- 投稿日:2021-03-29T23:13:25+09:00
AWS IoT Coreのカスタムジョブでシェルスクリプトを配信して実行させる
はじめに
今までGreengrassのOTAアップデートを何度か試してきました。
ただ、それだけでなく更新用のファイルを配信→実行までしたい、ということでカスタムジョブを使ってみます。今回は以下の記事を大いに参考にさせていただきました。
参考:AWS IoTのジョブ機能とモノの動的グループを利用してデバイスに配布するソフトウェアを管理する1 必要なファイルの作成
今回はデバイスにシェルスクリプトを配信→実行ができるかまでを検証します。
実行できたことも分かるよう、シェルスクリプトは/tmp配下にログを吐くようなものを作成しました。1.以下の通りシェルスクリプトを作成する
test.sh#!/bin/bash DIR=/tmp FILE=$DIR/"update-test.log" DATE=`date "+%Y-%m-%D %H:%M:%S"` if [ -f $FILE ] ; then touch $FILE fi #/tmp配下に実行時刻を記録する「update-test.log」を作成 echo "$DATE update" >> $FILE次に、ジョブドキュメントを作成します。
今回は参考サイトのものをそのまま利用します。2 配信元S3の作成
1.配信元のS3バケットを作成する
2.S3バケットにtest.shをアップロードする
3.今回は作成したバケットを静的ウェブホスティングで公開しtest.shを取得できるようにする
4.S3のマネジメントコンソールで対象のバケット > アクセス許可タブ の順にクリック
5.ブロックパブリックアクセス (バケット設定)の「編集する」をクリック
6.「パブリックアクセスをすべてブロックする」からチェックを外し、「変更の保存」の順にクリック
7.プロパティタブ > 静的ウェブサイトホスティングの「編集する」の順にクリック
8.以下の通り設定を変更して、「変更の保存」をクリック
- 静的ウェブサイトホスティング:有効にする
- ホスティングタイプ:静的ウェブサイトをホストする
- インデックスドキュメント:test.sh ※配信ファイル
9.アクセス許可タブ > バケットポリシーの「編集する」の順にクリック
10.以下の通りバケットポリシーを設定して「」をクリック{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadGetObject", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::[バケット名]/*" } ] }11.オブジェクトタブでアップロードした配信ファイルをクリック > 「オブジェクトURL」を控える
3 ジョブ実行の準備
次に、ジョブドキュメントとデバイス側でジョブを受けて処理をするプログラムを用意します、
ジョブドキュメントは参考サイトのものをそのまま利用し、デバイスで実行するプログラムは参考サイトのモノに少し手を入れています。1.ローカルでジョブドキュメントを作成する
update-test-0001.json{ "app_url": "先ほどの手順で控えた実行ファイルのオブジェクトURL", "app_version": "2.0" }2.作成したジョブドキュメントをS3にアップロードする
※任意のバケット
3.デバイスで実行プログラムを作成する
※参考サイト同様AWS IoT Device SDK for Pythonのsamples/jobsのjobsSample.pyに少し手を加えた
AWS IoT Device SDK for Pythonの導入は以下を参照のこと(下記手順のあと、作業ディレクトリにjobsSample.pyをコピーして実行した)
参考:モジュール 4: AWS IoT Greengrass グループでのデバイスの操作jobsSample.py#主な修正箇所のみ記載 #---前略--- import threading import logging import time import datetime import argparse import json #以下のライブラリを追加でimport import urllib.request import os import subprocess #---中略--- def executeJob(self, execution): print('Executing job ID, version, number: {}, {}, {}'.format(execution['jobId'], execution['versionNumber'], execution['executionNumber'])) print('With jobDocument: ' + json.dumps(execution['jobDocument'])) #参考サイトよりコピペ、ジョブドキュメントのURLをもとに配信ファイルをダウンロードする app_url = execution['jobDocument']['app_url'] self.app_version = execution['jobDocument']['app_version'] urllib.request.urlretrieve(app_url, 'app.sh') #配信ファイルに実行権限を付与して実行する os.chmod('test.sh', 0o777) subprocess.run('./test.sh') #---後略---4 カスタムジョブの実行
IoT Coreのマネジメントコンソールからジョブを実行し、
test.shの配信と実行を確認します。
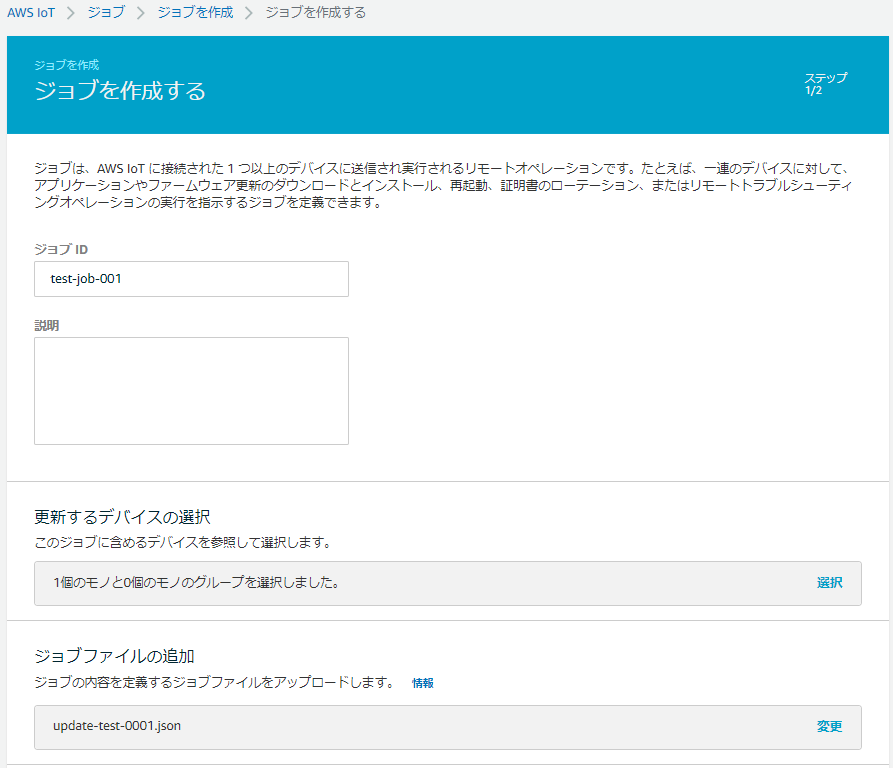
なお、実行中jobsSample.pyから実行結果が$aws/events/配下のtopicに送られてくるので、テスト画面で$aws/events/#をサブスクライブしても状況を見ることができます。1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > ジョブ > ジョブを作成する の順にクリック
2.「カスタムジョブを作成」をクリック
3.以下の通り設定して「次へ」をクリック
- ジョブID:任意の名称 ※ただし既存のジョブIDと被ってはいけない
- 更新するデバイスの選択:任意のデバイスまたはグループ
- ジョブファイルの追加:「3.ジョブ実行の準備」で作成したジョブドキュメントを選択
- ジョブタイプ:ジョブは、選択したデバイス/グループへのデプロイ後に完了します (スナップショット)
4.デフォルト設定のまま「作成」をクリック
5.デバイス側でjobsSample.pyを以下の通り実行するpython jobsSample.py --endpoint [エンドポイントのURL] \ --rootCA [ルートCA証明書] --cert [デバイス証明書] --key [秘密鍵] \ --thingName [モノの名前]6.プロンプトが返ってきたら、マネジメントコンソールでジョブの実行状況を確認する
※詳細画面でジョブドキュメントも確認できる
5 実行結果の確認
まず、デバイスで
jobsSample.pyを実行したディレクトリ(カレントディレクトリ)にtest.shがダウンロードできていました。
以下の通り、権限も変更されています。ls -la test.sh -rwxrwxrwx 1 root root 156 3月 29 20:05 test.shまた、
test.shを実行した証跡として期待通りログが出力されていました。cat /tmp/update-test.log 2021-03-03/29/21 20:05:22 update6 おわりに
当初目的としていた以下は達成できました。
- 実行ファイルを配信する
- 配信したファイルを実行する
以下については今後もう少し工夫してみようと思います
- デバイス側でジョブを処理するプログラムを手動実行しないで済むようにする
- 署名付きURLを使ったジョブの実行
7 参考文献(本文中で登場していないもの)
- AWS IoT Core - Jobs
- AWS IoT ジョブを使う
- AWS IoT SDK for JavaScript - jobs-agent.js
- ジョブドキュメントでいろいろ設定できそうだが今回はうまくいかなかった






- 投稿日:2021-03-29T21:45:09+09:00
AWS Data Pipelineってなんだろ?
名前だけは聞いたことあるけど、どんなサービスなのか知らないので調べてみました。
ドキュメント
AWS Data Pipeline(データの移動や変換を簡単に自動化)| AWS
ざっくり
- データの移動や変換を簡単に自動化
- 指定された間隔で、AWS のサービスやオンプレミスのデータソース間で信頼性の高いデータ処理やデータ移動を行うことを支援するウェブサービス
- 保存場所にあるお客様のデータに定期的にアクセス
- 必要なスケールのリソースで変換と処理を行い、その結果を Amazon S3、Amazon RDS、Amazon DynamoDB、Amazon EMR のような AWS サービスに効率的に転送
- 耐障害性があり、繰り返し可能で、高可用性を備えた、複雑なデータ処理ワークロードを簡単に作成
3行でまとめると、
保存場所にあるデータに定期的にアクセスし、 最低限のリソースで変換や処理を行い、 AWSサービスに転送することができるサービスというかんじでしょうか。
ざっくりメリット
- 信頼性
- 使いやすさ
- 柔軟性
- スケーラブル
- 低コスト
- 透過的
イメージ
AWS Data Pipeline を使用して、クリックストリームデータを Amazon S3 から Amazon Redshift に移動します。よくある質問
よくある質問 - Amazon Data Pipeline | AWS
AWS Data Pipeline とは何ですか?
- AWS クラウドでの定期的なデータ移動やデータ処理といったアクティビティのスケジュールを簡単に設定できるウェブサービス
- Data Pipeline によりオンプレミスとクラウドベースのストレージシステムが統合されるため、開発者はそれらのデータを必要なときに、使用したい場所で、必要な形式で使用できる
- データソース、送信先、および「パイプライン」と呼ばれるデータ処理アクティビティ (あらかじめ定義されたアクティビティまたはカスタムアクティビティ) から成る依存関係をすばやく定義できる
- パイプラインは、定義したスケジュールに基づき、処理アクティビティを定期的に実行
冒頭の3行とほぼ同じですが、
データ処理の流れや方法を定義し、 オンプレとクラウドのデータ移動や処理を スケジュールに基づいて定期的に実行するウェブサービスとまとめてみました。
AWS Data Pipeline を使用して何ができますか?
- パイプラインの準備がすばやく簡単に行えるようになり、日次データ運用の管理に必要な開発とメンテナンスの手間が省けるため、そのデータを基にした将来の予測を立てることに集中できる
- 処理アクティビティの実行とモニタリングは、高い信頼性があり耐障害性を備えたインフラストラクチャ上で行われる
- Amazon S3 と Amazon RDS 間でのデータコピーや、Amazon S3 ログデータに対するクエリの実行など、一般的なアクションの組み込みアクティビティが用意されている
一言でまとめると
本来必要な業務に集中できる
だと思います。そのために、Data Pipelineは「すぐに準備ができて」、「信頼性と耐障害性を備え」、「よくある処理は準備されている」ということだと思います。
AWS Data Pipeline と Amazon Simple Workflow Service の違いは何ですか?
- 両サービスとも、追跡、再試行、例外処理、任意のアクションの実行といった機能を提供
- AWS Data Pipeline では特にデータ駆動型ワークフローの大半に共通する特定の手順を簡素化
- 入力データが特定の準備基準に一致した場合にアクティビティを実行する、異なるデータストア間で簡単にデータをコピーする、変換スケジュールを簡単に設定するなど
- Data Pipeline は特定の手順に高度に特化しているため、コーディングやプログラミングの知識がなくても、ワークフロー定義を簡単に作成できる
「よく行われる処理は手順を簡素化してるから、プログラミングできなくても使える」というのがData Pipelineの特徴のようです。
「よく行われる処理」の例として、「データストア間で簡単にデータをコピーする」などが挙げられています。パイプラインとは何ですか?
- AWS Data Pipeline のリソース
- データソースの依存関係の定義、送信先、およびビジネスロジックの実行に必要な定義済みまたはカスタムのデータ処理アクティビティなど
冒頭の図全体をイメージし、Data Pipeline全体で扱うリソースと捉えました。
データノードとは何ですか?
- お客様のビジネスデータを表したもの
- 例えば、データノードは特定の Amazon S3 パスを参照できる
- s3://example-bucket/my-logs/logdata-#{scheduledStartTime('YYYY-MM-dd-HH')}.tgz のように指定
データそのものではなく、データのある場所を示す用語というかんじがします。
アクティビティとは何ですか?
- AWS Data Pipeline がパイプラインの一部としてお客様の代わりに実行するアクション
- 例としては、EMR または Hive ジョブ、コピー、SQL クエリ、コマンドラインスクリプトなど
シンプルに考えると、実際の処理のことだと思います。
前提条件とは何ですか?
- 準備状況のチェックのこと
- オプションでデータソースまたはアクティビティに関連付けることができる
- データソースに前提条件チェックがある場合、そのデータソースを使用するアクティビティが起動される前に、その前提条件チェックが正常に完了しなければならない
- アクティビティに前提条件がある場合は、アクティビティが実行される前に前提条件チェックが正常に完了しなければならない
- 高額なコンピューティングアクティビティを実行していて、一定の基準を満たすまではそのアクティビティを実行すべきでない場合に有用
処理を開始するための条件だと思います。
以下のような流れになりそうです。条件をチェック → チェックが正常に完了 → 処理実行例として、処理に結構なお金がかかる場合が挙げられています。
「途中までやったけど失敗した」となると、その分も課金されてしまうので、条件をクリアするまでは実行しないという使い方が良いと記述されています。スケジュールとは何ですか?
- パイプラインのアクティビティが実行されるタイミング、およびサービスがお客様のデータを利用できると想定する頻度
- すべてのスケジュールには開始日と頻度の設定が必要
- オプションで終了日を指定できる
- 終了日以降は、AWS Data Pipeline サービスはいかなるアクティビティも実行しない
処理のタイミングと頻度ですね。
必須なのは「開始日」、「頻度」で
オプションで「終了日」の指定ができるようです。
終了日以降は何もしないことも記述されていますね。いったんまとめてみる
ここまでを簡単にまとめてみます。
- オンプレとクラウドのデータ移動や処理を、スケジュールに基づいて定期的に実行するウェブサービス
- よく行われる処理は手順を簡素化してるから、プログラミングできなくても使える
- パイプラインとは、Data Pipeline全体で扱うリソース
- データノードは、データのある場所を示す
- アクティビティは、実行するアクション
- 前提条件とは、処理を開始するための条件
- スケジュールには開始日、頻度、終了日(オプション)を指定する
ドキュメント以外
今日もお世話になります。
AWS再入門 AWS Data Pipeline編 | DevelopersIOポイント
- AWSのマネージドサービスである
- ノード間でのデータ移行やETL処理を実行することができる
- 一般的なスケジューラの機能を持っている(時間指定やサイクリック、依存関係設定など)
- オンプレの処理にも使える
- Data Pipelineはあくまでデータ移行に関するベースの機能を提供
- データの変換と加工については、別途プログラミングが必要
ドキュメントに記載されている「プログラミング不要」というのは「データ移行に関しては」の話だったんですね。
AWSのマネージドサービスである
ハードの調達や管理、運用などなど面倒なことはAWSにお任せってやつですね。
データ移行やETL処理を実行することができる
- 開発用のGUI
- AWSサービス間の単純なデータ移行くらいであれば、簡単なマウスとキーボードの操作だけで処理を作り、実行できる
- 複雑な変換や加工の処理を実行したい場合でも、自前で開発したプログラムをData Pipelineで実行させることができる
ドキュメントにも、「ウェブサービス」としての提供と書かれていましたね。
専用のGUIで簡単にできる部分は簡単にでき、自前のプログラムも実行できるようです。一般的なスケジューラの機能を持っている
- 複数に分割されたデータ移行やETL処理を連携して実行できる
- 意図した時間に実行できる
- サイクリック実行も可能
- エラーになった場合のアクションも設定可能
単なるスケジューラではなく、エラー時のアクションも設定できるのもいいですね。
オンプレの処理にも使える
- Task RunnerというJavaのプログラムをインストールするだけで、オンプレのサーバだとしてもData Pipelineで扱うことができるようになる
これでクラウドでもオンプレでもデータ移動などができるようになるんですね。
ユースケース
図をお借りします。
既存のRDBからRedshiftにデータを投入するパターンということです。
- 既存のRDBからはS3に対してソースデータをエクスポート
- Redshiftのテーブルに合わせて変換と加工
- 最終的にRedshiftにインポート
いったんまとめからの追加
- データの変換と加工については、別途プログラミングが必要
- 自前で開発したプログラムをData Pipelineで実行可能
- エラー時のアクションも設定可能
- Task RunnerというJavaのプログラムをインストールしてオンプレで利用する
ちょっとコンソールを覗いてみる
実際に試すのは次の機会として、コンソールだけチラ見してみます。
パイプラインの設定
処理のテンプレート
スケジュールの設定
パイプラインのログ設定かな?
IAMによるアクセス権限の設定
タグ
GUI
Step Functionを触ったことがあるのでとても親近感が沸きます
これだけ見ると、確かに簡単なデータ移動だけならノーコーディング & GUIでササっとできそうです。
まとめ
今回はAWS Data Pipelineの基本について勉強してみました。
何となく難しそうだと思っていましたが、簡単な処理の構築なら触れそうなサービスだということが分かりました。
今度は実際に触ってみる時間も作りたいと思います。基本的な内容ですが、どなたかの参考になれば幸いです。
ご覧頂きありがとうございました!










- 投稿日:2021-03-29T21:41:58+09:00
【備忘録】Greengrass(V1)のMQTTサーバ証明書について
1 概要
Greengrass(V1)では、GreengrassデバイスがGreengrassコアデバイス(以下、コアデバイス)接続する際にグループ証明書を使っています。
Greengrassデバイスはデバイス証明書を用いてコアデバイスのMQTTサーバ証明書を検証します。
参考:AWS IoT Greengrass セキュリティの概要コアデバイスのMQTTサーバ証明書はデフォルトの有効期限が7日間となっています。
有効期限が切れる前のタイミングでコアデバイスがIoT Greengrassサービス(クラウド側)に接続し、新たなMQTTサーバ証明書を取得します。
当然、このタイミングでクラウド側と接続できる必要があります。MQTTサーバ証明書の有効期限はデフォルトの7日から30日まで変更できます。
ベストプラクティスは短い期間でのローテーションです。
※ただし、申請すれば31日以上にもできるとのこと
参考:AWS IoT Greengrass のデバイス認証と認可 - ローカル MQTT サーバーの証明書ローテーションMQTTサーバ証明書の更新はマネジメントコンソールから手動でも可能です。
今回は触ってみた際の結果を残しておきます。2 更新してみる
MQTTサーバ証明書を更新すると、MQTTサーバがいったん再起動するため、接続がいったん切断されます。
また、Greengrassデバイスはグループ証明書の再取得が必要になります。
今回は、AWS IoT Device SDK for PythonのSample実行時にどのような挙動をしたか備忘録として残します。
※サンプルコードの中身をまだ十分咀嚼できていないので、目に見える動きと試した手順を残すに留める1.IoT Coreのマネジメントコンソールで左のメニューから Greengrass > クラシック(V1) > グループ の順にクリック
2.対象のグループをクリックし、設定 をクリック
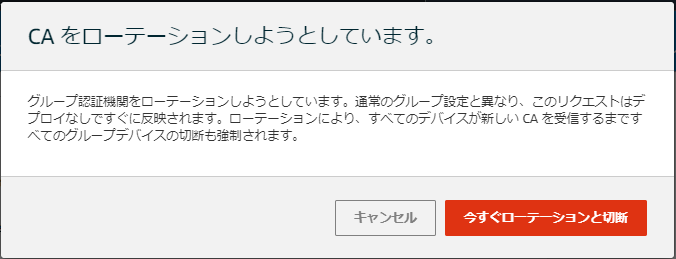
3.「CAのローテーション」をクリックし、モーダルウィンドウで「今すぐローテーションと切断」をクリック
4.画面上部に「グループのCAが正常にローテーションされました」と表示されたら完了
3 結果
どのファイルが更新されているのか、ローテーション時に動いていたコアデバイス-Greengrassデバイス間のメッセージのやり取りがどうなっていたかの備忘録です。
更新されたファイル
ローテーションの実行は
/greengrass/ggc/var/log/system/GGDeviceCertificateManager.logに記載がありました。GGDeviceCertificateManager.log[2021-03-29T21:17:54.888+09:00][INFO]-Message from cloud {"topic": "$aws/things/Greengrass_Test_Core_20210308-gcm/shadow/update/delta"} [2021-03-29T21:17:54.888+09:00][INFO]-New CertificateManagerService version: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx [2021-03-29T21:17:54.888+09:00][INFO]-Starting the workflow of Certificate generationファイルとしては、以下が更新されていました。
- /greengrass/ggc/var/state/server/server.crt
- /greengrass/ggc/var/state/server/server.key
グループ内でのMQTTのやり取り
今回は、AWS IoT SDK for Pythonの samples/greengrass にある
basicDiscovery.pyを実行しています。
GitHub:AWS IoT SDK for Python
※AWS IoT SDK for PythonのインストールとbasicDiscovery.pyの実行までの手順は以下を参照のこと
モジュール 4: AWS IoT Greengrass グループでのデバイスの操作MQTTサーバ証明書をローテーションする前のタイミングから、2台のGreengrassデバイス(ラズパイとMac)でそれぞれ以下を実施していました。
- ラズパイ:MQTTメッセージを送り続ける
- Mac:MQTTメッセージをサブスクライブし続ける
結果として、ローテーションのタイミングでいずれもいったん処理が止まりました。
ラズパイは少しの停止後、再度メッセージを送り続けていましたが、Mac側はサブスクライブは再開しませんでした。なお、グループ証明書は
basicDiscovery.pyを実行したディレクトリ(カレントディレクトリで実行した)にgroupCA/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx_CA_xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx.crtとして取得されました。4 おわりに
MQTTサーバ証明書のローテーション後、再接続、グループCAの再取得が必要になります。
サンプルコードでどのようにしているか整理し、次は自身でプログラムを書いてみようと思います。5 参考文献(文中で登場していないもの)


