- 投稿日:2019-02-09T19:05:20+09:00
Lambda Function の開発について悩んだところをまとめてみた
はじめに
仕事で Serverless なアプリケーションを実装することがあり、設計や実装にあたって悩んだことをまとめてみました。
同じようなところで悩んでいる人の助けになるかな、と思い。LambdaFunction の大きさについて
1つの大きなLambdaFunctionにする(以後 "Monolith" と表記します)のと、小さなLambdaFunctionをStepFunctionsで組わせて実装する(以後 "MicroFunctions" と表記します)やり方の両極端が考えられます。
"MicroFunctions" で実装するメリット
- 関数の影響範囲を分離しやすい
- 失敗した箇所の特定がしやすい
- 処理に失敗したときに、失敗したところだけが再試行されるので再試行の処理時間が平均的に短縮されることが期待できる
- 1つ1つのコードの処理時間が短くなるので、timeout するリスクが減る
"MicroFunctions" で実装するデメリット
- StepFunctions は処理時間でなく状態遷移の回数で課金されるため、分割を小さくすればするほど、コストパフォーマンスが悪くなる。
- 分割数が増えるほど、コールスタックの解析がしにくくなるので、分散トレースのしくみを検討する必要がある
コードがある程度規模が大きくて複雑な場合は、長期的な保守のしやすさを考えて最初から "MicroFunctions" で設計しておくのがおくのが良いと思います。コードの規模が小さい場合や、とりあえず早く作りたい場合は"Monolith"で実装して、あとから"MicroFunctions"に移行してもいいと思います。
Test 戦略について
まずは、和田卓人さんのスライドに目を通してください。Lambda Function のテストについて、大切な概念がとてもわかり易くまとまっていて、さらに実践的なコードも載っています。
基本的な戦略は以下です:
- 依存性の注入(dependency injection) によって、ローカルでテスト可能な部分を、そうでない部分と分離する。
- ローカルでテスト可能な部分を限りなく増やすことで、開発サイクルを高速化する
- 手作業によるテスト: 30分 => ローカルで実行する自動テスト: 5秒
ローカルでテストができるようになることで、 コードを書いて実行結果を得る、というフィードバックサイクルが劇的に早くなります。テストコードが実装されていることで、リファクタリングががんがんできるメリットもあります。
なお、このスライドの内容をもとにサンプルコードを作ってみましたので、こちらも参考にしてみてください。
共通コードの管理について
実をいうと、上で紹介したテスト戦略を採用すると、Lambda関数自体の中身はほぼすっからかんになるので、自然と独自のライブラリが成長していきます。
いまのところ、独自のライブラリを安全にデプロイする場所としては Lambda Layer一択かな、と思います。
開発ツールは何を使えばいいか?
AWS SAM, Serverless, APEX を検討しました。それぞれの特徴は以下です。
APEX
- 3つの中だと最もシンプルなツール。必要最低限なことだけやってくれる
- Role/Lambda Function の作成
- zip化 & アップロード
- apex 自身は周辺リソースの作成はやってくれない
apex infraという terraform の wrapper コマンドが実装されているが、YAMLでリソース定義ができるほかの2つと比べるとインフラの定義のコストがそこそこ大きい- メインのコミッターが最近ほかのプロジェクトをメインに開発しているせいか、コミュニティの開発スピードが緩やかになっているように感じる。
Serverless
- Lambda関数のデプロイに加えて、周辺リソースの作成もやってくれる
- 企業でコミットしているので割と開発スピードが早い
AWS SAM CLI
- Lambda関数のデプロイに加えて、周辺リソースの作成もやってくれる
- デプロイのフローが3つの中では最も堅牢性が高い
- Lambda Function のビルドを docker container 上で行うオプションがある
- デプロイ用の資材をS3に配置する(package) ことができる
- Amazon 純正のツールなので、AWS側の変更に対するキャッチアップが早いことが期待できる
- Policy Template など、リソース定義を簡単にするための便利な機能がある
ぶっちゃけ好みの問題だと思いますが、これから開発ツールを選択する場合は Serverless か AWS SAM CLI が良いと個人的には思います。
参考
- 投稿日:2019-02-09T18:50:19+09:00
CloudWatch Agentをインストールしてゲスト内メトリクスとログファイルデータを収集する (2台目以降)
CloudWatch Agentを起動済みのEC2インスタンス(Amazon Linux 2)にインストールしてゲスト内メトリクスとログファイル内データを収集します。本メモは2台目以降の設定方法です。
前提条件
- AWS CLIがインストールされており、クレデンシャル/リージョンが設定されている。
- JSONファイル検証用にjsonlintがインストールされている。
- ログインできるEC2インスタンス(Linux) が起動されていること。今回はAmazon Linux 2。
- EC2インスタンスがインターネットまたはVPCエンドポイント経由でCloudWatch、CloudWatch Logs、SSMエンドポイントにアクセスできる。
- CloudWatch Agnentの1台目の構築時に、設定をSSMパラメータストアに保存している。
EC2実行用ロールの作成およびEC2インスタンスへの紐付け
RunCommandでCloudWatch Agentをインストール/構成するための"AmazonEC2RoleforSSM"ポリシーおよびCloudWatchAgentのための"CloudWatchAgentServerPolicy"ポリシーを持つロールを作成します。さらにEC2インスタンスにロールを紐付けるためにインスタンスプロファイルを作成してロールを付与し、インスタンスに紐付けます。
*"CloudWatchAgentAdminPolicy"はCloudWatch Agentのコンフィグを再利用するためSSMパラメータストアに書き込むための権限が含まれるため2台目以降は使用しない。
Assume Role Documentの作成
作業フォルダの作成
コマンドls -d ${HOME}/tmp/ # 存在しない場合 mkdir -p ${HOME}/tmp/変数の設定
コマンド# Assume Role Document ディレクトリ DIR_IAM_ROLE_DOC="${HOME}/tmp" # Role名 IAM_ROLE_NAME='CloudWatchAgentInstanceServerRole' # Principle名 IAM_PRINCIPAL='ec2.amazonaws.com'ファイル名の設定
コマンドFILE_IAM_ROLE_DOC="${DIR_IAM_ROLE_DOC}/${IAM_ROLE_NAME}.json" \ && echo ${FILE_IAM_ROLE_DOC}Output例/Users/xxxxx/tmp/CloudWatchAgentInstanceServerRole.jsonAssume Role Documentの作成
コマンドcat << EOF > ${FILE_IAM_ROLE_DOC} { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "${IAM_PRINCIPAL}" }, "Effect": "Allow", "Sid": "" } ] } EOF cat ${FILE_IAM_ROLE_DOC}Output例{ "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] }jsonlintでjsonファイルが壊れていないかチェックします。問題なければ何も出力されません。
コマンドjsonlint -q ${FILE_IAM_ROLE_DOC}IAMロールの作成
コマンドaws iam create-role \ --role-name ${IAM_ROLE_NAME} \ --assume-role-policy-document file://${FILE_IAM_ROLE_DOC}Output例{ "Role": { "Path": "/", "RoleName": "CloudWatchAgentInstanceServerRole", "RoleId": "AROAJBP27QT6327XBN3VQ", "Arn": "arn:aws:iam::xxxxxxxxxxxx:role/CloudWatchAgentInstanceServerRole", "CreateDate": "2019-02-09T08:53:09Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] } } }IAMポリシーのアタッチ
AmazonEC2RoleforSSM
変数の設定
コマンドIAM_POLICY_NAME="AmazonEC2RoleforSSM" IAM_POLICY_ARN=$( \ aws iam list-policies \ --scope AWS \ --max-items 1000 \ --query "Policies[?PolicyName==\`${IAM_POLICY_NAME}\`].Arn" \ --output text \ ) \ && echo "${IAM_POLICY_ARN}"Output例arn:aws:iam::aws:policy/service-role/AmazonEC2RoleforSSMポリシーをロールへアタッチ
コマンドaws iam attach-role-policy \ --role-name ${IAM_ROLE_NAME} \ --policy-arn ${IAM_POLICY_ARN}Output例出力なしCloudWatchAgentAdminPolicy
変数の設定
コマンドIAM_POLICY_NAME="CloudWatchAgentServerPolicy" IAM_POLICY_ARN=$( \ aws iam list-policies \ --scope AWS \ --max-items 1000 \ --query "Policies[?PolicyName==\`${IAM_POLICY_NAME}\`].Arn" \ --output text \ ) \ && echo "${IAM_POLICY_ARN}"Output例arn:aws:iam::aws:policy/CloudWatchAgentAdminPolicyポリシーをロールへアタッチ
