- 投稿日:2021-02-21T23:53:45+09:00
【駆け出しエンジニアメモGit解説②】リモートリポジトリとローカルリポジトリの関係性を簡単に図にしてみた。
前回の内容
前回はGitとGitHubの違いについて書きました。Gitはバージョン管理ツールであり、GitHubはGitを利用した、開発者を支援するWebサービスでした。
前回の内容はこちらから。リモートリポジトリとは?
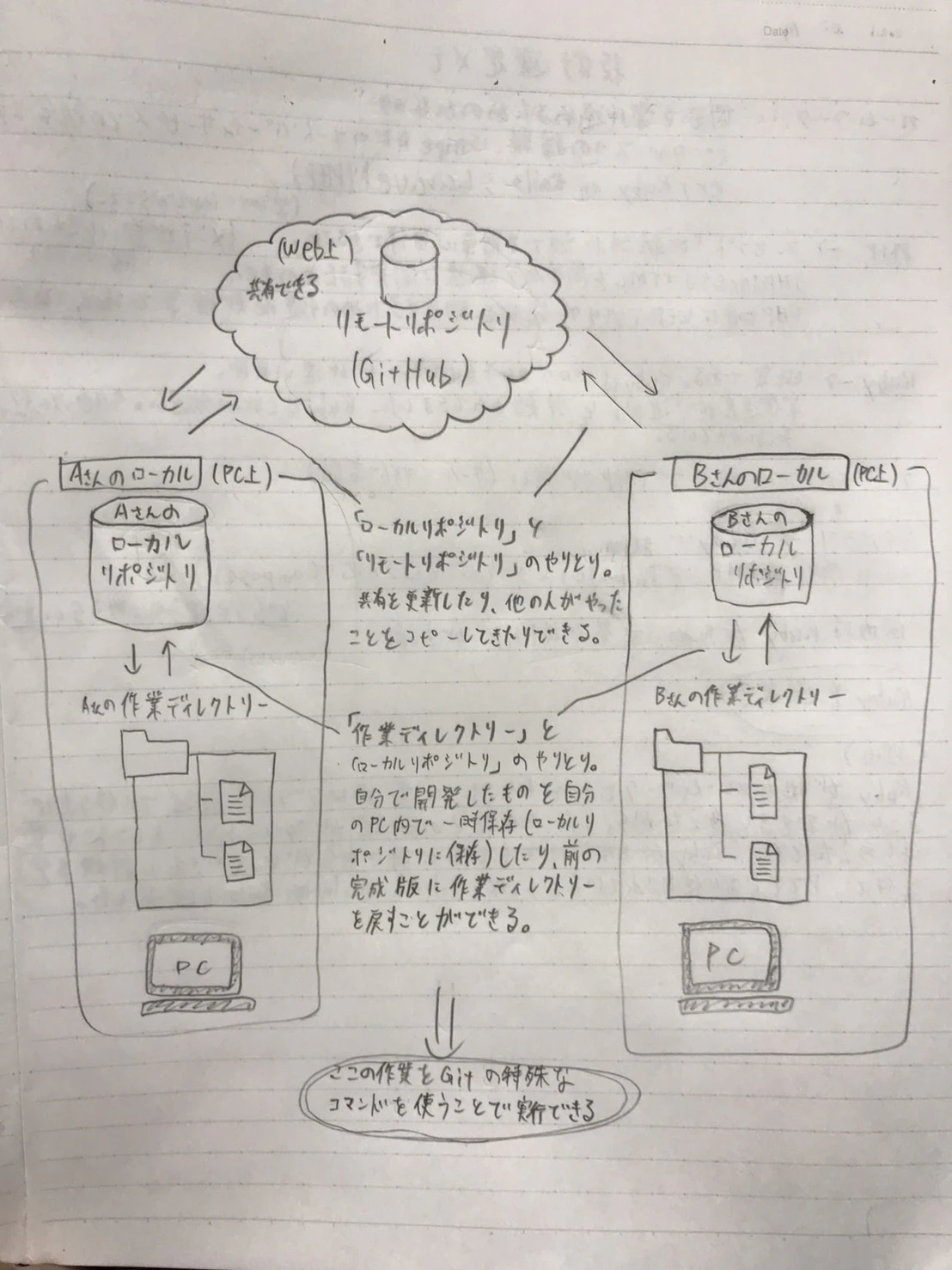
リモートリポジトリとは、リモート上にあるリポジトリのことで、いわゆるGitHubで管理されているリポジトリのことを言います。こちらも、リポジトリですので、木の枝のように枝分かれしているイメージを持つと分かりやすいです。雲の上にあり、ネットに繋がっているリポジトリですね。ネットに繋がっているので、許可されていれば他の共同開発者も一緒にその枝をい削除したり、追加したりすることができます!
