- 投稿日:2021-03-29T23:30:26+09:00
pythonでバブルソート
pythonで実装練習2
■ バブルソート
N = int(input()) L = list(map(int,input().split())) for i in range(1,N): for j in range(1,N-i+1): if L[-j] < L[-j-1]: tmp = L[-j] L[-j] = L[-j-1] L[-j-1] = tmp print(L)■ input
5 5 3 2 4 1■output
[5, 3, 2, 1, 4] [5, 3, 1, 2, 4] [5, 1, 3, 2, 4] [1, 5, 3, 2, 4] [1, 5, 3, 2, 4] [1, 5, 2, 3, 4] [1, 2, 5, 3, 4] [1, 2, 5, 3, 4] [1, 2, 3, 5, 4] [1, 2, 3, 4, 5]
- 投稿日:2021-03-29T23:09:24+09:00
pythonで挿入ソートを実装
pythonでプログラミングの基礎練習1
*注意 pythonではL.sort()で並び替え可能ですが、アルゴリズム実装の練習として、コメントいただければ幸いです!■ 挿入ソートの実装
N = int(input()) L = list(map(int,input().split())) for i in range(N): for j in range(i): if L[i] < L[j]: ins = L[i] L[j+1:i+1] = L[j:i] L[j] = ins print(L)■ input例
6 5 4 2 3 1 6■ output例
[4, 5, 2, 3, 1, 6] [2, 4, 5, 3, 1, 6] [2, 3, 4, 5, 1, 6] [1, 2, 3, 4, 5, 6]
- 投稿日:2021-03-29T22:49:02+09:00
車窓の映像から加速度を求める!?(yahoo hackday2021)
生配信されたプレゼンでひろゆきさんの真似をして、信じられないくらいすべりました。。。
はじめに
hackdayに初参加して一週間がたちました。
自分の学んだことの整理として、記事を描こうと思い立ち、いつもお世話になっているQiitaの記事を頑張って書いてみようと思いました。
初めて書くのでわかり辛い部分、不完全な部分あると思いますがお手柔らかによろしくお願いします。目次
製作物の概要
発表当日が緊急事態宣言がされた日ということもあり、皮肉も込めて電車通勤体験キットを作りました。
具体的にはつり革を自宅に設置し、映像と連携しながら通勤を体験できるというものです。
今回紹介する技術
実装のなかで映像(車窓の風景)からある程度の加速度を予測するということをしました。
今回はその紹介をさせていただきます。アイデアとしては動画から一定時間ごとに静止画を抽出し、時間的に隣会う画像の類似度を求め、それを速度に見立てて加速度を推測するというものです。
類似度が高い→あまり移動がない→遅い
類似度が低い→結構移動している→早い今回求めたいのは加速度なので、類似度がどのように変化しているかに注目して大まかな加速度を推測しました。
動画から静止画を抽出
extract_images.pyimport cv2 import os def save_all_frames(video_path, dir_path, basename, ext='jpg'): cap = cv2.VideoCapture(video_path) if not cap.isOpened(): return os.makedirs(dir_path, exist_ok=True) base_path = os.path.join(dir_path, basename) digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)))) n = 0 while True: ret, frame = cap.read() if ret: cv2.imwrite('{}_{}.{}'.format(base_path, str(n).zfill(digit), ext), frame) n += 1 print(n) else: return save_all_frames('video_path', 'dir_path', 'sample_video_img') save_all_frames('video_path', 'dir_path', 'sample_video_img', 'png') video_path = 'video_path' dir_path = 'output_path' save_all_frames(video_path, dir_path, 'train')記事を参考にしているので、中枢の部分は参考文献をご参照ください。
この後の都合のために保存するファイル名を変えるくらいの変更をしました。類似度を推測
hist_matching.pyimport cv2 import os def add_zeros(path_number): if (len(path_number) == 1): return '000' + path_number elif (len(path_number) == 2): return '00' + path_number elif (len(path_number) == 3): return '0' + path_number else: return path_number IMG_DIR = os.path.abspath(os.path.dirname(__file__)) + 'data_path' IMG_SIZE = (200, 200) temp = 0 for i in range(6901): # print(i) j = i + 1 i = str(i) j = str(j) i = add_zeros(i) j = add_zeros(j) target_img_path = IMG_DIR + 'train_' + i + '.jpg' target_img = cv2.imread(target_img_path) target_img = cv2.resize(target_img, IMG_SIZE) target_hist = cv2.calcHist([target_img], [0], None, [256], [0, 256]) comparing_img_path = IMG_DIR + 'train_' + j + '.jpg' # print('FILE: %s : %s' % ('train_' + i + '.jpg', 'train_' + j + '.jpg')) comparing_img = cv2.imread(comparing_img_path) comparing_img = cv2.resize(comparing_img, IMG_SIZE) comparing_hist = cv2.calcHist([comparing_img], [0], None, [256], [0, 256]) ret = cv2.compareHist(target_hist, comparing_hist, 0) # print(file, ret) print(ret - temp) temp = ret記事を参考にしているので、中枢の部分は参考文献をご参照ください。
データのファイル名を変えるくらいの変更をしました。いや、先頭のゼロ埋めしてくれる関数の存在は知ってたんですが、なんかうまくいかなくて自作しました、、、
類似度を推測
analysis.pyimport matplotlib.pyplot as plt import time y = [] input_file = open('speed.txt', 'r', encoding = 'utf_8') i = 0 while True: line = input_file.readline() if line: i += 1 y.append(1 - float(line)) time.sleep(0.33) print(1 - float(line)) else: break # RGBごとのヒストグラム計算とプロット for i, channel in enumerate(colors): histgram = cv2.calcHist([img_a], [i], None, [256], [0, 256]) plt.plot(histgram, color=channel) plt.xlim([0, 256])
出てきたグラフと映像を見比べるといい感じで一番興奮した瞬間でした。製作物(実際のプレゼン)
もう少し技術力があれば、、、(反省)
- 映像とグラフを比較すると実際には止まっているのに速度変化があると認識している部分があります。(動画2:30,グラフx:3500くらい) 原因は止まっている時に向かい側の電車が出発して類似度に変化があったことです。
- 加速度の向きも求めたかったなと思っています。
- プレゼンふざけすぎて一番大事な技術を伝えられなかった。
参考文献


- 投稿日:2021-03-29T22:38:54+09:00
【Windows10Home】DockerによるPython開発環境の構築
Windows 10 Homeで特定バージョンのPython保持しなければならなくなったので、その際やったことを記事にまとめます。
オーソドックスにWSL2でDockerを動かし、コンテナ上にPython環境を構築してみようと思います。対象読者
開発初心者の方。特にPython。
そもそもWSLって? Dockerって名前は聞いたことあるけど、実際どんなものなの? という方にも(なるべく)理解してもらえる(といいなぁ)よう、頑張ります。対象マシン
Windows 10 Home
x64システムの場合、バージョン 1903 以降、ビルド 18362 以上が必要です。そもそも
なぜ特定バージョンのPythonを保持しなければならなくなったのかといえば、そのバージョンでしか(まともに)動かない機械学習Modelを作ってしまったからです。
だからPythonのアップデートはしたくないんだけど、別のModelでは別のバージョンを使いたい……なんてことは、Pythonの開発をやっていると稀によくあります。
pyenvなどでも1つのマシンに異なるバージョンを保持することができますが、Dockerのコンテナにプロジェクトの開発環境をまるっと保持してしまえばよりシンプルに、かつ移植性も高い環境を構築できるため、こちらを採用しました。
(ぶっちゃけpyenvよくわかってない)でもその前に
ただ、初心者は特にですが、必要性がなければこんなことをする必要もないです。
機械学習といえばGPUだ! Ubuntuだ! となりいきなり壮大な環境構築を頑張ろうとして躓いて嫌になって……。てなるのも悲しいので。
それでもPythonの開発ではライブラリの導入を含めたトライ&エラーが頻発します。
そのたびにインストール&アンインストールを繰り返しているとローカルの開発環境がぐっちゃぐちゃに汚れ、このライブラリどこにパス通ってるんだ……? なんてことにもしばしば。
そうなったら新規一転、開発環境を仮想化してしまうのも手です。あとは自然言語処理でMeCab使いたいけど、Windowsだと文字コードでバグりまくる……という場合も、簡単にLinux系の環境を用意できるのも利点ですね。
開発初心者の方はこんな風に、必要に迫られた段階でステップアップとして取り組むと良いと思います。用語
何となく仮想環境を構築したい理由はわかったよ。じゃあWSLって? Dockerって? という方に。
Dockerとは
仮想化技術の一つです。
非常に手軽にWEBサーバーやAPサーバー、DBサーバーをデプロイできることからWEB開発の現場では広く使われている(らしい)技術です。おれWEB畑じゃないからね。
Hyper-VやVirtualBoxと何が違うの? と思われる方がいるかもしれませんが、これらは物理マシンのネットワークスイッチなどをエミュレートできるのに対し、DockerではベースとなるOSと完全に分離せず、OSのカーネル上にコンテナを配置する形をとります。
(前者をホスト型仮想化、後者をコンテナ型仮想化といいます)
例えばHyper-Vではホストとは異なるOSを積んだり、個別にネットワークアダプタを割り当てることが可能ですが、それらの点でいうとDockerは劣ります。
なのになぜDockerを使うのかと言われれば、やはりその軽量さ、手軽さが大きな理由でしょうか。
DockerではOS上にほかのプロセスと切り離された環境にコンテナを作るので、仮想環境の動作をホスト型仮想化よりも少ないリソースで実現できるのです。WSL(2)とは
Windows Subsystem for Linuxの略で、そのまんま、Windows上でLinuxを動かすための技術です。
じゃあやっぱHyper-Vでいいじゃん! って感じですが、Windows 10 HomeじゃHyper-V使えないし、さらにいうとHyper-Vより少ないリソースでLinuxを動かすことができて、んでもって動作も軽量軽快。
個人的に一番違いを感じるのは起動ですね。
また今回はDocker Desktop for Winodwsという製品を使いたいのですが、本来こちらはHyper-Vの仮想化とネットワークを利用します。
前述の通りHomeではHyper-Vが使えないのですが、WSL2にUbuntuをインストールすることで、Docker Desktop for Windowsのバックエンドとして機能させることができるのです。要はWSL2でUbuntuを動かして、そこにDockerをインストールするってことですね。
環境のイメージ
以上を踏まえ、今回はこんなイメージの環境を構築してみたいと思います。
やっと図が出てきた。
ホストのWindowsでWSL2を起動し、そこでUbuntuを動かします。UbuntuやDockerの制御はPowerShell等からでもできるのですが、今回はWindows Terminalからコントロールします。
そのUbuntu上にDocker(Docker Desktop for Windows)を導入。
Docker上にコンテナを配置し、それらを開発環境として利用します。
今回はAnacondaのDockerイメージをDockerHubから引っ張ってきます。DockerHubってのはDockerのコンテナを公開できる、GitHubみたいなもんだね。
んでAnacondaのコンテナでJupyter Labを動かし、Windowsのブラウザから操作したりプロジェクトをVS Codeでいじくったりできるようになろうってのが今回の目標です。ちょっと注意
ここまで言っておいて水差すつもりはないんですけど、製品版のWindowsではWSL2をバックエンドとしたDockerコンテナではGPUを使えません。
(2021年3月19日現在)
Insider Previewならできるのですが、そちらは自己責任となりますのでご注意を。
自分はGPUを使うプロジェクトに関してはローカルでやりくりしています。WSL2のインストール
やぁ、前置きがウルトラ長くなってしまった。
まずはWSL2のインストールからはじめましょ。
公式ドキュメント:https://docs.microsoft.com/ja-jp/windows/wsl/install-win10コマンドラインからのインストールは現在(2021/3/19)プレビュー版でしか利用できないようです。
PowerShellの起動
Windowsの検索機能で「PoweShell」と入力します。表示されたアイコンを右クリックし、「管理者として実行」を選んでください。
Linux用Windowsサブシステム、仮想マシンの機能の有効化
起動したPowerShellから下記のコマンドを入力し、必要な機能を有効化します。
Linux用Windowsサブシステムdism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart仮想マシンの機能
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestartどちらもすぐに処理は完了すると思います。
Linuxカーネル更新プログラムパッケージのダウンロード
以下のリンクからLinuxカーネル更新プログラムパッケージをダウンロードします。
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msiダウンロードしたパッケージをダブルクリックし、インストールします。
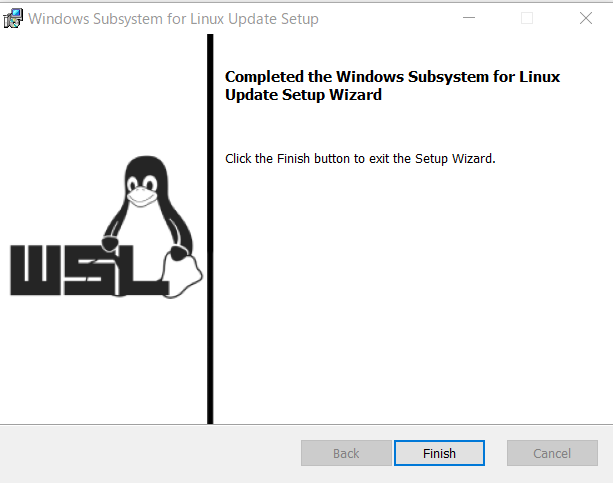
手順に従って進み、以下の画面となればOKです。
WSL2を既定のバージョンとして設定
再度管理者としてPowerShellを開いて、次のコマンドを実行します。
wsl --set-default-version 2新たにLinux系OSをインストールする際に使用するWSLの規定バージョンを2に指定しています。
これでひとまずWSL2の準備は完了。
Ubuntuのインストール
続いてはWSL2に乗っけるOS(Linuxディストリビューション)をインストールします。
WSL2ではDebian GNU/Linuxなどのディストリビューションも利用可能とのことですが、今回は機械学習の開発環境を構築することが目的なのでよく使われるUbuntuを使うことにします。
バージョンは16.04 LTS / 18.04 LTS / 20.04 LTSから選びます。
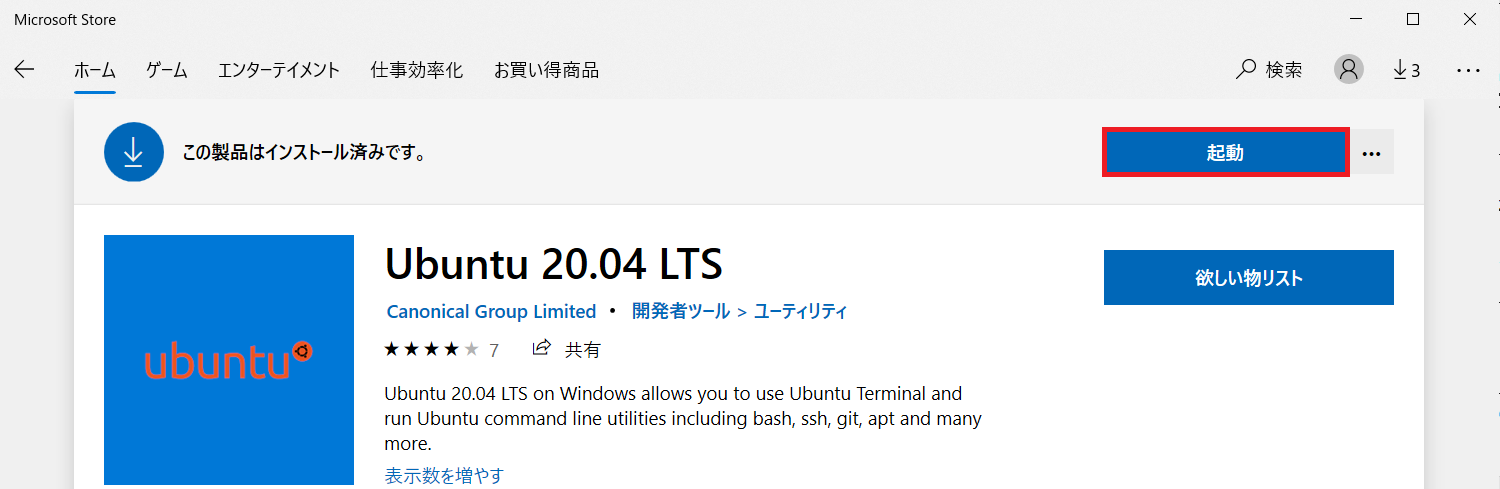
自分は20.04 LTSをインストールしますが、それ以外のバージョンでも手順は同じ(はず)です。Microsoft StoreからUbuntuをダウンロード
スタートメニューから「Microsoft Store」を開き、検索窓に「Ubuntsu」と入力します。
(MSのアカウントでサインインしていなくてもDLできました)
画面右上の「インストール」ボタンをクリックします。
Ubuntuの起動
インストールが完了すると「インストール」のボタンが「起動」に変わっているので、クリックしてUbuntuを起動します。
Ubuntuを起動すると初期化が行われ、続いてユーザー名とパスワードの入力が求められます。
ご自身のものを入力してください。あとちなみにスタートメニューに「Ubuntu 20.04 LTS」が追加されていると思います。
起動状況の確認
念のためPowerShellからUbuntuの起動状況を確認しましょう。
(別に管理者権限で開かなくてもいいです)
以下のコマンドを実行してください。wsl --list --verboseこれはWSLにインストールされているLinuxディストリビューションの一覧と起動状況、使用するWSLのバージョンを表示するコマンドです。
Ubuntu-20.04がVERSION「2」としてインストールされていますね。
大丈夫そうです。Windows Terminalのインストール(おまけ)
これはオプションなので別にやらなくてもいいんですけど、自分はUbuntuの操作はWindows Terminalから行っています(結構使いやすい)。
Windows TerminalもMicrosoft Storeからインストールできますできます。
(検索窓に「Windows Terminal」と入力してください)
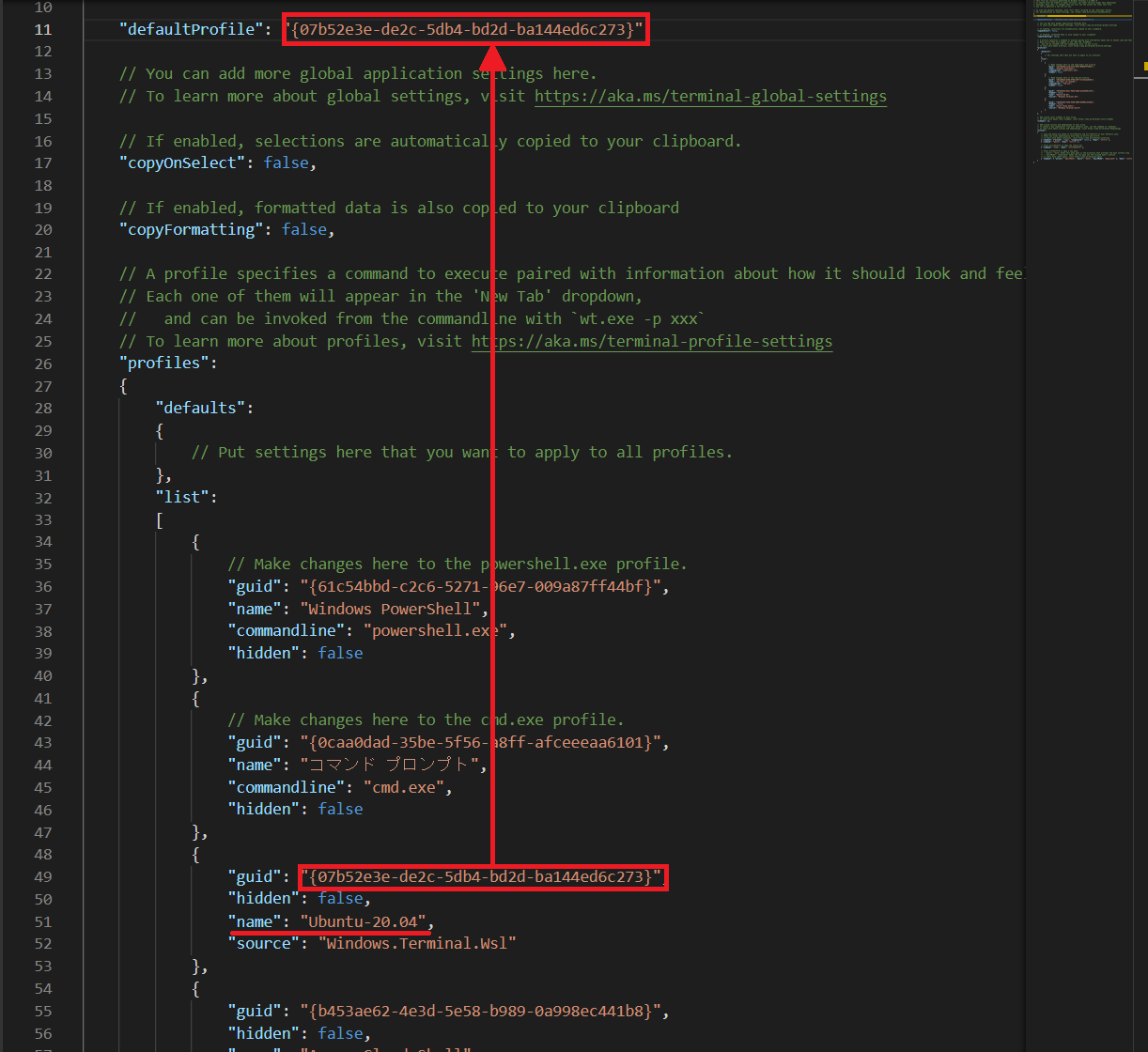
用途としてはUbuntuの制御がメインなので、起動時にUbuntuのシェルが立ち上がるよう規定値を変更します。
タブの「▽」をクリックし、「設定」を選択してください。
「Setting.json」というjsonファイルが開かれます。
上のほうに「defaultProfile」という項目があります。
ここに起動時に立ち上げたいシェルのguidを入力することで規定値を変更することができます。
少しスクロールすると「profiles」→「list」というところに各シェルの情報が格納されているのがわかります。
Ubuntuがインストールされていれば「"name": "Ubuntu-20.04"」の項目があるはずなので、そのguidをコピーし、先ほどのdefaultProfileの値に貼り付けます。
これでWindows Terminalを起動するとデフォルトでUbuntuのシェルが立ち上がるようになりました。
Docker Desktop for Windowsのインストール
バックエンド環境が準備できたところで、Dockerをインストールしましょう。
公式ドキュメント:https://docs.docker.jp/docker-for-windows/install.htmlインストーラーのダウンロード
インストーラーはDocker Hubからダウンロードできます。
https://hub.docker.com/editions/community/docker-ce-desktop-windows/「Get Docker」をクリックするとダウンロードが始まります。
特にSign upしなくてもDLできます。インストール
ダウンロードしたインストーラーをダブルクリックして起動します。
「Install required Windows Components for WSL 2」にチェックし、「OK」をクリックします。
完了です。
試しにDockerを起動してみましょう。
もちろん空っぽです。
このあとコンテナ入れるので、チュートリアルはスキップして良いです。
Dockerディスク領域の変更(オプション)
Docker Desktopをインストールすると問答無用でシステムドライブに仮想環境が作られます。
↑の手順でもマウントするパスの指定とかなかったしね。
コンテナを立てていくとCドライブの容量を圧迫してしまうので、データドライブに領域を移します。なおWSLのインストール一覧は下記のコマンドで確認することができます。
wsl --listWindows Terminalでの実行結果です。このとき接続先のシェルはPowerShellにしてください。
(先の手順でデフォルトがUbuntuになっているので)
領域を移したいのはこの「docker-desktop-data」ってやつです。
ちなみに上記のイメージの実態は
%LocalAppData%\Docker\wsl\distro\ext4.vhdxというものです。
エクスプローラーで%LocalAppData%\Docker\wsl\distroと入力すると、ext4.vhdxというファイルがあります。
(多分デフォルトだとC:\Users\(ユーザー名)\AppData\Local\Docker\wsl\distroとかじゃないかな)
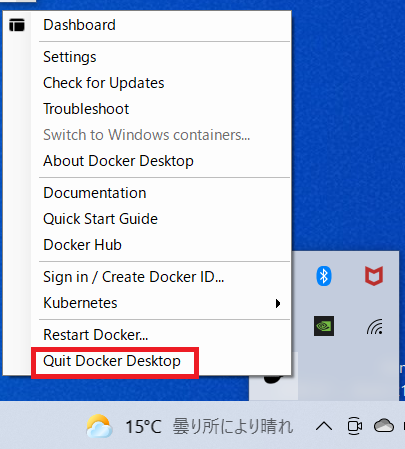
あ、ちなみにvhdxはVirtualHardDiskって意味ね。Docker / WSLの停止
まずはDocker Desktopを停止します。
タスクバーの「△」を選択し、Dockerのクジラみたいなアイコンを右クリックすると操作一覧が表示されるので「Quit Docker Desktop」を選択します。
続いてPowerShellで下記のコマンドを実行します。
wsl --shutdown念のため起動状況を確認します。
wsl --list --verboseSTATEがすべて「Stopped」になっていればOKです。
データのエクスポート
docker-desktop-dataの移動先のフォルダを作っておきます。
データドライブにD:\01_Dockerというフォルダを予めつくっておきました。フォルダ名は気にしないでください。下記のコマンドで、上記フォルダの中に
docker-desktop-data.tarというファイルをエクスポートします。wsl --export docker-desktop-data D:\01_Docker\docker-desktop-data.tarコンテナは空っぽの状態なんで、すぐに終わります。
docker-desktop-dataの登録の解除
WSLにおけるdocker-desktop-dataの登録を解除します。
wsl --unregister docker-desktop-data.tarファイルのインポート
上記でデータドライブにエクスポートしておいた.tarファイルをインポートします。
D:\01_Dockerフォルダの直下にdataフォルダを作成します。
下記のコマンドを実行し、D:\01_Docker\docker-desktop-data.tarファイルをD:\01_Docker\dataフォルダにインポートします。> wsl --import docker-desktop-data D:\01_Docker\data D:\01_Docker\docker-desktop-data.tar
D:\01_Docker\dataフォルダにext4.vhdxが作成されています。
WSL / Dockerの起動
WSLとDockerを起動しましょう。
WSLはPowerShellでwslと入力すれば起動します。
DockerはアイコンをクリックすればOK。Dockerコンテナの作成
ちょっと話が脇道にズレてしまいましたが、いよいよ最終目的である仮想開発環境を構築しましょう!