コマンドaws iam attach-role-policy \ --role-name ${IAM_ROLE_NAME} \ --policy-arn ${IAM_POLICY_ARN}Output例出力なしアタッチされたポリシーの確認
コマンドaws iam list-attached-role-policies \ --role-name ${IAM_ROLE_NAME} \ --query "AttachedPolicies[].PolicyName"Output例[ "AmazonEC2RoleforSSM", "CloudWatchAgentServerPolicy" ]インスタンスプロファイルの作成
変数の設定
コマンドIAM_INSTANCE_PROFILE_NAME='CloudWatchAgentInstanceServerProfile'インスタンスプロファイルの作成
コマンドaws iam create-instance-profile \ --instance-profile-name ${IAM_INSTANCE_PROFILE_NAME}Output例{ "InstanceProfile": { "Path": "/", "InstanceProfileName": "CloudWatchAgentInstanceServerProfile", "InstanceProfileId": "AIPAJJIV2ATCBNDDRTQXS", "Arn": "arn:aws:iam::xxxxxxxxxxxx:instance-profile/CloudWatchAgentInstanceServerProfile", "CreateDate": "2019-02-09T08:55:37Z", "Roles": [] }インスタンスプロファイルへのロールのアタッチ
コマンドaws iam add-role-to-instance-profile \ --instance-profile-name ${IAM_INSTANCE_PROFILE_NAME} \ --role-name ${IAM_ROLE_NAME}Output例出力なしEC2インスタンスへのインスタンスプロファイルのアタッチ
変数の設定
INSTANCE_ID="インスタンスプロファイルを紐付けるインスタンスID"インスタンスへのアタッチ
コマンドaws ec2 associate-iam-instance-profile \ --iam-instance-profile "Name=${IAM_INSTANCE_PROFILE_NAME}" \ --instance-id ${INSTANCE_ID}Output例{ "IamInstanceProfileAssociation": { "AssociationId": "iip-assoc-086fefee2bcb2a5ac", "InstanceId": "i-0ae3a2e7317e5e8d0", "IamInstanceProfile": { "Arn": "arn:aws:iam::xxxxxxxxxxxx:instance-profile/CloudWatchAgentInstanceServerProfile", "Id": "AIPAJJIV2ATCBNDDRTQXS" }, "State": "associating" } }確認
コマンドaws ec2 describe-iam-instance-profile-associations \ --query "IamInstanceProfileAssociations[?InstanceId==\`${INSTANCE_ID}\`].State"Output例[ "associated" ]Systems Manager(SSM)からCloudWatch Agentをインストールする
マネージドインスタンスの登録確認
マネージドインスタンスとして登録されているかを確認します。今回はAmazon Linux 2を使用しているため初めからSSMエージェントがインストールされており、マネージドインスタンスとして認識されます。インストールされないOSの場合やバージョンが古い場合は別途インストール/アップデートが必要です。
コマンドaws ssm describe-instance-information \ --query "InstanceInformationList[?InstanceId==\`${INSTANCE_ID}\`]"Output例[ { "InstanceId": "i-0ae3a2e7317e5e8d0", "PingStatus": "Online", "LastPingDateTime": 1549703111.672, "AgentVersion": "2.3.372.0", "IsLatestVersion": false, "PlatformType": "Linux", "PlatformName": "Amazon Linux", "PlatformVersion": "2", "ResourceType": "EC2Instance", "IPAddress": "172.31.30.106", "ComputerName": "ip-172-31-30-106.ap-northeast-1.compute.internal" } ]CloudWatch Agentのインストール
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_COMMAND_DOCUMENT_NAME="AWS-ConfigureAWSPackage" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="action=Install, name=AmazonCloudWatchAgent, version=latest"Run CommandでCloudWatch Agentをインストール
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "3c303421-1328-4613-9602-d041533b24b1", "DocumentName": "AWS-ConfigureAWSPackage", (...省略...) "RequestedDateTime": 1549185898.031, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
コマンドSSM_COMMAND_ID="3c303421-1328-4613-9602-d041533b24b1" #上記の結果からコピー aws ssm list-command-invocations \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query "CommandInvocations[].Status" \ --output textOutput例SuccessCloudWatch Agentの設定
collectdのインストール
このままCloudWatch Agentを起動するとcollectdがないと怒られるので、collectdをSSM RunCommandの"AWS-RunShellScript"ドキュメントを使用していインストールします。
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_COMMAND_DOCUMENT_NAME="AWS-RunShellScript" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="commands=sudo amazon-linux-extras install -y epel && sudo yum -y install collectd"RunCommandでcollectdをインストール
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "da0bb8b3-9c9a-466f-a7e2-f4543ef11c49", "DocumentName": "AWS-RunShellScript", (...省略...) "RequestedDateTime": 1549185898.031, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
コマンドSSM_COMMAND_ID="da0bb8b3-9c9a-466f-a7e2-f4543ef11c49" #上記の結果からコピー aws ssm list-command-invocations \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query "CommandInvocations[].Status" \ --output textOutput例SuccessCloudWatch Agentの構成、起動
SSM経由でCloudWatch Agentを構成、起動します。1台目を構築した際に設定がSSMパラメータストアに"AmazonCloudWatch-linux"というキーで保存されているためそちらを利用できます。
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_CONFIG_PARAMETER_NAME="AmazonCloudWatch-linux" SSM_COMMAND_DOCUMENT_NAME="AmazonCloudWatch-ManageAgent" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="action=configure, mode=ec2, optionalConfigurationSource=ssm, optionalConfigurationLocation=${SSM_CONFIG_PARAMETER_NAME}, optionalRestart=yes"Run CommandでCloudWatch Agentを起動
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "813175eb-8e52-4ffb-a833-d258eb3e7064", "DocumentName": "AmazonCloudWatch-ManageAgent", (...省略...) "RequestedDateTime": 1549190668.591, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
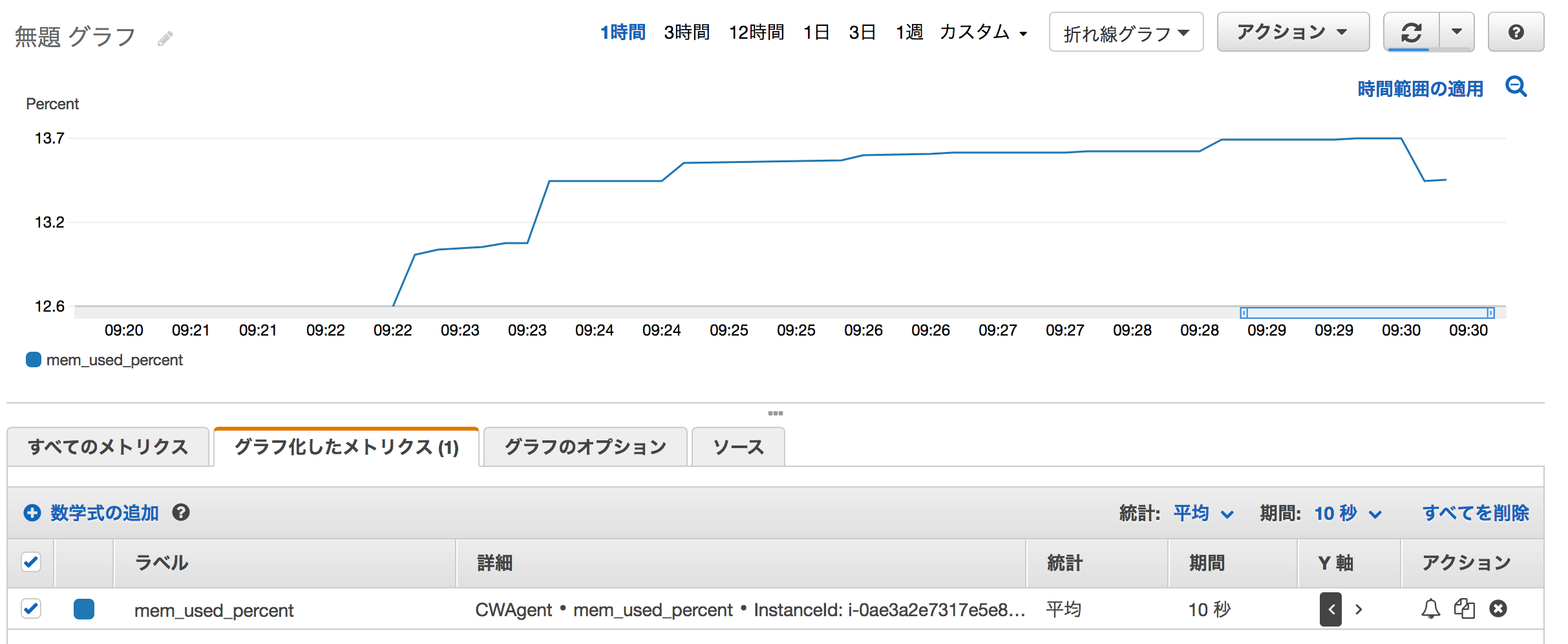
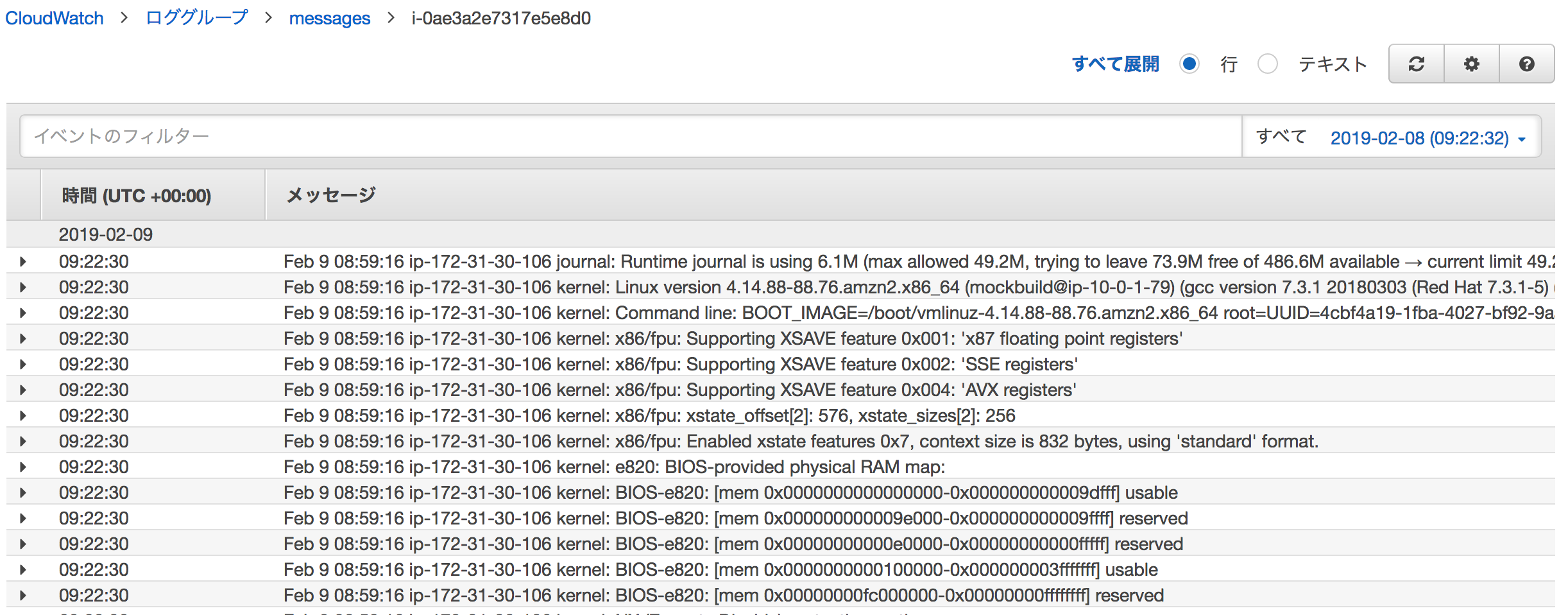
コマンドSSM_COMMAND_ID="813175eb-8e52-4ffb-a833-d258eb3e7064" #上記の結果からコピー aws ssm list-command-invocations \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query "CommandInvocations[].Status" \ --output textOutput例Success取得されたメトリクス/ログの確認