ローカルリポジトリとは?
ローカルリポジトリとは、リモートとは逆で自分のPC上にあるリポジトリの事です。こちらはネットに繋がってはいないので、他の人が枝を追加したり、削除したりすることはできないです。ただし、ネットに繋がっていないと言いましたが、Gitの機能を使うことで、リモートリポジトリに自分のリポジトリを反映させたり、リモートリポジトリをコピーしてローカルリポジトリを作ったりすることができます!
全体の関係性とイメージ図
こちらが全体の関係性を簡単に図にしてみたものです!
汚くてごめんなさい、、、また、分かりづらかったらごめんなさい、、、
まとめ
- リモートリポジトリは、雲の上(ネット上)にあるリポジトリのこと。みんなで共有できる。
- ローカルリポジトリは、自分のPC上にあるリポジトリのこと。みんなで共有するにはリモートに上げる必要がある。
参考サイト
https://www.r-staffing.co.jp/engineer/entry/20190621_1
https://techacademy.jp/magazine/6235最後に
最後までお読みになってくださりありがとうございます。もし、参考になったり、少しでも役に立った、良い記事だなと感じていただけましたら"LGTM"を押してくださるととても励みになります!!!お願いします!ポチっと押してくださいー!
この記事は、駆け出しエンジニアの筆者が自分のメモと理解向上のため、自分と同じ駆け出しエンジニアでも分かるように、分かりやすく解説することを目的とした記事です。誤った記載をしてしまうかもしれませんがご了承下さい。誤ってる際はコメントにてご指摘してくださると幸いです。
少しでも駆け出しエンジニアの方の力になれると幸いです。また、同じく駆け出しエンジニアの方々、一緒に頑張っていきましょう!
Twitterもやっているのでぜひフォローしてください→https://twitter.com/EngineerShige
- 投稿日:2021-02-21T22:29:48+09:00
Gitをちゃんと使う 1人pullリクエスト開発
pullリクエストベースの開発をしてみたい
人様に見せるコード(開発履歴付き)として考えると、リポジトリのネットワーク図が横棒一本線でmainが伸び続けるというのも格好が悪い。
ちゃんと機能開発ごとに枝ワケして、mainに帰ってくる、マングローブみたいな開発をしたいなということで。pullリクエストと承認・マージ
軽くググってみてみると、以下のような手順が紹介されています。
- 機能追加を行う対象とする、既存のリポジトリ(開発者アカウント配下のリポジトリ)をフォークする。
- フォークして、自分アカウント管理配下にもってきたリポジトリに対して、開発用branchを作る
- branch上で開発して、自分のリポジトリにpushする
- 自分のリポジトリから、開発者に対してpullリクエストを発行する
- 開発者が、開発者リポジトリからリクエストの内容を確認し、マージする
1人開発だと、フォークが必須となるというのがちょっと違和感があり。
(一応、prodとstgの2アカを用意してあるので、そのような運用も全然出来はするのだけど)また、このリクエストと承認管理の履歴はどこに保存されてるんだ、、?というのが気になったこともありまして、調べてみました。
Forkて必須なの??
