- 投稿日:2019-02-03T23:55:40+09:00
Python手遊び(base64)
この記事、何?
ちょっとしたスクリプトを作ろうという話の一つ。
今回はBase64。
たまに、末尾が「==」で終わる乱数チックな文字列を見るのでなんだろ思ったので気になってた。
たまに照合したりするのでEncode/Decodeをできるように。どういう人向け?
まあ・・・自分あて。
アピールできるほどの記事ではないので・・・
ただ、たまに「昔やったんだけどなぁ・・・細かいパラメータが分からないわ~」ってなるのを避けるため、将来の自分あて。参考にした記事
■Pythonでbase64エンコード・デコードする方法
http://yut.hatenablog.com/entry/20110825/1314228258■Base64デコード・エンコード
https://qiita.com/mas9612/items/5d3bf90b04bf19a1bf20できたコード
#18-01.py (エンコード) import sys import base64 args = sys.argv arg = args[1] print(arg) print(base64.b64encode(arg.encode('utf-8'))) #18-02.py (デコード) import sys import base64 args = sys.argv arg = args[1] print(arg) print(base64.b64decode(arg.encode('utf-8')))(実行イメージ) >python 18-01.py abcdefg abcdefg b'YWJjZGVmZw==' >python 18-02.py YWJjZGVmZw== YWJjZGVmZw== b'abcdefg'ということで、[abcdefg] から [YWJjZGVmZw==] が取得された。
で、戻して原文が取得できた。あっ、クリップボードに欲しかったら | clip って書いてください。
あと、テキストファイルに欲しかったら > text.txt とかで。感想
記事が薄いわぁ・・・
pythonいいな、という話以前に、他の方の書いたのを数行写経して終わり・・・
いや、今週はほら、いろいろイベントあって忙しかったし・・・今度はもうちょっとましなものを投稿します。。。
C#で再起ロジック書いてみたかったのでやってみようかな、と思ってま~す。
- 投稿日:2019-02-03T23:41:16+09:00
【プログラミング初心者】Django tutorial -- Part 1--
はじめに
個人用のメモ書きです。Djangoの公式ドキュメント「はじめてのDjangoアプリ作成」をもとに作成しています。
環境
- PC : MacBook Air (13-inch, Early 2014)
- OS : macOS Mojave Ver. 10.14.2
- python : Ver. 3.7
- Django : Ver. 2.1.5
前提条件
Python、Djangoは既にインストール済であることを前提としています。
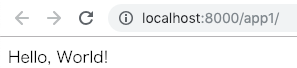
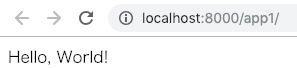
完成イメージ
ブラウザ上に「Hello, World!」を表示します。
プロジェクトを作成する
デモ用にプロジェクトを新規作成します。プロジェクト名は 「sample_project」とします。
コマンドライン$ django-admin startproject sample_project以下のファイルが生成されます。
sample_project/ manage.py sample_project/ __init__.py settings.py urls.py wsgi.py外側のsample_project/ ルートディレクトリはDjangoに依存しないため、名前は好きなものに変更できます。既に存在するディレクトリにプロジェクトを作成する場合は、プロジェクト名に続いてディレクトリを入力して実行します。
コマンドライン$ django-admin startproject sample_project (任意のディレクトリ)なお、プロジェクト名に 「-(ハイフン)」は使用できません。また、プロジェクト名に限らず、予約語や組み込み関数名と衝突しないよう注意しましょう。
アプリケーションを作成する
プロジェクトを作成したら、次はアプリケーションを作成します。アプリケーション名を「app1」とします。
コマンドライン$ python manage.py startapp app1アプリケーションは実際に何らかの処理を行う個別のアプリーケーションを指します。プロジェクトはあるウェブサイト向けに設定とアプリケーションを集めたものです。例えば、販売管理システム(プロジェクト)に対し、売上管理アプリ、在庫管理アプリ、予算管理アプリ(アプリケーション)といった具合です。
ビューを作成する
views.pyを開き、以下のpythonコードを書きます。
app1/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world!")URLconfを作成する
先ほど書いたビューを呼ぶために、URLを対応付けします。
まず、app1ディレクトリにurls.pyというファイルを作ります。アプリのディレクトリは以下のようになります。app1/ __init__.py admin.py migrations/ __init__.py models.py tests.py urls.py views.py作成した app1/urls.py に以下のコードを書きます。
app1/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]次に、作成したアプリのURLconfをプロジェクト側のURLconfに反映させます。
今度は sample_project/urls.py に以下を追加します。sample_project/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('app1/', include('app1.urls')), path('admin/', admin.site.urls), ]結果
コマンドラインで開発用サーバを動かします。
コマンドライン$ python manage.py runserverブラウザで http://localhost:8000/app1/ にアクセスすると「Hello World!」が表示されます。
おわりに
公式により丁寧な説明がありますので、基本はそちらを使って勉強するのがよいと思います。ただ動かすだけであれば、プログラミング未経験者でも迷うポイントはあまりないと思います。
個人的引っかかりポイントは、プロジェクトとアプリケーションの区別(どのような単位でアプリケーションを作ればよいか?)とそれぞれの名前の付け方でした。
- 投稿日:2019-02-03T23:26:07+09:00
役にたつか立たないかわからないInteliJIDEの話 【随時更新していくよ!!】
はじめに
勢いでIntelliJ All Products Pack買いました!
衝動買い楽しい。
せっかくだしちゃんと勉強しながら色々と使いこなせるようにメモします。
この機能の紹介をぜひー!とかこれ忘れてないなどあればどんどんお教えいただけますと幸いです。追記していきます!!
あと、サムライズムさんとかIntelliJとかお金もらってかいているわけではないです。色々あるけど・・・
いろんな機能があって色々と扱えるものも違ってきます。
ちなみに最強はIntelliJ IDEA Ultimate Editionです。
plugin で追加さえすればめちゃめちゃ捗ります。僕がweb開発とアプリする人間なので、それ以外にどうするべきなのかはわからないです。
値段は年間ですが、3年目まで毎年安くなっていきます。JavaScripter
webStormで要件を満たせます。
年間6300円で、三年目だと3700円です。webStormは、HTML/CSS、js, ts, coffe scriptを扱うことができます。なので、フロントエンドだろうが、バックエンド(nodeでの話)だろうがこれ一個で大丈夫です。
goに関してはプラグインでなんとかできるけど辛いみたい・・・。
そして、WebStormはかなり安いです。ただし、こいつでDBを覗き見たりするのはpluginでできなくもないですが、Data Gripを買った方がいいかと。
二郎を食べたことない人が二郎の美味しさがわからないてきな感じでData Gripを触らない限りは他のフリーツールでも満足してやっていけます。
ただし、free trialでもData Grip触ろうものなら、もう戻ってこれなくなります。pythoner
pyCharm professional Edition(PE)で要件を満たせます。
年間9600円で三年目だと5700円です**pythonはCommunity Edition(CE)って無償のバージョンがありますが、これは基本的にはデータサイエンス向けでweb開発用に転用していくのは結構無理がでます。データサイエンスだけのためならCEでよいです!jupyterも動かせます!
そして、こいつはなんとHTML/CSS, js, ts, CoffeScriptも扱うことができます!
なのでこれを買えば、フロンエンドだろうが、バックエンド(python or node)だろうがこれ一個で大丈夫です。
ただし、値段はちょっと高いです。phper
phpStormです。
年間9600円で三年目だと5700円です
webStormの上位互換ににあたります。
そして、こいつもなんとHTML/CSS, js, ts, CoffeScriptも扱うことができます!
なのでこれを買えば、フロンエンドだろうが、バックエンド(php or node)だろうがこれ一個で大丈夫です。
上位互換なので値段はやっぱちょっと高いです。Rubyer
RubyMineです。
年間9600円で三年目だと5700円です**
僕はあんまりRubyに関して明るくないです・・・。
が、Rubyを扱うことができ、こいつもなんとHTML/CSS, js, ts, CoffeScriptも扱うことができます!
ということでこれもフロンエンドだろうが、バックエンド(ruby or node)だろうがこれ一個で大丈夫です。go langer
go landです。
年間9600円で三年目だと5700円ですかっこいいですね。
これはHTML/CSS, js, tsを扱うことができます!javer
IntelliJ IDEA ultimate Edition(UE)を使うことができます。
年間16100円で三年目だと9600円です一応無償のCommunity Edition(UE)もありますが、で開店としてはHTML/CSS, js, markdownとかに対応していない点です。
java, kotolin, androidとかならCEで十分ですが、フロント周りをやろうとするならこれだとできないです。
pulanginをいれることで、多少python、Goなどに対して耐性をつけることもできます。
これだけ機能がたくさんあるためややお高い値段設定になっています。swifter Objective-Cer
AppCodeがあります。
年間9600円で三年目だと5700円ですいままでXCode使ってきたので使用感はちょっと不明です・・・。というかReact Nativeエンジニアなので、そこまで必要なものでもない。
これは、swift, Objective-C/C++のほか、HTML/CSS、JavaScriptを扱えますが、ts、Coffieはできません。
なのでReact Nativeやる人からしてみてもAppCode買うかは微妙なところですね。SQLer
Data Gripがあります。
年間9600円で三年目だと5700円です
これはめっちゃ良くてかなり重宝しています。All Product Packは買いなの?
はっきし言ってAll Product Packは結構たかいです。
年間26900円で三年目だと16100円です普通に開発しててもなんだかんだで2言語ぐらいできたら結構十分かと思います。
基本的に元を取ろうと思ったら3製品はちゃんと使わないともったいないです。
ですが、js系のものはだいたいどれもあつかえるので3製品使おうとするのは結構難しいです。たとえば、僕の場合、
- フロントエンドやる
- アプリやるけどReact Nativeなのでswift、javaはそんなに触らない
- バックエンド node or python
- データサイエンスやる
- データベースみる
とかになってくると、pyCharmとDataGripあれば十分かなと言ったところです。
それと、基本的にアップデートの速さは固有の製品の方が早いみたいなので、前線をいく人は前線をいけるような製品チョイスを心がけた方がいいかもしれません。
なので中なかなかに絶妙な値段設定をしている感じがしますね・・・。値段のまとめ
26900円コース
All Product Pack
16100円コース
IntelliJ IDEA Ultimate Edition
9600円コース
phpStorm, RubyMine, PyCharm, DataGrip, Goland, AppCode
6300円コース
webStorm
と言った感じです。なので、ここから自分に何が必要なのかを吟味して選んでいくといいかと思います!
あと、僕みたいに心配性だったり考えるのめんどくさ買ったりする人はAll Product Packを買うといいと思います。intention Actions
option + enter
いろんなことができます。
例えば、勢いでコード書いたけどファイルつくってなかった時とか、ここからさささっと作ることができます。
post completion
あと出しでコードを書く機能。
みてもらったほうが早い機能。そんなにいらないんじゃないって思うかもですが、なんだかんだ言って覚えれば便利な機能です。
一覧はpreference > editor > general > Postfix Completionからみれます。
独自定義もできます。
割と便利な
console.log({ a, b, });を作りました。
live template
色々な機能がある。アロー関数をfarrowとして追加してみた。
こちらを参考にした。タブを押すたびに引数、処理と言ったことができる。
こんな感じで追加する。ワーニングっぽいのでてたらどの言語でできているかわからないっていっているので、どの言語で使えるかを設定してあげましょう。
($PARAMS$) => ({ $BODY$ })$END$;こんな感じで定義すると、param -> body -> endにtabを押すたびに遷移する。
一応、テンプレート的なのは、範囲を選択 -> tools -> save as livetemplateっていうのを押すと、選択範囲のコードが入った状態で始められる親切設計。expand selection
いい感じに選択範囲をする機能です。
option + ↑で回数に応じて範囲が広がります。逆に戻したい場合はoption + ↓です。
変数化とインライン化
名前的に変数化したかったり、戻したりを一瞬でできます。
cmd + option + v 変数化します。
cmd + option + n で戻します。
parameter hint name
若干物議をかもすこの機能。
こんな形でパラーメーター名を表示できます。
設定はここで切り替えられます。
ショートカット
効果 コマンド Undo cmd + z Redo cmd + shift + z 検索 cmd + f or cmd + shift + f (プロジェクト全体) 置換 cmd + r or cmd + shift + r (プロジェクト全体) 複製 cmd + d プロジェクトにwindowを開く閉じる cmd + 1 ファイル作成 cmd + n コードの折りみと展開 cmd + . preferenceを開く cmd + , help or Action cmd + shift + a expand selection option + ↑ (回数で変わる) 予測補完を出す(macだとデフォで行けないので後述。ここに書いたのは自分用メモ) cmd + 4 smart補完を出す(macだとデフォで行けないので後述。ここに書いたのは自分用メモ) cmd + 5 intention Actions option + enter 変数化 cmd + option + v インライン化 cmd + option + n パラメーターヒント cmd + p 定義元ジャンプ(とにかく素晴らしい) cmd + b











- 投稿日:2019-02-03T23:02:24+09:00
【初心者向け】ブラウザ上でオプション理論価格計算&複合ポジのグラフ描画が出来るページを作成してみた(α版)
簡単な使い方
- ブラウザで⇒アクセス Gooogle colabo のページ
- (パラメータ変更して)実行ボタンを押す
内部の概略
Quantlibからよく使われるブラックショールズ式を簡単に呼び出せるラッパークラスを作成。
インストールする場合
pip install simple_option主なクラス
Portfolio
Option
Payoff(後ほど追記)
- 投稿日:2019-02-03T23:02:24+09:00
ブラウザ上でオプション理論価格計算&複合ポジのグラフ描画が出来るページを作成してみた(α版)
簡単な使い方
- ブラウザで⇒アクセス Gooogle colabo のページ
- (パラメータ変更して)実行ボタンを押す
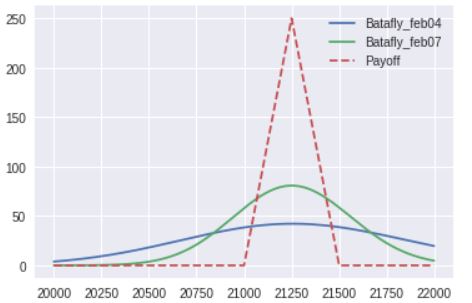
パラメータ変更例1:
# 3月限ショートストラングル p = Portfolio( """ 03/C21000[-1] 03/P20000[-1] """) #マーケット情報設定書式 #setting(原資産価格, IV(%), 日付【yyyymmdd】) setting(20250, 25, 20190204)内部の概略
Quantlibからよく使われるブラックショールズ式を簡単に呼び出せるラッパークラスを作成。
インストールする場合
pip install simple_option主なクラス
Portfolio
Option
Payoffクラス利用例:
Example1 --------- from simpleOption import * #Simple Example o = Option('02/P20500') op_price = o.v(20625, 20.8, 20190124) print(f"{o}@{op_price:.2f} (nk=20625,IV=20.8%) jan24 ") OUTPUT 1 --------- 02/P20500@285.49 (nk=20625,IV=20.8%) jan24 Example2 --------- #underlying change: 20625 >>20500 op_price2 = o.v(20500) print(f"{o}@{op_price2:.2f} (nk=20500,IV=20.8%) jan24") OUTPUT 2 --------- 02/P20500@285.49 (nk=20625,IV=20.8%) jan24 Example3 --------- #underlying & IV change: 20625>>20000 &IV=25% op_price3 = o.v(20000, 25) print(f"{o}@{op_price3:.2f} (nk=20000,IV=25%) jan24") OUTPUT 3 --------- 02/P20500@703.62 (nk=20000,IV=25%) jan24 Example4 --------- #use keyword op = Option('02/P20500') op_price4 = op( underlying=20250, iv=25, evaluationDate=20190122 ) """
- 投稿日:2019-02-03T22:58:30+09:00
Pythonの状態遷移パッケージ(transitions)を理解する【コールバック編1】
transitionsはPythonで状態遷移を実現するためのパッケージですが、今回は状態遷移時に実施されるアクションを実現するために「コールバック」について紹介したいと思います。
この記事では状態遷移を実現するソフトウェア的な機構をステートマシンと呼んでいます。この記事の対象者と今回の内容
Pythonで状態遷移を実装したり動作確認をしたい方に、Pythonの状態遷移パッケージ「transitions」の使い方を説明していきたいと思います。状態遷移そのものは組込みとか制御などでよく使われるものですが、それをPythonで実現したい場合にこのパッケージが有用かと思います。
状態遷移を実現するだけであれば状態と遷移を定義しステートマシンを作れますが、実際はトリガーイベントが発生した際や遷移時に何か処理をすることも多いです。こういったトリガーイベント起因による処理をアクションなどといい、ソフトウェア的にはコールバック(callback)として実装されることが多いかと思います。transitionsパッケージでもこのコールバックを実装できますので詳細について説明していきたいと思います。
この状態遷移におけるアクションは必須ではありませんが、状態遷移を使って制御機構を実装する場合に非常に重要ですのでtransitionsで状態遷移を実現する場合は当記事の内容を参考に頂けたらと思います。その他、transitionsの概要やインストール方法、当記事で作成している状態遷移図といったグラフ表示機能の導入(GraphMachine)や設定については準備編の記事を参照頂けたらと思います。
※今回の記事でも公式チュートリアルにならい遷移をtransitionsと呼んでますが、パッケージ名のtransitionsとややこしいので、当パッケージそのものを示す場合はtransitionsパッケージと明示することにします。transitionsにおけるコールバック
transitionsパッケージにおけるコールバックについて、簡単なサンプルコードを例に説明します。
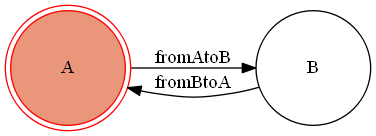
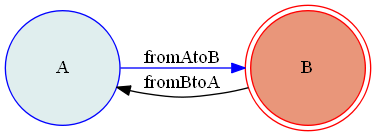
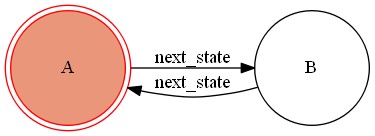
まずはコールバックをもつステートマシンの定義になります。コールバック定義のサンプルfrom transitions import Machine states = ['A', 'B'] #状態の定義 transitions = [ {'trigger':'fromAtoB', 'source':'A', 'dest':'B', 'after':'action_after'}, {'trigger':'fromBtoA', 'source':'B', 'dest':'A'}, ] class Model(object): # afterのコールバック(自メソッド名を表示するだけ) def action_after(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) model = Model() machine = Machine(model=model, states=states, transitions=transitions, initial=states[0], auto_transitions=False, ordered_transitions=False)上記コードはAとBの2状態で、AからBの遷移にafterコールバックを定義したものとなります。
上記で定義したステートマシンに対し、トリガーイベントを起こし、コールバックを呼んでみます。コールバック動作のサンプル>>> model.state # 初期状態の確認 'A' >>> model.fromAtoB() # トリガーイベントを起こす do "action_after" True >>> model.state # 遷移後状態の確認 'B'遷移を図示すると以下の通りになります。
今回はこの青矢印の遷移が起こった時にコールバックが呼ばれ実行されたことになります。
トリガーイベント(fromAtoB)を起こし、その際にtransitionリスト内の定義である'after'に指定された'action_after'メソッドが呼ばれている事を確認できると思います。
このようにtransitionsパッケージにおけるコールバックは、(一部を除いて)基本的にトリガーイベントを起点として発生する事になります。
またコールバックに指定するものは、Machineの引数modelに指定するオブジェクト内のメソッド(例ではmodelオブジェクトのクラスメソッド)になります。コールバックの種類
冒頭の例では非常に簡単なコールバックですが、transitionsパッケージで定義できるコールバックは大きく分けて3つになります。
- 遷移に紐付くコールバック(trantisions辞書で設定)
- 各状態に紐付くコールバック(Stateクラス/state辞書で設定)
- 全状態に紐付くコールバック(Machineクラス/machineオブジェクトで設定)
上記以外にtimeout等特殊なコールバックもあります。今回は順次それぞれについて詳細説明します。
遷移に紐付くコールバック
こちらは遷移編1と内容が被る部分がありますが再度内容を記しておきます。
遷移に紐付くコールバックは、その名の通り遷移それぞれに対し個別にコールバックを設定できます。従って「ある遷移にのみコールバックを設定したい場合」にこちらの定義方法を利用することになります。遷移準備/遷移前/遷移後コールバックについて
まずは遷移に関する基本的なコールバックになります。
冒頭の例もこの遷移に紐付くコールバックであり、以下の通りtransitions辞書などで設定できます。transitions = [ {'trigger':'fromAtoB', 'source':'A', 'dest':'B', 'after':'action_after'}, ]上記はfromAtoBトリガーイベントが起こった際の状態Aから状態Bへの遷移定義ですが、afterキーがコールバック定義の一つで、afterキーに指定しているaction_afterがコールバックされるクラス内メソッドになります。このようにコールバックとして呼び出されるクラス内メソッド名を文字列で記載します。
なお遷移に紐付くコールバックはトリガーイベントが起こった際、遷移元(source)と遷移後(dest)どちらで行うかでいくつか種類が別れています。
項目 定義名 実施される状態 説明 遷移準備コールバック prepare 遷移元 (souce) triggerが発生した際に実行されるコールバック 遷移前コールバック before 遷移元 (souce) 状態が遷移する前に呼び出されるコールバック 遷移後コールバック after 遷移先 (dest ) 状態が遷移した後に呼び出されるコールバック 冒頭の例ではafterのみしか設定していませんが、複数種類のコールバックを一度に定義することも可能です。
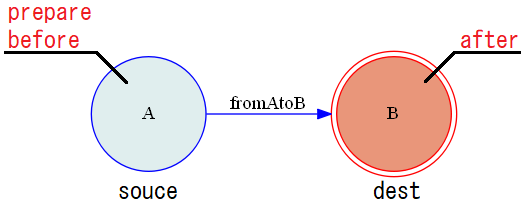
もちろんこれらprepareやbeforeコールバックを実行するクラス内メソッドをModelクラス内に定義しなければ実行エラーになりますので注意が必要です。# prepare, before, afterを一つの遷移に設定した場合 transitions = [ {'trigger':'fromAtoB', 'source':'A', 'dest':'B', 'prepare':'action_prepare', 'before':'action_before', 'after':'action_after'} ]上記を図示すると以下の通りになります。
この図は、状態AにおいてfromAtoBトリガーイベントを起こした直後になります。
状態Aにおいてトリガーイベントを起こしprepare, beforeが実施され、その後状態Bに移ってafterのコールバックが実施されることになります。ガード判定について
UMLなどでもあるガードも実装することができ、transitionsパッケージにおいてガードは遷移に紐付くコールバックになります。(当記事ではガードを便宜上ガード判定と呼んでいます)
ガード判定は遷移を伴うトリガーイベントが起こったとしても、特定の条件を満たしていないと遷移をさせないというものになります。
この判定をコールバックとして実現しているのがtrantisionsパッケージのガード判定コールバックになります。trantisionsパッケージにおけるガード判定の定義は以下二種があげられます。
項目 定義名 実施される状態 説明 ガード判定(True) conditions 遷移元 (souce) 指定されたコールバックがTrue時に遷移を許可 ガード判定(False) unless 遷移元 (souce) 指定されたコールバックがFalse時に遷移を許可 遷移編の焼き直しになりますが、ガード判定の簡単な例について示します。
遷移成立時(conditions)の定義例import sys from transitions import Machine states = ['A', 'B'] # 状態の定義 transitions = [ {'trigger':'fromAtoB', 'source':'A', 'dest':'B', 'conditions':'action_conditions'} ] class Model(object): # ガード判定用コールバック(conditionsやunlessはbool型の戻り値が必要) def action_conditions(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) return False # conditionsではTrueを返すと遷移を許可する(unlessではFalse時に遷移を許可) model = Model() machine = Machine(model=model, states=states, transitions=transitions, initial=states[0], auto_transitions=False, ordered_transitions=False)上記コード定義後、以下のコードにより動作させてみると、conditionsに設定したクラス内メソッドがコールバックされ実施されている事が分かります。
内部的な一連の動きとしては、トリガーイベント発生 → condisionsのコールバック実施 → コールバックよりFalseが返る → 遷移阻止という流れになります。遷移成立時(conditions)の挙動>>> model.state 'A' >>> model.fromAtoB() # トリガーイベントを起こしてみる do "action_conditions" on state (A) False >>> model.state # 状態はAのままで遷移できていない 'A'上記conditionsの定義において、action_conditionsの戻り値をTrueにすると、状態AにおいてfromAtoBトリガーイベントが起きた際、通常どおり状態Bに遷移する事になります。
unlessについてはconditionsと論理が逆になるだけ(Falseを返した際に遷移を許可)で、基本的な動作は変わりません。
また、conditionsとunlessを同時設定することも可能で、その場合はconditionsの判定が行われた後unlessが実施され、conditionsで遷移不許可となった場合はunlessは実施されない事に注意ください。なお、prepareとbeforeの役割や違い、実行順については遷移編1でも述べてますが、以下コールバックの優先順位にて全コールバックの優先順位と絡めて述べたいと思います。
各状態に紐付くコールバック
こちらは状態編と内容が被る部分がありますが、もう少し詳しく説明したいと思います。
enterとexitコールバックについて
当コールバック設定は状態定義(stateリスト)で行うものになります。まずはサンプルコードを示します。
各状態に紐付くコールバックの定義例from transitions import Machine, State #状態の定義 states = [State(name='A', on_exit=['action_on_exit']), # Stateクラスで定義可能 {'name':'B', 'on_enter':'action_on_enter'}] # 辞書でも定義可能 transitions = {'trigger':'fromAtoB', 'source':'A', 'dest':'B'} class Model(object): # on_enterのコールバック def action_on_enter(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) # on_exitのコールバック def action_on_exit(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) model = Model() machine = Machine(model=model, states=states, transitions=transitions, initial='A', auto_transitions=False, ordered_transitions=False)状態のみを定義する場合は、冒頭のサンプルコードの通りstate=['A', 'B']と文字列のリストのみで良いですが、各状態に「入った際」や「出た際」にコールバックを起こす際は、以下のように設定します。
states = [State(name='A', on_exit=['action_on_exit']), # Stateクラス版(Machine.Stateのimportが必要) {'name':'B', 'on_enter':'action_on_enter'}] # 辞書版上記サンプルコードに対し実際に動作させてみます。
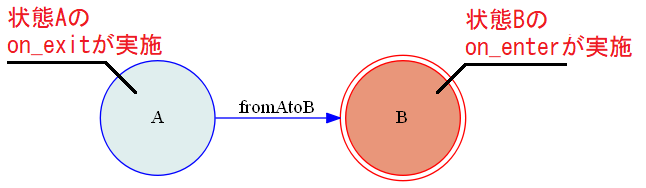
状態に紐付くコールバックの動作例>>> model.state 'A' >>> model.fromAtoB() do "action_on_exit" on state (A) do "action_on_enter" on state (B) True >>> model.state 'B'上記の結果を図示すると以下の通りになります。
fromAtoBトリガーイベントが発生し遷移が行われ状態Aから抜けます。この際状態Aに定義されたon_exitのコールバックaction_on_exitが実施されてます。
その後、状態Bに入り、状態Bに定義されたon_enterのコールバックaction_on_enterが実施されているという流れになります。このように、on_enterは定義した状態に入った時、on_exitは定義した状態から出た時に実施されることになります。
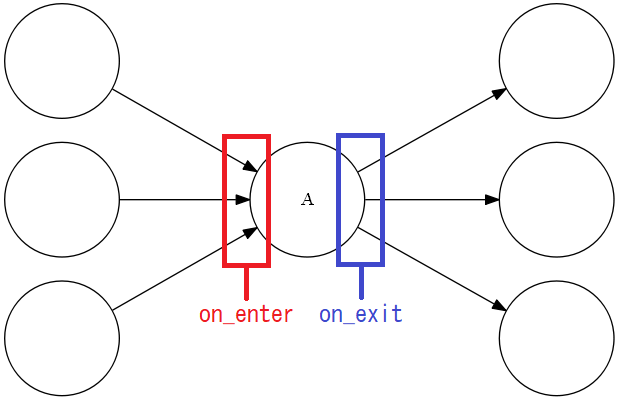
こちらを図示すると以下のようなイメージとなります。
時間切れコールバックについて
こちらはちょっと特殊なコールバックになりますが、状態に紐付くコールバックになります。
ある状態に入って、その状態にtimeoutで指定した時間滞在すると実施されるコールバックになります。定義例を以下に示します。時間切れコールバックの定義例from time import sleep from transitions import Machine from transitions.extensions.states import add_state_features, Timeout @add_state_features(Timeout) class MachineWithTimeout(Machine): pass states = ['A', Timeout(name='B', timeout=10, on_timeout='action_timeout')] #上記は{'name': 'B', 'timeout': 10, 'on_timeout': 'action_timeout'}でも良い class Model: # on_timeoutのコールバック def action_timeout(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) model= Model() machine = MachineWithTimeout(model=model, states=states, initial='A', auto_transitions=False, ordered_transitions=True)注意が必要なのはtimeoutはtransitionsパッケージの拡張機能になるので「transitions.extensions.states」でTimeoutクラスとadd_state_fuaturesのimportおよび定義が必要になります。
上記は状態Bに遷移後、状態Bの状態に10秒間滞在するとon_timeoutコールバックが呼ばれるものになります。実際に動作させてみます。時間切れコールバックの動作例>>> model.state 'A' >>> model.next_state() True >>> model.state 'B' >>> sleep(30) do "action_timeout" on state (B)このように、sleep中にtimeoutコールバックが発生している事がわかります(next_state実施後、状態Bに移って10秒後に発生)
なお、timeout時間が設定されているのにもかかわらず、on_timeoutコールバックが指定されていない場合はtimeout例外が発生します。各状態に関するコールバックのまとめ
各状態に関するコールバックをまとめると以下のとおりになります。
あくまでもコールバックが行われるのは「各状態に関するコールバック」が定義された"状態"になります。
項目 定義名 説明 enterコールバック on_enter 定義された状態に入った際に実施されるコールバック exitコールバック on_exit 定義された状態から出る際に実施されるコールバック 時間切れコールバック on_timeout 定義された状態にtimeout時間経過した際に実施されるコールバック 全状態に紐付くコールバック
最後に全状態に紐付くコールバックになります。
動作としては各状態に紐付くコールバックに近いものになりますが、ここで設定したコールバックは全状態が対象になります。
以下サンプルを見てみましょう。全状態に紐付くコールバックの定義例from transitions import Machine states = ['A', 'B'] #状態の定義 class Model(object): # prepare_eventのコールバック def action_prepare_event(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) # before_state_changeのコールバック def action_before_state_change(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) # after_state_changeのコールバック def action_after_state_change(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) # finalize_eventのコールバック def action_finalize_event(self): print('do "{}" on state ({})'.format(sys._getframe().f_code.co_name, self.state)) model = Model() machine = Machine(model=model, states=states, initial=states[0], auto_transitions=False, ordered_transitions=True, prepare_event='action_prepare_event', before_state_change='action_before_state_change', after_state_change='action_after_state_change', finalize_event='action_finalize_event')上記定義はステートマシンとしては単純な状態Aと状態Bによる2状態の順序遷移になります。
全状態に紐付くコールバックであるprepare_event、before_state_change、after_state_change、finalize_eventの4つ全てを定義しています。
こちらを実際に動かしてみます。
以下のサンプルでは状態A→状態Bへ遷移し、その後状態B→状態Aへと遷移する動作例になります。全状態に紐付くコールバックの動作例>>> model.state # 初期状態の確認 'A' >>> model.next_state() # トリガーイベント:状態A→状態Bへ do "action_prepare_event" on state (A) do "action_before_state_change" on state (A) do "action_after_state_change" on state (B) do "action_finalize_event" on state (B) True >>> model.state # 遷移後状態の確認 'B' >>> model.next_state() # トリガーイベント:状態B→状態Aへ do "action_prepare_event" on state (B) do "action_before_state_change" on state (B) do "action_after_state_change" on state (A) do "action_finalize_event" on state (A) True >>> model.state # 遷移後状態の確認 'A'動作例を見ると分かる通り、stateやtransitionsのコールバック設定がされていないのにも関わらず、状態遷移が発生する度に登録されたコールバックが呼ばれている事が確認できると思います。
このように、全状態に関するコールバックは設定したコールバックが各状態に入った際や出た際などで起こりますので、各状態における共通の初期化などに使えると思います。なお、prepare_eventとfinalize_eventは少々特殊で、こちらは遷移してもしなくても実施されるコールバックになります。
したがって、ガード判定などで遷移が阻害されたとしても、prepare_eventはトリガーイベントが発生したらすぐに、finalize_eventは最後に実施されるコールバックになります。