メトリクス
CloudWatchにカスタムメトリクスのmem_used_percentが取得されています。
ログ
CloudWatch Logsに/var/log/messagesのログが取得されています。
まとめ
今回はすでに起動済みのEC2インスタンスに対してCloudWatch Agentをインストールしましたが、EC2インスタンス起動時にインストールするにはUserDataを利用するのが良いでしょう。
参考: 新しいCloudWatch Agentを有効化したEC2オートスケール環境をCloudFormationで設定してみたAMIに仕込む場合はログストリーム名がAMIを作成したインスタンスIDとなってしまうため起動時に再構成が必要後なるようです。
参考:CloudWatch Agent 仕込み済み AMI からEC2インスタンスを作成するときの注意参考
AWS CLIの書き方はJAWS-UG CLI専門支部の過去資料が大変参考になります。
https://jawsug-cli.doorkeeper.jp/
- 投稿日:2019-02-09T18:32:13+09:00
CloudFormation"Value of property SourceArn must be of type String"の解決方法
AWS LambdaFunctionPermissionの設定で、以下のようなエラーが発生した。
Value of property SourceArn must be of type String
このとき、原因となった部分は以下の通り。problem.ymlLambdaPermission: Type: AWS::Lambda::Permission Properties: FunctionName: !GetAtt MyLambda.Arn Action: lambda:InvokeFunction Principal: s3.amazonaws.com SourceArn: - !Join - '' - - 'arn:aws:s3:::' - !Sub ${BucketPrefix}原因と対策
- !Joinは、!Join以下がリスト型であることを示している。つまり、このymlは以下のように認識されている。SourceArn.json{ ...., "Properties":{ "SourceArn":['arn:aws:s3:::{BucketPrefix}'] }, .... }しかし、この項目に入力すべきはStringであり、Listではない。これがエラーの原因だったようだ。
したがって、以下のように直した。
fixed.ymlDataDeliverAndConvertPermission: Type: AWS::Lambda::Permission Properties: FunctionName: !GetAtt MyLambda.Arn Action: lambda:InvokeFunction Principal: s3.amazonaws.com SourceArn: !Join - '' - - 'arn:aws:s3:::' - !Sub ${BucketPrefix}これで通った。
参考
- 投稿日:2019-02-09T16:25:01+09:00
DynamoDBのテーブル作成について
本エントリでは作成したアプリからAWSにアップロードしたデータを管理しているDynamoDBについて記述します。
筆者はこれまでRDBしか触ったことがなく、NOSQLについても不勉強から全く無知でした。今回敢えて知らないNOSQLにトライしてみました。
先のエントリでもちょくちょく触れていて改めて記載することはそれほど多くはないのですが、DynamoDBを利用する場合はコンソールからの設定は本当に限られていて、データの追加と参照しかしないのなら何とか。でもアップデートも伴うとなるとその時点でコマンドラインに頼るしかなくなるなと思いました。確かにRDBでもGUIからの設定は限られていて細かい所はDDLでやるしかないというのと同じといえば同じですが。今回のアプリを作成するにあたってもイイネ機能の実現のためにupdateを行うことが必要でした。ですので、最初はコンソールからテーブルを作っていましたが最終的にコマンドでテーブルを作成するようになりました。
以下が今回テーブルを作る際に使用したコマンドです(確かこれのはずです、曖昧ですいません)。aws dynamodb create-table --table-name XXXXXXX --attribute-definitions '[{"AttributeName": "datetimestr", "AttributeType": "S"}]' --key-schema '[{"AttributeName": "datetimestr", "KeyType": "HASH"}]' --provisioned-throughput '{"ReadCapacityUnits": 5, "WriteCapacityUnits": 5}'
一番肝要なのは--key-schemaのところで、このKeyTypeを指定するにはコマンドラインしか今は方法が無いようです。そしてこのHASHキーがないと抽出が厄介らしくて。。。DynamoDBの操作については基本的にコマンドで行うと認識して置いた方が良さそうです。
以上で今回行ったDynamoDBへの設定の説明を閉じさせて頂きたいと思います。
- 投稿日:2019-02-09T16:09:41+09:00
あっさり味なAPI Gatewayの設定について。
本エントリでは先に作成した三つのLambda関数を公開するためのAPI Gatewayの設定ついて記載します。
API Gatewayの設定については最初かなり色々試行錯誤しましたが実は割とあっさりと済ませようと思えば済ませられるのだと今は感じています。
それはこの投稿に書いたように基本的にJSONでやり取りすることにすれば湾パターンな設定でクリアできると思います(逆に言うとそれではこまるケースってそんなに無いかと)。
その設定について記載します。
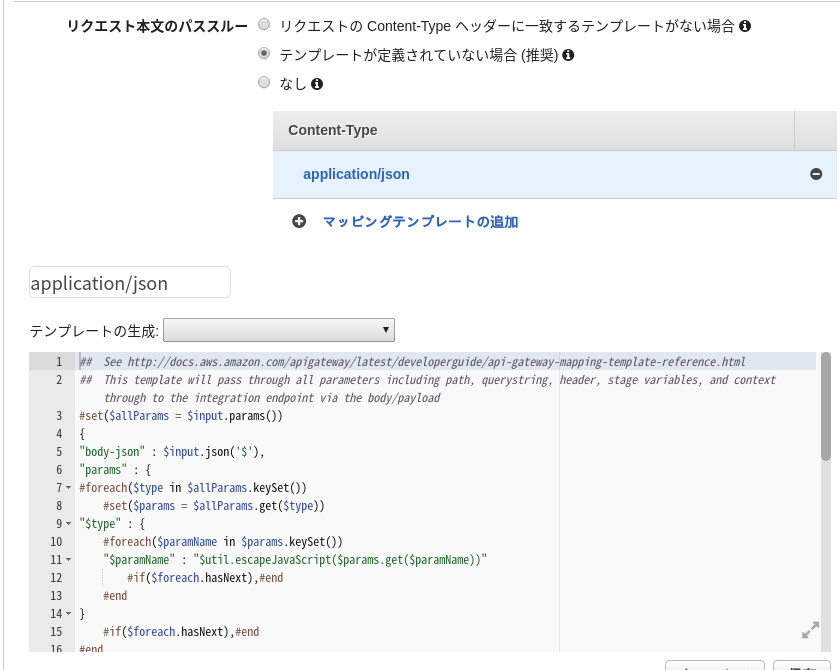
身も蓋もないですが、以下のようで良いかと。
これは統合リクエストのマッピングテンプレートの画面です。
基本的にJSONでやり取りを行うのであれば
Content-Typeは必然的にapplication/jsonになります。次にテンプレートですが自分で作成したり色々試しましたが結局テンプレートにある「メソッドリクエストのパススルー」がシンプルで良いと思います。この設定でLambdaの方でキー名を指定して自在にアプリからの送信内容受け取れましたので。以上でAPI Gatewayついての篇を閉じます。
…もちろん、本当にアプリを広く公開しようとすればAPI-KEYなどの設定が要りますが、今回のは試作品なので。。。また機会があったらセキュリティをしっかり考慮したケースについても取り組んでみたいです。
- 投稿日:2019-02-09T15:26:09+09:00
AWS Lambda関数(画像アップロード、S3へのファイル配置、DynamoDB更新など)
本エントリでは作成したアプリで使用するAPIの機能を実現するLambda関数について記載します。
目的のアプリには主に3つ
画像の取得とS3への配置(画像データの取得とファイル作成)
アップロードされたデータの参照(一覧用データの出力)
目的のデータの更新(イイネ機能)以上の三つを実現するためにそれぞれの目的用に三つのLambda関数を作成しました。順に紹介していきます。
画像の取得とS3への配置(画像データの取得とファイル作成)import json import boto3 import base64 from datetime import datetime from boto3.dynamodb.conditions import Key, Attr s3 = boto3.resource('s3') # ③S3オブジェクトを取得 def lambda_handler(event, context): print('START LOG') print(json.dumps(event['body-json'])) try: s3 = boto3.resource('s3') bucket = s3.Bucket('XXXX-XXXX') dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('XXXXXXXX') imageBody = base64.b64decode(event['body-json']['base64']) TextBody = event['body-json']['Text'] TextTime = datetime.now().strftime('%Y-%m-%d-%H-%M-%S') key = 'test_' + TextTime + '.jpg' bucket.put_object( Body = imageBody, Key = key ) table.put_item( Item={ 'datetimestr': TextTime, 'PictureFile': key, 'LikeNum':0, 'Comment':TextBody } ) print('success!') except Exception as e: print('Error!') print(e) # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda! ') }最初にここではファイル配置というS3へのアクセスと画像データの登録というDynamoDBへのアクセスを行います。S3へのアクセスはpythonでLambda関数を作るには必須の
import base64
だけで可能ですが、DynamoDBを使う場合は加えて
from boto3.dynamodb.conditions import Key, Attr
を読み込んでおいて下さい。またロールに
AmazonDynamoDBFullAccess
というポリシーを加えておいて下さい。アプリ側からの送信データとeventのキーが
event['body-json']['base64']
というように一致しているかとおもいます。この辺最初僕も割と悩みましたが別記事に記載するAPI Gatewayの設定を素直にしてやるとシンプルに送られてきたデータを取得することが出来ます。ここでは画像データ(base64)と入力されたコメント(Text)を取得しています。
ファイル名とデータを管理するDynamoDBに作成するテーブルのパーティションキーとなる文字列は時間を元に作成するので先にその時点の時刻で文字列を組み立ててファイル名とパーティションキーに挿入する変数に使用しています。
