- 投稿日:2021-02-21T23:31:17+09:00
[競プロ用]ダイクストラ法とベルマンフォード法まとめ
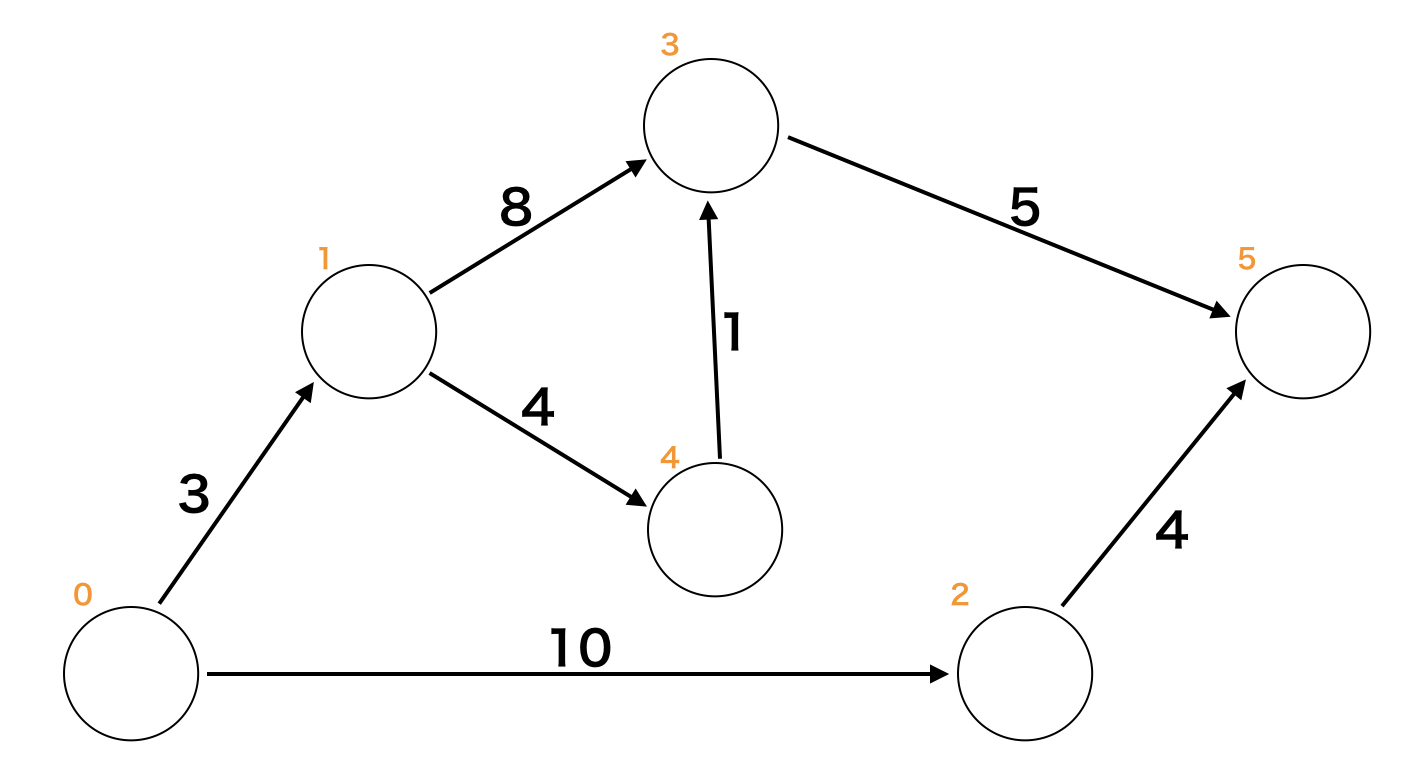
以下グラフを題材にダイクストラ法とベルマンフォード法の動きを見ていく。
始点を0、終点を5として最短経路を導き出す。
ダイクストラ法
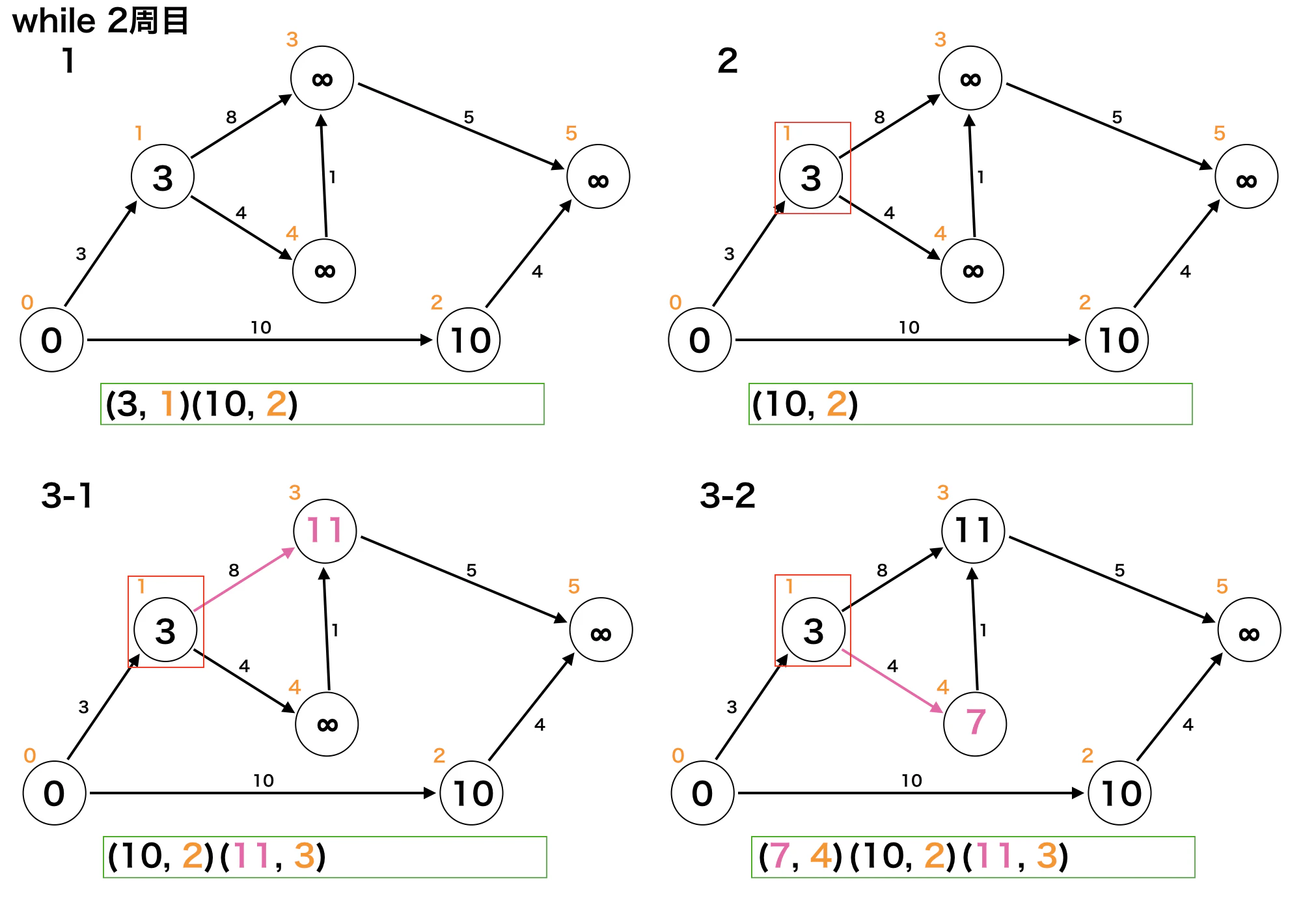
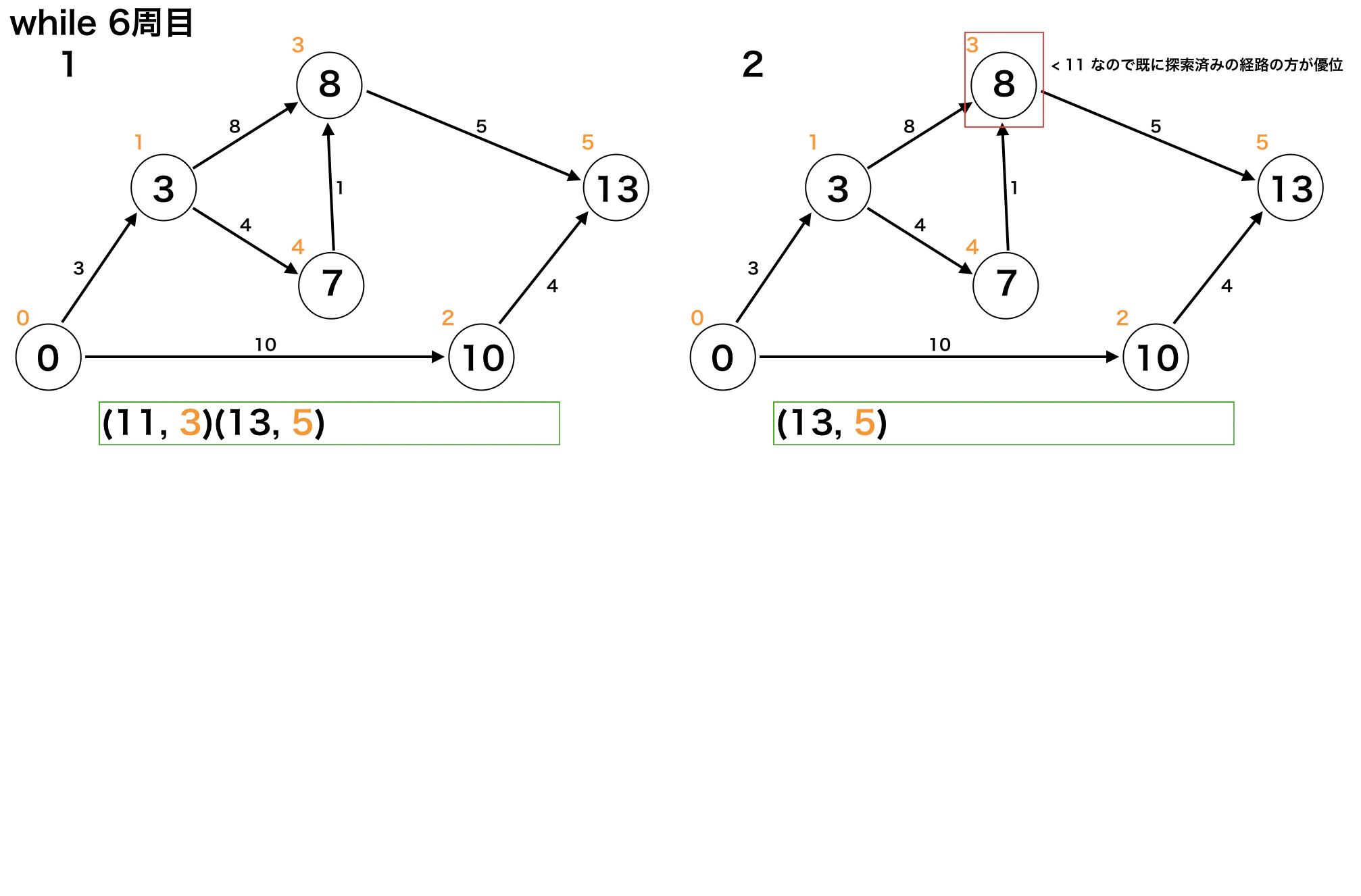
dijkstraimport heapq INF = 10 ** 9 # ---------------------------------------------------------------- # Input # 1. タプル(重み, 行先)の二次元配列(隣接リスト) # 2. 探索開始ノード(番号) # Output # スタートから各ノードへの最小コスト # ---------------------------------------------------------------- def dijkstra(edges: "List[List[(cost, to)]]", start_node: int) -> list: hq = [] heapq.heapify(hq) # Set start info dist = [INF] * len(edges) heapq.heappush(hq, (0, start_node)) dist[start_node] = 0 # dijkstra while hq: # ------------------------------------------- タイミング1 min_cost, now = heapq.heappop(hq) # ------------------------------------------- タイミング2 if min_cost > dist[now]: continue for cost, next in edges[now]: if dist[next] > dist[now] + cost: dist[next] = dist[now] + cost heapq.heappush(hq, (dist[next], next)) # --------------------------------------- タイミング3 return dist上記1~3の各タイミングでのグラフとキューの状態。
ベルマンフォード法
bellmanFordINF = 10 ** 16 # ---------------------------------------------------------------- # Input # 1. 辺のリスト: タプル(始点, 終点, 重み) # 2. 頂点数 # 3. 探索開始ノード(番号) # Output # リスト(スタートから各ノードへの最小コスト。ただし負閉路から到達可能なノードは-INF) # Note # 始点から到達不可能な負閉路の有無: × (ベルマンフォード法では発見されない) # 始点から到達可能だが終点に影響ない負閉路の有無: ○ (出力のリストに-INFが含まれるかどうか) # 始点から到達可能で終点に到達する負閉路の有無: ○ (出力のリストの終点へのコストが-INFかどうか) # ---------------------------------------------------------------- def bellmanFord(edges: "List[(from, to, to)]", vertex: int, start_node: int) -> list: # Initialize costs = [INF] * vertex costs[start_node] = 0 for i in range(vertex * 2): # ---- 外側のLoop for f, t, c in edges: # ---- 内側のLoop # ------------------------------------------- タイミング1 if costs[f] != INF and costs[t] > costs[f] + c: if i >= vertex - 1: costs[t] = -INF else: costs[t] = costs[f] + c return costs負閉路なしケース
今回の題材において、外側ループと内側ループそれぞれのタイミング1のグラフの状態。
最大でも頂点数分ループを回せば全ての頂点のコストが確定する。
負閉路あり(終点に到達する)ケース
負の辺を含む場合にベルマンフォード法が有効なため、題材を以下に変えてみる。
ただし、負閉路があると答えは必ず-∞かというとそうでもない。次の例をみる。
負閉路あり(終点に到達しない)ケース
この場合、負閉路があるもののゴールに繋がらないため影響しない。即ち、ゴールの値はループを回し続けても変化しない。このことを利用して、以下のように頂点数を超えても終点の更新があるかで判断できそうである。
{頂点数}回更新した後にゴールが更新される = 負閉路がある 〃 されない = 負閉路があったとしても影響しないしかし、これは次のような例では成立しない。次の例をみる。
負閉路あり(コストが莫大な辺がある)ケース
負閉路を1周回る毎にコストが -3 になるので、いつかは終点の値を更新するだろうが、それは頂点数6回だけ回しても訪れないため判断を誤る。
そのため、前述のコードは頂点数の2倍分ループを回し、以下の処理が入っている。
if i >= vertex - 1: costs[t] = -INF{頂点数}回を超えてからのループでは更新があったらそこを-∞に書き換える。
この負閉路から到達可能な箇所を-∞で書き換える処理を同じく{頂点数}回行うと正しい影響範囲がわかる
例題
ダイクストラ法
- http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=GRL_1_A&lang=ja
- https://atcoder.jp/contests/joi2008yo/tasks/joi2008yo_f
- https://atcoder.jp/contests/abc035/submissions/20218577
- https://atcoder.jp/contests/abc191/tasks/abc191_e
- https://atcoder.jp/contests/abc192/tasks/abc192_e
ベルマンフォード法
- http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=GRL_1_B&lang=ja
- https://atcoder.jp/contests/abc061/tasks/abc061_d
参考
ダイクストラ法
ベルマンフォード法


















- 投稿日:2021-02-21T23:27:43+09:00
[Python]機械学習で使えるサイトまとめ
概要 機械学習で勉強をする際に参考にしようと思っているサイトをまとめました。 メモ的に使ってますが、なにかよいさいとなどあれば教えていただけると幸いです。 機械学習の勉強 【保存版・初心者向け】独学でAIエンジニアになりたい人向けのオススメの勉強方法 数学に強いエンジニアむけの機械学習勉強法 SIGNATE Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ keras本などのソースコード ベースラインの作り方 データ分析初心者がチュートリアルから卒業するための特徴量生成の考え方 機械学習のアプリ あなたのポートフォリオを目立たせる8つの機械学習/AIプロジェクト TensorFlow.js で機械学習Webアプリを作る GCPの環境づくり GPUの割り当て方 基本的な操作 割り当てられない問題 画像処理 画像処理100本ノック 自然言語処理 自然言語処理100本ノック 画像コンペ Kaggleの画像コンペに初めて挑んでみた kaggle上位のとり方 Kaggleの概要を理解する(Titanicの次に向けて) AIプログラミングスクール卒業生の初心者がkaggle Expertになるまでの軌跡(riiidコンペ体験記) 画像の取り込み方 ↓のimg_loadの部分 Keras:VGG16、VGG19とかってなんだっけ??