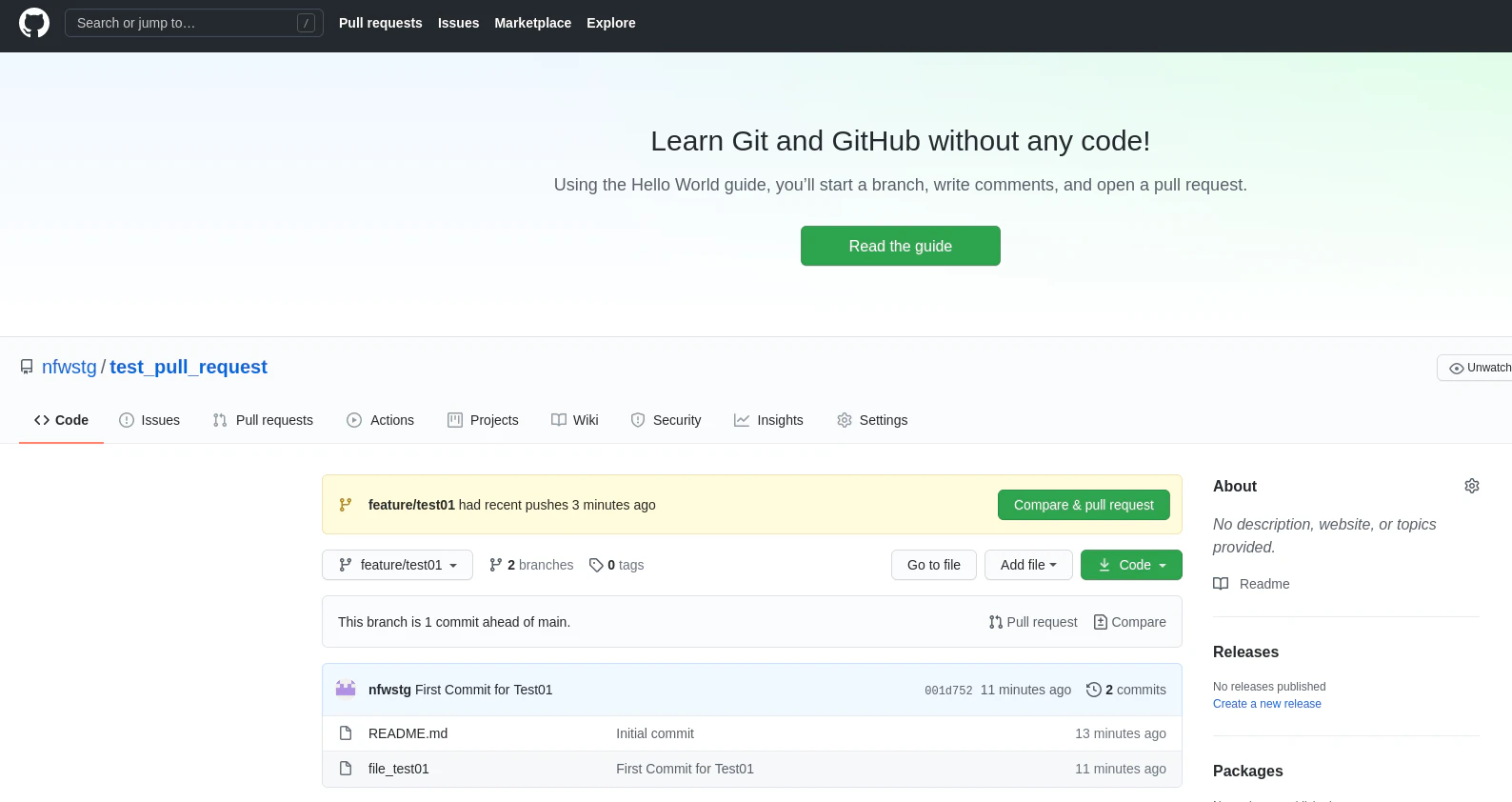
試しにForkせず、自分のアカウント配下のリポジトリでブランチを作ってみます。
すると、、# まず、ローカルで開発用のブラントとして feature/test01 というものを作ります。 $ git branch -v feature/test01 001d752 First Commit for Test01 * main 7522207 Initial commit $ git ls-files README.md $ git checkout feature/test01 && git ls-files Switched to branch 'feature/test01' README.md file_test01 # で、feature/test01をpushします。 $ git push origin feature/test01 remote: Create a pull request for 'feature/test01' on GitHub by visiting: remote: https://github.com/XXX/test_pull_request/pull/new/feature/test01 * [new branch] feature/test01 -> feature/test01で、Githubにログインすると、、
pullリクエストできる状態に。
forkしないとpullリクエストできないというわけではないのですね。Forkすべきなの?