冒頭のイメージ図でもふれたとおり、今回はDocker HubからAnacondaのコンテナをダウンロードします。作業フォルダの準備~Dockerfileの作成
Dockerではコンテナを作るときに
Dockerfileというファイルを作成し、そこにどんな構成のコンテナとするか~といった情報をコードとして記述します。
コンテナを立ち上げる時にDockerがこのファイルを参考にセットアップしてくれるんですね。まずはそのコンテナにおける作業フォルダを作成します。
本格的な運用をする場合には1プロジェクトにつき1コンテナとすることが多いので、コンテナ名=プロジェクト名するのが分かりやすいでしょう。
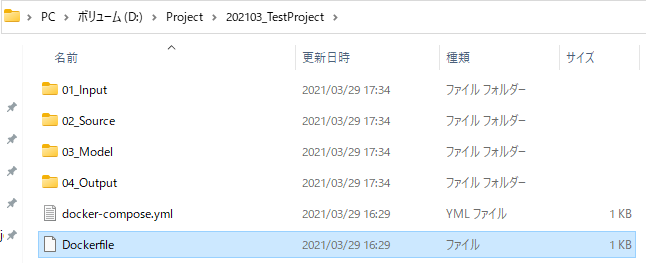
今回はD:\Project\202103_TestProjectというフォルダを作成しました。
ここでは半角英数にしておいたほうが賢明です。
特に スペースは全角半角問わずやめておいたほうが良いでしょう。作成したフォルダの直下で右クリック→新規作成→テキストドキュメントを選択します。
作成したファイル名を「Dockerfile」に変更します。
このとき、 「.txt」の拡張子を削除します。
Dockerfileに拡張子はないのです。
警告が出ても無視してください。
Dockerfileの記述
作成したDockerfileに「どんなコンテナを作るのか」という情報を記述していきます。
DOckerfileを選択し右クリック→プログラムから開くを選び、好きなテキストエディタから編集してください。今回は次のような命令を記述していきます。
FROM continuumio/anaconda3:2019.03 RUN pip install --upgrade pip && pip install Keras && pip install tensorflow WORKDIR /workdir EXPOSR 8888 ENTRYPOINT ["jupyter-lab", "--ip=0.0.0.0", "--port=8888", "--no-browzer", "--allow-root", "--NotebookApp.token=''"] CMD ["--notebook-dir=/workdir"]一つ一つ見ていきましょう。
FROM continuumio/anaconda3:2019.03ここでDocker Hubから「2019.03時点のAnaconda3を引っ張って来いよ」と明示しています。
RUN pip install --upgrade pip && pip install Keras && pip install tensorflowその後実行するコードです。
イメージとしてはcmdから実行すべきコマンドを記述している感じ。
WORKDIR /workdir命令を実行するときのカレントディレクトリを指定します。
上記によりコンテナに/workdirが作成され、各種命令はこの中で実行されることになります。
EXPOSE 8888ネットワーク上のポートを指定します。
ENTRYPOINT ["jupyter-lab", "--ip=0.0.0.0", "--port=8888", "--no-browzer", "--allow-root", "--NotebookApp.token=''"]実行対象に関する設定です。
今回はコンテナ上で起動するJupyter LabをホストのWindowsから利用したいのでそれに関する設定を行っています。
ローカルで完結する環境を想定しているためトークン認証は無効としていますが("--NotebookApp.token=''")、例えばクラウドで立ち上げる等であれば設定が必要でしょう。
CMD ["--notebook-dir=/workdir"]最後にJupyter labの作業ディレクトリを先ほど作成した/workdirに紐づけます。
以上で命令の記述は完了です!
保存してエディタを閉じます。docker-compose.ymlファイルの作成
次にアプリケーションを構成するサービスを「Docker-compose.yml」というファイルに記述します。
今回はDockerの起動にはDocker Composeというツールを使用します。
これは複数コンテナを定義し、実行するDockerアプリケーションを管理するためのツールです。YAMLというファイルにアプリケーションの各サービスの設定を記述することによって、Docker起動時にYAMLファイルを呼び出すだけで簡単にコンテナの生成、起動を行うことができます。
先ほど作成したDockerfileと同じディレクトリに、
docker-compose.ymlというファイルを作成してください。そこに以下のように記述します。
services: dev: build: context: . dockerfile: Dockerfile image:project01 ports: - "8080:8888" volumes: - .:/workdirimageにはご自身のプロジェクト名を入力してください。
また起動対象となるDockerfileもbuild内で指定します。そのためdocker-compose.ymlとDockerfileは同じディレクトリにないといけませんので、注意。
Dockerfileと同じくvolumesには作業ディレクトリとして/workdirを指定しましょう。ちなみに今回は割愛しますが、docker-compose.ymlファイルを使用しなくとも、シェルから
docker runというコマンドを実行しても起動できますよ。コンテナの起動
これでコンテナを起動する準備ができました。
Powershellを起動し、カレントディレクトリをDockerfile、docker-icompose.ymlが置かれたフォルダに移動します。cd D:\Project\202103_TestProject続いて下記のコマンドを実行します。
docker-compose upJupyter Labの起動
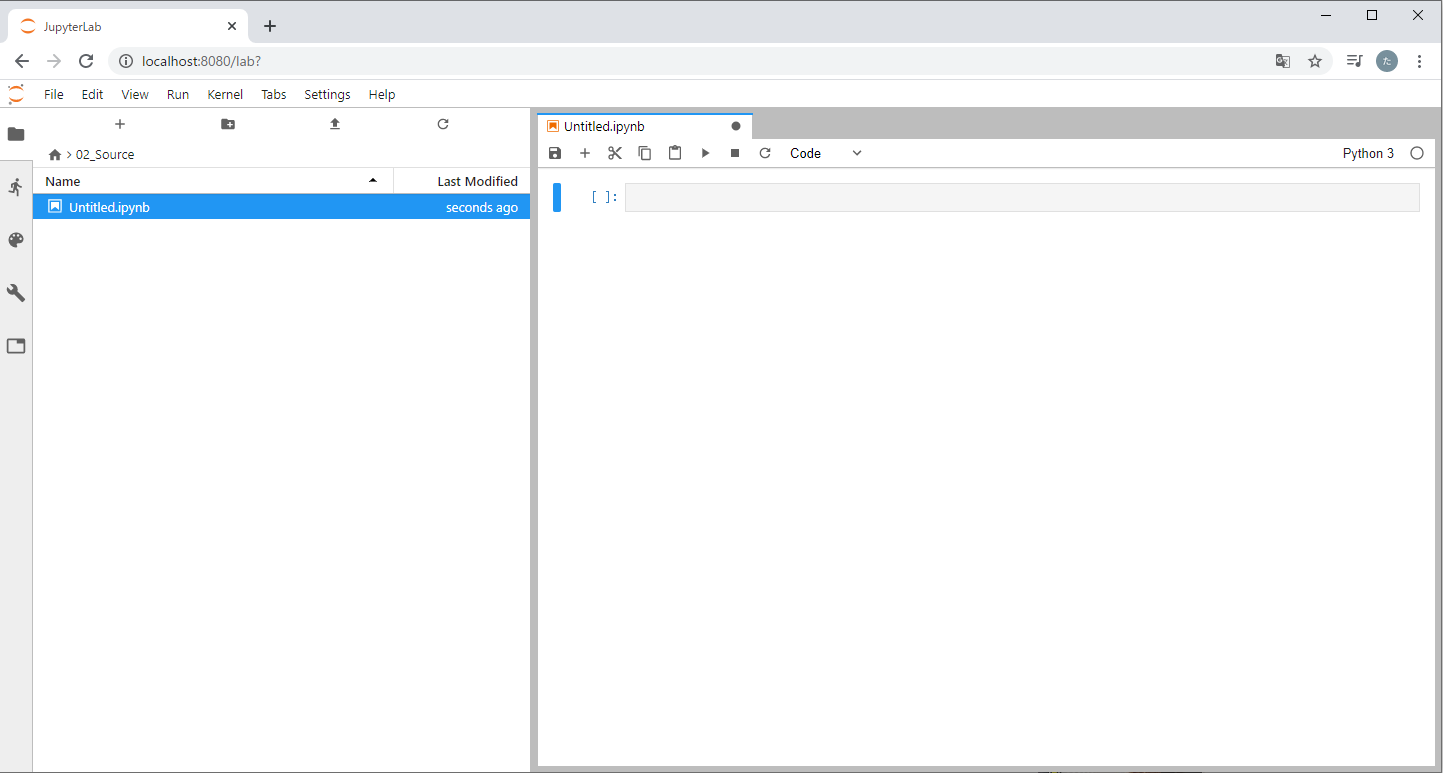
WindowsからコンテナのJupyter Labに接続しましょう。
コンテナが起動した状態で任意のブラウザを起動し、localhost:8080と入力してください。
Jupyter Labが起動すれば成功です!
Jupyterのナビゲーターを見ればわかる通り、JupyterのカレントディレクトリはそのままDockerfile、docker-compose.ymlが置かれたフォルダとなっています。
このフォルダの中身をコンテナは認識してくれますので、試しにこの直下に「01_Input」「02_Source」「03_Model」「04_Output」というフォルダを作成してみます。
Jupyterでも反映されていますね。
今度は逆にJupyter LabからPythonのNotebookを作ってみましょう。
「02_Source」に入り、Python Notebookを作成します。
Windows側のエクスプローラーから「02_Source」の中を見ると、作成した.ipynbファイル(とチェックポイント)があることが分かります。
これで無事WindowsとDockerコンテナの同期が取れていることが確認できました!
お疲れ様です、全作業完了です!
あとはもう、イカしたModelを作りまくって世の中に貢献しちゃってください。





















- 投稿日:2021-03-29T22:22:07+09:00
非情報系大学院生が一から機械学習を勉強してみた #8:リカレントニューラルネットワーク(LSTM)
はじめに
非情報系大学院生が一から機械学習を勉強してみました。勉強したことを記録として残すために記事に書きます。
進め方はやりながら決めますがとりあえずは有名な「ゼロから作るDeep-Learning」をなぞりながら基礎から徐々にステップアップしていこうと思います。環境はGoogle Colabで動かしていきます。最終回である第8回はリカレントニューラルネットワーク(RNN)についてです。目次
- リカレントニューラルネットワークとは
- LSTM
- LSTMの実装
- あとがき
1. リカレントニューラルネットワークとは
再帰型ニューラルネットワーク(RNN: Recurrent Neural Network)は内部にフィードバック構造を持ったニューラルネットワークで(時)系列データの処理に向いています。前回までのMLP、CNNではMNIST手書き数字を例にした画像認識の学習を行ってきました。それとは異なり今回は音声や言語、動画像といった系列データ、例えば文章を例に挙げると、ある文章内で単語の並びはこれまでの単語の並びに強く影響を受けると考えられます。このような$t$番目の単語まで与えられたとき$t+1$番目の単語を予測することを目指します。RNNはこのような文脈をうまく学習し、単語の予測を行うことができ、言語モデルとも呼ばれます。
RNNの構造
RNNの構想は下図のような順伝播型ネットワークと同様の構造を持ち、ただし中間層出力が自分自身に戻されるフィードバック回路を持つと考えることができます。
このRNNは各時刻$t$につき一つの入力$x^t$を受け取り、出力$y^t$を返します。その際ネットワーク内部のフィードバック回路によって過去に受け取ったすべての入力を考慮します。順伝播型が入力1つに対し出力1つを返したのに対し、RNNは理論上過去のすべての入力から1つの出力を返します。
RNNは下図のように時間方向に展開して表現することができます。こうすることでフィードバックの各層が全く別々に存在するかのように見なせます。つまりRNNは2層であってもDeep learningができることになります。
2. LSTM
前章で述べたようにRNNは理論的には過去の全ての入力が考慮されます。しかし実際は高々過去の10時刻分程度だと言われています。これは第6回で述べた勾配消失問題と同様です。層数の多い深いネットワークでは層の計算を行うと勾配は爆発的に大きくなるか0に消滅してしまいやすい性質があります。RNNは時間方向に展開すると深い順伝播ネットワークに置き換えられます。よってRNNは元々の層数は少なくても、深い層を扱っているのと同等になり勾配消失問題が発生してしまいます。よって基本的なRNNでは短期な記憶は実現できても、より長期の記憶を実現するのは難しいと言えます。
この問題を踏まえ、長期の記憶を実現できるようにしたのがLSTM(Long Short-Term Memory)です。LTSMは単純にフィードバックするだけでなく、下図のようにいくつかのゲートを挟んでフィードバックを行います。
状態量$c^k$は階層型RNNと同じである$\bar{z}^k$と入力ゲート出力$i^k$、忘却ゲート出力$f^k$からなります。入力ゲートで入力された短期の情報の影響を調整し、忘却ゲートで長期の記憶の影響を調整して$c^k$を更新します。最後に$c^k$を出力ゲートで調整して出力$z^k$を決定します。
3. LSTMの実装
以上を踏まえて実装を行います。今回はChainerを使用して映画のレビューテキストから感情を推定する下図のようなネットワークを実装します。
Chainer、訓練データ、必要なモジュールをインストールします。
パッケージの準備!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/README.md !wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/nets.py !wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/nlp_utils.py !wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/run_text_classifier.py !wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/text_datasets.py !wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/train_text_classifier.py !wget https://raw.githubusercontent.com/harvardnlp/sent-conv-torch/master/data/stsa.binary.train import random import numpy as np import chainer from chainer import Variable from chainer import functions as F from chainer import links as L import matplotlib.pyplot as plt続いてデータセットを準備します。
データセットの準備import text_datasets # Set dataset dataset = "stsa.binary" # Read dataset if dataset == 'dbpedia': train, test, vocab = text_datasets.get_dbpedia() elif dataset.startswith('imdb.'): train, test, vocab = text_datasets.get_imdb(fine_grained=dataset.endswith('.fine')) elif dataset in ['TREC', 'stsa.binary', 'stsa.fine', 'custrev', 'mpqa', 'rt-polarity', 'subj']: train, test, vocab = text_datasets.get_other_text_dataset(dataset) # Show dataset information print('# train data: {}'.format(len(train))) # train data: 6920 print('# test data: {}'.format(len(test))) # test data: 1821 print('# vocab: {}'.format(len(vocab))) # vocab: 7142 n_class = len(set([int(d[1]) for d in train])) print('# class: {}'.format(n_class)) # class: 2確認したように訓練データ数は6920、テストデータは1821です。単語は無数に存在するので学習に使用する単語数をあらかじめ絞っておきます。今回は7142語を使用します。出力は感情がpositive(1)、negetive(0)の2値です。
具体的に中身を確認してみます。
訓練データ中身の確認# Read source data f = open("stsa.binary.train", "r") lines = f.readlines() # Target line number n = 100 # Print source sentence print(lines[n]) # Show numerical train data and corresponding words for v_ in train[n][0]: for k, v in vocab.items(): if v_ == v: print(str(v) + " : " + k) # Print sentiment data print("Sentiment: " + str(train[n][1][0])) # =========以下出力========= # 0 you can taste it , but there 's no fizz . # 23 : you # 70 : can # 781 : taste # 11 : it # 4 : , # 17 : but # 53 : there # 10 : 's # 64 : no # 3163 : fizz # 2 : . # 0 : <eos> # Sentiment: 0このように
train内には文章が格納されており、train[n][0]にはn番目文章のそれぞれの単語の番号、train[n][1]にはn番目文章のそれぞれの感情が格納されています。ここから具体的なネットワークの構成に入ります。基本的に前回のCNN実装と同じです。まずモデルを定義します。
モデルの定義N_in = len(vocab) # vocabulary size N_i = 500 # input dimension N_l = 1 # LSTM layers N_h = 500 # state dimension dropout = 0.5 # dropout rate N_out = 2 # output size class LSTM(chainer.Chain): # Constructor def __init__(self, N_in, N_i, N_l, N_h, dropout, N_out, initializer = None): super().__init__( layer1 = L.EmbedID(N_in, N_i, initialW = initializer), layer2 = L.NStepLSTM(N_l, N_i, N_h, dropout), layer3 = L.Linear(N_h, N_out, initialW = initializer), ) # Forward operation def __call__(self, x, t = None): z1 = [self.layer1(item) for item in x] # EmbedID h, c, y = self.layer2(None, None, z1) # LSTM a3 = self.layer3(h[-1]) # Affine if chainer.config.train: return F.softmax_cross_entropy(a3, t) # Softmax3 with cross entropy error, training else: return F.softmax(a3) # Softmax3, evaluationEmbedID(入力サイズ, 出力サイズ, 初期重み, 無視する列)は訓練データを表したいものに割り振った次元のみ1、その他を0にしたone-hot-vector表現の処理に特化した層で、計算はAffine layerと同じです。
NStepLTSM(LSTMレイヤ数, 入力ベクトル次元, 出力ベクトル、内部状態次元数, ドロップアウトレート)は可変長の入力を受け付けることができるLSTM layerです。さきほど訓練データ内部を見てみたように文章の長さはそれぞれ異なるので可変である必要があります。前向き演算の際は引数が(初期内部状態変数, 初期メモリセル状態変数, 入力変数)となります。第1、2変数がNoneのときゼロベクトルが指定され、通常はNoneで問題ないそうです。あとは前回のCNNと同様にGPU定義、学習と評価を行います。CNNのときとほぼ同じなので説明は省きます。