ただし、他のコールバック内で例外などが発生してしまった場合は実施されませんので、その点はご注意ください。「全状態に紐付くコールバック」をまとめると以下の通りになります。
項目 定義名 実施される状態 説明 準備コールバック prepare_event 遷移元 (souce) triggerが発生した際に実行されるコールバック 状態変化前コールバック before_state_change 遷移元 (souce) 状態が遷移する前に呼び出されるコールバック 状態変化後コールバック after_state_change 遷移先 (dest ) 状態が遷移した後に呼び出されるコールバック 最終コールバック finalize_event ※ 最後に呼び出されるコールバック ※遷移出来た際は遷移先(dest)にて、ガード判定で遷移が中断された場合は遷移元(source)にて実施される。
コールバックの優先順位
さて、コールバックの種類として、「遷移に紐付くコールバック」「各状態に紐付くコールバック」「全状態に紐付くコールバック」の3種類を紹介しましたが、もちろんこれらコールバックは全て合わせて定義可能です。
一方で各種コールバックを複数合わせた際に気になるのが実施順だと思いますが、実施順には明確な定義があります。
以下、実施順序について記します。
なんらかのトリガーイベントが発生した時、下表の上から順に実施されることを示しています。
また下表において「遷移阻止時も実施」列はunlessやconditionsにより遷移が中断された際にコールバックが実施されるかどうかを示しています。
定義名 定義先 状態 遷移阻止時も実施 prepare_event machine source YES prepare transitions source YES conditions transitions source YES ※3 unless transitions source YES ※3, ※4 before_state_change machine source NO before transitions source NO on_exit state source ※1 NO --- 状態変化 --- on_enter state dest ※2 NO after transitions dest NO after_state_change machine dest NO finalize_event machine source/dest YES ※5 ※1:遷移元(source)のstateで定義されたon_exitコールバックが呼ばれる
※2:遷移先(dest)のstateで定義されたon_enterコールバックが呼ばれる
※3:conditionsとunlessが同時設定されていた場合、両者の遷移条件が成立していないと遷移しません。
※4:conditionsとunlessが同時設定されていた場合、conditionsで遷移阻止された場合はunlessも実施されません。
※5:遷移中断時は遷移元で実施され、on_exitの後に実施される。全コールバックを定義した際のサンプルコード
これらを確認するためのサンプルコードを以下に示します。
少々長いですが、以下はtimeoutを除く全てのコールバックを定義してあります。
以下サンプルは状態Aのみで、トリガーイベントeventにより自己遷移(状態A → 状態A)するステートマシンになります全コールバックの定義例(timeout除く)from transitions import State, Machine states = [State(name='A', on_exit='action_on_exit', on_enter='action_on_enter')] transitions = {'trigger':'event', 'source':'A', 'dest':'=', 'prepare' : 'action_prepare', 'conditions' : 'action_conditions', 'unless' : 'action_unless', 'before' : 'action_before', 'after' : 'action_after'} class Model(object): # prepare_event(全遷移に紐付く)のコールバック def action_prepare_event(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # prepare(遷移に紐付く)のコールバック def action_prepare(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # conditions(遷移に紐付く)のコールバック def action_conditions(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) return True #遷移を許可 # unless(遷移に紐付く)のコールバック def action_unless(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) return False #遷移を許可 # before_state_change(全遷移に紐付く)のコールバック def action_before_state_change(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # before(遷移に紐付く)のコールバック def action_before(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # on_exit(状態に紐付く)のコールバック def action_on_exit(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) ### --- change state --- # on_enter(状態に紐付く)のコールバック def action_on_enter(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # after(遷移に紐付く)のコールバック def action_after(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # after_state_change(全遷移に紐付く)のコールバック def action_after_state_change(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) # finalize_event(全遷移に紐付く)のコールバック def action_finalize_event(self): print('do "{}"'.format(sys._getframe().f_code.co_name)) #ファイル出力する場合はMatter('test')等ファイル名指定する, Notebook上で表示する場合は引数に指定なし model = Model() machine = Machine(model=model, states=states, transitions=transitions, initial=states[0], auto_transitions=False, ordered_transitions=False) # 全状態に紐付くコールバック定義の追加 machine.prepare_event = 'action_prepare_event' machine.before_state_change = 'action_before_state_change' machine.after_state_change = 'action_after_state_change' machine.finalize_event = 'action_finalize_event'こちらを動作させると以下の通りになります。
全コールバックの動作例(timeout除く)>>> model.event() #トリガーイベント:状態A→状態A do "action_prepare_event" do "action_prepare" do "action_conditions" do "action_unless" do "action_before_state_change" do "action_before" do "action_on_exit" do "action_on_enter" do "action_after" do "action_after_state_change" do "action_finalize_event" Trueなお、もしもconditionsやunlessにより遷移が中断された場合は遷移や状態が変わった際のコールバックは実施されませんが、準備関連のコールバックや最終コールバックなどは実施されます。
以下にガード判定unlessでTrueを返し、遷移を阻止した場合の動作例を示します。unlessで阻止(Trueを返した)際の動作例>>> model.event() #トリガーイベント:状態A→状態A do "action_prepare_event" do "action_prepare" do "action_conditions" do "action_unless" do "action_finalize_event" Falseこのようにunlessにより遷移が阻止されても準備系(prepareやprepare_event)や最終コールバック(finalize_event)が実施されている事に注意下さい。
各コールバックの使い分け
これまでで各種コールバックの実施順やタイミングなどは理解できたと思います。
色々とコールバックの設定があって大変ですが、
- 遷移それぞれにコールバックを設定したい場合は「遷移に紐付くコールバック」
- ある状態に入ったり出ていった際に実施したい場合は「状態に紐付くコールバック」
- 全状態に共通に処理を行わせたい場合は「全状態に紐付くコールバック」
を定義してやれば良いことになります。
基本的に制御関連では「ある状態において、あるイベントが起きた時、あるアクションが起きて別の状態に遷移する」という風な目線で設計することが多いと思いますので、大多数は「遷移に紐付くコールバック」を設計していけば良いと思いますが、設計していく中で、ある状態に入ったり出た際の初期化は「状態に紐付くコールバック」を、状態が変わるごとに初期化をしたい場合は「全状態に紐付くコールバック」をする場合が多いとは思います。
また「遷移に紐付くコールバック」を設計していて共通化できるものは、各状態や全状態に紐付くコールバックにした方がコールバックの見通しは良くなるので、全てのコールバックを「遷移に紐付くコールバック」として実装するのではなく、通常のソフトウェア設計と同じくコールバックが実施される範囲や共通化といった事を意識して定義することをオススメします。prepare (prepare_event)やfinalize_eventの使いどころ
遷移阻止によらず実施されるコールバックとして、prepare(遷移に紐付く)、prepare_event(全状態に紐付く)、finalize_event(全状態に紐付く)がありますが、これらは使いどころが難しいかもしれません。
prepare(遷移に紐付くコールバック)は、特にガード判定の前処理として使う事をオススメします。
後のコールバック編2で紹介しますが、例えば「prepareコールバックでデータを受け取ったりして前処理を行い、前処理の結果、遷移しても良いと判定したら遷移許可を出す(conditionsコールバックの戻り値がTrueになるように処理する)」といった使い方も出来ると思います。特に遷移前のコールバックであるbeforeやbefore_state_changeは「遷移が確定しないと実施されない」ので、これらガード判定の前処理としては使えず注意が必要です。全遷移に対しトリガーイベントが発生した際に必ず実施されるfinalize_eventは、個人的には遷移結果の表示やGraphMachineを用いた画像出力などをこちらのコールバックとしてやらせることが多いです。
まとめ
今回はtransitionsパッケージで設定出来るコールバックの種類や定義方法、および実施順序などについて紹介しました。
冒頭でも述べたとおり、コールバックはステートマシンに必須の機能ではありませんがコールバックなしには状態遷移で制御を行う事は難しくなるので、是非活用してもらえればと思います。その際、当記事が少しでもお役に立てたら幸いです。今回も少々長くなってしまったので、一旦コールバック編をここで区切ります。次はコールバック編2としてコールバックメソッドへのデータの渡し方や、コールバックのキューといった内容について紹介する予定です。
- 投稿日:2019-02-03T22:00:01+09:00
強化学習の勉強 (3) Double DQN と Dueling Network
深層強化学習 PyTorchによる実践プログラミング の6章の内容です。
前回の Deep Q-Netowork の発展版として、Double DQN と Dueling Network の実装が紹介されていました。
Double DQN の結果がこれ。
Dueling Network の結果がこれ。
この課題だともう学習後の上手さの違いなどはよくわからない。上記の本では Dueling Network を使うと少ない試行数でも学習が進むという話が書いてあったけどそのような傾向は見られなかった。Double DQN
Main Q-Network: 次のステップで最大のQ値を持つようなaction、$a_m$を求めるネットワーク
Target Q-Network: $a_m$ の Q 値を評価するネットワーク
行動の決定と評価をそれぞれ別のネットワーク (ただし構造は同一) で行うことで学習を安定化させられるらしい。学習自体は Main Q-Network に対して行うが、たまに (下記の例では 2 エピソードに 1 回) Main Q-Network の weight を Target Q-Network にコピーしている。Dueling Network
行動価値関数 $ Q(s, a) $ には、$s$だけで決まってしまう要素 $V(s)$ と行動次第で決まる要素 $A(s,a)$ があると考える。例えば cartpole では棒がもう倒れそうな状態だったらそこから右に押そうが左に押そうがあまり関係ない、など。そこで Q-Network の出力を $V(s)$ を出力する部分と各行動に対する $A(s,a)$ を出力する部分に分岐させ、$V(s) + A(s,a) = Q(s, a)$ として Q 値を求める。
DDQN.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline import gym from JSAnimation.IPython_display import display_animation from matplotlib import animation from IPython.display import display def display_frames_as_gif(frames): plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0), dpi=72) patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=50) anim.save('movie_cart_ple_ddqn.mp4') display(display_animation(anim, default_mode='loop')) from collections import namedtuple Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward')) # 定数の設定 ENV = 'CartPole-v0' GAMMA = 0.99 MAX_STEPS = 200 NUM_EPISODES = 500 # 経験を保存するメモリクラスを定義します。 class ReplayMemory: def __init__(self, CAPACITY): self.capacity = CAPACITY # メモリの最大長さ self.memory = [] self.index = 0 def push(self, state, action, state_next, reward): if len(self.memory) < self.capacity: self.memory.append(None) #メモリが満タンじゃないときには追加 self.memory[self.index] = Transition(state, action, state_next, reward) self.index = (self.index + 1) % self.capacity def sample(self, batch_size): return random.sample(self.memory, batch_size) def __len__(self): return len(self.memory) # ニューラルネットワークの定義します。 import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self, n_in, n_mid, n_out): super(Net, self).__init__() self.fc1 = nn.Linear(n_in, n_mid) self.fc2 = nn.Linear(n_mid, n_mid) self.fc3 = nn.Linear(n_mid, n_out) def forward(self, x): h1 = F.relu(self.fc1(x)) h2 = F.relu(self.fc2(h1)) output = self.fc3(h2) return output import random import torch from torch import nn from torch import optim import torch.nn.functional as F BATCH_SIZE = 32 CAPACITY = 10000 # 行動決定を行うためのクラスです。 class Brain: def __init__(self, num_states, num_actions): self.num_actions = num_actions # メモリオブジェクトの生成 self.memory = ReplayMemory(CAPACITY) # ニューラルネットワークの構築 n_in, n_mid, n_out = num_states, 32, num_actions self.main_q_network = Net(n_in, n_mid, n_out) self.target_q_network= Net(n_in, n_mid, n_out) print(self.main_q_network) # オプティマイザの設定 self.optimizer = optim.Adam(self.main_q_network.parameters(), lr=0.0001) def replay(self): '''Experience Replay''' # メモリサイズの確認 # メモリサイズがミニバッチサイズより小さい間は何もしない。 if len(self.memory) < BATCH_SIZE: return # ミニバッチの作成 self.make_minibatch() # 教師信号Q(s_t, a_t)を求める self.expected_state_action_values = self.get_expected_state_action_values() # ネットワークのパラメータ更新 self.update_main_q_network() def decide_action(self, state, episode): '''state に応じて行動を決定する関数''' epsilon = 0.5 * (1 / (episode + 1)) if epsilon <= np.random.uniform(0, 1): self.main_q_network.eval() with torch.no_grad(): action = self.main_q_network(state).max(1)[1].view(1, 1) else: action = torch.LongTensor([[random.randrange(self.num_actions)]]) return action def make_minibatch(self): # ミニバッチの作成 transitions = self.memory.sample(BATCH_SIZE) batch = Transition(*zip(*transitions)) self.batch = batch self.state_batch = torch.cat(batch.state) self.action_batch = torch.cat(batch.action) self.reward_batch = torch.cat(batch.reward) self.non_final_next_states = torch.cat([s for s in batch.next_state if s is not None]) def get_expected_state_action_values(self): self.main_q_network.eval() self.target_q_network.eval() # state_batchをモデルに与え、推論結果からaction_batchで行った行動に対応するQ値を取ってくる # つまりあるstateにおける行ったactionの価値をとってきている。 self.state_action_value = self.main_q_network(self.state_batch).gather(1, self.action_batch) # max{Q(s_t+1, a)}を求める non_final_mask = torch.ByteTensor( tuple(map(lambda s: s is not None, self.batch.next_state))) next_state_values = torch.zeros(BATCH_SIZE) a_m = torch.zeros(BATCH_SIZE).type(torch.LongTensor) # 次の状態での最大Q値のa_mをmain_q_networkから求める a_m[non_final_mask] = self.main_q_network(self.non_final_next_states).detach().max(1)[1] # 次の状態があるものだけをフィルターし、sizeをBATCH_SIZEからBATCH_SIZE*1へ a_m_non_final_next_states = a_m[non_final_mask].view(-1, 1) #行動a_mのQ値をtarget_q_networkで推定する。 next_state_values[non_final_mask] = self.target_q_network(self.non_final_next_states).gather( 1, a_m_non_final_next_states).detach().squeeze() expected_state_action_values = self.reward_batch + GAMMA * next_state_values return expected_state_action_values def update_main_q_network(self): # main_q_networkのネットワークパラメータの更新 self.main_q_network.train() loss = F.smooth_l1_loss(self.state_action_value, self.expected_state_action_values.unsqueeze(1)) self.optimizer.zero_grad() loss.backward() self.optimizer.step() def update_target_q_network(self): #target_q_network のパラメータをmain_q_networkと同じにする。 self.target_q_network.load_state_dict(self.main_q_network.state_dict()) # エージェントを定義するクラスです。 class Agent: def __init__(self, num_states, num_actions): self.brain = Brain(num_states, num_actions) def update_q_function(self): self.brain.replay() def get_action(self, state, episode): action = self.brain.decide_action(state, episode) return action def memorize(self, state, action, state_next, reward): self.brain.memory.push(state, action, state_next, reward) def update_target_q_function(self): self.brain.update_target_q_network() # 環境を定義するクラスです。 class Environment: def __init__(self): self.env = gym.make(ENV) self.num_states = self.env.observation_space.shape[0] self.num_actions = self.env.action_space.n self.agent = Agent(self.num_states, self.num_actions) def run(self): episode_10_list = np.zeros(10) #直近10エピソードで振り子が立ち続けたステップ数を記録 complete_episodes = 0 episode_final = False frames = [] for episode in range(NUM_EPISODES): observation = self.env.reset() state = observation state = torch.from_numpy(state).type(torch.FloatTensor) state = torch.unsqueeze(state, 0) for step in range(MAX_STEPS): if episode_final is True: frames.append(self.env.render(mode='rgb_array')) action = self.agent.get_action(state, episode) #行動actionの実行によってs_t+1とdoneフラグを取得 observation_next, _, done, _ = self.env.step(action.item()) if done: state_next = None episode_10_list = np.hstack((episode_10_list[1:], step + 1)) if step < 195: reward = torch.FloatTensor([-1.0]) # 195ステップ未満で倒れたら報酬-1 complete_episodes = 0 else: reward = torch.FloatTensor([1.0]) complete_episodes = complete_episodes + 1 else: reward = torch.FloatTensor([0.0]) state_next = observation_next state_next = torch.from_numpy(state_next).type(torch.FloatTensor) state_next = torch.unsqueeze(state_next, 0) self.agent.memorize(state, action, state_next, reward) self.agent.update_q_function() state = state_next if done: print("%d episode: Finished after %d steps: 10試行の平均step数 = %.lf"%( episode, step + 1, episode_10_list.mean())) if episode % 2 == 0: self.agent.update_target_q_function() observation = self.env.reset() break if episode_final is True: display_frames_as_gif(frames) break if complete_episodes >= 10: print("10回連続成功") episode_final = True cartpole_env = Environment() cartpole_env.run()Dueling Network は Double DQN のネットワーク構造を以下のように変えるだけでよい。
DuelingNetwork.pyclass Net(nn.Module): def __init__(self, n_in, n_mid, n_out): super(Net, self).__init__() self.fc1 = nn.Linear(n_in, n_mid) self.fc2 = nn.Linear(n_mid, n_mid) self.fc3_adv = nn.Linear(n_mid, n_out) self.fc3_v = nn.Linear(n_mid, 1) def forward(self, x): h1 = F.relu(self.fc1(x)) h2 = F.relu(self.fc2(h1)) adv = self.fc3_adv(h2) val = self.fc3_v(h2).expand(-1, adv.size(1)) output = val + adv - adv.mean(1, keepdim=True).expand(-1, adv.size(1)) return output
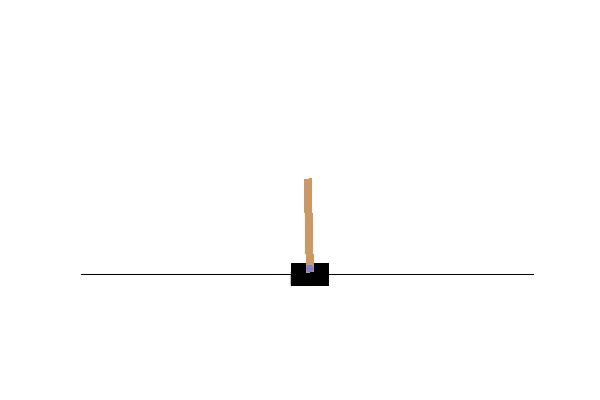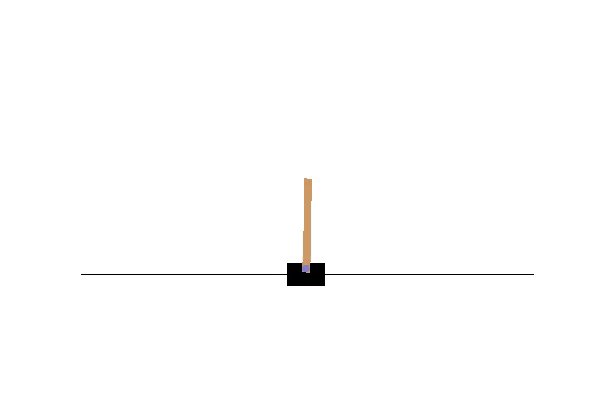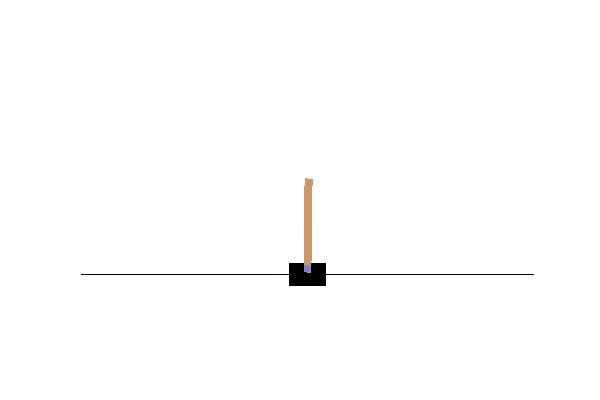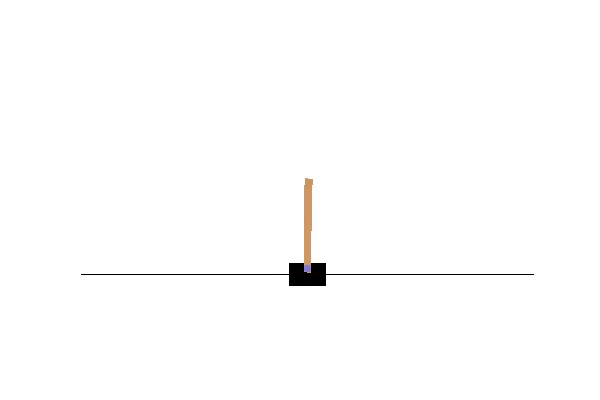
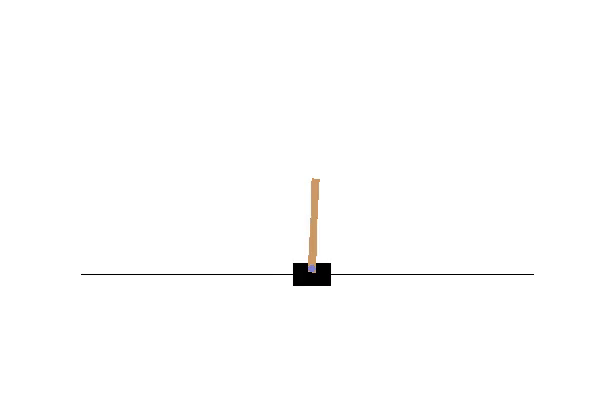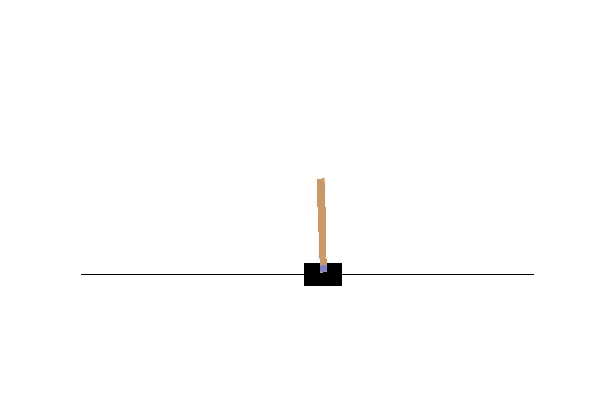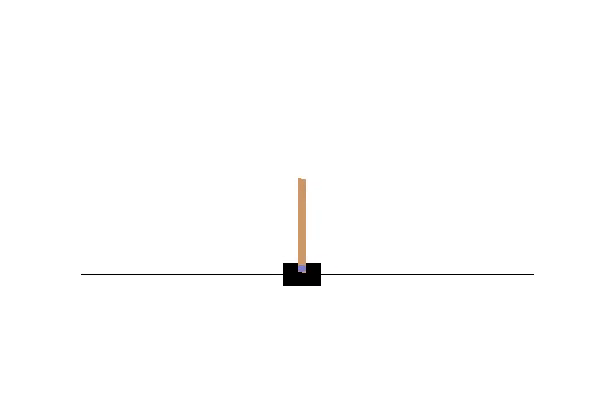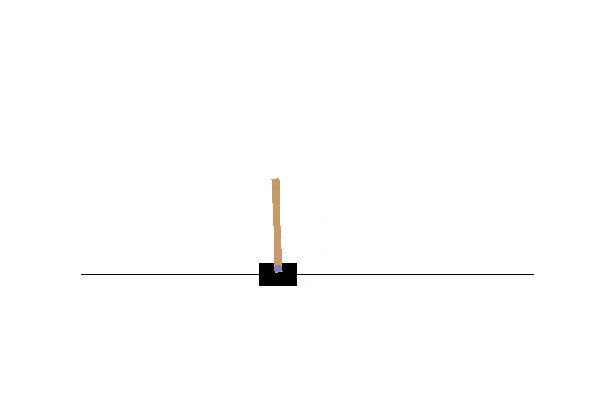
- 投稿日:2019-02-03T21:45:22+09:00
WindowsでPythonを始める
環境構築はさくっとできます
※Python 3.7.2時点インストール
下記ページから
https://www.python.org/downloads/windows/
今回は「Windows x86-64 executable installer」でexeをダウンロード
※個人のPCによるので32bitの人は「Windows x86 executable installer」の方ダウンロードしたらexe起動して「Install Now」をポチってインストールするだけ
この時に下の方にある「Add Python 3.7 to PATH」をチェックしてインストールすると後程やろうとしてる環境変数に追加してくれるみたいです(僕はやってないけど)環境変数に追加
下記2つをを環境変数の「Path」に追加
~\Python\Python37\
~\Python\Python37\Scripts\~は各自Pythonをインストールしたパス
コマンドで確認
>pipCommands:
…
ってコマンドリストが出てきたらPythonを使用できる準備完了!

- 投稿日:2019-02-03T21:35:58+09:00
[Python]とにかくわかりやすく!Djangoでアプリ開発!ーその3ー
前回の記事
前回の記事→とにかくわかりやすく!Djangoでアプリ開発!ーその2ー
本記事の目的
python初心者の方が、本記事を見たあとに、一人でアプリ開発できることを目的にしております。
※インストールや開発環境については記載しません環境
macOSX Sierra
python3.7
django 2.1.5前回まで
プロジェクトを立ち上げ(startproject)
→アプリの作成(startapp)
→view.pyを変更してレスポンスを書く
→urls.pyを修正する
→アプリの登録する
→index.html作る
→views.pyを直す
→htmlに変数入れる
→views.pyを直す
→複数ページ作るためにリンクつける
→views.pyを直す
→cssで装飾できるようにするとここまででした。
ここからはアプリらしくフォームを作成していきます。
フォームを作る
目に見える画面に用意するものなので、templatesのindex.htmlを修正します。
前回同様にformというURLへの書き出しを行います。このformは後ほどurlpatternsに追加します。
またCSRF対策タグもつけておきました。これでフォーム送信時に、このトークンも一緒に受け渡されて、チェックが行われるので安心です。
※一旦不要なsecondは消します。index.html{% load static %} <!doctype html> <html lang="ja"> <head> <meta charset="utf-8"> <title>{{title}}</title> <link rel="stylesheet" type="text/css" href="{% static 'app1/css/style.css' %}"/> </head> <body> <h1>{{title}}</h1> <p>{{msg}}</p> <form action= "{% url 'form' %}" method = "post"> <!--ここのフォーム使うとfromに飛びます--> {% csrf_token %} <!--CSRF対策--> <label for = "msg">ここに入力:</label> <!--入力項目ラベル--> <input id = "msg" type="text" name ="msg"> <!--入力フォーム--> <input type="submit" value="入力"> <!--ボタン--> </form> </body> </html>htmlを変えたので,それを制御するviews.pyの変更も行います。
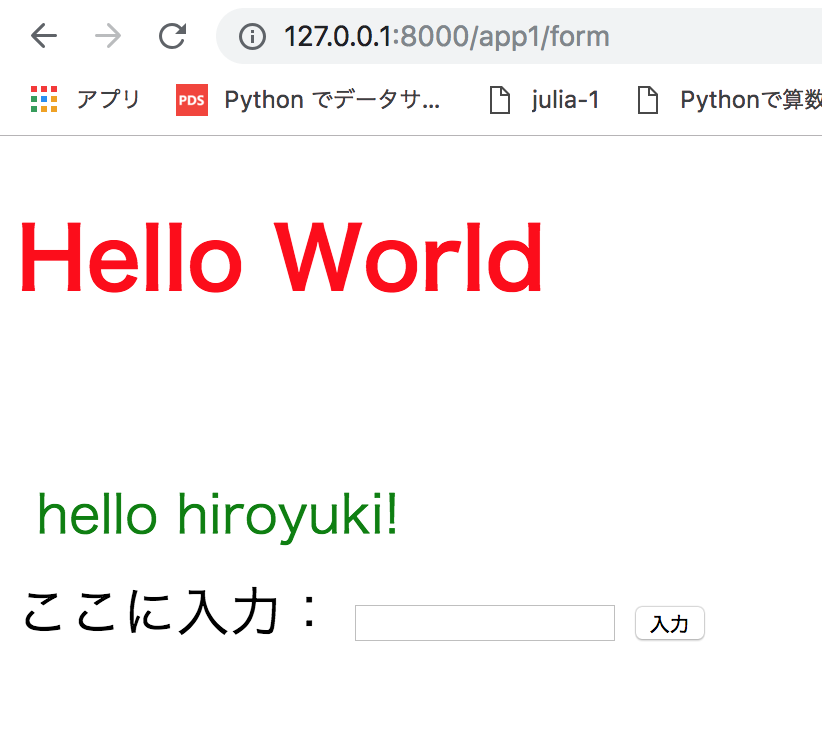
form関数を作ります。htmlのinputの部分に書いてある通り、ここで送信されたmsgと名付けられたtextを受け取るために、POSTメソッドを利用し送信された値を取り出します。
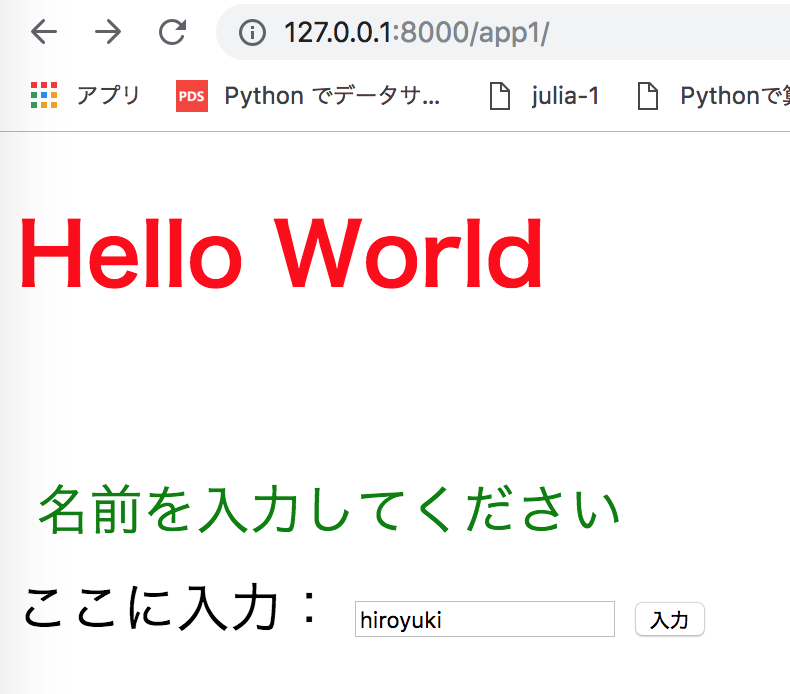
※一旦不要なsecondは消します。views.pyfrom django.shortcuts import render from django.http import HttpResponse def aisatsu(request): params = { 'title':'Hello World', 'msg':'名前を入力してください', } return render(request,'app1/index.html', params) def form(request): msg = request.POST['msg'] params = { 'title':'Hello World', 'msg':'hello '+msg+'!', } return render(request,'app1/index.html', params)新しい関数を定義したので、最後にこの関数を呼び出せるように、URLを準備します。urls.pyに追加を行います。 ここに追加することでhtmlのタグをつけるようになります。
urls.pyfrom django.urls import path from . import views urlpatterns = [ path("", views.aisatsu, name= "aisatsu"), path("form",views.form, name="form"), ]それではhttp://127.0.0.1:8000/app1/にアクセスして確認します。
※runserverしておいてください。キャッシュによって変更されない可能性があるので、その時はサーバーを止めてから、再度起動してください以下のようにフォームができています。
入力して、送信!画面が以下のようになればOK!
今後のために
実はこの使い方は、せっかく入力された名前がクリアになってしまうので、DB登録とのチェック機能やできないなどあまり汎用性がありません。なのでdjangoに用意されているFormクラスを使います。※最初からそれを記載してもよかったのですが...念のため...
ということでまずはapp1フォルダ配下にforms.pyを作成し、以下のようにします。
書いてあるまんまですが、テキスト(char)と整数(int)の入力フィールドを用意して、labelで名前をつけました。大文字小文字に気をつけてください。apps/forms.pyfrom django import forms class aisatsuform(forms.Form): name = forms.CharField(label="name") area = forms.CharField(label="area") age = forms.IntegerField(label="age")このフォームを利用できるような制御にするために、views.pyを修正していきます。
パラメタの中に、formを作ってインスタンスを入れています。
下の部分では、request.methodで、リクエストがPOSTかどうかチェックをして、そうだったらPOST用の処理を実施しします。GETならば、ページだけ返します。
※POSTとかGET:HTTPメソッド。フォームを使うならPOSTを利用します。他にもいくつかメソッドがありますが、メソッドを見れば、どんなことが行われているかわかるようになっています。
*波括弧の閉じる位置とreturnのインデントに注意views.pyfrom django.shortcuts import render from django.http import HttpResponse from .forms import AisatsuForm def aisatsu(request): params = { 'title':'Hello World', 'msg':'ちゃんと挨拶したいので情報の登録をしてください', 'form': AisatsuForm(), } if (request.method=='POST'): params['msg'] = 'こんにちは!'+request.POST['name']+'さん!<br>'+request.POST['area']+'にお住まいで<br>年齢は'+request.POST['age']+'歳なんですね!<br>よろしくお願いします。' params['form']= AisatsuForm(request.POST) return render(request,'app1/index.html', params)少し複雑ですね。冒頭でaisatsuformのインスタンスをformに代入し、もしPOSTリクエストだったら、もう一回POSTの内容でインスタンスを作って上書きを行なっています。同様にmsgも書き換えを行い、POSTされた情報を表示させるようにしています。ここでは<br>などのhtmlタグが埋め込まれているので、index.htmlで表示させる時に、そうなっていることを知らせなくてはなりません。下記で記述します。
それでは、画面表示直していきます。index.htmlを修正します。
先ほど作ったフォームは丸ごと置き換えます。
{{form}}のところをテーブル(as_table)にしたり、リスト(as_ul)にすることもできます。何も指定しないと横一列にフィールドが設置されます。※tableにする場合はタグが必要です。
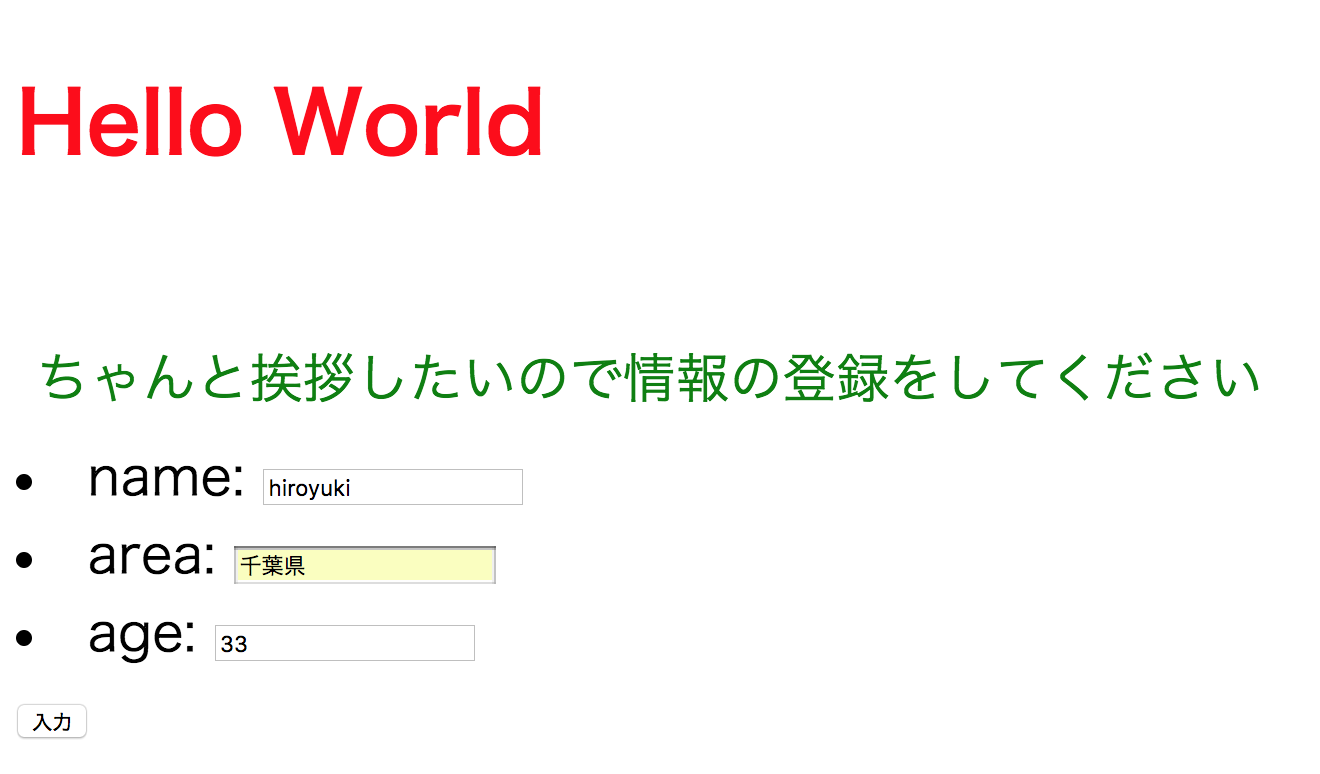
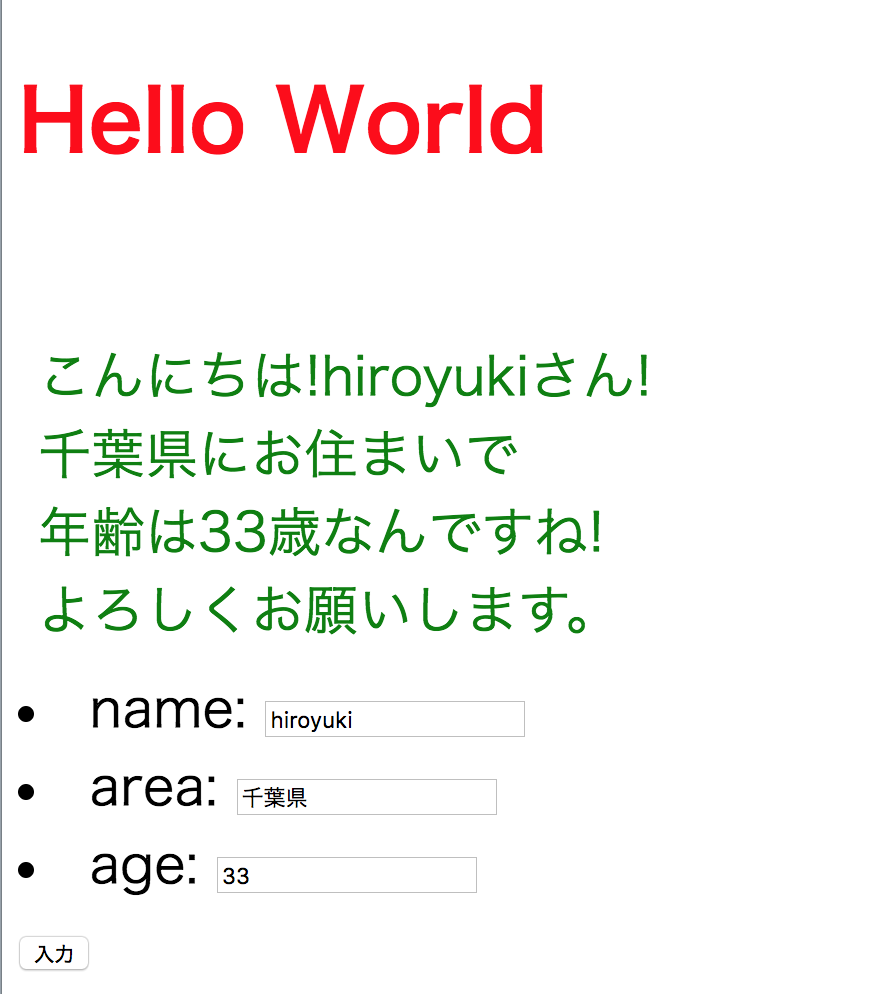
index.html{% load static %} <!doctype html> <html lang="ja"> <head> <meta charset="utf-8"> <title>{{title}}</title> <link rel="stylesheet" type="text/css" href="{% static 'app1/css/style.css' %}"/> </head> <body> <h1>{{title}}</h1> <p>{{msg|safe}}</p><!--ここでviews.pyのhtmlを有効化--> <form action= "{% url 'aisatsu' %}" method = "post"> {% csrf_token %} {{form.as_ul}} <!--ここ--> <input type="submit" value="入力"> </form> </body> </html>ここまできたら、http://127.0.0.1:8000/app1/
にアクセスしてみます。すごい怪しい感じになりました。
情報を送信してみるとこんな感じ
この記事はここまで
次回は続きを投稿していきます。そろそろDBを使います。
- 投稿日:2019-02-03T21:00:29+09:00
【Python】Beautiful SoupでスクレイピングしてJSON出力でデータ収集
環境 Windows Python3.7
これからやること
Beautiful Soup 4(以後bs4)を使ってスクレイピング。結果をJSONファイルで出力。
WEBから分析用のデータを収集する。
データ分析の勉強をしたかったが、そもそも良い感じのデータが無かったためスクレイピングで入手することに。スクレイピング対象
- ニコニコチャート(http://www.nicochart.jp/)
- ニコニコ動画(https://www.nicovideo.jp/)