上記調べといてですが、結論としてはすべきですかね。
公開系のプロジェクトに対して、ローカルに落としてリモートにアップして、、というのをホイホイやってると上げちゃいけないファイルアップしちゃったり、動作確認してない状態のコード取り込んじゃったり、が少なからずでてくる気がします。
featureブランチ編集してるつもりでmain編集しちゃったりとか、、
そのリスクを考えると、きちんと別アカウントを使って、Forkしてpullリクエスト管理していくべきですね。pullリクエストの情報てどこに管理されるの?
.gitの中に保存されてたりするのかな、、とおもって軽く調べたのですが、見つけられず。
これはgithubのサーバ上のみで管理される情報なのかな、、?
もうちょっと調べてみたいところですが、現状アイデアがないので、また思いついたら考えます。マージのときの考え化
逆にマージをかけるときですが、これもこれで考慮が必要。。
pypi展開と、setupファイルをどうする?
pypiは、versioを挙げないと展開できない。
現状、versionはsetup.pyにハードコードしている。
→コードの修正だけではなく、setup.py(場合によってはReadmeファイルも)の修正をしないといけない。普通に考えると、pypi展開はレポジトリの管理者がマージするときにせっとで実施すべきものであり、コード修正をpullリクエストしてくる人が更新版のsetup.pyを作成・提案してくるのはおかしい。
となると、開発者レポジトリでdevelop用のブランチを作っておいて、pullリクエストはそこで受け付けて、pypi展開などは改めてdevelopブランチをmainブランチにマージするときに行う、、というように考えるべきか??
あるいは、pypi展開はgitの管理と別に、管理者が適切だと思ったタイミングで手動で実施する(gitのコミット管理と必ずしも連動しない)とすべきか、、?ちゃんと考え方ありますね。。
https://www.atmarkit.co.jp/ait/articles/1708/01/news015.html
これ見て勉強します。。
まとめ。
公開アカウントと別に開発用アカウント作って、フォークしてpullリクエスト出すようにしたいと思います。
で、ブランチの使い方は、ちゃんとA successful Git branching modelを読み込ませていただく、と。
ちなみにこっちの勉強のために既知バグフィックスに着手できず!!
。。。本末転倒感はあるけれど、まぁ最小にちゃんとやらんとまた我流の変なくせついちゃうし、仕方あるまい。。
- 投稿日:2021-02-21T13:33:12+09:00
Gitをちゃんと使う add, clone, push(ちょっとだけ)
きちんとGitを使ってみる
これまでちょこちょことGitは使っていたけれど、せいぜい「Webストレージ」くらいの意識で使っていたというのが本音で、mainブランチに変更を上乗せしてpushする、、という使い方しかしてきませんでした。
人様に見せるつもりのレポジトリでそれを続けるのはさすがに恥ずかしいですし、、、ここらでちゃんとbranchを使い分けて、pullリクエストベースの管理を始めてみたいと思います。
その手始めに、これまで思考停止して打ち込んでたgitコマンドについて意味の再確認をしてみます。改めて。gitに関する用語と考え方。
https://docs.github.com/ja/github/getting-started-with-github/github-glossary#repository
リポジトリとレポジトリ
タイプするときの"re"positoryに引っ張られてレポジトリと読んでいたのですが、ちゃんと発音にあわすとリポジトリですね。。
座学だけでやってるとこういうのが多くなるので、注意しないとな。。リポジトリとブランチ
樹形図上に連なるブランチ群があり、それをまとめ上げたのがリポジトリ。
以下で書きますが、リモート(github)とローカル(自分のPC)の間のやり取りはブランチ単位で行うものであり、リポジトリまるごとをダウンロードしたりアップロードするものではない、と。思考停止してつかってたコマンド群の意味を改めて
自分のプロジェクトやコードを一通り修正完了し、一息つく前に思考停止して"git add ."、"git commit -m "XX", "git push -u origin main"の3点セットを叩く癖がついてしまっているので、改めて意味を学び直します。。
git add .