- 投稿日:2021-02-21T23:18:24+09:00
複数の形態素解析器と辞書を入れた Docker コンテナを作って Python で使う
はじめに
いくつかの形態素解析器(と辞書)を比較する機会があったので、まとめて動かせる環境を Docker コンテナにして Python で使えるようにしました。
やったこと
今回使ったのは、MeCab と spaCy と GiNZA の3つ、辞書は以下の通り MeCab 用の6つと spaCy 用の3つです。
- MeCab で使った辞書
- IPAdic
- UniDic(現代書き言葉版)
- JUMAN 辞書
- NAIST-jdic
- mecab-ipadic-NEologd
- mecab-unidic-NEologd
- spaCy で使った辞書
Docker コンテナを作る
これらをまとめて動かせる環境を Docker コンテナにできたら便利、というわけで、ネット上の情報1を参考にしながら、Ubuntu 20.04 の Docker イメージ をベースに必要なものをインストールする形で Dockerfile を書きました。
DockerfileFROM ubuntu:20.04 # basic libs RUN apt-get update -y && apt-get upgrade -y RUN apt-get install -y sudo vim wget curl git file unzip xz-utils RUN apt-get install -y build-essential zlib1g-dev gcc make # locale RUN apt-get install -y locales RUN locale-gen ja_JP.UTF-8 # python RUN apt-get install -y python3 python3-pip ENV PYTHONIOENCODING "utf-8" WORKDIR /usr/local/bin/ RUN ln -s `which python3` python RUN ln -s `which pip3` pip # mecab RUN apt-get install -y mecab libmecab-dev RUN apt-get install -y mecab-ipadic-utf8 unidic-mecab # mecab-ipadic-NEologd WORKDIR /usr/local/src RUN git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git RUN cd mecab-ipadic-neologd && ./bin/install-mecab-ipadic-neologd -n -y # mecab-unidic-NEologd WORKDIR /usr/local/src RUN git clone --depth 1 https://github.com/neologd/mecab-unidic-neologd.git RUN cd mecab-unidic-neologd && ./bin/install-mecab-unidic-neologd -n -y # mecab-naist-jdic WORKDIR /usr/local/src RUN wget https://ja.osdn.net/projects/naist-jdic/downloads/53500/mecab-naist-jdic-0.6.3b-20111013.tar.gz RUN tar xzvf mecab-naist-jdic-0.6.3b-20111013.tar.gz RUN cd mecab-naist-jdic-0.6.3b-20111013 && \ ./configure --with-charset=utf8 --with-mecab-config=/usr/bin/mecab-config && \ make && make install # mecabrc WORKDIR /etc RUN sed -i -e 's/dicdir = .*/dicdir = \/usr\/lib\/x86_64-linux-gnu\/mecab\/dic\/mecab-ipadic-neologd/g' mecabrc RUN cp mecabrc /usr/local/etc/mecabrc # python libs RUN pip install --upgrade pip RUN pip install mecab-python3 # python libs (spaCy & GiNZA) RUN pip install spacy ginza RUN python -m spacy download ja_core_news_sm RUN python -m spacy download ja_core_news_md RUN python -m spacy download ja_core_news_lg辞書のサイズが大きく(特に unidic 系)、イメージを作るのに結構な時間がかかります2。
Python で使う
立ち上げたコンテナに入れば、以下のような Python コードが動きます。
test.py# MeCab (辞書6パターン) import MeCab m_juman = MeCab.Tagger('-d /var/lib/mecab/dic/juman-utf8') m_ipadic = MeCab.Tagger('-d /var/lib/mecab/dic/ipadic-utf8') m_unidic = MeCab.Tagger('-d /var/lib/mecab/dic/unidic') m_naist_jdic = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/naist-jdic') m_ipadic_neologd = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd') m_unidic_neologd = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-unidic-neologd') # spaCy & GiNZA import spacy s_sm = spacy.load('ja_core_news_sm') s_md = spacy.load('ja_core_news_md') s_lg = spacy.load('ja_core_news_lg') s_ginza = spacy.load('ja_ginza') def parse_mecab(m, text): arr = [] node = m.parseToNode(text) while node: if len(node.surface) > 0: arr.append(node.surface) node = node.next return ' '.join(arr) def parse_spacy(s, text): arr = [] for token in s(text): arr.append(token.orth_) return ' '.join(arr) def parse(text): print('mecab-juman : {}'.format(parse_mecab(m_juman, text))) print('mecab-ipadic : {}'.format(parse_mecab(m_ipadic, text))) print('mecab-unidic : {}'.format(parse_mecab(m_unidic, text))) print('mecab-naist-jdic : {}'.format(parse_mecab(m_naist_jdic, text))) print('mecab-ipadic-NEologd: {}'.format(parse_mecab(m_ipadic_neologd, text))) print('mecab-unidic-NEologd: {}'.format(parse_mecab(m_unidic_neologd, text))) print('spaCy(news_sm) : {}'.format(parse_spacy(s_sm, text))) print('spaCy(news_md) : {}'.format(parse_spacy(s_md, text))) print('spaCy(news_lg) : {}'.format(parse_spacy(s_lg, text))) print('GiNZA : {}'.format(parse_spacy(s_ginza, text))) parse('複数の形態素解析エンジンを切り替えて使えるコンテナが便利です')出力は以下の通り。
mecab-juman : 複数 の 形態 素 解析 エンジン を 切り替えて 使える コンテナ が 便利です mecab-ipadic : 複数 の 形態素 解析 エンジン を 切り替え て 使える コンテナ が 便利 です mecab-unidic : 複数 の 形態 素 解析 エンジン を 切り替え て 使える コンテナ が 便利 です mecab-naist-jdic : 複数 の 形態素 解析 エンジン を 切り替え て 使える コンテナ が 便利 です mecab-ipadic-NEologd: 複数 の 形態素解析 エンジン を 切り替え て 使える コンテナ が 便利 です mecab-unidic-NEologd: 複数 の 形態素解析 エンジン を 切り替え て 使える コンテナ が 便利 です spaCy(news_sm) : 複数 の 形態 素 解析 エンジン を 切り 替え て 使える コンテナ が 便利 です spaCy(news_md) : 複数 の 形態 素 解析 エンジン を 切り 替え て 使える コンテナ が 便利 です spaCy(news_lg) : 複数 の 形態 素 解析 エンジン を 切り 替え て 使える コンテナ が 便利 です GiNZA : 複数 の 形態素 解析 エンジン を 切り替え て 使える コンテナ が 便利 ですおわりに
また形態素解析したくなったときには、即コンテナ化して使い始められます。
「dockerで動く mecab + python3 の環境を作る - Qiita」や「dockerでubuntu16+python3.6+mecab(neolog-ipadic)を構築する - メモ帳」などを参考にさせていただきました。ありがとうございます。 ↩
ネットワークなどの環境次第ですが、イメージの生成に数十分以上かかる場合もあると思います。また、生成されるイメージのサイズは 17GB ほどになります。 ↩
- 投稿日:2021-02-21T23:06:48+09:00
ツンデレの52%はツインテールで、28%は金髪である。
tldr
こんばんは。midzです。
いわゆる美少女ゲーム/ノベルゲーム/ビジュアルノベルと呼ばれるキャラクターのデータベースにvndbがあります。この記事は、そのキャラクターデータの統計をpythonで分析した結果をまとめたものです。目的
目的1.分析によって、ユーザーのバイアスを明らかにする。
目的2.統計を出すことによって、創作をする際の参考にできるようにする。分析対象データ:vndbとは
vndbは、visual novel databaseの略で、海外のビジュアルノベルのデータベースです。データベースとしてはかなり充実していて、各キャラクターの誕生日、体重、スリーサイズ、性格などがデータ化されています。また、データベースもダンプされていて、tsvの形式でダウンロードすることができます。
データはzst形式で保存されているので、以下のコマンドで解凍します。
zstの解凍にはzstdが必要です。zstd --decompress vndb-db-2021-01-11.tar.zst tar xvfz vndb-db-2021-01-11.tar解凍すると、色んなファイルが出てきますが、基本的にはchars.headerやcharsのように、tsvファイルのカラム名とデータに分かれてファイルが存在します。拡張子は書かれていませんが、tsv(tab separated value)形式です。
headerとデータファイル(<filename>.headerと<filename>)をつなげるとtsvファイルとしてpandasで扱えるようになります。
キャラクターの分析に使えそうなのはchars, traits, traits_parents, chars_traitsです。chars:名前身長性別誕生日スリーサイズなどのキャラクターの情報が書かれています。
traits:髪型や性格などの付加情報が書かれています。
chars_trait:traitのidとキャラクターのidが紐付けられた情報。
traits_parents:trait間の親子関係(髪traitは髪の長さtraitの親traitに該当する等)を記してある。欠損しているデータもありますが、約95000人のキャラクターのデータがあります。今回は女性キャラクターに限定して分析をします。
tsvファイルは以下のようにコマンドで読み込めます。import pandas chara_df = pandas.read_csv("chars",sep="\t")見やすいように身長200cm以上などの外れ値は除去します。
身長/体重
身長と体重のデータがあるキャラクター数は5988でした。
身長の平均値は157.82cm。体重は47.12でした。
現実の数値は少し古いですが、論文:若年成人女子の人体計測データからみた体格・体型特性を参考にします。(以下別府97と呼称。)
これによると、18歳〜22歳の日本人女性の平均身長は、158.46cm、体重は51.35でした。身長はほとんど一致していますが、体重は低めでした。BMIで言うと、実際の平均は20.4ですが、vndbの統計では18.9です。一般的にはBMI18.5以下であれば痩せなので、それよりギリギリ上に設定されている感じです。
まとめるとこうです。
身長 体重 BMI 別府97 158.46 51.35 20.4 vndb 157.92 47.12 18.9 体重(weight)の分布(ヒストグラム)を計算します。
グラフ出力にはseabornのdistplotを使います。import seaborn as sns sns.distplot( chara_df['s_bust'], bins=20, color='#123456', kde=False, rug=False )結果は以下のようになりました。
正規分布に近い分布になっているのではないでしょうか?
身長(height)の分布は以下です。
身長の分布は、正規分布にはならず、150cm前半、150cm代後半、160cm中盤、に3つの山があるように見えます。これは、低身長、中身長、高身長好きのように性癖がユーザー毎に異なるので3つに分散されていることの表れだと思います。
胸囲/腹囲/臀囲
別府97論文による、若年女子の平均胸囲/腹囲/臀囲とvndb上のデータを以下に比較します。
胸囲 腹囲 臀囲 別府97 83.45 62.80 90.57 vndb 84.17 56.54 83.17 胸囲はほぼ同じですが、腹囲、臀囲はかなり少なめになっていることがわかります。
身長(height)と胸囲(s_bust)の相関を散布図を出力します。
出力にはseabornのjointplotを使います。sns.jointplot('height','s_bust', data=chara_df)にすると以下のようになります。
これは不思議な図で、ある程度までは胸囲と身長に相関がありますが、ある程度身長が高くなると、突然胸囲だけが増えます。「身長は高すぎると困るが、胸囲は増えても良い」という需要があることがうかがえます。ちなみに、この図だと相関係数は0.610で、身長と胸囲に高い相関があります。
ところが別府97によると、胸囲と身長の相関係数は0.194で、現実では相関が低いようです。需要に応じてキャラクターが作られると仮定すると、低身長女子は貧乳であって欲しいが、高身長女子は巨乳であって欲しいという願望があることがうかがえます。髪型と髪の色
髪型は色々あるのですが、今回は数の多いロング(Long)、ショート(Short)、ツインテール(TwinTail)、ポニーテール(PonyTail)に絞って分析します。ちなみに、vndb上のデータだとTwinTailやPonyTailはLongやShortとMECEではない、つまりLongかつTwinTailの属性を持つキャラクターがいますが、今回の分析では、重複していた場合はTwinTailやPonyTailを優先します。また、肩までの長さ(Shoulder-length)という髪型もありましたが、パット見Shortと変わらなかったので同一視しました。
この辺は結構面倒くさい処理をしたので詳細は省きますが、おおまかには、髪型や後述の髪の色、性格の情報はtraitsやchars_traitsに分かれて格納されているので、それをpandas.mergeで結合するという処理をすると分析できます。
pandas.merge(chara_df,chara_traits_df,on="char_id")統計上の数値は以下です。
データ数 身長 胸囲 ロング 1,568 159.6 87.1 ショート 2,321 157.6 84.0 ツインテール 1,532 153.4 81.0 ポニーテール 1,112 160.4 86.8 身長はポニーテール>ロング>ショート>ツインテールの順になっています。
確かにツインテールが高身長という印象は無いので、イメージとも合っています。平均値はpandasのgroupbyとmeanを組み合わせると楽に計算できます。
name_yのところは集計したい属性のカラム(この場合は髪型)を入れるとOKです。chara_df.groupby("name_y").mean()次に髪の色の分析です。データ数が200以上ある髪の色を分析対象とします。
髪の色 データ数 身長 胸囲 Red 557 159.7 85.9 Black 1112 159.4 85.8 Violet 978 159.2 86.0 Blue 869 158.5 84.8 Grey 218 158.1 83.4 Brown 1,885 158.0 85.4 Green 359 157.8 84.5 Blond 1,398 157.6 85.1 Orange 463 156.4 83.6 White 414 155.8 82.4 Pink 750 155.3 83.7 身長順に並べています。身長や胸が大きいのは赤髪、黒髪、紫髪だという結果になりました。
最も貧乳は白髪で、ピンク髪が最も低身長です。カップサイズを割合でまとめた図は以下になります。
各髪型で正規化しているので、各髪型のA~Gの割合を足すと1になります。
ここではpandasのcross_tabとseabornのheatmapを使います。
Aカップの割合が多い順でいうと白>ピンク>灰>金髪になります。
髪の色が薄い方が貧乳が多いという傾向にあるようです。
(とはいえ、灰髪金髪はFカップの比率も高いですが)
こういうイメージは無かったので新たな知見が得られたと言えそうです。性格
次に性格を調査します。
性格 データ数 身長 胸囲 Relaxed(おっとり) 255 159.9 87.2 Tomboy(ボーイッシュ) 202 159.8 84.4 Serious(真面目) 390 159.6 85.8 Arrogant(傲慢) 226 159.2 85.2 Refined(洗練された) 508 159.0 86.2 Smart(賢い) 392 158.2 84.9 Kind(親切) 1247 158.1 86.0 Outgoing(社交的) 231 157.3 84.5 Airhead(アホの子) 248 157.2 85.0 Hardworker(努力家) 459 157.1 83.7 Stubborn(頑固) 230 157.0 83.1 Mischievous(お茶目) 309 157.0 83.2 Honest(正直) 207 156.9 83.6 Tsundere(ツンデレ) 240 156.4 83.4 Reserved(無口) 274 156.3 82.7 Deredere(デレデレ) 426 156.2 85.1 Stoic(ストイック) 274 156.0 81.0 Clumsy(ドジっ子) 316 155.4 83.8 Energetic(元気) 604 154.7 81.6 Naive(純粋) 287 154.6 82.6 Timid(臆病) 229 154.2 82.9 Brocon(ブラコン) 232 153.9 81.7 おっとり、ボーイッシュ、真面目、傲慢系が高身長となりました。
ドジっ子、元気系、純粋、臆病系が低身長です。
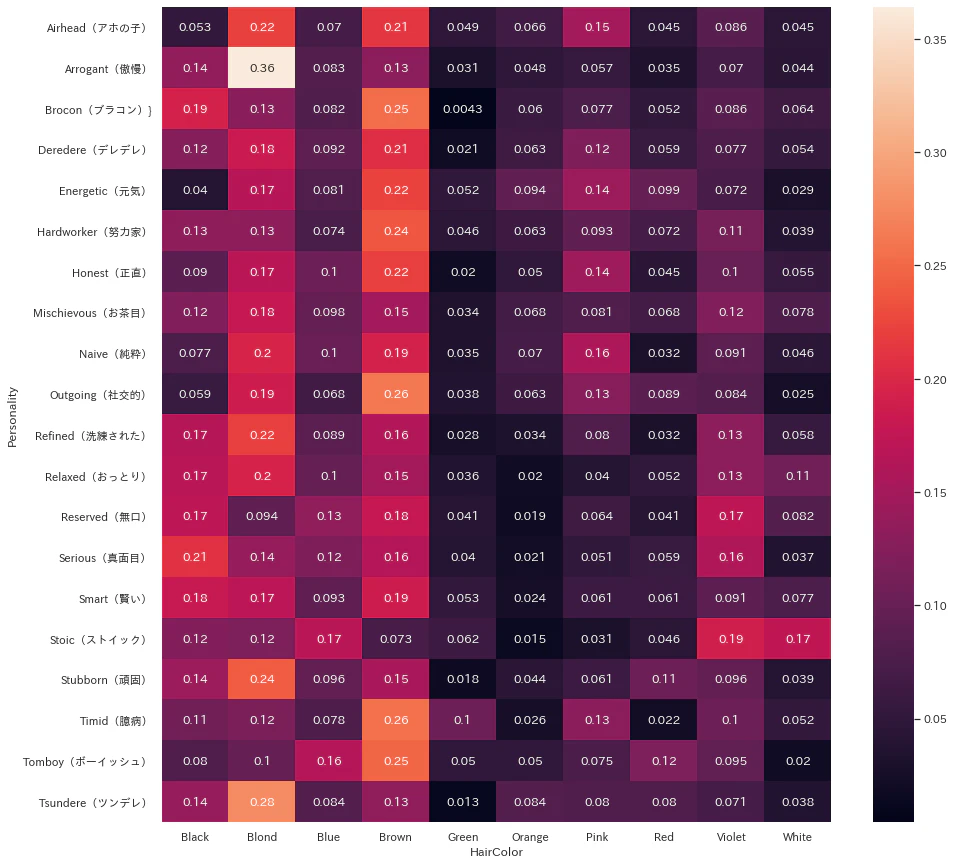
この辺はイメージと合っているのでは無いでしょうか。性格と髪の色を図にまとめます。
さきほどと同じように行毎に正規化しています。(横に数字を足していけば1になります)
図を見ると、傲慢キャラで一番多いのは36%の金髪、ツンデレキャラで一番多いのも28%の金髪です。
ツンデレは金髪が多いというステレオタイプに合致する結果となりました。次に、性格と髪型の図をまとめます。
なんとツンデレの52%がツインテールという結果になりました。圧倒的多数です。
まとめ
髪型、髪の色、性格、身長、胸囲などの観点からvndb(美少女ゲーム)のキャラの統計をまとめました。
キャラ作りなどの参考にしてください。
他にも面白い知見が得られたら更新します。
コードは(多分)後日githubにアップロードします。





- 投稿日:2021-02-21T22:57:55+09:00
【Python】Djangoで遊ぶ(管理画面)
この記事について
前回の記事でDjangoのセットアップをしてました。
【Python】Djangoで遊ぶ(セットアップ・HTMLファイル表示)今回はデフォルトでセットアップされる管理サイト(adminサイト)を少し触れてみます。
環境
OS:Windows10 Home
Python:3.9.2
Django:3.1.7管理サイト(adminサイト)とは
今回はローカル環境
http://127.0.0.1で構築したのですが、何も触ってなくてもhttp://127.0.0.1/adminにアクセスすると以下のページが表示されます。
ただ、ユーザー名・パスワードは分かりません。。
作成してログインしてみましょう。アカウント作成
以下のコマンドでアカウント作成ができます。
python manage.py createsuperuserすると何かエラーを吐きました・・・・
$ python manage.py createsuperuser You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. Traceback (most recent call last): File "C:\python39\lib\site-packages\django\db\backends\utils.py", line 84, in _execute return self.cursor.execute(sql, params) File "C:\python39\lib\site-packages\django\db\backends\sqlite3\base.py", line 413, in execute return Database.Cursor.execute(self, query, params) sqlite3.OperationalError: no such table: auth_user The above exception was the direct cause of the following exception: Traceback (most recent call last): File "C:\Works\Dev\Django\demosite\manage.py", line 22, in <module> main() File "C:\Works\Dev\Django\demosite\manage.py", line 18, in main execute_from_command_line(sys.argv) File "C:\python39\lib\site-packages\django\core\management\__init__.py", line 401, in execute_from_command_line utility.execute() File "C:\python39\lib\site-packages\django\core\management\__init__.py", line 395, in execute self.fetch_command(subcommand).run_from_argv(self.argv) File "C:\python39\lib\site-packages\django\core\management\base.py", line 330, in run_from_argv self.execute(*args, **cmd_options) File "C:\python39\lib\site-packages\django\contrib\auth\management\commands\createsuperuser.py", line 79, in execute return super().execute(*args, **options) File "C:\python39\lib\site-packages\django\core\management\base.py", line 371, in execute output = self.handle(*args, **options) File "C:\python39\lib\site-packages\django\contrib\auth\management\commands\createsuperuser.py", line 100, in handle default_username = get_default_username() File "C:\python39\lib\site-packages\django\contrib\auth\management\__init__.py", line 140, in get_default_username auth_app.User._default_manager.get(username=default_username) File "C:\python39\lib\site-packages\django\db\models\manager.py", line 85, in manager_method return getattr(self.get_queryset(), name)(*args, **kwargs) File "C:\python39\lib\site-packages\django\db\models\query.py", line 425, in get num = len(clone) File "C:\python39\lib\site-packages\django\db\models\query.py", line 269, in __len__ self._fetch_all() File "C:\python39\lib\site-packages\django\db\models\query.py", line 1308, in _fetch_all self._result_cache = list(self._iterable_class(self)) File "C:\python39\lib\site-packages\django\db\models\query.py", line 53, in __iter__ results = compiler.execute_sql(chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size) File "C:\python39\lib\site-packages\django\db\models\sql\compiler.py", line 1156, in execute_sql cursor.execute(sql, params) File "C:\python39\lib\site-packages\django\db\backends\utils.py", line 98, in execute return super().execute(sql, params) File "C:\python39\lib\site-packages\django\db\backends\utils.py", line 66, in execute return self._execute_with_wrappers(sql, params, many=False, executor=self._execute) File "C:\python39\lib\site-packages\django\db\backends\utils.py", line 75, in _execute_with_wrappers return executor(sql, params, many, context) File "C:\python39\lib\site-packages\django\db\backends\utils.py", line 84, in _execute return self.cursor.execute(sql, params) File "C:\python39\lib\site-packages\django\db\utils.py", line 90, in __exit__ raise dj_exc_value.with_traceback(traceback) from exc_value File "C:\python39\lib\site-packages\django\db\backends\utils.py", line 84, in _execute return self.cursor.execute(sql, params) File "C:\python39\lib\site-packages\django\db\backends\sqlite3\base.py", line 413, in execute return Database.Cursor.execute(self, query, params) django.db.utils.OperationalError: no such table: auth_userアカウント作成の前に
migrateをしてくれということで、以下のコマンドでmigrateします。python manage.py migrate$ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying auth.0012_alter_user_first_name_max_length... OK Applying sessions.0001_initial... OK成功しました。
デフォルトではdb.sqlite3にテーブルが作成されます。
この設定はsetting.pyの以下に記載されています。setting.py# Database # https://docs.djangoproject.com/en/3.1/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': BASE_DIR / 'db.sqlite3', } }ちなみに
db.sqlite3はこのような感じでテーブルが作成されています。
テーブルが作成されたので、改めてユーザーを作成します。
python manage.py createsuperuserユーザー名、メールアドレス、パスワードを入力します。
メールアドレスは未登録でも大丈夫ないようです。
これでアカウントが作成できました。ログイン
アカウントを作成したのでログインします。
デフォルトでグループとユーザーの設定を行う機能が使えるみたいです。
グループを設定するときのパーミッションも多くありますね。
最後に
今回はここまでです。
DBを変更したり、管理する項目を増やしたりするのはまた次の機会にでもします。




- 投稿日:2021-02-21T22:54:09+09:00
初めての機械学習環境構築(かんたん機械学習キット)
機械学習を始めたいけど、環境構築が難しそう?
