- 投稿日:2019-02-03T23:09:55+09:00
AWS Solution Architect - Associate (SAA) を取得するまでにやったお勉強のお話
はじめに
はじめまして、spinrockと申します。
AWS SAAを取得したので、そこまでにやった資格勉強と所感をまとめました。AWS Solution Architect - Associateとは
https://aws.amazon.com/jp/certification/certified-solutions-architect-associate/
こちらを参照のこと。事前知識
- AWSの実務経験は皆無
- AWSサービスは最低限触った程度(数ヶ月)
- EC2/S3/Lambdaを少し触ったことがある、程度(それ以外は皆無)
勉強開始〜合格までの期間
約1ヶ月ほど
(2週間ほど勉強した後に1度受験して落ちています)勉強資料
- 参考書
- 「合格対策 AWS認定ソリューションアーキテクト - アソシエイト」
- ホワイトペーパー(PDF)「アマゾン ウェブ サービスの概要」
- 問題集
- 「AWS WEB問題集で学習しよう」(https://aws.koiwaclub.com/)
たくさん問題を解くために有料会員になった(4,000円/2ヶ月)- 模擬試験
- 2,000円/回
勉強の流れ
- 参考書を1冊読みきりました。
(試験でメインで出題される、コンピュート/ストレージ/NW系をざっくり網羅しました)- 問題集を解きました。
(400/800問ほど解いたところで1度目の受験日となりました)- 模擬試験の受験
結果:85%くらい取れたので調子にのる
間違えた問題がわからないので全問復習した。- 受験(1度目)
結果:不合格 (20点ほど足りませんでした。。。)
敗因:AWSのサービス群をきちんと理解していなかった。。。
(1.の参考書で出てこなかったAWSサービスの用途が全くわからなかった)- 問題集の残りを解く。
(800問解き終えて、2周目を解いていました)- ホワイトペーパーを読む。
敗因の対策。
AWSのサービスがどういった用途のサービスなのかざっくり把握する。- 受験(2度目)
結果:合格!!試験で感じたこと
- (個人的には)模擬試験の結果はあまりあてになりませんでした。
問題の雰囲気は近かったが、難易度は低めで出題範囲が限られていたため- ホワイトペーパーは早めに読んでおくべきだった。
- 投稿日:2019-02-03T22:17:00+09:00
意識が低い運用監視ガイジでもAWSソリューションアーキテクトを取得する方法
正直言って私はQlitaに投稿するような人間ではありません。
初めての仕事は文系SEから始まり、限界を感じた為、現在カスみたいな業務アプリの運用監視をしています。
ただ時代の流れか、監視システムがオンプレミスからクラウドにリプレースすることが多く、AWSの知識を取得するのもありかなと…
というところに会社の報奨金うpの話があったので勉強してみました。
しかし「AWS ソリューションアーキテクト 合格」何かで調べると意識の高いブログしか出てこない。
http://nekootoko3.hatenablog.com/entry/2018/06/22/233502
https://qiita.com/tomoya_oka/items/a9cb2e1d5de745f8ccc2
Webプログラミング、ビックデータ。他の記事はコードがずらずら。
情報系大学・専門学校を出ているのが当たり前で日常的にAWS触っている人間の自己顕示欲発散場所にしか見えなかった。
私はコピペスクリプトくらいしか分かりません。
今はFor文やIF文も前のSEの時は使ってましたが、もうF8でデバックするのがかったるいのでそういうのは現場で強い人に任せてます。私は業務においてAWSは少し囓った程度です。
リプレースされたシステムに関してのリソースの監視、CloudWatchは便利ですね程度。
EC2はサーバみたいなもん。RDSはデータベース???フルマネージド???
分散処理?NoSQL?しらんわボケとかそんな感じです。それで、肝心の方法です。
AWSが準備してくれてますが、やるべきところとそうでないところがあります。
https://aws.amazon.com/jp/certification/certification-prep/
ステップ3の
・クラウドコンピューティングのアーキテクチャ: ベストプラクティス
・AWS Well-Architected ウェブページ
これは読みましょう。眠いですけど。
後よくある質問は読んでおきましょう。眠いですが。
ステップ1、ステップ4のハンズオンは英語なのでやらなくていいです。
SEは昼休みなり、ネット使えるオペレータは夜勤中に読んじゃいましょう。次は問題把握です。
https://aws.koiwaclub.com/
4000円課金してSAAの問題2周しましょう。
Ping-t的なアレですが、ぶっちゃけ本番の試験より難しいです。
運用監視ガイジはSOAPとかCIDRとか言われてもキツいっす。
でもココで出てくる問題文にある用語は今後の為にググっておきましょう。
後公式のサンプル問題は暗記必須。模擬問題は私は受けてないですが受けるの推奨らしいですね。そして問題把握した後にホワイトペーパーとかよくある質問もう一度読んでおきましょう。
意識高い人達がおすすめのBlackBeltはサービスの把握に良いですね。
https://aws.amazon.com/jp/aws-jp-introduction/
別に完全に理解しなくていいので概要だけでも良いです。
・Lamdba
・DynamoDB
・EFS
・ECS
とか概要だけ理解しておいた方が良いです。Dockerとかマジで訳分からん。書籍ベースですと、やる気あるなら紫本読んでおいた方が良いですね。
https://www.amazon.co.jp/dp/B06Y5ZSYY4/
基本的な構築が学べます。個人的にネットワークに関しては弱かったんで助かりました。
黒本最近でたらしいので、立ち読みした限りは良いと思います。
https://www.amazon.co.jp/dp/B07M7S9GDL/問題の傾向でいうと「当たり前の知識を問うもの」と「ベストプラクティス」
2つでした。特にレガシーシステムをAWSにリプレースする場合のそれ。
問題集暗記すればまぁ何となく掴めると思うので「可用性」とかその辺抑えると吉。会社の報奨金、GETしましょうね。
- 投稿日:2019-02-03T20:25:07+09:00
Cloudwatch Agentをインストールしてゲスト内メトリクスとログファイルデータを収集する (最初の1台目)
CloudWatch AgentをEC2インスタンス(Amazon Linux 2)にインストールしてゲスト内メトリクスとログファイル内データを収集します。本メモは最初の1台目の設定方法です。
前提条件
- AWS CLIがインストールされており、クレデンシャル/リージョンが設定されている。
- JSONファイル検証用にjsonlintがインストールされている。
- ログインできるEC2インスタンス(Linux) が起動されていること。今回はAmazon Linux 2。
- EC2インスタンスがインターネットまたはVPCエンドポイント経由でCloudWatch、CloudWatch Logs、SSMエンドポイントにアクセスできる。
EC2実行用ロールの作成およびEC2インスタンスへの紐付け
RunCommandでCloudWatch Agentをインストール/構成するための"AmazonEC2RoleforSSM"ポリシーおよびCloudWatchAgentのための"CloudWatchAgentAdminPolicy"ポリシーを持つロールを作成します。さらにEC2インスタンスにロールを紐付けるためにインスタンスプロファイルを作成してロールを付与し、インスタンスに紐付けます。
※"CloudWatchAgentAdminPolicy"はCloudWatch Agentのコンフィグを再利用するためSSMパラメータストアに書き込むための権限が含まれるため、コンフィグの書き込み完了以降は"CloudWatchAgentServerPolicy"に変更することが推奨されています。
Assume Role Documentの作成
作業フォルダの作成
コマンドls -d ${HOME}/tmp/ # 存在しない場合 mkdir -p ${HOME}/tmp/変数の設定
コマンド# Assume Role Document ディレクトリ DIR_IAM_ROLE_DOC="${HOME}/tmp" # Role名 IAM_ROLE_NAME='CloudWatchAgentInstanceRole' # Principle名 IAM_PRINCIPAL='ec2.amazonaws.com'ファイル名の設定
コマンドFILE_IAM_ROLE_DOC="${DIR_IAM_ROLE_DOC}/${IAM_ROLE_NAME}.json" \ && echo ${FILE_IAM_ROLE_DOC}Output例/Users/xxxxx/tmp/CloudWatchAgentInstanceRole.jsonAssume Role Documentの作成
コマンドcat << EOF > ${FILE_IAM_ROLE_DOC} { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "${IAM_PRINCIPAL}" }, "Effect": "Allow", "Sid": "" } ] } EOF cat ${FILE_IAM_ROLE_DOC}Output例{ "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] }jsonlintでjsonファイルが壊れていないかチェックします。問題なければ何も出力されません。
コマンドjsonlint -q ${FILE_IAM_ROLE_DOC}IAMロールの作成
コマンドaws iam create-role \ --role-name ${IAM_ROLE_NAME} \ --assume-role-policy-document file://${FILE_IAM_ROLE_DOC}Output例{ "Role": { "Path": "/", "RoleName": "CloudWatchAgentInstanceRole", "RoleId": "AROAJTMDKBJBF5JL7MNZ6", "Arn": "arn:aws:iam::xxxxxxxxxxxx:role/CloudWatchAgentInstanceRole", "CreateDate": "2019-02-02T13:56:13Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] } } }IAMポリシーのアタッチ
AmazonEC2RoleforSSM
変数の設定
コマンドIAM_POLICY_NAME="AmazonEC2RoleforSSM" IAM_POLICY_ARN=$( \ aws iam list-policies \ --scope AWS \ --max-items 1000 \ --query "Policies[?PolicyName==\`${IAM_POLICY_NAME}\`].Arn" \ --output text \ ) \ && echo "${IAM_POLICY_ARN}"Output例arn:aws:iam::aws:policy/service-role/AmazonEC2RoleforSSMポリシーをロールへアタッチ
コマンドaws iam attach-role-policy \ --role-name ${IAM_ROLE_NAME} \ --policy-arn ${IAM_POLICY_ARN}Output例出力なしCloudWatchAgentAdminPolicy
変数の設定
コマンドIAM_POLICY_NAME="CloudWatchAgentAdminPolicy" IAM_POLICY_ARN=$( \ aws iam list-policies \ --scope AWS \ --max-items 1000 \ --query "Policies[?PolicyName==\`${IAM_POLICY_NAME}\`].Arn" \ --output text \ ) \ && echo "${IAM_POLICY_ARN}"Output例arn:aws:iam::aws:policy/CloudWatchAgentAdminPolicyポリシーをロールへアタッチ
