- 投稿日:2021-03-25T23:08:42+09:00
機械学習を用いた株価予測
ユニクロの株価予測
公開データから2012年から2016年までのユニクロの株式情報に関するデータセットを用いて簡単な株価予測をします。
株価予測をするにあたって、「現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル」を参考にさせていただきました。
1. データセットの取り込み
必要なライブラリをインポートします。
%matplotlib inline import datetime import numpy as np import matplotlib.pyplot as plt import pandas as pd import sklearn import sklearn.linear_model import sklearn.model_selectionダウンロードしたデータセットの中身は以下のような状態で、データの欠損等は見られない綺麗なデータセットでした。
2. データ前処理
'Close'列、つまり、終値の値を基に株価予測をしたいと思います。
各日にちから30日前の値を入れた'Data 30 days ago'列を作成。'Data 30 days ago', 'Date'列を除いたデータセットの全ての値を標準正規化します。df['Data 30 days ago'] = df['Close'].shift(-30) X = np.array(df.drop(['Data 30 days ago', 'Date'], axis=1)) X = sklearn.preprocessing.scale(X)3. モデルの学習
訓練データとテストデータに分割して、ロジスティックス回帰を用いて訓練データを学習させます。
y_pred = X[-30:] X = X[:-30] y = np.array(df['Data 30 days ago']) y = y[:-30] X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split( X, y, test_size=0.2) # modelの学習する model = sklearn.linear_model.LinearRegression() model.fit(X_train,y_train)4. グラフの描画
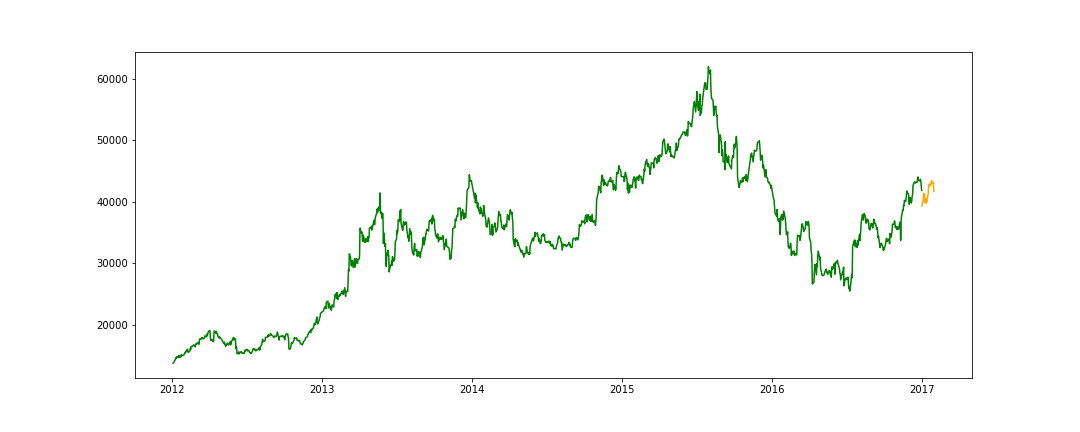
予測したデータと実際のデータのグラフを描画します。
df['Predict'] = np.nan last_date = datetime.datetime(int(df["Date"].iloc[-1].split("-")[0]), int(df["Date"].iloc[-1].split("-")[1]), int(df["Date"].iloc[-1].split("-")[2])) df["Date"] = df["Date"].apply(lambda x: datetime.datetime(int(x.split("-")[0]), int(x.split("-")[1]), int(x.split("-")[2]))) df.index = df["Date"] one_day = 86400 next_unix = last_date.timestamp() + one_day for data in pred: next_date = datetime.datetime.fromtimestamp(next_unix) next_unix += one_day df.loc[next_date] = np.append([np.nan]* (len(df.columns)-1), data) df = df.drop("Date", axis=1) fig, ax = plt.subplots(figsize=(15, 6)) ax.plot(df['Close'], color="green") ax.plot(df['Predict'], color="orange") plt.show()
- 予測データのグラフ
- 実データのグラフ
最後に
今回の株価予測の精度は良くありませんでしたが、今後も機械学習の勉強を続けて、kaggleやSIGNATEなどのコンペで精度の高いモデルをコーディングしたいと思います。
- 投稿日:2021-03-25T22:41:43+09:00
【DiscordBot】かわいい女の子に進捗管理してもらう【リファレンス】
はじめに 個人的にSQLのデータベースを扱った作品を作りたくなったので作りました.(まだまだ技術は浅いですが…) かわいい女の子が作業開始,終了宣言時に反応してくれたり,記録した開始時刻,終了時刻から進捗内容とその時間を把握して月の頭に先月の作業量を報告してくれたりします! マニュアル v1.1 マニュアルを兼ねた記事なので先に使用方法から. まだ開発段階なのでこれからも機能を追加すると思います. 不具合やBotが停止した場合は@PigeonsHouseまでご連絡ください. つまるところデバッグをお手伝いいただきたい. 導入 こちらのリンクから→進捗ちゃん 開始打刻 任意のボイスチャンネルに入って任意のテキストチャンネルで DO hogehoge(hogehogeは作業内容の名前) 終了打刻 任意のテキストチャンネルで END TASK もしくはボイスチャンネルを抜ける 進捗報告チャンネルの変更 進捗の報告をしてほしいチャンネルでSET HERE(メンション) 未設定の場合はsystem_channel(新規参加者が流れるテキストチャンネル)になっています. 使用技術 Bot:Pythonのライブラリ,Discord.py データベース:PostgreSQL 仕組みはそれほど難しくなく,on_message関数内でメッセージを受けて,データを保存し,返答しています. データは一度Python上にオブジェクトの型で保存しており,作業中に新しく宣言をするとそのオブジェクトから既に宣言済みか調べるためなどに使用します. @client.event async def on_message(message): ... if re.match(r'^DO .+', content): task = content[3:] if len(task) > 125: await m_channel.send(f'<@!{uid}>さん\nタスク名が長すぎるよ!\n短くまとめて宣言し直してくれたら嬉しいなっ!') return for data in Data: if data['user_id'] == uid: if data['task'] == task: await m_channel.send(f'<@!{uid}> さんが「{task}」をしてるのちゃんと見てるよ?\n応援してるよ!頑張ってね!') return else: await m_channel.send(f'<@!{uid}>さん\n作業を変更するときは一度終了してからもう一度宣言してね!') return if not searchGuild(guild_id): addGuild(message.guild, uid) if not (searchUser(uid) and searchGuildMember(guild_id, uid)): addUser(uid, name, guild_id) tid = searchTask(uid, task) await m_channel.send('<@!{uid}> さんは{task}をやるんだね!\n今日も頑張ろう!') Data.append({ 'user_id': uid, 'name': name, 'start_at': datetime.datetime.now().isoformat(), 'task': task, 'task_id': tid, 'channel': m_channel }) 終了の宣言をするとオブジェクトから該当の宣言を削除しDBに保存します. def addProgressTime(taskId, duration): with psycopg2.connect('postgresql://admin:admin@localhost:15432/admin') as conn: with conn.cursor() as cur: cur.execute("UPDATE progress_app.task SET duration=(duration+%s) WHERE id=%s", (duration, taskId)) conn.commit() ... @client.event async def on_message(message): ... if content == 'END TASK': for data in Data: if data['user_id'] == uid: duration = datetime.datetime.now() - datetime.datetime.fromisoformat(data['start_at']) task_name = data['task'] view_duration = view(duration) await m_channel.send(f'<@!{uid}>さん\n了解だよ!お疲れ様!\n【{task_name}】{view_duration}') addProgressTime(data['task_id'], duration) Data.remove(data) return await m_channel.send('<@!{uid}>さんはまだ作業開始の宣言をしてないよ?\n何の作業をしてるか教えてね!') そして月が変わったタイミングなのですが,Discord.pyの性質上Scheduleライブラリと併用できない(まだいまいちわかってない)っぽいのでon_ready関数内にwhile Trueを回してそこで時間を確認しています. Botで時刻をトリガーとした挙動とメッセージなどのDiscordの機能をトリガーとした挙動を併用する際にはわりと使えるのではないでしょうか. @client.event async def on_ready(): print('sintyokuBot is running') while True: nowTime = datetime.datetime.now() if nowTime.strftime('%d-%H:%M:%S') == '01-00:00:00': await reportTheirProgress() await asyncio.sleep(60) リポジトリ GithubのURLはこちら→sintyokuBot 即席かつ勉強中のソースなので汚いですが. readmeは用意していませんが,オープンソースなので理論上誰でも進捗ちゃんのデプロイは出来ちゃいます. (共同開発とかってできるんかな…できるならそこもお手伝いいただきたい…) おわりに デプロイを急いだためマニュアル含めまだまだ穴だらけですのでじゃんじゃん改善していきたいと思います! そして可愛い女の子に愛し愛され進捗管理されましょう!
- 投稿日:2021-03-25T20:34:16+09:00
LightGBMのハイパーパラメータチューニング(Optuna)をしてみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はLightGBMのハイパーパラメータチューニング(Optuna)を実装してみました。
はじめに
過去に回帰モデル系の記事は纏めておりますので、細かい内容は他の記事を参考にしてください
今回はLightGBMのハイパーパラメータチューニング(Optuna)について書きます。
LightGBMの実装
まずは、LightGBMをハイパーパラメータチューニングをせずに実装してみます。
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
項目 概要 データセット ・boston house-price サンプル数 ・506個 カラム数 ・14個 pythonのコードは下記の通りです。
# ライブラリーのインポート import os import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline # ボストンの住宅価格データ from sklearn.datasets import load_boston # 前処理 from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # LightGBM import lightgbm as lgb # 評価指標 from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error # データセットの読込み boston = load_boston() # 説明変数の格納 df = pd.DataFrame(boston.data, columns = boston.feature_names) # 目的変数の追加 df['MEDV'] = boston.target # データの中身を確認 df.head()
次にLightGBMの事前準備をします。
# ランダムシード値 RANDOM_STATE = 10 # 学習データと評価データの割合 TEST_SIZE = 0.2 # 学習データと評価データを作成 x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:df.shape[1]-1], df.iloc[:, df.shape[1]-1], test_size=TEST_SIZE, random_state=RANDOM_STATE) # trainのデータセットの3割をモデル学習時のバリデーションデータとして利用する x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=TEST_SIZE, random_state=RANDOM_STATE) # LightGBMを利用するのに必要なフォーマットに変換 lgb_train = lgb.Dataset(x_train, y_train) lgb_eval = lgb.Dataset(x_valid, y_valid, reference=lgb_train)次にハイパーパラメータの設定をします。
# LightGBMのパラメータ設定 params = { 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': {'l2', 'l1'}, 'num_leaves': 50, 'learning_rate': 0.05, 'feature_fraction': 0.9, 'bagging_fraction': 0.8, 'bagging_freq': 5, 'vervose': 0 }あとは、モデルの学習と予測を行います。
# LightGBM学習 gbm = lgb.train(params, lgb_train, num_boost_round=200, valid_sets=lgb_eval, early_stopping_rounds=50 ) # LightGBM推論 y_pred = gbm.predict(x_test, num_iteration=gbm.best_iteration) # 評価 def calculate_scores(true, pred): """全ての評価指標を計算する Parameters ---------- true (np.array) : 実測値 pred (np.array) : 予測値 Returns ------- scores (pd.DataFrame) : 各評価指標を纏めた結果 """ scores = {} scores = pd.DataFrame({'R2': r2_score(true, pred), 'MAE': mean_absolute_error(true, pred), 'MSE': mean_squared_error(true, pred), 'RMSE': np.sqrt(mean_squared_error(true, pred))}, index = ['scores']) return scores scores = calculate_scores(y_test, y_pred) print(scores)出力結果は下記のようになります。
R2 MAE MSE RMSE scores 0.782247 3.091336 22.772769 4.772082LightGBMのハイパーパラメータチューニング(Optuna)
次は、Optunaを使ってハイパーパラメータチューニングをしてみます。
# LightGBMのパラメータ設定 params = { 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': {'l2', 'l1'}, 'num_leaves': 50, 'learning_rate': 0.05, 'feature_fraction': 0.9, 'bagging_fraction': 0.8, 'bagging_freq': 5, 'vervose': 0 }あとは、モデルの学習と予測を行います。
# ライブラリーのインポート import os import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline # ボストンの住宅価格データ from sklearn.datasets import load_boston # 前処理 from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # LightGBM import optuna.integration.lightgbm as lgb # 評価指標 from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error # データセットの読込み boston = load_boston() # 説明変数の格納 df = pd.DataFrame(boston.data, columns = boston.feature_names) # 目的変数の追加 df['MEDV'] = boston.target # データの中身を確認 df.head() # ランダムシード値 RANDOM_STATE = 10 # 学習データと評価データの割合 TEST_SIZE = 0.2 # 学習データと評価データを作成 x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:df.shape[1]-1], df.iloc[:, df.shape[1]-1], test_size=TEST_SIZE, random_state=RANDOM_STATE) # trainのデータセットの3割をモデル学習時のバリデーションデータとして利用する x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=TEST_SIZE, random_state=RANDOM_STATE) # LightGBMを利用するのに必要なフォーマットに変換 lgb_train = lgb.Dataset(x_train, y_train) lgb_eval = lgb.Dataset(x_valid, y_valid, reference=lgb_train)ここからハイパーパラメータチューニングになります。
# ベストなパラメータ、途中経過を保存する params = { 'objective': 'mean_squared_error', 'metric': 'mae', "verbosity": -1, "boosting_type": "gbdt", } best_params, history = {}, [] # LightGBM学習 gbm = lgb.train(params, lgb_train, num_boost_round=200, valid_sets=[lgb_train, lgb_eval], early_stopping_rounds=50 ) best_params = gbm.params best_params最終的に得られたパラメータは下記です。
{'objective': 'mean_squared_error', 'metric': 'l1', 'verbosity': -1, 'boosting_type': 'gbdt', 'feature_pre_filter': False, 'lambda_l1': 6.927335476175293e-05, 'lambda_l2': 0.034542125556912426, 'num_leaves': 31, 'feature_fraction': 0.8999999999999999, 'bagging_fraction': 1.0, 'bagging_freq': 0, 'min_child_samples': 5, 'num_iterations': 200, 'early_stopping_round': 50}あとは、得られたハイパーパラメータを使って予測します。
# LightGBM推論 y_pred = gbm.predict(x_test, num_iteration=gbm.best_iteration) # 評価 def calculate_scores(true, pred): """全ての評価指標を計算する Parameters ---------- true (np.array) : 実測値 pred (np.array) : 予測値 Returns ------- scores (pd.DataFrame) : 各評価指標を纏めた結果 """ scores = {} scores = pd.DataFrame({'R2': r2_score(true, pred), 'MAE': mean_absolute_error(true, pred), 'MSE': mean_squared_error(true, pred), 'RMSE': np.sqrt(mean_squared_error(true, pred))}, index = ['scores']) return scores scores = calculate_scores(y_test, y_pred) print(scores)得られた結果は下記です。
R2 MAE MSE RMSE scores 0.847045 2.843303 15.996148 3.999518さいごに
最後まで読んで頂き、ありがとうございました。
今回LightGBMのハイパーパラメータチューニング(Optuna)をしてみました。
Optunaを使ったらパラメータチューニングはこんなに簡単にできるですね。便利なので、今後も使っていこうと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。
- 投稿日:2021-03-25T20:12:51+09:00
Pythonを使った彼ピッピの作り方
はじめに
彼氏 = 彼ピッピ
ならば
し = ぴっぴ
なのである
というわけで、"し"を"ぴっぴ"にする(以下、彼ピッピ化という)コードをPythonで書いていく
コード
from pykakasi import kakasi kakasi = kakasi() #オブジェクトをインスタンス化 kakasi.setMode('J', 'H') #モード設定 conv = kakasi.getConverter() txt = input('>>>') print(conv.do(txt).replace('し','ぴっぴ').replace('シ','ピッピ').replace('シ','シ')) #彼ピッピ化たったこれだけで彼ピッピ化してくれます。
>>>彼氏 かれぴっぴコピペして使いたい方は「pykakasi」を予めインストールしておいてください。
pip install pykakasi漢字をひらがなやカタカナ、ローマ字に変換してくれるライブラリです。
「pykakasi」の詳しい使い方は省きます。プログラミングをまとも(?)に初めて一ヶ月も経ってないような奴が、深夜テンションで書いたコードなんで、荒があっても許してください。
終わりに
彼ピッピ化とか何番煎じのネタなんだ?