GPUの準備# GPUの設定 gpu_device = 0 chainer.cuda.get_device(gpu_device).use() # モデル定義 model = LSTM(N_in, N_i, N_l, N_h, dropout, N_out, initializer = chainer.initializers.HeNormal()) # GPU転送 model.to_gpu(gpu_device) # 最適化エンジン設定 optimizer = chainer.optimizers.Adam() optimizer.use_cleargrads() optimizer.setup(model)学習と訓練# Set parameters and initialiation iters_num = 5000 train_size = len(train) test_size = len(test) batch_size = 100 iter_per_epoch = int(max(train_size / batch_size, 1)) train_acc_list = [] test_acc_list = [] # Training and evaluation for i in range(iters_num): # Set mini-batch batch_list = random.sample(train, batch_size) x_batch = [batch_list[j][0] for j in range(len(batch_list))] t_batch = np.array([batch_list[j][1] for j in range(len(batch_list))]).flatten() x_batch = chainer.cuda.to_gpu(x_batch, device = gpu_device) t_batch = chainer.cuda.to_gpu(t_batch, device = gpu_device) # Forward operation loss = model(x_batch, t_batch) # Backward operation model.cleargrads() loss.backward() # Update parameters optimizer.update() # Evaluation if i % iter_per_epoch == 0 or i == iters_num - 1: # Turn training flag off chainer.config.train = False # Evaluate training set y_train = [] for s in range(0, train_size, batch_size): train_batch = train[s:s + batch_size] x_batch = [train_batch[j][0] for j in range(len(train_batch))] x_batch = chainer.cuda.to_gpu(x_batch, device = gpu_device) y_train.extend(chainer.cuda.to_cpu(model(x_batch).data).tolist()) # Evaluate test set y_test = [] for s in range(0, test_size, batch_size): test_batch = test[s:s + batch_size] x_batch = [test_batch[j][0] for j in range(len(test_batch))] x_batch = chainer.cuda.to_gpu(x_batch, device = gpu_device) y_test.extend(chainer.cuda.to_cpu(model(x_batch).data).tolist()) # Compute accuracy t_train = np.array([train[j][1] for j in range(len(train))]).flatten() t_test = np.array([test[j][1] for j in range(len(test))]).flatten() train_acc = F.accuracy(np.array(y_train), t_train).data test_acc = F.accuracy(np.array(y_test), t_test).data train_acc_list.append(train_acc) test_acc_list.append(test_acc) print(i, train_acc, test_acc) # 4999 1.0 0.7732015376166941 # Turn training flag on chainer.config.train = True # Plot figure markers = {'train': 'o', 'test': 's'} x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()その結果以下のようなグラフがプロットされ、約77%の正答率で文章から感情を認識できるようになりました。(8割弱だと若干低いような気もしますが…)
4. あとがき
このシリーズは「なんでもいいから好きなことを勉強してみろ」との課題として全8回シリーズで書きました。結果、機械学習の基礎が理解できたので良い機会になりました。最近"AI"は「よく分からないけどなんでもできるすごいやつ」みたいな雰囲気が世間にある気がして嫌だな~と思っていましたが、自分で組んでみることでようはただパラメータの最適化が元になっていることや、こういう用途は得意だから積極的に使えるな、逆に機械学習は決して万能ではなくこっちの用途は苦手だから他の手法を考える必要がありそうだな、ということが考えられるようになったのは良かったです。これからは自分の専門分野×機械学習なんてことも考えていけたら良いです。一応月2本程度と決めて書いていましたが、メインの研究が忙しいときは減らしたり余裕があるときにまとめて進めたりとスケジューリングができたのも良かったです。
その一方、勉強や実装はもう少しいろいろやってみたのですが、時間や労力の都合で記事にするのはその途中までになってしまったのは残念でした。また、あくまで初学者の自分のアウトプットとして書いていてリアクションを求めていたわけではないですが内容がQiitaにしては当たり前すぎてリアクションが少ないのが残念でした。
練習で書いてみた自分の得意なTeXやMATLABの記事は着眼点がちゃんと必要としている人に刺さったのか、view数、LGTM、ストック、どれも多くの人に役立てていただけ、やりがいにつながりました。やっぱりこの世の中を生きていくためにはすべてが80点よりある一分野で120点の方が需要があると感じました。これからはまず自分の得意分野をとことん深めて社会で戦っていける武器を作りたいです。それから更に得意分野を広げられるように横の関連へどんどん触手をのばしていきたいですね。全8回お付き合いありがとうございました。参考文献
ゼロから作るDeep-Learning
ゼロから作るDeep-Learning GitHub
深層学習 (機械学習プロフェッショナルシリーズ)





- 投稿日:2021-03-29T22:15:48+09:00
pythonの数値・bytes相互変換(+おまけ:bytesを誤ってstr変換して保存してしまった場合)
はじめに
- intであれば、to_bytes, from_bytesを使ってもよい。
- ただしこの方法は、floatの場合は使えないなどのケースがあるため、structを使った方法を紹介する。
- 以降、数値はfloat 32bit little endianを例に記述する。
- 別の数値データを扱う場合は、
"<f"の場所を必要に応じて変更すること。import
import structfloat ⇔ bytes
structのpack/unpackで実現できる。
- float ⇒ bytes
val = 123.4 struct.pack('<f', val) # Out: b'\xcd\xcc\xf6B'
- bytes ⇒ float
struct.unpack('<f', b'\xcd\xcc\xf6B')[0] # tuple型になるので0番目を取り出す。 # Out: 123.4000015258789float配列 ⇔ bytes(要素数がわかっている場合)
"<ff"と必要な要素数分fを繰り返し書けば変換できる。
- float配列 ⇒ bytes
vals = [123.4, 234.5] struct.pack('<ff', *vals) # Out: b'\xcd\xcc\xf6B\x00\x80jC'
- bytes ⇒ float配列
list(struct.unpack('<ff', b'\xcd\xcc\xf6B\x00\x80jC')) # tuple型になるのでlistに変換 # Out: [123.4000015258789, 234.5]float配列 ⇔ bytes(要素数が分かっていない場合)
- float配列 ⇒ bytes
structのpackにbyte連結のjoinを組み合わせる。
vals = [123.4, 234.5, 345.6, 456.7] b''.join([struct.pack('<f', v) for v in vals]) # Out: b'\xcd\xcc\xf6B\x00\x80jC\xcd\xcc\xacC\x9aY\xe4C'
- bytes ⇒ float配列
structのiter_unpackで
'<f'のサイズ分ずつunpackできるので、これをlist内包表記と組み合わせる。[i[0] for i in struct.iter_unpack('<f', b'\xcd\xcc\xf6B\x00\x80jC\xcd\xcc\xacC\x9aY\xe4C')] # Out: [123.4000015258789, 234.5, 345.6000061035156, 456.70001220703125]おまけ
- もし、以下のようにbytes配列をstrにしてファイル出力してしまった場合に元に戻したい。
vals = [123.4, 234.5, 345.6, 456.7] bytes_data1 = b''.join([struct.pack('<f', v) for v in vals]) bytes_data1 # Out: b'\xcd\xcc\xf6B\x00\x80jC\xcd\xcc\xacC\x9aY\xe4C' str_data = str(bytes_data1) str_data # Out: "b'\\xcd\\xcc\\xf6B\\x00\\x80jC\\xcd\\xcc\\xacC\\x9aY\\xe4C'" # これでファイルに書き込んでしまった!!汗
- 以下のような関数で逆変換ができる。
- 実行方法はコード内コメントを参照。
def str_to_bytes(str_data): # 前後の"とbを削除してencodeする。 bytes_data = str_data[2:-1].encode() bytes_data = b"" for idx, _b in enumerate(str_data): if _b == 92 or _b == 120: # \とxはスキップ continue else: # \xの直後は、2文字で1byte情報となっている前半部分。ここで文字列を数値に変換する。 if str_data[idx-2] == 92 and str_data[idx-1] == 120: a = str_data[idx] b = str_data[idx+1] # 一旦16新数文字列に変換し、整数にする value = int("0x{}{}".format(chr(a), chr(b)), 0) # chrはアスキーコード(int)を文字に変換する value = value.to_bytes(length=1, byteorder="little", signed=False) bytes_data = bytes_data + value # \xの2個後ろは、2文字で1byte情報となっている後半部分。変換済みなのでスキップ elif str_data[idx-2] == 120 and str_data[idx-3] == 92: # 2 continue # どちらでもない場合、1文字で1byteの情報となっているため、そのまま数値として読み込みbyte変換する。 else: value = str_data[idx] value = value.to_bytes(length=1, byteorder="little", signed=False) bytes_data = bytes_data + value return bytes_data
- この関数を使って元に戻すことができる。
vals = [123.4, 234.5, 345.6, 456.7] bytes_data1 = b''.join([struct.pack('<f', v) for v in vals]) bytes_data1 # Out: b'\xcd\xcc\xf6B\x00\x80jC\xcd\xcc\xacC\x9aY\xe4C' str_data = str(bytes_data1) str_data # Out: "b'\\xcd\\xcc\\xf6B\\x00\\x80jC\\xcd\\xcc\\xacC\\x9aY\\xe4C'" bytes_data2 = str_to_bytes(str_data) bytes_data2 # Out: b'\xcd\xcc\xf6B\x00\x80jC\xcd\xcc\xacC\x9aY\xe4C'
- 投稿日:2021-03-29T22:15:06+09:00
初めてのPython学習-基礎③-
繰り返し処理
for文以外にもwhile文
while「ある条件に当てはまる間、処理を繰り返す」while 条件式:
例 x = 1 while x <= 100: print(x) x += 1①条件式で使う変数xを1と定義 ②xが100以下のとき以下の処理を繰り返す ③xを出力する ④xに1を足す(繰り返しのたびに1ずつ増えていく) ※while文では処理の最後に必ず変数の値を更新する ※変数の値を更新する記載は必ずwhile文の中(インデント) →無限ループ繰り返し処理の終了
breaknumbers = [1,2,3,4,5,6] for number in numbers: print(number) if number == 3: breakその周の処理だけをスキップ
continuenumbers = [1,2,3,4,5,6] for number in numbers: if number % 2 == 0: continue print(number)
- 投稿日:2021-03-29T21:00:03+09:00
【Python】CellIsRuleオブジェクト、FormulaRuleオブジェクトを使用して特定のセルや行の表示形式を変える。
pythonを使用してExcelファイルの操作を勉強しています。
本日の気づき(復習)は、条件付き書式に関してです。
pythonでExcelを操作するため、openpyxlというパッケージを使用しています。
上記のようなブック「商品リストを」
この様な表に変更したいです。
ここでのポイントは
- 原価率が55%以下の場合は文字を青色に変更
- 製造元が業者Bの行を灰色にする
CellIsRuleオブジェクト
CellIsRule(operator='条件', formula=[値], font=Fontオブジェクト, border=Borderオブジェクト, fill=PatternFillオブジェクト)条件を満たしたセルの書式を変更するには、まず、条件付き書式を作成します。
作成には上記のCellIsRuleオブジェクトを使います。operator引数に条件を設定し、
その条件はformula引数に記述した値に適用されます。operator引数の条件は以下の通りです。
- greaterThan:より大きい
- greaterThanOrEqual:以上
- lessThan:より小さい
- lessThanOrEqual:以下
- equal:等しい
- notEqual:等しくない
- between:値の間
- notBetween:値の間以外
font、border、fillの各引数には条件を満たした際に設定する書式を
Fontオブジェクト等で設定します。CellIsRuleオブジェクトを作成したら、どのセルに設定するのかを
Worksheetのconditional_formatting.addメソッドで設定してあげます。ws.conditional_formatting.add('条件付き書式を設定するセルの範囲', CellIsRule)FormulaRuleオブジェクト
FormulaRule(formula=[数式], font=Fontオブジェクト, border=Borderオブジェクト, fill=PatternFillオブジェクト)CellIsRuleオブジェクトに似ていますが
より詳細な条件指定や、行全体の書式変更時に使います。
数式を使用することが違うところでしょうか。どのセルに設定するのかは、CellIsRuleオブジェクトの時と同様
Worksheetのconditional_formatting.addメソッドで設定してあげます。最終的なコード
from openpyxl import load_workbook from openpyxl.styles import Font, PatternFill from openpyxl.formatting.rule import CellIsRule, FormulaRule wb = load_workbook('商品リスト.xlsx') ws = wb.active # フォントの設定 blue_font = Font(color='0000ff', bold=True) # セルの色を設定 gray_fill = PatternFill(bgColor='C0C0C0', fill_type='solid') # フォントを変更する範囲と条件式 cell_rule = CellIsRule(operator='lessThanOrEqual', formula=[0.55], font=blue_font) # セルの色を変更する範囲と条件式 formula_rule = FormulaRule(formula=['$H3="業者B"'], fill=gray_fill) ws.conditional_formatting.add('G3:G24', cell_rule) ws.conditional_formatting.add('B3:H24', formula_rule) wb.save('商品リスト_条件追加.xlsx')余談①
今回、PatternFillオブジェクトのfill_type引数を「solid」にしていたので
fgColor='C0C0C0'と記述していたのです。
そうすると何故か、セルの色が白色になってしまったのです。bgColor='C0C0C0'に変更すると指定通りの灰色になってくれました。
念のため、ほかのパターンも試してみましたが
そちらはちゃんと指定通りに色づけしてくれます。今後は
PatternFill(fgColor='C0C0C0', bgColor='C0C0C0', fill_type='solid')のように、どちらも同じ色を指定してあげると間違いがないようです。
余談②
条件付き書式はセルではなく、シートを対象に設定しています。
Excelの「ホーム」→「条件付き書式」→「ルールの管理」で確認する事が出来ます。意外とこの設定、地味に面倒くさいのですよね・・・。
毎回だとなおさら。プログラムは偉大ですね。


- 投稿日:2021-03-29T20:57:24+09:00
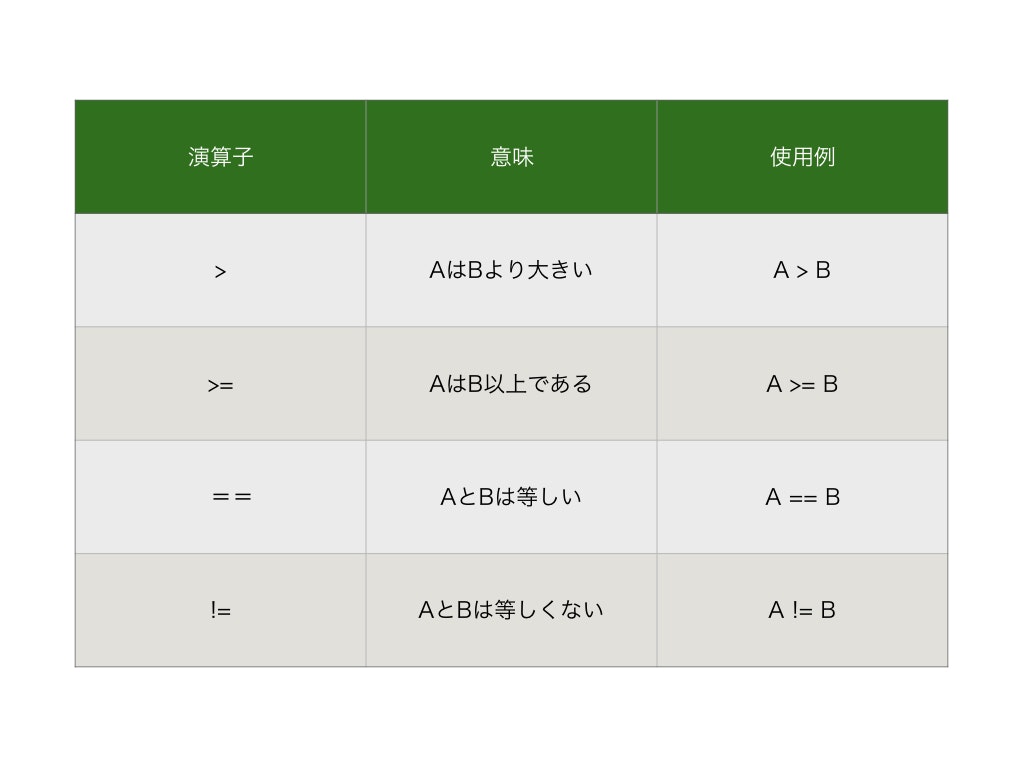
Pythonの比較演算子
どんなプログラミング言語にもある比較演算子。いろんな比較演算子があるのでまとめてみました。
以上です!
- 投稿日:2021-03-29T20:51:05+09:00
ダイヤルウィジェットがほしい
はじめに
python+mididingsで自作MIDIスイッチャを作り変えるにあたって、どうしてもGUIをつけたいんですが、
その前にどうしてもダイヤルウィジェットがほしい!!!まずググってさがしたところ以下のような感じっぽい:
- GtkExtra(libgtkextraパッケージ) ... ここにあれば一番よかったが、残念ながらダイヤルウィジェットはない。
- Gtk+のチュートリアル ... Cでカスタムウィジェットを作る時のサンプルとしてダイヤルウィジェットを作ってる
- GIW - GTK Instrumentation Widgets ... gtk2ベース、グラフプロット用ウィジェットにまぎれてダイヤルウィジェットがある
- python_dial_widget ... gtk2ベースだけど、pygtkで書かれてて小さいので改造するならこれかなぁ
- Dial widget (tk) ... 個人的にはすごく懐かしのtcl/tkで書かれたダイヤルウィジェット。これも参考にできそう
- libags-gui .... Advanced Gtk+ Sequencer用のウィジェット、わーお、ダイヤルもピアノもあるぞ!!!
QtとFLTK... 標準でダイヤルウィジェットがある。うーんなるほど、
Qt,FLTK,libags-guiに完成品がありますが、ダイヤルだけほしいんですよねー、pythonバインディングないのもあるし、うーーんどうしよっかな参考にできそうなソースもあるし、作るか ←
作り方
作り方の方針としては、なんか絵が描けるウィジェットにテキトーにダイヤルの絵かいて、
マウスイベント拾って中心からマウスがポイントしたところの角度出して、その角度から値設定してダイヤル再描画でいいんじゃね?
というカンジで作ります。
……
…………
(中略)
……………………
………………………………………
できました、以下解説です。Gtk.Frameの継承とコンストラクタ
いまだによくわからないんですけど、Gtkのウィジェット拡張して新しいウィジェット作る時って
どれを継承するのが正しいんですかね......
