- 投稿日:2021-02-21T22:18:04+09:00
5歳娘「パパ、レンタルサーバを契約しないで?」
無職ワイ、システム開発会社の面接を受ける
面接官「よろしくお願いします」
ワイ「よろしくお願いします」
面接官「JavaScriptがお得意みたいですが」
面接官「サーバサイドですか?フロントですか?」ワイ「フロントです」
ワイ「高卒で、18歳からフロントやってました」面接官「おお〜、大ベテランですね」
ワイ「(フロントいうても、カラオケ店のフロント業務やけどな・・・)」
ワイ「(でも、嘘は言うてへん・・・!)」面接官「では、サーバサイドの経験はどうですか?」
ワイ「サーバ側もよく触ってました」
ワイ「(ビールサーバとウォーターサーバを触ってたで)」面接官「頼もしいですね」
面接官「インフラとかはどうですか?」ワイ「インフラも一通り任されてました」
ワイ「(カラオケ屋の新店舗ができるとき、電気と水道の手続きはワイが任されたんや)」面接官「インフラもいけるんですね」
面接官「もしかして、モバイルアプリの経験とかもあります?」ワイ「はい」
ワイ「iOSだけですが経験あります」
ワイ「(AppStoreからアプリをダウンロードした経験やで。誤解せんといてな)」面接官「おお、フルスタックですね」
面接官「逆に、顧客対応などはどうでしょうか?」ワイ「顧客対応もよくしてました」
ワイ「(だってカラオケ屋のフロントやもん)」面接官「素晴らしいですね」
面接官「一次面接、合格です!」その日の夕方
ワイ「(カタカタカタカタ・・・)」
ワイ「ふ〜、忙しいな」娘(5歳)「ねぇパパ、それ何してるの?」
ワイ「ああ、今な」
ワイ「レンタルサーバを契約してたところや」娘「ふーん」
ワイ「実は今日、プログラマーとしての面接を受けてきてな」
ワイ「一次面接に受かったから、次はコーディング試験を受けることになったんや」娘「そっか」
娘「どんな試験内容なの?」ワイ「今週中にちょっとしたWebアプリケーションを作成して」
ワイ「どこかのサーバにデプロイせなあかんのや」娘「へぇ〜」
娘「それって、好きな技術スタックで作ればいいの?」ワイ「いや、確か条件があったな」
ワイ「↓こんな条件や」以下の条件で作成お願いいたします。
- OS
- CentOS
- サーバーソフトウェア
- NGINX
- データベース
- PostgreSQL
- プログラミング言語
- Node.js
娘「ふーん」
娘「さっきパパが契約したレンタルサーバのスペックも見せて?」ワイ「ええで」
レンタルサーバ仕様
- OS
- Linux
- サーバーソフトウェア
- Apache
- データベース
- MySQL
- プログラミング言語
- PHPが使用可能
ワイ「↑こんな感じや」
娘「パパ・・・」
娘「何もかも違うじゃん・・・」ワイ「Oh・・・」
レンタルサーバの提供元に問い合わせてみる
オペレータ「お電話ありがとうございます」
オペレータ「〇〇サーバ、カスタマーセンタでございます」ワイ「さっきレンタルサーバを契約したんですが」
ワイ「諸事情で、サーバのOSを変えたいんですわ」
ワイ「CentOSのプランってありまっか?」オペレータ「ご提供がございません」
ワイ「ほな、サーバーソフトウェアだけでも」
ワイ「NGINXに変えてもらえまへんか?」オペレータ「できかねます」
ワイ「なんででっか・・・」
オペレータ「今回ご契約いただいたプランは、共用サーバです」
オペレータ「1つの大きなサーバを、複数のお客様でシェアいただいている形です」
オペレータ「したがって、他のお客様に影響が及ぶようなカスタマイズはできかねます」ワイ「そらそうか・・・」
ワイ「ちなみにデータベースはMySQLだけかいな?」
ワイ「PostgreSQLなんかは・・・」オペレータ「ご用意がございません」
ワイ「Node.jsは、インストールできますかいな・・・?」
オペレータ「SSH接続ができますので、Node.jsのインストール自体はできる可能性がございます」
オペレータ「ただしroot権限がございませんので、思ったようにご利用いただけない可能性がございます」
オペレータ「そもそもPHP以外の言語のご利用は想定していないサービスですので」
オペレータ「動作保証はできかねます」ワイ「そうでっか・・・」
ワイ「ほな、契約キャンセルしたいんやけど・・・」オペレータ「キャンセルでなくご解約となり」
オペレータ「初期費用と、月額費用1ヶ月分が発生します」ワイ「Oh・・・」
オペレータ「ですが、今回はご利用の実態もないようですので」
オペレータ「費用なしでキャンセルとさせていただきます」ワイ「ホンマ、おおきにやで・・・」
じゃあ何を使おう
ワイ「今回の場合、共用サーバではアカンかったんやな」
ワイ「ほな、今度は〇〇サーバのVPSってやつを契約してみよか」
ワイ「VPSってのはバーチャル・プライベート・サーバの略で・・・」
ワイ「つまり仮想専用サーバや」
ワイ「物理的には他のユーザーさんと共用なんやけど」
ワイ「root権限を持ってるから、ワイ専用のサーバみたいに使えるやつやな」娘「パパ、もうレンタルサーバを契約しないで?」
ワイ「え・・・」
ワイ「ほな、どうするん・・・?」
ワイ「サーバコンピュータを買ってきて自前で構築するん・・・?」娘「パパ、そんなことできないでしょ?」
ワイ「それな」
娘「それより、勉強も兼ねてクラウド使おうよ」
ワイ「クラウド・・・」
ワイ「AWSとか、GCPとか、Azureとか、そういうやつかいな・・・?」娘「そうそう」
娘「AWSのEC2でいいじゃん」ワイ「EC2なら、OSとかも選べるん?」
娘「選べるよ」
娘「OS、サーバーソフトウェア、データベース、プログラミング言語・・・」
娘「好きなものをインストールして使えるよ」ワイ「自社サーバ並に自由なんやな」
娘「うん、しかもね」
- 初期費用なし
- 月額料金でなく、秒単位の従量課金
娘「↑こういう料金体系だから」
娘「今回のパパの状況にもピッタリじゃない?」ワイ「おお、秒単位の従量課金か」
ワイ「今回はコーディング試験の提出用に使うだけやから」
ワイ「1ヶ月も使用せへん。数日間だけの利用や」
ワイ「せやから、月額じゃないのは助かるわ」娘「そうでしょ?」
娘「最初の数百時間は無料!とかもあるしね」ワイ「そうなんやね」
ワイ「だいぶ柔軟な料金体系なんやな」娘「ほかにも柔軟なところがあるよ」
娘「メモリやCPUなどのスペックを、ブラウザ上からサクッと変更できるの」
娘「だから、サーバへのアクセスが増えて動作が重くなってきた場合にも」
娘「簡単にサーバをスケールアップできるの」ワイ「ほうほう」
ワイ「今回のワイみたいな、ちょっとした規模のものから」
ワイ「もっと大規模なサービスまで、柔軟に対応できるわけか」娘「そう」
娘「レンタルサーバだと、メモリやCPUを変更できないこともあるしね」
娘「できたとしても、移行に時間がかかったり、色々と制限があったり」ワイ「なるほどなぁ」
ワイ「レンサバに比べて、EC2はだいぶ柔軟なんやね」娘「そうだね」
娘「EC2 の E は Elastic」
娘「つまり柔軟って意味だからね」ワイ「なるほどな」
ワイ「そもそもEC2って何の略なん?」娘「Elastic Compute Cloudだよ」
娘「クラウド上で柔軟にコンピューターを用意できる」
娘「そんなサービスだね!」ワイ「なるほどなぁ」
レンタルサーバは不要?
ワイ「ほな、いまどきレンタルサーバは誰も使わへんってこと?」
娘「全然そんなことないよ」
娘「例えば・・・」
- Linux
- Apache
- MySQL
- PHP
- WordPress
娘「↑みたいな、よくある構成のWebサイトを作るなら」
娘「レンタルサーバの方が簡単でいいんじゃない?」
娘「それほど専門知識がなくても使いやすいと思うしね」
娘「WordPressのインストールとかも、レンタルサーバの管理画面からボタン1つで出来たりするし」
娘「エンジニア以外の人は、レンタルサーバの方が絶対に使いやすいと思うよ」ワイ「確かにな」
ワイ「色々と柔軟に選ぶことはできなくても」
ワイ「決まったスペックのものをサクッと利用開始できるのは、簡単でええよな」娘「そうだね」
娘「逆に、システム開発会社とかでガッツリ使うのには限界があるかもね」
娘「言語のバージョンとかも自由には選べないし」ワイ「確かにな」
まとめ
AWS EC2の特徴
- 柔軟・自由
- けっこう知識は必要
レンタルサーバの特徴
- よくある構成のWEBサーバを、簡単に利用開始できる
VPSの特徴
- 共用サーバよりだいぶカスタマイズ可能
- EC2よりは少ない設定で使える
ワイ「↑こんな感じやな!」
娘「そうだね!」
娘「今回のケースだと、別にVPSでも良かったかもね!」ワイ「それな」
そして晩ご飯タイム
ワイ「・・・」
娘「パパ、ご飯を食べながら寝ないで?」
ワイ「おお、すまん・・・」
ワイ「連日の就職活動で、もう1ヶ月間も寝てへんもんやから・・・」娘「パパ、無理し過ぎじゃない?」
ワイ「そんなこと言うても」
ワイ「早く就職して、貯金を貯めて」
ワイ「将来を安定させなアカンのや・・・」
ワイ「幸せな将来を作るために、今は苦しくても我慢や・・・!」娘「苦しい一日を積み上げて、幸せな人生なんて出来ないでしょ」
ワイ「えっ・・・」
娘「一日一日を楽しく過ごしてさ」
娘「そして、それを積み上げていく」
娘「それが結果的に幸せな人生になるんじゃないの?」ワイ「う・・・そういう側面もあるかも・・・」
娘「将来のために生きる、幸せな未来のために今は我慢する」
娘「それも一つのいい人生の作り方だけど」
娘「もう少しだけ今にフォーカスを当ててもいいと思う」ワイ「今にフォーカス、か・・・」
娘「このままだと、死ぬ直前に・・・」
ワイ「思えば我慢ばっかりして、辛い人生だったなぁ・・・」
娘「って思っちゃうかもしれないよ?」
娘「それよりも、楽しい一日を積み上げたほうが」ワイ「いうて幸せな人生やったな・・・」
娘「って思えるかもよ?」
ワイ「せやな・・・」
ワイ「将来と今、どっちもバランスよく幸せにならんとな」
ワイ「これからは、もう少しだけ意識して・・・」
ワイ「意識して・・・」
ワイ「意識・・・」(ガクッ)
よめ太郎「あっ」
よめ太郎「意識失ってもうた」娘「パパーッ!!」
〜おしまい〜
AWS EC2の勉強にオススメの動画
- 投稿日:2021-02-21T20:57:33+09:00
【AWS初学者向け】テスト用EC2作成時の面倒くさいことを、代わりにシェルスクリプトにやってもらおう!
1.はじめに
AWSというのはとても便利で、重いサーバー,ラックを用意しなくても誰でも簡単にサーバー構築が出来る。
そしてそれと同じように簡単にサーバーを削除することが出来る。
作っては消して作っては消してを世のハンズオンドキュメント,動画の数だけ行うのだ。
しかし何度も何度も構築するにあたってやりたいことは違えど毎回同じ作業が発生するのだ。
駆け出しであろうとIT従事者であるからには、そういう同じ無駄な作業を無くしていかなければならない。
今回はシェルでの無駄作業を自分は一切コマンドを打つことなく、代わりにシェルスクリプトに自動でやってもらおうというハンズオン記事である。
(ハンズオンと言ってもシェルスクリプトを書くだけだが..)
同時にシェルスクリプト、viの訓練にもなるので初学者の方は是非見ていって欲しい。2.概要
今回の流れは、
"EC2(Amazon Linux2)を構築する際、作成時の「ステップ3:インスタンスの詳細の設定」「ユーザーデータ(テキストで)」にあらかじめ作成しておいたシェルスクリプトを挿入、構築後の面倒なコマンド操作を自動でシェルスクリプトに行ってもらう"
となっている。
注意事項として既にネットワーク周りの設定(VPC,Subnet等)は構築済でEC2を構築した段階で外と通信が行われる前提で話を進めていく。※使用イメージはAmazon Linux2です。
3.シェルスクリプトの作成
早速だが本題のシェルスクリプトを作成する。
下記コードが今回の"面倒くさいから自動化しちゃおうスクリプト"になる。#!/bin/bash -ex exec > >(tee /var/log/user-data.log|logger -t user-data -s 2>/dev/console) 2>&1 # まずは全てのパッケージをアップデート yum update -y # 言語設定 echo "LANG=ja_JP.UTF-8" > /etc/sysconfig/i18n # 時刻同期 sed -ie 's/ZONE=\"UTC\"/ZONE=\"Asia\/Tokyo\"/g' /etc/sysconfig/clock sed -ie 's/UTC=true/UTC=false/g' /etc/sysconfig/clock ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime # ホスト名の変更 HOST_F=hostname.domainname sed -ie "s/localhost\.localdomain/${HOST_F}/g" /etc/sysconfig/network #/etc/hostsにホスト名を追加 ip addr show | grep "inet.*eth0" | awk {'print $2'} | sed -e 's/\(.*\)\/.*$/\1/g' | xargs -I{} echo "{} ${HOST_F} ${HOST_S}" >> /etc/hosts # ユーザの作成 & passwd設定 ※testuserを貴方の好きなユーザー名に、testpasswdを好きなパスワードに変更して下さい。 useradd testuser echo "testpasswd" | sudo passwd --stdin testuser # su権限を与える sed -i -e '$ a testuser ALL=(ALL) NOPASSWD:ALL' /etc/sudoers # パスワード認証でのSSH接続の許可 sed -i -e 's/PasswordAuthentication no/PasswordAuthentication yes/g' /etc/ssh/sshd_config # sshdを再起動し、設定を反映 ※これで作成したユーザーによるSSH接続(passwd認証)が可能になります。 systemctl restart sshd # ec2-userの削除 userdel ec2-user # 王道のApacheをセットアップ ※nginxを使用する際はhttpdをnginxに変える amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2 yum install -y httpd mariadb-server systemctl start httpd systemctl enable httpd usermod -a -G apache ec2-user chown -R ec2-user:apache /var/www chmod 2775 /var/www find /var/www -type d -exec chmod 2775 {} \; find /var/www -type f -exec chmod 0664 {} \; echo "<?php phpinfo(); ?>" > /var/www/html/phpinfo.php # おまけ touch sample.txt echo "blogyondekuretearigatougozaimasu" > sample.txtテスト用インスタンスに必要な初期設定はこれくらいになるはず。
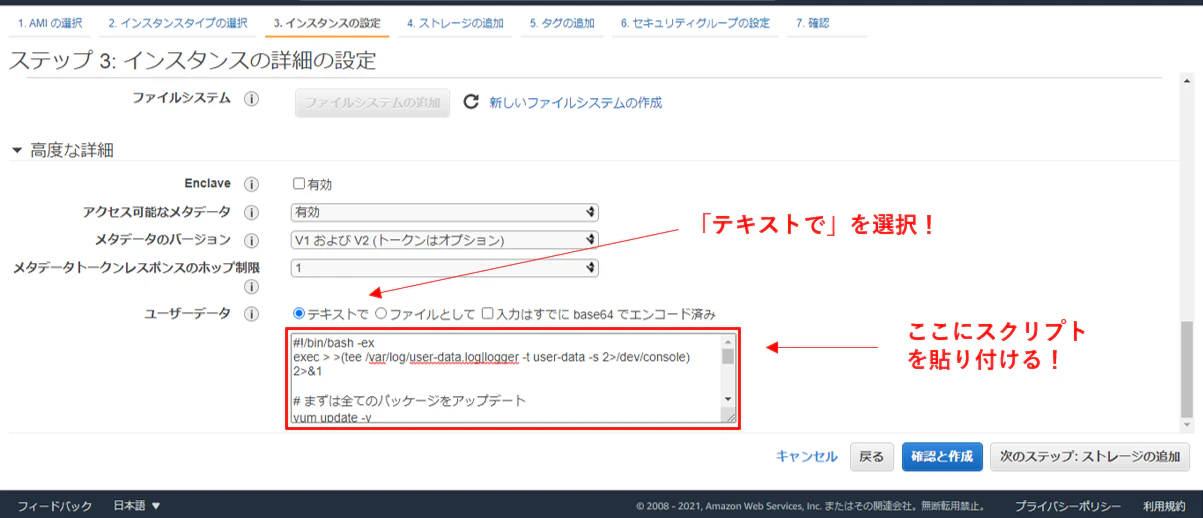
こんなんも自動化したら楽になるといったものがあれば是非コメントでいただきたい。4.EC2の構築
では実際にシェルスクリプトをユーザーデータに貼り付けてEC2を構築してみよう。
EC2の構築講座ではないので構築手順等については他の記事がいくらでもあるので参照していただきたい。手順1:上記スクリプトの必要箇所を修正してコピー
手順2:EC2を作成、ステップ3のユーザーデータにスクリプト貼り付け ※下記画像参照
手順3:SSH接続 ※作成したユーザー名とパスワードを入力して下さい
手順4:各設定が反映されているか確認 ※下記コマンド参照・コマンド確認
# ホスト名が変わっているか cat /etc/hosts #時刻同期が出来ているか date #ユーザー名が変わっているか cat /etc/passwd | grep 設定したユーザー名 #ec2-userが削除できているか cat /etc/passwd | grep ec2-user・Apache確認
EC2インスタンスのPublicIPAddressをコピーしてブラウザのURLに貼り付けて検索実行。
Apacheのページが表示されたら確認OK。5.まとめ
といった感じでうまい具合に面倒くさい作業が自動化されたわけだ。
もちろん人によって面倒くさいは変わってくると思うので、各々が好きにスクリプトをカスタムするのをおすすめする。
実はシェルスクリプト以外にもユーザーデータを使用しての自動化は行えるが、今回は一番ポピュラーなシェルスクリプトを使用させていただいた。
上記でも書いたがこういうことを構築時に自動化したい等あれば是非コメント等いただきたい。
では以上で失礼します。この記事はAWS初学者を導く体系的な動画学習サービス
「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com
- 投稿日:2021-02-21T20:12:14+09:00
EC2で構築した本番環境のログを確認して、エラーを修正した後デプロイするまで(備忘録)
開発環境
Mac OS Catalina 10.15.7
ruby 2.6系
rails 6.0系本番環境
nginx 1.18.0
AWS(EC2, S3, ALB, Route53)前提
備忘録の意味合いが強い記事です
capistranoのによる自動デプロイを導入しています
EC2にログイン
# ターミナル ssh -i [ダウンロードした鍵の名前].pem ec2-user@[インスタンスのElastic IP]ディレクトリを移動
コマンドを実行してlogディレクトリまで移動する
[ec2-user@ip-xxx-xx-xx-xxx~]$ cd /var/www/アプリケーションの名前[ec2-user@ip-xxx-xx-xx-xxx <アプリケーション名>]$ cd current[ec2-user@ip-xxx-xx-xx-xxx current]$ cd log[ec2-user@ip-xxx-xx-xx-xxx log]$ ls production.log unicorn.stderr.log unicorn.stdout.logログを確認
# 実行すると最新のログを10行分表示 [ec2-user@ip-xxx-xx-xx-xxx log]$ tail -f production.log実際に本番環境でエラーになっている機能を試したり、エラーになっているページに遷移した際のログを読みエラー内容を把握する
修正した後、再びデプロイする
# プロセスIDを確認 [ec2-user@ip-xxx-xx-xx-xxx <アプリケーション名>]$ ps aux | grep unicorn ec2-user 19728 ←この数字の部分(killするのはmaster)# プロセスIDをkillする [ec2-user@ip-xxx-xx-xx-xxx <アプリケーション名>]$ kill 19728# 再びデプロイ(ローカルから) bundle exec cap production deploy注意として、デプロイし直した際に画像データが消えてしまうが、S3に画像の保存先を変えることで解決できる
以上です。
- 投稿日:2021-02-21T18:02:05+09:00
Buildkitを「docker-compose build」で使う方法
皆さんこんにちは!
まだまだ毎日投稿しているのですがネタ尽きないっす。
なんならもっと書きたいぐらい。
色々記事書いてるので、ぜひ時間のある方はほかの記事もご覧ください!
さて、今回はDockerの記事です。
Dockerで作ったイメージをAWSのECRにプッシュしようとしたら以下のような警告が表示されました。
[+] Building 0.1s (2/2) FINISHED => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 2B 0.0s => CANCELED [internal] load .dockerignore 0.0s => => transferring context: 0.0s failed to solve with frontend dockerfile.v0: failed to read dockerfile: open /var/lib/docker/tmp/buildkit-mount119702719/Dockerfile: no such file or directory明らかにビルドできてない気がする。
実際にECSでこのイメージを使ってもエラーが表示される。
ってことで半日くらいかかった末にようやく答えが出た。
僕自身WindowsでDockerの開発を行っているのですが、Windowsだとこの現象が起きるらしいです。
悲し。。。
なので、
docker-composeでビルドしちゃえばいいんじゃねって思って半日近くの時間を費やしようやく答えを見つけた!どうやら
docker-composeはデフォルトではBuildkitに対応していないらしい。なので、
docker-composeでBuildkitを有効にする魔法のコマンドを打つ!!!Mac
COMPOSE_DOCKER_CLI_BUILD=1 docker-compose buildWindows
set "COMPOSE_DOCKER_CLI_BUILD=1" & set "DOCKER_BUILDKIT=1" & docker-compose build
COMPOSE_DOCKER_CLI_BUILD=1という環境変数を追加してあげることでBuildkitを使用してコンテナをビルドできるそうです。Dockerは習い始めて約2週間、AWSは約1週間くらいなのですが、なれるまでに時間がかかりそうですね。
以上、「[Docker]Buildkitを「docker-compose build」で使う方法」でした!
良ければ、LGTM、コメントお願いします。
また、何か間違っていることがあればご指摘頂けると幸いです。
他にも初心者さん向けに記事を投稿しているので、時間があれば他の記事も見て下さい!!