というか彼ピッピ自体死語おまけ
discordのボットも作った
- 投稿日:2021-03-25T19:06:03+09:00
ROSの勉強 第29弾:移動ロボットの作成(2)
#プログラミング ROS< 移動ロボットの作成(2) >
はじめに
1つの参考書に沿って,ROS(Robot Operating System)を難なく扱えるようになることが目的である.その第29弾として,「移動ロボットの作成(2)」を扱う.
環境
仮想環境
ソフト VMware Workstation 15 実装RAM 2 GB OS Ubuntu 64 ビット isoファイル ubuntu-mate-20.04.1-desktop-amd64.iso コンピュータ
デバイス MSI プロセッサ Intel(R) Core(TM) i5-7300HQ CPU @ 2.50GHz 2.50GHz 実装RAM 8.00 GB (7.89 GB 使用可能) OS Windows (Windows 10 Home, バージョン:20H2) ROS
Distribution noetic プログラミング言語 Python 3.8.5 移動ロボットの作成
ROSを使って,ほとんどの新しいロボットを制御する手順は次のようである.
1. ROSのメッセージインタフェースを決める.
2. ロボットのモータ用ドライバを書く.
3. ロボットの物理構造を書く.
4. Gazeboのシミュレーションで使用できるようにモデルに物理的特性を追加する.
5. tfを介して座標変換データを配信し,rvizでそれを可視化する.
6. センサを追加する.ドライバとシミュレーションのサポートも必要.
7. ナビゲーション等の標準的なアルゴリズムを適用する.移動ロボットを例にその流れを確認していく.
今回は,3についてまとめて移動ロボットの作成(2)として扱うこととする.手順3:ロボットのモデリング: URDF
例:TortoiseBot
- ロボットをたくさんの標準的なROSツールで使用するには,そのロボットの運動学上のモデルを書き下ろす必要がある.⇒ロボットの物理的な構成を記述する必要がある.
いくつ車輪を持っているか?
それらがどこに置かれているか?
どの方向に向いているか? などこの情報は,rvizでロボットの状態を可視化したり,gazeboでロボットをシミュレート
したり,ナビゲーションスタックのようなシステムで何らかの目的を持って実世界を
移動させたりするのに使われる.
- ROSでは,URDF(Unified Robot Description Format)と呼ばれるXMLによる記述形式でロボットモデルを表現する.
この形式は,2輪の玩具から歩行型ロボットまで多種多様なロボットを表現できる.これは,Gazebo環境の構築のために用いるSDFに似ている.GazeboはURDFも解釈することができ,ほとんどのROSツールはURDFを必要としている.したがって,新しいロボットをモデル化するのはURDFを用いるのが最も良い.
- リンクは剛体で,台座や車輪など
- 関節は2つのリンクを接続し,それらが互いに対してどのように動くことができるかを示している.
関節タイプ 説明 continuous 1つの軸の周りに無限に回転できる関節 revolute 無限回転機構を持つ関節に似ているが,角度の上限下限の制限付きの関節 prismatic 位置の上限下限の制限付きの単一軸に沿って直線的にスライドする関節 planar 平面上の並進とその平面に対して垂直な軸で回転することができる関節 floating 完全な6次元の並進と回転ができる関節 fixed 固定された関節.どんな動作もしない特殊な関節タイプ 実装
以下では,少しずつロボットを構築する様子をコードと共に示す.また,
urdf_to_graphizを使って,パーツの関係性を示す.ステップ1:台座のモデリング
ソースコード
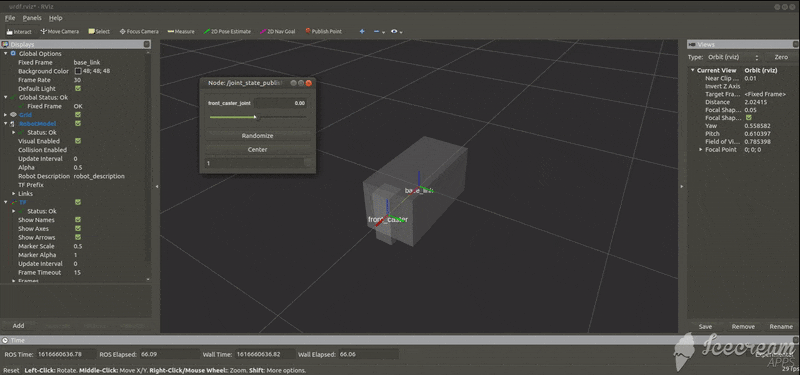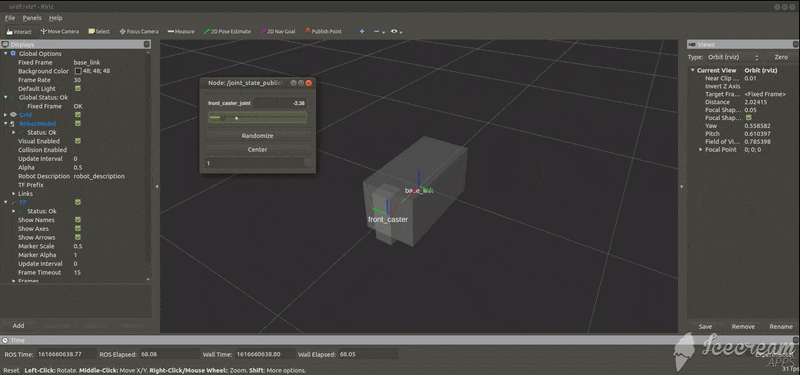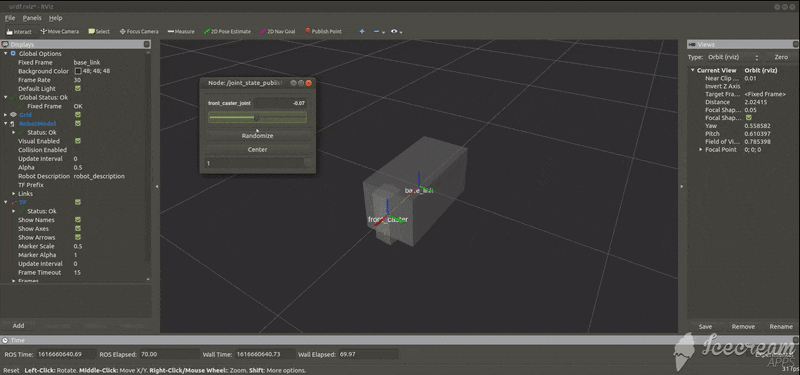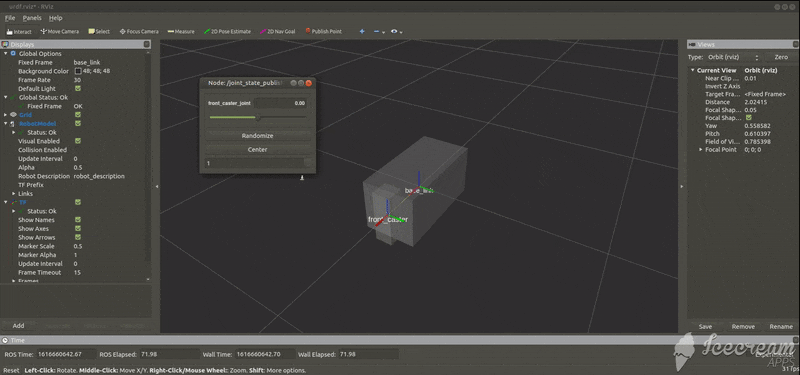
base_model.urdf<?xml version="1.0"?> <robot name="tortoisebot"> <!--台座のモデル--> <link name="base_link"> <visual> <geometry> <box size="0.6 0.3 0.3"/> </geometry> <material name="silver"> <color rgba="0.75 0.75 0.75 1"/> </material> </visual> </link> </robot>rvizでの様子
パーツの関係図
ステップ2:キャスターのモデリング
ソースコード
add_caster.urdf<?xml version="1.0"?> <robot name="tortoisebot"> <!--台座のモデル--> <link name="base_link"> <visual> <geometry> <box size="0.6 0.3 0.3"/> </geometry> <material name="silver"> <color rgba="0.75 0.75 0.75 1"/> </material> </visual> </link> <!--キャスターのモデル--> <link name="front_caster"> <visual> <geometry> <box size="0.1 0.1 0.3"/> </geometry> <material name="silver"/> </visual> </link> <!--台座とキャスターをつなぐジョイント--> <joint name="front_caster_joint" type="continuous"> <axis xyz="0 0 1"/> <parent link="base_link"/> <child link="front_caster"/> <origin rpy="0 0 0" xyz="0.3 0 0"/> </joint> </robot>rvizでの様子
パーツの関係図
また,次のコマンドを実行することで,キャスタの動きをGUIにより手動で確認することができる.
yuya@ubuntu:~$ roslaunch make_robot1 display.launch gui:=True
なお,display.launchのソースコードについては,後に示す.ステップ3:車輪のモデリング
ソースコード
add_wheels.urdf<?xml version="1.0"?> <robot name="tortoisebot"> <!--台座のモデル--> <link name="base_link"> <visual> <geometry> <box size="0.6 0.3 0.3"/> </geometry> <material name="silver"> <color rgba="0.75 0.75 0.75 1"/> </material> </visual> </link> <!--キャスターのモデル--> <link name="front_caster"> <visual> <geometry> <box size="0.1 0.1 0.3"/> </geometry> <material name="silver"/> </visual> </link> <!--台座とキャスターをつなぐ関節--> <joint name="front_caster_joint" type="continuous"> <axis xyz="0 0 1"/> <parent link="base_link"/> <child link="front_caster"/> <origin rpy="0 0 0" xyz="0.3 0 0"/> </joint> <!--前輪のモデル--> <link name="front_wheel"> <visual> <geometry> <cylinder length="0.05" radius="0.035"/> </geometry> <material name="black"/> </visual> </link> <!--前輪とキャスターをつなぐ関節--> <joint name="front_wheel_joint" type="continuous"> <axis xyz="0 0 1"/> <parent link="front_caster"/> <child link="front_wheel"/> <origin rpy="-1.5708 0 0" xyz="0.05 0 -.15"/> </joint> <!--右後方車輪のモデル--> <link name="right_wheel"> <visual> <geometry> <cylinder length="0.05" radius="0.035"/> </geometry> <material name="black"> <color rgba="0 0 0 1"/> </material> </visual> </link> <!--右後方車輪と台車をつなぐ関節--> <joint name="right_wheel_joint" type="continuous"> <axis xyz="0 0 1"/> <parent link="base_link"/> <child link="right_wheel"/> <origin rpy="-1.5708 0 0" xyz="-0.2825 -0.125 -.15"/> </joint> <!--左後方車輪のモデル--> <link name="left_wheel"> <visual> <geometry> <cylinder length="0.05" radius="0.035"/> </geometry> <material name="black"/> </visual> </link> <!--左後方車輪と台車をつなぐ関節--> <joint name="left_wheel_joint" type="continuous"> <axis xyz="0 0 1"/> <parent link="base_link"/> <child link="left_wheel"/> <origin rpy="-1.5708 0 0" xyz="-0.2825 0.125 -.15"/> </joint> </robot>rvizでの様子
パーツの関係図
実行launchファイル
上記の実行時に用いたlaunchファイルを以下に示す.ここで示すlaunchファイルは
urdf_tutorialのdisplay.launchを一部改編したものである.display.launch<launch> <arg name="model" default="$(find make_robot1)/urdf/add_wheels.urdf"/> <arg name="gui" default="true" /> <arg name="rvizconfig" default="$(find urdf_tutorial)/rviz/urdf.rviz" /> <param name="robot_description" command="$(find xacro)/xacro $(arg model)" /> <node if="$(arg gui)" name="joint_state_publisher" pkg="joint_state_publisher_gui" type="joint_state_publisher_gui" /> <node unless="$(arg gui)" name="joint_state_publisher" pkg="joint_state_publisher" type="joint_state_publisher" /> <node name="robot_state_publisher" pkg="robot_state_publisher" type="robot_state_publisher" /> <node name="rviz" pkg="rviz" type="rviz" args="-d $(arg rvizconfig)" required="true" /> </launch>改編部分は,
<arg name="model" default="$(find make_robot1)/urdf/add_wheels.urdf"/>である.また,上での実装ではadd_wheels.urdfの部分を変えて実行している.rvizの設定はそのままにしている.感想
今回はURDFについて学んだ.関節タイプもまとめることができ,実際に少しずつ構築する中で理解も深められたのではないかと思う.なお,URDFのソースコードは参考文献に乗っているものから抜粋して少しずつ構築した.そのなかで,
material name='black'ではblackが定義されていないという警告が表示された.エラーではないため放っているが,必要であれば変えればよいと思っている.参考文献
プログラミングROS Pythonによるロボットアプリケーション開発
Morgan Quigley, Brian Gerkey, William D.Smart 著
河田 卓志 監訳
松田 晃一,福地 正樹,由谷 哲夫 訳
オイラリー・ジャパン 発行






- 投稿日:2021-03-25T18:34:20+09:00
自動化プログラムを作る中で気づいたこと【音楽制作視点】
こんにちは。KHUFRUDAMO NOTESのYoshito Kimuraです。
最近、RPA(ロボティック・プロセス・オートメーション)が流行っているようですね。
いろいろ課題・問題もあるようですが。
僕は、音楽制作の全工程(作曲から楽器演奏、アートワーク周りまで)を基本的に一人でやる人です。
そして、制作の効率化のためPython(PyAutoGuiなど)で自動化プログラムをしばしば自作しています。
今回は、創作活動に関係する作業の自動化プログラムを作る中での気付きをまとめてみました!"創造的"な時間か否か をより意識するようになった。
音楽をはじめとした"創造的"な分野は、自動化による業務効率とそこまで相性が良くないイメージがあるかもしれません。
しかし、実際は「ファイルの書き出し」や「音価の計算」など"創造的"ではない時間も多く存在します。
(むしろ、"創造的"ではない時間の方が多い気もします。)したがって、芸術関係の分野で自動化プログラムを作るときは、"創造的"ではない時間を意識して見つけるのが大切だと感じています。
「自動化できそうか」考えるだけで意味があった。
「自動化できない作業」はあります。
自動化を阻む理由には、技術、費用、美学…などいろいろな"壁"があると思います。ただ、その手前に「明確なワークフローが完成していない」壁があると気付きました。
自動化プログラムを作るためには、明確なワークフローの確立が必要です。
また、ワークフローを考える中で、そもそも自動化プログラムを作るよりも
ショートカットキーやテンプレートで対応した方が良いと気付くケースもあります。
そういった意味で「ワークフローを考える行為」自体が、制作の効率化に繋がると感じました。
ちなみに、芸術界隈では、ワークフローなど"型"に沿って作品を作るのを好まない風習もある気がします。
しかし、「"型"を持っているけど、あえて使わない」のと「"型"が無い」のには大きな差があると考えます。個人的には、"型"は多い方が柔軟な創作ができると感じています。
手を付ける順番が分かりやくなった。
自分の作業を大まかに
①「自動化できる作業」
②「自動化できるけど、自分でやった方がクオリティが上がる作業」
③「(色んな意味で)自動化できない作業」の3つに分けて考えるようになりました。
すると、「自動化できない作業」→「自動化できるけど、自分でやった方がクオリティが上がる作業」の順番で作業に取り組めば"締切までに作品が完成しない"などの事故が起こるリスクを減らせる気がしました。
結果的に、優先順位の把握はクオリティの安定に繋がるのではないかと感じます。
さいごにちょこっと宣伝
前に音楽理論や音楽制作に役立つウェブアプリ「O-TO」↓を作りました。
音楽制作の効率化に使えるはずです。
KHUFRUDAMO NOTESのYouTubeチャンネル↓