セクションタイトル通りですが、「機械学習を始めたいけど、環境構築が難しそう」と思っている方はいませんか?
そんな方に「かんたん機械学習キット」と題して、最低限用意したいものとその導入手順をご紹介します!※ 導入手順はWindows10を前提としていますが、キットの内容はどのOSでも参考になると思います。
※ 今回書くのは導入までです。各ライブラリの基本的な使い方などは、今後別の記事にしてここにリンク貼ります。かんたん機械学習キット
- 言語
- Python
- エディタ
- Jupyter Notebook
- ライブラリ
- scikit-learn
- NumPy
- SciPy
- matplotlib
- pandas
言語
Python
Pythonは、多くのデータサイエンティストの共通語となっていて、「データのロード」「可視化」「統計」「自然言語処理」「画像処理」などに使える便利なライブラリがたくさん用意されています。
【導入手順】
公式サイトのダウンロードページへアクセスする
latest version のインストーラをダウンロードする
ダウンロードしたインストーラを実行する
「Add Python 3.x to PATH」にチェックを入れて、「Install Now」をクリックする
【確認】
- 下記のコマンドを実行して、「Python」と「pip」のバージョンが表示されたらOK
python --version pip --versionエディタ
Jupyter Notebook
Jupyter Notebookは、ブラウザ上でコードを実行できるインタラクティブな環境です。
【導入手順】
- 下記のコマンドを実行する
pip install jupyterlab【確認】
- 任意の場所で下記のコマンドを実行する(ブラウザは普段よく使うものを選んで大丈夫です)
jupyter notebook
- 下図のような画面が表示されればOK

ライブラリ
scikit-learn
scikit-learnは、オープンソースで公開されている機械学習ライブラリです。
多くの機械学習アルゴリズムが実装されている点、どのアルゴリズムでも同じような書き方で使える点から、初心者にも扱いやすいライブラリだと思います。【導入手順】
- 下記のコマンドを実行する
pip install scikit-learnNumPy
NumPyは、数値計算を高速に効率的に行うことができるライブラリです。
上で紹介したscikit-learnで使用するデータはNumPy配列に変換しなければいけないことを覚えておいてください。【導入手順】
- 下記のコマンドを実行する
pip install numpySciPy
SciPyは、高度な科学計算を行うための関数を集めたライブラリで、「線形代数処理」「信号処理」「統計分布」など様々な機能を持ちます。
【導入手順】
- 下記のコマンドを実行する
pip install scipymatplotlib
matplotlibは、Pythonで最も広く使われているグラフ描画ライブラリです。
データや解析結果を様々な視点から可視化することは、データ分析・機械学習において非常に重要です。【導入手順】
- 下記のコマンドを実行する
pip install matplotlibpandas
pandasは、データの変換や解析に使用するライブラリです。
テーブル(表)のようなDataFrameという構造でデータを扱います。【導入手順】
- 下記のコマンドを実行する
pip install pandas各ライブラリの確認
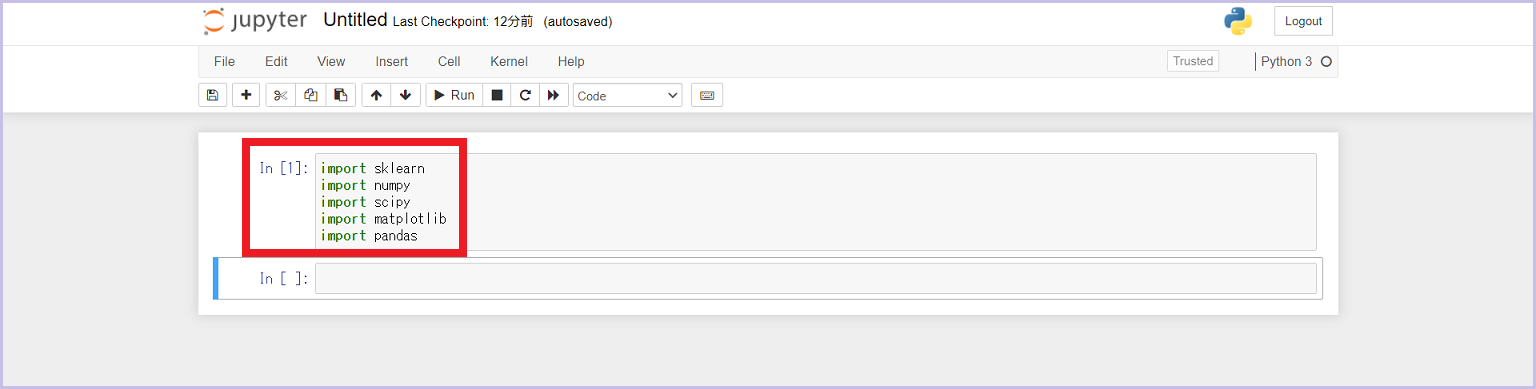
各ライブラリが正常にインストールできているかを、Jupyter Notebookを使って確認してみましょう。
- Jupyter Notebookを開いたら、画面右上の「New > Python 3」をクリック
- 作成したファイルで各import文を書き、「shift + enter」で実行し、エラーにならなけらばOK
import sklearn import numpy import scipy import matplotlib import pandas
おわりに
機械学習を始めるにあたっておすすめなのが、世界中のデータサイエンティストが参加するコミュニティサイト「Kaggle」で入門コンペとして用意されている「Titanic - Machine Learning from Disaster」に挑戦することです。(無料、無期限)
このコンペを通して「データの前処理」「学習モデルの構築」「モデルの評価・検証」など、機械学習に必要な一通りの手順の基本を学ぶことができます。
それでは、良い機械学習ライフを。


- 投稿日:2021-02-21T22:30:44+09:00
pip installに失敗した時の対処法(ERROR: Command errored out with exit status 1:)
t-SNEを試すためにbhtsneをインストールしようとして失敗しました。
使用環境
- Mac OS Big Sur
- Anaconda
エラー内容
入力!pip install bhtsne出力Using cached bhtsne-0.1.9.tar.gz (86 kB) Requirement already satisfied: numpy in /Users/apple/opt/anaconda3/envs/Test1/lib/python3.8/site-packages (from bhtsne) (1.19.2) Requirement already satisfied: cython in /Users/apple/opt/anaconda3/envs/Test1/lib/python3.8/site-packages (from bhtsne) (0.29.22) Building wheels for collected packages: bhtsne Building wheel for bhtsne (setup.py) ... error ERROR: Command errored out with exit status 1: ...... (省略) ...... error: command 'gcc' failed with exit status 1解決策
原因はXcodeのセットアップツールがインストールされていないことだったようです。
Xcodeを起動してインストールするか、Terminalでxcode-select --installを入力・実行する。
私は後者を実施して解決しました。
- 投稿日:2021-02-21T22:25:25+09:00
【はじめてのFlask】会員制の掲示板を作ってみる。
概要
クジラ飛行机さんの PythonではじめるWebサービス&スマホアプリの書きかた・作りかた を読んで、Flaskっていいな、Webサービスっていいなってなったので、せっかくなので自分でも試行錯誤しながら会員制の掲示板を作ってみることにした。
タイトル【はじめてのFlask】って書いてますが、Webサービス開発自体初めてです。ファイルの構成
my_bbs/ ├ app.py └ templates/ ├ index.html └ login.htmlとりあえずURLルーティング
メインのapp.pyにURLルーティングの部分だけ書いてみる。
これでhtmlファイルを2つ作ってから、python app.pyしてブラウザからそれぞれのURLにアクセスしてURLがちゃんと回るかを確認する。from flask import Flask, render_template, url_for, redirect app = Flask(__name__) @app.route('/login') def login(): return render_template('login.html') @app.route('/try_login') def try_login(): return redirect(url_for('index')) @app.route('/') def index(): return render_template('index.html') @app.route('/write') def write(): return redirect(url_for('index')) @app.route('/logout') def logout(): return redirect(url_for('login')) if __name__ == "__main__": app.run(debug=True, host='127.0.0.1')index.htmlは
<!DOCTYPE html> <html> <head> <title> 会員制の掲示板 </title> </head> <body> 会員制の掲示板 <br> テストページ </body> </html>login.htmlは
<!DOCTYPE html> <html> <head> <title>会員制の掲示板のログインページ</title> </head> <body> ログインページ </body> </html>ほんとにガワだけって感じでひとまずOK。
Gitでバージョン管理も始める。
$git init $git add * $git commit -m 'first commit' $git push origin masterToDo
ひとまずURLは回ったので、次は
/と/writeの中身を書いていく。
- 投稿日:2021-02-21T22:23:13+09:00
openpyxlで書き込み処理を行うときはlxmlと一緒に使う
はじめに
PythonでExcel形式のファイルを作るとき、openpyxlを使うことが多いと思います。
しかし、そのままのopenpyxlは遅い&メモリー効率が悪いという欠点があります。解決方法
上述の欠点はデフォルトのXMLモジュールの性能が原因です。
実は、openpyxlはlxmlというより性能の良いXMLモジュールの使用にも対応しています。
https://foss.heptapod.net/openpyxl/openpyxl/-/blob/branch/3.0/openpyxl/cell/_writer.py#L72
lxmlはデフォルトのモジュールより高速かつ省メモリーに動作するため、lxmlの使用を有効化するとopenpyxlの書き込み処理の高速化&省メモリー化を期待できます。lxmlの使用の有効化
openpyxlはlxmlモジュールを自動で読み込むため、
(https://foss.heptapod.net/openpyxl/openpyxl/-/blob/branch/3.0/openpyxl/xml/__init__.py#L8)
pip install lxmlしてlxmlモジュールをインストールするだけで有効化されます。性能測定
測定コード(時間)
openpyxl_test.pyfrom line_profiler import LineProfiler import memory_profiler import openpyxl def time(): wb = openpyxl.Workbook(write_only=True) ws = wb.create_sheet() for _ in range(10000): ws.append(['%d' % i for i in range(100)]) wb.save("test.xlsx") prof = LineProfiler() prof.add_function(time) prof.runcall(time) prof.print_stats()結果(時間)
lxmlなし.txtTimer unit: 1e-06 s Total time: 61.3903 s File: /xxx/openpyxl_test.py Function: time at line 6 Line # Hits Time Per Hit % Time Line Contents ============================================================== 6 def time(): 7 1 1633.0 1633.0 0.0 wb = openpyxl.Workbook(write_only=True) 8 1 724.0 724.0 0.0 ws = wb.create_sheet() 9 10001 8888.0 0.9 0.0 for _ in range(10000): 10 10000 20477116.0 2047.7 33.4 ws.append(['%d' % i for i in range(100)]) 11 1 40901916.0 40901916.0 66.6 wb.save("test.xlsx")lxmlあり.txtTimer unit: 1e-06 s Total time: 27.064 s File: /xxx/large_xlsx_write.py Function: time at line 6 Line # Hits Time Per Hit % Time Line Contents ============================================================== 6 def time(): 7 1 1612.0 1612.0 0.0 wb = openpyxl.Workbook(write_only=True) 8 1 759.0 759.0 0.0 ws = wb.create_sheet() 9 10001 10565.0 1.1 0.0 for _ in range(10000): 10 10000 26444344.0 2644.4 97.7 ws.append(['%d' % i for i in range(100)]) 11 1 606738.0 606738.0 2.2 wb.save("test.xlsx")
wb.save("test".xml)が、lxmlなしの場合は40.9秒かかっているのに対して、lxmlありの場合は 0.6秒 です。測定コード(メモリー)
openpyxl_test.pyfrom line_profiler import LineProfiler import memory_profiler import openpyxl @memory_profiler.profile def memory(): wb = openpyxl.Workbook(write_only=True) ws = wb.create_sheet() for _ in range(10000): ws.append(['%d' % i for i in range(100)]) wb.save("test.xlsx") memory()結果(メモリー)
lxmlなし.txtFilename: /xxx/large_xlsx_write.py Line # Mem usage Increment Occurences Line Contents ============================================================ 5 46.6 MiB 46.6 MiB 1 @memory_profiler.profile 6 def memory(): 7 46.6 MiB 0.0 MiB 1 wb = openpyxl.Workbook(write_only=True) 8 46.6 MiB 0.0 MiB 1 ws = wb.create_sheet() 9 767.4 MiB 0.6 MiB 10001 for _ in range(10000): 10 767.4 MiB 720.1 MiB 1030000 ws.append(['%d' % i for i in range(100)]) 11 102.6 MiB -664.8 MiB 1 wb.save("test.xlsx")lxmlあり.txtFilename: /xxx/large_xlsx_write.py Line # Mem usage Increment Occurences Line Contents ============================================================ 5 49.0 MiB 49.0 MiB 1 @memory_profiler.profile 6 def memory(): 7 49.0 MiB 0.0 MiB 1 wb = openpyxl.Workbook(write_only=True) 8 49.0 MiB 0.0 MiB 1 ws = wb.create_sheet() 9 49.1 MiB 0.0 MiB 10001 for _ in range(10000): 10 49.1 MiB 0.1 MiB 1030000 ws.append(['%d' % i for i in range(100)]) 11 49.7 MiB 0.5 MiB 1 wb.save("test.xlsx")lxmlなしの場合は、ループ中に764.4-46.6=717.8MiB、
wb.save("test".xml)時点でも102.6-46.6=56MiB使っているのに対し、
lxmlなしの場合は、 最大でも49.7-49.0=0.7MiB です。ほか
StackOverflowのこの質問によるとlxmlなしでメモリーを17.2GB使っていた ものが、 lxmlありにすると40.1MBになった との報告もあります。
結論
openpyxlで書き込み処理する場合は何も考えずに
pip install lxmlしておこう。
- 投稿日:2021-02-21T22:23:13+09:00
openpyxlで書き込み処理を行うときはlxmlと一緒に使うと高速化・省メモリー化できる
はじめに
PythonでExcel形式のファイルを作るとき、openpyxlを使うことが多いと思います。
しかし、そのままのopenpyxlは遅い&メモリー効率が悪いという欠点があります。解決方法
上述の欠点はデフォルトのXMLモジュールの性能が原因です。
実は、openpyxlはlxmlというより性能の良いXMLモジュールの使用にも対応しています。
https://foss.heptapod.net/openpyxl/openpyxl/-/blob/branch/3.0/openpyxl/cell/_writer.py#L72
lxmlはデフォルトのモジュールより高速かつ省メモリーに動作するため、lxmlの使用を有効化するとopenpyxlの書き込み処理の高速化&省メモリー化を期待できます。lxmlの使用の有効化
openpyxlはlxmlモジュールを自動で読み込むため、
(https://foss.heptapod.net/openpyxl/openpyxl/-/blob/branch/3.0/openpyxl/xml/__init__.py#L8)
pip install lxmlしてlxmlモジュールをインストールするだけで有効化されます。性能測定
測定コード(時間)
openpyxl_test.pyfrom line_profiler import LineProfiler import memory_profiler import openpyxl def time(): wb = openpyxl.Workbook(write_only=True) ws = wb.create_sheet() for _ in range(10000): ws.append(['%d' % i for i in range(100)]) wb.save("test.xlsx") prof = LineProfiler() prof.add_function(time) prof.runcall(time) prof.print_stats()結果(時間)
lxmlなし.txtTimer unit: 1e-06 s Total time: 61.3903 s File: /xxx/openpyxl_test.py Function: time at line 6 Line # Hits Time Per Hit % Time Line Contents ============================================================== 6 def time(): 7 1 1633.0 1633.0 0.0 wb = openpyxl.Workbook(write_only=True) 8 1 724.0 724.0 0.0 ws = wb.create_sheet() 9 10001 8888.0 0.9 0.0 for _ in range(10000): 10 10000 20477116.0 2047.7 33.4 ws.append(['%d' % i for i in range(100)]) 11 1 40901916.0 40901916.0 66.6 wb.save("test.xlsx")lxmlあり.txtTimer unit: 1e-06 s Total time: 27.064 s File: /xxx/large_xlsx_write.py Function: time at line 6 Line # Hits Time Per Hit % Time Line Contents ============================================================== 6 def time(): 7 1 1612.0 1612.0 0.0 wb = openpyxl.Workbook(write_only=True) 8 1 759.0 759.0 0.0 ws = wb.create_sheet() 9 10001 10565.0 1.1 0.0 for _ in range(10000): 10 10000 26444344.0 2644.4 97.7 ws.append(['%d' % i for i in range(100)]) 11 1 606738.0 606738.0 2.2 wb.save("test.xlsx")
wb.save("test".xml)が、lxmlなしの場合は40.9秒かかっているのに対して、lxmlありの場合は 0.6秒 です。測定コード(メモリー)
openpyxl_test.pyfrom line_profiler import LineProfiler import memory_profiler import openpyxl @memory_profiler.profile def memory(): wb = openpyxl.Workbook(write_only=True) ws = wb.create_sheet() for _ in range(10000): ws.append(['%d' % i for i in range(100)]) wb.save("test.xlsx") memory()結果(メモリー)
lxmlなし.txtFilename: /xxx/large_xlsx_write.py Line # Mem usage Increment Occurences Line Contents ============================================================ 5 46.6 MiB 46.6 MiB 1 @memory_profiler.profile 6 def memory(): 7 46.6 MiB 0.0 MiB 1 wb = openpyxl.Workbook(write_only=True) 8 46.6 MiB 0.0 MiB 1 ws = wb.create_sheet() 9 767.4 MiB 0.6 MiB 10001 for _ in range(10000): 10 767.4 MiB 720.1 MiB 1030000 ws.append(['%d' % i for i in range(100)]) 11 102.6 MiB -664.8 MiB 1 wb.save("test.xlsx")lxmlあり.txtFilename: /xxx/large_xlsx_write.py Line # Mem usage Increment Occurences Line Contents ============================================================ 5 49.0 MiB 49.0 MiB 1 @memory_profiler.profile 6 def memory(): 7 49.0 MiB 0.0 MiB 1 wb = openpyxl.Workbook(write_only=True) 8 49.0 MiB 0.0 MiB 1 ws = wb.create_sheet() 9 49.1 MiB 0.0 MiB 10001 for _ in range(10000): 10 49.1 MiB 0.1 MiB 1030000 ws.append(['%d' % i for i in range(100)]) 11 49.7 MiB 0.5 MiB 1 wb.save("test.xlsx")lxmlなしの場合は、ループ中に764.4-46.6=717.8MiB、
wb.save("test".xml)時点でも102.6-46.6=56MiB使っているのに対し、
lxmlなしの場合は、 最大でも49.7-49.0=0.7MiB です。ほか
StackOverflowのこの質問によるとlxmlなしでメモリーを17.2GB使っていた ものが、 lxmlありにすると40.1MBになった との報告もあります。
結論
openpyxlで書き込み処理する場合は何も考えずに
pip install lxmlしておこう。
