSQL文の投げていたところをexecutemanyに変更することで処理時間を短く簡単なコードでその目的を達成することが出来ます。
- データテーブルから指定データの取り出し
DB_Manipulate/SELECT_Columndef SELECT_Column(self, table_name, *input_column_name): for i in range(len(input_column_name)): if i == 0: column_name = input_column_name[0] else: column_name = column_name + ',' + input_column_name[i] sql = "SELECT " + column_name + " from " + table_name self.cur.execute(sql) return self.cur.fetchall()データの取り出しについてですが任意のカラムを引っ張れるようなコードにしてみました。
input_column_nameで複数の引数を入力できるようにしてfor文で適当なSQL文の形に修正しています。
ちなみにinput_column_nameに"*"を入力すると通常のSQL文同様全カラムのデータを取得するようになっています。
executeでSQL文を投げた後return のfetchallで取得したデータを返しています。コード全文
DB_Manipulateimport MySQLdb class cl_DB_Manipulate: #Properties sql_DBactive = "use " sql_cretable = "CREATE TABLE IF NOT EXISTS " sql_insert = "INSERT INTO " #constructor def __init__(self): # Connect self.conn = MySQLdb.connect( user='root', passwd='password', host='localhost', db='mysql' ) # Encoding self.conn.set_character_set('utf8') self.cur = self.conn.cursor() self.cur.execute('SET NAMES utf8;') self.cur.execute('SET CHARACTER SET utf8;') self.cur.execute('SET character_set_connection=utf8;') #method def DB_activate(self, DBname): sql = self.sql_DBactive + DBname self.cur.execute(sql) def CREATETABLE_City_ID_Name(self, table_name): self.table_name = table_name sql = self.sql_cretable +\ self.table_name +\ " (ID INT," +\ "City CHAR(100)," +\ "Country CHAR(100))" self.cur.execute(sql) def INSERT_City_ID_Name(self, city_data): sql = self.sql_insert +\ self.table_name+\ " (ID, City, Country) VALUES (%s, %s, %s)" self.cur.executemany(sql, city_data) self.conn.commit() def SELECT_Column(self, table_name, *input_column_name): for i in range(len(input_column_name)): if i == 0: column_name = input_column_name[0] else: column_name = column_name + ',' + input_column_name[i] sql = "SELECT " + column_name + " from " + table_name self.cur.execute(sql) return self.cur.fetchall() def __del__(self): self.conn.close()このコード私個人が使いやすい形にしているだけなので使用する場合は各々使いやすい形にしてもらえればと思います。
また、クラスを使った理由はコンストラクタとデストラクタでクラスを定義した時にMySQLと接続、開放した時に接続を切る処理を行ってくれるためです。
Pythonの詳しいクラスの使い方はPython基礎講座(13 クラス)
まとめ
データを効率的に扱いたいと言うのが独学でDBを扱うモチベーションかなと思いまずは大量データ書き込みをメインに話を進めていきました。