コマンドaws iam attach-role-policy \ --role-name ${IAM_ROLE_NAME} \ --policy-arn ${IAM_POLICY_ARN}Output例出力なしアタッチされたポリシーの確認
コマンドaws iam list-attached-role-policies \ --role-name ${IAM_ROLE_NAME} \ --query "AttachedPolicies[].PolicyName"Output例[ "AmazonEC2RoleforSSM", "CloudWatchAgentAdminPolicy" ]インスタンスプロファイルの作成
変数の設定
コマンドIAM_INSTANCE_PROFILE_NAME='CloudWatchAgentInstanceProfile'インスタンスプロファイルの作成
コマンドaws iam create-instance-profile \ --instance-profile-name ${IAM_INSTANCE_PROFILE_NAME}Output例{ "InstanceProfile": { "Path": "/", "InstanceProfileName": "CloudWatchAgentInstanceProfile", "InstanceProfileId": "AIPAI37ND6UTLOF7QWRBY", "Arn": "arn:aws:iam::xxxxxxxxxxxx:instance-profile/CloudWatchAgentInstanceProfile", "CreateDate": "2019-02-02T14:47:25Z", "Roles": [] } }インスタンスプロファイルへのロールのアタッチ
コマンドaws iam add-role-to-instance-profile \ --instance-profile-name ${IAM_INSTANCE_PROFILE_NAME} \ --role-name ${IAM_ROLE_NAME}Output例出力なしEC2インスタンスへのインスタンスプロファイルのアタッチ
変数の設定
INSTANCE_ID="インスタンスプロファイルを紐付けるインスタンスID"インスタンスへのアタッチ
コマンドaws ec2 associate-iam-instance-profile \ --iam-instance-profile "Name=${IAM_INSTANCE_PROFILE_NAME}" \ --instance-id ${INSTANCE_ID}Output例{ "IamInstanceProfileAssociation": { "AssociationId": "iip-assoc-00eba20147c23b77e", "InstanceId": "i-0f6392abb1e0eba21", "IamInstanceProfile": { "Arn": "arn:aws:iam::xxxxxxxxxxxx:instance-profile/CloudWatchAgentInstanceProfile", "Id": "AIPAI37ND6UTLOF7QWRBY" }, "State": "associating" } }確認
コマンドaws ec2 describe-iam-instance-profile-associations \ --query "IamInstanceProfileAssociations[?InstanceId==\`${INSTANCE_ID}\`].State"Output例[ "associated" ]Systems Manager(SSM)からCloudWatch Agentをインストールする
マネージドインスタンスの登録確認
マネージドインスタンスとして登録されているかを確認します。今回はAmazon Linux 2を使用しているため初めからSSMエージェントがインストールされており、マネージドインスタンスとして認識されます。インストールされないOSの場合やバージョンが古い場合は別途インストール/アップデートが必要です。
コマンドaws ssm describe-instance-information \ --query "InstanceInformationList[?InstanceId==\`${INSTANCE_ID}\`]"Output例{ "InstanceId": "i-0f6392abb1e0eba21", "PingStatus": "Online", "LastPingDateTime": 1549184853.467, "AgentVersion": "2.3.372.0", "IsLatestVersion": false, "PlatformType": "Linux", "PlatformName": "Amazon Linux", "PlatformVersion": "2", "ResourceType": "EC2Instance", "IPAddress": "172.31.35.234", "ComputerName": "ip-172-31-35-234.ap-northeast-1.compute.internal" } ]CloudWatch Agentのインストール
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_COMMAND_DOCUMENT_NAME="AWS-ConfigureAWSPackage" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="action=Install, name=AmazonCloudWatchAgent, version=latest"Run CommandでCloudWatch Agentをインストール
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "3c303421-1328-4613-9602-d041533b24b1", "DocumentName": "AWS-ConfigureAWSPackage", (...省略...) "RequestedDateTime": 1549185898.031, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
コマンドSSM_COMMAND_ID="3c303421-1328-4613-9602-d041533b24b1" #上記の結果からコピー aws ssm get-command-invocation \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query Status \ --output textOutput例SuccessCloudWatch Agentの設定
設定ファイルの作成
EC2インスタンスにログイン
CloudWatch AgentがインストールされているEC2インスタンスにSSHログインします。
(オプション) 一般的な設定を変更
プロキシ設定、認証情報(IAMロールをつけている場合は不要)などを設定する場合は以下のファイルを編集します。今回は省略。
コマンドvi /opt/aws/amazon-cloudwatch-agent/etc/common-config.tomlウィザードを利用して設定ファイルを作成する
設定ウィザードを起動します。
コマンドsudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizardウィザードに剃ってパラメータを決定していきます。(各パラメータの選択の意図は後日元気のあるときに追記)
例============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows default choice: [1]: 1 Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [1]: 1 Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: 1 Which port do you want StatsD daemon to listen to? default choice: [8125] 8125 What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]: 1 What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]: 1 Do you want to monitor metrics from CollectD? 1. yes 2. no default choice: [1]: 1 Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: 1 Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: 1 Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available? 1. yes 2. no default choice: [1]: 1 Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: 2 Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: 3 Current config as follows: { "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 0 }, "cpu": { "measurement": [ "cpu_usage_idle", "cpu_usage_iowait", "cpu_usage_user", "cpu_usage_system" ], "metrics_collection_interval": 10, "resources": [ "*" ], "totalcpu": false }, "disk": { "measurement": [ "used_percent", "inodes_free" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "diskio": { "measurement": [ "io_time", "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 10 }, "netstat": { "measurement": [ "tcp_established", "tcp_time_wait" ], "metrics_collection_interval": 10 }, "statsd": { "metrics_aggregation_interval": 0, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 10 } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: 1 Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? 1. yes 2. no default choice: [2]: 2 Do you want to monitor any log files? 