- 投稿日:2021-03-29T20:30:18+09:00
AWS AmplifyでWebアプリケーションを作ってみた
背景
自己紹介
エンジニア1年目です。あと3日で2年目突入です(!)。1年間あっという間でした。AWSを使ったWebアプリケーションに興味を持っています。FacebookやTwitterのように世界中から利用されるうようなアプリを自分でも作ってみたいです。クラウドプラクティショナーの資格を持っています。SAAは先日受験しましたが落ちました。AWSは8ヵ月程度の経験があります。普段はEC2やEFSを使うことが多いです。
作成に関して
作成期間は15日です。最低限の実装はできたと思い、今回紹介することにしました。スタイルはbootstrapを使っているくらいでほとんど手をつけていません。今後の課題です。
苦労したこと
業務ではまったく違うことをしているのでWebアプリケーションの勉強は土日・帰宅後に取り組んでいます。帰宅後だとなかなか時間が取れず、その日の開発がハマって終わるのが辛かったです。アプリの開発もしたい、資格の勉強もしたいということでとにかく時間が足りないです。開発面では非同期処理にとても苦労しました。まだ理解が足りていない点が多いです。
今後の課題
- 更新ボタンや戻るボタンを実装せずとも、ユーザー情報を保持できるようにする
- ログアウト機能
- スタイルを整える
- 非同期処理の勉強
- セキュリティについての基礎知識
構成図
どんなアプリか
URLはこちらになります。
https://www.irreg-yuta.com用語メモアプリです。以下の機能を実装しました。
- メモしたい用語を登録する
- 登録した用語の一覧を表示する
- 登録した用語の中から検索する
参考記事
本記事では引用していませんが、作成するにあたって参考にした記事です。


- 投稿日:2021-03-29T20:19:49+09:00
Red Hat OpenShift Service on AWS (ROSA) Walkthrough
はじめに
やっとROSA(Red Hat OpenShift Service on AWS)がGAされました。- AWSのブログに以下文言がありましたが、OpenShiftが実家になりつつある人々にはGood newsなのです。
we are continually thinking about how we can make them feel at home on AWS.- 尚、以降の手順等はかなり適当に実行しているので、誤りやセキュリティ的な問題を抱えているものがあると思います。悪しからず。
ROSAとは
- 詳細は、AWSのサイト、若しくは、Red Hatのサイトを参照しましょう。
- 有り体に言えば、OpenShiftのControl PlaneやData Planeの運用・管理をAWSやRed HatのSREチームと共有できるサービスと理解しています。
- 既にARO(Azure)やROKS(IBM Cloud)といった、Managed OpenShiftは世の中に出ており、ROSA(AWS)もこれらと同等のサービスなのでしょう。
ROSAのドキュメント
- 前提条件
- クラスタ作成に必要なIAM、SCP権限、アクセス要件、セキュリティ要件などが記載されています。
- クイックスタート
- クイックスタートを含む、ROSAのドキュメントリソースが詰まっていました。
- 役割分担
- Red Hat・AWSと利用者の役割分担のマトリクスが記載されています。
ROSAの前提条件
当該ページにはいくつか重要なことが記載されています。
- ROSAのクラスターは、AWS Organizationのサブアカウント上でホストすることを推奨している
- サブアカウントにはSCPが適用できるので、サブアカウント内で扱えるアクセスを許可を制限できるから(Red HatのSREチームのアクティビティを制限できるから)
- Red HatのSREチームは、SCPを制御することはできない
- ROSAのクラスターを管理するために必要なアクセス許可(
AdministratorAccess)をRedHatに与えるお、おう。(汗
きっと、役割分担の話なのだろうけど、利用者は真面目にPolicy切らないと、いろんなリスクシナリオが出来上がっちゃいそうな気がするのです。規約みたいなものがあるのかな。利用者側の前提条件
利用者側の前提条件が記載されています。(自分の理解を書いたので、誤りがあるかも)
Account
- ROSAをサポートするのに十分なリソースが確保できる。
- ROSAをデプロイするAWSアカウントはSCPが適用されたAWS Organizationに属している必要がある。
- OrganizationやSCPは必須ではないけど、後述にリストされているすべてのアクションを実行できる権限を持っている。
- AWSアカウントをRedHatに譲渡するような構成にしない。
- SREチームの活動に対し、使用制限を課すことはできない。制限を課すと著しくサービスレベルが下がるため。
Access requirements
- ROSAを適切に管理するには、RedHatがAdministratorAccessが適用された管理者ロールを持つ必要がある。
- Red Hatは、AWSコンソールへのアクセスが必要となる。このアクセスは、RedHatによって保護および管理されている。
- 利用者は、パーミッションを昇格させるためにROSA内でAWSアカウントを利用してはいけない。
- (ちょっと意味がわからない。文字通りAWSアカウントの強い権限の行使が駄目なのか、Assume Roleが駄目なのか、SecretにAccess KeyやSecretを持つのが駄目なのか?)
- ROSA CLI、または、OCMはAWSアカウントで直接実行してはいけない。
Support requirements
- AWSのBusiness Supportに入ることを推奨とする。
- Red Hatは、利用者に代わってAWS Supportをリクエストする権限を持つ。
- Red Hatは、利用者に代わってAWSの上限緩和申請をリクエストする権限を持つ。
- Red Hatは、特に指定されていない限り、AWSクラスター上のすべてのROSAを同じ方法で管理する。
Security requirements
- ボリュームのスナップショットは、利用者が指定したAWSアカウント内、リージョン内に残る。
- Red Hatは、許可されたIPアドレスからEC2、及び、APIへのアクセス権を持っている必要がある。
- システムログと監査ログをRedHatが管理するログスタックに転送するアクセスが許可されている必要がある。
かなり強い権限、接点をRed HatのSREチームに許可しないといけないようです。
利用者側の必要な手順
続いて、利用者側での手順です。
AWS Organization管理下の既存、または、新規のAWSアカウントを用意する
AWS Organizationのドキュメントを参照しながら作成します。
Red Hatが必要なアクションを実行できるようにするために、SCPを作成する
SCPのドキュメントを参照しながら作成します。
適用するポリシーは以下の通りです。ガバガバだなあ、どこまで制限していいのだろう。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "autoscaling:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "s3:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "iam:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "elasticloadbalancing:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "cloudwatch:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "events:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "logs:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "support:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "kms:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "sts:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "tag:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "route53:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "servicequotas:ListServices", "servicequotas:GetRequestedServiceQuotaChange", "servicequotas:GetServiceQuota", "servicequotas:RequestServiceQuotaIncrease", "servicequotas:ListServiceQuotas" ], "Resource": [ "*" ] } ] }SCPをAWSアカウントに紐付ける
AWS Organization → アカウント → 作成したアカウントを選択します。
さらに、画面右部に表示されるメニューより、サービスコントロールポリシーを選択します。
そこで、先程作成したSCPをアタッチします。(Full-Accessはデタッチ必要?必要そうな気がする。)
Red Hatが使うIAM User
Red Hatは、以下のIAM Policy、IAM User、IAM Roleを作成し、管理をするとのことです。
- IAM Policy
AdministratorAccessを利用- IAM User
osdManagedAdminを利用(勝手に作成される)ROSAが作成するAWSリソース
ROSAの構成の概要は以下の通り。
結構派手に使いますね~。普段、ローカルでOpenShift動かしてヾ(´∀`)ノキャッキャしてる勢には辛い。
- EC2
- Three m5.xlarge minimum (control plane nodes)
- Two m5.xlarge minimum (infrastructure nodes)
- Two m5.xlarge minimum but highly variable (worker nodes)
- EBS
- Control Plane Volume
- Size: 350GB
- Type: io1
- Input/Output Operations Per Second: 1000
- Infrastructure Volume
- Size: 300GB
- Type: gp2
- Input/Output Operations Per Second: 100
- Worker Volume
- Size: 300GB
- Type: gp2
- Input/Output Operations Per Second: 100
- ELB
- NLBが2つ(API用)、ELBが最大2つ(アプリ用)
- S3
- EBSのスナップショット用に使う
- VPC
- 1つのクラスタに対し、1VPC
- Subnet
- 1つのAZの場合は2つのSubnet。複数のAZの場合は6つのSubnet。
- Router tables
- PrivateのSubnet毎に、1つのRoute Table。更に1つのクラスタ毎に1つの追加のRoute Table。
- Internet gateways
- 1つのクラスタ毎に1つのIGW。
- NAT gateways
- PublicのSubnet毎に1つのNAT Gateway。
- Security groups
環境のセットアップ
環境のセットアップをする。
Red Hat アカウントを作成する
ROSAのインストールに必要とのことです。アカウント作成手順は省略します(既に持っているので)。
アカウント作成後はこちらのURLからトークンを取得できます。ROSAを有効化する
Organizationで作成したAWSアカウントのROSAにアクセスし、Enable OpenShiftをクリックします。
有効化後は以下の表示になります。
AWS CLIをセットアップする
CloudShell上でAWS CLIをセットアップしていきます。ドキュメントはこちらを参照のこと。
ただ、ここで使用するIAM Userに紐づくIAM Policyなどの指示が無い気がします。ここでは適当にAdministratorAccessを持つIAM Userを利用することとします。$ aws configure AWS Access Key ID [None]: ...snip... AWS Secret Access Key [None]: ...snip... Default region name [None]: ap-northeast-1 Default output format [None]: json $ aws sts get-caller-identity { "UserId": "...snip...", "Account": "...snip...", "Arn": "arn:aws:iam::...snip...:user/rosaCli" }ROSA CLIをインストールする
curlでダウンロードして、展開する。
$ curl -OL https://mirror.openshift.com/pub/openshift-v4/x86_64/clients/rosa/latest/rosa-linux.tar.gz % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 14.8M 100 14.8M 0 0 2350k 0 0:00:06 0:00:06 --:--:-- 3284k $ sudo tar -zxvf rosa-linux.tar.gz -C /usr/local/bin/ rosa $ rosa Command line tool for Red Hat OpenShift Service on AWS. Usage: rosa [command] Available Commands: completion Generates bash completion scripts create Create a resource from stdin ...snip...前提条件等の確認
十分な権限を持っているかを確認します。
$ rosa verify permissions I: Validating SCP policies... I: AWS SCP policies ok十分なサービスクオータがあるかを確認します。
$ rosa verify quota --region=ap-northeast-1 I: Validating AWS quota... E: Insufficient AWS quotas E: Service ec2 quota code L-1216C47A Running On-Demand Standard (A, C, D, H, I, M, R, T, Z) instances not valid, expected quota of at least 100, but got 5EC2インスタンスのクオータ設定が少なすぎるようでした...。
上限緩和申請後に、リトライします。
$ rosa verify quota --region=ap-northeast-1 I: Validating AWS quota... I: AWS quota okrosaコマンドでログインします。ここのトークンは先程Red Hatのサイトから取得したものを使います。
$ rosa login --token="\ eyJ ...snip..." I: Logged in as 'rh-rosa-user' on 'https://api.openshift.com'Red HatとAWSの認証情報がセットアップされていることを確認します。
$ rosa whoami AWS Account ID: ...snip... AWS Default Region: ap-northeast-1 AWS ARN: arn:aws:iam::...snip...:user/rosaCli OCM API: https://api.openshift.com OCM Account ID: ...snip... OCM Account Name: ...snip... OCM Account Username: 1ksen OCM Account Email: ...snip...@...snip... OCM Organization ID: ...snip... OCM Organization Name: ...snip... OCM Organization External ID: ...snip...良い感じですね。
初期化処理
ここまでで、準備は一通り完了です。いざ、初期化処理の実行へ。
$ rosa init I: Logged in as '1ksen' on 'https://api.openshift.com' I: Validating AWS credentials... I: AWS credentials are valid! I: Validating SCP policies... I: AWS SCP policies ok I: Validating AWS quota... I: AWS quota ok I: Ensuring cluster administrator user 'osdCcsAdmin'... I: Admin user 'osdCcsAdmin' created successfully! I: Validating SCP policies for 'osdCcsAdmin'... I: AWS SCP policies ok I: Validating cluster creation... I: Cluster creation valid I: Verifying whether OpenShift command-line tool is available... W: OpenShift command-line tool is not installed. Run 'rosa download oc' to download the latest version, then add it to your PATH.この
rosa initの処理では、CloudFormationのテンプレートが実行されているとのこと。
一応内容を確認しますが、rosa whoamiで、ap-northeast-1を指定しているのに、CFnのStackはus-east-1で作成されていました。
IAMに関するStackって、ap-northeast-1からでも作れなかったっけ。まあ、いっか。
内容自体はAdministratorAccessのPolicyを要求するosdCcsAdminというIAM Userが作成されています。(IAM User)$ aws cloudformation describe-stacks --region us-east-1 { "Stacks": [ { "StackId": "arn:aws:cloudformation:us-east-1:...snip...:stack/osdCcsAdminIAMUser/...snip...", "StackName": "osdCcsAdminIAMUser", "CreationTime": "...snip...", "RollbackConfiguration": {}, "StackStatus": "CREATE_COMPLETE", "DisableRollback": false, "NotificationARNs": [], "Capabilities": [ "CAPABILITY_IAM", "CAPABILITY_NAMED_IAM" ], "Tags": [], "DriftInformation": { "StackDriftStatus": "NOT_CHECKED" } } ] } $ aws cloudformation get-template --stack-name osdCcsAdminIAMUser --region us-east-1 { "TemplateBody": { "Resources": { "osdCcsAdmin": { "Type": "AWS::IAM::User", "Properties": { "ManagedPolicyArns": [ "arn:aws:iam::aws:policy/AdministratorAccess" ], "UserName": "osdCcsAdmin" } } } }, "StagesAvailable": [ "Original", "Processed" ] }ocコマンドのセットアップ
rosaコマンドからダウンロードできるようです。
$ rosa download oc I: Verifying whether OpenShift command-line tool is available... W: OpenShift command-line tool is not installed. Run 'rosa download oc' to download the latest version, then add it to your PATH. I: Downloading https://mirror.openshift.com/pub/openshift-v4/clients/ocp/latest/openshift-client-linux.tar.gz Downloading... 24 MB complete I: Successfully downloaded openshift-client-linux.tar.gz $ ls openshift-client-linux.tar.gz rosa-linux.tar.gz $ sudo tar zxvf openshift-client-linux.tar.gz -C /usr/local/bin/ README.md oc kubectl $ rosa verify oc I: Verifying whether OpenShift command-line tool is available... I: Current OpenShift Client Version: 4.7.3ROSA Clusterの作成
クラスタを作成します。
※ドキュメントの例では15文字以上のcluster-nameを指定しているのに、実際は通らないです。$ rosa create cluster --cluster-name=rosa-poc-cluster1 E: Cluster name must consist of no more than 15 lowercase alphanumeric characters or '-', start with a letter, and end with an alphanumeric character. $ rosa create cluster --cluster-name=rosa-poc-1 I: Creating cluster 'rosa-poc-1' I: To view a list of clusters and their status, run 'rosa list clusters' I: Cluster 'rosa-poc-1' has been created. I: Once the cluster is installed you will need to add an Identity Provider before you can login into the cluster. See 'rosa create idp --help' for more information. I: To determine when your cluster is Ready, run 'rosa describe cluster -c rosa-poc-1'. I: To watch your cluster installation logs, run 'rosa logs install -c rosa-poc-1 --watch'. Name: rosa-poc-1 ID: ...snip... External ID: OpenShift Version: Channel Group: stable DNS: rosa-poc-1....snip....openshiftapps.com AWS Account: ...snip... API URL: Console URL: Region: ap-northeast-1 Multi-AZ: false Nodes: - Master: 3 - Infra: 2 - Compute: 2 (m5.xlarge) Network: - Service CIDR: 172.30.0.0/16 - Machine CIDR: 10.0.0.0/16 - Pod CIDR: 10.128.0.0/14 - Host Prefix: /23 State: pending (Preparing account) Private: No Created: ...snip... Details Page: https://cloud.redhat.com/openshift/details/...snip...尚、オプション指定せずに実行すると、Single-AZの構成となるみたいです。
オプションは多く受け付けられるようになっており、本番向けには設計しないとですね。$ rosa create cluster --help Create cluster. Usage: rosa create cluster [flags] Examples: # Create a cluster named "mycluster" rosa create cluster --cluster-name=mycluster # Create a cluster in the us-east-2 region rosa create cluster --cluster-name=mycluster --region=us-east-2 Flags: -c, --cluster-name string Name of the cluster. This will be used when generating a sub-domain for your cluster on openshiftapps.com. ...snip...クラスタの構築には40分程度かかるみたい。
rosa describe clusterコマンドで確認できます。
※ドキュメントには-cのオプション記載が無いが、実際は必要でした。$ rosa describe cluster -c rosa-poc-1 Name: rosa-poc-1 ID: ...snip... External ID: ...snip... OpenShift Version: Channel Group: stable DNS: rosa-poc-1....snip....openshiftapps.com AWS Account: ...snip... API URL: Console URL: Region: ap-northeast-1 Multi-AZ: false Nodes: - Master: 3 - Infra: 2 - Compute: 2 (m5.xlarge) Network: - Service CIDR: 172.30.0.0/16 - Machine CIDR: 10.0.0.0/16 - Pod CIDR: 10.128.0.0/14 - Host Prefix: /23 State: installing Private: No Created: ...snip... Details Page: https://cloud.redhat.com/openshift/details/...snip...ふと、us-east-1のEC2インスタンスを見たところ、クラスタ作成時に何かが作られた形跡があります。bootstrap的な何かなんだろうけど、特定リージョンしか許可されていないOrganization Unitなら悲しい気持ちになりそう?
$ aws ec2 describe-instances --region us-east-1 { "Reservations": [ { "Groups": [], "Instances": [ { "AmiLaunchIndex": 0, "ImageId": "ami-000db10762d0c4c05", ...snip...ROSA Clusterへのアクセス
40分後、再度
rosa describe clusterコマンドで確認します。$ rosa describe cluster -c rosa-poc-1 | grep State: State: ready
rosa create adminコマンドで、ログインパスワードの払い出しをします。
尚、この手順の実行前にIdPやLDAPとの統合をおすすめされています。真面目に作るときは適用しましょう。$ rosa create admin -c rosa-poc-1 W: It is recommended to add an identity provider to login to this cluster. See 'rosa create idp --help' for more information. I: Admin account has been added to cluster 'rosa-poc-1'. I: Please securely store this generated password. If you lose this password you can delete and recreate the cluster admin user. I: To login, run the following command: oc login https://api.rosa-poc-1....snip....openshiftapps.com:6443 --username cluster-admin --password ...snip... I: It may take up to a minute for the account to become active.
oc loginします。$ oc login https://api.rosa-poc-1....snip....openshiftapps.com:6443 --username cluster-admin --password ...snip... $ oc whoami cluster-adminWeb Consoleへもアクセスしてみます。
$ rosa describe cluster -c rosa-poc-1 | grep Console Console URL: https://console-openshift-console.apps.rosa-poc-1.xcfa.p1.openshiftapps.comブラウザでアクセスすると、以下の通り。SREチームもここから入ってくるのね。
先程の
rosa create adminで作成されたcluster-adminでログインします。
なんとかなったね?
ROSA Clusterの削除
個人でお試しするにはお財布に厳しいので
rosa delete clusterコマンド、rosa initコマンドで削除します。グッバイ?$ rosa delete cluster --cluster=rosa-poc-1 --watch ? Are you sure you want to delete cluster rosa-poc-1? Yes I: Cluster 'rosa-poc-1' will start uninstalling now W: Logs for cluster 'rosa-poc-1' are not available ...snip... $ rosa init --delete-stack I: Logged in as '1ksen' on 'https://api.openshift.com' I: Validating AWS credentials... I: AWS credentials are valid! I: Deleting cluster administrator user 'osdCcsAdmin'... I: Admin user 'osdCcsAdmin' deleted successfully!ROSAがGAされました
また、時間あるときに触ってみよう。以下はメモです。
- 簡単にOpenShiftのクラスタのセットアップが可能。しかもRed HatのSREチームが面倒を見てくれるし、on EC2より安い!
- 組織のポリシーと設計を踏まえた事前の仕込み(SCPの折り合い、`rosa create clusterの引数)が非常に大変そう。
- 恐らく、事前の仕込みを捗らせるには、役割分担の理解が重要になりそう。
- ROSAが持っている権限を用いるアプリケーションアーキテクチャの場合、SREの権限でs3覗けたり、鍵消せたりしちゃう気がするのだけど、このへんのPolicy設計どうするのだろう。
おしまい。