ニコニコ動画ゲームカテゴリランキングの上位100に入った動画と投稿者の情報を取得する。
Q. なぜニコニコ動画?
A. 私も投稿者だからです(宣伝)。https://www.nicovideo.jp/user/35233530取得したい情報
- 動画情報
- 動画ID
- 投稿日時
- 再生時間
- 過去最高ランク
- タグ
- 投稿者情報
- 投稿者ID
- ユーザー登録時のニコニコ動画のバージョン
- フォロワー数
- 投稿動画数
Beautiful Soupについて
事前準備
BeautifulSoupをインストール
$ pip install beautifulsoup4基本的な使い方
import urllib.request from bs4 import BeautifulSoup url="対象のURL" html = urllib.request.urlopen(url) soup = BeautifulSoup(html, "html.parser") #引数はどれか1つ以上でOK。最初に見つかったタグが返される。 hoge = soup.find("HTMLタグ名",class_="タグのクラス名",id="タグのID") #条件に一致する全てのタグが返される。 hoge = soup.find_all("HTMLタグ名",class_="タグのクラス名",id="タグのID") #あるタグの子要素に限定して検索することも可能。 hogehoge=hoge.find("HTMLタグ名",class_="タグのクラス名",id="タグのID") #タグのテキストを取得 print(hoge.text) #タグの属性値を取得 print(hoge["href"])エラー対策
ネットワークエラーの対策。
503エラーが発生することがあるので。
時間を空けてリトライ。それでもダメなら諦め。try: html = urllib.request.urlopen(_Url) except urllib.error.HTTPError as e: print(e.code) sleep(60) html = urllib.request.urlopen(_Url) soup = BeautifulSoup(html, "html.parser")タグが見つからないエラーの対策。
HTMLが上手く読めてない可能性があるので時間を空けてリトライ。
それでもダメなら諦め。try: tag_panel=soup.find(class_="クラス名1").find(class_="クラス名2") except: try: print("error") sleep(60) #再読み込み html = urllib.request.urlopen(_Url) soup = BeautifulSoup(html, "html.parser") tag_panel=soup.find(class_="クラス名1").find(class_="クラス名2") result=tag_panel.text except: print("error") result = Noneスクレイピングの注意点
- サイトの規約を読みましょう。
- 相手のサーバーに負担をかけるため、sleep等でリクエストの間隔を空けましょう。1秒以上は空けたほうが良さげ。
JSON出力
辞書型からJSONファイルで出力。エンコードはUTF-8で出力。Shift_Jisは文字化けしたり何かと厄介。
ensure_ascii=Falseも忘れずに。
ほんとはwith句でやると安全。fw = open("ファイル名",'w',encoding='utf-8') json.dump(_dictionary,fw,indent=4,ensure_ascii=False) fw.close()実際にやってみた
エラー対策は頻発する箇所のみ実施。
#%% import urllib.request import re import datetime import json import sys from bs4 import BeautifulSoup from time import sleep #ニコニコチャートからスクレイピング ###ランキングページを開く def setRankPage(_dateStr): url="http://www.nicochart.jp/ranking/game/"+_dateStr html = urllib.request.urlopen(url) print(url) soup = BeautifulSoup(html, "html.parser") return soup ##動画IDと動画URLと投稿者名、IDとURLの取得 def getRankInfo(_soup,_num): rank=_soup.find(id="rank"+str(_num)) link=rank.find(class_="title").find("a") infoUrl="http://www.nicochart.jp/"+str(link["href"]) videoId=re.findall('\d+',link["href"])[0] print(infoUrl,videoId) ##投稿者名とURLの取得 nameInfo=rank.find("em",class_="user") if not nameInfo: return {"videoId":videoId,"videoUrl":infoUrl,"userName":None,"userUrl":None} nameInfo=nameInfo.find("a") nameUrl=str(nameInfo["href"]) userId=re.findall('\d+',nameUrl)[0] nameUrl += "/video" name=rank.find("em",class_="name").find("a").text print(name,nameUrl) return {"videoId":videoId,"videoUrl":infoUrl,"userName":name,"userId":userId,"userUrl":nameUrl} ###動画URLからタグ、投稿日時、最高ランク、再生時間の取得 def getVideoInfo(_infoUrl): try: html = urllib.request.urlopen(_infoUrl) except urllib.error.HTTPError as e: print(e.code) sleep(60) html = urllib.request.urlopen(_infoUrl) soup = BeautifulSoup(html, "html.parser") ##タグの取得 try: tag_panel=soup.find(class_="tab-panel").find(class_="cloud") tags=tag_panel.find_all("a",class_="word") tagWords=list(map(lambda tag: tag.text, tags)) except: try: print("error") sleep(60) html = urllib.request.urlopen(_infoUrl) soup = BeautifulSoup(html, "html.parser") tag_panel=soup.find(class_="tab-panel").find(class_="cloud") tags=tag_panel.find_all("a",class_="word") tagWords=list(map(lambda tag: tag.text, tags)) except: print("error") tagWords=None print(tagWords) ##投稿日時の取得 date=soup.find("dd",class_="first-retrieve").find("span").text ##再生時間の取得 length=soup.find("span",class_="length").text ##最高ランクの取得 nicoRank=soup.find(class_="point-data").find_all("td",class_="fav") nicoRank=list(map(lambda rank:rank.find_all("a"),nicoRank)) nicoRank=list(map(lambda rank:sys.maxsize if len(rank)==0 else int(rank[len(rank)-1].text),nicoRank)) nicoRank=min(nicoRank) print(nicoRank) return {"tags":tagWords,"date":date,"length":length,"maxRank":nicoRank} ###投稿者情報から投稿者の基本情報を取得 #投稿者URLからフォロワー数、投稿動画数、ユーザーID、ニコ動Verを取得。 def getUserInfo(_nameUrl): try: html = urllib.request.urlopen(_nameUrl) except urllib.error.HTTPError as e: print(e.code) return {"followerNum":None,"videoNum":None,"nicoVer":None} soup = BeautifulSoup(html, "html.parser") ##基本情報の取得 followerNum=soup.find(class_="stats channel_open_mb8").find_all(class_="num")[1].text followerNum=followerNum.replace(',',"") videoNum=soup.find(class_="content",id="video").find("h3").text videoNum=re.findall('\d+', videoNum) if videoNum: videoNum=videoNum[0] else: videoNum=None idInfo=soup.find(class_="accountNumber").find("span").text nicoVer=re.findall('(?<=\().*?(?=\))',idInfo)[0] print(followerNum,videoNum,nicoVer) return {"followerNum":followerNum,"videoNum":videoNum,"nicoVer":nicoVer} ###ランキングから動画URLと投稿者情報の取得 def getRankDataDay(_dateStr): soup=setRankPage(_dateStr) rankData=[] for rankNum in range(1,100): print("//////",rankNum,"//////") rankData.append(getRankInfo(soup,rankNum)) print(rankData) ###動画一覧、投稿者一覧の作成 videoData={} userData={} user_videoData={} num=0 for rank in rankData: num +=1 videoId=rank["videoId"] videoData[videoId]={"videoUrl":rank["videoUrl"]} if not "userId" in rank: continue userId=rank["userId"] user_videoData[videoId]={"userId":rank["userId"]} if not userId in userData: userData[userId]={"userName":rank["userName"],"userUrl":rank["userUrl"]} ###動画一覧にタグ情報を追加 for video in videoData.values(): print("/////////",video["videoUrl"]) videoInfo=getVideoInfo(video["videoUrl"]) video.update(videoInfo) sleep(2) ###投稿者一覧に投稿者情報を追加 for user in userData.values(): userInfo=getUserInfo(user["userUrl"]) user.update(userInfo) sleep(1) print(videoData) print(userData) return {"videoData":videoData,"userData":userData,"user_videoData":user_videoData} ###Json出力 def outputJson(_dateStr,_data): fw = open("VideoData/"+ _dateStr +".json",'w',encoding='utf-8') json.dump(_data,fw,indent=4,ensure_ascii=False) fw.close() return ###指定期間分のデータを取得。指定日の前日から取得開始。 date = datetime.date(2018,10,19) count=200 for num in range(count): date -=datetime.timedelta(days=1) dateStr=date.strftime("%Y%m%d") rankDataDay=getRankDataDay(dateStr) outputJson(dateStr,rankDataDay["videoData"]) outputJson(dateStr,rankDataDay["userData"]) outputJson(dateStr,rankDataDay["user_videoData"])結果
データ収集が完了。JSON形式で出力。
次回はこのデータをSQLデータベースにシュウウウウウウ!!!!超!!!エキサイティン!!!!!。参考
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-beautiful-soup
- 投稿日:2019-02-03T20:52:38+09:00
キーワード抽出をpythonでする。(yahooさんの力を借りて)
1 動機
yahooさんのapiを使ってのキーワード抽出をしたいと思ったがサンプルコードがPHPしかなかった。
(https://developer.yahoo.co.jp/sample/jlp/sample3.html)
pythonでしたいよ〜2 できること
文章を入れると、キーワード単語とその重要度が出力される。
3 サンプルリクエストURL
https://jlp.yahooapis.jp/KeyphraseService/V1/extractappid="yahoocliantID"&sentence=<対象のテキスト>
yahooのcliant ID取得:(https://developer.yahoo.co.jp/yconnect/v2/registration.html)4 コード
keyword.pyimport urllib.request import sys import xml.etree.ElementTree as ET #sentence=解析したい文章 def key(sentence): url="https://jlp.yahooapis.jp/KeyphraseService/V1/extract?appid=<yahooのcliant ID>&sentence="+urllib.parse.quote(sentence) req = urllib.request.Request(url) with urllib.request.urlopen(req) as res: body = res.read() root = ET.fromstring(body) output=[] for child in root: sen=child[0].text+":"+child[1].text output.append(sen) return output[参照]
・URLに日本語を含む時の対処(https://note.nkmk.me/python-urllib-parse-quote-unquote/)
・xmlを取得(https://qiita.com/Takaki_/items/4ba7f5e327296d403e65)
- 投稿日:2019-02-03T20:40:29+09:00
No.024【Python】 setの集合演算について④
今回も引き続き、「setの集合演算」の続きについて書いていきます。
I'll write about "set operations in python" continuously on this page.■ len関数により、setの要素数を調べる
Research the number of elements with len function・ リストやタプルと同じように、setの要素数をlen関数で知ることができます。
As same as lists and tuples, you can get the number of elements with "len function".
>>> sandwich_set = {"egg", "bread", "mayonnaise", "salt", "pepper"} >>> >>> len(sandwich_set) 5■ 演算子でsetの要素を調べる
Search elements of set with "in" or "notin" operators.
setに特定の値が含まれているかどうかを、in または notin 演算子にて調べることができます。
You can search for specific value in a set with "in" or "notin" operators.>>> set = {"egg", "bread", "mayonnaise", "salt", "pepper"} >>> >>> "egg" in set True >>> >>> "oiveoil" in set False■ setの比較 (Comparison of sets)
・set同士を比較する方法は、以下の3つに分けられます。
There are three methods to compare sets below;
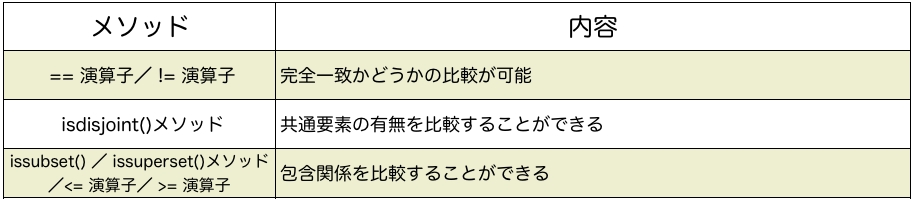
・ 「==」演算子により、setの完全一致の比較をする
Compare elements for perfect matching>>> a = {1, 2, 3} >>> >>> b = {3, 1, 2} >>> >>> c = {1, 2, 3, 4} >>> >>> a == b True >>> >>> a == c False >>> >>> # aとbが一致していないかの比較 >>> >>> a != b False >>> >>> # aとcが一致していないかの比較 >>> >>> a != c True■isdisjoint()メソッドにより、共通要素の有無を比較する
Know "presence or absence" for common elements with "isdisjoint()method">>> a = {"egg", "bread", "mayonnaise"} >>> >>> b = {"pepper", "salt"} >>> >>> c = {"egg", "oliveoil"} >>> >>> #aとbに共通要素がない場合、True >>> a.isdisjoint(b) True >>> >>> #aとcに共通要素がない場合、False >>> a.isdisjoint(c) False■ issubset() / issuperset()メソッドにより、集合の包含関係を比較する
Compare the inclusion relation for sets with issubset() / issuperset() methods・2つのset(集合)を比較した際、どちらかが片方の要素を全て含んでいるかを調べることができます。
aの要素の全てがbに含まれている場合...・「サブセット(部分集合)」: aがbに対して
・「スーパーセット(上位集合)」: bはaに対して
>>> a = {"egg", "bread"} >>> >>> b = {"egg", "bread", "mayonnaise", "salt", "pepper"} >>> >>> a.issubset(b) True >>> >>> #<= 演算子とissubset()メソッドは同じである >>> >>> a <= b True >>> >>> #bはaのスーパーセットなので、Trueとなる >>> >>> b.issuperset(a) True >>> >>> #issuperset()メソッドは、>= 演算子と同じである >>> >>> b >= a Trueいかがでしたでしょうか
How was my post?
本ブログは、随時に更新していきますので、
定期的な購読をよろしくお願いします。I'll update my blogs at all times.
So, please subscribe my blogs from now on.本ブログについて、
何か要望等ありましたら、気軽にメッセージをください!If you have some requests, please leave some messages! by You-Tarin
また、「Qiita」へ投稿した内容は、随時ブログへ移動して行きたいと思いますので、よろしくお願いします。

- 投稿日:2019-02-03T20:38:48+09:00
ラズパイ(Raspbian Jessie)でpythonのvenvしたときにErrorで詰まった話
環境
- Raspberry Pi 3
- Raspbian Jessie
- Python 3.4 (Python 2系と共存)
起きたこと
ラズパイでFlask開発しようと思い,本家ページを見ながら導入しようとしたとき,以下のエラーが発生
$ python3 -m venv app Error: Command '['/(パス)/app/bin/python3', '-Im', 'ensurepip', '--upgrade', '--default-pip']' returned non-zero exit status 1このエラーを調べると,次のようにpipインストールを回避して,後からpip入れればいいやん,という対策が多くヒット.
$ python3 -m venv --without-pip appただこの後のpipインストールが仮想環境を構築するたび毎回するのは面倒.
対策
色々試していると,どうも
ensurepipのモジュールが入っていない様子.
sh
$ python3 -m ensurepip
/usr/bin/python3: No module named ensurepip
以下コマンドでvenvできるようになりました.
$ sudo apt install python3-venv
- 投稿日:2019-02-03T20:34:52+09:00
テレビ放送から諸々扱えそうなテキストを取得する
はじめに
マイニングに使われていたらしい「ビデオ出力のないビデオカード(RX470)」と「PCIExpress x1が10個以上あるマザーボード(CPU込)」を入手しました。「目的のためのお買い物」ではなく「目的は買ってから考える」のはいつものこと^^;、ということで。
今更マイニングもないし、機械学習とかかな?チャットボット作ってみたいな~、と調べてみると、大量の学習データが必要とか。学習データ、どうやって調達するのかしら?と先人の業を見るに、ネットにある会話コーパスを利用したり、twitterでreplyを集めたり、とからしく。
他に会話を集める方法はないのかしら?と考えていたら
「放送電波に垂れ流しになってる会話を利用すればいいんじゃね?」
となにかが降りてきました。
そういえば、データ放送に文字情報ってあるよね?目的
というわけで。テレビの放送電波に乗ってる文字情報を、いろいろに喰わせられるテキストにしてみたいと思います。
実際になにをやるか、というと、地上波放送を録画したTSファイル、たとえば2019/01/07 23:50 から NHK総合 で放送された 「みんなで筋肉体操 腕立て伏せ(2)」 の録画ファイルから皆さん 筋トレしてますか?
「みんなで筋肉体操」です。
筋トレは 継続して行わなければ効果は上がりません。
楽しんで 筋肉を追い込んでいきましょう。
今日は 腕立て伏せです。
分厚い胸板力強い上半身を作りましょう。
1種目目は 60秒インターミッテント・プッシュアップです。……といったテキストファイルを得る、というのを目的とします。
楽しんで「筋肉は裏切らない」を学習させていきましょう(ぇー環境
- OS: Ubuntu18.04
- 地上デジタルTVチューナー: PX-S1UD V2.0
- 録画ソフト: recdvb
今回は文字情報が目的になります。画質などは重要ではないですし、ワンセグで充分ですのでB-CASカードやカードリーダーは不要になります。つか、B-CASカードだのカードリーダーを用意するのがめんどい^^;。
ワンセグにしたのは画質が必要ない、と同時に、フルセグを録画したファイルとかサイズがバカでかいのでね……厳しいのですよ、HDDの容量的に。
フルセグチューナーをワンセグチューナーとして利用するのもなんですが、PX-S1UD が家で利用場所もなく転がっていましたので。秋葉原あたりで500円くらいで売ってるワンセグチューナーはLinuxで使うにはちょっとキツいしね、というのもあります。ここではすでに PX-S1UD を使って recdvb で録画できる状態にある、ということで話を進めさせていただきます。
字幕抽出
字幕抽出、の前に。実験用に放送を実際に録画してファイルにしておきましょう。
recdvb --sid 1seg 27 120 test.m2ts問題はこの録画したファイルに字幕テキストが入っているかどうか?です。VLCなどで再生できる環境があるのでしたら、字幕を表示することができますので見ておいてください。
NHKの番組であれば、日付変わってから朝7時くらいまでの放送以外はほぼ入っているようです。
NHKと契約していないなどで観れない場合、NHK以外の在京キー局の放送では、ドラマなどはほぼ入っていましたが、生放送では入ってない番組もあるようです。
私が確認した範囲では、日曜日の午前8時30分からのテレビ朝日の番組では字幕が入っていることを確認しています(んー?。字幕抽出ソフト選択
字幕を抽出する方法ですが、今回以下の方法を試してみました。
- Python3 で ariblib を利用して出力
- Windows用のCaption2AssC.exe を wine を使って利用して出力
- assdumperを利用して出力
まず 1.ですが、今回録画したワンセグファイルを入れた場合には、なにも出力されませんでした。ちなみに、家で録画PC(Windows10)で録画したフルセグ動画もなにも出力されず、でした(ちゃんと試していないのでおそらくですが、recdvb でフルセグ録画した場合は出力されると思います)。
次に 2.については、録画WinPCによるフルセグ動画からは字幕情報が取れましたが、今回録画したワンセグファイルからは出力できず。
最後に、3.は今回録画したワンセグファイルから出力できました。なので、今回の用途では 3.を使います。
今回使用する 3. のassdumper(あるいは2.のCaption2AssC)では、Advanced SubStation Alpha(以下 ASS)という字幕の形式になります。これを後に通常のテキストにしていくことにします。assdumperビルド
ソースを持ってきます
$ svn export https://github.com/eagletmt/eagletmt-recutils/trunk/assdumperassdumper をそのままビルドしたのでは、話者を識別するために字幕でよく使われる文字色が出力されません。なので出力を追加します。
今回は「色が変わったことだけわかればいい」という考えなので、これをそのまま字幕として別のソフトなどに喰わせてもいいものかは知りませんので注意。--- assdumper/assdumper.cc 2017-01-19 21:34:56.000000000 +0900 +++ assdumper_/assdumper.cc 2019-02-02 22:18:58.967834742 +0900 @@ -204,6 +204,8 @@ public: { const unsigned char *end = str + len; std::string ans; + unsigned char prev_color = 7; + std::string colors[] = {"000000","0000ff","00ff00","00ffff","ff0000","ff00ff","ffff00","ffffff"}; for (const unsigned char *p = str; p < end; ++p) { if (0xa0 < *p && *p < 0xff) { char eucjp[3]; @@ -233,7 +235,11 @@ public: } ++p; } else if (0x80 <= *p && *p <= 0x87) { - // color code. ignore + if( prev_color == (*p - 0x80)){ + }else{ + ans += "{\\c&H" + colors[*p - 0x80] + "&}"; + } + prev_color = *p - 0x80; } else if (*p == 0x0d) { // CR -> LF ans += "\\n";パッチを当てたら、
makeして出来た assdumper をパスが通った場所にでも置いてください。字幕抽出結果
2019/01/27 08:30 からテレビ朝日で放送された「HUGっと!プリキュア」が入った録画ファイルを入れるとこのようになります。
$ assdumper rec/20190127/rec24_20190127080818.m2ts program_number = 1448, program_map_PID = 8136 1 pmt_pids 8136 388 caption pid, PCR_PID = 257 [Script Info] ScriptType: v4.00+ Collisions: Normal ScaledBorderAndShadow: yes Timer: 100.0000 [Events] : (中略) : Dialogue: 0,00:14:18.76,00:14:22.46,Default,,,,,, {\c&H00ffff&}・うぅぅぅ…・\n{\c&Hffffff&}・(さあや)はい 息はいて〜・ Dialogue: 0,00:14:22.46,00:14:25.93,Default,,,,,, {\c&H00ffff&}はぁ〜! うぅぅ… Dialogue: 0,00:14:25.93,00:14:31.02,Default,,,,,, {\c&H00ffff&}あぁぁぁ〜…\n{\c&Hffffff&}(さあや)上手 上手 Dialogue: 0,00:14:31.02,00:14:37.04,Default,,,,,, ・(ほまれ)はな!・\n{\c&H00ffff&}うぅっ はぁ… Dialogue: 0,00:14:37.04,00:14:40.74,Default,,,,,, (ダイガン)おぉ!\n{\c&H00ffff&}ほまれ… Dialogue: 0,00:14:40.74,00:14:43.05,Default,,,,,, 間に合ったね Dialogue: 0,00:14:43.05,00:14:46.52,Default,,,,,, {\c&H00ffff&}来てくれたんだ Dialogue: 0,00:14:46.52,00:14:50.92,Default,,,,,, はな! フレフレ! Dialogue: 0,00:14:50.92,00:14:53.23,Default,,,,,, {\c&H00ffff&}わぁ… Dialogue: 0,00:14:53.23,00:14:54.85,Default,,,,,, がんばれ! Dialogue: 0,00:14:54.85,00:14:56.93,Default,,,,,, {\c&H00ffff&}うん Dialogue: 0,00:14:56.93,00:15:00.40,Default,,,,,, さぁ いくよ 赤ちゃん がんばってる! Dialogue: 0,00:15:00.40,00:15:06.65,Default,,,,,, {\c&H00ffff&}うん! Dialogue: 0,00:15:06.65,00:15:09.89,Default,,,,,, {\c&H00ffff&}<子どもの頃 なりたかったわたしに Dialogue: 0,00:15:09.89,00:15:14.05,Default,,,,,, {\c&H00ffff&}わたしは なれたのかな…> Dialogue: 0,00:15:14.05,00:15:17.06,Default,,,,,, {\c&H00ffff&}うぅぅ〜 あぁ〜 Dialogue: 0,00:15:17.06,00:15:20.30,Default,,,,,, {\c&H00ffff&}うぅ〜… Dialogue: 0,00:15:20.30,00:15:23.30,Default,,,,,, {\c&H00ffff&}<未来は 楽しいことばかりじゃない> Dialogue: 0,00:15:23.30,00:15:26.77,Default,,,,,, {\c&H00ffff&}<めげそうになることも いっぱいある> : (以下略) :このように、ASSの形式で出力されます。
このままでは使い勝手が悪いので、使いやすいようテキスト整形をしていきます。テキスト整形
assの字幕ファイルを整形していくわけですが、これが困ったことに「タグ〇〇が入ったら話者が変わる」「××が表れたら一文が終了」などという決まりはないようです。局によって、あるいは番組によってかなりまちまちなようです。あくまで映像・音声とともに流れる字幕ですので、字幕を読んだ人が他の情報と統合して補う、ということなのでしょう。
とはいえ、整形にはある程度ルールを決めていかないと仕方ないので、ルールを決めて整形をしていくことにします。
整形ルール
とりあえず、今回は以下のような整形ルールで整形をするようにします。
- 字幕文字列が空の場合は無視する
- 「音符 + "~"」の場合は音楽が流れているだけとみなし無視する
- 字幕表示開始時間が、直前の字幕表示終了時刻から5秒以上経過していた場合は、別の文章・会話とする(ブランク行を入れる)
- 文字色が直前と比較して変化した場合は、別の文章・人の発言とする
- 「。(読点)」「!」「?」等が字幕行末に来た場合は、次の字幕は別の文章・人の発言とする
- 字幕行末に「→」等、矢印の記号が来た場合は次の字幕に文章が続くとする
- 丸括弧の中は、発言している人の名前、または状況説明とみなしてテキストには出力しない
- カギ括弧(「」)、角括弧([])、山括弧(<>)などの中は発言や思ってることとしてテキストに出力する
これで "見ている範囲" では "今のところ" は "それなりに" 整形されているようです。
あくまで私が「今のところ」「見ている範囲」ですので頼りすぎるのは危険ですし、後述しますが、すでに駄目な場合もあります。あくまで「それなり」です(責任逃れの防壁準備)。
このルールについてはうまく整形できてない例を見つけ次第、適宜決めていくしかないような気がします。皆さんにも「テレビを見ているときに迂闊に字幕をONにしてしまい、整形がうまくいきそうにない字幕を見つけて苦しむ」呪いがかかるといいと思います(ぁ?。
整形用スクリプト
整形のために作成したPythonスクリプトを示します。
ass2text.py#!/usr/bin/python3 # -*- coding: utf-8 -*- import sys import re noserif = ['♬~', '♬〜', '♪~'] cmark = ['→', '➡'] eos = ['。', '。', '!', '!', '?', '?', '⁉', '‼'] ndbraket = ['<', '>', '〈', '〉', '《', '》', '≪', '≫', '\[', '\]', '[', ']'] reb = '|'.join(ndbraket) + '|「|」[。。]{0,1}'; ndbraket.extend(['「', '」', '」。', '」。']) def HMSms2as(t): ht = re.split('[:.]', t) r = ( int(ht[0]) * 60 * 60 * 100 ) + \ ( int(ht[1]) * 60 * 100) + \ ( int(ht[2]) * 100 ) + \ ( int((ht[3]+"0")[:2]) % 100 ) return r def ass2array(fn): b = False r = [] try: f = open(fn) l = f.readline() while l: s = l.replace("\n","") if 0 < len(s): if '[' == s[0]: if '[events]' == s[0:8].lower(): b = True l = f.readline() continue else: b = False else: if b: if 'dialogue:' == s[0:9].lower(): c = 'ffffff' d = s[10:].split(',') if 'default' == d[3].lower(): txt = [x for x in re.split('({|})', ','.join(d[9:]).strip()) if not ''==x] st = HMSms2as(d[1]) et = HMSms2as(d[2]) tb = False buf = [] for t in txt: if "{" == t: tb = True continue if "}" == t and tb: tb = False continue if tb: m = re.search('\\\d{0,1}c&H([0-9a-fA-F]+)', t) if m: c = m.group(1) else: ta = [x for x in re.split('\\\\[nN]', t.replace('\\h', ' ')) if not ''==x] for tf in ta: buf = [tf, c, st, et] r.append(buf) l = f.readline() f.close except Exception as e: print(e) pass return r def tsplit(text): r = [] ta = [x.strip() for x in re.split('(\(|\)|(|)|' + reb + ')', text) if not ''==x] tb = False for t in ta: if t in ['(', '(']: tb = True continue if t in [')', ')']: tb = False continue if t in ndbraket: continue if tb: pass else: if not t in noserif: r.append(t) return r if __name__ == '__main__': if 2 != len(sys.argv): print('Usage: # python %s filename' % sys.argv[0]) quit() aary = ass2array(sys.argv[1]) j=0 tary = [] t = "" for i in range(len(aary)): if aary[i][0] in noserif: continue if 0 < i: if 500 > ( aary[i][2] - aary[i-1][3]): if aary[(i-1)][1] != aary[i][1]: tary.extend(tsplit(t)) t = aary[i][0] else: if t[-1:] in eos: tary.extend(tsplit(t)) t = aary[i][0] elif t[-1:] in cmark: t = t[:-1] + aary[i][0] else: t = t + aary[i][0] else: tary.extend(tsplit(t)) tary.append("") t = aary[i][0] else: t = aary[i][0] if "" != t: tary.extend(tsplit(t)) for t in tary: print (t)整形結果
先に挙げました「HUGっと!プリキュア」のASSファイルをスクリプトを通して整形した結果、以下のようになりました。
・うぅぅぅ…・ ・ はい 息はいて〜・ はぁ〜! うぅぅ…あぁぁぁ〜… 上手 上手・ はな!・ うぅっ はぁ… おぉ! ほまれ… 間に合ったね 来てくれたんだ はな! フレフレ! わぁ… がんばれ! うん さぁ いくよ 赤ちゃん がんばってる! うん! 子どもの頃 なりたかったわたしにわたしは なれたのかな… うぅぅ〜 あぁ〜うぅ〜… 未来は 楽しいことばかりじゃない めげそうになることも いっぱいある複数人の発言が一行に入っていたのが複数行になっている(「はぁ〜! うぅぅ…あぁぁぁ〜…」「上手 上手」とか)、1人のセリフが複数行にわたっていたのが1行になっている(「子どもの頃 なりたかったわたしにわたしは なれたのかな」とか)、というのがわかりますでしょうか。
このプリキュアの例ではあまり整形効果なさそうに見えますが(じゃぁなぜ例として挙げた^^;)、最初に挙げた筋肉体操では
Dialogue: 0,0:00:31.13,0:00:34.96,Default,,0000,0000,0000,,{\pos(264,438)\c&H00ffff&}筋トレは 継続して行わなければ\N Dialogue: 0,0:00:31.13,0:00:34.96,Default,,0000,0000,0000,,{\pos(290,518)\c&H00ffff&}効果は上がりません。\N Dialogue: 0,0:00:34.96,0:00:38.26,Default,,0000,0000,0000,,{\pos(184,518)\c&H00ffff&}楽しんで 筋肉を追い込んでいきましょう。\N Dialogue: 0,0:00:40.77,0:00:43.17,Default,,0000,0000,0000,,{\pos(344,518)\c&H00ffff&}今日は 腕立て伏せです。\N Dialogue: 0,0:00:43.17,0:00:46.67,Default,,0000,0000,0000,,{\pos(370,438)\c&H00ffff&}分厚い胸板\N Dialogue: 0,0:00:43.17,0:00:46.67,Default,,0000,0000,0000,,{\pos(397,518)\c&H00ffff&}力強い上半身を作りましょう。\Nと一文が複数行(複数字幕)にわたることが多いため、整形の効果はわかっていただけるのではないでしょうか?
ただ、先にも書いたとおり「駄目な場合」もありました。先に挙げたプリキュアのASS、別の箇所にある次のような出力を見てみます。
Dialogue: 0,15:29:47.81,15:29:52.21,Default,,,,,, {\c&H00ffff&}実はわたし みんなを守るプリキュアなの Dialogue: 0,15:29:52.21,15:29:54.75,Default,,,,,, {\c&H00ffff&}あっ この子は 空からふってきた Dialogue: 0,15:29:54.75,15:29:58.45,Default,,,,,, {\c&H00ffff&}不思議な赤ちゃん はぐたん\n{\c&Hffffff&}はぎゅ!整形結果はこうなります。
実はわたし みんなを守るプリキュアなのあっ この子は 空からふってきた不思議な赤ちゃん はぐたん はぎゅ!「なの」と「あっ」の間、同じ人物(同じ文字色)のセリフですが、読点や字幕の時間などでは文章の区切りがわからないため一行になってしまっています。
今回はこれについては妥協します。
こういった場合を機械的に別の文章とできる、なにかいい方法をご存知の方いましたら教えてくださいまし。課題・問題
テレビ放送からテキストを取得する、という目的はおおよそ達成できたと思います。会話とかチャットボットの学習に使えるかはともかく(あれ?。
キャスターが淡々と伝えるようなニュース番組では、さすがに会話とはなりませんが、文章素材としてはかなり有用に使えるのではないかと思います。
トーク系のバラエティ番組では会話が取得できる、と思いきや、そうもいかないようです。以下は 2019/01/27 11:25 からテレビ東京で放送された「男子ごはん」のオープニングトーク部分です。
突然ですが 問題です。
わかりました。
はい 太一さん。
ブーッ!
ブーッ!
腹立つな。
ラストチャンス!
ピンポーン!
やった~!
大正解です。「問題です」「ブーッ!」「ピンポーン!」などのやりとりの中で問題や解答をちゃんと言っているのですが、字幕テキストに入ってきていません。
画面の映像にはテロップ文字が出てきますから、映像にテロップで文字を入れているから字幕として入れる必要はない、という判断なのでしょう。そのようになってる番組は多く見られます。
このような場合は字幕だけを追っても会話が成立しないことになります。
バラエティ番組などでは、発言や対するツッコミなどがテロップ側に出る番組が多くなっていますので、こういったことが発生しやすいようです。字幕を会話をデータとして取得したいならば、ドラマやアニメなどを中心に集めた方がいいかもしれません。……若干偏った会話になりそうな気はしますが(ぉ?。
もちろんバラエティ番組全てが会話を取得できないわけではなく、たとえば、司会者が「毎度おなじみ流浪の番組……」と言って始まる番組では、結構綺麗に会話が取得できます。
NHKがほぼ全ての番組で字幕テキストがあるのも印象的でした(2018年の紅白歌合戦の「勝手にシンドバッド」の曲中に「la la la…桑田君!」が入ってきてたくらい)。ただしETVについては、子供向け番組が多いせいでしょうか、漢字がほとんど含まれない番組も多く見られましたので、気に留めておくべきかもしれません。
テキストをどの用途によって使うか、という観点から番組を選択していく必要もあるでしょう。その際は放送波から抽出できる番組情報を使うことを考えていった方がいいかもしれません。
最後に
本当は、「切りかえしていこう」「なにが切りかえすのよ」「まぁまぁ無かった事にして」「後世まで語り継ぐよ」とか「負けて悔いなし」「さぁさぁ急ぎましょう」「キミの乗った馬車のように」とかの会話を取り出したかったのですが。現在関東で放送されているClassicには字幕情報はないようです。残念。
「ぼくはギャングスターになる」というアニメの「覚悟はいいか?オレはできてる」などのセリフも、と考えていたのですが。こちらも字幕情報がありませんでした。無念。
当初目的に対しての残念無念はありましたが、それなりに面白かったので、よしとしましょう。
「放送に含まれる字幕テキストを字幕以外に使う」というのが調べても、あまり出てこないように思えるのですが、「テキスト情報が常に得られるデバイス」と考えればなかなかに使いでがありそうに思えます。どうでしょう?
そうなるとバラエティ番組などで、映像側テロップに入ってるからと字幕には入ってこないような発言が取得できない、というのは非常に惜しいんですよね。どうにか字幕に入れてほしい、というのは、さすがにわがままですね。余談
放送局ごとに別々のチャットボットに学習させていった場合、同じ質問をしたときに個性など出るのでしょうか?