1. yes 2. no default choice: [1]: 1 Log file path: /var/log/messages Log group name: default choice: [messages] Log stream name: default choice: [{instance_id}] Do you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]: 2 Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully. Current config as follows: { "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/messages", "log_group_name": "messages", "log_stream_name": "{instance_id}" } ] } } }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 0 }, "cpu": { "measurement": [ "cpu_usage_idle", "cpu_usage_iowait", "cpu_usage_user", "cpu_usage_system" ], "metrics_collection_interval": 10, "resources": [ "*" ], "totalcpu": false }, "disk": { "measurement": [ "used_percent", "inodes_free" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "diskio": { "measurement": [ "io_time", "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 10 }, "netstat": { "measurement": [ "tcp_established", "tcp_time_wait" ], "metrics_collection_interval": 10 }, "statsd": { "metrics_aggregation_interval": 0, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 10 } } } } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: 1 What parameter store name do you want to use to store your config? (Use 'AmazonCloudWatch-' prefix if you use our managed AWS policy) default choice: [AmazonCloudWatch-linux] Trying to fetch the default region based on ec2 metadata... Which region do you want to store the config in the parameter store? default choice: [ap-northeast-1] Which AWS credential should be used to send json config to parameter store? 1. ASIATWB6MCKPTDHEQ3IX(From SDK) 2. Other default choice: [1]: 1 Successfully put config to parameter store AmazonCloudWatch-linux. Program exits now.上記のウィザードによってローカルの設定ファイル
/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.tomlに設定が保存されます。
また、パラメータストアに設定ファイルを保存する指定をした場合はそちら(デフォルトパラメータ名はAmazonCloudWatch-linux
)にもJson形式で保存されます。これにより、2台目以降はウィザードを実行せずにパラメータストアを参照して構成できます。collectdのインストール
このままCloudWatch Agentを起動するとcollectdがないと怒られるのでインストールします。
コマンドsudo amazon-linux-extras install -y epel sudo yum install collectdOutput例省略CloudWatch Agentの構成、起動
SSM経由でCloudWatch Agentを構成、起動します。
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_CONFIG_PARAMETER_NAME="AmazonCloudWatch-linux" SSM_COMMAND_DOCUMENT_NAME="AmazonCloudWatch-ManageAgent" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="action=configure, mode=ec2, optionalConfigurationSource=ssm, optionalConfigurationLocation=${SSM_CONFIG_PARAMETER_NAME}, optionalRestart=yes"Run CommandでCloudWatch Agentを起動
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "91cae632-5469-4917-84f6-a939abda9f97", "DocumentName": "AmazonCloudWatch-ManageAgent", (...省略...) "RequestedDateTime": 1549190668.591, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
コマンドSSM_COMMAND_ID="91cae632-5469-4917-84f6-a939abda9f97" #上記の結果からコピー aws ssm get-command-invocation \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query Status \ --output textOutput例Success取得されたメトリクス/ログの確認
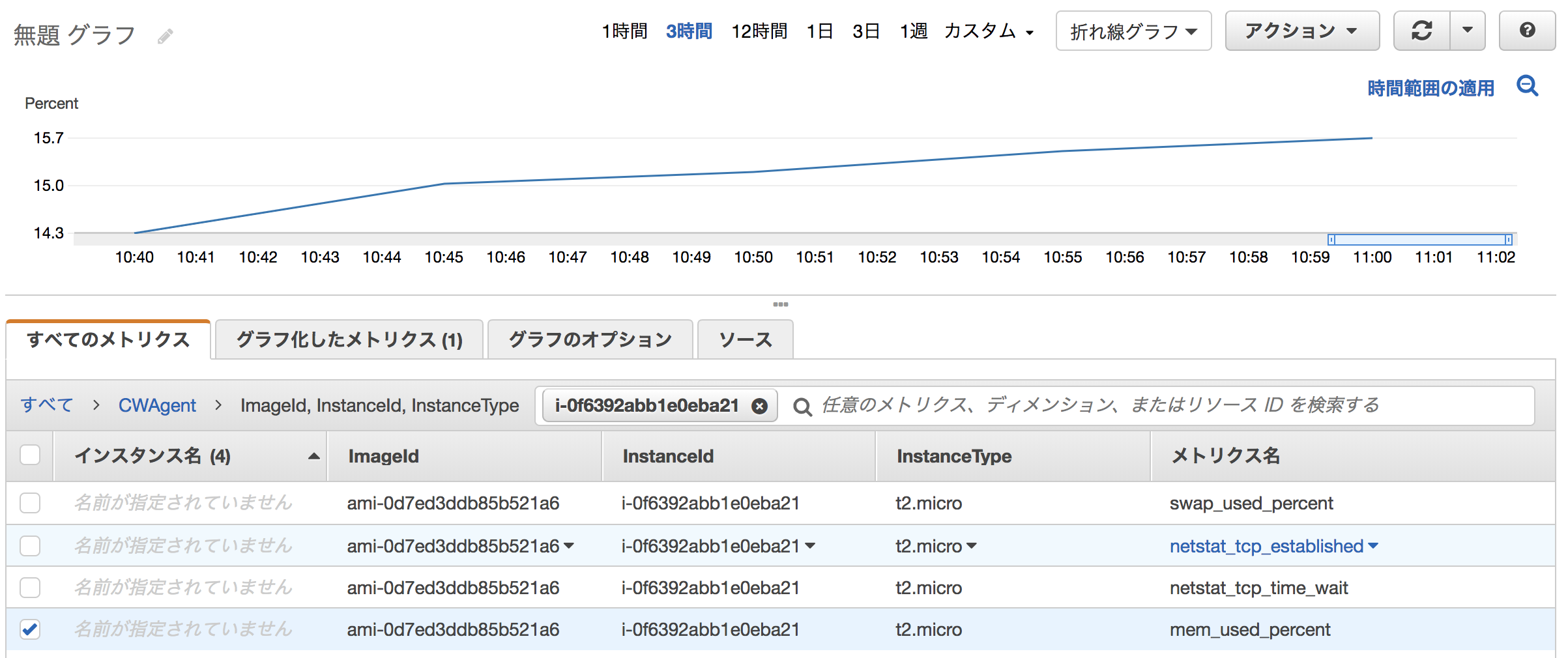
メトリクス
CloudWatchにカスタムメトリクスのmem_used_percentが取得されています。
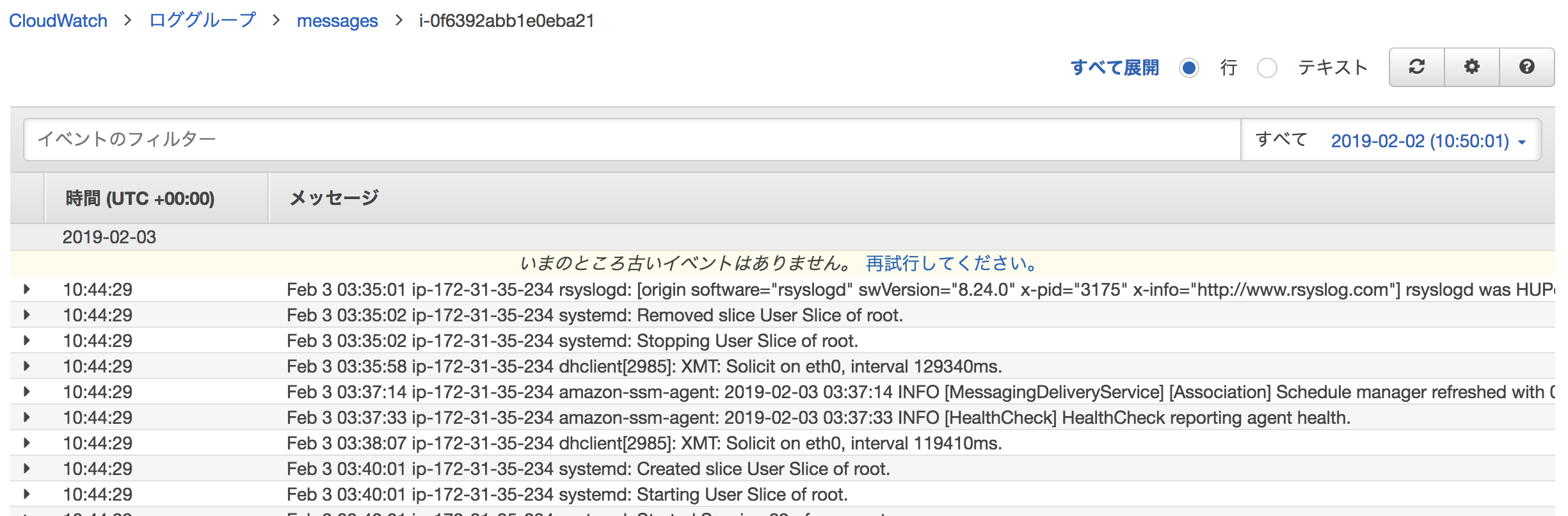
ログ
CloudWatch Logsに/var/log/messagesのログが取得されています。
Next Step
2台目以降はパラメータストアに保存した設定を簡略化できるためそちらも試す。
"CloudWatchAgentAdminPolicy"は設定ファイル作成/更新時以外は不要のため"CloudWatchAgentServerPolicy"に変更する。参考
AWS CLIの書き方はJAWS-UG CLI専門支部の過去資料が大変参考になります。
https://jawsug-cli.doorkeeper.jp/
- 投稿日:2019-02-03T20:25:07+09:00
CloudWatch Agentをインストールしてゲスト内メトリクスとログファイルデータを収集する (最初の1台目)
CloudWatch AgentをEC2インスタンス(Amazon Linux 2)にインストールしてゲスト内メトリクスとログファイル内データを収集します。本メモは最初の1台目の設定方法です。
前提条件
- AWS CLIがインストールされており、クレデンシャル/リージョンが設定されている。
- JSONファイル検証用にjsonlintがインストールされている。
- ログインできるEC2インスタンス(Linux) が起動されていること。今回はAmazon Linux 2。
- EC2インスタンスがインターネットまたはVPCエンドポイント経由でCloudWatch、CloudWatch Logs、SSMエンドポイントにアクセスできる。
EC2実行用ロールの作成およびEC2インスタンスへの紐付け
RunCommandでCloudWatch Agentをインストール/構成するための"AmazonEC2RoleforSSM"ポリシーおよびCloudWatchAgentのための"CloudWatchAgentAdminPolicy"ポリシーを持つロールを作成します。さらにEC2インスタンスにロールを紐付けるためにインスタンスプロファイルを作成してロールを付与し、インスタンスに紐付けます。
※"CloudWatchAgentAdminPolicy"はCloudWatch Agentのコンフィグを再利用するためSSMパラメータストアに書き込むための権限が含まれるため、コンフィグの書き込み完了以降は"CloudWatchAgentServerPolicy"に変更することが推奨されています。
Assume Role Documentの作成
作業フォルダの作成
コマンドls -d ${HOME}/tmp/ # 存在しない場合 mkdir -p ${HOME}/tmp/変数の設定
コマンド# Assume Role Document ディレクトリ DIR_IAM_ROLE_DOC="${HOME}/tmp" # Role名 IAM_ROLE_NAME='CloudWatchAgentInstanceRole' # Principle名 IAM_PRINCIPAL='ec2.amazonaws.com'ファイル名の設定
コマンドFILE_IAM_ROLE_DOC="${DIR_IAM_ROLE_DOC}/${IAM_ROLE_NAME}.json" \ && echo ${FILE_IAM_ROLE_DOC}Output例/Users/xxxxx/tmp/CloudWatchAgentInstanceRole.jsonAssume Role Documentの作成
コマンドcat << EOF > ${FILE_IAM_ROLE_DOC} { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "${IAM_PRINCIPAL}" }, "Effect": "Allow", "Sid": "" } ] } EOF cat ${FILE_IAM_ROLE_DOC}Output例{ "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] }jsonlintでjsonファイルが壊れていないかチェックします。問題なければ何も出力されません。
コマンドjsonlint -q ${FILE_IAM_ROLE_DOC}IAMロールの作成
コマンドaws iam create-role \ --role-name ${IAM_ROLE_NAME} \ --assume-role-policy-document file://${FILE_IAM_ROLE_DOC}Output例{ "Role": { "Path": "/", "RoleName": "CloudWatchAgentInstanceRole", "RoleId": "AROAJTMDKBJBF5JL7MNZ6", "Arn": "arn:aws:iam::xxxxxxxxxxxx:role/CloudWatchAgentInstanceRole", "CreateDate": "2019-02-02T13:56:13Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] } } }IAMポリシーのアタッチ
AmazonEC2RoleforSSM
変数の設定
コマンドIAM_POLICY_NAME="AmazonEC2RoleforSSM" IAM_POLICY_ARN=$( \ aws iam list-policies \ --scope AWS \ --max-items 1000 \ --query "Policies[?PolicyName==\`${IAM_POLICY_NAME}\`].Arn" \ --output text \ ) \ && echo "${IAM_POLICY_ARN}"Output例arn:aws:iam::aws:policy/service-role/AmazonEC2RoleforSSMポリシーをロールへアタッチ
コマンドaws iam attach-role-policy \ --role-name ${IAM_ROLE_NAME} \ --policy-arn ${IAM_POLICY_ARN}Output例出力なしCloudWatchAgentAdminPolicy
変数の設定
コマンドIAM_POLICY_NAME="CloudWatchAgentAdminPolicy" IAM_POLICY_ARN=$( \ aws iam list-policies \ --scope AWS \ --max-items 1000 \ --query "Policies[?PolicyName==\`${IAM_POLICY_NAME}\`].Arn" \ --output text \ ) \ && echo "${IAM_POLICY_ARN}"Output例arn:aws:iam::aws:policy/CloudWatchAgentAdminPolicyポリシーをロールへアタッチ