- 投稿日:2021-03-25T18:03:19+09:00
Djangoアプリを外部サーバにデプロイする方法
レンタルサーバを選ぶ
作成したWebアプリをそのままGitHubに上げて、ソースコードをダウンロードしてもらい、実行してもらうことで、アプリを使ってもらうことも可能であるが、その場合ソースコードをダウンロードする必要があったり、実行に必要な依存ライブラリもダウンロードしてもらう必要があるなど、手間がかかる。そこで、作成したアプリを簡単に利用してもらうために外部サーバにデプロイするという方法がある。
外部サーバにデプロイするためにはサーバを借りる必要がある。サーバを借りるといっても有料のサーバは敷居が高いため無料で使えるサーバを借りることにする。Pythonが使用でき、無料で利用できる有名なサーバには以下のようなものがある。
- Heroku
- PythonAnywhere
- AWS
今回は、一番簡単にデプロイできそうなPythonAnywhereを使用した。
PythonAnywhereの特徴
以下にPythonAnywhereの無料枠の特徴について簡単にまとめた。
- いつアクセスしてもプログラムからレスポンスをもらうことができる
- ユーザ名がそのままドメイン名になる
- ディスク容量は500MBまで
- 1つのアカウントにつき1つのアプリしか公開できない
- アプリを起動させ続けるには 3ヶ月に一回はログインして黄色のボタンを押す必要がある
- 以上の条件で良ければ永久無料で使用可能である
セキュリティ対策
使うサーバは決まったが、開発環境で使っているソースコードをそのままアップロードするのはセキュリティ上よくないので、セキュリティ対策をしていく。まず開発環境と本番環境で設定ファイルを変えるために、configフォルダに新たにlocal_settings.pyという名前で空のファイルを作る。configフォルダはsettings.pyがあるフォルダである。本番環境では「settings.py」を使い、開発環境では「settings.pyの設定の一部をlocal_settings.pyで上書きしたもの」を使う。
DEBUGの設定
まずsettings.pyのDEBUGをFalseに変更する。
DEBUG = False「現場で覚えるDjangoの教科書」では、DEBUGについて以下のように説明されている。
「DEBUG」は、開発モードと本番モードを切り替えられるようにする設定。開発時はTrueにしておくことで、エラー発生時に画面にデバッグ情報が出力されるなど開発に便利な機能が提供されている。本番稼働時にはセキュリティ面を考慮してこの「DEBUG」設定をFalseにしておく必要がある。
ということで開発環境ではDEBUGをTrueにするために、local_settings.pyに以下の文を追加する。
DEBUG = TrueALLOWED_HOSTSの設定
次にALLOWED_HOSTSを編集する。settings.pyのALLOWED_HOSTSを以下のように変更する。
ALLOWED_HOSTS = ['localhost', '.pythonanywhere.com', '{|ユーザ名|}.pythonanywhere.com']この設定に関してはあまり情報がなく詳しい説明はできない。これより少ないコードでもできるかもしれない。デプロイしてアクセスした後にBad Requestが出たらこのALLOWED_HOSTSを疑った方が良い。
備考:
{|ユーザ名|}ではPythonAnywhereのユーザ名を指定する必要がある。まだPythonAnywhereのアカウントは作成していないため、作成するつもりのユーザ名を入れてほしい。例えばユーザ名を pa_name という名前で登録するつもりならALLOWED_HOSTSには次のように設定する。
ALLOWED_HOSTS = ['localhost', '.pythonanywhere.com', 'pa_name.pythonanywhere.com']一方、local_settings.pyには以下の文を追加する。
ALLOWED_HOSTS = [‘*’]HTTPS関連の設定
settings.pyに以下の文を追加する。
CSRF_COOKIE_SECURE = True SESSION_COOKIE_SECURE = TrueCSRF_COOKIE_SECUREをTrueにすることで、誤ってHTTPによりクッキーを送信してしまうのを防ぐ。
SESSION_COOKIE_SECUREをTrueにすることで、誤ってHTTPによりセッションクッキーを送信してしまうのを防ぐ。シークレットキーを隠す
まずシークレットキーとは何かという話を始める前にトークンについて知る必要がある。トークンはWebアプリのユーザを識別するために使用する識別子である。つまりWebアプリを使用するAさんのトークンが誰かに知られると、その誰かはAさんのふりをしてWebアプリを使用できる可能性がある。
Djangoのシークレットキーは、Webアプリのユーザのトークンの生成をするときのシード値のようなものになっている。このシークレットキーからトークンを生成する方法はDjangoの仕様を見ればわかるらしいので、シークレットキーが誰かにばれることでトークンもばれやすくなる。トークンがばれると、Webアプリのユーザが被害を受けるが、シークレットキーが誰かにばれることで、その誰かはWebアプリの開発者のふりもできたりすることがある。そのほかにも、Webアプリのユーザとのやり取りを暗号化したりするときの秘密鍵にもなっていたり、様々な用途があるらしい。
シークレットキーはデフォルトでDjangoのソースコードに組み込まれていて、実際に運用する際にシークレットキーがソースコードに書かれているとばれやすいため、ソースコードにはシークレットキーの「乱数を用いた生成方法」だけ書いて、実際のシークレットキーは本番環境(サーバ側)で生成することにする。
シークレットキーは、悪意ある攻撃者に推測されないように十分長くてランダムな(単純でない)文字列であることが求められるが、生成する関数がdjangoに標準で用意されているため、それを呼ぶことにする。以下のコードをsettings.pyに追加する。
from django.core.management.utils import get_random_secret_key SECRET_KEY = get_random_secret_key().gitignoreの設定
無駄なファイルをPythonAnywhereにアップロードしないようにするために、.gitignoreに以下の内容を書いてプロジェクトディレクトリ直下に保存する。
*.pyc *~ /.vscode /.spyproject __pycache__ myvenv db.sqlite3 /static .DS_Store pickle local_settings.py最後のlocal_settings.pyが特に重要である。local_settings.pyは開発環境での設定ファイルなので、本番環境には上げないこと。
local_settings.pyを読み込む
local_settings.pyに設定を書いてきたが、local_settings.pyは今のところどのプログラムからも読み込まれていないため、settings.pyから読み込むようにする。その時に、本番環境ではlocal_settings.pyがないため、local_settings.pyがなくてもエラーでプログラムが落ちないようにtry文を使う。以下はsettings.pyの一番最後に追加する。
try: from .local_settings import * except: passPythonAnywhereへのデプロイ方法
本内容は、Django Girlsのチュートリアル の補足説明的な立ち位置なので、基本的に「Django Girlsのチュートリアル」の指示に従って、手順を進めてほしい。
GitHubのセットアップ
まず、PythonAnywhereにソースコードをアップする必要がある。PythonAnywhereにソースコードを直接アップすることもできるみたいだがセキュリティ上よくないためGitHubにいったん上げてからPythonAnywhereにクローンする方法をとる。
Gitのインストール
自分のパソコンにGitがインストールされていない場合、公式のページからすべてデフォルトの設定でインストールする。
https://gitforwindows.orgAnacondaでもGitを使えるようにする
Djangoのプロジェクトの編集にAnacondaの仮想環境を使っている場合は、以下のサイトを参考にパスを通して仮想環境からもGitを使えるようにする。
https://qiita.com/masa_ramen/items/0111ed3508d7f2e8e9a6GitHubにソースコードをアップする
https://github.com からリポジトリを作成し、そこにソースコードをアップする。リポジトリを作るときはできればプライベートリポジトリにした方が良い。
$ git init $ git config user.name {|ユーザ名|} $ git config user.email {|メールアドレス|} $ git add . $ git commit -m “first commit” $ git remote add origin https://github.com/{|ユーザ名|}/{|リポジトリ名|}.git $ git push origin masterこのへんのコマンドは新しいリポジトリを作った後に表示されるサイトに載っているのをコピペすればよい。そのサイトではブランチmainを作成しているがしなくても大丈夫。またgit push -u origin mainのようにuオプションをつけることで次回からgit pushとするだけで自動的にorigin mainにコードを上げてくれるようになる。今回はuオプションなしでやった(個人の好みの問題)。
備考1:
コマンドの最初に書かれているドルマーク(= $)は、そのあとの文がコマンドであることを示すものなので、実際にコマンドプロンプトなどに打ち込むときは、その右にある文を打ち込む。備考2:
{|ユーザ名|}ではGitHubのユーザ名を指定する必要がある。例えばユーザ名が git_name なら2個目のコマンドは以下のように打ちこむ。
git config user.name git_name備考3:
{|メールアドレス|}では{|ユーザ名|}で指定したGitHubアカウントのメールアドレスを指定する必要がある。例えばメールアドレスがが email_name@gmail.com なら3個目のコマンドは以下のように打ちこむ。
git config user.email email_name@gmail.comPythonAnywhereにユーザ登録をする
次にPythonAnywhereの 公式サイト にアクセスしてユーザ登録をする。このときユーザ名がそのままドメイン名になるため注意する。
登録が終わるとダッシュボードのチュートリアルが始まる。ダッシュボードはPythonAnywhereのシステムをGUIで操作できるようにしたものというイメージで大丈夫。ダッシュボードのコンソールはwindowsでいうコマンドプロンプト、Macでいうターミナルのような感じでコマンド操作をすることができる。厳密にはBashというものである。
ダッシュボードのFilesではファイルをGUIで管理することができる。もちろんファイル管理はコンソールから行うこともできるがグラフィカルで直感的に操作することができる。
ダッシュボードのWeb appsではPythonAnywhere上でWebサイトを作ることができる。
ダッシュボードのNotebooksは有料サービスで、Jupyter Notebookを使える機能である。APIトークンを作成する
- 画面右上の「Account」と書いているボタンをクリック
- 「API Token」と書かれているタブを選ぶ
- 「Create a new API tokne」のボタンを押す
APIキーについて
基本的には以下のサイトを見てもらうと理解できると思う。
https://www.contents.digitallab.jp/api.htmlPythonAnywhereでのAPIとは
ただ、APIというけどPythonAnywhereでWebアプリを作るときの「APIを提供する側」と「APIを利用する側」は何なのかというと、それぞれ「PythonAnywhere」と「自分で作ってPythonAnywhereにアプロードしたWebアプリ」にあたる。つまり自分で作ったWebアプリを公開するためにPythonAnywhereのAPIを使っているということになる。
じゃあPythonAnywhereはどういう仕様を公開しているのかというと「ソースコードをサーバ上でデプロイするコマンド」等である(この解釈があってるかは分からん)。
PythonAnywhereでのAPIキーとは
PythonAnywhereはWebアプリからの要求にこたえるためにそれぞれのWebアプリに設定されたAPIキーが必要となる。このAPIキーはもちろん「APIを提供する側」であるPythonAnywhereから発行される。
つまりPythonAnywhereが、ある「WebアプリA」にAPIキー「abc123」というのを発行したとする(実際はもっと複雑なキーが発行される)。すると「WebアプリA」はAPIアクセスをするときにこのAPIキーも同時に渡すことで、「WebアプリA」からのアクセスであり「WebアプリB」や「WebアプリC」からのアクセスではないことをPythonAnywhereに伝える。
別の言い方をすると、PythonAnywhereは「WebアプリA」に、APIアクセスするときにはこのAPIキーを使いなさいと指示する。するとPythonAnywhereはAPIアクセスがあったときにそれがどのWebアプリからのアクセスか、はたまたWebアプリ以外の悪意のある攻撃者からのアクセスなのかなどを判断することができる。
APIキーについての考察
でもPythonAnywhereで生成されたAPIキーは、ソースコードにも埋め込んでないしそれ以外にも使ってないため、裏で自動的にAPIキーをPythonAnywhereに送信してるのだと思われる。だから始めにAPIキーを生成することでWebアプリをPythonAnywhereに登録・認識させているのだと思う。
APIトークンの確認方法
APIトークンを忘れてしまったときはPythonAnywhereのコンソールから$API_TOKENと打つことで確認できる。
HTTPSに対応させる
httpでは通信情報が平文で送られる。それを暗号化するためにhttpで接続してきたとしてもhttpsにリダイレクトさせるように設定する。PythonAnywhereではボタンを押すだけでできる。
- ダッシュボードの右上にある「Web」ボタンをクリック
- ページ下の方の「Force HTTPS」の横のDisableと書かれているところを押してEnableにする
設定を反映するには、ページ上側にある「Reload {|ユーザ名|}.pythonanywhere.com」と書かれた緑のボタンを押す必要がある。
デプロイ手順
PythonAnywhereのパッケージインストール
以下のコマンドはPythonAnywhereのBashに打ち込む。
$ pip3 install --user pythonanywhere備考1:
普段Windows等ではPython3系かPython2系のどちらかしか入れないが、PythonAnywhereではPython2系とPython3系が共存しているためコマンドを打つとき2系なのか3系なのかきちんと明示してあげる必要がある。備考2:
上記コマンドを打つと以下のようなエラーが出るが、無視して大丈夫だと思われる。ERROR: py2neo 4.3.0 has requirement click==7.0, but you'll have click 7.1.2 which is incompatible.このエラーを解決しようとするとまた別のエラーが出てきて、その二つのエラーを同時に解決することができなかった。
ヘルパーの実行
GitHub からアプリを自動的に構成するためのヘルパーを実行する。
$ pa_autoconfigure_django.py --python=3.8 https://github.com/{|ユーザ名|}/{|リポジトリ名|}.git備考:
Pythonのバージョンは自分の開発環境で$ python –versionと打って確認する。今回はPython 3.8.8だったが最後の数字8は多分いらない。
するとGitHubのユーザ名とパスワードを求められるので入力する。入力が終わると、いろいろログが表示されてインストールが完了した。
追加パッケージのインストール
ヘルパーを実行したときのログに「numpyがインストールされてない」というようなエラーが出ていたような気がしたので、pipコマンドでnumpyをインストールするコマンドを打ち込んだ。
$ pip3 install numpyすると以下のようなログが出てきた。
Requirement already satisfied: numpy in /usr/lib/python3.8/site-packages (1.17.3)既に入っていたようだ。
本来今回のnumpyのように必要なパッケージはrequirements.txtに書いておくべきである。requirements.txtについては「Django Girls記事のDjangoのインストール」という項目で解説されている。
後から分かったことだが、pipコマンドはWebボタンから「Start a console in this virtualenv」というのを押して、仮想環境のコンソールから打ち込む必要があるみたい。仮想環境のコンソールからpip3 listで確認するとnumpyが入っていなかったため、インストールした。
動作確認
ここまでの手順を行うと、以下のURLにサイトが作成されている。
https://{|ユーザ名|}.pythonanywhere.comこのURLはダッシュボード右上の「Web」ボタンを押すと遷移するページの一番上にある「Configuration for」という文字のところにも書かれている。
再デプロイする方法
まずデプロイのときと同じようにGitHubにソースコードを上げ直す必要がある。例えば以下のように打ちこむ。
$ git add -a $ git commit -m “second commit” $ git push origin master新しくGitHubに上げたソースコードをサーバにインストールし直すのは、最初サーバにダウンロードしたときのコマンドに --nukeオプション をつけ足せば良い。--nukeオプションはコマンド中のどこにつけても良い。
$ pa_autoconfigure_django.py --nuke --python=3.8 https://github.com/{|ユーザ名|}/{|リポジトリ名|}.git入力し終わったらもう一度ユーザ名とパスワードの入力を求められるので入力する。PythonAnywhere側で再インストールのためにすることはこれだけなので、Bashの様子を見て作業が終わってそうなら、きちんとデプロイできたかどうか確認する。
リロードしないとインストールした結果が反映されないことがまれにあるみたい。リロードはダッシュボード右上にあるWebボタンを押してからページ上らへんに表示される緑のボタンを押すことでできる。
- 投稿日:2021-03-25T17:30:44+09:00
Python Selenium Javascriptのポップアップをクリックする
前提:
python 3.8
Seleniumを使う
Windows10Javascriptのアラート(ポップアップ)をクリックする必要があったのでメモ
最近のアラートはスタイルシートのものが多いですが、久しぶりにJavascriptのアラートに出会ったのでメモします。
※ちなみにスタイルシートで作成されたアラートを操作するときはCSSセレクターで。xpathやIDだとうまくいかないことおおいです。参考サイト
①アラートがでてくるまで待つ:alert_is_present
②アラートを操作する
↑文字入力やベーシック認証の解説もあります。前提:
python:変数driverにはSeleniumのクロームドライバーがすでに設定済みとするimport time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.alert import Alert wait = WebDriverWait(driver,10) try: wait.until(EC.alert_is_present()) #Javascriptのアラートがでてくるまで待つ Alert(driver).accept() #アラート受け入れる(OKを押す) time.sleep(1) #1秒まつ except Exception as e: print("アラートの処理でエラー")ただクリックするだけなら、
簡単でした。time.sleep(1)はあまりにも早すぎると止められたり、処理でているかわからないと指摘をうけるのであえていれています。
- 投稿日:2021-03-25T15:45:32+09:00
boto3でCloudSearch検索ドメインに複合クエリ問合せをする
↑をboto3でやってみました。
cloudsearchdomain.pyimport boto3 endpoint_url = 'https://search-todofuken-XXXXXXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.cloudsearch.amazonaws.com' cloudsearchdomain = boto3.client( 'cloudsearchdomain', endpoint_url=endpoint_url) query = """ (and prefecture:'{prefecture}' city:'{city}' (range field=zip [{from_zip}, {to_zip}] ) ) """.format(prefecture='宮城県', city='仙台市', from_zip=9830000, to_zip=9830100) returnFields = [ 'city', 'kana_town', ] results = cloudsearchdomain.search( query=query, queryParser='structured', returnFields=','.join(returnFields), size=3) print('found:%d' % results["hits"]["found"]) print('count:%d' % len(results["hits"]["hit"])) for item in results["hits"]["hit"]: print(item["fields"])$ python cloudsearchdomain.py found:34 count:3 {'city': ['仙台市宮城野区'], 'kana_town': ['タゴ']} {'city': ['仙台市宮城野区'], 'kana_town': ['タゴニシ']} {'city': ['仙台市宮城野区'], 'kana_town': ['ツルマキ']}CloudSearchのboto3のサンプルコードあんまり転がってないので参考になれば。
- 投稿日:2021-03-25T15:45:32+09:00
boto3でCloudSearch検索ドメインに複合クエリを実行する
↑をboto3でやってみました。
cloudsearchdomain.pyimport boto3 endpoint_url = 'https://search-todofuken-XXXXXXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.cloudsearch.amazonaws.com' cloudsearchdomain = boto3.client( 'cloudsearchdomain', endpoint_url=endpoint_url) query = """ (and prefecture:'{prefecture}' city:'{city}' (range field=zip [{from_zip}, {to_zip}] ) ) """.format(prefecture='宮城県', city='仙台市', from_zip=9830000, to_zip=9830100) returnFields = [ 'city', 'kana_town', ] results = cloudsearchdomain.search( query=query, queryParser='structured', returnFields=','.join(returnFields), size=3) print('found:%d' % results["hits"]["found"]) print('count:%d' % len(results["hits"]["hit"])) for item in results["hits"]["hit"]: print(item["fields"])$ python cloudsearchdomain.py found:34 count:3 {'city': ['仙台市宮城野区'], 'kana_town': ['タゴ']} {'city': ['仙台市宮城野区'], 'kana_town': ['タゴニシ']} {'city': ['仙台市宮城野区'], 'kana_town': ['ツルマキ']}CloudSearchのboto3のサンプルコードあんまり転がってないので参考になれば。
- 投稿日:2021-03-25T15:39:45+09:00
signate:日本取引所グループ ニュース分析チャレンジ②
今回は、公開されているsignateチュートリアルの2章の部分を描いていきたいと思います。
こちらのチュートリアルでは、「ファンダメンタルズ分析チャレンジ」に関するものです。
コンペ概要
ここら辺は、チュートリアルに詳しく書いているので、詳しくはチュートリアルを見てください。要約すると、株式市場をデータ分析したい人が最初の足掛かりとして取り組むのに良いプログラムです。
うんうん。データ分析以外の株式市場の知識も得られそうで一石二鳥になりそうですね。
それでは始めます。
2.1章
株式情報の使用用途や本コンペにおける評価指標が示されています。
評価指標は、難しかったので随時理解次第こちらの記事を訂正したいと思います。
2.2章
開示されているデータファイルについて、まとめられている。
stock_list
銘柄の名前や業種区分などの基本情報をメインに書かれている。
例えば、銘柄の業種区分や発行済株式数等々が書かれているstock_price
各銘柄の各日付毎の始値や終値などの株価情報が記録。
stock_fin
株式投資における、ファンダメンタル情報について記載。
ファンダメンタル情報とは、純資産に関する財務情報や当期純利益といった業績状況を表す情報です。
これは、本コンペ関係なく、今後の企業の成長性や安全性、収益性等の判断材料になることから、より重要度が高い情報を持っていることがわかると思います。※お金に関する勉強を今後始めようと思うので、別記事、もしくはnoteでこれらの詳細の情報は開示していきたいなと思います。
stock_fin_price
上記二つのデータをjoinしたもの
stock_labels
予測対象に関するデータ
2.3章 実行環境・ライブラリー
これはチュートリアル通りです。
colabが一番手軽かなって思います。2.4章 データセットの読み込み
ここからの章は、プログラミングを使って、データを扱うといったことをやっています。
私の記事としては、コードの概要というより、それぞれの章での用語の説明ややっていることを説明したいなっと思います。この章は、単にデータを読み込んでいるだけです。
2.5章 データセットの可視化
使用しているモジュールは、matplotlibとseabornです。
可視化ツールとして、めっちゃ王道のものを使用していますね。2.5.1では、財務諸表のデータを読み込み可視化しています。
これらをすることで、各銘柄の財務状況や特徴を分析することが容易になります。その後は、複数銘柄の比較をgroupbyを使用して行ったり、numpy等のモジュールを使って移動平均や価格変化率を元絵mグラフでプロットしています。
この章での一番難しい点は、「ヒストリカル・ボラティリティ」だと考えてます。
これは、あるサイトによると
「オプション取引で用いられる用語で、株式、為替、債券、コモディティなどの原資産価格の過去一定期間の値動きデータに基づいて算出した将来の変動率(ボラティリティー)。
「歴史的変動率」とも呼ばれ、英語表記「historical volatility」の略で「HV」ということもあります。統計学の標準偏差を利用して、ある一定期間のボラティリティを年率換算したものです。過去にその原資産の価格がどの程度変動したかを示す指標で、ヒストリカルボラティリティーが高いほど価格変動リスク高く(安全性が低い)、低いほど価格変動リスクが低い(安全性が高い)といえます。」(※引用「https://www.daiwa.jp/glossary/YST2343.html」)要するに、原資産の価格変動を表したもので、安全性を判断する指標として活用されているようです。これは、めちゃめちゃ大切そうな特徴量ですね。
これに関しても、numpy.rolling等を使用して計算してます。2.6章 データセットの前処理
前処理はめっちゃ大事ですよね。
①欠損値処理
②正規化
③特徴量生成
④バリデーション戦略
⑤モデル構築ざっくりした流れです。
じゃあ、本コンペにおける前処理を見ていきましょう!!
①欠損値処理は方法として、
・平均値埋め
・リストワイズほう
・多重代入法
いろいろあります今回は、0を入れることで対処しています、ただし、欠損値としての0の意味合いを込めた欠損値処理をしているのでご注意を
2.7章 特徴量生成
②を超えて、③にきましたね
②は今回は木構造の機械学習モデルを用いるので必要ないと判断し記述していないのでしょう。
ただ、NN等のモデルを使用する場合は必要なのでご注意ください③特徴量生成
これの重要な点はここにあります。
「ドメイン知識や専門性を活かして特徴量を設計する」といったことにあります。
そのため、対象モデルについて詳しく知識を保有し、細かい部分の影響を考えることでより、予測精度を高めるといった点で重要になります。しかし、end-to-end学習の方法もあります。これは、どんな人でも活用できるように生のデータのまま学習させ、データ間の関係性を見つける手法もあるので、この場合そこまで生成をする必要はありません。
今回は前者の方法を採用し、金融知識を高めながらデータ分析をしていく手法をとっていくそうです。
その上での最重要な点は、
「仮説を立て、仮説を遂行するために必要な特徴量を考える」である。今回は金融の領域で重要な判断材料となる、ボラリティリティや移動平均を元に特徴量生成をしています。
2.8章
④バリデーション戦略
これは、学習させてモデルの汎化性能を上げるために行なっている作業です。
過学習を防ぐためにやっています。2.9章 モデルの構築
モデルは木構造をチョイスしてますね。
それに加えて、一つの銘柄に対して、一つのモデルを構築するように学習しています。2.10章 モデルの推論
バリデーションしたものに関して、推論し、精度の確認や予測結果の可視化をしています。
2.11章
モデルの予測に寄与した特徴量の分析
2.12章 モデルの評価
個人的にはこの章が一番大事だと思う。
なぜならば、全ての取り組みの結果を評価するのがこの章だからだ。その上で評価している内容は、
RMSE: 2乗平均平方根 -> 予測値と実際の値の差
accuracy: 目的変数の符号と予測した目的変数の符号の精度
spearmanc_corr: スペアマンの順位相関 -> 絶対値が大きいほど、相関関係は高い
corr: ピアソンの相関係数 -> 正の相関があるか負の相関があるか
R^2score: 単回帰した時のばらつきこれにより、どのモデルにどのデータセットを適応させるのがいいのか評価し、判断していきましょう!
終わりに
今回は2章をざっくりと説明しました。
次回以降は3章等々を紹介していきたいなと思います。
- 投稿日:2021-03-25T15:34:34+09:00
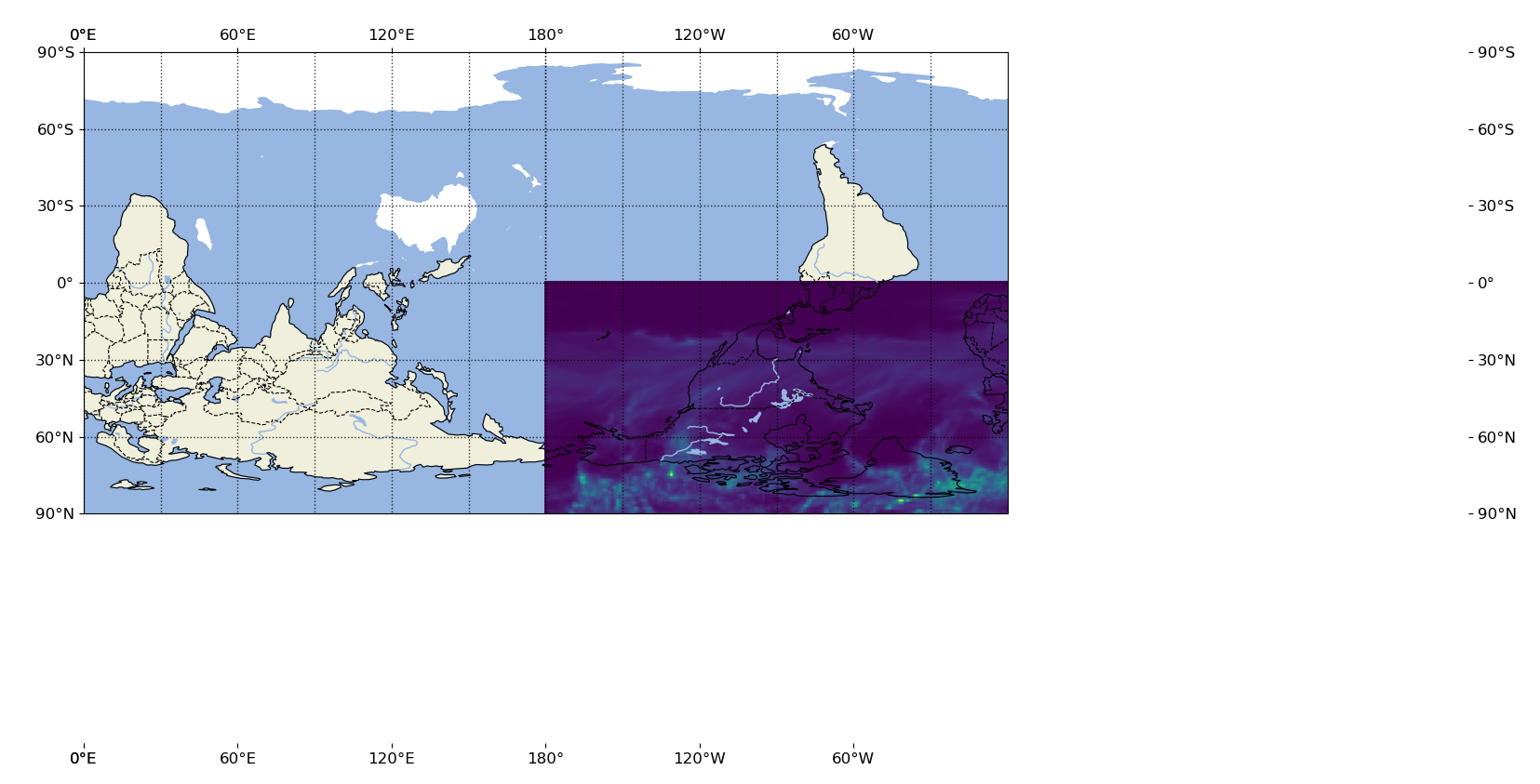
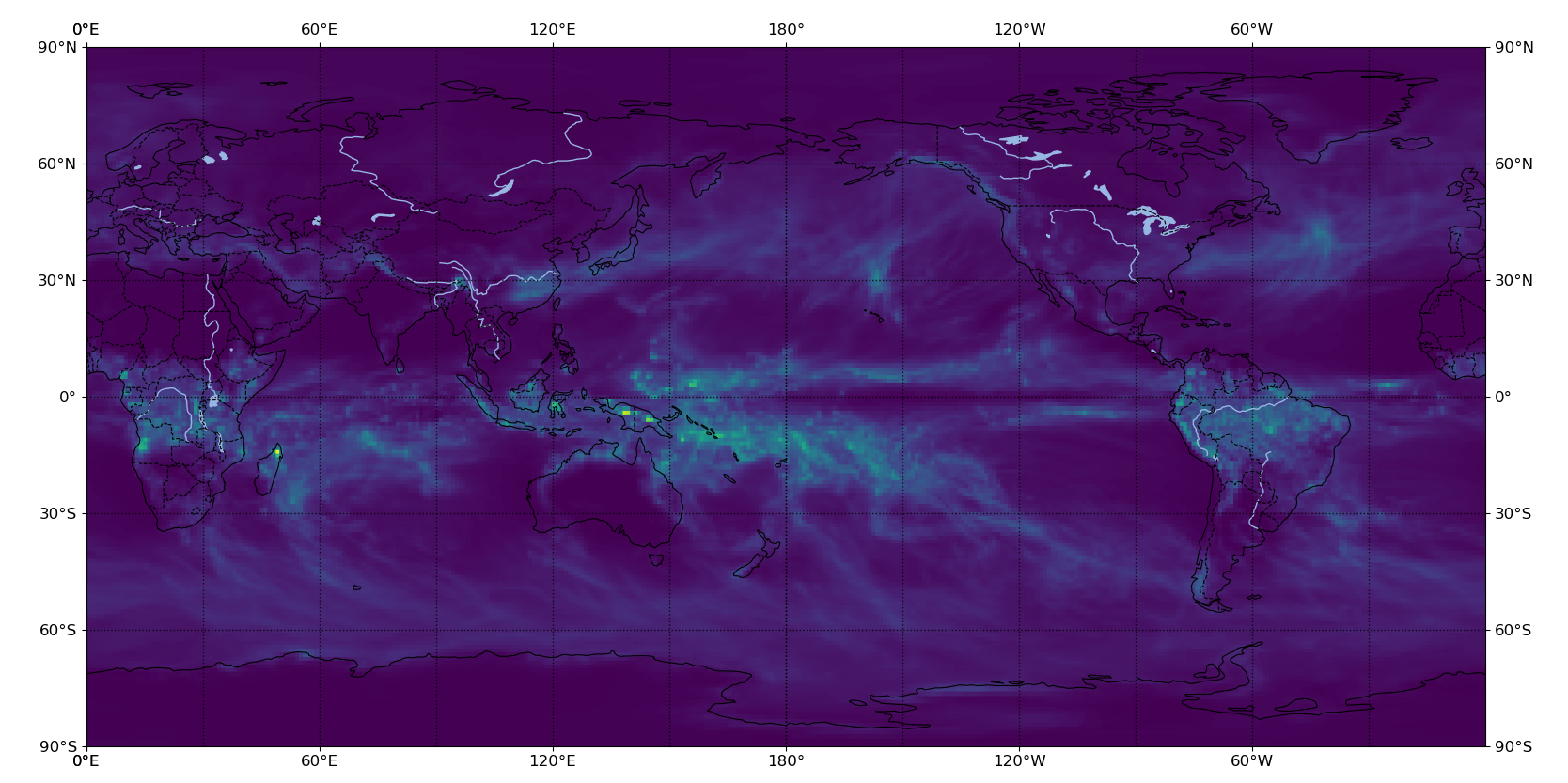
cartopy世界地図上にデータプロットできない!