PythonでDBを扱ってみたい方の助けになればと思います。現在はwebアプリにMySQLを絡めた簡単ものを作成中です。
完成したらそちらも投稿しようと思います。
- 投稿日:2019-02-09T15:22:33+09:00
PowerShellで行列計算
PowerShell for MathNet.NumericsでPowerShellから.NET用の数値計算ライブラリを呼び出せることを知り,Python, Fortran, F#とパフォーマンスを比較してみることにした。
コードはnumerics_testに置いた。
マシン
Pythonや.NETはクロスプラットフォームだし,Fortranもコンパイルし直すだけだが,今回はWindowsで。
- Intel Core i5-6500 @ 3.2 GHz 16GB RAM(自作)
- Windows 10 1803
Python
- Official Python 3.7.1 + pipでインストールしたnumpy。
numpy.show_config()によるとOpenBLASとリンクされている。- MKLはcondaに作ったIntel Pythonの仮想環境。Python 3.6.5, Numpy 1.15.4, MKL 2019.2
Pythonのみtimeitモジュールで計測
Fortran
- PGI Community Editon 1810
- Intel Math Kernel Library 2019 update 2
MKLはネットワークインストーラを使用。インストール時に64ビット版のみ,pgiサポートありにカスタマイズ。
pgfortran -mp -Minfo -fast svd -lblas -llapack -o svd pgfortran -mp -Minfo -fast -o svd_mkl svd.f90 -L"$MKLPATH" mkl_intel_lp64.lib mkl_pgi_thread.lib mkl_core.libF
- Visual Studio 2017でインストール。
- .NET Core 2.2 Windows
プロジェクトの作成
プロジェクトを作成し,必要なパッケージを追加する。
パッケージは%USERPROFILE%\.nuget\packagesにインストールされる。> dotnet new console -lang F# -o fsharp > cd fsharp > dotnet add package MathNet.Numerics > dotnet add package MathNet.Numerics.MKL.Win-x64コンパイル
dotnet runでは遅かったので,publishでexeを作成。> dotnet publish -c Release -r win-x64結果
mutmul eig svd inv det PowerShell 3369 15602 11685 10723 627 PowerShell MKL 474 825 486 81 59 Python 2167 12884 6609 593 324 Python MKL 2146 7168 2814 544 254 Fortran 1840 1468 718 309 126 Fortran MKL 539 950 583 225 76 F# 3259 14538 10810 10961 616 F# MKL 582 960 580 172 142
- 10回ずつしか試しておらず,Windowsは他のプロセスも多数動いている点は考慮する必要がある。
- なぜかPowerShell MKLが一番速い。
- OpenBLASのOfficial Pythonはmutmulでは善戦(つまりBLASは速いがLAPACKが遅い。)
- Official BLAS/LAPCKを使っていると思われるPowerShellとF#はとても遅い。
- MKLを使えばF#やPowerShellでもネイティブな速度が出る。.NETのオーバーヘッドは感じられない。
- F#はコードが短くて楽。
- fsi/fsharpiはdllをロードするのが手間(なのでここでは使ってない)。
- 投稿日:2019-02-09T15:10:09+09:00
【初心者】Chainer でオプション価格とGreeks計算(3月限C21000)@ブラウザ
Chainerで微分方程式を解き、オプションのGreeksを求めている記事 を参考に、実際の市場データを入れてブラウザ上で試してみました。
利用した実際の市場データ
⇒03/C21000@100 (2月9日先物価格20290)
出力結果:
C21000 = 99.65
delta = 0.21コメント:
結果は(当然ながら)ほぼ一致。
ブラウザ開いて5分で試せるGoogle Colab は素晴らしい。ソースコード