- 投稿日:2021-03-29T20:12:25+09:00
AWS主要サービス概要
はじめに
今回、普段利用しているAWSについて一から勉強し直すことにしました。
それに伴い、自分なりにまとめた内容をここにまとめていきます。そもそもAWSとは
AWSサービス開始までの経緯
AWS(Amazon Web Service)は、Amazon社が提供するクラウドサービスです。
元々、Amazon社が自社のサイト、Amazonがどんどん大きくなり、世界有数のECサイトへと成長しました。
しかし、成長する上でさらなるビジネス課題が生まれました。
- リコメンド等で活用するために、過去の注文履歴を保存しておきたい。
- Amazonアソシエイト(アフィリエイト)プログラムの支払い計算の遅延
これらの他にもビジネスが成長する過程で様々な課題が生まれました。
これらの課題を解決するために、Amazon社は自前でクラウド上でのコンピューティングサービスやサーバを自社のためだけでなく、一般向けにサービスとして提供することとなりました。
こういった経緯で2006年にオンラインストレージのAmazon Simple Storage Service(S3)と、仮想コンピュータであるAmazon Elastic Compute Cloud(EC2)をもって、AWSがサービス開始されました。
*AWSとしてのサービス開始以前にキューサービスであるAmazon Simple Queue Service(SQS)が2004年に開始されています。
*クラウドコンピューティング(Wikipediaより)
「クラウド(クラウドサービス、クラウドコンピューティング)」とは、クラウドサービスプラットフォームからインターネット経由でコンピューティング、データベース、ストレージ、アプリケーションをはじめとした、さまざまな IT リソースをオンデマンドで利用することができるサービスの総称です。クラウドサービスでは、必要なときに必要な量のリソースへ簡単にアクセスすることができ、ご利用料金は 実際に使った分のお支払いのみといった従量課金が一般的です。クラウドコンピューティングのサービス形態
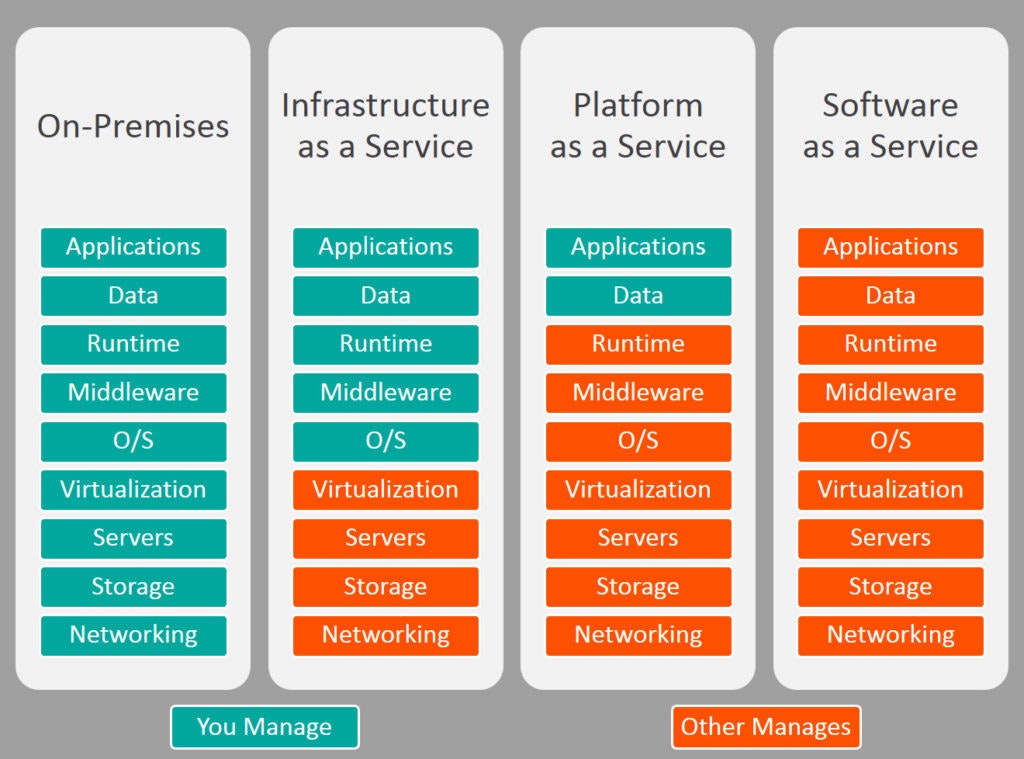
クラウドコンピューティングサービスにも様々な形態があります。
左から、オンプレミス、IaaS、PaaS、SaaSといったように分かれます。
オンプレミス
自身で物理的にサーバを用意し、ネットワークからアプリケーションまで全て自前で用意する形態。
個人で導入するにはハードルが高い。IaaS(Infrastructure as a Service)
仮想サーバやストレージ等のリソースをインターネット経由で提供するサービス形態。
ユーザーはOSより上のレイヤーを管理する必要があります。
物理的なハードウェアを用意する必要がないため、オンプレミスより導入コストが低い傾向にあります。AWSでのサービス例) EC2
PaaS(Platform as a Service)
データベースやアプリケーションサーバなどのミドルウェアを提供するサービス形態。
IaaSよりも管理する範囲が狭くなり、アプリケーションやデータのみを管理すれば良くなるため、サーバなどのインフラなどを気にすることなく、アプリケーション開発に集中することができます。
OSを管理する必要がないため、セキュリティソフトなどの管理コストも不要となります。AWSでのサービス例) Lambda、Fargate(サーバレス構成)
SaaS(Software as a Service)
ソフトウェアやアプリケーションの機能をインターネット経由で提供するサービス形態。
サービス例)DropBox、SalesForce、Gmail等
AWSでのサービス例) S3、CloudWatch今回は、AWSの主要サービスである下記の4サービスについてまとめます。
- VPC
- EC2
- IAM
- RDS
VPC
まずは、AWSにおいて最初に学ぶべきサービスの一つであるVPCについてです。
VPCとはAmazon Virtual Private Cloudの略で、仮想的なプライベートネットワークを構築できるサービスです。
セキュリティやAWSの全てのサービスに関連してくるものです。VPCの説明に入る前に、AWSにおける大事な用語であるリージョンとアベイラビリティゾーン、エッジロケーションについて記載します。
リージョン
AWSがサービスを提供している拠点(国と地域)のことを指します。(下記の画像のオレンジの円が該当します。)
2021年3月現在では、24の国・地域にリージョンが展開されています。
日本にはこれまで東京リージョンと大阪ローカルリージョンが展開されていました。
ローカルリージョンとは、後述するアベイラビリティゾーンが通常のリージョンには複数存在しているのに対し、
ローカルリージョンはアベイラビリティゾーンが1つしか展開されていません。*2021年3月2にAWSはこの大阪ローカルリージョンを通常のリージョンに格上げすると発表しました。
これで国内に2つ目となるリージョンが開設されます。アベイラビリティゾーン
アベイラビリティゾーン(AZ)はAWSが保有するデータセンターです。
前述したとおり、1つのリージョンに複数のAZで構成されています。
東京リージョンには4つのAZ、大阪には3つのAZが用意されており、各AZ間は専用のネットワーク回線で接続されています。
これらの複数のAZを利用した構成をマルチAZ構成と言い、可用性や耐障害性の観点からマルチAZ構成を取ることが推奨されています。エッジロケーション
エッジロケーションはエッジサーバが存在する地域のことを指します。(下記の画像の青の円が該当します。)
CDNサービスであるCloudFrontやRoute53、AWSWAFで用いられ、コンテンツがキャッシュされる際に用いられます。
日本には、東京と大阪に存在します。また、VPCについて話す上で必要となるIPアドレス、サブネット等のインフラの基本的な知識に関しましては、今回は割愛させていただきます。
ざっくり、
IPアドレス → インターネットにつながっている機器の住所
サブネット → 大きなネットワークを小さい単位で分けて管理しやすくするためのネットワーク
と考えていただければいいかと思います。また、先にVPCのおいて重要となる単語について軽く説明致します。
ルートテーブル
- サブネットに関連付けて使用します。
- サブネットから外に出る通信をどこに向けるかを管理するルール・定義です。
- ルートと呼ばれるルールで構成されます。
- 最も明確なルールが優先的に適用されます。
- 下記の例では10.0.0.0/21のVPC内の通信が優先され、それ以外の通信はインターネットに飛びます。

インターネットゲートウェイ
- VPC内のAWSリソースとインターネットを繋げる役割になります。
- 負荷が高くなった場合も、自動でスケールするため可用性が高い。
- サブネットのルートテーブルにて設定し、使用します。
- 上記のルートテーブルのようにVPC内以外の通信(デフォルト)の宛先が指定されているゲートウェイをデフォルトゲートウェイと呼ぶ
- デフォルトゲートウェイにインターネットゲートウェイが設定されているサブネットをパブリックサブネット、デフォルトゲートウェイにインターネットゲートウェイが設定されていないサブネットをプライベートサブネットと呼びます。
NATゲートウェイ
- インターネットに接続ができないプライベートサブネットからインターネット接続を可能にするためのゲートウェイ
- アウトバウンドは可能だが、インバウンドはできない
- 自動でスケールするため可用性が高い
ENI(Elastic Network Interface)
- 仮想ネットワークインタフェース
- EC2インスタンスのIPアドレスはENIに付与される
- 同じAZ内のインスタンスにアタッチ・デタッチすることが可能
ElasticIPアドレス
- インスタンスにアタッチ・デタッチが可能
- インスタンスが再起動・停止・終了しても変更されない、静的なパブリックIPアドレス
セキュリティグループ
- AWSの仮想ファイアウォールサービス
- より広い範囲のルールが適用される
- インバウンド・アウトバウンドが設定可能
- 適用範囲はサブネット単位ではなく、インスタンス(ENI)単位で適用
- アウトバウンドの返りの通信を考慮する必要がない(ステートフルインスペクション型)
ネットワークACL
- サブネット単位で設定するファイアウォール
- ルールは番号で管理され、番号が小さい順で評価される。
- アウトバウンドの戻りは考慮されない(ステートレスインスペクション型)
- セキュリティグループの補助的な利用方法が推奨されています。
上記のような構成の場合、インターネットゲートウェイがアタッチされている10.0.0.0/24のサブネットはパブリックサブネットと呼ばれ、インターネットに接続可能なサブネットとなります。
インターネットゲートウェイがアタッチされていない10.0.2.0/24のサブネットはプライベートサブネットと呼ばれ、インターネット接続が不可能となります。プライベートサブネットにはセキュリティレベルが高いものを配置するのが良いとされています。
上記の例ではEC2インスタンスを配置していますが、データベースなどを配置します。プライベートサブネットに配置されているリソースにアクセスするためには、パブリックサブネットにあるEC2インスタンスAに一度ログインした後に、インスタンスAからプライベートサブネットのリソースにログインします。このログインの方法を踏み台、インスタンスAを踏み台サーバと呼びます。
EC2
EC2(Elastic Compute Cloud)とは、AWSが提供する仮想サーバです。
仮想サーバとは、AWSが管理するデータセンター(サーバ)上に個別に利用する論理的なサーバを作成し、利用することです。
上記に記載した、リージョン・AZから自身が利用するエリアを選択し、そこへEC2インスタンスを起動させて利用します。EC2の料金は、リージョンや後述するインスタンスタイプによって異なるので、公式サイトで確認するようにしてください。
EC2を起動させるにあたって、利用用途にあったサーバを選択する必要があります。
どういった種類があるかを紹介していきます。AMI
AMI(Amazon Machine Image)はEC2インスタンス作成時に必要な情報となります。
EC2作成時にAMIを指定し、EC2インスタンスを作成します。
このAMIにOSの情報が含まれています。
EC2では、AWS特有のAmazonLinuxを始め、CentOSやWindowsServerなど様々なOSが利用可能です。
*最近では、EC2のOSにMacOSが登場したことでも話題になりました。
AMIではOSのみならず、ソフトウェアが含まれているAMIも利用できます。
AMIにWordPressが含まれており、すぐにブログが開設できたりもします。
インスタンスタイプ
AMIにて、OSを決めたらこれらを起動するサーバのスペックを選定します。
EC2において、CPUの処理速度やメモリサイズ等のスペックを決める物がインスタンスタイプです。
代表的な例として、無料枠で利用できる下記のt2.microで記載致します。
- t:ファミリー名
- 2:世代番号
- micro:インスタンスサイズ
インスタンスタイプを表す文字にはそれぞれ、上記のような意味合いがあります。
ファミリー名は後述します。
基本的には、世代番号は大きいもの、インスタンスサイズは利用用途にあったものを選択しましょう。では、下記にインスタンスタイプの種類についてざっくり記載します。
t3系 テスト向き
t系インスタンスはCPUバーストが可能な汎用インスタンスタイプです。
基本的にテスト環境・開発環境で利用するケースが多いです。
t3系インスタンスにはt3とt3aがありますが、t3はCPUがIntel社製、t3aはCPUがAMD製で10%ほど安価といった特徴があります。M系 汎用タイプ
M系は汎用タイプのインスタンスタイプです。
バランスの取れた、CPUやメモリとなっており、インスタンスタイプで迷った場合は、こちらを選択しておけばいいといったタイプ。C系 コンピューティング最適化
C系はCPUの性能を要する処理に最適化されています。
処理が多いWebサーバや、モデリング、機械学習等に向いています。R系 メモリ最適化
R系はメモリを要する処理に向いているタイプとなります。
高いパフォーマンスが必要なデータベースや、ビッグデータを扱う処理に向いてます。P系 高速コンピューティング
一番の特徴はGPUがついていることです。
3DCGやグラフィックに関連する処理に用いられます。
上記の処理以外にも、機械学習やデータマイニングに向いています。H系 ストレージ最適化
H系はストレージ最適化のタイプとなります。
ストレージの高性能なディスクスループット(読み書き速度)が特徴となります。
16TBの大容量ストレージを利用することも可能です。EBS
EBS(Elastic Block Store)は、EC2にアタッチして使用する外付けディスクです。
種類に応じてIOPS(読み書き性能)が異なる。
スナップショット(バックアップ)が取得可能です。
*異なるAZに配置されたEC2にEBSをアタッチすることは不可能
タイプ 種類 説明 SSD 汎用 SSD EC2作成時にデフォルトで作成される。 SSD プロビジョンド IOPS SSD 汎用SSDより性能が良い。課金して読み書き性能を自身で指定することができる。 HDD スループット最適化 HDD ビッグデータ等を溜め込むためのデータウェアハウスとしての利用に向いている。SSDに比べ安価。 HDD Cold HDD 保管用。利用頻度が低いデータの保管に利用される。スループット最適化HDDよりも安価。 IAM
IAM(Identity and Access Management)とは、AWSにおける権限管理を行うためのサービスとなります。
まずはIAMにおけるユーザー管理について記載します。IAMユーザー
AWSを利用するために、最初に作成する際にメールアドレス、パスワード、クレジットカード情報、連絡先情報を登録しアカウントを作成します。
この時にメールアドレスとパスワードを用いてログインするアカウント(ユーザー)のことをルートユーザーと呼びます。
ルートユーザーは全てのAWSリソースに対してフル権限、請求情報の閲覧可能、パスワードの変更が可能といったように、全ての作業を実行できるアカウントとなってます。
但し、ルートユーザーは日常の作業では利用しないようにAWS公式からも推奨されています。では、どういったユーザーでAWS上で作業を行うかです。
ここで出て来るのが、IAMユーザーです。
IAMユーザーとはAWSアカウントの範囲内で個別に作成し利用するユーザーです。
最初に作成した、ルートユーザーから個別のIAMユーザーを作成し、それぞれのIAMユーザーに必要なだけの権限を付与し作業を行います。
この際に作業担当(開発・テスト・運用)ごとに必要な権限を最小に抑えることで、ミスを防ぎセキュリティレベルを上げることが推奨されています。
この権限を最小に抑えることを最小権限の原則という形でAWSのベストプラクティスとしています。*AWS環境構築におけるベストプラクティス集のことをAWS Well-Architected フレームワークという形で公開されていますので、一度目を通すのがいいかと思います。
IAMユーザーは人が利用するものに限らず、プログラムが利用する場合もあります。
- 人が利用する場合は、マネジメントコンソールへログインするためのパスワードをします。
- プログラムが利用する場合は、アクセスキー・シークレットアクセスキーを利用してプログラムからAWSリソースにアクセスします。
AWSマネジメントコンソール
アクセスキーを利用するとどこからでもAWSのリソースの操作が可能となります。
アクセスキーが悪意のある他人に流出して、知らない間に数万〜数十万の請求が来たといった話もよく見かけます。
アクセスキーなんか流出しないだろうと思われるかもしれませんが、よく聞く原因として、
アクセスキーをプログラムのコードにベタ書きして、gitの公開されているリポジトリに上げるといったケースが多いようです。
こうならないように、自分は大丈夫とは思わず日頃から本当に公開していいコードかということを気を付けましょう。IAMグループ
複数のIAMユーザーをまとめ、管理しやすくするためのものです。
IAMユーザーはそれぞれに認証情報を持っているが、IAMグループは正式な認証情報ではありません。IAMポリシー
AWSリソースを操作できる権限を表したものです。
下記の画像のようにJSON形式の設定ファイルで記述されます。
認証主体(Identity)にアタッチして利用します。
IAMポリシーには管理ポリシーとインラインポリシーがあります。
- 管理ポリシー
- 管理ポリシーはIAMユーザーやIAMロールにアタッチして利用する独立したIAMのポリシー機能です。
- 管理ポリシーには更にAWS管理ポリシーとカスタマー管理ポリシーに分かれます。
- AWS管理ポリシー
- あらかじめAWS側で用意されているポリシーです。
- フルアクセス権限や、サービス毎のリードオンリー権限等が用意されています。
- AWS側で管理されているポリシーのため、サービス追加・更新に伴い自動でポリシーが更新されることがあります。
- カスタマー管理ポリシー
- ユーザー側で自由に作成・設定ができるポリシーです。
- 細かい設定を行う場合には、こちらのポリシーを利用しましょう。
- インラインポリシー
- 特定のIAMユーザー、IAMグループ、IAMロールに直接付与するポリシーです。
- 基本的には管理ポリシーを利用しますが、特定のユーザーにのみ権限を付与したい場合はインラインポリシーを使います。
IAMロール
IAMポリシーをアタッチして使用します。
IAMロールは複数のIAMポリシーをまとめてアタッチし、権限管理を行います。
スイッチロールという機能を利用することで、別アカウントのAWSリソースの利用が可能となります。IAM関連の用語について
・アイデンティティ(Identity、ID)
AWSリソースの内、IAMポリシーを割り当てる事ができるもの。
・エンティティ
AWSが認証に利用するリソース・プリンシパル
AWSリソースにリクエストを出すもの
(IAMグループは正式なプリンシパルではない。)
*参考資料
RDS
マネージド型データベースサービス
上記、「クラウドコンピューティングのサービス形態」の図のPaasが該当します。
利用するデータベースのアプリケーション・データのみの管理で利用することができます。下記にRDSの特徴を一部抜粋して記載致します。
選べるデータベースエンジン
RDSでは利用可能なデータベースエンジンが用意されており、ケースに合わせて適切なデータベースエンジンを選択することができます。
AWSが提供しているAuroraを始め、オープンソースのMySQLや商用であるORACLEなども選択可能です。
AWSでは、MySQLやPostgreSQLと互換性があり、MySQLの5倍のスループットが実現可能なAuroraを推奨しています。
マスター - スレーブ構成
マスター - スレーブ構成は、メインで利用するマスターのインスタンスとサブ的な扱いのスレーブを別のAZへ配置する構成です。
マスターのデータを更新した際に、リアルタイムで更新内容をスレーブへ複製(レプリケーション)します。
また、RDSへのアクセスをIPアドレスではなく、エンドポイントでアクセスすることで、マスターに障害を検知した場合でも接続先を自動的にスレーブの方へ更新されます。
この構成を取ることで可用性を高めることができます。
リードレプリカ
リードレプリカは、参照・読み込み用のインスタンスと、更新のインスタンスを分けることで、マスターへの負荷を軽減させようという構成です。
その他
スナップショット
定期スナップショットや、手動でのスナップショットを取得することにより、データを保護します。
パッチ当て機能
時間指定をしてパッチを当てる時間をコントロールし、自動でパッチを適用できます。
パラメータ設定
パラメータグループを使って設定値を変える事ができます。
あとがき
AWSの基本的なサービスについて、ざっくり書くつもりでしたが、思っていた以上に長くなってしまいました。
今回記載したサービスについても、まだまだ書ききれていない機能やサービスがあります。
まだ知らない機能等については、構築・削除が簡単にできるというクラウドサービスの特徴を活かし、学んでいきたいと思います。他サービスや、今回記載したサービスについても別途記事を書いていきたいと思いますので、間違っている点等がございましたらご指摘いただけますと幸いです。
ここまで読んでいただき、ありがとうございました。





