Thank you for reading
- 投稿日:2021-02-21T14:29:51+09:00
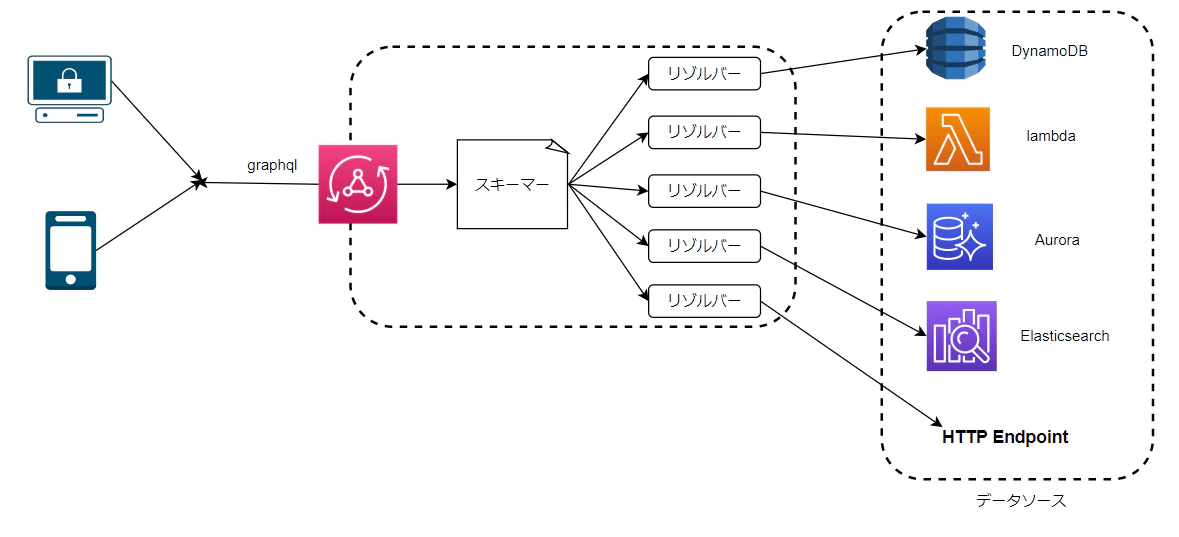
Slack の Slash Command から、API Gateway + Lambda を呼び出す
はじめに
Slack の Slash コマンドは、チャット欄にスラッシュから始まる各種機能を利用する仕組みです。例えば、最初から使える
/dmコマンドは、特定のアカウントにダイレクトメッセージを送るための コマンドです。こんな感じに、チャット欄から直接DMを送れます。
Slash Command は独自にアプリケーションを開発できます。自分たちで作ったアプリケーションと連携することで、様々な自動化が実現できます。今回の記事では、独自の Slash Command から AWS の API Gateway と Lambda と連携する手順を紹介します。Hello World 的な、クイックスタートの手順です。
Create a Slack App
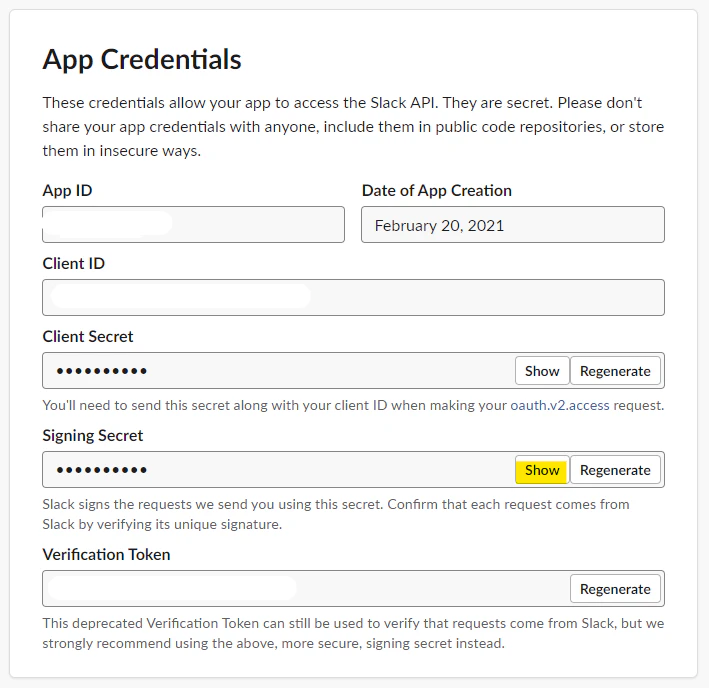
まず、Slack 上で、Slack App を作成します。次の URL にアクセスして、適当に作成しましょう。
Create an App を選びます。
適当に名前や、対象の Slack Workspace を選びます。
App Credentials の Signing Secret をコピーします。この記事では、あとで Systems Manager の Parameter Store に保存するので、メモっておきます。
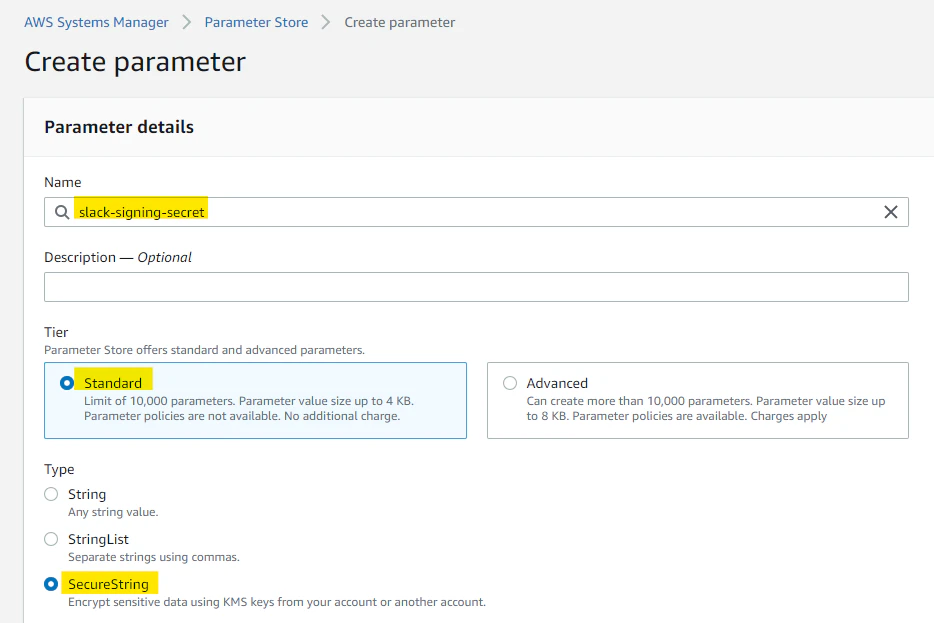
Systems Manager の Parameter Store に、Slack Signing Secret を保存
Systems Manager の Parameter Store に、先ほどメモした Signing Secret の値を格納します。他の方法で、Secret Manager を使う選択肢もありますが、1 Secret あたり 0.4 USD かかってしまうので、今回は、Systems Manager を使っていきます。
適当にパラメータ入力します
slack-signing-secret
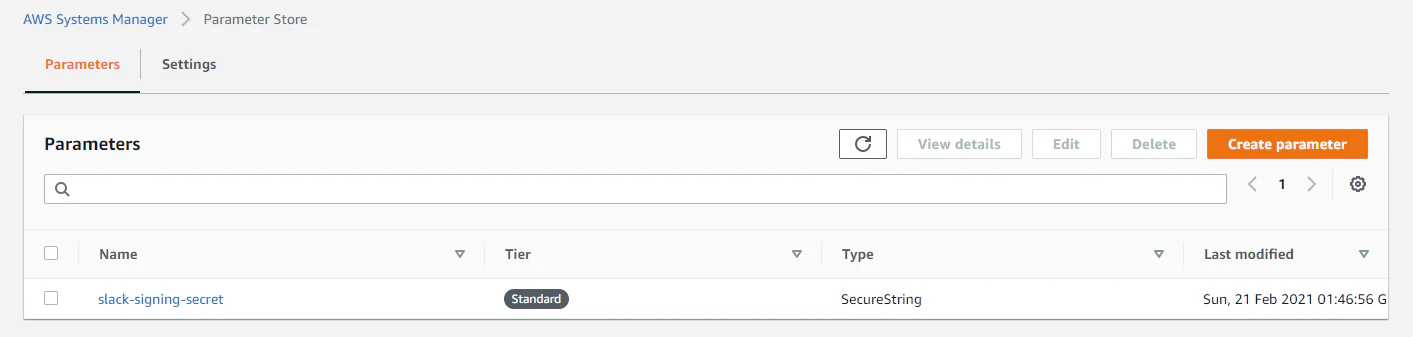
Slack の Signing Secret を入力して、Create parameter を押します
作成完了
Lambda の Python ソースコード
この記事では詳細は割愛しますが、SAM (Serverless Application Model) で作っていきます。Python のソースコードはこんな感じです。Slack 上の Slash Command で受け取ったユーザー名とテキストメッセージを、概ねそのまま返答する内容です。
print で debug を雑に入れていますが、気にしないでください・・・。
import os import json import boto3 import hmac import hashlib import datetime from urllib import parse import logging logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) TOKYO = 'ap-northeast-1' # Get credentials secret_name = os.environ['SLACK_API_SIGNING_SECRET'] ssm = boto3.client('ssm', region_name=TOKYO) resp = ssm.get_parameters( Names=[secret_name], WithDecryption=True ) print("!!!!!!!!!!ssm!!!!!!!!!") print(resp) secret = resp['Parameters'][0]['Value'] print(secret) def verify(headers, body): try: signature = headers["X-Slack-Signature"] request_ts = int(headers["X-Slack-Request-Timestamp"]) now_ts = int(datetime.datetime.now().timestamp()) print("!!!!!!!!!!!!!!!!!signature!!!!!!!!!!!!!!!!!") print(signature) print("!!!!!!!!!!!!!!!!!request_ts!!!!!!!!!!!!!!!!!") print(request_ts) print("!!!!!!!!!!!!!!!!!now_ts!!!!!!!!!!!!!!!!!") print(now_ts) message = "v0:{}:{}".format(headers["X-Slack-Request-Timestamp"], body) print("!!!!!!!!!!!!!!!!!message!!!!!!!!!!!!!!!!!") print(message) expected = "v0={}".format(hmac.new( bytes(secret, 'UTF-8'), bytes(message, 'UTF-8'), hashlib.sha256).hexdigest()) print("!!!!!!!!!!!!!!!!!expected!!!!!!!!!!!!!!!!!") print(expected) except Exception: print("!!!!!!!!!!!!!!iam exeption!!!!!!!!!!!!!!") return False else: print("!!!!!!!!!!!!!!iam else!!!!!!!!!!!!!!") if (abs(request_ts - now_ts) > (60 * 5) or not hmac.compare_digest(expected, signature)): print("!!!!!!!!!!!iam false!!!!!!!!!!!!!!") return False return True def lambda_handler(event, context): print("!!!!!!!!event!!!!!!!!!!!") logger.info(json.dumps(event,indent=4)) if verify(event['headers'], event['body']): username = parse.parse_qs(event['body'])['user_name'][0] text = parse.parse_qs(event['body'])['text'][0] payload = { "text": 'よお!' + username + '! あんた「' + text + '」って言ったか?', } response = { "statusCode": 200, "body": json.dumps(payload) } return response else: logger.info("Error: verify request") return {"statusCode": 400}
/hello-slack おっす!おらスギ!てな感じに、Slack 上で Slash Command を実行すると、次のように Bot が返ってくる実装です
SAM Template
SAM の template.yaml で気にするべきポイントが2点あります
- Systems Manager の Parameter Store に保存した、
slack-signing-secretという key 名を環境変数に指定- API Gateway の Endpoint は、GET ではなく、POSTを指定 (Slack の Slash Command は、POST でリクエストされるので)
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > hello-slash-command Sample SAM Template for hello-slash-command # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 10 Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_slash_command/ Handler: app.lambda_handler Runtime: python3.6 Environment: Variables: SLACK_API_SIGNING_SECRET: slack-signing-secret Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello_slash_command Method: post Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello_slash_command/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.ArnDeploy
詳細は省略しますが、SAM で Deploy すると、API Gateway と Lambda が自動的に出来上がります
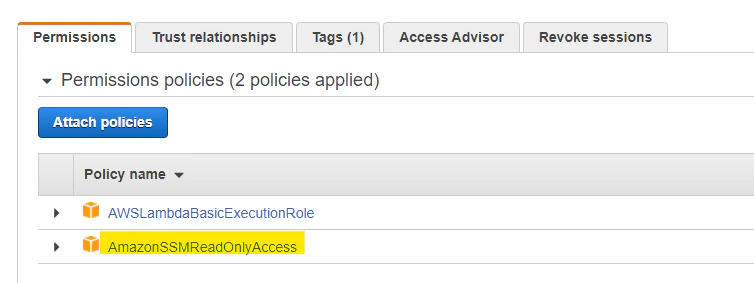
sam build sam deployIAM Role の権限調整
SAM によって自動設定された、Lambda Function の IAM Role の権限を変更します。Systems Manager の Parameter Store に対して、読み取り権限を設定します。Attach policies から、
AmazonSSMReadOnlyAccessを追加します。
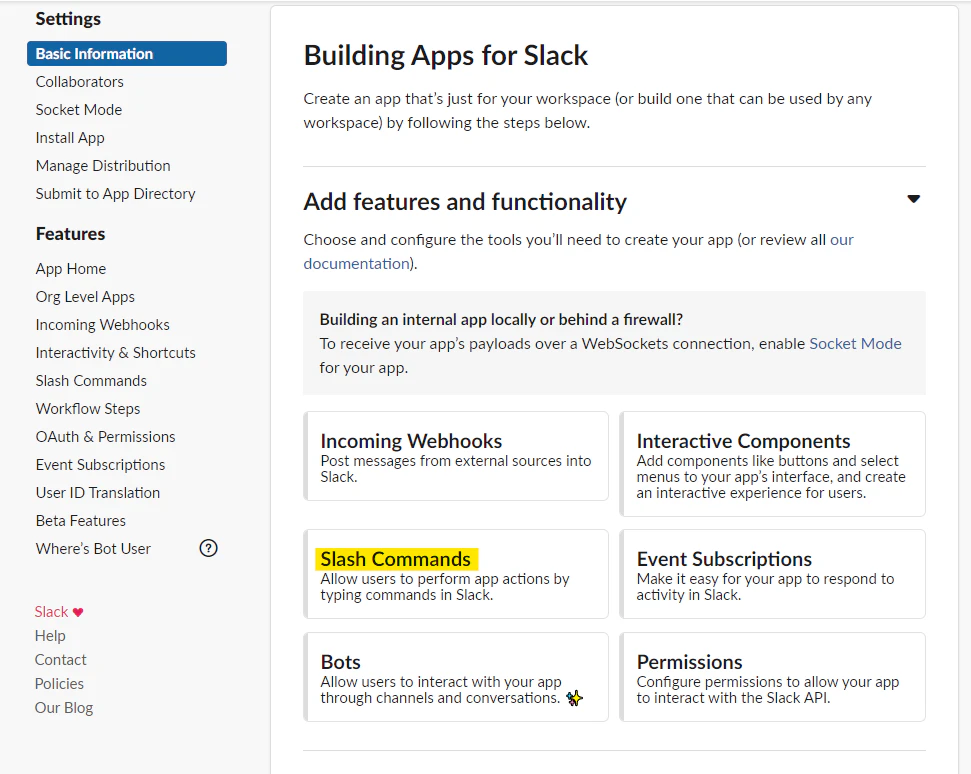
Slack App から、API Gateway を呼び出し設定
Slack の管理ページで、Slash Commands を選びます
Create New Command を押します
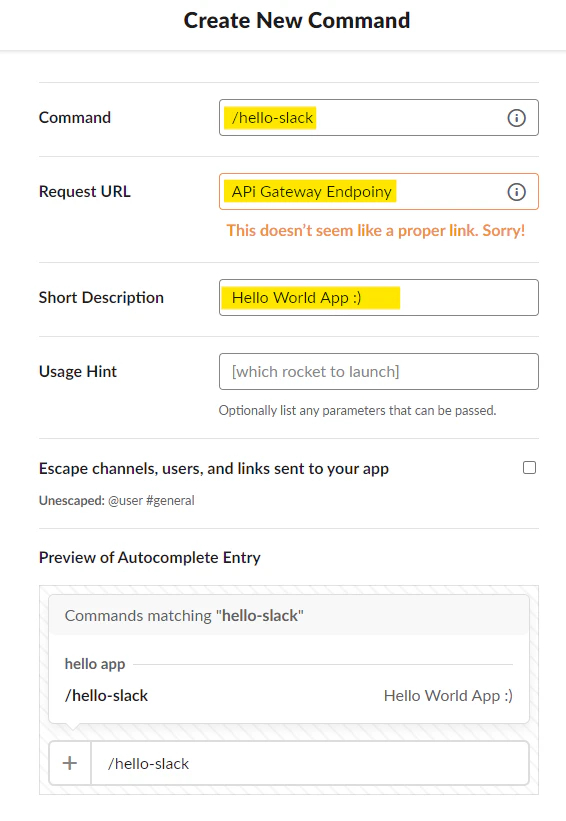
API Gateway の Endpoint を指定して、作成します。
Slack Workspace に、作成した Slack App を Install
Install to Workspace を押して、自分の Workspace に作成した Application をインストールします
動作確認
これで設定完了です。Slack 上で動作確認をしてみましょう。こんな感じにチャット欄に打ちます
自動的に、hello app bot が返答をしてくれます。
付録 : Slack Slash Command Event
Slack の Slash Command を経由して、AWS Lambda が受け取る Event を JSON で出力します。
X-Slack-Signatureやbodyなどの部分に、Slack 上のさまざまな情報が含まれています。本格的な実装をするときには、このあたりを確認してみるとよいでしょう。{ "resource": "/hello_slash_command", "path": "/hello_slash_command/", "httpMethod": "POST", "headers": { "Accept": "application/json,*/*", "Accept-Encoding": "gzip,deflate", "CloudFront-Forwarded-Proto": "https", "CloudFront-Is-Desktop-Viewer": "true", "CloudFront-Is-Mobile-Viewer": "false", "CloudFront-Is-SmartTV-Viewer": "false", "CloudFront-Is-Tablet-Viewer": "false", "CloudFront-Viewer-Country": "US", "Content-Type": "application/x-www-form-urlencoded", "Host": "xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com", "User-Agent": "Slackbot 1.0 (+https://api.slack.com/robots)", "Via": "1.1 xxxxxxxxxxxxxxxxxxxxxxxxx.cloudfront.net (CloudFront)", "X-Amz-Cf-Id": "fLDItaNwCxQ0mdnsfuB6B8yfqDo1DAyiUaYOOyom203UAbOVa8XDsw==", "X-Amzn-Trace-Id": "Root=1-6031d5ad-10791ca3111bbf736ad507b7", "X-Forwarded-For": "18.206.59.21, 130.176.98.164", "X-Forwarded-Port": "443", "X-Forwarded-Proto": "https", "X-Slack-Request-Timestamp": "1613878701", "X-Slack-Signature": "v0=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }, "multiValueHeaders": { "Accept": [ "application/json,*/*" ], "Accept-Encoding": [ "gzip,deflate" ], "CloudFront-Forwarded-Proto": [ "https" ], "CloudFront-Is-Desktop-Viewer": [ "true" ], "CloudFront-Is-Mobile-Viewer": [ "false" ], "CloudFront-Is-SmartTV-Viewer": [ "false" ], "CloudFront-Is-Tablet-Viewer": [ "false" ], "CloudFront-Viewer-Country": [ "US" ], "Content-Type": [ "application/x-www-form-urlencoded" ], "Host": [ "xxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com" ], "User-Agent": [ "Slackbot 1.0 (+https://api.slack.com/robots)" ], "Via": [ "1.1 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.cloudfront.net (CloudFront)" ], "X-Amz-Cf-Id": [ "fLDItaNwCxQ0mdnsfuB6B8yfqDo1DAyiUaYOOyom203UAbOVa8XDsw==" ], "X-Amzn-Trace-Id": [ "Root=1-6031d5ad-10791ca3111bbf736ad507b7" ], "X-Forwarded-For": [ "18.206.59.21, 130.176.98.164" ], "X-Forwarded-Port": [ "443" ], "X-Forwarded-Proto": [ "https" ], "X-Slack-Request-Timestamp": [ "1613878701" ], "X-Slack-Signature": [ "v0=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" ] }, "queryStringParameters": null, "multiValueQueryStringParameters": null, "pathParameters": null, "stageVariables": null, "requestContext": { "resourceId": "kkohuo", "resourcePath": "/hello_slash_command", "httpMethod": "POST", "extendedRequestId": "bE5TIGpaNjMFjUg=", "requestTime": "21/Feb/2021:03:38:21 +0000", "path": "/Prod/hello_slash_command/", "accountId": "xxxxxxxxxxxx", "protocol": "HTTP/1.1", "stage": "Prod", "domainPrefix": "d2k8taas2f", "requestTimeEpoch": 1613878701501, "requestId": "5c4d6ad2-cdd2-4811-a702-c934f655ff9d", "identity": { "cognitoIdentityPoolId": null, "accountId": null, "cognitoIdentityId": null, "caller": null, "sourceIp": "18.206.59.21", "principalOrgId": null, "accessKey": null, "cognitoAuthenticationType": null, "cognitoAuthenticationProvider": null, "userArn": null, "userAgent": "Slackbot 1.0 (+https://api.slack.com/robots)", "user": null }, "domainName": "xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com", "apiId": "d2k8taas2f" }, "body": "token=xxxxxxxxxxxxxxxxxxxxxxxx&team_id=T01N7S6GULB&team_domain=sugimountspace&channel_id=C01NNGPMUMR&channel_name=emoji&user_id=U01NXFH8HEC&user_name=sugi.mount&command=%2Fhello-slack&text=konnitiwa&api_app_id=xxxxxxxxxx&is_enterprise_install=false&response_url=https%3A%2F%2Fhooks.slack.com%2Fcommands%2FT01N7S6GULB%2F1775959830099%2FuZFJRIZzqXV1oGptZxNhmvEG&trigger_id=1772668744117.1755890572691.7dcc5fd41718fb89b0c75c6eb666bc26", "isBase64Encoded": false }参考URL
【入門】Slack のコマンドを作ってみよう!(同期実行版)
https://dev.classmethod.jp/articles/lets-make-slack-commands-synchronous-execution-version/AWS SDK for Python (Boto3) で AWS Systems Manager パラメータストアから情報を取得する
https://dev.classmethod.jp/articles/get-data-from-system-manager-parameter-store-using-boto3-ja/Slack の Slash Command をサーバーレスで実装
https://hacknote.jp/archives/39319/





- 投稿日:2021-02-21T14:13:39+09:00
AWSのボリュームを変更して反映する
概要
掲題の通りです。
たまにしかやらないせいで毎回やり方調べるハメになるので、備忘として手順やらまとめておきます。結論
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/recognize-expanded-volume-linux.html
に載ってる通りにやればいいよ手順
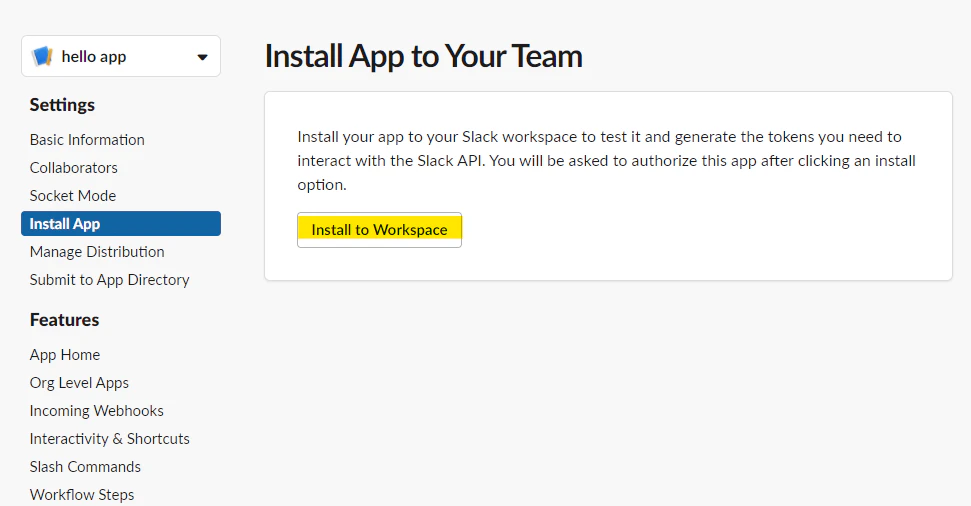
コンソール側での作業
いつのまにか、AWSコンソール上からでもボリュームの変更はできるようになっていました。
増やす分には特にデータ消えたりみたいな問題にはならないので、淹れたてのコーヒーにミルクを注ぐくらいの気持ちでポチっと押します。
CLI側での作業
EC2にログインして作業します。
# 状況確認 $ df -hT ファイルシス タイプ サイズ 使用 残り 使用% マウント位置 /dev/xvda1 xfs 16G 12G 4.3G 74% / tmpfs tmpfs 395M 0 395M 0% /run/user/1000 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 32G 0 disk # 32GBに反映されてる └─xvda1 202:1 0 16G 0 part / # 実際に拡張する $ sudo growpart /dev/xvda 1 CHANGED: partition=1 start=4096 old: size=33550303 end=33554399 new: size=67104735 end=67108831 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 32G 0 disk └─xvda1 202:1 0 32G 0 part / # 反映された $ df -hT ファイルシス タイプ サイズ 使用 残り 使用% マウント位置 /dev/xvda1 xfs 16G 12G 4.3G 74% / #こっちはまだ $ sudo xfs_growfs /dev/xvda1 meta-data=/dev/xvda1 isize=512 agcount=9, agsize=524159 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1 spinodes=0 data = bsize=4096 blocks=4193787, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 data blocks changed from 4193787 to 8388091 $ df -hT ファイルシス タイプ サイズ 使用 残り 使用% マウント位置 /dev/xvda1 xfs 32G 12G 21G 37% / # OK!ちなみに、
grawpart [device] [number]の[number]部分には、パーティションの番号を指定します。
今回は/dev/xvda1が対象だったので、 1 を指定しています。
- 投稿日:2021-02-21T14:13:23+09:00
【未経験PF / Rails / React / AWS / Docker / CircleCI】独学+メンターでここまで出来た!Web知識ゼロからモダンな技術アプリ開発までに利用した5つのサービス
0. はじめに
こんにちは!辻野(@ddpmtcpbr)と申します。
当記事は、「Webエンジニアへのキャリアチェンジを目指している開発未経験者が、モダンな技術を備えたアプリを開発するまでの学習過程」についてまとめたものです。
現在筆者は非IT系企業の社員として働いており、Web開発エンジニアとしての実務経験はありません。
そんな筆者がWebエンジニアとしてのキャリアチェンジをするためのポートフォリオとして、本アプリを開発しました。
学習開始から現時点までにおいて、プログラミングスクール等には通っておらず、学習はほぼ全て独学&一部メンターサービス利用の布陣で進めてきました。
独学中心でアプリ開発に挑戦したい、ポートフォリオを作成してWebエンジニアへのキャリアチェンジを進めていきたい、と考えている方々にとって、参考になればと思います。
最初に、今回私が開発したアプリの概要を紹介します。
アプリ名: 積読解消アプリ 「Yomukatsu!」
「あなたの積読解消をサポートします」をスローガンに掲げたSPA風Webアプリです(”風”の詳細は後述)。
読書メンタルマップという手法を用いて、ユーザーの書籍完読に向けたモチベーション維持をサポートします。
Web URL: https://yomukatsu.com/
【3分動画】Yomukatsu 字幕解説
アプリの使い方を3分でまとめています。
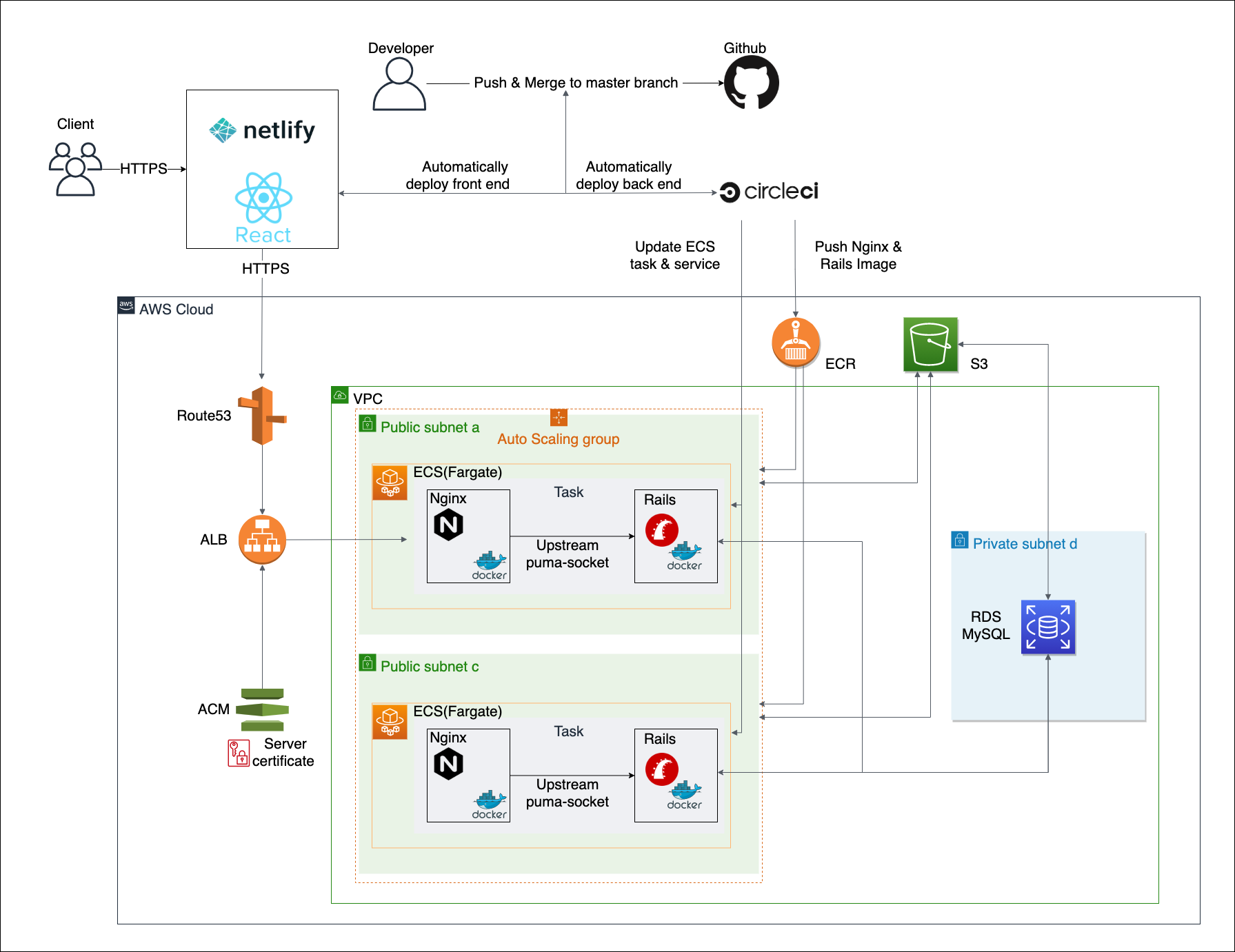
使用技術
Backend: Rails ( API mode / Rspec / rubocop) + Nginx ( upstream puma-socket )Frontend: React ( create-react-app / Redux / Material-UI / eslint&prettier)Infra: AWS ( ECS Fargate/ ECR / RDS / ALB / Route53 ), Netlify, Docker&docker-compose, CircleCI各項目の詳細は後述しています。
インフラ構成
モダンな技術を採用したWeb系企業が提供している、中・大規模なアプリケーションを想定したインフラ構成にしています(そのため、個人開発アプリとしてみるとちょっと仰々しいかもです(;’∀’))
詳細は後述しています。
機能一覧
ユーザー利用機能
- Twitterアカウントを利用したユーザー登録(OAuthによるSNS認証)
- ゲストログイン機能
- Google Books APIを用いた書籍検索機能
- Google Books、Amazon、楽天ブックスへのリンクボタン配置
- Twitterシェア機能
- ハッシュタグ「#yomukatsu」付きTweet
- Twitter card 表示
- Twitter card用にリサイズした書籍画像をAWS S3へ保存・管理
- Redux による state 管理を活用したローディング画面
- Slack Incomming Webhookを利用したお問い合わせ機能
- Route53 による独自ドメイン + SSL化
非ユーザー利用機能
- Netlify の Pre-reidering 機能活用による動的なOGP情報の保持( Twitter card 表示用)
- Docker による開発環境の完全コンテナ化
- CircleCI による自動 CI/CD パイプライン構築
- CI: Rspec, rubocop, eslint&prettier
- CD: AWS ECR
- その他セキュリティ対策(XXS, CSPF等)
まず触ってみてもらうのが一番良いかと思います!今回はフロントエンドに React を採用しているため、メニューモーダルの開閉や通知バー表示など、アニメーション的な表現も実装できているのが伝わるかと思います。
ゲストユーザー機能もありますので、気軽に利用してみてほしいです!レスポンシブにも対応しています。(推奨ブラウザはChrome、Safariになります)
アプリURL: https://yomukatsu.com/
※現在α版としてのリリースのため、配信内容が予告無く変更される可能性がございます
あわせて、
Githubも公開していますので、よかったら参考にしてください。Github URL: https://github.com/ddpmntcpbr/rails_react_docker