コマンドaws iam attach-role-policy \ --role-name ${IAM_ROLE_NAME} \ --policy-arn ${IAM_POLICY_ARN}Output例出力なしアタッチされたポリシーの確認
コマンドaws iam list-attached-role-policies \ --role-name ${IAM_ROLE_NAME} \ --query "AttachedPolicies[].PolicyName"Output例[ "AmazonEC2RoleforSSM", "CloudWatchAgentAdminPolicy" ]インスタンスプロファイルの作成
変数の設定
コマンドIAM_INSTANCE_PROFILE_NAME='CloudWatchAgentInstanceProfile'インスタンスプロファイルの作成
コマンドaws iam create-instance-profile \ --instance-profile-name ${IAM_INSTANCE_PROFILE_NAME}Output例{ "InstanceProfile": { "Path": "/", "InstanceProfileName": "CloudWatchAgentInstanceProfile", "InstanceProfileId": "AIPAI37ND6UTLOF7QWRBY", "Arn": "arn:aws:iam::xxxxxxxxxxxx:instance-profile/CloudWatchAgentInstanceProfile", "CreateDate": "2019-02-02T14:47:25Z", "Roles": [] } }インスタンスプロファイルへのロールのアタッチ
コマンドaws iam add-role-to-instance-profile \ --instance-profile-name ${IAM_INSTANCE_PROFILE_NAME} \ --role-name ${IAM_ROLE_NAME}Output例出力なしEC2インスタンスへのインスタンスプロファイルのアタッチ
変数の設定
INSTANCE_ID="インスタンスプロファイルを紐付けるインスタンスID"インスタンスへのアタッチ
コマンドaws ec2 associate-iam-instance-profile \ --iam-instance-profile "Name=${IAM_INSTANCE_PROFILE_NAME}" \ --instance-id ${INSTANCE_ID}Output例{ "IamInstanceProfileAssociation": { "AssociationId": "iip-assoc-00eba20147c23b77e", "InstanceId": "i-0f6392abb1e0eba21", "IamInstanceProfile": { "Arn": "arn:aws:iam::xxxxxxxxxxxx:instance-profile/CloudWatchAgentInstanceProfile", "Id": "AIPAI37ND6UTLOF7QWRBY" }, "State": "associating" } }確認
コマンドaws ec2 describe-iam-instance-profile-associations \ --query "IamInstanceProfileAssociations[?InstanceId==\`${INSTANCE_ID}\`].State"Output例[ "associated" ]Systems Manager(SSM)からCloudWatch Agentをインストールする
マネージドインスタンスの登録確認
マネージドインスタンスとして登録されているかを確認します。今回はAmazon Linux 2を使用しているため初めからSSMエージェントがインストールされており、マネージドインスタンスとして認識されます。インストールされないOSの場合やバージョンが古い場合は別途インストール/アップデートが必要です。
コマンドaws ssm describe-instance-information \ --query "InstanceInformationList[?InstanceId==\`${INSTANCE_ID}\`]"Output例{ "InstanceId": "i-0f6392abb1e0eba21", "PingStatus": "Online", "LastPingDateTime": 1549184853.467, "AgentVersion": "2.3.372.0", "IsLatestVersion": false, "PlatformType": "Linux", "PlatformName": "Amazon Linux", "PlatformVersion": "2", "ResourceType": "EC2Instance", "IPAddress": "172.31.35.234", "ComputerName": "ip-172-31-35-234.ap-northeast-1.compute.internal" } ]CloudWatch Agentのインストール
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_COMMAND_DOCUMENT_NAME="AWS-ConfigureAWSPackage" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="action=Install, name=AmazonCloudWatchAgent, version=latest"Run CommandでCloudWatch Agentをインストール
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "3c303421-1328-4613-9602-d041533b24b1", "DocumentName": "AWS-ConfigureAWSPackage", (...省略...) "RequestedDateTime": 1549185898.031, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
コマンドSSM_COMMAND_ID="3c303421-1328-4613-9602-d041533b24b1" #上記の結果からコピー aws ssm list-command-invocations \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query "CommandInvocations[].Status" \ --output textOutput例SuccessCloudWatch Agentの設定
設定ファイルの作成
EC2インスタンスにログイン
CloudWatch AgentがインストールされているEC2インスタンスにSSHログインします。
(オプション) 一般的な設定を変更
プロキシ設定、認証情報(IAMロールをつけている場合は不要)などを設定する場合は以下のファイルを編集します。今回は省略。
コマンドvi /opt/aws/amazon-cloudwatch-agent/etc/common-config.tomlウィザードを利用して設定ファイルを作成する
設定ウィザードを起動します。
コマンドsudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizardウィザードに剃ってパラメータを決定していきます。(各パラメータの選択の意図は後日元気のあるときに追記)
例============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows default choice: [1]: 1 Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [1]: 1 Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: 1 Which port do you want StatsD daemon to listen to? default choice: [8125] 8125 What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]: 1 What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]: 1 Do you want to monitor metrics from CollectD? 1. yes 2. no default choice: [1]: 1 Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: 1 Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: 1 Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available? 1. yes 2. no default choice: [1]: 1 Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: 2 Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: 3 Current config as follows: { "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 0 }, "cpu": { "measurement": [ "cpu_usage_idle", "cpu_usage_iowait", "cpu_usage_user", "cpu_usage_system" ], "metrics_collection_interval": 10, "resources": [ "*" ], "totalcpu": false }, "disk": { "measurement": [ "used_percent", "inodes_free" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "diskio": { "measurement": [ "io_time", "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 10 }, "netstat": { "measurement": [ "tcp_established", "tcp_time_wait" ], "metrics_collection_interval": 10 }, "statsd": { "metrics_aggregation_interval": 0, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 10 } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: 1 Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? 1. yes 2. no default choice: [2]: 2 Do you want to monitor any log files? 