- 投稿日:2021-03-29T19:39:46+09:00
室内の温度と湿度をDynamoDBに書き込む
HiLetgo ESP32 ESP-32S NodeMCU開発ボード2.4GHz WiFi + Bluetoothデュアルモードの記事で ESP32ボードの動作確認ができました。今度は、室内の温度と湿度をAWS IoTを使って、DynamoDBに書き込んでみました。温度と湿度の取得にはDHT22センサを使用しました。
Building an AWS IoT Core device using AWS Serverless and an ESP32の記事を参考に、
- ESP32から室温と湿度をパブリッシュする機能を追加
- 外部から送信された任意のメッセージをESP32でサブスクライブする機能は省略
しました。
なお、AWSアカウントは開設済みで、AWSコンソールには AdministratorAccess のポリシーがアタッチされたIAMユーザでログインしていることが前提です。使用する Serverless Application Repository の lambda-iot-rule でデプロイされる DynamoDB は、Read/write capacity mode が On-demand になっているため、FreeTier 対象外と思われます(AWS料金を確認のこと)。
IoTデバイスの作成
- AWSコンソールの AWS IoTで Manage > Things を開き、Create > Create a single thing を選ぶ。
- MySokuteiESP32 と Name フィールドに入力し、他はデフォルトのままにして Nextを選ぶ。
- Create certificateを選ぶ。ESP32での接続に a certificate for this thing、a private key、Amazon Root CA1 のダウンロードが必要。ダウンロードしたらセキュアな場所に保存しておく。
- Activate、Attach a policy をクリックする。
- ポリシーの追加はスキップして、Register Thing をクリックする。
- AWS IoT のサイドメニューから Secure > Policies を選び、Create をクリックする。
SokuteiPolicyと Name フィールドに入力し、Advanced mode を選ぶ。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iot:Connect", "Resource": "arn:aws:iot:REGION:ACCOUNT_ID:client/MySokuteiESP32" }, { "Effect": "Allow", "Action": "iot:Publish", "Resource": "arn:aws:iot:REGION:ACCOUNT_ID:topic/esp32/pub" } ] }REGION には使っているリージョン名を入れる(東京リージョンなら、
ap-northeast-1)。リージョン名は、AWSコンソールの右上で確認できる。ACCOUNT_ID を自分のものに変更する。Account Settings で確認できる。
Create をクリックする。
AWS IoT のサイドメニューから Secure > Certificates を選ぶ。そして、いま作成した証明書を選び、Actions > Attach policy を選ぶ。
SokuteiPolicyにチェックを入れて、Attatch をクリックする。ここまででESP32をAWS IoTに接続するためのAWSコンソールでの設定が完了。トピック
esp32/pubにパブリッシュが可能である。Arduino IDEの設定
- Arduino IDEを起動する。
- スケッチ > ライブラリをインクルード > ライブラリを管理 を選ぶ。
- MQTT を検索し、Joel Gaehwiler の最新バージョンをインストールする。
- 同様に
ArduinoJsonもインストールする。ESP32の設定
- Arduino IDE で ファイル > 新規ファイル を選ぶ。
- 新規タブ を選び、新規ファイルの名前 に
secrets.hを入力し、OKをクリックする。以下の secrets ファイルをペーストする。
#include <pgmspace.h> #define SECRETS #define THINGNAME "" const char WIFI_SSID[] = ""; const char WIFI_PASSWORD[] = ""; const char AWS_IOT_ENDPOINT[] = "xxxxx.amazonaws.com"; // 証明書 static const char AWS_CERT_CRT[] PROGMEM = R"CRT( -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- )CRT"; // プライベートキー static const char AWS_CERT_PRIVATE[] PROGMEM = R"PRK( -----BEGIN RSA PRIVATE KEY----- -----END RSA PRIVATE KEY----- )PRK"; // ルートCA証明書 static const char AWS_CERT_CA[] PROGMEM = R"RCA( -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- )RCA";THINGNAME に
MySokuteiESP32を設定する。Wifiに接続するため、SSID と PASSWORD を設定する。
AWS_IOT_ENDPOINT は、AWS IoT のサイドメニューから Settings のページで確認できる。
証明書、プライベートキー、ルートCA証明書をそれぞれ
secrets.hファイルに書き込む。メインスケッチのタブを開き、以下のコードをペーストする。ファイル > 保存 を選んで、プロジェクト名を設定して保存する。
#include "secrets.h" #include <WiFiClientSecure.h> #include <MQTTClient.h> #include <ArduinoJson.h> #include "WiFi.h" // ESP32からパブリッシュするMQTTトピック #define AWS_IOT_PUBLISH_TOPIC "esp32/pub" WiFiClientSecure net = WiFiClientSecure(); MQTTClient client = MQTTClient(256); void connectAWS() { WiFi.mode(WIFI_STA); WiFi.begin(WIFI_SSID, WIFI_PASSWORD); Serial.println("Wi-Fiに接続中.."); while (WiFi.status() != WL_CONNECTED){ delay(500); Serial.print("."); } // AWS IoTの認証情報を使用するようにWiFiClientSecureを設定 net.setCACert(AWS_CERT_CA); net.setCertificate(AWS_CERT_CRT); net.setPrivateKey(AWS_CERT_PRIVATE); // AWSエンドポイントのMQTTブローカーに接続 client.begin(AWS_IOT_ENDPOINT, 8883, net); Serial.print("AWS IoTに接続中.."); while (!client.connect(THINGNAME)) { Serial.print("."); delay(100); } if(!client.connected()){ Serial.println("AWS IoTがタイムアウトしました!"); return; } Serial.println("AWS IoTに接続しました!"); } void publishMessage() { StaticJsonDocument<200> doc; doc["time"] = millis(); doc["temp"] = "20.1"; doc["hum"] = "60.5"; char jsonBuffer[512]; serializeJson(doc, jsonBuffer); // JSON形式のデータを生成 client.publish(AWS_IOT_PUBLISH_TOPIC, jsonBuffer); } void setup() { Serial.begin(9600); connectAWS(); } void loop() { publishMessage(); client.loop(); delay(10000); }ESP32にプログラムを書き込む
lambda-iot-rule AWS SARアプリケーションのデプロイ
ここまででAWS IoTに接続できるようになったので、AWS Serverless Application Repository のアプリケーションをデプロイする。
- AWSコンソールの AWS Serverless Application Repository のアプリケーション lambda-iot-rule のページで AWS IoT デバイスのリージョンと同じリージョンになっていることを確認する。
- Deploy をクリックする。
- Application settings で、SubscribeTopic に
esp32/pubを入力する。PublishTopic は使わないため、そのままでOK。- "I acknowledge that this app creates custom IAM roles." にチェックして、Deploy をクリックする。
- Deployments タブを開き、Deployment history の Status が "Create complete" となればデプロイ完了。
デバイスからパブリッシュされたデータの確認
- AWSコンソールの Services から DynamoDB を開く。
- サイドメニューの Tables から作成されたテーブルを選ぶ。
- Itemsタブを選ぶと、デバイスから送信されたデータが payload と timestamp が記録されていることが確認できる。
室内の気温と湿度の記録
温湿度センサ DHT11 on arduino-esp32を参考に温度センサーとESP32を接続し、温度と湿度が取得できることを確認しておきます。ここでは DHT11の代わりにDHT22を使用し、DHT22のOUTは16番ピンに接続しました。
先頭の #include 行の後ろに次のコードを追加する。
#include "DHTesp.h" #define DHTPIN 16 DHTesp dht;
publishMessage()関数を次のコードに置き換える。void publishMessage() { TempAndHumidity newValues = dht.getTempAndHumidity(); if (dht.getStatus() != 0) { Serial.println("DHT22 error status: " + String(dht.getStatusString())); } float temp = newValues.temperature; float hemi = newValues.humidity; Serial.print(temp); Serial.print(" "); Serial.println(hemi); StaticJsonDocument<200> doc; doc["time"] = millis(); doc["temp"] = temp; doc["hum"] = hemi; char jsonBuffer[512]; serializeJson(doc, jsonBuffer); // JSON形式のデータを生成 client.publish(AWS_IOT_PUBLISH_TOPIC, jsonBuffer); }
setup()関数を次のコードに置き換える。void setup() { Serial.begin(9600); dht.setup(DHTPIN,DHTesp::DHT22); connectAWS(); }マイコンに書き込む をクリックする。
書き込みが完了すれば、DynamoDB の payload に現在の温度と湿度が10秒毎に書き込まれる。
以上のように、ESP32 を AWS IoT に接続して、DHT22を使って測定した温度・湿度を DynamoDB に書き込むということが、とても簡単にできることが分かりました。参考

- 投稿日:2021-03-29T18:38:56+09:00
AWSソリューションアーキテクト - プロフェッショナルの勉強方法について書いていきます
はじめに
少し前の話になりますが、ソリューションアーキテクト - プロフェッショナル(SA-Pro)に合格したので記憶が薄れる前に勉強方法をメモっておきたいと思います。
受験の動機なんかは以下の記事にも書いていますので、もし興味がある方はご覧ください。
ちなみに以下に記載している内容は、あくまで私が試行錯誤しつつ実践したものとなります。勉強方法は千差万別なので、人によって合う合わないがあると思いますので予めご了承ください。
勉強期間
2020年の2月にソリューションアーキテクト - アソシエイトに合格し、その後6月にSA-Proを取得しました。期間的には4か月間くらありましたが、この間ずっと集中して勉強していたわけでもないので賞味1か月半~2か月くらいかと思います。
私の場合色々あって間延びしてしまいましたが、ズルズルいくと勉強自体が苦痛になってしまうので、短期的に集中して早く成果を出していくほうがモチベーションを保てると思います。SA-Pro勉強方法
以下、私が実践した勉強方法について記載していきます。
ソリューションアーキテクト - アソシエイトの取得
SA-Proを受ける前提として、アソシエイトレベルの知識は必須となります。アソシエイトであれば市販の対策本も充実してるので、しっかり読み込み、巻末の問題集を解けば合格レベルの知識は身につくはずです。まずは取ってしまいましょう。
ちなみに私が読んだ本はこちらです。上の方はいい感じだったので3周読みました。
ホワイトペーパーを読む
アソシエイトが取れればAWS関連の基礎知識が得られますが、SA-Proとなるとそれ以上に広範囲かつ深い知識を要求されます。またアソシエイトと異なり対策本なども(当時は)なかったので、足りない知識を補うためにまずAWSのホワイトペーパーを読み込みました。とはいえホワイトペーパーは量が膨大で何が試験に出て何が出ないのかわかりにくいため、色々探して以下のサイトに行きつきました。
英語のサイトですが、試験に必要なホワイトペーパーがいい感じにまとまってます。すばらしいです。Chromeならブラウザの翻訳機能も使えるので問題ありません。ページ末尾に感謝のコメントが連なってるあたり、受験にあたってこのページを参考にされている方も多いようです。ほぼ海外ですが。
私は暗記するつもりでこのホワイトペーパーを読み込みましたが、今になって思うとここに時間をかけすぎる必要はなかったように思います。深い知識はこの後つけていくことになるので、この時点では斜め読みくらいの気持ちでもよいのかなあと。なにより分量が多いので、興味がある分野であればともかく、そうでない個所を真面目に読んでると気が萎えてしまいます。私は若干萎えました。とりあえずこの段階では、まずはこういうサービスもあるんだな、くらいの感覚でよいかと思います。深く学習する - ①問題集を解く
前述の通りSA-Proには体系だった学習本が存在しませんが、問題集はわりと販売されていたりするので、それらを購入してひたすら解きまくるのが合格の近道かと思います。たくさん問題を解いて実戦ベースで足りない知識を埋めていく感じです。
私の場合は色々調べた結果、以下Udemyの問題集に行きつきました。個人的には上の方がおすすめです。問題の解説も充実しておりレビュー評価も非常に高いです。英語ですが、前述と同じくChromeの翻訳機能を使えば問題ないかと。機械翻訳の悪文にも慣れることができます。
深く学習する - ②分からなかった問題を調べ倒す
上記の問題集を解いて、分からなかった個所の解説を読み込みます。勉強の初期段階では解説の意味すら分からないケースもあるので、この場合は当該サービスのBlackBeltを見たり、ホワイトペーパーやFAQを探して読み込んだりするのもよいかと。クラスメソッドさんのブログにも大変お世話になりました。
最初のうちは理解度が浅く1つ問題を解く度に調べて暗記を繰り返すので、1問につき30分以上かかるケースもあったと思います。全然進まないので心が折れそうになりますが、めげずに問題を解き続けていれば、だんだん知識量が増えてきてコツもつかめてくるので徐々に楽になってくるはずです。BlackBeltのリンクを以下に貼っておきます。受験勉強において一番参考になりました。PDFと動画版がありますが、PDFを見ても意味が分からない場合、動画を見ればすっきり理解できることが多いです。時間があれば動画を視聴することをお勧めします。
深く学習する - ③分からなかった個所をノートに書き出し、繰り返し覚える
人の記憶は薄れやすいです。私の場合、最初は「メモなんか取らなくていいっしょ」と気楽に構えて一通り問題集を解き、2周目に突入してから全然解けずに泣けてきたことを覚えています。
SA-Proはともかく出題範囲が広いので、1周しただけで全て覚えきるのは難しいです。問題集の2周目以降を効率的に進めるためにも、上記②で苦労して調べた内容は逐一ノートに取った方がよいと思います。そして定期的にノートを見返して暗記することで、最終的にトータルの学習効率を上げることができると思います。
私の場合はSA-Proだけでノート1冊分になりました。12冠では全部で4冊ほどです。人によってはノートPCやタブレットを使ったり、マインドマップ等のツールを活用しているケースもあるようなので、この辺りは自分に合ったスタイルを採用するのがいいのではと思います。上記①~③をひたすら繰り返す
あとはひたすら①~③を繰り返します。これを1~2か月続ければ合格ラインに達すると思います。1日時1時間の勉強でだいたい30~60時間くらいでしょうか。ほかの人のブログを見ても、かけている時間はそれくらいではないかという気がします。
受験の目安ですが、上記で紹介した問題であれば「90分で75問、正解率8~9割」で解けるようになればOKかと。私の場合は大体3周くらいやりました。模試を受ける
本番の雰囲気を把握するためにも事前に模試を受けておいた方がよいと思います。アソシエイトに合格すれば特典としてAWSの模試を無料で受けられるチケットを入手できるので、このタイミングで使ってしまいましょう。
上記の通り勉強していれば模試でも合格ラインに達している可能性が高いですが、ダメだった場合は再勉強しましょう。あと、模試のキャプチャを取っておいて繰り返し解くのも重要です。
以上をこなせば大体の準備はできていると思いますので、問題なければ本番の試験を受験しましょう。本番試験え必要な準備と心構え
こうした方がよかったな、というとこも含めて覚えてる限り書いてみます。
- この試験はとにかく長文の問題が大量に出るので、いかにそれに対応できるかがポイントになります。単純な暗記だけでは合格できません。いかに問題と選択肢を早く読み、出題者の意図を予測できるかが勝負になります。また問題文は機械翻訳なので、悪文にも慣れておく必要もあります。練習問題を解くときはスピードを意識しましょう。(特に2~3周目)
- 問題の選択肢は「ほぼ書かれていることが同じで、ごく一部だけ違う」ようなケースが非常に多いので、目Diff力は必須です。練習問題を解くときに意識して鍛えましょう。目Diff力が上がれば問題を解くスピードも格段に上がります。
- 前日は早めに寝てしっかりと睡眠をとりましょう。大量の長文問題を3時間説き続けるのはとてつもなくしんどいです。寝不足の状態では集中力が30分も持たないので、ちゃんと寝ましょう。
- 試験中は30問くらい解いたら一度目をつぶって深呼吸しましょう。消耗した集中力が若干回復します。
- 問題を解く際にはできるだけ2択まで絞り込みましょう。2択までいって分からなかったらあとは直感で。3択でもOKです。
- 気分の問題も大きいと思いますが、AWS試験は前半に難しい問題が集まっている気がします。もし前半の問題で躓いたとしても焦らず、それっぽい回答を選んでさっさと次に進んでしまいましょう。自分の場合は1回目の試験で見事にこれに躓いて時間を食ってしまい、結局最後まで取り戻せませんでした。2回目はそんなもんだと割り切り、解けない問題はさっさと飛ばしたのでその辺もよかったのではと思ってます。ただし、分からないなりにそれっぽい選択肢を選んでおくのは大事です。
- 試験当日は仕事を休みにしましょう。できるだけ余計なことを考えずにすむ状況にしないと集中力が続きません。
- 試験の後には予定を入れないようにしましょう。試験後は消耗しきってるので何しても楽しめませんし、仕事する気なんか微塵も起きません。この日はビール飲んでさっさと寝ましょう。
- あと、アソシエイトに受かった際に本番試験の半額チケットも発行されてます。忘れずに使いましょう。
終わりに
というわけで色々と覚えていることを書かせていただきました。
SA-ProはAWS関連のサービスについて問われることはもちろんですが、AWS以外にも専門的な知識を身につけないと合格することが難しいです。受かれば最高ですが、そうでなくても勉強を通して培った知識は必ず業務に役立つはずなので、皆さんももし興味があればチャレンジしてもらえると嬉しいです。AWSは知れば知るほど楽しいですよ。今回の記事が誰かのお役に立てると幸いです。
- 投稿日:2021-03-29T17:44:16+09:00
Amazon SageMakerで実現する機械学習モデルの監視技術
初版: 2021年3月29日
著者: 株式会社日立製作所 橋本恭佑、Nguyen Ba Hungはじめに
AI技術への注目の高まりに伴い、機械学習技術をビジネスへ適用するニーズが増えています。
ビジネスに機械学習技術を用いる場合、企業はまず業務に関係するデータを用いて機械学習モデルを作成します。
このとき利用されるデータは特定の時点より前のデータであり、時間が経過しても変化しません。一方で、実際の業務で利用されるデータは時間の経過とともに変化します。
作成した機械学習モデルを業務へ適用してしばらくすると、データの傾向が変化し、作成した機械学習モデルの精度が低下したり、性別や住所の様な特定のデータに偏った推論が行われる現象が起こります。前者の現象はデータドリフト、後者の現象はバイアスと呼ばれ、機械学習モデルをビジネスへ適用するSEにとって、データドリフトやバイアスなどの発生を迅速に検知することは、
機械学習モデルをビジネスへ効果的に適用する上で極めて重要といえます。本投稿では、機械学習モデルをビジネスへ適用するSEを対象として、機械学習モデル及びデータの傾向の監視技術を解説し、
AWSのマネージドサービスであるAmazon SageMakerによって、これらの監視技術を利用可能になることを示します。
次回以降の投稿では米国の電話会社の顧客解約予測を題材として、
監視技術(精度の可視化、データ品質監視、モデルの説明可能性、バイアス監視)について実機検証した結果を紹介します。AWSを利用した機械学習モデルの監視の概要
機械学習モデルの監視手法
図1は機械学習モデル構築のライフサイクルを示しています。機械学習モデル構築のライフサイクルは、データの生成、モデルの訓練、モデルのデプロイの3パートから構成されます。
本投稿で扱う機械学習モデル及びデータの傾向の監視技術は、モデルのデプロイを実行した後に、機械学習モデルのパフォーマンスを監視し評価する部分に相当します。
図1: 機械学習モデル作成のライフサイクル(出典: AWSホームページ, https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html)
機械学習モデルの監視には、図2に示す4つの手法があります。図2は携帯電話会社の顧客の解約率を予測する機械学習モデルを例として、説明変数を顧客の特性(契約月数やプランなど)、目的変数を解約の有無として示しています。
図2: 機械学習モデルの監視手法
① 精度の可視化
推論結果と正解ラベルを比較し、正答率などを算出します。精度を評価する指標の例としては、正答率や再現率、F値があります。
②データ品質監視
データドリフトが起こっていないかを監視します。次の3つの方法があるといわれています1。
- 機械学習モデルの誤答率変化の検知: 精度の変化をデータドリフトとして検知します。
- データの分布変化の検出: 学習用データの分布と推論用データの分布の違いをデータドリフトとして検知します。
- 多重仮説検定の実行: データドリフトが起こっている場合に、こういう試行をするとこのくらいの確率でこういう結果になる、といった仮説を立てて検定を実施し、仮説を満たす場合にデータドリフトとして検知します。
③ 説明性の監視
推論用データと推論結果を比較して、機械学習モデルの推論結果の根拠を監視します。次の3つのアプローチがあるといわれています2。
- Deep Explanation: 説明可能な説明変数を学習する様に、深層学習技術を作り変える。
- Interpretable Models: より構造的で、解釈しやすく、因果関係がわかりやすいモデルを利用する。
- Model Induction: モデルの入出力を推論するモデルを利用する。
④ バイアスの監視
推論用データと推論結果を比較して、推論結果に偏りがないかを監視します。
Amazon SageMakerが提供する機械学習モデルの監視手法
Amazon SageMaker Model Monitor
Amazon SageMaker Model Monitor は、本番環境におけるAmazon SageMakerの機械学習モデルと推論データの品質を監視します。
Amazon SageMaker Model Monitor を使用すると、モデルの品質変化に関するアラートを設定できます。
変化を検出することで、モデルの再学習や、システムの監査、データ品質の問題の修正などを決定できます。図3にSageMaker Model Monitorの概略図を示します。図3の緑色のバケツはS3ストレージを示しています。
図3: Amazon SageMaker Model Monitor(出典: AWSホームページ, https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html)
Amazon SageMaker Model Monitorは、ベースライン処理ジョブ(Baseline Processing Job)とスケジュールされた監視ジョブ(Monitoring Job)の2つのジョブで構成され、それぞれが学習用データと推論用データを利用します。
ベースライン処理ジョブは、学習用データを元に、ベースライン統計(データの欠損、平均、最小、最大、標準偏差など、学習用データに関する簡単な統計値)と制約条件(特徴量の型や値の範囲、データの形式など)を作成します。
その後、スケジュールされた監視ジョブは定期的(毎時、毎日などの事前定義された期間)にベースライン統計および制約条件と推論用データとを比較し、推論用データの統計値と、推論用データに含まれる違反値を抽出します。
抽出した結果はAmazon CloudWatch(図3の中央左のピンク色のアイコン)とAWS S3ストレージ(図3の中央右の緑色のバケツ)へ転送されます。
最後に、しきい値などのあらかじめ定めた基準に基づいて、Amazon SageMaker Model Monitorの監視結果が顧客や開発者に送信されます。Amazon SageMaker Clarify
Amazon SageMaker Clarify(Clarify)は、説明変数の推論結果への寄与度を算出し可視化します。
また、特定の説明変数に関する正解ラベルや推論結果の偏りが、訓練用データや機械学習モデルに含まれることを検知します。
Clarifyによって、説明性の監視や、バイアスの監視が可能になります。Amazon SageMaker Studio
Amazon SageMaker Studio(Studio)は、AWSにおける機械学習のための統合開発環境です。
図1のライフサイクルをAWSマネジメントコンソール画面の様にウェブベースのインターフェース上で行うことができ、SageMaker Studio Notebookを呼び出して機械学習モデルの精度を可視化することや、Model MonitorやClarifyが出力したレポートを確認することができます。Model Monitor, Clarify, Studioを組み合わせることで、4つの監視技術を実現できます。
①: 精度の可視化(Model MonitorとStudio): 推論結果と正解ラベルを比較して精度などを算出し可視化します。
②: データ品質監視(Model MonitorとStudio): 推論用データの分布と学習用データの分布を比較します。
③: 説明可能性の可視化(ClarifyとStudio): SHapley Additive exPlanations(SHAP)3を使用して、機械学習モデルの推論結果がどの説明変数により強く依存するかを可視化します。
④: バイアスの監視(ClarifyとStudio): 特定の説明変数に対する機械学習モデルの推論結果の偏りを、複数のバイアスメトリックを算出して可視化します。バイアスメトリックには、KLダイバージェンス(2つの正規分布の類似度を定量化する指標)などがあります。おわりに
今回の投稿では、機械学習モデルの監視技術の概要と、Amazon SageMakerで実現できる監視技術の概要を紹介しました。
次回以降の投稿では、米国の電話会社の顧客解約予測を題材として、Amazon SageMakerを利用して機械学習モデルの精度の可視化とデータ品質監視を実証した例を紹介します。注釈
Jie Lu, et al., ”Learning under Concept Drift: A Review”, IEEE Transaction on Knowledge and Data Engineering, 2019. ↩
DARPA, “Explainable Artificial, Intelligence”, https://www.darpa.mil/program/explainable-artificial-intelligence ↩
Lundberg, S.M. and Lee, S.I., "A Unified Approach to Interpreting Model Predictions", 31st Conference on Neural Information Processing Systems (NIPS 2017), pp. 4765-4774. ↩