import numpy as np import chainer from chainer import Variable import chainer.functions as F stock_price = 20290.0 strike = 21000.0 years = 1.0/12 risk_free_rate = 0.01 volatility = 0.143 n_paths = 100000 n_steps = 100 times = np.linspace(0, years, n_steps, dtype=np.float64) r = risk_free_rate v = volatility k = strike T = years initial_stocks = Variable(stock_price * np.ones((n_paths,), dtype=np.float64)) currents = initial_stocks for c, n in zip(times[:-1], times[1:]): dt = n - c zs = np.random.normal(0.0, 1.0, currents.shape) currents = currents * F.broadcast(np.exp((r - 0.5 * v * v) * dt + v * dt ** 0.5 * zs)) #call_price = F.average(exp(-r * T) * F.softplus(currents - k, beta=10)) # you should smooth the relu to calculate gamma call_price = F.average(np.exp(-r * T) * F.relu(currents - k)) deltas = F.sum(chainer.grad([call_price], [initial_stocks], enable_double_backprop=True)[0]) print(f'C21000 = {call_price.data:.2f}') print(f'delta = {deltas.data:.2f}')
- 投稿日:2019-02-09T14:46:16+09:00
sakura.ioのincoming-webhookを利用してデバイスにデータ送信
概要
外部からsakura.ioのデバイス(SCM-LTE-01)に向けてデータを送信します。色々と方法はありますが、ここでは、incoming-webhookを使用し、PC上のプログラム(Python/F#)からデバイスに向けてデータを送ってみたいと思います。
これを行なうためにやるべきことは、次の3つです。
- デバイス側で実行する受信プログラム(Python)を作成する
- sakura.ioプラットホームでincoming-webhookサービスを有効化する
- PC側で実行する送信プログラム(F#/Python)を作成する
受信プログラムの作成・実行
受信側は「SCM-LTE-01(sakura.io)」+「Raspi HAT(SCO-RPI-01)」+「RaspberryPi 3 model B+」という構成を想定します。プログラムは、SakuraIOSMBus というライブラリを使用してPython3.6で書いていきます。
基本的には、(1) 受信キュー内にデータが届いているかを
get_rx_queue_lengthで調べて、(2) データがあればdequeue_rx_raw()によりそれを取り出すという流れになります。なお、dequeue_rx_raw()の代わりにpeek_rx_raw()を使うとキューに残したままデータを取得することができます。import time from sakuraio.hardware.rpi import SakuraIOSMBus sakuraio = SakuraIOSMBus() if sakuraio.get_is_online() : while True: if (sakuraio.get_rx_queue_length()).get('queued') : print(sakuraio.dequeue_rx_raw()) time.sleep(1) else : print(f'デバイスがLTE回線に接続できていません。')sakura.ioプラットホームの設定
PCからデバイスに対して、直接、データを送信することはできません。ここでは、sakura.ioプラットホームが提供する incoming-webhook というサービスを経由してPCからデバイスに向けてデータを送信する方法をとります。この方法では、incoming-webhook サービスにより指定されるURLに対して、デバイスに送りたいデータを含んだ HTTP POST リクエストメッセージを送れば、あとはsakura側でデバイスまでデータを届けてくれます。
連携サービスにincoming-webhookを追加
ブラウザからsakura.ioコントロールパネルにアクセスして、プロジェクトを選択して「連携サービスの追加」を行ないます。連携サービスとして次のように「incoming-webhook」を選択します。
incoming-webhook の設定
名前とSecretを設定します。ここでは、名前を「Webhookでデバイスにデータ送信」、Secretを「1234」とします。