……若干黒い考えも思い浮かびましたが、検証はおまかせします > ここまで読んでくださった面々
- 投稿日:2019-02-03T20:06:59+09:00
pytest:フィクスチャの使い方
はじめに
pytestはPython用のテストツールです。
標準の
unittestに比べ、テストエラー時の結果が分かりやすいのが特徴です。例として、辞書オブジェクトを比較する以下のテストコードをunittestとpytestそれぞれで実行してみます。
# test_dict.py import unittest dict1 = {'name': 'Tom', 'age': 20} dict2 = {'name': 'John', 'age': 23} class TestUnitTest(unittest.TestCase): def test_one(self): assert dict1 == dict2unittestでの実行例。
$ python -m unittest F ====================================================================== FAIL: test_one (test_dict.TestUnitTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/Users/gaizaku/Develop/pytest_learning/test_dict.py", line 12, in test_one assert dict1 == dict2 AssertionError ---------------------------------------------------------------------- Ran 1 test in 0.000s FAILED (failures=1)一方、pytestでの実行例。
$ pytest -vv test_dict.py ================================ test session starts ================================ platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 1 item test_dict.py::TestUnitTest::test_one FAILED [100%] ===================================== FAILURES ====================================== _______________________________ TestUnitTest.test_one _______________________________ self = <test_dict.TestUnitTest testMethod=test_one> def test_one(self): > assert dict1 == dict2 E AssertionError: assert {'age': 20, 'name': 'Tom'} == {'age': 23, 'name': 'John'} E Differing items: E {'name': 'Tom'} != {'name': 'John'} E {'age': 20} != {'age': 23} E Full diff: E - {'age': 20, 'name': 'Tom'} E ? ^ ^ ^ E + {'age': 23, 'name': 'John'} E ? ^ ^ ^^ test_dict.py:12: AssertionError ============================= 1 failed in 0.08 seconds ==============================見ての通り、pytestはキー・バリューの差分まで表示してくれるので、何故テストが失敗したのか非常に分かりやすいです。
また、pytestにはプラグイン機構等のいくつかの機能があります。
その中でも特に便利な
フィクスチャ機能について、公式ドキュメントを参考に使い方をまとめました。フィクスチャ(fixture)とは
テストの前処理(DBをセットアップする、モックを作成するなど)を行うためのpytestの機能です。
個人的には、フィクスチャがあるからpytestを使っている言っても過言ではありません。
前処理はテストコードの保守性を低くする大きな原因ですが、フィクスチャ機能を上手に使うことでテストコードをクリーンに保つことが可能になります。
フィクスチャの概要
仮想的なデータベースオブジェクト
Usersクラスを使ってフィクスチャの概要を紹介します。# users_db.py class Users: def __init__(self): self.last_insert_id = 0 self.rows = {} def insert(self, name, age): self.last_insert_id += 1 self.rows[self.last_insert_id] = { 'id': self.last_insert_id, 'name': name, 'age': age, } def get(self, id_): return self.rows[id_]上記Usersクラスをテストするコードを記述します。
以下のテストコードでは
dbフィクスチャ(フィクスチャ関数とも言う)を定義しています。dbフィクスチャはダミーレコードを追加したUsersデーターベースを作成するという前処理を行っています。
テストケースの中でそのデーターベースを使いたい場合は、テストケースの引数に
dbと追加するだけでデーターベースを利用出来るようになります。# test_fixture_sample.py import pytest from users_db import Users # これがフィクスチャ @pytest.fixture def db(): users = Users() users.insert('Bob', 10) users.insert('Alice', 12) return users # dbフィクスチャを利用するテストケース def test_one(db): assert db.get(1)['name'] == 'Bob' # フィクスチャは複数のテストケースで共有できる def test_two(db): assert db.get(2)['name'] == 'Alice' # クラスベースのテストでも利用できる class TestUers: def test_one(self, db): assert db.get(1)['name'] == 'Bob'複数のフィクスチャを同時に使いたい場合は、単に引数に列挙すればOKです。
@pytest.fixture def fixture1(): pass @pytest.fixture def fiture2(): pass def test_foo(fixture1, fiture2): passunittestとの比較
比較として、unittestで同様のテストコードを記述してみます。
# test_unittest_setup.py import unittest from users_db import Users class TestUnittest(unittest.TestCase): def setUp(self): self.db = Users() self.db.insert('Bob', 10) self.db.insert('Alice', 12) def test_one(self): assert self.db.get(1)['name'] == 'Bob' def test_two(self): assert self.db.get(2)['name'] == 'Alice'$ python -m unittest test_unittest_setup.py .. ---------------------------------------------------------------------- Ran 2 tests in 0.000s OKconftest.pyによるフィクスチャの共有
先ほどのテストコードは規模も小さいので、unittestと比較した場合のフィクスチャのメリットが良く分からないかもしれません。
フィクスチャの真価はテスト間で共有出来る事にあります。
conftest.pyというファイルにフィクスチャを記述すると、そのフィクスチャは複数のテストコードから呼び出すことが出来るようになります。例として、先ほどの
dbフィクスチャをconftest.pyに移動します。# conftest.py import pytest from users_db import Users @pytest.fixture def db(): users = Users() users.insert('Bob', 10) users.insert('Alice', 12) return usersフィクスチャを移動した後でもテストは問題なくパスします。
$ pytest -q test_fixture_sample.py ... [100%] 3 passed in 0.02 secondsこれで今後テストが増えたとしても、引数に
dbと記述するだけでフィクスチャを利用出来ます。unittestの場合は毎回setUpメソッドを記述しないといけないので、フィクスチャがテストコードをシンプルに保つのに便利な機能で有ることが分かります。
スコープ
フィクスチャには
スコープ(scope)という概念があります。スコープを理解すると、フィクスチャ関数が実行される
粒度を制御出来るようになります。まず、以下にスコープの種類と実行粒度をまとめます。
スコープ名 実行粒度 function テストケースごとに1回実行される(デフォルト) class テストクラス全体で1回実行される module テストファイル全体で1回実行される session テスト全体で1回だけ実行される スコープの動作を理解するために
conftest.pyに4つのフィクスチャを追加します。各々のフィクスチャは実行されると自身のスコープ名をprintするので、これらを使ってスコープ毎の実行粒度を検証します。
@pytest.fixture(scope='function') def fixture_function(): print('function') @pytest.fixture(scope='class') def fixture_class(): print('class') @pytest.fixture(scope='module') def fixture_module(): print('module') @pytest.fixture(scope='session') def fixture_session(): print('session')次に、3つのテストコードを作成します。
# test_scope_sample1.py class TestScopeSample1: def test_one(self, fixture_function, fixture_class, fixture_module, fixture_session): pass def test_two(self, fixture_function, fixture_class, fixture_module, fixture_session): pass# test_scope_sample2.py class TestScopeSample2: def test_one(self, fixture_function, fixture_class, fixture_module, fixture_session): pass def test_two(self, fixture_function, fixture_class, fixture_module, fixture_session): pass# test_scope_sample3.py # 注:このテストコードはfixture_classは使わない def test_one(fixture_function, fixture_module, fixture_session): pass def test_two(fixture_function, fixture_module, fixture_session): passテストを実行します。
$ pytest -vs test_scope_sample* ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 6 items test_scope_sample1.py::TestScopeSample1::test_one session module class function PASSED test_scope_sample1.py::TestScopeSample1::test_two function PASSED test_scope_sample2.py::TestScopeSample2::test_one module class function PASSED test_scope_sample2.py::TestScopeSample2::test_two function PASSED test_scope_sample3.py::test_one module function PASSED test_scope_sample3.py::test_two function PASSED =========================== 6 passed in 0.06 seconds ===========================出力結果から、各フィクスチャの実行回数をまとめます。
functionスコープのフィクスチャが最も頻繁に実行され、逆にsessionスコープのフィクスチャはテスト全体を通して1回しか実行されていません。つまり、下に行くほどコストが高い前処理に適している事が分かります。
スコープ名 実行回数 function 6回(テストケース数と等しい) class 2回(クラス数と等しい) module 3回(テストファイル数と等しい) session 1回(テスト開始直後に1回だけ実行) なお、
function以外のスコープを使う場合、フィクスチャがpytestにキャッシュされる点に注意します。下記の
moduled_dbフィクスチャはmoduleスコープなので、フィクスチャにより作成されたUsersデーターベースの中身はテスト全体で共有されており、test_threeは全てのレコードを参照することが出来ています。# test_fixture_cache.py import pytest from users_db import Users @pytest.fixture(scope='module') def moduled_db(): users = Users() return users def test_one(moduled_db): moduled_db.insert('Bob', 10) def test_two(moduled_db): moduled_db.insert('Alice', 12) def test_three(moduled_db): assert moduled_db.get(1)['name'] == 'Bob' assert moduled_db.get(2)['name'] == 'Alice'$ pytest -q test_fixture_cache.py ... [100%] 3 passed in 0.02 seconds終了処理(teardown)
テストが終了した後に何らかの
終了処理(DB接続のクローズや一時ファイルの削除等)をしたいシチュエーションは多いと思います。フィクスチャを使う場合、2種類の方法で終了処理を記述出来ます。
yieldを使うパターン
フィクスチャからテストケースに対してデータを渡す際、通常は
returnを使用しますが、代わりにyieldを使用するとテストの終了後に任意の処理を実行出来ます。例として、テスト終了時に全レコードを表示するという終了処理を記述してみます。
まず、データベースオブジェクトに全レコードを返させる
allメソッドを追加します。# users_db.py class Users: def all(self): return self.rows.values()次にフィクスチャとテストコードを作成します。
dbフィクスチャはyieldした段階でブロックされ、処理がテストケースへと移動します。
テストが終了すると処理はフィクスチャに戻り、yield以降の処理が実行されます。
# test_teardown_sample.py import pytest from users_db import Users @pytest.fixture def db(): users = Users() yield users print() for v in users.all(): print(v) def test_one(db): db.insert('Bob', 10) def test_two(db): db.insert('Tom', 15) db.insert('Alice', 12)テストを実行すると期待通りに全レコードが出力されます。
$ pytest -vs test_teardown_sample.py ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 2 items test_teardown_sample.py::test_one PASSED {'id': 1, 'name': 'Bob', 'age': 10} test_teardown_sample.py::test_two PASSED {'id': 1, 'name': 'Tom', 'age': 15} {'id': 2, 'name': 'Alice', 'age': 12} =========================== 2 passed in 0.01 seconds ===========================終了処理はテストの成否や例外の有無を問わず実行されるので、フィクスチャ内で例外キャッチ等のエラーハンドリングは必要ありません。(ただし、フィクスチャ関数内で発生するエラーは別です)
# test_teardown_sample.py def test_three(db): db.insert('Tom', 15) raise db.insert('Alice', 12)$ pytest -s test_teardown_sample.py::test_three ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 1 item test_teardown_sample.py F {'id': 1, 'name': 'Tom', 'age': 15} =================================== FAILURES =================================== __________________________________ test_three __________________________________ db = <users_db.Users object at 0x104d8ecc0> def test_three(db): db.insert('Tom', 15) > raise E RuntimeError: No active exception to reraise test_teardown_sample.py:29: RuntimeError =========================== 1 failed in 0.10 seconds ===========================また、functionスコープ以外のフィクスチャでは、終了処理はそのフィクスチャを利用する全テストが終わった後に1回だけ実行されます。
# test_teardown_sample.py @pytest.fixture(scope='module') # <-- スコープを変更 def db(): ...$ pytest -vs test_teardown_sample.py ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 3 items test_teardown_sample.py::test_one PASSED test_teardown_sample.py::test_two PASSED test_teardown_sample.py::test_three FAILED {'id': 1, 'name': 'Bob', 'age': 10} {'id': 2, 'name': 'Tom', 'age': 15} {'id': 3, 'name': 'Alice', 'age': 12} {'id': 4, 'name': 'Tom', 'age': 15} =================================== FAILURES =================================== __________________________________ test_three __________________________________ db = <users_db.Users object at 0x106433cf8> def test_three(db): db.insert('Tom', 15) > raise E RuntimeError: No active exception to reraise test_teardown_sample.py:29: RuntimeError ====================== 1 failed, 2 passed in 0.11 seconds ======================addfinalizerを使うパターン
yield以外には
addfinalizerを用いるパターンがあります。yieldと比較すると、addfinalizerには3つの大きな違いがあります。
- 終了処理をコールバック関数として登録する
- コールバック関数は複数登録できる
- フィクスチャ内で例外が起きたとしても必ず実行される
以下にシンプルなメールクライアントを用いたaddfinalizerの例を示します。
clientsフィクスチャが受け取っているrequestsはpytestが渡してくれる特殊なフィクスチャで、addfinalizerメソッドを使って終了処理を登録する事が出来ます。# test_addfinalizer_sample.py import pytest class MailClient: def close(self): print(f'Close smtp connection:', self) @pytest.fixture def clients(request): ret = [] for i in range(3): client = MailClient() request.addfinalizer(client.close) ret.append(client) return ret def test_one(clients): passテストを実行すると、メールクライアントの
closeメソッドが期待通りに3回呼ばれている事が分かります。$ pytest -sv test_addfinalizer_sample.py ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 1 item test_addfinalizer_sample.py::test_one PASSEDClose smtp connection: <test_addfinalizer_sample.MailClient object at 0x10ef6a940> Close smtp connection: <test_addfinalizer_sample.MailClient object at 0x10ef6a908> Close smtp connection: <test_addfinalizer_sample.MailClient object at 0x10ef6a8d0> =========================== 1 passed in 0.01 seconds ===========================ここで、clientsフィクスチャに意図的に例外を仕込んでみます。
# test_addfinalizer_sample.py @pytest.fixture def clients(request): ret = [] for i in range(3): client = MailClient() request.addfinalizer(client.close) raise # <-- 例外を追加 ret.append(client) yield retテストを実行すると、メールクライアントの生成は1つ目で終わってしまっていますが、生成されたクライアントに対するcloseメソッドはちゃんと呼ばれている事が分かります。
$ pytest -sv test_addfinalizer_sample.py ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 1 item test_addfinalizer_sample.py::test_one ERRORClose smtp connection: <test_addfinalizer_sample.MailClient object at 0x10561b828> ==================================== ERRORS ==================================== __________________________ ERROR at setup of test_one __________________________ request = <SubRequest 'clients' for <Function test_one>> @pytest.fixture def clients(request): ret = [] for i in range(3): client = MailClient() request.addfinalizer(client.close) # 終了処理を登録 > raise E RuntimeError: No active exception to reraise test_addfinalizer_sample.py:17: RuntimeError =========================== 1 error in 0.08 seconds ============================ファクトリ・フィクスチャ
これまで作成してきたフィクスチャは全て何らかの固定的なデータを返す物でした。
しかし、動的なデータが欲しいシチュエーションも多いと思います。
そういう時は、データを生成するための関数(ファクトリ)を返すフィクスチャを定義すると便利です。
そういったフィクスチャの事を公式ドキュメントでは
ファクトリ・フィクスチャと呼んでいます。以下は「任意の名前と長さを持つPersonオブジェクトのリスト」を返すファクトリ・フィクスチャの例です。
# test_factory_fixture.py import pytest class Person: def __init__(self, name): self.name = name def __repr__(self): return self.name @pytest.fixture def persons_factory(): def factory(names): return [Person(v) for v in names] return factory def test_one(persons_factory): persons1 = persons_factory(['Tom', 'Bob']) persons2 = persons_factory(['Alice', 'Nancy']) print(persons1, persons2)$ pytest -qs test_factory_fixture.py [Tom, Bob] [Alice, Nancy] . 1 passed in 0.01 secondsパラメタライズド・フィクスチャ
複数の入力値による網羅的なテストを行いたい場合はパラメタライズド・フィクスチャが便利です。
pytest.fixtureデコレータのparams引数にlist等のiterableを指定すると、含まれている各要素をパラメータとしたフィクスチャが自動で生成されます。以下は
Studentクラスをテストするコードです。Studentクラスは生徒が小学生なのか中学生なのかを教えてくれる
school_typeプロパティを持っているので、そのプロパティの動作をテストしています。# test_params_sample.py import pytest class Student: ELEMENTARY_SCHOOL = 1 JUNIOR_HIGH_SCHOOL = 2 def __init__(self, name, age): self.name = name self.age = age @property def school_type(self): if self.age >= 13: return self.JUNIOR_HIGH_SCHOOL else: return self.ELEMENTARY_SCHOOL @pytest.fixture(params=[('Tom', 10), ('Bob', 15), ('Alice', 12)]) def student(request): return Student(request.param[0], request.param[1]) def test_one(student): if student.age <= 12: assert student.school_type == 1 else: assert student.school_type == 2
studentフィクスチャは3つのStudentオブジェクトを返すので、それに合わせて3つのテストケースが実行されます。$ pytest -sv test_params_sample.py ============================= test session starts ============================== platform darwin -- Python 3.7.1, pytest-4.1.1, py-1.7.0, pluggy-0.8.1 -- /Users/gaizaku/.pyenv/versions/3.7.1/envs/pytest_learning/bin/python cachedir: .pytest_cache rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 3 items test_params_sample.py::test_one[student0] PASSED test_params_sample.py::test_one[student1] PASSED test_params_sample.py::test_one[student2] PASSED =========================== 3 passed in 0.02 seconds ===========================フィクスチャからフィクスチャを使う
フィクスチャには他のフィクスチャを利用できるという特性があります。
小さいメソッドが集まる事で複雑なクラスが出来上がるように、フィクスチャ同士を組み合わせる事で複雑な前処理を実現出来ます。
以下の例では、モック化されたメールサーバ接続を返す
mock_connectionフィクスチャと、それを利用してモック化されたメールクライアントを返すclientフィクスチャを定義しています。# test_fixture_in_fixture.py import pytest class MailClient: def __init__(self, connection): self.connection = connection def send(self, message): return self.connection.send(message) @pytest.fixture def mock_connection(): class MockConnection: def __init__(self): self.sents = [] def send(self, message): self.sents.append(message) return True return MockConnection() @pytest.fixture def client(mock_connection): return MailClient(mock_connection) def test_send(client): msg = 'Hello, world!' client.send(msg) assert client.connection.sents[0] == msg$ pytest test_fixture_in_fixture.py =================================== test session starts =================================== platform darwin -- Python 3.7.2, pytest-4.2.0, py-1.7.0, pluggy-0.8.1 rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 1 item test_fixture_in_fixture.py . [100%] ================================ 1 passed in 0.02 seconds =================================テストクラス・モジュール全体にフィクスチャを自動摘要する
pytest.mark.usefixturesを使うと、テストクラスやテストモジュール(test_*.py)全体にフィクスチャを自動で摘要出来るようになります。例としてまず、テストケース毎に初期化された一時ディレクトリを作成してくれるフィクスチャをconftest.pyに定義します。
# conftest.py import tempfil @pytest.fixture def tmpdir(): with tempfile.TemporaryDirectory() as dirname: os.chdir(dirname) yield上記フィクスチャを使う場合、もちろんテストケースの引数として記述しても良いのですが、このフィクスチャは何のデータも返さないので引数として受け取り意味をあまり感じません。
また、テストケースが増える度にいちいちフィクスチャ名を記述するのも冗長です。
そういった時は以下の様にテストクラスを
pytest.mark.usefixturesでデコレートしてあげると、各テストケースの実行前に自動でフィクスチャが実行されるようになります。# test_usefixtures_class.py import pytest @pytest.mark.usefixtures('tmpdir') class TestUseFixtures: def test_one(self): with open('hoge.csv', 'w') as f: f.write('Hello, world!') def test_two(self): with pytest.raises(FileNotFoundError): open('hoge.csv', 'r')$ pytest -q test_usefixtures_class.py .. [100%] 2 passed in 0.02 secondsまた、テストモジュール(.pyファイル)で利用する場合は以下の様にします。(
pytestmarkという変数に代入しないと動作しないので注意)# test_usefixtures_module.py import pytest pytestmark = pytest.mark.usefixtures('tmpdir') def test_one(): with open('hoge.csv', 'w') as f: f.write('Hello, world!')複数フィクスチャを利用する場合は列挙すればOKです。
pytest.mark.usefixtures('fixture1', 'fixture2', 'fixtureN')conftest.pyの階層化とオーバーライド
テストコードが階層構造を持っている場合、前述の
conftest.pyも各階層に配置することが出来ます。その場合、テストケースは
自身と同階層にあるconftest.pyと自身より上位層にあるconftest.pyに定義してあるフィクスチャを利用出来ます。また、子階層のフィクスチャは上位層のフィクスチャをオーバーライドする事も出来ます。
以下に階層構造のテストコードの例を示します。
$ tree hier_conftest/ hier_conftest/ ├── conftest.py ├── sub │ ├── conftest.py │ └── test_sub.py └── test_root.pyこれは上位層のconftest.pyです。
# hier_conftest/conftest.py import pytest @pytest.fixture def username(): return 'username'これは子階層のconftest.pyで、親の
usernameフィクスチャを利用しつつ、その結果をオーバーライドしています。# hier_conftest/sub/conftest.py import pytest @pytest.fixture def username(username): return 'sub-' + username親階層のテストコードです。
# hier_conftest/test_root.py def test_username(username): assert username == 'username'子階層のテストコードです。
# hier_conftest/sub/test_sub.py def test_username(username): assert username == 'sub-username'テストを実行すると期待通りにオーバーライドされている事が分かります。
$ pytest hier_conftest/ =========================== test session starts =========================== platform darwin -- Python 3.7.2, pytest-4.2.0, py-1.7.0, pluggy-0.8.1 rootdir: /Users/gaizaku/Develop/pytest_learning, inifile: collected 2 items hier_conftest/test_root.py . [ 50%] hier_conftest/sub/test_sub.py . [100%] ======================== 2 passed in 0.03 seconds =========================
- 投稿日:2019-02-03T19:09:57+09:00
統計局のデータをプロットしてみる
概要
統計局e-stat APIからデータをCSV保存し、それをPandasで整形してプロット
工業統計2017
データ取得までを
コピー参照させていただいたサイト*ここでは上記サイト手法によりすでに全統計表目録データを入手したものとします。
まずは全統計表目録データを取得
# 表のリスト読み込み strとしないと0始まりのデータが0消える。 df = pd.read_csv('data_04/all_stats_list.csv', dtype=str) # 2017年のデータにする df = df[df['SURVEY_DATE'].str.startswith('2017')]カラム項目はどの程度あるのか確認します。
print(df.columns) ''' Index(['id', 'CYCLE', 'GOV_ORG_val', 'GOV_ORG_code', 'MAIN_CATEGORY_val', 'MAIN_CATEGORY_code', 'OPEN_DATE', 'OVERALL_TOTAL_NUMBER', 'SMALL_AREA', 'STATISTICS_NAME', 'STATISTICS_NAME_SPEC_TABULATION_CATEGORY', 'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY1', 'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY2', 'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY3', 'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY4', 'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY5', 'STAT_NAME_val', 'STAT_NAME_code', 'SUB_CATEGORY_val', 'SUB_CATEGORY_code', 'SURVEY_DATE', 'TITLE', 'TITLE_val', 'TITLE_no', 'TITLE_SPEC_TABLE_CATEGORY', 'TITLE_SPEC_TABLE_NAME', 'TITLE_SPEC_TABLE_SUB_CATEGORY1', 'TITLE_SPEC_TABLE_SUB_CATEGORY2', 'TITLE_SPEC_TABLE_SUB_CATEGORY3', 'UPDATED_DATE'], dtype='object') '''
STAT_NAME_valに統計の種類名があるのでユニークな要素を全部出します。print('STAT_NAME_valユニーク数合計', df['STAT_NAME_val'].nunique()) print(df['STAT_NAME_val'].unique()) ''' STAT_NAME_valユニーク数合計 21 ['住民基本台帳人口移動報告' '人口推計' '就業構造基本調査' '科学技術研究調査' '法人企業統計調査' '学校基本調査' '就労条件総合調査' '農業物価統計調査' '漁業産出額' '農業構造動態調査' '漁業就業動向調査' '作物統計調査' '畜産統計調査' '食品産業企業設備投資動向調査' '工業統計調査' '商業動態統計調査' '特定サービス産業実態調査' '経済産業省企業活動基本調査' '経済産業省生産動態統計調査' '製造工業生産能力・稼働率指数' 'ガス事業生産動態統計調査'] '''面白そうなので
工業統計調査をみてみます。
はじめに紹介したサイトの手法により工業統計調査の中の全ての統計表をCSVにし、その中の0003237750[都道府県別、東京特別区・政令指定都市別統計表 (1)従業者4人以上の事業所に関する統計表 1 産業中分類別の事業所数、従業者数、現金給与総額、原材料使用額等、製造品出荷額等及び付加価値額]という統計データの中の各都道府県別の棒グラフをプロットします。# 数値変換して例外文字は0フィル df["value"] = pd.to_numeric(df["value"], errors='coerce').fillna(0) for i in df.columns: print('-----------------------') print('カラム', i, 'のユニーク数', df[i].nunique()) print(df[i].unique()[:25]) ''' ----------------------- カラム cat01_code のユニーク数 6 [17000000 18000000 20000000 21000000 22000000 23000000] ----------------------- カラム 確報(産業編)・集計項目(H25から) のユニーク数 6 ['事業所数' '従業者数(人)' '現金給与総額(百万円)' '原材料使用額等(百万円)' '製造品出荷額等(百万円)' '付加価値額(従業者29人以下は粗付加価値額)(百万円)'] ----------------------- カラム cat02_code のユニーク数 25 [ 0 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32] ----------------------- カラム 産業中分類(コード付加) のユニーク数 25 ['【00】製造業計' '【09】食料品製造業' '【10】飲料・たばこ・飼料製造業' '【11】繊維工業' '【12】木材・木製品製造業(家具を除く)' '【13】家具・装備品製造業' '【14】パルプ・紙・紙加工品製造業' '【15】印刷・同関連業' '【16】化学工業' '【17】石油製品・石炭製品製造業' '【18】プラスチック製品製造業(別掲を除く)' '【19】ゴム製品製造業' '【20】なめし革・同製品・毛皮製造業' '【21】窯業・土石製品製造業' '【22】鉄鋼業' '【23】非鉄金属製造業' '【24】金属製品製造業' '【25】はん用機械器具製造業' '【26】生産用機械器具製造業' '【27】業務用機械器具製造業' '【28】電子部品・デバイス・電子回路製造業' '【29】電気機械器具製造業' '【30】情報通信機械器具製造業' '【31】輸送用機械器具製造業' '【32】その他の製造業'] ----------------------- カラム area_code のユニーク数 73 [ 12 13 14 15 2000 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000 13000 14000 15000 16000 17000 18000 19000 20000 21000 22000] ----------------------- カラム 都道府県及び東京特別区・政令指定都市(H29から) のユニーク数 73 ['全国計(2012年)' '全国計(2013年)' '全国計(2014年)' '全国計(2015年)' '全国計' '北海道' '青森' '岩手' '宮城' '秋田' '山形' '福島' '茨城' '栃木' '群馬' '埼玉' '千葉' '東京' '神奈川' '新潟' '富山' '石川' '福井' '山梨' '長野'] ----------------------- カラム unit のユニーク数 0 [nan] ----------------------- カラム value のユニーク数 8459 [216262. 208029. 202410. 217601. 191339. 5189. 1386. 2081. 2618. 1800. 2496. 3620. 5154. 4218. 4794. 10975. 4815. 10789. 7697. 5339. 2717. 2861. 2161. 1764. 4994.] '''統計表の各カラムに対するユニーク数とユニーク名を取得しています。
CSVを開いてみれば良いものをなぜこんな手間を掛けるかというと、20メガバイトもあり
エクセルはおろかテキストエディタでもハングするからです。
今回は都道府県別に各産業別の統計表を作りたいのですがこのデータの中には全国計(つまり合計値)と各市町村、製造業計(つまり合計値)が含まれているのでドロップします。# 全国集計と各市町村を落とす(都道府県のみにする) droplist = ['全国計(2012年)', '全国計(2013年)', '全国計(2014年)', '全国計(2015年)', '全国計', '札幌市', '仙台市', 'さいたま市', '千葉市', '東京特別区', '横浜市', '川崎市', '相模原市', '新潟市', '静岡市', '浜松市', '名古屋市', '京都市', '大阪市','堺市', '神戸市', '岡山市', '広島市', '北九州市', '福岡市', '熊本市'] for i in droplist: df = df[df['都道府県及び東京特別区・政令指定都市(H29から)'] != i] # 製造業計のみにする df = df[(df['産業中分類(コード付加)'] == '【00】製造業計')]そしてそれをプロットします。
g = sns.barplot(x='都道府県及び東京特別区・政令指定都市(H29から)', y='value', hue='確報(産業編)・集計項目(H25から)', data=df) g.set_xlabel('都道府県') g.set_title( '2017年 地域別 1. 都道府県別、東京特別区・政令指定都市別統計表 (1)従業者4人以上の事業所に関する統計表 1 産業中分類別の事業所数、従業者数、現金給与総額、原材料使用額等、製造品出荷額等及び付加価値額') plt.xticks(rotation=90)
愛知が大きいのは自動車産業がありその影響でしょうか。
確か社会の時間に習ったような気もします。人口統計2018
続いて今度は各都道府県別人工の入出統計をプロットします。
df = pd.read_csv(file) # 各カラムのユニーク数とユニークの種類をn個以下なら排出 for i in df.columns: print('-----------------------') print('カラム', i, 'のユニーク数', df[i].nunique()) print(df[i].unique()[:10]) print(type(df[i].unique())) ''' ----------------------- カラム cat01_code のユニーク数 1 [0] ----------------------- カラム 性別 のユニーク数 1 ['総数'] ----------------------- カラム cat02_code のユニーク数 7 [ 0 201 202 203 204 205 206] ----------------------- カラム 年齢 のユニーク数 7 ['総数' '0~4歳' '5~9歳' '10~14歳' '15~19歳' '20~24歳' '25~29歳'] ----------------------- カラム cat03_code のユニーク数 4 [1 2 3 4] ----------------------- カラム 都市間移動者数・その他 のユニーク数 4 ['他市町村からの転入者数' '他市町村への転出者数' '転入超過数' 'その他'] ----------------------- カラム cat04_code のユニーク数 2 [60000 61000] ----------------------- カラム 国籍 のユニーク数 2 ['移動者(外国人含む)' '日本人移動者'] ----------------------- カラム area_code のユニーク数 2386 [ 0 1 2 1000 1001 1002 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1202 ] '''都道府県以外のいらない項目データが混じっているのでドロップします。
df_pr = df[(df['全国・都道府県・市区町村2018~'].str.endswith(('都', ' 道 ', '府 ', '県')))]そしてまずは入出者別でプロット
g = sns.barplot(x='全国・都道府県・市区町村2018~', y='value', hue='都市間移動者数・その他', data=df_pr) g.set_ylabel('人') g.set_title('各都道府県移動者数 入出者別') plt.xticks(rotation=90)
このグラフは統計局のデータと合っている。
見事に東京都とその近辺のみ人口が増えていて、それ以外は減少していることがわかりますね。
東京はいったいどこまで人口が増えていくのでしょうか。次に国籍別でプロット
g = sns.barplot(x='全国・都道府県・市区町村2018~', y='value', hue='国籍', data=df_pr) g.set_ylabel('人') g.set_title('各都道府県移動者数 国籍別') plt.xticks(rotation=90)
青色は常に日本人と外国人の合算なので、純増は差分を見ることになります。
次に年齢別でプロット
g = sns.barplot(x='全国・都道府県・市区町村2018~', y='value', hue='年齢', data=df_pr[(df_pr['年齢'] != '総数')]) g.set_ylabel('人') g.set_title('各都道府県移動者数 年齢別') plt.xticks(rotation=90)
統計局のデータはなぜか5歳区分で29歳までのデータしかありませんでした。
社会人になった20代以降の移動が多いことが見て取れます。
10~14歳よりも5~9歳のほうが移動が多いのはなぜなのでしょうね。詰まったこと
統計局のデータは単純にカラムで分けられているわけではなく行内でも区分されているので
分類が難しかった。ひとつひとつ見ていくことが必要。
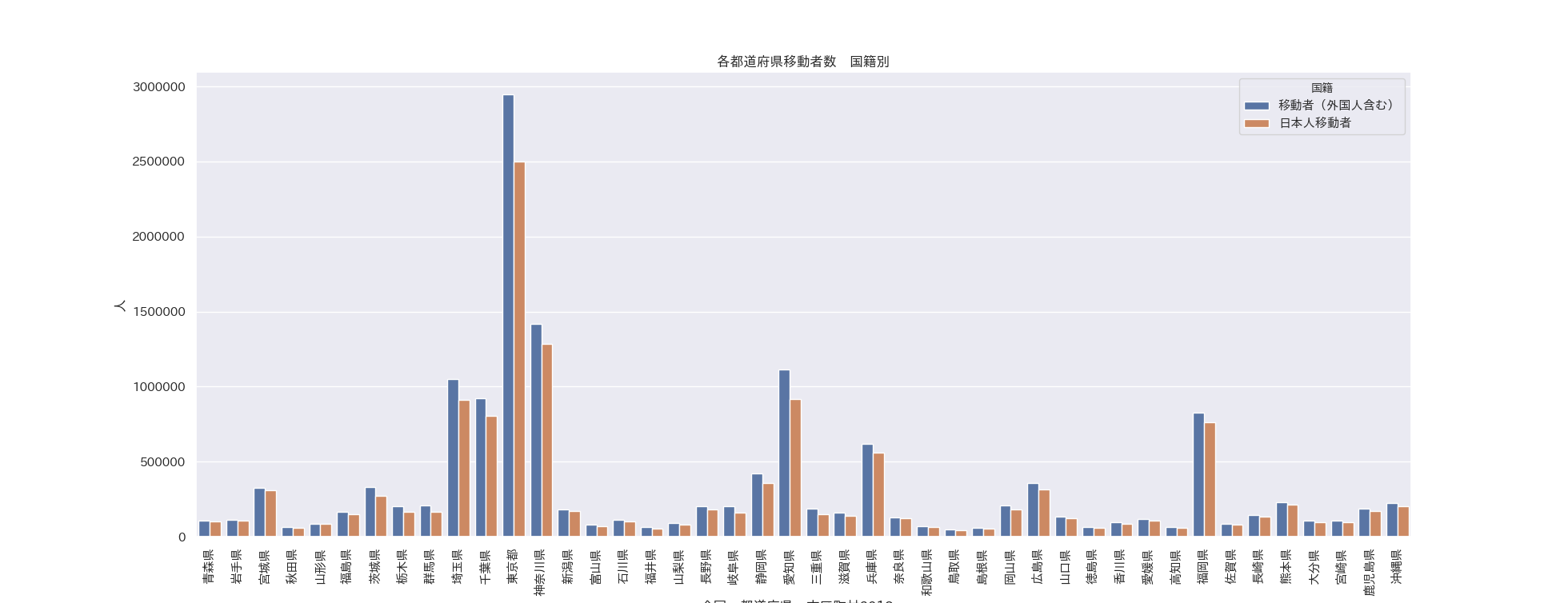
- 投稿日:2019-02-03T18:12:52+09:00
SymPy を使って効用関数から需要関数,間接効用関数を求める
はじめに
本稿は,西村和雄著『ミクロ経済学』の「2.3 需要の決定」に沿って書いています。
技術的な話や経済学の話が入り混じることになるため読みづらいかと思いますが,
読んだり試したりしたものを組み合わせてメモとして残したいと考えています。なお,使用している環境については下部に記載しています。
設定
インテリセンスの有効化
Jupyter Notebook ではデフォルトでインテリセンスが有効になっておらず,不便なため有効化します。
%config IPCompleter.greedy=True使用するパッケージなど
SymPy
数式を扱うので当該パッケージを使用します。
init_printing は,数式を表示する際に使うようですが,よくわからないです(´・ω・`)import sympy from sympy import plot, init_printing, var, solve, symbols, Eq init_printing()その他
operator は演算子です。
functools はリストを操作する際に使います。
reduce は,総和とか総乗に使います。from operator import mul, add from functools import reduce変数の定義
通常の変数
使用する変数を定義します。
一部しか使わないのですが,とりあえず a ~ z を対象にします。なお,全微分する際に使いやすいように,定義したものをリストとして,sym_list へ格納しておきます。
※まぁ今回は不要ですが。sym_list = list(var("a:z")) sym_list$$\left [ a, \quad b, \quad c, \quad d, \quad e, \quad f, \quad g, \quad h, \quad i, \quad j, \quad k, \quad l, \quad m, \quad n, \quad o, \quad p, \quad q, \quad r, \quad s, \quad t, \quad u, \quad v, \quad w, \quad x, \quad y, \quad z\right ]$$
偏微分にて用いる記号
わざわざ書くほどのことではないのですが,偏微分の記号を定義しておきます。
※symbols として定義していない点に注意rd = "∂"財の消費量及び価格体系
今回対象となる財の種類は2つとします。
財の消費量は x とします。
財の数だけ添え字を振っていくこととなるため,リスト内包表記を使います。価格は p とします。
添字は財の種類と対応させています。N = 2 x = [symbols("x" + str(i+1)) for i in range(N)] p = [symbols("p" + str(i+1)) for i in range(N)] x, p$$\left ( \left [ x_{1}, \quad x_{2}\right ], \quad \left [ p_{1}, \quad p_{2}\right ]\right )$$
効用関数の定義
ここでは財の消費量をすべて掛けたものを効用関数としています。
逓減していないので,使えば使うほど効用が増すってことですかね(´・ω・`)ちなみに mul は,掛け算を意味しています。
reduce は引数として渡されたリストに対し,指定された演算子に従って計算します。
※回りくどい言い方をしましたが,要するに総乗します。u_ = sympy.Eq(u, reduce(mul, x)) u_$$u = x_{1} x_{2}$$
予算制約式の定義
予算を I とします。
予算制約式は,
「財の消費量 × 価格 をすべての財について足したものが予算と一致する式」
ですね。zip 関数とリスト内包表記を使って掛けます。
本当は予算以下であればいいのですが,効用を最大化させるという前提があるため,
「使える予算はすべて使う」
ということになり,上記の通り予算と一致することになります。I = sympy.Symbol("I") i_ = sympy.Eq(I, sum([x * p for (x, p) in zip(x, p)])) i_$$I = p_{1} x_{1} + p_{2} x_{2}$$
ラグランジュ関数の定義
制約の中で効用を最大化させるため,ラグランジュの未定乗数法を使います。
ラグランジュ乗数を λ,ラグランジュ関数を L とします。ラグランジュ関数についてですが,
- 予算制約式の右辺をすべて左辺に移行させる。
- ラグランジュ乗数を掛ける。
- ラグランジュ乗数を掛けたものを効用関数へ加算する。
という手順で作ります。
rg = sympy.Symbol("λ") L = sympy.Symbol("L") con_ = i_.lhs - i_.rhs L_ = sympy.Eq(L, u_.rhs + rg * con_) L_$$L = x_{1} x_{2} + λ \left(I - p_{1} x_{1} - p_{2} x_{2}\right)$$
ラグランジュ関数を偏微分する
偏微分する変数をリスト化する
財の消費量とラグランジュ乗数で偏微分するためリスト化します。
※以下,「偏微分リスト」と呼びます。der_ = x der_.append(rg) der_$$\left [ x_{1}, \quad x_{2}, \quad λ\right ]$$
偏微分する
対象の関数について,偏微分リストの内容に基づいて偏微分します。
# 偏微分の対象となる関数 der_l_ = L_.lhs # 偏微分 f_der_ = [sympy.Eq(sympy.symbols(rd + str(der_l_)) / sympy.symbols(rd + str(li)), L_.rhs.diff(li)) for li in der_ if L_.rhs.diff(li) != 0] f_der_keys_ = [li.lhs for li in f_der_] f_der_$$\left [ \frac{∂L}{∂x1} = - p_{1} λ + x_{2}, \quad \frac{∂L}{∂x2} = - p_{2} λ + x_{1}, \quad \frac{∂L}{∂λ} = I - p_{1} x_{1} - p_{2} x_{2}\right ]$$
一階条件を求める
偏微分したものについて,一階条件を求めます。
(各式の左辺を0をおきます。)fod_ = [sympy.Eq(li.rhs, 0) for li in f_der_] fod_$$\left [ - p_{1} λ + x_{2} = 0, \quad - p_{2} λ + x_{1} = 0, \quad I - p_{1} x_{1} - p_{2} x_{2} = 0\right ]$$
通常の需要関数を求める
2財の場合はラグランジュ乗数と合わせて、3次元n次方程式になります。
solve は,
- 第1引数 … 対象の式
- 第2引数 … 求める変数
を指定することにより解が返ってきます。
連立方程式の場合は,それらをリストとして渡します。そのため,ここではラグランジュ関数の一階条件のリストと偏微分リストを渡します。
result = sympy.solve(fod_, der_) result = [sympy.Eq(li, result[li]) for li in der_] result$$\left [ x_{1} = \frac{I}{2 p_{1}}, \quad x_{2} = \frac{I}{2 p_{2}}, \quad λ = \frac{I}{2 p_{1} p_{2}}\right ]$$
解のうち,左辺が財の消費量の式を「通常の需要関数」というようです。
間接効用関数を求める
通常の需要関数を効用関数へ代入します。
subs は,
- 第1引数 … 対象となる変数名
- 第2引数 … 代入する値
を指定することにより計算されます。
しかし,今回のように代入したい値が複数ある場合には辞書型の引数を渡します。このため,
- 第1引数 … {対象となる変数名 : 代入する値}
といった形で指定します。
V = sympy.Symbol("V") v_ = u_.subs({li.lhs : li.rhs for li in result}) v_ = sympy.Eq(V, v_.rhs) v_$$V = \frac{I^{2}}{4 p_{1} p_{2}}$$
定義により,効用関数は財の消費量の関数です。
一方で,上記のように通常の需要関数を代入することにより,予算と価格体系の関数を導出することができました。この関数を「間接効用関数」というようです。
間接効用関数は V とします。ラグランジュ乗数の意味について
通常の需要関数を求めたとき,解に左辺がラグランジュ乗数の式が含まれていました。
ラグランジュ乗数とはそもそもどのようなものなのか,という話ですが,書籍の P.32 に以下の通り記載されています。λは、“価格を一定として所得を1単位増加するときに、(需要の変化 dx1, …, dxn を通じて)得られる追加的効用”と等しい
つまり、間接効用関数 V を所得 I で偏微分したものと等しくなるようです。
rg_test_ = sympy.diff(v_.rhs, I) rg_test_$$\frac{I}{2 p_{1} p_{2}}$$
偏微分した結果を,ラグランジュ乗数の式と比較します。
re_ = [li.rhs for li in result if li.lhs == rg][0] rg_test_ == re_True無事に一致しましたね(´・ω・`)
おわりに
題材とした『ミクロ経済学』は丁寧に解説が書かれています。
内容としては,恐らく手を動かしながら数式を解いていくことを前提としているように思えます。実際に数式を解いていくうえでは非常にありがたいのですが,
そもそもどのような意図でそのような操作を行っているのかが見えづらかったりします。そこで,「数式を Python で解いてみる」という試みにより,
別の角度から理解することができたように思います。今後も今回のように SymPy を使って『ミクロ経済学』を読んでいきたいと思います。
まだまだ不勉強ではありますが,「Python を使って『ミクロ経済学』を読む」みたいなシリーズでも書いてみたいですね。※結構時間が掛かるので更新頻度は少ないかと思いますが(´・ω・`)
補足
使用している環境について
今回使っていないものも含まれていますが,念のため載せておきます。
IDEとかパッケージとか バージョン Python 3.6.0 Anaconda 4.3.0 (64-bit) PyCharm 2018.1.2 (Community Edition) numpy 1.16.0 sympy 1.3 matplotlib 3.0.2
- 投稿日:2019-02-03T18:06:44+09:00
venvでDjangoの環境を作成してみたった(Python3.3以降)
venvとは?
venv: Python 仮想環境管理によれば、
venv は virtualenv が Python 3.3 から標準機能として取り込まれたもの
らしい。
前提
以下のエントリーにてPython3系のインストールまでやってください。
Vagrant + Ubuntu + VirtualBoxでPythonの環境構築したった
venvでPython環境を構築する
Django Girls Tutorial
現在Rails Tutorialのように日本語でDjangoを学べるネット教材で人気がありそうなのは以下
まずは上記にしたがってコマンドを実行していく。
専用の環境を作成する
python3 -m venv myvenvアクティベートする
source myvenv/bin/activatevenv が起動すると、プロンプトの行頭に(myvenv)が現れます。
※必要ならpipをインストール
(私の環境ではすでにインストールされていた模様、、、たぶんvenvのpipじゃないと思うんだけど、この辺よくわかってない)python3 -m pip install --upgrade pip # 私の環境ではすでにあるぜ!って言われてアンスコしてた、、、設定ファイルを作成する
設定ファイル作成
touch requirements.txtインストールしたいDjangoのバージョンを指定する
echo Django~=2.0.6 >> requirements.txt確認する
cat requirements.txtDjangoをインストールする
pip install -r requirements.txtマイグレーション
python manage.py migrateサーバ起動
python manage.py runserver 0.0.0.0:8080トラブルシューティング
Invalid HTTP_HOST header: '192.168.33.10:8080'. You may need to add '192.168.33.10' to ALLOWED_HOSTS.
mysite/settings.pyにて以下を記載する。ALLOWED_HOSTS = ['192.168.33.10']完成
http://192.168.33.10:8080/にアクセスする。※vagrantの
public_networkとかのIPを見てください。config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1" config.vm.network "forwarded_port", guest: 8000, host: 9080, host_ip: "127.0.0.1" config.vm.network "private_network", ip: "192.168.33.10"
こんな感じになれば成功!!