まずこいつで編集・追加したファイル群をgitの管理対象として登録して、公開したくないものが混ざり込んだらrmで消す、、という考えでしたが、結構改めないといけないですね。。
コマンドの意味
そもそもコマンドの意味は、レポジトリにファイルを「追加」する。
"."は、カレントディレクトリ配下の、.gitignoreで除外登録されているもの以外のすべてのファイル。ワーキングディレクトリにファイルがバラバラと置かれていても、gitに管理されるのは、あくまで「追加」されたファイルだけ。
あと、新規に作ったファイルだけではなく、変更したファイルも追加しないと、commit時に取り込んでもらえない。追従させたくないものは.gitignoreに追加しておいて、"add ."の際に追加対象からはずすという、まず全部拾ってからいらないものを弾く、という考え方をしてました。
あくまで「管理したいものを選択的にaddする」という考え方に矯正しないといけないですね。。
結局やることは変わらないでしょうけれど、心がけの問題で。git rm --cached
”git add .”して、”git status"で追加されたファイル群見て、追加するつもりがなかったものが見つかったら、このコマンドで追加解除する、、としてました。
一方、"git reset "とすることもできると知りまして。この2つの違いはというと、、
新規に作ったファイルを追加してコミットしようという場合は違いはないのですが、既存ファイルを変更した場合に大きな違いがでるんですね。実際にやってみると、、
# 比較のため、内容を変えないファイル(unchanged)、変えるファイル(changed)、追加するファイル(added)を用意します。 $ git ls-files changed_for_reset.txt changed_for_rm.txt unchanged_for_reset.txt unchanged_for_rm.txt $ date > ./changed_for_reset.txt $ date > ./changed_for_rm.txt $ touch ./added_for_reset.txt $ touch ./added_for_rm.txt $ git add . # 準備完了 $ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) new file: added_for_reset.txt new file: added_for_rm.txt modified: changed_for_reset.txt modified: changed_for_rm.txt # 新規ファイルに対してrm, resetすると? # -> rm --cachedもresetも同じ結果になる。 $ git reset ./added_for_reset.txt $ git rm --cached ./added_for_rm.txt rm 'added_for_rm.txt' $ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) modified: changed_for_reset.txt modified: changed_for_rm.txt Untracked files: (use "git add <file>..." to include in what will be committed) added_for_reset.txt added_for_rm.txt # 既存ファイルに対してrm, resetすると? # resetは、編集前の状態に戻す。 -> この状態commitすると、対象ファイルは編集前のバージョンの内容のままレポジトリに残る。 # rmは、レポジトリ自体から削除される。 # -> この状態でcommitすると、対象ファイルは編集前に戻るのではなく、削除になる。 # ちなみにどっちの場合も、ワーキングディレクトリには編集後の状態のファイルは残る。 $ git reset ./changed_for_reset.txt Unstaged changes after reset: M changed_for_reset.txt $ git rm --cached ./changed_for_rm.txt rm 'changed_for_rm.txt' $ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) deleted: changed_for_rm.txt Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: changed_for_reset.txt Untracked files: (use "git add <file>..." to include in what will be committed) added_for_reset.txt added_for_rm.txt changed_for_rm.txtオペミスリスクを考えると、resetを使うべきですね。。
指を矯正します。。git commit -m "Comment"
ファイルをローカルにセーブする、位のつもりで叩いてました。
これは、あまり大きく改める必要がある部分はないかな、、?実際はCommitの記載内容のルールを定めなければいけないですね。。現状はまだノーアイデア。
チケットベースで作業を管理していれば、チケットIDを入れるので確定でいいのですが、現状そこまでの管理にするつもりもないし。git push -u origin main
ローカルのデータを、gitサーバにアップロードする、くらいのつもりで叩いてましたが、、、、
あってはいるけど、かなり無駄なコマンド叩いてました。コマンドの意味
ローカルにあるmainブランチを、.git/configに登録してあるリモートgitサーバの中で「origin」という名称で登録しているものにアップロードし、さらに、「(pushが成功したら)上流ブランチとしてoriginを登録する」。