この記事について
当記事は3章構成になっております。
まず、「1.自己紹介」で、簡単に自己紹介をさせていただきます。
次に、「2.開発アプリ解説」で、今回の開発アプリ開発について、コンセプト決定の流れから、実装機能/技術スタックについて詳しく紹介します。「転職用PF作りたいけど、どんなアプリを作ればいいか分からない」という方にとって、参考になることがあれば幸いです。
最後に、「3. 学習ロードマップ」で、Web知識ゼロだった筆者が、当アプリの開発にまでに利用した
5つの教材およびサービスについて、時系列に沿って紹介したいと思います。特に独学では、「まず何を学べば良いのか」「どんな教材を選べば良いのか」というところから自身で考える必要があります。そういった方々にとって参考になり得る情報と思います。1. 自己紹介
1.1 筆者スペック
- 20代後半 男
- 工学部機械系 修士卒 → 非IT系 日系製造業 技術開発職(現職)
- 大学から現職において、データ分析ツールとしてプログラミングを経験(matlab / python)
- Webエンジニアへのキャリアチェンジを目指し、社会人になってから独学を開始
大学入学以降、授業や研究データの分析ツールとしてプログラミングに触れる機会はありました。もともと自動化や効率化に興味があったことからプログラミングにだんだんとのめり込み、研究室ではプログラミングに多く触れられそうな研究テーマ(データ分析系)を選びました。
したがって、「プログラミング自体が完全に未経験」というわけではありませんでした。しかし、いわゆる”Web系”の知識は社会人以降の独学を開始するまではゼロ、という状態で、最初は HTML すら知らないところからのスタートでした( ̄▽ ̄;)。そのため当記事では「Web知識ゼロ」という表現をしています。
キャリアチェンジ志望の理由は、ざっくりと言えば、
1. もっとプログラミングがしたい
2. モノづくりで誰かの役に立ちたい
3. 非効率・非生産的な仕事を無くしたいここについては当記事の趣旨ではないので、詳細については省略します。
2. 開発アプリ解説
2.1 コンセプト方針
転職用PFアプリのコンセプトを決めるにあたり、満たすべき用件としては、下記3点を考えました。
(a) 実際の企業が採用しているようなモダンな技術を盛り込む
(b) 具体的な解決課題を明確にする
(c) サービスの利用が個人で完結する(a) 実際の企業が採用しているようなモダンな技術を採用する
未経験からエンジニア転職において、高品質なポートフォリオは必須と考えました。
「モダンな技術をポートフォリオに組み込むことで、技術力の高さをアピールする」というのが基本的な考え方になるとは思いますが、個人的な解釈としては、ポートフォリオで証明すべきは「技術力」ではなく「自走力」だと考えています。
ぶっちゃけた話、実際の現場を経験したエンジニアと比べれば、未経験者間での能力差というものはどんぐりの背比べのようなものだと思います。多くの企業が「実務経験1年以上」をエンジニアの採用項目にあげていることからも、実務経験というのはそれだけ重い価値があり、未経験者とは大きな隔たりがあるのだと思います。
したがって、ポートフォリオの技術レベルの高さそのものはあまり重要ではなく、そこに到達するまでの過程の方が大事であり、「自走力=必要な情報は自らキャッチアップして吸収する能力」があることを示す方が、企業人事側としては採用しやすいのではないか?と考えました。
「スクールの制作アプリをそのまま提出する未経験者が足切りされてしまう」という話は多く聞きますが、これはそのアプリの技術力が低いからではなく、そのアプリから当人の「自走力」が主張できないから、だと私は考えています。私が独学ベースにこだわったのは、単純にお金の問題だけではなく、独学ベースでアプリを開発することができれば、自然とそれが「自走力の証明」につながると考えたからです。
今回のアプリにおいては、「独学:メンター=8:2」 くらいの割合で、上記技術を採用できるラインまで行くことができています。「メンター利用は独学からは外れるのでは?」という指摘もあるかもしれませんが、
- プログラミングでは、個人ではどうにもならないようなエラーに遭遇してしまうことが多々ある
- 実際に企業に入ってからは、先輩エンジニアの方々に分からないことを質問しながら業務を進めることになるため、「質問力」も重要な能力である
- 完全独学オンリーだと、誤った癖が身についてしまっているリスクが高くなる
といった観点から、独学者が適宜メンターサービスを利用することは、かえって採用人事側にとって安心感を与える材料になるのでは、と考えたので、自信を持って「メンターサービスを使いました」と主張しています。
※ 具体的なモダンな技術リスト
Rails API+ JSフレームワーク(React.js)の構成Dockerで実行環境を完全コンテナ化Herokuではなく、AWSでアプリをデプロイ(ECS Fargate & ECR)Circle CIによるCI/CDパイプラインの構築(b) 具体的な解決課題を明確にする
さて、前章とは一見真逆のことを言いますが、アプリ開発において、モダンな技術を採用することそのものには本来何の価値もない、と考えています。
なぜなら、アプリの目的はあくまでも「ユーザーにとって価値を提供できるか」であり、技術はそれを実現するための手段でしかないはずだからです。(保守・運用面でのメリットも考えられますが、保守・運用の最終目的もユーザーへの価値提供であることから、この点も包含した解釈になります)
これは、技術というものを下に見ているというわけでは決してありません。むしろ「新しい技術をどんどん使ってみたい!」という技術に対する好奇心、探究心は人一倍強い自負があります。現職はIT系ではありませんが、技術開発職という立場で業務に取り組んでおり、知的好奇心を満たせるという意味では、今の仕事に面白みを感じています。
しかしながら、かつては行き過ぎた技術先行思想によって「手段の目的化」が発生し、「最新技術を駆使した誰にとっても役に立たない技術」を開発してしまったという苦い過去の経験があったりもします。結果として「やっぱり技術は人の役に立ってなんぼ」というのが、約3年間技術職として働いてきて培った、技術者としての小さな矜持だったりします(この辺の話は直接お会いした方にはお話できるかと思います)
転職用PFであれば、技術ありきな考え方になることはある程度は仕方がないことでしょう。しかし「せっかく作るのであれば、誰かにとって役に立ち得るものを目指そう」くらいのことは転職用PF作成においても考えていいんじゃないかな?と思いました。あるいは、もう少し目線を下げて「自分が欲しいものを作ろう」という程度でも十分でしょう。大事なのは、まず課題があり、それを解決する手段として技術があるという順番だと思いました。
もちろん今回の開発アプリは転職用PFが趣旨である以上、中には「技術力を証明したいから」という理由で選定した技術もあり、全てに対して課題が明確だったわけではありません。また、初心者の個人開発アプリがいきなりバズることは現実的には厳しいとは思います。しかし、そこを目指す姿勢があるかというのは、エンジニアとして本格的にキャリアを進めていく上では、長期的には大きな差異になると考えています。
また、
- 課題が明確な方が採用した技術や実装した機能の根拠も明確にできるため、開発の方針を立てやすい
- 自身がユーザー目線に立てることで、改善点を見つけやすい
- 純粋にモチベーションを維持しやすい
といった点でもメリットもあると感じましたので、この方針は間違っていなかったと思います。
(c) サービスの利用が個人で完結する
「せっかく作るのであれば、誰かにとって役に立ち得るものを目指そう」を、もう一歩深く考えた方針です。
例えば Rails を対象として考えたとき、一般的な転職用PFとしては、
TwitterライクなSNS系アプリや、メルカリライクなEC系アプリが多いかと思います。理由は、ユーザー認証、CRUD操作、DB間のリレーションなど、基本的なサーバーサイド技術を一通り抑えられるものであるから、だと思います。「Railsの一般的な知識を持っていることを証明する」手段と考えれば、妥当な方針でしょう。
しかしながら、
未経験者が転職用に開発した上記アプリが実際にユーザーに継続して使われるということは、まず無いでしょう。SNS系アプリは「ユーザー数が多ければ多いほどサービスとして質が高まる」性質があるため、アプリとして軌道に載せること自体が非常に難しいです。EC系アプリは BtoC であれば出品企業がいないとサービスが成り立たない、CtoCであればより SNS として要素が強まる & いよいよメルカリで十分、という壁があります。これらアプリの難しさは、ユーザーどうしがつながることを前提としている点にあります。裏を返せば「個人で完結するアプリであれば、活路はある」とも言えると考え、この方針でコンセプトを詰めていくことにしました。
2.2 コンセプト内容
上記3点を念頭に置きながら、自分自身の生活の中で"課題"を探し、最終的にたどり着いたものが「
読書メンタルマップ術の電子化」というコンセプトでした。そもそも皆様は、読書メンタルマップ術というものをご存知でしょうか?
読書メンタルマップ術とは、ハーバード大学の先生が提唱している積読解消術です。読破したい書籍に対して、
1. 完読したい本について、それを読む“理由”や“目的”を3つ、紙に書きだす
2. 飽きてきたら、それを見返すを繰り返すことで、完読までモチベーションを維持するというシンプルな読書手法です。
積読というものは、だいたい「最初は読む気があったけど、次第に読む気がなくなってしまった」書籍です。この「最初の読む気」を事前に明文化・保存しておくことで、いつでも最初の頃に新鮮な気持ちを取り戻せるようにしておこう、というイメージになります。
自分自身、実際に活用している技術ではあるのですが、少し困ったことがあります。それは、電子書籍との相性が悪いことです。
通常であれば紙とペンを用いるものですが、例えば出先でスマホやタブレットで電子書籍を読んでいるような状況では、必ずしもこれらの道具があるとは限りません。特に私は、外に出る時はあまりものを多く持ちたく無い性分なので、外ではスマホと財布くらいしか持っていないことが多いです。
仮に持っていたとしても、例えば電車の中で紙とペンを出して色々と書き始めるのは、少し億劫だったりします。
「これを全部ペーパーレスで完結できるようなアプリがあったら便利だな」と思ったのが、このコンセプトを思いついたきっかけになっています。
もちろん、これだけであればスマホのメモ帳だけでもできてしまうものですが、このアプリには、
- Google Books APIを活用した書籍検索・保存機能
- メンタルマップ作成のヒント機能
- Google Books, Amazon, 楽天ブックスへのリンクボタン配置(特に書籍レビューはメンタルマップ作成の大きなヒントになる)
- Twitterでの読書仲間への気軽なシェア機能
といった機能が備わっており、より読書メンタルマップ術を使用しやすい環境を整えています。
先ほどの「2. 具体的な解決課題を明確にする」に照らし合わせて考えると、このアプリの解決課題は、ユーザーの積読を解消すること、もっと言えば、読書メンタルマップ術をペーパーレスで実行できるすることで電子書籍で読書するユーザーにとっても扱いやすくすること、になります。
また、「3. サービスの利用が個人で完結する」も満たしています。当アプリには、ユーザー同士がつながる機能は一切実装されていません。
代わりとして、Twitterとの連携にはかなり重きを置いて実装機能を決めました。具体的には、
- Twitterアカウントを利用したユーザー登録
- ワンタップでハッシュタグ付きツイート
- 充実した Twitter カード表示
を機能として実装しています。原則的には個人でサービスが完結しつつも、ユーザーどうしの繋がりはTwitter内の既存のネットワークに乗っかる、ことを狙ったコンセプトになっています。
2.3 技術スタック
再度、インフラ構成を載せます。
この内容について、ひとつひとつ解説します。
Back-end
Rails API+Nginxの組み合わせにしています。サーバーサイドフレームワークとしては他にも
Laravel,Django,Node.jsなどもあります。恐らく大体のことは、どれを選んでも実装・実現できる、と思うのですが、その中で今回 Rails を選んだ理由は、
- 採用している企業数が多い
- 日本語の教材が豊富なため学習のハードルが低い
- 国内コミュニティが発達しているため、インターネット上での日本語ドキュメントが豊富
最初の学習言語として Rails を選択する初学者の方は多くいるかと思います。その一方で、「Railsはオワコン」という説が各所で言われていることについて、不安に感じる初学者の方もいると思います。
この点に関して、あくまで個人的な見解を述べますと、初学者であった自分が、少なくとも最初に学ぶ言語/FW として Rails は間違いではなかった、と考えています。
正直、初学者である私には、「なぜ Rails がオワコンであるのか」について技術ベースで語ることはできません。しかし、
現時点で Rails を採用している企業の絶対数は多く存在すること日本国内において、Rails に替わるサーバーサイドのデファクトスタンダードな技術が、まだ定まっていないことは事実と言ってよいかと思います。
もしかしたら、長期的に見れば日本国内でも Rails を採用する企業が減っていく流れにはあるのかもしれません。しかし、微分値と絶対値はセットで捉えないと判断を誤ることになります。初心者が目指すべきは「今すぐに仕事を得られる技術を身に着けること」であり「将来必要になってくる技術」ではない、自分が今学ぶべきはやはり Rails である、と判断をしました。
また、オワコンというのは裏を返せば、技術的に枯れていて、初心者にとっては学びやすい言語/FWである、とも言えます。
特に日本国内での(過去含めた)使用者が多いため、日本語のドキュメントが多く存在します。事実、Rails開発で遭遇するエラーは、Google検索すれば何かしらの日本語記事がヒットします。
最先端の技術は過去の技術の欠点を補う要素を持って生まれてきているのは事実ですが、検索しても欲しい情報が見つからなかったり、あったとしても英語ドキュメントだけだったりします。私自身は、このアプリの開発を通じてWebフレームワークに基本的な概念が身についてきているため英語でも大丈夫になってきましたが、ベースラインすら乏しい状態の初学者がいきなり英語のドキュメントを読み解いていくのは、二重にしんどいです。
以上が、私が最初の言語/FWとして
Railsを選んだ根拠になります。主要gem
devise_token_auth: APIモードでの devise。トークン認証を簡単に実装twitter_omniauth:Twitter認証を簡単に実装active_model_serializer: Rails APIからのレスポンスJSONを制御imageMagic: 画像のリサイズを実行。特に、Twitter card用に書籍画像をリサイズする際に使用aws-fog/carrierwave: リサイズした書籍画像を AWS S3 に保存rspec: デファクトスタンダードになっているRubyテスト用フレームワークrubocop: Rubyの静的コード解析TwitterアカウントでのOAuth認証は、過去の実装例が少なく、非常に苦労したところでもありました。しかし、「Twitterとの連携を重視」という今回のコンセプト上では絶対に欲しい機能と考え、頑張って実装しました。
AWS S3については元々採用予定はなかった(Google Books APIの画像リンクをそのまま引っ張ってくる予定だった)のですが、Twitter card で書籍画像を表示させる時にどうしても画像サイズを適切に制御する必要が出てきたので、imageMagic と合わせて Rails で画像リサイズ & S3保存、を実装することにしました。
Front-end
今回フロントエンドとしては、JSフレームワークである
React.jsを採用しました(細かいこと言えば React はフレームワークではなくライブラリですが、ここではフレームワークとして扱います)。モダンな技術採用を謳う以上、Rails + jQuery/bootstrap の構成では心許ないと考えました。JSフレームワークとしては、国内企業での採用状況から考えるに、
React.jsかVue.jsか、の二択になると思います。その中でもReact.jsを選んだ理由は、
- 自分が調べた範囲では、バックエンドに Rails を採用している企業群のうち、フロントに React を採用している企業の割合が高かった
- Vue.js よりも規約が厳格であり、初学者の自分であっても自然と可読性の高いコードを書くことができそう
- たまたま、React を効率的に学べる良い教材を見つけた
特に最後については、第3章で後述しています。
アプリ開発を通じて
React.jsが割と気に入ってきたので良い選択だったとは思いますが、この点に関してはどちらを選んでも間違いではなかったかな、とは思います。主要ライブラリ等
create-react-app: Facebookが提供するオープンソースのReact開発パッケージRedux: Stateの一元管理するフレームワーク。Redux関連ファイルは、reducksパターン則って管理Redux-thunk: Redux state の非同期処理を制御react-helmet: 動的なmetaタグの挿入によるOGP情報の保持(Twitter card用)react-share: Twitter含めたSNSシェア用ボタンを簡単に配置Material-UI: Google が提供する UI コンポーネントライブラリ。簡単におしゃれな UI コンポーネントをアプリ内に配置できるeslint & prettier: javascriptに対する静的コード解析。eslint は create-react-appに標準搭載されているものをベースに少しプラグインを追加 & prettier はイチから導入今回はユーザーの利用シーンを考えると、Web上でもネイティブアプリのようにサクサク動く、JSリッチなアプリケーションにしたいと考えました。この点からも、jQuery+bootstrap ではなく React.js を採用してよかったと思います。
React の実装には、特に
Material-UIが強力で、開閉モーダルや通知バー表示などのアニメーション演出や、ページ全体のレスポンシブ対応などがかなり簡単に実装できました。このライブラリを使えたというだけでも、React を採用した価値があったと思えるほどでした。Infra
Docker/docker-compose開発環境は、全てDockerコンテナ内で完結させています。docker-compose.ymlのサービス構成としては、
- db: MySQL
- api: Rails
- web: Nginx
- front: Node.js (React)
としています。
後述しますが、AWS ECS(Fargate)へのコンテナデプロイを利用することで、開発環境と本番環境の差異を小さくすることができています。
AWS(Amazon Web Service)バックエンド( Rails + Nginx )のデプロイに使用。Railsチュートリアルなどではアプリの本番環境へのデプロイには
Herokuを用いることが一般的ですが「モダンな技術を採用したい」という観点から、AWSに挑戦しました。稼働させるまでめちゃくちゃ苦労しました。ここを完全独学で完結させるのは相当しんどいと思います。第3章で触れていますが、AWSの学習については、メンターさんをかなり頼らせてもらいました。
※ 利用サービス
ECS (Fargate): コンテナ向けサーバーレスコンピューティングエンジン。この中に Rails と Nginx の Docker イメージを入れて稼働させるECR: Rails と Nginx の Docker イメージを保存しておくリポジトリRDS (MySQL): AWS が用意しているスケーラブルなデータベースエンジンALB: 負荷分散を担うロードバランシングサービスRoute53: サイトの独自ドメイン化に使用ACM: サイトの https 化に使用S3: 静的ホスティングサービス。書籍画像も保存・管理に使用
Netlifyフロントエンド(create-react-app)のホスティングで利用。
最初はバックエンドに合わせてフロントも AWS ( Amplify Console ) でホスティングしていたのですが、create-react-appはSPAとしてのアプリ開発となることから、metaタグ無いにOGP情報を保持できない = Twitterでページをシェアした時のカード表示を動的に制御できない、という問題が出てきました。
おそらくは AWS でも解決する手段はあると思うのですが、今回は Netlify の
Pre-rendering機能を使うことで解決することにしました。この機能を使うことで、 create-react-app であっても、サーバー側で javascript をレンダリングしてからブラウザが解釈できるようになります ( あと単純に、無料で利用できるのもメリット )この問題にあたってから、最近ホットな React フレームワークの
Next.jsの有り難みが自然と分かるようになってきた(Next.jsは SPA/SSG/SSRを選択可能 )のですが、今回はすでに開発を始めていたこともあり、create-react-app+Netlifyの構成で最後まで開発しました。CircleCI
国内ではデファクトスタンダードとされている、Saas型のCI/CDサービスです。今回CircleCIで自動化した処理は、
- Rspec
- rubocop
- eslint&prettier
- AWS ECR への Image push
- AWS ECS のタスク&サービスの更新
Netlifyにはもともと自動デプロイ機能がついていることから、CircleCIを導入することで、Github上の master ブランチに merge しただけで、本番環境への再デプロイが完了する、という状態に持っていくことができました。一度ありがたみが分かると、もう手放せないですね( ´ ▽ ` )
3. 学習ロードマップ
さて、いよいよ本題です。ここまでで開発したアプリについて解説をしてきましたが、ここからは、このアプリ開発に至るまでの学習過程をたどっていきます。
第1章でもお伝えした通り、筆者はプログラミング経験自体はあっても、いわゆる「Web系」の知識はゼロからのスタートでした。繰り返しますが、HTMLすら知らなかった状態から、独学ベースで上記技術スタックをアプリに盛り込めるレベルまで到達することができました。
独学ベースでの学習になると、「どの学習教材を選ぶべきか」というところから自分で考える必要があります。いろいろと紆余曲折ありましたが「これは役に立った!」と思うものを厳選し、時系列に沿ってお伝えします。
※下記サービスのWebリンクや、ロゴ画像、ホームページのスクリーンショットについては、事前に各運営者様に使用許可をいただいております。改めまして運営者皆様、利用快諾していただきありがとうございました。
3.1 Progate
皆大好きProgate。今からエンジニアを目指す方は、全員ここから入門して間違い無いでしょう。
URL: https://prog-8.com/
自分は手当たり次第に色々な講座をやってみていましたが、
- HTML&CSS
- Javascript(ES6)
- jQuery
- Ruby
- Ruby on Rails
次いで
- Command line
- Git
- SQL
辺りを押さえておけば十分だったかと思います。
各講座の序盤のレッスンは無料会員でも受けることができますが、本気でエンジニアを目指すのであれば、有料会員限定のコースも含めて取り組んでいきましょう。
これだけでもそれなりにボリュームはありますが、挫折しにくいよう学習ステップがかなり細かく設定されているので、初心者にとっても易しいつくりになっています。
ただ、Rails講座だけはさすがに難易度が高かったです。。。これは、Progateさんの講座の作り云々ではなく、Webフレームワークという概念が初学者にとって「始めまして」になるので、多少仕方がない部分ではあると思います。
1周目で全体像の把握、2週目以降で詳細理解に努める、というスタンスでよいかと思います。
3.2 Ruby on Railsチュートリアル
皆大好き(?) Rails チュートリアル。
URL: https://railstutorial.jp/
色々賛否ある教材ですが、無料かつ、ここまで体系的に「RailsのWebアプリ開発」を学べる教材は他にないと思います。
本教材の謳っているところでもありますが、「単にRuby, Railsの学習に終始せず、Webアプリ開発の全体像を俯瞰する」ものですので、本教材での知識は、他言語・他フレームワークで開発をする場合でも大いに活きると思います。
確かに、当教材に対する否定的な意見はいくつか見受けられ、
- テストフレームワークとして、国内企業でデファクトスタンダードになっている
Rspecではなく、Railsに標準搭載されているminitestを使用している- 採用技術が古くなってきてしまっている
という点がよく指摘されています。
ただ、前者については、株式会社YassLab代表のコチラのYoutube動画の動画でも説明がある通り、「かつて(第2版まで)は Rspec を Rails チュートリアルでも採用していたが、Rspec 自体の学習コストが高いこともあり、それによる脱落者を多く出していた」という背景を受けてのものになります。
また後者については、例えば現在の Rails企業の多くは、Rails単体のアプリケーション(フロントはjQery/bootstrap)ではなく、APIとしてRailsを利用し、フロントはJSフレームワーク(Vue.jsやReact.js)を使うのが一般的になってきています。しかし、Rails初学者が、いきなりAPI開発から始めるのは、理解の階段を飛ばしすぎている、というのも事実でしょう(これについては、同者のコチラのYoutube動画も参考になるかもしれません)
つまり、Rails チュートリアルは「Railsを初めて触る人がなるべく挫折しにくい難易度設定を目指す」ということを念頭に置いた教材であり、最前線の現場で使用されているような本格的なRailsの習得の橋渡しをするようは役割である、と考えることができるかと思います。逆に、これ以上現場に近づけた本格的な内容にしてしまうと、それこそ多くの初学者が挫折してしまうと思います。
したがって、Rails初学者は、今この時代であっても、自信を持って当教材取り組んでよいと思います。少なくとも自分は、この後にも続くRails学習において、ベースとなるような知識をつけることができた、と感じています。
ただ、いくら難易度を落としているとはいってもRails初学者に取ってはかなり難しく、かつ量も膨大であるのは事実です。そのため、Railsチュートリアル完走を一つのマイルストーンとして設定し、内容につまづいたら「ひたすらググる」あるいは「適宜Progateに戻る」という進め方が効率的かと思います。
私も、一度はあまりの量と難易度に挫折してしまったのですが、社会人としてすでに働いており、ある程度お金に余裕があったので、動画版を購入して最後までやり切りました。個人的には、人が解説してくれている形式の方が理解がスムーズで、モチベーションの維持もしやすかったで、お金に余裕のある方にはオススメです。
Railsチュートリアルで身につく知識を整理すると、
- バックエンド:
Rails(シングルアプリケーション)- フロントエンド:
jQuey+bootstrap(Railsの一部として内包)- テスト:
minitest- 開発環境:
AWS cloud9- デプロイ:
Heroku全くの初心者からWebアプリとして求められる一通りの機能を実装し、本番環境へデプロイするところまでできるのは、やはり教材として素晴らしいと思います。
しかし先ほども述べた通り、当教材はあくまでも橋渡しの位置付けです。未経験からの転職という自分自身の立場を鑑みると、Web系企業への転職用PF作成の準備としては、技術面でまだ心許ない、と考えました。