とりあえず今回はGtk.Frameを継承してみました。Dial.pyclass Dial(Gtk.Frame): def __init__(self,min=0,max=255,initial_value=0, meter_scale=16,label=""): super(Dial, self).__init__(label=label)コンストラクタの引数としては
- min ... ダイヤルのとる値の最小値:int
- max ... ダイヤルのとる値の最大値:int
- initial_value ... ダイヤルの初期値:int
- meter_scale ... ダイヤルの目盛りをいくつ作るか:int
- label ... ダイヤルのラベル、そのままGtk.Frameに渡す
で構築します。cairoと座標系のはなし
なんか色んなサンプルだと、図を書くのに
Gtk.DrawingAreaを作ってexposeイベントもらったときにcairoからSurfaceオブジェクト再作成して描画してる例があったのですが、drawイベントのコールバックにはwidgetとcairoオブジェクトが渡されるようなので、わざわざGtk.DrawingAreaを新たに作ることはしてません(Gtk.Widgetを継承してるクラスなら自由にcairo使って描画できる仕組みらしい)。あと図を書くにあたって、座標系がy軸が下に向かって伸びてるので(まぁこれは大昔、パソコンにBASICが付属してた頃からの慣例ですが)
円を描く時、円周上の点を(r*cosθ,r*sinθ)としてθを増やしながらプロットする場合、時計まわりになります。これはcairoのarc(x,y,r,begin_rad,end_rad)メソッドも同じです。
ダイヤルの目盛りを書く
まず、コンストラクタで目盛りの情報を作っておきます
Dial.pyのDial.__init__()self.mouth_size = 60 # degree self.meter_scale = int(meter_scale) self.meter_begin = 2*math.pi*((90+self.mouth_size/2)/360) self.meter_end = 2*math.pi*((360+90-self.mouth_size/2)/360) self.meter_range = (self.meter_end-self.meter_begin)イメージとしてはパックマンみたいな形の図形が下向きに60度口をあけてて、口の所以外に目盛りと線をひく感じです。
self.meter_beginがダイヤルのメーターの始点、self.meter_endがダイヤルのメーターの終点の角度です。角度は(r,0)を始点に時計回りの90+30度〜360+90-30度が表示上のダイヤルのとる値になります。実際の描画はこんな感じです
Dial.pydef _get_center(self): return (self.get_allocated_width()/2,self.get_allocated_height()/2) def on_draw(self, widget, cr): cx,cy = self._get_center() maxr = cx if cy > cx else cy # mk meter_scale cr.set_line_width(0.5) cr.arc(cx, cy, maxr*0.6, self.meter_begin, self.meter_end ) cr.stroke() for i in range(self.meter_scale+1): rad_i = self.meter_begin+self.meter_range*(i/self.meter_scale) cr.move_to(cx+maxr*0.6*math.cos(rad_i),cy+maxr*0.6*math.sin(rad_i)) cr.line_to(cx+maxr*0.7*math.cos(rad_i),cy+maxr*0.7*math.sin(rad_i)) cr.stroke()ウィジェットの中心(
_get_center()で求める奴)から半径maxr(ウィジェットの縦横の長さのどっちか小さい方を1/2にした値)を最大半径として、self.meter_beginの角度からself.meter_endの角度まで円と目盛りを描くイメージです。ダイヤルを書く
ダイヤルそのものはタダの円なのでサクっと
arc()メソッドにウィジェットの中心から半径maxrを基準にテキトーに0〜2*math.piの角度で弧をひいてねーって渡します。
ダイヤルのノッチ部分はself.valueを角度に変換して描画しますDial.pyのDial.on_draw()# mk dial cr.set_line_width(2) cr.arc(cx, cy, maxr*0.5, 0, 2*math.pi) cr.stroke() # draw value cr.set_line_width(5) rad = self.meter_begin + (self.meter_end - self.meter_begin)*self.value/self.max cr.move_to(cx+maxr*0.2*math.cos(rad),cy+maxr*0.2*math.sin(rad)) cr.line_to(cx+maxr*0.5*math.cos(rad), cy+maxr*0.5*math.sin(rad)) cr.stroke()イベントを受け取って値を設定する
次にマウスがクリックされたり、ドラッグされたまま動かした時のコールバックを書くのですが、なんと、
Gtk.Frameはbutton_press_eventもbutton_release_eventもmotion_notify_event(ドラッグしたまま動かした時のイベント)も全部受け付けません。
Gtk.FrameはGtk.Widgetを継承してるはずなのに、なんでやねん!!!、と思いましたが、Gtk.EventBoxを子ウィジェットにしてイベントを受け付けることにしました。Dial.pyのDial.__init__self.evb = Gtk.EventBox() self.add(self.evb) self.evb.connect("button_press_event", self.on_changed) self.evb.connect("button_release_event", self.on_changed) self.evb.connect("motion_notify_event",self.on_changed)
on_changedはイベントをうけとって、マウスの位置とウィジェットの中心から方向ベクトルを作って、方向ベクトルを元に角度を計算して、実際の値を計算しますDial.pyの_get_value_from_xyとon_changeddef _get_value_from_xy(self, posx, posy): cx,cy = self._get_center() vx,vy = (posx-cx,posy-cy) radadj = math.atan2(vy,vx ) #-(90/360)*2*math.pi if radadj < 0 : radadj += 2*math.pi if radadj > 0 and radadj < (1./2.)*math.pi: radadj += 2*math.pi if radadj <= self.meter_begin: radadj = self.meter_begin if radadj > self.meter_end: radadj = self.meter_end val = ((radadj - self.meter_begin)/self.meter_range)*self.max return int(val) def on_changed(self, widget, ev): self.value = self._get_value_from_xy(ev.x, ev.y) self.queue_draw()_get_value_from_xyでマウスのポイントされた位置とウィジェットの中心を結ぶ方向ベクトルから角度を出してます。
arctan2(y,x)は渡された方向ベクトルから角度を返してくれますが、マイナスの値を返すこともあるのでそれらは+360度して正にします。
また、0度〜90度は360度〜360+90度として値がほしいので、これについても補正します。
で、下に30度口をあけてるので、self.meter_beginとself.meter_endの間に入るように値を補正してから、マウスのポイント角度から値を算出します。値を設定したら
queue_draw()で再描画させます。できあがり
できあがりはこんなカンジです。
ちょっと拡張してGtk.SpinButtonとくっつけてみました。
おわりに
とりあえずは、いろんなソースを参考にしてコードを仕上げました。
Gtkのリファレンス見てみましたが、色んな所でdeprecatedの嵐....
主に「ボタンの色変えるのにCSS使え、ただしテーマの一部を勝手に変えるのはおすすめしないぜ」、の所でしたが、シグナル名まで変わったりしてて色々混乱しました。まぁロジック的には角度求めるのに
arctan2(y,x)使うのがミソでしたね。
算数苦手なんで久々に勉強しましたなんか本来は最大最小+値を操作するようなウィジェットには
Gtk.Adjustmentを使ってレンジ情報をまとめるべきとか,実はGtk.Scaleを継承して作った方がよかったのかもしれない、とか色々ありますが、まぁあんまり調べる気もなかったのでテキトーに作りました。
そのへん、詳しい人教えてplz次はピアノウィジェットだナ


- 投稿日:2021-03-29T20:34:01+09:00
-忘備録- Python基礎
参考書籍 最短距離でゼロからしっかり学ぶ Python入門 必修編 はじめに 上記書籍を読んでPythonを用いたプログラミングの基礎について忘備録をまとめてます。 普段swiftを触ることが多いので、swiftと比べて感想を書いているところがあります。 基本 コメントアウト #でコメント メモ ・VSCodeを使用する際は、cmd+/でコメントアウトできる 変数 文字列は"または'でも可能 hoge = "hello world hoge" fuga = 'hello world hoge' 複数代入可能 x, y, z = 1, 2, 3 数値は_で区切れる want = 5000_0000_0000_0000 型変換 message = '1' x = int(message) print(x + 2) #変換したので計算で利用できる #3 メモ ・型指定がない ・"も使えるので使いたくなってしまうが、参考書籍には'の方が優先的に使われていた。 print文 文字だけ出力 print("hello world") 変数を出力する時はfをつけて{}でかこむ hoge = 'hello world hoge' print(f"{hoge}") メモ ・()ではなく{} (この間違いで何回もコンパイルエラーに) リスト (配列) 正直配列の方が馴染み深い 基礎 hoge_list = ['hoge', 'fuga', 'piyo','poyo', 'abc'] print(hoge_list) # ['hoge', 'fuga', 'piyo', 'poyo', 'abc'] print(hoge_list[0]) # hoge -1で最後の配列にアクセスできる。-2だったら後ろから2番目の配列にアクセス print(hoge_list[-1]) # abc 配列の要素を上書き print(hoge_list) # ['hoge', 'fuga', 'piyo', 'poyo', 'abc'] hoge_list[0] = 'hogefuga' print(hoge_list) # ['hogefuga', 'fuga', 'piyo', 'poyo', 'abc'] インデックスを指定して要素を削除 - del - print(hoge_list) # ['hogefuga', 'fuga', 'piyo', 'poyo', 'abc'] del hoge_list[1] print(hoge_list) # ['hogefuga', 'piyo', 'poyo', 'abc'] 値を指定して要素を削除 - remove() - print(hoge_list) # ['hogefuga', 'piyo', 'poyo'] hoge_list.remove("hogefuga") print(hoge_list) # ['piyo', 'poyo'] 配列最後の要素を削除して取り出す - pop() - print(hoge_list) # ['hogefuga', 'piyo', 'poyo', 'abc'] poped_list = hoge_list.pop() print(hoge_list) # ['hogefuga', 'piyo', 'poyo'] print(poped_list) # abc # インデックスを指定することもできる # poped_list = hoge_list.pop(1) 永続的な並び替え - sort() - sort_list = ['momo', 'ringo', 'apple', 'mikan'] sort_list.sort() print(sort_list) # ['apple', 'mikan', 'momo', 'ringo'] sort_list.sort(reverse=True) print(sort_list) # ['ringo', 'momo', 'mikan', 'apple'] 一時的な並び替え - sorted() - sort_list = ['momo', 'ringo', 'apple', 'mikan'] print(sorted(sort_list)) # ['apple', 'mikan', 'momo', 'ringo'] print(sort_list) # ['momo', 'ringo', 'apple', 'mikan'] メモ ・配列操作はメソッドの種類がいくつかあるので用途に合わせた使い分け大事 ・-で後ろの要素にアクセスできる for文 names = ['alice', 'david', 'hoge'] for name in names: print(name) print('インデントあり') print('インデントなし') #(↓↓↓出力結果↓↓↓) alice インデントあり david インデントあり hoge インデントあり インデントなし メモ ・pythonではforなど{}で囲むわけではなくインデントで区別する リスト作成 - range() - numbers = list(range(1,11)) print(numbers) #[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] range()を使ったfor文の省略 #省略前 squares = [] for value in range(1,11): square = value ** 2 ##**でべき乗 squares.append(square) print(squares) #[1, 4, 9, 16, 25, 36, 49, 64, 81, 100] #省略後 squares = [value ** 2 for value in range(1,11)] print(squares) #[1, 4, 9, 16, 25, 36, 49, 64, 81, 100] スライス スライス: リストの一部を利用する squares = [value ** 2 for value in range(1,11)] #1番目から4番目まで print(squares[1:4]) # [4, 9, 16] #4番目まで print(squares[:4]) # [1, 4, 9, 16] #1番目から print(squares[1:]) # [4, 9, 16, 25, 36, 49, 64, 81, 100] #全部 print(squares[:]) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100] スライスによるループ for square in squares2[:4]: print(square) ###出力結果 1 4 9 16 スライスを使ったリストのコピー #__スライスを使う場合__ my_food = ["団子", "白玉"] friend_food = my_food[:] my_food.append("抹茶") friend_food.append("チョコ") print("私の食べ物") print(my_food) print("友達のの食べ物") print(friend_food) ###出力結果 私の食べ物 ['団子', '白玉', '抹茶'] 友達のの食べ物 ['団子', '白玉', 'チョコ'] ###ここまで #__スライスを使わないで代入する場合__ #スライスを使わないとコピーではなく同じものとして扱われる my_food = ["団子", "白玉"] friend_food = my_food my_food.append("抹茶") friend_food.append("チョコ") print("私の食べ物") print(my_food) print("友達のの食べ物") print(friend_food) ###出力結果 私の食べ物 ['団子', '白玉', '抹茶', 'チョコ'] 友達のの食べ物 ['団子', '白玉', '抹茶', 'チョコ'] メモ ・単に代入するだけではコピーできないのでスライスを使う (そもそも代入じゃないかも) タプル(不変なリスト) 変更できない値をイミュータブル(不変)といい、イミュータブルなリストをタプルと呼ぶ #[]の代わりに()を使ってリストを定義 dimensions = (200, 50) print(dimensions[0]) # 200 下記のようなコードはエラーになる dimensions[0] = 300 forも使える for dimension in dimensions: print(dimension) ###出力結果 200 50 上書きしたいときはタプルそのものを上書きできる dimensions = (300, 50) print(dimensions[0]) # 300 メモ ・タプルというとSwiftでは異なる型をまとめて扱うもの指すが、Pythonでは不変なリストのことを指す。 条件式 等しい==, 等しくない!= print("a"=="a") #True print("a"!="b") #True and条件はand, or条件はor print("a"=="a" and 1==1) #True print("a"=="a" and 1==2) #False print("a"=="a" or 1==1) #True print("a"=="a" or 1==2) #True 値がリストに存在することを確認する lunch = ["ラーメン", "うどん", "パスタ"] print("ラーメン" in lunch) #True print("そば" in lunch) #False #否定形 print("ラーメン" not in lunch) #False print("そば" not in lunch) #True if文, elif文, else文 ages = [20, 1, 15] for age in ages: if age < 5: print("子供料金") elif age < 18: print("学生料金") else: print("大人料金") ###出力 大人料金 子供料金 学生料金 リストの空欄チェック list = [] #list = [1] とすると trueになる if list: print("中身あり") else: print("空") メモ ・Pythonではelse if文ではなく elif文。気づかずコンパイルエラーになることも 辞書 yusya = {'NAME':'yusya', 'LV':5} print(yusya["LV"]) # 5 キーと値の追加 yusya['quest'] = "魔王を倒す" print(yusya) #{'NAME': 'yusya', 'LV': 5, 'quest': '魔王を倒す'} #空の辞書からでも追加できる maou = {} maou['LV'] = 99 maou['status'] = '無敵' print(maou) #{'LV': 99, 'status': '無敵'} キーと値を消す maou = {'LV': 99, 'status': '無敵'} del maou['status'] print(maou) #{'LV': 99} キーがあれば取得 - get() - maou = {'LV': 99} #print(maou['status']) #キーがない場合エラーになる print(maou.get('status', 'ステータスなし')) #キーが無い場合ステータスなしの文字列を返す #ステータスなし 辞書をループする user_0 = { 'name' : 'hoge', 'first' : 'hoge', 'flast': 'fuga', } for key, value in user_0.items(): #ここでkeyとvalueの順番を逆にしたら入れ替わってしまうので注意 print(f"キー:{key}") print(f"値:{value}") ###出力結果 キー:name 値:hoge キー:first 値:hoge キー:flast 値:fuga メモ ・[]ではなく{}で囲む。(個人的に癖で[]で囲みがちなので注意) While文 current_number = 1 while current_number <= 5: print(current_number) current_number += 1 ###出力結果 1 2 3 4 5 関数 def hoge_fuga(hoge, fuga): print(hoge_name) print(fuga_name) hoge_fuga(1, 2) hoge_fuga("fuga", "hoga") ###出力結果 1 2 fuga hoga 引数指定もできる hoge_fuga(fuga=2, hoge=1) hoge_fuga(1, fuga=2) ダメな呼び方 hoge_fuga(fuga_name=2, 1) #コンパイルエラーになる 戻り値ありの関数 def fuga(): return 111 print(fuga()) #111 可変長の引数を持つ関数 def print_names(*names): for name in names: print(name) print_names('a', 'b', 'c') ###出力結果 a b c ・関数呼び出しするときの自由度が高い ・順番通りに書くなら引数名を書いても書かなくてもいい ・引数名を書く場合は順番を守らなくてもいい クラス class Dog: # selfを引数に書かないといけない def __init__(self, name, age): self.name = name self.age = age def sit(self): print(f"{self.name}はお座りしている") # selfを引数に書かないといけない def birthday(self): self.age = self.age + 1 インスタンス生成 my_dog = Dog('ポチ', 1) 属性(メンバー変数?)にアクセス print(f"{my_dog.name}は{my_dog.age}才") #ポチは1才 メソッドを呼び出す my_dog.sit() #ポチはお座りしている 属性の値を直接編集 my_dog.age = 2 print(f"{my_dog.age}") #2 my_dog.birthday() print(f"{my_dog.age}") #3 クラスの継承 class Chihuahua(Dog): def __init__(self, name, age, coat): super().__init__(name, age) self.coat = coat # オーバーライド def birthday(self): print("誕生日おめでとう") my_chihuahua = Chihuahua("チワワ", 1, "hoge") my_chihuahua.sit() #チワワはお座りしている my_chihuahua.birthday() #誕生日おめでとう print(f"{my_chihuahua.age}") #上書きしたのでage+1されない #2 メモ ・initを宣言するときに__で囲まないといけない。(正直手間だしなんでこのように書くのかわかってない) ・クラス内でselfを使うときは引数にselfを宣言する。呼び出すときはself以外の引数だけ指定する モジュール(別ファイル)の関数を使う method.py def method1(name, *hobbys): print(f"{name}さんの趣味一覧") for hobby in hobbys: print(hobby) def method2(): print("method2") 全部インポート hoge.py import method method.method1("hoge1", "movie", "game") method.method2() 一部関数だけインポート hoge.py from method import method1 #ファイル名を省略できる method1("hoge2", "movie", "game") 全部の関数インポート hoge.py from method import * method1("hoge4", "movie", "game") method2() モジュール(別ファイル)のクラスを使う tesy_class.py class Hoge: # selfを引数に書かないといけない def __init__(self, hoge): self.hoge = hoge def log(self): print(f"{self.hoge}") class Fuga(Hoge): # selfを引数に書かないといけない def __init__(self, hoge, fuga): super().__init__(hoge) self.fuga = fuga モジュールからクラスをインポート") hoge.py from test_class import Fuga fuga = Fuga("hoge", "fuga") fuga.log() #hoge 複数のクラスをインポート hoge.py from test_class import Hoge, Fuga hoge = Hoge("hoge") hoge.log() メモ ・クラス名はキャメルケースで書く、インスランスやモジュールはスネークケースでかく
- 投稿日:2021-03-29T20:29:36+09:00
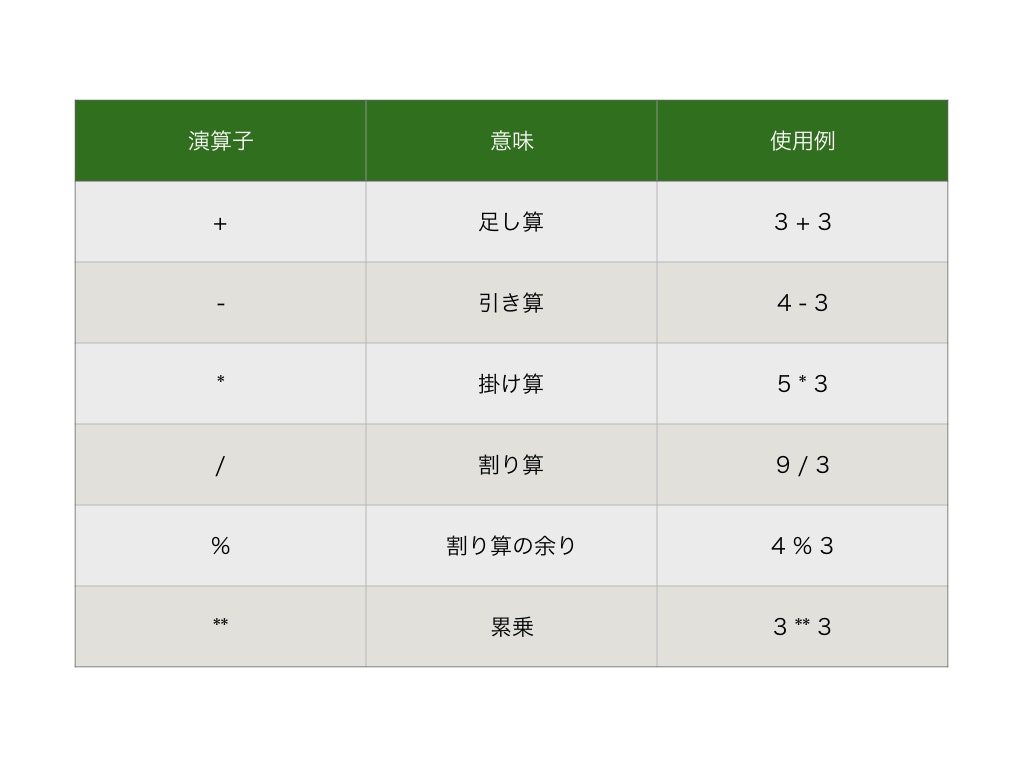
Pythonの算術演算子
今日初めてPythonに触れたので今日学んだことをまとめていきます
全てのプログラミング言語で算術演算子というものがあります。簡単にいうと足し算引き算とかです。下にまとめておきました。
何かと便利なんですけど忘れそうなのでまとめておきました!
因みにpythonでは複素数の表記もできます。例えば、4+5iを書きたいときは4+5jというふうにiでなくjを使って表します。上記の演算も同様にできます!