まず、アップするのは指定したbranchだけで、リポジトリ全体をまるごとアップするわけではない。
わざわざ引数にmainを取ってるのだからそりゃそうなのだけど、まったく意識してなかった。。また"-u"の方も。
意味をちゃんと確認せずに使っていたのですが、これはが「今回使ったリモートgitサーバを、ローカルのmainブランチにとっての標準のリモートサーバ(上流ブランチ)として記憶しておけ、という意味なんですね。。
一回-uつきでcommitして、成功すれば、上流ブランチが保存されます。
それ以降は"git push"だけでリモートへのpushが完了します。上流ブランチは、以下のように.git/configの、mainブランチ用の設定として自動登録されます。
# .git/configに以下が登録されます。 $ cat .git/config [branch "main"] remote = origin merge = refs/heads/main # コマンドで見ると、、 # remoteがリモートサーバの名称(originの具体的なurlなどの情報は、別途"remote"のセッションで定義されている) # medgeが、リモートのどのブランチに対してマージするかの設定。 $ git config --list branch.main.remote=origin branch.main.merge=refs/heads/main # あるいは。ブランチ名後部の[]の中に表示されます。 $ git branch -vv* main 4dbbbc8 [origin/main] Commentちなみに以下で解除できます。
$ git branch --unset-upstream
何を、どこにpushするのか?
https://www.slideshare.net/ikdysfm/5gitrefspec
漠然と使っていた"git push -u origin main"は、手元のmainブランチを、リモートのoriginリポジトリのmainブランチに対してpushするというものでした。
これ、"main"をちゃんと書くことで、ローカルのどのブランチをリモートのどのブランチにpushするのか、細かく指定できるのですね。
https://git-scm.com/book/ja/v2/Git%E3%81%AE%E5%86%85%E5%81%B4-Refspec例えば、ローカルでpatch01というブランチを作り、そこで新たに作ったファイルや変更を、リモートのmainにpushしたいなら、、
$ git push origin patch01:mainとなる。
リモートとローカルでブランチの構造がチグハグになるので、この使い方をしてメリットがあるケースは今の所思いつかないけれど、一応記憶しておきます。
今日のところは
ここまで。
- 投稿日:2021-02-21T12:22:31+09:00
【やらかし記事】Githubにデータベース情報を公開してしまった…
背景
・PHP/MySQLを学習し終え、簡単なアプリ開発をしたので、Herokuにデプロイしました。(これが人生初デプロイでした。)
・ポートフォリオの説明用にQiita記事(※)を投稿し、そこにGithubのURLを張り付けていました。
※書いたQiita記事はこちらです。きっかけ
投稿したQiita記事に以下の内容のコメントをいただきました。
コメント
「すぐにデータベース情報を消して!Herokuなら環境変数も使えるよ!」※要点を絞って記載しております。元コメントは抜粋しておりません。
しかし、
自分
「データベース情報を消す理由は?環境変数とは??そもそもデータベース情報を記事に記載していないはず…」と「?」しか浮かびませんでした。
※ここでいうデータベース情報とは以下の
heroku configの結果で表示される情報です。$ heroku config === arcane-ravine-17252 Config Vars CLEARDB_DATABASE_URL: mysql://<username>:<password>@<hostname>/<dbname>?reconnect=trueこちらの記事などを参考にして
・Herrokuアカウントの作成
・Herokuアプリケーションの作成
・HerokuCLIのインストール
・ClearDBのインストール
が全て完了したら取得できるものです。当初の認識
元々、データベース情報(ユーザー名/パスワード/ホスト名/データベース名)は個人情報と同じようなもので、管理に注意が必要であることは知っていたのでQiita記事を書く際やTwitterでアウトプットする際も気を付けていたつもりでした。
ですが、コメントを頂いたのでDB情報が記事内に書かれているのか再度見返しました。重大なミスが発覚…
すると、、、Qiita記事に貼っていたGithub上のコードにDB情報を公開していることに気づきました(汗)
今回のアプリの開発で、普段から何気なくGithubにコード管理のためにプッシュしていたのですが、そのプッシュの内容に本番環境用のデータベース情報がしっかり入っていました(;^ω^)
この時点で、この行為自の危険性を初めて認識しました。対処方法
コメント頂いた通り、すぐに以下を実行しました。
・Herokuで作成した当初アプリを削除
・再度新しいアプリを作成
・本番環境用のDBを作成し環境変数を使ってデプロイ
⇒デプロイの際に参考にした記事はこちらです
【PHP】Heroku×PHP×MySQLの環境設定原因
大きく分けて2点です。
1.Github上のコードは公開されているということの意識の欠乏
Githubはコードを管理すると同時に、「コードは公開されている」ということを忘れていたことが理由の一つです。
2. ステージング方法の悪い癖
私は普段Gitでのコミット時、ステージングを
git add .