改めて複数企業の採用ページから実際に企業で使用されている技術を確認し、上記の学習知識と比較して整理をすると、
- フロントは、
Vue.jsやReact.jsといったJavaScriptフレームワークを使用するのが一般的。それに伴い、Railsは単独アプリとしてではなく、APIモードで開発する- テストフレームワークは、minitestではなく、
Rspecがデファクトスタンダード- 開発環境はPCローカルに構築する(
Vagrantで仮想マシンを構築するか、Dockerでコンテナ化するか)- アプリケーションのデプロイは、小規模であれば Heroku を使うこともあるが、企業が提供するような中・大規模なアプリケーションであれば、
AWSやGCPなどをよく用いられる次に習得すべきは、ここの技術領域であることが分かりました(個人的な話ですが、この辺りの時期からエンジニア採用ページに書かれている各技術がスタックが、どういった内容であるかが理解できるようになってきており、成長を実感していました)。
Railsチュートリアルを完走した方は、完走者向けのロードマップ紹介ページもありますので、まずはここを見てみるものよいかと思います。しかし私は、洗い出した上記項目をより体系的に学ぶことができるものがないかと考え、自分なりに色々と教材を探してみた結果、以下のサービスに辿りつきました。
3.3 Take off Rails
URL: https://freelance.cat-algorithm.com/lp/take-off-rails
『あなたを「初心者エンジニア」から「現場で活躍できるエンジニア」まで引き上げます。』というスローガンを掲げた教材とメンターがセットになったサービスで、Rails チュートリアルと実際の企業の間の穴埋めを狙った内容になっています。
基本的にはすでに作成された教材に則っとりながら自分のペースでアプリを開発していくのですが、都度 Slack でメンターさんに質問を投げることができるというのが大きな特徴です。。
最終的な教材のゴールとしてはQiitaのクローンサイトを開発することになります。これの技術スタックは下記の通りです。
- バックエンド:
Rails APIモード- フロントエンド:
Vue.js(ソースコードは作成済みのものを使用。あくまで Rails との繋ぎ込みまでを扱う)- テスト:
Rspec(+Factory_bot)- 開発環境:
ローカル + DB(MySQL) は Docker コンテナを利用- アプリのデプロイ: Heroku
- その他:
CircleCI による rspec, rubocop の自動化※ 私の当サイト用のリポジトリ: https://github.com/ddpmntcpbr/qiita_clone
Railsチュートリアル時点での技術スタックと比べると、かなり実務に近い技術が盛り込まれていることが分かるかと思います。
こちら、決して安い金額ではないサービスだと思います(スクール等に比べれば全然安いですが)。ただ、当時欲しいと思っていた知識が一気に身に着けられると考えて、購入を決意しました。
結果、良い買い物だったと思います。自分が学びたい内容がきれいに体系化されていたこともそうですが、何より、教材内容についてメンターさんへ質問ができるのも有意義だと感じました。遅くとも24時間以内にはレスポンスが返ってくるのもありがたく、「料金分を回収してやるぞ!」という気持ちで、たくさん質問させてもらいました笑
本教材では、上記技術の学習だけでなく、
- Git commit の適切な粒度や、コミットメッセージの書き方
- Github での PR の出し方や、コードレビューの流れ
- Slack でのやり取り(意図が伝わりやすい質問の仕方など)
といった、「独学ではなかなか身につかない」けど「チーム開発では必須になる」ような周辺知識について学べた点も、非常に有用だったと思います。Railsチュートリアルの内容がおおよそ理解できていれば前提知識としては十分な難易度で、大きく挫折をすることがなかった点もプラスです。
さて、ここまでで、Railsに関しては、比較的モダンな開発手法に触れることができました。
しかし、当教材ではあくまでも Rails の開発に的を絞ったものであり、フロントエンドは既存のソースコードを流用する形での学習でした。この教材の内容を自身の転職用PFに組み込むためには、フロントエンド側についても自身で開発する知識が必要と考えました。
フロントエンドフレームワークの選定について、第2章でもお伝えしたとおり、「Reactの方がなんとなくよさそうかなー」と考えていたところ、次の教材を見つけたことをきっかけに、正式に React の学習を始めることにしました。
3.4 【とらゼミ】トラハックのエンジニア学習講座
現役の React エンジニアである トラハックさん ( @torahack_ )が、Youtube上で公開している講座で、Reactについて基礎の基礎から学ぶことができます。
動画チャンネルURL: https://www.youtube.com/user/1492tiger
こちらの教材の特長は、
- Reactの基礎の基礎から体系的に学べる( Progate の JavaScript 講座完了が受講目安)
- 動画によるハンズオン形式
- 教材範囲にモダンなフロントエンドの開発手法を含む( Redux 等)
- 動画のほぼ全てがYoutube上でなぜか無料公開されている
特に最後については完全にバグとしか思えない点で、Udemyなどで有料販売されていても動画講座と比べても遜色ないクオリティだと思います。
動画教材にありがちな「準備した原稿丸読み」のような堅い口調ではなく、フランクな若手予備校教師の授業(?)のような語り口のため、硬い喋りが苦手な人にもお勧めできます。私は復習のために、一度見た動画を耳だけで聞き返したりして、記憶の定着を図りました。
講座はいくつかのシリーズに分かれており、私が視聴をしたのは、
1.『日本一わかりやすいReact入門』シリーズ
2. 『日本一わかりやすいReact入門【実践編】』シリーズ
3. 『日本一わかりやすいReact-Redux入門』シリーズの3シリーズです。
最終的な成果物の技術スタックは、
create-react-appRedux & redux-thunkMaterial-UIFirebase: Google が提供する mBaaS。バックエンド+インフラを手軽にセットアップできるです。
※ 私のGithubリポジトリ: https://github.com/ddpmntcpbr/react-ec-app
こちらの動画については、学習備忘録記事をQiitaに投稿しております。よろしければこちらもご参考下さい。
参考ページ: 『日本一わかりやすいReact入門【実践編】#1~5 学習備忘録』
本学習講座を全て受講するためには、有料コミュニティ『とらゼミ』への加入が必要になりますが、筆者は無料公開範囲の動画で必要な知識は十分に身に付いたと感じたため、加入はしておりません。(代わりの記事として書くことで、宣伝として少しでもお役に立てればと思っています笑)
さて、ここまででフロント側も自力で開発ができる基礎が身に付きました。これくらいの時期に並行してアプリのコンセプトが決定していましたので、いよいよポートフォリオ作成に取り掛かり始めました。
しかし、開発を始めるといくつも壁が出てきます。基本的にはググりながらの解決をしていきましたが、どうしても解決できないエラーにもぶち当たりました。特に、
- ReactとRailsの繋ぎ合わせ
- AWSでのアプリの公開方法
- その他インフラ知識全般
あたりが、個人的な難所でした。その過程で頼らせてもらったのが、次のメンターサービスです。
3.5 TechTrain
有名企業のエンジニアから実務を学べるオンラインコミュニティです。URL: https://techbowl.co.jp/techtrain
特長を列挙すると、
- 現役エンジニアであるメンターさんと、1 on 1でのオンライン面談が可能
- メンターの方々の技術領域は多種多様
- 全てのメンターと面談が可能で、技術トピックに応じて切り替えることが可能
- 面談はこちらからのタイミングで入れることができる
なぜか全て無料で利用できるはっきり言います。これだけのことができて完全無料なのは完全にバグです。これからエンジニア就職を目指しているU30の学生・社会人は、全員登録した方がいいレベルです
TechTrain の中ではいくつかの Mission が設けられており、それをメンターと一緒に取り組んでいくことで知識を習得していく、ということが可能です。 Mission は実際のIT企業とのコラボで作成されており、中には「Missionをクリアできた人は一次面接をスキップできる」のような特典もついていたりします。
ただ私は Misson には取り組まず、あくまでの個人開発のサポートとして利用させてもらっていました。基本的には自身の既存知識とググり力でPF作成を進めつつ、どうしても解決できない課題が出てきたときにピンポイントで面談予約を入れる、というイメージで、個々人の利用したい形式/ペースで利用できる点も大変ありがたかったです。
異なる技術領域を持ったエンジニアの方々全員と面談をするが可能なため、
Rails,React,AWSそれぞれで、別のメンターの方に質問をさせてもらっていました。特に自力での解決が難しかったのがAWS周りの本番環境構築で、本サービス無しでは乗り越えられなかったと思います。
AWSのことをAWS現役社員に無料で聞けるサービスと表現すれば、このサービスのやばさが伝わるかと思います。最終的には、自身のググり力 + TechTrain で都度メンターを利用、を繰り返すことで、無事アプリを完成させることができました!
3.6 番外編
上記以外で役に立ったものについて、ざっくばらんに紹介します。
Udemy 『Git:はじめてのGitとGitHub』
無料で Git の基礎を学べる講座です。「Gitよう分からん!」って人は、まずこれから触れてみましょう
『キタミ式イラストIT塾 基本情報技術者』
基本情報処理の定番本です。コンピューターサイエンス領域の基礎知識が体系的に学べます。イラストが豊富であり、文章表現も柔らかいので初心者にも優しいです。資格自体の取る/取らないに関わらず一読をオススメします。
『米国AI開発者がゼロから教えるDocker講座』
Dockerについて一から学べる動画教材です。作者様はデータサイエンス領域の方ですが、Webアプリ開発を目的とした人であっても問題ありません(実際に、講座後半では、docker-composeを利用したRailsコンテナの構築まで扱っています)
非常にボリューミーな内容にも関わらず、Udemy講座の中ではかなり良心的な価格設定です。
『【AWS 入門】EC2とDockerでHello Worldしよう』
AWSについて何にも分からない状態から、「nginxだけのシンプルなコンテナアプリを動かす」ところまで、ハンズオン形式で学習ができます。
AWSのとっつきにくさは、「①インフラの概念が分からない」「②専門用語が分からない」に集約されると思います。まずは手を動かしながら、AWSでアプリをデプロイ流れを全体像で掴むことができます。
3.7 アプリの改善点
一通りアプリを完成させてみて、初めて見えてくる改善点が多くありましたので、合わせて列挙します。
AWSサーバー代高すぎ!!!
スケーラビリティの高い中・大規模向けインフラ構成になっているため、サーバー代がめっちゃ高い笑
長く公開するためには、どこかのタイミングで無料サーバーへ移管する必要があるかなと思います。Heroku の無料枠で上手にやりくりできれば、解決できるかもしれないです。
フロントエンド は
Next.js+Typescriptで実装したいNext.js はレンダリングのタイミングを制御できるので、OGP情報の保持が簡単に実現できます。
また、それ以外でも、
- ルーティング設定が簡単
- パフォーマンスをよくするような機能も豊富
- Typescriptの導入が用意
というメリットもあり、とても気になっているフレームワークです。次、全く同じアプリを開発するとするのであれば、絶対に採用したい技術です。
デザインがあやしい気がする・・・?
アプリを開発して気づいたのは、
アプリにおけるデザインの重要性です。これを思った理由は単純で、開発途中で「なんか自分のアプリ、イケてなくない?」と感じたからです笑
Webアプリにおけるデザインは、単なるお洒落さに関するものだけでは決してありません。デザインは、ユーザーにとって必要な情報を適切に配置することであり、ユーザーの価値提供のための最前線領域です。
ユーザー側から価値提供の流れ(バリューチェーンと表現するのでしょうか)をざっっっくり並べると、
ユーザー -> UI/UXデザイン -> フロントエンド -> バックエンド -> インフラ
のようになっていると思っています。
「エンジニアになろう!」と意気込んでから、後ろ3つについてはそこそこ勉強してきました。しかしデザイン領域については、開発初期は完全素人の状態で、途中までは勘でやっていました。。。
一応、付け焼き刃程度ではありますが、デザインの名著である『ノンデザイナーズ・デザインブック』に目を通し、途中からは意識できる範囲ではデザインのことを意識して、フロントを実装しました。
うまく取り込めているかは分かりませんが、少なくとも「デザインはセンスではなく論理」であることが学べただけでも、よい勉強になりました。こちらの書籍も、転職用PF作成者にオススメしておきます。
4. さいごに
以上、大変長い記事でしたが、最後まで読んでいただきありがとうございました。タイトルでは「学習ロードマップ」と銘打っておきながら、私自身の思考プロセスや価値観についても多く書かせてもらいました。
「エンジニアになりたい!」と思い立ってから、学習自体はほぼ一人で淡々と進めてきました。しかし、ほぼ独学でここまで学習を進めることができたのは、多くの先輩エンジニアの方々が様々な情報をインターネットに投稿し、それをオープンに取得できる環境にあったからだと思っております。
それであれば、次は自分自信が、他の駆け出しエンジニアの方々の助けになるような情報を発信できれば、と思い、この記事を書くこととしました。参考になったという方がいらっしゃったら幸いです。
是非LGTM、ストック、twitterでのシェアお願いします!また、私自身もtwitterをやっておりますので、気軽にフォローしてもらえるとうれしいです(^^)
よろしくお願いします!
Twitter: https://twitter.com/ddpmntcpbr
Github: https://github.com/ddpmntcpbr/rails_react_docker






- 投稿日:2021-02-21T14:13:23+09:00
【未経験】独学+メンターでここまで出来た!Web知識ゼロからモダンな技術アプリ開発までに利用した5つのサービス【Rails / React / AWS / Docker / CircleCI】
0. はじめに
こんにちは!辻野(@ddpmtcpbr)と申します。
当記事は、「Webエンジニアへのキャリアチェンジを目指している開発未経験者が、モダンな技術を備えたアプリを開発するまでの学習過程」についてまとめたものです。
現在筆者は非IT系企業の社員として働いており、Web開発エンジニアとしての実務経験はありません。
そんな筆者がWebエンジニアとしてのキャリアチェンジをするためのポートフォリオとして、本アプリを開発しました。
学習開始から現時点までにおいて、プログラミングスクール等には通っておらず、学習はほぼ全て独学&一部メンターサービス利用の布陣で進めてきました。
独学中心でアプリ開発に挑戦したい、ポートフォリオを作成してWebエンジニアへのキャリアチェンジを進めていきたい、と考えている方々にとって、参考になればと思います。
最初に、今回私が開発したアプリの概要を紹介します。
アプリ名: 積読解消アプリ 「Yomukatsu!」
「あなたの積読解消をサポートします」をスローガンに掲げたSPA風Webアプリです(”風”の詳細は後述)。
読書メンタルマップという手法を用いて、ユーザーの書籍完読に向けたモチベーション維持をサポートします。
Web URL: https://yomukatsu.com/
【3分動画】Yomukatsu 字幕解説
アプリの使い方を3分でまとめています。
使用技術
Backend: Rails ( API mode / Rspec / rubocop) + Nginx ( upstream puma-socket )Frontend: React ( create-react-app / Redux / Material-UI / eslint&prettier)Infra: AWS ( ECS Fargate/ ECR / RDS / ALB / Route53 ), Netlify, Docker&docker-compose, CircleCI各項目の詳細は後述しています。
インフラ構成
モダンな技術を採用したWeb系企業が提供している、中・大規模なアプリケーションを想定したインフラ構成にしています(そのため、個人開発アプリとしてみるとちょっと仰々しいかもです(;’∀’))
詳細は後述しています。
機能一覧
ユーザー利用機能
- Twitterアカウントを利用したユーザー登録(OAuthによるSNS認証)
- ゲストログイン機能
- Google Books APIを用いた書籍検索機能
- Google Books、Amazon、楽天ブックスへのリンクボタン配置
- Twitterシェア機能
- ハッシュタグ「#yomukatsu」付きTweet
- Twitter card 表示
- Twitter card用にリサイズした書籍画像をAWS S3へ保存・管理
- Redux による state 管理を活用したローディング画面
- Slack Incomming Webhookを利用したお問い合わせ機能
- Route53 による独自ドメイン + SSL化
非ユーザー利用機能
- Netlify の Pre-reidering 機能活用による動的なOGP情報の保持( Twitter card 表示用)
- Docker による開発環境の完全コンテナ化
- CircleCI による自動 CI/CD パイプライン構築
- CI: Rspec, rubocop, eslint&prettier
- CD: AWS ECR
- その他セキュリティ対策(XXS, CSPF等)
まず触ってみてもらうのが一番良いかと思います!今回はフロントエンドに React を採用しているため、メニューモーダルの開閉や通知バー表示など、アニメーション的な表現も実装できているのが伝わるかと思います。
ゲストユーザー機能もありますので、気軽に利用してみてほしいです!レスポンシブにも対応しています。(推奨ブラウザはChrome、Safariになります)
アプリURL: https://yomukatsu.com/
※現在α版としてのリリースのため、配信内容が予告無く変更される可能性がございます
あわせて、
Githubも公開していますので、よかったら参考にしてください。Github URL: https://github.com/ddpmntcpbr/rails_react_docker
この記事について
当記事は3章構成になっております。
まず、「1.自己紹介」で、簡単に自己紹介をさせていただきます。
次に、「2.開発アプリ解説」で、今回の開発アプリ開発について、コンセプト決定の流れから、実装機能/技術スタックについて詳しく紹介します。「転職用PF作りたいけど、どんなアプリを作ればいいか分からない」という方にとって、参考になることがあれば幸いです。
最後に、「3. 学習ロードマップ」で、Web知識ゼロだった筆者が、当アプリの開発にまでに利用した
5つの教材およびサービスについて、時系列に沿って紹介したいと思います。特に独学では、「まず何を学べば良いのか」「どんな教材を選べば良いのか」というところから自身で考える必要があります。そういった方々にとって参考になり得る情報と思います。1. 自己紹介
1.1 筆者スペック
- 20代後半 男
- 工学部機械系 修士卒 → 非IT系 日系製造業 技術開発職(現職)
- 大学から現職において、データ分析ツールとしてプログラミングを経験(matlab / python)
- Webエンジニアへのキャリアチェンジを目指し、社会人になってから独学を開始
大学入学以降、授業や研究データの分析ツールとしてプログラミングに触れる機会はありました。もともと自動化や効率化に興味があったことからプログラミングにだんだんとのめり込み、研究室ではプログラミングに多く触れられそうな研究テーマ(データ分析系)を選びました。
したがって、「プログラミング自体が完全に未経験」というわけではありませんでした。しかし、いわゆる”Web系”の知識は社会人以降の独学を開始するまではゼロ、という状態で、最初は HTML すら知らないところからのスタートでした( ̄▽ ̄;)。そのため当記事では「Web知識ゼロ」という表現をしています。
キャリアチェンジ志望の理由は、ざっくりと言えば、
1. もっとプログラミングがしたい
2. モノづくりで誰かの役に立ちたい
3. 非効率・非生産的な仕事を無くしたいここについては当記事の趣旨ではないので、詳細については省略します。
2. 開発アプリ解説
2.1 コンセプト方針
転職用PFアプリのコンセプトを決めるにあたり、満たすべき用件としては、下記3点を考えました。
(a) 実際の企業が採用しているようなモダンな技術を盛り込む
(b) 具体的な解決課題を明確にする
(c) サービスの利用が個人で完結する(a) 実際の企業が採用しているようなモダンな技術を採用する
未経験からエンジニア転職において、高品質なポートフォリオは必須と考えました。
「モダンな技術をポートフォリオに組み込むことで、技術力の高さをアピールする」というのが基本的な考え方になるとは思いますが、個人的な解釈としては、ポートフォリオで証明すべきは「技術力」ではなく「自走力」だと考えています。
ぶっちゃけた話、実際の現場を経験したエンジニアと比べれば、未経験者間での能力差というものはどんぐりの背比べのようなものだと思います。多くの企業が「実務経験1年以上」をエンジニアの採用項目にあげていることからも、実務経験というのはそれだけ重い価値があり、未経験者とは大きな隔たりがあるのだと思います。
したがって、ポートフォリオの技術レベルの高さそのものはあまり重要ではなく、そこに到達するまでの過程の方が大事であり、「自走力=必要な情報は自らキャッチアップして吸収する能力」があることを示す方が、企業人事側としては採用しやすいのではないか?と考えました。
「スクールの制作アプリをそのまま提出する未経験者が足切りされてしまう」という話は多く聞きますが、これはそのアプリの技術力が低いからではなく、そのアプリから当人の「自走力」が主張できないから、だと私は考えています。私が独学ベースにこだわったのは、単純にお金の問題だけではなく、独学ベースでアプリを開発することができれば、自然とそれが「自走力の証明」につながると考えたからです。
今回のアプリにおいては、「独学:メンター=8:2」 くらいの割合で、上記技術を採用できるラインまで行くことができています。「メンター利用は独学からは外れるのでは?」という指摘もあるかもしれませんが、
- プログラミングでは、個人ではどうにもならないようなエラーに遭遇してしまうことが多々ある
- 実際に企業に入ってからは、先輩エンジニアの方々に分からないことを質問しながら業務を進めることになるため、「質問力」も重要な能力である
- 完全独学オンリーだと、誤った癖が身についてしまっているリスクが高くなる
といった観点から、独学者が適宜メンターサービスを利用することは、かえって採用人事側にとって安心感を与える材料になるのでは、と考えたので、自信を持って「メンターサービスを使いました」と主張しています。
※ 具体的なモダンな技術リスト
Rails API+ JSフレームワーク(React.js)の構成Dockerで実行環境を完全コンテナ化Herokuではなく、AWSでアプリをデプロイ(ECS Fargate & ECR)Circle CIによるCI/CDパイプラインの構築(b) 具体的な解決課題を明確にする
さて、前章とは一見真逆のことを言いますが、アプリ開発において、モダンな技術を採用することそのものには本来何の価値もない、と考えています。
なぜなら、アプリの目的はあくまでも「ユーザーにとって価値を提供できるか」であり、技術はそれを実現するための手段でしかないはずだからです。(保守・運用面でのメリットも考えられますが、保守・運用の最終目的もユーザーへの価値提供であることから、この点も包含した解釈になります)
これは、技術というものを下に見ているというわけでは決してありません。むしろ「新しい技術をどんどん使ってみたい!」という技術に対する好奇心、探究心は人一倍強い自負があります。現職はIT系ではありませんが、技術開発職という立場で業務に取り組んでおり、知的好奇心を満たせるという意味では、今の仕事に面白みを感じています。
しかしながら、かつては行き過ぎた技術先行思想によって「手段の目的化」が発生し、「最新技術を駆使した誰にとっても役に立たない技術」を開発してしまったという苦い過去の経験があったりもします。結果として「やっぱり技術は人の役に立ってなんぼ」というのが、約3年間技術職として働いてきて培った、技術者としての小さな矜持だったりします(この辺の話は直接お会いした方にはお話できるかと思います)
転職用PFであれば、技術ありきな考え方になることはある程度は仕方がないことでしょう。しかし「せっかく作るのであれば、誰かにとって役に立ち得るものを目指そう」くらいのことは転職用PF作成においても考えていいんじゃないかな?と思いました。あるいは、もう少し目線を下げて「自分が欲しいものを作ろう」という程度でも十分でしょう。大事なのは、まず課題があり、それを解決する手段として技術があるという順番だと思いました。
もちろん今回の開発アプリは転職用PFが趣旨である以上、中には「技術力を証明したいから」という理由で選定した技術もあり、全てに対して課題が明確だったわけではありません。また、初心者の個人開発アプリがいきなりバズることは現実的には厳しいとは思います。しかし、そこを目指す姿勢があるかというのは、エンジニアとして本格的にキャリアを進めていく上では、長期的には大きな差異になると考えています。
また、
- 課題が明確な方が採用した技術や実装した機能の根拠も明確にできるため、開発の方針を立てやすい
- 自身がユーザー目線に立てることで、改善点を見つけやすい
- 純粋にモチベーションを維持しやすい
といった点でもメリットもあると感じましたので、この方針は間違っていなかったと思います。
(c) サービスの利用が個人で完結する
「せっかく作るのであれば、誰かにとって役に立ち得るものを目指そう」を、もう一歩深く考えた方針です。
例えば Rails を対象として考えたとき、一般的な転職用PFとしては、
TwitterライクなSNS系アプリや、メルカリライクなEC系アプリが多いかと思います。理由は、ユーザー認証、CRUD操作、DB間のリレーションなど、基本的なサーバーサイド技術を一通り抑えられるものであるから、だと思います。「Railsの一般的な知識を持っていることを証明する」手段と考えれば、妥当な方針でしょう。
しかしながら、
未経験者が転職用に開発した上記アプリが実際にユーザーに継続して使われるということは、まず無いでしょう。SNS系アプリは「ユーザー数が多ければ多いほどサービスとして質が高まる」性質があるため、アプリとして軌道に載せること自体が非常に難しいです。EC系アプリは BtoC であれば出品企業がいないとサービスが成り立たない、CtoCであればより SNS として要素が強まる & いよいよメルカリで十分、という壁があります。これらアプリの難しさは、ユーザーどうしがつながることを前提としている点にあります。裏を返せば「個人で完結するアプリであれば、活路はある」とも言えると考え、この方針でコンセプトを詰めていくことにしました。
2.2 コンセプト内容
上記3点を念頭に置きながら、自分自身の生活の中で"課題"を探し、最終的にたどり着いたものが「
読書メンタルマップ術の電子化」というコンセプトでした。そもそも皆様は、読書メンタルマップ術というものをご存知でしょうか?