まず画像データをS3に配置するのはものすごくシンプルでbase64をデコードしてバイナリに戻しファイル名(key)をセットしてput_objectを実行するだけです。バケットのどこか別のフォルダ(という言い方は正確ではないでしょうが)に配置したい時はこのファイル名の頭にパスを指定するようです。
次のDynamoDBへの登録については挿入についてはすごくシンプルでこれも一関数のみで完了します。尚、別の記事にも記載しますがDynamoDB(NOSQL系全般そうなのでしょうか?)テーブル設計時はキー項目しか設定しないので(ここではdatetimestrのみ)謂わばこの挿入のタイミングでテーブルの構造が決まるとも言えます。以上がまず画像の取得とS3への配置用のLambda関数でした。
アップロードされたデータの参照(一覧用データの出力)
import json import boto3 from datetime import datetime from boto3.dynamodb.conditions import Key, Attr s3 = boto3.resource('s3') # ③S3オブジェクトを取得 # ------------------------- DECIMAL FORMAT ------------------------------ def lambda_handler(event, context): # TODO implement dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('XXXXXX') res = table.scan() bodydic = [] picurl = 'https://s3-XXXXXXX.amazonaws.com/XXXX-XXXX/' + i['PictureFile'] for i in res['Items']: dic = {'datetimestr':i['datetimestr'],'PictureFile':picurl,'LikeNum':i['LikeNum'],'Comment':i['Comment']} bodydic.append(dic) return { 'isBase64Encoded': False, 'statusCode': 200, 'headers': {}, 'body':bodydic }非常にシンプルです。
res = table.scan()
はテーブルの全件取得です。それほど件数が来ることを想定していないので特に絞り込みをかけていません。
DynamoDBの返却値は'Items'とし格納されているようです。
取得したデータを後にJSONとして出力できるようにキーと値の形で辞書型に格納していっています。後の簡単のためにS3へ画像を参照するURLをここで組み立てています。
出来上がった辞書をbodyに入れてそのまま出力しています。目的のデータの更新(イイネ機能)
import json import boto3 from boto3.dynamodb.conditions import Key, Attr def lambda_handler(event, context): # TODO implement dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('FirstPicAndItem') print(json.dumps(event)) response = table.query(KeyConditionExpression=Key('datetimestr').eq(event['body-json']['datetimestr'])) print(response) for i in response['Items']: likenum = i['LikeNum'] likenum+=1 print('likenum:'+str(likenum)) response = table.update_item( Key= { 'datetimestr': event['body-json']['datetimestr'] }, UpdateExpression="ADD #name :increment", ExpressionAttributeNames={ '#name':'LikeNum' }, ExpressionAttributeValues={ ":increment": 1 }, ReturnValues="UPDATED_NEW" ) return { 'statusCode': 200, 'body': json.dumps('Increment Success!!') }まず本Lambda関数はイイネ数をインクリメントする為のものです。
event['body-json']['datetimestr']
でアプリから渡されたイイネ数をインクリメントする対象のdatetimestrを取得。
次にその値でテーブルに参照に行きます。テーブルのdatetimestrはハッシュキーにしているのでqueryで絞り込めます。
queryの結果として返却された値response['Items']はdatetimestrがユニークな値なので一件しか無いはずです。一件しかないはずですがfor in で取り出すのが流儀のようなので回します。ここでは'LikeNum'の値が必要なので取得します。
次にこのLikeNumの値をインクリメントし結果をDynamoDBに反映します。DynamoDBの更新は(RDBの感覚で言うと)更新対象のレコードを指定するのにかなり制約がありハッシュキーかパーティションキーとソートキーとの複合条件で行うようです(逆に言うとこういう制約を考慮するのがテーブル設計の勘所のようです)。ここではdatetimestrをハッシュキーとしているのでdatetimestrのみで更新をかけます。
ここで困ったのはUpdateExpressionのADDでこれは数値型にしか使えません。SETなら文字型でも使えるようですが…割と手こずったところでした。以上で作成した三つのLambda関数の説明を閉じさせて頂きたいと思います。
- 投稿日:2019-02-09T14:48:46+09:00
Laravel Forgeを使ってAWSのサーバー構築を15分で終わらせる
業務でAWSに本番サーバーを立てる必要があり、サクッと環境構築+デプロイできる都合の良いツールはないかなぁと探していたら、ありました。
ありましたと言っても、公式で紹介されているんですけどねw(※有料です)Forgeによるデプロイ
https://readouble.com/laravel/5.7/ja/deployment.html環境構築に時間をかけるのはやめよう!
AWSでのサーバー構築に慣れていない場合、VPC作成〜EC2インスタンス作成〜必要なモジュールのインストール、等々で1時間以上かかってしまうこともあります。ところが、Forgeだと最低限の設定であれば15分程度で済ませることができてしまうんですよね。インフラ初心者でもAWSのややこしいコンソールはほとんど見る必要がなくなります。(とはいえ、業務レベルになるとAWSの知識や設定方法の理解は必要になりますが。。)
設定手順
AWSのアカウントを取得していることを前提で話を進めます。
事前準備
IAMの設定
AWSのIAMから「ユーザーを追加」から、「AmazonEC2FullAccess」にチェック✓を入れ、IAMユーザーを作成します。
アクセスキーIDとシークレットアクセスキーは、Forgeで使います!
Forgeの設定
サインアップ
https://forge.laravel.com/
必要な項目を記入し、登録します。
APIキーの登録
Forgeにログインすると、画面の下の方にサービスを選択する箇所があるので、AWSを選択します。先程確認したIAMのアクセスキーIDとシークレットアクセスキーを入力し、Connectをクリックしましょう。
画面上部にGreat! Now let's connect to a source control and server provider so we can create servers!と表示されれば成功です!
(うまくいかない場合は、IAMの設定もしくはキーの入力間違いがないかを確認してみてください)
Service Providersの登録
Forgeの右上のメニューから、MyAccountを選択し管理画面へ移動します。
Service ProviderからAmazonを選択し、Profile NameとIAMのアクセスキーIDとシークレットアクセスキーを入力しましょう。
(Profile Nameは自分が分かれば何でも構いません。後からでも変更は可能です!)
EC2インスタンスの作成
さて、Forgeの初期設定が終わったら、いよいよサーバーを立てていきます!
Forge画面トップのCreate ServerからAWSを選択しましょう。
(Connectが完了しているのにCreate Serverが表示されない場合は、画面上部にお知らせが表示されていると思うので「Skip For Now」を選択)Credentials: Server Providersで登録したProfile Name
Name: サーバー名(EC2のインスタンス名)
Region: リージョンを選択(分からなければTokyoを選択)
Server Size: お財布と相談してください。
VPC: 新規に作成する場合は、Create New。既存のVPCに作成したい場合は、それを選択してください。
(VPC作成済なのに表示されない場合は、Regionが間違っている可能性があります)
VPC Name: 作成するVPC名(既存のVPCに作成する場合は、サブネットが選択できるようになります)
PHP Version: インストールするPHPのバージョン
Post-Provision Recipe: インストール後に起動するスクリプト(今回は作成していません)
Database: 作成するデータベース(作成しない場合はNoneを選択)
Database Name: データベース名
Provision As Load Balancer: ロードバランサーとして作成する場合はチェック✓。今回はしない。入力できたら、Create Serverをクリックします。
すると、インスタンスが作成されPHPやNginx等Laravelに必要なものがサーバーにインストールされます。
インスタンスの作成には10分程かかるので、のんびり待ちましょう!
インスタンスの作成が完了したら、サーバーのSudoパスワードとデータベースのパスワードが記載されたメールが届きます。
構築完了!
Connectionの矢印をクリックし、接続できていればSuccessfulが表示されます。
デプロイ
今回は、Githubを使います。
上部メニューのSitesからdefaultをクリックすると、Git Repositoryが選択できます。
リポジトリのインストール
記載されているサーバーの公開鍵を、Githubの指定のリポジトリに設定します。
リポジトリのアドレスとブランチを設定すれば、Install Repositoryをクリックし、インストールが終わるのを待ちましょう!
デプロイする
インストールが完了すれば、右上のDeploy Nowをクリックするのみです!
以上で最低限の設定は完了です!