- 投稿日:2021-03-29T17:14:16+09:00
AWS Amplifyの認証情報を他のAWSサービスのSDKで流用した[Swift Storyboard]
AWS Amplifyを使うとモバイルアプリで簡単に認証機能を搭載できますが、Amplifyの対応していないAWSサービスを使わなければならない場面があったのでメモ。
AWS歴半年の初学者の備忘録ですので、誤り等あればご指摘いただけると幸いです。前提
- Amplify CLIでプロジェクトに認証機能を追加している(参考:AWS AmplifyによるiOSアプリ開発入門(Part1))
- 対応するIDプールのIAMロールに必要なポリシーをアタッチしている
具体的には amplify-xxxx-yyyy-zzzz-authRole-idp のようなロール名です実装
認証が必要なSDKの直前で以下を追記
let credentialsProvider = AWSMobileClient.default().getCredentialsProvider() let configuration = AWSServiceConfiguration(region:.APNortheast1, credentialsProvider:credentialsProvider) AWSServiceManager.default().defaultServiceConfiguration = configuration動かないときは
- IDプールに対応するIAMロールで実行したいアクションが許可されているかを確認する。
AWSMobileClient.sharedInstance()~としている箇所があればAWSMobileClient.default()~と変更する。
前者のメソッドは今後は後者に移行されていくようです。
- 投稿日:2021-03-29T16:29:10+09:00
AWS SAP (Solution Architect Professional) 受験記
はじめに
_s__o_ です。
ちょうど 1 年ぐらい前に AWS SAP (AWS ソリューションアーキテクチャープロフェッショナル) 試験を受験したので、他の方の今後の参考になればと、記録を残します。
※2020 年の受験記のため、2021 年 3 月現在の試験制度と内容が乖離している可能性があります。あらかじめ、ご了承ください。AWS Solution Architect Professional
受験の背景 (動機)
しばらく AWS から離れているので、記憶の気化を防ぐ目的で、受験を決意しました。
AWS SAP の特徴
下記のサンプル問題をご参照ください (英語)。
サンプル問題
※一部邦訳したものは、このサイトに記載されています。……目を通してもらえば分かると思いますが、選択肢・問題文ともに、大量です。下手をすれば、各選択肢で 3~4 行、問題文で 10 行の文章量に及びます。
その問題を 180 分以内に 75 問解きます。約 3 時間です。
※大学受験も含めて、自分が経験してきた中で、最長の試験でした。さらには、求められる正答率は「75 %」です。旧試験では「65 %」だったようですが、何年か前に仕組みがあがって、「75 %」まで引き上げられたらしいです。
そのため、求められるのは、知識は勿論ですが、強い忍耐力と集中力です。
※実際、本番試験中は何度か心が折れそうになりました。。。勉強期間
約 3 ヶ月です。当時 PM をやっていた案件は AWS と関係がなかったので、完全に自己研鑽です。
勉強材料 (メイン)
双方とも Web 問題集です (有料)。
「koiwaclub」は 7 問で構成されるセクションを、48 セクション (2020 年 2 月時点) 解いていきます。各問題毎に正誤 & 解説が表示されるので、時間が無いときにさっとやるのは便利です。
「Udemy」の方は本番試験のように 75 問を 180 分で解くので、本番の雰囲気になれるという意味でも有用だとあと思います。あと、すべての受験記録が残るので、後で見返したい場合に便利でした。ちなみに全部英語ですが、Google 翻訳でまったく不自由なく使えました。
本番試験でのデジャブ感で言えば「koiwaclub」の方がよく、問題・解説・ツールの質で言うと「Udemy」がよかったです。総問題数としては、上記 2 つで 650 問近くを解きました。
勉強材料 (サブ)
「試験のデジタルトレーニング」は AWS 公式の無料トレーニングで、設問に対する解答アプローチが懇切丁寧に説明されています。解き方のイメージアップにつながるので、このトレーニングは視聴しておいたほうがいいです。
「AWS Black Belt」は、こちらも AWS の公式ですね。Youtube のチャンネルを登録して、いろんなテーマを流しで見ていました。
「Jayendra's Blog」は海外の有志のブログで、学習すべきポイントなどがよくまとまっていて分かりやすかったです。
試験
想像の 1.5 倍ぐらい難しかったです。「koiwaclub」や「Udemy」で出てきた内容よりもさらに捻った問題 (*1) がたくさん出てきました。勉強教材の丸暗記では対応できず、その場その場でしっかりと考えていく必要がありました。
あと、日本語訳が壊滅的でした。「を」が「お」になっていたりとか、誤変換 (例 : 「と置換」→「土地勘」) とか、本当に公式試験として世に出していいのかを疑うレベルでした。ですので、本番の際は日本語 ⇔ 英語をちょこちょこ切替ながら問題を解いてました。
試験結果は 777 点/1000 点でギリギリ合格。あとで試験結果を見て、ヒヤリとしました。。。
(*1) 捻った問題の一例
「500 Mbps の DX 接続、1 Gbps の ISP 接続 (利用可能帯域 100%) の回線を持つ DC がある。この DC から 20 TB のデータを AWS に移行する場合、最もコスト効率がよく、且つ、最短で運べる方法を選べ。
(A) Snowball
(B) DX 経由でデータ転送
(C) S3 Transfer Acceleration
→ 80 TB とかなら文句なしに「(A)」ですが、数字がやらしく設定されていたため、今回は「(B)」を選択しました (500 Mbps、20 TB なら 3~4 日で転送可能……なはず)。総費用 (ざっくり)
公式模擬試験 : 0 円 (クーポン利用)
学習サイト (koiwaclub) : 5,000 円
学習サイト (Udemy) : 1,500 円 (クーポン利用)
試験 : 15,000 円 (クーポン利用)
計 : 21,500 円※クーポンをフル活用したので、AWS SAA よりも安く済みました。
学習や試験の所感
よく出るサービス
登場する AWS サービスにばらつきがありました (AWS の好み?)。直感的なランキングは下記のイメージです。よく出るサービスについては、BlackBelt などで深掘りをしておいた方がよいと思います。
- CloudFront
- S3
- DynamoDB
- Kinesis
- API Gateway
特に CloudFront は頻出中の頻出なので、基本機能は勿論、細かな仕様なども押さえておいた方が良いと感じました。
副次効果
試験を通して、ほんのりとアーキテクトの考え方・視点 (「要求」と「要件」から最適構成を考える、みたいな) も少し養うことができた気がします。さすが、「AWS ソリューションアーキテクチャー」と銘打つだけはありますね。
あと、SQS のおかげで、「疎結合・密結合」の概念への理解が深まりました。この理解は、現在推進中の Prj の運用スクリプト設計に役立ってたりしてます。
今後
しばらく AWS 系の試験はもういいかなと。満腹です。。。
※合格特典のクーポンは、「CLF-C01」を受験予定の妻に譲渡しました。
- 投稿日:2021-03-29T16:13:07+09:00
IAM Access Analyzer とは
勉強前イメージ
IAMのアクセスした分析見れる的な?
調査
IAM Access Analyzer とは
リソースのポリシーを確認して、意図せぬ公開設定などがされていないか
検出し、可視化する機能になります。対応しているリソース
- s3
- IAMロール
- KMSキー
- lambda関数・レイヤー
- SQSキュー
- Secrets Managerシークレット
※2021/03/29時点
詳細は AWS Identity and Access Management のユーザガイド をご確認ください設定方法
- マネジメントコンソールから確認
IAM > アクセスレポート > Access Analyzer から設定することが出来ます
- 設定内容
以下が設定内容になります。
名前だけ指定するだけでアナライザーを作成できます。
費用
IAM Access Analyzer の利用費用は、追加料金無しに使用できるので
設定し、確認するのが良いかと思います。注意点
- サポートされているリソースが限定される
すべてのリソースがサポートされているわけではないので、
これを有効にするだけで大丈夫、とはならないです
- リージョン単位の設定
複数リージョン利用する際は、リージョンごとに設定を有効にする必要があります。
勉強後イメージ
なんかAWS config とか似たようなことしてなかったっけ・・?
また今度気が向いたら勉強します。
とりあえずそんな機能があるってことを知った。参考


- 投稿日:2021-03-29T15:05:54+09:00
WordPressの引っ越し(CentOS7→Amazon Linux 2)
概要
個人の備忘録メインのため、不備が多いかと思います。よろしければご指摘ください。
これまで自宅サーバー(CentOS7)でWordPressのブログを運営してきましたが、EC2に引っ越ししてみます。
ついでにWebサーバーをApacheからNginxに変更してみます(ただの興味)。EC2
インスタンスの起動、Elastic IPの割り当て、セキュリティグループ設定は割愛します。
初期設定
基本、ルート権限で作業します。
$ sudo -s1. ホスト名の変更
# vi /etc/hostname2. タイムゾーンの設定
# rm -f /etc/localtime; ln -sf /usr/share/zoneinfo/Japan /etc/localtime # vi /etc/sysconfig/clock ZONE="UTC"のUTCをAsia/Tokyoに変更3. 日本語対応
# vi /etc/sysconfig/i18n LANG=en_US.UTF-8のen_US.UTF-8をja_JP.UTF-8に変更 # source /etc/sysconfig/i18n4. 再起動
# reboot参考URL
https://qiita.com/2no553/items/e166c00790c3397acf2d
http://mktktmr.hatenablog.jp/entry/2016/12/07/154736Nginx、PHPインストール
# amazon-linux-extras … 38 nginx1 available [ =stable ] … 42 php7.4 available [ =stable ] … # amazon-linux-extras install nginx1 php7.4 … # systemctl start nginx # systemctl enable nginx … # yum install php-mbstringMariaDBインストール
1. yumでインストール
# yum install mariadb-server2. 文字コード設定
# vi /etc/my.cnf.d/server.cnf … [mysqld] character-set-server = utf8 ← 追記 …3. 起動
# systemctl start mariadb # systemctl enable mariadb4. 初期設定
# mysql_secure_installation … Enter current password for root (enter for none): ← 空Enter … Set root password? [Y/n] ← 空Enter New password: ← rootパスワード Re-enter new password: ← rootパスワード … Remove anonymous users? [Y/n] ← 空Enter … Disallow root login remotely? [Y/n] ← 空Enter … Remove test database and access to it? [Y/n] ← 空Enter … Reload privilege tables now? [Y/n] ← 空Enter …参考URL
https://centossrv.com/mariadb.shtmlWordPress用の設定
MariaDB
以下の設定とする。
データベース名:wordpress
ユーザー名:wordpress# mysql -u root -p > create database wordpress; > grant all privileges on wordpress.* to wordpress@localhost identified by '(任意のパスワード)';PHP-FPM
# vi /etc/php-fpm.d/www.conf … user = nginx ← apacheから変更 group = nginx ← 〃 … # systemctl restart php-fpm # systemctl enable php-fpm旧サーバーからのデータ移動
1. 旧サーバー処理
旧サーバーのディレクトリは以下にある。
/var/www/wordpress### WordPress ### # cd /var/www # tar cvf wordpress.tar.gz wordpress # mv wordpress.tar.gz (ユーザーのホームディレクトリ) ### MariaDB ### # mysqldump wordpress -u wordpress -p > dump.sql2. 新サーバー処理
新サーバーのディレクトリは以下にする。
/usr/share/nginx/html/blog### データコピー ### # sftp (ユーザー名)@(旧サーバーのアドレス) > get wordpress.tar.gz > get dump.sql > quit ### WordPress ### # tar zxvf wordpress.tar.gz # mv wordpress /usr/share/nginx/html/blog # chown -R nginx. /usr/share/nginx/html/blog ### MariaDB ### # mysql -u wordpress -p -D wordpress < dump.sqlHTTPS対応
Let's Encrypt導入
# amazon-linux-extras install epel # yum install certbot-nginx # certbot --nginx … Enter email address (used for urgent renewal and security notices) (Enter 'c' to cancel): ← メールアドレスを入力してEnter … (Y)es/(N)o: ← 1回目ライセンス関連:Yを入力してEnter … (Y)es/(N)o: ← 2回目メールアドレスの共有:YかNを入力してEnter … name(s) (comma and/or space separated) (Enter 'c' to cancel): fugiters.net ← ホスト名を入力してEnter …参考URL
https://qiita.com/ntm718/items/37d1d0a7de2d1edb4e7cNginx設定
設定ファイル(/etc/nginx/nginx.conf)の「Settings for a TLS enabled server.」の下の設定をコメントを外し、
# vi /etc/nginx/nginx.conf … server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name fugiters.net; ← ホスト名 root /usr/share/nginx/html; ssl_certificate "/etc/letsencrypt/live/fugiters.net/cert.pem"; ← 証明書 ssl_certificate_key "/etc/letsencrypt/live/fugiters.net/privkey.pem"; ← 秘密鍵 ssl_session_cache shared:SSL:1m; ssl_session_timeout 10m; # ssl_ciphers PROFILE=SYSTEM; ← 不明 ssl_prefer_server_ciphers on; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; ← これが無いとPHP動かず(ここでハマった) error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } } … # systemctl restart nginx参考URL
https://ja.wordpress.org/support/article/nginx/
https://note.com/hiroki_hachisuka/n/nc1d5342c3a9b
- 投稿日:2021-03-29T15:03:04+09:00
AWSで「●●ができないんですが!」って言われたときに気にするところ
良く障害調査とか起きた時に
”この辺怪しいな”って経験則に基づくアレ、あるじゃないですか
備忘(まあ忘れないけど)のために書いておこうかなと。なんかわからないけど「つながりません!」って言われる
- SG
- ネットワークACL
- ルートテーブル
- 接続先のインスタンスが起動してない
だいたいこの辺。ほとんど1。
その次に多いのが4。
いつも動いてる時間に止まってたりすると…仕方ない。「S3にアクセスできません!」って言われる
- そもそもSG
- IAMポリシー
- S3のバケットポリシー
VPC エンドポイントがS3とDynamoDBはGatewayタイプなので
443のpl-XXXXみたいなのを追加しなきゃいけない。
(私もたまに忘れます。)2と3に関しても誤記載はよく耳にします。
s3://test-bucket/"*" 最後の"*"忘れはよく聞く。あとはのちのち編集します
- 投稿日:2021-03-29T14:49:20+09:00
「AWS 認定データアナリティクス 専門知識」 取得に向けた学習まとめ
はじめに
先日、AWS 認定データアナリティクス 専門知識の認定試験を受験し、無事合格しました。自分が実施した学習の流れとそれぞれの概要について、実施した順に記載をしています。「データアナリティクス 専門知識」に限らず、他の認定試験を受ける際に参考になる部分もあるかと思うので、良かったら読んでみてください。
受験目的
- 数ヶ月前にデータ分析やデータ活用をメインとして扱う会社に転職。
- データ分析に関わるAWSサービスを体系的に学ぶべく、本認定試験を受験することに。
前提
- ソリューションアーキテクト・アソシエイトの資格は取得しており、AWSのサービスの基本は把握済。
- テスト範囲のサービスの中には、自分が関わっているPJの中で使われているものもあったが、ゼロからの構築、設定経験はほぼ無し。
学習手順
試験ガイド
まずはこの認定試験の試験内容を把握しましょう。試験の出題形式や、分野及び観点が記載されています。
「AWS 認定試験に備える」ページ
- https://aws.amazon.com/jp/certification/certification-prep/
- AWSの各認定試験ごとに、学習すべきリソースへのリンクをまとめてくれています。
- こちらの「データ分析 – 専門知識」項目における「AWSホワイトペーパーと、よくある質問を読む」を見ると、認定試験の出題対象となるサービスの一覧を確認することができます。
- 試験対象となるサービスについて、明示的に記載がある箇所はここ以外にないようなので(少なくとも私は見つけられませんでした)、ぜひ確認してみてください。
書籍
- 図解即戦力 ビッグデータ分析のシステムと開発がこれ1冊でしっかりわかる教科書
- https://www.amazon.co.jp/dp/429710881X
- ビッグデータ分析システムを構成する要素にどういったものがあるのか、概要を掴む上で非常に役立つ書籍かと思います。
- AWSで始めるデータレイク
- https://www.amazon.co.jp/dp/491031301X
- こちらはよりAWSサービスに特化した書籍になります。各サービスの具体的なユースケースや利用手順が平易な文章で書かれていて、概要を理解するのにもってこいな書籍かと思います。
- AWSの中の人が書いている点と、最近出版されている点(2021/03/29執筆時点)からも、信頼のおける学習教材だと思います。
サンプル問題
- https://d1.awsstatic.com/ja_JP/training-and-certification/docs-data-analytics-specialty/AWS-Certified-Data-Analytics-Specialty_Sample-Questions.pdf
- ざっくりとデータ分析に関わるAWSサービスの概要を理解したタイミングで、公式が提供しているサンプル問題(無料)に取り組むのがおすすめです。先の試験ガイドに記載のあった観点が、どういった切り口で問われるのかを確認できます。意外と深掘りされるな、とか、同系統サービスの比較で問われることが多いな、とかを感じられるかなと思います。
公式ドキュメント
- やはり一番大事なのは公式ドキュメントです。当たり前ですが、ここの記載が認定試験における正解となります。各種サービスの公式ドキュメントに一通り目を通しましょう。
- 基本的には日本語訳が整備されていますが、たまに不自然な表現に出くわすことがあります(目的語や主語が文末に突然現れるようなものなど。読んだことある方は分かっていただけるはずw)。英語が得意な方は英語の方が読みやすい部分もあるかもしれないです。
- ちなみに試験問題自体も日本語版が提供されているんですが、1, 2問ほど日本語訳が分かりづらいものがありました。英語の問題文も表示可能なので、不安に思った際にはそちらも試しに見てみるのもおすすめです。
- 公式ドキュメントに簡単なチュートリアルがあるサービスもあります。触ってみることで、各種設定値の意味や設定タイミングなどを一気に理解しやすくなると思います。業務の中で触ったことのないサービスについては一度は触れてみることを強くおすすめします。
- ただし、課金には重々気をつけてください。笑 ものによっては無料利用枠のない場合があります。チュートリアルが終わってその後使わない場合はすぐにリソースを削除して、課金金額を最小限に抑えましょう。
クラウドサービス活用資料集
- AWS公式側が用意しているWebinarなどの発表資料です。プレゼン資料なので視覚的な情報を中心に分かりやすくまとまっています。公式ドキュメントを読むのに疲れた時にはこちらもおすすめです
- https://aws.amazon.com/jp/aws-jp-introduction/https://www.slideshare.net/AmazonWebServicesJapan/presentations
ブログ
- AWSのサービスに関する情報は公式以外にもWeb上に沢山あります。より具体的な利用事例や、触ってみた的な記事を見て、実利用のイメージを膨らますことができるかと思います。特にクラスメソッドさんが運営されているDevelopersIOは記事の速報性も高く、記事数も多いため、学習の上で非常に役立つソースの一つかなと思います(私はとてもお世話になりました、、!
模擬試験
- AWS公式が提供している20問の模擬試験の受験が可能です。
- この時点で理解度不足を痛感する可能性もあるので、本試験受験日からある程度余裕を持たせて受験することをおすすめします。
- 過去にAWS関連の認定試験に合格している場合は、一度だけ模擬試験を無料で受験することができます。ぜひ活用してみてください。
- 注意点: 模擬試験の受験を終了した後、確認できるのは点数のみです。各問題の正誤及び正答は確認できませんのでご注意ください。
よくある質問
- 実際に出た問題の中には、このよくある質問から出ていたものもありました。理解を深めるためにも役立つかと思うので、こちらにも目を通してみることをおすすめします。
受験を終えての感想
- 当たり前ではありますが、データ分析に関わる各AWSサービスの概要とユースケース、パフォーマンスやセキュリティ面での勘所を体系的に学ぶことができました。当初の目的は達成できたかなと思います。
- 副次的なところで言うと、業務の中で不明点が出てきた時に、公式ドキュメントを抵抗なく読む習慣がつき、また理解するスピードも上がった気がします。
- まだ業務で使用していないサービスについては、深いところまで理解しきれていない部分も多少あるとは思います。その点については、社内で機会があれば積極的に挑戦して、知識を実践に結びつけていきたいと思います。
- AWSでしっかり基礎を身につけておけば、仮に他のクラウドを使うことになっても、キャッチアップしやすいんじゃないかなとは思っているので、適度に復習もしつつ、業務でも活用しつつ、さらなる知識の定着に努めたいなと思います。
- 投稿日:2021-03-29T14:49:20+09:00
「AWS 認定データアナリティクス 専門知識」 認定取得に向けた学習記録
はじめに
先日、AWS 認定データアナリティクス 専門知識の認定試験を受験し、無事合格しました。自分が実施した学習の流れとそれぞれの概要について、実施した順に記載をしています。「データアナリティクス 専門知識」に限らず、他の認定試験を受ける際に参考になる部分もあるかと思うので、良かったら読んでみてください。
受験目的
- 数ヶ月前にデータ分析やデータ活用をメインとして扱う会社に転職。
- データ分析に関わるAWSサービスを体系的に学ぶべく、本認定試験を受験することに。
前提
- ソリューションアーキテクト・アソシエイトの資格は取得しており、AWSのサービスの基本は把握済。
- テスト範囲のサービスの中には、自分が関わっているPJの中で使われているものもあったが、ゼロからの構築、設定経験はほぼ無し。
学習手順
試験ガイド
まずはこの認定試験の試験内容を把握しましょう。試験の出題形式や、分野及び観点が記載されています。
「AWS 認定試験に備える」ページ
- https://aws.amazon.com/jp/certification/certification-prep/
- AWSの各認定試験ごとに、学習すべきリソースへのリンクをまとめてくれています。
- こちらの「データ分析 – 専門知識」項目における「AWSホワイトペーパーと、よくある質問を読む」を見ると、認定試験の出題対象となるサービスの一覧を確認することができます。
- 試験対象となるサービスについて、明示的に記載がある箇所はここ以外にないようなので(少なくとも私は見つけられませんでした)、ぜひ確認してみてください。
書籍
- 図解即戦力 ビッグデータ分析のシステムと開発がこれ1冊でしっかりわかる教科書
- https://www.amazon.co.jp/dp/429710881X
- ビッグデータ分析システムを構成する要素にどういったものがあるのか、概要を掴む上で非常に役立つ書籍かと思います。
- AWSで始めるデータレイク
- https://www.amazon.co.jp/dp/491031301X
- こちらはよりAWSサービスに特化した書籍になります。各サービスの具体的なユースケースや利用手順が平易な文章で書かれていて、概要を理解するのにもってこいな書籍かと思います。
- AWSの中の人が書いている点と、最近出版されている点(2021/03/29執筆時点)からも、信頼のおける学習教材だと思います。
サンプル問題
- https://d1.awsstatic.com/ja_JP/training-and-certification/docs-data-analytics-specialty/AWS-Certified-Data-Analytics-Specialty_Sample-Questions.pdf
- ざっくりとデータ分析に関わるAWSサービスの概要を理解したタイミングで、公式が提供しているサンプル問題(無料)に取り組むのがおすすめです。先の試験ガイドに記載のあった観点が、どういった切り口で問われるのかを確認できます。意外と深掘りされるな、とか、同系統サービスの比較で問われることが多いな、とかを感じられるかなと思います。
公式ドキュメント
- やはり一番大事なのは公式ドキュメントです。当たり前ですが、ここの記載が認定試験における正解となります。各種サービスの公式ドキュメントに一通り目を通しましょう。
- 基本的には日本語訳が整備されていますが、たまに不自然な表現に出くわすことがあります(目的語や主語が文末に突然現れるようなものなど。読んだことある方は分かっていただけるはずw)。英語が得意な方は英語の方が読みやすい部分もあるかもしれないです。
- ちなみに試験問題自体も日本語版が提供されているんですが、1, 2問ほど日本語訳が分かりづらいものがありました。英語の問題文も表示可能なので、不安に思った際にはそちらも試しに見てみるのもおすすめです。
- 公式ドキュメントに簡単なチュートリアルがあるサービスもあります。触ってみることで、各種設定値の意味や設定タイミングなどを一気に理解しやすくなると思います。業務の中で触ったことのないサービスについては一度は触れてみることを強くおすすめします。
- ただし、課金には重々気をつけてください。笑 ものによっては無料利用枠のない場合があります。チュートリアルが終わってその後使わない場合はすぐにリソースを削除して、課金金額を最小限に抑えましょう。
クラウドサービス活用資料集
- AWS公式側が用意しているWebinarなどの発表資料です。プレゼン資料なので視覚的な情報を中心に分かりやすくまとまっています。公式ドキュメントを読むのに疲れた時にはこちらもおすすめです
- https://aws.amazon.com/jp/aws-jp-introduction/https://www.slideshare.net/AmazonWebServicesJapan/presentations
ブログ
- AWSのサービスに関する情報は公式以外にもWeb上に沢山あります。より具体的な利用事例や、触ってみた的な記事を見て、実利用のイメージを膨らますことができるかと思います。特にクラスメソッドさんが運営されているDevelopersIOは記事の速報性も高く、記事数も多いため、学習の上で非常に役立つソースの一つかなと思います(私はとてもお世話になりました、、!
模擬試験
- AWS公式が提供している20問の模擬試験の受験が可能です。
- この時点で理解度不足を痛感する可能性もあるので、本試験受験日からある程度余裕を持たせて受験することをおすすめします。
- 過去にAWS関連の認定試験に合格している場合は、一度だけ模擬試験を無料で受験することができます。ぜひ活用してみてください。
- 注意点: 模擬試験の受験を終了した後、確認できるのは点数のみです。各問題の正誤及び正答は確認できませんのでご注意ください。
よくある質問
- 実際に出た問題の中には、このよくある質問から出ていたものもありました。理解を深めるためにも役立つかと思うので、こちらにも目を通してみることをおすすめします。
受験を終えての感想
- 当たり前ではありますが、データ分析に関わる各AWSサービスの概要とユースケース、パフォーマンスやセキュリティ面での勘所を体系的に学ぶことができました。当初の目的は達成できたかなと思います。
- 副次的なところで言うと、業務の中で不明点が出てきた時に、公式ドキュメントを抵抗なく読む習慣がつき、また理解するスピードも上がった気がします。
- まだ業務で使用していないサービスについては、深いところまで理解しきれていない部分も多少あるとは思います。その点については、社内で機会があれば積極的に挑戦して、知識を実践に結びつけていきたいと思います。
- AWSでしっかり基礎を身につけておけば、仮に他のクラウドを使うことになっても、キャッチアップしやすいんじゃないかなとは思っているので、適度に復習もしつつ、業務でも活用しつつ、さらなる知識の定着に努めたいなと思います。
- 投稿日:2021-03-29T14:34:04+09:00
AWSでControl Towerを使わずにマルチアカウントを実装してみた(④GuardDuty編)
はじめに
前回記載した①概要編、②Organizations編、③CloudTrail編の続きとなります。今回はOrganizations内の全アカウント、全リージョンに対しGuardDutyを有効化する方法を記載します。
今回の前提となるマルチアカウント環境の全体的な構成や、GuardDutyで何ができるか?については以下の概要編を参照ください。
全体構成
概要図はこんな感じです。Organizations内に複数のアカウントがありますが、これらのアカウントのGuradDutyを有効化します。さらに、全リージョンに対してGuardDutyを適用します。
対応手順
以下、対応手順を記載します。Organizationsコンソールは現時点では画面デザインが新しいものと古いものの両方を使えますが、今回は新しい方を使っていきます。
GuardDutyの委任(東京リージョン)
まずはOrganizationsのメンバーアカウント(セキュリティアカウント)に対し、GuardDutyの権限を委任します。これにより、セキュリティアカウントで組織内のGuardDutyをコントロールできるようになります。以降の手順は管理アカウントで実施します。
管理アカウントでコンソールにログイン後、東京リージョンに切り替えます。続いてGuardDutyコンソールを開きます。画面内の「今すぐ始める」をクリックします。
下記の画面が表示されるので、「委任された管理者アカウントID」にセキュリティアカウントのID(12桁の数字)を入力します。
管理者の委任が完了しました。
GuardDuty有効化(東京リージョン)
ここからは委任先のセキュリティアカウントで操作を行います。
セキュリティアカウントのAWSコンソールへログイン後、東京リージョンへ切り替えます。続いてGuardDutyコンソールを開き、左メニューの「設定→アカウント」をクリックします。画面上部に青いバーが出ていますので、「有効化」ボタンをクリックします。
無事有効化されました。この時点で、選択されている1リージョン(ここでは東京)に対し、Organizations内の全アカウントのGuardDutyが有効になります。
GuardDutyの委任(その他リージョン)
さて、この時点では東京リージョン以外のGuardDutyは無効化されている状態です。上でやったのと同じことを繰り返してもよいですが、ここでは委任操作をCLIで実施したいと思います。
最近CloudShellという便利なサービスが出たのでこれを利用してみます。管理アカウントでAWSコンソールを開き、とりあえず東京リージョンを選択した状態でCloudShellコンソールを起動します。
※下記は検索窓に「CloudShell」と打った状態です
しばらく経つと以下の画面が表示されます。恐らくですが、裏で何がしかのコンテナが割り当てられて起動しているものと思われます。このコンソール上でAWS CLIの実行が可能です。ブラウザ上でCLI操作まで完結してしまうとは、何とも素晴らしい時代になったものです。。
というわけで全リージョン分の委任コマンドを実行します。委任先のアカウントIDには12桁の数字を入力してください。また下記のコマンドは東京リージョンも含めていますので、必要に応じ外してください。
aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ap-northeast-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ap-northeast-2" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ap-northeast-3" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ap-south-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ap-southeast-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ap-southeast-2" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "ca-central-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "eu-central-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "eu-north-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "eu-west-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "eu-west-2" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "eu-west-3" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "sa-east-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "us-east-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "us-east-2" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "us-west-1" aws guardduty enable-organization-admin-account --admin-account-id 委任先のアカウントID --region "us-west-2"GuardDuty有効化(その他リージョン)
セキュリティアカウントのAWSコンソールへログイン後、上記東京リージョンで対応したのと同じ要領で、画面からGuardDutyを有効化していきます。手順は全く同じなので割愛します。
最後に
無事全リージョン、全アカウントでGuardDutyを有効化することができました。次回はAWS Configの有効化方法について書ければと思っています。
今回の記事が誰かのお役に立てると幸いです。