読書メンタルマップ術とは、ハーバード大学の先生が提唱している積読解消術です。読破したい書籍に対して、
1. 完読したい本について、それを読む“理由”や“目的”を3つ、紙に書きだす
2. 飽きてきたら、それを見返すを繰り返すことで、完読までモチベーションを維持するというシンプルな読書手法です。
積読というものは、だいたい「最初は読む気があったけど、次第に読む気がなくなってしまった」書籍です。この「最初の読む気」を事前に明文化・保存しておくことで、いつでも最初の頃に新鮮な気持ちを取り戻せるようにしておこう、というイメージになります。
自分自身、実際に活用している技術ではあるのですが、少し困ったことがあります。それは、電子書籍との相性が悪いことです。
通常であれば紙とペンを用いるものですが、例えば出先でスマホやタブレットで電子書籍を読んでいるような状況では、必ずしもこれらの道具があるとは限りません。特に私は、外に出る時はあまりものを多く持ちたく無い性分なので、外ではスマホと財布くらいしか持っていないことが多いです。
仮に持っていたとしても、例えば電車の中で紙とペンを出して色々と書き始めるのは、少し億劫だったりします。
「これを全部ペーパーレスで完結できるようなアプリがあったら便利だな」と思ったのが、このコンセプトを思いついたきっかけになっています。
もちろん、これだけであればスマホのメモ帳だけでもできてしまうものですが、このアプリには、
- Google Books APIを活用した書籍検索・保存機能
- メンタルマップ作成のヒント機能
- Google Books, Amazon, 楽天ブックスへのリンクボタン配置(特に書籍レビューはメンタルマップ作成の大きなヒントになる)
- Twitterでの読書仲間への気軽なシェア機能
といった機能が備わっており、より読書メンタルマップ術を使用しやすい環境を整えています。
先ほどの「2. 具体的な解決課題を明確にする」に照らし合わせて考えると、このアプリの解決課題は、ユーザーの積読を解消すること、もっと言えば、読書メンタルマップ術をペーパーレスで実行できるすることで電子書籍で読書するユーザーにとっても扱いやすくすること、になります。
また、「3. サービスの利用が個人で完結する」も満たしています。当アプリには、ユーザー同士がつながる機能は一切実装されていません。
代わりとして、Twitterとの連携にはかなり重きを置いて実装機能を決めました。具体的には、
- Twitterアカウントを利用したユーザー登録
- ワンタップでハッシュタグ付きツイート
- 充実した Twitter カード表示
を機能として実装しています。原則的には個人でサービスが完結しつつも、ユーザーどうしの繋がりはTwitter内の既存のネットワークに乗っかる、ことを狙ったコンセプトになっています。
2.3 技術スタック
再度、インフラ構成を載せます。
この内容について、ひとつひとつ解説します。
Back-end
Rails API+Nginxの組み合わせにしています。サーバーサイドフレームワークとしては他にも
Laravel,Django,Node.jsなどもあります。恐らく大体のことは、どれを選んでも実装・実現できる、と思うのですが、その中で今回 Rails を選んだ理由は、
- 採用している企業数が多い
- 日本語の教材が豊富なため学習のハードルが低い
- 国内コミュニティが発達しているため、インターネット上での日本語ドキュメントが豊富
最初の学習言語として Rails を選択する初学者の方は多くいるかと思います。その一方で、「Railsはオワコン」という説が各所で言われていることについて、不安に感じる初学者の方もいると思います。
この点に関して、あくまで個人的な見解を述べますと、初学者であった自分が、少なくとも最初に学ぶ言語/FW として Rails は間違いではなかった、と考えています。
正直、初学者である私には、「なぜ Rails がオワコンであるのか」について技術ベースで語ることはできません。しかし、
現時点で Rails を採用している企業の絶対数は多く存在すること日本国内において、Rails に替わるサーバーサイドのデファクトスタンダードな技術が、まだ定まっていないことは事実と言ってよいかと思います。
もしかしたら、長期的に見れば日本国内でも Rails を採用する企業が減っていく流れにはあるのかもしれません。しかし、微分値と絶対値はセットで捉えないと判断を誤ることになります。初心者が目指すべきは「今すぐに仕事を得られる技術を身に着けること」であり「将来必要になってくる技術」ではない、自分が今学ぶべきはやはり Rails である、と判断をしました。
また、オワコンというのは裏を返せば、技術的に枯れていて、初心者にとっては学びやすい言語/FWである、とも言えます。
特に日本国内での(過去含めた)使用者が多いため、日本語のドキュメントが多く存在します。事実、Rails開発で遭遇するエラーは、Google検索すれば何かしらの日本語記事がヒットします。
最先端の技術は過去の技術の欠点を補う要素を持って生まれてきているのは事実ですが、検索しても欲しい情報が見つからなかったり、あったとしても英語ドキュメントだけだったりします。私自身は、このアプリの開発を通じてWebフレームワークに基本的な概念が身についてきているため英語でも大丈夫になってきましたが、ベースラインすら乏しい状態の初学者がいきなり英語のドキュメントを読み解いていくのは、二重にしんどいです。
以上が、私が最初の言語/FWとして
Railsを選んだ根拠になります。主要gem
devise_token_auth: APIモードでの devise。トークン認証を簡単に実装twitter_omniauth:Twitter認証を簡単に実装active_model_serializer: Rails APIからのレスポンスJSONを制御imageMagic: 画像のリサイズを実行。特に、Twitter card用に書籍画像をリサイズする際に使用aws-fog/carrierwave: リサイズした書籍画像を AWS S3 に保存rspec: デファクトスタンダードになっているRubyテスト用フレームワークrubocop: Rubyの静的コード解析TwitterアカウントでのOAuth認証は、過去の実装例が少なく、非常に苦労したところでもありました。しかし、「Twitterとの連携を重視」という今回のコンセプト上では絶対に欲しい機能と考え、頑張って実装しました。
AWS S3については元々採用予定はなかった(Google Books APIの画像リンクをそのまま引っ張ってくる予定だった)のですが、Twitter card で書籍画像を表示させる時にどうしても画像サイズを適切に制御する必要が出てきたので、imageMagic と合わせて Rails で画像リサイズ & S3保存、を実装することにしました。
Front-end
今回フロントエンドとしては、JSフレームワークである
React.jsを採用しました(細かいこと言えば React はフレームワークではなくライブラリですが、ここではフレームワークとして扱います)。モダンな技術採用を謳う以上、Rails + jQuery/bootstrap の構成では心許ないと考えました。JSフレームワークとしては、国内企業での採用状況から考えるに、
React.jsかVue.jsか、の二択になると思います。その中でもReact.jsを選んだ理由は、
- 自分が調べた範囲では、バックエンドに Rails を採用している企業群のうち、フロントに React を採用している企業の割合が高かった
- Vue.js よりも規約が厳格であり、初学者の自分であっても自然と可読性の高いコードを書くことができそう
- たまたま、React を効率的に学べる良い教材を見つけた
特に最後については、第3章で後述しています。
アプリ開発を通じて
React.jsが割と気に入ってきたので良い選択だったとは思いますが、この点に関してはどちらを選んでも間違いではなかったかな、とは思います。主要ライブラリ等
create-react-app: Facebookが提供するオープンソースのReact開発パッケージRedux: Stateの一元管理するフレームワーク。Redux関連ファイルは、reducksパターン則って管理Redux-thunk: Redux state の非同期処理を制御react-helmet: 動的なmetaタグの挿入によるOGP情報の保持(Twitter card用)react-share: Twitter含めたSNSシェア用ボタンを簡単に配置Material-UI: Google が提供する UI コンポーネントライブラリ。簡単におしゃれな UI コンポーネントをアプリ内に配置できるeslint & prettier: javascriptに対する静的コード解析。eslint は create-react-appに標準搭載されているものをベースに少しプラグインを追加 & prettier はイチから導入今回はユーザーの利用シーンを考えると、Web上でもネイティブアプリのようにサクサク動く、JSリッチなアプリケーションにしたいと考えました。この点からも、jQuery+bootstrap ではなく React.js を採用してよかったと思います。
React の実装には、特に
Material-UIが強力で、開閉モーダルや通知バー表示などのアニメーション演出や、ページ全体のレスポンシブ対応などがかなり簡単に実装できました。このライブラリを使えたというだけでも、React を採用した価値があったと思えるほどでした。Infra
Docker/docker-compose開発環境は、全てDockerコンテナ内で完結させています。docker-compose.ymlのサービス構成としては、
- db: MySQL
- api: Rails
- web: Nginx
- front: Node.js (React)
としています。
後述しますが、AWS ECS(Fargate)へのコンテナデプロイを利用することで、開発環境と本番環境の差異を小さくすることができています。
AWS(Amazon Web Service)バックエンド( Rails + Nginx )のデプロイに使用。Railsチュートリアルなどではアプリの本番環境へのデプロイには
Herokuを用いることが一般的ですが「モダンな技術を採用したい」という観点から、AWSに挑戦しました。稼働させるまでめちゃくちゃ苦労しました。ここを完全独学で完結させるのは相当しんどいと思います。第3章で触れていますが、AWSの学習については、メンターさんをかなり頼らせてもらいました。
※ 利用サービス
ECS (Fargate): コンテナ向けサーバーレスコンピューティングエンジン。この中に Rails と Nginx の Docker イメージを入れて稼働させるECR: Rails と Nginx の Docker イメージを保存しておくリポジトリRDS (MySQL): AWS が用意しているスケーラブルなデータベースエンジンALB: 負荷分散を担うロードバランシングサービスRoute53: サイトの独自ドメイン化に使用ACM: サイトの https 化に使用S3: 静的ホスティングサービス。書籍画像も保存・管理に使用
Netlifyフロントエンド(create-react-app)のホスティングで利用。
最初はバックエンドに合わせてフロントも AWS ( Amplify Console ) でホスティングしていたのですが、create-react-appはSPAとしてのアプリ開発となることから、metaタグ無いにOGP情報を保持できない = Twitterでページをシェアした時のカード表示を動的に制御できない、という問題が出てきました。
おそらくは AWS でも解決する手段はあると思うのですが、今回は Netlify の
Pre-rendering機能を使うことで解決することにしました。この機能を使うことで、 create-react-app であっても、サーバー側で javascript をレンダリングしてからブラウザが解釈できるようになります ( あと単純に、無料で利用できるのもメリット )この問題にあたってから、最近ホットな React フレームワークの
Next.jsの有り難みが自然と分かるようになってきた(Next.jsは SPA/SSG/SSRを選択可能 )のですが、今回はすでに開発を始めていたこともあり、create-react-app+Netlifyの構成で最後まで開発しました。CircleCI
国内ではデファクトスタンダードとされている、Saas型のCI/CDサービスです。今回CircleCIで自動化した処理は、
- Rspec
- rubocop
- eslint&prettier
- AWS ECR への Image push
- AWS ECS のタスク&サービスの更新
Netlifyにはもともと自動デプロイ機能がついていることから、CircleCIを導入することで、Github上の master ブランチに merge しただけで、本番環境への再デプロイが完了する、という状態に持っていくことができました。一度ありがたみが分かると、もう手放せないですね( ´ ▽ ` )
3. 学習ロードマップ
さて、いよいよ本題です。ここまでで開発したアプリについて解説をしてきましたが、ここからは、このアプリ開発に至るまでの学習過程をたどっていきます。
第1章でもお伝えした通り、筆者はプログラミング経験自体はあっても、いわゆる「Web系」の知識はゼロからのスタートでした。繰り返しますが、HTMLすら知らなかった状態から、独学ベースで上記技術スタックをアプリに盛り込めるレベルまで到達することができました。
独学ベースでの学習になると、「どの学習教材を選ぶべきか」というところから自分で考える必要があります。いろいろと紆余曲折ありましたが「これは役に立った!」と思うものを厳選し、時系列に沿ってお伝えします。
※下記サービスのWebリンクや、ロゴ画像、ホームページのスクリーンショットについては、事前に各運営者様に使用許可をいただいております。改めまして運営者皆様、利用快諾していただきありがとうございました。
3.1 Progate
皆大好きProgate。今からエンジニアを目指す方は、全員ここから入門して間違い無いでしょう。
URL: https://prog-8.com/
自分は手当たり次第に色々な講座をやってみていましたが、
- HTML&CSS
- Javascript(ES6)
- jQuery
- Ruby
- Ruby on Rails
次いで
- Command line
- Git
- SQL
辺りを押さえておけば十分だったかと思います。
各講座の序盤のレッスンは無料会員でも受けることができますが、本気でエンジニアを目指すのであれば、有料会員限定のコースも含めて取り組んでいきましょう。
これだけでもそれなりにボリュームはありますが、挫折しにくいよう学習ステップがかなり細かく設定されているので、初心者にとっても易しいつくりになっています。
ただ、Rails講座だけはさすがに難易度が高かったです。。。これは、Progateさんの講座の作り云々ではなく、Webフレームワークという概念が初学者にとって「始めまして」になるので、多少仕方がない部分ではあると思います。
1周目で全体像の把握、2週目以降で詳細理解に努める、というスタンスでよいかと思います。
3.2 Ruby on Railsチュートリアル
皆大好き(?) Rails チュートリアル。
URL: https://railstutorial.jp/
色々賛否ある教材ですが、無料かつ、ここまで体系的に「RailsのWebアプリ開発」を学べる教材は他にないと思います。
本教材の謳っているところでもありますが、「単にRuby, Railsの学習に終始せず、Webアプリ開発の全体像を俯瞰する」ものですので、本教材での知識は、他言語・他フレームワークで開発をする場合でも大いに活きると思います。
確かに、当教材に対する否定的な意見はいくつか見受けられ、
- テストフレームワークとして、国内企業でデファクトスタンダードになっている
Rspecではなく、Railsに標準搭載されているminitestを使用している- 採用技術が古くなってきてしまっている
という点がよく指摘されています。
ただ、前者については、株式会社YassLab代表のコチラのYoutube動画の動画でも説明がある通り、「かつて(第2版まで)は Rspec を Rails チュートリアルでも採用していたが、Rspec 自体の学習コストが高いこともあり、それによる脱落者を多く出していた」という背景を受けてのものになります。
また後者については、例えば現在の Rails企業の多くは、Rails単体のアプリケーション(フロントはjQery/bootstrap)ではなく、APIとしてRailsを利用し、フロントはJSフレームワーク(Vue.jsやReact.js)を使うのが一般的になってきています。しかし、Rails初学者が、いきなりAPI開発から始めるのは、理解の階段を飛ばしすぎている、というのも事実でしょう(これについては、同者のコチラのYoutube動画も参考になるかもしれません)
つまり、Rails チュートリアルは「Railsを初めて触る人がなるべく挫折しにくい難易度設定を目指す」ということを念頭に置いた教材であり、最前線の現場で使用されているような本格的なRailsの習得の橋渡しをするようは役割である、と考えることができるかと思います。逆に、これ以上現場に近づけた本格的な内容にしてしまうと、それこそ多くの初学者が挫折してしまうと思います。
したがって、Rails初学者は、今この時代であっても、自信を持って当教材取り組んでよいと思います。少なくとも自分は、この後にも続くRails学習において、ベースとなるような知識をつけることができた、と感じています。
ただ、いくら難易度を落としているとはいってもRails初学者に取ってはかなり難しく、かつ量も膨大であるのは事実です。そのため、Railsチュートリアル完走を一つのマイルストーンとして設定し、内容につまづいたら「ひたすらググる」あるいは「適宜Progateに戻る」という進め方が効率的かと思います。
私も、一度はあまりの量と難易度に挫折してしまったのですが、社会人としてすでに働いており、ある程度お金に余裕があったので、動画版を購入して最後までやり切りました。個人的には、人が解説してくれている形式の方が理解がスムーズで、モチベーションの維持もしやすかったで、お金に余裕のある方にはオススメです。
Railsチュートリアルで身につく知識を整理すると、
- バックエンド:
Rails(シングルアプリケーション)- フロントエンド:
jQuey+bootstrap(Railsの一部として内包)- テスト:
minitest- 開発環境:
AWS cloud9- デプロイ:
Heroku全くの初心者からWebアプリとして求められる一通りの機能を実装し、本番環境へデプロイするところまでできるのは、やはり教材として素晴らしいと思います。
しかし先ほども述べた通り、当教材はあくまでも橋渡しの位置付けです。未経験からの転職という自分自身の立場を鑑みると、Web系企業への転職用PF作成の準備としては、技術面でまだ心許ない、と考えました。
改めて複数企業の採用ページから実際に企業で使用されている技術を確認し、上記の学習知識と比較して整理をすると、
- フロントは、
Vue.jsやReact.jsといったJavaScriptフレームワークを使用するのが一般的。それに伴い、Railsは単独アプリとしてではなく、APIモードで開発する- テストフレームワークは、minitestではなく、
Rspecがデファクトスタンダード- 開発環境はPCローカルに構築する(
Vagrantで仮想マシンを構築するか、Dockerでコンテナ化するか)- アプリケーションのデプロイは、小規模であれば Heroku を使うこともあるが、企業が提供するような中・大規模なアプリケーションであれば、
AWSやGCPなどをよく用いられる次に習得すべきは、ここの技術領域であることが分かりました(個人的な話ですが、この辺りの時期からエンジニア採用ページに書かれている各技術がスタックが、どういった内容であるかが理解できるようになってきており、成長を実感していました)。
Railsチュートリアルを完走した方は、完走者向けのロードマップ紹介ページもありますので、まずはここを見てみるものよいかと思います。しかし私は、洗い出した上記項目をより体系的に学ぶことができるものがないかと考え、自分なりに色々と教材を探してみた結果、以下のサービスに辿りつきました。
3.3 Take off Rails
URL: https://freelance.cat-algorithm.com/lp/take-off-rails
『あなたを「初心者エンジニア」から「現場で活躍できるエンジニア」まで引き上げます。』というスローガンを掲げた教材とメンターがセットになったサービスで、Rails チュートリアルと実際の企業の間の穴埋めを狙った内容になっています。
基本的にはすでに作成された教材に則っとりながら自分のペースでアプリを開発していくのですが、都度 Slack でメンターさんに質問を投げることができるというのが大きな特徴です。。
最終的な教材のゴールとしてはQiitaのクローンサイトを開発することになります。これの技術スタックは下記の通りです。
- バックエンド:
Rails APIモード- フロントエンド:
Vue.js(ソースコードは作成済みのものを使用。あくまで Rails との繋ぎ込みまでを扱う)- テスト:
Rspec(+Factory_bot)- 開発環境:
ローカル + DB(MySQL) は Docker コンテナを利用- アプリのデプロイ: Heroku
- その他:
CircleCI による rspec, rubocop の自動化※ 私の当サイト用のリポジトリ: https://github.com/ddpmntcpbr/qiita_clone
Railsチュートリアル時点での技術スタックと比べると、かなり実務に近い技術が盛り込まれていることが分かるかと思います。
こちら、決して安い金額ではないサービスだと思います(スクール等に比べれば全然安いですが)。ただ、当時欲しいと思っていた知識が一気に身に着けられると考えて、購入を決意しました。
結果、良い買い物だったと思います。自分が学びたい内容がきれいに体系化されていたこともそうですが、何より、教材内容についてメンターさんへ質問ができるのも有意義だと感じました。遅くとも24時間以内にはレスポンスが返ってくるのもありがたく、「料金分を回収してやるぞ!」という気持ちで、たくさん質問させてもらいました笑
本教材では、上記技術の学習だけでなく、
- Git commit の適切な粒度や、コミットメッセージの書き方
- Github での PR の出し方や、コードレビューの流れ
- Slack でのやり取り(意図が伝わりやすい質問の仕方など)
といった、「独学ではなかなか身につかない」けど「チーム開発では必須になる」ような周辺知識について学べた点も、非常に有用だったと思います。Railsチュートリアルの内容がおおよそ理解できていれば前提知識としては十分な難易度で、大きく挫折をすることがなかった点もプラスです。
さて、ここまでで、Railsに関しては、比較的モダンな開発手法に触れることができました。
しかし、当教材ではあくまでも Rails の開発に的を絞ったものであり、フロントエンドは既存のソースコードを流用する形での学習でした。この教材の内容を自身の転職用PFに組み込むためには、フロントエンド側についても自身で開発する知識が必要と考えました。
フロントエンドフレームワークの選定について、第2章でもお伝えしたとおり、「Reactの方がなんとなくよさそうかなー」と考えていたところ、次の教材を見つけたことをきっかけに、正式に React の学習を始めることにしました。
3.4 【とらゼミ】トラハックのエンジニア学習講座
現役の React エンジニアである トラハックさん ( @torahack_ )が、Youtube上で公開している講座で、Reactについて基礎の基礎から学ぶことができます。
動画チャンネルURL: https://www.youtube.com/user/1492tiger
こちらの教材の特長は、
- Reactの基礎の基礎から体系的に学べる( Progate の JavaScript 講座完了が受講目安)
- 動画によるハンズオン形式
- 教材範囲にモダンなフロントエンドの開発手法を含む( Redux 等)
- 動画のほぼ全てがYoutube上でなぜか無料公開されている
特に最後については完全にバグとしか思えない点で、Udemyなどで有料販売されていても動画講座と比べても遜色ないクオリティだと思います。
動画教材にありがちな「準備した原稿丸読み」のような堅い口調ではなく、フランクな若手予備校教師の授業(?)のような語り口のため、硬い喋りが苦手な人にもお勧めできます。私は復習のために、一度見た動画を耳だけで聞き返したりして、記憶の定着を図りました。
講座はいくつかのシリーズに分かれており、私が視聴をしたのは、
1.『日本一わかりやすいReact入門』シリーズ
2. 『日本一わかりやすいReact入門【実践編】』シリーズ
3. 『日本一わかりやすいReact-Redux入門』シリーズの3シリーズです。
最終的な成果物の技術スタックは、
create-react-appRedux & redux-thunkMaterial-UIFirebase: Google が提供する mBaaS。バックエンド+インフラを手軽にセットアップできるです。
※ 私のGithubリポジトリ: https://github.com/ddpmntcpbr/react-ec-app
こちらの動画については、学習備忘録記事をQiitaに投稿しております。よろしければこちらもご参考下さい。
参考ページ: 『日本一わかりやすいReact入門【実践編】#1~5 学習備忘録』
本学習講座を全て受講するためには、有料コミュニティ『とらゼミ』への加入が必要になりますが、筆者は無料公開範囲の動画で必要な知識は十分に身に付いたと感じたため、加入はしておりません。(代わりの記事として書くことで、宣伝として少しでもお役に立てればと思っています笑)
さて、ここまででフロント側も自力で開発ができる基礎が身に付きました。これくらいの時期に並行してアプリのコンセプトが決定していましたので、いよいよポートフォリオ作成に取り掛かり始めました。
しかし、開発を始めるといくつも壁が出てきます。基本的にはググりながらの解決をしていきましたが、どうしても解決できないエラーにもぶち当たりました。特に、
- ReactとRailsの繋ぎ合わせ
- AWSでのアプリの公開方法
- その他インフラ知識全般
あたりが、個人的な難所でした。その過程で頼らせてもらったのが、次のメンターサービスです。
3.5 TechTrain
有名企業のエンジニアから実務を学べるオンラインコミュニティです。URL: https://techbowl.co.jp/techtrain
特長を列挙すると、
- 現役エンジニアであるメンターさんと、1 on 1でのオンライン面談が可能
- メンターの方々の技術領域は多種多様
- 全てのメンターと面談が可能で、技術トピックに応じて切り替えることが可能
- 面談はこちらからのタイミングで入れることができる
なぜか全て無料で利用できるはっきり言います。これだけのことができて完全無料なのは完全にバグです。これからエンジニア就職を目指しているU30の学生・社会人は、全員登録した方がいいレベルです
TechTrain の中ではいくつかの Mission が設けられており、それをメンターと一緒に取り組んでいくことで知識を習得していく、ということが可能です。 Mission は実際のIT企業とのコラボで作成されており、中には「Missionをクリアできた人は一次面接をスキップできる」のような特典もついていたりします。
ただ私は Misson には取り組まず、あくまでの個人開発のサポートとして利用させてもらっていました。基本的には自身の既存知識とググり力でPF作成を進めつつ、どうしても解決できない課題が出てきたときにピンポイントで面談予約を入れる、というイメージで、個々人の利用したい形式/ペースで利用できる点も大変ありがたかったです。
異なる技術領域を持ったエンジニアの方々全員と面談をするが可能なため、
Rails,React,AWSそれぞれで、別のメンターの方に質問をさせてもらっていました。特に自力での解決が難しかったのがAWS周りの本番環境構築で、本サービス無しでは乗り越えられなかったと思います。
AWSのことをAWS現役社員に無料で聞けるサービスと表現すれば、このサービスのやばさが伝わるかと思います。最終的には、自身のググり力 + TechTrain で都度メンターを利用、を繰り返すことで、無事アプリを完成させることができました!