- 投稿日:2021-02-21T21:50:37+09:00
vosk test_simple.py
googlecolab"""google colab """ !pip install vosk !git clone https://github.com/alphacep/vosk-api %cd vosk-api/python/example !wget https://alphacephei.com/kaldi/models/vosk-model-small-en-us-0.15.zip !unzip vosk-model-small-en-us-0.15.zip %mv vosk-model-small-en-us-0.15 model """ """ #!/usr/bin/env python3 from vosk import Model, KaldiRecognizer, SetLogLevel from IPython.display import Audio import sys import os import wave path = '/content/vosk-api/python/example/' SetLogLevel(0) if not os.path.exists("model"): print ("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.") exit (1) wf = wave.open(path+'/test.wav',"rb") if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != "NONE": print ("Audio file must be WAV format mono PCM.") exit (1) model = Model("model") rec = KaldiRecognizer(model, wf.getframerate()) while True: data = wf.readframes(4000) if len(data) == 0: break if rec.AcceptWaveform(data): print(rec.Result()) else: print(rec.PartialResult()) print(rec.FinalResult()) """ """ Audio(path+'/test.wav'){ "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "one" } { "partial" : "one zero" } { "partial" : "one zero zero" } { "partial" : "one zero zero" } { "partial" : "one zero zero zero" } { "partial" : "one zero zero zero one" } { "partial" : "one zero zero zero one" } { "partial" : "one zero zero zero one" } { "partial" : "one zero zero zero one" } { "result" : [{ "conf" : 1.000000, "end" : 1.110000, "start" : 0.840000, "word" : "one" }, { "conf" : 1.000000, "end" : 1.530000, "start" : 1.110000, "word" : "zero" }, { "conf" : 1.000000, "end" : 1.920000, "start" : 1.530000, "word" : "zero" }, { "conf" : 1.000000, "end" : 2.310000, "start" : 1.920000, "word" : "zero" }, { "conf" : 1.000000, "end" : 2.610000, "start" : 2.310000, "word" : "one" }], "text" : "one zero zero zero one" } { "partial" : "" } { "partial" : "" } { "partial" : "nah no" } { "partial" : "nah no" } { "partial" : "nah no to" } { "partial" : "nah no to i know" } { "partial" : "nah no to i know" } { "partial" : "nah no to i know" } { "result" : [{ "conf" : 0.560920, "end" : 4.110000, "start" : 3.930000, "word" : "nah" }, { "conf" : 0.616773, "end" : 4.290000, "start" : 4.110000, "word" : "no" }, { "conf" : 0.693737, "end" : 4.560000, "start" : 4.290000, "word" : "to" }, { "conf" : 0.498214, "end" : 4.620000, "start" : 4.560000, "word" : "i" }, { "conf" : 0.785683, "end" : 4.980000, "start" : 4.620000, "word" : "know" }], "text" : "nah no to i know" } { "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "zero" } { "partial" : "zero one" } { "partial" : "zero one eight six" } { "partial" : "zero one eight zero" } { "partial" : "zero one eight zero" } { "partial" : "zero one eight zero three" } { "partial" : "zero one eight zero three" } { "result" : [{ "conf" : 1.000000, "end" : 6.690000, "start" : 6.240000, "word" : "zero" }, { "conf" : 1.000000, "end" : 6.900000, "start" : 6.690000, "word" : "one" }, { "conf" : 1.000000, "end" : 7.110000, "start" : 6.930000, "word" : "eight" }, { "conf" : 1.000000, "end" : 7.500000, "start" : 7.110000, "word" : "zero" }, { "conf" : 1.000000, "end" : 7.980000, "start" : 7.500000, "word" : "three" }], "text" : "zero one eight zero three" }
- 投稿日:2021-02-21T21:50:37+09:00
VOSK test_simple.py
VOSK
中国語の機械学習の学習済みの言語モデルを使いたかったので、ローカルで機能する VOSK をセットアップしてみた。
GoogleColab に。日本語の音声認識をしたいところですが、日本語のモデルがあるのか、無いのか、今のところ行きついていないのと、言語学習モデルを作るというための日本語コーパスも入手難ですので、言語の形態の近い韓国語、ロマン語と比べたらちょっとは近い中国語、トルコ語、噂によるとタミル語など、そういったとこの人が関わっているものの方が、ひょっとしたらゆっくりでも進展があるのかな?と感じているところです(ただ単に、お気持ち)。
このページの記事では、もともと VOSK のインストールの説明として紹介されている
.pyのファイルをターミナルで python3 コマンドで呼び出す入力待ち受け方式(というのかな、pythom3 ./test_simple.py test.wavみたいにコマンドでやるやつのことです)のサンプルプログラムを、googlecolab(jupyter) 用に実行できるように変えたということです。
VOSK 自体がどういうものかわからなかったので、とりあえず googlecolab 上で VOSK が動作するところまでです、この記事の範囲は。
できることがわかれば、次に展開していくつもりです。
今は全くの無知な地点に立っています。VOSK については、たまたまこの youtube を見かけたので、気になっていたのですが、Baido の DeepSpeech モデルの mozilla 版のセットアップまでを先にやっていました(ちなみにですが、mozilla 版ではない DeepSpeech2 on PaddlePaddle というものもありましたが、おそらくロマン語系の人は Chinese, Korean, Japanese についてはあまり介入してないので、言語モデルについて、どう違ってどう同じなのか確認しにくいと思います。不明です。)。
セットアップの過程までで deepspeech 0.9.3 には中国語の学習済み言語モデルがあるなと見てましたが、日本語に関しては未だわかりません、あるのかもしれないし、ドキュメント等を掘り進めないとわかりませんが、mozilla のプロジェクトのスレッドを見ると、どれだけ情報があるのか探すには、ややわかりづらいような気がしますので、知りたいことがわかるまで時間がかかりそうです。
そもそも日本語の音から意味への落とし込みは英語とは違うようになるのが自然なような気もするし、どこまで最適化できるのかが想像つきませんから、音、ピンインから言葉の意味へ推移する中国語の音声認識のクオリティが良ければ、そちらの方が近いのではないかと想像しますが、まだスタート地点前です。VOSK とは
Vosk是言语识别工具包。Vosk最好的事情是:
- 支持十七种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语, 越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语
- 移动设备上脱机工作-Raspberry Pi,Android,iOS
- 使用简单的 pip3 install vosk 安装
- 每种语言的手提式模型只有是50Mb, 但还有更大的服务器模型可用
- 提供流媒体API,以提供最佳用户体验(与流行的语音识别python包不同)
- 还有用于不同编程语言的包装器-java / csharp / javascript等
- 可以快速重新配置词汇以实现最佳准确性
- 支持说话人识别
Simple test on GoogleColab
for testing test_simple.py on GoogleColab
動作までの流れ YouTubeディレクトリの移動、チェンジディレクトリ=
cdと、ムーブかな?=mvをどうするか、googlecolab でターミナルコマンドを使うときの詳細がわからなかったけど、%cdと%mvで期待通りの代替できました。python のコードでもなんとかるのかもしれないけども、今のところ大した知識はないのでそれでいい。また、googlecolab のストレージのファイルありのフォルダを消すには、jupyter セルの中で、
!rm -rf フォルダ名とセルを実行すると、ファイルありのフォルダも消せました。これは正しいのかどうか知りませんが、今のところその他の方法を知りません。なぜか、googlecolab の GUI でのフォルダ操作だとパーミッション操作までできないので、フォルダにファイルが存在していると、フォルダごと消すことができないため、圧縮ファイルが階層深くフォルダとファイルに展開されていると、つまりたくさんフォルダがあって、そのほとんどが必要ないって場合に、GUI でファイル操作して削除していくのはきっと大変でしょう。なので、ディレクトリ移動=
%cdしつつ、!rmで削除していくことになると思います。これも、他にいい方法があるやもしれない。ぐらいですかね、よくわからないのは。
googlecolab"""google colab cell 01 """ !pip install vosk !git clone https://github.com/alphacep/vosk-api %cd vosk-api/python/example !wget https://alphacephei.com/kaldi/models/vosk-model-small-en-us-0.15.zip !unzip vosk-model-small-en-us-0.15.zip %mv vosk-model-small-en-us-0.15 model """cell 02 """ !pwd """cell 03 """ #!/usr/bin/env python3 from vosk import Model, KaldiRecognizer, SetLogLevel from IPython.display import Audio import sys import os import wave path = '/content/vosk-api/python/example/' SetLogLevel(0) if not os.path.exists("model"): print ("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.") exit (1) wf = wave.open(path+'/test.wav',"rb") if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != "NONE": print ("Audio file must be WAV format mono PCM.") exit (1) model = Model("model") rec = KaldiRecognizer(model, wf.getframerate()) while True: data = wf.readframes(4000) if len(data) == 0: break if rec.AcceptWaveform(data): print(rec.Result()) else: print(rec.PartialResult()) print(rec.FinalResult()) """cell 04 """ Audio(path+'/test.wav'){ "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "one" } { "partial" : "one zero" } { "partial" : "one zero zero" } { "partial" : "one zero zero" } { "partial" : "one zero zero zero" } { "partial" : "one zero zero zero one" } { "partial" : "one zero zero zero one" } { "partial" : "one zero zero zero one" } { "partial" : "one zero zero zero one" } { "result" : [{ "conf" : 1.000000, "end" : 1.110000, "start" : 0.840000, "word" : "one" }, { "conf" : 1.000000, "end" : 1.530000, "start" : 1.110000, "word" : "zero" }, { "conf" : 1.000000, "end" : 1.920000, "start" : 1.530000, "word" : "zero" }, { "conf" : 1.000000, "end" : 2.310000, "start" : 1.920000, "word" : "zero" }, { "conf" : 1.000000, "end" : 2.610000, "start" : 2.310000, "word" : "one" }], "text" : "one zero zero zero one" } { "partial" : "" } { "partial" : "" } { "partial" : "nah no" } { "partial" : "nah no" } { "partial" : "nah no to" } { "partial" : "nah no to i know" } { "partial" : "nah no to i know" } { "partial" : "nah no to i know" } { "result" : [{ "conf" : 0.560920, "end" : 4.110000, "start" : 3.930000, "word" : "nah" }, { "conf" : 0.616773, "end" : 4.290000, "start" : 4.110000, "word" : "no" }, { "conf" : 0.693737, "end" : 4.560000, "start" : 4.290000, "word" : "to" }, { "conf" : 0.498214, "end" : 4.620000, "start" : 4.560000, "word" : "i" }, { "conf" : 0.785683, "end" : 4.980000, "start" : 4.620000, "word" : "know" }], "text" : "nah no to i know" } { "partial" : "" } { "partial" : "" } { "partial" : "" } { "partial" : "zero" } { "partial" : "zero one" } { "partial" : "zero one eight six" } { "partial" : "zero one eight zero" } { "partial" : "zero one eight zero" } { "partial" : "zero one eight zero three" } { "partial" : "zero one eight zero three" } { "result" : [{ "conf" : 1.000000, "end" : 6.690000, "start" : 6.240000, "word" : "zero" }, { "conf" : 1.000000, "end" : 6.900000, "start" : 6.690000, "word" : "one" }, { "conf" : 1.000000, "end" : 7.110000, "start" : 6.930000, "word" : "eight" }, { "conf" : 1.000000, "end" : 7.500000, "start" : 7.110000, "word" : "zero" }, { "conf" : 1.000000, "end" : 7.980000, "start" : 7.500000, "word" : "three" }], "text" : "zero one eight zero three" }
- 投稿日:2021-02-21T21:20:51+09:00
Retinaディスプレイ上でのPyAutoGUIで使う座標に関して
PyAutoGUIで座標指定してスクショ取るとき、下記のように書くことができます
sc = pyautogui.screenshot(region=(100, 200, 300, 400))問題
その際、「cmd」+「shift」+「4」で座標を図ることができるのですが、きちんと測ってもかなりずれてしまう
原因
Retinaディスプレイの画面出力のピクセル数が、通常ディスプレイの2倍あることが問題らしい
解決策
座標も2倍すれば良い
上のコードで言うと
sc = pyautogui.screenshot(region=(200, 400, 300, 400))とすれば本来取りたかった位置でスクショ取る事ができた
- 投稿日:2021-02-21T21:11:09+09:00
pandasで特定の列を、何番目と何番目というように、数値で抽出する(listで[2,5,8]など)
複数カラムあるデータフレームで、特定の列だけ番号で複数指定して抽出したいという
シチュエーションは皆さんよくあることだと思いますが、
私は書く度にググってるのので自分用のメモを書いときます。dfの2番目、5番目、8番目の列を抽出したいときは次のようになります。
df.iloc[:,[2,5,8]]これを見ると、なんだー、という感じなのですが、ググってもなかなか出てきません。。
特定の列をカラム名で指示して抽出する方法はこちらにのっていました。
https://qiita.com/guai3/items/f5ce0ab817f51e0a5d04
- 投稿日:2021-02-21T21:09:57+09:00
PyAutoGUIのライブラリ使用時に「'_idat' object has no attribute 'fileno'」が出て詰まった話


- 投稿日:2021-02-21T20:58:07+09:00
Tkinter基本操作
概要
Webアプリではなく、デスクトップアプリを作成して配布したい!という要望に答えてくれそうなツールです。なんとPythonの標準ライブラリです。
基本操作をメモ程度にまとめます。基本操作まとめ
空のアプリケーションウィンドウを表示
import tkinter as tk root = tk.Tk() root.title('Top') root.geometry('370x300+100+300') root.mainloop()上から空のウインドウ作成、タイトルを表示、ウィンドウのサイズを決める、命令待ち状態にしておく、といった感じです。
サイズですが、最初の2つの数字で起動時の大きさを決め、最後の2つの数字でデスクトップの左上からx,yにどのくらいオフセットさせて表示させるか決めます。テキスト表示
label = tk.Label(root, text='テキストです') lable.place(x=30, y=20)Labelを使って先に定義したrootにテキストを入れます。引数でtext=''を指定すれば、表示させる文字を決められます。
最後にx,y座標を指定してplaceすれば完了。テキストボックス作成
text_box = tk.Entry(root, width=20) text_box.place(x=30, y=30)Entryでrootに幅20のテキストボックスを作成します。最後にplaceで座標を指定すれば完了。
ボタン作成
button = tk.Button(root, text='送信', command=lambda:関数名) button.place(x=50, y=100)流れはほぼ同じなので割愛。問題はcommandというところ。やり方は1つではないのですが、とりあえずこれを知っていれば汎用性は高いかなと思いました。自分で作成したdef 関数名()を渡してあげれば、ボタンを押した時に関数のコードが実行されます。
ちなみに、ボタンを押してファイルを選択し、ファイルの絶対パスを取得する状況では、
from tkinter import filedialog def openFile(text_box): ftype = [('','*')] dir = '.' filename = filedialog.askopenfilename(filetypes=ftype, initialdir=dir) text_box.insert(0, filename) button = tk.Button(root, text='送信', command=lambda:openfile(text_box)) button.place(x=50, y=100)tkinterからfiledialogをインポートしておきます。openfile関数を定義しておいて、ボタンを押したらopenfileが実行されるようにします。
openfileは、filedialogのaskopenfilenameを使ってファイル選択をするダイアログを立ち上げます。その際、引数にファイルの種類とダイアログを開いた時どの階層にいるか指定します。'.'は現在のディレクトリを示します。そしてファイルを選択したら、text_boxにfilenameを挿入する流れになっています。プルダウンリストの作成
import tkinter.ttk as ttk combo = ttk.Combobox(root, state='readonly') combo["values"] = ("test1", "test2", "test3") combo.current(0) combo.pack()ttkのComboboxを使います。readonlyはリストの値を編集不可にします。combo.current(0)は初期値をリストの1つめ(ここでいうとtest1)にしますという意味です。
ExcelのA1セルに100を入れるプログラム
適当なアプリを作ります。(こんなのどこで使うねん...)