- 投稿日:2021-03-29T14:32:48+09:00
コンテナLambdaをデプロイしてみた(躓いたポイントとリソース削除)
はじめに
AWS builders-flashにコンテナLambdaの記事が出ていたので試してみました。
躓いたポイントと試した後に実行したリソース削除コマンドだけ書いておきます。
躓いたポイント
awscli 2.1.6 未満だとコマンド実行エラーになる
aws lambda create-function \
--function-name func1-container \
--package-type Image \
--code ImageUri=\${ACCOUNTID}.dkr.ecr.\${REGION}.amazonaws.com/func1@\${DIGEST} \
--role ${ROLE_ARN}コンテナLambdaは新しくサポートされた機能なので、バージョンは最新化すべきですね。
2.1.5と2.1.6の必須パラメータの違い
bash#必須項目が変わっているので、2.1.5以前でコンテナLambda作成コマンドを叩くとエラーになります docker run --rm -ti -v ~/.aws:/root/.aws amazon/aws-cli:2.1.5 lambda create-function help #コマンド結果抜粋 SYNOPSIS create-function --function-name <value> --runtime <value> --role <value> --handler <value> [--code <value>] [--description <value>] docker run --rm -ti -v ~/.aws:/root/.aws amazon/aws-cli:2.1.6 lambda create-function help #コマンド結果抜粋 SYNOPSIS create-function --function-name <value> [--runtime <value>] --role <value> [--handler <value>] [--code <value>] [--description <value>]amazon/aws-cliでawsコマンドを実行していると環境変数が正しくセットされない
REGION=\$(aws configure get region)
ACCOUNTID=\$(aws sts get-caller-identity --output text --query Account)amazon/aws-cliを利用した場合としない場合で出力結果が違うよう。
ローカルのawscliとamazon/aws-cliの出力結果の違い
bash#amazon/aws-cliを利用すると余計な内容が出力されているので、amazon/aws-cliの実行結果を直接環境変数に入れると、環境変数を使う際にコマンド実行エラーが起きる #amazon/aws-cliを使ってもよいやり方があるのかも知れないですが、今回はローカルにawscliを入れて実行しました。 alias aws #aliasがない状態 aws sts get-caller-identity --output text --query Account | cat -e #コマンド結果 XXXXXXXXXXXX$ alias aws='docker run --rm -ti -v ~/.aws:/root/.aws amazon/aws-cli:2.1.32' aws sts get-caller-identity --output text --query Account | cat -e #コマンド結果 ^[[?1h^[=^MXXXXXXXXXXXX^[[m^M$ ^M^[[K^[[?1l^[>%IAMRoleのポリシー不足で権限エラー
できるだけ最小権限で実行したく、ポリシーを見直しました。
今回設定したポリシー
bash"ecr:BatchCheckLayerAvailability" "ecr:BatchDeleteImage" "ecr:CompleteLayerUpload" "ecr:CreateRepository" "ecr:DeleteRepository" "ecr:GetRepositoryPolicy" "ecr:InitiateLayerUpload" "ecr:ListImages" "ecr:PutImage" "ecr:SetRepositoryPolicy" "ecr:UploadLayerPart" "iam:CreateRole" "iam:DeleteRole" "iam:PassRole" "lambda:CreateFunction" "lambda:DeleteFunction" "lambda:InvokeFunction"コンテナLambdaをデプロイしてみる
ここはAWS builders-flashと同じなので、ここには記載しません。
不要リソースを削除
試したあとはリソース削除しておきたいので削除コマンドを記載。
bashaws lambda delete-function --function-name func1 aws lambda delete-function --function-name func1-container aws ecr delete-repository --repository-name func1 --force aws iam delete-role --role-name lambda-ex
- 投稿日:2021-03-29T12:53:11+09:00
TerraformでAWS RDSのDBユーザを管理する
はじめに
MySQLやPostgreSQLのユーザをTerraformで管理するときの備忘録としてこの記事を残します。
前提条件
基盤はAWS、DBはPostgreSQLでDBがいるネットワークは内部ネットワークでインターネットのアクセスがないです。TerraformはローカルPC(Mac)から実行するものとします。
実行方法
Terraform
こちらのPostgreSQL用のTerraform providerを使い実行します。
provider "postgresql" { scheme = "awspostgres" # AWSを使う場合はこれを指定 host = var.db_host username = "postgres" port = 5432 password = var.db_password superuser = false }バージョンはこのように指定します。
required_providers { postgresql = { source = "cyrilgdn/postgresql" version = "1.11.2" } }PostgreSQLのユーザを追加します。
resource "postgresql_role" "my_role" { name = "my_role" login = true password = var.my_role_password } resource "postgresql_grant" "readonly_my_role" { database = "test_db" role = postgresql_role.my_role.name schema = "public" object_type = "table" privileges = ["SELECT"] }ローカル
ローカルから直接PostgreSQLを触ることはできないので、踏み台サーバを経由してSSHトンネリングすることで、アクセスします。
sshトンネリング用のコマンドを実行します。
# ssh -N -L [ローカル側で転送に使用するPort(10000〜60000)]:[DBのHostName]:[DBが解放しているPort] -i [IdentityFile(秘密鍵のパス)] -p [踏み台が解放しているPort] [踏み台のUser]@[踏み台のHostName] ssh -N -L 5432:test_db.XXX.ap-northeast-1.rds.amazonaws.com:5432 -i ~/.ssh/bastion.pem -p 22 ec2-user@XXX後述するSSL証明書エラーになるので、ホストを偽装します。
/etc/hostsにlocalhost 127.0.0.1 test_db.XXX.ap-northeast-1.rds.amazonaws.comを追加してください。これでTerraformを実行するとPostgreSQLへのユーザ追加ができます。
Tips
SSL証明書エラー
上記に記載されているsshトンネリングコマンドを実行し、
ssh -N -L 5432:test_db.XXX.ap-northeast-1.rds.amazonaws.com:5432 -i ~/.ssh/bastion.pem -p 22 ec2-user@XXXsshトンネリングで
localhostの5432ポートにアクセスするとPostgreSQLにアクセスできるようになったので、Terraformのproviderのhost名をlocahostに指定して、Terraformを実行させます。provider "postgresql" { scheme = "awspostgres" # AWSを使う場合はこれを指定 host = "localhost" username = "postgres" port = 5432 password = var.db_password superuser = false }そうすると、SSL証明書の確認でホスト名が異なるとエラーが出てしまいます。
Error: error detecting capabilities: error PostgreSQL version: x509: certificate is valid for stg-knew-rds.coh5dxpjppgc.ap-northeast-1.rds.amazonaws.com, not localhostセッションマネージャーを使ったポートフォワード
セッションマネージャーを使ってポートフォワードができないかと調べたが、
結局ポートフォワードはできなかった。cf. https://dev.classmethod.jp/articles/port-forwarding-using-aws-system-manager-sessions-manager/

- 投稿日:2021-03-29T12:45:50+09:00
ChaliceとCloud9の連携方法について記載してみます(AWS)
はじめに
みなさんChaliceはご存知でしょうか?AWSでサーバレスアプリケーションを構築する際に、爆速の開発効率を誇るフレームワークです。
今回はこのChaliceを使い、AWS謹製のIDEであるCloud9上で開発を行うための手順について記載したい思います。Chaliceとは何か?
上にも記載していますが、ChaliceはAWSが開発したサーバレスアプリケーション向けのフレームワークです。Python向けのライブラリとして提供されており、pipでインストールができます。
サーバレスフレームワークと言えばSAMやAmplifyなんかもありそれぞれ一長一短ありますが、こと開発効率においてはChaliceの右に出るものはいないと思います。(たぶん。。)
Chaliceはコマンド一発でAPI Gateway + Lambdaの環境を構築できてしまう優れものです。ゴチャゴチャ書く前にまずはサンプルコードを見て頂きましょう。from chalice import Chalice app = Chalice(app_name='example') @app.route('/') def index(): return {'hello': 'world'}Chaliceでプロジェクトを作成した際に自動生成される、HELLO WORLD用のサンプルアプリケーションです。エンドポイント(/)にアクセスすると簡単なJSONを返してくれます。
このアプリケーションのデプロイ方法ですが、以下の通りコマンド一発でできてしまいます。(Linuxコンソールでの例です)$ chalice deployこれだけで必要なLambda関数だけでなく、API Gatewayまで勝手に作ってくれます。感激です。
エンドポイントを複数切りたい場合はこんな感じに書きます。from chalice import Chalice app = Chalice(app_name='example') @app.route('/') def index(): return {'hello': 'world'} @app.route('/hoge') def hoge(): return {'hello': 'hoge'} @app.route('/fuga') def fuga(): return {'hello': 'fuga'}これだけで /、 /hoge、 /fuga という3つのエンドポイントが作れてしまいます。最高。。
というわけで、Chaliceに興味を持たれて詳しく知りたくなった方は以下AWSのBlackBeltをご覧ください。できれば動画で見るのがよいと思います。理解度が全然違いますので。
Cloud9とは何か?
AWS謹製の統合開発環境(IDE)です。ブラウザ上で動き、AWSコンソールにログインするだけで使えてしまうので場所を選ばずに開発を行うことができます。ブラウザさえあれば何とかなるので端末も問いません。スタバでコーヒー片手にiPadで優雅にコーディング、なんてこともできてしまいます。
詳細については言わずもがなのBlackBeltを参照ください。動画も貼っておきます。
Cloud9上でChaliceを動かしてしまおう
そんな素敵なChaliceとCloud9ですので、当然連携して使いたくなります。というわけで以下、手順をしたためていきたいと思います。
ちなみにこの手順はChalice + Cloud9でシステム開発案件を行った2020年7月頃の情報に基づいており、さらにPython初心者(Java屋)の私が知識ゼロから手探りで調べて対応したものです。間違ってるよ! とか もっといいやり方あるよ! とかあればお気軽にご指摘頂けると助かります。Cloud9環境の作成
まずはCloud9環境を作成します。トップメニューからCloud9コンソールに遷移し、画面上の「Create environment」をクリックしてあとはポチポチするだけです。最初に決める名前以外は全てデフォルトでもOKなので、ここで何か迷うことはないと思います。
Cloud9環境を立ち上げると、内部的には専用のEC2インスタンスが割り当てられ、このインスタンス上でCloud9が実行されることになります。Cloud9用のロール作成と付与
Cloud9にはAMTCという機能が用意されており、デフォルトでONになっています。AMTCにより、AWSコンソールにログインしたユーザと概ね同じ権限がCloud9(のEC2)に与えられるため便利なのですが、全権限が付与されるわけではなく、IAMなどの一部については制限がかかるようです。
この状態ではChaliceが使えないため、AMTCをOFFにして専用のIAMロールをEC2へ割り当てていきたいと思います。IAMロールの作成
IAMコンソールから新規ロールを作成します。流れは以下の通りです。
- IAMコンソールにアクセスし、左メニューの「ロール」を選択し、画面内に表示される「ロールの作成」をクリックします。
- 続いて表示される画面で「信頼されたエンティティの種類」に「AWSサービス」を、「ユースケースの選択」に「EC2」を選択して「次へ」をクリックします。
- 次の画面でロールを選択します。ここではAdministratorAccessを選択した前提で話を進めますが、必要に応じて権限レベルは見直してください。選択後「次へ」をクリックします。
- 次の画面でタグを指定します。何も入れなくてOKです。
- 最後にロール名を指定します。任意の文字列を入力後、「ロールの作成」をクリックすれば終了です。
ロールのEC2へのアタッチ
上記で作成したロールをCloud9用のEC2インスタンスへ割り当てます。流れは以下の通りです。
- EC2コンソールにアクセスし、左メニューの「インスタンス」を選択します。
- インスタンス一覧が表示されるので、Cloud9用のEC2を選択し、「右クリック→セキュリティ→IAMロールを変更」を選択します。なおCloud9で生成したインスタンス名には「aws-cloud9-」の接頭語が割り当たるようです。
- IAMロールの割り当て画面が表示されますので、先ほど作成したロールを選択し、「保存」ボタンをクリックします。
Cloud9でのAMTCを無効化
先程記載した通り、デフォルトONになっているAMTCを無効化します。
Cloud9のコンソールを開き、「アイコン(9の雲マーク)→Preference」を選択します。
設定画面が開くので、左メニューの「AWS Settings→AWS Resources」を選択。「AWS managed temporary credentials」をOFFにします。
Cloud9に対し、デフォルトリージョンを設定
AMTCを無効化すると、リージョンの設定もなくなってしまうようなので、以下の手順に従い設定を入れます。
まずは左メニューからトップ階層のディレクトリを右クリックし、「Open Terminal Here」を選択します。これによりCloud9コンソールからEC2インスタンスに対してSSHアクセスできます。超便利。
コンソールはこんな感じです。
コンソール上で「aws configure list」を実行します。以下の通り、リージョンの割り当てはありません。
$ aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ****************V6LL iam-role secret_key ****************PW2P iam-role region <not set> None None設定ファイルの有無を確認します。初期状態であればたぶん存在しないはずです。
$ ll -a ~/.aws/ total 4 drwxr-xr-x 2 ec2-user ec2-user 6 Mar 29 01:52 . drwx------ 13 ec2-user ec2-user 4096 Mar 29 01:36 ..というわけで作成します。
$ vi ~/.aws/config ※以下入力して保存(:wq) [default] region = ap-northeast-1 $ ll ~/.aws/ total 4 -rw-rw-r-- 1 ec2-user ec2-user 36 Mar 29 02:01 config $ cat ~/.aws/config [default] region = ap-northeast-1リージョン設定が完了しましたので、再確認します。ちゃんと入ってくれたようです。
$ aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ****************V6LL iam-role secret_key ****************PW2P iam-role region ap-northeast-1 config-file ~/.aws/configChaliceのインストール
引き続きCloud9のターミナルで作業していきます。
カレントディレクトリを確認します。/home/ec2-user/environment にいなければ移動してください。$ pwd /home/ec2-user/environmentChaliceをEC2インスタンスへインストールします。
$ sudo pip install chalice WARNING: Running pip install with root privileges is generally not a good idea. Try `pip install --user` instead. Collecting chalice Downloading https://files.pythonhosted.org/packages/26/de/79e471e7eb590586880b0e90f29742881eb60dffdc2fcb3e340db5f13367/chalice-1.22.3-py2.py3-none-any.whl (384kB) ~~~(略)~~~ Installing collected packages: wcwidth, blessed, readchar, python-editor, inquirer, attrs, click, wheel, typing, mypy-extensions, chalice Successfully installed attrs-20.3.0 blessed-1.17.6 chalice-1.22.3 click-7.1.2 inquirer-2.7.0 mypy-extensions-0.4.3 python-editor-1.0.4 readchar-2.0.1 typing-3.6.4 wcwidth-0.2.5 wheel-0.36.2無事インストールされました。続けてChalice用のプロジェクトを作成します。以下のコマンドをコンソール上で実行するだけでOKです。ここでのプロジェクト名はとりあえず helloworld にしました。
chalice new-project [プロジェクト名]$ chalice new-project helloworld Your project has been generated in ./helloworldプロジェクトができました。フォルダ構成とデフォルトで作成されるサンプルアプリ(app.py)はこんな感じです。
サンプルアプリをデプロイしてみます。以下の通り、コマンド一発でAPI GatewayとLambdaが自動作成されます。ステキ。。なお、デプロイ前にコンソール上でプロジェクトフォルダへ移動する必要があるのでご注意ください。
$ cd helloworld/ $ chalice deploy Creating deployment package. Reusing existing deployment package. Creating IAM role: helloworld-dev Creating lambda function: helloworld-dev Creating Rest API Resources deployed: - Lambda ARN: arn:aws:lambda:ap-northeast-1:123456789:function:helloworld-dev - Rest API URL: https://xxxxxx.ap-northeast-1.amazonaws.com/api/上記結果の最終行にAPIのURLが記載されています。このURLからAPIをキックすることができるので、コンソールからCurlコマンドで試してみます。
$ curl https://xxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/ {"hello":"world"}無事JSONが返却されました。とても楽ちんで素晴らしいですね。
テストが終わったらAPI GatewayとLambdaは消しておきましょう。これもコマンド一発です。$ chalice delete Deleting Rest API: xxxxxxxxxx Deleting function: arn:aws:lambda:ap-northeast-1:123456789:function:helloworld-dev Deleting IAM role: helloworld-dev最後に
Cloud9+Chaliceの連携方法と簡単な使い方だけ記載しました。次回以降はもうちょっと踏み込んだ内容を解説できればと思っています。
今回の記事が誰かのお役に立てると幸いです。