サーバを停止する
以下の画面にて
ctrl + Cするとコマンド受付状態に戻る。
ちなみにサーバ起動状態は(サーバ)コンソールとかって言う。(myvenv) vagrant@ubuntu-xenial:~/tmp/djangogirls$ python manage.py runserver 0.0.0.0:8080 Performing system checks... System check identified no issues (0 silenced). February 03, 2019 - 17:36:41 Django version 2.0.10, using settings 'mysite.settings' Starting development server at http://0.0.0.0:8080/ Quit the server with CONTROL-C. [03/Feb/2019 17:37:21] "GET / HTTP/1.1" 200 16510virtualenvをディアクティーベート(無効化)する
サーバ停止できたらvenvも止めておく。
環境が消えるわけではない!(電源を消しておくイメージ!)deactivateその他
dictionary
ディクショナリーというオブジェクトの型の名前。
辞書型と呼ぶ。
このオブジェクトはキーと値のペアの集合で表される。
Rubyで言うところのHash。setdefaultメソッド
要素の追加
mydict = {"ai":1, "apple":2, "attribute":3} mydict.setdefault("authenticate", 4) print(mydict) # => {"ai":1, "apple":2, "attribute":3, "authenticate": 4}popメソッド
要素の削除
# (続き) mydict.pop("apple") print(mydict) # => {"ai":1, "attribute":3, "authenticate": 4}clearメソッド
要素の一括削除
# (続き) mydict.clear() print(mydict) # => {}条件分岐
"else if〜"みたいな書き方は
elifと書く。
Rubyならelsifだし言語ごとに色がある。if name == 'Ola': print('Hi Ola!') elif name == 'Sonja': print('Hi Sonja!') else: print('Hi anonymous!')繰り返し(ループ)
for i in range(1, 6): print(i)
- 投稿日:2019-02-03T18:01:10+09:00
music21を使う環境構築
はじめに
http://miso-soup3.hateblo.jp/entry/2018/12/20/223705
こちらの記事から環境構築を行った時の備忘録です。
インストール
$ python3 -m venv env $ . env/bin/activate $ pip install jupyter $ pip install music21 $ pip install pyknon $ brew cask install lilypond $ brew cask install musescorejupyter 入れた後は 再読み込みが必要でした。
設定
MuseScoreのバージョンが2から3にあがっていたので、初期設定のままではうごきませんでした。
environment.pyのMuseScoreの設定はここ
http://web.mit.edu/music21/doc/usersGuide/usersGuide_24_environment.html
より
下記を実行すると~/.music21に設定が保存されます。from music21 import environment us = environment.UserSettings() us.create() us['musescoreDirectPNGPath'] = '/Applications/MuseScore 3.app/Contents/MacOS/mscore' us['musicxmlPath'] = '/Applications/MuseScore 3.app/Contents/MacOS/mscore'~/.music21を消した場合は再起動するまでメモリ上で設定を保持しているような挙動でした。
VS Codeでの動作確認用
#%% from music21 import environment us = environment.UserSettings() us.getSettingsPath() #%% from music21 import environment us = environment.UserSettings() us.create() us['musescoreDirectPNGPath'] = '/Applications/MuseScore 3.app/Contents/MacOS/mscore' us['musicxmlPath'] = '/Applications/MuseScore 3.app/Contents/MacOS/mscore' #%% from music21 import note,stream stream1 = stream.Stream() note = note.Note("C4", quarterLength = 1) stream1.repeatAppend(note, 4) stream1.show()参考
http://web.mit.edu/music21/doc/installing/installAdditional.html
さいごに
VSCode1つで開発できてしまって
環境構築はコマンドライン完了できるのは素敵です。

- 投稿日:2019-02-03T17:37:21+09:00
Daskでmatplotlibを並列化
はじめに
netcdfのデータをxarrayで開いて、matplotlibで図にするのを、daskで並列化(multiprocess)してみた。
データは、NCEP/NCAR reanalysisの地表面付近の毎月の温位("pottmp.sig995.mon.mean.nc")で、NOAAのESRLで入手した。
データ
import xarray as xr ds=xr.open_dataset("pottmp.sig995.mon.mean.nc") print(ds)<xarray.Dataset> Dimensions: (lat: 73, lon: 144, time: 852) Coordinates: * lat (lat) float32 90.0 87.5 85.0 82.5 80.0 ... -82.5 -85.0 -87.5 -90.0 * lon (lon) float32 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5 * time (time) datetime64[ns] 1948-01-01 1948-02-01 ... 2018-12-01 Data variables: pottmp (time, lat, lon) float32 ... Attributes: Conventions: COARDS description: Data from NCEP initialized reanalysis (4x/day). These ar... platform: Model NCO: 20121012 history: Created 2011/06/27 by ESRL/PSD Web & Data Team\nConverted... title: monthly mean pottmp.sig995 from the NCEP Reanalysis References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana... dataset_title: NCEP-NCAR Reanalysis 1print(ds["pottmp"].max(),ds["pottmp"].min())<xarray.DataArray 'pottmp' ()> array(334.699951) <xarray.DataArray 'pottmp' ()> array(214.599854)ds.close()1度データxarrayでデータを開いて見てみると、データは852か月分ある。最初のデータは最大約335K、最低は約215Kであり、コンターのレベルの参考にする。
plot
import matplotlib.pyplot as plt import numpy as np import cartopy.crs as ccrs図化にはmatplotlibを使い、緯度経度座標で図にするためにcartopyを使用する。
test 1 (parallel)
import dask@dask.delayed def plot_month(n): ds=xr.open_dataset("pottmp.sig995.mon.mean.nc") pottmp=ds["pottmp"].isel(time=n) fig=plt.figure() proj=ccrs.PlateCarree() proj180=ccrs.PlateCarree(central_longitude=180) ax = fig.add_subplot(111, projection=proj180) ax.coastlines() cl=ax.contourf(pottmp.lon,pottmp.lat,pottmp,np.arange(200,350,20),transform=proj) ax.set_title(pottmp.time.data) fig.colorbar(cl,shrink=0.5) plt.tight_layout() fig.savefig("pottmp_{n}.png".format(n=n+1)) plt.close() ds.close()%%time _ = dask.compute(*[plot_month(n) for n in range(852)],scheduler="processes")CPU times: user 5.83 s, sys: 281 ms, total: 6.11 s Wall time: 3min 6sDaskで852か月分の作図をmultiprocessにしたコード。実行時間は3分6秒。実行環境は手元の4コアのノートPC (Panasonic CF-NX2)。
例として最初の図はこのようになる。
test 2 (serial)
def plot_month(n): ds=xr.open_dataset("pottmp.sig995.mon.mean.nc") pottmp=ds["pottmp"].isel(time=n) fig=plt.figure() proj=ccrs.PlateCarree() proj180=ccrs.PlateCarree(central_longitude=180) ax = fig.add_subplot(111, projection=proj180) ax.coastlines() cl=ax.contourf(pottmp.lon,pottmp.lat,pottmp,np.arange(200,350,20),transform=proj) ax.set_title(pottmp.time.data) fig.colorbar(cl,shrink=0.5) plt.tight_layout() fig.savefig("pottmp_{n}.png".format(n=n+1)) plt.close() ds.close()%%time _ = [plot_month(n) for n in range(852)]CPU times: user 4min 27s, sys: 28.4 s, total: 4min 55s Wall time: 4min 57s同じコードを並列化しない場合の実行時間は4分57秒。4コアを使っても4倍になるわけではないけれども、並列化した場合の方が速い。
test 3 (serial)
ds=xr.open_dataset("pottmp.sig995.mon.mean.nc") pottmp=ds["pottmp"]def plot_month(pottmp,n): pottmpn=pottmp.isel(time=n) fig=plt.figure() proj=ccrs.PlateCarree() proj180=ccrs.PlateCarree(central_longitude=180) ax = fig.add_subplot(111, projection=proj180) ax.coastlines() cl=ax.contourf(pottmpn.lon,pottmpn.lat,pottmpn,np.arange(200,350,20),transform=proj) ax.set_title(pottmpn.time.data) fig.colorbar(cl,shrink=0.5) plt.tight_layout() fig.savefig("pottmp_{n}.png".format(n=n+1)) plt.close()%%time _ = [plot_month(pottmp,n) for n in range(852)]CPU times: user 4min 19s, sys: 12.4 s, total: 4min 31s Wall time: 4min 32stest1とtest2ではfucntionの中でいちいちnetcdfを開いているが、多分並列化の場合はその方が問題がなさそう。並列化しない場合、Test3のようにnetcdfを1度開いてからそこからデータを読みにいってもたいして速いわけではない。
注
matplotlibを並列化すると、図にする順番によってはフォントが乱れることがある。よくわからないがフォントのキャッシュによるもの?
参考
Matplotlibをmultiprocessing.Poolで並列化する際の覚書 (Qiita)
Matplotlib multiprocessing fonts corruption using savefig (stack overflow)
- 投稿日:2019-02-03T17:09:14+09:00
PyhtonTexで図を生成しGrid出力する
概要
PythonTexを使うと、texの文書中にpythonのコードを埋め込むことができます。ここではtex文書中で図の作成とその表示・出力を行います。
特に図を連続出力したい場合にPythonTexがその実力を発揮するため、
複数の図を作成し、グリッドにして表示させます。画像のGrid表示
今回は自動で出力した図をgridで表示するために
minipage環境を利用します。PythonTexを使わず、愚直に書くと以下のようなコードです。
たくさんの図を出力する際は非常に面倒ですね...\begin{figure}[ht] \begin{minipage}[ht]{0.48\textwidth} \centering \includegraphics[width= 6 cm]{sin.png} \caption{sin curve} \label{sin} \end{minipage} \hfill \begin{minipage}[ht]{0.48\textwidth} ... \end{minipage} \end{figure}実行コード
特別なものとして
pythontexを指定します。
PythonTexの環境構築はこちらの記事が参考になります。
pycode環境にpythonのコードを埋め込み、
\py{}で呼び出すことでtex文書中に生成したtexコードを出力させます。\documentclass{article} \usepackage[dvipdfmx]{graphicx} \usepackage{mediabb} \usepackage{pythontex} \begin{document} \begin{pycode} import matplotlib.pyplot as plt import numpy as np ## 図の作成 def draw_func(x, y, name): plt.figure(figsize=(10, 7)) plt.plot(x, y) plt.savefig('{}.png'.format(name)) def sin(): x = np.arange(-3, 3, 0.01) y = np.sin(x) draw_func(x, y, 'sin') def cos(): x = np.arange(-3, 3, 0.01) y = np.cos(x) draw_func(x, y, 'cos') def exp(): x = np.arange(-3, 3, 0.01) y = np.exp(x) draw_func(x, y, 'exp') def square(): x = np.arange(-3, 3, 0.01) y = np.square(x) draw_func(x, y, 'square') # ファイル名、caption, labelの指定 images = [ \ ('sin.png', 'sin curve', 'sin'), \ ('cos.png', 'cos curve', 'cos'), \ ('exp.png', 'exp curve', 'exp'), \ ('square.png', 'square curve', 'square'), \ ] def insert_grid_images(): # 2*N grid # 図の生成 sin() cos() exp() square() # Gridで表示するためにfigure環境にminipageを作る head = r"\begin{figure}[ht]" # 反復部分 content = "" for i in images: tmp = r"\ \begin{minipage}[ht]{0.48\textwidth} \ \centering \ \includegraphics[width= 6 cm]{FILENAME} \ \caption{CAPTION} \ \label{LABEL} \ \end{minipage} \ \hfill" property = { "FILENAME" : i[0], "CAPTION" : i[1], "LABEL" : i[2], } # ファイル名、caption, labelを置換 for key, value in property.items(): tmp = tmp.replace(key, value) content += tmp foot = r"\end{figure}" # 生成した文字列を返す return head+content+foot \end{pycode} sin curve(Figure \ref{sin}), % 引用も可能 cos curve(Figure \ref{cos}), exp curve(Figure \ref{exp}), square curve(Figure \ref{square}) % ここでinsert_grid_images()を実行し、texのコードを出力する \py{insert_grid_images()} \end{document}完成図
生成した図が 正しくgridで表示されています。tex本文中での引用もうまくいっています。
参考
Tex Wiki PythonTex
TECH ACADEMY Pythonで複数箇所の文字列を置換する方法リソース
こちらのリポジトリに実行コードがあります。
- 投稿日:2019-02-03T16:54:48+09:00
Python + Django + ag-grid で一括処理
「Python + Django + SlickGrid で一覧表示」で、gridライブラリを使った一覧表示を試してみましたが、Slick Gridより、簡単に実装できる「ag-grid」というライブラリに出会ったので、Djangoと連携する例を投稿しておきます。
1.インストール
ag-gridは、javascript, angular, react, vueなどで使用できると書いてありますが、今回は、javascript版を使用します。
(1)ダウンロード
GitHUBからダウンロードします。必要なcss, jsファイルは、distフォルダの中にあります。
(2)アプリケーションを作成する。
Djangoなので、サンプルアプリケーションを作成します。
- 今回のメインとなるアプリケーションを作成する
python manage.py startapp hellojson2
- db用のアプリケーションを使います。
Python+DjangoでDBの検索処理をモジュール化してみる
python manage.py startapp commons
- model用のアプリケーション
modelはすべてのアプリケーションで使うので、別でアプリケーションを作成しておきます。
python manage.py startapp entities
- アプリケーションの構成
以下のようなファイル構成になります。
staticフォルダの下のcss, jsフォルダに、ダウンロードしたag-gridのcss, jsを配置します。
※ ag-gridのほかに、JQueryも使います。bootstrapは好みに合わせて配置してください。myproject │ db.sqlite3 │ manage.py │ ├─commons ・・・ │ │ dbutils.py ・・・ │ ├─entities │ │ admin.py │ │ models.py ・・・ ├─hellojson2 │ │ admin.py │ │ apps.py │ │ models.py │ │ tests.py │ │ urls.py │ │ views.py ・・・ ├─myproject │ │ settings.py │ │ urls.py │ │ wsgi.py │ │ __init__.py ・・・ ├─static ・・・ │ ├─css │ │ ag-grid.css │ │ ag-theme-balham.css │ │ bootstrap.min.css │ │ bootstrap.min.css.map ・・・ │ ├─js │ │ ag-grid-community.min.noStyle.js │ │ bootstrap.bundle.min.js │ │ bootstrap.bundle.min.js.map │ │ jquery-3.3.1.min.js ・・・2.アプリケーションの概要
- 従業員マスタのメールアドレスを一括更新するアプリケーションです。
- 画面に、従業員マスタの一覧を表示し、ユーザは、更新対象とする行をチェックして更新します。
- 初期表示時は、一覧は表示されません。検索ボタンで表示します。
- 更新ボタンを押すと、従業員マスタのメールアドレスを「bbb@localhost.com」に変更します。
3.実装
(1)model
- modelの作成
entities\models.pyfrom django.db import models # Register your models here class Department(models.Model): """ 所属マスタ """ deptid = models.CharField(max_length=16) deptname = models.CharField(max_length=64) upperdeptid = models.CharField(max_length=16) def __str__(self): return self.deptname class Employee(models.Model): """ 従業員マスタ """ empid = models.CharField(max_length=16) empname = models.CharField(max_length=64) deptid = models.CharField(max_length=16) mailaddress = models.CharField(max_length=128) def __str__(self): return self.empname
- プロジェクトにアプリケーションを追加する
myproject\settings.pyINSTALLED_APPS = [ ・・・ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'bootstrap4', #追加 'entities', #追加 'hellojson2', #追加 ]
- migrate
python manage.py makemigrations entities python manage.py migrate entities(2)HTML
htmlのコメントにポイントを入れています。
ag-gridの使い方などは、hellojson2\templates\hellojson2\index.html{% extends 'commons/base.html' %} {% load static %} {% block links %} <link rel="stylesheet" href="{% static 'css/ag-grid.css' %}" type="text/css"/> <link rel="stylesheet" href="{% static 'css/ag-theme-balham.css' %}" type="text/css"/> <style media="screen"> .form-control{border: none !important;} </style> <script src="{% static 'js/ag-grid-community.min.noStyle.js' %}"></script> {% endblock %} {% block headertitle %} 一括更新 サンプル {% endblock %} {% block content %} <br/> <div class="form-control"> <p>選択した行のメールアドレスを一括更新します。</p> </div> <div class="form-control text-right"> <button class="btn btn-sm btn-primary" onclick="search(); return false;">検索</button> <button class="btn btn-sm btn-primary" onclick="sendData(); return false;">更新</button> </div> <div id="myGrid" style="height: 600px; width:100%; margin-top:10px;" class="ag-theme-balham"></div> <script type="text/javascript"> // ※DjangoとAjax通信するときは、CSRF対策をしておく必要がある。 // django CSRF対策 ここから function getCookie(name) { var cookieValue = null; if (document.cookie && document.cookie != '') { var cookies = document.cookie.split(';'); for (var i = 0; i < cookies.length; i++) { var cookie = jQuery.trim(cookies[i]); // Does this cookie string begin with the name we want? if (cookie.substring(0, name.length + 1) == (name + '=')) { cookieValue = decodeURIComponent(cookie.substring(name.length + 1)); break; } } } return cookieValue; } var csrftoken = getCookie('csrftoken'); function csrfSafeMethod(method) { // these HTTP methods do not require CSRF protection return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method)); } $.ajaxSetup({ crossDomain: false, // obviates need for sameOrigin test beforeSend: function(xhr, settings) { if (!csrfSafeMethod(settings.type)) { xhr.setRequestHeader("X-CSRFToken", csrftoken); } } }); // django CSRF対策 ここまで //検索ボタン function search(){ //fetchを fetch("{% url 'hellojson2:getlist' %}").then(function(response) { return response.json(); }).then(function(data) { gridOptions.api.setRowData(data); }) } //更新ボタン function sendData() { //ag-grid:選択した行の一覧を取得する。 var selectedNodes = gridOptions.api.getSelectedNodes() var selectedData = selectedNodes.map( function(node) { return node.data }) if (selectedData.length == 0) { alert("選択してください。") return; } //fetchではなく、JQuery Ajaxを使う例。 $.ajax('/hellojson2/senddata/', { type: 'post', data: { query: JSON.stringify(selectedData) }, 'dataType': 'json' } ) // 更新成功時に{"status": "OK"}が返ってくる .done(function(data) { alert(JSON.stringify(data)); }) // 検索失敗時には、その旨をダイアログ表示 .fail(function( jqXHR, textStatus, errorThrown ) { window.alert('通信エラーが発生しました。 status=' + textStatus); }) .always(function( jqXHR, textStatus ) { }); } // ag-grid: 列定義 // empidにcheckboxSelectionをセットすることで、checkboxを表示 // headerCheckboxSelectionは、ヘッダにcheckboxを表示 // empidは、リンクボタンで表示するようにしています。 var columns = [ {headerName: "従業員コード", field: "empid", headerCheckboxSelection: true, checkboxSelection: true, filter: true, editable: true, cellRenderer: function(params) { //将来的には、詳細表示などのURLをセットする。ひとまずgoogleのサイトを開く return '<a href="https://www.google.com" target="_blank">'+ params.value+'</a>' }, }, {headerName: "氏名", field: "empname", filter: true}, {headerName: "メールアドレス", field: "mailaddress", filter: true}, {headerName: "所属コード", field: "deptid", filter: true}, {headerName: "所属名", field: "deptname", filter: true} ]; //ag-grid: データ(JSON) var data = {{data|safe}} //ag-grid: Options //複数行選択にしています。 var gridOptions = { columnDefs: columns, rowSelection: 'multiple' // rowData: data }; // ag-grid: lookup the container we want the Grid to use var eGridDiv = document.querySelector('#myGrid'); // ag-grid: create the grid passing in the div to use together with the columns & data we want to use new agGrid.Grid(eGridDiv, gridOptions); // ag-grid: 初期表示時のデータをセットしておく。 gridOptions.api.setRowData(data); </script> {% endblock %}(3)ルーティング
hellojson2\urls.pyfrom django.urls import path from . import views app_name = 'hellojson2' urlpatterns = [ path('', views.index, name='index'), # 初期表示 path('getlist/', views.getlist, name='getlist'), # 検索 path('senddata/', views.senddata, name='senddata'), # 更新 ](4)view.py
hellojson2\views.pyfrom django.shortcuts import render, get_object_or_404, redirect from django.http import HttpResponse import json from commons.dbutils import exec_query from django.views.decorators.csrf import ensure_csrf_cookie from entities.models import Employee #list def index(request): data = [] jsondata = json.dumps(data, ensure_ascii=False, indent=2) return render(request, 'hellojson2/index.html', {'form_name': 'hellojson2', 'data': jsondata}) def getlist(request): sqltext="""SELECT a.id , a.empid , a.empname , a.deptid , a.mailaddress , b.deptname FROM public.entities_employee a INNER JOIN public.entities_department b on a.deptid=b.deptid ORDER BY a.id ; """ emplist=exec_query(sqltext); jsondata = json.dumps(emplist, ensure_ascii=False); return HttpResponse(jsondata) @ensure_csrf_cookie def senddata(request): txt = request.POST['query'] datas = json.loads(txt) for element in datas: # print(element) entity = Employee.objects.filter(id=element['id']).first() entity.mailaddress = 'bbb@localhost.com' entity.save() data = {'status': 'OK'} json_str = json.dumps(data, ensure_ascii=False, indent=2) return HttpResponse(json_str)(5)プロジェクトのルーティング
最後に、myproject\urls.pyに、アプリのルーティングを追加します。
myproject\urls.pyurlpatterns = [ path('hellojson2/', include('hellojson2.urls')), # ←ここを追加 path('admin/', admin.site.urls), ]4.動作確認
- webサーバ起動
python manage.py runserver
- アプリにアクセスしてみます。
http://localhost:8000/hellojson2/
5.最後に
Slick Gridでここまでやろうと思ったら、pluginの追加やjavascriptの実装が複雑になりがちですが、ag-gridは実装も少なくてとってもいい感じです。大量データの表示も高速に表示できるので、私的にはag-gridかなと思いました。

- 投稿日:2019-02-03T16:13:58+09:00
openCV入門(python)-(1)
ETロボコンでopenCVを利用する機会が出そうだったので、画像処理について学習した事をここにまとめておきます
(実際にETロボコンで使用する際はC++でコードを書くことになりそうですが・・・)あと書いていたらかなり多くなってしまったので2つに分けようかと思っています
画像処理とは
画像→画素の集まり(RGB値)
画像処理→画像を解析しやすくする、情報を抽出しやすくする
画像処理の例
- グレースケール化
- 平滑化→画像を滑らかにする
- Canny エッジ(輪郭)の検出
OpenCVとは
open source(一部特許があるものもある。)
マルチプラットフォーム、C++, Python, java, matlab
機能としては画像、動画の読み込みや表示を行ったりもできる
カメラモデル、機械学習用のライブラリもある
画像の座標は基本的に左上に原点。下へy軸、右へx軸をとる
pythonでは、numpy array にy、x、colorの順に格納される(openCV独自の配列の設定)
- colorというのは、RGB値(もしくはHSV値)を並べた16bitの値のことを言う
C++の方が速いが、コードが長くなる。Pythonの方がコードが短くかけるが、書き方次第でC++よりは遅い。ほかのライブラリとの連携は強い
- ただし、Python+openCVは情報が少ない
色空間とグレースケール
RGB
R(red),G(green),B(blue)それぞれの値で一つの座標を決めることで色を決定する。値の範囲はそれぞれ0~255
openCVでは、RGB値は(B,G,R)の順番で数値を並べる
HSV
H:色相
- 値の範囲は0~359。角度によって色の種類を表す
S:彩度
- 値の範囲は0~100。Hで決められた色がどのくらい含まれているか。0に行くほど白に近い
V:明度
- 値の範囲は0~100。色の明るさを表す。0は黒を示す。100は明るく白に近づく
HSVのメリットは色が表しやすい
- openCVでは各値を以下の範囲で表現する
- H 0~179 (0-359を2で割った値と考える)
- S 0~255
- V 0~255
グレースケール
演算量を抑えるためによく使われる。2値化にも長けている。RGB値を以下の式でグレースケールに変換できる
- Gray = 0.2989 R + 0.5870 G + 0.1140 B
RGB, HSVと違い一つのパラメータのみで演算が可能なので、演算にも相性が良い
画像処理のライブラリ
基本的に使用頻度の高そうなものから説明。以下のimport文は省略してあるので、使用する際はこの import文を使用すること
import cv2基本的な画像の読み出し関連全般
画像を読み出す際の、RGB,HSV,グレースケールでの読み出し方を以下に示す
# 画像をRGB表現で読み出し img = cv2.imread("sample.jpg") # 「sample.jpg」はファイルパス # 画像を読み出し、HSV表現にコンバート img = cv2.imread("sample.jpg") # 「sample.jpg」はファイルパス img_hsv = cv2.cvtColor(img, cv2.COLOR_RGB2HSV ) # RGBからHSVへ変換 # 画像をグレースケールで読み出し img = cv2.imread("sample.jpg",0) # 「sample.jpg」はファイルパス # 画像の大きさ(おまけ) img.shape # 画像のデータ概要(y,x,color)が入っている基本的な画像の書き出し関連全般
同ディレクトリにグレースケール化した画像を書き出すサンプルを以下に示す。
img = cv2.imread("sample.jpg",0) # 「sample.jpg」はファイルパス # 「sample.jpg」をグレースケール化した「sample_gray.jpg」を作成 cv2.imwrite("sample_gray.jpg",img)画像のリサイズ
img = cv2.imread("sample.jpg") # 「sample.jpg」はファイルパス size = (300,200) # (幅、高さ) img_resize = cv2.resize(img, size) # sizeの大きさでリサイズ画像の2値化
画像の2値化とは、画像を白と黒だけで表現する事を意味する。この2値化を行う際、白か黒かを判断する閾値が必要になる。その閾値をユーザが設定する場合としない場合があるので、その2つに分けて説明する。
閾値をユーザが設定する場合
img = cv2.imread("sample.jpg") # 「sample.jpg」はファイルパス threshold = 100 # 閾値。閾値以上の値は255にする ret,img_th = cv2.threshold(img, threshold,255, cv2.THRESH_BINARY)閾値をユーザが設定しない場合
閾値をユーザが設定しない場合はいくつかパターンがあるので別に説明します。
大津の2値化
分離度が最も大きくなるときの閾値を求める。ヒストグラムも関わってくるので説明は割愛。
こちらを参考のこと→https://algorithm.joho.info/image-processing/otsu-thresholding/
img = cv2.imread("sample.jpg") # 「sample.jpg」はファイルパス ret2,img_o = cv2.threshold(img,0,255,cv2.THRESH_OTSU) # ret2に閾値が入る適応的二値化処理
- ある一定範囲内でそれぞれ閾値を設定する。よって相対的に明るいものは白と判断される。以下の場合は周囲3近傍で閾値を決定
img = cv2.imread("sample.jpg") # 「sample.jpg」はファイルパス img_ada = cv2.adaptiveThreshold(img, 255,cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 3, 1)
- 投稿日:2019-02-03T16:03:03+09:00
PyMC3でsample_posterior_predictiveが使えない
Abstract
PyMCでMCMCをやるときに、時々遭遇するこのエラー。
度々調べて、もう調べたくないのでメモ。AttributeError: 'module' object has no attribute 'sample_posterior_predictive'やること
pip install -U pymc3とりあえず、普通にこれで使えるようになります。
もしバージョンをあげたくないなら、# pm.sample_posterior_predictive(trace, sample=1000, model=model) pm.sample_ppc(trace, sample, model=model)でいけます。
ただし、注意が必要です。本当は、sample_ppcは廃止なので
本当はsample_posterior_predictiveでかける方が良いです。https://docs.pymc.io/api/inference.html?highlight=sample_ppc
Ref
- 投稿日:2019-02-03T16:00:55+09:00
dequeでlistのようにある範囲の値を取得したい時
0. 筆者環境
Windows 10 64bit
Python 3.6.7 64bit1. 問題点・実例
dequeを使用した際に、listのようにsliceで値を取得しようとしたらslice自体使えない模様。
末尾からx個の値を取得したい等、必要な時はあると思われるため、下記にまとめた。2. 対処法
itertoolsのisliceを用いる方法
import collections import itertools # dequeに1-1000の値を格納 dq = collections.deque(range(1000)) # yにdqの900-1000個の値を格納 y = list(itertools.islice(dq, 900, 1000))リスト内包表記を用いる方法
import collections import itertools # dequeに1-1000の値を格納 dq = collections.deque(range(1000)) # yにdqの900-1000個の値を格納 y = [dq[i] for i in range(900, 1000)]どっちが早いかは場合によって変わるため、計測しながら使う。
- 投稿日:2019-02-03T15:55:18+09:00
ガウス関数のFFTについての考察
ガウス関数は正規分布の書き方だと,平均$x_0$と分散$\sigma$を用いて
f(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp \Bigl({-\frac{(x-x_0)^2}{2 \sigma^2}} \Bigr)となります.今回はこのガウス関数のフーリエ変換について,理論式を計算した結果とFFT(高速フーリエ変換)の結果を比較します.
目次
・理論式によるフーリエ変換
・FFTによるフーリエ変換
・両者の比較
・FFT実行のためのコード(Python)理論式によるフーリエ変換
計算過程は省略しますが,ガウス関数のフーリエ変換$F$はまたガウス関数になります.
\begin{eqnarray} F(k) &=& \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}f(x)e^{-ikx}dx \\ &=& \sigma e^{-\frac{\sigma^2k^2}{2}}e^{-ikx_0} \\ \\ \end{eqnarray}振幅スペクトル$|F|=\sigma e^{-\frac{\sigma^2k^2}{2}}$と,
位相(偏角の主値)${\rm Arg}(F)={\rm Arg}(e^{-ikx_0})$を$k \geq 0$で描画します.
上が振幅スペクトル,下が位相($/\pi$)です.フーリエ変換と言えば振幅スペクトルの事を指すことが多い気がします.位相は$-kx_0$と書けますが,今回は$[-\pi \ \pi]$の主値を採用しているので,端を越えると下にジャンプします.また,振幅スペクトルが落ち込んだ先の位相情報は,意味が無いので無視します.
(ところでこのグラフは横軸が波数なので,そのまま角周波数に読み替えることは出来ますが,振動数で読むためには$2\pi$で割る必要があることに注意してください.)
FFTによるフーリエ変換
FFTの実行方法の説明は他に譲るとして,ここでは理論式とFFTの結果が一致するのかを検証します.自分はPythonのNumPyモジュールで実行しました(参考コードを最後に記載しておきます).
先程と同様の関数をFFTした結果から得られる,振幅スペクトルと位相のグラフを示します.
スペクトルの最大値が先程と違いますが,概形は似たものになりました.ちなみにデータ数を多めに取らないと,きれいな結果になりませんでした.両者の比較
二つの結果が一致しているのか検証します.
振幅スペクトルは比を,位相は差を取って比較しました.
理論値とFFTで得た値をそれぞれ下付き添字1,2で表しています.
$k \leq 4$では比が一定,差が0という結果になりました.FFTで求まる振幅スペクトルの最大値は異なっていますが,全体が定数倍されているだけなので,定性的には問題無いと言えそうです.