import openpyxl import tkinter as tk from tkinter import filedialog from tkinter import messagebox import tkinter.ttk as ttk #Excelファイル選択ダイアログ表示、ファイルパス取得 def OpenFile(text_box): ftype = [('','*')] #.は現在のディレクトリを表す dir = '.' filename = filedialog.askopenfilename(filetypes=ftype, initialdir=dir) tbox.insert(0, filename) def test(file_text): file_path = text_box.get() if file_path == '': messagebox.showerror('エラー', 'Excelファイルを指定して下さい') return wb = openpyxl.load_workbook(file_path) ws = wb.worksheets[0] ws.cell(1,1).value = 100 wb.save(file_path) messagebox.showinfo('お知らせ', '完了しました') root = tk.Tk() root.title('TopPage') root.geometry('370x300+100+300') #Excelファイルダイアログ label = tk.Label(root, text='Excelファイル') label.place(x=30, y=10) text_box = tk.Entry(root, width=20) text_box.place(x=30, y=30) button = tk.Button(root, text='ファイル選択', command=lambda:OpenFile(text_box)) button.place(x=250, y=30) test_button = tk.Button(root, text='Go!', command=lambda:test(file_text)) test_button.place(x=100, y=200) root.mainloop()こんな感じでしょうか。
text_box.get()でテキストボックスの文字列を取得できます。
おまけ:アプリ配布
py2appを使います。
ターミナルで、この.pyファイルの階層へいき、py2applet --make-setup app.pyなどとします。pythonファイルをバイナリ化するためのsetup.pyができるので、
python3 setup.py py2appとすればOK。ただし、いくつか注意点が、、
1.ローカル環境でこれらの作業をするとアプリがめちゃくちゃ重くなるので、仮想環境を作ってからの方がいいでしょう。仮想環境の作り方は以前自分がUPしました。
※pipが古い場合はアップデートしてから使いましょう。pip install --upgrade piphttps://qiita.com/SotaChambers/items/976e27ecefc275c67b65
2.Anacondaユーザーはpy2appをpipで入れると具合が悪くなったという話の聞いたことありますので、やはり仮想環境を作りましょう。
windowsの場合は...まだ調べてないのでよくわかりませんが、誰か必ず記事にしているでしょう。。
参考
https://senablog.com/python-tkinter/
ものすごく丁寧に書いてありました。https://ebi-works.com/python-desktop-app/
いきなりアプリを作成してみたい方に最適
- 投稿日:2021-02-21T20:46:40+09:00
openpyxl.utils.exceptions.IllegalCharacterErrorを正しく解決する
tl;dr
- CSV -> XLSXに変換するときにopenpyxl.utils.exceptions.IllegalCharacterErrorや_csv.Errorが出たので解決した
- コピペで対処したらちょっとハマった
- 最終的にはこうなった↓
import re import os import openpyxl _ILLEGAL_CHARACTERS_RE = re.compile(r"[\000-\010]|[\013-\014]|[\016-\037]") def _fix_csv(self, csv_file_path: str, fixed_csv_path: str): with open(csv_file_path, "r") as fi: with open(fixed_csv_path, "w") as fo: line = fi.readline() while line: fixed_line =_ILLEGAL_CHARACTERS_RE.sub("", line) fo.write(fixed_line) line = fi.readline() def csv_to_xlsx(csv_file_path: str, output_file_path: str) fixed_csv_path = '.temp.csv' try: _fix_csv(csv_file_path, fixed_csv_path) wb = openpyxl.Workbook(write_only=True) wb.create_sheet('Sheet1') wb.active = wb.sheetnames.index(sheet_name) ws = wb.active with open(fixed_csv_path, "r") as f: reader = csv.reader(f) for row in reader: ws.append(row) wb.save(output_file_path) finally: if os.path.exists(fixed_csv_path): os.remove(fixed_csv_path) csv_to_xlsx("入力のcsvファイル.csv", "出力のxlsxファイル.xlsx")はじめに
PythonでCSV -> XLSX変換をやろうとしたら思ったより時間がかかったのでメモ。
環境
- Python: 3.8.7
- openpyxl: 3.0.6
問題1:CSV -> XLSX変換時にopenpyxl.utils.exceptions.IllegalCharacterErrorが出る
CSV形式ファイルをXLSX形式ファイルに変換するのに、Pythonのopenpyxlを使って変換することにした。
が、特定のCSVを変換・保存するときに
openpyxl.utils.exceptions.IllegalCharacterErrorが送出され、失敗した。原因2:不正な文字列を含んでいる。
openpyxlでは文字列に不正な文字列を含んでいると例外が送出されるようなセーフティーの処理が組み込まれている。
https://foss.heptapod.net/openpyxl/openpyxl/-/blob/branch/3.0/openpyxl/cell/cell.py#L161実は、今回入力となるCSVはユーザーが好き勝手に入力したテキストを含んでいるため、文字列として一切の正規化がされておらず、変な文字が入っていることがあるのだが、そのせいで例外が送出されていたようだ。
正しくなかった解決:コピペ
openpyxl.utils.exceptions.IllegalCharacterErrorでググると似たような記事が引っかかるのでその解決のコードをコピペしてみたところ、例外が送出されなくなった。問題2:改行が消える
よしよしと思い、変換に成功したcsvファイルを見てみると 改行が消えている 。
原因2:消してはいけない文字まで消している
コピペした解決のコードは、openpyxlで不正として扱われる文字列を、openpyxlに渡す前にあらかじめ消しておくという意図のコードだった。
openpyxlでの不正な文字列は以下の正規表現で表される。
'[\000-\010]|[\013-\014]|[\016-\037]' # 16進表現だと `[\x00-08][\x0b-\x0c][\x0e-\x1f]`もう少しわかりやすくUnicode表を使って表現すると
+0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F 0 NUL SOH STX ETX EOT ENQ ACK BEL BS VT FF SO SI 10 DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US が不正である(空白のセルは不正ではない文字)。
が、コピペ元の記事ではこの正規表現にカスタマイズが加えられており、
+0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F 0 NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SO SI 10 DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US と、
+0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F 70 DEL 80 PAD HOP BPH NBH IND NEL SSA ESA HTS HTJ VTS PLD PLU RI SS2 SS3 90 DCS PU1 PU2 STS CCH MW SPA EPA SOS SGCI SCI CSI ST OSC PM APC と、おまけに
\uffffが除去される対象になっていた。見てわかるとおり、これでは改行として使われるLFやCRも取り除かれてしまう。おそらくコピペ元の記事の著者の環境では改行コードが元々含まれないデータであり、かつ
DEL〜APCが邪魔をするような状況だったのであろう。一方、筆者の環境では、 このカスタマイズが邪魔をしていた1 のだ。
解決2:不正な文字列を
'[\000-\010]|[\013-\014]|[\016-\037]'にするコピペ元の記事のカスタマイズされてしまった部分を元に戻せばよい。
除去の正規表現を'[\000-\010]|[\013-\014]|[\016-\037]'に書き換えた。問題3:CSVの読み込みで
_csv.Error: line contains NULL byteが出る今度こそ解決だと思ったら、今度は、先程までとは別のCSVの読み込みでエラーが出た。
原因3:NULL(
\x00)を含んでいた問題2まではopenpyxlモジュールの問題だったが今度はcsvモジュールの問題だった。
どうやら、csvモジュールはNULL文字(\x00)を含むファイルは読み込めないようだ。
上述のとおり、openpyxlのための不正な文字列の対象にはNULL文字も含まれているのだが、除去処理はcsvモジュールでの読み込みの後に入れているため、エラーが出てしまった。解決3:テキストとして読み込んで除去する
csvモジュールでの読み込みの前に不正な文字を除去するように、除去のタイミングを前倒しにした。
最終的なソースコード
最終的なソースコードは「tl;dr」を参照のこと。
ソースコードでははじめにCSVを単なるテキストファイルとして読み込み、不正な文字列の除去を行ってから一時ファイルに出力するようにした。
そして、その一時ファイルをCSVモジュールに読み込ませ、openpyxlに渡しすようにした。おわりに
安易なコピペはだめ(戒め)。
筆者が最初にコピペした記事を そのまま鵜呑みにして書いたであろう別の記事が存在しており、 「2つもソースがあるから正しいだろう」との思い込みがハマりポイントになってしまった。 ↩
- 投稿日:2021-02-21T20:30:37+09:00
【Python】読込むブック名とセルの値をパラメーターにする。②
pythonを使用してExcelファイルの操作を勉強しています。
本日の気づき(復習)は、パラメーターに関してです。
pythonでExcelを操作するため、openpyxlというパッケージを使用しています。後々レイアウトを変更したり、プログラムで読み込むブック名やセルの値を変えてしまうかもしれない時の対処法です。
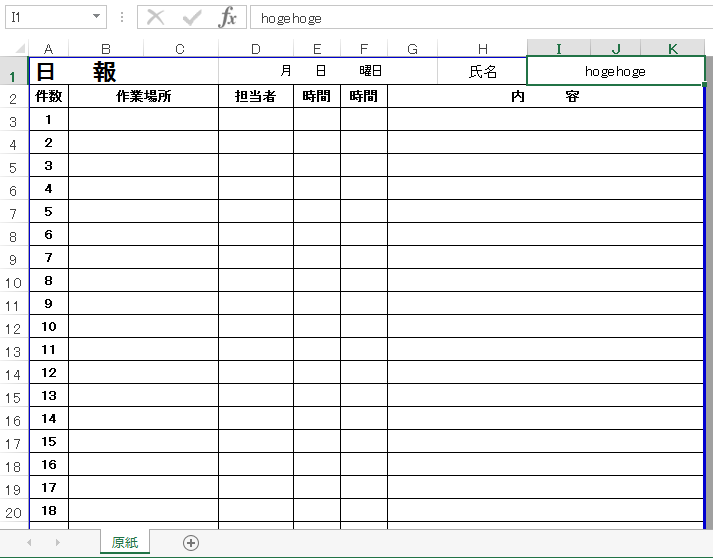
なんだかちょっと実戦形式っぽくてワクワクしてます。今回はこちらのブック「日報.xlsx」を、使用します。
input関数
input関数を使うとプログラム実行時に対話形式でパラメーターを入力できることが強みですね。
input(コマンドラインに表示する文言)input_arguments.pyfrom openpyxl import load_workbook filename = input('読込むブック名: ') cellno = input('読込むセル名(例 A1): ') wb = load_workbook(filename, read_only=True) ws = wb.active print(ws[cellno].value)読込むブック名: 日報.xlsx 読込むセル名(例 A1): I1 -->hogehoge以前勉強したところでもあり、こちらはすんなり腹に降りてきてくれました。
- 投稿日:2021-02-21T20:09:01+09:00
Pythonの引数評価戦略は"参照渡し"ではないと何度でも主張すべきそうすべき
Google検索すると、いまだにPythonの引数は参照渡しされるとする記事が後を絶たないので注意喚起。
なんで?
A. 公式ドキュメントにそう書かれているからです。
まず、当該部分の原文はこう。
Remember that arguments are passed by assignment in Python. Since assignment just creates references to objects, there’s no alias between an argument name in the caller and callee, and so no call-by-reference per se. You can achieve the desired effect in a number of ways.
Pythonに"call-by-reference"自体は存在しないとはっきり書かれています。
そして、当該部分の日本語訳は次のようになっています。
出力引数のある関数 (参照渡し) はどのように書きますか? - プログラミング FAQ — Python 3.8.8 ドキュメント
前提として、Python では引数は代入によって渡されます。代入はオブジェクトへの参照を作るだけなので、呼び出し元と呼び出し先にある引数名の間にエイリアスはありませんし、参照渡しそれ自体はありません。望む効果を得るためには幾つかの方法があります。
少なくともPythonのドキュメントにおいては"call-by-reference"="参照渡し"であり、そしてそれはPythonにはないと書かれていることがわかります。
Q1. 日本語訳と行っても所詮は非公式では?
Pythonにおいて、日本語を含むいくつかの翻訳版ドキュメントはPEP 545を通してPythonソフトウェア財団の活動に取り込まれた公式ドキュメントです。1
そこで用いられている用語の定義に異議があるならば、寄稿規約に従ってIssueを立て修正の合意を取り付ける必要があります。Q2. 評価戦略の用語は混乱しがちなので、言語固有の事情に従って説明すべきでは?
私もそう思います。
ただ、言語公式のドキュメントで表明されているからにはそれに従うのが正しいと思います。Q3. じゃあPythonの引数評価戦略はなんなの?
先の引用の通り、Pythonにおける引数は代入であるとされていますが、具体的にこの戦略の名前が明記されているわけではありません。振る舞いとしては"call-by-sharing"などと称される戦略と同じですが、この用語が公式ドキュメント中で用いられているわけでもないようです。誤解を生まない範囲で自由な語句を使って表現すればよい、というところですが、それが簡単にできるならきっと本稿も無用の長物なのでしょう。
そんな訳で、『Pythonの引数は参照渡し』は明確に誤りです。
特に新人の方は公式ドキュメントをよく読んで、正しい知識を身につけることを大事にしましょう。
余談ですが、日本語は原文を除けばもっとも翻訳完了率の高い言語だそうです。翻訳プロジェクトの方々には頭が上がりません。 ↩
- 投稿日:2021-02-21T20:03:05+09:00
機械学習初心者による自然言語処理考察②
はじめに
自然言語処理100本ノック第7章で「階層型クラスタリング」が出てきたので、初心者の私なりに理解できた部分を記載する。
第7章-68 問題文
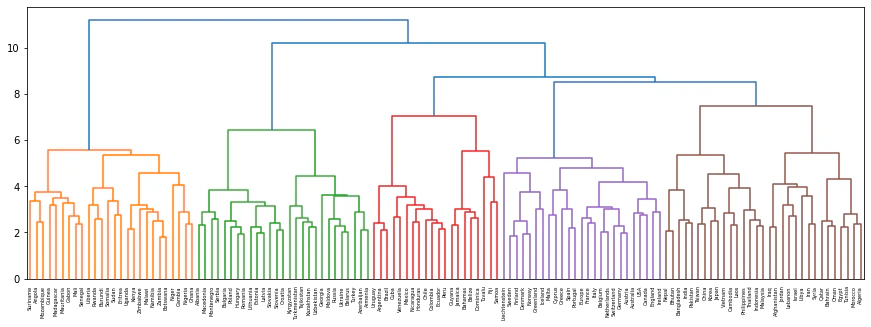
国名に関する単語ベクトルに対し,Ward法による階層型クラスタリングを実行せよ.さらに,クラスタリング結果をデンドログラムとして可視化せよ.