で必ず実行する癖がついていました。これでは意図しないファイルまでステージング/コミットしてしまうことにつながるので、ステージングは
git add -p <ファイル名>
も使用する必要があると学習しました。学んだこと
エンジニアはデータベース上の顧客の個人情報を扱うことになるので、課題解決と同時にセキュリティ上の問題にも十分注意して仕事を進めなければいけないのだ、と実感しました。
このような事態が起こったのがエンジニアとして実務をする前の、個人開発のタイミングで本当によかったと感じました。
- 投稿日:2021-02-21T06:47:58+09:00
git コマンド
railsチュートリアル の学習で git につまったのでメモ。
1. git config で設定
インストールした Git を使う前に、最初に 1 回だけ設定を行う必要があり。
これは system セットアップと呼ばれ、コンピュータ 1 台につき 1 回だけ行う。git config --global user.name "名前を入力" git config --global user.email ここにメールアドレスを入力@users.github.com2. git init でセットアップ
まずアプリケーションのルートディレクトリに移動してから、新しいリポジトリの初期化を行う。
git init3. 全てステージング
ステージング (Staging) という一種の待機用リポジトリに置かれ、コミットを待つ。安全のため、いきなりコミットしないようになっている。ステージングの状態を知るには
git statusコマンド。git add -A4. ステージングしたものをメッセージ付きでコミット
コミット:開発しているファイルをローカルリポジトリに保存
-m フラグ:コミットメッセージをコマンドラインで直接指定git commit -m "ここにメッセージを入力"5.リモートリポジトリ(GitHub など) への追加との初回プッシュ
通常のプッシュは
git pushgit remote add origin [url] git push -u origin --all6. 以降
- ステージング(変更したいファイルを選択)
- コミット(ローカルリポジトリにステージングファイルを保存)
- リモートへプッシュを繰り返す
git add -A git commit -m "ここにメッセージを入力" git push
備考
versionを戻す
- 戻したいversionのIDを見つけて
git checkout1.履歴確認
git log commit 989d476c5ab7fb30bb0eb1ca8f5b917860c9c719` Author: Jun Nishii Date: Wed May 24 13:22:45 2017 +0900 First commit2.最新ファイルとの比較
git show 989d476c5ab7fb30bb0eb1ca8f5b917860c9c719 --word-diff=color3.
git checkoutでversionを戻すgit checkout 989d476c5ab7fb30bb0eb1ca8f5b917860c9c719 *remote ブランチ強制削除
ブランチ削除参考サイト
例:リモート origin の main ブランチを削除する場合git push --delete origin mainブランチを切る(作成してそのブランチを選択)
static-pages ブランチを切る例
git checkout -b static-pages
おまけ
rails で削除してみる
ls app/controllers/ application_controller.rb concerns/ rm -rf app/controllers/ ls app/controllers/ ls: app/controllers/: No such file or directory現在の「作業ツリー」内のみでの削除で、まだコミット (保存) されていない状況なら、以前のコミットを checkout コマンドでチェックアウトすれば、削除前の状態に戻せる。
checkout : ブランチ切り替え
-f : forceの意味。現在までの変更を強制的に上書きして元に戻すgit checkout -f git status # On branch master nothing to commit (working directory clean) ls app/controllers/ application_controller.rb concerns/