- 投稿日:2021-03-29T11:40:23+09:00
RDSの自動起動と自動停止スクリプト
RDSは起動しっぱなしだとお金がかかる。
しかし、停止しても7日後に再度起動してしまう。
特に検証用とかで使用しない間が多い場合、いちいち起動したら停止するという運用はかなり面倒。
そのため、検証時以外は、起動したらすぐ停止するというスクリプトを作成して、無駄なコストがかからないようにする。
そこで使用するのが、AWSのLambdaを使う。
Lambdaとは何?
Lambdaと聞いてもわからないので調べた。
AWSの「サーバレスコンピューティングとアプリケーション」と言われる。
これまではPHPやPythonをうごかすためのwebサーバーが必要だったが、Lambdaならサーバーレスのため、サーバーを準備しなくても環境が揃っていると言うことである。
LambdaはJava、Node.js、C#、Pythonのプログラミング言語に対応しているので、各種「機能」(プログラム)はこの言語で開発すればOK、ということのようです。
「S3にアップされた画像のサムネイル化」で考えると、S3に画像ファイルがアップされるのを監視するためのサーバを用意して、監視し続けるプログラムを用意して、ファイルがアップされたことを検知したら、リサイズする処理を行う必要があったのが、Lambdaならこの「リサイズする処理」だけを作ればOKということ。
今回はこのLambdaを利用し、指定された時間に関数を実行すると言うことを実装し、RDSの起動停止を自動で実施する。
流れ
IAMによるロール(権限)作成
IAMページでロールの作成を実施。
「信用されたエンティティの種類を選択」については、「AWS サービス」を選択。「このロールを使用するサービスを選択」は「Lambda」を選択します。
Attach(アタッチ)する権限ポリシーは、
・CloudWatchFullAccess
・AmazonRDSFullAccess
Lambdaの設定でStartとStopの関数を作成
Lambdaで関数を作成する。関数はStartとStopの二つ。
スクリプトは下記を登録する。
import boto3 region = 'ap-northeast-1' instance = 'RDSインスタンス名' def lambda_handler(event, context): rds = boto3.client('rds', region_name=region) rds.start_db_instance(DBInstanceIdentifier=instance) print('started instance: ' + instance)import boto3 region = 'ap-northeast-1' instance = 'RDSインスタンス名' def lambda_handler(event, context): rds = boto3.client('rds', region_name=region) rds.stop_db_instance(DBInstanceIdentifier=instance) print('stoped instance: ' + instance)また、関数起動を自動でやるため、cronで動かすようにも設定する。
cronによる起動はトリガーの追加で「CloudWatch Events」を選択する。
〇RDS の起動時間
cron(15 23 */6 * ? *)〇RDS の停止時間
cron(45 23 0/6 * ? *)テスト
起動が大丈夫かをテストできる。
失敗したらスクリプトをチェックする。
RDS 自動停止を実装する際の実行時間の考え方
設定に関して少し蛇足になりますが、RDS インスタンスが7日後に再起動する仕様について。
コストを下げる基本的な考え方として、AWS 側のシステムで再起動を発生させないことが良いと思います。
そのため一定時間ごとに RDS を起動して1時間以内に停止命令を送る実装をすれば良いです。
※aws は1時間以内の起動時間は1時間の使用としてコストが計上されるため
そこで今回は6日間隔で1時間以内の起動と停止を繰り返す設定を行っています。
つまり毎月1日、7日、13日、19日、25日、29日にスクリプトを実行します。
参考記事


- 投稿日:2021-03-29T09:12:36+09:00
AWS認定セキュリティ(SCS)を取得しました
AWS認定セキュリティ(SCS)を受験し無事合格しました。
資格取得までに参考にしたものを投稿します。
私のAWSの知識
以下の4資格を取得しています。
- クラウドプラクティショナー
- ソリューションアーキテクト
- デベロッパーアソシエイト
- SysOpsアドミニストレータ業務では、EC2,RDS,Lambda,S3を軽く触っている程度になります。
AWSサービスをガッツリ使うことは基本ありません。勉強時間
30時間程度だと思います。(1日1時間を1ヶ月)
試験範囲の確認
要点整理から攻略する『AWS認定 セキュリティ-専門知識』を読む
めちゃくちゃ良かったです。
試験で出るサービスがほぼ網羅されていると思います。サービスに対しての説明は少し不足していると思うので、BlackBeltや公式サイトで補完した方がよいと思います。
チュートリアルのリンクとかもあるので、
実際手を動かして試すことも良いと思います。公式の模擬試験を受ける
他の試験を合格していたので、無料で受けることができました。
自分の苦手分野や出題傾向の雰囲気を掴むことができると思います。AWS公式のトレーニング(無料)を受ける
模擬試験や章末問題は必ず理解した方が良いです。
https://www.aws.training/Details/eLearning?id=45684Black Beltを見る
以下のサービスのは見といたほうがよいと思います。(重要そうな順に並べました)
- IAM
- KMS
- S3
- CloudWatch
- AWS Config
- SystemsManager
- Cognito
- CloudFront
- AWS WAF
- Trusted Advisor
- Athena
- Shiled
- Detective
- Lambda
- GuradDuty
- Macie
- CloudTrail
- Active Directory
- AD Connector
試験を受けての感想
AWSの裏側の暗号化の扱い方や、セキュアなインフラ構成など、
広く知ることができたので、とても良い試験だと思います。試験中はそんなに迷う問題も無く、高得点で終えられたの良かったです。
その他、勉強中に重要そうと思ったまとめ
- KMSのキーポリシー
- KMSのCMK自動ローテーション
- KMSのEncryption Context
- KMSのインポートキー
- S3のぼーるとロック
- CloudFrontのルール
- ALBにアクセスする古いOS(Windows XPとか)の挙動
- CloudFrontとALBの証明書の設置
- VPCフローログの見方
- CloudTrailのデフォルトで保持してくれる期間と、その期間過ぎた後のログの扱い
- 投稿日:2021-03-29T05:58:27+09:00
SSLの独自ドメイン静的Webサイトを低コストで15分で立ち上げる (Route53 + S3 + CloudFront + AWS Certificate Manager)
こんな人向け
- VPSよりAWS使うのが好きな人
- 静的WebサイトなのにわざわざEC2立てて運用している人
- 現在S3で静的Webサイトを公開しているけどSSLに対応していない人
- AWS使ってみたいけどハードルが高そうと思っている人
- そもそもwebサイトをインターネットに公開するのが初めてな人
今回、タイトル通りの構成で静的Webサイトをネット上に公開するやり方を紹介していきます。
高可用性・高耐久性の爆速Webサイトが多分15分くらいでできちゃいます。この構成は世の中に沢山記事が出ていますが、
独自にハマったこともあるため防備録として記事にすることにしました。この記事でやらないこと
- お名前.com等での独自ドメインの取得方法、ネームサーバーの変更方法
- awsのアカウント作成
- awsのIAMの設定
- 各サービスの詳細な説明
- 各種チューニング
前準備
独自ドメインの取得。
今回はRoute53で取得しました。本題
以下、順番にやっていきます。
Route53でホストゾーンを作成する(Route53でドメインを取得した場合は省略)
Route53 >> ホストゾーン
に入り「ホストゾーンの作成」をクリックします。
ドメイン名に取得した独自ドメインを入力し、他はデフォルトのまま「ホストゾーンを作成」を押下。
このように2件のレコードが入った状態で作成されます。
Route53でドメインを取得した場合、この状態が自然と出来上がっています。
独自ドメインのネームサーバーをRoute53に向ける
当記事はRoute53でドメイン取得しちゃったので省略しますが、
お名前.com等でドメインを取得している場合、
ドメインの管理画面からネームサーバーを変更する必要があります。
ドメインを取得した会社のデフォルトのネームサーバーになっていると思いますので、
ホストゾーンのNSレコードに表示されている4件のネームサーバーに変更します。変更のやり方はネットに情報が溢れていますので、
「お名前.com DNS変更」とかでググってください。S3バケットの作成
実際のコンテンツをいれるバケットを作成します。
S3に入り「バケットの作成」をクリック
バケット名に独自ドメインを入力
リージョンは日本で運用するなら東京か大阪を選択したいところですが、
初めてのお試し段階では段階ではバージニア北部を選択するのが無難です(※理由は後述)
他はすべてデフォルトのまま作成します。
S3を静的Webサイトとしてホスティングする場合、
パブリックアクセスを有効にしたりしますが、今回の構成ではパブリックアクセスはブロックのままで大丈夫です(むしろブロックしててください)S3にファイルをアップロード
作成したバケットを選択して、ページから簡単にアップロードできます
SSL証明書の作成
CertificateManagerに入り、リージョンをバージニア北部に変更します。
このリージョン変更は必ず行います
S3のバケットが東京や大阪にある場合でも、SSL証明書の作成はバージニア北部で行います。
パブリック証明書のリクエスト で次へ
ドメイン名に独自ドメインを。
別名に*.独自ドメインを設定し次へ
今回「www.独自ドメイン」でもアクセスさせたいので別名を追加しています。
*.独自ドメインでも単にwww.独自ドメインでも大丈夫です。
DNSの検証で次へ
タグは別にいらないのでそのまま次へ
そのまま確定とリクエスト
ここでそのまま続行せずに表示されているドメイン名をクリックします。
ここでRoute53でのレコード作成をします。
別名が複数ある場合はすべてに対して行います。
少し待って、このように、お客様によるアクションは必要ありませんと表示されたらラッキーです。
すべてがうまく行っています。
以下のように追加のアクションが必要ですと表示された場合は、ガイドに従って必要なアクションをしてください。
ドメイン管理サイトのネームサーバーの変更に時間がかかっている場合もこうなります。
間違っている気がしない場合は少し時間を置いてみましょう。続行してしばらく待つとこのようにステータスが発行済になります。
Route53でホストゾーンを見るとCNAMEレコードが追加されています。
CroudFrontの作成
サービス一覧からCloudFrontに入りCreateDistributionをクリック
以下のように設定します。
Origin Domain Name:作成したs3バケットを選択
Restrict Bucket Access:Yes
Origin Access Identity:Create a New Identity
Grant Read Permissions on Bucket: Yes,Update Bucket Policy
Viewer Protocol Policy:Redirect HTTP to HTTPS
Cache Policy:Managed-ChathingDisabled
Alternate Domain Names(CNAMEs):独自ドメインと、独自ドメインの別名
SSL Certificate:Customを選択し、作成したSSL証明書を選択
Default Root Object:index.htmlOrigin IDは自動で入ります。
※CloudFrontの売りであるキャッシュをここで無効にしているのは、理由があります。
初めての構築でハマることもあると思います。
他の設定も色んなところを弄って遊んでみることもあると思います。
その時に、キャッシュが効いていたら設定した内容の動きをしているのか、していないのかさっぱりわからない状況になってしまいます。
変にイジって動かなくなって、頑張って戻してやっと成功したと思って時間が立ったらまた動かなくなってる。みたいなこともあるかと思います。
いつぞやのたまたまうまくいっている設定がキャッシュされているパターンですね。ですので、スタートアップ時はキャッシュを無効にしておいて、運用開始直前でキャッシュを有効にするのがいいです。
ここで選択するSSL証明書はバージニア北部のリージョンで作成したものしかリストアップされません。
SSL証明書をバージニア北部で作成する必要があったのはこのためです。Restrict Bucket Accessで作成したアクセスポリシーがs3バケットに反映されていると思います。
見てみましょう。
サービスからS3 -> 作成したバケット -> アクセス許可
これでS3自体はパブリックアクセスをすべてブロックしていて、静的ウェブサイトホスティングも有効にしていませんが、
CloudFrontからはアクセスできるようになります。Route53の設定(独自ドメインへのアクセスをCloudFrontに向ける)
作成したホストゾーンに入り、「レコードの作成」をクリック
以下のように作成
エイリアスで作成したCloudFrontが選択できるようになっています。
wwwも受ける。CNAMEとかではエイリアスが出てこないのでAレコードでwwwなしを指定してます。
以上で終わりです。
スムーズにいけばおそらく15分〜30分程度で完了したんではないでしょうか?
独自ドメインでweb上に公開されているか確認しましょう。大丈夫そうなら運用開始前に忘れずにCloudFrontのキャッシュを有効化してください。
以下のようにキャッシュポリシーを変更します。
料金について
それぞれのサービスで従量課金の利用料がかかりますが、
アクセスの少ない個人営業飲食店などのサイトだったらほとんど無料枠でいけちゃうと思います。
行っても月1000円程度?もっと安いか。
アフィリエイト入れているサイトなら仮に運用費が高くついても収入と比べて赤字になることは無いと思います。
ちゃんと試算していませんので気になる方は公式の料金表や試算している方のサイトをご覧ください。公式の料金表ページを貼っておきます。
certificate-managerは無料です。つまりSSLは無料。
10年前ならコストが高いリッチな構成が今ではただみたいな料金でできます。
時代の進化はすごいですね。おまけ
CloudFrontのキャッシュクリア方法
Invalidationsからキャッシュを削除したいパスを入力します。
すべて削除するなら /* のように入力します。
こちらは無料枠がありますが、無料枠を超えるとファイル毎に料金がかかりますのでお気をつけください。
悲しいお話を見つけました。
S3を北部バージニアで作成した理由
詳しくはS3+CloudFrontでS3のURLにリダイレクトされてしまう場合の対処法をご参照ください。
自分も一回ハマりました。
別にすぐ解決できるから好きなリージョンで作ればいいと思いますが、
チュートリアルであまりコケて諦めてほしくないのでS3のリージョンをバージニア北部に指定しました。
SSLがバージニア北部で作成する必要があるので合わせた方がわかり良いかなという思いもあります。日本での運用では大阪か東京にすると思いますが、
正直CloudFrontが前にいるので別にバージニアでいい気がします。最後に
簡単でしたか?
S3のホスティング機能でWebサイトを公開している方は沢山いると思いますが
S3ってsslつけれないんですよね。
最近のブラウザはsslじゃないとすぐ煽ってくるのでSSL化が当たり前の時代になっています。
この機会にチャレンジしてみてはいかがでしょうか。気に入った所
・すごい構成なのに安い
・簡単(いらんことしてハマらなければ)気に入らない所
・www有りはwww無しにリダイレクトしたいけど、このままの構成ではできない
・S3へのアップロードが昔ながらのFTPで上げているみたいでなんかいやだしめんどくさい(上げ漏れとか起きそう)
でもWebデザイナーさんにも使えるようになってほしい構成なのでAWS CLIを使わせるのは気が引けるこのあたりは解決策がありますのでまた記事をあげようと思います。
その他
モザイク処理が面倒くさかった。次はしない(かも)
特に参考にさせていただきました。








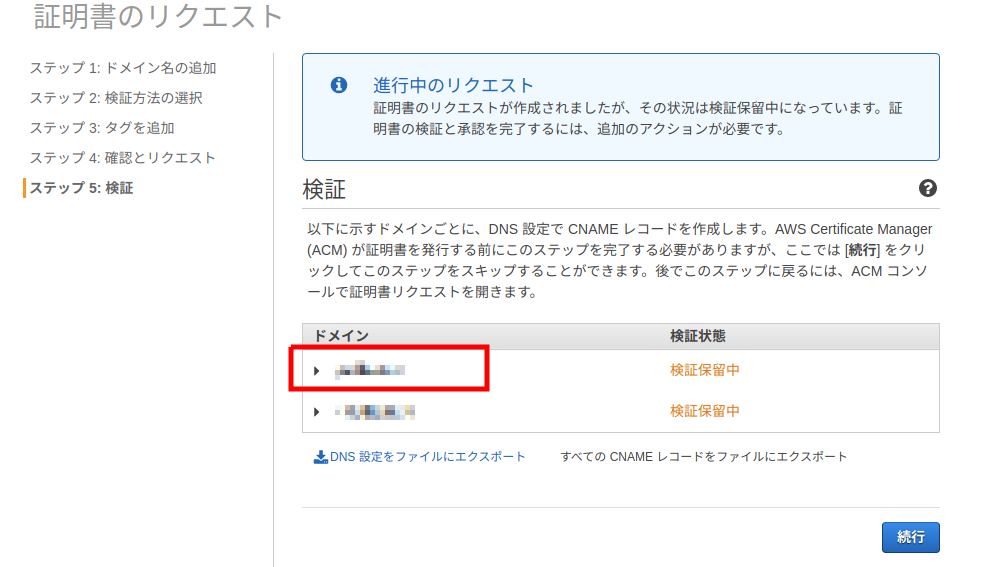















- 投稿日:2021-03-29T03:41:07+09:00
SAMでSlack通知Lambdaをデプロイ
はじめに
AWS Lambda Container Image Support や EventBridgeのcron設定、Secrets Managerからシークレット情報の取得を試してみたかったので、以下のような構成図で一気に試してみます。
構成図
- SAMでSlackにメッセージを通知するLambdaをデプロイする
- Lambdaはイメージ化してECRで管理する
- LambdaはEventBridgeで定期実行する
- SlackのWebhook URLをSecrets Managerで管理する
手順
- ECRにリポジトリを作成しておく
- Secrets ManagerにSlackのWebhook URLを設定する
- sam initでテンプレート作成
- template.yamlの修正
- Slackにメッセージ通知するLambda関数を作成
- デプロイ
- テスト
1. ECRにリポジトリを作成しておく
イメージのプッシュ先のリポジトリを事前に登録しておきます。
2. Secrets ManagerにSlackのWebhook URLを設定する
SlackのWebhook URLをSecrets Managerに登録します。
設定が完了すると、シークレット情報取得のサンプルコードが確認できるので、後でこれをベースにLambda関数を実装します。
3. sam initでテンプレート作成
事前準備ができたので、次はSAMのテンプレートを作成していきます。
適当にディレクトリを作成し、
$ sam initを実行します。$ sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 What package type would you like to use? 1 - Zip (artifact is a zip uploaded to S3) 2 - Image (artifact is an image uploaded to an ECR image repository) Package type: 2 Which base image would you like to use? 1 - amazon/nodejs14.x-base 2 - amazon/nodejs12.x-base 3 - amazon/nodejs10.x-base 4 - amazon/python3.8-base 5 - amazon/python3.7-base 6 - amazon/python3.6-base 7 - amazon/python2.7-base 8 - amazon/ruby2.7-base 9 - amazon/ruby2.5-base 10 - amazon/go1.x-base 11 - amazon/java11-base 12 - amazon/java8.al2-base 13 - amazon/java8-base 14 - amazon/dotnet5.0-base 15 - amazon/dotnetcore3.1-base 16 - amazon/dotnetcore2.1-base Base image: 10 Project name [sam-app]: notification Cloning app templates from https://github.com/aws/aws-sam-cli-app-templates ----------------------- Generating application: ----------------------- Name: notification Base Image: amazon/go1.x-base Dependency Manager: mod Output Directory: . Next steps can be found in the README file at ./notification/README.md先ほど作成したECRにイメージをプッシュしたいので、
What package type would you like to use?は2 - Image (artifact is an image uploaded to an ECR image repository)を選択します。
ランタイムについては、goを選択しました。
$ sam init実行後のディレクトリ構成は以下です。(notificationディレクトリを作成し、その配下で$ sam initを実行しています。)notification/ ├── README.md ├── samconfig.toml ├── hello-world │ ├── Dockerfile │ ├── go.mod │ ├── go.sum │ ├── main.go │ └── main_test.go └── template.yamlpackage typeにimageを選択したため、Dockerfileが作成されています。
中身は以下のようになっています。DockerfileFROM golang:1.14 as build-image WORKDIR /go/src COPY go.mod main.go ./ RUN go build -o ../bin FROM public.ecr.aws/lambda/go:1 COPY --from=build-image /go/bin/ /var/task/ # Command can be overwritten by providing a different command in the template directly. CMD ["hello-world"]4. template.yamlの修正
次に、
$ sam initで作成されたtemplate.yamlに修正を加え、以下のようになりました。AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: notify slack Globals: Function: Timeout: 5 Resources: SlackRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: lambda.amazonaws.com Action: "sts:AssumeRole" Policies: - PolicyName: "GetSecretsPolicy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - "logs:CreateLogGroup" - "logs:CreateLogStream" - "logs:PutLogEvents" - "secretsmanager:GetSecretValue" Resource: "*" SlackFunction: Type: AWS::Serverless::Function Properties: Role: !GetAtt SlackRole.Arn PackageType: Image Events: Notification: Type: Schedule Properties: Schedule: cron(0 0 * * ? *) # JST 9:00 Metadata: DockerTag: go1.x-v1 DockerContext: ./slack Dockerfile: Dockerfile Outputs: SlackFunction: Description: "Notify Slack Lambda Function ARN" Value: !GetAtt SlackFunction.Arn SlackFunctionIamRole: Description: "Implicit IAM Role created for Slack function" Value: !GetAtt SlackRole.Arn大きな修正点としては以下です。
- Role
- 実行スケジュール
Role
デフォルトで生成されるCloudWatch用のポリシーに、 Secrets Managerからシークレット情報取得用のsecretsmanager:GetSecretValueを加えたロールを作成します。
(ロールの設定をここで記述しない場合、デフォルトでLambda実行に必要なロールが付与されます。)Resources: SlackRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: lambda.amazonaws.com Action: "sts:AssumeRole" Policies: - PolicyName: "GetSecretsPolicy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - "logs:CreateLogGroup" - "logs:CreateLogStream" - "logs:PutLogEvents" - "secretsmanager:GetSecretValue" Resource: "*" SlackFunction: Type: AWS::Serverless::Function Properties: Role: !GetAtt SlackRole.Arn実行スケジュール
EventBridgeのスケジュールをトリガーにしたいので、以下のように設定します。
Events: Notification: Type: Schedule Properties: Schedule: cron(0 0 * * ? *) # JST 9:005. Slackにメッセージ通知するLambda関数を作成
Secrets ManagerからSlackのWebhook URLを取得して、Slackにメッセージを送信します。
package main import ( "encoding/json" "fmt" "io/ioutil" "net/http" "net/url" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/secretsmanager" ) // Secrets Managerで設定したキーとリージョン var ( secretName string = "SlackWebhookUrl" region string = "ap-northeast-1" ) type SlackEvent struct { Text string `json:"text"` } func Modify(se *SlackEvent) { se.Text = "test message" } // シークレット情報取得用function func getSecret() (string, error) { svc := secretsmanager.New(session.New(), aws.NewConfig().WithRegion(region)) input := &secretsmanager.GetSecretValueInput{ SecretId: aws.String(secretName), VersionStage: aws.String("AWSCURRENT"), } // GetSecretValue関数にキー名を渡して、値を取得 result, err := svc.GetSecretValue(input) if err != nil { return "", err } // SecretString配下にJSON形式でシークレット情報がレスポンスされます secretString := aws.StringValue(result.SecretString) res := make(map[string]interface{}) if err := json.Unmarshal([]byte(secretString), &res); err != nil { return "", err } return res["WEBHOOK_URL"].(string), nil } func handler() error { webhoolUrl, err := getSecret() if err != nil { return err } se := &SlackEvent{} Modify(se) params, err := json.Marshal(se) if err != nil { return err } // slackにメッセージ送信 resp, err := http.PostForm( webhoolUrl, url.Values{"payload": {string(params)}}, ) if err != nil { return err } body, _ := ioutil.ReadAll(resp.Body) defer resp.Body.Close() fmt.Printf("response code:%s, response body:%s, hook:%s\n", resp.Status, body, webhoolUrl) return nil } func main() { lambda.Start(handler) }6. デプロイ
ここまで設定ができたら、デプロイしていきます。
$ sam build→$ sam deployの順に実行します。修正内容に不備がなければ、以下のように
$ sam buildが成功します。Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedビルドが完了したら、
$ sam deployを実行してデプロイします。
はじめての実行の場合、以下のように--guidedオプションを付けることで、対話形式でデプロイの設定ができるので便利です。$ sam deploy --guided Configuring SAM deploy ====================== Looking for config file [samconfig.toml] : Found Reading default arguments : Success Setting default arguments for 'sam deploy' ========================================= Stack Name [notify-slack]: AWS Region [ap-northeast-1]: Image Repository for SlackFunction [xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/notify-slack]: slackfunction:go1.x-v1 to be pushed to xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/notify-slack:slackfunction-eb1817a25a39-go1.x-v1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [Y/n]: Y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: Y Save arguments to configuration file [Y/n]: Y SAM configuration file [samconfig.toml]: SAM configuration environment [default]:これで、CloudFormationにスタックが作成されます。
7. テスト
Scheduleを適当な時間に調整し、Webhook URLに設定したSlackチャンネルにメッセージが届けば確認完了です。
Events: Notification: Type: Schedule Properties: Schedule: cron(0 0 * * ? *) # JST 9:00備考
コンソールのLambda関数の画面からテスト実行することもできます。
secretsmanager:GetSecretValueのポリシーをロールにアタッチしていない場合、エラーとなりAPIが呼び出せないので注意が必要です。AccessDeniedException: User: arn:aws:sts::901071604628:assumed-role/notify-slack-SlackFunctionRole-1IND13I9826OF/notify-slack-SlackFunction-AL8RRMO0EQ8H is not authorized to perform: secretsmanager:GetSecretValue on resource: SlackWebhookUrl