第7章-68 解答
以下のコードが正解となっている。(こちらの記事より引用)
from sklearn.cluster import KMeans # k-meansクラスタリング kmeans = KMeans(n_clusters=5) kmeans.fit(countries_vec) for i in range(5): cluster = np.where(kmeans.labels_ == i)[0] #cluster毎に分類されたcuntriesのラベル(3,17,18,...)を取得 print('cluster', i) print(', '.join([countries[k] for k in cluster])) #取得したラベルに紐づくcuntries(3:Zambia,17:Sudan,18:Namibia,...)を表示出力cluster 0 Zambia, Sudan, Namibia, Uganda, Guinea, Kenya, Zimbabwe, Angola, Gabon, Rwanda, Nigeria, Mozambique, Mauritania, Algeria, Madagascar, Ghana, Mali, Tunisia, Liberia, Niger, Senegal, Malawi, Eritrea, Burundi, Gambia, Botswana cluster 1 Albania, Kazakhstan, Russia, Slovakia, Montenegro, Ukraine, Hungary, Turkey, Azerbaijan, Poland, Greece, Bulgaria, Romania, Lithuania, Slovenia, Moldova, Estonia, Belarus, Macedonia, Serbia, Latvia, Croatia, Armenia, Georgia, Cyprus, Uzbekistan, Turkmenistan cluster 2 Ecuador, Guyana, Fiji, Suriname, Samoa, Nicaragua, Belize, Chile, Cuba, Bahamas, Peru, Tuvalu, Mexico, Jamaica, Colombia, Dominica, Venezuela, Honduras cluster 3 England, Morocco, Switzerland, Greenland, Uruguay, Europe, Germany, Austria, Argentina, Australia, USA, Sweden, Ireland, Iceland, Belgium, Spain, Denmark, Finland, Canada, Netherlands, Liechtenstein, France, Norway, Malta, Brazil, Portugal, Italy, Japan cluster 4 Indonesia, Iraq, Taiwan, India, Korea, Kyrgyzstan, Vietnam, Libya, Somalia, Iran, Jordan, Bangladesh, Qatar, Egypt, Nepal, China, Thailand, Cambodia, Lebanon, Bhutan, Malaysia, Tajikistan, Bahrain, Syria, Oman, Pakistan, Laos, Afghanistan, Philippines, Israelfrom matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage plt.figure(figsize=(15, 5)) Z = linkage(countries_vec, method='ward') dendrogram(Z, labels=countries) plt.show()
linkage関数
ここで理解に苦しんだのは「linkage関数」である。
linkageはScipyに含まれるパッケージであり、以下のような構造となっている。scipy.cluster.hierarchy.linkage(df, method='ward', metric='euclidean', optimal_ordering=False)引数methodで、階層型クラスタリングの手法を選択している。
- method = 'single':最小結合法
- method = 'complite':最大結合法
- method = 'average':群平均法
- method = 'ward':ウォード法
今回選択した「ウォード法」とは、凝集型階層的クラスタリングと呼ばれるクラスタリングの手法の1つ。
凝集型階層的クラスタリングとは、
1.全ての点が別々のクラスタである状態から始める
2.「今あるクラスタの中で、最も距離が近い2つのクラスタを選んで1つのクラスタに合体する」という操作を行う
3.合体を目標のクラスタ数になるまで繰り返す
という手法となっている。
引用元:ウォード法によるクラスタリングのやり方なお、
metric='euclidean'については、点どうしの距離をユークリッド距離(2点間の直線距離)で定義するという意味である。他にもミンコフスキー距離・コサイン距離などを選択できるようだが、基本的にユークリッド距離を選択すれば良いようなので割愛する。話を戻すと、
Z = linkage(countries_vec, method='ward') dendrogram(Z, labels=countries)ここではlinkage関数を用いて、countries_vec(国名一覧を単語ベクトルで表したもの)をウォード法により目標のクラスタ数(=5)になるまでクラスタリングを繰り返している、ということになる。

- 投稿日:2021-02-21T19:22:06+09:00
kivyMDチュートリアル其の肆 Themes - Color Definitions篇
さあ、今週もやってまいりました。kivyMDチュートリアルのお時間です。
今週初めくらいから爆弾低気圧が来た影響でHPが2くらいしか残ってないですが、
みなさんの体調はどうでしょうか。気持ちだけはめげずに、今日も元気にやって
いこうと思います。# 少し今日は省エネモードかもColor Definitions
冒頭では前々回くらいからあるように色の決まりごととか見ておいてねという
案内から始まってます。ここではMaterialDesignタグを入れてますが、ほとんど
詐欺のような形で触れません。興味ある方は見ておいてくださいということで次に
進んでいこうと思います。See also
Material Design spec, The color system
https://material.io/design/color/the-color-system.htmlMaterial Design spec, The color tool
https://material.io/resources/color/#!/?view.left=0&view.right=0ですが、ここもさらっと行こうと思ったんですけど上記The Color toolは面白いと思ったので
少し紹介しておきます。これはあらかじめUIのフレームとかは定義されていましたが、色のテーマ
とかをカスタム含め好きな色を決めてアプリのイメージを決められるツールとなっています。適当に触ってみただけなのですが、意外とそれっぽく作れる感じはあります。
キャプチャは下の通りです。
色のセンスねーなとかいうツッコミはなしの方向でww
あくまで適当に選んだだけなので。これを実際に使ってみたいなーという方には朗報です。
なんと色のテーマを定義したファイルをエクスポートすることも出来ます。
種類としてはAndroid, Swift, CodePenと3種類で残念ながらkivyMDは
ありませんでしたー泣。まぁ、こだわりたいという方はカスタムかもしくは
今日紹介する形で落としどころを決めましょう。Material colors palette to use in kivymd.theming.ThemeManager.
colors is a dict-in-dict where the first key is a value
from palette and the second key is a value from hue.
Color is a hex value, a string of 6 characters (0-9, A-F) written in uppercase.For example, colors["Red"]["900"] is "B71C1C".
kivymd.theming.ThemeManagerで使用するマテリアルカラーパレット。
色はdict-in-dictで、最初のキーはパレットからの値で、2番目のキーは色相からの値です。
色は16進値で、大文字で書かれた6文字(0-9、A-F)の文字列です。たとえば、colors ["Red"] ["900"]は "B71C1C"です。
と、いきなり翻訳を依頼しましたが今日のテーマとして非常に重要なので
このkivymd.theming.ThemeManagerの仕様については覚えておきましょう。
テストがあったら絶対に出るところでしょう。API - kivymd.color_definitions
kivymd.color_definitions.colors
Color palette. Taken from 2014 Material Design color palettes.
To demonstrate the shades of the palette, you can run the following code:
とまぁ、さっそくkivymd.color_definitionsのAPIの説明に入ってますが、
カラーパレットについては2014年にマテリアルデザインが公表されてそれをもとに
使うからねーという説明になっています。あとはコードの説明に入っていってます。省略省略かい!とツッコミが出そうですが、なぜか動きませんでしたー!w
結構ところどころ動かないサンプルがあるので困ったものです。
# 解析しろやと言われそうですがそんな技術力はどこにもありません
動いてたら説明が少ないのでコードの説明とかも交えようかなと思ってた
のですが、今日は動かなかったので一部だけ。class Palette(MDApp): title = "Colors definitions" 省略 def on_tab_switch(self, instance_tabs, instance_tab, instance_tabs_label, tab_text): self.screen.ids.box.clear_widgets() for value_color in colors[tab_text]: self.screen.ids.box.add_widget( ItemColor( color=get_color_from_hex(colors[tab_text][value_color]), text=value_color, ) ) 省略今日の肝で先ほどテスト出るよといったところになりますが、
さっそくマテリアルカラーパレットが出てきていますね。まず、メソッドとしてはタブの切り替え専用メソッドを宣言して、そこでタブを切り替えたときに
色を変えれるようにロジックを組んでいます。メソッドの引数の説明とかはMDTabsを触ったときにまた改めて。
初めにself.screen.ids.box.clear_widgets()で切り替え時にリセットされるようにしているのかな。
ここでids.boxと見慣れないものが出てきましたが、このようにすることでkvファイルで決めておいた
UIパーツとバインディングして中身をいじれるようになっています。これからkivy・kivyMD関係なく
このような形がよく出てくるので覚えておいて損はないです。よく見るとdemoで定義したkvレイアウトでは、
以下のようにScrollViewが宣言されています。demo = ''' <Root@BoxLayout> orientation: 'vertical' MDToolbar: title: app.title MDTabs: id: android_tabs on_tab_switch: app.on_tab_switch(*args) size_hint_y: None height: "48dp" tab_indicator_anim: False ScrollView: MDList: id: box (省略)上記のようにkv側でもid: boxとちゃんと宣言されていますね。他にもMDTabsとかでもid: android_tabs
とあったりパーツを宣言する上ではこのような形がよく出てきます(kivyとかkivyMD関係なく)。んで、メソッドの方に戻りますが、そのあとはfor value_color in colors[tab_text]:とイテレートして
同色の色相を取り出して、その色が反映されるようItemColorオブジェクトにカラーパレットを流し込んでいます。
このItemColorオブジェクトは色を16進数値にしないとちゃんと反映されないのかな。んでそのItemColorって
なんなのよっていうと、kv側で以下のように定義されていますね。demo = ''' (省略) <ItemColor>: size_hint_y: None height: "42dp" canvas: Color: rgba: root.color Rectangle: size: self.size pos: self.pos MDLabel: text: root.text halign: "center"どうやらItemColorというのはcanvasとMDLabelで構成されているようです。
MDLabelはこれまでも出てきているしで、説明するまでもないですがまた機会が
あればそこで。canvasはもともと図形描画用のウィジェットなのですが、ここでは
巧みにそのウィジェットを使用しています。そうしてサンプルのような色付きの矩形を
表現できるようにしています。あ、あとcanvasの詳しい仕様は以下にて。Canvas
https://kivy.org/doc/stable/api-kivy.graphics.instructions.htmlここまでくると最初から説明した方がいいかもですね(出来ないけど)。
またまた、メソッドの方に戻りますがこれらがself.screen.ids.box.add_widget( ItemColor( color=get_color_from_hex(colors[tab_text][value_color]), text=value_color, ) )をよく表しています。要はkv側で決めておいたパーツにこれらを流し込みたかったのですね。
最後に作ったItemColorをMDList(box)に流し込んで表示するということをやっていました。
とまぁ、コードの説明はこの辺りで。あとはPropertyとかon_start側のon_tab_switch(
呼び出し側)とかも気になるところですが、またUIパーツで触るしで今度の機会ということで。
自分の気になるところでいうと、Factory.Root()とScreenオブジェクトでscreenを生成
するのは何が違うんだろうと思ってしまいます。# 自分へのメモこれでいったん、コードの方は手じまいということで。
じゃぁねーと終わりたいところですが、まだ残っています。とほほ。kivymd.color_definitions.palette = ['Red', 'Pink', 'Purple', 'DeepPurple', 'Indigo', 'Blue', 'LightBlue', 'Cyan', 'Teal', 'Green', 'LightGreen', 'Lime', 'Yellow', 'Amber', 'Orange', 'DeepOrange', 'Brown', 'Gray', 'BlueGray']
Valid values for color palette selecting.
これだけの色が選べるんだぜということですね。恩恵を授かりましょう。
kivymd.color_definitions.hue = ['50', '100', '200', '300', '400', '500', '600', '700', '800', '900', 'A100', 'A200', 'A400', 'A700']
Valid values for color hue selecting.
こちらは色相になります。これも恩恵を授かりましょう。
この2つは特に重要なので、おさらいをしておきます。
さっきのコード上のカラーパレットでいうとこのような形をしていました。
colors[tab_text][value_color]このtab_textがまさにパレット(kivymd.color_definitions.palette)の選択で、value_colorが
色相(kivymd.color_definitions.hue)の選択なのでした。これらのことは大事なので、今日は3回ほど
言いました。kivymd.color_definitions.text_colors
Text colors generated from light_colors. “000000” for light and “FFFFFF” for dark.
How to generate text_colors dict
コード上では触れられてませんが、テキストカラーも黒か白を選べるようです。
確かに色の組み合わせでは読みにくくなりますからね。コードは載せませんが、
一応こんな感じの使い方もできるぜというサンプルも挙げられています。kivymd.color_definitions.theme_colors = ['Primary', 'Secondary', 'Background', 'Surface', 'Error', 'On_Primary', 'On_Secondary', 'On_Background', 'On_Surface', 'On_Error']
Valid theme colors.
テーマカラーを選べるようです。使い方は一向にわかりません。
メイン側でプロパティとして読み取るのかしら。まとめ
さぁ、今回はいかがでしたでしょうか。
若干、消化不良感は否めませんがこれにて締めくくりたいと思います。
まぁ、動かなかったらしょうがないですよねーと自分を甘やかしておきます。
次回はiconについてになります。それでは、ごきげんよう。
参照
Color Definitions
https://kivymd.readthedocs.io/en/latest/themes/color-definitions/

- 投稿日:2021-02-21T18:58:58+09:00
pythonのsubprocessで標準出力を文字列として受け取る
概要
pythonでsubprocessを使って処理を行なった後,標準出力を文字列として受け取りたいことがあります.
ちょくちょく行う処理なのですが,いつもどうやるのか忘れるのでメモしておきます.version
python3.9.2
(python3.5以降は同じはず)やり方
subprocessの実行は最近(python3.5以降)では公式ドキュメントによると
subprocess.runを使うのが良いみたいです.
一発で標準出力を文字列として受け取るには以下のようにします.>>> import subprocess >>> output_str = subprocess.run('ls', capture_output=True, text=True).stdout(
'ls'は実行したいコマンドの例です.)その結果,
>>> print(output_str) 'Dockerfile\nLICENSE\nREADME.md\nsrc\n' >>> print(type(output_str)) <class 'str'>標準出力を文字列として受け取ることができています!
capture_output=Trueで出力が受け取れるようになり,
text=Trueを渡すことで出力をバイナリではなく文字列として返してくれるようになります.さらに
subprocess.runはCompletedProcessというクラスを返すのですが,
そのクラスの変数であるstdoutにアクセスすることで標準出力を受け取っています.>>> subprocess.run('ls', capture_output=True, text=True) CompletedProcess(args='ls', returncode=0, stdout='Dockerfile\nDockerfile:cpu\nDockerfile:cuda10.2-cudnn7\nLICENSE\nREADME.md\ndata\nresult\nsrc\ntrained_model.npz\n', stderr='')標準エラー出力や戻り値にアクセスしたい場合はそれぞれ
stderr,returncodeにアクセスすれば良いです.
- 投稿日:2021-02-21T18:55:35+09:00
Python Migration Toolを徹底比較してみた
概要
Djangoのようなフレームワークを使う際にはMigration Toolが内蔵されていますので特にどのツールを使おうか悩むことはないかと思いますが、FastAPIやFlaskなどの軽量フレームワークを使う際、Migration Toolを選定する必要があるかと思います。
そんな方のために現時点において主要な三つのPythonのMigration Toolをまとめてみました。
(2021/2/20現在)
Github Github Stars Github最終更新日 対応DB DSL/RawSQL ドキュメント alembic https://github.com/sqlalchemy/alembic 834 11 hours ago MySQL, SQLServer,Postgresql, SQLite Python/Raw SQL https://alembic.sqlalchemy.org/en/latest/ simple-db-migrate https://github.com/guilhermechapiewski/simple-db-migrate 186 5 months ago MySQL Raw SQL Githubのみ yoyo-migration https://github.com/marcosschroh/yoyo-database-migrations 9 13 months ago PostgreSQL, MySQL, SQLite Python / Raw SQL https://ollycope.com/software/yoyo/latest/ ざっと比較表を見るとalembicが圧倒的ですね。
実際Flaskによく使われるFlask-migrationもalembicをwrapしたものであり、Flaskに次ぐ軽量フレームワークのFastAPIも公式はalembicを推奨しています(https://fastapi.tiangolo.com/ja/tutorial/sql-databases/#alembic-note)現時点においてはalembicとsimple-db-migrateが二大勢力といった感じでしょうか。
ですのでこの記事では主要な二つのPython Migration Toolであるalembicとsimple-db-migrateを比較していこうと思います!それではまずalembicから使い方とメリデメを見ていきましょう!
alembic
Alembic is a database migrations tool written by the author of SQLAlchemy.
とGithubのREADMEに書いてあるとおり、sqlalchemyの作者が作っただけあってsqlalchemyとの互換性は抜群です。
autogenerateという機能を備え、sqlalchemyで定義したschemaから自動でMigration scriptを作成できます。基本的な使い方
install
pip install alembic(適宜使っているpackage管理ツールに置き換えてください)
alembic環境構築
alembicはテンプレートの中から目的にあった設定ファイルをサクッと作ることができます。
$ alembic list_templates Available templates: generic - Generic single-database configuration. multidb - Rudimentary multi-database configuration. pylons - Configuration that reads from a Pylons project environment. Templates are used via the 'init' command, e.g.: alembic init --template pylons ./scriptshttps://alembic.sqlalchemy.org/en/latest/tutorial.html#creating-an-environment
マイグレーションファイルの作成
基本的な作成方法は以下のコマンドを打って作成されるファイルにPythonまたはRawSQLでスクリプトを追加していくことです。
$ alembic revision -m "Add a column" Generating /path/to/yourapp/alembic/versions/ae1027a6acf_add_a_column.py... doneae1027a6acf_add_a_column.py"""Add a column Revision ID: ae1027a6acf Revises: 1975ea83b712 Create Date: 2011-11-08 12:37:36.714947 """ # revision identifiers, used by Alembic. revision = 'ae1027a6acf' down_revision = '1975ea83b712' from alembic import op import sqlalchemy as sa def upgrade(): # Migration適応内容記入 # 例 op.add_column('account', sa.Column('last_transaction_date', sa.DateTime)) def downgrade(): # rollback時適応内容記入 # 例 op.drop_column('account', 'last_transaction_date')しかしこのような使い方をしているのではalembicの恩恵を十分に受けられません。
alembic最大の強みはsqlalchemyで定義したモデルschemaを元に自動でMigration Scriptを生成してくれることです!
Auto generate機能
https://alembic.sqlalchemy.org/en/latest/autogenerate.html
Auto generate機能を使うにはデフォルトで作成された
env.pyファイルの中身を以下のように変更する必要があります。env.py(変更前)# add your model's MetaData object here # for 'autogenerate' support # from myapp import mymodel # target_metadata = mymodel.Base.metadata target_metadata = Noneenv.py(変更後)from myapp.mymodel import Base (sqlalchemyで定義したモデルからdeclarative_baseをimport) target_metadata = Base.metadata変更後--autogenerateをつけるだけでmodel schemaを元に自動でMigration Scriptが作成されます!
$ alembic revision --autogenerate -m "Added account table" INFO [alembic.context] Detected added table 'account' Generating /path/to/foo/alembic/versions/27c6a30d7c24.py...done27c6a30d7c24.py"""empty message Revision ID: 27c6a30d7c24 Revises: None Create Date: 2011-11-08 11:40:27.089406 """ # revision identifiers, used by Alembic. revision = '27c6a30d7c24' down_revision = None from alembic import op import sqlalchemy as sa def upgrade(): ### commands auto generated by Alembic - please adjust! ### op.create_table( 'account', sa.Column('id', sa.Integer()), sa.Column('name', sa.String(length=50), nullable=False), sa.Column('description', sa.VARCHAR(200)), sa.Column('last_transaction_date', sa.DateTime()), sa.PrimaryKeyConstraint('id') ) ### end Alembic commands ### def downgrade(): ### commands auto generated by Alembic - please adjust! ### op.drop_table("account") ### end Alembic commands ###Auto generate...強力ですね!
自分も最初使った時は思わず「alembic様、天才!」と声をあげそうになりました。こうして作られたMigration scriptを実行していきましょう。
マイグレーションの実行
alembic upgrade headこのコマンド一発でDBにMigration Scriptが実行されます。
DBを見てみるとalembic_versionと言うテーブルが作られており、version_numというカラムの中に最後に当てられたMigration fileのrevisionが保存されます。この値を元にalembicはバージョン管理をし、rollbackを可能にしています。
rollbackをするには
alembic downgrade -1で一つ前のmigrationを取り消すことができ、複数前のrevisionまでrollbackするには、
alembic historyでrevision情報を表示し、戻りたいrevisionを指定し
alembic downgrade {revision}で遡ることができます。
以上が基本的な使い方ですが他の機能も紹介しておきたいと思います。
tips
メリット
メリットとしては以下の点があげられます。
sqlalchemyで定義したschemaからmigration scriptを自動生成するauto generate機能
複数DB接続 / 環境によってDBを切り替えられる
Python、Raw SQLの両方でMigration scriptをかける
Communityが大きい/SQLAlchemyの作者がContributeしていることから今後も機能拡張される
デメリット
一番の欠点はautogenerateと言う素晴らしい機能を備えていますが、必ずしも万能ではないことです。
Auto generateで検知できない変更として以下の点があります。
- テーブル名の変更(drop/addになりデータが初期化されます)
- カラム名の変更(drop/addになりデータが初期化されます)
- 名前の付いていないユニーク制約 (変更を検知するにはユニーク制約に名前をつけることは必須(e.g.