これでアプリケーションの開発に集中できますね!参考
php開発環境の管理に超便利なLaravel Forgeの始め方 (上)
https://qiita.com/MasaGon/items/ab75001477192ecd51b5
Laracasts - EPISODE 3 Your First Project
https://laracasts.com/series/learn-laravel-forge/episodes/3










- 投稿日:2019-02-09T14:30:32+09:00
AWSのS3をファイル置き場として利用する
AWSのS3は画像ファイル置き場として利用しています。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AddPerm", "Effect": "Allow", "Principal": "*", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": "arn:aws:s3:::XXXX-XXX/*" } ] }S3はもちろん設定をすればかなりの程度高度な設定が出来るのでしょうが差し当って今回は画像ファイルを配置し、また外から参照できるようになればすればよいのでシンプルです。
ポイントはActionのところで
"s3:GetObject"
が取得の許可。
"s3:PutObject"
はLambda関数からですが書き込みの許可です。
あとそんなことするのは僕ぐらいかもしれませんが、Versionは日付けではなくそのままに「バージョン」なので変更しないように。僕はそれでまた時間食ってしまいました。
S3の設定については画面からも出来そうですがネットに情報が豊富にあるのでパケットポリシーのJSONで設定した方が良さそうですね。以上でAWSのS3についての篇を閉じます。
- 投稿日:2019-02-09T13:53:58+09:00
React Nativeでのカメラ機能と画像のアップロードについて
本エントリでは作成したアプリで使用したいくつかのテクニックの一つのカメラ機能について記載します。
React Native(以下 RN と記載)でカメラを使う場合幾つか方法があるようですが筆者はreact-native-cameraを使用しました。
react-native-cameraは本家サイトを見るとバーコードを読めたり動画とれたり顔認識なども出来るようですが本アプリではそこまで必要なかったのでシンプルにカメラ機能のみを使用しました。
以下カメラ機能を実装しているコンポーネントのソースですHomeCamera.js
import React, {Component} from 'react'; import {Platform, StyleSheet, Text, TouchableOpacity, View} from 'react-native'; import { NavigationActions } from "react-navigation"; import {RNCamera} from 'react-native-camera' const PendingView = () => ( <View style={{ flex: 1, backgroundColor: 'lightgreen', justifyContent: 'center', alignItems: 'center', }} > <Text>Waiting</Text> </View> ); export default class HomeCamera extends Component<Props> { //コンストラクタ constructor(props){ super(props); //必ず呼ぶ this.state = { url: null } } render() { let { url } = this.state; // ...(4) return ( <View style={styles.container}> <RNCamera style={styles.preview} type={RNCamera.Constants.Type.back} captureAudio={false} flashMode={RNCamera.Constants.FlashMode.on} permissionDialogTitle={'Permission to use camera'} permissionDialogMessage={'We need your permission to use your camera phone'} > {({ camera, status }) => { if (status !== 'READY') return <PendingView />; return ( <View style={{ flex: 0, flexDirection: 'row', justifyContent: 'center' }}> <TouchableOpacity onPress={() => this.takePicture(camera)} style={styles.capture}> <Text style={{ fontSize: 14 }}> SNAP </Text> </TouchableOpacity> </View> ); }} </RNCamera> </View> ); } takePicture = async function(camera) { const options = { quality: 0.5, base64: true ,fixOrientation:true}; const data = await camera.takePictureAsync(options); // eslint-disable-next-linse this.props.navigation.navigate("Conf",{url:data.uri,base64:data.base64}); }; } const styles = StyleSheet.create({ container: { flex: 1, flexDirection: 'column', backgroundColor: 'aliceblue', }, preview: { flex: 1, justifyContent: 'flex-end', alignItems: 'center', }, capture: { flex: 0, backgroundColor: '#fff', borderRadius: 5, padding: 15, paddingHorizontal: 20, alignSelf: 'center', margin: 20, }, });ほぼサンプルのままですがポイントはオプションです。
const options = { quality: 0.5, base64: true ,fixOrientation:true};base64形式にしたのは、後々AWSに写真をアップロードしたいのでbase64形式で受け取った方が便利だからです。変換する必要なく機能として備わっているのはとても助かりました。
それとfixOrientationを設定したのはオプション無しだと撮影した写真が傾いていたためです。本オプションを設定することで問題が解消されました。ただ公式によると本機能はAndroidでしか効かないということでiOSへ対応するなどということになったら他のライブラリを使用することになりそうです。
またcaptureAudioがデフォルトではONになっているようで何もしないと画面にWARNINGが出てきました。ですのでfalseにしています。
撮影したのちに画像を表示また投稿する画面に遷移するためthis.props.navigation.navigate("Conf",{url:data.uri,base64:data.base64});としています。この遷移の際に次のコンポーネントに引数として渡すことができます。
ではカメラで撮影した後に遷移される写真を表示、またAWSに転送するコンポーネントに移ります。以下ソースです。
HomeConf.js
import React, {Component} from 'react'; import {Platform, StyleSheet, Text,View,TouchableOpacity,Image, TextInput} from 'react-native'; import { NavigationActions } from "react-navigation"; import axios from 'axios'; export default class HomeConf extends Component<Props> { //コンストラクタ constructor(props){ super(props); //必ず呼ぶ this.state = { path: null, inputValue: "You can change me!" } } onPressPostBtn(path) { var fileSelect = path; //console.log('path:' + fileSelect); axios.post('https://XXXXXXX.execute-api.XXXXXXXX.amazonaws.com/dev/image_upload',{base64:fileSelect,Text:this.state.inputValue},{ headers: {Accept: 'application/json','Content-Type': 'application/json'}}) .then((response) => { console.log(response) }) .catch((err) => { console.log(err) }); } _onChangeText = (text) => { this.setState({ inputValue:text }); } render() { const { navigation } = this.props; const