- 投稿日:2021-03-29T03:32:39+09:00
AWS EC2の利用メモ
AWS EC2を用いてSSH接続するまでの流れ(メモ)
AWS初心者がつまづいた点を自分用としてメモ書きとして残します。
環境はMac Windowsは違った内容になります。AWS起動までの流れ
AWSの登録に関してはこちらの記事を参照
URLを貼るまとめるとAWSのアカウントを登録、EC2を起動する
SSH接続するところまでは参照先と同じ操作EC2インスタンスを起動後、SSH接続することについて
AWSのSSH接続に関してはこちらの記事を参照
https://qiita.com/ai-2723/items/eb156cd4dd3ccfac8791まとめるとMacのターミナルを起動して、コマンドを入力
ターミナルでセキュリティを弱くする。(400とか600とか)
キーのディレクトリと同じディレクトリで実行することSSH接続はAWS公式サイトに準拠した
EC2 -> インスタンス -> インスタンスを選択 -> インスタンスに接続を選択ログは以下の通りとなった。(秘密鍵はmykey.pem)
ohata@oohatakazushinoMacBook-Pro Downloads % ssh -i "mykey1.pem" ec2-user@ec2-13-231-201-108.ap-northeast-1.compute.amazonaws.com __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ No packages needed for security; 10 packages available Run "sudo yum update" to apply all updates. [ec2-user@ip-172-31-46-110 ~]$ client_loop: send disconnect: Broken pipeSSH解除はexitと入力
ohata@oohatakazushinoMacBook-Pro Downloads % exit Saving session... ...copying shared history... ...saving history...truncating history files... ...completed. Deleting expired sessions...none found. [プロセスが完了しました]編集はここまで
今後追加する可能性あり
- 投稿日:2021-03-29T00:28:50+09:00
UnityからRekognitionを使ってみた
R&D成果発表会Vol.2
こんにちは。ノベルワークスR&Dチームのともやんです。
今回はUnityと表情分析でうにゃうにゃした際の報告です。
この記事がVol.100くらいになるころには、なにかおもしろいものがお目見えしているかもしれません。
それでは早速!Amazon Rekognitionとは
Amazon Rekognitionとは、AWSのサービスの一つで、画像や動画を投げると、顔比較や感情分析など高度なことを、簡単に行える便利なものです。今回はこのサービスを使って、感情分析を行っていきます。
AWS SDK for .Netについて
unityでのAWSSDK導入方法については基本ここ参照。
https://qiita.com/nshinya/items/0a71d4658e7f4a650844Rekognitionを使いたいので、AWS SDK.Rekognition.dllを入れてください
やりかた
やり方として
1.unityでwebカメラを使う
2.Rekognitionにwebカメラの画像を投げる
3.返ってきたJson風データから感情値を取り出す
の三つで説明していきます
完成コード(雑です)
using System; using System.Linq; using System.Threading; using System.Threading.Tasks; using System.IO; using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.UI; using Amazon.Rekognition; using Amazon.Rekognition.Model; public class DetectFaces : MonoBehaviour { public RawImage rawImage; WebCamTexture webCamTexture; //textureをtexture2dにする関数 public Texture2D ToTexture2D(Texture self) { var sw = self.width; var sh = self.height; var format = TextureFormat.RGBA32; var result = new Texture2D(sw, sh, format, false); var currentRT = RenderTexture.active; var rt = new RenderTexture(sw, sh, 32); Graphics.Blit(self, rt); RenderTexture.active = rt; var source = new Rect(0, 0, rt.width, rt.height); result.ReadPixels(source, 0, 0); result.Apply(); RenderTexture.active = currentRT; return result; } //Amazon Rekognition public async Task Example(Amazon.Rekognition.Model.DetectFacesRequest image) { //AmazonRekognitionClient AmazonRekognitionClient rekognitionClient = new AmazonRekognitionClient("AWSのアクセスキー", "AWSのシークレットキー"); var response = await rekognitionClient.DetectFacesAsync(image); foreach(var i in response.FaceDetails[0].Emotions) { Debug.Log(i.Confidence); Debug.Log(i.Type); } } //start public void Start() { webCamTexture = new WebCamTexture(); rawImage.texture = webCamTexture; webCamTexture.Play(); } public async void UseReko() { var img2d = ToTexture2D(webCamTexture); var img = img2d.EncodeToJPG(); var stream = new MemoryStream(img); List<string> att = new List<string>() { "ALL" }; var rekoImg = new Amazon.Rekognition.Model.Image { Bytes = stream }; var reqImg = new DetectFacesRequest {Attributes=att, Image = rekoImg }; await Example(reqImg); }1.Webカメラ
RawImageにwebカメラで取得した画像をはっつけます。顔見たいからです。別に顔を画面で見たくねえよって人はrawImageなんていりません。
略 public RawImage rawImage; WebCamTexture webCamTexture; 略 public void Start(){ webCamTexture=new WebCamTexture(); rawImage.texture=webCamTexture; webCamTexture.Play() } }んで、webCamTextreなんですが、これをそのままImageとしてRekognitionに投げるわけにはいきません。
というのも、Amazon.Rekognition.Model.DetectFacesRequestクラスのImageを投げなきゃいけないのです。ということで、
WebCamTexture>Texture2D>JPG形式>MemoryStream>DetectFacesRequestという順序で変換していきます。WebCamTexture>Texture2D
WebCamTextureは一見Texture2Dなんですが、残念ながら違うんです。WebCamTextureというクラスなんです。だから、いったんToTexture2D()をつかって変換します。
var img2d = ToTexture2D(webCamTexture);Texture2D>JPG
これも関数一発ドーンってやつです
var img = img2d.EncodeToJPG();JPG>MemoryStream
DetectFacesRequestを作るには、Byte列としてMemoryStreamを作る必要があります。MemoryStreamがなんだかはよくわかっていません。これもドーンです。
var stream = new MemoryStream(img);MemoryStream>DetectFacesRequest
これはnewするときの引き数にMemoryStreamを入れるだけです。
var rekoImg = new Amazon.Rekognition.Model.Image { Bytes = stream };これで投げる画像はOKです。あと、どんな情報が返ってくるかの指定として、ALLを指定しておきます。ALLじゃないと感情値とかは返ってきません。
List<string> att = new List<string>() { "ALL" };んで最後に
var reqImg = new DetectFacesRequest {Attributes=att, Image = rekoImg };というようにRekognitionに投げるものを作ってあげれば終了です。
RekognitionにWebカメラの画像を投げる
AmazonRekognitionClient rekognitionClient = new AmazonRekognitionClient("AWSのアクセスキー", "AWSのシークレットキー"); var response = await rekognitionClient.DetectFacesAsync(image);ここで、DetectFacesAsync()をつかって投げています。ここで大事なのが、DetectFacesじゃなくてDetectFacesAsyncを使わなくちゃいけないということです。非同期なのでそこら辺のことも書き足さなきゃデス。
Asynchronous operations (methods ending with Async) in the table below are for .NET 4.5 or higher. For .NET 3.5 the SDK follows the standard naming convention of BeginMethodName and EndMethodName to indicate asynchronous operations - these method pairs are not shown in the table below.
(APIリファレンスにちっちゃく書いてある)きちんとリファレンス読むべきですね。(Asyncないとerrorとしてinaccesible due to のやつが出てきます)
返ってきたJson風データから感情値を取り出す
返ってくるデータはこんな形です。
{ "FaceDetails": [ { "AgeRange": { "High": number, "Low": number }, "Beard": { "Confidence": number, "Value": boolean }, "BoundingBox": { "Height": number, "Left": number, "Top": number, "Width": number }, "Confidence": number, "Emotions": [ { "Confidence": number, "Type": "string" } ], "Eyeglasses": { "Confidence": number, "Value": boolean }, "EyesOpen": { "Confidence": number, "Value": boolean }, "Gender": { "Confidence": number, "Value": "string" }, "Landmarks": [ { "Type": "string", "X": number, "Y": number } ], "MouthOpen": { "Confidence": number, "Value": boolean }, "Mustache": { "Confidence": number, "Value": boolean }, "Pose": { "Pitch": number, "Roll": number, "Yaw": number }, "Quality": { "Brightness": number, "Sharpness": number }, "Smile": { "Confidence": number, "Value": boolean }, "Sunglasses": { "Confidence": number, "Value": boolean } } ], "OrientationCorrection": "string" }さっき、返ってくるデータ指定したけれど、DefaultだとBoundingBox, Confidence, Pose, Quality, Landmarksだけ返ってきます。
foreachでちょちょいと出してあげればOKです。以上、Rekognitionの簡単な使い方でした。感情値データを使えばいろいろなことができるので遊んでみてください。
あと、動くけれどここのやり方違うとかあるかもなので、そこんところは教えてくれると嬉しいです。
- 投稿日:2021-03-29T00:28:36+09:00
素人基盤エンジニアがDockerでDjango REST Frameworkとreactを触るシリーズ③:reactの導入
素人基盤エンジニアがDockerでDjango REST Frameworkとreactを触るシリーズ②:Django REST Frameworkのつづき。
①からみたい場合はこちら。素人基盤エンジニアがDockerでDjango REST Frameworkとreactを触るシリーズ①:Djangoの導入reactの導入
最終的には、S3上にreactのアプリを配置してCloudFront経由で表示させたいが、構築/テストまでは同じEC2上でreactとdocker上のDjango REST frameworkを動作させて連携させることとする。
動作が確認出来たら、ビルドしS3に移行する。node.jsの導入
reactのビルド環境として、node.jsが必要なので、下記手順に従いインストールする。
https://docs.aws.amazon.com/ja_jp/sdk-for-javascript/v2/developer-guide/setting-up-node-on-ec2-instance.htmlcurl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash. ~/.nvm/nvm.shnvm install nodenode -e "console.log('Running Node.js ' + process.version)"Running Node.js v15.12.0
↑のような形でバージョンが表示されたらインストールは完了。create-react-app
今回は、reactアプリを簡単に作成することができるツールであるcreate-react-appを利用する。
(本格的にreactアプリを作成したい場合は自分で一から作成したほうが良いと思うが、今回はあくまでreactとDjango REST Frameworkを利用してとりあえず動くものを作るというところを目標とする。)
djangoのためのファイル群をbackendというディレクトリに作成したので、一旦/home/ec2-userまで戻り、下記コマンドを実行する。cd /home/ec2-user npm install -g yarn yarn global add create-react-app create-react-app frontendしばらくすると、frontendというディレクトリが作成され、下記のような構成になっているはず。
frontend ∟node_modules ∟パッケージ多数 ∟package.json ∟public ∟favicon.ico ∟index.html ∟logo192.png ∟logo512.png ∟manifest.json ∟robots.txt ∟README.md ∟src ∟App.css ∟App.test.js ∟index.js ∟reportWebVitals.js ∟App.js ∟index.css ∟logo.svg ∟setupTests.js ∟yarn.lockまずはデフォルトの状態で、reactアプリを起動させてみる。
cd frontend yarn starthttp://<ip-address>:3000
にアクセスする。
reactアプリが動作していることがわかる。
ctrl+Cで一旦終了し、下記ソースを修正してみる。public/index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8" /> <link rel="icon" href="%PUBLIC_URL%/favicon.ico" /> <link href="https://use.fontawesome.com/releases/v5.6.1/css/all.css" rel="stylesheet"> <title>ReactSampleApp</title> </head> <body> <h1 class="title">ToDo Apps(React+DjangoRestFramework)</h1> <div id="root"></div> </body> </html>src/App.jsimport React, { Component } from 'react'; import axios from 'axios'; class App extends Component { constructor(props) { super(props); this.state = { todos: [], hostname: "" }; } componentDidMount() { this.getTodos(); this.getHostname(); } getTodos() { axios .get('http://<ip-address>:8000/api/todos/') .then(res => { this.setState({ todos: res.data }); }) .catch(err => { console.log(err); }); } getHostname() { axios .get('http://<ip-address>:8000/api/hostname/') .then(res => { this.setState({ hostname: res.data }); }) .catch(err => { console.log(err); }); } render() { return ( <div> {this.state.todos.map(item => ( <div key={item.id}> <h2>{item.title}</h2> <p className="item_body">{item.body}</p> </div> ))} <div className="box30"> <div className="box-title">HOSTNAME</div> <p>{this.state.hostname.hostname}</p> </div> </div> ); } } export default App;<ip-address>の部分を、EC2のIPアドレスにすることを忘れないように注意。
ここは、CloudFrontでの構成に移行すればIPアドレスを書かなくてもよくなる。src/index.cssbody { margin: 0; font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen', 'Ubuntu', 'Cantarell', 'Fira Sans', 'Droid Sans', 'Helvetica Neue', sans-serif; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } code { font-family: source-code-pro, Menlo, Monaco, Consolas, 'Courier New', monospace; } h1.title { font-family: 'Segoe Print',sans-serif; padding: 0.5em; color: #494949;/*文字色*/ background: #fffaf4;/*背景色*/ border-left: solid 5px #ffaf58;/*左線(実線 太さ 色)*/ } .box30 { margin: 0 auto 0 20px; width: 300px; background: #f1f1f1; box-shadow: 0 2px 4px rgba(0, 0, 0, 0.22); } .box30 .box-title { font-size: 1.2em; background: #5fc2f5; padding: 4px; text-align: center; color: #FFF; font-weight: bold; letter-spacing: 0.05em; } .box30 p { text-align: center; padding: 15px 20px; margin: 0 0; } h2 { position: relative; padding: 8px 15px; margin-left: 40px; background: #def3ff; border-radius: 20px; } h2:before { font-family: "Font Awesome 5 Free"; content: "\f111"; position: absolute; font-size: 15px; left: -40px; bottom: 0; color: #def3ff; } h2:after { font-family: "Font Awesome 5 Free"; content: "\f111"; position: absolute; font-size: 23px; left: -23px; bottom: 0; color: #def3ff; } p.item_body { font-family: 'Mv Boli',sans-serif; margin-left: 80px; }ソース内で、axiosというパッケージを利用しているので、frontendディレクトリで下記コマンドを利用してパッケージを追加しておく。
yarn add axiosまた、Django側の設定も、別サイトからのクロスオリジンアクセスがあるため、下記のように書き換える。
backend/todo_project/settings.pyMIDDLEWARE = [ 'corsheaders.middleware.CorsMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] CORS_ORIGIN_ALLOW_ALL = True一行目のcorsheaders~と最後のCORS_ORIGIN_ALLOW_ALLを追加。
docker-compose upでdbとdjangoのコンテナを起動する。
(この後reactも起動したいのでバックエンドで起動する。)cd backend docker-compose up &コンテナを起動させたまま、reactを起動。
cd ../frontend yarn starthttp://<ip-address>:3000/
にアクセスしてみる。
無事、todoとhostnameが表示されていることがわかる。
次回は、今回構築したreactアプリをビルドしS3へ配置して最終系であるCloudfrontの形に変更する。つづく

- 投稿日:2021-03-29T00:12:59+09:00
【AWS】用語を整理しながら学ぶAWS - part5 Cloud Formation - 3
はじめに
この記事では AWS Cloud Tech を通して Cloud Formation を学習して実践していく記事です。
主な内容としては実践したときのメモを中心に書きます。(忘れやすいことなど)
誤りなどがあれば書き直していく予定です。
前回までのおさらい
テンプレートの定義には
Resources 以外に Outputs というオプションが存在する。Outputs で出力されたパラメータはエクスポート名という名前で参照できる。
エクスポート名はクロススタック参照という方法で利用できる。また、テンプレート内の値を参照する場合は組み込み関数を利用することで
動的に参照することが可能である。【AWS】用語を整理しながら学ぶ AWS - part5 Cloud Formation - 2
前回の内容を実践
よくある VPC ネットワークを構築してみる。
ファイル名 用途 vpc_network.yml VPC の構成を管理 public_network.yml パブリックサブネットの構成を管理 private_network.yml プライベートサブネットの構成を管理 VPC ネットワークを定義する。
vpc_network.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: MainVpc: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/21 EnableDnsSupport: true Tags: - Key: Name Value: MainVpcfromCF Outputs: MainVpc: Value: !Ref MainVpc Export: Name: MainVpcIdパブリックサブネットを定義する。
public_subnet.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: subnetName: Type: AWS::EC2::Subnet Properties: AvailabilityZone: "ap-northeast-1a" VpcId: !ImportValue MainVpcId CidrBlock: 10.0.2.0/24 Tags: - Key: Name Value: PublicSubnet secGroupName: Type: AWS::EC2::SecurityGroup Properties: GroupName: PublicSecGrp GroupDescription: PublicSecGrp VpcId: !ImportValue MainVpcId SecurityGroupIngress: - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: 0.0.0.0/0 Tags: - Key: Name Value: MainVpc Outputs: PublicSubnet: Value: !Ref subnetName Export: Name: PublicSubnet PublicSecGrp: Value: !GetAtt secGroupName.GroupId Export: Name: PublicSecGrp続いてプライベートサブネットを定義する。
private_subnet.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: subnetName: Type: AWS::EC2::Subnet Properties: AvailabilityZone: "ap-northeast-1a" VpcId: !ImportValue MainVpcId CidrBlock: 10.0.1.0/24 Tags: - Key: Name Value: PrivateSubnet Outputs: PrivateSubnet: Value: !Ref subnetName Export: Name: PrivateSubnet次にやること
プライベートネットワークとパブリックサブネット内に EC2 を配置する。
ファイル名 用途 public_ec2.yml パブリックサブネット内の EC2 を管理 private_ec2.yml プライベートサブネットの内の EC2 を管理 次回の Part5 - 4 に持ち越し
EC2 を テンプレートで定義すると
仮にですが、思いつきでパッどEC2を定義してみると...
public_ec2.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: myEC2Instance: Type: AWS::EC2::Instance Properties: KeyName: Mykeypair ImageId: ami-0992fc94ca0f1415a InstanceType: t2.micro Monitoring: false SecurityGroupIds: - !ImportValue PublicSecGrp SubnetId: !ImportValue PublicSubnet Tags: - Key: Name Value: CFec2こんな感じになるかと思うのですが
個人的には幾つか気に入らない点がありまして文字数気に入らない点
キーペアの管理
鍵を管理するのが面倒くさい。
AMI のID
コード内にIDをハードコートしたくない。
というのもリージョンごとに異なるIDとなる為
冗長化するときに一々、AMI IDを調べないといけない。じゃあどうするか
鍵は管理しない代わりにSSMを利用する。
AMIのIDは常に最新に保とうとしましたが
AMIが変わったことによる不具合などに悩まされたくないので一旦、ハードコートする。良い方法を後程、考えます。
まとめ
Cloud Formatinを利用してVPCネットワークを構築してサブネットを切りました。
次回はこのネットワークにEC2を構築します。おわり