3.6 番外編
上記以外で役に立ったものについて、ざっくばらんに紹介します。
Udemy 『Git:はじめてのGitとGitHub』
無料で Git の基礎を学べる講座です。「Gitよう分からん!」って人は、まずこれから触れてみましょう
『キタミ式イラストIT塾 基本情報技術者』
基本情報処理の定番本です。コンピューターサイエンス領域の基礎知識が体系的に学べます。イラストが豊富であり、文章表現も柔らかいので初心者にも優しいです。資格自体の取る/取らないに関わらず一読をオススメします。
『米国AI開発者がゼロから教えるDocker講座』
Dockerについて一から学べる動画教材です。作者様はデータサイエンス領域の方ですが、Webアプリ開発を目的とした人であっても問題ありません(実際に、講座後半では、docker-composeを利用したRailsコンテナの構築まで扱っています)
非常にボリューミーな内容にも関わらず、Udemy講座の中ではかなり良心的な価格設定です。
『【AWS 入門】EC2とDockerでHello Worldしよう』
AWSについて何にも分からない状態から、「nginxだけのシンプルなコンテナアプリを動かす」ところまで、ハンズオン形式で学習ができます。
AWSのとっつきにくさは、「①インフラの概念が分からない」「②専門用語が分からない」に集約されると思います。まずは手を動かしながら、AWSでアプリをデプロイ流れを全体像で掴むことができます。
3.7 アプリの改善点
一通りアプリを完成させてみて、初めて見えてくる改善点が多くありましたので、合わせて列挙します。
AWSサーバー代高すぎ!!!
スケーラビリティの高い中・大規模向けインフラ構成になっているため、サーバー代がめっちゃ高い笑
長く公開するためには、どこかのタイミングで無料サーバーへ移管する必要があるかなと思います。Heroku の無料枠で上手にやりくりできれば、解決できるかもしれないです。
フロントエンド は
Next.js+Typescriptで実装したいNext.js はレンダリングのタイミングを制御できるので、OGP情報の保持が簡単に実現できます。
また、それ以外でも、
- ルーティング設定が簡単
- パフォーマンスをよくするような機能も豊富
- Typescriptの導入が用意
というメリットもあり、とても気になっているフレームワークです。次、全く同じアプリを開発するとするのであれば、絶対に採用したい技術です。
デザインがあやしい気がする・・・?
アプリを開発して気づいたのは、
アプリにおけるデザインの重要です。これを思った理由は単純で、開発途中で「なんか自分のアプリ、イケてなくない?」と感じたからです笑
Webアプリにおけるデザインは、単なるお洒落さに関するものだけでは決してありません。デザインは、ユーザーにとって必要な情報を適切に配置することであり、ユーザーの価値提供のための最前線領域です。
ユーザー側から価値提供の流れ(バリューチェーンと表現するのでしょうか)をざっっっくり並べると、
ユーザー -> UI/UXデザイン -> フロントエンド -> バックエンド -> インフラ
のようになっていると思っています。「エンジニアになろう!」と意気込んで後ろ3つについてはそこそこ勉強してきましたが、デザイン領域については開発初期は完全素人の状態で、途中までは勘でやっていました。。。
一応、付け焼き刃程度ではありますが、デザインの名著である『ノンデザイナーズ・デザインブック』に目を通し、途中からは意識できる範囲ではデザインのことを意識して、フロントを実装しました。
うまく取り込めているかは分かりませんが、少なくとも「デザインはセンスではなく論理」であることが学べただけでも、よい勉強になりました。こちらの書籍も、転職用PF作成者にオススメしておきます。
4. さいごに
以上、大変長い記事でしたが、最後まで読んでいただきありがとうございました。タイトルでは「学習ロードマップ」と銘打っておきながら、私自身の思考プロセスや価値観についても多く書かせてもらいました。
「エンジニアになりたい!」と思い立ってから、学習自体はほぼ一人で淡々と進めてきました。しかし、ほぼ独学でここまで学習を進めることができたのは、多くの先輩エンジニアの方々が様々な情報をインターネットに投稿し、それをオープンに取得できる環境にあったからだと思っております。
それであれば、次は自分自身も。他の駆け出しエンジニアの方々の助けになるような情報を発信できれば、と思い、この記事を書くこととしました。
もし、参考になったという方がいましたら、せひLGTM、ストック、twitterでのシェアお願いします!
また、私自身もtwitterをやっておりますので、気軽にフォローしてもらえるとうれしいです(^^)
よろしくお願いします!
Twitter: https://twitter.com/ddpmntcpbr
Github: https://github.com/ddpmntcpbr/rails_react_docker
- 投稿日:2021-02-21T14:09:20+09:00
SAMをつかったサーバーレスな郵便番号APIを紹介!
SAMをつかったサーバーレスな郵便番号APIを紹介!
はじめに
郵便番号から住所を検索するAPIってなんで無料で存在しないんだってよく思います。(ほんとにないかはよく調べてないので知りませんが。)
なので簡単にデプロイして公開して自動更新までしてくれるアプリケーションをSAMをつかって作成したので紹介します。
またSAMのチュートリアルに丁度いいくらいの量だと思いますので、ぜひ実装解説も見てみてください。
この記事で紹介しているソースコードはこちらです。
https://github.com/Cohey0727/zip-code-app構成について
日本郵便株式会社は郵便番号と住所を紐づけたCSVファイルを公開しています。https://www.post.japanpost.jp/zipcode/download.html
ですがCSVファイルのままだとWeb画面などで利用するのは難しいです。
そこでLambdaでファイルをダウンロードして検索可能な状態でDynamoDBに格納する関数とそれをAPIとして公開する関数、定期的にそれらを更新するイベントをSAMで作成しています。
SAMとは
SAMとはAWSのマネージドなサービスを組み合わせて、サーバーレスアプリケーションを構築できるフレームワークです。
cliが提供されており、この記事の実装やデプロイの際にインストールが必要になります。
AWS SAM CLI のインストール
環境
項目 バージョン SAM CLI 1.6.2 Python 3.8 とにかく動作させたい方へ
実装等はどうでもいいので、とにかく動作させたいという方は、
git clone https://github.com/Cohey0727/zip-code-app.gitをしてデプロイ&動作確認の章から読んでください。
またmasterブランチでは定期的に郵便番号を更新するプログラムを含みます。不要な場合はブランチをnone_scheduleに切り替えてからデプロイ&動作確認を実施してください。実装解説
ここでは具体的なプログラムや構成の解説をしていきます。
逐次デプロイ&動作確認しながらやるとより理解が深まると思います。初期化
sam initコマンドで初期化します。
以下のパラメータで初期化しています。
項目 選択 値 template source AWS Quick Start Templates 1 runtime python3.8 2 Project name - zip-code-app application templates Hello World Example 1
クリックでコマンド結果を展開
$ sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore3.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8.al2 13 - java8 14 - dotnetcore2.1 Runtime: 2 Project name [sam-app]: zip-code-app AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World 3 - EventBridge App from scratch (100+ Event Schemas) 4 - Step Functions Sample App (Stock Trader) 5 - Elastic File System Sample App Template selection: 1 ----------------------- Generating application: ----------------------- Name: zip-code-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./zip-code-app/README.md
今回は
srcフォルダを作成しそこにプログラムを書くことにします。
またsrc/requirements.txtに必要なライブラリを追記します。$ mkdir src $ touch src/__init__.py $ touch src/requirements.txt $ echo "requests" >> src/requirements.txtまた不要なファイルと不要なリソースを削除します。
$ rm -rf hello_worldAWSで利用するリソースは
template.yamlに記述していきます。
不要な部分を削除しておきます。--- a/template.yaml +++ b/template.yaml Resources: - HelloWorldFunction: - Type: AWS::Serverless::Function ## More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction - Properties: - CodeUri: hello_world/ - Handler: app.lambda_handler - Runtime: python3.8 - Events: - HelloWorld: - Type: Api ## More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api - Properties: - Path: /hello - Method: get最終的なフォルダ構成は以下のようになります。
. ├── README.md ├── __init__.py ├── events │ └── event.json ├── src │ ├── __init__.py │ └── requirements.txt ├── template.yaml └── tests ├── __init__.py ├── integration │ ├── __init__.py │ └── test_api_gateway.py ├── requirements.txt └── unit ├── __init__.py └── test_handler.pyDBの設計・実装
AWSのDyanamoDBを利用して作成します。
郵便番号 -> 住所で検索したいので郵便番号に該当するカラムにPrimaryIndexを指定します。
今回は郵便番号のカラムをzipCodeとしました。
また、WriteCapacityUnitsは初回のデータ取り込み時を除いて全く必要ないので最小の1ユニットを指定します。以下のコードを
template.yamlのResourcesのブロックに追記します。template.yamlZipCodeTable: Type: AWS::DynamoDB::Table Properties: TableName: ZipCode AttributeDefinitions: - AttributeName: zipCode AttributeType: S ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 1 KeySchema: - AttributeName: zipCode KeyType: HASHDyanamoDBはスキーマレスなので、インデックスに指定しないカラムは記述しません。なのでこれでDBに関する記述は終了です。デプロイするとコンソール画面からテーブルが作成されていることが確認できます。
郵便番号の取り込みを実装
郵便番号の取り込み用のソースコードのは
import.pyファイルに記述していきます。$ touch src/import.py定数と初期化
先に作業用ディレクトリ、ダウンロードファイル名、解凍ファイル名、ダウンロードURLを定数にしておきます。
また、boto3よりテーブルリソースを取得しておきます。import boto3 import csv import os import requests import zipfile WORKSPACE = f'/tmp' ZIP_FILE_NAME = 'ken_all.zip' CSV_FILE_NAME = 'KEN_ALL.CSV' ZIP_CODE_URL = 'https://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip' table_name = 'ZipCode' zip_code_table = boto3.resource('dynamodb').Table(table_name)ファイルのダウンロードと解凍
ファイルをダウンロード、解凍します。
## ファイルダウンロード res = requests.get(ZIP_CODE_URL, stream=True) ## ファイル保存 with open(f'{WORKSPACE}/{ZIP_FILE_NAME}', 'wb') as f: for chunk in res.iter_content(chunk_size=1024): if chunk: f.write(chunk) f.flush() ## ファイル解凍 with zipfile.ZipFile(f'{WORKSPACE}/{ZIP_FILE_NAME}', 'r') as zip_file: zip_file.extractall(WORKSPACE)データの整形と取り込み
日本郵政からダウンロードしたCSVファイルは以下のような構成になっています。
参考
No 内容 1 全国地方公共団体コード 2 旧郵便番号(5桁) 3 郵便番号(7桁) 4 都道府県名カナ 5 市区町村名カナ 6 町域名カナ 7 都道府県名 8 市区町村名 9 町域名 3カラム目の
郵便番号(7桁)がPrimaryIndexであるzipCodeを当てはまります。
それ以外にはそれっぽい英語のカラムを適用します。## 整形 zip_codes = [] with open(f'{WORKSPACE}/{CSV_FILE_NAME}', "r", encoding="ms932", errors="", newline="") as csv_file: reader = csv.reader(csv_file) for row in reader: zip_codes.append(dict( zipCode=row[2], prefecture=row[6], prefectureKana=row[3], city=row[7], cityKana=row[4], street=row[8], streetKana=row[5] )) ## 取り込み with zip_code_table.batch_writer(overwrite_by_pkeys=['zipCode']) as batch: for zip_code in zip_codes: batch.put_item(Item=zip_code)定期取り込みの登録
初回取り込みのみで問題ないという場合は、この章は呼び飛ばしてください。
このアプリケーションの場合、書き込みキャパシティーがデータ取り込み時とそうでないときで大きな差があるためそれを管理する必要があります。
処理の流れとしてはキャパシティーを拡張→10分待つ→実行→キャパシティーを元に戻すと処理が少し複雑になります。(キャパシティーモードをオンデマンドにすれば解決しますが、無料枠でどうにかしたかったのでこの方法を採用しています)まず、書き込みキャパシティを拡張する関数とそれを元に戻す関数を
import.pyに追記します。## import.py def write_capacity_scaleup(*args, **kwargs): zip_code_table.update( ProvisionedThroughput={ 'ReadCapacityUnits': 5, 'WriteCapacityUnits': 1000 } ) def write_capacity_scaledown(*args, **kwargs): zip_code_table.update( ProvisionedThroughput={ 'ReadCapacityUnits': 5, 'WriteCapacityUnits': 1 } )続いて関数が定期実行されるように
template.yamlに追記しきます。write_capacity_scaledownは取り込み処理の最後に追記します。
今回は毎年、日本時間の4月10日のAM00:00分にスケールアップ→4月1日のAM00:10に取り込み処理開始&スケールダウンするようにしています。以下のコードを
template.yamlのResourcesのブロックに追記します。ImportZipCodeFunc: Type: AWS::Serverless::Function Properties: CodeUri: src/ Handler: import.main Runtime: python3.8 Policies: - DynamoDBCrudPolicy: TableName: ZipCode - DynamoDBReconfigurePolicy: TableName: ZipCode Timeout: 600 MemorySize: 512 Events: ScheduleImport: Type: Schedule Properties: Schedule: cron(10 15 31 3 ? *) TableScaleUpFunc: Type: AWS::Serverless::Function Properties: CodeUri: src/ Handler: import.write_capacity_scaleup Runtime: python3.8 Policies: - DynamoDBReconfigurePolicy: TableName: ZipCode Events: ScheduleImport: Type: Schedule Properties: Schedule: cron(0 15 31 3 ? *)完成形
以下がデータ取り込みの最終的なソースコードとなります。
import boto3 import csv import os import requests import zipfile WORKSPACE = '/tmp' ZIP_FILE_NAME = 'ken_all.zip' CSV_FILE_NAME = 'KEN_ALL.CSV' ZIP_CODE_URL = 'https://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip' table_name = 'ZipCode' zip_code_table = boto3.resource('dynamodb').Table(table_name) def main(*args, **kwargs): try: ## ファイルダウンロード print('ファイルダウンロード開始') res = requests.get(ZIP_CODE_URL, stream=True) ## ファイル保存 print('ファイル保存開始') with open(f'{WORKSPACE}/{ZIP_FILE_NAME}', 'wb') as f: for chunk in res.iter_content(chunk_size=1024): if chunk: f.write(chunk) f.flush() ## ファイル解凍 print('ファイル解凍開始') with zipfile.ZipFile(f'{WORKSPACE}/{ZIP_FILE_NAME}', 'r') as zip_file: zip_file.extractall(WORKSPACE) ## データ整形 print('データ整形開始') zip_codes = [] with open(f'{WORKSPACE}/{CSV_FILE_NAME}', "r", encoding="ms932", errors="", newline="") as csv_file: reader = csv.reader(csv_file) for row in reader: zip_codes.append(dict( zipCode=row[2], prefecture=row[6], prefectureKana=row[3], city=row[7], cityKana=row[4], street=row[8], streetKana=row[5] )) ## 取り込み print('取り込み開始') with zip_code_table.batch_writer(overwrite_by_pkeys=['zipCode']) as batch: for zip_code in zip_codes: batch.put_item(Item=zip_code) finally: write_capacity_scaledown() os.remove(f'{WORKSPACE}/{ZIP_FILE_NAME}') os.remove(f'{WORKSPACE}/{CSV_FILE_NAME}') def write_capacity_scaleup(*args, **kwargs): zip_code_table.update( ProvisionedThroughput={ 'ReadCapacityUnits': 5, 'WriteCapacityUnits': 1000 } ) def write_capacity_scaledown(*args, **kwargs): zip_code_table.update( ProvisionedThroughput={ 'ReadCapacityUnits': 5, 'WriteCapacityUnits': 1 } )検索用APIの実装
検索用プログラム
検索用のソースコードは
search.pyファイルに記述していきます。$ touch src/search.py今回は
https://xxx.amazonaws.com/zipcode/123-4567のようにパスパラメータとして郵便番号を受け取ることにします。import boto3 import json table_name = 'ZipCode' zip_code_table = boto3.resource('dynamodb').Table(table_name) def main(event, context): zip_code_str = event['pathParameters'].get('zipCode').replace('-', '') params = {'zipCode': zip_code_str} zip_code = zip_code_table.get_item(Key=params).get('Item') return {'statusCode': 200, 'body': json.dumps(zip_code)} if zip_code else {'statusCode': 404}パスパラメータはLambdaをハンドルしている関数の第一引数から
pathParametersキーで取得できます。
またパスパラメータ内でのキーはtemplate.yamlで宣言することができ、今回はzipCodeとしています。