1. yes 2. no default choice: [1]: 1 Log file path: /var/log/messages Log group name: default choice: [messages] Log stream name: default choice: [{instance_id}] Do you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]: 2 Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully. Current config as follows: { "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/messages", "log_group_name": "messages", "log_stream_name": "{instance_id}" } ] } } }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 0 }, "cpu": { "measurement": [ "cpu_usage_idle", "cpu_usage_iowait", "cpu_usage_user", "cpu_usage_system" ], "metrics_collection_interval": 10, "resources": [ "*" ], "totalcpu": false }, "disk": { "measurement": [ "used_percent", "inodes_free" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "diskio": { "measurement": [ "io_time", "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 10, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 10 }, "netstat": { "measurement": [ "tcp_established", "tcp_time_wait" ], "metrics_collection_interval": 10 }, "statsd": { "metrics_aggregation_interval": 0, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 10 } } } } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: 1 What parameter store name do you want to use to store your config? (Use 'AmazonCloudWatch-' prefix if you use our managed AWS policy) default choice: [AmazonCloudWatch-linux] Trying to fetch the default region based on ec2 metadata... Which region do you want to store the config in the parameter store? default choice: [ap-northeast-1] Which AWS credential should be used to send json config to parameter store? 1. ASIATWB6MCKPTDHEQ3IX(From SDK) 2. Other default choice: [1]: 1 Successfully put config to parameter store AmazonCloudWatch-linux. Program exits now.上記のウィザードによってローカルの設定ファイル
/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.tomlに設定が保存されます。
また、パラメータストアに設定ファイルを保存する指定をした場合はそちら(デフォルトパラメータ名はAmazonCloudWatch-linux)にもJson形式で保存されます。これにより、2台目以降はウィザードを実行せずにパラメータストアを参照して構成できます。collectdのインストール
このままCloudWatch Agentを起動するとcollectdがないと怒られるのでインストールします。
コマンドsudo amazon-linux-extras install -y epel sudo yum install collectdOutput例省略CloudWatch Agentの構成、起動
SSM経由でCloudWatch Agentを構成、起動します。
変数の設定
コマンドINSTANCE_ID="インストール先のインスタンスID" SSM_CONFIG_PARAMETER_NAME="AmazonCloudWatch-linux" SSM_COMMAND_DOCUMENT_NAME="AmazonCloudWatch-ManageAgent" SSM_COMMAND_TARGETS="Key=instanceids,Values=${INSTANCE_ID}" SSM_COMMAND_PARAMETERS="action=configure, mode=ec2, optionalConfigurationSource=ssm, optionalConfigurationLocation=${SSM_CONFIG_PARAMETER_NAME}, optionalRestart=yes"Run CommandでCloudWatch Agentを起動
コマンドaws ssm send-command \ --document-name ${SSM_COMMAND_DOCUMENT_NAME} \ --targets ${SSM_COMMAND_TARGETS} \ --parameters "${SSM_COMMAND_PARAMETERS}"Output例{ "Command": { "CommandId": "91cae632-5469-4917-84f6-a939abda9f97", "DocumentName": "AmazonCloudWatch-ManageAgent", (...省略...) "RequestedDateTime": 1549190668.591, "Status": "Pending", "StatusDetails": "Pending", (...省略...) }確認
コマンドSSM_COMMAND_ID="3c303421-1328-4613-9602-d041533b24b1" #上記の結果からコピー aws ssm list-command-invocations \ --command-id ${SSM_COMMAND_ID} \ --instance-id ${INSTANCE_ID} \ --query "CommandInvocations[].Status" \ --output textOutput例Success取得されたメトリクス/ログの確認
メトリクス
CloudWatchにカスタムメトリクスのmem_used_percentが取得されています。
ログ
CloudWatch Logsに/var/log/messagesのログが取得されています。
Next Step
2台目以降はパラメータストアに保存した設定を簡略化できるためそちらも試す。
"CloudWatchAgentAdminPolicy"は設定ファイル作成/更新時以外は不要のため"CloudWatchAgentServerPolicy"に変更する。参考
AWS CLIの書き方はJAWS-UG CLI専門支部の過去資料が大変参考になります。
https://jawsug-cli.doorkeeper.jp/
- 投稿日:2019-02-03T20:00:19+09:00
AWS CLIでEC2インスタンス作成・削除・再作成
AWS CLIを使ってEC2インスタンスの作成・削除・再作成をやってみました。
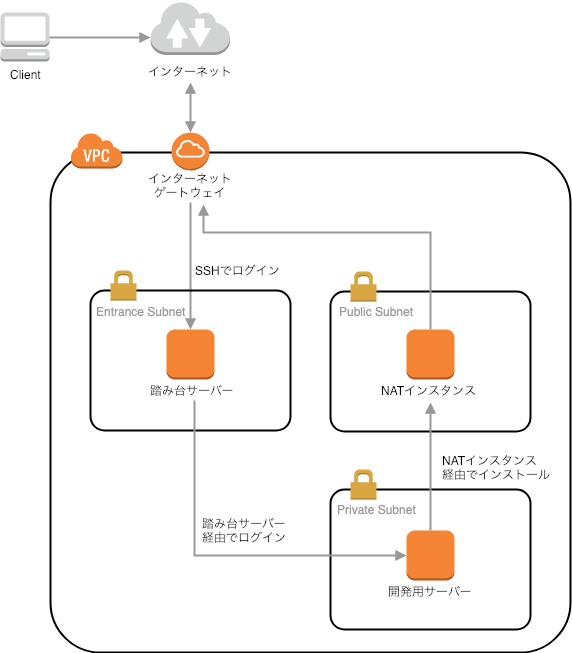
事前に作成済みの踏み台サーバーから、プライベートネットワークに開発用サーバーを作成・削除・再作成します。
目次
- 踏み台サーバーに権限付与
- インスタンスの作成
- インスタンスにPython3関係をインストール
- AMIの作成
- インスタンスの停止・削除
- 作成したAMIからインスタンスを作成
前提条件
- VPC, サブネット、インターネットゲートウェイ、セキュリテイグループ、キーペア、等々は作成済み
- 踏み台サーバーとNATインスタンスは作成済み
- 踏み台サーバーからインスタンスの作成・削除・再作成を行う
手順
[1] 踏み台サーバーに権限付与
IAMで踏み台サーバーに権限を付与します。
EC2に関するアクセスを全て許可する「AmazonEC2FullAccess」を付与します。
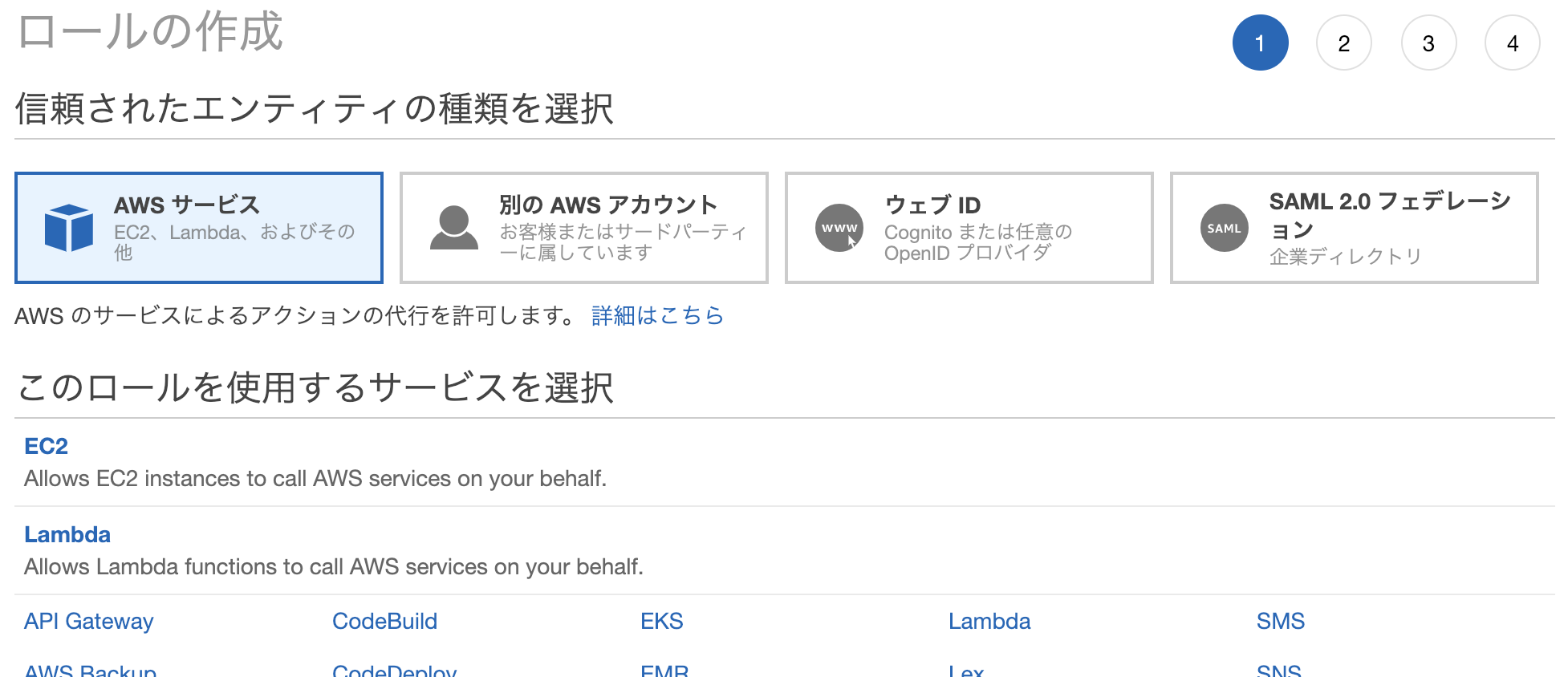
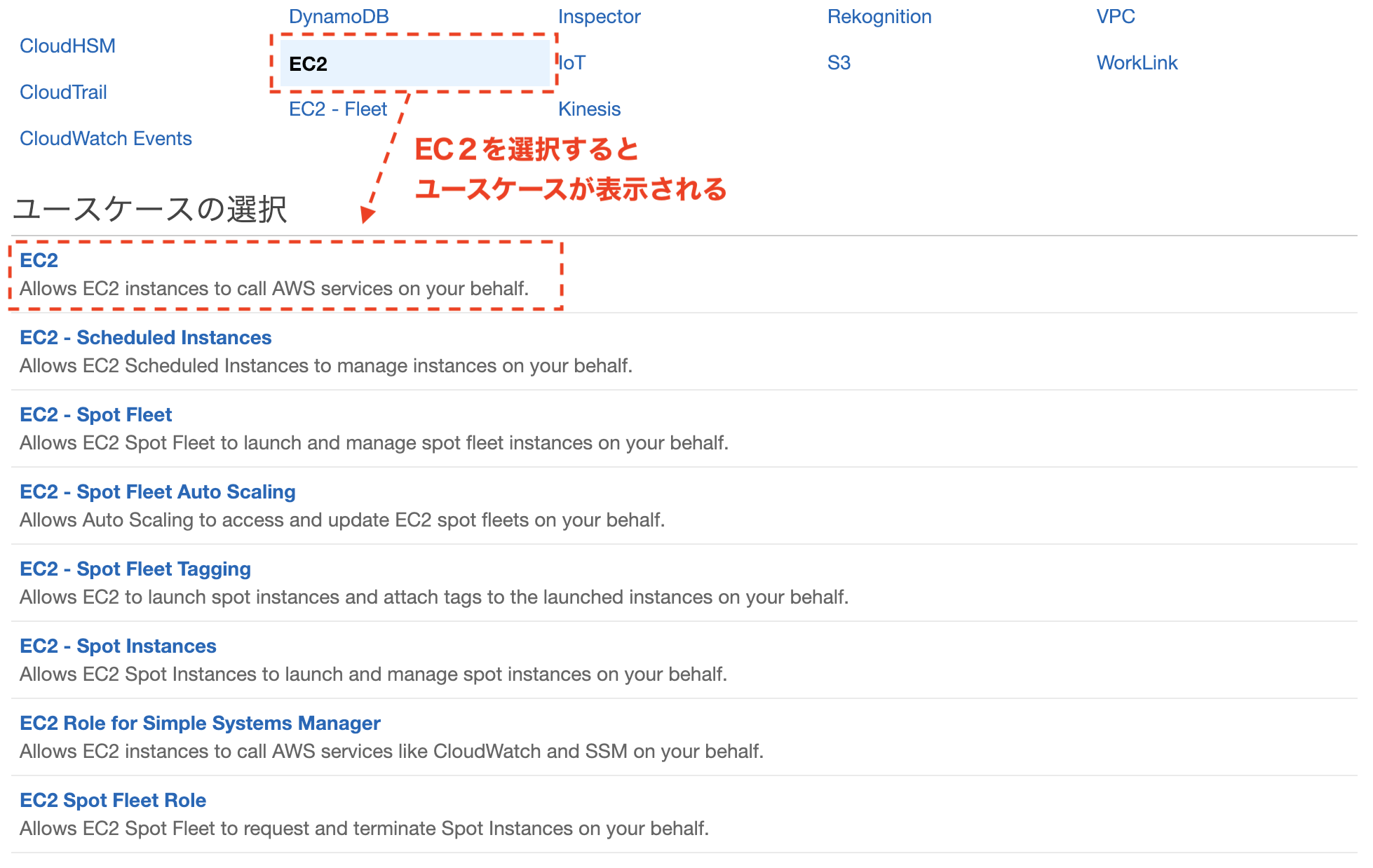
- マネージメントコンソールのIAMの画面から[ロールの作成]を選択
- このロールを使用するサービスで[EC2]を選択
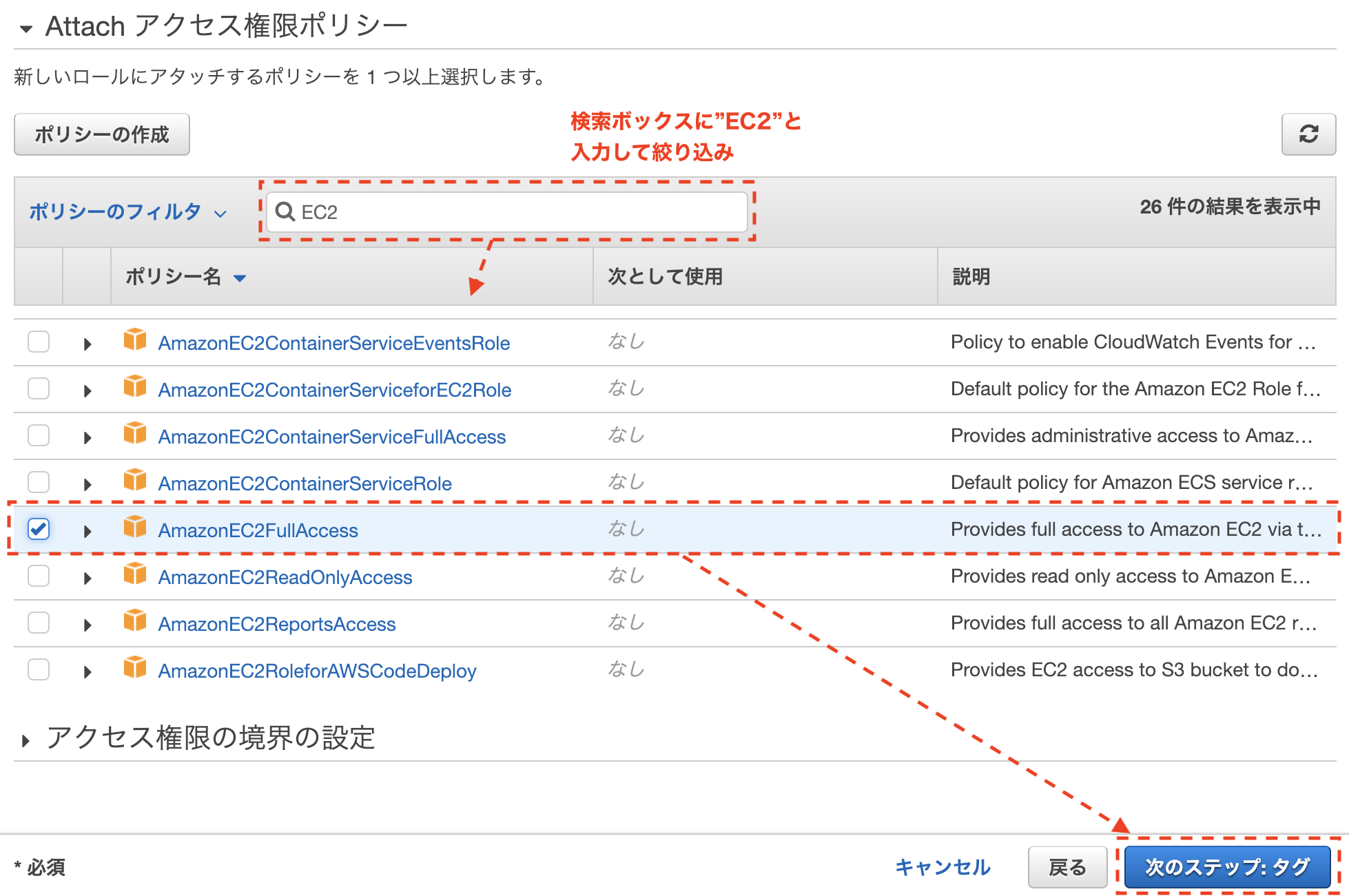
- アクセス権限ポリシーの画面で"EC2"で検索し[AmazonEC2FullAccess]を選択
- タグの追加は設定無し
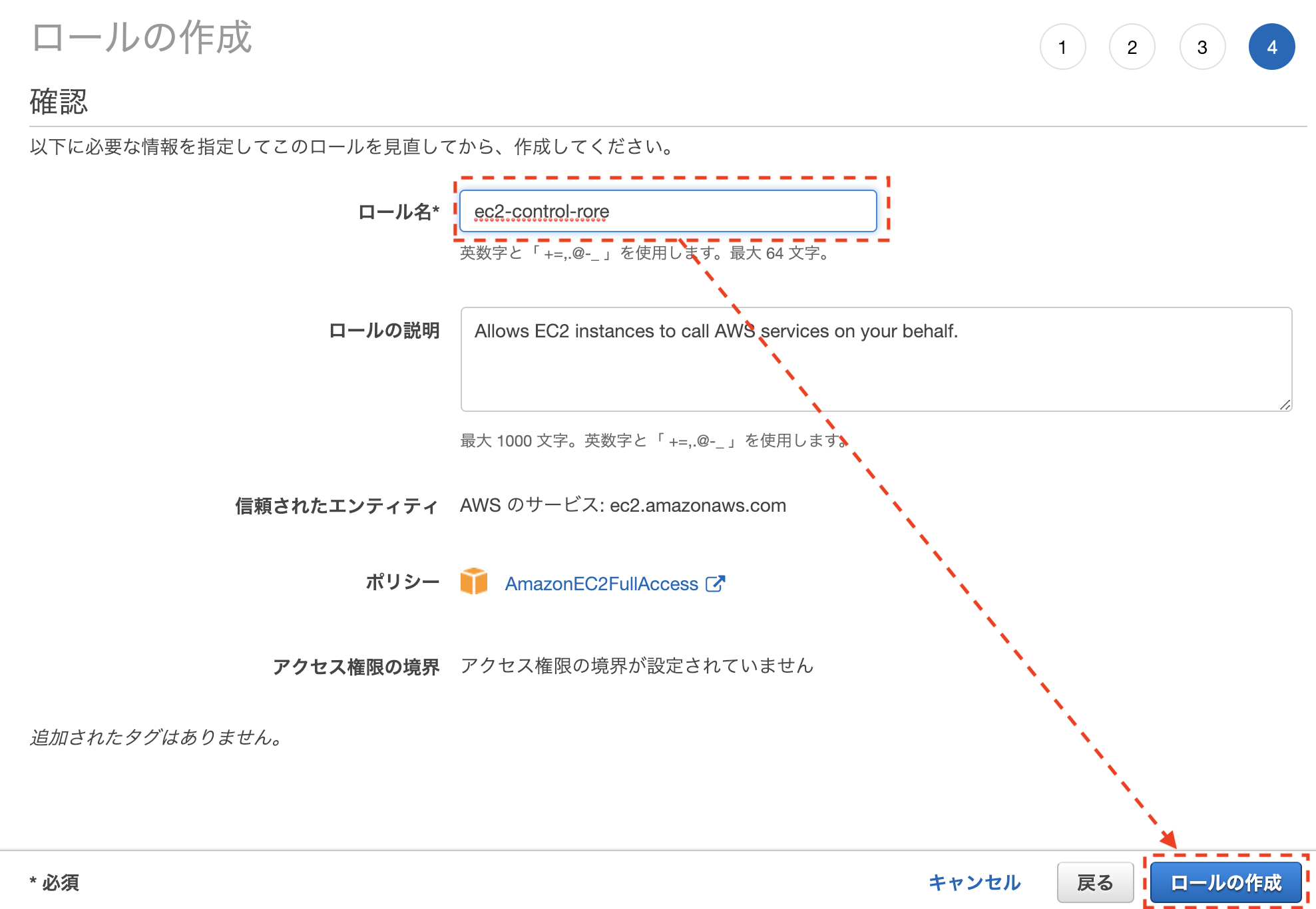
- ロールの作成でロール名を入力
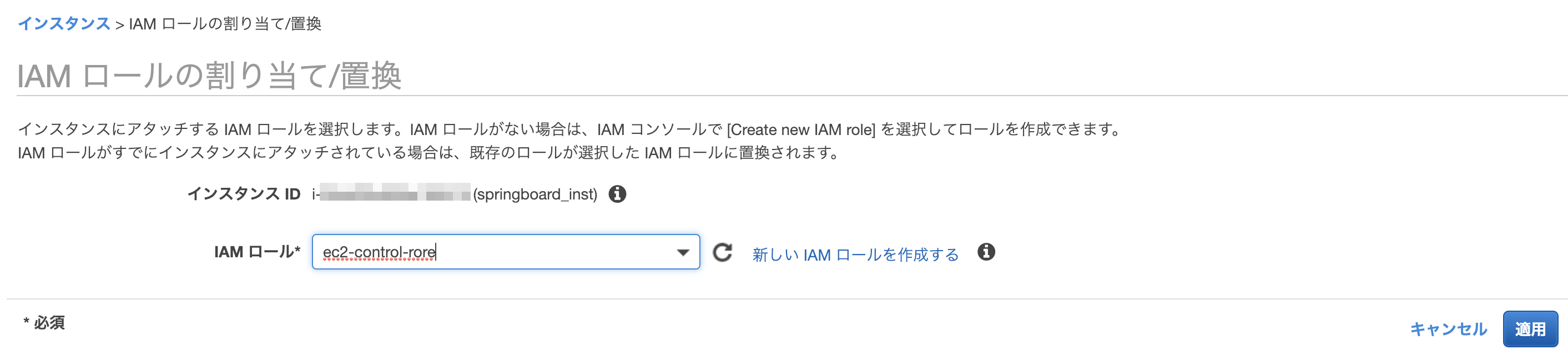
- 踏み台サーバーに作成したロールの割り当て
[2] インスタンスの作成
踏み台サーバーはOSがAmazon Linuxなので、デフォルトでAWS CLIがインストールされています。
$ aws --version aws-cli/1.15.80 Python/2.7.14 Linux/4.14.88-88.76.amzn2.x86_64 botocore/1.10.79AWS CLIでの操作ではJSON形式でデータを扱うため、便利のために"jq"コマンドをインストールします。
$ sudo yum -y install jq[2-1] AWS CLIを試す
試しに作成済みインスタンスの情報をAWS CLIで取得してみます。
$ aws ec2 describe-instances | jq '.Reservations[].Instances[] | {InstanceId, Tags}' You must specify a region. You can also configure your region by running \ "aws configure".リージョンを指定しないとダメなようです。
$ aws ec2 describe-instances --region ap-northeast-1 \ | jq '.Reservations[].Instances[] | {InstanceId}' { "InstanceId": "i-xxxxxxxxx" } { "InstanceId": "i-xxxxxxxxxxxx", }今度は上手くいきました。
作成したIAMロールが踏み台サーバーに割り当てられていることが確認できました。[2-2] インスタンスの種類を決める
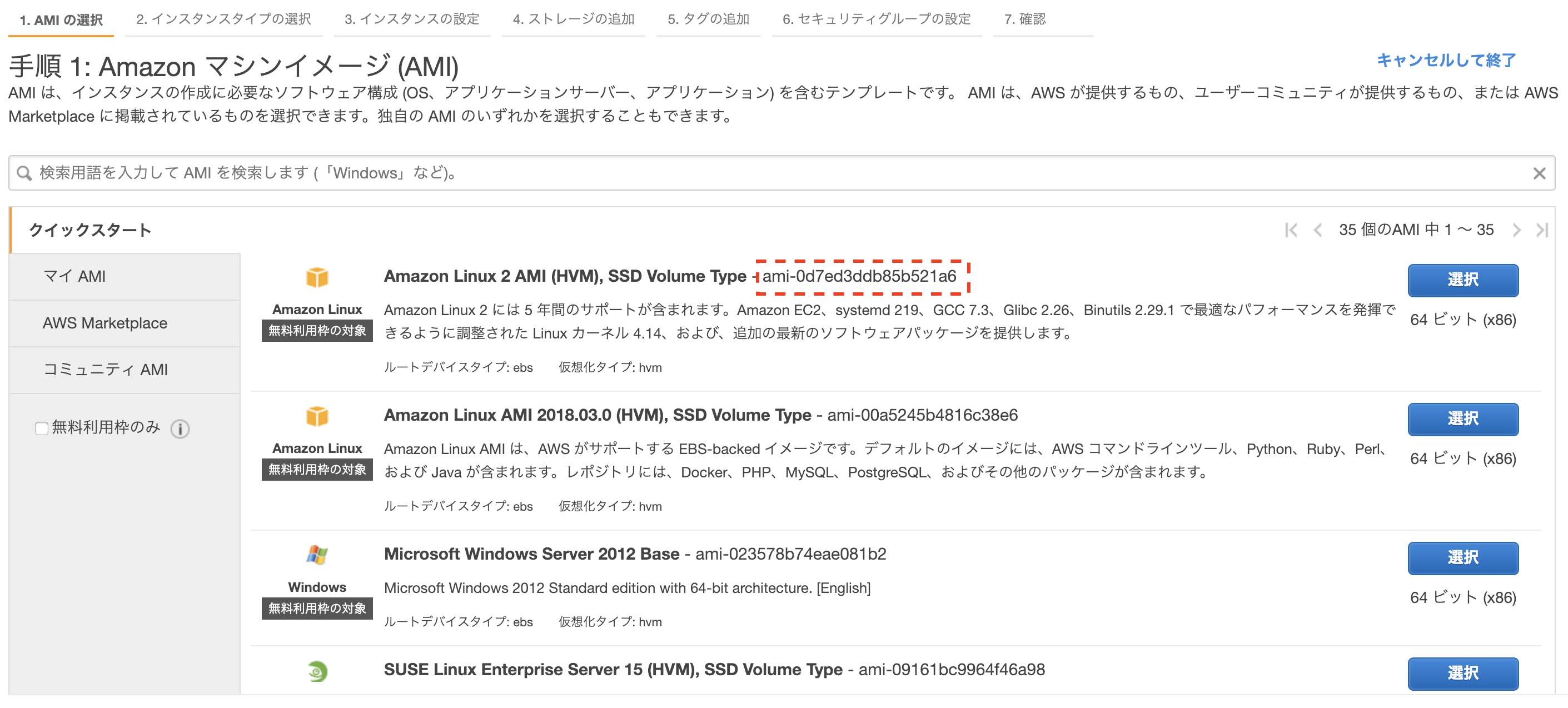
インスタンスを作成する前に、インスタンスタイプやAMI(OS)を決めます。
セキュリティグループ、サブネット、キーペアは事前に作成しました。
項目 内容 AWSで設定するときの値 AMI Amazon Linux 2 AMI ami-0d7ed3ddb85b521a6 インスタンスタイプ t3.nano t3.nano 作成するインスタンスの数 1 1 キーペア - (キーペアの名称) サブネット - subnet-xxxxxx プライベートIP 10.xx.xx.xx 10.xx.xx.xx セキュリティグループ - sg-xxxxxx タグ Name=private-inst Tags=[{Key=Name,Value=private-inst}] T2/T3 無制限 無効 standard AMIのIDはマネジメントコンソールから確認するのが簡単です。
[2-3] dry-runで試す
実際にインスタンスを作成する前に、dry-runオプションを付けてエラーがないか確認していきます。
$ aws ec2 run-instances --dry-run --region ap-northeast-1 \ --image-id ami-0d7ed3ddb85b521a6 --count 1 \ --instance-type t3.nano --key-name (キーペアの名称) \ --subnet-id subnet-xxxxxx --private-ip-address 10.xx.xx.xx \ --security-group-ids sg-xxxxxx \ --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=private-inst}]' \ --credit-specification CpuCredits=standard An error occurred (DryRunOperation) when calling the RunInstances operation: \ Request would have succeeded, but DryRun flag is set.上手くいくだろう("Request would have succeeded")と返ってきました。