なお、Secretは、HTTPリクエストメッセージが改ざんされていないことを確認したり、誰かが勝手にデバイスに対してデータを送信することを防ぐために使う値です。運用時には別の文字列を使い、他人には知られないようにしてください。なお、Secretを空欄にすることもできます。
HTTPリクエストを送信する宛先URLの確認
連携サービスの一覧から、先ほど作成したincoming-webhookの設定にアクセスします。
URL欄とToken欄を確認しておきます。後ほど、このURLに対して所定のJSON形式でHTTP POSTリクエストメッセージを送信することになります。
データ送信テスト
HTTPリクエストを送るプログラムを作成しなくとも、ブラウザを使って送信テストをすることができます。
Secretを設定したままではテストが面倒なので、ここでは、一旦、Secretを空欄にして保存ボタンを押して、Token欄のテキストをコピーしてから「Incoming Webhook APIドキュメント」をクリックしてください。
移動したら、Token欄にコピーしておいたテキストをペーストします。また、module欄にモジュールIDを設定します。このモジュールIDは、sakura.ioコントロールパネルのモジュールカテゴリの以下の画面から確認できます。
その他、次のように設定します(チャンネル1に98という整数値を送信する例になっています)。
設定ができたら、先に作成しておいた受信側のプログラムを起動してから「Try it out!」のボタンを押します。次のようにResponse Codeが200になっていれば成功で、デバイス側では、コンソールに
{'channel': 1, 'type': 'i', 'data': [98, 0, 0, 0, 0, 0, 0, 0], 'offset': 673}のような出力がされていると思います。
うまくいかない?
Incoming WebhookにSecret「1234」を設定したままであったり、X-Sakura-SignatureにSecret値をそのまま設定している場合は、Response Codeが「401」で失敗します。X-Sakura-Signatureにすべき値(文字列)は、Secret と RequestBody を使ってHMAC-SHA1というハッシュ計算を行なった結果の文字列になります。
送信プログラムの作成
Incoming Webhook に対して、次のようなHTTP POSTリクエストメッセージを送信することができれば、Pythonでも、C#でも、JavaScriptでも、どんなプログラム言語でも送信プログラムを作成することができます。プログラムを作成しなくとも、コマンドの組合せで送信することもできます。
POST https://api.sakura.io/incoming/v1/xxxxxxxx-xxxxxxxxx-xxxx-xxxxxxxxxxxx HTTP/1.1 Accept: application/json Content-Type: application/json Content-Length: 104 Host: api.sakura.io {"type":"channels","module":"uxxxxxxxxxxx","payload":{"channels":[{"channel":0,"type":"i","value":10}]}}以降は、sakuraコントロールパネルで、Secretを「1234」に戻したという想定でのプログラムになります。
送信プログラム Python3.6版
import hmac import hashlib import http import json import requests def genHMACSHA1(key,msg): key = key.encode() msg = msg.encode() return hmac.new(key,msg,hashlib.sha1).hexdigest() Token = 'xxxxxxxx-xxxxxxxxx-xxxx-xxxxxxxxxxxx' # 要変更 ModuleID = 'uxxxxxxxxxxx' # 要変更 Secret = '1234' # 要変更 channelData = list() channelData.append( {'channel':0,'type':'i','value':10} ) # 要変更 channelData.append( {'channel':1,'type':'i','value':20} ) # 要変更 postBody = dict() postBody['type'] = 'channels' postBody['module'] = ModuleID postBody['payload'] = {'channels':channelData} jsonString = json.dumps(postBody) #print(jsonString) headers = dict() headers['Accept']='application/json' headers['Content-Type']='application/json' headers['X-Sakura-Signature'] = genHMACSHA1(Secret,jsonString) ApiURL = f'https://api.sakura.io/incoming/v1/{Token}' resMsg = requests.post(ApiURL, jsonString, headers=headers) resMsgStatusLine= f'{resMsg.status_code} ' resMsgStatusLine+= f'{http.client.responses[resMsg.status_code]} HTTP/' resMsgStatusLine+= '.'.join(list(str(resMsg.raw.version))) resMsgHeader = '\n'.join(f'{k}: {v}' for k, v in resMsg.headers.items())+'\n' resMsgBody = resMsg.text; print(resMsgStatusLine) print(resMsgHeader) print(resMsgBody)実行結果
200 OK HTTP/1.1 Server: nginx Date: Sat, 09 Feb 2019 04:36:43 GMT Content-Type: application/json Content-Length: 15 Connection: keep-alive {"status":"ok"}送信プログラム F#版
open System open System.Text open System.Security open RestSharp open Newtonsoft.Json open System.Runtime.Serialization open Microsoft.FSharp.Collections [<DataContract>] type tChannelData = { [<DataMember>] channel:int [<DataMember(Name="type")>] type_:string [<DataMember>] value:int } [<DataContract>] type tPayload = { [<DataMember>] channels:List<tChannelData> } [<DataContract>] type tPostData = { [<DataMember(Name="type")>] type_:string [<DataMember(Name="module")>] module_:string [<DataMember>] payload:tPayload } let genHMACSHA1 (key:string) (msg:string) = let bKey = Encoding.UTF8.GetBytes(key); let bMsg = Encoding.UTF8.GetBytes(msg) let hmac = new Cryptography.HMACSHA1(bKey); let bs = hmac.ComputeHash(bMsg); do hmac.Clear() BitConverter.ToString(bs).ToLower().Replace("-", ""); [<EntryPoint>] let main argv = let token = "xxxxxxxx-xxxxxxxxx-xxxx-xxxxxxxxxxxx" // 要変更 let moduleID = "uxxxxxxxxxxx" // 要変更 let secret = "1234"; // 要変更 let postBody = { type_ = "channels" module_ = moduleID payload = { channels = [ { channel=0; type_="i"; value=10 } // 要変更 { channel=1; type_="i"; value=20 } ] // 要変更 } } let jsonString = JsonConvert.SerializeObject(postBody) let signature = jsonString |> genHMACSHA1 secret //printfn "%s" jsonString let request = new RestRequest( Method.POST) request.AddHeader("Accept", "application/json") |> ignore request.AddHeader("X-Sakura-Signature",signature) |> ignore request.AddParameter("application/json", jsonString, ParameterType.RequestBody) |> ignore