purl = navigation.getParam('url', 'NO-URL'); const pbase64 = navigation.getParam('base64', 'NO-BASE64'); const path = JSON.stringify(purl); const base64 = JSON.stringify(pbase64); return ( <View style={styles.container}> {base64 && <Image source={{uri: 'data:image/jpeg;base64,' + base64}} style={{ width: 250, height: 250,margin: 20}} />} <TextInput style={styles.input} onChangeText={this._onChangeText} underlineColorAndroid='transparent'/> <TouchableOpacity onPress={() => this.onPressPostBtn(base64)} style={styles.capture}> <Text style={{ fontSize: 14 }}> POST</Text> </TouchableOpacity> <TouchableOpacity onPress={() => this.props.navigation.navigate("Home")} style={styles.capture}> <Text style={{ fontSize: 14 }}> Home</Text> </TouchableOpacity> </View> ) } } const styles = StyleSheet.create({ container: { flex: 1, flexDirection: 'column', backgroundColor: 'aliceblue', alignItems: 'center' }, input: { height: 40, width: 230, borderBottomWidth: 1, borderBottomColor: '#008080', margin: 7 }, capture: { flex: 0, borderRadius: 5, padding: 15, backgroundColor: '#fff', paddingHorizontal: 20, alignSelf: 'center', margin: 20, } });撮影した後に遷移される際に引数として渡された画像のuriと画像そのもののBase64データと描画の前に
const purl = navigation.getParam('url', 'NO-URL'); const pbase64 = navigation.getParam('base64', 'NO-BASE64'); const path = JSON.stringify(purl); const base64 = JSON.stringify(pbase64);として取り出しています。取り出したデータはbase64の方はImageにそのまま入れています(uriはテストようだったので現段階のソースに記載はありません)。
画像の下にテキストボックスを配置しコメントを入力してもらって、POSTをタップするとコメントと画像が転送する機能を提供しています。実現する為にイベントハンドラに引数としてBase64データを渡しています。テキストはstateに持っています。※※※※※※※※※※※※※※※※※※※※※※※※※
ここで個人的にハマったので記載します。
当初このイベントハンドラは
と記載していました。
<TouchableOpacity onPress={this.props.navigation.navigate("Home")} style={styles.capture}>
上記の書き方だとTextInputに値が入力されている間onChangeTextでstateが更新され続けるので再描画され、その度にTouchableOpacityのonPressが発火して、結果何度も画像が転送されるという事象に悩まされました。調べた結果現在のように書くと良いという記事を見つけて助けてもらいました。実は恥ずかしながらこの引数なしの関数でreturnするという理屈が未だにきちんと理解できていないのですが。。。
※※※※※※※※※※※※※※※※※※※※※※※※※転送はaxiosを使っています。当初上手くいかずFetch APIなどで実現していたこともあったのですが、axiosで実現できたので本アプリの通信回りをaxiosで統一出来ました。
別のエントリでも記載しますが、最初AWSのAPI Gatewayでバイナリがサポートされたとのことでそちらを使おうと思ったのですが僕には上手くいきませんでした。調べたところBase64で転送する発想を見つけて試していました。最初はテキストデータなのでtext/plainで試行錯誤していたのですがこれも上手くいかず。更に調査をするとどうやらtext/plainだとAWSの方で何やら加工するらしく。。。なのでJSONで転送すると良いという記載を見つけて試しました。最初は難航しましたがその理由はAPI Gatewayと転送の際に付与しているheaderの整合性でした。
非常に困りましたが、結論として特段事情がない限りは転送は全てJSONで行うのが良さそうです。以上でカメラ機能とバイナリ転送についての篇を閉じます。
- 投稿日:2019-02-09T12:21:20+09:00
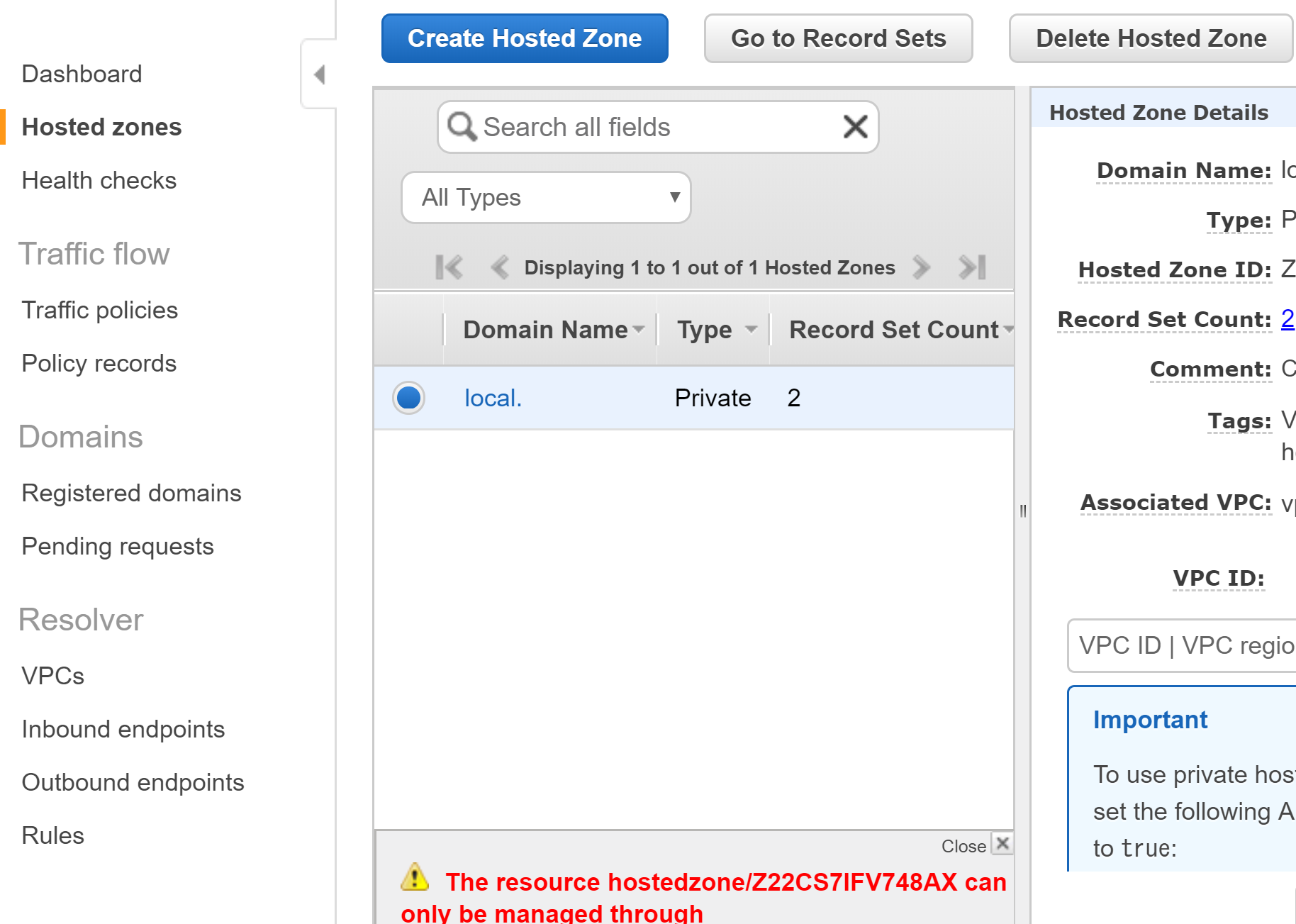
AWS Route53のホステッドゾーンが削除できない
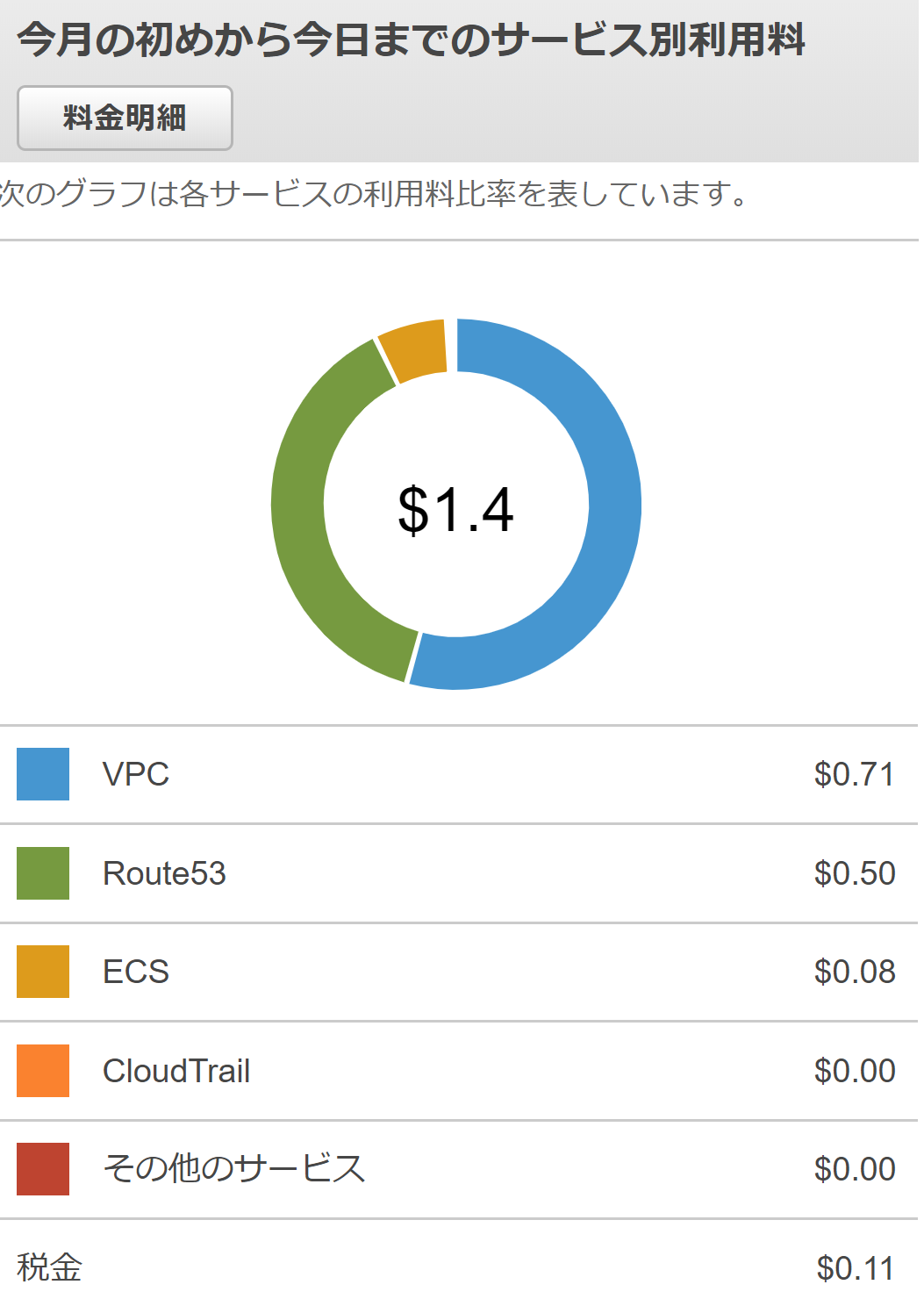
今月の利用料金を見てみると、Route53に$0.5の請求が。。
あれ、何か使ったっけと思いながらコンソールから削除しようとするとエラーでできない。。
ネットを色々調べた結果、ECSのサービスがRoute53を使っているのではという情報を見ました。
コンソールを確認
⇒サービスなし
CLIで確認
⇒サービスあり!
なぜ、コンソールで見れないと思いながら、
サービスを削除しホステッドゾーンも削除しました。これにより解決。
コマンド'サービスの確認 aws servicediscovery list-services 'サービスの削除 aws servicediscovery delete-service --id=srv-xxxxxxxxxxxxxxxx ・ネームスペースの確認 aws servicediscovery list-namespaces ・ネームスペースの削除 aws servicediscovery delete-namespace --id=ns-xxxxxxxxxxxxxxxx

- 投稿日:2019-02-09T11:56:21+09:00
amply でチームで開発するときは amplify cli の multienv を使おう
はじめに
amplify で作ったリソースを Git 管理するさい、何をコミットして何をコミットしないかで困ったことはありませんか?
そんなときは amplify-cli の beta版 である multienv [1] を試してみましょう。
[!] 注意: 公式ドキュメント [1] にもあるとおり、 multienv版をインストールすると、もともとあった amplicy-cli が multienv 版に置き換わります 。既存のプロジェクトに意図しない影響を与える可能性があるので、すでに amplify-cli で環境構築してある場合は注意してください(グローバルでなく、まずはローカルにインストールしてみて試してみるなど)。
amplify-cli multienv を使うメリット
- デプロイ環境の分離
- amplify init 時にコミットしなくて良い資材を .gitignore に自動追加してくれる
私の場合はとりあえず 2番目の目的のためにインストールしました(何を gitignore に追加するべきなのかについて、公式ドキュメントに記載が見つけられなかったので。。こちらの github issue でも multienv を使うようにガイドされています。)。デプロイ環境の分離もできるようなので、これからリソースを作ろうとしている人は multienv 版を試してみることをおすすめします。
インストール
@aws-amplify/cliでなく@aws-amplify/cli@multienvをインストールします。npm install -g @aws-amplify/cli@multienvサンプルプロジェクトの作成
mkdir amplify-multienv-example cd amplify-multienv-exampleamplify init普通の amplify-cli と同様、対話的に設定の入力を求められます。
multienv を使った場合の違いとして environment について聞かれます。
ここでは開発環境としてdevを指定します。? Enter a name for the environment devすべての質問を入力し終えると、
.gitignoreが自動的に作成され、コミットする必要のない資材のパスが追加されています。.gitignore#amplify amplify/\#current-cloud-backend amplify/.config/local-* amplify/backend/amplify-meta.json aws-exports.js awsconfiguration.json参考
- 投稿日:2019-02-09T11:56:21+09:00
amply でチームで開発するときは amplify cli の multienv 版を使おう
はじめに
amplify で作ったリソースを Git 管理するさい、何をコミットして何をコミットしないかで悩んだことはありませんか? また、チームの他のメンバーがコミットしたリソースを自分の環境にチェックアウトしたとき、デプロイができなくなった経験はないでしょうか?