[2-4] 本番コマンド実行
dry-runオプションを削除して実行します。
$ aws ec2 run-instances --region ap-northeast-1 \ --image-id ami-0d7ed3ddb85b521a6 --count 1 \ --instance-type t3.nano --key-name (キーペアの名称) \ --subnet-id subnet-xxxxxx --private-ip-address 10.xx.xx.xx \ --security-group-ids sg-xxxxxx \ --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=private-inst}]' \ --credit-specification CpuCredits=standard { "Instances": [ { ...(以下、省略)...作成されたインスタンスの情報が返ってきたので、作成に成功したようです。
念の為、マネジメントコンソールから確認すると、インスタンスが追加されていました。
ルートデバイスの容量はデフォルトで8GiBになるようです。[3] インスタンスにPython3関係をインストール
踏み台サーバーから、作成したインスタンスにログインします。
$ ssh -i ./xxxx.pem ec2-user@10.xx.xx.xxPython3, pip3, virtualenvをインストールします。
$ sudo yum install python3 python3-pip $ sudo pip3 install virtualenv[4] AMIの作成
踏み台サーバーからAMIの作成を行います。
$ aws ec2 create-image --region ap-northeast-1 --instance-id i-xxxxxx \ --name "python3-base-ami" --reboot { "ImageId": "ami-xxxxxx" }作成したAMIのIDが返ってきます。
describe-imagesで確認すると、AMIが作成されていることが分かります。$ aws ec2 describe-images --region ap-northeast-1 --image-id ami-xxxxxx \ | jq '.Images[]' { ...(途中省略)... "Name": "python3-base-ami", "Hypervisor": "xen", "EnaSupport": true, "SriovNetSupport": "simple", "ImageId": "ami-xxxx", "State": "available", "BlockDeviceMappings": [ { "DeviceName": "/dev/xvda", "Ebs": { "Encrypted": false, "DeleteOnTermination": true, "VolumeType": "gp2", "VolumeSize": 8, "SnapshotId": "snap-xxxxxx" } } ], ...(途中省略)... }[5] インスタンスの停止・削除
インスタンスの停止と削除を行います。
$ aws ec2 stop-instances --region ap-northeast-1 --instance-ids i-xxxxxx $ aws ec2 terminate-instances --region ap-northeast-1 --instance-ids i-xxxxxxStateを確認すると"terminated"になっています。
$ aws ec2 describe-instances --region ap-northeast-1 --instance-ids i-xxxxxx \ | jq '.Reservations[].Instances[] | {InstanceId,Tags,State}' { "InstanceId": "i-xxxxxx", "Tags": [ { "Value": "private-inst", "Key": "Name" } ], "State": { "Code": 48, "Name": "terminated" } }[6] 作成したAMIからインスタンスを作成
[6-1] ルートデバイスの容量を拡張する
インスタンスを作成する際、ルートデバイスの容量はデフォルトだと8GiBですが、16GiBに拡張してみます。
拡張するための設定をJSONファイルに記述します。
- DeviceNameはデフォルトのルートデバイスと合わせる
- SnapshotIdに作成したAMIのSnapshotIdを設定する
device-mapping.json[ { "DeviceName": "/dev/xvda", "Ebs": { "DeleteOnTermination": true, "VolumeType": "gp2", "VolumeSize": 16, "SnapshotId": "snap-xxxxxx" } } ][6-2] インスタンス作成
"--image-id"に作成したAMIのID、"--block-device-mappings"にルートデバイス拡張のJSONファイルのパスを設定します。
$ aws ec2 run-instances --dry-run --region ap-northeast-1 --image-id ami-xxxxxx \ --block-device-mappings file://device-mapping.json --count 1 \ --instance-type t3.nano --key-name (キーペアの名称) \ --subnet-id subnet-xxxxxx --private-ip-address 10.0.2.10 \ --security-group-ids sg-xxxxxx \ --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=private-inst}]' \ --credit-specification CpuCredits=standard作成したインスタンスのボリュームを確認すると16GiBになっていることが分かります。
$ aws ec2 describe-volumes --region ap-northeast-1 | jq '.Volumes[] | \ select(.Attachments[].InstanceId=="i-xxxxxx")' { "AvailabilityZone": "ap-northeast-1d", "Attachments": [ { "AttachTime": "2019-02-03T09:51:34.000Z", "InstanceId": "i-xxxxxx", "VolumeId": "vol-xxxxx", "State": "attached", "DeleteOnTermination": true, "Device": "/dev/xvda" } ], "Encrypted": false, "VolumeType": "gp2", "VolumeId": "vol-xxxxxx", "State": "in-use", "Iops": 100, "SnapshotId": "snap-xxxxxx", "CreateTime": "2019-02-03T09:51:34.102Z", "Size": 16 }[6-3] ライブラリ・ツールの確認
AMI作成前にインストールしたPython3, pip3, virtualenvがインストールされていることを確認します。
$ python3 --version Python 3.7.1 $ pip3 --version pip 9.0.3 from /usr/lib/python3.7/site-packages (python 3.7) $ virtualenv --version 16.3.0参考資料
AWS Cli自分用Tips - Qiita
AWS-CLI EC2でおなじものをつくるよ - Qiita
AWS CLI Command Reference — AWS CLI 1.16.96 Command Reference
EC2 インスタンスを起動、リスト、および終了する - AWS Command Line Interface
コマンドラインからの EBS ボリュームの変更 - Amazon Elastic Compute Cloud

- 投稿日:2019-02-03T19:41:31+09:00
AWS開発中に機能が追加されていく。。最新情報のチェック方法は?
仕事でAWS関連の設計・開発作業を行っているのですが、こんなことがありました。
開発中に最新機能がリリースされました。
そして、一週間後に気が付いて、あ、これ使える。。
ほんと、たまたま、気づきました。
そこで最新情報のチェック方法を整理しようと思います。最新情報がのっているページ
https://aws.amazon.com/jp/new/
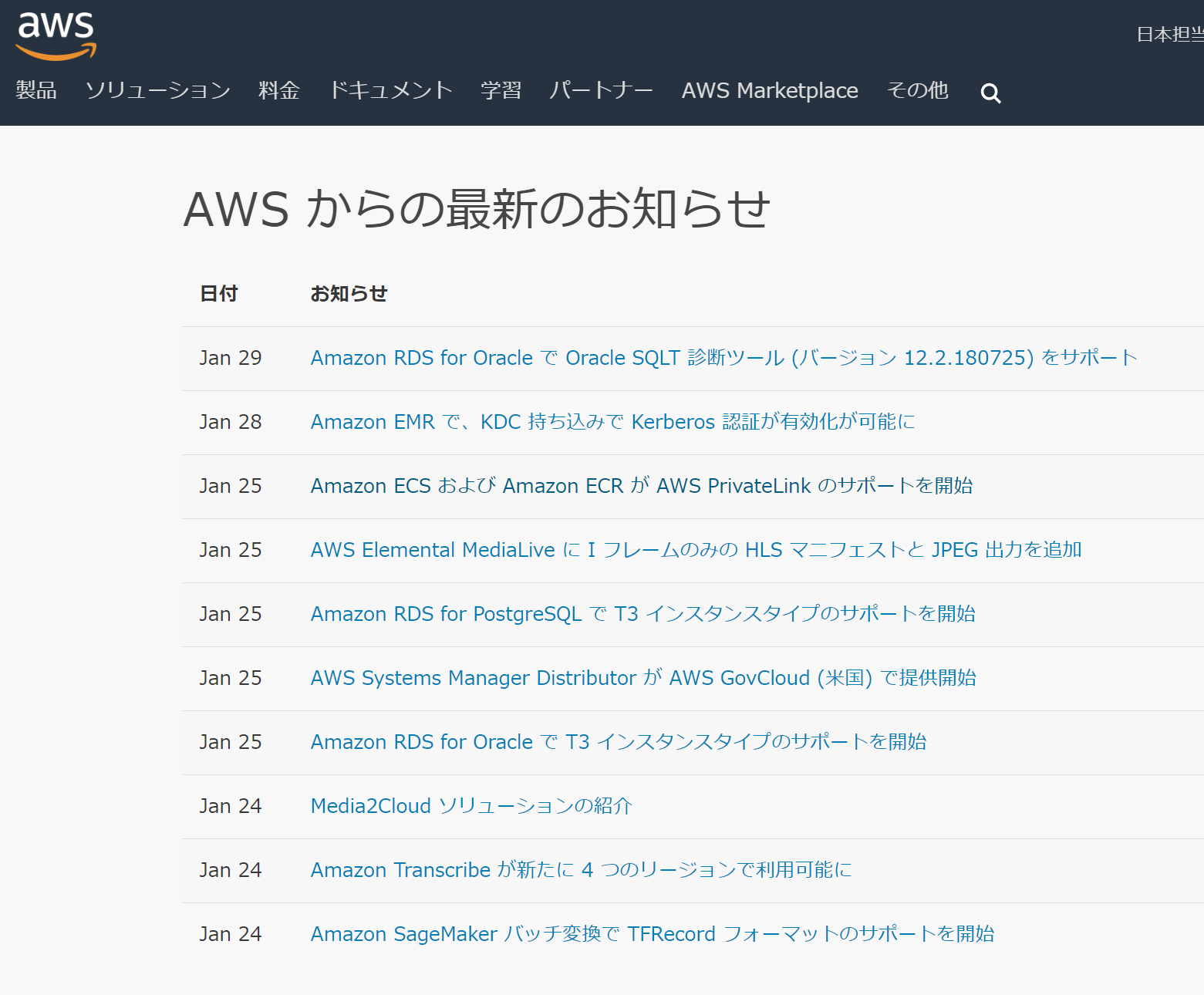
とりあえず、毎日「AWSからの最新のお知らせ」だけ、ちらみする。
↓↓↓
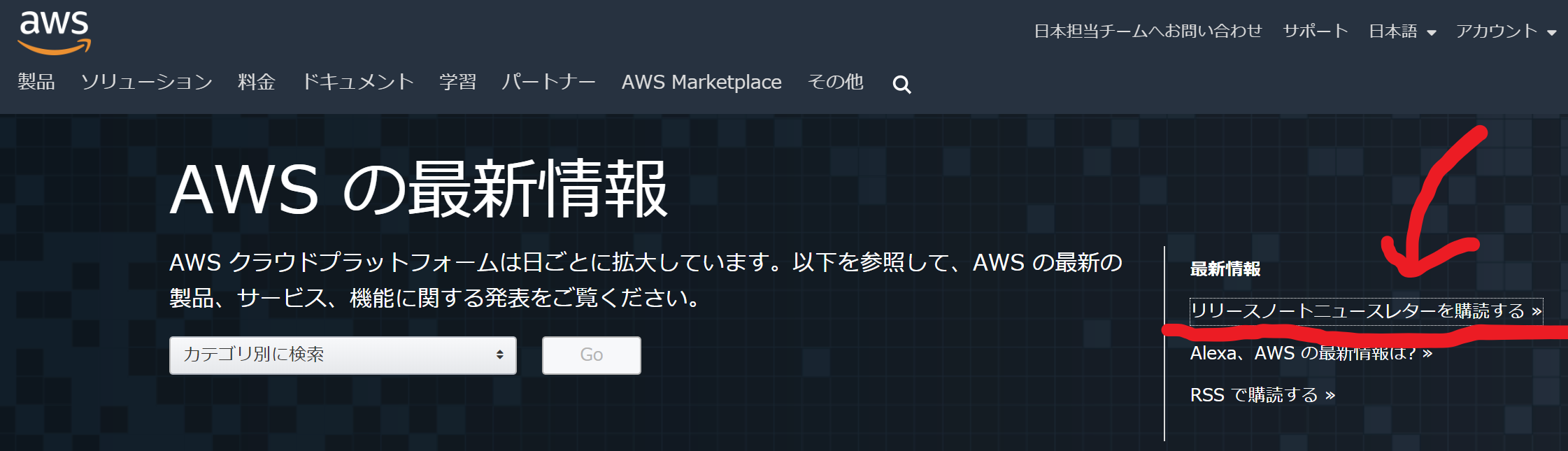
ただし、まぁ見るの忘れてしまうし、最新情報がないときにページを開くのも不毛かな。メールでお知らせしてもらうようにする
先ほどと同じページの一番上です。
リリースノート、ニュースレターを購読する。を選択
ここでメールアドレスを登録
↓↓↓
現在、私はここでメールアドレスを登録した状態です。
まだ、一通もメールが来ていないので、
メールが来たら最新情報ページの内容が届いているか見比べてみようと思います。追加(コンテナのロードマップ)
https://github.com/aws/containers-roadmap/projects/1
このようなものもあるのですね~。
- 投稿日:2019-02-03T18:06:39+09:00
Amazon Linux/Amazon Linux 2 の AMI ID の場所
この記事の内容
Amazon Linux と Amazon Linux 2 の AMI ID 一覧が記載されているページへのリンク。
Terraform にて AMI ID の変数に入れる値一覧を探していて Amazon Linux についてはすぐにページを見つけられたものの、Amazon Linux 2 はなかなか見つけられなかったためメモ。Amazon Linux
- リージョン、種別ごとに表になっていて見やすいです。
- https://aws.amazon.com/jp/amazon-linux-ami/
Amazon Linux 2
- Amazon Linux 2 AMI ID という見出し部分に記載されています。
- リージョンごとに AMI ID が記載されていますが、表ではないので若干見にくいです。
- https://aws.amazon.com/jp/amazon-linux-2/release-notes/
- 投稿日:2019-02-03T16:25:26+09:00
S3へのアウトプット
こんにちは。AWS lambdaのAPIでS3のアウトプットについて簡単ながら書いていきます。
内容は言語はNode.jsで書いてますが、どの言語でもエッセンスは関係ない基礎的なところかなと思います。
参考文献:
https://www.amazon.co.jp/AWS%E3%81%AB%E3%82%88%E3%82%8B%E3%82%B5%E3%83%BC%E3%83%90%E3%83%BC%E3%83%AC%E3%82%B9%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3-Peter-Sbarski/dp/4798155160/ref=sr_1_1?ie=UTF8&qid=1549178089&sr=8-1&keywords=%E3%82%B5%E3%83%BC%E3%83%90%E3%83%AC%E3%82%B9%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3ではAWS LambdaのAPIで「バケット1」から、バケット内のファイルをアウトプットしましょう!!