というわけで,ガウス関数のフーリエ変換の理論式とFFTの結果を比較し,一致することが確認できました.FFT実行のためのコード(Python)
参考までに,今回FFTを実行するにあたって用いたコードを掲載しておきます.
import numpy as np from matplotlib import pyplot as plt import matplotlib as mpl sigma = 1.0 dx = 0.01 x0 = 5 x = np.arange(0, 1000, dx) N = len(x) def y(x): return 1 / (np.sqrt(2 * np.pi) * sigma) \ * np.exp(-(x - x0) ** 2 / (2 * sigma ** 2)) fourier = np.fft.fft(y(x)) fourier_abs = np.abs(fourier) fourier_phase = np.arctan2(np.real(fourier), np.imag(fourier)) omega = np.linspace(0, 1/dx, N) * 2 * np.pi fig = plt.figure() ax1 = fig.add_subplot(211) ax2 = fig.add_subplot(212) ax1.plot(k, np.abs(fourier), linewidth=1, color='black') ax1.set_ylabel('Amplitude') ax2.plot(k, np.arctan2(np.real(fourier), np.imag(fourier)) / np.pi, linewidth=1, color='black') ax2.set_xlabel('k') ax2.set_ylabel('Phase[rad]') ax1.set_xlim([0.0, 6.0]) ax2.set_xlim([0.0, 6.0]) mpl.rcParams['axes.xmargin'] = 0 mpl.rcParams['axes.ymargin'] = 0 plt.show()

- 投稿日:2019-02-03T14:55:24+09:00
Pythonで素数を求めてみる
今回の記事では、ある自然数N以下の素数を表示するプログラムを書いていきます(N>=2)
初投稿
こんにちは、kageyasaiと申します。
qiitaへの投稿は備忘録として使っていきたいと思います
よろしくお願いします。動作環境
Windows10 Pro
Python3.6.2素数とは
1 より大きい自然数で、正の約数が 1 と自分自身のみであるもののことである。
素数 - Wikipedia素数を求める
私が最初に思いついた素数を求める手順を以下に書いていきます。
① 2からNまでの数字を一つずつ取り出す
② 取り出した数字(以下numとする)を2からnum-1までの数字で割る
③ もしnumが割り切れたなら①に戻る
2019/2/3追記
偶数の素数って2だけなんですね
そりゃそうか2以外の偶数は2の倍数だからね
また素数の判定には素数で割るといいみたいです①3からNまでの奇数を一つずつ取り出す
②取り出した数字(以下numとする)を素数リストの要素で割る
③もし素数リストの要素で割れなければ素数リストに追加して①に戻る@shiracamusさんの指摘内容を参考に素数を求める手順を変更致しました
実際に上記を元にコードを書いてみました
Prime_number.pydef get_primenumber(N): #素数リスト prime_list = [2] #3からNまでの数字を一つずつ取り出す for num in range(3,N+1,2): #取り出した数字が素数リストの要素で割れなければ素数リストに追加する if all( num % prime != 0 for prime in prime_list): prime_list.append(num) return prime_list def main(): while True: number = int(input("自然数:")) if number > 1: break else: print("2以上の自然数を入力してください") print(get_primenumber(number)) if __name__ == "__main__": main()get_primenumber(N)が素数を求めている関数です
main()では入力した自然数をget_primenumberに渡しています実行結果
PS C:\Python\math> python .\Prime_number.py 自然数:100 [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]ちゃんと100以下の素数を求めれていますね
ただ、今の素数を求める手順だと自然数の値によって処理が終わるまでかなり時間がかかってしまいます
現状の処理時間を計測して簡単にまとめてみました
自然数 処理時間(秒) 100 0.0 1000 0.0029988288 10000 0.0959968566 100000 6.3189933300 10000から100000になると処理時間が約70倍になっています
1000000になると3分待っても終了しませんでした何か他に素数を求める方法が無いか調べました
調べていくとエラトステネスの篩というアルゴリズムが簡単に素数を求めれそうでした
では実際にエラトステネスの篩を実装していきます
エラトステネスの篩 - Wikipedia
↑上記のサイトに書いてあるアルゴリズムを元にコードを書いてみましたエラトステネスの篩
Eratosthenes.pyimport math #----エラトステネスの篩-------- def get_primenumber(number): prime_list = [] #2からnumberまでの数字をsearch_listに入れる search_list = list(range(2,number+1)) while True: #search_listの先頭の値が√nの値を超えたら処理終了 if search_list[0] > math.sqrt(number): #prime_listにsearch_listを結合 prime_list.extend(search_list) break else: #search_listの先頭をprime_listに入れる head_num = search_list[0] prime_list.append(head_num) #search_listの先頭をpopする search_list.pop(0) #head_numの倍数を取り除く search_list = [num for num in search_list if num % head_num != 0] return prime_list def main(): print(""" --------------------------------------------------------------------- エラトステネスの篩を用いたプログラムです(整数 >= 2) ex) 整数:10 結果:[2,3,5,7] --------------------------------------------------------------------- """) while True: num = int(input("整数:")) if num > 1: break print(get_primenumber(num)) if __name__ == "__main__": main()アルゴリズムが分かっているとコードが書きやすいですね。
実行結果も載せときます実行結果
PS C:\Python\math> python .\Eratosthenes.py --------------------------------------------------------------------- エラトステネスの篩を用いたプログラムです(整数 >= 2) ex) 整数:10 結果:[2,3,5,7] --------------------------------------------------------------------- 整数:100 結果:[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]エラトステネスの篩を用いたときの処理時間
自然数 処理時間(秒) 100 0.0 1000 0.0 10000 0.0049240589 100000 0.0850005149 100000の時の処理時間が6.31秒から0.085秒になっています
約74倍速くなっています
ちなみに1000000の時だと2.75秒でした
速い( ゚д゚ )クワッ!!まとめ
今回はエラトステネスの篩を用いた実装を行いましたが他の素数を求めるアルゴリズムもいつか実装してみたいですね。
これからも先人の知恵をもっと利用していきたいですね
参考
エラトステネスの篩 - Wikipedia
素数 - Wikipedia
【詳しく解説】1は素数ではない理由と判定方法!最大の素数も!
- 投稿日:2019-02-03T14:27:21+09:00
【Scipy】FFT、STFTとwavelet変換で遊んでみた♬~⑦リアルタイム・スペクトログラム;完成したよ♬
前回の記事は、リアルタイム・スペクトログラムのアプリの高速化について記載したが、今回はさらに高速化して、しかも前回の周波数が間違っていたバグを解消した。。。
とりあえずの目標
以下のとおり、
※リンクされているものは記事にしたものであり、その記事を前提知識として書いて行くので、参照すると理解し易いと思います。
①Scipy環境を作る
・環境の確認
②不確定原理について
・FFT変換・逆変換してみる;時間軸が消える
・STFT変換・逆変換してみる;窓関数について
・wavelet変換・逆変換してみる;スペクトログラムの解釈と不確定原理
③音声や地震データや株価や、。。。とにかく一次元の実時系列データに応用する
音声データ入力編
④FFTからwavelet変換まで簡単にたどってみる(上記以外のちょっと理論)
⑤二次元データに応用してみる
⑥天体観測データに応用してみる
⑦リアルタイムにスペクトログラムしてみる
前回の高速化コードは以下に置きました
・Scipy-Swan/pyaudio_realtime_last.py
やったこと
・さらなる高速化とトリガー拾ってサンプリング開始
・パラメータを変更したときの時報のGifアニメーション・さらなる高速化とトリガー拾ってサンプリング開始
まず、以下のおまけに掲載のコードでinputとdataの中身が異なるのかというのを検証した。
結論から言うと、inputとdataは全く同じであった。
ということで、わざわざ出力してから再度読み込むなどということはしなくても処理ができることが分かった。
※コード見ればわかるだろうと思うので、説明は省略していますということで、サンプリング開始のためのトリガー関数start_mesure()というのを以下のとおり作成しました。
※ちょっと解説付けます# -*- coding:utf-8 -*- import pyaudio import time import matplotlib.pyplot as plt import numpy as np import wave from scipy.fftpack import fft, ifft from scipy import signalサンプリングに必要なものだけを定義します。
def start_measure(): CHUNK=1024 RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() input = [] stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) input =stream.read(CHUNK) sig = np.frombuffer(input, dtype="int16")/32768.0sigが一定レベル(今は0.001)を超えたら、この関数終了します。
while True: if max(sig) > 0.001: break input =stream.read(CHUNK) sig = np.frombuffer(input, dtype="int16")/32768.0 #print(max(sig))サンプリングがすごくシンプルになり、
input =stream.read(CHUNK)だけになりました。
一応、関数を抜ける前にこのサンプリングはcloseしておきます。stream.stop_stream() stream.close() p.terminate() return input利用は以下のとおり。