template.yamlのResourceブロックに以下を追記します。ZipCodeSearchApi: Type: AWS::Serverless::Function Properties: CodeUri: src/ Handler: search.main Runtime: python3.8 Policies: - DynamoDBReadPolicy: TableName: ZipCode Events: ListSearchUser: Type: Api Properties: Path: /zipcode/{zipCode} Method: getデプロイ後にAPIのURLを表示
template.yamlのOutputsのブロックには、デプロイが完了したあとにAPIのURLを出力することができます。Outputs: ZipCodeSearchApi: Description: "API Gateway endpoint URL for Search Address from Zip Code" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/zipcode/100-0000"デプロイ&動作確認
デプロイ
以下のコマンドでアプリケーションをデプロイします。
スタック名やリージョンは、必要に応じて変更してください。$ sam build $ sam deploy --guided Stack Name [sam-app]: zip-code-app AWS Region [us-east-1]: ap-northeast-1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [y/N]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: Y HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: y Save arguments to configuration file [Y/n]: Y SAM configuration file [samconfig.toml]: SAM configuration environment [default]:デプロイ後に出力されるURLがAPIのURLです。動作確認で利用するのでメモしておきます。
なおこちらAWSコンソールからいつでも確認できます。API Gateway > zip-code-app > ステージ > Prod初回取り込み
上記のデプロイのみだと定期実行の日付までデータが存在しないので住所検索を利用することができません。
そのため初回のデータ取り込みが必要になります。実行する前に書き込みキャパシティーユニットを拡張する必要があります。
私の実行したときは、500ユニットほどで頭打ちになったので1000ユニットあれば十分です。
AWSコンソールのDynamoDB > テーブル > ZipCode > キャパシティ > 書き込みキャパシティーユニットから変更できます。
変更の反映には数分かかります。テーブルの更新が完了するまで待ってLambdaのダッシュボード画面から取り込み関数を実行します。
Lambda > 関数 > zip-code-app-ImportZipCodeFunc-xxxx > 設定から実行できます。
テストイベントを作成する必要がありますが、中身は参照しないのでサンプルをそのまま利用して問題ありません。
郵便番号は全部で約12万件あるので数分かかります。
完了したら、データが作成されていることと書き込みキャパシティーユニットが1に戻っていることを確認します。
動作確認
デプロイ後に出力されたURLをブラウザ等に貼り付けて動作を確認します。
Unicodeエスケープされているのでわかりにくいですが、レスポンスに住所情報が乗っています。(開発者ツールのNetwork > 対象のリクエスト > PreviewでUnicodeエスケープをデコードしてくれます。)
さいごに
住所検索を利用・実装する際の選択肢のひとつになればと思います。
あとSAMやCloudFormationなどInfrastructure as Codeフレームワークはこうしたアプリケーションの公開も簡単でとてもいいですね。

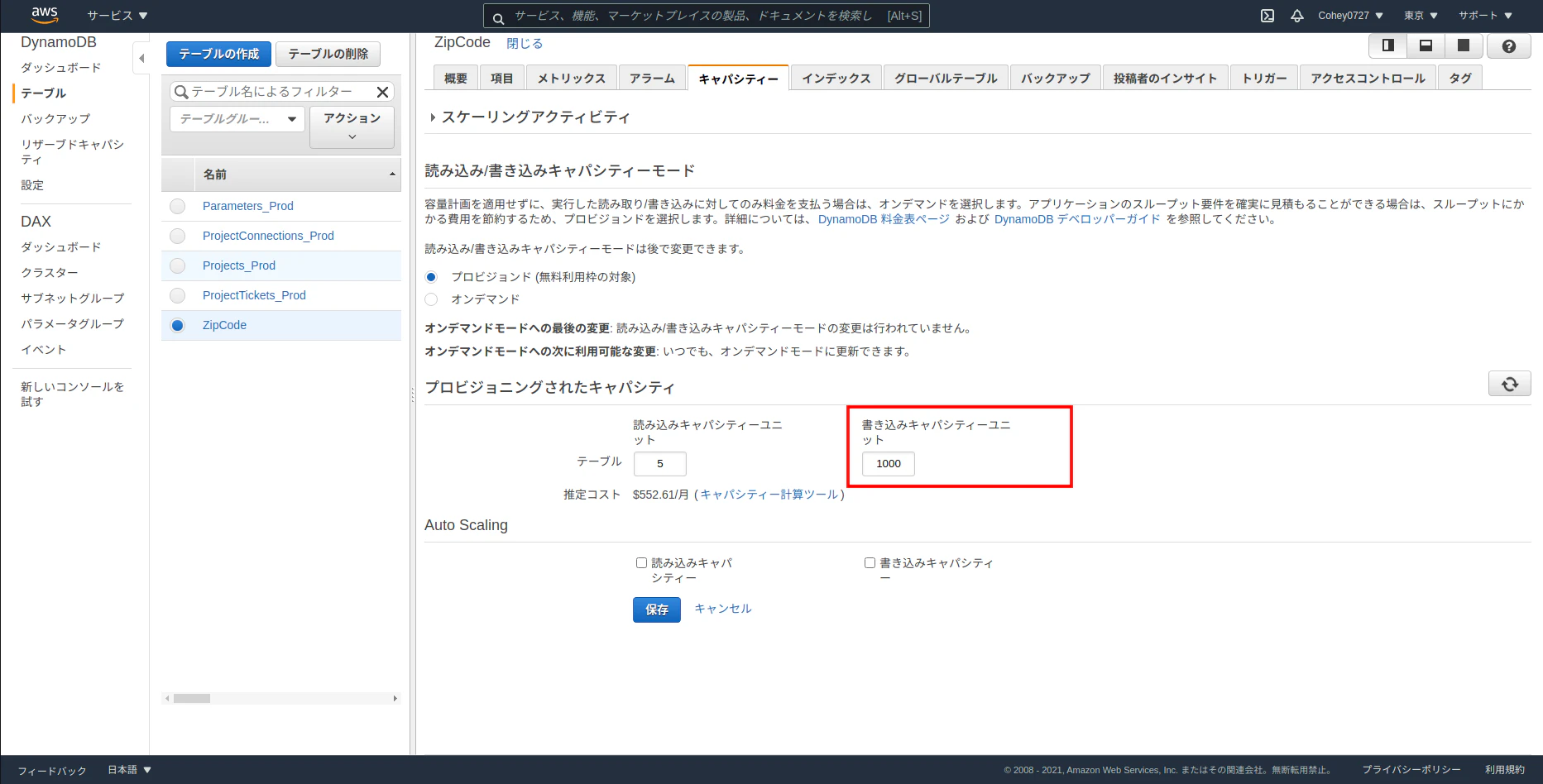
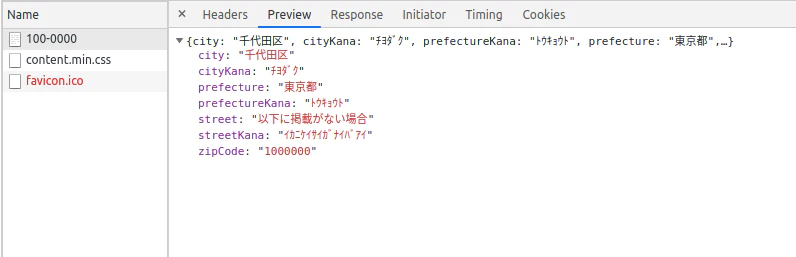
- 投稿日:2021-02-21T11:35:32+09:00
【Rails6】AWS EC2デプロイ時に背景画像を表示
前提
・AWS EC2は導入済み
・背景画像は『app/assets/images』フォルダに格納している
バージョン
rubyのバージョン ruby-2.6.5
Railsのバージョン Rails:6.0.0はじめに
background-imageプロパティを使って、Herokuやローカル上では背景画像が表示されているのに
AWS EC2でデプロイしたら、背景画像が表示されないので、それを解決したい方向けの記事となっています。概要
以下2点を変更して、再度デプロイすると背景画像が表示されます。
①CSSファイルをSCSSファイルに変更する。
②背景画像を指定するCSSの記述をbackground-image: image-url("画像名");に変更する。
詳細
①CSSファイルをSCSSファイルに変更する。
以下のどちらかのパターンで行えます。
・ファイル名の拡張子を、 .CSS → .SCSSに変更する。
・背景画像を表示させているviewの拡張子.SCSSファイルに、②の内容を記述する。※私は後者を選びました。というのも、SCSSに拡張子を変更してしまうと、それまで記述したCSSの記述に影響が出るためです。
②背景画像を指定するCSSの記述をbackground-image: image-url("画像名");に変更する。
SCSSファイルの内容を以下のように変更します。
(変更前)
app/assets/stylesheets/~.scssbackground-image: url(画像名);↓
(変更後)
app/assets/stylesheets/~.scssbackground-image: image-url("画像名");※""(ダブルクォーテーション)を忘れないようにしてください
③デプロイして確認
確認し問題なければ終了です。
なお、ローカル内でも、同様の表示ができます。背景画像が表示されない理由
表示されない理由としては、Asset Pipelinの仕組みが関係しています。
仕組みの1つとして、※1)キャッシュされていた既存のアセットを無効化を行います。というのも、キャッシュの効果を使った悪用を防ぎ、デプロイさせる役割をしているためです。
変更前のbackground-image: url(画像名);記述では、「url」がファイル名は以前と変化していないと認識され、既存のキャッシュとしてみなされます。
したがって、既存の古いキャッシュでは読み込めない状態となるので、、画像を読み込んでもらえません。
(変更前)
app/assets/stylesheets/~.scssbackground-image: url(画像名);そこで、
「url」を指定するのではなく、Railsが指定している「image-url」メソッドを使うことで、デプロイ時にapp/assetsから読み込めるようにします。(変更後)
app/assets/stylesheets/~.scssbackground-image: image-url("画像名");※1) キャッシュとは、データを一時的に保存することで、データの処理速度を速める考え方、仕組みのこと。
補足
AWS EC2をデプロイする方法を以下に載せていますので、よろしければご参考ください。
https://qiita.com/narimiya/items/2e642b60baa4002c4beeassetsディレクトリに関しても以下に載せていますので、よろしければご参考ください。
https://qiita.com/narimiya/items/73ca907c74b4c615f39d以上です。
- 投稿日:2021-02-21T11:26:44+09:00
コピペで出来る!LambdaとAPI Gatewayを使って簡単にAPIを作る手順
散々既出ですが、自分の備忘録を兼ねてメモを残しておきます。
構成
Webクライアント - API Gateway - Lambda (Python) - S3
S3上にあるjsonオブジェクトを単純に返すだけのシンプルなAPIです。
S3にjsonを配置する
Bucket名は何でも良いですがグローバルでユニークである必要があるので適当な数字をつけるなど工夫して下さい。
今回はtest-lambda-api-12345としました。(※1)
以下のようなjsonを作り、
hello.jsonという名前でBucket上に保存します。{ "greeting": "Hello, World!" }
Lambda関数の設定
Lambda>関数の作成に進みます。
関数名を適当に指定します。今回は
test-lambda-get-s3-12345としました。(※2)
ランタイムはPythonの最新版を選択します。執筆時はPython 3.8が最新でした。
その他は何も変更せず、「一から作成」を選択し、関数の作成を押下します。
ロールを一から作る場合、10-20秒程度待つ必要があります。
関数ができると以下のような画面になります。
関数コードのlambda_function.pyの中に、APIを処理を実装していきます。
今回は以下をコピペします。
import json import boto3 # バケット名,オブジェクト名 BUCKET_NAME = '※1' OBJECT_KEY_NAME = 'hello.json' s3 = boto3.resource('s3') def lambda_handler(event, context): bucket = s3.Bucket(BUCKET_NAME) obj = bucket.Object(OBJECT_KEY_NAME) response = obj.get() body = response['Body'].read() return { 'statusCode': 200, 'body': body.decode('utf-8') }※1は、上記で作成したS3 Bucket名を指定してください
コードの説明は不要だとは思いますが、S3からオブジェクトを取得し、botyをjsonで返しているだけです。
コードが出来たら、オレンジ色の「Deploy」を押下してください。
私はこれを忘れてしまっていて、バグを修正しても治らない・・・とか30秒くらい悩みました。Deployが完了すると、すぐ右にあるステータス「Changes not deployed」が緑色の「Changes deployed」に変わります。

LambdaからS3 Getの疎通確認
ここまで出来たら、右上の「テスト」を押下してみましょう。
「実行結果: 成功」と出力されたらOKです。
失敗と表示されたら以下を確認してください。
- Bucket名
- ファイル名
- ロールで権限が割り当てられているか下のほうに「Execution Results」としても実行結果が表示されていますので、よく読めば解決できます。
API Gateway の設定
右上にある「APIを作成」を押下します。
今回はREST APIで作成します。「構築」を押下します。
API名は適当に
test_lambda_apiとしました。
エンドポイントタイプは、リージョンとして全世界に公開です。
※重要:テスト後は、エンドポイントタイプを「プライベート」にするか、このAPIを削除してください。
呼び出されまくるとAWS利用料金が痛いことになります。
アクションから「リソースの作成」を選択します。
リソース名は適当に「test」として作成します。
アクションから「メソッドの作成」を選択します。
httpメソッドは「GET」を選択します。
統合タイプは「Lambda関数」を選択したまま、Lambda関数に、※2で設定したLambda関数名を指定します。
権限追加を確認されますので、OKを押下します。
以下のような画面が表示されます。
クライアントの「テスト(稲妻アイコン)」をクリックします。
何も設定せず「テスト」を押下します。
テスポンスが返ってきたら成功です。
APIのデプロイ
アクションから「APIのデプロイ」を選択します。
デプロイされるステージは「新しいステージ」を選択します。
ステージ名に「test」を入れて、「デプロイを押下します。
以下のように、公開されたAPIのURLが表示されます。
このURLは/ステージ/までとなっていますので、最後に/リソース/まで指定してブラウザアクセスが可能です。
まとめ
画面ポチポチするだけで、サーバレスなAPIを公開することが出来ました。便利な世の中になりましたね。
動作確認するレベルであればこの手順で良いですが、本番で使う時は、ポリシーやネーミング設定など、本番に則した設定としてください。
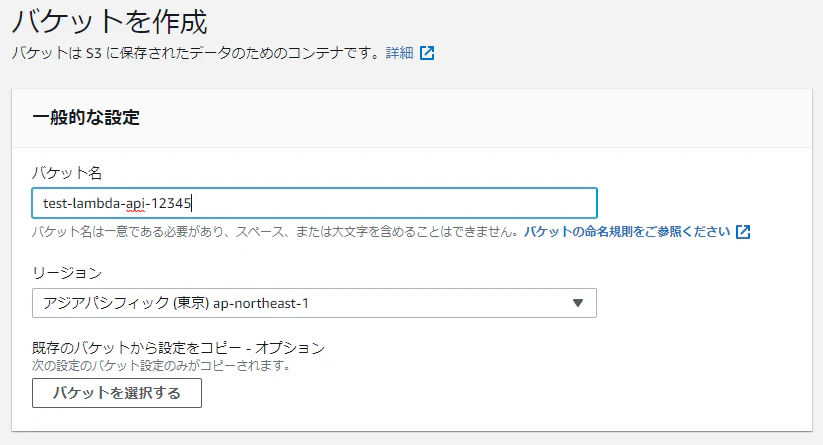


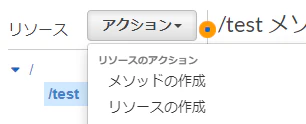
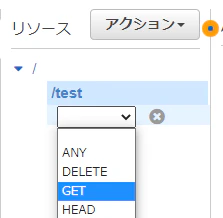
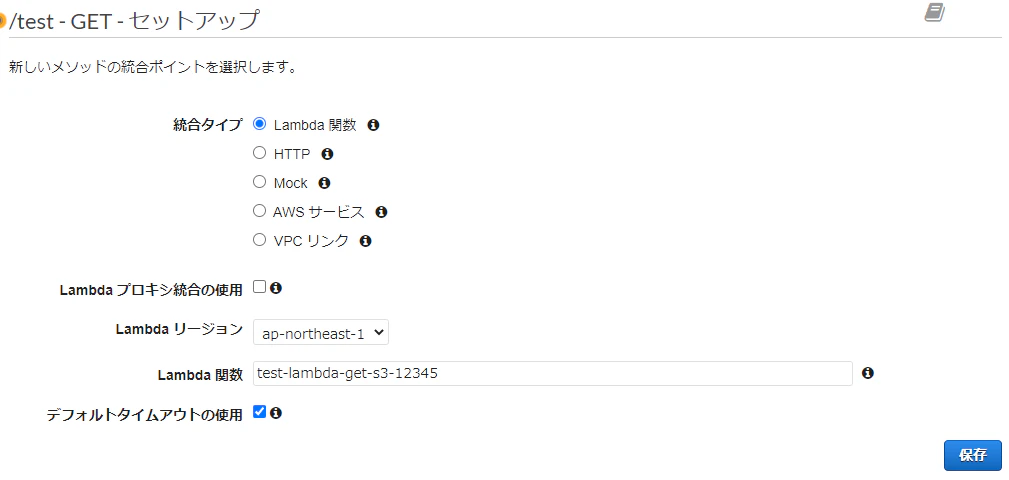
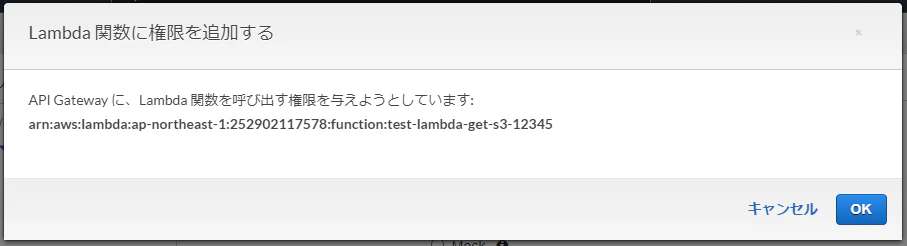

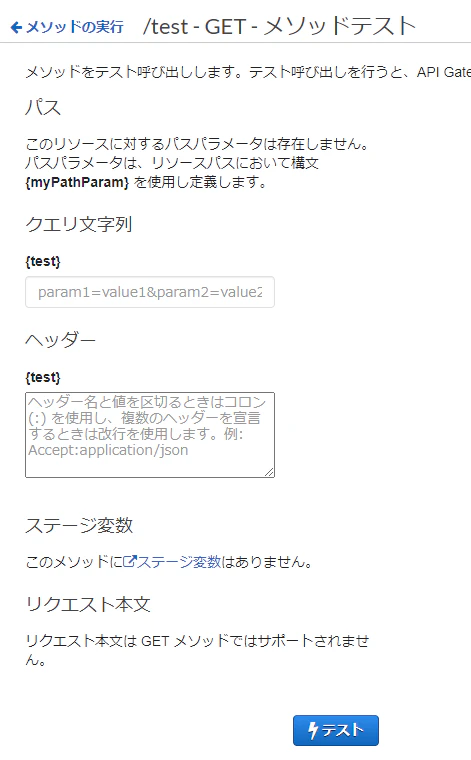
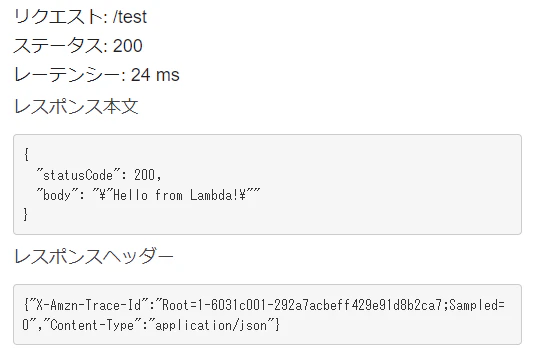

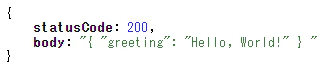
- 投稿日:2021-02-21T09:27:13+09:00
ロードバランサー背後のWebサーバのログでグローバルIPを記録する
ロードバランサーの背後のWebサーバでは、ロードバランサーのプライベートIPが記録されます。
やはり、どこからアクセスがあったかは気になるところです。
Apache の場合これを実現するには以下で可能です。
#LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined LogFormat "%{X-Forwarded-For}i %h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
- 投稿日:2021-02-21T03:12:05+09:00
AWS Route53 とは
Route53とは
AWSのRoute53はDNSサービスを提供します。
主な機能は下記通りです。
ーーーーーーーーーー
Domain registration
DNS management
Health check
ーーーーーーーーーーDomain registration
タイトル通り、ドメインを登録する。
設定したいドメイン名を入力して、登録可能のドメイン名が表示されます。
⇧ドメインの価格。通常は12ドルです。(年間費用)DNS management
ドメイン名をホストゾーンの作成に入力し、タイプを選び、作成ボタンを押していただき、ホストゾーンの作成が完了となります。
★タイプ:public、privateの二種類。
privateを選んだ場合、VPCに関連付けます。
Health check
DNS レコードタイプ
reference:https://docs.aws.amazon.com/ja_jp/Route53/latest/DeveloperGuide/ResourceRecordTypes.html
・SOA – Start of Authority
(ドメイン名の色んな情報を記録する。例えば:Primary Name Server、Responsible Mail Address、Serial、Refresh、Retry、 Expire、Default TTL)・A – ホスト名とIPアドレスの関連づけを定義するレコード。
(ドメイン名をIPv4アドレスに変換する。)・CNAME – Canonical Name
(正規ホスト名に対する別名を定義するレコード。特定のホスト名を別のドメイン名に転送する時などに利用する。)
例えば、aws.houka.comはhouka.comに

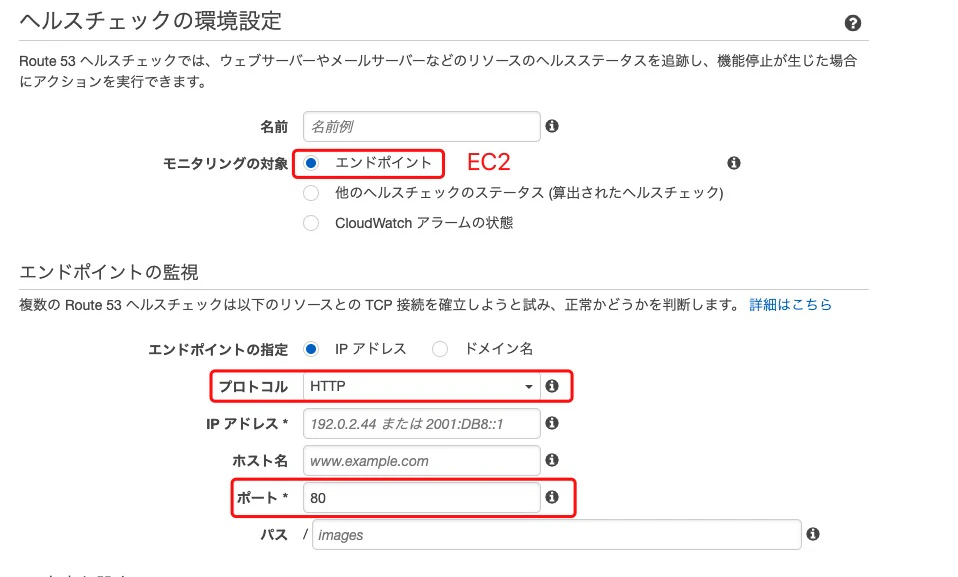
- 投稿日:2021-02-21T02:05:50+09:00
【Rails】業務未経験者がRailsを使用して情報資産共有アプリを開発したので共有します
はじめに
こんにちは!2020年10月よりRubyやRailsを中心に学習しているyutaro(@yutaro48)と申します。
このたび、Railsを使用して情報資産共有アプリ「KnowHow」を開発しましたので紹介させていただきます。アプリ概要
情報資産共有アプリ「KnowHow」を作成しました。
このアプリでできることは以下の3点です!
① ノウハウをアウトプットする
誰でも簡単にアウトプットできます。Markdownにも対応しています。下書きとして一時保存することもできます。
② ノウハウを検索する
自分が求めるノウハウを検索することができます。ブックマークをして他の人のノウハウを自分のものにできます。
閲覧履歴表示やカテゴリー表示も実装しています。
③ 気になる人をフォローする
気になる人をフォローすることができます。フォローした人のノウハウはタイムラインに表示されます。
作成背景
「新卒社員 × 在宅勤務」によって顕在化した課題を解決するために作成
僕は2020年4月に某総合電機メーカーに新卒入社しました。
しかし、コロナウイルスの大流行により入社直後から在宅勤務になり、緊急事態宣言明けも在宅勤務が基本となりました。(緊急事態宣言後も用事がある時以外は基本在宅勤務という形態)
このように「新卒入社 × 在宅勤務」という特殊な状況下で私や同期は以下の3つの課題に直面しました。課題1 会社ノウハウを学ぶ(社員の経験から学ぶ)機会の減少
会社独自のノウハウは属人的であり、先輩社員や同期との雑談などから学ぶことが多いが、リモート環境では雑談などから学ぶ機会がほとんどなくなってしまう。
そのため、学べることが限定的になってしまうという課題がある。課題2 自身の学びをアウトプットする機会やレビューしていただく機会の減少
リモート環境では、自身の学んだことや経験したことを言語化したり、
他の社員の方からレビューしていただく機会が少なくなってしまう。
そのため、PDCAを回しづらい状況になってしまうという課題がある。課題3 同期社員と情報共有する機会の減少
新卒社員の中では、同期が現在どのような仕事をしているか気になっている人が多い。通常であれば雑談や飲み会などの機会に情報共有をすることが多いと思う。
しかし、コロナ禍という状況下ではそのような機会が持てなくなってしまっているという課題がある。
これらの課題を解決したいと思い、情報資産共有アプリ「KnowHow」の作成に至りました。機能一覧
上記の課題を解決するために実装した機能は以下の通りです。
基本機能
機能 Gem ① ログイン機能 devise ② ゲストログイン機能 ③ プロフィール機能 課題1(会社ノウハウを学ぶ機会の減少)を解決するための機能
機能 Gem ① 検索機能 ② ブックマーク機能(Ajax) ③ カテゴリー別表示機能 ④ 閲覧履歴表示機能 ⑤ ページネーション機能 kaminari 検索機能を実装し、自分が知りたいノウハウを検索できるようにしました。
カテゴリー別表示機能、閲覧履歴表示機能やページネーション機能を実装し、検索しやすいようにしました。
またブックマークをすることで他者のノウハウを自分のものにできます。
これらにより、様々な社員の経験から多くを学ぶことができるようになります。課題2(自身の学びをアウトプットする機会やレビューしていただく機会の減少)を解決するための機能
機能 Gem ① ノウハウのアウトプット機能(CRUD) ② コメント機能(CRUD) ③ 下書き保存機能 ④ マークダウン投稿機能 ノウハウのアウトプット機能を実装し、自身の学びや経験をアウトプットできるようにしました。また、MarkDown投稿機能や下書き機能を実装し、アウトプットの体験価値向上を狙っています。
また、コメントで他の社員からレビューしていただくことも可能です。
これらにより、自身の経験についてPDCAを回すことができるようになります。課題3(同期社員がどのようなことをしているのか情報共有する機会の減少)を解決するための機能
機能 Gem ① フォロー機能 ② タイムライン表示機能 同期などが現在どのような仕事をしているかを確認するためにフォロー機能を実装しました。フォローした人のノウハウはタイムラインに表示されます。
これらにより、同期や気になる社員の動向を確認することができるようになります。使用技術と選定理由
使用技術
- 開発環境
- macOS Catalina(10.15.6)
- Visual Studio Code
- フロントエンド
- Haml/Sass/JavaScript(jQuery)
- Semantic UI
- Bootstrap
- バックエンド
- ruby 2.6.5p114
- Rails 6.0.3.4
- インフラ
- PostgreSQL(13.0)
- Heroku
選定理由
バックエンドにRailsを採用した理由は2つあります。
1つ目は、Qiita、note、GitHubなどプログラミング学習の際の知識のインプットやアウトプットに使用したサービスにRailsが使用されていたからです。
今回作成した「KnowHow」は社内ノウハウのインプットやアウトプットをテーマにしたアプリであるため、開発前段階からこれらのアプリの特徴を取り入れようと考えていました。
そのため、バックエンドはRailsで作成することに決めました。2つ目は、様々な情報にアクセスしやすいからです。
PHP,Pythonなど他のプログラミング言語も検討しましたが、日本国内のコミュニティや参考資料が多く学習しやすいRubyとフレームワークRailsを選択しました。
Rubyの学習によって得た知見を活かし、他の言語も学んでいきたいと思っております。データベース設計
draw.ioを使用して作成
インフラ構成図
(AWSにデプロイでき次第掲載いたします)
工夫した点
(設計面)
- 実際に同期にヒアリングを行い課題設定を行なったこと
- ユーザーのストレスがないようにUI/UXをとにかくシンプルにしたこと
- 「誠実さ」を表現するためにベースカラーを青に設定したこと
(可読性向上)
- 部分テンプレート化
- デコレータを使用し、Modelの肥大化を回避
- 基本7アクションしか使わない(チームメンバーが理解しやすいように)
(保守性向上)
- 部分テンプレート化
- 「namespace」や「scope」を使用したルーティングの整備
(その他)
- 「チーム開発」を意識して、毎回ブランチを作りプルリクベースで開発
- commitを細かく行ったこと
苦労した点
検索機能の実装(ActionTextを使用した場合)
検索機能はransack(gem)を使用すれば簡単に実装できますが、Rails6で導入されたActionTextを使用しているとransackによる検索が機能しなかったため、SQLを使用して自作で検索機能を作成しました。
とても苦労したと同時に「gemに頼らない機能実装」はとても良い経験だったので、別途記事にまとめました。
また、以前会社で学んだSQLの復習にもなりました!今後やりたいこと
- AWSにデプロイ
- セキュリティの強化
- テストのサンプル数を増やす
- レスポンシブ対応
- Vue.jsの導入
- Docker / CircleCIの導入
感想
私は、前職在職時に自分自身や同期が本気で悩んでいた課題をどうにか解決できないかと思い、本アプリの開発を決めました。
しかし、自分で考えたWebアプリを形にするということは想像以上に大変でした。
「この処理はどこに書けばいいのか?」「この機能は本当に必要なのか?」「このUI/UXで使いやすいのか?」と常に自問自答を繰り返しながら開発していました。
ですが、開発を振り返ってみると大変だった記憶ではなく、楽しかった記憶や充実感ばかりが思い出されます。
なにより、エラーに直面しながらも自分自身のやりたいことを形にできた時の感動は一入でした。このアプリ自体はこれで完成ではなく、インフラ面や機能面など課題がてんこ盛りなので、これからも改善を重ねていきたいと思っております!
最後までご覧いただきありがとうございました?♂️
これからも自身の学習したことや気づいたことなどあったらアウトプットしていきますので、もしよろしければLGTMやフォローよろしくお願いいたします!