- 投稿日:2021-03-29T19:19:20+09:00
「S3 + Athena」 で実行していたことを 「BLOB + Azure Data Explorer」 で実現してみました
STEP-1 : Azure Data Explorer クラスターとデータベースを作成する
概要
AWSの「S3 + Athena」 で実行できること、つまり、S3に保存されているJSON形式等のデータ(以下、JSONデータ)を Athenaで提供されているSQLライクな構文を用いてクエリ実行することによりデータ抽出が可能となっています。同様なことをAzure上の「BLOB + Azure Data Explorer」構成においても可能であることを確認しました。なお、「Web UI」と「Pythonプログラム」の両方で実現しております。
Azure Data Explorer は、ログや利用統計情報データ等のための高速で拡張性に優れたデータ探索サービスです。
Azure Data Explorer を使用するには、最初にクラスターを作成し、そのクラスター内に 1 つまたは複数のデータベースを作成します。
その後、クエリを実行できるように、JSONデータ等をデータベースに取り込み (読み込み) ます。以下の3つのステップで順次説明します。今回は STEP-1 についてとなります。
STEP-1 : Azure Data Explorer クラスターとデータベースを作成する
STEP-2 : Azure Data Explorer の Web UI でデータベースへのクエリを実行する
STEP-3 : Azure Data Explorer の Python ライブラリを使用してデータベースへのクエリを実行するローカル環境
macOS Big Sur 11.1
python 3.8.3
Microsoft Edge 89.0.774.63(Safariでは Azure Data Explorer がうまく動きませんでした)ローカル上での事前準備
Azure Storega Exploere がインストールされていること。
Azure上での事前準備
今回は、「ストレージアカウント:storageituru」で「BLOBコンテナー:test20210226」を作成し、そこに「ADX2222_test-iot-dummy-2.json」のJSONデータを用意しました。下図は Azure Storage Explorer での確認となります。
そのJSONデータはこの記事 にある「IoTSample-write.py」で 2222件生成したものとなります。データ構成は以下となります(プログラムの一部抜粋)。
(抜粋)IoTSample-write.py# ダミーデータ作成のための Faker の使用 Faker = Factory.create fake = Faker() fake = Faker("ja_JP") # IoT機器のダミーセクション(小文字アルファベットを定義) section = string.ascii_uppercase # IoT機器で送信JSONデータの作成 def iot_json_data(count, proc): iot_items = json.dumps({ 'items': [{ 'id': i, # id 'time': generate_time(), # データ生成時間 'proc': proc, # データ生成プロセス名 'section': random.choice(section), # IoT機器セクション 'iot_num': fake.zipcode(), # IoT機器番号 'iot_state': fake.prefecture(), # IoT設置場所 'vol_1': random.uniform(100, 200), # IoT値−1 'vol_2': random.uniform(50, 90) # IoT値−2 } for i in range(count) ] }, ensure_ascii=False).encode('utf-8') return iot_itemsBLOBコンテナーのSAS(Shared Access Signature)の取得
Azure Data Explorer のデータベースの作成で必要となるBLOBコンテナーのSASを事前に取得しておきます。
1. Azure Storage Explorer 画面の左タブで「BLOBコンテナー:test20210226」を選択し、右クリックで、「Shared Access Signatureの取得...」を選択します。
2.表示された「Shared Access Signature」ダイアログにおいて、「開始時刻」と「有効期限」を設定し、画面の下部にある [作成] を選択します。
3.表示されたダイアログには、BLOB コンテナーと共に、ストレージリソースへのアクセスに使用できる URL とクエリ文字列が表示されます。 クリップボードにコピーする URL の横にある [コピー] を選択します。この値を後ほど使用します。コピーが完了したら、画面下部の [閉じる] を選択します。
Azure Data Explorer クラスターの作成
コンピューティング リソースとストレージ リソースの定義済みセットを使って、Azure リソース グループ内に Azure Data Explorer クラスターを作成します。
1.Azureポータルにサインインします。
2.ポータルの左上隅にある [+ リソースの作成] ボタンを選択します。
3.Azure Data Explorer を検索します。
4.[Azure Data Explorer] で、画面の下部にある [作成] を選択します。
5.次の情報を基本クラスターの詳細として入力します。
6.[確認と作成] を選択してクラスターの詳細を確認し、 [作成] を選択してクラスターをプロビジョニングします。 プロビジョニングには 約15分 かかりました。 完了後 [リソースに移動] を選択します。
Azure Data Explorer データベースの作成
1.[概要] タブで [データベースの作成] を選択します。
2.フォームに次の情報を入力します。入力後、フォーム画面下部の[作成] を選択してデータベースを作成します。
3.作成にかかる時間は 1 分未満でした。 プロセスが完了すると、クラスターの [概要] タブに表示が戻ります。
4.[概要] タブで [新しいデータの取り込み] を選択します。「Ingest new data」フォームが表示されます。
5.そのフォームの「Table」欄には新規に作成するデータベース名を入力します。
6.そのフォームの「Source type」欄では「BLOBコンテナーから」を選択します。
7.そのフォームの「Link to source」欄には、対象となるBLOBコンテナーのSASを入力します(先述の「BLOBコンテナーのSASの取得」の「3」のURLの値)。
8.フォームの入力が完了したら、画面下部の[Edit schema] を選択します。
9.表示された画面の内容に問題なければ。画面下部の[Start ingestion] を選択します。作成にかかる時間は 1 分未満でした。
10.クラスターにデータベースが作成されたことを確認できます。
Azure Data Explorer データベースで基本コマンドを実行する
問題なくアクセス可能か確認します。
作成したクラスターで [クエリ] を選択します。「.show databases」コマンドを「クエリ ウィンドウ」に入力後、 [実行] を選択します。結果セットには、このクラスター内の唯一のデータベースである 「IoTDummyDatabase」 が表示されます。
次のステップでは、Azure Data Explorer の Web UI でデータベースへのクエリを実行してみます。
本課題のシリーズ情報
3つのステップ
STEP-1.Azure Data Explorer クラスターとデータベースを作成する
STEP-2.Azure Data Explorer の Web UI でデータベースへのクエリを実行する
[STEP-3.Azure Data Explorer の Python ライブラリを使用してデータベースへのクエリを実行する] → Coming soon
















- 投稿日:2021-03-29T18:23:39+09:00
【Python】例外処理をジャンケンで使ってみる
書くこと
Pythonでジャンケンアプリのミニアプリを作成しました。
今回書くのは
その時に引っかかった、「例外処理」について環境
Python 3.9.2
例外処理とは
wikiを参照すると
システムの設計で想定されておらず、ユーザー操作によって解決できない問題に対処するための処理である。
と書かれていますが、よくわからないのでもう少し噛み砕くと
文法的には正しいけど、システム的にまずいから、対応できるように書く処理
といった感じでしょうか。
ちなみに文法を間違えていると、構文エラーという定義になります。
(参考: Pythonの例外処理!try-exceptをわかりやすく解説!)課題としたこと
さて、ざっくり例外処理がわかったところで早速僕の引っかかったところを説明します。
[完成したソースコードはこちら()]
まずは、ソースコードをご覧下さい。
junken.pyprint("0: グー, 1: チョキ, 2: パー") #ジャンケンの手を配列に junkens = ["グー", "チョキ", "パー"] #プレイヤーの手を、数字として変数に代入 my_hand = input("最初はグー、ジャンケン...") #my_handを用いて、junkens配列から手を取得 my_result = junkens[int(my_hand)] #my_result(=プレイヤーの手)を出力 print(my_result)さて、ここで考えられる例外として、
「ユーザーが、0, 1, 2以外を入力する」
が考えられます。
これに対応するにはどうすればいいかということを課題に抱えました。例えば、数字の3を入力されると、例外と判定されます。
つまり、文法的に間違っているのではなく、用意しているシステム的にまずい状態です。
(配列には、インデックスとして0~2しか用意していないため)このままだと、例外が起きた時点で処理が止まります。
それだと使ってくれる人に申し訳ないので、止まらないように別の処理を作っておきましょう。
この処理が、例外処理です。具体的な記述
では、どのように解決したか
以下のソースコードのように改変しました。
junken.pyprint("0: グー, 1: チョキ, 2: パー") #ジャンケンの手を配列に junkens = ["グー", "チョキ", "パー"] #プレイヤーの手を変数に代入 #0~2以外の入力=例外が行われた時の処理を記述 while True: try: #例外ではない時の処理 my_hand = input("最初はグー、ジャンケン...") my_result = junkens[int(my_hand)] break except IndexError: #例外が発生した時の処理1 print("0~2の数字を入力してください") except ValueError: #例外が発生した時の処理2 print("数字を入力してください")このように、
tryとexceptを用いて例外処理を構築しました。
つまり
- 例外が起きない場合(=入力が0~2の整数)である場合、先ほどのように変数に代入。
- 例外が起きた場合1 (=入力が0~2の整数以外)である場合、文字列を出力した後に、もう一度tryの処理を実行
- 例外が起きた場合2(=何も入力されなかった場合)、文字列を出力した後に、もう一度tryの処理を実行
このようにして、例外処理を作成することで、例外が起きても処理が止まることを防ぐことができるようになりました。
完成品(一応動きますが、コピペはオススメしません)
junken.pyimport random print("0: グー, 1: チョキ, 2: パー") #ジャンケンの手を配列に junkens = ["グー", "チョキ", "パー"] #プレイヤーの手を変数に代入 #0~2以外の入力=例外が行われた時の処理を記述 while True: try: #例外ではない時の処理 my_hand = input("最初はグー、ジャンケン...") my_result = junkens[int(my_hand)] break except IndexError: #例外が発生した時の処理1 print("0~2の数字を入力してください") except ValueError: #例外が発生した時の処理2 print("数字を入力してください") #コンピュータ側の手を変数に代入 computer_hand = random.randint(0,2) computer_result = junkens[int(computer_hand)] #勝敗を判断させるメソッドを定義 def judge(my_hand, computer_hand): if int(my_hand) == computer_hand: result = "あいこです" elif int(my_hand) == 0 and computer_hand == 1: result = "勝ちです" elif int(my_hand) == 1 and computer_hand == 2: result = "勝ちです" elif int(my_hand) == 2 and computer_hand == 0: result = "勝ちです" else: result = "負けです" return result print("あなたの手: " + my_result) print("相手の手: " + computer_result) print(judge(my_hand, computer_hand))はい、このように1vs1のジャンケンアプリを作成することができました。
最後に
最後まで読んでいただき、ありがとうございます。
ソースコード、記事の書き方について「もっとこうしたほうがいいよ!」というご意見、「そこどうなっているの?」というご質問など、お待ちしております。参考文献
- 投稿日:2021-03-29T17:17:39+09:00
Python用日本語文字列変換ライブラリjaconv 0.3の説明
ちゃお……†
久しぶりにまいおり……†
ネオ東京文京区からやってきてPython用日本語文字列変換ライブラリjaconvを0.3にアップデートをしました。変更点は下記の通りです。
- バグ修正
- ひらがなからJuliusの音素表現への変換に対応
バグはアルファベットからひらがなに変換する
alphabet2kana関数の修正です。使ってる人多分少なそうだからあんまり影響ないかも。そして新機能!ひらがなから音声認識システムJuliusの音素表現に変換する
hiragana2julius関数です!どんなものかというと以下のようにちょっと気の利いた処理をしつつJuliusの音素表現に変換するのです。
>>> import jaconv >>> print(jaconv.hiragana2julius('てんきすごくいいいいいい')) t e N k i s u g o k u i:"いいいいいい" の部分を長音扱いにします。
ただし実装が細かくないので以下のような問題も起こります……。
>>> print(jaconv.hiragana2julius('てんきいい')) t e N k i:"てんき" の "き" の母音 "i" と "いい (ii)" がくっついて "てんきー" となってしまうのです……。
これを解決するにはMeCab等の形態素解析器を使いましょう。具体的には、形態素ごとに
hiragana2juliusで変換するのです。これでだいぶ問題が減るはず。それでもだめなときはある (特に固有名詞でありそう) ので、そこは自分の目で確かみてみろ!なんでも機械だけに頼っていてはだめです。あくまでもサポート役と考えましょう。わかっていてあえて実装しないのは、jaconvはミニマルなライブラリという位置づけでいたいので外部ライブラリを使いたくないからです。半角⇔全角の変換しか使わない人にまでMeCabをインストールさせるのは気が重いし……。
そういえばJuliusって「ジュリウス」って呼ぶ人と「ジュリアス」って呼ぶ人と「ユリウス」って呼ぶ人にこれまで出会ってきたけど、開発チーム内では「ジュリアス」と呼ぶそうです。豆知識?ジュリアナっぽいやつと覚えれば良さそうですね??
ところで終電大丈夫?じゃあね。Bye.
- 投稿日:2021-03-29T17:11:53+09:00
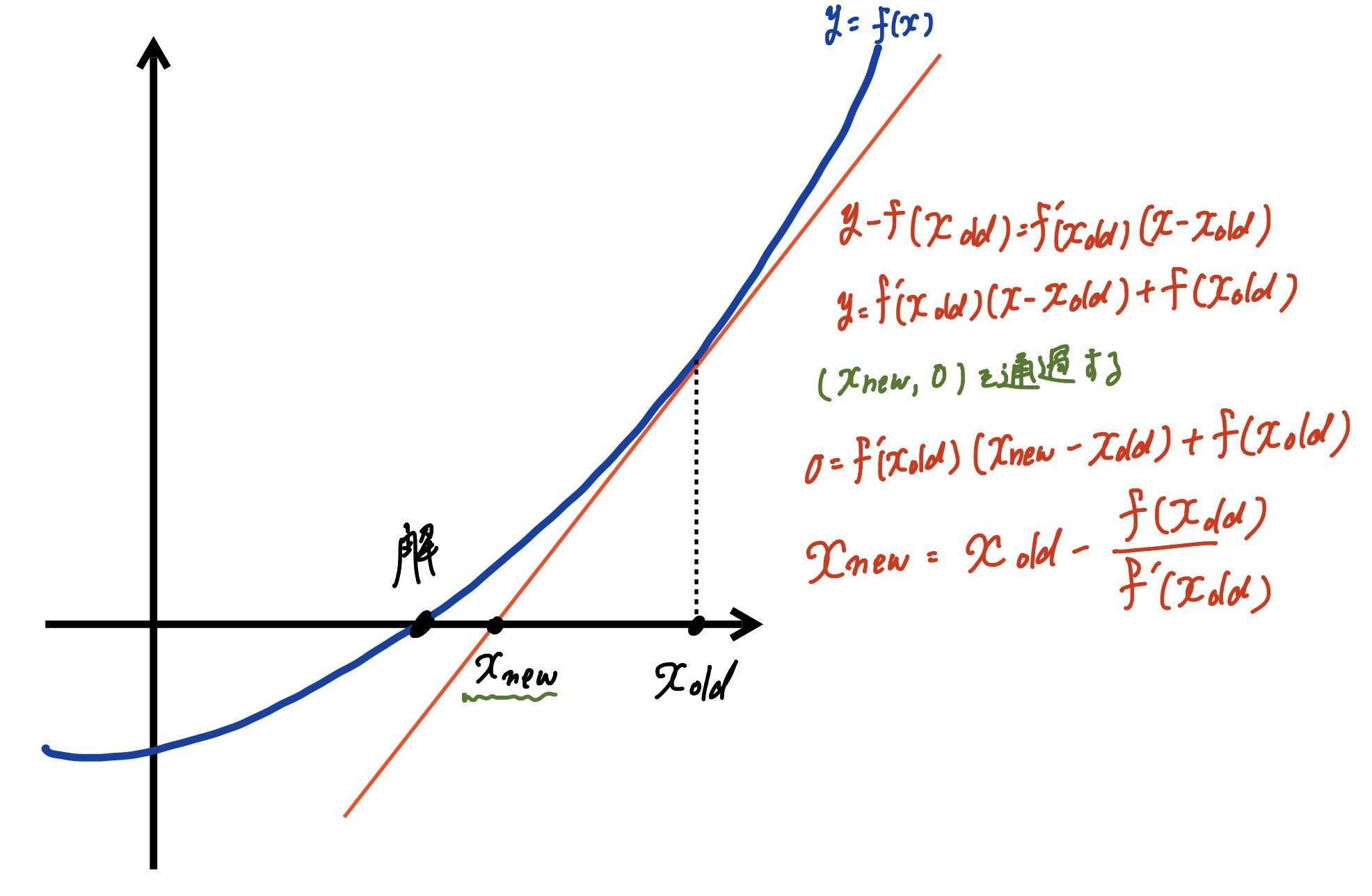
ニュートン法
任意の方程式(関数)に対してニュートン法で1つの解を求めるプログラムを1から書いてみた。
欠陥あるかもしれません。ニュートン法
$x_{new}=x_{old}-\frac{f(x_{old})}{f(x_{old})^{\prime}}$
設定するもの
・解きたい方程式(関数)
・初期値(真の解に近めが望ましいが、そんなんに気にしない。)
・許容誤差def newton_method(func, initial_x, r_error):こういう書き出しで作ってみます。
更新の流れ
$x_{new}=x_{old}-\frac{f(x_{old})}{f(x_{old})^{\prime}}$
に基づいて、
$|f(x_{初期値})| >$ 許容誤差 ならば
$x_{初期値}-\frac{f(x_{初期値})}{f(x_{初期値})^{\prime}}=x_{更新値1}$
$|f(x_{更新値1})| >$ 許容誤差 ならば
$x_{初期値}$ の部分を $x_{更新値1}$と改めた上で 次の 更新値2 を求める。
$x_{更新値1}-\frac{f(x_{更新値1})}{f(x_{更新値1})^{\prime}}=x_{更新値2}$
繰り返していけばそのうち
$|f(x_{更新値n})| <$ 許容誤差 となり許容誤差の範囲に入る。
関数次第では収束しない場合もある。
実装1
# 実装 def newton_method(func, initial_x, r_error): """ funcの部分はlambda関数で設定する。 func = lambda x : x**2 - 7 """ count = 0 while True: count += 1 y_f = func(initial_x) # 許容誤差との比較 if abs(y_f) < r_error: break # 許容誤差を満たさない場合は更新 # 微分係数を求めて更新 # 微分係数は中心差分を用いる y_d = (func(initial_x + 1e-10) - func(initial_x - 1e-10)) / (2 * 1e-10) # 更新値を求める x_new = initial_x - (y_f / y_d) print("{}回目:X_new = {}".format(count,x_new)) # 更新 initial_x = x_new関数次第で無限ループします。
実装2で離脱する設定を追加しています。試運転
$\sqrt{7}の近似$
方程式(関数):$x^2-7=0$
初期値は適当に30
許容誤差:0.001# 関数部分はlambda関数で指定する newton_method(lambda x : x**2 - 7, 30, 0.001)
実装の補足
代入処理
$f(x_{old})$の代入処理について。
今回は関数が最初から決まっておらず、任意に決定できるようにしてあります。
このような場合に代入処理は、あんまり直球すぎると処理されません。
余興で、設定した関数に対して、xを代入する、『代入machine』を作ってみます。
def dainyuu_machine(func, x): y = func return y dainyuu_machine(x**2-4,3)これは x is not defined のエラーが返ってきます。
funcの部分は式を突っ込むのではなく、関数を使うことにします。(lambda関数を使います。)
def dainyuu_machine(func, x): y = func(x) return y dainyuu_machine(lambda x : x**2-4,3)これだと $f(3)=3^2-4$ が計算されます。
任意の式を設定してから代入への流れはこの仕組みを使ってます。lambda関数
def func(a): return a + 1 func(3) # lambda関数 x = lambda a: a + 1 x(3)微分係数の近似について
鉛筆を持って、$f(x)=x^2-7$を微分するのは造作もないことですが、
プログラムで動かすとなると、何次式になるかなどの場合分けがあり、
サクッと式の形に落として、プログラムとして実装することがなかなか難しそうです。今回は代入した値が求まればそれで良いので、
導関数の定義式?的なので近似します。
$$f(a)^{\prime}= \frac{f(a+h)-f(a)}{a+h-a}= \frac{f(a+h)-f(a)}{h}$$これを使っても良いのですが、より誤差が少ない中心差分公式を用いて微分係数を返してみました。
$$f(a)^{\prime}= \frac{f(a+h)-(a-h)}{2h}$$$a$の部分は$x_{old}$に該当。代入の処理はlambda関数を使用。
hの部分は微小誤差として、勝手に1e-10としていますが、
計算効率に関わってくる部分っぽいので、本当はあんまり勝手に決めない方が良いのかもしれません。実装2
・countと誤差の推移のグラフを追加
・100回で収束しない場合の撤退を追加import matplotlib.pyplot as plt import numpy as np # 実装 def newton_method(func, initial_x, r_error): """ funcの部分はlambda関数で設定する。 func = lambda x : x**2 - 7 """ count = 0 # 折線表示のために誤差結果の保存 y_f_value_list = [] while True: count += 1 y_f = func(initial_x) # 誤差リストに追加 y_f_value_list.append(abs(y_f)) # 許容誤差との比較 if abs(y_f) < r_error: break # 許容誤差を満たさない場合は更新 # 微分係数を求めて、更新 # 微分係数は中心差分を用いる y_d = (func(initial_x + 1e-10) - func(initial_x - 1e-10)) / (2 * 1e-10) # 更新値を求める x_new = initial_x - (y_f / y_d) print("{}回目:X_new = {}".format(count,x_new)) # 更新 initial_x = x_new # 100回tiralで収束しない場合、計算を止める if count == 100: print("近似解見つからず。") break # countと誤差の推移 x = np.arange(1, count+1, 1) # 1 ~ n回 y = np.array(y_f_value_list) # 1 ~ n回の各誤差 plt.plot(x, y) # 横軸と縦軸のラベルを追加 plt.xlabel('trial') plt.ylabel('r_error') # 許容誤差の横線 plt.hlines(r_error, 1, count,color="red",linestyles='dashed') # 折れ線と許容誤差のボーダーを一括で表示 plt.show()$x^2-7=0$ を初期値20から近似する。
newton_method(lambda x : x**2 - 7, 20, 0.001)
実装3
実装1,2は許容誤差を高さに設定して、近似している。
ここではニュートン法による横の動きの更新が浅くなったら近似解にする感じのプログラムも書いてみた。
今回、関数は最初に外に出して定義。
x_ini:初期値
JJ:繰り返し回数
EPS:許容誤差$\frac{|x_{new}-x_{old}|}{|x_{old}|} > EPS $
で評価する。
$|x_{new}-x_{old}|$が小さくなればなるほど収束していると考えられる。