グローバルマップ上に気象データをプロットしたいのになんか違う...
- 世界地図と降水データのサイズあべこべ...
- なぜか世界地図がさかさま...
- 横軸・縦軸があらぬ方向に...
とにかくcartopyで苦戦したので,その解決法を載せときます
答えからいうと"plt.imshow(extent)"を使おう
お急ぎの方は,googleで'plt imshow extent'と検索すると幸せになれると思います.
from netCDF4 import Dataset import matplotlib.pyplot as plt import cartopy.crs as ccrs #降水データを読み込んでます. ds = Dataset(path,'r').variables['prec'][0][0][0][:][:] img_extent = (-180.5,180.5,-91.0,91.0) fig = plt.figure(figsize=(10,10)) proj = ccrs.PlateCarree(central_longitude = 180) ax = fig.add_subplot(1,1,1, projection=proj) tp = ax.imshow(ds, origin='lower', extent=img_extent, transform=proj) ax.set_global() ax.coastlines() plt.show()ポイントになるのはplt.imshowのAPIに含まれるextentとoriginの機能.
extentはタプルを与えると(left,right,bottom,top)の順で表示する範囲を指定できる.
originは数値を'lower'か'upper'の2種類が選べ,数値をどちらから詰めるかを指定できる.今回のデータはds.shape = [181,360]の形をもっていたので,試行錯誤的にimg_extentを調整してます.
- 投稿日:2021-03-25T13:56:21+09:00
任意サイトのサブドメインを列挙する
何?
あるサイトのサブドメインを探して列挙したい。
例えばexample.comならftp.example.comやws3.example.comなどがサブドメインに当たる。
調べたところいくつかツールがヒットした。その中でもsublist3rがシンプルで良かったので紹介する。
sublist3raboul3la/Sublist3rは、各検索エンジンのクローラが拾ったレコードからサブドメインを検索し列挙するコマンド。(メンテされてるか微妙だが2020-03-25現在使用できた。)
インストールは:
Terminal# pypiには第三者がアップロードしているので本家repoから $ git clone https://github.com/aboul3la/Sublist3r && cd Sublist3r $ pip install -r requirements.txt $ pip install -e . $ sublist3r --helpHelpusage: sublist3r [-h] -d DOMAIN [-b [BRUTEFORCE]] [-p PORTS] [-v [VERBOSE]] [-t THREADS] [-e ENGINES] [-o OUTPUT] [-n] OPTIONS: -h, --help show this help message and exit -d DOMAIN, --domain DOMAIN Domain name to enumerate it's subdomains -b [BRUTEFORCE], --bruteforce [BRUTEFORCE] Enable the subbrute bruteforce module -p PORTS, --ports PORTS Scan the found subdomains against specified tcp ports -v [VERBOSE], --verbose [VERBOSE] Enable Verbosity and display results in realtime -t THREADS, --threads THREADS Number of threads to use for subbrute bruteforce -e ENGINES, --engines ENGINES Specify a comma-separated list of search engines -o OUTPUT, --output OUTPUT Save the results to text file -n, --no-color Output without color Example: python /home/eggplants/.local/bin/sublist3r -d google.com実際に列挙
sublist3r -d <domain>で実行できる。プレーンテキストで保存するには-o <filename>を使う。今回は筑波大学のドメイン
tsukuba.ac.jpで試してみる。Terminal$ LANG=C date Thu Mar 25 11:25:01 JST 2021 $ sublist3r -d tsukuba.ac.jp -o subdomains.txt ...(略)... $ wc -l subdomains.txt 13876結果はこちら
応用
Terminal# 自己責任で $ (echo 'url,res_code,content_type,res_time' cat subdomains.txt | xargs -n 1 -P 5 -I@ \ curl "@" -m 2 -s -o /dev/null \ -w "@,%{http_code},%{content_type},%{time_starttransfer}s\n" | sort) > res.csv # httpでなにか配信されているものの列挙 $ (sed 1\!d res.csv;grep -v ,, res.csv | grep ,200,) > res_200.csv $ echo $[`wc -l<res_200.csv`-1] 279 # httpsとかへの転送(301) $ (sed 1\!d res.csv;grep -v ,, res.csv | grep ,301,) > res_301.csv $ echo $[`wc -l<res_301.csv`-1] 180結果はこちら
またこれらの処理をまとめたスクリプトを書いた。結論
お手軽。
- 投稿日:2021-03-25T12:41:23+09:00
PythonでGoogleNewsを日本語かつjsonで取得する
Googleのニュースは、例えばビットコイン関連のニュースが取得したい場合、実は以下のようなURLで取得できる
https://news.google.com/rss/search?q=ビットコイン&hl=ja[参考]↓
Google News Rss(API)ただ、これだと結果がxmlなのでちょっと扱いづらい…
検索すると以下のようなライブラリがあったので使用してみた
ドキュメントの通り、以下のように書いて動かしてみたが、エラーが出る
from GoogleNews import GoogleNews googlenews = GoogleNews(lang='ja', encode='utf-8') googlenews.get_news('ビットコイン') result = googlenews.results() print(result[0])'ascii' codec can't encode characters in position 14-19: ordinal not in range(128)Pythonが3になって以来、とんと見かけなくなったエラーだったので焦ったが、どうやら以下の記事によると、日本語や中国語に対応していないらしい。
なので、引数をurlエンコードして渡してやればうまく動いた。
from GoogleNews import GoogleNews import urllib.parse googlenews = GoogleNews(lang='ja', encode='utf-8') googlenews.get_news(urllib.parse.quote('ビットコイン')) result = googlenews.results() print(result[0])2021/03/25 12:40時点での実行結果は以下の通り
{'title': '指標が示すビットコインの強気相場:リザーブリスクとは', 'desc': 'ブロックチェーン・データは、保有者や購入検討者にとってビットコインが依然として魅力的であることを示している。相場は最高値をつけた以降、小康状態に ...', 'date': '19 時間前', 'datetime': datetime.datetime(2021, 3, 24, 8, 7, 25), 'link': 'news.google.com/./articles/CAIiEJ1D6QqbEkjOiubGSaHHO8oqMwgEKioIACIQKQ8vX7rIbv4J-a3Vk64LmCoUCAoiECkPL1-6yG7-Cfmt1ZOuC5gwtazdBg?hl=ja&gl=JP&ceid=JP%3Aja', 'img': 'https://lh3.googleusercontent.com/UMKcCAW6LczwEg3VALRBEq2G4NMvb3qoL7daQxDrnY62oGIhQf3NIb002kqxWK5ENcX-3N6uJ51M5vJiRf5J=-p-df-h100-w100', 'media': None, 'site': 'コインデスク・ジャパン'}
- 投稿日:2021-03-25T12:36:14+09:00
Google workspace や Gmailのメールアドレスを使って、pythonから送信する。
本記事の対象者
- GCPでサービスを作り、メールを送信する仕組みを無料で作りたい人。(サービスのホスティングが無料ではなく、メール送信部分だけ)
目的
sendgridなどの外部のサービスを使わずに、pythonを使ってgmailを送信する。
必要なもの
- Gmail または、Google workspaceのアカウント (Google workspaceは管理者権限が必要)
- pythonを動かす環境
メールの設定
送信者の設定
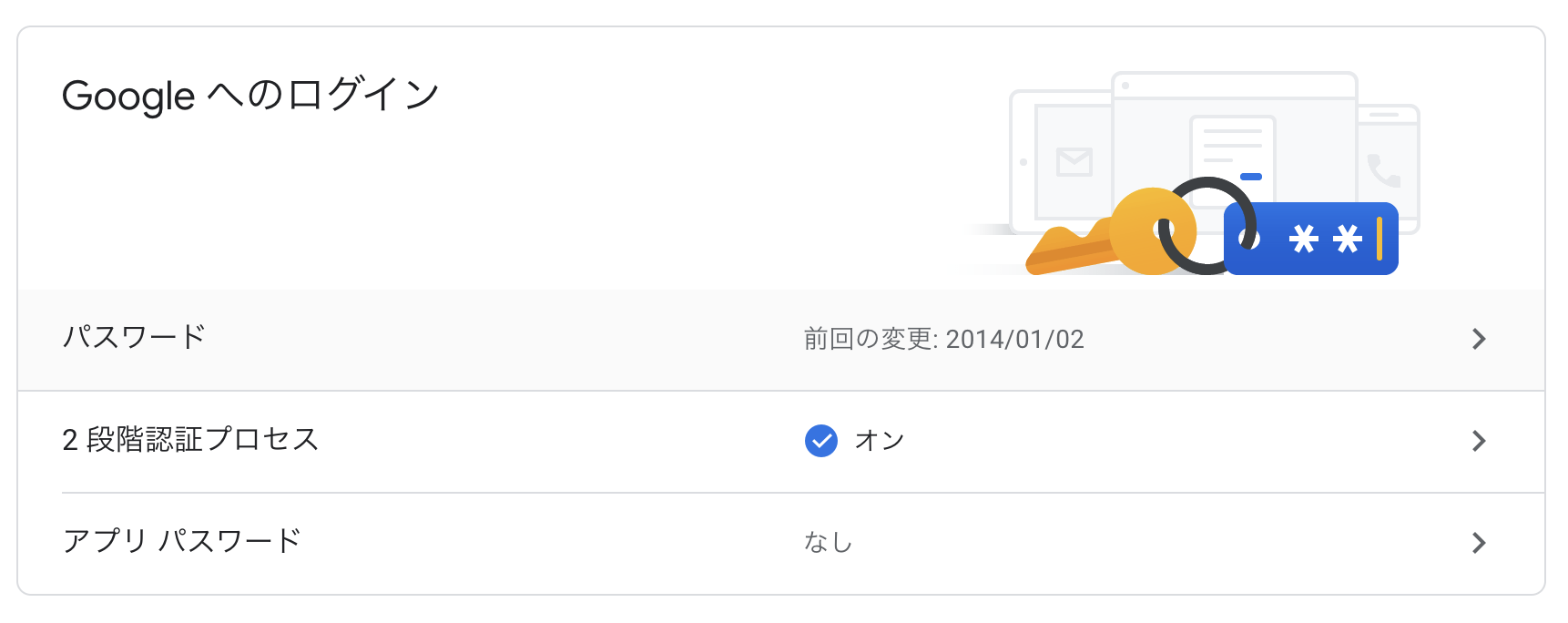
設定から二段階認証を有効にする
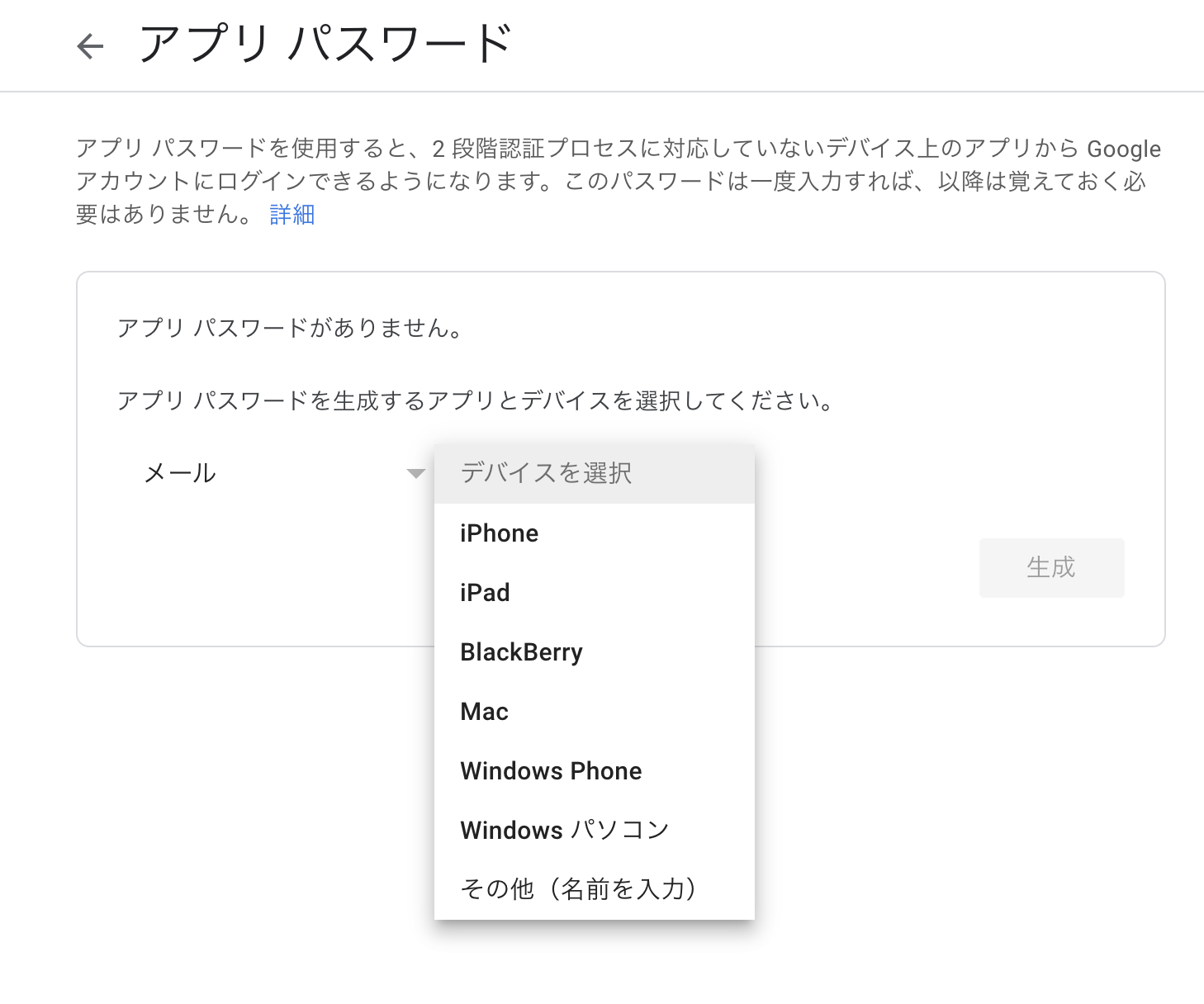
二段階認証有効後、アプリパスワードを作成する
メールを選択し、「その他」を選び、「〇〇用」などとラベルを決める
「生成」ボタンを押すと、パスワードが表示される(再表示は不可能)ので、パスワードをメモする。
Google workspaceの設定
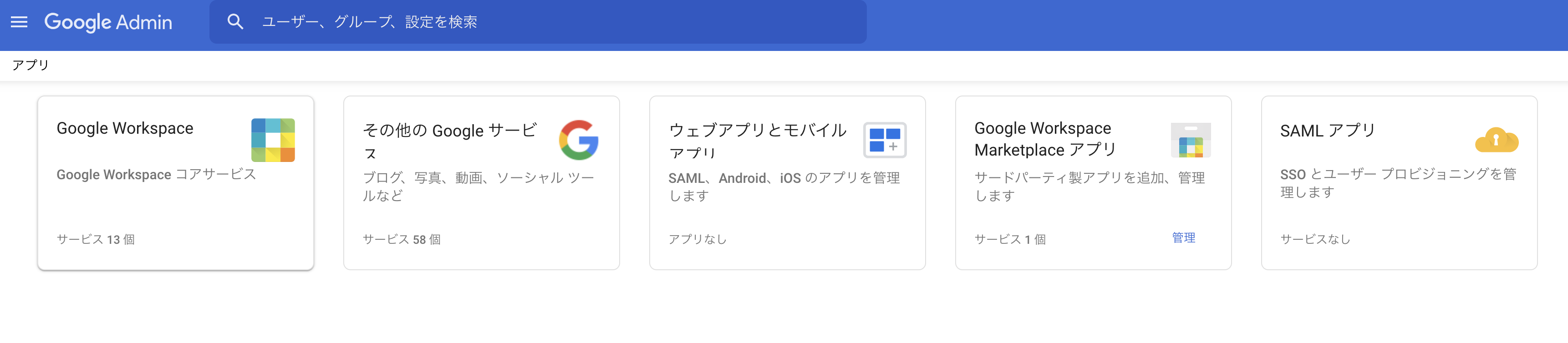
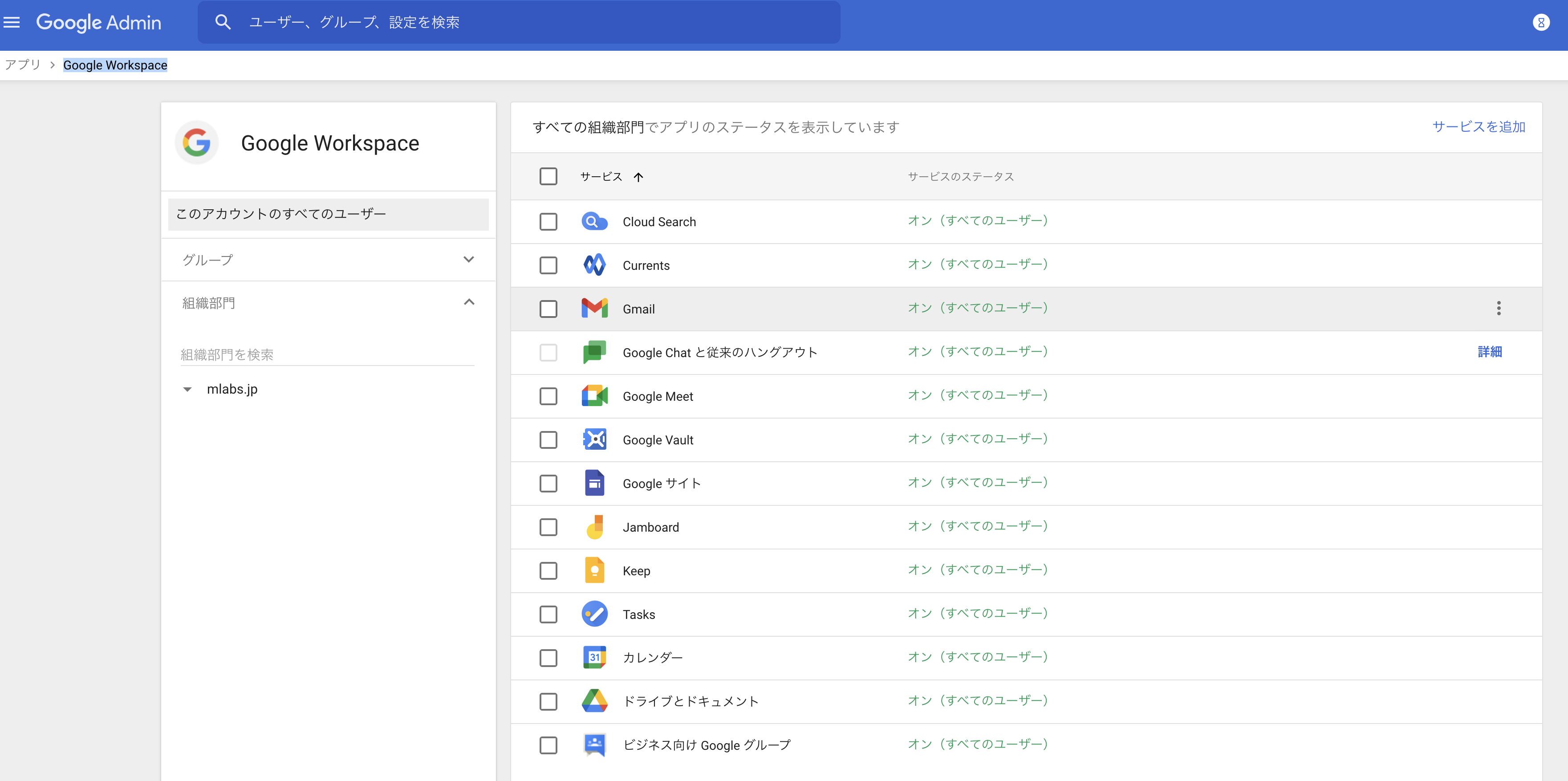
管理画面からアプリを選択
アプリから「Google Workspace」を選択
「Gmail」を選択
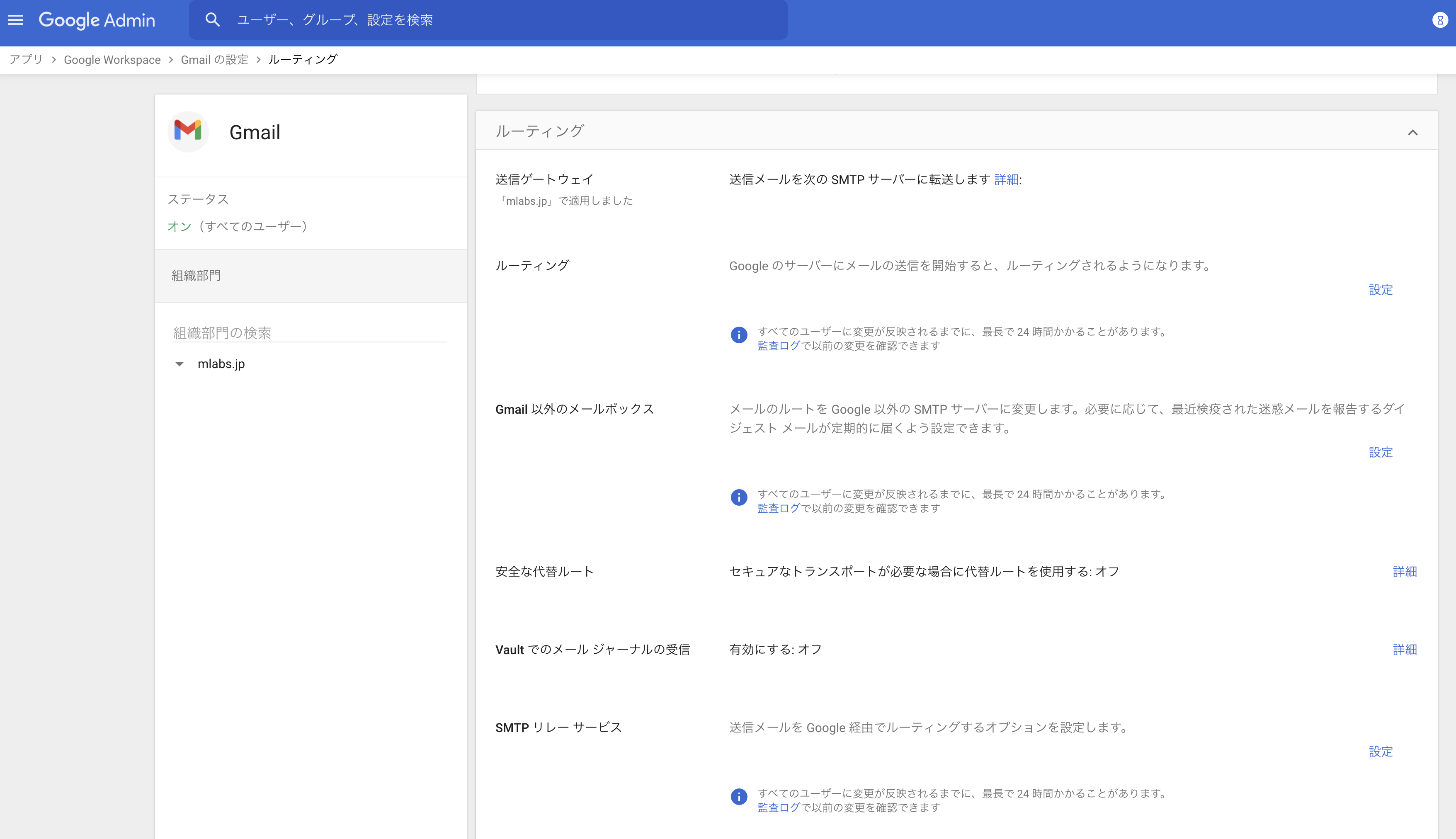
「ルーティング」を選択
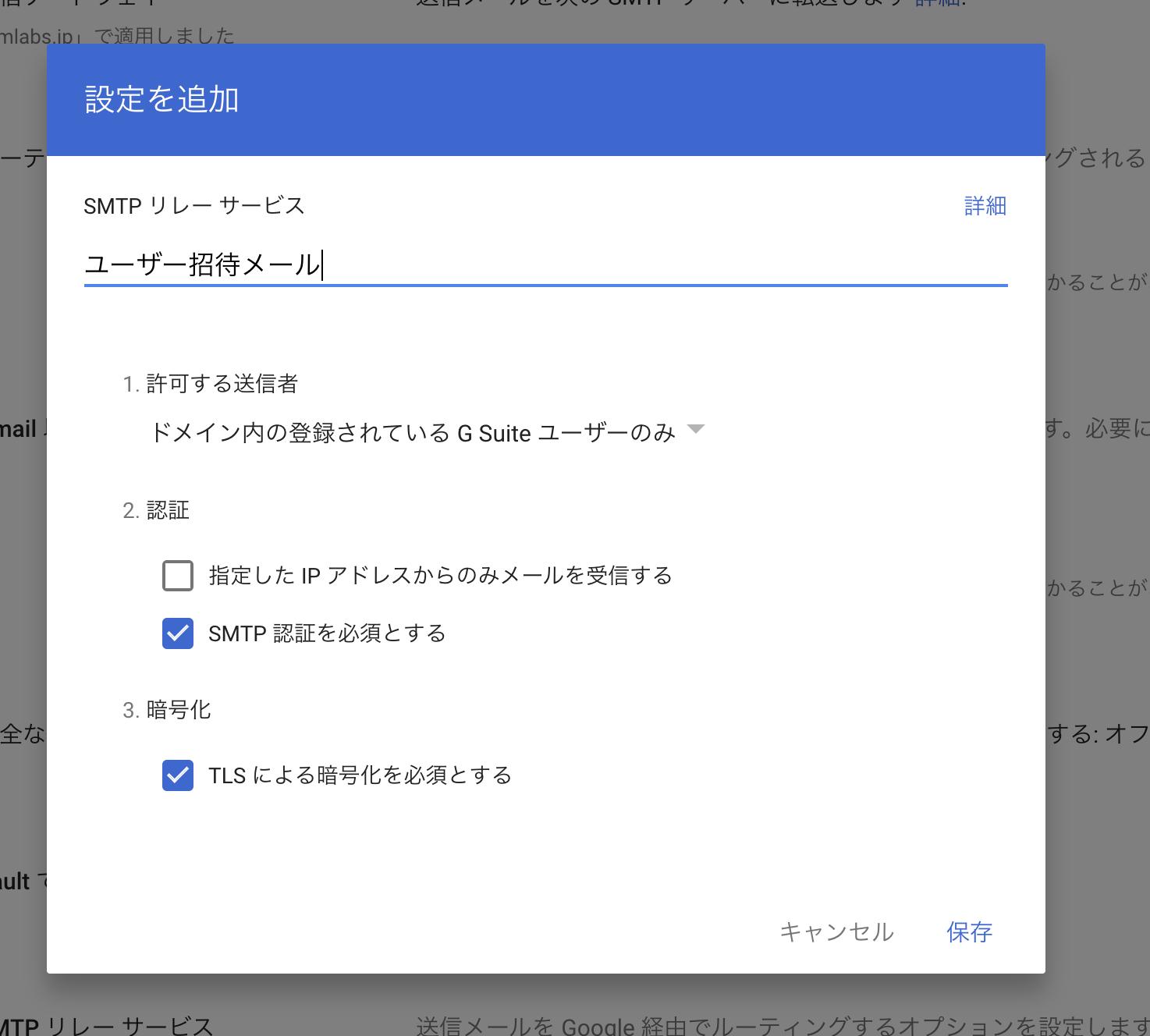
SMTPリレーサービスの設定をクリック
設定項目を下記のように入力(名前は利用内容を書いてください)して保存
pythonでの処理
import smtplib from email.mime.text import MIMEText message = "メール本文" msg = MIMEText(message, "html") msg["Subject"] = "メール表題" # 587はポート番号 smtpobj = smtplib.SMTP('smtp.gmail.com', 587) smtpobj.ehlo() (250, b'smtp.gmail.com at your service, [27.82.28.239]\nSIZE 35882577\n8BITMIME\nSTARTTLS\nENHANCEDSTATUSCODES\nPIPELINING\nCHUNKING\nSMTPUTF8') smtpobj.starttls() (220, b'2.0.0 Ready to start TLS') smtpobj.ehlo() (250, b'smtp.gmail.com at your service, [27.82.28.239]\nSIZE 35882577\n8BITMIME\nAUTH LOGIN PLAIN XOAUTH2 PLAIN-CLIENTTOKEN OAUTHBEARER XOAUTH\nENHANCEDSTATUSCODES\nPIPELINING\nCHUNKING\nSMTPUTF8') smtpobj.login("送信設定したメールアドレス", "生成したアプリパスワード(メールのパスワードではない)") (235, b'2.7.0 Accepted') # 送信実施 smtpobj.sendmail("送信設定したメールアドレス(from)", "送信するメールアドレス(to)", msg.as_string())