- 投稿日:2021-02-21T01:29:35+09:00
EKS上のPodからEFSアクセスポイントを利用するときのバックアップ・リストア方法
はじめに
EKS上のPodからEFSをPersistentVolumeとして使用する方法の1つとしてEFS CSI Driverが選択肢としてあります。
今回はEFSアクセスポイントを使用した際のバックアップとリストアの方法を説明します。
EKSは1.16を使用しています。前準備
EFS CSI Driver
EFS CSI Driverを以下のコマンドでデプロイします。
$ kubectl apply -k "github.com/kubernetes-sigs/aws-efs-csi-driver/deploy/kubernetes/overlays/stable/ecr/?ref=release-1.0"次に、PersistentVolumeでEFSを使用するためにStorageClassを定義します。
efs-sc.yamlkind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: efs-sc provisioner: efs.csi.aws.com$ kubectl apply -f efs-sc.yamlEFS
EFSアクセスポイントを以下のようにパス
/accesspoint、ルートディレクトリ作成情報を200:200(0777)にします。今回はアプリケーションの実行ユーザを200にするためにこのような設定を入れます。
0:0(0777)で作成して後でinit containerでchownしてもいいですが、データ量が大きいと処理に時間がかかるのでEFS側で設定しておくことをお勧めします。
アプリケーション
今回はデータのバックアップ・リストアを確かめるためなのでCentosのDockerイメージを使用します。
SecurityContextで実行ユーザを200にしています。efs-app.yamlapiVersion: v1 kind: PersistentVolume metadata: name: efs-pv spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: efs-sc csi: driver: efs.csi.aws.com volumeHandle: fs-60ab6340::fsap-047db38c5e2c3486c --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: efs-claim spec: accessModes: - ReadWriteMany storageClassName: efs-sc resources: requests: storage: 5Gi --- apiVersion: v1 kind: Pod metadata: name: efs-app spec: containers: - name: app image: centos command: ["/bin/sh"] args: ["-c", "while true; do sleep 5; done"] volumeMounts: - name: efs-volume mountPath: /mnt securityContext: runAsUser: 200 runAsGroup: 200 fsGroup: 200 volumes: - name: efs-volume persistentVolumeClaim: claimName: efs-claim$ kubectl apply -f efs-app.yamlファイルとディレクトリを作成しておきます。
$ kubectl exec -it efs-app /bin/bash $ mkdir /mnt/test $ touch /mnt/test.txt $ ls -l /mnt total 8 drwxr-xr-x 2 200 200 6144 Feb 20 15:42 test -rw-r--r-- 1 200 200 0 Feb 20 15:41 test.txtバックアップ
AWS Backupでファイルシステムのバックアップを行います。
今回はオンデマンドバックアップを作成します。
バックアップが完了したらコンテナ内のディレクトリとファイルを削除します。
$ kubectl exec -it efs-app /bin/bash $ rm -r /mnt/test $ rm /mnt/test.txt $ ls -l /mnt total 0リストア
AWS Backupでデータの復元をしていきます。
「項目レベルの復元」を選択して復元を実行します。実行までに10分かかります。
復元されたデータはファイルシステムのルートディレクトリ直下に格納されます。
そのためルートディレクトリにアクセス可能なPodを別に立ててリストアを行います。PersistentVolumeの
spec.csi.volumeHandleには今回アクセスポイントを指定していません。efs-app-restore.yamlapiVersion: v1 kind: PersistentVolume metadata: name: efs-pv-restore spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: efs-sc csi: driver: efs.csi.aws.com volumeHandle: fs-60ab6340 --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: efs-claim-restore spec: accessModes: - ReadWriteMany storageClassName: efs-sc resources: requests: storage: 5Gi --- apiVersion: v1 kind: Pod metadata: name: efs-app-restore spec: containers: - name: app image: centos command: ["/bin/sh"] args: ["-c", "while true; do sleep 5; done"] volumeMounts: - name: efs-volume mountPath: /mnt-restore securityContext: runAsUser: 200 runAsGroup: 200 volumes: - name: efs-volume persistentVolumeClaim: claimName: efs-claim-restore$ kubectl apply -f efs-app-restore.yamlリストア用コンテナに入りバックアップデータをアプリ用コンテナのマウント先にコピーします。
実行ユーザをアプリケーション同様200にしているために後でchownをする必要がなくなります。データ量が大きいときにchownの処理も入れると時間がかかるので注意しましょう。$ kubectl exec -it efs-app-restore /bin/bash $ ls -l /mnt-restore/ total 8 drwxrwxrwx 2 200 200 6144 Feb 20 15:46 accesspoint drwxr-xr-x 4 root root 6144 Feb 20 15:03 aws-backup-restore_2021-02-20T16-05-41-036Z $ ls -l /mnt-restore/accesspoint/ total 0 $ ls -l /mnt-restore/aws-backup-restore_2021-02-20T16-05-41-036Z/accesspoint/ total 8 drwxr-xr-x 2 200 200 6144 Feb 20 15:42 test -rw-r--r-- 1 200 200 0 Feb 20 15:41 test.txt $ cp -R /mnt-restore/aws-backup-restore_2021-02-20T16-05-41-036Z/accesspoint/* /mnt-restore/accesspoint/ $ ls -l /mnt-restore/accesspoint/ total 8 drwxr-xr-x 2 200 200 6144 Feb 20 16:15 test -rw-r--r-- 1 200 200 0 Feb 20 16:15 test.txtアプリコンテナでもリストアされているか確認をします。
$ kubectl exec -it efs-app -- ls -l /mnt total 8 drwxr-xr-x 2 200 200 6144 Feb 20 16:15 test -rw-r--r-- 1 200 200 0 Feb 20 16:15 test.txtまとめ
EKS上のPodからEFSアクセスポイントを使用する際のデータのバックアップとリストアの方法を説明しました。
AWS Backupでは復元データはルートディレクトリ直下に配置されるので、それを考慮してリストアを実行する必要があります。参考
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/efs-csi.html
https://github.com/kubernetes-sigs/aws-efs-csi-driver/blob/master/examples/kubernetes/access_points/specs/example.yaml
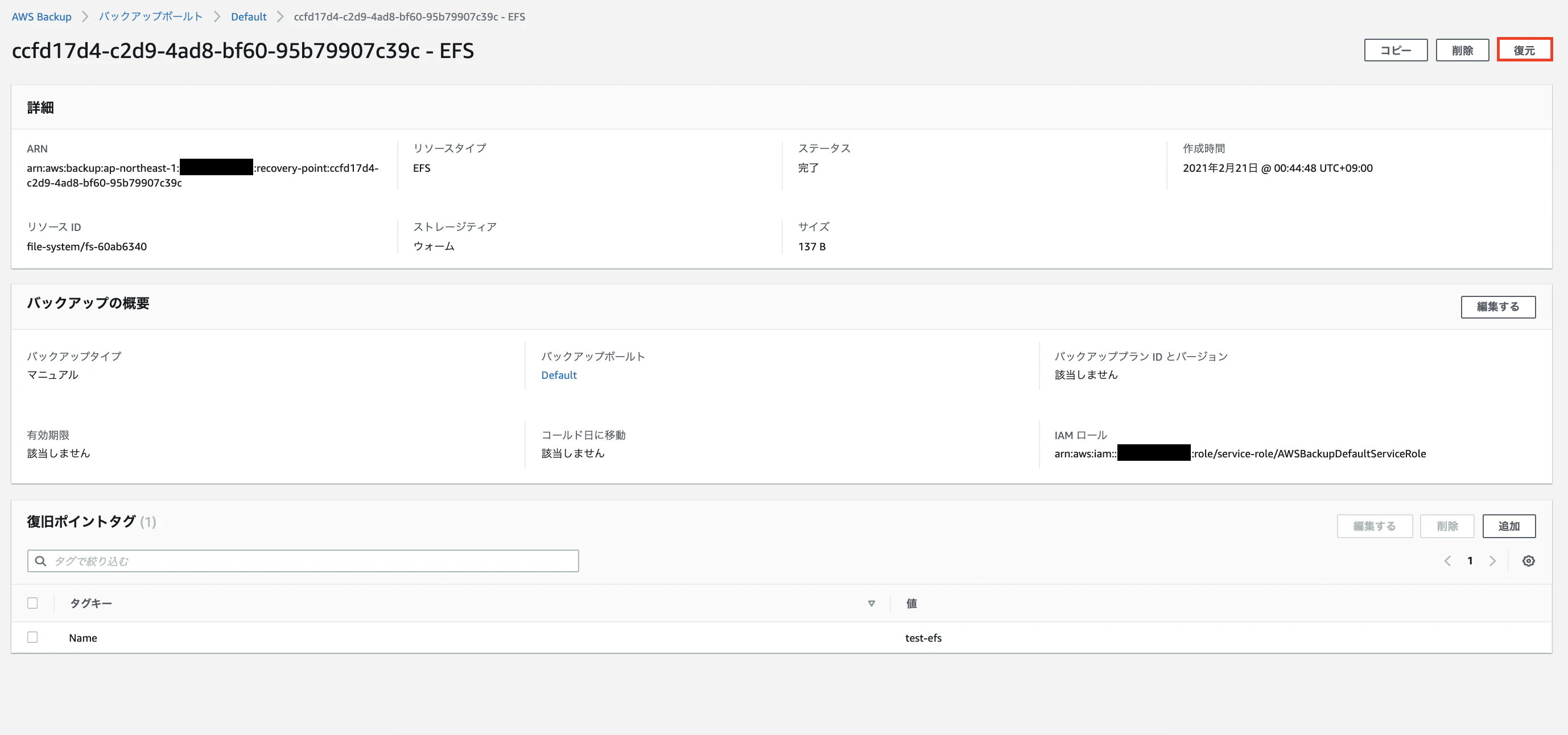
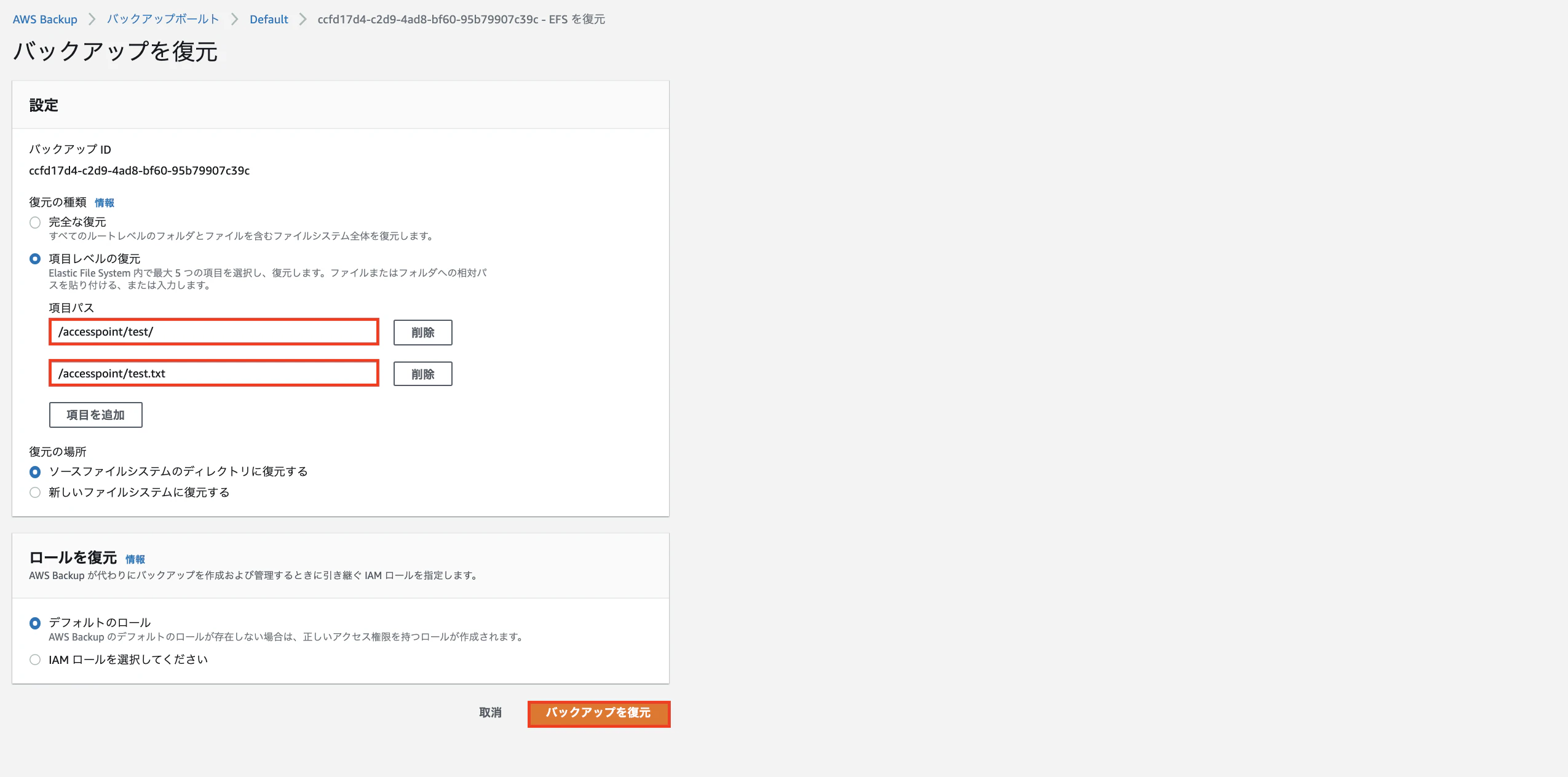
- 投稿日:2021-02-21T01:15:04+09:00
AWSを試しに使う場合はどのリージョンがオススメ? リージョンの比較をしてみた
選択するリージョンについて
AWSでリージョンを選択するときは一般的には自分が住んでいる国(地域)のリージョンを選択すると思います。
自分の場合は日本に住んでいますので通常はパシフィック(東京)リージョンを選択します。
ですが、米国東部(バージニア北部)リージョンが対応サービスが一番多いですし、
試しにAWSを使いたい時や、新機能を使いたい時に米国西部(オレゴン)リージョンが便利という情報を得ましたので、
今回はどのリージョンがオススメか筆者なりの意見を書きたいと思います。リージョンの比較
リージョンの比較をする際に下記の点について比較を行いました。
- リージョンの使用料金
- リージョンによる対応サービス
- リージョンの応答速度
- リージョンの使用料金・応答速度を考慮した料金比較
米国西部(オレゴン)リージョンと比較するのは米国東部(バージニア北部)、アジアパシフィック (東京)としています。
1.リージョンの使用料金
リージョン t2.micro のコスト(USD/時間) 米国西部(オレゴン) 0.0116 米国東部(バージニア北部) 0.0116 アジアパシフィック (東京) 0.0152 ※2021/2/20時点
米国西部(オレゴン)と米国東部(バージニア北部)はリージョンの使用料金が同じなんですね。またこの2つと比べてアジアパシフィック (東京)は高いです。
2.リージョンによる対応サービス
リージョン 対応サービス数 米国西部(オレゴン) 185 米国東部(バージニア北部) 190 アジアパシフィック (東京) 168 ※2021/2/20時点
比較すると東京リージョンに比べてバージニア北部リージョンやオレゴンリージョンのサービスの数は多いですね。
では対応サービスの種類は何が違うのかみていきたいと思います。2-1.バージニア北部リージョンとオレゴンリージョンの対応サービス比較
2-1-1.バージニア北部リージョンにあってオレゴンリージョンにないサービス
AWS Cost Explorer
AWS Cost and Usage Report
AWS DeepComposer
AWS DeepLens
AWS DeepRacer
Alexa for Business
Amazon Managed Blockchain
Amazon RDS on VMware2-1-2.バージニア北部リージョンになくてオレゴンリージョンにあるサービス
AWS Device Farm
AWS Ground Station
Amazon Honeycode2-2.オレゴンリージョンと東京リージョンの対応サービス比較
2-2-1.オレゴンリージョンにあって東京リージョンにないサービス
AWS Control Tower
AWS Device Farm
AWS Ground Station
AWS IoT SiteWise
AWS Network Firewall
AWS Snowcone
AWS Snowmobile
Amazon Braket
Amazon Cloud Directory
Amazon Comprehend Medical
Amazon Fraud Detector
Amazon Honeycode
Amazon IVS
Amazon Kendra
Amazon Textract
Amazon Timestream
Amazon WorkLink
Amazon WorkMail
Amazon WorkSpaces Application Manager2-2-2.オレゴンリージョンになくて東京リージョンにあるサービス
AWS DeepLens
Amazon Managed Blockchainバージニア北部リージョンとオレゴンリージョンについて、サービス数の比較をすると5つしかないように思いますが、実際のサービスの違いを見ると5つ以上ありました。
また、オレゴンリージョンで対応してないサービスで気になったのはアレクサ、ブロックチェーンといったサービスが対応してないことです。
東京リージョンもアレクサのサービスは対応してなさそうです。
3.リージョンの応答速度
リージョン 東京リージョンからの応答速度(ms) 米国西部(オレゴン) 100.28 米国東部(バージニア北部) 168.26 アジアパシフィック (東京) 2.36 下記サイトを参考(【条件】Percentile:Average(Legency)、Timeframe:1Day)
AWS Latency Monitoringこの応答速度の目安については下記の通りです。(こちらのサイトを参考にしましたレイテンシとは:定義から計測サイトまで用語にまつわるトピックを解説)
応答速度 評価 15ms以下 非常に速い 30ms以下 速い 50ms未満 普通 50ms以上 やや遅め 100ms以上 遅い オレゴンリージョンもバージニア北部リージョンも100ms以上なので、応答速度は遅い分類に入ります。
ただ、バージニア北部リージョンはオレゴンリージョンの約1.7倍なのでかなり遅く感じるかもしれません...4.リージョンの使用料金・応答速度を考慮した料金比較
AWSの料金体系は使用する時間によって料金が決まるので、リージョンの使用料金と応答速度を踏まえた料金を比較したいと思います。
リージョン t2.micro のコスト(USD/時間) × 東京リージョンからの応答速度(ms) 米国西部(オレゴン) 1.1632 米国東部(バージニア北部) 1.9518 アジアパシフィック (東京) 0.0359 ※料金を比較するため単位は気にせず計算しております
単位時間あたりの料金で見た場合はバージニア北部リージョンとオレゴンリージョンが安いですが、
利用時間に影響する応答速度も考慮すると総合的に東京リージョンがコストを抑えられそうです。
ただし、利用している時間の中で待機時間が長くなる場合についてはコストの比較が難しくなりますので、
東京リージョンを利用してサクサク検証を済ませて、検証が終わったらサービスをすぐに削除するのが良さそうです。まとめ
以上より、筆者の見解としては、AWSを試しに使う場合、単位時間あたりのコスト×応答速度の観点から見て東京リージョンを選択するのが良い判断しました。
しかし利用用途によっては他のリージョンを選択しなければならないので、筆者としては下記の使用状況に分けてリージョン選択したいと思います。
- アレクサを使用する場合
→米国東部(バージニア北部)
- その他
→アジアパシフィック (東京)
参考URL
・AWS基礎入門チュートリアル – AWS のリージョンの選び方
・AWS Latency Monitoring
・レイテンシとは:定義から計測サイトまで用語にまつわるトピックを解説
- 投稿日:2021-02-21T00:43:33+09:00
【学習メモ】AWS Best Practices
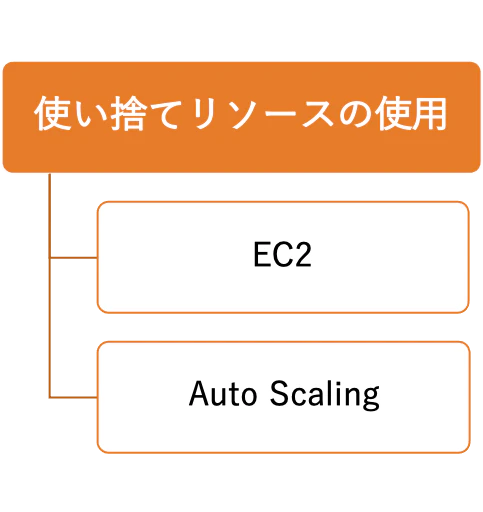
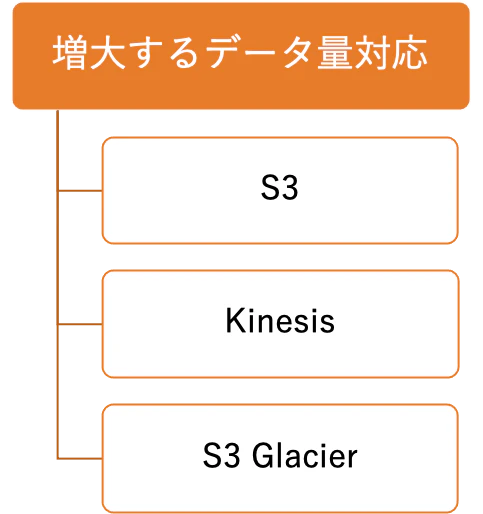
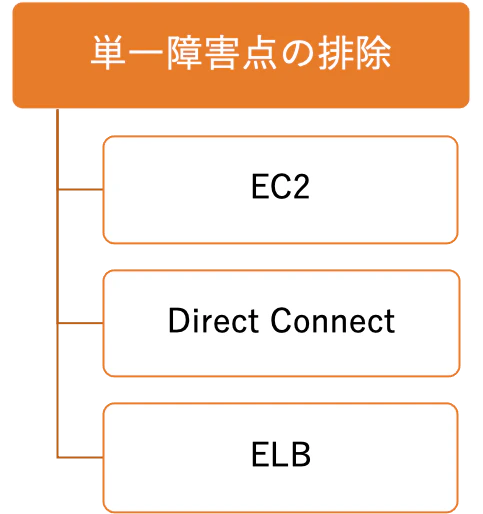
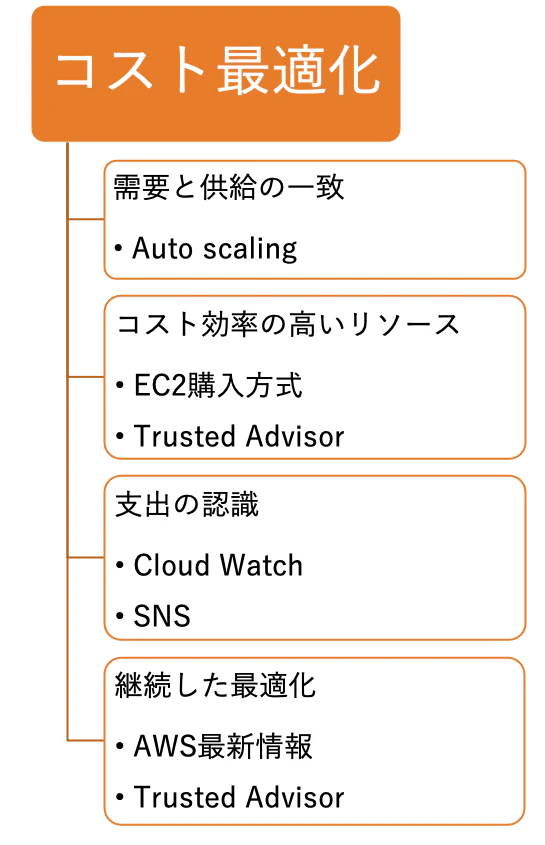
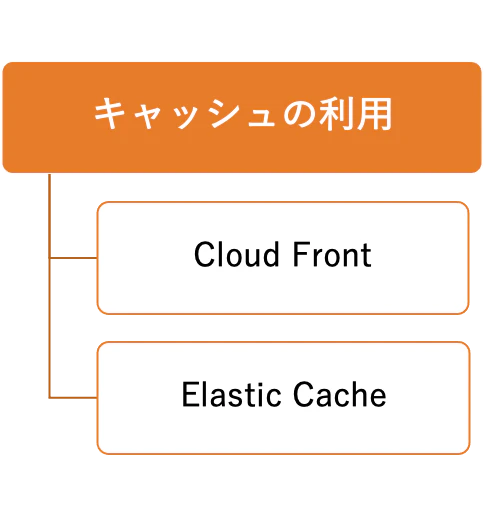
- 投稿日:2021-02-21T00:23:00+09:00
AppSyncとは?
勉強前イメージ
アプリケーションのデータをsyncするとか・・?
調査
AppSyncとは?
GraphQLというWebAPIを用いてデータにアクセスでき、処理を行うことができるもの
WebAPI とは?
APIやりとりをHTTP,HTTPSベースで行うAPI
RESTやSOAPなどがあり、そこにGraphQLというものもあります。GraphQL とは?
acebookが2015年に公開したAPIの規格で、
RESTでは以下のような課題がありました。
- REST API の課題
- ドキュメント管理が大変
- 使い方難しい
- ドキュメントと実装がずれる
RESTでの課題を解決し、RESTが適合しないときに使うものとして開発されました。
改めての AppSyncとは?
GraphQLのマネージドサービス。
GraphQLを簡単に使うことができます。接続イメージ
PCやmobileからのリクエストをAppSyncはGraphQLで処理します。
スキーマーとデータソースを繋ぐ役割のリゾルバー
データソースは DynamoDB, lambda, Aurora, Elasticsearch, HTTP Endpoint が指定できます。AppSyncの特徴
- シンプルかつ安全なデータアクセス
GraphQL からの単一のネットワークリクエストで複数のデータソースからデータの取得が行なえます。
- 組み込まれたリアルタイム & オフラインの機能
データの更新をリアルタイムでプッシュでき、
モバイルのアプリケーションのために、オフライン時のアクセスと、オンラインに復帰した際に競合を解決するための機能を備えた、データ同期機能を提供します。
- サーバー管理が不要
完全マネージド型なので、セットアップ、管理、保守は必要ありません。
ユースケース
- ダッシュボード
- リアルタイムでのデータ更新
- 複数ユーザが同時編集するようなもの
- コラボレーションをするもの
- 自動更新ができる
- ソーシャルメディア・チャット
- 複数ユーザ間のメッセージ管理ができる
- オフライン時でも操作可能で、接続後自動sync
勉強後イメージ
APIで自動でデータ取りに行ってくれたりする・・のイメージ
実際に触ってないからまだふんわりとしか理解できてない。参考