例
Outputs: [ Key: "任意のファイル名"+ '.mp4等、ファイルの種類' ]でlanbdaの中でアウトプットを作ることが出来ます。
ファイルだけじゃなくてフォルダを作りたい!という方は
ファイル名の前にOutputs: [ Key: "任意のフォルダ名" + "/" + "任意のファイル名" + '.mp4等、ファイルの種類' ]のように "/" を付けるとフォルダが出来上がって、ファイルが格納されている状態になっちゃいます。
複数のファイルをアウトプットに入れたい場合は
Outputs: [ {Key: "任意のフォルダ名" + "/" + "任意のファイル名" + '.mp4等、ファイルの種類'}, {.............}, {.............}・・・ ]と続けていけばいいです。
ここで、フォルダ名を同一のものにすると、同一フォルダに複数ファイルが格納された状態になります。
以上です。
読んでくださってありがとうございました!
- 投稿日:2019-02-03T10:28:01+09:00
AWS S3にアップロードされたExcelファイルをLambdaで処理
概要
- AWSのS3にアップされたExcelファイルをLamda関数を使って処理する方法を試したので、手順を共有する。
課題
- 定型のExcelファイルを使ってデータを納品する業務をシステム化したい。
- なぜExcelか? 古い業界なので、いまでもExcelが活躍している。Excelマクロを組めるとヒーローだ。CSV/TSVのほうが機械処理には楽だが、人間にとってはExcelのほうが運用性・業務親和性が高い。
- そこで担当者がExcelファイルをS3にアップしたら、その内容を自動的にRDSやDynamoに登録するような仕組みを実現したい
課題解決の方針
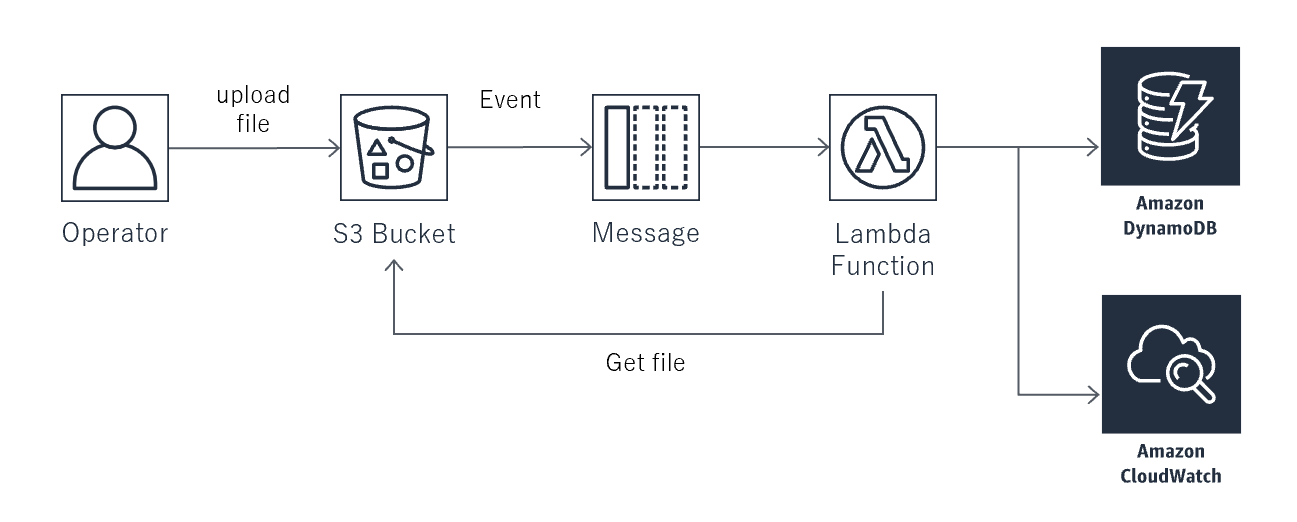
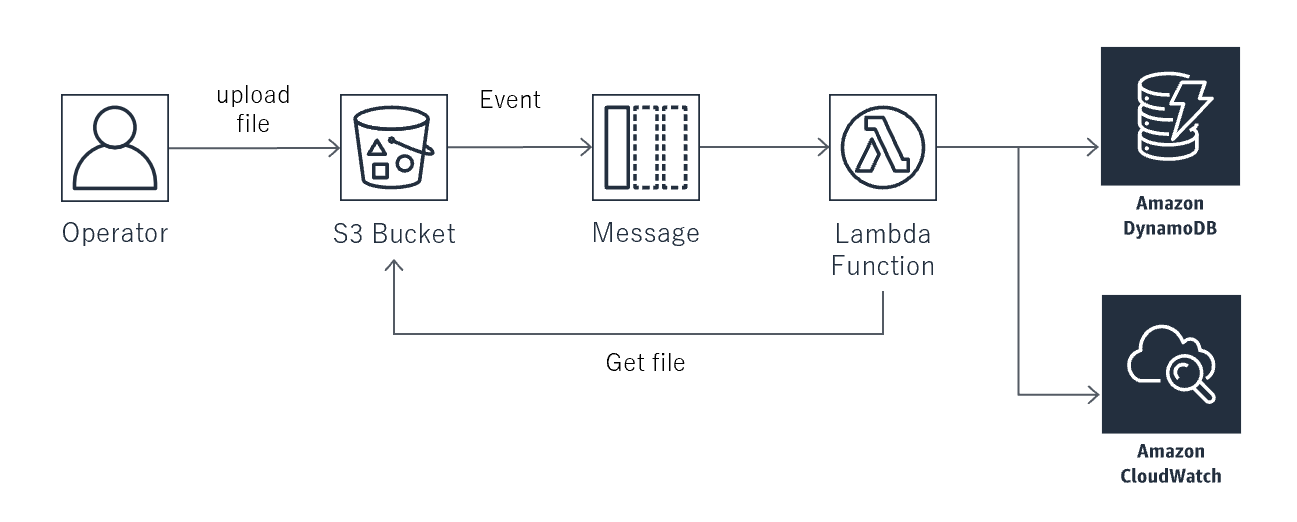
- S3にExcelファイルがアップされたらEvent機能でSQSに通知して、それをLamda関数で処理するまでの範囲を本稿で検討する。S3EventからLambdaを直接キックしないのは、エラー再処理などの運用性を考慮しているからである。
- システム構成図
- 運用者がExcelファイルをS3の特定パスにアップすることは別のソリューションで行う。S3互換のファイル転送ソフトなどを用いることも可能。
手段の検討
- Lambdaは、ランタイムでPython3系を選択する1。同期処理を考えなくてもよいバッチ処理のようなコーディングには簡易だからである。
- Excelファイル読み取りでxlrdというライブラリを選択する。もしかすると古いExcelファイルも処理したくなるかもしれないので。他のライブラリは試していないので、これがベストな選択かどうかはわからない。そのあとの処理で集計するならPandasもよさそうだ。
- xlrdを使うために、対象ファイルをローカルに取得する必要がある。Lambdaでは一般的にローカル領域として/tmpを使うのだが、インスタンスを共有しているのでファイル名がぶつからないように考慮する。/tmpが満杯になるともちろん処理が失敗するので、処理が終わったらファイルは削除するべき。
参考 AWS Lambda の制限構築手順
- AWSで 実用的なLambda関数をつくったことがあるレベルの人を前提に以降で手順を紹介する。
S3バケットの作成
- 新規バケットを作成する。バケット名、ARNをメモしておく。
SQSキューを作成
- S3バケットと同じリージョンで、マネジメントコンソールからSQSを選択。
- 新規キューを作成する。
キュー名は notify_upload_excelfile (任意)
標準キューを指定
キューの詳細設定はデフォルトのままでよい。後で実際の業務にあわせて調整すればよい
- キューが作成されたら、キューのURLとARNをメモしておく。
- キューを選択して、アクセス許可でS3を追加する。
方法は以下を参考に。サンプルのポリシーをコピペして、環境にあわせて修正すればよい。
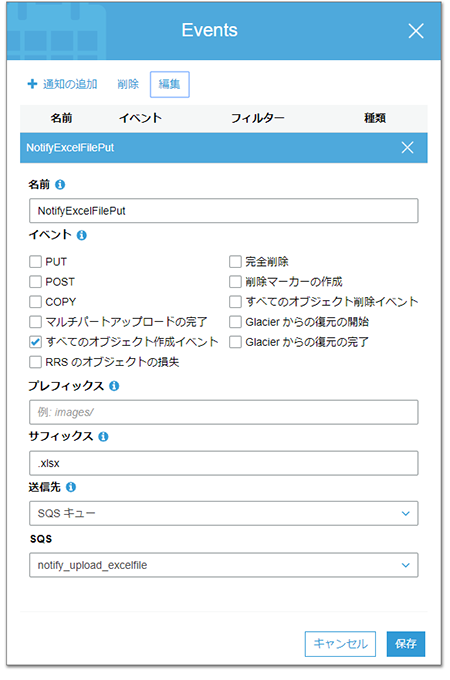
バケットを通知用に設定する (メッセージの宛先: SNS トピックおよび SQS キュー)S3バケットにイベント通知を設定する
- 作成したバケットのプロパティからEventsをクリック
通知の追加
名前 : NotifyExcelFilePut(任意)
「すべてのオブジェクト作成イベント」にチェック
サフィックス: .xlsx
送信先 SQSで上記で作成したキューARNを指定する。Lambda 関数の作成
- マネジメントコンソールのLambda画面で「一から作成」を選択
名前 : function_readExcelfile
ランタイム : Python 3.7
- ロールは新規作成
ロール名 : lambdaexec_readExcelfile(任意)
作成後に以下アクセス許可を追加
sqs:ChangeMessageVisibility
sqs:DeleteMessage
sqs:GetQueueAttributes
sqs:ReceiveMessage
IAMポリシーの例{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "sqs:DeleteMessage", "s3:GetObject", "logs:CreateLogStream", "sqs:ChangeMessageVisibility", "sqs:ReceiveMessage", "sqs:GetQueueAttributes", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:*:*:*", "arn:aws:sqs:us-west-2:xxxxxxxxxxx:notify_upload_excelfile(キューARN)", "arn:aws:s3:::xxxxxxxxxxxxx(バケットARN)/*" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "logs:CreateLogGroup", "Resource": "arn:aws:logs:*:*:*" } ] }参考: チュートリアル: AWS Lambda 関数をトリガーするように Amazon SQS キューへの着信メッセージを設定する
- Lambda関数の作成
ローカルPC上で適当なフォルダで以下のPythonファイルを作成する。lambda_function.pyimport logging import os import json import boto3 import urllib.parse from datetime import datetime import xlrd import random import pprint logger = logging.getLogger() logger.setLevel(logging.INFO) count_success=0 s3 = boto3.resource('s3') def read_file(bucket,key): global count_success # ローカルの一時ファイルパスを生成する local_file_path = '/tmp/tmp_file_' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S-') + str(random.randint(0,999999)) logger.info('local_path: ' + local_file_path) try: # S3からファイルを一時パスにダウンロード bucket = s3.Bucket(bucket) bucket.download_file(key, local_file_path) # ダウンロードしたファイルをExcelと解釈して読み込む(エラー処理はしていない) wb = xlrd.open_workbook(local_file_path) sheet = wb.sheet_by_index(0) # 特定のセルから値を取得する例 #logger.info("Cell A01 is {0}".format(sheet.cell_value(rowx=0, colx=0))) # 各行を取り出して成形して表示(実際の処理ではこの部分をカスタマイズする) for rx in range(sheet.nrows): print(sheet.row(rx)) count_success+=1 # 不要な一時ファイルを削除 if os.path.exists(local_file_path): os.remove(local_file_path) # logger.info('tmp-file removed : ' + local_file_path) except Exception as e: logger.info(str(e)) def parce_message(messages): messages_dict = json.loads(messages) if ('Records' in messages_dict): for record in messages_dict['Records']: input_backet = record['s3']['bucket']['name'] input_key = urllib.parse.unquote_plus(record['s3']['object']['key'], encoding='utf-8') # logger.info('update:' + input_backet + ':' + input_key) read_file(input_backet,input_key) else: logger.warning('ignore invalid SQS message: ' + str(messages_dict)) def lambda_handler(event, context): for record in event['Records']: parce_message(record["body"]) logger.info('Success ' + str(count_success) + ' files')
- ライブラリをダウンロードしZipファイルを作成
以下でローカルフォルダにxlrdライブラリを取得。キャッシュファイルは削除して、Zipファイルに固めるpip install xlrd -t .