let ApiURL = "https://api.sakura.io/incoming/v1/" + token let client = new RestClient(ApiURL) let res = client.Execute(request) printfn "%d %s" (int res.StatusCode) res.StatusDescription let nl = System.Environment.NewLine let rec headerText (headers:List<Parameter>) = match headers with | h::t -> h.Name+":"+(string h.Value)+nl+(headerText t) | [] -> String.Empty printfn "%s" (List.ofSeq(res.Headers) |> headerText ) printfn "%s" (res.Content) Console.ReadKey() |> ignore 0実行結果
200 OK Server:nginx Date:Sat, 09 Feb 2019 05:36:11 GMT Connection:keep-alive Content-Type:application/json Content-Length:15 {"status":"ok"}
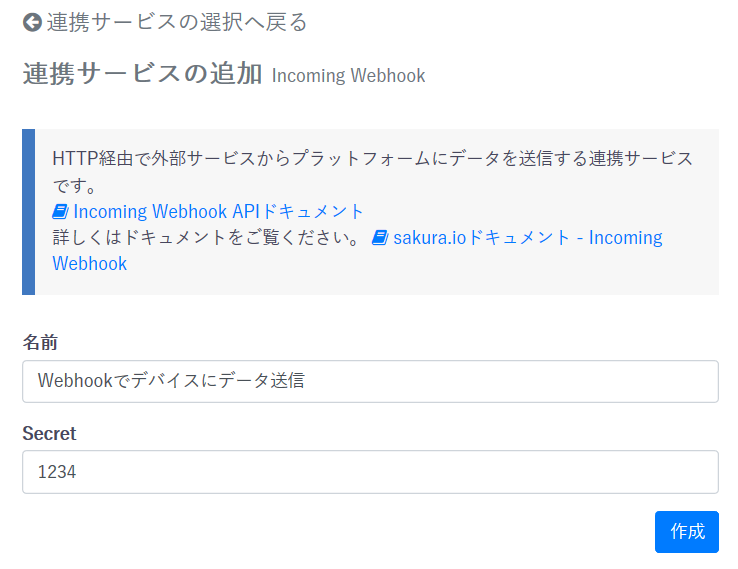
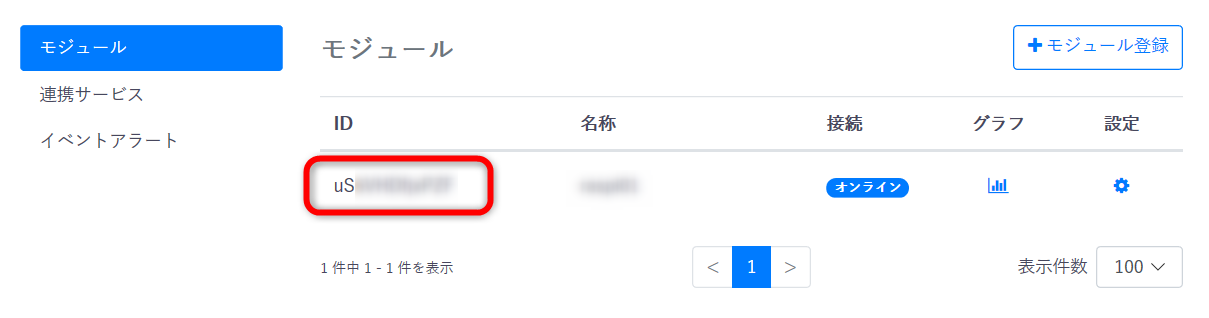
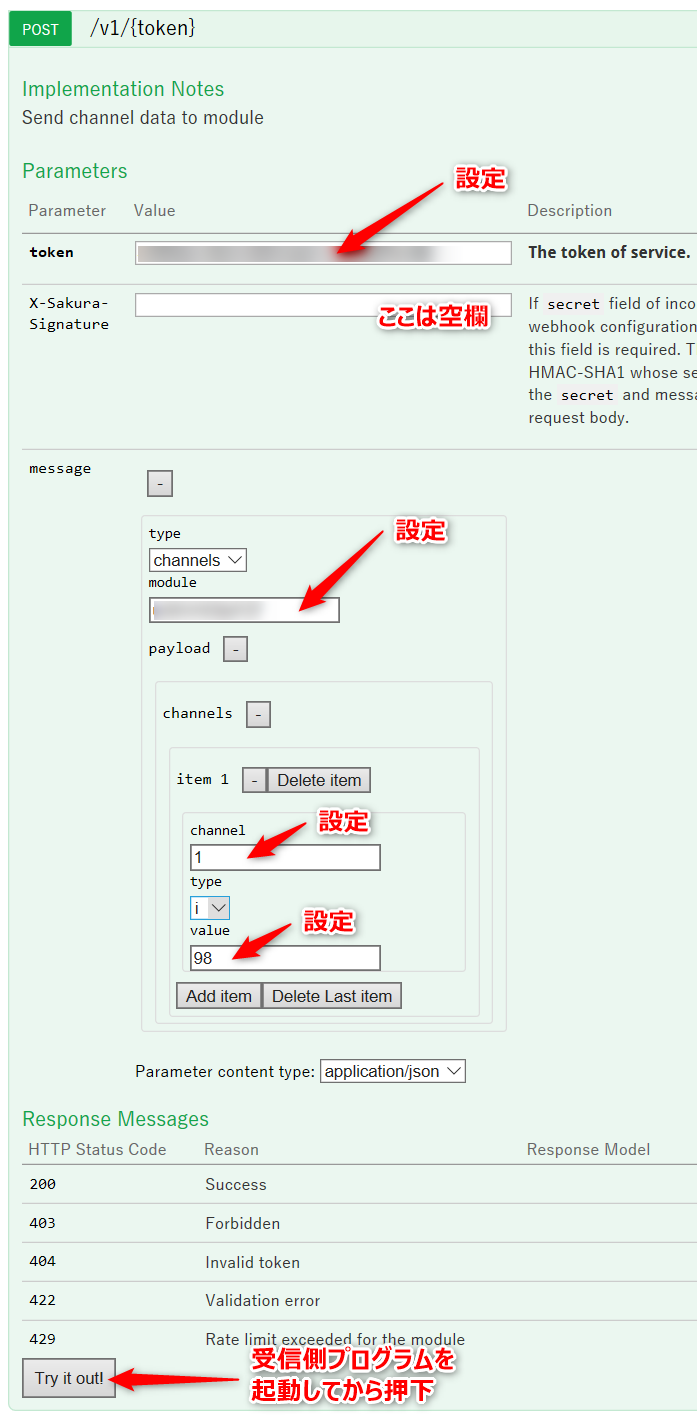
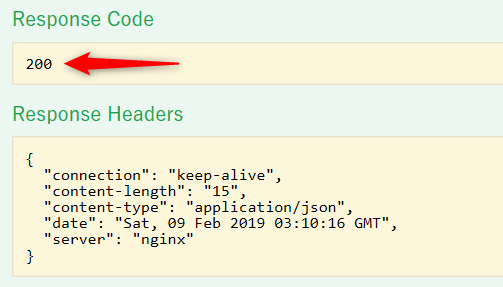
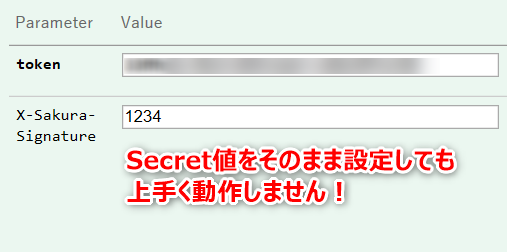
- 投稿日:2019-02-09T14:09:41+09:00
Django TemplateViewの参考記事
Djangoにおけるクラスベース汎用ビューの入門と使い方サンプル
https://qiita.com/felyce/items/7d0187485cad4418c073
- 投稿日:2019-02-09T13:47:27+09:00
axis
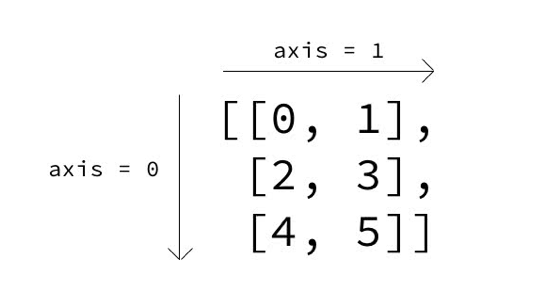
- 投稿日:2019-02-09T13:40:49+09:00
Raspberry Pi(Raspbian)でLEDを点灯/消灯させるプログラムを作る
はじめに
Raspberry Pi(Raspbian)でLEDを点灯/消灯させるプログラムの紹介です。
必要なもの
- RaspbianがインストールされているRaspberry Pi
- ブレッドボード
- LEDx2
- 抵抗(100Ω)x2
- ジャンパー線(オス/メス)x3
- ジャンパー線(オス/オス)x2
配線
GPIOとGNDならどこでも可ですが、今後の拡張性などを考えるとGPIOのみのピン(3, 5, 8, 10, 19, 21, 23, 24, 25以外)を使う方が無難だと思います。
この投稿では33(GPIO13), 35(GPIO19), 39(GND)ピンを使用しています。
プログラム
led.py#Import Files import RPi.GPIO as GPIO import time #GPIO Settings GPIO.setmode(GPIO.BCM) GPIO.setup(13, GPIO.OUT) GPIO.setup(19, GPIO.OUT) #Main try: while True: GPIO.output(13, GPIO.LOW) GPIO.output(19, GPIO.HIGH) time.sleep(1) GPIO.output(13, GPIO.HIGH) GPIO.output(19, GPIO.LOW) time.sleep(1) except KeyboardInterrupt: GPIO.cleanup()解説
- スイッチの制御に使用する
RPi.GPIOライブラリをインポートする- 時間を取得するために使用する
timeライブラリをインポートする- GPIOのモードをBCMに設定する(物理的なピン番号ではなく、GPIO**を使用する)
- GPIO13, GPIO19を出力端子に設定する(Hi=点灯, Low=消灯)
- LEDを点滅させ続けるので
while True:で無限ループさせる- LEDを1秒周期で交互に点滅させる
- 解説6に遷移 or プログラムが終了するのを待つ
- Control+Cが押されたらGPIOを解放してプログラムを終了する
プログラムを実行してみる
- プログラムを実行する
- LEDが1秒周期で交互に点滅する

写真を撮るプログラムに組み込んでみる
以前作成した写真を撮るプログラムのcamera_func(x)にLEDの点灯/消灯処理を組み込んでみた。