そんなときは amplify-cli の beta版 である multienv [1] を試してみましょう。amplify-cli multienv を使うメリット
- デプロイ環境の分離
- amplify init 時にコミットしなくて良い資材を .gitignore に自動追加してくれる
私の場合はとりあえず 2番目の目的のためにインストールしました(何を gitignore に追加するべきなのかについて、公式ドキュメントに記載が見つけられなかったので。。こちらの github issue でも multienv を使うようにガイドされています。)。デプロイ環境の分離もできるようなので、これからリソースを作ろうとしている人は multienv 版を試してみることをおすすめします。
インストール
@aws-amplify/cliでなく@aws-amplify/cli@multienvをインストールします(注1)。npm install -g @aws-amplify/cli@multienv
[!] 注1: 公式ドキュメント [1] にもあるとおり、 multienv版をインストールすると、もともとあった amplicy-cli が multienv 版に置き換わります 。既存のプロジェクトに意図しない影響を与える可能性があるので、すでに amplify-cli で環境構築してある場合は注意してください(グローバルでなく、まずはローカルにインストールしてみて試してみるなど)。
サンプルプロジェクトの作成
mkdir amplify-multienv-example cd amplify-multienv-exampleamplify init普通の amplify-cli と同様、対話的に設定の入力を求められます。
multienv を使った場合の違いとして environment について聞かれます。
ここでは開発環境としてdevを指定します。? Enter a name for the environment devすべての質問を入力し終えると、
.gitignoreが自動的に作成され、コミットする必要のない資材のパスが追加されています。.gitignore#amplify amplify/\#current-cloud-backend amplify/.config/local-* amplify/backend/amplify-meta.json aws-exports.js awsconfiguration.jsonmultienv で amplify init したときのもう一つ違いとして、
team-provider-info.jsonというファイルがamplifyフォルダに作られていることがわかります。amplify/team-provider-info.json{ "dev": { "awscloudformation": { "AuthRoleName": "amplifymultienvexamp-20190209112419-authRole", "UnauthRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/amplifymultienvexamp-20190209112419-unauthRole", "AuthRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/amplifymultienvexamp-20190209112419-authRole", "Region": "ap-northeast-1", "DeploymentBucketName": "amplifymultienvexamp-20190209112419-deployment", "UnauthRoleName": "amplifymultienvexamp-20190209112419-unauthRole", "StackName": "amplifymultienvexamp-20190209112419", "StackId": "arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/amplifymultienvexamp-20190209112419/ce6b1060-2c11-11e9-ade2-0a29b069fc22" } } }amplify リソースを作成したときの Cloudformation stack の情報が記載されていることがわかります。このファイルをメンバーとシェアすることで、同じ CloudFormation Stack に対して push/pull することができるようになります。
注意: AWSアカウントIDなどが記載されているので、リポジトリを Public に公開する場合は上記のファイルはコミットしないようにしましょう。
終わりに
これで、複数のメンバーで amplify のプロジェクトを共有することが問題なくできるようになりました。
気が向いたらデプロイ環境の分離についても試してみようと思います。参考
- 投稿日:2019-02-09T11:23:55+09:00
Terraformのassociate_public_ip_addressの差分をなくす
はじめに
terraform planとかterraform applyした時に出てくるassociate_public_ip_addressの差分をなくす方法
associate_public_ip_addressを設定している状態でインスタンスが停止してたりすると出てきます結論
associate_public_ip_addressの設定は削除- サブネットの設定に
map_public_ip_on_launch=Trueを追加これでパブリックIPアドレスを付与しつつ、Terraformでの変更がいかなる場合も出なくなります。
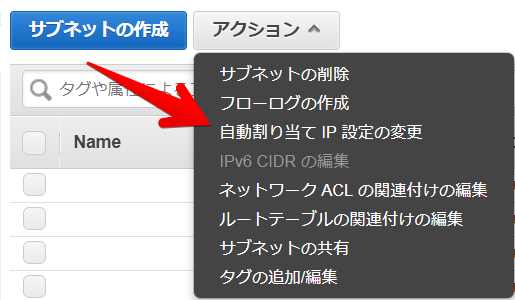
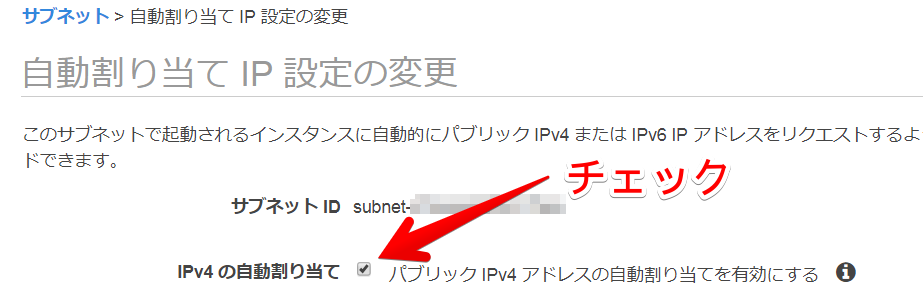
参考までに2.のサブネットの設定はコンソール画面だとこうです
サブネットの設定で自動割り当てIP設定の変更を有効にする
パブリックIPアドレスの付与
インスタンスにパブリックIPアドレスを付与する方法は大きく分けて以下の3つです。
- 自動割り当てIPの設定が有効になっているサブネットにインスタンスを立てる
- Terraformの
map_public_ip_on_launchで設定- インスタンスの起動時のパブリック IP アドレス割り当てを有効にする
- Terraformの
associate_public_ip_addressで設定- EIPをインスタンスに割り当てる
AWS公式:IPアドレス指定
設定の組み合わせによるパブリックIPアドレスの付与
上で説明した設定を有効にしたり、無効にしたりした時のIPアドレスの状態が以下の表です。
インスタンスの設定が優先されます
No. サブネットの設定 インスタンスの設定 パブリックIPアドレス付与される? 1 有効 有効 付与される 2 有効 無効 付与されない 3 有効 設定なし(デフォルト) 付与される 4 無効 有効 付与される 5 無効 無効 付与されない 6 無効 設定なし(デフォルト) 付与されない なぜ差分が出るのか?
タイトルのような差分が何故出てしまうのかというと、インスタンスを停止すると自動割り当てのパブリックIPアドレスが解放され、associate_public_ip_addressの設定状態と差分が出るからです
No. サブネットの設定 インスタンスの設定 パブリックIPアドレス付与される? インスタンス停止状態のTerraform差分 1 有効 有効 付与される 差分あり 2 有効 無効 付与されない 差分なし 3 有効 設定なし(デフォルト) 付与される 差分なし 4 無効 有効 付与される 差分あり 5 無効 無効 付与されない 差分なし 6 無効 設定なし(デフォルト) 付与されない 差分なし パブリックIPアドレスが付与されるかつインスタンス停止状態でもTerraformの差分が出ない設定の組み合わせが3.の組み合わせです。
EIP付与状態時の差分について
associate_public_ip_addressの設定を無効(FALSE)にするとEIPを付与した時に差分となってしまいます。
No. サブネットの設定 インスタンスの設定 EIP付与状態時のTerraform差分 1 有効 有効 差分なし 2 有効 無効 差分あり 3 有効 設定なし(デフォルト) 差分なし 4 無効 有効 差分なし 5 無効 無効 差分あり 6 無効 設定なし(デフォルト) 差分なし そのため結論に書いたとおり
- インスタンスに
associate_public_ip_addressの設定はしない(デフォルト状態にする)- サブネットの設定は有効にする(
map_public_ip_on_launch=True)としておくのが一番平和です。

- 投稿日:2019-02-09T03:53:25+09:00
EKS東京リージョンでGPUコンテナクラスタを立ててみる
EKSクラスタの構築
AWSの公式ドキュメントではCloudFormationなどを駆使して、EKSクラスタを構築する方法が記載されていますが、ここではそれらを隠蔽してくれるeksctlを使います。
eksctlのインストール
$ brew tap weaveworks/tap $ brew install weaveworks/tap/eksctlクラスタの作成
ここではp2.xlarge * 1のクラスタを構築します。
$ eksctl create cluster --name gpu-cluster --region ap-northeast-1 --nodes 1 --nodes-min 1 --nodes-max 1 --node-type p2.xlarge --version=1.11NVIDIA device pluginのインストール
GPUのスケジューリングを有効にするためにNVIDIA device pluginをインストールします。
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml(Optional) GPU Mutating Webhookの追加
nvidia.com/gpuリソースを指定しないコンテナからGPUが見えてしまう問題のために、Mutating Admission Webhookを追加します。
クライアントCAの取得・アップロード
EKSではGKEなどと違い、kube-systemのConfigMap:extension-apiserver-authenticationにclient-ca-fileが入っていないので入れておきます。
$ aws eks describe-cluster \ --region=ap-northeast-1 \ --name=gpu-cluster \ --output=text \ --query 'cluster.{certificateAuthorityData: certificateAuthority.data, endpoint: endpoint}' | \ awk '{print $1}' | \ base64 -Dで出力されたCAをConfigMapに入れます。
$ kubectl edit configmap extension-apiserver-authentication -n kube-system apiVersion: v1 data: + client-ca-file: | + -----BEGIN CERTIFICATE----- + xxxx + -----END CERTIFICATE----- requestheader-allowed-names: '["front-proxy-client"]' requestheader-client-ca-file: | -----BEGIN CERTIFICATE----- xxxx -----END CERTIFICATE----- requestheader-extra-headers-prefix: '["X-Remote-Extra-"]' requestheader-group-headers: '["X-Remote-Group"]' requestheader-username-headers: '["X-Remote-User"]' kind: ConfigMapgpu-mutating-webhookのデプロイ
$ git clone https://github.com/takmatsu/gpu-mutating-webhook.git $ cd gpu-mutating-webhook$ kubectl apply -f deployment/namespace.yaml $ ./deployment/webhook-create-signed-cert.sh $ cat deployment/mutatingwebhook.yaml | \ deployment/webhook-patch-ca-bundle.sh > \ deployment/mutatingwebhook-ca-bundle.yaml $ kubectl apply -f deployment/deployment.yaml $ kubectl apply -f deployment/service.yaml $ kubectl apply -f deployment/mutatingwebhook-ca-bundle.yaml(Optional) EFS Provisonerの追加
EKSではデフォルトでPersistent VolumeとしてAWSElasticBlockStoreが使えますが、ReadWriteOnceのみしか使えないため、ReadWriteManyなどが使いたい場合はEFS Provisonerを使用するとRWXなPVがDynamic Provisioningできます。
EFSの作成
aws efs create-file-system --creation-token gpu-nfs --region ap-northeast-1EFSにSecurityGroupの設定
- EFSのIDの確認
$ aws efs describe-file-systems
- サブネットの確認
$ aws ec2 describe-subnets --filters Name=tag:Name,Values=\*gpu-cluster\* Name=tag:aws\:cloudformation\:logical-id,Values=\*Public\* --query 'Subnets[].{SubnetId: SubnetId}' --output text
- セキュリティグループの確認
$ aws ec2 describe-security-groups --filters Name=group-name,Values=\*gpu-cluster\* --query 'SecurityGroups[].{GroupName: GroupName, GroupId: GroupId}' --output text | grep ClusterSharedNodeSecurityGroup | awk {'print $1'}
- 設定
$ aws efs create-mount-target --file-system-id fs-****** --subnet-id subnet-****** --security-groups sg-******×サブネット分
efs-provisonerのデプロイ
$ git clone https://github.com/kubernetes-incubator/external-storage.git $ cd external-storage/aws/efs
- namespaceの作成
$ NAMESPACE=efs-provisioner $ kubectl create namespace $NAMESPACE
- RBACの設定
$ sed -i '' "s/namespace:.*/namespace: $NAMESPACE/g" ./deploy/rbac.yaml $ kubectl apply -f deploy/rbac.yaml -n $NAMESPACE
- manifestの編集
$ vi deploy/manifest.yaml @@ -4,8 +4,8 @@ kind: ConfigMap metadata: name: efs-provisioner data: - file.system.id: yourEFSsystemid - aws.region: regionyourEFSisin + file.system.id: fs-***** + aws.region: ap-northeast-1 provisioner.name: example.com/aws-efs dns.name: "" --- @@ -53,7 +53,7 @@ spec: volumes: - name: pv-volume nfs: - server: yourEFSsystemID.efs.yourEFSregion.amazonaws.com + server: fs-*****.efs.ap-northeast-1.amazonaws.com path: /