ZipファイルをマネジメントコンソールのLambda関数の関数コードの箇所で、Zipファイルをロードして保存
Lamda関数のトリガーにSQSを指定
上記キューのARNを指定
バッチサイズは 1S3バケットにExcelファイルをアップして、CloudWatchログで出力を確認する。
まとめ
- S3にExcelファイルをアップして、Lambda関数で自動的に取得しExcelファイルの内容にアクセスできることを確認した。
- 日本語処理については完全性は保証できないが、Windows10環境のOffice2016で作成したExcelファイル名が日本語、データに日本語を含む場合に日本語を処理できたことは確認した。
今後の課題
- Excelファイルはxlrdの処理前にチェックしていないが、Lambda関数の実行リソースに制限があるのでExcelファイルが信用できない場合は、対策が必要である2。
- 現状のコードだと、コード中のtryで囲った範囲外でエラーした場合は、何度もリトライして処理が詰まる状態になる。キューのメッセージ数の監視と、エラーになった場合の処理フローや、キュー設定のチューニング、デッドレターキュー設定を検討すべきである。
- SQSの仕様上、標準キューはメッセージ順序、排他取得を保証していない。またLambdaの処理が開始する前に、同じExcelファイルが更新される可能性があるので、Excelの処理ロジックは疎連携を考慮した内容にすべきである3。
参考文献
- xlrdのドキュメント
https://github.com/python-excel/xlrd- PythonでExcelファイルを扱うライブラリの比較
https://note.nkmk.me/python-excel-library/- PythonでExcelファイルを読み込み・書き込みするxlrd, xlwtの使い方
https://note.nkmk.me/python-xlrd-xlwt-usage/- S3からのファイル取得とローカル保存
https://recipe.kc-cloud.jp/archives/10035- AWS Lambda を利用する上で知っておいたほうがよいこと
https://www.bokukoko.info/entry/2015/09/17/AWS_Lambda_%E3%82%92%E5%88%A9%E7%94%A8%E3%81%99%E3%82%8B%E4%B8%8A%E3%81%A7%E7%9F%A5%E3%81%A3%E3%81%A6%E3%81%8A%E3%81%84%E3%81%9F%E3%81%BB%E3%81%86%E3%81%8C%E3%82%88%E3%81%84%E3%81%93%E3%81%A8
- 投稿日:2019-02-03T10:11:08+09:00
aws周りのメモ4
https://blog.adminfactory.net/allow-access-to-s3-bucket-only-from-ec2-instances.html
s3を限定的にホスティングとしてつかう
http://www.apro-soken.co.jp/blog/yonesaka/2012/11/s3sphinx.html
sphinx
AWS CDK
awslabs/aws-cdk: The AWS Cloud Development Kit is a framework for defining cloud infrastructure in code
https://github.com/awslabs/aws-cdkAWS CDK (AWS Cloud Development Kit) がとても便利そうなので触ってみた - YOMON8.NET
https://yomon.hatenablog.com/entry/2018/08/14/AWS_CDK%28AWS_Cloud_Development_Kit%29%E3%81%8C%E3%81%A8%E3%81%A6%E3%82%82%E4%BE%BF%E5%88%A9%E3%81%9D%E3%81%86%E3%81%AA%E3%81%AE%E3%81%A7%E8%A7%A6%E3%81%A3%E3%81%A6%E3%81%BF%E3%81%9FAWS CDKをKotlinで試した - Qiita
https://qiita.com/tiibun/items/7d3a06c5b2eb672d6e1dkotlinもつかえるのか
AWS Lambda ( Typescript ) の Lambda Layers 活用、開発、デプロイ考察 | DevelopersIO
https://dev.classmethod.jp/server-side/serverless/aws-lambda-typescript-lambda-layers-deploy/layersを使う例
AWS CDKでサーバーレスアプリケーションを構築する - kentarom
https://scrapbox.io/kentarom/AWS_CDK%E3%81%A7%E3%82%B5%E3%83%BC%E3%83%90%E3%83%BC%E3%83%AC%E3%82%B9%E3%82%A2%E3%83%97%E3%83%AA%E3%82%B1%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3%E3%82%92%E6%A7%8B%E7%AF%89%E3%81%99%E3%82%8Bシンプルで試すのに良かった
lambda
アプリケーションという概念についてキャッチアップ
[アップデート]Lambdaコンソールにアプリケーションの管理とモニタリングをするメニューができました | DevelopersIO
https://dev.classmethod.jp/cloud/aws/aws-update-lambda-application-console/AWS Lambda アプリケーション - AWS Lambda
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/deploying-lambda-apps.htmllambdaのデプロイやリリースなどをひとまとめに管理する箱的なことか。。
lambda@Edgeまわり
AWS CloudFront Lambda@Edge の罠たち | d.sunnyone.org
http://d.sunnyone.org/2018/03/aws-cloudfront-lambdaedge.htmlリージョンが違うとレプリカ関数というのが作られたりするのね
ダイナミック レンダリングの使用方法 | 検索 | Google Developers
https://developers.google.com/search/docs/guides/dynamic-rendering?hl=jaGAになったLambda@Edgeを使ってSPAをSSR無しでOGPとかに対応させてみる - Qiita
https://qiita.com/kiida/items/17e804765f424fd990dbAWS Toolkit
新発表 – AWS Toolkits for PyCharm、IntelliJ(プレビュー)、Visual Studio Code(プレビュー) | Amazon Web Services ブログ
https://aws.amazon.com/jp/blogs/news/new-aws-toolkits-for-pycharm-intellij-preview-and-visual-studio-code-preview/便利。。
Installing the AWS SAM CLI on macOS - AWS Serverless Application Model
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install-mac.htmlsamを入れ直す
想定外にいろいろと連動して依存ブツがインストールされだした。。Installing the AWS SAM CLI on macOS - AWS Serverless Application Model
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install-mac.htmlcdkで作ったやつをtoolkitに紐づけたい
template.yamlが接点になってる気がするのだけど。。
AWSTemplateFormatVersion: '2010-09-09'をテンプレートに追記してみたりしてちょっと進んだけどうまくいかず。
うーん。。ひとまずcdkでいいかな。sam
aws-sam-local 改め aws-sam-cli の新機能 sam init を試す - Qiita
https://qiita.com/hayao_k/items/841026f9675d163b58d5
- 投稿日:2019-02-03T08:46:48+09:00
[備忘]AWS認定クラウドプラクティショナー受験→取得した
いつか、知り合いにも受ける人が出てくるかもしれないので、備忘の意味で残しておきます。
きっかけ
転職した先で、「今後、オンプレのサーバ全部クラウド(AWS)に移行していくから勉強してね」と言われたので。
これまでの職歴でインフラ周りは一切触ったことありませんでした。(基本情報取るとき勉強した位)勉強方法
後述の参考先に書かれていた勉強方法とほぼ同じですが、
・Amazon Web Services 基礎からのネットワーク&サーバー構築を見ながら、実際にサーバ立ててみる
→なんか難しいなとなって、AWSをはじめように切り替え。インフラ初心者には、こっちの方がオススメです。
・青い本を読む
・公式のサンプル問題(Blackbeltの後半スライド)解く
・他、各種blackbelt読む
・模擬試験受けるを2ヶ月くらいかけてやって、受かりました。
試験時間90分を30分くらいで解き終わって、855/1000点だったので、
もっと早く受けても大丈夫だったなと思います。いろんなサイトに書いてあった通り、模擬試験より遥かに出題方法が難しめでした。
(模擬試験・・どういう形式で出てくるかということがわかるだけなので、ぶっちゃけ2000円勿体無いし受けなくてもよかったなぁと思います。)
一通りサービスの名称と概要覚えておけば消去法使って何とかなると思います。
(Amazon Inspectorって何!そもそもサービスにあったか? とならないように。)参考
公式の試験ガイド等は割愛。(もちろん、一番最初に読みましょう!)
AWS 認定クラウドプラクティショナー 合格しました!
https://server-recipe.com/334/【合格体験記】AWS 認定クラウドプラクティショナー試験(AWS Certified Cloud Practitioner)
https://saikyouse.com/aws-cloud-practitioner-review/AWS Cloud Practitioner取得時のおすすめ学習法など
https://qiita.com/marbledmeat/items/c2903d6cb165aeaee1d2AWS Black Belt Online Seminar AWS 認定クラウドプラクティショナー取得に向けて
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-aws-124130272AWS White Belt Online Seminar AWS利用開始時に最低限おさえておきたい10のこと
https://aws.amazon.com/jp/blogs/news/aws-white-belt-online-seminar-aws-10/その他
どんな試験でも言えることですが、不測の事態がおきても落ち着きましょう。
今回は、30分前に着いて受付はじめたのに、テストセンターからのアクセスが繋がらない?とか言われて、もう一人の人と一緒に1時間以上待たされました。ワンオペでやってて、ほかの試験の人たちの受付にも影響出てて気の毒でした。次は、4月にソリューションアーキテクトーアソシエイトを受ける予定です。
(ちょうど黒い本出ましたね。)
- 投稿日:2019-02-03T02:28:25+09:00
API GatewayからDynamoDBの読み書きを行う
はじめに
AWSのAPI Gatewayから前回作ったLambda関数を起動することによりDynamoDBを読み書きする方法です。Lambdaでは書き込み専用、読み込み専用として別々の関数を作りましたが、今回は一つのAPI Gateway中にGET機能とPOST機能を持たせます。
・ API Gatewayの管理画面にアクセスします。
・ RESTプロトコルを選択します。
・ 適当なAPI名をつけます。
・ エンドポイントタイプはリージョンを選択します。
・ APIの作成を押すとメソッド画面が開きます。GETコマンドの設定
・ アクションからリソースの作成を選択します。
・ リソース名に[comments]と入力しリソースの作成を押します。
・ アクションからメソッドの作成を選びます。
・ GETを選んでチェックマークを押します。
・ GETセットアップにて、統合タイプはLambda関数、関数名には読み込み用のLambda関数名を入力して保存します。
・「 API GatewayにLambda関数を呼び出す権限を与えようとしています」のメッセージが出るのでOKを押します。
・ メソッドのリクエストをクリックします。
・ URLクエリ文字列パラメーターを開きます。
・ クエリ文字列の追加をクリックし名前にDBのプライマリーキーである[track]と入力してチェックマークを押します。(全データを呼び出すことになる)
・ メソッドの実行をクリックして前の画面に戻ります。
・ 統合リクエストをクリックします。
・ マッピングテンプレートを選択して開きます。
・ テンプレートが定義されていない場合(推奨)を選んでマッピングプレートの追加をクリックします。
・ [Context-Type]に[application/json]と入力し、右のチェックを押します。
・ [application/json]をクリックし以下をコピーし保存します。#set($inputRoot = $input.path('$')) { "track": "$input.params('track')" }・ メソッドの実行をクリックして前の画面に戻リます。
・ これでGET時にLambda関数を介してDynamoDBへQueryを実行できるようになります。
・ テストを押します。
・ クエリ文字列に[track=Test]と入力してテストボタンを押します。
・ 画面右側にDynamoDBの値が出力されれば成功です。
・ メソッドの実行をクリックして前の画面に戻ります。POSTコマンドの設定
・ アクションからメソッドの作成を選びます。
・ POSTを選び右側のチェックを押します。
・ POSTセットアップにて、統合タイプはLambda関数、関数名には読み込み用のLambda関数名を入力して保存します。
・ 「API GatewayにLambda関数を呼び出す権限を与えようとしています」のメッセージが出るのでOKを押します。
・ 統合リクエストをクリックします。
・ マッピングテンプレートを選択して開きます。
・ テンプレートが定義されていない場合(推奨)を選んでマッピングプレートの追加をクリックします。
・ [Context-Type]に[application/json]と入力し、右のチェックを押します。
・ [application/json]をクリックし以下をコピーし保存します。$input.json('$’)・ メソッドの実行をクリックして前の画面に戻ります。
・ テストを押します。
・ リクエスト本文に以下を記入します。{ "track": "Test", "comment": "Hello API GW", "name": "zzzz" }・ テストを押します。
・ レスポンスに{}と表示されれば成功です。
・ DynamoDBの管理画面でデータが追加されていることを確認します。以上でREST APIが完成です。
デプロイとテスト
・ アクションからAPIのデプロイを選択します。
・ デプロイされるステージで新しいステージを選び、ステージ名に[demo]と入力しDeployボタンを押します。
・ 画面にURLが表示されるのでコピーします。
・ ブラウザのアドレスバーにペーストし、最後に[/comments?track=Test]を追記します。
・ GETの結果としてQuery結果が表示されます。POSTについては手作業でのテストは行えません。POSTMAN(www.getpostman.com)などでテストを行う必要があります。