値が極端に大きい時にも対応できるように$|x_{old}|$で正規化したものを使った。def ff(x): return x**2-7 # 微分係数を返す関数(中心差分を用いる) def df(x): return (ff(x + 1e-10) - ff(x - 1e-10)) / (2 * 1e-10) def newton_method(x_ini, JJ, EPS): x_old = x_ini for i in range(JJ): x_new = x_old - ff(x_old)/df(x_old) # 評価部分 if (abs(x_new-x_old)/abs(x_old)) < EPS: break else: x_old = x_new if i == JJ-1: print("Do not CONVERGE") else: return x_new if (__name__=='__main__'): JJ = 100 EPS = 0.001 x_ini = 20 x_sol = newton_method(x_ini, JJ , EPS) print("solution:{}".format(x_sol))



- 投稿日:2021-03-29T16:21:42+09:00
プログラミングをやってみよう【Python編Part1】
あいさつ 皆さんはじめまして.C3の鳩屋敷です. 今回はPythonを使ってプログラミングの基礎を学んでいきたいと思います. 準備するもの ・パソコン(今回はWindows10基準で教えます) ・VSCode(好みのエディタがあればそちらでも) ・Python3(揃えた方が楽なので最新版を使う) ・気合い ・おやつ(バナナも可) 準備の手順 一応準備するまでの流れも掲載しておきます. パソコン パソコンは買ってください. エディタ エディタはVSCodeを推奨します(今回VSCodeを使って教えるので).こちらから「今すぐダウンロード」でダウンロードしてください→Visual Studio Code 好きなエディタがメモ帳ならそちらでもどうぞ. Python3 最後にPythonの言語のライブラリをダウンロードします.このサイト(Download Python)を開いてWindowsユーザーは一番上のでかいボタンからダウンロードしてください.インストーラを起動したら進める前にAdd Python 3.X.X to PATHのチェックを忘れ内容にしてください.後はインストーラの手順に従いましょう. おやつ 食べる時間は設けませんので適宜食べましょう.たけのこの里が好ましい. 実行の準備 VSCodeを開いて,上のツールバーからファイル > フォルダーを開く…で好きな所のフォルダを開きます.開いたらファイル > 新規ファイルで新規ファイルを作ります.新規ファイルの名前はchoukankaku.pyのように最後に.pyを付けましょう.うっかり変え忘れても後から変えられるので焦らなくても大丈夫です.これでpythonのプログラムを書く準備は完成です. ファイルを実行するためのターミナルも用意しましょう.せっかく作っても実行できなければ意味がありませんね.上のツールバーからターミナル > 新しいターミナルでターミナルを出します.選択肢が出てきた場合は多分一番上を選べばなんとかなると思います. ターミナルに python3 choukankaku.py (choukankaku.pyの部分は自分のファイル名に置き換える) と書いてEnterキーを押せば実行できます. やってみよう その前に コメントアウト プログラミングのファイルには日本語でメモすることは出来ません.それぞれの言語の文法があるからです. それでもコメントを残したいと思うタイミングはあると思います.そんな時にはコメントアウトを使ってみましょう.今からやっていくことで忘れそうなところにメモとしてコメントを書いてもいいかも知れませんね. choukankaku.py # Pythonの馬鹿!! ''' 複数行のコメントアウトも こうやったらできるよ Pythonの阿呆!! ''' この記事でも,命令の説明や使い方などでコメントを使っています. また,(本来の使い方はこっちな気もしますが,)プログラムが上手く動かない時に悪さをしていそうな記述を一旦消して後でもとに戻したいときにも使えます. ちなみにVSCodeでコメントアウトしたい行を選択してCtrl+/を押すと一気にコメントアウトしてくれます.(もう一度押すとコメントアウト解除) 1: 自己紹介を表示する(print) まずは出力(表示)を覚えましょう.下の文をPythonファイルに記述します.(名前は適宜変えましょう.) choukankaku.py print("私の名前は鳰屋敷です.") これを実行するとコマンドプロンプトに私の名前は鳰屋敷です.と表示されます. もっと増やして自己紹介にしてみましょう. choukankaku.py print("私の名前は鳰屋敷です.") print("鳰屋敷の年齢は19歳です.") print("鳰屋敷の年齢は19歳なのでお酒は飲めません.") これを実行すると上記の通り表示されますね. 2: 変数を使う うっかりしてました.私の名前は「鳩屋敷」なのですが,鳩が鳰になっています.書き直しましょう. 今回は修正箇所は3行で済みましたが,これがもっと書いた後だったらもっと大変でした. こんな時に役立つのが変数です.変数の中に名前を入れてそれを使い回せば必ず同じ名前が表示されるし,変数の中身を1箇所変えるだけで何百行使っていようが全部修正できます.これで楽できますね. 変数の使い方はこうです. # 変数の定義(nameという変数の中に「鳩屋敷」という文字列が入っている) name = "鳩屋敷" # 変数の使用 print(f"{ name }だよ~") このように,変数の中身を一度定義してあげると変数を使えばずっと同じ値を使えます. 文字列の中に変数を使う時はf"{name}"のように,変数を{}で括り,""の前にfを付けてあげる必要があります.こういうもんだと割り切ってください笑 では書いてみましょう. 年齢もついでに変数にしておきました. choukankaku.py name = "鳩屋敷" age = 19 print(f"私の名前は{ name }です.") print(f"{ name }の年齢は{ age }歳です.") print(f"{ name }の年齢は{ age }歳なのでお酒は飲めません.") nameという変数の中に"鳩屋敷"という値を保存することでnameという変数を全部"鳩屋敷"という値に置き換えてくれます. ""(ダブルクォート)の前のfは文字列の中に変数を使うために必要な表記です.変数のみprintするときには不必要です. 3: キーボード入力を受け付ける(input) さて皆さんは19歳でしょうか.この講座を受けてる人は18の人が多いでしょうしこの記事を読んでる人は19歳であるほうが珍しいでしょう.名前も実行する人によって変えたいですよね. 実行する人の名前と年齢を確認してから自己紹介を表示しましょう.キーボードで文字入力をさせます. 書き方はこうです. # Enterキーを押すまで待機し,それまでに入力した文字列を変数に代入 key = input() # 試しにプリント print(key) ではinput()を使って入力させてみましょう. choukankaku.py print("名前を入力してください.") name = input() print("年齢を入力してください.") age = input() # 文頭のfは文章の中に変数を使うために必要な記述 print(f"私の名前は{ name }です.") print(f"{ name }の年齢は{ age }歳です.") print(f"{ name }の年齢は{ age }歳なのでお酒は飲めません.") input()が出てきましたね.これは文字入力させて,エンターを押すと入力した文字列を変数に代入する関数です. 4: 条件で分岐させる(if) ですが20歳以上の人はどうでしょうか.お酒は飲めます.これでは自己紹介が嘘になりますね. 年齢を条件に分岐してprintする文字列を変更したいですね. こんな時に役立つのがif文です. if <条件文>: <処理1> else: <処理2> こんな風に書くと,条件文を満たすと処理1が,満たさないと処理2が実行されます. 処理の部分はタブキーで必ず一つ高く上げましょう. 自己紹介に実装するとこうなります. choukankaku.py print("名前を入力してください.") name = input() print("年齢を入力してください.") age = int( input() ) print(f"私の名前は{ name }です.") print(f"{ name }の年齢は{ age }歳です.") if age < 20: print(f"{ name }の年齢は{ age }歳なのでお酒は飲めません.") else: print(f"{ name }の年齢は{ age }歳なのでお酒は飲めます.") 5: ループ文と配列(while) さて次は2人分の自己紹介を表示できるようにしてみましょう. コピペっ. choukankaku.py print("1人目の名前を入力してください.") name_1 = input() print("1人目の年齢を入力してください.") age_1 = int( input() ) print("2人目の名前を入力してください.") name_2 = input() print("2人目の年齢を入力してください.") age_2 = int( input() ) print(f"1人目の名前は{ name_1 }です.") print(f"{ name_1 }の年齢は{ age_1 }歳です.") if age_1 < 20: print(f"{ name_1 }の年齢は{ age_1 }歳なのでお酒は飲めません.") else: print(f"{ name_1 }の年齢は{ age_1 }歳なのでお酒は飲めます.") print(f"2人目の名前は{ name_2 }です.") print(f"{ name_2 }の年齢は{ age_2 }歳です.") if age_2 < 20: print(f"{ name_2 }の年齢は{ age_2 }歳なのでお酒は飲めません.") else: print(f"{ name_2 }の年齢は{ age_2 }歳なのでお酒は飲めます.") じゃあこれを3人分にしましょう.5人分,100人分にしてみましょう. …大変ですね.せっかくプログラミングするので楽しましょう. ループ文と配列を使っていきます. ループ文は今回whileを使います.書き方はこう. while <条件文>: <処理> 処理を行う直前に条件文を確認し,条件を満たしたら処理を行います.処理を行ったら必ず条件文の確認に戻ります.英単語としても「~の間~する」という意味なのでそのままですね.これで条件を満たしている間ずっと同じ処理を行えます. 次に配列です.変数をまとめて扱いたい時に便利です.配列の何番目かを指定すれば配列から変数一個分取り出すことが出来ます.ちなみに0番目からカウントするので3番目に追加した値は2番目を指定すれば取り出せます. 何番目かを指定する数字は数字が入った変数を入れることが出来ます.これが配列の良い点です. list = [] list.append(12) list.append(33) list.append(42) list.append(21) print(list) print(list[2]) # 表示結果 # [12, 33, 42, 21] # 42 これら2つを使えば先ほどの自己紹介を何人分でも書くことが出来ます.それがこちら. choukankaku.py count = 5 index = 0 name_list = [] age_list = [] while index < count: print(f"{index+1}人目の名前を入力してください.") name = input() name_list.append(name) print(f"{index+1}人目の年齢を入力してください.") age = int( input() ) age_list.append(age) index = index + 1 index = 0 while index < count: print(f"{index+1}人目の名前は{ name_list[index] }です.") print(f"{ name_list[index] }の年齢は{ age_list[index] }歳です.") if age_list[index] < 20: print(f"{ name_list[index] }の年齢は{ age_list[index] }歳なのでお酒は飲めません.") else: print(f"{ name_list[index] }の年齢は{ age_list[index] }歳なのでお酒は飲めます.") index = index + 1 これで何人分でも自己紹介ができるプログラムの完成です! このままでは何人分か決めて実行する必要がありますのでcountをinput()で取得してもいいですね. 好きな食べ物を聞いてみてもいいかもしれないですね. 終わりに これでプログラミングの基礎の基礎は学べたと思います.ですが,大事なのはprintやinput,if,whileなどを暗記することではありません.これらの使い方は調べればすぐに出てきます.大事なのは自分の作りたいものに対してどういう関数が必要なのか,どういう構成で書けば短く済むか意識することが大事なのです.初めは冗長なコードになっても大丈夫です.それを意識していくだけであっという間につよつよプログラマになれるでしょう.
- 投稿日:2021-03-29T16:06:09+09:00
オブジェクト指向が分からない…乃木坂・櫻坂・日向坂に頼ってみた
オブジェクト指向の定義に入る前に…
明確な定義はない!
ということを頭の隅に入れておいてください。例えば、愛とは?恋とは?乃木坂の良さとは?
って言われてもその答えは人それぞれで、一つに定まらないのと同じです。なので、ざっくり雰囲気を理解することが大事だということを覚えてください!
オブジェクト指向とは?
概念・考え方の一つです!
(目に見えない・触れない。つまり無体物なのです!)どんな概念・考え方?
いかに効率よく開発を行うかを突き詰めた考え方!
例えば、エンジニアチームがプロジェクトを行うときは、"オブジェクト指向に基づいてプログラムを作成しましょう!"と言って作業に取り掛かります。
効率の良い考え方とは?
①カプセル化
他のプログラムから干渉されないようにする考え方!
乃木坂・櫻坂・日向坂のOFFICIAL WEB SITEを作る際に、
乃木坂のサイトのプログラムと櫻坂のサイトのプログラムと日向坂のサイトのプログラムがそれぞれ独立した環境にすること!
(互いに"干渉"を受けないようにすること!)②継承
同じようなプログラムは"共通化"して使う考え方!
乃木坂・櫻坂・日向坂のOFFICIAL WEB SITEのベースとして
個人の名前・生年月日・身長などの情報が共通して存在しています。であれば、
初めに乃木坂のOFFICIAL WEB SITEを作った際に、櫻坂・日向坂でも共通化できる部分は同じコードを書かないで、継承しようという考え方です。
③ポリモーフィズム
汎用的な形に出来るようにしましょうという考え方!
"②継承"によってベースを作成した後に、
独自に派生したプログラムを追加・修正出来るようにする考え方!例えば、
【変更前】 >>>>>>>>>>>>>>>>>>>>>【変更後】





- 投稿日:2021-03-29T16:00:23+09:00
ScikitAllStars: 主要なscikit-learnの教師あり機械学習法を全部Optunaでチューニングしてスタッキングまでやっちゃうツール
教師あり機械学習法はたくさんありますが、scikit-learn に入ってるもののうち主なものを全部使って、optunaでハイパーパラメーターチューニングして、できたモデルをさらにstackingしてしまうという一連の作業をまとめて行うライブラリ ScikitAllStars を作りました。
なぜこんなツールを作ったかって?めんどいからです。
また、ScikitAllStars の特徴として、教師あり機械学習が「回帰問題」なのか「分類問題」なのかという違いをほとんど意識せずに使えるというところもあります。
以下のコードは全て Google Colaboratory 上で動作を確認済みです。
必要なツールのインストール
# Optuna のインストール !pip install optuna# ScikitAllStars のインストール !pip install git+https://github.com/maskot1977/scikitallstars.gitデータの用意
下記は Numpy array 形式のデータを用いていますが、Pandas DataFrame 形式のデータでも使えるはずです。
まず、分類用データを使ってみましょう。
import sklearn.datasets dataset = sklearn.datasets.load_breast_cancer() # 分類用データ例 #dataset = sklearn.datasets.load_diabetes() # 回帰用データ例訓練データ・テストデータへ分割を行います。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(dataset.data, dataset.target, test_size=.4) # 訓練データ・テストデータへのランダムな分割AllStarsモデルの学習
次のようにして、ScikitAllStarsに登録してある全ての手法に対してoputunaでチューニングしながら学習を行います。feature_selection=True とすることで、RandomForestによる特徴選択を事前に行ないます。
from scikitallstars import allstars, depict allstars_model = allstars.fit(X_train, y_train, timeout=1000, n_trials=100, feature_selection=True)feature selection: X_train (341, 30) -> (341, 9)feature_selection=True とした場合は、次のようにすると、重要な特徴量についての知見が得られます。
depict.feature_importances(allstars_model)
次のようにして、学習経過のサマリーが得られます。
depict.training_summary(allstars_model)
次のようにして、手法ごとのベストモデルの性能を確認できます。
depict.best_scores(allstars_model)
depict.all_metrics(allstars_model, X_train, y_train)
depict.all_metrics(allstars_model, X_test, y_test)
AllStarsモデル全体でのベストモデルの性能は次のようにして確認できます。
allstars_model.score(X_train, y_train), allstars_model.score(X_test, y_test)(0.9976689976689977, 0.9690721649484537)depict.metrics(allstars_model, X_train, y_train, X_test, y_test)
ベストモデルを用いた新規予測は次のようにして行えます。
allstars_model.predict(X_test)array([1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1])スタッキングモデルの学習
上記のようにして学習した AllStars モデルを用いて、下記のようなコードでスタッキングモデルを組んでハイパラチューニングしながら学習することができます。
stacking_model = allstars.get_best_stacking(allstars_model, X_train, y_train, timeout=1000, n_trials=100)得られたスタッキングのベストモデルの性能は次のようにして確認できます。
stacking_model.score(X_train, y_train), stacking_model.score(X_test, y_test)(0.9882697947214076, 0.9517543859649122)depict.metrics(stacking_model, X_train, y_train, X_test, y_test)
AllStarsベストモデルと比較してみましょう。
depict.metrics(allstars_model, X_train, y_train, X_test, y_test)
スタッキングのベストモデルにおける、各機械学習手法の重要度が次のようにして確認できます。
depict.model_importances(stacking_model)
スタッキングのベストモデルによる新規予測は次のようにして得られます。
stacking_model.predict(X_test)array([1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1])分類モデル、回帰モデルの切り替え
ScikitAllStars では、取り扱う問題が分類なのか回帰なのかという違いをほとんど意識せずに使える設計を心がけています。なぜって?めんどいからです。
上記のコードのうち、データの部分だけを次のように書き換えるだけで、自動的に「回帰問題」だと認識して回帰モデルを全部やっちゃってくれます。他の部分は書き換える必要がありません。
import sklearn.datasets #dataset = sklearn.datasets.load_breast_cancer() # 分類用データ例 dataset = sklearn.datasets.load_diabetes() # 回帰用データ例結果は省略。気になる方は、各自試してみてくださいね。
今後
細かい設定が色々あるんですが、最小限の動作は上記のコードを参考に行えると思います。詳しくは https://github.com/maskot1977/scikitallstars.git のコードを読んでみてください。








- 投稿日:2021-03-29T15:46:02+09:00
CNN高速化シリーズ ~Overlap-Add法とOverlap-Save法~
概要
前回の記事で述べましたが、FCNNの畳み込みは非常にメモリ効率が悪いことが知られています。
そこでOverlap-Add: OVAまたはOLA: 重畳加算法の導入が提案されました。これによりフィルタサイズと入力サイズとを揃える必要がなくなり、メモリ効率が大幅に向上しました。
この手法はもともと信号処理での畳み込み演算に利用されている手法ですが、同じ畳み込み(仮)ですのでCNNにも適用することができます。
本記事ではそのOVA法と、ついでにOVA法と類似のOverlap-Save: OVSまたはOLS: 重畳保留法について触れています。何かの役に立てばぜひLGTM、ストック、コメントしていただけると励みになります。
目次
Overlap-Add法
OVerlap-Add: OVA法はもともと信号処理の分野で非常に長い入力信号に対して随時畳み込みをかけることで結果的に高速に全体を畳み込みするための手法です。まずは1次元でのアルゴリズムを見てみましょう。
入力の長さ$I$、フィルタサイズ$F$とすると
- 入力をブロック長$F$のブロックに重複なく分割する
- フィルタと分割ブロックとを線形畳み込みする
- 各ブロックを$F-1$だけ重ねて、重なっている部分を足し算しつつブロックを繋げる
となります。シンプルですね〜
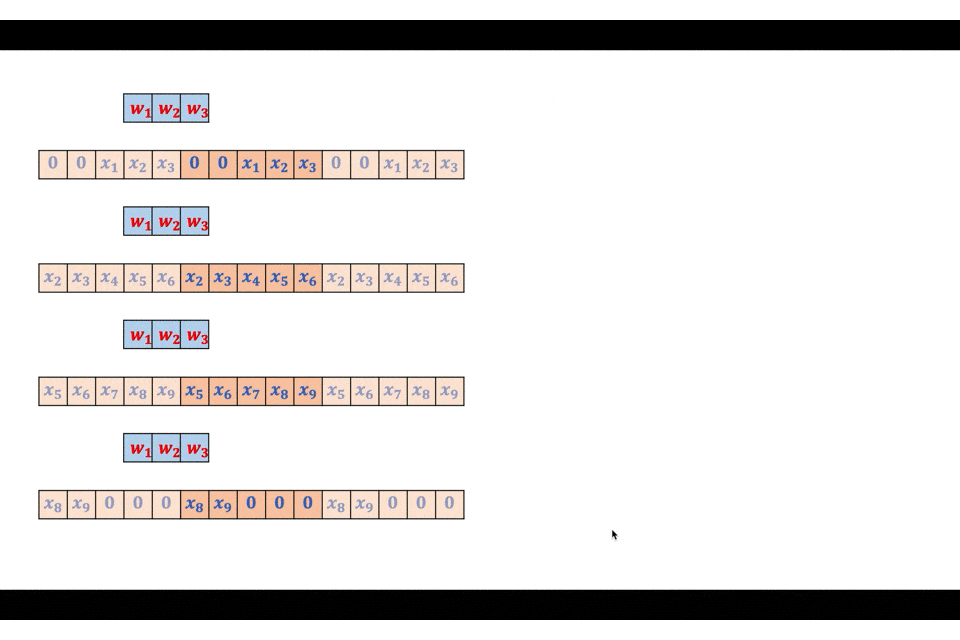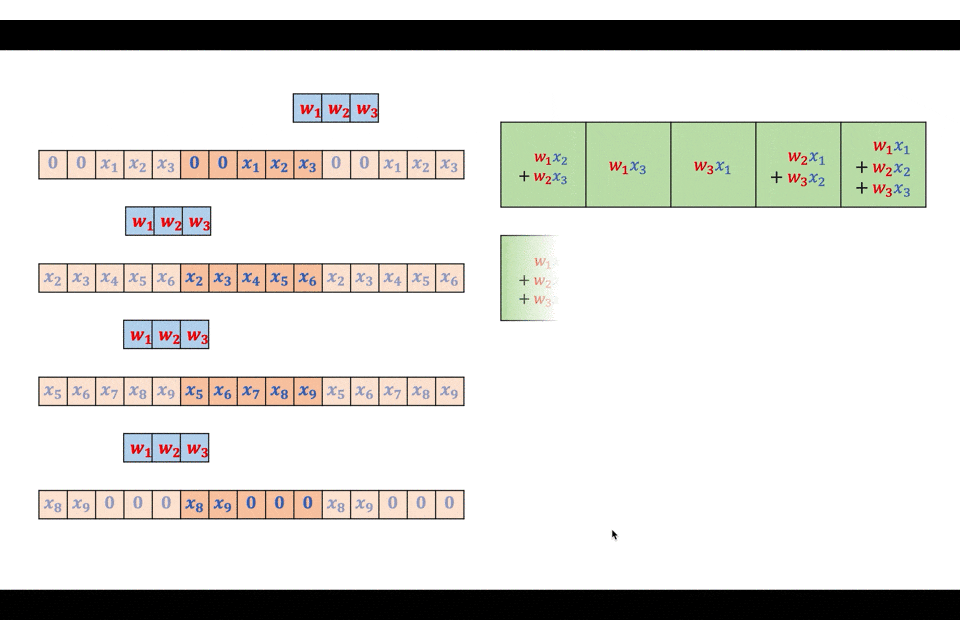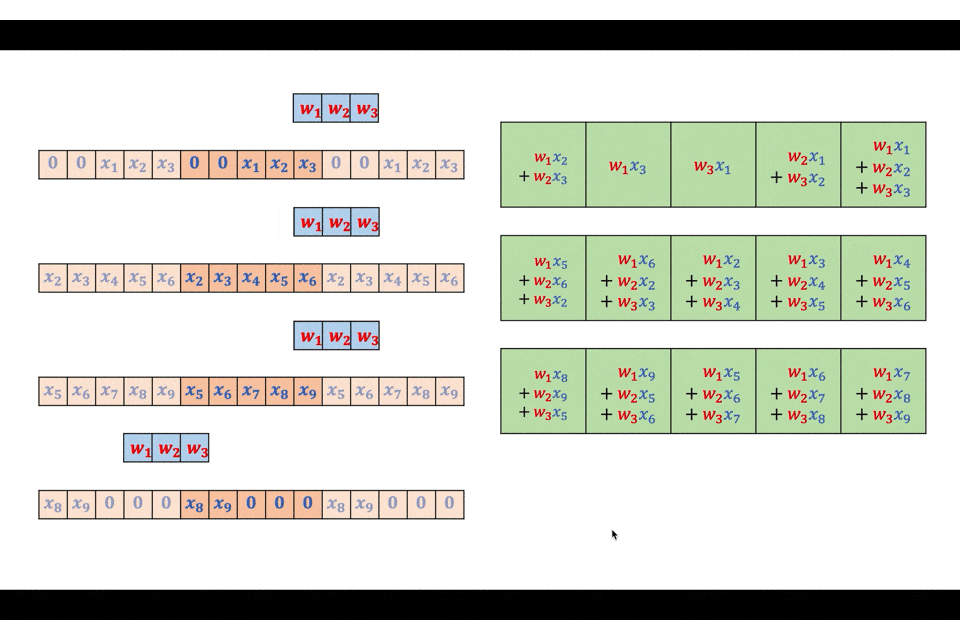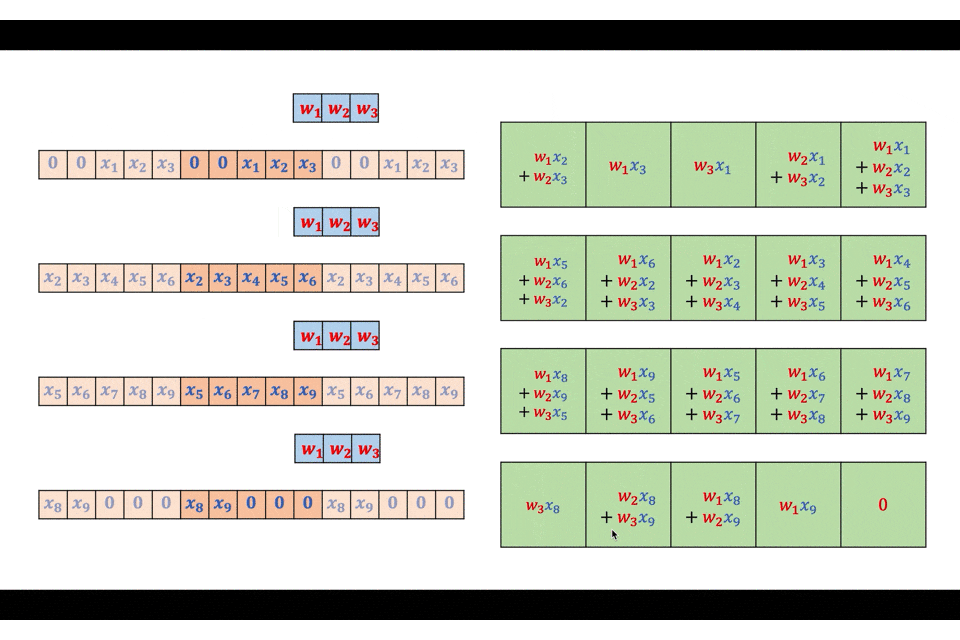
実際に図を交えながら詳細に見ていきましょう。入力を$(x_1, x_2, \ldots, x_9)$、フィルタを$(w_1, w_2, w_3)$とします。
まずは入力をフィルタと同サイズのブロックに分割します。
この分割それぞれとフィルタとを線形畳み込みで畳み込みます。
こうして計算された出力を、$F-1$だけ重ね合わせて配置し、重なっている部分は足し算することで最終的な出力を得ることができます。
しっかり線形畳み込みの結果になっていますね!Overlap-Save法
続いてOverlap-Save: OVS法について紹介します。こちらはちょっとわかりづらい&あまり解説しているサイトが見当たらなかったので間違っている部分もあるかもしれません...