camera_v2.py#Import Files import RPi.GPIO as GPIO import picamera import time #GPIO Settings GPIO.setmode(GPIO.BCM) GPIO.setup(13, GPIO.OUT) GPIO.setup(19, GPIO.OUT) GPIO.setup(26, GPIO.IN, pull_up_down=GPIO.PUD_UP) #Camera Settings CAM_DIR = "/home/pi/python/_photo/" camera = picamera.PiCamera() #Camera Function def camera_func(x): if GPIO.input(26) == 0: GPIO.output(19, GPIO.HIGH) filename = time.strftime("%Y%m%d%H%M%S") + ".jpeg" save_dir_filename = CAM_DIR + filename camera.capture(save_dir_filename) GPIO.output(19, GPIO.LOW) else: GPIO.output(13, GPIO.HIGH) time.sleep(1) GPIO.output(13, GPIO.LOW) #Interrupt GPIO.add_event_detect(26, GPIO.FALLING, callback=camera_func, bouncetime=200) #Main try: while True: pass except KeyboardInterrupt: GPIO.cleanup()変更前はスイッチを押しても写真を撮れているのかわからなかったが、変更後はスイッチを押した際、正常(写真が撮れている場合)なら緑色、異常(写真が撮れていない場合)なら赤色のLEDが点灯するので、何も無いよりはわかりやすくなった。
参考




- 投稿日:2019-02-09T13:27:14+09:00
Gitlabとpythonでの開発
※Git初心者の備忘録なので悪しからず。
初めてファイルをあげる
.gitigonoreの設置は以下を参照
・あとからまとめて.gitignoreする方法
https://qiita.com/yuuAn/items/b1d1df2e810fd6b92574
・github/gitigonre
https://github.com/github/gitignore/blob/master/Python.gitignore#gitの準備 $ cd existing_folder $ git init //gitリポジトリの作成 $ git remote add origin <GitURL> //リモートリポジトリの指定 #git ignore の設置 $ vim .gitignore #vimが開くので、iキーを押してインサートモードにしたのち、 https://github.com/github/gitignore/blob/master/Python.gitignore をコピーして貼り付け escキーを押してモードを切り替え :wq!キーで保存 #initial commit $ git add . //変更対象のファイル等を指定する $ git commit -m "Initial commit" //変更状態の保存 $ git push -u origin master //リポジトリアップロード #.gitignoreの設置ブランチの作成
$ git checkout -b 作成するブランチ名編集していくとき
・まず、全ブランチを引っ張ってくる
※参考
全ブランチをリモートリポジトリからpullする
https://qiita.com/muraikenta/items/e590a380191971f9c4c3$ for remote in `git branch -r`; do git branch --track ${remote#origin/} $remote; done $ git fetch --all $ git pull --all・編集したいブランチに移動し、devブランチの状態に合わせる。
$ git checkout 作業ブランチ名 $ git merge dev・内容に何らかの変更を加える
#任意の編集作業・変更内容をローカルに保存
#add -Aは変更を全部記録する $ git add -A $ git commit -m commitの名前・変更内容をリモートに保存
$ git push origin 作業ブランチ名・変更内容をdevブランチにも適用する
#被適用ブランチに移動 $ git checkout dev $ git merge 適用ブランチ #リモートに適用 $ git push origin dev・devの変更内容をmasterブランチにもマージする(なるべく開発責任者only)
#devブランチをAWS環境用に編集したうえで $ git checkout master $ git merge dev $ git push origin mastermergeがconflictしたとき
#略