input=start_measure() print(input)サンプリング本体とFFTなどの本体合わせた全体のコード
以下のとおりです。。
※上記と重複している部分は省略します# -*- coding:utf-8 -*- import pyaudio ... def start_measure(): CHUNK=1024 ... returnここから実際のサンプリング開始です。
Nでサンプリングの長さを変更します。
RATEは三種類変更可です。N=50 CHUNK=1024*N RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True)グラフ表示は、ax1;生データ、ax2;STFT、そしてax3;FFTのグラフです。
fig = plt.figure(figsize=(12, 10)) ax1 = fig.add_subplot(311) ax1.set_xlabel('Time [sec]') ax1.set_ylabel('Signal') ax2 = fig.add_subplot(312) ax2.set_ylabel('Freq[Hz]') ax2.set_xlabel('Time [sec]') ax3 = fig.add_subplot(313) ax3.set_xlabel('Freq[Hz]') ax3.set_xscale('log') ax3.set_ylabel('Power')時間取得して、サンプリング時間、不感時間などを取得しました。
※本番では不要ですstart=time.time() stop_time=time.time() stp=stop_timeこれは重要で、NやRATEを変更したとき自動的に生データ、FFTやSTFTの軸制御するためにfr, fn, fsを定義します。
fr = RATE fn=51200*N/50 #*RATE/44100 fs=fn/fr print(fn,fs)ここから本体。
毎回、start_measure()で閾値超えると、サンプリング開始です。for s in range(30): start_measure()生データとFFTのグラフは、毎回再描画します。
※軸などは残して測定値だけ描画したかったのですが、そういうのが見つかりませんでした。やろうとすると全部書かないとなので今回はやめときますfig.delaxes(ax1) fig.delaxes(ax3) ax1 = fig.add_subplot(311) ax1.set_title('passed time; {:.2f}(sec)'.format(time.time()-start)) ax1.set_xlabel('Time [sec]') ax1.set_ylabel('Signal') ax3 = fig.add_subplot(313)時間計測は本番では不要ですが、あっても割と速いです。
input = [] start_time=time.time() input = stream.read(CHUNK) stop_time=time.time() print(stop_time-start_time)生データのグラフ表示です。
sig = np.frombuffer(input, dtype="int16") /32768.0 t = np.linspace(0,fs, fn, endpoint=False) ax1.set_ylim(-0.0075,0.0075) ax1.set_xlim(0,fs) ax1.plot(t, sig)STFTの計算及びグラフ表示です。
※$N$や$RATE$を変更したときにうまく表示するようにスケールしてますが、$f_r,fn$に集約したので、ここではな~んだという位シンプルになりましたnperseg = 1024 f, t, Zxx = signal.stft(sig, fs=fn, nperseg=nperseg) ax2.pcolormesh(fs*t, f/fs/2, np.abs(Zxx), cmap='hsv') ax2.set_xlim(0,fs) ax2.set_ylim(20,20000) ax2.set_yscale('log')FFTの計算及びグラフ表示です。
※$N$や$RATE$を変更したときにうまく表示するようにスケールしてます。ここではax3.plotは若干調整が入ります。freq =fft(sig,int(fn)) Pyy = np.sqrt(freq*freq.conj())*2/fn f = np.arange(20,20000,(20000-20)/int(fn)) #RATE11025,22050;N50,100 ax3.set_ylim(0,0.000075) ax3.set_xlim(20,20000) ax3.set_xlabel('Freq[Hz]') ax3.set_ylabel('Power') ax3.set_xscale('log') ax3.plot(f*RATE/44100,Pyy)plt.pause(0.01)で表示していますが、この0.01は最適化していません。
そして、ぱらぱらGifアニメーションのために画像を一枚一枚保存します。plt.pause(0.01) plt.savefig('out_jihou_test/figure'+str(s)+'.jpg')for文が完了すると終了します。
stream.stop_stream() stream.close() p.terminate() print( "Stop Streaming")パラメータを変更したときの時報のGifアニメーション
時報を徹底的に分析して、周波数のバグを上記のコードで解消しました。
【参考】
・インターネット時報※基準周波数がオーディオや短波とか。。。なんかすぐ用意できませんでした
ということで、時報をパラメータを変更して取得したので掲載しておきます。
出力は1秒おきにピピピ。。。と鳴って、10秒ごとにピーンとなり、1分おきに時報でボボボボーンという感じでなっています。
※まあ、具体的には上のサイトをのぞいてみてください
まとめ
・さらなる高速化を実施した
・周波数のバグを解消してFFTとSTFTのリアルタイム・スペクトログラムが完成した
・トリガーでサンプリング開始するようにした・音声認識、DL導入を実施したいと思う
おまけ
コードの下に出力例を置いています。
※iput,data,そしてframesの出力例
inputとdataは全く同じframesは[]がついているだけ異なる。# -*- coding:utf-8 -*- import pyaudio import time import matplotlib.pyplot as plt import numpy as np import wave from scipy.fftpack import fft, ifft from scipy import signal def start_measure(): CHUNK=1024 RATE=44100 #11025 #22050 #44100 CHANNELS = 1 # 1;monoral 2;ステレオ- p=pyaudio.PyAudio() WAVE_OUTPUT_FILENAME = "output1.wav" FORMAT = pyaudio.paInt16 # int16型 input = [] stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにする input =stream.read(CHUNK) frames = [] frames.append(input) wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close() wavfile = WAVE_OUTPUT_FILENAME wr = wave.open(wavfile, "rb") ch = CHANNELS #wr.getnchannels() width = p.get_sample_size(FORMAT) #wr.getsampwidth() fr = RATE #wr.getframerate() fn = wr.getnframes() fs = fn / fr origin = wr.readframes(wr.getnframes()) data = origin[:fn] wr.close() sig = np.frombuffer(data, dtype="int16")/32768.0 sig1 = np.frombuffer(input, dtype="int16")/32768.0 #print(max(sig)) while True: if max(sig1) > 0.001: break input =stream.read(CHUNK) frames = [] frames.append(input) wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close() wavfile = WAVE_OUTPUT_FILENAME wr = wave.open(wavfile, "rb") ch = CHANNELS #wr.getnchannels() width = p.get_sample_size(FORMAT) #wr.getsampwidth() fr = RATE #wr.getframerate() fn = wr.getnframes() fs = fn / fr origin = wr.readframes(wr.getnframes()) data = origin[:fn] wr.close() sig = np.frombuffer(data, dtype="int16")/32768.0 sig1 = np.frombuffer(input, dtype="int16")/32768.0 print(max(sig),max(sig1)) stream.stop_stream() stream.close() p.terminate() return data,input,frames data,input,frames=start_measure() print("data=",data,"input=",input,"frames=",frames)以下出力です。
>python pyaudio_test.py data= b'\x02\x00\x03\x00\x02\x00\x01\x00\x01\x00\x01\x00\x01\x00\x03\x00\x06\x00\t\x00\x0c\x00\x0e\x00\x10\x00\x10\x00\x10\x00\x10\x00\x0f\x00\x0f\x00\x0e\x00\x0e\x00\x0e\x00\x0e\x00\x0c\x00\x0b\x00\t\x00\x05\x00\x01\x00\xfe\xff\xfb\xff\xfb\xff\xfb\xff\xfd\xff\xff\xff\x01\x00\x01\x00\x00\x00\xff\xff\xfb\xff\xf7\xff\xf4\xff\xf1\xff\xf0\xff\xf0\xff\xf2\xff\xf3\xff\xf5\xff\xf7\xff\xf8\xff\xf9\xff\xfa\xff\xfa\xff\xfb\xff\xfc\xff\xfe\xff\xff\xff\...\xfd\xff\xf8\xff\xf2\xff\xee\xff\xea\xff\xe9\xff\xe9\xff\xea\xff\xec\xff\xed\xff\xee\xff\xef\xff\xef\xff\xf0\xff\xf1\xff\xf2\xff\xf3\xff\xf5\xff\xf6\xff\xf7\xff\xf9\xff\xfc\xff\xff\xff\x03\x00\x06\x00\x08\x00\x0b\x00\x0c\x00\x0f\x00\x10\x00\x14\x00\x17\x00\x1a\x00\x1d\x00\x1d\x00\x1d\x00\x1c\x00\x19\x00\x16\x00\x15\x00\x14\x00\x14\x00\x16\x00\x16\x00\x16\x00\x16\x00\x13\x00\x0f\x00\x0b\x00\x06\x00\x02\x00\xfd\xff\xfa\xff\xf7\xff\xf4\xff\xf2\xff\xf0\xff\xee\xff\xec\xff\xea\xff\xe8\xff\xe6\xff\xe5\xff\xe5\xff\xe6\xff\xe7\xff\xea\xff\xec\xff\xef\xff\xf3\xff' input= b'\x02\x00\x03\x00\x02\x00\x01\x00\x01\x00\x01\x00\x01\x00\x03\x00\x06\x00\t\x00\x0c\x00\x0e\x00\x10\x00\x10\x00\x10\x00\x10\x00\x0f\x00\x0f\x00\x0e\x00\x0e\x00\x0e\x00\x0e\x00\x0c\x00\x0b\x00\t\x00\x05\x00\x01\x00\xfe\xff\xfb\xff\xfb\xff\xfb\xff\xfd\xff\xff\xff\x01\x00\x01\x00\x00\x00\xff\xff\xfb\xff\xf7\xff\xf4\xff\xf1\xff\xf0\xff\xf0\xff\xf2\xff\xf3\xff\xf5\xff\xf7\xff\xf8\xff\xf9\xff\xfa\xff\xfa\xff\xfb\xff\xfc\xff\xfe\xff\xff\xff\...