先ほどと同じように定数を設定します。また、ブロック長を$N$とします。この$N$は任意数です。ただし$N$は入力長$I$の倍数になっている方がパディングする必要もなくていいかもしれません。
各ブロック$F-1$だけ重ねてブロック長$N$となるように分割します。
続いてこの各ブロックとフィルタとを循環畳み込みで畳み込みます。
このように計算された出力の、$F-1$だけ破棄したものを結合することで最終的な出力を得ることができます。
CNNに適用する
ここまででOVA法、OVS法の1次元での動作を見てきました。ここからはCNNに適用することを考えます。
といっても、ただ単に2次元に拡張してあげればOKです。
また、色々と調べている中でFCNNにおいてOVS法を使用している例は見つからなかったため、OVA法のみ載せます。
まあシンプルな線形畳み込みです。CNNでの畳み込みとは微妙に異なりますが、周囲$(F_h-1, F_w-1)$だけカットすればCNNでの畳み込みと同等になりますね。もちろん添字を反転させる必要もあります。詳しくは前回の記事参照。FCNNに適用する
さて、Fourier CNNに適用しましょう。どうやって適用するのか、色々な論文などを流し読みしてみたりしましたが、どれもこれも微妙...流し読みしてるせいかもしれませんが笑
ということで自分で色々考えて試しに手計算してみたりしたのですが、結局以下のようにするしかなさそうという結論になりました。
図中のFFT,IFFTは高速フーリエ変換と高速逆フーリエ変換を意味しています。
また、流石にきちんと図中に記述するのは無理だったのでフーリエ変換結果などは省略して大文字で表してあります。
メモ代わりに少しだけ計算式を載せておきます。X^{(0)}_{m,n} = \sum_{k=0}^{F_h-1}{\sum_{l=0}^{F_w-1}{x_{k,l}e^{i\frac{2\pi}{F_h}km}e^{i\frac{2\pi}{F_w}ln}}} \\ W_{m,n} = \sum_{k=0}^{F_h-1}{\sum_{l=0}^{F_w-1}{w_{k,l}e^{i\frac{2\pi}{F_h}km}e^{i\frac{2\pi}{F_w}ln}}} \\ y^{(0)}_{m,n} = \frac{1}{F_h}\sum_{k=0}^{F_h-1}{\frac{1}{F_w}\sum_{l=0}^{F_w-1}{X^{(0)}_{k,l}W_{k,l}e^{-i\frac{2\pi}{F_h}km}e^{-i\frac{2\pi}{F_w}ln}}}このように分割した部分ごとにフーリエ変換→要素積→逆フーリエ変換とした後でOVA法に則って計算していけば、省メモリを実現しつつ求めたい畳み込み演算結果を得ることができるわけです。
計算量の比較
- ただの線形畳み込み
- OVA法を利用した線形畳み込み
- 高速フーリエ変換を利用した線形畳み込み
- OVA法と高速フーリエ変換を利用した線形畳み込み
について、それぞれ時間計算量・空間計算量を調べてみます。
ただし、簡略化のために入力、フィルタ、出力の形状は全て正方形であるとします。なお様々な参考資料を独自解釈して考えているため、間違いがある可能性があります。
また、オーダ記法$\mathcal{O}$はできる限り採用していません。1. ただの線形畳み込み
- 時間計算量:$2O^2F^2$
- 空間計算量:$I^2+F^2+O^2$
ただの線形畳み込みは以下の数式で表すことができます。
y_{m,n} = \sum_{k=0}^{F-1}{\sum_{l=0}^{F-1}{x_{m-k,n-l}w_{k,l}}}この部分の時間計算量は$F^2$回の足し算と$F^2$回の掛け算であり、これが出力サイズの回数分だけ実行されるため、$2O^2F^2$が最終的な時間計算量となります。
ストライド1、パディング0の場合なら$O=I-F+1$などと計算できますね。
空間計算量については、もともとの入力$I^2$と重み$F^2$、出力の$O^2$を足し合わせたものになります。2. OVA法を利用した線形畳み込み
- 時間計算量:$\frac{I^2}{F^2}-1 + 2(F+1)^2F^2 + 2 \left( \frac{I}{F}-1 \right)O(F-1) + \frac{1}{2}\frac{I}{F} \times \frac{1}{2}\frac{I}{F}(F-1)^2$
- 空間計算量:$I^2+F^2+O^2$
OVA法についての正確な計算量の導出は不明なのですが、とりあえず独自解釈を交えて考えてみます。
間違っていればご指摘ください。まず、アルゴリズムを再掲します。
- 入力をブロック長$F$のブロックに重複なく分割する
- 重みと分割ブロックとを線形畳み込みする
- 各ブロックを$F-1$だけ重ねて、重なっている部分を足し算しつつブロックを繋げる
一つずつ考えてみましょう。ただし、簡略化のためにパディング不要などの色々といい感じの条件下でのことにします。
- 入力を分割する回数は$$\frac{I^2}{F^2}-1回$$生成されるブロックのサイズは$F \times F$
- それぞれを線形畳み込みするのに必要な計算回数は$$2(F+1)^2F^2回$$生成される出力ブロックは$o \times o$
- ブロックの数は$\frac{I}{F} \times \frac{I}{F}$個であり、先の図で言う色の濃い帯は$2 \times \left( \frac{I}{F}-1 \right)$本、帯の幅が$F-1$となるため、足し算の回数は$$2 \left( \frac{I}{F}-1 \right)O(F-1)回$$ただし、$2\times2$個のブロックセットにつき$(F-1)(F-1)$回ずつ、数えられていない足し算が存在するので、それら$\frac{1}{2}\frac{I}{F} \times \frac{1}{2}\frac{I}{F}(F-1)^2$回も考慮した$$2 \left( \frac{I}{F}-1 \right)O(F-1) + \frac{1}{2}\frac{I}{F} \times \frac{1}{2}\frac{I}{F}(F-1)^2回$$
よって、時間計算量はこれら全てを足し合わせた
\frac{I^2}{F^2}-1 + 2(F+1)^2F^2 + 2 \left( \frac{I}{F}-1 \right)O(F-1) + \frac{1}{2}\frac{I}{F} \times \frac{1}{2}\frac{I}{F}(F-1)^2となります。
空間計算量については、あらかじめ出力サイズ$O \times O$のメモリを確保しておき、ブロックごとの線形畳み込みによる出力ブロックをこのメモリの該当箇所に足し合わせていく、と考えれば$O^2$となります。
もちろん入力、重みの空間計算量$I^2$と$F^2$も加算します。3. 高速フーリエ変換を利用した線形畳み込み
- 時間計算量:$2I^2\log_2I + 2F^2\log_2F + 2O^2\log_2O + 6O^2$
- 空間計算量:$6O^2$
高速フーリエ変換を利用する場合、入力やフィルタを出力サイズに拡張しつつフーリエ変換を行う必要があります。このフーリエ変換に必要な時間計算量は、高速フーリエ変換の場合は入力、重みそれぞれについて$2I^2\log_2I$と$2F^2\log_2F$となります。
そして入力と重みとの要素積を取るのですが、この時の要素積は複素数積であることに注意すると$$(a+bi)(c+di)=ac-bd+i(ad+bc)$$より積4回和1回差1回となり、通常の6倍の演算量であると見なすことができるので、$6O^2$となる。
最後に出力を逆フーリエ変換する必要があるため、その計算量$2O^2\log_2O$が加えられます。
空間計算量については、入力及び重み、出力の3つがそれぞれ$O \times O$必要で、さらに複素数として保持する必要があるため実数と比較して倍のメモリが必要となり、$6O^2$となります。ちなみに高速フーリエ変換の時間計算量は厳密な計算量の出し方がわからなかったので、厳密なものではなくオーダです。
4. OVA法と高速フーリエ変換を利用した線形畳み込み
- 時間計算量:$\frac{I^2}{F^2}-1 + 2 \left( \frac{I^2}{F^2}+1 \right)F^2\log_2F + 6\frac{I^2}{F^2}o^2 + 2\frac{I^2}{F^2}o^2\log_2o$
- 空間計算量:$I^2 + 2 \left( 1 + \frac{I^2}{F^2} \right)o^2 + O^2$
OVA法を利用する場合のアルゴリズムは以下のようになります。
- 入力をブロック長$F$のブロックに重複なく分割
- 各入力ブロックと重みを高速フーリエ変換
- 重みと入力ブロックとを要素積
- 生成された出力ブロックを逆フーリエ変換
- 各ブロックを$F-1$だけ重ねて、重なっている部分を足し算しつつブロックを繋げる
1と5は先の議論から$\frac{I^2}{F^2}-1$回と$2 \left( \frac{I}{F}-1 \right)O(F-1) + \frac{1}{2}\frac{I}{F} \times \frac{1}{2}\frac{I}{F}(F-1)^2$回ですね。それ以外の部分を見ていきます。
- 各入力ブロックと重みはサイズ$F \times F$なので、高速フーリエ変換の計算量は$2F^2\log_2F$であり、全部で$\frac{I}{F} \times \frac{I}{F} + 1$個あるため$$2 \left( \frac{I^2}{F^2}+1 \right)F^2\log_2F$$となります。また、生成されるブロックサイズを$o \times o$としておきます
- 重みと入力ブロックの要素積に必要な計算回数は、複素数積であることを考慮すると$6o^2$であり、これが$\frac{I}{F} \times \frac{I}{F}$回行われるので$$6\frac{I^2}{F^2}o^2回$$
- 出力ブロックのサイズは$o \times o$で、それが$\frac{I}{F} \times \frac{I}{F}$個あるため$$2\frac{I^2}{F^2}o^2\log_2o$$
以上から、時間計算量は総じて
\frac{I^2}{F^2}-1 + 2 \left( \frac{I^2}{F^2}+1 \right)F^2\log_2F + 6\frac{I^2}{F^2}o^2 + 2\frac{I^2}{F^2}o^2\log_2oとなります。
空間計算量については、入力の$I^2$と出力$O^2$はもちろん、重みや入力ブロックごとに$2o^2$必要となります。おわりに
GIFアニメーションの手抜きっぷりよ...気が向いたらもう少しマシなの作ります。
CNN高速化シリーズ







- 投稿日:2021-03-29T15:34:13+09:00
【pysen README和訳】: あの「Preferred Networks」が作ったpython linter/formatter 管理アプリ「pysen」のREADMEを和訳してみた
github: https://github.com/pfnet/pysen
はじめに
pysenはpreferred networksが公開するpython用のlinter/formatterの管理用アプリです。
複数人でコードを作成するとき、ある程度の可読性を確保するためにコーディングの約束を決めるものですが、それを自動的に判定/整形しようというのがlinter/formatterです。しかし、python用のlinter/formatterは複数あり、プロジェクトごとに様々で、linter/formatterの整備自体が形骸化するのが問題でした。そこで、preferred networksではlinter/formatterの管理用アプリを作って統合しようと作ったのがpysenです。ただ、preferred networksのgithubのREADME.mdには英語のドキュメントしかなかったので、和訳したのが以下です。(執筆時 2021/03/29)
pysen って何?
「pysenは日々の開発用のツールを統合すること」を目標に提供されるツールです。
次のように使うことを想定しています。
pysen run lint,pysen run formatを実行することで、プロジェクト内のすべてのコードをチェックして、フォーマットするpyproject.toml内での数行書くことで標準化用のコードスタイルを定義するpysenは各々のチームが蓄積した知見やコード、特にpythonのlinterについて中央集権的に共有します。実行はsetup.pyと私たちのコマンドラインツールのどちらからでも実行可能です。現在、以下のツールの設定ファイルを管理可能です。
- linter
- flake8
- isort
- mypy
- black
- utility
- (2021/03/29現在:予定)protoc
pysenで「できない」こと
- pysen自体はlinterではありません。
pysen run lintは複数のpythonのlinterをpysenのより抽象的な設定ファイルに則って自動的に各々のlinterの設定を構築します。- pysenはあなたの環境の依存性やパッケージを管理するものではありません。パッケージマネージャには
pipenvやpoetryを使い、pysenが使うツール(isort, mypy, flake8, blackなど)のバージョンを固定することを推奨します。pysenが対応するバージョンはsetup.py内のextra_requires/lintを確認してください。pip install pysen[lint]によるlinterのバージョン管理は非推奨です。- pysenはlintだけに限って作られたものではありません。是非、「プラグイン」を見て詳細を確認してみてください。
インストール方法
[訳注]以下のいずれかを使用してください。ただし、pipは非推奨です。
# pip pip install "pysen[lint]" # pipenv pipenv install --dev "pysen[lint]==0.9.1" # poetry poetry add -D pysen==0.9.1 -E lintクイックスタート: pysenでのlinterの管理方法
まずは、あなたのpythonパッケージ内で、以下の設定をpysenの設定ファイル
pyproject.tomlに記入してみてください。[tool.pysen] version = "0.9" [tool.pysen.lint] enable_black = true enable_flake8 = true enable_isort = true enable_mypy = true mypy_preset = "strict" line_length = 88 py_version = "py37" [[tool.pysen.lint.mypy_targets]] paths = ["."]次に、次のコマンドを実行します。
$ pysen run lint $ pysen run format # ここでformatter(black, isort)を使ったコードの自動修正を試みますこれでお終りです!