- 投稿日:2021-03-25T12:27:02+09:00
Docker/Kubernetes構成のためのPython開発プロジェクトの雛形
はじめに
PythonスクリプトをPipenv環境で開発し、実行するためのコンテナをEKS上で起動するというケースを想定しています。
次のソフトウェアを用います。
- vim(ほかのエディタでも構いません)
- venv
- Pipenv
- Python3.8
- Docker
- Amazon ECR
- Amazon EKS
次の事項は扱いません。
- 各構成要素のPros/Cons的な話
- Amazon ECR/EKSのセットアップ(eksctlなどでクラスタを作れるようになっている必要があります)
構成ファイル
. ├── Pipenv(Pythonの環境管理) ├── Dockerfile(Pythonスクリプトを動作させるコンテナを定義) ├── deployment.yaml(Kubernetes上でコンテナを動作させるデプロイメント定義) ├── src │ ├── main.py(開発対象のPythonスクリプト)Python開発
サンプルスクリプト(./src/main.py)を作成して動作確認します。
サンプルスクリプト
今回は次のサンプルスクリプトを使用します。
仕様:1秒毎に標準出力に現在時刻を表示する。./src/main.py# # 一秒毎に時刻を表示するプログラム # import time import datetime while 1 == 1: print("{}".format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))) time.sleep(1)今回は解説しませんが、Amazon Container Insightsを使うとKubernetesのPodのLogs(標準出力を含む)をCloud Watchで取得できるため、ローカル/Docker/Kubernetesのログ回りを単一のコードで実現できて便利です。サイドカー+Fluentなど専用のコードを入れる場合に比べ柔軟性は低いですが。
Pipenv環境を作る
次のPipfileを用意します。
dev-packagesの中身はvim環境のためのものなので、無くても実行できます。
(ご参考:『最低限の手間で、開発にも使えるVim環境を構築する。』)./Pipfile[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [scripts] dev = "python ./src/main.py" [dev-packages] flake8 = "*" jedi = "*" python-vim = "*" pylint = "*" [packages] [requires] python_version = "3.8"Venv環境のセットアップ
# venv環境のセットアップ # Python3が入っていない場合は事前に入れておいてください。 python3 -m venv .venvVenv環境を有効にする
# b系シェルの場合 source .venv/bin/activate # fishシェルの場合 source .venv/bin/activate.fishPipenv/必要パッケージをインストール
# Pipenvをインストール pip install pipenv # Pipfileを元に必要パッケージをインストール pipenv installPythonスクリプトを実行する
venv環境を有効にした状態で、次のようにPipenvを用いてPythonスクリプトを実行します。
現在日時が一秒毎に表示されれば成功です。pipenv run dev > 2021/03/25 02:24:20 > 2021/03/25 02:24:21 > 2021/03/25 02:24:22 > 2021/03/25 02:24:23コンテナの作成と実行
上記で作成したPythonプログラムを実行するコンテナを作成します
教科書通りのMulti-stage Build構成です。./Dockerfile# # ビルダーコンテナ # FROM python:3.8-buster as builder WORKDIR /app COPY requirements.lock /app RUN pip3 install -r requirements.lock # # メインコンテナ # FROM python:3.8-slim-buster as main COPY --from=builder /usr/local/lib/python3.8/site-packages /usr/local/lib/python3.8/site-packages COPY src /app WORKDIR /app ENTRYPOINT ["python", "/app/main.py"]マルチステートビルドは本記事のスクリプト程度ではメリットを感じにくいですが、ミドルウェアを(特にコンパイルして)利用するプロジェクトなどでは実稼働コンテナに不要ファイルを生成する必要が無く有用です。
コンテナをビルド
# パッケージ情報を作成 # pipenvのパッケージ情報を出力します pipenv lock -r > requirements.lock # ビルドしてイメージを作成 # (一括してビルドする場合) docker build -t <コンテナ名>:latest . # 前段と後段を別々にビルドしたい場合は次の2つ docker build --target builder -t <コンテナ名>:builder . docker build --target main -t <コンテナ名>:latest .コンテナを実行
docker run -it --rm <コンテナ名>:latest > 2021/03/25 02:24:20 > 2021/03/25 02:24:21 > 2021/03/25 02:24:22 > 2021/03/25 02:24:23Pipenvで実行した場合と同様、日時が1秒毎に表示されれば成功です。
Amazon EKSへデプロイする
次の事項はあらかじめ済ませておいてください。
・ECRのセットアップ
・ECRリポジトリの作成
・EKSのセットアップ
・eksctlのセットアップ(クラスタ作成で利用する場合)ECRへコンテナイメージをプッシュする
ECRに作成したリポジトリにコンテナイメージをプッシュします。
リポジトリのURLは確認しておいてください。手順は他のクラウドやDocker HUBと同様ですが、
ECRでは認証情報を引き込む必要があります。# イメージプッシュ用のタグを作成 docker tag <コンテナ名>:latest <リポジトリURL>:latest # ECRの認証情報をローカルに引き込む aws ecr get-login-password --region <リージョン名:ap-northeast-1> | docker login --username AWS --password-stdin <リポジトリURLルート部分> # プッシュを実行 docker push <リポジトリURL>:latestEKSへデプロイ
本記事ではeksctlを用いてテスト用のクラスタを起動します。
EKSは更新が速いので、オプション構成は都度見直した方が良いかもしれません。
手元では起動に約20分かかります。eksctl create cluster \ --vpc-cidr 10.0.0.0/16 \ --vpc-nat-mode HighlyAvailable \ --name <クラスタ名> \ --version 1.18 \ --region <リージョン名:ap-northeast-1> \ --nodegroup-name <ノードグループ名> \ --node-type t3.large \ --nodes 3 \ --nodes-min 1 \ --nodes-max 4つぎの内容でデプロイメント用のyamlファイルを作成します
ネームスペースは別途作成しても良いですが、今回は同居させました。deployment.yamlapiVersion: v1 kind: Namespace metadata: name: <ネームスペース名> labels: name: <ネームスペース名> --- apiVersion: apps/v1 kind: Deployment metadata: name: <ワークロード名> namespace: <ネームスペース名> labels: app: <ワークロード名> spec: replicas: 1 progressDeadlineSeconds: 300 revisionHistoryLimit: 10 selector: matchLabels: app: <ワークロード名> template: metadata: labels: app: <ワークロード名> namespace: <ネームスペース名> spec: containers: - name: <コンテナ名> image: <リポジトリURL> imagePullPolicy: IfNotPresent resources: requests: cpu: "250m" memory: "256Mi" limits: cpu: "250m" memory: "256Mi" restartPolicy: Always securityContext: {} terminationGracePeriodSeconds: 30次のコマンドでデプロイを実施します
kubectl apply -f deployment.yamlデプロイ結果の確認
様々な方法があると思いますがシンプルにpod名を調べてlogsで確認してみます。
ワークロードの起動完了までに数分かかります。起動完了前でもkubectl logsコマンドを実行できますが何も取得できません。# pod名を確認 # (本クラスタには記事のワークロードのみデプロイしていると想定しています) kubectl get pods -n <ネームスペース名> # podの出力を表示 # Pythonが一秒毎に表示している日付文字列が表示されれば成功です kubectl logs <pod名> -n <ネームスペース名> > 2021/03/25 02:24:20 > 2021/03/25 02:24:21 > 2021/03/25 02:24:22 > 2021/03/25 02:24:23
- 投稿日:2021-03-25T12:17:14+09:00
PythonでNewsAPIの日本語記事を取得する方法
NewsAPIで日本語記事を取得しようと思ったらうまくいかなかったのでメモ
上記のライブラリを使用する。
上のドキュメントを参考にすれば、
# /v2/top-headlines top_headlines = newsapi.get_top_headlines(q='ビットコイン', language='ja', country='jp')とかすれば取れそうだが、これだと取得できない。
どうやらlanguage項目に'ja'がないらしい。
というわけで、# /v2/top-headlines top_headlines = newsapi.get_top_headlines(q='ビットコイン', country='jp')とかやってみたら取れるかと思ったらこれまた取れない…
ライブラリを覗いてみると、newsapi_client.pydef get_top_headlines( # noqa: C901 self, q=None, qintitle=None, sources=None, language="en", country=None, category=None, page_size=None, page=None ):なんとlangugeのデフォルトの引数が"en"に設定されている。
なので明示的にNoneを渡してやれば動く。# /v2/top-headlines top_headlines = newsapi.get_top_headlines(q='ビットコイン', language=None, country='jp')これで取得できた
- 投稿日:2021-03-25T11:57:30+09:00
Macにgrpcをインストールする方法
解決方法
Mac(Big Sur)にfirebase-admminをインストールしようとしたらgrpcのpipでコケたので対応した。
以下の環境変数を設定するとうまくいったexport GRPC_PYTHON_BUILD_SYSTEM_ZLIB=trueどうやらCatalinaとBig Surだとうまくいかないらしい。
参考
https://stackoverflow.com/questions/65807966/poetry-install-grpcio-fails-with-envcommanderror