\xfd\xff\xf8\xff\xf2\xff\xee\xff\xea\xff\xe9\xff\xe9\xff\xea\xff\xec\xff\xed\xff\xee\xff\xef\xff\xef\xff\xf0\xff\xf1\xff\xf2\xff\xf3\xff\xf5\xff\xf6\xff\xf7\xff\xf9\xff\xfc\xff\xff\xff\x03\x00\x06\x00\x08\x00\x0b\x00\x0c\x00\x0f\x00\x10\x00\x14\x00\x17\x00\x1a\x00\x1d\x00\x1d\x00\x1d\x00\x1c\x00\x19\x00\x16\x00\x15\x00\x14\x00\x14\x00\x16\x00\x16\x00\x16\x00\x16\x00\x13\x00\x0f\x00\x0b\x00\x06\x00\x02\x00\xfd\xff\xfa\xff\xf7\xff\xf4\xff\xf2\xff\xf0\xff\xee\xff\xec\xff\xea\xff\xe8\xff\xe6\xff\xe5\xff\xe5\xff\xe6\xff\xe7\xff\xea\xff\xec\xff\xef\xff\xf3\xff' frames= [b'\x02\x00\x03\x00\x02\x00\x01\x00\x01\x00\x01\x00\x01\x00\x03\x00\x06\x00\t\x00\x0c\x00\x0e\x00\x10\x00\x10\x00\x10\x00\x10\x00\x0f\x00\x0f\x00\x0e\x00\x0e\x00\x0e\x00\x0e\x00\x0c\x00\x0b\x00\t\x00\x05\x00\x01\x00\xfe\xff\xfb\xff\xfb\xff\xfb\xff\xfd\xff\xff\xff\x01\x00\x01\x00\x00\x00\xff\xff\xfb\xff\xf7\xff\xf4\xff\xf1\xff\xf0\xff\xf0\xff\xf2\xff\xf3\xff\xf5\xff\xf7\xff\xf8\xff\xf9\xff\xfa\xff\xfa\xff\xfb\xff\xfc\xff\xfe\xff\xff\xff\...\xfd\xff\xf8\xff\xf2\xff\xee\xff\xea\xff\xe9\xff\xe9\xff\xea\xff\xec\xff\xed\xff\xee\xff\xef\xff\xef\xff\xf0\xff\xf1\xff\xf2\xff\xf3\xff\xf5\xff\xf6\xff\xf7\xff\xf9\xff\xfc\xff\xff\xff\x03\x00\x06\x00\x08\x00\x0b\x00\x0c\x00\x0f\x00\x10\x00\x14\x00\x17\x00\x1a\x00\x1d\x00\x1d\x00\x1d\x00\x1c\x00\x19\x00\x16\x00\x15\x00\x14\x00\x14\x00\x16\x00\x16\x00\x16\x00\x16\x00\x13\x00\x0f\x00\x0b\x00\x06\x00\x02\x00\xfd\xff\xfa\xff\xf7\xff\xf4\xff\xf2\xff\xf0\xff\xee\xff\xec\xff\xea\xff\xe8\xff\xe6\xff\xe5\xff\xe5\xff\xe6\xff\xe7\xff\xea\xff\xec\xff\xef\xff\xf3\xff']

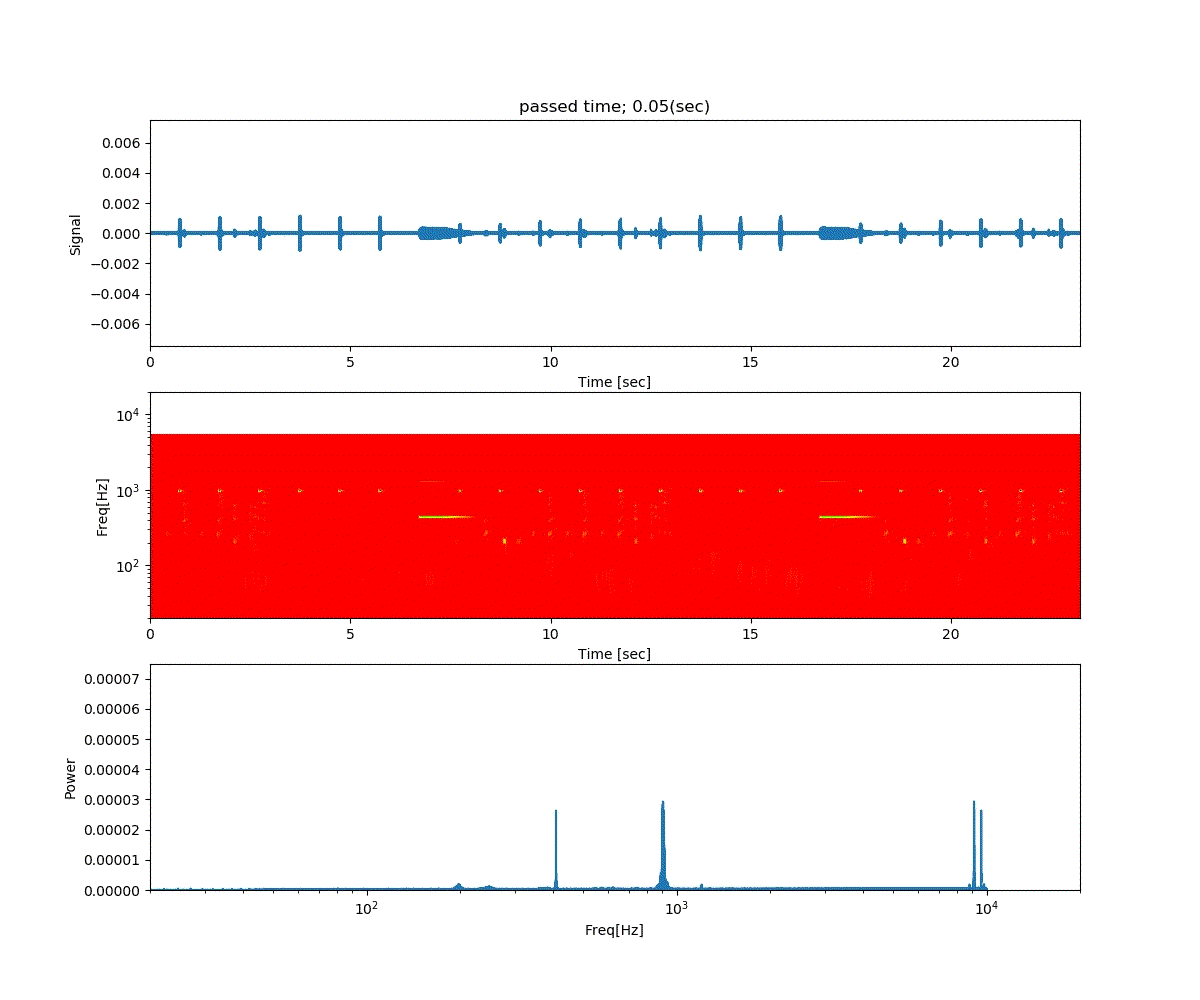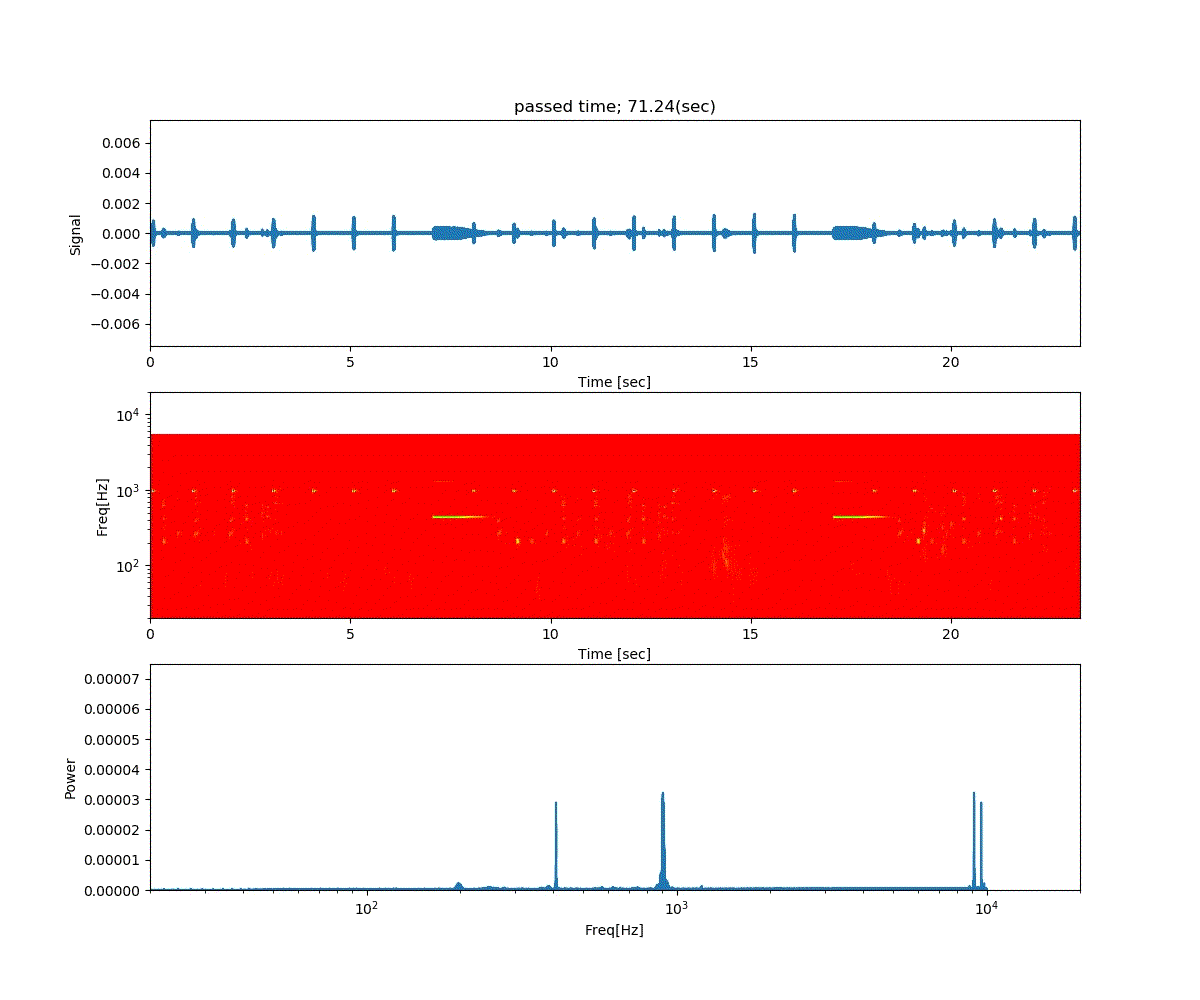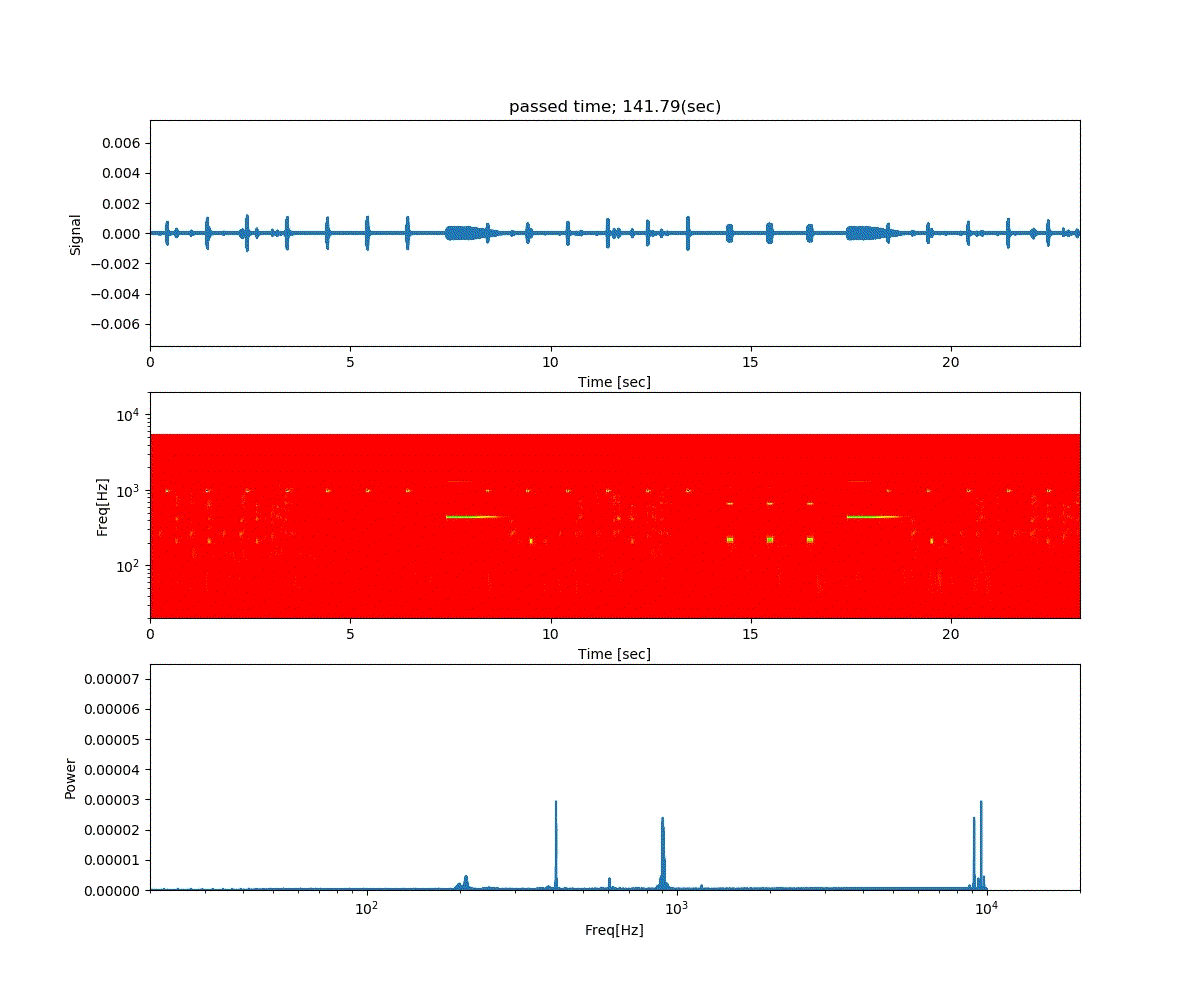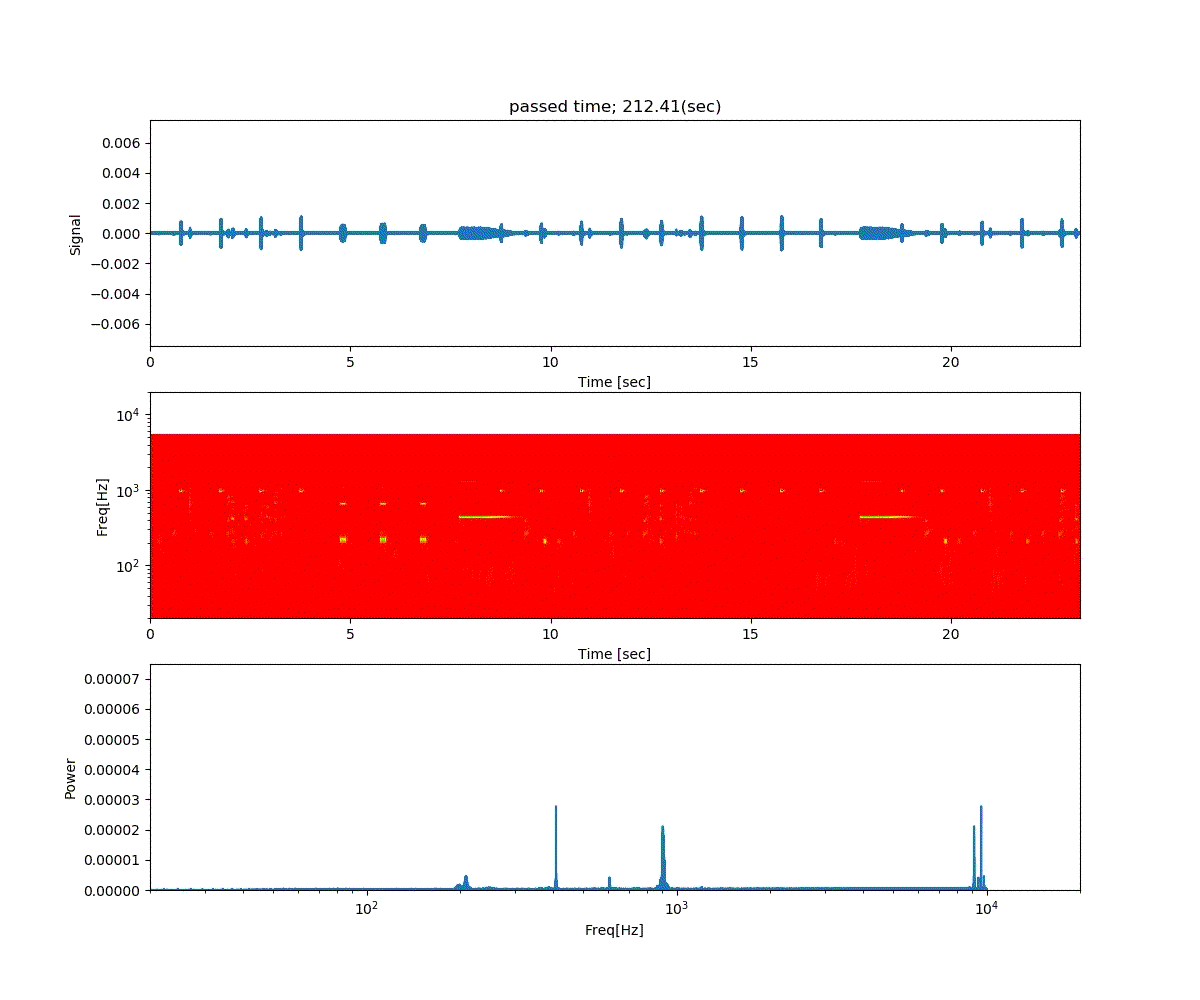
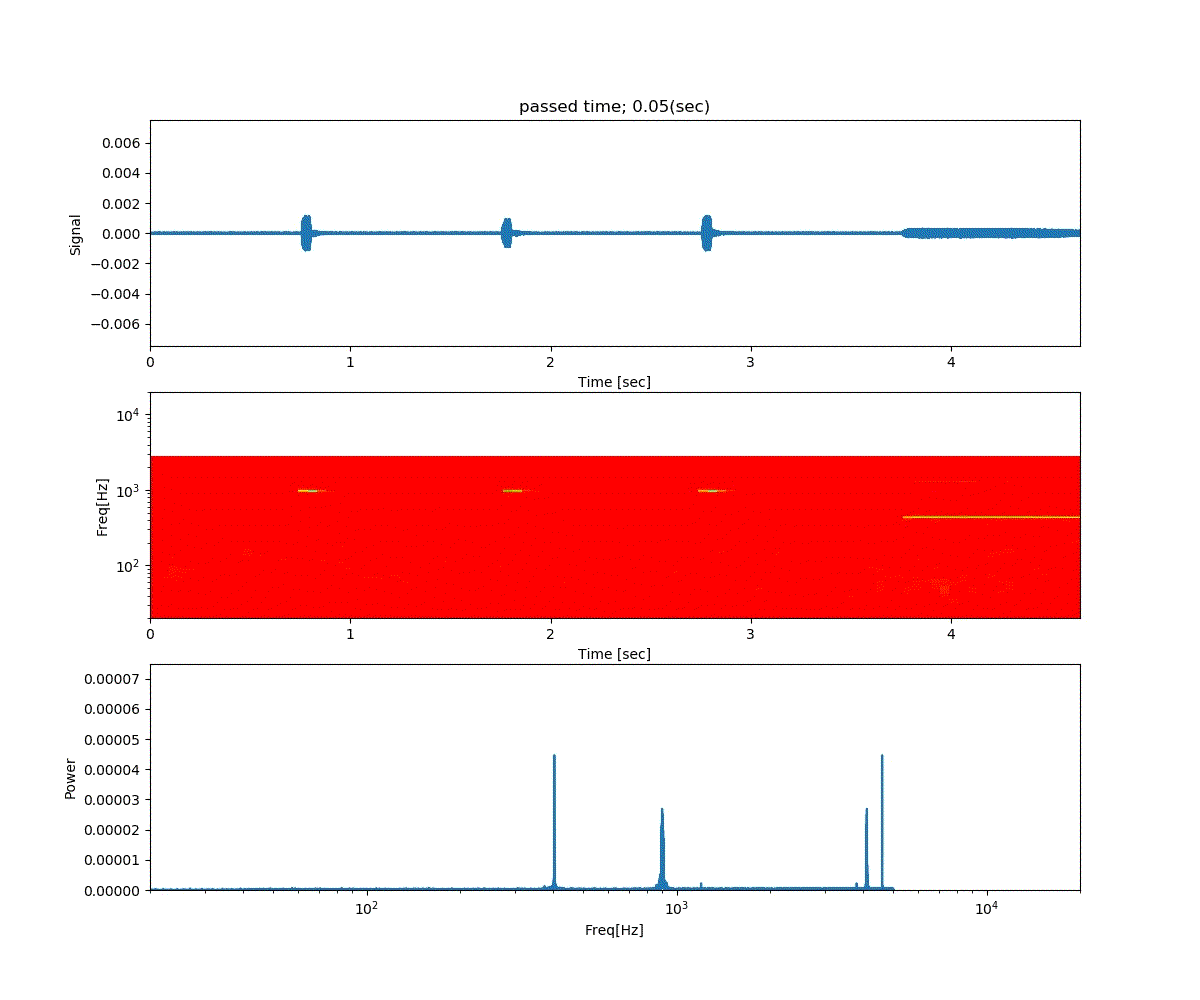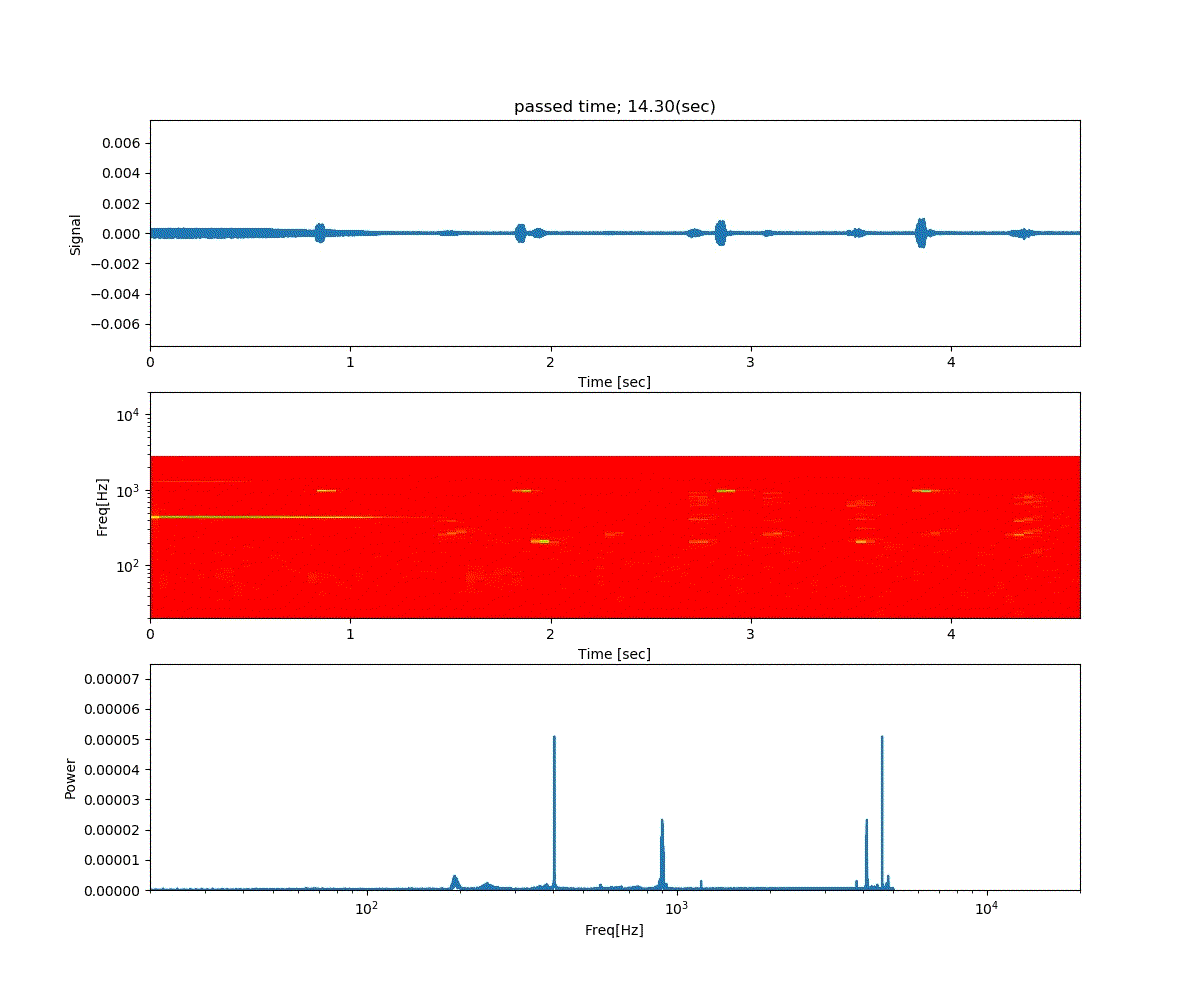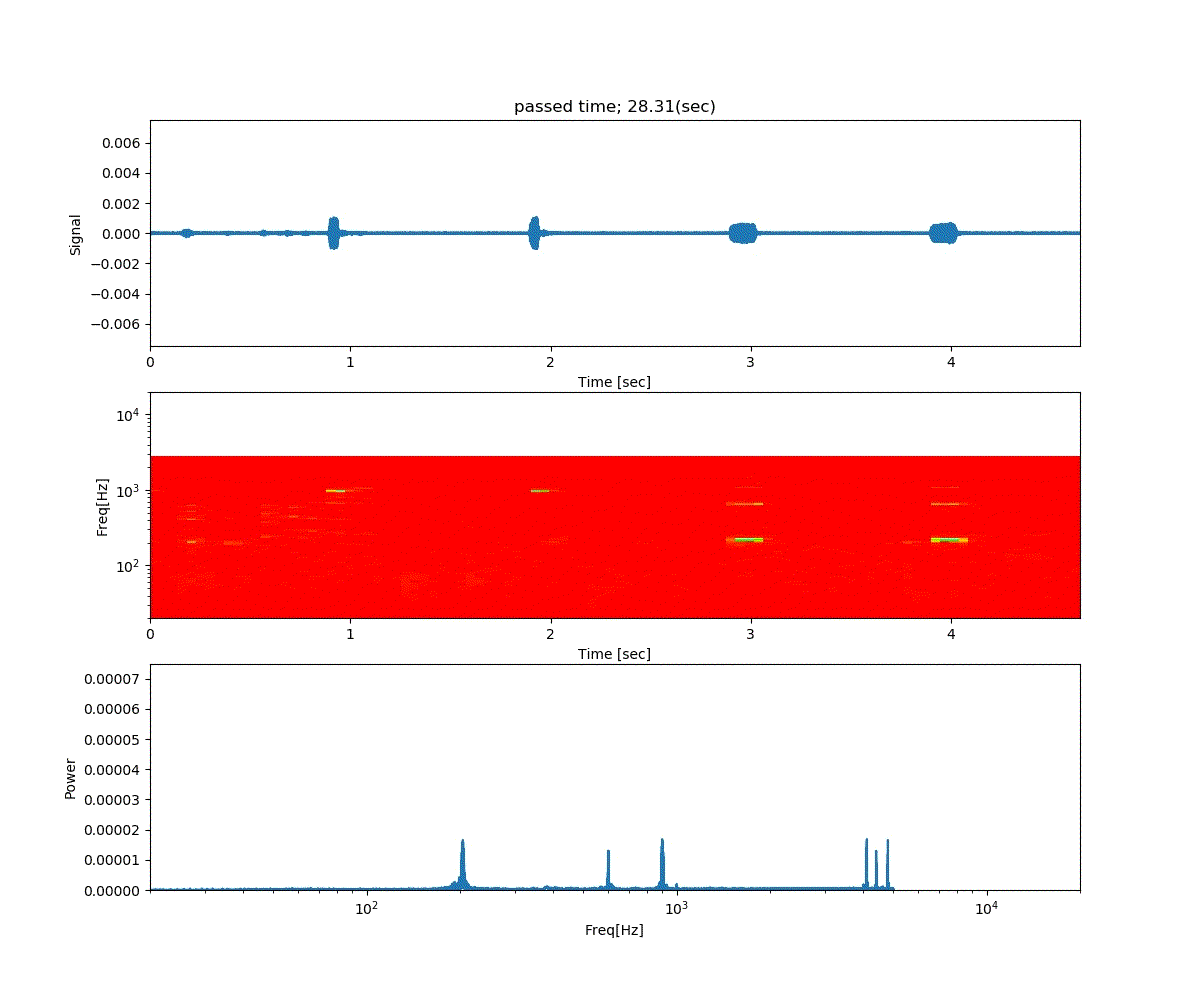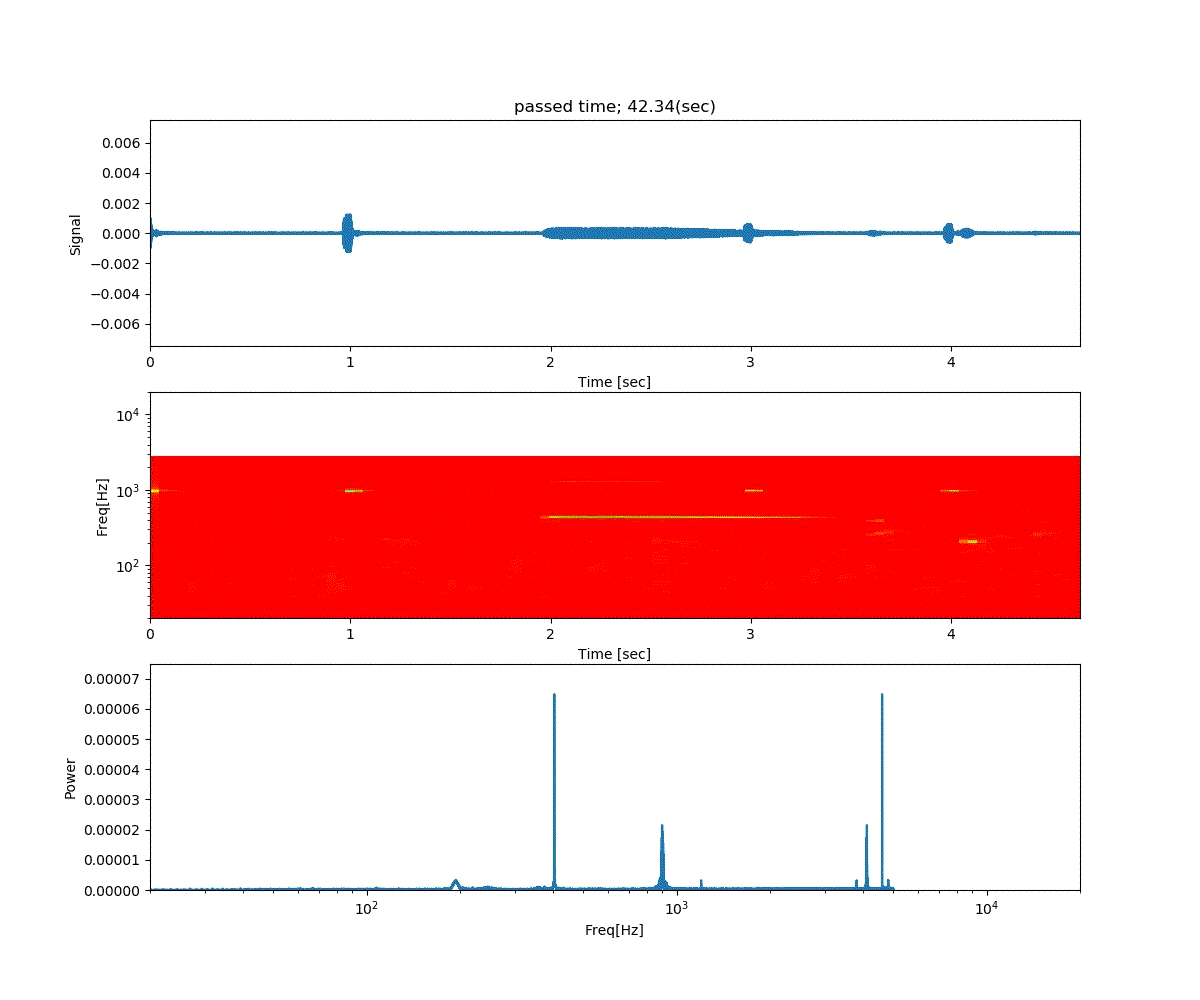
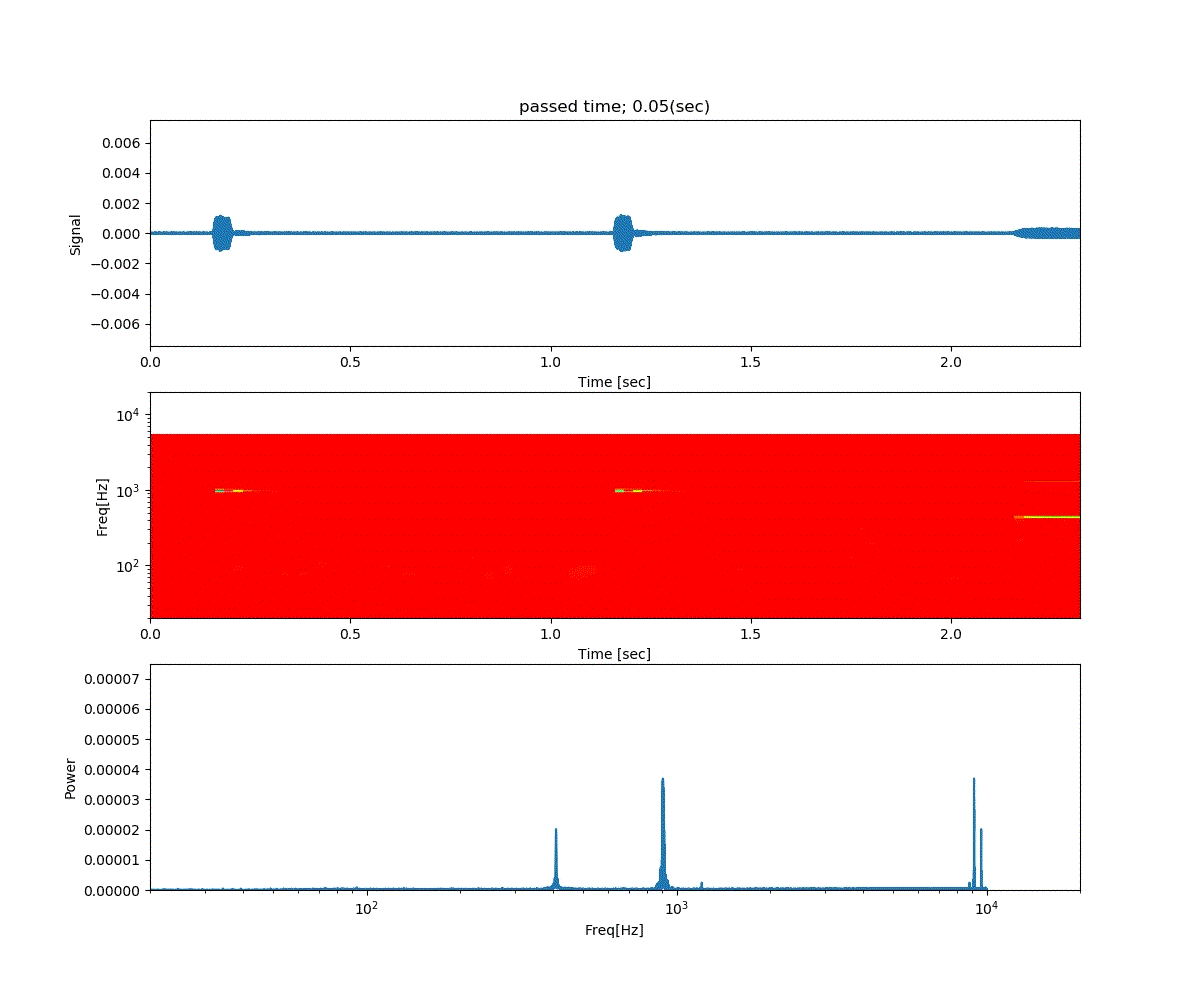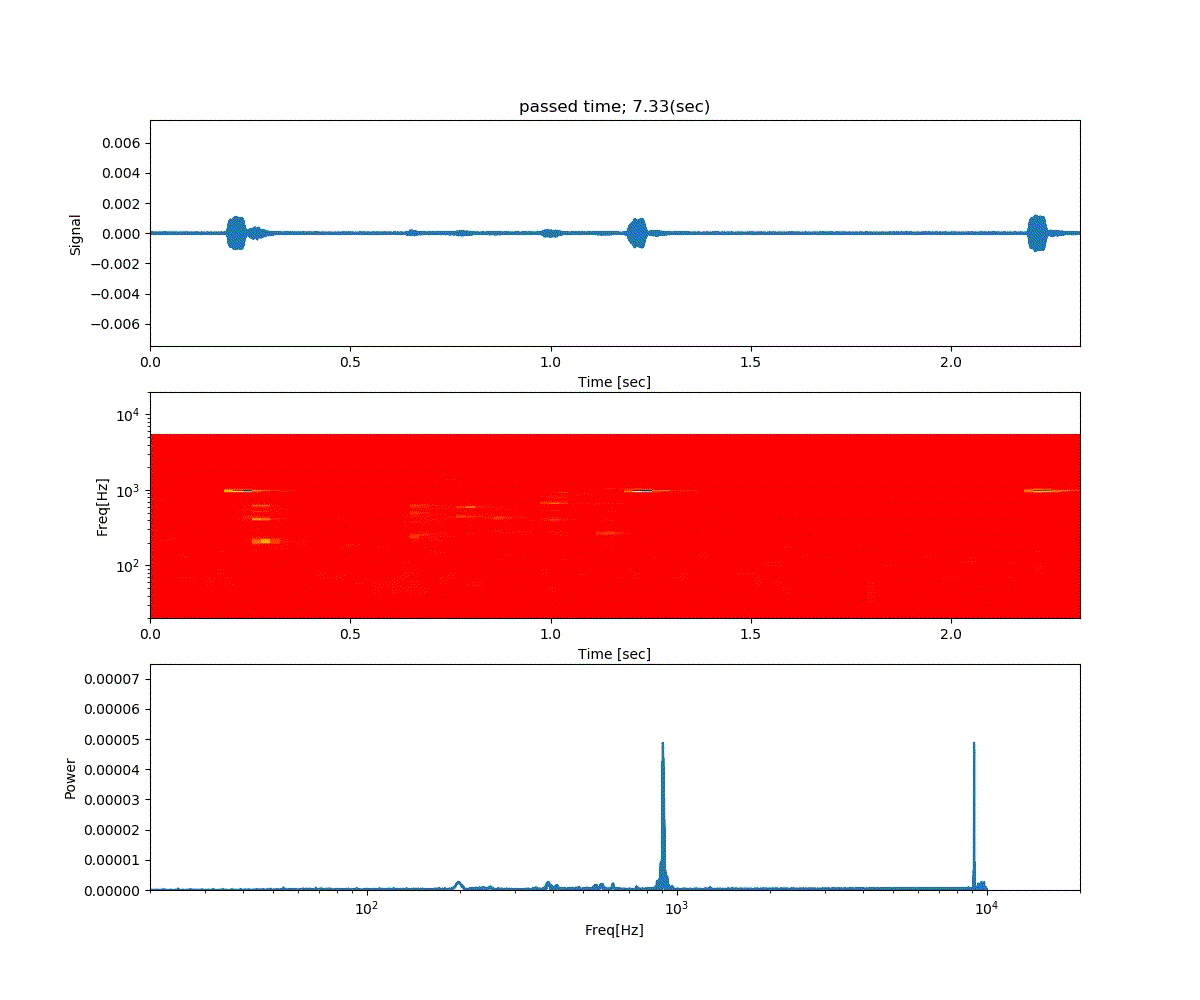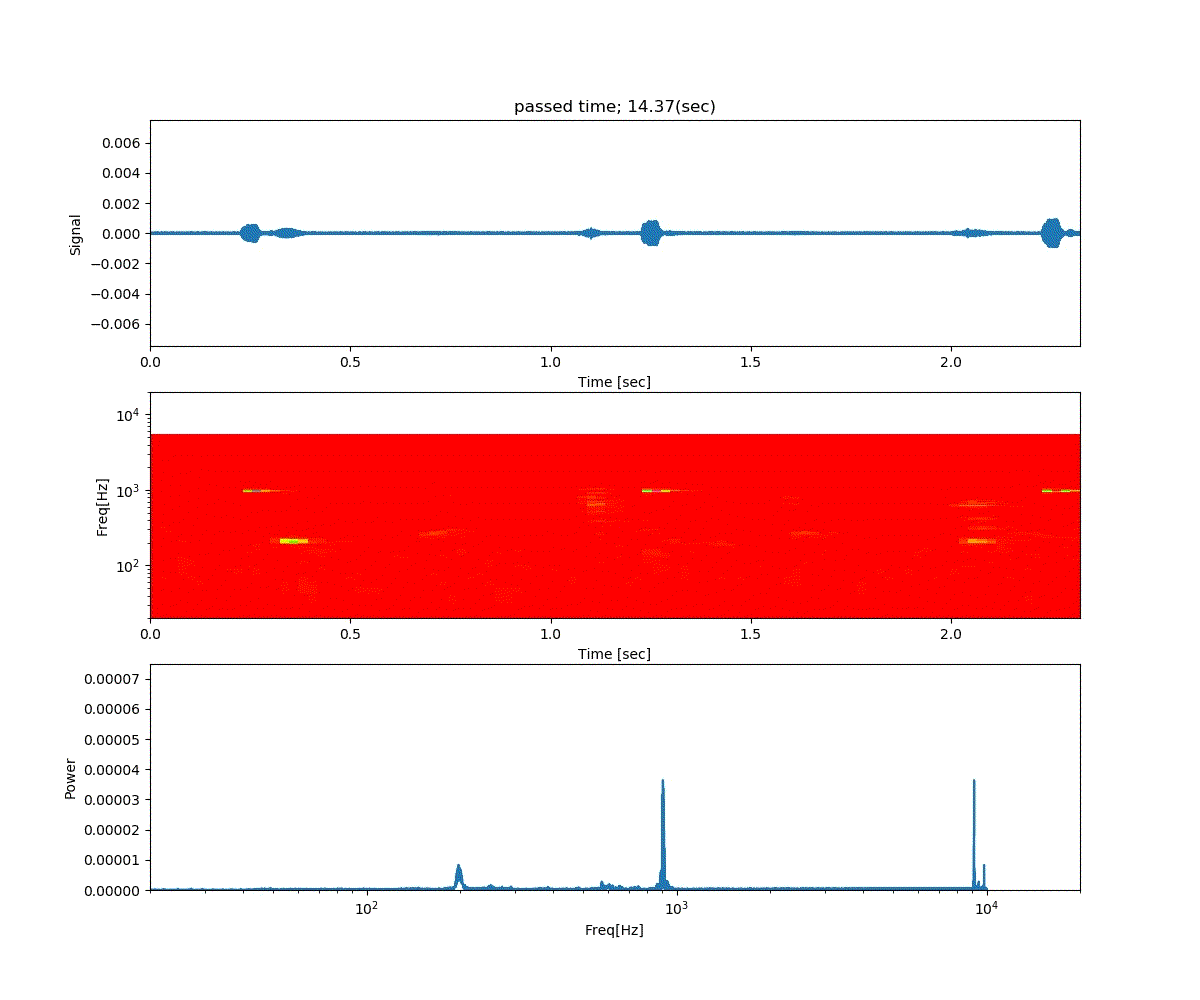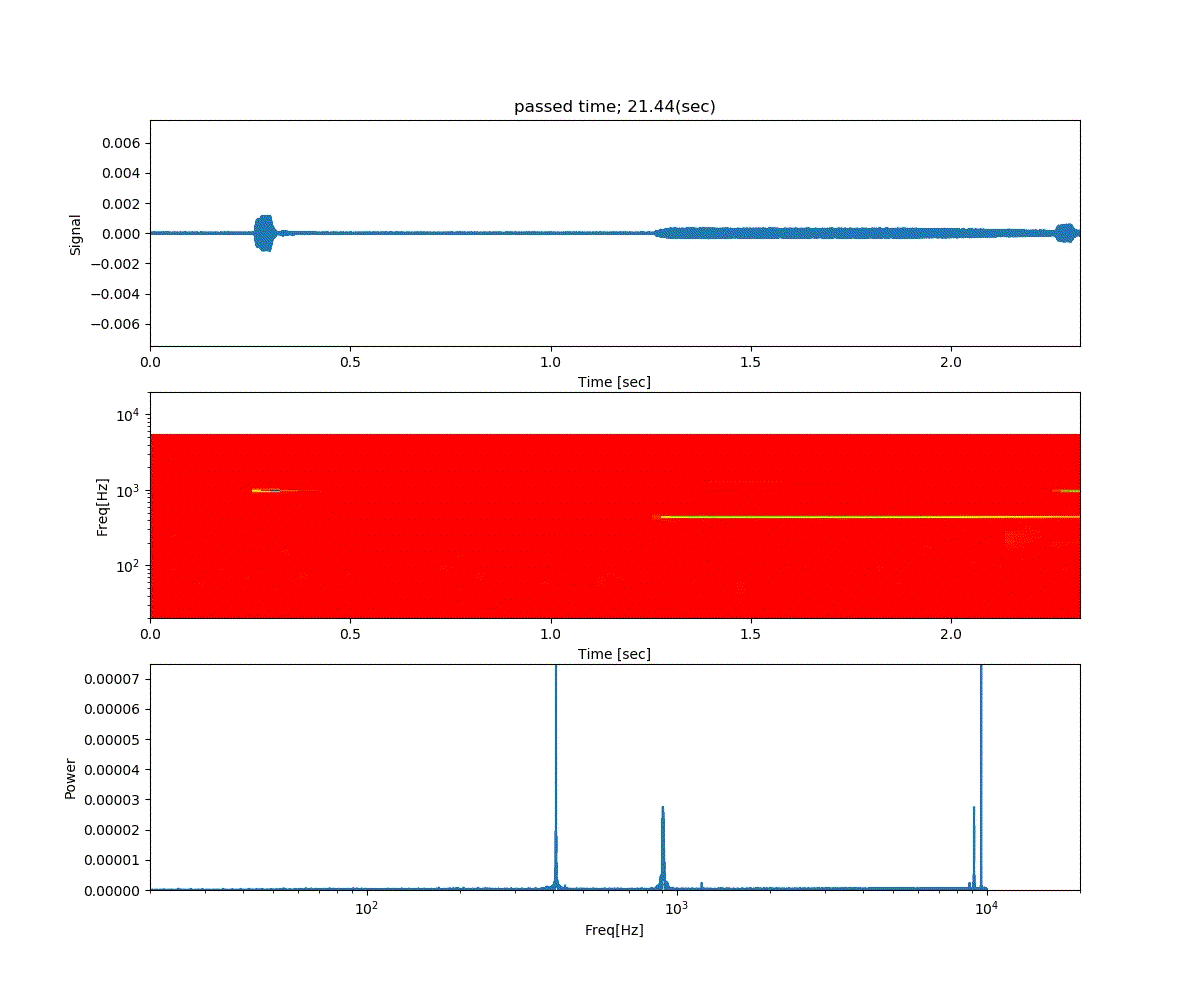
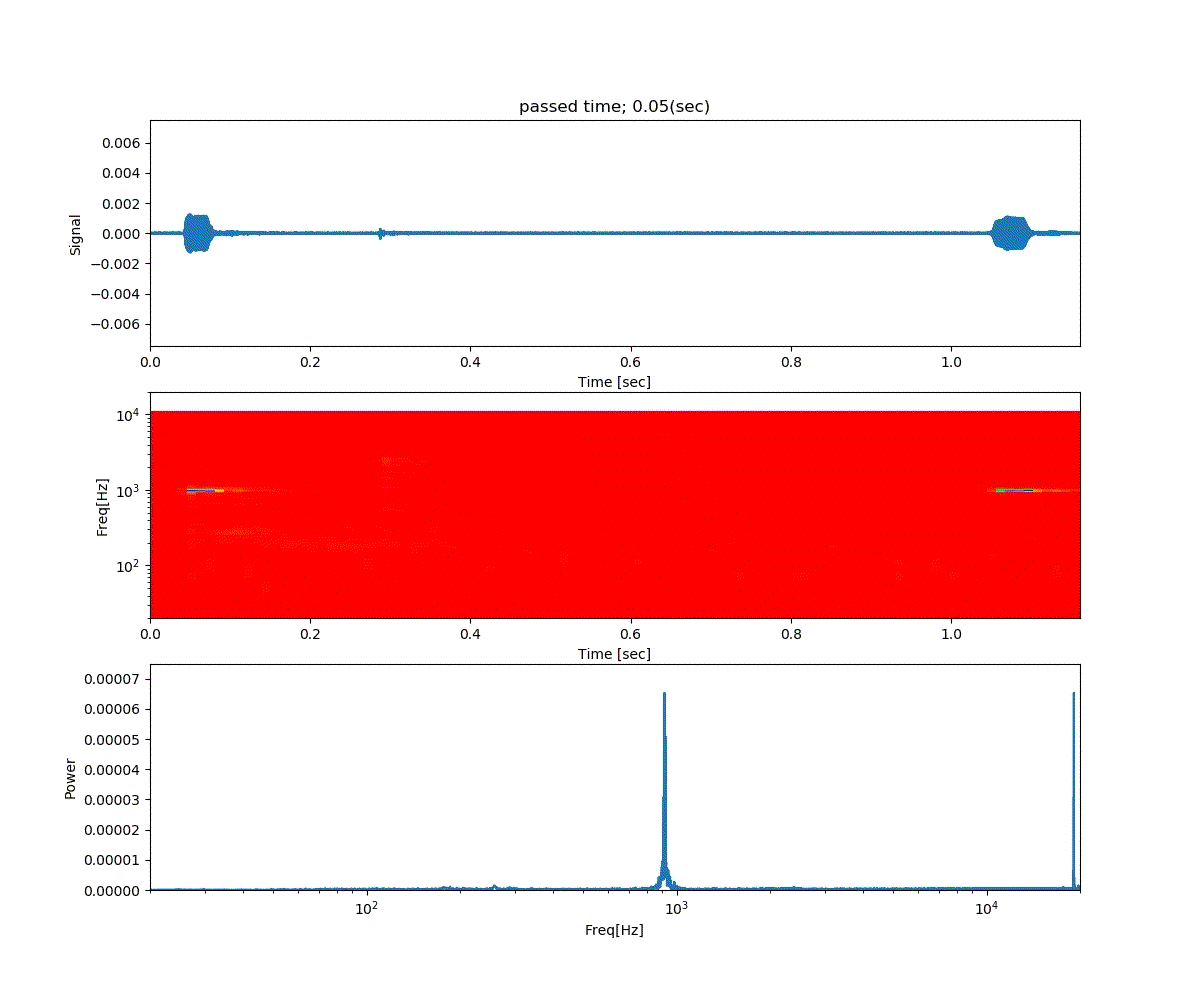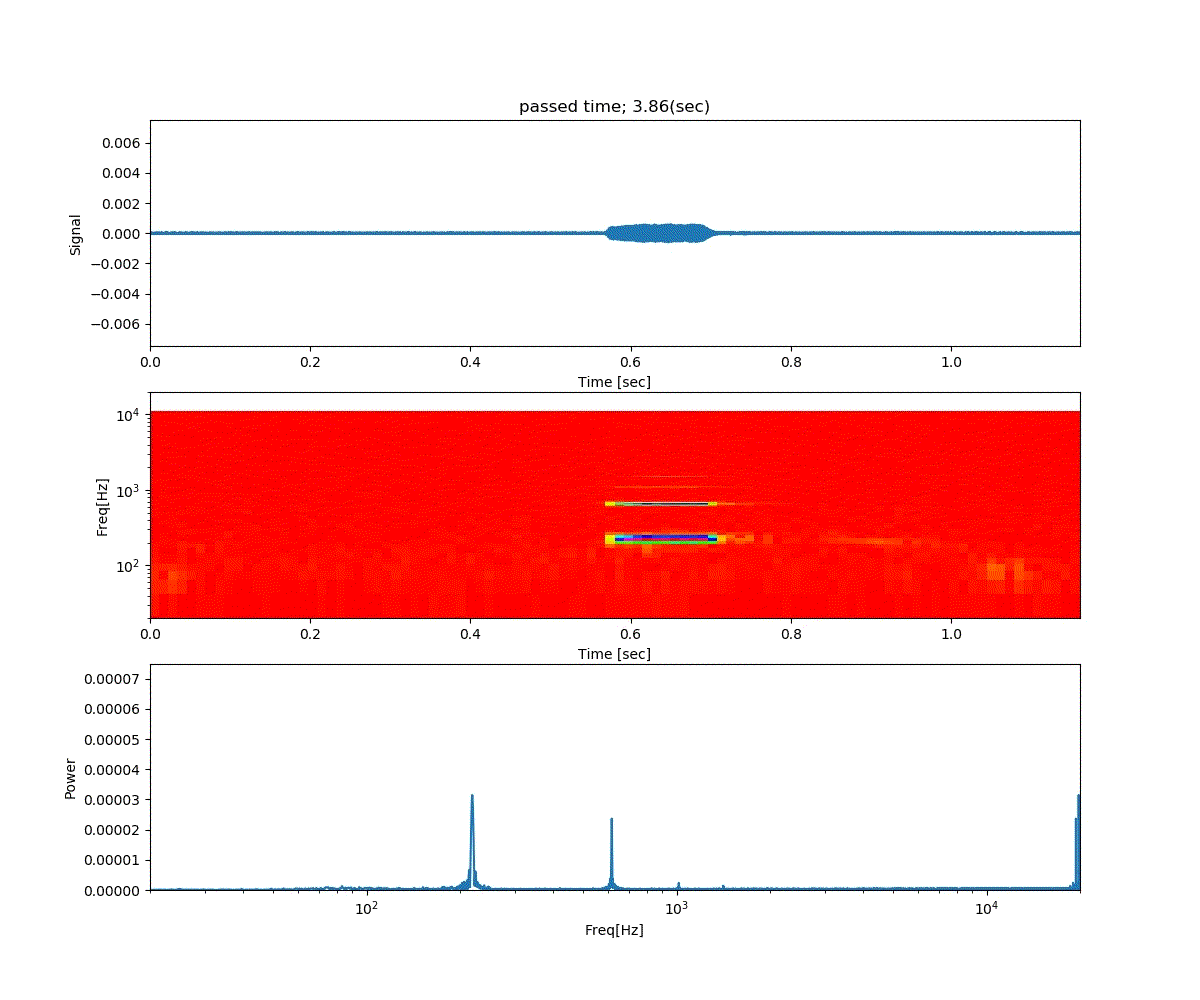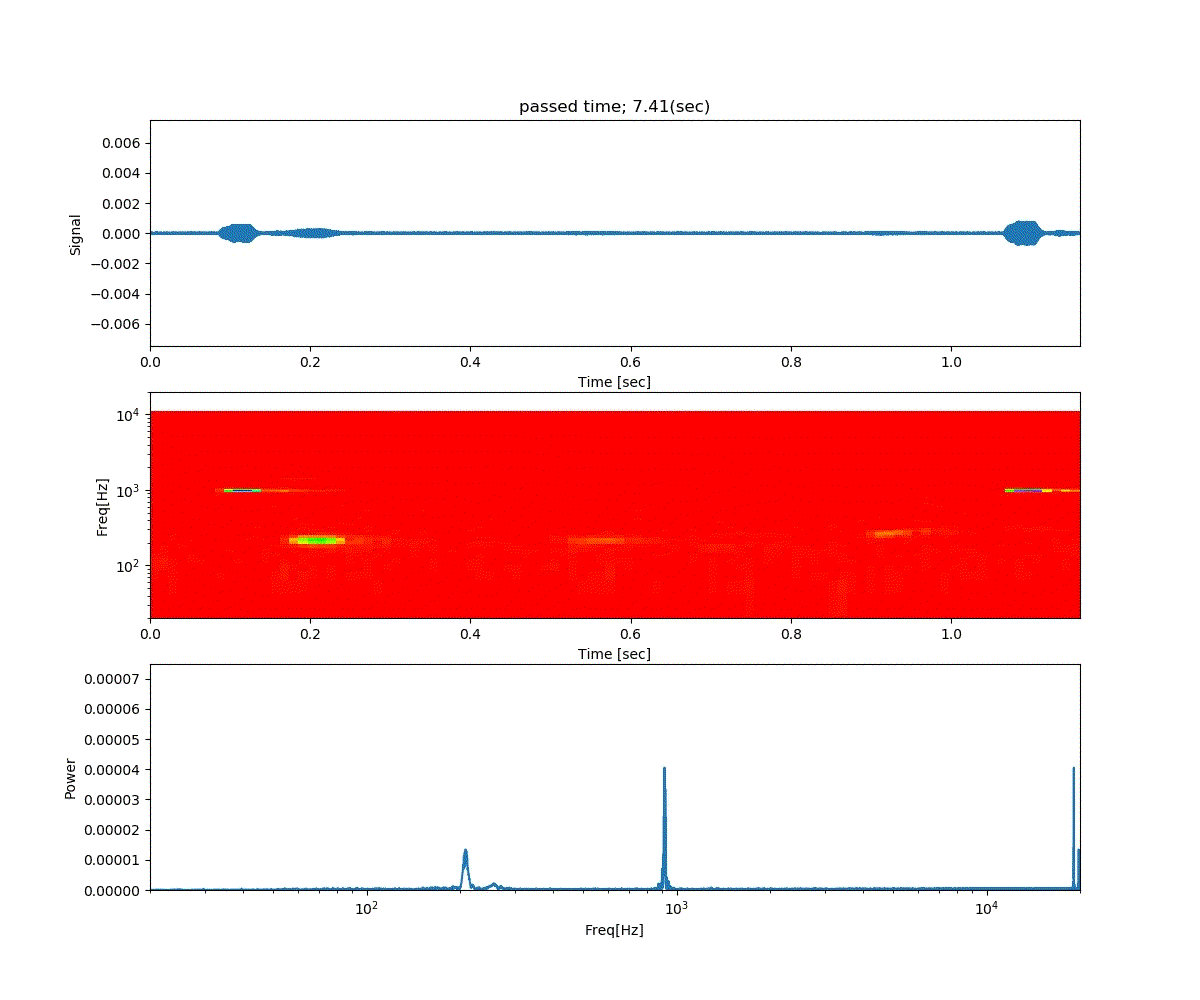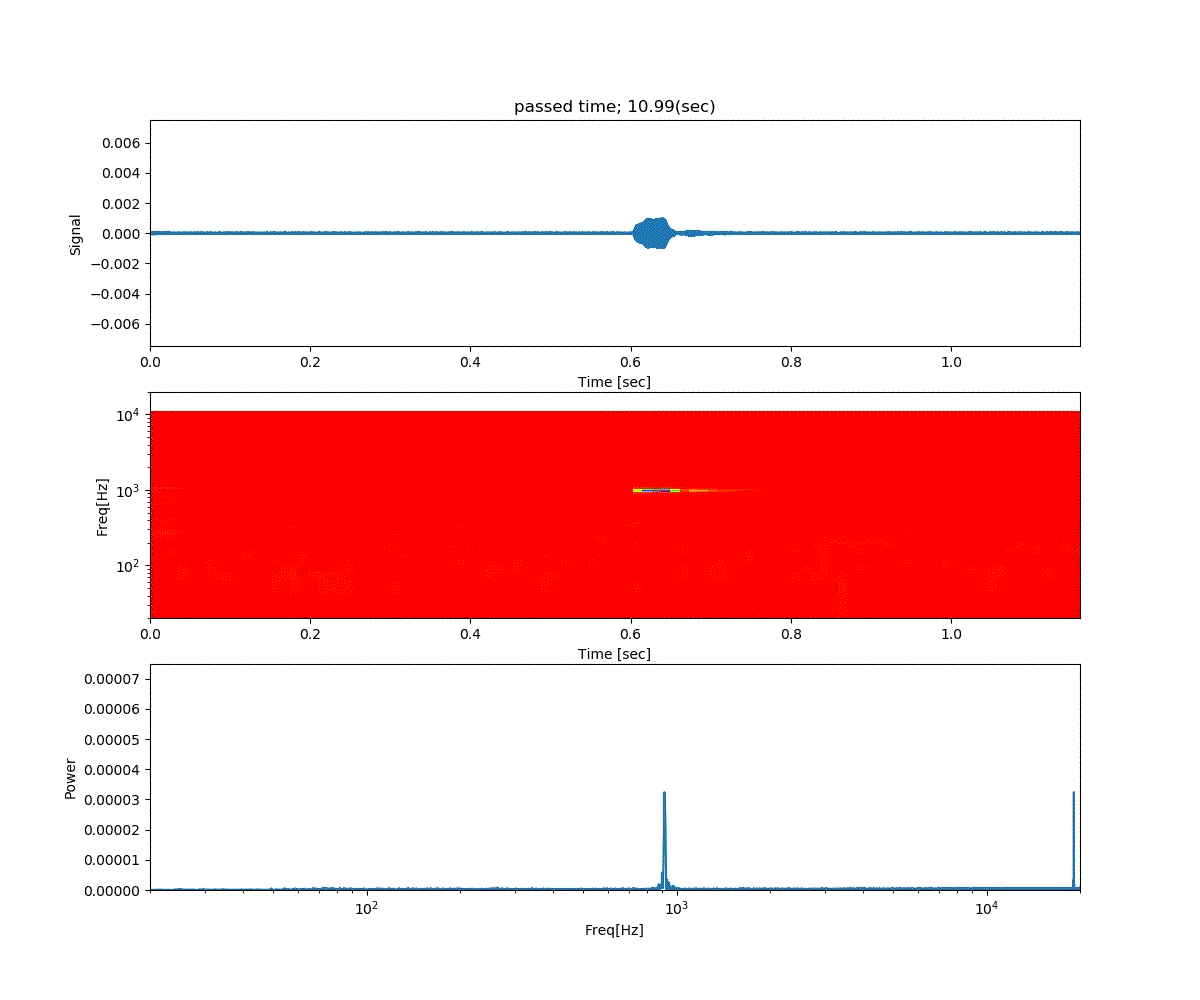
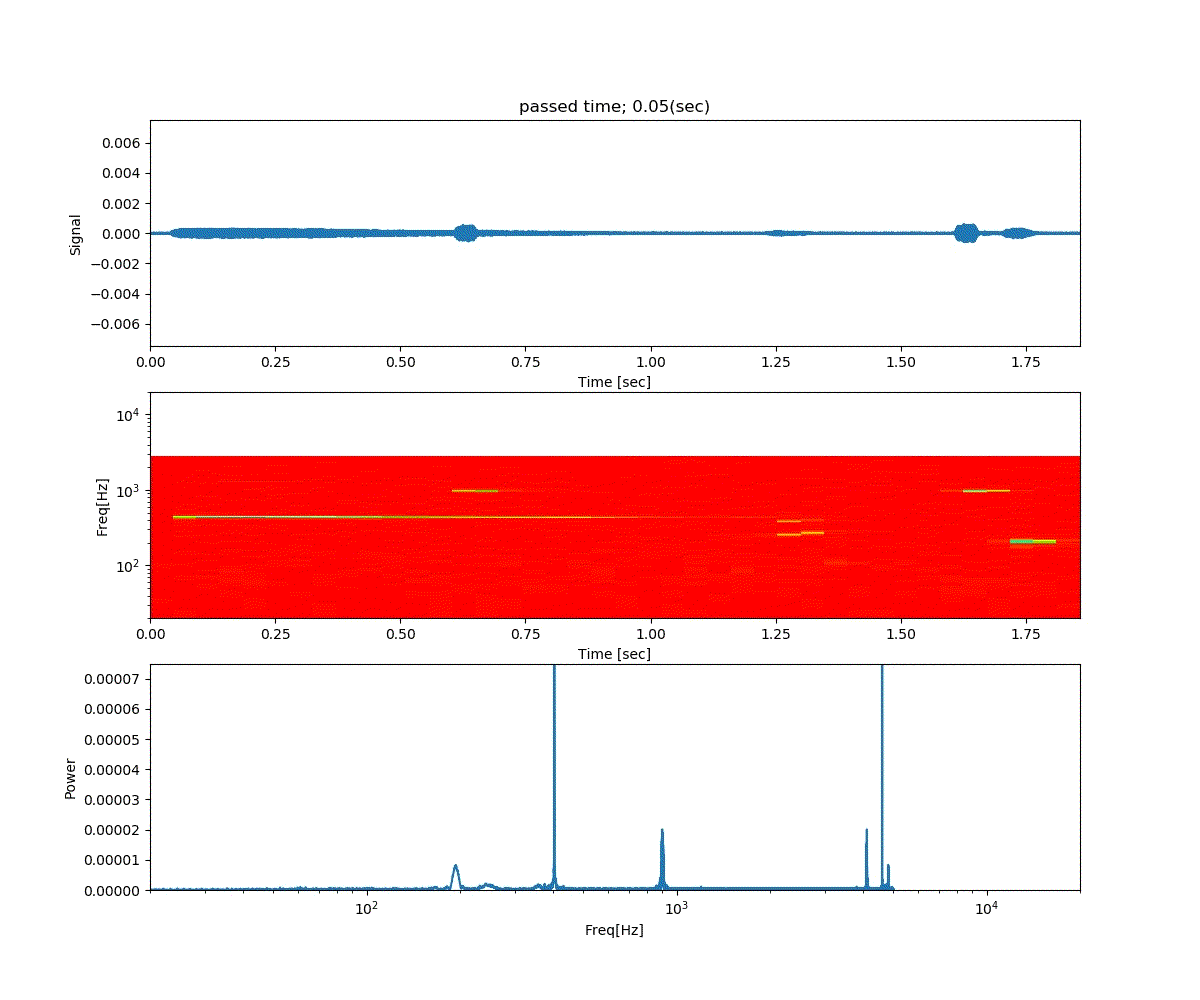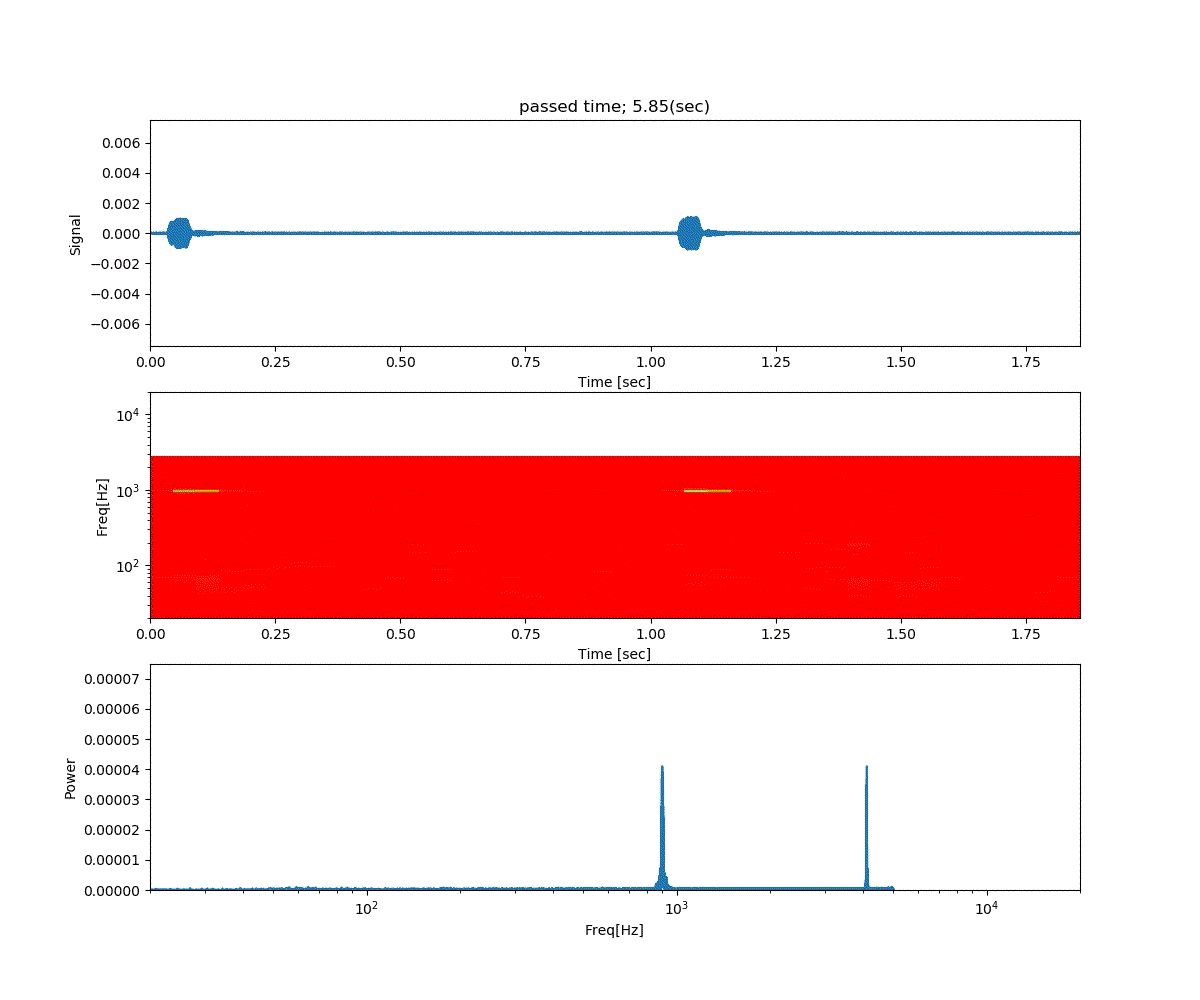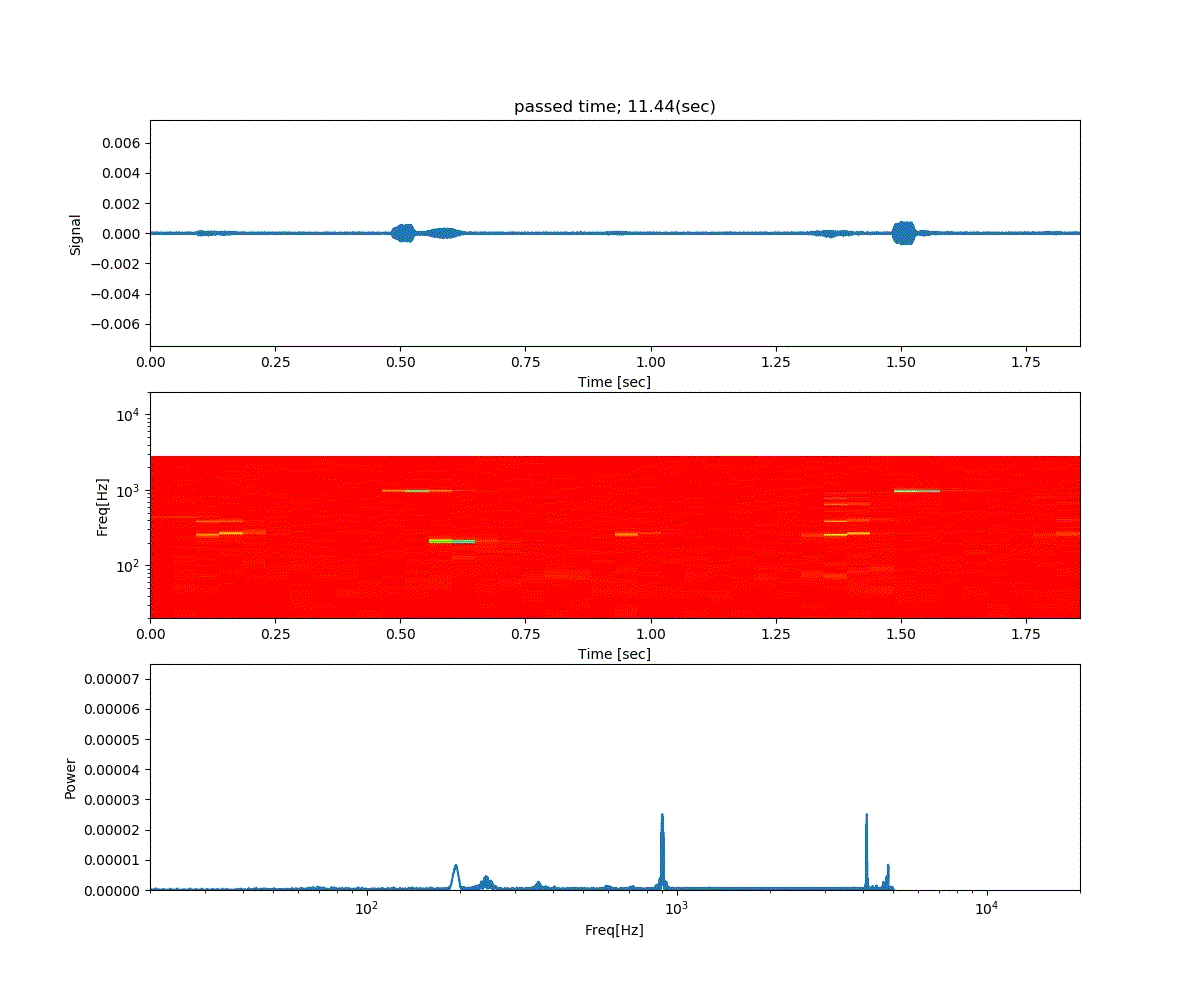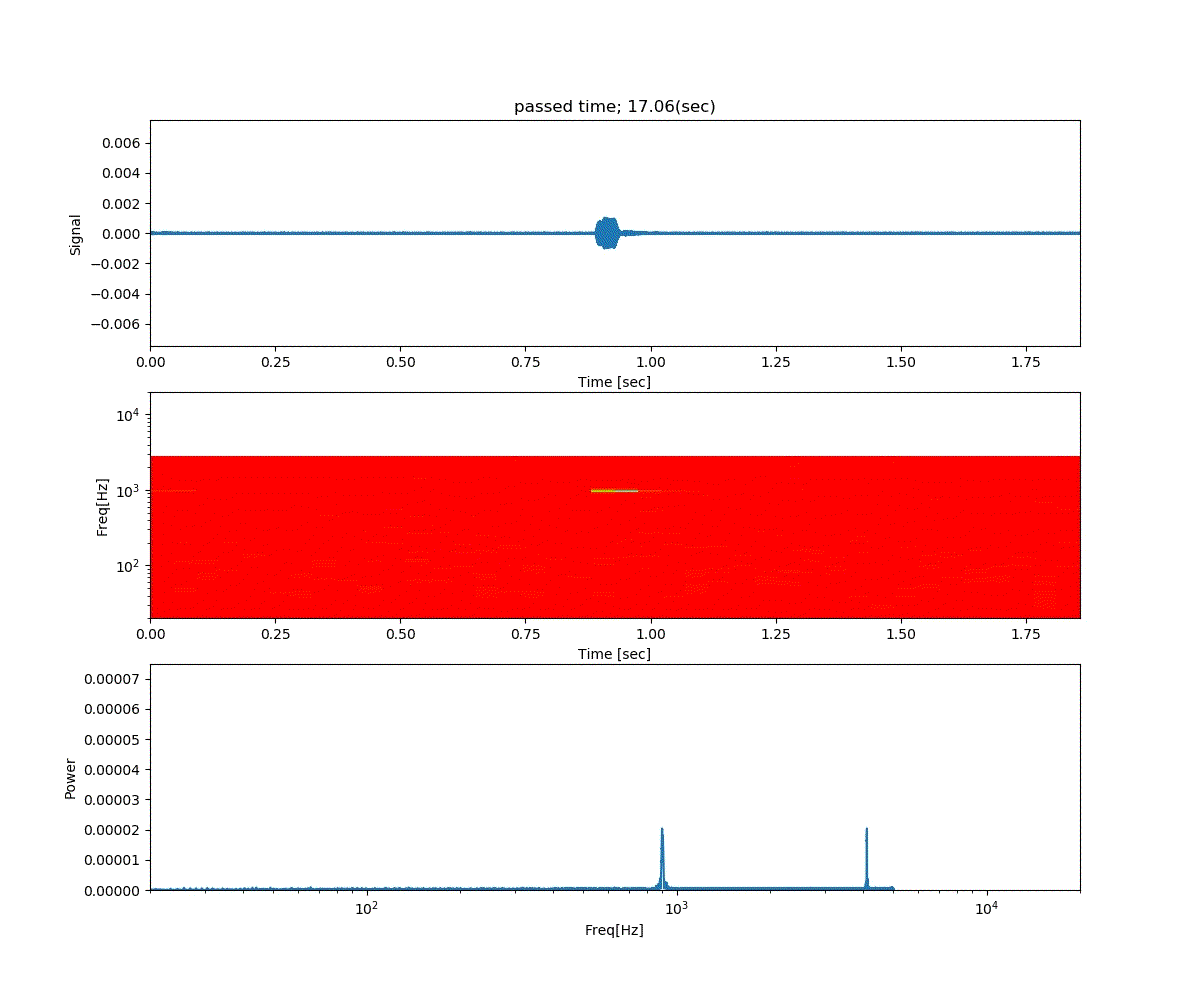
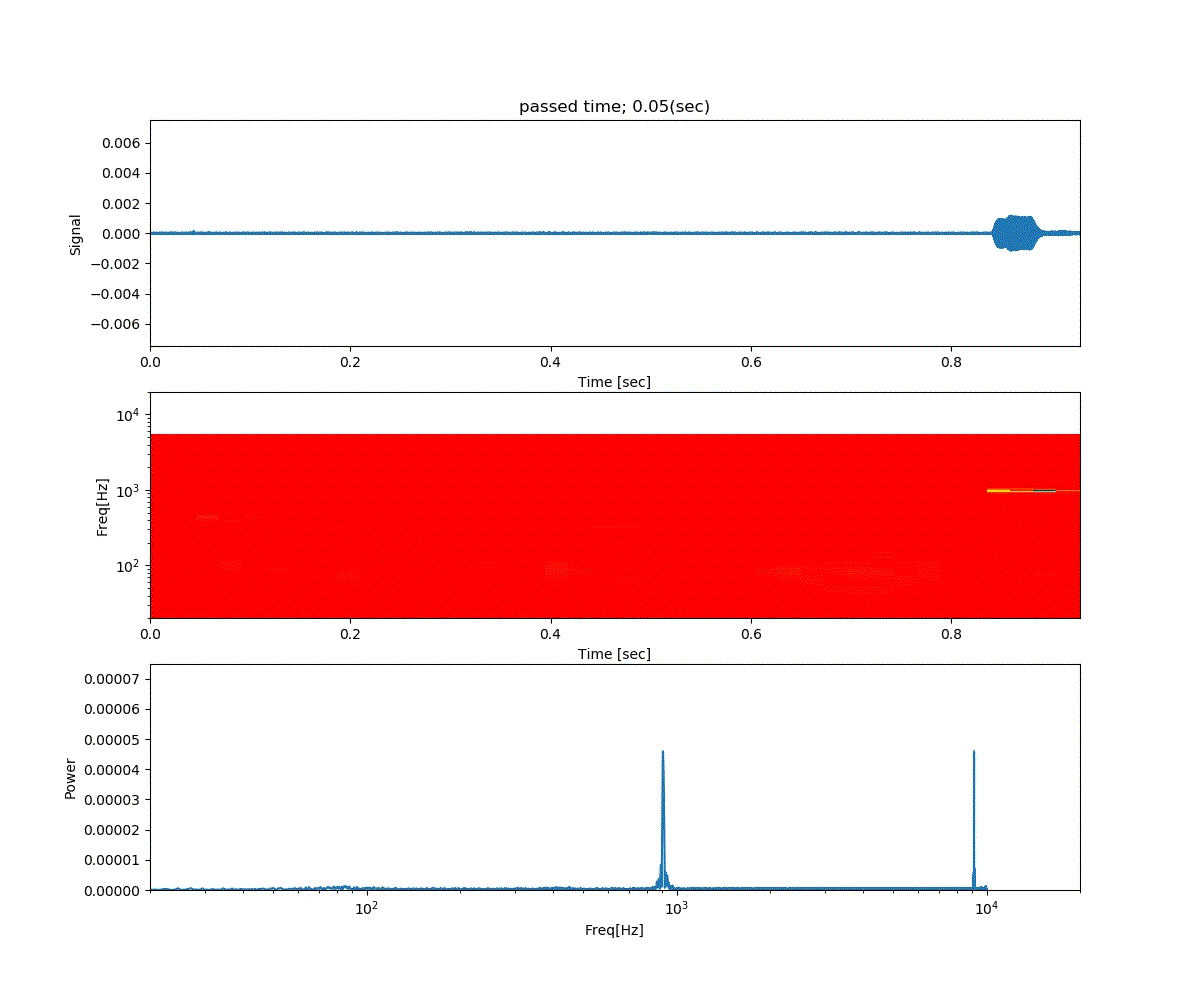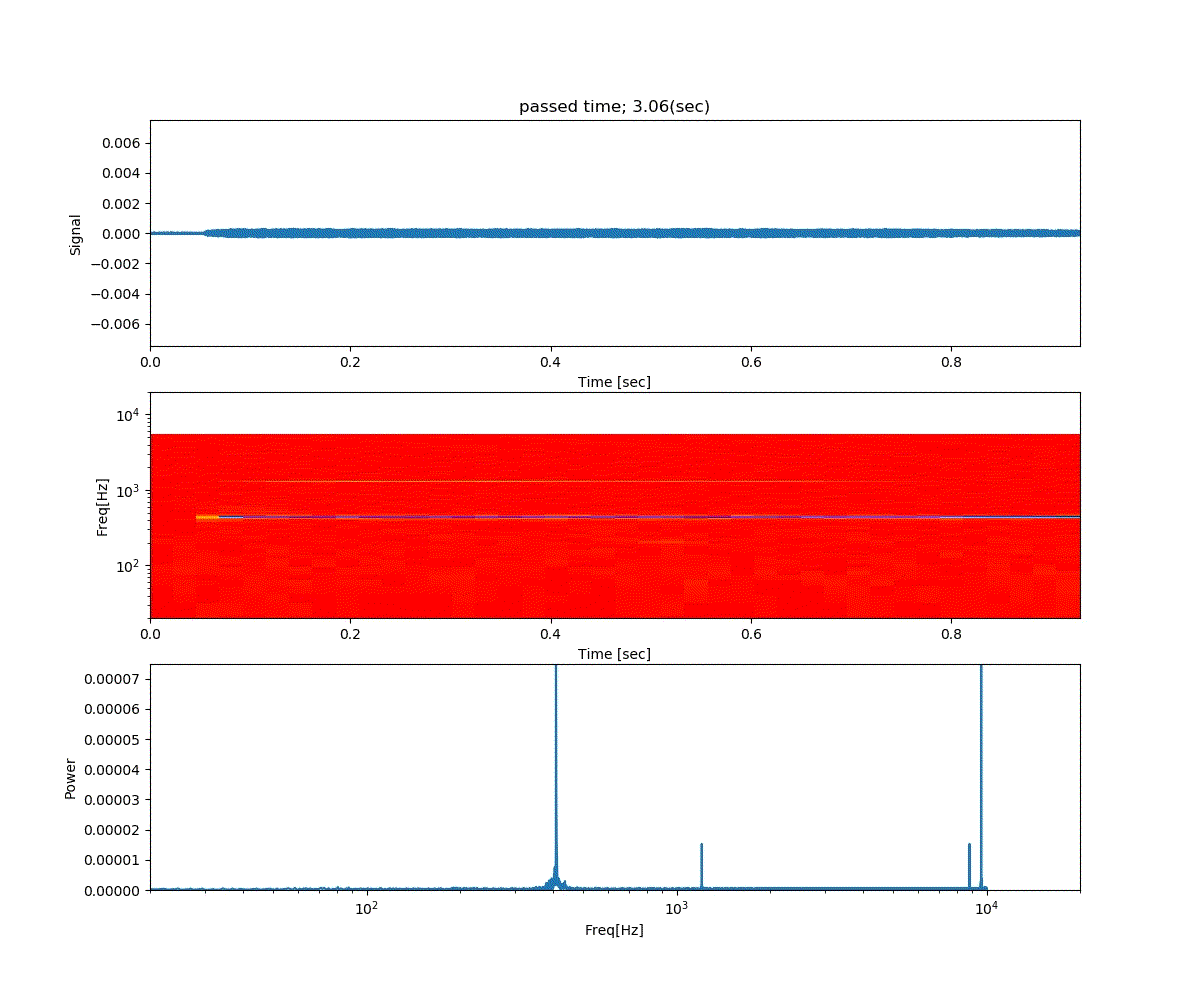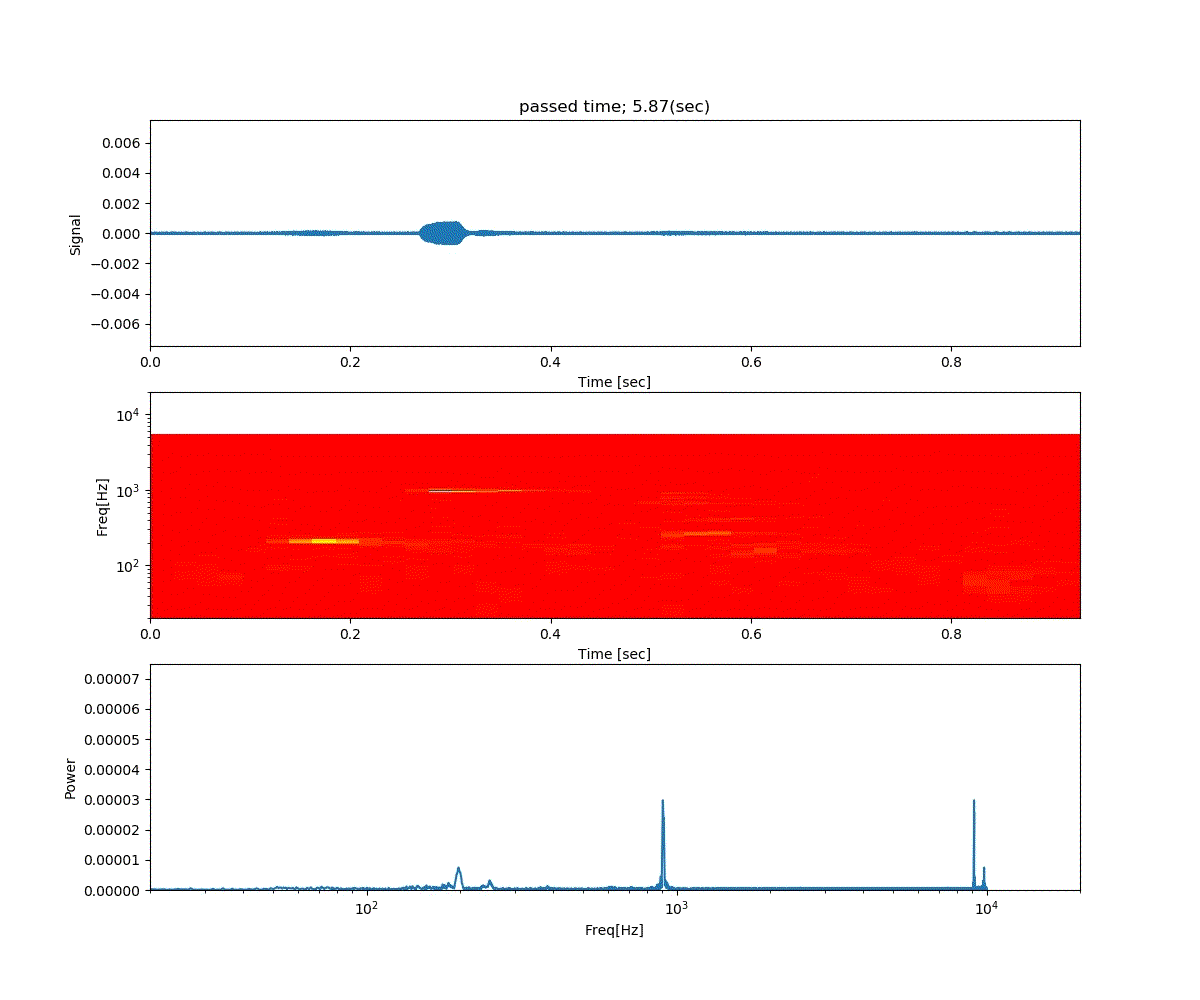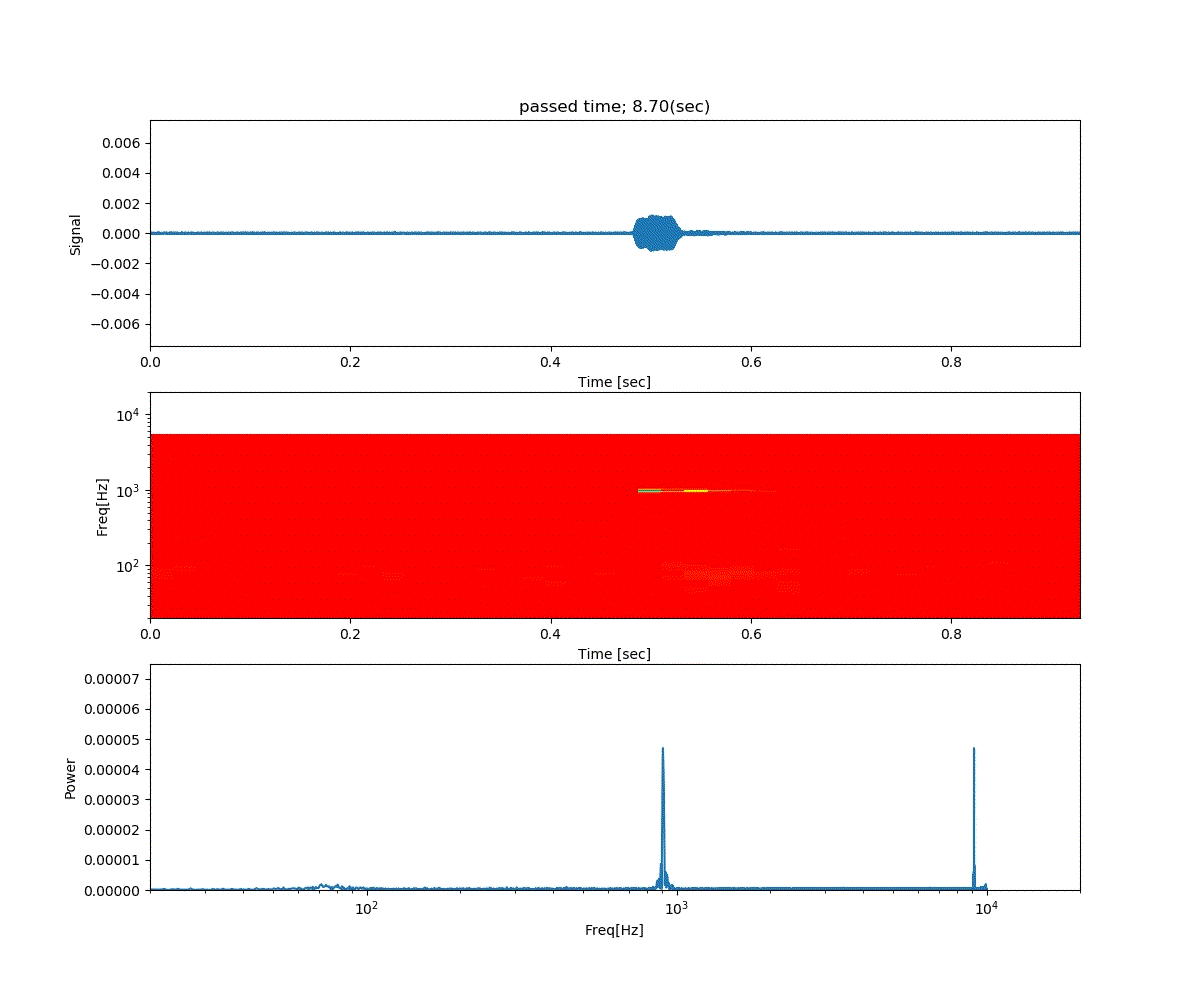
- 投稿日:2019-02-03T13:31:00+09:00
subprocessでシェルコマンドを呼び出し、標準出力は捨てる(/dev/nullに出力する)
環境:Python3
#!/usr/bin/env python3 import subprocess subprocess.run(['ls', '-l'], stdout=subprocess.DEVNULL)https://docs.python.org/ja/3/library/subprocess.html#using-the-subprocess-module
subprocess.callもrunと同じように使えるが、callの方が少し古い。Python 3.5 より前のバージョンでは、サブプロセスに対して以下の 3 つの関数からなる高水準 API が用意されていました。現在多くの場合 run() の使用で済みますが、既存の多くのコードではこれらの関数が使用されています。
https://docs.python.org/ja/3/library/subprocess.html#subprocess.call
- 投稿日:2019-02-03T12:46:47+09:00
lxmlメモ
はじめに
今回の内容はスクレイピングする上で用いたとあるライブラリについての個人的感想です。
どんなことができるのか、使ってみた感想をつらつらと書いていきます。スクレイピングとは
Web上のページから情報を引き抜くこと。機械学習など大量のデータが欲しい時に、データの取得をプログラミングで自動化できるのでとても便利なものである。
lxmlとは
スクレイピングを実現するためのPythonモジュールのひとつ。他にもhtmllibやBeautiful Soupなどがある。
特徴
- とにかく高速、おそらくモジュールがCを使って書かれたため?
- HTMLの要素をDOM(Document Object Model)構造に変換する
- XPath(次で説明)というものを使って抜き取る要素を指定
使い方
lxmlで要素を抜き取りたいときは、XPathというもので要素の場所を指定する必要がある。
XPathの使い方はこちらのものを引用しつつ説明する。XPath(XML Path Language)とは、XML形式の文書から、特定の部分を指定して抽出するための簡潔な構文(言語)です。HTML形式の文書にも対応します。
CSSではセレクタを使ってHTML文書内の特定の部分を抽出しますが、XPathはより簡潔かつ柔軟に指定ができるとされています。例としてbody以下のリンク要素(hogeクラス)を取り出す書き方を挙げる。
- CSSセレクタ:
html > body a.hoge- XPath:
/html/body//a[@class="hoge"]または//a[@class="hoge"]このようにXPathは要素を階層的に指定できる。
さらにXPathでは絶対パス形式と相対パス形式で要素を指定できるので柔軟に要素を抜き取ることができる。具体例として以下のようなHTMLファイルから要素を抜き取るとする。
sample.html<html> <head> <title>sample page</title> </head> <body> <div class="test1"> <h1>Hello World!!</h1> </div> <div class="table"> <table border="1"> <tr> <th>名前</th> <th>一言</th> </tr> <tr> <td>サンプル1</td> <td>よろしく</td> </tr> <tr> <td>サンプル2</td> <td>はじめまして</td> </tr> <tr> <td>サンプル3</td> <td>これはテストです</td> </tr> </table> </div> </body> </html>このとき、テーブル内の一言を抽出したい場合は、次のようにXPathを指定する。
//table/tr/td[2]もしサンプル2が発している「はじめまして」を抽出するなら
//td[4]と指定しても良い。
ただし、tdの数の変動を考慮するならば次のように指定する。//table//td[contains(*,'サンプル2')]/following-sibling::td[1]こうすることで中身がサンプル2であるtdの後ろにある要素(今回はtd)を抽出することができる。
XPathにはこうした細かい条件を指定できる関数もあるので、非常に便利である。
ここまでをコードとしてまとめる。import lxml.html import requests # Webページのソースを取得するのに用いる。今回はこれについての説明は省く url = 'http://example.com/' # URLの一例、今回は上のsample.htmlを指すものとする r = requests.get(url) # URLにあるページのソースを取得 html = lxml.html.fromstring(r.text) # 取得したソースをHtmlElementオブジェクトに変換 td = html.xpath("//table//td[contains(*,'サンプル2')]/following-sibling::td[1]") # >>> print(td) # '<td>はじめまして</td>'指定された要素の中身(ex.文字列やURL)を抽出するには以下の文を最後に追加する。
text = td.text()ただし、もしtdの中身が
はじめまして<br />僕はサンプル2ですの場合、text()ははじめましてしか抽出できない。そういったときは次のようなメソッドを使う。text = td.text_content()こうするとtextには
はじめまして僕の名前はサンプル2ですが代入され、要素内の全文字列を取得することができる。
その他様々なデータの抽出方法はこちらを参考に感想
大量のデータをとるときでもわずか数分で取得できたのは神だった。
スクレイピングする際は「とりあえずlxml」の気持ちで生きていきたい。参考文献