pysenは特定のlinter(black, isort, mypy, flake8)の設定ファイルを生成し、適切に実行します。
pyproject.tomlに関して、より詳細を知りたい場合はpysen/pyproject_model.pyを参照してください。セットアップ用のコマンドはあなたのpythonのパッケージに追加することも可能です。次のコードを、あなたのパッケージ内の
setup.pyに追記して、実行してみてください。import pysen setup = pysen.setup_from_pyproject(__file__)$ python setup.py lintまた、設定をカスタマイズしたり、pysenを拡張するためのPythonインターフェースも提供しています。詳しい内容は以下を参照してください。
- Pythonを使った設定例:examples/advanced_example/config.py[訳注] 3/29現在このファイルは存在しません。おそらくlint.pyのこと
- pysenのプラグイン例:examples/plugin_example/plugin.pyどう動いているか?: 設定ファイルのディレクトリ
水面下では、pysenが動くときはlinterに使われるファイルを一時的に生成しています。もし、このファイルをディスクに取っておきたい場合(例えば、エディタで使いたいときなど)、以下のコマンドを実行して保存先を指定してください。
$ pysen generate [保存先ディレクトリ]
pysen run実行時に、pysenの使用する設定ディレクトリを指定することも可能です。次のセクションをpyproject.tomlに追加してください。[tool.pysen-cli] settings_dir = "path/to/generate/settings"指定したディレクトリが既に設定ファイルを含んでいた場合、pysenはマージします。よって、
settings_dirを指定しなかった時と異なる挙動になるかもしれません。このオプションはpysenのCLIを介して使用する場合のみ適用されることに注意してください。pre-commitやsetuptoolsを使用する場合は、引数に
settings_dirを指定する必要があります。Tips: IDE/テキストエディタ との統合
[訳注] 私がvimやemacsに明るくないので訳がおかしな箇所があるかもしれません。分かりづらい箇所あれば原文をお読みください(修正歓迎です)
vim
pysenの出力するエラーはクイックフィックスウィンドウに次のコードで加えることができます
:cex system("pysen run_files lint --error-format gnu ".expand('%:p'))他にも、pysenを
makeprgに設定する方法もあります
set makeprg=pysen\ run_files\ --error-format\ gnu\ lint\ %そして、
:makeを実行するとクイックフィックスウィンドウにエラーを表示できます。これは、:Dispatchの代わりに:Makeを呼び出す限り、vim-dispatchでも動作します。実行結果は以下のようになります。
Emacs
Comliation modeを参照してください。
以下はpythonのフックの例です。(add-hook 'python-mode-hook (lambda () (set (make-local-variable 'compile-command) (concat "pysen run_files lint --error-format gnu " buffer-file-name))))VSCode
設定例のjsonを参考にしてみてください。実行すると、PROBLEMSウィンドウに以下のようなエラーが表示されます。
※注意※
VSCodeの拡張機能からflake8のようなlinterを別途導入していた場合、重複してエラーが出力される可能性があります。pysenはすべてのファイルをチェックし時間がかかる可能性があります。よって、大規模なプロジェクトにおいて、ファイルの変更をトリガーにしてpysenを実行することは推奨しておりません。pysenの設定
pysenを設定するための方法は2つあります。
- 1つ目の方法は、
project.tomlの[tool.pysen.lint]セクションに書く方法です。この方法は最もシンプルな方法ですが、設定できる事項は限定的です。- 2つ目の方法は、pysenを直接設定するpythonのスクリプトを書く方法です。もし、pysenのコマンドライン引数やpysenの挙動、pysenの生成する設定ファイルをカスタマイズしたい場合、この方法を使うことを推奨します。より詳しい例は
pysen/examplesを参照してください。pyproject.toml で設定する場合
最新のものは
pysen/pyproject_model.pyを参照してください。[訳注]3/29現在、参照先がありませんでした。pysen/project.tomlを参照すれば良いと思います。以下は、基本的な設定例になります。
[tool.pysen] version = "0.9" [tool.pysen.lint] enable_black = true enable_flake8 = true enable_isort = true enable_mypy = true mypy_preset = "strict" line_length = 88 py_version = "py37" isort_known_third_party = ["numpy"] isort_known_first_party = ["pysen"] mypy_ignore_packages = ["pysen.generated.*"] mypy_path = ["stubs"] [[tool.pysen.lint.mypy_targets]] paths = [".", "tests/"] [tool.pysen.lint.source] includes = ["."] include_globs = ["**/*.template"] excludes = ["third_party/"] exclude_globs = ["**/*_grpc.py"] [tool.pysen.lint.mypy_modules."pysen.scripts"] preset = "entry" [tool.pysen.lint.mypy_modules."numpy"] ignore_errors = trueプラグインを設計して、pysenをカスタマイズしよう
内製のツールや設定ファイルの管理、セットアップ用コマンドなどのためにプラグイン用インターフェースを用意しています。
より詳しい内容は、pysen/examples/plugin_exampleを参照してください。開発
私たちの開発環境を運用したい場合は
pipenvが必要になります.
- 環境構築
# setup your environment $ pipenv sync # activate the environment $ pipenv shell
Pipfile.lockの依存関係の更新$ pipenv lock --pre
- 全テストの実行
$ pipenv run toxContributing
pysenの公開レポジトリはPreferred Networksのプライベートレポジトリのミラーです。現在、いかなるプルリクエストも受ける予定はありません。意欲のある開発者様はフォークしてからパッチを適用されることを推奨いたします。
また、私たちの人的リソースにも限りがあるため、Preferred Networks特有の要求を満たす開発を優先せざるを得ないときがあります。そのため、Issueを当面の間、閉鎖致します。心苦しいことではありますが、すべての質問、トラブルシューティング、feature request、バグレポートはすべて
dev/nullにダイレクトします。



- 投稿日:2021-03-29T14:47:42+09:00
Jupyter notebook でtqdmが使えない場合の対処法
使い方
Jupyter notebook または Jupyter lab では次のようにしてtqdmを用います。
from tqdm.notebook import tqdm total = 0 for i in tqdm(range(1,11)): total += iエラーと対処法
次のようなエラーが出た場合、
HBox(children=(IntProgress(value=0, max=5), HTML(value='')))Jupyter notebook の拡張機能がインストールされていないことが原因のため、次の2つをshellで実行してインストールします。
jupyter nbextension enable --py widgetsnbextensionjupyter labextension install @jupyter-widgets/jupyterlab-managerインストール後にnotebookを再起動すれば、 下の図のようなプログレスバーを表示させることができます。
参考

- 投稿日:2021-03-29T14:36:27+09:00
pandas で文字コードがShift-JISであるcsvファイルを読み込む方法
- 投稿日:2021-03-29T14:12:08+09:00
Pandas 構文メモ
- 投稿日:2021-03-29T13:23:12+09:00
PyCharmショートカットキー
よく使うPyCharmのショートカットキーを整理していきます。 移動 メソッドやクラスに移動 Ctrl + B タブ移動 Alt + ← or → 検索 ファイル内検索 Ctrl + Shift + F クラス検索 クラス名で検索する。 Ctrl + N ファイル検索 ファイル名で検索する。 Ctrl + Shift + N リファクタリング ファイルのフォーマット PEP8に合わせてフォーマットする。 Alt + Shift + Enter 名前変更 ファイル名・変数名・メソッド名などを変更する。 Shift + F6 import追加 Alt + Enter import最適化 Ctrl + Alt + O 実行 RUN Shift + F10 RERUN Ctrl + F5
- 投稿日:2021-03-29T13:21:29+09:00
Matplotlib Tips - よく使うコード集 -
今回はMatplotlibについて、自分が良く使うコードの部品を以下に書いていきます。
解説については、冒頭に挙げた参考ページを見ていただければと思います。また、各項目にもリンクを貼ってあります。項目ごとのリンク集としても使えるかなと思います。随時更新していきます。
動作確認:Python 3.7.9、Matplotlib 3.3.1
よく参考にするページ
- グラフの基本構造 -Anatomy of a figure-(本家サイトより)
- Python♪提出資料で使えるmatplotlibグラフ書式例1
- Python♪提出資料で使えるmatplotlibグラフ書式例2
- Python matplotlib 説明図を書いてみる(改訂版)
- matplotlibのめっちゃまとめ
基本設定
import matplotlib.pyplot as plt import numpy as np %matplotlib inline # 日本語の使用 from matplotlib import rcParams rcParams['font.family'] = 'sans-serif' rcParams['font.sans-serif'] = ['Meirio', 'Hiragino Maru Gothic Pro', 'Yu Gothic', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP']色の設定
plotのパターン
Marker character description '.' point marker ',' pixel marker 'o' circle marker 'v' triangle_down marker '^' triangle_up marker '<' triangle_left marker '>' triangle_right marker '1' tri_down marker '2' tri_up marker '3' tri_left marker '4' tri_right marker '8' octagon marker 's' square marker 'p' pentagon marker 'P' plus (filled) marker '*' star marker 'h' hexagon1 marker 'H' hexagon2 marker '+' plus marker 'x' x marker 'X' x (filled) marker 'D' diamond marker 'd' thin_diamond marker '|' vline marker '_' hline marker Line Styles character description '-' solid line style '--' dashed line style '-.' dash-dot line style ':' dotted line styleシンプルなプロット(パターン1)
import matplotlib as mpl import matplotlib.pyplot as plt from matplotlib.ticker import AutoMinorLocator, MultipleLocator import numpy as np #日本語fontの設定 from matplotlib import rcParams rcParams['font.family'] = 'sans-serif' rcParams['font.sans-serif'] = ['Meirio', 'Hiragino Maru Gothic Pro', 'Yu Gothic', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP'] %matplotlib inline # データの作成 x = np.linspace(0, 20, 1000) y1 = 0.8 * np.sin(x) y2 = 0.8 * np.cos(x) # 作図パラメータの設定 figsize = (10, 5) #図のプロットサイズ hspace, wspace = 0.4, 0.4 #プロットの間隔(サブプロットの幅と高さに対する比率(0.2→20%)) xmin, xmax, dx = 0, 20, 1.0 # lower limit, upper limit and increment of of axis ymin, ymax, dy = -1, 1, 0.2 nAutoMinorLoc_x, nAutoMinorLoc_y = 4, 4 # Number of AutoMinorLocator title = 'Fig. Sample1' xlabel, ylabel = 'x軸 [単位]', 'y axis [Unit]' # 作図 fig = plt.figure(figsize=figsize) fig.subplots_adjust(hspace=hspace, wspace=wspace) ax = fig.add_subplot(1, 1, 1) ax.plot(x, y1, linewidth=2, color='royalblue', label="sin x") ax.plot(x, y2, '--', linewidth=1, color='orangered', label="cos x") ax.plot(x[100], y1[100], 'o', markersize=10, markeredgecolor='navy', markeredgewidth=2.0, markerfacecolor='0.8', label='') # 図のタイトル ax.set_title(title, fontsize=20) # 軸の設定 ax.set(xlim=(xmin, xmax), ylim=(ymin, ymax)) ax.set_xlabel(xlabel, fontsize=12) ax.set_ylabel(ylabel, fontsize=12) ax.xaxis.set_major_locator(MultipleLocator(dx)) #指定した数の倍数に主目盛りが設定される ax.xaxis.set_minor_locator(AutoMinorLocator(nAutoMinorLoc_x)) ax.yaxis.set_major_locator(MultipleLocator(dy)) ax.yaxis.set_minor_locator(AutoMinorLocator(nAutoMinorLoc_y)) ax.tick_params(which='both', direction='in', width=1.0, labelsize=12, labelcolor='black') ax.tick_params(which='major', length=6) ax.tick_params(which='minor', length=3); ax.grid(which='major', axis='both', linestyle="-", linewidth=0.5, color='0.5') #, zorder=-10 # y=0のラインの追加 ax.axhline(0, 0, 1, linestyle="-", linewidth=1, color='black') # 凡例の設定 ax.legend(bbox_to_anchor=(1.01, 1), loc='upper left', borderaxespad=0, fontsize=12) # 図の出力 fig.savefig("case1.jpg", bbox_inches='tight', pad_inches=0.1, dpi=200);
以下、更新中
- 投稿日:2021-03-29T12:30:22+09:00
Pythonで月末・月初を取得
メジャーな方法は下記2パターン
・カレンダーで最終日を取得して組み合わせる
・翌月の1日前を計算する翌月の1日前を計算する方が個人的にしっくりくるので書いてみた
from datetime import date,timedelta #月末は「翌月初日の1日前」として計算する year = 2021 for month in range(1,13): month_first_day = date(year,month,1) #月の初日 #date関数は月の引数に13以上が入ると1~12に収めろとエラーするので対応 if month == 12: exec_year = year + 1; next_month = 1 else: exec_year = year; next_month = month + 1 next_month_first_day = date(exec_year,next_month,1) #翌月の初日 month_end_day = next_month_first_day - timedelta(days=1) #月の最終日(翌月の初日-1日) print(str(year)+'年'+str(month).zfill(2)+'月の月初='+str(month_first_day)) print(str(year)+'年'+str(month).zfill(2)+'月の月末='+str(month_end_day))実行結果
2021年01月の月初=2021-01-01 2021年01月の月末=2021-01-31 2021年02月の月初=2021-02-01 2021年02月の月末=2021-02-28 2021年03月の月初=2021-03-01 2021年03月の月末=2021-03-31 2021年04月の月初=2021-04-01 2021年04月の月末=2021-04-30 2021年05月の月初=2021-05-01 2021年05月の月末=2021-05-31 2021年06月の月初=2021-06-01 2021年06月の月末=2021-06-30 2021年07月の月初=2021-07-01 2021年07月の月末=2021-07-31 2021年08月の月初=2021-08-01 2021年08月の月末=2021-08-31 2021年09月の月初=2021-09-01 2021年09月の月末=2021-09-30 2021年10月の月初=2021-10-01 2021年10月の月末=2021-10-31 2021年11月の月初=2021-11-01 2021年11月の月末=2021-11-30 2021年12月の月初=2021-12-01 2021年12月の月末=2021-12-31
- 投稿日:2021-03-29T12:09:25+09:00
pyenvでインストール時に「BUILD FAILED (OS X 10.15.7 using python-build 20180424)」が発生した場合の対処法
概要
macのpyenvでpythonをインストールしようとした際に、以下のエラーが発生しました。
以下の手順で動くようになったので、対処法を記載しますエラー内容
$ pyenv install 3.5.6 : : python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.5.6.tar.xz... -> https://www.python.org/ftp/python/3.5.6/Python-3.5.6.tar.xz Installing Python-3.5.6... python-build: use readline from homebrew python-build: use zlib from xcode sdk BUILD FAILED (OS X 10.15.7 using python-build 20180424)対処法
エラーメッセージに従い、zlibを追加して環境変数に追加することで解決しました
- brewでzlibをインストールする
$ brew install zlib : : ######################################################################## 100.0% ==> Pouring zlib-1.2.11.catalina.bottle.tar.gz ==> Caveats zlib is keg-only, which means it was not symlinked into /usr/local, because macOS already provides this software and installing another version in parallel can cause all kinds of trouble. For compilers to find zlib you may need to set: export LDFLAGS="-L/usr/local/opt/zlib/lib" export CPPFLAGS="-I/usr/local/opt/zlib/include" For pkg-config to find zlib you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/zlib/lib/pkgconfig" ==> Summary ? /usr/local/Cellar/zlib/1.2.11: 12 files, 376.4KB
- シェルの設定ファイルに加える
※zsh以外のシェルを使用している場合、対応する設定ファイルに追記して下さい$ echo 'export LDFLAGS="-L/usr/local/opt/zlib/lib"' >> ~/.zshrc $ echo 'export CPPFLAGS="-I/usr/local/opt/zlib/include"' >> ~/.zshrc $ echo 'export PKG_CONFIG_PATH="/usr/local/opt/zlib/lib/pkgconfig"' >> ~/.zshrc
- ターミナルを再起動する
※ 下記のようにsourceコマンドで設定ファイルを再読み込みしても可能$ source ~/.zshrc参考サイト
- 投稿日:2021-03-29T12:09:17+09:00
当月の祝日を取得
内閣府で公示されている資料をもとに特定の月の祝日の一覧を求めます。内包表記多めです。
資料はWebでCSV形式で公開されているのでPandasを使うと一発です。エンコードがShift_JIS(cp932との厳密な違いはよく知らない)になっているのが注意点です。
Jupyterで実行すると下記のような結果が得られます。
In[1]:
import pandas as pd h_ = pd.read_csv('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv',encoding='cp932') h_Out[1]:
国民の祝日・休日月日 国民の祝日・休日名称 0 1955/1/1 元日 1 1955/1/15 成人の日 2 1955/3/21 春分の日 3 1955/4/29 天皇誕生日 4 1955/5/3 憲法記念日 ... ... ... 970 2022/9/19 敬老の日 971 2022/9/23 秋分の日 972 2022/10/10 スポーツの日 973 2022/11/3 文化の日 974 2022/11/23 勤労感謝の日 975 rows × 2 columns
生まれる前の年代から翌年までの祝日一覧が得られます。今回は日付にしか興味がないのでdatetimeを使ってdate型にします。最後部の40件を表示します。
In[2]:
import datetime [datetime.datetime.strptime(h,'%Y/%m/%d').date() for h in h_['国民の祝日・休日月日']][-40:]Out[2]:
[datetime.date(2020, 7, 23), datetime.date(2020, 7, 24), datetime.date(2020, 8, 10), datetime.date(2020, 9, 21), datetime.date(2020, 9, 22), datetime.date(2020, 11, 3), datetime.date(2020, 11, 23), datetime.date(2021, 1, 1), datetime.date(2021, 1, 11), datetime.date(2021, 2, 11), datetime.date(2021, 2, 23), datetime.date(2021, 3, 20), datetime.date(2021, 4, 29), datetime.date(2021, 5, 3), datetime.date(2021, 5, 4), datetime.date(2021, 5, 5), datetime.date(2021, 7, 22), datetime.date(2021, 7, 23), datetime.date(2021, 8, 8), datetime.date(2021, 8, 9), datetime.date(2021, 9, 20), datetime.date(2021, 9, 23), datetime.date(2021, 11, 3), datetime.date(2021, 11, 23), datetime.date(2022, 1, 1), datetime.date(2022, 1, 10), datetime.date(2022, 2, 11), datetime.date(2022, 2, 23), datetime.date(2022, 3, 21), datetime.date(2022, 4, 29), datetime.date(2022, 5, 3), datetime.date(2022, 5, 4), datetime.date(2022, 5, 5), datetime.date(2022, 7, 18), datetime.date(2022, 8, 11), datetime.date(2022, 9, 19), datetime.date(2022, 9, 23), datetime.date(2022, 10, 10), datetime.date(2022, 11, 3), datetime.date(2022, 11, 23)]
ある月の日付の部分のみを抽出する内包表記です。
(e.year,e.month)==(2021,3)の部分がそのフィルタです。In[3]:
[e.day for e in [datetime.datetime.strptime(h,'%Y/%m/%d').date() for h in h_['国民の祝日・休日月日']] if (e.year,e.month)==(2021,3)]Out[3]:
[20]
上記を総合すると、下記の1行で当月の祝日の日付一覧が得られることになります(長いけど一行です)。
※実行時点で2021年3月末です。In[4]:
[e.day for e in [datetime.datetime.strptime(h,'%Y/%m/%d').date() for h in pd.read_csv('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv',encoding='cp932')['国民の祝日・休日月日']] if (e.year,e.month)==(datetime.datetime.today().year,datetime.datetime.today().month)]Out[4]:
[20]
- 投稿日:2021-03-29T11:40:23+09:00
RDSの自動起動と自動停止スクリプト
RDSは起動しっぱなしだとお金がかかる。
しかし、停止しても7日後に再度起動してしまう。
特に検証用とかで使用しない間が多い場合、いちいち起動したら停止するという運用はかなり面倒。
そのため、検証時以外は、起動したらすぐ停止するというスクリプトを作成して、無駄なコストがかからないようにする。
そこで使用するのが、AWSのLambdaを使う。
Lambdaとは何?
Lambdaと聞いてもわからないので調べた。
AWSの「サーバレスコンピューティングとアプリケーション」と言われる。
これまではPHPやPythonをうごかすためのwebサーバーが必要だったが、Lambdaならサーバーレスのため、サーバーを準備しなくても環境が揃っていると言うことである。
LambdaはJava、Node.js、C#、Pythonのプログラミング言語に対応しているので、各種「機能」(プログラム)はこの言語で開発すればOK、ということのようです。
「S3にアップされた画像のサムネイル化」で考えると、S3に画像ファイルがアップされるのを監視するためのサーバを用意して、監視し続けるプログラムを用意して、ファイルがアップされたことを検知したら、リサイズする処理を行う必要があったのが、Lambdaならこの「リサイズする処理」だけを作ればOKということ。
今回はこのLambdaを利用し、指定された時間に関数を実行すると言うことを実装し、RDSの起動停止を自動で実施する。
流れ
IAMによるロール(権限)作成
IAMページでロールの作成を実施。
「信用されたエンティティの種類を選択」については、「AWS サービス」を選択。「このロールを使用するサービスを選択」は「Lambda」を選択します。
Attach(アタッチ)する権限ポリシーは、
・CloudWatchFullAccess
・AmazonRDSFullAccess
Lambdaの設定でStartとStopの関数を作成
Lambdaで関数を作成する。関数はStartとStopの二つ。
スクリプトは下記を登録する。
import boto3 region = 'ap-northeast-1' instance = 'RDSインスタンス名' def lambda_handler(event, context): rds = boto3.client('rds', region_name=region) rds.start_db_instance(DBInstanceIdentifier=instance) print('started instance: ' + instance)import boto3 region = 'ap-northeast-1' instance = 'RDSインスタンス名' def lambda_handler(event, context): rds = boto3.client('rds', region_name=region) rds.stop_db_instance(DBInstanceIdentifier=instance) print('stoped instance: ' + instance)また、関数起動を自動でやるため、cronで動かすようにも設定する。
cronによる起動はトリガーの追加で「CloudWatch Events」を選択する。
〇RDS の起動時間
cron(15 23 */6 * ? *)〇RDS の停止時間
cron(45 23 0/6 * ? *)テスト
起動が大丈夫かをテストできる。
失敗したらスクリプトをチェックする。
RDS 自動停止を実装する際の実行時間の考え方
設定に関して少し蛇足になりますが、RDS インスタンスが7日後に再起動する仕様について。
コストを下げる基本的な考え方として、AWS 側のシステムで再起動を発生させないことが良いと思います。
そのため一定時間ごとに RDS を起動して1時間以内に停止命令を送る実装をすれば良いです。
※aws は1時間以内の起動時間は1時間の使用としてコストが計上されるため
そこで今回は6日間隔で1時間以内の起動と停止を繰り返す設定を行っています。
つまり毎月1日、7日、13日、19日、25日、29日にスクリプトを実行します。
参考記事