https://bleepcoder.com/fr/grpc/737099678/grpc-does-not-compile-on-mac-os-catalina-10-15-6-big-sur-11
- 投稿日:2021-03-25T11:16:59+09:00
ロジスティック回帰(備忘録)
ロジスティック回帰分析ついての備忘録。(個人メモ)
ロジスティック回帰とロジットリンク関数
確率分布に二項分布(Binomial Distribution)、リンク関数にロジットリンク関数を指定した一般化線形モデル(GLM)が、ロジスティック回帰。
二項分布では、事象の発生確率 $p_i$ を指定する必要があり、$p_i$ の値の範囲 0≥$p_i$≥1 (確率なので0~100%の範囲)を表現するために適したリンク関数が、ロジットリンク関数。
ロジスティック関数
ロジットリンク関数は、ロジスティック関数の逆関数。ロジスティック関数は、以下の式で表現される。
$z_i$ は線形予測子 $z_i=α_1+β_1x_1+β_2x_2…$ ・・・α:切片 $β_i$:係数$$ p_i=logistic(x_i)=\frac{1}{1+\exp(-z_i)} $$
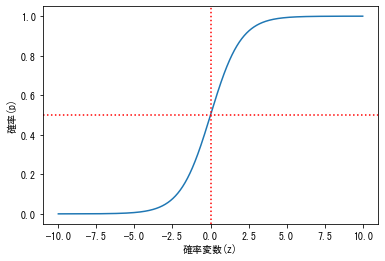
ロジスティック関数を描画(シグモイドカーブ)
上記の式の $z$ を -10〜10 で変化させた時の曲線を描画してみる。
$z$ がどのような値になっても 0≥??≥1 に収まっていて都合が良いこと、またz=0でp=0.5となることに着目!# -6~6の間で等間隔に1000個の値を取得 x = np.linspace(-10,10,1000) # 1/(1+np.exp(-x)) がロジスティック関数 plt.plot(x, ( 1/(1+np.exp(-x))) ) plt.axvline(x=0, color='red', linestyle='dotted') plt.axhline(y=0.5, color='red', linestyle='dotted') plt.ylabel("確率(p)") plt.xlabel("確率変数(z)") plt.show()下記のようなグラフが描画される。
ロジットリンク関数
ロジスティック関数を $z_i$= の形に変形すると以下のようになる。
$$ \log \frac{p_i}{1-p_i}=z_i $$
※ちなみに、$z_i=α_1+β_1x_1+β_2x_2…$ ・・・α:切片 $β_i$:係数この左辺をロジット関数という。これってつまり以下のようなこと。
$$ α_1+β_1x_1+β_2x_2… = \log \frac{p_i}{1-p_i} $$
ロジスティック回帰によるパラメータの推定
ロジスティック回帰によるパラメータの推定。
(線形結合の式(線形予測子)の切片や各係数*の推定)尤度関数と対数尤度関数は以下で定義され、$\log L$ を最大にする推定値 $\hat{\beta_j}$ を探し出します。
$$ L(\beta_j)=\prod_i{}_n\mathrm{C}_rp_i^{y_i}(1-p_i)^{N_i-y_i} $$両辺の対数をとると
$$ \log L({\beta_j})=\sum_i (\log {}_n \mathrm{C} _r+y_i\log(p_i)+(N_i-y_i)\log(1-p_i)) $$
実装
適当にデータを用意。
# 説明変数となるデータを1項目用意 X_train_list = np.r_[np.random.normal(3 ,1, size=50), np.random.normal(-1,1,size=50)] # 目的変数となるデータを用意 y_train_list = np.r_[np.ones(50),np.zeros(50)] # データフレームに変換 df = pd.DataFrame(data=[X_train_list,y_train_list]).T df.rename(columns={0:"X",1:"Y"}, inplace=True) # 目的変数と説明変数を分ける X_train = df[["X"]] y_train = df[["Y"]] display(X_train.head()) display(y_train.head())X 0 5.207395 1 2.692299 2 1.560036 3 3.853632 4 4.804304 Y 0 1.0 1 1.0 2 1.0 3 1.0 4 1.0sklearn.linear_model.LogisticRegressionの場合
モデル作成
from sklearn.linear_model import LogisticRegression # モデルのインスタンス化 model = LogisticRegression() # 学習 model.fit(X_train,y_train)予測(フラグ)
モデル名.predict(説明変数データ)0と1のリストが返ってくる。デフォルトでは、閾値の0.5 (=50%)を超える場合には1、そうでない場合には0で設定されているとのこと。
引数で渡す説明変数データはDataFrameじゃないとエラーになるみたい。Serieseだとエラーになってしまった。model.predict(X_train)array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])予測(確率)
モデル名.predict_proba(説明変数データ)array形式で、0に分類される確率、1に分類される確率の各確率が返ってくる。
model.predict_proba(X_train.iloc[0:10])array([[2.63082246e-05, 9.99973692e-01], [1.51340331e-02, 9.84865967e-01], [2.12846522e-01, 7.87153478e-01], [8.10623998e-04, 9.99189376e-01], [7.30213967e-05, 9.99926979e-01], [1.51565245e-02, 9.84843475e-01], [6.95446239e-04, 9.99304554e-01], [7.48031608e-02, 9.25196839e-01], [1.88389023e-02, 9.81161098e-01], [5.45899840e-04, 9.99454100e-01]])ちなみに、1に分類される確率だけを出力する場合は、
モデル名.predict_proba(評価用の説明変数データ)[:, 1]statsmodels.apiの場合
モデル作成
ポイントは、sm.add_constant(説明変数データ)をしないと、回帰式の切片が出てこないところ。
import statsmodels.api as sm # 定数項(切片)のために行う X_train = sm.add_constant(X_train) glm_binom = sm.GLM( y_train, X_train, family=sm.families.Binomial()) res = glm_binom.fit() print(res.summary())Generalized Linear Model Regression Results ============================================================================== Dep. Variable: Y No. Observations: 100 Model: GLM Df Residuals: 98 Model Family: Binomial Df Model: 1 Link Function: logit Scale: 1.0000 Method: IRLS Log-Likelihood: -8.8540 Date: Thu, 25 Mar 2021 Deviance: 17.708 Time: 10:54:26 Pearson chi2: 48.1 No. Iterations: 8 Covariance Type: nonrobust ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ const -3.1340 1.046 -2.995 0.003 -5.185 -1.083 X 3.3071 0.952 3.476 0.001 1.442 5.172 ==============================================================================予測
1に分類される確率が返ってくる。
predictする前に、引数で渡す説明変数は、sm.add_constant(説明変数データ)をしないとエラーになります。モデル.predict(説明変数データ)res.predict(X_train)0 0.527843 1 0.999978 2 0.999281 3 0.997063 4 0.995389 ... 95 0.001322 96 0.000229 97 0.004302 98 0.000940 99 0.000040AIC(赤池情報量基準)の出力
res.aicstatsmodels.formula.apiの場合
statsmodels.apiよりも細かい指定ができるというものなのだろうか・・・
モデル作成
formulaで 目的変数と説明変数を列挙
Rのように「全体から、この列とこの列を抜く!」という指定はできないのだろうか・・・import statsmodels.formula.api as smf # 線形予測子を定義 「1+」は切片 formula = "Y~1+X" # リンク関数を選択 link = sm.genmod.families.links.logit # 誤差構造(損失関数)を選択 family = sm.families.Binomial(link=link) mod = smf.glm(formula=formula, data=df, family=family ) result = mod.fit() print(result.summary())Generalized Linear Model Regression Results ============================================================================== Dep. Variable: Y No. Observations: 100 Model: GLM Df Residuals: 98 Model Family: Binomial Df Model: 1 Link Function: logit Scale: 1.0000 Method: IRLS Log-Likelihood: -8.8540 Date: Thu, 25 Mar 2021 Deviance: 17.708 Time: 11:11:39 Pearson chi2: 48.1 No. Iterations: 8 Covariance Type: nonrobust ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ Intercept -3.1340 1.046 -2.995 0.003 -5.185 -1.083 X 3.3071 0.952 3.476 0.001 1.442 5.172 ==============================================================================予測
1に分類される確率が返ってくる。
predictする前に、引数で渡す説明変数は、sm.add_constant(説明変数データ)をしないとエラーになります。モデル.predict(説明変数データ)result.predict(X_train)0 0.527843 1 0.999978 2 0.999281 3 0.997063 4 0.995389 ... 95 0.001322 96 0.000229 97 0.004302 98 0.000940 99 0.000040AIC(赤池情報量基準)の出力
result.aic解釈
ロジット関数の線形予測子を、得られた係数の値で置き換えると、以下の式になります。
例えば、切片が -19.54 $β_1$が1.95 $β_2$が2.02 だったとすると・・・$$ \frac{p_i}{1-p_i}=\exp(\alpha+\beta_1x_i+\beta_2f_i)=\exp(\alpha)+\exp(\beta_1x_i)+\exp(\beta_2f_i)=\exp(-19.54)+\exp(1.95x_i)+\exp(2.02f_i) $$
左辺は (事象が発生する確率)/(事象が発生しない確率) のオッズになっており、例えば$x$が1増加するとオッズ比は $exp(1.95)=7.06$ 倍になる。あくまで、オッズが7.06倍になる点に注意!