UniqueConstraint('col1', 'col2', name="my_name"))- EnumなどのSQLAlchemy特有のカラムの変更
- Columnの順番の指定
What does Autogenerate Detect (and what does it not detect?)
なので運用方法としては基本的にはauto generate、うまく生成されない場合は自分でマニュアルで記入する対応が必要になりそうです。
simple-db-migrate
simple-db-migrate is damn simple. The best way to understand how it works is by installing and using it.
https://github.com/guilhermechapiewski/simple-db-migrate
続いてsimple-db-migrateを試してみましょう。
simple-db-migrateはその名の通りめちゃめちゃシンプルなMigration Toolです。基本的な使い方
install
$ pip install simple-db-migrate設定ファイルの作成
$ touch simple-db-migrate.confsimple-db-migrate.confDATABASE_HOST = "localhost" DATABASE_USER = "root" DATABASE_PASSWORD = "" DATABASE_NAME = "migration_example" DATABASE_MIGRATIONS_DIR = "."準備は上記のような設定ファイルを作成するだけです!
とってもSimple!マイグレーションファイルを作成する
$ db-migrate --create {Migration名(e.g. create_table_users)}マイグレーションを実行する
$ db-migrate以上です!
簡単にマイグレーションを実行することができました。実行するとDB内に
__db_version__と言う名前のテーブルが作られversion管理されるようになっていきます。
--config, ---envオプションにより環境ごとに切り替えられ--migrationオプションにより指定のrevisionまでrollbackできます。tips
メリット
- 複数DB / envに対応している
- simpleで導入が簡単
simple-db-migrationの一番のメリットはそのシンプルさ、導入の容易さですね!
デメリット
- RawSQLしか使えない
- MySQLしか対応していない
- Auto generateのような機能はない
まとめ
いかがだったでしょうか?
sqlalchemyと高い互換性を誇りautogenerateのような画期的な機能をもつalembicと、できる限りsimpleにバージョン管理を実現するsimple-db-migrationを比較してみました。個人的にはalembicのauto generationがEnumのサポート、Column Orderの指定ができない点が少し残念に感じました。
autogenerateでなんでも変更検知されるはず、と思い込んでいると思わぬ事故を招きそうですね...simple-db-migrationはその点、流すスクリプトもRawSQLでできることに制約はなく、最低限の機能は揃っているので実運用だとこちらに軍配があがる気がしました。(ただしMySQLを使用している場合に限りますが)
もしalembicのautogenerateの制約でワークアラウンド等ありましたら、コメント頂けるとありがたいです。(alembicのドキュメント量すごすぎて理解が追いついていない部分もあるかと思うので...)
- 投稿日:2021-02-21T18:15:20+09:00
魚眼カメラでQRコードを読み込んでみようとした
はじめに
Paypayや楽天ペイなどの普及でより身近になった感じがあるQRコードですが、ふとした時に「これって魚眼カメラでも読み取れるのかな?」と思ったので、実際にやってみました。
やったこと
Jatson NanoにインタニヤのラズベリーパイVR220カメラを接続し、スマホ(iPhone XS)画面に表示したQRコードを読み取るプログラムを開発ました。
ソースコードはGithubにアップしています。
ざっくりとした仕組みを説明すると、
- 撮影
- QRコードの位置を検出
- QRコード周辺の魚眼歪みの除去
- QRコード読み取り
という処理の流れになっています。
撮影・検出・歪み除去の様子は下記Youtubeで見れます。(画像クリックでYoutubeへジャンプ)
以下、仕組みの簡単な説明を記述します。
撮影
Jetson NanoでRaspberry Piのカメラを動作させるにはgstreamerを使います。こちらの記事を参考に撮影してみました。
とりあえず何も考えずに撮影した結果はこちら↓
上の画像のようにiPhoneの画面が明るすぎてQRコードがまともに写っていませんでした
(※プライバシーを考慮してぼかしを入れています)
露出が合っていないようです。これは魚眼カメラあるあるだと思うのですが、露出をオートで撮影すると、画角が広すぎて画面内にいろんな明るさのものが映り込んでしまうため、狙ったところが狙った明るさにならないことがあります。特にスマホの画面のような明るさが強いものだと簡単に白飛びしてしまいます。
今回はQRコードを読み取ることが目的なので、gstreamerの露出やゲインを抑えて暗めに撮影してスマホ画面がきれいに撮影できるようにしてみました。
gstreamerの露出設定部分はここになります。これでiPhoneに表示したQRコードを撮影するとこのようになります。
明るさを抑えてQRコードのみ浮き上がっている状態で撮影することができました。
撮影ができたらすぐさまQRコードを読み取りたいところですが、QRコードがカメラの真正面ならともかく、画角の外側に写るとQRコードの形状が歪んでしまうので読み取りができません。
せっかく魚眼で撮影するからには画角の外側のQRコードも読み取りたいところです。
今回はQRコードの箇所を狙い撃ちで歪み除去したいと思います。QRコードの位置を検出
QRコードの歪みを取るために、まず画像中のどこにQRコードが写っているかを検出する必要があります。
機械学習などで検出する方法を考えましたがデータを集めるのが面倒だったので、ルールベースで検出します。今回は幸か不幸か撮影画像は画面(QRコード)のみが明るく、他の部分は暗い画像になっています。
この画像の特徴を使って、次のようにQRコードの画像上の位置を検出することにしました。
1. 2値化処理で明るい部分とそれ以外を分ける
2. 明るい部分の輪郭を検出
3. 検出した輪郭から重心の位置を算出
この部分のコードはこれになります。QRコードの画像上の位置を求めたら、カメラに対してどの方向にそれがあるかを算出します。
なお、この処理にはOpenCVのomnidirモジュールのキャリブレーションパラメータを使用するので、予めパラメータを算出しておく必要があります。
キャリブレーションについては過去の記事をご参照ください。
OpenCVのomnidirモジュールのカメラモデルでは、魚眼の撮影画像を「カメラ中心を原点とした半径1の天球(単位球)の球面に投影したもの」として扱うことができます。
したがって、画像上の重心の座標(u,v)を天球面の座標(x,y,z)に変換し、さらにそれを極座標(r,θ,φ)に変換すると、カメラに対するQRコードの方向が算出できます。
重心を単位球面の座標に変換するコードはここ、球面の座標を極座標に変換するコードはここになります。QRコード周辺の魚眼歪みの除去
算出した極座標の角度成分θ・φから回転行列を算出し、キャリブレーションパラメータとともにOpenCVのomnidir::UndistortImageへ渡すと、歪みが除去された画像を取得できます。
歪み除去の範囲
歪み除去済みの画像
歪み除去の部分のコードはここになります。
QRコード読み取り
QRコードの歪みが取れたら、QR読み取りモジュールに画像を渡して、QRコードから情報を取得します。
今回はpyzbarを使ってQRコードを読み取っています。撮影から読み取りまでの手順は以上です。
終わりに
魚眼カメラでQRコードを読み込んでみました。
あえてQRコードの読み取りに魚眼カメラを使う利点はなさそうですが(汗)、処理の手順の一つ一つは魚眼カメラを使うアプリケーションの開発に役に立ちそうな要素を含んでいると思います。





- 投稿日:2021-02-21T18:09:31+09:00
SQLiteによるデータベースの操作
SQLiteは非常にお手軽なデータベースです.
軽量でありながらデータベースの操作言語SQLを利用して本格的なデータベース操作が行えるという点に注目が集まっています.
ファイル1つが1つのデータベースであり,組み込み用途でよく利用されています.
Pythonから使う場合,標準ライブラリのsqlite3を利用する宣言だけで使うことができるのもメリット.例)shuto.sqliteというデータベースに,リンゴやバナナの値段を挿入し,それを抽出する.
import sqlite3 # sqliteのデータベースに接続 dbpath = "shuto.sqlite" conn = sqlite3.connect(dbpath) # テーブルを作成し、データを挿入する cur = conn.cursor() cur.executescript(""" /* itemsテーブルが既にあれば削除する */ DROP TABLE IF EXISTS items; /* テーブルの作成 */ CREATE TABLE items( item_id INTEGER PRIMARY KEY, name TEXT UNIQUE, price INTEGER ); /* データを挿入 */ INSERT INTO items(name, price)VALUES('Apple', 800); INSERT INTO items(name, price)VALUES('Orange', 780); INSERT INTO items(name, price)VALUES('Banana', 430); """) # データベースに反映させる conn.commit() # データを抽出する cur = conn.cursor() cur.execute("SELECT item_id,name,price FROM items") item_list = cur.fetchall() # 一行ずつ表示 for it in item_list: print(it)(1, 'Apple', 800) (2, 'Orange', 780) (3, 'Banana', 430)import sqlite3 # データベースに接続 filepath = "test2.sqlite" conn = sqlite3.connect(filepath) # テーブルを作成 cur = conn.cursor() cur.execute("DROP TABLE IF EXISTS items") cur.execute(""" CREATE TABLE items ( item_id INTEGER PRIMARY KEY, name TEXT, price INTEGER)""") conn.commit() # 単発でデータを挿入 cur = conn.cursor() cur.execute( "INSERT INTO items (name,price) VALUES (?,?)", ("Orange", 520)) conn.commit() # 連続でデータを挿入 cur = conn.cursor() data = [("Mango",770), ("Kiwi",400), ("Grape",800), ("Peach",940),("Persimmon",700),("Banana", 400)] cur.executemany( "INSERT INTO items(name,price) VALUES (?,?)", data) conn.commit() # 400-700円のデータを抽出して表示 cur = conn.cursor() price_range = (400, 700) cur.execute( "SELECT * FROM items WHERE price>=? AND price<=?", price_range) fr_list = cur.fetchall() for fr in fr_list: print(fr)(1, 'Orange', 520) (3, 'Kiwi', 400) (6, 'Persimmon', 700) (7, 'Banana', 400)ここで注目したいのは,SQL内で実際に挿入する値を「?」を使って表現します.そしてexecute()メソッドの第二引数で実際の値を指定します.すると「?」の部分が値に置換されます.
この仕組みを使えば,セキュリティの脅威を防ぐことができるだけでなく,意図しないSQLの破壊を防ぐことができます.
- 投稿日:2021-02-21T18:01:42+09:00
macOS Big Surにアップデート後、pyenvを使用したpython3.8.5~のインストールが失敗するようになった問題の対処法
・MacOS Big Sur 11.2.1
・xcode.app: 12.4
・pyenv: 1.2.22こんなエラー
BUILD FAILED (OS X 11.2.1 using python-build 20180424) Inspect or clean up the working tree at /var/folders/7t/s4sxvwqd5pqcy3jh_n5vfpjr0000gn/T/python-build.20210221175447.57865 Results logged to /var/folders/7t/s4sxvwqd5pqcy3jh_n5vfpjr0000gn/T/python-build.20210221175447.57865.log Last 10 log lines: extern int _NSGetExecutablePath(char* buf, uint32_t* bufsize) __OSX_AVAILABLE_STARTING(__MAC_10_2, __IPHONE_2_0); ^ clang -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g -fwrapv -O3 -Wall -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include -std=c99 -Wextra -Wno-unused-result -Wno-unused-parameter -Wno-missing-field-initializers -Wstrict-prototypes -Werror=implicit-function-declaration -I./Include/internal -I. -I./Include -I/usr/local/opt/readline/include -I/usr/local/opt/readline/include -I/Users/~/.pyenv/versions/3.8.2/include -I/usr/local/opt/readline/include -I/usr/local/opt/readline/include -I/Users/~/.pyenv/versions/3.8.2/include -DPy_BUILD_CORE_BUILTIN -DPy_BUILD_CORE_BUILTIN -I./Include/internal -c ./Modules/posixmodule.c -o Modules/posixmodule.o ./Modules/posixmodule.c:9197:15: error: implicit declaration of function 'sendfile' is invalid in C99 [-Werror,-Wimplicit-function-declaration] ret = sendfile(in, out, offset, &sbytes, &sf, flags); ^ 1 error generated. make: *** [Modules/posixmodule.o] Error 1 make: *** Waiting for unfinished jobs.... 1 warning generated.試したこと
・App StoreからXcodeをインストールする(時間掛かるカモ)
・アクティブデベロッパディレクトリにインストールしたXcodeアプリケーションのDeveloperディレクトリを指定する
$ sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer・xcodebuildを実行する。
sudo xcodebuild -runFirstLaunch・pythonをインストールする
$ pyenv install 3.8.5 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.8.5... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.8.5 to /Users/~/.pyenv/versions/3.8.5
python3.8.2 および それより下のバージョンについては相変わらずエラーが出てしまう状態。
issuesより、下記コマンドで3.8.2はインストールできました。
ただ、修正対応も頑張ってくれているっぽい。$ CFLAGS="-I$(brew --prefix openssl)/include -I$(brew --prefix bzip2)/include -I$(brew --prefix readline)/include -I$(xcrun --show-sdk-path)/usr/include" LDFLAGS="-L$(brew --prefix openssl)/lib -L$(brew --prefix readline)/lib -L$(brew --prefix zlib)/lib -L$(brew --prefix bzip2)/lib" pyenv install --patch 3.8.2 < <(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)
3.7系は上記コマンドでも相変わらずエラー。。。(上記patchはMacOS v11サポート用だから、v3.7はまた別?)
3.7系はpyenv installで普通にインストールでけた$ pyenv install 3.7.8 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.7.8... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.8 to /Users/~/.pyenv/versions/3.7.8

- 投稿日:2021-02-21T18:01:42+09:00
macOS Big Surにアップデート後、pyenvを使用したインストールが失敗するようになった問題の対処法
・xcode.app: 12.4
・pyenv: 1.2.22こんなエラー
BUILD FAILED (OS X 11.2.1 using python-build 20180424) Inspect or clean up the working tree at /var/folders/7t/s4sxvwqd5pqcy3jh_n5vfpjr0000gn/T/python-build.20210221175447.57865 Results logged to /var/folders/7t/s4sxvwqd5pqcy3jh_n5vfpjr0000gn/T/python-build.20210221175447.57865.log Last 10 log lines: extern int _NSGetExecutablePath(char* buf, uint32_t* bufsize) __OSX_AVAILABLE_STARTING(__MAC_10_2, __IPHONE_2_0); ^ clang -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g -fwrapv -O3 -Wall -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include -std=c99 -Wextra -Wno-unused-result -Wno-unused-parameter -Wno-missing-field-initializers -Wstrict-prototypes -Werror=implicit-function-declaration -I./Include/internal -I. -I./Include -I/usr/local/opt/readline/include -I/usr/local/opt/readline/include -I/Users/~/.pyenv/versions/3.8.2/include -I/usr/local/opt/readline/include -I/usr/local/opt/readline/include -I/Users/~/.pyenv/versions/3.8.2/include -DPy_BUILD_CORE_BUILTIN -DPy_BUILD_CORE_BUILTIN -I./Include/internal -c ./Modules/posixmodule.c -o Modules/posixmodule.o ./Modules/posixmodule.c:9197:15: error: implicit declaration of function 'sendfile' is invalid in C99 [-Werror,-Wimplicit-function-declaration] ret = sendfile(in, out, offset, &sbytes, &sf, flags); ^ 1 error generated. make: *** [Modules/posixmodule.o] Error 1 make: *** Waiting for unfinished jobs.... 1 warning generated.試したこと
・App StoreからXcodeをインストールする(時間掛かるカモ)
・アクティブデベロッパディレクトリにインストールしたXcodeアプリケーションのDeveloperディレクトリを指定する
$ sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer・xcodebuildを実行する。
sudo xcodebuild -runFirstLaunch・pythonをインストールする
$ pyenv install 3.8.5 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.8.5... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.8.5 to /Users/~/.pyenv/versions/3.8.5
python3.8.2 および それより下のバージョンについては相変わらずエラーが出てしまう状態。
issuesより、下記コマンドでインストールできました。
コマンドはクソ長いですが、... pyenv install --patch 3.8.2 ...のバージョン(3.8.2)を希望のものに変えるだけです。
ただ、修正対応も頑張ってくれているっぽい。$ CFLAGS="-I$(brew --prefix openssl)/include -I$(brew --prefix bzip2)/include -I$(brew --prefix readline)/include -I$(xcrun --show-sdk-path)/usr/include" LDFLAGS="-L$(brew --prefix openssl)/lib -L$(brew --prefix readline)/lib -L$(brew --prefix zlib)/lib -L$(brew --prefix bzip2)/lib" pyenv install --patch 3.8.2 < <(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)
- 投稿日:2021-02-21T18:01:42+09:00
macOS Big Surにアップデート後、pyenvを使用したpythonインストールが失敗するようになった問題の対処法
・MacOS Big Sur 11.2.1
・xcode.app: 12.4
・pyenv: 1.2.22こんなエラー
BUILD FAILED (OS X 11.2.1 using python-build 20180424) Inspect or clean up the working tree at /var/folders/7t/s4sxvwqd5pqcy3jh_n5vfpjr0000gn/T/python-build.20210221175447.57865 Results logged to /var/folders/7t/s4sxvwqd5pqcy3jh_n5vfpjr0000gn/T/python-build.20210221175447.57865.log Last 10 log lines: extern int _NSGetExecutablePath(char* buf, uint32_t* bufsize) __OSX_AVAILABLE_STARTING(__MAC_10_2, __IPHONE_2_0); ^ clang -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g -fwrapv -O3 -Wall -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include -std=c99 -Wextra -Wno-unused-result -Wno-unused-parameter -Wno-missing-field-initializers -Wstrict-prototypes -Werror=implicit-function-declaration -I./Include/internal -I. -I./Include -I/usr/local/opt/readline/include -I/usr/local/opt/readline/include -I/Users/~/.pyenv/versions/3.8.2/include -I/usr/local/opt/readline/include -I/usr/local/opt/readline/include -I/Users/~/.pyenv/versions/3.8.2/include -DPy_BUILD_CORE_BUILTIN -DPy_BUILD_CORE_BUILTIN -I./Include/internal -c ./Modules/posixmodule.c -o Modules/posixmodule.o ./Modules/posixmodule.c:9197:15: error: implicit declaration of function 'sendfile' is invalid in C99 [-Werror,-Wimplicit-function-declaration] ret = sendfile(in, out, offset, &sbytes, &sf, flags); ^ 1 error generated. make: *** [Modules/posixmodule.o] Error 1 make: *** Waiting for unfinished jobs.... 1 warning generated.App StoreからXcodeをインストールする(時間掛かるカモ)
アクティブデベロッパディレクトリに、先ほどインストールしたXcodeアプリケーションのDeveloperディレクトリを指定する
$ sudo xcode-select --switch /Applications/Xcode.app/Contents/Developerxcodebuildを実行する。
sudo xcodebuild -runFirstLaunch↓とりあえずエンターキー押す。
You have not agreed to the Xcode license agreements. You must agree to both license agreements below in order to use Xcode. Hit the Return key to view the license agreements at '/Applications/Xcode.app/Contents/Resources/English.lproj/License.rtf'↓agree と入力してエンター
. .. ... By typing 'agree' you are agreeing to the terms of the software license agreements. Type 'print' to print them or anything else to cancel, [agree, print, cancel]By typing 'agree' you are agreeing to the terms of the software license agreements. Type 'print' to print them or anything else to cancel, [agree, print, cancel] agree You can view the license agreements in Xcode's About Box, or at /Applications/Xcode.app/Contents/Resources/English.lproj/License.rtf Install Started 1%.........20.........40.........60.........80........Install SucceededInstall Succeededが表示されれば完了です
python3.8.5インストール
$ pyenv install 3.8.5 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.8.5... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.8.5 to /Users/~/.pyenv/versions/3.8.5python 3.9.0もインストールできた。
python3.8.2インストール
python3.8.2 および それより下のバージョンについては相変わらずエラーが出てしまう状態。
issuesより、下記コマンドで3.8.2はインストールできました。
ただ、修正対応も頑張ってくれているっぽい。$ CFLAGS="-I$(brew --prefix openssl)/include -I$(brew --prefix bzip2)/include -I$(brew --prefix readline)/include -I$(xcrun --show-sdk-path)/usr/include" LDFLAGS="-L$(brew --prefix openssl)/lib -L$(brew --prefix readline)/lib -L$(brew --prefix zlib)/lib -L$(brew --prefix bzip2)/lib" pyenv install --patch 3.8.2 < <(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)python3.7.8インストール
3.7系は上記コマンドでも相変わらずエラー。。。(上記patchはMacOS v11サポート用だから、v3.7はまた別?)