- デプロイ
kubectl apply -f deploy/manifests.yaml -n $NAMESPACEその他
- GPUインスタンスは高いので、使わないときにワーカーノードに使っているAuto Scaling Groupを0にするLambdaなどを書くといいかもしれない、K8sを使っているとステートを持つ情報はコントロールプレーンか外部ストレージに入っているので戻すと自動復旧する(はず)
- 投稿日:2019-02-09T01:54:20+09:00
[Java]Amazon Corretto8のインストール
はじめに
AWSが先日2月4日にAmazon Corretto 8(独自OpenJDK)を正式リリースしたという記事を読みまして、試しにインストールしてみることにしました。
前提
Macで実施します。
手順
ダウンロード
まずこちらのAWSのサイトからJDKをダウンロードしてきます。
私の場合はMacなのでmacOS x64の「amazon-corretto-8.202.08.2-macosx-x64.pkg」を選びました。各自のOSに合わせたものをDLします。
インストール
DLしたpkgファイルをダブルクリックしてウィザードに従ってインストールします。以下のような画面が出ますが、とりえあず特殊なことをしたい場合を除き、何もカスタマイズせず続けて完了させます。
設定
モノは/Library/Java/JavaVirtualMachines/に入りますが、最後にターミナルで以下のコマンドを打ってインストールを完了させます。また、JAVA_HOMEを設定したい場合は結果に表示されたパスをexportコマンドで指定してあげます。#コマンド $ /usr/libexec/java_home --verbose #結果出力 $ Matching Java Virtual Machines (2): 1.8.0_202, x86_64: "Amazon Corretto 8" /Library/Java/JavaVirtualMachines/amazon-corretto-8.jdk/Contents/Home #(任意)JAVA_HOME設定 export JAVA_HOME=/Library/Java/JavaVirtualMachines/amazon-corretto-8.jdk/Contents/Home以上です。
上記はAWSのサイトに書かれている手順なので一応間違ってはいないかと思います。
(JAVA_HOMEの設定はプロファイルとかに書くべきですかね)私は普段Eclipseを使っているので、一応適当なプロジェクトでこのJDKを指定して、(当たり前ですが)きちんと動くことを確認しました。
終わりに
正式リリースとしてはまだJava8だけのようですが、そのうち11もリリースされるようです。サポート期限の違いはあれどAdoptOpenJDKという選択肢もありますね。いずれにしても、これでJavaもまだまだ生き続けるかなと。


- 投稿日:2019-02-09T00:56:38+09:00
Lumenを導入したEC2とDynamoDBとSNS
はじめに
EC2にLumenを導入し、小さなwebアプリケーションを作成する機会がありました。
要件を満たすために、新たに作成するDBとのI/Oとメール送信を実装する必要があり、
DynamoDBとSimple Notification Service(SNS)を利用したので、その時に得た知見をまとめます。
- 触れる内容
- LumenでDynamoDBとSNSを利用する方法
- 触れない内容
- Lumenの導入と設定
- webアプリケーションのインフラの設定、ミドルウェアのインストール
- ローカル環境の構築方法
各種バージョン
- PHP 7.2.10
- Lumen 5.7.7
- aws/aws-sdk-php 3.82.0
- laravel-dynamodb 4.11.2
LumenとDynamoDB
laravel-dynamodb導入
ORMを使うためのライブラリlaravel-dynamodbを導入します。
まずはcomposerでインストールします。
composer require baopham/dynamodb
そしてbootstrap/app.phpに下記を追記します。
(この手順はLaravelの場合と異なるので注意が必要です。)bootstrap/app.php// ... $app = new Laravel\Lumen\Application( dirname(__DIR__) ); $app->withFacades(); // Load dynamodb config file $app->configure('dynamodb'); $app->withEloquent(); // ... $app->register(BaoPham\DynamoDb\DynamoDbServiceProvider::class);認証
config/dynamodb.phpを作成します。
config/dynamodb.php<?php return [ /* |-------------------------------------------------------------------------- | Default DynamoDb Connection Name |-------------------------------------------------------------------------- | | Here you may specify which of the DynamoDb connections below you wish | to use as your default connection for all DynamoDb work. */ 'default' => env('DYNAMODB_CONNECTION', 'local'), /* |-------------------------------------------------------------------------- | DynamoDb Connections |-------------------------------------------------------------------------- | | Here are each of the DynamoDb connections setup for your application. | | Most of the connection's config will be fed directly to AwsClient | constructor http://docs.aws.amazon.com/aws-sdk-php/v3/api/class-Aws.AwsClient.html#___construct */ 'connections' => [ 'aws' => [ 'credentials' => [ 'key' => env('DYNAMODB_KEY'), 'secret' => env('DYNAMODB_SECRET'), // If using as an assumed IAM role, you can also use the `token` parameter 'token' => env('AWS_SESSION_TOKEN'), ], 'region' => env('DYNAMODB_REGION'), // if true, it will use Laravel Log. // For advanced options, see http://docs.aws.amazon.com/aws-sdk-php/v3/guide/guide/configuration.html 'debug' => env('DYNAMODB_DEBUG'), ], 'aws_iam_role' => [ 'region' => env('DYNAMODB_REGION'), 'debug' => true, ], 'local' => [ 'credentials' => [ 'key' => 'key', 'secret' => 'secret', ], 'region' => 'region', // see http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Tools.DynamoDBLocal.html 'endpoint' => env('DYNAMODB_LOCAL_ENDPOINT'), 'debug' => true, ], 'test' => [ 'credentials' => [ 'key' => 'key', 'secret' => 'secret', ], 'region' => 'region', 'endpoint' => env('DYNAMODB_LOCAL_ENDPOINT'), 'debug' => true, ], ], ];今回はlocal環境とdev環境とtest環境とprod環境の4つの環境を準備する必要があったので、
それぞれのenvファイルを作成します。.env.localDYNAMODB_CONNECTION=local DYNAMODB_LOCAL_ENDPOINT=http://localhost:4569LocalStackを使ってDynamoDBをエミュレートしていることを前提としています。
利用するポートは4569です。.env.dev、.env.test、.env.prodDYNAMODB_CONNECTION=aws_iam_role DYNAMODB_REGION=ap-northeast-1dev,test,prod環境全てでIAMを使って認証させています。
IAMを使うと認証情報をソースコードに記述する必要がないので良いです。Modelの作成例
DynamoDbModelクラスを継承したModelクラスを作成します。
Text.php/** * textテーブルの操作 * * Class Text * @package App\Model */ class Text extends DynamoDbModel { /** * @var string テーブル名 */ protected $table = 'text'; /** * @var string Hash Key */ protected $primaryKey = 'text_id'; /** * @var array カラム一覧 */ protected $fillable = [ 'text_id', 'title', 'created_user', 'created_at', ]; }利用してみた感想
今回はsave()とall()を使いました。特に問題はなかったです。
ただ、RDBではないDBに対してEloquent ORMを利用するのはどうなのだろうと思ってしまいます。
ライブラリの中身を詳しく読んでいないので、互換性の取り方まで把握していません。
気になる方はライブラリを読んでください。LumenとSNS
Simple Email Service(SES)を用いてメール送信する方法が最適だと考えました。
しかし、今回は色々事情があり東京リージョンを使う必要があり、SESには東京リージョンがないため使えませんでした。(2019-02-09)
よってSNSでメール送信しています。PHPでSNSに特化したライブラリはなく、AWS SDKを使って実装します。
設定
bootstrap/app.phpに下記を追記します。
bootstrap/app.php// ... // Load sns config file $app->configure('sns'); // ...config/sns.phpを作成します。
config/sns.php<?php return [ 'default' => env('SNS_CONNECTION', 'dev'), 'connections' => [ 'prod' => [ 'topic_arn' => env('SNS_TOPIC_ARN'), 'options' => [ 'version' => env('SNS_VERSION'), 'region' => env('SNS_REGION'), ] ], 'test' => [ 'topic_arn' => env('SNS_TOPIC_ARN'), 'options' => [ 'version' => env('SNS_VERSION'), 'region' => env('SNS_REGION'), ] ], 'dev' => [ 'topic_arn' => env('SNS_TOPIC_ARN'), 'options' => [ 'version' => env('SNS_VERSION'), 'region' => env('SNS_REGION'), ] ], 'local' => [ 'topic_arn' => env('SNS_TOPIC_ARN'), 'options' => [ 'version' => env('SNS_VERSION'), 'region' => env('SNS_REGION'), 'credentials' => [ 'key' => 'key', 'secret' => 'secret', ], 'endpoint' => env('SNS_LOCAL_ENDPOINT'), ] ] ], ];envファイル
.env.localSNS_CONNECTION=local SNS_VERSION=latest SNS_LOCAL_ENDPOINT=http://localhost:4575 SNS_TOPIC_ARN=arn:aws:sns:ap-northeast-1:hoge:local SNS_REGION=ap-northeast-1LocalStackを使ってSNSをエミュレートしていることを前提としています。
ローカルで作成済みのトピックのARNをSNS_TOPIC_ARNに記載します。
利用するポートは4575です。.env.dev、.env.test、.env.prodSNS_CONNECTION=dev // test or prod SNS_VERSION=latest SNS_TOPIC_ARN=arn:aws:sns:ap-northeast-1:hoge:topic SNS_REGION=ap-northeast-1クラウド上で作成済みのトピックのARNをSNS_TOPIC_ARNに記載します。
SNS_CONNECTIONは各環境で変更。メール送信の実装例
SnsMail.php<?php /** * SNSによるメール送信するためのclass * * Class SnsMail * @package App\Library */ class SnsMail { /** * @var string AWSの環境 */ private $connection; /** * @var string SNSのtopic */ private $topicArn; /** * @var SnsClient SNSのクライアント */ private $snsClient; /** * SnsMail constructor. */ public function __construct() { $connection = Config::get('sns.default'); $this->connection = $connection; $this->topicArn = Config::get("sns.connections.{$connection}.topic_arn"); $this->snsClient = new SnsClient(Config::get("sns.connections.{$connection}.options")); } /** * SNSを用いたメール送信 * * @param string $subject * @param string $message * @return void */ public function publish(string $subject, string $message): void { $subject = "{$subject}({$this->connection}環境)"; $this->snsClient->publish([ 'TopicArn' => $this->topicArn, 'Subject' => $subject, 'Message' => $message, ]); } }利用してみた感想
トピック作成時に飛ぶ承認メールの
Confirm subscriptionのリンクを踏まないとメールは飛びません...
このリンクを踏む作業を忘れていて、1時間とられましたw最後に
気が向いた時にLocalStackを使ったローカル環境の構築とCloudFormationを使ったインフラ構築の記事を書きます。