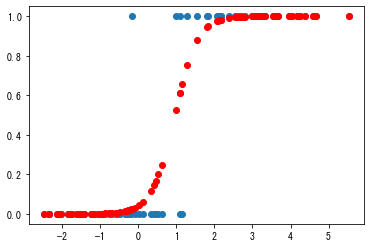
おまけ
予測結果を可視化
シグモイドカーブ描いてるね!plt.scatter(df["X"],df["Y"]) plt.plot(df["X"],result.predict(df["X"]),"-o",linestyle='None',color="red") plt.show()
モデルの評価については、別で。
おしまい
- 投稿日:2021-03-25T03:50:59+09:00
Pythonのデコレータってなんですか? と採用面接で聞かれて答えられなかった話
先日、面接の際にわかりますか? って聞かれてなんだっけ? となって結局わかりませんと答えてしまったので、情けなく感じたので復習します。
現役の方のツッコミや実践的な例等ご教授ありましたら是非コメント欄へお願いします。
すごく助かります。結論
デコレータは関数を引数にとって、さらに新たな関数を返すcallable()(指定した引数が呼び出し可能かどうかを判定する関数)のようなものである。
ここから転じて引数の関数の中身を変えずに、実行結果を修飾(語弊があるが感覚としては編集)することができる。
似たようなのにOverrideがあるけれど、こちらは親クラスのメソッドを上書きして子クラス等で使うもので、デコレータを使うのとではその違いが見れる。
以下参考記事の例を参照したものです。# まず基本のクラス # 初期値としてx,yの座標を受け取って座標を返すというメソッドを持つ class Coordinate: # 初期値セット def __init__(self, x, y): self.x = x self.y = y # 返り値 def __repr__(self): return "Coord: " + str(self.__dict__) # Coordinateクラスのメソッドを新しく返す関数(デコレータ) def add(a, b): return Coordinate(a.x + b.x, a.y + b.y) def sub(a, b): return Coordinate(a.x - b.x, a.y - b.y) # ここから実際に使ってみる # 引数にCoordinateクラスのメソッドで得られた座標を引数として、新たな座標を計算して返してほしい one = Coordinate(100,200) two = Coordinate(300,200) three = Coordinate(-100, -100) # 結果 add(one, two) # Coord: {'x': -200, 'y': 0} add(one, three) # Coord: {'x': 0, 'y': 100} # このように本来xとyの座標を受け取って返すだけだったCoordinate()がある2点の座標を受け取って任意の計算を行い、新たな座標を返す関数として修飾されたことがわかる # 以下は更に修飾を行う例となる # 計算結果がマイナス座標だった場合、0へ切り上げる処理を追加している(= 扱う座標系は0が下限である必要があるという条件を満たすようにする) def wrapper(func): def checker(a,b): if a.x < 0 or a.y < 0: a = Coordinate(a.x if a.x > 0 else 0, a.y if a.y > 0 else 0) if b.x < 0 or b.y < 0: b = Coordinate(b.x if b.x > 0 else 0, b.y if b.y > 0 else 0) ret = func(a,b) if ret.x < 0 or ret.y < 0: ret = Coordinate(ret.x if ret.x > 0 else 0, ret.y if ret.y > 0 else 0) return ret return checker # デコレータであったそれぞれの関数がさらに修飾された形になる証拠が以下の書き方 # これで先程定義したadd()とsub()ではなく、それぞれwrapperの処理が追加された状態で以後は呼び出されることになる # 結果 add = wrapper(add) sub = wrapper(sub) sub(one,two) # Coord: {'x': 0, 'y': 0} add(one,three) # Coord: {'x': 100, 'y': 200}で、基本的には
add = wrapper(add)な書き方はせず@wrapper def add(a,b): return Coordinate(a.x + b.x, a.y + b.y)と使用するのが一般的。
ちなみに上記は必ず2つの引数を取る前提の書き方になるので、実際の引数は
def sample(x,y,*args)(x,y以外に任意の数の引数を取る)
def sample2(**kwargs)(任意の数の辞書形式の引数を取る)
→ ex. sample2(x=1, y=1) → {'x': 1, 'y': 1}といったような形式で書かれることが多い。
なのでDjangoとかでたまにみかける@classmethodもデコレータの一種だったということになる。
Pythonの組み込みのデコレータでクラス内でこのデコレータで修飾されたメソッドはクラスをインスタンス化せずとも、メソッドとして呼び出せるようになる。具体的には以下のような例である。
参考: DjangoBrothers BLOG
【Python】@classmethod及びデコレータとは?# まずはクラスの基本 class Person: goal = "シーズン優勝" count = 0 def __init__(self, first, last): self.first = first self.last = last Person.count += 1 # インスタンス化 person1 = Person("井上", "明") person2 = Person("八神", "太一") print(person1.goal) # シーズン優勝 print(person2.goal) # シーズン優勝 # privateじゃないクラス変数は書き換えられる Person.goal = "オールシーズン優勝" print(person1.goal) # オールシーズン優勝 print(person2.goal) # オールシーズン優勝 # classmethodを使ってみる class Person: # 引数に*argsを使ってみる def __init__(self, name, rank, *args): self.name = name self.rank = rank self.score = args # こちらは普通のメソッド def sample1(self): score = sum(self.score) if not score: return print("{0}のランクは{1}で今シーズンはまだ参加がありません".format(self.name,self.rank)) else: return print("{0}のランクは{1}で今シーズンのスコアは{2}です".format(self.name,self.rank,score)) # クラスメソッド @classmethod def sample2(cls,str,*args): name,rank = str.split(",") score = sum(args) return cls(name,rank,score) # まずは普通にインスタンス化 test = Person("test","R") print(test.name) # test print(test.rank) # R # メソッド使用 test.sample1() # testのランクはRで今シーズンはまだ参加がありません # 今度はクラスメソッドでインスタンスを作る test = Person.sample2("test,R",7,3,7) # メソッドを使用、先程と結果が異なることを確認 test.sample1() # testのランクはRで今シーズンのスコアは17です参考ページを元に書いてみましたが、こうやって基本に帰ったものを書くと腑に落ちました。
つまり、@classmethodでデコレートしたメソッドは通常のメソッドのようにインスタンス化せずに直接ClassName.MethodNameの形で使用することができるが、それは@classmethodでデコレートされたメソッドがクラスと引数からインスタンスを返してくれるからだったという至極当たり前なことだったわけです。
参考記事や私の書いた例はかなり単純かつ易しい例であると思いますが、要はインスタンス化ごとにある処理をして、それを変数にしてインスタンスを作るなんてことはやってられないので、クラス自体にその処理を関数化しておき、引数だけ与えればそれだけでインスタンスが生成されれば話は早いでしょうということですね。
で、その場合インスタンスが返ってきて欲しいので@classmethodのデコレータを使う……ということの一例になるわけなのですね。勉強になります。
で、デコレータ本来の意味に戻ると@classmethodはデコレートした関数(メソッド)にクラスメソッドの役割を持たせるように修飾するデコレータということになりますね。最後に
Djangoで開発してるのにPythonのデコレータもわからないのか……と落胆もされてしまい、そもそもそれ以外の要因もおそらく多数あっただろうと思いますが、採用面接は見事に落ちてしまいましたが、基本的なところがやっぱりまだまだ足りないなということを痛感したので今回おさらいしてみました。
こういうところはどうしてもガッツリPythonやDjangoに集中して開発しないと中々身につきませんね……
- 投稿日:2021-03-25T01:17:52+09:00
定期的にネットワーク速度を計測してスプレッドシートにまとめる part2
できたもの
こんな感じで1時間ごとに自宅のネットワーク速度を計測してGoogleスプレッドシートにまとめてくれるようになりました。
ネットワーク計測とGASにPOSTをリクエストするスクリプトの作成とGASでウェブアプリの作成が主な作業内容です。
下記を参考に作成しました。
part1でネットワーク速度の計測までできたので、
スプレッドシートにまとめられるようにウェブアプリケーションを作成します。GASでウェブアプリケーション作成
スプレッドシートをひらいて 拡張機能 -> App Script を選択します。
開いた先で、下記のコード記述します。var prop = PropertiesService.getScriptProperties(); var verifyToken = prop.getProperty('VERIFY_TOKEN'); var sheetId = prop.getProperty('SHEET_ID'); var sheetName = prop.getProperty('SHEET_NAME'); function doPost(e) { // トークンの検証 var params = JSON.parse(e.postData.getDataAsString()); var token = params.token; if (verifyToken !== token) { throw new Error(`invalid token. token=${token}`); } // スプレッドシート設定 var ss = SpreadsheetApp.openById(sheetId); var sh = ss.getSheetByName(sheetName); // 最終行を取得 var lastrow = sh.getLastRow(); var date = params.data.date; if (lastrow === 1) { sh.insertRowAfter(lastrow); lastrow++; sh.getRange(lastrow, 1).setValue(date); } else { // yyyy-MM-dd形式で最終行の日付を取得 var lastdate = Utilities.formatDate(sh.getRange(lastrow, 1).getValue(), 'Asia/Tokyo', 'yyyy-MM-dd'); // 取得した日付とPOSTの日付が異なる場合 if (lastdate !== date) { // 最終行の1行下に新しく用意 sh.insertRowAfter(lastrow); lastrow++; sh.getRange(lastrow, 1).setValue(date); } } // 時刻 var hour = params.data.hour; // ネット速度 var speed = params.data.speed; // 最終行と時刻に対応した列を指定して、速度の値を設定 sh.getRange(lastrow, hour + 2).setNumberFormat('0.00').setValue(speed); return ContentService.createTextOutput('OK'); }下記のページを参考にプロパティを設定します。
VERIFY_TOKEN:任意の文字列(あとでスクリプトに設定する)
SHEET_ID:スプレッドシートのID
スプレッドシートのURLから取得できます。
下記のようなURLの場合は
https://docs.google.com/spreadsheets/d/abc1234567/edit#gid=0
abc1234567がIDになります。
SHEET_NAME:シート名(スプレッドシートの名前ではなく、シート自体の名前)ウェブアプリのデプロイ
AppScriptのページの右上の デプロイ ボタンからデプロイします。
新しいデプロイ から ウェブアプリ を選択して実行します。
表示されたURLはコピーしておきます。スプレッドシートの準備
スプレッドシートに1列めの時間の行だけ入力が必要です。
できたものを参考に入力しておいてください。スクリプトの修正
スクリプトを下記のように修正しました。
ログ出力とGASへのPOSTができるようになっています。test.sh#!/bin/bash ######################################## # スピードテスト用スクリプト # # ######################################## # ログ出力先ディレクトリ OUTPUT_DIR=~/logs/ # ログ出力先ファイル OUTPUT_NAME=speedtest.log # GASで公開したスクリプトのURL URL=**コピーしたURL** # 認証用の文字列(GASのVERIFY_TOKENと合わせる) TOKEN=**GASで設定したVERIFY_TOKEN** # スピードテストコマンド command="/opt/anaconda3/bin/speedtest --simple" ######################################## echo "Start speed test!" NEXT_WAIT_TIME=0 until RET=`$command` || [ $NEXT_WAIT_TIME -eq 3 ]; do # リトライ回数×60秒後にリトライ sleep $(( (NEXT_WAIT_TIME++) * 60 )) done echo $RET # ログ出力ディレクトリが存在しなければ作成 if [ ! -d $OUTPUT_DIR ]; then echo "create log directory." mkdir $OUTPUT_DIR fi # ログ出力ファイルが存在しなければ作成 if [ ! -f $OUTPUT_DIR$OUTPUT_NAME ] ;then echo "create log file." touch "$OUTPUT_DIR$OUTPUT_NAME" fi # 下記形式でログ出力 # 2021/03/22 00:39:35 Ping: 13.054 ms Download: 88.29 Mbit/s Upload: 63.94 Mbit/s echo `date "+%Y/%m/%d %H:%M:%S"` $RET >> "$OUTPUT_DIR$OUTPUT_NAME" # 日付取得 DATE=`date "+%Y-%m-%d"` # 時刻取得 HOUR=`date "+%-H"` # ダウンロード速度 DOWNLOAD_SPEED=`echo $RET | awk '{print $5}'` # アップロード速度 UPLOAD_SPEED=`echo $RET | awk '{print $8}'` # スプレッドシートに出力 curl "$URL" -v -d'{ "token":"'$TOKEN'", "data" :{ "date":"'$DATE'", "hour":'$HOUR', "speed":"'$DOWNLOAD_SPEED'" } }' -H "Content-Type:application/json" -X POST echo "End speed test!"実行結果
スクリプトを実行してみると
~/logs/speedtest.logにログが出力され、
スプレッドシートには日付とネットワーク速度が出力されていると思います。定期実行
crontabで1時間ごとに実行されるように設定します。
まずはcronファイルを作成します。
ここで設定しているスクリプトの場所は実際にスクリプトを保存している場所に変更してください。speedtest_cron.conf0 * * * * 「スクリプトのあるディレクトリ」/test.sh下記を実行して0分になる度にスクリプトが実行されるようにします。
$ crontab speedtest_cron.conf下記のように設定されていれば完了です。
$ crontab -l 0 * * * * 「スクリプトのあるディレクトリ」/test.sh最後に
1時間ごとに速度計測をしてスプレッドシートに出力できるようになりました。
参考

- 投稿日:2021-03-25T01:17:04+09:00
定期的にネットワーク速度を計測してスプレッドシートにまとめる part1
できたもの
こんな感じで1時間ごとに自宅のネットワーク速度を計測してGoogleスプレッドシートにまとめてくれるようになりました。
ネットワーク計測とGASにPOSTをリクエストするスクリプトの作成とGASでウェブアプリの作成が主な作業内容です。
下記を参考に作成しました。
ネットワーク速度の計測
pythonのツールであるspeedtestを使用して計測します。
まずはインストールします。
$ pip install speedtest-cliこれで計測できるようになりました。
下記が例です。$ speedtest --simple Ping: 10.21 ms Download: 83.54 Mbit/s Upload: 90.17 Mbit/s速度計測用スクリプトの作成
後々、GASにPOSTすることも考慮して、スクリプトを作成します。
下記が作成したスクリプトです。
速度の計測に失敗した場合は3回までリトライするようにしています。test.sh#!/bin/bash ######################################## # スピードテスト用スクリプト # # ######################################## # スピードテストコマンド command="/opt/anaconda3/bin/speedtest --simple" ######################################## echo "Start speed test!" NEXT_WAIT_TIME=0 until RET=`$command` || [ $NEXT_WAIT_TIME -eq 3 ]; do # リトライ回数×60秒後にリトライ sleep $(( (NEXT_WAIT_TIME++) * 60 )) done echo $RET echo "End speed test!"スクリプトを実行できるようになりました。
$ sh test.sh Start speed test! Ping: 13.226 ms Download: 88.75 Mbit/s Upload: 5.55 Mbit/s End speed test!最後に
コマンドでネットワーク速度を計測できるようになったところで part2 に続きます。
参考