3.7.8はpyenv installで普通にインストールできたので、3.7系も大丈夫かな・・・。(3.7.Xによってはエラーになるかもしれない)$ pyenv install 3.7.8 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.7.8... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.8 to /Users/~/.pyenv/versions/3.7.8
- 投稿日:2021-02-21T17:53:17+09:00
単語の分散表現とTensorBoardによる3次元空間での可視化
はじめに
単語をベクトル化する分散表現と、Tensorboardを使用して3次元空間上にプロットして可視化する方法についてまとめました。
※実装では、言語はPython、環境はGoogle Colaboratoryを使用しています。ご自身の環境に合わせて読み替えて下さい。
目次
単語の分散表現とは
自然言語処理といった分野があります。
自然言語とは、我々が日常的に話したり書いたりしている言葉のことです。
そういった自然言語をコンピュータで扱おうとした場合、そのままの形で扱うことは難しく、一旦数字に置き換える必要があります。
数値に置き換える方法は色々とあるのですが、今回は分散表現というものを使用します。
分散表現とは、単語を実数値のベクトルで表したものです。
ベクトルとは数値がいくつか並んだものだと考えて下さい。
例えば、Python, Ruby, Javaといった単語を分散表現で表すと以下のようになります(数値は適当な値です)。
ベクトルの性質について簡単に説明します。
「ベクトルとは数値がいくつか並んだもの」と上述しました。
この数値がいくつ並んでいるか、が次元と呼ばれます。
数値が2つの場合は2次元、3つの場合は3次元、…となります。
ベクトルでは、足し算や引き算、内積その他の演算が定義されています。
※下図では、簡単のため2次元ベクトルの図を使用しています。
分散表現により、自然言語である単語をベクトル化することができれば、単語同士についても同様の計算ができるようになります。それは、
- 意味的な足し算や引き算
- どれだけ意味的に近いか
を計算することに相当します。
実装
モデルの準備
今回は、ゼロから単語の分散表現のモデルを作成することはせず、公開されている学習済みの単語分散表現を使用します。
以下のモデルをダウンロードして下さい(注釈)。!wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gzダウンロードができたら、モデルとしてインポートします。
ここでは、gensimという自然言語処理を扱うためのPythonライブラリを使用してモデルをロードします。
※ロードにはしばらく時間がかかります。import gensim model = gensim.models.KeyedVectors.load_word2vec_format('cc.ja.300.vec.gz', binary=False)ロードが完了したら、早速モデルを使用してみましょう。
試しに、「Python」という単語の分散表現を見てみます。model['Python'] # array([ 7.000e-03, 1.310e-02, 5.500e-03, -3.660e-02, -8.600e-03, # -2.430e-02, -7.050e-02, 5.920e-02, 8.370e-02, 3.600e-02, # ︙ # 2.110e-02, 4.180e-02, -5.470e-02, 2.350e-02, 2.200e-02], # dtype=float32)実数値が並んだベクトルとなっており、確かに分散表現で表されています。
今回のモデルでは、ベクトルの次元は300次元となっています。
model['Python'].shape # (300,)次に、Pythonに近い単語上位10コを表示してみます。
model.most_similar('Python', topn=10) # [('python', 0.7935450077056885), # ('Clojure', 0.7304115295410156), # ('OCaml', 0.7204216718673706), # ('Cython', 0.7158461809158325), # ('Ruby', 0.706175684928894), # ('Perl', 0.7045886516571045), # ('Haskell', 0.6954647302627563), # ('Java', 0.6816721558570862), # ('Erlang', 0.6776419878005981), # ('IPython', 0.6646149754524231)]では次に、単語同士の足し算・引き算を計算してみます。
ここでは、例としてよく挙げられる
『王様−男性+女性=女王様』
について、実際にそういった結果になるかを確認してみます。
model.most_similar(positive=['王様', '女性'], negative=['男性'], topn=10) # [('女王', 0.5497723817825317), # ('王妃', 0.5333674550056458), # ('お姫様', 0.5282727479934692), # ('王さま', 0.5261490345001221), # ('ラジオキッズ', 0.5149459838867188), # ('お姫さま', 0.5045803785324097), # ('王女', 0.5034000873565674), # ('タプチム', 0.499458909034729), # ('ブランチ', 0.4980105757713318), # ('乃女', 0.49398326873779297)]確かに、「女王」「王妃」「お姫様」といった、期待する答えが上位に並んでいますね。
せっかくなので、もうひとつ。
『日本−東京+ロンドン』の結果は何になるでしょうか?
国名である日本から首都である東京を引き算し、首都であるロンドンを足し算したものは…?
model.most_similar(positive=['日本', 'ロンドン'], negative=['東京'], topn=10) # [('イギリス', 0.6945440769195557), # ('英国', 0.6216877698898315), # ('ヨーロッパ', 0.6075816750526428), # ('アメリカ', 0.5903184413909912), # ('イングランド', 0.5594041347503662), # ('各国', 0.549339234828949), # ('欧米', 0.537621259689331), # ('米国', 0.5245243906974792), # ('オーストラリア', 0.5227084159851074), # ('欧州', 0.5212200284004211)]正解は「イギリス」でした!
このように、分散表現では単語同士の意味的な足し算や引き算ができるようになります。
色々と遊んでみると面白いかと思います。2つの単語の類似度を計算することもできます。
PythonとRuby、PythonとAppleの類似度をそれぞれ計算するとどうなるでしょうか?model.similarity('Python', 'Ruby') # 0.70617557 model.similarity('Python', 'Apple') # 0.33666733PythonとRubyはともにプログラミング言語なので類似度は高く、PythonとフルーツのAppleは関連性がなさそうなので類似度は低い、といった想定に近い結果が得られたと思います。
TensorBoardによる3次元空間での可視化
次に、分散表現を3次元空間へプロットすることを考えます。
※分散表現は数百(今の場合300)次元のベクトルなので、そのまま可視化することはできません。詳細は割愛しますが、次元削減という方法を用いて3次元に落とし込みます(注釈)。TensorBoardを使用することで、分散表現を3次元空間へプロットして可視化することができます。TensorBoardとは、TensorFlowの可視化ツールで機械学習ではよく用いられています(公式HP)。
それでは、まず必要なライブラリをインストールします。
!pip install gensim torch tensorboardX tensorflow次に、可視化したい分散表現を用意します。ここでは、すでに用意している学習済み分散表現のモデル
modelを使用しています。また、プロットする単語数は30,000としました。import gensim import torch from tensorboardX import SummaryWriter writer = SummaryWriter() weights = model.vectors labels = model.index2word weights = weights[:30000] labels = labels[:30000] writer.add_embedding(torch.FloatTensor(weights), metadata=labels)それでは、TensorBoardを使って分散表現をプロットしてみましょう。
※プロットする単語数が多いほど(今回は30000語)、表示に時間がかかります。時間がかかりすぎる、あるいは表示できない場合には、単語数を減らしてみて下さい。%load_ext tensorboard %tensorboard --logdir runs
各単語が3次元空間上にプロットされています(注釈)。
ではここで、試しに「プログラミング」という特定の単語に着目してみます。すると、以下の場所に位置していました。
「プログラミング」という単語の周辺にはどういった単語が分布しているでしょうか。
近づいて見てみると以下のようになっていました。
「Javascript」「ソフトウェア」「コンピュータ」「アルゴリズム」といった、意味的に近いと思われる単語が分布している様子が見てとれます(注釈)。
まとめ
今回は、単語をベクトル化する分散表現と、Tensorboardを使用して3次元空間上にプロットして可視化する方法についてまとめました。
分散表現では、数値のベクトルと同じように計算することができます。
意味的な足し算や引き算、3次元空間へプロットすることで単語同士の意味的な関連性を見ることができます。注釈
- 本記事は、『Python Charity Talks in Japan 2021.02』で私がLTした内容をまとめたものです。
- Facebookが公開している単語の分散表現モデル。日本語WikipediaをMeCabで分かち書きした後、fastTextというアルゴリズムによって計算したもの(詳細は公式HPをご参照下さい)。
- 次元削減にはいくつかの方法がありますが、今回は「PCA(主成分分析)」を使用しました。次元削減の方法については、こちらの記事がわかりやすかったです。
- 今回、次元削減でPCAを使用していますが、TensorBoardではそれ以外を選択することも可能です。
- 意味的に近くない単語も含まれてしまっていますが、現在プロットしている30,000単語より単語数を増やすことで、より関連性の高い単語が得られるようになるハズです。
参考文献








- 投稿日:2021-02-21T17:47:24+09:00
pixivpyでログインできなくなったので、新しいログイン方法の紹介
要約
https://github.com/upbit/pixivpy/issues/158
こちらのスレッドの内容の紹介ログイン方法が
original.pyapi = AppPixivAPI() api.login("username", "password") aapi = AppPixivAPI() aapi.login("username", "password")だったものを
new.pyapi = AppPixivAPI() api.auth(refresh_token=REFRESH_TOKEN) aapi = AppPixivAPI() aapi.auth(refresh_token=REFRESH_TOKEN)に変える。
なおREFRESH_TOKENは
https://gist.github.com/upbit/6edda27cb1644e94183291109b8a5fde
こちらのスクリプトを使用して取得した。このスクリプトをは有志が作ったものであり、公式のものではありません。
そのためログイン時のユーザーid、passwordは流出してもいいように捨て垢を使うなどの方法を使うことをお勧めします。また何か問題が起きても自己責任でお願いします。
はじめに
2021年2月上旬ごろにpixiv.pyを使ったスクリプトが動かなくなってしまった。
PixivError: [ERROR] auth() failed! check username and password. HTTP 400: {"has_error":true,"errors":{"system":{"message":"Invalid grant_type parameter or parameter missing","code":1508}},"error":"invalid_grant"}https://github.com/upbit/pixivpy/issues/158
こちらによると、pixivpyはもともとandroidアプリを通してログインをしていましたが、アップデートでログイン方法が変わったため、現在ログインできなくなったそうです。有志によっていろいろ検討がなされた結果、リフレッシュトークンを使用することで今まで通り使用できるようになりました。
しかしトークンを一定期間ごとに手動で取得しなければならない可能性があり、完全自動化から半自動化に変わってしまう恐れがあるとのことです。
まだスレッドの内容を完全に理解していないので、間違いなどありましたらご指摘ください。前準備
1.chromeが必要なので、ダウンロードしてください。
https://www.google.com/intl/ja_jp/chrome/
2.seleniumをダウンロードしてください
pip install seleniumseleniumとは、pythonでchromeを動かすライブラリです。
Python + Selenium で Chrome の自動操作を一通り
こちらを参考にしてください。3.chromedriver.exeをダウンロードしてください。
chromedriver.exeはseleniumでchromeを動かすために必要なものです。
検索するとバイナリでダウンロードする方法などがあるそうですが、
今回はホームページから直接zipをダウンロードします。https://chromedriver.chromium.org/downloads
ここからchromeのバージョンとosにあったものをダウンロード、
そして解凍バージョンについては
https://qiita.com/iHacat/items/9c5c186f0d146bc98784
こちらを参考に4.REFRESH_TOKENの取得
https://gist.github.com/upbit/6edda27cb1644e94183291109b8a5fde
こちらに従って実行してください。
ディレクトリ
このような配置にして、
プログラム
サイトのプログラムコピペです。
https://gist.github.com/upbit/6edda27cb1644e94183291109b8a5fde内容は理解していないうえ、実行してログインしなければならないので、何が起きるかわかりません。
そのためログイン時のユーザーid、passwordは流出してもいいように捨て垢を使うなどの方法を使うことをお勧めします。
自己責任でお願いします。pixiv_auth.py#!/usr/bin/env python import time import json import re import requests from argparse import ArgumentParser from base64 import urlsafe_b64encode from hashlib import sha256 from pprint import pprint from secrets import token_urlsafe from sys import exit from urllib.parse import urlencode from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities # Latest app version can be found using GET /v1/application-info/android USER_AGENT = "PixivAndroidApp/5.0.234 (Android 11; Pixel 5)" REDIRECT_URI = "https://app-api.pixiv.net/web/v1/users/auth/pixiv/callback" LOGIN_URL = "https://app-api.pixiv.net/web/v1/login" AUTH_TOKEN_URL = "https://oauth.secure.pixiv.net/auth/token" CLIENT_ID = "MOBrBDS8blbauoSck0ZfDbtuzpyT" CLIENT_SECRET = "lsACyCD94FhDUtGTXi3QzcFE2uU1hqtDaKeqrdwj" def s256(data): """S256 transformation method.""" return urlsafe_b64encode(sha256(data).digest()).rstrip(b"=").decode("ascii") def oauth_pkce(transform): """Proof Key for Code Exchange by OAuth Public Clients (RFC7636).""" code_verifier = token_urlsafe(32) code_challenge = transform(code_verifier.encode("ascii")) return code_verifier, code_challenge def print_auth_token_response(response): data = response.json() try: access_token = data["access_token"] refresh_token = data["refresh_token"] except KeyError: print("error:") pprint(data) exit(1) print("access_token:", access_token) print("refresh_token:", refresh_token) print("expires_in:", data.get("expires_in", 0)) def login(): caps = DesiredCapabilities.CHROME.copy() caps["goog:loggingPrefs"] = {"performance": "ALL"} # enable performance logs driver = webdriver.Chrome("./chromedriver", desired_capabilities=caps) code_verifier, code_challenge = oauth_pkce(s256) login_params = { "code_challenge": code_challenge, "code_challenge_method": "S256", "client": "pixiv-android", } driver.get(f"{LOGIN_URL}?{urlencode(login_params)}") while True: # wait for login if driver.current_url[:40] == "https://accounts.pixiv.net/post-redirect": break time.sleep(1) # filter code url from performance logs code = None for row in driver.get_log('performance'): data = json.loads(row.get("message", {})) message = data.get("message", {}) if message.get("method") == "Network.requestWillBeSent": url = message.get("params", {}).get("documentURL") if url[:8] == "pixiv://": code = re.search(r'code=([^&]*)', url).groups()[0] break driver.close() print("[INFO] Get code:", code) response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "code": code, "code_verifier": code_verifier, "grant_type": "authorization_code", "include_policy": "true", "redirect_uri": REDIRECT_URI, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def refresh(refresh_token): response = requests.post( AUTH_TOKEN_URL, data={ "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET, "grant_type": "refresh_token", "include_policy": "true", "refresh_token": refresh_token, }, headers={"User-Agent": USER_AGENT}, ) print_auth_token_response(response) def main(): parser = ArgumentParser() subparsers = parser.add_subparsers() parser.set_defaults(func=lambda _: parser.print_usage()) login_parser = subparsers.add_parser("login") login_parser.set_defaults(func=lambda _: login()) refresh_parser = subparsers.add_parser("refresh") refresh_parser.add_argument("refresh_token") refresh_parser.set_defaults(func=lambda ns: refresh(ns.refresh_token)) args = parser.parse_args() args.func(args) if __name__ == "__main__": main()実行
python pixiv_auth.py login実行するとchromeが立ち上がり、ログイン画面が出てくるので、入力してログインしてください。
結果
❯ python3 pixiv_auth.py login [INFO] Get code: 3s3Xc075wd7njPLJBXgXc4qS-... access_token: Fp9WaXhNapC8myQltgEn... refresh_token: uXooTT7xz9v4mflnZqJ... expires_in: 3600そうするとこのように表示されるので、
refresh_token:
に続くuXooTT7xz9v4mflnZqJ...をコピーしてくださいプログラムの書き換え
original.pyapi = AppPixivAPI() api.login("username", "password") aapi = AppPixivAPI() aapi.login("username", "password")だったものを
new.pyapi = AppPixivAPI() api.auth(refresh_token=REFRESH_TOKEN) aapi = AppPixivAPI() aapi.auth(refresh_token=REFRESH_TOKEN)に変える。
REFRESH_TOKEN先ほどコピーしたものにしてください。さいごに
有志が集まって新しいログイン方法を見つけだしていたので、まとめました。
何度も言いますが、自己責任でよろしくお願いします。
特に中国語の翻訳はgoogleさんにお願いしているので、何か間違っている可能性があります。
間違いなどありましたらご指摘お願いします。m(__)m

